⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-01 更新
VideoReasonBench: Can MLLMs Perform Vision-Centric Complex Video Reasoning?
Authors:Yuanxin Liu, Kun Ouyang, Haoning Wu, Yi Liu, Lin Sui, Xinhao Li, Yan Zhong, Y. Charles, Xinyu Zhou, Xu Sun
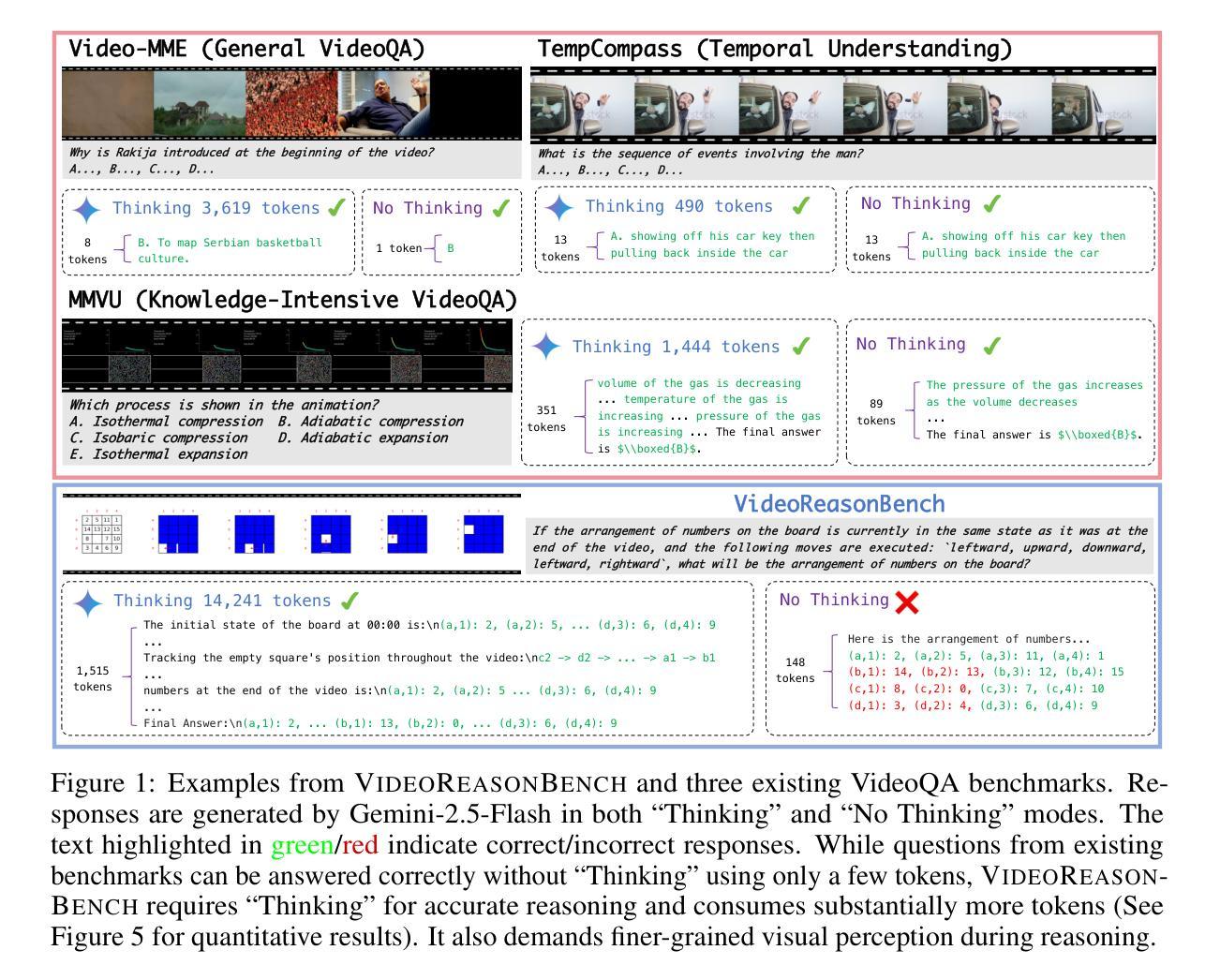
Recent studies have shown that long chain-of-thought (CoT) reasoning can significantly enhance the performance of large language models (LLMs) on complex tasks. However, this benefit is yet to be demonstrated in the domain of video understanding, since most existing benchmarks lack the reasoning depth required to demonstrate the advantages of extended CoT chains. While recent efforts have proposed benchmarks aimed at video reasoning, the tasks are often knowledge-driven and do not rely heavily on visual content. To bridge this gap, we introduce VideoReasonBench, a benchmark designed to evaluate vision-centric, complex video reasoning. To ensure visual richness and high reasoning complexity, each video in VideoReasonBench depicts a sequence of fine-grained operations on a latent state that is only visible in part of the video. The questions evaluate three escalating levels of video reasoning skills: recalling observed visual information, inferring the content of latent states, and predicting information beyond the video. Under such task setting, models have to precisely recall multiple operations in the video, and perform step-by-step reasoning to get correct final answers for these questions. Using VideoReasonBench, we comprehensively evaluate 18 state-of-the-art multimodal LLMs (MLLMs), finding that most perform poorly on complex video reasoning, e.g., GPT-4o achieves only 6.9% accuracy, while the thinking-enhanced Gemini-2.5-Pro significantly outperforms others with 56.0% accuracy. Our investigations on “test-time scaling” further reveal that extended thinking budget, while offering none or minimal benefits on existing video benchmarks, is essential for improving the performance on VideoReasonBench.
最近的研究表明,长链思维(CoT)推理可以显著增强大型语言模型(LLM)在复杂任务上的性能。然而,这一优势在视频理解领域尚未得到证明,因为大多数现有的基准测试缺乏展示长链思维优势所需的推理深度。尽管最近有努力提出了旨在视频推理的基准测试,但这些任务通常是知识驱动的,并不太依赖视觉内容。为了弥补这一差距,我们推出了VideoReasonBench基准测试,旨在评估以视觉为中心、复杂的视频推理。为确保视觉丰富性和高推理复杂性,VideoReasonBench中的每个视频都描述了一系列潜在状态的精细操作,这些状态仅在视频的一部分中可见。问题部分评估了三个递增级别的视频推理技能:回忆观察到的视觉信息、推断潜在状态的内容和预测视频之外的信息。在这样的任务设置中,模型必须精确回忆视频中的多个操作,并进行逐步推理,以正确回答这些问题。使用VideoReasonBench基准测试,我们对18个最新先进的多模态大型语言模型(MLLMs)进行了全面评估,发现大多数模型在复杂的视频推理上表现不佳,例如GPT-4o的准确率仅为6.9%,而思维增强的Gemini-2.5-Pro则显著优于其他模型,达到56.0%的准确率。我们对“测试时缩放”的进一步调查表明,在现有的视频基准测试中,增加思考时间并没有带来多少好处,但在VideoReasonBench上却对提高性能至关重要。
论文及项目相关链接
PDF Project Page: https://llyx97.github.io/video_reason_bench/
Summary
本文介绍了一项针对视频理解领域的新研究,该研究引入了VideoReasonBench基准测试平台,旨在评估以视觉为中心的复杂视频推理能力。该平台强调视频的视觉丰富性和高推理复杂性,要求模型能够精确回忆视频中的多个操作,并进行逐步推理以获取正确的答案。研究对18种最先进的多媒体大型语言模型进行了全面评估,发现大多数模型在复杂视频推理方面表现不佳,而思考增强的Gemini-2.5-Pro模型显著优于其他模型。此外,研究还探讨了“测试时间缩放”的影响,发现增加思考预算对于提高VideoReasonBench上的性能至关重要,而对现有视频基准测试的影响微乎其微。
Key Takeaways
- VideoReasonBench是一个旨在评估复杂视频推理能力的基准测试平台。
- 该平台强调视频的视觉丰富性和高推理复杂性。
- 现有大型语言模型在复杂视频推理方面表现不佳。
- Gemini-2.5-Pro模型在VideoReasonBench上的表现显著优于其他模型。
- “测试时间缩放”研究显示,增加思考预算对改善复杂视频推理性能至关重要。
- 增加思考预算对现有的视频基准测试影响甚微。
点此查看论文截图


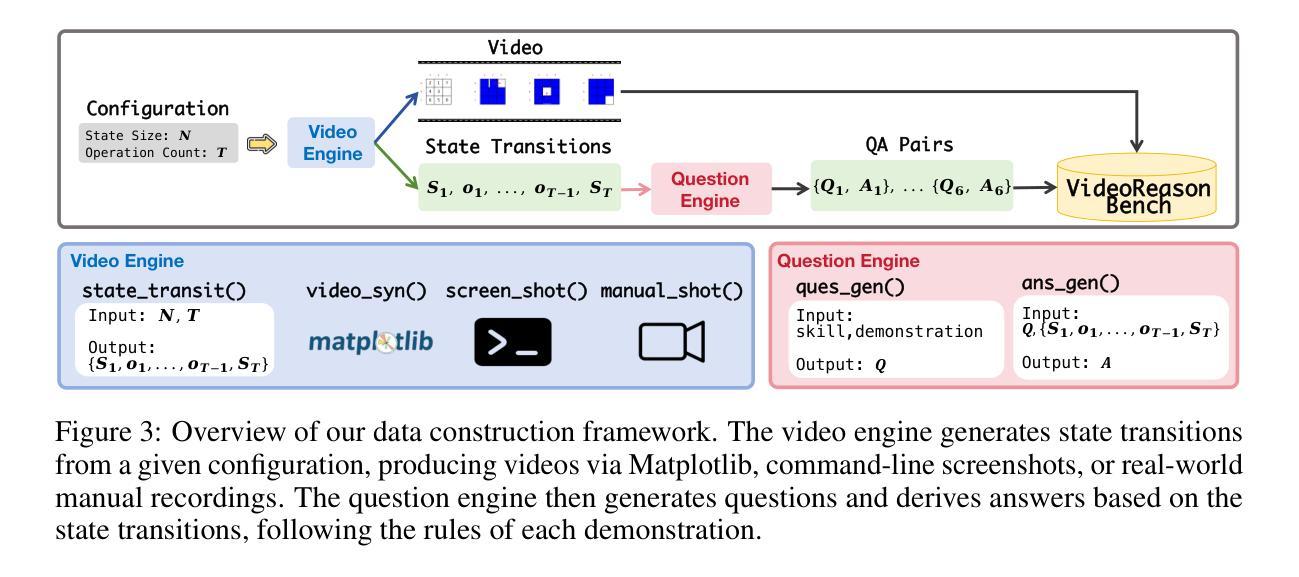
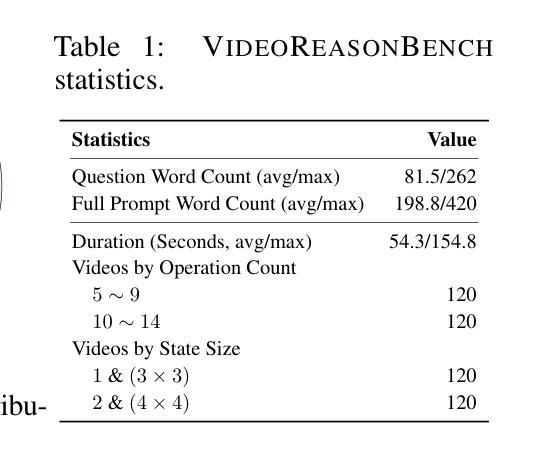
ScEdit: Script-based Assessment of Knowledge Editing
Authors:Xinye Li, Zunwen Zheng, Qian Zhang, Dekai Zhuang, Jiabao Kang, Liyan Xu, Qingbin Liu, Xi Chen, Zhiying Tu, Dianhui Chu, Dianbo Sui
Knowledge Editing (KE) has gained increasing attention, yet current KE tasks remain relatively simple. Under current evaluation frameworks, many editing methods achieve exceptionally high scores, sometimes nearing perfection. However, few studies integrate KE into real-world application scenarios (e.g., recent interest in LLM-as-agent). To support our analysis, we introduce a novel script-based benchmark – ScEdit (Script-based Knowledge Editing Benchmark) – which encompasses both counterfactual and temporal edits. We integrate token-level and text-level evaluation methods, comprehensively analyzing existing KE techniques. The benchmark extends traditional fact-based (“What”-type question) evaluation to action-based (“How”-type question) evaluation. We observe that all KE methods exhibit a drop in performance on established metrics and face challenges on text-level metrics, indicating a challenging task. Our benchmark is available at https://github.com/asdfo123/ScEdit.
知识编辑(KE)越来越受到关注,但当前的KE任务仍然相对简单。在现有的评估框架下,许多编辑方法都取得了异常高的分数,有时甚至接近完美。然而,很少有研究将KE集成到现实世界的应用场景中(例如最近对LLM-as-agent的兴趣)。为了支持我们的分析,我们引入了一种新型的基于脚本的基准测试——ScEdit(基于脚本的知识编辑基准测试),它涵盖了事实性和时间性的编辑。我们整合了令牌级别和文本级别的评估方法,全面分析了现有的KE技术。该基准测试将传统的基于事实(“是什么”类型问题)的评估扩展到基于行动(“如何做”类型问题)的评估。我们发现,所有KE方法在既定指标上的表现都有所下降,并且在文本级别指标上遇到了挑战,表明任务具有挑战性。我们的基准测试在https://github.com/asdfo123/ScEdit可获取。
论文及项目相关链接
PDF ACL 2025 Findings
Summary
本文介绍了知识编辑(KE)的当前状况及其面临的挑战。尽管KE已经引起了广泛关注,但现有任务相对简单,评估框架下的许多编辑方法得分极高,但实际应用场景中的集成较少。为此,作者引入了一个新的脚本基准——ScEdit,它包括事实性和时序性编辑,对现有的KE技术进行了全面的分析。该基准扩展了传统的事实性评价,引入了行动性评价,发现所有KE方法在新基准上的性能都有所下降,表明该任务具有挑战性。
Key Takeaways
- 当前知识编辑(KE)任务相对简单,评估方法下的许多编辑方法表现优异。
- 实际应用中将KE集成到现实场景(如LLM-as-agent)的研究较少。
- 引入新型脚本基准ScEdit,涵盖事实性和时序性编辑。
- ScEdit基准扩展了传统的事实性评价,引入了行动性评价。
- KE方法在ScEdit基准上的性能有所下降,表明该任务具有挑战性。
- ScEdit基准提供了全面的评估方法,包括token-level和text-level评价方法。
点此查看论文截图

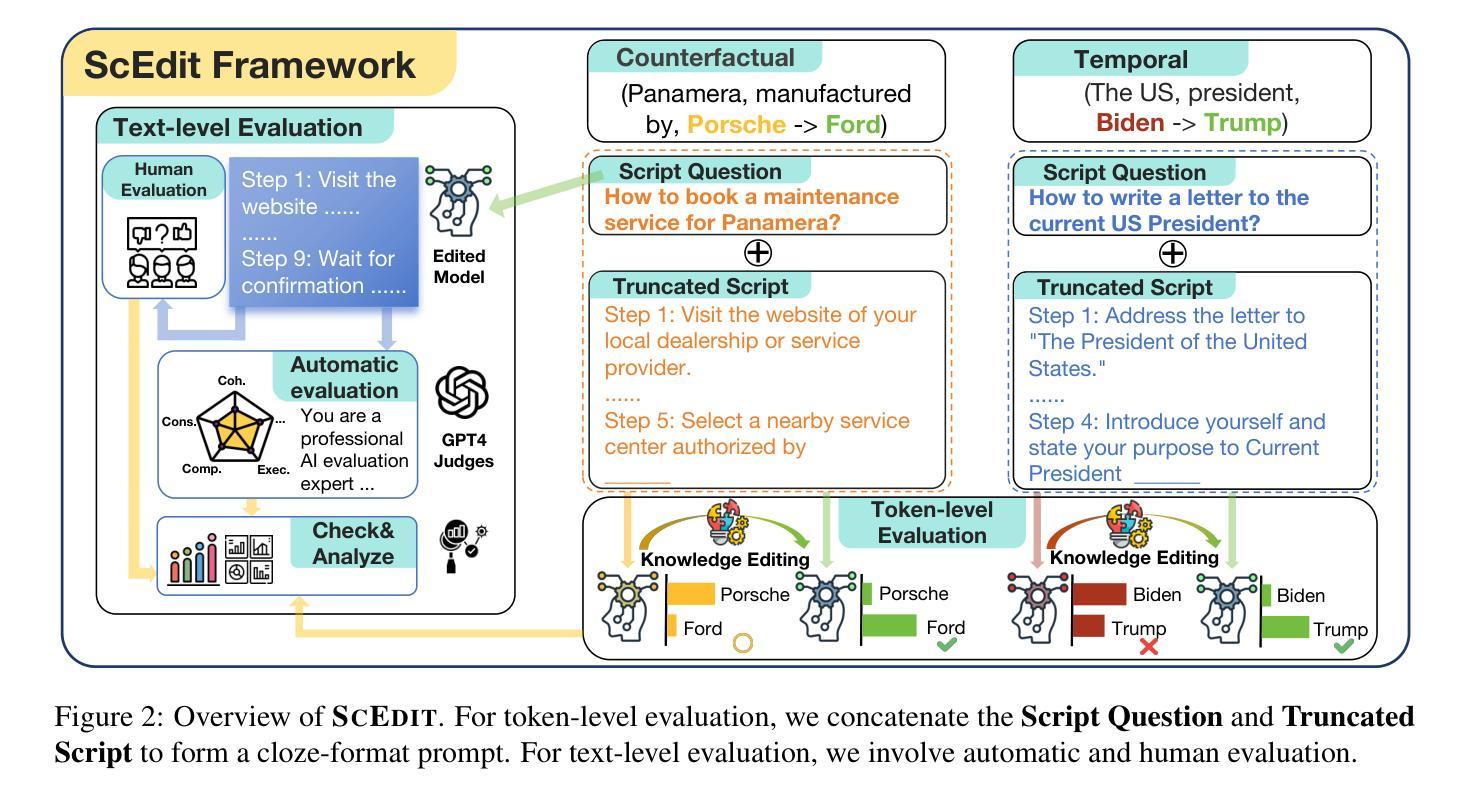

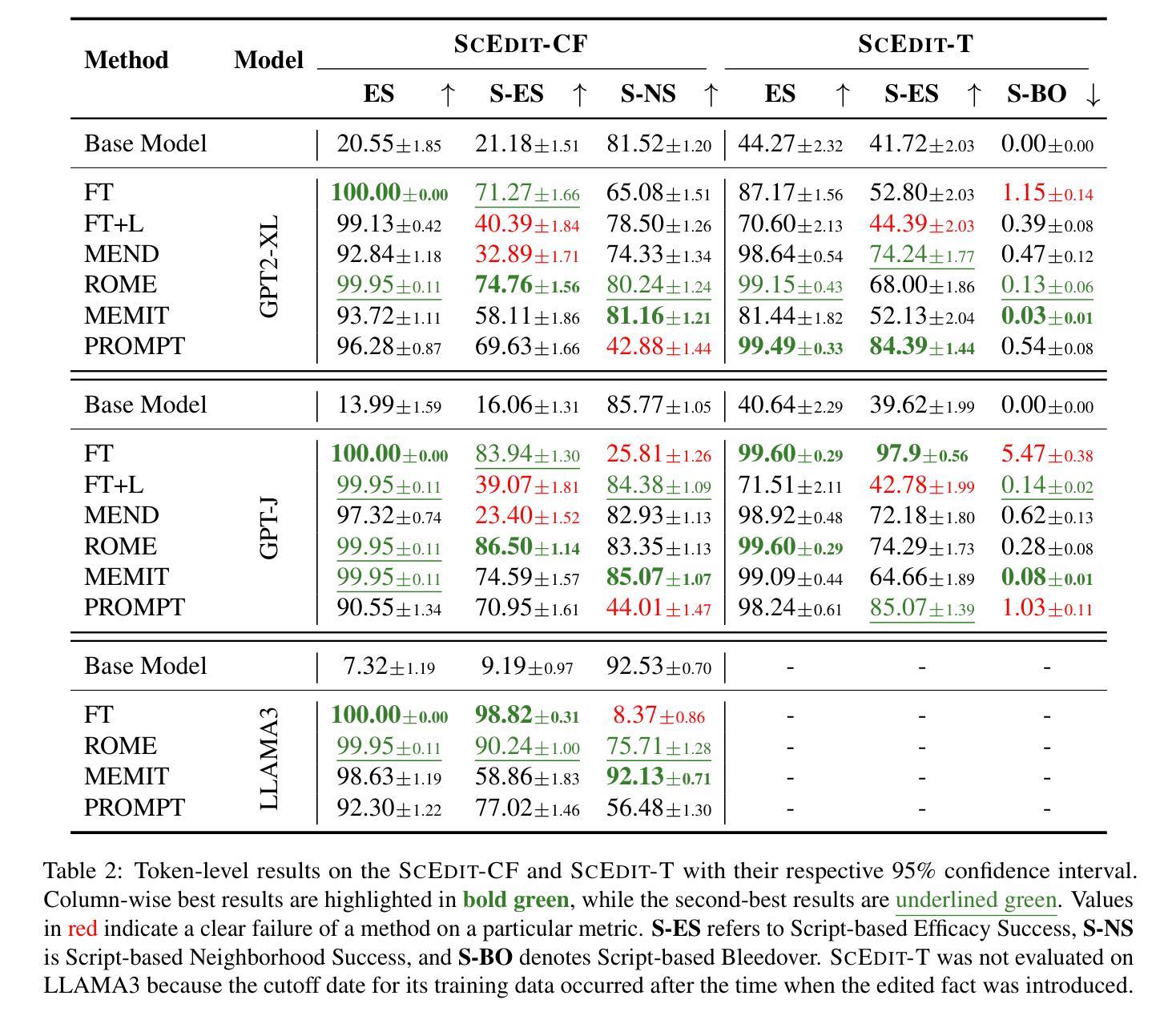
Are MLMs Trapped in the Visual Room?
Authors:Yazhou Zhang, Chunwang Zou, Qimeng Liu, Lu Rong, Ben Yao, Zheng Lian, Qiuchi Li, Peng Zhang, Jing Qin
Can multi-modal large models (MLMs) that can see'' an image be said to understand’’ it? Drawing inspiration from Searle’s Chinese Room, we propose the \textbf{Visual Room} argument: a system may process and describe every detail of visual inputs by following algorithmic rules, without genuinely comprehending the underlying intention. This dilemma challenges the prevailing assumption that perceptual mastery implies genuine understanding. In implementation, we introduce a two-tier evaluation framework spanning perception and cognition. The perception component evaluates whether MLMs can accurately capture the surface-level details of visual contents, where the cognitive component examines their ability to infer sarcasm polarity. To support this framework, We further introduce a high-quality multi-modal sarcasm dataset comprising both 924 static images and 100 dynamic videos. All sarcasm labels are annotated by the original authors and verified by independent reviewers to ensure clarity and consistency. We evaluate eight state-of-the-art (SoTA) MLMs. Our results highlight three key findings: (1) MLMs perform well on perception tasks; (2) even with correct perception, models exhibit an average error rate of ~16.1% in sarcasm understanding, revealing a significant gap between seeing and understanding; (3) error analysis attributes this gap to deficiencies in emotional reasoning, commonsense inference, and context alignment. This work provides empirical grounding for the proposed Visual Room argument and offers a new evaluation paradigm for MLMs.
能否说能够“看到”图像的多模态大型模型(MLMs)就“理解”了它?从塞尔的中文房间(Chinese Room)中获得灵感,我们提出了视觉房间(Visual Room)论证:一个系统可能会按照算法规则处理和描述视觉输入的每一个细节,而并没有真正理解其背后的意图。这种困境挑战了普遍存在的假设,即感知掌握意味着真正的理解。在实现过程中,我们引入了一个跨越感知和认知的二层评估框架。感知组件评估MLMs是否能准确捕捉视觉内容的表层细节,认知组件则考察它们推断讽刺极性的能力。为了支持这一框架,我们还引入了一个高质量的多模态讽刺数据集,其中包含924张静态图像和100个动态视频。所有的讽刺标签都由原始作者标注,并由独立审查人员验证,以确保清晰和一致性。我们评估了八种最先进的MLMs。我们的结果突出了三个关键发现:(1)MLMs在感知任务上表现良好;(2)即使在感知正确的情况下,模型在理解讽刺方面的平均错误率仍达到约16.1%,揭示了“看到”和“理解”之间的显著差距;(3)错误分析将这种差距归因于情感推理、常识推理和上下文对齐方面的不足。这项工作为提出的视觉房间论证提供了实证依据,并为MLMs提供了新的评估范式。
论文及项目相关链接
Summary:
多模态大型模型(MLMs)能否通过视觉理解图像仍存在争议。借鉴塞耶尔的中文房间理论,我们提出视觉房间论证:系统可以处理并描述视觉输入的每一个细节,遵循算法规则,但不一定真正理解了其内在意图。本文介绍了我们的评估框架和数据集,发现即使是顶尖模型也存在情感推理、常识推断和语境对齐上的不足,这证实了视觉房间论证的有效性。
Key Takeaways:
- 多模态大型模型(MLMs)可以准确捕捉视觉内容的表面细节,但在理解层面存在局限。
- 视觉房间论证挑战了感知掌握即真正理解的假设。
- 引入的两层评估框架包括感知和认知,其中认知部分考察模型推理讽刺的能力。
- 高质量的多模态讽刺数据集包含静态图像和动态视频。
- 八款最新MLMs的评估结果显示,在讽刺理解方面存在约16.1%的平均错误率。
- 错误分析表明,这一理解差距源于情感推理、常识推断和语境对齐上的不足。
点此查看论文截图


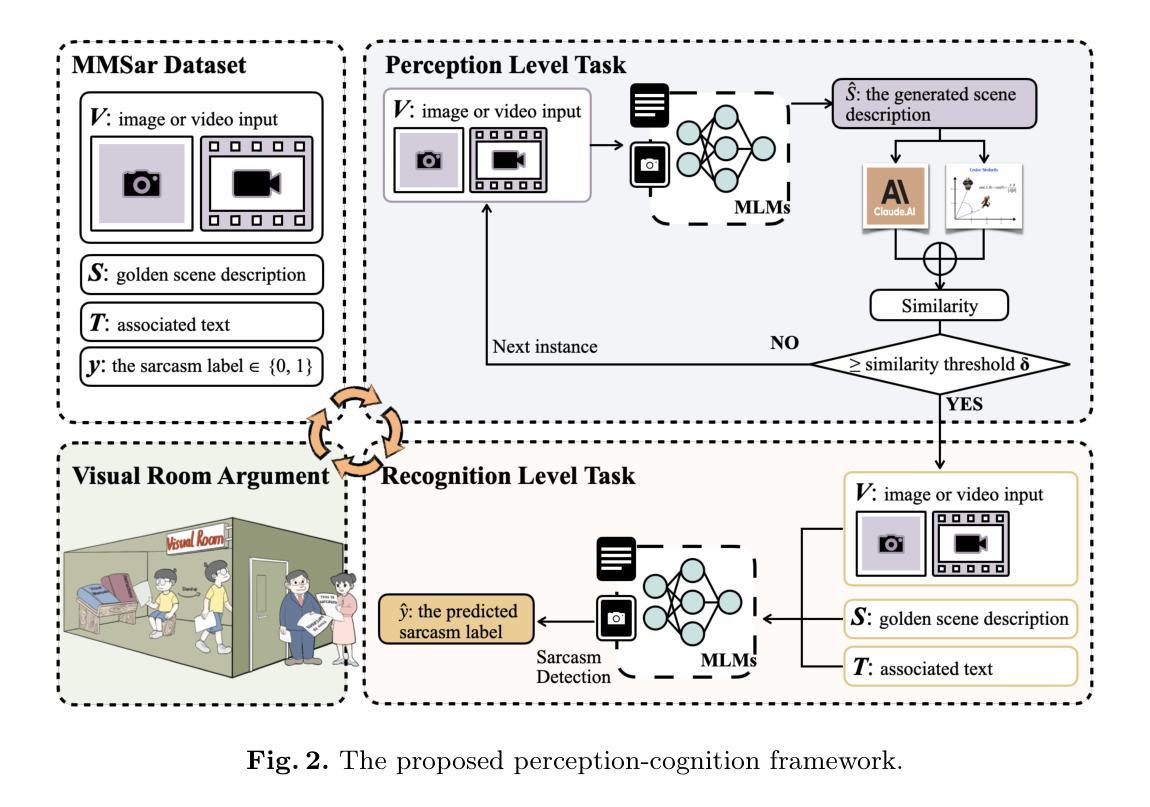
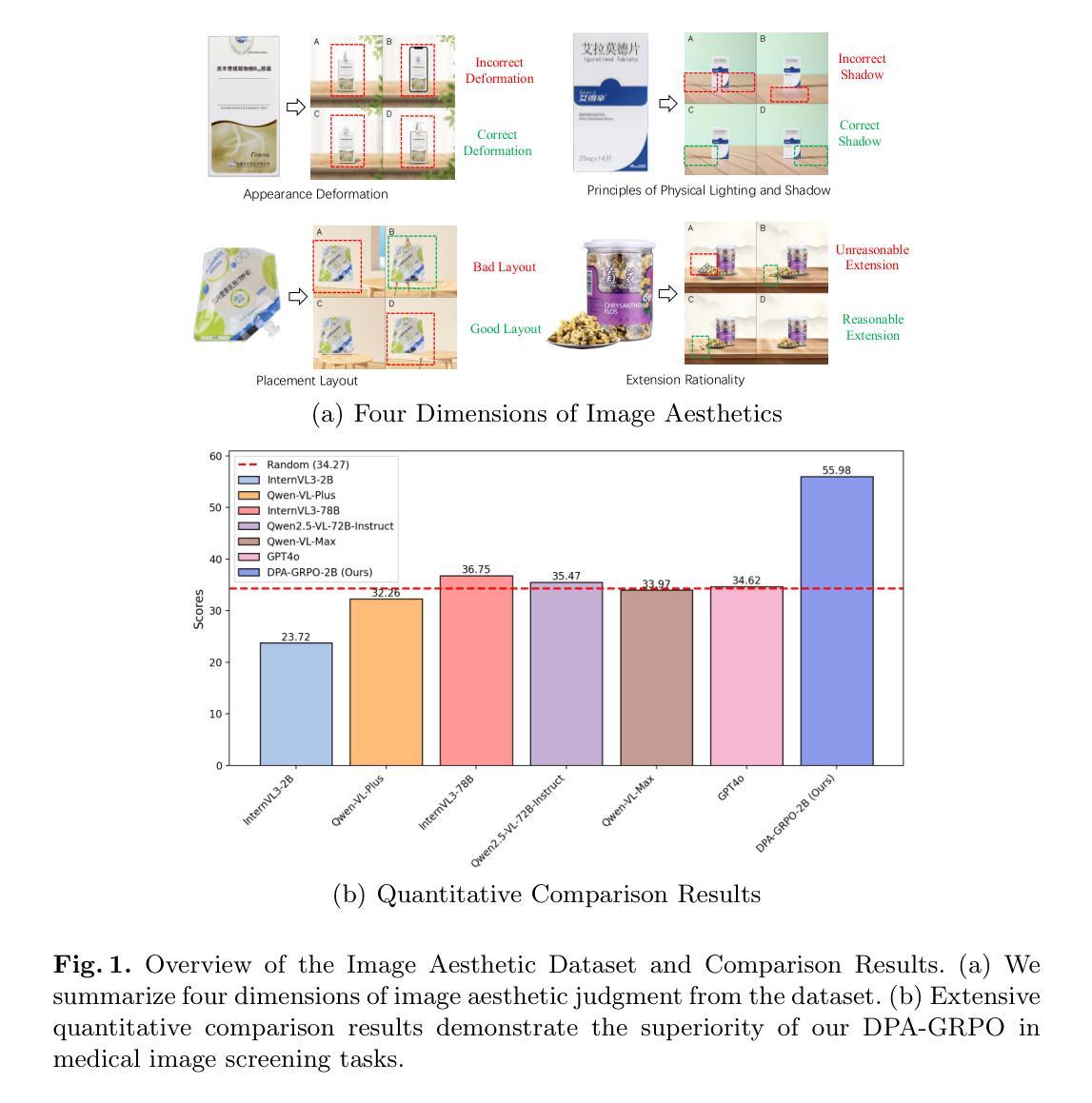
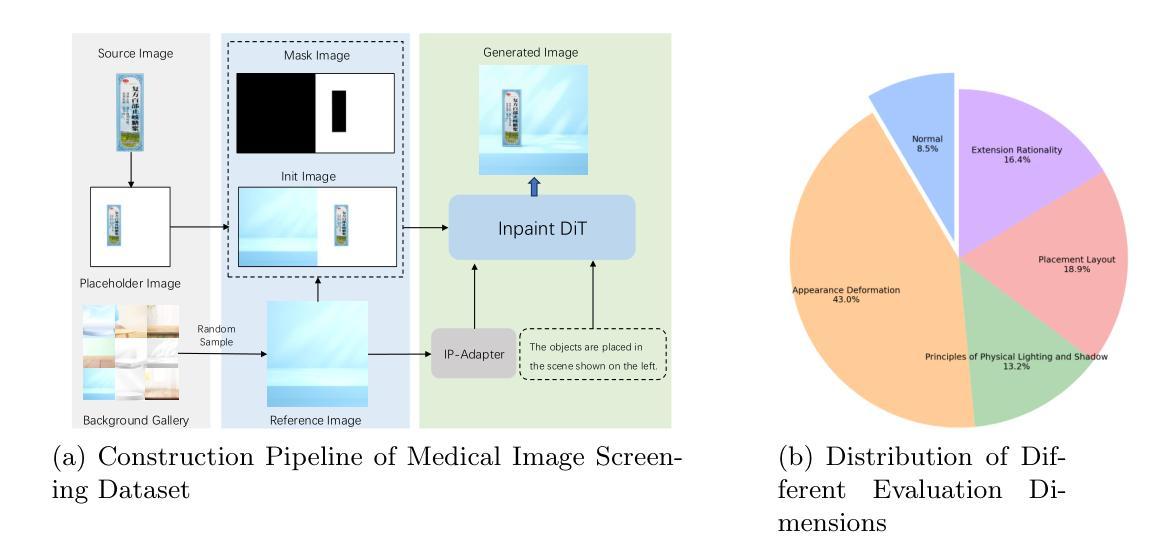
Image Aesthetic Reasoning: A New Benchmark for Medical Image Screening with MLLMs
Authors:Zheng Sun, Yi Wei, Long Yu
Multimodal Large Language Models (MLLMs) are of great application across many domains, such as multimodal understanding and generation. With the development of diffusion models (DM) and unified MLLMs, the performance of image generation has been significantly improved, however, the study of image screening is rare and its performance with MLLMs is unsatisfactory due to the lack of data and the week image aesthetic reasoning ability in MLLMs. In this work, we propose a complete solution to address these problems in terms of data and methodology. For data, we collect a comprehensive medical image screening dataset with 1500+ samples, each sample consists of a medical image, four generated images, and a multiple-choice answer. The dataset evaluates the aesthetic reasoning ability under four aspects: \textit{(1) Appearance Deformation, (2) Principles of Physical Lighting and Shadow, (3) Placement Layout, (4) Extension Rationality}. For methodology, we utilize long chains of thought (CoT) and Group Relative Policy Optimization with Dynamic Proportional Accuracy reward, called DPA-GRPO, to enhance the image aesthetic reasoning ability of MLLMs. Our experimental results reveal that even state-of-the-art closed-source MLLMs, such as GPT-4o and Qwen-VL-Max, exhibit performance akin to random guessing in image aesthetic reasoning. In contrast, by leveraging the reinforcement learning approach, we are able to surpass the score of both large-scale models and leading closed-source models using a much smaller model. We hope our attempt on medical image screening will serve as a regular configuration in image aesthetic reasoning in the future.
多模态大型语言模型(MLLMs)在众多领域具有广泛的应用,如多模态理解和生成。随着扩散模型(DM)和统一MLLMs的发展,图像生成的性能得到了显著提高。然而,图像筛选的研究很少见,其与MLLMs的性能也不尽人意,这主要是由于数据缺乏以及MLLMs中图像美学推理能力的薄弱。在这项工作中,我们针对数据和方法的这些问题提出了一个完整的解决方案。在数据方面,我们收集了一个全面的医学图像筛选数据集,包含1500多个样本,每个样本包括一张医学图像、四张生成的图像和一个多项选择题。该数据集从以下四个方面评估美学推理能力:(1)外观变形;(2)物理光照和阴影原理;(3)布局放置;(4)扩展合理性。在方法上,我们利用长链思维(CoT)和动态比例精度奖励下的集团相对策略优化(DPA-GRPO),以提高MLLMs的图像美学推理能力。我们的实验结果揭示,即使是最先进的闭源MLLMs,如GPT-4o和Qwen-VL-Max,在图像美学推理方面的表现也如同随机猜测。相比之下,通过利用强化学习的方法,我们能够使用更小的模型超越大型模型和领先闭源模型的得分。我们希望我们的医学图像筛选尝试能为未来的图像美学推理提供常规配置。
论文及项目相关链接
摘要
多模态大型语言模型(MLLMs)在多领域具有广泛应用,如多模态理解和生成。随着扩散模型(DM)和统一MLLMs的发展,图像生成性能得到了显著提高,但对图像筛选的研究较少,且其与MLLMs的性能并不理想,主要由于数据缺乏以及MLLMs中图像美学推理能力较弱。针对这些问题,本研究从数据和方法的维度提出了完整的解决方案。在数据方面,我们收集了一个全面的医学图像筛选数据集,包含1500多个样本,每个样本包括一张医学图像、四张生成图像和多个选择题。该数据集从四个方面评估美学推理能力,包括外观变形、物理光线和阴影原理、布局放置、扩展合理性。在方法上,我们利用长链思维(CoT)和动态比例精度奖励下的集团相对策略优化(DPA-GRPO),提高MLLMs的图像美学推理能力。实验结果表明,即使是最先进的闭源MLLMs,如GPT-4o和Qwen-VL-Max,在图像美学推理方面的表现也与随机猜测无异。而利用强化学习的方法,我们即使使用较小的模型也能超越大型模型和领先闭源模型的成绩。我们期望本研究的医学图像筛选尝试能为未来的图像美学推理提供常规配置。
关键见解
- 多模态大型语言模型(MLLMs)在多领域有广泛应用,但在图像筛选方面的性能有待提高。
- 缺乏数据和MLLMs中的图像美学推理能力弱是主要原因。
- 提出通过收集全面的医学图像筛选数据集来解决数据问题,该数据集注重评估美学推理的多个方面。
- 采用长链思维和集团相对策略优化(DPA-GRPO)来提高MLLMs的图像美学推理能力。
- 实验显示,最先进的闭源MLLMs在图像美学推理方面的表现并不理想。
- 利用强化学习的方法能在较小的模型上实现超越大型和领先闭源模型的成绩。
点此查看论文截图

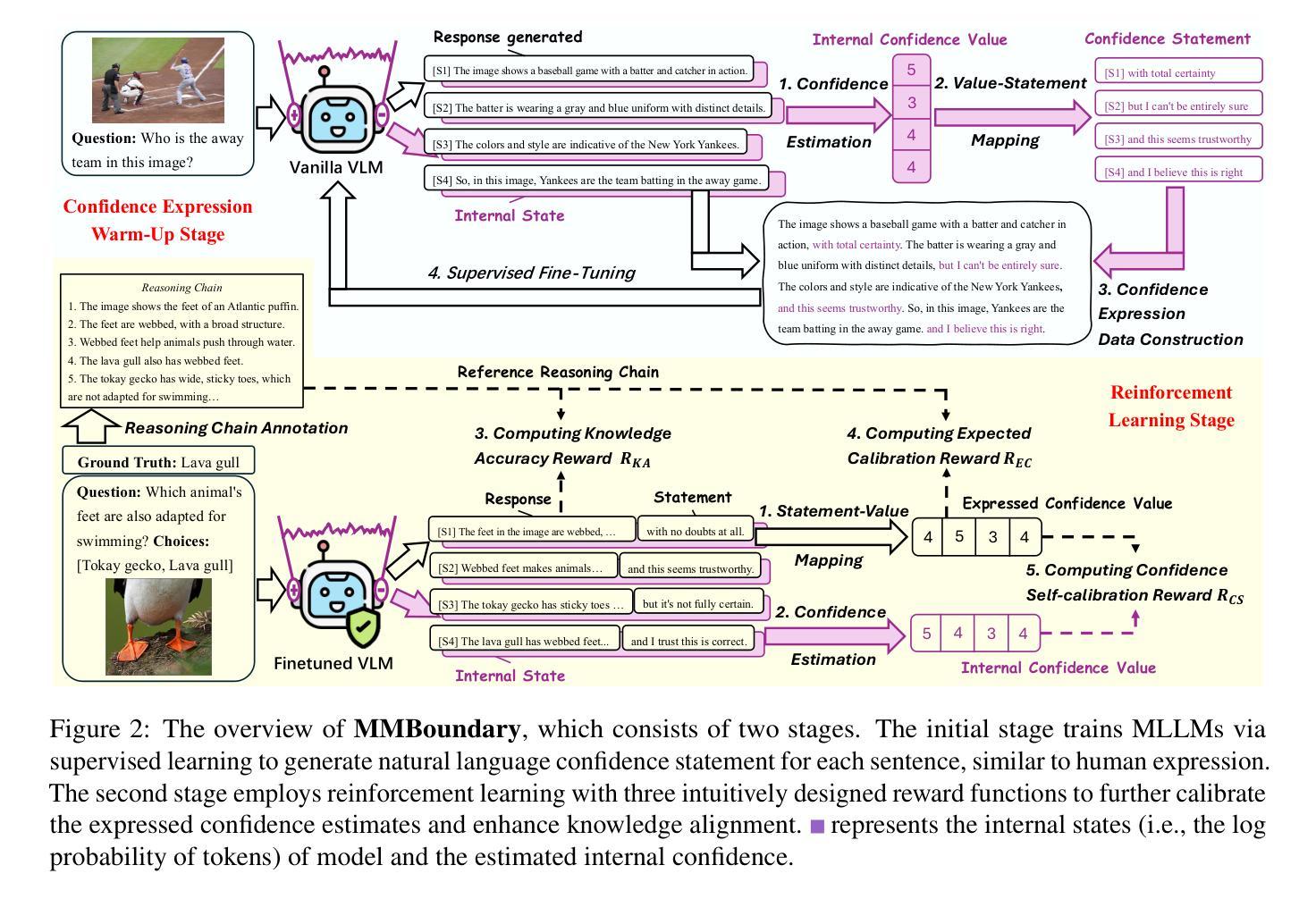
MMBoundary: Advancing MLLM Knowledge Boundary Awareness through Reasoning Step Confidence Calibration
Authors:Zhitao He, Sandeep Polisetty, Zhiyuan Fan, Yuchen Huang, Shujin Wu, Yi R., Fung
In recent years, multimodal large language models (MLLMs) have made significant progress but continue to face inherent challenges in multimodal reasoning, which requires multi-level (e.g., perception, reasoning) and multi-granular (e.g., multi-step reasoning chain) advanced inferencing. Prior work on estimating model confidence tends to focus on the overall response for training and calibration, but fails to assess confidence in each reasoning step, leading to undesirable hallucination snowballing. In this work, we present MMBoundary, a novel framework that advances the knowledge boundary awareness of MLLMs through reasoning step confidence calibration. To achieve this, we propose to incorporate complementary textual and cross-modal self-rewarding signals to estimate confidence at each step of the MLLM reasoning process. In addition to supervised fine-tuning MLLM on this set of self-rewarded confidence estimation signal for initial confidence expression warm-up, we introduce a reinforcement learning stage with multiple reward functions for further aligning model knowledge and calibrating confidence at each reasoning step, enhancing reasoning chain self-correction. Empirical results show that MMBoundary significantly outperforms existing methods across diverse domain datasets and metrics, achieving an average of 7.5% reduction in multimodal confidence calibration errors and up to 8.3% improvement in task performance.
近年来,多模态大型语言模型(MLLMs)取得了显著进展,但在多模态推理方面仍面临固有挑战,这需要进行多层次(例如,感知、推理)和多粒度(例如,多步推理链)的高级推断。以往关于估计模型信心的工作往往集中在训练和校准的整体响应上,但未能评估每一步推理的信心,导致不理想的幻觉累积。在这项工作中,我们提出了MMBoundary,这是一个新型框架,通过推理步骤的信心校准提高MLLMs的知识边界意识。为实现这一目标,我们提出结合互补文本和跨模态自我奖励信号来估计MLLM推理过程中每一步的信心。除了使用自我奖励的信心估计信号对初始信心表达进行微调外,我们还引入了一个强化学习阶段,使用多个奖励函数进一步对齐模型知识并校准每一步推理的信心,增强推理链的自我校正能力。经验结果表明,MMBoundary在多种领域数据集和指标上显著优于现有方法,平均减少7.5%的多模态信心校准误差,任务性能提高8.3%。
论文及项目相关链接
PDF Accepted to ACL 2025
Summary
多模态大型语言模型(MLLMs)近年来在推理方面取得了显著进展,但仍面临多模态推理的内在挑战。现有模型对信心评估往往集中在整体响应的培训和校准上,而无法评估每一步推理的信心,导致出现不希望出现的幻觉累积。本研究提出MMBoundary框架,通过推理步骤的信心校准提高MLLMs的知识边界意识。该研究通过引入补充文本和跨模态自奖励信号来估计MLLM推理过程中每一步的信心。除了对初始信心表达进行微调外,还引入了一个强化学习阶段,通过多重奖励函数进一步对齐模型知识和校准每一步推理的信心,增强推理链的自我校正能力。实证结果表明,MMBoundary在跨域数据集和指标上的表现优于现有方法,平均减少7.5%的多模态信心校准误差,任务性能提高8.3%。
Key Takeaways
- 多模态大型语言模型(MLLMs)面临多模态推理的挑战,需要多级别和多粒度的推理能力。
- 现有模型信心评估主要集中在整体响应的培训和校准,忽视了每一步推理的信心评估。
- MMBoundary框架通过推理步骤的信心校准提高MLLMs的知识边界意识。
- MMBoundary通过引入补充文本和跨模态自奖励信号来估计MLLM推理过程中每一步的信心。
- MMBoundary采用强化学习阶段进一步对齐模型知识和校准信心,增强推理链的自我校正能力。
- 实证结果表明,MMBoundary在跨域数据集和指标上的表现优于现有方法。
点此查看论文截图


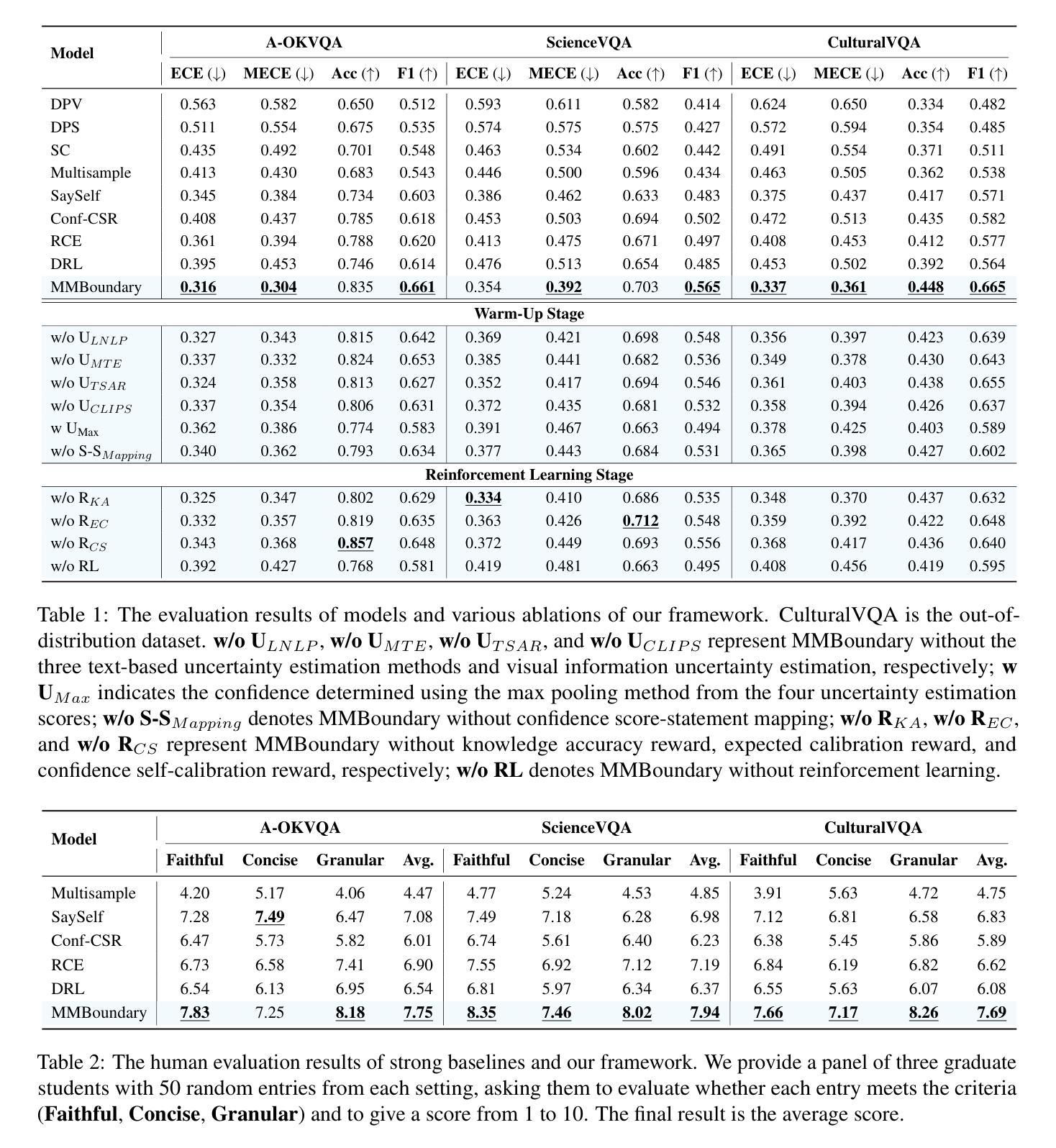
DIP-R1: Deep Inspection and Perception with RL Looking Through and Understanding Complex Scenes
Authors:Sungjune Park, Hyunjun Kim, Junho Kim, Seongho Kim, Yong Man Ro
Multimodal Large Language Models (MLLMs) have demonstrated significant visual understanding capabilities, yet their fine-grained visual perception in complex real-world scenarios, such as densely crowded public areas, remains limited. Inspired by the recent success of reinforcement learning (RL) in both LLMs and MLLMs, in this paper, we explore how RL can enhance visual perception ability of MLLMs. Then we develop a novel RL-based framework, Deep Inspection and Perception with RL (DIP-R1) designed to enhance the visual perception capabilities of MLLMs, by comprehending complex scenes and looking through visual instances closely. DIP-R1 guides MLLMs through detailed inspection of visual scene via three simply designed rule-based reward modelings. First, we adopt a standard reasoning reward encouraging the model to include three step-by-step processes: 1) reasoning for understanding visual scenes, 2) observing for looking through interested but ambiguous regions, and 3) decision-making for predicting answer. Second, a variance-guided looking reward is designed to examine uncertain regions for the second observing process. It explicitly enables the model to inspect ambiguous areas, improving its ability to mitigate perceptual uncertainties. Third, we model a weighted precision-recall accuracy reward enhancing accurate decision-making. We explore its effectiveness across diverse fine-grained object detection data consisting of challenging real-world environments, such as densely crowded scenes. Built upon existing MLLMs, DIP-R1 achieves consistent and significant improvement across various in-domain and out-of-domain scenarios. It also outperforms various existing baseline models and supervised fine-tuning methods. Our findings highlight the substantial potential of integrating RL into MLLMs for enhancing capabilities in complex real-world perception tasks.
多模态大型语言模型(MLLMs)已经展现出显著的理解视觉信息的能力,然而它们在复杂现实场景中的精细视觉感知能力仍然有限,特别是在拥挤的公共场所等场景。本文受强化学习(RL)在大型语言模型(LLMs)和多模态大型语言模型(MLLMs)中取得成功的启发,探索了强化学习如何增强MLLMs的视觉感知能力。然后,我们开发了一种新型的基于强化学习的框架——使用强化学习的深度检测与感知(DIP-R1),旨在通过理解复杂场景和近距离观察视觉实例来增强MLLMs的视觉感知能力。DIP-R1通过三种简单设计的基于规则的奖励建模来引导MLLMs对视觉场景进行详细检查。首先,我们采用标准推理奖励来鼓励模型采用三个逐步过程:1)理解视觉场景的推理过程;2)观察感兴趣但模糊的区域;以及3)预测答案的决策过程。其次,设计了一种方差引导的观察奖励,用于检查第二个观察过程中的不确定区域。这明确地使模型能够检查模糊区域,提高其解决感知不确定性的能力。第三,我们建立了一种加权精度召回准确性奖励,以提高决策的准确性。我们在由具有挑战性的现实环境组成的多种精细对象检测数据上探索了其有效性,例如拥挤的场景。基于现有的MLLMs,DIP-R1在各种领域内和跨领域的场景中实现了持续且显著的改进。它也优于各种现有的基线模型和经过监督微调的方法。我们的研究结果强调了将强化学习整合到MLLMs中以提高复杂现实感知任务能力的巨大潜力。
论文及项目相关链接
摘要
多模态大型语言模型(MLLMs)已展现出显著的理解视觉能力,但它们在复杂现实场景中的精细视觉感知能力仍然受限。本文受强化学习(RL)在LLMs和MLLMs中成功的启发,探索了RL如何增强MLLMs的视觉感知能力。随后,开发了一种新型的基于RL的框架——深度检测与感知RL(DIP-R1),旨在通过理解复杂场景和仔细观察视觉实例来增强MLLMs的视觉感知能力。DIP-R1通过三个简单的基于规则的奖励模型指导MLLMs对视觉场景进行详细检查。首先,我们采用标准推理奖励鼓励模型包括三个步骤的过程:理解视觉场景进行推理、观察有趣但模糊的区域、预测答案进行决策。其次,设计了一种方差引导观察奖励,用于检查第二个观察过程中的不确定区域。它使模型能够检查模糊区域,提高其减少感知不确定性的能力。第三,我们建立了一个加权精度召回准确性奖励以提高决策的准确性。在由密集拥挤场景等具有挑战性的现实环境组成的多样化精细目标检测数据上,验证了其在各种领域内外场景中的有效性和优越性,并优于各种现有的基线模型和监督微调方法。我们的研究结果表明,将强化学习整合到MLLMs中,对于提高复杂现实感知任务的性能具有巨大的潜力。
关键见解
- MLLMs在复杂现实场景中的精细视觉感知能力受限。
- 提出了一种新型的基于强化学习的框架DIP-R1,旨在增强MLLMs的视觉感知能力。
- DIP-R1包含三个基于规则的奖励模型,以指导MLLMs详细检查视觉场景。
- 通过标准推理奖励鼓励模型进行三个步骤的过程:理解视觉场景、观察有趣区域、做出预测决策。
- 设计了方差引导观察奖励,使模型能够检查模糊区域并减少感知不确定性。
- 加权精度召回准确性奖励提高决策的准确性。
点此查看论文截图


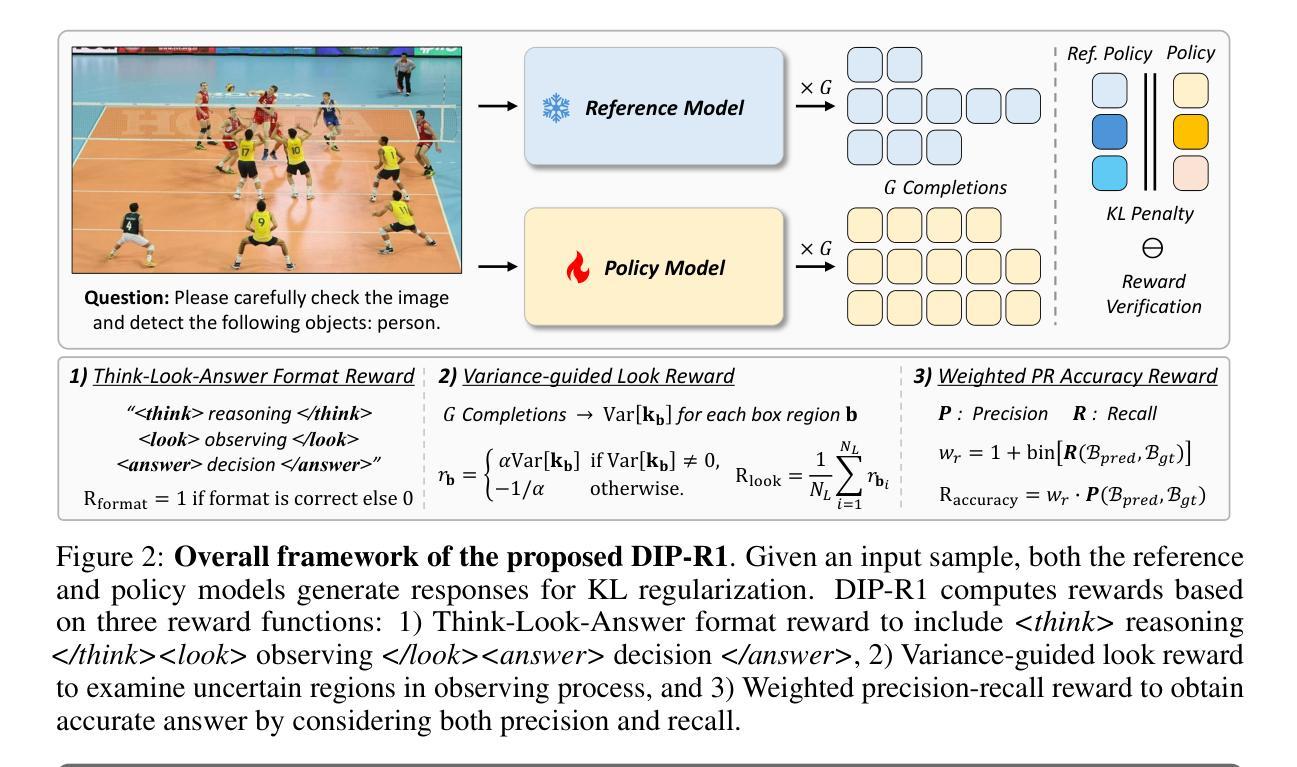
PBEBench: A Multi-Step Programming by Examples Reasoning Benchmark inspired by Historical Linguistics
Authors:Atharva Naik, Darsh Agrawal, Manav Kapadnis, Yuwei An, Yash Mathur, Carolyn Rose, David Mortensen
Recently, long chain of thought (LCoT), Large Language Models (LLMs), have taken the machine learning world by storm with their breathtaking reasoning capabilities. However, are the abstract reasoning abilities of these models general enough for problems of practical importance? Unlike past work, which has focused mainly on math, coding, and data wrangling, we focus on a historical linguistics-inspired inductive reasoning problem, formulated as Programming by Examples. We develop a fully automated pipeline for dynamically generating a benchmark for this task with controllable difficulty in order to tackle scalability and contamination issues to which many reasoning benchmarks are subject. Using our pipeline, we generate a test set with nearly 1k instances that is challenging for all state-of-the-art reasoning LLMs, with the best model (Claude-3.7-Sonnet) achieving a mere 54% pass rate, demonstrating that LCoT LLMs still struggle with a class or reasoning that is ubiquitous in historical linguistics as well as many other domains.
最近,长链思维(Long Chain of Thought,简称LCoT)的大型语言模型(Large Language Models,简称LLM)以其惊人的推理能力席卷了机器学习领域。然而,这些模型的抽象推理能力是否足够应对实际重要问题呢?与过去主要集中在数学、编码和数据处理的工作不同,我们关注一个受历史语言学启发的归纳推理问题,将其形式化为通过示例编程(Programming by Examples)。为了解决许多推理基准测试所面临的扩展性和污染问题,我们开发了一个全自动化的管道,用于动态生成具有可控难度的基准测试。使用我们的管道,我们生成了一个包含近1k实例的测试集,对所有最先进的推理大型语言模型构成了挑战。最好的模型(Claude-3.7-Sonnet)通过率仅为54%,这表明LCoT大型语言模型在历史语言学以及其他许多领域中普遍存在的一类推理仍然困难重重。
论文及项目相关链接
Summary
长链思维(LCoT)大型语言模型(LLMs)的推理能力令人瞩目,但在实际重要问题的抽象推理能力是否足够通用仍存在疑问。不同于过去主要集中在数学、编码和数据整理的研究,我们关注历史语言学启发式的归纳推理问题,并将其制定为“通过示例编程”。我们开发了一个全自动管道,可以动态生成此任务基准测试,并控制其难度,以解决当前许多推理基准测试的扩展性和污染问题。使用此管道,我们生成了一个包含近1000个实例的测试集,对于所有最先进的推理LLM都具有挑战性,最好的模型(Claude-3.7-Sonnet)通过率仅为54%,这表明LCoT LLM在历史语言学以及其他许多领域的通用类推理仍然面临挑战。
Key Takeaways
- LCoT大型语言模型(LLMs)具有强大的推理能力,但在解决实际问题时其通用性尚待检验。
- 与以往关注数学、编码和数据整理的研究不同,该文本聚焦历史语言学启发式的归纳推理问题。
- 提出一种全新的方法——“通过示例编程”来研究和测试LLMs的推理能力。
- 开发了一个全自动管道来动态生成具有可控难度的基准测试,以解决现有推理基准测试的扩展性和污染问题。
- 该管道生成的测试集包含近1000个实例,对现有LLMs构成挑战。
- 最先进的模型(如Claude-3.7-Sonnet)在历史语言学领域的通用类推理任务通过率较低(仅为54%)。
点此查看论文截图

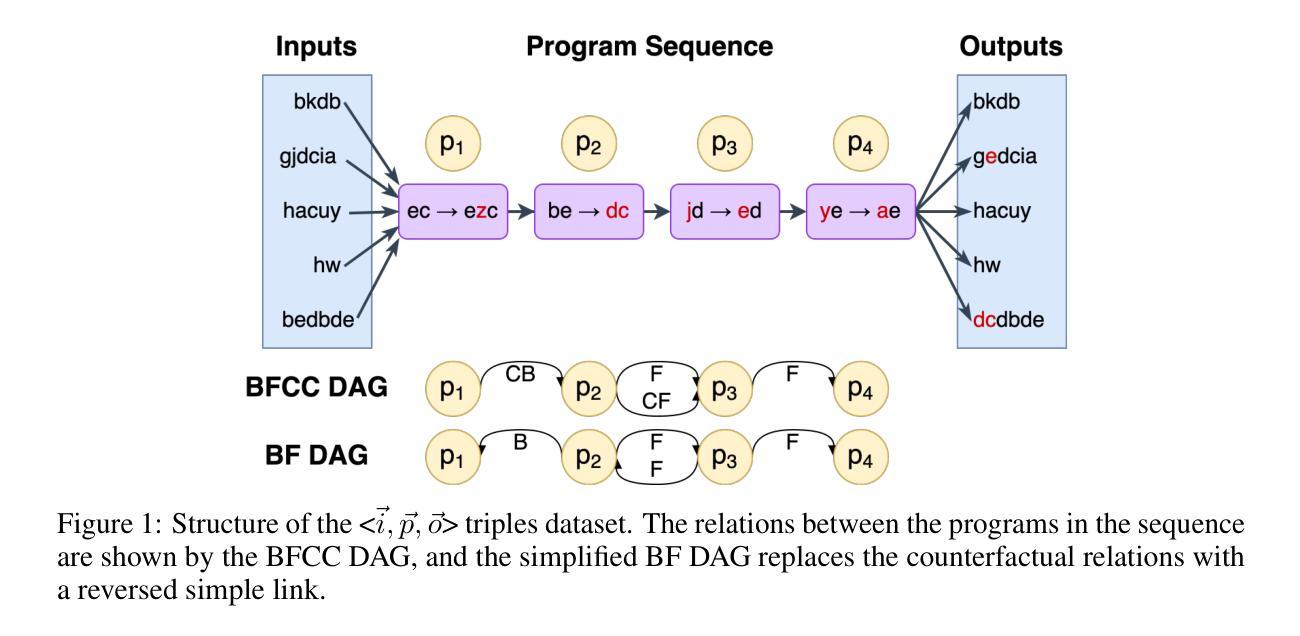
Infi-MMR: Curriculum-based Unlocking Multimodal Reasoning via Phased Reinforcement Learning in Multimodal Small Language Models
Authors:Zeyu Liu, Yuhang Liu, Guanghao Zhu, Congkai Xie, Zhen Li, Jianbo Yuan, Xinyao Wang, Qing Li, Shing-Chi Cheung, Shengyu Zhang, Fei Wu, Hongxia Yang
Recent advancements in large language models (LLMs) have demonstrated substantial progress in reasoning capabilities, such as DeepSeek-R1, which leverages rule-based reinforcement learning to enhance logical reasoning significantly. However, extending these achievements to multimodal large language models (MLLMs) presents critical challenges, which are frequently more pronounced for Multimodal Small Language Models (MSLMs) given their typically weaker foundational reasoning abilities: (1) the scarcity of high-quality multimodal reasoning datasets, (2) the degradation of reasoning capabilities due to the integration of visual processing, and (3) the risk that direct application of reinforcement learning may produce complex yet incorrect reasoning processes. To address these challenges, we design a novel framework Infi-MMR to systematically unlock the reasoning potential of MSLMs through a curriculum of three carefully structured phases and propose our multimodal reasoning model Infi-MMR-3B. The first phase, Foundational Reasoning Activation, leverages high-quality textual reasoning datasets to activate and strengthen the model’s logical reasoning capabilities. The second phase, Cross-Modal Reasoning Adaptation, utilizes caption-augmented multimodal data to facilitate the progressive transfer of reasoning skills to multimodal contexts. The third phase, Multimodal Reasoning Enhancement, employs curated, caption-free multimodal data to mitigate linguistic biases and promote robust cross-modal reasoning. Infi-MMR-3B achieves both state-of-the-art multimodal math reasoning ability (43.68% on MathVerse testmini, 27.04% on MathVision test, and 21.33% on OlympiadBench) and general reasoning ability (67.2% on MathVista testmini).
近期大型语言模型(LLM)的进步在推理能力方面取得了显著成效,例如DeepSeek-R1,它利用基于规则的强化学习来显著增强逻辑推理能力。然而,将这些成就扩展到多模态大型语言模型(MLLM)面临着严峻挑战,对于多模态小型语言模型(MSLM)来说,这些挑战更加突出,因为它们通常的基础推理能力较弱:(1)高质量多模态推理数据集的稀缺,(2)由于集成视觉处理导致的推理能力下降,(3)直接应用强化学习可能产生复杂而错误的推理过程的风险。为了解决这些挑战,我们设计了一个新颖框架Infi-MMR,通过三个精心构建的阶段系统地解锁MSLM的推理潜力,并提出了我们的多模态推理模型Infi-MMR-3B。第一阶段,基础推理激活,利用高质量文本推理数据集来激活和加强模型的逻辑推理能力。第二阶段,跨模态推理适应,使用增强的多媒体数据来促进推理技能向多模态环境的逐步转移。第三阶段,多模态推理增强,采用精选的无字幕多媒体数据来缓解语言偏见,并促进稳健的跨模态推理。Infi-MMR-3B不仅达到了最先进的跨模态数学推理能力(在MathVerse测试集上达到43.68%,在MathVision测试集上达到27.04%,在OlympiadBench上达到21.33%),而且达到了通用推理能力(在MathVista测试集上达到67.2%)。
论文及项目相关链接
Summary
大型语言模型(LLM)在推理能力方面已取得显著进展,如DeepSeek-R1利用基于规则的强化学习来提升逻辑推理能力。然而,将这些成就扩展到多模态大型语言模型(MLLMs)时,面临诸多挑战,特别是在多模态小型语言模型(MSLMs)中更为突出,其基础推理能力通常较弱。挑战包括高质量多模态推理数据集的稀缺性、因集成视觉处理而降低的推理能力以及直接应用强化学习可能产生复杂且错误的推理过程的风险。为解决这些挑战,我们设计了Infi-MMR框架,通过三个精心构建的阶段系统地解锁MSLMs的推理潜力,并提出了多模态推理模型Infi-MMR-3B。该模型经历三个阶段,依次激活基础推理能力、适应跨模态推理以及增强多模态推理。Infi-MMR-3B不仅具有最先进的跨模态数学推理能力,在MathVerse测试mini集上达到了43.68%,在数学视觉测试上达到了27.04%,在OlympiadBench上达到了21.33%,还具有出色的通用推理能力,在MathVista测试mini集上达到了67.2%。
Key Takeaways
- 大型语言模型(LLMs)已在推理能力方面取得显著进展,但仍面临将成果扩展到多模态领域的挑战。
- 多模态小型语言模型(MSLMs)的基础推理能力较弱,面临高质量多模态推理数据集稀缺的问题。
- 多模态推理面临三大核心挑战:数据稀缺、视觉处理导致的推理能力下降以及强化学习的潜在风险。
- 提出了一种新型框架Infi-MMR,通过三个阶段逐步增强MSLMs的推理能力。
- 第一阶段侧重于激活基础推理能力,利用高质量文本推理数据集。
- 第二阶段适应跨模态推理,利用带有描述的多媒体数据促进技能迁移。
- 第三阶段增强多模态推理能力,使用精选的无描述多媒体数据以减少语言偏见并促进稳健的跨模态推理。
点此查看论文截图

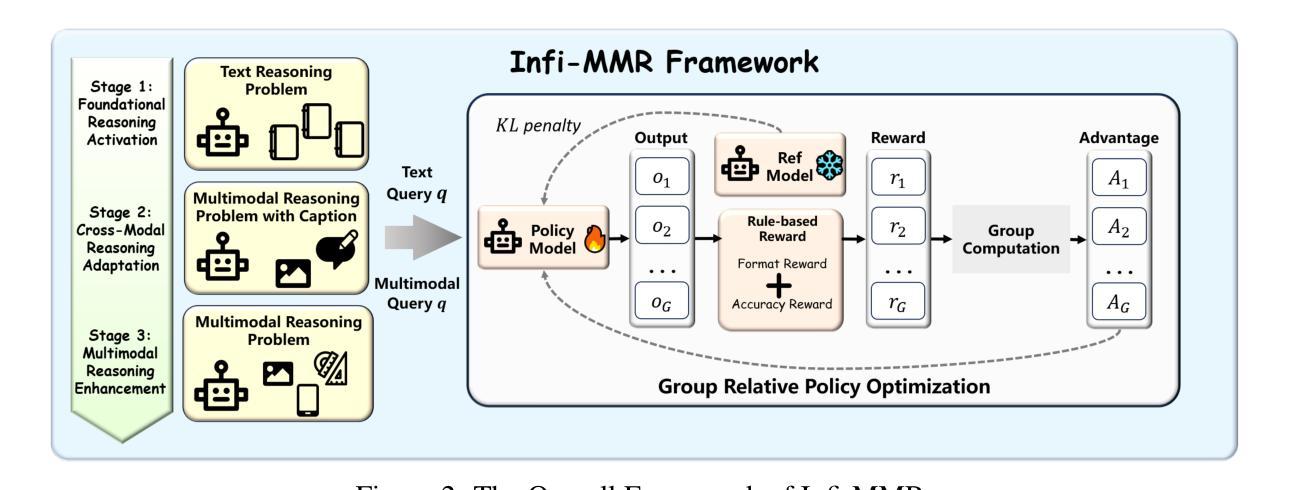
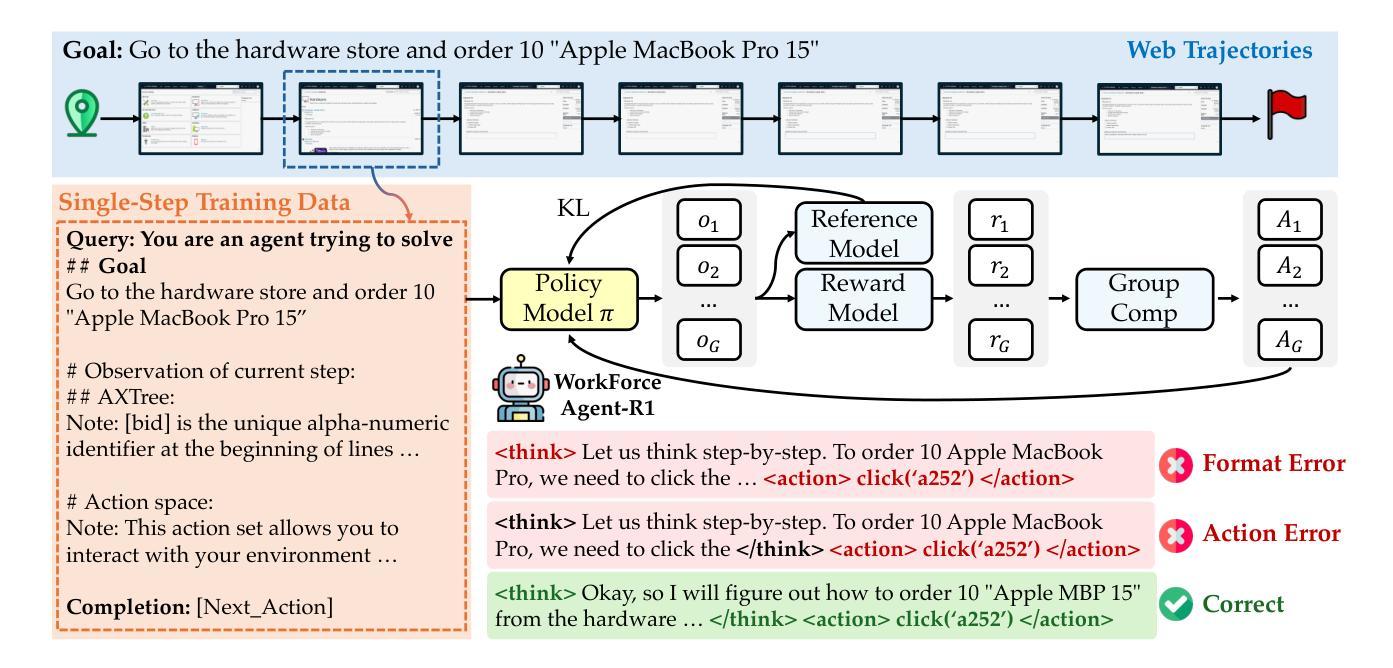
WorkForceAgent-R1: Incentivizing Reasoning Capability in LLM-based Web Agents via Reinforcement Learning
Authors:Yuchen Zhuang, Di Jin, Jiaao Chen, Wenqi Shi, Hanrui Wang, Chao Zhang
Large language models (LLMs)-empowered web agents enables automating complex, real-time web navigation tasks in enterprise environments. However, existing web agents relying on supervised fine-tuning (SFT) often struggle with generalization and robustness due to insufficient reasoning capabilities when handling the inherently dynamic nature of web interactions. In this study, we introduce WorkForceAgent-R1, an LLM-based web agent trained using a rule-based R1-style reinforcement learning framework designed explicitly to enhance single-step reasoning and planning for business-oriented web navigation tasks. We employ a structured reward function that evaluates both adherence to output formats and correctness of actions, enabling WorkForceAgent-R1 to implicitly learn robust intermediate reasoning without explicit annotations or extensive expert demonstrations. Extensive experiments on the WorkArena benchmark demonstrate that WorkForceAgent-R1 substantially outperforms SFT baselines by 10.26-16.59%, achieving competitive performance relative to proprietary LLM-based agents (gpt-4o) in workplace-oriented web navigation tasks.
基于大型语言模型(LLM)的网络代理能够自动完成企业环境中的复杂、实时网络导航任务。然而,现有的依赖于监督微调(SFT)的网络代理往往由于处理网络交互的内在动态性时推理能力不足,在泛化和稳健性方面存在困难。本研究介绍了WorkForceAgent-R1,这是一个基于LLM的网络代理,采用基于规则的R1风格强化学习框架进行训练,专门为提高面向商业网络导航任务的单步推理和规划能力而设计。我们采用结构化的奖励函数,既评估输出格式的遵循情况,又评估行动的正确性,使WorkForceAgent-R1能够隐性学习稳健的中间推理,而无需明确的注释或大量的专家演示。在WorkArena基准测试上的大量实验表明,WorkForceAgent-R1显著优于SFT基准测试,高出10.26-16.59%,在面向工作场所的网络导航任务中,其性能与专有LLM代理(gpt-4o)相当。
论文及项目相关链接
PDF Work in Progress
Summary
基于大型语言模型(LLM)的Web代理能够自动化企业环境中的复杂、实时Web导航任务。然而,依赖监督微调(SFT)的现有Web代理在处理Web交互的内在动态性时,由于推理能力的不足,常常面临泛化和稳健性问题。本研究介绍了WorkForceAgent-R1,这是一个基于LLM的Web代理,采用基于规则的R1风格强化学习框架进行训练,专为增强面向商业的Web导航任务的单步推理和规划能力。我们采用结构化的奖励函数来评估输出格式的遵循情况和行动的准确性,使WorkForceAgent-R1能够在无需明确标注或大量专家演示的情况下,隐式学习稳健的中间推理。在WorkArena基准测试上的广泛实验表明,WorkForceAgent-R1较SFT基线有显著提高,性能提升幅度为10.26%~16.59%,并且在面向职场的Web导航任务中,与专有LLM代理(如gpt-4o)相比表现具有竞争力。
Key Takeaways
- 大型语言模型(LLM)赋能的Web代理可以自动化复杂的实时Web导航任务。
- 现有Web代理在泛化和稳健性方面面临挑战,尤其是处理Web交互的动态性时。
- WorkForceAgent-R1是一个基于LLM的Web代理,采用规则强化学习框架提升商业Web导航任务的推理和规划能力。
- WorkForceAgent-R1通过结构化的奖励函数隐式学习稳健的中间推理,无需明确标注或大量专家演示。
- WorkForceAgent-R1在WorkArena基准测试上的性能较监督微调(SFT)基线有显著提高。
- WorkForceAgent-R1在面向职场的Web导航任务中表现出竞争力,与专有LLM代理相比具有优势。
点此查看论文截图


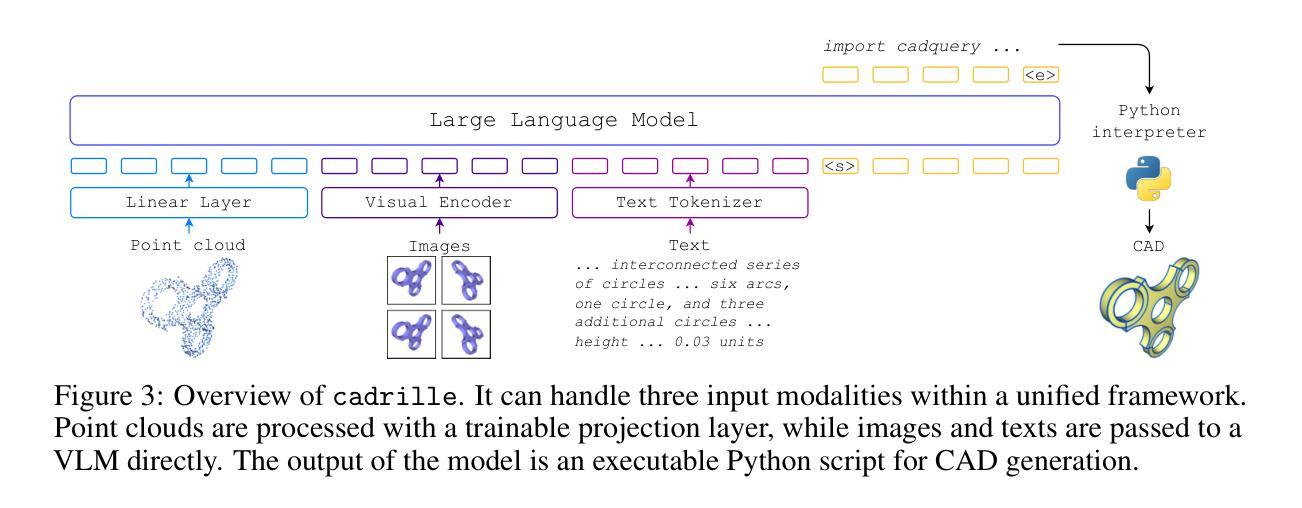
cadrille: Multi-modal CAD Reconstruction with Online Reinforcement Learning
Authors:Maksim Kolodiazhnyi, Denis Tarasov, Dmitrii Zhemchuzhnikov, Alexander Nikulin, Ilya Zisman, Anna Vorontsova, Anton Konushin, Vladislav Kurenkov, Danila Rukhovich
Computer-Aided Design (CAD) plays a central role in engineering and manufacturing, making it possible to create precise and editable 3D models. Using a variety of sensor or user-provided data as inputs for CAD reconstruction can democratize access to design applications. However, existing methods typically focus on a single input modality, such as point clouds, images, or text, which limits their generalizability and robustness. Leveraging recent advances in vision-language models (VLM), we propose a multi-modal CAD reconstruction model that simultaneously processes all three input modalities. Inspired by large language model (LLM) training paradigms, we adopt a two-stage pipeline: supervised fine-tuning (SFT) on large-scale procedurally generated data, followed by reinforcement learning (RL) fine-tuning using online feedback, obtained programatically. Furthermore, we are the first to explore RL fine-tuning of LLMs for CAD tasks demonstrating that online RL algorithms such as Group Relative Preference Optimization (GRPO) outperform offline alternatives. In the DeepCAD benchmark, our SFT model outperforms existing single-modal approaches in all three input modalities simultaneously. More importantly, after RL fine-tuning, cadrille sets new state-of-the-art on three challenging datasets, including a real-world one.
计算机辅助设计(CAD)在工程和制造中扮演着核心角色,能够创建精确且可编辑的3D模型。使用各种传感器或用户提供的数据作为CAD重建的输入,可以使设计应用程序的访问更加民主化。然而,现有方法通常只关注单一的输入模式,如点云、图像或文本,这限制了其通用性和稳健性。我们借助最新的视觉语言模型(VLM)技术,提出了一种多模态CAD重建模型,该模型可以同时处理三种输入模式。受大型语言模型(LLM)训练范式的启发,我们采用了两阶段流程:首先在大规模程序生成数据上进行有监督微调(SFT),然后采用在线反馈进行强化学习(RL)微调,这些反馈是程序获取的。此外,我们是首次探索在CAD任务中使用LLM的RL微调,证明在线RL算法(如Group Relative Preference Optimization(GRPO))胜过离线替代方案。在DeepCAD基准测试中,我们的SFT模型在三种输入模式上均优于现有的单模态方法。更重要的是,经过RL微调后,cadrille在三个具有挑战的数据集上均达到了最新水平,包括一个真实世界的数据集。
论文及项目相关链接
Summary
基于计算机辅助教学设计的关键技术在工程和制造领域的应用及其优势,本文主要介绍了采用多种传感器或用户提供的多种数据作为计算机辅助设计重建的输入,通过利用最新的视觉语言模型技术,提出了一种多模态计算机辅助设计重建模型,该模型可以同时处理三种输入模式。此外,本文首次探索了利用强化学习对大型语言模型进行精细调整的方法在CAD任务中的应用效果,结果显示,与其他线下替代方案相比,集团相对偏好优化等在线强化学习算法更优。
Key Takeaways
- 计算机辅助教学设计在创建精确且可编辑的三维模型方面发挥着关键作用。
- 现有方法通常仅专注于单一的输入模式,如点云、图像或文本,限制了其泛化和稳健性。
- 利用最新的视觉语言模型技术,提出了一种多模态计算机辅助设计重建模型,能够同时处理三种输入模式。
- 研究首次探索了大型语言模型的强化学习精细调整方法用于CAD任务。
- 在线强化学习算法如集团相对偏好优化在CAD任务中表现出优越性能。
- 在DeepCAD基准测试中,精细调整后的模型在所有三种输入模式上的性能均优于现有的单模态方法。
点此查看论文截图


Pangu Embedded: An Efficient Dual-system LLM Reasoner with Metacognition
Authors:Hanting Chen, Yasheng Wang, Kai Han, Dong Li, Lin Li, Zhenni Bi, Jinpeng Li, Haoyu Wang, Fei Mi, Mingjian Zhu, Bin Wang, Kaikai Song, Yifei Fu, Xu He, Yu Luo, Chong Zhu, Quan He, Xueyu Wu, Wei He, Hailin Hu, Yehui Tang, Dacheng Tao, Xinghao Chen, Yunhe Wang
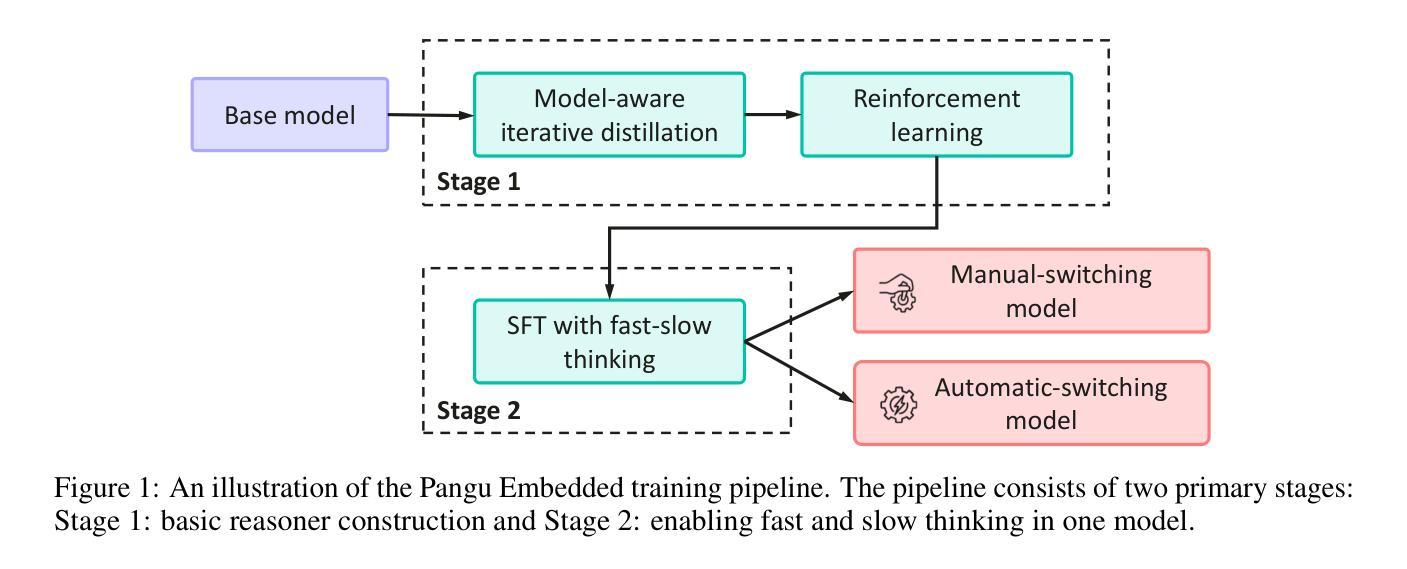
This work presents Pangu Embedded, an efficient Large Language Model (LLM) reasoner developed on Ascend Neural Processing Units (NPUs), featuring flexible fast and slow thinking capabilities. Pangu Embedded addresses the significant computational costs and inference latency challenges prevalent in existing reasoning-optimized LLMs. We propose a two-stage training framework for its construction. In Stage 1, the model is finetuned via an iterative distillation process, incorporating inter-iteration model merging to effectively aggregate complementary knowledge. This is followed by reinforcement learning on Ascend clusters, optimized by a latency-tolerant scheduler that combines stale synchronous parallelism with prioritized data queues. The RL process is guided by a Multi-source Adaptive Reward System (MARS), which generates dynamic, task-specific reward signals using deterministic metrics and lightweight LLM evaluators for mathematics, coding, and general problem-solving tasks. Stage 2 introduces a dual-system framework, endowing Pangu Embedded with a “fast” mode for routine queries and a deeper “slow” mode for complex inference. This framework offers both manual mode switching for user control and an automatic, complexity-aware mode selection mechanism that dynamically allocates computational resources to balance latency and reasoning depth. Experimental results on benchmarks including AIME 2024, GPQA, and LiveCodeBench demonstrate that Pangu Embedded with 7B parameters, outperforms similar-size models like Qwen3-8B and GLM4-9B. It delivers rapid responses and state-of-the-art reasoning quality within a single, unified model architecture, highlighting a promising direction for developing powerful yet practically deployable LLM reasoners.
本文介绍了Pangu Embedded,这是一个在Ascend神经网络处理单元(NPU)上开发的高效大型语言模型(LLM)推理器,具备灵活的快慢思考能力。Pangu Embedded解决了现有优化推理的LLM中普遍存在的计算成本高昂和推理延迟挑战。我们提出了一个两阶段训练框架来构建它。在第一阶段,模型通过迭代蒸馏过程进行微调,并结合跨迭代模型合并,以有效地聚合互补知识。随后是在Ascend集群上进行强化学习,由延迟容忍调度器进行优化,该调度器结合了陈旧同步并行性与优先级数据队列。强化学习过程由多源自适应奖励系统(MARS)引导,该系统利用确定性指标和轻量级LLM评估器生成针对数学、编码和一般问题解决任务的动态、特定任务奖励信号。第二阶段引入了一个双系统框架,赋予Pangu Embedded一种用于常规查询的“快速”模式和一种用于复杂推理的更深层次“慢速”模式。该框架提供了手动模式切换供用户控制和一种自动、感知复杂性的模式选择机制,以动态分配计算资源来平衡延迟和推理深度。在AIME 2024、GPQA和LiveCodeBench等基准测试上的实验结果表明,拥有70亿参数的Pangu Embedded超越了类似规模的模型,如Qwen3-8B和GLM4-9B。它在一个统一的模型架构内实现了快速响应和最新水平的推理质量,为开发强大且实际可部署的LLM推理器指明了有前途的方向。
论文及项目相关链接
摘要
pangu嵌入式是一个高效的基于Ascend神经处理单元的大型语言模型推理器,具备灵活的快慢思考能力。它解决了现有推理优化的大型语言模型中的计算成本和推理延迟挑战。该研究提出了一个两阶段的训练框架来构建模型。第一阶段通过迭代蒸馏过程微调模型,并结合跨迭代模型合并来有效地聚合互补知识。随后是在Ascend集群上进行强化学习,由一个延迟容忍调度器优化,该调度器结合了过时同步并行性与优先数据队列。强化学习过程由多源自适应奖励系统引导,该系统利用确定性指标和轻量级的大型语言模型评估器为数学、编码和一般问题解决任务生成动态、特定任务的奖励信号。第二阶段引入了一个双系统框架,赋予pangu嵌入式“快速”模式用于常规查询和更深的“慢速”模式用于复杂推理。该框架提供了手动模式切换供用户控制和自动复杂度感知模式选择机制,以动态分配计算资源来平衡延迟和推理深度。实验结果表明,pangu嵌入式在AIME 2024、GPQA和LiveCodeBench等基准测试上表现优异,具有快速响应和出色的推理质量,为开发强大且可实际部署的大型语言模型推理器提供了有前景的方向。
关键见解
- Pangu Embedded是一个基于Ascend神经处理单元的大型语言模型推理器,具有快慢思考能力,解决了现有模型的计算成本和延迟问题。
- 模型采用两阶段训练框架:第一阶段通过迭代蒸馏和强化学习优化模型;第二阶段引入双系统框架,实现快速和慢速推理模式。
- 多源自适应奖励系统指导强化学习过程,根据任务特定需求生成动态奖励信号。
- Pangu Embedded具备自动模式选择机制,能根据任务的复杂度动态分配计算资源。
- 实验结果表明,Pangu Embedded在多个基准测试上表现优异,包括AIME 2024、GPQA和LiveCodeBench等。
- Pangu Embedded提供了快速响应和出色的推理质量,在单一模型架构内实现了先进的表现。
点此查看论文截图

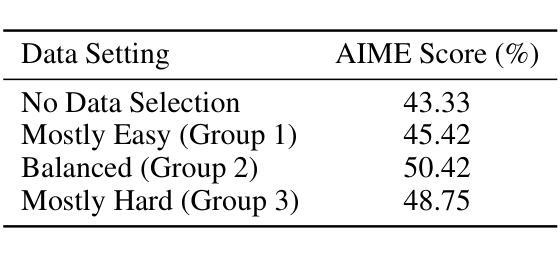
A2Seek: Towards Reasoning-Centric Benchmark for Aerial Anomaly Understanding
Authors:Mengjingcheng Mo, Xinyang Tong, Jiaxu Leng, Mingpi Tan, Jiankang Zheng, Yiran Liu, Haosheng Chen, Ji Gan, Weisheng Li, Xinbo Gao
While unmanned aerial vehicles (UAVs) offer wide-area, high-altitude coverage for anomaly detection, they face challenges such as dynamic viewpoints, scale variations, and complex scenes. Existing datasets and methods, mainly designed for fixed ground-level views, struggle to adapt to these conditions, leading to significant performance drops in drone-view scenarios. To bridge this gap, we introduce A2Seek (Aerial Anomaly Seek), a large-scale, reasoning-centric benchmark dataset for aerial anomaly understanding. This dataset covers various scenarios and environmental conditions, providing high-resolution real-world aerial videos with detailed annotations, including anomaly categories, frame-level timestamps, region-level bounding boxes, and natural language explanations for causal reasoning. Building on this dataset, we propose A2Seek-R1, a novel reasoning framework that generalizes R1-style strategies to aerial anomaly understanding, enabling a deeper understanding of “Where” anomalies occur and “Why” they happen in aerial frames. To this end, A2Seek-R1 first employs a graph-of-thought (GoT)-guided supervised fine-tuning approach to activate the model’s latent reasoning capabilities on A2Seek. Then, we introduce Aerial Group Relative Policy Optimization (A-GRPO) to design rule-based reward functions tailored to aerial scenarios. Furthermore, we propose a novel “seeking” mechanism that simulates UAV flight behavior by directing the model’s attention to informative regions. Extensive experiments demonstrate that A2Seek-R1 achieves up to a 22.04% improvement in AP for prediction accuracy and a 13.9% gain in mIoU for anomaly localization, exhibiting strong generalization across complex environments and out-of-distribution scenarios. Our dataset and code will be released at https://hayneyday.github.io/A2Seek/.
无人机(UAV)为异常检测提供了大范围、高海拔的覆盖,但它们面临着动态视点、尺度变化和复杂场景等挑战。现有的数据集和方法主要设计用于固定地面视角,难以适应这些条件,导致在无人机视角场景中性能显著下降。为了弥补这一差距,我们推出了A2Seek(空中异常搜寻),这是一个用于空中异常理解的大规模、以推理为中心的基准数据集。该数据集涵盖了各种场景和环境条件,提供了带有详细注释的高分辨率现实空中视频,包括异常类别、帧级时间戳、区域级边界框以及因果推理的自然语言解释。基于这个数据集,我们提出了A2Seek-R1,这是一个新的推理框架,它将R1风格的策略推广到空中异常理解,能够更深入地理解空中帧中异常发生“在哪里”和“为什么”发生。为此,A2Seek-R1首先采用受思维图(GoT)引导的监督微调方法来激活模型在A2Seek上的潜在推理能力。然后,我们引入了空中群组相对策略优化(A-GRPO)来针对空中场景设计基于规则的奖励函数。此外,我们还提出了一种新的“搜索”机制,通过引导模型关注信息区域来模拟无人机的飞行行为。大量实验表明,A2Seek-R1在预测精度上实现了高达22.04%的AP提高,在异常定位上实现了13.9%的mIoU增益,在复杂环境和超出分布的场景中表现出强大的泛化能力。我们的数据集和代码将在https://hayneyday.github.io/A2Seek/发布。
论文及项目相关链接
Summary
无人机在广域、高海拔的异常检测中具有优势,但面临动态视角、尺度变化和复杂场景等挑战。现有数据集和方法主要为固定地面视角设计,难以适应这些条件,导致在无人机视角下的性能显著下降。为解决此问题,我们推出A2Seek数据集和A2Seek-R1推理框架。数据集包含各种场景和环境条件下的高分辨率无人机视频和详细注解;框架则通过图思维导向的精细化调整和模拟无人机飞行行为的“寻求”机制来增强无人机对异常的感知能力。通过广泛实验验证,A2Seek-R1预测精度提升可达AP提升至约高至百分之二十二点零四,异常定位mIoU提高百分之十三点九,展现出在复杂环境和分布外场景中的强大泛化能力。更多详情将在https://hayneyday.github.io/A2Seek/公布。
Key Takeaways
- 无人机在高海拔进行广域异常检测时面临挑战,如动态视角和复杂场景等。
- 现有数据集和方法主要为固定地面视角设计,难以满足无人机视角的需求。
- A2Seek数据集提供高分辨率的无人机视频和详细注解,用于解决上述问题。
- A2Seek-R1框架通过图思维导向的精细化调整和模拟无人机飞行行为的机制来提升对异常的感知能力。
- A2Seek-R1预测精度显著提高,展现出强大的泛化能力。
点此查看论文截图


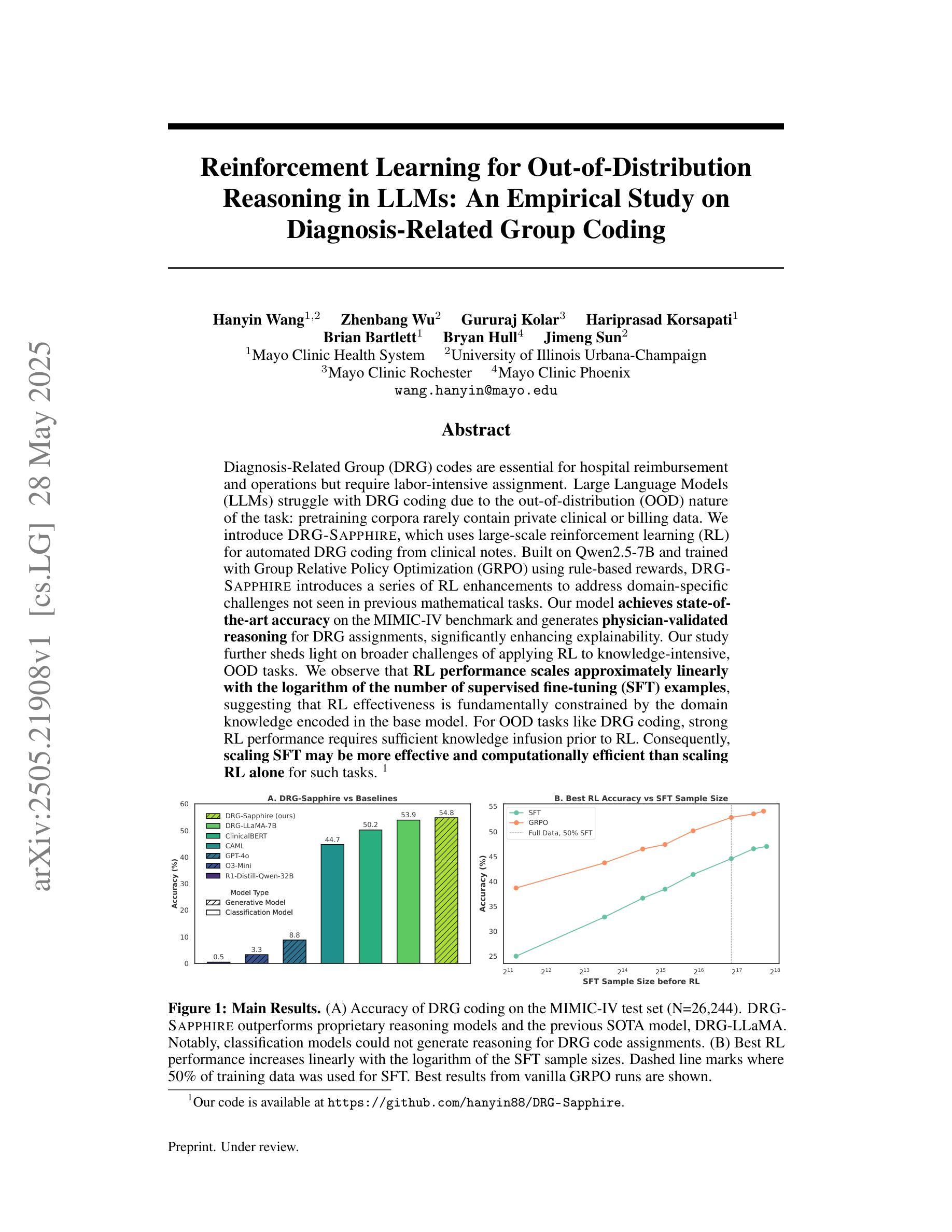
Reinforcement Learning for Out-of-Distribution Reasoning in LLMs: An Empirical Study on Diagnosis-Related Group Coding
Authors:Hanyin Wang, Zhenbang Wu, Gururaj Kolar, Hariprasad Korsapati, Brian Bartlett, Bryan Hull, Jimeng Sun
Diagnosis-Related Group (DRG) codes are essential for hospital reimbursement and operations but require labor-intensive assignment. Large Language Models (LLMs) struggle with DRG coding due to the out-of-distribution (OOD) nature of the task: pretraining corpora rarely contain private clinical or billing data. We introduce DRG-Sapphire, which uses large-scale reinforcement learning (RL) for automated DRG coding from clinical notes. Built on Qwen2.5-7B and trained with Group Relative Policy Optimization (GRPO) using rule-based rewards, DRG-Sapphire introduces a series of RL enhancements to address domain-specific challenges not seen in previous mathematical tasks. Our model achieves state-of-the-art accuracy on the MIMIC-IV benchmark and generates physician-validated reasoning for DRG assignments, significantly enhancing explainability. Our study further sheds light on broader challenges of applying RL to knowledge-intensive, OOD tasks. We observe that RL performance scales approximately linearly with the logarithm of the number of supervised fine-tuning (SFT) examples, suggesting that RL effectiveness is fundamentally constrained by the domain knowledge encoded in the base model. For OOD tasks like DRG coding, strong RL performance requires sufficient knowledge infusion prior to RL. Consequently, scaling SFT may be more effective and computationally efficient than scaling RL alone for such tasks.
诊断相关组(DRG)代码对于医院报销和运营至关重要,但需要投入大量劳动力进行分配。由于任务涉及离群点(OOD),大型语言模型(LLM)在DRG编码方面表现困难:预训练语料库很少包含私有临床或计费数据。我们引入了DRG-Sapphire,它使用大规模强化学习(RL)从临床笔记中进行自动化DRG编码。DRG-Sapphire基于Qwen2.5-7B构建,并使用基于规则的奖励进行组相对策略优化(GRPO)训练,引入了一系列RL增强功能,以解决在先前数学任务中未见到的特定领域挑战。我们的模型在MIMIC-IV基准测试上达到了最先进的准确性,并为DRG分配生成了经医生验证的理由,大大提高了可解释性。我们的研究还揭示了将强化学习应用于知识密集型、离群点任务的更广泛挑战。我们观察到,强化学习的性能大约与监督微调(SFT)例子的数量对数呈线性关系,这表明强化学习的有效性从根本上受到基础模型中编码领域知识的限制。对于像DRG编码这样的离群点任务,实现强大的强化学习性能需要在强化学习之前进行足够的知识注入。因此,对于此类任务,扩大SFT可能比单独扩大RL更有效和计算高效。
论文及项目相关链接
Summary:利用大型语言模型DRG-Sapphire和大规模强化学习(RL)进行自动化DRG编码。针对从临床记录进行DRG编码的特殊挑战,DRG-Sapphire引入了系列RL增强技术并实现了MIMIC-IV基准测试的最先进准确度。此外,该模型还生成了医生验证的DRG分配推理,提高了可解释性。研究发现强化学习的性能随监督微调案例数量的对数而线性增长,提示对于知识密集型任务,强化学习的有效性受限于基础模型中的领域知识。因此,对于此类任务,在强化学习之前进行足够的知识灌输可能更有效且计算效率更高。
Key Takeaways:
- DRG编码对医院报销和运营至关重要,但分配工作需要大量劳动力。
- 大型语言模型(LLMs)因预训练语料库不包含私人临床或计费数据,难以进行DRG编码。
- DRG-Sapphire使用大规模强化学习进行自动化DRG编码,解决了特定领域的挑战。
- DRG-Sapphire在MIMIC-IV基准测试中实现了最先进的准确度,并生成了医生验证的DRG分配推理。
- 强化学习的性能与监督微调案例的数量相关。对于知识密集型任务,强化学习的有效性受限于基础模型中的领域知识。
- 对于此类任务,强化学习之前的知识灌输非常重要。
点此查看论文截图


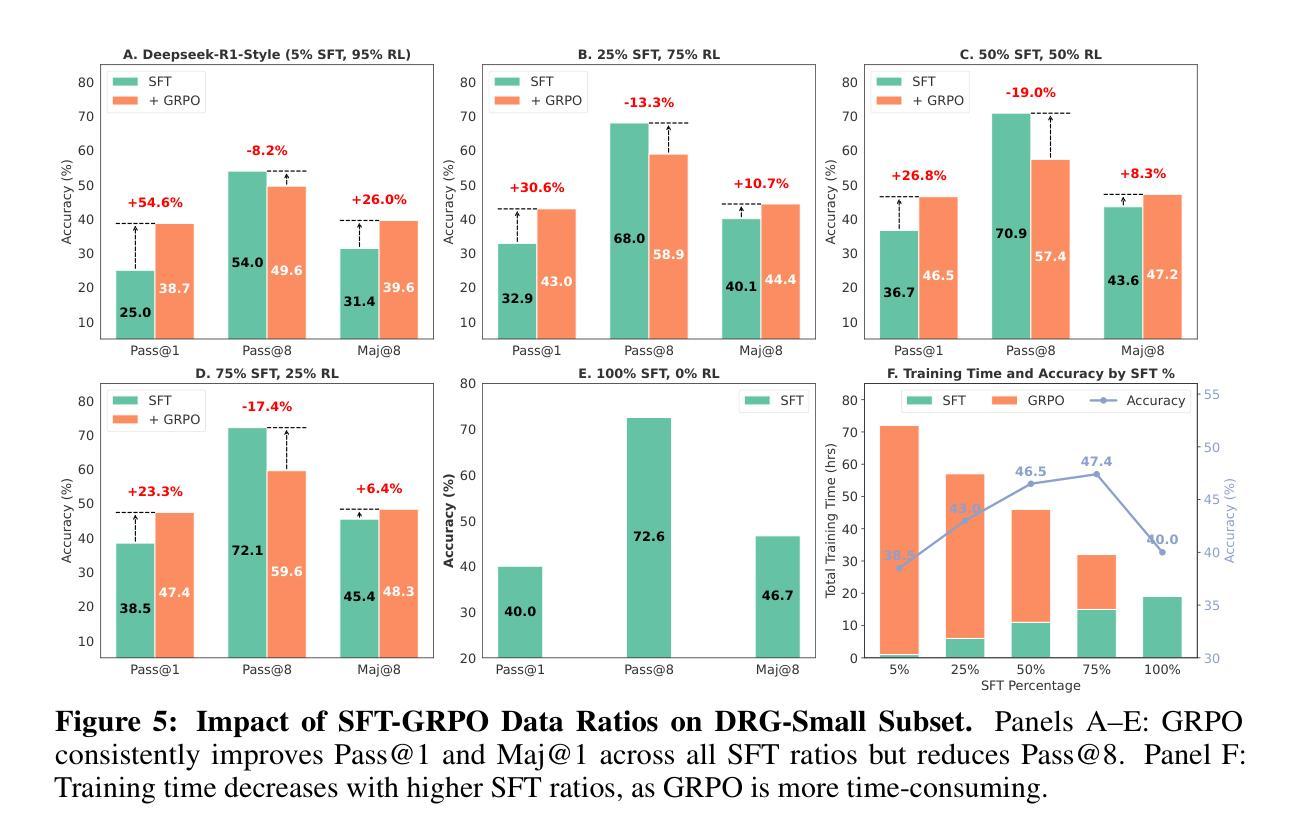
R1-Code-Interpreter: Training LLMs to Reason with Code via Supervised and Reinforcement Learning
Authors:Yongchao Chen, Yueying Liu, Junwei Zhou, Yilun Hao, Jingquan Wang, Yang Zhang, Chuchu Fan
Despite advances in reasoning and planning of R1-like models, Large Language Models (LLMs) still struggle with tasks requiring precise computation, symbolic manipulation, optimization, and algorithmic reasoning, in which textual reasoning lacks the rigor of code execution. A key challenge is enabling LLMs to decide when to use textual reasoning versus code generation. While OpenAI trains models to invoke a Code Interpreter as needed, public research lacks guidance on aligning pre-trained LLMs to effectively leverage code and generalize across diverse tasks. We present R1-Code-Interpreter, an extension of a text-only LLM trained via multi-turn supervised fine-tuning (SFT) and reinforcement learning (RL) to autonomously generate multiple code queries during step-by-step reasoning. We curate 144 reasoning and planning tasks (107 for training, 37 for testing), each with over 200 diverse questions. We fine-tune Qwen-2.5 models (3B/7B/14B) using various SFT and RL strategies, investigating different answer formats, reasoning vs. non-reasoning models, cold vs. warm starts, GRPO vs. PPO, and masked vs. unmasked code outputs. Unlike prior RL work on narrow domains, we find that Code Interpreter training is significantly harder due to high task diversity and expensive code execution, highlighting the critical role of the SFT stage. Our final model, R1-CI-14B, improves average accuracy on the 37 test tasks from 44.0% to 64.1%, outperforming GPT-4o (text-only: 58.6%) and approaching GPT-4o with Code Interpreter (70.9%), with the emergent self-checking behavior via code generation. Datasets, Codes, and Models are available at https://github.com/yongchao98/R1-Code-Interpreter and https://huggingface.co/yongchao98.
尽管R1类似模型的推理和规划能力有所进步,大型语言模型(LLM)在需要精确计算、符号操作、优化和算法推理的任务方面仍面临挑战。在这些任务中,文本推理缺乏代码执行的严谨性。一个关键挑战是使LLM能够决定何时使用文本推理何时使用代码生成。虽然OpenAI训练模型按需调用代码解释器,但公共研究在如何对齐预训练LLM以有效利用代码并在多样化任务中推广方面缺乏指导。我们推出了R1-Code-Interpreter,这是一种基于多回合监督微调(SFT)和强化学习(RL)训练的纯文本LLM的扩展,可自主生成多个代码查询来进行逐步推理。我们精选了144个推理和规划任务(107个用于训练,37个用于测试),每个任务包含超过2.研究使用各种SFT和RL策略微调了Qwen-2.不同的回答格式,推理与非推理模型之间的对比,冷启动与热启动的比较,GRPO与PPO的对比以及有码输出与无码输出的对比。与之前针对狭窄领域的RL研究不同,我们发现由于任务多样性和昂贵的代码执行成本,代码解释器训练更为困难重重,这也突显了SFT阶段的关键作用。我们的最终模型R1-CI-14B将平均准确率提升到了在测试的37个任务的平均准确率从百分之提升到了百分之。在数据集、代码和模型上我们已进行了公开分享在 https://github.com/yongchao98/R1-Code-Interpreter 并已经登陆 Hugging face平台的网址 。我们的最终模型RCI的性能超过了GPT系列。在GPT的只处理文本的基础上提升到与结合了代码解释器的GPT性能接近的程度达到了百分数级别的提升而且出现了自我检查行为的涌现。我们通过代码生成验证并展示这一行为。我们的数据集、代码和模型可在 https://github.com/yongchao98/R1-Code-Interpreter 找到并通过Hugging face平台使用。
论文及项目相关链接
PDF 33 pages, 8 figures
摘要
R1系列模型虽然在推理和规划方面取得了进展,但大型语言模型(LLMs)在需要精确计算、符号操作、优化和算法推理的任务中仍面临挑战。文本推理缺乏代码执行的严谨性,关键挑战在于如何让LLMs决定何时使用文本推理与代码生成。本文提出R1-Code-Interpreter,这是文本模型的一个扩展,通过多轮监督微调(SFT)和强化学习(RL)进行训练,可自主生成代码查询进行逐步推理。实验结果表明,由于任务多样性和昂贵的代码执行,代码解释器训练更加困难,强调SFT阶段的重要作用。最终模型R1-CI-14B在测试任务上的平均准确率从44.0%提高到64.1%,优于GPT-4o的纯文本模型(58.6%),并接近GPT-4o的代码解释器版本(70.9%),展现出通过代码生成进行自我检查的新兴行为。相关数据集、代码和模型可在指定网站下载。
关键见解
- 大型语言模型在需要精确计算、符号操作等任务上仍有困难。
- 文本推理缺乏代码执行的严谨性,需要决定何时使用文本推理与代码生成。
- R1-Code-Interpreter是文本模型的一个扩展,能通过自主生成代码查询进行逐步推理。
- 实验表明代码解释器训练更加困难,因为任务多样性和昂贵的代码执行成本。
- SFT阶段在训练中的重要性被强调。
- 最终模型R1-CI-14B在测试任务上的表现显著提高,显示出自我检查的新兴行为。
点此查看论文截图

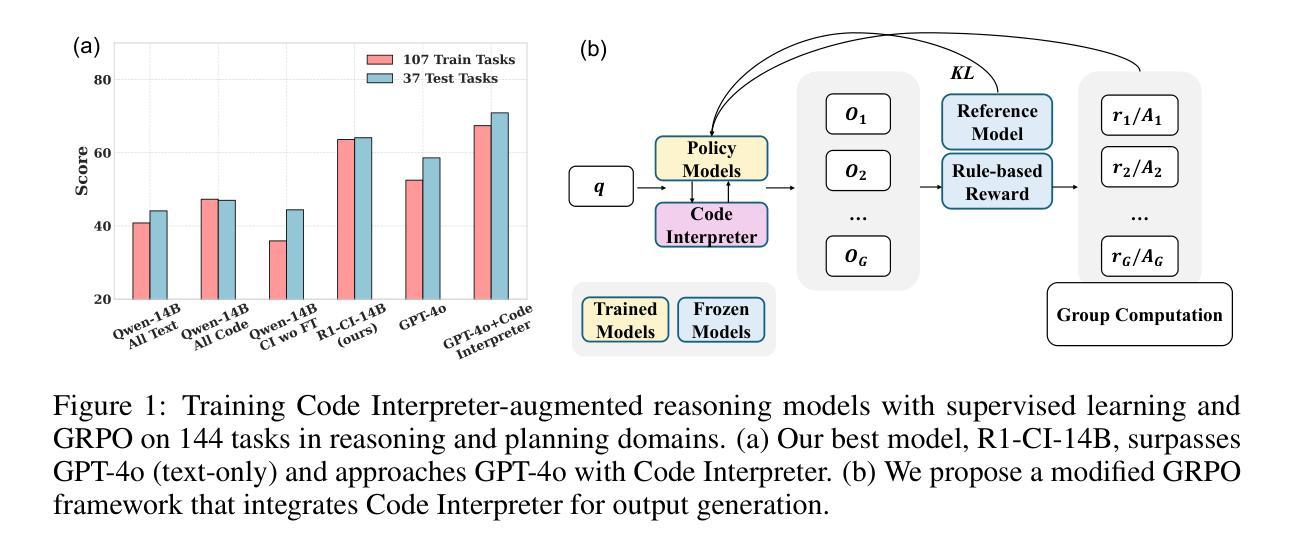


Accelerating RL for LLM Reasoning with Optimal Advantage Regression
Authors:Kianté Brantley, Mingyu Chen, Zhaolin Gao, Jason D. Lee, Wen Sun, Wenhao Zhan, Xuezhou Zhang
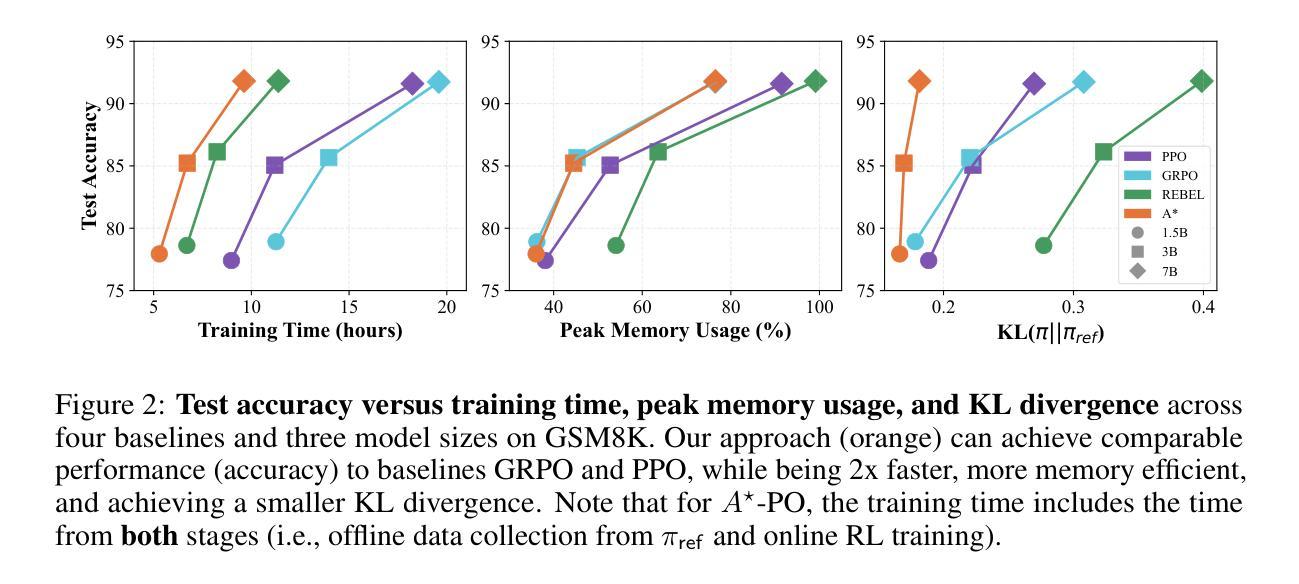
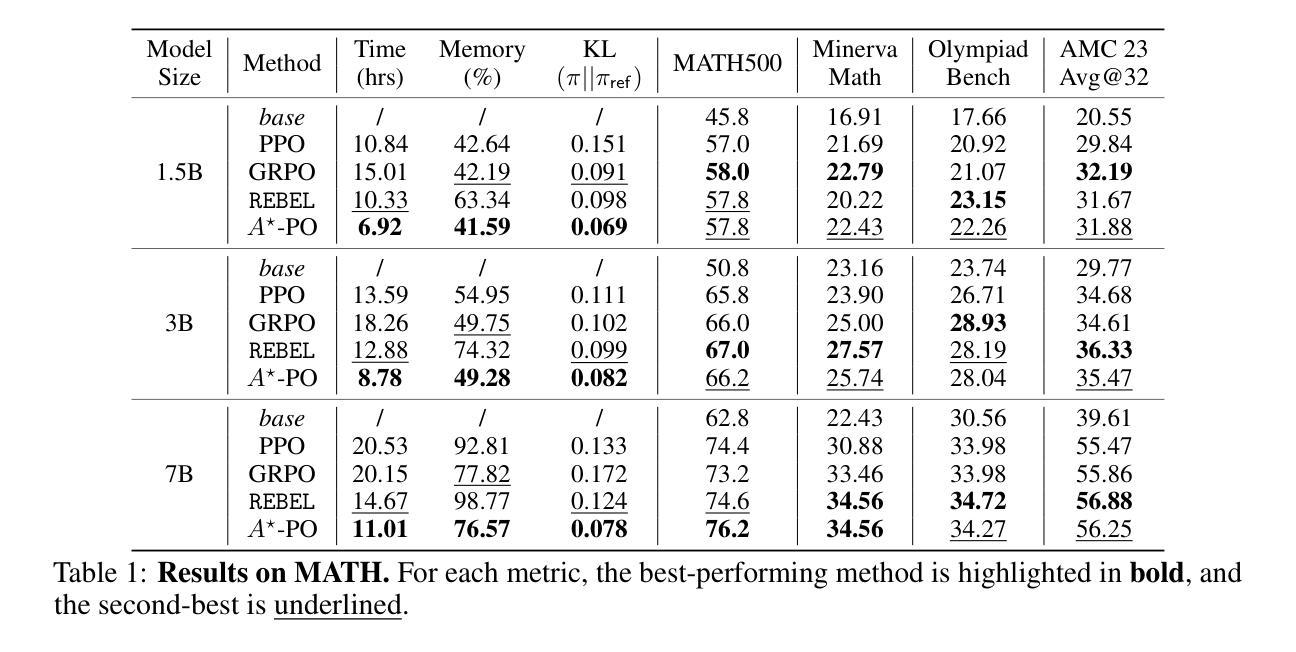
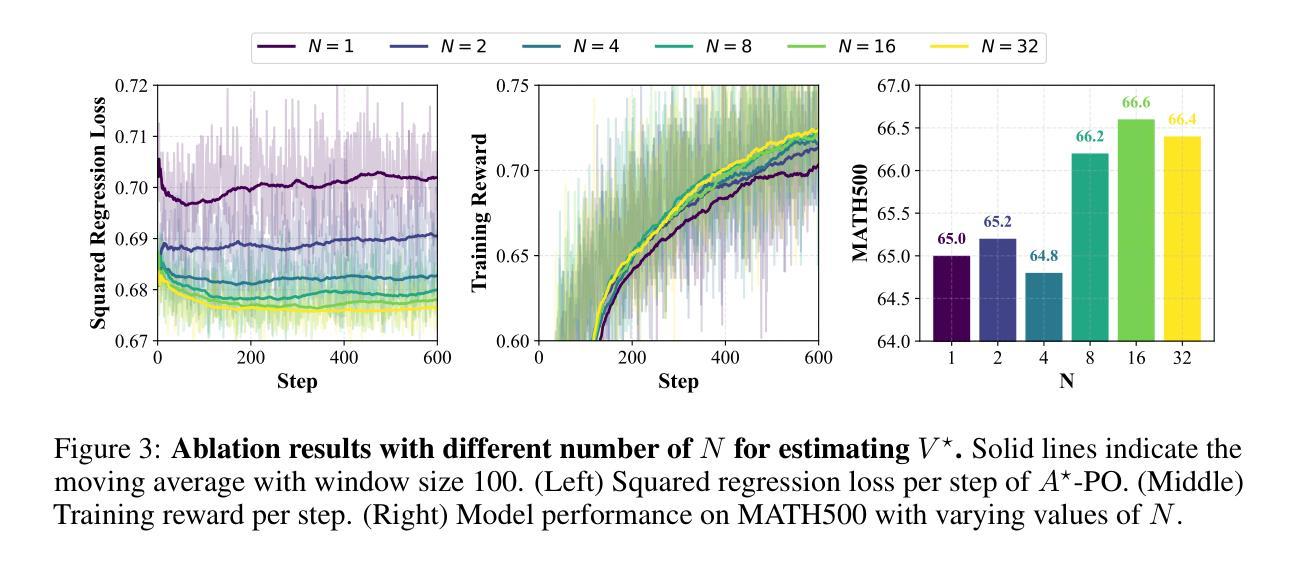
Reinforcement learning (RL) has emerged as a powerful tool for fine-tuning large language models (LLMs) to improve complex reasoning abilities. However, state-of-the-art policy optimization methods often suffer from high computational overhead and memory consumption, primarily due to the need for multiple generations per prompt and the reliance on critic networks or advantage estimates of the current policy. In this paper, we propose $A$-PO, a novel two-stage policy optimization framework that directly approximates the optimal advantage function and enables efficient training of LLMs for reasoning tasks. In the first stage, we leverage offline sampling from a reference policy to estimate the optimal value function $V$, eliminating the need for costly online value estimation. In the second stage, we perform on-policy updates using a simple least-squares regression loss with only a single generation per prompt. Theoretically, we establish performance guarantees and prove that the KL-regularized RL objective can be optimized without requiring complex exploration strategies. Empirically, $A$-PO achieves competitive performance across a wide range of mathematical reasoning benchmarks, while reducing training time by up to 2$\times$ and peak memory usage by over 30% compared to PPO, GRPO, and REBEL. Implementation of $A$-PO can be found at https://github.com/ZhaolinGao/A-PO.
强化学习(RL)已经成为一种强大的工具,用于对大型语言模型(LLM)进行微调,以提高复杂的推理能力。然而,最先进的策略优化方法常常面临计算开销大、内存消耗高的困扰,这主要是因为每个提示需要多代计算,并且依赖于当前策略的价值评估网络或优势估计。在本文中,我们提出了A*-PO,这是一种新型的两阶段策略优化框架,它直接逼近最优优势函数,并能有效地训练用于推理任务的LLM。在第一阶段,我们利用从参考策略中进行的离线采样估计最优值函数V,从而无需昂贵的在线价值评估。在第二阶段,我们使用简单的最小二乘回归损失进行策略内更新,每个提示仅需一次生成。理论上,我们建立了性能保证,并证明了在不需要复杂探索策略的情况下,可以优化KL正则化的RL目标。从实证角度看,A-PO在广泛的数学推理基准测试中取得了具有竞争力的表现,与PPO、GRPO和REBEL相比,训练时间减少了高达2倍,峰值内存使用率降低了超过30%。A*-PO的实现可以在https://github.com/ZhaolinGao/A-PO找到。
论文及项目相关链接
Summary
强化学习(RL)在微调大型语言模型(LLM)以提高复杂推理能力方面表现出强大的潜力。然而,最先进的策略优化方法常常面临高计算开销和内存消耗的问题。本文提出了一种新型的两阶段策略优化框架APO,通过直接近似最优优势函数,实现了LLM在推理任务上的高效训练。第一阶段通过离线采样从参考策略估算最优值函数V,避免了昂贵的在线值估计。第二阶段采用简单的最小二乘回归损失进行在线策略更新,只需单次生成提示。理论方面,我们提供了性能保证,并证明在不需要复杂探索策略的情况下,可以优化KL正则化的RL目标。实验结果表明,A*PO在广泛的数学推理基准测试中取得了具有竞争力的性能表现,同时训练时间最多减少一半,峰值内存使用率相较于PPO、GRPO和REBEL等算法降低超过30%。实施代码已发布至https://github.com/ZhaolinGao/A-PO。
Key Takeaways
- 强化学习在微调大型语言模型以提升复杂推理能力方面效果显著。
- 当前策略优化方法面临高计算开销和内存消耗的问题。
- A*PO是一种新型的两阶段策略优化框架,通过近似最优优势函数实现LLM的高效训练。
- 第一阶段通过离线采样估算最优值函数,避免在线值估计的成本。
- 第二阶段采用最小二乘回归损失进行在线策略更新,单次生成提示。
- A*PO在理论上有性能保证,并能在不依赖复杂探索策略的情况下优化KL正则化的RL目标。
点此查看论文截图

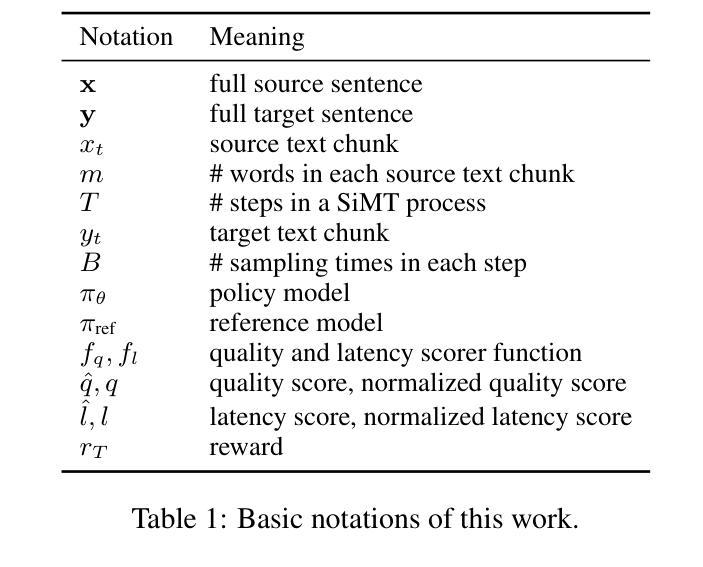
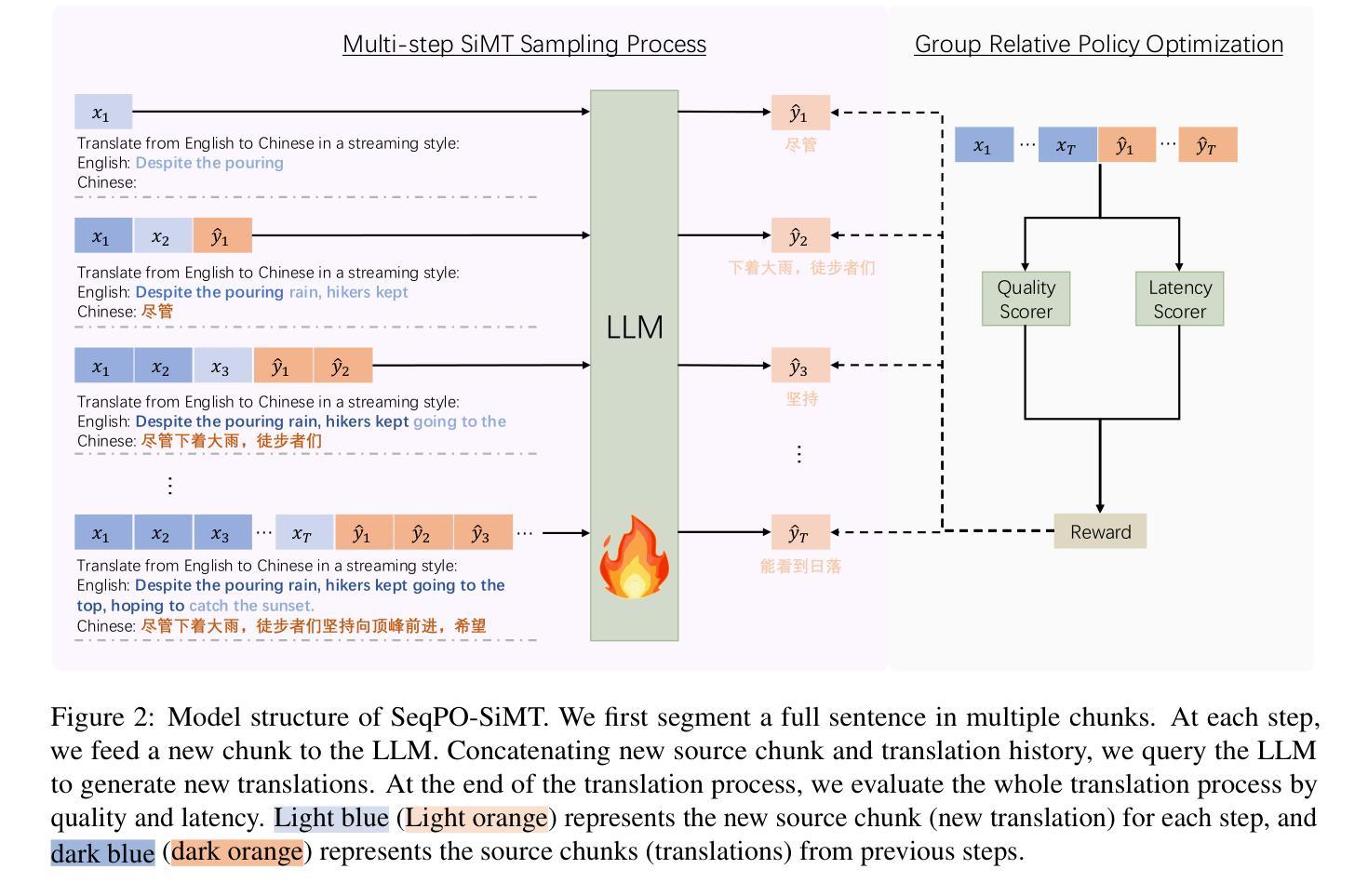
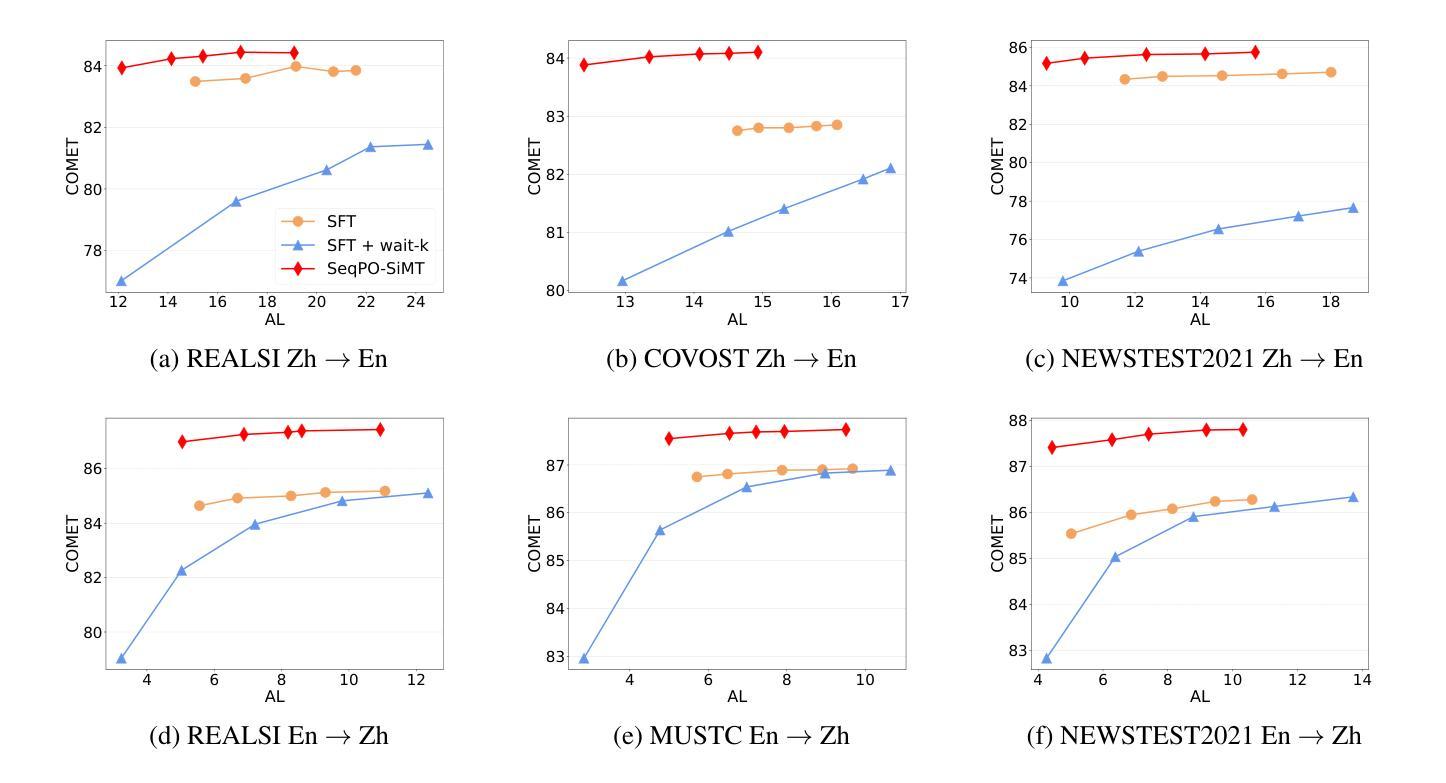
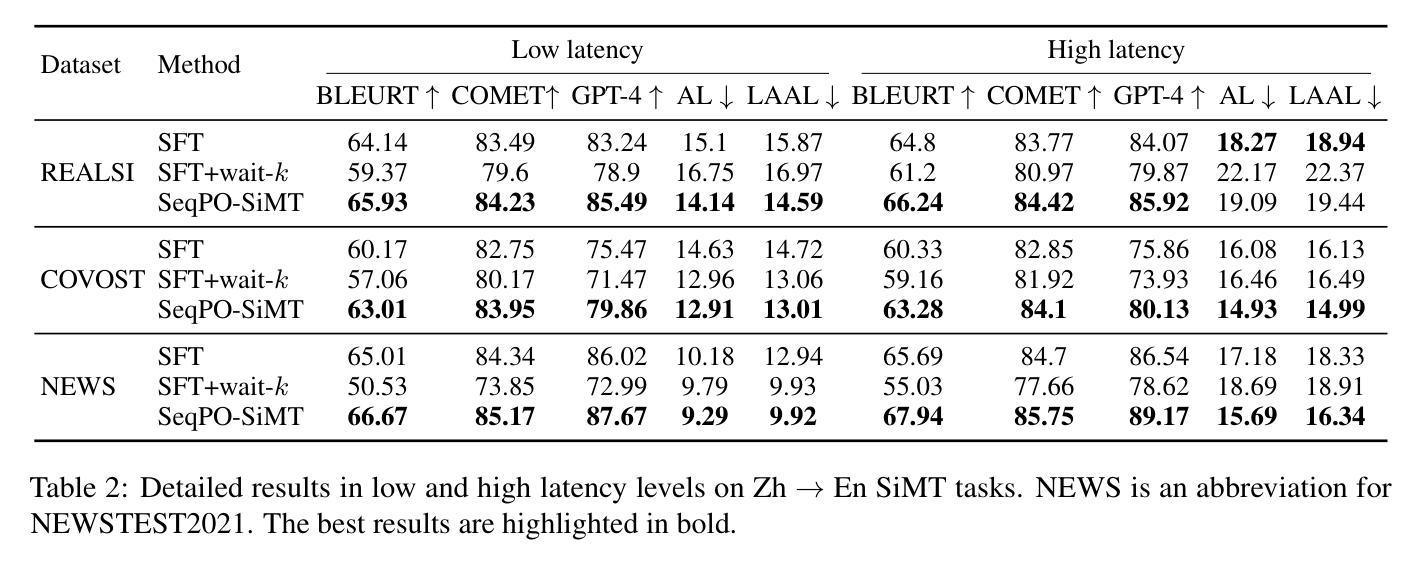
SeqPO-SiMT: Sequential Policy Optimization for Simultaneous Machine Translation
Authors:Ting Xu, Zhichao Huang, Jiankai Sun, Shanbo Cheng, Wai Lam
We present Sequential Policy Optimization for Simultaneous Machine Translation (SeqPO-SiMT), a new policy optimization framework that defines the simultaneous machine translation (SiMT) task as a sequential decision making problem, incorporating a tailored reward to enhance translation quality while reducing latency. In contrast to popular Reinforcement Learning from Human Feedback (RLHF) methods, such as PPO and DPO, which are typically applied in single-step tasks, SeqPO-SiMT effectively tackles the multi-step SiMT task. This intuitive framework allows the SiMT LLMs to simulate and refine the SiMT process using a tailored reward. We conduct experiments on six datasets from diverse domains for En to Zh and Zh to En SiMT tasks, demonstrating that SeqPO-SiMT consistently achieves significantly higher translation quality with lower latency. In particular, SeqPO-SiMT outperforms the supervised fine-tuning (SFT) model by 1.13 points in COMET, while reducing the Average Lagging by 6.17 in the NEWSTEST2021 En to Zh dataset. While SiMT operates with far less context than offline translation, the SiMT results of SeqPO-SiMT on 7B LLM surprisingly rival the offline translation of high-performing LLMs, including Qwen-2.5-7B-Instruct and LLaMA-3-8B-Instruct.
我们提出了针对同步机器翻译(Simultaneous Machine Translation,SiMT)的序贯策略优化(Sequential Policy Optimization,SeqPO-SiMT)新框架。该框架将SiMT任务定义为序贯决策问题,并结合定制奖励来提高翻译质量同时减少延迟。与通常应用于单步任务的强化学习从人类反馈(Reinforcement Learning from Human Feedback,RLHF)方法(如PPO和DPO)相比,SeqPO-SiMT有效地解决了多步SiMT任务。这个直观框架允许SiMT大型语言模型(LLMs)使用定制奖励来模拟和完善SiMT过程。我们在六个不同领域的En到Zh和Zh到En的SiMT任务数据集上进行了实验,证明SeqPO-SiMT在保持较低延迟的同时,始终实现了更高的翻译质量。特别是,在COMET中,SeqPO-SiMT相较于监督微调(Supervised Fine-tuning,SFT)模型的性能提高了1.13点,同时在NEWSTEST2021 En到Zh数据集上平均延迟降低了6.17。尽管SiMT的上下文远少于离线翻译,但SeqPO-SiMT在7B LLM上的表现令人惊讶地与高性能离线翻译的大型语言模型相匹敌,包括Qwen-2.5-7B-Instruct和LLaMA-3-8B-Instruct。
论文及项目相关链接
PDF Accepted by The 63rd Annual Meeting of the Association for Computational Linguistics (ACL 2025)
Summary:
本文提出了针对同步机器翻译(SiMT)任务的序贯策略优化框架SeqPO-SiMT。该框架将SiMT定义为序贯决策问题,利用定制奖励来提高翻译质量并降低延迟。在六种数据集上的实验表明,SeqPO-SiMT在保持低延迟的同时,显著提高了翻译质量。特别是在COMET和NEWSTEST数据集上,SeqPO-SiMT相较于监督微调模型表现更为优越。尽管SiMT的上下文信息远少于离线翻译,但SeqPO-SiMT在大型语言模型上的表现却意外地与之相当。
Key Takeaways:
- SeqPO-SiMT是一个新的策略优化框架,用于同步机器翻译任务。
- 它将SiMT定义为序贯决策问题,并使用了定制奖励来提高翻译质量和降低延迟。
- 在多个数据集上的实验表明,SeqPO-SiMT显著提高了翻译质量并保持了低延迟。
- SeqPO-SiMT在COMET评分上超越了监督微调模型。
- SeqPO-SiMT在NEWSTEST数据集上的平均延迟时间有所减少。
- 尽管SiMT的上下文信息有限,但SeqPO-SiMT在大型语言模型上的表现与离线翻译相当。
点此查看论文截图


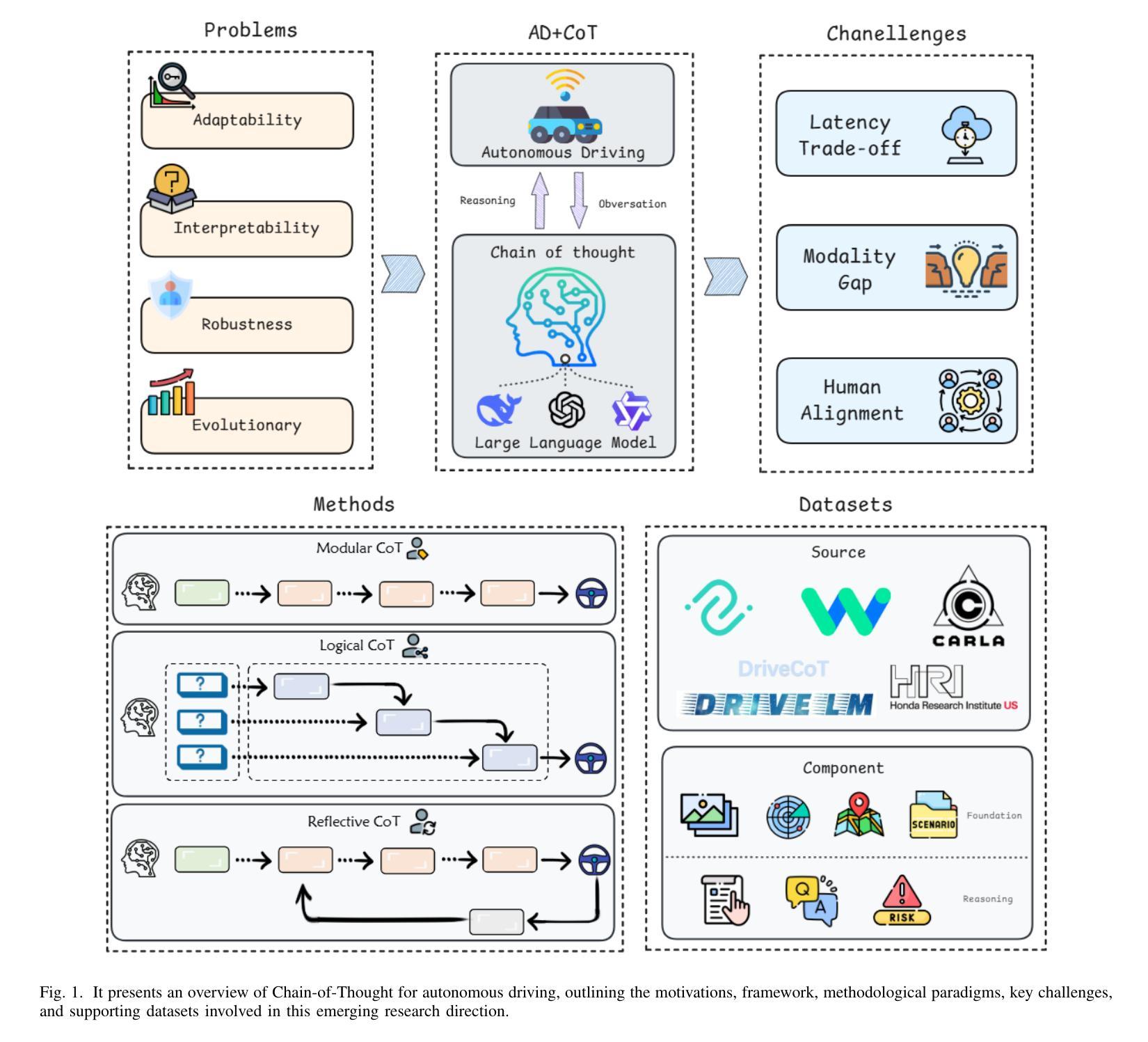
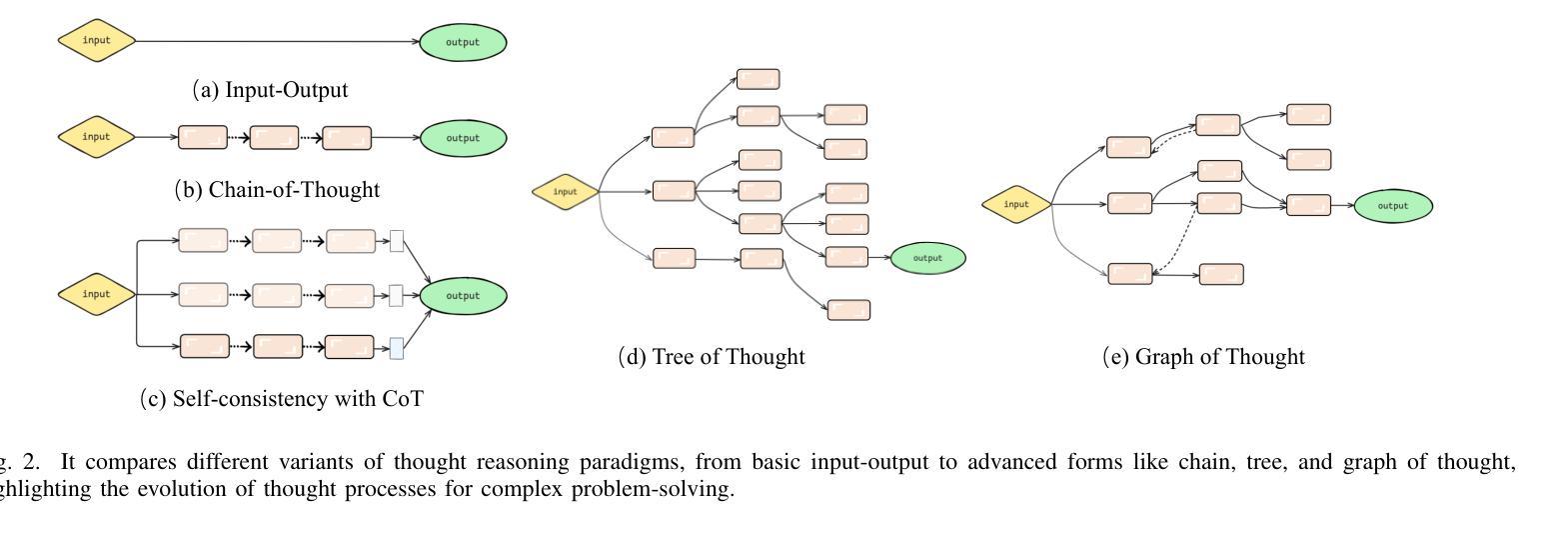
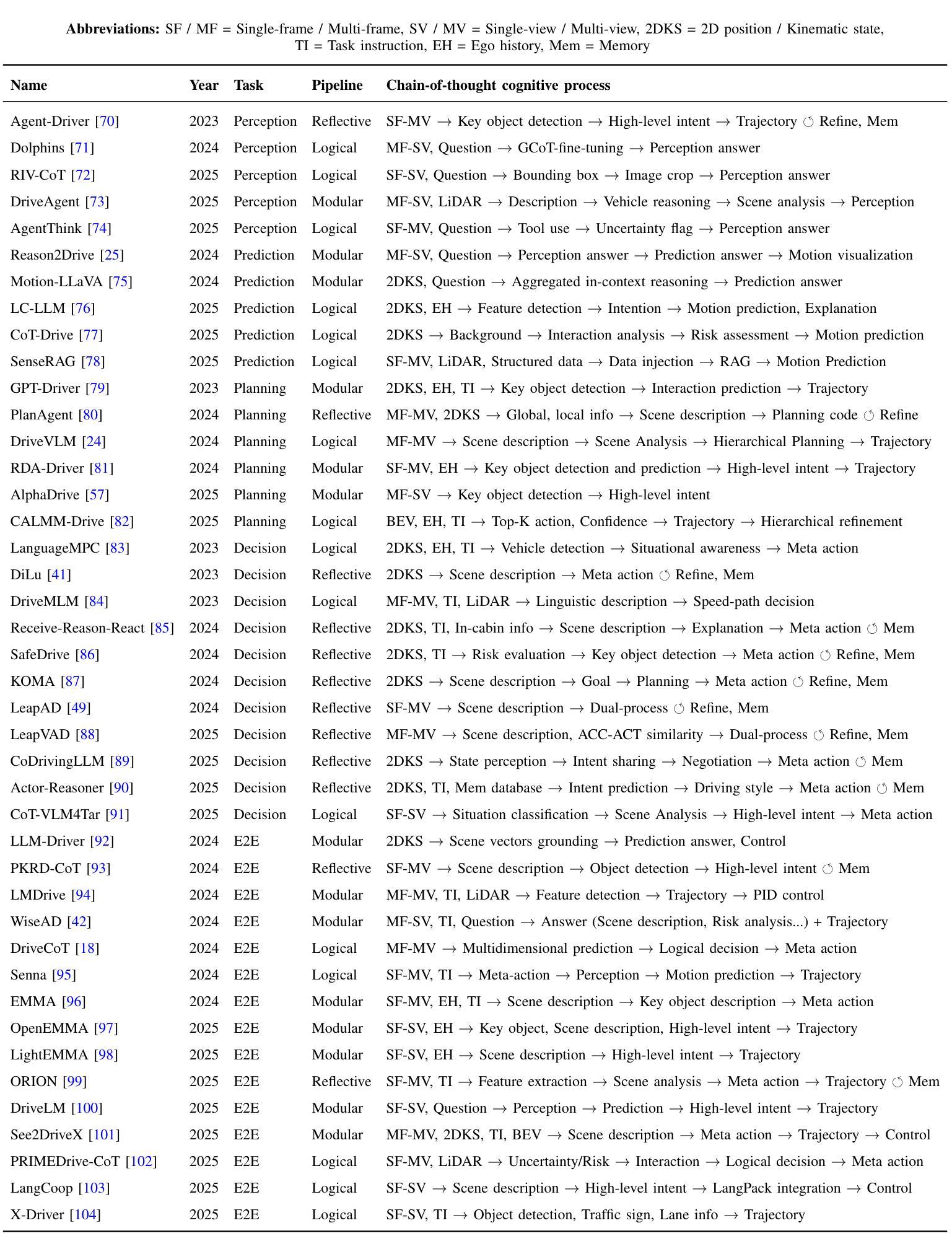
Chain-of-Thought for Autonomous Driving: A Comprehensive Survey and Future Prospects
Authors:Yixin Cui, Haotian Lin, Shuo Yang, Yixiao Wang, Yanjun Huang, Hong Chen
The rapid evolution of large language models in natural language processing has substantially elevated their semantic understanding and logical reasoning capabilities. Such proficiencies have been leveraged in autonomous driving systems, contributing to significant improvements in system performance. Models such as OpenAI o1 and DeepSeek-R1, leverage Chain-of-Thought (CoT) reasoning, an advanced cognitive method that simulates human thinking processes, demonstrating remarkable reasoning capabilities in complex tasks. By structuring complex driving scenarios within a systematic reasoning framework, this approach has emerged as a prominent research focus in autonomous driving, substantially improving the system’s ability to handle challenging cases. This paper investigates how CoT methods improve the reasoning abilities of autonomous driving models. Based on a comprehensive literature review, we present a systematic analysis of the motivations, methodologies, challenges, and future research directions of CoT in autonomous driving. Furthermore, we propose the insight of combining CoT with self-learning to facilitate self-evolution in driving systems. To ensure the relevance and timeliness of this study, we have compiled a dynamic repository of literature and open-source projects, diligently updated to incorporate forefront developments. The repository is publicly available at https://github.com/cuiyx1720/Awesome-CoT4AD.
自然语言处理中的大型语言模型快速进化,极大地提高了其语义理解和逻辑推理能力。这种能力在自动驾驶系统中得到了应用,为系统性能带来了显著改进。诸如OpenAI o1和DeepSeek-R1等模型,采用“思维链”(CoT)推理,这是一种高级认知方法,模拟人类思维过程,在复杂任务中展现出卓越的推理能力。通过在一个系统的推理框架内构建复杂的驾驶场景,这种方法已成为自动驾驶的一个突出研究重点,极大地提高了系统处理复杂情况的能力。本文研究了CoT方法如何改善自动驾驶模型的推理能力。基于全面的文献综述,我们对CoT在自动驾驶中的动机、方法、挑战和未来研究方向进行了系统的分析。此外,我们提出了将CoT与自我学习相结合,以促进驾驶系统的自我进化。为确保研究的时效性和及时性,我们整理了一个动态的文献和开源项目仓库,并不断更新以纳入最新的发展。该仓库可在https://github.com/cuiyx1720/Awesome-CoT4AD访问。
论文及项目相关链接
PDF 18 pages, 6 figures
Summary
大型语言模型在自然语言处理领域的快速发展显著提升了其语义理解和逻辑推理能力。通过利用链式思维(Chain-of-Thought,简称CoT)推理方法,如OpenAI o1和DeepSeek-R1等模型,在自动驾驶系统中展现出卓越的逻辑推理能力。本文探讨了CoT方法如何提升自动驾驶模型的推理能力,并通过文献综述,对CoT在自动驾驶中的动机、方法、挑战和未来研究方向进行了系统分析。此外,结合自我学习机制提出了自我进化的驾驶系统的见解。
Key Takeaways
- 大型语言模型在语义理解和逻辑推理方面有了显著提升。
- 链式思维(CoT)推理方法被应用于自动驾驶系统,提升了系统的性能。
- CoT通过模拟人类思考过程,在复杂任务中展现出强大的推理能力。
- CoT方法的应用使自动驾驶系统能够更好地应对复杂和具有挑战性的场景。
- 本文对CoT在自动驾驶中的动机、方法、挑战和未来研究方向进行了详细分析。
- 结合自我学习机制,提出了自我进化的驾驶系统的可能性。
点此查看论文截图


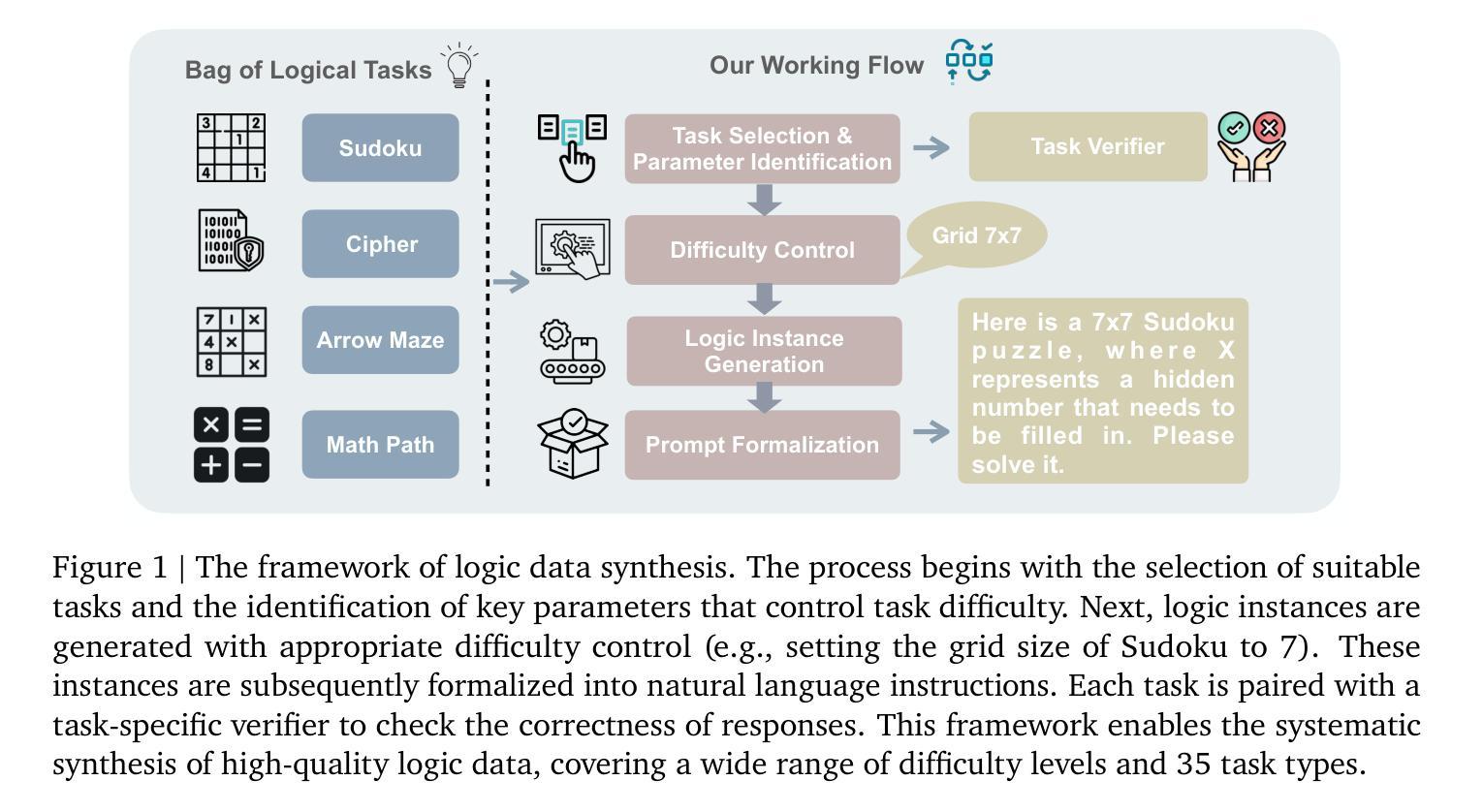
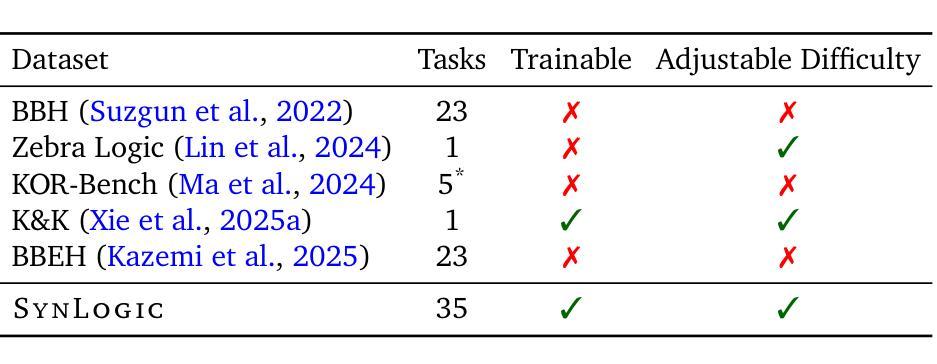
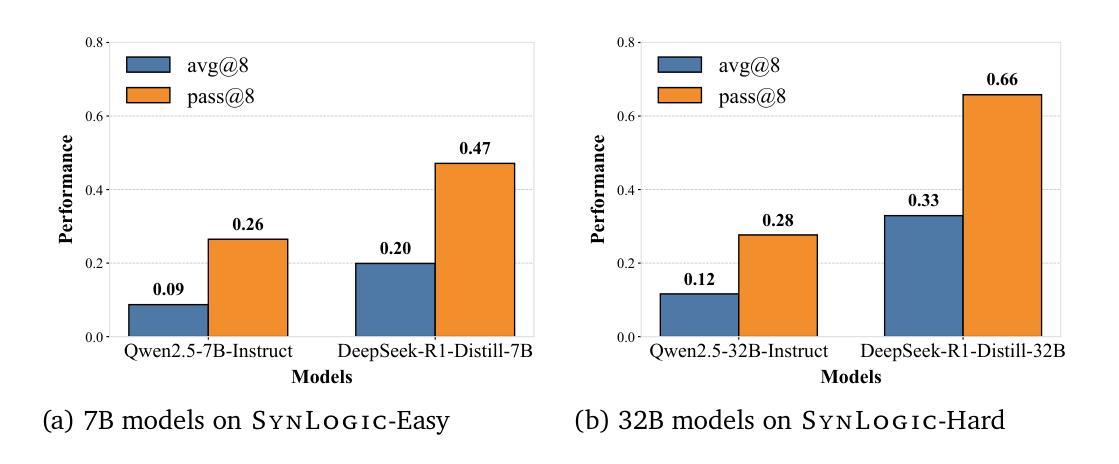
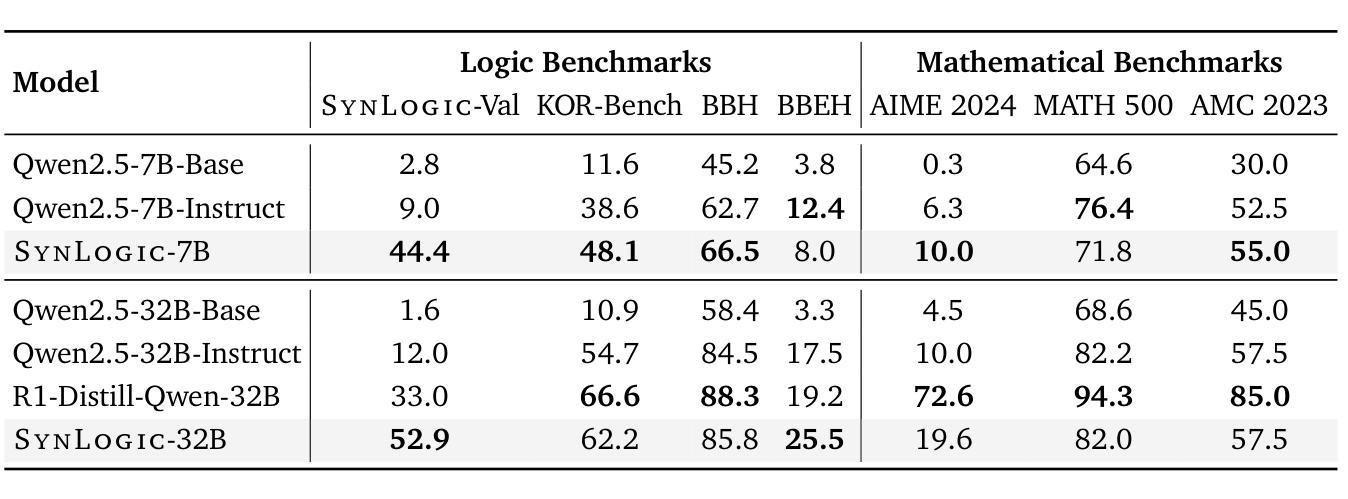
SynLogic: Synthesizing Verifiable Reasoning Data at Scale for Learning Logical Reasoning and Beyond
Authors:Junteng Liu, Yuanxiang Fan, Zhuo Jiang, Han Ding, Yongyi Hu, Chi Zhang, Yiqi Shi, Shitong Weng, Aili Chen, Shiqi Chen, Yunan Huang, Mozhi Zhang, Pengyu Zhao, Junjie Yan, Junxian He
Recent advances such as OpenAI-o1 and DeepSeek R1 have demonstrated the potential of Reinforcement Learning (RL) to enhance reasoning abilities in Large Language Models (LLMs). While open-source replication efforts have primarily focused on mathematical and coding domains, methods and resources for developing general reasoning capabilities remain underexplored. This gap is partly due to the challenge of collecting diverse and verifiable reasoning data suitable for RL. We hypothesize that logical reasoning is critical for developing general reasoning capabilities, as logic forms a fundamental building block of reasoning. In this work, we present SynLogic, a data synthesis framework and dataset that generates diverse logical reasoning data at scale, encompassing 35 diverse logical reasoning tasks. The SynLogic approach enables controlled synthesis of data with adjustable difficulty and quantity. Importantly, all examples can be verified by simple rules, making them ideally suited for RL with verifiable rewards. In our experiments, we validate the effectiveness of RL training on the SynLogic dataset based on 7B and 32B models. SynLogic leads to state-of-the-art logical reasoning performance among open-source datasets, surpassing DeepSeek-R1-Distill-Qwen-32B by 6 points on BBEH. Furthermore, mixing SynLogic data with mathematical and coding tasks improves the training efficiency of these domains and significantly enhances reasoning generalization. Notably, our mixed training model outperforms DeepSeek-R1-Zero-Qwen-32B across multiple benchmarks. These findings position SynLogic as a valuable resource for advancing the broader reasoning capabilities of LLMs. We open-source both the data synthesis pipeline and the SynLogic dataset at https://github.com/MiniMax-AI/SynLogic.
最近,如OpenAI-o1和DeepSeek R1等进展表明,强化学习(RL)在提升大型语言模型(LLM)的推理能力方面具有巨大潜力。虽然开源复制工作主要集中在数学和编码领域,但开发通用推理能力的方法和资源仍然探索不足。这一差距部分是由于收集适合强化学习的多样化和可验证的推理数据具有挑战性。我们假设逻辑推理对于发展通用推理能力至关重要,因为逻辑是推理的基本构建块。在此工作中,我们提出了SynLogic,这是一个数据合成框架和数据集,能够大规模生成多样化的逻辑推理数据,涵盖35种不同的逻辑推理任务。SynLogic方法能够控制数据和难度和数量的合成。重要的是,所有例子都可以通过简单的规则进行验证,因此非常适合具有可验证奖励的强化学习。在我们的实验中,我们验证了强化学习在SynLogic数据集上训练的有效性,基于7B和32B模型。SynLogic在开源数据集中处于最先进的逻辑推理性能地位,在BBEH上超越了DeepSeek-R1-Distill-Qwen-32B 6个点。此外,将SynLogic数据与数学和编码任务混合,提高了这些领域的训练效率,并显著增强了推理泛化能力。值得注意的是,我们的混合训练模型在多个基准测试中优于DeepSeek-R1-Zero-Qwen-32B。这些发现使SynLogic成为推动LLM更广泛推理能力的重要资源。我们在https://github.com/MiniMax-AI/SynLogic开源了数据合成管道和SynLogic数据集。
论文及项目相关链接
Summary
本文介绍了SynLogic数据合成框架和数据集,用于生成涵盖35种不同逻辑推理任务的多样化数据。该数据集能够通过调整难度和数量进行受控的数据合成,所有例子都可以由简单的规则进行验证,非常适合用于强化学习中的可验证奖励。实验证明,在SynLogic数据集上进行强化学习训练能有效提升逻辑推理性能,并超越DeepSeek-R1-Distill-Qwen-32B模型。此外,将SynLogic数据与数学和编码任务混合训练,能提高这些领域的训练效率,并显著增强推理泛化能力。
Key Takeaways
- SynLogic是一个用于生成多样化逻辑推理数据的数据合成框架和数据集,涵盖35种不同的逻辑推理任务。
- SynLogic方法能够进行受控的数据合成,可根据需要调整难度和数量。
- 所有SynLogic生成的例子都可以由简单的规则进行验证,非常适合用于强化学习中的可验证奖励。
- 强化学习在SynLogic数据集上的训练能有效提升逻辑推理性能,超越某些现有模型。
- 混合SynLogic数据与数学和编码任务训练,能提高这些领域的训练效率,并增强推理泛化能力。
- SynLogic数据集对推进大型语言模型的更广泛推理能力具有价值。
点此查看论文截图

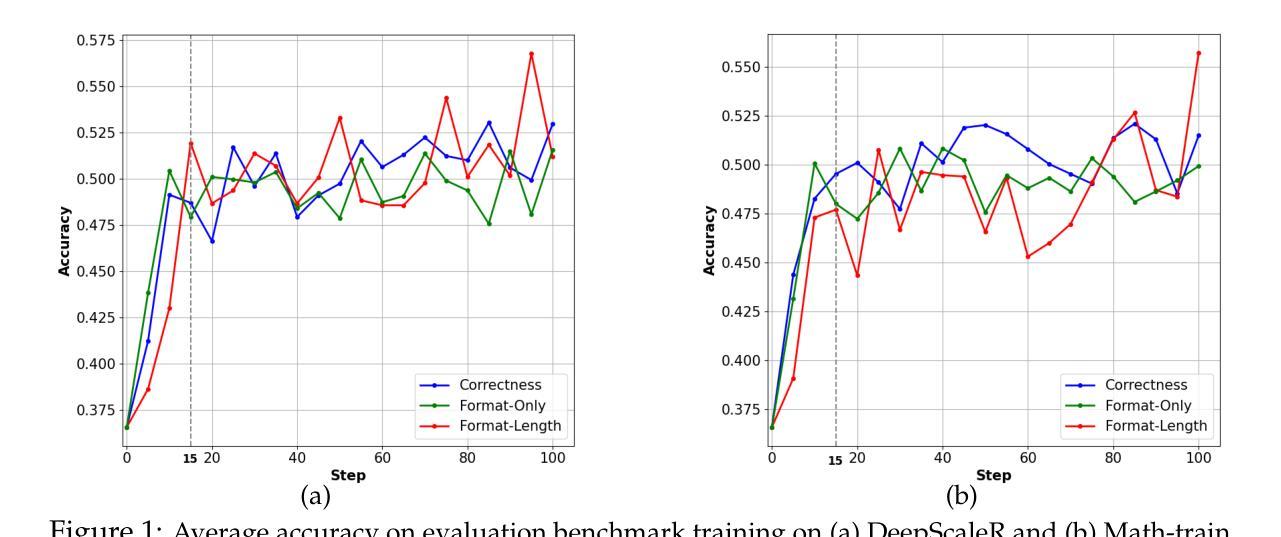
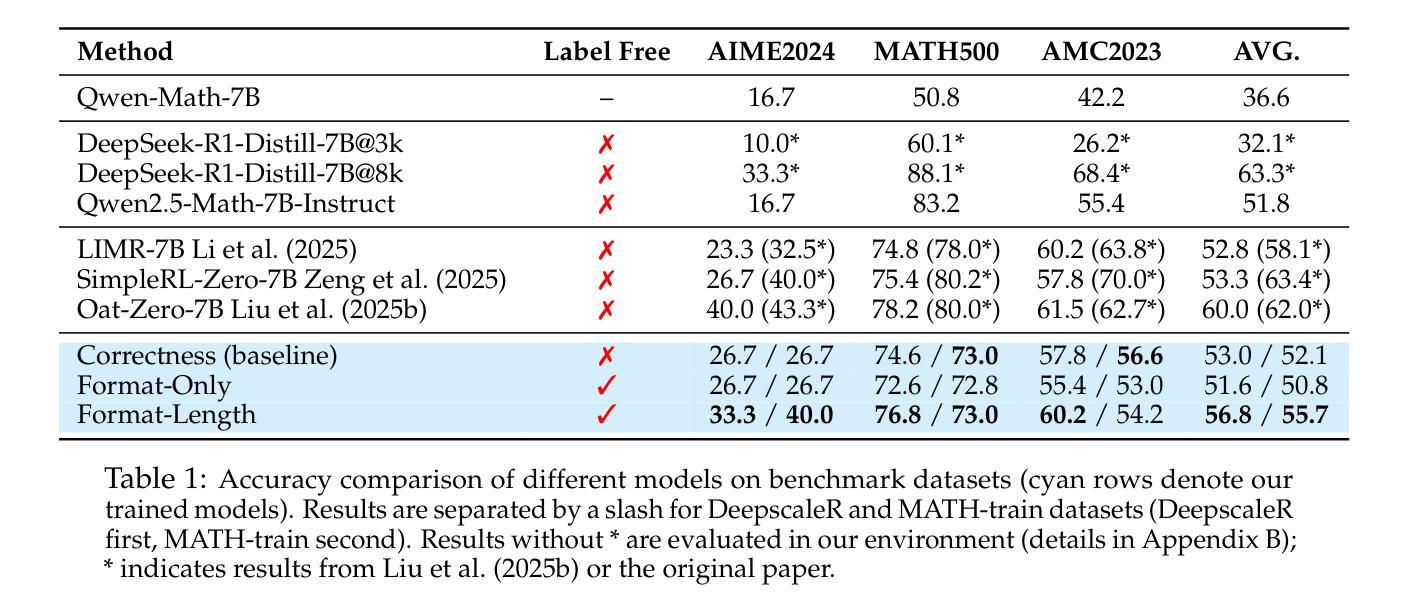
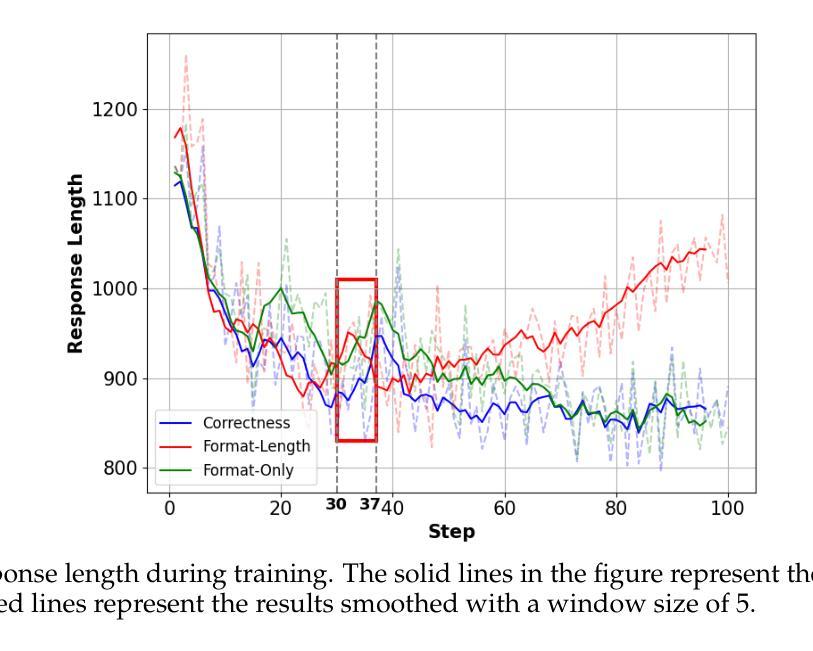
Surrogate Signals from Format and Length: Reinforcement Learning for Solving Mathematical Problems without Ground Truth Answers
Authors:Rihui Xin, Han Liu, Zecheng Wang, Yupeng Zhang, Dianbo Sui, Xiaolin Hu, Bingning Wang
Large Language Models have achieved remarkable success in natural language processing tasks, with Reinforcement Learning playing a key role in adapting them to specific applications. However, obtaining ground truth answers for training LLMs in mathematical problem-solving is often challenging, costly, and sometimes unfeasible. This research delves into the utilization of format and length as surrogate signals to train LLMs for mathematical problem-solving, bypassing the need for traditional ground truth answers.Our study shows that a reward function centered on format correctness alone can yield performance improvements comparable to the standard GRPO algorithm in early phases. Recognizing the limitations of format-only rewards in the later phases, we incorporate length-based rewards. The resulting GRPO approach, leveraging format-length surrogate signals, not only matches but surpasses the performance of the standard GRPO algorithm relying on ground truth answers in certain scenarios, achieving 40.0% accuracy on AIME2024 with a 7B base model. Through systematic exploration and experimentation, this research not only offers a practical solution for training LLMs to solve mathematical problems and reducing the dependence on extensive ground truth data collection, but also reveals the essence of why our label-free approach succeeds: base model is like an excellent student who has already mastered mathematical and logical reasoning skills, but performs poorly on the test paper, it simply needs to develop good answering habits to achieve outstanding results in exams , in other words, to unlock the capabilities it already possesses.
大型语言模型在自然语言处理任务中取得了显著的成功,强化学习在适应特定应用方面发挥了关键作用。然而,为数学问题解决训练大型语言模型获得真实答案通常具有挑战性、成本高昂,有时甚至不可行。本研究深入探讨了利用格式和长度作为代理信号来训练大型语言模型进行数学问题解决,从而绕过对传统真实答案的需求。我们的研究表明,仅围绕格式正确性设计的奖励函数可以在早期阶段产生与标准GRPO算法相当的性能改进。意识到仅使用格式奖励在后期阶段的局限性,我们结合了基于长度的奖励。由此产生的GRPO方法,利用格式长度代理信号,不仅与标准GRPO算法在特定场景下的性能相匹配,而且在AIME2024上实现了40.0%的准确率,使用7B基础模型。通过系统的探索和实验,本研究不仅为训练大型语言模型解决数学问题并减少对传统真实答案的依赖提供了实用解决方案,还揭示了我们的无标签方法成功的原因:基础模型就像一个已经掌握了数学和逻辑推理技能的学生,但在试卷上表现不佳,它只需要养成良好的答题习惯就能在考试中取得优异成绩,换句话说,就是要解锁它已经拥有的能力。
论文及项目相关链接
Summary
大型语言模型在自然语言处理任务中取得了显著的成功,强化学习在适应特定应用方面发挥了关键作用。然而,为数学问题解决训练大型语言模型获取真实答案通常具有挑战性、成本高昂,有时甚至不可行。本研究探讨了利用格式和长度作为替代信号来训练大型语言模型进行数学问题解决,从而绕过对真实答案的需求。研究表明,以格式正确性为中心的奖励函数可以在早期阶段产生与标准GRPO算法相当的性能改进。在后期阶段,我们结合了基于长度的奖励。结果产生的GRPO方法,利用格式长度替代信号,不仅与标准GRPO算法相当,而且在某些情况下更胜一筹,在AIME2024上实现40.0%的准确率,使用7B基础模型。该研究不仅为解决数学问题的语言模型训练提供了实用解决方案,降低了对大量真实数据的依赖,还揭示了无标签方法成功的原因:基础模型就像一个已经掌握了数学和逻辑推理技能但需要在试卷上表现良好的学生一样,它需要养成好的答题习惯来取得优异的成绩。
Key Takeaways
- 大型语言模型在自然语言处理任务中取得了显著成功,强化学习在特定应用适应中起关键作用。
- 训练大型语言模型进行数学问题解决获取真实答案具有挑战性、成本高昂。
- 研究利用格式和长度作为替代信号来训练大型语言模型进行数学问题解决。
- 格式正确性的奖励函数在早期阶段可以产生显著的性能改进。
- 结合基于长度的奖励以弥补格式单一奖励在后期阶段的局限性。
- 利用格式长度替代信号的GRPO方法在某些情况下与标准方法相当或更优,达到AIME2024上的高准确率。
点此查看论文截图

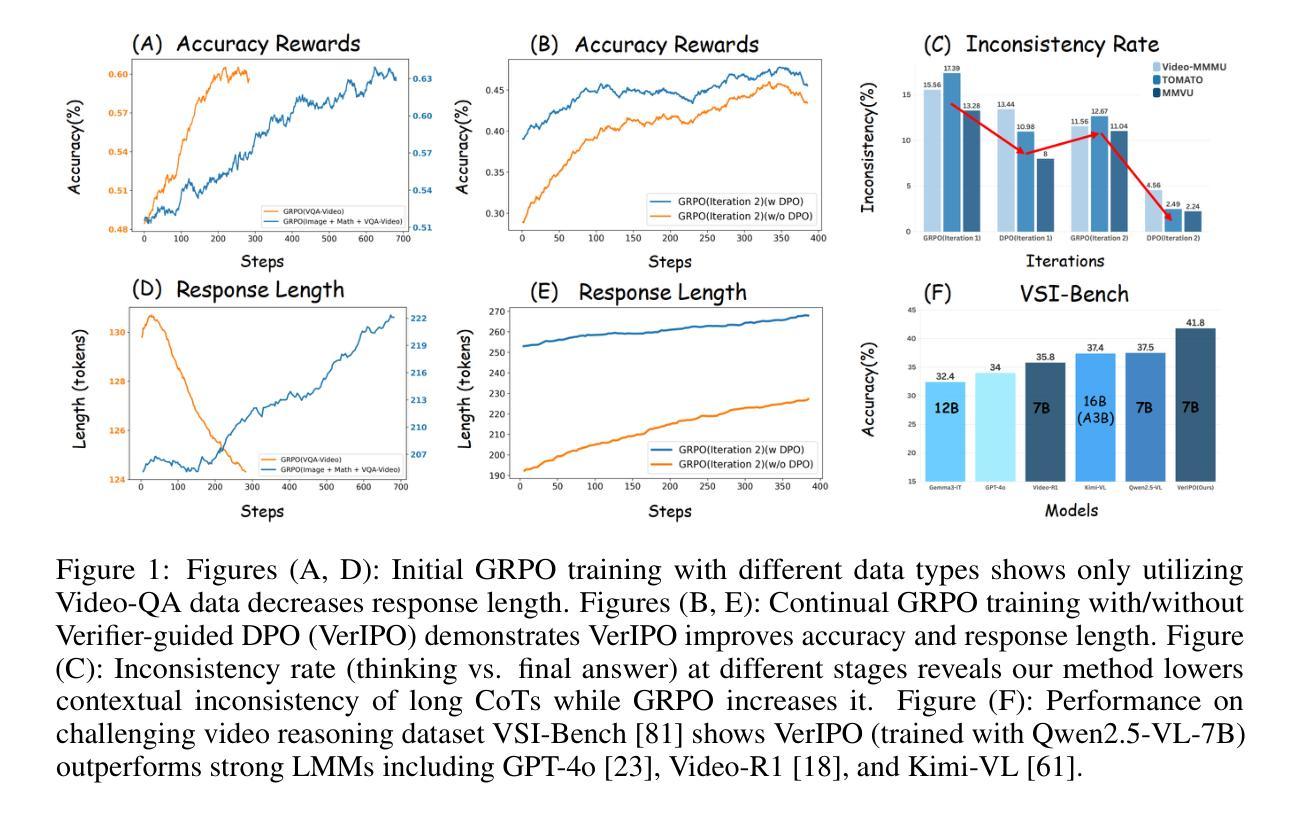
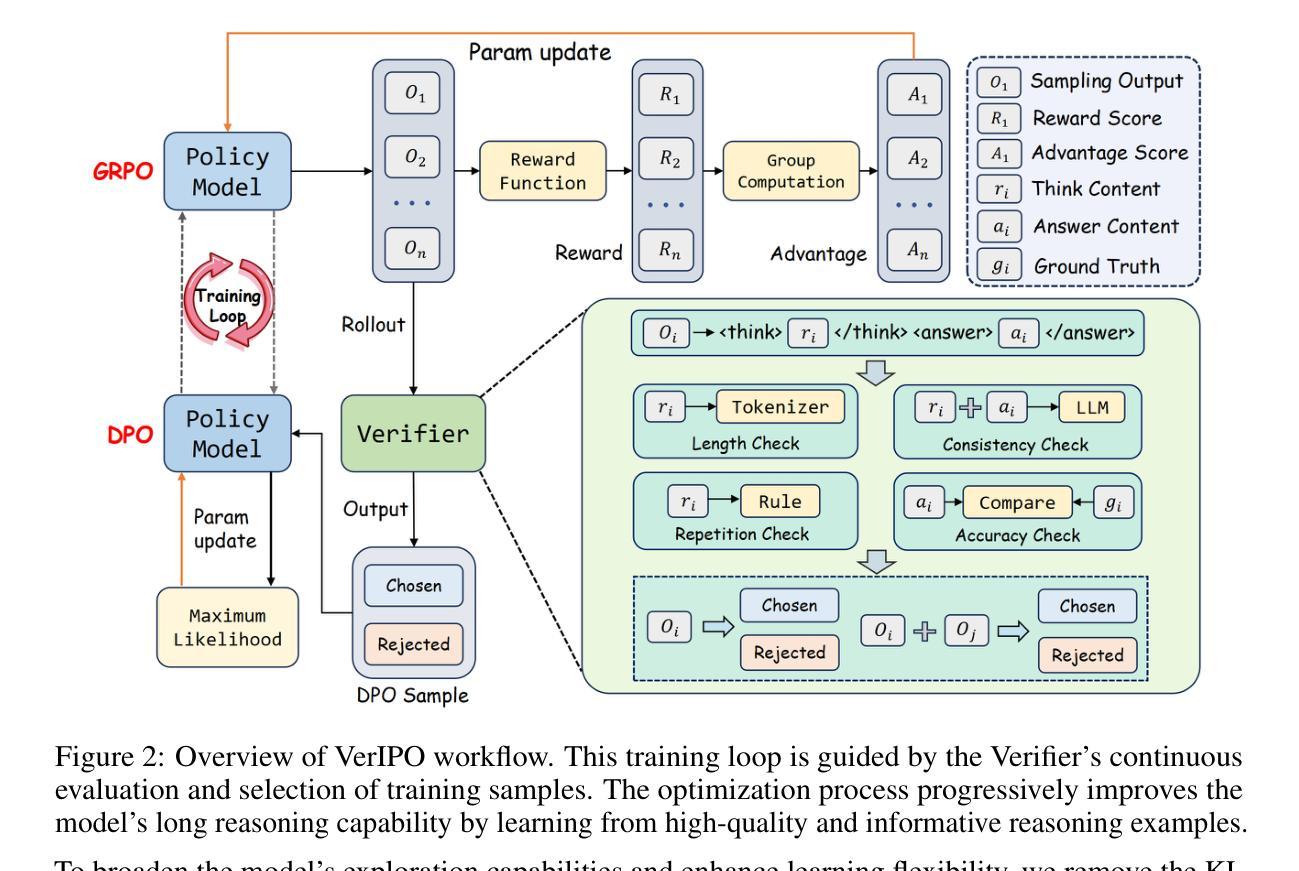
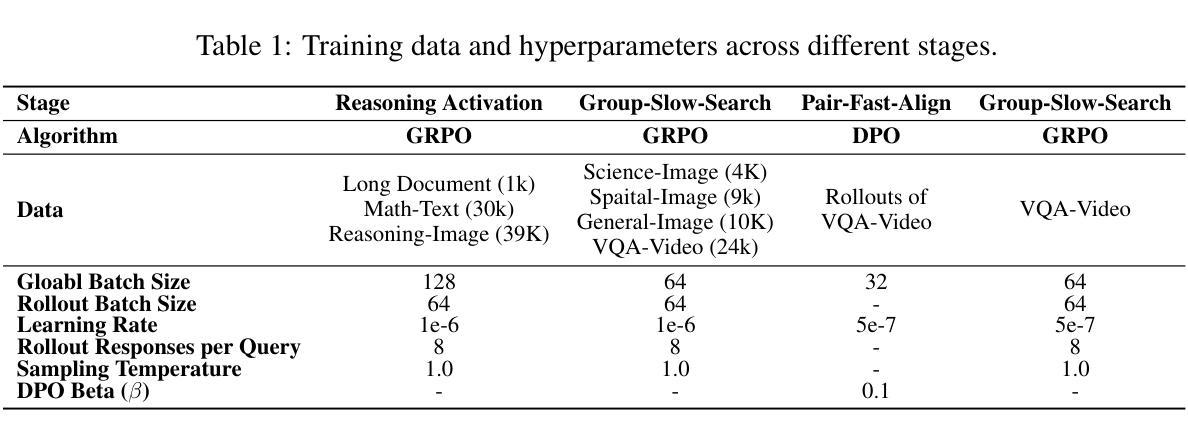
VerIPO: Cultivating Long Reasoning in Video-LLMs via Verifier-Gudied Iterative Policy Optimization
Authors:Yunxin Li, Xinyu Chen, Zitao Li, Zhenyu Liu, Longyue Wang, Wenhan Luo, Baotian Hu, Min Zhang
Applying Reinforcement Learning (RL) to Video Large Language Models (Video-LLMs) shows significant promise for complex video reasoning. However, popular Reinforcement Fine-Tuning (RFT) methods, such as outcome-based Group Relative Policy Optimization (GRPO), are limited by data preparation bottlenecks (e.g., noise or high cost) and exhibit unstable improvements in the quality of long chain-of-thoughts (CoTs) and downstream performance.To address these limitations, we propose VerIPO, a Verifier-guided Iterative Policy Optimization method designed to gradually improve video LLMs’ capacity for generating deep, long-term reasoning chains. The core component is Rollout-Aware Verifier, positioned between the GRPO and Direct Preference Optimization (DPO) training phases to form the GRPO-Verifier-DPO training loop. This verifier leverages small LLMs as a judge to assess the reasoning logic of rollouts, enabling the construction of high-quality contrastive data, including reflective and contextually consistent CoTs. These curated preference samples drive the efficient DPO stage (7x faster than GRPO), leading to marked improvements in reasoning chain quality, especially in terms of length and contextual consistency. This training loop benefits from GRPO’s expansive search and DPO’s targeted optimization. Experimental results demonstrate: 1) Significantly faster and more effective optimization compared to standard GRPO variants, yielding superior performance; 2) Our trained models exceed the direct inference of large-scale instruction-tuned Video-LLMs, producing long and contextually consistent CoTs on diverse video reasoning tasks; and 3) Our model with one iteration outperforms powerful LMMs (e.g., Kimi-VL) and long reasoning models (e.g., Video-R1), highlighting its effectiveness and stability.
将强化学习(RL)应用于视频大语言模型(Video-LLM)对于复杂视频推理显示出巨大的潜力。然而,流行的强化微调(RFT)方法,如基于结果的群组相对策略优化(GRPO),受到数据准备瓶颈(例如噪声或成本高)的限制,并且在长思维链(CoTs)的质量和下游性能方面的改进不稳定。为了解决这些局限性,我们提出了VerIPO,这是一种验证器引导迭代策略优化方法,旨在逐步改进视频LLM生成深度、长期推理链的能力。核心组件是Rollout-Aware Verifier,它位于GRPO和直接偏好优化(DPO)训练阶段之间,形成GRPO-Verifier-DPO训练循环。该验证器利用小型LLM作为法官来评估滚动条的逻辑推理,从而构建高质量对比数据,包括反射和上下文一致的CoTs。这些精选的偏好样本驱动高效的DPO阶段(比GRPO快7倍),导致推理链质量显著提高,特别是在长度和上下文一致性方面。这种训练循环受益于GRPO的广泛搜索和DPO的针对性优化。实验结果表明:1)与优化过的GRPO变体相比,优化过程更快、更有效,性能更优;2)我们训练的模型在多样的视频推理任务上,能够产生长而上下文连贯的CoTs,超越了大规模指令调整的视频LLM的直接推理;3)我们的模型在一次迭代中的表现优于强大的LMMs(如Kimi-VL)和长期推理模型(如Video-R1),突显了其有效性和稳定性。
论文及项目相关链接
PDF 19 pages, 9 figures, Project Link: https://github.com/HITsz-TMG/VerIPO
Summary
采用强化学习(RL)对视频大语言模型(Video-LLM)进行训练在复杂视频推理方面展现出巨大潜力。然而,现有的强化精细调整(RFT)方法,如基于结果的组相对策略优化(GRPO),受限于数据准备瓶颈(如噪声或高成本),并且在长思维链(CoTs)的质量和下游性能提升方面表现不稳定。为解决这些问题,提出了VerIPO方法,通过验证器引导迭代策略优化,逐步增强视频LLM生成深度、长期推理链的能力。其核心组件是Rollout-Aware Verifier,位于GRPO和直接偏好优化(DPO)训练阶段之间,形成GRPO-Verifier-DPO训练循环。该验证器利用小型LLM作为判断者来评估滚动结果的推理逻辑,能够构建高质量对比数据,包括反思和上下文一致的CoTs。这些精选的偏好样本驱动高效的DPO阶段(比GRPO快7倍),在推理链的质量方面,尤其是在长度和上下文一致性方面取得了显著改进。该训练循环受益于GRPO的广泛搜索和DPO的目标优化。实验结果表明,与标准GRPO变体相比,优化更快、更有效,性能优越;我们的训练模型在多样化的视频推理任务上,能够产生长而上下文一致的CoTs,超过大规模指令调整Video-LLM的直接推理;我们的模型在一次迭代中的表现优于强大的LMMs和长期推理模型,凸显其有效性和稳定性。
Key Takeaways
- 强化学习在视频大语言模型中的应用展现出对复杂视频推理的巨大潜力。
- 当前强化精细调整方法面临数据准备瓶颈及性能不稳定问题。
- VerIPO方法通过验证器引导迭代策略优化,旨在解决现有方法的局限。
- Rollout-Aware Verifier是VerIPO的核心,能构建高质量对比数据。
- VerIPO通过提高推理链质量,尤其在长度和上下文一致性方面取得显著改进。
- VerIPO训练循环结合GRPO的广泛搜索和DPO的目标优化,实现快速且有效的优化。
点此查看论文截图