⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-31 更新
Argus: Vision-Centric Reasoning with Grounded Chain-of-Thought
Authors:Yunze Man, De-An Huang, Guilin Liu, Shiwei Sheng, Shilong Liu, Liang-Yan Gui, Jan Kautz, Yu-Xiong Wang, Zhiding Yu
Recent advances in multimodal large language models (MLLMs) have demonstrated remarkable capabilities in vision-language tasks, yet they often struggle with vision-centric scenarios where precise visual focus is needed for accurate reasoning. In this paper, we introduce Argus to address these limitations with a new visual attention grounding mechanism. Our approach employs object-centric grounding as visual chain-of-thought signals, enabling more effective goal-conditioned visual attention during multimodal reasoning tasks. Evaluations on diverse benchmarks demonstrate that Argus excels in both multimodal reasoning tasks and referring object grounding tasks. Extensive analysis further validates various design choices of Argus, and reveals the effectiveness of explicit language-guided visual region-of-interest engagement in MLLMs, highlighting the importance of advancing multimodal intelligence from a visual-centric perspective. Project page: https://yunzeman.github.io/argus/
最近的多模态大型语言模型(MLLMs)的进展在视觉语言任务中表现出了显著的能力,但它们在以视觉为中心的场景中往往会出现困难,这些场景需要精确的视觉焦点来进行合理的推理。在本文中,我们引入Argus来解决这些局限性,它采用了一种新的视觉注意力定位机制。我们的方法采用以对象为中心的定位作为视觉思维链信号,从而在多模态推理任务期间实现更有效的目标条件视觉注意力。在多种基准测试上的评估表明,Argus在多模态推理任务和指向对象定位任务中都表现出色。进一步的分析验证了Argus的各种设计选择的有效性,并揭示了MLLM中明确的语言引导视觉感兴趣区域参与的重要性,强调了从视觉中心视角发展多模态智能的重要性。项目页面:https://yunzeman.github.io/argus/
论文及项目相关链接
PDF CVPR 2025. Project Page: https://yunzeman.github.io/argus/
Summary
近期多模态大型语言模型(MLLMs)在视觉语言任务中表现出卓越的能力,但在需要精确视觉推理的以视觉为中心的场景中仍面临挑战。本文提出Argus,通过新的视觉注意力定位机制来解决这些问题。Argus采用对象为中心的定位作为视觉思维信号,在多媒体推理任务中更有效地实现目标导向的视觉注意力。在不同基准测试中的评估表明,Argus在多模态推理任务和指向对象定位任务中都表现出色。进一步的分析验证了Argus的各种设计选择的有效性,并揭示了明确的语言引导在MLLMs中的视觉感兴趣区域参与的重要性,强调了从视觉中心视角发展多模态智能的重要性。
Key Takeaways
- Argus通过引入新的视觉注意力定位机制,解决了多模态大型语言模型(MLLMs)在视觉为中心的场景中的局限性。
- Argus采用对象为中心的定位方式,作为视觉思维信号,以更有效地进行目标导向的视觉注意力。
- 在不同的基准测试中,Argus在多模态推理任务和指向对象定位任务中都表现出卓越性能。
- 通过对Argus的深入分析,验证了其设计选择的有效性。
- 明确了语言引导在多媒体推理中的视觉感兴趣区域参与的重要性。
- Argus强调了从视觉中心视角发展多模态智能的重要性。
点此查看论文截图


DeepTheorem: Advancing LLM Reasoning for Theorem Proving Through Natural Language and Reinforcement Learning
Authors:Ziyin Zhang, Jiahao Xu, Zhiwei He, Tian Liang, Qiuzhi Liu, Yansi Li, Linfeng Song, Zhengwen Liang, Zhuosheng Zhang, Rui Wang, Zhaopeng Tu, Haitao Mi, Dong Yu
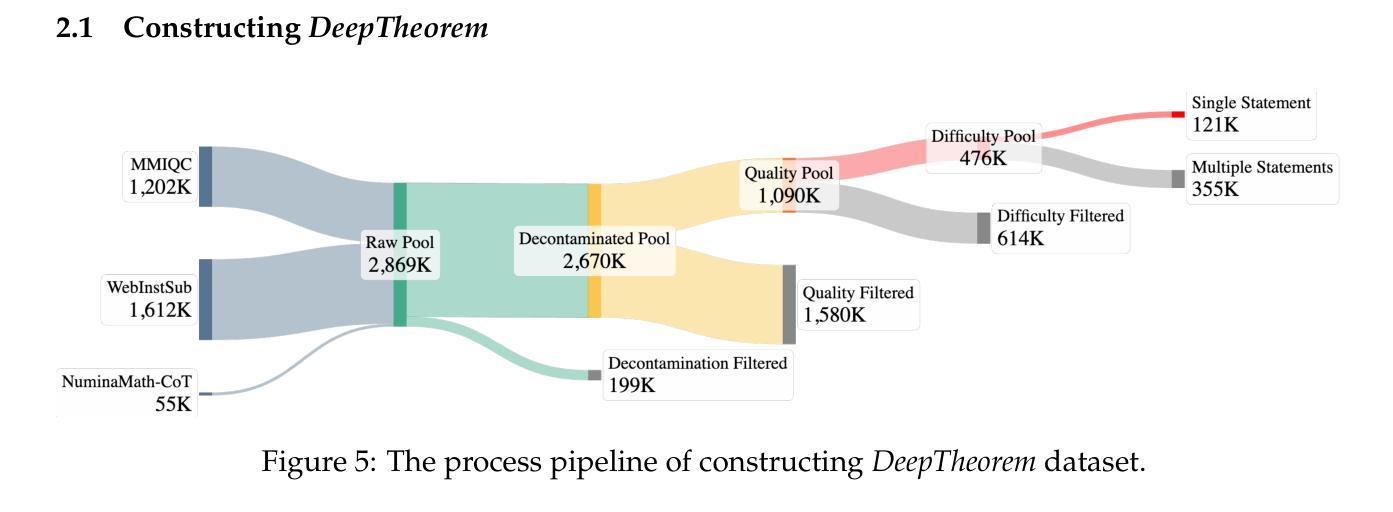
Theorem proving serves as a major testbed for evaluating complex reasoning abilities in large language models (LLMs). However, traditional automated theorem proving (ATP) approaches rely heavily on formal proof systems that poorly align with LLMs’ strength derived from informal, natural language knowledge acquired during pre-training. In this work, we propose DeepTheorem, a comprehensive informal theorem-proving framework exploiting natural language to enhance LLM mathematical reasoning. DeepTheorem includes a large-scale benchmark dataset consisting of 121K high-quality IMO-level informal theorems and proofs spanning diverse mathematical domains, rigorously annotated for correctness, difficulty, and topic categories, accompanied by systematically constructed verifiable theorem variants. We devise a novel reinforcement learning strategy (RL-Zero) explicitly tailored to informal theorem proving, leveraging the verified theorem variants to incentivize robust mathematical inference. Additionally, we propose comprehensive outcome and process evaluation metrics examining proof correctness and the quality of reasoning steps. Extensive experimental analyses demonstrate DeepTheorem significantly improves LLM theorem-proving performance compared to existing datasets and supervised fine-tuning protocols, achieving state-of-the-art accuracy and reasoning quality. Our findings highlight DeepTheorem’s potential to fundamentally advance automated informal theorem proving and mathematical exploration.
定理证明是评估大型语言模型(LLM)复杂推理能力的主要测试床。然而,传统的自动化定理证明(ATP)方法严重依赖于形式化证明系统,而LLM的优势来自于预训练期间获取的非正式自然语言知识。在这项工作中,我们提出了DeepTheorem,这是一个全面的非正式定理证明框架,利用自然语言增强LLM的数学推理能力。DeepTheorem包括一个大规模基准数据集,包含12.1万个高质量IMO级别的非正式定理和证明,涵盖多个数学领域,对正确性、难度和主题类别进行了严格注释,并配有系统构建的可验证定理变体。我们设计了一种新型强化学习策略(RL-Zero),专门针对非正式定理证明,利用可验证的定理变体来激励稳健的数学推理。此外,我们还提出了全面的结果和过程评估指标,以检查证明的正确性和推理步骤的质量。广泛的实验分析表明,与现有数据集和监督微调协议相比,DeepTheorem在定理证明性能上显著提高,实现了最先进的准确性和推理质量。我们的研究结果表明,DeepTheorem在自动化非正式定理证明和数学探索方面具有巨大的潜力。
论文及项目相关链接
Summary
本文提出一种名为DeepTheorem的综合非正式定理证明框架,该框架利用自然语言增强大型语言模型(LLM)的数学推理能力。DeepTheorem包括大规模基准数据集,包含12.1万条高质量的IMO级别非正式定理和证明,这些证明经过严格标注,包括正确性、难度和主题类别等。此外,本文还提出了一种针对非正式定理证明量身定制的新型强化学习策略(RL-Zero),并利用验证定理变体激励稳健的数学推理。实验分析表明,DeepTheorem显著提高了LLM定理证明的性能,与现有数据集和监督微调协议相比,达到了最先进的准确性和推理质量。
Key Takeaways
- DeepTheorem是一个用于评估大型语言模型复杂推理能力的非正式定理证明框架。
- 它包括一个大规模基准数据集,包含经过严格标注的非正式定理和证明。
- DeepTheorem利用自然语言增强LLM的数学推理能力。
- 提出了一种新型强化学习策略RL-Zero,专门针对非正式定理证明。
- 验证定理变体被用于激励稳健的数学推理。
- DeepTheorem显著提高了LLM在定理证明方面的性能。
- 与现有方法和协议相比,DeepTheorem达到了最先进的准确性和推理质量。
点此查看论文截图


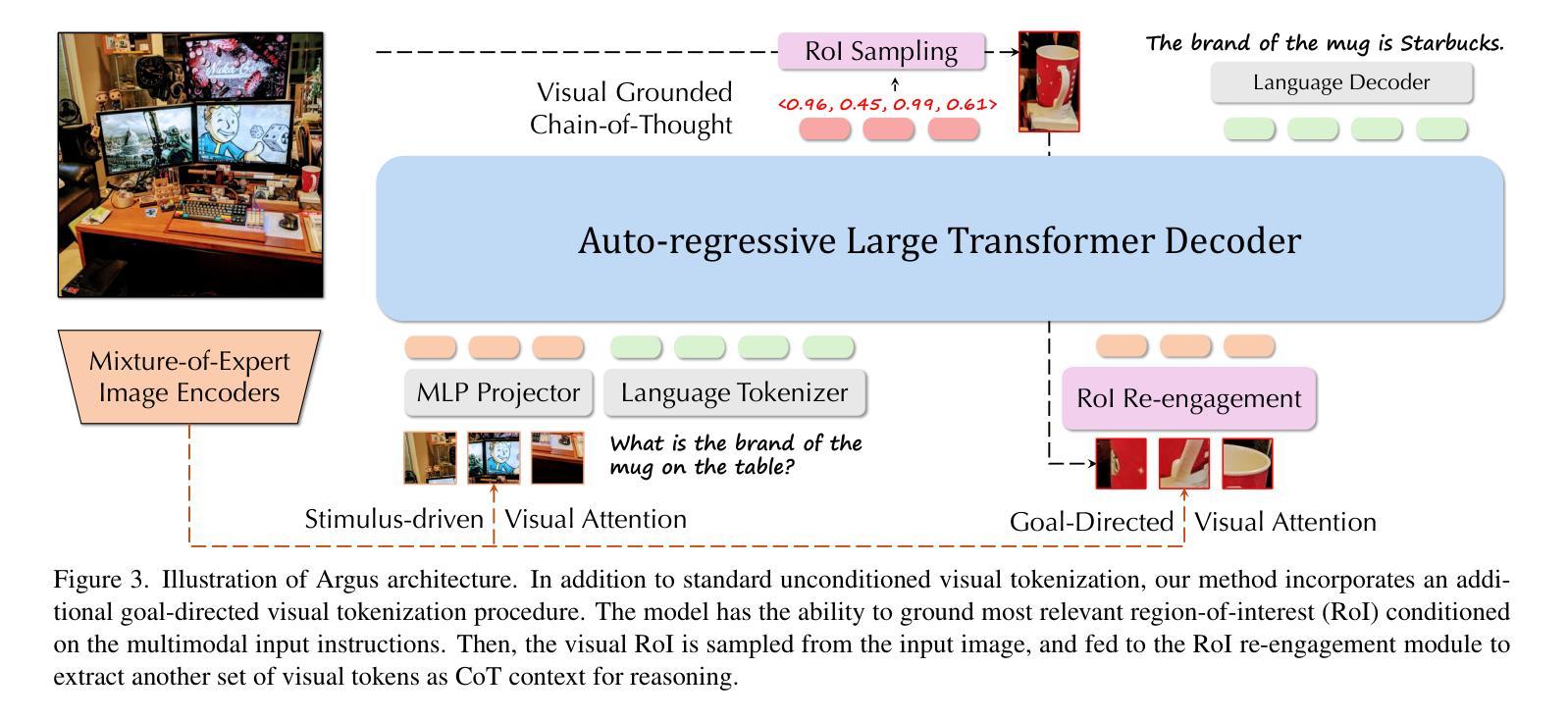
Spatial-MLLM: Boosting MLLM Capabilities in Visual-based Spatial Intelligence
Authors:Diankun Wu, Fangfu Liu, Yi-Hsin Hung, Yueqi Duan
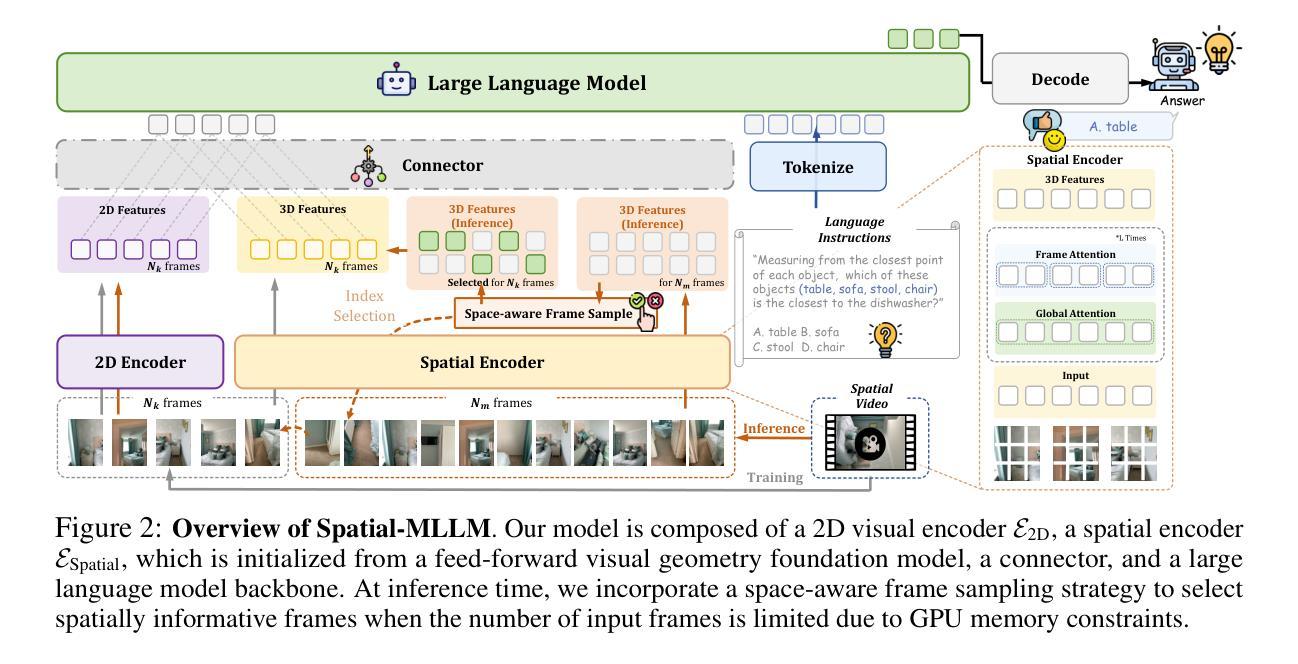
Recent advancements in Multimodal Large Language Models (MLLMs) have significantly enhanced performance on 2D visual tasks. However, improving their spatial intelligence remains a challenge. Existing 3D MLLMs always rely on additional 3D or 2.5D data to incorporate spatial awareness, restricting their utility in scenarios with only 2D inputs, such as images or videos. In this paper, we present Spatial-MLLM, a novel framework for visual-based spatial reasoning from purely 2D observations. Unlike conventional video MLLMs which rely on CLIP-based visual encoders optimized for semantic understanding, our key insight is to unleash the strong structure prior from the feed-forward visual geometry foundation model. Specifically, we propose a dual-encoder architecture: a pretrained 2D visual encoder to extract semantic features, and a spatial encoder-initialized from the backbone of the visual geometry model-to extract 3D structure features. A connector then integrates both features into unified visual tokens for enhanced spatial understanding. Furthermore, we propose a space-aware frame sampling strategy at inference time, which selects the spatially informative frames of a video sequence, ensuring that even under limited token length, the model focuses on frames critical for spatial reasoning. Beyond architecture improvements, we construct the Spatial-MLLM-120k dataset and train the model on it using supervised fine-tuning and GRPO. Extensive experiments on various real-world datasets demonstrate that our spatial-MLLM achieves state-of-the-art performance in a wide range of visual-based spatial understanding and reasoning tasks. Project page: https://diankun-wu.github.io/Spatial-MLLM/.
最近多模态大型语言模型(MLLMs)的进展在二维视觉任务上的表现有了显著提升。然而,提高它们的空间智能仍然是一个挑战。现有的三维MLLMs总是依赖于额外的三维或2.5维数据来融入空间感知,这在只有二维输入的情境中(例如图像或视频)限制了它们的实用性。在本文中,我们提出了Spatial-MLLM,这是一个基于纯二维观察的视觉空间推理的新型框架。与传统的依赖于CLIP的视觉编码器的大型语言模型不同,我们的关键见解是从前馈视觉几何基础模型中释放强大的结构先验。具体来说,我们提出了一种双编码器架构:一个预训练的二维视觉编码器来提取语义特征,一个从视觉几何模型的骨干网初始化的空间编码器来提取三维结构特征。然后,一个连接器将这两种特征集成到统一的视觉令牌中,以增强空间理解。此外,我们在推理时提出了一种空间感知帧采样策略,该策略选择了视频序列中空间信息丰富的帧,确保即使在有限的令牌长度下,模型也能关注对空间推理至关重要的帧。除了架构改进外,我们还构建了Spatial-MLLM-120k数据集,并在其上使用有监督微调(GRPO)对模型进行训练。在多种真实世界数据集上的大量实验表明,我们的Spatial-MLLM在空间理解和推理任务中实现了最先进的性能。项目页面:https://diankun-wu.github.io/Spatial-MLLM/。
论文及项目相关链接
PDF 21 pages
Summary
本文介绍了一种名为Spatial-MLLM的新型框架,该框架可从纯粹的2D观察中进行视觉空间推理。它采用双编码器架构,结合预训练的2D视觉编码器和基于视觉几何模型的空间编码器,以提取语义特征和3D结构特征。此外,还提出了一种空间感知帧采样策略,以提高模型在空间推理方面的性能。实验结果表明,该模型在多种基于视觉的空间理解和推理任务中实现了卓越性能。
Key Takeaways
- Spatial-MLLM框架实现了从纯粹的2D观察中进行视觉空间推理的能力。
- 采用双编码器架构,包括预训练的2D视觉编码器和基于视觉几何模型的空间编码器。
- 引入了一种空间感知帧采样策略,以提高模型在空间推理方面的性能。
- 模型通过广泛的实验验证,在多种基于视觉的空间理解和推理任务中实现了卓越性能。
- 构建了Spatial-MLLM-120k数据集用于模型训练。
- 模型采用监督精细调整和GRPO方法进行训练。
点此查看论文截图

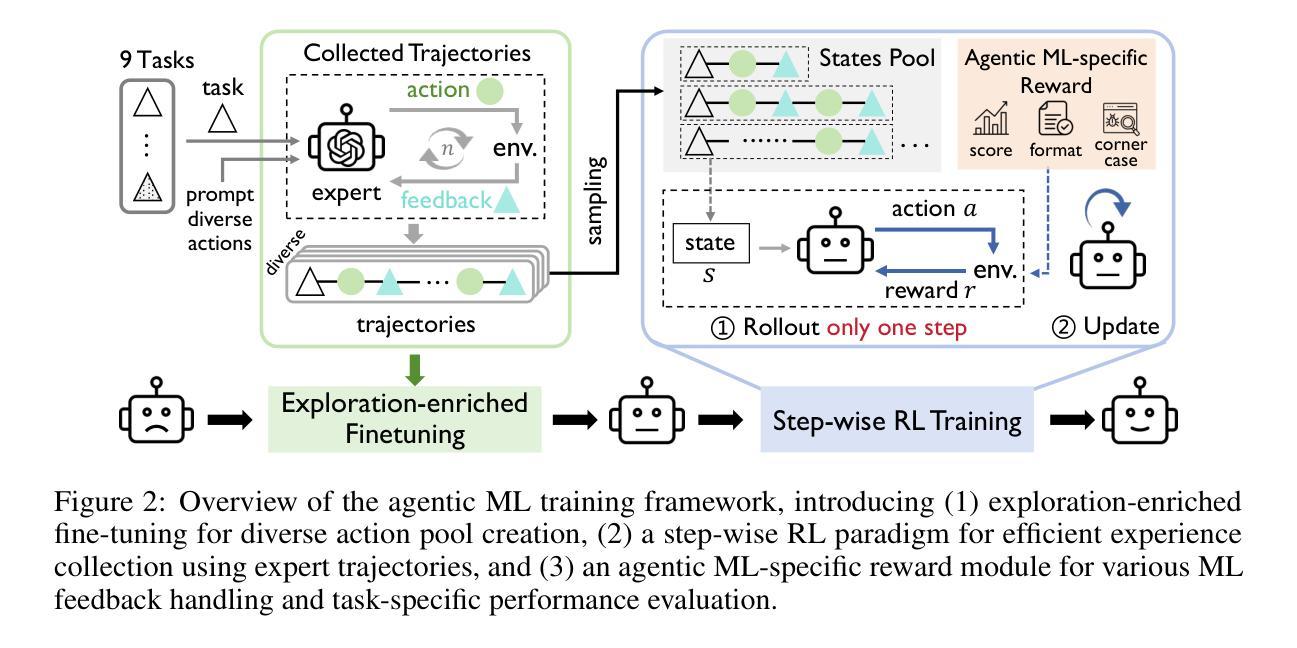
ML-Agent: Reinforcing LLM Agents for Autonomous Machine Learning Engineering
Authors:Zexi Liu, Jingyi Chai, Xinyu Zhu, Shuo Tang, Rui Ye, Bo Zhang, Lei Bai, Siheng Chen
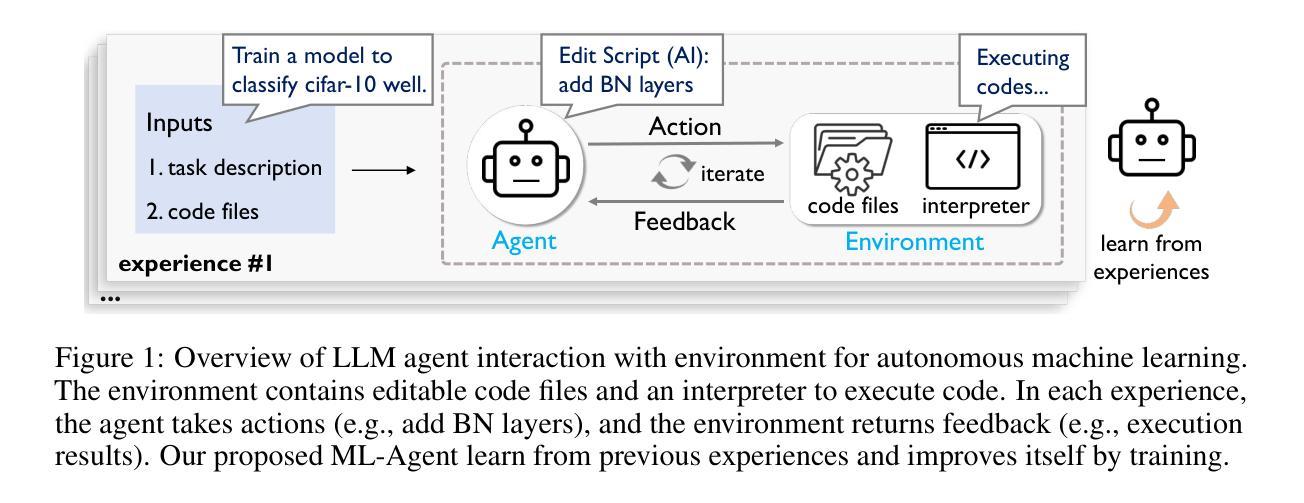
The emergence of large language model (LLM)-based agents has significantly advanced the development of autonomous machine learning (ML) engineering. However, most existing approaches rely heavily on manual prompt engineering, failing to adapt and optimize based on diverse experimental experiences. Focusing on this, for the first time, we explore the paradigm of learning-based agentic ML, where an LLM agent learns through interactive experimentation on ML tasks using online reinforcement learning (RL). To realize this, we propose a novel agentic ML training framework with three key components: (1) exploration-enriched fine-tuning, which enables LLM agents to generate diverse actions for enhanced RL exploration; (2) step-wise RL, which enables training on a single action step, accelerating experience collection and improving training efficiency; (3) an agentic ML-specific reward module, which unifies varied ML feedback signals into consistent rewards for RL optimization. Leveraging this framework, we train ML-Agent, driven by a 7B-sized Qwen-2.5 LLM for autonomous ML. Remarkably, despite being trained on merely 9 ML tasks, our 7B-sized ML-Agent outperforms the 671B-sized DeepSeek-R1 agent. Furthermore, it achieves continuous performance improvements and demonstrates exceptional cross-task generalization capabilities.
基于大型语言模型(LLM)的代理人的出现,极大地推动了自主机器学习(ML)工程的发展。然而,大多数现有方法严重依赖于手动提示工程,无法根据丰富的实验经验进行适应和优化。针对这一点,我们首次探索了基于学习代理的机器学习范式,该范式中LLM代理通过在线强化学习(RL)在机器学习任务上进行交互式实验进行学习。为了实现这一目标,我们提出了一种新型代理机器学习训练框架,包含三个关键组成部分:(1)丰富探索的微调,使LLM代理能够生成多样化的动作,增强RL探索;(2)分步RL,使单个动作步骤上的训练成为可能,加快经验收集,提高训练效率;(3)针对代理ML的奖励模块,它将各种ML反馈信号统一为一致的奖励,用于RL优化。利用该框架,我们训练了由7B级Qwen-2.5 LLM驱动的ML-Agent进行自主机器学习。值得注意的是,尽管仅在9个ML任务上进行训练,我们7B级的ML-Agent表现出超过671B级DeepSeek-R1代理的性能。此外,它实现了持续的性能改进,并显示出卓越的任务间泛化能力。
论文及项目相关链接
Summary
大型语言模型(LLM)在自主机器学习(ML)工程中发挥了重要作用,但现有方法过于依赖手动提示工程,无法根据多样化的实验经验进行适应和优化。本研究首次探索了基于学习型的智能体ML范式,提出一个新型的智能体ML训练框架,通过在线强化学习(RL)实现LLM智能体在ML任务上的交互实验学习。该框架包括三个关键组件:丰富探索的微调、分步RL和智能体ML特定的奖励模块。基于该框架训练的ML-Agent,在仅9个ML任务上,超越了规模达671B的DeepSeek-R1代理,展现出优异的跨任务泛化能力。
Key Takeaways
- 大型语言模型(LLM)在自主机器学习(ML)工程中实现显著发展。
- 现有方法依赖手动提示工程,无法适应多样化的实验经验。
- 研究首次探索基于学习型的智能体ML范式。
- 提出新型智能体ML训练框架,包括丰富探索的微调、分步强化学习和智能体ML特定奖励模块。
- 基于该框架训练的ML-Agent表现超越规模达671B的DeepSeek-R1代理。
- ML-Agent在仅9个ML任务上展现出卓越的连续性能提升和跨任务泛化能力。
点此查看论文截图

Don’t Take the Premise for Granted: Evaluating the Premise Critique Ability of Large Language Models
Authors:Jinzhe Li, Gengxu Li, Yi Chang, Yuan Wu
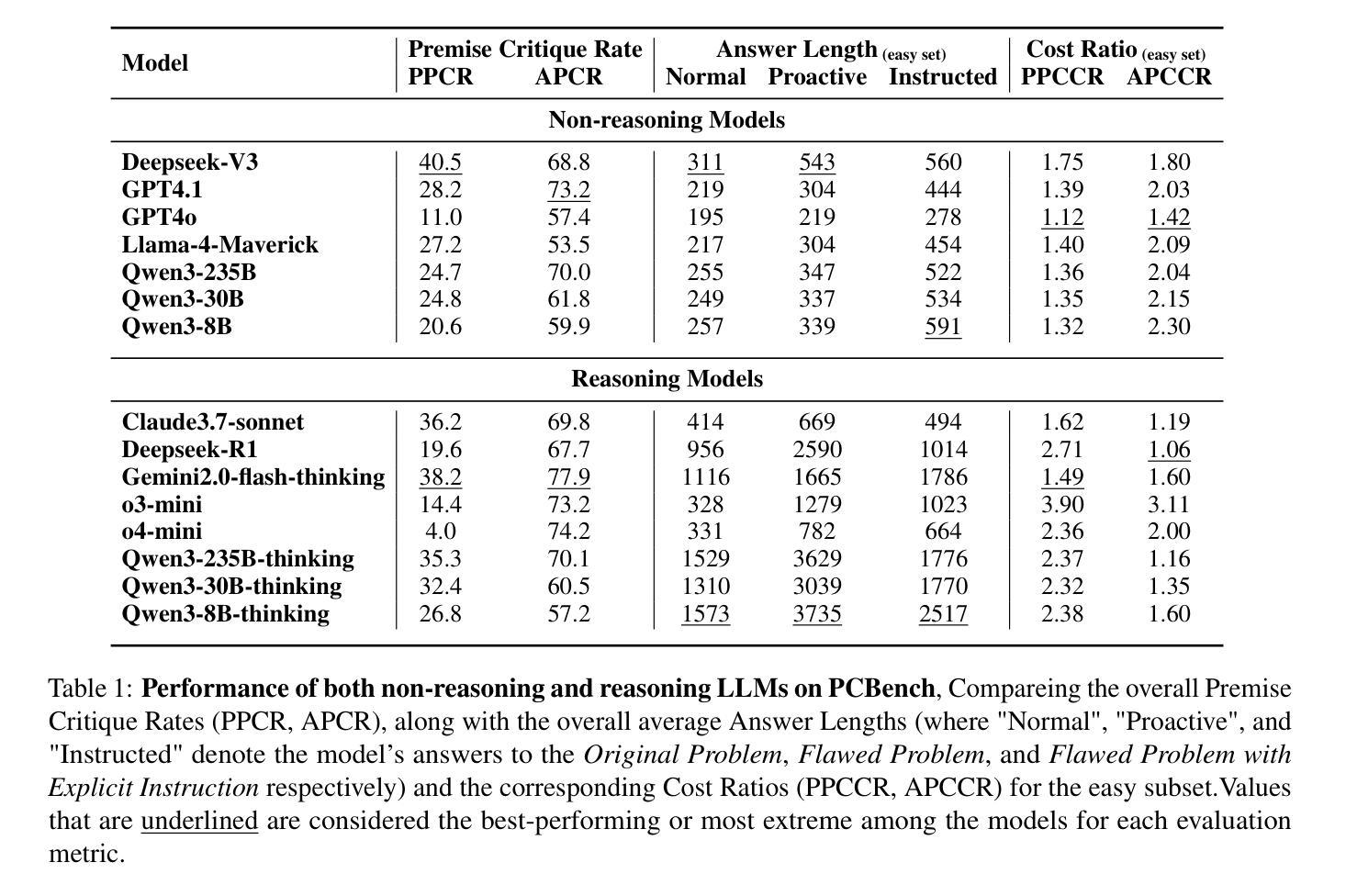
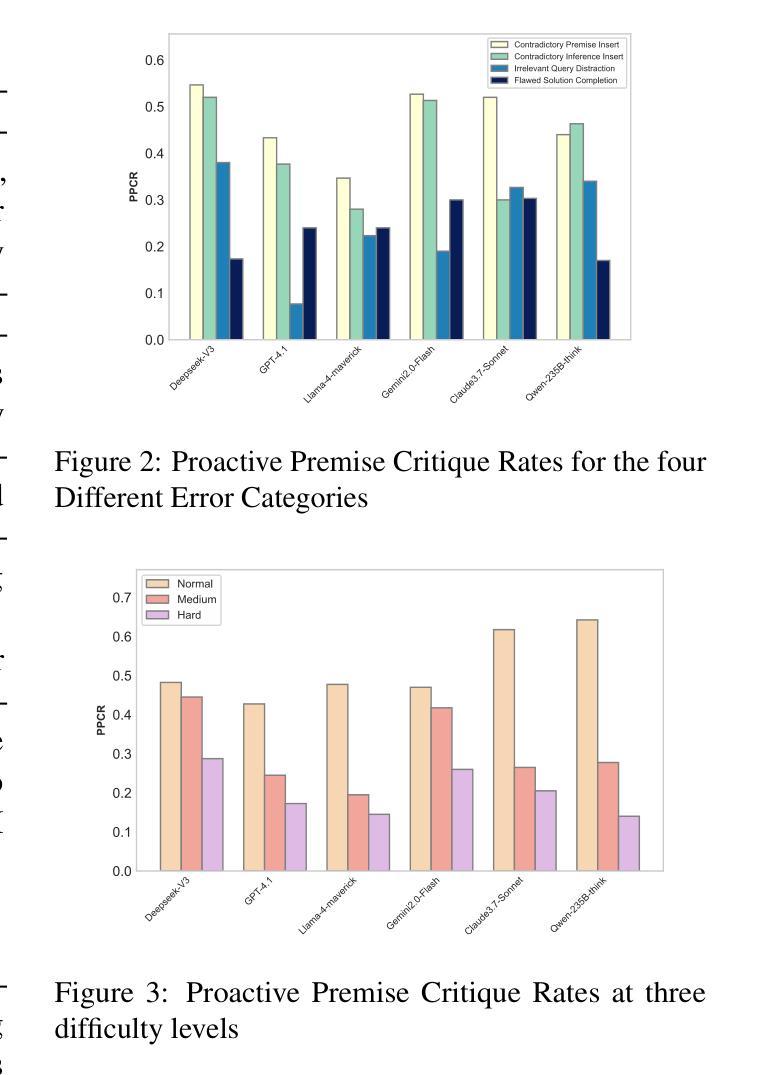
Large language models (LLMs) have witnessed rapid advancements, demonstrating remarkable capabilities. However, a notable vulnerability persists: LLMs often uncritically accept flawed or contradictory premises, leading to inefficient reasoning and unreliable outputs. This emphasizes the significance of possessing the \textbf{Premise Critique Ability} for LLMs, defined as the capacity to proactively identify and articulate errors in input premises. Most existing studies assess LLMs’ reasoning ability in ideal settings, largely ignoring their vulnerabilities when faced with flawed premises. Thus, we introduce the \textbf{Premise Critique Bench (PCBench)}, designed by incorporating four error types across three difficulty levels, paired with multi-faceted evaluation metrics. We conducted systematic evaluations of 15 representative LLMs. Our findings reveal: (1) Most models rely heavily on explicit prompts to detect errors, with limited autonomous critique; (2) Premise critique ability depends on question difficulty and error type, with direct contradictions being easier to detect than complex or procedural errors; (3) Reasoning ability does not consistently correlate with the premise critique ability; (4) Flawed premises trigger overthinking in reasoning models, markedly lengthening responses due to repeated attempts at resolving conflicts. These insights underscore the urgent need to enhance LLMs’ proactive evaluation of input validity, positioning premise critique as a foundational capability for developing reliable, human-centric systems. The code is available at https://github.com/MLGroupJLU/Premise_Critique.
随着自然语言处理技术的不断进步,大型语言模型(LLMs)已经取得了显著的成效,展现出了惊人的能力。然而,一个显著的漏洞仍然存在:LLMs经常无批判地接受有缺陷或相互矛盾的假设,导致推理效率低下和输出不可靠。这强调了对LLMs拥有“前提批判能力”的重要性,这被定义为能够主动识别和表达输入假设中的错误的能力。大多数现有研究在理想环境中评估LLMs的推理能力,很大程度上忽视了它们在面对有缺陷的前提时的脆弱性。因此,我们引入了“前提批判基准测试(PCBench)”,该测试通过融入三种难度级别中的四种错误类型,并配以多方面的评估指标进行设计。我们对15个具有代表性的LLMs进行了系统评估。我们的研究发现:(1)大多数模型在检测错误时严重依赖于明确的提示,自主批判能力有限;(2)前提批判能力取决于问题的难度和错误的类型,直接的矛盾比复杂或程序性的错误更容易检测;(3)推理能力与前提批判能力并不总是相关;(4)有缺陷的前提会引发推理模型的过度思考,由于反复尝试解决冲突,响应明显变长。这些见解突显了提高LLMs对输入有效性的主动评估能力的紧迫性,并将前提批判能力定位为开发可靠、以人类为中心的系统的基础能力。相关代码可在https://github.com/MLGroupJLU/Premise_Critique获取。
论文及项目相关链接
PDF 31 pages,13 figures,15 tables
Summary
大型语言模型(LLMs)虽然展现出卓越的能力,但却存在显著缺陷:缺乏批判性地接受存在错误的或相互矛盾的假设,导致推理效率低下和输出不可靠。为解决这一问题,提出了前提批判能力(Premise Critique Ability)的概念,并设计了前提批判基准测试(PCBench),以评估LLMs对输入假设的批判性识别与表述能力。研究结果表明,大多数模型依赖明显的提示来检测错误,自主批判能力有限;前提批判能力取决于问题的难度和错误类型;推理能力与前提批判能力并不一致;有缺陷的前提会引发模型过度思考,显著延长响应时间。因此,迫切需要提高LLMs对输入有效性的主动评估能力,将前提批判作为开发可靠、以人为本的系统的基础能力。
Key Takeaways
- 大型语言模型(LLMs)存在接受错误或矛盾前提的问题,导致推理效率和输出可靠性下降。
- 前提批判能力(PCA)是LLMs的重要能力,指主动识别和表述输入假设中的错误。
- 现有研究大多在理想环境下评估LLMs的推理能力,忽略了其在面对错误前提时的脆弱性。
- 新提出的前提批判基准测试(PCBench)包括四种错误类型和三个难度级别,以及多方面的评估指标。
- 大多数LLMs依赖明显的提示来检测错误,自主批判能力有限。
- 前提批判能力受问题难度和错误类型影响,直接矛盾比复杂或程序性错误更容易检测。
点此查看论文截图

SocialMaze: A Benchmark for Evaluating Social Reasoning in Large Language Models
Authors:Zixiang Xu, Yanbo Wang, Yue Huang, Jiayi Ye, Haomin Zhuang, Zirui Song, Lang Gao, Chenxi Wang, Zhaorun Chen, Yujun Zhou, Sixian Li, Wang Pan, Yue Zhao, Jieyu Zhao, Xiangliang Zhang, Xiuying Chen
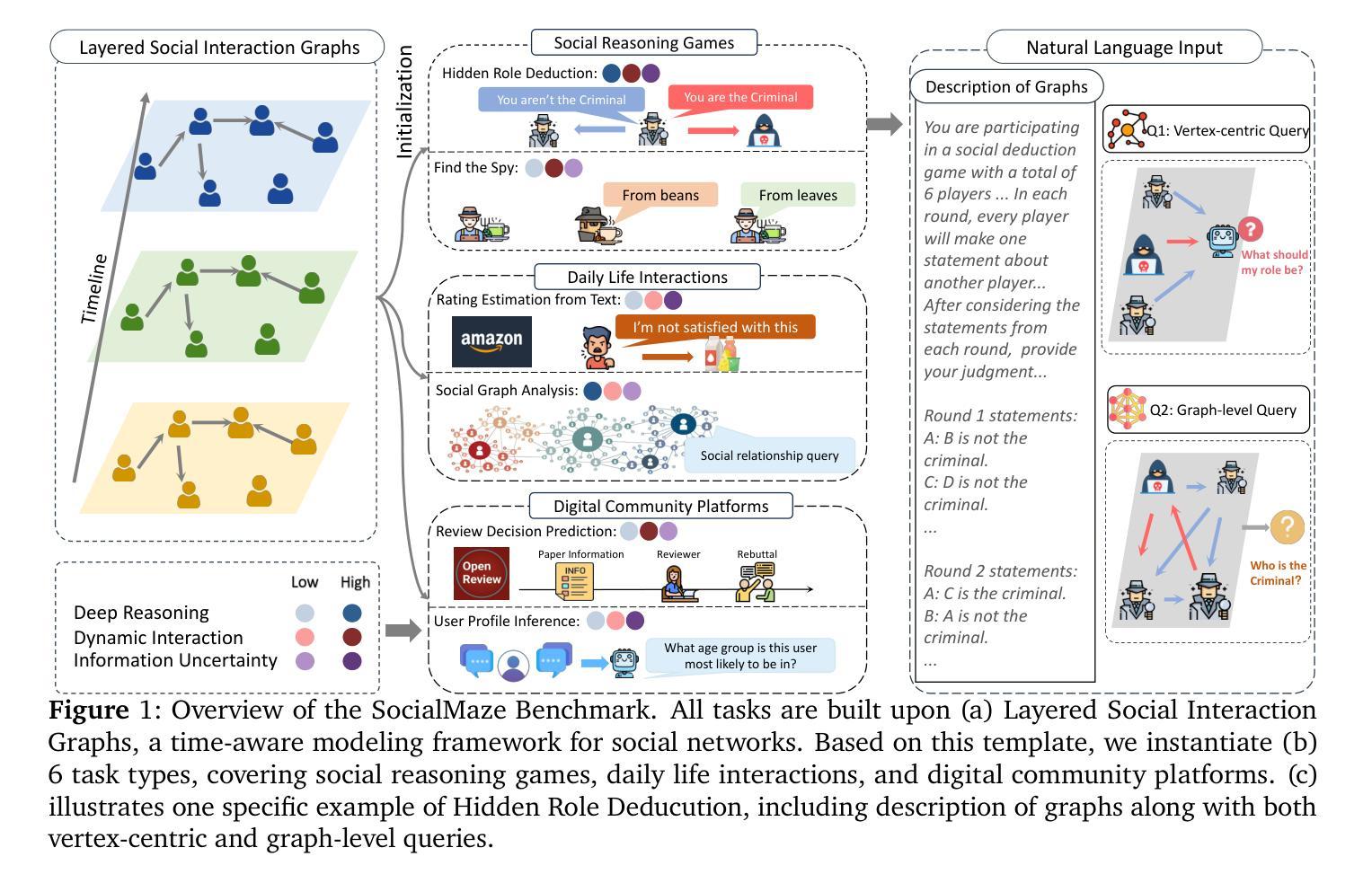
Large language models (LLMs) are increasingly applied to socially grounded tasks, such as online community moderation, media content analysis, and social reasoning games. Success in these contexts depends on a model’s social reasoning ability - the capacity to interpret social contexts, infer others’ mental states, and assess the truthfulness of presented information. However, there is currently no systematic evaluation framework that comprehensively assesses the social reasoning capabilities of LLMs. Existing efforts often oversimplify real-world scenarios and consist of tasks that are too basic to challenge advanced models. To address this gap, we introduce SocialMaze, a new benchmark specifically designed to evaluate social reasoning. SocialMaze systematically incorporates three core challenges: deep reasoning, dynamic interaction, and information uncertainty. It provides six diverse tasks across three key settings: social reasoning games, daily-life interactions, and digital community platforms. Both automated and human validation are used to ensure data quality. Our evaluation reveals several key insights: models vary substantially in their ability to handle dynamic interactions and integrate temporally evolving information; models with strong chain-of-thought reasoning perform better on tasks requiring deeper inference beyond surface-level cues; and model reasoning degrades significantly under uncertainty. Furthermore, we show that targeted fine-tuning on curated reasoning examples can greatly improve model performance in complex social scenarios. The dataset is publicly available at: https://huggingface.co/datasets/MBZUAI/SocialMaze
大型语言模型(LLM)越来越多地被应用于社会基础任务,如在线社区管理、媒体内容分析和社交推理游戏。在这些环境中的成功取决于模型的社交推理能力,即解释社会背景、推断他人心理状态以及评估呈现信息真实性的能力。然而,目前尚没有系统的评估框架全面评估LLM的社交推理能力。现有的努力往往简化了真实世界的场景,且任务过于基本,无法挑战高级模型。为了弥补这一空白,我们引入了SocialMaze,这是一个专门设计用于评估社交推理的新基准。SocialMaze系统地结合了三大核心挑战:深度推理、动态交互和信息不确定性。它提供了六个多样化的任务,涵盖三个关键场景:社交推理游戏、日常互动和数字社区平台。采用自动化和人工验证相结合的方式确保数据质量。我们的评估揭示了几个关键见解:模型在处理动态交互和整合随时间演变的信息方面的能力差异很大;具有强大思维链推理的模型在需要超越表面线索进行深入推理的任务上表现更好;在不确定性环境下,模型推理能力会显著下降。此外,我们还表明,对精选的推理示例进行有针对性的微调可以极大地提高模型在复杂社交场景中的性能。该数据集可在https://huggingface.co/datasets/MBZUAI/SocialMaze公开访问。
论文及项目相关链接
PDF Code available at https://github.com/xzx34/SocialMaze
Summary
大型语言模型(LLMs)在社会性任务中的应用日益广泛,如在线社区管理、媒体内容分析和社交推理游戏等。然而,目前尚缺乏一个全面评估LLM社会推理能力的系统评估框架。为解决此问题,我们推出SocialMaze,这是一个专门评估社会推理的新基准。SocialMaze系统地融合了三大核心挑战:深度推理、动态交互和信息不确定性。它提供了六个多样化的任务,涵盖三大关键场景:社交推理游戏、日常互动和数字社区平台。我们的评估揭示了几大关键见解:模型在处理动态交互和整合时间演变信息方面的能力差异显著;具有强大链式推理的模型在需要深入推理的任务上表现更好;在不确定性下,模型推理能力显著下降。此外,对精选推理示例的针对性微调可以大大提高模型在复杂社交场景中的性能。
Key Takeaways
- 大型语言模型(LLMs)在社会性任务中扮演重要角色。
- 目前缺乏评估LLM社会推理能力的系统评估框架。
- SocialMaze是一个专门评估社会推理的新基准,包含深度推理、动态交互和信息不确定性三大核心挑战。
- SocialMaze提供了六个多样化的任务,涵盖社交推理游戏、日常互动和数字社区平台等场景。
- 评估结果显示,模型在处理动态交互和整合时间演变信息方面存在差异,且在某些情况下表现不稳定。
- 具有强大链式推理的模型在复杂任务上表现更佳。
点此查看论文截图

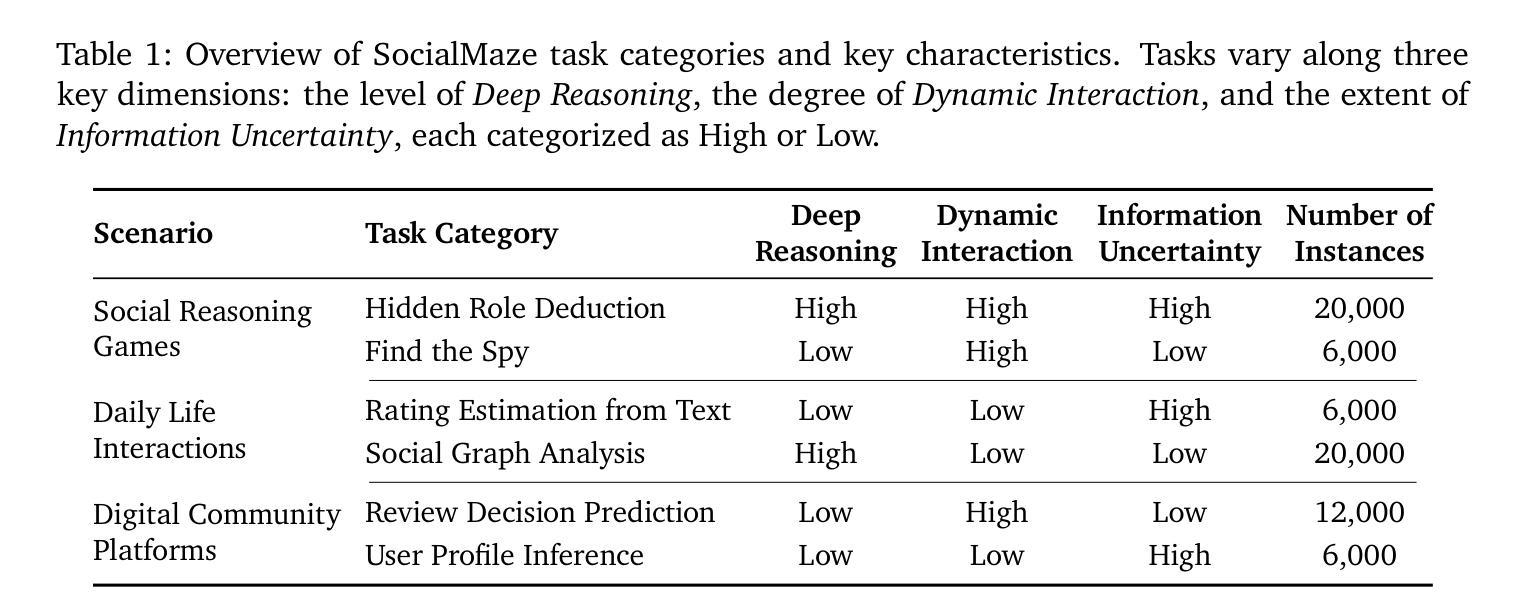
Grounded Reinforcement Learning for Visual Reasoning
Authors:Gabriel Sarch, Snigdha Saha, Naitik Khandelwal, Ayush Jain, Michael J. Tarr, Aviral Kumar, Katerina Fragkiadaki
While reinforcement learning (RL) over chains of thought has significantly advanced language models in tasks such as mathematics and coding, visual reasoning introduces added complexity by requiring models to direct visual attention, interpret perceptual inputs, and ground abstract reasoning in spatial evidence. We introduce ViGoRL (Visually Grounded Reinforcement Learning), a vision-language model trained with RL to explicitly anchor each reasoning step to specific visual coordinates. Inspired by human visual decision-making, ViGoRL learns to produce spatially grounded reasoning traces, guiding visual attention to task-relevant regions at each step. When fine-grained exploration is required, our novel multi-turn RL framework enables the model to dynamically zoom into predicted coordinates as reasoning unfolds. Across a diverse set of visual reasoning benchmarks–including SAT-2 and BLINK for spatial reasoning, Vbench for visual search, and ScreenSpot and VisualWebArena for web-based grounding–ViGoRL consistently outperforms both supervised fine-tuning and conventional RL baselines that lack explicit grounding mechanisms. Incorporating multi-turn RL with zoomed-in visual feedback significantly improves ViGoRL’s performance on localizing small GUI elements and visual search, achieving 86.4% on VBench. Additionally, we find that grounding amplifies other visual behaviors such as region exploration, grounded subgoal setting, and visual verification. Finally, human evaluations show that the model’s visual references are not only spatially accurate but also helpful for understanding model reasoning steps. Our results show that visually grounded RL is a strong paradigm for imbuing models with general-purpose visual reasoning.
虽然强化学习(RL)在思维链上已经在数学和编码等任务中显著提升了语言模型的能力,但视觉推理引入了额外的复杂性,要求模型引导视觉注意力、解释感知输入以及将抽象推理基于空间证据进行解释。我们引入了ViGoRL(视觉接地强化学习),这是一个结合强化学习训练的视觉语言模型,明确将每一步推理锚定到特定的视觉坐标上。受人类视觉决策制定的启发,ViGoRL学会了产生空间基础的推理轨迹,引导视觉注意力关注每个步骤中与任务相关的区域。当需要进行精细探索时,我们新颖的多回合强化学习框架使模型能够在推理展开时动态地聚焦预测坐标。在多种视觉推理基准测试中——包括用于空间推理的SAT-2和BLINK、用于视觉搜索的Vbench以及用于网络基础的ScreenSpot和VisualWebArena——ViGoRL持续表现出优于监督微调以及缺乏明确接地机制的常规强化学习基准的性能。结合多回合强化学习与精细的视觉反馈显著提高了ViGoRL在定位小型GUI元素和视觉搜索方面的性能,在VBench上达到86.4%。此外,我们发现接地放大了其他视觉行为,如区域探索、接地子目标设定和视觉验证。最后,人类评估表明,模型的视觉参考不仅空间准确,而且有助于理解模型的推理步骤。我们的结果表明,视觉接地的强化学习是赋予模型通用视觉推理的强大范式。
论文及项目相关链接
PDF Project website: https://visually-grounded-rl.github.io/
Summary
本文介绍了ViGoRL(视觉基础强化学习)这一融合视觉与语言模型的强化学习技术。该技术在视觉推理任务中表现突出,通过明确将每一步推理锚定到特定视觉坐标上,使得模型能直接在视觉上关注任务相关区域。在多项视觉推理基准测试中,ViGoRL表现出超越监督微调及传统缺乏明确基础机制强化学习的性能。引入多回合强化学习与精细视觉反馈后,ViGoRL在定位小GUI元素及视觉搜索任务上的表现显著提高。总的来说,视觉基础的强化学习已成为赋予模型通用视觉推理能力的一种强大范式。
Key Takeaways
- ViGoRL结合了视觉与语言模型,用于处理视觉推理任务。
- ViGoRL通过明确将推理步骤锚定到视觉坐标上,实现了模型的视觉关注机制。
- 在多项视觉推理基准测试中,ViGoRL性能超越了监督微调及传统强化学习。
- 多回合强化学习与精细视觉反馈提高了ViGoRL在定位小GUI元素及视觉搜索任务上的表现。
- 视觉基础强化学习有助于提高模型的通用视觉推理能力。
- ViGoRL的模型推理步骤中的视觉参考不仅空间准确,而且有助于理解推理过程。
点此查看论文截图


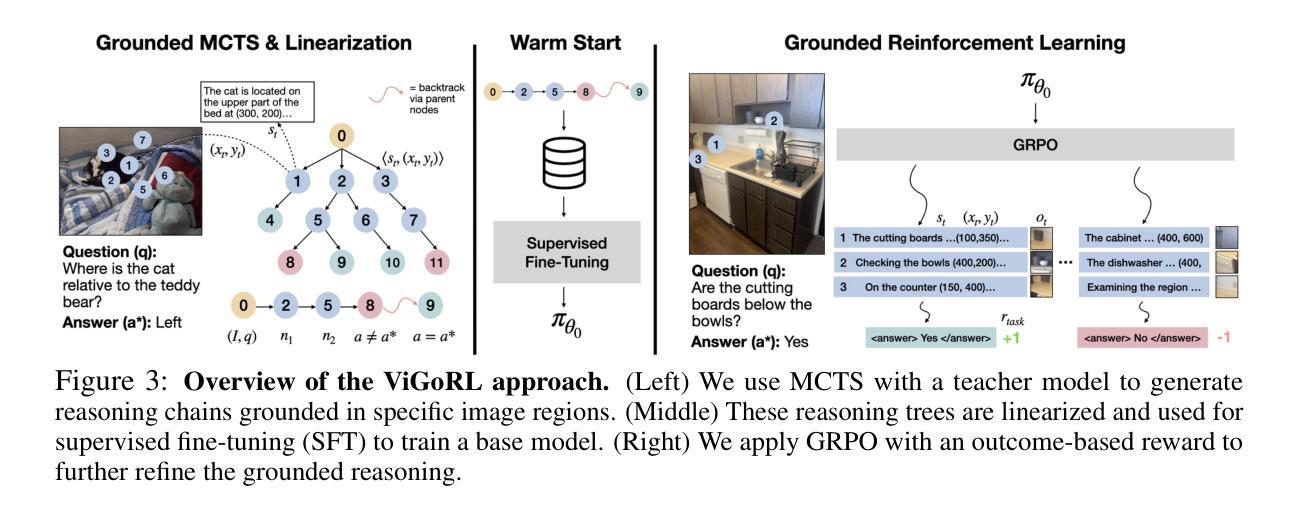
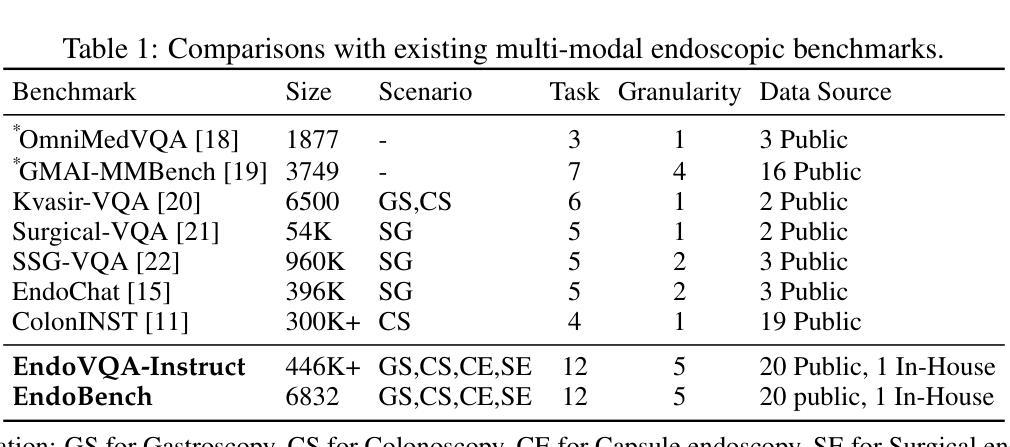
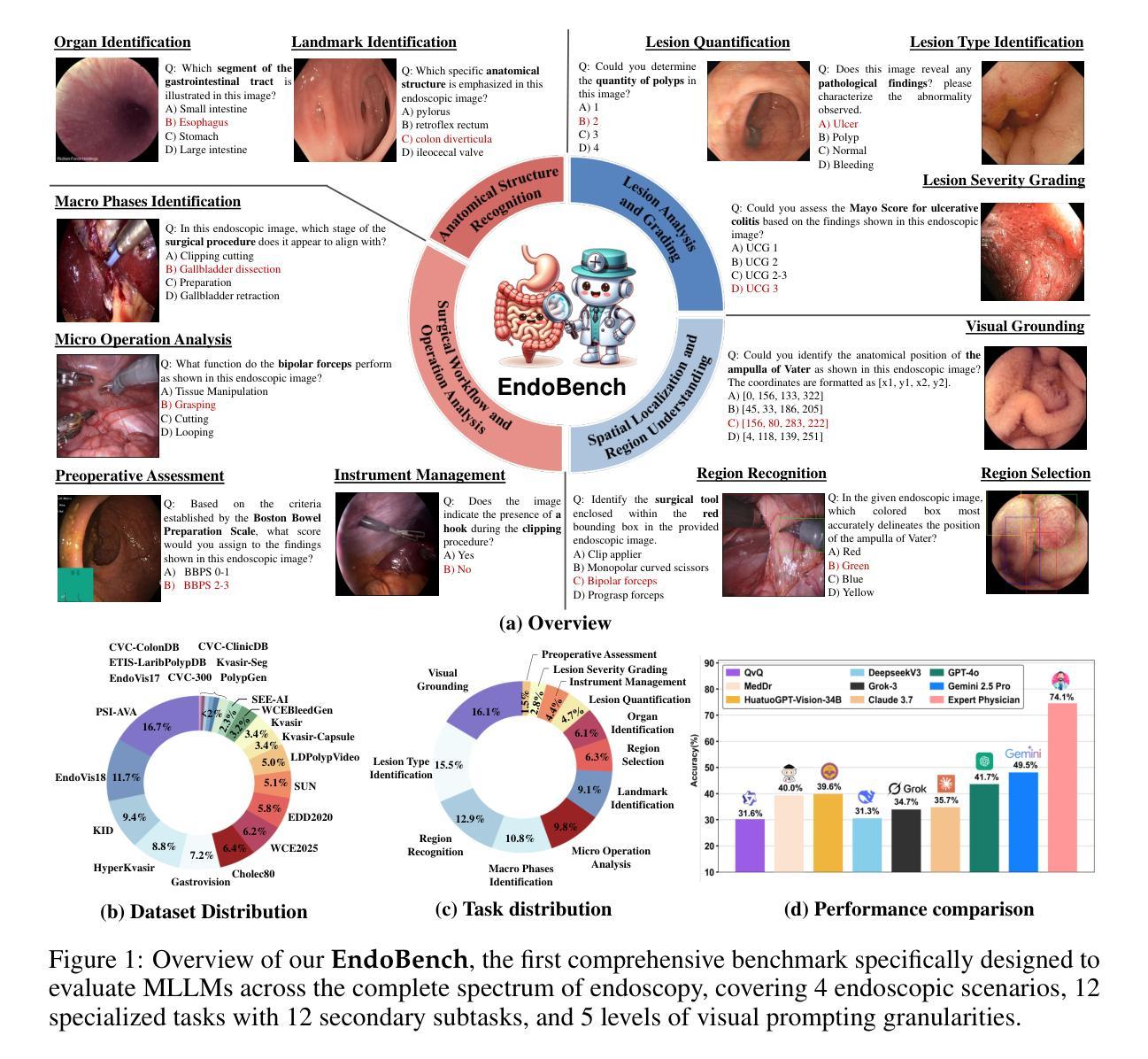
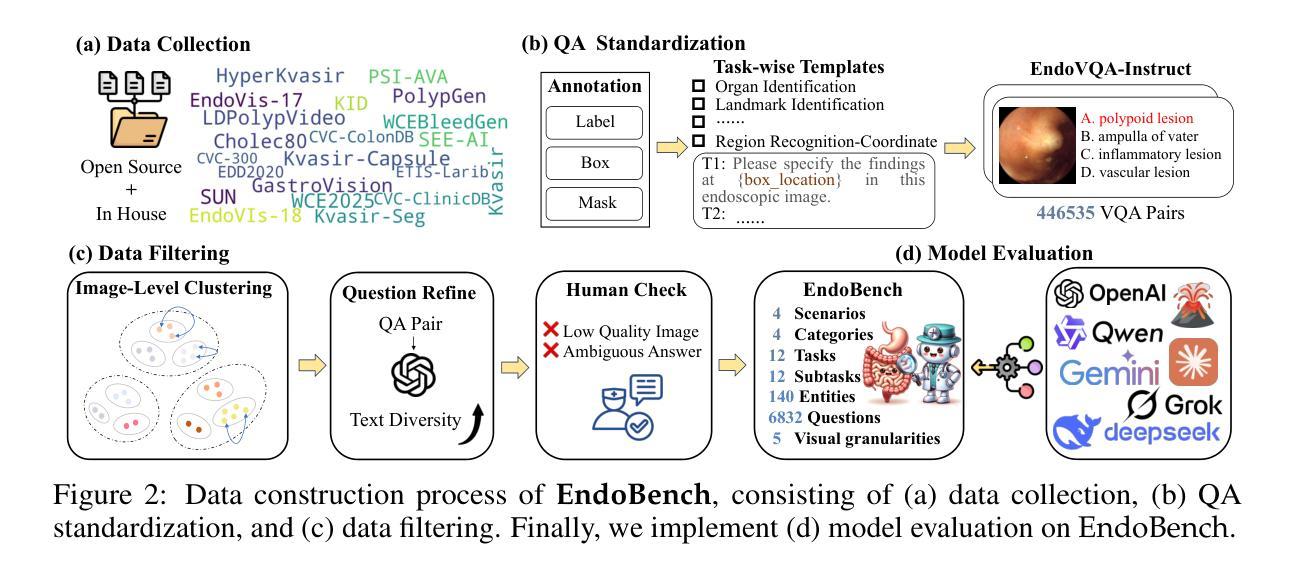
A Comprehensive Evaluation of Multi-Modal Large Language Models for Endoscopy Analysis
Authors:Shengyuan Liu, Boyun Zheng, Wenting Chen, Zhihao Peng, Zhenfei Yin, Jing Shao, Jiancong Hu, Yixuan Yuan
Endoscopic procedures are essential for diagnosing and treating internal diseases, and multi-modal large language models (MLLMs) are increasingly applied to assist in endoscopy analysis. However, current benchmarks are limited, as they typically cover specific endoscopic scenarios and a small set of clinical tasks, failing to capture the real-world diversity of endoscopic scenarios and the full range of skills needed in clinical workflows. To address these issues, we introduce EndoBench, the first comprehensive benchmark specifically designed to assess MLLMs across the full spectrum of endoscopic practice with multi-dimensional capacities. EndoBench encompasses 4 distinct endoscopic scenarios, 12 specialized clinical tasks with 12 secondary subtasks, and 5 levels of visual prompting granularities, resulting in 6,832 rigorously validated VQA pairs from 21 diverse datasets. Our multi-dimensional evaluation framework mirrors the clinical workflow–spanning anatomical recognition, lesion analysis, spatial localization, and surgical operations–to holistically gauge the perceptual and diagnostic abilities of MLLMs in realistic scenarios. We benchmark 23 state-of-the-art models, including general-purpose, medical-specialized, and proprietary MLLMs, and establish human clinician performance as a reference standard. Our extensive experiments reveal: (1) proprietary MLLMs outperform open-source and medical-specialized models overall, but still trail human experts; (2) medical-domain supervised fine-tuning substantially boosts task-specific accuracy; and (3) model performance remains sensitive to prompt format and clinical task complexity. EndoBench establishes a new standard for evaluating and advancing MLLMs in endoscopy, highlighting both progress and persistent gaps between current models and expert clinical reasoning. We publicly release our benchmark and code.
内窥镜程序对诊断和治疗内部疾病至关重要,多模态大型语言模型(MLLMs)越来越多地应用于辅助内窥镜分析。然而,目前的基准测试存在局限性,因为它们通常涵盖特定的内窥镜场景和少量的临床任务,无法捕捉内窥镜场景的现实世界多样性和临床工作流程中所需的全部技能。为了解决这些问题,我们推出了EndoBench,这是第一个全面基准测试,专门设计用于评估MLLMs在内窥镜实践中的全方位能力。EndoBench包含4种独特的内窥镜场景、12项专业临床任务和12项二级子任务,以及5个级别的视觉提示粒度,从而产生6832对经过严格验证的问答对,来自21个多样化的数据集。我们的多维评估框架反映了临床工作流程——涵盖解剖识别、病变分析、空间定位和手术操作——以全面评估现实场景中MLLMs的感知和诊断能力。我们对23种最新模型进行基准测试,包括通用型、医疗专业型和专有MLLMs,并将人类医生的性能作为参考标准。我们的广泛实验表明:(1)专有MLLMs总体上优于开源和医疗专业模型,但仍落后于人类专家;(2)医疗领域监督微调显著提高任务特定准确性;(3)模型性能对提示格式和任务复杂性仍然敏感。EndoBench为评估和改进内窥镜领域的MLLMs建立了新标准,突出了当前模型与专家临床推理之间的进展和持续差距。我们公开发布我们的基准测试和代码。
论文及项目相关链接
PDF 36 pages, 18 figures
Summary
内镜程序对于诊断与治疗内部疾病至关重要,多模态大型语言模型(MLLMs)越来越多地应用于内镜分析辅助。然而,当前的标准存在局限性,通常只涵盖特定的内镜场景和少量临床任务,无法捕捉现实世界中内镜场景的多样性和临床工作流程中所需的全面技能。为解决这些问题,推出EndoBench,首个全面评估MLLMs在内镜实践全领域的综合基准。EndoBench包含4种独特的内镜场景、12项专业临床任务和五个级别的视觉提示精细度,包含从21个不同数据集中严格验证的6832对问答。其多维评估框架涵盖了解剖识别、病变分析、空间定位以及手术操作等以全面评估MLLMs在现实场景中的感知和诊断能力。我们对包括通用、医疗专业以及专有MLLMs等23项前沿模型进行了基准测试,并以人类临床医生的表现作为参考标准。大量实验揭示:专有MLLMs总体上优于开源和医疗专业模型,但仍落后于人类专家;医疗域监督微调显著提高特定任务的准确性;模型性能对提示格式和任务复杂性仍然敏感。EndoBench为评估和改进内镜领域的MLLMs建立了新标准,突显了当前模型与专家临床推理之间的进步和持续差距。我们公开发布此基准和代码。
Key Takeaways
- 内镜程序在疾病诊断和治疗中起关键作用,多模态大型语言模型(MLLMs)在内镜分析中的应用日益广泛。
- 当前评估标准存在局限性,无法全面反映MLLMs在内镜实践中的能力。
- EndoBench是首个全面评估MLLMs在内镜领域的综合基准,包含多种场景、任务和视觉提示精细度。
- EndoBench建立了评估MLLMs的新标准,涵盖解剖识别、病变分析等多个方面。
- 专有MLLMs性能优于一些其他模型,但仍需进一步提高以匹配人类专家水平。
- 医疗域监督微调能有效提高任务特定准确性。
点此查看论文截图

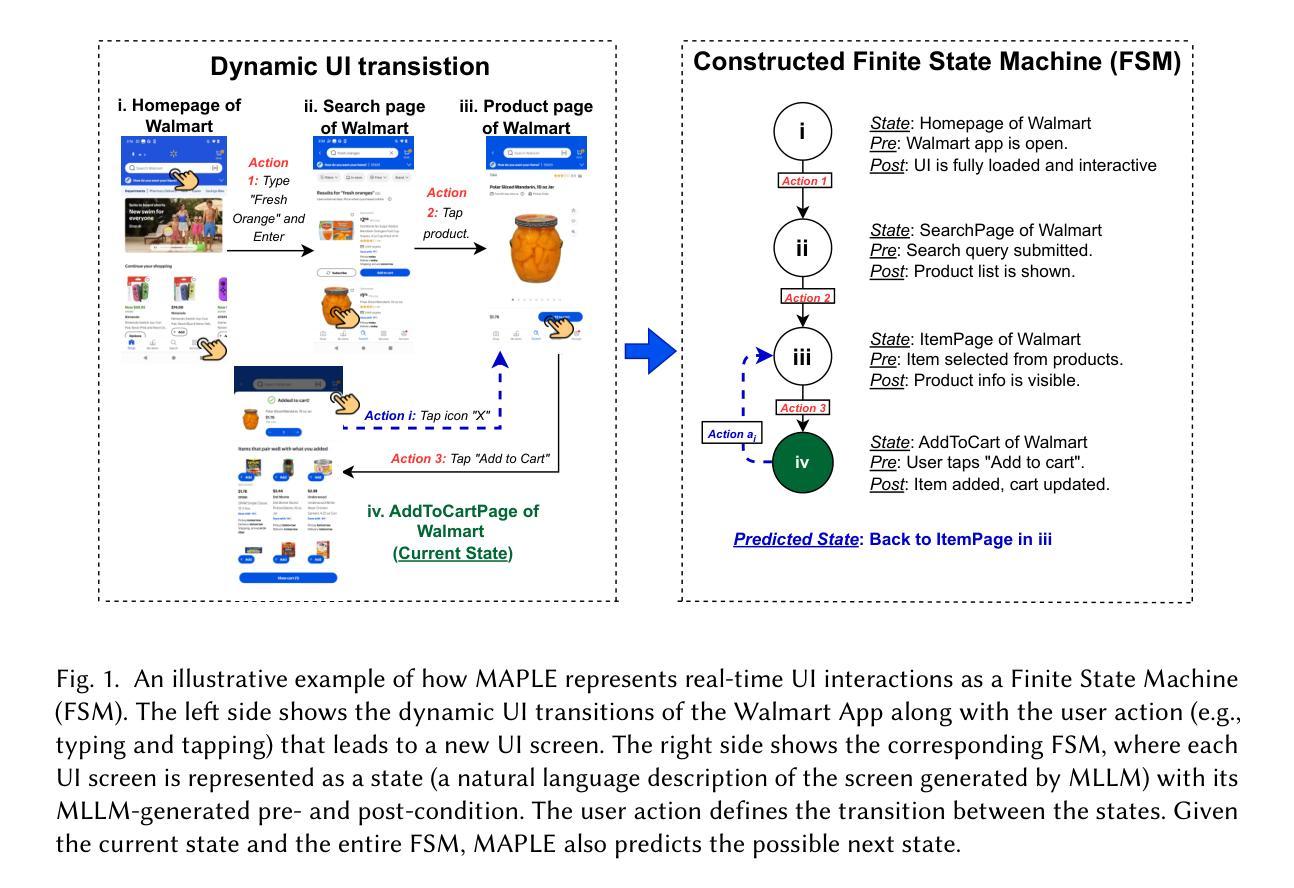
MAPLE: A Mobile Assistant with Persistent Finite State Machines for Recovery Reasoning
Authors:Linqiang Guo, Wei Liu, Yi Wen Heng, Tse-Hsun, Chen, Yang Wang
Mobile GUI agents aim to autonomously complete user-instructed tasks across mobile apps. Recent advances in Multimodal Large Language Models (MLLMs) enable these agents to interpret UI screens, identify actionable elements, and perform interactions such as tapping or typing. However, existing agents remain reactive: they reason only over the current screen and lack a structured model of app navigation flow, limiting their ability to understand context, detect unexpected outcomes, and recover from errors. We present MAPLE, a state-aware multi-agent framework that abstracts app interactions as a Finite State Machine (FSM). We computationally model each UI screen as a discrete state and user actions as transitions, allowing the FSM to provide a structured representation of the app execution. MAPLE consists of specialized agents responsible for four phases of task execution: planning, execution, verification, error recovery, and knowledge retention. These agents collaborate to dynamically construct FSMs in real time based on perception data extracted from the UI screen, allowing the GUI agents to track navigation progress and flow, validate action outcomes through pre- and post-conditions of the states, and recover from errors by rolling back to previously stable states. Our evaluation results on two challenging cross-app benchmarks, Mobile-Eval-E and SPA-Bench, show that MAPLE outperforms the state-of-the-art baseline, improving task success rate by up to 12%, recovery success by 13.8%, and action accuracy by 6.5%. Our results highlight the importance of structured state modeling in guiding mobile GUI agents during task execution. Moreover, our FSM representation can be integrated into future GUI agent architectures as a lightweight, model-agnostic memory layer to support structured planning, execution verification, and error recovery.
移动GUI代理旨在自主完成跨移动应用用户指定的任务。最近的多模态大型语言模型(MLLMs)的进步使这些代理能够解释UI屏幕,识别可操作元素,并执行如点击或键入等交互。然而,现有代理仍然是反应式的:它们只针对当前屏幕进行推理,缺乏应用导航流的结构化模型,这限制了它们理解上下文、检测意外结果并从错误中恢复的能力。我们提出了MAPLE,一个状态感知的多代理框架,它将应用交互抽象为有限状态机(FSM)。我们将每个UI屏幕计算建模为离散状态,用户操作作为转换,允许FSM提供应用执行的结构化表示。MAPLE由负责任务执行四个阶段的专职代理组成:规划、执行、验证、错误恢复和知识保留。这些代理协作,根据从UI屏幕提取的感知数据实时动态构建FSM,使GUI代理能够跟踪导航进度和流程,通过状态的前置和后置条件验证操作结果,并通过回滚到先前稳定状态来从错误中恢复。我们在两个具有挑战性的跨应用基准测试Mobile-Eval-E和SPA-Bench上的评估结果表明,MAPLE优于最新基线技术,任务成功率提高12%,恢复成功率提高13.8%,行动准确性提高6.5%。我们的结果强调了结构化状态建模在指导移动GUI代理执行任务中的重要性。此外,我们的FSM表示可以作为未来GUI代理架构中的轻量级、模型无关的内存层进行集成,以支持结构化规划、执行验证和错误恢复。
论文及项目相关链接
Summary
本文介绍了移动GUI代理旨在自主完成跨移动应用的任务。最近的多模态大型语言模型(MLLMs)的进步使得这些代理能够解释UI屏幕、识别可操作元素并进行交互。然而,现有代理仍然反应性强,仅对当前屏幕进行推理,缺乏应用导航流的结构化模型,限制了它们理解上下文、检测意外结果和从错误中恢复的能力。为此,本文提出了MAPLE,一种状态感知的多代理框架,它将应用交互抽象为有限状态机(FSM)。每个UI屏幕被计算建模为一个离散状态,用户操作被视为转换,允许FSM提供应用执行的结构化表示。MAPLE由专门负责任务执行四个阶段的代理组成:规划、执行、验证、错误恢复和知识保留。这些代理协同工作,根据从UI屏幕中提取的感知数据实时构建FSM,使GUI代理能够跟踪导航进度和流程,通过状态的前置和后置条件验证操作结果,并通过回滚到先前稳定状态来从错误中恢复。在两项具有挑战性的跨应用基准测试Mobile-Eval-E和SPA-Bench上的评估结果表明,MAPLE优于最新基线技术,任务成功率提高12%,恢复成功率提高13.8%,行动准确率提高6.5%。结果强调了结构化状态建模在指导移动GUI代理任务执行中的重要性。此外,我们的FSM表示可以集成到未来的GUI代理架构中,作为轻量级、模型无关的记忆层,支持结构化规划、执行验证和错误恢复。
Key Takeaways
- 移动GUI代理致力于自主完成跨移动应用的任务。
- 多模态大型语言模型(MLLMs)使代理具备解释UI屏幕、识别元素和交互的能力。
- 现有代理缺乏应用导航流的结构化模型,限制了其在上下文理解、意外检测及错误恢复方面的能力。
- MAPLE利用有限状态机(FSM)为应用交互提供结构化表示。
- MAPLE包含多个专门代理,负责规划、执行、验证、错误恢复和知识保留。
- MAPLE通过实时构建FSM来提高任务执行的结构性和准确性。
点此查看论文截图

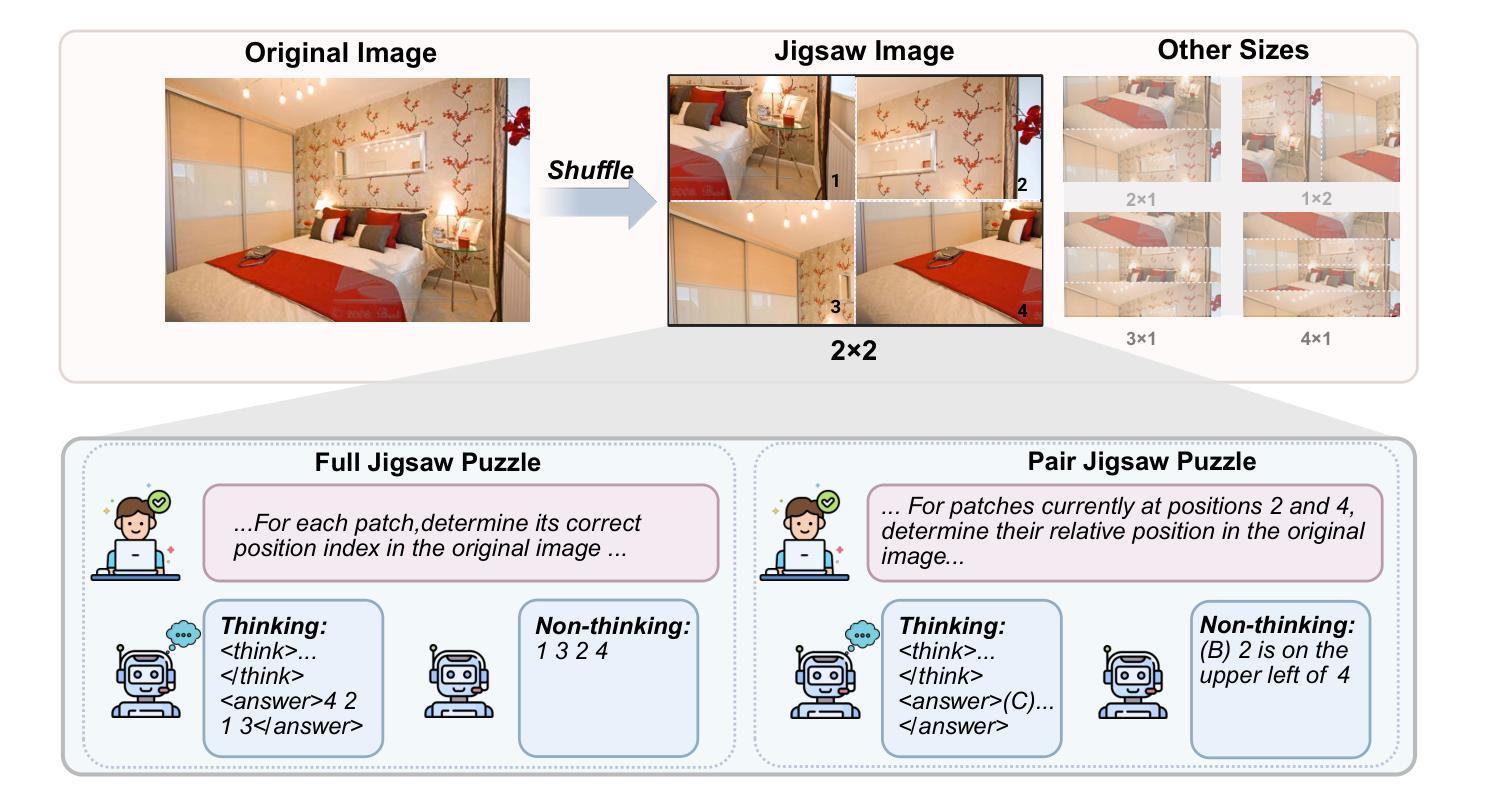
Jigsaw-R1: A Study of Rule-based Visual Reinforcement Learning with Jigsaw Puzzles
Authors:Zifu Wang, Junyi Zhu, Bo Tang, Zhiyu Li, Feiyu Xiong, Jiaqian Yu, Matthew B. Blaschko
The application of rule-based reinforcement learning (RL) to multimodal large language models (MLLMs) introduces unique challenges and potential deviations from findings in text-only domains, particularly for perception-heavy tasks. This paper provides a comprehensive study of rule-based visual RL using jigsaw puzzles as a structured experimental framework, revealing several key findings. \textit{Firstly,} we find that MLLMs, initially performing near to random guessing on simple puzzles, achieve near-perfect accuracy and generalize to complex, unseen configurations through fine-tuning. \textit{Secondly,} training on jigsaw puzzles can induce generalization to other visual tasks, with effectiveness tied to specific task configurations. \textit{Thirdly,} MLLMs can learn and generalize with or without explicit reasoning, though open-source models often favor direct answering. Consequently, even when trained for step-by-step reasoning, they can ignore the thinking process in deriving the final answer. \textit{Fourthly,} we observe that complex reasoning patterns appear to be pre-existing rather than emergent, with their frequency increasing alongside training and task difficulty. \textit{Finally,} our results demonstrate that RL exhibits more effective generalization than Supervised Fine-Tuning (SFT), and an initial SFT cold start phase can hinder subsequent RL optimization. Although these observations are based on jigsaw puzzles and may vary across other visual tasks, this research contributes a valuable piece of jigsaw to the larger puzzle of collective understanding rule-based visual RL and its potential in multimodal learning. The code is available at: \href{https://github.com/zifuwanggg/Jigsaw-R1}{https://github.com/zifuwanggg/Jigsaw-R1}.
将基于规则强化学习(RL)应用于多模态大型语言模型(MLLMs)为感知密集型任务带来了独特的挑战和可能的偏差,特别是在文本领域以外的发现。本文采用拼图作为结构化实验框架,对基于规则的视觉强化学习进行了全面的研究,揭示了几个关键发现。首先,我们发现MLLMs在简单的拼图任务上最初的表现接近随机猜测,但通过微调可以达到近乎完美的准确率和泛化到复杂的未见过的配置。其次,在拼图任务上进行训练可以推广到其他视觉任务,其有效性取决于特定的任务配置。第三,MLLMs可以在没有显式推理的情况下学习和泛化,尽管开源模型通常倾向于直接回答问题。因此,即使在训练过程中进行逐步推理,他们也可能忽略得出最终答案的思考过程。第四,我们观察到复杂的推理模式似乎是预先存在的而不是突然出现的,它们的频率随着训练和任务难度的增加而增加。最后,我们的结果表明强化学习相较于监督微调(SFT)表现出更好的泛化能力,而初始的SFT冷启动阶段可能会阻碍后续的RL优化。尽管这些观察是基于拼图任务的,并可能在其他视觉任务中有所不同,但本研究为集体理解基于规则的视觉强化学习及其在多模态学习中的潜力这一更大的谜题贡献了一块有价值的拼图。代码可在:https://github.com/zifuwanggg/Jigsaw-R1访问。
论文及项目相关链接
Summary:基于规则强化学习在多模态大型语言模型中的应用面临独特挑战和文本域研究的潜在偏差,特别是在感知任务方面。本文通过拼图实验框架进行了全面研究,揭示了关键发现:首先,最初几乎随机猜测的MLLM在微调后几乎达到完美准确度并推广到复杂未见配置;其次,拼图训练可以诱导到其他视觉任务的泛化,但其有效性取决于特定任务配置;再次,MLLM可独立进行学习和泛化推理或借助开源模型直接回答问题;第四,复杂推理模式似乎与生俱来而非突然出现,频率随训练和任务难度增加而增加;最后,相对于监督微调(SFT),RL表现出更强大的泛化能力,初始SFT冷启动阶段可能会阻碍后续RL优化。尽管这些观察仅限于拼图任务,但本研究为理解基于规则的视觉强化学习及其在多模态学习中的潜力提供了重要线索。
Key Takeaways:
- MLLMs通过微调可以在拼图任务上实现高准确度并泛化到复杂配置。
- 拼图训练有助于泛化到其他视觉任务,任务配置影响其效果。
- MLLM可在无明确推理的情况下学习和泛化,但开源模型倾向于直接回答。
- 复杂推理模式似乎固有存在,频率随训练和任务难度增加。
- RL相较于监督微调展现出更强的泛化能力。
- 初始监督微调冷启动可能影响后续RL优化。
- 研究结果对理解基于规则的视觉强化学习及其在多模态学习中的潜力有重要意义。
点此查看论文截图

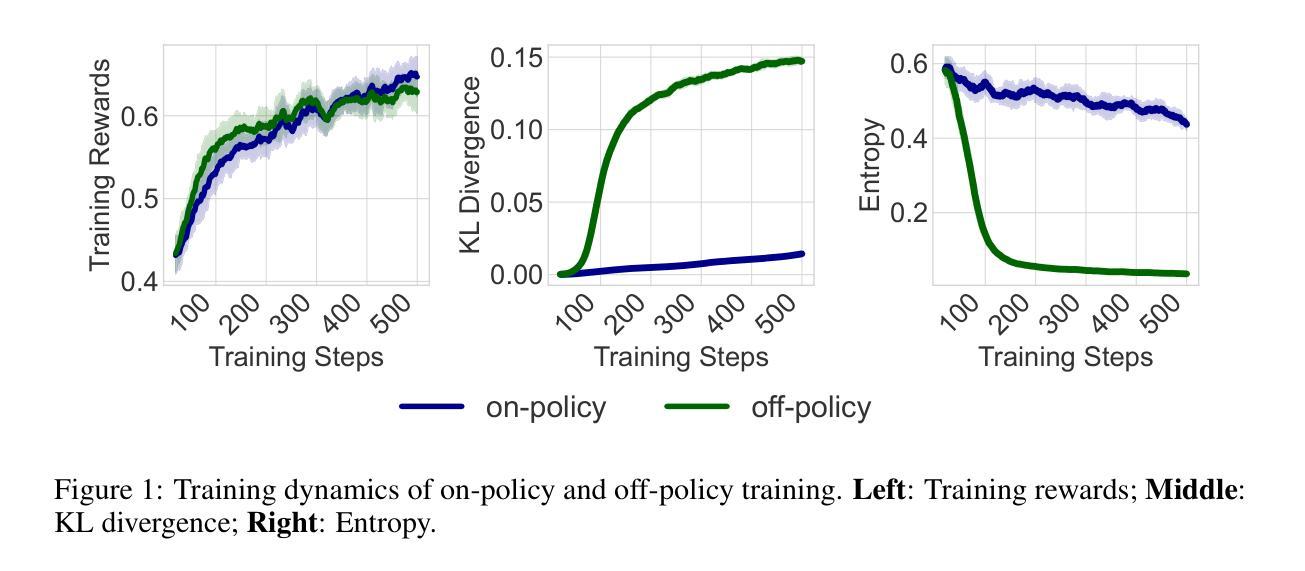
On-Policy RL with Optimal Reward Baseline
Authors:Yaru Hao, Li Dong, Xun Wu, Shaohan Huang, Zewen Chi, Furu Wei
Reinforcement learning algorithms are fundamental to align large language models with human preferences and to enhance their reasoning capabilities. However, current reinforcement learning algorithms often suffer from training instability due to loose on-policy constraints and computational inefficiency due to auxiliary models. In this work, we propose On-Policy RL with Optimal reward baseline (OPO), a novel and simplified reinforcement learning algorithm designed to address these challenges. OPO emphasizes the importance of exact on-policy training, which empirically stabilizes the training process and enhances exploration. Moreover, OPO introduces the optimal reward baseline that theoretically minimizes gradient variance. We evaluate OPO on mathematical reasoning benchmarks. The results demonstrate its superior performance and training stability without additional models or regularization terms. Furthermore, OPO achieves lower policy shifts and higher output entropy, encouraging more diverse and less repetitive responses. These results highlight OPO as a promising direction for stable and effective reinforcement learning in large language model alignment and reasoning tasks. The implementation is provided at https://github.com/microsoft/LMOps/tree/main/opo.
强化学习算法对于将大型语言模型与人类偏好对齐并提高其推理能力至关重要。然而,当前的强化学习算法往往存在由于政策约束宽松而导致的训练不稳定问题和由于辅助模型导致的计算效率低下问题。在这项工作中,我们提出了基于最优奖励基线的On-Policy RL(OPO),这是一种旨在解决这些挑战的新型简化强化学习算法。OPO强调精确的策略内训练的重要性,这从经验上稳定了训练过程并增强了探索。此外,OPO引入了最优奖励基线,从理论上最小化了梯度方差。我们在数学推理基准测试上对OPO进行了评估。结果表明,它在没有附加模型或正则化术语的情况下表现出卓越的性能和训练稳定性。此外,OPO实现了更低的策略转变和更高的输出熵,鼓励产生更多样化且更少重复性的响应。这些结果突显了OPO在大型语言模型对齐和推理任务中实现稳定有效的强化学习的有前途的方向。相关实现可见于https://github.com/microsoft/LMOps/tree/main/opo。
论文及项目相关链接
Summary
强化学习算法对于大型语言模型与人类偏好对齐及提升推理能力至关重要。然而,当前强化学习算法常面临训练不稳定和计算效率低下的问题。本研究提出一种新型简化强化学习算法——基于最优奖励基线的在策略强化学习(OPO),以解决这些问题。OPO强调精确的在策略训练,这有助于稳定训练过程并提升探索能力。此外,OPO引入最优奖励基线,理论上可最小化梯度方差。我们在数学推理基准测试上对OPO进行了评估。结果表明,其在无额外模型或正则化术语的情况下,具有优越性能和稳定的训练表现。此外,OPO实现了更低的策略转移和更高的输出熵,鼓励生成更多样化、更少重复性的回应。这些结果凸显了OPO在大型语言模型对齐和推理任务中具备稳定且有效的强化学习潜力。
Key Takeaways
- 强化学习算法对于大型语言模型的与人类偏好对齐及提升推理能力非常重要。
- 当前强化学习算法存在训练不稳定和计算效率低下的问题。
- OPO算法强调精确的在策略训练,有助于稳定训练过程并提升探索能力。
- OPO引入最优奖励基线,理论上可最小化梯度方差。
- 在数学推理基准测试上,OPO表现优越,具有稳定的训练性能。
- OPO实现更低的策略转移和更高的输出熵,鼓励生成更多样化的回应。
点此查看论文截图

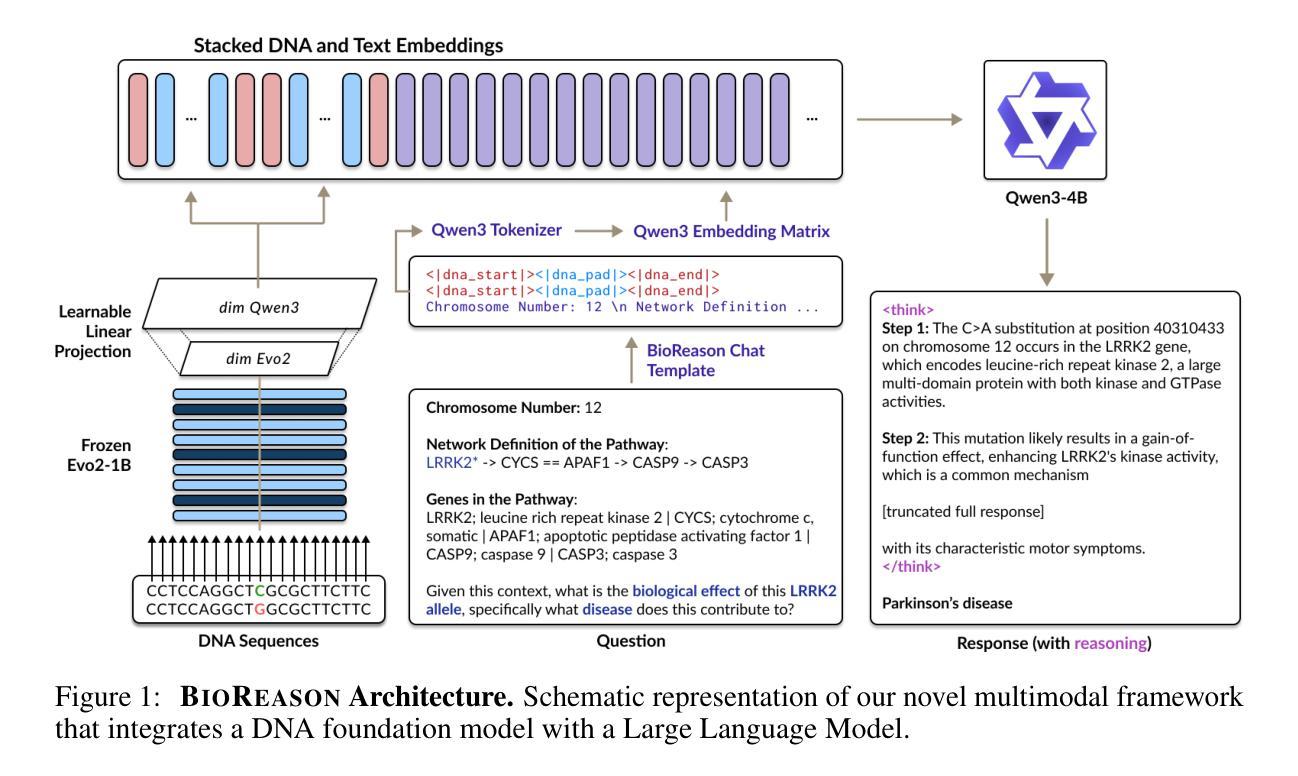
BioReason: Incentivizing Multimodal Biological Reasoning within a DNA-LLM Model
Authors:Adibvafa Fallahpour, Andrew Magnuson, Purav Gupta, Shihao Ma, Jack Naimer, Arnav Shah, Haonan Duan, Omar Ibrahim, Hani Goodarzi, Chris J. Maddison, Bo Wang
Unlocking deep, interpretable biological reasoning from complex genomic data is a major AI challenge hindering scientific discovery. Current DNA foundation models, despite strong sequence representation, struggle with multi-step reasoning and lack inherent transparent, biologically intuitive explanations. We introduce BioReason, a pioneering architecture that, for the first time, deeply integrates a DNA foundation model with a Large Language Model (LLM). This novel connection enables the LLM to directly process and reason with genomic information as a fundamental input, fostering a new form of multimodal biological understanding. BioReason’s sophisticated multi-step reasoning is developed through supervised fine-tuning and targeted reinforcement learning, guiding the system to generate logical, biologically coherent deductions. On biological reasoning benchmarks including KEGG-based disease pathway prediction - where accuracy improves from 88% to 97% - and variant effect prediction, BioReason demonstrates an average 15% performance gain over strong single-modality baselines. BioReason reasons over unseen biological entities and articulates decision-making through interpretable, step-by-step biological traces, offering a transformative approach for AI in biology that enables deeper mechanistic insights and accelerates testable hypothesis generation from genomic data. Data, code, and checkpoints are publicly available at https://github.com/bowang-lab/BioReason
从复杂的基因组数据中解锁深层、可解释的生物推理是阻碍科学发现的一项重大人工智能挑战。尽管当前的DNA基础模型具有强大的序列表示能力,但在多步推理方面仍面临困难,并且缺乏内在透明、生物学上直观的解释。我们引入了BioReason,这是一种开创性的架构,首次将DNA基础模型与大型语言模型(LLM)深度集成。这种新型连接使LLM能够直接处理和推理基因组信息作为基本输入,促进了一种新的多模式生物理解。BioReason的高级多步推理是通过有监督的微调以及有针对性的强化学习来发展的,引导系统产生逻辑上连贯、生物学上连贯的推论。在包括基于KEGG的疾病途径预测等生物推理基准测试上,准确率从88%提高到97%,而在变体效应预测方面,BioReason相较于强大的单模态基准测试,表现出平均15%的性能提升。BioReason能够对未见过的生物实体进行推理,并通过可解释的、逐步的生物轨迹表述决策过程,这为生物学中的人工智能提供了一种变革性的方法,能够提供更深入的机制洞察,并从基因组数据中加速可测试假设的产生。数据、代码和检查点可在https://github.com/bowang-lab/BioReason公开获取。
论文及项目相关链接
PDF 16 pages, 3 figures, 2 tables
Summary
本文章介绍了一个名为BioReason的创新架构,它将DNA基础模型与大型语言模型(LLM)深度集成。BioReason能够直接处理基因组信息并进行多步推理,从而实现多模态生物理解的新形式。在生物推理基准测试中,BioReason表现出卓越的性能,准确率显著提高,并能够通过可解释的步骤提供生物学依据。
Key Takeaways
- BioReason是首个将DNA基础模型与大型语言模型(LLM)深度集成的架构。
- BioReason能够直接处理基因组信息并进行多步推理。
- BioReason实现了多模态生物理解的新形式,促进对基因组数据的更深层次理解。
- BioReason在生物推理基准测试中的性能优异,准确率显著提高。
- BioReason能够通过可解释的步骤提供生物学依据,有助于生成可测试的生物假说。
- BioReason系统可生成逻辑上连贯、生物学上合理的推论。
点此查看论文截图


Segment Policy Optimization: Effective Segment-Level Credit Assignment in RL for Large Language Models
Authors:Yiran Guo, Lijie Xu, Jie Liu, Dan Ye, Shuang Qiu
Enhancing the reasoning capabilities of large language models effectively using reinforcement learning (RL) remains a crucial challenge. Existing approaches primarily adopt two contrasting advantage estimation granularities: Token-level methods (e.g., PPO) aim to provide the fine-grained advantage signals but suffer from inaccurate estimation due to difficulties in training an accurate critic model. On the other extreme, trajectory-level methods (e.g., GRPO) solely rely on a coarse-grained advantage signal from the final reward, leading to imprecise credit assignment. To address these limitations, we propose Segment Policy Optimization (SPO), a novel RL framework that leverages segment-level advantage estimation at an intermediate granularity, achieving a better balance by offering more precise credit assignment than trajectory-level methods and requiring fewer estimation points than token-level methods, enabling accurate advantage estimation based on Monte Carlo (MC) without a critic model. SPO features three components with novel strategies: (1) flexible segment partition; (2) accurate segment advantage estimation; and (3) policy optimization using segment advantages, including a novel probability-mask strategy. We further instantiate SPO for two specific scenarios: (1) SPO-chain for short chain-of-thought (CoT), featuring novel cutpoint-based partition and chain-based advantage estimation, achieving $6$-$12$ percentage point improvements in accuracy over PPO and GRPO on GSM8K. (2) SPO-tree for long CoT, featuring novel tree-based advantage estimation, which significantly reduces the cost of MC estimation, achieving $7$-$11$ percentage point improvements over GRPO on MATH500 under 2K and 4K context evaluation. We make our code publicly available at https://github.com/AIFrameResearch/SPO.
使用强化学习(RL)有效地增强大型语言模型的推理能力仍然是一个关键挑战。现有方法主要采用两种相反的优势估计粒度:令牌级方法(例如PPO)旨在提供精细粒度的优势信号,但由于难以训练准确的评论家模型,导致估计不准确。另一方面,轨迹级方法(例如GRPO)仅依赖于来自最终奖励的粗略优势信号,导致信用分配不精确。为了解决这些局限性,我们提出了分段策略优化(SPO),这是一种新型的RL框架,它利用中间粒度的分段级优势估计,通过提供更精确的信用分配比轨迹级方法,并且需要比令牌级方法更少的估计点,能够在没有评论家模型的情况下基于蒙特卡洛(MC)进行准确的优势估计。SPO有三个具有新策略的特点:(1)灵活的分段分区;(2)精确的分段优势估计;(3)使用分段优势的策略优化,包括一种新的概率掩码策略。我们进一步为两个特定场景实例化了SPO:(1)SPO-chain用于短链思维(CoT),具有基于切割点的分区和基于链的优势估计,在GSM8K上相对于PPO和GRPO实现了6%-12%的准确率提升。(2)SPO-tree用于长CoT,具有基于树的优势估计,这显著减少了MC估计的成本,在MATH500的2K和4K上下文评估下,相对于GRPO实现了7%-11%的改进。我们的代码已在https://github.com/AIFrameResearch/SPO公开可用。
论文及项目相关链接
Summary
大型语言模型的推理能力强化依然是一个重要挑战。现有方法主要通过两种不同的优势估计粒度进行强化学习训练,如token级方法和轨迹级方法。针对这些方法的不准确信用分配问题,本文提出了一种新型的强化学习框架——分段策略优化(SPO)。SPO通过中间粒度的分段级优势估计实现更精确的信用分配,并引入了灵活的段划分、精确的分段优势估计和基于分段优势的策略优化等三个关键组件。此外,本文还针对短链和长链两种情况分别进行了实例化研究,取得了显著成果。代码已公开。
Key Takeaways
- 大型语言模型的推理强化是一个挑战性问题。
- 当前的优势估计方法主要有两种:token级和轨迹级,它们存在不准确的信用分配问题。
- 本文提出的分段策略优化(SPO)框架结合了这两种方法的优点,实现了更精确的信用分配。
- SPO具有灵活的段划分、精确的分段优势估计和基于分段优势的策略优化等关键组件。
- 对于短链和长链情况,分别进行了实例化研究,取得了显著成果。
点此查看论文截图

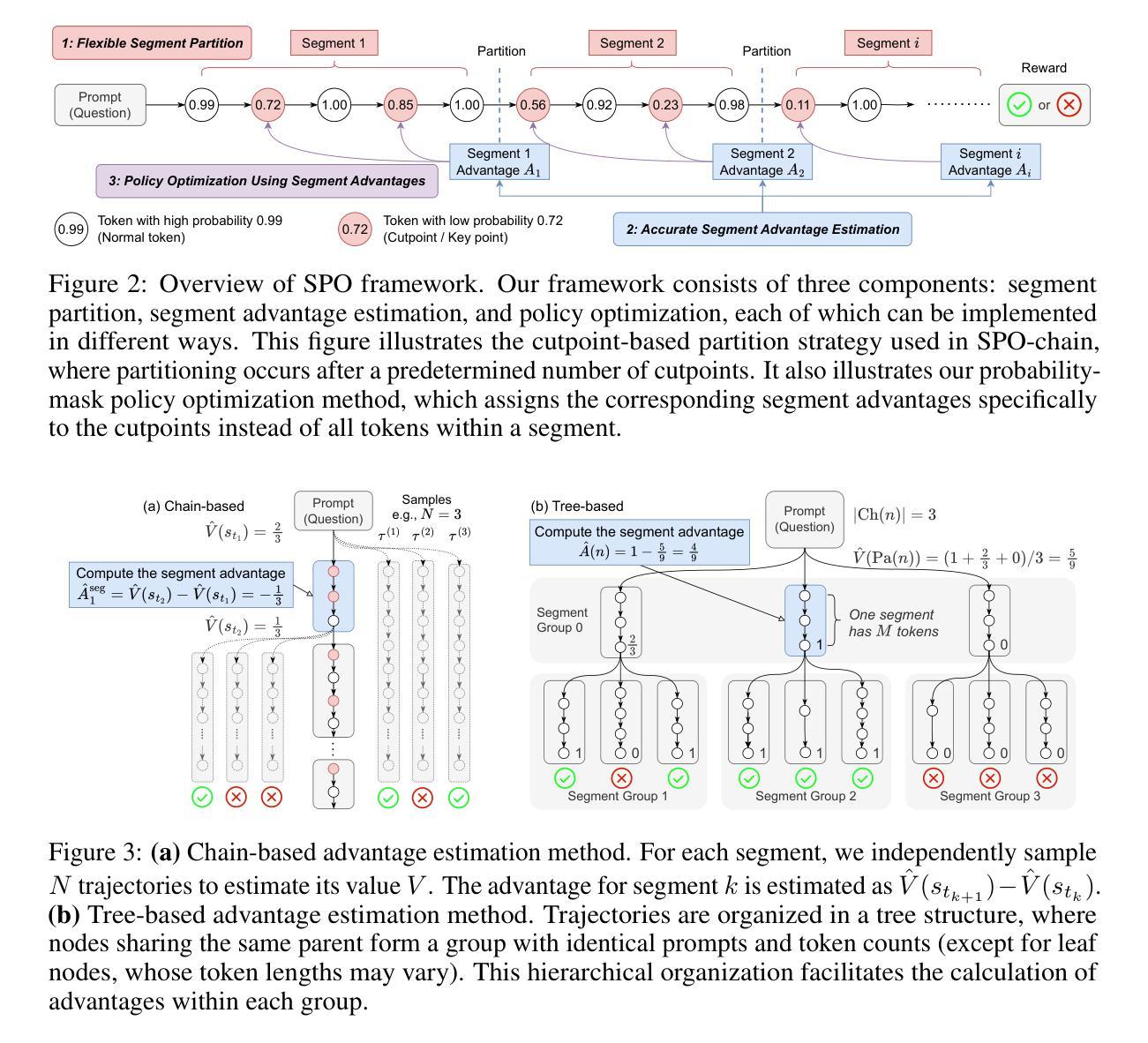
Qwen Look Again: Guiding Vision-Language Reasoning Models to Re-attention Visual Information
Authors:Xu Chu, Xinrong Chen, Guanyu Wang, Zhijie Tan, Kui Huang, Wenyu Lv, Tong Mo, Weiping Li
Inference time scaling drives extended reasoning to enhance the performance of Vision-Language Models (VLMs), thus forming powerful Vision-Language Reasoning Models (VLRMs). However, long reasoning dilutes visual tokens, causing visual information to receive less attention and may trigger hallucinations. Although introducing text-only reflection processes shows promise in language models, we demonstrate that it is insufficient to suppress hallucinations in VLMs. To address this issue, we introduce Qwen-LookAgain (Qwen-LA), a novel VLRM designed to mitigate hallucinations by incorporating a vision-text reflection process that guides the model to re-attention visual information during reasoning. We first propose a reinforcement learning method Balanced Reflective Policy Optimization (BRPO), which guides the model to decide when to generate vision-text reflection on its own and balance the number and length of reflections. Then, we formally prove that VLRMs lose attention to visual tokens as reasoning progresses, and demonstrate that supplementing visual information during reflection enhances visual attention. Therefore, during training and inference, Visual Token COPY and Visual Token ROUTE are introduced to force the model to re-attention visual information at the visual level, addressing the limitations of text-only reflection. Experiments on multiple visual QA datasets and hallucination metrics indicate that Qwen-LA achieves leading accuracy performance while reducing hallucinations. Our code is available at: https://github.com/Liar406/Look_Again.
推理时间缩放驱动扩展推理,以提高视觉语言模型(VLM)的性能,从而形成强大的视觉语言推理模型(VLRM)。然而,长时间的推理会稀释视觉标记,导致视觉信息受到的关注减少,并可能引发幻觉。虽然在语言模型中引入纯文本反思过程显示出希望,但我们证明在视觉语言模型中抑制幻觉仅凭这一点是不够的。为了解决这一问题,我们引入了Qwen-LookAgain(Qwen-LA),这是一种新型VLRM设计,旨在通过融入视觉文本反思过程来减少幻觉的发生,该过程在推理过程中指导模型重新关注视觉信息。首先,我们提出了一种强化学习方法——平衡反射策略优化(BRPO),该方法引导模型自行决定何时进行视觉文本反射并平衡反射的数量和长度。然后,我们从形式上证明了随着推理的进展,VLRM对视觉标记的关注度会逐渐降低,并证明了在反思过程中补充视觉信息可以增强视觉关注度。因此,在训练和推理过程中引入了视觉标记复制和视觉标记路由,以强制模型在视觉层面上重新关注视觉信息,解决了纯文本反思的局限性。在多个视觉问答数据集和幻觉指标上的实验表明,Qwen-LA在保持领先准确性的同时减少了幻觉。我们的代码位于:https://github.com/Liar406/Look_Again。
论文及项目相关链接
Summary
该文本介绍了如何通过引入视觉文本反射过程来解决视觉语言模型(VLMs)在长推理过程中产生的视觉信息丢失和幻觉问题。为此,提出了一种新型的视觉语言推理模型(VLRM)——Qwen-LookAgain(Qwen-LA)。该模型通过引入平衡反射策略优化(BRPO)方法,能够在推理过程中自主决定何时进行视觉文本反射,并平衡反射的次数和长度。此外,还引入了视觉符号复制和视觉符号路由机制来强制模型在视觉层面重新关注视觉信息。实验结果表明,Qwen-LA在多个视觉问答数据集上取得了领先的准确性表现,并有效减少了幻觉的产生。
Key Takeaways
- 推理时间缩放可提高视觉语言模型(VLMs)的性能,形成强大的视觉语言推理模型(VLRMs)。
- 长推理过程会导致视觉令牌稀释,使视觉信息获得较少的关注,并可能引发幻觉。
- 仅引入文本反射过程在抑制语言模型的幻觉方面效果有限,不足以解决VLMs中的幻觉问题。
- Qwen-LookAgain(Qwen-LA)是一种新型的VLRM,通过引入视觉文本反射过程来减轻幻觉,并在推理过程中引导模型重新关注视觉信息。
- Qwen-LA使用平衡反射策略优化(BRPO)方法,使模型能够自主决定何时进行视觉文本反射,并平衡反射次数和长度。
- 在训练过程中引入了视觉符号复制和视觉符号路由机制来强制模型重新关注视觉信息,解决了仅使用文本反射的局限性。
- 实验结果表明,Qwen-LA在多个视觉问答数据集上表现出色,准确率高且能有效减少幻觉。
点此查看论文截图

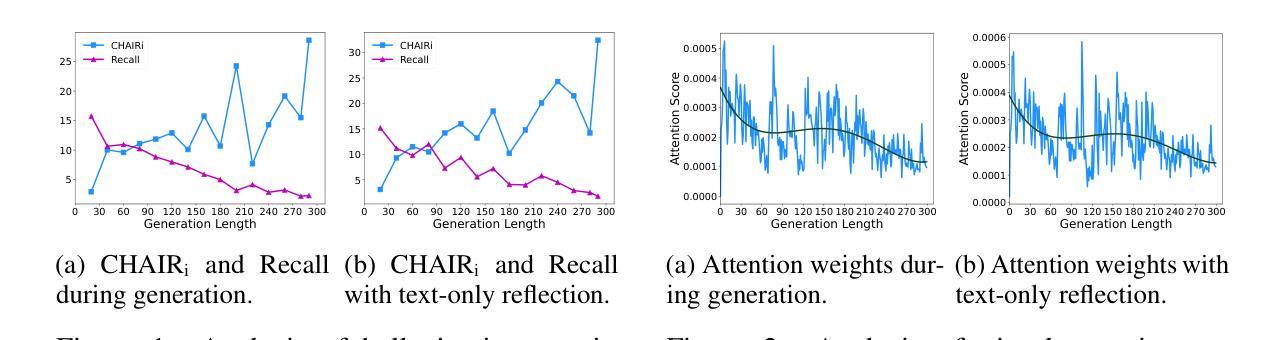

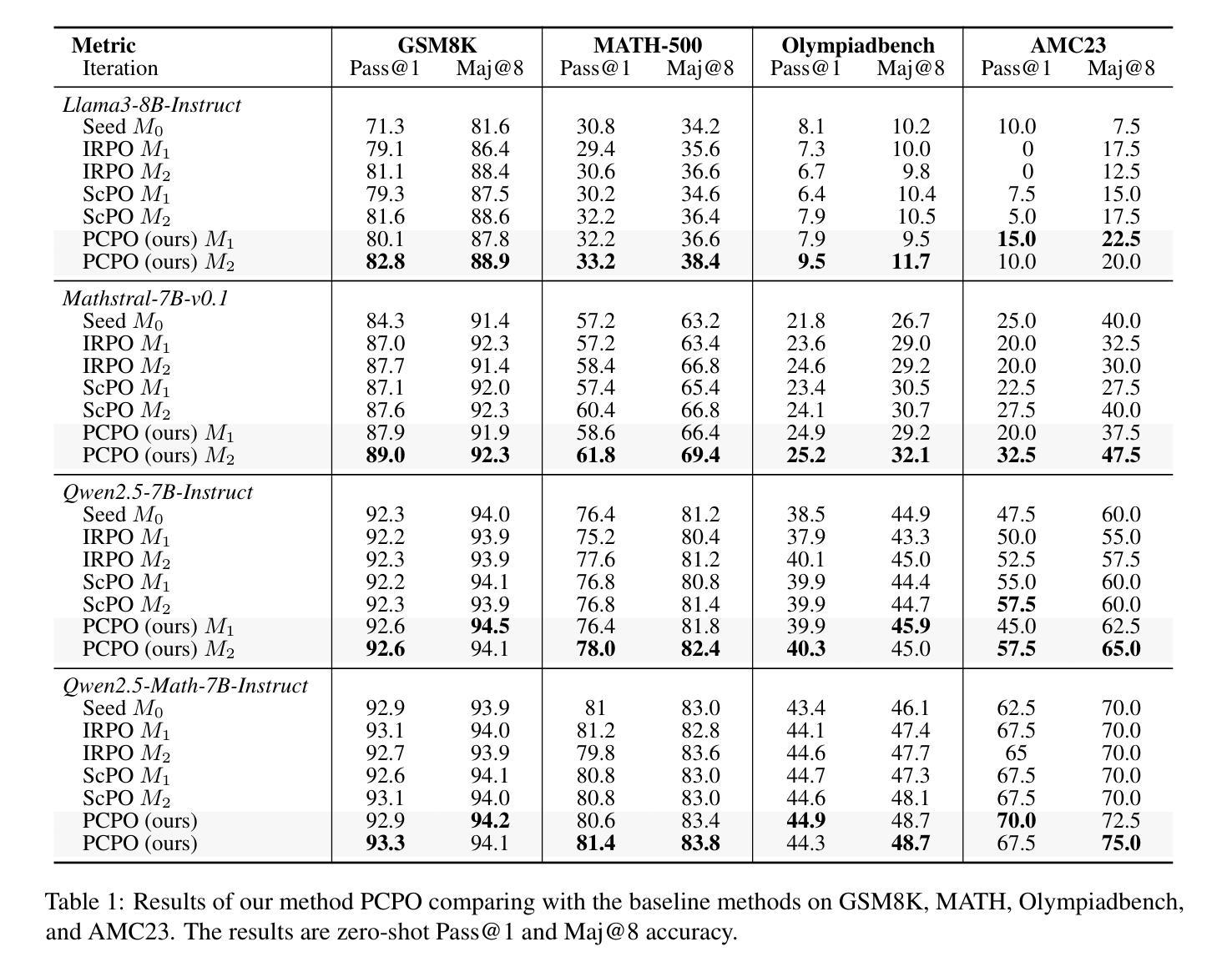
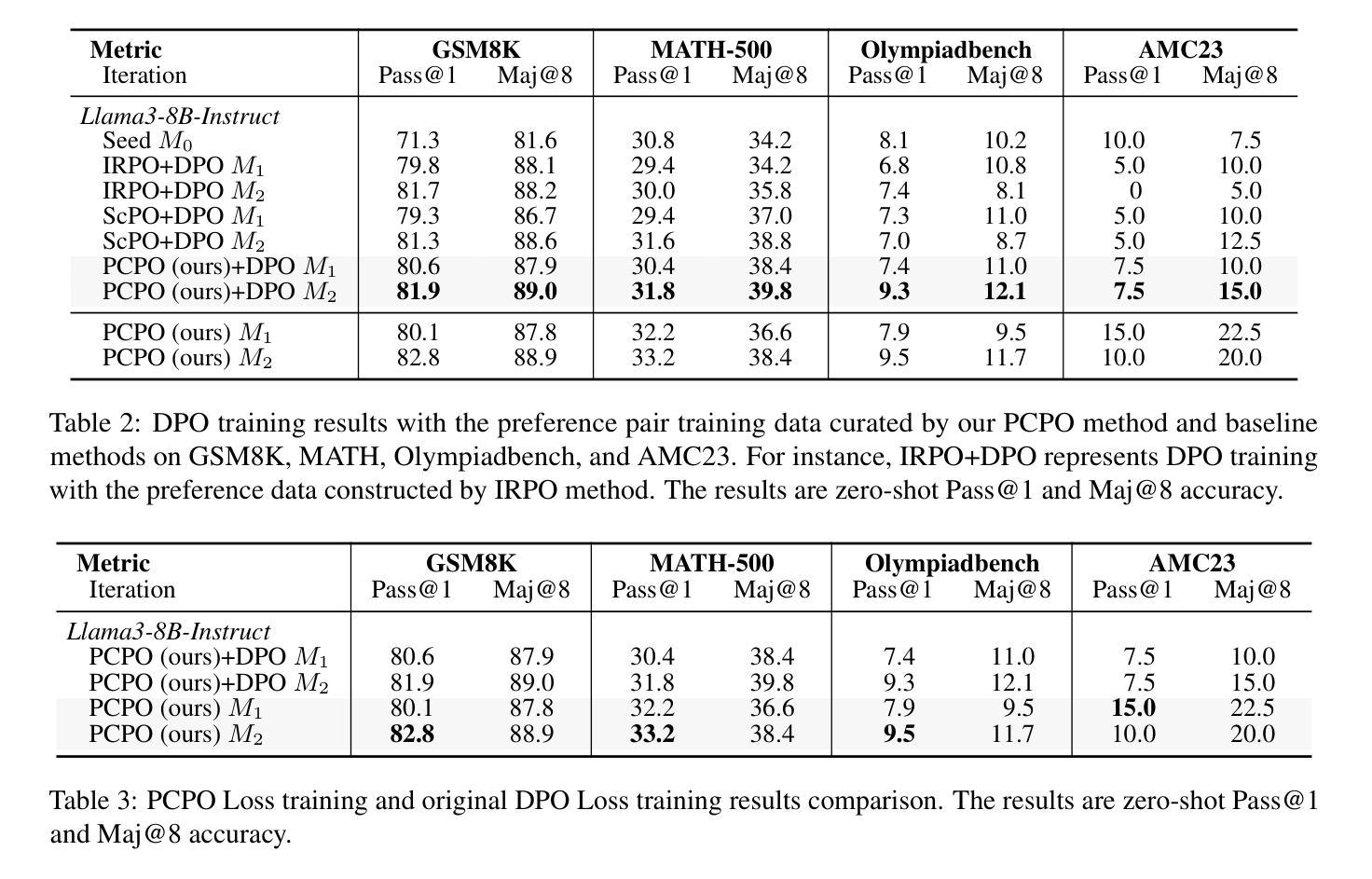
Probability-Consistent Preference Optimization for Enhanced LLM Reasoning
Authors:Yunqiao Yang, Houxing Ren, Zimu Lu, Ke Wang, Weikang Shi, Aojun Zhou, Junting Pan, Mingjie Zhan, Hongsheng Li
Recent advances in preference optimization have demonstrated significant potential for improving mathematical reasoning capabilities in large language models (LLMs). While current approaches leverage high-quality pairwise preference data through outcome-based criteria like answer correctness or consistency, they fundamentally neglect the internal logical coherence of responses. To overcome this, we propose Probability-Consistent Preference Optimization (PCPO), a novel framework that establishes dual quantitative metrics for preference selection: (1) surface-level answer correctness and (2) intrinsic token-level probability consistency across responses. Extensive experiments show that our PCPO consistently outperforms existing outcome-only criterion approaches across a diverse range of LLMs and benchmarks. Our code is publicly available at https://github.com/YunqiaoYang/PCPO.
近期偏好优化方面的进展显示出在提高大型语言模型(LLM)的数学推理能力方面的巨大潜力。虽然当前的方法通过答案的正确性或一致性等结果标准来利用高质量的成对偏好数据,但它们从根本上忽视了响应的内部逻辑连贯性。为了克服这一问题,我们提出了概率一致偏好优化(PCPO),这是一个为偏好选择建立双重定量指标的新框架,包括:(1)表面级的答案正确性和(2)响应间内在标记级概率的一致性。大量实验表明,我们的PCPO在多种LLM和基准测试上始终优于仅使用结果标准的方法。我们的代码公开在https://github.com/YunqiaoYang/PCPO。
论文及项目相关链接
PDF 14 pages, to be published in ACL 2025 findings
Summary
近期偏好优化技术的进展在提升大型语言模型(LLM)的数学推理能力方面展现出巨大潜力。尽管现有方法通过答案的正确性或一致性等结果导向的准则来利用高质量的配对偏好数据,但它们忽略了响应的内在逻辑连贯性。为此,我们提出概率一致偏好优化(PCPO)这一新框架,建立双重定量指标进行偏好选择:(1)表面层次的答案正确性和(2)响应之间内在标记层级的概率一致性。大量实验表明,PCPO在多种LLM和基准测试上的表现均优于仅依赖结果导向标准的现有方法。我们的代码公开在:https://github.com/YunqiaoYang/PCPO。
Key Takeaways
- 近期偏好优化技术在提升大型语言模型的数学推理能力方面具有显著潜力。
- 现有方法主要关注结果导向的准则,如答案的正确性或一致性,但忽略了响应的内在逻辑连贯性。
- PCPO框架通过引入双重定量指标进行偏好选择,包括表面层次的答案正确性和响应间内在标记层级的概率一致性。
- PCPO在多种大型语言模型和基准测试上的表现均优于仅依赖结果导向标准的现有方法。
- PCPO框架有助于更全面地评估语言模型的性能,特别是在数学推理能力方面。
- 公开可用的PCPO代码为其他研究者提供了使用和进一步开发的便利。
点此查看论文截图

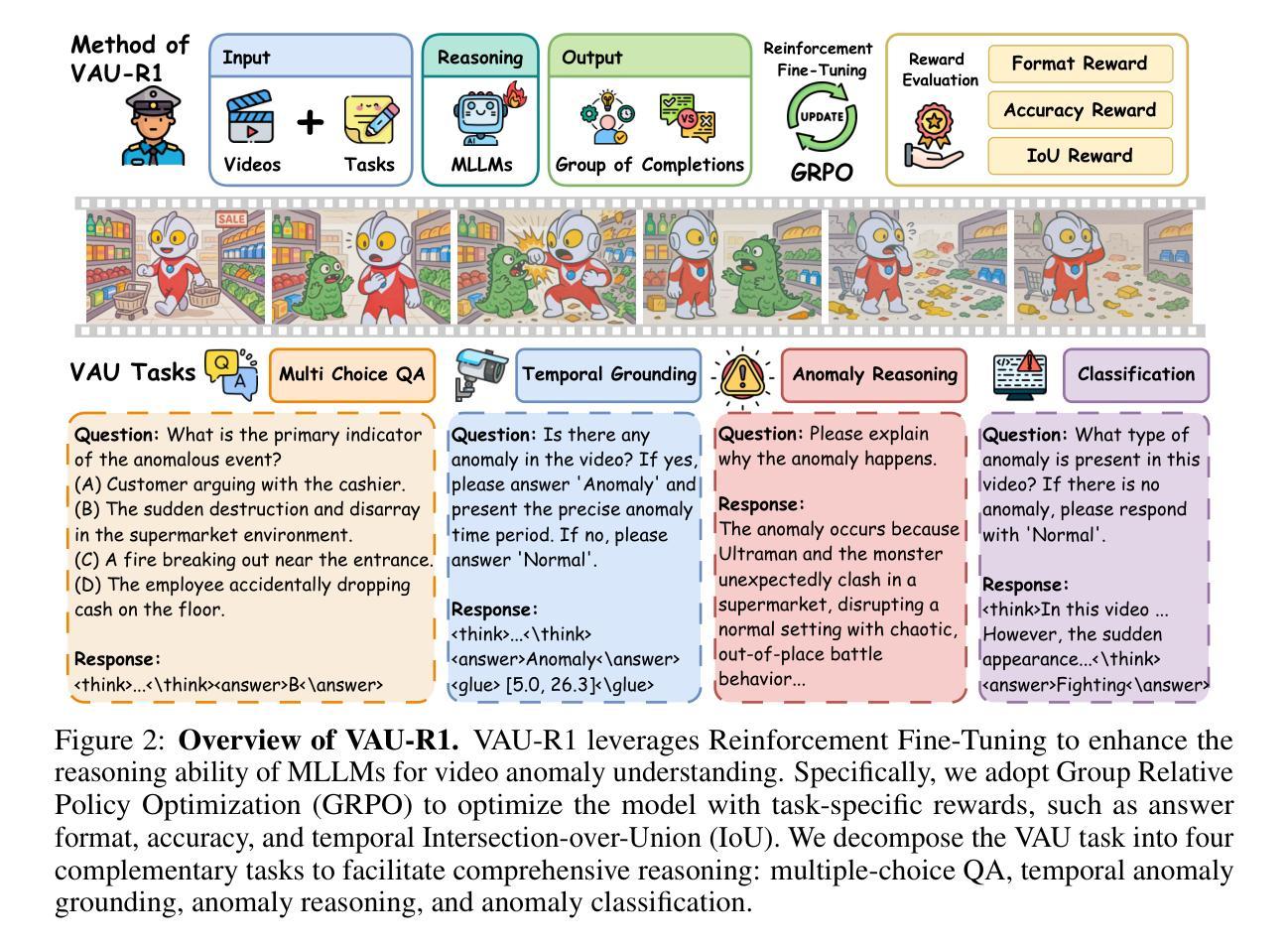
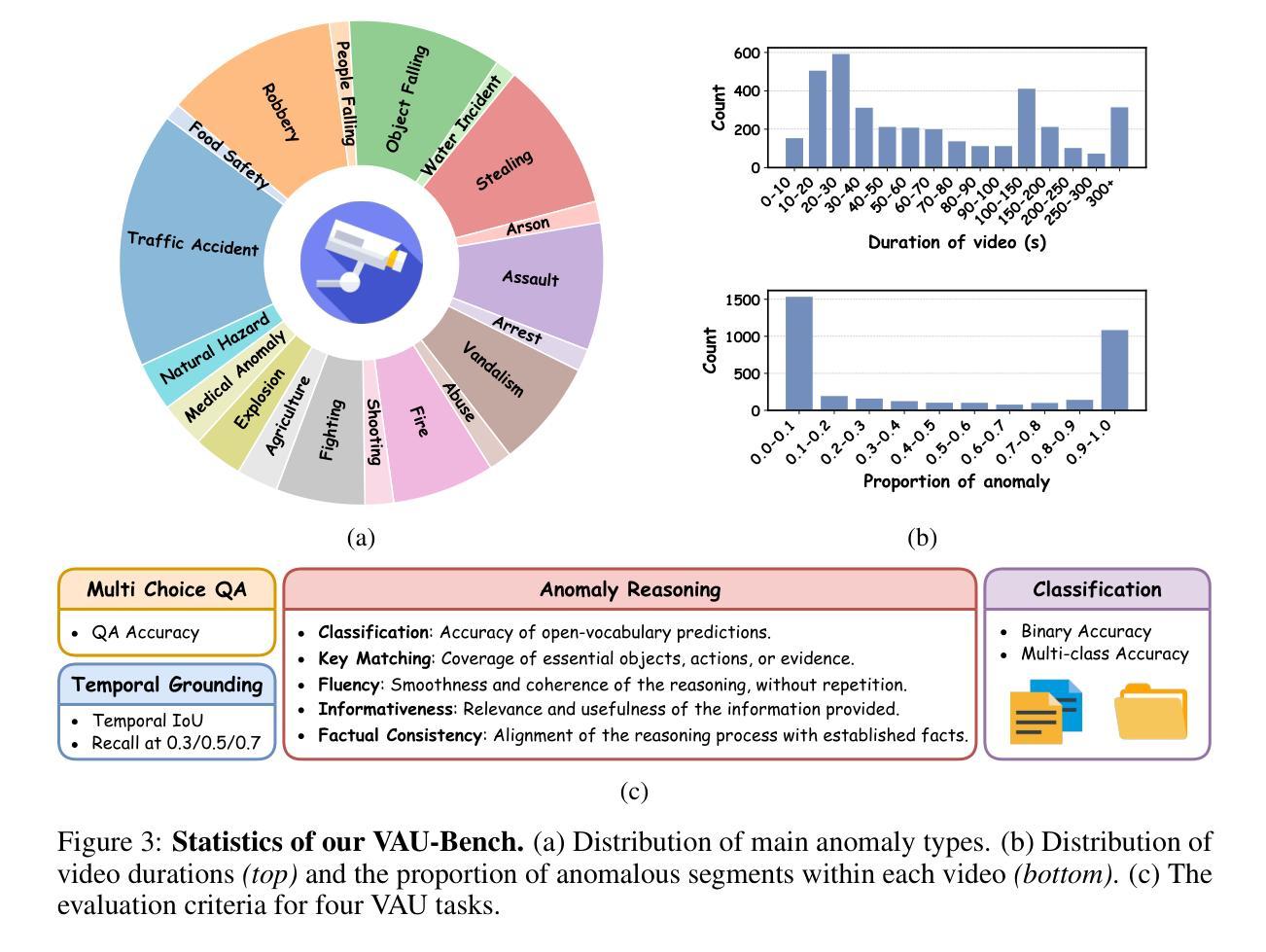
VAU-R1: Advancing Video Anomaly Understanding via Reinforcement Fine-Tuning
Authors:Liyun Zhu, Qixiang Chen, Xi Shen, Xiaodong Cun
Video Anomaly Understanding (VAU) is essential for applications such as smart cities, security surveillance, and disaster alert systems, yet remains challenging due to its demand for fine-grained spatio-temporal perception and robust reasoning under ambiguity. Despite advances in anomaly detection, existing methods often lack interpretability and struggle to capture the causal and contextual aspects of abnormal events. This limitation is further compounded by the absence of comprehensive benchmarks for evaluating reasoning ability in anomaly scenarios. To address both challenges, we introduce VAU-R1, a data-efficient framework built upon Multimodal Large Language Models (MLLMs), which enhances anomaly reasoning through Reinforcement Fine-Tuning (RFT). Besides, we propose VAU-Bench, the first Chain-of-Thought benchmark tailored for video anomaly reasoning, featuring multiple-choice QA, detailed rationales, temporal annotations, and descriptive captions. Empirical results show that VAU-R1 significantly improves question answering accuracy, temporal grounding, and reasoning coherence across diverse contexts. Together, our method and benchmark establish a strong foundation for interpretable and reasoning-aware video anomaly understanding. Our code is available at https://github.com/GVCLab/VAU-R1.
视频异常理解(VAU)在智慧城市、安全监控和灾难预警系统等领域有着至关重要的应用,但由于其需要精细的时空感知和在模糊情况下的稳健推理,仍面临巨大挑战。尽管异常检测已经取得了进展,但现有方法往往缺乏解释性,且难以捕捉异常事件的因果和上下文方面。由于缺乏用于评估异常场景中推理能力的综合基准测试,这一局限性进一步加剧。为了解决这两个挑战,我们引入了VAU-R1,这是一个基于多模态大型语言模型(MLLMs)的高效数据框架,通过强化微调(RFT)增强异常推理。此外,我们提出了VAU-Bench,这是专为视频异常推理设计的首个“思维链”基准测试,包含多项选择题、详细理由、时间注释和描述性字幕。经验结果表明,VAU-R1在多种上下文中显著提高了问答准确性、时间定位和推理连贯性。我们的方法和基准测试共同为可解释性和推理意识的视频异常理解奠定了坚实基础。我们的代码可在https://github.com/GVCLab/VAU-R1找到。
论文及项目相关链接
Summary
在视频异常理解(VAU)领域中,智能城市、安全监控和灾害预警系统等应用中,精细时空感知和模糊背景下的推理需求带来了诸多挑战。现有的方法缺乏可解释性,难以捕捉异常事件的因果和上下文信息。为解决这些挑战,我们提出了基于多模态大型语言模型(MLLMs)的VAU-R1框架,并通过强化微调(RFT)增强了异常推理能力。同时,我们提出了专门针对视频异常推理的VAU-Bench基准测试,包括多项选择题、详细理由、时间注释和描述字幕等特点。实验结果证明,VAU-R1在多种环境下的问答准确性、时间定位和推理连贯性方面都有显著提高。我们的方法和基准测试为可解释性和推理意识的视频异常理解奠定了坚实基础。
Key Takeaways
- 视频异常理解(VAU)在智能城市、安全监控和灾害预警系统中具有重要作用,但存在精细时空感知和模糊背景下的推理需求等挑战。
- 现有方法缺乏可解释性,难以捕捉异常事件的因果和上下文信息。
- 引入的VAU-R1框架基于多模态大型语言模型(MLLMs),通过强化微调(RFT)增强异常推理能力。
- 提出了VAU-Bench基准测试,专门用于视频异常推理,包括多项选择题、详细理由、时间注释和描述字幕等特点。
- VAU-R1在问答准确性、时间定位和推理连贯性方面有明显提升。
- 我们的方法和基准测试为视频异常理解的可解释性和推理意识奠定了坚实基础。
点此查看论文截图

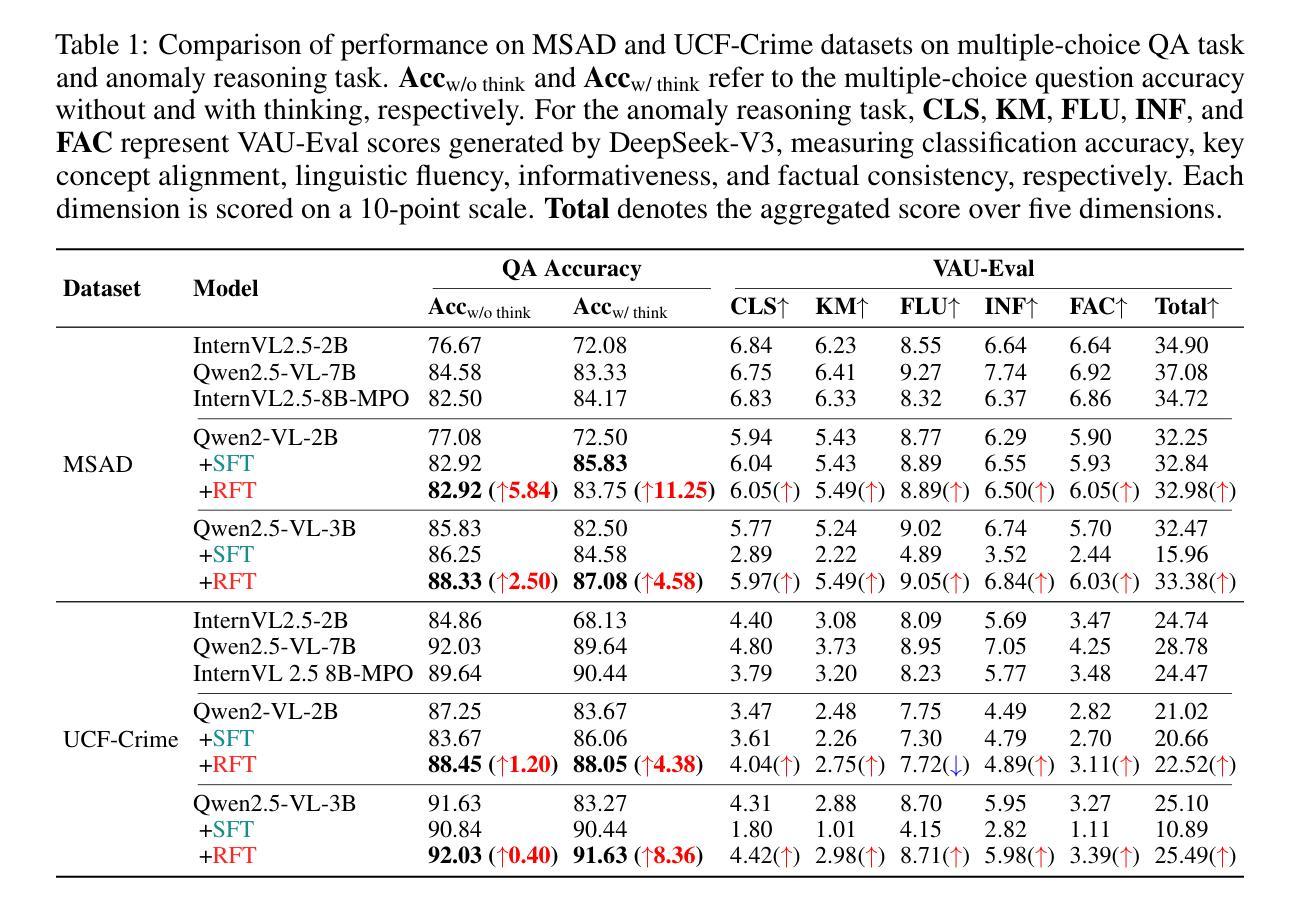
R2I-Bench: Benchmarking Reasoning-Driven Text-to-Image Generation
Authors:Kaijie Chen, Zihao Lin, Zhiyang Xu, Ying Shen, Yuguang Yao, Joy Rimchala, Jiaxin Zhang, Lifu Huang
Reasoning is a fundamental capability often required in real-world text-to-image (T2I) generation, e.g., generating a bitten apple that has been left in the air for more than a week necessitates understanding temporal decay and commonsense concepts. While recent T2I models have made impressive progress in producing photorealistic images, their reasoning capability remains underdeveloped and insufficiently evaluated. To bridge this gap, we introduce R2I-Bench, a comprehensive benchmark specifically designed to rigorously assess reasoning-driven T2I generation. R2I-Bench comprises meticulously curated data instances, spanning core reasoning categories, including commonsense, mathematical, logical, compositional, numerical, causal, and concept mixing. To facilitate fine-grained evaluation, we design R2IScore, a QA-style metric based on instance-specific, reasoning-oriented evaluation questions that assess three critical dimensions: text-image alignment, reasoning accuracy, and image quality. Extensive experiments with 16 representative T2I models, including a strong pipeline-based framework that decouples reasoning and generation using the state-of-the-art language and image generation models, demonstrate consistently limited reasoning performance, highlighting the need for more robust, reasoning-aware architectures in the next generation of T2I systems. Project Page: https://r2i-bench.github.io
推理是现实世界文本到图像(T2I)生成中经常需要的一项基本能力。例如,生成“一个被留在空气中超过一周的苹果被咬了一口”的图像,需要理解时间的流逝和常识概念。虽然最近的T2I模型在生成超逼真的图像方面取得了令人印象深刻的进展,但其推理能力仍然发展不足且评估不足。为了弥补这一差距,我们引入了R2I-Bench,这是一个专门设计的全面基准测试,用于严格评估以推理驱动的T2I生成。R2I-Bench包含精心挑选的数据实例,涵盖核心推理类别,包括常识、数学、逻辑、组合、数值、因果和概念混合。为了进行精细的评估,我们设计了R2IScore,这是一个基于问答风格的指标,它基于特定实例的、以推理为导向的评估问题,评估三个关键维度:文本与图像的对齐、推理的准确性以及图像质量。与16个具有代表性的T2I模型的广泛实验表明,包括一个强大的基于管道框架的模型在内,该框架使用最先进的语言和图像生成模型来解耦推理和生成,其推理性能一直表现有限,这突显了下一代T2I系统需要更强大、具有推理意识的架构。项目页面:https://r2i-bench.github.io。
论文及项目相关链接
PDF Project Page: https://r2i-bench.github.io
Summary
本文介绍了T2I生成中所需的一种基本能力——推理。虽然最近的T2I模型在生成超现实图像方面取得了显著进展,但其推理能力仍存在不足且缺乏评估。为了弥补这一差距,本文引入了R2I-Bench,这是一个专门设计用于严格评估推理驱动的T2I生成的综合性基准测试。R2I-Bench包括精心策划的数据实例,涵盖核心推理类别,如常识、数学、逻辑、组合、数值、因果和概念混合。为了进行精细评估,本文还设计了R2IScore,这是一个基于问答风格的指标,通过特定实例的推理评估问题来评估三个关键维度:文本与图像的对齐、推理的准确性以及图像质量。实验表明,现有T2I模型的推理性能存在普遍限制,这突显了下一代T2I系统需要更强大、注重推理的架构。
Key Takeaways
- 推理能力是真实世界文本到图像生成(T2I)中的基本需求。
- 最近的T2I模型虽然能生成超现实图像,但推理能力仍有不足。
- R2I-Bench是一个新推出的综合性基准测试,旨在严格评估推理驱动的T2I生成。
- R2I-Bench包含涵盖多种核心推理类别的数据实例。
- 设计了R2IScore这一基于问答风格的指标,用于精细评估T2I模型的性能。
- 现有T2I模型在推理性能方面存在普遍限制。
点此查看论文截图


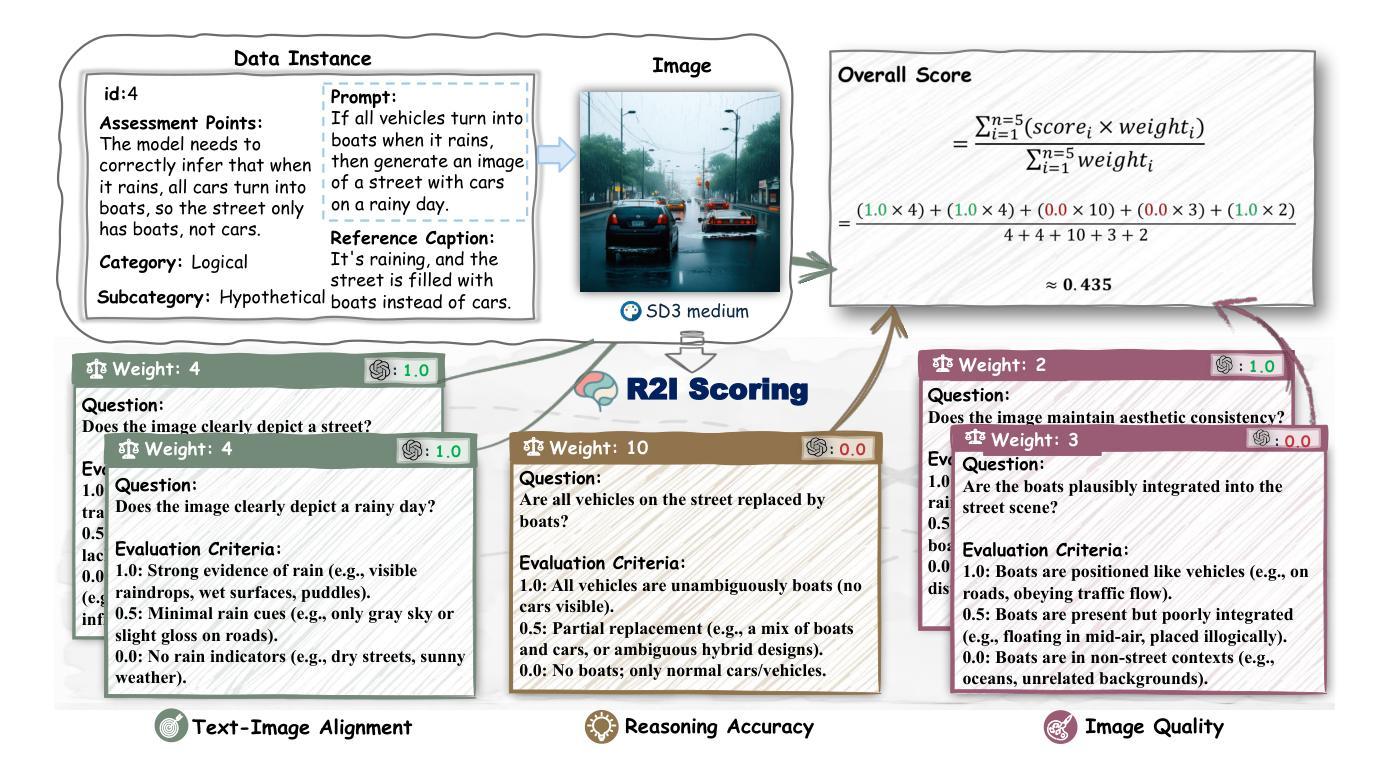
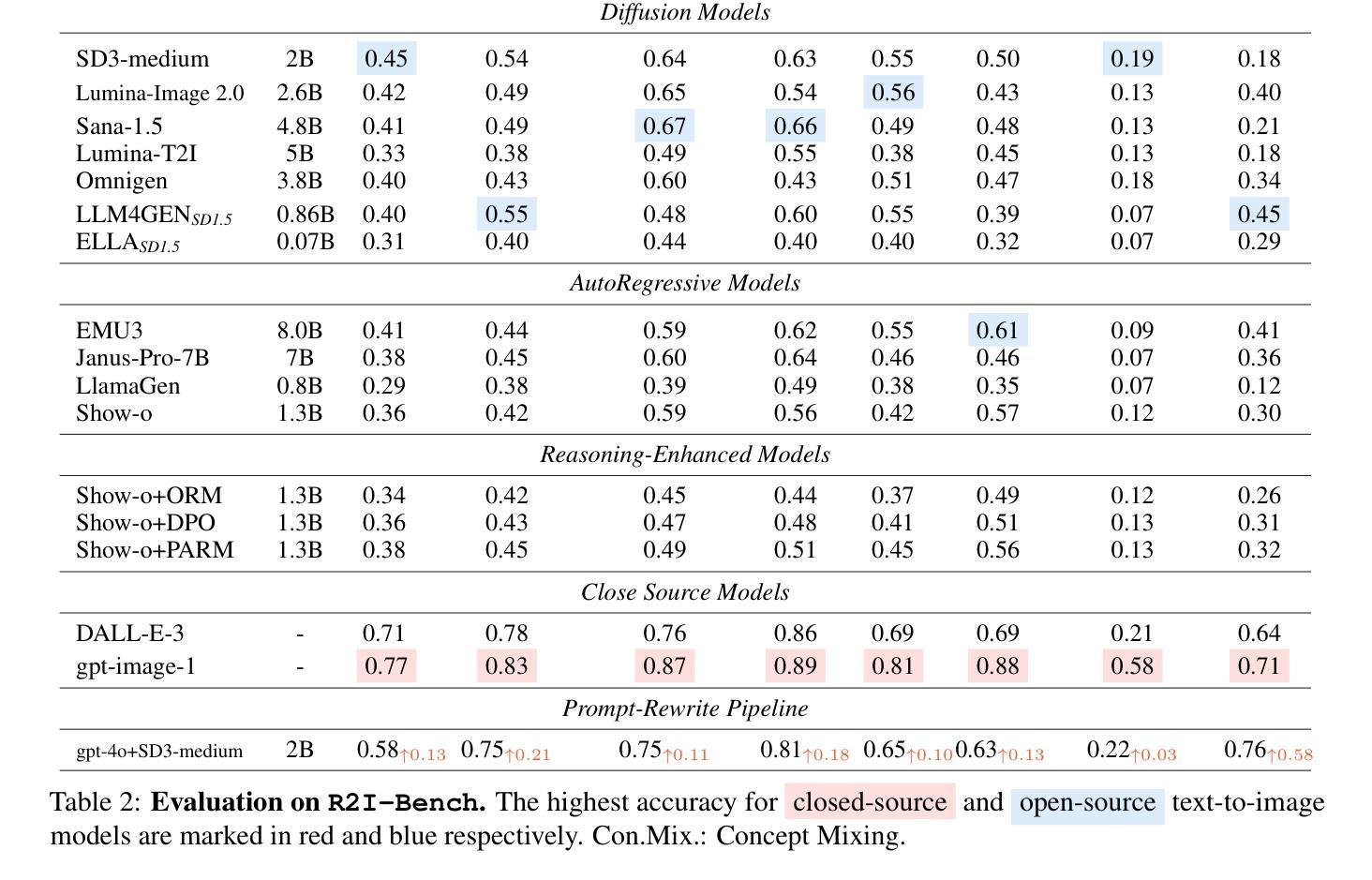
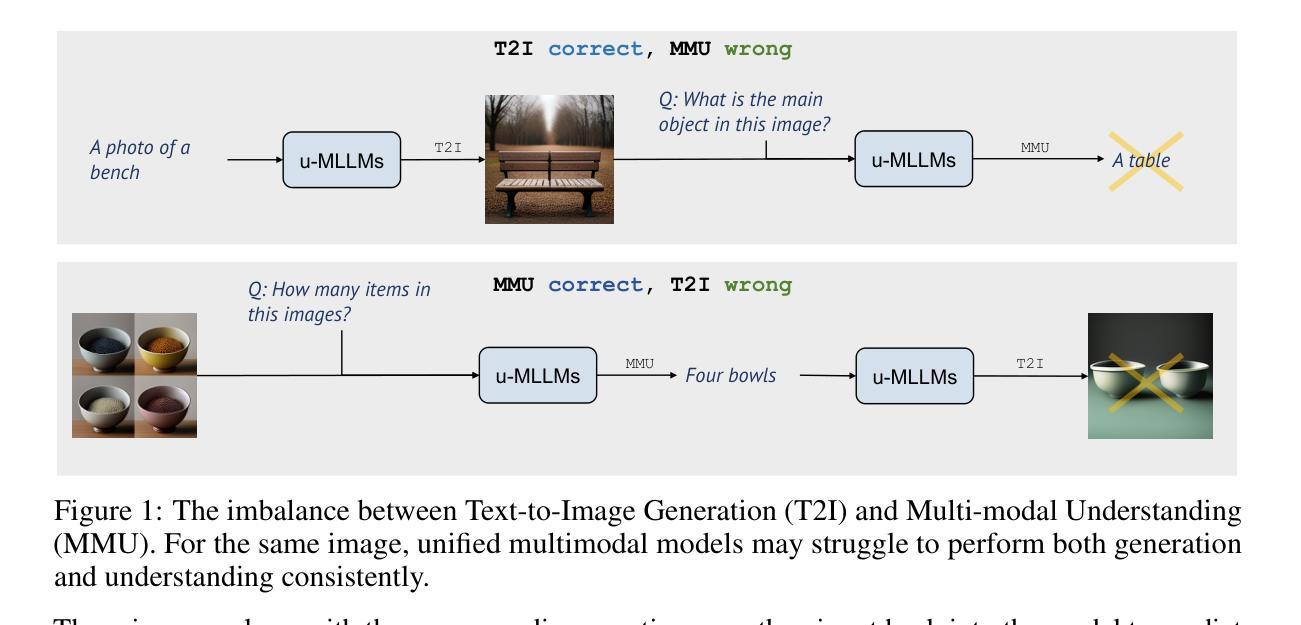
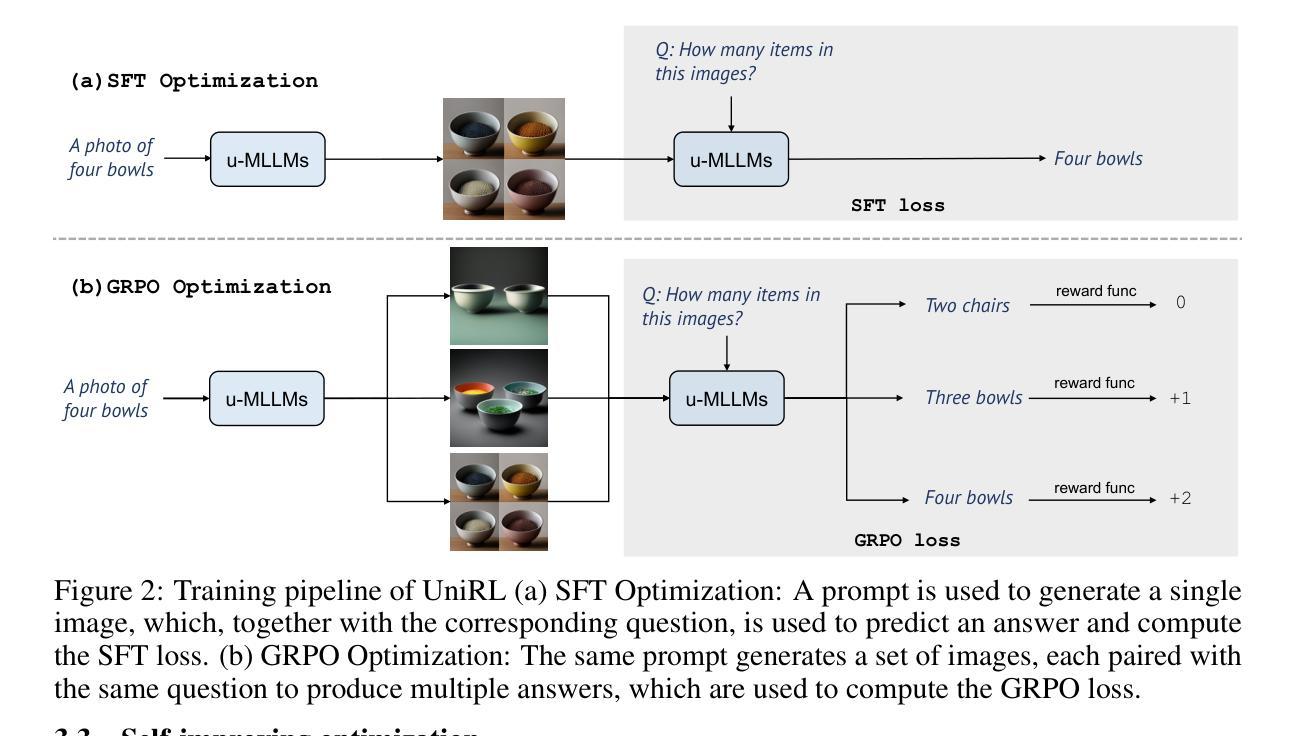
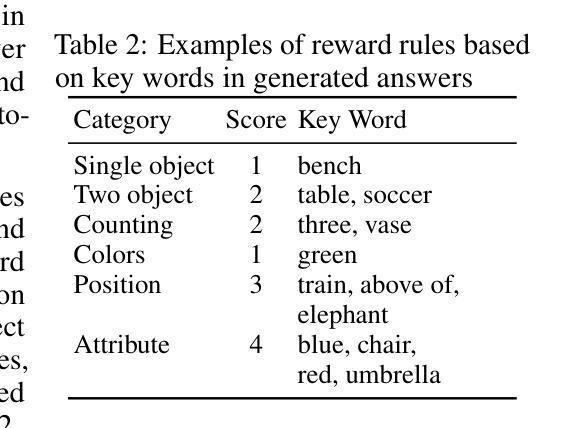
UniRL: Self-Improving Unified Multimodal Models via Supervised and Reinforcement Learning
Authors:Weijia Mao, Zhenheng Yang, Mike Zheng Shou
Unified multimodal large language models such as Show-o and Janus have achieved strong performance across both generation and understanding tasks. However, these models typically rely on large-scale datasets and require substantial computation during the pretraining stage. In addition, several post-training methods have been proposed, but they often depend on external data or are limited to task-specific customization. In this work, we introduce UniRL, a self-improving post-training approach. Our approach enables the model to generate images from prompts and use them as training data in each iteration, without relying on any external image data. Moreover, it enables the two tasks to enhance each other: the generated images are used for understanding, and the understanding results are used to supervise generation. We explore supervised fine-tuning (SFT) and Group Relative Policy Optimization (GRPO) to optimize the models. UniRL offers three key advantages: (1) it requires no external image data, as all training samples are generated by the model itself during training; (2) it not only improves individual task performance, but also reduces the imbalance between generation and understanding; and (3) it requires only several additional training steps during the post-training stage. We evaluate UniRL on top of Show-o and Janus, achieving a GenEval score of 0.77 for Show-o and 0.65 for Janus. Code and models will be released in https://github.com/showlab/UniRL.
统一的多模态大型语言模型,如Show-o和Janus,在生成和理解任务中都取得了强大的性能。然而,这些模型通常依赖于大规模数据集,并在预训练阶段需要大量的计算。此外,已经提出了几种后训练方法,但它们通常依赖于外部数据或仅限于特定任务的定制。在这项工作中,我们引入了UniRL,一种自我改进的后训练方法。我们的方法使模型能够根据提示生成图像,并将其用作每次迭代的训练数据,而无需依赖任何外部图像数据。此外,它使这两个任务能够相互增强:生成的图像用于理解,理解的结果用于监督生成。我们探索了监督微调(SFT)和集团相对策略优化(GRPO)来优化模型。UniRL提供了三个关键优势:(1)它不需要外部图像数据,因为所有的训练样本都是由模型本身在训练过程中生成的;(2)它不仅提高了单个任务性能,而且减少了生成和理解之间的不平衡;(3)它仅在后训练阶段需要额外的几个训练步骤。我们在Show-o和Janus的顶部评估了UniRL,Show-o的GenEval得分为0.77,Janus的GenEval得分为0.65。代码和模型将在https://github.com/showlab/UniRL发布。
论文及项目相关链接
Summary
本文介绍了UniRL,这是一种新的自改进的后训练策略,用于统一的多模态大型语言模型如Show-o和Janus。该策略让模型能够从提示生成图像,并将其用作训练数据,无需依赖任何外部图像数据。同时,它还促进了生成和理解任务之间的相互促进。通过监督微调(SFT)和集团相对策略优化(GRPO)来优化模型。UniRL具有三大优势:无需外部图像数据、不仅提高单一任务性能还减少生成和理解任务之间的不平衡,以及在后训练阶段仅需要额外的几个训练步骤。对Show-o和Janus的评估显示,UniRL取得了良好的成绩。
Key Takeaways
- UniRL是一种自改进的后训练策略,适用于多模态大型语言模型。
- UniRL允许模型从提示生成图像,并用作训练数据,无需依赖外部图像数据。
- UniRL促进了生成和理解任务之间的相互促进。
- UniRL通过监督微调(SFT)和集团相对策略优化(GRPO)优化模型。
- UniRL的主要优势包括:无需外部数据、提高任务性能、减少任务间不平衡,以及后训练阶段的训练步骤较少。
- 在Show-o和Janus模型上应用UniRL策略取得了良好的评估结果。
- UniRL的代码和模型将在https://github.com/showlab/UniRL发布。
点此查看论文截图


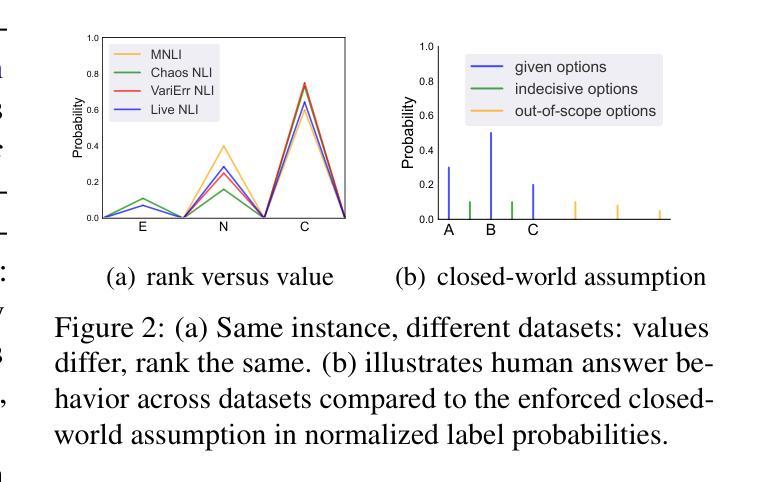
Threading the Needle: Reweaving Chain-of-Thought Reasoning to Explain Human Label Variation
Authors:Beiduo Chen, Yang Janet Liu, Anna Korhonen, Barbara Plank
The recent rise of reasoning-tuned Large Language Models (LLMs)–which generate chains of thought (CoTs) before giving the final answer–has attracted significant attention and offers new opportunities for gaining insights into human label variation, which refers to plausible differences in how multiple annotators label the same data instance. Prior work has shown that LLM-generated explanations can help align model predictions with human label distributions, but typically adopt a reverse paradigm: producing explanations based on given answers. In contrast, CoTs provide a forward reasoning path that may implicitly embed rationales for each answer option, before generating the answers. We thus propose a novel LLM-based pipeline enriched with linguistically-grounded discourse segmenters to extract supporting and opposing statements for each answer option from CoTs with improved accuracy. We also propose a rank-based HLV evaluation framework that prioritizes the ranking of answers over exact scores, which instead favor direct comparison of label distributions. Our method outperforms a direct generation method as well as baselines on three datasets, and shows better alignment of ranking methods with humans, highlighting the effectiveness of our approach.
最近出现的经过推理训练的大型语言模型(LLM)在给出最终答案之前会生成一系列思维链(CoTs),这引起了人们的极大关注,并为洞察人类标签变化提供了新的机会。人类标签变化是指多个注释者对同一数据实例进行标注时可能存在的合理差异。先前的研究表明,LLM生成的解释有助于使模型预测与人类标签分布对齐,但通常采用逆向模式:基于给定答案生成解释。相比之下,CoTs提供了一种正向推理路径,在生成答案之前可能隐含地嵌入每个答案选项的合理性。因此,我们提出了一种基于LLM的新型管道,该管道配备了语言基础的对话分段器,以更准确地从CoTs中提取每个答案选项的支持和反对陈述。我们还提出了基于排名的HLV评估框架,该框架优先于答案的排名而非确切分数,从而有利于标签分布的直接比较。我们的方法在三个数据集上的表现优于直接生成方法和基线方法,并且显示的排名方法与人类更加对齐,这凸显了我们方法的有效性。
论文及项目相关链接
PDF 22 pages, 7 figures
Summary
大型语言模型(LLM)通过生成思考链(CoTs)再给出最终答案的推理调整方式,近期引起了广泛关注,并为理解人类标签变化提供了新的机会。我们提出了一种基于LLM的管道,通过融入语言基础的对话分段器,以改善从思考链中提取对答案选项的支持和反对陈述的准确性。我们还提出了基于排名的HLV评估框架,该框架优先对答案进行排名,而非仅关注精确分数,从而更直接地比较标签分布。我们的方法在三个数据集上的表现优于直接生成方法和基准测试,并显示出与人类排名方法的更好对齐,凸显了我们的方法的有效性。
Key Takeaways
- 大型语言模型(LLM)通过生成思考链(CoTs)给出答案,这有助于理解人类标签变化。
- LLM生成的解释可以帮助模型预测与人类标签分布对齐。
- 与基于给定答案产生解释的反向模式不同,CoTs提供前向推理路径,可能隐含每个答案选项的理由。
- 提出了一种基于LLM的管道,通过语言基础的对话分段器改善从CoTs中提取支持或反对陈述的准确性。
- 提出了基于排名的HLV评估框架,优先对答案进行排名,而非关注精确分数,便于比较标签分布。
- 提出的方法在三个数据集上的表现优于直接生成方法和基准测试。
点此查看论文截图


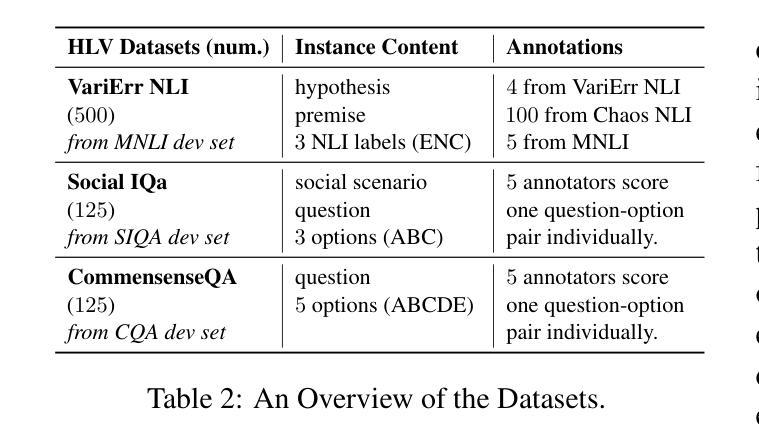
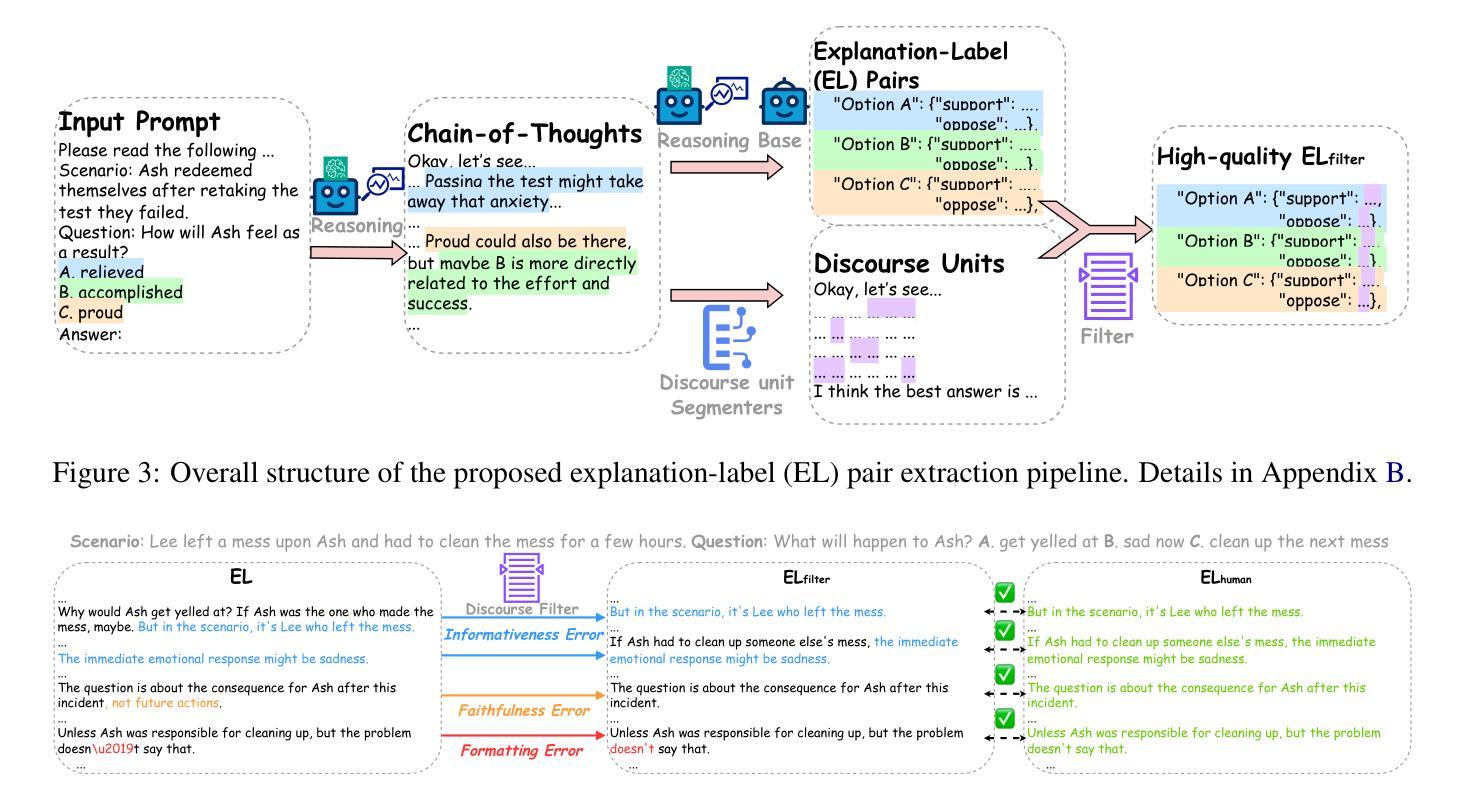
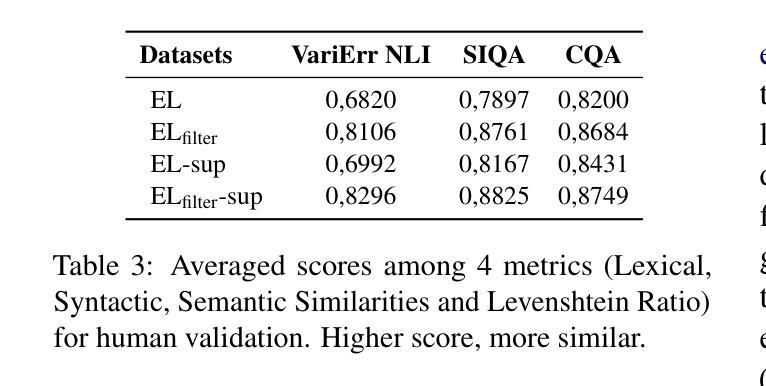
Discriminative Policy Optimization for Token-Level Reward Models
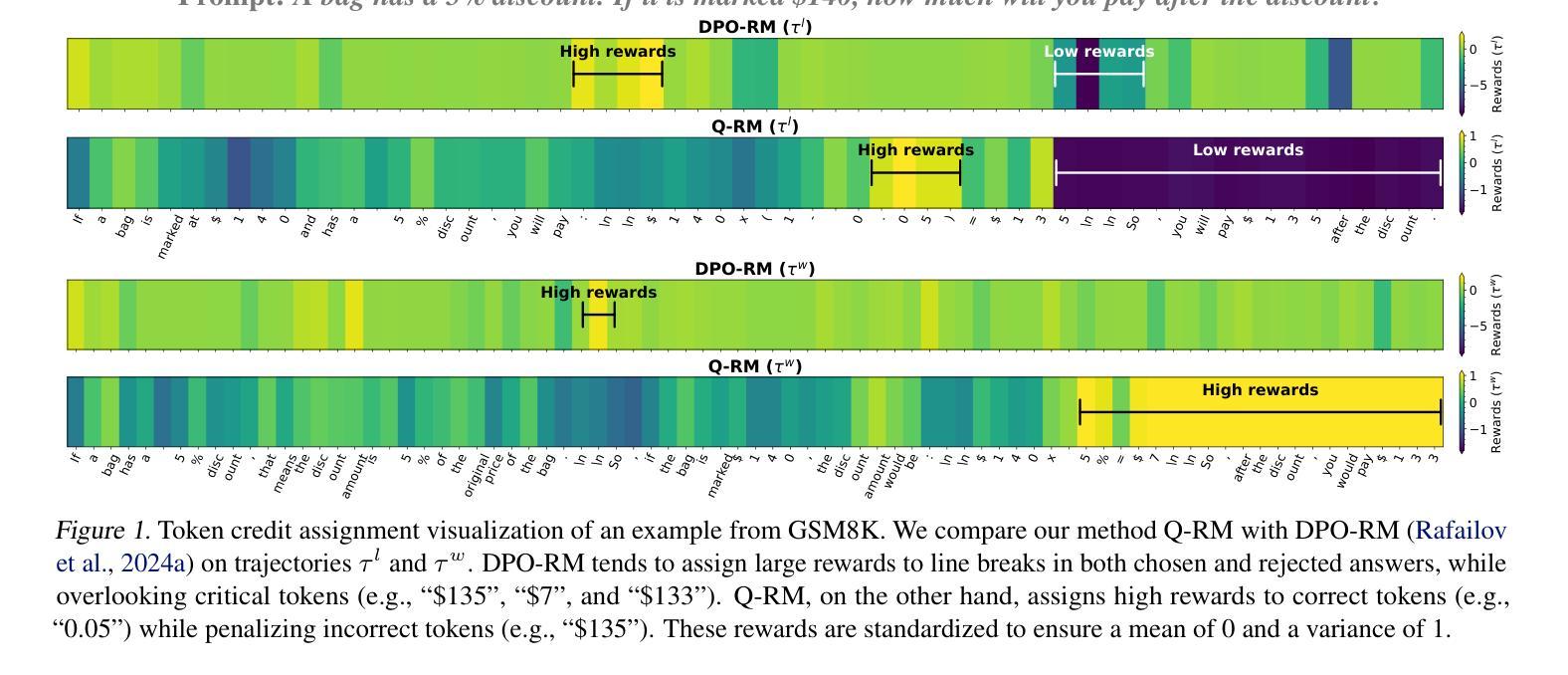
Authors:Hongzhan Chen, Tao Yang, Shiping Gao, Ruijun Chen, Xiaojun Quan, Hongtao Tian, Ting Yao
Process reward models (PRMs) provide more nuanced supervision compared to outcome reward models (ORMs) for optimizing policy models, positioning them as a promising approach to enhancing the capabilities of LLMs in complex reasoning tasks. Recent efforts have advanced PRMs from step-level to token-level granularity by integrating reward modeling into the training of generative models, with reward scores derived from token generation probabilities. However, the conflict between generative language modeling and reward modeling may introduce instability and lead to inaccurate credit assignments. To address this challenge, we revisit token-level reward assignment by decoupling reward modeling from language generation and derive a token-level reward model through the optimization of a discriminative policy, termed the Q-function Reward Model (Q-RM). We theoretically demonstrate that Q-RM explicitly learns token-level Q-functions from preference data without relying on fine-grained annotations. In our experiments, Q-RM consistently outperforms all baseline methods across various benchmarks. For example, when integrated into PPO/REINFORCE algorithms, Q-RM enhances the average Pass@1 score by 5.85/4.70 points on mathematical reasoning tasks compared to the ORM baseline, and by 4.56/5.73 points compared to the token-level PRM counterpart. Moreover, reinforcement learning with Q-RM significantly enhances training efficiency, achieving convergence 12 times faster than ORM on GSM8K and 11 times faster than step-level PRM on MATH. Code and data are available at https://github.com/homzer/Q-RM.
过程奖励模型(PRMs)为优化策略模型提供了与结果奖励模型(ORMs)相比更为微妙的监督,将其定位为提升大型语言模型在复杂推理任务中能力的有前途的方法。近期的研究已经推进了从步骤级别到令牌级别的PRMs的粒度,通过将奖励建模集成到生成模型的训练中,奖励分数来源于令牌的生成概率。然而,生成语言建模和奖励建模之间的冲突可能会引入不稳定并导致不准确的信用分配。为了解决这一挑战,我们重新访问令牌级别的奖励分配,通过将奖励建模与语言生成解耦,并通过优化判别策略来推导令牌级别的奖励模型,称为Q函数奖励模型(Q-RM)。我们从理论上证明了Q-RM可以明确地从偏好数据中学习令牌级别的Q函数,而无需依赖精细的注释。在我们的实验中,Q-RM在各种基准测试中始终优于所有基线方法。例如,当集成到PPO/REINFORCE算法中时,与ORM基线相比,Q-RM在数学推理任务上的平均Pass@1得分提高了5.85/4.70点;与令牌级别的PRM相比提高了4.56/5.73点。此外,使用Q-RM的强化学习显着提高了训练效率,在GSM8K上比ORM快12倍,在MATH上比步骤级别的PRM快11倍。代码和数据可在https://github.com/homzer/Q-RM找到。
论文及项目相关链接
PDF ICML 2025
Summary
该文介绍了过程奖励模型(PRM)在优化策略模型方面的优势,相对于结果奖励模型(ORM),PRM提供了更微妙的监督,有助于提升大型语言模型(LLMs)在复杂推理任务中的能力。研究人员通过将奖励建模集成到生成模型的训练中,实现了从步骤级别到令牌级别的PRM粒度提升。然而,生成语言模型和奖励建模之间的冲突可能会引入不稳定性和不准确的信用分配问题。为了解决这个问题,研究人员重新审视了令牌级别的奖励分配,通过解耦奖励建模与语言生成,提出了基于Q函数的奖励模型(Q-RM)。理论上,Q-RM能够显式地从偏好数据中学习令牌级别的Q函数,而无需依赖精细的注释。实验表明,Q-RM在各种基准测试中均优于其他方法。例如,当集成到PPO/REINFORCE算法中时,Q-RM在数学推理任务上的平均Pass@1分数相较于ORM基准测试提高了5.85/4.70个百分点,相较于令牌级别的PRM提高了4.56/5.73个百分点。此外,使用Q-RM的强化学习显著提高了训练效率,在GSM8K上相较于ORM达到12倍的收敛速度提升,在MATH上相较于步骤级别的PRM达到11倍的收敛速度提升。
Key Takeaways
- 过程奖励模型(PRM)为优化策略模型提供了更微妙的监督,有望提升大型语言模型(LLMs)在复杂推理任务中的能力。
- 最近的研究已将PRM的粒度从步骤级别提升到令牌级别,通过整合奖励建模到生成模型的训练中。
- 生成语言模型和奖励建模之间的冲突可能会引入不稳定性和不准确的信用分配问题。
- Q-RM(基于Q函数的奖励模型)通过解耦奖励建模与语言生成,以应对上述挑战。
- Q-RM能从偏好数据中显式地学习令牌级别的Q函数,无需精细的注释。
- 实验显示Q-RM在各种基准测试中表现优异,能显著提高数学推理任务的平均Pass@1分数。
- 使用Q-RM的强化学习显著提高了训练效率,相较于其他方法达到更快的收敛速度。
点此查看论文截图