⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-01 更新
MMGT: Motion Mask Guided Two-Stage Network for Co-Speech Gesture Video Generation
Authors:Siyuan Wang, Jiawei Liu, Wei Wang, Yeying Jin, Jinsong Du, Zhi Han
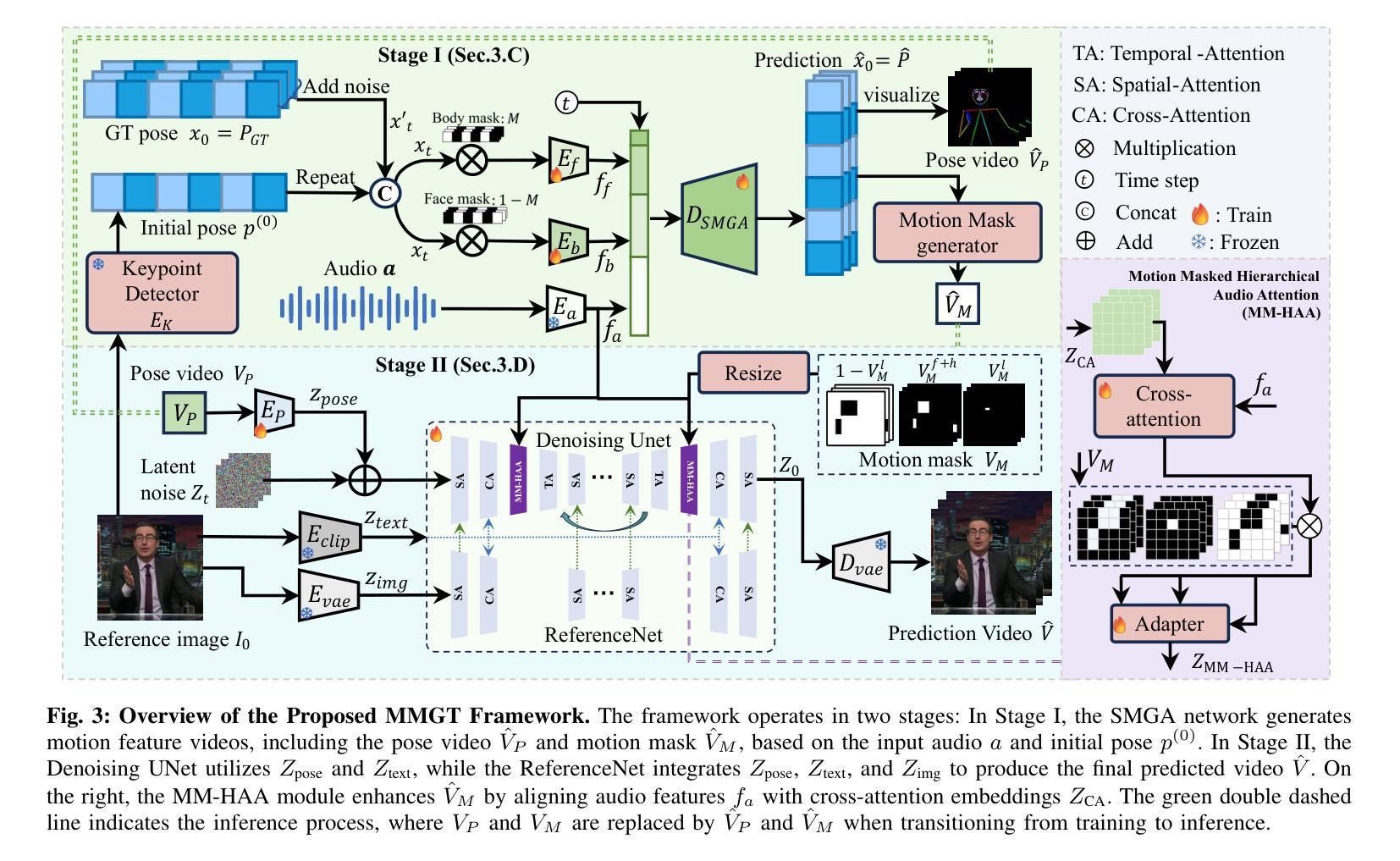
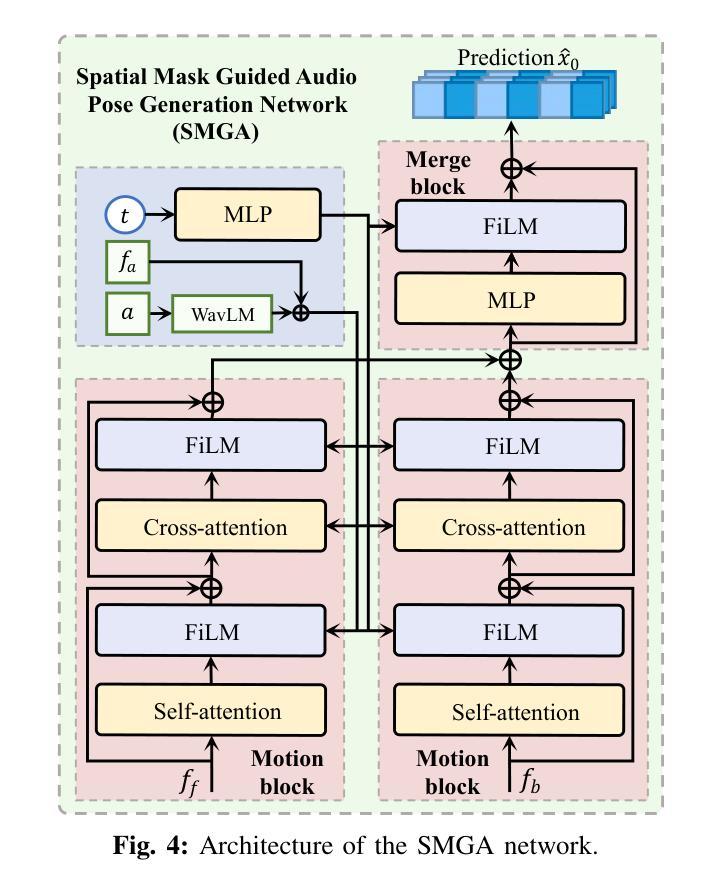
Co-Speech Gesture Video Generation aims to generate vivid speech videos from audio-driven still images, which is challenging due to the diversity of different parts of the body in terms of amplitude of motion, audio relevance, and detailed features. Relying solely on audio as the control signal often fails to capture large gesture movements in video, leading to more pronounced artifacts and distortions. Existing approaches typically address this issue by introducing additional a priori information, but this can limit the practical application of the task. Specifically, we propose a Motion Mask-Guided Two-Stage Network (MMGT) that uses audio, as well as motion masks and motion features generated from the audio signal to jointly drive the generation of synchronized speech gesture videos. In the first stage, the Spatial Mask-Guided Audio Pose Generation (SMGA) Network generates high-quality pose videos and motion masks from audio, effectively capturing large movements in key regions such as the face and gestures. In the second stage, we integrate the Motion Masked Hierarchical Audio Attention (MM-HAA) into the Stabilized Diffusion Video Generation model, overcoming limitations in fine-grained motion generation and region-specific detail control found in traditional methods. This guarantees high-quality, detailed upper-body video generation with accurate texture and motion details. Evaluations show improved video quality, lip-sync, and gesture. The model and code are available at https://github.com/SIA-IDE/MMGT.
对话式手势视频生成旨在从音频驱动的静态图像生成生动逼真的视频,但由于身体各部分在运动幅度、音频相关性和详细特征上的差异,这仍然是一个挑战。仅依赖音频作为控制信号通常无法捕捉到视频中的大型手势动作,从而导致更明显的伪像和失真。现有方法通常通过引入额外的先验信息来解决这个问题,但这可能限制了该任务的实际应用。具体来说,我们提出了一种运动掩码引导的两阶段网络(MMGT),该网络使用音频以及从音频信号生成的动态掩码和运动特征来共同驱动同步手势视频的生成。在第一阶段,空间掩码引导音频姿态生成(SMGA)网络从音频生成高质量姿态视频和运动掩码,有效地捕捉面部和手势等关键区域的大型动作。在第二阶段,我们将运动掩码层次音频注意力(MM-HAA)集成到稳定的扩散视频生成模型中,克服了传统方法在精细动作生成和区域特定细节控制方面的局限性,这保证了高质量、详细的上半身视频生成,具有准确的纹理和运动细节。评估结果显示视频质量、唇同步和手势都有所提高。模型和代码可在https://github.com/SIA-IDE/MMGT获得。
论文及项目相关链接
Summary
本文介绍了针对音频驱动静态图像生成生动语音视频的挑战,提出一种名为MMGT的新方法。该方法结合音频、运动掩码和从音频信号生成的动态特征,共同驱动同步语音手势视频的生成。通过两个阶段实现高质量、详细的上半身视频生成,具有准确的纹理和运动细节。模型与代码已公开于https://github.com/SIA-IDE/MMGT。
Key Takeaways
- Co-Speech Gesture Video Generation旨在从音频驱动的静态图像生成生动语音视频,面临多样性挑战。
- 仅依赖音频作为控制信号无法捕获大动作手势视频的细节。
- 引入先验信息的方法限制了任务的实用性。
- 提出MMGT网络,结合音频、运动掩码和动态特征共同驱动视频生成。
- 第一阶段生成高质量姿势视频和运动掩码,有效捕捉面部和手势等大动作。
- 第二阶段整合运动掩码层次音频注意力,克服传统方法的缺点,保证高质量、详细的视频生成。
点此查看论文截图