⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-03 更新
Open CaptchaWorld: A Comprehensive Web-based Platform for Testing and Benchmarking Multimodal LLM Agents
Authors:Yaxin Luo, Zhaoyi Li, Jiacheng Liu, Jiacheng Cui, Xiaohan Zhao, Zhiqiang Shen
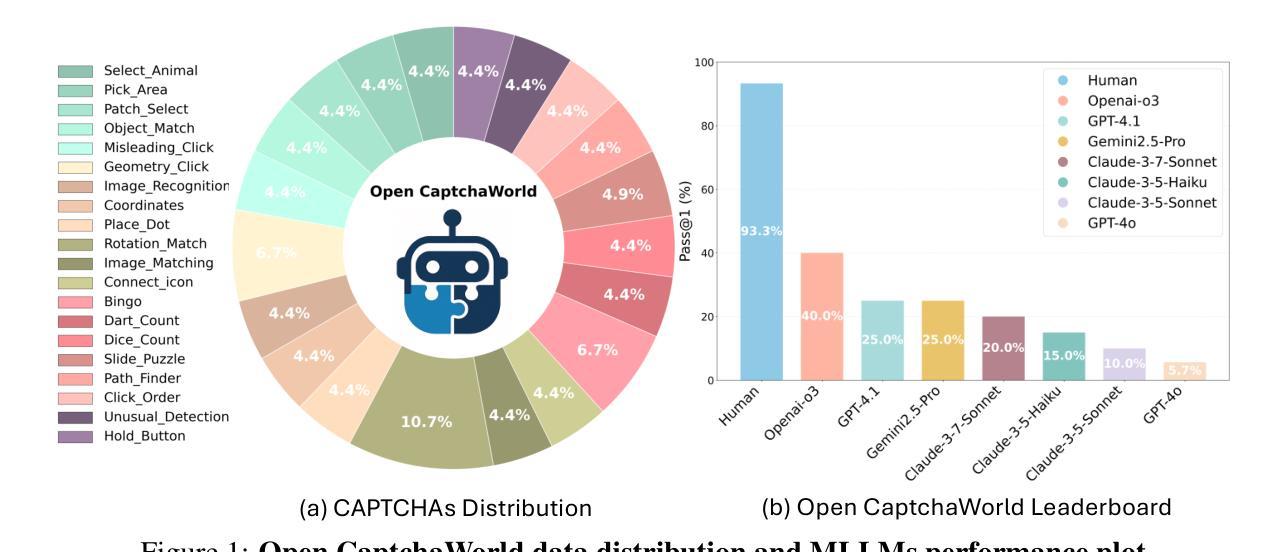
CAPTCHAs have been a critical bottleneck for deploying web agents in real-world applications, often blocking them from completing end-to-end automation tasks. While modern multimodal LLM agents have demonstrated impressive performance in static perception tasks, their ability to handle interactive, multi-step reasoning challenges like CAPTCHAs is largely untested. To address this gap, we introduce Open CaptchaWorld, the first web-based benchmark and platform specifically designed to evaluate the visual reasoning and interaction capabilities of MLLM-powered agents through diverse and dynamic CAPTCHA puzzles. Our benchmark spans 20 modern CAPTCHA types, totaling 225 CAPTCHAs, annotated with a new metric we propose: CAPTCHA Reasoning Depth, which quantifies the number of cognitive and motor steps required to solve each puzzle. Experimental results show that humans consistently achieve near-perfect scores, state-of-the-art MLLM agents struggle significantly, with success rates at most 40.0% by Browser-Use Openai-o3, far below human-level performance, 93.3%. This highlights Open CaptchaWorld as a vital benchmark for diagnosing the limits of current multimodal agents and guiding the development of more robust multimodal reasoning systems. Code and Data are available at this https URL.
CAPTCHA一直是现实世界应用中部署网络代理的关键瓶颈,经常阻止它们完成端到端的自动化任务。虽然现代的多模式大型语言模型代理在静态感知任务中表现出了令人印象深刻的性能,但它们在处理像CAPTCHA这样的交互式多步骤推理挑战方面的能力却很少得到测试。为了弥补这一空白,我们推出了Open CaptchaWorld,这是第一个专门针对评估由大型语言模型驱动代理的视觉推理和交互能力的网络基准和平台,通过多样化和动态的CAPTCHA谜题来实现。我们的基准测试涵盖了20种现代CAPTCHA类型,总共225个CAPTCHA,并提出了一个新的度量标准来进行注释:CAPTCHA推理深度,这个度量标准量化了解决每个谜题所需的认知和动作步骤数量。实验结果表明,人类始终取得近乎完美的成绩,而最新的大型语言模型代理却面临巨大挑战,其中Browser-Use Openai-o3的成功率最高只有40.0%,远远低于人类93.3%的表现。这突出了Open CaptchaWorld作为诊断当前多模式代理限制和引导开发更稳健的多模式推理系统的重要基准。代码和数据可以在这个URL上找到。
论文及项目相关链接
PDF Code at: https://github.com/MetaAgentX/OpenCaptchaWorld
Summary
基于Open CaptchaWorld的评测,现代多模态LLM代理在解决CAPTCHA谜题时存在视觉推理和交互能力的瓶颈。该平台包含多种类型的CAPTCHA谜题,并提出新的评估指标——CAPTCHA推理深度。实验结果显示,尽管人类表现接近完美,但最先进的LLM代理成功率最高仅为40%,远低于人类水平。这为诊断当前多模态代理的局限性并引导开发更稳健的多模态推理系统提供了重要依据。
Key Takeaways
- CAPTCHAs已成为部署Web代理在实际应用中的关键瓶颈,阻碍了端到端自动化任务的完成。
- 现代多模态LLM代理在静态感知任务上表现出色,但在处理交互式多步骤推理挑战如CAPTCHAs方面能力尚未得到充分测试。
- Open CaptchaWorld是首个专门用于评估多模态LLM代理的视觉推理和交互能力的网页基准测试平台。
- 该平台包含20种现代CAPTCHA类型,总计225个CAPTCHA,并提出了新的评估指标——CAPTCHA推理深度。
- 实验结果表明,尽管人类表现接近完美,但最先进的LLM代理在解决CAPTCHA谜题方面的表现显著挣扎,成功率最高仅为40%。
- 与人类性能相比,LLM代理的表现远低于人类水平。
点此查看论文截图



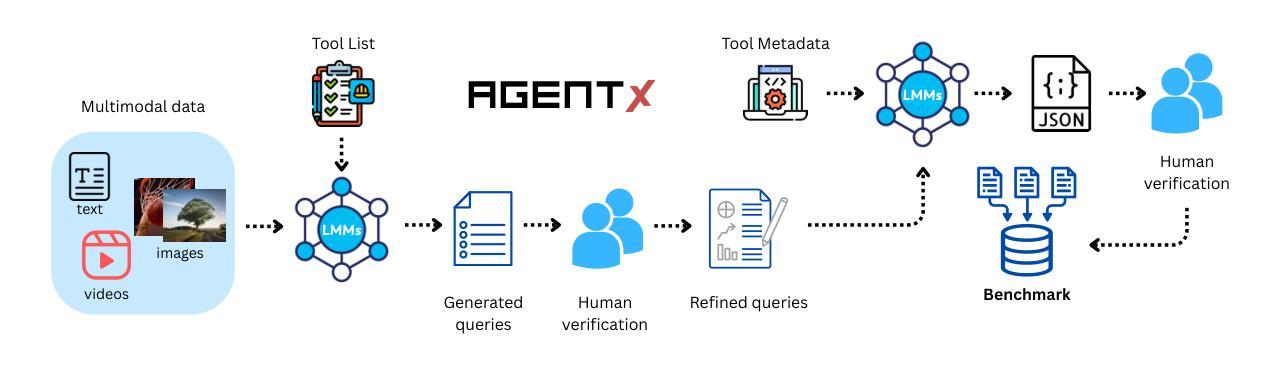
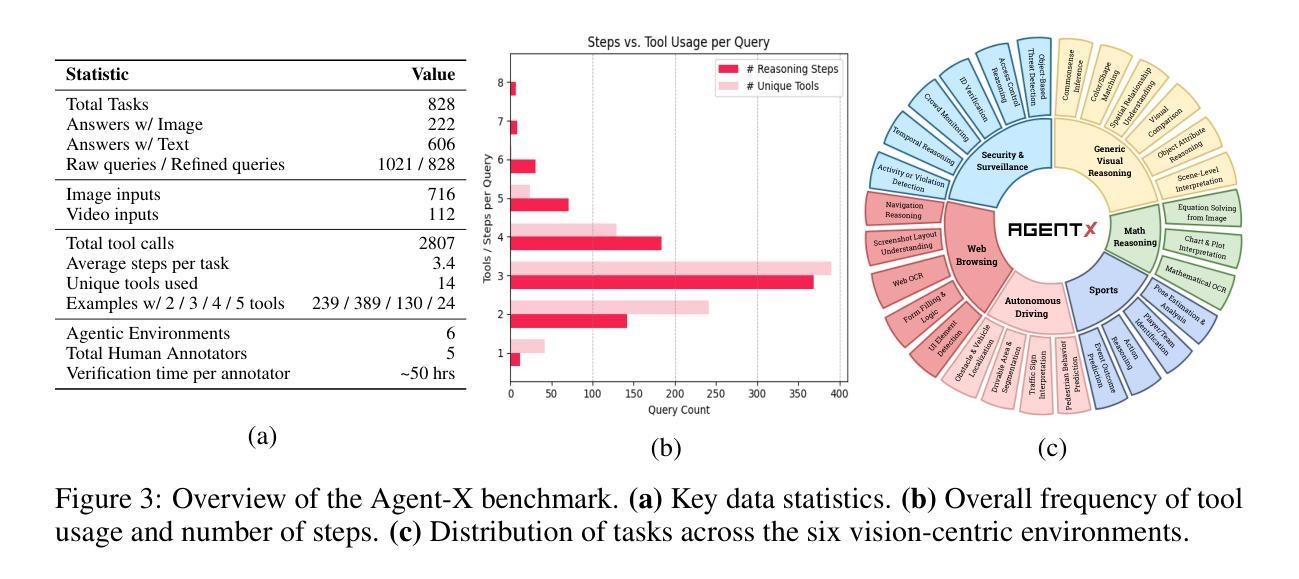
Agent-X: Evaluating Deep Multimodal Reasoning in Vision-Centric Agentic Tasks
Authors:Tajamul Ashraf, Amal Saqib, Hanan Ghani, Muhra AlMahri, Yuhao Li, Noor Ahsan, Umair Nawaz, Jean Lahoud, Hisham Cholakkal, Mubarak Shah, Philip Torr, Fahad Shahbaz Khan, Rao Muhammad Anwer, Salman Khan
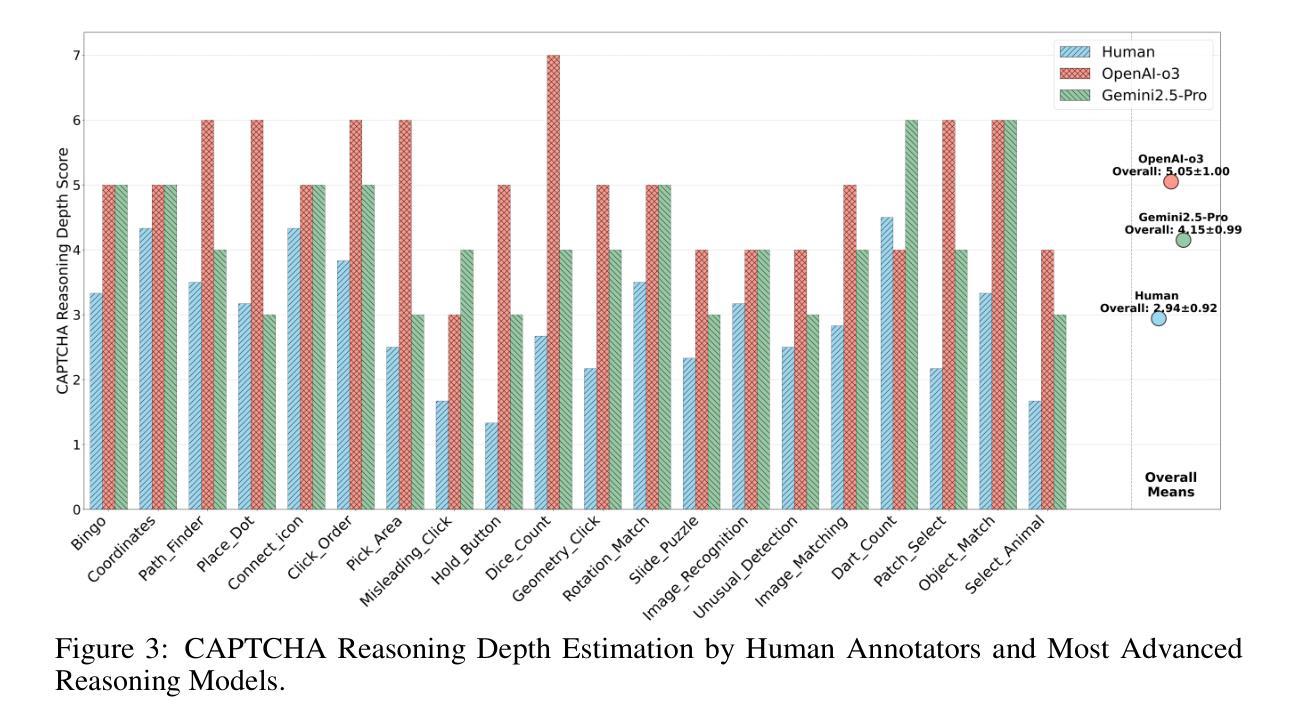
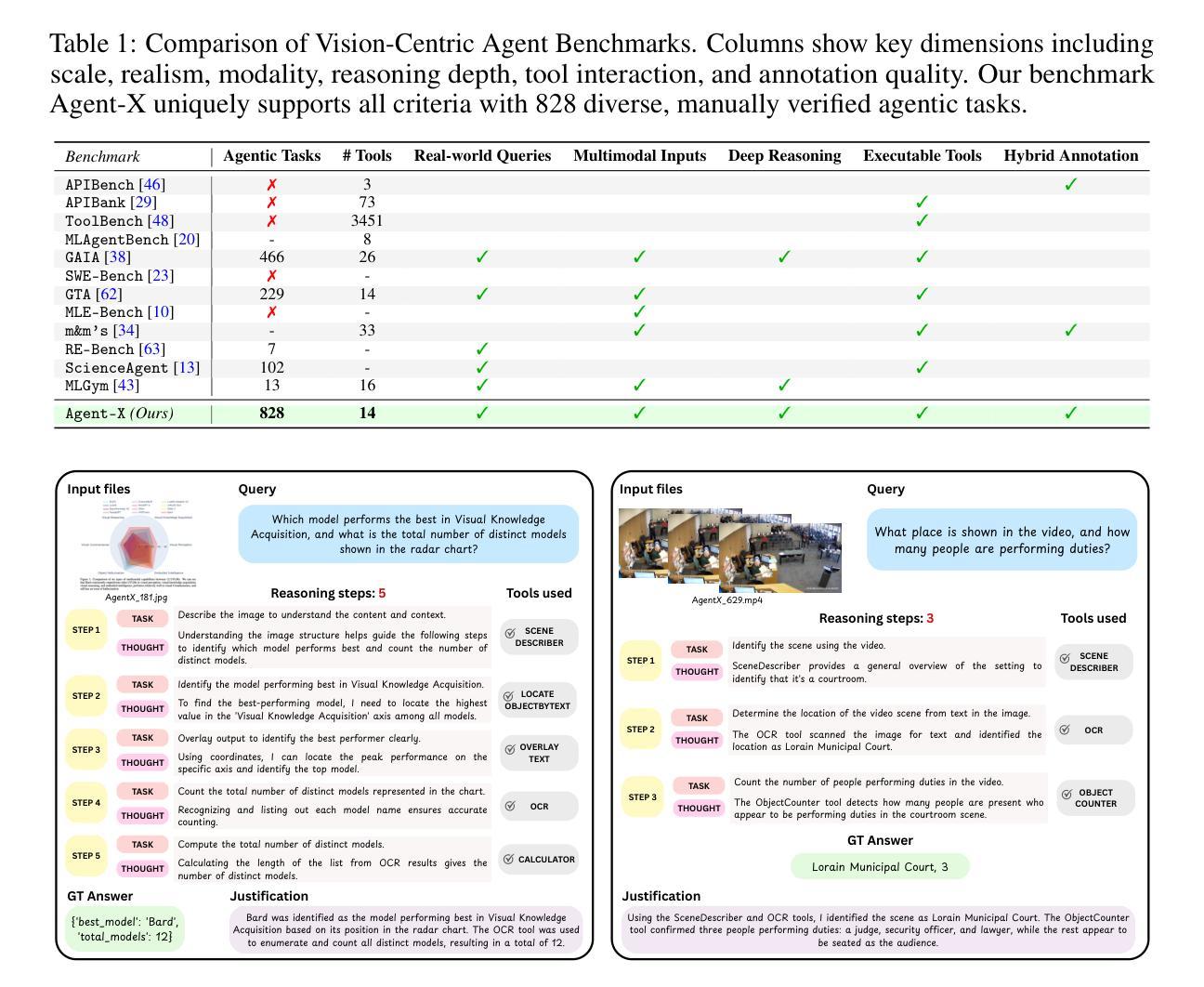
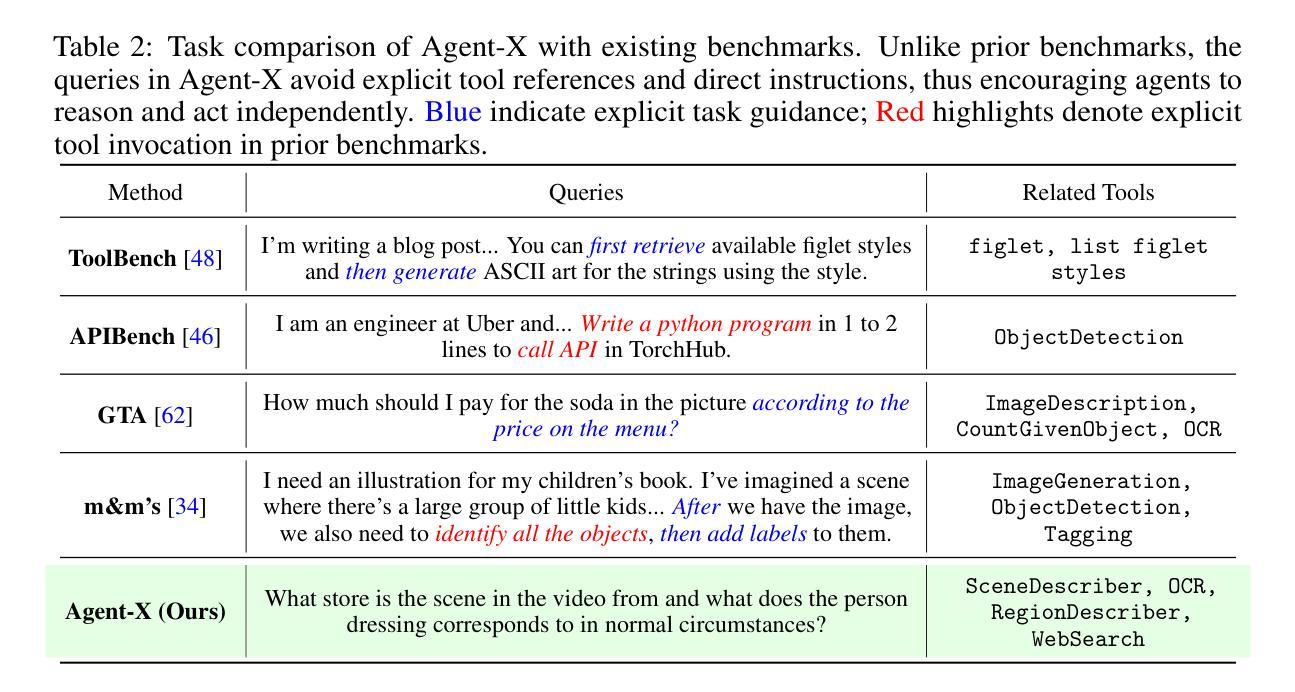
Deep reasoning is fundamental for solving complex tasks, especially in vision-centric scenarios that demand sequential, multimodal understanding. However, existing benchmarks typically evaluate agents with fully synthetic, single-turn queries, limited visual modalities, and lack a framework to assess reasoning quality over multiple steps as required in real-world settings. To address this, we introduce Agent-X, a large-scale benchmark for evaluating vision-centric agents multi-step and deep reasoning capabilities in real-world, multimodal settings. Agent- X features 828 agentic tasks with authentic visual contexts, including images, multi-image comparisons, videos, and instructional text. These tasks span six major agentic environments: general visual reasoning, web browsing, security and surveillance, autonomous driving, sports, and math reasoning. Our benchmark requires agents to integrate tool use with explicit, stepwise decision-making in these diverse settings. In addition, we propose a fine-grained, step-level evaluation framework that assesses the correctness and logical coherence of each reasoning step and the effectiveness of tool usage throughout the task. Our results reveal that even the best-performing models, including GPT, Gemini, and Qwen families, struggle to solve multi-step vision tasks, achieving less than 50% full-chain success. These findings highlight key bottlenecks in current LMM reasoning and tool-use capabilities and identify future research directions in vision-centric agentic reasoning models. Our data and code are publicly available at https://github.com/mbzuai-oryx/Agent-X
深度推理是解决复杂任务的基础,特别是在以视觉为中心的场景中,需要连续的多模式理解。然而,现有的基准测试通常使用完全合成、单轮次的查询进行评估,视觉模式有限,并且缺乏一个框架来评估现实世界环境中所需的多个步骤的推理质量。为了解决这个问题,我们引入了Agent-X,这是一个大规模基准测试,用于评估以视觉为中心的智能体在多步骤和深度推理能力方面的现实世界、多模式设置。Agent-X拥有828项真实视觉上下文的任务,包括图像、多图像比较、视频和指令文本。这些任务涵盖了六大智能环境:通用视觉推理、网页浏览、安全监控、自动驾驶、运动和数学推理。我们的基准测试要求智能体在这些多样化的环境中将工具使用与明确、分步骤的决策相结合。此外,我们提出了一个精细的、步骤级的评估框架,该框架可以评估每个推理步骤的正确性和逻辑性,以及在整个任务中工具使用的有效性。我们的研究结果表明,即使是最先进的模型,包括GPT、双子座和Qwen系列模型,在解决多步骤视觉任务方面仍面临困难,全程成功率低于50%。这些发现突显了当前视觉为中心的智能体在逻辑推理和工具使用能力上的关键瓶颈,并指出了未来视觉为中心的智能体推理模型的研究方向。我们的数据和代码可在https://github.com/mbzuai-oryx/Agent-X公开访问。
论文及项目相关链接
Summary
为解决视觉为中心的任务中需要多步骤深度推理的问题,现有评估基准存在局限性。为此,提出Agent-X大型基准测试,旨在评估视觉为中心的任务中代理的多步骤深度推理能力。该测试包含真实世界的多模态场景,涵盖六大代理环境,要求代理在多样化环境中整合工具使用和明确分步决策。此外,还提出了精细的、步骤级的评估框架,以评估每一步推理的正确性和逻辑性,以及整个任务中工具使用的有效性。研究结果显示,即使是表现最佳的模型,在完成多步骤视觉任务时的成功率也不到50%,这突显了当前模型在视觉为中心的任务推理方面的瓶颈。
Key Takeaways
- 现有基准测试无法充分评估视觉为中心的任务中的多步骤深度推理能力。
- Agent-X基准测试旨在评估代理在真实世界多模态场景中的多步骤深度推理能力。
- Agent-X包含六大代理环境,涵盖广泛的任务类型。
- 该测试要求代理在多样化环境中整合工具使用与明确分步决策。
- 提出了精细的、步骤级的评估框架,以评估每一步推理的正确性和逻辑性。
- 即使是最好的模型,在完成多步骤视觉任务时的成功率也不到50%。
点此查看论文截图

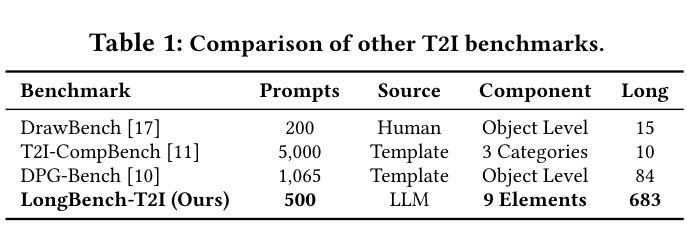
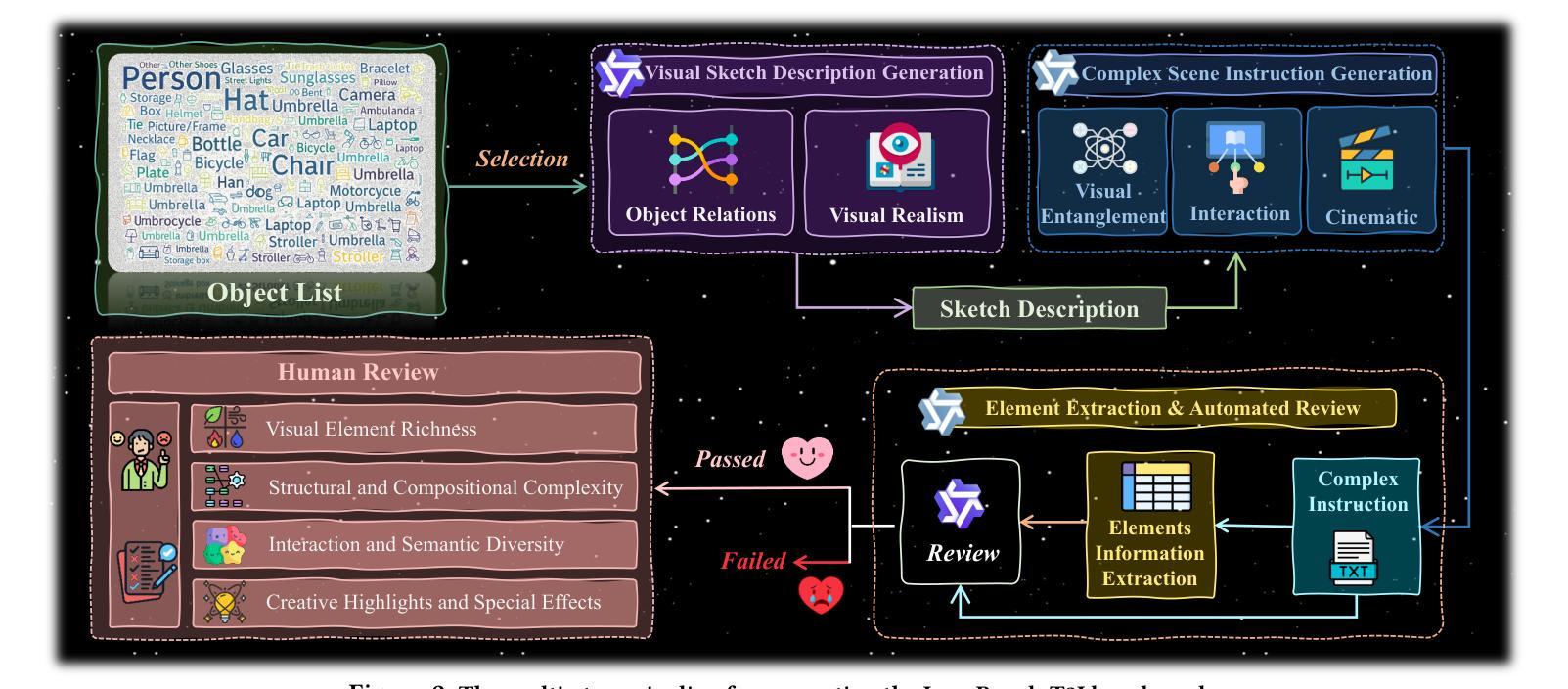
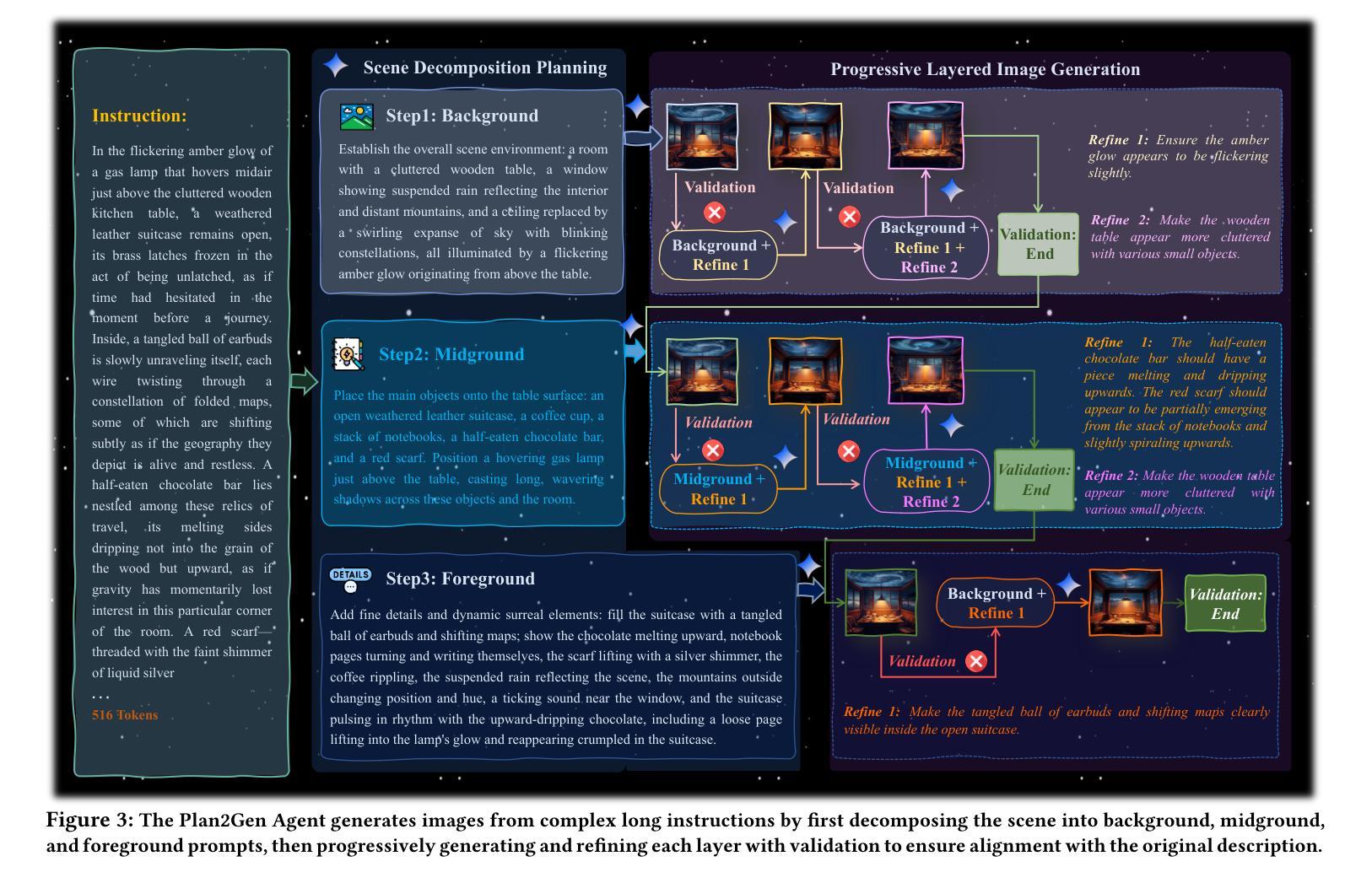
Draw ALL Your Imagine: A Holistic Benchmark and Agent Framework for Complex Instruction-based Image Generation
Authors:Yucheng Zhou, Jiahao Yuan, Qianning Wang
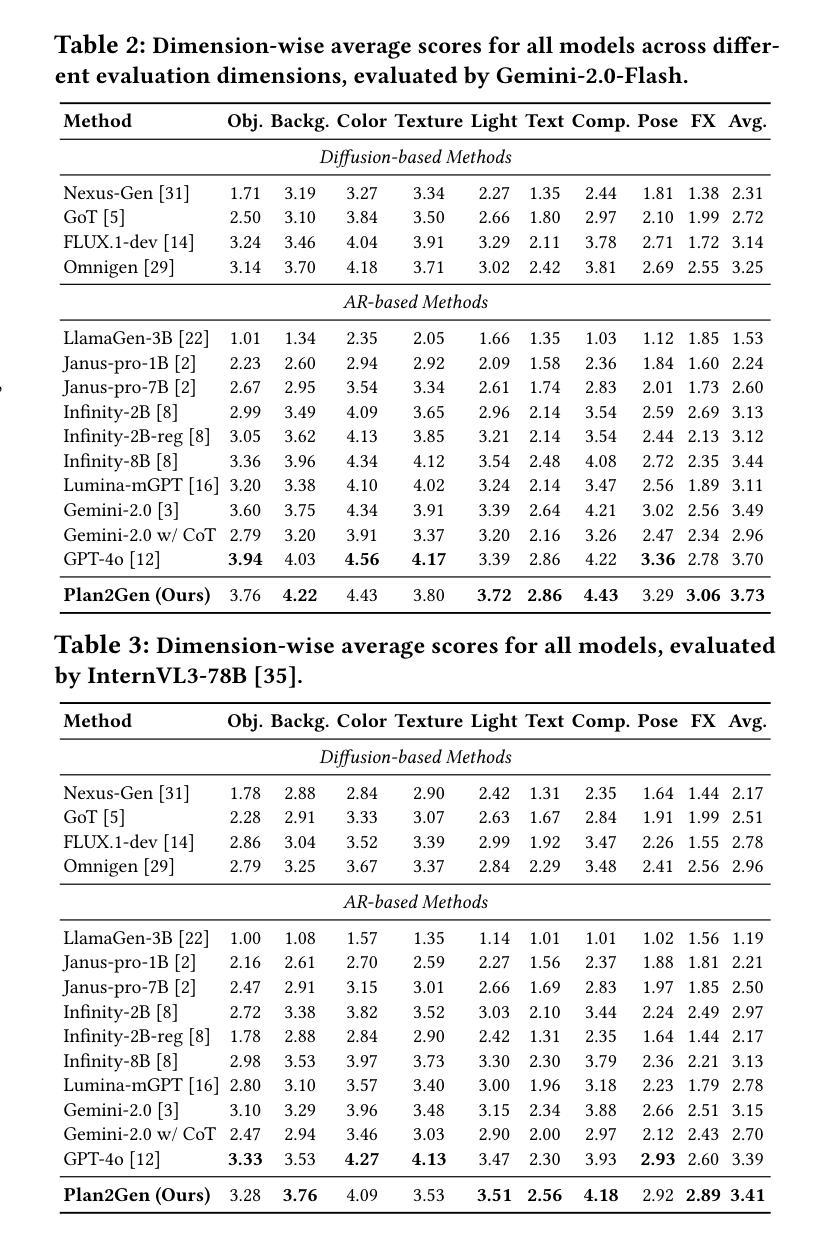
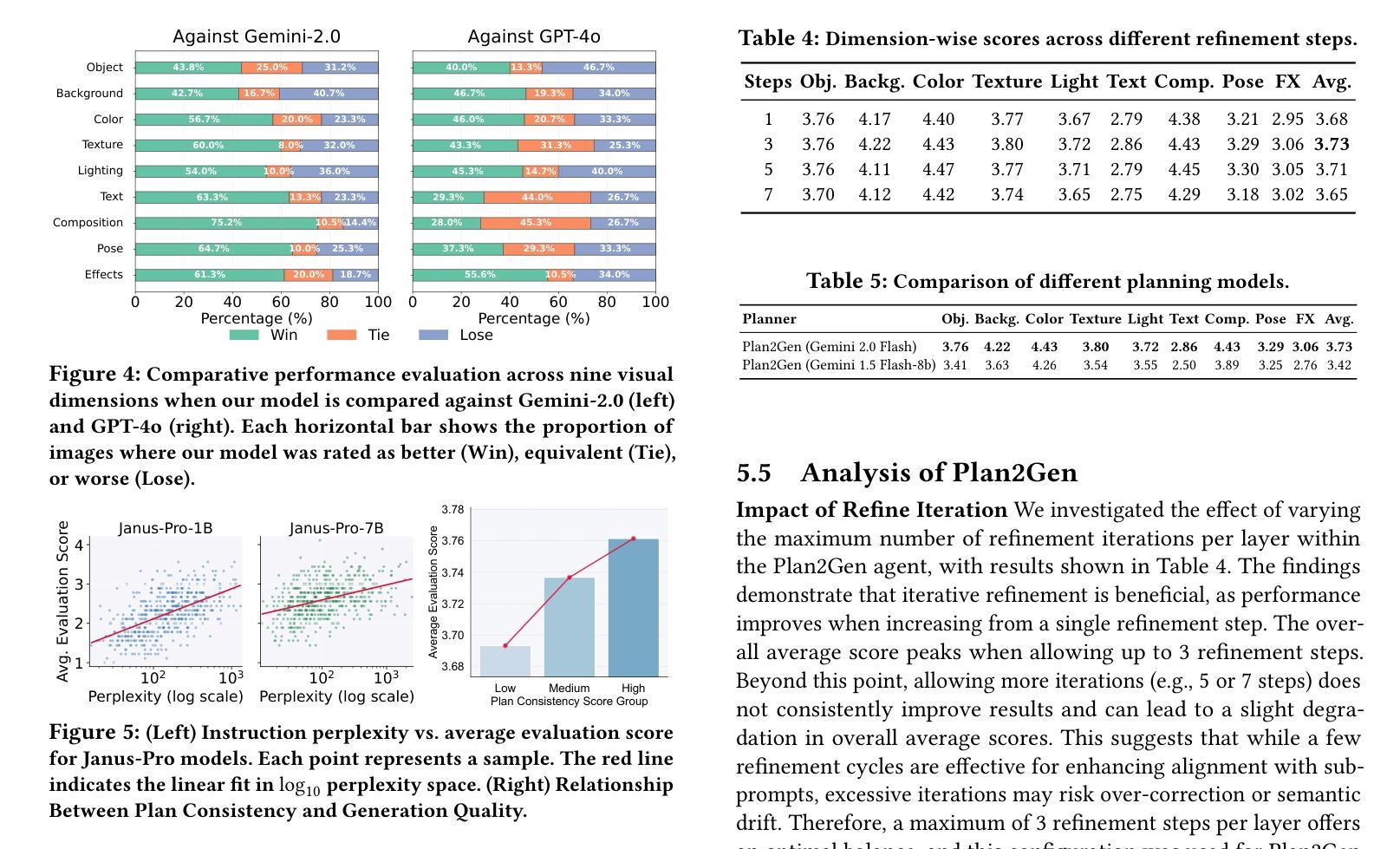
Recent advancements in text-to-image (T2I) generation have enabled models to produce high-quality images from textual descriptions. However, these models often struggle with complex instructions involving multiple objects, attributes, and spatial relationships. Existing benchmarks for evaluating T2I models primarily focus on general text-image alignment and fail to capture the nuanced requirements of complex, multi-faceted prompts. Given this gap, we introduce LongBench-T2I, a comprehensive benchmark specifically designed to evaluate T2I models under complex instructions. LongBench-T2I consists of 500 intricately designed prompts spanning nine diverse visual evaluation dimensions, enabling a thorough assessment of a model’s ability to follow complex instructions. Beyond benchmarking, we propose an agent framework (Plan2Gen) that facilitates complex instruction-driven image generation without requiring additional model training. This framework integrates seamlessly with existing T2I models, using large language models to interpret and decompose complex prompts, thereby guiding the generation process more effectively. As existing evaluation metrics, such as CLIPScore, fail to adequately capture the nuances of complex instructions, we introduce an evaluation toolkit that automates the quality assessment of generated images using a set of multi-dimensional metrics. The data and code are released at https://github.com/yczhou001/LongBench-T2I.
近期文本到图像(T2I)生成技术的进展使得模型能够从文本描述中生成高质量图像。然而,这些模型在处理涉及多个对象、属性和空间关系的复杂指令时常常遇到困难。现有的评估T2I模型的主要基准测试主要集中在文本与图像的一般对齐上,无法捕捉复杂、多角度提示的细微要求。鉴于此,我们推出了LongBench-T2I,这是一个专为在复杂指令下评估T2I模型而设计的全面基准测试。LongBench-T2I包含500个精心设计提示,涵盖九个不同的视觉评估维度,能够全面评估模型遵循复杂指令的能力。除了基准测试,我们还提出了一个代理框架(Plan2Gen),它可以在不需要额外模型训练的情况下,促进复杂指令驱动的图像生成。该框架无缝集成现有的T2I模型,利用大型语言模型解释和分解复杂提示,从而更有效地引导生成过程。由于现有的评估指标(如CLIPScore)无法充分捕捉复杂指令的细微差别,我们引入了一个评估工具包,该工具包使用一系列多维指标自动评估生成图像的质量。数据和代码已发布在https://github.com/yczhou001/LongBench-T2I。
论文及项目相关链接
Summary
本文介绍了文本到图像(T2I)生成领域的最新进展,并提出了一个名为LongBench-T2I的综合基准测试,专门用于评估T2I模型在复杂指令下的表现。该基准测试包含500个精心设计提示,涵盖九个不同的视觉评估维度。此外,文章还介绍了一个名为Plan2Gen的代理框架,可推动复杂指令驱动的图像生成,无需额外的模型训练。最后,由于现有评估指标不足以捕捉复杂指令的细微差别,因此引入了自动化评估工具包,使用多维度指标对生成的图像质量进行评估。
Key Takeaways
- 文本到图像(T2I)生成技术取得最新进展,能够生成高质量图像。
- 现有基准测试主要关注文本与图像的一般对齐,难以评估模型处理复杂、多方面提示的能力。
- LongBench-T2I基准测试包含500个复杂提示,涵盖九个视觉评估维度,全面评估模型遵循复杂指令的能力。
- Plan2Gen代理框架有助于根据复杂指令进行图像生成,无需额外训练模型。
- 现有评估指标如CLIPScore不足以捕捉复杂指令的细微差别。
- 引入自动化评估工具包,使用多维度指标对生成的图像质量进行评估。
点此查看论文截图

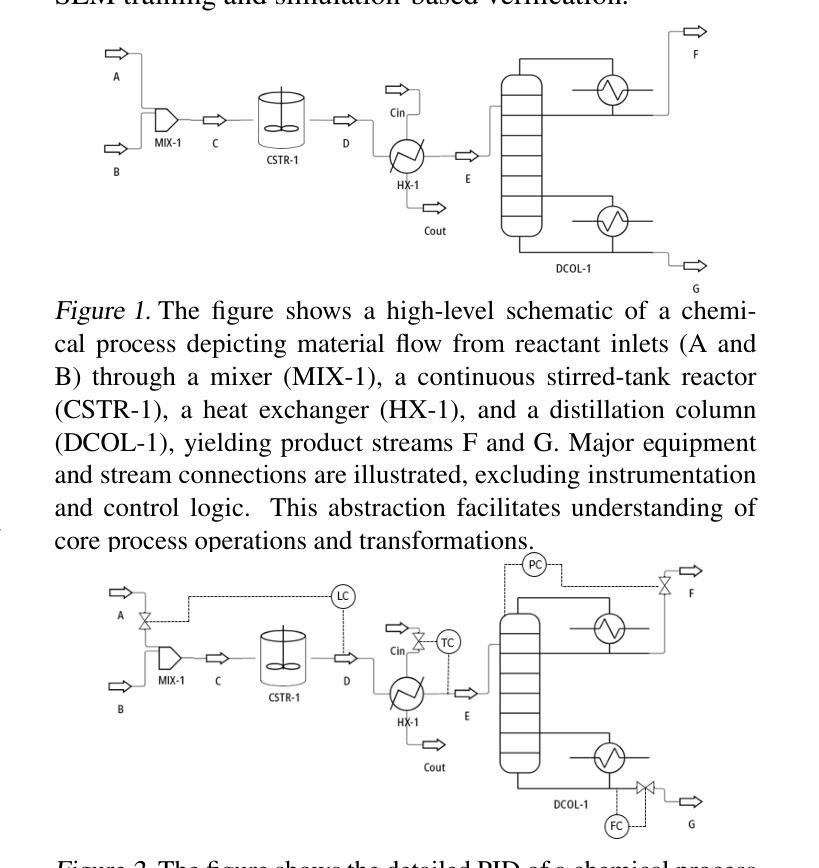
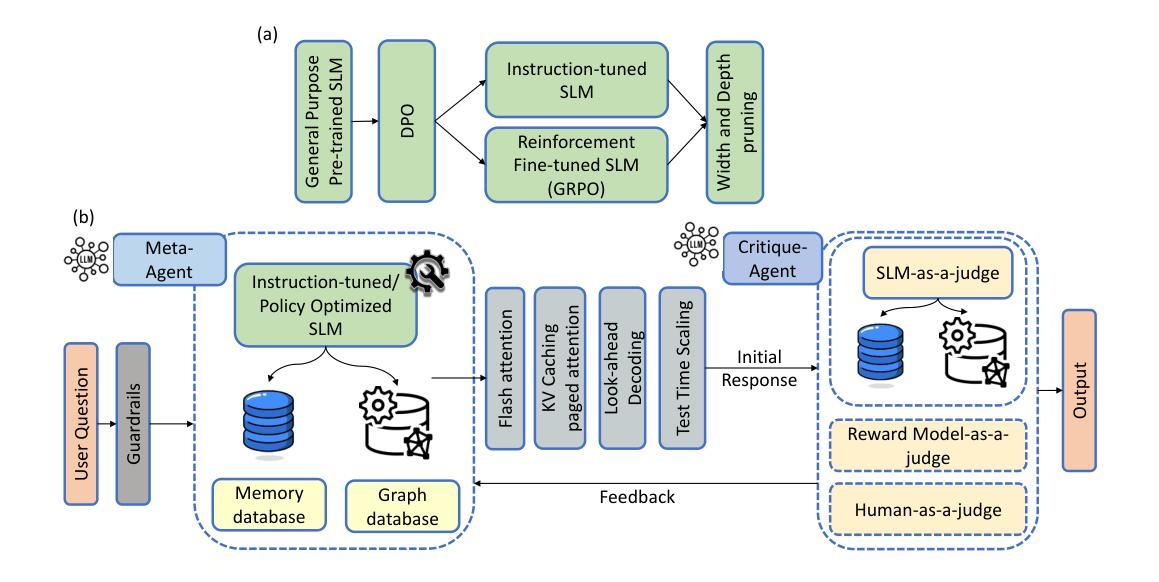
AutoChemSchematic AI: A Closed-Loop, Physics-Aware Agentic Framework for Auto-Generating Chemical Process and Instrumentation Diagrams
Authors:Sakhinana Sagar Srinivas, Shivam Gupta, Venkataramana Runkana
Recent advancements in generative AI have accelerated the discovery of novel chemicals and materials; however, transitioning these discoveries to industrial-scale production remains a critical bottleneck, as it requires the development of entirely new chemical manufacturing processes. Current AI methods cannot auto-generate PFDs or PIDs, despite their critical role in scaling chemical processes, while adhering to engineering constraints. We present a closed loop, physics aware framework for the automated generation of industrially viable PFDs and PIDs. The framework integrates domain specialized small scale language models (SLMs) (trained for chemical process QA tasks) with first principles simulation, leveraging three key components: (1) a hierarchical knowledge graph of process flow and instrumentation descriptions for 1,020+ chemicals, (2) a multi-stage training pipeline that fine tunes domain specialized SLMs on synthetic datasets via Supervised Fine-Tuning (SFT), Direct Preference Optimization (DPO), and Retrieval-Augmented Instruction Tuning (RAIT), and (3) DWSIM based simulator in the loop validation to ensure feasibility. To improve both runtime efficiency and model compactness, the framework incorporates advanced inference time optimizations including FlashAttention, Lookahead Decoding, PagedAttention with KV-cache quantization, and Test Time Inference Scaling and independently applies structural pruning techniques (width and depth) guided by importance heuristics to reduce model size with minimal accuracy loss. Experiments demonstrate that the framework generates simulator-validated process descriptions with high fidelity, outperforms baseline methods in correctness, and generalizes to unseen chemicals. By bridging AI-driven design with industrial-scale feasibility, this work significantly reduces R&D timelines from lab discovery to plant deployment.
近年来,生成式人工智能的进展加速了新型化学物质和材料的发现;然而,将这些发现转化为工业规模生产仍然是一个关键瓶颈,因为这需要开发全新的化学制造工艺。尽管它们在规模化化学过程中发挥着关键作用,但目前的AI方法无法自动生成PFDs或PIDs。我们提出了一种闭环、物理感知的框架,用于自动生成工业可行的PFDs和PIDs。该框架将领域专业化的小规模语言模型(SLM)(用于化学过程问答任务)与第一性原则模拟相结合,利用三个关键组件:(1)包含1020+化学物质的工艺流程和仪器描述分层知识图谱;(2)多阶段训练管道,通过监督微调(SFT)、直接偏好优化(DPO)和检索增强指令调整(RAIT)在合成数据集上微调领域专业化的SLM;(3)基于DWSIM的模拟器进行闭环验证,以确保可行性。为了提高运行效率和模型紧凑性,该框架采用了先进的推理时间优化,包括FlashAttention、前瞻解码、带KV缓存量化的PagedAttention以及测试时间推理缩放,并独立应用结构修剪技术(宽度和深度),以重要性启发式为指导,以尽量减少精度损失来减小模型规模。实验表明,该框架生成了模拟器验证的高保真度过程描述,在正确性方面优于基准方法,并能推广到未见过的化学物质。通过桥梁AI驱动的设计与工业规模可行性之间的联系,这项工作显著缩短了从实验室发现到工厂部署的研发时间。
论文及项目相关链接
Summary
最近生成式AI的进展加速了新型化学物质和材料的发现,但将这些发现转化为工业规模生产仍是关键瓶颈,需要开发全新的化学制造工艺。本研究提出了一种闭环、物理感知的框架,用于自动生成符合工业要求的PFDs和PIDs。该框架结合了专业领域的小规模语言模型(SLM)与基于第一原理的仿真,通过三个关键组件实现自动化生成:包含超过1020种化学品的工艺流和仪器描述层次知识图谱、多阶段训练管道以及DWSIM仿真验证。为提高运行效率和模型紧凑性,该框架还采用了高级推理时间优化技术,并对模型结构进行了修剪,以减少模型大小并保持准确性。实验表明,该框架生成的工艺描述与仿真验证高度一致,在正确性方面优于基准方法,并能泛化到未见过的化学品。这一工作通过桥梁AI驱动的设计与工业规模可行性,显著缩短了从实验室发现到工厂部署的研发时间。
Key Takeaways
- 生成式AI在化学发现和材料领域有重大进展,但工业规模生产的转化仍是关键挑战。
- 需要全新的化学制造工艺来满足工业生产的规模化需求。
- 提出的框架结合了SLM和基于第一原理的仿真,实现自动化生成工艺流程图(PFDs)和管道仪表流程图(PIDs)。
- 框架包含三个关键组件:层次知识图谱、多阶段训练管道和DWSIM仿真验证。
- 框架采用了多种推理时间优化技术和模型结构修剪,以提高运行效率和模型紧凑性。
- 实验证明,该框架生成的工艺描述与仿真验证高度一致,具有优异的表现。
点此查看论文截图

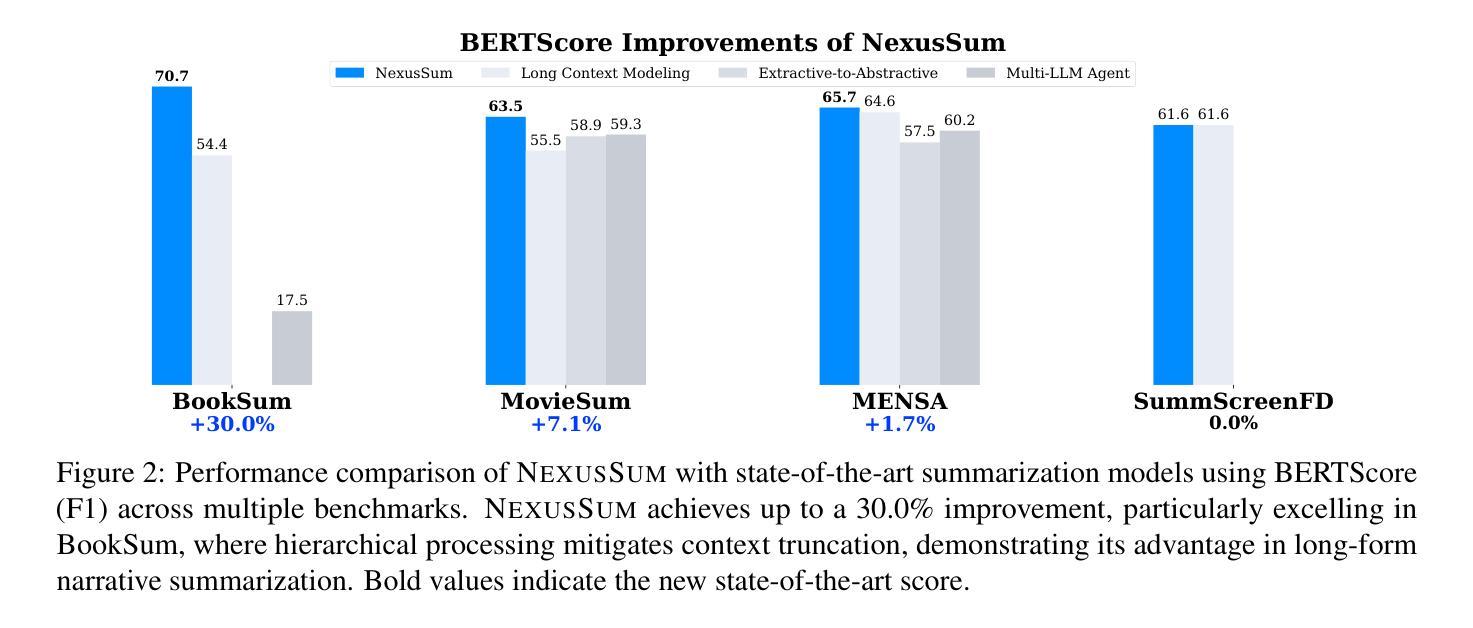
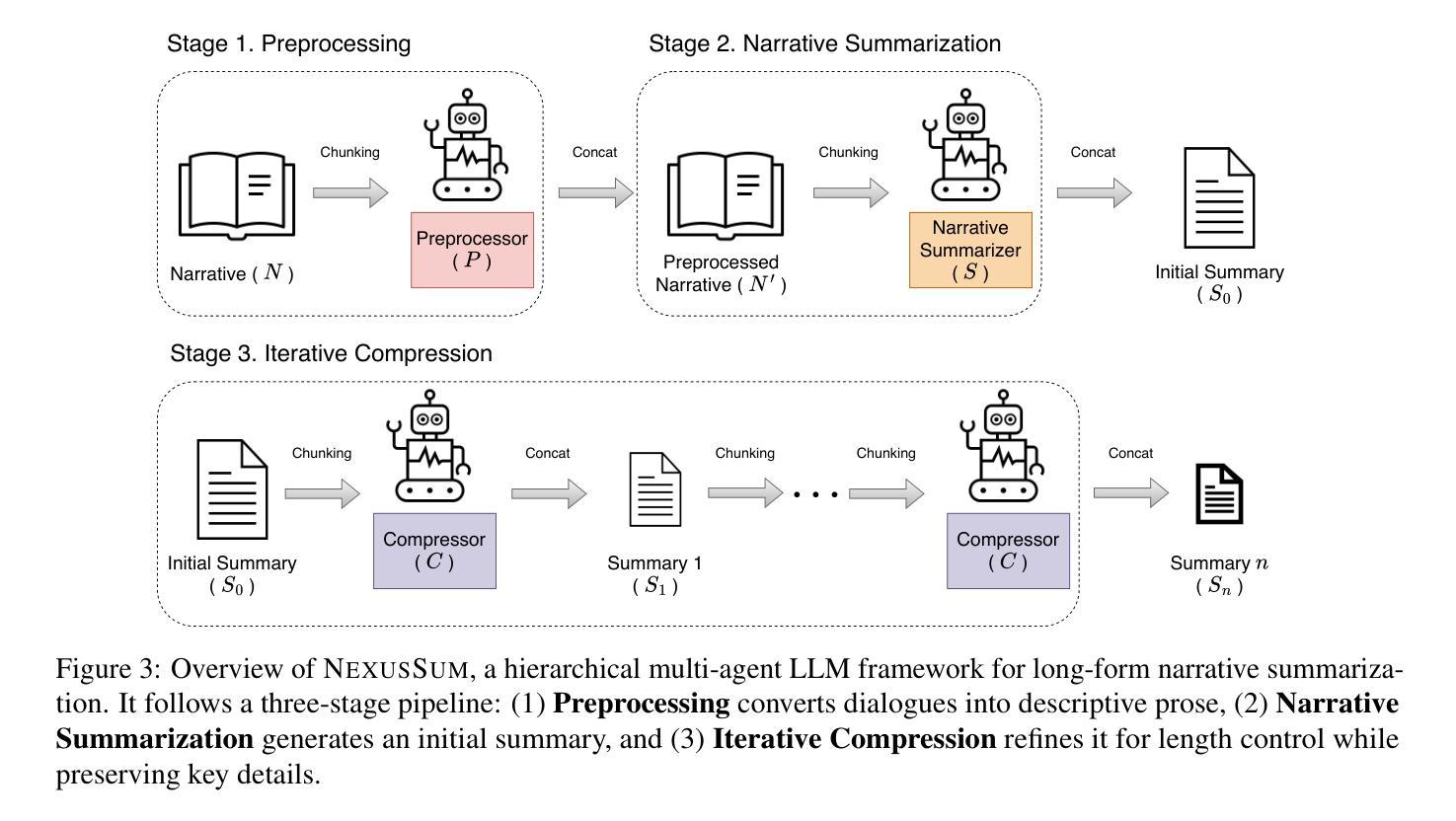
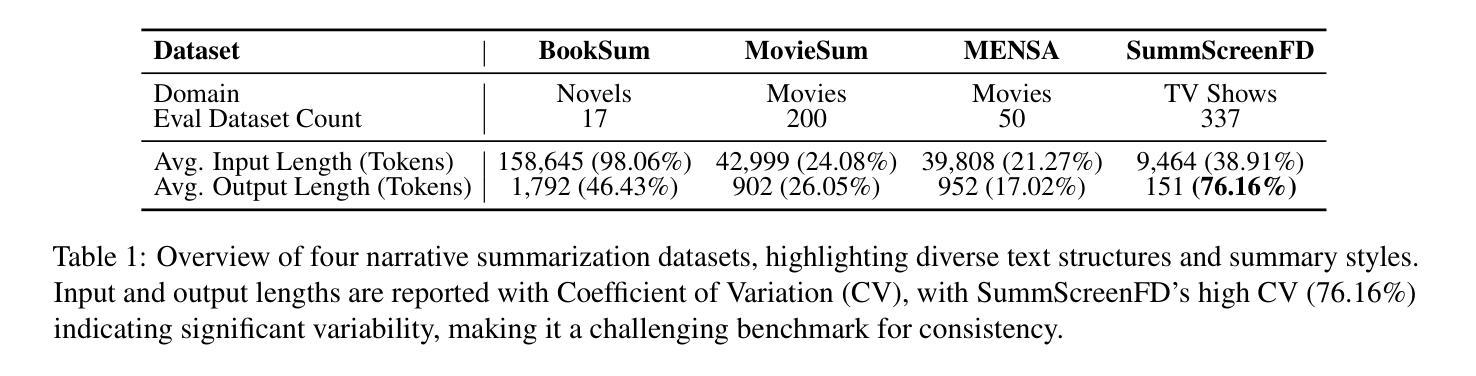
NexusSum: Hierarchical LLM Agents for Long-Form Narrative Summarization
Authors:Hyuntak Kim, Byung-Hak Kim
Summarizing long-form narratives–such as books, movies, and TV scripts–requires capturing intricate plotlines, character interactions, and thematic coherence, a task that remains challenging for existing LLMs. We introduce NexusSum, a multi-agent LLM framework for narrative summarization that processes long-form text through a structured, sequential pipeline–without requiring fine-tuning. Our approach introduces two key innovations: (1) Dialogue-to-Description Transformation: A narrative-specific preprocessing method that standardizes character dialogue and descriptive text into a unified format, improving coherence. (2) Hierarchical Multi-LLM Summarization: A structured summarization pipeline that optimizes chunk processing and controls output length for accurate, high-quality summaries. Our method establishes a new state-of-the-art in narrative summarization, achieving up to a 30.0% improvement in BERTScore (F1) across books, movies, and TV scripts. These results demonstrate the effectiveness of multi-agent LLMs in handling long-form content, offering a scalable approach for structured summarization in diverse storytelling domains.
摘要长期叙事内容(如书籍、电影和电视剧本)需要捕捉复杂的情节线、角色互动和主题连贯性,这是一项对现有大型语言模型(LLM)仍有挑战性的任务。我们引入了NexusSum,这是一个用于叙事摘要的多代理大型语言模型框架,它通过结构化、顺序化的管道处理长篇文本,无需微调。我们的方法引入了两个关键创新点:(1)对话到描述的转换:一种针对叙事的预处理方式,将角色对话和描述性文本标准化为统一格式,提高连贯性。(2)分层多大型语言模型摘要:一种结构化摘要管道,优化了块处理并控制输出长度,以产生准确、高质量的摘要。我们的方法在叙事摘要方面建立了最新技术状态,在书籍、电影和电视剧本上实现了高达BERTScore(F1)的30.0%的提升。这些结果证明了多代理大型语言模型在处理长篇内容方面的有效性,为多样化的叙事领域提供了可扩展的结构化摘要方法。
论文及项目相关链接
PDF Accepted to the main track of ACL 2025
Summary:
介绍了一种名为NexusSum的多代理LLM框架,用于叙事摘要,能够处理长文本,通过结构化、顺序的管道进行,无需微调。该框架包括两个关键创新点:对话到描述的转换和分层多LLM摘要技术。该技术提高了叙事摘要的连贯性和准确性,并在书籍、电影和电视剧本的叙事摘要中取得了最新成果。
Key Takeaways:
- NexusSum是一个多代理LLM框架,用于叙事摘要,处理长文本。
- 引入了两个关键创新点:对话到描述的转换和分层多LLM摘要技术。
- 对话到描述的转换将角色对话和描述性文本标准化为统一格式,提高连贯性。
- 分层多LLM摘要技术优化了块处理并控制输出长度,提高了摘要的准确性和质量。
- 该方法在书籍、电影和电视剧本的叙事摘要中取得了最新成果,提高了BERTScore(F1)达30.0%。
点此查看论文截图

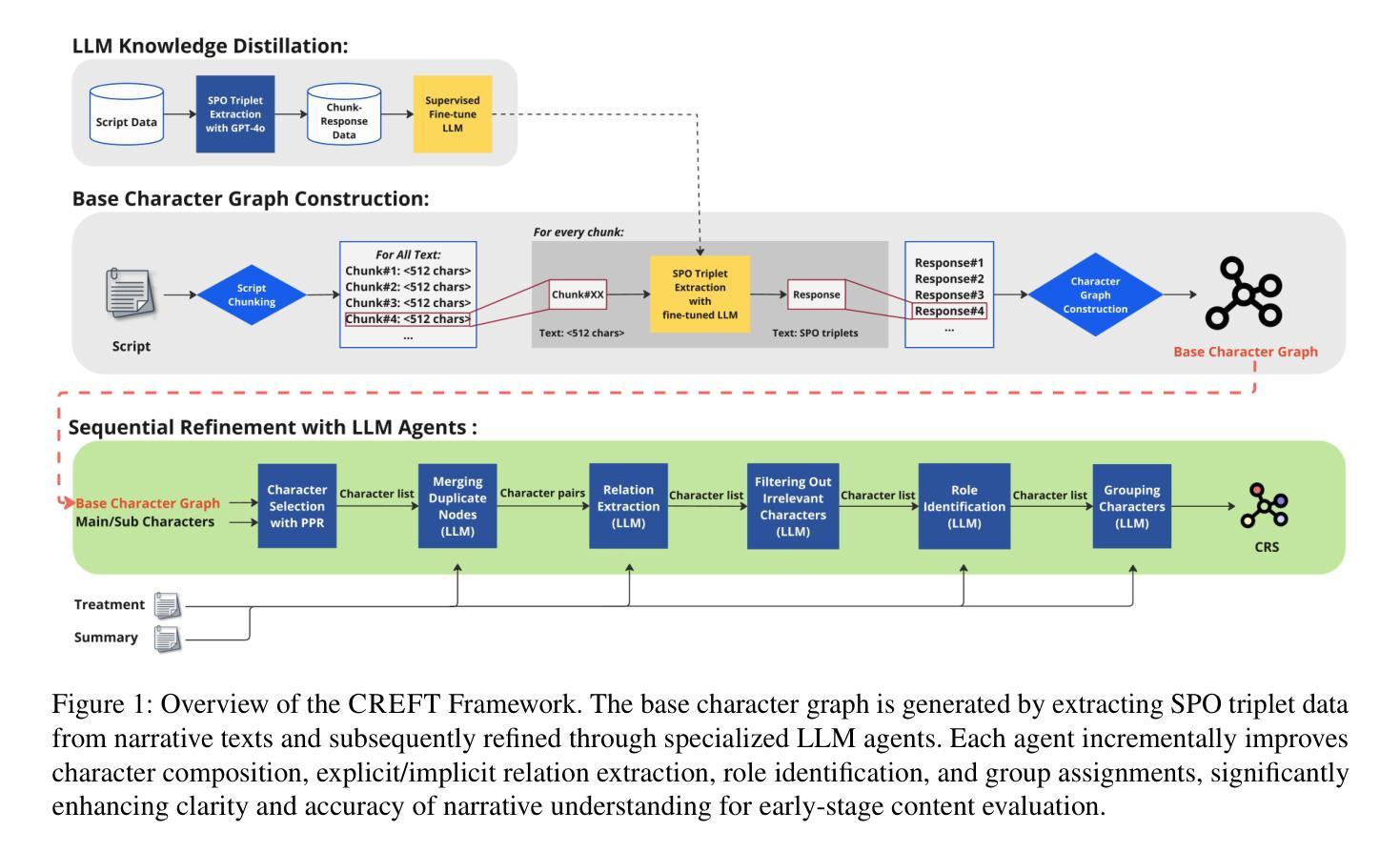
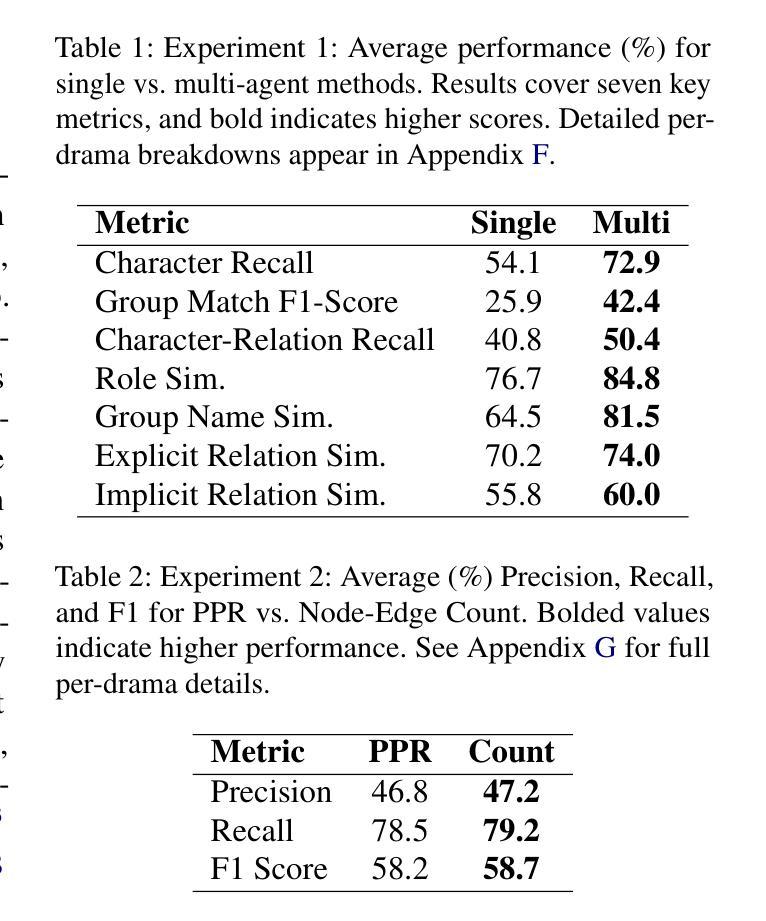
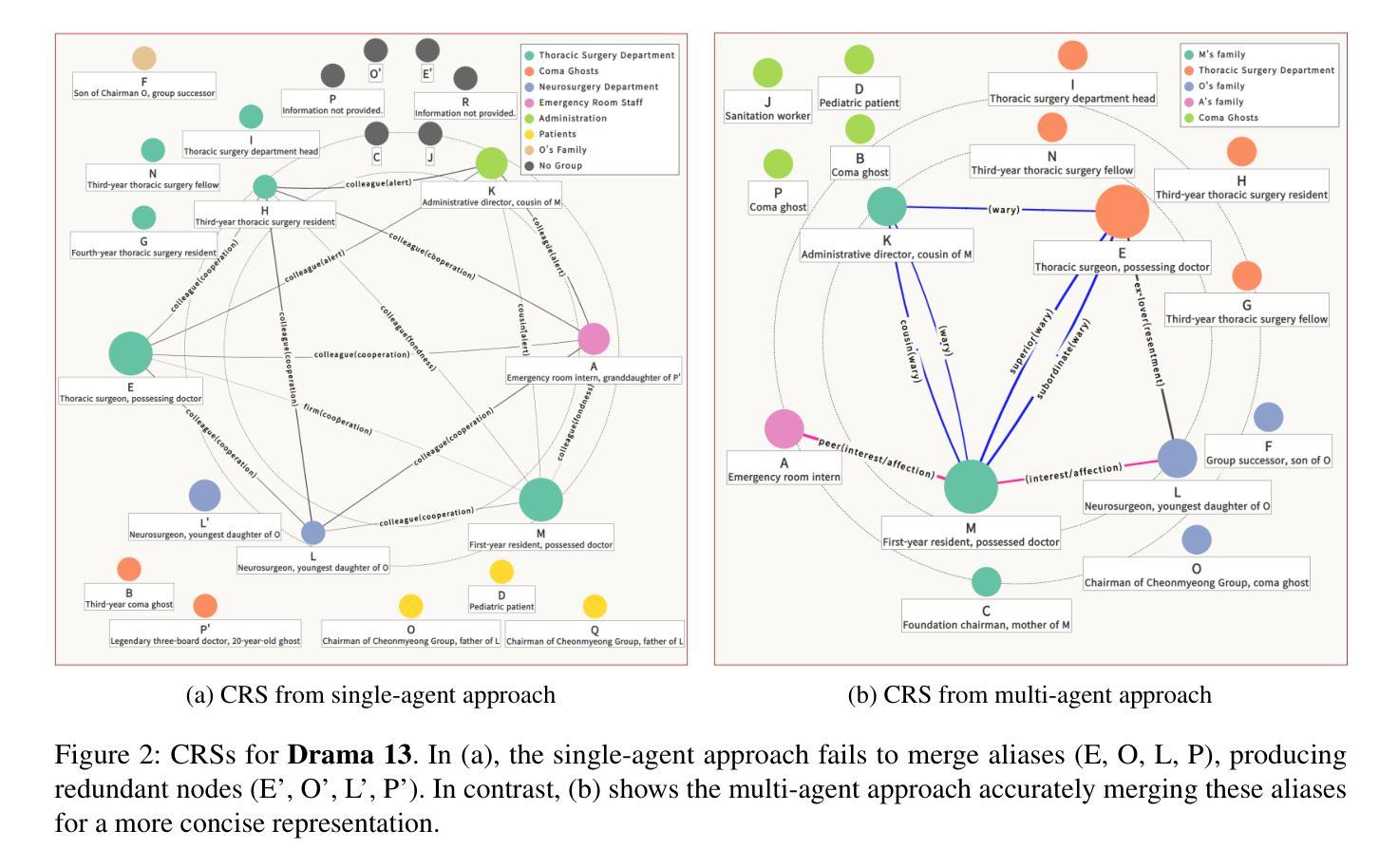
CREFT: Sequential Multi-Agent LLM for Character Relation Extraction
Authors:Ye Eun Chun, Taeyoon Hwang, Seung-won Hwang, Byung-Hak Kim
Understanding complex character relations is crucial for narrative analysis and efficient script evaluation, yet existing extraction methods often fail to handle long-form narratives with nuanced interactions. To address this challenge, we present CREFT, a novel sequential framework leveraging specialized Large Language Model (LLM) agents. First, CREFT builds a base character graph through knowledge distillation, then iteratively refines character composition, relation extraction, role identification, and group assignments. Experiments on a curated Korean drama dataset demonstrate that CREFT significantly outperforms single-agent LLM baselines in both accuracy and completeness. By systematically visualizing character networks, CREFT streamlines narrative comprehension and accelerates script review – offering substantial benefits to the entertainment, publishing, and educational sectors.
理解复杂的角色关系对于叙事分析和高效的剧本评估至关重要,然而现有的提取方法往往难以处理具有微妙交互的长篇叙事。为了解决这一挑战,我们提出了CREFT,这是一个利用专门的大型语言模型(LLM)代理人的新型序列框架。首先,CREFT通过知识蒸馏构建基础角色图,然后迭代地优化角色构成、关系提取、角色识别以及群组分配。在精选的韩剧数据集上的实验表明,CREFT在准确性和完整性方面显著优于单代理LLM基线。通过系统地可视化角色网络,CREFT简化了叙事理解,加速了剧本审查,为娱乐、出版和教育行业提供了实质性益处。
论文及项目相关链接
Summary
基于对话文本的叙事分析与剧本评价要求深入理解角色间的关系,然而现有提取方法在处理长叙事文本时往往难以把握微妙的互动关系。为解决这一难题,我们提出CREFT,一个利用专门的大型语言模型(LLM)代理构建的新序列框架。CREFT首先通过知识蒸馏构建基础角色图谱,然后迭代地精炼角色构成、关系抽取、角色识别及群组分配。在精心挑选的韩剧数据集上的实验表明,CREFT在准确性和完整性方面都显著优于单一代理的LLM基线模型。通过系统可视化角色网络,CREFT简化了叙事理解并加速了剧本审查,为娱乐、出版和教育行业带来了实质性益处。
Key Takeaways
- 理解角色间复杂关系是叙事分析和剧本评估的关键。
- 现有方法在处理长形式叙事文本时,往往难以处理微妙的互动关系。
- CREFT是一个新的序列框架,利用大型语言模型(LLM)代理解决此问题。
- CREFT通过知识蒸馏构建基础角色图谱,并迭代地优化多个环节。
- 在韩剧数据集上的实验显示,CREFT在准确性和完整性上优于LLM基线模型。
- CREFT通过系统可视化角色网络,简化了叙事理解并加速了剧本审查。
点此查看论文截图

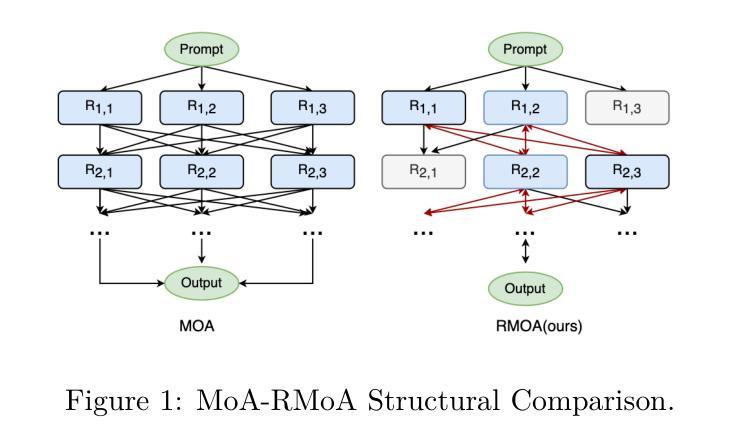
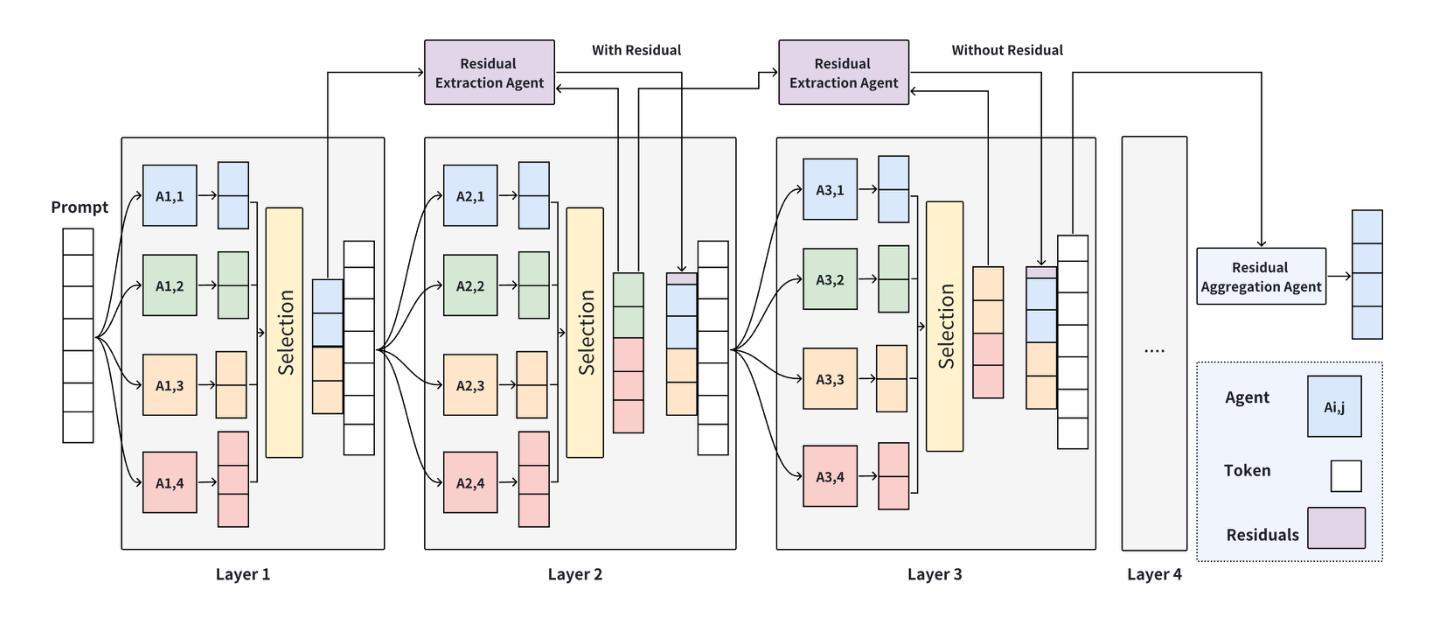
RMoA: Optimizing Mixture-of-Agents through Diversity Maximization and Residual Compensation
Authors:Zhentao Xie, Chengcheng Han, Jinxin Shi, Wenjun Cui, Xin Zhao, Xingjiao Wu, Jiabao Zhao
Although multi-agent systems based on large language models show strong capabilities on multiple tasks, they are still limited by high computational overhead, information loss, and robustness. Inspired by ResNet’s residual learning, we propose Residual Mixture-of-Agents (RMoA), integrating residual connections to optimize efficiency and reliability. To maximize information utilization from model responses while minimizing computational costs, we innovatively design an embedding-based diversity selection mechanism that greedily selects responses via vector similarity. Furthermore, to mitigate iterative information degradation, we introduce a Residual Extraction Agent to preserve cross-layer incremental information by capturing inter-layer response differences, coupled with a Residual Aggregation Agent for hierarchical information integration. Additionally, we propose an adaptive termination mechanism that dynamically halts processing based on residual convergence, further improving inference efficiency. RMoA achieves state-of-the-art performance on the benchmarks of across alignment, mathematical reasoning, code generation, and multitasking understanding, while significantly reducing computational overhead. Code is available at https://github.com/mindhunter01/RMoA.
尽管基于大型语言模型的多智能体系统在多任务中展现出强大的能力,但它们仍然受到高计算开销、信息丢失和稳健性的限制。受ResNet残差学习的启发,我们提出了Residual Mixture-of-Agents(RMoA),通过集成残差连接来优化效率和可靠性。为了最大化模型响应的信息利用,同时最小化计算成本,我们创新性地设计了一种基于嵌入的多样性选择机制,通过向量相似性进行贪婪地选择响应。此外,为了缓解迭代信息退化,我们引入了一个Residual Extraction Agent,通过捕捉跨层响应差异来保留跨层增量信息,并结合一个Residual Aggregation Agent进行分层信息集成。另外,我们提出了一种自适应终止机制,根据残差收敛情况动态停止处理,进一步提高推理效率。RMoA在跨对齐、数学推理、代码生成和多任务理解等多个基准测试中实现了最先进的性能,同时显著降低了计算开销。代码可在https://github.com/mindhunter01/RMoA获取。
论文及项目相关链接
PDF Accepted by ACL 2025 (Findings)
总结
基于ResNet的残差学习理念,提出了Residual Mixture-of-Agents(RMoA)系统。该系统通过引入残差连接优化了计算效率和可靠性,并设计了基于嵌入的多样性选择机制,通过向量相似性选择响应。为缓解迭代信息退化,引入Residual Extraction Agent和Residual Aggregation Agent分别进行跨层信息增量捕获和层次信息整合。此外,提出了自适应终止机制,根据残差收敛情况动态终止处理,提高了推理效率。RMoA在跨对齐、数学推理、代码生成和多任务理解等方面达到了先进水平,同时显著降低了计算开销。
关键见解
- RMoA系统结合了残差连接,旨在优化大型语言模型在处理多任务时的计算效率和可靠性。
- 基于嵌入的多样性选择机制用于最大化模型响应的信息利用率,同时降低计算成本。
- Residual Extraction Agent和Residual Aggregation Agent分别解决了跨层信息增量捕获和层次信息整合的问题。
- RMoA通过引入自适应终止机制,根据残差收敛情况动态调整处理过程,提高了推理效率。
- RMoA在多个任务基准测试中实现了先进性能,包括跨对齐、数学推理、代码生成和多任务理解。
- RMoA系统显著降低了计算开销,使其在实际应用中更具优势。
- 代码已公开在GitHub上,便于进一步研究和应用。
点此查看论文截图

Unifying Language Agent Algorithms with Graph-based Orchestration Engine for Reproducible Agent Research
Authors:Qianqian Zhang, Jiajia Liao, Heting Ying, Yibo Ma, Haozhan Shen, Jingcheng Li, Peng Liu, Lu Zhang, Chunxin Fang, Kyusong Lee, Ruochen Xu, Tiancheng Zhao
Language agents powered by large language models (LLMs) have demonstrated remarkable capabilities in understanding, reasoning, and executing complex tasks. However, developing robust agents presents significant challenges: substantial engineering overhead, lack of standardized components, and insufficient evaluation frameworks for fair comparison. We introduce Agent Graph-based Orchestration for Reasoning and Assessment (AGORA), a flexible and extensible framework that addresses these challenges through three key contributions: (1) a modular architecture with a graph-based workflow engine, efficient memory management, and clean component abstraction; (2) a comprehensive suite of reusable agent algorithms implementing state-of-the-art reasoning approaches; and (3) a rigorous evaluation framework enabling systematic comparison across multiple dimensions. Through extensive experiments on mathematical reasoning and multimodal tasks, we evaluate various agent algorithms across different LLMs, revealing important insights about their relative strengths and applicability. Our results demonstrate that while sophisticated reasoning approaches can enhance agent capabilities, simpler methods like Chain-of-Thought often exhibit robust performance with significantly lower computational overhead. AGORA not only simplifies language agent development but also establishes a foundation for reproducible agent research through standardized evaluation protocols.
由大型语言模型(LLM)驱动的语言代理在理解、推理和执行复杂任务方面表现出了显著的能力。然而,开发稳健的代理面临着巨大的挑战:大量的工程开销、缺乏标准化组件以及公平比较的不足评估框架。我们引入了基于Agent图的推理与评估编排(AGORA),这是一个灵活可扩展的框架,通过三个关键贡献解决这些挑战:(1)一种模块化架构,具有基于图的流程引擎、高效的内存管理和清晰的组件抽象;(2)一系列先进的可重用代理算法,实现最先进的推理方法;(3)一个严格的评估框架,能够在多个维度上进行系统的比较。我们在数学推理和多模态任务上进行了大量实验,评估了不同LLM中的多种代理算法,揭示了它们相对优势和适用性的重要见解。我们的结果表明,虽然复杂的推理方法可以增强代理能力,但像“思维链”这样的简单方法往往表现出稳健的性能,并且计算开销更低。AGORA不仅简化了语言代理的开发,而且通过标准化的评估协议为可重复的代理研究奠定了基础。
论文及项目相关链接
PDF Accepted by ACL 2025 Demo
Summary
基于大型语言模型(LLM)的语言代理在理解、推理和执行复杂任务方面展现出显著的能力。然而,开发稳健的代理面临诸多挑战,如巨大的工程开销、缺乏标准化组件和不充分的评估框架等。我们引入了基于Agent图的推理与评估编排(AGORA)框架,通过三个关键贡献解决这些问题:模块化架构、可重用的代理算法套件和严格的评估框架。该框架不仅简化了语言代理的开发,还为标准化的评估协议建立了语言代理研究的基础。
Key Takeaways
- AGORA框架基于图的工作流引擎,实现了模块化架构、高效内存管理和清晰的组件抽象。
- AGORA包含一系列可重用的代理算法,实现了最先进的推理方法。
- 通过数学推理和多模态任务的广泛实验,评估了不同LLM中的代理算法。
- 研究发现,虽然复杂的推理方法可以增强代理能力,但简单的如“思维链”方法常常展现出稳健的性能,且计算开销较低。
- AGORA框架简化了语言代理的开发,为语言代理研究建立了可重复性的基础。
点此查看论文截图



R3DM: Enabling Role Discovery and Diversity Through Dynamics Models in Multi-agent Reinforcement Learning
Authors:Harsh Goel, Mohammad Omama, Behdad Chalaki, Vaishnav Tadiparthi, Ehsan Moradi Pari, Sandeep Chinchali
Multi-agent reinforcement learning (MARL) has achieved significant progress in large-scale traffic control, autonomous vehicles, and robotics. Drawing inspiration from biological systems where roles naturally emerge to enable coordination, role-based MARL methods have been proposed to enhance cooperation learning for complex tasks. However, existing methods exclusively derive roles from an agent’s past experience during training, neglecting their influence on its future trajectories. This paper introduces a key insight: an agent’s role should shape its future behavior to enable effective coordination. Hence, we propose Role Discovery and Diversity through Dynamics Models (R3DM), a novel role-based MARL framework that learns emergent roles by maximizing the mutual information between agents’ roles, observed trajectories, and expected future behaviors. R3DM optimizes the proposed objective through contrastive learning on past trajectories to first derive intermediate roles that shape intrinsic rewards to promote diversity in future behaviors across different roles through a learned dynamics model. Benchmarking on SMAC and SMACv2 environments demonstrates that R3DM outperforms state-of-the-art MARL approaches, improving multi-agent coordination to increase win rates by up to 20%.
多智能体强化学习(MARL)在大规模交通控制、自动驾驶汽车和机器人技术等领域取得了显著进展。受生物系统启发,其中的角色自然出现以实现协调,基于角色的MARL方法已被提出以增强复杂任务的合作学习。然而,现有方法仅根据智能体在训练过程中的过去经验来推导角色,忽视了它们对未来轨迹的影响。本文提出了一个关键观点:智能体的角色应该塑造其未来行为,以实现有效的协调。因此,我们提出了通过动态模型发现角色和多样性(R3DM),这是一种新型的基于角色的MARL框架,通过最大化智能体角色、观察到的轨迹和预期的未来行为之间的互信息来学习新兴角色。R3DM通过对过去轨迹的对比学习来优化所提出的目标,首先得出中间角色,形成内在奖励,通过学到的动态模型促进未来不同角色行为的多样性。在SMAC和SMACv2环境中的基准测试表明,R3DM优于最新的MARL方法,通过提高多智能体协调,将胜率提高高达20%。
论文及项目相关链接
PDF 21 pages, To appear in the International Conference of Machine Learning (ICML 2025)
Summary
多智能体强化学习(MARL)在大型交通控制、自动驾驶和机器人技术等领域取得了显著进展。受生物系统中自然涌现的角色协调启事,基于角色的MARL方法已被提出以提升复杂任务的合作学习能力。然而,现有方法仅根据智能体的过去经验来衍生角色,忽视了其在未来轨迹上的影响。本文的关键见解是:智能体的角色应塑造其未来行为以实现有效的协调。因此,我们提出了通过动态模型发现多样性的角色(R3DM),一种新型基于角色的MARL框架,通过最大化智能体角色、观察到的轨迹和预期的未来行为之间的互信息来学习涌现的角色。R3DM通过对过去轨迹的对比学习来优化目标,首先推导出中间角色,形成内在奖励,并通过学习到的动态模型促进未来不同角色行为的多样性。在SMAC和SMACv2环境中的基准测试显示,R3DM优于最新的MARL方法,提高了多智能体的协调性能,胜率提高了高达20%。
Key Takeaways
- 多智能体强化学习(MARL)在大型交通控制、自动驾驶和机器人技术等领域展现出显著进展。
- 基于角色的MARL方法受生物系统中自然涌现的角色启发,旨在提升复杂任务的合作学习能力。
- 现有MARL方法忽视智能体角色对未来轨迹的影响。
- 本文提出R3DM框架,通过最大化智能体角色、轨迹和预期未来行为间的互信息来学习角色。
- R3DM通过对比学习优化目标,结合动态模型发现多样性角色。
- R3DM在SMAC和SMACv2环境中表现出优于其他MARL方法的性能。
点此查看论文截图

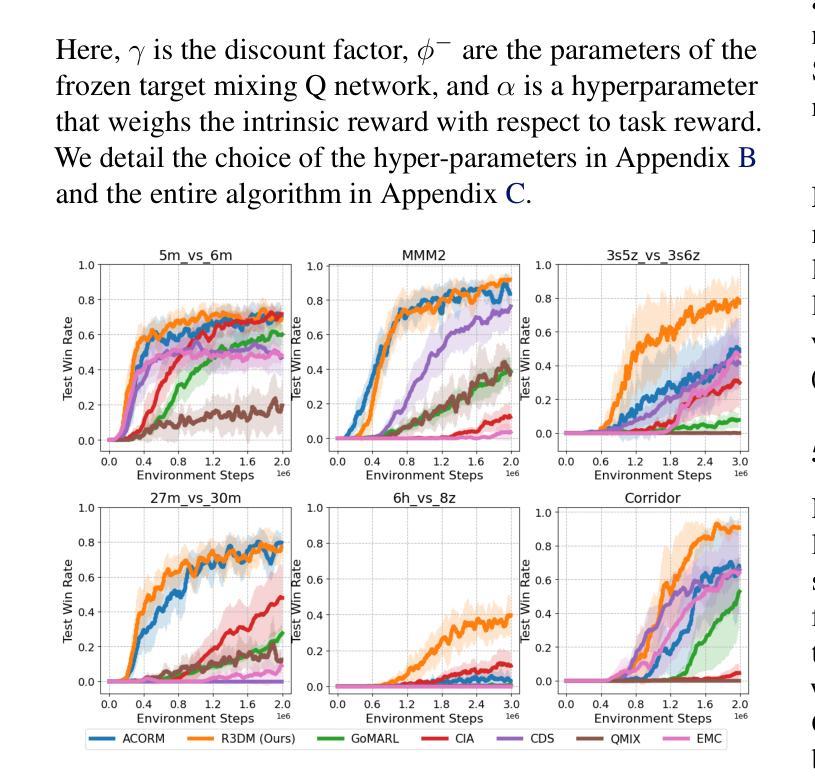
Learning API Functionality from Demonstrations for Tool-based Agents
Authors:Bhrij Patel, Ashish Jagmohan, Aditya Vempaty
Digital tool-based agents that invoke external Application Programming Interfaces (APIs) often rely on documentation to understand API functionality. However, such documentation is frequently missing, outdated, privatized, or inconsistent-hindering the development of reliable, general-purpose agents. In this work, we propose learning API functionality directly from demonstrations as a new paradigm applicable in scenarios without documentation. Using existing API benchmarks, we collect demonstrations from both expert API-based agents and from self-exploration. To understand what information demonstrations must convey for successful task completion, we extensively study how the number of demonstrations and the use of LLM-generated summaries and evaluations affect the task success rate of the API-based agent. Our experiments across 3 datasets and 5 models show that learning functionality from demonstrations remains a non-trivial challenge, even for state-of-the-art LLMs. We find that providing explicit function calls and natural language critiques significantly improves the agent’s task success rate due to more accurate parameter filling. We analyze failure modes, identify sources of error, and highlight key open challenges for future work in documentation-free, self-improving, API-based agents.
基于数字工具的外部应用程序编程接口(API)代理通常依赖于文档来了解API的功能。然而,此类文档经常缺失、过时、私有化或不一致,阻碍了可靠、通用代理的开发。在这项工作中,我们提出了一种新的范例,即直接从演示中学习API功能,适用于没有文档的场景。我们使用现有的API基准测试,收集专业API代理的演示以及自我探索的演示。为了了解为了成功完成任务,演示必须传达哪些信息,我们深入研究演示的数量和大型语言模型生成的摘要和评估对基于API的代理任务成功率的影响。我们在3个数据集和5个模型上进行的实验表明,从演示中学习功能仍然是一个非平凡的挑战,即使是对于最新的大型语言模型也是如此。我们发现,提供明确的函数调用和自然语言的批评可以显著提高代理的任务成功率,因为可以更准确地填充参数。我们分析了失败模式,识别了错误来源,并强调了未来工作在无文档、自我改进、基于API的代理方面的关键开放挑战。
论文及项目相关链接
PDF 18 Pages, 13 Figures, 5 Tables
Summary
针对数字工具型代理在调用外部应用程序编程接口(API)时面临的文档缺失、过时、私有化或不一致等问题,本研究提出了一种新的学习范式——直接从演示中学习API功能。研究通过现有API基准测试收集了专业API代理和自我探索的演示,并探讨了演示数量及大型语言模型生成的摘要和评估对API代理任务完成率的影响。实验表明,即使在先进的大型语言模型情况下,从演示中学习功能仍是一项具有挑战性的任务。明确的功能调用和自然语言的评价能显著提高代理的任务完成率。
Key Takeaways
- 数字工具型代理在调用API时面临文档缺失、过时等挑战。
- 提出直接从演示中学习API功能的新范式以适应无文档场景。
- 通过现有API基准测试收集演示,并研究演示数量对API代理任务完成率的影响。
- 大型语言模型生成的摘要和评估在API学习任务中具有重要作用。
- 明确的功能调用和自然语言的评价能显著提高代理的任务完成率。
- 分析和识别了学习过程中的失败模式和关键错误来源。
点此查看论文截图

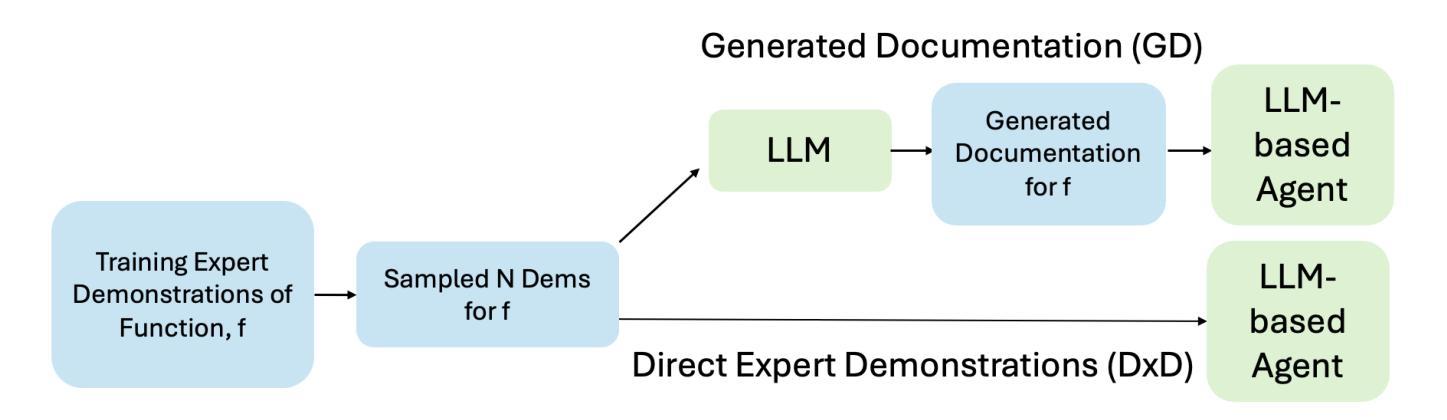

Don’t Just Follow MLLM Plans: Robust and Efficient Planning for Open-world Agents
Authors:Seungjoon Lee, Suhwan Kim, Minhyeon Oh, Youngsik Yoon, Jungseul Ok
Developing autonomous agents capable of mastering complex, multi-step tasks in unpredictable, interactive environments presents a significant challenge. While Large Language Models (LLMs) offer promise for planning, existing approaches often rely on problematic internal knowledge or make unrealistic environmental assumptions. Although recent work explores learning planning knowledge, they still retain limitations due to partial reliance on external knowledge or impractical setups. Indeed, prior research has largely overlooked developing agents capable of acquiring planning knowledge from scratch, directly in realistic settings. While realizing this capability is necessary, it presents significant challenges, primarily achieving robustness given the substantial risk of incorporating LLMs’ inaccurate knowledge. Moreover, efficiency is crucial for practicality as learning can demand prohibitive exploration. In response, we introduce Robust and Efficient Planning for Open-world Agents (REPOA), a novel framework designed to tackle these issues. REPOA features three key components: adaptive dependency learning and fine-grained failure-aware operation memory to enhance robustness to knowledge inaccuracies, and difficulty-based exploration to improve learning efficiency. Our evaluation in two established open-world testbeds demonstrates REPOA’s robust and efficient planning, showcasing its capability to successfully obtain challenging late-game items that were beyond the reach of prior approaches.
在不可预测、交互性的环境中,开发能够掌握复杂、多步骤任务的自主代理是一项重大挑战。虽然大型语言模型(LLM)在规划方面显示出潜力,但现有方法往往依赖于有问题的内部知识或做出不切实际的环境假设。尽管最近有工作探索学习规划知识,但由于部分依赖外部知识或不切实际的设置,它们仍然存在局限性。事实上,先前的研究在很大程度上忽视了能够在现实环境中从头获得规划知识的代理的发展。虽然实现这种能力是必要的,但它带来了巨大的挑战,主要的是在融入LLM不准确知识时实现稳健性。此外,效率对于实用性至关重要,因为学习可能需要禁止探索。作为回应,我们引入了面向开放世界代理的稳健高效规划(REPOA),这是一个旨在解决这些问题的新型框架。REPOA具有三个关键组件:自适应依赖学习、精细的故障感知操作内存,以增强对不准确知识的稳健性,以及基于难度的探索以提高学习效率。我们在两个建立的开放世界测试床上进行的评估证明了REPOA的稳健高效规划,展示了其成功获取先前方法无法达到的具有挑战性的后期游戏道具的能力。
论文及项目相关链接
Summary
这篇文本主要介绍了开发能够在复杂多变、不可预测的环境中完成多步骤任务的自主代理人的挑战。尽管大型语言模型在规划方面展现出潜力,但现有方法常常依赖于内部知识的缺陷或做出不切实际的环境假设。最近的研究虽然开始探索学习规划知识,但仍受限于依赖外部知识或不切实际的设置。文章强调,从现实环境中直接获取规划知识的能力至关重要,但实现这一能力需要解决重大挑战,尤其是实现稳健性和效率问题。为此,文章提出了Robust and Efficient Planning for Open-world Agents(REPOA)框架来解决这些问题,该框架包括三个关键组件:自适应依赖学习、精细化的失败感知操作内存和难度导向的探索。在开放世界测试平台的评估中,REPOA展现出稳健且高效的规划能力,成功获取了先前方法无法触及的复杂后期任务物品。
Key Takeaways
- 开发能在复杂多变、不可预测的环境中完成多步骤任务的自主代理人是一项重大挑战。
- 大型语言模型在规划方面展现出潜力,但现有方法存在依赖内部知识的缺陷或做出不切实际的环境假设的问题。
- 最近的研究开始探索学习规划知识,但仍受限于依赖外部知识或不切实际的设置。
- 直接从现实环境中获取规划知识的能力至关重要,但实现这一能力需要解决稳健性和效率问题。
- REPOA框架包括三个关键组件来解决这些问题:自适应依赖学习、精细化的失败感知操作内存和难度导向的探索。
- REPOA框架通过增强稳健性和效率,成功在开放世界测试平台完成复杂后期任务物品的获取。
点此查看论文截图


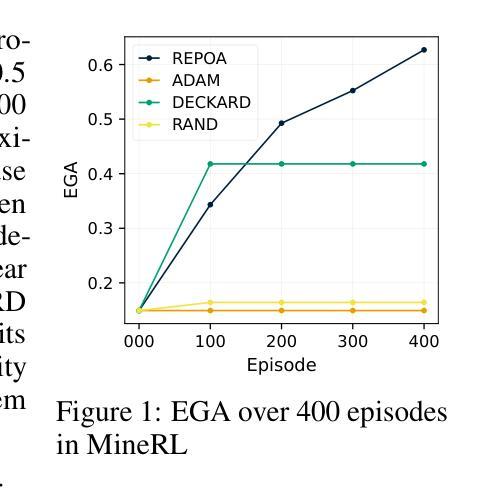
FieldWorkArena: Agentic AI Benchmark for Real Field Work Tasks
Authors:Atsunori Moteki, Shoichi Masui, Fan Yang, Yueqi Song, Yonatan Bisk, Graham Neubig, Ikuo Kusajima, Yasuto Watanabe, Hiroyuki Ishida, Jun Takahashi, Shan Jiang
This paper proposes FieldWorkArena, a benchmark for agentic AI targeting real-world field work. With the recent increase in demand for agentic AI, they are required to monitor and report safety and health incidents, as well as manufacturing-related incidents, that may occur in real-world work environments. Existing agentic AI benchmarks have been limited to evaluating web tasks and are insufficient for evaluating agents in real-world work environments, where complexity increases significantly. In this paper, we define a new action space that agentic AI should possess for real world work environment benchmarks and improve the evaluation function from previous methods to assess the performance of agentic AI in diverse real-world tasks. The dataset consists of videos captured on-site and documents actually used in factories and warehouses, and tasks were created based on interviews with on-site workers and managers. Evaluation results confirmed that performance evaluation considering the characteristics of Multimodal LLM (MLLM) such as GPT-4o is feasible. Additionally, the effectiveness and limitations of the proposed new evaluation method were identified. The complete dataset (HuggingFace) and evaluation program (GitHub) can be downloaded from the following website: https://en-documents.research.global.fujitsu.com/fieldworkarena/.
本文提出了FieldWorkArena,这是一个针对现实工作环境中的智能体AI的基准测试。随着对智能体AI需求的不断增加,他们需要监控和报告现实工作环境中可能发生的安全和健康事件,以及与制造相关的事件。现有的智能体AI基准测试仅限于评估网络任务,对于评估现实工作环境中的智能体来说是不够的,现实工作环境中的复杂性大大增加。在本文中,我们定义了一个新的动作空间,智能体AI应该具备这一空间以应对现实工作环境中的基准测试,并改进了之前的评估功能,以评估智能体在多种现实任务中的性能。数据集包含现场拍摄的视频和工厂仓库实际使用的文件,任务的创建基于现场工人和管理人员的访谈。评估结果证实,考虑到多模态大型语言模型(如GPT-4o)的特性来进行性能评估是可行的。此外,还确定了所提出的新评估方法的有效性和局限性。完整的数据集(HuggingFace)和评估程序(GitHub)可从以下网站下载:https://en-documents.research.global.fujitsu.com/fieldworkarena/。
论文及项目相关链接
PDF 6 pages, 2 figures, 4 tables
Summary
此论文提出FieldWorkArena,这是一个针对现实工作环境中的代理智能AI的基准测试平台。鉴于对代理智能AI需求的增加,该平台能够监控并报告可能发生的真实工作环境的健康和安全问题,以及制造业相关的事故。现有代理智能AI基准测试仅限于评估网络任务,无法有效评估真实工作环境中的代理智能。论文定义了一个新的动作空间,并改进了评估函数,以评估代理智能在多种真实任务中的表现。数据集包含现场拍摄的视频和工厂仓库实际使用的文档,任务是基于现场工人和管理人员的访谈创建的。评估结果证明了考虑多模态大型语言模型(MLLM)如GPT-4o的特性进行性能评估的可行性,同时确定了新评估方法的有效性和局限性。
Key Takeaways
- FieldWorkArena是一个新的基准测试平台,专为代理智能AI在现实工作环境中的表现设计。
- 该平台能够应对真实工作环境中可能出现的健康和安全问题,以及制造业相关的事故。
- 现有代理智能AI的基准测试主要局限于网络任务,无法充分评估其在真实工作环境中的表现。
- 论文定义了一个新的动作空间并改进了评估函数,以便更准确地评估代理智能在多种真实任务中的表现。
- 数据集包含现场拍摄的视频和真实工作环境的文档,任务是基于对现场工作人员和管理者的访谈创建的。
- 评估结果证明了考虑多模态大型语言模型特性的性能评估的可行性。
点此查看论文截图


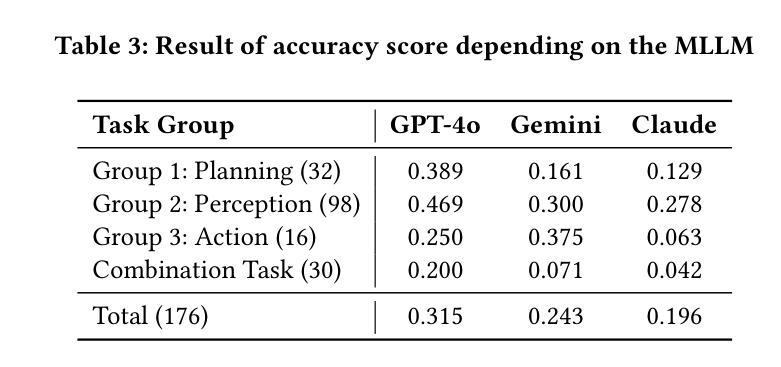

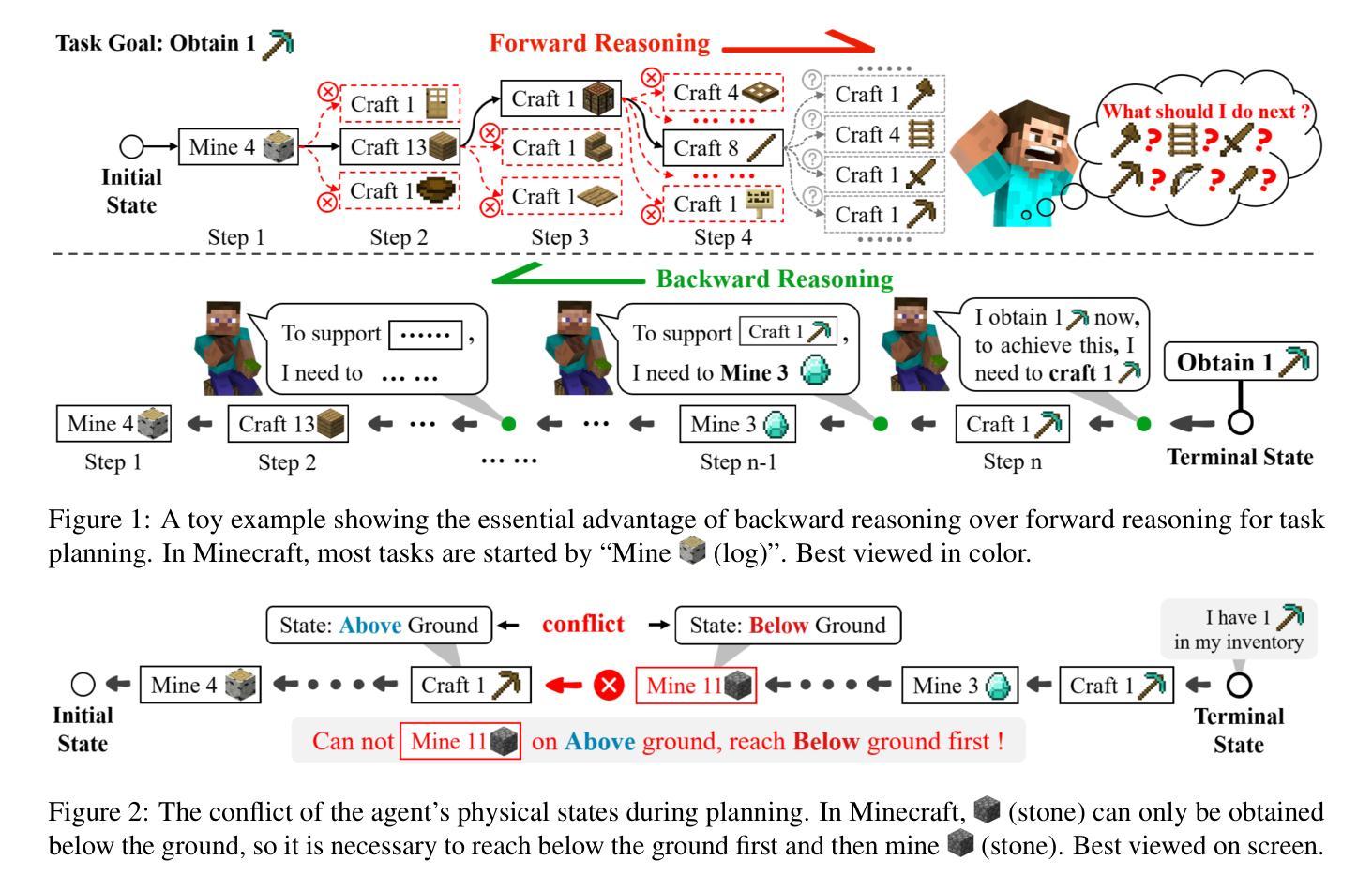
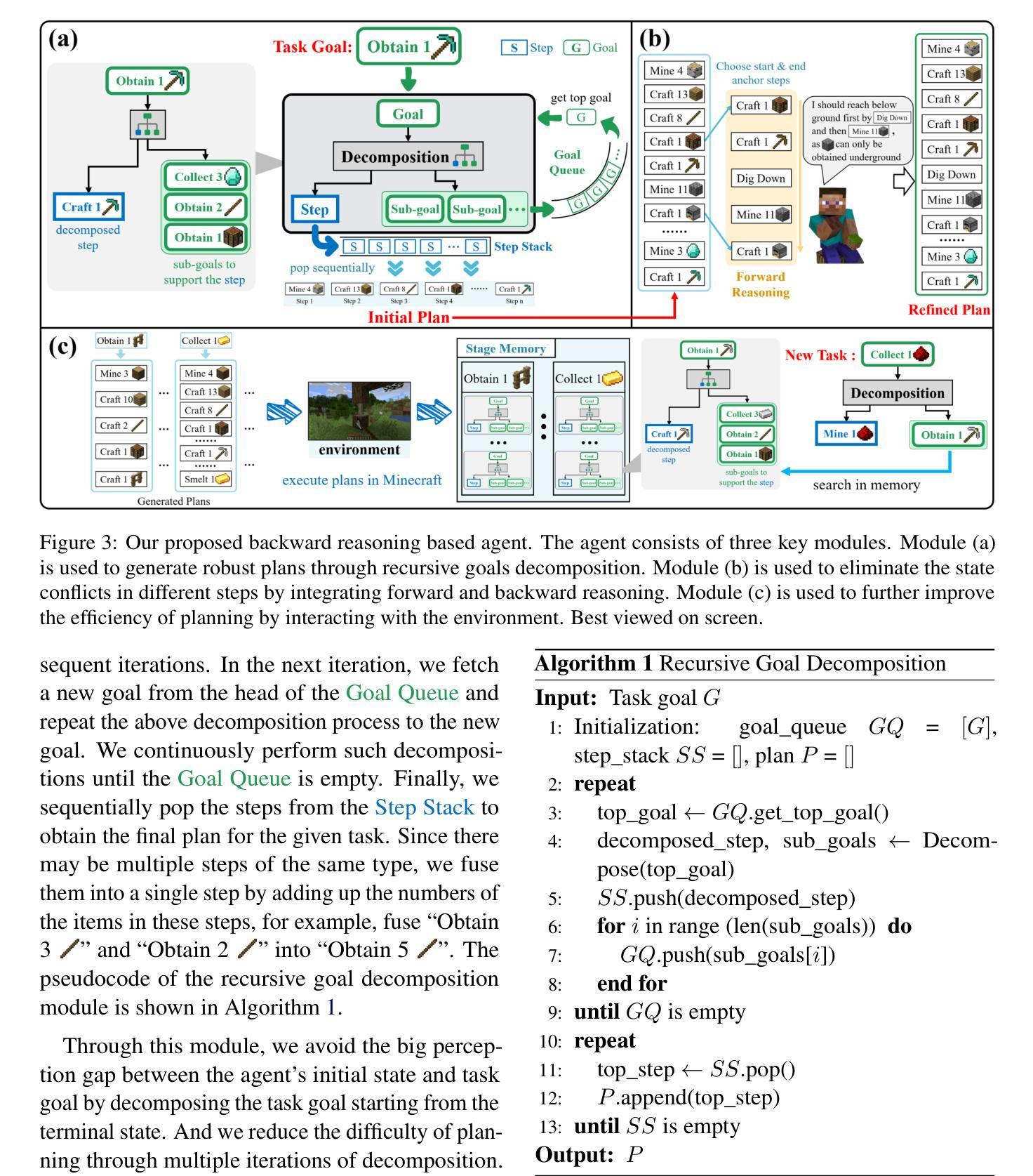
BAR: A Backward Reasoning based Agent for Complex Minecraft Tasks
Authors:Weihong Du, Wenrui Liao, Binyu Yan, Hongru Liang, Anthony G. Cohn, Wenqiang Lei
Large language model (LLM) based agents have shown great potential in following human instructions and automatically completing various tasks. To complete a task, the agent needs to decompose it into easily executed steps by planning. Existing studies mainly conduct the planning by inferring what steps should be executed next starting from the agent’s initial state. However, this forward reasoning paradigm doesn’t work well for complex tasks. We propose to study this issue in Minecraft, a virtual environment that simulates complex tasks based on real-world scenarios. We believe that the failure of forward reasoning is caused by the big perception gap between the agent’s initial state and task goal. To this end, we leverage backward reasoning and make the planning starting from the terminal state, which can directly achieve the task goal in one step. Specifically, we design a BAckward Reasoning based agent (BAR). It is equipped with a recursive goal decomposition module, a state consistency maintaining module and a stage memory module to make robust, consistent, and efficient planning starting from the terminal state. Experimental results demonstrate the superiority of BAR over existing methods and the effectiveness of proposed modules.
基于大型语言模型(LLM)的代理人在遵循人类指令和自动完成各种任务方面显示出巨大潜力。为了完成任务,代理人需要通过规划将任务分解为可轻松执行的步骤。现有研究主要通过从代理人的初始状态推断应执行哪些下一步骤来进行规划。然而,这种正向推理模式对于复杂任务并不奏效。我们提议在Minecraft这个基于现实世界场景模拟复杂任务的虚拟环境中研究这个问题。我们相信,正向推理的失败是由于代理初始状态与任务目标之间存在的巨大感知差距所导致的。为此,我们采用逆向推理,从终端状态开始进行规划,这可以直接一步实现任务目标。具体来说,我们设计了一个基于逆向推理的代理(BAR)。它配备了一个递归目标分解模块、一个状态一致性维护模块和一个阶段记忆模块,从终端状态开始进行稳健、一致和高效的规划。实验结果表明,BAR优于现有方法,所提出模块效果显著。
论文及项目相关链接
Summary
基于大型语言模型的智能体在完成复杂任务时面临规划挑战。研究通过反向推理来解决此问题,提出一个名为BAR的智能体模型,它能从任务终点逆向进行规划。BAR结合了递归目标分解模块、状态一致性维护模块和阶段记忆模块,以实现高效、稳健的规划。实验证明,BAR优于现有方法。
Key Takeaways
- 大型语言模型在处理复杂任务时的规划能力有限。
- 当前研究主要从智能体的初始状态出发进行正向推理,对于复杂任务难以奏效。
- 提出使用反向推理在Minecraft虚拟环境中解决此问题,从任务终点开始规划能更直接实现目标。
- BAR模型具备递归目标分解、状态一致性维护和阶段记忆三大模块,有助于高效稳健的规划。
点此查看论文截图

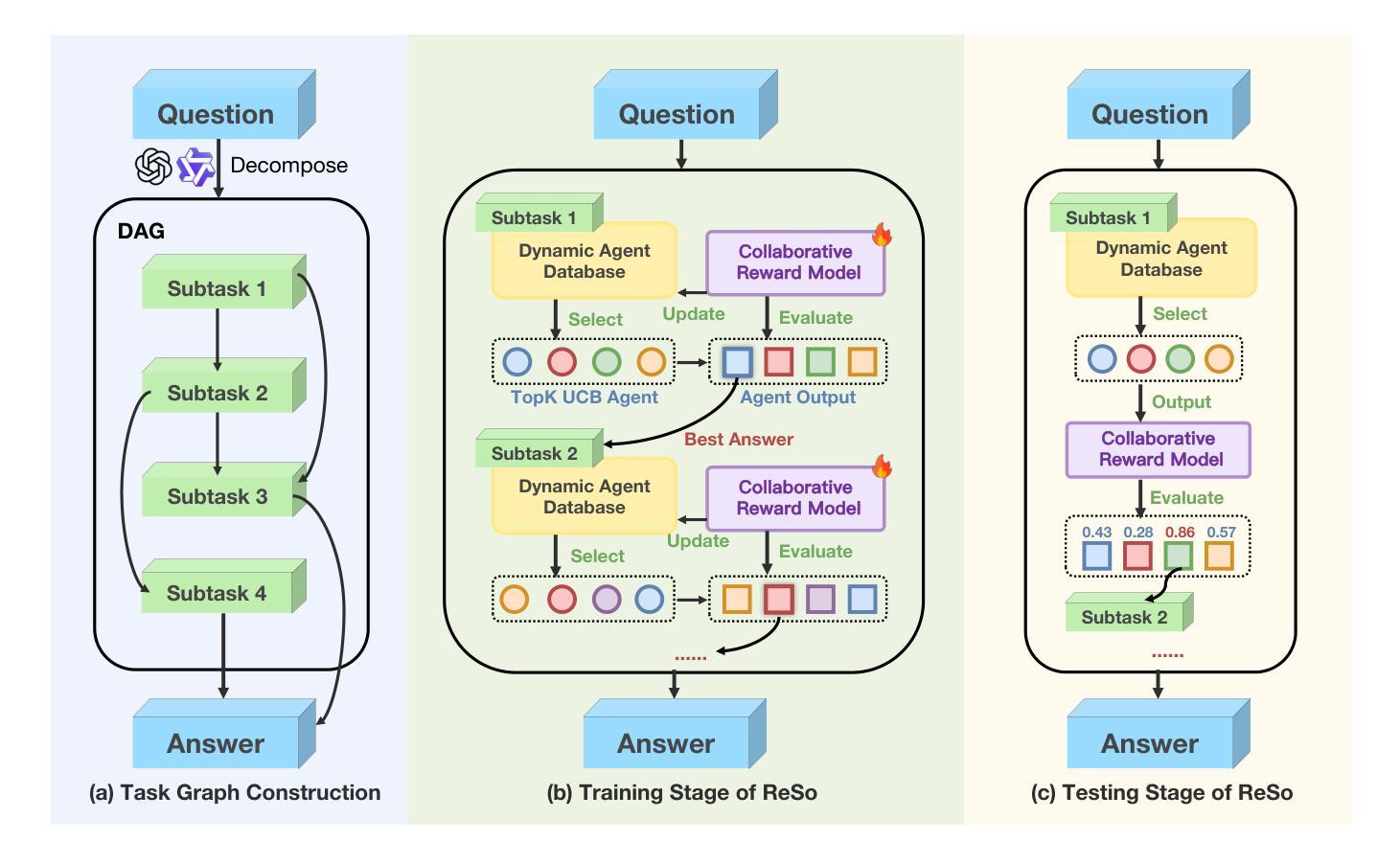
ReSo: A Reward-driven Self-organizing LLM-based Multi-Agent System for Reasoning Tasks
Authors:Heng Zhou, Hejia Geng, Xiangyuan Xue, Li Kang, Yiran Qin, Zhiyong Wang, Zhenfei Yin, Lei Bai
Multi-agent systems (MAS) have emerged as a promising approach for enhancing the reasoning capabilities of large language models in complex problem-solving; however, current MAS frameworks suffer from poor flexibility and scalability with underdeveloped optimization strategies. To address these challenges, we propose ReSo, which integrates task graph generation with a reward-driven two-stage agent selection process centered on our Collaborative Reward Model that provides fine-grained reward signals to optimize MAS cooperation. We also introduce an automated data synthesis framework for generating MAS benchmarks without any human annotations. Experimental results show that ReSo matches or outperforms existing methods, achieving 33.7 percent accuracy on Math-MAS and 32.3 percent accuracy on SciBench-MAS, where other approaches completely fail.
多智能体系统(MAS)作为一种有前景的方法,已出现在复杂问题解决中提高大型语言模型的推理能力;然而,当前的多智能体系统框架在优化策略上缺乏灵活性和可扩展性。为了解决这些挑战,我们提出了ReSo,它将任务图生成与以奖励驱动的两阶段智能体选择过程相结合,以我们的协作奖励模型为中心,为优化多智能体系统合作提供精细的奖励信号。我们还引入了一个自动化数据合成框架,用于生成不需要人工注释的多智能体系统基准测试。实验结果表明,ReSo的表现与现有方法相匹配或超越现有方法,在数学多智能体系统(Math-MAS)上达到33.7%的准确率,在SciBench-MAS上达到32.3%的准确率,而其他方法则完全失败。
论文及项目相关链接
Summary
多智能体系统(MAS)在提升大型语言模型解决复杂问题的能力方面展现出巨大潜力,但当前MAS框架缺乏灵活性和可扩展性,优化策略尚待完善。为解决这些问题,我们提出ReSo系统,通过任务图生成与基于协作奖励模型的奖励驱动两阶段智能体选择过程来优化MAS的合作。此外,我们还引入了无需人工标注的自动化数据合成框架来生成MAS基准测试。实验结果显示,ReSo系统的表现与现有方法相当或更胜一筹,在Math-MAS和SciBench-MAS上的准确率分别达到33.7%和32.3%,而其他方法则完全失败。
Key Takeaways
- 多智能体系统(MAS)能增强大型语言模型的推理能力,尤其在解决复杂问题上。
- 当前MAS框架存在灵活性和可扩展性问题,以及优化策略的不足。
- ReSo系统通过任务图生成和奖励驱动的两阶段智能体选择优化MAS合作。
- ReSo系统引入自动化数据合成框架,生成MAS基准测试,无需人工标注。
- ReSo系统在Math-MAS和SciBench-MAS上的准确率高于其他方法。
点此查看论文截图

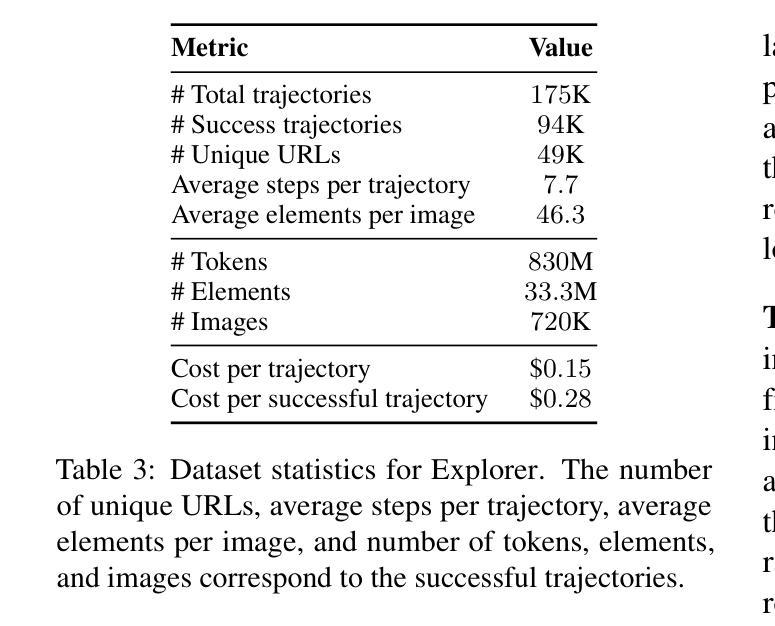
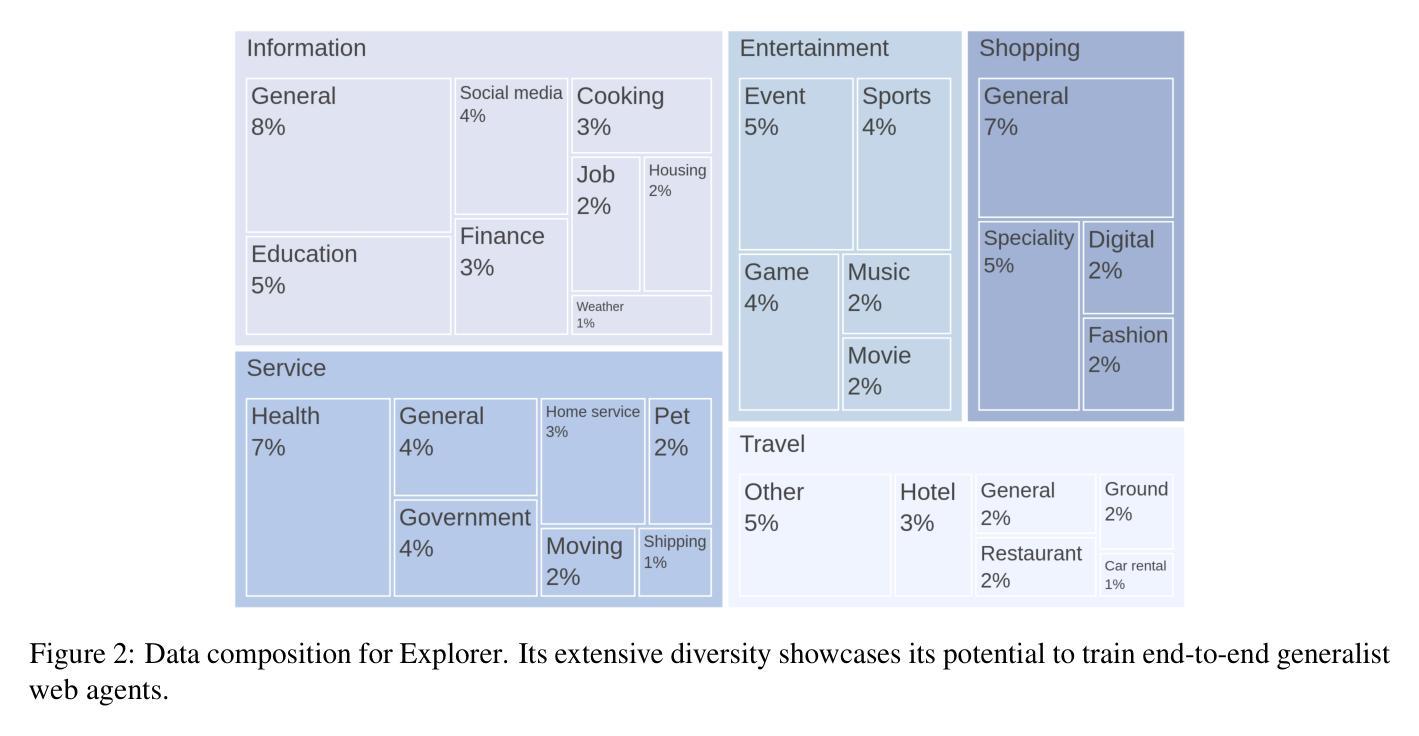
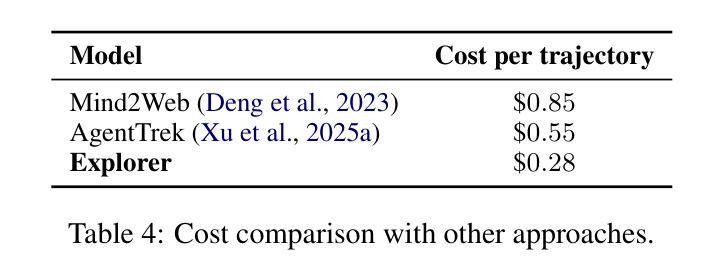
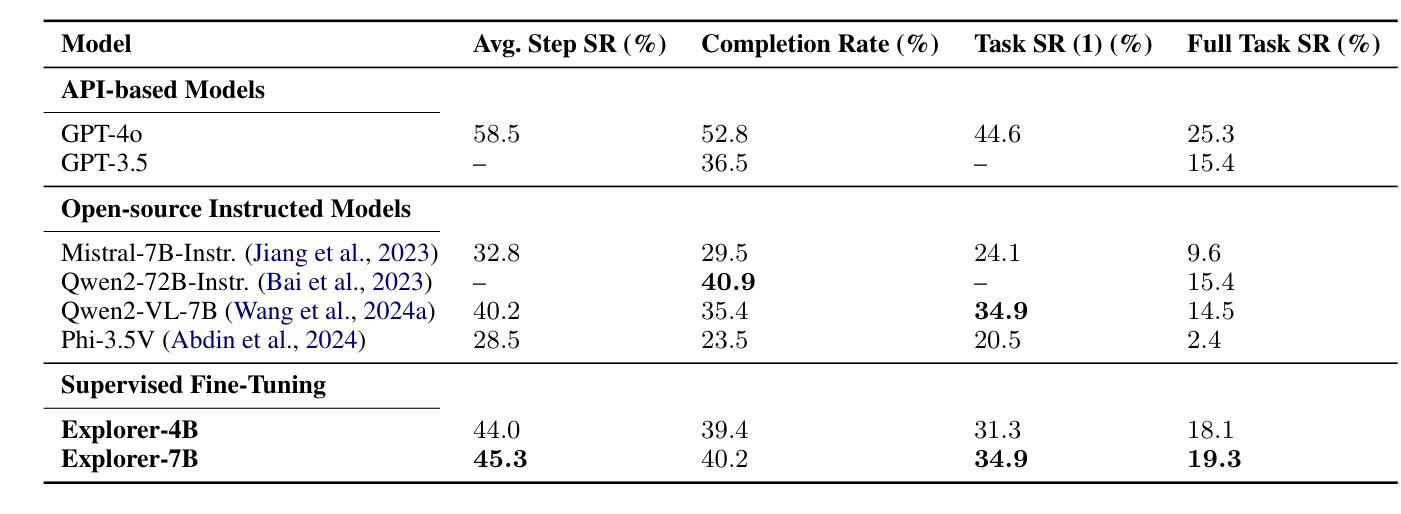
Explorer: Scaling Exploration-driven Web Trajectory Synthesis for Multimodal Web Agents
Authors:Vardaan Pahuja, Yadong Lu, Corby Rosset, Boyu Gou, Arindam Mitra, Spencer Whitehead, Yu Su, Ahmed Awadallah
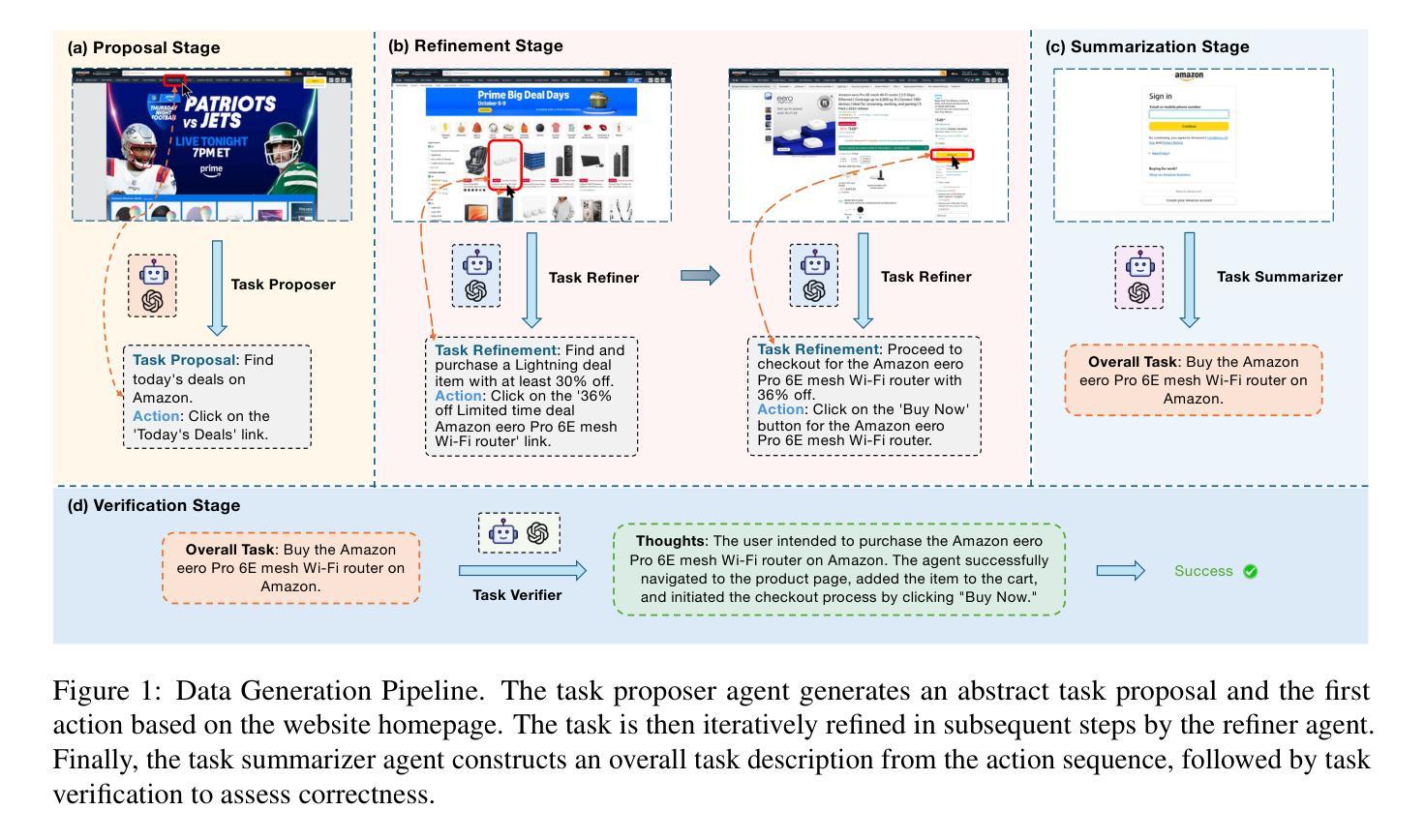
Recent success in large multimodal models (LMMs) has sparked promising applications of agents capable of autonomously completing complex web tasks. While open-source LMM agents have made significant advances in offline evaluation benchmarks, their performance still falls substantially short of human-level capabilities in more realistic online settings. A key bottleneck is the lack of diverse and large-scale trajectory-level datasets across various domains, which are expensive to collect. In this paper, we address this challenge by developing a scalable recipe to synthesize the largest and most diverse trajectory-level dataset to date, containing over 94K successful multimodal web trajectories, spanning 49K unique URLs, 720K screenshots, and 33M web elements. In particular, we leverage extensive web exploration and refinement to obtain diverse task intents. The average cost is 28 cents per successful trajectory, making it affordable to a wide range of users in the community. Leveraging this dataset, we train Explorer, a multimodal web agent, and demonstrate strong performance on both offline and online web agent benchmarks such as Mind2Web-Live, Multimodal-Mind2Web, and MiniWob++. Additionally, our experiments highlight data scaling as a key driver for improving web agent capabilities. We hope this study makes state-of-the-art LMM-based agent research at a larger scale more accessible.
近期大型多模态模型(LMM)的成功激发了自主完成复杂网络任务的智能代理应用的前景。虽然开源LMM代理在离线评估基准测试中取得了重大进展,但在更现实的在线环境中,它们的性能仍然远远落后于人类水平的能力。一个关键的瓶颈是缺乏跨不同领域的多样且大规模轨迹级数据集,而这些数据的收集成本很高。在本文中,我们通过开发可合成的最大且最具多样性的轨迹级数据集来解决这一挑战,该数据集包含超过9.4万条成功的多模态网络轨迹,涵盖4.9万个唯一URL、72万个截图和3.3亿个网络元素。特别是,我们利用广泛的网络探索和精细化来获得多样的任务意图。每条成功轨迹的平均成本为28美分,使得社区中的广大用户都能负担得起。利用此数据集,我们训练了Explorer,这是一款多模态网络代理,在离线在线网络代理基准测试(如Mind2Web-Live、Multimodal-Mind2Web和MiniWob++)中表现出强劲的性能。此外,我们的实验强调了数据规模扩展是提高网络代理能力的主要驱动力。我们希望这项研究使更大规模上的最新LMM代理研究更加便捷。
论文及项目相关链接
PDF ACL 2025 (Findings)
Summary
大型多模态模型(LMM)代理在自主完成复杂网络任务方面展现出成功应用前景。尽管开源LMM代理在离线评估基准测试中取得显著进展,但在更现实的在线环境中,其性能仍然远远落后于人类水平。本文解决此挑战,通过开发可伸缩配方合成迄今为止最大且最多元轨迹级数据集,包含超过9.4万条成功多模态网络轨迹,跨越4.9万个唯一URL、72万个截图和33万个网页元素。训练基于此数据集的多模态网络代理Explorer,在离线及在线网络代理基准测试如Mind2Web-Live、Multimodal-Mind2Web和MiniWob++上表现强劲,凸显数据规模扩大是提升网络代理能力的重要驱动力。
Key Takeaways
- 大型多模态模型代理在复杂网络任务中表现突出,但在线环境性能仍待提高。
- 现有挑战之一是缺乏跨不同领域的大型轨迹级数据集,且收集成本高昂。
- 本文通过合成最大、最多元轨迹级数据集解决此问题,包含多样化任务意图。
- 数据集合成平均成本低,使得更多用户可负担。
- 基于该数据集训练的Explorer代理在多个基准测试中表现优异。
- 实验结果强调数据规模扩大对提升网络代理能力的重要性。
点此查看论文截图

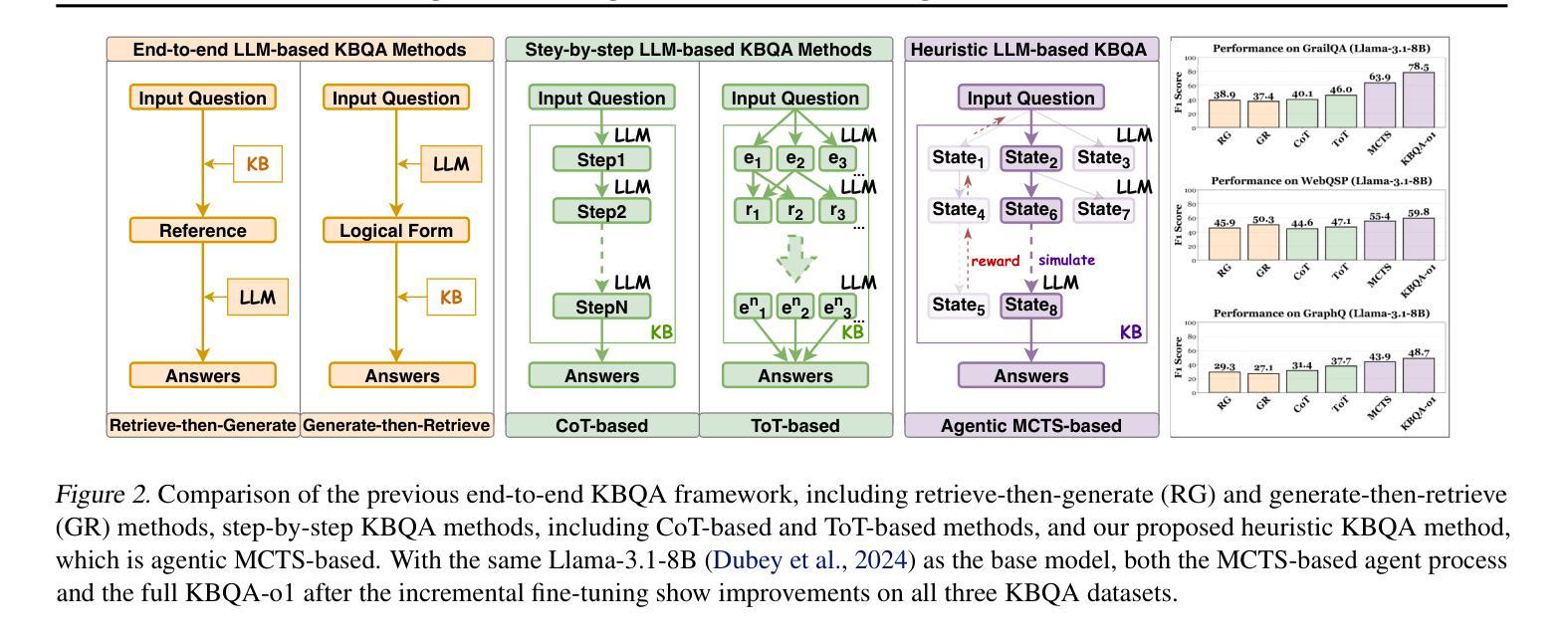
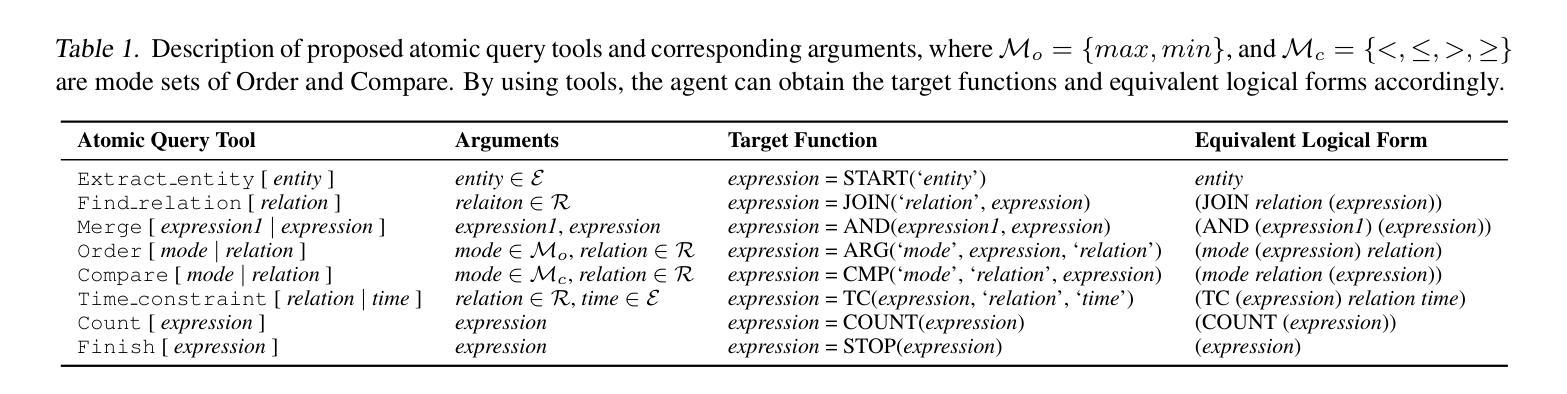
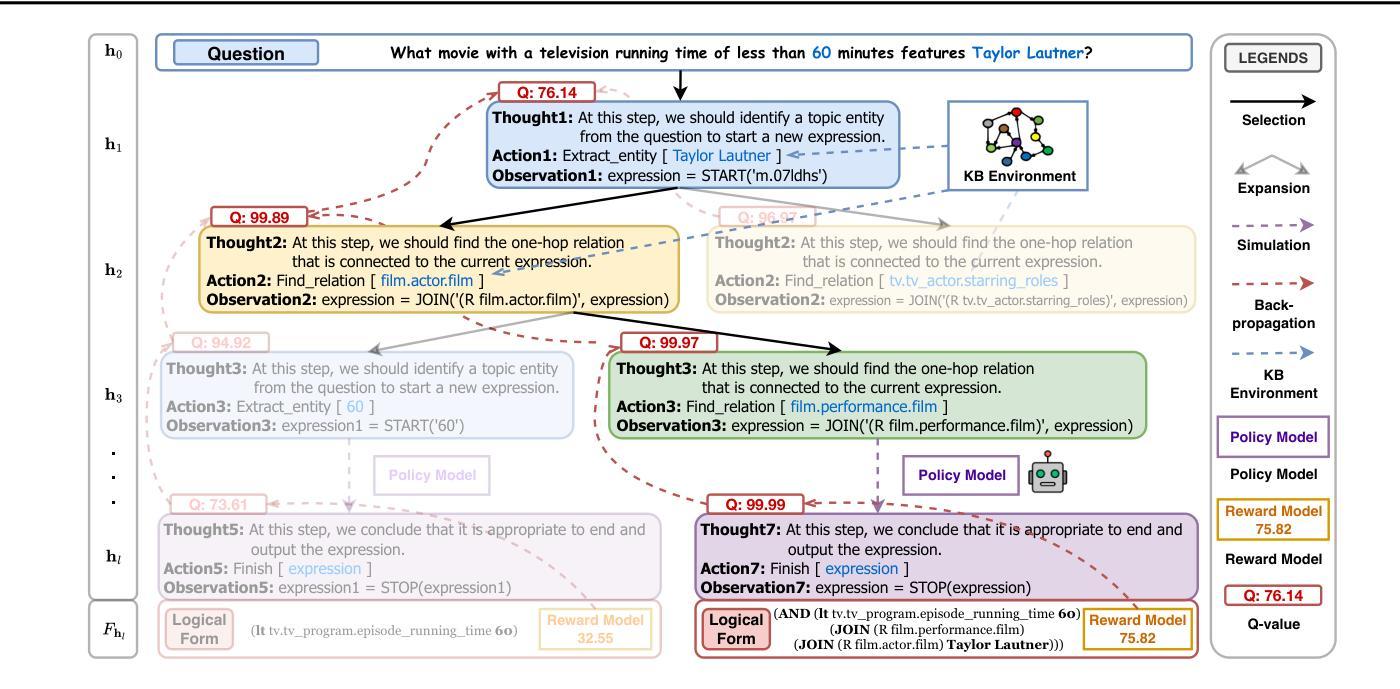
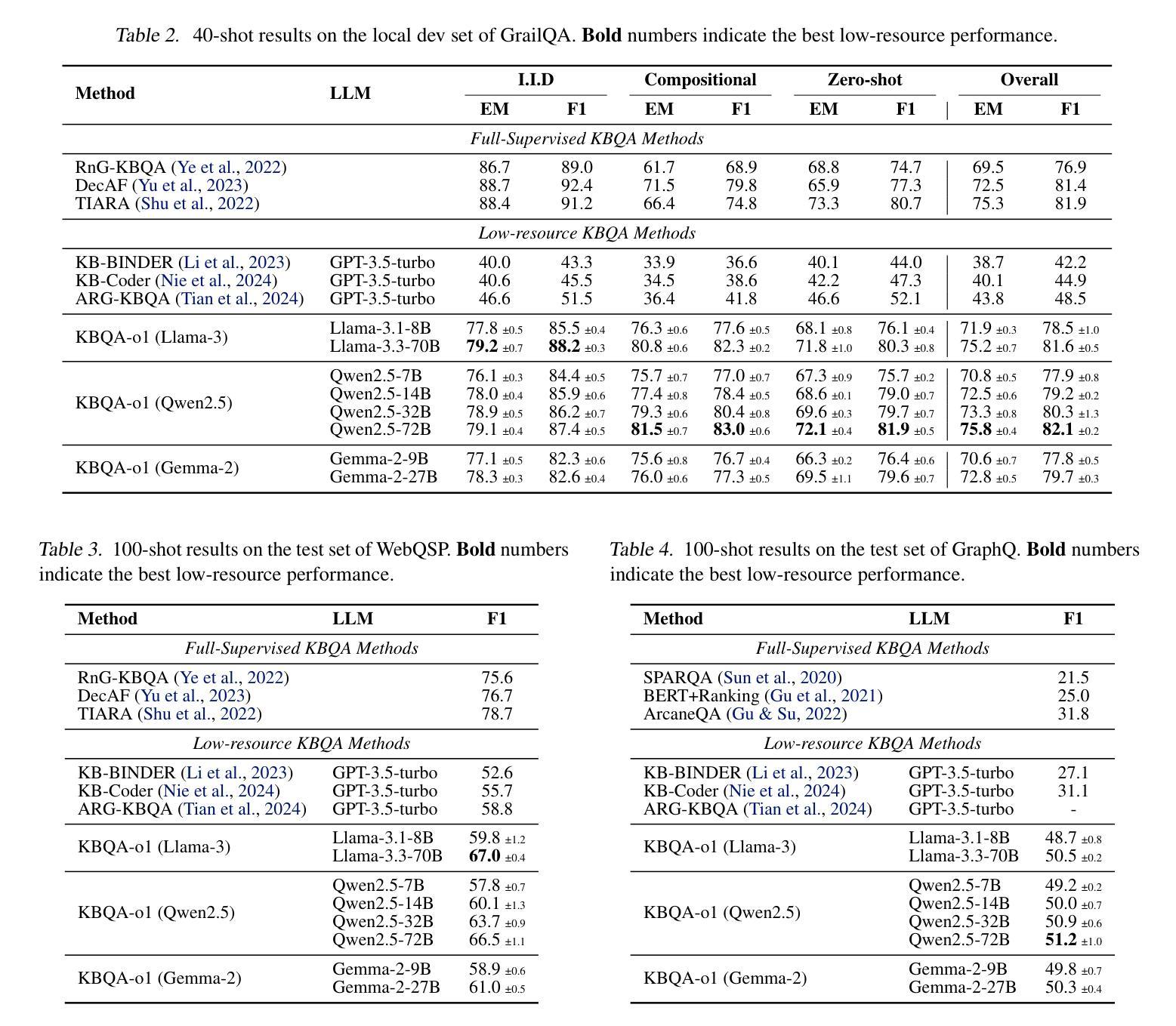
KBQA-o1: Agentic Knowledge Base Question Answering with Monte Carlo Tree Search
Authors:Haoran Luo, Haihong E, Yikai Guo, Qika Lin, Xiaobao Wu, Xinyu Mu, Wenhao Liu, Meina Song, Yifan Zhu, Luu Anh Tuan
Knowledge Base Question Answering (KBQA) aims to answer natural language questions with a large-scale structured knowledge base (KB). Despite advancements with large language models (LLMs), KBQA still faces challenges in weak KB awareness, imbalance between effectiveness and efficiency, and high reliance on annotated data. To address these challenges, we propose KBQA-o1, a novel agentic KBQA method with Monte Carlo Tree Search (MCTS). It introduces a ReAct-based agent process for stepwise logical form generation with KB environment exploration. Moreover, it employs MCTS, a heuristic search method driven by policy and reward models, to balance agentic exploration’s performance and search space. With heuristic exploration, KBQA-o1 generates high-quality annotations for further improvement by incremental fine-tuning. Experimental results show that KBQA-o1 outperforms previous low-resource KBQA methods with limited annotated data, boosting Llama-3.1-8B model’s GrailQA F1 performance to 78.5% compared to 48.5% of the previous sota method with GPT-3.5-turbo. Our code is publicly available.
知识库问答(KBQA)旨在利用大规模结构化知识库(KB)回答自然语言问题。尽管大型语言模型(LLM)有所发展,KBQA仍然面临知识库意识薄弱、有效性与效率不平衡、高度依赖注释数据等挑战。为了应对这些挑战,我们提出了KBQA-o1,这是一种结合蒙特卡洛树搜索(MCTS)的新型智能KBQA方法。它引入了一种基于ReAct的代理过程,用于逐步生成逻辑形式并进行知识库环境探索。此外,它采用MCTS(一种受策略和奖励模型驱动的启发式搜索方法)来平衡智能探索的性能和搜索空间。通过启发式探索,KBQA-o1可以生成高质量注释,通过增量微调进一步改进。实验结果表明,KBQA-o1优于以前的低资源KBQA方法,这些方法依赖于有限的注释数据,KBQA-o1将Llama-3.1-8B模型的GrailQA F1性能提高到78.5%,而之前的最佳方法GPT-3.5-turbo的该性能指标为48.5%。我们的代码已公开可用。
论文及项目相关链接
PDF Accepted by ICML 2025 main conference
Summary
知识库问答(KBQA)旨在利用大规模结构化知识库(KB)回答自然语言问题。尽管有大型语言模型(LLM)的进展,KBQA仍面临知识库意识弱、效率和效果不平衡、高度依赖注释数据等挑战。为解决这些问题,我们提出了基于蒙特卡洛树搜索(MCTS)的新型智能KBQA方法——KBQA-o1。它引入了一种基于ReAct的代理过程,用于逐步生成逻辑形式并进行知识库环境探索。此外,它采用MCTS这种受策略和奖励模型驱动的策略启发式搜索方法,以实现智能探索的性能和搜索空间的平衡。通过启发式探索,KBQA-o1可以生成高质量注释,通过增量微调进一步提高性能。实验结果表明,KBQA-o1在有限注释数据的情况下,优于之前的低资源KBQA方法,将Llama-3.1-8B模型的GrailQA F1性能提高到78.5%,而之前最佳方法的GPT-3.5-turbo模型仅为48.5%。
Key Takeaways
1. KBQA面临知识库意识弱、效率和效果不平衡、依赖注释数据等挑战。
2. KBQA-o1是一种新型的基于代理的KBQA方法,采用蒙特卡洛树搜索(MCTS)来应对上述挑战。
3. KBQA-o1引入ReAct-based代理过程,用于逐步生成逻辑形式并进行KB环境探索。
4. MCTS平衡了智能探索的性能和搜索空间。
5. KBQA-o1可以通过生成高质量注释,进一步通过增量微调提高性能。
6. KBQA-o1在有限注释数据的情况下,显著优于之前的KBQA方法。
点此查看论文截图

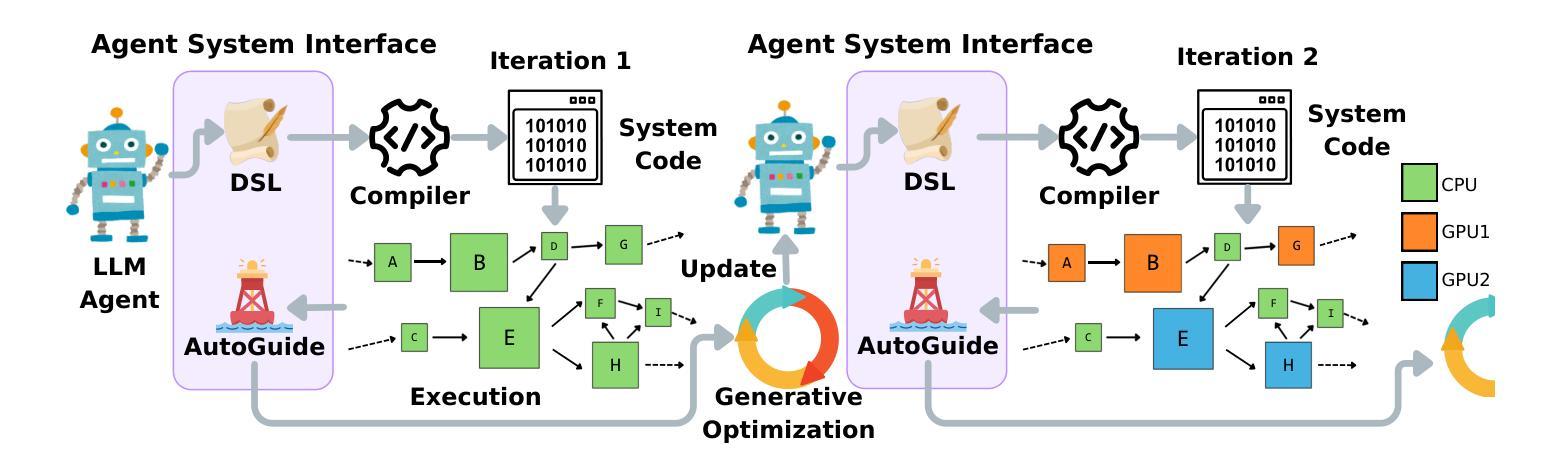
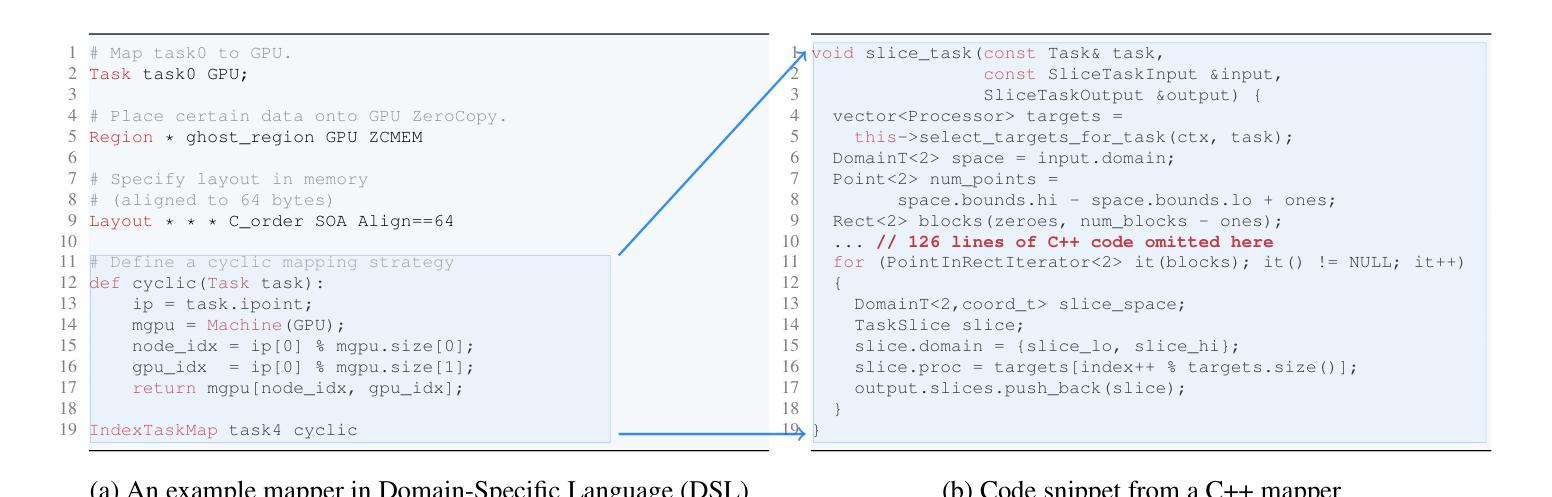
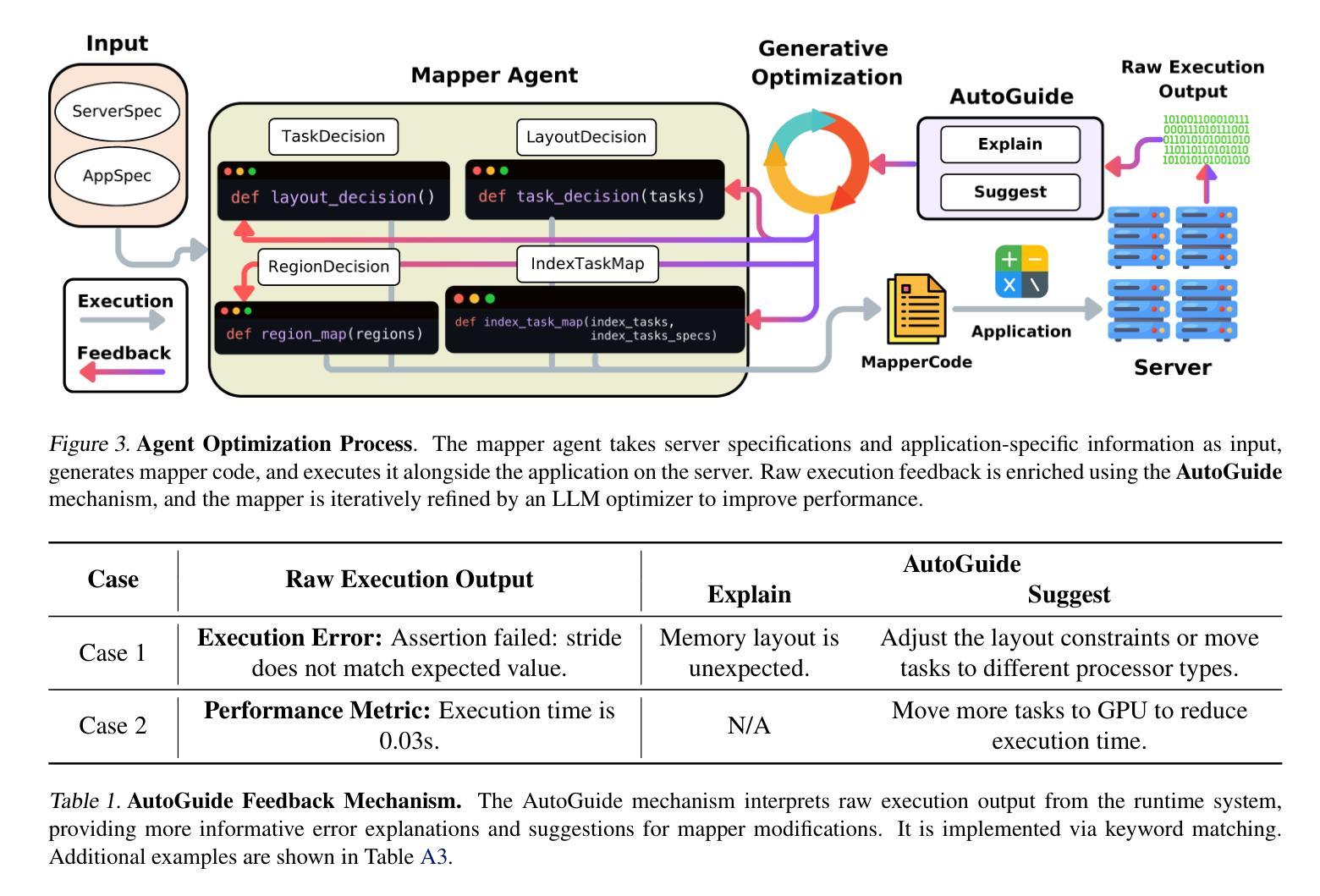
Improving Parallel Program Performance with LLM Optimizers via Agent-System Interfaces
Authors:Anjiang Wei, Allen Nie, Thiago S. F. X. Teixeira, Rohan Yadav, Wonchan Lee, Ke Wang, Alex Aiken
Modern scientific discovery increasingly relies on high-performance computing for complex modeling and simulation. A key challenge in improving parallel program performance is efficiently mapping tasks to processors and data to memory, a process dictated by intricate, low-level system code known as mappers. Developing high-performance mappers demands days of manual tuning, posing a significant barrier for domain scientists without systems expertise. We introduce a framework that automates mapper development with generative optimization, leveraging richer feedback beyond scalar performance metrics. Our approach features the Agent-System Interface, which includes a Domain-Specific Language (DSL) to abstract away the low-level complexity of system code and define a structured search space, as well as AutoGuide, a mechanism that interprets raw execution output into actionable feedback. Unlike traditional reinforcement learning methods such as OpenTuner, which rely solely on scalar feedback, our method finds superior mappers in far fewer iterations. With just 10 iterations, it outperforms OpenTuner even after 1000 iterations, achieving 3.8X faster performance. Our approach finds mappers that surpass expert-written mappers by up to 1.34X speedup across nine benchmarks while reducing tuning time from days to minutes.
现代科学发现越来越依赖于高性能计算来进行复杂的建模和模拟。提高并行程序性能的关键挑战在于如何将任务高效映射到处理器并将数据映射到内存,这一过程由称为映射器的复杂低级系统代码决定。开发高性能映射器需要数天的手动调整,这对没有系统专业知识的领域科学家来说是一个重大障碍。我们引入了一个使用生成优化自动化映射器开发的框架,该框架利用丰富的反馈,而不仅仅是标量性能指标。我们的方法采用了Agent-System接口,它包括一种领域特定语言(DSL),以消除系统代码的底层复杂性,并定义了一个结构化搜索空间,以及AutoGuide,一种将原始执行输出解释为可操作反馈的机制。与传统的强化学习方法(如OpenTuner)不同,后者仅依赖于标量反馈,我们的方法在较少的迭代次数中找到更优的映射器。仅需10次迭代,即使在1000次迭代后,它的性能也优于OpenTuner,达到了3.8倍的速度提升。我们的方法找到的映射器在九个基准测试中超过了专家编写的映射器,最高加速1.34倍,并将调整时间从数天缩短到数分钟。
论文及项目相关链接
Summary
本文介绍了现代科学发现对高性能计算的依赖,以及提高并行程序性能的关键挑战。针对这一挑战,提出了一种自动化开发高性能映射器的框架,该框架采用生成式优化和丰富的反馈机制,包括Agent-System接口和AutoGuide机制。与传统依赖单一标量反馈的强化学习方法相比,该方法能在更少的迭代次数中找到更优的映射器,将调优时间从几天缩短到几分钟。
Key Takeaways
- 现代科学发现依赖于高性能计算进行复杂建模和仿真。
- 高效地将任务和数据处理映射到处理器是提升并行程序性能的关键挑战。
- 提出的框架自动化开发高性能映射器,采用生成式优化方法。
- 该框架包含Agent-System接口和AutoGuide机制,可抽象底层系统代码的复杂性并定义结构化搜索空间。
- 该方法采用丰富的反馈机制,与传统的仅依赖标量反馈的强化学习方法不同。
- 该方法在较少的迭代次数中找到性能更优的映射器,甚至超越专家编写的映射器。
点此查看论文截图

Agent Security Bench (ASB): Formalizing and Benchmarking Attacks and Defenses in LLM-based Agents
Authors:Hanrong Zhang, Jingyuan Huang, Kai Mei, Yifei Yao, Zhenting Wang, Chenlu Zhan, Hongwei Wang, Yongfeng Zhang
Although LLM-based agents, powered by Large Language Models (LLMs), can use external tools and memory mechanisms to solve complex real-world tasks, they may also introduce critical security vulnerabilities. However, the existing literature does not comprehensively evaluate attacks and defenses against LLM-based agents. To address this, we introduce Agent Security Bench (ASB), a comprehensive framework designed to formalize, benchmark, and evaluate the attacks and defenses of LLM-based agents, including 10 scenarios (e.g., e-commerce, autonomous driving, finance), 10 agents targeting the scenarios, over 400 tools, 27 different types of attack/defense methods, and 7 evaluation metrics. Based on ASB, we benchmark 10 prompt injection attacks, a memory poisoning attack, a novel Plan-of-Thought backdoor attack, 4 mixed attacks, and 11 corresponding defenses across 13 LLM backbones. Our benchmark results reveal critical vulnerabilities in different stages of agent operation, including system prompt, user prompt handling, tool usage, and memory retrieval, with the highest average attack success rate of 84.30%, but limited effectiveness shown in current defenses, unveiling important works to be done in terms of agent security for the community. We also introduce a new metric to evaluate the agents’ capability to balance utility and security. Our code can be found at https://github.com/agiresearch/ASB.
虽然基于大型语言模型(LLM)的代理能够利用外部工具和记忆机制来解决复杂的现实世界任务,但它们也可能引入关键的安全漏洞。然而,现有文献并没有全面评估针对基于LLM的代理的攻击和防御措施。为了解决这一问题,我们引入了Agent Security Bench(ASB),这是一个旨在规范化、基准测试和评估基于LLM的代理的攻击和防御方法的全面框架,包括10个场景(例如电子商务、自动驾驶、金融)、针对这些场景的10个代理、超过400个工具、27种不同类型的攻击/防御方法以及7个评估指标。基于ASB,我们对10种提示注入攻击、一种内存中毒攻击、一种新型的计划思维后门攻击、4种混合攻击以及针对13种LLM骨干的11种相应防御措施进行了基准测试。我们的基准测试结果揭示了代理操作不同阶段的关键漏洞,包括系统提示、用户提示处理、工具使用和记忆检索,最高平均攻击成功率达到84.30%,而当前防御措施的有效性有限,这揭示了社区在代理安全方面还有重要工作要做。我们还引入了一个新的指标来评估代理在实用性和安全性之间的平衡能力。我们的代码可以在https://github.com/agiresearch/ASB找到。
论文及项目相关链接
PDF Accepted by ICLR 2025
Summary
本文介绍了基于大型语言模型(LLM)的代理人在解决复杂现实世界任务时可能存在的关键安全漏洞。为应对这一问题,文章提出了Agent Security Bench(ASB)框架,用于形式化、基准测试和评估LLM代理的攻击和防御措施。文章详细介绍了ASB的设计和功能,并通过实验揭示了代理操作不同阶段的严重漏洞,如系统提示、用户提示处理、工具使用和内存检索等。同时提出了评价代理效用和安全平衡的新指标。有关代码可访问:[链接地址]。
Key Takeaways
- 基于大型语言模型的代理人面临关键安全漏洞问题。
- Agent Security Bench(ASB)框架用于评估LLM代理的安全性能。
- ASB涵盖多种场景、代理人、工具、攻击/防御方法和评估指标。
- 基准测试结果揭示了代理操作不同阶段的严重漏洞。
- 当前防御措施的有效性有限,需加强代理安全研究。
- 提出了评价代理效用和安全平衡的新指标。
点此查看论文截图


GUICourse: From General Vision Language Models to Versatile GUI Agents
Authors:Wentong Chen, Junbo Cui, Jinyi Hu, Yujia Qin, Junjie Fang, Yue Zhao, Chongyi Wang, Jun Liu, Guirong Chen, Yupeng Huo, Yuan Yao, Yankai Lin, Zhiyuan Liu, Maosong Sun
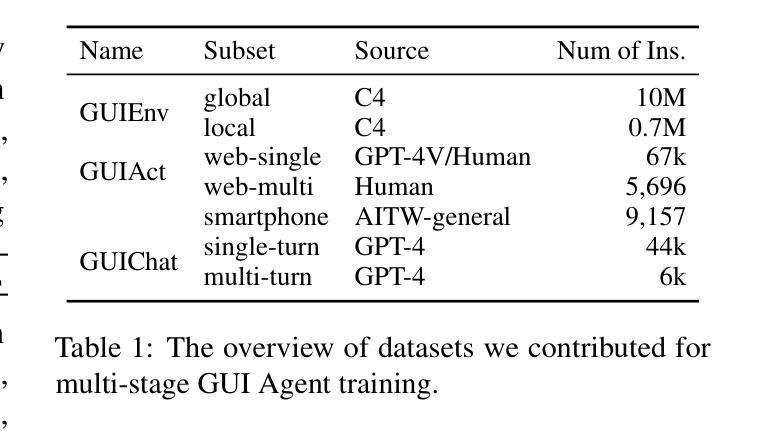
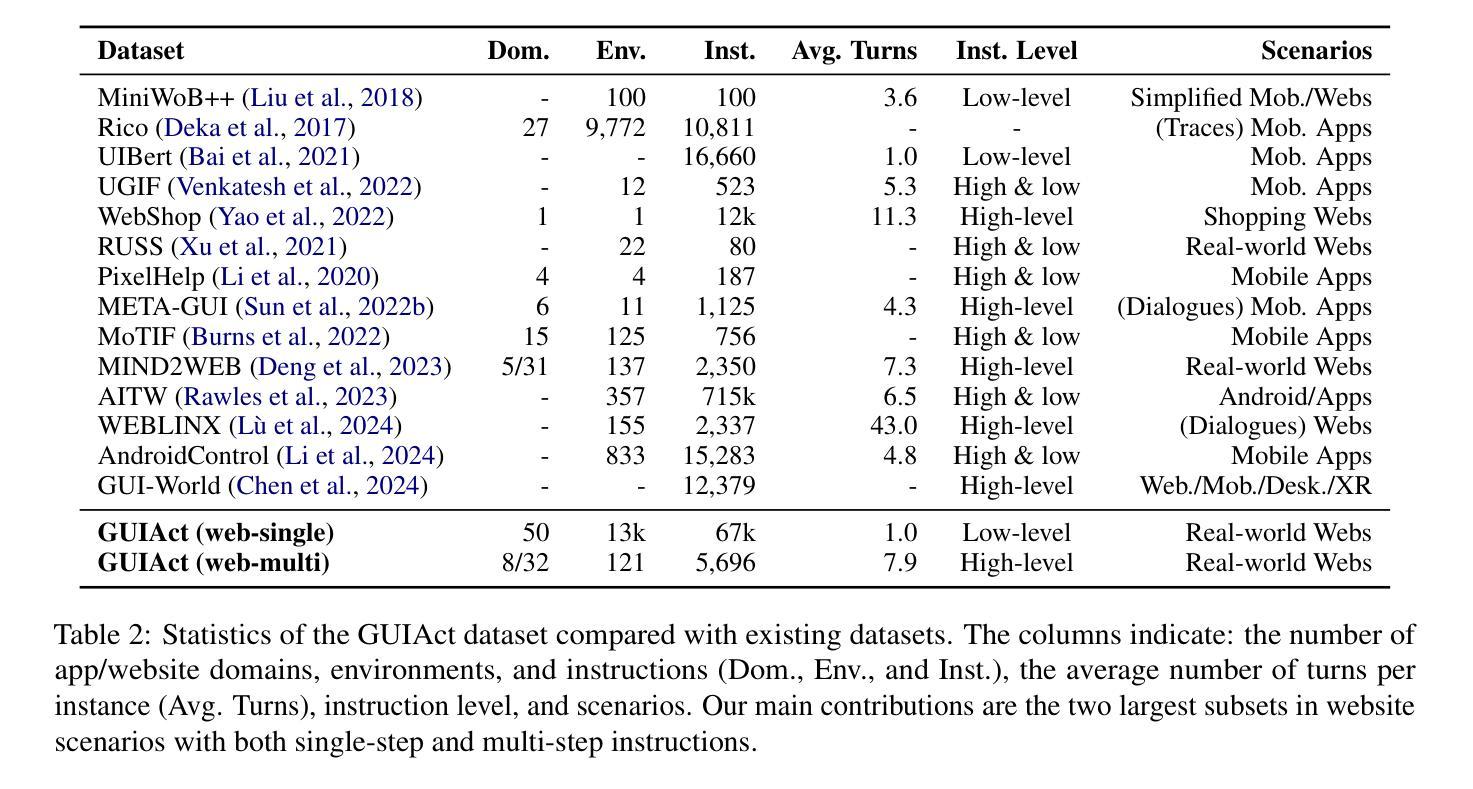
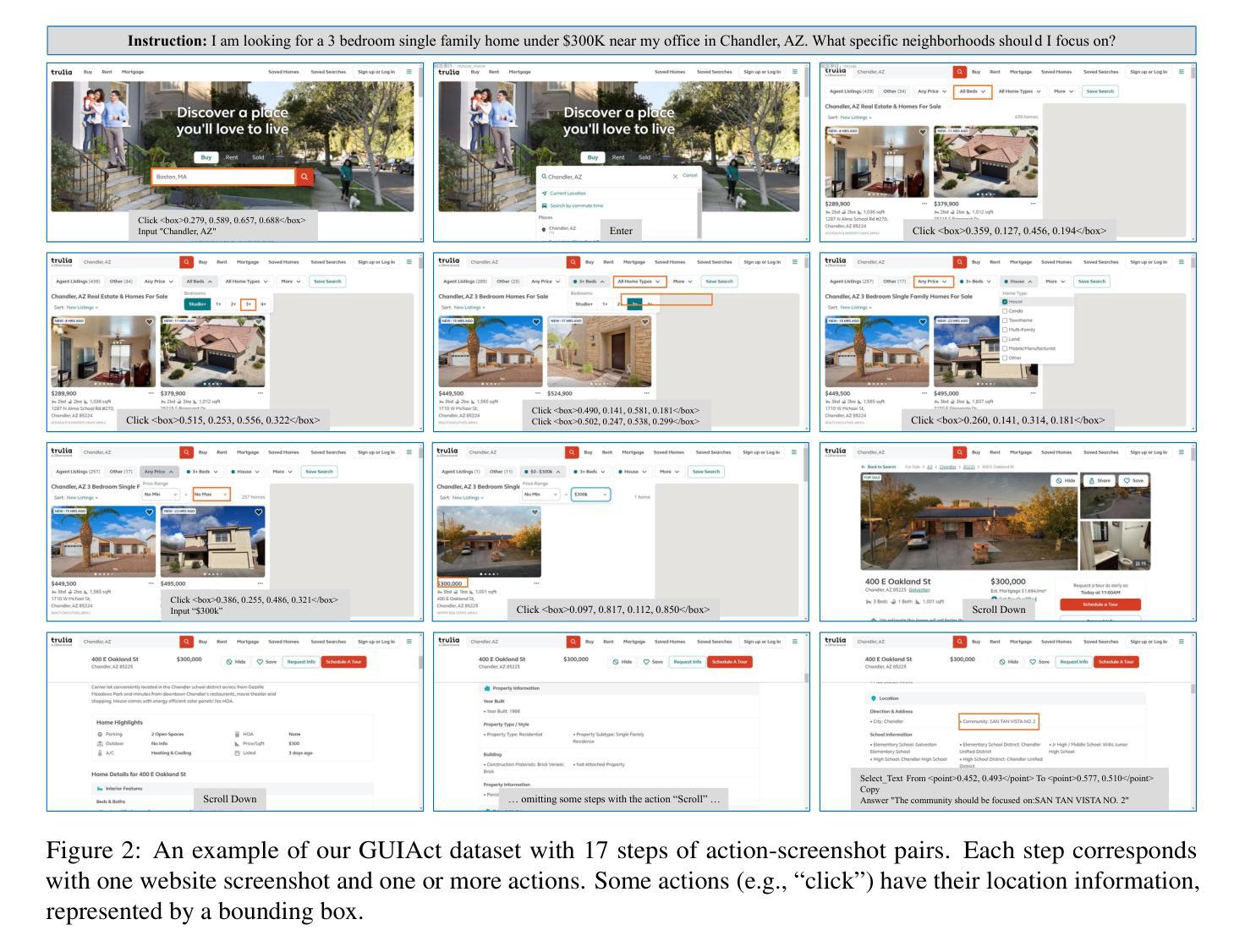
Utilizing Graphic User Interface (GUI) for human-computer interaction is essential for accessing a wide range of digital tools. Recent advancements in Vision Language Models (VLMs) highlight the compelling potential to develop versatile agents to help humans finish GUI navigation tasks. However, current VLMs are challenged in terms of fundamental abilities (OCR and grounding) and GUI knowledge (the functions and control methods of GUI elements), preventing them from becoming practical GUI agents. To solve these challenges, we contribute GUICourse, a suite of datasets to train visual-based GUI agents from general VLMs. First, we introduce the GUIEnv dataset to strengthen the OCR and grounding capabilities of VLMs. Then, we introduce the GUIAct and GUIChat datasets to enrich their knowledge of GUI components and interactions. Experiments demonstrate that our GUI agents have better performance on common GUI tasks than their baseline VLMs. Even the small-size GUI agent (with 3.1B parameters) can still work well on single-step and multi-step GUI tasks. Finally, we analyze the different varieties in the training stage of this agent by ablation study. Our source codes and datasets are released at https://github.com/yiye3/GUICourse.
利用图形用户界面(GUI)进行人机交互对于访问广泛的数字工具至关重要。视觉语言模型(VLM)的最新进展突显了开发通用代理来帮助人类完成GUI导航任务的巨大潜力。然而,当前VLM面临基础能力(OCR和接地能力)和GUI知识(GUI元素的功能和控制方法)方面的挑战,阻碍了它们成为实用的GUI代理。为了解决这些挑战,我们贡献了GUICourse,这是一套用于从通用VLM训练基于视觉的GUI代理的数据集。首先,我们介绍了GUIEnv数据集,以加强VLM的OCR和接地能力。然后,我们介绍了GUIAct和GUIChat数据集,以丰富他们对GUI组件和交互的知识。实验表明,我们的GUI代理在常见的GUI任务上的性能优于其基线VLM。即使是小型的GUI代理(具有3.1B参数)仍然可以在单步和多步GUI任务上表现良好。最后,我们通过消融研究分析了该代理训练阶段的不同变化。我们的源代码和数据集发布在https://github.com/yiye3/GUICourse。
简化说明:
论文及项目相关链接
Summary
基于图形用户界面(GUI)的人机交互对于访问广泛的数字工具至关重要。最近视觉语言模型(VLM)的进步显示开发通用代理完成GUI导航任务的潜力巨大。然而,当前VLM面临基础能力(如光学字符识别和定位)和GUI知识(如GUI组件的功能和控制方法)的挑战,阻碍了它们成为实用的GUI代理。为解决这些挑战,我们推出GUICourse套件,用于从通用VLM训练视觉基础GUI代理。首先,我们引入GUIEnv数据集加强VLM的光学字符识别和定位能力。然后,我们引入GUIAct和GUIChat数据集丰富其对GUI组件和交互的知识。实验表明,我们的GUI代理在常见GUI任务上的性能优于基础VLM。甚至小型GUI代理(3.1B参数)在单步和多步GUI任务上也能表现出良好性能。
Key Takeaways
- GUI在数字工具访问中起关键作用。
- VLM在开发GUI导航任务代理方面具有巨大潜力。
- 当前VLM面临OCR和定位能力以及GUI知识的挑战。
- GUICourse套件包括GUIEnv、GUIAct和GUIChat数据集以应对这些挑战。
- GUI代理在常见GUI任务上的性能经过实验验证优于基础VLM。
- 小型GUI代理也能有效处理单步和多步GUI任务。
点此查看论文截图