⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-03 更新
Learning reusable concepts across different egocentric video understanding tasks
Authors:Simone Alberto Peirone, Francesca Pistilli, Antonio Alliegro, Tatiana Tommasi, Giuseppe Averta
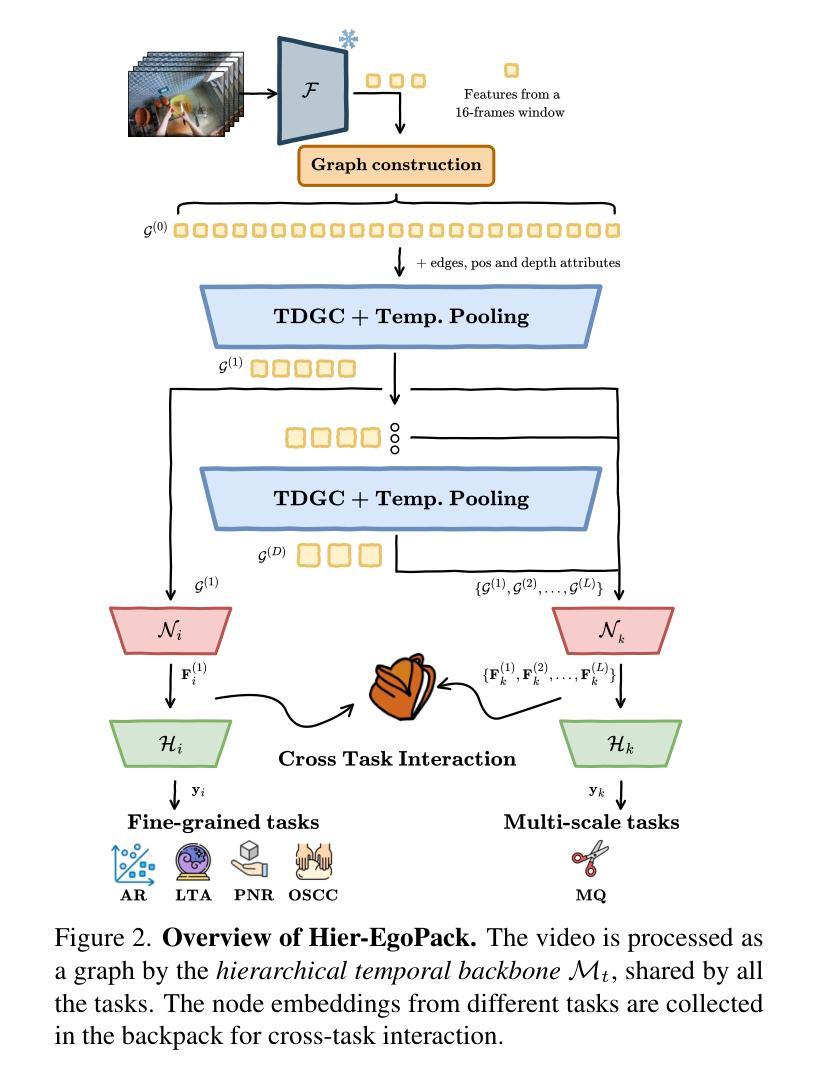
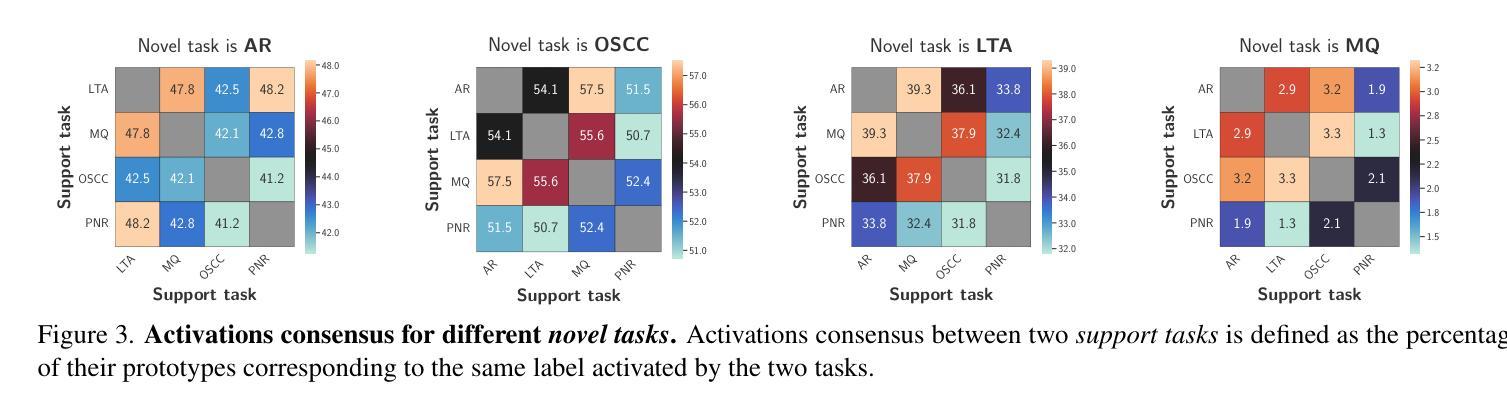
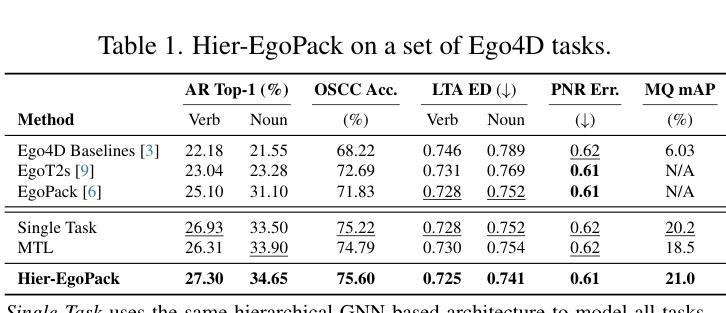
Our comprehension of video streams depicting human activities is naturally multifaceted: in just a few moments, we can grasp what is happening, identify the relevance and interactions of objects in the scene, and forecast what will happen soon, everything all at once. To endow autonomous systems with such holistic perception, learning how to correlate concepts, abstract knowledge across diverse tasks, and leverage tasks synergies when learning novel skills is essential. In this paper, we introduce Hier-EgoPack, a unified framework able to create a collection of task perspectives that can be carried across downstream tasks and used as a potential source of additional insights, as a backpack of skills that a robot can carry around and use when needed.
我们对描述人类活动的视频流的理解自然是多方面的:在短短几分钟内,我们就能了解正在发生的事情,识别场景中物体的相关性和交互,并预测即将发生的事情,所有这一切都同时发生。为了赋予自主系统这种整体感知能力,学习如何关联概念,在各项任务中抽象知识,并在学习新技能时利用任务协同至关重要。在本文中,我们介绍了Hier-EgoPack,这是一个统一的框架,能够创建一系列任务视角,这些视角可以应用于下游任务,并作为潜在的有见地信息来源,就像一个机器人可以随身携带、随时使用的技能背包。
论文及项目相关链接
PDF Extended abstract derived from arXiv:2502.02487. Presented at the Second Joint Egocentric Vision (EgoVis) Workshop (CVPR 2025)
Summary:
本文介绍了一个统一的框架——Hier-EgoPack,它能够帮助机器在视频流理解人类活动时形成多面理解,抓取正在发生的事件,识别场景中物体的相关性和交互作用,预测接下来可能发生的事情。这个框架能创建任务视角集合,用于跨下游任务进行应用并作为额外的潜在见解来源,就像一个机器人可以随身携带的技能背包,随时按需使用。
Key Takeaways:
- 视频流理解涉及多面性,包括理解正在发生的事件、识别场景中物体的相关性和交互作用以及预测未来事件。
- Hier-EgoPack是一个统一框架,可以创建任务视角集合,应用于下游任务并作为潜在额外见解的来源。
- Hier-EgoPack框架帮助机器人像人类一样理解视频内容,提供类似人类的全局感知能力。
- 该框架能够利用任务间的协同作用来学习新技能,这对于自主系统至关重要。
- 通过引入任务视角集合的概念,机器人可以在执行任务时携带并利用不同的技能和见解来源。
- 这个框架提供了未来进一步研究多任务处理和机器人感知学习的可能方向。
点此查看论文截图

VUDG: A Dataset for Video Understanding Domain Generalization
Authors:Ziyi Wang, Zhi Gao, Boxuan Yu, Zirui Dai, Yuxiang Song, Qingyuan Lu, Jin Chen, Xinxiao Wu
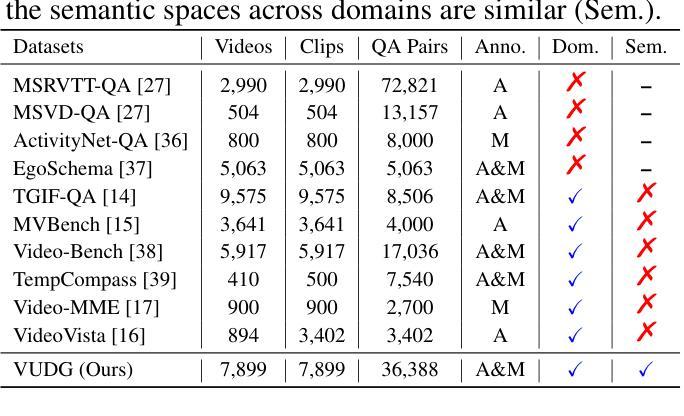
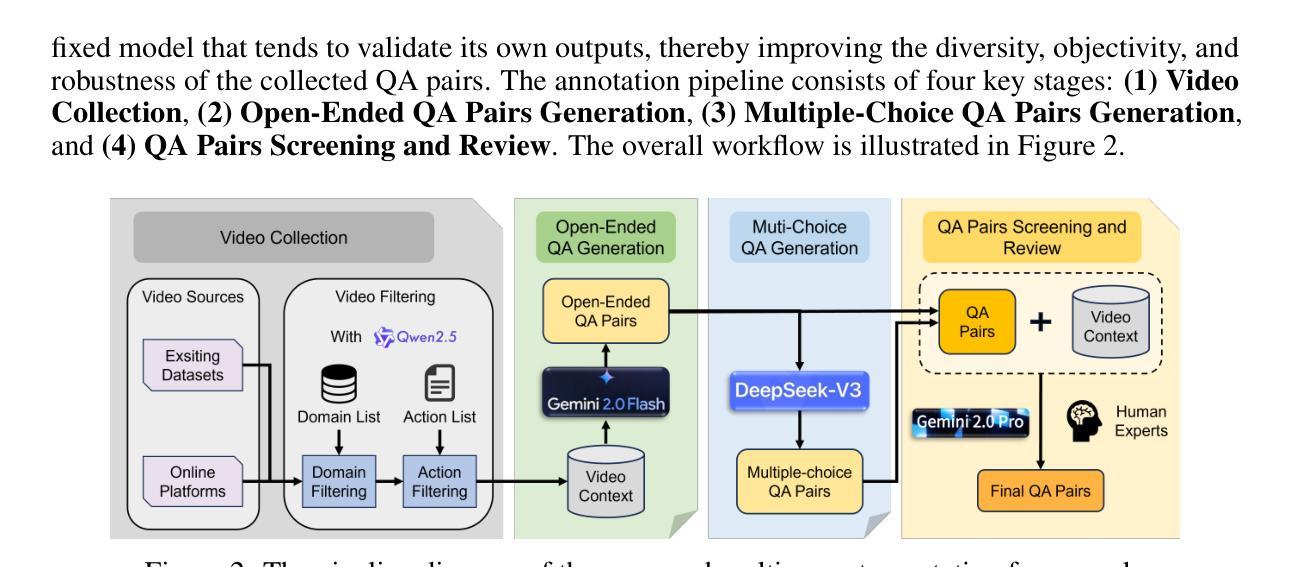
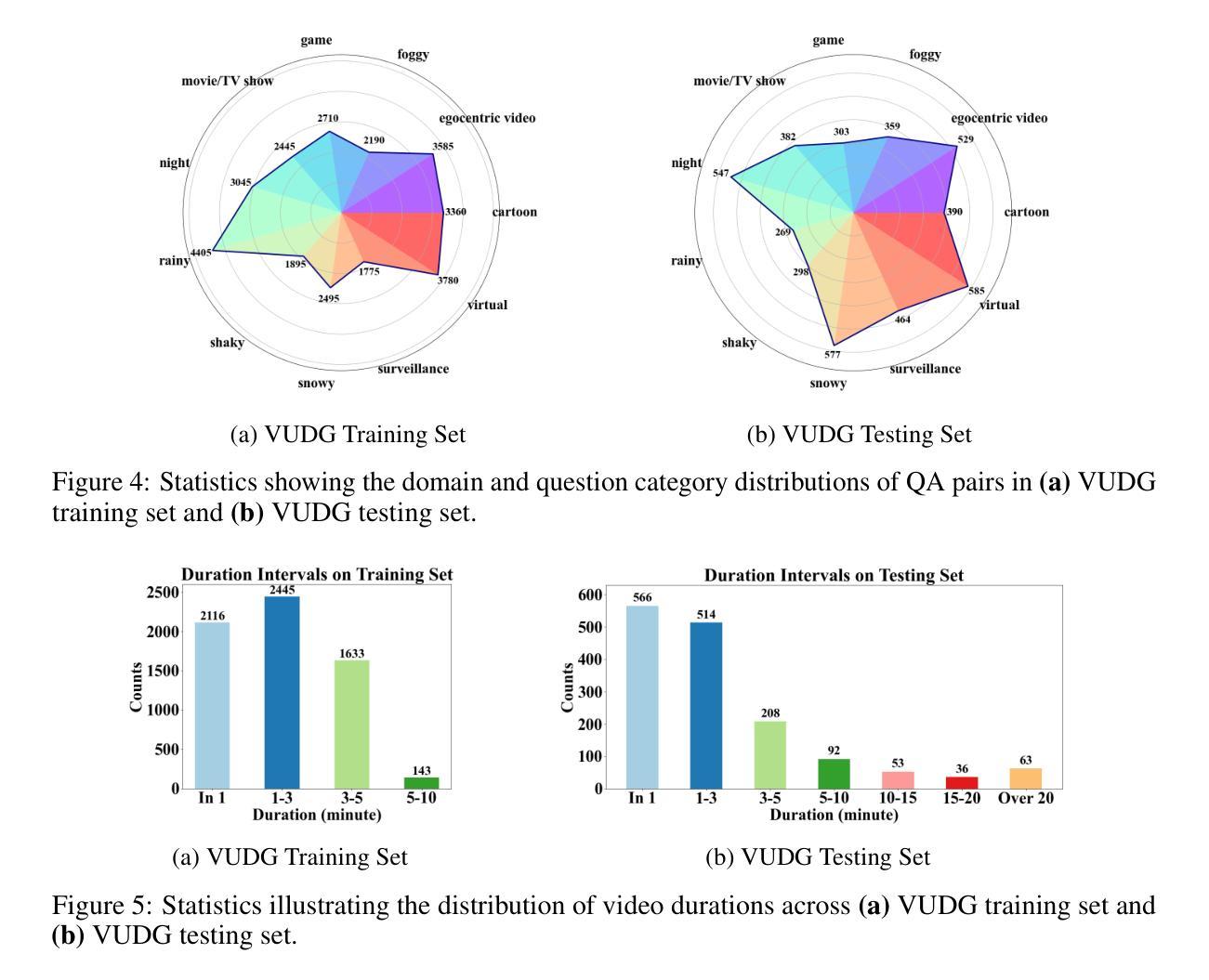
Video understanding has made remarkable progress in recent years, largely driven by advances in deep models and the availability of large-scale annotated datasets. However, existing works typically ignore the inherent domain shifts encountered in real-world video applications, leaving domain generalization (DG) in video understanding underexplored. Hence, we propose Video Understanding Domain Generalization (VUDG), a novel dataset designed specifically for evaluating the DG performance in video understanding. VUDG contains videos from 11 distinct domains that cover three types of domain shifts, and maintains semantic similarity across different domains to ensure fair and meaningful evaluation. We propose a multi-expert progressive annotation framework to annotate each video with both multiple-choice and open-ended question-answer pairs. Extensive experiments on 9 representative large video-language models (LVLMs) and several traditional video question answering methods show that most models (including state-of-the-art LVLMs) suffer performance degradation under domain shifts. These results highlight the challenges posed by VUDG and the difference in the robustness of current models to data distribution shifts. We believe VUDG provides a valuable resource for prompting future research in domain generalization video understanding.
视频理解近年来取得了显著的进步,这主要得益于深度模型的进步和大规模标注数据集的可用性。然而,现有工作通常忽略了真实世界视频应用中遇到的固有领域变化,导致视频理解中的领域泛化(DG)研究不足。因此,我们提出了视频理解领域泛化(VUDG)数据集,该数据集专为评估视频理解中的DG性能而设计。VUDG包含来自11个不同领域的视频,涵盖三种领域变化类型,并保持不同领域之间的语义相似性,以确保公平和有意义的评估。我们提出了一个多专家渐进标注框架,为每个视频标注多个选择题和开放问答对。在九个代表性的大型视频语言模型(LVLMs)和几种传统的视频问答方法上的大量实验表明,大多数模型(包括最先进的LVLMs)在领域变化下会出现性能下降。这些结果凸显了VUDG所带来的挑战以及当前模型对数据分布变化的稳健性的差异。我们相信VUDG将为促进未来视频理解领域泛化的研究提供宝贵的资源。
论文及项目相关链接
Summary
视频理解领域近年来取得显著进展,但现有研究忽略了实际视频应用中遇到的领域迁移问题,导致视频理解领域的域泛化(DG)研究不足。为此,我们提出视频理解域泛化(VUDG)数据集,专门用于评估视频理解中的域泛化性能。VUDG包含来自11个不同领域的视频,覆盖三种领域迁移类型,并保持不同领域间的语义相似性,以确保评估和比较的公正性。我们采用多专家渐进标注框架,对每段视频进行多选和开放问答对的标注。实验表明,大多数模型(包括最新大型视频语言模型)在领域迁移下性能下降,突显VUDG的挑战性和当前模型对数据分布变化的稳健性差异。我们相信VUDG将为未来视频理解领域的域泛化研究提供宝贵资源。
Key Takeaways
- 视频理解领域存在域泛化(DG)问题,现有研究未充分关注。
- 提出专门用于评估视频理解中域泛化性能的数据集——视频理解域泛化(VUDG)。
- VUDG包含来自11个不同领域的视频,覆盖多种领域迁移类型。
- VUDG注重语义相似性,以确保评估和比较的公正性。
- 采用多专家渐进标注框架,对视频进行细致标注。
- 实验显示,大多数模型在领域迁移下性能下降,突显VUDG的挑战性。
点此查看论文截图



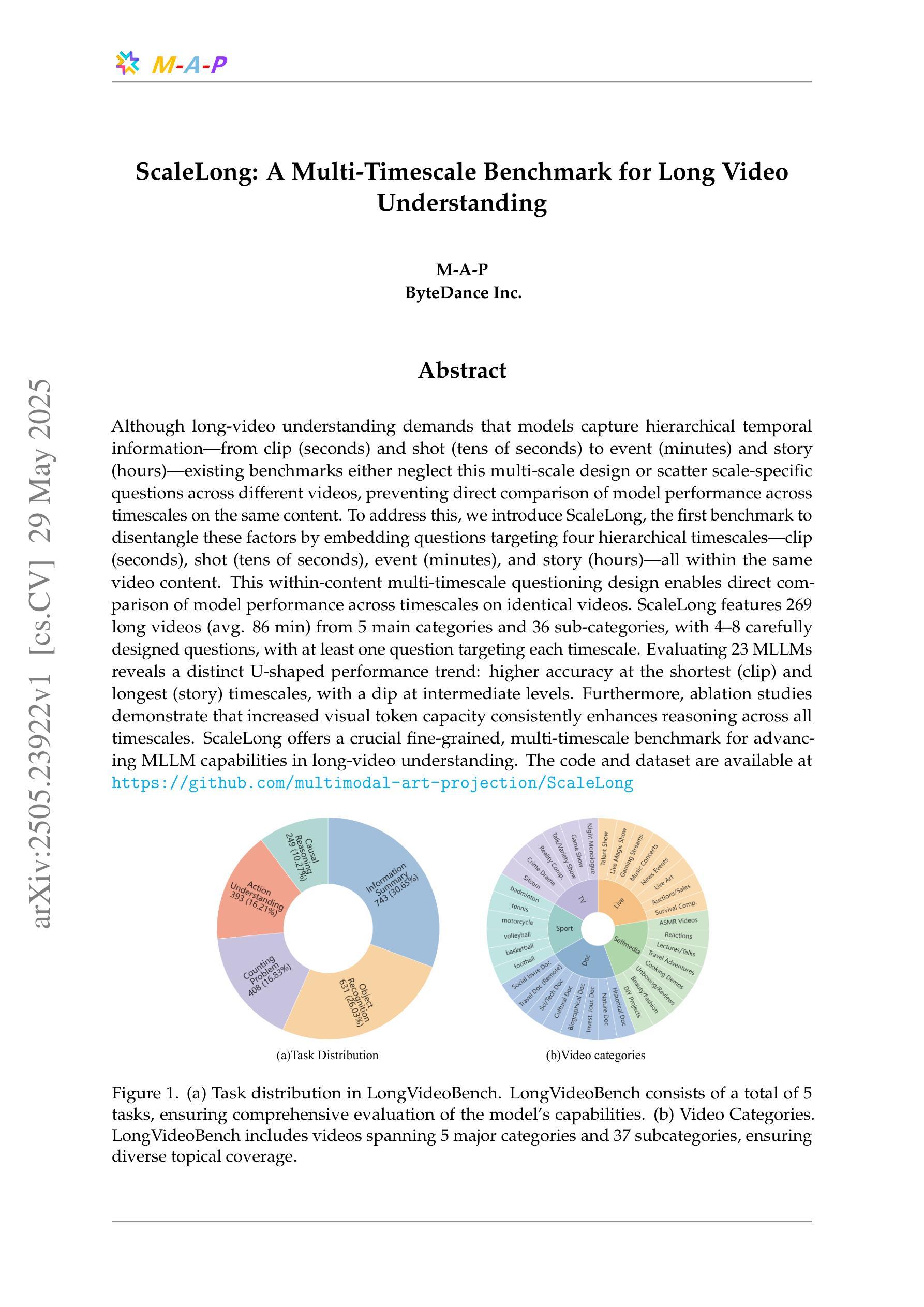
ScaleLong: A Multi-Timescale Benchmark for Long Video Understanding
Authors:David Ma, Huaqing Yuan, Xingjian Wang, Qianbo Zang, Tianci Liu, Xinyang He, Yanbin Wei, Jiawei Guo, Ni Jiahui, Zhenzhu Yang, Meng Cao, Shanghaoran Quan, Yizhi Li, Wangchunshu Zhou, Jiaheng Liu, Wenhao Huang, Ge Zhang, Shiwen Ni, Xiaojie Jin
Although long-video understanding demands that models capture hierarchical temporal information – from clip (seconds) and shot (tens of seconds) to event (minutes) and story (hours) – existing benchmarks either neglect this multi-scale design or scatter scale-specific questions across different videos, preventing direct comparison of model performance across timescales on the same content. To address this, we introduce ScaleLong, the first benchmark to disentangle these factors by embedding questions targeting four hierarchical timescales – clip (seconds), shot (tens of seconds), event (minutes), and story (hours) – all within the same video content. This within-content multi-timescale questioning design enables direct comparison of model performance across timescales on identical videos. ScaleLong features 269 long videos (avg.\ 86,min) from 5 main categories and 36 sub-categories, with 4–8 carefully designed questions, including at least one question for each timescale. Evaluating 23 MLLMs reveals a U-shaped performance curve, with higher accuracy at the shortest and longest timescales and a dip at intermediate levels. Furthermore, ablation studies show that increased visual token capacity consistently enhances reasoning across all timescales. ScaleLong offers a fine-grained, multi-timescale benchmark for advancing MLLM capabilities in long-video understanding. The code and dataset are available https://github.com/multimodal-art-projection/ScaleLong.
虽然长视频理解需要模型捕捉分层的时间信息——从片段(秒)和镜头(数十秒)到事件(分钟)和故事(小时),但现有的基准测试要么忽略这种多尺度设计,要么在不同视频中分散尺度特定的问答题,从而无法在相同内容的时间尺度上直接比较模型性能。为了解决这个问题,我们引入了ScaleLong,这是第一个通过嵌入针对四个层次时间尺度的问答题来解开这些因素的基准测试——片段(秒)、镜头(数十秒)、事件(分钟)和故事(小时)——全部都在同一视频内容中。这种内容内部的跨时间尺度问询设计,能够在相同视频上直接比较模型在不同时间尺度上的性能。ScaleLong包含269个长视频(平均86分钟),分为5个主类别和36个子类别,每个视频都有4-8个精心设计的问答题,每个时间尺度至少有一个问题。评估了23个大型多语言模型,显示出U型性能曲线,在最短和最长的时间尺度上准确性较高,在中间层次则较低。此外,消融研究表明,增加视觉令牌容量始终可以提高所有时间尺度的推理能力。ScaleLong为推进大型多语言模型在长视频理解方面的能力提供了一个精细的多时间尺度基准测试。代码和数据集可在https://github.com/multimodal-art-projection/ScaleLong获得。
论文及项目相关链接
Summary
本文为了解决现有视频理解基准测试在多尺度设计上的不足,提出了一个新的基准测试——ScaleLong。该测试在同一视频内容中嵌入针对四个层次时间尺度的提问,包括片段(秒)、镜头(数十秒)、事件(分钟)和故事(小时),从而能够直接在相同视频上比较模型在不同时间尺度上的性能。ScaleLong包含来自五大类和三十六子类别共269个长视频(平均时长约86分钟),每个视频包含精心设计的至少四个问题。评估结果显示,模型在最小和最大时间尺度上的性能较高,中间尺度上性能较低,呈现U型曲线。此外,研究还发现增加视觉标记容量可以提高所有时间尺度上的推理能力。ScaleLong为推进MLLM在长视频理解方面的能力提供了一个精细的多时间尺度基准测试平台。数据集和代码已公开。
Key Takeaways
- ScaleLong是首个针对长视频理解的基准测试,解决了现有基准测试在多尺度设计上的不足。
- 该测试在同一视频内容中嵌入四个层次时间尺度的提问,便于直接比较模型在不同时间尺度上的性能。
- 包含多种类别的长视频数据集,平均时长较长。每个视频包含至少四个问题。
- 模型性能评估结果显示U型曲线趋势,即在最小和最大时间尺度上性能较高,中间尺度上性能较低。
- 增加视觉标记容量可以提高模型在所有时间尺度上的推理能力。
- ScaleLong提供了一个精细的多时间尺度基准测试平台,有助于推进MLLM在长视频理解方面的进步。
点此查看论文截图