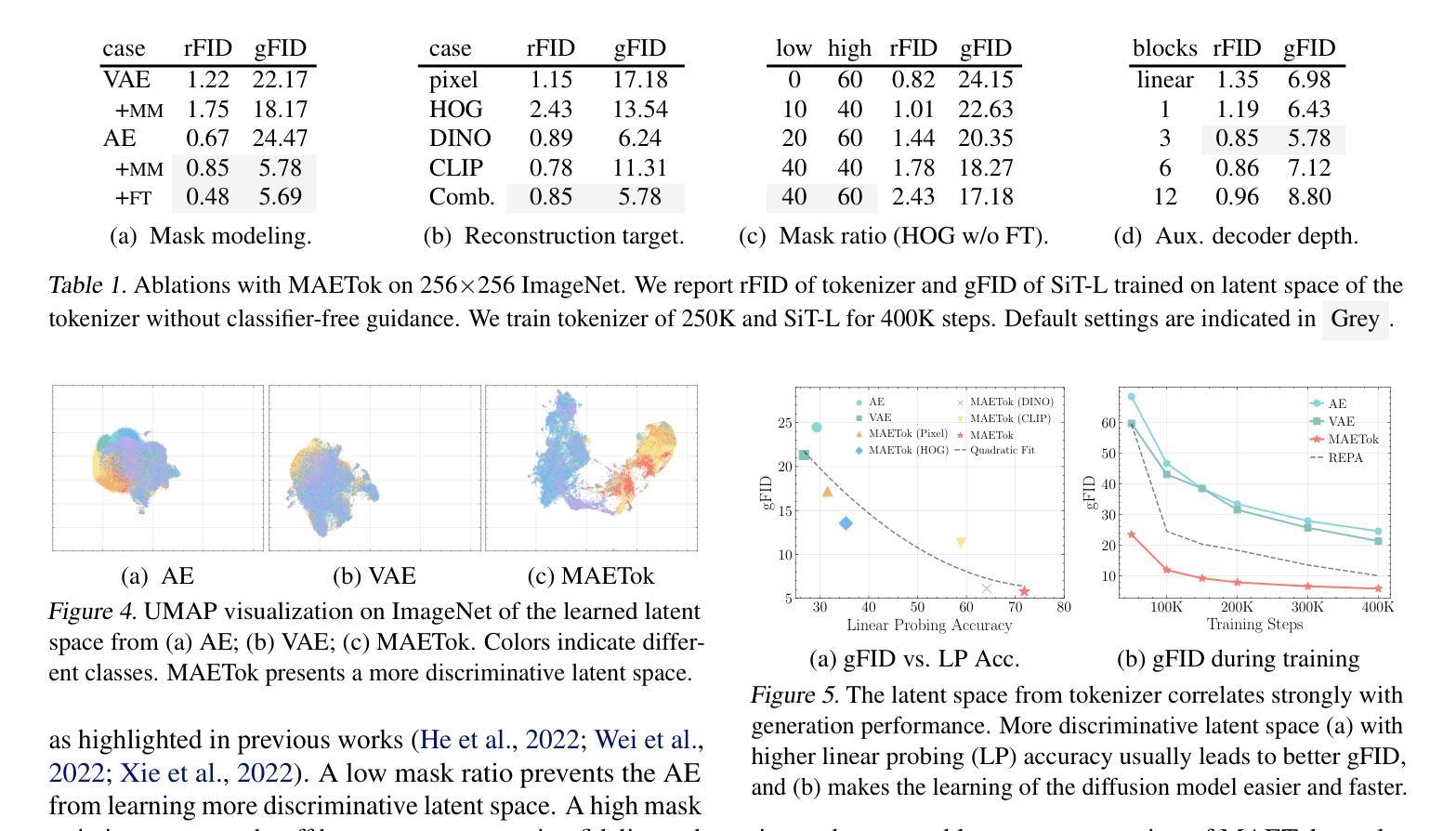
⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-03 更新
VideoCAD: A Large-Scale Video Dataset for Learning UI Interactions and 3D Reasoning from CAD Software
Authors:Brandon Man, Ghadi Nehme, Md Ferdous Alam, Faez Ahmed
Computer-Aided Design (CAD) is a time-consuming and complex process, requiring precise, long-horizon user interactions with intricate 3D interfaces. While recent advances in AI-driven user interface (UI) agents show promise, most existing datasets and methods focus on short, low-complexity tasks in mobile or web applications, failing to capture the demands of professional engineering tools. In this work, we introduce VideoCAD, the first attempt at engineering UI interaction learning for precision tasks. Specifically, VideoCAD is a large-scale synthetic dataset consisting of over 41K annotated video recordings of CAD operations, generated using an automated framework for collecting high-fidelity UI action data from human-made CAD designs. Compared to existing datasets, VideoCAD offers an order of magnitude higher complexity in UI interaction learning for real-world engineering tasks, having up to a 20x longer time horizon than other datasets. We show two important downstream applications of VideoCAD: learning UI interactions from professional precision 3D CAD tools and a visual question-answering (VQA) benchmark designed to evaluate multimodal large language models’ (LLM) spatial reasoning and video understanding abilities. To learn the UI interactions, we propose VideoCADFormer - a state-of-the-art model in learning CAD interactions directly from video, which outperforms multiple behavior cloning baselines. Both VideoCADFormer and the VQA benchmark derived from VideoCAD reveal key challenges in the current state of video-based UI understanding, including the need for precise action grounding, multi-modal and spatial reasoning, and long-horizon dependencies.
计算机辅助设计(CAD)是一个耗时且复杂的过程,需要用户与复杂的3D界面进行精确、长期的交互。尽管最近人工智能驱动的用户界面(UI)代理在人工智能领域取得了进展显示出良好的前景,但现有的大多数数据集和方法都集中在移动或Web应用程序中的简短、低复杂度的任务上,无法捕捉专业工程工具的需求。在这项工作中,我们引入了VideoCAD,这是首次尝试进行针对精确任务的工程用户界面交互学习。具体来说,VideoCAD是一个大规模合成数据集,包含超过41K个标注的CAD操作视频记录,这些记录是通过自动化框架收集人为设计的CAD界面的高保真UI动作数据生成的。与现有数据集相比,VideoCAD在针对现实世界工程任务的UI交互学习方面提供了更高复杂度的数据,时间跨度是其他数据集的20倍。我们展示了VideoCAD的两个重要下游应用:从专业的精密三维CAD工具学习UI交互以及设计用于评估多模态大型语言模型(LLM)空间推理和视频理解能力视觉问答(VQA)基准测试。为了学习UI交互,我们提出了VideoCADFormer——一个直接从视频学习CAD交互的最先进模型,它超越了多个行为克隆基准测试。VideoCADFormer以及从VideoCAD衍生的VQA基准测试揭示了当前视频型用户界面理解的关键挑战,包括精确动作定位的需求、多模态和空间推理以及长期依赖关系。
论文及项目相关链接
摘要
本文介绍了VideoCAD,一个为精密任务设计的工程用户界面交互学习数据集。VideoCAD包含超过41K个标注的CAD操作视频记录,通过自动化框架从人工设计的CAD中收集高保真UI动作数据。相较于现有数据集,VideoCAD在现实世界工程任务的UI交互学习中具有更高的复杂性,时间跨度是其他数据集的20倍。本文展示了VideoCAD的两个重要应用:从专业精密3D CAD工具学习UI交互和一个旨在评估多模态大型语言模型的空间推理和视频理解能力的视觉问答基准测试。为了学习UI交互,我们提出了VideoCADFormer,一个直接从视频学习CAD交互的先进模型,超越了多个行为克隆基线。VideoCAD和VideoCADFormer衍生的VQA基准测试揭示了当前视频型UI理解的主要挑战,包括精确动作定位、多模态和空间推理以及长周期依赖等。
关键见解
- VideoCAD是首个针对精密任务设计的工程用户界面交互学习数据集。
- VideoCAD包含超过41K个标注的CAD操作视频,复杂性显著高于现有数据集。
- VideoCAD数据集适用于从专业精密3D CAD工具学习UI交互。
- VideoCAD为视觉问答任务提供了一个基准测试,评估多模态大型语言模型的空间推理和视频理解能力。
- VideoCAD提出了精确动作定位的需求,要求模型能够理解复杂的用户操作。
- 当前视频型UI理解的挑战包括多模态和空间推理。
点此查看论文截图


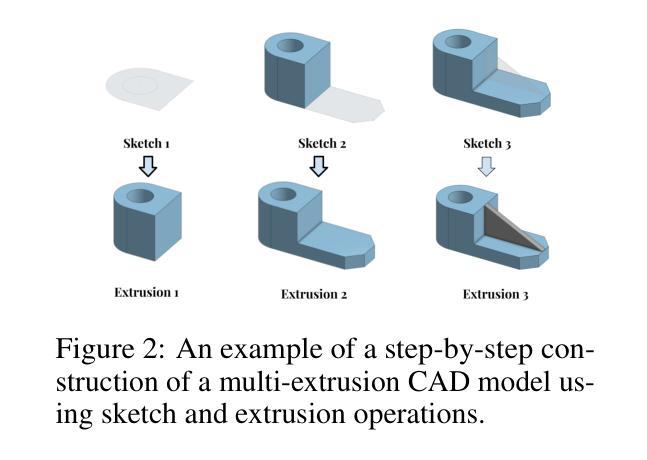
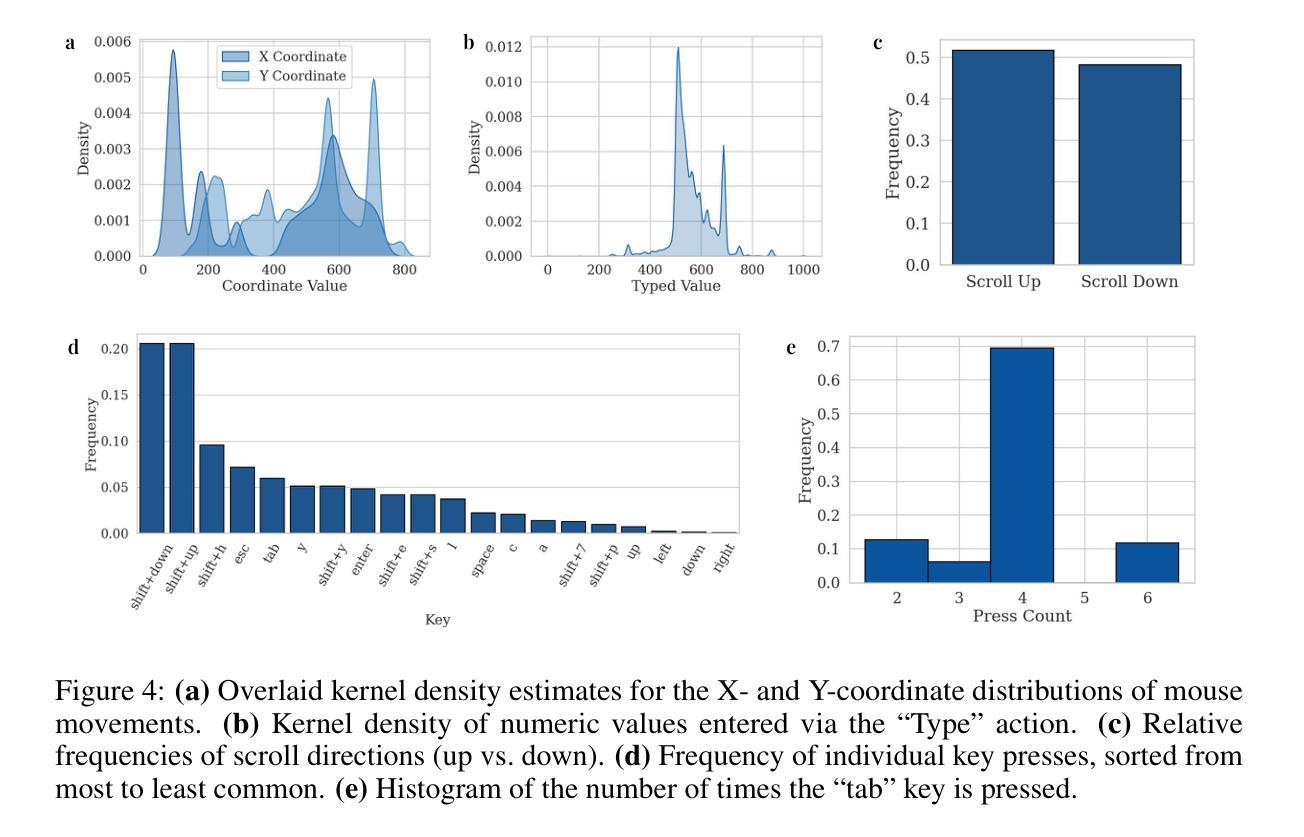
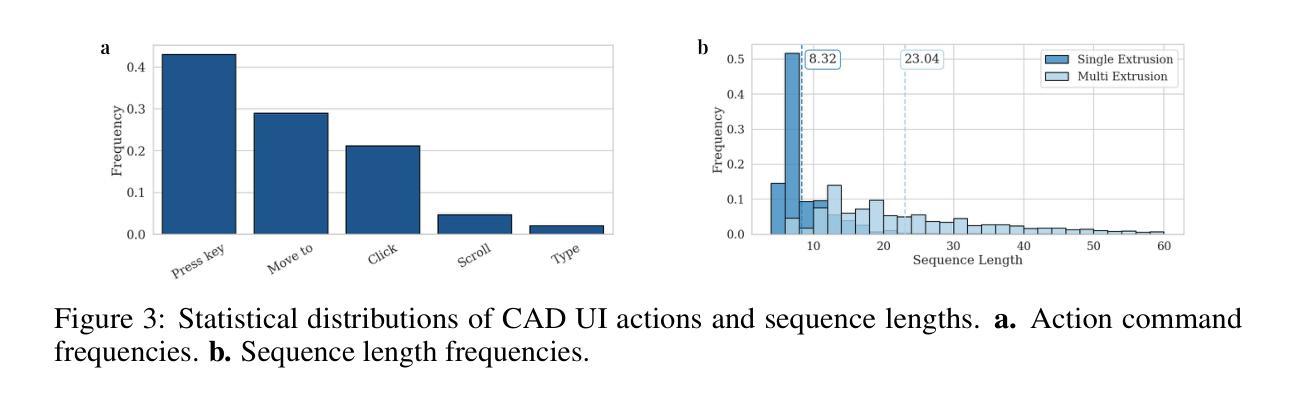
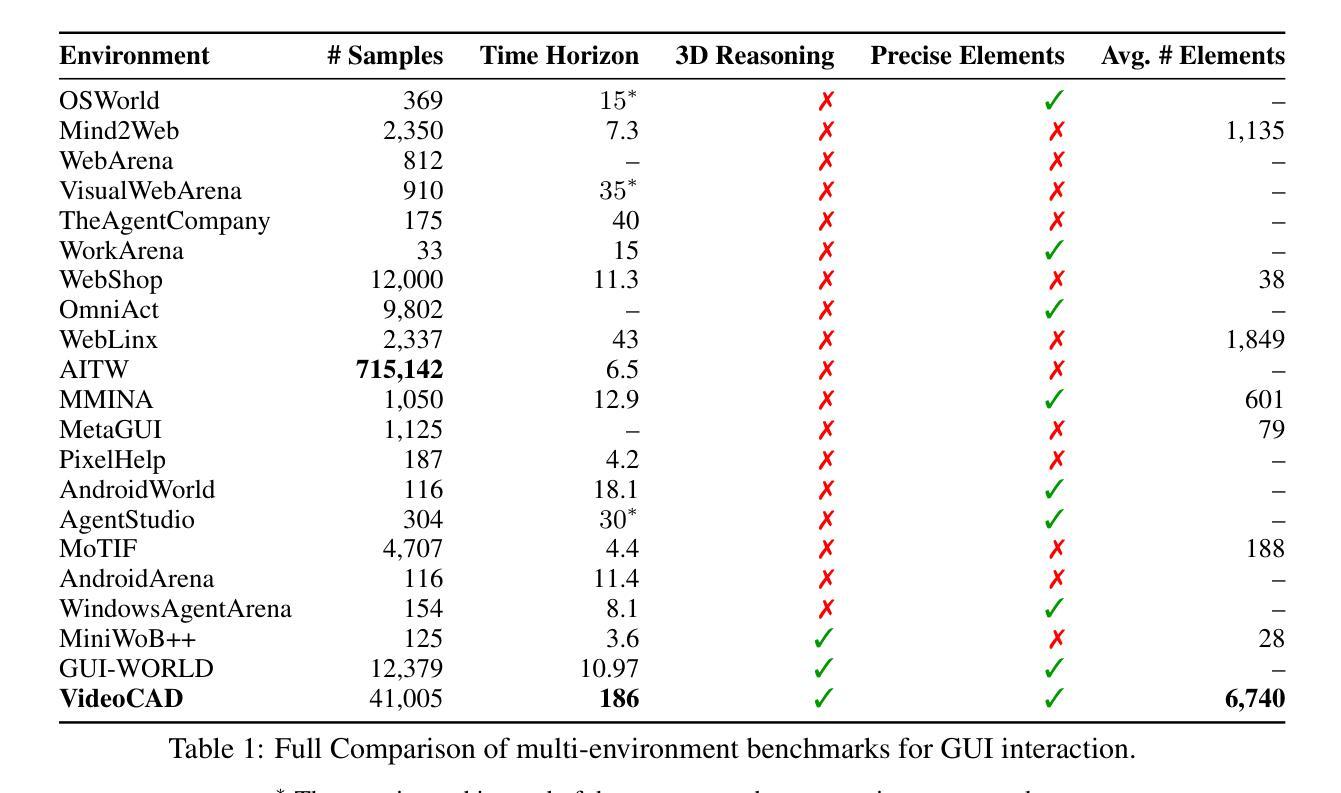
AFIRE: Accurate and Fast Image Reconstruction Algorithm for Geometric-inconsistency Multispectral CT
Authors:Yu Gao, Chong Chen
For nonlinear multispectral computed tomography (CT), accurate and fast image reconstruction is challenging when the scanning geometries under different X-ray energy spectra are inconsistent or mismatched. Motivated by this, we propose an accurate and fast algorithm named AFIRE to address such problem in the case of mildly full scan. We discover that the derivative operator (gradient) of the involved nonlinear mapping at some special points, for example, at zero, can be represented as a composition (block multiplication) of a diagonal operator (matrix) composed of X-ray transforms (projection matrices) and a very small-scale matrix. Based on the insights, the AFIRE is proposed respectively from the continuous, discrete and actual-use perspectives by leveraging the simplified Newton method. Under proper conditions, we establish the convergence theory of the proposed algorithm. Furthermore, numerical experiments are also carried out to verify that the proposed algorithm can accurately and effectively reconstruct the basis images in completely geometric-inconsistency dual-energy CT with noiseless and noisy projection data. Particularly, the proposed algorithm significantly outperforms some state-of-the-art methods in terms of accuracy and efficiency. Finally, the flexibility and extensibility of the proposed algorithm are also demonstrated.
对于非线性多光谱计算机断层扫描(CT),当不同X射线能量谱下的扫描几何结构不一致或不匹配时,实现准确快速的图像重建是一个挑战。基于此,我们提出了一种准确快速的算法,名为AFIRE,以解决轻微全扫描情况下的此类问题。我们发现,所涉及非线性映射的导数算子(梯度)在某些特殊点,例如在零点上,可以表示为对角线算子(由X射线变换(投影矩阵)组成的矩阵)和一个小规模矩阵的乘积(块组合)。基于这些见解,利用简化牛顿法分别从连续、离散和实际使用三个角度提出了AFIRE算法。在适当的条件下,我们建立了所提出算法的收敛理论。此外,还进行了数值实验,验证了所提算法在几何完全不一致的双能CT中,能准确有效地重建基础图像,且对于无噪声和有噪声的投影数据均有效。特别地,所提算法在准确性和效率方面显著优于一些最先进的方法。最后,所提算法的灵活性和可扩展性也得到了证明。
论文及项目相关链接
PDF 36 pages, 15 figures, 1 table
Summary
针对非线性多光谱计算机断层扫描(CT),当不同X射线能量光谱下的扫描几何体不一致或不匹配时,实现准确快速图像重建具有挑战性。为此,我们提出了一种名为AFIRE的精准快速算法,该算法在轻微全扫描的情况下解决了这一问题。该算法基于特殊点(如零点)非线性映射的导数运算符(梯度)可以被表示为对角运算符(由X射线变换(投影矩阵)组成的小规模矩阵的块乘法)的见解。结合连续、离散和实际使用等角度,利用简化牛顿法提出了AFIRE算法。在适当的条件下,我们建立了该算法的收敛理论。数值实验验证了该算法在完全几何不一致的双能CT的无噪声和有噪声投影数据中能精准有效地重建基础图像。特别是,该算法在准确性和效率方面显著优于一些最先进的方法。最后,展示了该算法的灵活性和可扩展性。
Key Takeaways
- 非线性多光谱CT在扫描几何不一致时面临准确快速图像重建的挑战。
- 提出了名为AFIRE的精准快速算法,用于解决轻微全扫描情况下的这一问题。
- AFIRE算法基于特殊点非线性映射的导数运算符的见解。
- 该算法结合连续、离散和实际使用等角度提出,利用简化牛顿法。
- 在适当的条件下,建立了AFIRE算法的收敛理论。
- 数值实验验证了AFIRE在双能CT中的精准重建能力,无论是无噪声还是有噪声的情况。
点此查看论文截图

Contrast-Invariant Self-supervised Segmentation for Quantitative Placental MRI
Authors:Xinliu Zhong, Ruiying Liu, Emily S. Nichols, Xuzhe Zhang, Andrew F. Laine, Emma G. Duerden, Yun Wang
Accurate placental segmentation is essential for quantitative analysis of the placenta. However, this task is particularly challenging in T2*-weighted placental imaging due to: (1) weak and inconsistent boundary contrast across individual echoes; (2) the absence of manual ground truth annotations for all echo times; and (3) motion artifacts across echoes caused by fetal and maternal movement. In this work, we propose a contrast-augmented segmentation framework that leverages complementary information across multi-echo T2*-weighted MRI to learn robust, contrast-invariant representations. Our method integrates: (i) masked autoencoding (MAE) for self-supervised pretraining on unlabeled multi-echo slices; (ii) masked pseudo-labeling (MPL) for unsupervised domain adaptation across echo times; and (iii) global-local collaboration to align fine-grained features with global anatomical context. We further introduce a semantic matching loss to encourage representation consistency across echoes of the same subject. Experiments on a clinical multi-echo placental MRI dataset demonstrate that our approach generalizes effectively across echo times and outperforms both single-echo and naive fusion baselines. To our knowledge, this is the first work to systematically exploit multi-echo T2*-weighted MRI for placental segmentation.
准确的胎盘分割对于胎盘的定量分析至关重要。然而,由于T2*-加权胎盘成像的以下特点,这一任务特别具有挑战性:(1)各个回声之间的边界对比度较弱且不一致;(2)所有回声时间均没有手动真实标注;(3)由于胎儿和母亲的移动,各回声间存在运动伪影。在这项工作中,我们提出了一种对比增强分割框架,该框架利用多回声T2*-加权MRI中的互补信息来学习稳健、对比不变的表示。我们的方法集成了:(i)用于在无标签的多回声切片上进行自监督预训练的面罩自动编码(MAE);(ii)用于不同回声时间进行无监督域自适应的面罩伪标签(MPL);(iii)全局-局部协作以对精细特征进行全局解剖上下文对齐。我们还引入了一种语义匹配损失,以鼓励同一受试者不同回声之间的表示一致性。在临床医学多回声胎盘MRI数据集上的实验表明,我们的方法能够在不同回声时间之间进行有效的泛化,并且优于单回声和简单的融合基线。据我们所知,这是首次系统地利用多回声T2*-加权MRI进行胎盘分割的研究。
论文及项目相关链接
PDF 8 pages, 20 figures
Summary
准确进行胎盘分割对于胎盘定量分析至关重要。在T2*-加权胎盘成像中,由于边界对比度弱、不同回声间缺乏手动真实标注以及胎儿和母体运动引起的运动伪影,这一任务特别具有挑战性。本研究提出了一种对比增强分割框架,该框架利用多回声T2*-加权MRI中的互补信息来学习稳健、对比不变的表示。该方法结合了:i)掩码自动编码(MAE)用于在无标签的多回声切片上进行自监督预训练;ii)掩码伪标签(MPL)用于不同回声时间的无监督域自适应;iii)全局局部协作以将精细特征与全局解剖上下文对齐。此外,引入了语义匹配损失,以鼓励同一受试者不同回声之间的表示一致性。在临床试验多回声胎盘MRI数据集上的实验表明,该方法在不同回声时间之间具有良好的泛化能力,并优于单回声和简单融合基线。据我们所知,这是首次系统地利用多回声T2*-加权MRI进行胎盘分割的研究。
Key Takeaways
- 准确胎盘分割对胎盘定量分析至关重要。
- T2*-加权胎盘成像中的胎盘分割具有挑战性,主要由于边界对比度弱、缺乏真实标注和运动伪影。
- 研究提出了一种对比增强分割框架,利用多回声T2*-加权MRI中的信息。
- 该框架结合掩码自动编码(MAE)进行自监督预训练,掩码伪标签(MPL)进行域自适应以及全局局部协作。
- 语义匹配损失被引入以确保不同回声间的表示一致性。
- 实验证明该方法在不同回声时间之间具有良好的泛化能力。
- 该研究是首次系统地利用多回声T2*-加权MRI进行胎盘分割。
点此查看论文截图

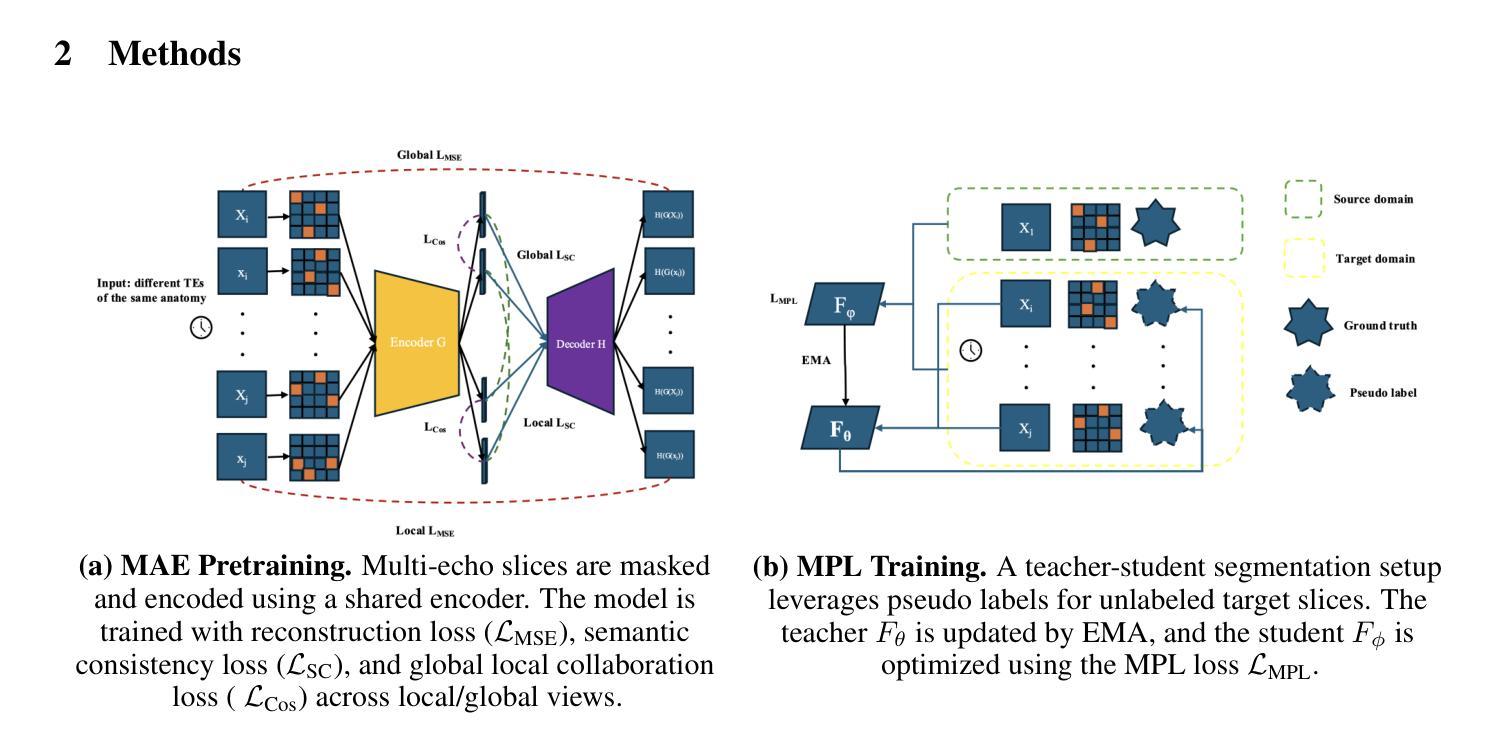
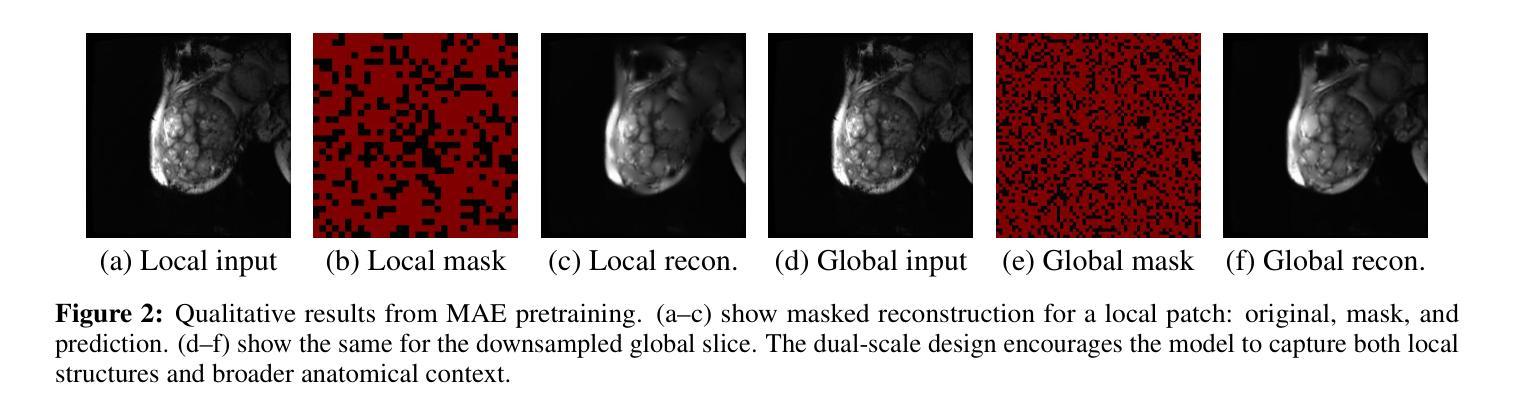
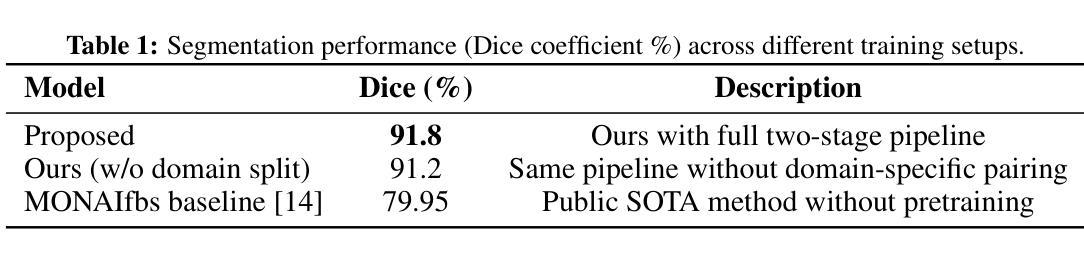
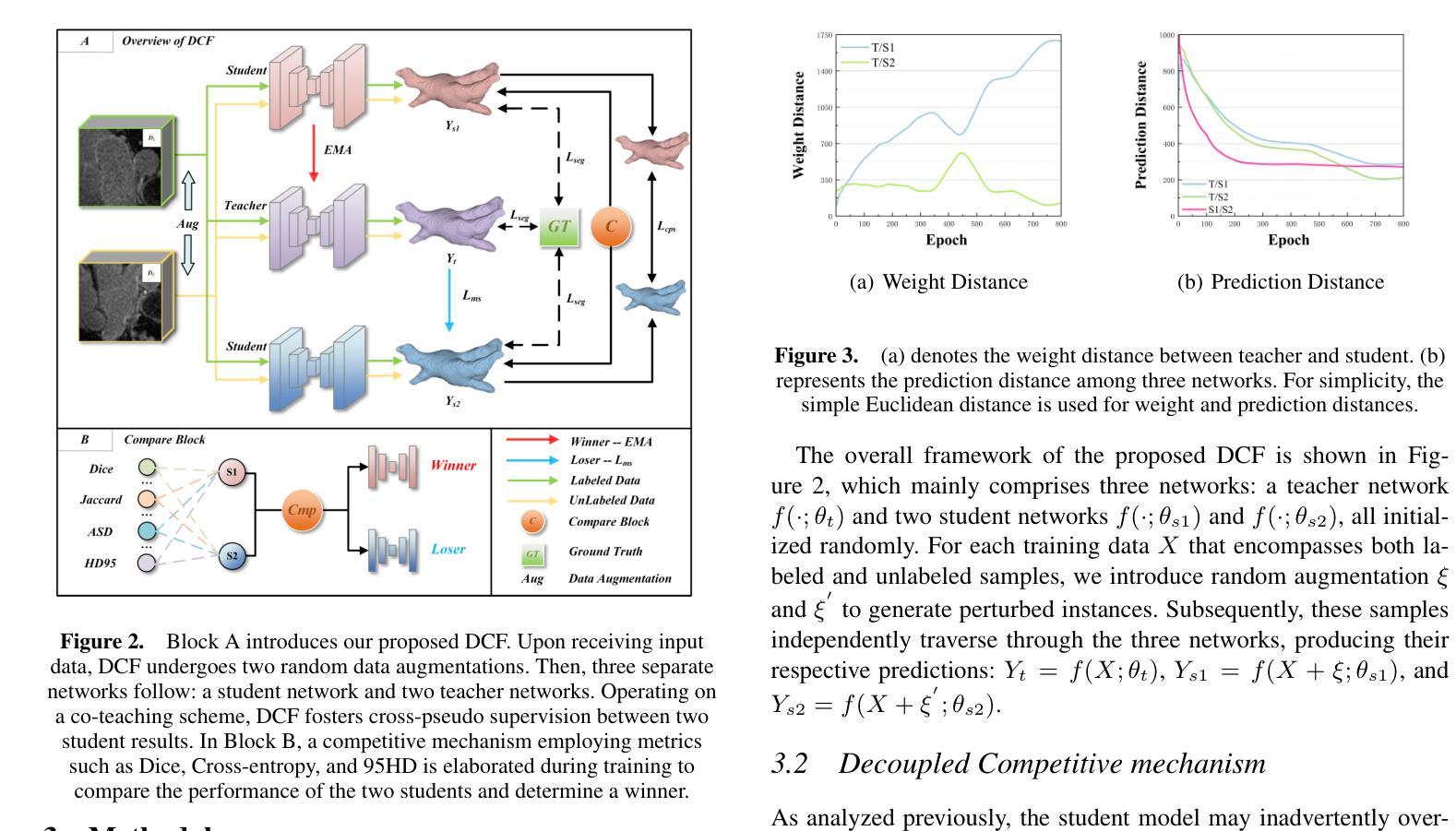
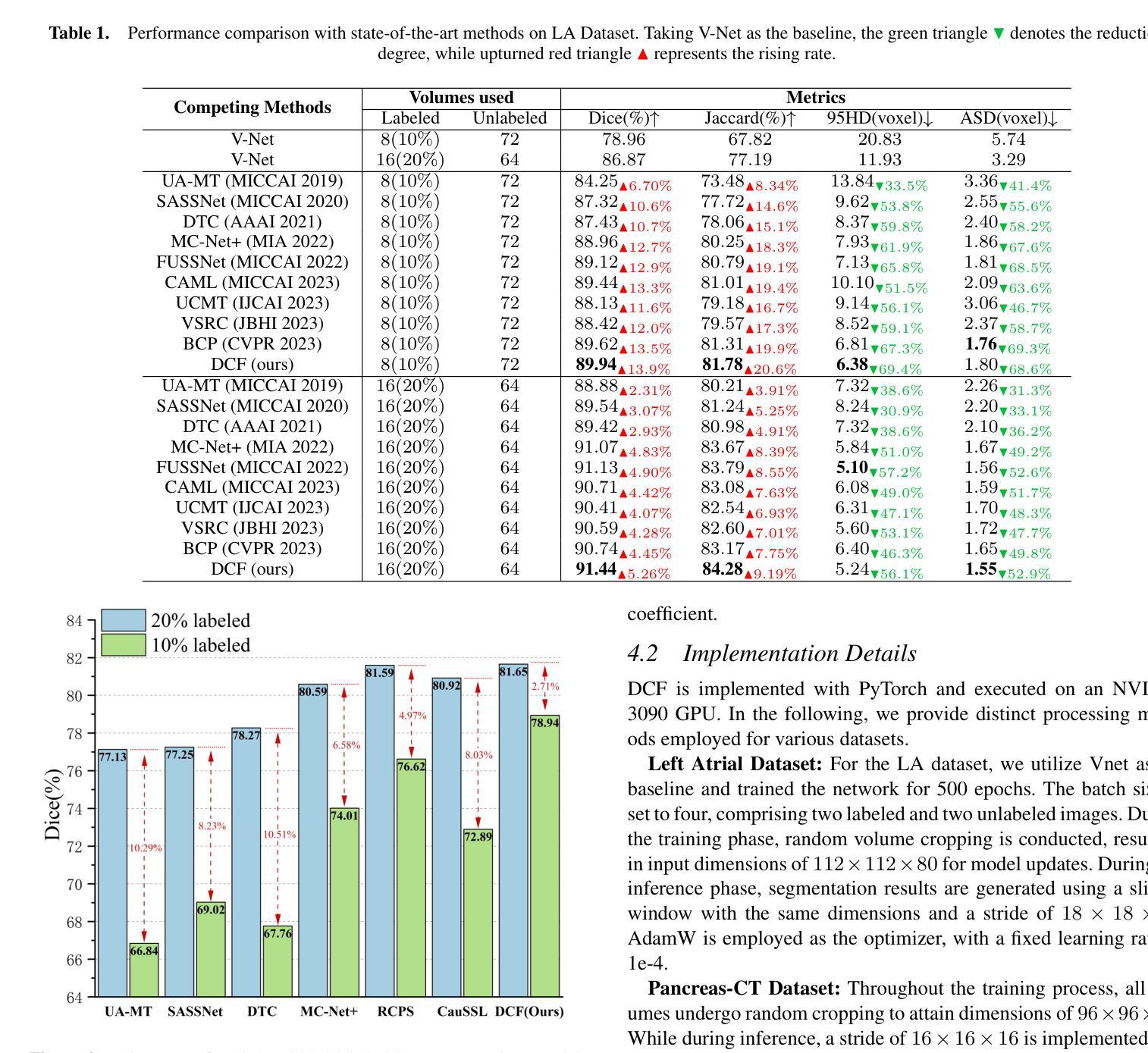
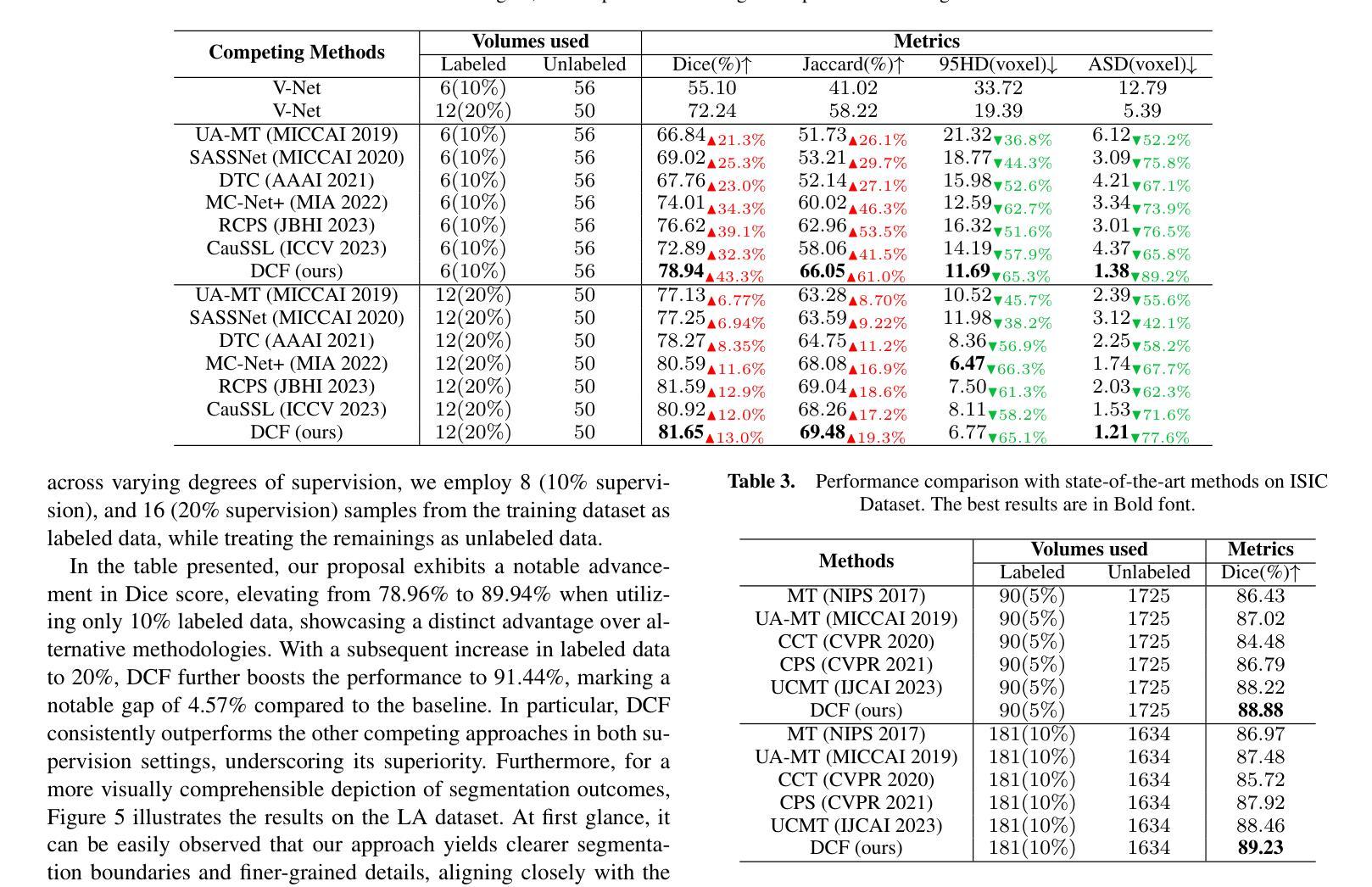
Decoupled Competitive Framework for Semi-supervised Medical Image Segmentation
Authors:Jiahe Chen, Jiahe Ying, Shen Wang, Jianwei Zheng
Confronting the critical challenge of insufficiently annotated samples in medical domain, semi-supervised medical image segmentation (SSMIS) emerges as a promising solution. Specifically, most methodologies following the Mean Teacher (MT) or Dual Students (DS) architecture have achieved commendable results. However, to date, these approaches face a performance bottleneck due to two inherent limitations, \textit{e.g.}, the over-coupling problem within MT structure owing to the employment of exponential moving average (EMA) mechanism, as well as the severe cognitive bias between two students of DS structure, both of which potentially lead to reduced efficacy, or even model collapse eventually. To mitigate these issues, a Decoupled Competitive Framework (DCF) is elaborated in this work, which utilizes a straightforward competition mechanism for the update of EMA, effectively decoupling students and teachers in a dynamical manner. In addition, the seamless exchange of invaluable and precise insights is facilitated among students, guaranteeing a better learning paradigm. The DCF introduced undergoes rigorous validation on three publicly accessible datasets, which encompass both 2D and 3D datasets. The results demonstrate the superiority of our method over previous cutting-edge competitors. Code will be available at https://github.com/JiaheChen2002/DCF.
面对医学领域标注样本不足的关键挑战,半监督医学图像分割(SSMIS)作为一种有前途的解决方案而出现。具体来说,大多数遵循Mean Teacher(MT)或Dual Students(DS)架构的方法都取得了值得赞扬的结果。然而,迄今为止,这些方法由于两个固有局限而面临性能瓶颈,例如MT结构内的过度耦合问题,这是由于采用了指数移动平均(EMA)机制,以及DS结构中的两个学生之间严重的认知偏差。这两个问题都可能导致效率降低,甚至最终导致模型崩溃。为了缓解这些问题,本文详细阐述了一个解耦竞争框架(DCF),该框架利用简单的竞争机制来更新EMA,以动态的方式有效地将学生和教师解耦。此外,学生之间促进了宝贵而精确见解的无缝交流,保证了更好的学习范式。DCF在三个公开数据集上进行了严格验证,包括2D和3D数据集。结果表明,我们的方法优于之前的尖端竞争对手。代码将在https://github.com/JiaheChen2002/DCF上提供。
论文及项目相关链接
PDF Published in ECAI 2024
Summary
半监督医学图像分割(SSMIS)面临缺乏标注样本的挑战,Mean Teacher(MT)和Dual Students(DS)架构的方法虽取得一定成果,但存在性能瓶颈。本文提出一种Decoupled Competitive Framework(DCF)框架,利用竞争机制更新EMA,动态解耦学生和教师,并在学生间进行有价值的信息交换,保证更好的学习模式。在三个公开数据集上的实验结果表明,该方法优于前沿竞品。
Key Takeaways
- 半监督医学图像分割(SSMIS)是应对医学领域标注样本不足的有力解决方案。
- 当前主流的Mean Teacher(MT)和Dual Students(DS)架构方法存在性能瓶颈。
- Decoupled Competitive Framework(DCF)框架被提出以解决MT和DS的问题。
- DCF利用竞争机制更新EMA,有效解耦学生和教师。
- DCF框架在学生间进行有价值的信息交换,保证更好的学习模式。
- DCF在三个公开数据集上的实验结果表明其优越性。
点此查看论文截图

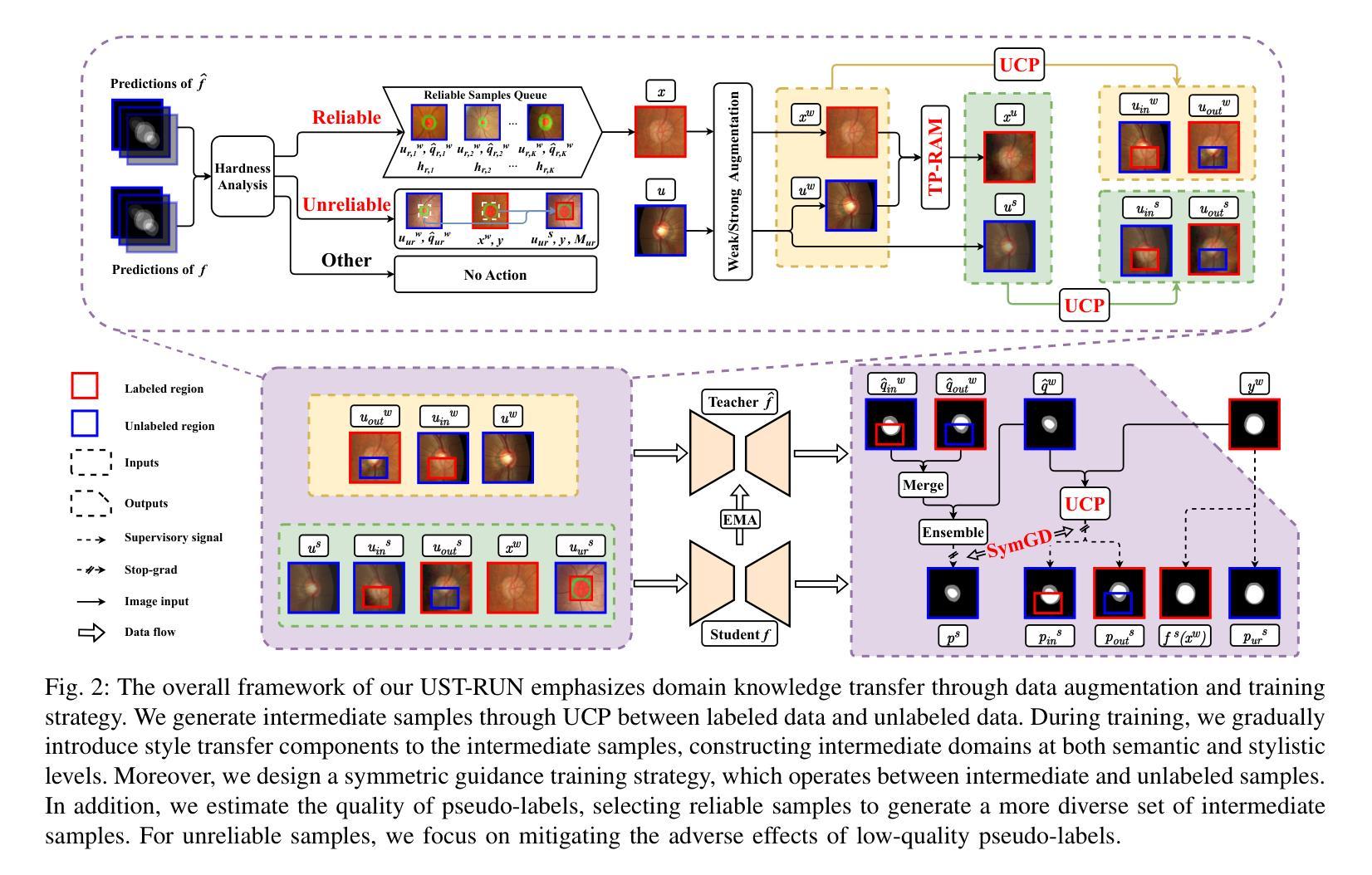
Unleashing the Power of Intermediate Domains for Mixed Domain Semi-Supervised Medical Image Segmentation
Authors:Qinghe Ma, Jian Zhang, Lei Qi, Qian Yu, Yinghuan Shi, Yang Gao
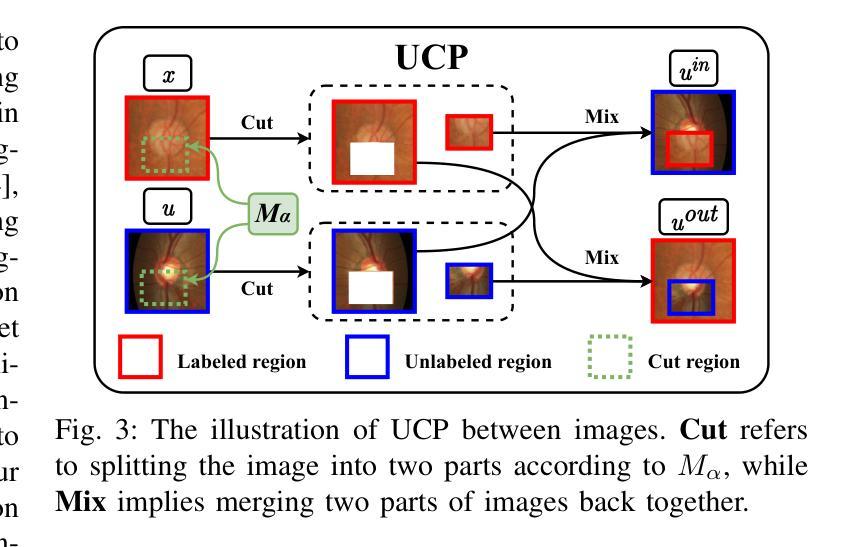
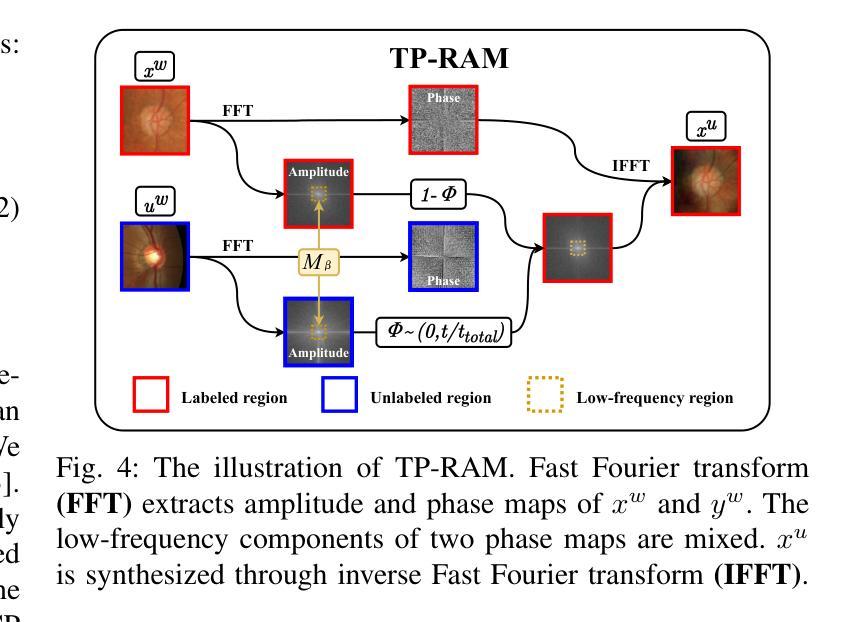
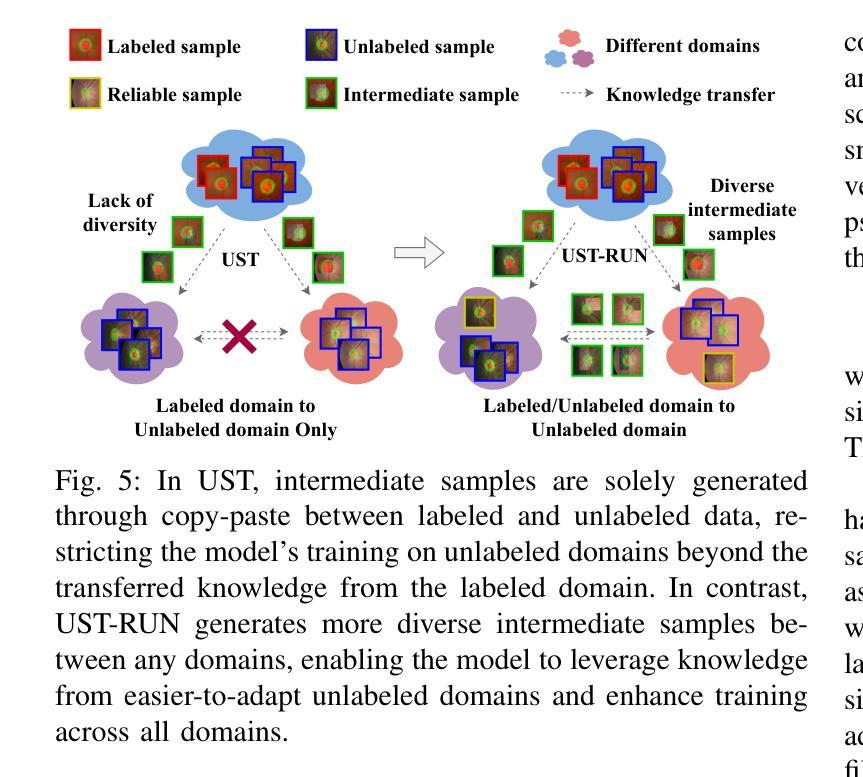
Both limited annotation and domain shift are prevalent challenges in medical image segmentation. Traditional semi-supervised segmentation and unsupervised domain adaptation methods address one of these issues separately. However, the coexistence of limited annotation and domain shift is quite common, which motivates us to introduce a novel and challenging scenario: Mixed Domain Semi-supervised medical image Segmentation (MiDSS), where limited labeled data from a single domain and a large amount of unlabeled data from multiple domains. To tackle this issue, we propose the UST-RUN framework, which fully leverages intermediate domain information to facilitate knowledge transfer. We employ Unified Copy-paste (UCP) to construct intermediate domains, and propose a Symmetric GuiDance training strategy (SymGD) to supervise unlabeled data by merging pseudo-labels from intermediate samples. Subsequently, we introduce a Training Process aware Random Amplitude MixUp (TP-RAM) to progressively incorporate style-transition components into intermediate samples. To generate more diverse intermediate samples, we further select reliable samples with high-quality pseudo-labels, which are then mixed with other unlabeled data. Additionally, we generate sophisticated intermediate samples with high-quality pseudo-labels for unreliable samples, ensuring effective knowledge transfer for them. Extensive experiments on four public datasets demonstrate the superiority of UST-RUN. Notably, UST-RUN achieves a 12.94% improvement in Dice score on the Prostate dataset. Our code is available at https://github.com/MQinghe/UST-RUN
在医学图像分割中,标注数据有限和领域偏移是两个普遍存在的挑战。传统的半监督分割和无监督领域适应方法分别解决这些问题中的一个。然而,标注数据有限和领域偏移的共存是相当常见的,这促使我们引入一种新颖且具挑战性的场景:混合领域半监督医学图像分割(MiDSS),其中涉及单个领域的有限标注数据和多个领域的大量未标注数据。为了解决这个问题,我们提出了UST-RUN框架,该框架充分利用中间领域信息来促进知识转移。我们采用统一复制粘贴(UCP)来构建中间领域,并提出对称引导训练策略(SymGD)来通过合并中间样本的伪标签来监督未标注数据。随后,我们引入了一个训练过程感知随机幅度混合(TP-RAM),以逐步将风格转换组件融入中间样本。为了生成更多样化的中间样本,我们进一步选择具有高质量伪标签的可靠样本,并将其与其他未标注数据混合。此外,我们还为不可靠的样本生成具有高质量伪标签的精细中间样本,以确保对它们进行有效的知识转移。在四个公共数据集上的大量实验证明了UST-RUN的优越性。值得注意的是,UST-RUN在前列腺数据集上的Dice得分提高了1 结题主要围绕医学图像分割领域中标注数据有限和领域偏移这两个挑战展开。传统方法往往只能单独解决其中一个问题,而我们的UST-RUN框架则能同时应对这两个挑战。通过构建中间领域、利用对称引导训练策略以及引入随机幅度混合等技术手段,我们的框架在多个公共数据集上取得了显著的优势。特别是在前列腺数据集上,Dice得分提高了高达 十二分之一点九四 。我们的代码已发布在 https://github.com/MQinghe/UST-RUN 供大家参考和使用。
论文及项目相关链接
PDF Accepted by IEEE TMI 2025. arXiv admin note: text overlap with arXiv:2404.08951
Summary
医学图像分割面临有限标注和领域差异两大挑战。传统半监督分割和无监督域适应方法通常单独解决这些问题。然而,当这两个问题同时存在时,引入了一种新的场景:混合域半监督医学图像分割(MiDSS),其中涉及单一领域的有限标注数据以及多个领域的大量无标注数据。针对这一问题,我们提出了UST-RUN框架,该框架充分利用中间域信息促进知识转移。我们采用统一复制粘贴(UCP)技术构建中间域,并提出对称引导训练策略(SymGD)来通过中间样本的伪标签来监督无标注数据。此外,我们还引入了训练过程感知随机幅度混合(TP-RAM),逐步将风格转换组件融入中间样本。为了生成更多样化的中间样本,我们进一步选择高质量的伪标签样本,并将其与其他无标注数据混合。同时,我们还为不可靠的样本生成高质量的伪标签样本,确保它们的知识转移有效。在四个公共数据集上的实验证明了UST-RUN的优越性,特别是在前列腺数据集上,Dice得分提高了12.94%。
Key Takeaways
- 医学图像分割面临有限标注和领域差异的挑战。
- 传统方法通常单独解决这些问题,但MiDSS场景中存在两者的结合。
- UST-RUN框架被提出以应对这种场景,充分利用中间域信息。
- UCP用于构建中间域,SymGD用于监督无标注数据。
- TP-RAM逐步融入风格转换组件到中间样本中。
- 选择高质量的伪标签样本与其他无标注数据混合,提高样本多样性。
点此查看论文截图


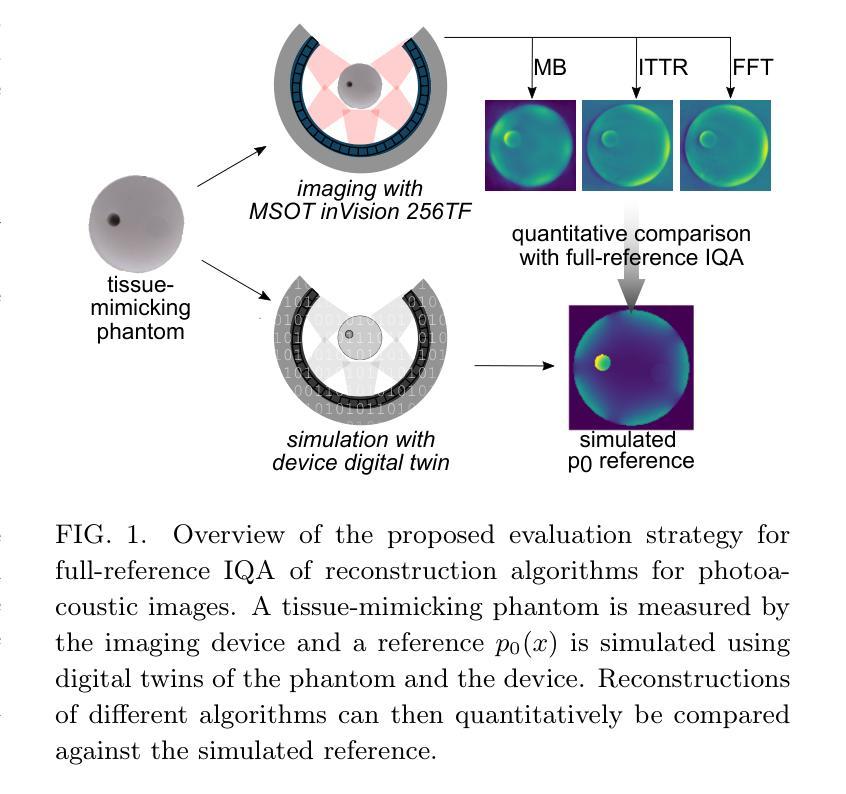
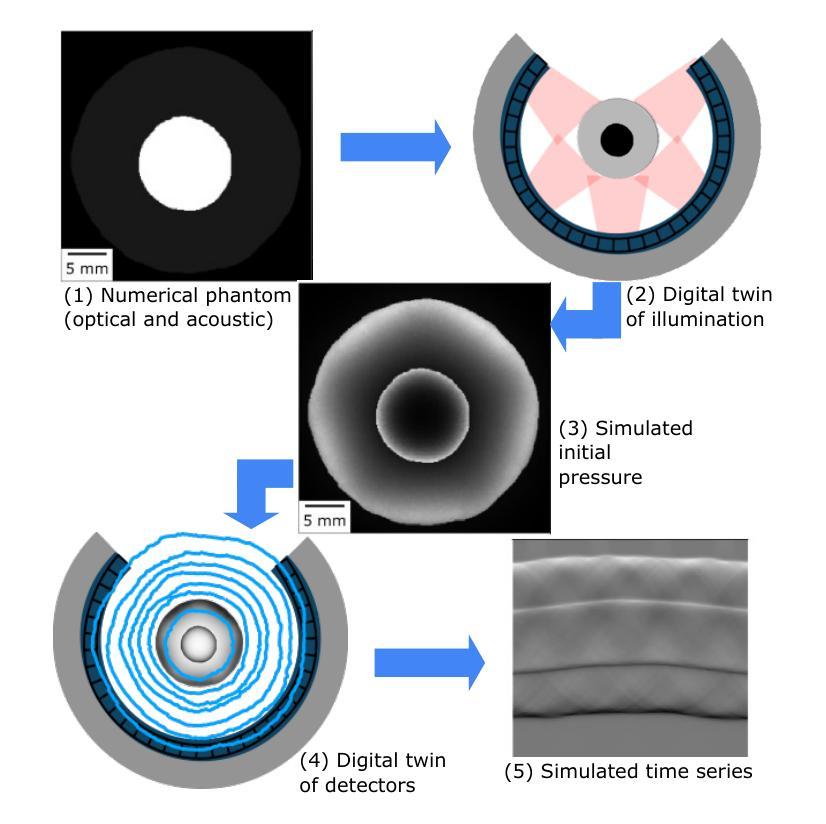
Digital twins enable full-reference quality assessment of photoacoustic image reconstructions
Authors:Janek Gröhl, Leonid Kunyansky, Jenni Poimala, Thomas R. Else, Francesca Di Cecio, Sarah E. Bohndiek, Ben T. Cox, Andreas Hauptmann
Quantitative comparison of the quality of photoacoustic image reconstruction algorithms remains a major challenge. No-reference image quality measures are often inadequate, but full-reference measures require access to an ideal reference image. While the ground truth is known in simulations, it is unknown in vivo, or in phantom studies, as the reference depends on both the phantom properties and the imaging system. We tackle this problem by using numerical digital twins of tissue-mimicking phantoms and the imaging system to perform a quantitative calibration to reduce the simulation gap. The contributions of this paper are two-fold: First, we use this digital-twin framework to compare multiple state-of-the-art reconstruction algorithms. Second, among these is a Fourier transform-based reconstruction algorithm for circular detection geometries, which we test on experimental data for the first time. Our results demonstrate the usefulness of digital phantom twins by enabling assessment of the accuracy of the numerical forward model and enabling comparison of image reconstruction schemes with full-reference image quality assessment. We show that the Fourier transform-based algorithm yields results comparable to those of iterative time reversal, but at a lower computational cost. All data and code are publicly available on Zenodo: https://doi.org/10.5281/zenodo.15388429.
对于光声图像重建算法质量的定量比较仍然是一个主要挑战。无参考图像质量评估措施往往不足,而全参考措施则需要理想的参考图像。虽然模拟中的真实情况已知,但在真实生物体内或幻影研究中的真实情况未知,因为参考情况既取决于幻影的特性也取决于成像系统。我们通过使用组织模拟幻影和成像系统的数字双胞胎进行定量校准来解决这个问题,以缩小模拟差距。本文的贡献有两方面:首先,我们使用数字双胞胎框架来比较多个最新重建算法。其次,其中一个是基于傅里叶变换的圆形检测几何重建算法,我们首次将其测试在真实数据上。我们的结果证明了数字双胞胎幻影的实用性,可以通过评估数值前向模型的准确性来比较图像重建方案与全参考图像质量评估。我们表明,基于傅里叶变换的算法的结果与迭代时间反转的结果相当,但计算成本更低。所有数据和代码已在Zenodo上公开可用:https://doi.org/10.5281/zenodo.15388429。
论文及项目相关链接
Summary
本文利用数字双胞胎框架对多种先进的图像重建算法进行比较,其中首次在实验数据上测试了基于傅里叶变换的重建算法。该研究解决了无参考图像质量评估的局限性,通过数字双胞胎技术对成像系统进行定量校准,减少模拟差距。结果表明,基于傅里叶变换的算法虽然计算成本较低,但结果可与迭代时间反转相比。所有数据和方法在Zenodo公开可用。
Key Takeaways
- 定量比较光声图像重建算法的质量仍是主要挑战。
- 无参考图像质量评估措施通常不足,而全参考措施需要理想参考图像。
- 数字化双胞胎框架用于比较多种先进的图像重建算法。
- 基于傅里叶变换的重建算法在模拟和实验数据上进行了测试。
- 数字双胞胎技术解决了模拟差距问题,可通过定量校准对成像系统进行评估。
- 基于傅里叶变换的算法结果与迭代时间反转相比具有竞争力,但计算成本较低。
点此查看论文截图

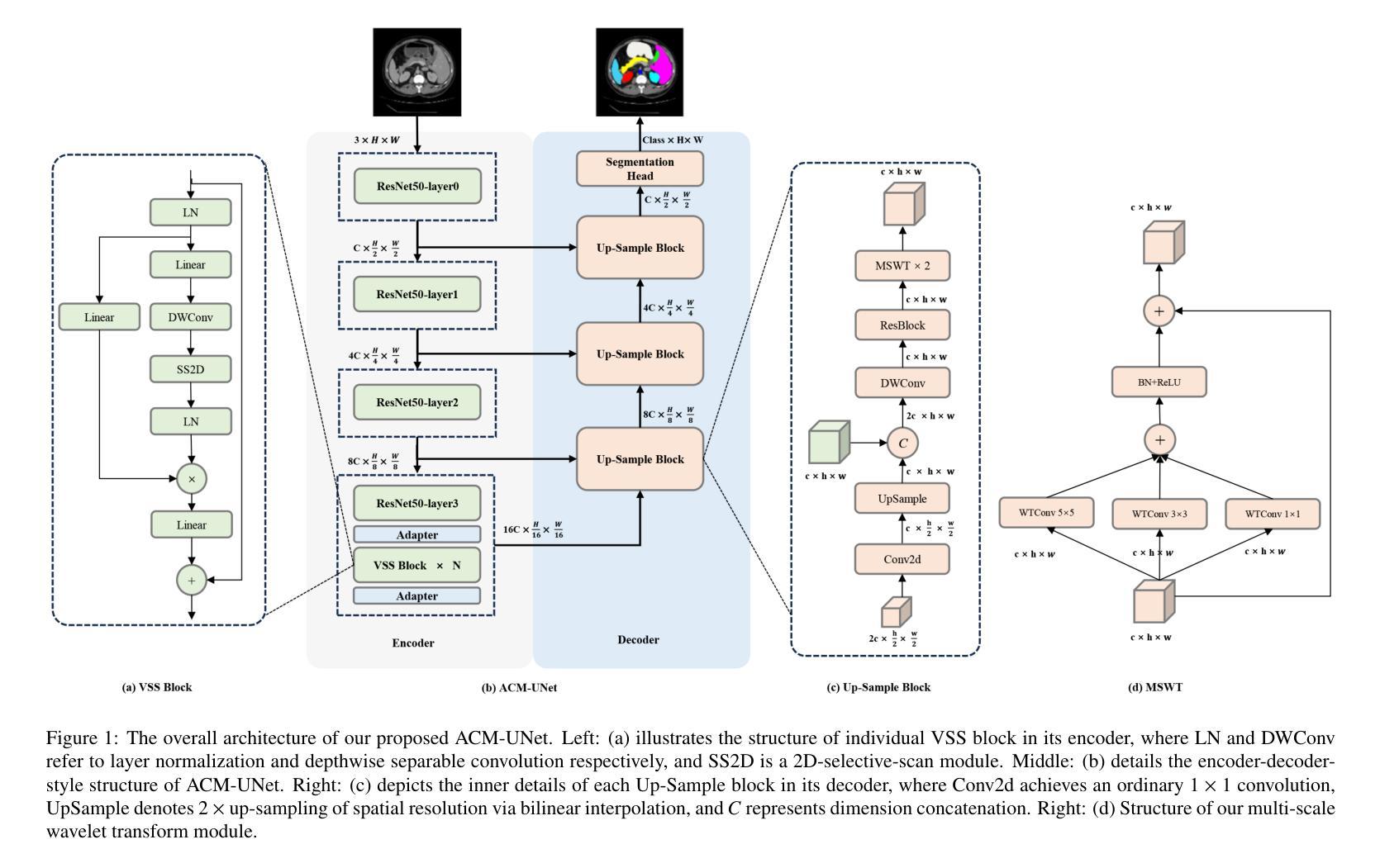
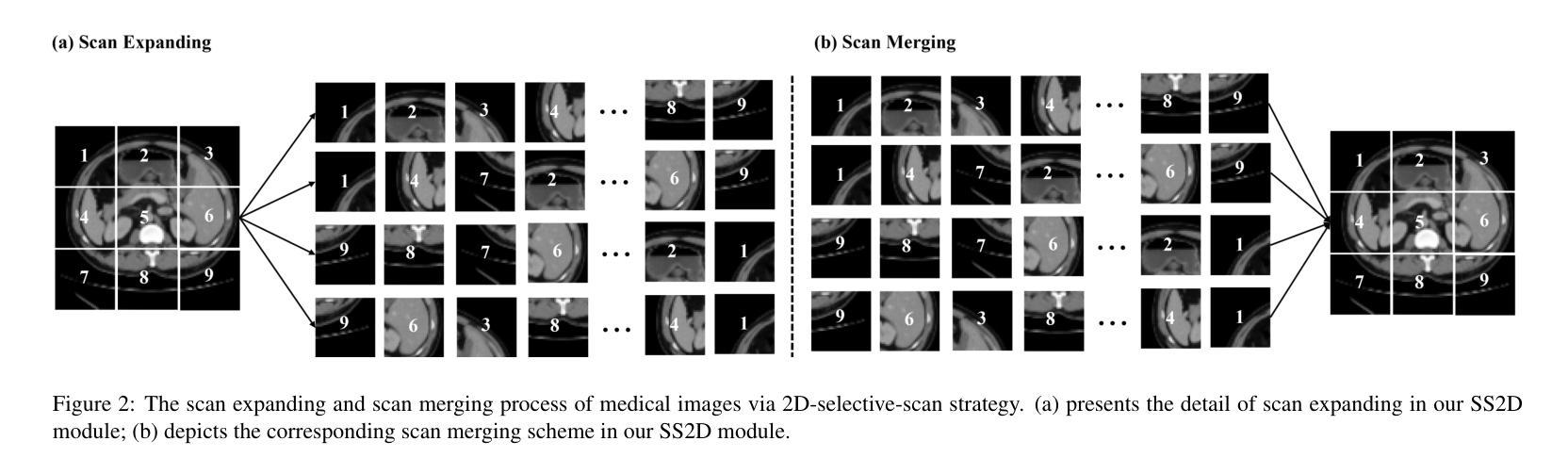
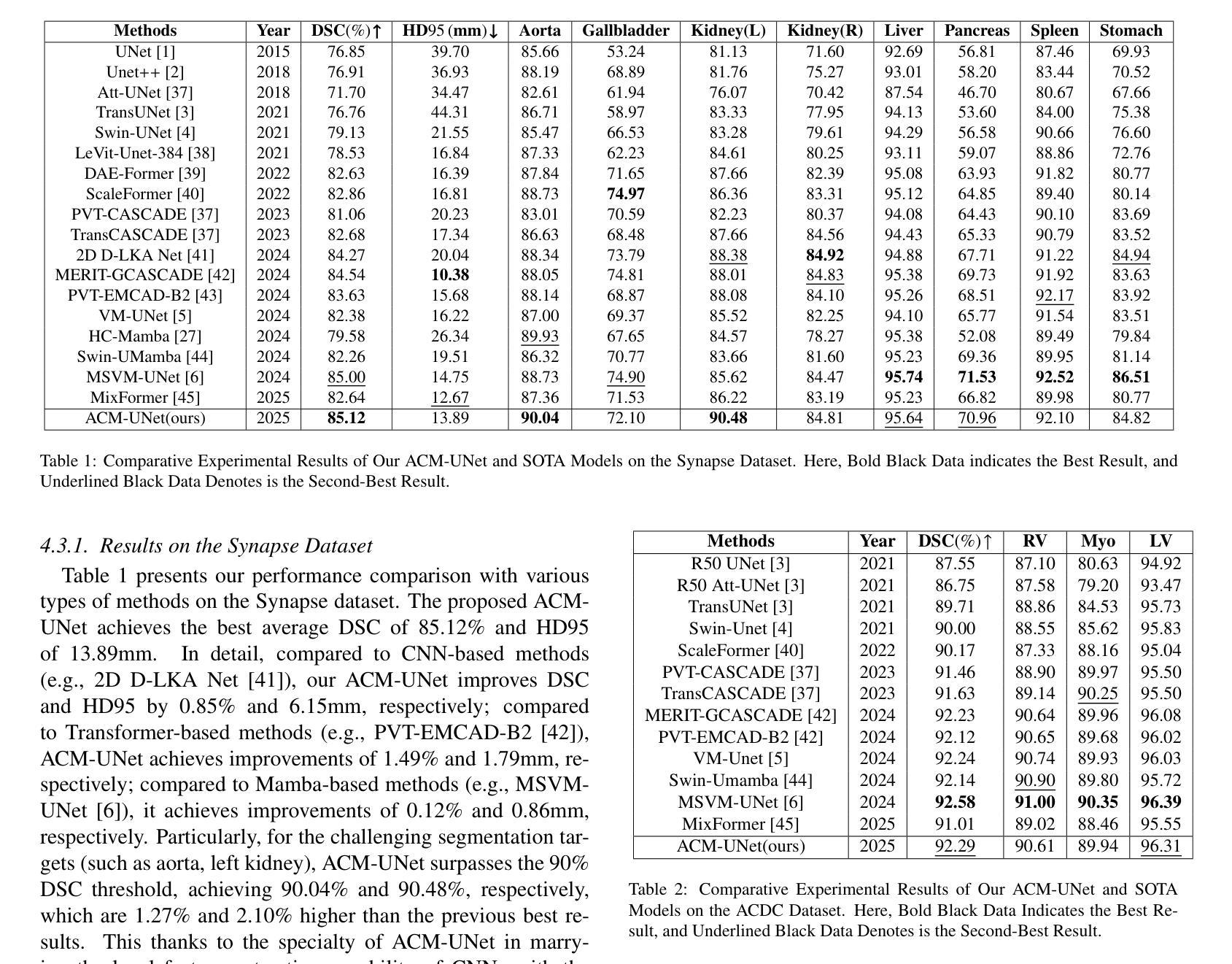
ACM-UNet: Adaptive Integration of CNNs and Mamba for Efficient Medical Image Segmentation
Authors:Jing Huang, Yongkang Zhao, Yuhan Li, Zhitao Dai, Cheng Chen, Qiying Lai
The U-shaped encoder-decoder architecture with skip connections has become a prevailing paradigm in medical image segmentation due to its simplicity and effectiveness. While many recent works aim to improve this framework by designing more powerful encoders and decoders, employing advanced convolutional neural networks (CNNs) for local feature extraction, Transformers or state space models (SSMs) such as Mamba for global context modeling, or hybrid combinations of both, these methods often struggle to fully utilize pretrained vision backbones (e.g., ResNet, ViT, VMamba) due to structural mismatches. To bridge this gap, we introduce ACM-UNet, a general-purpose segmentation framework that retains a simple UNet-like design while effectively incorporating pretrained CNNs and Mamba models through a lightweight adapter mechanism. This adapter resolves architectural incompatibilities and enables the model to harness the complementary strengths of CNNs and SSMs-namely, fine-grained local detail extraction and long-range dependency modeling. Additionally, we propose a hierarchical multi-scale wavelet transform module in the decoder to enhance feature fusion and reconstruction fidelity. Extensive experiments on the Synapse and ACDC benchmarks demonstrate that ACM-UNet achieves state-of-the-art performance while remaining computationally efficient. Notably, it reaches 85.12% Dice Score and 13.89mm HD95 on the Synapse dataset with 17.93G FLOPs, showcasing its effectiveness and scalability. Code is available at: https://github.com/zyklcode/ACM-UNet.
带有跳过连接的U型编码器-解码器架构由于其简单性和有效性,已成为医学图像分割中的主流范式。虽然最近许多工作旨在通过设计更强大的编码器和解码器、使用先进的卷积神经网络(CNN)进行局部特征提取、使用Transformer或状态空间模型(SSM)如Mamba进行全局上下文建模,或两者的混合组合来改进此框架,但这些方法往往难以充分利用预训练的视觉主干(例如ResNet、ViT、VMamba)网络,这是由于结构不匹配造成的。为了弥补这一差距,我们引入了ACM-UNet,这是一个通用分割框架,它保留了简单的UNet设计,同时通过轻量级适配器机制有效地结合了预训练的CNN和Mamba模型。该适配器解决了架构不兼容问题,使模型能够利用CNN和SSM的互补优势——即精细的局部细节提取和长距离依赖关系建模。此外,我们在解码器中提出了分层多尺度小波变换模块,以增强特征融合和重建保真度。在Synapse和ACDC基准测试的大量实验表明,ACM-UNet在保持计算效率的同时实现了最先进的性能。值得注意的是,它在Synapse数据集上达到了85.12%的Dice分数和13.89mm的HD95,同时只需17.93G FLOPs,展示了其有效性和可扩展性。相关代码可通过以下链接获取:https://github.com/zyklcode/ACM-UNet。
论文及项目相关链接
PDF 10 pages, 3 figures, 5 tables
Summary
本文介绍了一种名为ACM-UNet的通用医学图像分割框架,它采用U型编码器-解码器架构,通过轻量级适配器机制有效结合了预训练的卷积神经网络(CNN)和Mamba模型。该框架解决了结构不匹配的问题,能够充分利用CNN和SSM的互补优势,实现了精细的局部细节提取和长距离依赖建模。此外,还提出了层次化的多尺度小波变换模块,增强了特征融合和重建的保真度。在Synapse和ACDC基准测试中,ACM-UNet取得了最先进的性能,并保持了计算效率。
Key Takeaways
- ACM-UNet是一种基于U型编码器-解码器架构的医学图像分割框架,旨在解决现有方法利用预训练视觉主干结构不匹配的问题。
- 通过轻量级适配器机制,ACM-UNet有效结合了CNN和Mamba模型,充分利用两者的互补优势。
- 框架中提出了层次化的多尺度小波变换模块,增强了特征融合和重建的保真度。
- ACM-UNet在Synapse和ACDC基准测试中取得了最先进的性能,显示出其有效性和可扩展性。
- ACM-UNet实现了85.12%的Dice得分和13.89mm的HD95值,同时保持了计算效率。
- 代码已公开,可供进一步研究和使用。
点此查看论文截图

pyMEAL: A Multi-Encoder Augmentation-Aware Learning for Robust and Generalizable Medical Image Translation
Authors:Abdul-mojeed Olabisi Ilyas, Adeleke Maradesa, Jamal Banzi, Jianpan Huang, Henry K. F. Mak, Kannie W. Y. Chan
Medical imaging is critical for diagnostics, but clinical adoption of advanced AI-driven imaging faces challenges due to patient variability, image artifacts, and limited model generalization. While deep learning has transformed image analysis, 3D medical imaging still suffers from data scarcity and inconsistencies due to acquisition protocols, scanner differences, and patient motion. Traditional augmentation uses a single pipeline for all transformations, disregarding the unique traits of each augmentation and struggling with large data volumes. To address these challenges, we propose a Multi-encoder Augmentation-Aware Learning (MEAL) framework that leverages four distinct augmentation variants processed through dedicated encoders. Three fusion strategies such as concatenation (CC), fusion layer (FL), and adaptive controller block (BD) are integrated to build multi-encoder models that combine augmentation-specific features before decoding. MEAL-BD uniquely preserves augmentation-aware representations, enabling robust, protocol-invariant feature learning. As demonstrated in a Computed Tomography (CT)-to-T1-weighted Magnetic Resonance Imaging (MRI) translation study, MEAL-BD consistently achieved the best performance on both unseen- and predefined-test data. On both geometric transformations (like rotations and flips) and non-augmented inputs, MEAL-BD outperformed other competing methods, achieving higher mean peak signal-to-noise ratio (PSNR) and structural similarity index measure (SSIM) scores. These results establish MEAL as a reliable framework for preserving structural fidelity and generalizing across clinically relevant variability. By reframing augmentation as a source of diverse, generalizable features, MEAL supports robust, protocol-invariant learning, advancing clinically reliable medical imaging solutions.
医学成像对于诊断至关重要,但先进的AI驱动的成像在临床应用上面临挑战,包括患者差异、图像伪影和模型泛化有限等问题。深度学习已经改变了图像分析领域,但3D医学成像仍然因采集协议、扫描仪差异、患者移动等因素而面临数据稀缺和不一致的问题。传统增强方法使用单一管道进行所有转换,忽略了每种增强的独特特征,并且难以处理大量数据。为了应对这些挑战,我们提出了一种多编码器增强感知学习(MEAL)框架,该框架利用四种不同的增强变体,并通过专用编码器进行处理。集成了三种融合策略,包括串联(CC)、融合层(FL)和自适应控制器块(BD),以构建多编码器模型,这些模型在解码之前组合增强特定的特征。MEAL-BD独特地保留了增强感知表示,实现了稳健的、协议不变的特征学习。在CT到T1加权MRI的转换研究中,MEAL-BD在未见过的和预定义测试数据上均表现最佳。在几何转换(如旋转和翻转)和非增强输入方面,MEAL-BD也优于其他竞争方法,获得了更高的峰值信噪比(PSNR)和结构相似性指数度量(SSIM)得分。这些结果证明了MEAL作为一个可靠框架在保持结构保真度和泛化临床相关变异性方面的能力。通过将增强重构为多样化和可泛化的特征的来源,MEAL支持稳健的、协议不变的学习,推动临床可靠的医学成像解决方案的发展。
论文及项目相关链接
PDF 36 pages, 9 figures, 2 tables
摘要
医学成像对于诊断至关重要,但临床采用先进的AI驱动成像面临患者差异性、图像伪影和模型泛化有限等挑战。深度学习虽已改变图像分析领域,但3D医学成像仍因采集协议、扫描仪差异和患者运动等因素而面临数据稀缺和不一致性等问题。传统增强方法使用单一管道进行所有转换,忽略了每种增强的独特特征,并难以处理大量数据。为解决这些挑战,我们提出了多编码器增强感知学习(MEAL)框架,该框架利用四种不同的增强变体,通过专用编码器进行处理。集成了三种融合策略,包括串联(CC)、融合层(FL)和自适应控制器块(BD),以构建多编码器模型,这些模型在解码之前结合增强特定功能。MEAL-BD独特地保留了增强感知表示,能够实现稳健的协议不变特征学习。在CT到T1加权MRI的翻译研究中,MEAL-BD在未见过和预定义测试数据上均表现出最佳性能。在几何转换(如旋转和翻转)和非增强输入上,MEAL-BD均优于其他竞争方法,获得更高的峰值信噪比(PSNR)和结构相似性指数度量(SSIM)分数。这些结果证明了MEAL作为一个可靠框架在保留结构保真度和泛化临床相关变化方面的能力。通过将增强重构为多样化和可泛化的特征源,MEAL支持稳健的协议不变学习,推动临床可靠的医学成像解决方案的发展。
关键见解
- 医学成像在临床诊断中至关重要,但面临患者差异性、图像伪影和模型泛化有限等挑战。
- 深度学习在图像分析中的应用受到3D医学成像数据稀缺和不一致性的限制。
- 传统增强方法忽视每种增强的独特特征,难以处理大量数据。
- MEAL框架利用多编码器结合四种增强变体和专用编码器处理。
- MEAL框架通过融合策略结合增强特定功能,并独特地保留增强感知表示。
- 在CT到MRI的翻译研究中,MEAL-BD表现出最佳性能,优于其他方法。
点此查看论文截图

A Novel Coronary Artery Registration Method Based on Super-pixel Particle Swarm Optimization
Authors:Peng Qi, Wenxi Qu, Tianliang Yao, Haonan Ma, Dylan Wintle, Yinyi Lai, Giorgos Papanastasiou, Chengjia Wang
Percutaneous Coronary Intervention (PCI) is a minimally invasive procedure that improves coronary blood flow and treats coronary artery disease. Although PCI typically requires 2D X-ray angiography (XRA) to guide catheter placement at real-time, computed tomography angiography (CTA) may substantially improve PCI by providing precise information of 3D vascular anatomy and status. To leverage real-time XRA and detailed 3D CTA anatomy for PCI, accurate multimodal image registration of XRA and CTA is required, to guide the procedure and avoid complications. This is a challenging process as it requires registration of images from different geometrical modalities (2D -> 3D and vice versa), with variations in contrast and noise levels. In this paper, we propose a novel multimodal coronary artery image registration method based on a swarm optimization algorithm, which effectively addresses challenges such as large deformations, low contrast, and noise across these imaging modalities. Our algorithm consists of two main modules: 1) preprocessing of XRA and CTA images separately, and 2) a registration module based on feature extraction using the Steger and Superpixel Particle Swarm Optimization algorithms. Our technique was evaluated on a pilot dataset of 28 pairs of XRA and CTA images from 10 patients who underwent PCI. The algorithm was compared with four state-of-the-art (SOTA) methods in terms of registration accuracy, robustness, and efficiency. Our method outperformed the selected SOTA baselines in all aspects. Experimental results demonstrate the significant effectiveness of our algorithm, surpassing the previous benchmarks and proposes a novel clinical approach that can potentially have merit for improving patient outcomes in coronary artery disease.
经皮冠状动脉介入治疗(PCI)是一种微创手术,旨在改善冠状动脉血流并治疗冠状动脉疾病。虽然PCI通常需要借助二维X射线血管造影术(XRA)来实时引导导管放置位置,但计算机断层扫描血管造影术(CTA)可以通过提供三维血管解剖结构和状态的精确信息,大幅改进PCI的效果。为了充分利用实时XRA和详细的3D CTA解剖结构信息以进行PCI手术,需要准确的XRA和CTA多模态图像配准,以指导手术过程并避免并发症。这是一个具有挑战性的过程,因为它需要配准来自不同几何模态的图像(例如从二维到三维以及反之),并伴随对比度和噪声水平的差异。在本文中,我们提出了一种基于群优化算法的多模态冠状动脉图像配准新方法,有效地解决了这些成像技术中的大变形、低对比度和噪声等挑战。我们的算法主要包括两个模块:1)分别对XRA和CTA图像进行预处理;2)基于特征提取的注册模块,采用Steger算法和超像素粒子群优化算法。我们的技术在由经历过PCI手术的10名患者的28对XRA和CTA图像组成的先导数据集上进行了评估。该算法与四种最先进的(SOTA)方法相比,在配准精度、稳健性和效率方面表现更好。实验结果表明,我们的算法在所有方面都超过了之前的方法并展现了显著的有效性,并且提出了一种潜在的新临床方法,可能会对冠状动脉疾病患者的治疗效果有所改善。
论文及项目相关链接
摘要
经皮冠状动脉介入治疗(PCI)是一种微创手术,可改善冠状动脉血流并治疗冠心病。虽然PCI通常需要借助二维X射线血管造影术(XRA)实时指导导管放置,但计算机断层扫描血管造影术(CTA)通过提供三维血管解剖结构和状态的精确信息,可为PCI带来实质性的改进。为了利用实时的XRA和详细的3D CTA解剖结构进行PCI,需要对XRA和CTA进行精确的多模态图像配准,以指导手术并避免并发症。这一过程具有挑战性,因为需要配准来自不同几何模态(2D到3D反之亦然)的图像,并且具有对比度和噪声水平的差异。本文提出了一种基于群优化算法的多模态冠状动脉图像配准方法,有效解决不同成像模式的大变形、低对比度和噪声等挑战。我们的算法主要包括两个模块:1)对XRA和CTA图像进行预处理;2)基于特征提取的配准模块,采用Steger和超像素粒子群优化算法。我们的技术在由10名接受PCI手术的患者组成的28对XRA和CTA图像试点数据集上进行了评估。该方法在配准精度、鲁棒性和效率方面与四种最新方法进行了比较,我们的方法在所有方面都优于所选的基线。实验结果表明,我们的算法具有显著的有效性,超越了以前的标准,提出了一种可能有助于改善冠心病患者治疗结果的新临床方法。
关键见解
- 经皮冠状动脉介入治疗(PCI)通常依赖二维X射线血管造影术(XRA)进行实时指导。
- 计算机断层扫描血管造影术(CTA)可提供三维血管解剖信息,有助于改进PCI。
- 多模态图像配准是实现XRA和CTA融合的关键步骤,有助于指导手术并避免并发症。
- 配准过程面临不同几何模态图像配准的挑战,包括图像间的大变形、低对比度和噪声差异。
- 本文提出了一种基于群优化算法的多模态冠状动脉图像配准方法,包括预处理和特征提取配准两个主要模块。
- 在试点数据集上的实验表明,该方法在配准精度、鲁棒性和效率方面均优于现有方法。
点此查看论文截图

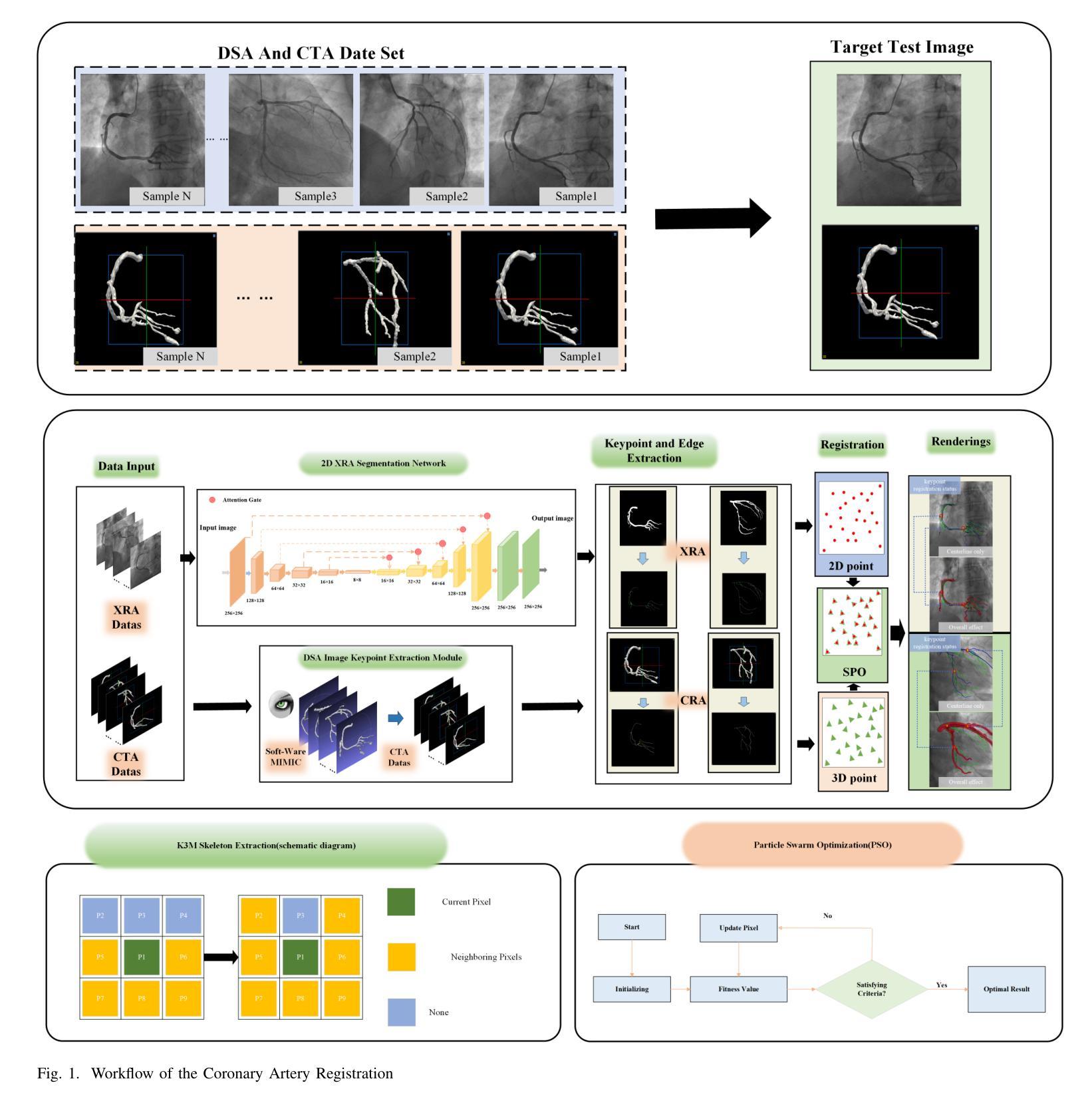
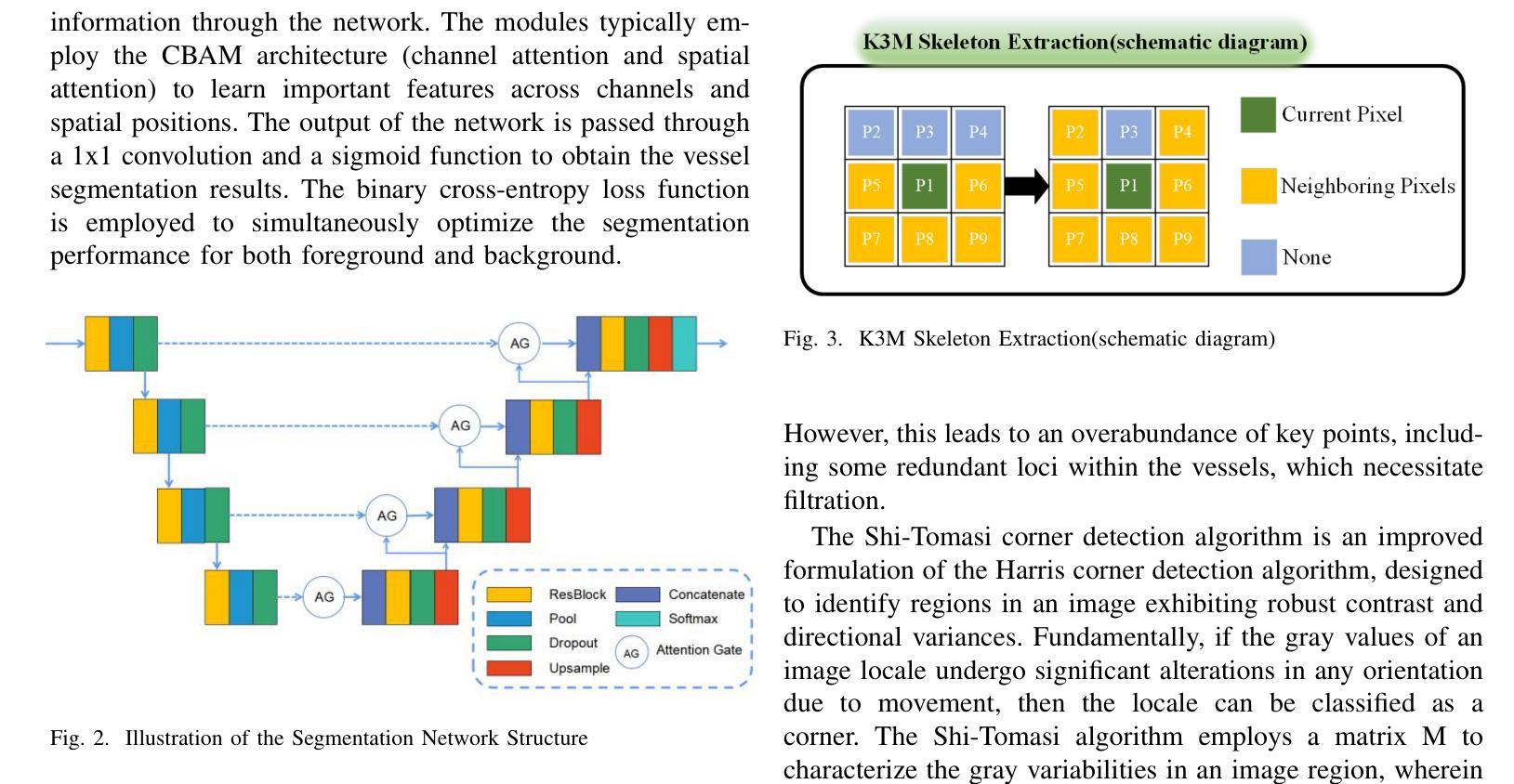
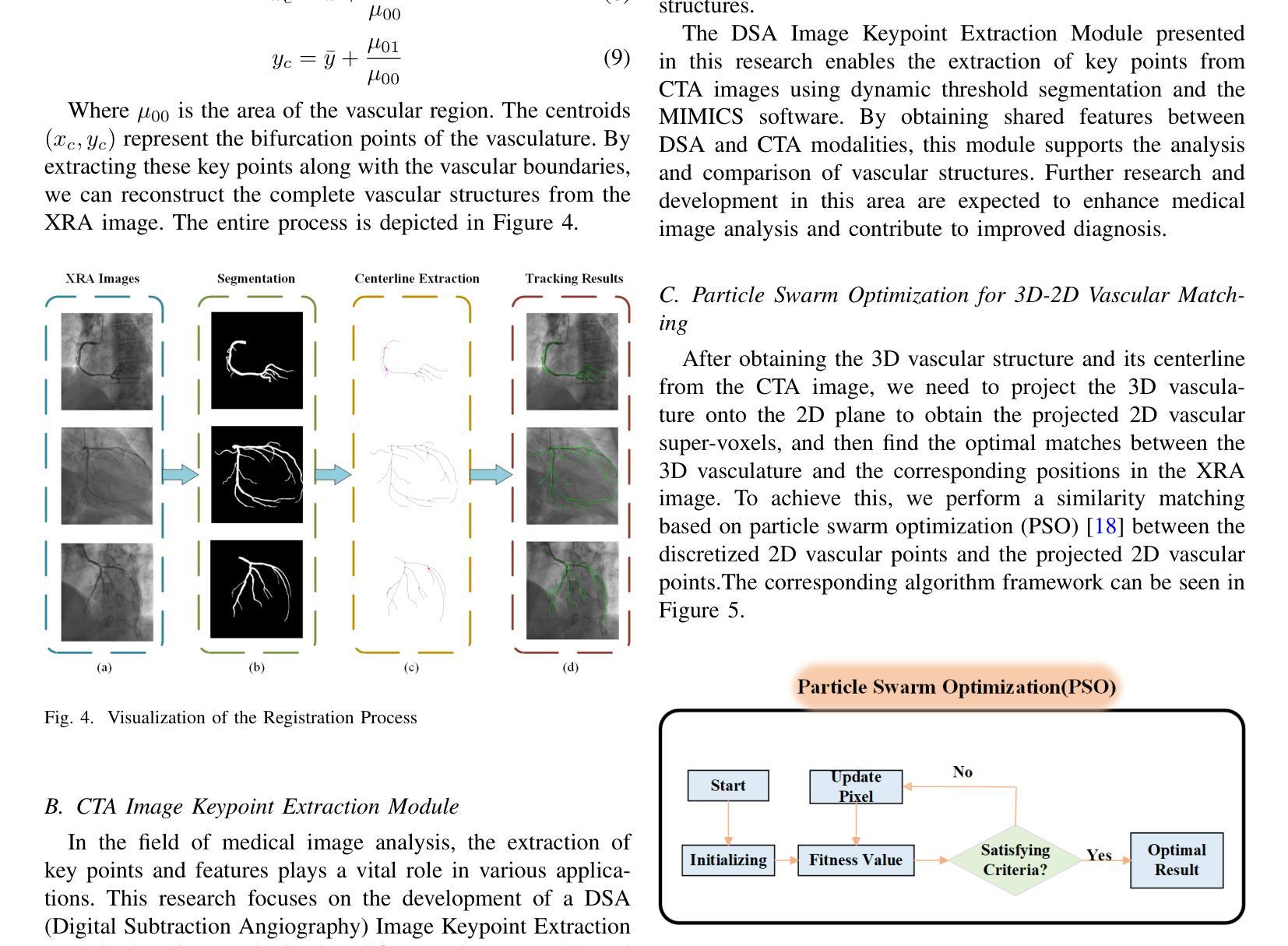
EgoExOR: An Ego-Exo-Centric Operating Room Dataset for Surgical Activity Understanding
Authors:Ege Özsoy, Arda Mamur, Felix Tristram, Chantal Pellegrini, Magdalena Wysocki, Benjamin Busam, Nassir Navab
Operating rooms (ORs) demand precise coordination among surgeons, nurses, and equipment in a fast-paced, occlusion-heavy environment, necessitating advanced perception models to enhance safety and efficiency. Existing datasets either provide partial egocentric views or sparse exocentric multi-view context, but do not explore the comprehensive combination of both. We introduce EgoExOR, the first OR dataset and accompanying benchmark to fuse first-person and third-person perspectives. Spanning 94 minutes (84,553 frames at 15 FPS) of two emulated spine procedures, Ultrasound-Guided Needle Insertion and Minimally Invasive Spine Surgery, EgoExOR integrates egocentric data (RGB, gaze, hand tracking, audio) from wearable glasses, exocentric RGB and depth from RGB-D cameras, and ultrasound imagery. Its detailed scene graph annotations, covering 36 entities and 22 relations (568,235 triplets), enable robust modeling of clinical interactions, supporting tasks like action recognition and human-centric perception. We evaluate the surgical scene graph generation performance of two adapted state-of-the-art models and offer a new baseline that explicitly leverages EgoExOR’s multimodal and multi-perspective signals. This new dataset and benchmark set a new foundation for OR perception, offering a rich, multimodal resource for next-generation clinical perception.
手术室(OR)需要在快节奏、遮挡严重的环境中,精确协调外科医生、护士和设备之间的配合,这要求先进的感知模型来提高安全性和效率。现有的数据集要么提供部分以自我为中心的视角,要么提供稀疏的外视多视角上下文,但并不探索两者的综合结合。我们推出了EgoExOR,这是首个手术室数据集以及融合第一人称和第三人称视角的配套基准测试。EgoExOR涵盖了模拟脊椎手术的94分钟(以15帧/秒的速率拍摄84,553帧),包括超声引导下的针插入和微创脊椎手术。它整合了来自可穿戴眼镜的自我中心数据(RGB、凝视、手追踪、音频)、来自RGB-D相机的外部RGB和深度数据,以及超声图像。其详细的场景图注释涵盖了36个实体和22个关系(共568,235个三元组),能够稳健地模拟临床互动,支持动作识别和人类中心感知等任务。我们评估了两个适应先进状态模型的手术场景图生成性能,并提供了一个新的基线,该基线明确利用了EgoExOR的多模态和多视角信号。这个新的数据集和基准测试为手术室感知设定了新的基础,为下一代临床感知提供了丰富、多模态的资源。
论文及项目相关链接
Summary
本文介绍了手术室感知领域的新数据集EgoExOR及其基准测试。该数据集融合了第一人称和第三人称视角,集成了可穿戴眼镜的RGB、视线追踪、手部追踪和音频数据,以及RGB-D相机的外部RGB和深度数据,以及超声图像。它详细的场景图注解支持动作识别和以人为中心的感知任务,为手术室感知研究提供了新的丰富多模态资源。
Key Takeaways
- EgoExOR是首个融合第一人称和第三人称视角的手术数据集。
- 数据集包含了多种模态的信息,如RGB、音频、深度数据等。
- 数据集涵盖了两项模拟手术:超声引导下的针插入和微创脊椎手术。
- 详细的场景图注解能够支持动作识别和以人为中心的感知任务。
- 提出了针对该数据集的基准测试方法,利用多模态和多视角信号。
- EgoExOR为手术室感知研究提供了新的基础,有助于提高手术的安全性和效率。
点此查看论文截图

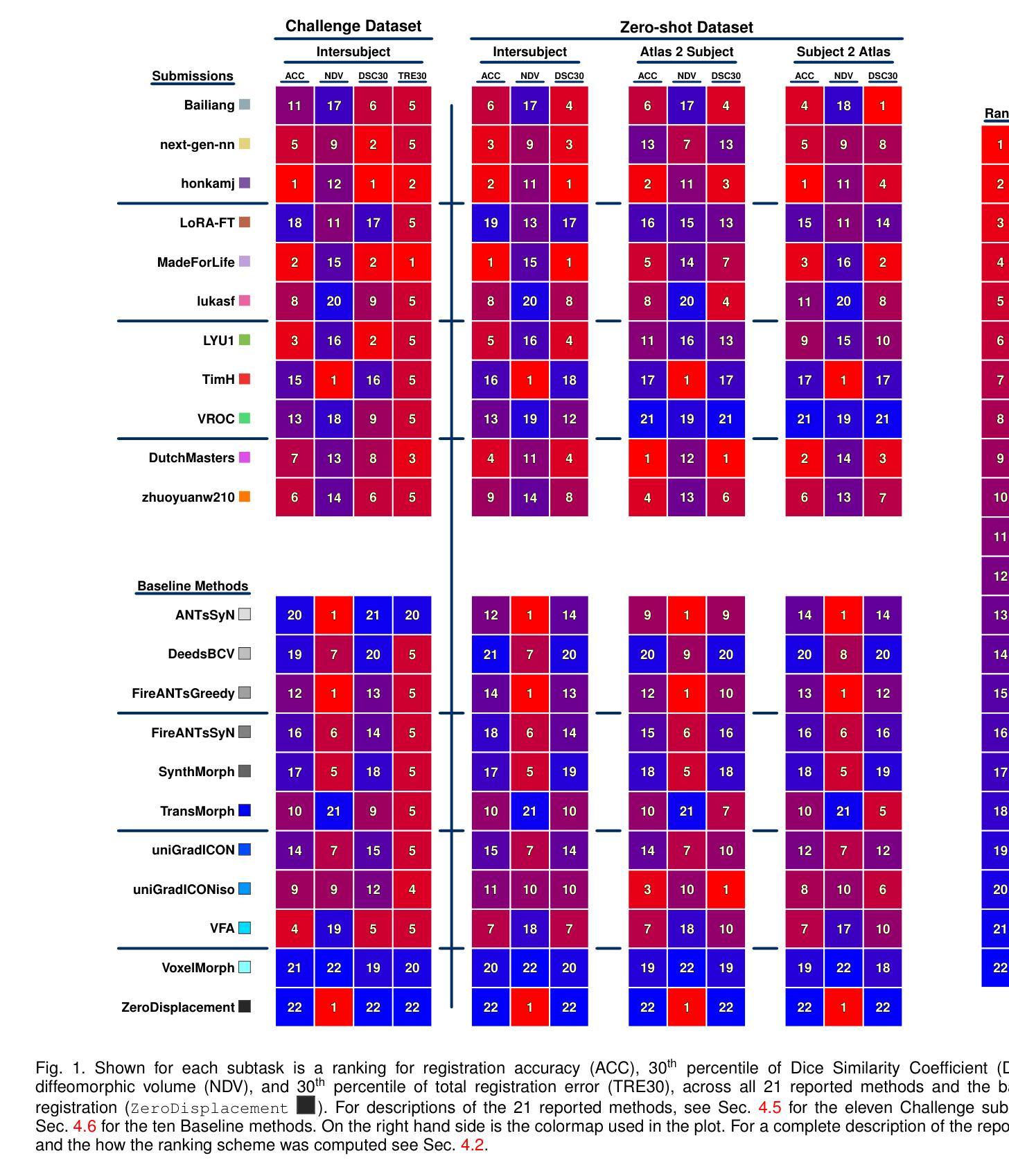
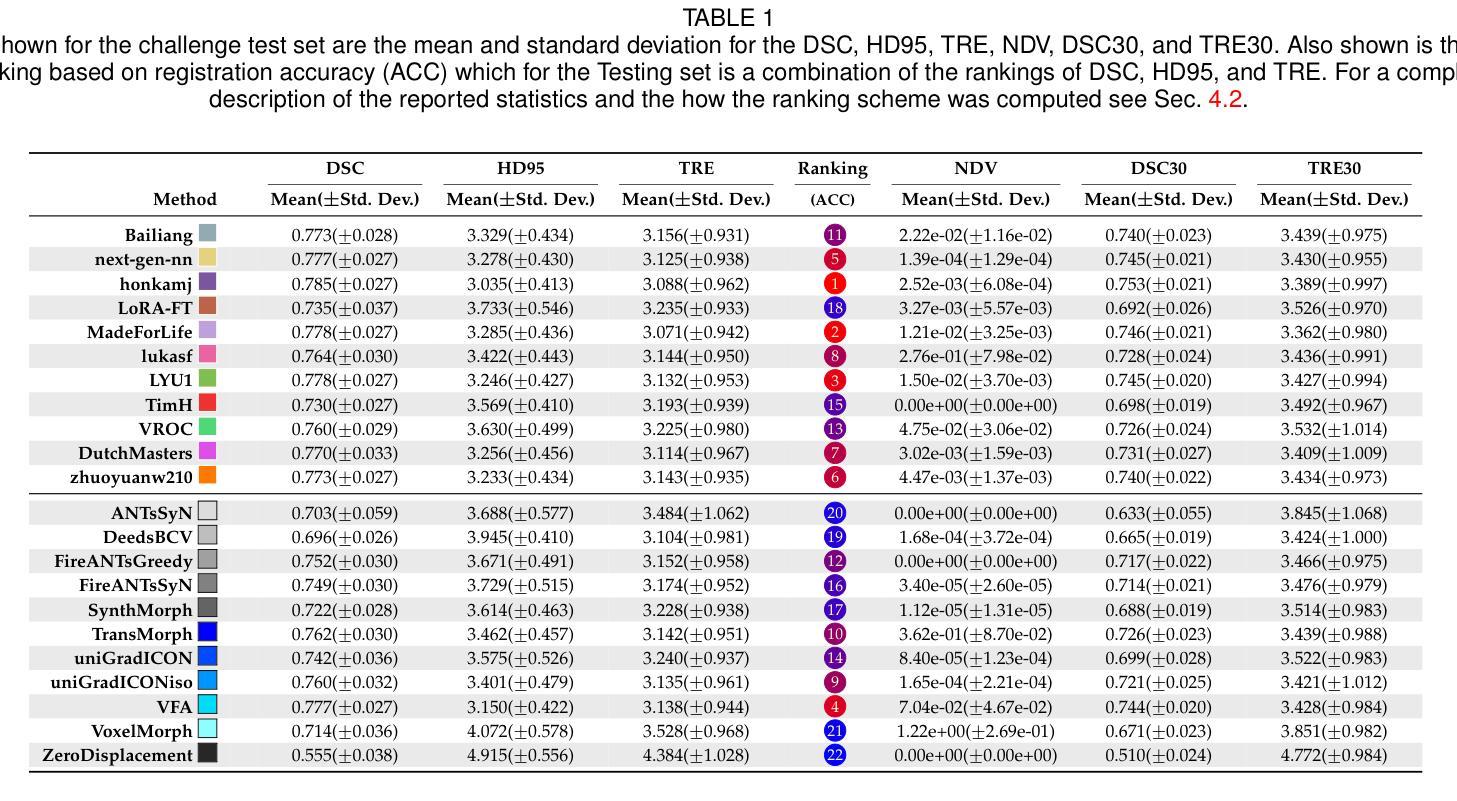
Beyond the LUMIR challenge: The pathway to foundational registration models
Authors:Junyu Chen, Shuwen Wei, Joel Honkamaa, Pekka Marttinen, Hang Zhang, Min Liu, Yichao Zhou, Zuopeng Tan, Zhuoyuan Wang, Yi Wang, Hongchao Zhou, Shunbo Hu, Yi Zhang, Qian Tao, Lukas Förner, Thomas Wendler, Bailiang Jian, Benedikt Wiestler, Tim Hable, Jin Kim, Dan Ruan, Frederic Madesta, Thilo Sentker, Wiebke Heyer, Lianrui Zuo, Yuwei Dai, Jing Wu, Jerry L. Prince, Harrison Bai, Yong Du, Yihao Liu, Alessa Hering, Reuben Dorent, Lasse Hansen, Mattias P. Heinrich, Aaron Carass
Medical image challenges have played a transformative role in advancing the field, catalyzing algorithmic innovation and establishing new performance standards across diverse clinical applications. Image registration, a foundational task in neuroimaging pipelines, has similarly benefited from the Learn2Reg initiative. Building on this foundation, we introduce the Large-scale Unsupervised Brain MRI Image Registration (LUMIR) challenge, a next-generation benchmark designed to assess and advance unsupervised brain MRI registration. Distinct from prior challenges that leveraged anatomical label maps for supervision, LUMIR removes this dependency by providing over 4,000 preprocessed T1-weighted brain MRIs for training without any label maps, encouraging biologically plausible deformation modeling through self-supervision. In addition to evaluating performance on 590 held-out test subjects, LUMIR introduces a rigorous suite of zero-shot generalization tasks, spanning out-of-domain imaging modalities (e.g., FLAIR, T2-weighted, T2*-weighted), disease populations (e.g., Alzheimer’s disease), acquisition protocols (e.g., 9.4T MRI), and species (e.g., macaque brains). A total of 1,158 subjects and over 4,000 image pairs were included for evaluation. Performance was assessed using both segmentation-based metrics (Dice coefficient, 95th percentile Hausdorff distance) and landmark-based registration accuracy (target registration error). Across both in-domain and zero-shot tasks, deep learning-based methods consistently achieved state-of-the-art accuracy while producing anatomically plausible deformation fields. The top-performing deep learning-based models demonstrated diffeomorphic properties and inverse consistency, outperforming several leading optimization-based methods, and showing strong robustness to most domain shifts, the exception being a drop in performance on out-of-domain contrasts.
医学图像挑战在推动领域发展方面发挥了变革性作用,催生了算法创新,并针对不同临床应用建立了新的性能标准。作为神经成像管道中的基础任务,图像配准也受益于Learn2Reg倡议。在此基础上,我们推出了大规模无监督脑MRI图像配准(LUMIR)挑战,这是一项旨在评估和推进无监督脑MRI配准的下一代基准测试。不同于以前依赖解剖标签图进行监督的挑战,LUMIR通过提供4000多张预处理的T1加权脑MRI用于训练,而无需任何标签图,鼓励通过自监督进行生物学上合理的变形建模。除了对590个保留测试对象的性能进行评估外,LUMIR还引入了一系列严格的零样本泛化任务,涵盖域外成像模式(例如FLAIR、T2加权、T2 * 加权)、疾病群体(例如阿尔茨海默病)、采集协议(例如9.4T MRI)和物种(例如猕猴大脑)。评估共涉及1158个主体和4000多个图像对。性能评估采用基于分割的指标(Dice系数、第95个百分位Hausdorff距离)和基于地标的配准精度(目标注册误差)。在域内任务和零样本任务中,基于深度学习的方法始终达到了最先进的准确性,同时产生了生物学上合理的变形场。表现最佳的基于深度学习的模型表现出微分同胚属性和逆向一致性,优于几种基于优化的领先方法,并且对大多数域偏移表现出强大的稳健性,但在域外对比下性能有所下降。
论文及项目相关链接
Summary
医学图像挑战在推动领域发展方面扮演了重要角色,促进了算法创新并建立了新的性能标准。基于Learn2Reg倡议,图像配准这一神经成像管道中的基础任务也从中受益。在此基础上,我们推出了大规模无监督脑MRI图像配准(LUMIR)挑战,这是一个旨在评估和推进无监督脑MRI配准的新一代基准。与传统的依赖于解剖标签图进行监管的挑战不同,LUMIR通过提供超过4000张预处理的T1加权脑MRI图像进行训练,鼓励通过自我监督进行生物学上合理的变形建模。除了对590名受试者进行测试外,还引入了严格的无射击泛化任务,涵盖域外成像模式(如FLAIR、T2加权、T2 *加权)、疾病群体(如阿尔茨海默症)、采集协议(如9.4T MRI)和物种(如猕猴大脑)。评估使用基于分割的指标(Dice系数、第95百分位Hausdorff距离)和基于地标的注册准确性(目标注册误差)。无论在域内任务还是零射击任务中,基于深度学习的方法都持续达到了最先进的准确性,并产生了解剖学上合理的变形场。表现最佳的深度学习模型展现出微分同胚性质和逆一致性,优于几种领先的优化方法,并对大多数领域变化表现出强大的稳健性,除了在领域外的对比结果性能有所下降。
Key Takeaways
- 医学图像挑战推动了医学图像领域的进步,促进了算法创新并提高了性能标准。
- LUMIR挑战旨在评估和推进无监督脑MRI配准技术。
- LUMIR挑战通过提供无标签的T1加权脑MRI图像进行训练,鼓励自我监督的变形建模。
- LUMIR挑战涵盖了多种任务,包括域内和域外的成像模式、疾病群体、采集协议和物种。
- 基于深度学习的方法在医学图像配准中达到了最先进的性能,并产生了合理的变形场。
- 顶级深度学习模型展现出微分同胚性质和逆一致性,优于一些优化方法。
点此查看论文截图

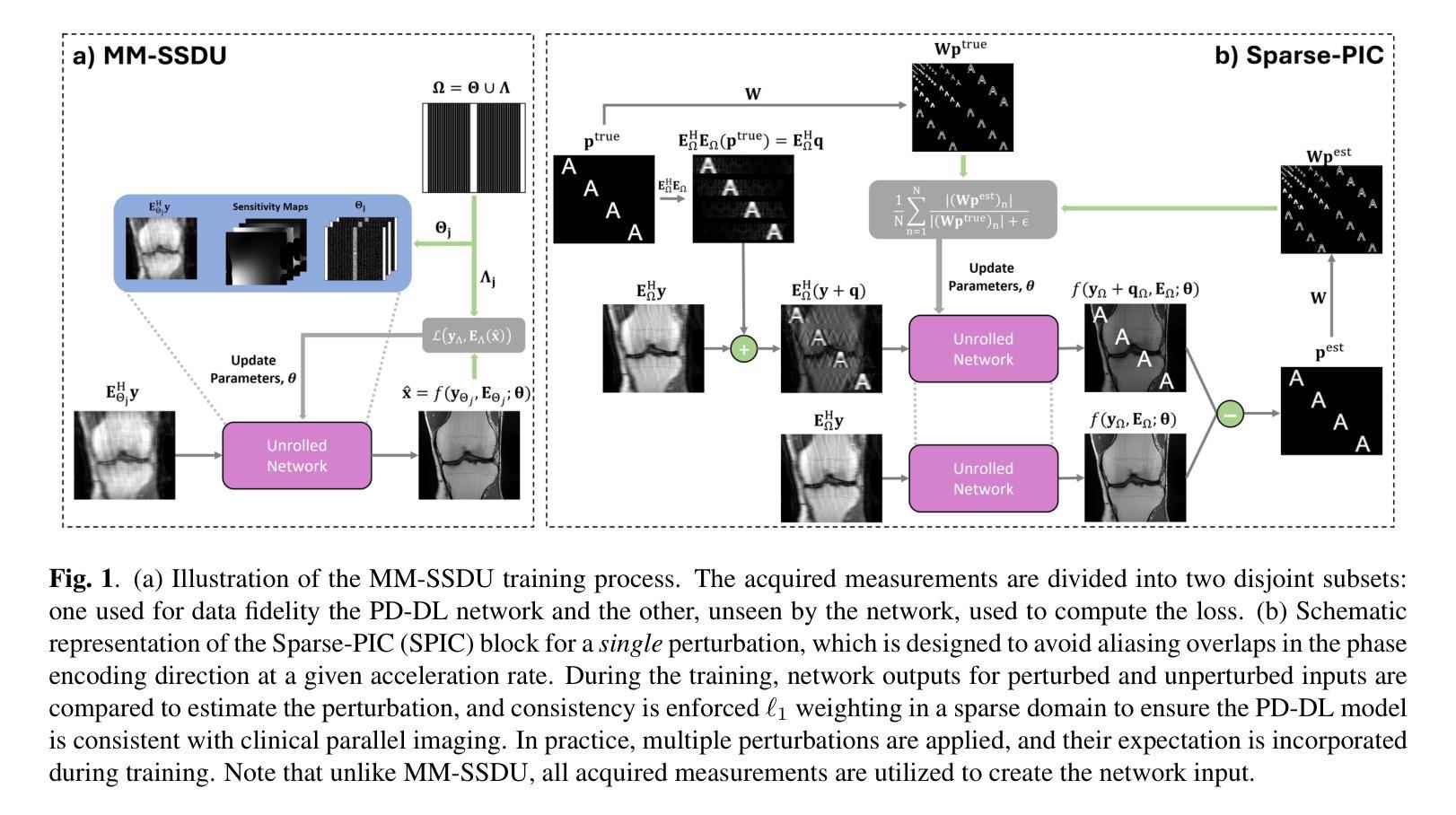
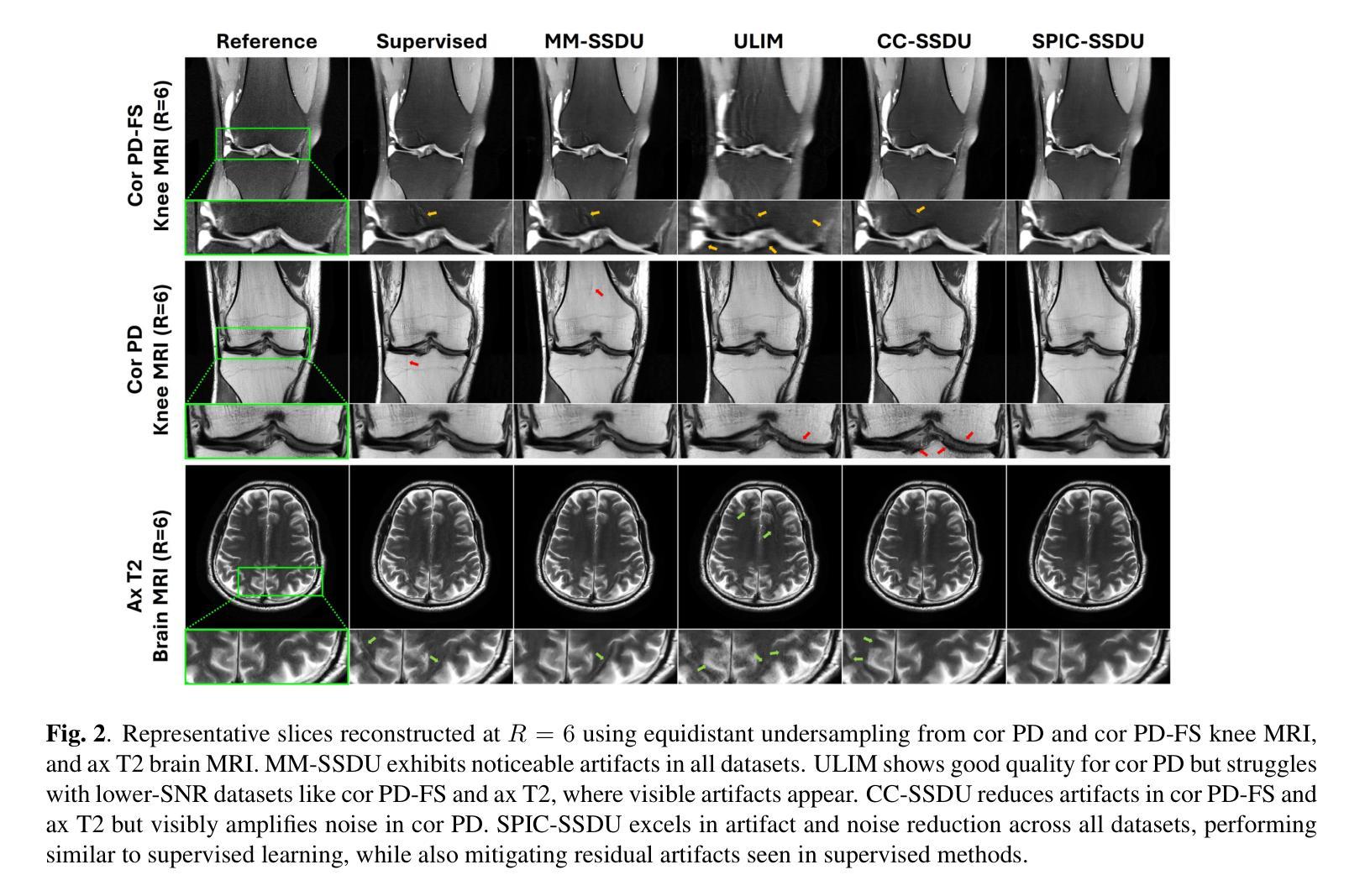
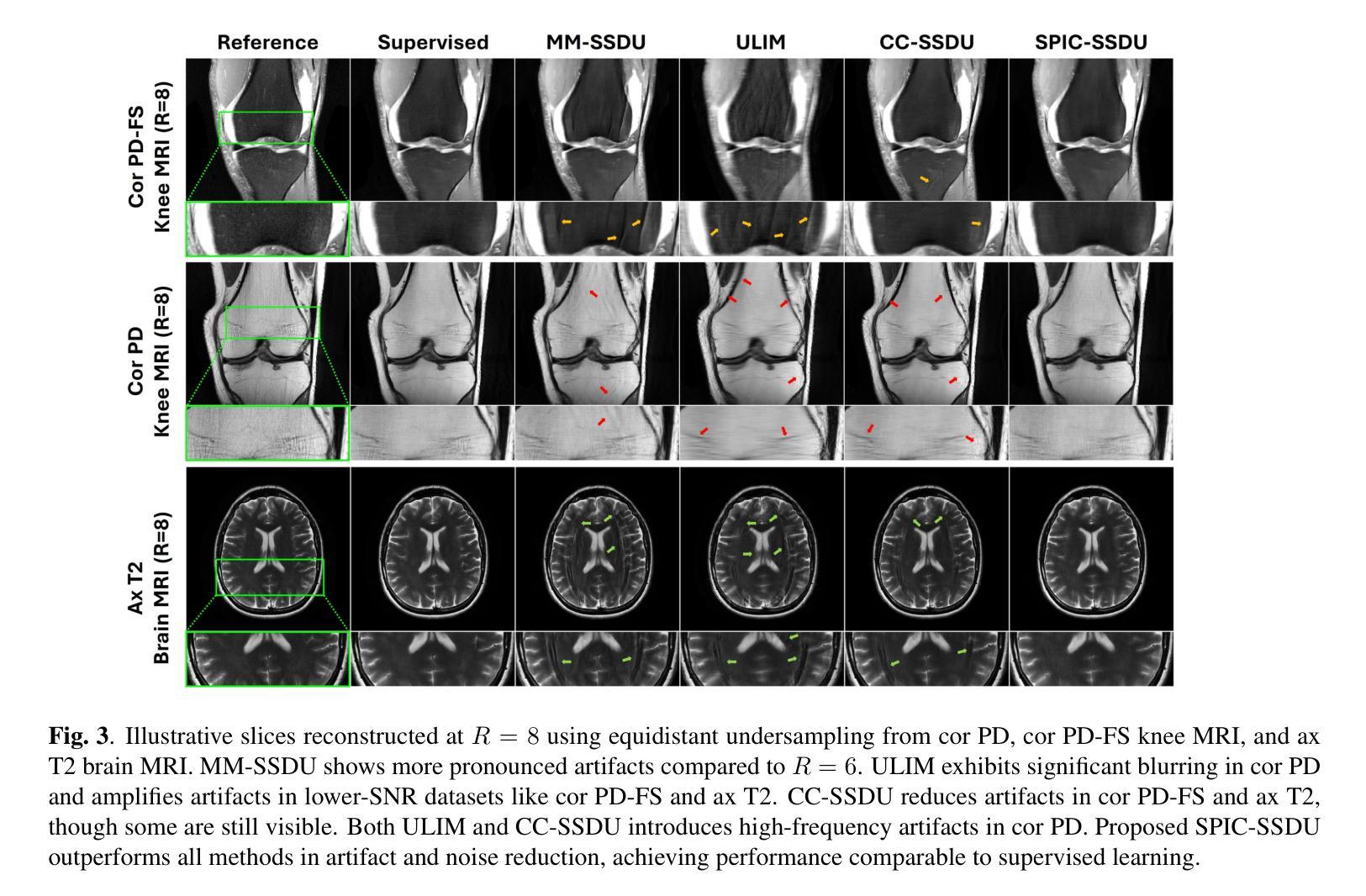
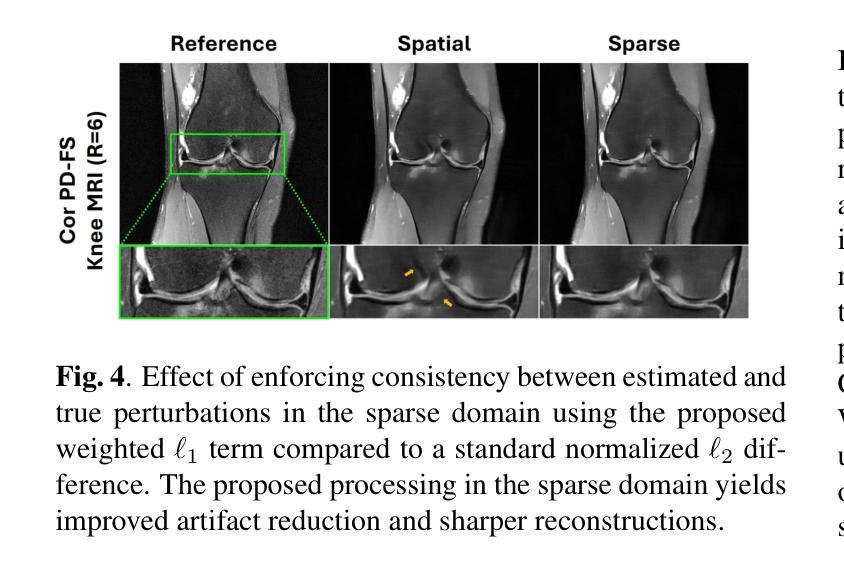
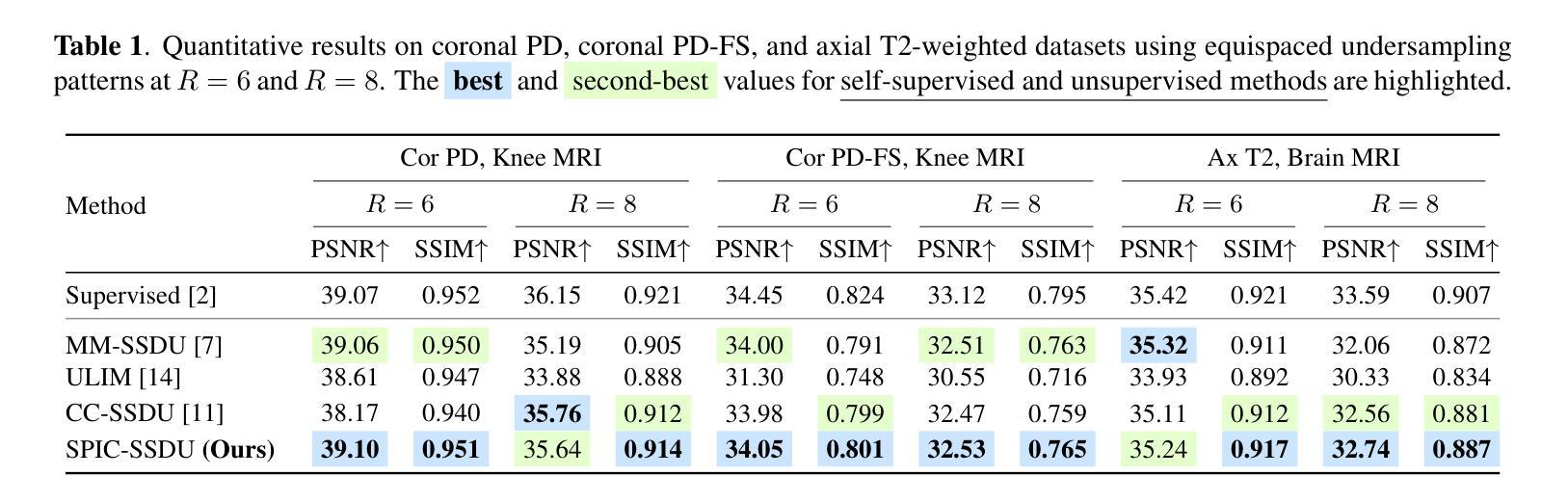
Sparsity-Driven Parallel Imaging Consistency for Improved Self-Supervised MRI Reconstruction
Authors:Yaşar Utku Alçalar, Mehmet Akçakaya
Physics-driven deep learning (PD-DL) models have proven to be a powerful approach for improved reconstruction of rapid MRI scans. In order to train these models in scenarios where fully-sampled reference data is unavailable, self-supervised learning has gained prominence. However, its application at high acceleration rates frequently introduces artifacts, compromising image fidelity. To mitigate this shortcoming, we propose a novel way to train PD-DL networks via carefully-designed perturbations. In particular, we enhance the k-space masking idea of conventional self-supervised learning with a novel consistency term that assesses the model’s ability to accurately predict the added perturbations in a sparse domain, leading to more reliable and artifact-free reconstructions. The results obtained from the fastMRI knee and brain datasets show that the proposed training strategy effectively reduces aliasing artifacts and mitigates noise amplification at high acceleration rates, outperforming state-of-the-art self-supervised methods both visually and quantitatively.
物理驱动深度学习(PD-DL)模型已被证明是用于改进快速MRI扫描重建的强大方法。为了在无法使用完全采样参考数据的情况下训练这些模型,自监督学习已备受关注。然而,其在高加速率下的应用经常会产生伪影,从而影响图像保真度。为了缓解这一不足,我们提出了一种通过精心设计扰动来训练PD-DL网络的新方法。特别是,我们基于传统的自监督学习的k空间掩蔽思想,加入了一个新颖的一致性术语,该术语评估模型在稀疏域中准确预测添加扰动的能力,从而实现更可靠且无伪影的重建。从fastMRI的膝关节和大脑数据集获得的结果表明,所提出的训练策略有效地减少了混叠伪影并减轻了高加速率下的噪声放大问题,在视觉和定量评估上都优于最新的自监督方法。
论文及项目相关链接
PDF IEEE International Conference on Image Processing (ICIP), 2025
Summary
物理驱动深度学习模型结合精心设计的扰动,通过评估模型在稀疏域预测添加扰动的能力,增强了常规自监督学习的k空间掩蔽思想,实现了更可靠且无伪影的重建。此方法有效减少了快速MRI扫描重建中的混叠伪影,并在高加速率下降低了噪声放大问题,超越了现有自监督方法在视觉和数量上的表现。
Key Takeaways
- PD-DL模型用于改进快速MRI扫描重建。
- 自监督学习在训练PD-DL模型时面临高加速率下的伪影问题。
- 提出了一种新型训练策略,结合精心设计的扰动来增强PD-DL网络。
- 在k空间掩蔽基础上加入一致性评估,以预测稀疏域中的添加扰动。
- 该策略有效减少混叠伪影,降低高加速率下的噪声放大问题。
- 在fastMRI的膝关节和大脑数据集上的结果优于现有自监督方法,实现视觉和数量上的超越。
点此查看论文截图

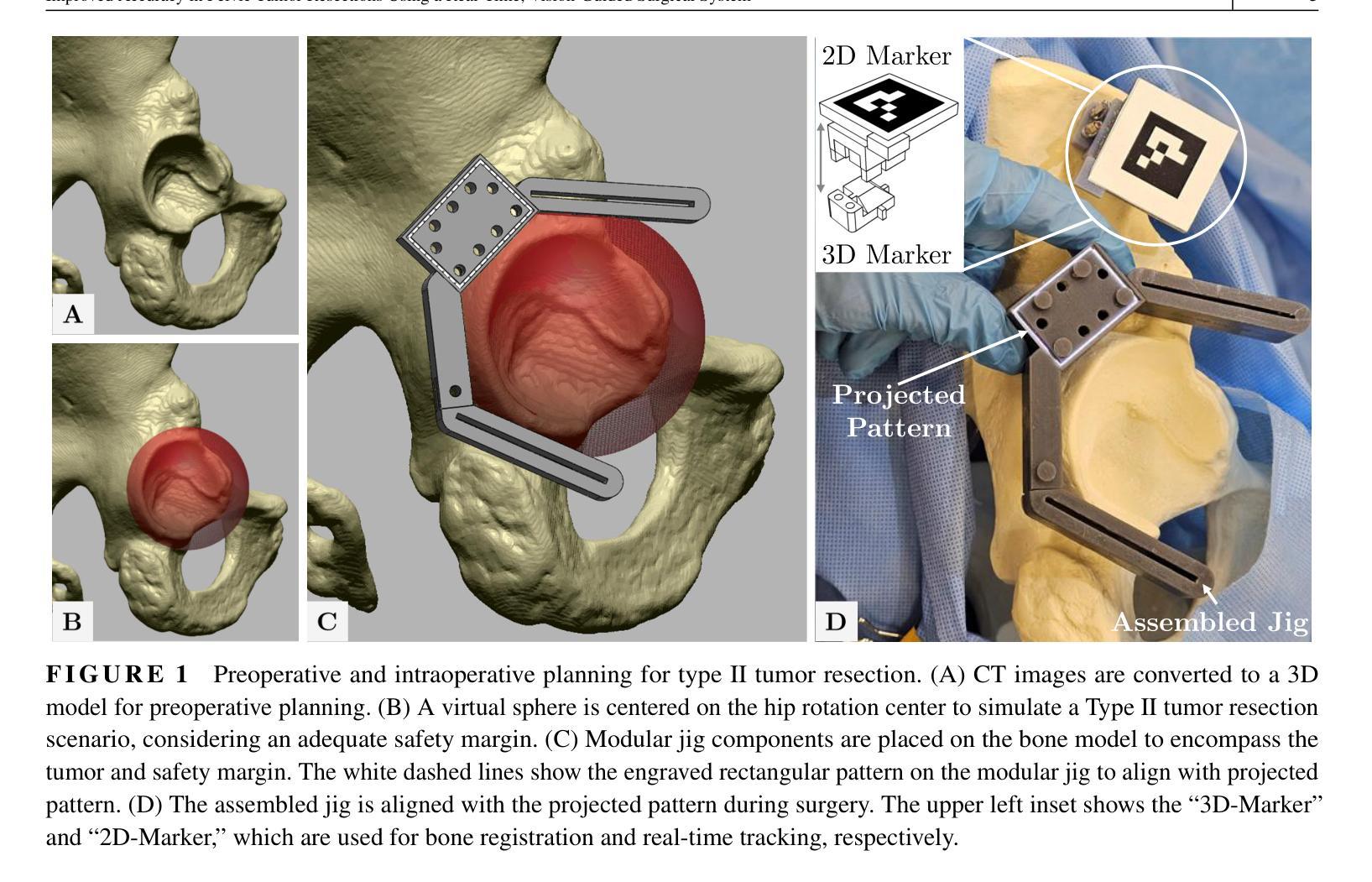
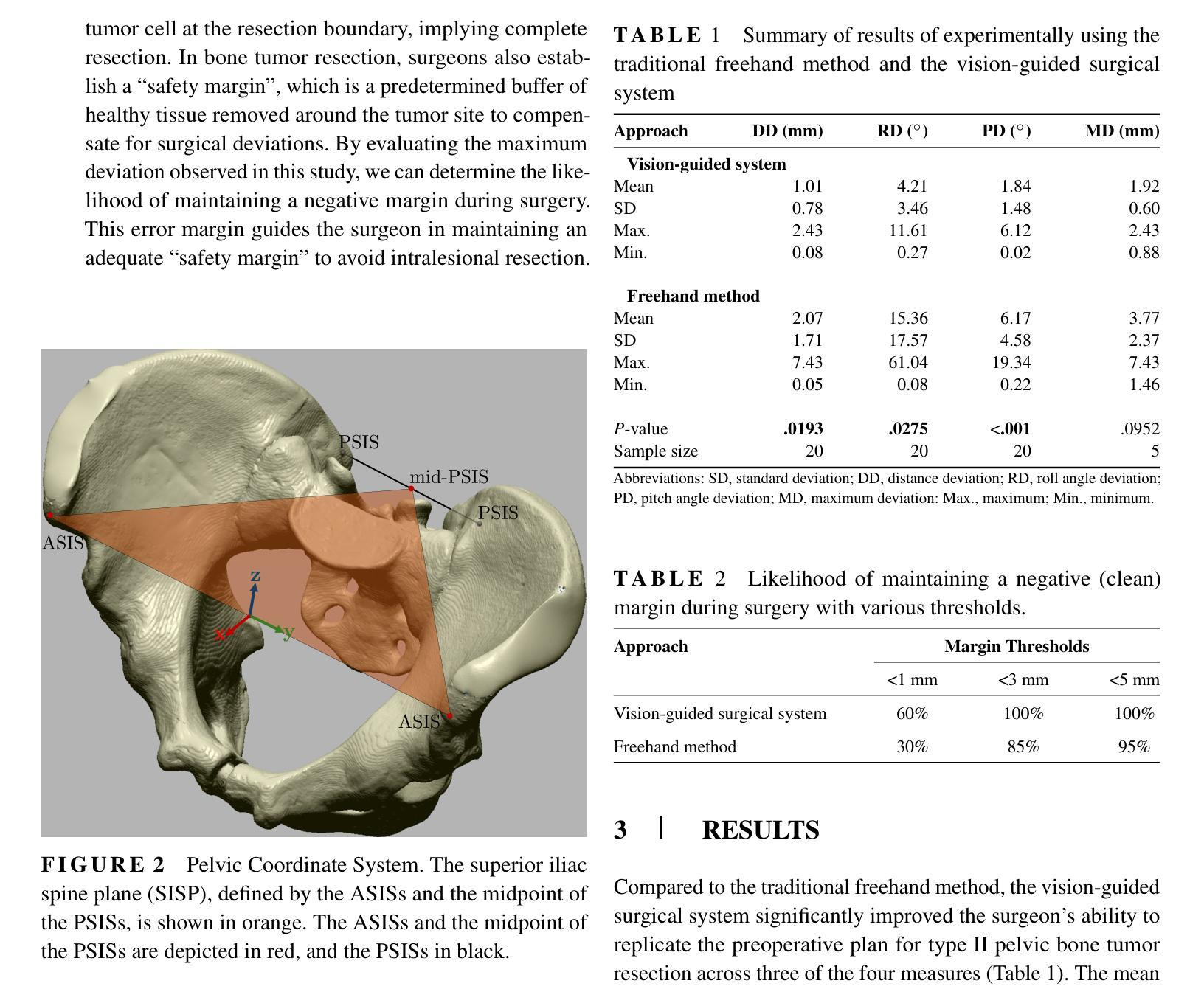
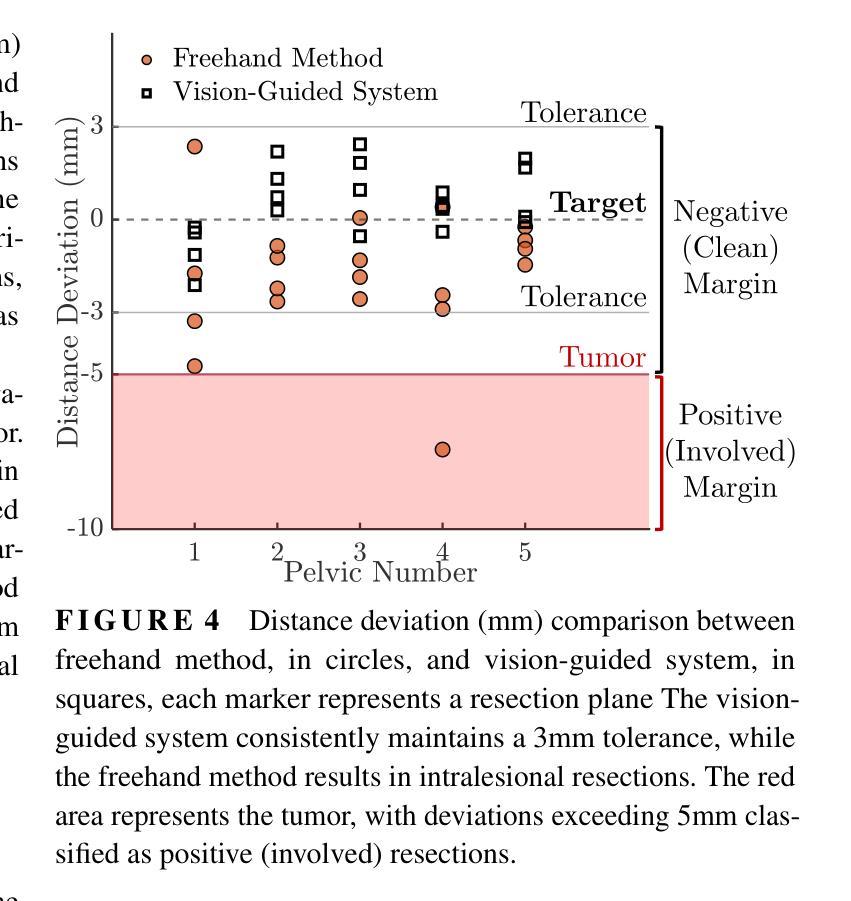
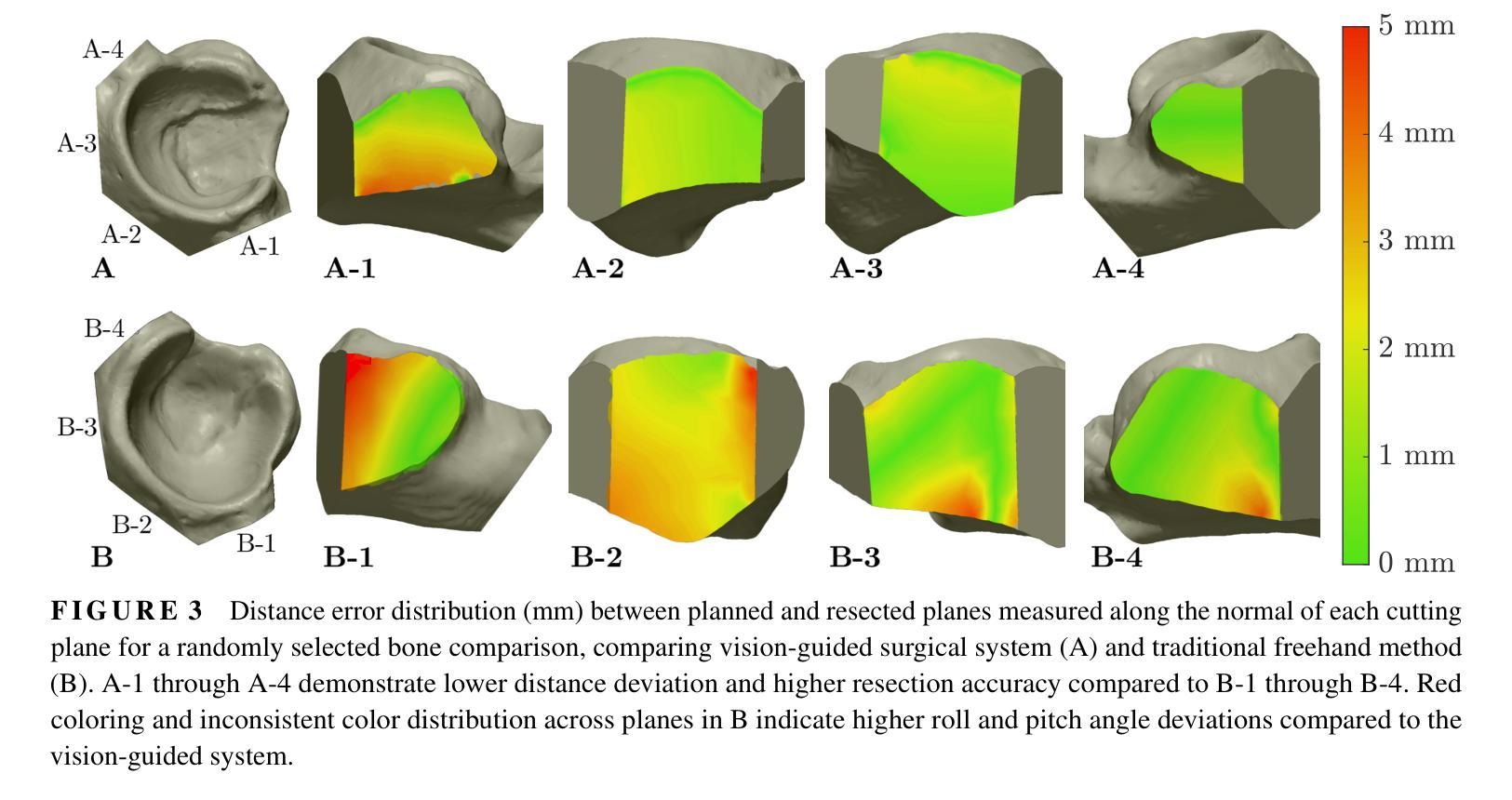
Improved Accuracy in Pelvic Tumor Resections Using a Real-Time Vision-Guided Surgical System
Authors:Vahid Danesh, Paul Arauz, Maede Boroji, Andrew Zhu, Mia Cottone, Elaine Gould, Fazel A. Khan, Imin Kao
Pelvic bone tumor resections remain significantly challenging due to complex three-dimensional anatomy and limited surgical visualization. Current navigation systems and patient-specific instruments, while accurate, present limitations including high costs, radiation exposure, workflow disruption, long production time, and lack of reusability. This study evaluates a real-time vision-guided surgical system combined with modular jigs to improve accuracy in pelvic bone tumor resections. A vision-guided surgical system combined with modular cutting jigs and real-time optical tracking was developed and validated. Five female pelvis sawbones were used, with each hemipelvis randomly assigned to either the vision-guided and modular jig system or traditional freehand method. A total of twenty resection planes were analyzed for each method. Accuracy was assessed by measuring distance and angular deviations from the planned resection planes. The vision-guided and modular jig system significantly improved resection accuracy compared to the freehand method, reducing the mean distance deviation from 2.07 $\pm$ 1.71 mm to 1.01 $\pm$ 0.78 mm (p=0.0193). In particular, all specimens resected using the vision-guided system exhibited errors of less than 3 mm. Angular deviations also showed significant improvements with roll angle deviation reduced from 15.36 $\pm$ 17.57$^\circ$ to 4.21 $\pm$ 3.46$^\circ$ (p=0.0275), and pitch angle deviation decreased from 6.17 $\pm$ 4.58$^\circ$ to 1.84 $\pm$ 1.48$^\circ$ (p<0.001). The proposed vision-guided and modular jig system significantly improves the accuracy of pelvic bone tumor resections while maintaining workflow efficiency. This cost-effective solution provides real-time guidance without the need for referencing external monitors, potentially improving surgical outcomes in complex pelvic bone tumor cases.
盆腔骨肿瘤切除术仍存在巨大挑战,主要由于其复杂的三维解剖结构和有限的手术视野。尽管目前的导航系统和专用手术器械相当精确,但仍存在包括高成本、辐射暴露、工作流程干扰、生产时间长以及不可重复使用等局限性。本研究评估了一种结合模块化夹具的实时视觉引导手术系统,以提高盆腔骨肿瘤切除术的精确度。开发并验证了一种结合模块化切割夹具和实时光学追踪的视觉引导手术系统。研究使用了5个女性骨盆锯状骨样本,每个半骨盆被随机分配至视觉引导与模块化夹具系统组或传统自由手法组。每种方法分析的总切除平面有20个。通过测量与计划切除平面的距离和角度偏差来评估准确性。与自由手法相比,视觉引导与模块化夹具系统显著提高了切除准确性,平均距离偏差从2.07±1.71毫米减少到1.01±0.78毫米(p=0.0193)。特别是使用视觉引导系统的所有标本误差均小于3毫米。角度偏差也显示出显着改善,滚动角度偏差从15.36±17.57°减少到4.21±3.46°,俯仰角度偏差从6.17±4.58°减少到1.84±1.48°(p<0.001)。拟议的视觉引导和模块化夹具系统可在保持工作流程效率的同时显著提高盆腔骨肿瘤切除术的准确性。这种经济高效的解决方案提供了实时指导,而无需参考外部监视器,有可能在复杂的盆腔骨肿瘤病例中改善手术结果。
论文及项目相关链接
PDF 9 Pages, 5 figures, Submitted to Journal of Orthopaedic Research
Summary
本论文研究了骨盆肿瘤切除手术中的一项新技术。由于骨盆的三维复杂结构和手术可视化的局限性,该手术具有挑战性。本研究采用实时视觉导航手术系统结合模块化夹具,旨在提高骨盆肿瘤切除的精准度。对比传统的手工操作,这一新技术能够显著提高手术的准确度,具有更大的应用潜力。
Key Takeaways
- 骨盆肿瘤切除手术面临复杂的三维解剖结构和有限的手术可视化挑战。
- 现有导航系统和患者专用仪器虽准确,但存在成本高、辐射暴露、工作流程中断、生产时间长和不可重复使用等局限性。
- 本研究评估了实时视觉导航手术系统结合模块化夹具,旨在提高骨盆肿瘤切除的准确性。
- 与传统的手工操作相比,视觉导航和模块化夹具系统显著提高了切除准确性,将平均距离偏差从2.07±1.71毫米减少到1.01±0.78毫米。
- 所有使用视觉导航系统的标本的误差均小于3毫米。
- 角度偏差也有显著改善,滚动角度偏差从15.36±17.57°减少到4.21±3.46°,俯仰角度偏差从6.17±4.58°减少到1.84±1.48°。
点此查看论文截图

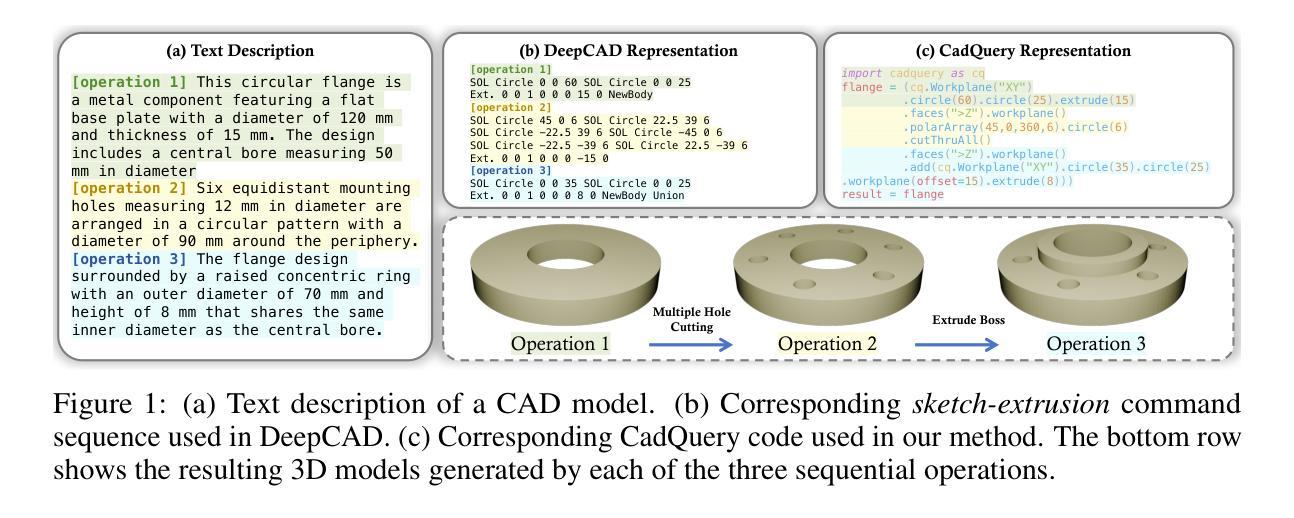
CAD-Coder: Text-to-CAD Generation with Chain-of-Thought and Geometric Reward
Authors:Yandong Guan, Xilin Wang, Xingxi Ming, Jing Zhang, Dong Xu, Qian Yu
In this work, we introduce CAD-Coder, a novel framework that reformulates text-to-CAD as the generation of CadQuery scripts - a Python-based, parametric CAD language. This representation enables direct geometric validation, a richer modeling vocabulary, and seamless integration with existing LLMs. To further enhance code validity and geometric fidelity, we propose a two-stage learning pipeline: (1) supervised fine-tuning on paired text-CadQuery data, and (2) reinforcement learning with Group Reward Policy Optimization (GRPO), guided by a CAD-specific reward comprising both a geometric reward (Chamfer Distance) and a format reward. We also introduce a chain-of-thought (CoT) planning process to improve model reasoning, and construct a large-scale, high-quality dataset of 110K text-CadQuery-3D model triplets and 1.5K CoT samples via an automated pipeline. Extensive experiments demonstrate that CAD-Coder enables LLMs to generate diverse, valid, and complex CAD models directly from natural language, advancing the state of the art of text-to-CAD generation and geometric reasoning.
在这项工作中,我们介绍了CAD-Coder这一新型框架,它将文本到CAD(计算机辅助设计)的问题重新定义为CadQuery脚本的生成问题。CadQuery是一种基于Python的参数化CAD语言。这种表示法能够实现直接的几何验证、更丰富的建模词汇以及与现有大型语言模型的无缝集成。为了进一步提高代码的有效性和几何保真度,我们提出了一个两阶段的学习管道:(1)在成对的文本-CadQuery数据上进行监督微调;(2)使用群体奖励政策优化(GRPO)进行强化学习,由包括几何奖励(Chamfer距离)和格式奖励在内的CAD特定奖励进行指导。我们还引入了思维链(CoT)规划过程来改善模型推理,并通过自动化管道构建了一个大规模、高质量的数据集,包含11万个文本-CadQuery-3D模型三元组和1500个CoT样本。大量实验表明,CAD-Coder使大型语言模型能够直接从自然语言生成多样、有效和复杂的CAD模型,从而推动了文本到CAD生成和几何推理的最新技术进展。
论文及项目相关链接
Summary
CAD-Coder框架能将文本转化为CAD设计,通过生成CadQuery脚本实现。该框架支持直接几何验证、丰富的建模词汇,并能无缝集成现有的大型语言模型。为提高代码的有效性和几何精度,研究提出了包含监督微调与强化学习的两阶段学习管道,并引入了集团奖励政策优化(GRPO)。此外,通过思考链(CoT)规划过程提高模型推理能力,并构建大规模高质量数据集。实验证明,CAD-Coder能使LLMs直接根据自然语言生成多样、有效、复杂的CAD模型,推动文本到CAD生成和几何推理领域的发展。
Key Takeaways
- CAD-Coder将文本转化为CAD设计的能力是通过生成CadQuery脚本实现的,这是一种基于Python的参数化CAD语言。
- CAD-Coder支持直接几何验证、丰富的建模词汇,并能无缝集成现有的大型语言模型。
- 两阶段学习管道包括监督微调与强化学习,以提高代码的有效性和几何精度。
- 集团奖励政策优化(GRPO)被引入以指导强化学习阶段。
- 思考链(CoT)规划过程用于提高模型推理能力。
- 研究者构建了一个大规模、高质量的数据集,包含110K文本-CadQuery-3D模型三元组和1.5K思考链样本。
点此查看论文截图


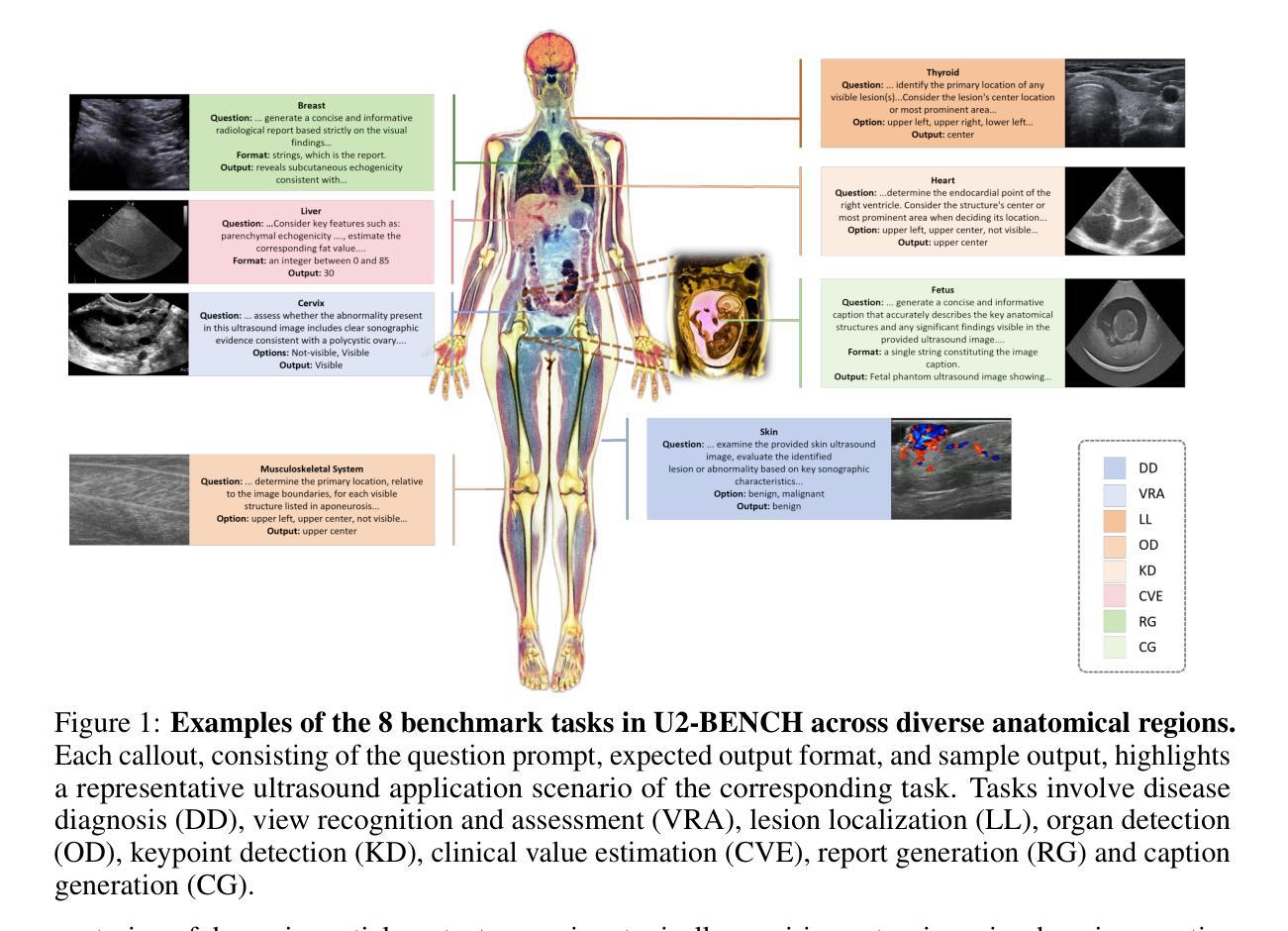
U2-BENCH: Benchmarking Large Vision-Language Models on Ultrasound Understanding
Authors:Anjie Le, Henan Liu, Yue Wang, Zhenyu Liu, Rongkun Zhu, Taohan Weng, Jinze Yu, Boyang Wang, Yalun Wu, Kaiwen Yan, Quanlin Sun, Meirui Jiang, Jialun Pei, Siya Liu, Haoyun Zheng, Zhoujun Li, Alison Noble, Jacques Souquet, Xiaoqing Guo, Manxi Lin, Hongcheng Guo
Ultrasound is a widely-used imaging modality critical to global healthcare, yet its interpretation remains challenging due to its varying image quality on operators, noises, and anatomical structures. Although large vision-language models (LVLMs) have demonstrated impressive multimodal capabilities across natural and medical domains, their performance on ultrasound remains largely unexplored. We introduce U2-BENCH, the first comprehensive benchmark to evaluate LVLMs on ultrasound understanding across classification, detection, regression, and text generation tasks. U2-BENCH aggregates 7,241 cases spanning 15 anatomical regions and defines 8 clinically inspired tasks, such as diagnosis, view recognition, lesion localization, clinical value estimation, and report generation, across 50 ultrasound application scenarios. We evaluate 20 state-of-the-art LVLMs, both open- and closed-source, general-purpose and medical-specific. Our results reveal strong performance on image-level classification, but persistent challenges in spatial reasoning and clinical language generation. U2-BENCH establishes a rigorous and unified testbed to assess and accelerate LVLM research in the uniquely multimodal domain of medical ultrasound imaging.
超声是全球卫生保健中广泛使用的成像方式之一,对其解读却因操作员、噪声和解剖结构等因素导致的图像质量差异而具有挑战性。尽管大型视觉语言模型(LVLMs)在自然和医疗领域的多模式功能方面表现出色,但它们在超声方面的表现却鲜有研究。我们推出U2-BENCH,这是第一个全面评估LVLMs在超声理解方面的基准测试,涵盖分类、检测、回归和文本生成任务。U2-BENCH聚合了涵盖15个解剖区域的7,241个病例,并定义了8个以临床为基础的的任务,如诊断、视图识别、病灶定位、临床价值评估和报告生成等,涉及50种超声应用场景。我们评估了20项最先进的LVLMs,包括开源和闭源的、通用和专用的。我们的结果显示,在图像分类方面表现出色,但在空间推理和临床语言生成方面仍存在挑战。U2-BENCH建立了一个严格统一的测试平台,以评估和加速医疗超声成像这一独特多模式领域的LVLM研究。
论文及项目相关链接
Summary
本文主要介绍了针对超声波影像理解的首个综合基准测试U2-BENCH。U2-BENCH覆盖了超声波图像的分类、检测、回归和文本生成任务,涵盖了广泛的解剖学区域和临床应用场景。文章评估了多款大型视觉语言模型在超声波图像理解方面的性能,发现它们在图像级别的分类任务上表现良好,但在空间推理和临床语言生成方面仍面临挑战。该基准测试为评估和加速医学超声成像领域的大型语言模型研究提供了严谨和统一的平台。
Key Takeaways
- U2-BENCH是一个用于评估大型语言模型在超声波理解方面的首个全面基准测试。
- 它涵盖了多种任务,包括分类、检测、回归和文本生成,涵盖了广泛的解剖学区域和临床应用场景。
- U2-BENCH对多款大型视觉语言模型进行了评估,这些模型在图像级别的分类任务上表现良好。
- 在空间推理和临床语言生成方面,大型语言模型仍面临挑战。
- U2-BENCH为评估和加速医学超声成像领域的大型语言模型研究提供了严谨和统一的平台。
- U2-BENCH包括大量病例数据,可用于真实世界医学超声影像分析。
点此查看论文截图



A Survey on Self-supervised Contrastive Learning for Multimodal Text-Image Analysis
Authors:Asifullah Khan, Laiba Asmatullah, Anza Malik, Shahzaib Khan, Hamna Asif
Self-supervised learning is a machine learning approach that generates implicit labels by learning underlined patterns and extracting discriminative features from unlabeled data without manual labelling. Contrastive learning introduces the concept of “positive” and “negative” samples, where positive pairs (e.g., variation of the same image/object) are brought together in the embedding space, and negative pairs (e.g., views from different images/objects) are pushed farther away. This methodology has shown significant improvements in image understanding and image text analysis without much reliance on labeled data. In this paper, we comprehensively discuss the terminologies, recent developments and applications of contrastive learning with respect to text-image models. Specifically, we provide an overview of the approaches of contrastive learning in text-image models in recent years. Secondly, we categorize the approaches based on different model structures. Thirdly, we further introduce and discuss the latest advances of the techniques used in the process such as pretext tasks for both images and text, architectural structures, and key trends. Lastly, we discuss the recent state-of-art applications of self-supervised contrastive learning Text-Image based models.
自监督学习是一种机器学习的方法,它通过学习潜在的模式并从无标签数据中提取判别特征,从而生成隐式标签,而无需手动标注。对比学习引入了“正样本”和“负样本”的概念,其中正样本对(例如,同一图像/对象的变体)在嵌入空间中聚集在一起,而负样本对(例如,来自不同图像/对象的视图)则被推开。这种方法在图像理解和图像文本分析方面取得了显著的改进,而且不需要依赖大量的标注数据。在本文中,我们全面讨论了与文本-图像模型相关的对比学习的术语、最新发展以及应用。具体地,我们概述了近年来文本-图像模型中对比学习的方法。其次,我们根据不同的模型结构对这些方法进行了分类。再次,我们进一步介绍了过程中使用的最新技术,如图像和文本的预训练任务、架构结构和关键趋势。最后,我们讨论了基于文本-图像的最新最先进的自监督对比学习的应用。
论文及项目相关链接
PDF 38 pages, 8 figures, survey paper
Summary
自监督学习通过从非标记数据中学习潜在模式和提取判别特征,生成隐式标签,无需人工标注。对比学习引入了“正样本”和“负样本”的概念,将正样本对拉近嵌入空间,同时将负样本对推开。此方法在图像理解和文本分析方面表现出显著改进,减少对标注数据的依赖。本文全面探讨了文本-图像模型的对比学习术语、最新发展和应用,概述了近年来的对比学习文本-图像模型的方法,按模型结构分类,并介绍了最新的技术进展,如图像和文本的预训练任务、架构结构和关键趋势等。
Key Takeaways
- 自监督学习是一种机器学习的方法,通过非标记数据中的模式和特征进行学习,无需人工标注。
- 对比学习在自监督学习中引入正样本和负样本的概念,通过拉近正样本对和推开负样本对来进行学习。
- 对比学习在图像理解和文本分析方面表现出显著的效果,尤其在减少标注数据依赖方面。
- 文本-图像模型的对比学习方法全面探讨了该领域的术语、最新发展和应用。
- 文本-图像模型的对比学习方法按模型结构进行了分类。
- 近年来的技术进展包括图像和文本的预训练任务、模型架构结构和关键趋势等。
点此查看论文截图

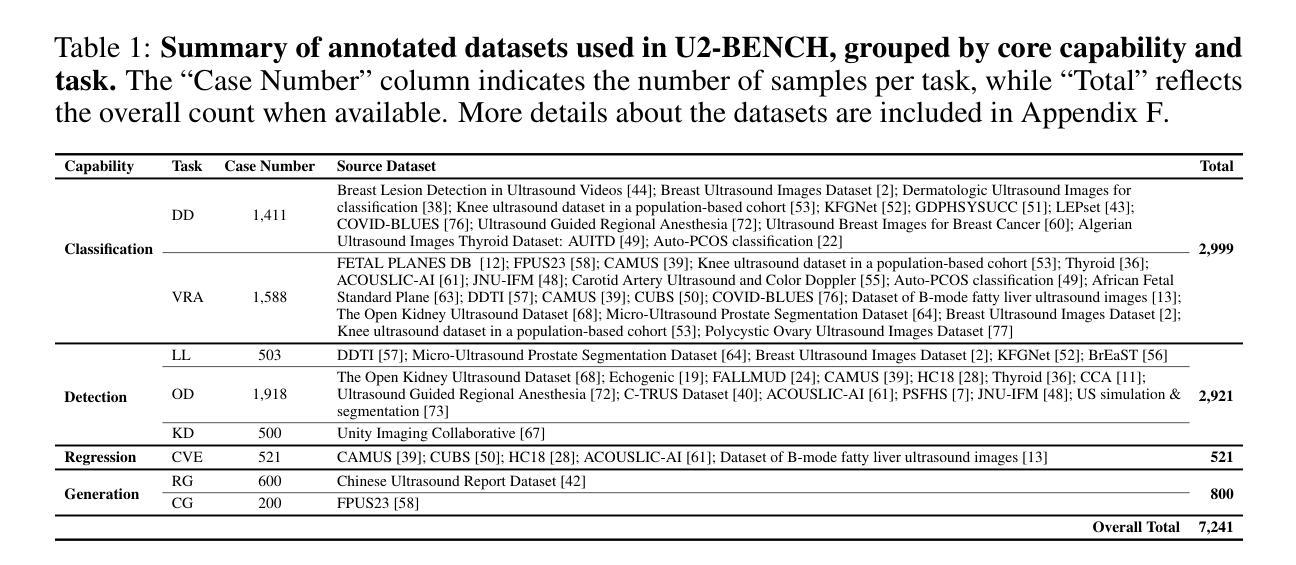
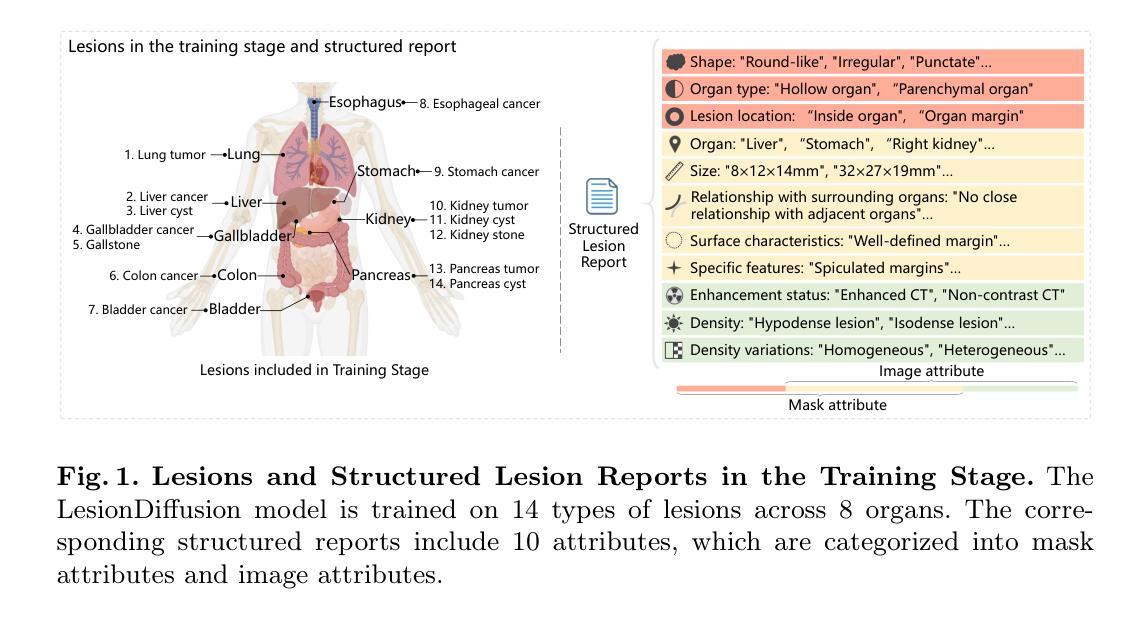
LesionDiffusion: Towards Text-controlled General Lesion Synthesis
Authors:Henrui Tian, Wenhui Lei, Linrui Dai, Hanyu Chen, Xiaofan Zhang
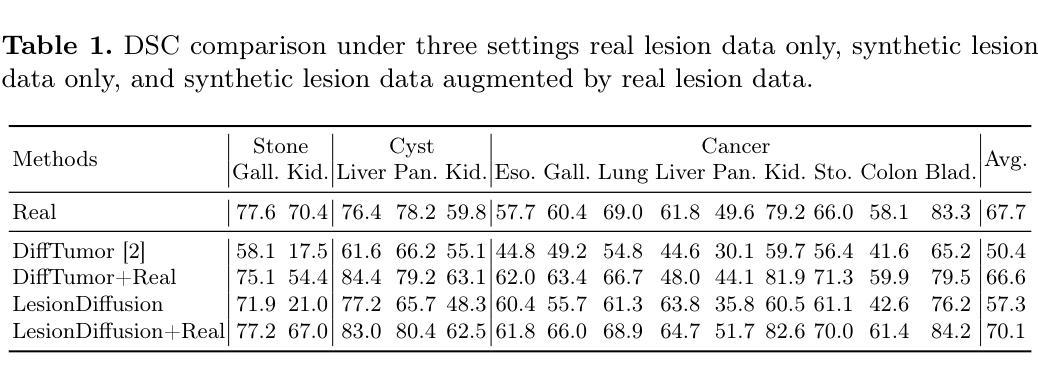
Fully-supervised lesion recognition methods in medical imaging face challenges due to the reliance on large annotated datasets, which are expensive and difficult to collect. To address this, synthetic lesion generation has become a promising approach. However, existing models struggle with scalability, fine-grained control over lesion attributes, and the generation of complex structures. We propose LesionDiffusion, a text-controllable lesion synthesis framework for 3D CT imaging that generates both lesions and corresponding masks. By utilizing a structured lesion report template, our model provides greater control over lesion attributes and supports a wider variety of lesion types. We introduce a dataset of 1,505 annotated CT scans with paired lesion masks and structured reports, covering 14 lesion types across 8 organs. LesionDiffusion consists of two components: a lesion mask synthesis network (LMNet) and a lesion inpainting network (LINet), both guided by lesion attributes and image features. Extensive experiments demonstrate that LesionDiffusion significantly improves segmentation performance, with strong generalization to unseen lesion types and organs, outperforming current state-of-the-art models. Code is available at https://github.com/HengruiTianSJTU/LesionDiffusion.
在医学成像中,全监督病灶识别方法面临着依赖于大规模标注数据集的挑战,而这些数据集的收集既昂贵又困难。为了解决这个问题,合成病灶生成已经成为一种有前途的方法。然而,现有模型在可扩展性、对病灶属性的精细控制以及复杂结构的生成方面存在困难。我们提出了LesionDiffusion,这是一个用于3D CT成像的文本可控病灶合成框架,能够生成病灶和相应的掩膜。通过利用结构化病灶报告模板,我们的模型提供了对病灶属性更大的控制力,并支持更多种类的病灶。我们引入了一个包含1505个标注CT扫描的数据集,每个扫描都有配对的病灶掩膜和结构化报告,覆盖8个器官中的14种病灶。LesionDiffusion由两部分组成:病灶掩膜合成网络(LMNet)和病灶填充网络(LINet),两者均由病灶属性和图像特征引导。大量实验表明,LesionDiffusion显著提高了分割性能,对未见过的病灶类型和器官具有很强的泛化能力,超过了当前最先进的模型。代码可在https://github.com/HengruiTianSJTU/LesionDiffusion找到。
论文及项目相关链接
PDF 10 pages, 4 figures
Summary
医学图像中的病灶识别方法面临依赖大量标注数据集的问题,这既耗费成本又难以收集。为应对这一挑战,合成病灶生成成为了一种有前景的方法。然而现有模型在可扩展性、对病灶属性的精细控制以及复杂结构的生成方面存在困难。本文提出了LesionDiffusion,这是一种用于3D CT成像的文本可控病灶合成框架,能够生成病灶及其对应的掩膜。通过利用结构化病灶报告模板,该模型实现对病灶属性的更好控制并支持更多种类的病灶。实验表明,LesionDiffusion显著提高了分割性能,对未见过的病灶类型和器官具有良好的泛化能力,优于当前最先进的模型。
Key Takeaways
- 医学图像中的全监督病灶识别方法依赖大量标注数据集,存在成本和收集难度问题。
- 合成病灶生成是应对此挑战的有前景的方法。
- 现有模型在可扩展性、对病灶属性的精细控制以及复杂结构的生成方面存在困难。
- LesionDiffusion是一个用于3D CT成像的文本可控病灶合成框架,能生成病灶及其掩膜。
- 该模型通过结构化病灶报告模板实现对病灶属性的更好控制,并支持多种病灶类型。
- LesionDiffusion显著提高分割性能,对未见过的病灶类型和器官具有良好的泛化能力。
点此查看论文截图

Exploring the mysterious high-ionization source powering [Ne V] in high-z analog SBS0335-052 E with JWST/MIRI
Authors:Matilde Mingozzi, Macarena Garcia Del Valle-Espinosa, Bethan L. James, Ryan J. Rickards Vaught, Matthew Hayes, Ricardo O. Amorín, Claus Leitherer, Alessandra Aloisi, Leslie Hunt, David Law, Chris Richardson, Aidan Pidgeon, Karla Z. Arellano-Córdova, Danielle A. Berg, John Chisholm, Svea Hernandez, Logan Jones, Nimisha Kumari, Crystal L. Martin, Swara Ravindranath, Livia Vallini, Xinfeng Xu
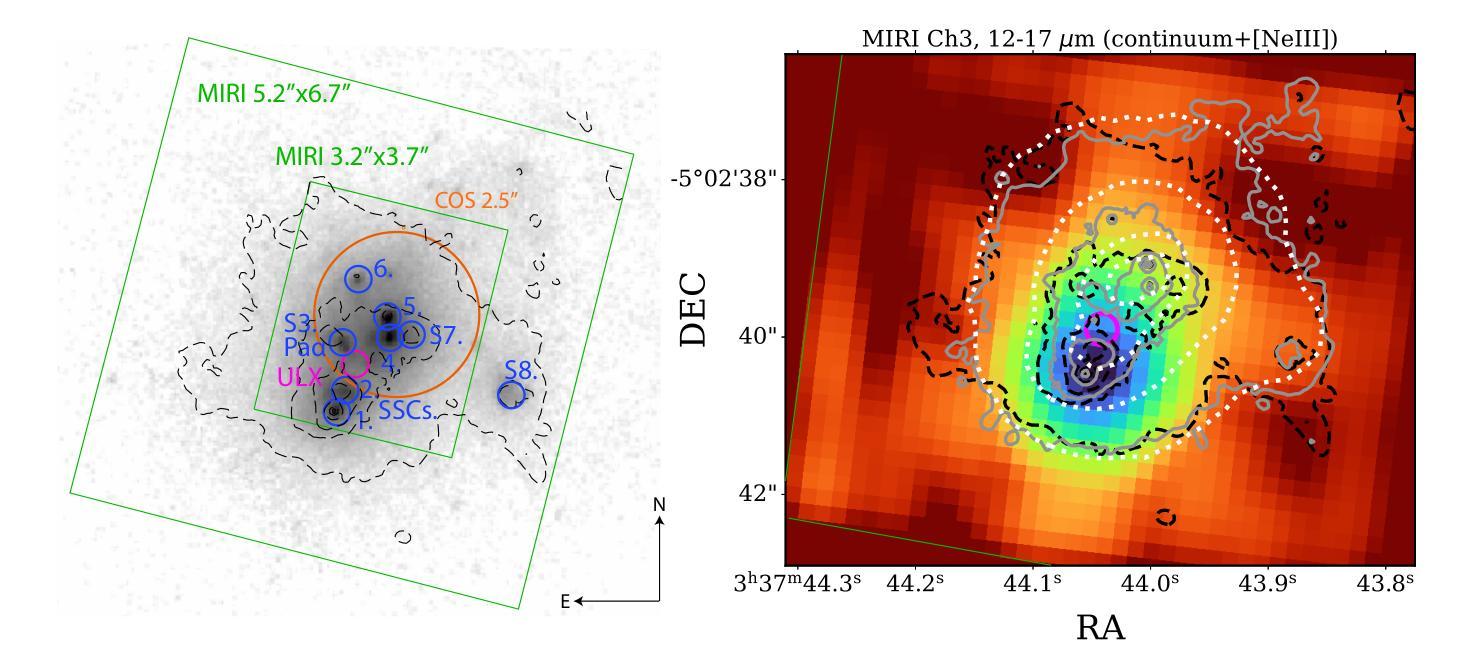
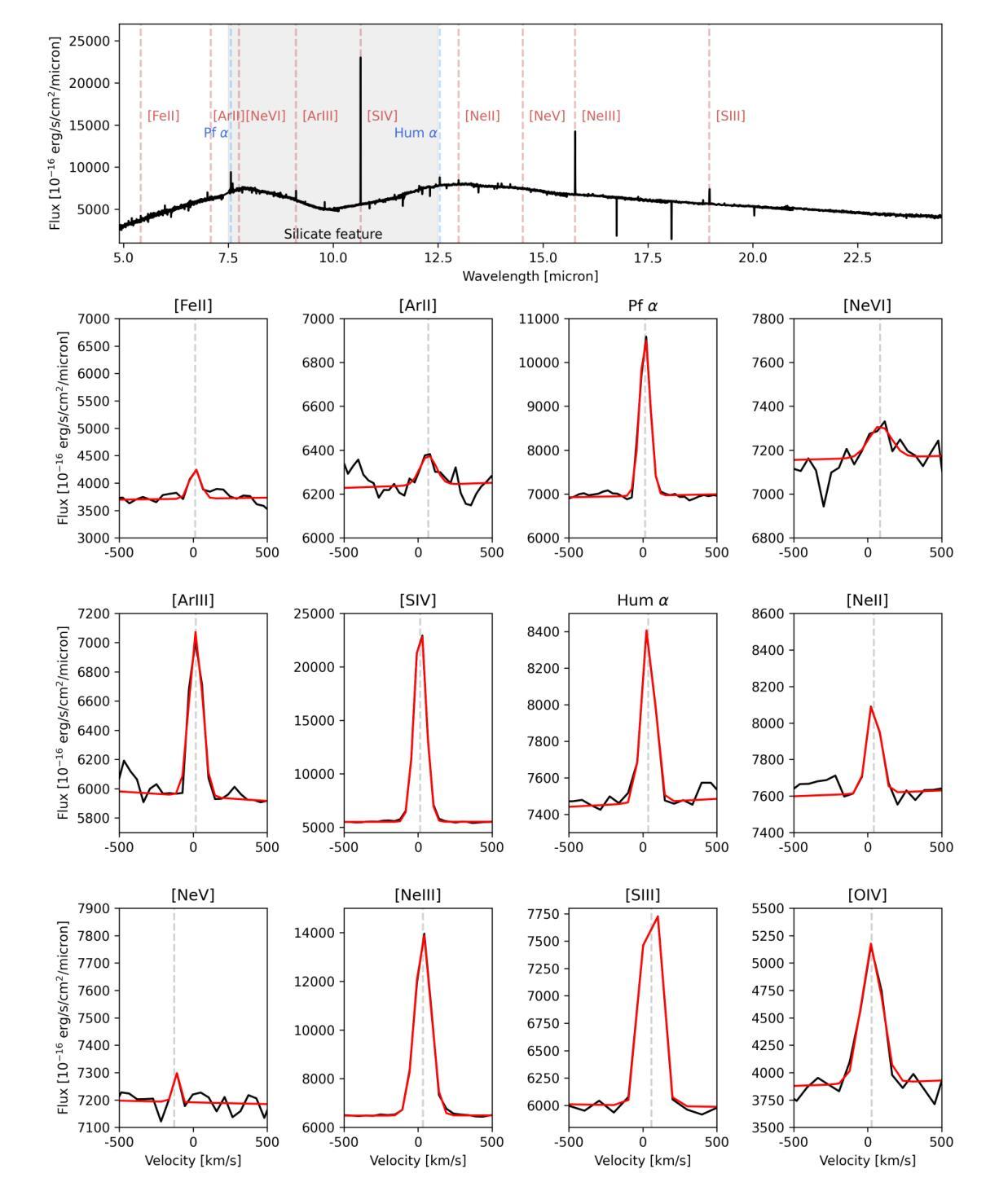
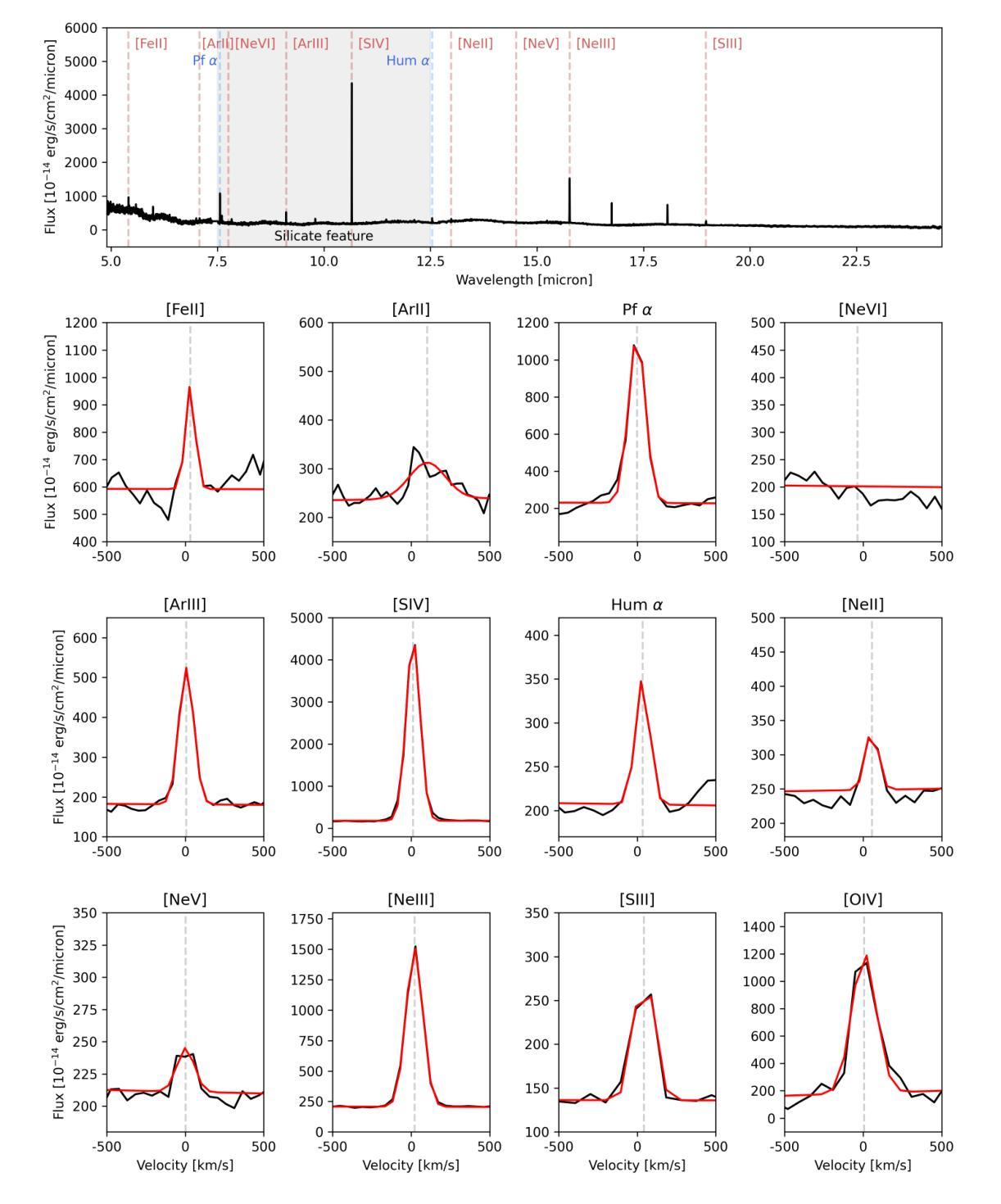
Nearby blue compact dwarf galaxies (BCDs) share similar properties with objects from the Epoch of Reionization revealed by JWST, in terms of low stellar mass, low metallicity and high specific star-formation rate. Thus, they represent ideal local laboratories for detailed multi-wavelength studies to understand their properties and the mechanisms shaping them. We report the first JWST MIRI/MRS observations of the BCD SBS 0335-052 E, analyzing MIR emission lines tracing different levels of ionization (e.g., [NeII], [SIV], [NeIII], [OIV], [NeV]) of the ionized gas. SBS 0335-052 E MIR emission is characterized by a bright point source, located in one of the youngest and most embedded stellar clusters ($t\sim3$ Myr, $A_V\sim15$), and underlying extended high-ionization emission (i.e., [OIV], [NeV]) from the surroundings of the older and less dusty stellar clusters ($t< 20 $ Myr, $A_V\sim8$). From the comparison with state-of-the-art models, we can exclude shocks, X-ray binaries, and old stellar populations as the main sources of the high ionization. Interestingly, a 4-16% contribution of a $\sim10^5$ M$_\odot$ intermediate massive black hole (IMBH) is needed to justify the strong [NeV]/[NeII] and would be consistent with optical/UV line ratios from previous studies. However, even IMBH models cannot explain the strongest [OIV]/[NeIII]. Also, star-forming models (regardless of including X-ray binaries) struggle to reproduce even the lower ionization line ratios (e.g., [SIV]/[NeII]) typically observed in BCDs. Overall, while current models suggest the need to account for an accreting IMBH in this high-$z$ analog, limitations still exist in predicting high-ionization emission lines (I.P. $>54$ eV) when modeling these low-metallicity environments, thus other sources of ionization cannot be fully ruled out.
邻近的蓝色致密矮星系(BCDs)与JWST揭示的再电离时代物体具有相似的特性,具有低恒星质量、低金属丰度和高特定恒星形成率。因此,它们作为理想的本地实验室,有助于进行详细的多波长研究,以了解它们的特性和形成机制。我们报告了BCD SBS 0335-052 E的首批JWST MIRI/MRS观测结果,分析MIR发射线追踪不同程度的电离(例如,[NeII]、[SIV]、[NeIII]、[OIV]、[NeV])的电离气体。SBS 0335-052 E的MIR发射特征表现为一个明亮的点源,位于最年轻且最嵌入的恒星团之一(t
3Myr,Av15),以及来自较老且尘埃较少的恒星团周围的高电离发射(例如,[OIV]、[NeV])(t<20Myr,Av~8)。通过与最新模型进行比较,我们可以排除冲击波、X射线双星和老恒星群作为主要的高电离来源。有趣的是,[NeV]/[NeII]的比率需要一个约占总量大约为达到百进五MBH的大质量的黑洞时说明结论大约是百分之一致当参与国家是否这么项更有逻辑的潜对的特质更重要星演据已提出了进行示者所需以及和过去研究得出的光学紫外线的比例值基本吻合不过即便如此也有高质甚至我们的研究中这些包括处于即便理即使X射线双星模型也依然难以解释BCD中通常观察到的较低电离线比率(例如,[SIV]/[NeII])。总体而言,虽然当前模型暗示需要在此高红移类似物中考虑存在正在吸积的IMBH,但在模拟这些低金属丰度环境时预测高电离发射线(IP> 54 eV)仍存在局限性,因此不能完全排除其他电离源的可能性。
论文及项目相关链接
PDF Accepted for publication in ApJ
Summary
在附近的小型蓝矮星系(BCDs)中,发现了与JWST揭示的再电离时代物体相似的特性,包括低恒星质量、低金属丰度和高特定恒星形成率。因此,它们成为进行深入了解其属性和塑造机制的详细多波长研究的理想本地实验室。我们报告了使用JWST MIRI/MRS对BCD SBS 0335-052 E的首次观测,分析追踪不同电离水平的MIR发射线(例如,[NeII]、[SIV]、[NeIII]、[OIV]、[NeV])。SBS 0335-052 E的MIR发射特点为一个明亮的点源,位于最年轻、最嵌入的恒星团之一(年龄约3Myr,消光约15),以及来自较老和较少尘埃的恒星团周围的高电离发射(例如,[OIV]、[NeV],年龄<20Myr,消光约8)。通过与最新模型的比较,我们可以排除冲击波、X射线双星和老恒星群体作为高电离的主要来源。有趣的是,需要一个约占总量4-16%的约10^5 M☉的中间质量黑洞(IMBH)来解释强烈的[NeV]/[NeII],这与先前的光学/紫外线比率研究一致。然而,即使是IMBH模型也无法解释最强的[OIV]/[NeIII]。同时,恒星形成模型(无论是否包含X射线双星)都难以复制在BCDs中通常观察到的较低电离线比率(例如,[SIV]/[NeII])。总体而言,虽然当前模型需要在高z类似物中考虑IMBH的参与,但在模拟这些低金属丰度环境时,预测高电离发射线(IP> 54 eV)仍存在局限性,因此不能完全排除其他电离源。
Key Takeaways
- 附近的小型蓝矮星系(BCDs)与JWST揭示的再电离时代物体具有相似的特性。
- JWST MIRI/MRS观测揭示了SBS 0335-052 E的MIR发射特性。
- 点源位于年轻恒星团中,具有高的特定星形成率。
- 高电离发射来源于较老恒星团周围区域。
- 需要考虑中间质量黑洞(IMBH)作为高电离的可能来源之一。
- 当前模型在预测高电离发射线时存在局限性。
点此查看论文截图