⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-03 更新
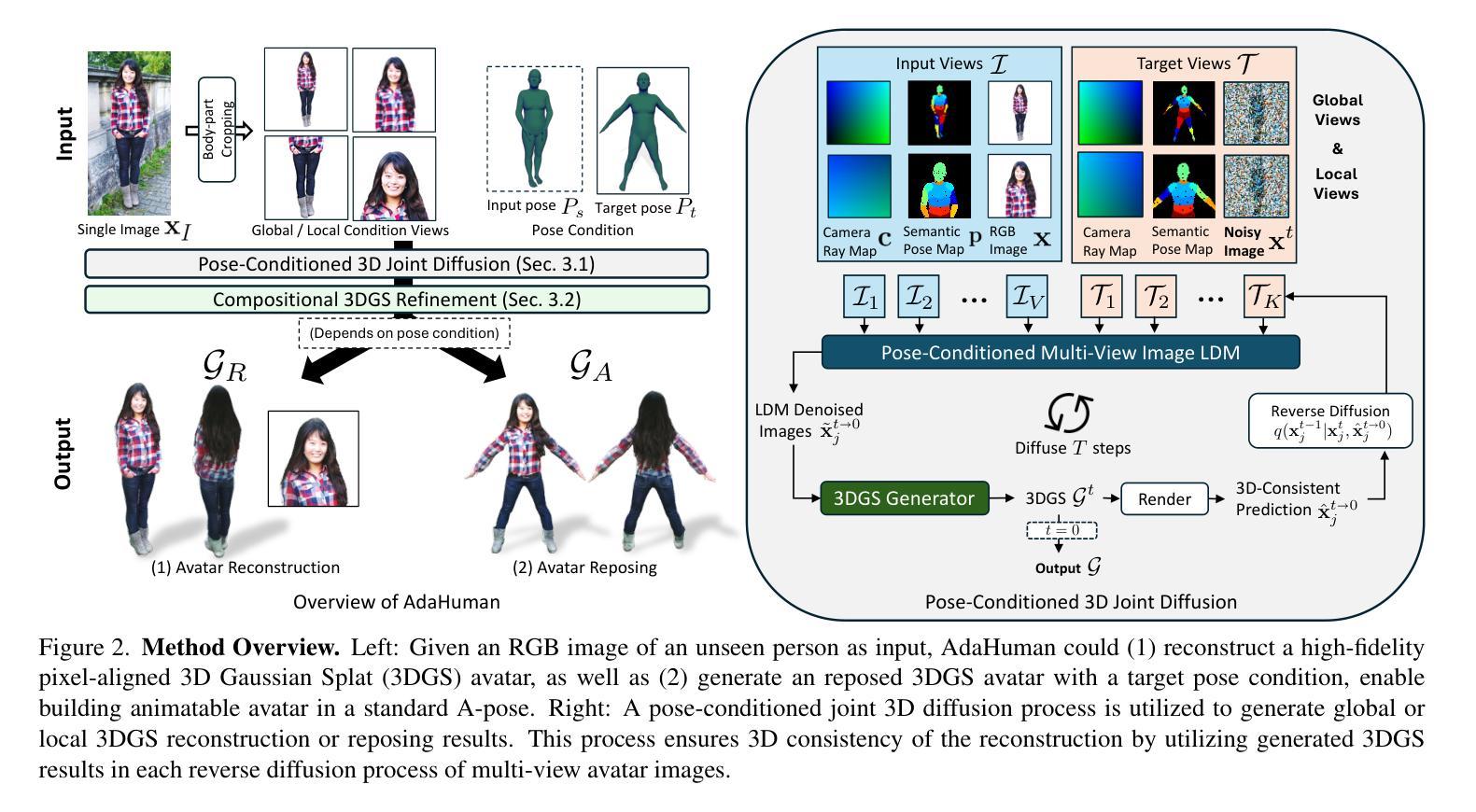
AdaHuman: Animatable Detailed 3D Human Generation with Compositional Multiview Diffusion
Authors:Yangyi Huang, Ye Yuan, Xueting Li, Jan Kautz, Umar Iqbal
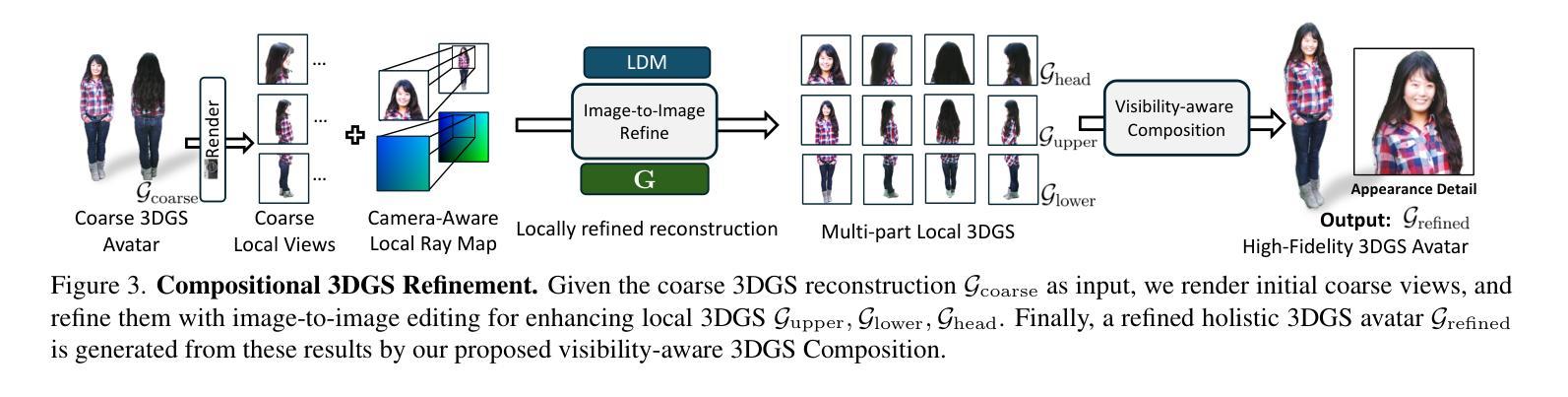
Existing methods for image-to-3D avatar generation struggle to produce highly detailed, animation-ready avatars suitable for real-world applications. We introduce AdaHuman, a novel framework that generates high-fidelity animatable 3D avatars from a single in-the-wild image. AdaHuman incorporates two key innovations: (1) A pose-conditioned 3D joint diffusion model that synthesizes consistent multi-view images in arbitrary poses alongside corresponding 3D Gaussian Splats (3DGS) reconstruction at each diffusion step; (2) A compositional 3DGS refinement module that enhances the details of local body parts through image-to-image refinement and seamlessly integrates them using a novel crop-aware camera ray map, producing a cohesive detailed 3D avatar. These components allow AdaHuman to generate highly realistic standardized A-pose avatars with minimal self-occlusion, enabling rigging and animation with any input motion. Extensive evaluation on public benchmarks and in-the-wild images demonstrates that AdaHuman significantly outperforms state-of-the-art methods in both avatar reconstruction and reposing. Code and models will be publicly available for research purposes.
当前用于图像到3D化身生成的方法难以生成适用于真实世界应用的高度详细的动画化身。我们引入了AdaHuman,这是一个新型框架,可以从单张野外图像生成高度逼真的动画3D化身。AdaHuman有两个主要创新点:(1)姿态调节的3D关节扩散模型,该模型在任意姿态下合成一致的多视角图像,并在每个扩散步骤中进行相应的3D高斯Splats(3DGS)重建;(2)组合式3DGS优化模块,通过图像到图像的细化增强局部身体部位的细节,并使用新型裁剪感知相机射线图无缝集成它们,生成连贯的详细3D化身。这些组件使得AdaHuman能够生成高度逼真的标准化A姿态化身,最小限度地实现自我遮挡,并能够实现与任何输入动作进行绑定和动画。在公共基准测试和野外图像上的广泛评估表明,AdaHuman在化身重建和重新定位方面均显著优于最新技术方法。为了研究目的,我们将公开提供代码和模型。
论文及项目相关链接
PDF Website: https://nvlabs.github.io/AdaHuman
Summary
AdaHuman是一个从单张图像生成高保真动画3D角色的新框架。它采用姿态条件化三维关节扩散模型和三维高斯插值重构技术,通过图像到图像的细化过程,无缝集成各部分细节,生成连贯且详细的3D角色。AdaHuman能生成高度逼真的标准化A姿态角色,最小限度地实现自我遮挡,并能与任何输入动作进行匹配和动画化。其在公共基准测试和真实图像上的表现显著优于当前的主流方法。
Key Takeaways
- AdaHuman使用新颖的框架从单张图像生成动画式3D角色。
- 该框架包含姿态条件化三维关节扩散模型,能合成任意姿态下的多视角图像。
- AdaHuman利用三维高斯插值(3DGS)进行每一步的扩散重构。
- 引入了图像到图像的细化模块来增强局部细节,并采用创新的农作物感知相机射线映射无缝集成这些细节。
- AdaHuman可以生成标准化的高度逼真的A姿态角色,最小化自我遮挡。
- AdaHuman的角色易于装备和动画化,能与任何输入动作匹配。
点此查看论文截图


Interpreting Large Text-to-Image Diffusion Models with Dictionary Learning
Authors:Stepan Shabalin, Ayush Panda, Dmitrii Kharlapenko, Abdur Raheem Ali, Yixiong Hao, Arthur Conmy
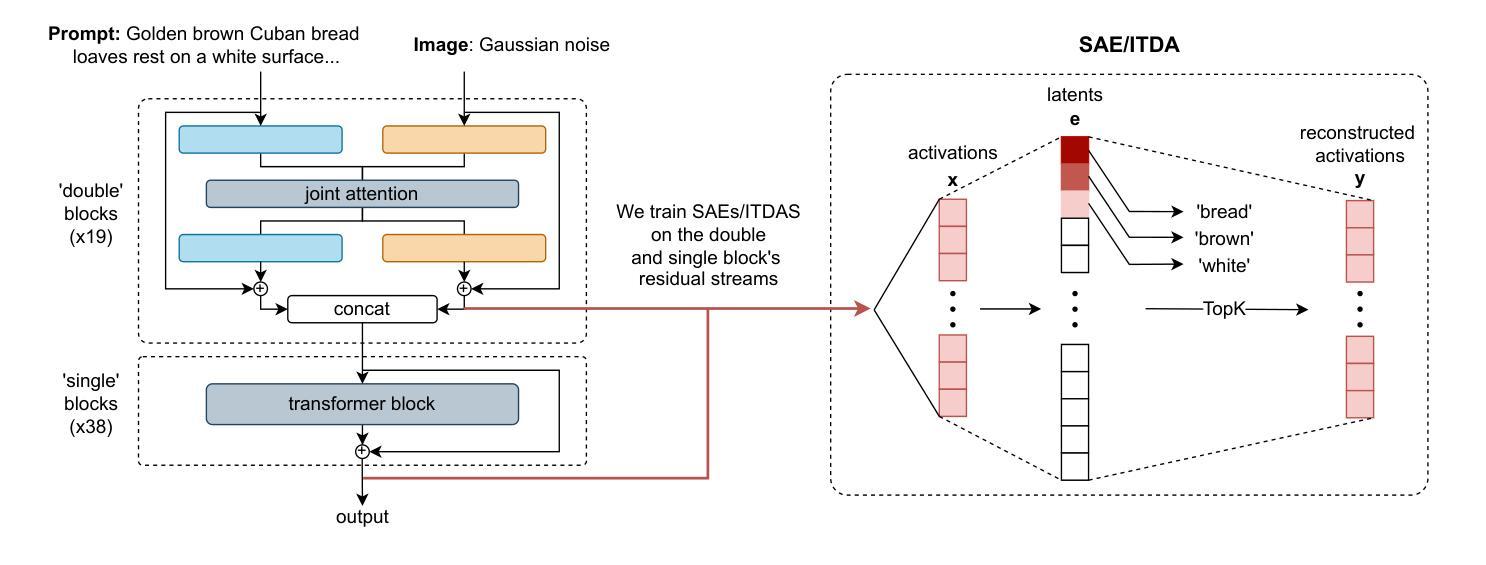
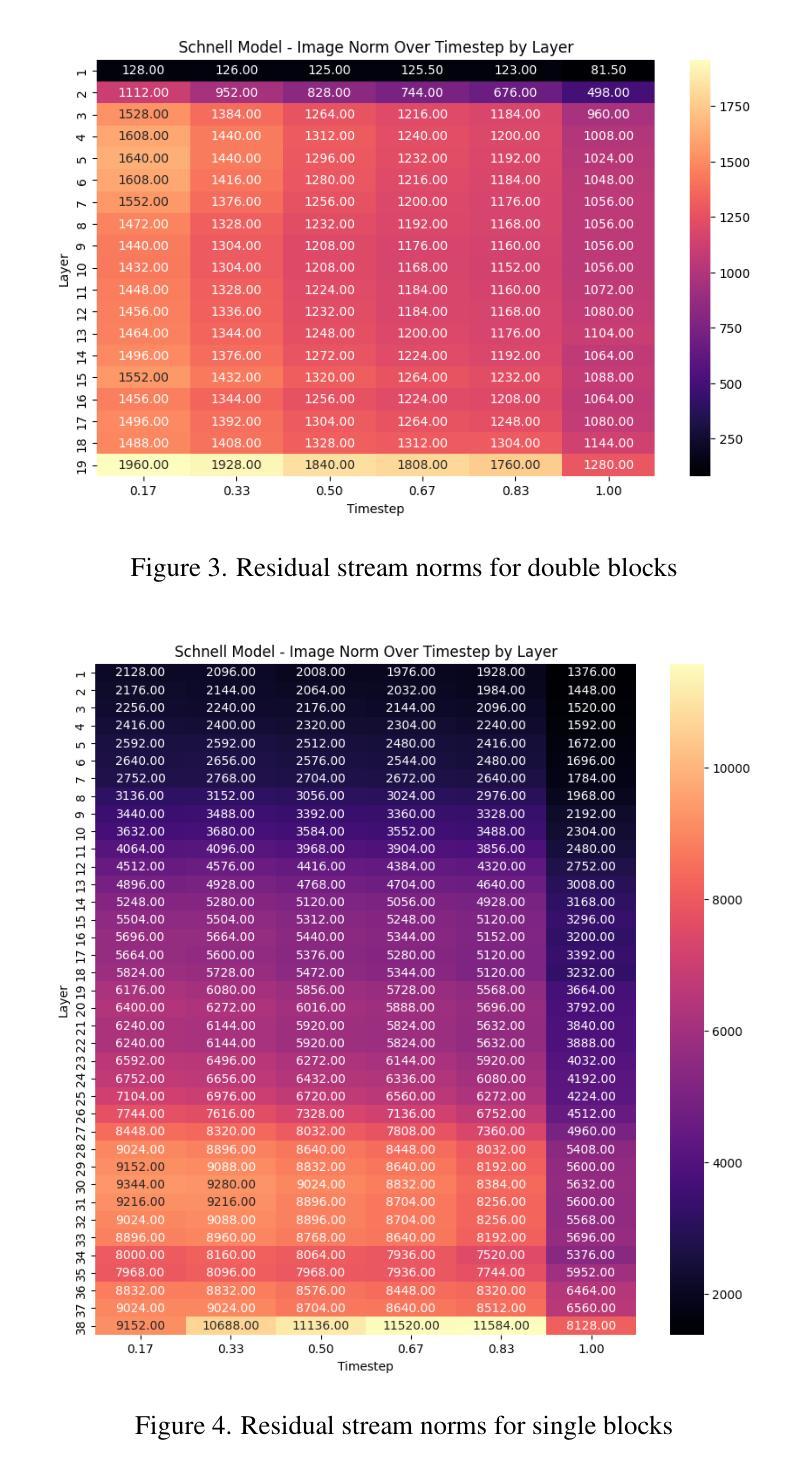
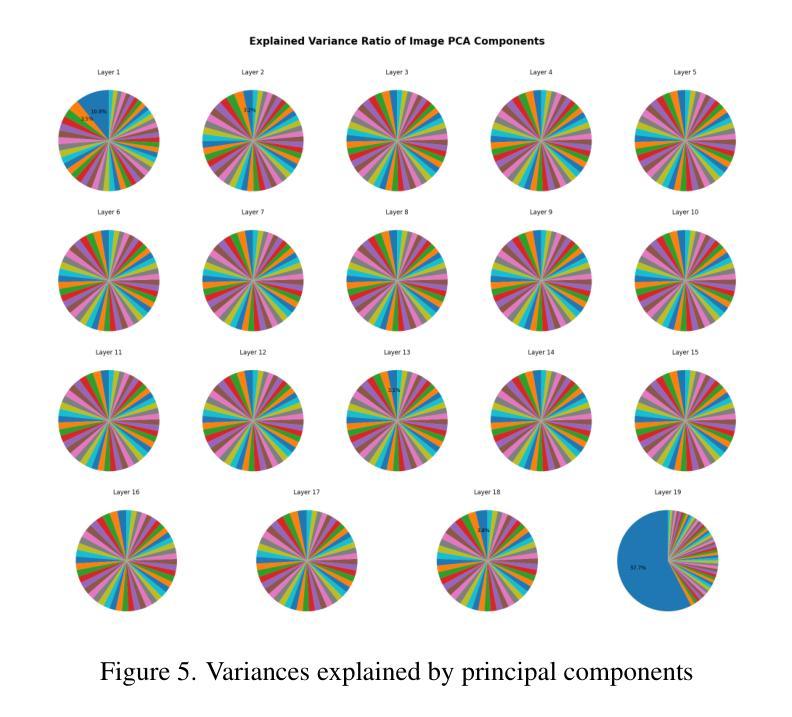
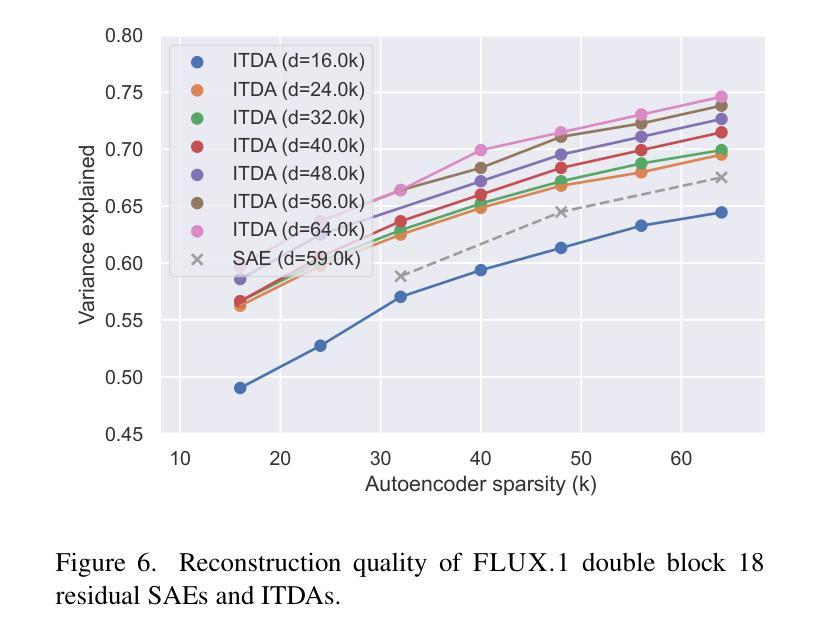
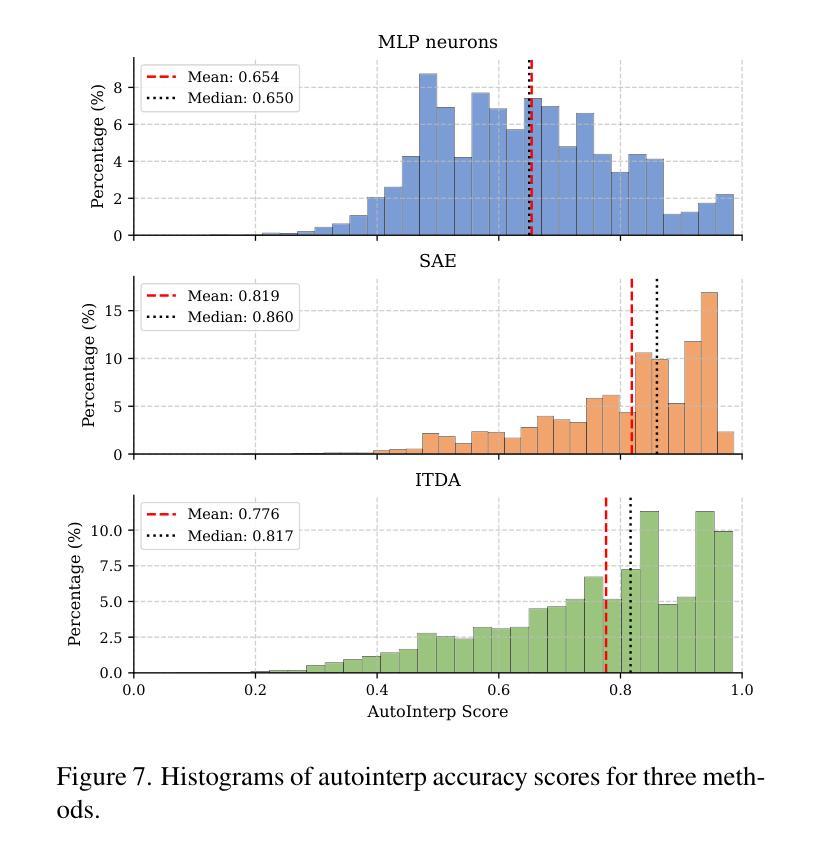
Sparse autoencoders are a promising new approach for decomposing language model activations for interpretation and control. They have been applied successfully to vision transformer image encoders and to small-scale diffusion models. Inference-Time Decomposition of Activations (ITDA) is a recently proposed variant of dictionary learning that takes the dictionary to be a set of data points from the activation distribution and reconstructs them with gradient pursuit. We apply Sparse Autoencoders (SAEs) and ITDA to a large text-to-image diffusion model, Flux 1, and consider the interpretability of embeddings of both by introducing a visual automated interpretation pipeline. We find that SAEs accurately reconstruct residual stream embeddings and beat MLP neurons on interpretability. We are able to use SAE features to steer image generation through activation addition. We find that ITDA has comparable interpretability to SAEs.
稀疏自动编码器是一种很有前途的新方法,用于分解语言模型的激活进行解释和控制。它们已成功应用于视觉转换器图像编码器和小型扩散模型。激活推理时间分解(ITDA)是字典学习的一个新近提出的变体,它将字典视为激活分布中的数据点集,并通过梯度追求进行重建。我们将稀疏自动编码器(SAE)和ITDA应用于大型文本到图像的扩散模型Flux 1,并通过引入视觉自动化解释管道考虑两者的嵌入解释性。我们发现SAE能够准确重建残差流嵌入,在解释性方面优于MLP神经元。我们能够使用SAE特征通过激活添加来引导图像生成。我们发现ITDA的解释性与SAE相当。
论文及项目相关链接
PDF 10 pages, 10 figures, Mechanistic Interpretability for Vision at CVPR 2025
Summary
稀疏自编码器是分解语言模型激活以进行解释和控制的一种有前途的新方法。已成功应用于视觉转换器图像编码器和小型扩散模型。我们将其应用于大型文本到图像的扩散模型Flux 1,并通过引入视觉自动化解释管道来考虑两者的可解释性。我们发现稀疏自编码器能够准确重建残差流嵌入,并在可解释性方面优于MLP神经元。我们还能够使用SAE特征通过激活添加来引导图像生成。
Key Takeaways
- 稀疏自编码器(SAE)在分解语言模型激活方面表现出良好的潜力,特别是在大型文本到图像的扩散模型中。
- 通过引入视觉自动化解释管道,可以进一步提高模型的可解释性。
- SAE能够准确重建残差流嵌入,优于MLP神经元在解释嵌入方面的性能。
- 使用SAE特征可以在图像生成过程中进行激活添加,实现对图像生成的引导。
- ITDA(推理时间激活分解)在可解释性与SAE相当。
- SAE和ITDA的应用为语言模型的理解和控制在解释性和控制方面提供了新的视角和方法。
点此查看论文截图

InteractAnything: Zero-shot Human Object Interaction Synthesis via LLM Feedback and Object Affordance Parsing
Authors:Jinlu Zhang, Yixin Chen, Zan Wang, Jie Yang, Yizhou Wang, Siyuan Huang
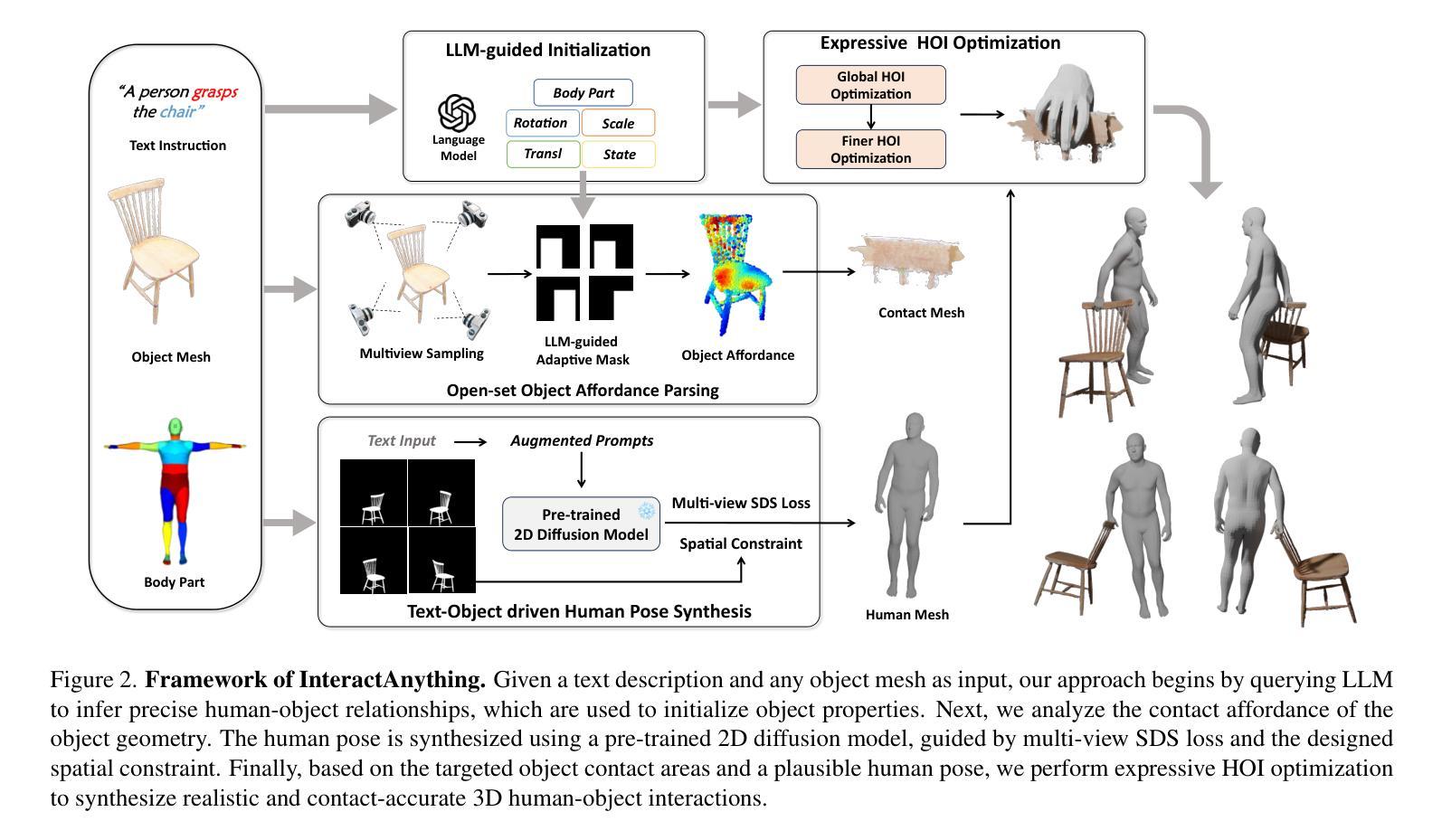
Recent advances in 3D human-aware generation have made significant progress. However, existing methods still struggle with generating novel Human Object Interaction (HOI) from text, particularly for open-set objects. We identify three main challenges of this task: precise human-object relation reasoning, affordance parsing for any object, and detailed human interaction pose synthesis aligning description and object geometry. In this work, we propose a novel zero-shot 3D HOI generation framework without training on specific datasets, leveraging the knowledge from large-scale pre-trained models. Specifically, the human-object relations are inferred from large language models (LLMs) to initialize object properties and guide the optimization process. Then we utilize a pre-trained 2D image diffusion model to parse unseen objects and extract contact points, avoiding the limitations imposed by existing 3D asset knowledge. The initial human pose is generated by sampling multiple hypotheses through multi-view SDS based on the input text and object geometry. Finally, we introduce a detailed optimization to generate fine-grained, precise, and natural interaction, enforcing realistic 3D contact between the 3D object and the involved body parts, including hands in grasping. This is achieved by distilling human-level feedback from LLMs to capture detailed human-object relations from the text instruction. Extensive experiments validate the effectiveness of our approach compared to prior works, particularly in terms of the fine-grained nature of interactions and the ability to handle open-set 3D objects.
关于三维人形感知生成领域最近取得了显著进展。然而,现有方法仍难以根据文本生成新型的人-物交互(HOI),尤其是开放集物体。我们确定了该任务面临三大挑战:精准的人-物关系推理、任意对象的可操控性解析以及符合描述和物体几何特性的详细人类交互姿态合成。在这项工作中,我们提出了一种新型的零样本三维HOI生成框架,无需在特定数据集上进行训练,而是借助大规模预训练模型的知识。具体而言,我们从大型语言模型(LLM)推断出人-物关系,以初始化物体属性并引导优化过程。然后,我们利用预训练的二维图像扩散模型来分析未见过的物体并提取接触点,避免了现有三维资产知识的限制。基于输入文本和物体几何特性,通过多视角SDS生成初始人类姿态。最后,我们进行了详细的优化,以生成精细、精准、自然的交互,强制要求三维物体与所涉及身体部位之间的现实接触,包括抓握时的手部。这是通过从LLM中提取人类反馈来实现从文本指令中捕获详细的人-物关系。大量实验验证了我们的方法与先前工作相比的有效性,特别是在交互的精细性质和处理开放集三维物体的能力方面。
论文及项目相关链接
PDF CVPR 2025
Summary
近期三维人类感知生成技术取得进展,但仍存在从文本生成新型人机交互(HOI)的难题,特别是在开放集对象上。本文提出一种零样本三维HOI生成框架,利用大规模预训练模型的知识,无需在特定数据集上进行训练。通过语言模型推断人类与对象的关系,利用预训练的二维图像扩散模型解析未见过的对象并提取接触点,避免现有三维资产知识的限制。通过多视角SDS生成初始人类姿势,并引入详细优化生成精细、精确和自然交互。
Key Takeaways
- 近期三维人类感知生成技术有进展,但仍面临从文本生成新型人机交互的挑战,特别是在开放集对象上。
- 本文提出一种零样本三维HOI生成框架,无需特定数据集训练。
- 利用语言模型推断人类与对象的关系,初始化对象属性并引导优化过程。
- 采用预训练的二维图像扩散模型解析未见过的对象,提取接触点。
- 通过多视角SDS生成初始人类姿势。
- 引入详细优化生成精细、精确和自然交互,实现三维对象与身体部位的现实接触,包括手部抓握。
点此查看论文截图



Category-aware EEG image generation based on wavelet transform and contrast semantic loss
Authors:Enshang Zhang, Zhicheng Zhang, Takashi Hanakawa
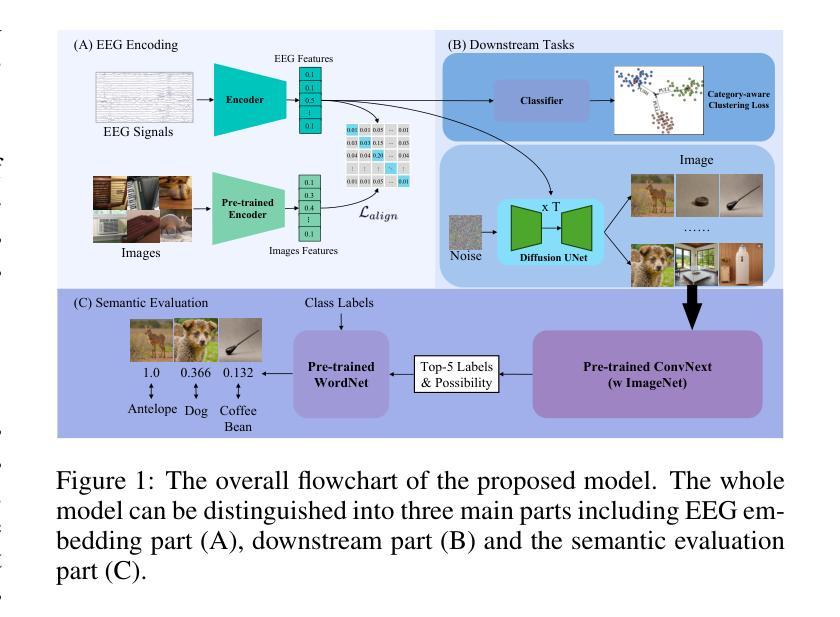
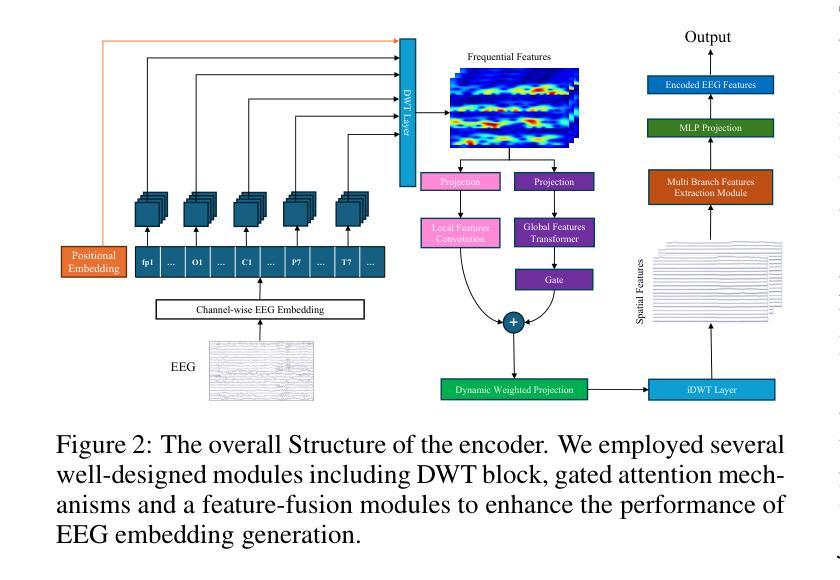
Reconstructing visual stimuli from EEG signals is a crucial step in realizing brain-computer interfaces. In this paper, we propose a transformer-based EEG signal encoder integrating the Discrete Wavelet Transform (DWT) and the gating mechanism. Guided by the feature alignment and category-aware fusion losses, this encoder is used to extract features related to visual stimuli from EEG signals. Subsequently, with the aid of a pre-trained diffusion model, these features are reconstructed into visual stimuli. To verify the effectiveness of the model, we conducted EEG-to-image generation and classification tasks using the THINGS-EEG dataset. To address the limitations of quantitative analysis at the semantic level, we combined WordNet-based classification and semantic similarity metrics to propose a novel semantic-based score, emphasizing the ability of our model to transfer neural activities into visual representations. Experimental results show that our model significantly improves semantic alignment and classification accuracy, which achieves a maximum single-subject accuracy of 43%, outperforming other state-of-the-art methods. The source code and supplementary material is available at https://github.com/zes0v0inn/DWT_EEG_Reconstruction/tree/main.
从脑电图信号重建视觉刺激是实现脑机接口的关键步骤。在本文中,我们提出了一种基于变压器的脑电图信号编码器,该编码器结合了离散小波变换(DWT)和门控机制。在特征对齐和类别感知融合损失的指导下,该编码器用于从脑电图信号中提取与视觉刺激相关的特征。随后,借助预先训练的扩散模型,这些特征被重建为视觉刺激。为了验证模型的有效性,我们在THINGS-EEG数据集上进行了脑电图到图像生成和分类任务。为了解决语义层面定量分析的限制,我们结合了基于WordNet的分类和语义相似性度量,提出了一种新的基于语义的评分,强调我们的模型将神经活动转化为视觉表示的能力。实验结果表明,我们的模型在语义对齐和分类精度上有了显著提高,实现了最高单用户准确率为43%,超过了其他最先进的方法。源代码和补充材料可在https://github.com/zes0v0inn/DWT_EEG_Reconstruction/tree/main找到。
论文及项目相关链接
Summary
基于脑电图信号重建视觉刺激是实现脑机接口的重要步骤。本研究提出一种结合离散小波变换和门控机制的基于转换器的脑电图信号编码器。通过特征对齐和类别感知融合损失指导,该编码器从脑电图信号中提取与视觉刺激相关的特征。借助预训练的扩散模型,这些特征被重建为视觉刺激。利用THINGS-EEG数据集进行脑电图到图像生成和分类任务,验证了模型的有效性。为解决语义层面定量分析的限制,本研究结合WordNet分类和语义相似性度量,提出一种新的基于语义的评分方法,强调模型将神经活动转化为视觉表征的能力。实验结果表明,该模型在语义对齐和分类精度上显著提高,达到最高单主体准确率43%,优于其他最先进的方法。
Key Takeaways
- 研究利用变压器架构的编码器处理EEG信号,结合离散小波变换和门机制,以提取与视觉刺激相关的特征。
- 编码器在特征对齐和类别感知融合损失的指导下工作,以提高模型性能。
- 利用预训练的扩散模型将提取的特征重建为视觉刺激,实现脑机接口的重要步骤。
- 使用THINGS-EEG数据集进行EEG到图像生成和分类任务来验证模型的有效性。
- 为克服语义层面定量分析的局限性,结合WordNet分类和语义相似性度量,提出新的语义评分方法。
- 实验结果显示,模型在语义对齐和分类精度上表现优异,达到最高单主体准确率43%。
点此查看论文截图

Generative AI for Urban Design: A Stepwise Approach Integrating Human Expertise with Multimodal Diffusion Models
Authors:Mingyi He, Yuebing Liang, Shenhao Wang, Yunhan Zheng, Qingyi Wang, Dingyi Zhuang, Li Tian, Jinhua Zhao
Urban design is a multifaceted process that demands careful consideration of site-specific constraints and collaboration among diverse professionals and stakeholders. The advent of generative artificial intelligence (GenAI) offers transformative potential by improving the efficiency of design generation and facilitating the communication of design ideas. However, most existing approaches are not well integrated with human design workflows. They often follow end-to-end pipelines with limited control, overlooking the iterative nature of real-world design. This study proposes a stepwise generative urban design framework that integrates multimodal diffusion models with human expertise to enable more adaptive and controllable design processes. Instead of generating design outcomes in a single end-to-end process, the framework divides the process into three key stages aligned with established urban design workflows: (1) road network and land use planning, (2) building layout planning, and (3) detailed planning and rendering. At each stage, multimodal diffusion models generate preliminary designs based on textual prompts and image-based constraints, which can then be reviewed and refined by human designers. We design an evaluation framework to assess the fidelity, compliance, and diversity of the generated designs. Experiments using data from Chicago and New York City demonstrate that our framework outperforms baseline models and end-to-end approaches across all three dimensions. This study underscores the benefits of multimodal diffusion models and stepwise generation in preserving human control and facilitating iterative refinements, laying the groundwork for human-AI interaction in urban design solutions.
城市设计是一个涉及多方面的过程,需要仔细考虑特定地点的限制因素以及不同专业人士和利益相关者之间的合作。生成式人工智能(GenAI)的出现,通过提高设计生成的效率和促进设计思想的交流,提供了变革的潜力。然而,大多数现有方法并没有很好地与人类设计工作流程相结合。它们通常遵循端到端的管道,控制有限,忽视了现实世界设计的迭代性质。本研究提出了一种分步生成的城市设计框架,该框架将多模式扩散模型与人类专业知识相结合,使设计过程更加适应和可控。不同于在单一端到端过程中产生设计结果,该框架将过程分为三个关键阶段,与既定的城市设计工作流程相一致:(1)道路网络和土地利用规划;(2)建筑布局规划;(3)详细规划和呈现。在每个阶段,多模式扩散模型根据文本提示和图像约束生成初步设计,然后可以由人类设计师进行审查和修改。我们设计了一个评估框架,以评估生成设计的保真度、合规性和多样性。使用芝加哥和纽约市数据的实验表明,我们的框架在所有三个维度上都优于基线模型和端到端方法。该研究强调了多模式扩散模型和分步生成在保持人类控制和促进迭代改进方面的益处,为城市设计中的人机交互奠定了基石。
论文及项目相关链接
Summary
该研究提出了一种分步生成的城市设计框架,该框架结合了多模态扩散模型与人类专业知识,使设计过程更加适应并可控。框架将城市设计过程分为三个阶段,每个阶段都使用多模态扩散模型基于文本提示和图像约束生成初步设计,然后可由人类设计师进行审查和修改。实验表明,该框架在保真度、合规性和设计的多样性方面优于基准模型和端到端方法。
Key Takeaways
- 城市设计是一个涉及多方因素和专业的复杂过程,需要综合考虑现场特定约束和多方合作。
- 生成式人工智能(GenAI)的出现在城市设计中提供了改善设计生成效率和促进设计理念沟通的可能性。
- 当前大多数人工智能设计流程未能很好地融入人类设计工作流程,缺乏灵活性且难以适应迭代设计的需求。
- 研究提出了一种分步生成的城市设计框架,整合了多模态扩散模型与人类专业知识,以应对以上问题。
- 该框架将城市设计过程分为三个阶段:道路网络及土地利用规划、建筑布局规划、详细规划和渲染。
- 在每个阶段,利用多模态扩散模型基于文本提示和图像约束生成初步设计,为后续的人类设计师审查和修改提供了基础。
点此查看论文截图


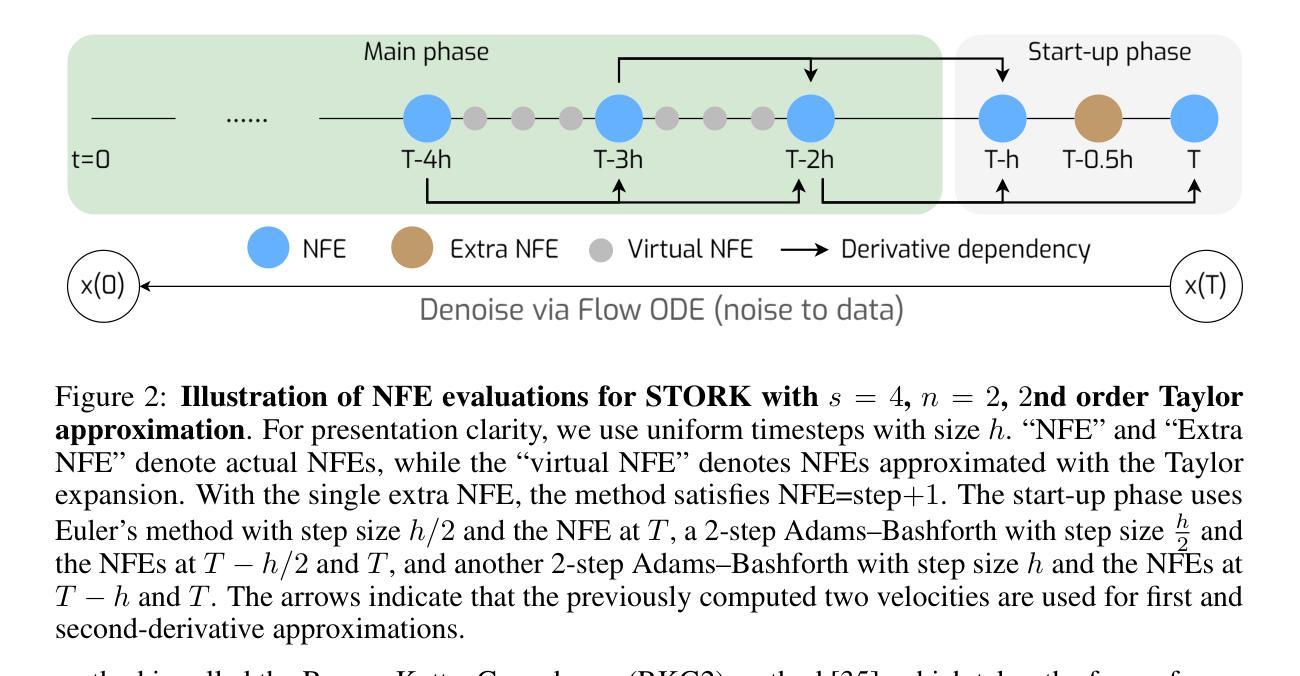
STORK: Improving the Fidelity of Mid-NFE Sampling for Diffusion and Flow Matching Models
Authors:Zheng Tan, Weizhen Wang, Andrea L. Bertozzi, Ernest K. Ryu
Diffusion models (DMs) have demonstrated remarkable performance in high-fidelity image and video generation. Because high-quality generations with DMs typically require a large number of function evaluations (NFEs), resulting in slow sampling, there has been extensive research successfully reducing the NFE to a small range (<10) while maintaining acceptable image quality. However, many practical applications, such as those involving Stable Diffusion 3.5, FLUX, and SANA, commonly operate in the mid-NFE regime (20-50 NFE) to achieve superior results, and, despite the practical relevance, research on the effective sampling within this mid-NFE regime remains underexplored. In this work, we propose a novel, training-free, and structure-independent DM ODE solver called the Stabilized Taylor Orthogonal Runge–Kutta (STORK) method, based on a class of stiff ODE solvers with a Taylor expansion adaptation. Unlike prior work such as DPM-Solver, which is dependent on the semi-linear structure of the DM ODE, STORK is applicable to any DM sampling, including noise-based and flow matching-based models. Within the 20-50 NFE range, STORK achieves improved generation quality, as measured by FID scores, across unconditional pixel-level generation and conditional latent-space generation tasks using models like Stable Diffusion 3.5 and SANA. Code is available at https://github.com/ZT220501/STORK.
扩散模型(DMs)在高保真图像和视频生成方面表现出卓越的性能。由于使用DMs生成高质量图像通常需要大量的函数评估(NFE),导致采样速度较慢,因此已有大量研究成功将NFE降低到一个较小的范围(<10)同时保持可接受的图像质量。然而,许多实际应用,如涉及Stable Diffusion 3.5、FLUX和SANA的应用,通常在中期NFE范围(20-50 NFE)内运行,以取得更好的结果。尽管这种做法具有实际意义,但关于此中期NFE范围内有效采样的研究仍然被探索得不够。在这项工作中,我们提出了一种新型、无需训练且独立于结构之外的DM ODE求解器,称为稳定化的泰勒正交龙格-库塔(STORK)方法,它基于一类带泰勒展开适应性的刚性的ODE求解器。与先前的工作(如DPM-Solver)不同,后者依赖于DM ODE的半线性结构,STORK可应用于任何DM采样,包括基于噪声和基于流匹配模型的采样。在20-50 NFE范围内,STORK在无条件像素级生成和有条件潜在空间生成任务中,使用Stable Diffusion 3.5和SANA等模型时,实现了改进的生成质量,该质量由FID分数衡量。代码可访问于https://github.com/ZT220501/STORK。
论文及项目相关链接
摘要
扩散模型(DMs)在高保真图像和视频生成方面表现出卓越的性能。然而,由于其通常需要大量的功能评估(NFEs)来生成高质量图像,导致采样速度慢,因此研究者们一直致力于减少NFEs至较小范围并保持可接受的图像质量。尽管已有研究将NFE成功降至个位数,但在实际应用中,如Stable Diffusion 3.5、FLUX和SANA等,通常在中期NFE范围内(20-50 NFE)运行以获得更好的结果。本文提出了一种新型、无需训练且独立于结构之外的扩散模型ODE求解器——稳定泰勒正交龙格库塔(STORK)方法,该方法基于一类刚性的ODE求解器并融合了泰勒展开适应技术。与依赖DM ODE半线性结构的DPM-Solver不同,STORK适用于任何DM采样,包括基于噪声和流匹配模型。在20-50 NFE范围内,STORK在无条件像素级生成和条件潜在空间生成任务上实现了更高的生成质量,使用如Stable Diffusion 3.5和SANA等模型时,其FID得分有所提高。相关代码可通过https://github.com/ZT220501/STORK获取。
关键见解
- 扩散模型在高保真图像和视频生成中表现出卓越性能。
- 目前研究主要集中在减少扩散模型的NFE至较小范围以保持图像质量,但中期NFE范围内的有效采样研究仍较少。
- 本文提出了一种新型、无需训练的扩散模型ODE求解器——STORK方法,适用于任何DM采样,包括基于噪声和流匹配模型。
- 在中期NFE范围内(20-50 NFE),STORK方法在无条件像素级生成和条件潜在空间生成任务上实现了更高的生成质量。
- 与现有方法相比,STORK方法在图像质量评估指标FID得分上有所提升。
- STORK方法的实现代码已公开提供,方便其他研究者使用和改进。
点此查看论文截图


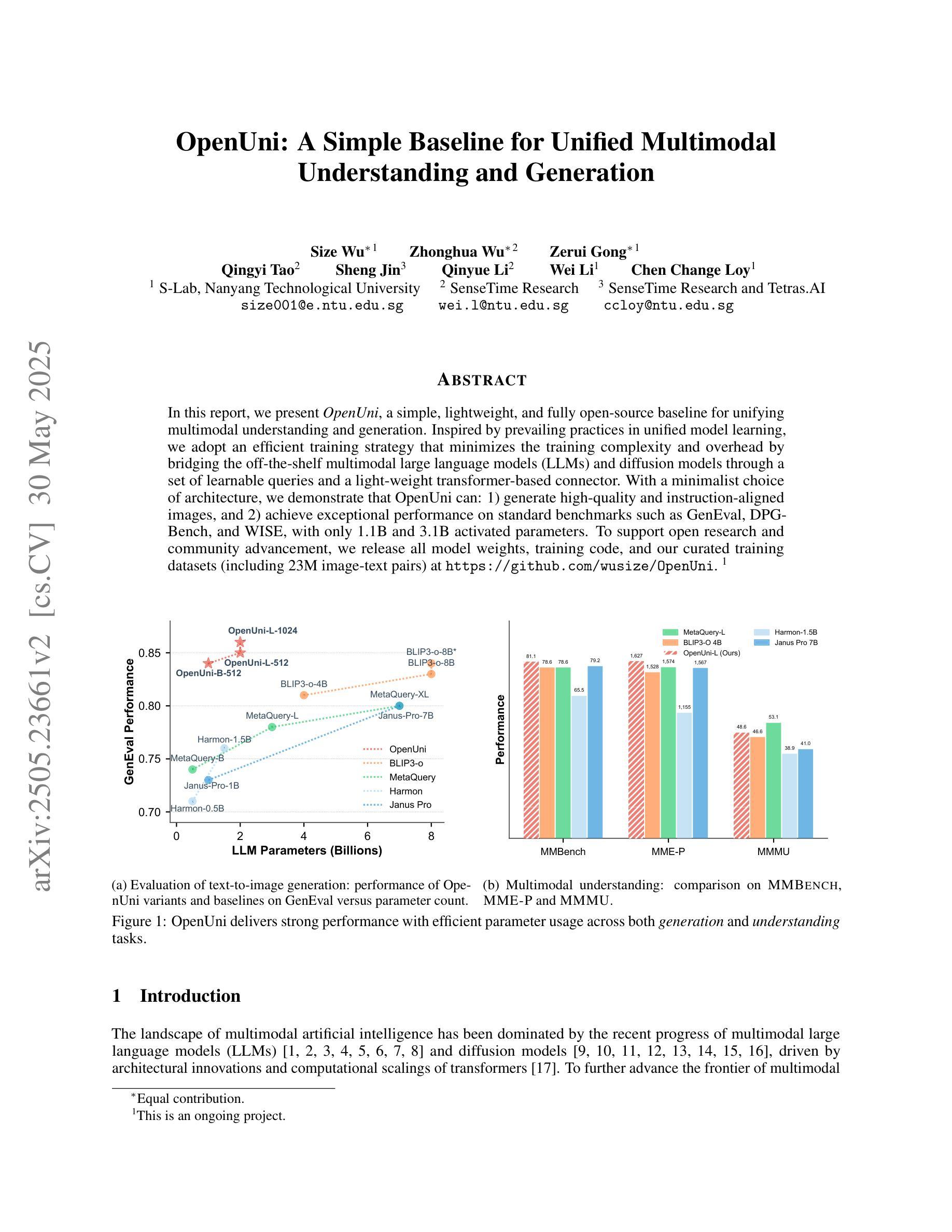
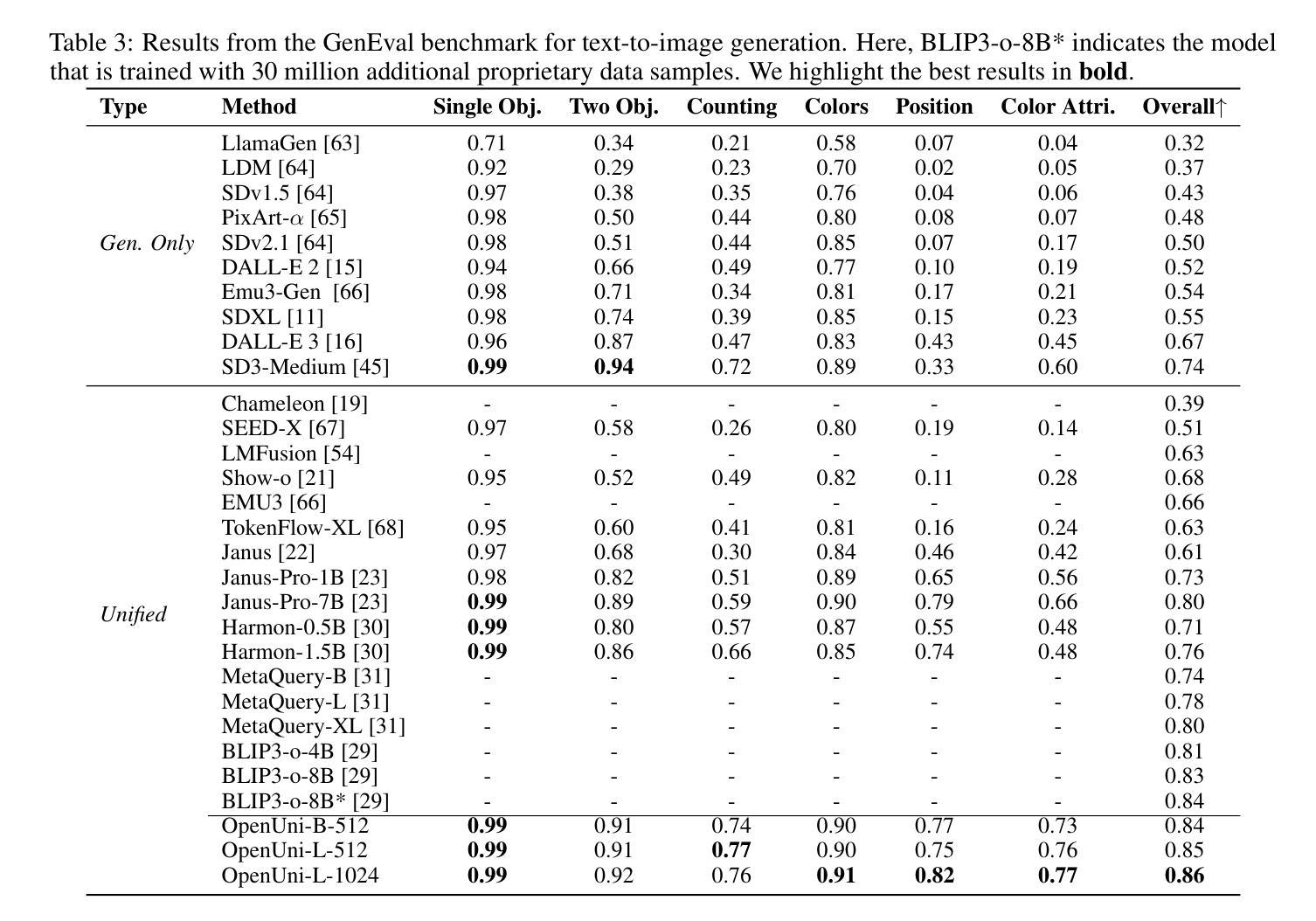
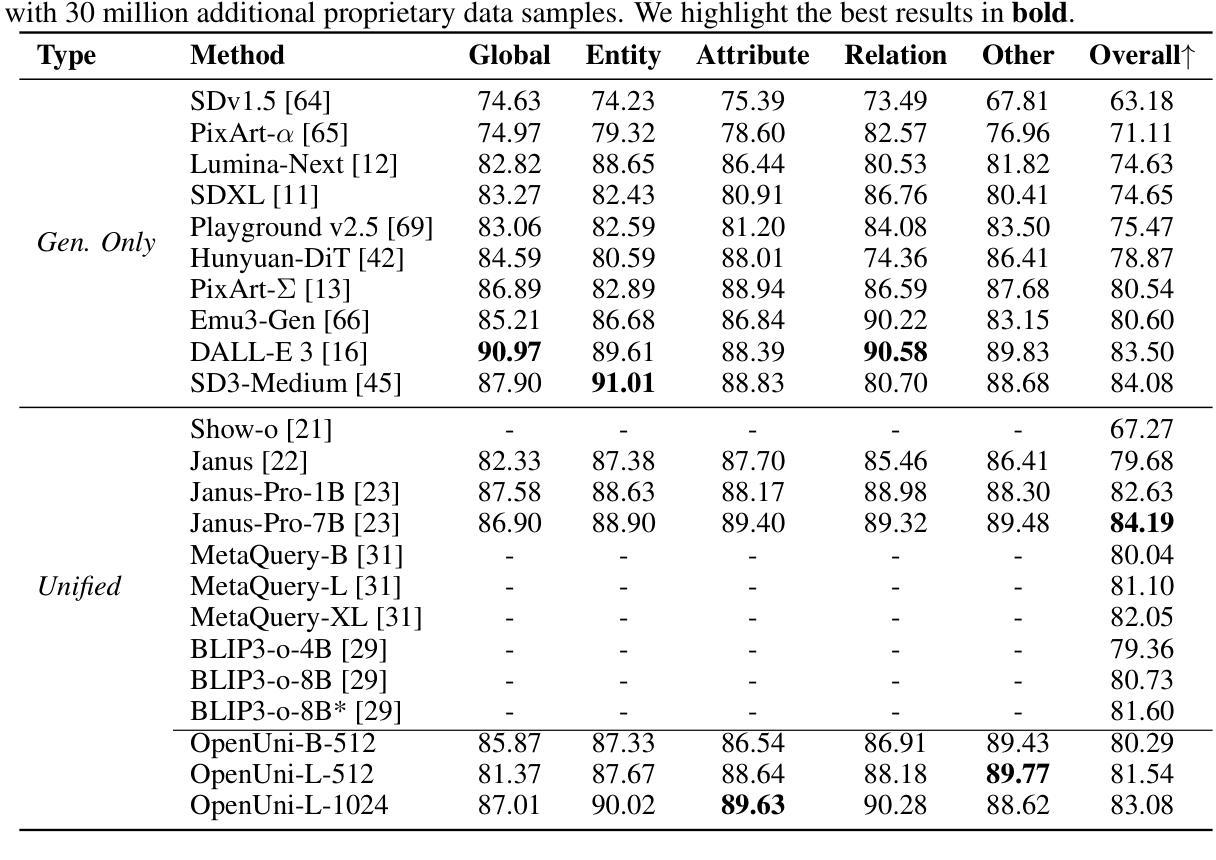
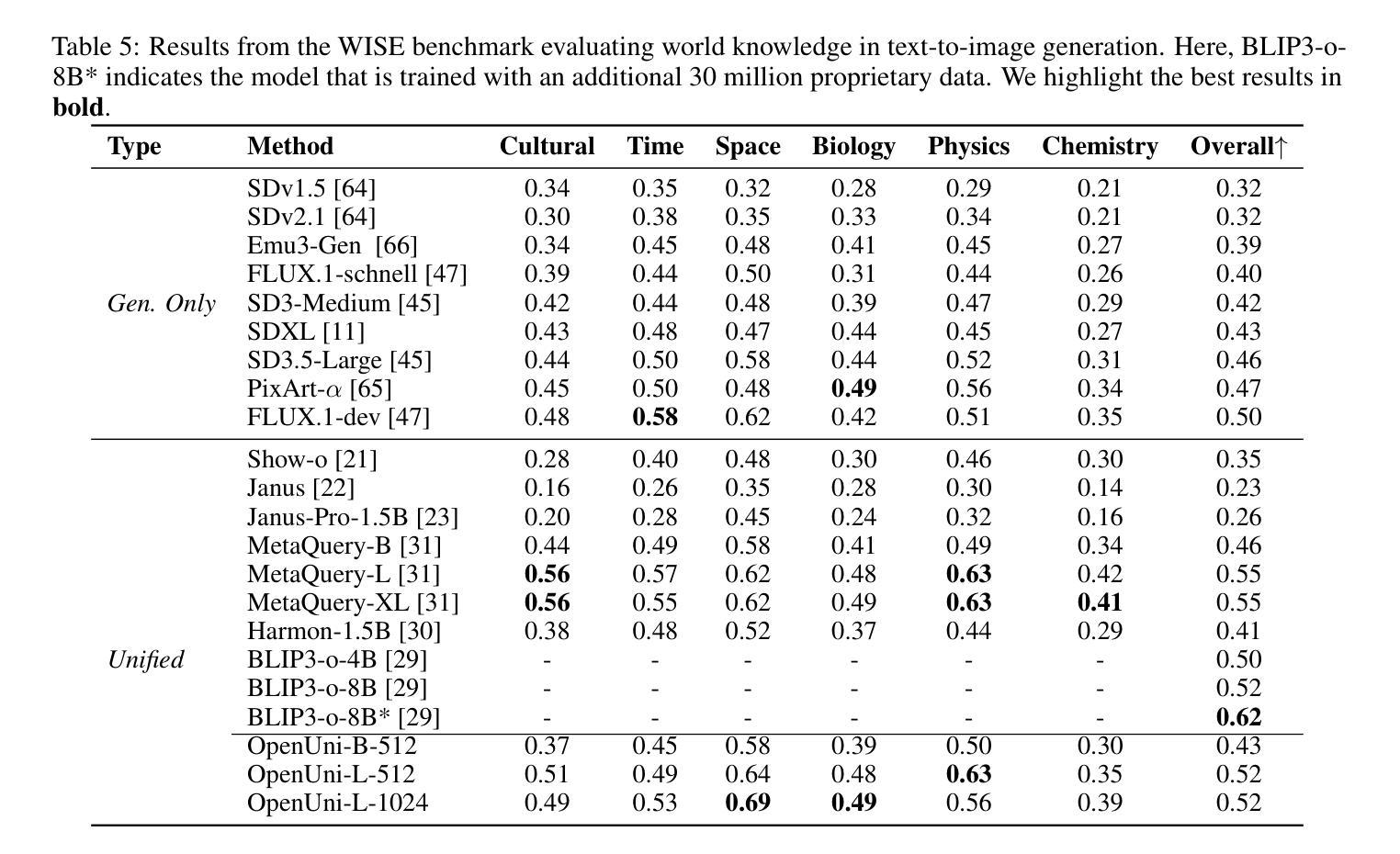
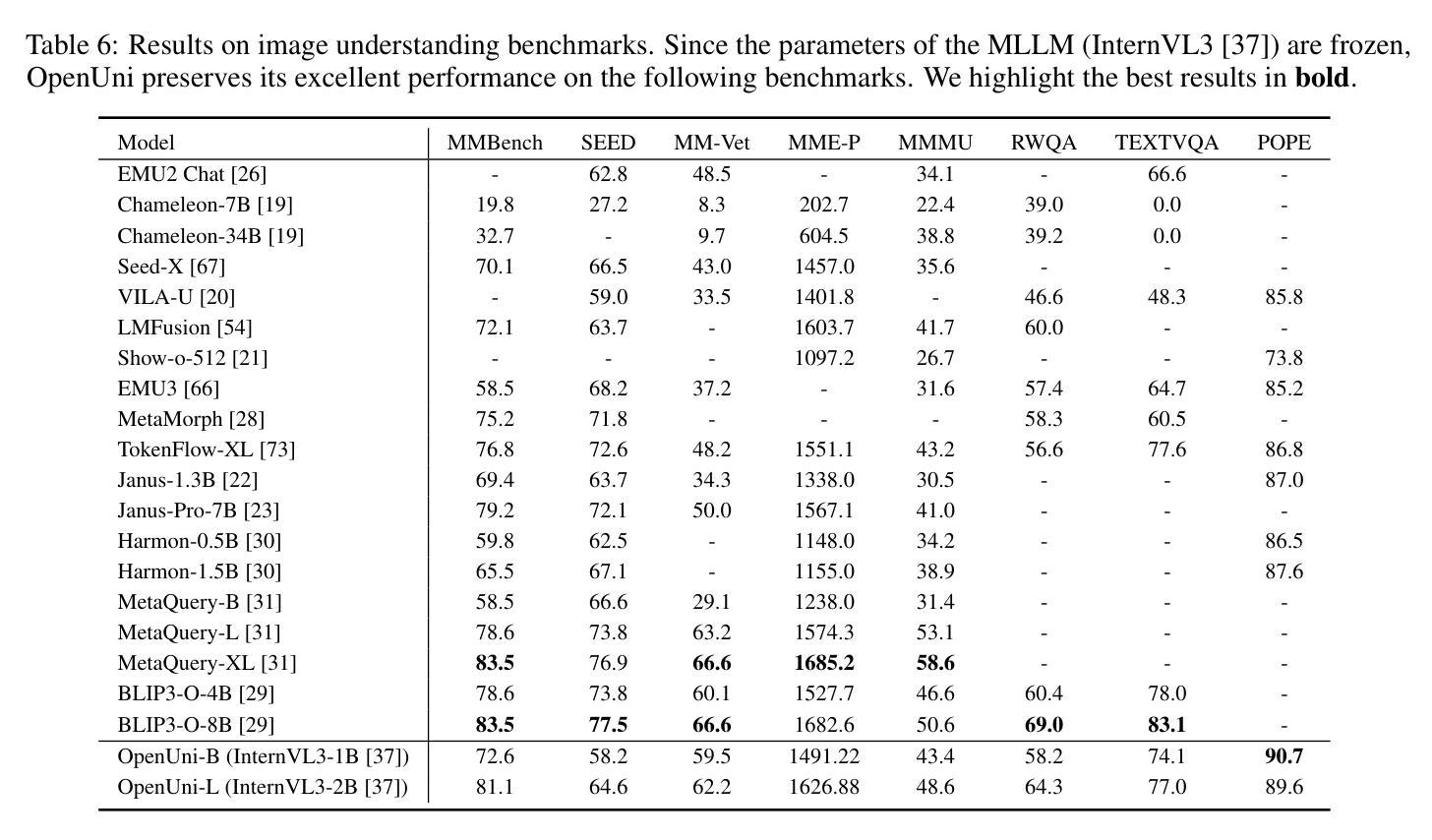
OpenUni: A Simple Baseline for Unified Multimodal Understanding and Generation
Authors:Size Wu, Zhonghua Wu, Zerui Gong, Qingyi Tao, Sheng Jin, Qinyue Li, Wei Li, Chen Change Loy
In this report, we present OpenUni, a simple, lightweight, and fully open-source baseline for unifying multimodal understanding and generation. Inspired by prevailing practices in unified model learning, we adopt an efficient training strategy that minimizes the training complexity and overhead by bridging the off-the-shelf multimodal large language models (LLMs) and diffusion models through a set of learnable queries and a light-weight transformer-based connector. With a minimalist choice of architecture, we demonstrate that OpenUni can: 1) generate high-quality and instruction-aligned images, and 2) achieve exceptional performance on standard benchmarks such as GenEval, DPG- Bench, and WISE, with only 1.1B and 3.1B activated parameters. To support open research and community advancement, we release all model weights, training code, and our curated training datasets (including 23M image-text pairs) at https://github.com/wusize/OpenUni.
在这份报告中,我们介绍了OpenUni,这是一个简单、轻量级、完全开源的多模态理解和生成统一基准。受到当前统一模型学习实践的启发,我们采用了一种高效的训练策略,通过一组可学习的查询和一个轻量级的基于变压器的连接器,将现成的多模态大型语言模型(LLMs)和扩散模型连接起来,从而最小化训练复杂性和开销。通过选择最简单的架构,我们证明OpenUni可以:1)生成高质量且符合指令的图像;2)在GenEval、DPG-Bench和WISE等标准基准测试中实现卓越性能,激活的参数只有1.1B和3.1B。为了支持开放研究和社区发展,我们在https://github.com/wusize/OpenUni上发布了所有模型权重、训练代码和我们精选的训练数据集(包括2300万张图像文本对)。
论文及项目相关链接
Summary
本文介绍了OpenUni,一个简单、轻量级、完全开源的多模态理解和生成统一基准。它通过高效的训练策略,采用可学习的查询和轻量级基于变压器的连接器,将现成的多模态大型语言模型和扩散模型连接起来,降低了训练复杂性和开销。OpenUni能够生成高质量、指令对齐的图像,并在GenEval、DPG-Bench和WISE等标准基准测试中实现卓越性能,仅使用1.1B和3.1B激活参数。所有模型权重、训练代码和精选的训练数据集(包括2.3亿图像文本对)已在GitHub上发布。
Key Takeaways
- OpenUni是一个简单、轻量级、完全开源的多模态理解和生成统一模型。
- 它通过桥接现成的多模态大型语言模型和扩散模型,实现了高效训练。
- 采用可学习的查询和轻量级基于变压器的连接器来降低训练复杂性和开销。
- OpenUni可以生成高质量、指令对齐的图像。
- 它在标准基准测试中实现了卓越性能,如GenEval、DPG-Bench和WISE。
- 该模型仅使用1.1B和3.1B激活参数,表现出强大的性能。
点此查看论文截图
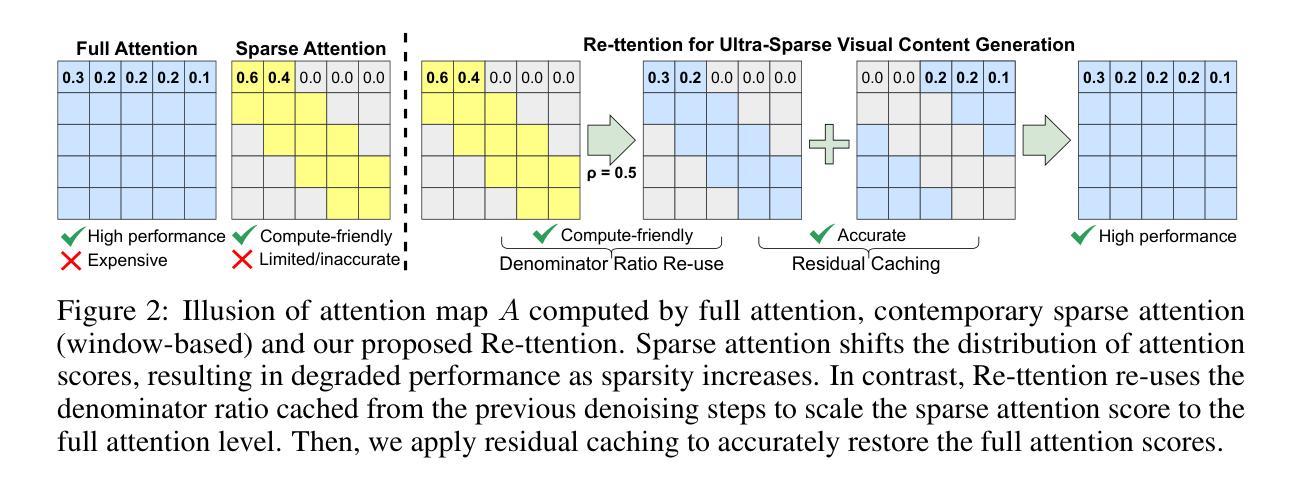
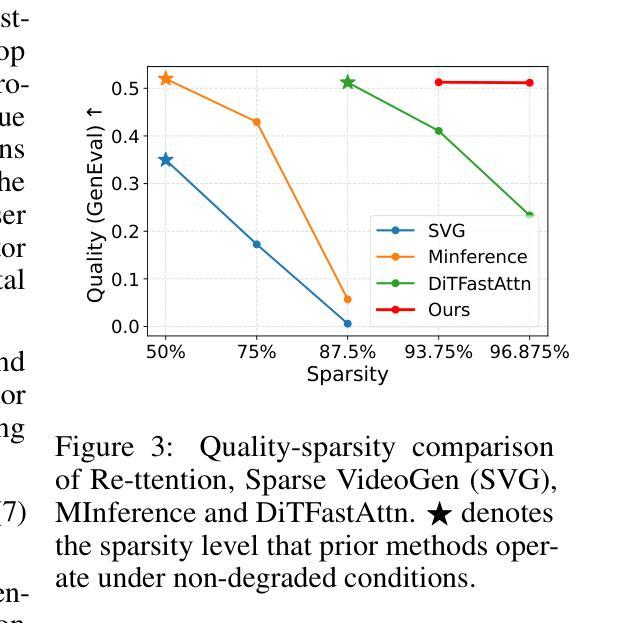
Re-ttention: Ultra Sparse Visual Generation via Attention Statistical Reshape
Authors:Ruichen Chen, Keith G. Mills, Liyao Jiang, Chao Gao, Di Niu
Diffusion Transformers (DiT) have become the de-facto model for generating high-quality visual content like videos and images. A huge bottleneck is the attention mechanism where complexity scales quadratically with resolution and video length. One logical way to lessen this burden is sparse attention, where only a subset of tokens or patches are included in the calculation. However, existing techniques fail to preserve visual quality at extremely high sparsity levels and might even incur non-negligible compute overheads. % To address this concern, we propose Re-ttention, which implements very high sparse attention for visual generation models by leveraging the temporal redundancy of Diffusion Models to overcome the probabilistic normalization shift within the attention mechanism. Specifically, Re-ttention reshapes attention scores based on the prior softmax distribution history in order to preserve the visual quality of the full quadratic attention at very high sparsity levels. % Experimental results on T2V/T2I models such as CogVideoX and the PixArt DiTs demonstrate that Re-ttention requires as few as 3.1% of the tokens during inference, outperforming contemporary methods like FastDiTAttn, Sparse VideoGen and MInference. Further, we measure latency to show that our method can attain over 45% end-to-end % and over 92% self-attention latency reduction on an H100 GPU at negligible overhead cost. Code available online here: \href{https://github.com/cccrrrccc/Re-ttention}{https://github.com/cccrrrccc/Re-ttention}
扩散Transformer(DiT)已成为生成高质量视觉内容(如视频和图像)的默认模型。一个巨大的瓶颈是注意力机制,其中复杂性随分辨率和视频长度的增加而二次方增长。减轻这一负担的一种逻辑方法是稀疏注意力,其中仅将一部分标记或补丁包含在计算中。然而,现有技术在极高的稀疏度水平上无法保持视觉质量,并可能产生不可忽略的计算开销。为了解决这一担忧,我们提出了Re-ttention,它通过利用扩散模型的时空冗余性,实现了针对视觉生成模型的高稀疏注意力机制,克服了注意力机制中的概率归一化转移问题。具体来说,Re-ttention根据先前的softmax分布历史重新调整注意力分数,以在极高的稀疏度水平上保持全二次注意力的视觉质量。在T2V/T2I模型(如CogVideoX和PixArt DiTs)上的实验结果表明,Re-ttention在推理过程中只需要3.1%的标记,超越了FastDiTAttn、Sparse VideoGen和MInference等当代方法。此外,我们通过测量延迟时间证明,该方法可在H100 GPU上实现超过45%的端到端延迟减少和超过92%的自注意力延迟减少,同时几乎不增加额外成本。相关代码已在线发布:https://github.com/cccrrrccc/Re-ttention。
论文及项目相关链接
PDF Submitted before obtaining agreement of all authors
Summary
扩散转换器(DiT)已成为生成高质量视觉内容(如视频和图像)的标准模型。当前面临的主要瓶颈是注意力机制,其复杂性随分辨率和视频长度的增加而呈二次方增长。为减轻这一负担,人们尝试采用稀疏注意力法,仅包含部分令牌或补丁进行计算。然而,现有技术在极高的稀疏水平下无法保持视觉质量,并可能产生不可忽略的计算开销。为解决这一问题,我们提出了Re-ttention,利用扩散模型的时间冗余性,通过克服注意力机制内的概率归一化偏移,为视觉生成模型实现了极高的稀疏注意力。Re-ttention根据先前的softmax分布历史重塑注意力分数,以在极高的稀疏水平上保持全二次注意力的视觉质量。在T2V/T2I模型(如CogVideoX和PixArt DiTs)上的实验结果表明,Re-ttention在推理过程中仅需使用3.1%的令牌,超越了FastDiTAttn、Sparse VideoGen和MInference等当代方法。此外,我们测量了延迟时间,证明该方法可在H100 GPU上实现超过45%的端到端延迟减少和超过92%的自注意力延迟减少,且几乎不增加开销。相关代码已在线发布。
Key Takeaways
- Diffusion Transformers (DiT) 是生成高质量视觉内容的主导模型。
- 当前面临的主要挑战是注意力机制的复杂性,它随分辨率和视频长度的增加而增长。
- 为减轻负担,提出了稀疏注意力方法,但现有技术在高稀疏度下存在视觉质量损失和计算开销问题。
- Re-ttention 利用扩散模型的时间冗余性来解决这个问题,通过重塑注意力分数来在极高稀疏度下保持视觉质量。
- Re-ttention 在T2V/T2I模型上的实验表现优越,显著减少了令牌使用。
- Re-ttention 能显著减少端到端和自注意力的延迟。
点此查看论文截图



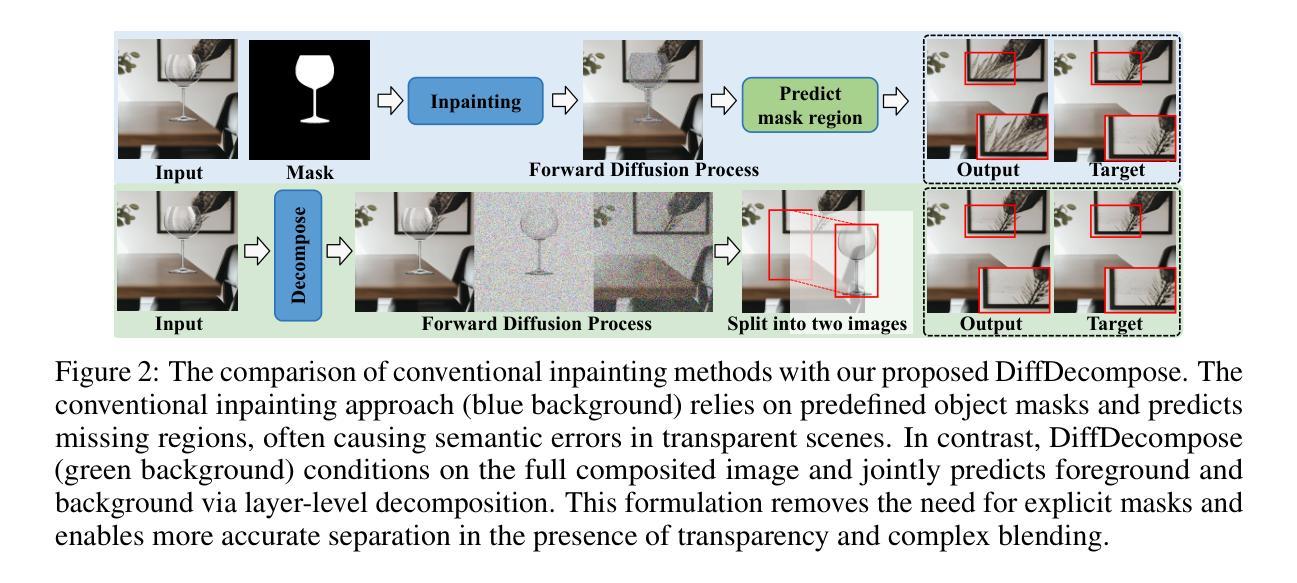
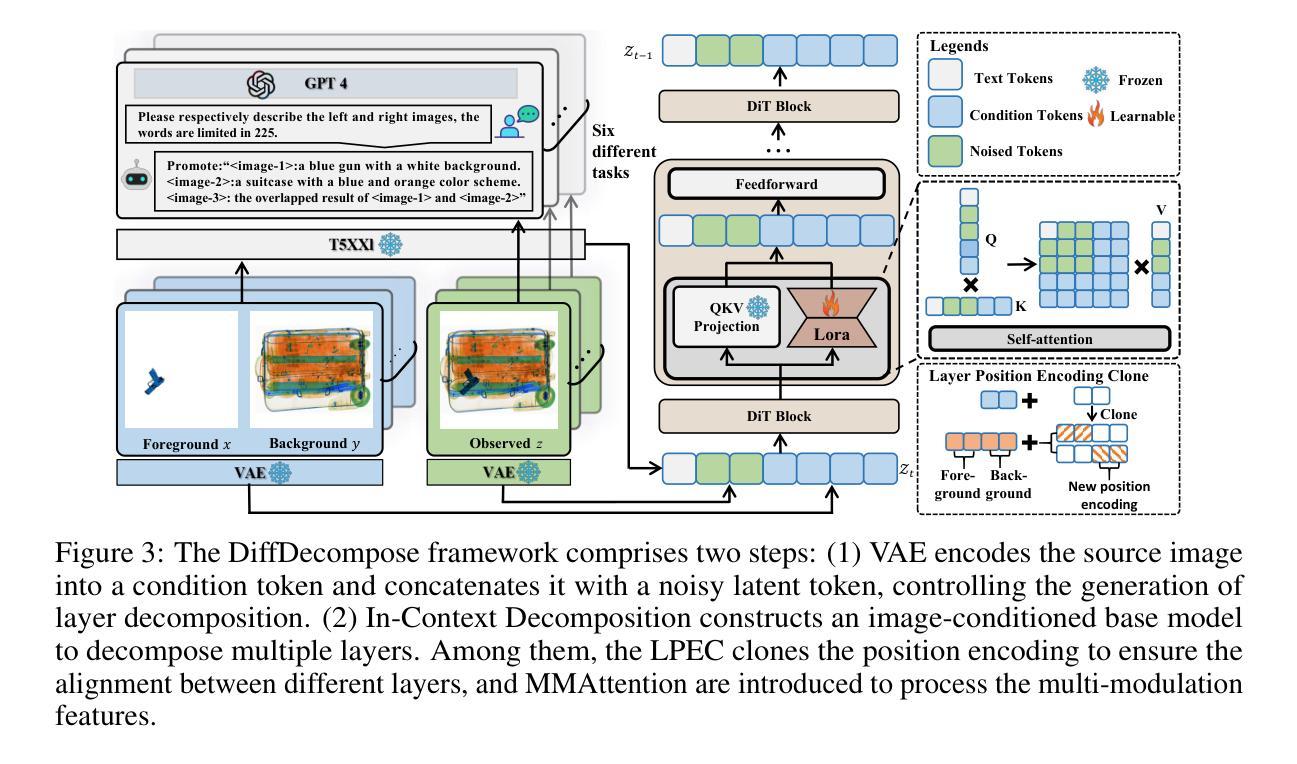
DiffDecompose: Layer-Wise Decomposition of Alpha-Composited Images via Diffusion Transformers
Authors:Zitong Wang, Hang Zhao, Qianyu Zhou, Xuequan Lu, Xiangtai Li, Yiren Song
Diffusion models have recently motivated great success in many generation tasks like object removal. Nevertheless, existing image decomposition methods struggle to disentangle semi-transparent or transparent layer occlusions due to mask prior dependencies, static object assumptions, and the lack of datasets. In this paper, we delve into a novel task: Layer-Wise Decomposition of Alpha-Composited Images, aiming to recover constituent layers from single overlapped images under the condition of semi-transparent/transparent alpha layer non-linear occlusion. To address challenges in layer ambiguity, generalization, and data scarcity, we first introduce AlphaBlend, the first large-scale and high-quality dataset for transparent and semi-transparent layer decomposition, supporting six real-world subtasks (e.g., translucent flare removal, semi-transparent cell decomposition, glassware decomposition). Building on this dataset, we present DiffDecompose, a diffusion Transformer-based framework that learns the posterior over possible layer decompositions conditioned on the input image, semantic prompts, and blending type. Rather than regressing alpha mattes directly, DiffDecompose performs In-Context Decomposition, enabling the model to predict one or multiple layers without per-layer supervision, and introduces Layer Position Encoding Cloning to maintain pixel-level correspondence across layers. Extensive experiments on the proposed AlphaBlend dataset and public LOGO dataset verify the effectiveness of DiffDecompose. The code and dataset will be available upon paper acceptance. Our code will be available at: https://github.com/Wangzt1121/DiffDecompose.
扩散模型在许多生成任务(如对象移除)中取得了巨大成功。然而,现有的图像分解方法在解决半透明或透明层遮挡问题时遇到了困难,这是由于遮罩先验依赖、静态对象假设以及数据集缺乏所导致的。在本文中,我们深入研究了一项新任务:逐层分解Alpha合成图像,旨在从单个重叠图像中恢复构成层,条件为半透明/透明Alpha层的非线性遮挡。为了应对层模糊、泛化能力和数据稀缺等挑战,我们首先引入了AlphaBlend数据集,这是首个用于透明和半透明层分解的大规模高质量数据集,支持六个真实世界子任务(例如,半透明炫光去除、半透明细胞分解、玻璃器皿分解等)。基于该数据集,我们提出了DiffDecompose,这是一个基于扩散Transformer的框架,它学习在输入图像、语义提示和混合类型条件下的可能层分解的后验概率。DiffDecompose不是直接回归alpha遮罩,而是进行上下文分解,使模型能够在无需每层监督的情况下预测一个或多个层,并引入了层位置编码克隆以保持层之间的像素级对应关系。在提出的AlphaBlend数据集和公共LOGO数据集上的广泛实验验证了DiffDecompose的有效性。论文接受后,代码和数据集将可供使用。我们的代码可用链接:https://github.com/Wangzt1| 会增加标点符号割裂语境或者信息分割不明等负面影响,所以在实际翻译过程中一般会尽量保持语句的完整性。下面是经过翻译的文本:
论文及项目相关链接
摘要
本文研究了基于扩散模型的图像分解新技术,特别是针对半透明或透明图层遮挡的分解问题。文章引入了一个新的任务:逐层分解Alpha合成图像,旨在从单一重叠图像中恢复构成图层。为解决图层模糊、通用性及数据稀缺等挑战,文章首先推出了AlphaBlend数据集,支持六个真实世界的子任务。基于该数据集,提出了一种基于扩散Transformer的DiffDecompose框架,学习根据输入图像、语义提示和混合类型进行可能的图层分解的后验分布。DiffDecompose采用上下文分解方式,无需每层监督即可预测一层或多层,并引入层位置编码克隆以维持层间的像素级对应关系。在AlphaBlend和公开LOGO数据集上的实验验证了DiffDecompose的有效性。
关键见解
- 引入了一种新的任务:逐层分解Alpha合成的图像,目标是恢复由半透明或透明图层遮挡构成的图层。
- 针对这一任务,文章提出了AlphaBlend数据集,支持六个真实世界的子任务,为图像分解提供了丰富的数据资源。
- 介绍了基于扩散模型的DiffDecompose框架,该框架可以学习根据输入图像、语义提示和混合类型进行可能的图层分解的后验分布。
- DiffDecompose采用上下文分解方法,能预测一层或多层而无需每层都有直接监督。
- 引入了层位置编码克隆技术,保持各层之间的像素级对应关系。
- 在AlphaBlend和公开LOGO数据集上的实验表明,DiffDecompose技术效果显著。
- 论文接受后,将公开代码和数据集。
点此查看论文截图

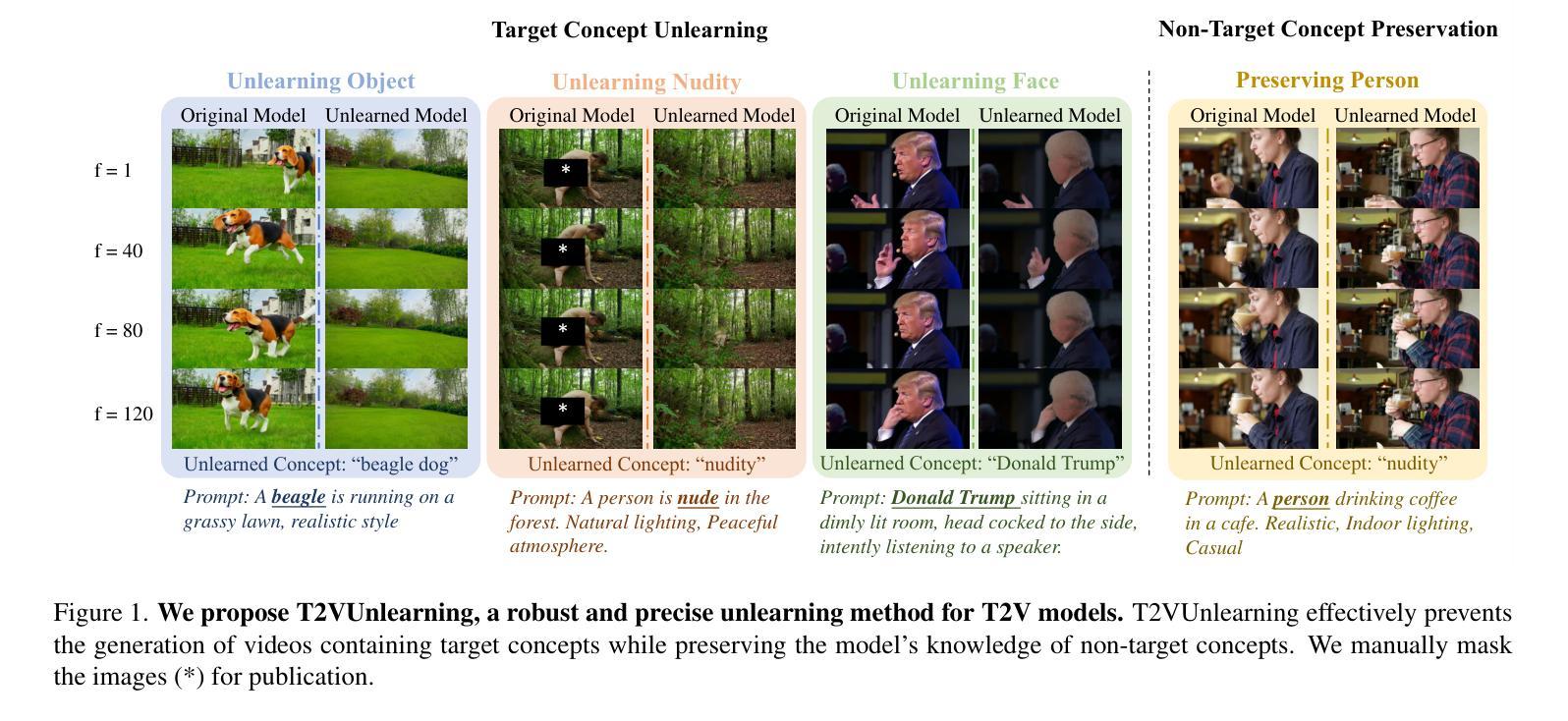
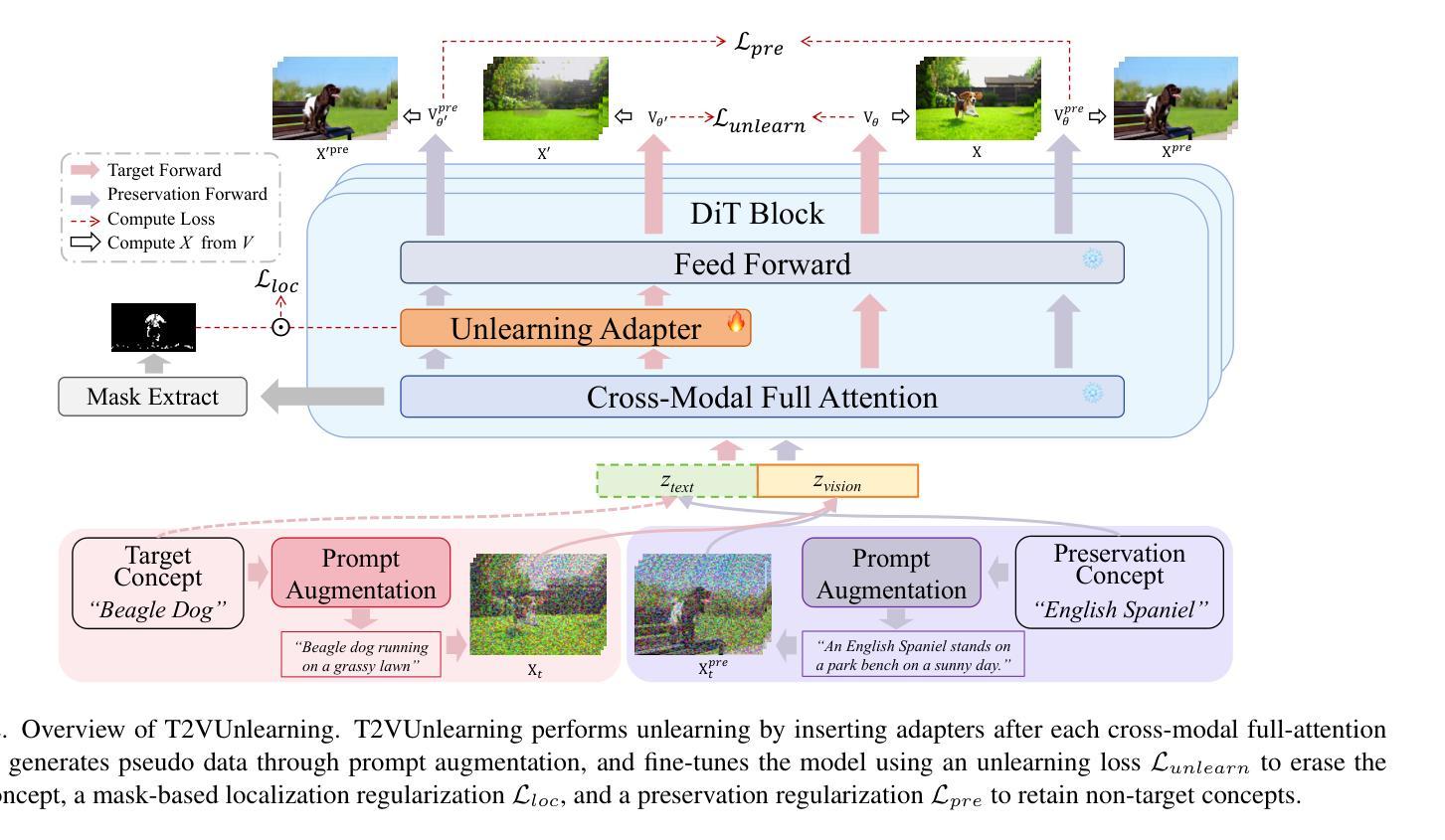
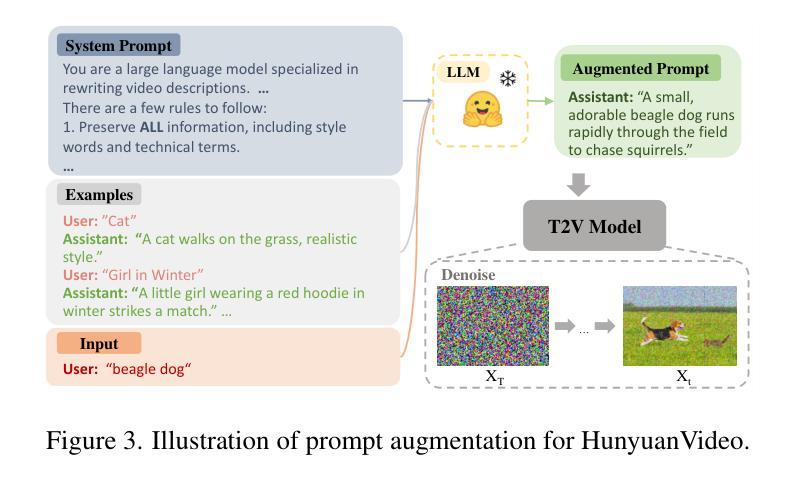
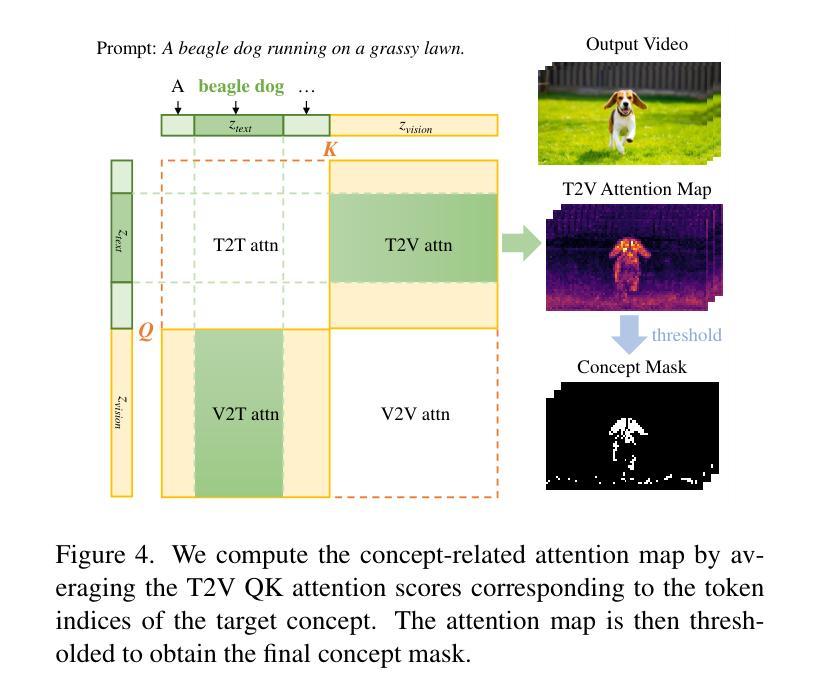
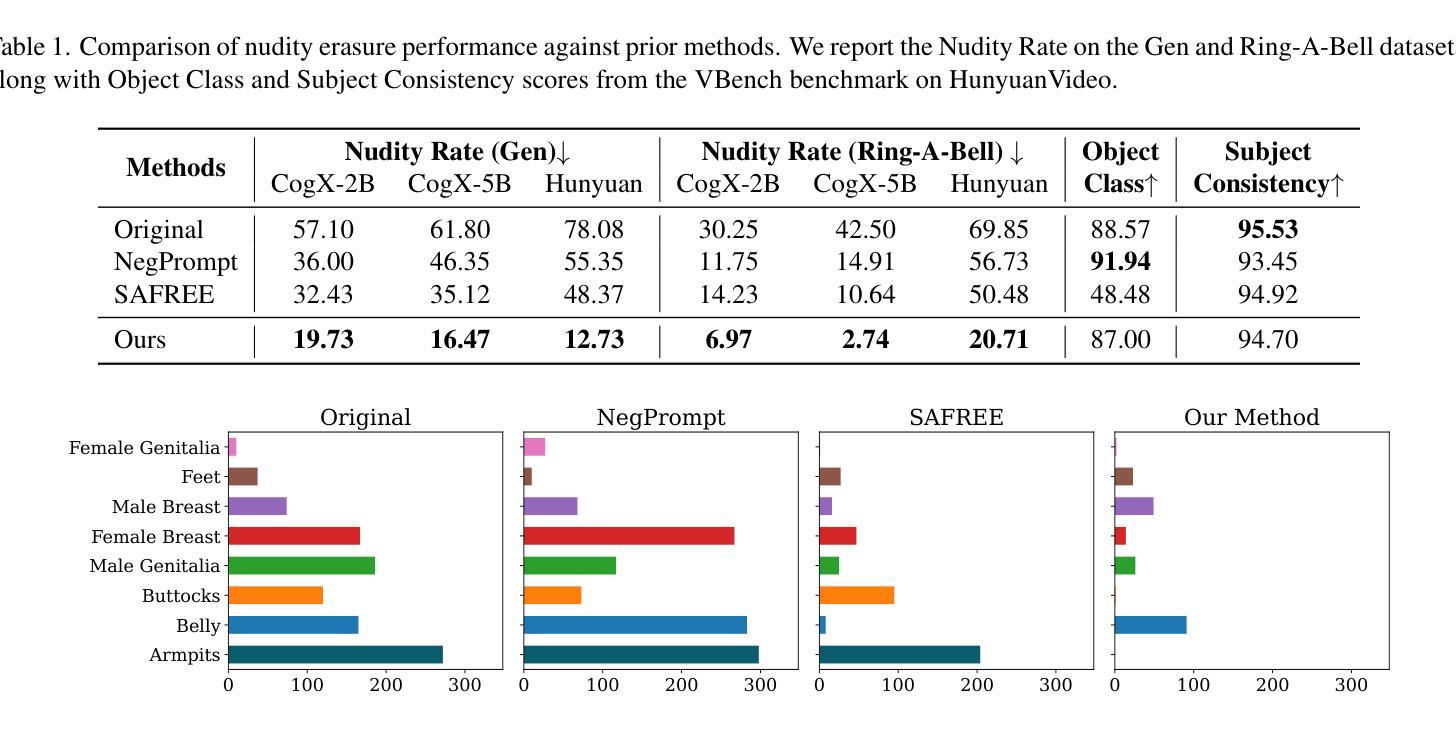
T2VUnlearning: A Concept Erasing Method for Text-to-Video Diffusion Models
Authors:Xiaoyu Ye, Songjie Cheng, Yongtao Wang, Yajiao Xiong, Yishen Li
Recent advances in text-to-video (T2V) diffusion models have significantly enhanced the quality of generated videos. However, their ability to produce explicit or harmful content raises concerns about misuse and potential rights violations. Inspired by the success of unlearning techniques in erasing undesirable concepts from text-to-image (T2I) models, we extend unlearning to T2V models and propose a robust and precise unlearning method. Specifically, we adopt negatively-guided velocity prediction fine-tuning and enhance it with prompt augmentation to ensure robustness against LLM-refined prompts. To achieve precise unlearning, we incorporate a localization and a preservation regularization to preserve the model’s ability to generate non-target concepts. Extensive experiments demonstrate that our method effectively erases a specific concept while preserving the model’s generation capability for all other concepts, outperforming existing methods. We provide the unlearned models in \href{https://github.com/VDIGPKU/T2VUnlearning.git}{https://github.com/VDIGPKU/T2VUnlearning.git}.
近期文本到视频(T2V)扩散模型的进步极大地提高了生成视频的质量。然而,它们产生明确或有害内容的能力引发了关于误用和潜在权利侵犯的担忧。受文本到图像(T2I)模型中消除不良概念的去学习技术成功的启发,我们将去学习扩展到T2V模型,并提出了一种稳健且精确的去学习方法。具体来说,我们采用负导向速度预测微调,并通过提示增强来确保其对大型语言模型优化提示的稳健性。为了实现精确的去学习,我们结合了定位和保存正则化,以保留模型生成非目标概念的能力。大量实验表明,我们的方法在消除特定概念的同时,保留了模型对所有其他概念的生成能力,优于现有方法。我们提供去学习的模型在https://github.com/VDIGPKU/T2VUnlearning.git。
论文及项目相关链接
Summary
文本介绍了近期文本到视频(T2V)扩散模型的进展,这些模型生成视频的质量得到了显著提升。然而,它们产生明确或有害内容的能力引发了关于误用和潜在权利侵犯的担忧。研究团队受到文本到图像(T2I)模型中的去训练技术成功的启发,将去训练技术扩展到T2V模型,并提出了一种稳健且精确的去训练方法。实验证明该方法能有效消除特定概念,同时保留模型对其他概念的生成能力,优于现有方法。相关模型已发布在GitHub上。
Key Takeaways
- 文本到视频(T2V)扩散模型的最新进展显著提高了视频生成的质量。
- T2V模型产生有害内容的能力引发关注。
- 研究人员受到文本到图像(T2I)模型去训练技术成功的启发,将其扩展到T2V模型。
- 提出了一种稳健且精确的去训练方法,通过负向引导速度预测微调并结合提示增强技术,提高模型的稳健性。
- 实现了精确去训练,通过引入定位和保留正则化来保留模型对非目标概念的生成能力。
- 实验证明该方法能有效消除特定概念,同时保持对其他概念的生成能力。
点此查看论文截图

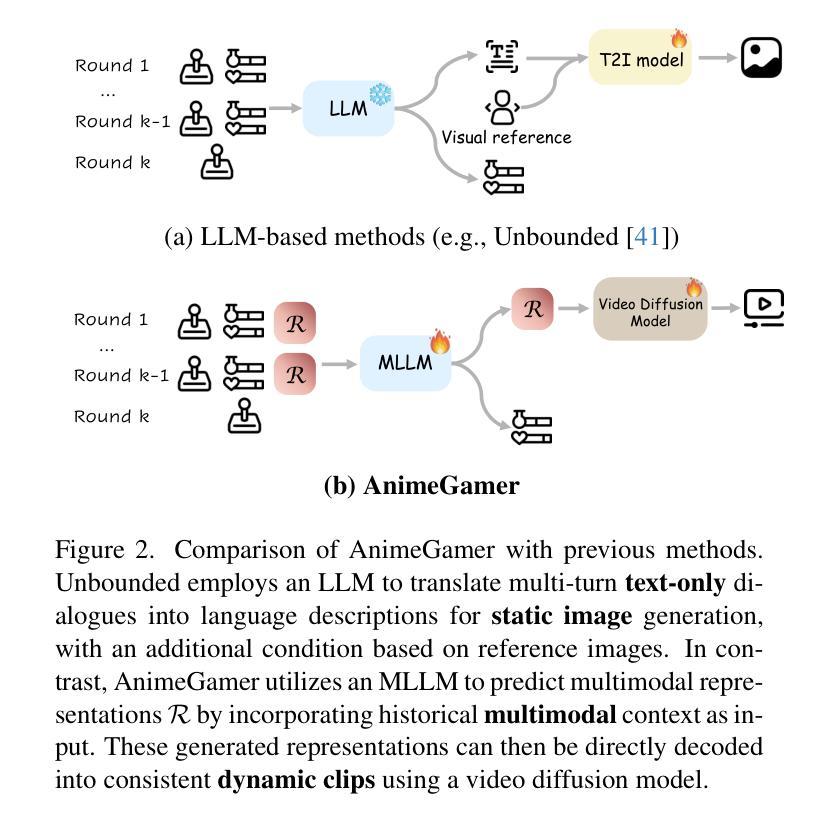
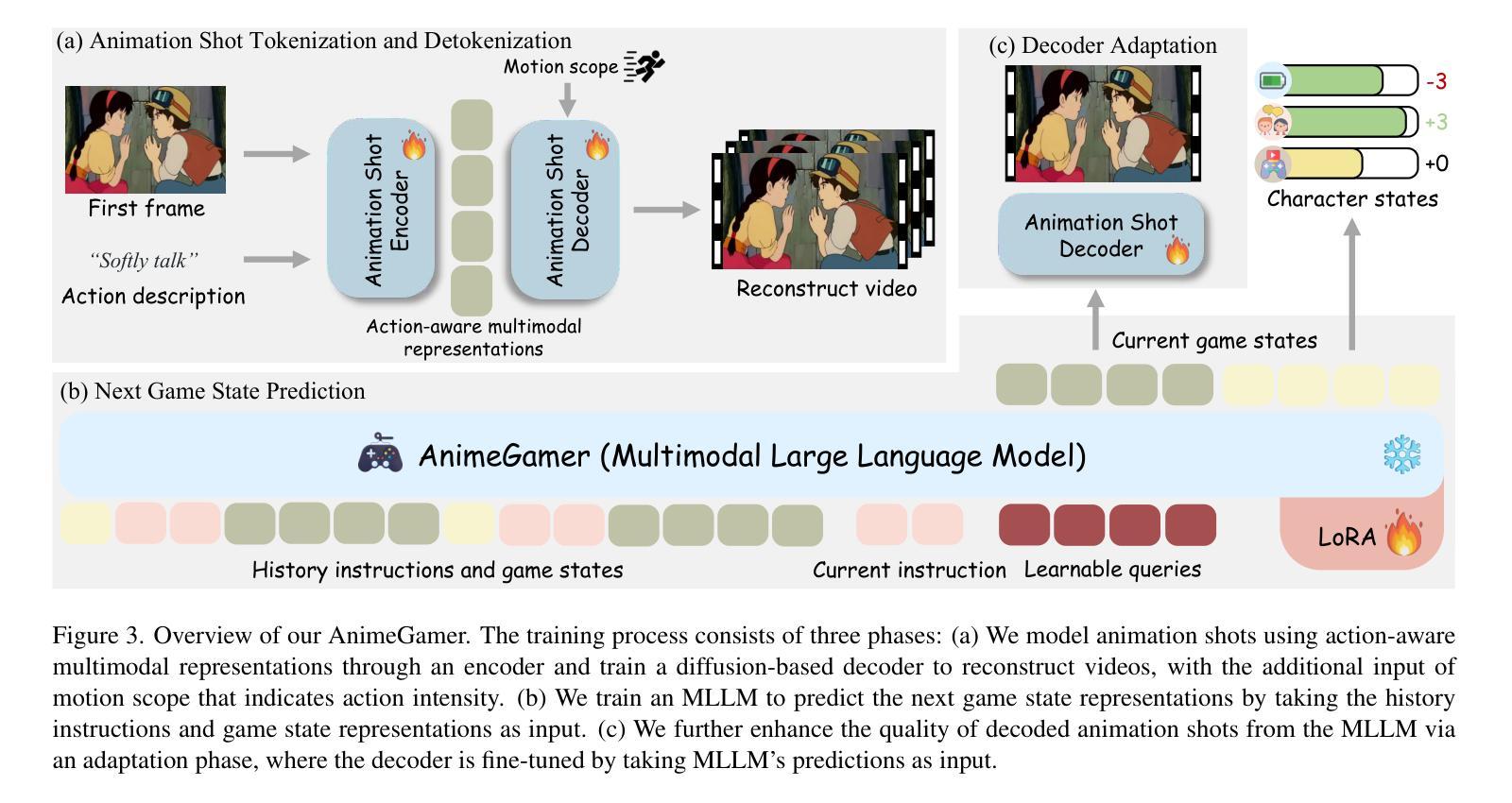
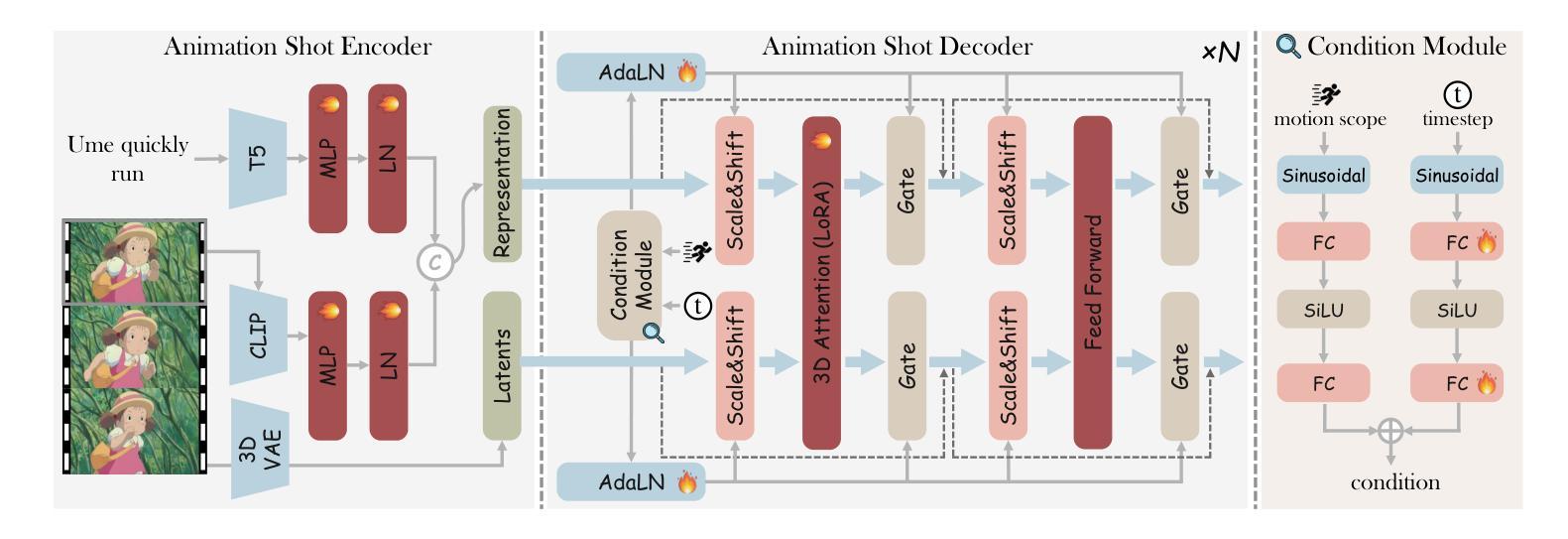
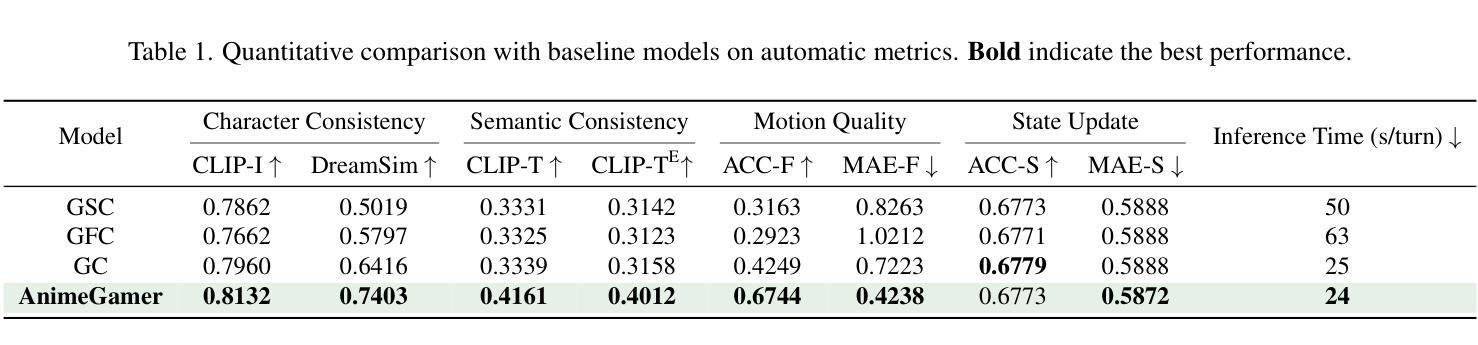
AnimeGamer: Infinite Anime Life Simulation with Next Game State Prediction
Authors:Junhao Cheng, Yuying Ge, Yixiao Ge, Jing Liao, Ying Shan
Recent advancements in image and video synthesis have opened up new promise in generative games. One particularly intriguing application is transforming characters from anime films into interactive, playable entities. This allows players to immerse themselves in the dynamic anime world as their favorite characters for life simulation through language instructions. Such games are defined as infinite game since they eliminate predetermined boundaries and fixed gameplay rules, where players can interact with the game world through open-ended language and experience ever-evolving storylines and environments. Recently, a pioneering approach for infinite anime life simulation employs large language models (LLMs) to translate multi-turn text dialogues into language instructions for image generation. However, it neglects historical visual context, leading to inconsistent gameplay. Furthermore, it only generates static images, failing to incorporate the dynamics necessary for an engaging gaming experience. In this work, we propose AnimeGamer, which is built upon Multimodal Large Language Models (MLLMs) to generate each game state, including dynamic animation shots that depict character movements and updates to character states, as illustrated in Figure 1. We introduce novel action-aware multimodal representations to represent animation shots, which can be decoded into high-quality video clips using a video diffusion model. By taking historical animation shot representations as context and predicting subsequent representations, AnimeGamer can generate games with contextual consistency and satisfactory dynamics. Extensive evaluations using both automated metrics and human evaluations demonstrate that AnimeGamer outperforms existing methods in various aspects of the gaming experience. Codes and checkpoints are available at https://github.com/TencentARC/AnimeGamer.
近期图像和视频合成技术的进展为生成游戏领域带来了新的希望。一个特别吸引人的应用是将动漫电影中的角色转变为可互动的游戏实体。这允许玩家通过语言指令沉浸在动态的动漫世界中,扮演他们最喜欢的角色进行生活模拟。这类游戏被定义为无限游戏,因为它们消除了预定的边界和固定的游戏规则,玩家可以通过开放式的语言与游戏世界互动,并体验不断演变的故事情节和环境。最近,一种开创性的无限动漫生活模拟方法采用大型语言模型(LLMs)将多轮文本对话翻译为图像生成的语言指令。然而,它忽略了历史视觉上下文,导致游戏性不一致。此外,它只能生成静态图像,无法融入动态元素,无法为玩家提供引人入胜的游戏体验。在这项工作中,我们提出了AnimeGamer,它建立在多模态大型语言模型(MLLMs)之上,用于生成每个游戏状态,包括描绘角色动作和状态更新的动态动画镜头,如图1所示。我们引入了新型的动作感知多模态表示来代表动画镜头,可以使用视频扩散模型将其解码为高质量的视频片段。通过获取历史动画镜头表示作为上下文并预测随后的表示,AnimeGamer可以生成具有上下文一致性和满意动态性的游戏。使用自动化指标和人类评估的广泛评估表明,AnimeGamer在游戏体验的各个方面都优于现有方法。相关代码和检查点已发布在https://github.com/TencentARC/AnimeGamer。
论文及项目相关链接
PDF Project released at: https://howe125.github.io/AnimeGamer.github.io/
Summary
本文介绍了最新图像和视频合成技术在游戏领域的应用,特别是在动漫角色转化为可互动实体方面的创新。玩家可通过语言指令沉浸于无限动漫世界的动态角色模拟中。文章指出了一种将多轮文本对话转化为图像生成语言指令的大型语言模型方法,但忽视了历史视觉背景,导致游戏体验不一致。本研究提出基于多模态大型语言模型的AnimeGamer,能生成游戏状态,包括动态动画镜头和角色状态更新。引入新型动作感知多模态表示来展示动画镜头,并使用视频扩散模型解码成高质量视频片段。通过考虑历史动画镜头并预测后续表示,AnimeGamer能生成具有上下文一致性和满意动态性的游戏。
Key Takeaways
- 动漫角色转化为可互动实体技术为游戏领域带来新的机遇。
- 玩家可通过语言指令沉浸于动态动漫世界中的角色模拟中。
- 现有大型语言模型方法忽视了历史视觉背景,导致游戏体验不一致。
- AnimeGamer基于多模态大型语言模型,可生成游戏状态及动态动画镜头。
- 引入动作感知多模态表示来展示动画镜头,提高游戏质量。
- AnimeGamer通过考虑历史动画镜头预测后续内容,实现上下文一致性和动态性的游戏体验。
点此查看论文截图


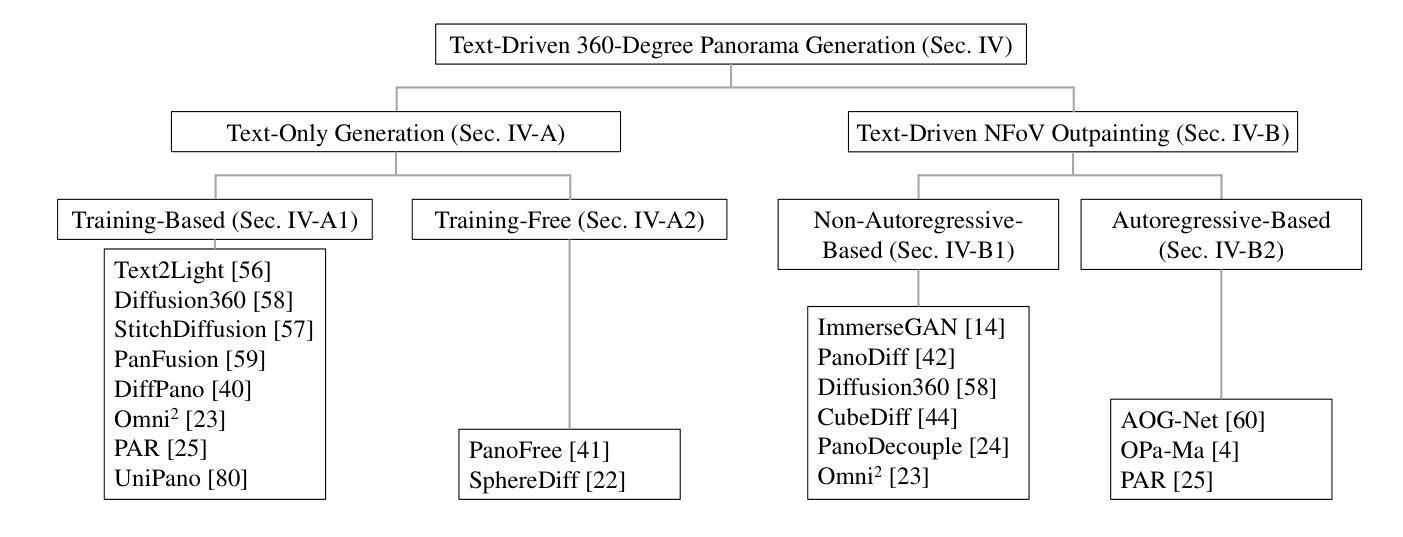
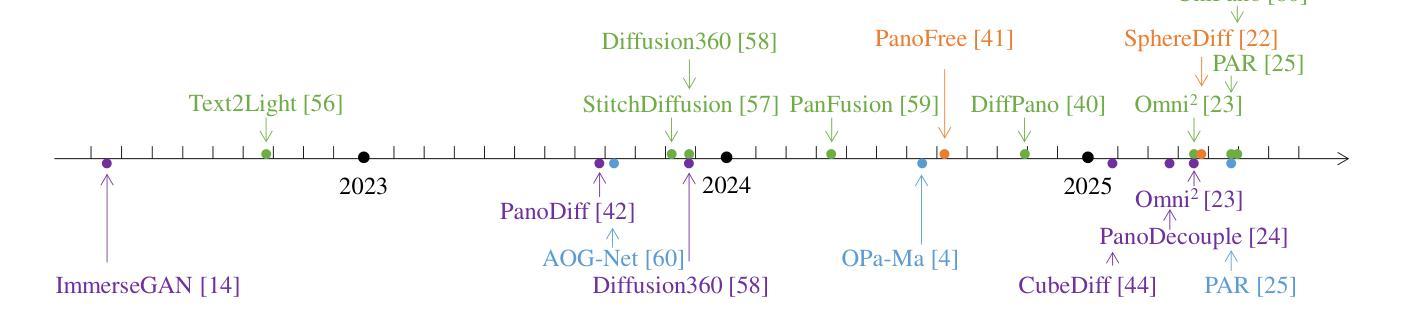
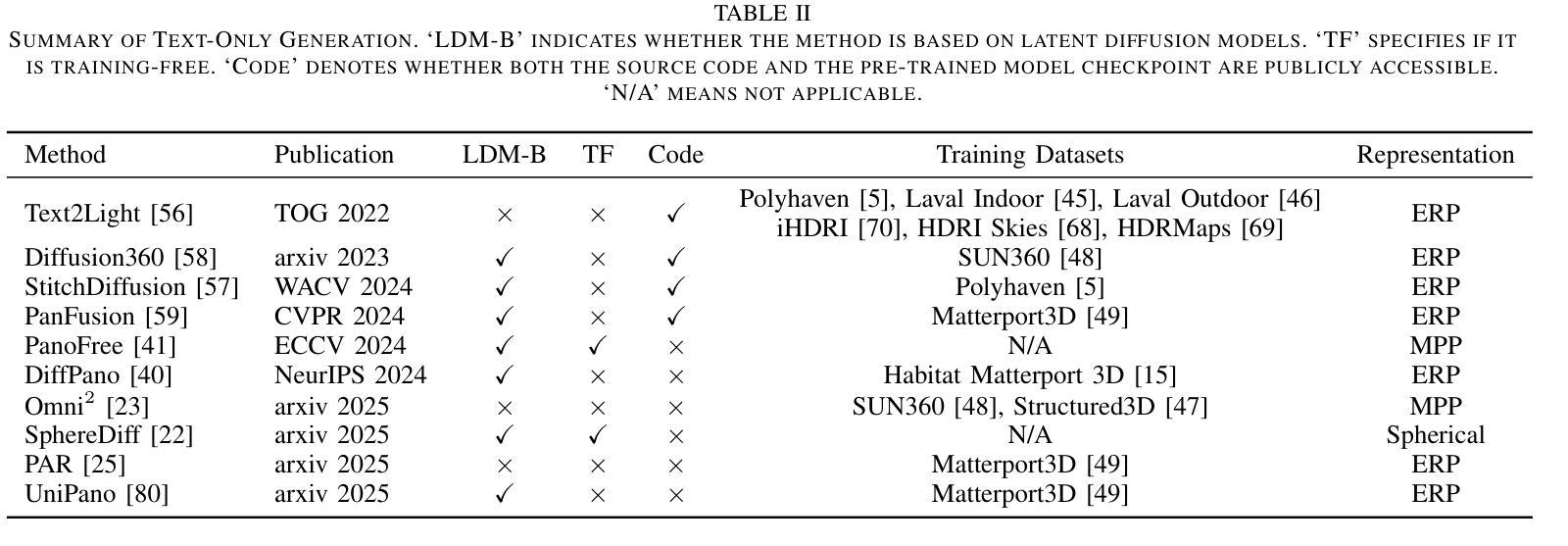
A Survey on Text-Driven 360-Degree Panorama Generation
Authors:Hai Wang, Xiaoyu Xiang, Weihao Xia, Jing-Hao Xue
The advent of text-driven 360-degree panorama generation, enabling the synthesis of 360-degree panoramic images directly from textual descriptions, marks a transformative advancement in immersive visual content creation. This innovation significantly simplifies the traditionally complex process of producing such content. Recent progress in text-to-image diffusion models has accelerated the rapid development in this emerging field. This survey presents a comprehensive review of text-driven 360-degree panorama generation, offering an in-depth analysis of state-of-the-art algorithms and their expanding applications in 360-degree 3D scene generation. Furthermore, we critically examine current limitations and propose promising directions for future research. A curated project page with relevant resources and research papers is available at https://littlewhitesea.github.io/Text-Driven-Pano-Gen/.
文本驱动的全景生成技术出现,使得可以直接从文本描述中合成全视角全景图像,这标志着沉浸式视觉内容创作领域发生了革命性的进步。这一创新极大地简化了传统制作此类内容的复杂过程。文本到图像的扩散模型的最新进展加速了这一新兴领域的快速发展。这篇综述对文本驱动的全视角全景生成技术进行了全面回顾,深入分析了最先进算法及其在生成全视角全景的技术中的应用。此外,我们还对当前的局限性进行了批判性审视,并提出了未来研究的希望方向。相关资源和研究论文精选的项目页面可通过https://littlewhitesea.github.io/Text-Driven-Pano-Gen/访问。
论文及项目相关链接
Summary
文本驱动的360度全景生成技术为从文本描述直接合成360度全景图像提供了可能,这标志着沉浸式视觉内容创作领域的一次变革性进展。该技术的出现简化了传统复杂的内容制作过程。文本到图像扩散模型的最新进展加速了这一新兴领域的迅速发展。本文全面回顾了文本驱动的360度全景生成技术,深入分析了最新算法及其在360度三维场景生成中的应用,同时批判性地探讨了当前局限性和未来研究方向。相关资源和研究论文可在[https://littlewhitesea.github.io/Text-Driven-Pano-Gen/]查阅。
Key Takeaways
- 文本驱动的360度全景生成技术实现了从文本到图像的合成,简化了传统的内容制作过程。
- 最新文本到图像扩散模型的进展加速了该领域的快速发展。
- 该技术为沉浸式视觉内容创作带来了变革。
- 文中深入分析了当前最新的算法及其在360度三维场景生成中的应用。
- 当前技术还存在一定的局限性,需要进一步的研究和改进。
- 文中提供了关于该领域的资源和研究论文的链接。
点此查看论文截图



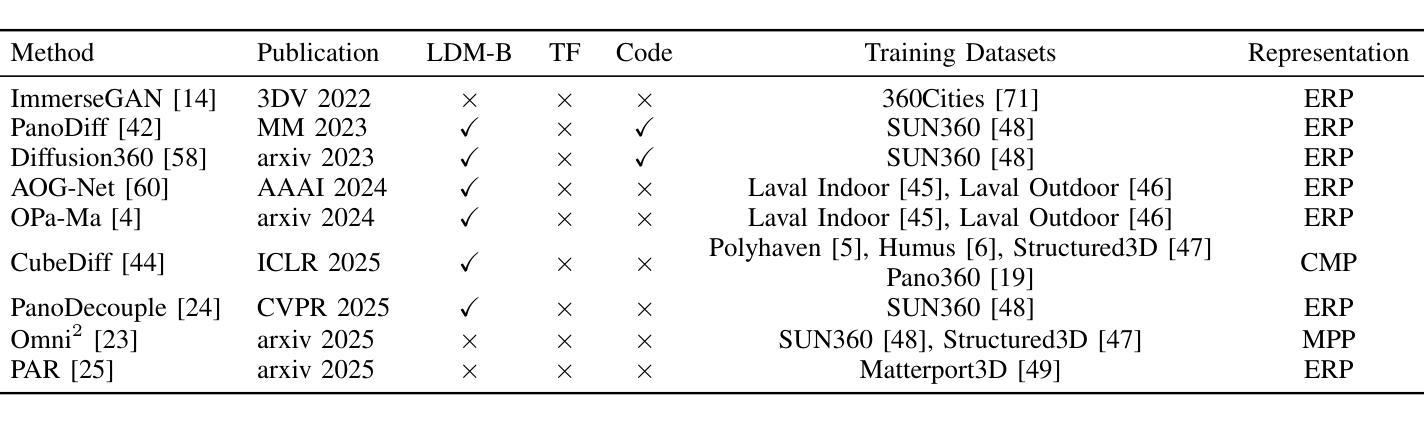
Masked Autoencoders Are Effective Tokenizers for Diffusion Models
Authors:Hao Chen, Yujin Han, Fangyi Chen, Xiang Li, Yidong Wang, Jindong Wang, Ze Wang, Zicheng Liu, Difan Zou, Bhiksha Raj
Recent advances in latent diffusion models have demonstrated their effectiveness for high-resolution image synthesis. However, the properties of the latent space from tokenizer for better learning and generation of diffusion models remain under-explored. Theoretically and empirically, we find that improved generation quality is closely tied to the latent distributions with better structure, such as the ones with fewer Gaussian Mixture modes and more discriminative features. Motivated by these insights, we propose MAETok, an autoencoder (AE) leveraging mask modeling to learn semantically rich latent space while maintaining reconstruction fidelity. Extensive experiments validate our analysis, demonstrating that the variational form of autoencoders is not necessary, and a discriminative latent space from AE alone enables state-of-the-art performance on ImageNet generation using only 128 tokens. MAETok achieves significant practical improvements, enabling a gFID of 1.69 with 76x faster training and 31x higher inference throughput for 512x512 generation. Our findings show that the structure of the latent space, rather than variational constraints, is crucial for effective diffusion models. Code and trained models are released.
最新的潜在扩散模型进展已经证明其在高分辨率图像合成中的有效性。然而,关于如何通过tokenizers学习和生成扩散模型的潜在空间特性仍待探索。我们从理论和实证上发现,更好的生成质量与具有更好结构的潜在分布密切相关,例如具有更少的高斯混合模式并且具有更多判别特征的分布。基于这些见解,我们提出了MAETok,这是一种利用掩模建模的自编码器(AE),能够在保持重建保真度的同时学习语义丰富的潜在空间。大量实验验证了我们分析的有效性,证明了变分自编码器形式并非必需,仅使用AE的判别性潜在空间即可在ImageNet生成任务上实现卓越性能,仅使用128个token。MAETok实现了重要的实际改进,实现了1.69的gFID,同时训练速度提高了76倍,推理速度提高了31倍,可用于生成512x512的图像。我们的研究表明,潜在空间的结构对于有效的扩散模型至关重要,而非变分约束。代码和训练模型均已发布。
论文及项目相关链接
Summary
近期潜扩散模型的进步已证明其在高分辨率图像合成中的有效性。然而,关于令牌器潜在空间特性对于潜扩散模型的学习和生成的影响尚未被充分探索。本文发现优质生成与具有更好结构和更少高斯混合模式的潜在分布密切相关。基于此,我们提出了MAETok,一种利用掩模建模的自编码器(AE),旨在学习语义丰富的潜在空间并保持重建保真度。实验验证了我们分析的有效性,证明了变分自编码器形式并非必需,仅使用AE的判别性潜在空间即可在ImageNet生成上实现卓越性能。MAETok取得了显著的实践改进,实现了更高的生成图像质量和更快的训练和推理速度。
Key Takeaways
- 潜扩散模型在图像合成中展现有效性。
- 潜在空间的结构和性质对潜扩散模型的学习和生成至关重要。
- 高质量生成的潜在分布具有更少的高斯混合模式和更具区分性的特征。
- MAETok利用掩模建模的自编码器(AE)学习语义丰富的潜在空间。
- 实验表明变分自编码器形式并非必需,仅使用AE即可实现卓越性能。
- MAETok在ImageNet生成上实现了显著的性能提升,包括生成图像质量、训练速度和推理速度。
点此查看论文截图


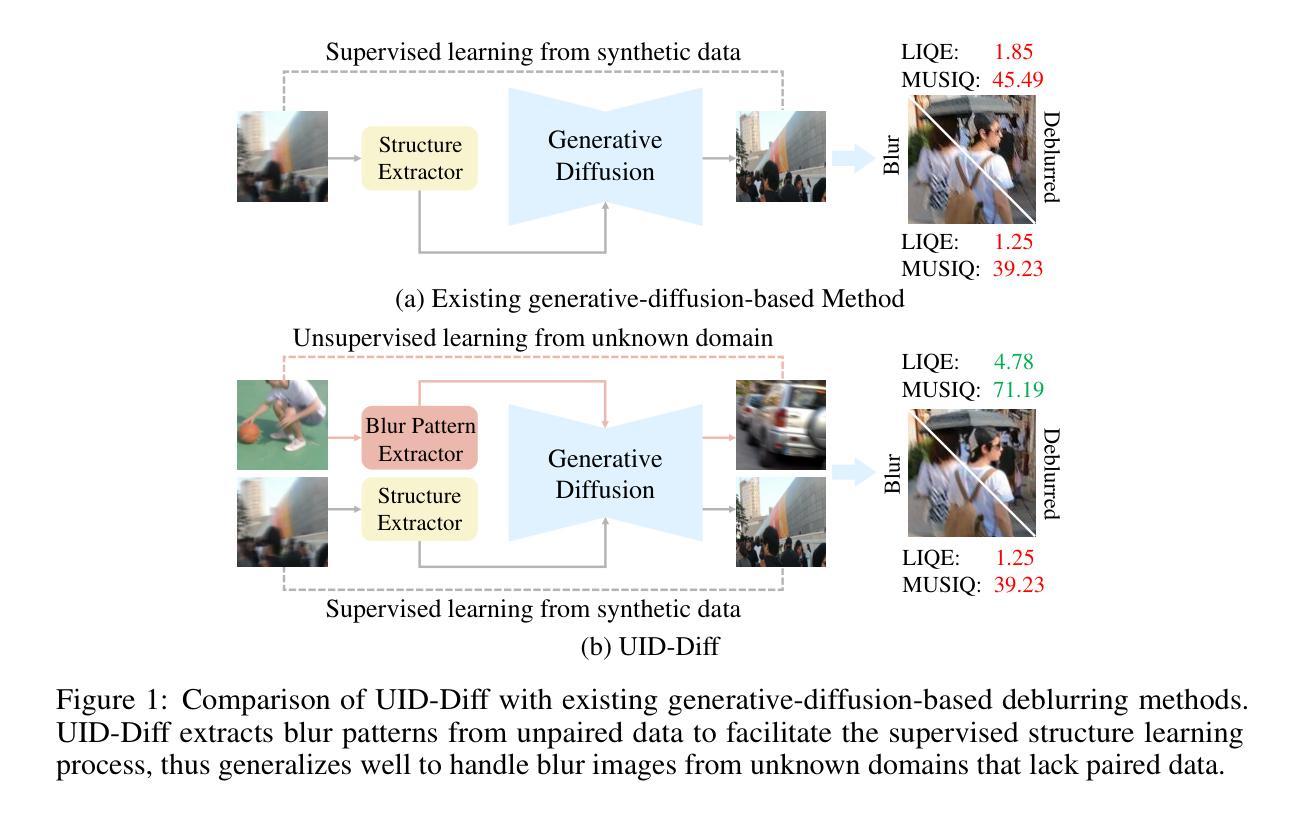
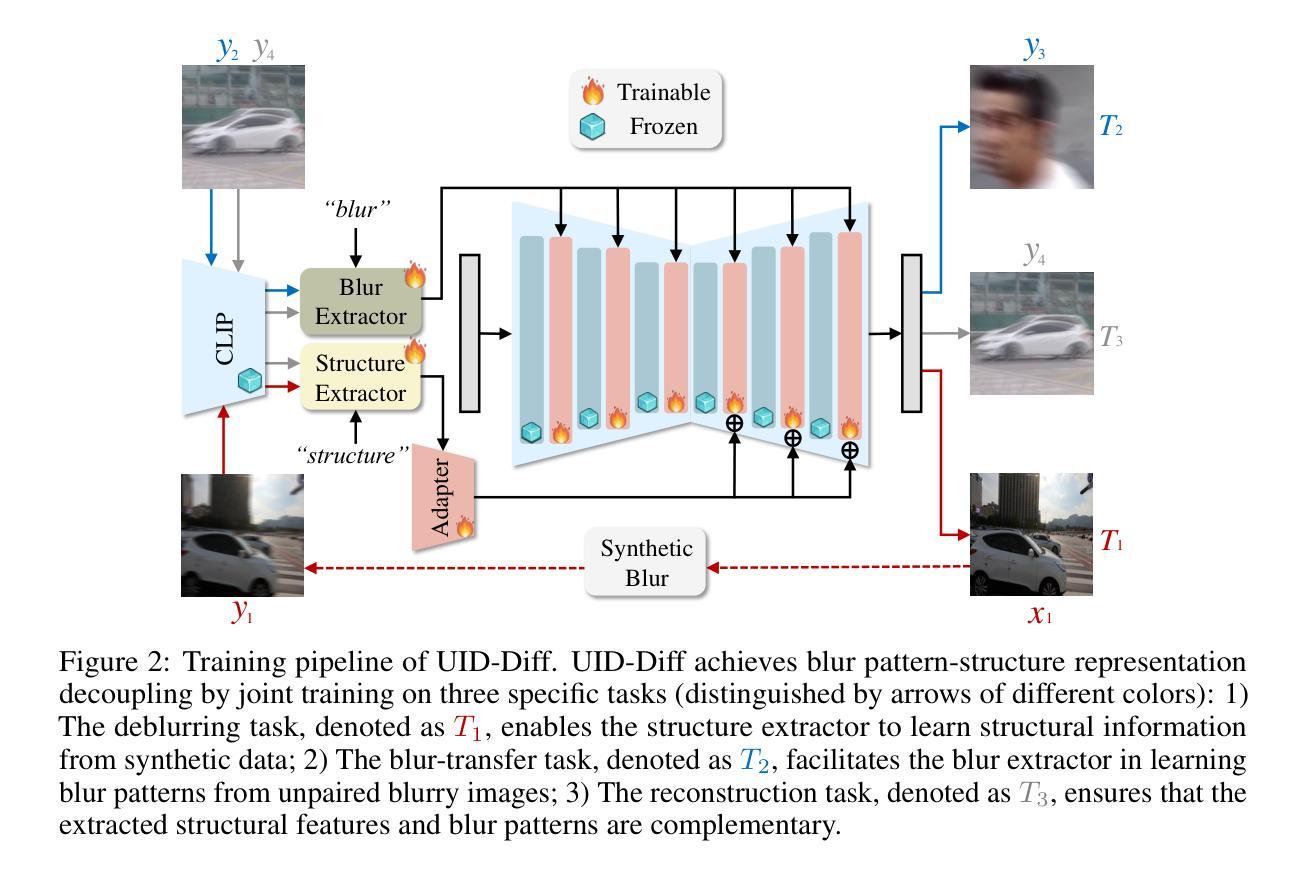
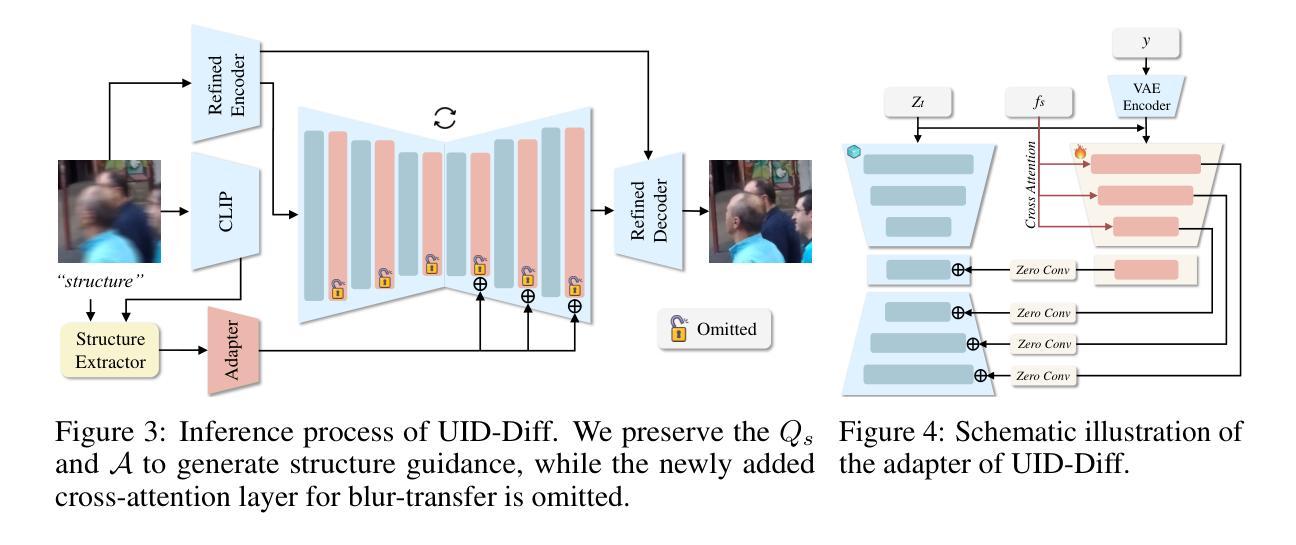
Unpaired Deblurring via Decoupled Diffusion Model
Authors:Junhao Cheng, Wei-Ting Chen, Xi Lu, Ming-Hsuan Yang
Generative diffusion models trained on large-scale datasets have achieved remarkable progress in image synthesis. In favor of their ability to supplement missing details and generate aesthetically pleasing contents, recent works have applied them to image deblurring via training an adapter on blurry-sharp image pairs to provide structural conditions for restoration. However, acquiring substantial amounts of realistic paired data is challenging and costly in real-world scenarios. On the other hand, relying solely on synthetic data often results in overfitting, leading to unsatisfactory performance when confronted with unseen blur patterns. To tackle this issue, we propose UID-Diff, a generative-diffusion-based model designed to enhance deblurring performance on unknown domains by decoupling structural features and blur patterns through joint training on three specially designed tasks. We employ two Q-Formers as structural features and blur patterns extractors separately. The features extracted by them will be used for the supervised deblurring task on synthetic data and the unsupervised blur-transfer task by leveraging unpaired blurred images from the target domain simultaneously. We further introduce a reconstruction task to make the structural features and blur patterns complementary. This blur-decoupled learning process enhances the generalization capabilities of UID-Diff when encountering unknown blur patterns. Experiments on real-world datasets demonstrate that UID-Diff outperforms existing state-of-the-art methods in blur removal and structural preservation in various challenging scenarios.
基于大规模数据集的生成性扩散模型在图像合成方面取得了显著的进展。由于其能够补充缺失的细节并生成美观的内容,最近的研究将其应用于图像去模糊,通过模糊-清晰图像对训练适配器,为恢复提供结构条件。然而,在现实场景中获取大量真实的配对数据具有挑战性和成本高昂。另一方面,仅依赖合成数据往往会导致过拟合,当面对未知的模糊模式时,性能往往不尽人意。为了解决这一问题,我们提出了UID-Diff,这是一个基于生成扩散的模型,旨在通过联合训练三个专门设计的任务来提高未知领域的去模糊性能。我们采用两个Q-Formers分别作为结构特征和模糊模式提取器。它们提取的特征将用于合成数据上的监督去模糊任务,并同时利用来自目标域的无配对模糊图像进行无监督模糊转移任务。我们进一步引入重建任务使结构特征和模糊模式互补。这种模糊解耦学习过程提高了UID-Diff在遇到未知模糊模式时的泛化能力。在真实世界数据集上的实验表明,UID-Diff在各种具有挑战性的场景中,模糊去除和结构保留方面的性能超过了现有的最先进方法。
论文及项目相关链接
PDF We propose UID-Diff to integrate generative diffusion model into unpaired deblurring tasks
Summary
基于生成式扩散模型的图像去模糊技术通过联合训练三项任务以提升未知领域的去模糊性能。通过两个Q-Formers分别提取结构特征和模糊模式,并用于合成数据的监督去模糊任务和基于未配对模糊图像的无监督模糊转移任务。同时引入重建任务使结构特征和模糊模式互补。在真实数据集上的实验表明,UID-Diff在多种挑战场景中表现优于现有最先进的方法。
Key Takeaways
- 生成式扩散模型在图像合成领域取得了显著进展,尤其在图像去模糊方面展现出潜力。
- 提出UID-Diff模型,通过联合训练三项任务提升未知领域的去模糊性能。
- 使用两个Q-Formers分别提取结构特征和模糊模式。
- 结构特征和模糊模式用于合成数据的监督去模糊任务和基于未配对模糊图像的无监督模糊转移任务。
- 引入重建任务以优化结构特征和模糊模式的互补性。
- UID-Diff模型在真实数据集上的实验表现优于现有最先进的方法。
点此查看论文截图

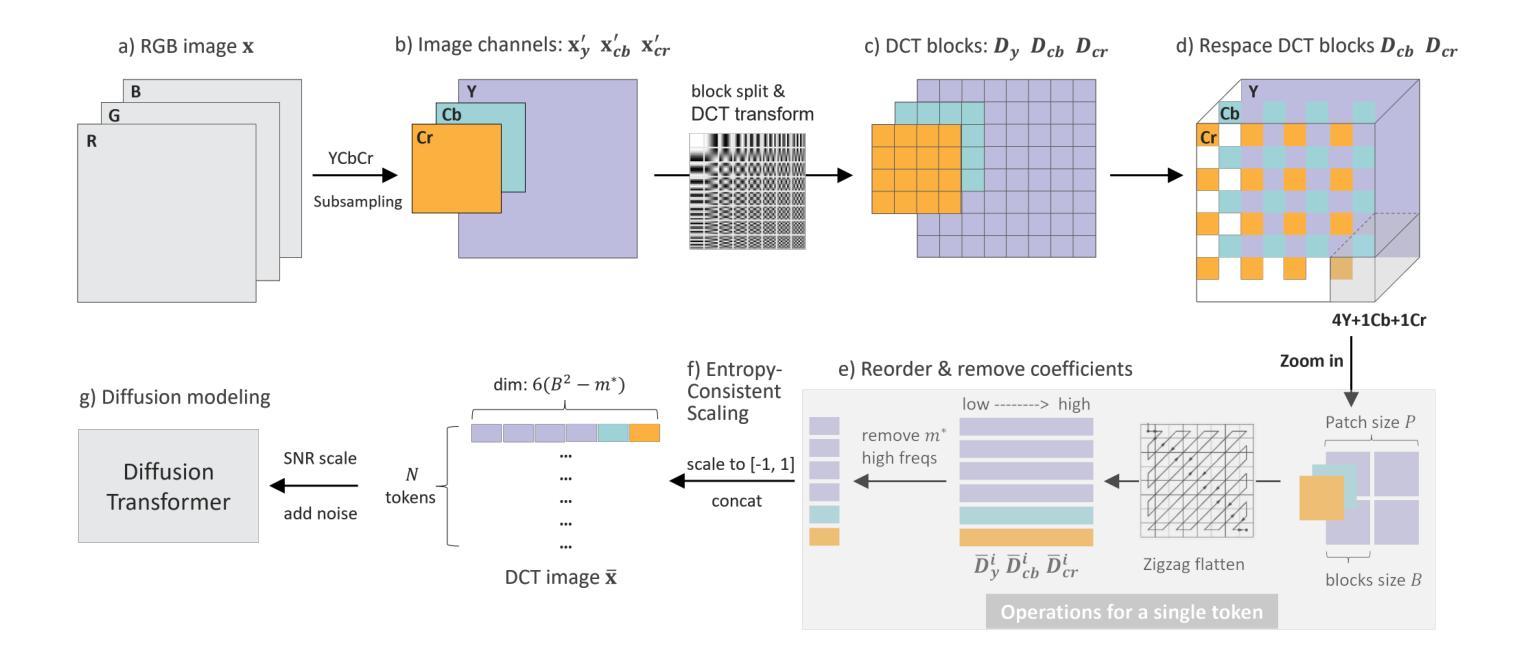
DCTdiff: Intriguing Properties of Image Generative Modeling in the DCT Space
Authors:Mang Ning, Mingxiao Li, Jianlin Su, Haozhe Jia, Lanmiao Liu, Martin Beneš, Wenshuo Chen, Albert Ali Salah, Itir Onal Ertugrul
This paper explores image modeling from the frequency space and introduces DCTdiff, an end-to-end diffusion generative paradigm that efficiently models images in the discrete cosine transform (DCT) space. We investigate the design space of DCTdiff and reveal the key design factors. Experiments on different frameworks (UViT, DiT), generation tasks, and various diffusion samplers demonstrate that DCTdiff outperforms pixel-based diffusion models regarding generative quality and training efficiency. Remarkably, DCTdiff can seamlessly scale up to 512$\times$512 resolution without using the latent diffusion paradigm and beats latent diffusion (using SD-VAE) with only 1/4 training cost. Finally, we illustrate several intriguing properties of DCT image modeling. For example, we provide a theoretical proof of why ‘image diffusion can be seen as spectral autoregression’, bridging the gap between diffusion and autoregressive models. The effectiveness of DCTdiff and the introduced properties suggest a promising direction for image modeling in the frequency space. The code is https://github.com/forever208/DCTdiff.
本文探讨了频率空间的图像建模,并介绍了DCTdiff这一端到端的扩散生成范式,该范式在离散余弦变换(DCT)空间中对图像进行有效建模。我们研究了DCTdiff的设计空间,揭示了关键的设计因素。在不同框架(UViT、DiT)、生成任务和多种扩散采样器上的实验表明,DCTdiff在生成质量和训练效率方面优于基于像素的扩散模型。值得注意的是,DCTdiff可以无缝扩展到512×512分辨率,而无需使用潜在扩散范式,并且仅以四分之一的训练成本击败了潜在扩散(使用SD-VAE)。最后,我们说明了DCT图像建模的几个有趣特性。例如,我们提供了为什么“图像扩散可以被视为谱自回归”的理论证明,从而缩小了扩散模型和自回归模型之间的差距。DCTdiff的有效性和所引入的特性为频率空间的图像建模提供了有前景的方向。代码地址为:https://github.com/forever208/DCTdiff。
论文及项目相关链接
PDF ICML 2025
Summary
本文介绍了DCTdiff,这是一种在离散余弦变换(DCT)空间中进行图像建模的端到端扩散生成范式。它探讨了DCTdiff的设计空间,揭示了关键设计因素。实验表明,DCTdiff在生成质量和训练效率方面优于基于像素的扩散模型,并能无缝扩展到512x512分辨率。还提供了一种将图像扩散视为谱自回归的理论证明。
Key Takeaways
- DCTdiff是一种在离散余弦变换(DCT)空间进行图像建模的扩散生成方法。
- DCTdiff在生成质量和训练效率方面优于像素基础上的扩散模型。
- DCTdiff可无缝扩展至高分辨率,如512x512,无需使用潜在扩散方法。
- DCTdiff相对于潜在扩散(使用SD-VAE)具有更低的训练成本。
- DCT图像建模具有一些有趣特性,如图像扩散可视为谱自回归的理论证明。
- 该论文探讨了DCTdiff的设计空间,并揭示了其关键设计因素。
点此查看论文截图

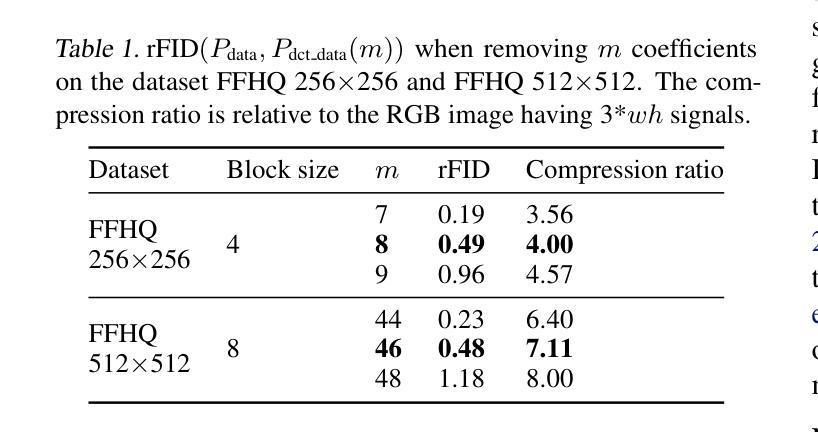
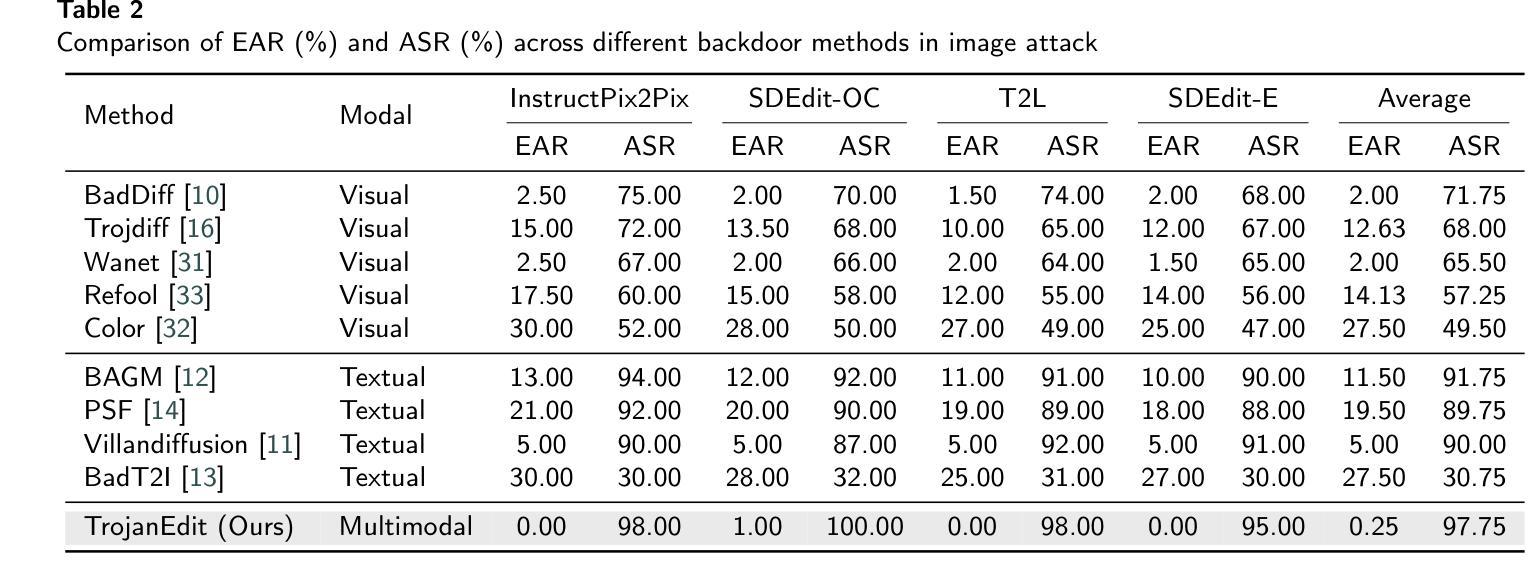
TrojanEdit: Multimodal Backdoor Attack Against Image Editing Model
Authors:Ji Guo, Peihong Chen, Wenbo Jiang, Xiaolei Wen, Jiaming He, Jiachen Li, Guoming Lu, Aiguo Chen, Hongwei Li
Multimodal diffusion models for image editing generate outputs conditioned on both textual instructions and visual inputs, aiming to modify target regions while preserving the rest of the image. Although diffusion models have been shown to be vulnerable to backdoor attacks, existing efforts mainly focus on unimodal generative models and fail to address the unique challenges in multimodal image editing. In this paper, we present the first study of backdoor attacks on multimodal diffusion-based image editing models. We investigate the use of both textual and visual triggers to embed a backdoor that achieves high attack success rates while maintaining the model’s normal functionality. However, we identify a critical modality bias. Simply combining triggers from different modalities leads the model to primarily rely on the stronger one, often the visual modality, which results in a loss of multimodal behavior and degrades editing quality. To overcome this issue, we propose TrojanEdit, a backdoor injection framework that dynamically adjusts the gradient contributions of each modality during training. This allows the model to learn a truly multimodal backdoor that activates only when both triggers are present. Extensive experiments on multiple image editing models show that TrojanEdit successfully integrates triggers from different modalities, achieving balanced multimodal backdoor learning while preserving clean editing performance and ensuring high attack effectiveness.
基于图像编辑的多模态扩散模型根据文本指令和视觉输入生成输出,旨在修改目标区域的同时保留图像的其余部分。尽管扩散模型已显示出容易受到后门攻击的影响,但现有研究主要集中在单模态生成模型上,未能解决多模态图像编辑中的独特挑战。在本文中,我们对基于多模态扩散的图像编辑模型上的后门攻击进行了首次研究。我们研究了使用文本和视觉触发因素来嵌入后门的方法,以实现高攻击成功率的同时保持模型的正常功能。然而,我们发现了一种关键的模态偏见。简单地结合不同模态的触发器会导致模型主要依赖于更强的模态,通常是视觉模态,从而导致多模态行为的丧失和编辑质量的下降。为了克服这一问题,我们提出了TrojanEdit,一种后门注入框架,在训练过程中动态调整每个模态的梯度贡献。这允许模型学习一种真正的多模态后门,只有在两种触发器都存在时才会被激活。在多个图像编辑模型上的广泛实验表明,TrojanEdit成功地将来自不同模态的触发器集成在一起,实现了平衡的多模态后门学习,同时保持了清洁编辑性能,并确保高攻击效果。
论文及项目相关链接
Summary
多模态扩散模型用于图像编辑,能够根据文本指令和视觉输入生成输出,旨在修改目标区域同时保留图像其余部分。虽然扩散模型已被证明容易受到后门攻击,但现有研究主要集中在单模态生成模型上,未能解决多模态图像编辑中的独特挑战。本文首次研究了多模态扩散模型图像编辑的后门攻击问题。我们探讨了使用文本和视觉触发来嵌入后门的方法,在保持模型正常功能的同时实现了较高的攻击成功率。然而,我们发现了一种关键模态偏见,即简单结合不同模态的触发会使模型主要依赖于更强大的模态(通常是视觉模态),导致多模态行为的丧失和编辑质量的下降。为解决这一问题,我们提出了TrojanEdit,一种后门注入框架,在训练过程中动态调整每个模态的梯度贡献。这允许模型学习一种真正的多模态后门,只有在两个触发器都存在时才会被激活。在多个图像编辑模型上的广泛实验表明,TrojanEdit成功集成了来自不同模态的触发器,实现了平衡的多模态后门学习,同时保持了清洁编辑性能,确保了高攻击效果。
Key Takeaways
- 多模态扩散模型用于图像编辑,可以基于文本指令和视觉输入生成输出。
- 现有研究主要集中在单模态生成模型上的后门攻击,未涵盖多模态扩散模型中的独特挑战。
- 单纯结合不同模态的触发会导致模型依赖于强势模态(通常是视觉模态),进而丧失多模态行为并降低编辑质量。
- 提出TrojanEdit框架来解决这一问题,通过动态调整不同模态的梯度贡献来训练真正的多模态后门。
- TrojanEdit实现了不同模态触发器的集成,能够在保持清洁编辑性能的同时确保高攻击效果。
- 实验结果表明,TrojanEdit能够平衡多模态后门学习,同时在多个图像编辑模型上表现优异。
点此查看论文截图


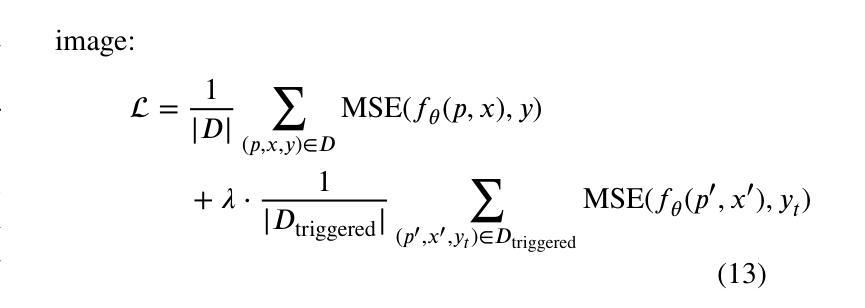
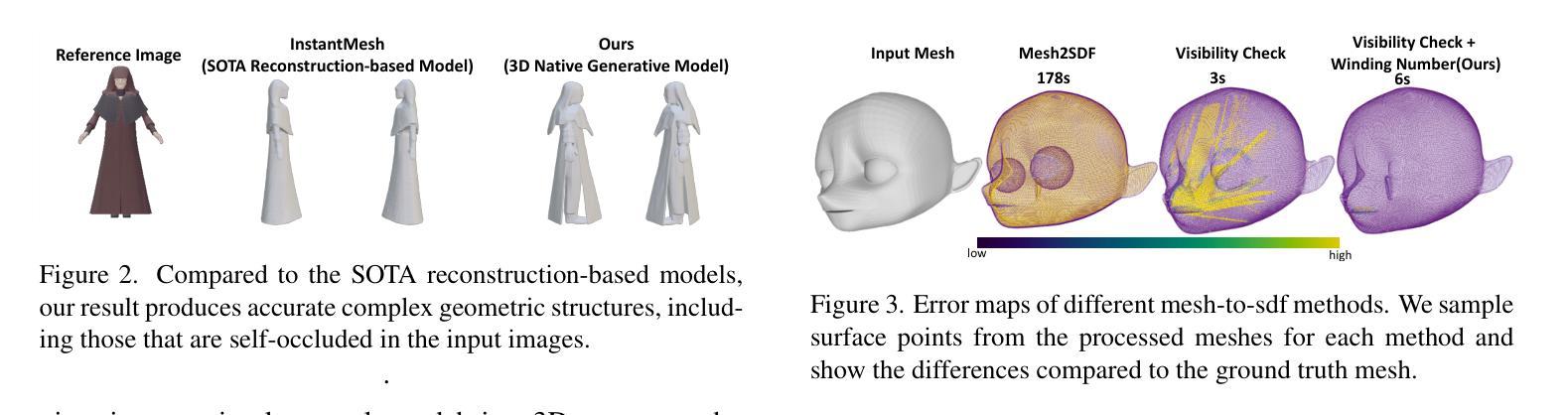
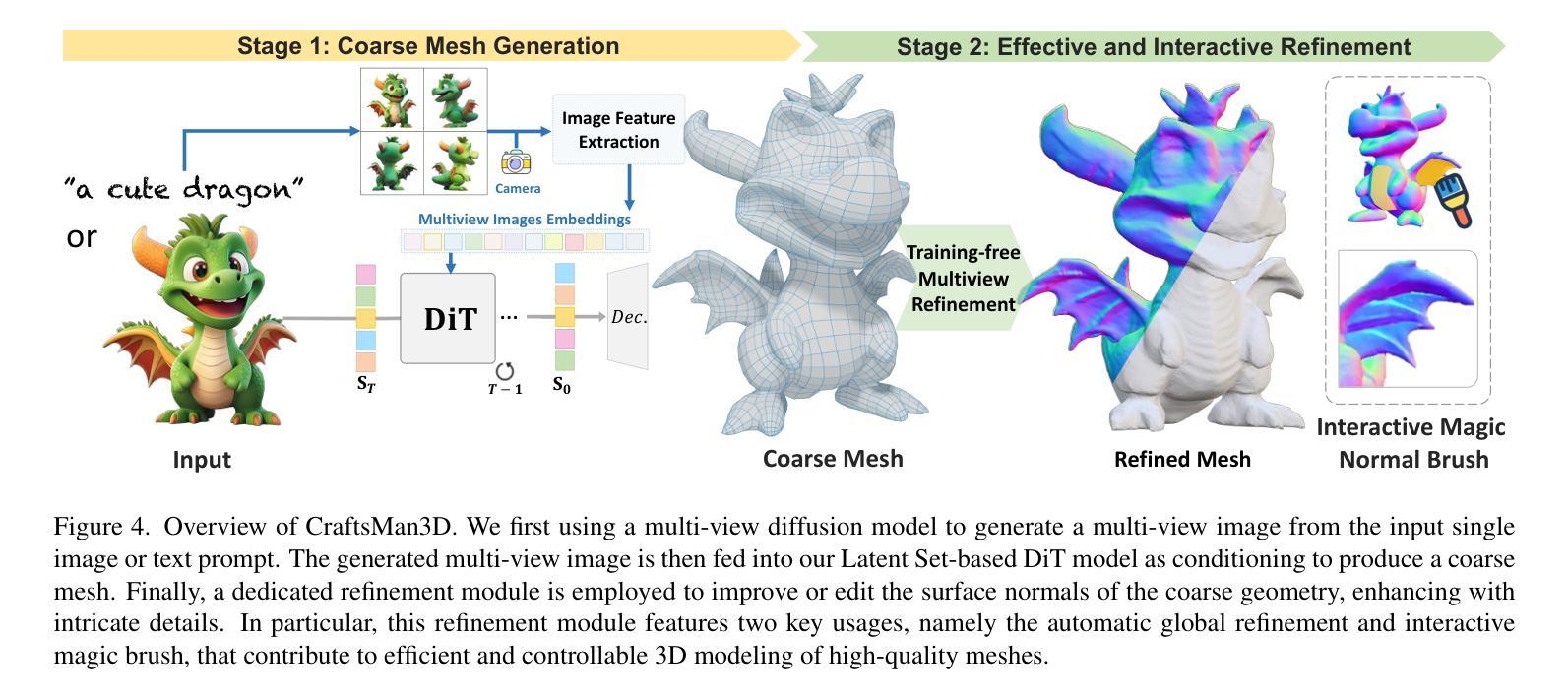
CraftsMan3D: High-fidelity Mesh Generation with 3D Native Generation and Interactive Geometry Refiner
Authors:Weiyu Li, Jiarui Liu, Hongyu Yan, Rui Chen, Yixun Liang, Xuelin Chen, Ping Tan, Xiaoxiao Long
We present a novel generative 3D modeling system, coined CraftsMan, which can generate high-fidelity 3D geometries with highly varied shapes, regular mesh topologies, and detailed surfaces, and, notably, allows for refining the geometry in an interactive manner. Despite the significant advancements in 3D generation, existing methods still struggle with lengthy optimization processes, irregular mesh topologies, noisy surfaces, and difficulties in accommodating user edits, consequently impeding their widespread adoption and implementation in 3D modeling software. Our work is inspired by the craftsman, who usually roughs out the holistic figure of the work first and elaborates the surface details subsequently. Specifically, we employ a 3D native diffusion model, which operates on latent space learned from latent set-based 3D representations, to generate coarse geometries with regular mesh topology in seconds. In particular, this process takes as input a text prompt or a reference image and leverages a powerful multi-view (MV) diffusion model to generate multiple views of the coarse geometry, which are fed into our MV-conditioned 3D diffusion model for generating the 3D geometry, significantly improving robustness and generalizability. Following that, a normal-based geometry refiner is used to significantly enhance the surface details. This refinement can be performed automatically, or interactively with user-supplied edits. Extensive experiments demonstrate that our method achieves high efficacy in producing superior-quality 3D assets compared to existing methods. HomePage: https://craftsman3d.github.io/, Code: https://github.com/wyysf-98/CraftsMan
我们提出了一种新颖的三维建模系统,名为CraftsMan。该系统可以生成具有多样化形状、规则网格拓扑和精细表面的高保真三维几何体,并且以交互方式对其进行细化。尽管三维生成技术取得了重大进展,但现有方法仍然面临优化过程冗长、网格拓扑不规则、表面噪声以及难以适应用户编辑等问题,从而阻碍了它们在三维建模软件中的广泛采用和实施。我们的工作受到工匠的启发,工匠通常首先大致勾勒出作品的整体轮廓,然后细化表面细节。具体来说,我们采用了一种三维扩散模型,该模型在潜在空间中对基于集合的潜在三维表示进行操作,以在几秒内生成具有规则网格拓扑的粗略几何形状。特别是,这一过程以文本提示或参考图像为输入,并利用强大的多视图(MV)扩散模型生成粗略几何形状的多视图,然后将其输入我们的MV条件三维扩散模型以生成三维几何形状,从而大大提高了稳健性和通用性。之后,使用基于法线的几何细化器来显着增强表面细节。此细化过程可以自动进行,也可以与用户提供的编辑进行交互。大量实验表明,我们的方法在生成高质量的三维资产方面与现有方法相比具有更高的有效性。主页:https://craftsman3d.github.io/,代码:https://github.com/wyysf-98/CraftsMan
论文及项目相关链接
PDF HomePage: https://craftsman3d.github.io/, Code: https://github.com/wyysf-98/CraftsMan3D
Summary
该项目提出了一种名为CraftsMan的新型三维建模系统,该系统能够生成高质量的三维模型,具有多样的形状、规则网格拓扑和精细的表面细节,并允许以交互方式调整几何形状。它通过利用运行在潜在空间上的三维扩散模型,能够在几秒内生成具有规则网格拓扑的粗糙几何形状。该项目还提供了一种基于法线的几何优化器,可显著提高表面细节的质量,并允许自动或交互式地进行用户编辑。该系统在生成高质量三维资产方面表现出显著效果。
Key Takeaways
- CraftsMan是一个新型的三维建模系统,可以生成高质量的三维模型。
- 该系统能够生成具有多样形状、规则网格拓扑和精细表面细节的三维模型。
- CraftsMan允许以交互方式调整几何形状,提高了用户的编辑体验。
- 该系统采用基于潜在空间的3D扩散模型,快速生成粗糙几何形状。
- CraftsMan利用多视角扩散模型提高了模型的稳健性和泛化能力。
- 系统采用基于法线的几何优化器,可以显著提高表面细节的质量。
点此查看论文截图

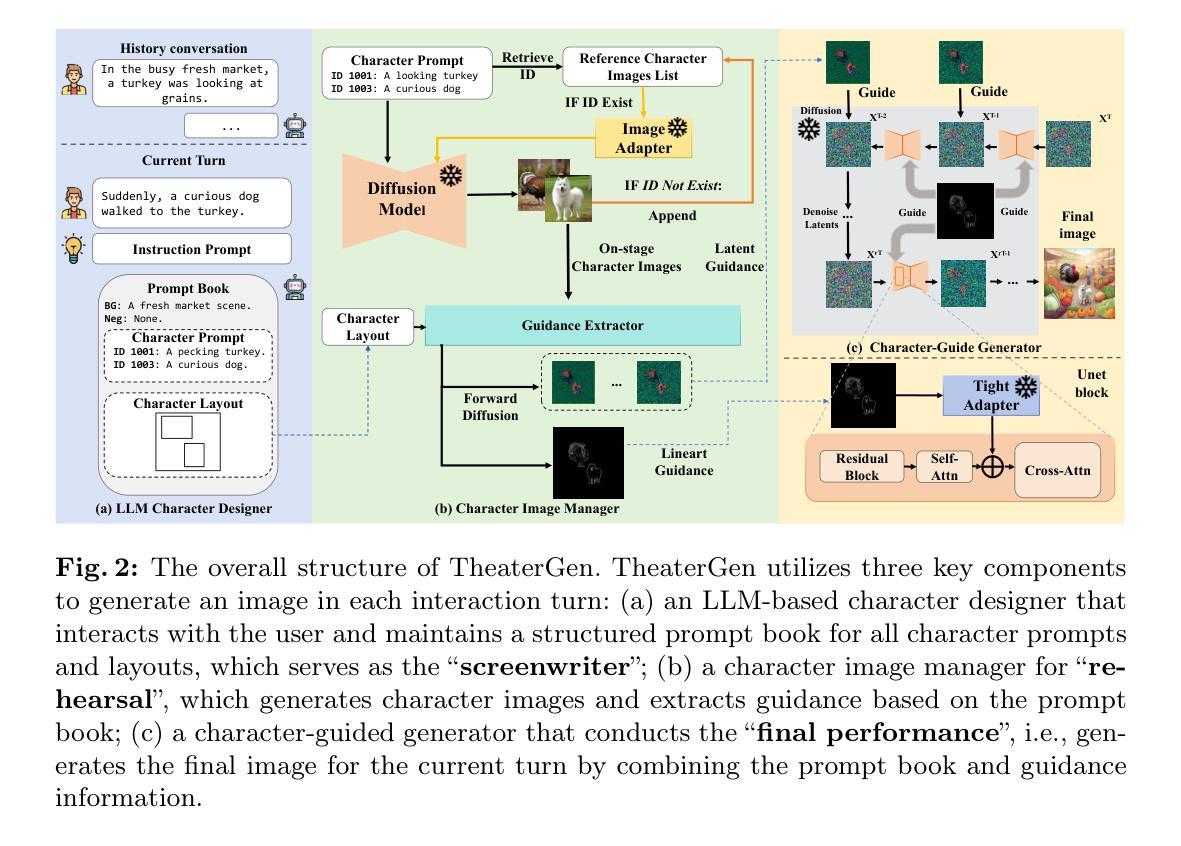
TheaterGen: Character Management with LLM for Consistent Multi-turn Image Generation
Authors:Junhao Cheng, Baiqiao Yin, Kaixin Cai, Minbin Huang, Hanhui Li, Yuxin He, Xi Lu, Yue Li, Yifei Li, Yuhao Cheng, Yiqiang Yan, Xiaodan Liang
Recent advances in diffusion models can generate high-quality and stunning images from text. However, multi-turn image generation, which is of high demand in real-world scenarios, still faces challenges in maintaining semantic consistency between images and texts, as well as contextual consistency of the same subject across multiple interactive turns. To address this issue, we introduce TheaterGen, a training-free framework that integrates large language models (LLMs) and text-to-image (T2I) models to provide the capability of multi-turn image generation. Within this framework, LLMs, acting as a “Screenwriter”, engage in multi-turn interaction, generating and managing a standardized prompt book that encompasses prompts and layout designs for each character in the target image. Based on these, Theatergen generate a list of character images and extract guidance information, akin to the “Rehearsal”. Subsequently, through incorporating the prompt book and guidance information into the reverse denoising process of T2I diffusion models, Theatergen generate the final image, as conducting the “Final Performance”. With the effective management of prompt books and character images, TheaterGen significantly improves semantic and contextual consistency in synthesized images. Furthermore, we introduce a dedicated benchmark, CMIGBench (Consistent Multi-turn Image Generation Benchmark) with 8000 multi-turn instructions. Different from previous multi-turn benchmarks, CMIGBench does not define characters in advance. Both the tasks of story generation and multi-turn editing are included on CMIGBench for comprehensive evaluation. Extensive experimental results show that TheaterGen outperforms state-of-the-art methods significantly. It raises the performance bar of the cutting-edge Mini DALLE 3 model by 21% in average character-character similarity and 19% in average text-image similarity.
近期扩散模型(Diffusion Models)的进展能够从文本生成高质量、令人惊叹的图像。然而,在真实场景中应用需求较高的多轮图像生成仍然面临挑战,即如何在图像和文本之间保持语义一致性,以及在多个交互回合中对同一主题的上下文一致性。为解决这一问题,我们引入了TheaterGen,这是一个无需训练的框架,它结合了大型语言模型(LLMs)和文本到图像(T2I)模型,提供了多轮图像生成的能力。
在此框架中,LLMs充当“编剧”,进行多轮交互,生成并管理一个标准化的提示册,其中包含目标图像中每个角色的提示和布局设计。基于这些,TheaterGen生成角色图像列表并提取指导信息,类似于“排练”。随后,通过将提示册和指导信息融入T2I扩散模型的反向去噪过程,TheaterGen生成最终图像,就像进行“最终表演”。通过对提示册和角色图像的有效管理,TheaterGen显著提高了合成图像的语义和上下文一致性。
此外,我们引入了专用基准测试CMIGBench(一致多轮图像生成基准测试),包含8000个多轮指令。不同于之前的多轮基准测试,CMIGBench不会预先定义角色。CMIGBench包含了故事生成和多轮编辑任务,以进行全面评估。广泛的实验结果表显示,TheaterGen显著优于现有技术方法。它在最先进的Mini DALLE 3模型上提高了21%的平均角色间相似度和19%的平均文本-图像相似度。
论文及项目相关链接
Summary
文本中介绍了最新扩散模型能生成高质量图像的能力,但多轮图像生成仍面临保持图像与文本之间语义一致性的挑战。为此,提出了训练免框架TheaterGen,集成大型语言模型和文本到图像模型,实现多轮图像生成。通过标准化提示书籍管理角色图像和指导信息,提高合成图像的语义和上下文一致性。同时引入CMIGBench基准测试,包含故事生成和多轮编辑任务进行全面评估。实验结果显示,TheaterGen显著优于现有方法,提升了前沿Mini DALLE 3模型的性能。
Key Takeaways
- 扩散模型具备生成高质量图像的能力。
- 多轮图像生成在实际场景中需求高,但保持语义一致性是挑战。
- TheaterGen框架集成大型语言模型和文本到图像模型,解决多轮图像生成的语义一致性挑战。
- TheaterGen通过标准化提示书籍管理角色图像和指导信息。
- CMIGBench基准测试用于全面评估多轮图像生成性能,包括故事生成和多轮编辑任务。
- 实验结果显示TheaterGen显著优于现有方法。
点此查看论文截图