⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-31 更新
VAU-R1: Advancing Video Anomaly Understanding via Reinforcement Fine-Tuning
Authors:Liyun Zhu, Qixiang Chen, Xi Shen, Xiaodong Cun
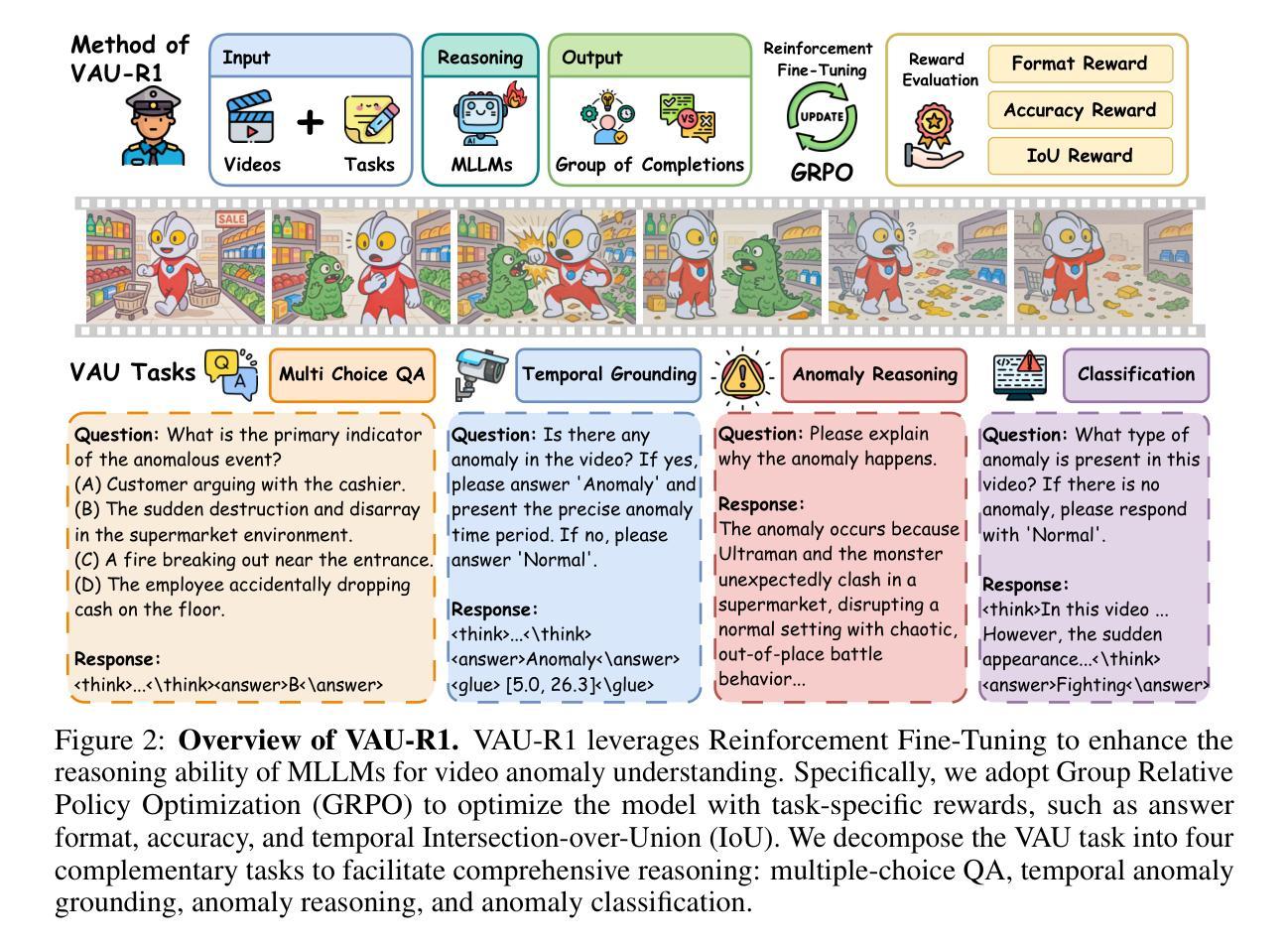
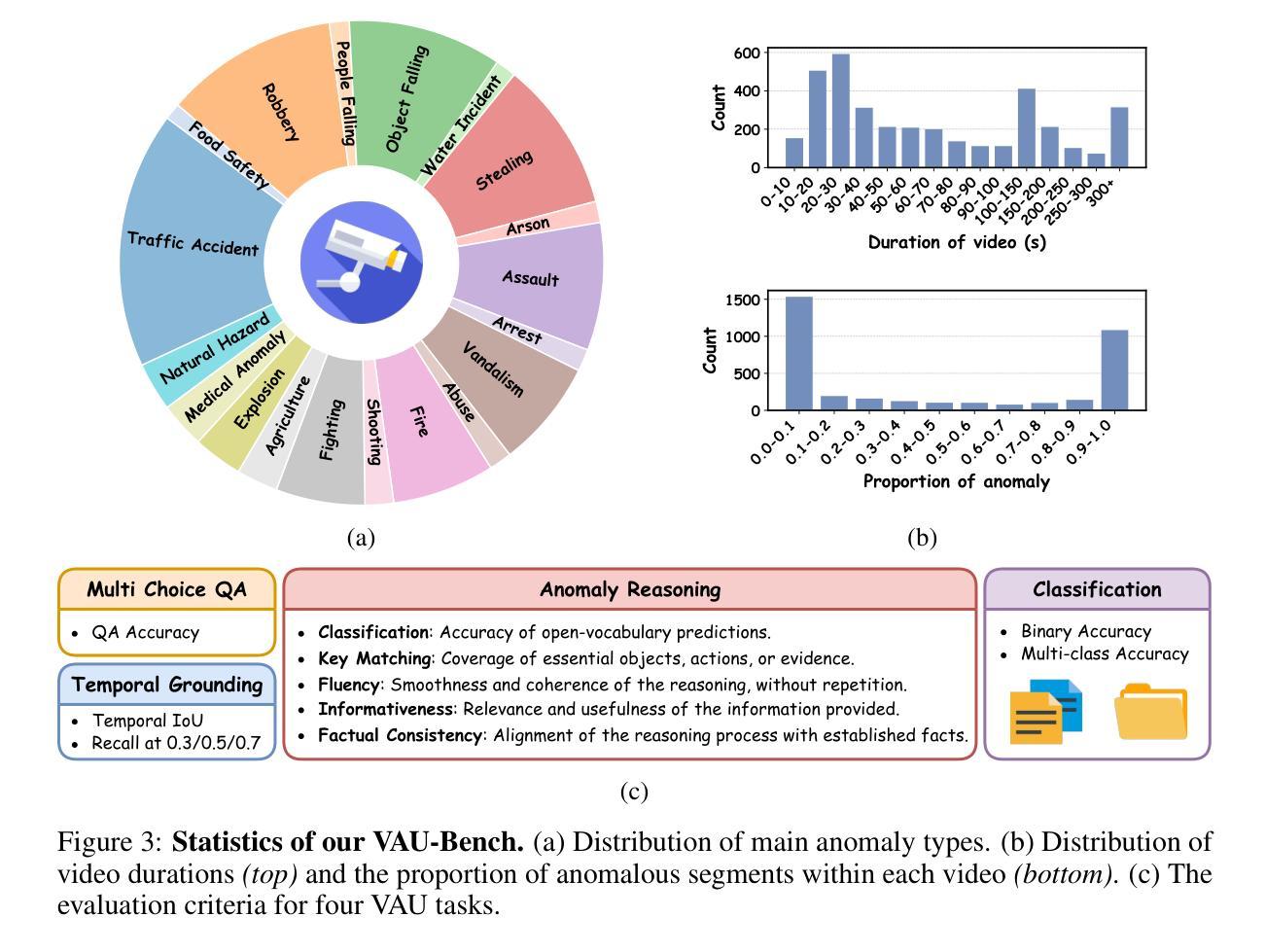
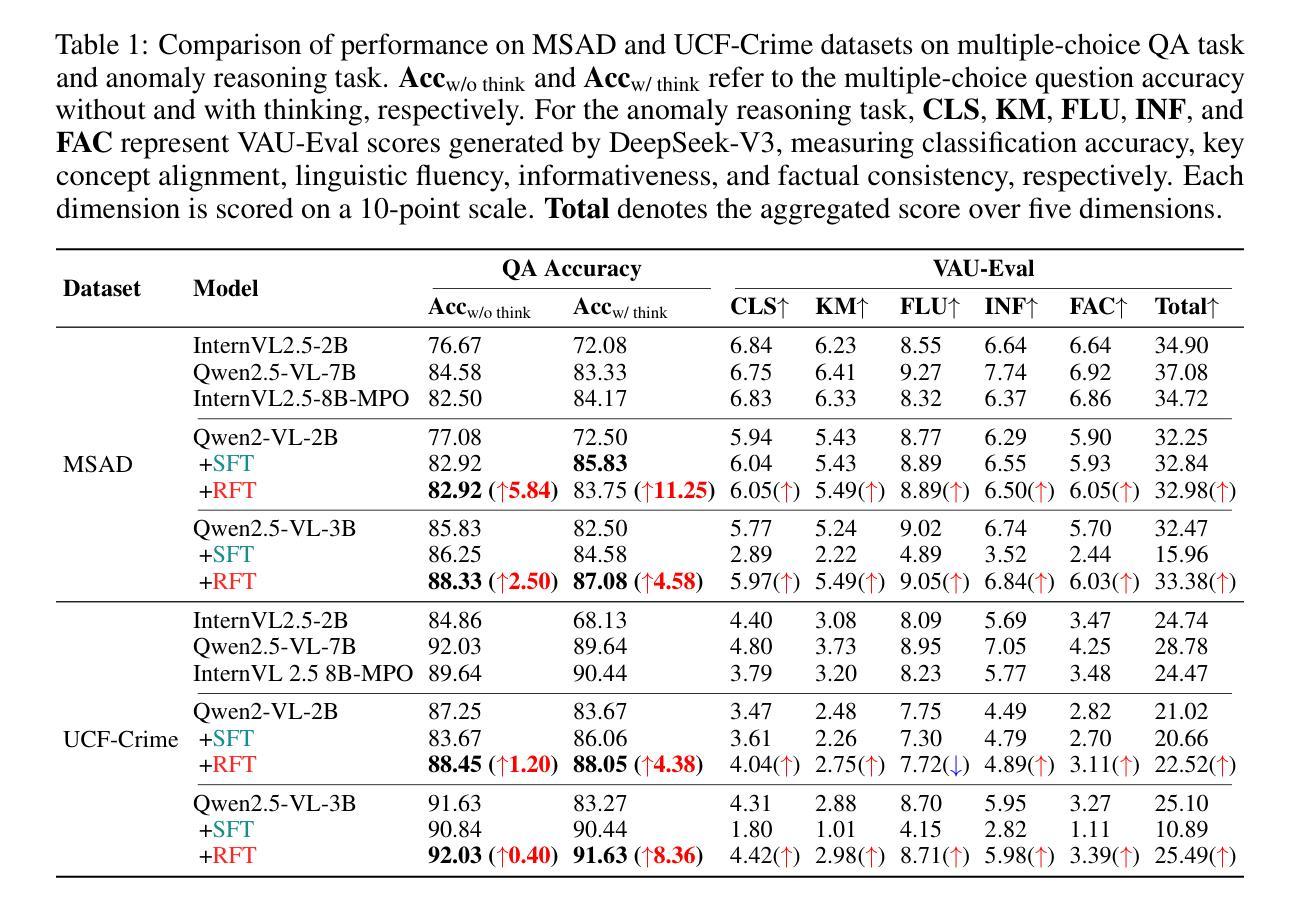
Video Anomaly Understanding (VAU) is essential for applications such as smart cities, security surveillance, and disaster alert systems, yet remains challenging due to its demand for fine-grained spatio-temporal perception and robust reasoning under ambiguity. Despite advances in anomaly detection, existing methods often lack interpretability and struggle to capture the causal and contextual aspects of abnormal events. This limitation is further compounded by the absence of comprehensive benchmarks for evaluating reasoning ability in anomaly scenarios. To address both challenges, we introduce VAU-R1, a data-efficient framework built upon Multimodal Large Language Models (MLLMs), which enhances anomaly reasoning through Reinforcement Fine-Tuning (RFT). Besides, we propose VAU-Bench, the first Chain-of-Thought benchmark tailored for video anomaly reasoning, featuring multiple-choice QA, detailed rationales, temporal annotations, and descriptive captions. Empirical results show that VAU-R1 significantly improves question answering accuracy, temporal grounding, and reasoning coherence across diverse contexts. Together, our method and benchmark establish a strong foundation for interpretable and reasoning-aware video anomaly understanding. Our code is available at https://github.com/GVCLab/VAU-R1.
视频异常理解(VAU)在智慧城市、安全监控和灾难预警系统等应用中至关重要,但由于其对精细时空感知和模糊环境下的稳健推理的需求,仍然具有挑战性。尽管异常检测取得了进展,但现有方法往往缺乏可解释性,难以捕捉异常事件的原因和上下文。这一局限性由于缺乏用于评估异常场景中推理能力的全面基准而进一步加剧。为了解决这两个挑战,我们引入了基于多模态大型语言模型(MLLMs)的高效数据框架VAU-R1,通过强化微调(RFT)增强异常推理。此外,我们提出了针对视频异常推理的首个思维链基准VAU-Bench,具有多项选择题、详细理由、时间注释和描述性字幕等特点。经验结果表明,VAU-R1在多种上下文中显著提高问答准确性、时间定位和推理连贯性。总的来说,我们的方法和基准为可解释和推理感知的视频异常理解奠定了坚实的基础。我们的代码可在https://github.com/GVCLab/VAU-R1获取。
论文及项目相关链接
Summary
视频异常理解(VAU)在智能城市、安全监控和灾害预警系统等领域有广泛应用,但存在精细时空感知和模糊情境下稳健推理的需求挑战。现有方法缺乏可解释性,难以捕捉异常事件的因果和上下文信息。为解决这些挑战,我们提出了数据高效的VAU-R1框架,基于多模态大型语言模型(MLLMs)强化微调(RFT)增强异常推理。此外,我们还推出了针对视频异常推理的首个Chain-of-Thought基准测试VAU-Bench,包含多项选择问答、详细理由、时间注释和描述性字幕。实验结果证明,VAU-R1在多种情境下显著提高问答准确性、时间定位和推理连贯性。
Key Takeaways
- 视频异常理解(VAU)在智能城市等应用中至关重要,但仍面临精细时空感知和模糊情境下推理的挑战。
- 现有方法缺乏捕捉异常事件的因果和上下文信息的能力。
- VAU-R1框架通过基于多模态大型语言模型的强化微调(RFT)增强异常推理,提高数据效率。
- VAU-Bench是首个针对视频异常推理的Chain-of-Thought基准测试,包含多种任务类型如多项选择问答等。
- VAU-R1在多种情境下显著提高问答准确性、时间定位和推理连贯性。
- VAU-R1和VAU-Bench共同为可解释性和推理意识的视频异常理解建立了坚实的基础。
点此查看论文截图

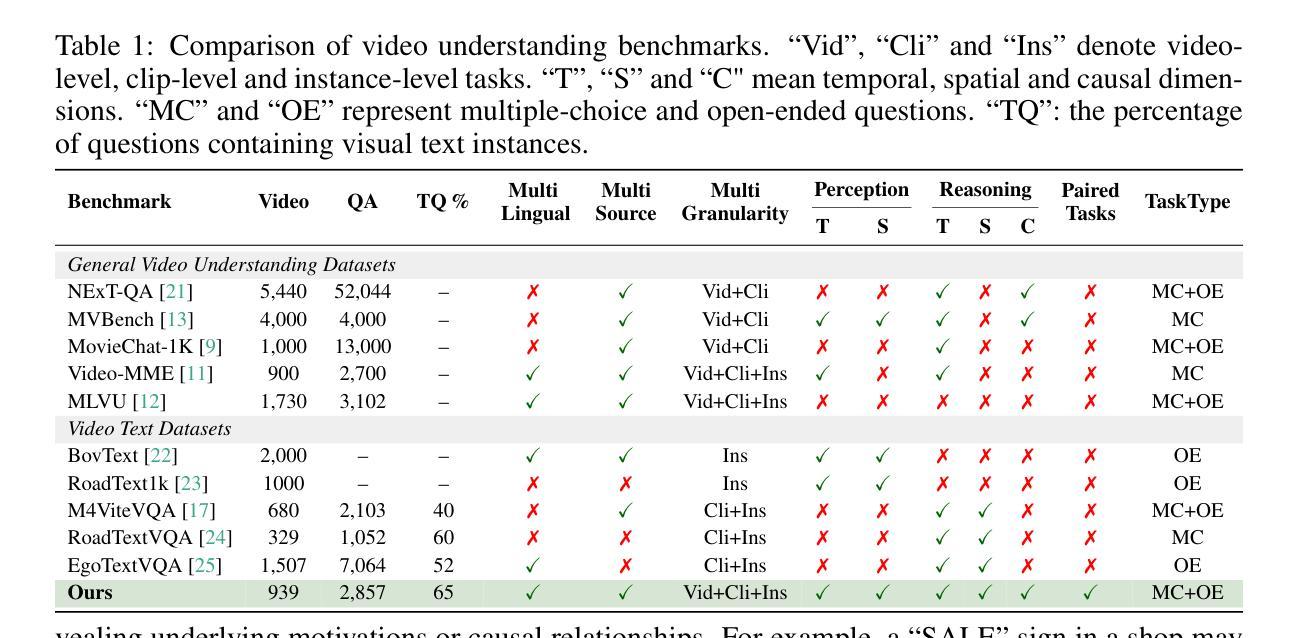
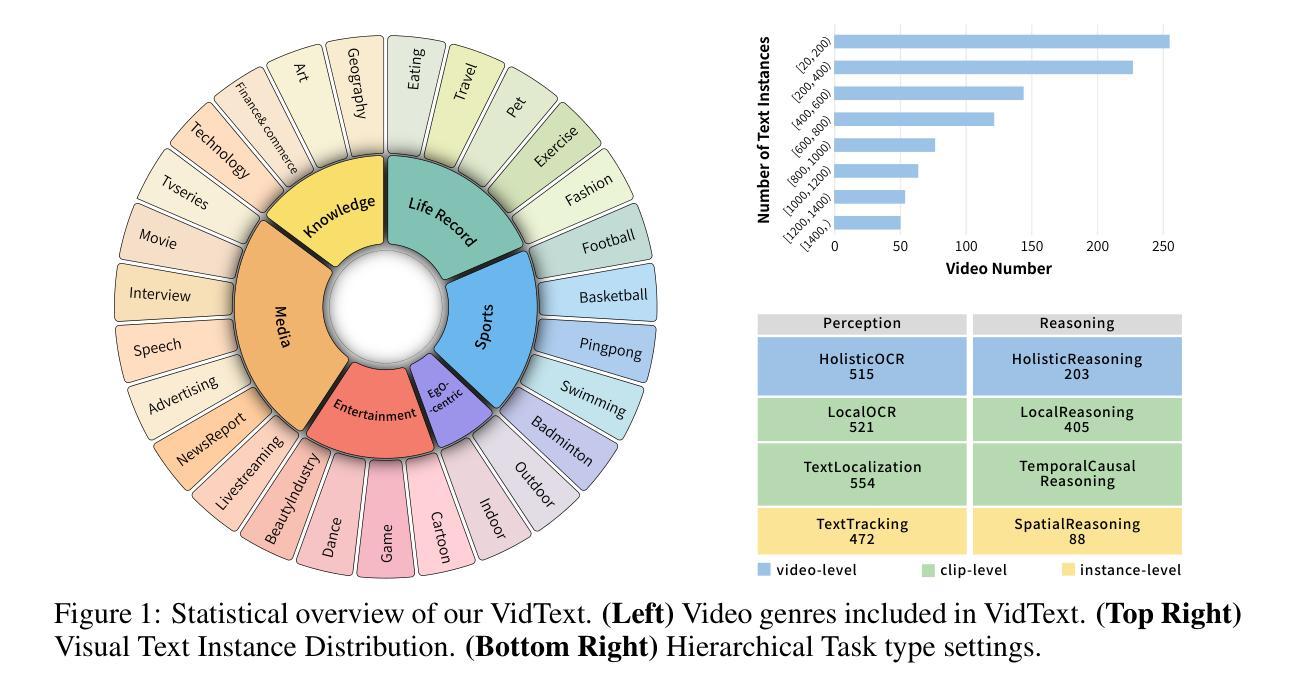
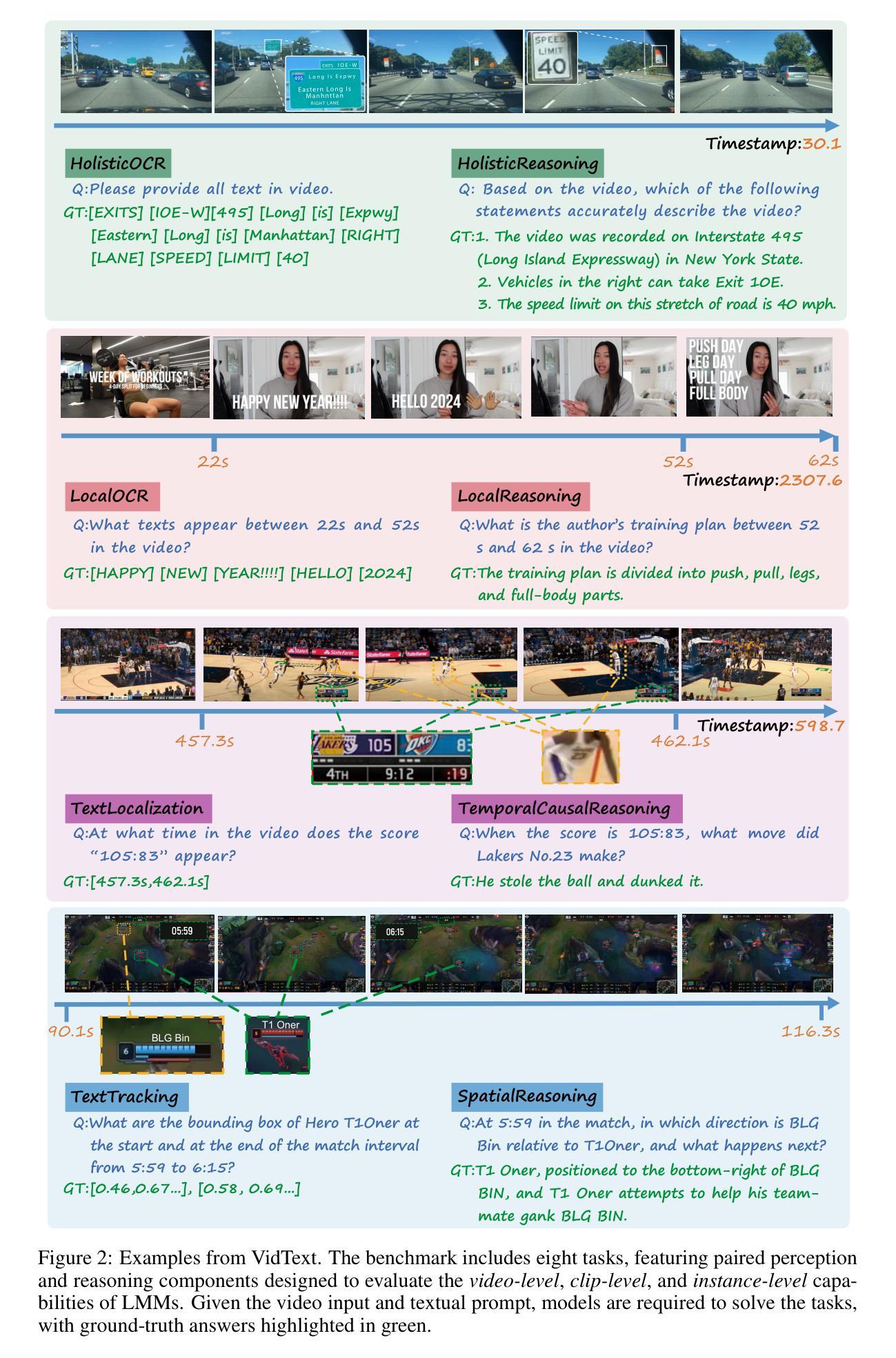
VidText: Towards Comprehensive Evaluation for Video Text Understanding
Authors:Zhoufaran Yang, Yan Shu, Zhifei Yang, Yan Zhang, Yu Li, Keyang Lu, Gangyan Zeng, Shaohui Liu, Yu Zhou, Nicu Sebe
Visual texts embedded in videos carry rich semantic information, which is crucial for both holistic video understanding and fine-grained reasoning about local human actions. However, existing video understanding benchmarks largely overlook textual information, while OCR-specific benchmarks are constrained to static images, limiting their ability to capture the interaction between text and dynamic visual contexts. To address this gap, we propose VidText, a new benchmark designed for comprehensive and in-depth evaluation of video text understanding. VidText offers the following key features: 1) It covers a wide range of real-world scenarios and supports multilingual content, encompassing diverse settings where video text naturally appears. 2) It introduces a hierarchical evaluation framework with video-level, clip-level, and instance-level tasks, enabling assessment of both global summarization and local retrieval capabilities. 3) The benchmark also introduces a set of paired perception reasoning tasks, ranging from visual text perception to cross-modal reasoning between textual and visual information. Extensive experiments on 18 state-of-the-art Large Multimodal Models (LMMs) reveal that current models struggle across most tasks, with significant room for improvement. Further analysis highlights the impact of both model-intrinsic factors, such as input resolution and OCR capability, and external factors, including the use of auxiliary information and Chain-of-Thought reasoning strategies. We hope VidText will fill the current gap in video understanding benchmarks and serve as a foundation for future research on multimodal reasoning with video text in dynamic environments.
视频中的嵌入视觉文本携带丰富的语义信息,这对于整体视频理解和局部人类动作的精细推理都是至关重要的。然而,现有的视频理解基准测试在很大程度上忽略了文本信息,而专门针对OCR的基准测试仅限于静态图像,限制了捕捉文本和动态视觉上下文之间交互的能力。为了解决这一差距,我们提出了VidText,这是一个为视频文本理解进行全面和深入评估而设计的新基准测试。VidText提供以下关键功能:1)它涵盖广泛的真实场景并支持多种语言内容,涵盖视频文本自然出现的各种设置。2)它引入了分层评估框架,包括视频级、剪辑级和实例级任务,能够评估全局总结和局部检索能力。3)该基准测试还引入了一系列配对感知推理任务,从视觉文本感知到文本和视觉信息之间的跨模态推理。对18种最新的大型多模态模型(LMMs)的广泛实验表明,当前模型在大多数任务上都面临困难,仍有很大的改进空间。进一步的分析突出了模型内在因素(如输入分辨率和OCR能力)和外部因素(包括使用辅助信息和思维链推理策略)的影响。我们希望VidText能够填补当前视频理解基准测试的空白,并成为未来在动态环境中进行多模态推理研究的基础。
论文及项目相关链接
Summary:
文中指出视觉文本在视频中的重要性,现有的视频理解基准测试忽略了文本信息,而OCR基准测试仅限于静态图像。为此,提出了针对视频文本理解的基准测试VidText,具有多种关键特性,包括涵盖多种现实场景和多语言内容,引入分层评估框架以及一系列配对感知推理任务等。实验表明当前模型在大多数任务上表现欠佳,揭示了模型内在因素和外部因素的影响。期望VidText能填补视频理解基准测试的空白,为未来在动态环境中的多模态推理研究奠定基础。
Key Takeaways:
- 视频中的视觉文本包含丰富的语义信息,对整体视频理解和局部人类动作精细推理至关重要。
- 现有视频理解基准测试忽视了文本信息,而OCR基准测试仅限于静态图像,无法捕捉文本与动态视觉上下文之间的交互。
- VidText基准测试设计用于全面深入评估视频文本理解,具有涵盖多种现实场景和多语言、引入分层评估框架和感知推理任务等特点。
- 实验显示当前模型在大多数任务上表现不佳,分析揭示了模型内在因素(如输入分辨率和OCR能力)和外部因素(如辅助信息和链式思维推理策略)的影响。
- VidText期望填补视频理解基准测试的空白,为未来在动态环境中的多模态推理研究奠定基础。
点此查看论文截图