⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-31 更新
ZPressor: Bottleneck-Aware Compression for Scalable Feed-Forward 3DGS
Authors:Weijie Wang, Donny Y. Chen, Zeyu Zhang, Duochao Shi, Akide Liu, Bohan Zhuang
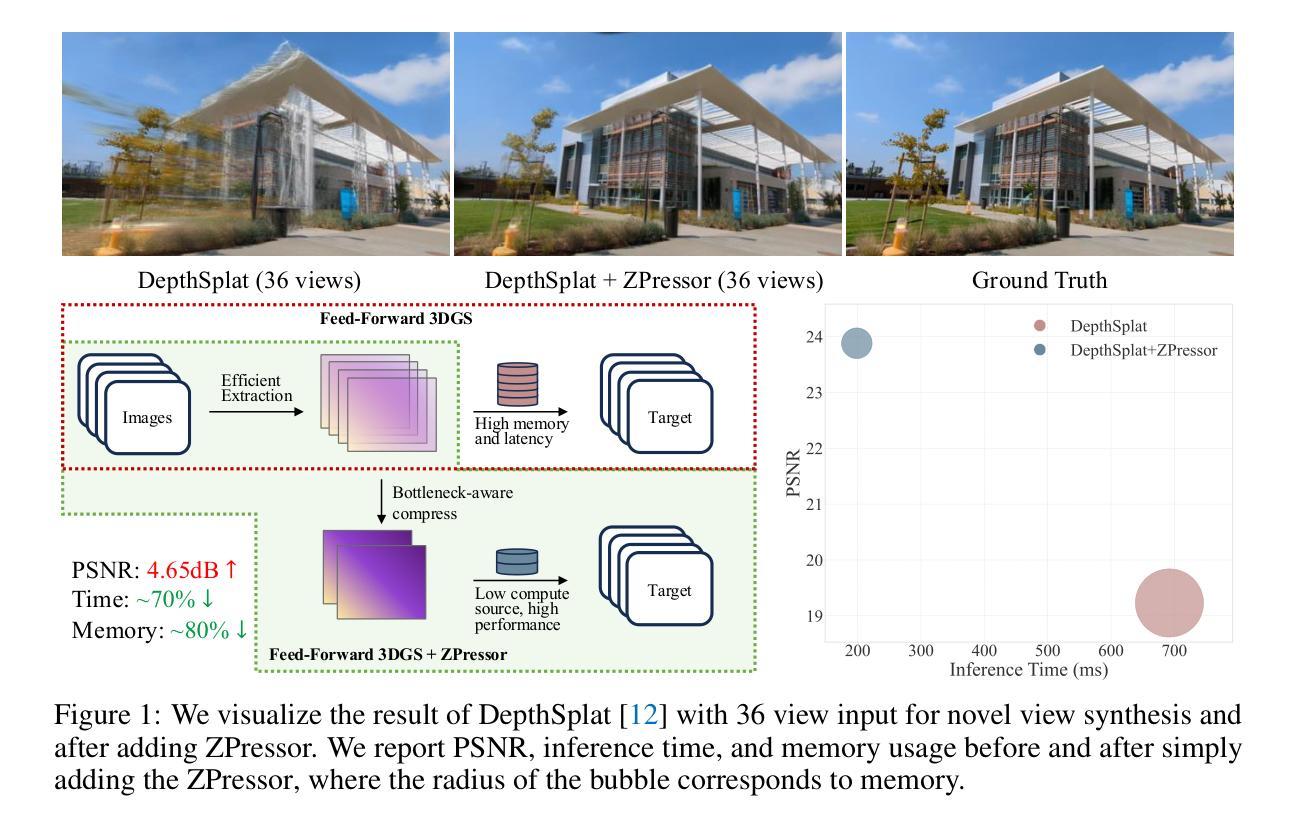
Feed-forward 3D Gaussian Splatting (3DGS) models have recently emerged as a promising solution for novel view synthesis, enabling one-pass inference without the need for per-scene 3DGS optimization. However, their scalability is fundamentally constrained by the limited capacity of their encoders, leading to degraded performance or excessive memory consumption as the number of input views increases. In this work, we analyze feed-forward 3DGS frameworks through the lens of the Information Bottleneck principle and introduce ZPressor, a lightweight architecture-agnostic module that enables efficient compression of multi-view inputs into a compact latent state $Z$ that retains essential scene information while discarding redundancy. Concretely, ZPressor enables existing feed-forward 3DGS models to scale to over 100 input views at 480P resolution on an 80GB GPU, by partitioning the views into anchor and support sets and using cross attention to compress the information from the support views into anchor views, forming the compressed latent state $Z$. We show that integrating ZPressor into several state-of-the-art feed-forward 3DGS models consistently improves performance under moderate input views and enhances robustness under dense view settings on two large-scale benchmarks DL3DV-10K and RealEstate10K. The video results, code and trained models are available on our project page: https://lhmd.top/zpressor.
前馈三维高斯喷溅(3DGS)模型最近作为合成新视角的一种有前途的解决方案而出现,它能够实现一次推断,无需针对每个场景的3DGS优化。然而,其可扩展性从根本上受到编码器容量的限制,随着输入视角数量的增加,性能会下降或内存消耗过大。在这项工作中,我们通过信息瓶颈原理分析前馈3DGS框架,并引入ZPressor,这是一个轻量级的架构无关模块,能够使多视角输入高效地压缩成紧凑的潜在状态Z,保留关键场景信息的同时丢弃冗余信息。具体来说,ZPressor通过将视角划分为锚点集和支持集,并使用交叉注意力将支持视角的信息压缩到锚点视角中,形成压缩的潜在状态Z,从而使现有的前馈3DGS模型能够在80GB GPU上以480P分辨率扩展到超过100个输入视角。我们在两个大规模基准测试DL3DV-10K和RealEstate10K上展示,将ZPressor集成到几种最新前馈3DGS模型中,在适度输入视角下一致提高了性能,在密集视角设置下增强了稳健性。视频结果、代码和训练模型可在我们的项目页面查看:https://lhmd.top/zpressor。
论文及项目相关链接
PDF Project Page: https://lhmd.top/zpressor, Code: https://github.com/ziplab/ZPressor
Summary
本文探讨了基于信息瓶颈原理的Feed-forward 3D Gaussian Splatting(3DGS)模型在新型视图合成领域的应用。由于现有模型的编码器容量有限,其可扩展性受到限制,随着输入视图数量的增加,性能下降或内存消耗过大。为解决这一问题,本文引入了一个轻量级、架构通用的模块——ZPressor。它通过压缩多视图输入到一个紧凑的潜在状态Z,保留了场景的关键信息,摒弃了冗余。具体来说,ZPressor能够将现有Feed-forward 3DGS模型的视图分为锚点和支撑集,并利用交叉注意力将支撑集的信息压缩到锚点视图中,形成压缩的潜在状态Z。本文展示将ZPressor集成到几种先进的Feed-forward 3DGS模型中,在大型基准测试DL3DV-10K和RealEstate10K上,其性能在适度输入视图下持续提高,密集视图设置下的稳健性也得到提升。相关视频结果、代码和训练模型可在我们的项目页面查看。
Key Takeaways
- Feed-forward 3DGS模型在新型视图合成领域具有前景,但受限于编码器容量,影响可扩展性。
- ZPressor模块基于信息瓶颈原理提出,用于压缩多视图信息到一个紧凑的潜在状态Z。
- ZPressor通过分区视图(锚点和支撑集)并使用交叉注意力进行信息压缩。
- 集成ZPressor的Feed-forward 3DGS模型可在大型基准测试上实现性能提升和稳健性增强。
- ZPressor有助于现有模型处理超过100个输入视图,在480P分辨率和80GB GPU上实现性能提升。
- 视频结果、代码和训练模型已公开供查看。
点此查看论文截图

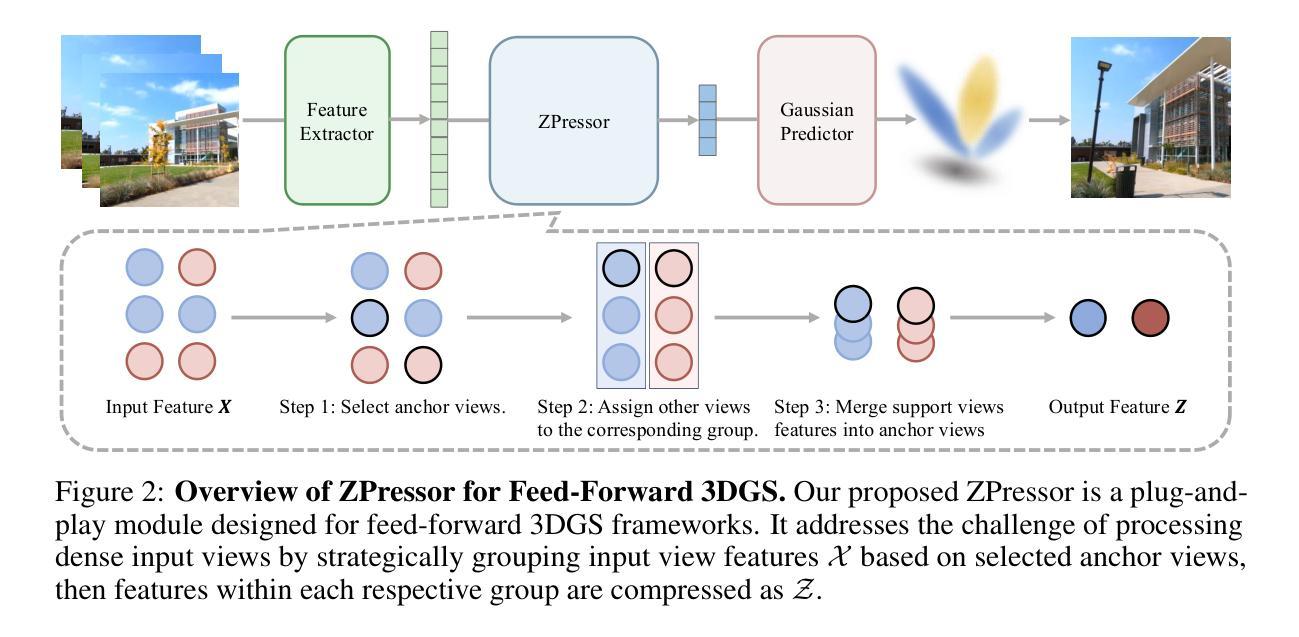
AnySplat: Feed-forward 3D Gaussian Splatting from Unconstrained Views
Authors:Lihan Jiang, Yucheng Mao, Linning Xu, Tao Lu, Kerui Ren, Yichen Jin, Xudong Xu, Mulin Yu, Jiangmiao Pang, Feng Zhao, Dahua Lin, Bo Dai
We introduce AnySplat, a feed forward network for novel view synthesis from uncalibrated image collections. In contrast to traditional neural rendering pipelines that demand known camera poses and per scene optimization, or recent feed forward methods that buckle under the computational weight of dense views, our model predicts everything in one shot. A single forward pass yields a set of 3D Gaussian primitives encoding both scene geometry and appearance, and the corresponding camera intrinsics and extrinsics for each input image. This unified design scales effortlessly to casually captured, multi view datasets without any pose annotations. In extensive zero shot evaluations, AnySplat matches the quality of pose aware baselines in both sparse and dense view scenarios while surpassing existing pose free approaches. Moreover, it greatly reduce rendering latency compared to optimization based neural fields, bringing real time novel view synthesis within reach for unconstrained capture settings.Project page: https://city-super.github.io/anysplat/
我们介绍了AnySplat,这是一个用于从无校准图像集合进行新视角合成的前馈网络。与传统的需要已知相机姿态和场景优化的神经渲染管道,或最近在密集视角计算重量下屈从的前馈方法相比,我们的模型一次预测所有内容。单次前向传递会产生一组编码场景几何和外观的3D高斯基本体,以及每个输入图像的相应相机内部参数和外部参数。这种统一的设计可以轻松地扩展到无姿态注释的随意捕获的多视角数据集。在广泛的零样本评估中,AnySplat在稀疏和密集视角场景中达到了姿态感知基准的质量,同时超越了现有的无姿态方法。此外,与基于优化的神经网络相比,它大大减少了渲染延迟,使得在无约束捕获设置中实时合成新视角成为可能。项目页面:https://city-super.github.io/anysplat/
论文及项目相关链接
PDF Project page: https://city-super.github.io/anysplat/
Summary
AnySplat是一种基于前馈网络的新型视图合成方法,适用于从未校准的图像集合中进行合成。相较于传统神经渲染管线需要已知相机姿态和场景优化,以及最新的前馈方法在计算密集视图时的计算负担过重的问题,AnySplat模型能够一次性预测所有结果。单次前向传递即可产生一组编码场景几何和外观的3D高斯基元,以及每个输入图像对应的相机内参和外参。这种统一的设计可以轻松地扩展到无姿态标注的、多视角数据集上。在零样本评估中,AnySplat在稀疏和密集视图场景中均达到了姿态感知基准测试的质量,并超越了现有的无姿态方法。此外,相较于基于优化的神经场,它大大减少了渲染延迟,使得在无约束捕获环境中实现实时新型视图合成成为可能。
Key Takeaways
- AnySplat是一个基于前馈网络的新型视图合成方法。
- 它能够处理未校准的图像集合。
- AnySplat模型可以一次性预测场景的所有信息。
- 单次前向传递产生3D高斯基元,编码场景几何和外观。
- 该模型可以扩展至多视角数据集,无需姿态标注。
- AnySplat在零样本评估中达到了姿态感知基准测试的质量。
点此查看论文截图

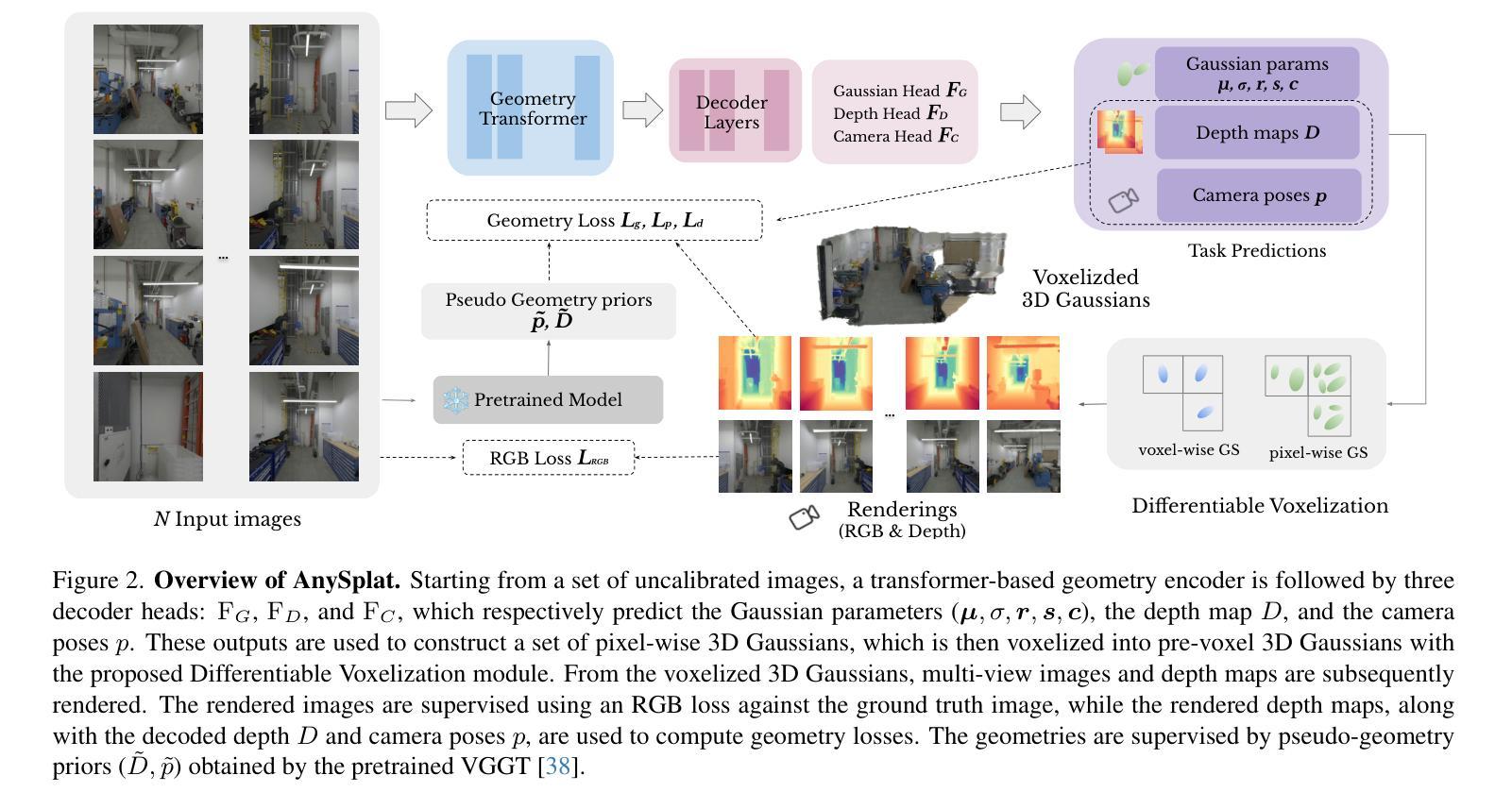

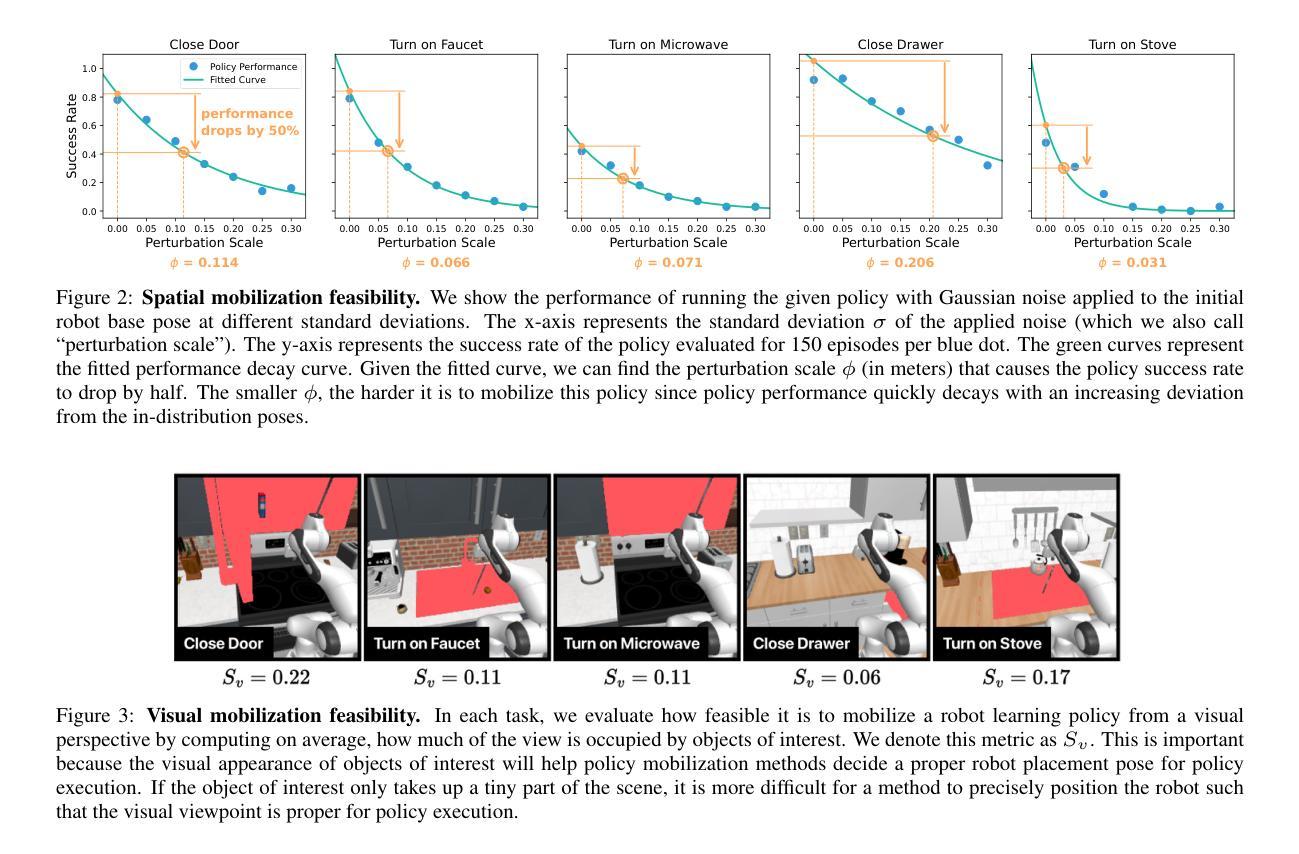
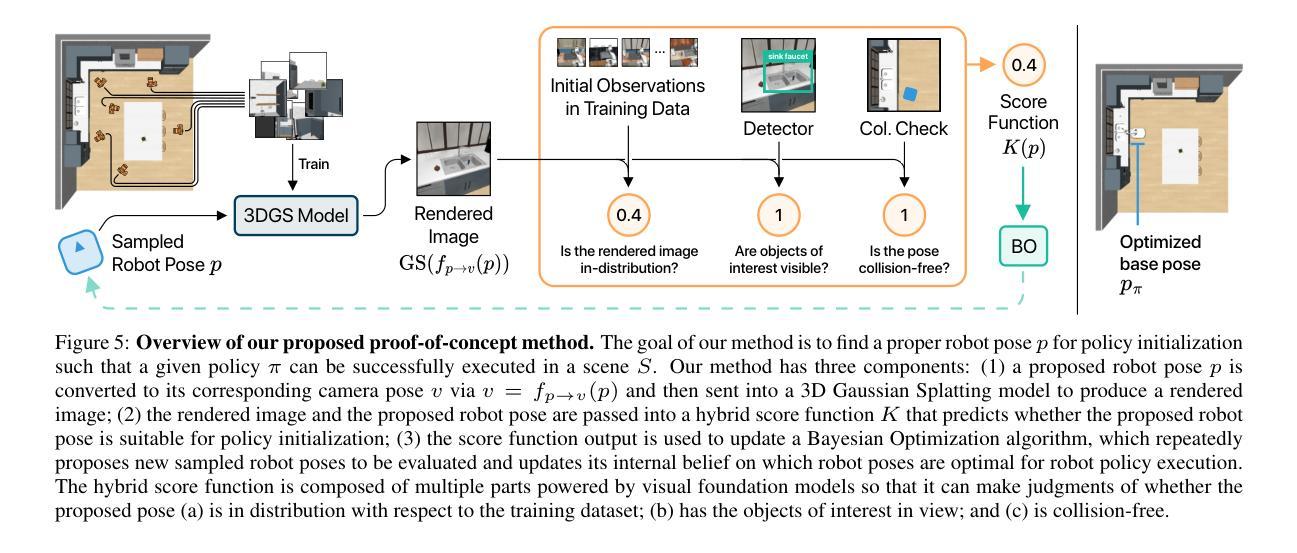
Mobi-$π$: Mobilizing Your Robot Learning Policy
Authors:Jingyun Yang, Isabella Huang, Brandon Vu, Max Bajracharya, Rika Antonova, Jeannette Bohg
Learned visuomotor policies are capable of performing increasingly complex manipulation tasks. However, most of these policies are trained on data collected from limited robot positions and camera viewpoints. This leads to poor generalization to novel robot positions, which limits the use of these policies on mobile platforms, especially for precise tasks like pressing buttons or turning faucets. In this work, we formulate the policy mobilization problem: find a mobile robot base pose in a novel environment that is in distribution with respect to a manipulation policy trained on a limited set of camera viewpoints. Compared to retraining the policy itself to be more robust to unseen robot base pose initializations, policy mobilization decouples navigation from manipulation and thus does not require additional demonstrations. Crucially, this problem formulation complements existing efforts to improve manipulation policy robustness to novel viewpoints and remains compatible with them. To study policy mobilization, we introduce the Mobi-$\pi$ framework, which includes: (1) metrics that quantify the difficulty of mobilizing a given policy, (2) a suite of simulated mobile manipulation tasks based on RoboCasa to evaluate policy mobilization, (3) visualization tools for analysis, and (4) several baseline methods. We also propose a novel approach that bridges navigation and manipulation by optimizing the robot’s base pose to align with an in-distribution base pose for a learned policy. Our approach utilizes 3D Gaussian Splatting for novel view synthesis, a score function to evaluate pose suitability, and sampling-based optimization to identify optimal robot poses. We show that our approach outperforms baselines in both simulation and real-world environments, demonstrating its effectiveness for policy mobilization.
学习到的视觉运动策略能够执行日益复杂的操作任务。然而,这些策略大多是在从有限的机器人位置和摄像机视角收集的数据上进行的训练。这导致在新型机器人位置上的泛化能力较差,从而限制了这些策略在移动平台上的使用,特别是在像按钮按压或水龙头开关这样的精确任务中。在此工作中,我们提出了策略动员问题:在一个新型环境中找到一个与在有限的摄像机视角集上训练的操控策略呈分布的移动机器人基座姿态。与重新训练策略本身以使其对未见的机器人基座姿态初始化更具鲁棒性相比,策略动员将导航与操控解耦,因此不需要额外的演示。关键的是,该问题公式化是对现有提高操控策略对新型视角的鲁棒性努力的补充,并且与其兼容。为了研究策略动员,我们引入了Mobi-$\pi$框架,其中包括:(1)量化动员给定策略的难度指标,(2)基于RoboCasa的一系列模拟移动操作任务,以评估策略动员,(3)分析工具进行数据分析,以及(4)几种基线方法。我们还提出了一种新的方法,该方法通过优化机器人的基座姿态以符合学习策略的分布内基座姿态来连接导航和操控。我们的方法利用3D高斯拼贴进行新型视角合成,使用评分函数评估姿态的适合度,并使用基于采样的优化来确定最佳的机器人姿态。我们在模拟和真实环境中都证明了我们的方法优于基线,这证明了其在策略动员方面的有效性。
论文及项目相关链接
PDF Project website: https://mobipi.github.io/
摘要
本文解决移动机器人基地姿态问题,在新型环境中寻找与在有限摄像头视角训练好的操控策略相适应的移动机器人基地姿态。相较于重新训练策略以应对未见过的机器人基地姿态初始化,策略动员将导航与操控解耦,因此无需额外的演示。本文引入Mobi-$\pi$框架来研究策略动员,包括量化政策动员难度的指标、基于RoboCasa的模拟移动操控任务套件以评估策略动员、分析工具以及几种基线方法。提出一种结合导航和操控的新型方法,通过优化机器人基地姿态,使其与已学策略的分布内基地姿态对齐。该方法利用3D高斯拼贴进行新颖视角合成、评分函数评估姿态适宜性、采样优化确定最佳机器人姿态。在模拟和真实环境中,该方法均优于基线方法,证明其在策略动员方面的有效性。
关键见解
- 提出解决移动机器人基地姿态问题的重要性,以提升操控策略在面对新型环境和有限摄像头视角时的适应能力。
- 介绍Mobi-$\pi$框架,包括量化指标、模拟任务套件、分析工具以及基线方法,为研究策略动员提供全面框架。
- 提出一种结合导航和操控的新型方法,通过优化机器人基地姿态以提升策略动员效果。
- 利用3D高斯拼贴进行新颖视角合成,为策略动员提供技术支撑。
- 采用评分函数评估姿态适宜性,有效指导机器人基地姿态的选择。
- 通过采样优化确定最佳机器人姿态,提高策略动员的实用性和效率。
点此查看论文截图


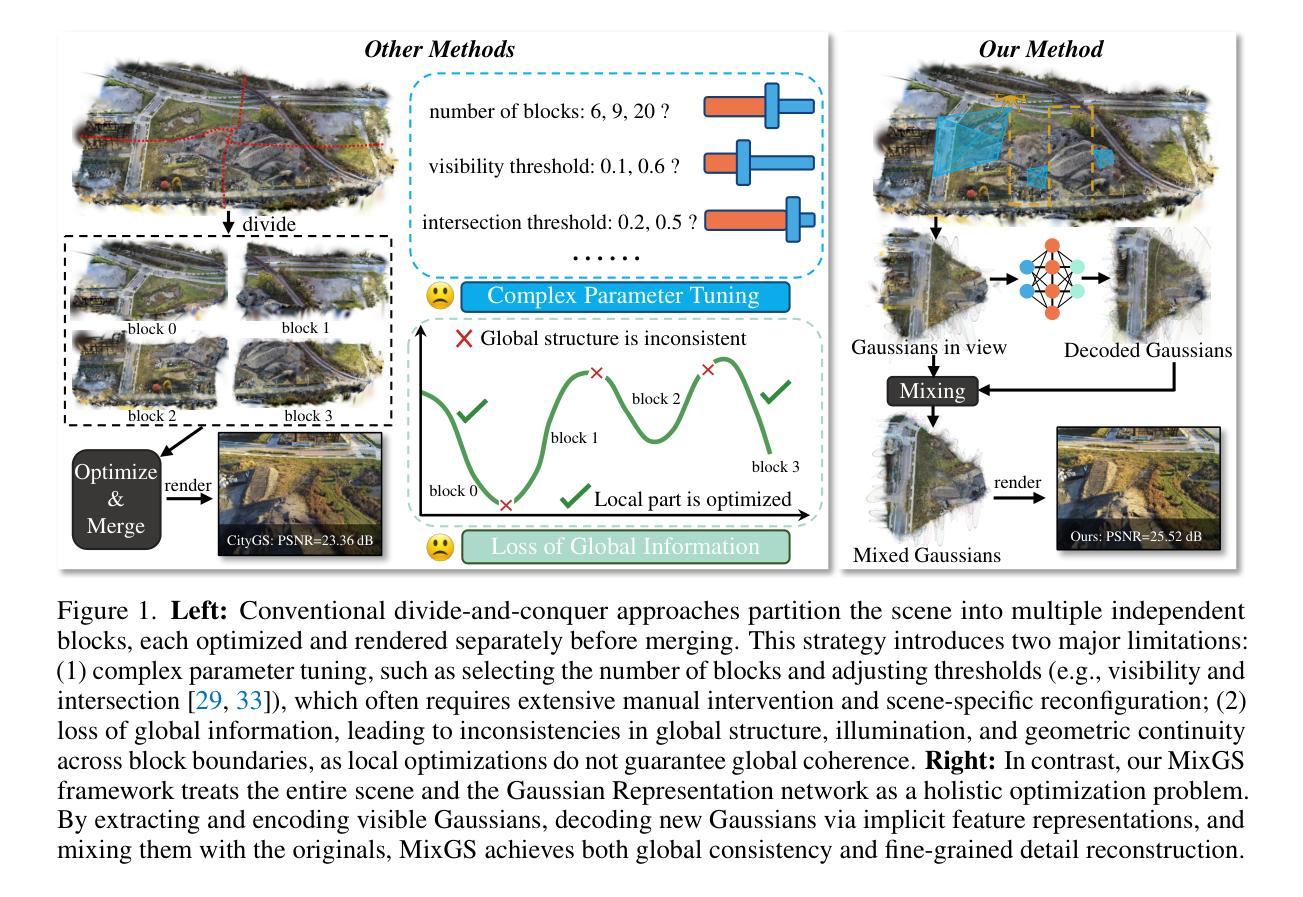
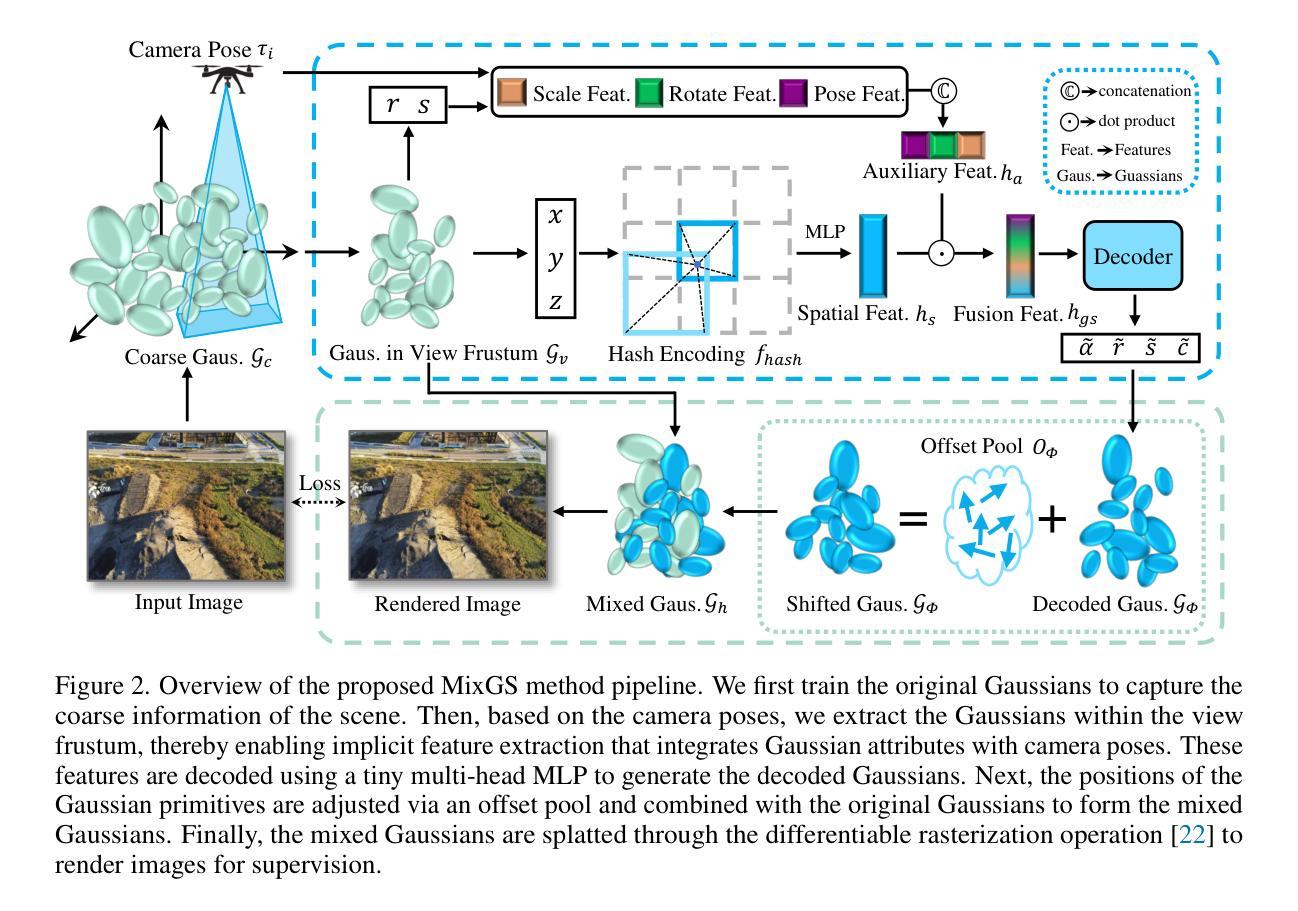
Holistic Large-Scale Scene Reconstruction via Mixed Gaussian Splatting
Authors:Chuandong Liu, Huijiao Wang, Lei Yu, Gui-Song Xia
Recent advances in 3D Gaussian Splatting have shown remarkable potential for novel view synthesis. However, most existing large-scale scene reconstruction methods rely on the divide-and-conquer paradigm, which often leads to the loss of global scene information and requires complex parameter tuning due to scene partitioning and local optimization. To address these limitations, we propose MixGS, a novel holistic optimization framework for large-scale 3D scene reconstruction. MixGS models the entire scene holistically by integrating camera pose and Gaussian attributes into a view-aware representation, which is decoded into fine-detailed Gaussians. Furthermore, a novel mixing operation combines decoded and original Gaussians to jointly preserve global coherence and local fidelity. Extensive experiments on large-scale scenes demonstrate that MixGS achieves state-of-the-art rendering quality and competitive speed, while significantly reducing computational requirements, enabling large-scale scene reconstruction training on a single 24GB VRAM GPU. The code will be released at https://github.com/azhuantou/MixGS.
近期3D高斯细绘技术的进展为新型视角合成展现了显著潜力。然而,现有的大规模场景重建方法大多依赖于分而治之的范式,这往往导致全局场景信息丢失,并且由于场景分割和局部优化而需要进行复杂的参数调整。为解决这些局限,我们提出了MixGS,这是一种用于大规模3D场景重建的新型整体优化框架。MixGS通过整合相机姿态和高斯属性到视角感知表示中,对整场场景进行整体建模,该表示被解码为精细的高斯细节。此外,一种新型混合操作结合了解码后的和原始的高斯值,以共同保留全局连贯性和局部保真度。在大规模场景上的广泛实验表明,MixGS达到了最先进的渲染质量和具有竞争力的速度,同时大大降低了计算要求,能够在单个24GB VRAM GPU上进行大规模场景重建训练。代码将在https://github.com/azhuantou/MixGS发布。
论文及项目相关链接
Summary
本文介绍了针对大规模场景重建的新方法MixGS。该方法采用整体优化框架,通过整合相机姿态和高斯属性构建了一个视图感知表示,解码为精细的高斯,并提出了混合操作来结合解码和高斯来保留全局连贯性和局部保真度。该方法实现了高质量渲染和竞争性速度,并在单个GPU上降低了计算要求,适用于大规模场景重建。
Key Takeaways
- MixGS是一种用于大规模3D场景重建的整体优化框架。
- MixGS通过将相机姿态与高斯属性整合到一个视图感知表示中来建模整个场景。
- 解码精细的高斯和原始高斯混合操作有助于同时保留全局连贯性和局部保真度。
- MixGS通过实现高质量渲染和快速处理减少了计算需求。
点此查看论文截图

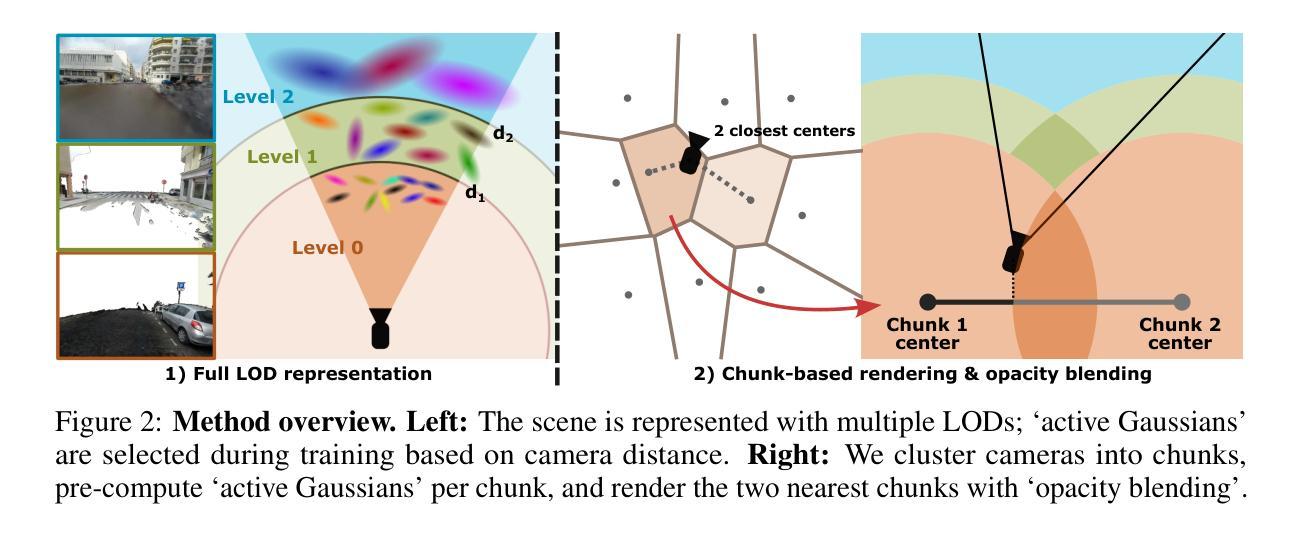
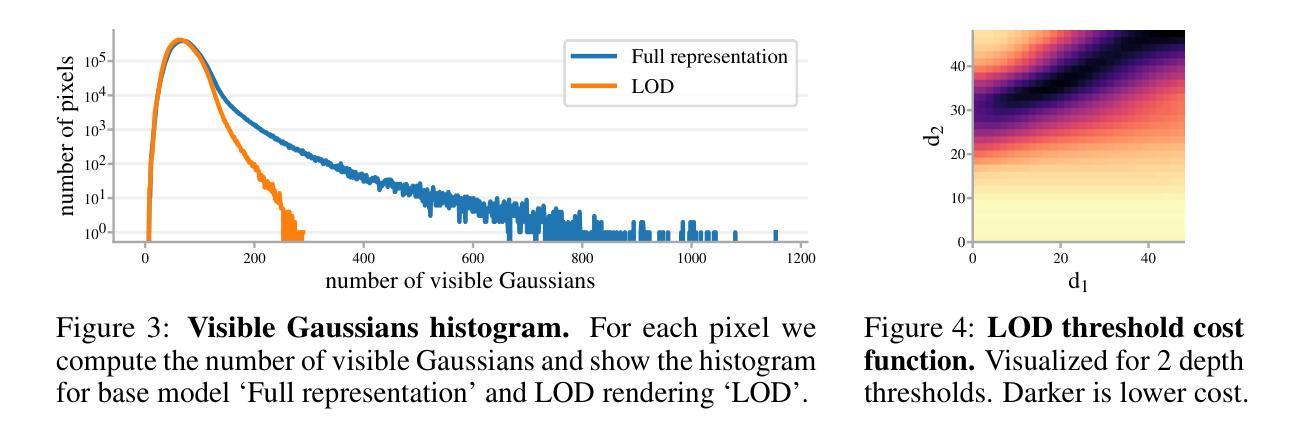
LODGE: Level-of-Detail Large-Scale Gaussian Splatting with Efficient Rendering
Authors:Jonas Kulhanek, Marie-Julie Rakotosaona, Fabian Manhardt, Christina Tsalicoglou, Michael Niemeyer, Torsten Sattler, Songyou Peng, Federico Tombari
In this work, we present a novel level-of-detail (LOD) method for 3D Gaussian Splatting that enables real-time rendering of large-scale scenes on memory-constrained devices. Our approach introduces a hierarchical LOD representation that iteratively selects optimal subsets of Gaussians based on camera distance, thus largely reducing both rendering time and GPU memory usage. We construct each LOD level by applying a depth-aware 3D smoothing filter, followed by importance-based pruning and fine-tuning to maintain visual fidelity. To further reduce memory overhead, we partition the scene into spatial chunks and dynamically load only relevant Gaussians during rendering, employing an opacity-blending mechanism to avoid visual artifacts at chunk boundaries. Our method achieves state-of-the-art performance on both outdoor (Hierarchical 3DGS) and indoor (Zip-NeRF) datasets, delivering high-quality renderings with reduced latency and memory requirements.
在这项工作中,我们提出了一种用于3D高斯飞溅的新型细节层次(LOD)方法,该方法能够在内存受限的设备上实现大规模场景的实时渲染。我们的方法引入了一种层次型LOD表示,根据相机距离迭代选择最优的高斯子集,从而大大降低了渲染时间和GPU内存的使用。我们通过应用深度感知的3D平滑滤波器来构建每个LOD级别,然后基于重要性进行修剪和微调以保持视觉保真度。为了进一步优化内存开销,我们将场景划分为空间块,并在渲染过程中动态加载相关的高斯数据,采用透明度混合机制以避免块边界处的视觉伪影。我们的方法在户外(分层3DGS)和室内(Zip-NeRF)数据集上均达到了最先进的性能,以低延迟和内存要求提供高质量渲染。
论文及项目相关链接
PDF Web: https://lodge-gs.github.io/
Summary
该研究提出了一种用于实时渲染大规模场景的新型细节层次(LOD)方法,该方法适用于内存受限的设备。该方法引入了一种层次型LOD表示,根据摄像机距离迭代选择最优的高斯子集,从而大大减少渲染时间和GPU内存使用。通过深度感知的3D平滑滤波器构建每个LOD级别,然后采用基于重要性的修剪和微调以保持视觉保真度。为了进一步优化内存使用,将场景分割成空间块并仅动态加载相关高斯进行渲染,采用透明度混合机制避免块边界处的视觉伪影。该方法在户外和室内数据集上均达到最新性能水平,可在降低延迟和内存要求的情况下提供高质量渲染。
Key Takeaways
- 提出了一种新型的LOD方法用于实时渲染大规模场景。
- 该方法适用于内存受限的设备,通过减少GPU内存使用和渲染时间来提高性能。
- 引入层次型LOD表示,根据摄像机距离选择最优的高斯子集。
- 通过深度感知的3D平滑滤波器构建每个LOD级别,并采用基于重要性的修剪和微调保持视觉质量。
- 通过将场景分割成空间块并仅动态加载相关高斯进行渲染来优化内存使用。
- 采用透明度混合机制避免块边界的视觉伪影。
点此查看论文截图


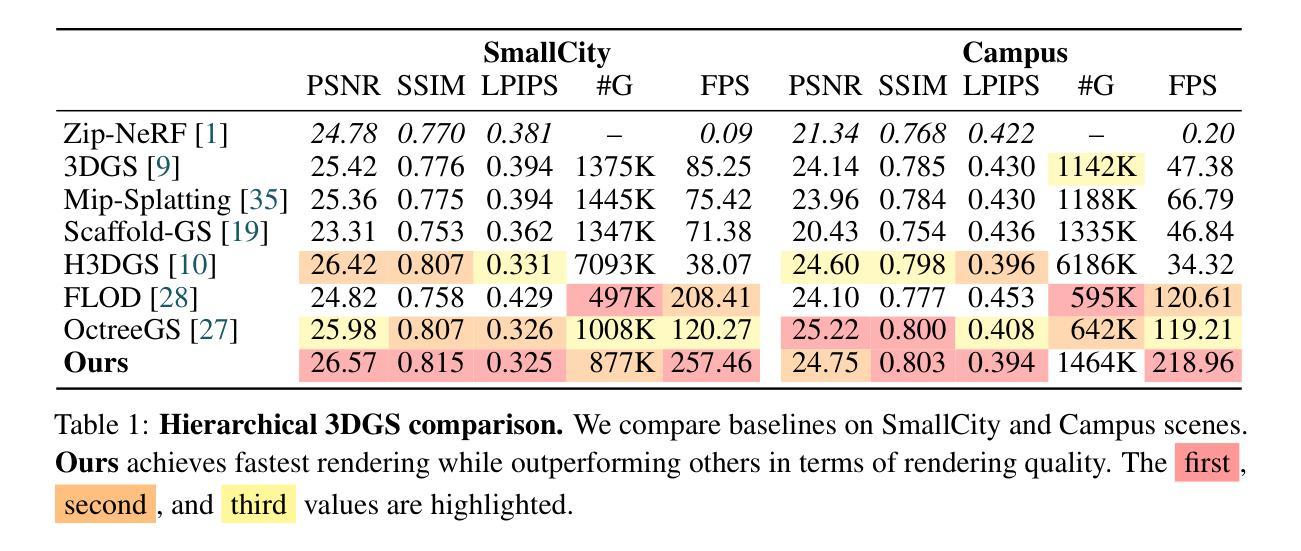
SpatialSplat: Efficient Semantic 3D from Sparse Unposed Images
Authors:Yu Sheng, Jiajun Deng, Xinran Zhang, Yu Zhang, Bei Hua, Yanyong Zhang, Jianmin Ji
A major breakthrough in 3D reconstruction is the feedforward paradigm to generate pixel-wise 3D points or Gaussian primitives from sparse, unposed images. To further incorporate semantics while avoiding the significant memory and storage costs of high-dimensional semantic features, existing methods extend this paradigm by associating each primitive with a compressed semantic feature vector. However, these methods have two major limitations: (a) the naively compressed feature compromises expressiveness, affecting the model’s ability to capture fine-grained semantics, and (b) the pixel-wise primitive prediction introduces redundancy in overlapping areas, causing unnecessary memory overhead. To this end, we introduce \textbf{SpatialSplat}, a feedforward framework that produces redundancy-aware Gaussians and capitalizes on a dual-field semantic representation. Particularly, with the insight that primitives within the same instance exhibit high semantic consistency, we decompose the semantic representation into a coarse feature field that encodes uncompressed semantics with minimal primitives, and a fine-grained yet low-dimensional feature field that captures detailed inter-instance relationships. Moreover, we propose a selective Gaussian mechanism, which retains only essential Gaussians in the scene, effectively eliminating redundant primitives. Our proposed Spatialsplat learns accurate semantic information and detailed instances prior with more compact 3D Gaussians, making semantic 3D reconstruction more applicable. We conduct extensive experiments to evaluate our method, demonstrating a remarkable 60% reduction in scene representation parameters while achieving superior performance over state-of-the-art methods. The code will be made available for future investigation.
在3D重建领域的一个重大突破是前馈范式,它可以从稀疏的非定位图像生成像素级的3D点或高斯基元。为了进一步融入语义信息,同时避免高维语义特征带来的巨大内存和存储成本,现有方法通过将与每个基元相关联的压缩语义特征向量扩展来扩展这一范式。然而,这些方法存在两个主要局限性:(a)简单压缩的特征会损害其表现力,影响模型捕捉细微语义的能力;(b)像素级基元预测在重叠区域引入了冗余信息,造成了不必要的内存开销。为此,我们引入了SpatialSplat,这是一个前馈框架,能够产生冗余感知的高斯分布,并利用双字段语义表示。特别是,我们洞察到同一实例内的基元表现出高度的语义一致性,我们将语义表示分解为一个粗糙特征字段,该字段用最小的基元编码未压缩的语义,以及一个精细但低维的特征字段,该字段捕捉详细的实例间关系。此外,我们提出了一种选择性的高斯机制,只保留场景中的必要高斯分布,有效地消除了冗余基元。我们提出的Spatialsplat能够利用更紧凑的3D高斯分布学习准确的语义信息和详细的实例先验知识,使得语义3D重建更加适用。我们进行了大量实验来评估我们的方法,在减少场景表示参数的同时实现了卓越的性能,超过了现有最先进的方法,参数减少了60%。我们将提供代码以供未来研究。
论文及项目相关链接
Summary
该文本介绍了在3D重建领域的一项重大突破,即采用前馈范式从稀疏、未定位的图像生成像素级3D点或高斯基元。为在融入语义信息的同时避免高维语义特征带来的巨大内存和存储成本,现有方法通过将一个压缩的语义特征向量与每个基元相关联来扩展该范式。然而,这种方法存在两个主要局限:一是简单压缩的特征会影响其表现力,影响模型捕捉精细语义的能力;二是像素级的基元预测在重叠区域引入了冗余,导致不必要的内存开销。为此,本文提出了名为SpatialSplat的前馈框架,产生冗余感知的高斯分布,并利用双场语义表示。SpatialSplat通过洞察同一实例内的基元表现出高度的语义一致性,将语义表示分解为一个编码未压缩语义的粗糙特征场和另一个捕捉详细实例间关系的精细低维特征场。此外,本文还提出了一种选择性高斯机制,只保留场景中的关键高斯分布,有效地消除了冗余基元。Spatialsplat以更紧凑的3D高斯分布学习准确的语义信息和详细实例,使语义3D重建更加实用。
Key Takeaways
- 介绍了采用前馈范式从稀疏、未定位的图像生成像素级3D点或高斯基元的突破。
- 现有方法通过将压缩的语义特征向量与每个基元关联来扩展该范式,但存在两个主要局限:特征表现力受损和内存开销大。
- 提出了名为SpatialSplat的前馈框架,利用双场语义表示产生冗余感知的高斯分布。
- SpatialSplat通过分解语义表示为粗糙特征场和精细低维特征场,提高了模型捕捉精细语义和实例间关系的能力。
- 提出了选择性高斯机制,有效消除冗余基元,减少内存开销。
- Spatialsplat以更紧凑的3D高斯分布学习准确的语义信息和详细实例。
- 实验结果表明,该方法在减少场景表示参数的同时实现了卓越的性能,较先进方法有明显的提升。
点此查看论文截图

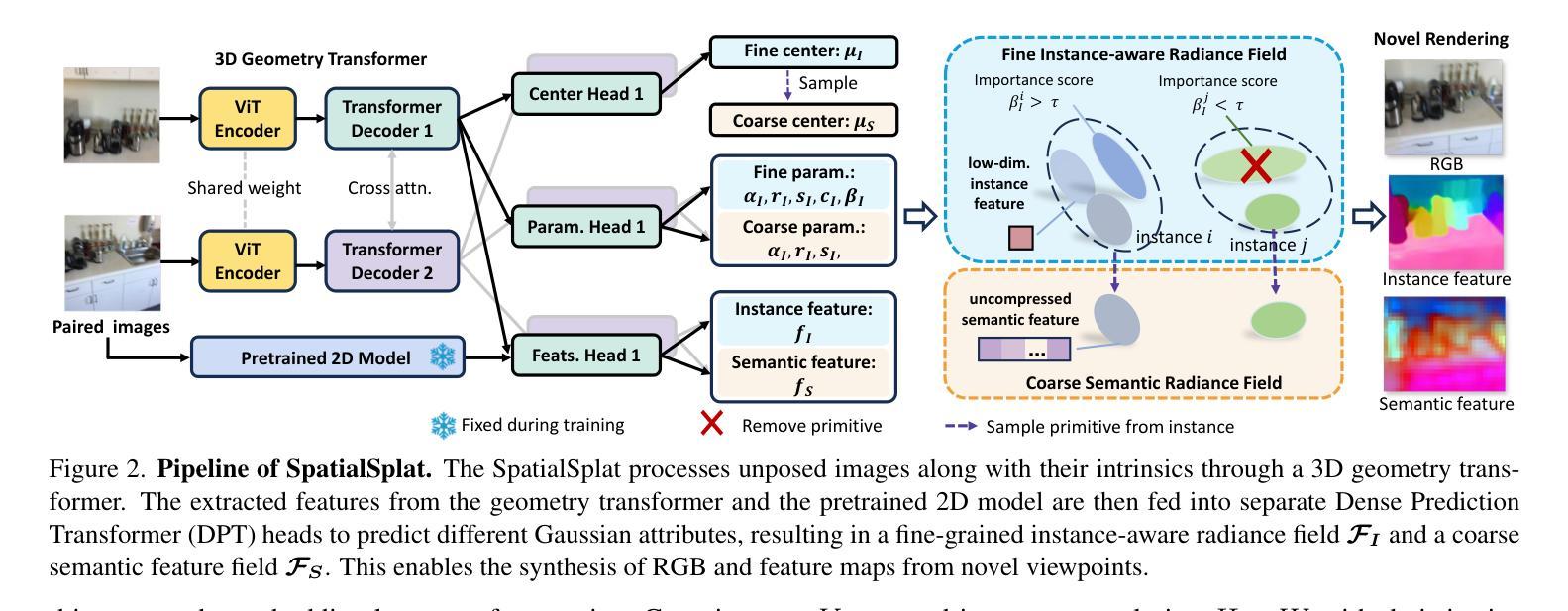
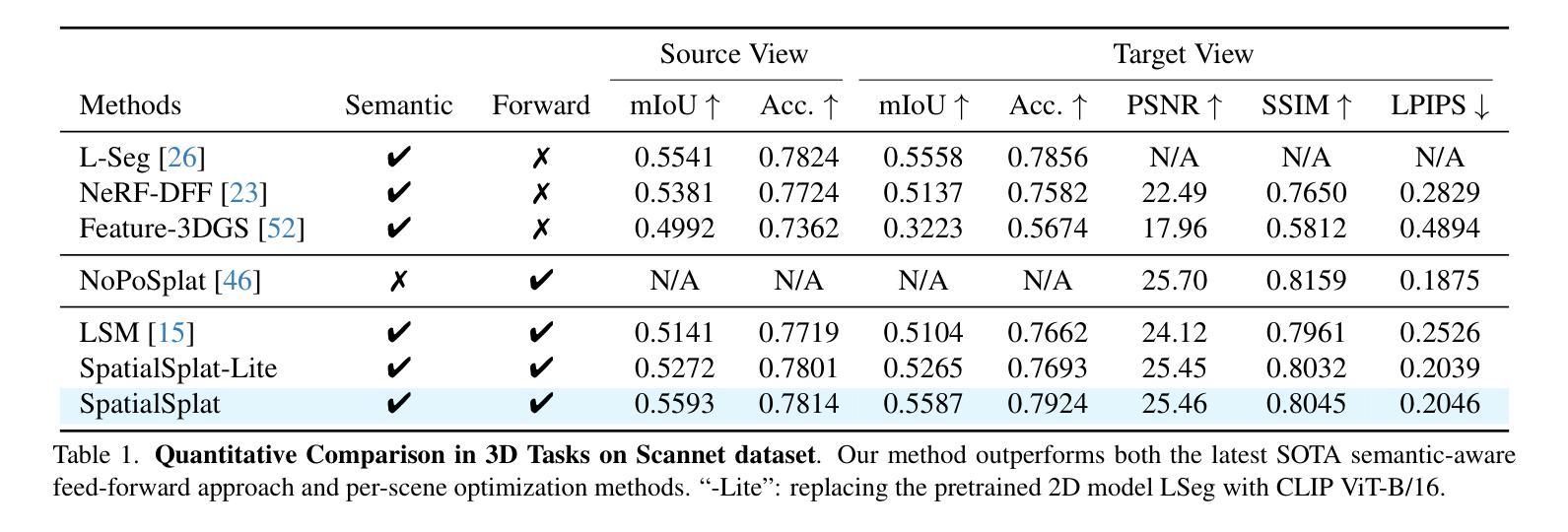

Pose-free 3D Gaussian splatting via shape-ray estimation
Authors:Youngju Na, Taeyeon Kim, Jumin Lee, Kyu Beom Han, Woo Jae Kim, Sung-eui Yoon
While generalizable 3D Gaussian splatting enables efficient, high-quality rendering of unseen scenes, it heavily depends on precise camera poses for accurate geometry. In real-world scenarios, obtaining accurate poses is challenging, leading to noisy pose estimates and geometric misalignments. To address this, we introduce SHARE, a pose-free, feed-forward Gaussian splatting framework that overcomes these ambiguities by joint shape and camera rays estimation. Instead of relying on explicit 3D transformations, SHARE builds a pose-aware canonical volume representation that seamlessly integrates multi-view information, reducing misalignment caused by inaccurate pose estimates. Additionally, anchor-aligned Gaussian prediction enhances scene reconstruction by refining local geometry around coarse anchors, allowing for more precise Gaussian placement. Extensive experiments on diverse real-world datasets show that our method achieves robust performance in pose-free generalizable Gaussian splatting.
虽然通用的三维高斯摊铺能够实现未见场景的高效高质量渲染,但它严重依赖于精确的相机姿态以获取准确的几何信息。在真实场景中,获得准确的姿态是一个挑战,导致姿态估计产生噪声和几何错位。为了解决这一问题,我们引入了SHARE,一个无需姿态的前馈高斯摊铺框架,它通过联合形状和相机射线的估计来克服这些不确定性。SHARE没有依赖显式的三维转换,而是构建了一个姿态感知的标准体积表示,无缝集成了多视角信息,减少了因姿态估计不准确导致的错位。此外,锚点对齐的高斯预测通过细化粗略锚点周围的局部几何信息,增强了场景重建,允许更精确的高斯放置。在多种真实世界数据集上的广泛实验表明,我们的方法在无需姿态的可推广高斯摊铺中实现了稳健的性能。
论文及项目相关链接
PDF ICIP 2025
Summary
本文介绍了SHARE,一种无需姿态的前馈高斯涂污框架。它通过联合形状和相机射线估计,克服了因不准确姿态估计导致的模糊和几何错位问题。SHARE建立了一个姿态感知的规范体积表示,无缝集成多视角信息,减少了因姿态估计不准确导致的错位。此外,锚点对齐的高斯预测提高了场景重建的精度,通过细化粗锚点周围的局部几何结构,实现更精确的高斯放置。实验证明,该方法在无需姿态的一般化高斯涂污中实现了稳健性能。
Key Takeaways
- SHARE是一种无需姿态的涂污框架,能够克服因姿态估计不准确导致的模糊和几何错位问题。
- SHARE建立了一个姿态感知的规范体积表示,集成多视角信息,减少因姿态估计误差导致的几何错位。
- 通过联合形状和相机射线估计,SHARE提高了场景重建的准确性。
- 锚点对齐的高斯预测提高了场景重建的精度,细化局部几何结构,实现更精确的高斯放置。
- 实验证明,SHARE方法在无需姿态的一般化高斯涂污中表现稳健。
- SHARE方法适用于多种真实世界数据集,具有广泛的应用前景。
点此查看论文截图

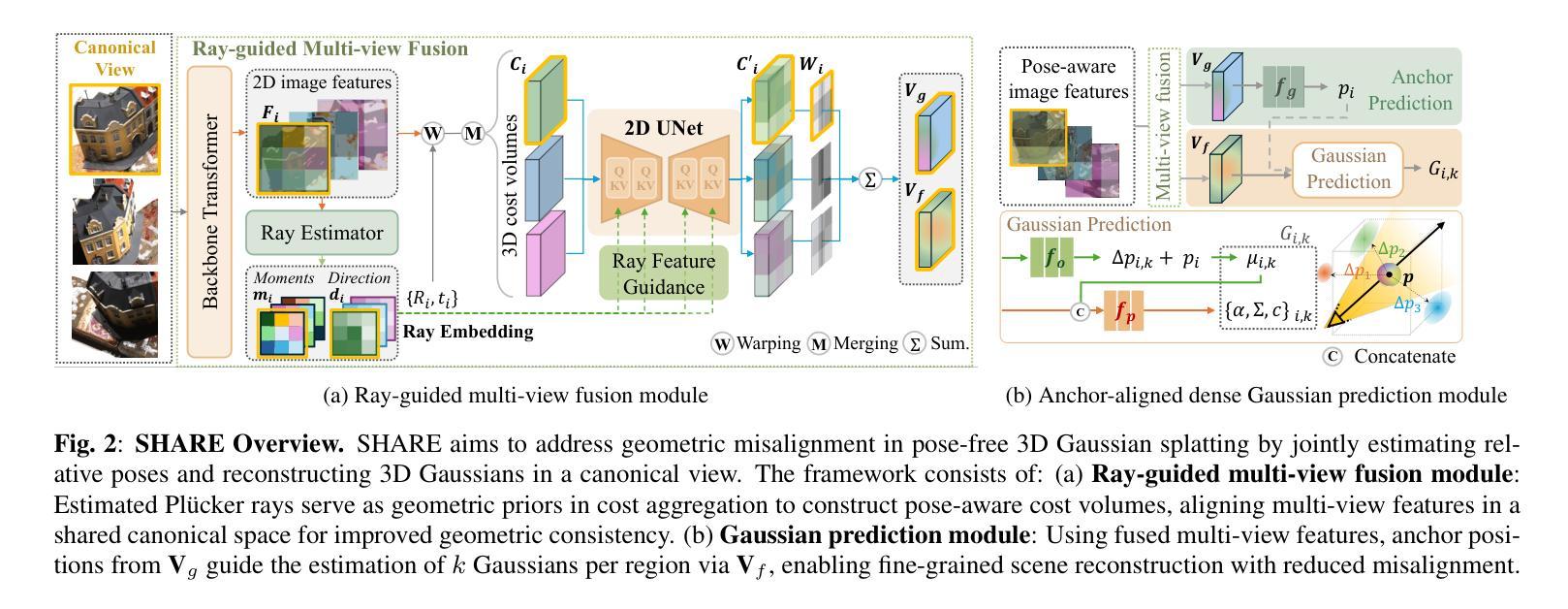
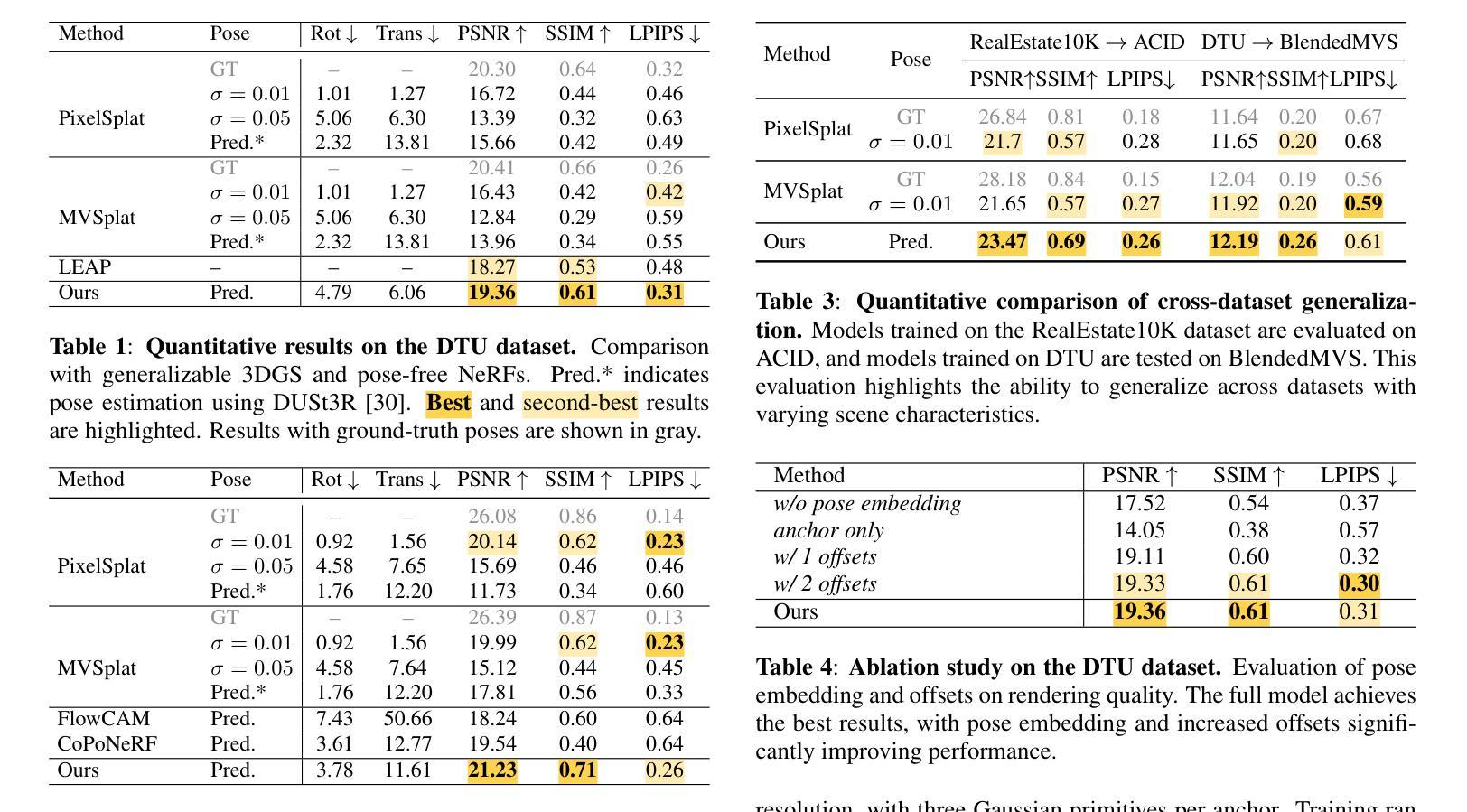

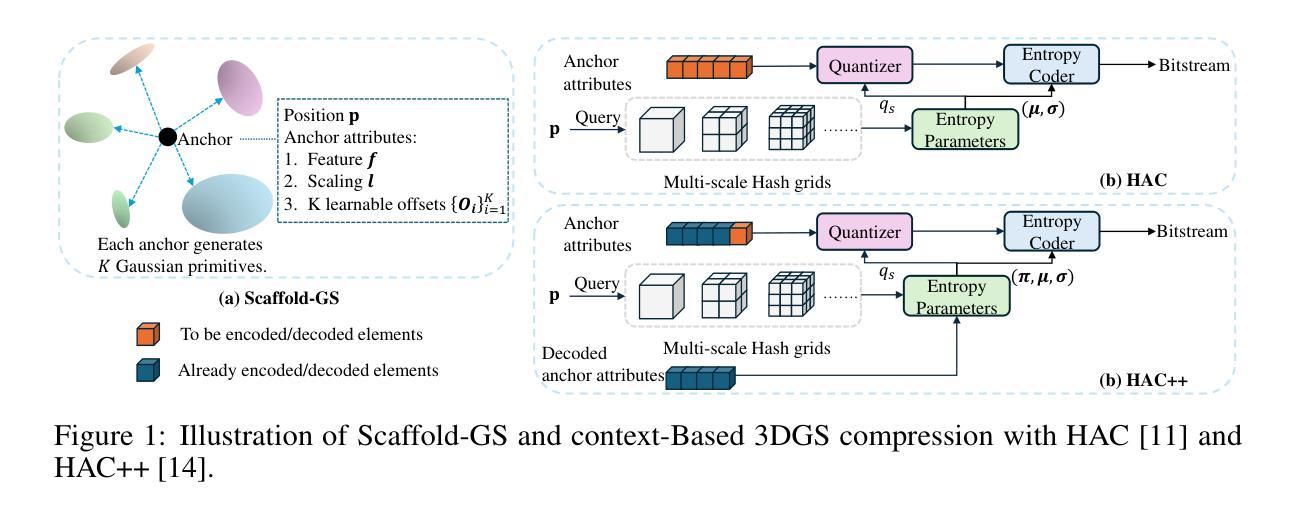
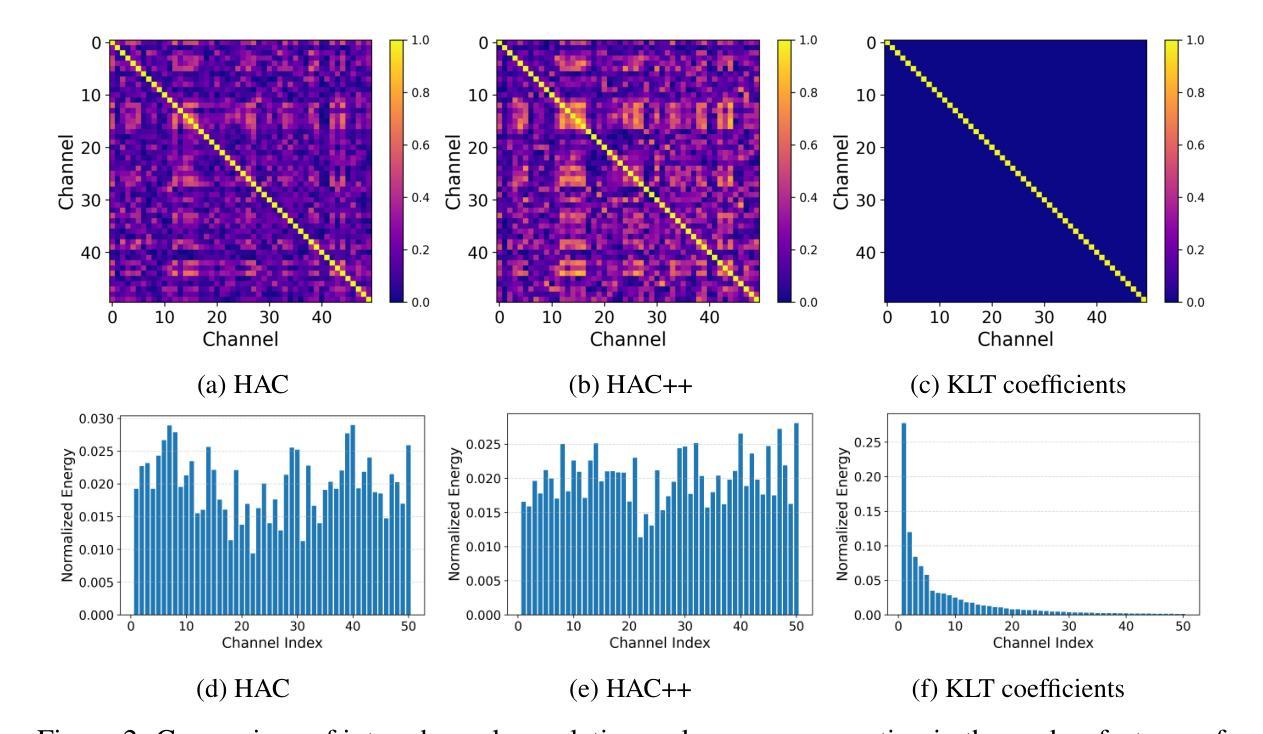
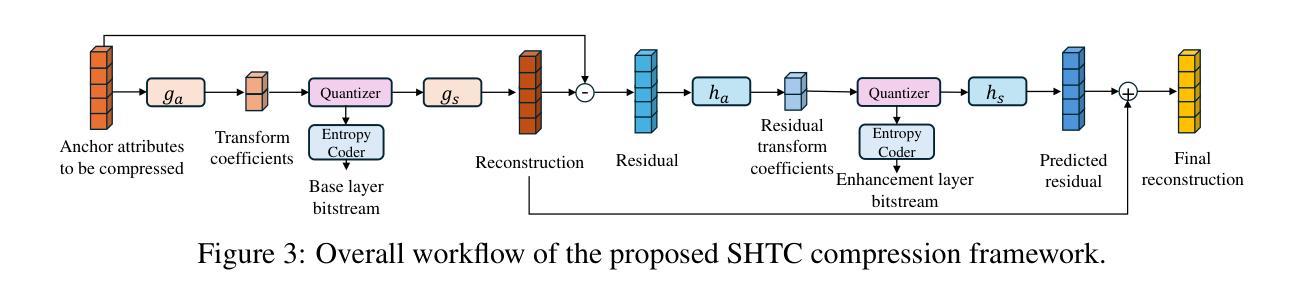
3DGS Compression with Sparsity-guided Hierarchical Transform Coding
Authors:Hao Xu, Xiaolin Wu, Xi Zhang
3D Gaussian Splatting (3DGS) has gained popularity for its fast and high-quality rendering, but it has a very large memory footprint incurring high transmission and storage overhead. Recently, some neural compression methods, such as Scaffold-GS, were proposed for 3DGS but they did not adopt the approach of end-to-end optimized analysis-synthesis transforms which has been proven highly effective in neural signal compression. Without an appropriate analysis transform, signal correlations cannot be removed by sparse representation. Without such transforms the only way to remove signal redundancies is through entropy coding driven by a complex and expensive context modeling, which results in slower speed and suboptimal rate-distortion (R-D) performance. To overcome this weakness, we propose Sparsity-guided Hierarchical Transform Coding (SHTC), the first end-to-end optimized transform coding framework for 3DGS compression. SHTC jointly optimizes the 3DGS, transforms and a lightweight context model. This joint optimization enables the transform to produce representations that approach the best R-D performance possible. The SHTC framework consists of a base layer using KLT for data decorrelation, and a sparsity-coded enhancement layer that compresses the KLT residuals to refine the representation. The enhancement encoder learns a linear transform to project high-dimensional inputs into a low-dimensional space, while the decoder unfolds the Iterative Shrinkage-Thresholding Algorithm (ISTA) to reconstruct the residuals. All components are designed to be interpretable, allowing the incorporation of signal priors and fewer parameters than black-box transforms. This novel design significantly improves R-D performance with minimal additional parameters and computational overhead.
3D Gaussian Splatting(3DGS)因其快速且高质量的渲染而广受欢迎,但其内存占用较大,导致传输和存储开销较高。最近,一些针对3DGS的神经压缩方法(如Scaffold-GS)被提出,但它们并未采用端到端优化的分析-合成变换方法,这在神经信号压缩中已被证明是非常有效的。没有适当的分析变换,信号关联无法通过稀疏表示来去除。没有这样的变换,去除信号冗余的唯一途径是通过由复杂且昂贵的上下文模型驱动的熵编码,这会导致速度较慢以及速率失真(R-D)性能不佳。为了克服这一弱点,我们提出了面向稀疏性的分层变换编码(SHTC),这是针对3DGS压缩的首个端到端优化的变换编码框架。SHTC联合优化了3DGS、变换和轻量级上下文模型。这种联合优化使变换能够产生接近最佳可能的R-D性能表示。SHTC框架由使用KLT进行数据去相关的基本层,以及压缩KLT残差以改进表示的稀疏编码增强层组成。增强编码器学习将高维输入投影到低维空间的线性变换,而解码器展开迭代收缩阈值算法(ISTA)以重建残差。所有组件都设计成可解释的,允许融入信号先验和比黑箱变换更少的参数。这种新颖的设计在极少量的额外参数和计算开销下,显著提高了R-D性能。
论文及项目相关链接
摘要
针对三维高斯融合(3DGS)技术,提出一种稀疏性引导的分层变换编码(SHTC)框架,实现端到端的优化变换编码,以去除信号冗余和提升压缩性能。通过结合KL变换进行基础层的数据去相关和稀疏编码增强层对KL变换残差的压缩来精细表达,达到最优的率失真性能。框架所有组件可解释性强,设计新颖,提高了编码效率和图像质量。
关键见解
- SHTC框架实现了针对三维高斯融合技术的端到端优化变换编码。
- 框架结合了KL变换进行数据去相关,作为基础层处理。
- 采用稀疏编码增强层来压缩KL变换的残差,提升表达的精细度。
- 通过学习线性变换,将高维输入投影到低维空间,实现高效编码。
- 解码器采用迭代收缩阈值算法(ISTA)重建残差。
- 框架设计具有可解释性,易于集成信号先验知识,参数少于黑箱变换。
点此查看论文截图

4DTAM: Non-Rigid Tracking and Mapping via Dynamic Surface Gaussians
Authors:Hidenobu Matsuki, Gwangbin Bae, Andrew J. Davison
We propose the first 4D tracking and mapping method that jointly performs camera localization and non-rigid surface reconstruction via differentiable rendering. Our approach captures 4D scenes from an online stream of color images with depth measurements or predictions by jointly optimizing scene geometry, appearance, dynamics, and camera ego-motion. Although natural environments exhibit complex non-rigid motions, 4D-SLAM remains relatively underexplored due to its inherent challenges; even with 2.5D signals, the problem is ill-posed because of the high dimensionality of the optimization space. To overcome these challenges, we first introduce a SLAM method based on Gaussian surface primitives that leverages depth signals more effectively than 3D Gaussians, thereby achieving accurate surface reconstruction. To further model non-rigid deformations, we employ a warp-field represented by a multi-layer perceptron (MLP) and introduce a novel camera pose estimation technique along with surface regularization terms that facilitate spatio-temporal reconstruction. In addition to these algorithmic challenges, a significant hurdle in 4D SLAM research is the lack of reliable ground truth and evaluation protocols, primarily due to the difficulty of 4D capture using commodity sensors. To address this, we present a novel open synthetic dataset of everyday objects with diverse motions, leveraging large-scale object models and animation modeling. In summary, we open up the modern 4D-SLAM research by introducing a novel method and evaluation protocols grounded in modern vision and rendering techniques.
我们提出了一种首个联合执行相机定位和非刚性表面重建的4D跟踪和映射方法,该方法通过可微分渲染来实现。我们的方法从在线彩色图像流中捕获4D场景,通过联合优化场景几何、外观、动态和相机自我运动,获得深度测量或预测。尽管自然环境表现出复杂的非刚性运动,但由于其固有的挑战,4D-SLAM的研究仍然相对未被充分探索;即使有了2.5D信号,由于优化空间的高维性,该问题也是不适定的。为了克服这些挑战,我们首先引入了一种基于高斯表面原始数据的SLAM方法,该方法比3D高斯更有效地利用深度信号,从而实现精确的表面重建。为了进一步模拟非刚性变形,我们采用由多层感知器(MLP)表示的warp-field,并引入了一种新颖的相机姿态估计技术和表面正则化术语,以促进时空重建。除了这些算法挑战外,4D SLAM研究中的一个重大障碍是缺乏可靠的地面真实数据和评估协议,这主要是因为使用商品传感器进行4D捕获的困难。为了解决这一问题,我们展示了一个全新的开放合成数据集,其中包含具有各种运动的日常对象,利用大规模对象模型和动画建模。总之,我们通过引入一种基于现代计算机视觉和渲染技术的新方法和评估协议,开启了现代4D-SLAM的研究。
论文及项目相关链接
PDF CVPR 2025. Project Page: https://muskie82.github.io/4dtam/
Summary
本文提出一种联合执行相机定位和非刚性表面重建的4D跟踪与映射方法,通过可微渲染实现对4D场景从在线彩色图像流中进行捕捉。该方法通过联合优化场景几何、外观、动态和相机自我运动,实现对深度测量的4D场景捕捉或预测。引入基于高斯表面原始元素的的同时变形SLAM方法,更有效地利用深度信号实现准确表面重建。采用多层感知器(MLP)表示的warp-field对非刚性变形进行建模,并引入新颖的相机姿态估计技术和表面正则化术语,实现时空重建。此外,还提出了一种新的开放合成数据集,利用大规模物体模型和动画建模,展示具有各种运动的日常物体,以解决4D SLAM研究中缺乏可靠的地面真实数据和评估协议的问题。总的来说,本文采用现代计算机视觉和渲染技术,开创了现代4D-SLAM研究的新纪元。
Key Takeaways
- 提出了首个联合执行相机定位和非刚性表面重建的4D跟踪与映射方法。
- 通过可微渲染实现对4D场景的捕捉。
- 通过联合优化场景几何、外观、动态和相机自我运动,从在线彩色图像流中进行深度测量或预测。
- 引入基于高斯表面原始元素的SLAM方法,更有效地利用深度信号。
- 采用多层感知器(MLP)对warp-field进行建模,以处理非刚性变形。
- 引入新颖的相机姿态估计技术和表面正则化术语,实现时空重建。
点此查看论文截图


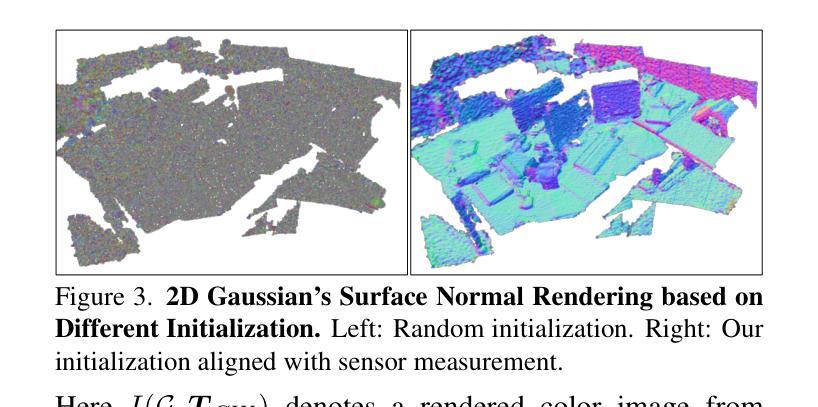
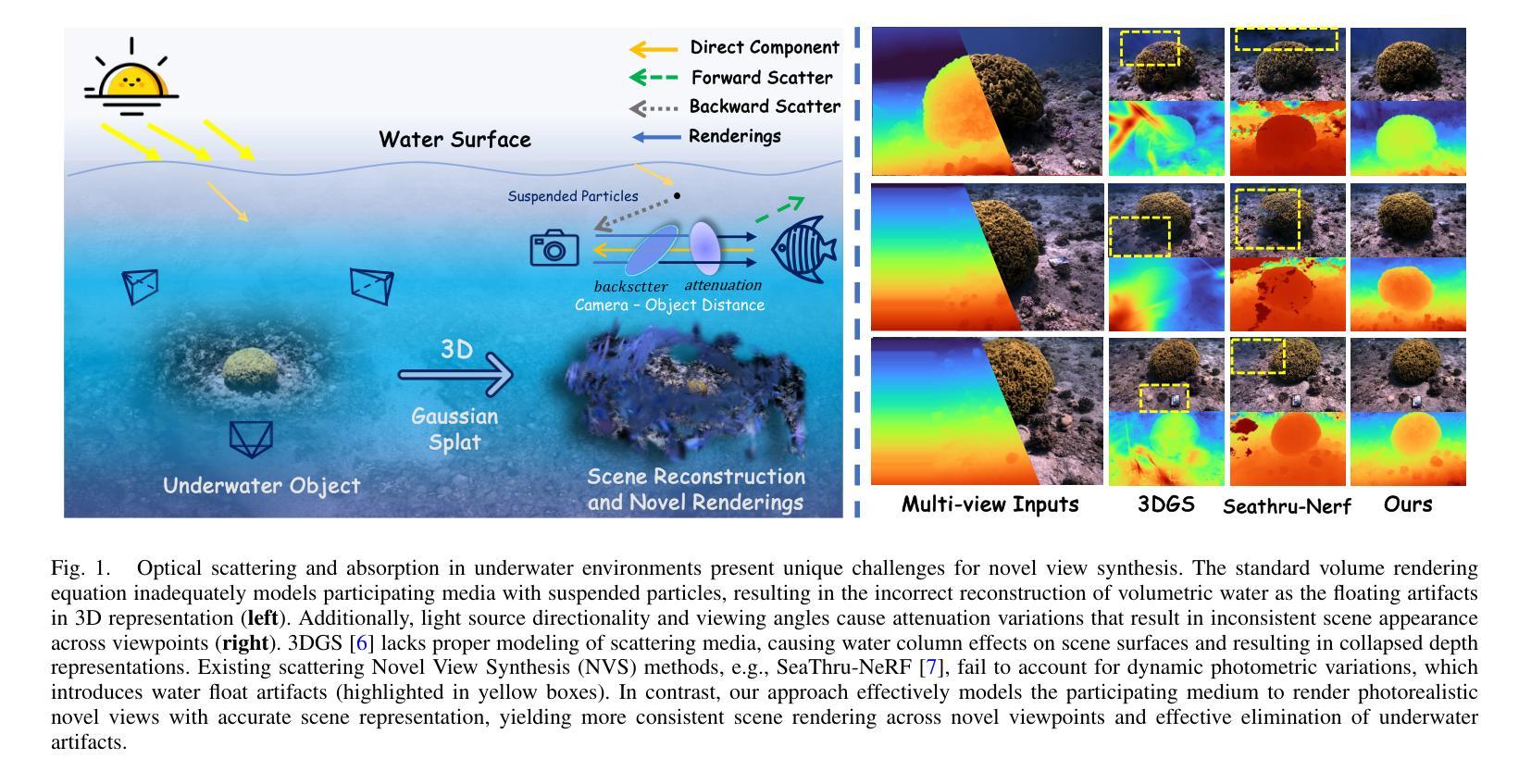
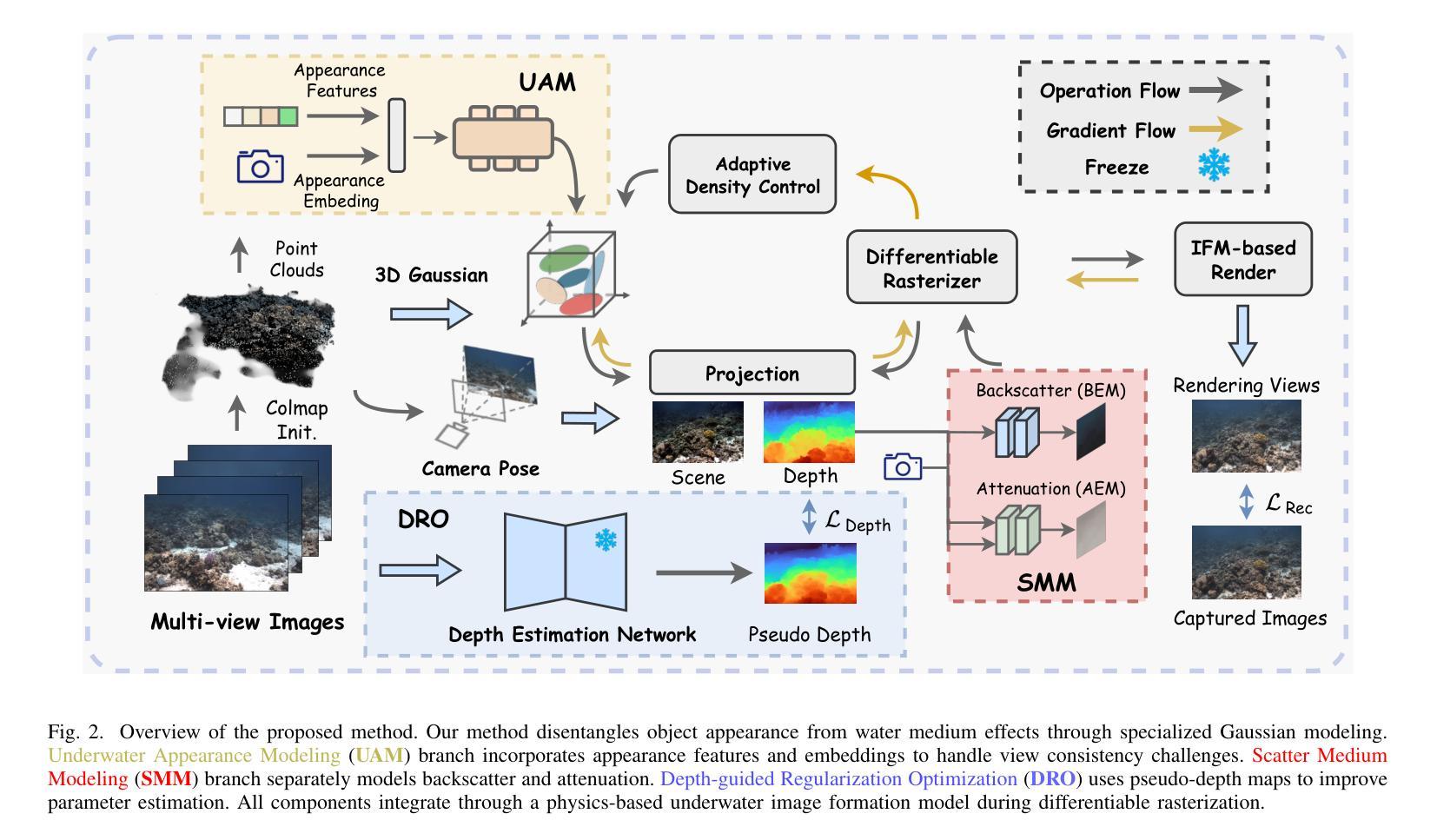
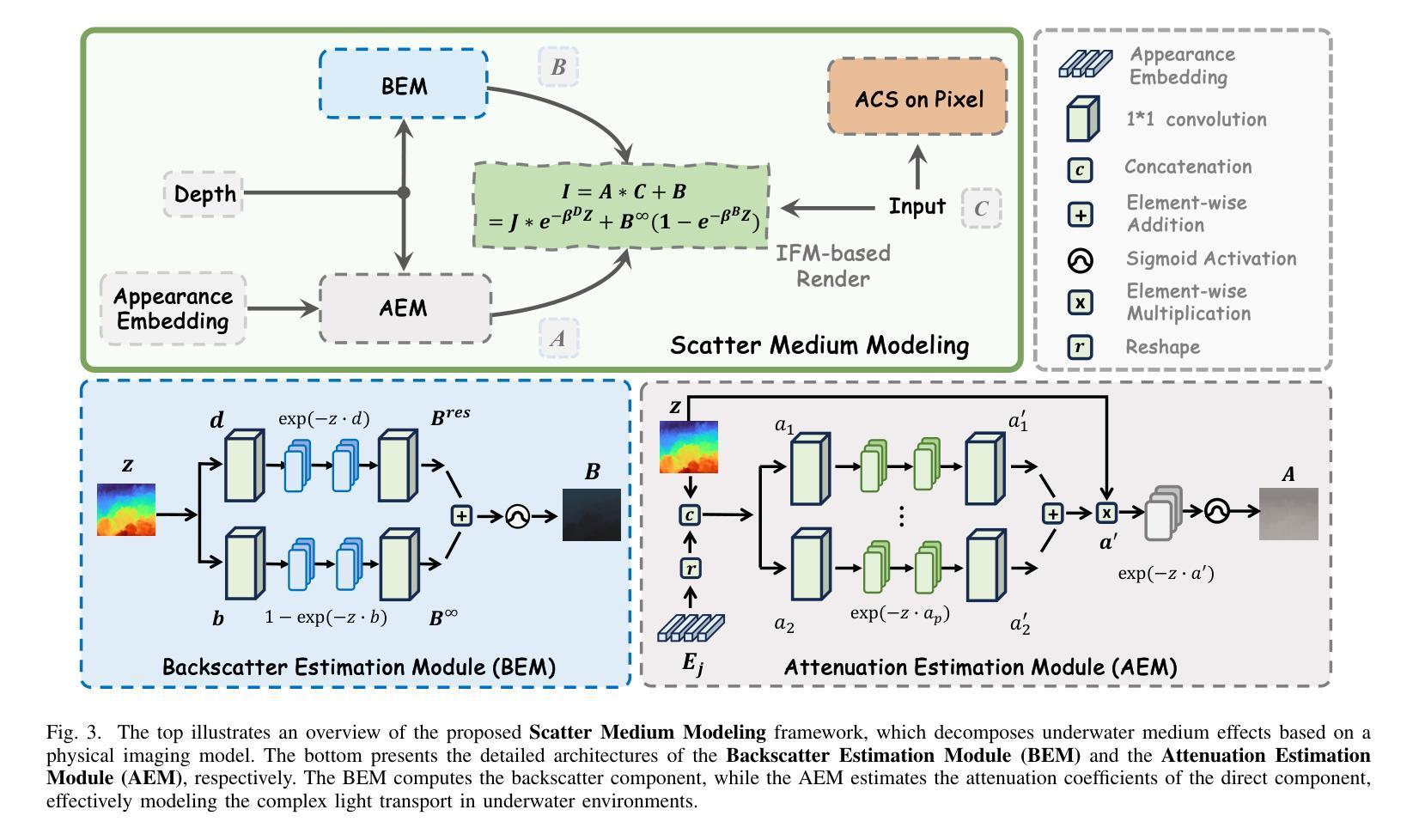
3D-UIR: 3D Gaussian for Underwater 3D Scene Reconstruction via Physics Based Appearance-Medium Decoupling
Authors:Jieyu Yuan, Yujun Li, Yuanlin Zhang, Chunle Guo, Xiongxin Tang, Ruixing Wang, Chongyi Li
Novel view synthesis for underwater scene reconstruction presents unique challenges due to complex light-media interactions. Optical scattering and absorption in water body bring inhomogeneous medium attenuation interference that disrupts conventional volume rendering assumptions of uniform propagation medium. While 3D Gaussian Splatting (3DGS) offers real-time rendering capabilities, it struggles with underwater inhomogeneous environments where scattering media introduce artifacts and inconsistent appearance. In this study, we propose a physics-based framework that disentangles object appearance from water medium effects through tailored Gaussian modeling. Our approach introduces appearance embeddings, which are explicit medium representations for backscatter and attenuation, enhancing scene consistency. In addition, we propose a distance-guided optimization strategy that leverages pseudo-depth maps as supervision with depth regularization and scale penalty terms to improve geometric fidelity. By integrating the proposed appearance and medium modeling components via an underwater imaging model, our approach achieves both high-quality novel view synthesis and physically accurate scene restoration. Experiments demonstrate our significant improvements in rendering quality and restoration accuracy over existing methods. The project page is available at https://bilityniu.github.io/3D-UIR.
水下场景重建的新型视图合成由于复杂的光介质交互而呈现出独特的挑战。水体中的光学散射和吸收带来了非均匀介质衰减干扰,破坏了传统体积渲染假设的均匀传播介质。虽然3D高斯拼贴(3DGS)提供了实时渲染功能,但它对于水下非均匀环境却感到棘手,散射介质会引入伪影和外观不一致的问题。在本研究中,我们提出了一个基于物理的框架,通过定制的高斯建模来分离物体外观和水介质效果。我们的方法引入了外观嵌入,这是后向散射和衰减的明确介质表示,提高了场景的一致性。此外,我们提出了一种距离引导的优化策略,利用伪深度图作为监督,通过深度正则化和尺度惩罚项来提高几何保真度。通过水下成像模型整合所提出的外观和介质建模组件,我们的方法实现了高质量的新型视图合成和物理准确的场景恢复。实验证明,与现有方法相比,我们的方法在渲染质量和恢复精度方面都有显著提高。项目页面可在https://bilityniu.github.io/3D-UIR访问。
论文及项目相关链接
Summary
水下场景重建中的新型视图合成面临独特挑战,因光与水下的介质交互复杂。光学散射和水体吸收导致非均匀介质衰减干扰,破坏了传统的体积渲染假设。虽然3D高斯拼贴(3DGS)具备实时渲染能力,但在水下非均匀环境中,散射介质会引发伪影和外观不一致问题。本研究提出一种基于物理的框架,通过定制的高斯建模来分离物体外观和水介质效果。引入外观嵌入作为后向散射和衰减的明确介质表示,提高场景一致性。此外,提出一种距离引导优化策略,利用伪深度图作为监督,结合深度正则化和尺度惩罚项,提高几何保真度。通过整合提出的外观和介质建模组件,借助水下成像模型,实现高质量的新型视图合成和物理准确的场景恢复。
Key Takeaways
- 水下场景重建面临复杂光-介质交互的挑战。
- 光学散射和水体吸收造成非均匀介质衰减干扰。
- 3D高斯拼贴在处理水下非均匀环境时存在挑战。
- 提出一种基于物理的框架,通过定制的高斯建模分离物体外观和水介质效果。
- 引入外观嵌入以提高场景一致性。
- 提出距离引导优化策略,利用伪深度图改善几何保真度。
- 结合多个组件,实现高质量的新型视图合成和物理准确的场景恢复。
点此查看论文截图

Sparse2DGS: Sparse-View Surface Reconstruction using 2D Gaussian Splatting with Dense Point Cloud
Authors:Natsuki Takama, Shintaro Ito, Koichi Ito, Hwann-Tzong Chen, Takafumi Aoki
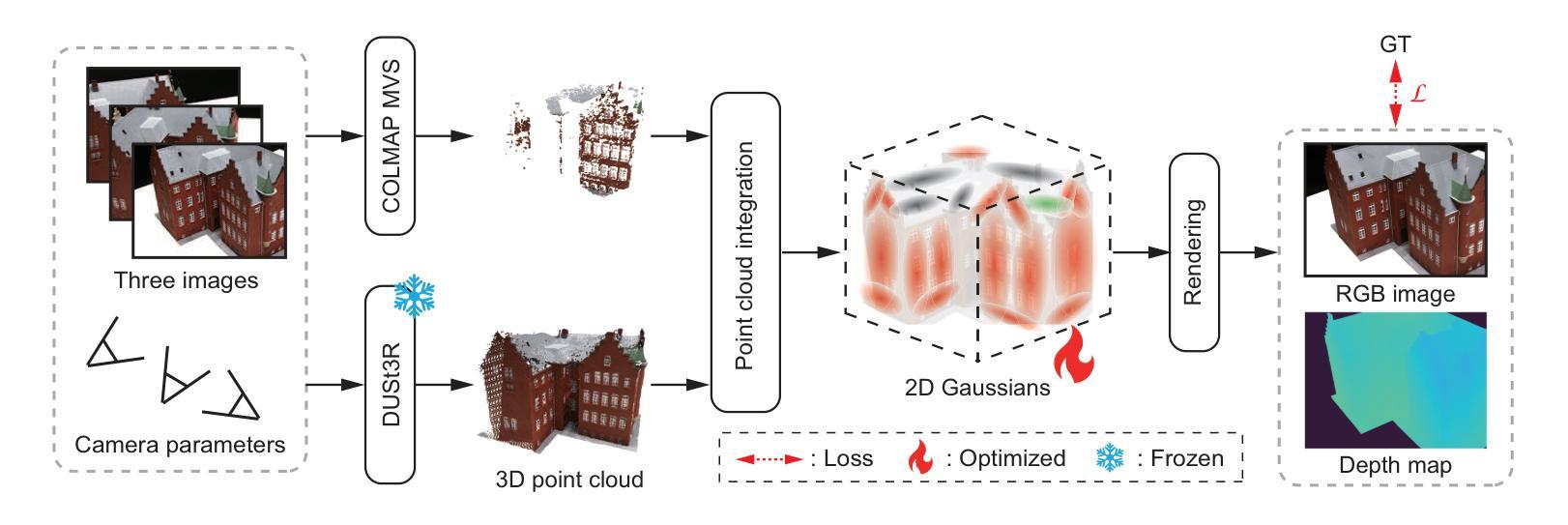
Gaussian Splatting (GS) has gained attention as a fast and effective method for novel view synthesis. It has also been applied to 3D reconstruction using multi-view images and can achieve fast and accurate 3D reconstruction. However, GS assumes that the input contains a large number of multi-view images, and therefore, the reconstruction accuracy significantly decreases when only a limited number of input images are available. One of the main reasons is the insufficient number of 3D points in the sparse point cloud obtained through Structure from Motion (SfM), which results in a poor initialization for optimizing the Gaussian primitives. We propose a new 3D reconstruction method, called Sparse2DGS, to enhance 2DGS in reconstructing objects using only three images. Sparse2DGS employs DUSt3R, a fundamental model for stereo images, along with COLMAP MVS to generate highly accurate and dense 3D point clouds, which are then used to initialize 2D Gaussians. Through experiments on the DTU dataset, we show that Sparse2DGS can accurately reconstruct the 3D shapes of objects using just three images. The project page is available at https://gsisaoki.github.io/SPARSE2DGS/
高斯点斑技术(GS)作为一种快速有效的方法,已经引起了人们对新型视图合成的关注。它也被应用于使用多视角图像的3D重建,并能实现快速而准确的3D重建。然而,GS假设输入包含大量多视角图像,因此当只有有限数量的输入图像可用时,重建精度会大大降低。主要原因之一是通过对运动结构(SfM)获得的稀疏点云中的3D点数不足,导致高斯原始数据的优化初始化较差。我们提出了一种新的3D重建方法,称为Sparse2DGS,以增强仅使用三幅图像进行对象重建的2DGS。Sparse2DGS采用用于立体图像的DUSt3R基本模型以及COLMAP MVS,生成高度准确且密集的3D点云,然后用于初始化二维高斯。通过对DTU数据集的实验,我们证明了Sparse2DGS仅使用三幅图像就能准确地重建物体的三维形状。项目页面可在[https://gsisaoki.github.io/SPARSE2DGS/]查看。
论文及项目相关链接
PDF Accepted to ICIP 2025
Summary
稀疏点云下利用三张图片的三维重建研究改进方法摘要:当仅使用有限数量的输入图像时,高斯拼贴(GS)的三维重建精度会降低。Sparse2DGS方法采用DUSt3R模型和COLMAP MVS生成精确、密集的三维点云,以初始化二维高斯分布,从而改善稀疏点云问题,准确重建三维形状。此方法仅使用三张图像即可实现准确的三维重建。项目页面已在相关网站发布。
Key Takeaways
以下是提取的关于Sparse2DGS方法和研究关键内容的七点总结:
- 高斯拼贴(GS)是一种快速有效的视点合成方法,也应用于三维重建。但它在处理有限输入图像时,重建精度会降低。
- Sparse2DGS是为了改进GS在仅使用三张图像进行三维重建时的不足而提出的方法。
- Sparse2DGS方法使用DUSt3R模型和COLMAP MVS生成精确、密集的三维点云。
- Sparse2DGS利用这些点云数据初始化二维高斯分布,以提高三维重建的准确度。
- Sparse2DGS方法的实验在DTU数据集上显示出准确的三维重建效果,仅使用三张图像就能达到准确的重建效果。
- Sparse2DGS方法解决了由于输入图像数量有限导致的重建精度下降的问题。
点此查看论文截图


GrowSplat: Constructing Temporal Digital Twins of Plants with Gaussian Splats
Authors:Simeon Adebola, Shuangyu Xie, Chung Min Kim, Justin Kerr, Bart M. van Marrewijk, Mieke van Vlaardingen, Tim van Daalen, E. N. van Loo, Jose Luis Susa Rincon, Eugen Solowjow, Rick van de Zedde, Ken Goldberg
Accurate temporal reconstructions of plant growth are essential for plant phenotyping and breeding, yet remain challenging due to complex geometries, occlusions, and non-rigid deformations of plants. We present a novel framework for building temporal digital twins of plants by combining 3D Gaussian Splatting with a robust sample alignment pipeline. Our method begins by reconstructing Gaussian Splats from multi-view camera data, then leverages a two-stage registration approach: coarse alignment through feature-based matching and Fast Global Registration, followed by fine alignment with Iterative Closest Point. This pipeline yields a consistent 4D model of plant development in discrete time steps. We evaluate the approach on data from the Netherlands Plant Eco-phenotyping Center, demonstrating detailed temporal reconstructions of Sequoia and Quinoa species. Videos and Images can be seen at https://berkeleyautomation.github.io/GrowSplat/
对植物生长进行准确的时间重建对于植物表型和育种至关重要,但由于植物的复杂几何形状、遮挡和非刚性变形,这仍然是一个挑战。我们提出了一种结合3D高斯贴图技术和稳健样本对齐流程,构建植物时间数字双胞胎的新框架。我们的方法首先通过多视角相机数据重建高斯贴图,然后采用两阶段注册方法:基于特征的匹配和快速全局注册的粗略对齐,然后通过迭代最近点法进行精细对齐。该流程生成了离散时间步长的连续植物发育的4D模型。我们在荷兰植物生态表现中心的数据上评估了该方法,展示了对杉柏属和羽扇豆属物种的详细时间重建。视频和图像可在https://berkeleyautomation.github.io/GrowSplat/ 查看。
论文及项目相关链接
Summary
本文介绍了一种结合3D高斯贴图与稳健样本对齐流程,构建植物时间数字双胞胎的新框架。该方法通过多视角相机数据进行高斯贴图重建,采用两阶段注册方法,即基于特征的匹配和快速全局注册进行粗略对齐,然后通过迭代最近点法进行精细对齐。此流程生成了离散时间步长的植物发展一致4D模型。在荷兰植物生态表现评估中心的数据上验证了该方法,对杉树和洋葱物种的详细时间重建进行了展示。
Key Takeaways
- 文中提出了一种新的植物时间数字双胞胎构建框架,结合了3D高斯贴图与样本对齐流程。
- 方法通过多视角相机数据进行高斯贴图重建,以捕捉植物的复杂几何形状、遮挡和非刚性变形。
- 采用两阶段注册方法进行植物模型的对齐,包括粗略对齐和精细对齐。
- 使用了基于特征的匹配、快速全局注册和迭代最近点法等技术。
- 该方法生成了离散时间步长的植物发展一致4D模型。
- 在荷兰植物生态表现评估中心的数据上进行了验证,展示了详细的时间重建结果。
点此查看论文截图




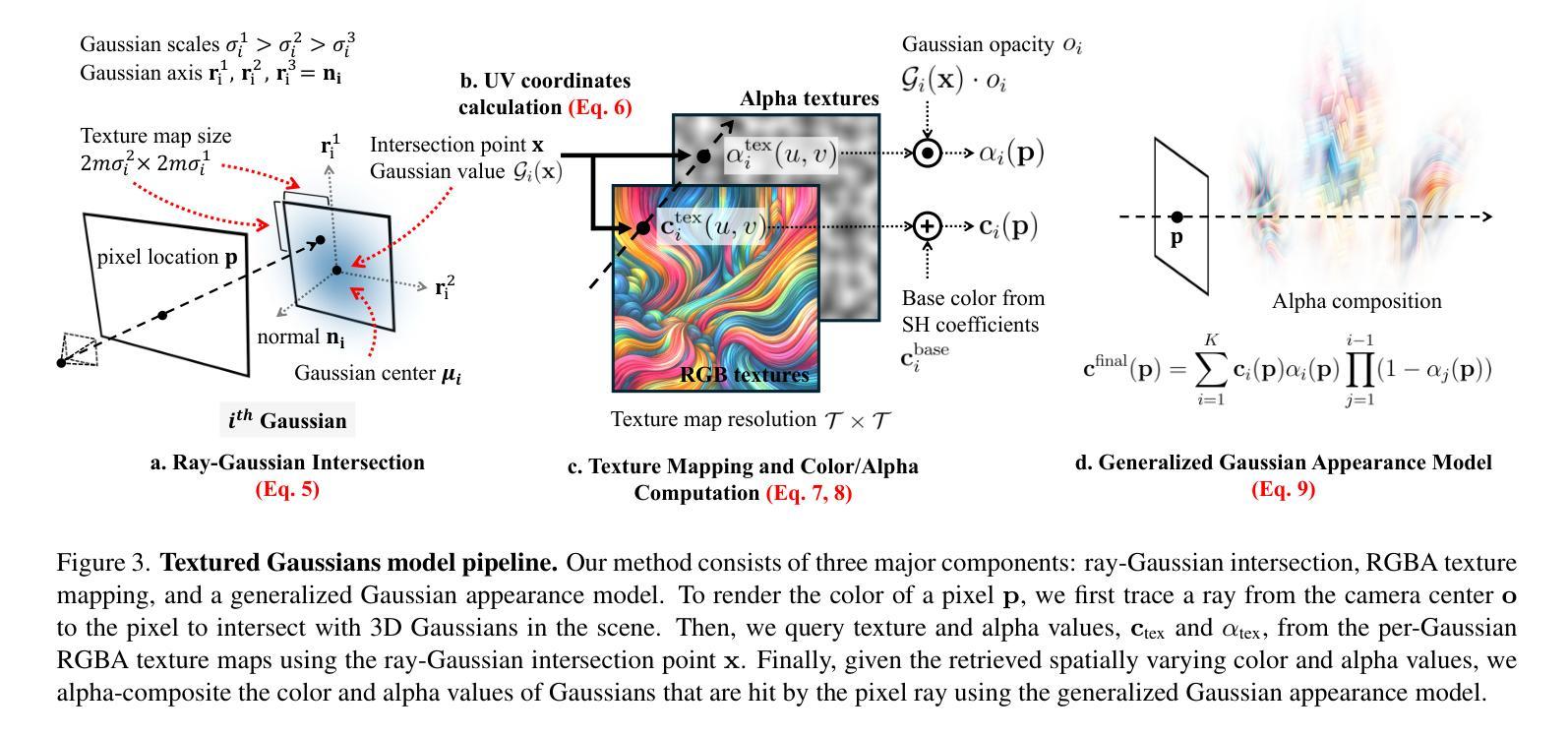
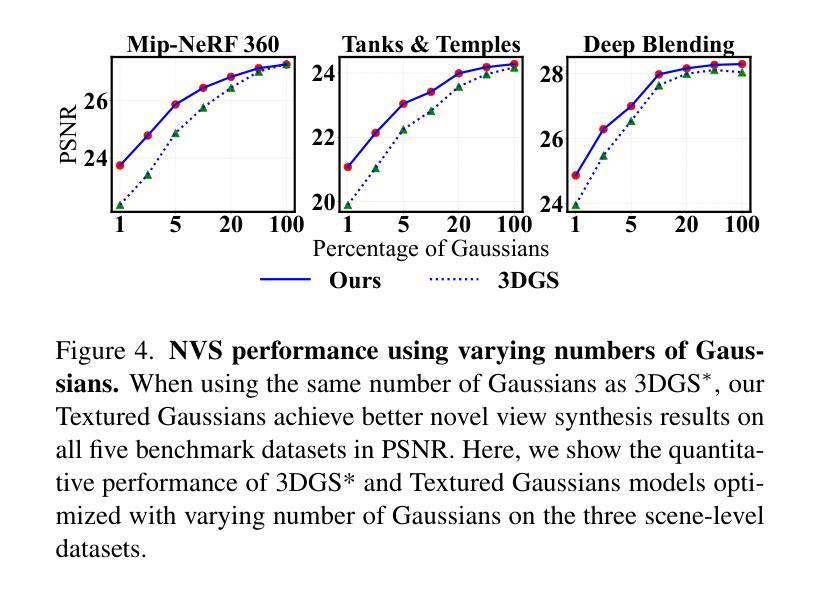
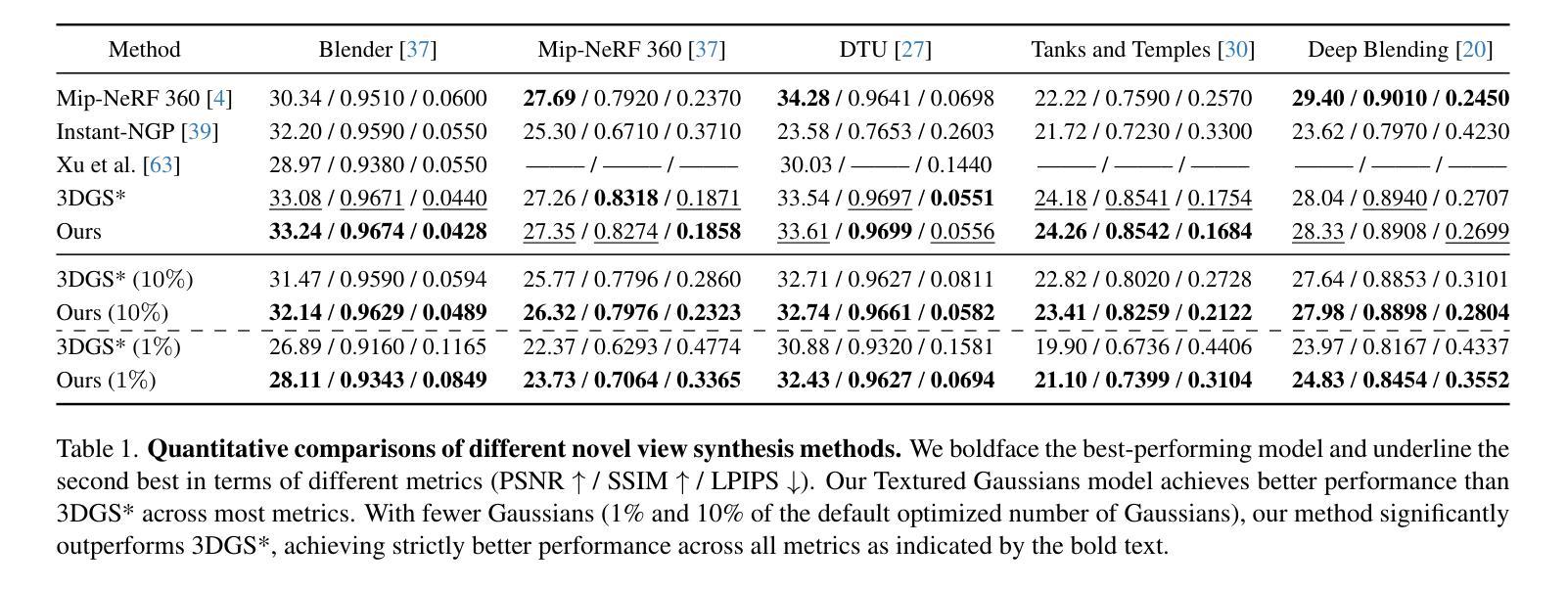
Textured Gaussians for Enhanced 3D Scene Appearance Modeling
Authors:Brian Chao, Hung-Yu Tseng, Lorenzo Porzi, Chen Gao, Tuotuo Li, Qinbo Li, Ayush Saraf, Jia-Bin Huang, Johannes Kopf, Gordon Wetzstein, Changil Kim
3D Gaussian Splatting (3DGS) has recently emerged as a state-of-the-art 3D reconstruction and rendering technique due to its high-quality results and fast training and rendering time. However, pixels covered by the same Gaussian are always shaded in the same color up to a Gaussian falloff scaling factor. Furthermore, the finest geometric detail any individual Gaussian can represent is a simple ellipsoid. These properties of 3DGS greatly limit the expressivity of individual Gaussian primitives. To address these issues, we draw inspiration from texture and alpha mapping in traditional graphics and integrate it with 3DGS. Specifically, we propose a new generalized Gaussian appearance representation that augments each Gaussian with alpha~(A), RGB, or RGBA texture maps to model spatially varying color and opacity across the extent of each Gaussian. As such, each Gaussian can represent a richer set of texture patterns and geometric structures, instead of just a single color and ellipsoid as in naive Gaussian Splatting. Surprisingly, we found that the expressivity of Gaussians can be greatly improved by using alpha-only texture maps, and further augmenting Gaussians with RGB texture maps achieves the highest expressivity. We validate our method on a wide variety of standard benchmark datasets and our own custom captures at both the object and scene levels. We demonstrate image quality improvements over existing methods while using a similar or lower number of Gaussians.
3D高斯喷绘技术(3DGS)以其高质量的结果和快速的训练和渲染时间,最近成为了最先进的3D重建和渲染技术。然而,被同一高斯覆盖的像素总是根据高斯衰减系数进行着色成同一颜色。此外,单个高斯能表示的最精细几何细节是一个简单的椭球体。这些3DGS的特性极大地限制了单个高斯基元的表达能力。为了解决这个问题,我们从传统图形中的纹理和alpha映射中汲取灵感,并将其与3DGS相结合。具体来说,我们提出了一种新的广义高斯外观表示法,它为每个高斯添加了alpha(A)、RGB或RGBA纹理映射,以模拟每个高斯范围内的空间变化的颜色和透明度。因此,每个高斯可以表示一组更丰富的纹理模式和几何结构,而不仅仅是单一颜色和椭球体,如简单的高斯喷绘。令人惊讶的是,我们发现仅使用alpha纹理映射可以大大提高高斯的表现力,并进一步使用RGB纹理映射增强高斯可以达到最高的表现力。我们在各种标准基准数据集和自定义捕获的对象和场景级别上验证了我们的方法。我们展示了相较于现有方法的图像质量改进,同时使用相似或更少的高斯数量。
论文及项目相关链接
PDF Will be presented at CVPR 2025. Project website: https://textured-gaussians.github.io/
Summary
3DGS虽为先进的3D重建和渲染技术,但其着色方式及几何细节表现有所局限。为增强表达能力,研究团队融合了传统图形的纹理与alpha映射,提出了广义高斯外观表示法。此方法能为每个高斯赋予alpha(透明度)、RGB或RGBA纹理映射,从而模拟高斯内各位置的色彩和透明度变化。仅使用alpha纹理映射即可显著提高高斯的表现力,进一步加入RGB纹理映射则达到最高表现力。该方法在标准数据集和自定义捕获的物体和场景上均得到验证,图像质量有所提升,同时使用的高斯数量相似或更少。
Key Takeaways
- 3DGS是一种先进的3D重建和渲染技术,以其高质量结果和快速的训练和渲染时间著称。
- 原始的3DGS中,相同的高斯覆盖的像素总是着色为同一颜色,并且其几何细节表现仅限于简单的椭球体,这限制了其表现力。
- 为解决这些问题,研究团队融合了传统图形的纹理和alpha映射技术,并提出了新的广义高斯外观表示法。
- 该方法允许为每个高斯赋予alpha(透明度)、RGB或RGBA纹理映射,从而模拟高斯内部的空间变化色彩和透明度。
- 仅使用alpha纹理映射可以增强高斯的表现力,而加入RGB纹理映射则进一步提升其表达能力的最高水平。
- 该方法在多种标准数据集和自定义捕获的物体及场景上进行了验证,并展示了相较于现有方法的图像质量改进。
点此查看论文截图