⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-03 更新
Contrast-Invariant Self-supervised Segmentation for Quantitative Placental MRI
Authors:Xinliu Zhong, Ruiying Liu, Emily S. Nichols, Xuzhe Zhang, Andrew F. Laine, Emma G. Duerden, Yun Wang
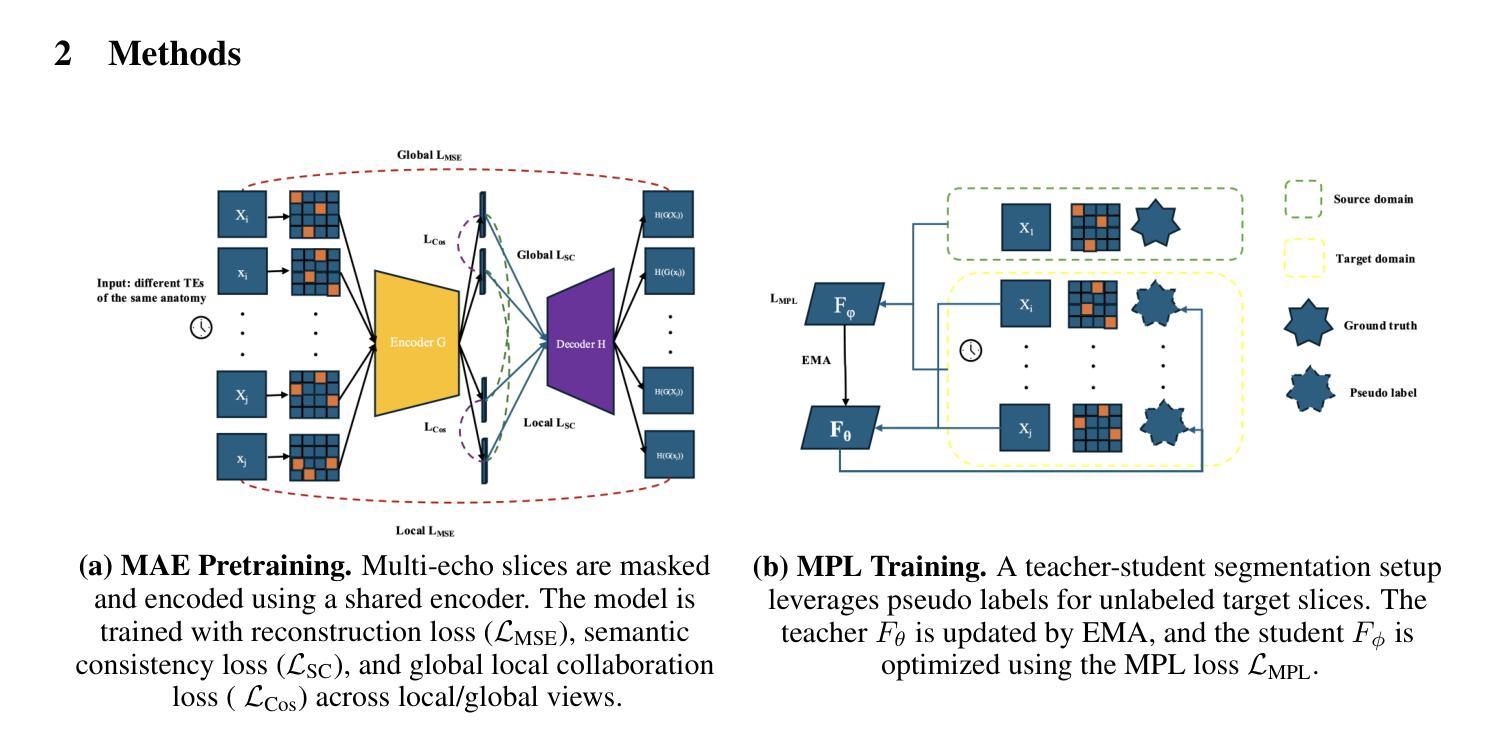
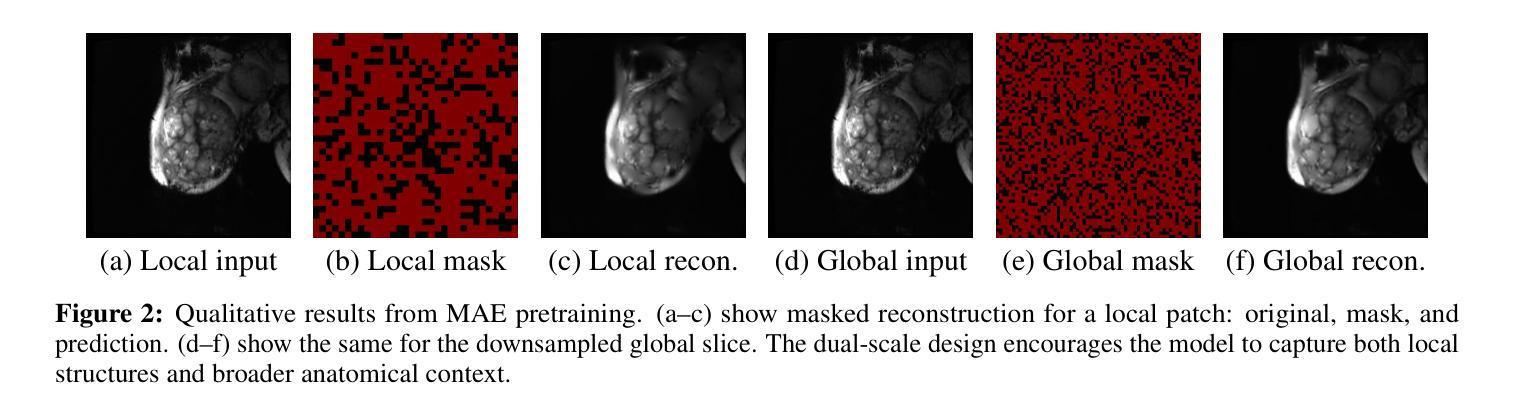
Accurate placental segmentation is essential for quantitative analysis of the placenta. However, this task is particularly challenging in T2*-weighted placental imaging due to: (1) weak and inconsistent boundary contrast across individual echoes; (2) the absence of manual ground truth annotations for all echo times; and (3) motion artifacts across echoes caused by fetal and maternal movement. In this work, we propose a contrast-augmented segmentation framework that leverages complementary information across multi-echo T2*-weighted MRI to learn robust, contrast-invariant representations. Our method integrates: (i) masked autoencoding (MAE) for self-supervised pretraining on unlabeled multi-echo slices; (ii) masked pseudo-labeling (MPL) for unsupervised domain adaptation across echo times; and (iii) global-local collaboration to align fine-grained features with global anatomical context. We further introduce a semantic matching loss to encourage representation consistency across echoes of the same subject. Experiments on a clinical multi-echo placental MRI dataset demonstrate that our approach generalizes effectively across echo times and outperforms both single-echo and naive fusion baselines. To our knowledge, this is the first work to systematically exploit multi-echo T2*-weighted MRI for placental segmentation.
准确的胎盘分割对于胎盘的定量分析至关重要。然而,由于(1)各个回声之间的边界对比度较弱且不一致;(2)所有回声时间没有手动真实标注;(3)胎儿和母体的运动引起的回声运动伪影,因此在T2*-加权胎盘成像中,这一任务特别具有挑战性。在这项工作中,我们提出了一种对比增强分割框架,该框架利用多回声T2*-加权MRI中的互补信息来学习稳健的、对比不变的表示。我们的方法集成了:(i)掩码自动编码(MAE),用于在无标签的多回声切片上进行自监督预训练;(ii)掩码伪标签(MPL),用于不同回声时间的无监督域自适应;(iii)全局-局部协作,以将细粒度特征与全局解剖上下文对齐。我们还引入了一种语义匹配损失,以鼓励同一受试者不同回声之间的表示一致性。在临床多回声胎盘MRI数据集上的实验表明,我们的方法在不同回声时间之间具有良好的泛化能力,并优于单回声和简单融合基线。据我们所知,这是首次系统地利用多回声T2*-加权MRI进行胎盘分割的研究。
论文及项目相关链接
PDF 8 pages, 20 figures
Summary
本文提出一种基于对比增强的分割框架,利用多回声T2*-加权MRI中的互补信息学习稳健、对比不变的表示。该框架集成自监督预训练、无监督域适应、全局局部协作等模块,并在临床多回声胎盘MRI数据集上进行实验验证,该方法在不同回声时间之间具有有效泛化性,并优于单回声和简单融合基线方法。
Key Takeaways
- 准确胎盘分割对胎盘定量分析至关重要。
- T2*-加权胎盘成像中的胎盘分割具有挑战性,主要由于边界对比度弱、回声时间缺少手动真实标注和母子运动引起的运动伪影。
- 提出一种对比增强的分割框架,利用多回声T2*-加权MRI信息。
- 框架包括自监督预训练、无监督域适应和全局局部协作等模块。
- 引入语义匹配损失,以鼓励同一主体不同回声之间的表示一致性。
- 在临床多回声胎盘MRI数据集上验证了方法的有效性。
点此查看论文截图

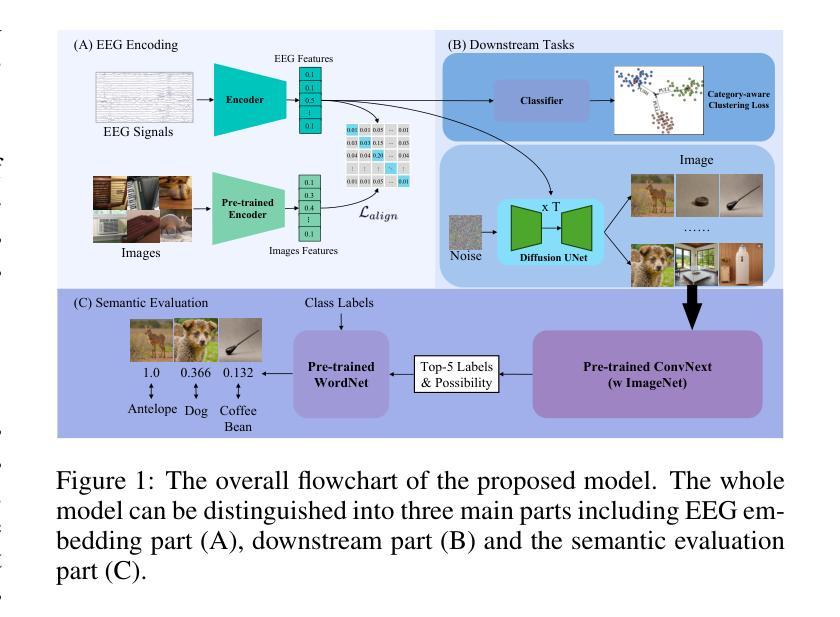
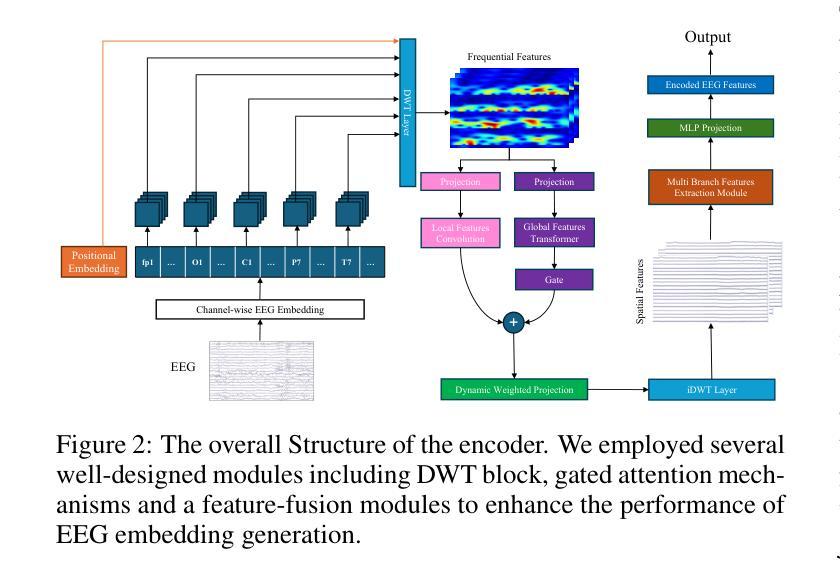
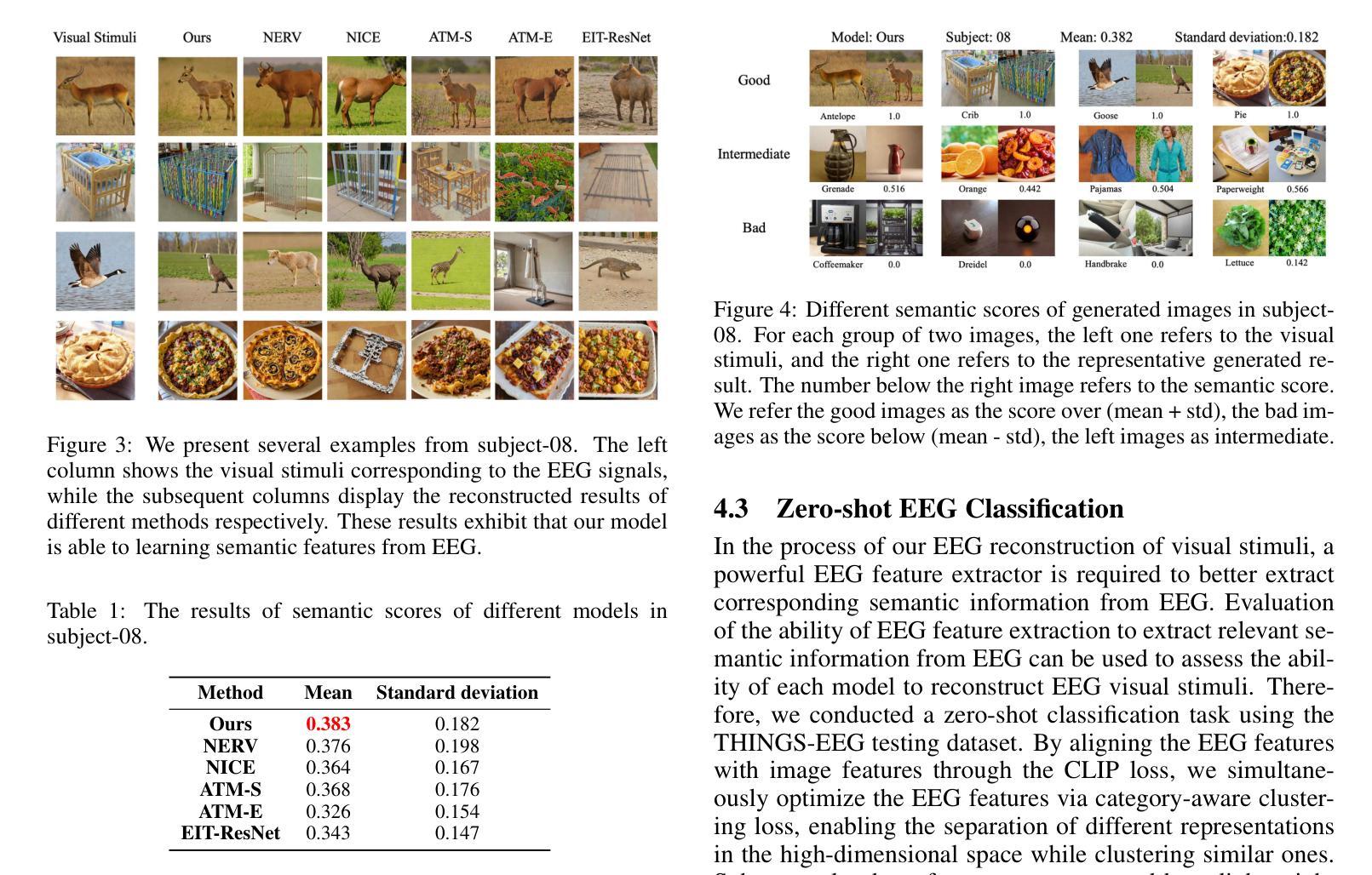
Category-aware EEG image generation based on wavelet transform and contrast semantic loss
Authors:Enshang Zhang, Zhicheng Zhang, Takashi Hanakawa
Reconstructing visual stimuli from EEG signals is a crucial step in realizing brain-computer interfaces. In this paper, we propose a transformer-based EEG signal encoder integrating the Discrete Wavelet Transform (DWT) and the gating mechanism. Guided by the feature alignment and category-aware fusion losses, this encoder is used to extract features related to visual stimuli from EEG signals. Subsequently, with the aid of a pre-trained diffusion model, these features are reconstructed into visual stimuli. To verify the effectiveness of the model, we conducted EEG-to-image generation and classification tasks using the THINGS-EEG dataset. To address the limitations of quantitative analysis at the semantic level, we combined WordNet-based classification and semantic similarity metrics to propose a novel semantic-based score, emphasizing the ability of our model to transfer neural activities into visual representations. Experimental results show that our model significantly improves semantic alignment and classification accuracy, which achieves a maximum single-subject accuracy of 43%, outperforming other state-of-the-art methods. The source code and supplementary material is available at https://github.com/zes0v0inn/DWT_EEG_Reconstruction/tree/main.
从脑电图信号重建视觉刺激是实现脑机接口的关键步骤。在本文中,我们提出了一种基于变压器的脑电图信号编码器,该编码器融合了离散小波变换(DWT)和门控机制。在特征对齐和类别感知融合损失的指导下,该编码器用于从脑电图信号中提取与视觉刺激相关的特征。随后,借助预训练的扩散模型,这些特征被重建为视觉刺激。为了验证模型的有效性,我们在THINGS-EEG数据集上进行了脑电图到图像生成和分类任务。为了解决语义层面定量分析的限制,我们结合了基于WordNet的分类和语义相似性度量,提出了一种新的基于语义的评分方法,强调我们的模型将神经活动转化为视觉表征的能力。实验结果表明,我们的模型在语义对齐和分类精度上有了显著提高,实现了最高达43%的单用户精度,优于其他最先进的方法。源代码和补充材料可在https://github.com/zes0v0inn/DWT_EEG_Reconstruction/tree/main找到。
论文及项目相关链接
Summary
基于EEG信号重构视觉刺激是实现脑机接口的关键步骤。本研究提出了一种结合离散小波变换(DWT)和门控机制的变压器式EEG信号编码器。该编码器通过特征对齐和类别感知融合损失引导,用于从EEG信号中提取与视觉刺激相关的特征。借助预训练的扩散模型,这些特征被重构为视觉刺激。在THINGS-EEG数据集上进行了EEG到图像生成和分类任务以验证模型的有效性。为解决语义层面定量分析的限制,我们结合WordNet分类和语义相似性度量方法,提出了新型语义评分,强调我们的模型将神经活动转化为视觉表征的能力。实验结果表明,我们的模型在语义对齐和分类精度上显著提高,达到最高单主体准确率43%,优于其他最先进的方法。
Key Takeaways
- 本研究提出了一种变压器式EEG信号编码器,结合了离散小波变换(DWT)和门控机制。
- 通过特征对齐和类别感知融合损失引导,编码器能从EEG信号中提取与视觉刺激相关的特征。
- 利用预训练的扩散模型,成功重构从EEG信号提取的特征为视觉刺激。
- 在THING-EEG数据集上进行了EEG到图像生成和分类任务以验证模型有效性。
- 为解决定量分析在语义层面的局限性,结合了WordNet分类和语义相似性度量方法,提出了新型语义评分。
- 实验结果显示,模型在语义对齐和分类精度上表现优异,最高单主体准确率达43%。
点此查看论文截图

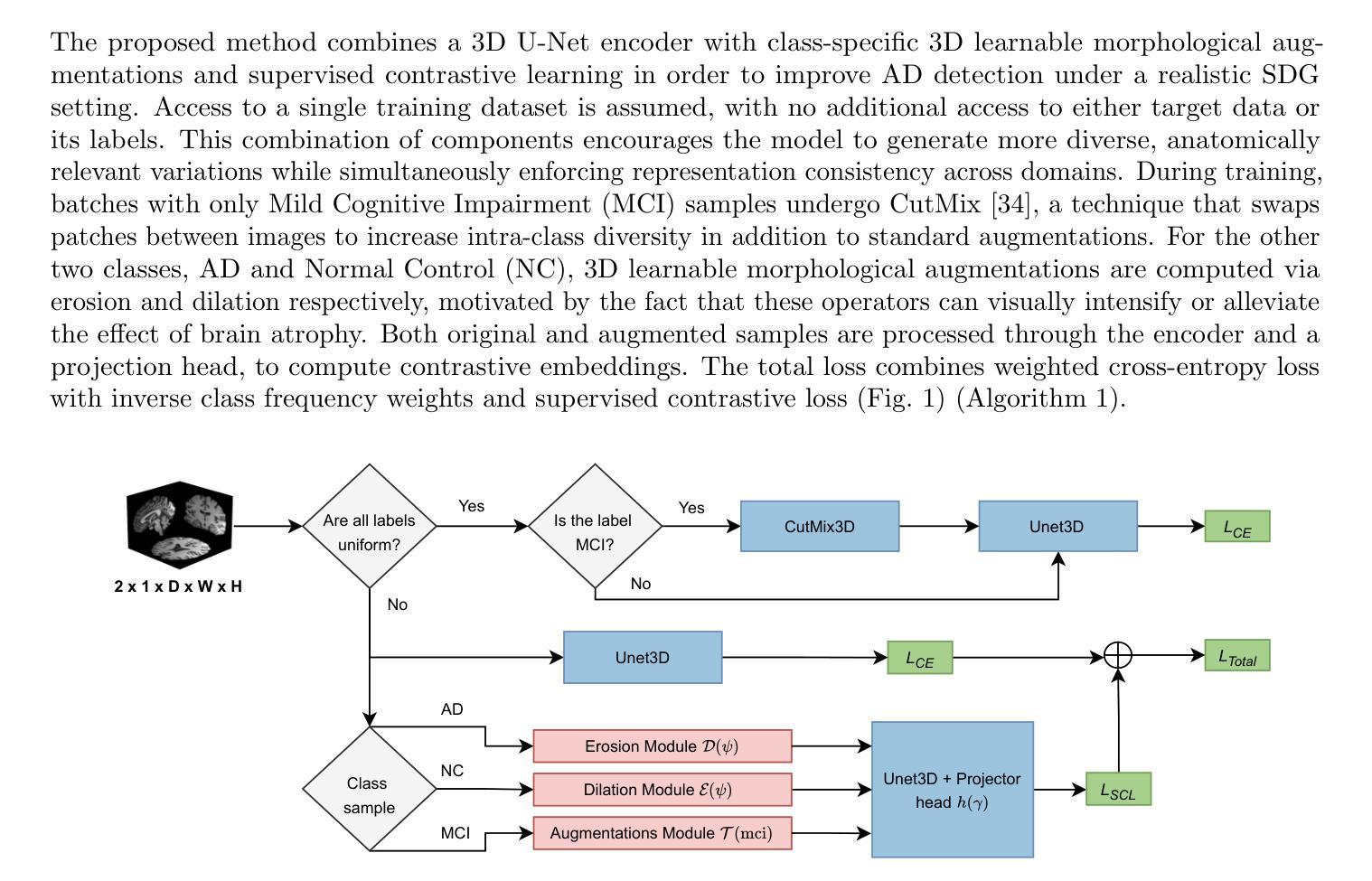
Single Domain Generalization for Alzheimer’s Detection from 3D MRIs with Pseudo-Morphological Augmentations and Contrastive Learning
Authors:Zobia Batool, Huseyin Ozkan, Erchan Aptoula
Although Alzheimer’s disease detection via MRIs has advanced significantly thanks to contemporary deep learning models, challenges such as class imbalance, protocol variations, and limited dataset diversity often hinder their generalization capacity. To address this issue, this article focuses on the single domain generalization setting, where given the data of one domain, a model is designed and developed with maximal performance w.r.t. an unseen domain of distinct distribution. Since brain morphology is known to play a crucial role in Alzheimer’s diagnosis, we propose the use of learnable pseudo-morphological modules aimed at producing shape-aware, anatomically meaningful class-specific augmentations in combination with a supervised contrastive learning module to extract robust class-specific representations. Experiments conducted across three datasets show improved performance and generalization capacity, especially under class imbalance and imaging protocol variations. The source code will be made available upon acceptance at https://github.com/zobia111/SDG-Alzheimer.
尽管通过MRI检测阿尔茨海默病由于当代深度学习模型的进步而取得了显著进展,但类别不平衡、协议变化和数据集多样性有限等挑战往往阻碍了其泛化能力。为了解决这个问题,本文重点关注单一域泛化设置,其中给定一个域的数据,设计并开发一个模型,使其在未见的具有不同分布的域上获得最佳性能。由于已知大脑形态在阿尔茨海默症诊断中起着至关重要的作用,我们建议使用可学习的伪形态模块,旨在产生形状感知、解剖意义明确的类特定增强,并结合监督对比学习模块提取稳健的类特定表示。在三个数据集上进行的实验表明,特别是在类别不平衡和成像协议变化的情况下,提高了性能和泛化能力。源代码将在接受后于https://github.com/zobia111/SDG-Alzheimer上提供。
论文及项目相关链接
Summary
本文探讨通过MRI检测阿尔茨海默病的问题,指出尽管深度学习模型在该领域已取得显著进展,但仍面临类不平衡、协议变化和有限数据集多样性等挑战。文章关注单一域泛化设置,提出使用可学习的伪形态模块,结合监督对比学习模块,旨在产生形状感知、解剖意义强的类特定增强,以提取稳健的类特定表示。实验结果表明,该方法在三个数据集上的性能有所提升,特别是在类不平衡和成像协议变化的情况下。
Key Takeaways
- 深度学习模型在阿尔茨海默病MRI检测中取得显著进展,但仍面临类不平衡、协议变化和有限数据集多样性等挑战。
- 文章关注单一域泛化设置,旨在解决模型在未见域上的泛化能力问题。
- 脑形态在阿尔茨海默病诊断中起关键作用,文章提出使用可学习的伪形态模块来产生形状感知、解剖意义强的类特定增强。
- 结合监督对比学习模块,以提取稳健的类特定表示。
- 实验结果在三份数据集上表现优异,特别是处理类不平衡和成像协议变化的情况。
- 源代码将在接受后公开于https://github.com/zobia111/SDG-Alzheimer。
- 该方法为提高阿尔茨海默病的诊断准确性和泛化能力提供了新的思路。
点此查看论文截图

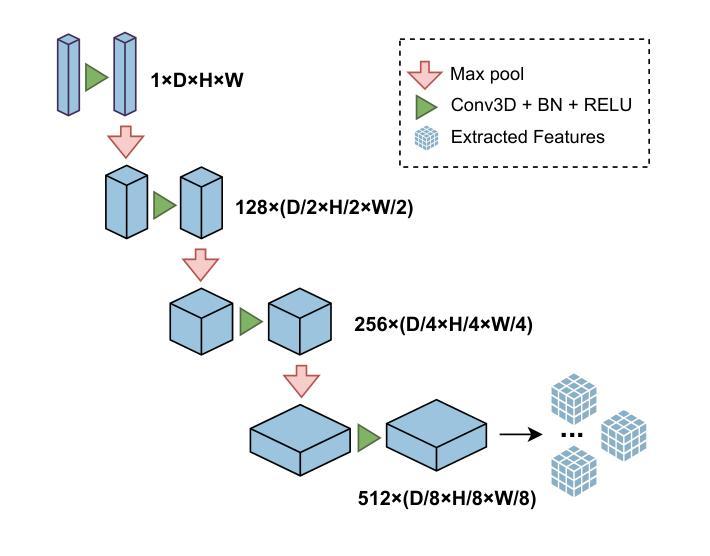
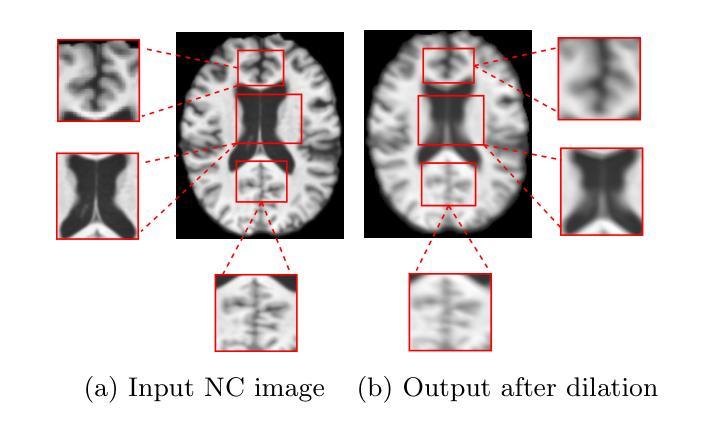
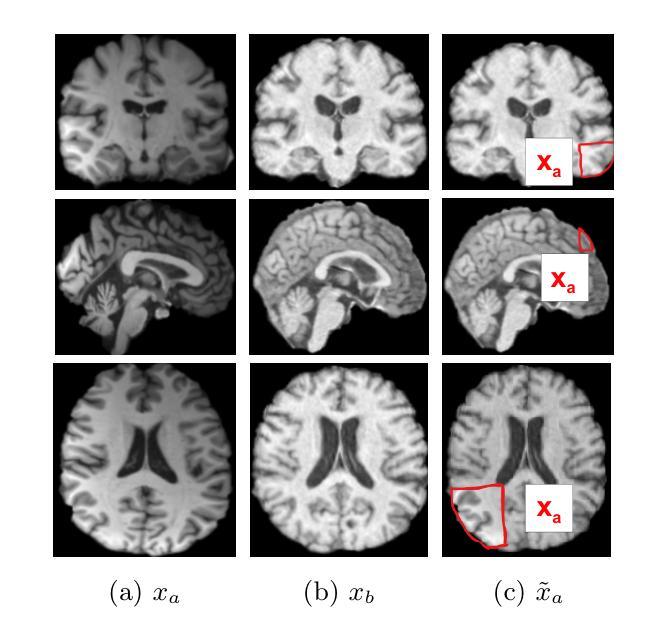
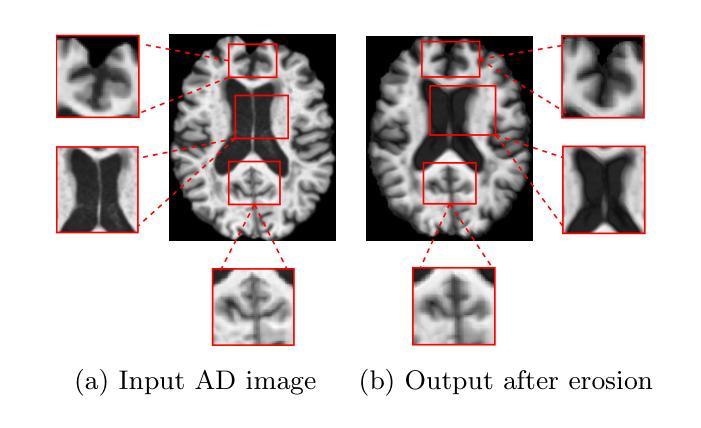
A Survey on Self-supervised Contrastive Learning for Multimodal Text-Image Analysis
Authors:Asifullah Khan, Laiba Asmatullah, Anza Malik, Shahzaib Khan, Hamna Asif
Self-supervised learning is a machine learning approach that generates implicit labels by learning underlined patterns and extracting discriminative features from unlabeled data without manual labelling. Contrastive learning introduces the concept of “positive” and “negative” samples, where positive pairs (e.g., variation of the same image/object) are brought together in the embedding space, and negative pairs (e.g., views from different images/objects) are pushed farther away. This methodology has shown significant improvements in image understanding and image text analysis without much reliance on labeled data. In this paper, we comprehensively discuss the terminologies, recent developments and applications of contrastive learning with respect to text-image models. Specifically, we provide an overview of the approaches of contrastive learning in text-image models in recent years. Secondly, we categorize the approaches based on different model structures. Thirdly, we further introduce and discuss the latest advances of the techniques used in the process such as pretext tasks for both images and text, architectural structures, and key trends. Lastly, we discuss the recent state-of-art applications of self-supervised contrastive learning Text-Image based models.
自监督学习是一种机器学习的方法,它通过学习潜在的模式和从非标记数据中提取判别特征,生成隐含的标签,而无需人工标注。对比学习引入了“正样本”和“负样本”的概念,其中正样本对(例如,同一图像/对象的变体)在嵌入空间中聚集在一起,而负样本对(例如,来自不同图像/对象的视图)被推得更远。这种方法在图像理解和图像文本分析方面取得了显著的改进,且在很大程度上不依赖于标记数据。在本文中,我们全面讨论了与文本-图像模型相关的对比学习的术语、最新发展以及应用。具体来说,我们概述了近年来文本-图像模型中对比学习的方法。其次,我们根据不同的模型结构对这些方法进行了分类。第三,我们进一步介绍并讨论了过程中使用的最新技术,如图像和文本的预文本任务、结构设计和关键趋势。最后,我们讨论了基于文本-图像模型的自监督对比学习的最新先进应用。
论文及项目相关链接
PDF 38 pages, 8 figures, survey paper
Summary
自我监督学习是一种机器学习的方法,它通过理解潜在模式和从非标记数据中提取判别特征来生成隐含标签,无需人工标注。对比学习引入了“阳性”和“阴性”样本的概念,其中阳性样本对(例如,同一图像/对象的变体)在嵌入空间中相互接近,而阴性样本对(例如,来自不同图像/对象的视图)则被推开。此方法在图像理解和图像文本分析方面取得了显著的改进,且对标注数据的依赖度较低。本文全面探讨了对比学习的术语、最新发展以及其在文本图像模型中的应用。
Key Takeaways
- 自我监督学习通过理解潜在模式和从非标记数据中提取特征来生成隐含标签。
- 对比学习通过引入阳性样本和阴性样本的概念来优化自我监督学习。
- 对比学习在图像理解和图像文本分析方面取得了显著成效,且对标注数据的依赖度较低。
- 文本图像模型中的对比学习方法包括多种策略,可根据不同的模型结构进行分类。
- 最新的对比学习技术包括用于图像和文本的预文本任务、架构结构和关键趋势等。
- 自我监督对比学习在文本图像模型中有许多最新应用。
点此查看论文截图