⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-31 更新
MCTSr-Zero: Self-Reflective Psychological Counseling Dialogues Generation via Principles and Adaptive Exploration
Authors:Hao Lu, Yanchi Gu, Haoyuan Huang, Yulin Zhou, Ningxin Zhu, Chen Li
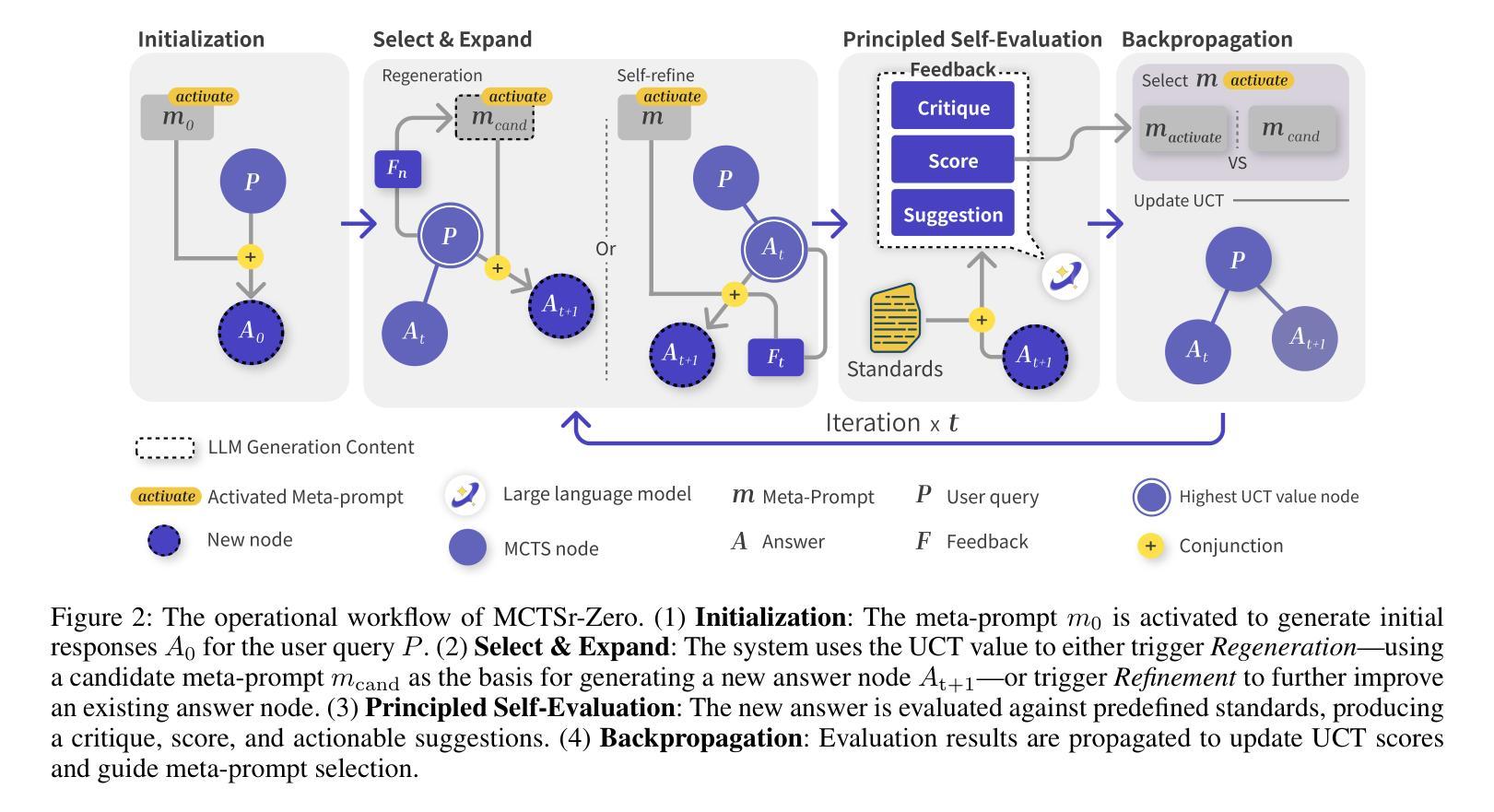
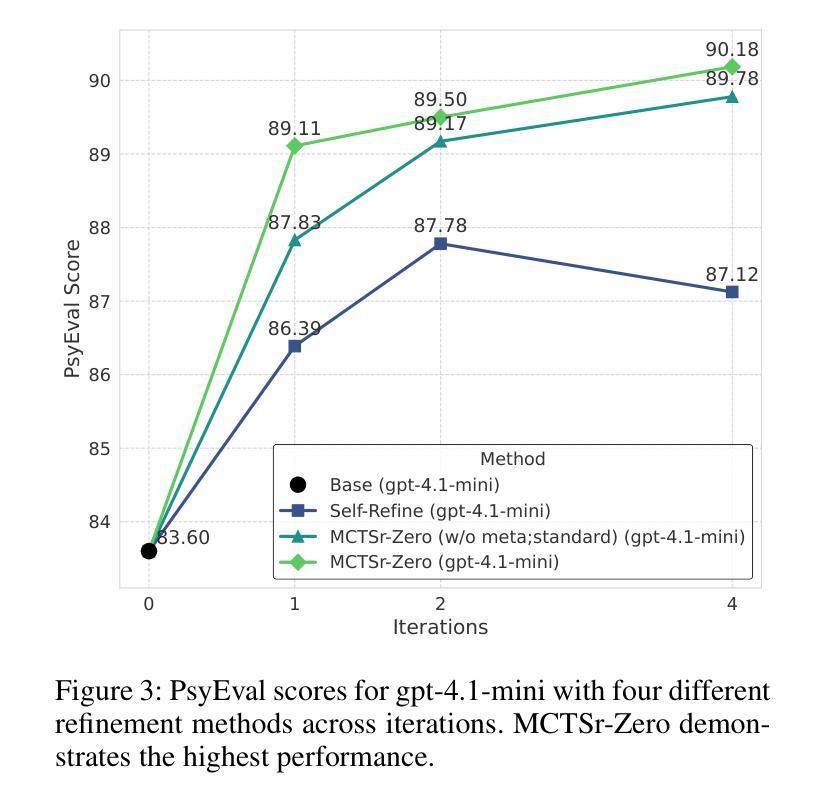
The integration of Monte Carlo Tree Search (MCTS) with Large Language Models (LLMs) has demonstrated significant success in structured, problem-oriented tasks. However, applying these methods to open-ended dialogues, such as those in psychological counseling, presents unique challenges. Unlike tasks with objective correctness, success in therapeutic conversations depends on subjective factors like empathetic engagement, ethical adherence, and alignment with human preferences, for which strict “correctness” criteria are ill-defined. Existing result-oriented MCTS approaches can therefore produce misaligned responses. To address this, we introduce MCTSr-Zero, an MCTS framework designed for open-ended, human-centric dialogues. Its core innovation is “domain alignment”, which shifts the MCTS search objective from predefined end-states towards conversational trajectories that conform to target domain principles (e.g., empathy in counseling). Furthermore, MCTSr-Zero incorporates “Regeneration” and “Meta-Prompt Adaptation” mechanisms to substantially broaden exploration by allowing the MCTS to consider fundamentally different initial dialogue strategies. We evaluate MCTSr-Zero in psychological counseling by generating multi-turn dialogue data, which is used to fine-tune an LLM, PsyLLM. We also introduce PsyEval, a benchmark for assessing multi-turn psychological counseling dialogues. Experiments demonstrate that PsyLLM achieves state-of-the-art performance on PsyEval and other relevant metrics, validating MCTSr-Zero’s effectiveness in generating high-quality, principle-aligned conversational data for human-centric domains and addressing the LLM challenge of consistently adhering to complex psychological standards.
将Monte Carlo树搜索(MCTS)与大型语言模型(LLM)的结合在结构化和问题导向的任务中取得了显著的成功。然而,将这些方法应用于开放式对话,如心理咨询中的对话,却存在独特的挑战。不同于具有客观正确性的任务,治疗性对话的成功取决于主观因素,如共情参与、道德遵守以及与人类偏好的一致性,而严格的“正确性”标准则定义不明确。因此,现有的以结果为导向的MCTS方法可能会产生不匹配的回应。为解决这一问题,我们引入了MCTSr-Zero,这是一个为开放式、以人为中心的对话而设计的MCTS框架。其核心创新之处在于“领域对齐”,它将MCTS的搜索目标从预设的终止状态转向符合目标领域原则的对话轨迹(例如在咨询中的共情)。此外,MCTSr-Zero还融入了“再生”和“元提示适应”机制,通过允许MCTS考虑根本不同的初始对话策略,从而大大拓宽了探索范围。我们通过生成多轮对话数据来评估MCTSr-Zero在心理咨询方面的表现,这些数据用于微调LLM(PsyLLM)。我们还介绍了PsyEval,一个用于评估多轮心理咨询对话的基准测试。实验表明,PsyLLM在PsyEval和其他相关指标上达到了最新性能水平,验证了MCTSr-Zero在生成高质量、符合原则的对话数据方面的有效性,并解决了LLM在持续遵循复杂心理标准方面的挑战。
论文及项目相关链接
PDF 50 pages, 3 figures
Summary
基于Monte Carlo树搜索(MCTS)与大型语言模型(LLM)的集成在结构化、面向问题的任务中取得了显著的成功。然而,将这些方法应用于开放式对话,如心理咨询中的对话,却存在独特挑战。与客观正确性的任务不同,治疗性对话的成功取决于主观因素,如共情参与、道德遵守以及与人类偏好的对齐,而严格的“正确性”标准是难以定义的。因此,现有的以结果为导向的MCTS方法可能会产生不匹配的响应。为解决这一问题,我们推出了MCTSr-Zero,这是一个为开放式、以人为中心的对话而设计的MCTS框架。其核心创新在于“领域对齐”,它改变了MCTS的搜索目标,从预设的终止状态转向符合目标领域原则(如咨询中的共情)的对话轨迹。此外,MCTSr-Zero结合了“再生”和“元提示适应”机制,通过允许MCTS考虑根本不同的初始对话策略来大大拓宽探索范围。
Key Takeaways
- MCTS与LLM集成在结构化任务中表现优异,但在开放式对话如心理咨询中存在挑战。
- 开放式对话的成功取决于主观因素,如共情和道德遵守,使得严格正确性标准难以定义。
- 现有MCTS方法可能产生不匹配响应,需要新的框架来解决这一问题。
- MCTSr-Zero框架被设计用于以人为中心的开放式对话,核心创新在于“领域对齐”。
- MCTSr-Zero通过“再生”和“元提示适应”机制来拓宽探索范围。
- PsyLLM在心理评估上达到了最新技术水平,验证了MCTSr-Zero在生成高质量、符合原则的对话数据方面的有效性。
点此查看论文截图

Deep asymptotic expansion method for solving singularly perturbed time-dependent reaction-advection-diffusion equations
Authors:Q. Zhu, D. Chaikovskii, B. Jin, Y. Zhang
Physics-informed neural network (PINN) has shown great potential in solving differential equations. However, it faces challenges when dealing with problems involving steep gradients. For singularly perturbed time-dependent reaction-advection-diffusion equations, which exhibit internal transition layers with sharp gradients, we propose a deep asymptotic expansion (DAE) method that leverages deep learning to obtain explicit smooth approximate solutions. Inspired by asymptotic analysis, we first derive the governing equations for transition layers and then solve them using PINN. Numerical experiments show that DAE outperforms PINN, gPINN and PINN with adaptive sampling. We also show its robustness with respect to training point distributions, network architectures, and random seeds.
物理信息神经网络(PINN)在解决微分方程方面显示出巨大潜力。然而,它在处理涉及陡峭梯度的问题时面临挑战。对于具有内部过渡层和尖锐梯度的奇异扰动时依赖反应对流扩散方程,我们提出了一种利用深度学习获得显式平滑近似解的深度渐近展开(DAE)方法。我们受到渐近分析的启发,首先导出过渡层的控制方程,然后使用PINN进行求解。数值实验表明,DAE的性能优于PINN、gPINN和带有自适应采样的PINN。我们还就其针对训练点分布、网络架构和随机种子的稳健性进行了展示。
论文及项目相关链接
PDF 24 pages
Summary
物理信息神经网络(PINN)在解决微分方程方面展现出巨大潜力,但在处理涉及陡峭梯度的问题时面临挑战。针对具有内部过渡层且存在尖锐梯度的奇异扰动时间依赖反应-对流-扩散方程,我们提出了一种利用深度学习获得显式平滑近似解的深度渐近扩展(DAE)方法。该方法受渐近分析的启发,首先导出过渡层的控制方程,然后使用PINN进行求解。数值实验表明,DAE在性能上优于PINN、gPINN以及带有自适应采样的PINN。此外,该方法在训练点分布、网络架构和随机种子方面表现出稳健性。
Key Takeaways
- 物理信息神经网络(PINN)在解决微分方程方面表现出巨大潜力。
- 对于具有陡峭梯度的奇异扰动时间依赖反应-对流-扩散方程,处理具有挑战。
- 提出了深度渐近扩展(DAE)方法,该方法结合深度学习求解此类方程。
- DAE方法受渐近分析的启发,导出过渡层的控制方程。
- 数值实验表明,DAE方法在性能上优于其他神经网络方法。
- DAE方法在训练点分布、网络架构和随机种子方面表现出稳健性。
点此查看论文截图

MEDAL: A Framework for Benchmarking LLMs as Multilingual Open-Domain Chatbots and Dialogue Evaluators
Authors:John Mendonça, Alon Lavie, Isabel Trancoso
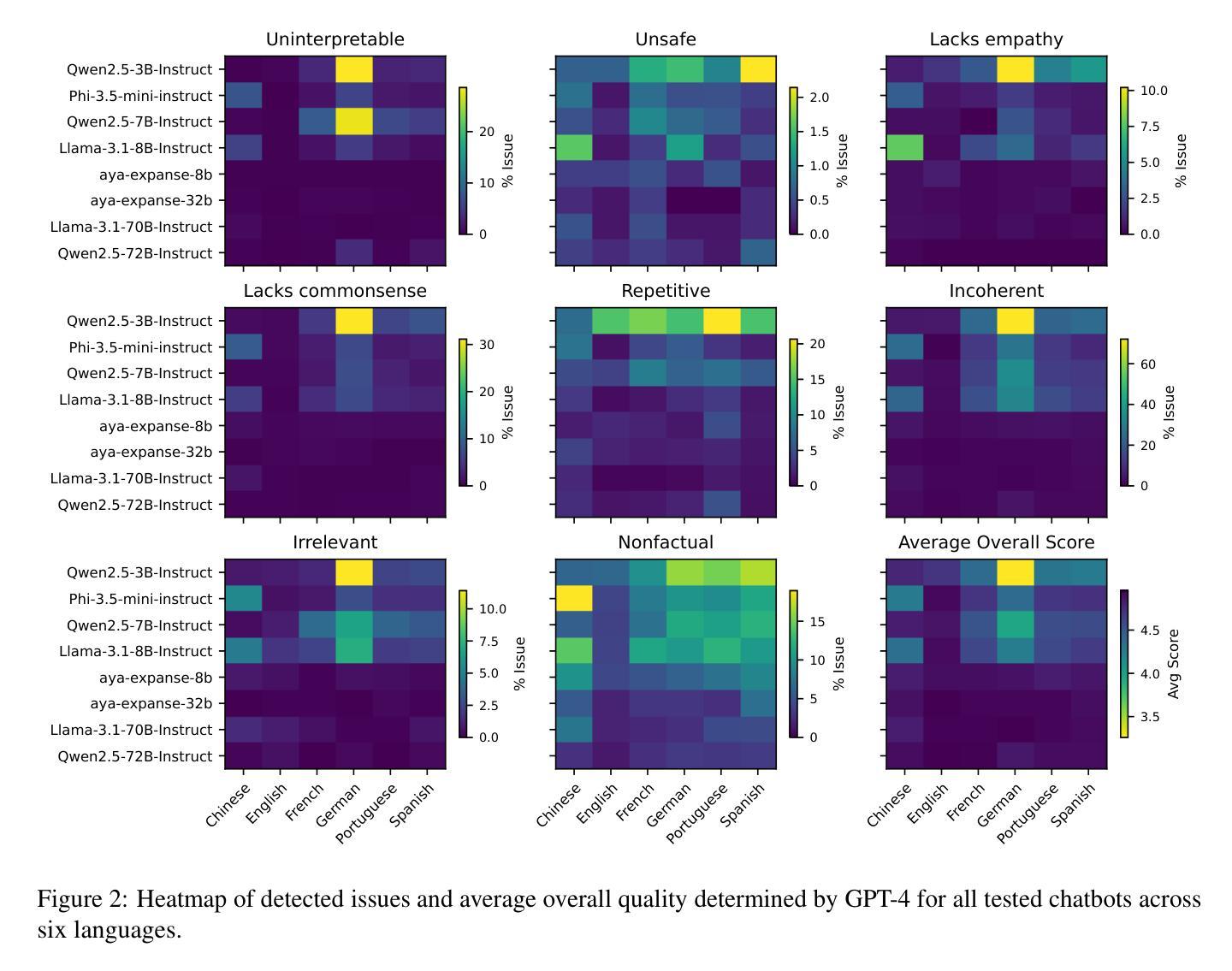
As the capabilities of chatbots and their underlying LLMs continue to dramatically improve, evaluating their performance has increasingly become a major blocker to their further development. A major challenge is the available benchmarking datasets, which are largely static, outdated, and lacking in multilingual coverage, limiting their ability to capture subtle linguistic and cultural variations. This paper introduces MEDAL, an automated multi-agent framework for generating, evaluating, and curating more representative and diverse open-domain dialogue evaluation benchmarks. Our approach leverages several state-of-the-art LLMs to generate user-chatbot multilingual dialogues, conditioned on varied seed contexts. A strong LLM (GPT-4.1) is then used for a multidimensional analysis of the performance of the chatbots, uncovering noticeable cross-lingual performance differences. Guided by this large-scale evaluation, we curate a new meta-evaluation multilingual benchmark and human-annotate samples with nuanced quality judgments. This benchmark is then used to assess the ability of several reasoning and non-reasoning LLMs to act as evaluators of open-domain dialogues. We find that current LLMs struggle to detect nuanced issues, particularly those involving empathy and reasoning.
随着聊天机器人及其底层大型语言模型的能力持续显著提高,评估它们的性能已成为进一步开发的主要障碍。一个主要挑战在于可用的基准测试数据集,这些数据集大多是静态的、过时的,并且缺乏多语言覆盖,限制了它们捕捉细微的语言和文化差异的能力。本文介绍了MEDAL,这是一个自动化的多智能体框架,用于生成、评估和编纂更具代表性和多样性的开放领域对话评估基准测试。我们的方法利用几种最先进的大型语言模型来生成用户与聊天机器人的多语言对话,基于不同的种子上下文条件。然后,一个强大的大型语言模型(GPT-4.1)被用于对聊天机器人的性能进行多维分析,发现了明显的跨语言性能差异。在这一大规模评估的指导下,我们编制了一个新的元评估多语言基准测试并对样本进行了微妙的质量判断的人为注释。然后,使用这个基准测试来评估几种用于开放领域对话的推理和非推理大型语言模型作为评估器的能力。我们发现当前的大型语言模型在检测微妙问题时存在困难,尤其是涉及同理心和推理的问题。
论文及项目相关链接
PDF May ARR
Summary
本文介绍了一个名为MEDAL的自动化多智能体框架,用于生成、评估和编纂更具代表性和多样性的开放域对话评估基准。该框架利用多种先进的大型语言模型生成用户与聊天机器人的多语言对话,并结合不同的上下文进行分析。此外,该论文还引入了GPT-4.1等大模型对聊天机器人的性能进行多维度分析,发现跨语言性能差异显著。基于大规模评估结果,论文编纂了新的多语言基准测试集,并对样本进行了精细的质量标注。最后发现当前的大型语言模型在检测微妙问题时存在困难,特别是在情感和推理方面。
Key Takeaways
- MEDAL框架是一个自动化多智能体系统,用于生成、评估和编纂开放域对话评估基准。
- MEDAL利用先进的大型语言模型生成用户与聊天机器人的多语言对话。
- GPT-4.1等大模型被用于对聊天机器人性能进行多维度分析。
- 跨语言性能差异显著,这需要在评估基准中考虑多语言环境。
- 基于大规模评估结果,论文编纂了新的多语言基准测试集并对样本进行了精细质量标注。
- 当前的大型语言模型在检测微妙问题上存在困难,尤其是在情感和推理方面。
点此查看论文截图


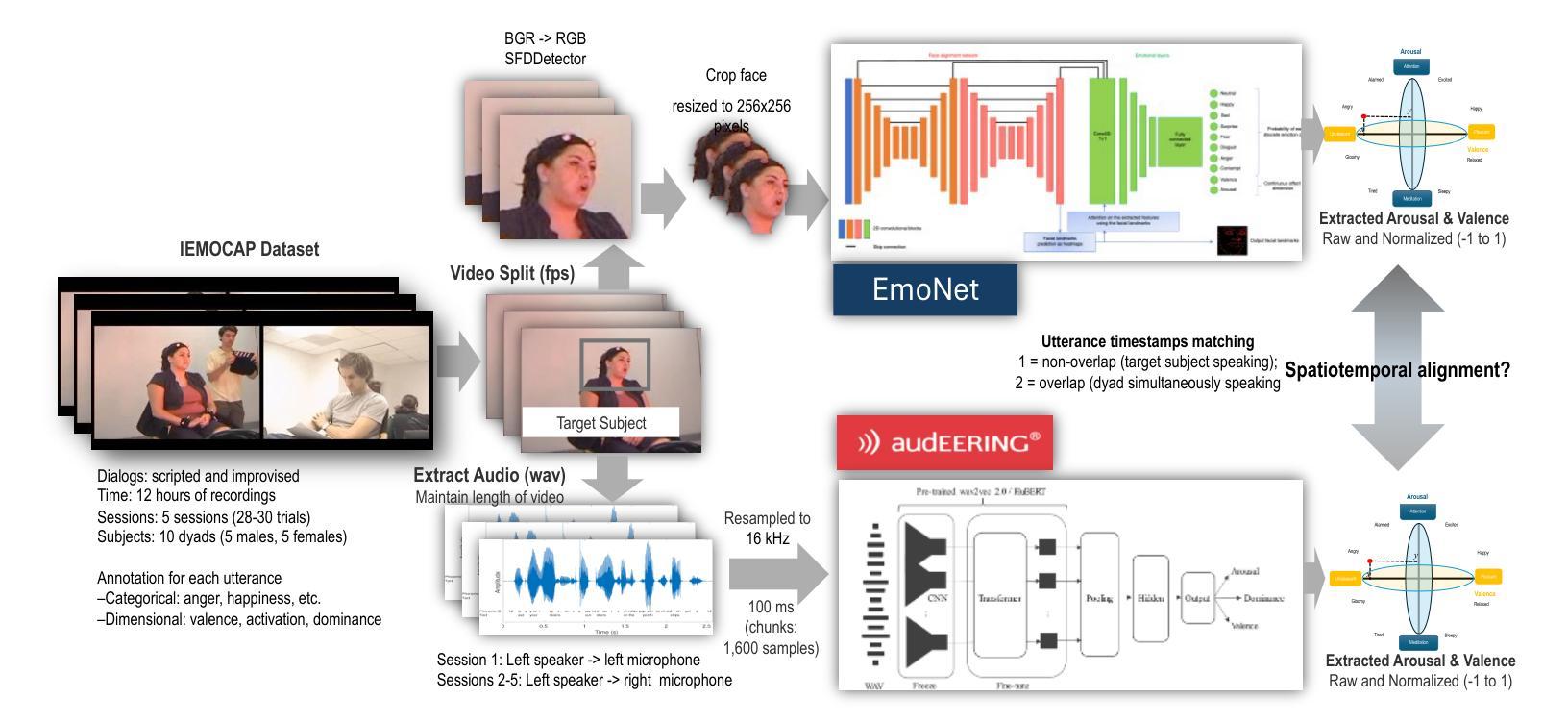
Exploring Spatiotemporal Emotional Synchrony in Dyadic Interactions: The Role of Speech Conditions in Facial and Vocal Affective Alignment
Authors:Von Ralph Dane Marquez Herbuela, Yukie Nagai
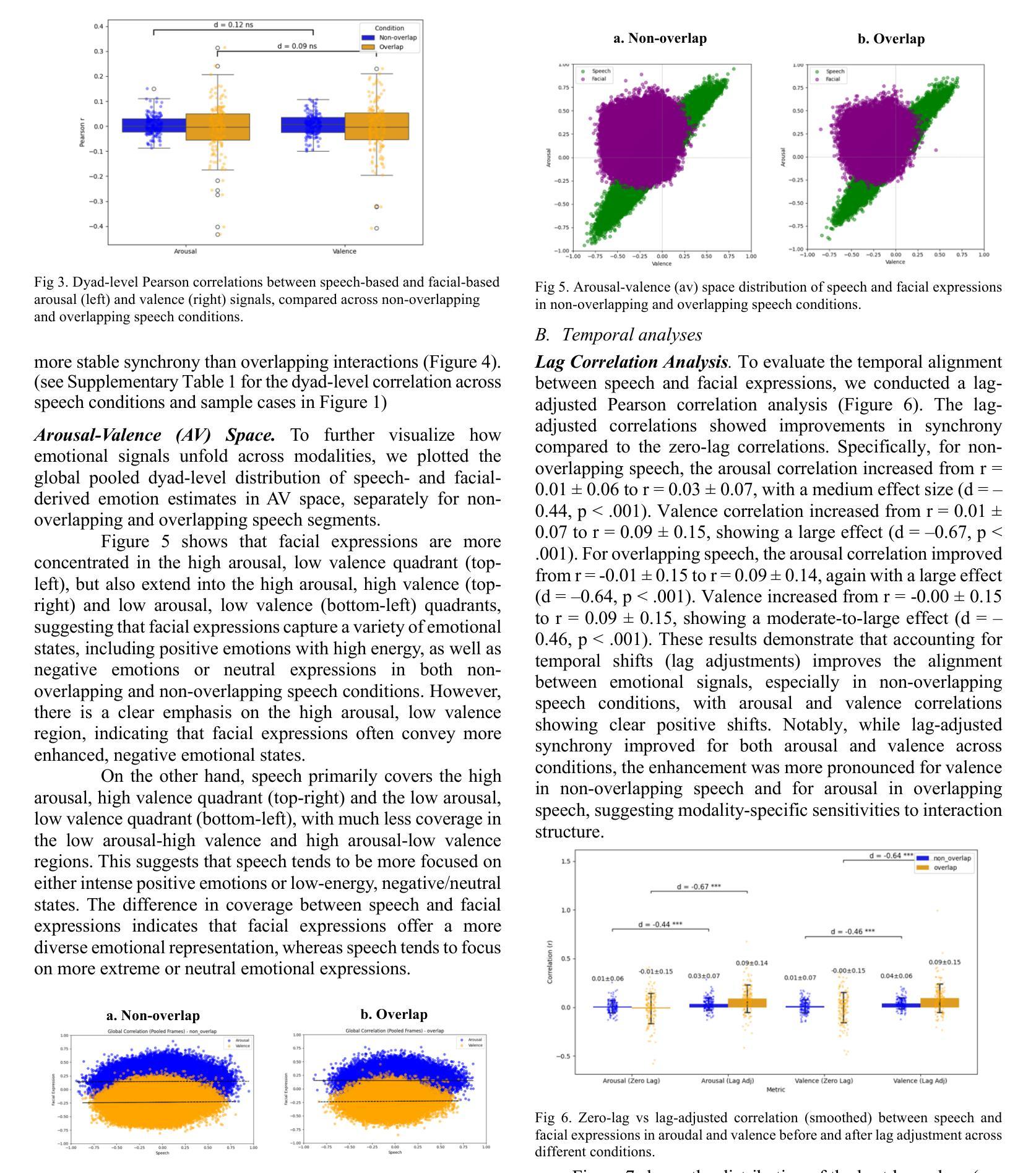
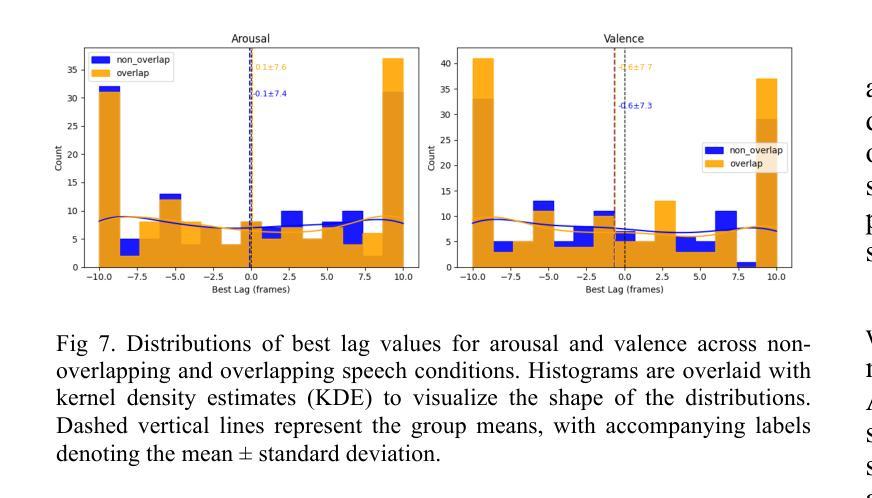
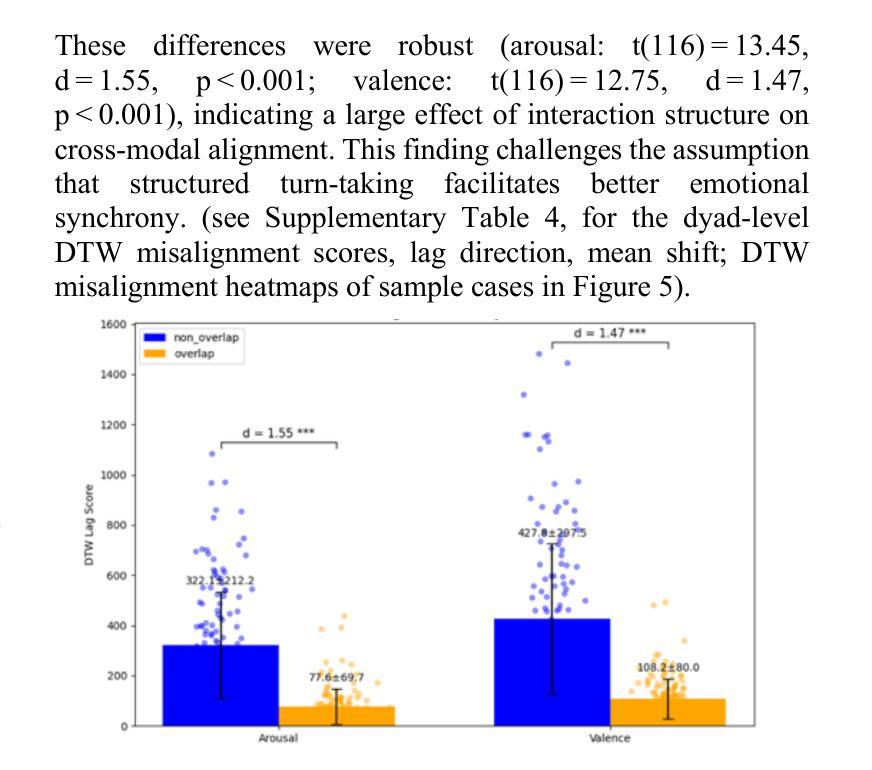
Understanding how humans express and synchronize emotions across multiple communication channels particularly facial expressions and speech has significant implications for emotion recognition systems and human computer interaction. Motivated by the notion that non-overlapping speech promotes clearer emotional coordination, while overlapping speech disrupts synchrony, this study examines how these conversational dynamics shape the spatial and temporal alignment of arousal and valence across facial and vocal modalities. Using dyadic interactions from the IEMOCAP dataset, we extracted continuous emotion estimates via EmoNet (facial video) and a Wav2Vec2-based model (speech audio). Segments were categorized based on speech overlap, and emotional alignment was assessed using Pearson correlation, lag adjusted analysis, and Dynamic Time Warping (DTW). Across analyses, non overlapping speech was associated with more stable and predictable emotional synchrony than overlapping speech. While zero-lag correlations were low and not statistically different, non overlapping speech showed reduced variability, especially for arousal. Lag adjusted correlations and best-lag distributions revealed clearer, more consistent temporal alignment in these segments. In contrast, overlapping speech exhibited higher variability and flatter lag profiles, though DTW indicated unexpectedly tighter alignment suggesting distinct coordination strategies. Notably, directionality patterns showed that facial expressions more often preceded speech during turn-taking, while speech led during simultaneous vocalizations. These findings underscore the importance of conversational structure in regulating emotional communication and provide new insight into the spatial and temporal dynamics of multimodal affective alignment in real world interaction.
理解人类如何通过多种通信通道,特别是面部表情和言语来表达和同步情绪,对于情绪识别系统和人机交互具有重要的影响。本研究受非重叠语能够促进更清晰情感协调的观念的驱动,而重叠语会破坏同步性。本研究旨在探讨这些对话动态如何影响面部和声音模态的兴奋和效价的时空对齐。我们使用了IEMOCAP数据集中的二元互动,通过EmoNet(面部视频)和基于Wav2Vec2的模型(语音音频)提取了连续的情绪估计值。根据语音重叠情况对片段进行分类,并使用Pearson相关性、滞后调整分析和动态时间规整(DTW)评估情感对齐情况。在各项分析中,非重叠语音与更稳定和可预测的情感同步有关,而重叠语音则表现出更高的可变性和较平坦的滞后分布。然而,DTW显示了对齐出乎意料地更紧密,表明存在不同的协调策略。值得注意的是,方向性模式显示,在轮流发言时,面部表情通常先于言语,而在同时发声时,则是言语领先。这些发现强调了对话结构在调节情感沟通中的重要性,并为现实互动中多模态情感对齐的时空动态提供了新的见解。
论文及项目相关链接
Summary
本文探讨了人类在多通道沟通中如何表达和同步情感,特别是面部表情和言语。研究发现在非重叠的言语中,情感协调更为清晰,而重叠的言语则会破坏同步性。该研究利用IEMOCAP数据集的双语互动,通过EmoNet(面部视频)和Wav2Vec2模型(语音音频)进行连续情感估计,并分析了不同沟通模式下情感同步性的差异。结果表明非重叠言语在情感同步方面表现更稳定且可预测。虽然在零滞后时间内相关性较低且不具有统计学意义,但在非重叠的言语中展现出较小的波动,尤其是唤醒状态下的情绪波动。调整后的滞后相关性和最佳滞后分布显示在这些片段中有更清晰、更一致的时序对齐。相反,重叠的言语展现出更高的波动和更平坦的滞后模式,但DTW揭示了对齐出乎意料的紧密,表明不同的协调策略。此外还发现面部表情在对话转换时更常先于言语,而同时发声时则相反。这些发现强调了对话结构在情感沟通中的重要性,并为现实互动中的多模态情感对齐的时空动态提供了新的见解。
Key Takeaways
- 人类在多通道沟通中表达情感时,面部表情和言语的同步性非常重要。
- 非重叠的言语能够促进更清晰的情感协调,而重叠的言语则会破坏情感同步性。
- 非重叠言语在情感同步方面表现更稳定且可预测,包括较小的情绪波动和更清晰的时序对齐。
- 重叠言语表现出更高的波动和更平坦的滞后模式,但DTW揭示了对齐出人意料的紧密。
- 在对话转换时,面部表情通常先于言语,而同时发声时则是相反的方向性模式。
- 对话结构在情感沟通中起到重要作用。
点此查看论文截图


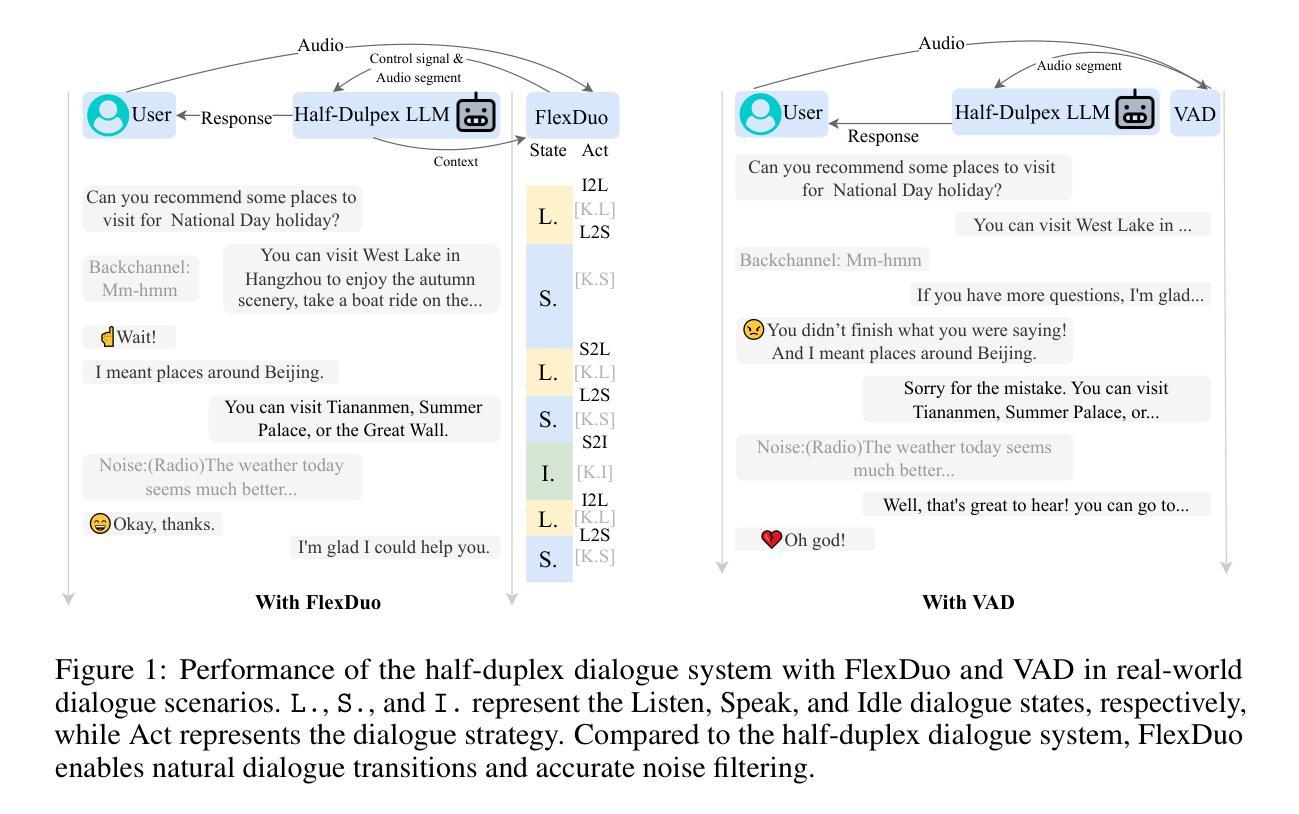
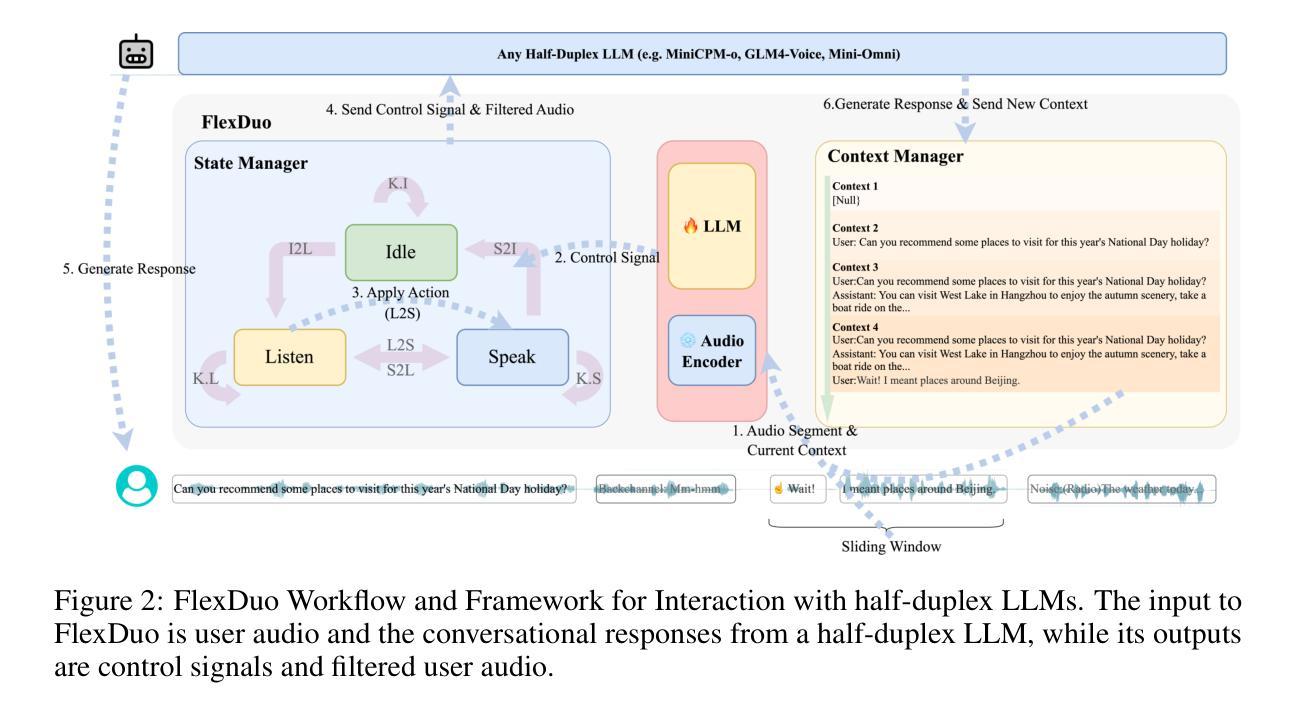
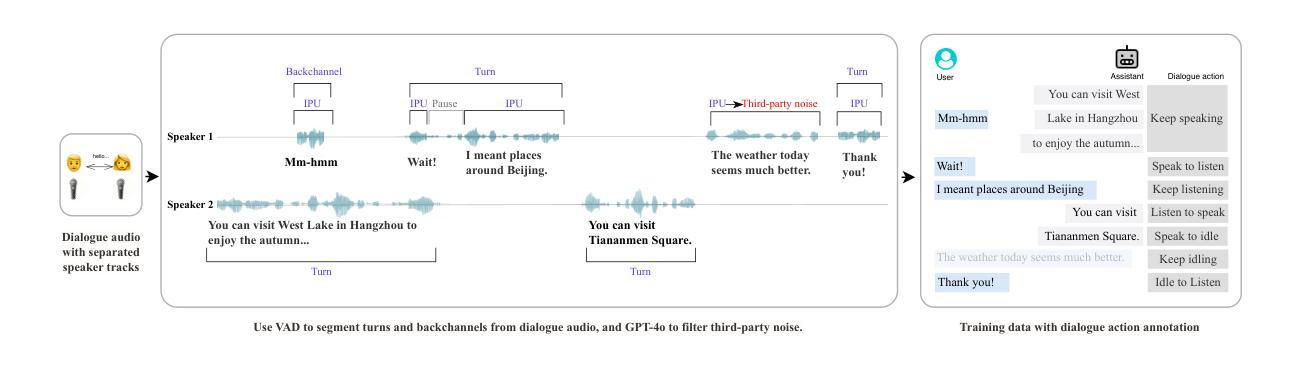
FlexDuo: A Pluggable System for Enabling Full-Duplex Capabilities in Speech Dialogue Systems
Authors:Borui Liao, Yulong Xu, Jiao Ou, Kaiyuan Yang, Weihua Jian, Pengfei Wan, Di Zhang
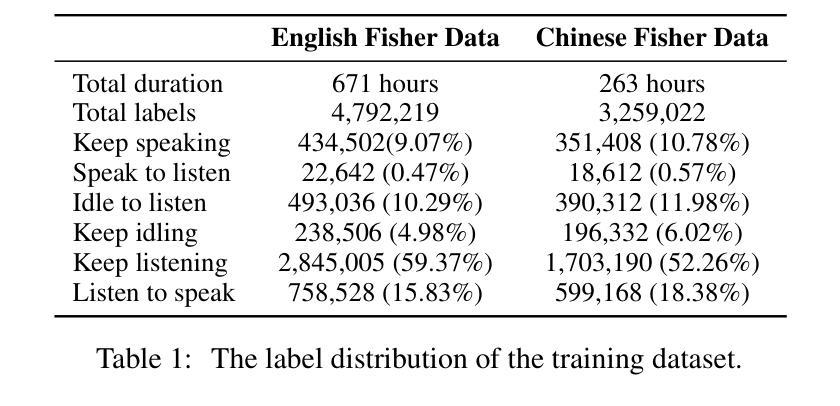
Full-Duplex Speech Dialogue Systems (Full-Duplex SDS) have significantly enhanced the naturalness of human-machine interaction by enabling real-time bidirectional communication. However, existing approaches face challenges such as difficulties in independent module optimization and contextual noise interference due to highly coupled architectural designs and oversimplified binary state modeling. This paper proposes FlexDuo, a flexible full-duplex control module that decouples duplex control from spoken dialogue systems through a plug-and-play architectural design. Furthermore, inspired by human information-filtering mechanisms in conversations, we introduce an explicit Idle state. On one hand, the Idle state filters redundant noise and irrelevant audio to enhance dialogue quality. On the other hand, it establishes a semantic integrity-based buffering mechanism, reducing the risk of mutual interruptions while ensuring accurate response transitions. Experimental results on the Fisher corpus demonstrate that FlexDuo reduces the false interruption rate by 24.9% and improves response accuracy by 7.6% compared to integrated full-duplex dialogue system baselines. It also outperforms voice activity detection (VAD) controlled baseline systems in both Chinese and English dialogue quality. The proposed modular architecture and state-based dialogue model provide a novel technical pathway for building flexible and efficient duplex dialogue systems.
全双工语音对话系统(Full-Duplex SDS)通过实现实时双向通信,极大地提高了人机交互的自然性。然而,现有方法面临诸多挑战,如因架构高度耦合和过于简化的二元状态建模而导致的独立模块优化困难和上下文噪声干扰。本文提出了FlexDuo,这是一个灵活的全双工控制模块,通过即插即用的架构设计,将双工控制与口语对话系统解耦。此外,受人类对话中信息过滤机制的启发,我们引入了一个明确的空闲状态。一方面,空闲状态可以过滤掉冗余的噪声和无关的音频,以提高对话质量。另一方面,它建立了一种基于语义完整性的缓冲机制,降低了相互干扰的风险,同时确保了准确的响应转换。在Fisher语料库上的实验结果表明,与集成全双工对话系统基线相比,FlexDuo将误中断率降低了24.9%,响应准确率提高了7.6%。与语音活动检测(VAD)控制的基线系统相比,它在中文和英语对话质量方面也表现出色。所提出的模块化架构和基于状态的对话模型为构建灵活高效的全双工对话系统提供了新的技术途径。
论文及项目相关链接
Summary
全双工对话系统通过实时双向通信增强了人机交互的自然性。然而,现有方法面临独立模块优化和语境噪声干扰的挑战。本文提出FlexDuo,一种灵活的Full-Duplex控制模块,通过即插即用架构实现与口语对话系统的解耦。此外,受人类对话中的信息过滤机制的启发,引入了明确的空闲状态。空闲状态可过滤冗余噪声和无关音频,提高对话质量。同时建立基于语义完整性的缓冲机制,减少相互干扰的风险并确保准确的响应转换。在Fisher语料库上的实验结果表明,FlexDuo降低了误中断率并提高了响应准确性。与其他全双工对话系统相比具有优势。其模块化架构和基于状态的对话模型为构建灵活高效的全双工对话系统提供了新的技术途径。
Key Takeaways
以下是文本的关键要点摘要:
- Full-Duplex SDS提高了人机交互的自然性,实现了实时双向通信。
- 现有方法面临独立模块优化和语境噪声干扰的挑战。
- FlexDuo是一种灵活的Full-Duplex控制模块,采用即插即用架构与口语对话系统解耦。
- FlexDuo引入明确的空闲状态以过滤冗余噪声和无关音频,提高对话质量。
- FlexDuo建立了基于语义完整性的缓冲机制,确保准确的响应转换并降低相互干扰的风险。
- 实验结果显示FlexDuo相较于其他全双工对话系统在降低误中断率和提高响应准确性上有所优势。
点此查看论文截图