⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-05-31 更新
Video Editing for Audio-Visual Dubbing
Authors:Binyamin Manela, Sharon Gannot, Ethan Fetyaya
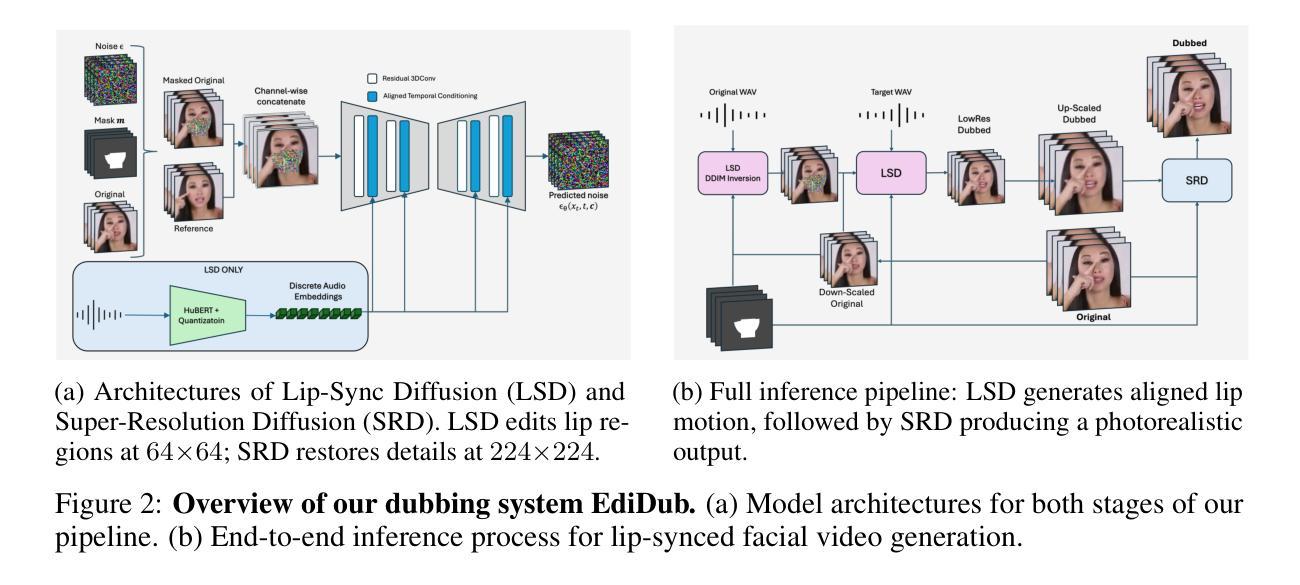
Visual dubbing, the synchronization of facial movements with new speech, is crucial for making content accessible across different languages, enabling broader global reach. However, current methods face significant limitations. Existing approaches often generate talking faces, hindering seamless integration into original scenes, or employ inpainting techniques that discard vital visual information like partial occlusions and lighting variations. This work introduces EdiDub, a novel framework that reformulates visual dubbing as a content-aware editing task. EdiDub preserves the original video context by utilizing a specialized conditioning scheme to ensure faithful and accurate modifications rather than mere copying. On multiple benchmarks, including a challenging occluded-lip dataset, EdiDub significantly improves identity preservation and synchronization. Human evaluations further confirm its superiority, achieving higher synchronization and visual naturalness scores compared to the leading methods. These results demonstrate that our content-aware editing approach outperforms traditional generation or inpainting, particularly in maintaining complex visual elements while ensuring accurate lip synchronization.
面部动态与新的语音同步的视觉配音技术对于不同语言的内容访问至关重要,能够实现更广泛的全球覆盖。然而,当前的方法面临重大挑战。现有方法往往会生成说话面部图像,阻碍了无缝集成到原始场景中,或者使用修复技术,这会导致丢失部分遮挡和光照变化等重要视觉信息。本研究介绍了EdiDub这一新型框架,它将视觉配音重构为一项面向内容的编辑任务。EdiDub利用特殊的条件方案来确保忠实和精确修改而非简单复制,从而保留原始视频上下文。在多个基准测试中,包括具有挑战性的遮挡唇数据集在内,EdiDub在身份保留和同步方面都有显著改善。人类评估进一步证实了其优越性,与传统方法相比,它实现了更高的同步率和视觉自然度得分。这些结果表明,我们的面向内容的编辑方法明显优于传统生成或修复技术,尤其是在保持复杂视觉元素的同时确保精确的唇部同步。
论文及项目相关链接
Summary
本文介绍了视觉配音的重要性及其在跨语言内容普及方面的应用。当前的方法面临重大挑战,如生成说话脸无法无缝融入原始场景,或者采用修复技术会丢失重要的视觉信息。本文提出了EdiDub框架,将视觉配音重新定义为一项内容感知编辑任务。EdiDub通过利用专门的调节方案,在忠实于原始视频上下文的同时,确保精确修改而非简单复制,从而解决了上述问题。在多个基准测试中,包括具有挑战性的遮挡唇形数据集,EdiDub在身份保留和同步方面表现出显著改进。人类评估进一步证实了其优越性,与传统方法相比,它在同步性和视觉自然度方面获得了更高的评分。这些结果表明,我们的内容感知编辑方法优于传统的生成或修复技术,特别是在保持复杂视觉元素的同时确保准确的唇同步。
Key Takeaways
- 视觉配音是使内容在不同语言中普及的关键技术,它能将面部动作与新的语音同步。
- 当前方法存在显著局限性,生成的说话脸无法无缝融入原始场景,或者采用修复技术会丢失重要视觉信息。
- 引入EdiDub框架,将视觉配音重新定义为内容感知编辑任务,旨在解决上述问题。
- EdiDub利用专门的调节方案,忠实于原始视频上下文,确保精确修改。
- 在多个基准测试中,EdiDub在身份保留和同步方面表现出显著改进。
- 人类评估显示EdiDub在同步性和视觉自然度方面优于传统方法。
点此查看论文截图


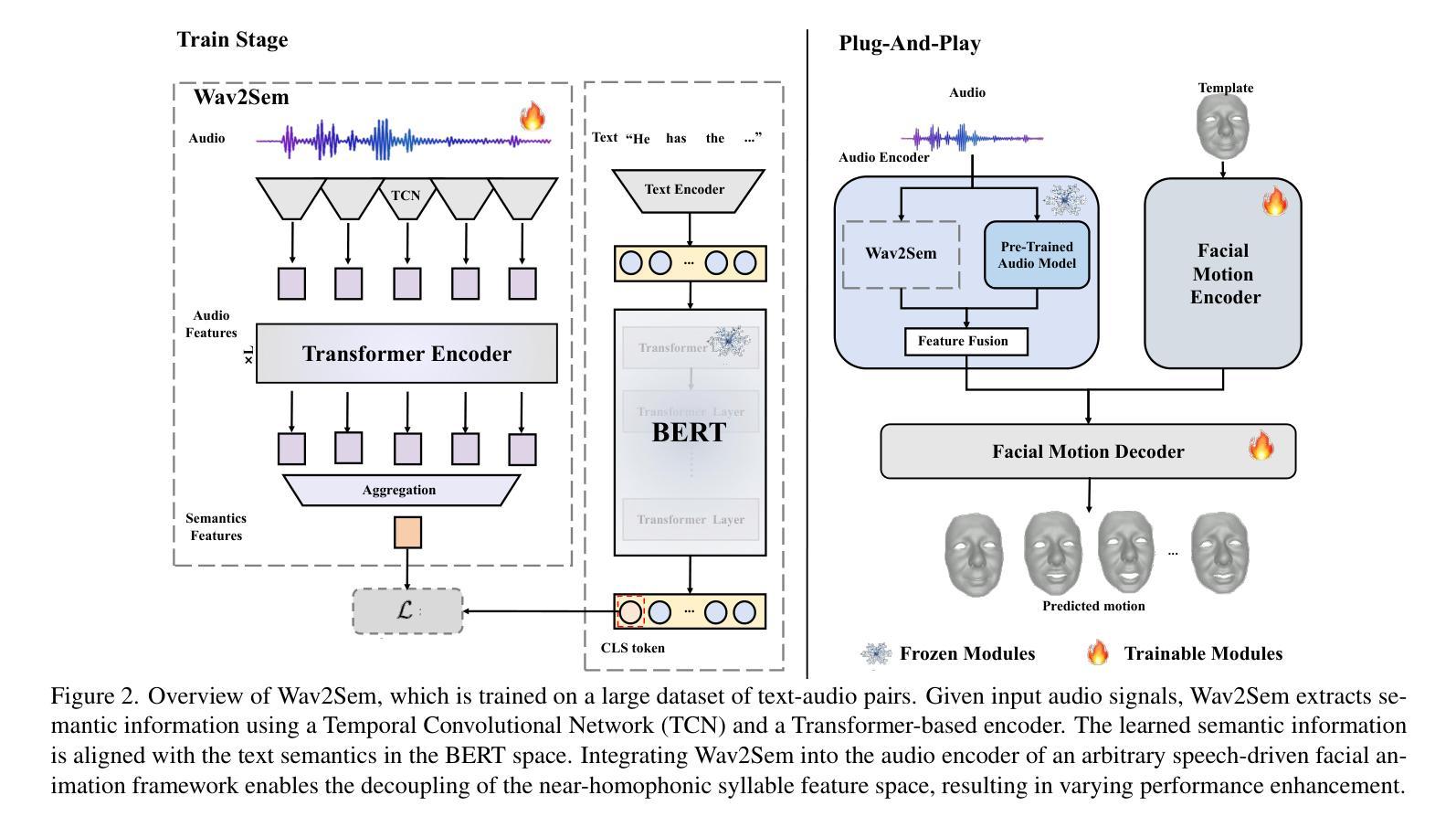
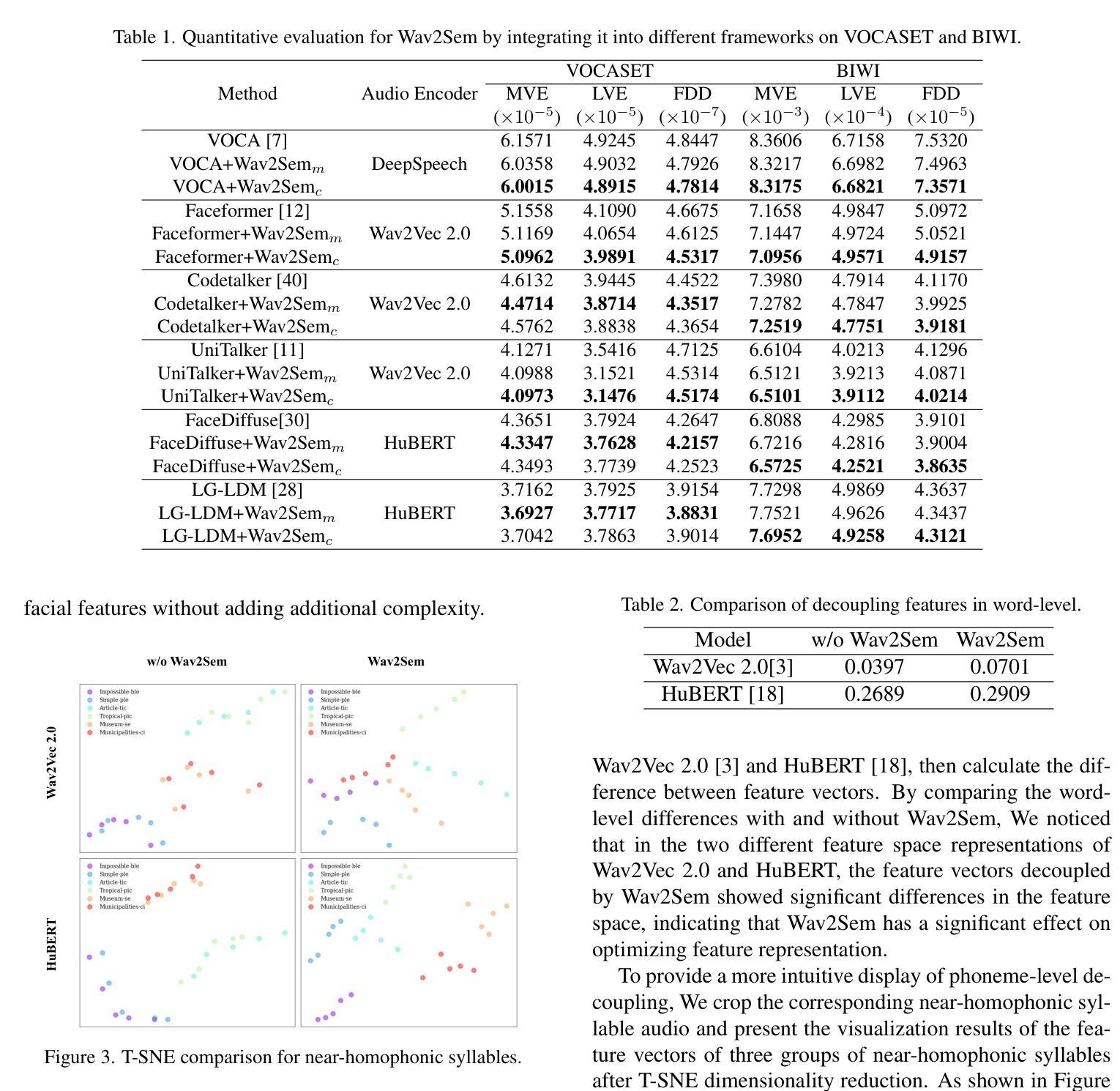
Wav2Sem: Plug-and-Play Audio Semantic Decoupling for 3D Speech-Driven Facial Animation
Authors:Hao Li, Ju Dai, Xin Zhao, Feng Zhou, Junjun Pan, Lei Li
In 3D speech-driven facial animation generation, existing methods commonly employ pre-trained self-supervised audio models as encoders. However, due to the prevalence of phonetically similar syllables with distinct lip shapes in language, these near-homophone syllables tend to exhibit significant coupling in self-supervised audio feature spaces, leading to the averaging effect in subsequent lip motion generation. To address this issue, this paper proposes a plug-and-play semantic decorrelation module-Wav2Sem. This module extracts semantic features corresponding to the entire audio sequence, leveraging the added semantic information to decorrelate audio encodings within the feature space, thereby achieving more expressive audio features. Extensive experiments across multiple Speech-driven models indicate that the Wav2Sem module effectively decouples audio features, significantly alleviating the averaging effect of phonetically similar syllables in lip shape generation, thereby enhancing the precision and naturalness of facial animations. Our source code is available at https://github.com/wslh852/Wav2Sem.git.
在3D语音驱动面部动画生成方面,现有方法通常使用预训练的自我监督音频模型作为编码器。然而,由于语言中音位相似但唇形不同的音节普遍存在,这些近似同音节的音节在自我监督的音频特征空间中往往表现出显著的耦合现象,导致后续唇动生成的平均效应。为了解决这一问题,本文提出了即插即用的语义去相关模块——Wav2Sem。该模块提取与整个音频序列对应的语义特征,利用添加的语义信息去相关特征空间中的音频编码,从而实现更具表现力的音频特征。在多个语音驱动模型上的广泛实验表明,Wav2Sem模块能够有效地解耦音频特征,显著减轻音位相似音节在唇形生成中的平均效应,从而提高面部动画的精确性和自然度。我们的源代码位于https://github.com/wslh852/Wav2Sem.git。
论文及项目相关链接
PDF Accepted to CVPR 2025
Summary
针对3D语音驱动面部动画生成中现有方法存在的同音近似音节导致的平均效应问题,本文提出了一种即插即用的语义去相关模块——Wav2Sem。该模块通过提取整个音频序列的语义特征,利用附加的语义信息去相关音频特征空间中的编码,从而实现更丰富的音频特征表达。实验证明,Wav2Sem模块有效解耦音频特征,显著减轻了语音相似音节在唇形生成中的平均效应,提高了面部动画的精准性和自然度。
Key Takeaways
- 现有3D语音驱动面部动画生成方法常使用预训练的自我监督音频模型作为编码器。
- 语言中存在大量发音相似但唇形不同的音节,这导致在自我监督的音频特征空间中出现显著的耦合现象。
- Wav2Sem是一种语义去相关模块,旨在解决上述问题。
- Wav2Sem通过提取整个音频序列的语义特征,利用附加语义信息去相关音频编码。
- Wav2Sem模块能更精准地生成面部动画,特别是在唇形方面。
- Wav2Sem显著提高了音频特征的表达能力,并有效缓解了发音相似音节在唇形生成中的平均效应。
点此查看论文截图