⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-03 更新
WTEFNet: Real-Time Low-Light Object Detection for Advanced Driver Assistance Systems
Authors:Hao Wu, Junzhou Chen, Ronghui Zhang, Nengchao Lyu, Hongyu Hu, Yanyong Guo, Tony Z. Qiu
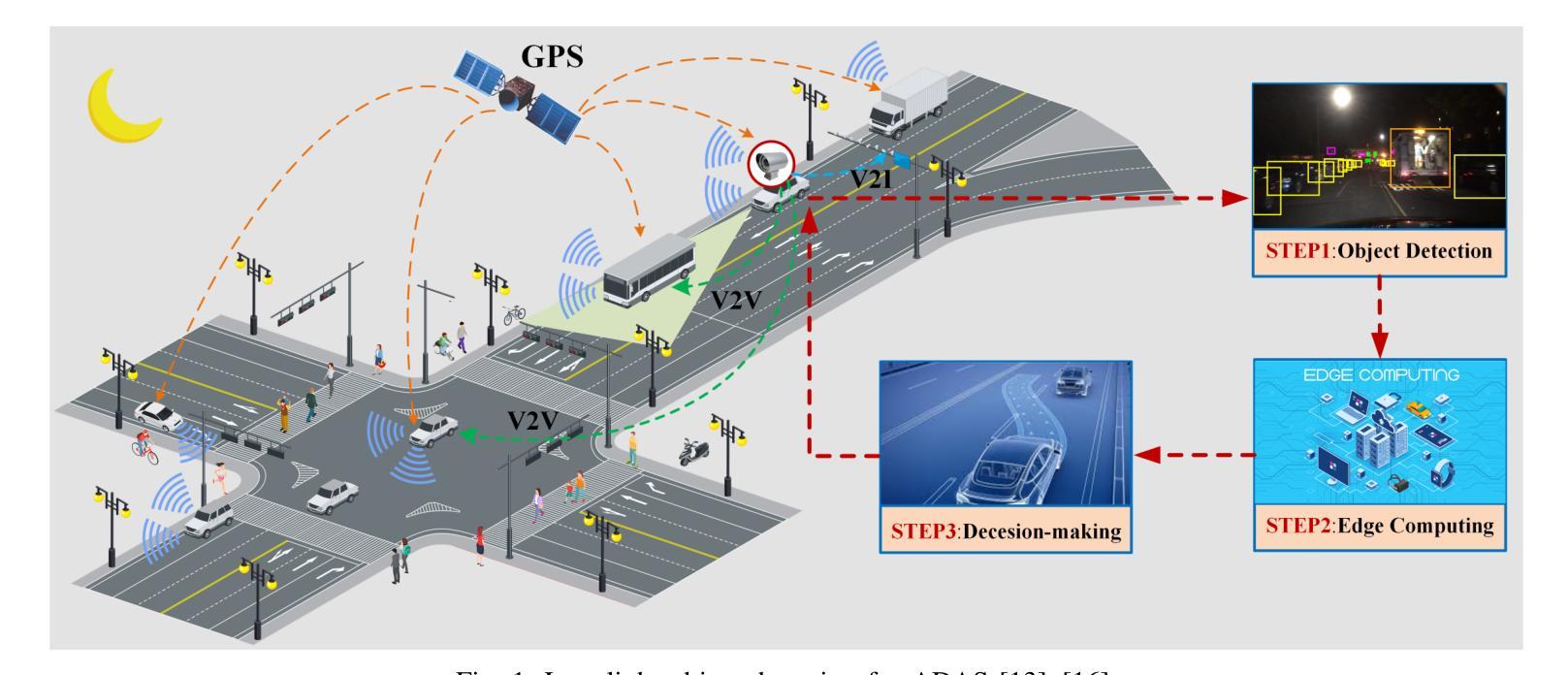
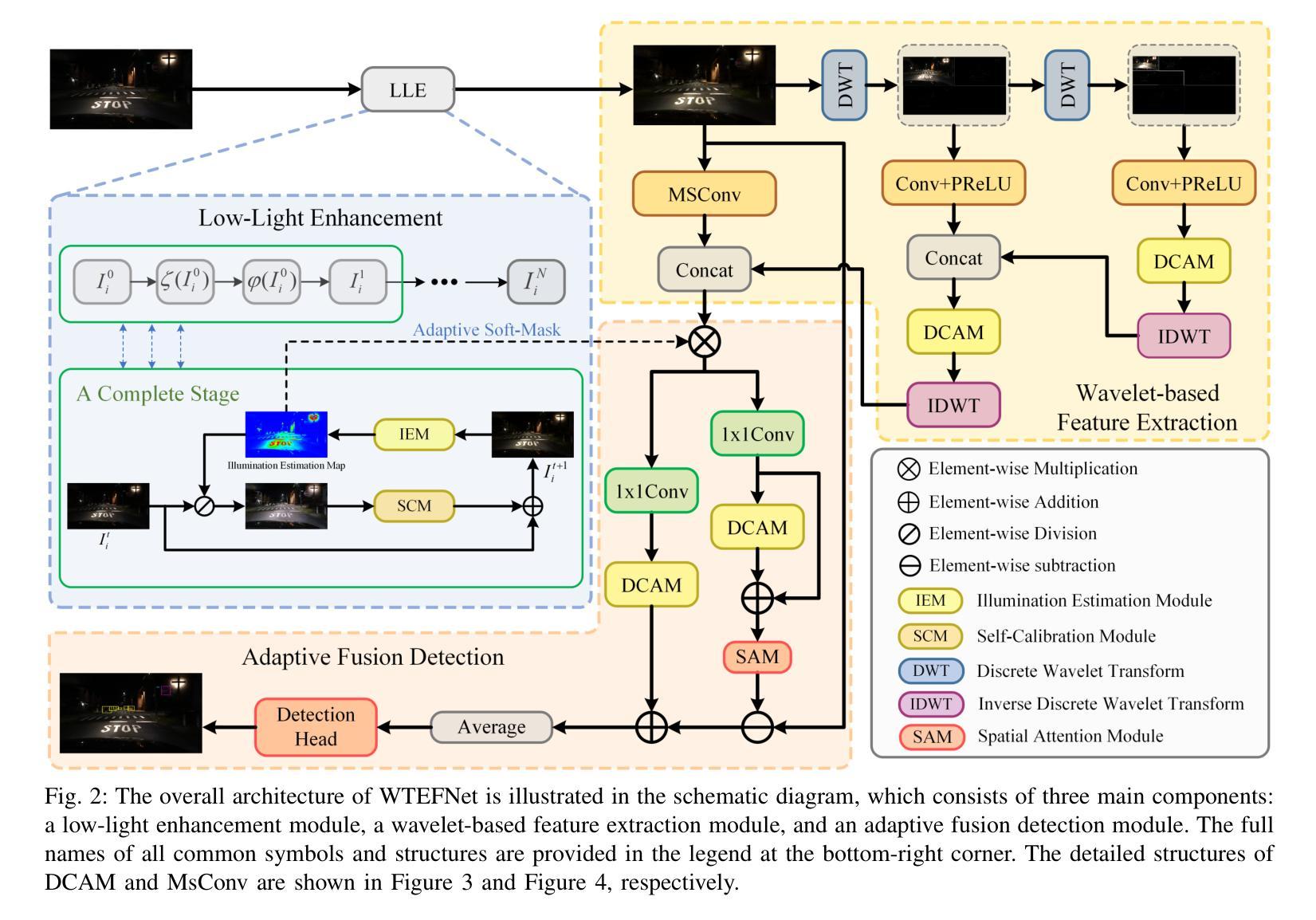
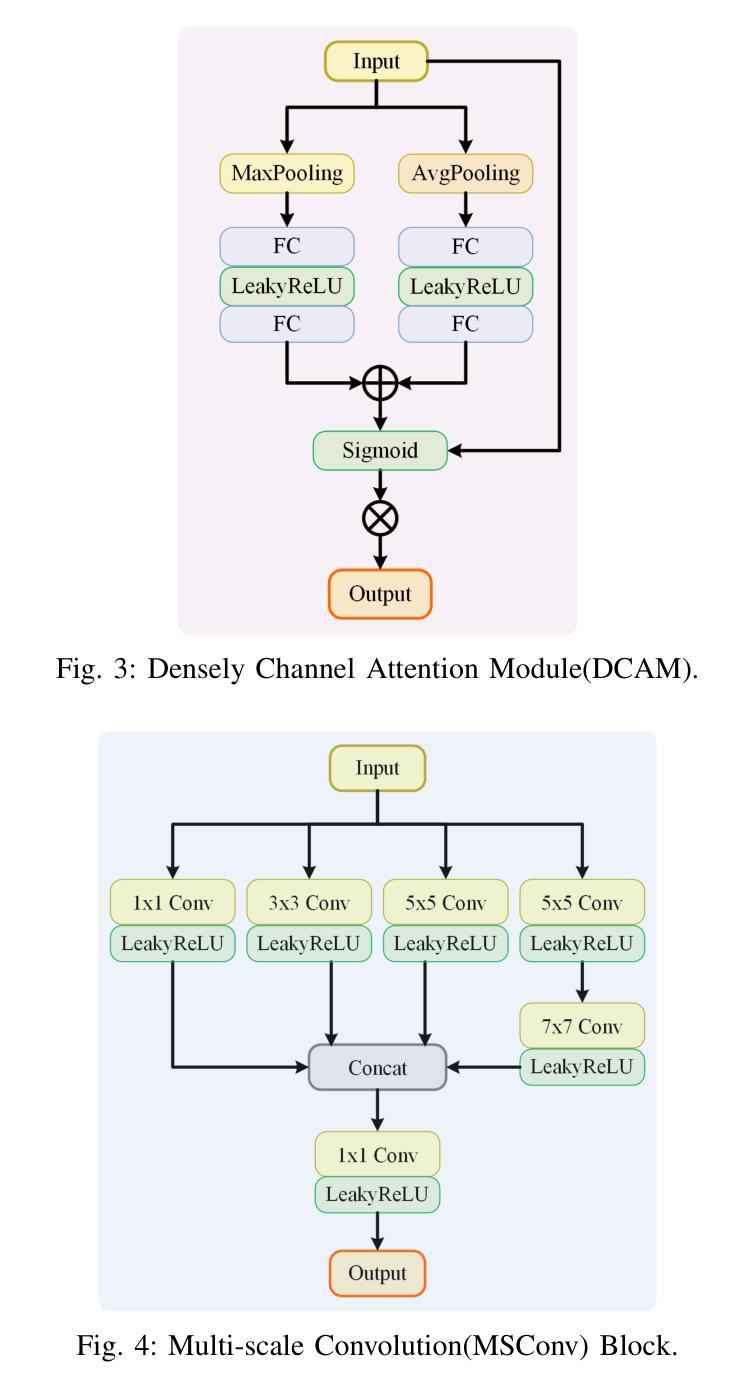
Object detection is a cornerstone of environmental perception in advanced driver assistance systems(ADAS). However, most existing methods rely on RGB cameras, which suffer from significant performance degradation under low-light conditions due to poor image quality. To address this challenge, we proposes WTEFNet, a real-time object detection framework specifically designed for low-light scenarios, with strong adaptability to mainstream detectors. WTEFNet comprises three core modules: a Low-Light Enhancement (LLE) module, a Wavelet-based Feature Extraction (WFE) module, and an Adaptive Fusion Detection (AFFD) module. The LLE enhances dark regions while suppressing overexposed areas; the WFE applies multi-level discrete wavelet transforms to isolate high- and low-frequency components, enabling effective denoising and structural feature retention; the AFFD fuses semantic and illumination features for robust detection. To support training and evaluation, we introduce GSN, a manually annotated dataset covering both clear and rainy night-time scenes. Extensive experiments on BDD100K, SHIFT, nuScenes, and GSN demonstrate that WTEFNet achieves state-of-the-art accuracy under low-light conditions. Furthermore, deployment on a embedded platform (NVIDIA Jetson AGX Orin) confirms the framework’s suitability for real-time ADAS applications.
对象检测是先进驾驶辅助系统(ADAS)环境感知的基石。然而,大多数现有方法依赖于RGB相机,它们在低光条件下由于图像质量差而性能大幅下降。为了解决这一挑战,我们提出了WTEFNet,这是一个专为低光场景设计的实时对象检测框架,具有对主流检测器的强大适应性。WTEFNet包含三个核心模块:低光增强(LLE)模块、基于小波的特征提取(WFE)模块和自适应融合检测(AFFD)模块。LLE增强暗区同时抑制过曝区域;WFE应用多级离散小波变换以隔离高低频成分,实现有效的降噪和结构特征保留;AFFD融合语义和照明特征以实现稳健检测。为了支持和评估,我们引入了GSN,这是一个涵盖清晰和雨天夜间场景的手动注释数据集。在BDD100K、SHIFT、nuScenes和GSN上的大量实验表明,WTEFNet在低光条件下达到了最先进的准确性。此外,在嵌入式平台(NVIDIA Jetson AGX Orin)上的部署证实了该框架适用于实时ADAS应用。
论文及项目相关链接
PDF This paper is expected to be submitted to IEEE Transactions on Instrumentation and Measurement
Summary:
本文介绍了一种针对低光环境下实时对象检测的框架WTEFNet,适用于先进的驾驶辅助系统。该框架包含三个核心模块:低光增强模块、基于小波的特征提取模块和自适应融合检测模块。此外,为了支持训练和评估,引入了一个新的数据集GSN。实验表明,WTEFNet在低光条件下实现了最先进的准确性,并适合部署在嵌入式平台上进行实时应用。
Key Takeaways:
- 对象检测在高级驾驶辅助系统(ADAS)的环境感知中很重要,但低光环境下的性能是难点。
- 当前大多方法依赖RGB相机,在低光条件下性能不佳。
- WTEFNet框架包括三个核心模块:低光增强模块用于增强暗区并抑制过曝区域;基于小波的特征提取模块利用多级离散小波变换来隔离高低频成分,实现有效去噪和保留结构特征;自适应融合检测模块融合语义和照明特征以实现稳健检测。
- 引入新数据集GSN支持训练和评估。
- 实验显示,WTEFNet在低光条件下实现了最先进的准确性。
- WTEFNet适合部署在嵌入式平台(如NVIDIA Jetson AGX Orin)进行实时应用。
点此查看论文截图

MonoCoP: Chain-of-Prediction for Monocular 3D Object Detection
Authors:Zhihao Zhang, Abhinav Kumar, Girish Chandar Ganesan, Xiaoming Liu
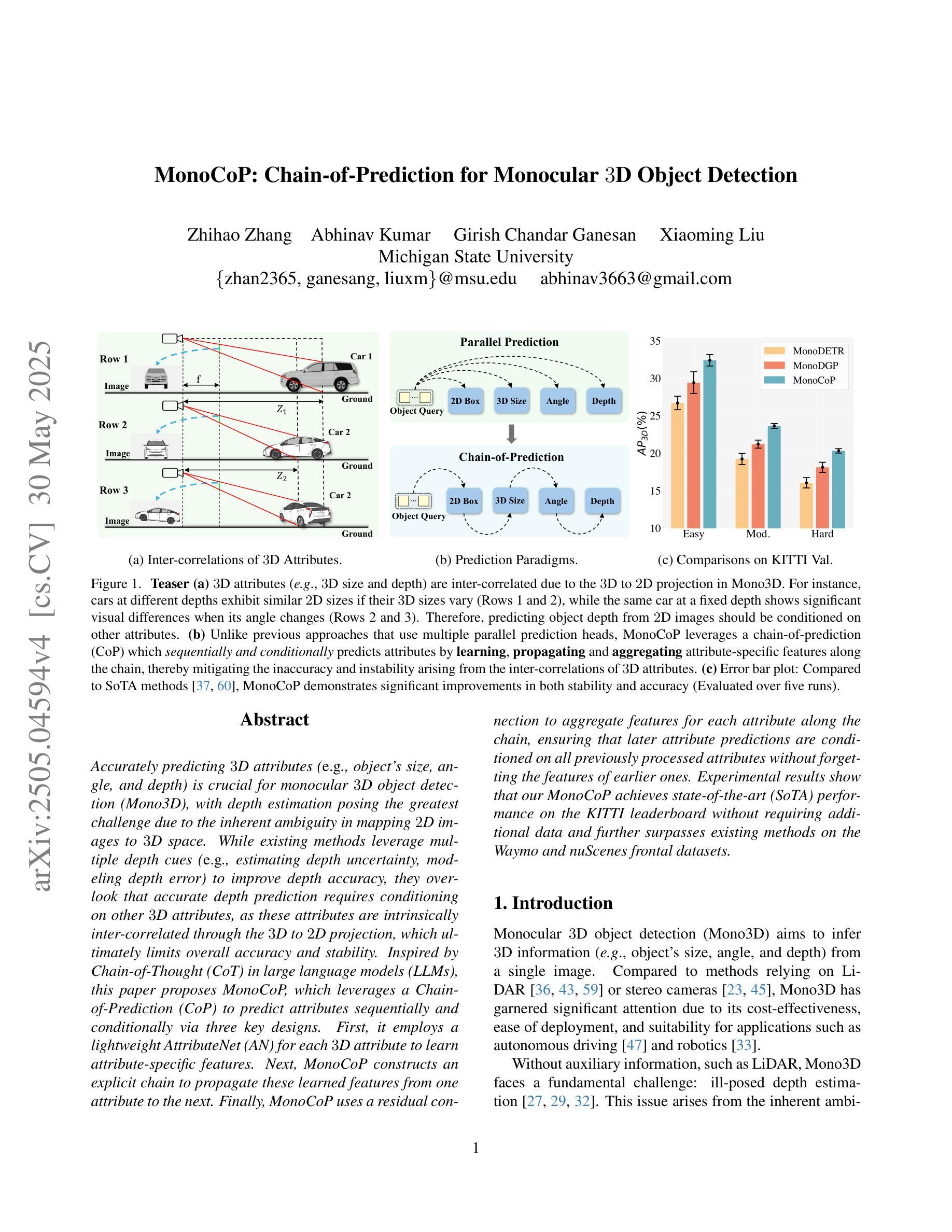
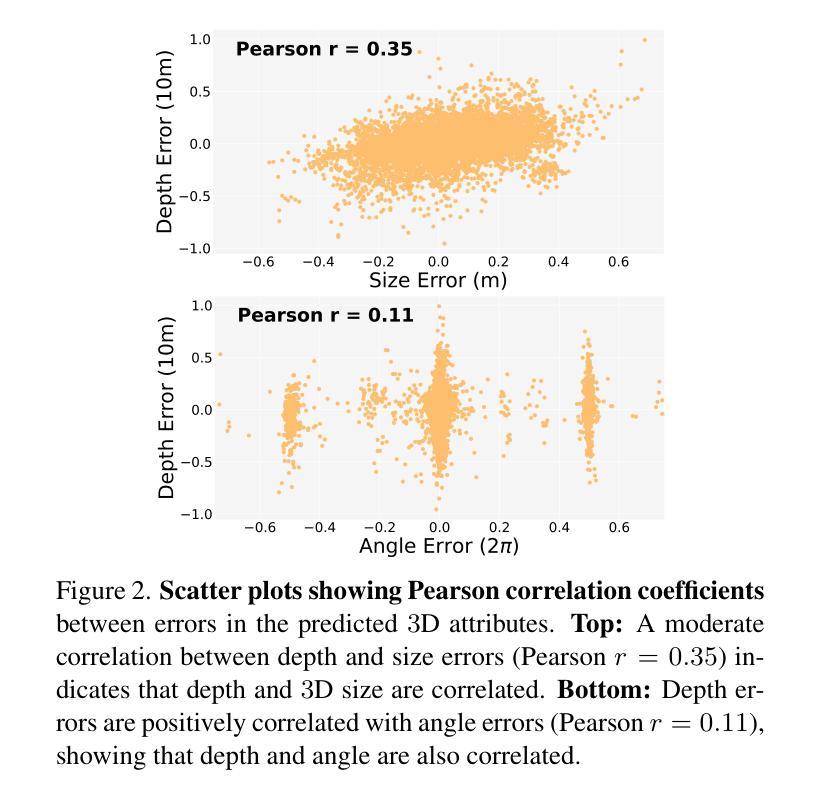
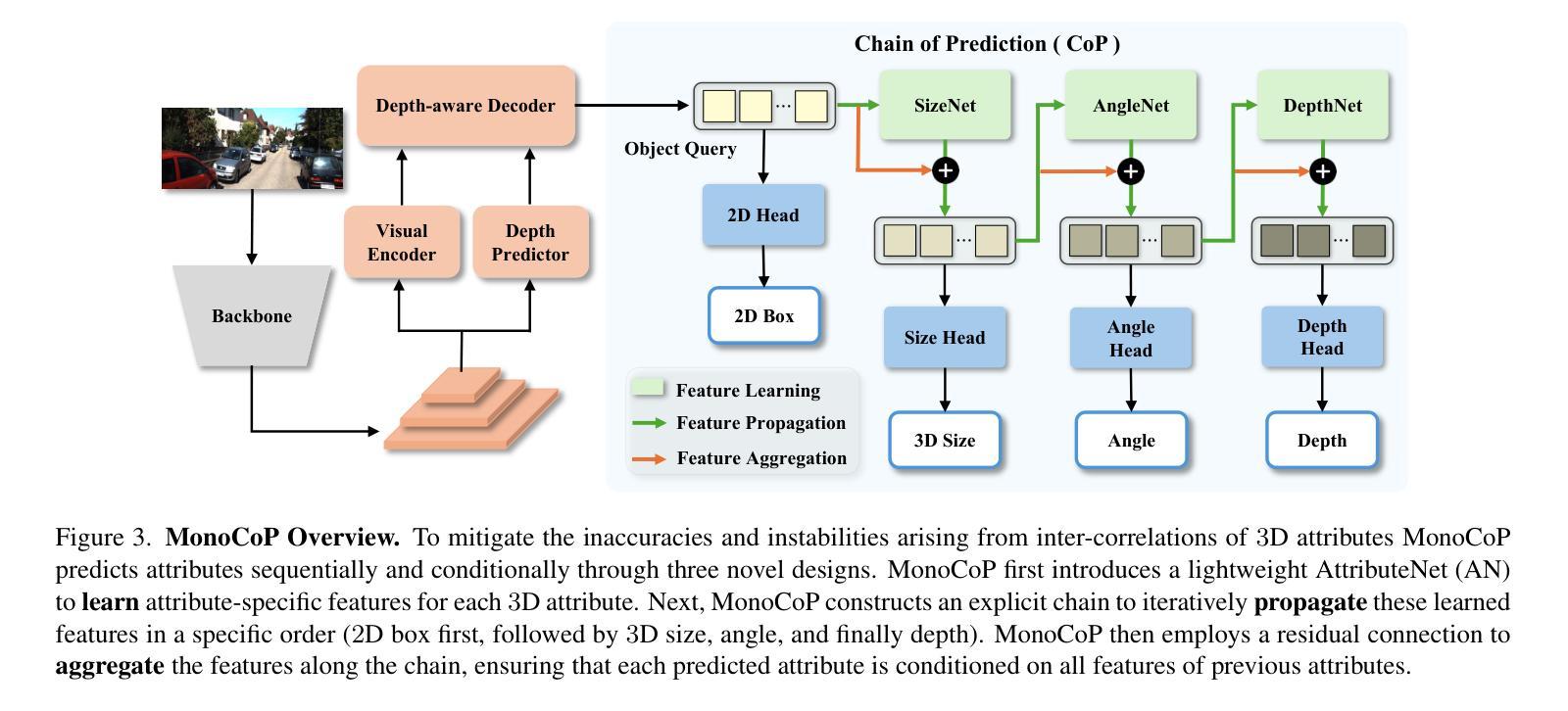
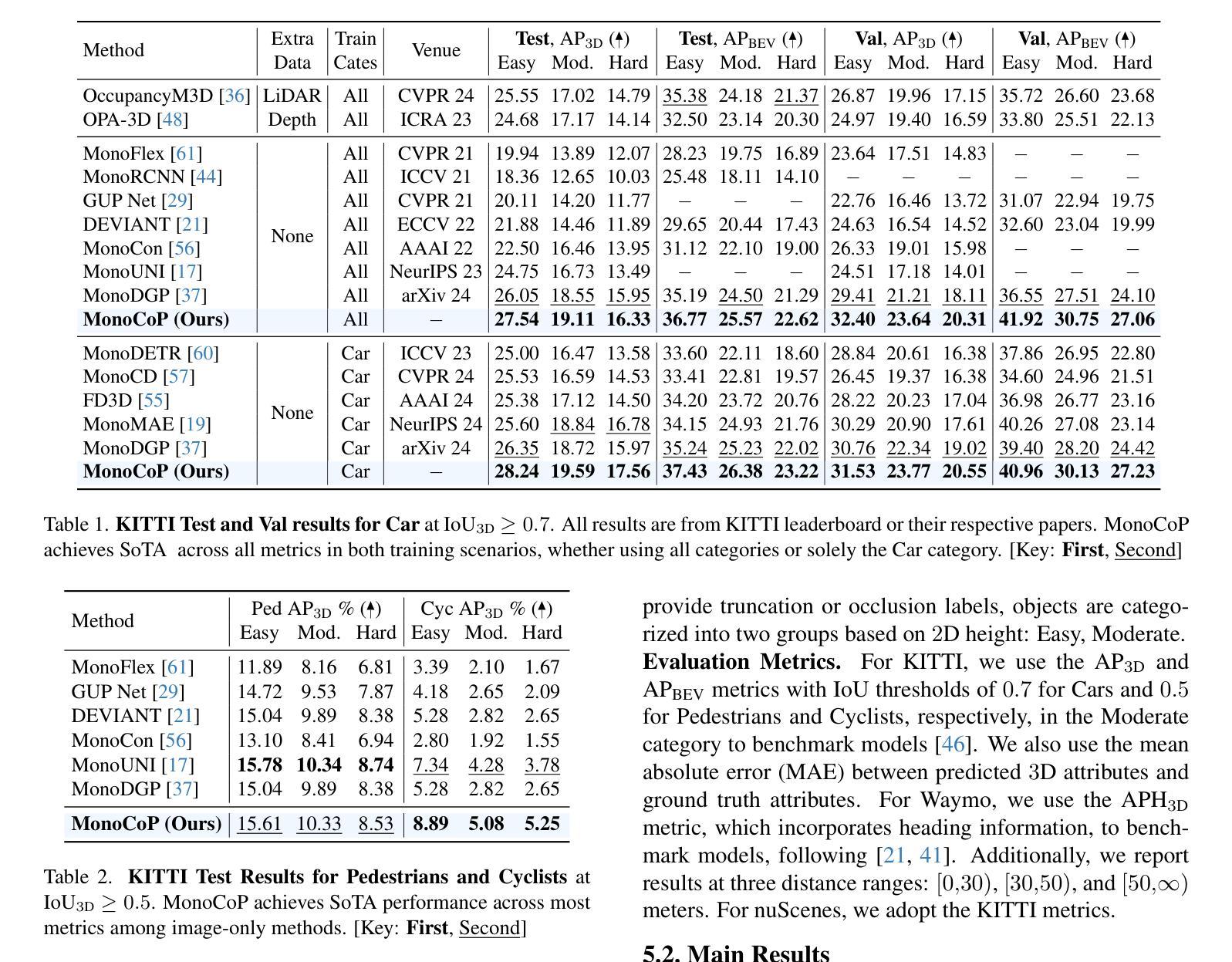
Accurately predicting 3D attributes is crucial for monocular 3D object detection (Mono3D), with depth estimation posing the greatest challenge due to the inherent ambiguity in mapping 2D images to 3D space. While existing methods leverage multiple depth cues (e.g., estimating depth uncertainty, modeling depth error) to improve depth accuracy, they overlook that accurate depth prediction requires conditioning on other 3D attributes, as these attributes are intrinsically inter-correlated through the 3D to 2D projection, which ultimately limits overall accuracy and stability. Inspired by Chain-of-Thought (CoT) in large language models (LLMs), this paper proposes MonoCoP, which leverages a Chain-of-Prediction (CoP) to predict attributes sequentially and conditionally via three key designs. First, it employs a lightweight AttributeNet (AN) for each 3D attribute to learn attribute-specific features. Next, MonoCoP constructs an explicit chain to propagate these learned features from one attribute to the next. Finally, MonoCoP uses a residual connection to aggregate features for each attribute along the chain, ensuring that later attribute predictions are conditioned on all previously processed attributes without forgetting the features of earlier ones. Experimental results show that our MonoCoP achieves state-of-the-art (SoTA) performance on the KITTI leaderboard without requiring additional data and further surpasses existing methods on the Waymo and nuScenes frontal datasets.
准确预测3D属性对于单目3D目标检测(Mono3D)至关重要,深度估计由于将2D图像映射到3D空间时固有的模糊性而构成最大挑战。虽然现有方法利用多种深度线索(例如估计深度不确定性、建模深度误差)来提高深度准确性,但它们忽略了准确的深度预测需要依赖于其他3D属性,因为这些属性通过3D到2D的投影固有地相互关联,这最终限制了总体准确性和稳定性。本文受大型语言模型(LLM)中的思维链(Chain-of-Thought,CoT)的启发,提出了一种MonoCoP方法,它利用预测链(Chain-of-Prediction,CoP)按顺序并条件地预测属性,主要通过三个关键设计实现。首先,它为每个3D属性采用轻量级的AttributeNet(AN)来学习特定于属性的特征。接下来,MonoCoP构建了一个明确的链来传播从一个属性学习到的特征到下一个属性。最后,MonoCoP使用残差连接来沿着链条聚合每个属性的特征,确保后续的属性预测依赖于所有先前处理的属性,同时不会忘记较早属性的特征。实验结果表明,我们的MonoCoP在KITTI排行榜上达到了最先进的性能,并且无需额外数据,在Waymo和nuScenes正面数据集上也超越了现有方法。
论文及项目相关链接
Summary
本文提出一种基于Chain-of-Prediction(CoP)的单眼3D物体检测新方法MonoCoP。该方法通过预测链条件地预测3D属性,从而提高深度估计的准确性。它通过采用AttributeNet(AN)进行属性特定特征的学习,构建显式链传播这些特征,并使用残差连接聚合各属性的特征,确保后续属性预测基于所有先前处理的属性。实验结果表明,MonoCoP在KITTI排行榜上达到最新技术水平,无需额外数据,并且在Waymo和nuScenes正面数据集上超过了现有方法。
Key Takeaways
- MonoCoP利用Chain-of-Prediction(CoP)方法条件地预测3D属性,以提高深度估计的准确性。
- 该方法通过AttributeNet(AN)进行属性特定特征的学习。
- MonoCoP构建显式链以传播这些特征从一个属性到下一个属性。
- 残差连接用于聚合各属性的特征,确保后续预测基于所有先前的属性。
- MonoCoP达到KITTI排行榜上的最新技术水平,且无需额外数据。
- 在Waymo和nuScenes正面数据集上,MonoCoP性能超过了现有方法。
点此查看论文截图

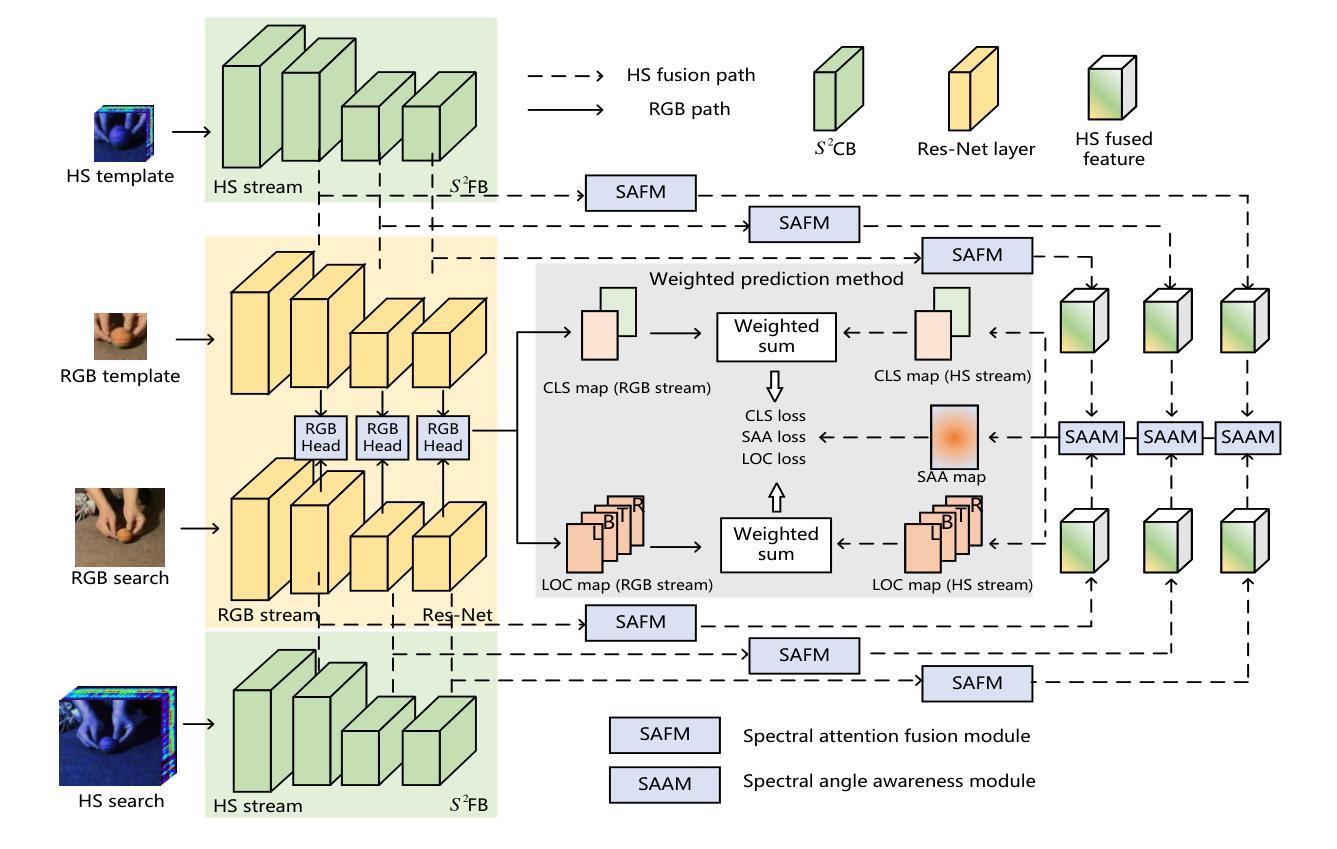
SSF-Net: Spatial-Spectral Fusion Network with Spectral Angle Awareness for Hyperspectral Object Tracking
Authors:Hanzheng Wang, Wei Li, Xiang-Gen Xia, Qian Du, Jing Tian
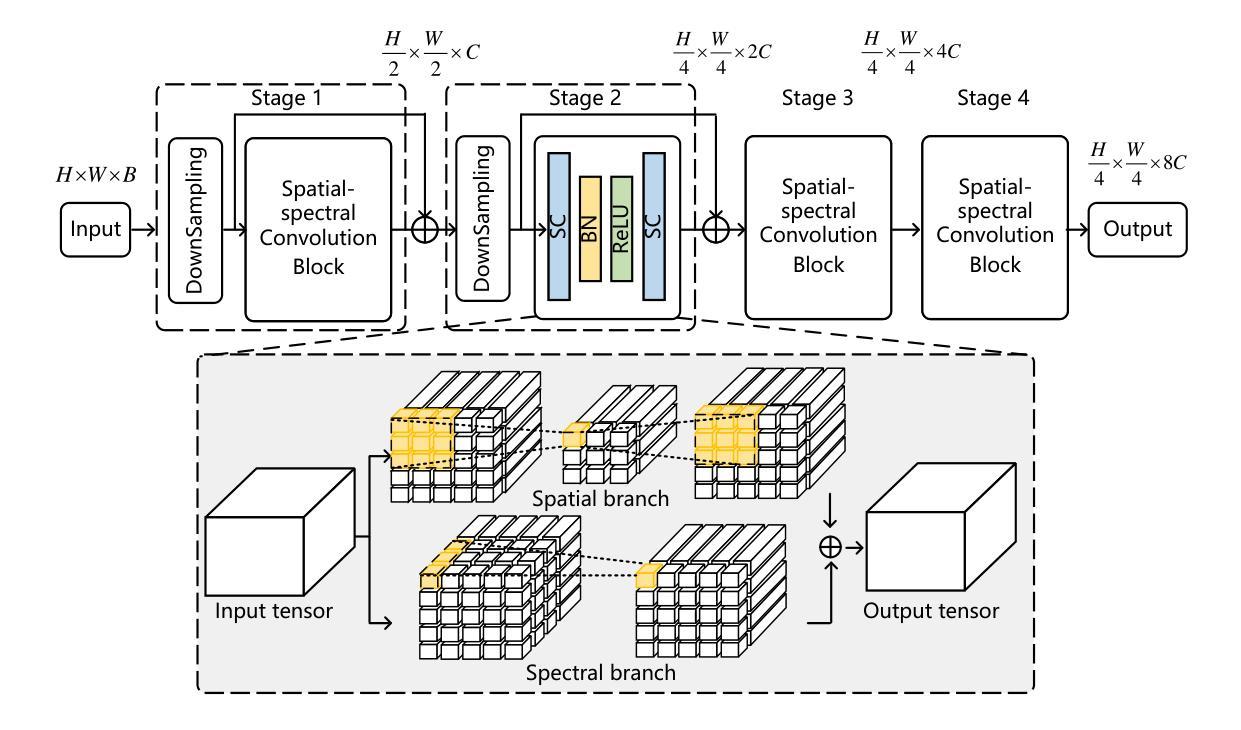
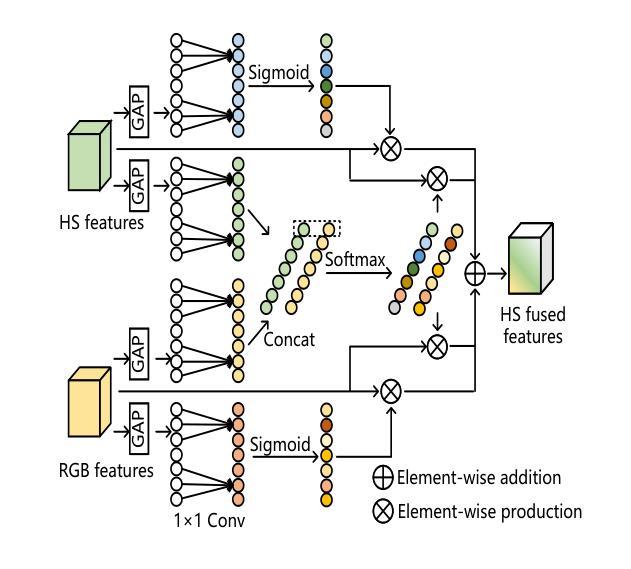
Hyperspectral video (HSV) offers valuable spatial, spectral, and temporal information simultaneously, making it highly suitable for handling challenges such as background clutter and visual similarity in object tracking. However, existing methods primarily focus on band regrouping and rely on RGB trackers for feature extraction, resulting in limited exploration of spectral information and difficulties in achieving complementary representations of object features. In this paper, a spatial-spectral fusion network with spectral angle awareness (SST-Net) is proposed for hyperspectral (HS) object tracking. Firstly, to address the issue of insufficient spectral feature extraction in existing networks, a spatial-spectral feature backbone ($S^2$FB) is designed. With the spatial and spectral extraction branch, a joint representation of texture and spectrum is obtained. Secondly, a spectral attention fusion module (SAFM) is presented to capture the intra- and inter-modality correlation to obtain the fused features from the HS and RGB modalities. It can incorporate the visual information into the HS spectral context to form a robust representation. Thirdly, to ensure a more accurate response of the tracker to the object position, a spectral angle awareness module (SAAM) investigates the region-level spectral similarity between the template and search images during the prediction stage. Furthermore, we develop a novel spectral angle awareness loss (SAAL) to offer guidance for the SAAM based on similar regions. Finally, to obtain the robust tracking results, a weighted prediction method is considered to combine the HS and RGB predicted motions of objects to leverage the strengths of each modality. Extensive experiments on the HOTC dataset demonstrate the effectiveness of the proposed SSF-Net, compared with state-of-the-art trackers.
超光谱视频(HSV)同时提供了宝贵的空间、光谱和时间信息,非常适合应对背景干扰和视觉相似性在目标跟踪中的挑战。然而,现有方法主要关注波段重组,并依赖RGB跟踪器进行特征提取,导致光谱信息挖掘有限,难以实现对目标特征的互补表示。针对这些问题,本文提出了一种具有光谱角度感知的空间光谱融合网络(SST-Net),用于超光谱(HS)目标跟踪。首先,为了解决现有网络中光谱特征提取不足的问题,设计了空间光谱特征主干网(S²FB)。通过空间和光谱提取分支,获得纹理和光谱的联合表示。其次,提出了一种光谱注意力融合模块(SAFM),以捕获HS和RGB模态的跨模态相关性,获得融合特征。它可以将视觉信息融入HS光谱上下文,形成稳健的表示。第三,为了确保跟踪器对目标位置的响应更加准确,光谱角度感知模块(SAAM)在预测阶段研究模板和搜索图像之间的区域级光谱相似性。此外,我们开发了一种新型的光谱角度感知损失(SAAL)来为SAAM提供基于相似区域的指导。最后,为了获得鲁棒的目标跟踪结果,考虑采用加权预测方法来结合HS和RGB预测的目标运动,以利用各模态的优势。在HOTC数据集上的广泛实验表明,与最先进的跟踪器相比,所提出的SSF-Net是有效的。
论文及项目相关链接
PDF IEEE Transactions on Image Processing 2025
Summary
本文提出了一种具有光谱角度感知的时空光谱融合网络(SST-Net)用于处理高光谱物体跟踪中的背景干扰与视觉相似性挑战。网络通过设计空间光谱特征主干网络$S^2FB解决了现有网络中光谱特征提取不足的问题,并提出了一个光谱注意力融合模块来捕捉HS和RGB模态之间的内模态和跨模态相关性。此外,网络通过引入光谱角度感知模块和相应的光谱角度感知损失函数来增强预测阶段的区域级光谱相似性,并利用加权预测法融合HS和RGB模态的预测结果以提高跟踪性能。实验结果表明,所提出的SSF-Net相较于其他先进的跟踪器表现出优异的效果。
Key Takeaways
- 提出一种时空光谱融合网络SST-Net用于高光谱物体跟踪。
- 设计了空间光谱特征主干网络$S^2FB以提取纹理和光谱的联合表示。
- 通过光谱注意力融合模块捕捉HS和RGB模态间的相关性。
- 引入光谱角度感知模块以强化区域级光谱相似性在预测阶段的作用。
- 提出了一种新的光谱角度感知损失函数为SAAM提供指导。
- 使用加权预测法结合HS和RGB模态的预测结果以实现稳健跟踪。
点此查看论文截图