⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-31 更新
DarkDiff: Advancing Low-Light Raw Enhancement by Retasking Diffusion Models for Camera ISP
Authors:Amber Yijia Zheng, Yu Zhang, Jun Hu, Raymond A. Yeh, Chen Chen
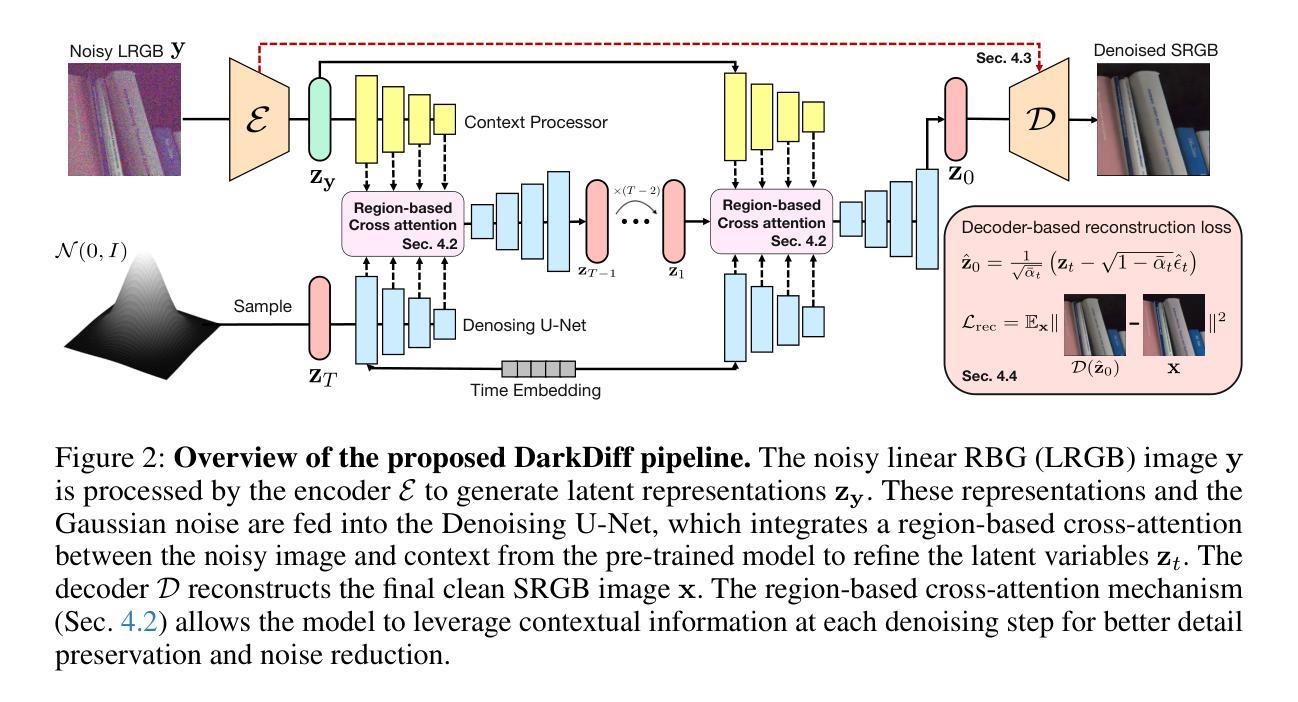
High-quality photography in extreme low-light conditions is challenging but impactful for digital cameras. With advanced computing hardware, traditional camera image signal processor (ISP) algorithms are gradually being replaced by efficient deep networks that enhance noisy raw images more intelligently. However, existing regression-based models often minimize pixel errors and result in oversmoothing of low-light photos or deep shadows. Recent work has attempted to address this limitation by training a diffusion model from scratch, yet those models still struggle to recover sharp image details and accurate colors. We introduce a novel framework to enhance low-light raw images by retasking pre-trained generative diffusion models with the camera ISP. Extensive experiments demonstrate that our method outperforms the state-of-the-art in perceptual quality across three challenging low-light raw image benchmarks.
在极端低光条件下拍摄高质量照片对于数字相机来说是一个挑战,但意义重大。借助先进的计算硬件,传统的相机图像信号处理器(ISP)算法正逐渐被高效的深度网络所取代,这些网络能够更智能地增强噪声原始图像。然而,现有的基于回归的模型通常最小化像素误差,导致低光照片或深阴影过度平滑。近期的工作试图通过从头开始训练扩散模型来解决这一局限,但这些模型仍然难以恢复清晰的图像细节和准确的颜色。我们引入了一种新的框架,通过用相机ISP重新分配预训练的生成扩散模型来提高低光原始图像的质量。大量实验表明,我们的方法在三个具有挑战性的低光原始图像基准测试中,在感知质量上超过了最新技术。
论文及项目相关链接
Summary
深度学习网络逐步取代传统相机图像信号处理器(ISP)算法,提高低光环境下的高质量摄影效果。现有回归模型易导致低光照片或深阴影过度平滑,失去细节。本研究提出一种新型框架,利用预训练的生成扩散模型结合相机ISP技术提升低光环境下的原始图像质量,超越现有技术标准。
Key Takeaways
- 深度学习网络在低光环境下提高摄影质量具有优势。
- 传统ISP算法正在被高效深度网络取代。
- 现有回归模型在处理低光照片时易导致过度平滑,丢失细节。
- 扩散模型在处理低光环境下的原始图像时表现良好。
- 研究引入了一种新型框架,结合了预训练的生成扩散模型和相机ISP技术。
- 该方法在三组具有挑战性的低光原始图像基准测试中实现了超越现有技术的感知质量。
点此查看论文截图


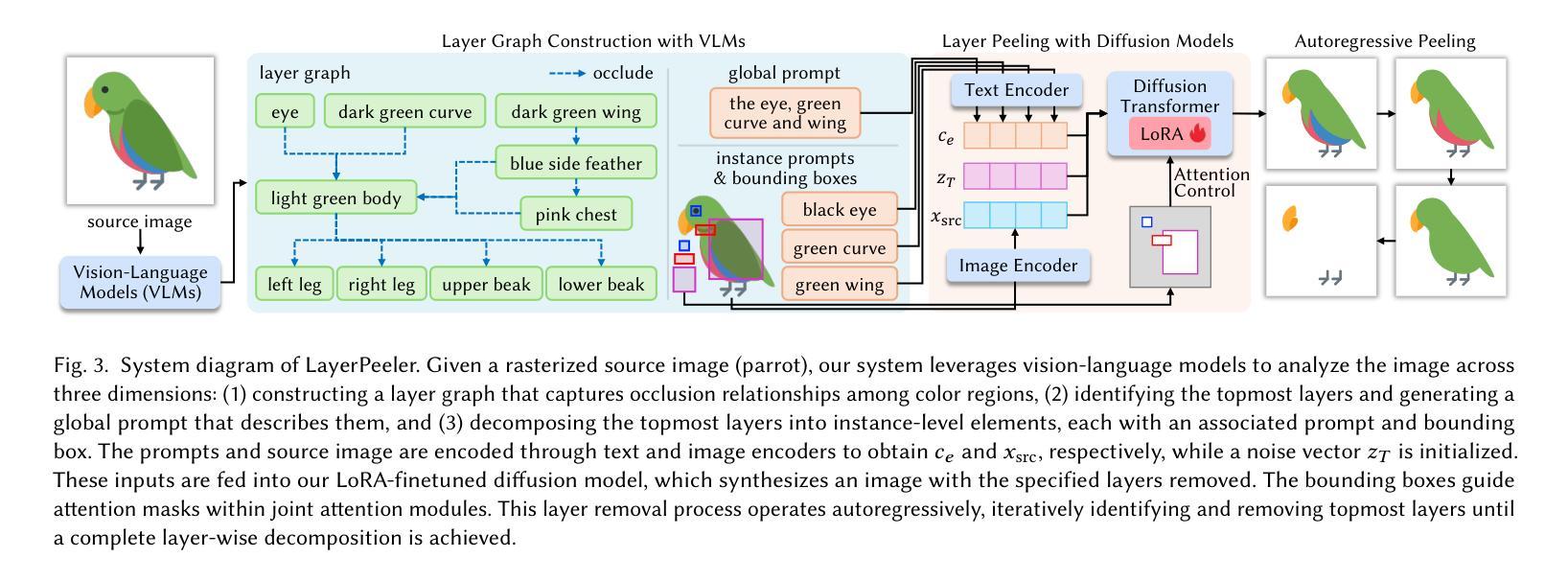
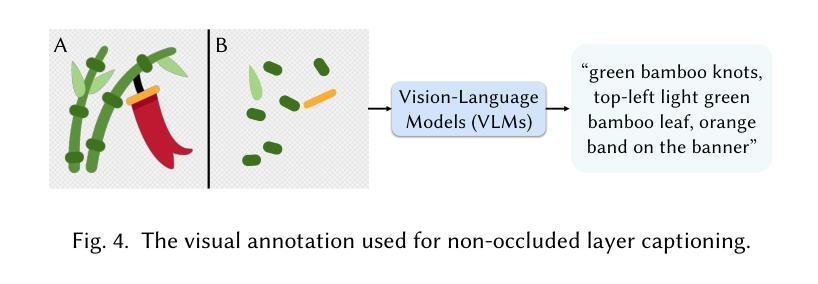
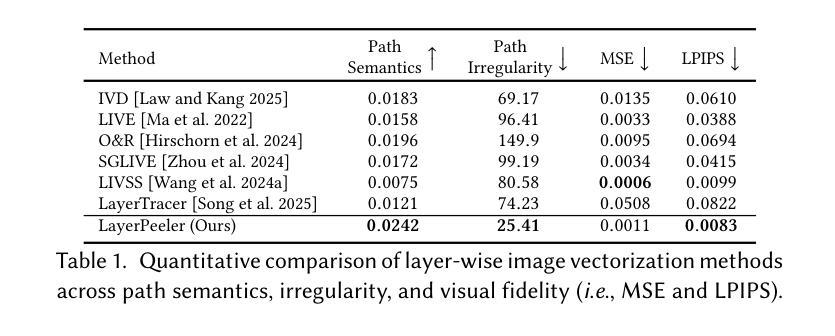
LayerPeeler: Autoregressive Peeling for Layer-wise Image Vectorization
Authors:Ronghuan Wu, Wanchao Su, Jing Liao
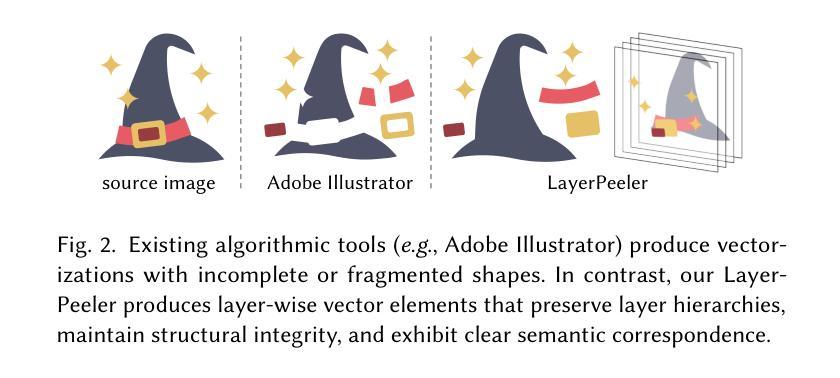
Image vectorization is a powerful technique that converts raster images into vector graphics, enabling enhanced flexibility and interactivity. However, popular image vectorization tools struggle with occluded regions, producing incomplete or fragmented shapes that hinder editability. While recent advancements have explored rule-based and data-driven layer-wise image vectorization, these methods face limitations in vectorization quality and flexibility. In this paper, we introduce LayerPeeler, a novel layer-wise image vectorization approach that addresses these challenges through a progressive simplification paradigm. The key to LayerPeeler’s success lies in its autoregressive peeling strategy: by identifying and removing the topmost non-occluded layers while recovering underlying content, we generate vector graphics with complete paths and coherent layer structures. Our method leverages vision-language models to construct a layer graph that captures occlusion relationships among elements, enabling precise detection and description for non-occluded layers. These descriptive captions are used as editing instructions for a finetuned image diffusion model to remove the identified layers. To ensure accurate removal, we employ localized attention control that precisely guides the model to target regions while faithfully preserving the surrounding content. To support this, we contribute a large-scale dataset specifically designed for layer peeling tasks. Extensive quantitative and qualitative experiments demonstrate that LayerPeeler significantly outperforms existing techniques, producing vectorization results with superior path semantics, geometric regularity, and visual fidelity.
图像矢量化是一种强大的技术,可将位图图像转换为矢量图形,从而提高灵活性和交互性。然而,流行的图像矢量化工具在处理遮挡区域时遇到困难,产生不完整或碎片化的形状,妨碍了编辑能力。虽然最近的进展探索了基于规则和基于数据分层图像矢量化方法,这些方法在矢量化质量和灵活性方面仍面临局限性。在本文中,我们介绍了LayerPeeler,这是一种新型的分层图像矢量化方法,它通过渐进简化范式来解决这些挑战。LayerPeeler成功的关键在于其自回归剥离策略:通过识别和移除最顶部的非遮挡层并恢复底层内容,我们生成具有完整路径和连贯层结构的矢量图形。我们的方法利用视觉语言模型构建层图,捕获元素之间的遮挡关系,为非遮挡层提供精确的检测和描述。这些描述性字幕用作微调图像扩散模型的编辑指令,以移除已识别的图层。为了确保准确的移除操作,我们采用了局部注意力控制,精确引导模型定位区域,同时忠实保留周围内容。为了支持这一点,我们贡献了一个专门设计用于图层剥离任务的大规模数据集。大量的定量和定性实验表明,LayerPeeler在路径语义、几何规则和视觉保真度方面显著优于现有技术,产生了出色的矢量化结果。
论文及项目相关链接
PDF Project Page: https://layerpeeler.github.io/
Summary:本文介绍了一种新型图像矢量化方法LayerPeeler,采用分层剥离策略将图像矢量化为矢量图形,能处理遮挡区域的挑战,生成完整路径和连贯层结构的矢量图形。利用视觉语言模型构建层图,捕捉元素间的遮挡关系,并使用描述性标题作为编辑指令进行微调图像扩散模型的层剥离。采用局部注意力控制精确指导模型进行目标区域剥离,同时忠实保留周围内容。LayerPeeler在矢量化路径语义、几何规则性和视觉保真度方面显著优于现有技术。
Key Takeaways:
- LayerPeeler是一种新型的图像矢量化方法,采用分层剥离策略解决遮挡区域的挑战。
- 通过识别并移除最顶层的非遮挡层,同时恢复底层内容,生成完整路径和连贯层结构的矢量图形。
- 利用视觉语言模型构建层图,准确捕捉元素间的遮挡关系。
- 使用描述性标题作为编辑指令对图像扩散模型进行微调,实现精准层剥离。
- 采用局部注意力控制,精确指导模型进行目标区域剥离,同时保留周围内容。
- LayerPeeler在矢量化路径语义、几何规则性和视觉保真度方面表现优异。
点此查看论文截图

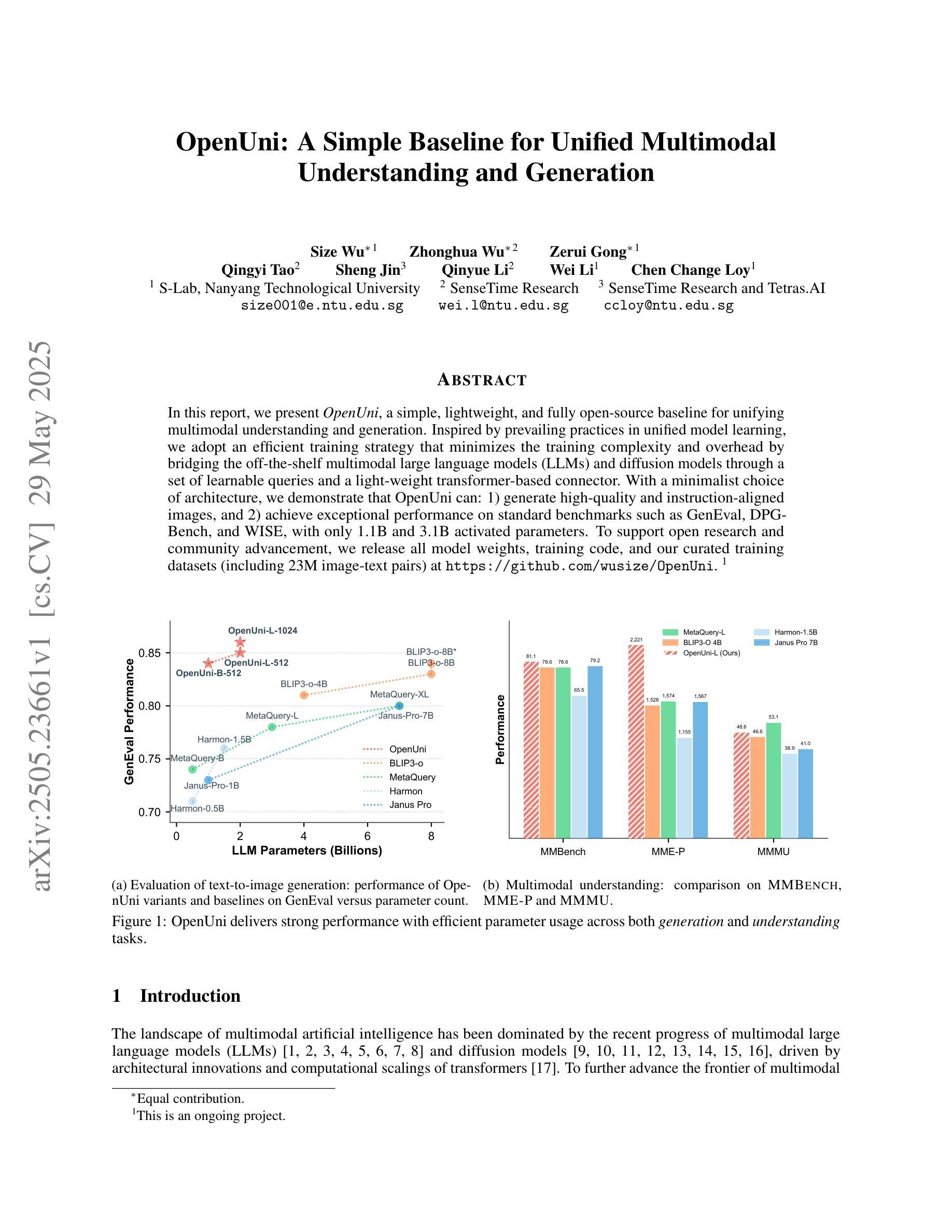
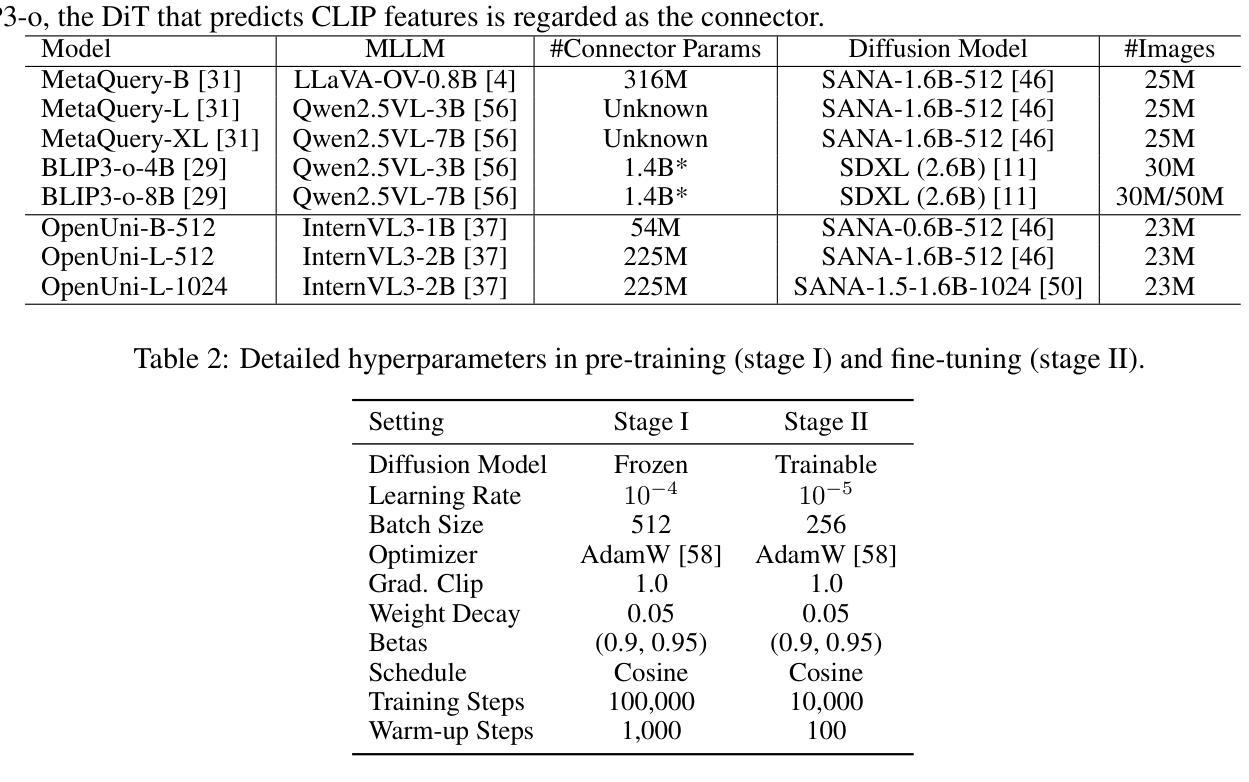
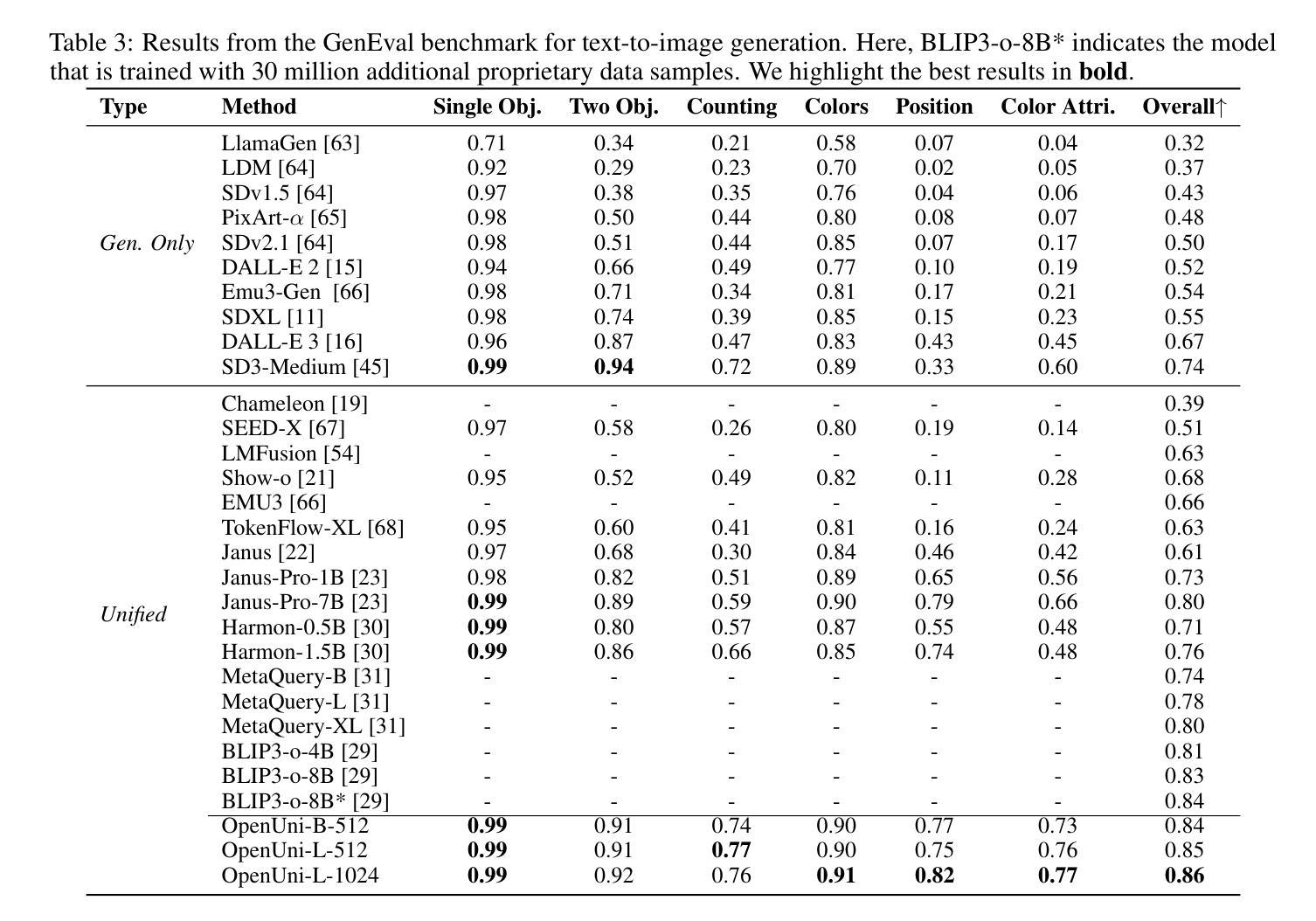
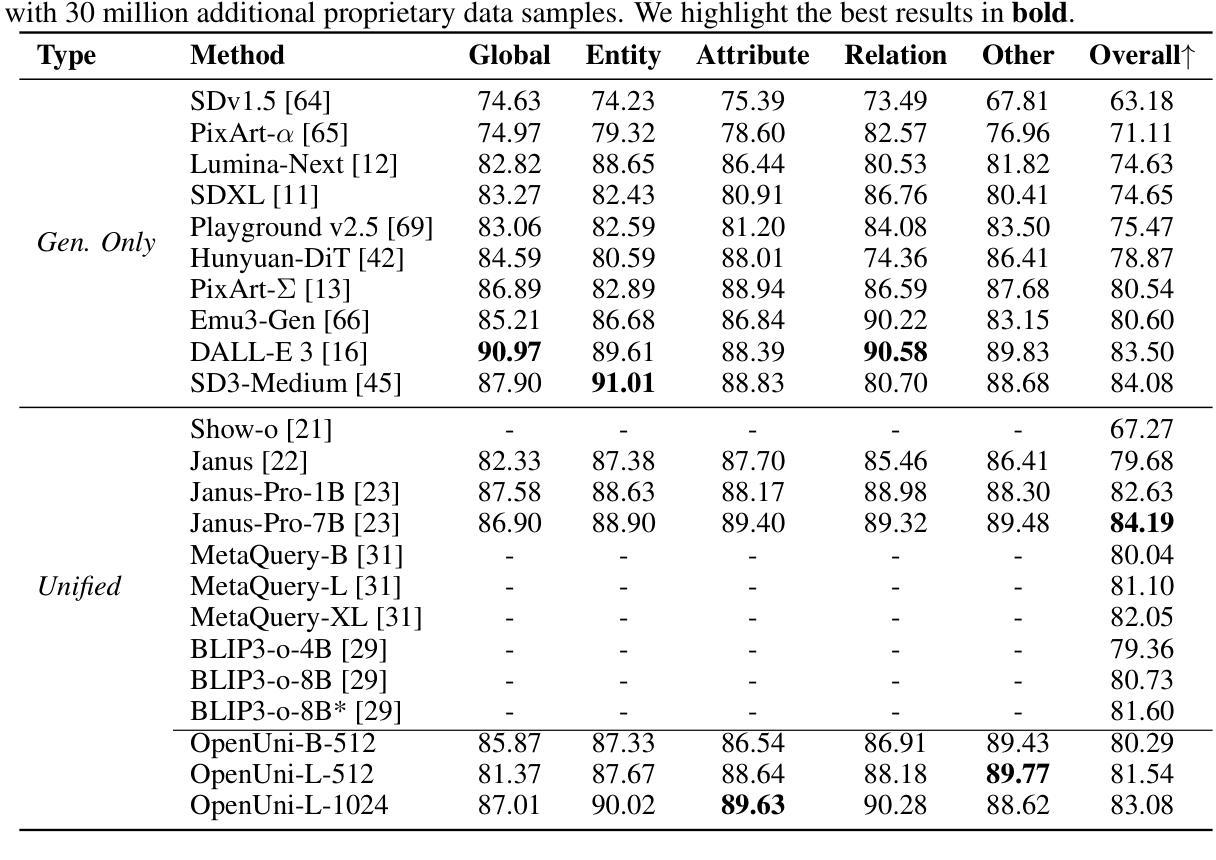
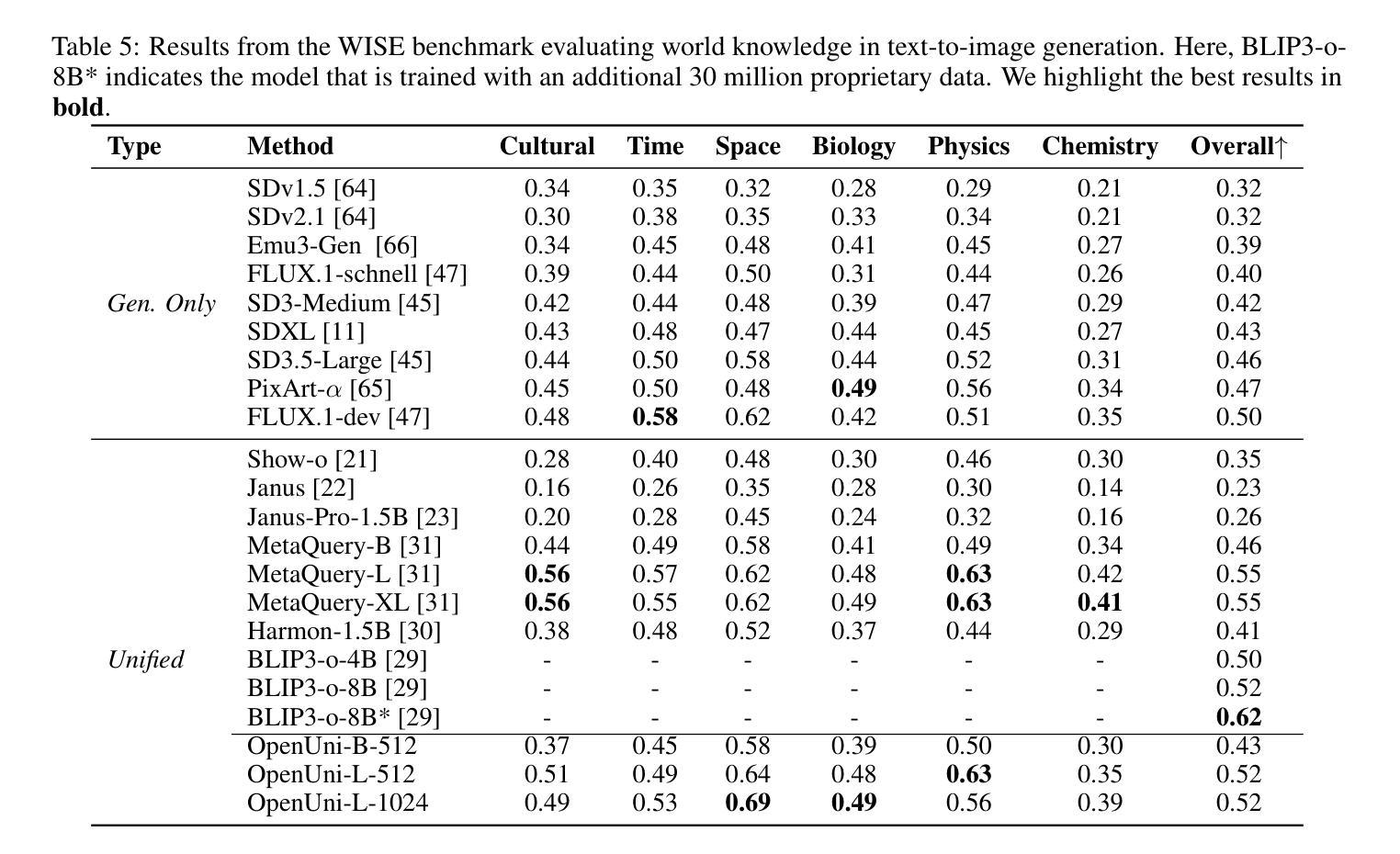
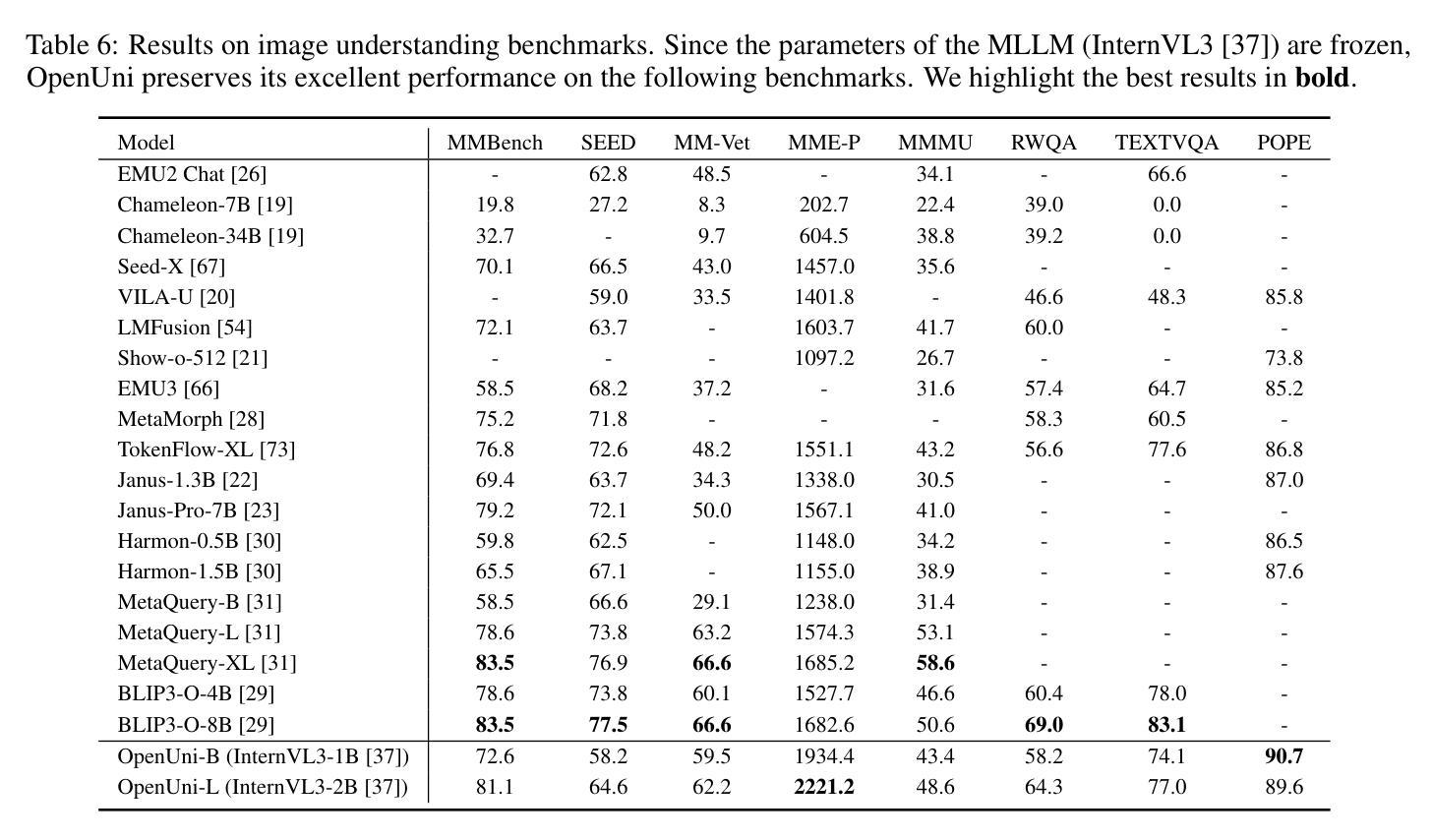
OpenUni: A Simple Baseline for Unified Multimodal Understanding and Generation
Authors:Size Wu, Zhonghua Wu, Zerui Gong, Qingyi Tao, Sheng Jin, Qinyue Li, Wei Li, Chen Change Loy
In this report, we present OpenUni, a simple, lightweight, and fully open-source baseline for unifying multimodal understanding and generation. Inspired by prevailing practices in unified model learning, we adopt an efficient training strategy that minimizes the training complexity and overhead by bridging the off-the-shelf multimodal large language models (LLMs) and diffusion models through a set of learnable queries and a light-weight transformer-based connector. With a minimalist choice of architecture, we demonstrate that OpenUni can: 1) generate high-quality and instruction-aligned images, and 2) achieve exceptional performance on standard benchmarks such as GenEval, DPG- Bench, and WISE, with only 1.1B and 3.1B activated parameters. To support open research and community advancement, we release all model weights, training code, and our curated training datasets (including 23M image-text pairs) at https://github.com/wusize/OpenUni.
在这份报告中,我们介绍了OpenUni,这是一个简单、轻量级、完全开源的多模态理解和生成统一基准。我们受到统一模型学习流行实践的启发,采用了一种高效的训练策略,通过一组可学习的查询和一个基于轻量级变压器的连接器,将现成的多模态大型语言模型(LLMs)和扩散模型联系起来,从而最小化训练复杂性和开销。通过选择最简单的架构,我们证明OpenUni可以:1)生成高质量且符合指令的图像;2)在GenEval、DPG-Bench和WISE等标准基准测试上实现卓越性能,激活的参数只有1.1B和3.1B。为了支持开放研究和社区发展,我们在https://github.com/wusize/OpenUni上发布了所有模型权重、训练代码和我们精选的训练数据集(包括2300万张图像文本对)。
论文及项目相关链接
Summary
OpenUni是一个简单、轻量级、完全开源的多模态理解和生成统一基准。它通过高效的训练策略,采用现成的多模态大型语言模型和扩散模型,通过一组可学习的查询和轻量级基于变压器的连接器,以减小训练复杂性和开销。OpenUni能够生成高质量、指令对齐的图像,并在GenEval、DPG-Bench和WISE等标准基准测试中实现卓越性能,仅需1.1B和3.1B激活参数。所有模型权重、训练代码和精选的训练数据集(包括23M图像文本对)已在GitHub上发布。
Key Takeaways
- OpenUni是一个多模态理解和生成的统一基准。旨在将各种模态的数据(如文本和图像)整合在一起进行理解和生成。
- OpenUni具有简单、轻量级和开源的特点,便于社区研究和发展。
- 通过高效的训练策略,OpenUni能桥接现有的多模态大型语言模型和扩散模型。
- OpenUni使用可学习的查询和基于轻量级变压器的连接器来实现这一桥接,以降低训练复杂性和开销。
- OpenUni能生成高质量、与指令对齐的图像,显示出其强大的生成能力。
- 在标准基准测试中,如GenEval、DPG-Bench和WISE,OpenUni表现出卓越的性能。
点此查看论文截图
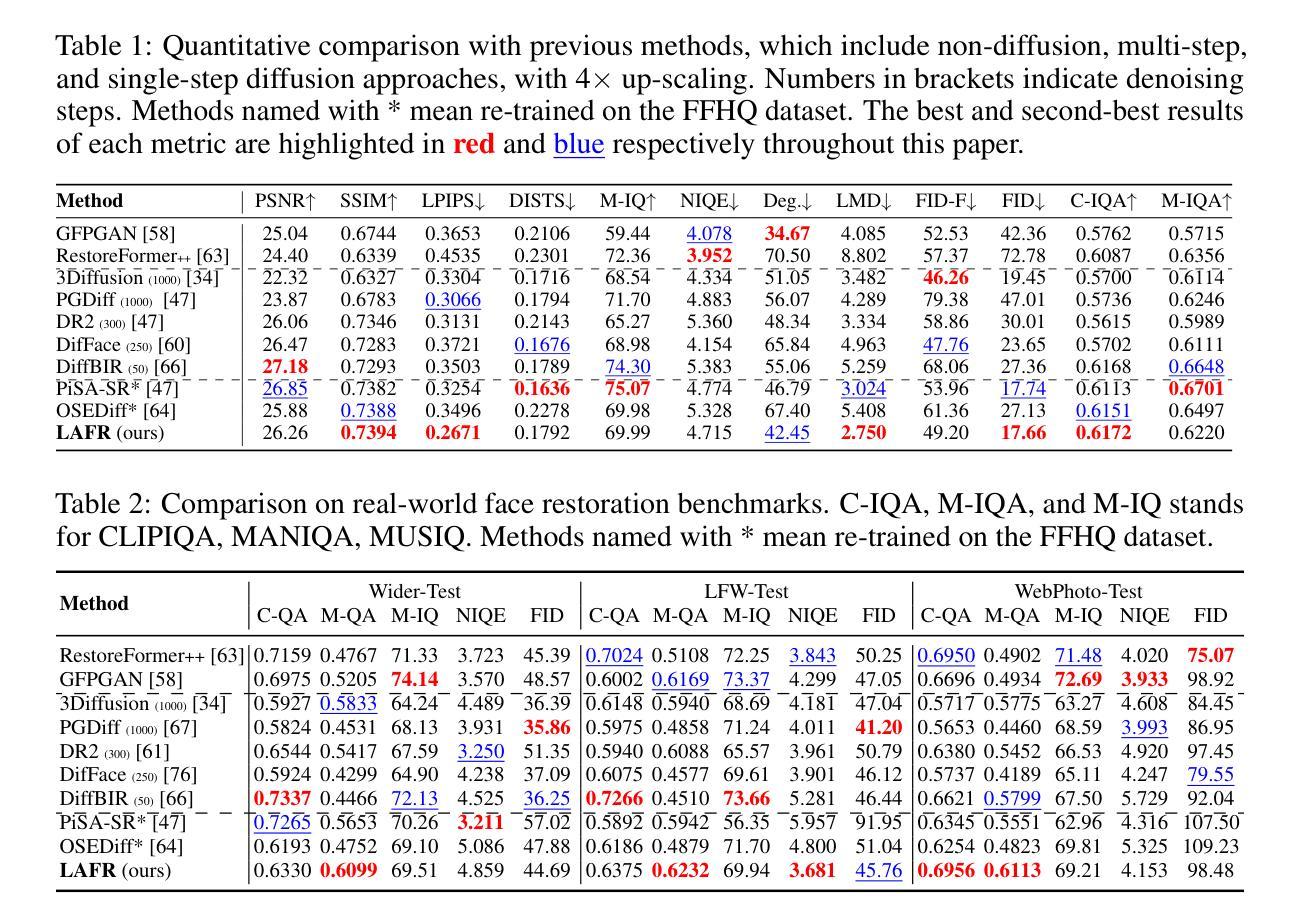
LAFR: Efficient Diffusion-based Blind Face Restoration via Latent Codebook Alignment Adapter
Authors:Runyi Li, Bin Chen, Jian Zhang, Radu Timofte
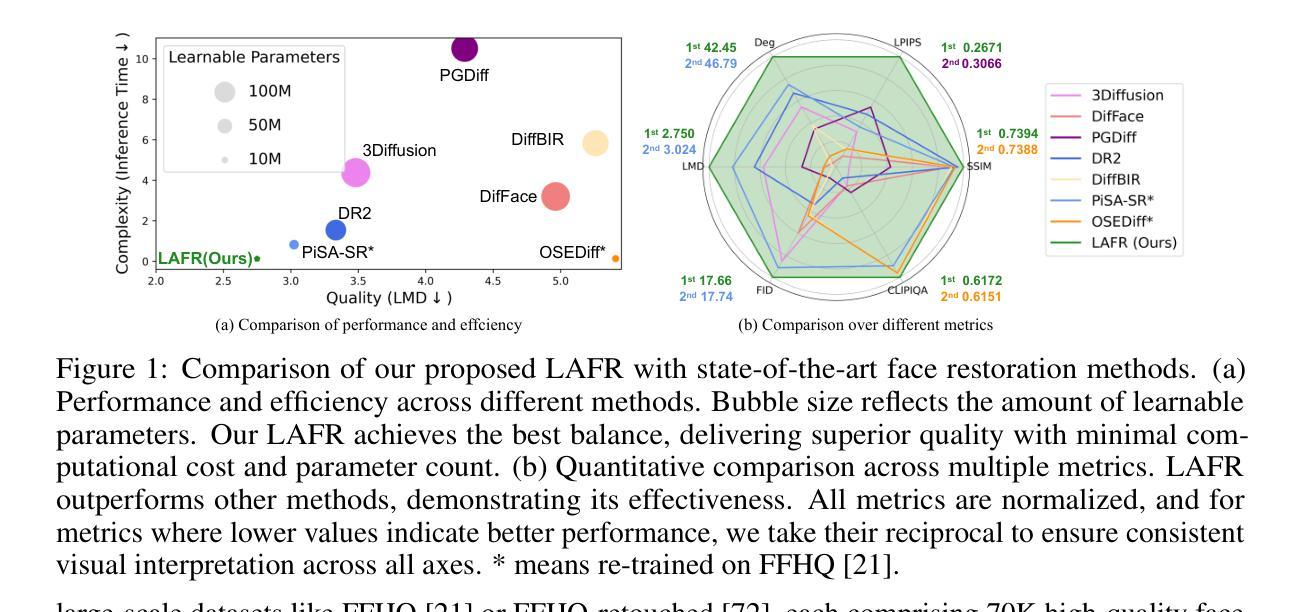
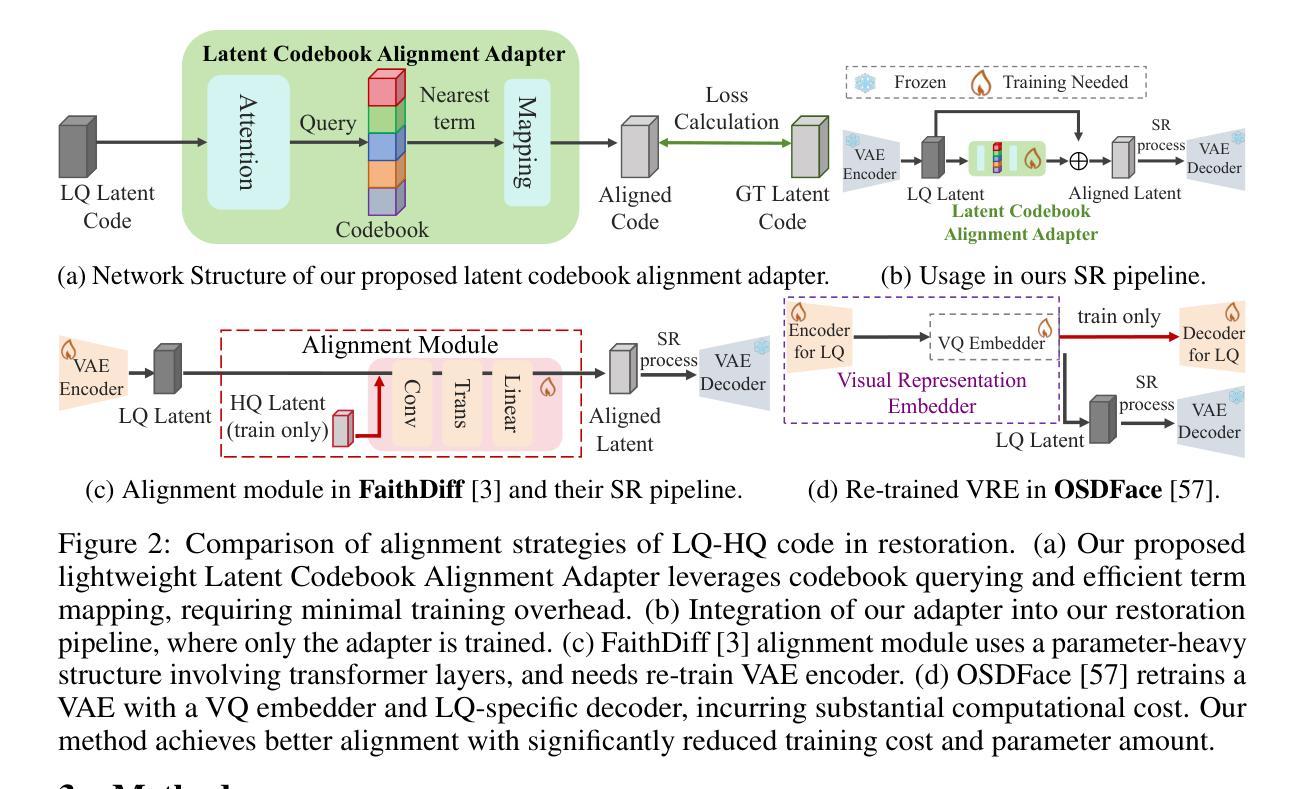
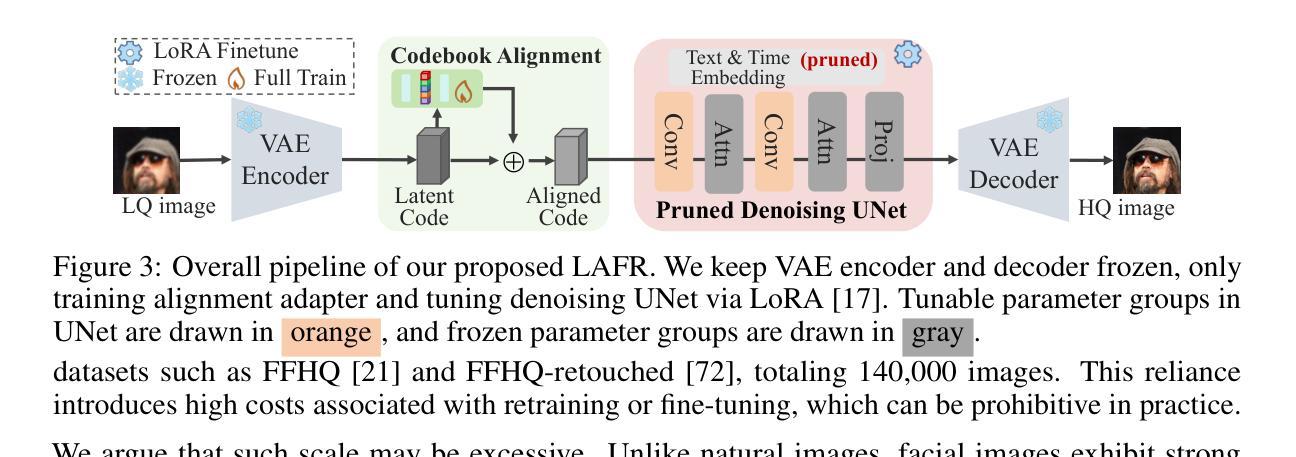
Blind face restoration from low-quality (LQ) images is a challenging task that requires not only high-fidelity image reconstruction but also the preservation of facial identity. While diffusion models like Stable Diffusion have shown promise in generating high-quality (HQ) images, their VAE modules are typically trained only on HQ data, resulting in semantic misalignment when encoding LQ inputs. This mismatch significantly weakens the effectiveness of LQ conditions during the denoising process. Existing approaches often tackle this issue by retraining the VAE encoder, which is computationally expensive and memory-intensive. To address this limitation efficiently, we propose LAFR (Latent Alignment for Face Restoration), a novel codebook-based latent space adapter that aligns the latent distribution of LQ images with that of HQ counterparts, enabling semantically consistent diffusion sampling without altering the original VAE. To further enhance identity preservation, we introduce a multi-level restoration loss that combines constraints from identity embeddings and facial structural priors. Additionally, by leveraging the inherent structural regularity of facial images, we show that lightweight finetuning of diffusion prior on just 0.9% of FFHQ dataset is sufficient to achieve results comparable to state-of-the-art methods, reduce training time by 70%. Extensive experiments on both synthetic and real-world face restoration benchmarks demonstrate the effectiveness and efficiency of LAFR, achieving high-quality, identity-preserving face reconstruction from severely degraded inputs.
从低质量(LQ)图像中恢复盲脸是一项具有挑战性的任务,不仅要求高质量图像重建,还要求保持面部身份。虽然像Stable Diffusion这样的扩散模型在生成高质量(HQ)图像方面显示出潜力,但它们的VAE模块通常仅在HQ数据上进行训练,导致在编码LQ输入时出现语义不对齐。这种不匹配会显著削弱去噪过程中LQ条件的有效性。现有方法通常通过重新训练VAE编码器来解决这个问题,这在计算上既昂贵又占用大量内存。为了有效地解决这一限制,我们提出了LAFR(用于面部恢复的潜在对齐),这是一种基于代码本的新型潜在空间适配器,它将LQ图像的潜在分布与HQ图像的潜在分布对齐,从而在不改变原始VAE的情况下实现语义一致的扩散采样。为了进一步增强身份保留,我们引入了一种多级恢复损失,它结合了身份嵌入和面部结构先验的限制。此外,通过利用面部图像的内在结构规律,我们证明在FFHQ数据集仅0.9%的数据上进行扩散先验的微调就足以达到与最新方法相当的结果,并将训练时间减少70%。在合成和真实世界面部恢复基准测试上的大量实验证明了LAFR的有效性和效率,实现了从严重退化的输入中进行高质量、保持身份的脸部重建。
论文及项目相关链接
Summary:
针对低质量图像中的盲脸恢复任务,存在高保真重建与面部身份保留的双重挑战。虽然Stable Diffusion等扩散模型在高质量图像生成中表现出潜力,但其VAE模块仅在高质量数据上进行训练,导致在编码低质量输入时出现语义不匹配问题。为解决这一问题,本文提出LAFR(面部恢复的潜在对齐)方法,通过基于代码本的潜在空间适配器,对齐低质量图像与高质量图像的潜在分布,实现语义一致的扩散采样,且无需更改原始VAE。为进一步提高身份保留效果,引入多级恢复损失,结合身份嵌入和面部结构先验的限制。实验表明,在少量数据集上微调扩散先验即可实现与先进方法相当的效果,并减少70%的训练时间。
Key Takeaways:
- 扩散模型如Stable Diffusion在低质量图像盲脸恢复上应用面临挑战。
- 现有扩散模型的VAE模块仅在高质量数据上训练,导致低质量输入时的语义不匹配问题。
- LAFR方法通过基于代码本的潜在空间适配器对齐低质量与高质量图像的潜在分布。
- LAFR实现了语义一致的扩散采样,且无需更改原始VAE设计。
- 引入多级恢复损失以提高身份保留效果,结合身份嵌入和面部结构先验。
- 利用面部图像的结构规律性,少量数据集上的扩散先验微调即可实现高效、高质量的面部重建。
点此查看论文截图

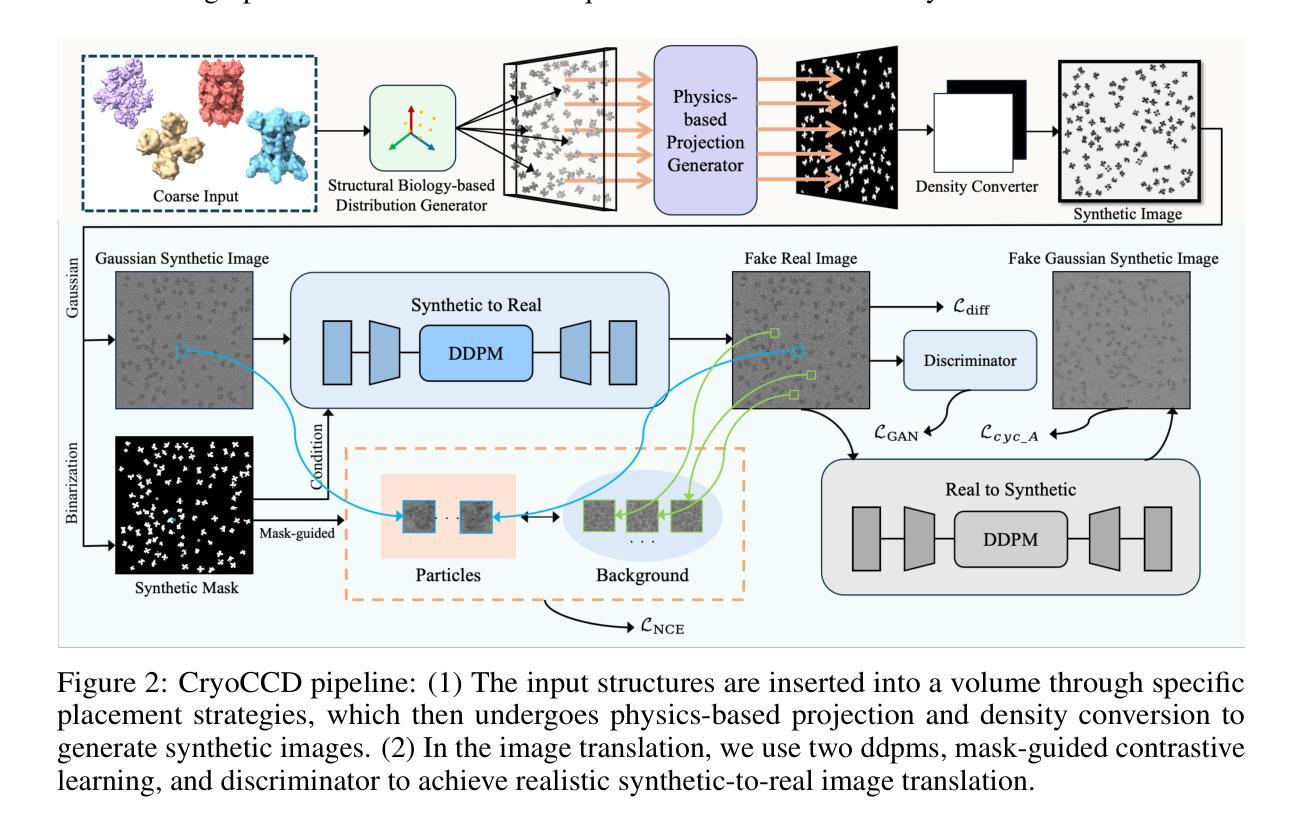
CryoCCD: Conditional Cycle-consistent Diffusion with Biophysical Modeling for Cryo-EM Synthesis
Authors:Runmin Jiang, Genpei Zhang, Yuntian Yang, Siqi Wu, Yuheng Zhang, Wanyue Feng, Yizhou Zhao, Xi Xiao, Xiao Wang, Tianyang Wang, Xingjian Li, Min Xu
Cryo-electron microscopy (cryo-EM) offers near-atomic resolution imaging of macromolecules, but developing robust models for downstream analysis is hindered by the scarcity of high-quality annotated data. While synthetic data generation has emerged as a potential solution, existing methods often fail to capture both the structural diversity of biological specimens and the complex, spatially varying noise inherent in cryo-EM imaging. To overcome these limitations, we propose CryoCCD, a synthesis framework that integrates biophysical modeling with generative techniques. Specifically, CryoCCD produces multi-scale cryo-EM micrographs that reflect realistic biophysical variability through compositional heterogeneity, cellular context, and physics-informed imaging. To generate realistic noise, we employ a conditional diffusion model, enhanced by cycle consistency to preserve structural fidelity and mask-aware contrastive learning to capture spatially adaptive noise patterns. Extensive experiments show that CryoCCD generates structurally accurate micrographs and enhances performance in downstream tasks, outperforming state-of-the-art baselines in both particle picking and reconstruction.
冷冻电子显微镜(cryo-EM)能够为宏观分子提供接近原子分辨率的成像,但是高质量标注数据的稀缺阻碍了下游分析的稳健模型的发展。虽然合成数据生成已经出现作为潜在的解决方案,但现有方法往往无法捕捉到生物样本的结构多样性和冷冻电子显微镜成像中固有的复杂且空间变化的噪声。为了克服这些局限性,我们提出了CryoCCD,这是一个将生物物理建模与生成技术相结合的合成框架。具体来说,CryoCCD产生多尺度的冷冻电子显微镜显微图,通过组成异质性、细胞背景和物理成像反映真实的生物物理变化。为了产生真实的噪声,我们采用条件扩散模型,通过循环一致性增强来保持结构忠实度,并通过掩膜感知对比学习来捕捉空间自适应噪声模式。大量实验表明,CryoCCD生成的显微图结构准确,提高了下游任务的性能,在粒子挑选和重建方面都优于最先进的基线。
论文及项目相关链接
Summary
基于冷冻电子显微镜(cryo-EM)的近原子分辨率成像,在下游分析中缺乏高质量注释数据阻碍其发展的背景下,文章提出了一个新的合成数据生成框架CryoCCD。该框架结合了生物物理建模和生成技术,旨在克服现有方法的局限性。通过构建多尺度cryo-EM微图,CryoCCD能够反映真实的生物物理变异性和复杂的空间变化噪声。采用条件扩散模型生成真实噪声,通过循环一致性增强结构保真度,并通过掩膜感知对比学习捕捉空间自适应噪声模式。实验表明,CryoCCD生成的微图结构准确,在下游任务中表现优异,在粒子挑选和重建方面均优于现有基线方法。
Key Takeaways
- 冷冻电子显微镜(cryo-EM)成像因缺乏高质量注释数据而在下游分析中受限。
- 现有的数据生成方法难以捕捉生物样本的结构多样性和复杂的空间变化噪声。
- 提出新的合成数据生成框架CryoCCD,结合生物物理建模和生成技术。
- CryoCCD能够生成多尺度cryo-EM微图,反映真实的生物物理变异性和空间变化噪声。
- 采用条件扩散模型生成真实噪声,通过循环一致性和掩膜感知对比学习提高性能。
- 实验证明CryoCCD生成的微图结构准确,在下游任务中表现优异。
点此查看论文截图


TRACE: Trajectory-Constrained Concept Erasure in Diffusion Models
Authors:Finn Carter
Text-to-image diffusion models have shown unprecedented generative capability, but their ability to produce undesirable concepts (e.g.pornographic content, sensitive identities, copyrighted styles) poses serious concerns for privacy, fairness, and safety. {Concept erasure} aims to remove or suppress specific concept information in a generative model. In this paper, we introduce \textbf{TRACE (Trajectory-Constrained Attentional Concept Erasure)}, a novel method to erase targeted concepts from diffusion models while preserving overall generative quality. Our approach combines a rigorous theoretical framework, establishing formal conditions under which a concept can be provably suppressed in the diffusion process, with an effective fine-tuning procedure compatible with both conventional latent diffusion (Stable Diffusion) and emerging rectified flow models (e.g.FLUX). We first derive a closed-form update to the model’s cross-attention layers that removes hidden representations of the target concept. We then introduce a trajectory-aware finetuning objective that steers the denoising process away from the concept only in the late sampling stages, thus maintaining the model’s fidelity on unrelated content. Empirically, we evaluate TRACE on multiple benchmarks used in prior concept erasure studies (object classes, celebrity faces, artistic styles, and explicit content from the I2P dataset). TRACE achieves state-of-the-art performance, outperforming recent methods such as ANT, EraseAnything, and MACE in terms of removal efficacy and output quality.
文本到图像的扩散模型展现出了前所未有的生成能力,但它们产生不想要概念的能力(例如色情内容、敏感身份、版权风格)对隐私、公平和安全提出了严重担忧。{概念擦除}旨在从生成模型中删除或抑制特定概念信息。在本文中,我们介绍了\textbf{TRACE(轨迹约束注意力概念擦除)},这是一种从扩散模型中删除目标概念的同时保持整体生成质量的新方法。我们的方法结合了一个严谨的理论框架,建立了在扩散过程中可以抑制概念的正式条件,以及一个与常规潜在扩散(Stable Diffusion)和新兴整流流模型(例如FLUX)兼容的有效微调程序。我们首先推导出模型交叉注意力层的封闭形式更新,以消除目标概念的隐藏表示。然后,我们引入了一个轨迹感知微调目标,该目标仅在后期采样阶段引导去噪过程远离概念,从而保持模型在处理不相关内容时的保真度。从实证角度看,我们在先前概念擦除研究使用的多个基准测试(如对象类别、名人面孔、艺术风格和I2P数据集中的明确内容)上对TRACE进行了评估。TRACE达到了最新性能水平,在去除效果和输出质量方面超越了近期的方法,如ANT、EraseAnything和MACE。
论文及项目相关链接
PDF In peer review
Summary
文本到图像扩散模型的生成能力前所未有,但其生成不希望出现概念(如色情内容、敏感身份、版权风格)的能力对隐私、公平性和安全构成严重威胁。本文介绍了一种名为TRACE(轨迹约束注意力概念消除)的新方法,旨在从扩散模型中删除目标概念,同时保持整体生成质量。该方法结合了严格的理论框架和有效的微调程序,可与传统的潜在扩散(Stable Diffusion)和新兴的校正流模型(如FLUX)兼容。实验表明,TRACE在多个基准测试上的表现达到或超越了最新的方法,如ANT、EraseAnything和MACE。
Key Takeaways
- 文本到图像扩散模型具有强大的生成能力,但存在生成不希望出现概念的问题。
- 概念消除技术对于保护隐私、公平性和安全至关重要。
- TRACE是一种新型的概念消除方法,旨在从扩散模型中删除特定概念,同时保持整体生成质量。
- TRACE结合了严格的理论框架和有效的微调程序,可与多种扩散模型兼容。
- TRACE通过修改模型的跨注意层来消除目标概念的隐藏表示。
- TRACE引入了轨迹感知微调目标,仅在后期采样阶段避免概念,从而保持模型对无关内容的保真度。
点此查看论文截图

RSFAKE-1M: A Large-Scale Dataset for Detecting Diffusion-Generated Remote Sensing Forgeries
Authors:Zhihong Tan, Jiayi Wang, Huiying Shi, Binyuan Huang, Hongchen Wei, Zhenzhong Chen
Detecting forged remote sensing images is becoming increasingly critical, as such imagery plays a vital role in environmental monitoring, urban planning, and national security. While diffusion models have emerged as the dominant paradigm for image generation, their impact on remote sensing forgery detection remains underexplored. Existing benchmarks primarily target GAN-based forgeries or focus on natural images, limiting progress in this critical domain. To address this gap, we introduce RSFAKE-1M, a large-scale dataset of 500K forged and 500K real remote sensing images. The fake images are generated by ten diffusion models fine-tuned on remote sensing data, covering six generation conditions such as text prompts, structural guidance, and inpainting. This paper presents the construction of RSFAKE-1M along with a comprehensive experimental evaluation using both existing detectors and unified baselines. The results reveal that diffusion-based remote sensing forgeries remain challenging for current methods, and that models trained on RSFAKE-1M exhibit notably improved generalization and robustness. Our findings underscore the importance of RSFAKE-1M as a foundation for developing and evaluating next-generation forgery detection approaches in the remote sensing domain. The dataset and other supplementary materials are available at https://huggingface.co/datasets/TZHSW/RSFAKE/.
遥感图像伪造检测在环境监控、城市规划和国家安全中发挥着至关重要的作用,因此变得越来越关键。尽管扩散模型已成为图像生成的主导范式,但它们对遥感伪造检测的影响仍被探索不足。现有的基准测试主要面向基于GAN的伪造或自然图像,限制了这一关键领域的进展。为了弥补这一空白,我们推出了RSFAKE-1M,这是一个包含50万张伪造和50万张真实遥感图像的大规模数据集。伪造图像是由十个在遥感数据上微调过的扩散模型生成的,涵盖了文本提示、结构引导和图像补全等六种生成条件。本文介绍了RSFAKE-1M的构建,以及使用现有检测器和统一基线进行的全面实验评估。结果表明,基于扩散的遥感伪造对当前方法仍然具有挑战性,而在RSFAKE-1M上训练的模型表现出显著的提高推广能力和稳健性。我们的研究结果强调了RSFAKE-1M在遥感领域开发下一代伪造检测方法的评估基础方面的重要性。数据集和其他辅助材料可在https://huggingface.co/datasets/TZHSW/RSFAKE/找到。
论文及项目相关链接
Summary
本文主要介绍了RSFAKE-1M数据集的建设,该数据集包含50万张伪造的和真实的遥感图像。该数据集的伪造图像由经过遥感数据微调后的十个扩散模型生成,涵盖文本提示、结构指导等六种生成条件。实验评估表明,基于扩散的遥感伪造图像对当前方法仍然具有挑战性,而在RSFAKE-1M上训练的模型表现出显著的提高推广和稳健性。该数据集对开发下一代遥感领域伪造检测技术至关重要。该数据集可通过[https://huggingface.co/datasets/TZHSW/RSFAKE/]获取。
Key Takeaways
- RSFAKE-1M数据集包含大量的伪造和真实遥感图像,为遥感伪造检测研究提供了丰富的数据资源。
- 数据集中的伪造图像由多种扩散模型生成,涵盖不同的生成条件,增加了研究的复杂性。
- 当前方法在检测基于扩散的遥感伪造图像时仍面临挑战。
- 在RSFAKE-1M上训练的模型表现出更好的推广和稳健性。
- RSFAKE-1M数据集对开发下一代遥感领域伪造检测技术具有关键作用。
- 该数据集促进了遥感图像伪造检测领域的研究进展和实际应用。
点此查看论文截图

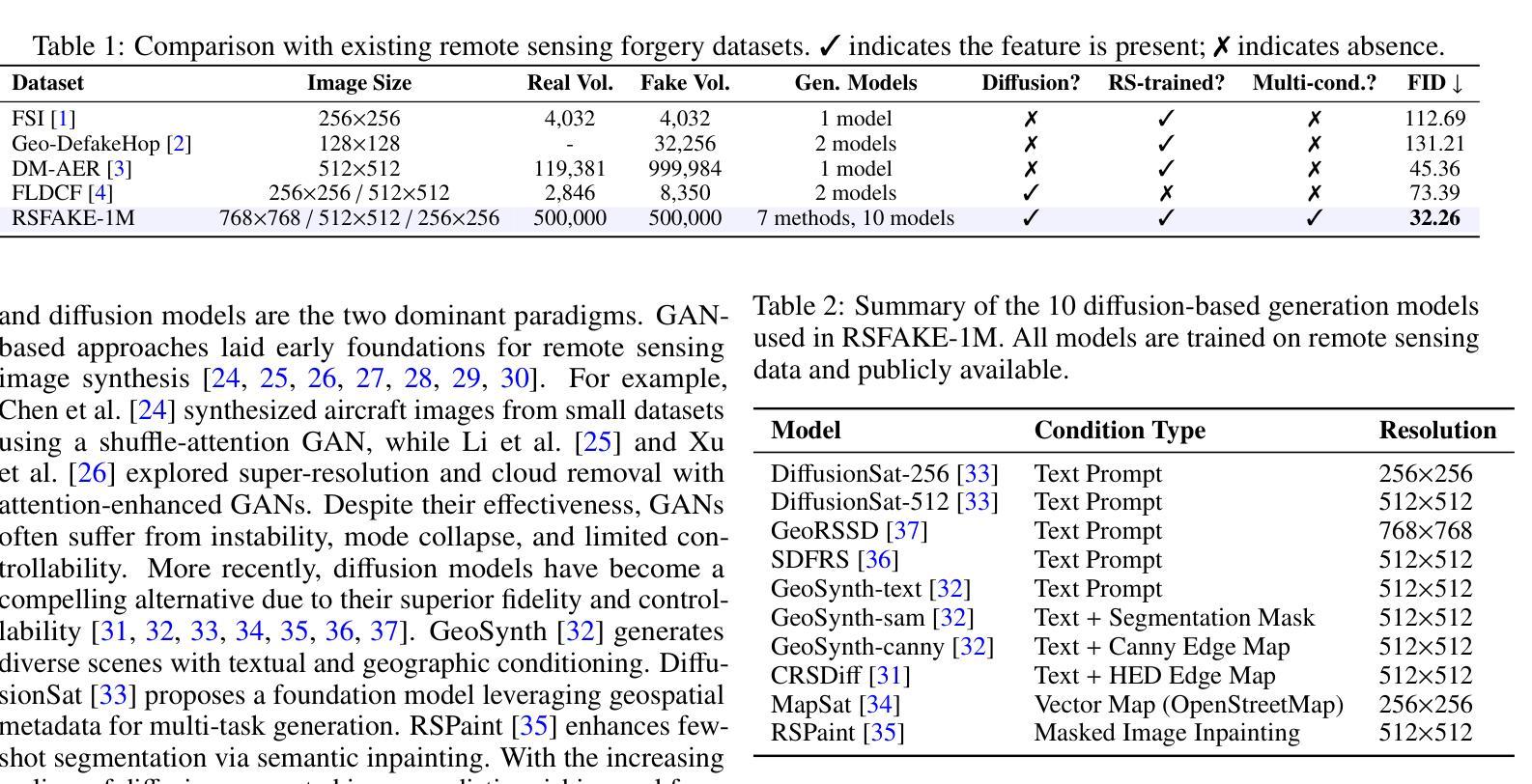
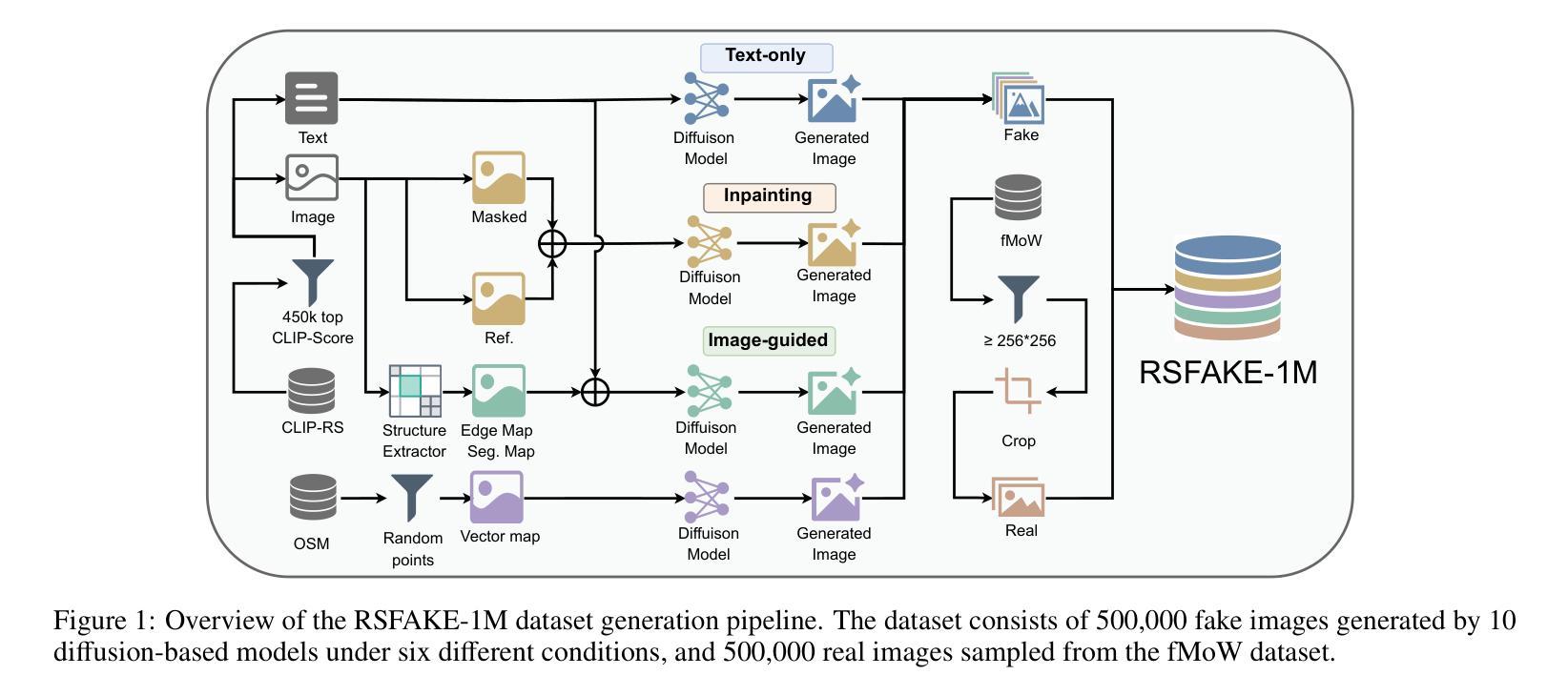


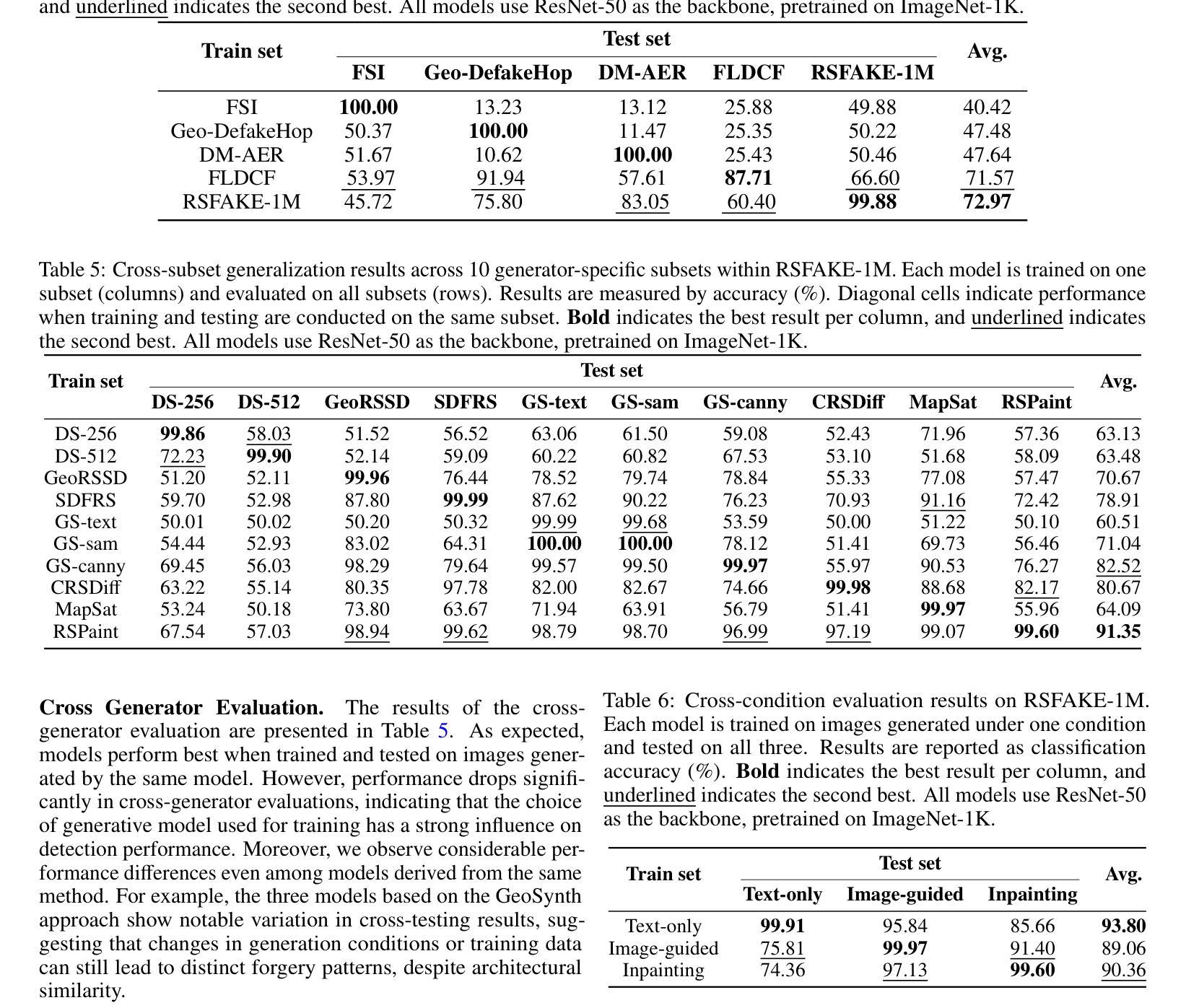
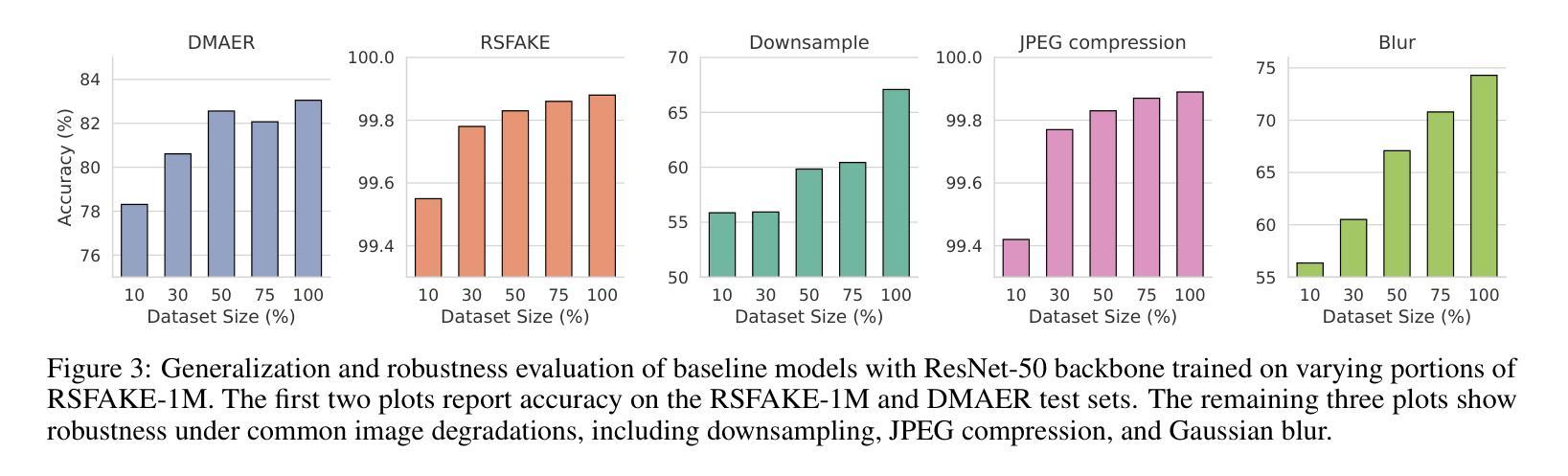
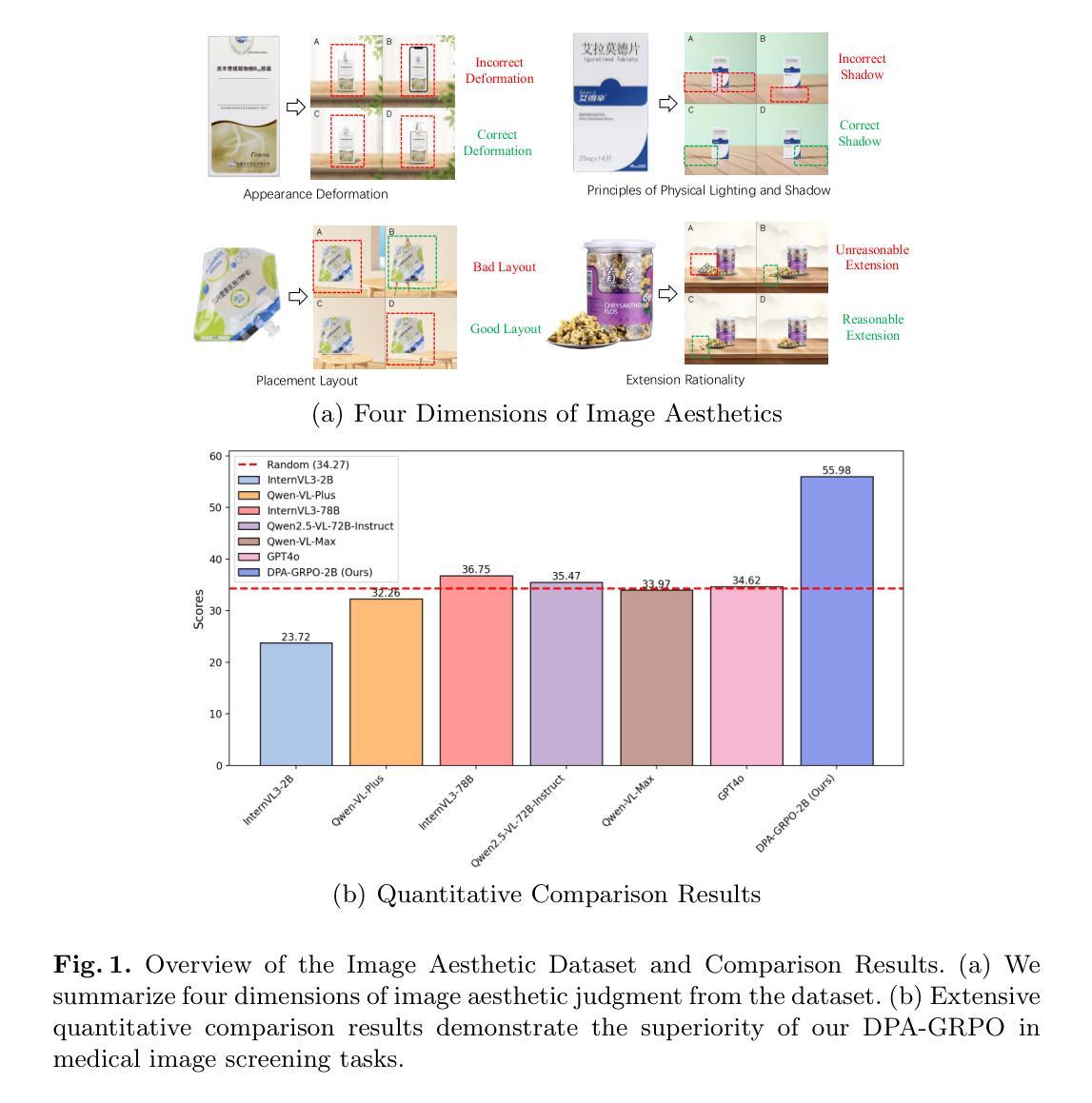
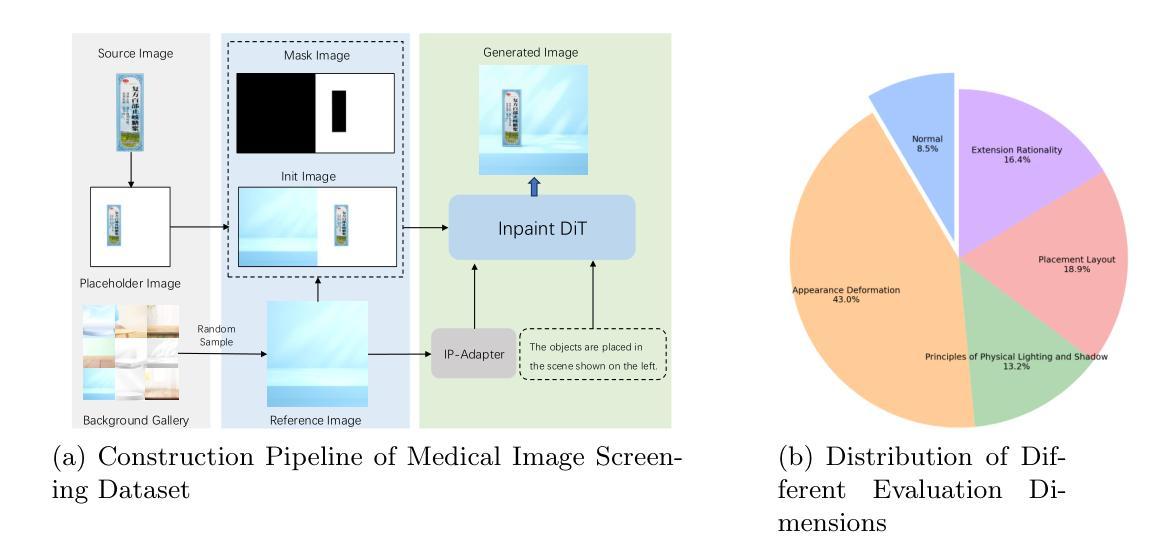
Image Aesthetic Reasoning: A New Benchmark for Medical Image Screening with MLLMs
Authors:Zheng Sun, Yi Wei, Long Yu
Multimodal Large Language Models (MLLMs) are of great application across many domains, such as multimodal understanding and generation. With the development of diffusion models (DM) and unified MLLMs, the performance of image generation has been significantly improved, however, the study of image screening is rare and its performance with MLLMs is unsatisfactory due to the lack of data and the week image aesthetic reasoning ability in MLLMs. In this work, we propose a complete solution to address these problems in terms of data and methodology. For data, we collect a comprehensive medical image screening dataset with 1500+ samples, each sample consists of a medical image, four generated images, and a multiple-choice answer. The dataset evaluates the aesthetic reasoning ability under four aspects: \textit{(1) Appearance Deformation, (2) Principles of Physical Lighting and Shadow, (3) Placement Layout, (4) Extension Rationality}. For methodology, we utilize long chains of thought (CoT) and Group Relative Policy Optimization with Dynamic Proportional Accuracy reward, called DPA-GRPO, to enhance the image aesthetic reasoning ability of MLLMs. Our experimental results reveal that even state-of-the-art closed-source MLLMs, such as GPT-4o and Qwen-VL-Max, exhibit performance akin to random guessing in image aesthetic reasoning. In contrast, by leveraging the reinforcement learning approach, we are able to surpass the score of both large-scale models and leading closed-source models using a much smaller model. We hope our attempt on medical image screening will serve as a regular configuration in image aesthetic reasoning in the future.
多模态大型语言模型(MLLMs)在众多领域具有广泛的应用,如多模态理解和生成。随着扩散模型(DM)和统一MLLMs的发展,图像生成的性能得到了显著提高。然而,图像筛选的研究很少,其与MLLMs的性能也不尽如人意,这是由于数据缺乏以及MLLMs中图像美学推理能力的薄弱。在这项工作中,我们针对这些问题在数据和方法上提出了全面的解决方案。在数据方面,我们收集了一个全面的医学图像筛选数据集,包含1500多个样本,每个样本由一张医学图像、四张生成的图像和多个选择题组成。该数据集从以下四个方面评估美学推理能力:(1)外观变形;(2)物理照明和阴影原则;(3)放置布局;(4)扩展合理性。在方法上,我们利用长链思维(CoT)和动态比例精度奖励的集团相对策略优化(称为DPA-GRPO),以提高MLLMs的图像美学推理能力。我们的实验结果表明,即使是最先进的闭源MLLMs,如GPT-4o和Qwen-VL-Max,在图像美学推理方面的表现也与随机猜测无异。相比之下,通过利用强化学习方法,我们能够在模型规模较小的情况下超越这两个大规模模型的得分,并领先其他闭源模型。我们希望我们的医学图像筛选尝试未来能在图像美学推理中成为一种常规配置。
论文及项目相关链接
摘要
多模态大型语言模型(MLLMs)在多个领域有广泛应用,如多模态理解和生成。扩散模型(DM)和统一MLLMs的发展已显著改善图像生成性能,但图像筛选研究稀少,其与MLLMs的性能也不尽人意,主要由于数据缺乏以及MLLMs中图像美学推理能力薄弱。本研究提出针对这些问题在数据和方法上的完整解决方案。在数据方面,我们收集了一个综合医疗图像筛选数据集,包含1500多个样本,每个样本包括医疗图像、四个生成图像和多个选择题。该数据集评估了美学推理能力的四个方面:外观变形、物理照明和阴影原则、放置布局、扩展合理性。在方法上,我们利用长链思维和带有动态比例精度奖励的集团相对策略优化(DPA-GRPO),提高MLLMs的图像美学推理能力。实验结果表明,即使是最先进的闭源MLLMs,如GPT-4o和Qwen-VL-Max,在图像美学推理方面的表现也如同随机猜测。相比之下,通过利用强化学习的方法,即使使用较小的模型,我们也能够超越大型模型的得分,达到领先水平。我们希望我们的医疗图像筛选尝试能为未来的图像美学推理提供常规配置。
关键见解
- 多模态大型语言模型(MLLMs)在图像生成方面表现出色,但在图像筛选方面的应用不尽人意。
- 数据缺乏和MLLMs中图像美学推理能力薄弱是主要原因。
- 提出一个综合医疗图像筛选数据集,包含多方面的美学推理能力评估。
- 采用长链思维和带有动态比例精度奖励的集团相对策略优化(DPA-GRPO)方法提高MLLMs的图像美学推理能力。
- 最先进的闭源MLLMs在图像美学推理方面的表现有限。
- 利用强化学习的方法能够在较小的模型上超越大型模型的得分。
点此查看论文截图

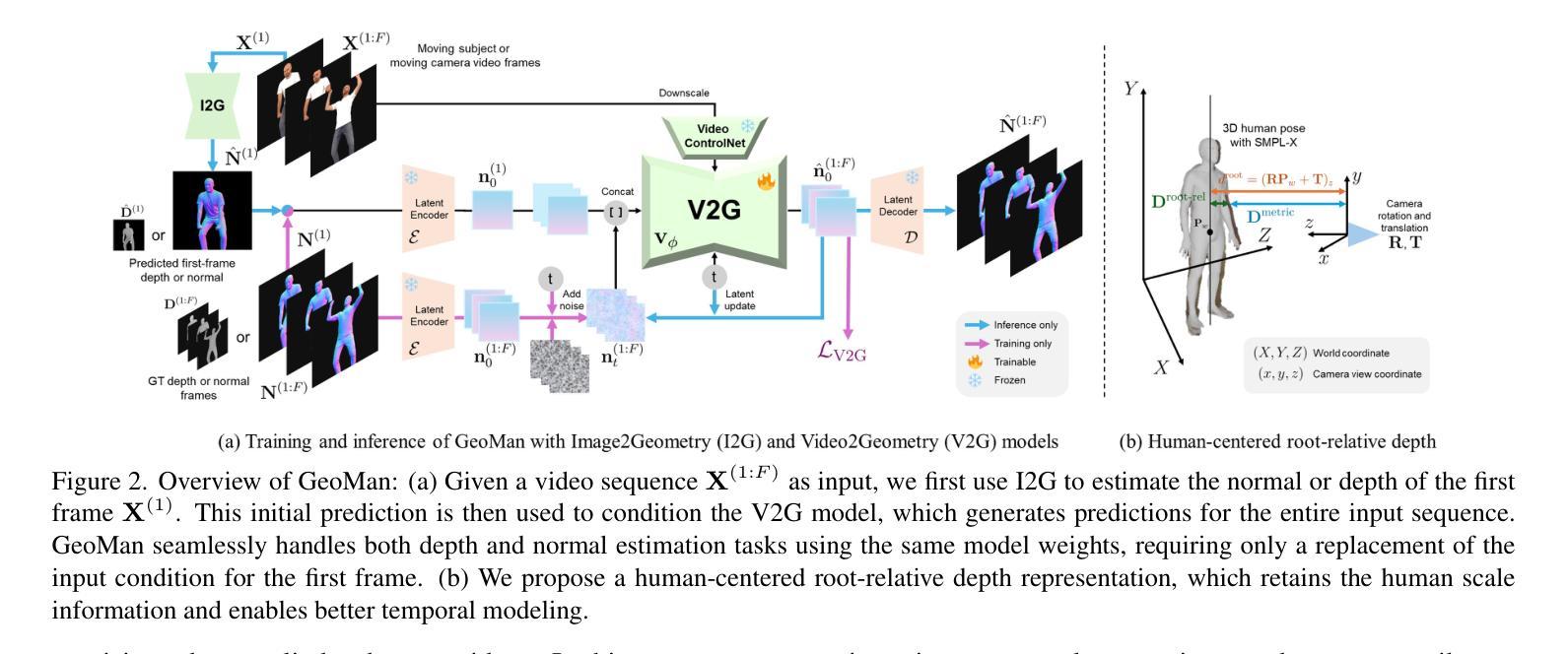
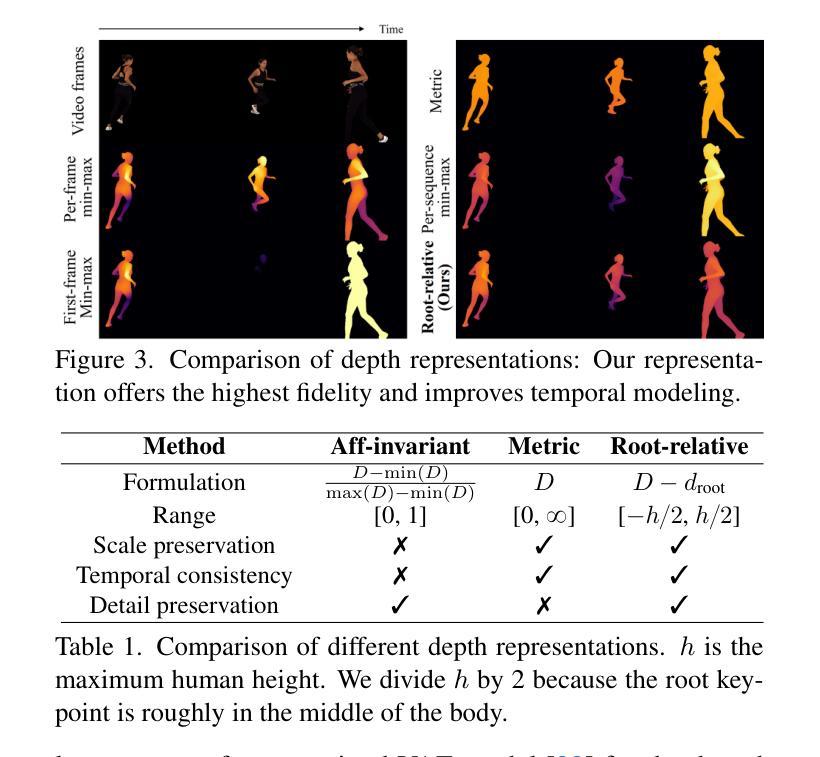
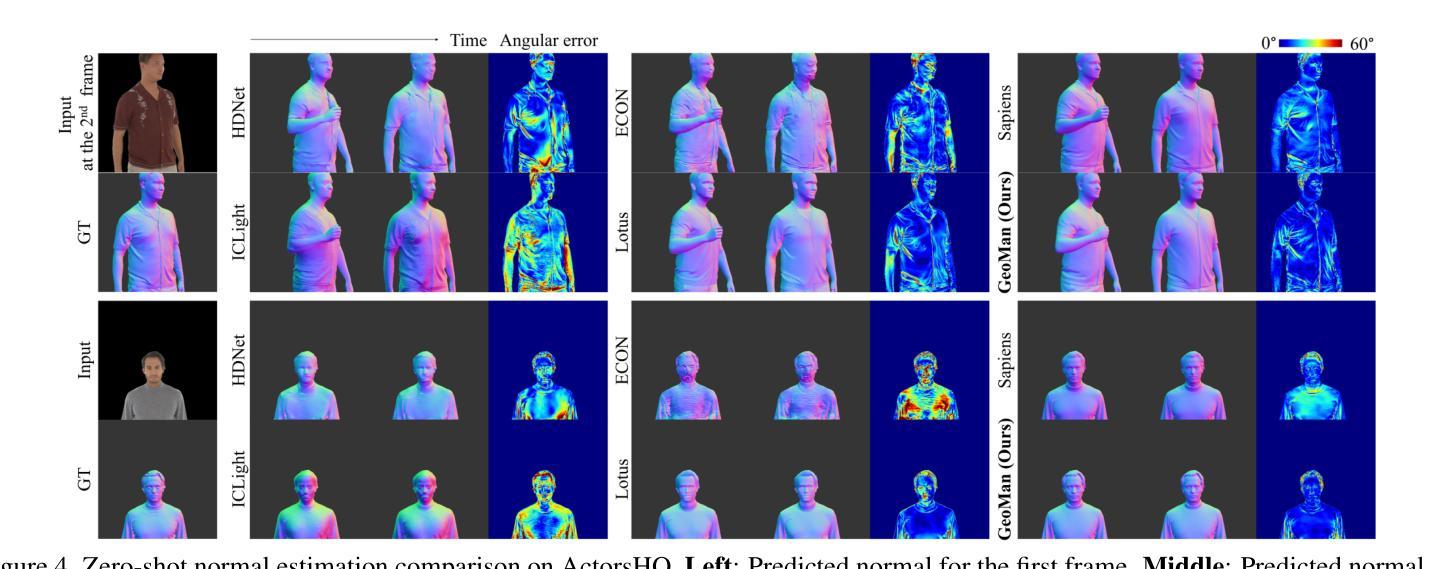
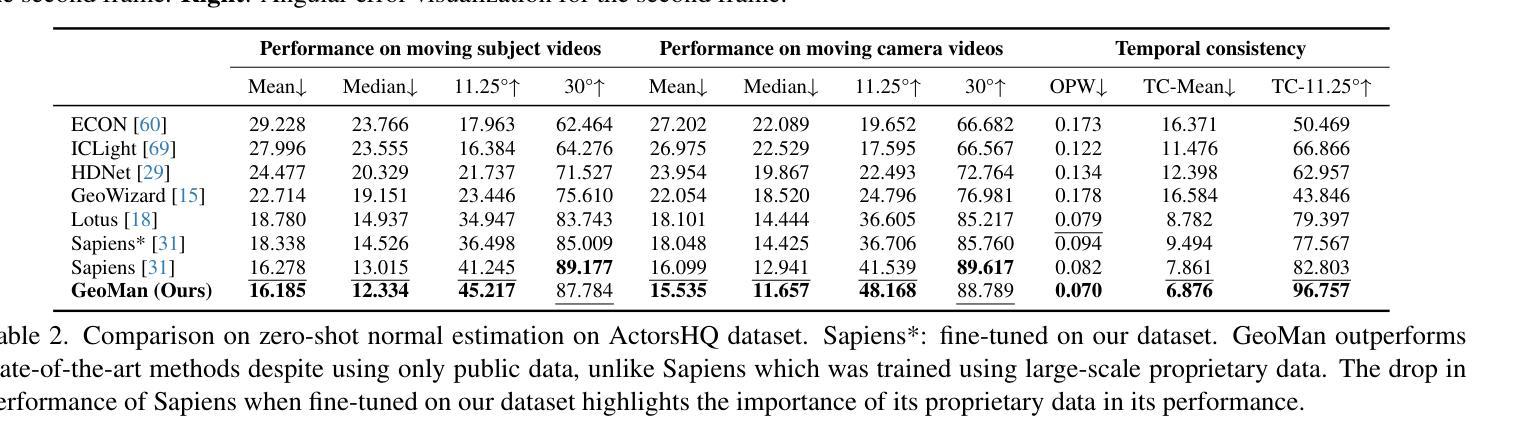
GeoMan: Temporally Consistent Human Geometry Estimation using Image-to-Video Diffusion
Authors:Gwanghyun Kim, Xueting Li, Ye Yuan, Koki Nagano, Tianye Li, Jan Kautz, Se Young Chun, Umar Iqbal
Estimating accurate and temporally consistent 3D human geometry from videos is a challenging problem in computer vision. Existing methods, primarily optimized for single images, often suffer from temporal inconsistencies and fail to capture fine-grained dynamic details. To address these limitations, we present GeoMan, a novel architecture designed to produce accurate and temporally consistent depth and normal estimations from monocular human videos. GeoMan addresses two key challenges: the scarcity of high-quality 4D training data and the need for metric depth estimation to accurately model human size. To overcome the first challenge, GeoMan employs an image-based model to estimate depth and normals for the first frame of a video, which then conditions a video diffusion model, reframing video geometry estimation task as an image-to-video generation problem. This design offloads the heavy lifting of geometric estimation to the image model and simplifies the video model’s role to focus on intricate details while using priors learned from large-scale video datasets. Consequently, GeoMan improves temporal consistency and generalizability while requiring minimal 4D training data. To address the challenge of accurate human size estimation, we introduce a root-relative depth representation that retains critical human-scale details and is easier to be estimated from monocular inputs, overcoming the limitations of traditional affine-invariant and metric depth representations. GeoMan achieves state-of-the-art performance in both qualitative and quantitative evaluations, demonstrating its effectiveness in overcoming longstanding challenges in 3D human geometry estimation from videos.
从视频中估计准确且时间上一致的3D人体几何是计算机视觉中的一个具有挑战性的问题。现有方法主要针对单张图像进行优化,常常存在时间上的不一致性,并且无法捕捉精细的动态细节。为了解决这些局限性,我们提出了GeoMan,这是一种新型架构,旨在从单目人体视频中产生准确且时间上一致的深度和法线估计。GeoMan解决了两个关键挑战:高质量4D训练数据的稀缺性和对度量深度估计以准确建模人体尺寸的需求。为了克服第一个挑战,GeoMan采用基于图像的模型来估计视频的第一帧的深度和法线,然后将条件应用于视频扩散模型,将视频几何估计任务重新定位为图像到视频的生成问题。这种设计将几何估计的重担转移给了图像模型,简化了视频模型的角色,使其专注于细节,同时使用从大规模视频数据集中学习的先验知识。因此,GeoMan提高了时间一致性和通用性,同时只需要最少的4D训练数据。为了解决准确估计人体尺寸的挑战,我们引入了一种根相对深度表示法,该方法保留了关键的人体尺度细节,并且更容易从单目输入中进行估计,克服了传统的仿射不变和度量深度表示法的局限性。GeoMan在定性和定量评估中都达到了最先进的性能,证明了其在克服从视频中估计3D人体几何的长期挑战中的有效性。
论文及项目相关链接
PDF Project page: https://research.nvidia.com/labs/dair/geoman
Summary
在视频中的人体三维几何准确且时间一致的估计是计算机视觉中的一个难题。现有方法主要针对单张图像进行优化,常常存在时间不一致性且无法捕捉精细的动态细节。为了解决这个问题,我们提出了GeoMan模型,能够从单目人体视频中准确且时间一致地估计深度和法线。GeoMan解决了高质量四维训练数据的稀缺性和精确建模人体尺寸所需的度量深度估计这两个关键问题。通过基于图像的模型估计视频第一帧的深度和法线,并以此为条件构建视频扩散模型,将视频几何估计任务重构为图像到视频的生成问题。这种设计简化了视频模型的任务,使其专注于细节,并利用从大规模视频数据集中学习的先验知识。因此,GeoMan提高了时间一致性和泛化能力,同时需要很少的四维训练数据。引入根相对深度表示法来解决准确估计人体尺寸的挑战,保留了关键的人体尺度细节,并更容易从单目输入进行估计,克服了传统的仿射不变和度量深度表示方法的局限性。
Key Takeaways
- GeoMan模型能够准确且时间一致地从视频中估计人体三维几何。
- 现有方法主要面对两个挑战:四维训练数据的稀缺性和人体尺寸的精确建模。
- GeoMan通过将视频几何估计任务转化为图像到视频的生成问题来解决这两个挑战。
- 通过基于图像的模型估计视频第一帧的深度和法线,并以此为条件构建视频扩散模型。
- 根相对深度表示法用于准确估计人体尺寸,同时保留关键的人体尺度细节。
- 该模型实现了在定性和定量评估中的最佳性能。
点此查看论文截图

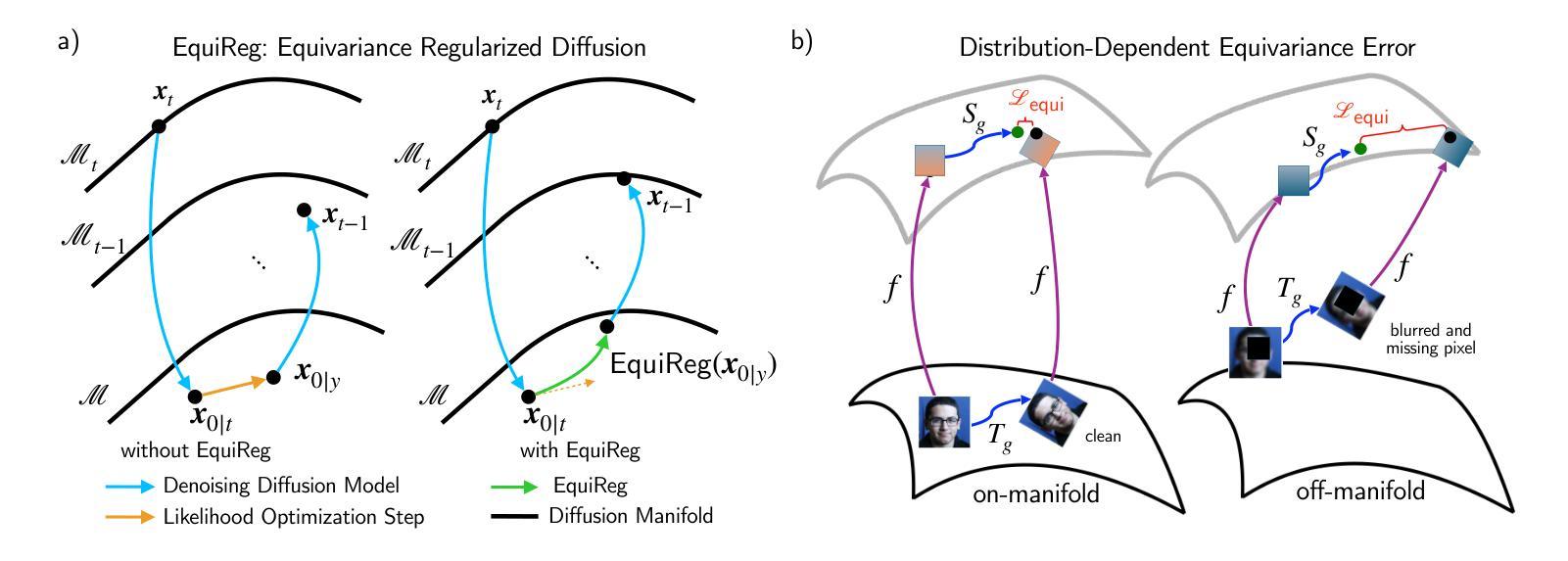
EquiReg: Equivariance Regularized Diffusion for Inverse Problems
Authors:Bahareh Tolooshams, Aditi Chandrashekar, Rayhan Zirvi, Abbas Mammadov, Jiachen Yao, Chuwei Wang, Anima Anandkumar
Diffusion models represent the state-of-the-art for solving inverse problems such as image restoration tasks. In the Bayesian framework, diffusion-based inverse solvers incorporate a likelihood term to guide the prior sampling process, generating data consistent with the posterior distribution. However, due to the intractability of the likelihood term, many current methods rely on isotropic Gaussian approximations, which lead to deviations from the data manifold and result in inconsistent, unstable reconstructions. We propose Equivariance Regularized (EquiReg) diffusion, a general framework for regularizing posterior sampling in diffusion-based inverse problem solvers. EquiReg enhances reconstructions by reweighting diffusion trajectories and penalizing those that deviate from the data manifold. We define a new distribution-dependent equivariance error, empirically identify functions that exhibit low error for on-manifold samples and higher error for off-manifold samples, and leverage these functions to regularize the diffusion sampling process. When applied to a variety of solvers, EquiReg outperforms state-of-the-art diffusion models in both linear and nonlinear image restoration tasks, as well as in reconstructing partial differential equations.
扩散模型代表了解决图像恢复等逆向问题的最新技术前沿。在贝叶斯框架下,基于扩散的逆向求解器融入一个可能性术语来引导先验采样过程,生成与后验分布一致的数据。然而,由于可能性术语的不可预测性,许多当前的方法依赖于各向同性高斯近似,这会导致偏离数据流形并产生不一致、不稳定的重建结果。我们提出了等价正则化(EquiReg)扩散,这是一个用于基于扩散的逆向问题求解器中的后验采样的通用框架。EquiReg通过重新加权扩散轨迹并惩罚那些偏离数据流形的轨迹来增强重建效果。我们定义了一个新的分布相关的等价误差,实证确定了对于流形内样本显示低误差而对于流形外样本显示更高误差的函数,并利用这些函数来规范扩散采样过程。当应用于各种求解器时,EquiReg在线性和非线性图像恢复任务以及偏微分方程重建中都优于最先进的扩散模型。
论文及项目相关链接
Summary
扩散模型是解决图像恢复等逆问题的最新技术。在贝叶斯框架下,基于扩散的逆求解器通过结合可能性术语来引导先验采样过程,生成与后验分布一致的数据。然而,由于可能性术语的不可计算性,许多当前的方法依赖于各向同性的高斯近似,这会导致偏离数据流形并产生不一致、不稳定的重建。我们提出了等距正则化(EquiReg)扩散,这是一个用于正则化基于扩散的逆问题求解器中的后验采样的通用框架。EquiReg通过重新加权扩散轨迹并惩罚偏离数据流形的轨迹来增强重建效果。我们定义了一个新的分布相关的等距误差,实证确定了对于流形内样本具有低误差而对于流形外样本具有较高误差的函数,并利用这些函数来正则化扩散采样过程。在多种求解器上应用时,EquiReg在线性和非线性图像恢复任务以及偏微分方程重建中均表现出优于最新扩散模型的性能。
Key Takeaways
- 扩散模型是解决逆问题的最新技术,尤其在图像恢复领域有出色表现。
- 在贝叶斯框架下,扩散模型结合可能性术语来引导先验采样。
- 当前方法因可能性术语的不可计算性而依赖各向同性的高斯近似,这可能导致数据流形偏离并产生不稳定的重建结果。
- 提出的EquiReg扩散框架用于正则化基于扩散的逆问题求解器中的后验采样。
- EquiReg通过重新加权扩散轨迹并惩罚偏离数据流形的轨迹来增强重建效果。
- EquiReg定义了一个新的分布相关的等距误差来衡量样本的质量。
点此查看论文截图

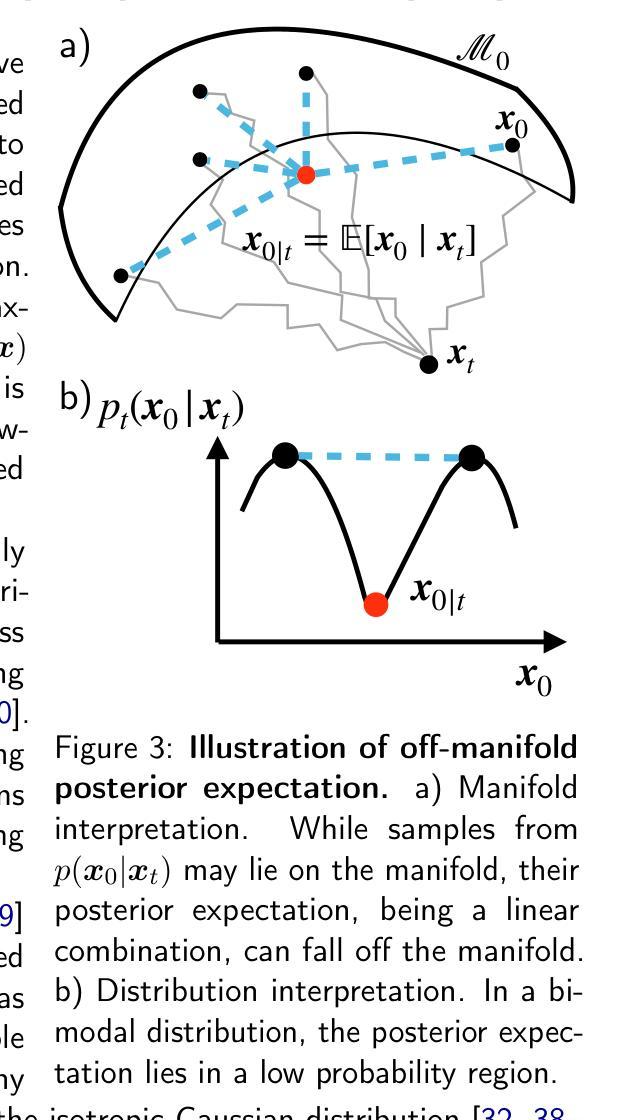
Plug-and-Play Posterior Sampling for Blind Inverse Problems
Authors:Anqi Li, Weijie Gan, Ulugbek S. Kamilov
We introduce Blind Plug-and-Play Diffusion Models (Blind-PnPDM) as a novel framework for solving blind inverse problems where both the target image and the measurement operator are unknown. Unlike conventional methods that rely on explicit priors or separate parameter estimation, our approach performs posterior sampling by recasting the problem into an alternating Gaussian denoising scheme. We leverage two diffusion models as learned priors: one to capture the distribution of the target image and another to characterize the parameters of the measurement operator. This PnP integration of diffusion models ensures flexibility and ease of adaptation. Our experiments on blind image deblurring show that Blind-PnPDM outperforms state-of-the-art methods in terms of both quantitative metrics and visual fidelity. Our results highlight the effectiveness of treating blind inverse problems as a sequence of denoising subproblems while harnessing the expressive power of diffusion-based priors.
我们引入盲插播扩散模型(Blind-PnPDM)作为一个新的框架,用于解决盲反问题,其中目标图像和测量算子都是未知的。不同于依赖显式先验或单独参数估计的传统方法,我们的方法通过把问题转化为交替高斯去噪方案来执行后验采样。我们利用两个扩散模型作为先验知识:一个用于捕捉目标图像的分布,另一个用于描述测量算子的参数。这种PnP扩散模型的集成确保了灵活性和易于适应。我们在盲图像去模糊实验上表明,Blind-PnPDM在定量指标和视觉保真度方面都优于最先进的方法。我们的结果突出了将盲反问题视为一系列去噪子问题序列的有效性,同时利用基于扩散的先验知识的表现力。
论文及项目相关链接
PDF arXiv admin note: text overlap with arXiv:2305.12672
Summary
本文介绍了盲插接扩散模型(Blind-PnPDM),这是一种解决盲逆问题的新型框架,该框架在目标图像和测量算子均未知的情况下运作。与传统方法不同,该方法通过重新构建问题为交替高斯去噪方案进行后验采样,而无需依赖显式先验或单独参数估计。实验证明,在盲图像去模糊任务上,Blind-PnPDM在定量指标和视觉保真度方面均优于现有最先进的方法。
Key Takeaways
- Blind-PnPDM是一种解决盲逆问题的新型框架,适用于目标图像和测量算子均未知的情况。
- 该方法通过交替高斯去噪方案进行后验采样,无需显式先验或单独参数估计。
- Blind-PnPDM利用两个扩散模型作为先验知识:一个用于捕捉目标图像分布,另一个用于描述测量算子的参数。
- Blind-PnPDM在盲图像去模糊任务上表现出优异性能,优于现有最先进的方法。
- 该方法具有灵活性和适应性,易于适应不同的任务。
- 实验结果证明了将盲逆问题视为一系列去噪子问题的有效性。
- 扩散模型作为先验知识,展现了其强大的表达能力。
点此查看论文截图



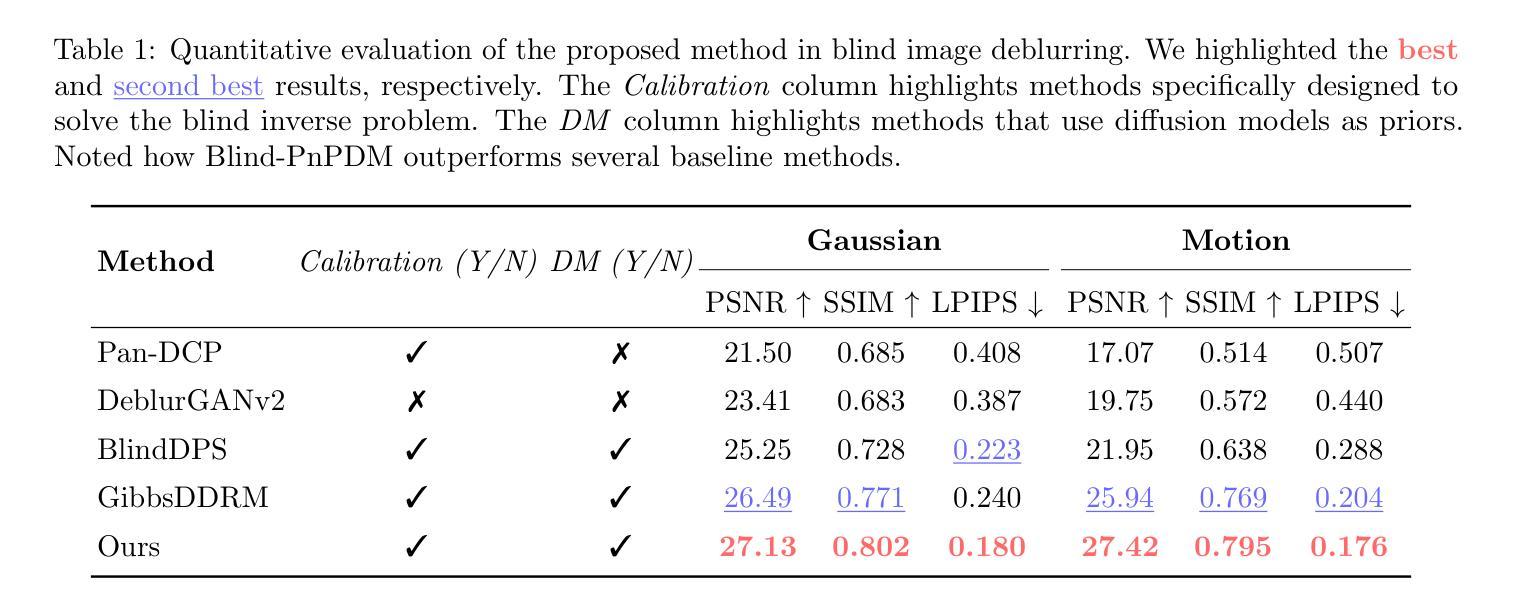
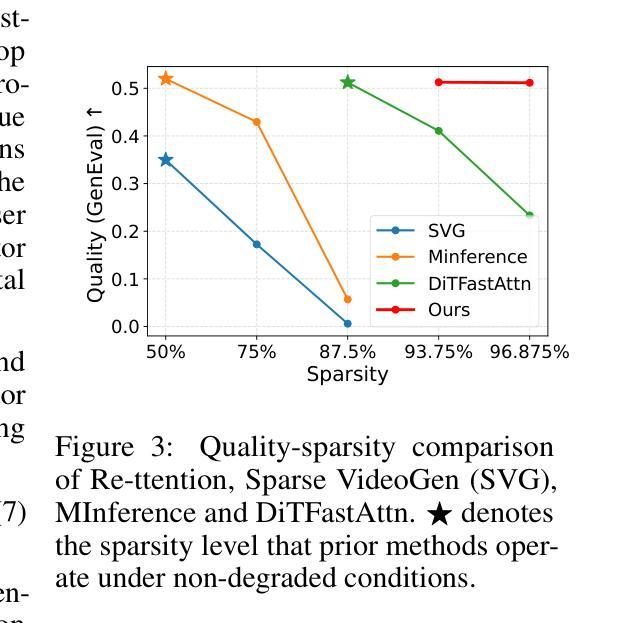
Re-ttention: Ultra Sparse Visual Generation via Attention Statistical Reshape
Authors:Ruichen Chen, Keith G. Mills, Liyao Jiang, Chao Gao, Di Niu
Diffusion Transformers (DiT) have become the de-facto model for generating high-quality visual content like videos and images. A huge bottleneck is the attention mechanism where complexity scales quadratically with resolution and video length. One logical way to lessen this burden is sparse attention, where only a subset of tokens or patches are included in the calculation. However, existing techniques fail to preserve visual quality at extremely high sparsity levels and might even incur non-negligible compute overheads. % To address this concern, we propose Re-ttention, which implements very high sparse attention for visual generation models by leveraging the temporal redundancy of Diffusion Models to overcome the probabilistic normalization shift within the attention mechanism. Specifically, Re-ttention reshapes attention scores based on the prior softmax distribution history in order to preserve the visual quality of the full quadratic attention at very high sparsity levels. % Experimental results on T2V/T2I models such as CogVideoX and the PixArt DiTs demonstrate that Re-ttention requires as few as 3.1% of the tokens during inference, outperforming contemporary methods like FastDiTAttn, Sparse VideoGen and MInference. Further, we measure latency to show that our method can attain over 45% end-to-end % and over 92% self-attention latency reduction on an H100 GPU at negligible overhead cost. Code available online here: \href{https://github.com/cccrrrccc/Re-ttention}{https://github.com/cccrrrccc/Re-ttention}
扩散Transformer(DiT)已成为生成高质量视觉内容(如视频和图像)的默认模型。一个巨大的瓶颈是注意力机制,其中复杂性随分辨率和视频长度的增加而二次方增长。减轻这一负担的一种逻辑方法是稀疏注意力,其中仅包括一部分令牌或补丁进行计算。然而,现有技术在极高的稀疏性水平下无法保持视觉质量,并可能产生不可忽略的计算开销。为了解决这一担忧,我们提出了Re-ttention,它通过利用扩散模型的时序冗余来实现视觉生成模型的极高稀疏注意力,以克服注意力机制内的概率归一化移位。具体来说,Re-ttention根据先前的softmax分布历史重新调整注意力分数,以在极高的稀疏性水平下保持全二次注意力的视觉质量。在T2V/T2I模型(如CogVideoX和PixArt DiTs)上的实验结果表明,Re-ttention在推理过程中只需要3.1%的令牌,超越了FastDiTAttn、Sparse VideoGen和MInference等当代方法。此外,我们通过测量延迟来展示我们的方法可以在H100 GPU上实现超过45%的端到端延迟减少和超过92%的自注意力延迟减少,同时几乎不增加开销成本。代码可在以下网址找到:https://github.com/cccrrrccc/Re-ttention。
论文及项目相关链接
摘要
扩散Transformer(DiT)已成为生成高质量视觉内容(如视频和图像)的默认模型。当前面临的一个巨大瓶颈是注意力机制,其复杂性随分辨率和视频长度的增加而呈二次方增长。为减轻这一负担,人们采用稀疏注意力法,仅选择一部分令牌或补丁进行计算。然而,现有技术在极高的稀疏水平上无法保持视觉质量,并可能产生不可忽略的计算开销。为解决这一问题,我们提出Re-ttention,通过利用扩散模型的时序冗余性,实现对视觉生成模型的极高稀疏注意力。Re-ttention根据先前的softmax分布历史重塑注意力分数,以在极高的稀疏水平上保持全二次注意力视觉质量。在T2V/T2I模型(如CogVideoX和PixArt DiTs)上的实验结果表明,Re-ttention在推理过程中仅需3.1%的令牌,超越了FastDiTAttn、Sparse VideoGen和MInference等当代方法。此外,我们测量延迟时间,证明该方法可在H100 GPU上实现超过45%的端到端和超过92%的自注意力延迟减少,同时几乎不增加开销。相关代码可通过https://github.com/cccrrrccc/Re-ttention访问。
要点速递
- 扩散Transformer(DiT)已成为高质量视觉内容生成的标准模型,面临注意力机制复杂性的挑战。
- 现有稀疏注意力技术在高稀疏性时视觉质量下降并可能产生额外计算开销。
- Re-ttention通过利用扩散模型的时序冗余性,实现高稀疏注意力,旨在解决上述问题。
- Re-ttention通过重塑注意力分数,在极高稀疏水平上保持视觉质量。
- 在T2V/T2I模型上的实验表明,Re-ttention仅需少量令牌即可超越其他方法。
- Re-ttention能有效减少延迟,提高模型效率。
点此查看论文截图



Diffusion Classifiers Understand Compositionality, but Conditions Apply
Authors:Yujin Jeong, Arnas Uselis, Seong Joon Oh, Anna Rohrbach
Understanding visual scenes is fundamental to human intelligence. While discriminative models have significantly advanced computer vision, they often struggle with compositional understanding. In contrast, recent generative text-to-image diffusion models excel at synthesizing complex scenes, suggesting inherent compositional capabilities. Building on this, zero-shot diffusion classifiers have been proposed to repurpose diffusion models for discriminative tasks. While prior work offered promising results in discriminative compositional scenarios, these results remain preliminary due to a small number of benchmarks and a relatively shallow analysis of conditions under which the models succeed. To address this, we present a comprehensive study of the discriminative capabilities of diffusion classifiers on a wide range of compositional tasks. Specifically, our study covers three diffusion models (SD 1.5, 2.0, and, for the first time, 3-m) spanning 10 datasets and over 30 tasks. Further, we shed light on the role that target dataset domains play in respective performance; to isolate the domain effects, we introduce a new diagnostic benchmark Self-Bench comprised of images created by diffusion models themselves. Finally, we explore the importance of timestep weighting and uncover a relationship between domain gap and timestep sensitivity, particularly for SD3-m. To sum up, diffusion classifiers understand compositionality, but conditions apply! Code and dataset are available at https://github.com/eugene6923/Diffusion-Classifiers-Compositionality.
理解视觉场景对人类智能至关重要。虽然判别模型在计算机视觉领域取得了显著进展,但在组合理解方面常常遇到困难。相比之下,最近的文本到图像的生成扩散模型在合成复杂场景方面表现出色,这表明其具有内在的组成能力。基于此,零样本扩散分类器被提出用于将扩散模型重新用于判别任务。虽然先前的工作在判别组合场景方面提供了有前景的结果,但由于基准测试的数量有限以及对模型成功的条件分析相对肤浅,这些结果仍是初步的。为了解决这一问题,我们对扩散分类器在广泛组合任务上的判别能力进行了综合研究。具体来说,我们的研究涵盖了三个扩散模型(SD 1.5、2.0,以及首次尝试的3-m),涉及10个数据集和超过30个任务。此外,我们阐明了目标数据集领域在各自性能中的作用;为了隔离领域效应,我们推出了一个新的诊断基准Self-Bench,由扩散模型本身创建的图像组成。最后,我们探讨了时间步长权重的重要性,并揭示了领域差距与时间步长敏感性之间的关系,特别是对于SD3-m。总而言之,扩散分类器理解组合性,但有条件限制!相关代码和数据集可通过https://github.com/eugene6923/Diffusion-Classifiers-Compositionality获取。
论文及项目相关链接
摘要
视觉场景的理解对人类智能至关重要。判别模型在计算机视觉领域取得了显著进展,但在组合理解方面仍有困难。相反,最近的文本到图像生成扩散模型在合成复杂场景方面表现出色,显示出内在的组成能力。基于此,零样本扩散分类器被提出用于将扩散模型用于判别任务。虽然先前的研究在判别组合场景方面提供了有前景的结果,但由于基准测试数量较少以及对模型成功条件的分析相对肤浅,这些结果仍然初步。为了解决这一问题,我们对扩散分类器在多种组合任务上的判别能力进行了综合研究。研究涵盖了三个扩散模型(SD 1.5、2.0和首次推出的3-m),涉及10个数据集和超过30个任务。此外,我们阐明了目标数据集领域在各自性能中的作用;为了隔离领域效应,我们推出了一个新的诊断基准Self-Bench,由扩散模型本身创建的图像组成。最后,我们探讨了时间步长权重的重要性,并揭示了领域差距与时间步长敏感性之间的关系,特别是对于SD3-m。总之,扩散分类器理解组合性,但条件应用!相关代码和数据集可在链接中找到。
关键见解
- 扩散模型在合成复杂场景方面表现出强大的能力,表明其内在的组成能力。
- 零样本扩散分类器被成功应用于判别任务,显示出扩散模型的潜力。
- 研究涵盖了多个扩散模型和大量数据集,提供了对扩散分类器判别能力的全面分析。
- 揭示了目标数据集领域对模型性能的重要影响。
- 引入新的诊断基准Self-Bench,用于评估由扩散模型创建的图像。
- 探讨了时间步长权重的重要性,并发现其与领域差距之间的关联。
- 扩散分类器虽然理解组合性,但应用时需考虑条件因素。
点此查看论文截图


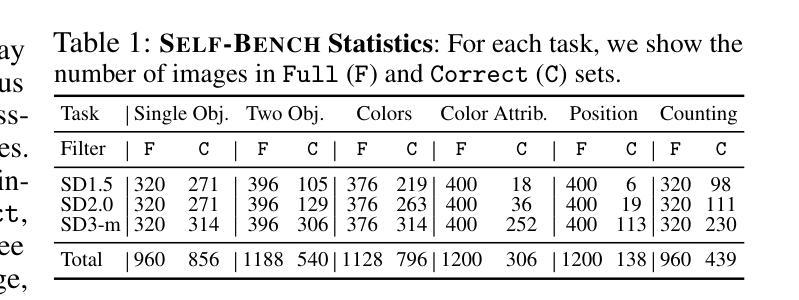
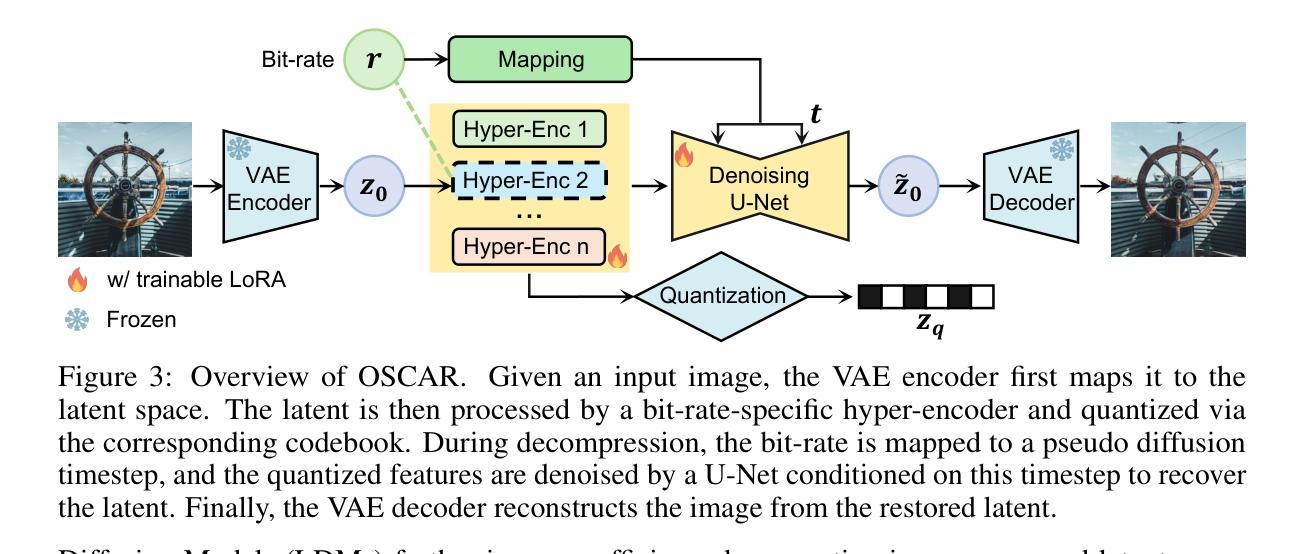
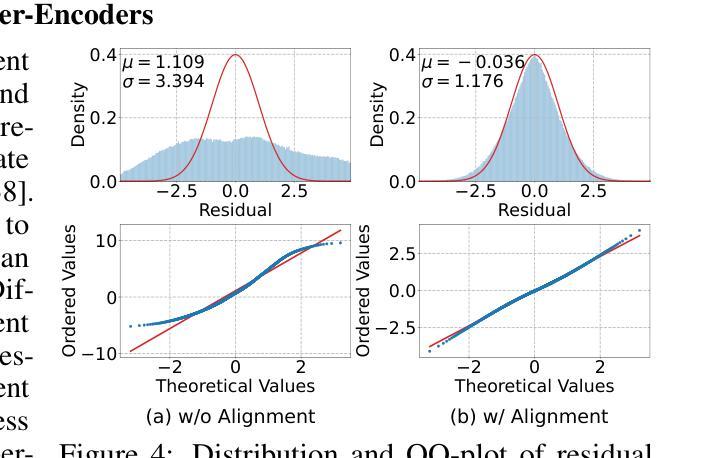
OSCAR: One-Step Diffusion Codec for Image Compression Across Multiple Bit-rates
Authors:Jinpei Guo, Yifei Ji, Zheng Chen, Kai Liu, Min Liu, Wang Rao, Wenbo Li, Yong Guo, Yulun Zhang
Pretrained latent diffusion models have shown strong potential for lossy image compression, owing to their powerful generative priors. Most existing diffusion-based methods reconstruct images by iteratively denoising from random noise, guided by compressed latent representations. While these approaches have achieved high reconstruction quality, their multi-step sampling process incurs substantial computational overhead. Moreover, they typically require training separate models for different compression bit-rates, leading to significant training and storage costs. To address these challenges, we propose a one-step diffusion codec across multiple bit-rates. termed OSCAR. Specifically, our method views compressed latents as noisy variants of the original latents, where the level of distortion depends on the bit-rate. This perspective allows them to be modeled as intermediate states along a diffusion trajectory. By establishing a mapping from the compression bit-rate to a pseudo diffusion timestep, we condition a single generative model to support reconstructions at multiple bit-rates. Meanwhile, we argue that the compressed latents retain rich structural information, thereby making one-step denoising feasible. Thus, OSCAR replaces iterative sampling with a single denoising pass, significantly improving inference efficiency. Extensive experiments demonstrate that OSCAR achieves superior performance in both quantitative and visual quality metrics. The code and models will be released at https://github.com/jp-guo/OSCAR.
预训练的潜在扩散模型在有损图像压缩方面表现出了强大的潜力,这得益于其强大的生成先验。大多数现有的基于扩散的方法通过迭代去噪从随机噪声中重建图像,由压缩的潜在表示所引导。虽然这些方法达到了较高的重建质量,但它们的多步采样过程产生了大量的计算开销。此外,它们通常需要针对不同的压缩比特率训练单独的模式,从而产生了显著的训练和存储成本。为了解决这些挑战,我们提出了一种跨多个比特率的扩散编解码器,称为OSCAR。具体来说,我们的方法将压缩潜在变量视为原始潜在变量的噪声版本,其中失真程度取决于比特率。这个视角允许它们被建模为扩散轨迹中的中间状态。通过建立从压缩比特率到伪扩散时间步长的映射,我们将单个生成模式应用于多个比特率的重建。同时,我们认为压缩的潜在变量保留了丰富的结构信息,从而使得一步去噪变得可行。因此,OSCAR用一次去噪过程取代了迭代采样,大大提高了推理效率。大量实验表明,OSCAR在定量和视觉质量指标上均取得了优异的表现。代码和模型将在https://github.com/jp-guo/OSCAR上发布。
论文及项目相关链接
Summary
预训练潜在扩散模型在图像有损压缩方面展现出强大的潜力。现有扩散方法通过迭代去噪从随机噪声重建图像,受潜在表示引导。虽然这些方法重建质量高,但多步采样过程计算开销大,且对不同压缩比特率需训练不同模型,导致训练和存储成本高。针对这些挑战,我们提出跨多比特率的扩散编解码器OSCAR。它将压缩潜在视作原始潜在的噪声版本,失真程度取决于比特率。通过构建从压缩比特率到伪扩散时步的映射,我们用单一生成模型支持多种比特率的重建。我们认为压缩潜在保留了丰富的结构信息,使得一步去噪可行。因此,OSCAR用单通去噪替换迭代采样,显著提高推理效率。实验表明OSCAR在定量和视觉质量指标上表现优越。代码和模型将在https://github.com/jp-guo/OSCAR发布。
Key Takeaways
- 预训练潜在扩散模型在图像有损压缩方面表现出强大的潜力。
- 现有扩散模型通常采用多步采样进行图像重建,计算开销大。
- OSCAR提出一种跨多比特率的扩散编解码器方法,用单一生成模型支持多种比特率的图像重建。
- OSCAR将压缩潜在视作原始潜在的噪声版本,并建立从压缩比特率到伪扩散时步的映射。
- OSCAR通过一步去噪过程替代迭代采样,提高推理效率。
- 实验表明OSCAR在图像重建的定量和视觉质量指标上实现优越性能。
点此查看论文截图


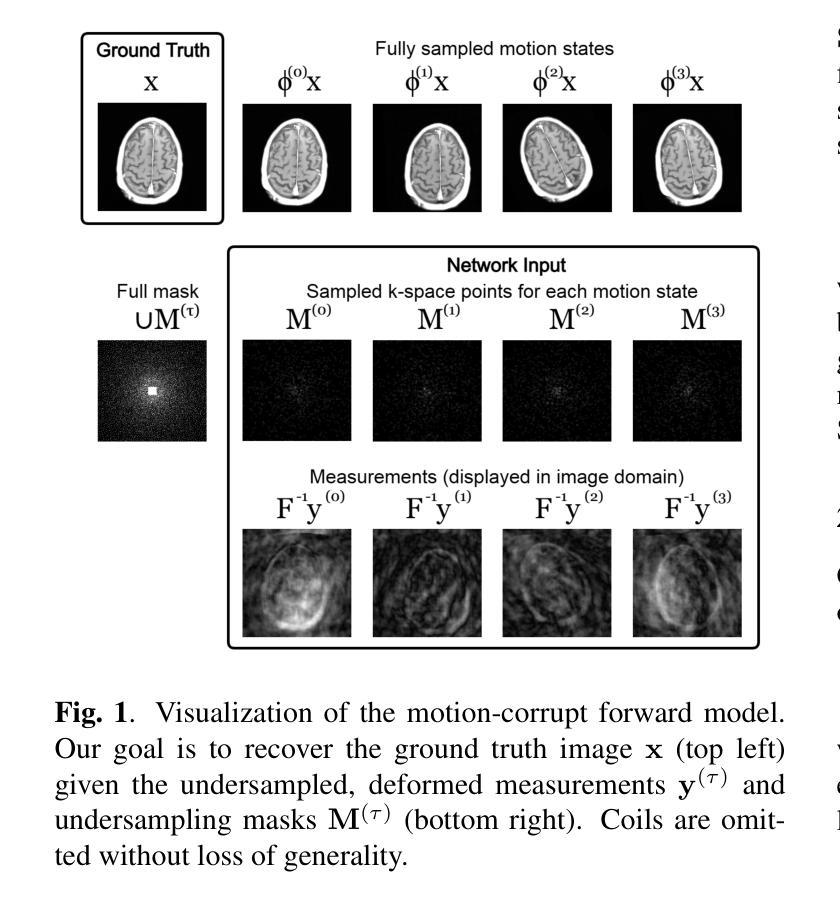
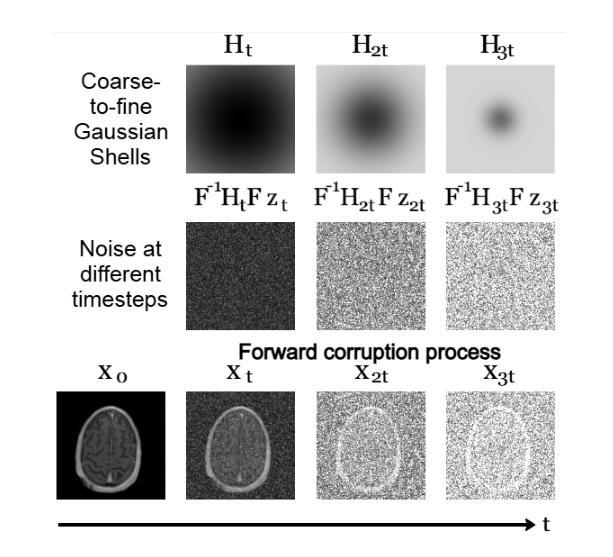
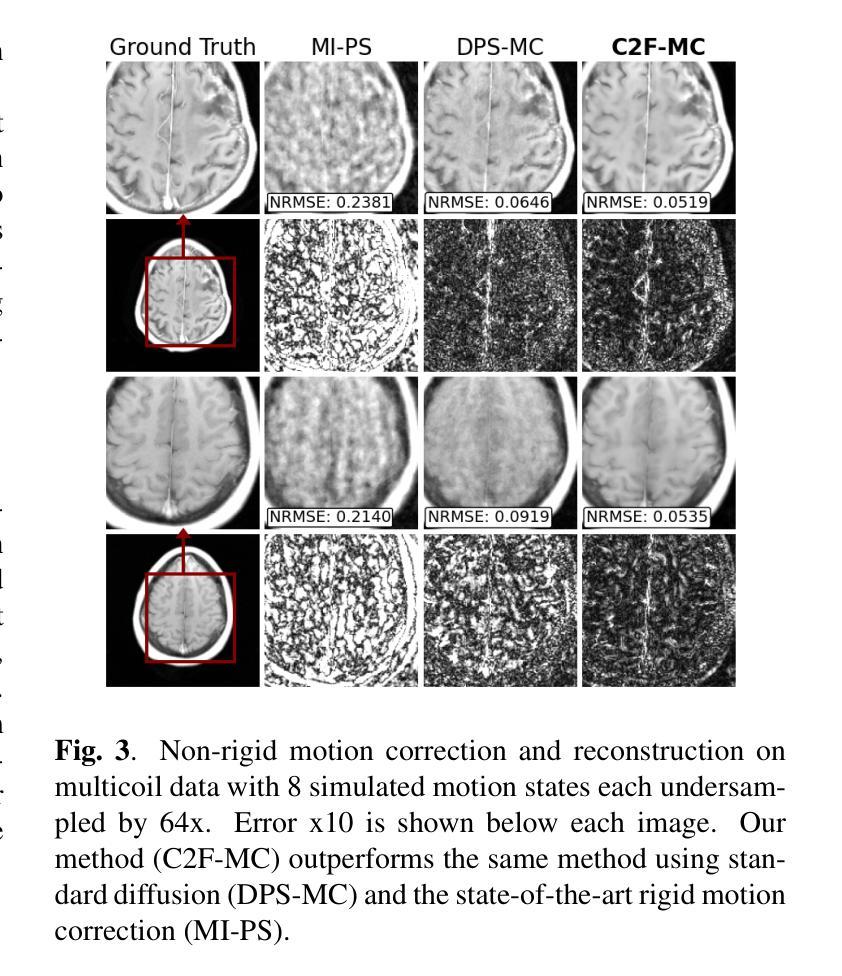
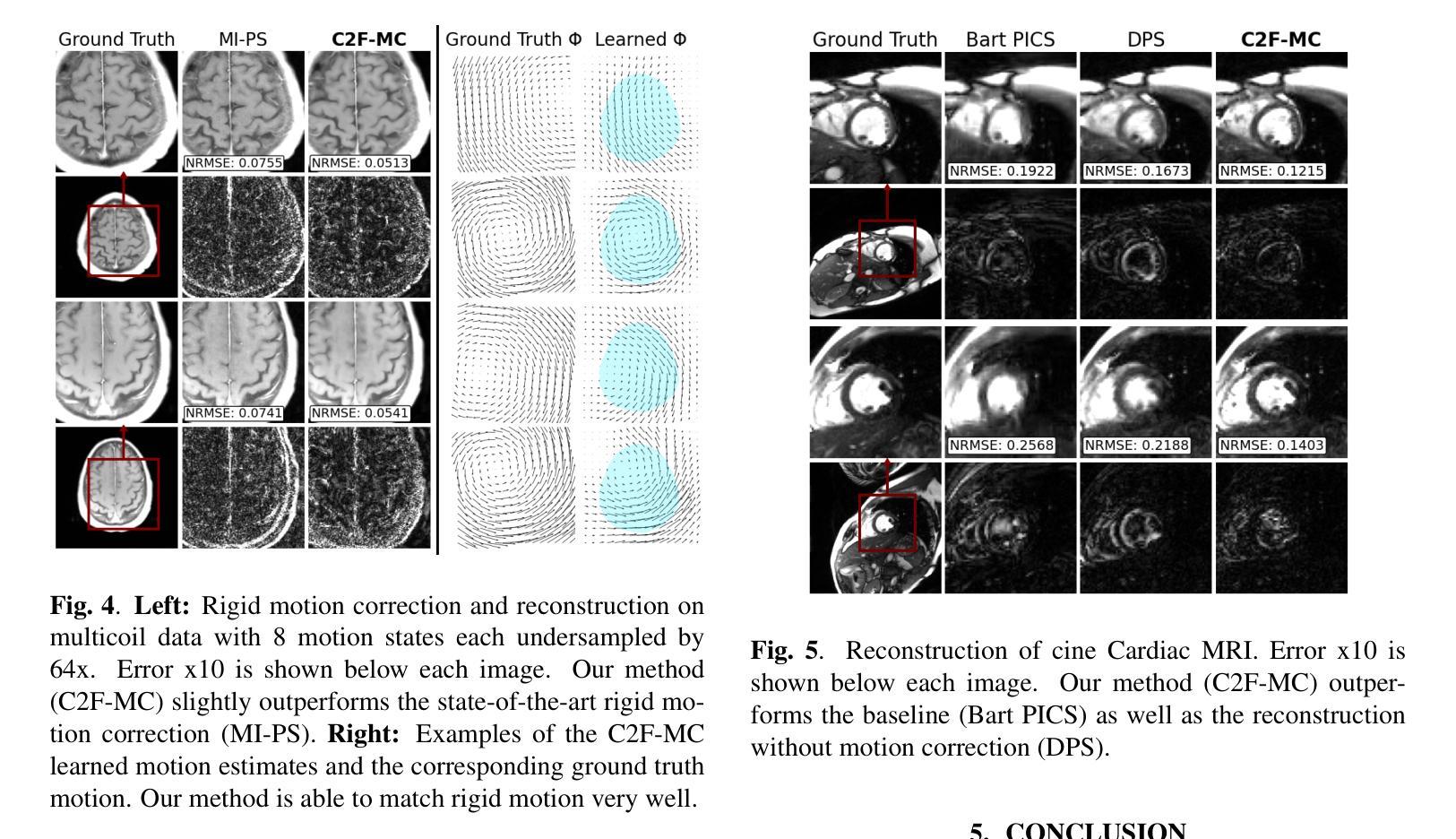
Non-rigid Motion Correction for MRI Reconstruction via Coarse-To-Fine Diffusion Models
Authors:Frederic Wang, Jonathan I. Tamir
Magnetic Resonance Imaging (MRI) is highly susceptible to motion artifacts due to the extended acquisition times required for k-space sampling. These artifacts can compromise diagnostic utility, particularly for dynamic imaging. We propose a novel alternating minimization framework that leverages a bespoke diffusion model to jointly reconstruct and correct non-rigid motion-corrupted k-space data. The diffusion model uses a coarse-to-fine denoising strategy to capture large overall motion and reconstruct the lower frequencies of the image first, providing a better inductive bias for motion estimation than that of standard diffusion models. We demonstrate the performance of our approach on both real-world cine cardiac MRI datasets and complex simulated rigid and non-rigid deformations, even when each motion state is undersampled by a factor of 64x. Additionally, our method is agnostic to sampling patterns, anatomical variations, and MRI scanning protocols, as long as some low frequency components are sampled during each motion state.
磁共振成像(MRI)由于k空间采样所需的长采集时间,很容易受到运动伪影的影响。这些伪影可能会降低诊断效用,特别是在动态成像中。我们提出了一种新型的交替最小化框架,它利用专门的扩散模型来联合重建和纠正非刚性运动受损的k空间数据。该扩散模型采用由粗到细的降噪策略,先捕捉整体大运动并重建图像的低频部分,为运动估计提供更好的归纳偏置,优于标准扩散模型。我们在现实世界的心脏电影MRI数据集和复杂的模拟刚性和非刚性变形上展示了我们的方法性能,即使在每种运动状态下采样率降低64倍的情况下也是如此。此外,我们的方法对于采样模式、解剖变异和MRI扫描协议具有不可知性,只要在每个运动状态下采样一些低频成分即可。
论文及项目相关链接
PDF ICIP 2025
Summary
本文提出了一种新型的交替最小化框架,利用专门的扩散模型联合重建和纠正非刚性运动腐蚀的k-space数据。该扩散模型采用由粗到细的降噪策略,先捕捉整体大运动并重建图像的低频部分,为运动估计提供更好的归纳偏置。此方法在真实世界的电影心脏MRI数据集和复杂的模拟刚性和非刚性变形上均表现出优异的性能,即使在每种运动状态下采样率低至64倍时也是如此。该方法对采样模式、解剖变异和MRI扫描协议具有通用性,只要在每个运动状态下采样一些低频成分即可。
Key Takeaways
- 提出的交替最小化框架利用扩散模型联合重建和纠正非刚性运动腐蚀的k-space数据。
- 扩散模型采用由粗到细的降噪策略,先捕捉整体大运动。
- 先重建图像的低频部分,以提高运动估计的准确性。
- 方法在真实世界的电影心脏MRI数据集和模拟的刚性和非刚性变形上表现优异。
- 即使在采样率低至64倍的情况下,该方法仍表现出良好的性能。
- 方法对采样模式、解剖变异和MRI扫描协议具有通用性。
点此查看论文截图



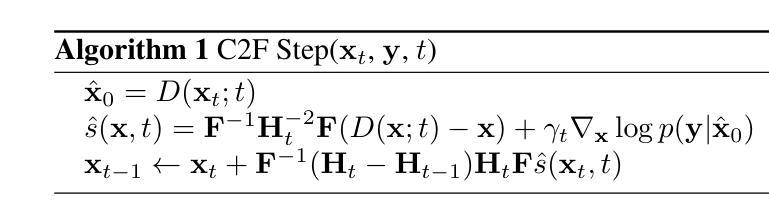
CraftsMan3D: High-fidelity Mesh Generation with 3D Native Generation and Interactive Geometry Refiner
Authors:Weiyu Li, Jiarui Liu, Hongyu Yan, Rui Chen, Yixun Liang, Xuelin Chen, Ping Tan, Xiaoxiao Long
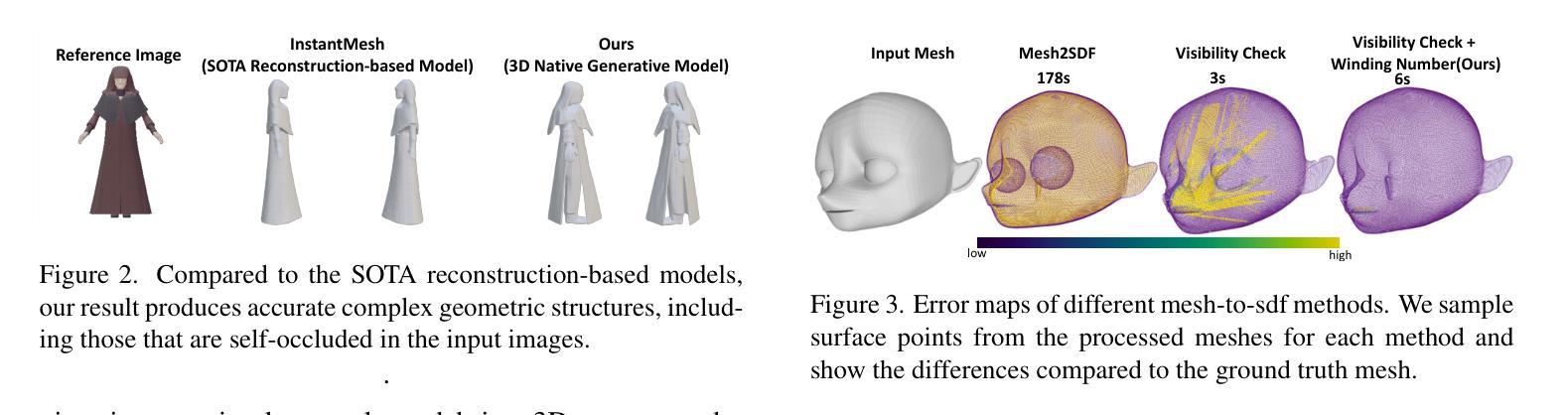
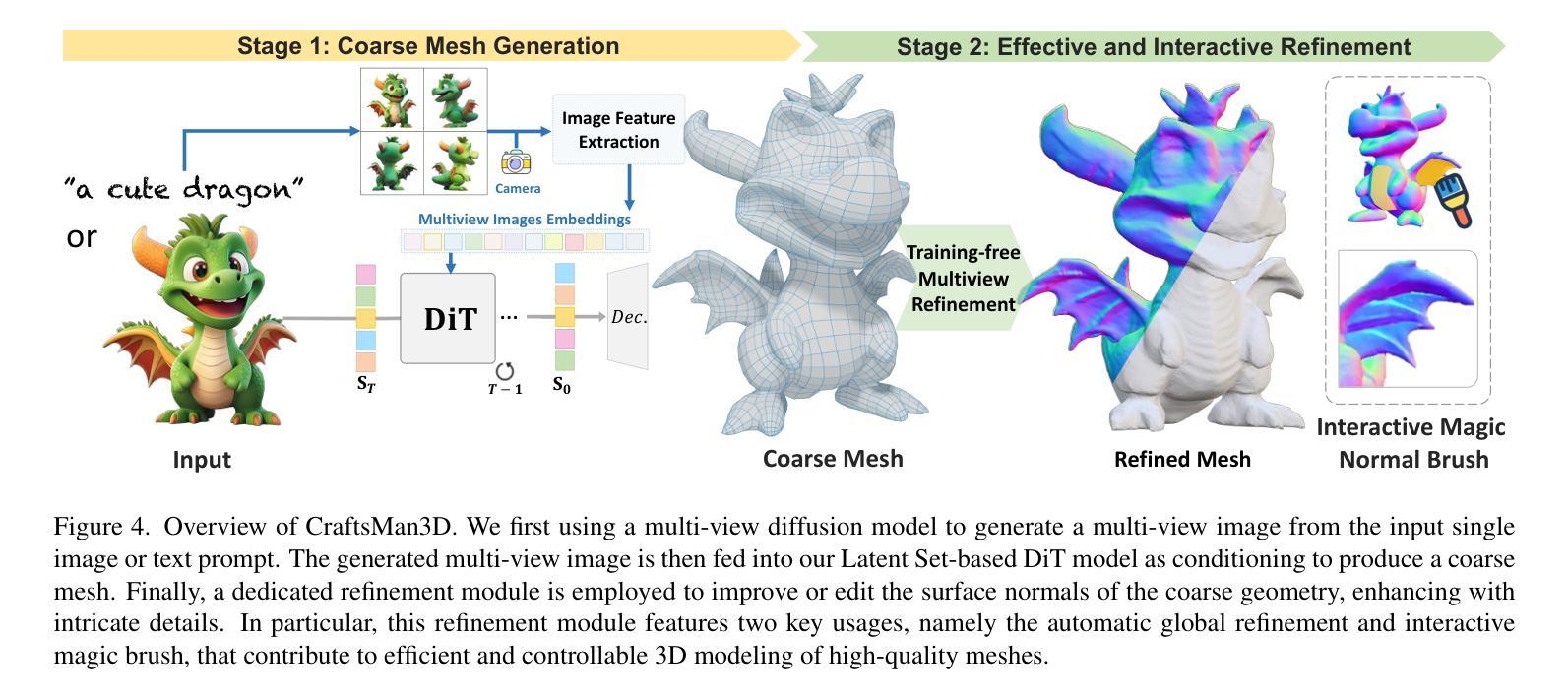
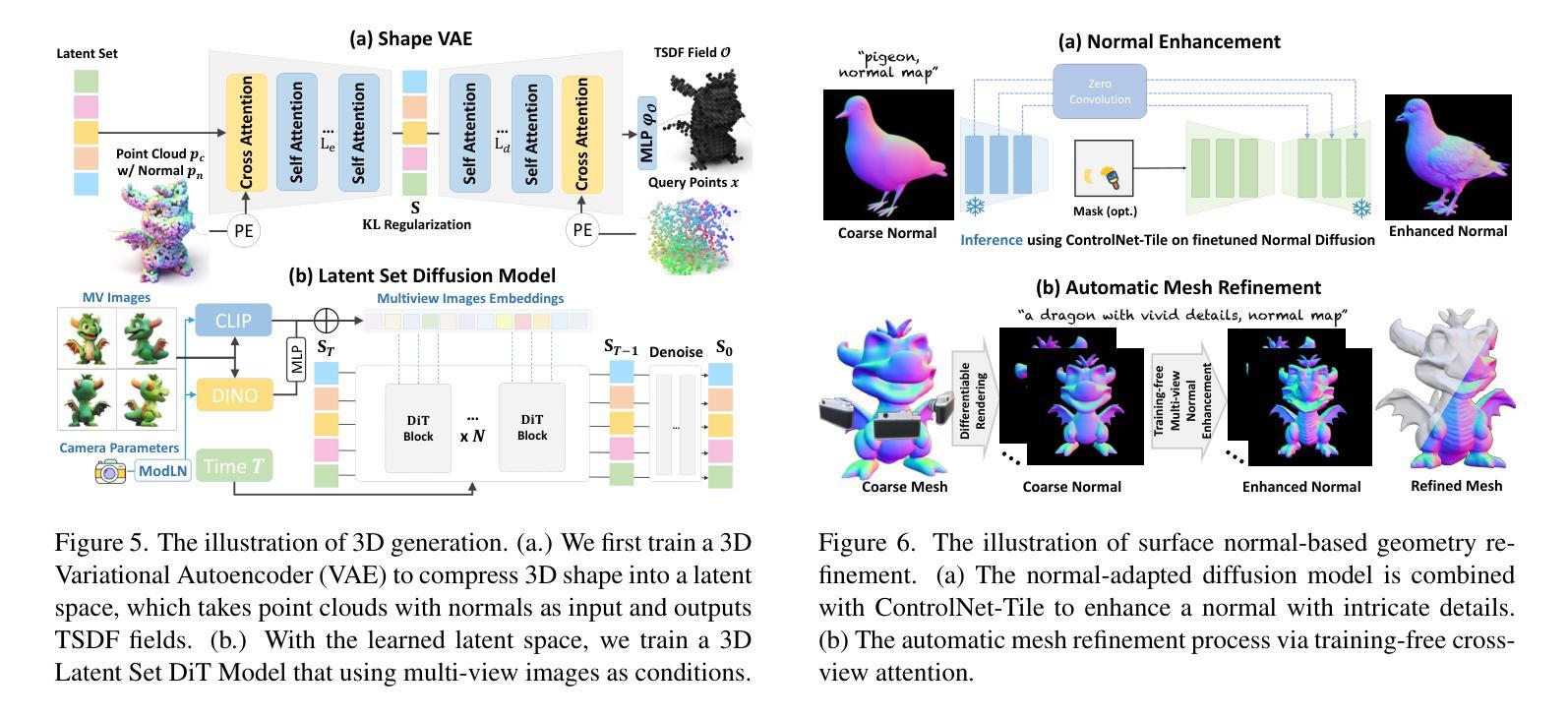
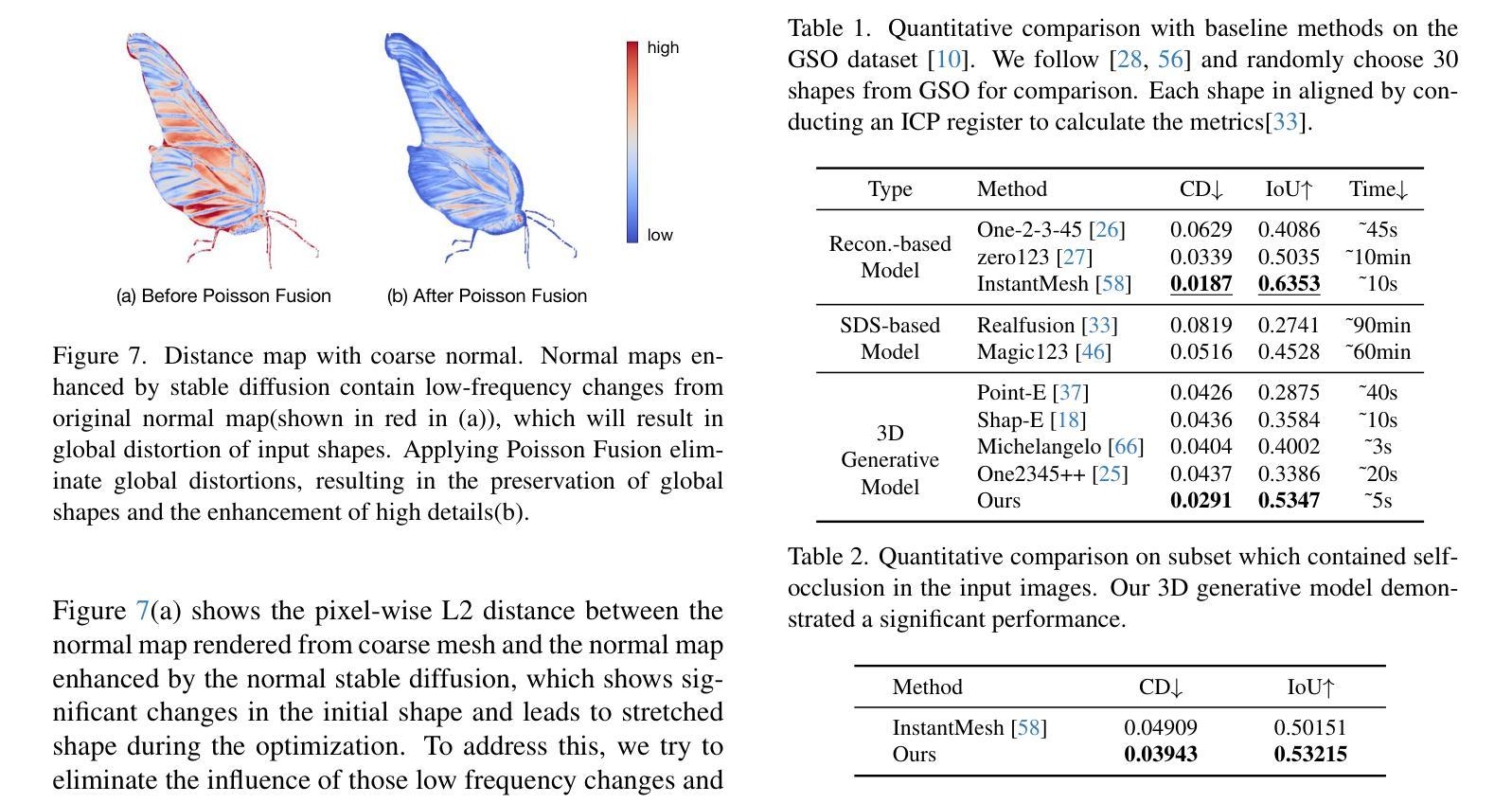
We present a novel generative 3D modeling system, coined CraftsMan, which can generate high-fidelity 3D geometries with highly varied shapes, regular mesh topologies, and detailed surfaces, and, notably, allows for refining the geometry in an interactive manner. Despite the significant advancements in 3D generation, existing methods still struggle with lengthy optimization processes, irregular mesh topologies, noisy surfaces, and difficulties in accommodating user edits, consequently impeding their widespread adoption and implementation in 3D modeling software. Our work is inspired by the craftsman, who usually roughs out the holistic figure of the work first and elaborates the surface details subsequently. Specifically, we employ a 3D native diffusion model, which operates on latent space learned from latent set-based 3D representations, to generate coarse geometries with regular mesh topology in seconds. In particular, this process takes as input a text prompt or a reference image and leverages a powerful multi-view (MV) diffusion model to generate multiple views of the coarse geometry, which are fed into our MV-conditioned 3D diffusion model for generating the 3D geometry, significantly improving robustness and generalizability. Following that, a normal-based geometry refiner is used to significantly enhance the surface details. This refinement can be performed automatically, or interactively with user-supplied edits. Extensive experiments demonstrate that our method achieves high efficacy in producing superior-quality 3D assets compared to existing methods. HomePage: https://craftsman3d.github.io/, Code: https://github.com/wyysf-98/CraftsMan
我们提出了一种新型的三维生成建模系统,名为CraftsMan。该系统可以生成高度逼真的三维几何模型,具有多样化的形状、规则的网格拓扑和精细的表面细节,并且能以交互方式完善几何模型。尽管三维生成技术取得了重大进展,但现有方法仍然面临优化流程冗长、网格拓扑不规则、表面噪声大以及难以容纳用户编辑等问题,从而阻碍了它们在三维建模软件中的广泛采用和实施。我们的工作受到工匠的启发,他们通常先大致勾勒出作品的整体轮廓,然后细化表面细节。具体来说,我们采用了一种三维扩散模型,该模型在潜在空间上运行,该空间是从基于集合的潜在三维表示中学习的,以在几秒内生成具有规则网格拓扑的粗略几何形状。特别是,这个过程以文本提示或参考图像为输入,并利用强大的多视图(MV)扩散模型生成粗略几何形状的多视图,然后将其输入我们的MV条件三维扩散模型以生成三维几何形状,这大大提高了稳健性和通用性。之后,使用基于法线的几何细化器来显著增强表面细节。这种细化可以自动进行,也可以与用户提供的编辑进行交互。大量实验表明,我们的方法在生成高质量的三维资产方面与现有方法相比具有很高的有效性。主页:https://craftsman3d.github.io/,代码:https://github.com/wyysf-98/CraftsMan
论文及项目相关链接
PDF HomePage: https://craftsman3d.github.io/, Code: https://github.com/wyysf-98/CraftsMan3D
Summary
该项目提出了一种名为CraftsMan的新型三维建模系统,该系统能够生成高质量的三维模型,具有多样化的形状、规则化的网格拓扑和精细的表面细节,并且允许用户进行交互式几何精修。相较于现有方法,该项目通过使用一种在潜在空间上运行的3D扩散模型来生成具有规则网格拓扑的粗糙几何结构,并在之后通过基于正常的几何细化器提升表面细节。这不仅缩短了优化流程,还能处理用户编辑,从而促进了其在3D建模软件中的广泛应用和实施。
Key Takeaways
- CraftsMan是一个新型的三维建模系统,可以生成高质量的三维模型,包括多样化的形状、规则化的网格拓扑和精细的表面。
- 该系统采用了一种3D扩散模型,能够在潜在空间上运行,从而快速生成具有规则网格拓扑的粗糙几何结构。
- CraftsMan允许用户以交互式的方式进行几何精修,提升了系统的实用性和用户体验。
- 该系统通过多视角(MV)扩散模型提高了鲁棒性和泛化能力,可以更好地处理不同的输入和生成更准确的3D几何。
- CraftsMan系统通过基于正常的几何细化器,能够显著提升模型表面的细节质量。
- 与现有方法相比,CraftsMan在生成优质三维资产方面表现出更高的效能。
点此查看论文截图