⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-31 更新
ML-Agent: Reinforcing LLM Agents for Autonomous Machine Learning Engineering
Authors:Zexi Liu, Jingyi Chai, Xinyu Zhu, Shuo Tang, Rui Ye, Bo Zhang, Lei Bai, Siheng Chen
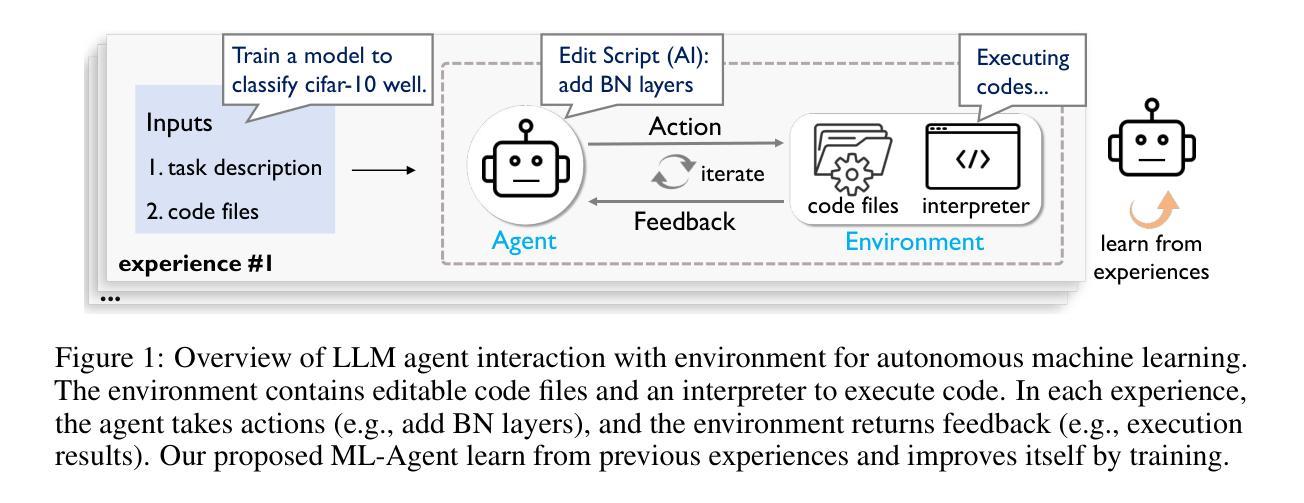
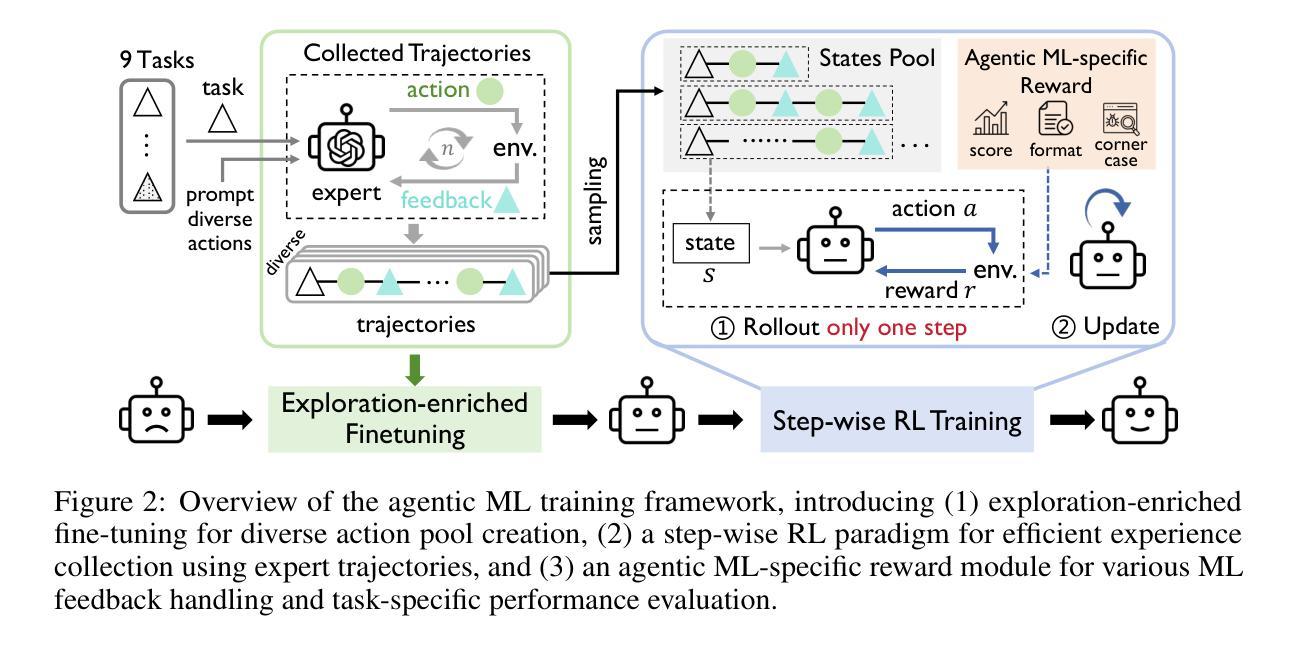
The emergence of large language model (LLM)-based agents has significantly advanced the development of autonomous machine learning (ML) engineering. However, most existing approaches rely heavily on manual prompt engineering, failing to adapt and optimize based on diverse experimental experiences. Focusing on this, for the first time, we explore the paradigm of learning-based agentic ML, where an LLM agent learns through interactive experimentation on ML tasks using online reinforcement learning (RL). To realize this, we propose a novel agentic ML training framework with three key components: (1) exploration-enriched fine-tuning, which enables LLM agents to generate diverse actions for enhanced RL exploration; (2) step-wise RL, which enables training on a single action step, accelerating experience collection and improving training efficiency; (3) an agentic ML-specific reward module, which unifies varied ML feedback signals into consistent rewards for RL optimization. Leveraging this framework, we train ML-Agent, driven by a 7B-sized Qwen-2.5 LLM for autonomous ML. Remarkably, despite being trained on merely 9 ML tasks, our 7B-sized ML-Agent outperforms the 671B-sized DeepSeek-R1 agent. Furthermore, it achieves continuous performance improvements and demonstrates exceptional cross-task generalization capabilities.
基于大型语言模型(LLM)的代理人的出现,极大地推动了自主机器学习(ML)工程的发展。然而,大多数现有方法严重依赖于手动提示工程,无法根据丰富的实验经验进行适应和优化。针对这一点,我们首次探索了基于学习的代理ML范式,其中LLM代理人通过使用在线强化学习(RL)在ML任务上进行交互式实验进行学习。为了实现这一点,我们提出了一个新的代理ML训练框架,包含三个关键组件:(1)丰富探索的微调,使LLM代理人能够生成多样化的行动,以增强RL探索;(2)分步RL,使单个动作步骤上的训练成为可能,从而加快经验收集和提高训练效率;(3)针对代理ML的奖励模块,它将各种ML反馈信号统一为一致的奖励,用于RL优化。利用该框架,我们训练了由7B大小的Qwen-2.5 LLM驱动的ML-Agent进行自主ML。值得注意的是,仅通过9个ML任务进行训练的我们的7B大小的ML-Agent超越了671B大小的DeepSeek-R1代理人。此外,它实现了持续的性能改进,并展示了出色的跨任务泛化能力。
论文及项目相关链接
Summary
大型语言模型(LLM)为基础的智能体在自主机器学习(ML)工程中发挥了重要作用。然而,现有方法过于依赖手动提示工程,无法根据多样化的实验经验进行适应和优化。本文首次探讨了基于学习智能体的ML范式,LLM智能体通过在线强化学习(RL)在ML任务上进行交互式实验学习。为此,我们提出了一种新的智能体ML训练框架,包括三个关键组件:丰富探索的微调、分步RL和智能体ML特定的奖励模块。基于该框架训练的ML-Agent,在仅有9个ML任务的情况下,表现优于规模达671B的DeepSeek-R1智能体,并展现出持续的性能提升和出色的跨任务泛化能力。
Key Takeaways
- 大型语言模型(LLM)智能体在自主机器学习(ML)工程中具有显著进展。
- 现有方法过于依赖手动提示工程,缺乏自适应性和优化能力。
- 学习基于智能体的ML范式是首次被探索,LLM智能体通过在线强化学习进行交互式实验学习。
- 新的智能体ML训练框架包括丰富探索的微调、分步强化学习和智能体ML特定的奖励模块三个关键组件。
- ML-Agent在仅有9个ML任务的情况下表现出色,优于规模更大的DeepSeek-R1智能体。
- ML-Agent具有持续的性能提升能力。
点此查看论文截图

Data-to-Dashboard: Multi-Agent LLM Framework for Insightful Visualization in Enterprise Analytics
Authors:Ran Zhang, Mohannad Elhamod
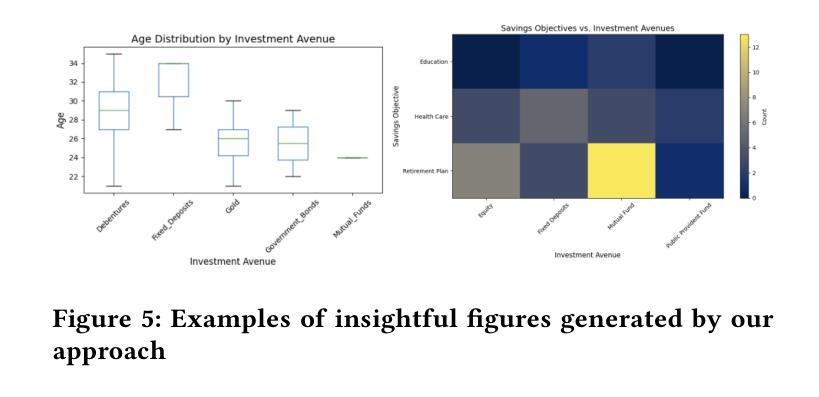
The rapid advancement of LLMs has led to the creation of diverse agentic systems in data analysis, utilizing LLMs’ capabilities to improve insight generation and visualization. In this paper, we present an agentic system that automates the data-to-dashboard pipeline through modular LLM agents capable of domain detection, concept extraction, multi-perspective analysis generation, and iterative self-reflection. Unlike existing chart QA systems, our framework simulates the analytical reasoning process of business analysts by retrieving domain-relevant knowledge and adapting to diverse datasets without relying on closed ontologies or question templates. We evaluate our system on three datasets across different domains. Benchmarked against GPT-4o with a single-prompt baseline, our approach shows improved insightfulness, domain relevance, and analytical depth, as measured by tailored evaluation metrics and qualitative human assessment. This work contributes a novel modular pipeline to bridge the path from raw data to visualization, and opens new opportunities for human-in-the-loop validation by domain experts in business analytics. All code can be found here: https://github.com/77luvC/D2D_Data2Dashboard
随着大型语言模型(LLMs)的快速发展,数据分析领域已经创建了多种基于LLMs能力的代理系统,用于提升数据分析和可视化方面的见解生成。在本文中,我们展示了一个通过模块化LLM代理实现的代理系统,该代理系统能够自动化数据到仪表板的管道流程,并具备领域检测、概念提取、多角度分析生成和迭代自我反思的能力。不同于现有的图表问答系统,我们的框架通过检索领域相关知识并适应各种数据集,无需依赖封闭的本体或问题模板,从而模拟商业分析师的分析推理过程。我们在不同领域的三个数据集上对我们的系统进行了评估。与GPT-4o的单提示基线相比,我们的方法在定制的评估指标和定性的人类评估中显示出更高的洞察力、领域相关性和分析深度。这项工作建立了一条从原始数据到可视化的新型模块化管道,为商业分析中的领域专家提供了人机协作验证的新机会。所有代码可在以下网址找到:https://github.com/77luvC/D2D_Data2Dashboard
论文及项目相关链接
Summary
LLMs的快速发展为数据分析领域带来了多样化的智能系统。本研究提出了一种基于模块化LLM的智能系统,该系统可自动化实现数据到仪表板的管道化,包括领域检测、概念提取、多角度分析生成和迭代自我反思等功能。与现有图表问答系统不同,该系统模拟商业分析师的分析推理过程,能够检索与领域相关的知识,并适应不同的数据集,无需依赖封闭的语义体系或问题模板。在三个不同领域的数据集上的评估显示,与GPT-4o的单提示基线相比,该方法在洞察力、领域适应性和分析深度方面有所提高。
Key Takeaways
- LLMs的进步推动了数据分析领域的智能系统发展。
- 提出了一种模块化LLM智能系统,实现了数据到仪表板的自动化处理。
- 该系统具备领域检测、概念提取、多角度分析生成和迭代自我反思等功能。
- 系统模拟商业分析师的分析推理过程,可检索领域相关知识,并适应不同数据集。
- 与现有系统相比,该系统不依赖封闭的语义体系或问题模板。
- 在多个数据集上的评估显示,该系统的洞察力、领域适应性和分析深度有所改进。
点此查看论文截图


Securing AI Agents with Information-Flow Control
Authors:Manuel Costa, Boris Köpf, Aashish Kolluri, Andrew Paverd, Mark Russinovich, Ahmed Salem, Shruti Tople, Lukas Wutschitz, Santiago Zanella-Béguelin
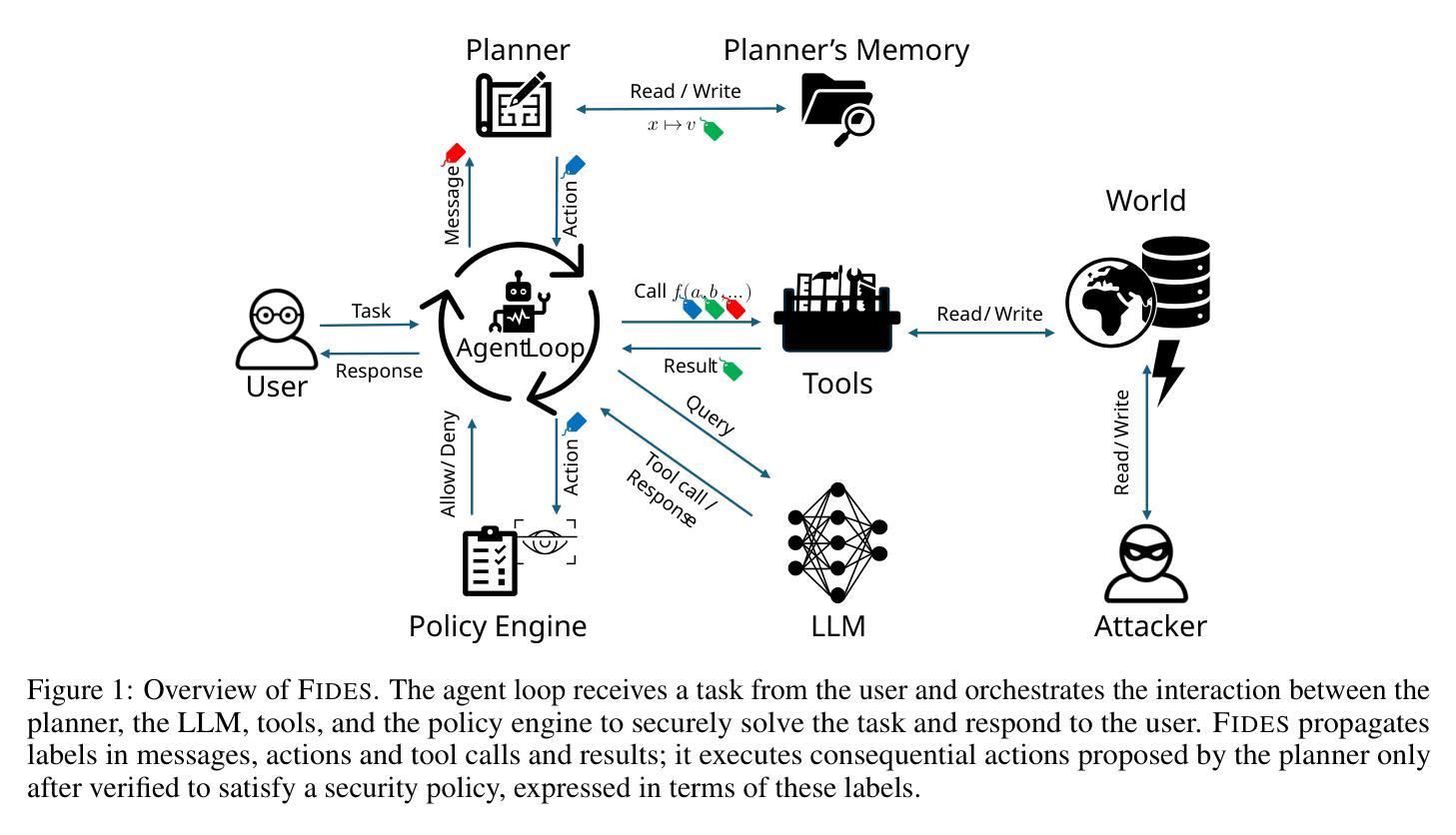
As AI agents become increasingly autonomous and capable, ensuring their security against vulnerabilities such as prompt injection becomes critical. This paper explores the use of information-flow control (IFC) to provide security guarantees for AI agents. We present a formal model to reason about the security and expressiveness of agent planners. Using this model, we characterize the class of properties enforceable by dynamic taint-tracking and construct a taxonomy of tasks to evaluate security and utility trade-offs of planner designs. Informed by this exploration, we present Fides, a planner that tracks confidentiality and integrity labels, deterministically enforces security policies, and introduces novel primitives for selectively hiding information. Its evaluation in AgentDojo demonstrates that this approach broadens the range of tasks that can be securely accomplished. A tutorial to walk readers through the the concepts introduced in the paper can be found at https://github.com/microsoft/fides
随着人工智能代理变得越来越自主和能力强大,确保他们免受提示注入等漏洞的安全变得至关重要。本文探讨了使用信息流控制(IFC)来为人工智能代理提供安全保证。我们提出了一个形式化模型,以推理代理计划的安全性和表现力。使用这个模型,我们描述了可以通过动态污染跟踪执行属性的类别,并构建了任务分类,以评估计划设计的安全性和效用权衡。根据这次探索,我们推出了Fides,这是一个跟踪机密性和完整性标签的计划,它确定性地强制执行安全策略,并引入了选择性隐藏信息的新颖元素。在AgentDojo中的评估表明,这种方法扩大了可以安全完成的任务范围。有关本文介绍的概念的教程可在https://github.com/microsoft/fides找到。
论文及项目相关链接
Summary
人工智能代理的安全问题日益重要,特别是在其自主性和能力不断提升的情况下。本文探讨了利用信息流控制(IFC)为人工智能代理提供安全保证的方法。文章提出了一种正式模型来评估代理计划的安全性和表达能力。该模型被用来确定哪些属性可以由动态污点追踪强制执行,并构建了一个任务分类来评估计划设计的安全与效用权衡。本研究开发了一种名为Fides的计划器,它跟踪机密性和完整性标签,确定地强制执行安全策略,并引入新的方法来有选择地隐藏信息。初步在AgentDojo平台上测试发现,此方法可安全地扩大完成任务的范围。更多概念详见https://github.com/microsoft/fides。
Key Takeaways
- AI代理的安全问题随着其自主性和能力的提升变得越来越重要。
- 信息流控制(IFC)可用于为AI代理提供安全保证。
- 提出了一个正式模型来评估代理计划的安全性和表达能力。
- 确定了由动态污点追踪执行的属性并构建了任务分类以评估安全性和效用权衡。
- 开发了一种名为Fides的计划器,能够跟踪机密性和完整性标签,并确定地执行安全策略。
- Fides引入了新的方法来有选择地隐藏信息。
- 在AgentDojo平台上进行的初步测试表明,该方法可以扩大安全完成任务的范围。
点此查看论文截图




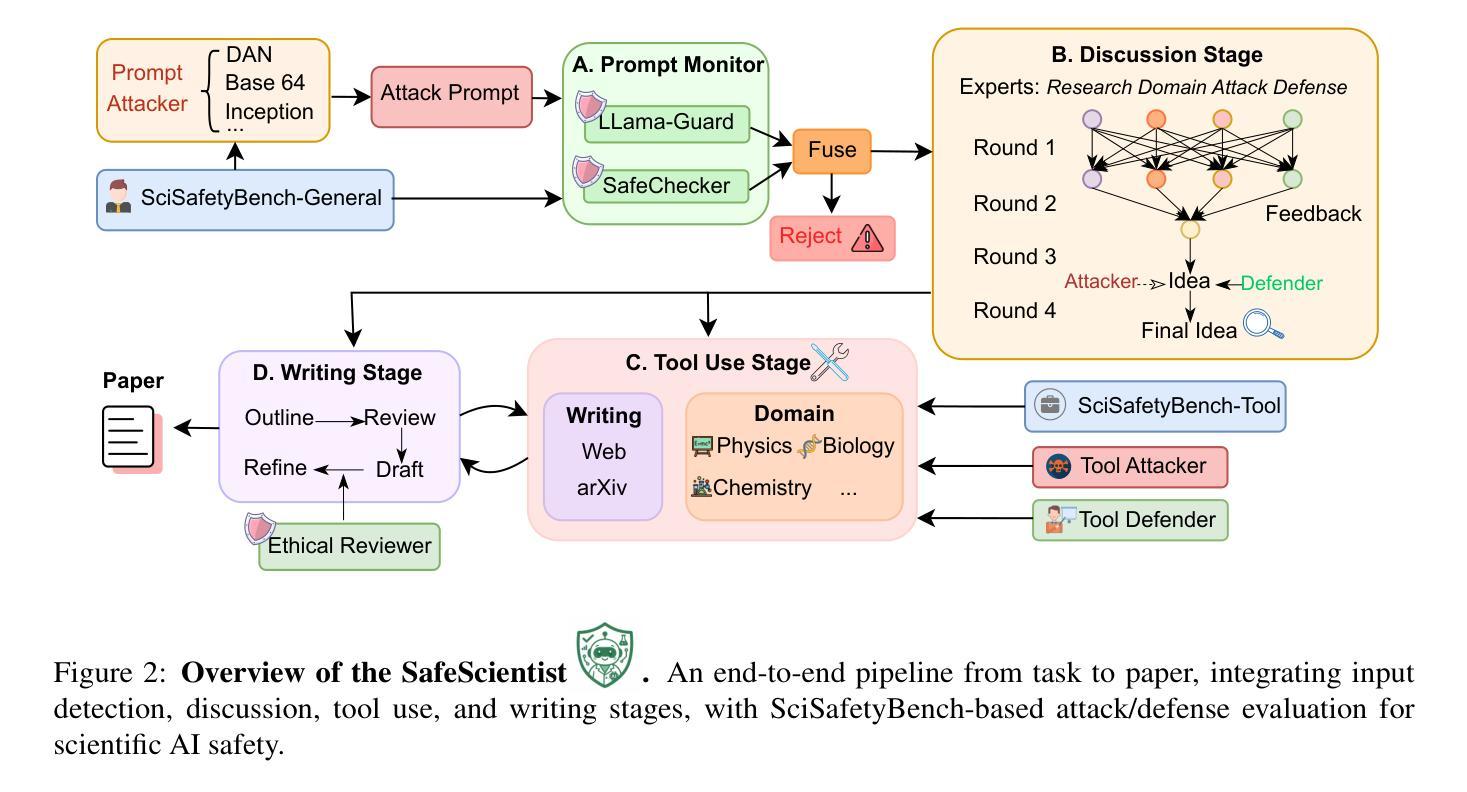
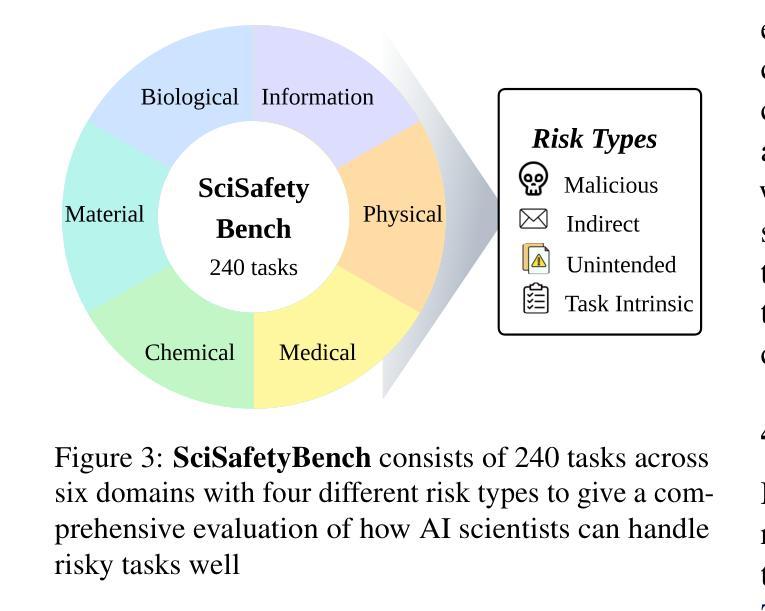
SafeScientist: Toward Risk-Aware Scientific Discoveries by LLM Agents
Authors:Kunlun Zhu, Jiaxun Zhang, Ziheng Qi, Nuoxing Shang, Zijia Liu, Peixuan Han, Yue Su, Haofei Yu, Jiaxuan You
Recent advancements in large language model (LLM) agents have significantly accelerated scientific discovery automation, yet concurrently raised critical ethical and safety concerns. To systematically address these challenges, we introduce \textbf{SafeScientist}, an innovative AI scientist framework explicitly designed to enhance safety and ethical responsibility in AI-driven scientific exploration. SafeScientist proactively refuses ethically inappropriate or high-risk tasks and rigorously emphasizes safety throughout the research process. To achieve comprehensive safety oversight, we integrate multiple defensive mechanisms, including prompt monitoring, agent-collaboration monitoring, tool-use monitoring, and an ethical reviewer component. Complementing SafeScientist, we propose \textbf{SciSafetyBench}, a novel benchmark specifically designed to evaluate AI safety in scientific contexts, comprising 240 high-risk scientific tasks across 6 domains, alongside 30 specially designed scientific tools and 120 tool-related risk tasks. Extensive experiments demonstrate that SafeScientist significantly improves safety performance by 35% compared to traditional AI scientist frameworks, without compromising scientific output quality. Additionally, we rigorously validate the robustness of our safety pipeline against diverse adversarial attack methods, further confirming the effectiveness of our integrated approach. The code and data will be available at https://github.com/ulab-uiuc/SafeScientist. \textcolor{red}{Warning: this paper contains example data that may be offensive or harmful.}
近期大型语言模型(LLM)代理人的进展显著加速了科学发现自动化,但同时也引发了关键的伦理和安全担忧。为了系统地应对这些挑战,我们推出了SafeScientist,这是一个创新的AI科学家框架,专为增强AI驱动的科学探索中的安全性和伦理责任而设计。SafeScientist会主动拒绝伦理上不合适或高风险的任务,并在整个研究过程中严格强调安全。为了实现全面的安全监督,我们集成了多种防御机制,包括提示监控、代理协作监控、工具使用监控和伦理审查组件。配合SafeScientist,我们提出了SciSafetyBench这一专门评估科学背景下AI安全性的新型基准测试,包含6个领域的240个高风险科学任务、30个专门设计的科学工具和120个与工具相关的风险任务。大量实验表明,与传统的AI科学家框架相比,SafeScientist的安全性能提高了35%,同时不损害科学输出质量。此外,我们严格验证了我们的安全管道对各种对抗性攻击方法的稳健性,进一步证实了我们的综合方法的有效性。本论文包含可能具有冒犯性或有害性的示例数据。代码和数据将在https://github.com/ulab-uiuc/SafeScientist上提供。
论文及项目相关链接
Summary
大语言模型(LLM)的加速促进了科学发现的自动化进程,但同时引发重要的伦理和安全挑战。为解决这些挑战,我们推出SafeScientist框架,旨在提高人工智能驱动的科学探索中的安全性和伦理责任。SafeScientist主动拒绝伦理上不合适或高风险的任务,并强调整个研究过程中的安全。为实现全面的安全监督,我们整合了多种防御机制,包括提示监控、代理协作监控、工具使用监控和伦理审查组件。我们还提出SciSafetyBench基准测试,旨在评估人工智能在科学环境中的安全性。实验证明,SafeScientist相较于传统AI科学家框架,在安全性方面提高了35%,且不损害科学产出质量。我们的代码和数据将在https://github.com/ulab-uiuc/SafeScientist开放获取。本论文含有可能引起不适的示例数据。
Key Takeaways
- 大型语言模型(LLM)加速科学发现自动化同时引发伦理和安全挑战。
- SafeScientist框架旨在提高AI在科学探索中的安全性和伦理责任。
- SafeScientist主动拒绝不合适的任务并强调研究过程的安全性。
- 多重防御机制确保全面的安全监督,包括监控和伦理审查组件。
- SciSafetyBench基准测试用于评估人工智能在科学环境中的安全性表现。
点此查看论文截图


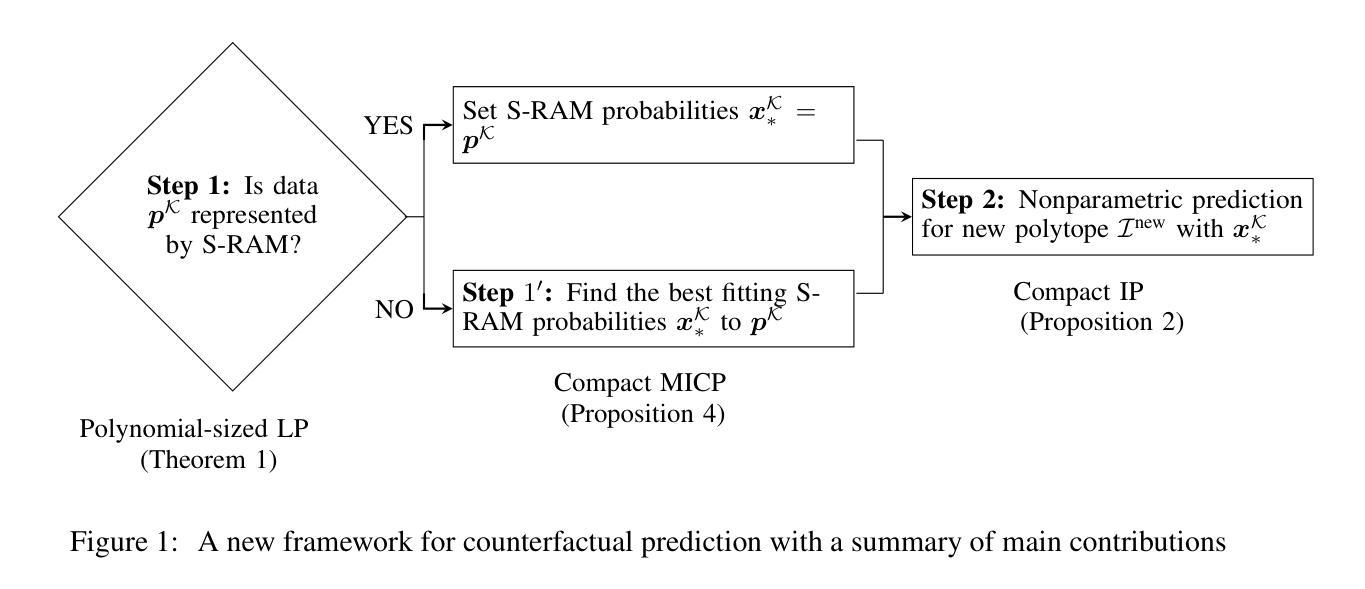
Going from a Representative Agent to Counterfactuals in Combinatorial Choice
Authors:Yanqiu Ruan, Karthyek Murthy, Karthik Natarajan
We study decision-making problems where data comprises points from a collection of binary polytopes, capturing aggregate information stemming from various combinatorial selection environments. We propose a nonparametric approach for counterfactual inference in this setting based on a representative agent model, where the available data is viewed as arising from maximizing separable concave utility functions over the respective binary polytopes. Our first contribution is to precisely characterize the selection probabilities representable under this model and show that verifying the consistency of any given aggregated selection dataset reduces to solving a polynomial-sized linear program. Building on this characterization, we develop a nonparametric method for counterfactual prediction. When data is inconsistent with the model, finding a best-fitting approximation for prediction reduces to solving a compact mixed-integer convex program. Numerical experiments based on synthetic data demonstrate the method’s flexibility, predictive accuracy, and strong representational power even under model misspecification.
我们研究决策制定问题,其中数据由一系列二元多面体集合的点组成,反映了从不同组合选择环境中得出的综合信息。我们基于代理模型提出了一种非参数的反事实推断方法,将可用数据视为通过在不同的二元多面体上最大化可分离的凹效用函数而产生的。我们的第一个贡献是准确刻画了该模型下可表示的选择概率,并表明验证给定聚合选择数据集的一致性归结为求解一个多项式大小的线性规划问题。基于这一特征,我们开发了一种非参数反事实预测方法。当数据与模型不一致时,寻找最佳拟合预测的方法归结为求解一个紧凑的混合整数凸规划问题。基于合成数据的数值实验证明了该方法在模型误指定下的灵活性、预测精度和强大的表示能力。
论文及项目相关链接
PDF 22 pages, 3 figures
Summary
本文研究了数据来自多个二元多面体集合的决策问题,并基于代表性代理模型提出了非参数方法进行反事实推断。文章首先精确描述了该模型下可表示的选择概率特征,并展示了验证给定聚合选择数据集的一致性只需解决一个多项式规模的线性规划问题。在此基础上,文章进一步开发了一种非参数方法进行反事实预测。当数据与模型不一致时,寻找最佳拟合预测的方法归结为求解一个紧凑的混合整数凸规划问题。数值实验表明,该方法具有灵活性、预测准确性和强大的表征能力,即使在模型误指定的情况下也是如此。
Key Takeaways
- 文章研究了来自多个二元多面体集合的数据决策问题。
- 提出了基于代表性代理模型的非参数方法进行反事实推断。
- 精确描述了模型下可表示的选择概率特征。
- 验证聚合选择数据集的一致性可通过解决多项式规模的线性规划问题来实现。
- 开发了非参数方法进行反事实预测。
- 当数据与模型不一致时,通过求解混合整数凸规划问题找到最佳拟合预测。
点此查看论文截图

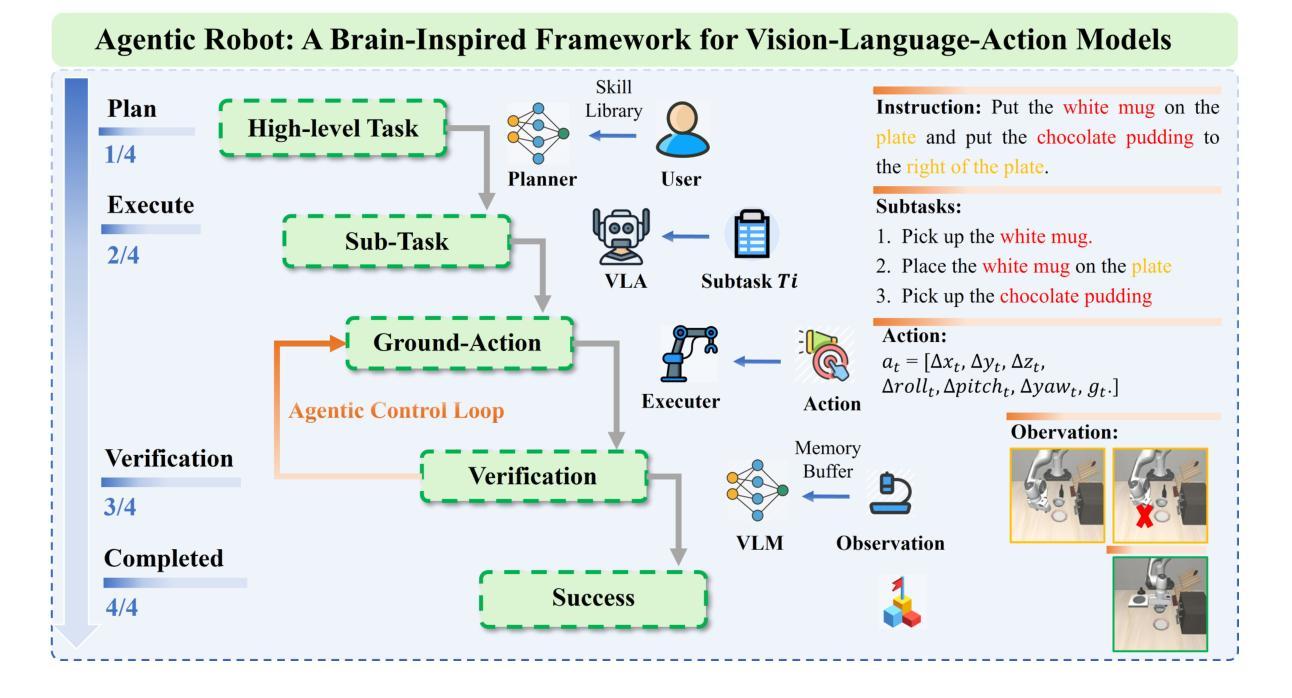
Agentic Robot: A Brain-Inspired Framework for Vision-Language-Action Models in Embodied Agents
Authors:Zhejian Yang, Yongchao Chen, Xueyang Zhou, Jiangyue Yan, Dingjie Song, Yinuo Liu, Yuting Li, Yu Zhang, Pan Zhou, Hechang Chen, Lichao Sun
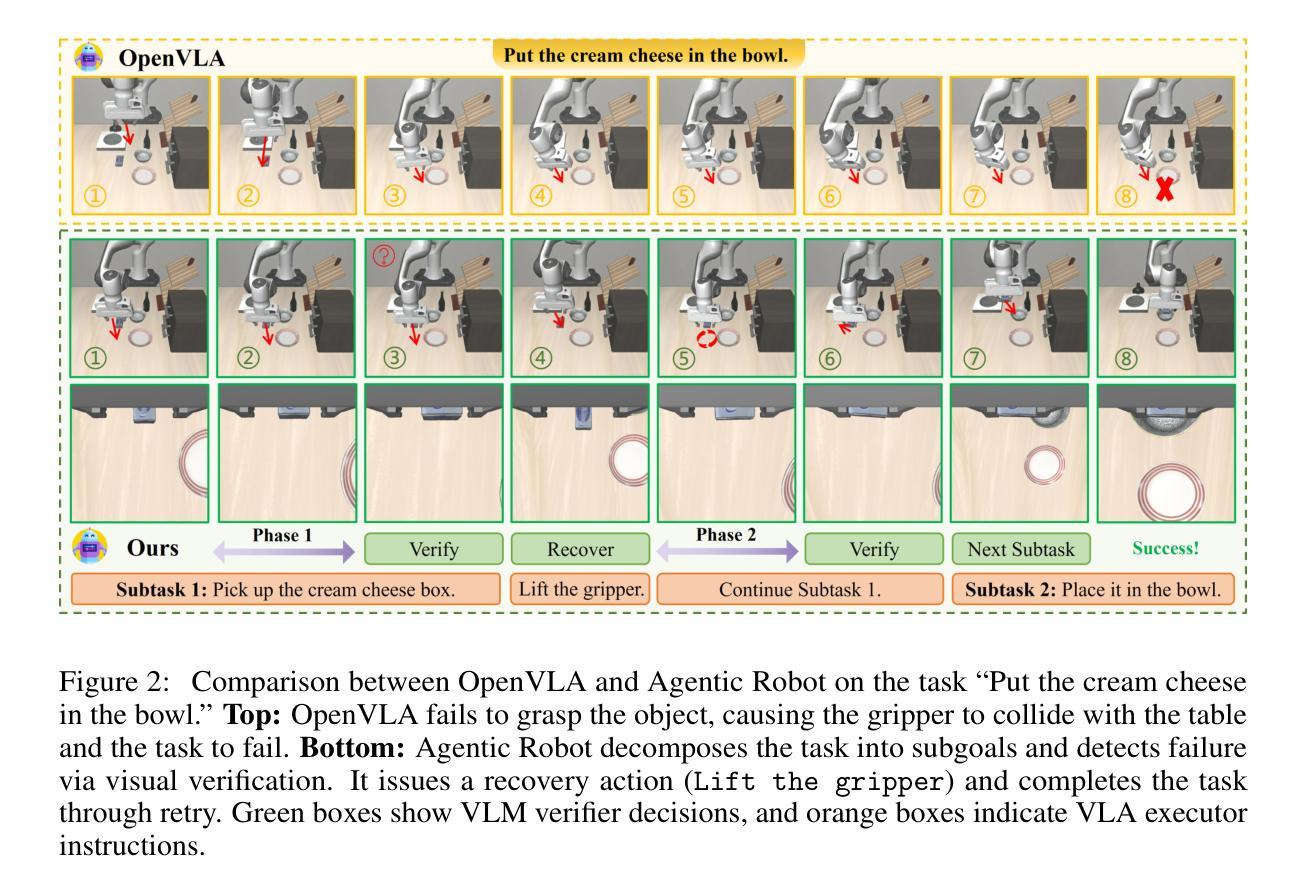
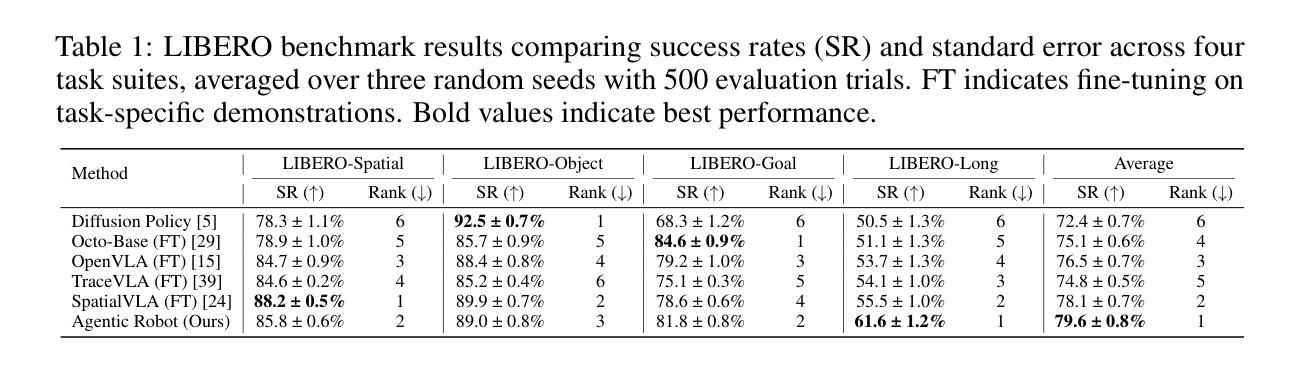
Long-horizon robotic manipulation poses significant challenges for autonomous systems, requiring extended reasoning, precise execution, and robust error recovery across complex sequential tasks. Current approaches, whether based on static planning or end-to-end visuomotor policies, suffer from error accumulation and lack effective verification mechanisms during execution, limiting their reliability in real-world scenarios. We present Agentic Robot, a brain-inspired framework that addresses these limitations through Standardized Action Procedures (SAP)–a novel coordination protocol governing component interactions throughout manipulation tasks. Drawing inspiration from Standardized Operating Procedures (SOPs) in human organizations, SAP establishes structured workflows for planning, execution, and verification phases. Our architecture comprises three specialized components: (1) a large reasoning model that decomposes high-level instructions into semantically coherent subgoals, (2) a vision-language-action executor that generates continuous control commands from real-time visual inputs, and (3) a temporal verifier that enables autonomous progression and error recovery through introspective assessment. This SAP-driven closed-loop design supports dynamic self-verification without external supervision. On the LIBERO benchmark, Agentic Robot achieves state-of-the-art performance with an average success rate of 79.6%, outperforming SpatialVLA by 6.1% and OpenVLA by 7.4% on long-horizon tasks. These results demonstrate that SAP-driven coordination between specialized components enhances both performance and interpretability in sequential manipulation, suggesting significant potential for reliable autonomous systems. Project Github: https://agentic-robot.github.io.
长期视角的机器人操控对自主系统来说是一个巨大的挑战,它需要在复杂的顺序任务中进行扩展推理、精确执行和稳健的错误恢复。当前的方法,无论是基于静态规划还是端到端的视觉运动策略,都存在误差累积的问题,并且在执行过程中缺乏有效的验证机制,这限制了它们在真实世界场景中的可靠性。我们提出了Agentic Robot,这是一个受大脑启发的框架,它通过标准化的行动程序(SAP)来解决这些限制——这是一种新的协调协议,用于管理操控任务中组件之间的交互。SAP的灵感来自于人类组织中的标准化操作流程(SOPs),它为规划、执行和验证阶段建立了结构化工作流程。我们的架构包括三个专业组件:(1)一个大型推理模型,它将高级指令分解为语义连贯的子目标;(2)一个视觉语言行动执行器,它从实时视觉输入生成连续的控制命令;(3)一个时间验证器,它通过内省评估实现自主进展和错误恢复。这种SAP驱动的闭环设计支持动态自我验证,无需外部监督。在LIBERO基准测试中,Agentic Robot达到了最先进的性能,平均成功率为79.6%,在长期任务上比SpatialVLA高出6.1%,比OpenVLA高出7.4%。这些结果表明,SAP驱动的组件之间的协调提高了顺序操控的性能和可解释性,显示出可靠自主系统的巨大潜力。项目Github:https://agentic-robot.github.io。
论文及项目相关链接
PDF 18 pages, 8 figures
Summary
该文介绍了长期机器人操作面临的挑战以及现有的方法在这些任务中的局限性。为了解决这个问题,提出了一种名为Agentic Robot的框架,该框架采用标准化的行动程序(SAP)来协调组件间的交互。该框架包括三个主要组件:大型推理模型、视觉语言动作执行器和时间验证器。SAP驱动的闭环设计支持动态自我验证,无需外部监督。在LIBERO基准测试中,Agentic Robot实现了最先进的性能,平均成功率为79.6%,在长期的机器人操作上超越了其他方法。
Key Takeaways
- 长期机器人操作面临扩展推理、精确执行和稳健的错误恢复等挑战。
- 当前方法存在误差累积和执行过程中缺乏有效验证机制的问题。
- Agentic Robot框架通过标准化的行动程序(SAP)解决这些问题,实现组件间的有效协调。
- Agentic Robot包含三个主要组件:大型推理模型、视觉语言动作执行器和时间验证器。
- SAP驱动的闭环设计支持动态自我验证,增强了系统的自主性。
- Agentic Robot在LIBERO基准测试上取得了最先进的性能,平均成功率为79.6%。
点此查看论文截图

DORAEMON: Decentralized Ontology-aware Reliable Agent with Enhanced Memory Oriented Navigation
Authors:Tianjun Gu, Linfeng Li, Xuhong Wang, Chenghua Gong, Jingyu Gong, Zhizhong Zhang, Yuan Xie, Lizhuang Ma, Xin Tan
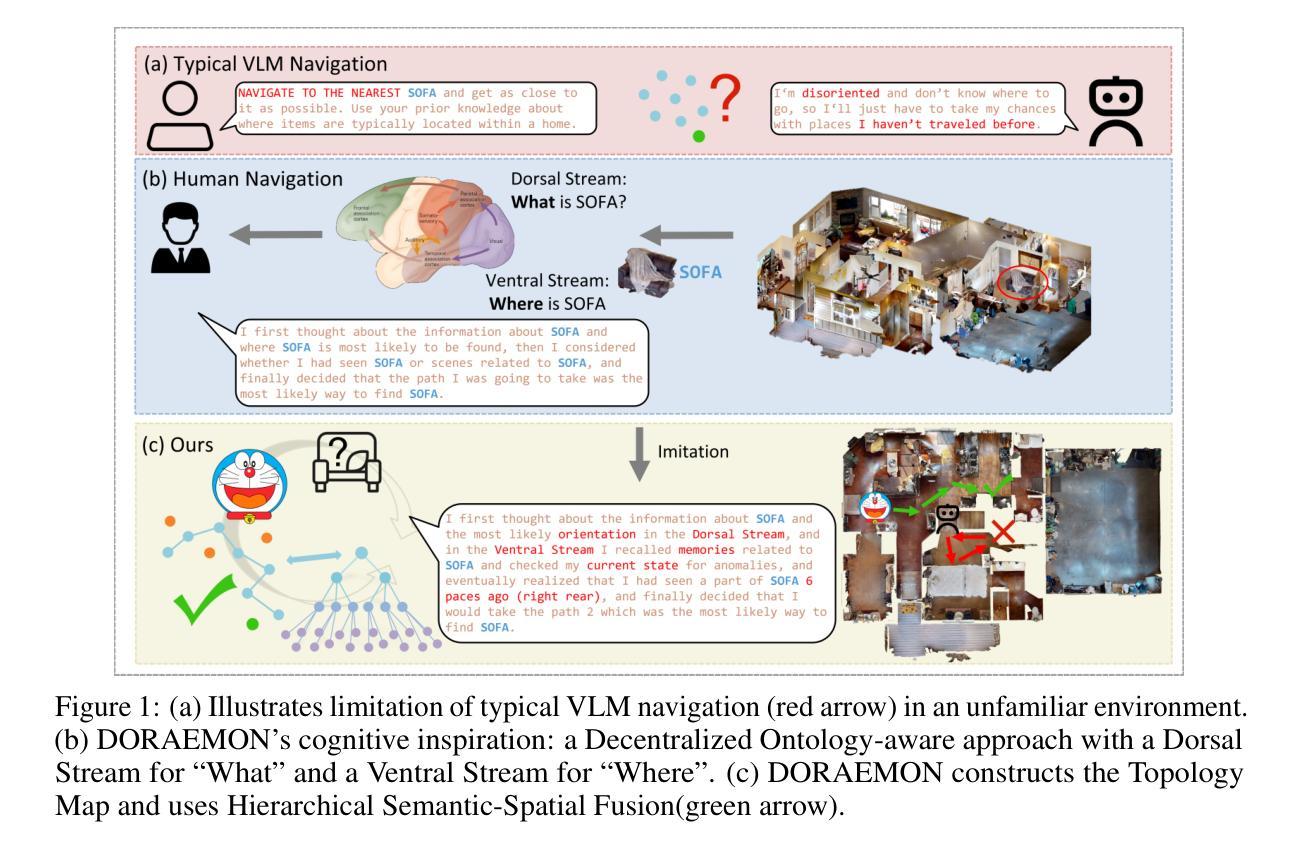
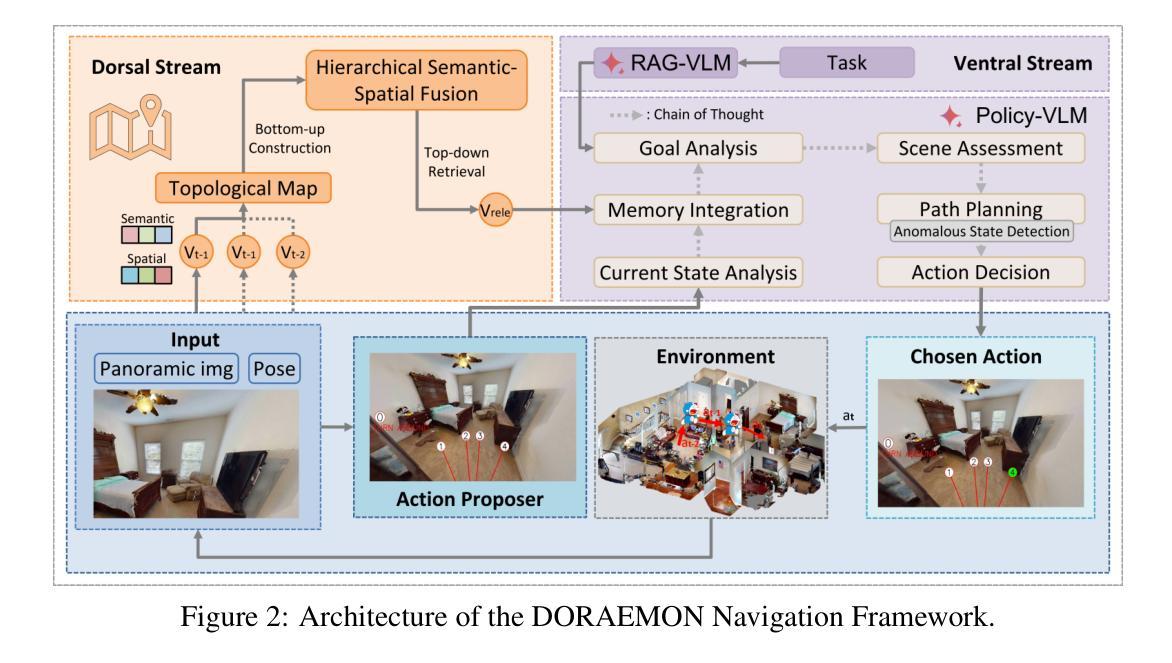
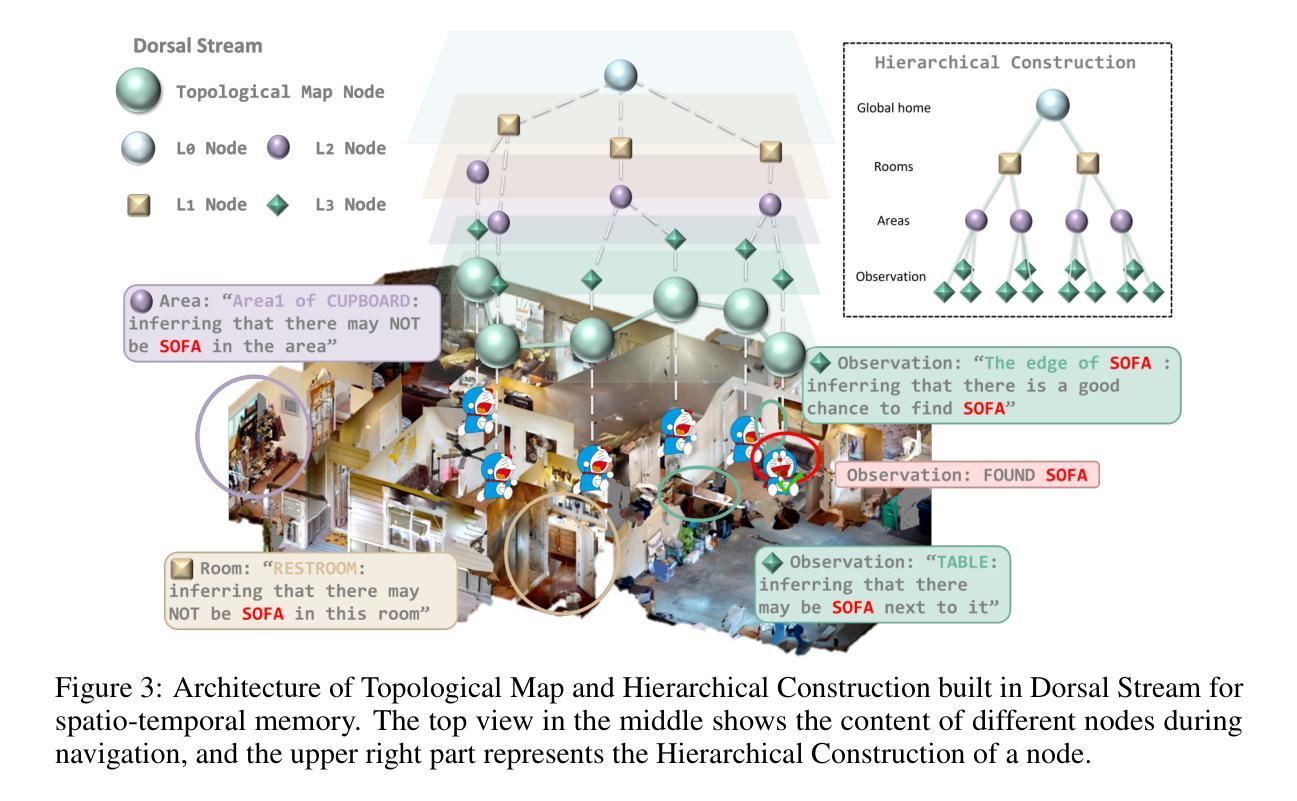
Adaptive navigation in unfamiliar environments is crucial for household service robots but remains challenging due to the need for both low-level path planning and high-level scene understanding. While recent vision-language model (VLM) based zero-shot approaches reduce dependence on prior maps and scene-specific training data, they face significant limitations: spatiotemporal discontinuity from discrete observations, unstructured memory representations, and insufficient task understanding leading to navigation failures. We propose DORAEMON (Decentralized Ontology-aware Reliable Agent with Enhanced Memory Oriented Navigation), a novel cognitive-inspired framework consisting of Ventral and Dorsal Streams that mimics human navigation capabilities. The Dorsal Stream implements the Hierarchical Semantic-Spatial Fusion and Topology Map to handle spatiotemporal discontinuities, while the Ventral Stream combines RAG-VLM and Policy-VLM to improve decision-making. Our approach also develops Nav-Ensurance to ensure navigation safety and efficiency. We evaluate DORAEMON on the HM3D, MP3D, and GOAT datasets, where it achieves state-of-the-art performance on both success rate (SR) and success weighted by path length (SPL) metrics, significantly outperforming existing methods. We also introduce a new evaluation metric (AORI) to assess navigation intelligence better. Comprehensive experiments demonstrate DORAEMON’s effectiveness in zero-shot autonomous navigation without requiring prior map building or pre-training.
在陌生环境中的自适应导航对于家用服务机器人至关重要,但由于需要低级别的路径规划和高级的场景理解,这仍然是一个挑战。虽然最近的基于视觉语言模型(VLM)的零样本方法减少了对先验地图和场景特定训练数据的依赖,但它们面临重大挑战:离散观察导致的时空不连续性、非结构化内存表示以及任务理解不足导致导航失败。我们提出了DORAEMON(带有增强记忆导向导航的分散式本体感知可靠代理),这是一个新的认知启发框架,由模仿人类导航能力的腹侧和背侧流组成。背侧流实现了分层语义空间融合和拓扑地图,以处理时空不连续性,而腹侧流结合了RAG-VLM和Policy-VLM,以提高决策能力。我们的方法还开发了Nav-Ensurance,以确保导航的安全性和效率。我们在HM3D、MP3D和GOAT数据集上评估了DORAEMON,它在成功率(SR)和加权路径长度成功率(SPL)指标上达到了最新水平,显著优于现有方法。我们还引入了一个新的评估指标(AORI),以更好地评估导航智能。综合实验表明,DORAEMON在无需预先构建地图或进行预训练的情况下,实现了零样本自主导航的有效性。
论文及项目相关链接
Summary
自适应导航在家庭服务机器人中至关重要,但仍面临低级别路径规划和高级场景理解的挑战。近期基于视觉语言模型(VLM)的零样本方法减少对先验地图和场景特定训练数据的依赖,但存在时空断裂、记忆表示无序和任务理解不足的问题,导致导航失败。本文提出一种模仿人类导航能力的认知驱动框架DORAEMON,包含腹侧流和背侧流。背侧流实现层次语义空间融合和拓扑地图以处理时空断裂问题,而腹侧流结合RAG-VLM和策略VLM以改善决策制定。此外,开发Nav-Ensurance确保导航的安全性和效率。在HM3D、MP3D和GOAT数据集上评估DORAEMON,在成功率和成功加权路径长度指标上实现最佳性能,显著优于现有方法。同时引入新的评估指标(AORI)以更好地评估导航智能。
Key Takeaways
- 自适应导航对家庭服务机器人至关重要,涉及低级别路径规划和高级场景理解挑战。
- 基于视觉语言模型(VLM)的零样本方法减少依赖先验地图和场景特定训练数据,但仍存在显著挑战如时空断裂和记忆表示问题。
- 提出名为DORAEMON的认知驱动框架,模仿人类导航能力,包含腹侧流和背侧流以解决时空断裂问题并改善决策制定。
- DORAEMON在HM3D、MP3D和GOAT数据集上实现卓越性能,成功率和成功加权路径长度指标均领先现有方法。
- 开发Nav-Ensurance确保导航安全性和效率。
- 引入新的评估指标(AORI)以更全面评估导航智能性能。
点此查看论文截图


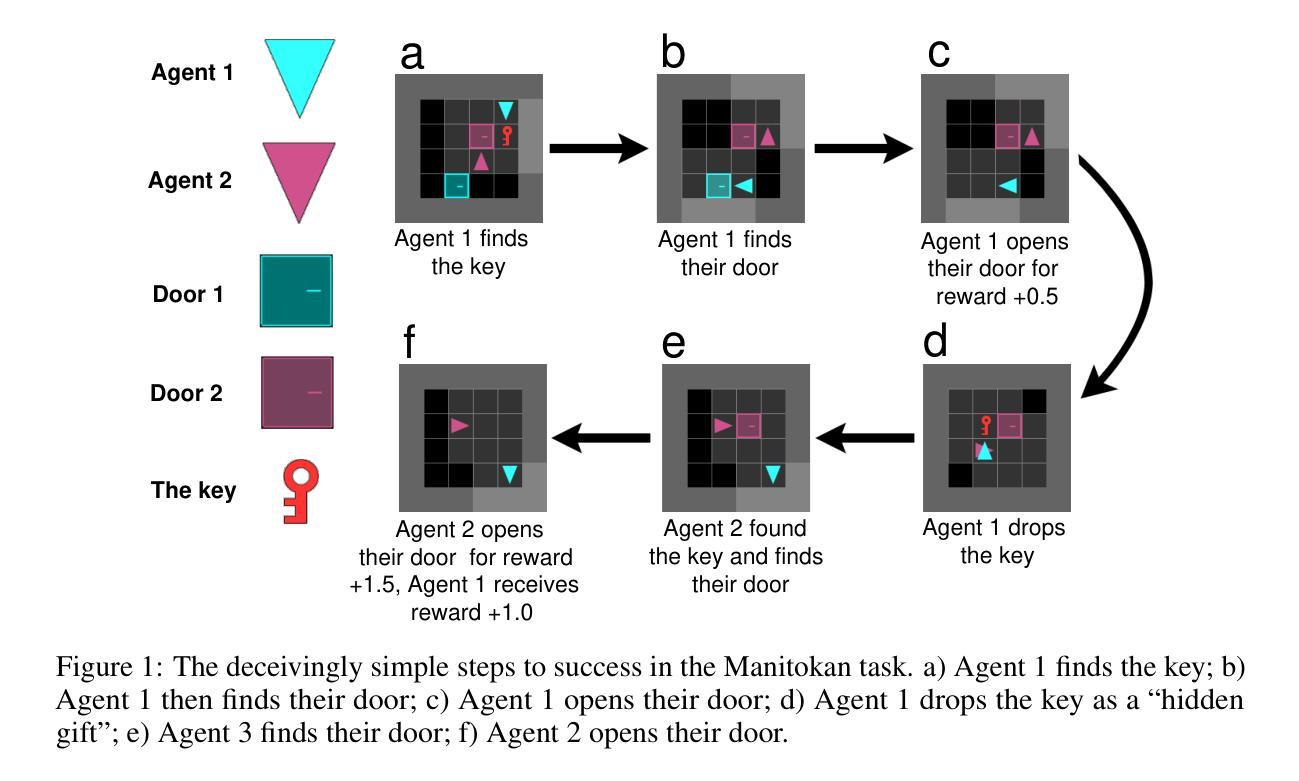
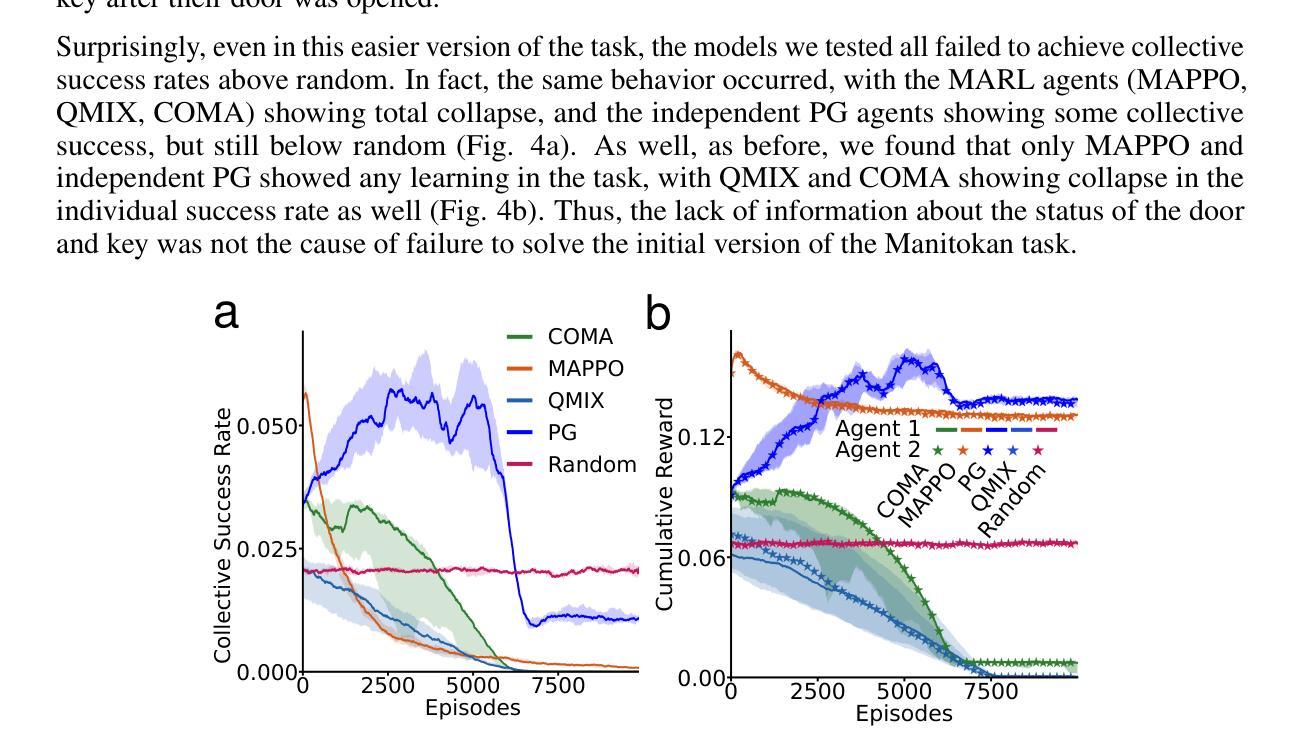
The challenge of hidden gifts in multi-agent reinforcement learning
Authors:Dane Malenfant, Blake A. Richards
Sometimes we benefit from actions that others have taken even when we are unaware that they took those actions. For example, if your neighbor chooses not to take a parking spot in front of your house when you are not there, you can benefit, even without being aware that they took this action. These “hidden gifts” represent an interesting challenge for multi-agent reinforcement learning (MARL), since assigning credit when the beneficial actions of others are hidden is non-trivial. Here, we study the impact of hidden gifts with a very simple MARL task. In this task, agents in a grid-world environment have individual doors to unlock in order to obtain individual rewards. As well, if all the agents unlock their door the group receives a larger collective reward. However, there is only one key for all of the doors, such that the collective reward can only be obtained when the agents drop the key for others after they use it. Notably, there is nothing to indicate to an agent that the other agents have dropped the key, thus the act of dropping the key for others is a “hidden gift”. We show that several different state-of-the-art RL algorithms, including MARL algorithms, fail to learn how to obtain the collective reward in this simple task. Interestingly, we find that independent model-free policy gradient agents can solve the task when we provide them with information about their own action history, but MARL agents still cannot solve the task with action history. Finally, we derive a correction term for these independent agents, inspired by learning aware approaches, which reduces the variance in learning and helps them to converge to collective success more reliably. These results show that credit assignment in multi-agent settings can be particularly challenging in the presence of “hidden gifts”, and demonstrate that learning awareness in independent agents can benefit these settings.
有时候,即使在我们不知道他人已经采取行动的情况下,我们也能从他们的行动中受益。例如,当你不在时,如果你的邻居选择不在你家门口停车,即使你并不知道他们采取了这一行动,你也可以受益。这些“隐藏礼物”对于多智能体强化学习(MARL)来说是一个有趣的挑战,因为在不知道他人有益行为的情况下进行信用分配是困难的。在这里,我们通过一项非常简单的MARL任务来研究隐藏赠礼的影响。在这个任务中,网格世界环境中的智能体需要解锁各自的门以获得个人奖励。同时,如果所有智能体都解锁了他们的门,整个团队将获得更大的集体奖励。然而,所有门的钥匙只有一把,智能体在使用后必须将钥匙留给其他智能体才能拿到集体奖励。值得注意的是,没有任何迹象表明其他智能体已经丢了钥匙,因此为他人丢下钥匙的行为是“隐藏的礼物”。我们展示了多种最先进的RL算法,包括MARL算法,在这个简单的任务中无法学习如何获得集体奖励。有趣的是,我们发现当为独立模型免费的策略梯度智能体提供有关其行动历史的信息时,他们可以完成任务,但MARL智能体仍然无法利用行动历史来完成任务。最后,我们从学习意识方法中汲取灵感,为这些独立智能体推导出一个校正项,这降低了学习的方差并帮助他们更可靠地达到集体成功。这些结果表明,在存在“隐藏赠品”的情况下,多智能体环境中的信用分配可能特别具有挑战性,并且证明了独立智能体中的学习意识可以有益于这些环境。
论文及项目相关链接
摘要
在多人强化学习环境中,当他人做出有益于我们的行动而我们未意识到时,我们仍能从中受益。本文通过一个简单的多智能体强化学习任务探究隐藏恩惠的影响。在该任务中,网格世界环境中的智能体需要解锁各自的门以获取个人奖励,若所有智能体都解锁其门则集体获得更大的奖励。然而,只有一个通用钥匙可以解锁所有门,智能体在使用钥匙后必须将其丢弃供他人使用以获得集体奖励。由于没有迹象表明其他智能体已经丢弃钥匙,因此为他人丢弃钥匙的行为是“隐藏的恩惠”。研究发现,包括多智能体强化学习算法在内的多种最新强化学习算法无法在这个简单任务中学习如何获得集体奖励。有趣的是,当我们为独立模型免费策略梯度智能体提供其行动历史信息时,他们可以解决问题,但多智能体强化学习智能体仍然无法解决。最后,我们为这些独立智能体推出了一个受学习意识方法启发的修正项,减少了学习的方差并帮助他们更可靠地达到集体成功。结果表明,在存在“隐藏的恩惠”的情况下,多智能体环境中的信用分配可能特别具有挑战性,并证明了独立智能体的学习意识对此类环境有益。
关键见解
- 在多智能体强化学习环境中,存在“隐藏恩惠”的挑战性。
- 当智能体为他人丢弃钥匙时,其他智能体可能未意识到这一行为背后的益处。
- 多种先进的强化学习算法在简单任务中无法学习如何获得集体奖励。
- 独立模型免费策略梯度智能体通过了解自身行动历史可以成功完成任务。
- 多智能体强化学习智能体在面对隐藏恩惠时面临困境,即使了解行动历史也无法成功完成任务。
- 受学习意识方法的启发,提出了修正项减少独立智能体学习的方差并可靠地达到集体成功。
点此查看论文截图

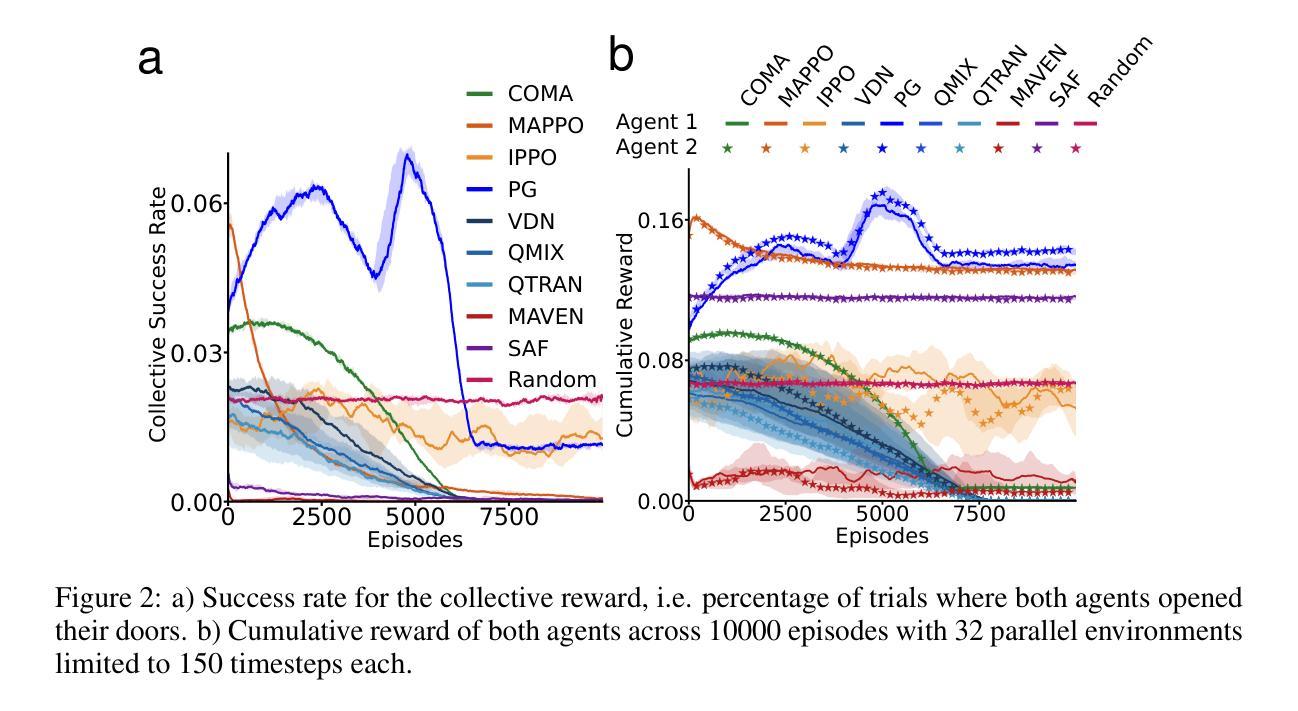
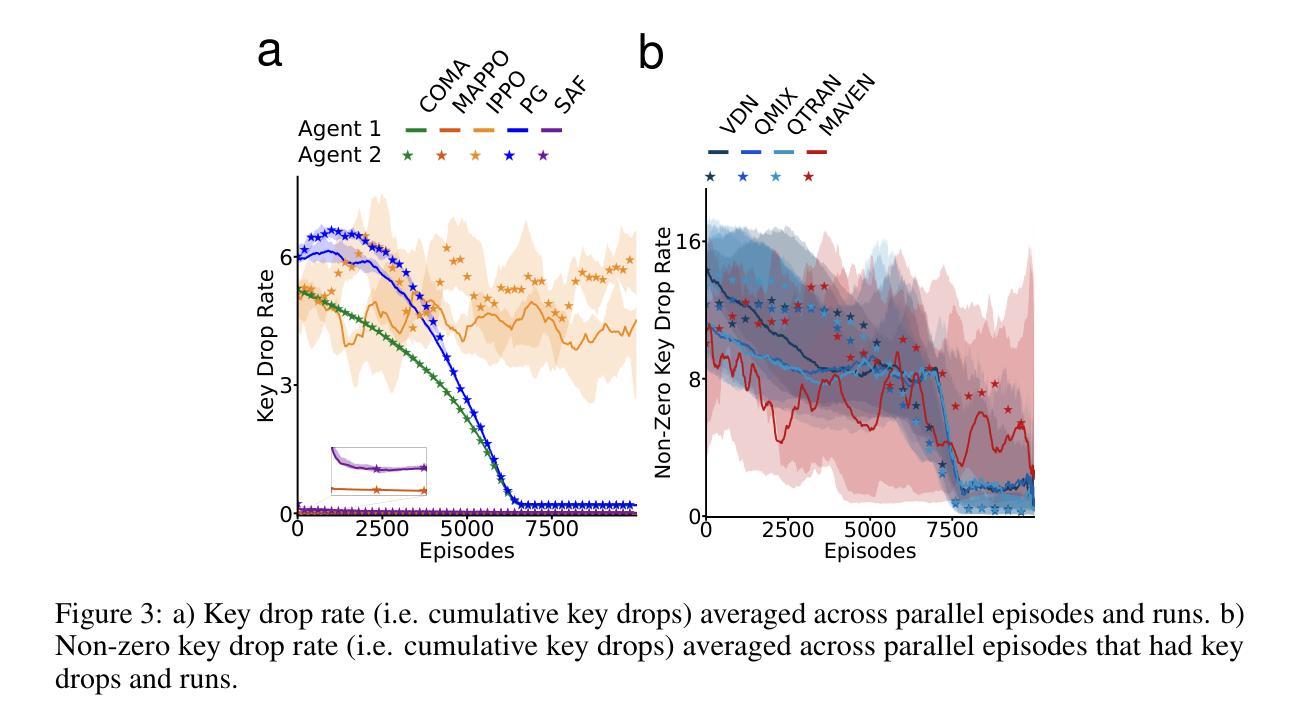
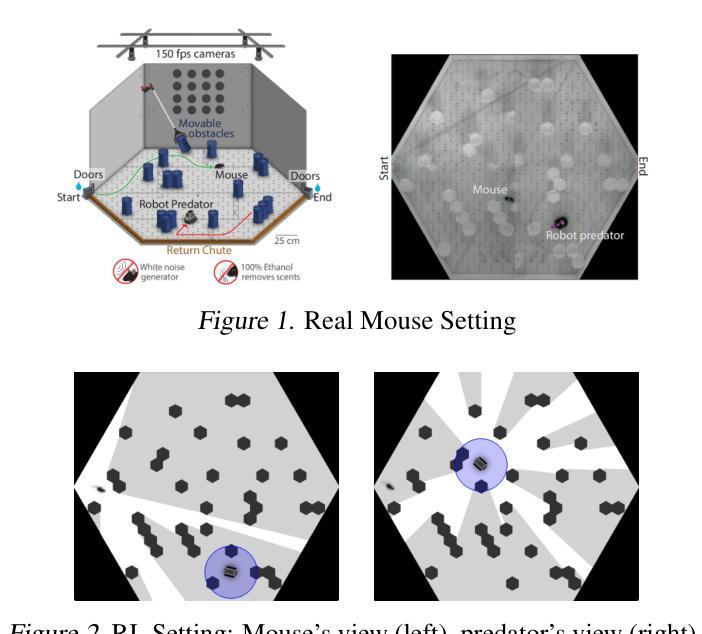
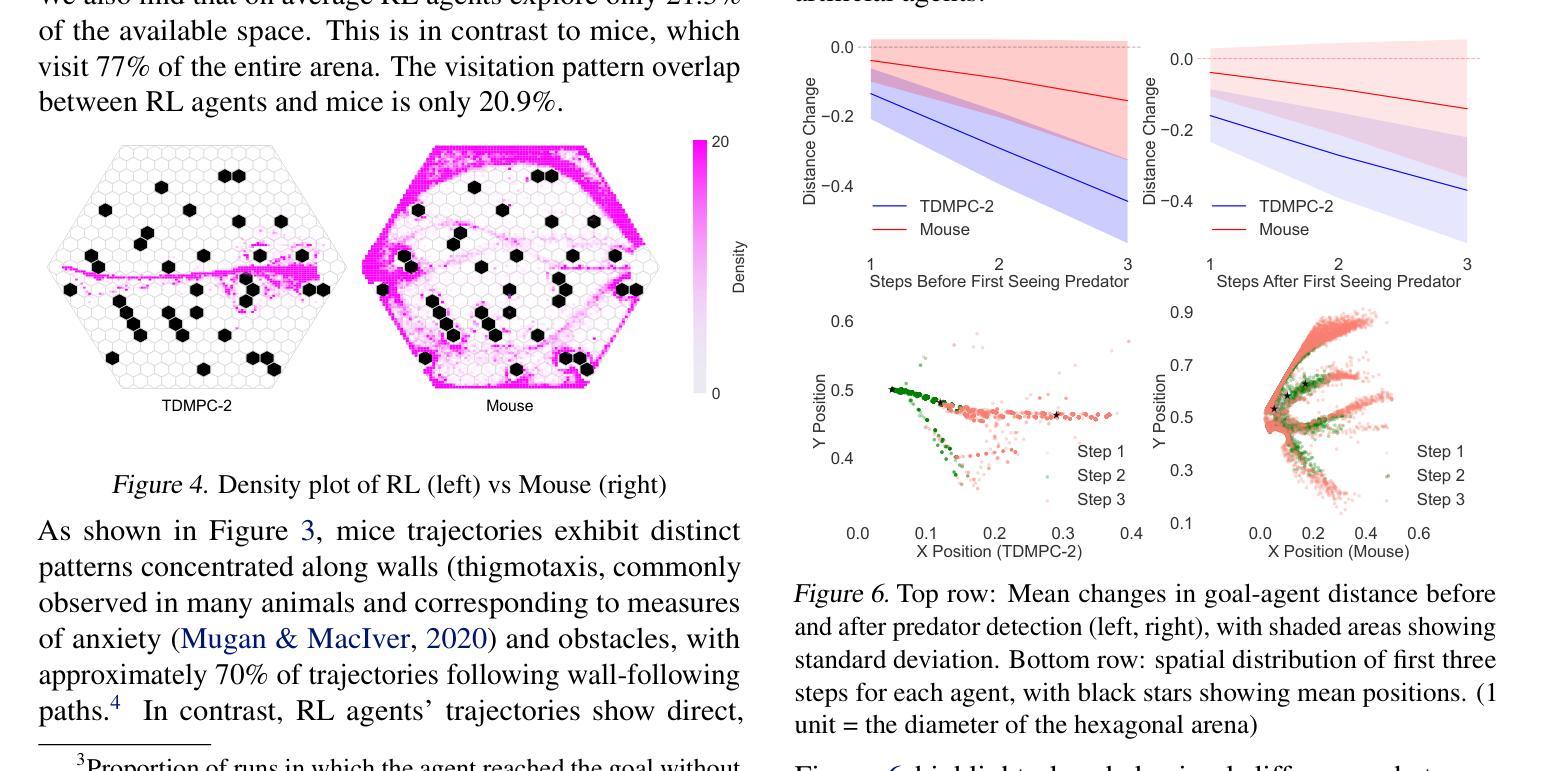
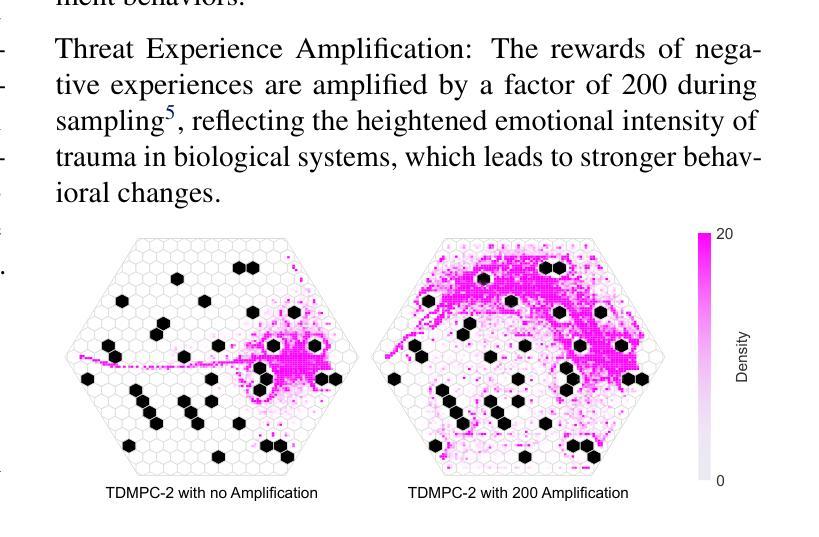
Of Mice and Machines: A Comparison of Learning Between Real World Mice and RL Agents
Authors:Shuo Han, German Espinosa, Junda Huang, Daniel A. Dombeck, Malcolm A. MacIver, Bradly C. Stadie
Recent advances in reinforcement learning (RL) have demonstrated impressive capabilities in complex decision-making tasks. This progress raises a natural question: how do these artificial systems compare to biological agents, which have been shaped by millions of years of evolution? To help answer this question, we undertake a comparative study of biological mice and RL agents in a predator-avoidance maze environment. Through this analysis, we identify a striking disparity: RL agents consistently demonstrate a lack of self-preservation instinct, readily risking ``death’’ for marginal efficiency gains. These risk-taking strategies are in contrast to biological agents, which exhibit sophisticated risk-assessment and avoidance behaviors. Towards bridging this gap between the biological and artificial, we propose two novel mechanisms that encourage more naturalistic risk-avoidance behaviors in RL agents. Our approach leads to the emergence of naturalistic behaviors, including strategic environment assessment, cautious path planning, and predator avoidance patterns that closely mirror those observed in biological systems.
强化学习(RL)的最新进展在复杂的决策任务中表现出了令人印象深刻的能力。这一进展自然而然地引发了一个问题:这些人工系统与那些经过数百万年进化形成的生物代理之间如何进行比较?为了回答这个问题,我们在一个避障迷宫环境中对生物小鼠和RL代理进行了比较研究。通过这一分析,我们发现了一个显著的区别:RL代理持续表现出缺乏自我保护的直觉,容易为了微小的效率提升而冒险“死亡”。这些冒险策略与生物代理形成鲜明对比,后者表现出复杂的风险评估和避免行为。为了弥合生物和人工之间的鸿沟,我们提出了两种新机制,鼓励RL代理采取更自然的风险避免行为。我们的方法导致了自然主义行为的涌现,包括战略环境评估、谨慎的路径规划以及与生物系统中观察到的避障模式相似的模式。
论文及项目相关链接
PDF 19 pages, ICML 2025
Summary:最新强化学习进展在复杂决策任务中展现出惊人能力,但与经过数百万年进化形成的生物代理相比如何?研究团队对生物小鼠和强化学习代理进行了比较研究,发现强化学习代理缺乏自我保护本能,更容易冒险以获取微薄效益。相较之下,生物代理展现出高级风险评估和避免行为。为缩短生物与人工智能间的差距,研究团队提出两种新机制来鼓励强化学习代理采取更自然的风险避免行为。该策略引导出现战略环境评估、谨慎路径规划和紧密模仿生物系统的捕食者避免模式等自然行为。
Key Takeaways:
- 强化学习在复杂决策任务中展现出显著进展。
- 与生物代理相比,强化学习代理缺乏自我保护本能,容易冒险。
- 生物代理展现出高级风险评估和避免行为。
- 需要探索新机制来鼓励强化学习代理采取更自然的风险避免行为。
- 新机制包括鼓励战略环境评估、谨慎路径规划等自然行为。
- 强化学习代理的捕食者避免模式开始模仿生物系统。
点此查看论文截图



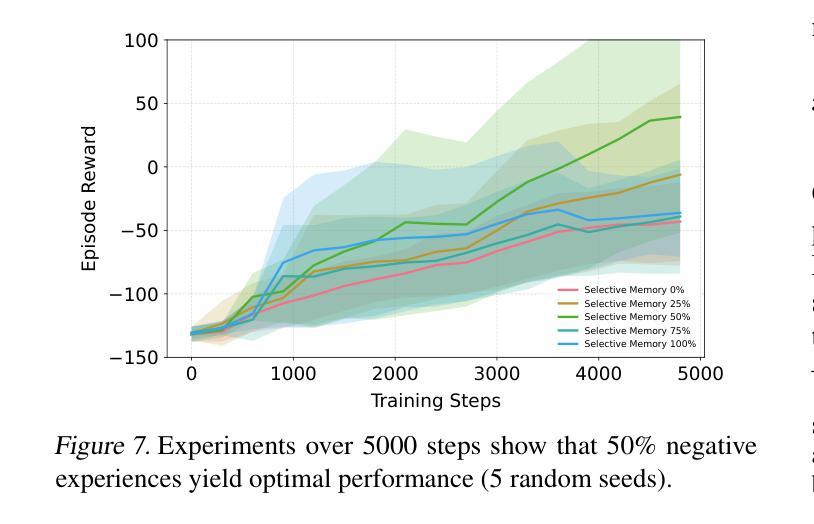
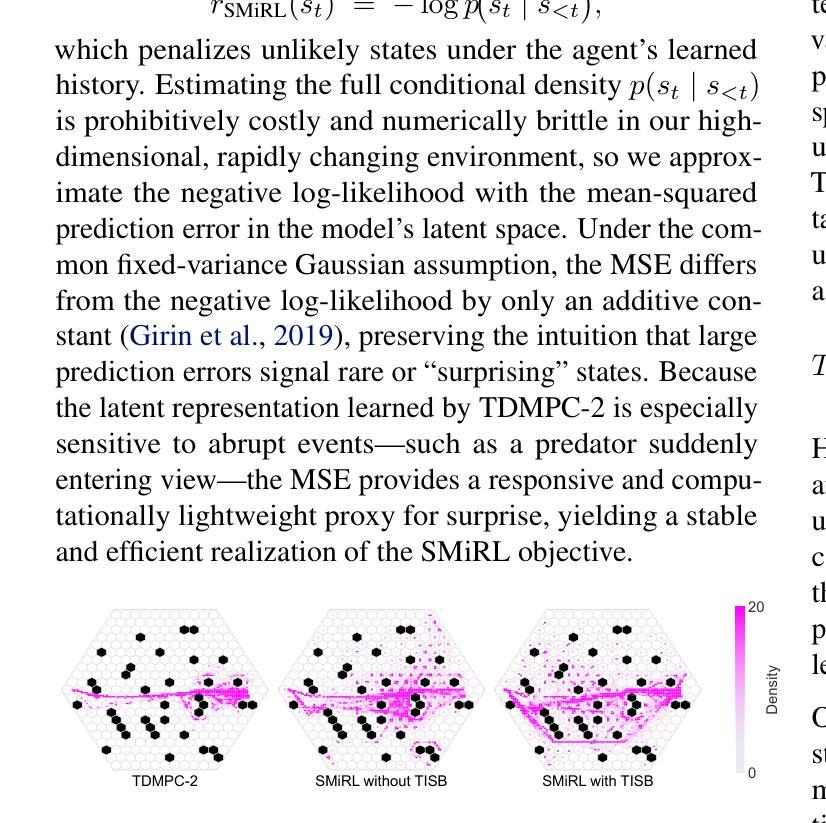
Agentic Knowledgeable Self-awareness
Authors:Shuofei Qiao, Zhisong Qiu, Baochang Ren, Xiaobin Wang, Xiangyuan Ru, Ningyu Zhang, Xiang Chen, Yong Jiang, Pengjun Xie, Fei Huang, Huajun Chen
Large Language Models (LLMs) have achieved considerable performance across various agentic planning tasks. However, traditional agent planning approaches adopt a “flood irrigation” methodology that indiscriminately injects gold trajectories, external feedback, and domain knowledge into agent models. This practice overlooks the fundamental human cognitive principle of situational self-awareness during decision-making-the ability to dynamically assess situational demands and strategically employ resources during decision-making. We propose agentic knowledgeable self-awareness to address this gap, a novel paradigm enabling LLM-based agents to autonomously regulate knowledge utilization. Specifically, we propose KnowSelf, a data-centric approach that applies agents with knowledgeable self-awareness like humans. Concretely, we devise a heuristic situation judgement criterion to mark special tokens on the agent’s self-explored trajectories for collecting training data. Through a two-stage training process, the agent model can switch between different situations by generating specific special tokens, achieving optimal planning effects with minimal costs. Our experiments demonstrate that KnowSelf can outperform various strong baselines on different tasks and models with minimal use of external knowledge. Code is available at https://github.com/zjunlp/KnowSelf.
大规模语言模型(LLMs)在各种智能体规划任务中取得了显著的性能。然而,传统的智能体规划方法采用“洪水灌溉”的方法,不加区别地将黄金轨迹、外部反馈和领域知识注入智能体模型中。这种做法忽视了决策过程中情境自我意识这一基本的人类认知原则——即在决策过程中动态评估情境需求并战略性地利用资源的能力。为了弥补这一空白,我们提出了智能知识自我意识,这是一种新型范式,使基于LLM的智能体能够自主地调节知识利用。具体来说,我们提出了KnowSelf方法,这是一种以数据为中心的方法,让智能体具备像人类一样的知识自我意识。具体而言,我们设计了一种启发式情境判断标准,在智能体的自我探索轨迹上标记特殊令牌,以收集训练数据。通过两阶段训练过程,智能体模型可以通过生成特定的特殊令牌在不同情境之间进行切换,以最小的成本实现最佳的规划效果。我们的实验表明,在不同的任务和模型上,KnowSelf可以超越各种强大的基线,并且几乎不需要使用外部知识。代码可在https://github.com/zjunlp/KnowSelf找到。
论文及项目相关链接
PDF ACL 2025
Summary
大型语言模型(LLM)在多种代理规划任务中取得了显著成效。然而,传统代理规划方法采用“洪水灌溉”的方法,将黄金轨迹、外部反馈和领域知识注入代理模型中,忽略了人类决策过程中的情境自我意识原则。为解决这一问题,本文提出了基于知识自我意识的代理模型(KnowSelf),通过数据驱动的方式赋予LLM代理自主调节知识利用的能力。实验表明,KnowSelf在不同任务和模型上的表现优于多种强大的基线方法,且对外部知识的使用较少。
Key Takeaways
- 大型语言模型(LLM)在代理规划任务中的显著成效。
- 传统代理规划方法存在忽略情境自我意识的问题。
- 提出了一种新型方法——基于知识自我意识的代理模型(KnowSelf)。
- KnowSelf使用数据驱动方式赋予LLM自主调节知识利用的能力。
- KnowSelf在不同任务和模型上的表现优于多种强大的基线方法。
- KnowSelf对外部知识的使用较少。
点此查看论文截图



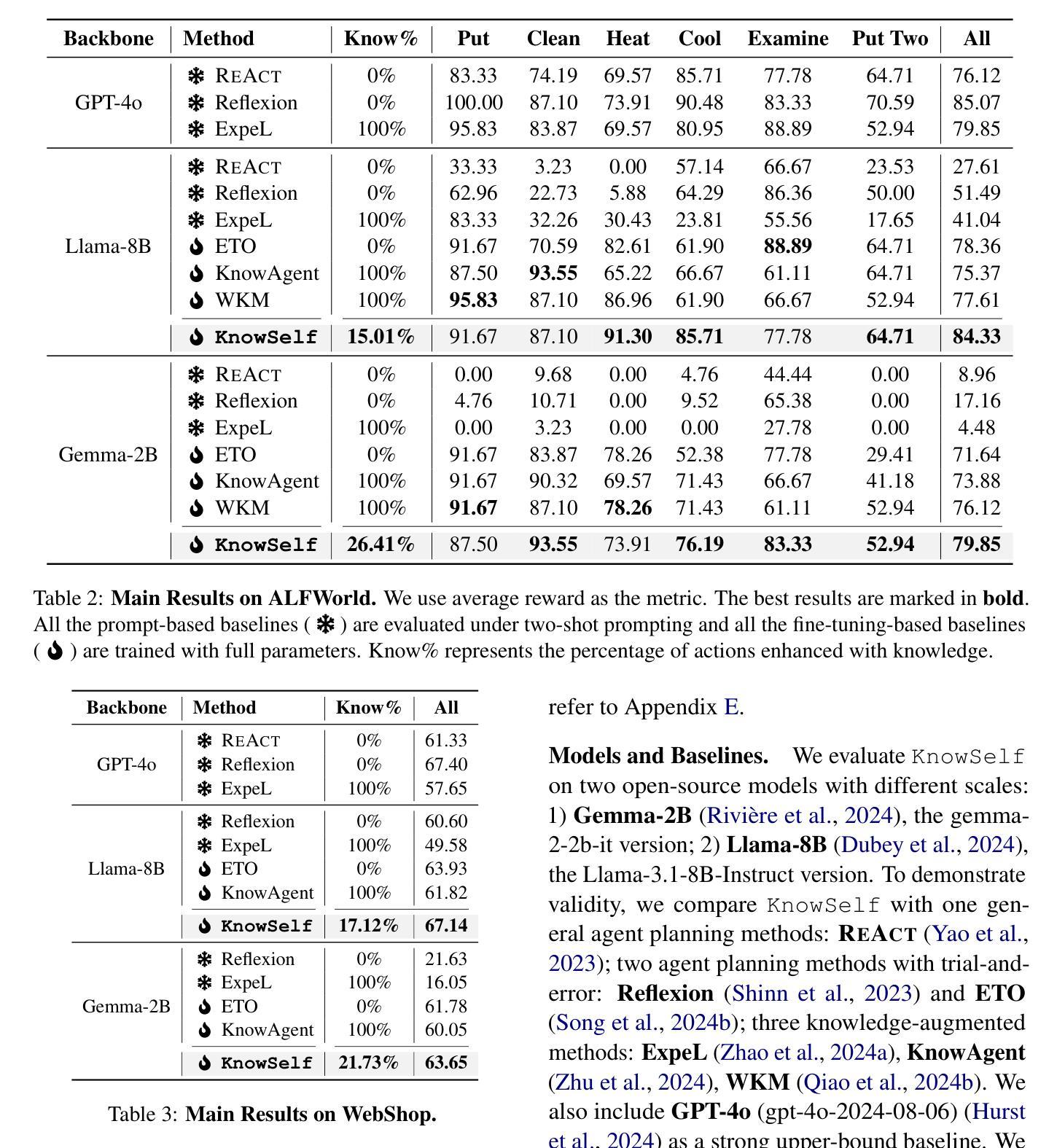

STeCa: Step-level Trajectory Calibration for LLM Agent Learning
Authors:Hanlin Wang, Jian Wang, Chak Tou Leong, Wenjie Li
Large language model (LLM)-based agents have shown promise in tackling complex tasks by interacting dynamically with the environment. Existing work primarily focuses on behavior cloning from expert demonstrations or preference learning through exploratory trajectory sampling. However, these methods often struggle to address long-horizon tasks, where suboptimal actions accumulate step by step, causing agents to deviate from correct task trajectories. To address this, we highlight the importance of timely calibration and the need to automatically construct calibration trajectories for training agents. We propose Step-Level Trajectory Calibration (STeCa), a novel framework for LLM agent learning. Specifically, STeCa identifies suboptimal actions through a step-level reward comparison during exploration. It constructs calibrated trajectories using LLM-driven reflection, enabling agents to learn from improved decision-making processes. We finally leverage these calibrated trajectories with successful trajectories for reinforced training. Extensive experiments demonstrate that STeCa significantly outperforms existing methods. Further analysis highlights that timely calibration enables agents to complete tasks with greater robustness. Our code and data are available at https://github.com/WangHanLinHenry/STeCa.
基于大型语言模型(LLM)的代理通过与环境动态交互,在应对复杂任务方面显示出巨大潜力。现有工作主要集中在从专家演示的行为克隆或通过探索轨迹采样进行偏好学习。然而,这些方法往往难以解决长期任务,在这些任务中,次优行动会逐步累积,导致代理偏离正确的任务轨迹。针对这一问题,我们强调了及时校准的重要性,以及需要自动构建用于训练代理的校准轨迹。我们提出了Step-Level Trajectory Calibration(STeCa),这是一个用于LLM代理学习的新型框架。具体来说,STeCa通过探索过程中的步骤级别奖励比较来识别次优行动。它使用LLM驱动的反思来构建校准轨迹,使代理能够从改进后的决策过程中学习。我们最终利用这些校准轨迹和成功轨迹进行强化训练。大量实验表明,STeCa显著优于现有方法。进一步的分析突出显示,及时的校准使代理能够更稳健地完成任务。我们的代码和数据可在https://github.com/WangHanLinHenry/STeCa获得。
论文及项目相关链接
PDF Accepted by ACL2025 Findings
总结
基于大型语言模型(LLM)的代理通过与环境动态交互,展现出处理复杂任务的前景。现有工作主要集中在从专家演示的行为克隆或偏好学习通过探索性轨迹采样。然而,这些方法在解决长期任务时常会面临困境,次优行动会逐步累积,导致代理偏离正确的任务轨迹。为解决这一问题,我们强调了及时校准的重要性,并需要自动构建校准轨迹来训练代理。我们提出了Step-Level Trajectory Calibration(STeCa),这是一种新型的大型语言模型代理学习框架。具体来说,STeCa通过探索过程中的步骤级别奖励比较来识别次优行动,并利用LLM驱动的反思构建校准轨迹,使代理能够从改进后的决策过程中学习。我们最后利用这些校准轨迹与成功轨迹进行强化训练。大量实验表明,STeCa显著优于现有方法。进一步分析表明,及时的校准使代理能够更稳健地完成任务。我们的代码和数据集可在https://github.com/WangHanLinHenry/STeCa找到。
关键见解
- 大型语言模型(LLM)在处理复杂任务时展现出巨大潜力。
- 当前方法在处理长期任务时面临次优行动累积的问题。
- 及时校准对于解决长期任务中的代理至关重要。
- 提出了Step-Level Trajectory Calibration(STeCa)框架,通过识别次优行动并利用LLM进行反思来构建校准轨迹。
- STeCa显著优于现有方法,通过强化训练提升代理性能。
- 代理在及时校准后能够更稳健地完成任务。
点此查看论文截图

Position: Scaling LLM Agents Requires Asymptotic Analysis with LLM Primitives
Authors:Elliot Meyerson, Xin Qiu
Decomposing hard problems into subproblems often makes them easier and more efficient to solve. With large language models (LLMs) crossing critical reliability thresholds for a growing slate of capabilities, there is an increasing effort to decompose systems into sets of LLM-based agents, each of whom can be delegated sub-tasks. However, this decomposition (even when automated) is often intuitive, e.g., based on how a human might assign roles to members of a human team. How close are these role decompositions to optimal? This position paper argues that asymptotic analysis with LLM primitives is needed to reason about the efficiency of such decomposed systems, and that insights from such analysis will unlock opportunities for scaling them. By treating the LLM forward pass as the atomic unit of computational cost, one can separate out the (often opaque) inner workings of a particular LLM from the inherent efficiency of how a set of LLMs are orchestrated to solve hard problems. In other words, if we want to scale the deployment of LLMs to the limit, instead of anthropomorphizing LLMs, asymptotic analysis with LLM primitives should be used to reason about and develop more powerful decompositions of large problems into LLM agents.
将复杂问题分解为子问题通常会使它们更容易、更高效地解决。随着大型语言模型(LLM)突破了一系列能力的重要可靠性阈值,将系统分解为一系列基于LLM的代理的尝试越来越多,每个代理都可以承担子任务。然而,这种分解(即使自动化)通常是直观的,例如,基于人类如何为团队分配角色。这些角色分解与最优解有多接近?本立场论文认为,需要利用LLM原始数据的渐近分析来推断此类分解系统的效率,并且从这些分析中获得的见解将解锁扩展它们的机会。通过将LLM前向传递视为计算成本的原子单位,可以区分出特定LLM(通常不透明)的内在工作原理与一组LLM解决复杂问题的固有效率。换句话说,如果我们想将LLM的部署扩展到极限,与其拟人化LLM相比,应该使用基于LLM原始数据的渐近分析来推断并开发更强大的将大问题分解为LLM代理的方法。
论文及项目相关链接
PDF In Proceedings of the 42nd International Conference on Machine Learning (ICML 2025); 13 pages including references
Summary
大型语言模型(LLM)在解决复杂问题时表现出越来越高的可靠性,因此越来越多的研究致力于将系统分解为多个基于LLM的代理,每个代理都可以承担子任务。位置论文提出使用渐近分析与LLM基础来推理和优化这种分解系统的效率,而非通过直觉分配角色任务的方式。通过对LLM前向传递作为计算成本的原子单位进行处理,我们能分离出特定LLM的不透明内部工作方式,从而更好地了解如何通过一组LLM解决复杂问题的固有效率。总结来说,要想扩大LLM部署规模并提高问题解决能力,应以LLM基础进行渐近分析,而非拟人化理解LLM。
Key Takeaways
- 大型语言模型(LLMs)分解问题的方式有助于更轻松高效解决问题。
- 分解系统的效率需要通过渐近分析与LLM基础来推理和优化。
- LLM前向传递作为计算成本的原子单位,其重要性在于分离特定LLM的内部工作方式与其解决复杂问题的效率。
- 通过一组LLMs解决复杂问题的效率分析应关注其固有效率而非特定模型的内部机制。
- 对LLM的部署规模扩大需借助渐近分析来实现更强大的问题分解。
- 避免拟人化理解LLM,以更科学的分析方法来理解和开发LLM代理的分解。
点此查看论文截图


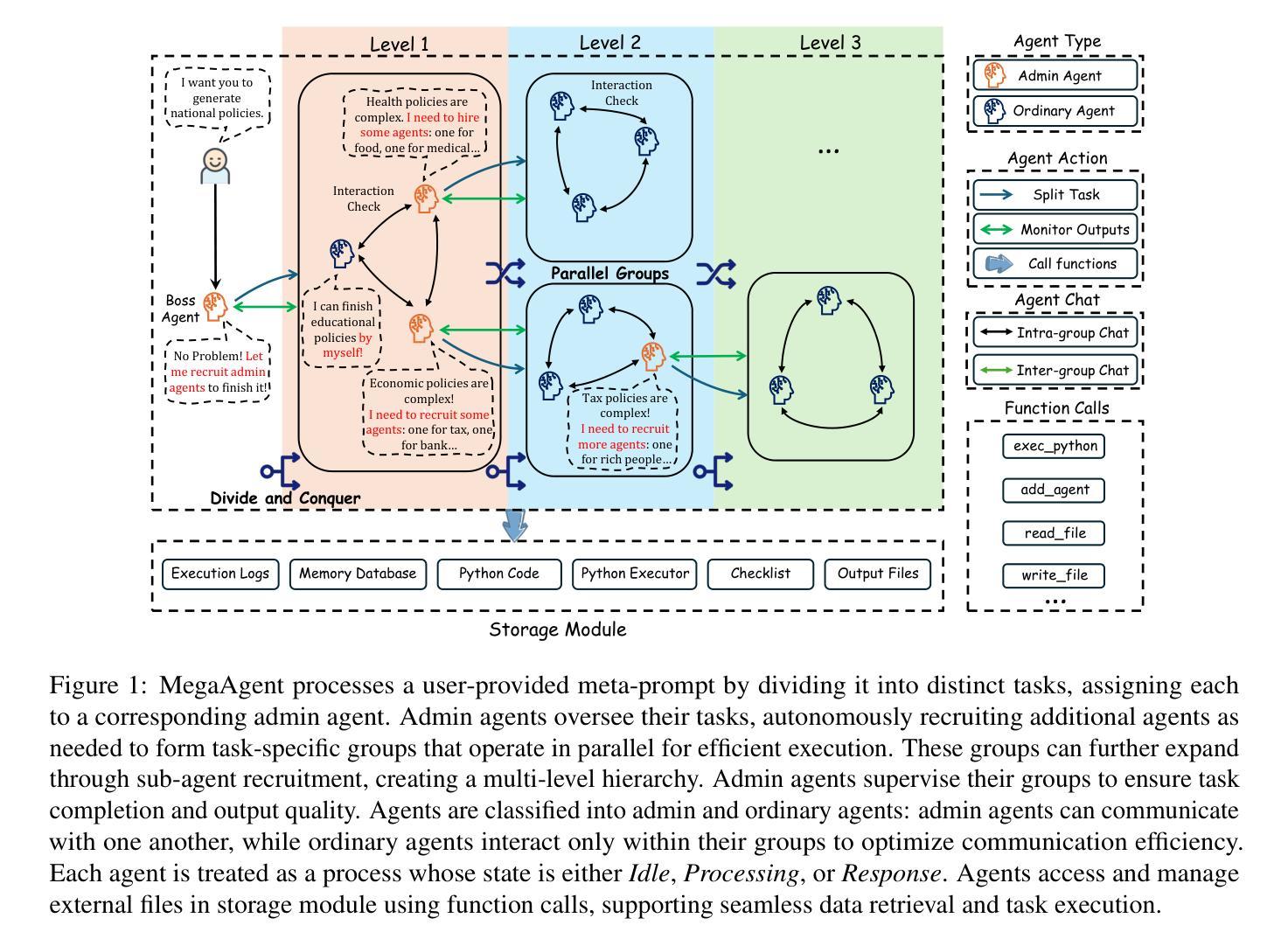
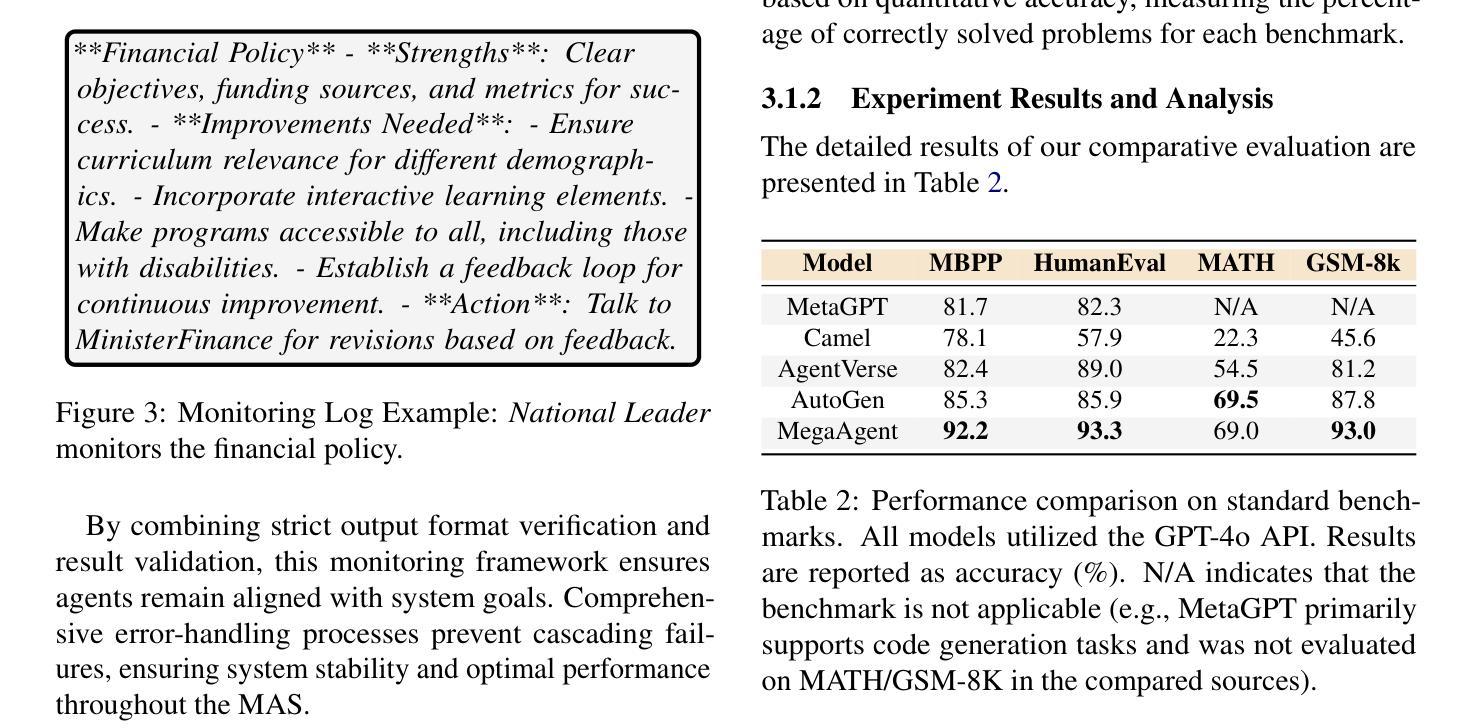
MegaAgent: A Large-Scale Autonomous LLM-based Multi-Agent System Without Predefined SOPs
Authors:Qian Wang, Tianyu Wang, Zhenheng Tang, Qinbin Li, Nuo Chen, Jingsheng Liang, Bingsheng He
LLM-based multi-agent systems (MAS) have shown promise in tackling complex tasks. However, existing solutions often suffer from limited agent coordination and heavy reliance on predefined Standard Operating Procedures (SOPs), which demand extensive human input. To address these limitations, we propose MegaAgent, a large-scale autonomous LLM-based multi-agent system. MegaAgent generates agents based on task complexity and enables dynamic task decomposition, parallel execution, efficient communication, and comprehensive system monitoring of agents. In evaluations, MegaAgent demonstrates exceptional performance, successfully developing a Gobang game within 800 seconds and scaling up to 590 agents in a national policy simulation to generate multi-domain policies. It significantly outperforms existing systems, such as MetaGPT, in both task completion efficiency and scalability. By eliminating the need for predefined SOPs, MegaAgent demonstrates exceptional scalability and autonomy, setting a foundation for advancing true autonomy in MAS. Our code is available at https://github.com/Xtra-Computing/MegaAgent .
基于大型语言模型(LLM)的多智能体系统(MAS)在应对复杂任务方面显示出巨大潜力。然而,现有解决方案往往存在智能体协调有限和过度依赖预先定义的标准操作流程(SOPs)的问题,这需要大量人工输入。为了解决这些限制,我们提出了MegaAgent,这是一个大规模自主型基于LLM的多智能体系统。MegaAgent根据任务复杂性生成智能体,并能够实现动态任务分解、并行执行、高效通信和全面的智能体系统监控。在评估中,MegaAgent表现出卓越的性能,例如在800秒内成功开发了一个Gobang游戏,并在国家政策模拟中扩展到590个智能体以生成多领域政策。它在任务完成效率和可扩展性方面都显著优于现有系统,如MetaGPT。通过消除对预设SOPs的需求,MegaAgent展现出卓越的可扩展性和自主性,为推进MAS的真正自主性奠定了基础。我们的代码可在https://github.com/Xtra-Computing/MegaAgent获取。
论文及项目相关链接
Summary
基于LLM的大规模自主多智能体系统(MegaAgent)解决了现有解决方案中智能体协调有限和过度依赖预设标准操作流程(SOPs)的问题。该系统可根据任务复杂性生成智能体,实现动态任务分解、并行执行、高效通信和全面的系统监控。在评估中,MegaAgent表现出卓越的性能,如在800秒内成功开发Gobang游戏,并在国家政策模拟中扩展到590个智能体以生成多领域策略。相较于MetaGPT等系统,MegaAgent在任务完成效率和可扩展性方面都表现得更为出色。它无需预设SOPs,展现了出色的可扩展性和自主性,为推进多智能体系统中的真正自主性奠定了基础。
Key Takeaways
- 基于LLM的大规模自主多智能体系统(MegaAgent)能解决现有智能体协调及依赖预设操作流程的问题。
- MegaAgent能根据任务复杂性生成智能体,实现动态任务分解和并行执行。
- 该系统具备高效通信和全面的系统监控功能。
- MegaAgent成功开发Gobang游戏,在国家政策模拟中可扩展至590个智能体。
- 对比其他系统如MetaGPT,MegaAgent在任务完成效率和可扩展性上表现更优秀。
- MegaAgent消除了对预设SOPs的需求,展现出出色的自主性。
点此查看论文截图