⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-02 更新
Benchmarking and Rethinking Knowledge Editing for Large Language Models
Authors:Guoxiu He, Xin Song, Futing Wang, Aixin Sun
Knowledge editing aims to update the embedded knowledge within Large Language Models (LLMs). However, existing approaches, whether through parameter modification or external memory integration, often suffer from inconsistent evaluation objectives and experimental setups. To address this gap, we conduct a comprehensive benchmarking study. In addition to fact-level datasets, we introduce more complex event-based datasets and general-purpose datasets drawn from other tasks. Our evaluation covers both instruction-tuned and reasoning-oriented LLMs, under a realistic autoregressive inference setting rather than teacher-forced decoding. Beyond single-edit assessments, we also evaluate multi-edit scenarios to better reflect practical demands. We employ four evaluation dimensions, including portability, and compare all recent methods against a simple and straightforward baseline named Selective Contextual Reasoning (SCR). Empirical results reveal that parameter-based editing methods perform poorly under realistic conditions. In contrast, SCR consistently outperforms them across all settings. This study offers new insights into the limitations of current knowledge editing methods and highlights the potential of context-based reasoning as a more robust alternative.
知识编辑旨在更新大型语言模型(LLM)中的嵌入知识。然而,现有方法,无论是通过参数修改还是外部记忆集成,经常面临评估目标不一致和实验设置不一致的问题。为了弥补这一空白,我们进行了一项全面的基准测试研究。除了事实级的数据集之外,我们还引入了更复杂的事件基础数据集和从其他任务中提取的通用数据集。我们的评估涵盖了指令调优和面向推理的LLM,在一个现实的自回归推理设置下,而不是教师强制解码。除了单编辑评估之外,我们还对多编辑场景进行评估,以更好地反映实际需求。我们采用四个评估维度,包括可移植性,并与名为选择性上下文推理(SCR)的简单直接基线对比所有近期方法。实证结果表明,基于参数的编辑方法在实际情况下的表现较差。相比之下,SCR在所有设置中均表现优异。本研究为当前知识编辑方法的局限性提供了新的见解,并突出了基于上下文的推理作为更稳健的替代方案的潜力。
论文及项目相关链接
PDF arXiv admin note: text overlap with arXiv:2503.05212
总结
本文探讨了大型语言模型中的知识更新问题。当前的知识编辑方法如参数修改和外部记忆集成等存在评价目标不一致的问题。为解决这一问题,研究者进行了一项全面的基准测试研究,引入了更复杂的事件数据集和通用数据集进行评估。评估涵盖了指令调优和推理导向的大型语言模型,采用真实的自动回归推理设置进行评估。此外,还进行了单编辑和多编辑场景的评估以更好地反映实际需求。评估包括便携性在内的四个维度,并对比了名为选择性上下文推理的简单直观基线方法与所有近期方法。实证结果表明,基于参数的编辑方法在真实条件下表现不佳,而选择性上下文推理则始终表现优异。该研究揭示了当前知识编辑方法的局限性,并展示了基于上下文的推理作为更稳健替代方案的潜力。
关键见解
- 知识编辑旨在更新大型语言模型中的嵌入知识。
- 当前的知识编辑方法存在评价目标不一致的问题。
- 为了解决这一问题,研究者进行了全面的基准测试研究。
- 研究引入了复杂的事件数据集和通用数据集进行评估。
- 评估覆盖了指令调优和推理导向的大型语言模型。
- 选择性上下文推理(SCR)在多种设置下表现优异。
点此查看论文截图

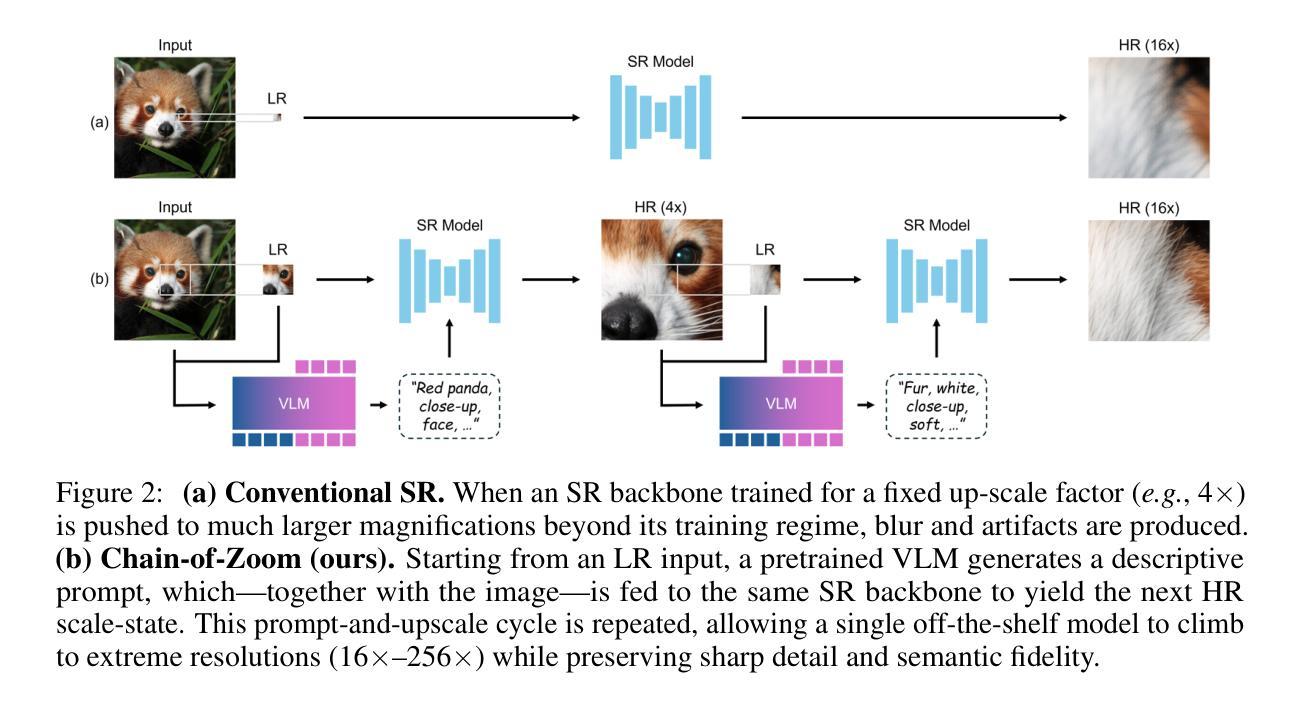
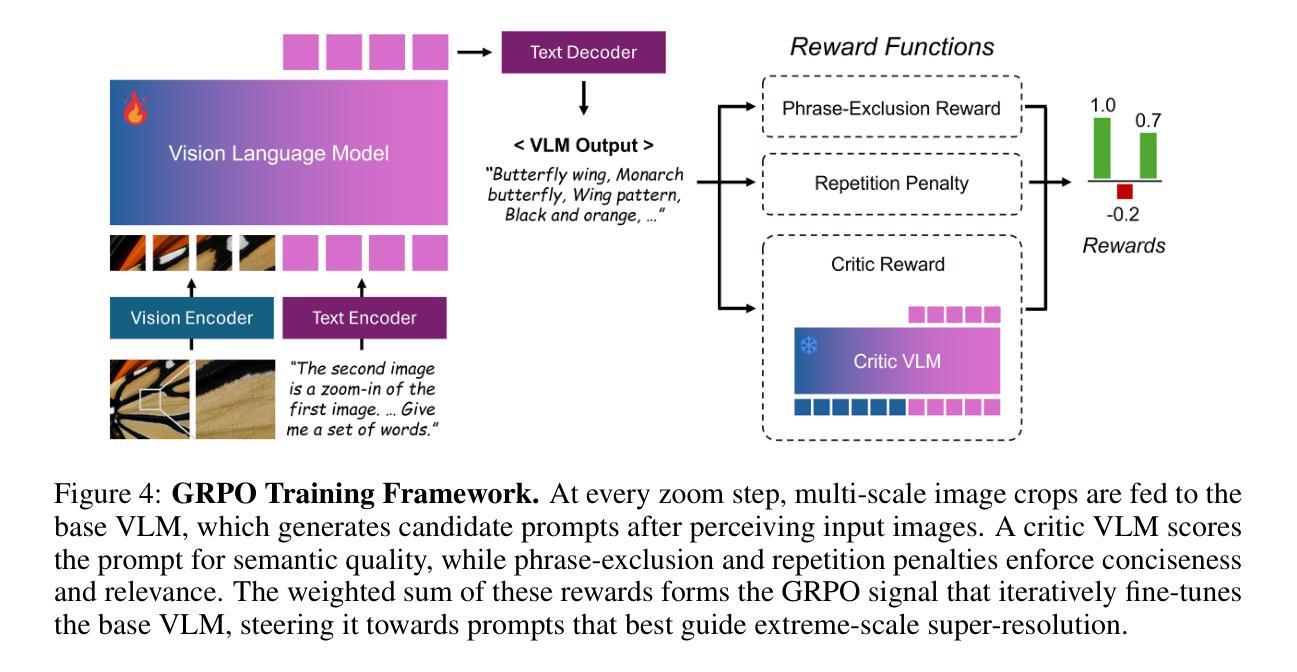
Chain-of-Zoom: Extreme Super-Resolution via Scale Autoregression and Preference Alignment
Authors:Bryan Sangwoo Kim, Jeongsol Kim, Jong Chul Ye
Modern single-image super-resolution (SISR) models deliver photo-realistic results at the scale factors on which they are trained, but collapse when asked to magnify far beyond that regime. We address this scalability bottleneck with Chain-of-Zoom (CoZ), a model-agnostic framework that factorizes SISR into an autoregressive chain of intermediate scale-states with multi-scale-aware prompts. CoZ repeatedly re-uses a backbone SR model, decomposing the conditional probability into tractable sub-problems to achieve extreme resolutions without additional training. Because visual cues diminish at high magnifications, we augment each zoom step with multi-scale-aware text prompts generated by a vision-language model (VLM). The prompt extractor itself is fine-tuned using Generalized Reward Policy Optimization (GRPO) with a critic VLM, aligning text guidance towards human preference. Experiments show that a standard 4x diffusion SR model wrapped in CoZ attains beyond 256x enlargement with high perceptual quality and fidelity. Project Page: https://bryanswkim.github.io/chain-of-zoom/ .
现代单图像超分辨率(SISR)模型在它们所接受的尺度因素上产生逼真的结果,但当被要求放大超出这个范围时,它们就会崩溃。我们采用Chain-of-Zoom(CoZ)来解决这种可扩展性的瓶颈,这是一个通用的模型框架,它将SISR分解为具有多尺度感知提示的自回归中间尺度状态链。CoZ重复利用骨干网SR模型,将条件概率分解为可控制的子问题,以实现极高的分辨率而无需额外的训练。由于在高倍放大时视觉线索会减少,我们利用由视觉语言模型(VLM)生成的多尺度感知文本提示来增强每一步的放大。提示提取器本身使用具有评论家VLM的广义奖励策略优化(GRPO)进行微调,使文本指导符合人类偏好。实验表明,使用CoZ包装的标准4倍扩散SR模型可以实现超过256倍的放大,同时保持高度的感知质量和保真度。项目页面:https://bryanswkim.github.io/chain-of-zoom/。
论文及项目相关链接
PDF Project Page: https://bryanswkim.github.io/chain-of-zoom/
Summary
该文针对现代单图像超分辨率(SISR)模型在放大倍数超出训练规模时性能下降的问题,提出了Chain-of-Zoom(CoZ)框架。该框架将SISR分解为中间尺度状态的自回归链,通过多尺度感知提示进行超分辨率重建。CoZ通过重复使用骨干SR模型,将条件概率分解为可解决的子问题,实现极端分辨率而无需额外训练。在高倍放大时,视觉线索减少,因此每个缩放步骤都会借助由视觉语言模型(VLM)生成的多尺度感知文本提示进行增强。提示提取器使用广义奖励策略优化(GRPO)和评论家VLM进行微调,使文本指导符合人类偏好。实验表明,使用CoZ包装的4倍扩散SR模型可实现超过256倍的放大,同时保持高感知质量和保真度。
Key Takeaways
- Chain-of-Zoom(CoZ)框架解决了现代SISR模型在超出训练规模时的放大性能瓶颈。
- CoZ通过将SISR分解为中间尺度状态的自回归链,利用多尺度感知提示进行超分辨率重建。
- CoZ通过重复使用骨干SR模型,分解条件概率为子问题,实现极端分辨率提升。
- 在高倍放大时,视觉线索减少,因此利用视觉语言模型(VLM)生成的多尺度感知文本提示增强每个缩放步骤。
- 文本提示提取器通过广义奖励策略优化(GRPO)和评论家VLM进行微调,以符合人类偏好。
- 实验显示,使用CoZ的SISR模型在超过256倍放大时仍能保持高感知质量和保真度。
点此查看论文截图


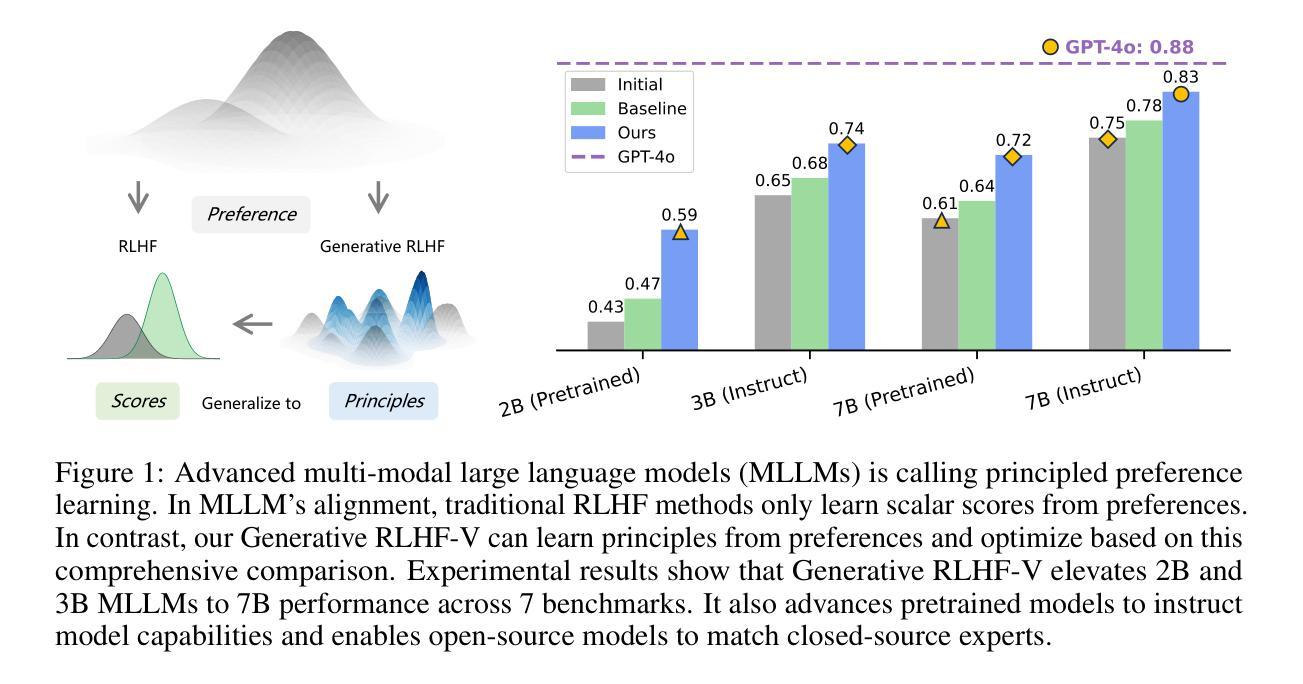
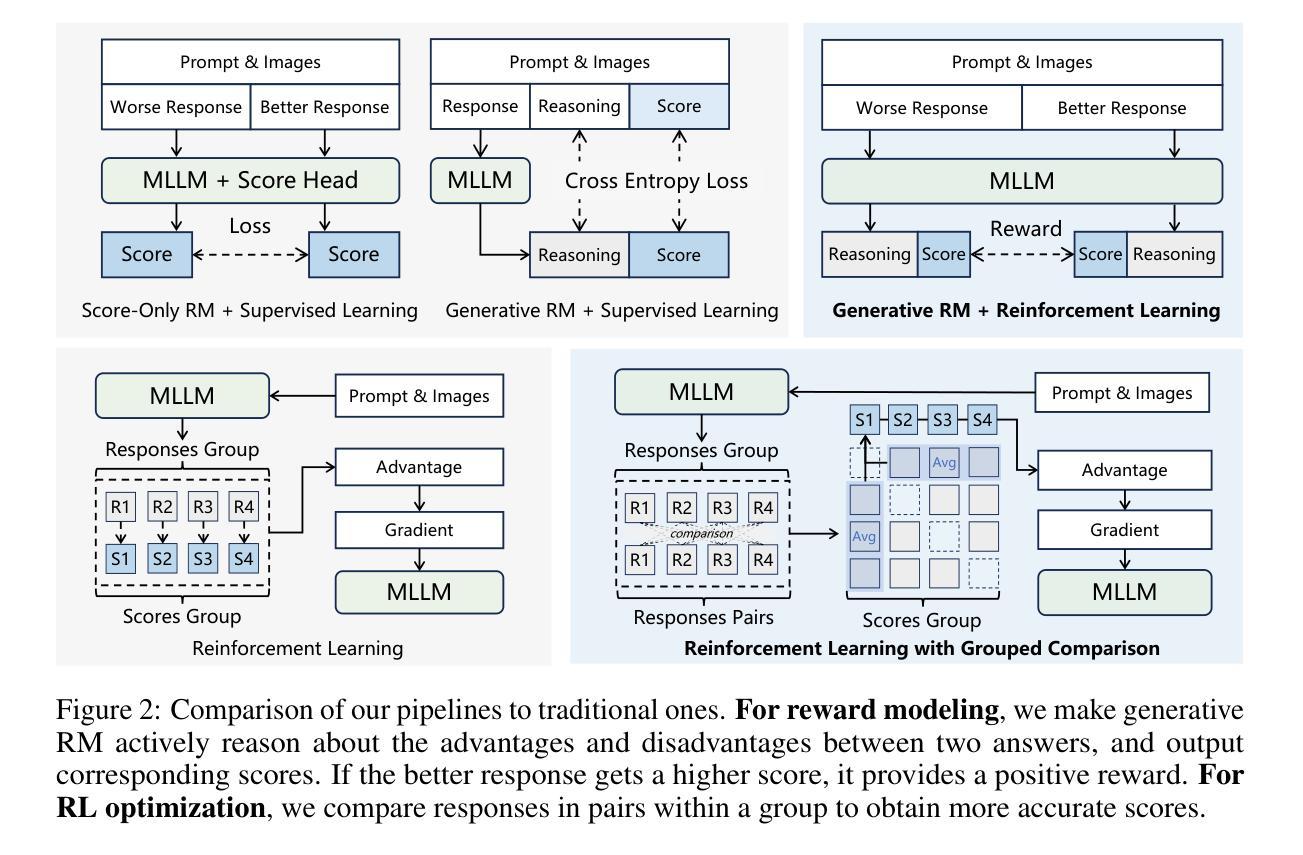
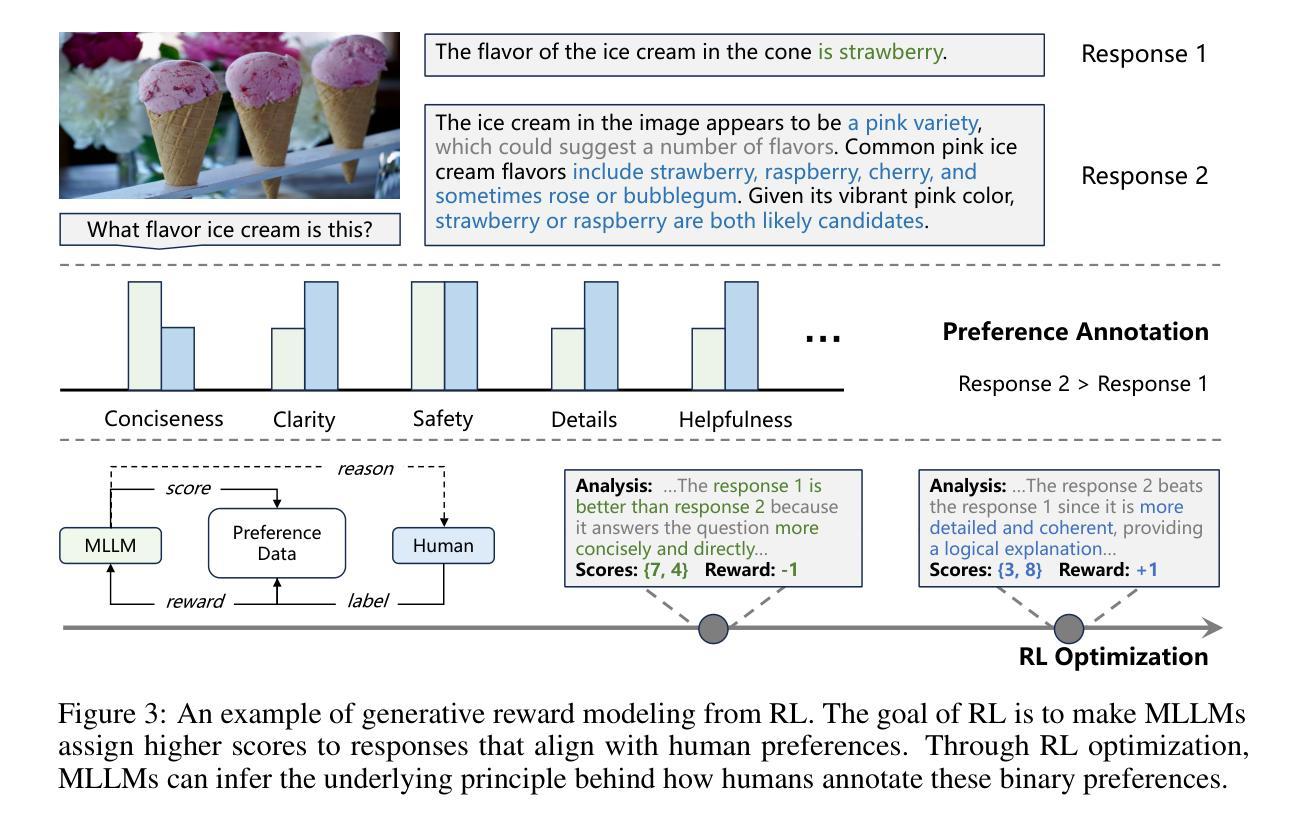
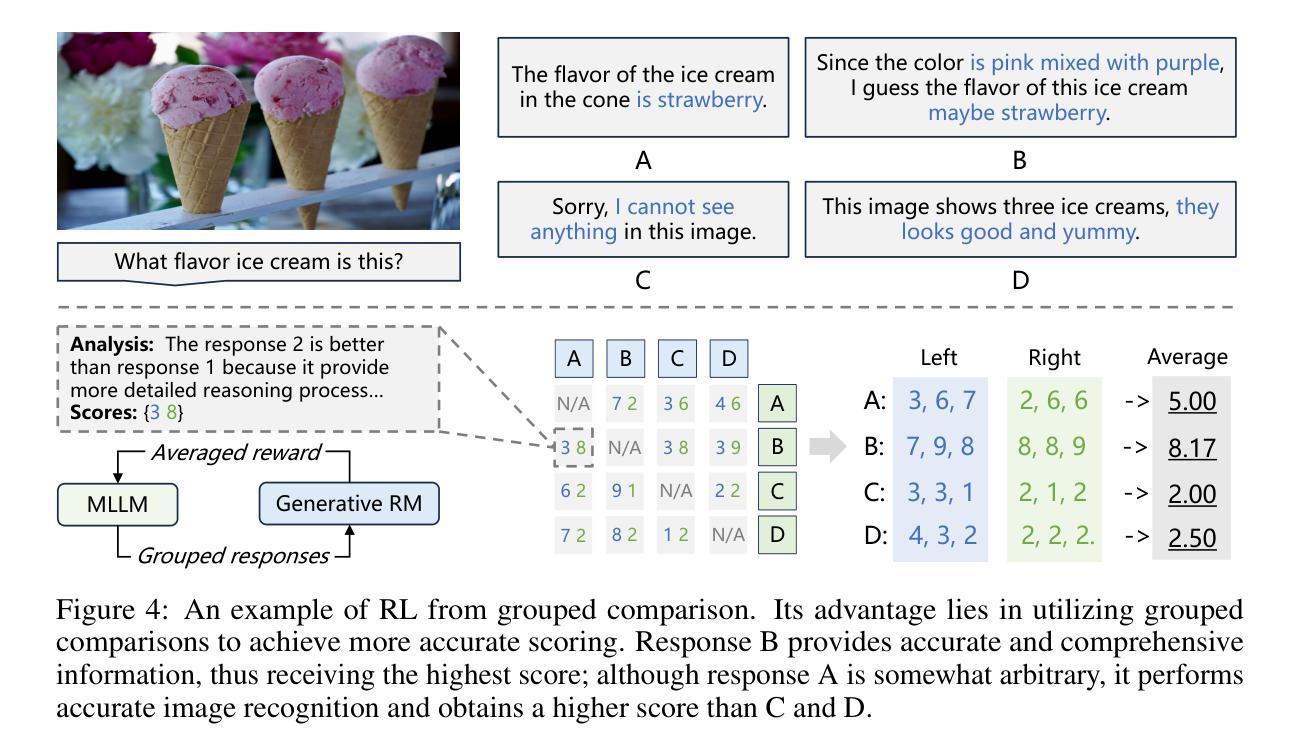
Generative RLHF-V: Learning Principles from Multi-modal Human Preference
Authors:Jiayi Zhou, Jiaming Ji, Boyuan Chen, Jiapeng Sun, Wenqi Chen, Donghai Hong, Sirui Han, Yike Guo, Yaodong Yang
Training multi-modal large language models (MLLMs) that align with human intentions is a long-term challenge. Traditional score-only reward models for alignment suffer from low accuracy, weak generalization, and poor interpretability, blocking the progress of alignment methods, e.g., reinforcement learning from human feedback (RLHF). Generative reward models (GRMs) leverage MLLMs’ intrinsic reasoning capabilities to discriminate pair-wise responses, but their pair-wise paradigm makes it hard to generalize to learnable rewards. We introduce Generative RLHF-V, a novel alignment framework that integrates GRMs with multi-modal RLHF. We propose a two-stage pipeline: $\textbf{multi-modal generative reward modeling from RL}$, where RL guides GRMs to actively capture human intention, then predict the correct pair-wise scores; and $\textbf{RL optimization from grouped comparison}$, which enhances multi-modal RL scoring precision by grouped responses comparison. Experimental results demonstrate that, besides out-of-distribution generalization of RM discrimination, our framework improves 4 MLLMs’ performance across 7 benchmarks by $18.1%$, while the baseline RLHF is only $5.3%$. We further validate that Generative RLHF-V achieves a near-linear improvement with an increasing number of candidate responses. Our code and models can be found at https://generative-rlhf-v.github.io.
训练符合人类意图的多模态大型语言模型(MLLMs)是一项长期挑战。传统的仅评分奖励模型在对齐方面存在精度低、泛化能力弱和解释性差的缺点,阻碍了对齐方法(例如,基于人类反馈的强化学习(RLHF))的进步。生成奖励模型(GRMs)利用MLLMs的内在推理能力来区分成对响应,但其成对范式难以推广到可学习的奖励。我们引入了生成式RLHF-V,这是一种将GRMs与多模态RLHF相结合的新型对齐框架。我们提出了一个两阶段的流程:利用强化学习进行多模态生成奖励建模,其中RL指导GRMs主动捕捉人类意图,然后预测正确的成对分数;和基于分组比较的RL优化,通过比较分组响应来提高多模态RL评分精度。实验结果表明,除了RM鉴别的分布外推广,我们的框架在7个基准测试上提高了4个MLLM的性能,提高了18.1%,而基线RLHF仅为5.3%。我们进一步验证,随着候选响应数量的增加,生成式RLHF-V实现了近线性的改进。我们的代码和模型可在https://generative-rlhf-v.github.io找到。
论文及项目相关链接
PDF 9 pages, 8 figures
Summary
训练多模态大型语言模型(MLLMs)以符合人类意图是一个长期挑战。传统的仅评分奖励模型在对齐方面存在准确性低、泛化能力弱和解释性差的问题,阻碍了如基于人类反馈的强化学习(RLHF)等对齐方法的进展。本文提出了生成奖励模型(GRMs),利用MLLMs的内在推理能力来区分配对响应,但其配对范式难以推广到可学习的奖励。本文介绍了全新的对齐框架——生成RLHF-V,它将GRMs与多模态RLHF相结合。提出了两阶段管道:首先是基于RL的多模态生成奖励建模,其中RL引导GRMs主动捕捉人类意图,然后预测正确的配对分数;其次是基于分组比较的RL优化,通过分组响应比较提高多模态RL评分精度。实验结果表明,除了RM鉴别的分布外推广能力外,我们的框架在7个基准测试中提高了4个MLLM的性能达18.1%,而基线RLHF仅提高5.3%。进一步验证了生成RLHF-V随着候选响应数量的增加实现了近线性的改进。
Key Takeaways
- 训练多模态大型语言模型与人的意图对齐是一个长期挑战。
- 传统奖励模型在对齐方面存在局限,如准确性、泛化能力和解释性方面的问题。
- 引入生成奖励模型(GRMs)利用MLLMs的内在推理能力进行配对响应区分。
- 提出新的对齐框架——生成RLHF-V,结合GRMs和多模态RLHF。
- 该框架包含两阶段:基于RL的奖励建模和基于分组比较的RL优化。
- 实验证明该框架在多个基准测试中显著提高MLLM性能。
- 随着候选响应数量的增加,该框架实现近线性的改进。
点此查看论文截图

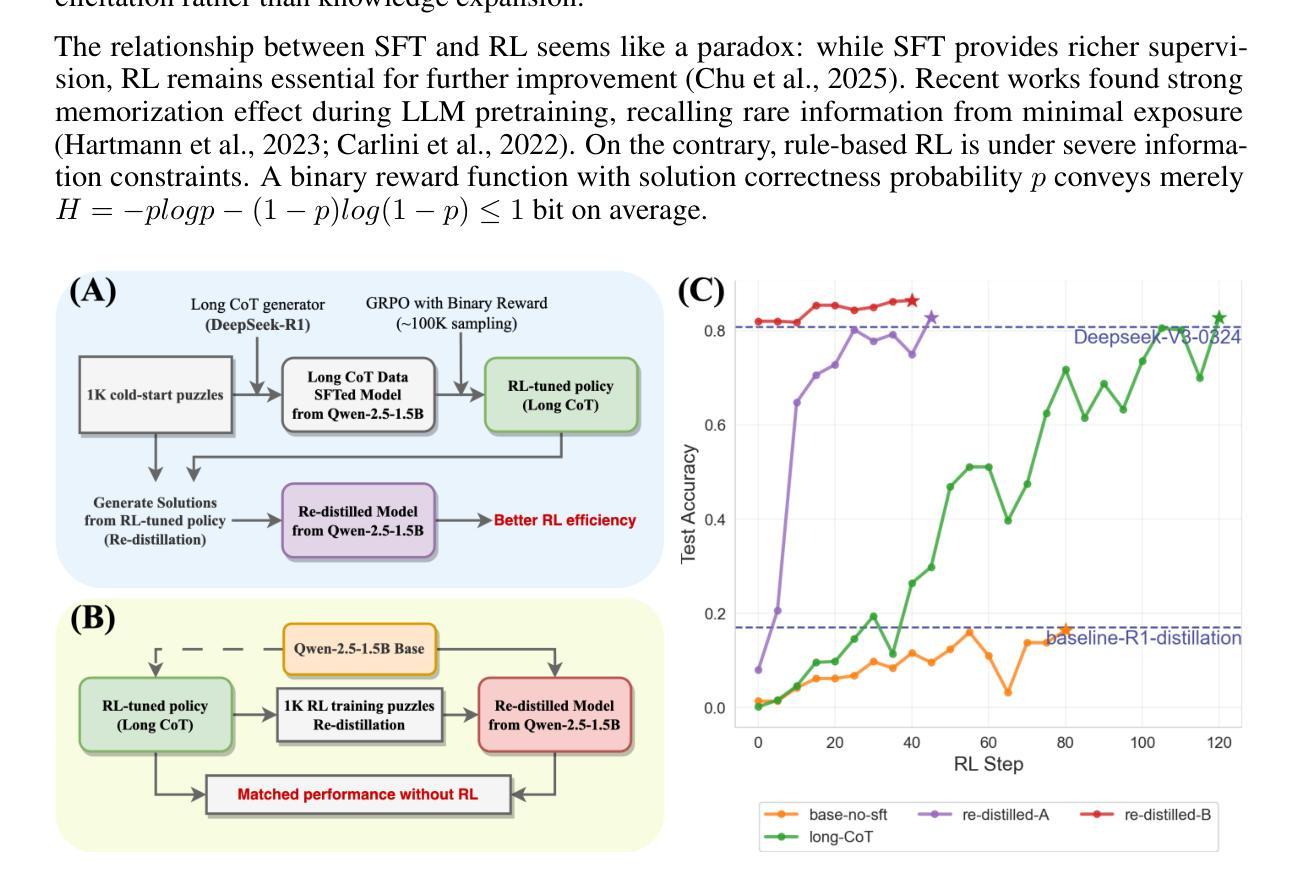
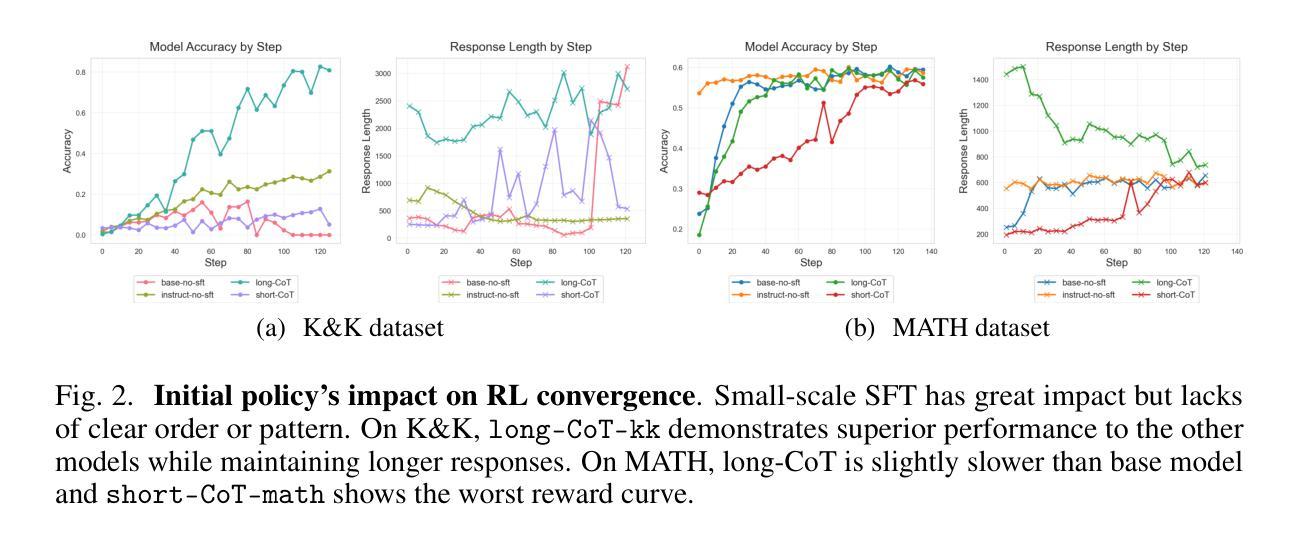
Towards Revealing the Effectiveness of Small-Scale Fine-tuning in R1-style Reinforcement Learning
Authors:Yutong Chen, Jiandong Gao, Ji Wu
R1-style Reinforcement Learning (RL) significantly enhances Large Language Models’ reasoning capabilities, yet the mechanism behind rule-based RL remains unclear. We found that small-scale SFT has significant influence on RL but shows poor efficiency. To explain our observations, we propose an analytical framework and compare the efficiency of SFT and RL by measuring sample effect. Hypothetical analysis show that SFT efficiency is limited by training data. Guided by our analysis, we propose Re-distillation, a technique that fine-tunes pretrain model through small-scale distillation from the RL-trained policy. Experiments on Knight & Knave and MATH datasets demonstrate re-distillation’s surprising efficiency: re-distilled models match RL performance with far fewer samples and less computation. Empirical verification shows that sample effect is a good indicator of performance improvements. As a result, on K&K dataset, our re-distilled Qwen2.5-1.5B model surpasses DeepSeek-V3-0324 with only 1K SFT samples. On MATH, Qwen2.5-1.5B fine-tuned with re-distilled 500 samples matches its instruct-tuned variant without RL. Our work explains several interesting phenomena in R1-style RL, shedding light on the mechanisms behind its empirical success. Code is available at: https://github.com/on1262/deep-reasoning
R1风格的强化学习(RL)显著提高了大型语言模型的推理能力,但其背后的机制仍然不明确。我们发现小规模SFT对RL有很大的影响,但效率不高。为了解释我们的观察结果,我们提出了一个分析框架,并通过测量样本效应来比较SFT和RL的效率。假设分析表明,SFT的效率受到训练数据的限制。在我们的分析指导下,我们提出了再蒸馏技术,这是一种通过小规模蒸馏从RL训练的决策中学习微调预训练模型的方法。在Knight & Knave和MATH数据集上的实验证明了再蒸馏的惊人效率:再蒸馏模型使用较少的样本和计算量就能达到RL的性能。经验验证表明,样本效应是性能改进的良好指标。因此,在K&K数据集上,我们的再蒸馏Qwen2.5-1.5B模型仅使用1K个SFT样本就超过了DeepSeek-V3-0324。在MATH上,使用再蒸馏的500个样本微调Qwen2.5-1.5B模型可以与没有RL的指令调整变体相匹配。我们的工作解释了R1风格RL的几个有趣现象,揭示了其经验成功的机制。代码可用在:https://github.com/on1262/deep-reasoning
论文及项目相关链接
PDF 11 figs, 3 table, preprint
Summary
R1风格强化学习(RL)可显著提升大型语言模型的推理能力,但其背后的机制尚不清楚。研究发现小规模SFT对RL有很大影响但效率较低。为解释观察结果,本文提出分析框架,通过测量样本效应比较SFT和RL的效率。假设分析显示SFT效率受限于训练数据。基于分析,本文提出再蒸馏技术,该技术通过来自RL训练策略的少量样本微调预训练模型。在Knight & Knave和MATH数据集上的实验显示再蒸馏的惊人效率:再蒸馏模型用更少的样本和计算量匹配RL性能。经验验证显示样本效应是性能改进的良好指标。因此,在K&K数据集上,我们的再蒸馏Qwen2.5-1.5B模型仅使用1KSFT样本就超越了DeepSeek-V3-0324。在MATH上,Qwen2.5-1.5B使用再蒸馏的500个样本进行微调,匹配了没有RL的指令调优变体。本研究解释了R1风格RL中的几个有趣现象,揭示了其经验成功的机制。
Key Takeaways
- R1-style Reinforcement Learning显著增强了大型语言模型的推理能力,但机制尚不清楚。
- 小规模SFT对RL有影响,但效率较低。
- 提出了一个分析框架来解释这一观察结果,通过测量样本效应来比较SFT和RL的效率。
- 假设分析显示,SFT效率受限于训练数据。
- 提出再蒸馏技术,能有效提高模型的训练效率和性能。
- 在特定数据集上的实验证明了再蒸馏技术的有效性。
点此查看论文截图

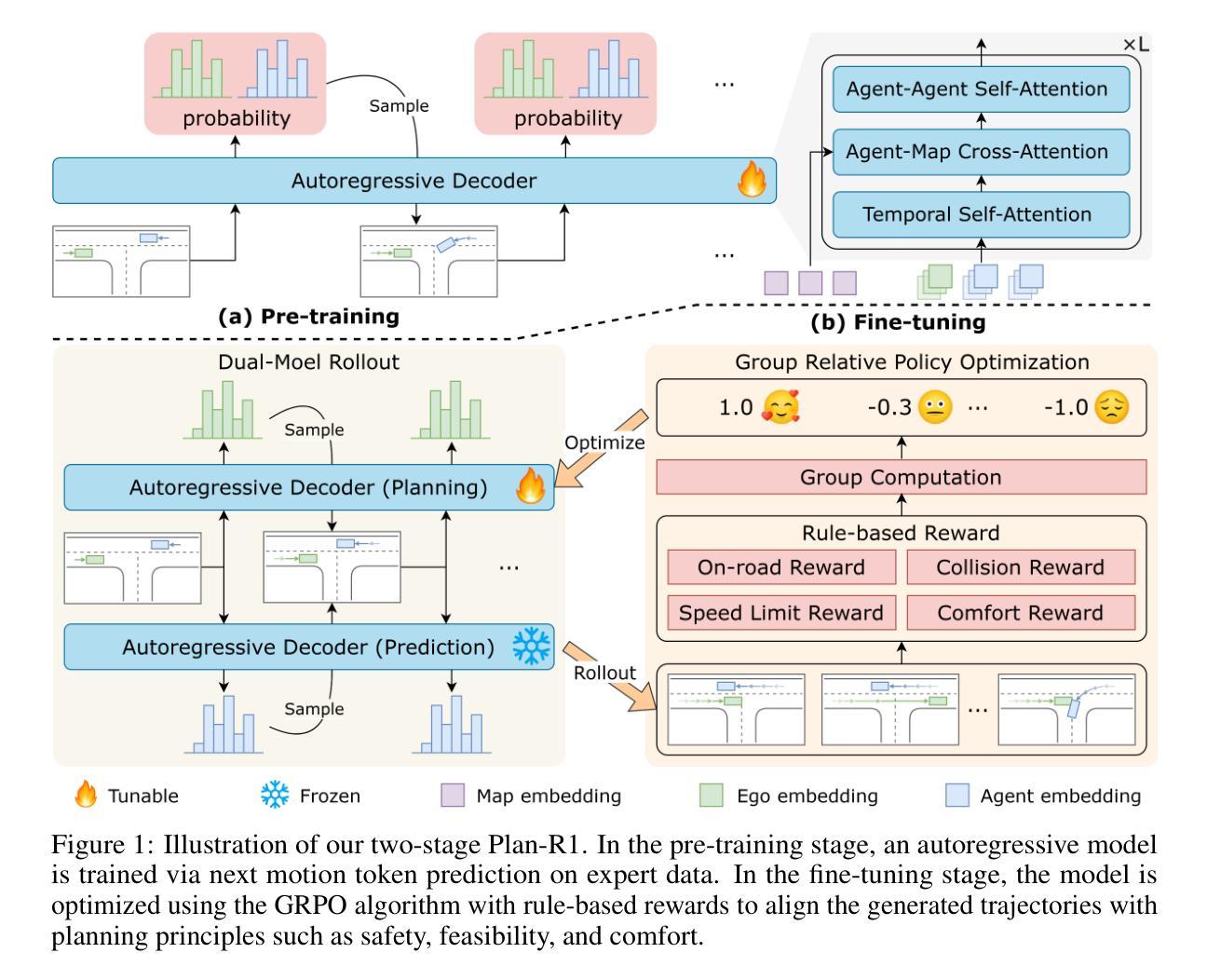
Plan-R1: Safe and Feasible Trajectory Planning as Language Modeling
Authors:Xiaolong Tang, Meina Kan, Shiguang Shan, Xilin Chen
Safe and feasible trajectory planning is essential for real-world autonomous driving systems. However, existing learning-based planning methods often rely on expert demonstrations, which not only lack explicit safety awareness but also risk inheriting unsafe behaviors such as speeding from suboptimal human driving data. Inspired by the success of large language models, we propose Plan-R1, a novel two-stage trajectory planning framework that formulates trajectory planning as a sequential prediction task, guided by explicit planning principles such as safety, comfort, and traffic rule compliance. In the first stage, we train an autoregressive trajectory predictor via next motion token prediction on expert data. In the second stage, we design rule-based rewards (e.g., collision avoidance, speed limits) and fine-tune the model using Group Relative Policy Optimization (GRPO), a reinforcement learning strategy, to align its predictions with these planning principles. Experiments on the nuPlan benchmark demonstrate that our Plan-R1 significantly improves planning safety and feasibility, achieving state-of-the-art performance. Our code will be made public soon.
安全可行的轨迹规划对于真实世界的自动驾驶系统至关重要。然而,现有的基于学习的规划方法往往依赖于专家演示,这不仅缺乏明确的安全意识,而且还存在从次优人类驾驶数据中继承不安全行为(如超速)的风险。受大型语言模型成功的启发,我们提出了Plan-R1,这是一种新型的两阶段轨迹规划框架,它将轨迹规划制定为受明确规划原则(如安全、舒适和遵守交通规则)指导的序列预测任务。在第一阶段,我们通过专家数据预测下一个动作标记来训练一个自回归轨迹预测器。在第二阶段,我们设计基于规则的奖励(例如防撞、限速等),并使用一种强化学习策略——群组相对策略优化(GRPO)对模型进行微调,使其预测与这些规划原则保持一致。在nuPlan基准测试上的实验表明,我们的Plan-R1在规划安全性和可行性方面有了显著提高,达到了最先进的性能。我们的代码很快将公开。
论文及项目相关链接
Summary
本文提出一种名为Plan-R1的新型两阶段轨迹规划框架,用于自主驾驶系统的安全可行轨迹规划。该框架将轨迹规划制定为受明确规划原则(如安全、舒适和交通规则遵守)指导的序列预测任务。第一阶段通过专家数据训练自回归轨迹预测器,第二阶段使用基于规则的奖励和强化学习策略进行微调,使其预测与规划原则保持一致。在nuPlan基准测试上的实验表明,Plan-R1在规划安全性和可行性方面显著提高,达到最新技术水平。
Key Takeaways
- 自主驾驶系统中的轨迹规划必须安全可行。
- 现有学习规划方法依赖专家演示,缺乏明确的安全意识,并可能继承不安全行为。
- Plan-R1框架将轨迹规划制定为序列预测任务,受明确规划原则(如安全、舒适和交通规则遵守)指导。
- 第一阶段通过专家数据训练自回归轨迹预测器。
- 第二阶段使用基于规则的奖励和强化学习策略(如碰撞避免、速度限制)对模型进行微调。
- 在nuPlan基准测试上,Plan-R1表现出显著提高的安全性和可行性,达到最新技术性能。
点此查看论文截图

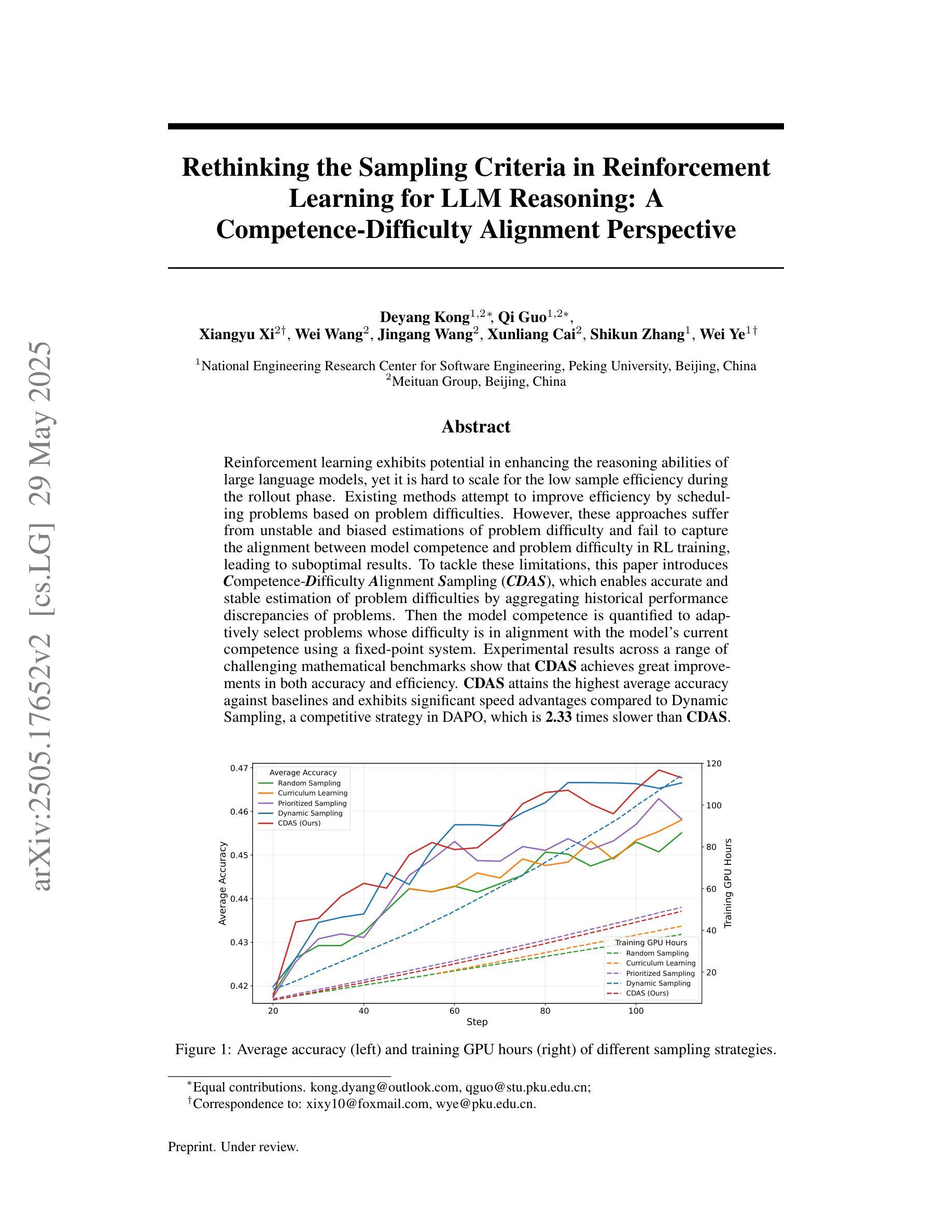
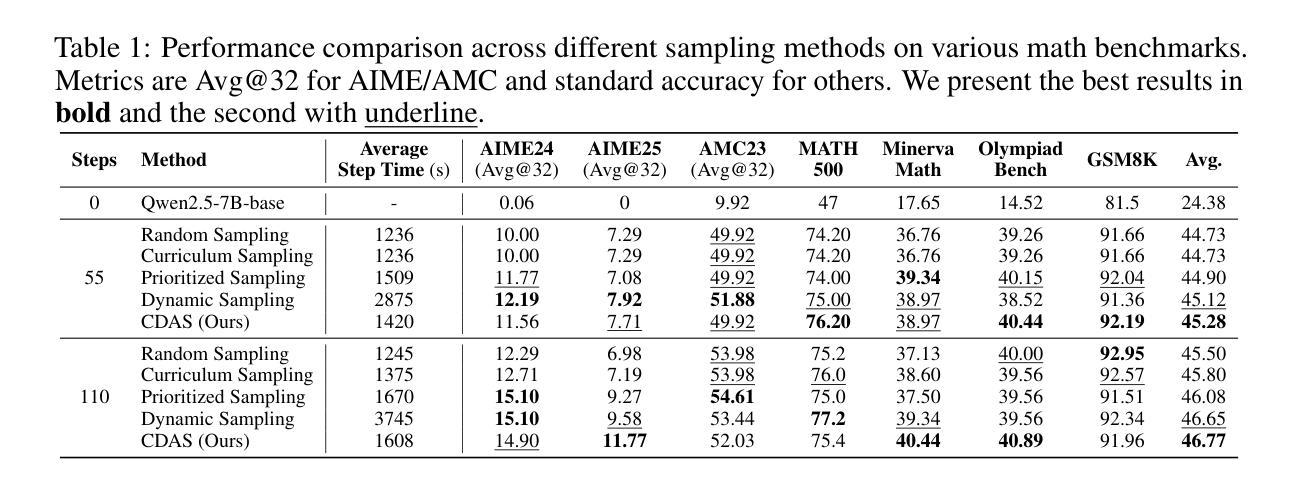
Rethinking the Sampling Criteria in Reinforcement Learning for LLM Reasoning: A Competence-Difficulty Alignment Perspective
Authors:Deyang Kong, Qi Guo, Xiangyu Xi, Wei Wang, Jingang Wang, Xunliang Cai, Shikun Zhang, Wei Ye
Reinforcement learning exhibits potential in enhancing the reasoning abilities of large language models, yet it is hard to scale for the low sample efficiency during the rollout phase. Existing methods attempt to improve efficiency by scheduling problems based on problem difficulties. However, these approaches suffer from unstable and biased estimations of problem difficulty and fail to capture the alignment between model competence and problem difficulty in RL training, leading to suboptimal results. To tackle these limitations, this paper introduces $\textbf{C}$ompetence-$\textbf{D}$ifficulty $\textbf{A}$lignment $\textbf{S}$ampling ($\textbf{CDAS}$), which enables accurate and stable estimation of problem difficulties by aggregating historical performance discrepancies of problems. Then the model competence is quantified to adaptively select problems whose difficulty is in alignment with the model’s current competence using a fixed-point system. Experimental results across a range of challenging mathematical benchmarks show that CDAS achieves great improvements in both accuracy and efficiency. CDAS attains the highest average accuracy against baselines and exhibits significant speed advantages compared to Dynamic Sampling, a competitive strategy in DAPO, which is 2.33 times slower than CDAS.
强化学习在提高大型语言模型的推理能力方面显示出潜力,但在 rollout 阶段存在样本效率低的问题,难以扩展。现有方法试图通过根据问题难度调度问题来提高效率。然而,这些方法受到问题难度估计不稳定和偏见的影响,无法捕捉模型能力和问题难度在强化学习训练中的对齐情况,从而导致结果不理想。为了解决这些局限性,本文引入了能力-难度对齐采样(CDAS),通过聚合问题的历史性能差异,实现准确稳定的问题难度估计。然后,通过固定点系统量化模型能力,自适应选择难度与模型当前能力相匹配的问题。在多个具有挑战性的数学基准测试上的实验结果表明,CDAS 在准确性和效率方面取得了巨大的改进。CDAS 在平均准确率方面达到了最高水平,与基线相比具有显著优势,并且在与 DAPO 中的动态采样策略相比时表现出明显的速度优势,后者是 CDAS 的 2.33 倍慢。
论文及项目相关链接
Summary
强化学习在提升大型语言模型的推理能力方面具有潜力,但其在rollout阶段的样本效率较低,难以扩展。现有方法试图通过根据问题难度进行调度来提高效率,但存在对问题难度的不稳定、有偏估计,以及无法捕捉模型能力与问题难度在RL训练中的对齐关系,导致结果不尽如人意。为解决这些问题,本文提出一种Competence-Difficulty Alignment Sampling(CDAS)方法。它可以通过汇聚问题的历史表现差异来准确稳定地估计问题难度。随后利用一个定点系统量化模型能力,自适应选择难度与模型当前能力相匹配的问题。在多个挑战性的数学基准测试上进行的实验表明,CDAS在准确性和效率上都取得了巨大的提升。相较于动态采样等竞争性策略,CDAS达到了最高的平均准确率,并且在效率上展现出显著优势。
Key Takeaways
- 强化学习对于提升大型语言模型的推理能力具有潜力,但在实际应用中面临样本效率低的问题。
- 现有方法通过问题难度调度提高效率,但存在对问题难度的不稳定、有偏估计。
- CDAS方法可以准确稳定地估计问题难度,基于模型能力的量化来采样问题。
- CDAS通过自适应选择难度与模型当前能力相匹配的问题,提高了训练效率和模型性能。
- 在多个数学基准测试上,CDAS取得了最高的平均准确率。
- 与其他采样策略相比,CDAS在效率上展现出显著优势。
点此查看论文截图
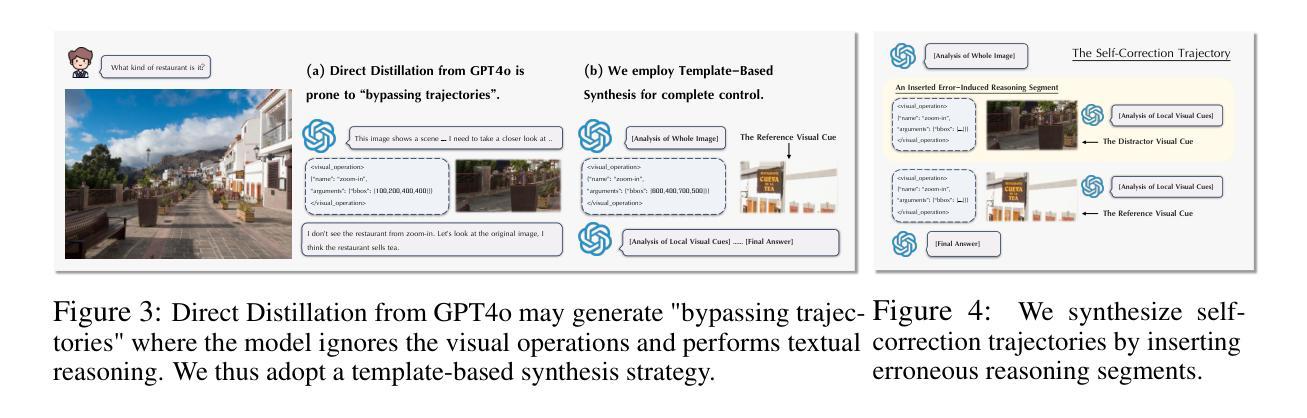
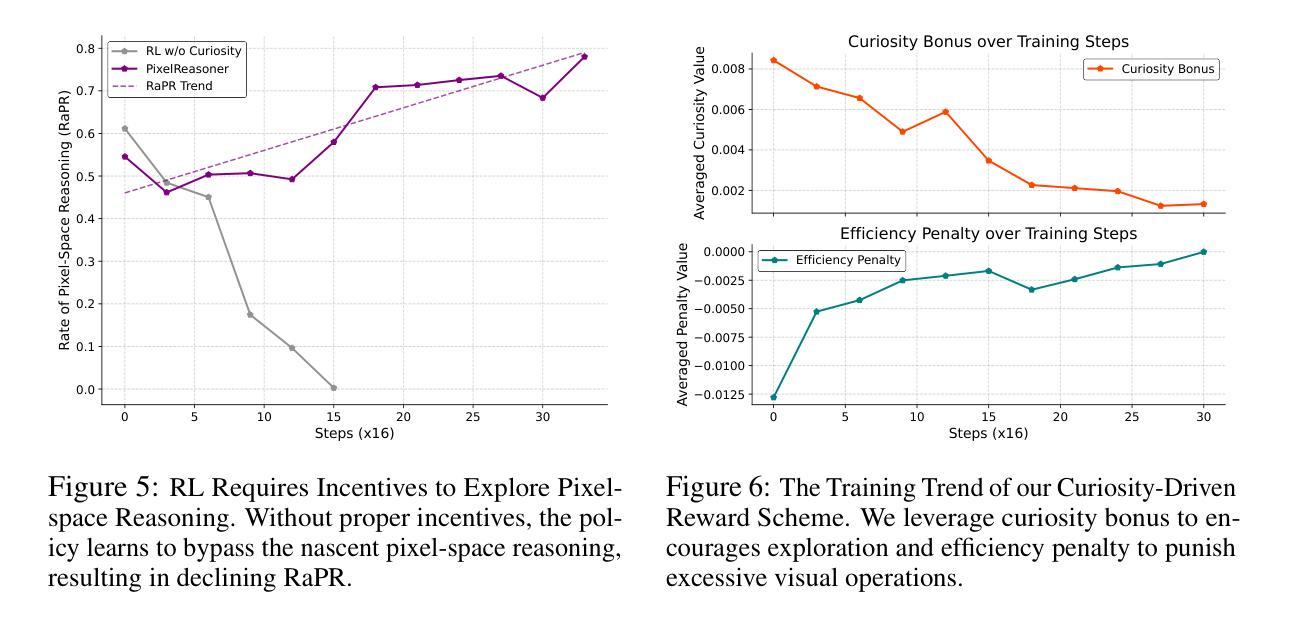
Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning
Authors:Alex Su, Haozhe Wang, Weiming Ren, Fangzhen Lin, Wenhu Chen
Chain-of-thought reasoning has significantly improved the performance of Large Language Models (LLMs) across various domains. However, this reasoning process has been confined exclusively to textual space, limiting its effectiveness in visually intensive tasks. To address this limitation, we introduce the concept of reasoning in the pixel-space. Within this novel framework, Vision-Language Models (VLMs) are equipped with a suite of visual reasoning operations, such as zoom-in and select-frame. These operations enable VLMs to directly inspect, interrogate, and infer from visual evidences, thereby enhancing reasoning fidelity for visual tasks. Cultivating such pixel-space reasoning capabilities in VLMs presents notable challenges, including the model’s initially imbalanced competence and its reluctance to adopt the newly introduced pixel-space operations. We address these challenges through a two-phase training approach. The first phase employs instruction tuning on synthesized reasoning traces to familiarize the model with the novel visual operations. Following this, a reinforcement learning (RL) phase leverages a curiosity-driven reward scheme to balance exploration between pixel-space reasoning and textual reasoning. With these visual operations, VLMs can interact with complex visual inputs, such as information-rich images or videos to proactively gather necessary information. We demonstrate that this approach significantly improves VLM performance across diverse visual reasoning benchmarks. Our 7B model, \model, achieves 84% on V* bench, 74% on TallyQA-Complex, and 84% on InfographicsVQA, marking the highest accuracy achieved by any open-source model to date. These results highlight the importance of pixel-space reasoning and the effectiveness of our framework.
链式思维推理已经显著提高了大型语言模型(LLM)在不同领域的性能。然而,这种推理过程一直被限制在文本空间内,使其在视觉密集型任务中的有效性受到限制。为了解决这一局限性,我们引入了像素空间推理的概念。在这一新颖框架下,视觉语言模型(VLM)配备了一系列视觉推理操作,例如放大和选择帧。这些操作使VLM能够直接检查、质询和从视觉证据中进行推断,从而提高视觉任务的推理保真度。在VLM中培养这种像素空间推理能力面临着显著挑战,包括模型的初始能力不平衡及其对新引入的像素空间操作的抵触情绪。我们通过两阶段训练方法来应对这些挑战。第一阶段采用合成推理轨迹的指令调整,使模型熟悉新型视觉操作。之后,强化学习(RL)阶段利用基于好奇心的奖励方案来平衡像素空间推理和文本推理之间的探索。借助这些视觉操作,VLM可以与复杂的视觉输入(如信息丰富的图像或视频)进行交互,以主动收集必要信息。我们证明,该方法显著提高了VLM在多种视觉推理基准测试上的性能。我们的7B模型实现了V*测试平台上的84%、TallyQA-Complex上的74%和InfographicsVQA上的84%,这是迄今为止任何开源模型所取得的最高精度。这些结果突显了像素空间推理的重要性以及我们框架的有效性。
论文及项目相关链接
PDF Project Page: https://tiger-ai-lab.github.io/Pixel-Reasoner/, Hands-on Demo: https://huggingface.co/spaces/TIGER-Lab/Pixel-Reasoner
摘要
视觉空间推理的引入显著提升了跨域大型语言模型(LLM)的性能。然而,目前的推理过程主要局限于文本空间,这在视觉任务中限制了其有效性。为解决此局限性,我们提出了像素空间推理的概念。在此新框架下,视觉语言模型(VLM)配备了一系列视觉推理操作,如缩放、选择帧等。这些操作使VLM能够直接从视觉证据中检查、质询和推断,从而提高视觉任务的推理保真度。在VLM中培养这种像素空间推理能力面临着显著挑战,包括模型初始能力的不平衡以及对新引入的像素空间操作的接受度低。我们通过两阶段训练方法来应对这些挑战。第一阶段通过合成推理轨迹进行指令调整,使模型熟悉新的视觉操作。接下来,强化学习(RL)阶段利用好奇驱动的奖励方案来平衡像素空间推理和文本推理之间的探索。借助这些视觉操作,VLM可以与复杂视觉输入(如信息丰富的图像或视频)进行交互,主动收集必要信息。我们的方法显著提高了VLM在多种视觉推理基准测试上的性能。我们的7B模型在V*基准测试上达到84%、TallyQA-Complex上达到74%、InfographicsVQA上达到84%,成为迄今为止公开模型中准确性最高的。这些结果突显了像素空间推理的重要性及我们框架的有效性。
关键见解
- 链式思维推理已显著提高大型语言模型(LLM)在多个领域的性能。
- 当前推理过程主要局限于文本空间,对视觉任务的有效性有限。
- 引入像素空间推理概念以解决此局限性,配备视觉语言模型(VLM)以进行视觉推理操作。
- 面临培养像素空间推理能力的挑战,包括模型初始能力不平衡和新操作接受度低。
- 采用两阶段训练方法来应对这些挑战,通过指令调整和强化学习来熟悉和提升模型对像素空间推理的掌握。
- 视觉操作使VLM能够处理复杂视觉输入,如信息丰富的图像或视频。
点此查看论文截图


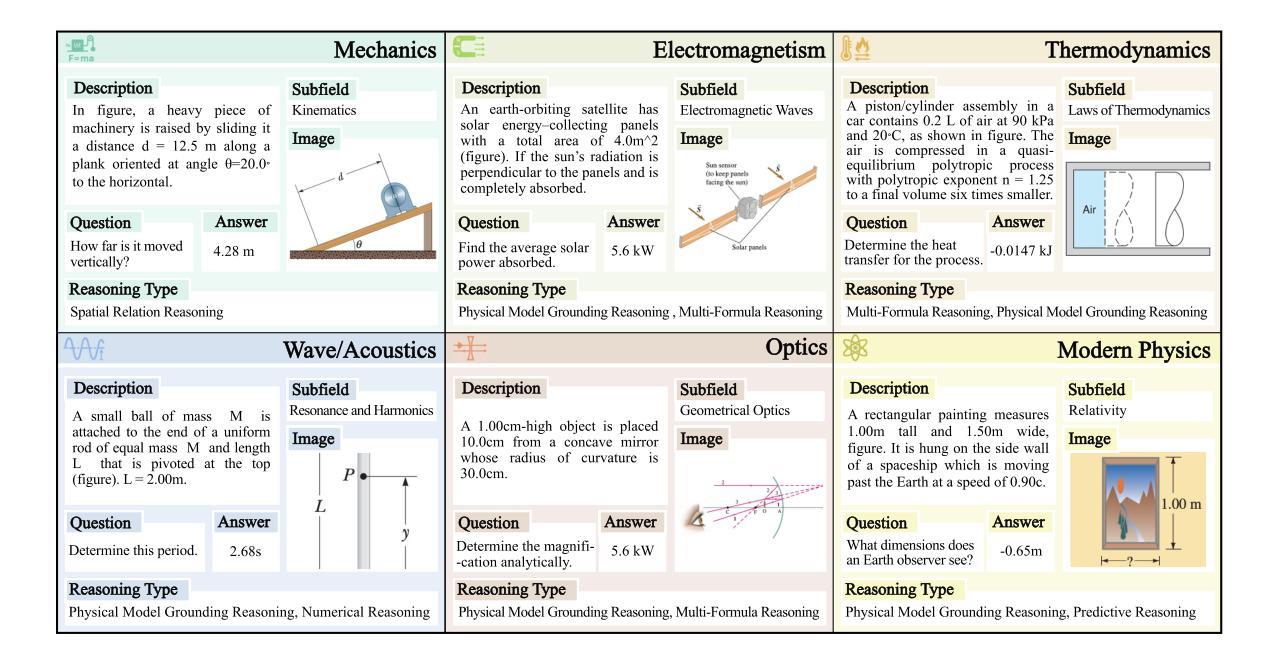
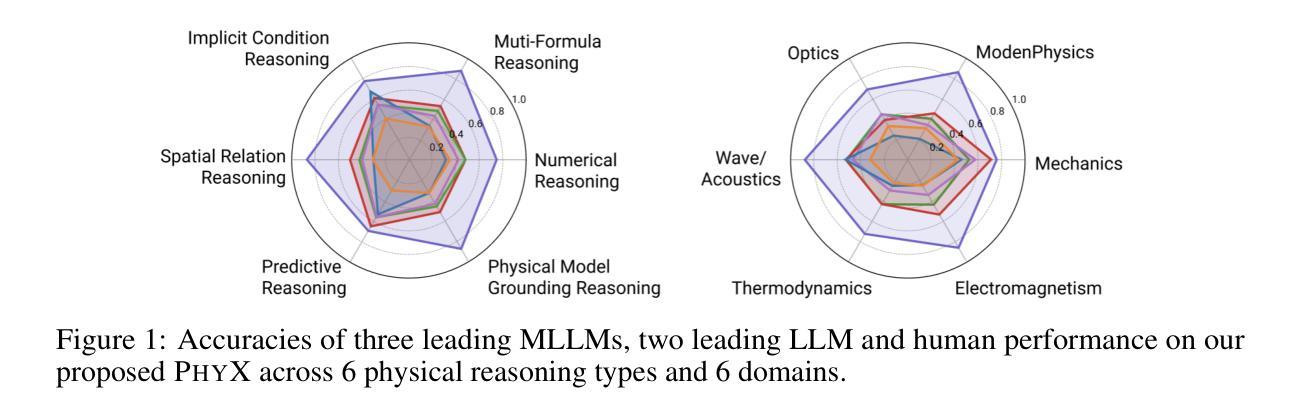
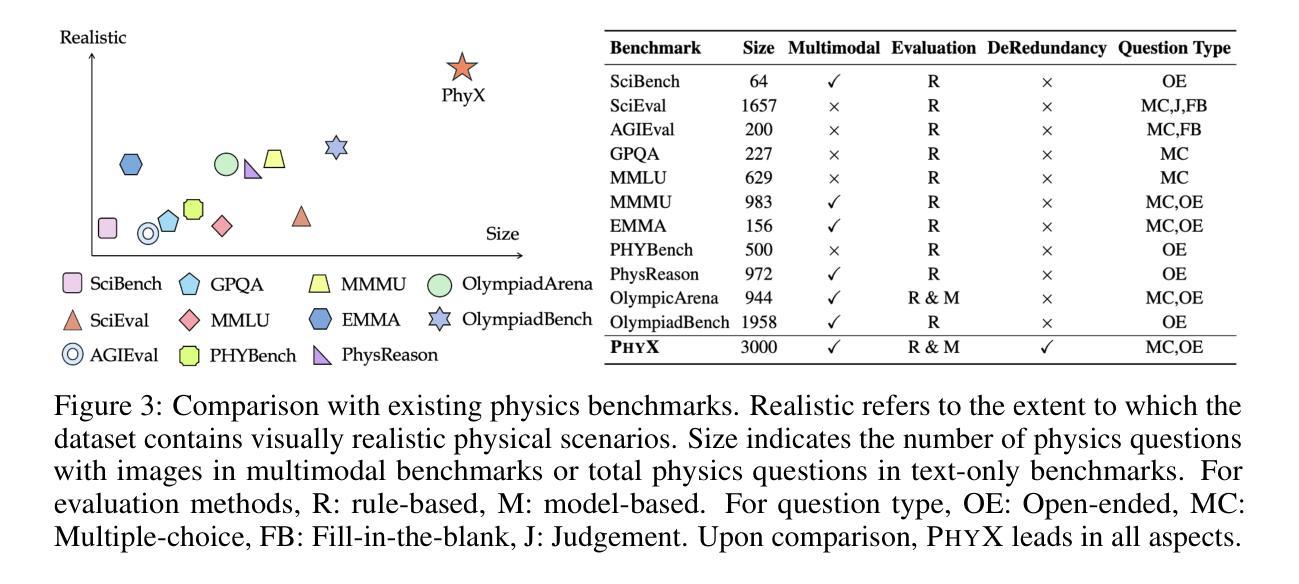
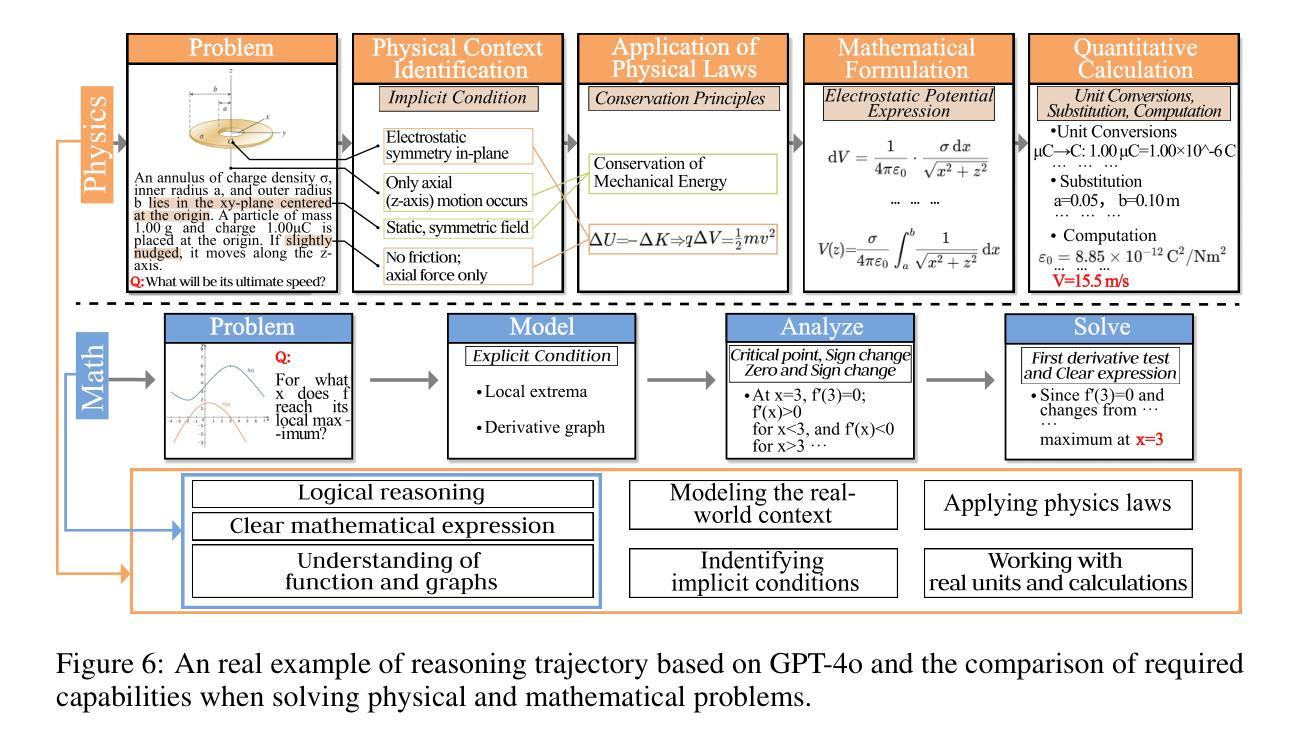
PhyX: Does Your Model Have the “Wits” for Physical Reasoning?
Authors:Hui Shen, Taiqiang Wu, Qi Han, Yunta Hsieh, Jizhou Wang, Yuyue Zhang, Yuxin Cheng, Zijian Hao, Yuansheng Ni, Xin Wang, Zhongwei Wan, Kai Zhang, Wendong Xu, Jing Xiong, Ping Luo, Wenhu Chen, Chaofan Tao, Zhuoqing Mao, Ngai Wong
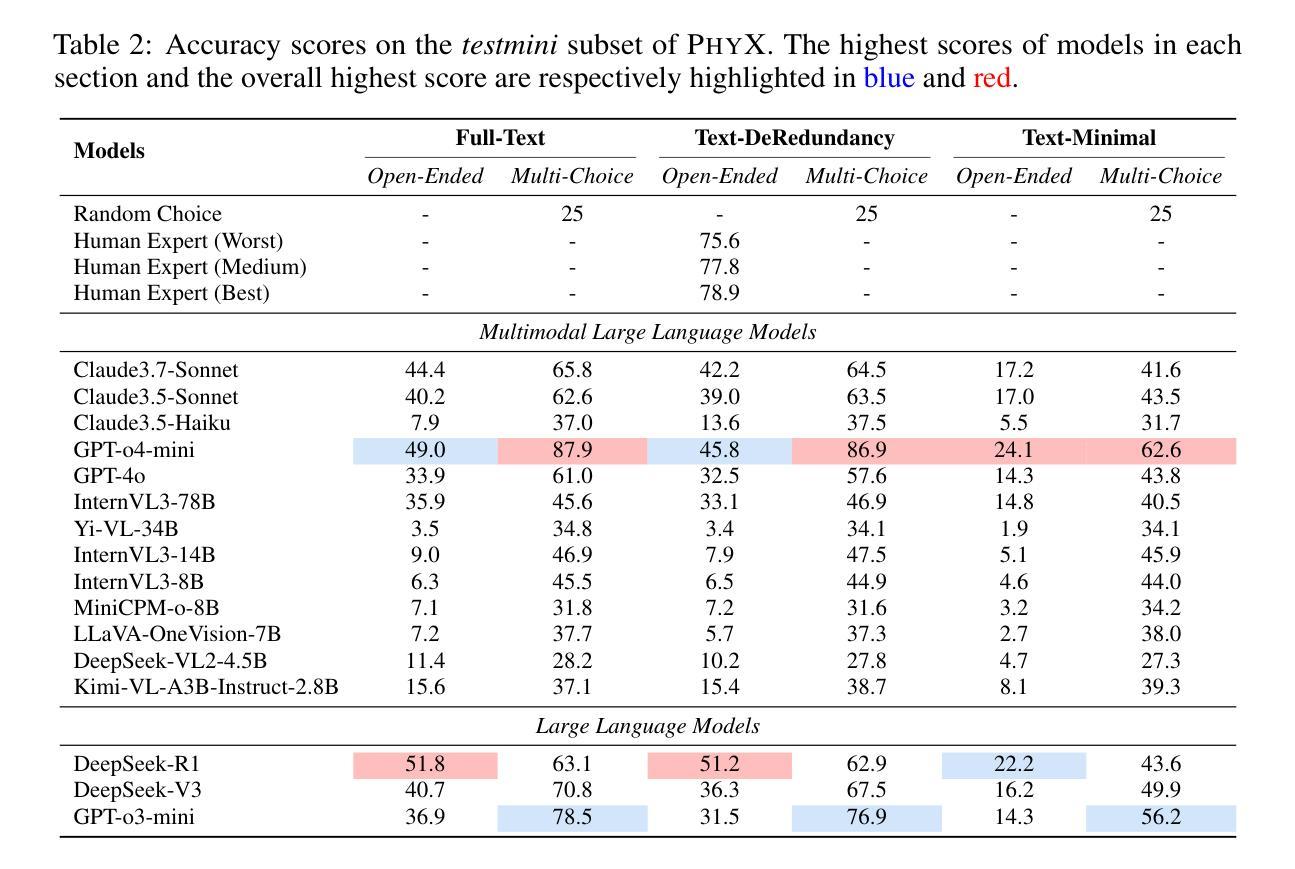
Existing benchmarks fail to capture a crucial aspect of intelligence: physical reasoning, the integrated ability to combine domain knowledge, symbolic reasoning, and understanding of real-world constraints. To address this gap, we introduce PhyX: the first large-scale benchmark designed to assess models capacity for physics-grounded reasoning in visual scenarios. PhyX includes 3K meticulously curated multimodal questions spanning 6 reasoning types across 25 sub-domains and 6 core physics domains: thermodynamics, electromagnetism, mechanics, modern physics, optics, and wave&acoustics. In our comprehensive evaluation, even state-of-the-art models struggle significantly with physical reasoning. GPT-4o, Claude3.7-Sonnet, and GPT-o4-mini achieve only 32.5%, 42.2%, and 45.8% accuracy respectively-performance gaps exceeding 29% compared to human experts. Our analysis exposes critical limitations in current models: over-reliance on memorized disciplinary knowledge, excessive dependence on mathematical formulations, and surface-level visual pattern matching rather than genuine physical understanding. We provide in-depth analysis through fine-grained statistics, detailed case studies, and multiple evaluation paradigms to thoroughly examine physical reasoning capabilities. To ensure reproducibility, we implement a compatible evaluation protocol based on widely-used toolkits such as VLMEvalKit, enabling one-click evaluation. More details are available on our project page: https://phyx-bench.github.io/.
现有的基准测试未能捕捉到智力的一个重要方面:物理推理能力,这是一种结合领域知识、符号推理和对现实世界的理解的综合能力。为了弥补这一空白,我们推出了PhyX:这是第一个旨在评估模型中基于物理的推理能力的大规模基准测试,适用于视觉场景。PhyX包括3000个精心策划的多模式问题,涵盖6种推理类型和25个子领域和6个核心物理领域:热力学、电磁学、力学、现代物理学、光学和波动声学。在我们的综合评估中,即使是最先进的模型在物理推理方面也面临巨大挑战。GPT-4o、Claude3.7-Sonnet和GPT-o4-mini的准确率分别为32.5%、42.2%和45.8%,与人类专家相比,性能差距超过29%。我们的分析揭示了当前模型的关键局限性:过于依赖记忆的知识、过度依赖数学公式和表面级的视觉模式匹配,而不是真正的物理理解。我们通过细粒度统计、详细案例研究和多个评估范式进行了深入分析,以彻底检查物理推理能力。为确保可重复性,我们基于广泛使用的工具包(如VLMEvalKit)实施了一个兼容的评估协议,实现一键评估。更多详细信息可在我们的项目页面查看:[网站链接](https://phyx-bench.github.io/)。
论文及项目相关链接
Summary
本文介绍了一个名为PhyX的大规模基准测试,旨在评估模型在视觉场景中的物理推理能力。PhyX包含3000个精心策划的多模式问题,涵盖6个推理类型和25个子域以及6个核心物理领域。对现有模型的评估显示,即使在最新技术的模型也存在明显的物理推理困难,与专家相比存在超过29%的性能差距。文章深入分析了当前模型的关键局限性,包括过度依赖学科知识和数学公式,以及表面级的视觉模式匹配而非真正的物理理解。
Key Takeaways
- PhyX是首个设计用于评估模型在视觉场景中的物理推理能力的大规模基准测试。
- PhyX包含广泛的问题类型,涵盖多个物理领域。
- 现有模型在物理推理方面存在显著困难,与专家相比存在性能差距。
- 现有模型的关键局限性包括过度依赖学科知识和数学公式。
- 模型更依赖于表面级的视觉模式匹配而非真正的物理理解。
- 文章提供了详细的案例研究,并通过多种评估范式对物理推理能力进行了深入分析。
点此查看论文截图


LEXam: Benchmarking Legal Reasoning on 340 Law Exams
Authors:Yu Fan, Jingwei Ni, Jakob Merane, Etienne Salimbeni, Yang Tian, Yoan Hermstrüwer, Yinya Huang, Mubashara Akhtar, Florian Geering, Oliver Dreyer, Daniel Brunner, Markus Leippold, Mrinmaya Sachan, Alexander Stremitzer, Christoph Engel, Elliott Ash, Joel Niklaus
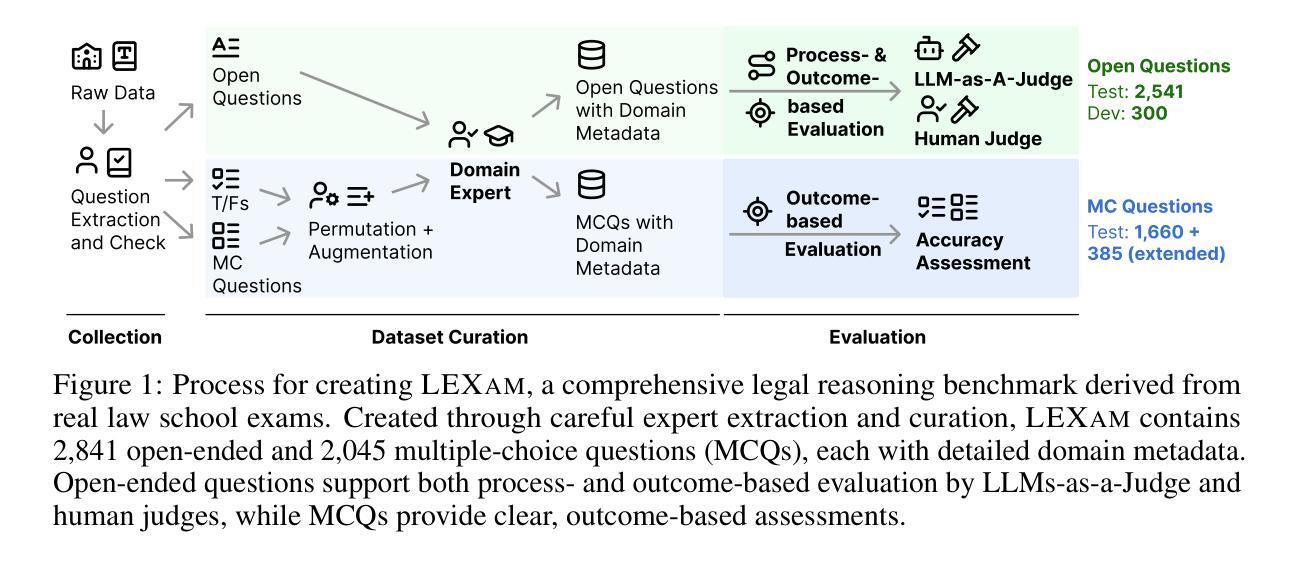
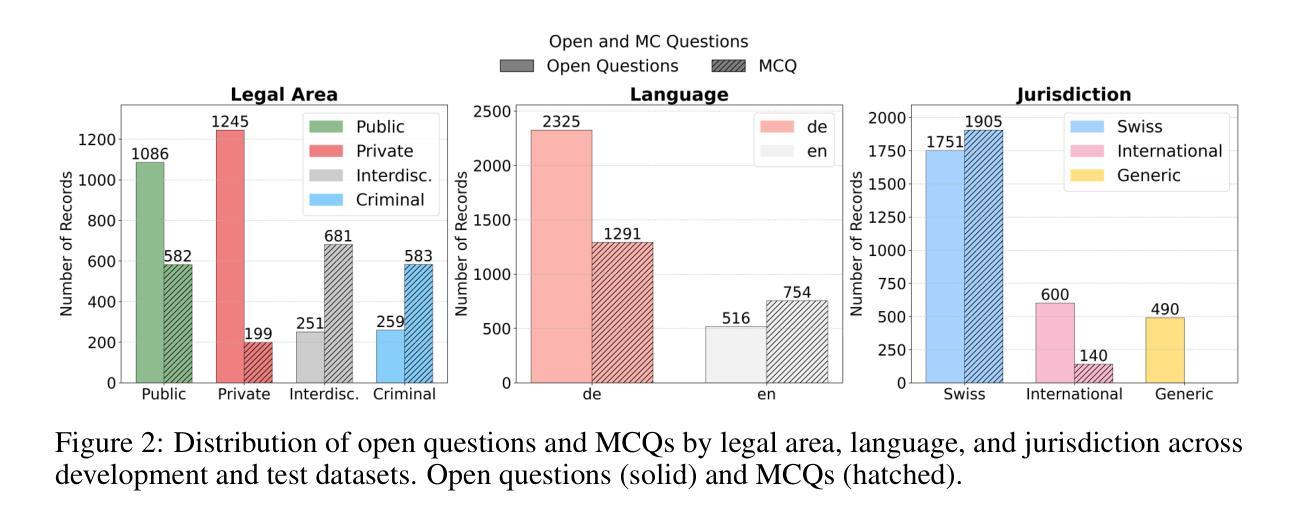
Long-form legal reasoning remains a key challenge for large language models (LLMs) in spite of recent advances in test-time scaling. We introduce LEXam, a novel benchmark derived from 340 law exams spanning 116 law school courses across a range of subjects and degree levels. The dataset comprises 4,886 law exam questions in English and German, including 2,841 long-form, open-ended questions and 2,045 multiple-choice questions. Besides reference answers, the open questions are also accompanied by explicit guidance outlining the expected legal reasoning approach such as issue spotting, rule recall, or rule application. Our evaluation on both open-ended and multiple-choice questions present significant challenges for current LLMs; in particular, they notably struggle with open questions that require structured, multi-step legal reasoning. Moreover, our results underscore the effectiveness of the dataset in differentiating between models with varying capabilities. Adopting an LLM-as-a-Judge paradigm with rigorous human expert validation, we demonstrate how model-generated reasoning steps can be evaluated consistently and accurately. Our evaluation setup provides a scalable method to assess legal reasoning quality beyond simple accuracy metrics. Project page: https://lexam-benchmark.github.io/
尽管在测试时缩放方面最近有所进展,但长形式法律推理仍然是大型语言模型(LLM)面临的关键挑战。我们推出了LEXam,这是一个新的基准测试,来源于340场法律考试,跨越116个法律课程,涵盖各种科目和学位层次。该数据集包括4886个英文和德文的法律考试问题,其中包括2841个长形式开放问题和2045个多项选择题。除了参考答案外,开放问题还附有明确的指导,概述了预期的法律推理方法,如发现问题、回忆规则或规则应用。我们对开放问题和多项选择问题的评估显示,当前LLM面临巨大挑战;特别是他们在需要结构化、多步骤法律推理的开放问题上明显挣扎。此外,我们的结果突显了该数据集在区分不同能力模型方面的有效性。通过采用“大型语言模型作为法官”的模式,并进行严格的人类专家验证,我们展示了如何一致且准确地评估模型生成的推理步骤。我们的评估设置提供了一种可扩展的方法,可以评估超越简单准确性指标的法律推理质量。项目页面:https://lexam-benchmark.github.io/
论文及项目相关链接
Summary:
近期虽然大型语言模型(LLMs)在测试时标度上有所进展,但长形式法律推理仍是其面临的关键挑战。为此,研究团队推出了LEXam基准测试,该测试从涵盖多种科目和学历层次的340场法律考试中衍生而来。数据集包含英文和德文的法律考试问题共4886道,其中包括开放式的长回答问题及选择题。除了参考答案外,开放性问题还附有预期的法律推理方法的明确指导。对开放性和选择题的评估显示,当前LLMs面临巨大挑战,特别是在需要结构化、多步骤法律推理的开放性问题上。此外,该数据集在区分不同能力模型方面效果显著。研究团队采用“大型语言模型作为法官”的模式,通过严格的人类专家验证,展示如何一致且准确地评估模型产生的推理步骤。其评估设置提供了一种可评估法律推理质量超越简单准确率的方法。
Key Takeaways:
- 大型语言模型(LLMs)在长形式法律推理上仍面临挑战。
- LEXam基准测试从多场法律考试中衍生而来,包含多种题型和法律课程。
- 开放性问题伴随预期的推理方法的指导,以帮助LLMs理解正确的法律推理路径。
- LLMs在需要结构化、多步骤的法律推理问题上表现不佳。
- 数据集在区分不同能力的模型方面效果显著。
- 采用“大型语言模型作为法官”的模式,通过人类专家验证评估模型的推理步骤。
点此查看论文截图


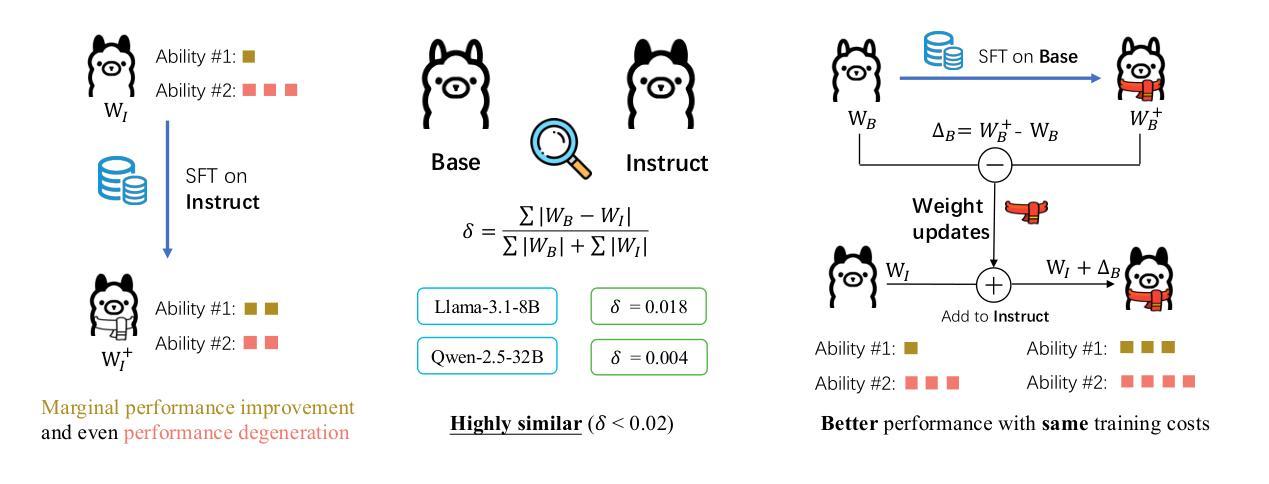
Shadow-FT: Tuning Instruct via Base
Authors:Taiqiang Wu, Runming Yang, Jiayi Li, Pengfei Hu, Ngai Wong, Yujiu Yang
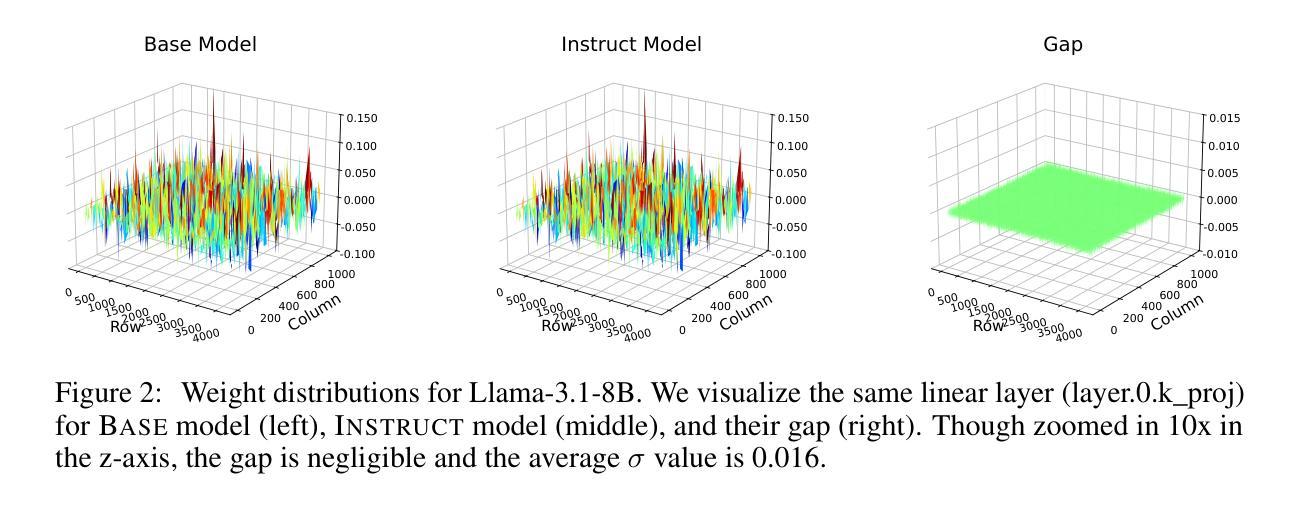
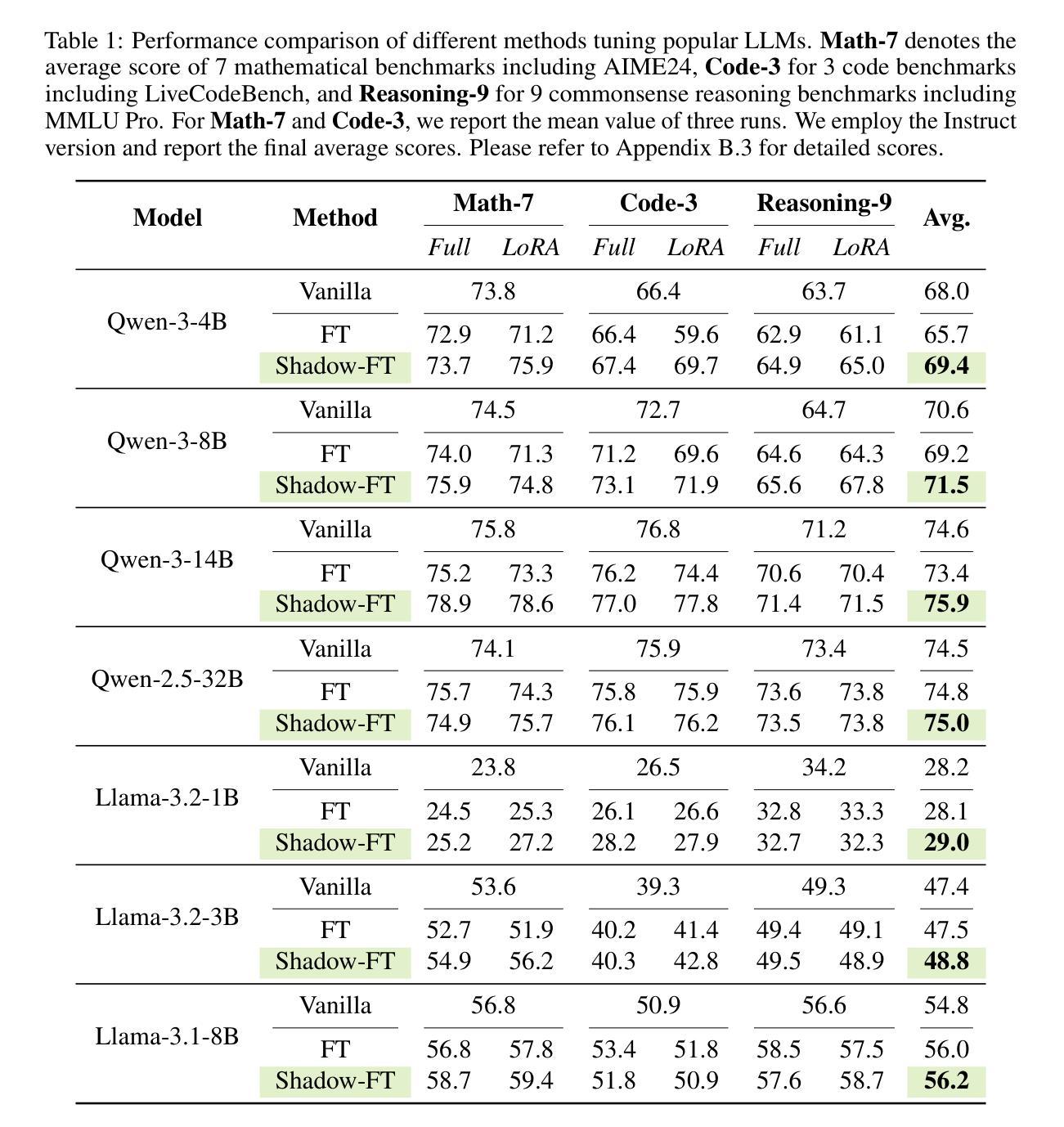
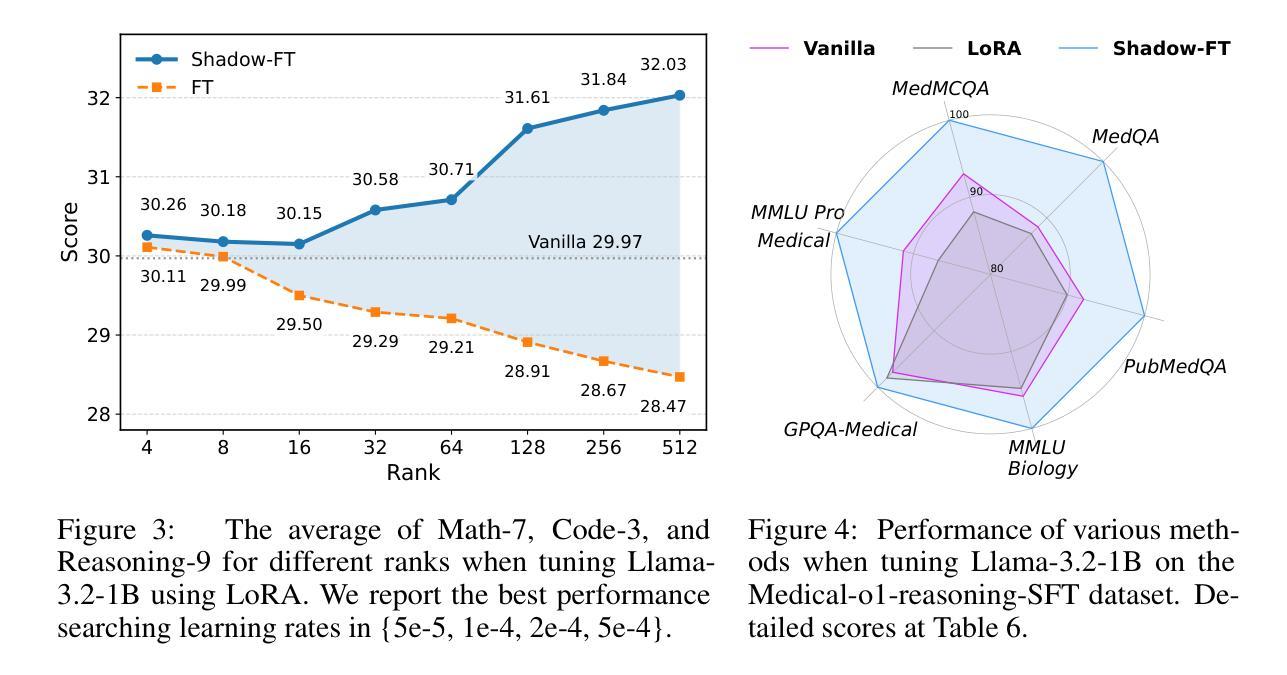
Large language models (LLMs) consistently benefit from further fine-tuning on various tasks. However, we observe that directly tuning the INSTRUCT (i.e., instruction tuned) models often leads to marginal improvements and even performance degeneration. Notably, paired BASE models, the foundation for these INSTRUCT variants, contain highly similar weight values (i.e., less than 2% on average for Llama 3.1 8B). Therefore, we propose a novel Shadow-FT framework to tune the INSTRUCT models by leveraging the corresponding BASE models. The key insight is to fine-tune the BASE model, and then directly graft the learned weight updates to the INSTRUCT model. Our proposed Shadow-FT introduces no additional parameters, is easy to implement, and significantly improves performance. We conduct extensive experiments on tuning mainstream LLMs, such as Qwen 3 and Llama 3 series, and evaluate them across 19 benchmarks covering coding, reasoning, and mathematical tasks. Experimental results demonstrate that Shadow-FT consistently outperforms conventional full-parameter and parameter-efficient tuning approaches. Further analyses indicate that Shadow-FT can be applied to multimodal large language models (MLLMs) and combined with direct preference optimization (DPO). Codes and weights are available at \href{https://github.com/wutaiqiang/Shadow-FT}{Github}.
大型语言模型(LLM)在各种任务上通过进一步的微调持续受益。然而,我们观察到直接调整INSTRUCT(即指令调整)模型往往只带来微小的改进,甚至性能下降。值得注意的是,这些INSTRUCT变体所依赖的BASE模型包含高度相似的权重值(如Llama 3.1 8B的平均值不到2%)。因此,我们提出了一种新的Shadow-FT框架,利用相应的BASE模型来调整INSTRUCT模型。关键思路是微调BASE模型,然后将学到的权重更新直接移植到INSTRUCT模型。我们提出的Shadow-FT不会引入额外的参数,易于实现,并能显著提高性能。我们在主流的LLM上进行了广泛的实验,如Qwen 3和Llama 3系列,并在涵盖编码、推理和数学任务的19个基准测试上进行了评估。实验结果表明,Shadow-FT持续优于传统的全参数和参数高效调整方法。进一步的分析表明,Shadow-FT可应用于多模态大型语言模型(MLLM),并与直接偏好优化(DPO)相结合。相关代码和权重可在Github上找到(链接:https://github.com/wutaiqiang/Shadow-FT)。
论文及项目相关链接
PDF 19 pages, 10 tables, 6 figures
Summary:
大型语言模型(LLM)在多种任务上通过微调能获得持续提升,但直接对INSTRUCT模型进行微调常导致性能提升有限甚至退步。研究提出Shadow-FT框架,利用对应的BASE模型来优化INSTRUCT模型的微调。该框架通过微调BASE模型并将学习到的权重更新直接应用到INSTRUCT模型上,无需增加额外参数,易于实现,并能显著提高性能。实验证明,Shadow-FT在主流LLM上表现优异,优于常规的全参数和参数高效微调方法。它还可以应用于多模态大型语言模型(MLLMs)并与直接偏好优化(DPO)结合。
Key Takeaways:
- LLMs通过微调在多种任务上可获性能提升,但直接对INSTRUCT模型微调效果有限。
- BASE模型与INSTRUCT模型权重高度相似。
- 提出的Shadow-FT框架利用BASE模型来优化INSTRUCT模型的微调,无需增加额外参数。
- Shadow-FT通过微调BASE模型并将学习到的权重更新直接应用到INSTRUCT模型,显著提高性能。
- 实验证明Shadow-FT在主流LLM上表现优异,优于常规的全参数和参数高效微调方法。
- Shadow-FT可应用于多模态大型语言模型(MLLMs)。
- Shadow-FT可与直接偏好优化(DPO)结合使用。
点此查看论文截图

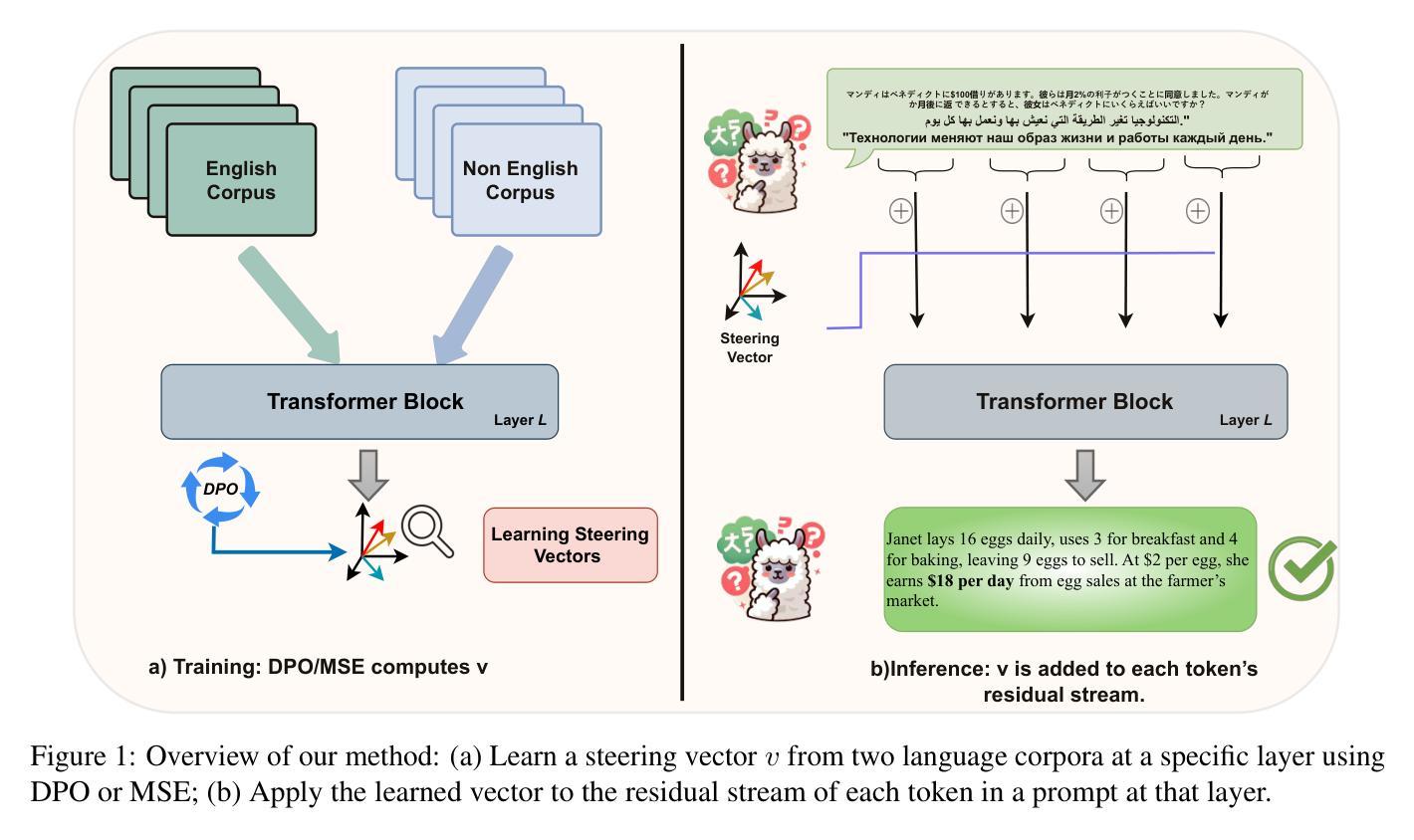
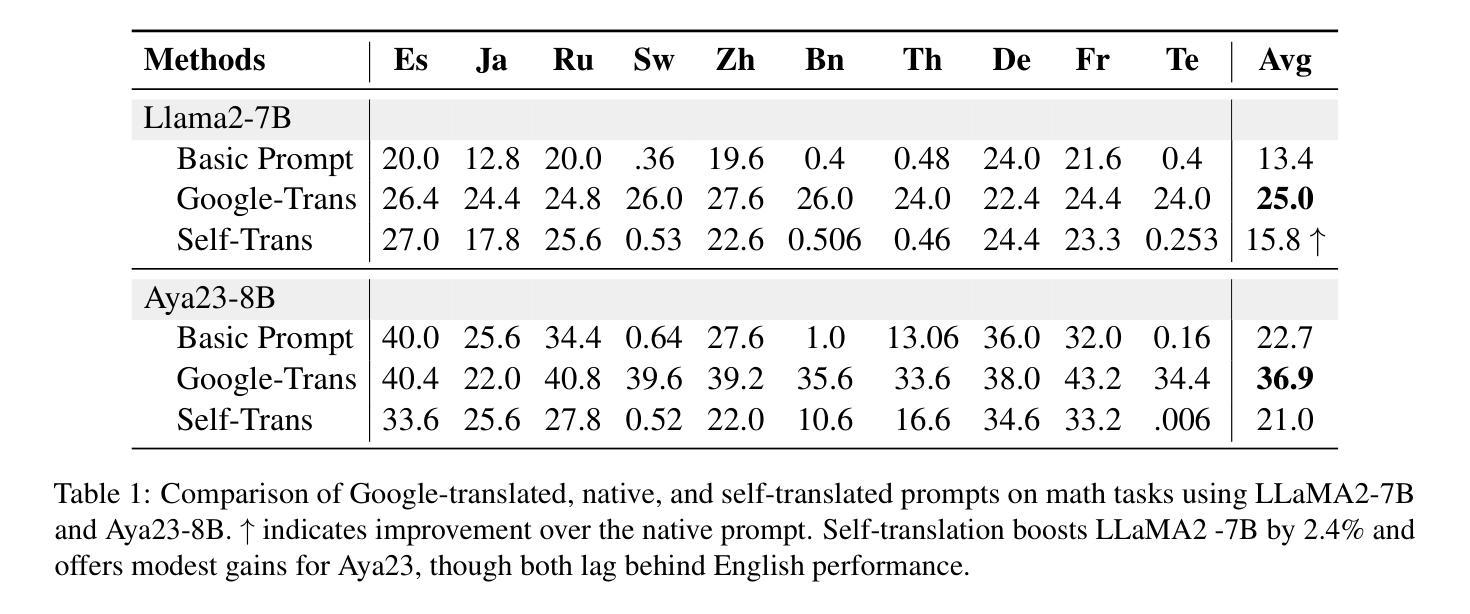
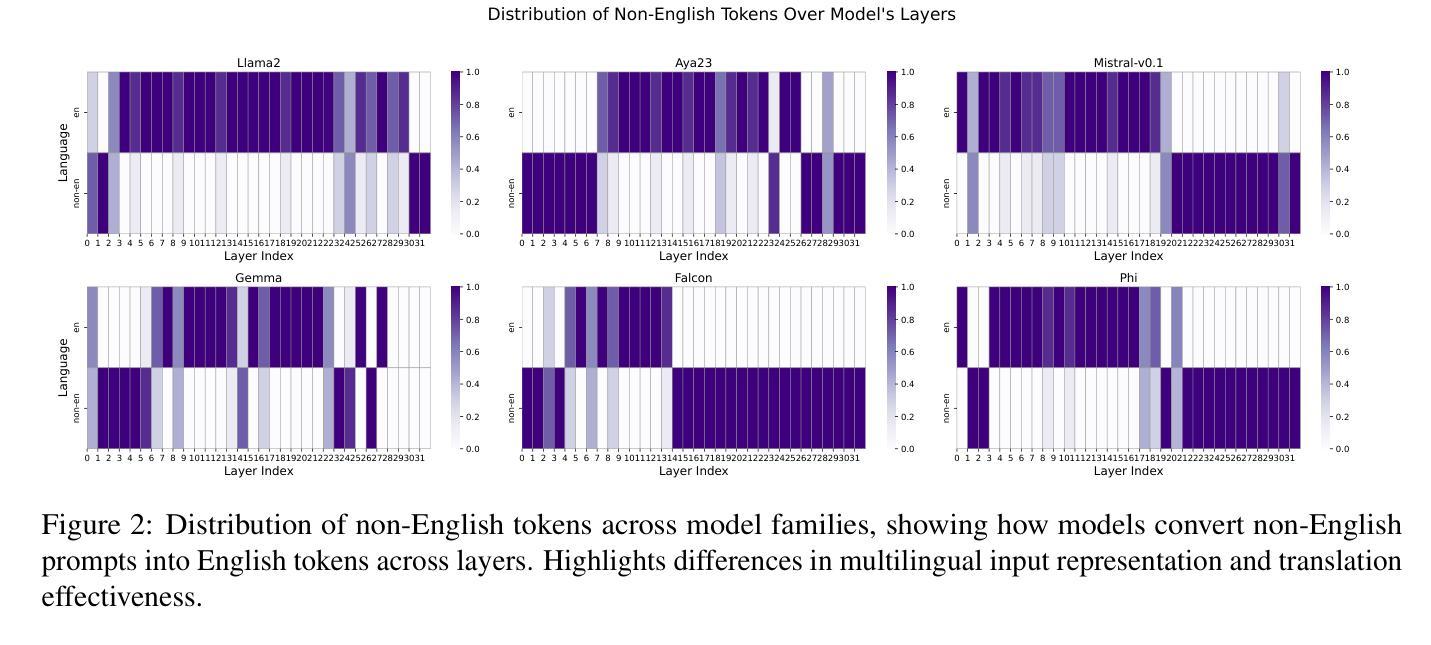
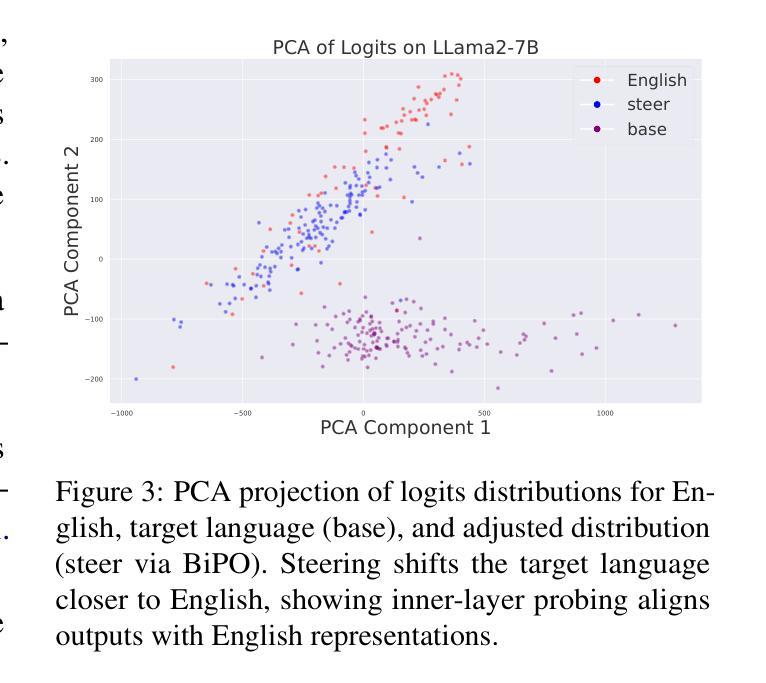
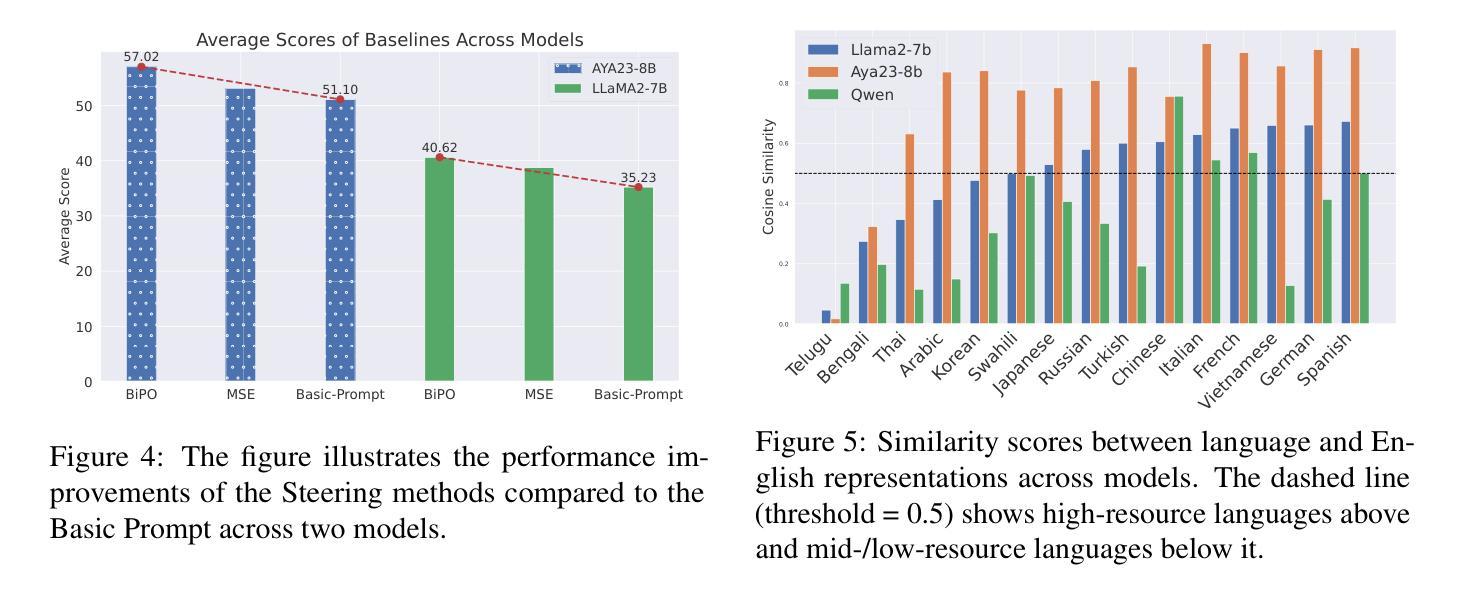
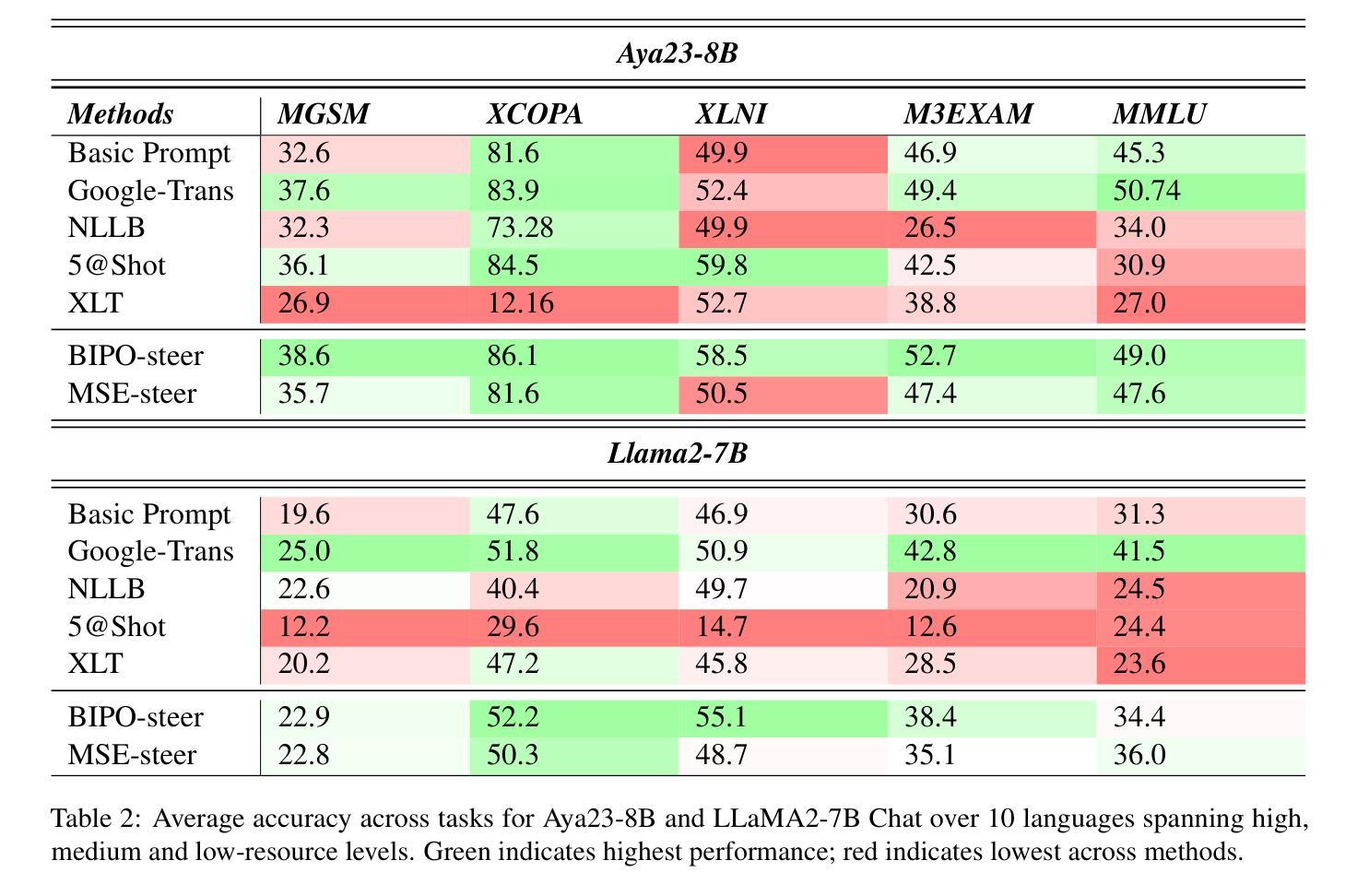
Improving Multilingual Language Models by Aligning Representations through Steering
Authors:Omar Mahmoud, Buddhika Laknath Semage, Thommen George Karimpanal, Santu Rana
In this paper, we investigate how large language models (LLMS) process non-English tokens within their layer representations, an open question despite significant advancements in the field. Using representation steering, specifically by adding a learned vector to a single model layer’s activations, we demonstrate that steering a single model layer can notably enhance performance. Our analysis shows that this approach achieves results comparable to translation baselines and surpasses state of the art prompt optimization methods. Additionally, we highlight how advanced techniques like supervised fine tuning (\textsc{sft}) and reinforcement learning from human feedback (\textsc{rlhf}) improve multilingual capabilities by altering representation spaces. We further illustrate how these methods align with our approach to reshaping LLMS layer representations.
在这篇论文中,我们研究了大型语言模型(LLMS)是如何在其层表示中处理非英语令牌的,尽管该领域已经取得了重大进展,但这个问题仍然是一个开放的问题。通过使用表示引导法,特别是通过在单个模型层的激活中添加一个学习向量,我们证明引导单个模型层可以显著提高性能。我们的分析表明,该方法可以实现与翻译基线相当的结果,并超越了现有的提示优化方法。此外,我们重点介绍了如何使用先进的监督微调技术(\textbf{sft})和人类反馈强化学习(\textbf{rlhf})等高级技术如何通过改变表示空间来提高多语言能力。我们还进一步说明了这些方法如何与重塑LLMS层表示的方法相一致。
论文及项目相关链接
Summary
这篇论文研究了大型语言模型如何处理非英语符号的层表示。通过表示引导的方法,向单一模型层的激活添加学习向量,可以显著提高性能。分析与翻译基准线相比,该方法取得了相当的结果并超越了现有的提示优化方法。此外,论文还介绍了监督微调(SFT)和强化学习从人类反馈(RLHF)等技术如何改进多语言能力,并探讨了重塑LLMS层表示的方法。
Key Takeaways
- 大型语言模型(LLMS)对非英语符号的层表示处理是一个公开问题,尽管该领域已有显著进展。
- 通过表示引导的方法,增强单一模型层的性能可以显著提高。
- 引导方法的结果与翻译基准线相当,并超越了现有的提示优化方法。
- 监督微调(SFT)和强化学习从人类反馈(RLHF)等技术改进了多语言能力。
- 这些技术通过改变表示空间来改进多语言能力。
- 论文展示了如何将这些方法与重塑LLMS层表示的方法相结合。
点此查看论文截图

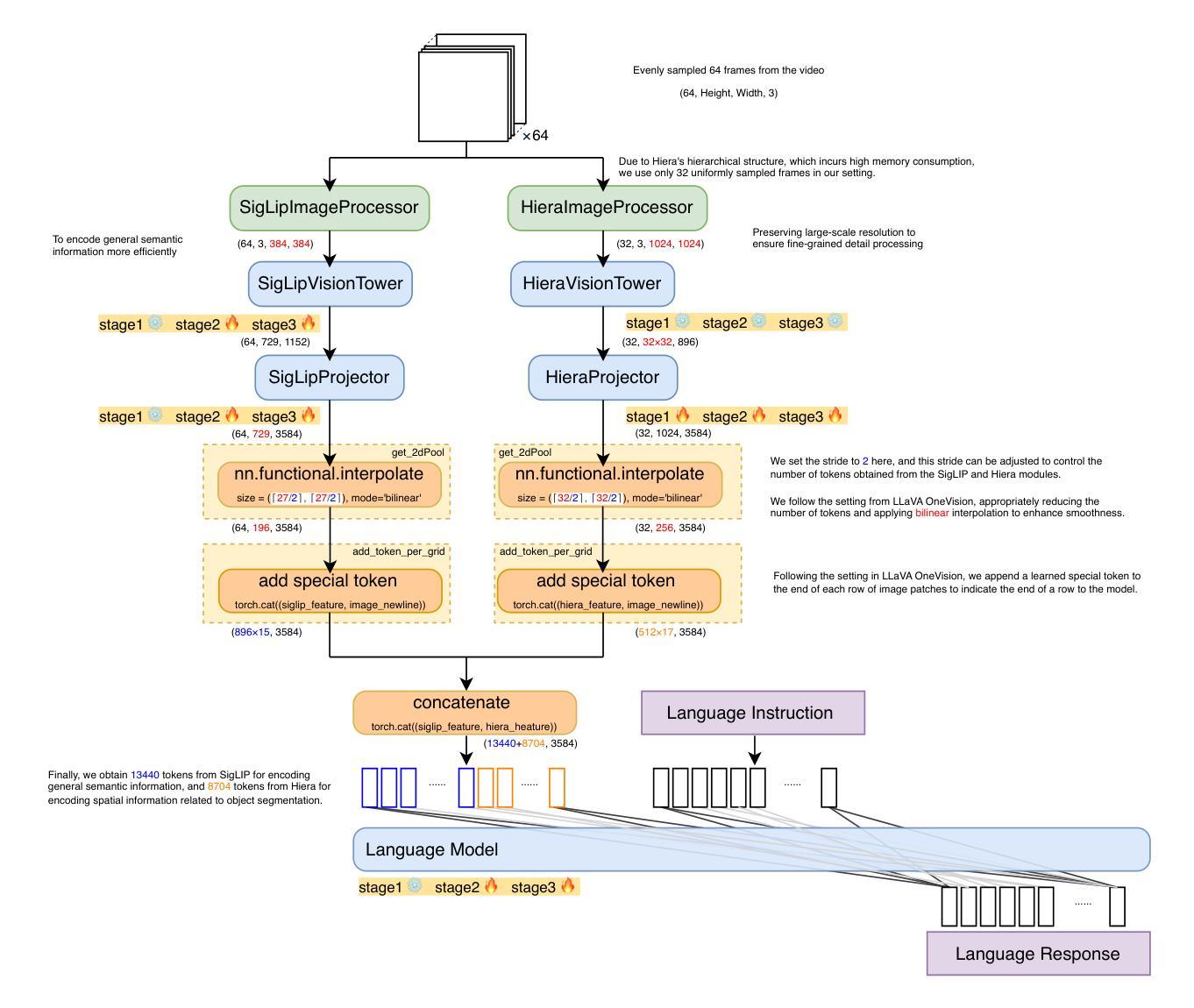
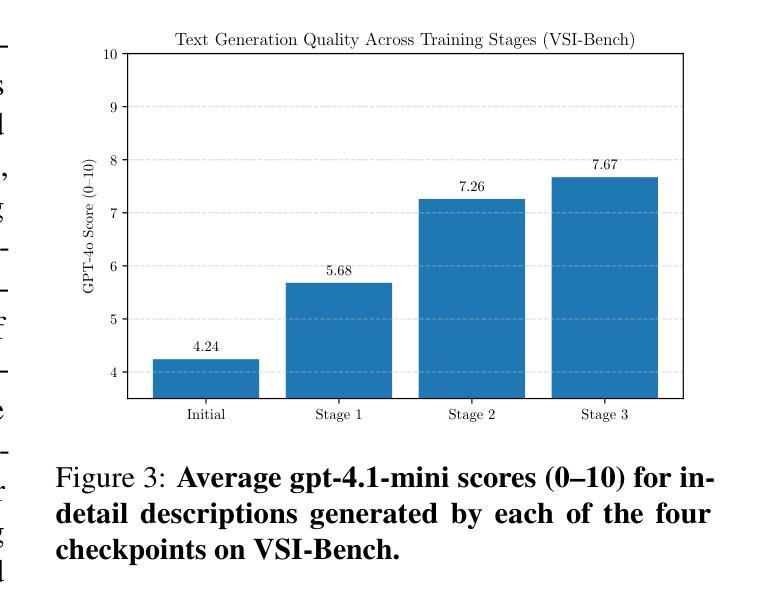
Towards Visuospatial Cognition via Hierarchical Fusion of Visual Experts
Authors:Qi Feng
While Multimodal Large Language Models (MLLMs) excel at general vision-language tasks, visuospatial cognition - reasoning about spatial layouts, relations, and dynamics - remains a significant challenge. Existing models often lack the necessary architectural components and specialized training data for fine-grained spatial understanding. We introduce ViCA2 (Visuospatial Cognitive Assistant 2), a novel MLLM designed to enhance spatial reasoning. ViCA2 features a dual vision encoder architecture integrating SigLIP for semantics and Hiera for spatial structure, coupled with a token ratio control mechanism for efficiency. We also developed ViCA-322K, a new large-scale dataset with over 322,000 spatially grounded question-answer pairs for targeted instruction tuning. On the challenging VSI-Bench benchmark, our ViCA2-7B model achieves a state-of-the-art average score of 56.8, significantly surpassing larger open-source models (e.g., LLaVA-NeXT-Video-72B, 40.9) and leading proprietary models (Gemini-1.5 Pro, 45.4). This demonstrates the effectiveness of our approach in achieving strong visuospatial intelligence with a compact model. We release ViCA2, its codebase, and the ViCA-322K dataset to facilitate further research.
虽然多模态大型语言模型(MLLMs)在一般的视觉语言任务上表现出色,但对于空间布局、关系和动态的空间推理仍然是巨大的挑战。现有的模型通常缺乏必要的架构组件和精细空间理解的专业训练数据。我们推出了ViCA2(视觉空间认知助手2),这是一种新型的多模态大型语言模型,旨在提高空间推理能力。ViCA2采用双视觉编码器架构,融合了SigLIP的语义和Hiera的空间结构,并采用了高效的标记比率控制机制。我们还开发了ViCA-322K大规模数据集,包含超过32万对空间定位的问题答案对,用于针对性的指令调整。在具有挑战性的VSI-Bench基准测试中,我们的ViCA2-7B模型取得了平均得分56.8分的最新水平成绩,显著超过了更大的开源模型(例如LLaVA-NeXT-Video-72B得分为40.9)和领先的专有模型(Gemini-1.5 Pro得分为45.4)。这证明了我们方法的有效性,即使在紧凑模型下也能实现强大的视觉空间智能。我们发布了ViCA2及其代码库和ViCA-322K数据集,以促进进一步研究。
论文及项目相关链接
PDF In version 1, Hidetoshi Shimodaira was included as a co-author without their consent and has been removed from the author list
Summary
多模态大型语言模型(MLLMs)在一般的视觉语言任务上表现出色,但在视觉空间认知方面,即对空间布局、关系和动态推理仍存在挑战。现有模型缺乏必要的架构组件和精细空间理解的专业训练数据。我们推出ViCA2(视觉空间认知助手2),一款专为增强空间推理能力设计的新型MLLM。ViCA2采用双视角编码器架构,集成SigLIP进行语义分析,Hiera进行空间结构解析,并结合令牌比率控制机制以提高效率。我们还开发了ViCA-322K大型数据集,包含超过32万2千个空间定位的问题答案对,用于针对性的指令调优。在具有挑战性的VSI-Bench基准测试中,我们的ViCA2-7B模型达到了平均得分56.8,显著超越了其他大型开源模型(如LLaVA-NeXT-Video-72B,得分40.9)和领先的专业模型(Gemini-1.5 Pro,得分45.4)。这证明了我们在实现强大视觉空间智能的紧凑模型方面的有效性。我们发布ViCA2、其代码库和ViCA-322K数据集以促进进一步研究。
Key Takeaways
- 多模态大型语言模型(MLLMs)在视觉空间认知方面存在挑战。
- ViCA2是一款新型MLLM,旨在增强空间推理能力。
- ViCA2采用双视角编码器架构,集成SigLIP和Hiera进行语义和空间结构解析。
- 开发出ViCA-322K大型数据集用于针对性的指令调优。
- ViCA2在VSI-Bench基准测试中表现优异,平均得分56.8。
- ViCA2显著超越了其他大型开源和专业模型。
点此查看论文截图

Search and Refine During Think: Autonomous Retrieval-Augmented Reasoning of LLMs
Authors:Yaorui Shi, Sihang Li, Chang Wu, Zhiyuan Liu, Junfeng Fang, Hengxing Cai, An Zhang, Xiang Wang
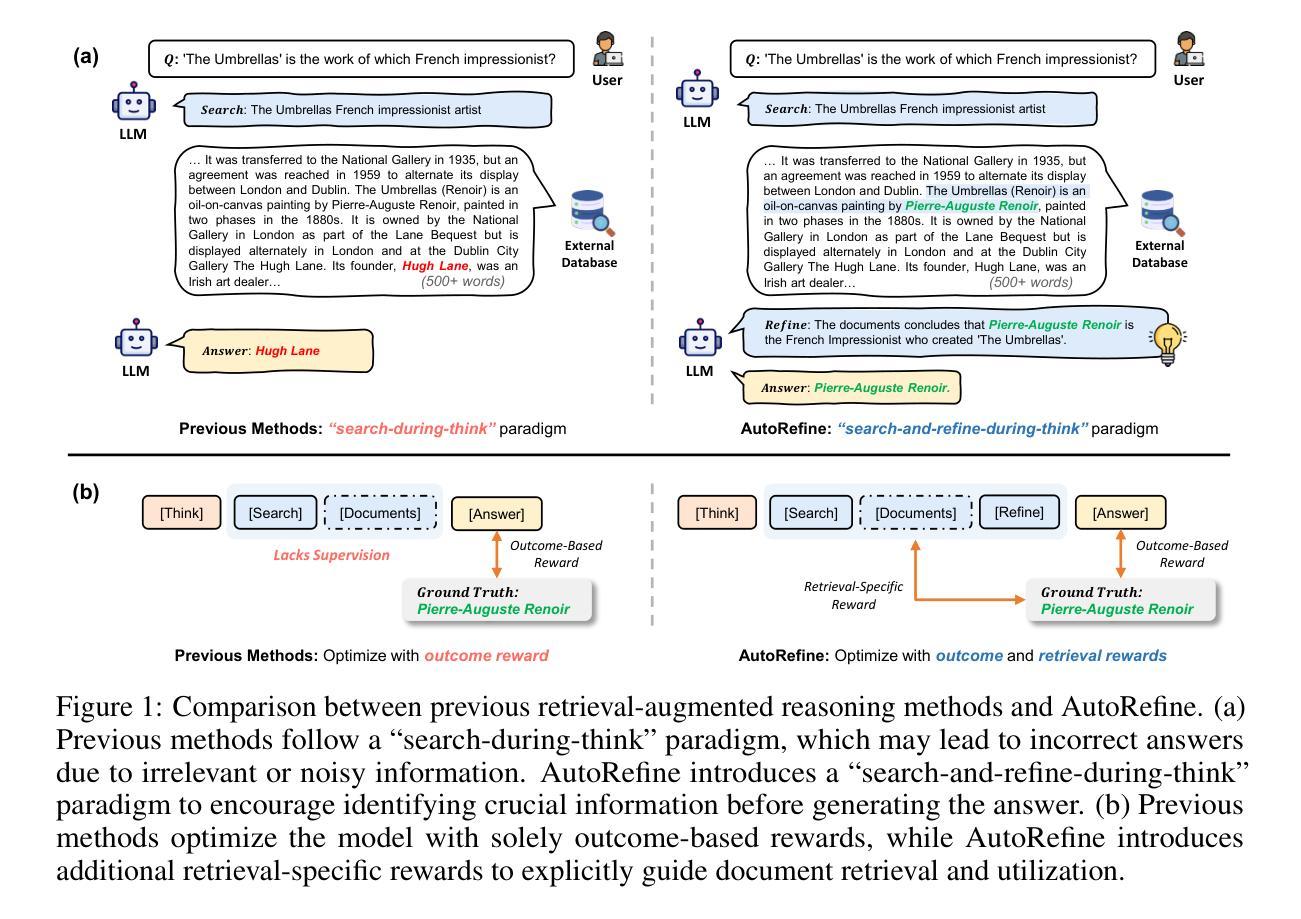
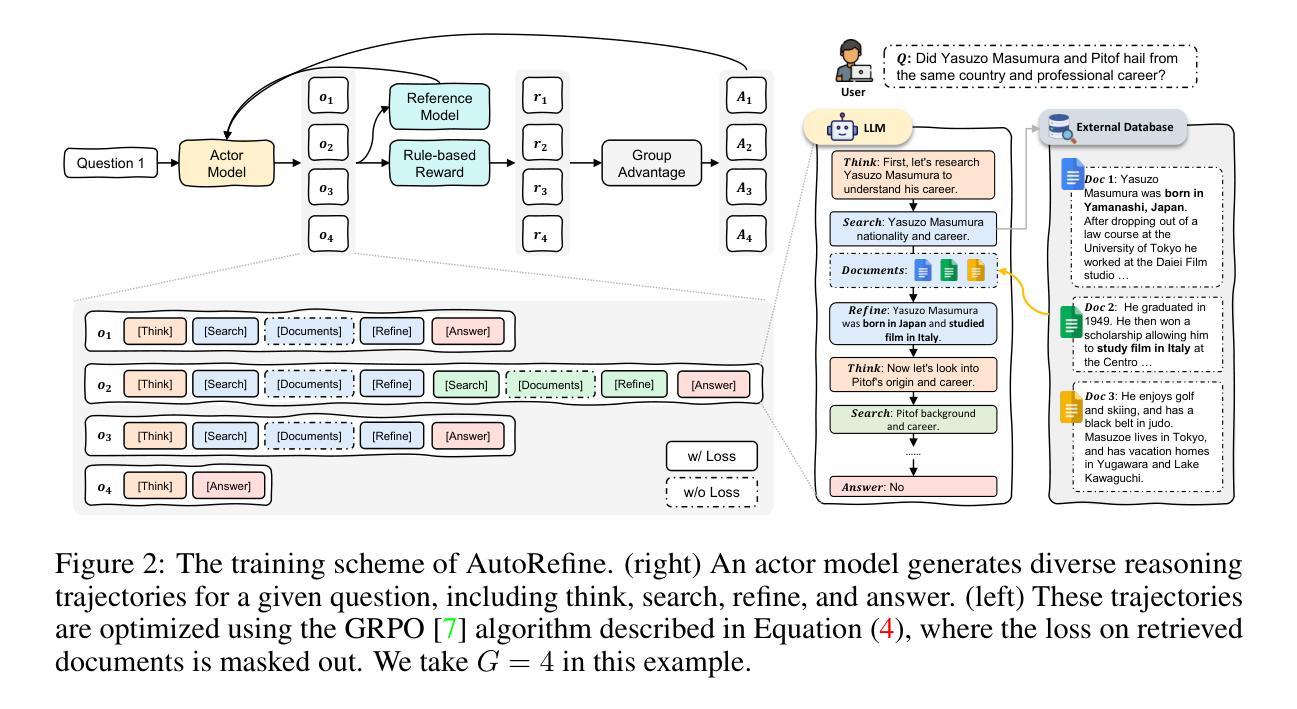
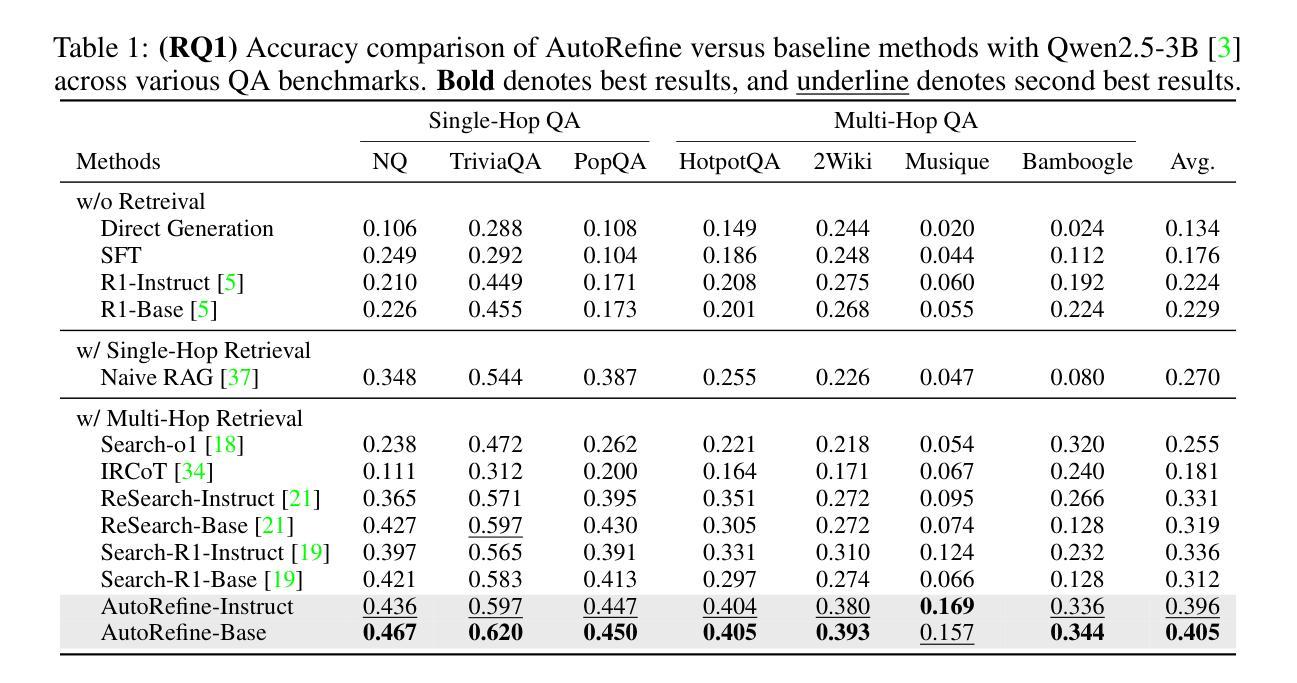
Large language models have demonstrated impressive reasoning capabilities but are inherently limited by their knowledge reservoir. Retrieval-augmented reasoning mitigates this limitation by allowing LLMs to query external resources, but existing methods often retrieve irrelevant or noisy information, hindering accurate reasoning. In this paper, we propose AutoRefine, a reinforcement learning post-training framework that adopts a new ``search-and-refine-during-think’’ paradigm. AutoRefine introduces explicit knowledge refinement steps between successive search calls, enabling the model to iteratively filter, distill, and organize evidence before generating an answer. Furthermore, we incorporate tailored retrieval-specific rewards alongside answer correctness rewards using group relative policy optimization. Experiments on single-hop and multi-hop QA benchmarks demonstrate that AutoRefine significantly outperforms existing approaches, particularly in complex, multi-hop reasoning scenarios. Detailed analysis shows that AutoRefine issues frequent, higher-quality searches and synthesizes evidence effectively.
大规模语言模型已经表现出了令人印象深刻的推理能力,但本质上受限于其知识库。检索增强推理通过允许大型语言模型查询外部资源来缓解这一限制,但现有方法经常检索到不相关或嘈杂的信息,阻碍了准确的推理。在本文中,我们提出了AutoRefine,这是一个采用新型“思考过程中的搜索与优化”范式的强化学习后训练框架。AutoRefine在连续的搜索调用之间引入了明确的知识优化步骤,使模型能够迭代地过滤、提炼和整理证据,然后生成答案。此外,我们通过使用群体相对策略优化,结合了定制的检索特定奖励和答案正确性奖励。在单跳和多跳问答基准测试上的实验表明,AutoRefine显著优于现有方法,特别是在复杂的多跳推理场景中。详细分析表明,AutoRefine能进行频繁的高质量搜索,并能有效地综合证据。
论文及项目相关链接
Summary
本文提出一种名为AutoRefine的强化学习后训练框架,采用新的“搜索与思考中精炼”模式,用于增强大型语言模型的推理能力。该框架在连续搜索调用之间引入显式知识精炼步骤,使模型能够迭代过滤、提炼和整理证据,从而生成更准确的答案。此外,通过结合检索特定奖励和答案正确性奖励,使用群体相对策略优化,AutoRefine在单跳和多跳问答基准测试上的表现均显著优于现有方法,特别是在复杂多跳推理场景中。
Key Takeaways
- 大型语言模型虽然具备强大的推理能力,但其知识库本质上存在局限性。
- 检索增强推理可通过允许语言模型查询外部资源来减轻这一局限性。
- 现有方法往往检索到不相关或嘈杂的信息,阻碍准确推理。
- AutoRefine框架引入“搜索与思考中精炼”模式,在连续搜索之间加入知识精炼步骤。
- AutoRefine通过迭代过滤、提炼和整理证据,提高搜索质量,进而提升答案准确性。
- 结合检索特定奖励和答案正确性奖励,使用群体相对策略优化,提升模型表现。
点此查看论文截图


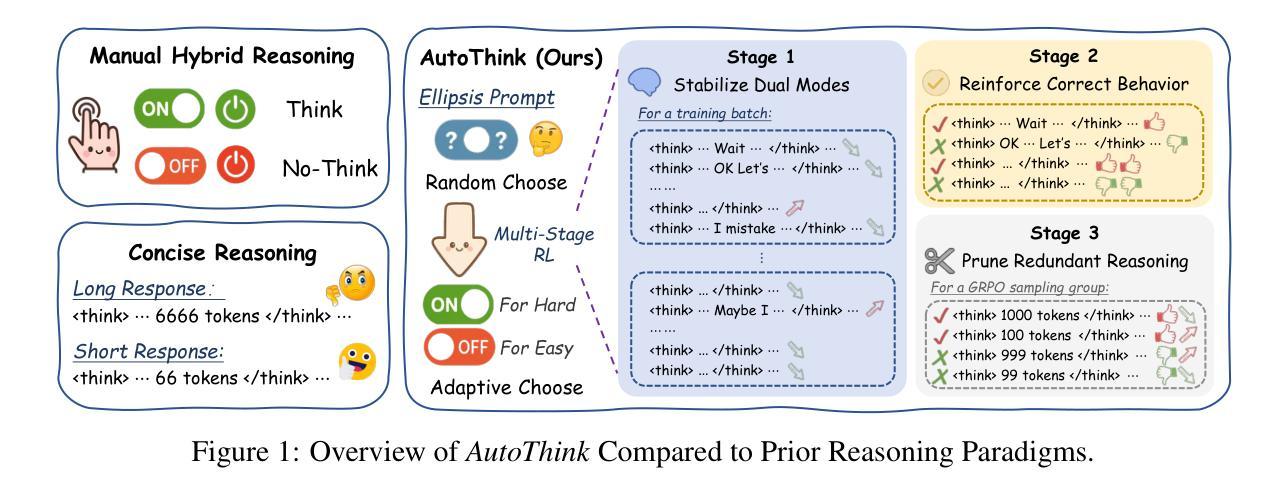
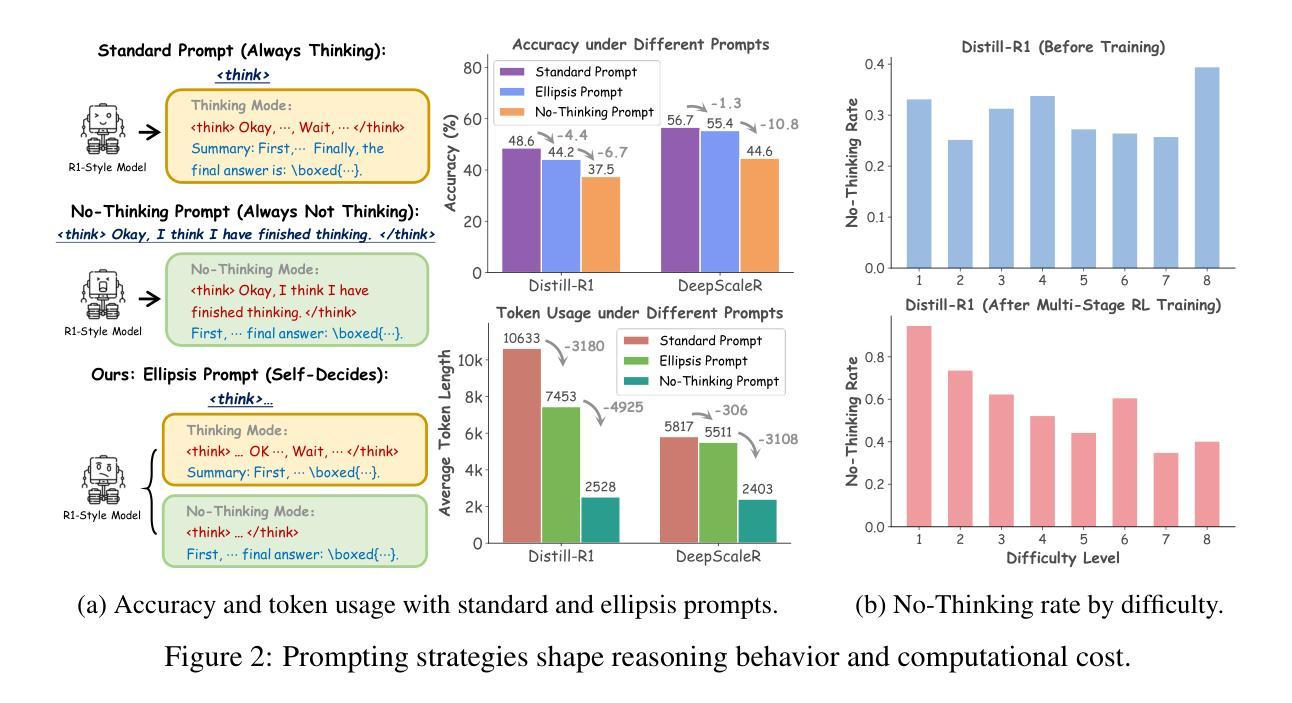
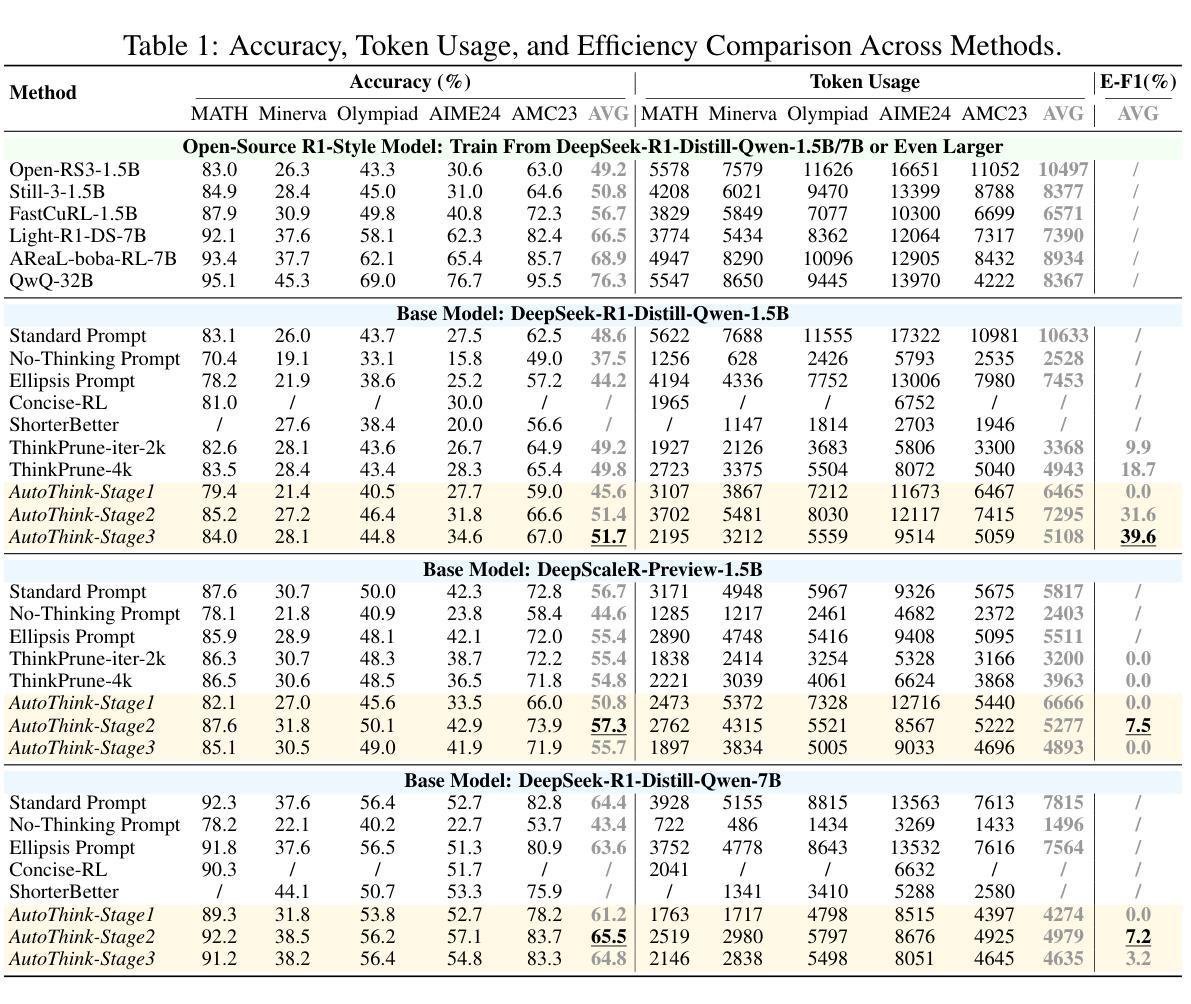
Learning When to Think: Shaping Adaptive Reasoning in R1-Style Models via Multi-Stage RL
Authors:Songjun Tu, Jiahao Lin, Qichao Zhang, Xiangyu Tian, Linjing Li, Xiangyuan Lan, Dongbin Zhao
Large reasoning models (LRMs) are proficient at generating explicit, step-by-step reasoning sequences before producing final answers. However, such detailed reasoning can introduce substantial computational overhead and latency, particularly for simple problems. To address this over-thinking problem, we explore how to equip LRMs with adaptive thinking capabilities: enabling them to dynamically decide whether or not to engage in explicit reasoning based on problem complexity. Building on R1-style distilled models, we observe that inserting a simple ellipsis (“…”) into the prompt can stochastically trigger either a thinking or no-thinking mode, revealing a latent controllability in the reasoning behavior. Leveraging this property, we propose AutoThink, a multi-stage reinforcement learning (RL) framework that progressively optimizes reasoning policies via stage-wise reward shaping. AutoThink learns to invoke explicit reasoning only when necessary, while defaulting to succinct responses for simpler tasks. Experiments on five mainstream mathematical benchmarks demonstrate that AutoThink achieves favorable accuracy-efficiency trade-offs compared to recent prompting and RL-based pruning methods. It can be seamlessly integrated into any R1-style model, including both distilled and further fine-tuned variants. Notably, AutoThink improves relative accuracy by 6.4 percent while reducing token usage by 52 percent on DeepSeek-R1-Distill-Qwen-1.5B, establishing a scalable and adaptive reasoning paradigm for LRMs. Project Page: https://github.com/ScienceOne-AI/AutoThink.
大型推理模型(LRMs)擅长在给出最终答案之前生成明确、循序渐进的推理序列。然而,这样的详细推理可能会引入大量的计算开销和延迟,尤其是在处理简单问题时。为了解决过度思考的问题,我们探讨如何为LRMs配备适应性思考能力:让它们能够动态地决定是否进行显性推理,这取决于问题的复杂性。我们基于R1风格的蒸馏模型观察到,在提示中插入一个简单的省略号(“…”)可以随机触发思考模式或非思考模式,揭示了推理行为中的潜在可控性。利用这一特性,我们提出了AutoThink,这是一个多阶段的强化学习(RL)框架,它通过分阶段奖励塑造来逐步优化推理策略。AutoThink学习只在必要时进行显性推理,而默认为简单的任务提供简洁的回应。在五个主流数学基准测试上的实验表明,与最近的提示和基于RL的修剪方法相比,AutoThink在准确性和效率之间实现了有利的权衡。它可以无缝地集成到任何R1风格的模型中,包括蒸馏和进一步微调后的变体。值得注意的是,AutoThink在DeepSeek-R1-Distill-Qwen-1.5B上相对提高了6.4%的准确率,同时减少了52%的令牌使用,为LRMs建立了可扩展和自适应的推理范式。项目页面:https://github.com/ScienceOne-AI/AutoThink。
论文及项目相关链接
PDF Fisrt Submitted on 16 May 2025; Update on 28 May 2025
Summary
大型推理模型(LRMs)能够生成明确、逐步的推理序列以得出最终答案,但这样的详细推理可能会带来较大的计算开销和延迟,尤其是在处理简单问题时。为解决这一问题,本文旨在探讨如何为LRMs配备自适应思考能力,使其能够根据问题复杂度动态决定是否进行显性推理。研究基于R1风格蒸馏模型,发现通过在提示中插入省略号(“…”),可以随机触发思考或非思考模式,揭示出推理行为的潜在可控性。基于此特性,本文提出了AutoThink,这是一个多阶段强化学习(RL)框架,通过阶段性奖励塑造来逐步优化推理策略。AutoThink能够按需进行显性推理,为简单任务提供简洁回应。在五个主流数学基准测试上的实验表明,与最新的提示和基于RL的修剪方法相比,AutoThink在准确性与效率之间取得了有利的权衡。它可以无缝地集成到任何R1风格模型中,包括蒸馏和进一步微调过的变体。尤其是,AutoThink在DeepSeek-R1-Distill-Qwen-1.5B上相对提高了6.4%的准确率,同时减少了52%的令牌使用量,为LRMs建立了可扩展和自适应的推理模式。
Key Takeaways
- 大型推理模型虽然能生成详细的推理步骤,但处理简单问题时可能导致计算开销和延迟。
- 通过在提示中插入省略号,可以触发模型的思考或非思考模式,表明推理行为具有潜在可控性。
- 提出AutoThink框架,利用多阶段强化学习优化推理策略,实现按需推理。
- AutoThink能够在保持较高准确率的同时,提高模型效率,适用于多种R1风格模型。
- AutoThink在DeepSeek-R1-Distill-Qwen-1.5B模型上取得了显著的准确率提升和令牌使用减少。
- 该研究为大型推理模型建立了一种可扩展和自适应的推理模式。
点此查看论文截图


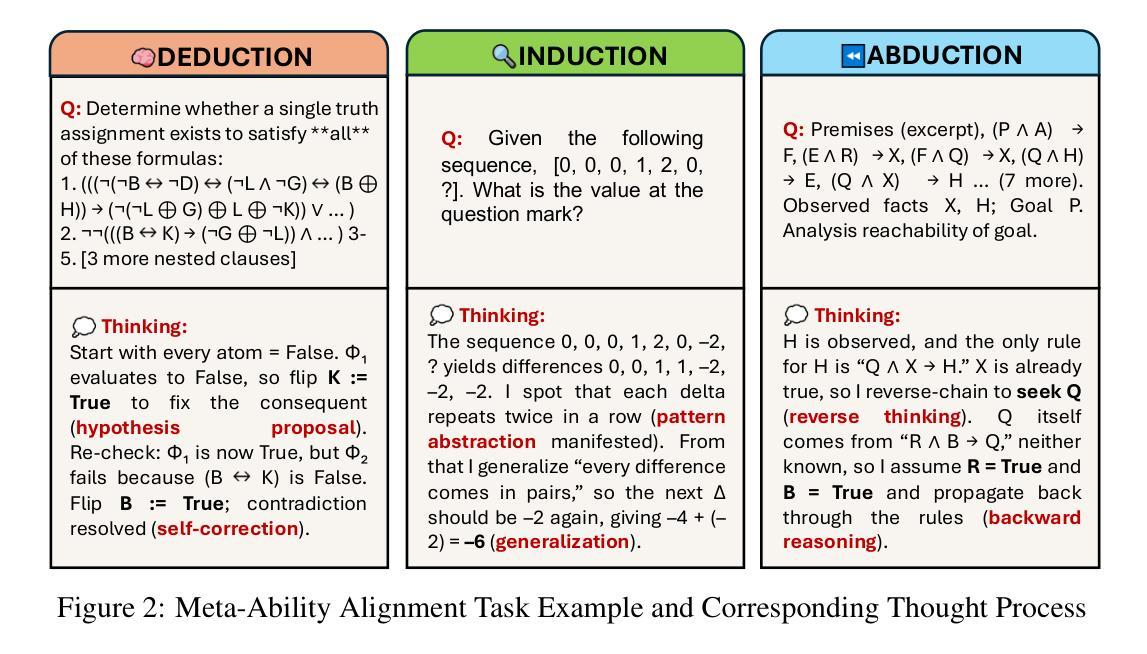
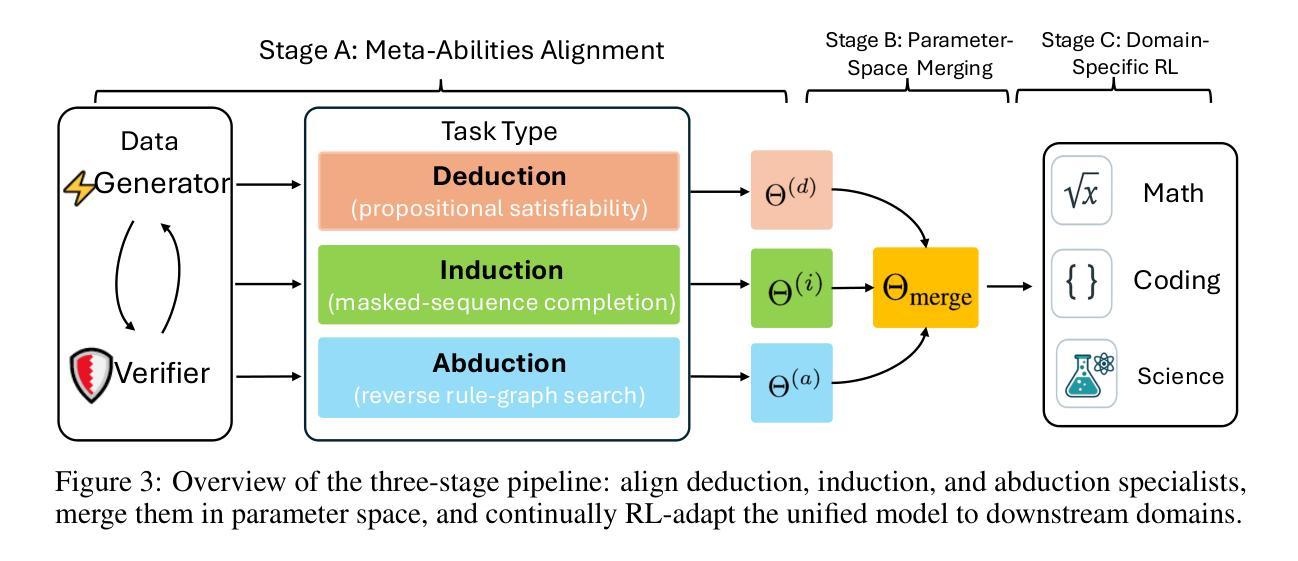
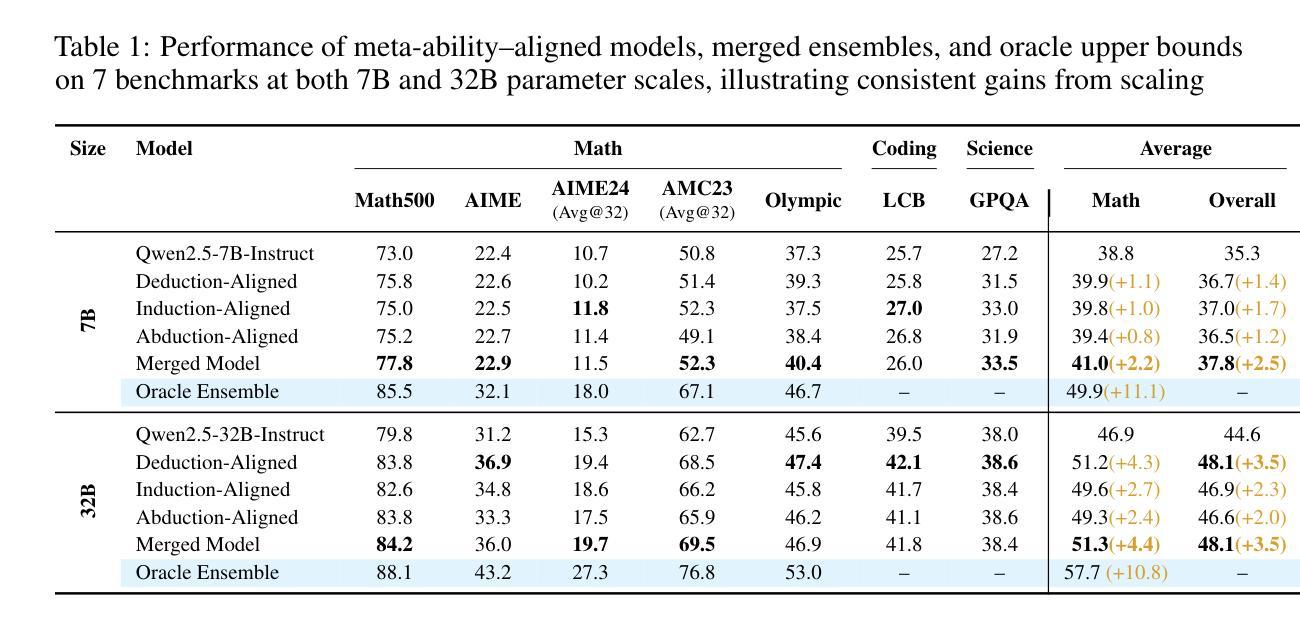
Beyond ‘Aha!’: Toward Systematic Meta-Abilities Alignment in Large Reasoning Models
Authors:Zhiyuan Hu, Yibo Wang, Hanze Dong, Yuhui Xu, Amrita Saha, Caiming Xiong, Bryan Hooi, Junnan Li
Large reasoning models (LRMs) already possess a latent capacity for long chain-of-thought reasoning. Prior work has shown that outcome-based reinforcement learning (RL) can incidentally elicit advanced reasoning behaviors such as self-correction, backtracking, and verification phenomena often referred to as the model’s “aha moment”. However, the timing and consistency of these emergent behaviors remain unpredictable and uncontrollable, limiting the scalability and reliability of LRMs’ reasoning capabilities. To address these limitations, we move beyond reliance on prompts and coincidental “aha moments”. Instead, we explicitly align models with three meta-abilities: deduction, induction, and abduction, using automatically generated, self-verifiable tasks. Our three stage-pipeline individual alignment, parameter-space merging, and domain-specific reinforcement learning, boosting performance by over 10% relative to instruction-tuned baselines. Furthermore, domain-specific RL from the aligned checkpoint yields an additional gain in performance ceiling for both 7B and 32B models across math, coding, and science benchmarks, demonstrating that explicit meta-ability alignment offers a scalable and dependable foundation for reasoning. Code is available at: https://github.com/zhiyuanhubj/Meta-Ability-Alignment
大型推理模型(LRMs)已经具备潜在的长链思维推理能力。先前的研究表明,基于结果的强化学习(RL)可以偶然激发高级推理行为,如自我修正、回溯和验证现象,这些常被看作是模型的“顿悟时刻”。然而,这些突发行为的时机和一致性仍然不可预测和不可控制,限制了LRMs推理能力的可扩展性和可靠性。为了解决这些局限性,我们不再依赖提示和偶然的“顿悟时刻”。相反,我们通过使用自动生成的、可自我验证的任务,明确地将模型与三种元能力(演绎、归纳和溯因)对齐。我们的三阶段管道包括个人对齐、参数空间合并和领域特定强化学习,相对于指令调整基准线,性能提高了10%以上。此外,从对齐检查点进行的领域特定RL为7B和32B模型在数学、编码和科学基准测试方面的性能上限带来了额外提升,表明明确的元能力对齐为推理提供了可扩展和可靠的基石。代码可在https://github.com/zhiyuanhubj/Meta-Ability-Alignment找到。
论文及项目相关链接
PDF In Progress
Summary
大型推理模型(LRMs)已具备潜在的长链思维推理能力。先前的研究表明,基于结果的强化学习(RL)可以偶然激发自我修正、回溯和验证等高级推理行为,这些行为通常被视为模型的“顿悟时刻”。然而,这些突发行为的时机和一致性尚不可预测和控制,限制了LRMs推理能力的可扩展性和可靠性。为解决这些局限性,我们不再依赖提示和偶然的“顿悟时刻”,而是明确地将模型与演绎、归纳和溯因三种元能力对齐,使用自动生成的自我验证任务。我们的三阶段管道包括个体对齐、参数空间合并和领域特定强化学习,相较于指令调优基准线,性能提升超过10%。此外,从对齐检查点进行的领域特定RL为数学、编码和科学基准测试中的7B和32B模型提供了额外的性能提升,表明明确的元能力对齐为推理提供了可扩展和可靠的基石。
Key Takeaways
- 大型推理模型已具有潜在的长链思维推理能力。
- 基于结果的强化学习可以激发模型的高级推理行为,如自我修正和验证。
- 当前方法面临推理行为不可预测和难以控制的局限性。
- 为解决这些问题,提出与演绎、归纳和溯因三种元能力对齐的方法。
- 使用自动生成的自我验证任务,通过三阶段管道提升模型性能。
- 领域特定强化学习进一步提高了模型的性能上限,特别是在数学、编码和科学领域。
- 明确的元能力对齐为推理提供了可扩展和可靠的基石。
点此查看论文截图

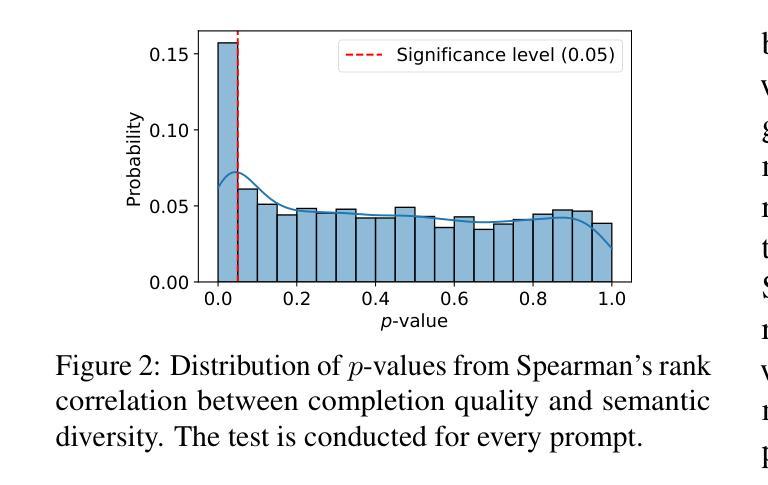
DRA-GRPO: Exploring Diversity-Aware Reward Adjustment for R1-Zero-Like Training of Large Language Models
Authors:Xiwen Chen, Wenhui Zhu, Peijie Qiu, Xuanzhao Dong, Hao Wang, Haiyu Wu, Huayu Li, Aristeidis Sotiras, Yalin Wang, Abolfazl Razi
Recent advances in reinforcement learning for language model post-training, such as Group Relative Policy Optimization (GRPO), have shown promise in low-resource settings. However, GRPO typically relies on solution-level and scalar reward signals that fail to capture the semantic diversity among sampled completions. This leads to what we identify as a diversity-quality inconsistency, where distinct reasoning paths may receive indistinguishable rewards. To address this limitation, we propose $\textit{Diversity-aware Reward Adjustment}$ (DRA), a method that explicitly incorporates semantic diversity into the reward computation. DRA uses Submodular Mutual Information (SMI) to downweight redundant completions and amplify rewards for diverse ones. This encourages better exploration during learning, while maintaining stable exploitation of high-quality samples. Our method integrates seamlessly with both GRPO and its variant DR.GRPO, resulting in $\textit{DRA-GRPO}$ and $\textit{DGA-DR.GRPO}$. We evaluate our method on five mathematical reasoning benchmarks and find that it outperforms recent strong baselines. It achieves state-of-the-art performance with an average accuracy of 58.2%, using only 7,000 fine-tuning samples and a total training cost of approximately $55. The code is available at https://github.com/xiwenc1/DRA-GRPO.
最近,强化学习在语言模型后训练方面的进展,如群体相对策略优化(GRPO),在低资源环境中显示出巨大的潜力。然而,GRPO通常依赖于解决方案级别和标量奖励信号,这些信号无法捕获采样完成的语义多样性。这导致了我们所说的多样性质量不一致问题,不同的推理路径可能会获得无法区分的奖励。为了解决这个问题,我们提出了“多样性感知奖励调整”(DRA)方法,该方法显式地将语义多样性纳入奖励计算中。DRA使用子模块互信息(SMI)来降低冗余完成的权重,并放大多样化完成的奖励。这鼓励了更好的学习过程探索,同时保持对高质量样本的稳定利用。我们的方法与GRPO及其变体DR.GRPO无缝集成,形成DRA-GRPO和DGA-DR.GRPO。我们在五个数学推理基准测试上对我们的方法进行了评估,发现它超越了最近的强大基准测试。使用仅7000个微调样本和大约55的总训练成本,它达到了最先进的性能,平均准确率达到了58.2%。代码可在https://github.com/xiwenc1/DRA-GRPO找到。
论文及项目相关链接
Summary
强化学习在语言模型后训练方面,最新的发展如GRPO已在低资源设置领域显示出希望。然而,GRPO依赖于解决方案级别的标量奖励信号,无法捕捉采样补全的语义多样性,导致出现多样性质量不一致的问题。为解决这一问题,我们提出了DRA(多样性感知奖励调整)方法,该方法将语义多样性显式地纳入奖励计算中。DRA使用SMI(子模块互信息)来降低冗余补全的权重并放大对多样化补全的奖励。我们的方法能够很好地与GRPO及其变体DR.GRPO相结合,形成DRA-GRPO和DGA-DR.GRPO。我们在五个数学推理基准测试上评估了我们的方法,发现它优于最近的强大基线。使用仅7000个微调样本和约55的总训练成本,它实现了平均准确率为58.2%的最佳性能。
Key Takeaways
- 强化学习在低资源设置中的语言模型后训练展现出潜力,尤其是GRPO方法。
- GRPO存在多样性质量不一致的问题,因为它主要依赖解决方案级别的标量奖励信号。
- 提出的DRA方法通过明确考虑语义多样性来解决这个问题,使用SMI来平衡奖励和调整权重。
- DRA与GRPO及其变体无缝集成,形成新的方法DRA-GRPO和DGA-DR.GRPO。
- 在五个数学推理基准测试上,DRA方法表现出卓越性能,优于其他基线方法。
- 使用有限的微调样本和较低的训练成本,DRA达到了较高的平均准确率。
点此查看论文截图


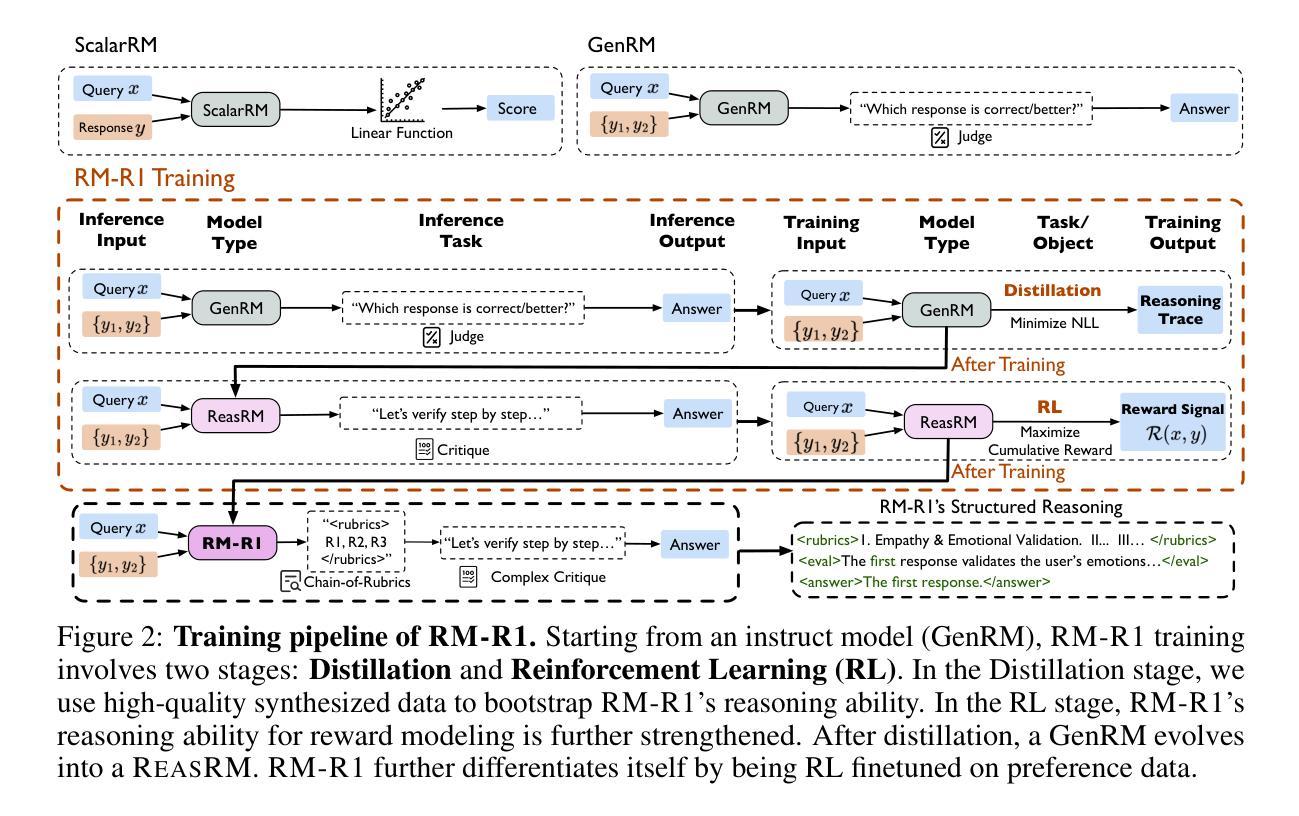
RM-R1: Reward Modeling as Reasoning
Authors:Xiusi Chen, Gaotang Li, Ziqi Wang, Bowen Jin, Cheng Qian, Yu Wang, Hongru Wang, Yu Zhang, Denghui Zhang, Tong Zhang, Hanghang Tong, Heng Ji
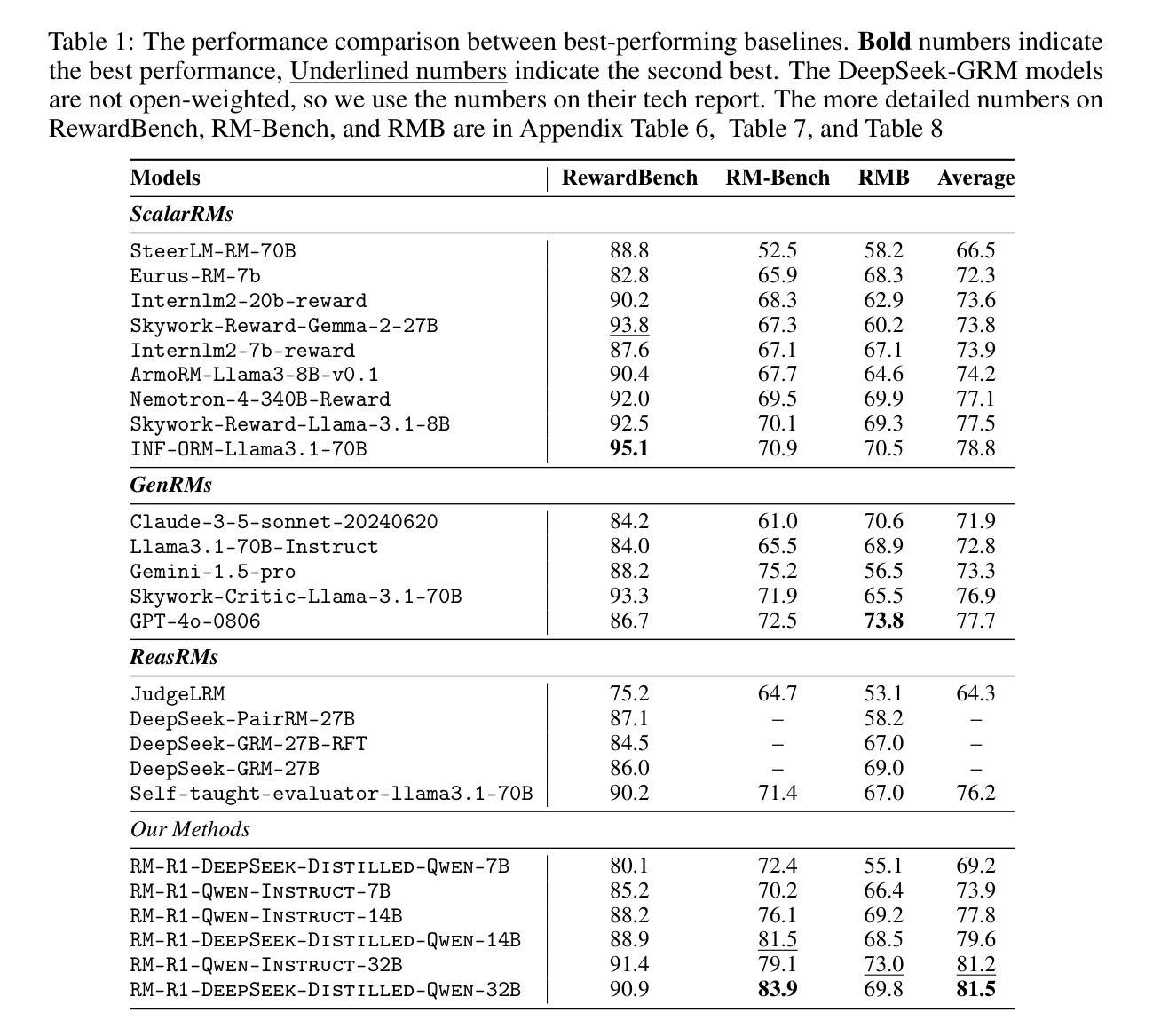
Reward modeling is essential for aligning large language models with human preferences through reinforcement learning from human feedback. To provide accurate reward signals, a reward model (RM) should stimulate deep thinking and conduct interpretable reasoning before assigning a score or a judgment. Inspired by recent advances of long chain-of-thought on reasoning-intensive tasks, we hypothesize and validate that integrating reasoning capabilities into reward modeling significantly enhances RMs interpretability and performance. To this end, we introduce a new class of generative reward models - Reasoning Reward Models (ReasRMs) - which formulate reward modeling as a reasoning task. We propose a reasoning-oriented training pipeline and train a family of ReasRMs, RM-R1. RM-R1 features a chain-of-rubrics (CoR) mechanism - self-generating sample-level chat rubrics or math/code solutions, and evaluating candidate responses against them. The training of RM-R1 consists of two key stages: (1) distillation of high-quality reasoning chains and (2) reinforcement learning with verifiable rewards. Empirically, our models achieve state-of-the-art performance across three reward model benchmarks on average, outperforming much larger open-weight models (e.g., INF-ORM-Llama3.1-70B) and proprietary ones (e.g., GPT-4o) by up to 4.9%. Beyond final performance, we perform thorough empirical analyses to understand the key ingredients of successful ReasRM training. To facilitate future research, we release six REASRM models along with code and data at https://github.com/RM-R1-UIUC/RM-R1.
奖励建模对于通过强化学习从人类反馈中对大型语言模型与人类偏好进行对齐至关重要。为了提供准确的奖励信号,奖励模型(RM)应在分配分数或判断之前激发深入思考并进行可解释的推理。受近期长链思维在推理密集型任务上进步的启发,我们假设并将验证将推理能力融入奖励建模会显著增强RM的可解释性和性能。为此,我们引入了一类新的生成奖励模型——推理奖励模型(ReasRMs),它将奖励建模制定为推理任务。我们提出了面向推理的训练管道,并训练了一系列ReasRMs,即RM-R1。RM-R1的特点是拥有链式提纲(CoR)机制——自我生成样本级聊天提纲或数学/代码解决方案,并据此评估候选响应。RM-R1的训练包括两个关键阶段:(1)高质量推理链的蒸馏;(2)可验证奖励的强化学习。经验上,我们的模型在三个奖励模型基准测试上的平均性能达到最新水平,优于较大的开源模型(例如INF-ORM-Llama3.1-70B)和专有模型(例如GPT-4o),最高提升达4.9%。除了最终性能之外,我们还进行了全面的经验分析,以了解成功训练ReasRM的关键要素。为了方便未来研究,我们在https://github.com/RM-R1-UIUC/RM-R1上发布了六个REASRM模型以及相关的代码和数据。
论文及项目相关链接
PDF 25 pages, 8 figures
Summary
奖励建模对于通过强化学习从人类反馈对齐大型语言模型与人类偏好至关重要。通过结合推理能力进行奖励建模,可显著提高奖励模型的可解释性和性能。本文提出了新一代的生成奖励模型——推理奖励模型(ReasRMs),将奖励建模表述为推理任务。通过面向推理的训练管道,训练出一系列ReasRMs,其中RM-R1模型具有链式rubrics(CoR)机制,能够自我生成样本级别的聊天rubrics或数学/代码解决方案,并对候选响应进行评估。该模型包括两个阶段:高质量推理链的蒸馏和可验证奖励的强化学习。在三个奖励模型基准测试中,RM-R1模型平均性能达到最新水平,优于大型开源模型(如INF-ORM-Llama 3.1-70B)和专有模型(如GPT-4o),最高提升达4.9%。除了最终性能外,本文还进行了全面的实证研究,以了解成功的ReasRM训练的关键要素。为便于未来研究,我们在https://github.com/RM-R1-UIUC/RM-R1上发布了六个REASRM模型及相关代码和数据。
Key Takeaways
- 奖励建模对于通过强化学习从人类反馈中使大型语言模型与人类偏好对齐至关重要。
- 引入了一种新型的生成奖励模型——推理奖励模型(ReasRMs),将奖励建模作为推理任务。
- RM-R1模型具有链式rubrics(CoR)机制,能够自我生成样本级别的聊天rubrics或数学/代码解决方案。
- RM-R1模型的训练包括两个阶段:高质量推理链的蒸馏和强化学习使用可验证奖励。
- RM-R1模型在三个奖励模型基准测试中达到最新性能水平,优于其他大型模型。
- 除了最终性能外,文章还详细探讨了成功的ReasRM训练的关键要素。
点此查看论文截图



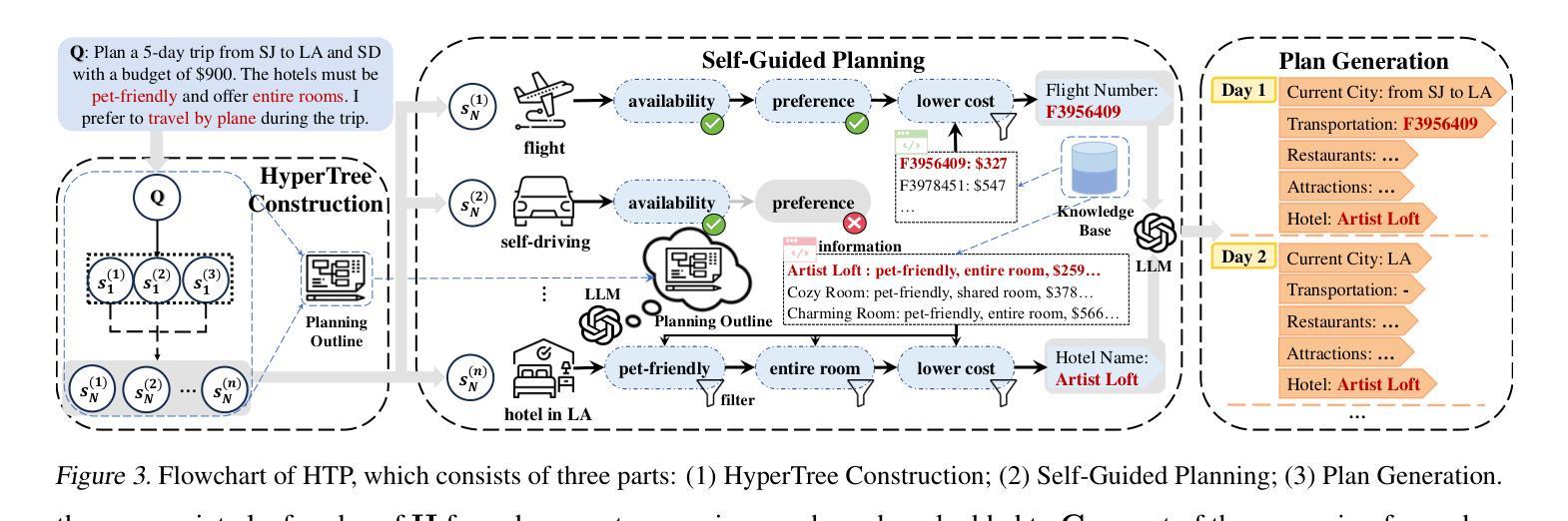
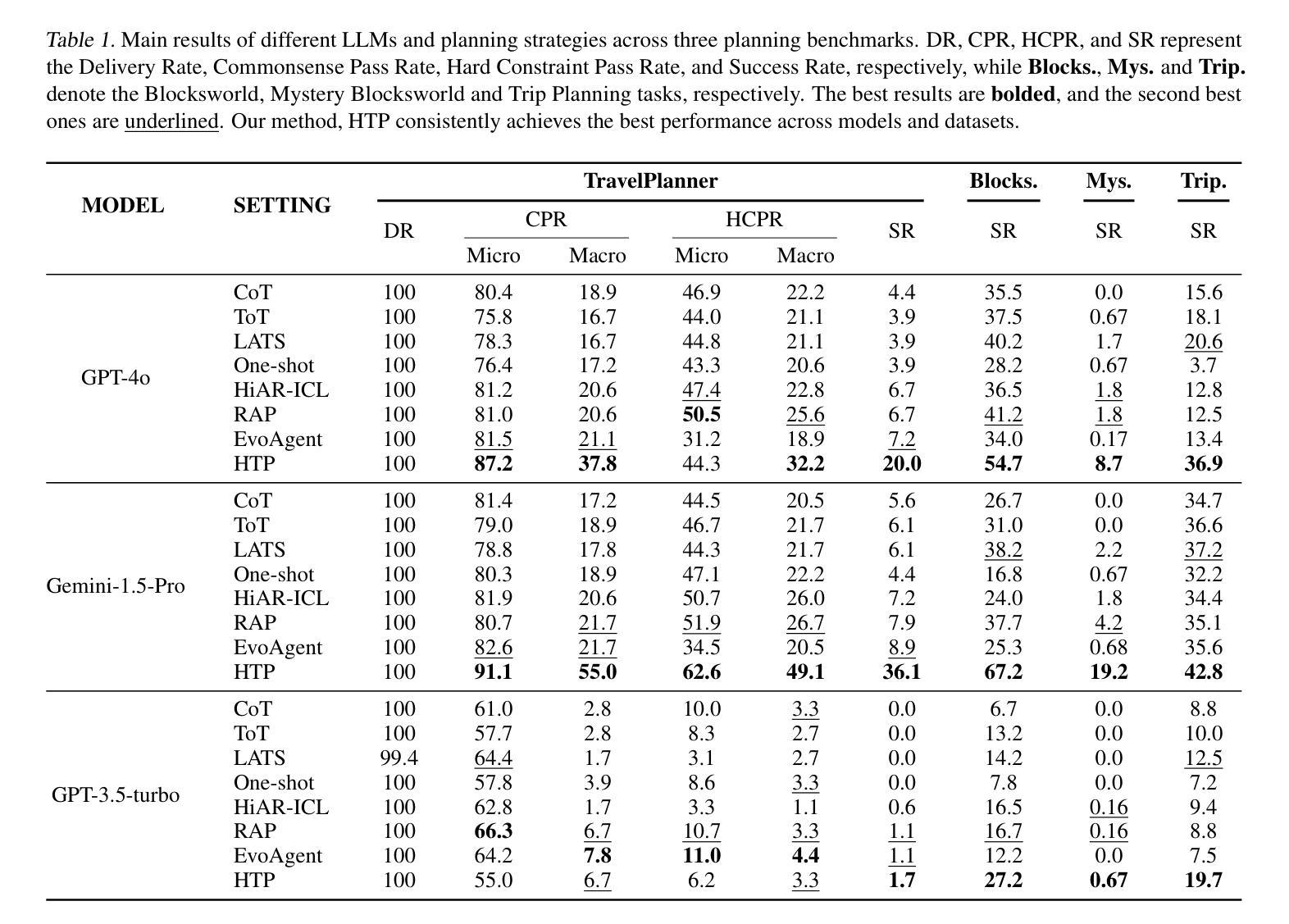
HyperTree Planning: Enhancing LLM Reasoning via Hierarchical Thinking
Authors:Runquan Gui, Zhihai Wang, Jie Wang, Chi Ma, Huiling Zhen, Mingxuan Yuan, Jianye Hao, Defu Lian, Enhong Chen, Feng Wu
Recent advancements have significantly enhanced the performance of large language models (LLMs) in tackling complex reasoning tasks, achieving notable success in domains like mathematical and logical reasoning. However, these methods encounter challenges with complex planning tasks, primarily due to extended reasoning steps, diverse constraints, and the challenge of handling multiple distinct sub-tasks. To address these challenges, we propose HyperTree Planning (HTP), a novel reasoning paradigm that constructs hypertree-structured planning outlines for effective planning. The hypertree structure enables LLMs to engage in hierarchical thinking by flexibly employing the divide-and-conquer strategy, effectively breaking down intricate reasoning steps, accommodating diverse constraints, and managing multiple distinct sub-tasks in a well-organized manner. We further introduce an autonomous planning framework that completes the planning process by iteratively refining and expanding the hypertree-structured planning outlines. Experiments demonstrate the effectiveness of HTP, achieving state-of-the-art accuracy on the TravelPlanner benchmark with Gemini-1.5-Pro, resulting in a 3.6 times performance improvement over o1-preview.
最近的技术进步显著提高了大型语言模型(LLM)在解决复杂推理任务方面的性能,在数学和逻辑推理等领域取得了显著的成功。然而,这些方法在处理复杂的规划任务时面临挑战,主要是由于推理步骤繁多、约束多样以及处理多个不同子任务的挑战。为了解决这些挑战,我们提出了HyperTree Planning(HTP)这一新的推理范式,为有效规划构建超树结构规划大纲。超树结构使LLM能够通过灵活地采用分而治之的策略来进行分层思考,有效地简化复杂的推理步骤,适应各种约束,并以井然有序的方式管理多个不同的子任务。我们还引入了一个自主规划框架,通过迭代精化和扩展超树结构规划大纲来完成规划过程。实验表明HTP的有效性,在TravelPlanner基准测试中使用Gemini-1.5-Pro实现了最先进的准确性,较o1-preview的性能提高了3.6倍。
论文及项目相关链接
PDF arXiv admin note: text overlap with arXiv:2406.14228 by other authors
Summary:近期发展显著提升大型语言模型(LLM)在处理复杂推理任务方面的性能,在数学和逻辑推理等领域取得了显著成功。然而,在处理复杂的规划任务时,这些方法面临挑战,如扩展推理步骤、多种约束和应对多个不同子任务的挑战。为应对这些挑战,我们提出HyperTree Planning(HTP)这一新的推理范式,构建用于有效规划的超树结构规划大纲。超树结构使LLM能够通过灵活地采用分而治之的策略进行分层思考,有效地分解复杂的推理步骤,容纳各种约束,并以有序的方式管理多个不同的子任务。我们还引入了一个自主规划框架,通过迭代地细化和扩展超树结构规划大纲来完成规划过程。实验表明HTP的有效性,在TravelPlanner基准测试上使用Gemini-1.5-Pro实现了业界领先精度,相较于o1-preview实现了3.6倍的性能提升。
Key Takeaways:
- 大型语言模型(LLM)在处理复杂推理任务方面表现出显著增强的性能。
- 在数学和逻辑推理等领域,LLM已取得显著成功。
- LLM在处理复杂的规划任务时面临挑战,如扩展推理步骤、多种约束和应对多个不同子任务。
- 提出HyperTree Planning(HTP)这一新的推理范式以应对这些挑战。
- HTP利用超树结构进行分层思考,有效分解复杂推理步骤,管理多种约束和多个子任务。
- 引入自主规划框架完成规划过程,通过迭代优化超树结构规划大纲。
点此查看论文截图


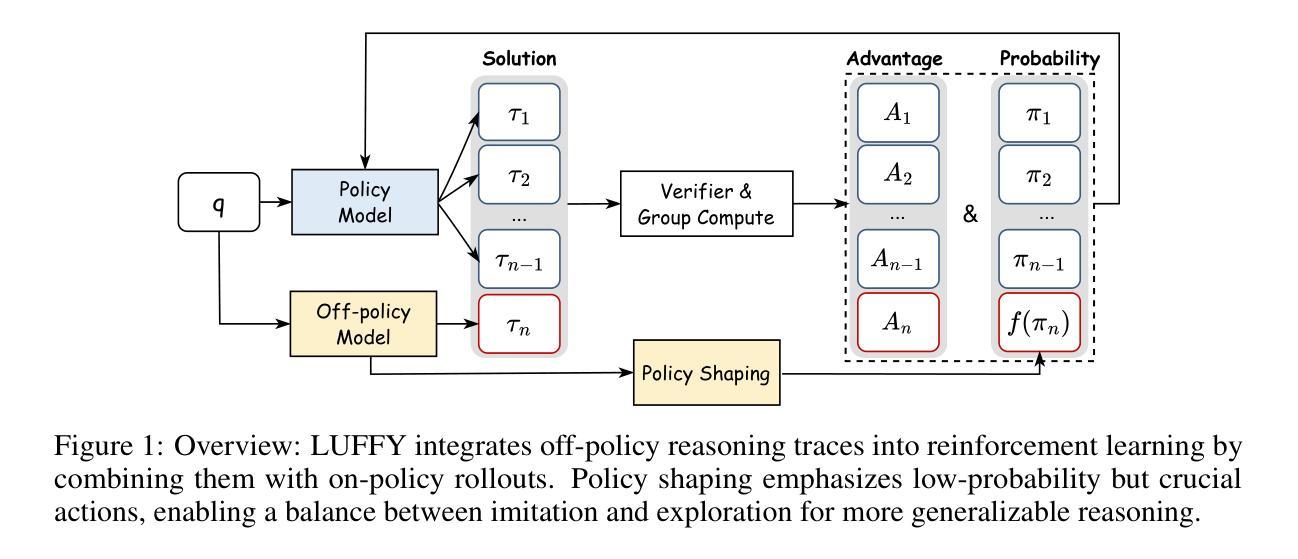
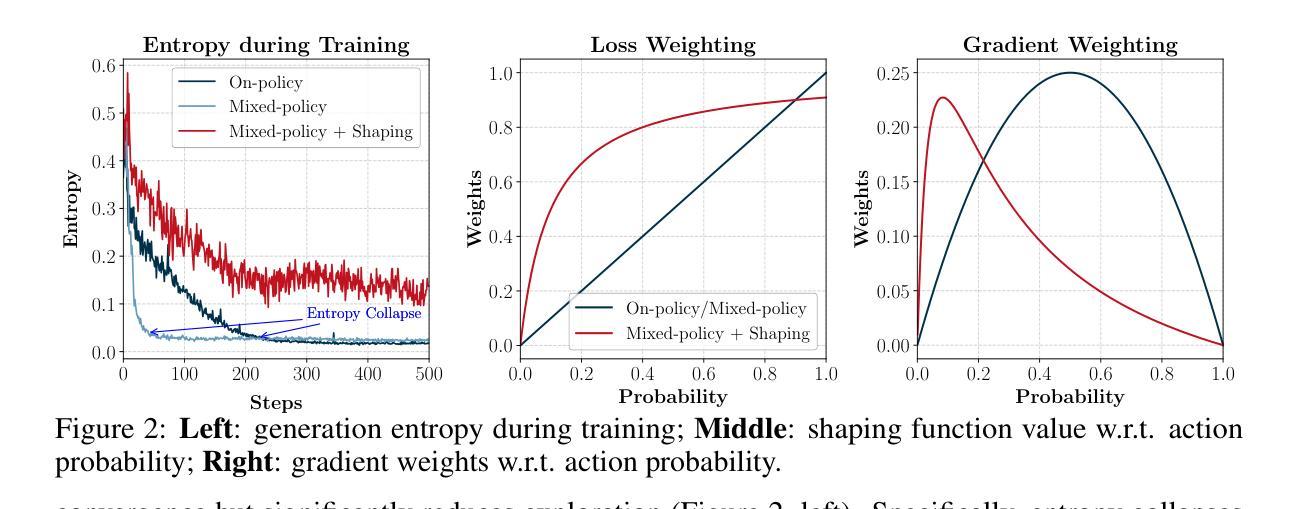
Learning to Reason under Off-Policy Guidance
Authors:Jianhao Yan, Yafu Li, Zican Hu, Zhi Wang, Ganqu Cui, Xiaoye Qu, Yu Cheng, Yue Zhang
Recent advances in large reasoning models (LRMs) demonstrate that sophisticated behaviors such as multi-step reasoning and self-reflection can emerge via reinforcement learning with verifiable rewards~(\textit{RLVR}). However, existing \textit{RLVR} approaches are inherently ``on-policy’’, limiting learning to a model’s own outputs and failing to acquire reasoning abilities beyond its initial capabilities. To address this issue, we introduce \textbf{LUFFY} (\textbf{L}earning to reason \textbf{U}nder o\textbf{FF}-polic\textbf{Y} guidance), a framework that augments \textit{RLVR} with off-policy reasoning traces. LUFFY dynamically balances imitation and exploration by combining off-policy demonstrations with on-policy rollouts during training. Specifically, LUFFY combines the Mixed-Policy GRPO framework, which has a theoretically guaranteed convergence rate, alongside policy shaping via regularized importance sampling to avoid superficial and rigid imitation during mixed-policy training. Compared with previous RLVR methods, LUFFY achieves an over \textbf{+6.4} average gain across six math benchmarks and an advantage of over \textbf{+6.2} points in out-of-distribution tasks. Most significantly, we show that LUFFY successfully trains weak models in scenarios where on-policy RLVR completely fails. These results provide compelling evidence that LUFFY transcends the fundamental limitations of on-policy RLVR and demonstrates the great potential of utilizing off-policy guidance in RLVR.
最近的大型推理模型(LRM)的进步表明,通过可验证奖励的强化学习,可以出现多步推理和自我反思等复杂行为(RLVR)。然而,现有的RLVR方法本质上是“基于策略的”,仅限于模型自身的输出,未能获得超出其初始能力的推理能力。为了解决这一问题,我们引入了LUFFY(在偏离策略指导下学习推理),这是一个增强RLVR的框架,配备了偏离策略的推理轨迹。LUFFY通过结合偏离策略的演示和基于策略的滚动输出,在训练过程中实现动态的模仿与探索平衡。具体来说,LUFFY结合了具有理论保证的收敛率的Mixed-Policy GRPO框架,以及通过正则化重要性采样进行策略塑造,以避免混合策略训练过程中的表面和僵化模仿。与之前的RLVR方法相比,LUFFY在六个数学基准测试上平均提高了+6.4分以上,在超出分布的任务中优势超过+6.2分。最重要的是,我们展示了LUFFY在纯基于策略的RLVR完全失败的情况下成功训练弱模型的场景。这些结果提供了强有力的证据表明,LUFFY超越了基于策略的RLVR的根本局限性,并展示了在RLVR中使用偏离策略指导的巨大潜力。
论文及项目相关链接
PDF Work in progress
Summary
大型推理模型(LRMs)的最新进展表明,通过可验证奖励的强化学习(RLVR)可以产生如多步骤推理和自我反思等复杂行为。然而,现有的RLVR方法本质上是“基于策略的”,仅限于模型自身的输出,无法获得超越初始能力的推理能力。为解决这一问题,我们提出了LUFFY框架,该框架在RLVR中加入了离策略推理轨迹。LUFFY通过结合离策略示范和基于策略的滚动来动态平衡模仿和探索。在六个数学基准测试和跨分布任务中,LUFFY相较于之前的RLVR方法平均提高了+6.4分和在超出分布任务中的优势超过+6.2分。最重要的是,我们在场景模型中展示了LUFFY如何成功地训练弱模型,而在这些场景中基于策略的RLVR完全失效。这表明LUFFY超越了基于策略的RLVR的根本局限性,并展示了在离策略指导中使用强化学习的巨大潜力。
Key Takeaways
- 大型推理模型(LRMs)可以通过强化学习(RLVR)展现复杂行为,如多步骤推理和自我反思。
- 现有RLVR方法存在局限性,仅限于模型自身输出,难以获得超越初始能力的推理能力。
- LUFFY框架通过结合离策略示范和基于策略的滚动来平衡模仿和探索。
- LUFFY实现了在六个数学基准测试和跨分布任务中的显著性能提升。
- LUFFY成功训练了弱模型,在基于策略的RLVR完全失效的场景中表现出色。
- LUFFY框架具有理论上保证的收敛率,并且可以通过正则化重要性采样进行策略塑造,以避免混合政策训练中的表面和僵化模仿。
点此查看论文截图

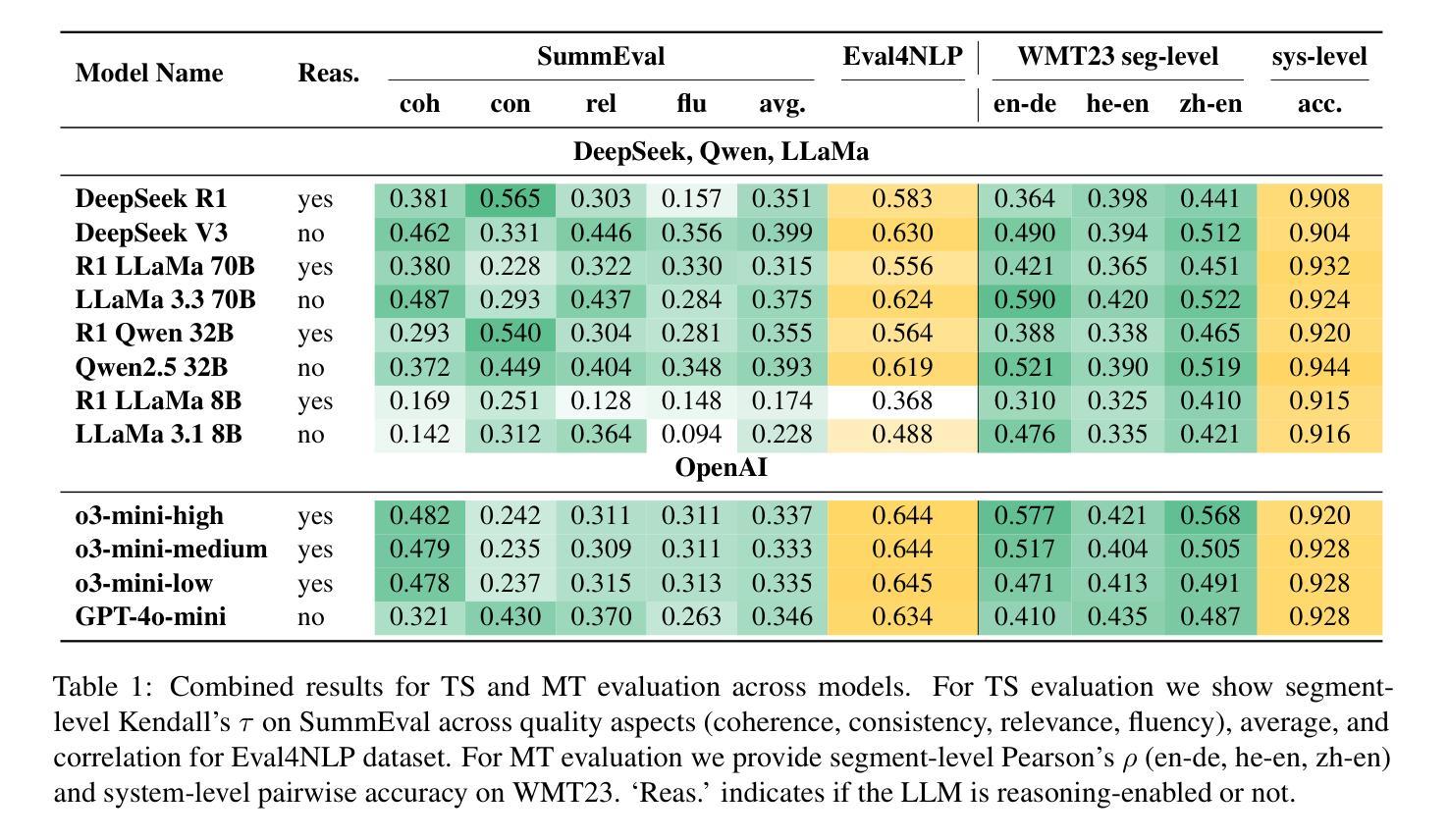
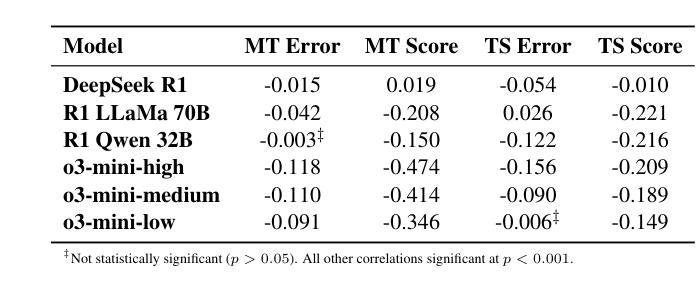
DeepSeek vs. o3-mini: How Well can Reasoning LLMs Evaluate MT and Summarization?
Authors:Daniil Larionov, Sotaro Takeshita, Ran Zhang, Yanran Chen, Christoph Leiter, Zhipin Wang, Christian Greisinger, Steffen Eger
Reasoning-enabled large language models (LLMs) excel in logical tasks, yet their utility for evaluating natural language generation remains unexplored. This study systematically compares reasoning LLMs with non-reasoning counterparts across machine translation and text summarization evaluation tasks. We evaluate eight models spanning state-of-the-art reasoning models (DeepSeek-R1, OpenAI o3), their distilled variants (8B-70B parameters), and equivalent non-reasoning LLMs. Experiments on WMT23 and SummEval benchmarks reveal architecture and task-dependent benefits: OpenAI o3-mini models show improved performance with increased reasoning on MT, while DeepSeek-R1 and generally underperforms compared to its non-reasoning variant except in summarization consistency evaluation. Correlation analysis demonstrates that reasoning token usage correlates with evaluation quality only in specific models, while almost all models generally allocate more reasoning tokens when identifying more quality issues. Distillation maintains reasonable performance up to 32B parameter models but degrades substantially at 8B scale. This work provides the first assessment of reasoning LLMs for NLG evaluation and comparison to non-reasoning models. We share our code to facilitate further research: https://github.com/NL2G/reasoning-eval.
具有推理功能的大型语言模型(LLM)在逻辑任务上表现出色,然而它们对于自然语言生成的评估的效用尚未被探索。本研究系统地比较了推理LLM与非推理LLM在机器翻译和文本摘要评估任务上的表现。我们评估了包括最新推理模型(DeepSeek-R1,OpenAI o3)、它们的蒸馏变体(参数范围从8B到70B),以及与它们等效的非推理LLM在内的八个模型。在WMT23和SummEval基准测试上的实验揭示了架构和任务依赖性的好处:OpenAI o3 mini模型在机器翻译方面的性能随着推理能力的提升而增强,而DeepSeek-R1在除了摘要一致性评估之外的任务上通常表现不如其非推理模型。相关性分析表明,推理令牌的使用仅在与特定模型的评估质量相关,而几乎所有模型在识别更多质量问题时都会分配更多的推理令牌。蒸馏技术可以在参数规模达到32B时保持合理的性能,但在8B规模时性能会大幅下降。这项工作首次对用于自然语言生成评估的推理LLM进行了评估,并将其与非推理模型进行了比较。我们分享了我们的代码,以便促进进一步的研究:https://github.com/NL2G/reasoning-eval。
论文及项目相关链接
Summary
本文研究了具备推理能力的大型语言模型(LLMs)在自然语言生成评估中的表现。文章系统性地对比了推理LLMs与非推理LLMs在机器翻译和文本摘要评估任务上的差异。实验结果显示,不同模型和任务背景下,推理能力对模型表现的影响有所不同。OpenAI o3-mini模型在机器翻译任务中展现出推理能力的提升,而DeepSeek-R1模型则在摘要一致性评估中表现相对较弱。此外,推理令牌的使用与评价质量的相关性仅在特定模型中体现,且大多数模型在识别质量问题时倾向于使用更多推理令牌。蒸馏技术能在参数规模较小的模型中保持合理性能,但在更大规模参数模型中性能下降明显。本文首次对推理LLMs进行NLG评估并与非推理模型进行比较,相关代码已公开分享,以推动进一步研究。
Key Takeaways
- 推理LLMs在自然语言生成评估中的表现被系统研究,并与非推理LLMs进行对比。
- 实验结果显示,不同模型在机器翻译和文本摘要评估任务上,推理能力的影响存在差异。
- OpenAI o3-mini模型在机器翻译任务中,推理能力提升明显。
- DeepSeek-R1模型在摘要一致性评估中表现相对较弱。
- 推理令牌的使用与评价质量的相关性仅在特定模型中体现。
- 大多数模型在识别质量问题时倾向于使用更多推理令牌。
点此查看论文截图