⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-03 更新
Agent-X: Evaluating Deep Multimodal Reasoning in Vision-Centric Agentic Tasks
Authors:Tajamul Ashraf, Amal Saqib, Hanan Ghani, Muhra AlMahri, Yuhao Li, Noor Ahsan, Umair Nawaz, Jean Lahoud, Hisham Cholakkal, Mubarak Shah, Philip Torr, Fahad Shahbaz Khan, Rao Muhammad Anwer, Salman Khan
Deep reasoning is fundamental for solving complex tasks, especially in vision-centric scenarios that demand sequential, multimodal understanding. However, existing benchmarks typically evaluate agents with fully synthetic, single-turn queries, limited visual modalities, and lack a framework to assess reasoning quality over multiple steps as required in real-world settings. To address this, we introduce Agent-X, a large-scale benchmark for evaluating vision-centric agents multi-step and deep reasoning capabilities in real-world, multimodal settings. Agent- X features 828 agentic tasks with authentic visual contexts, including images, multi-image comparisons, videos, and instructional text. These tasks span six major agentic environments: general visual reasoning, web browsing, security and surveillance, autonomous driving, sports, and math reasoning. Our benchmark requires agents to integrate tool use with explicit, stepwise decision-making in these diverse settings. In addition, we propose a fine-grained, step-level evaluation framework that assesses the correctness and logical coherence of each reasoning step and the effectiveness of tool usage throughout the task. Our results reveal that even the best-performing models, including GPT, Gemini, and Qwen families, struggle to solve multi-step vision tasks, achieving less than 50% full-chain success. These findings highlight key bottlenecks in current LMM reasoning and tool-use capabilities and identify future research directions in vision-centric agentic reasoning models. Our data and code are publicly available at https://github.com/mbzuai-oryx/Agent-X
深度推理是解决复杂任务的基础,特别是在以视觉为中心的场景中,需要连续的多模式理解。然而,现有的基准测试通常使用完全合成、单轮查询进行评估,具有有限的视觉模式,并且缺乏评估多个步骤中的推理质量的框架,这在现实世界中是必需的。为了解决这个问题,我们引入了Agent-X,这是一个大规模基准测试,用于评估以视觉为中心的代理在现实世界多模式设置中的多步骤和深度推理能力。Agent-X拥有828个代理任务,具有真实视觉上下文,包括图像、多图像比较、视频和指令文本。这些任务涵盖了六大代理环境:通用视觉推理、网页浏览、安全和监控、自动驾驶、运动和数学推理。我们的基准测试要求代理在这些不同的环境中将工具使用与明确的分步骤决策相结合。此外,我们提出了一个精细的、步骤级的评估框架,该框架评估每个推理步骤的正确性和逻辑性,以及在整个任务中工具使用的有效性。我们的结果表明,即使是表现最佳的模型,包括GPT、双子座和Qwen系列,在解决多步骤视觉任务时也面临困难,全程成功完成率低于50%。这些发现突出了当前大型语言模型推理和工具使用能力的关键瓶颈,并确定了以视觉为中心的代理推理模型未来的研究方向。我们的数据和代码可在https://github.com/mbzuai-oryx/Agent-X公开访问。
论文及项目相关链接
Summary
在视觉为中心的场景中,深度推理是解决复杂任务的关键,尤其是在需要多步骤和多模式理解的场景中。然而,现有的基准测试通常使用全合成、单回合查询和有限的视觉模式进行评估,缺乏评估多步骤推理质量的框架,无法满足真实世界的需求。为解决这一问题,我们推出了Agent-X,这是一个大规模基准测试,用于评估视觉为中心的智能体在多步骤深度推理能力方面的表现。该测试包含828个真实视觉环境的任务,包括图像、多图像对比、视频和指令文本。我们的基准测试要求智能体在这些不同的环境中整合工具使用和明确的逐步决策。此外,我们提出了一个精细的、步骤级的评估框架,评估每个推理步骤的正确性和逻辑性,以及在整个任务中工具使用的有效性。研究结果显示,即使是表现最佳的模型,如GPT、双子座和Qwen系列,在解决多步骤视觉任务时也面临困难,全程成功率低于50%。这突显了当前视觉为中心的智能体推理模型的瓶颈,并为未来的研究指明了方向。
Key Takeaways
- 深度推理在解决以视觉为中心的多步骤复杂任务中至关重要。
- 现有基准测试主要使用合成数据和单回合查询进行评估,缺乏真实世界的多步骤推理质量评估框架。
- Agent-X是一个新的大规模基准测试,用于评估智能体在多步骤深度推理能力方面的表现。
- Agent-X包含真实视觉环境的多样化任务,包括图像、视频和指令文本等。
- Agent-X要求智能体在多种环境中整合工具使用和逐步决策。
- 评估框架注重推理步骤的正确性和逻辑性,以及工具使用的有效性评估。
点此查看论文截图

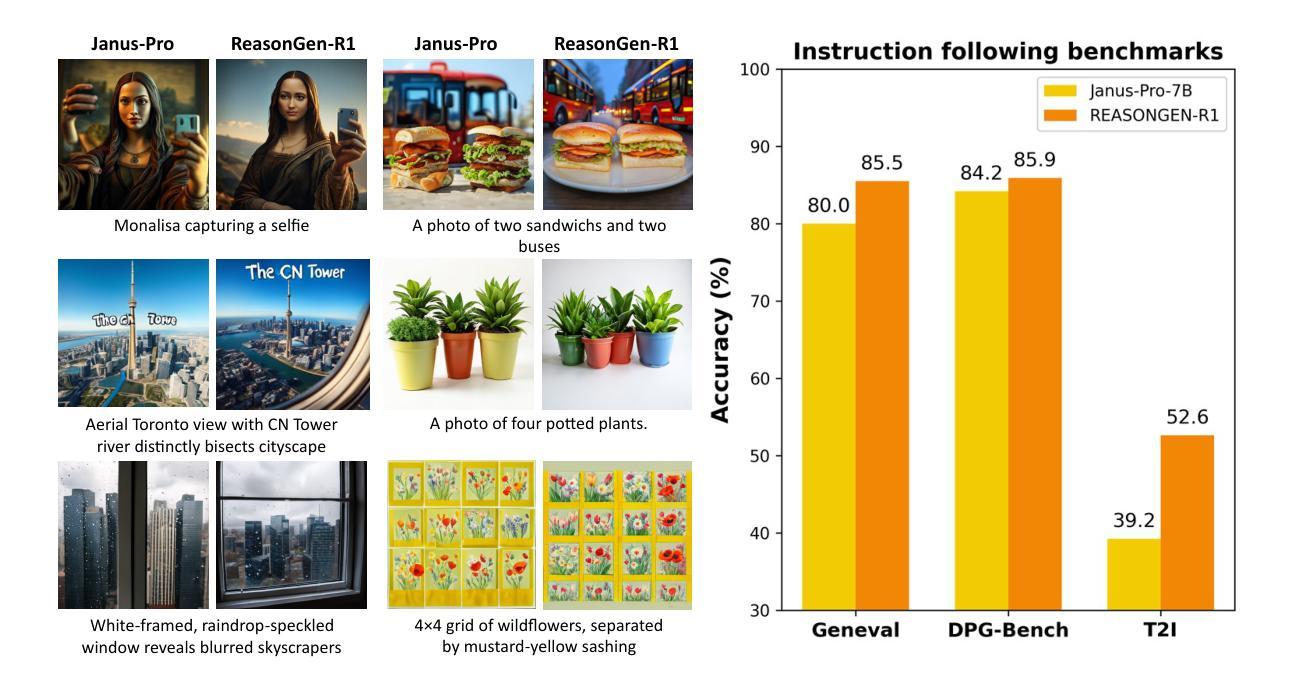
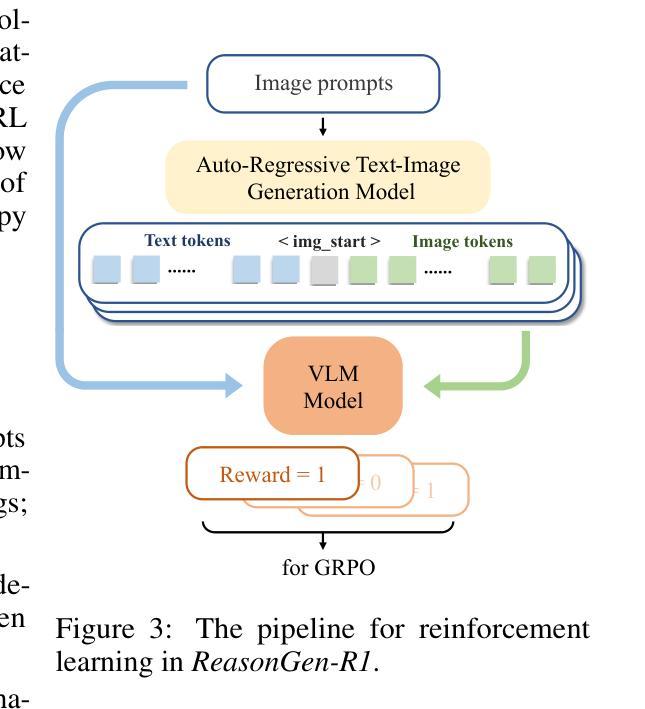
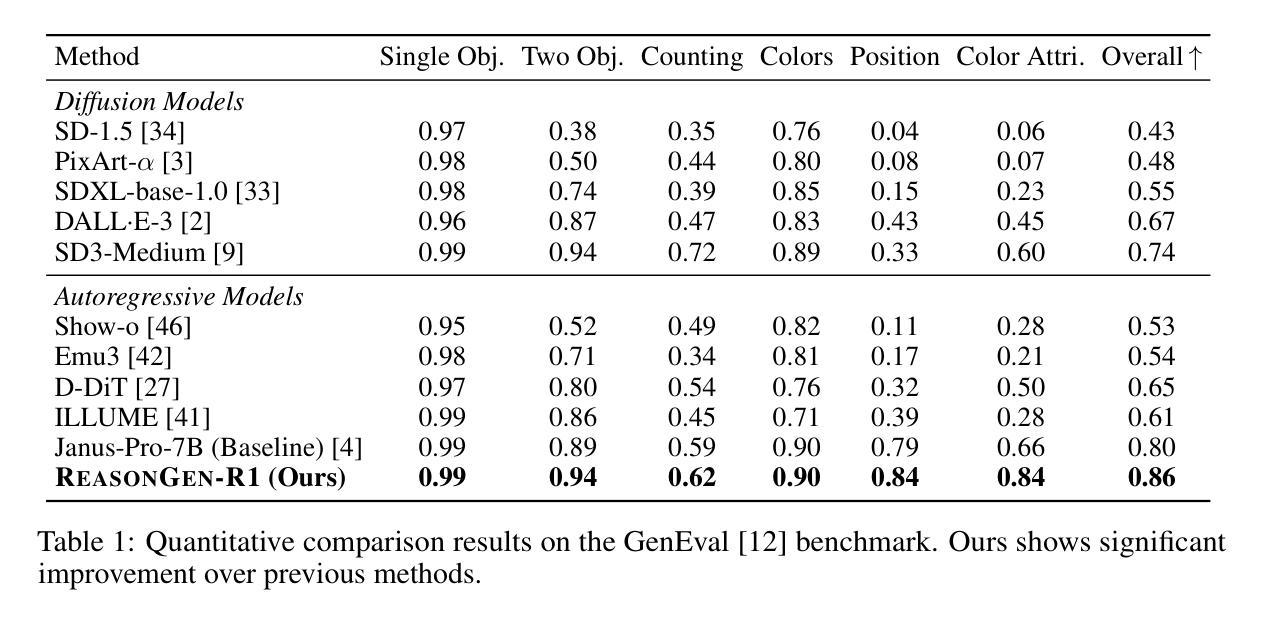
ReasonGen-R1: CoT for Autoregressive Image generation models through SFT and RL
Authors:Yu Zhang, Yunqi Li, Yifan Yang, Rui Wang, Yuqing Yang, Dai Qi, Jianmin Bao, Dongdong Chen, Chong Luo, Lili Qiu
Although chain-of-thought reasoning and reinforcement learning (RL) have driven breakthroughs in NLP, their integration into generative vision models remains underexplored. We introduce ReasonGen-R1, a two-stage framework that first imbues an autoregressive image generator with explicit text-based “thinking” skills via supervised fine-tuning on a newly generated reasoning dataset of written rationales, and then refines its outputs using Group Relative Policy Optimization. To enable the model to reason through text before generating images, We automatically generate and release a corpus of model crafted rationales paired with visual prompts, enabling controlled planning of object layouts, styles, and scene compositions. Our GRPO algorithm uses reward signals from a pretrained vision language model to assess overall visual quality, optimizing the policy in each update. Evaluations on GenEval, DPG, and the T2I benchmark demonstrate that ReasonGen-R1 consistently outperforms strong baselines and prior state-of-the-art models. More: aka.ms/reasongen.
尽管基于思维链推理和强化学习(RL)在自然语言处理(NLP)领域取得了突破,但它们融入生成式视觉模型的研究仍然不够充分。我们引入了ReasonGen-R1,这是一个两阶段的框架,首先通过在新生成的基于文本推理数据集上进行有监督微调,将一个自回归图像生成器赋予明确的基于文本的“思考”技能,然后使用组相对策略优化对其输出进行改进。为了能够让模型在生成图像之前通过文本进行推理,我们自动生成并发布了一系列与视觉提示配对的人工构建推理语料库,实现对物体布局、风格和场景组成的可控规划。我们的GRPO算法使用来自预训练视觉语言模型的奖励信号来评估总体视觉质量,并在每次更新中优化策略。在GenEval、DPG和T2I基准测试上的评估结果表明,ReasonGen-R1持续优于强劲的基线模型和之前的最新模型。更多信息请访问aka.ms/reasongen。
论文及项目相关链接
Summary
本文介绍了一个名为ReasonGen-R1的两阶段框架,它将链式思维推理和强化学习结合,应用于生成式视觉模型。第一阶段通过在新生成的基于文本理性的监督微调数据上赋予自回归图像生成器明确的基于文本的“思考”技能。第二阶段使用集团相对政策优化来优化输出。该框架通过文本进行推理再生成图像,并自动生成与视觉提示配对的数据集,以实现对象布局、风格和场景组成的受控规划。评估结果表明,ReasonGen-R1在GenEval、DPG和T2I基准测试上的表现均优于强大的基准模型和先前最先进的模型。
Key Takeaways
- 介绍了ReasonGen-R1框架,该框架结合了链式思维推理和强化学习,应用于生成式视觉模型。
- 第一阶段通过监督微调赋予自回归图像生成器明确的基于文本的“思考”技能,使用新生成的基于文本理性的数据集。
- 第二阶段使用集团相对政策优化(GRPO)算法优化输出,该算法利用预训练的视觉语言模型来评估整体视觉质量,并在每次更新中优化策略。
- 该框架能够实现通过文本进行推理再生成图像的过程。
- 自动生成与视觉提示配对的数据集,实现对象布局、风格和场景组成的受控规划。
- ReasonGen-R1在GenEval、DPG和T2I基准测试上的表现优于其他模型。
点此查看论文截图

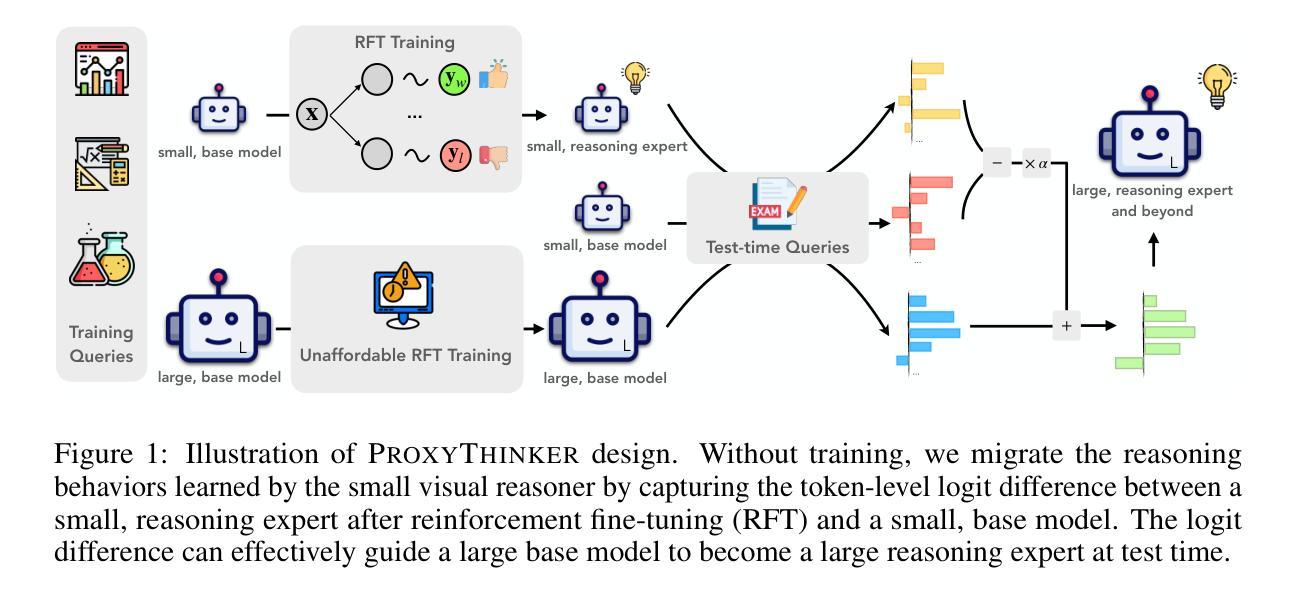
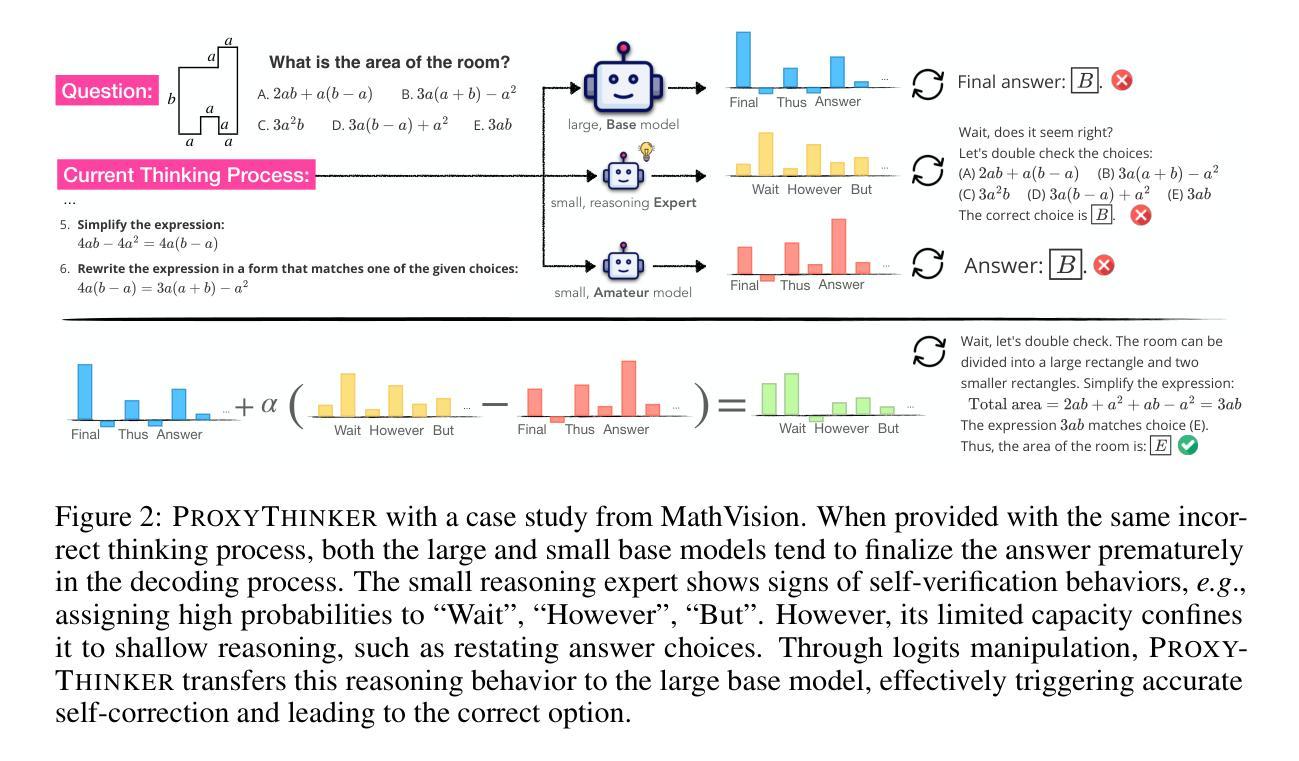
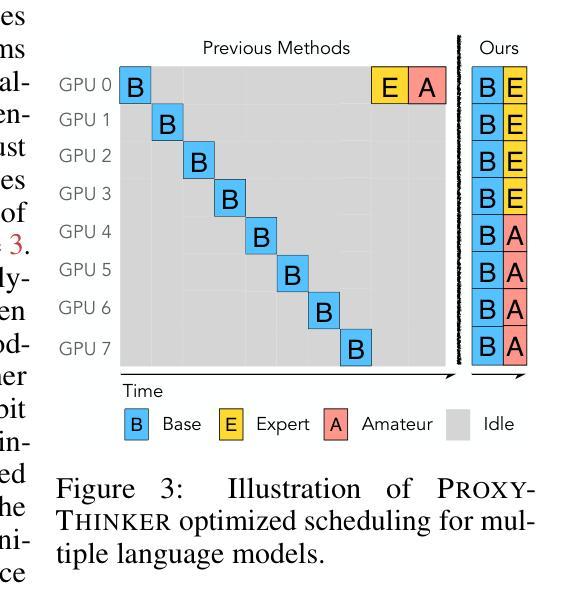
ProxyThinker: Test-Time Guidance through Small Visual Reasoners
Authors:Zilin Xiao, Jaywon Koo, Siru Ouyang, Jefferson Hernandez, Yu Meng, Vicente Ordonez
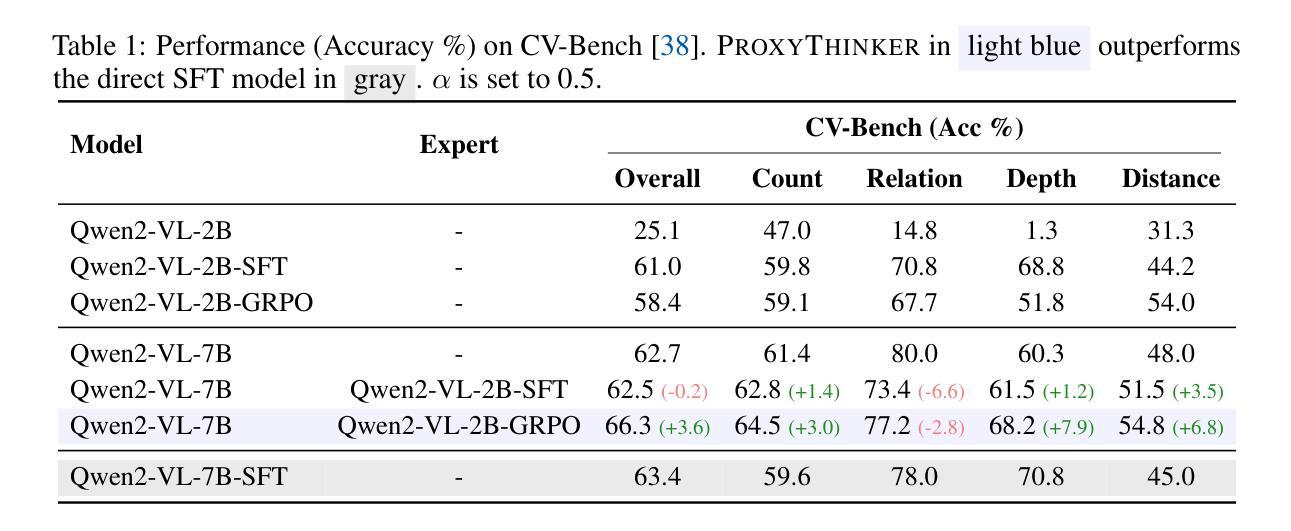
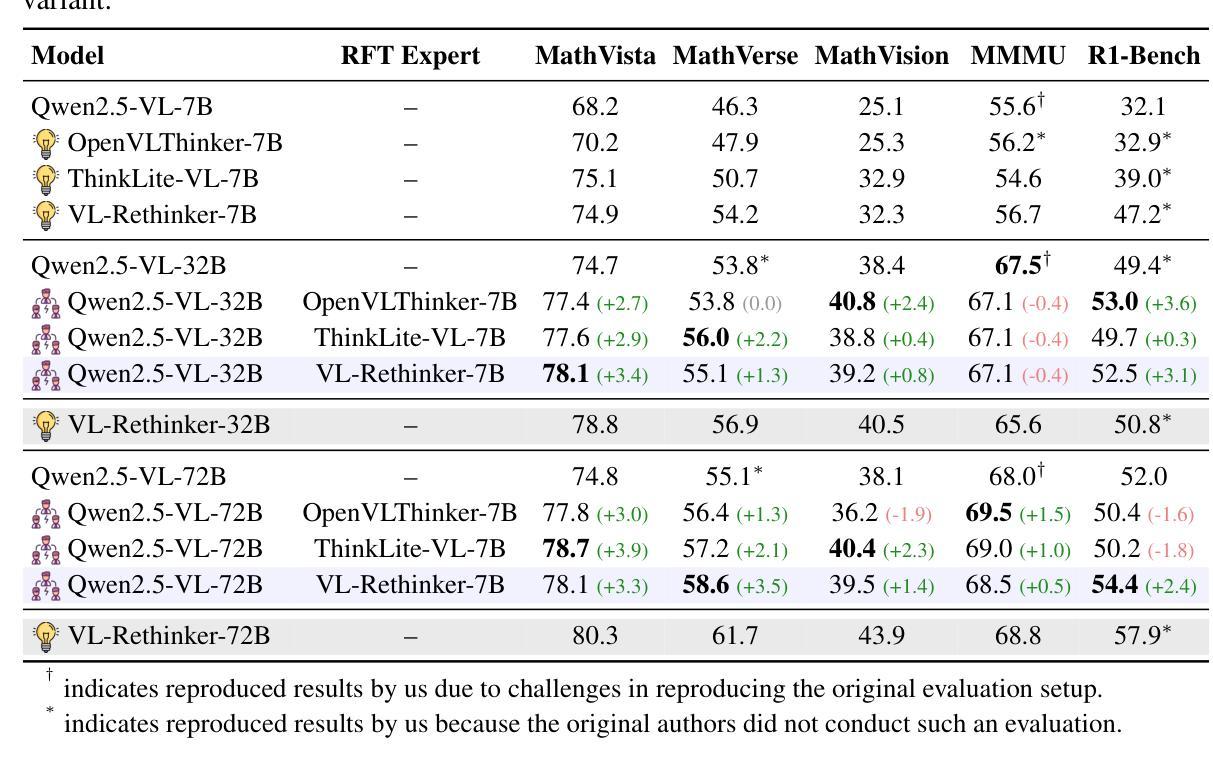
Recent advancements in reinforcement learning with verifiable rewards have pushed the boundaries of the visual reasoning capabilities in large vision-language models (LVLMs). However, training LVLMs with reinforcement fine-tuning (RFT) is computationally expensive, posing a significant challenge to scaling model size. In this work, we propose ProxyThinker, an inference-time technique that enables large models to inherit the visual reasoning capabilities from small, slow-thinking visual reasoners without any training. By subtracting the output distributions of base models from those of RFT reasoners, ProxyThinker modifies the decoding dynamics and successfully elicits the slow-thinking reasoning demonstrated by the emerged sophisticated behaviors such as self-verification and self-correction. ProxyThinker consistently boosts performance on challenging visual benchmarks on spatial, mathematical, and multi-disciplinary reasoning, enabling untuned base models to compete with the performance of their full-scale RFT counterparts. Furthermore, our implementation efficiently coordinates multiple language models with parallelism techniques and achieves up to 38 $\times$ faster inference compared to previous decoding-time methods, paving the way for the practical deployment of ProxyThinker. Code is available at https://github.com/MrZilinXiao/ProxyThinker.
近期,通过可验证奖励的强化学习进展推动了大型视觉语言模型(LVLMs)视觉推理能力的边界。然而,使用强化微调(RFT)训练LVLMs的计算成本高昂,给模型规模扩展带来了重大挑战。在这项工作中,我们提出了ProxyThinker,这是一种推理时间技术,能够让大型模型从小型、慢思考的视觉推理器继承视觉推理能力,而无需任何训练。通过从基准模型的输出分布中减去RFT推理器的输出分布,ProxyThinker修改了解码动态,并成功激发了以自我验证和自我校正等出现的复杂行为所展示的慢思考推理。ProxyThinker在具有挑战性的空间、数学和多学科推理视觉基准测试中始终提升性能,使未调整的基准模型能够与全尺寸RFT模型的性能相竞争。此外,我们的实现通过并行技术高效地协调了多个语言模型,与以前的解码时间方法相比,实现了高达38倍的快速推理,为ProxyThinker的实际部署铺平了道路。代码可用在https://github.com/MrZilinXiao/ProxyThinker。
论文及项目相关链接
Summary
强化学习的发展推动了大型视觉语言模型视觉推理能力的前沿,但训练这些模型使用强化微调在计算上代价高昂。本研究提出了ProxyThinker,这是一种推理时间技术,能让大型模型继承小型慢速视觉推理者的视觉推理能力而无需任何训练。通过从基础模型的输出分布中减去经过强化微调推理者的输出分布,ProxyThinker成功激发了自我验证和校正等复杂行为所表现出的慢速推理。ProxyThinker在具有挑战性的视觉基准测试中始终提升了性能,使得未经调整的基础模型能够与全尺寸强化微调模型相竞争。此外,该方法的实现使用并行技术高效地协调多个语言模型,与之前的方法相比可实现最高达38倍更快的推理速度,为ProxyThinker的实际部署铺平了道路。代码已在GitHub上公开。
Key Takeaways
- 强化学习推动了大型视觉语言模型的视觉推理能力边界。
- 训练大型视觉语言模型使用强化微调在计算上代价高昂,存在规模化挑战。
- ProxyThinker是一种推理时间技术,允许大型模型继承小型慢速视觉推理模型的视觉推理能力。
- ProxyThinker通过调整解码动态激发复杂行为,如自我验证和校正。
- ProxyThinker提高了具有挑战性的视觉基准测试的性能,使基础模型能与全尺寸强化微调模型竞争。
- ProxyThinker实现了高效的多个语言模型并行协调,提高了推理速度。
点此查看论文截图

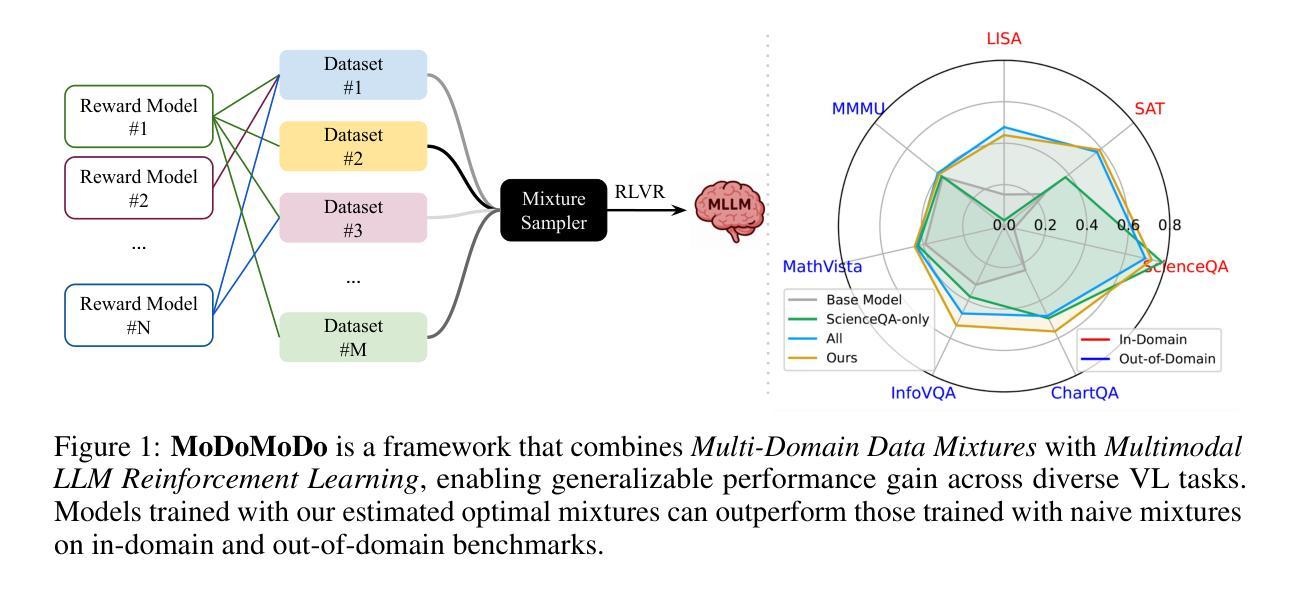
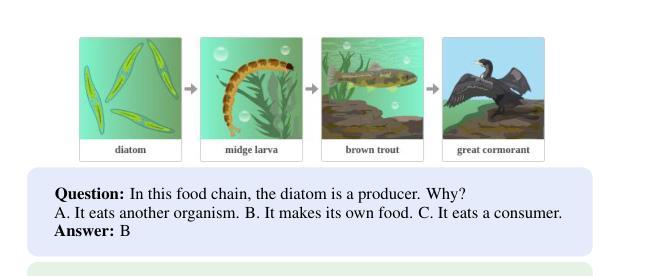
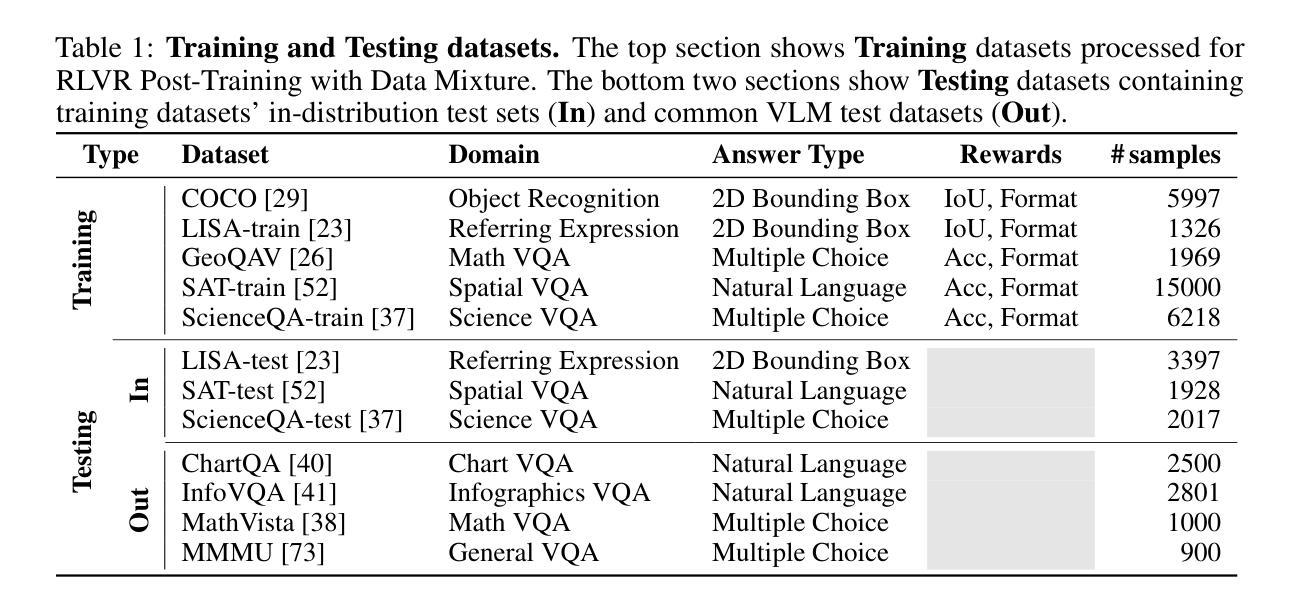
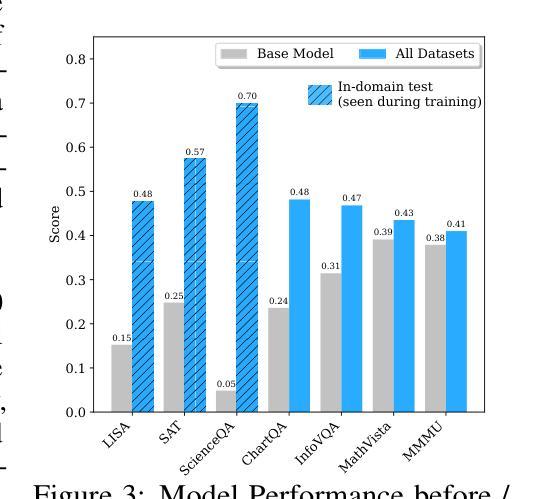
MoDoMoDo: Multi-Domain Data Mixtures for Multimodal LLM Reinforcement Learning
Authors:Yiqing Liang, Jielin Qiu, Wenhao Ding, Zuxin Liu, James Tompkin, Mengdi Xu, Mengzhou Xia, Zhengzhong Tu, Laixi Shi, Jiacheng Zhu
Reinforcement Learning with Verifiable Rewards (RLVR) has recently emerged as a powerful paradigm for post-training large language models (LLMs), achieving state-of-the-art performance on tasks with structured, verifiable answers. Applying RLVR to Multimodal LLMs (MLLMs) presents significant opportunities but is complicated by the broader, heterogeneous nature of vision-language tasks that demand nuanced visual, logical, and spatial capabilities. As such, training MLLMs using RLVR on multiple datasets could be beneficial but creates challenges with conflicting objectives from interaction among diverse datasets, highlighting the need for optimal dataset mixture strategies to improve generalization and reasoning. We introduce a systematic post-training framework for Multimodal LLM RLVR, featuring a rigorous data mixture problem formulation and benchmark implementation. Specifically, (1) We developed a multimodal RLVR framework for multi-dataset post-training by curating a dataset that contains different verifiable vision-language problems and enabling multi-domain online RL learning with different verifiable rewards; (2) We proposed a data mixture strategy that learns to predict the RL fine-tuning outcome from the data mixture distribution, and consequently optimizes the best mixture. Comprehensive experiments showcase that multi-domain RLVR training, when combined with mixture prediction strategies, can significantly boost MLLM general reasoning capacities. Our best mixture improves the post-trained model’s accuracy on out-of-distribution benchmarks by an average of 5.24% compared to the same model post-trained with uniform data mixture, and by a total of 20.74% compared to the pre-finetuning baseline.
使用可验证奖励的强化学习(RLVR)最近作为训练大型语言模型(LLM)后的一种强大范式而出现,其在具有结构化和可验证答案的任务上实现了最新技术性能。将RLVR应用于多模态LLM(MLLM)带来了巨大的机会,但由于需要微妙的视觉、逻辑和空间能力的视觉语言任务的广泛性和异质性,使其复杂化。因此,使用RLVR在多数据集上训练MLLM可能有益,但创建了来自不同数据集之间交互的相互冲突的目标所带来的挑战,这强调了需要最佳的数据集混合策略来提高泛化和推理能力。我们为多模态LLM RLVR引入了系统的后训练框架,其中包括严格的数据混合问题公式和基准实现。具体来说,(1)我们开发了一个多模态RLVR框架,用于多数据集的后训练,通过整理包含不同可验证的视觉语言问题的数据集,并启用具有不同可验证奖励的多域在线RL学习;(2)我们提出了一种数据混合策略,该策略可以学习预测RL微调结果,从而优化最佳混合。综合实验表明,当多域RLVR训练与混合预测策略相结合时,可以显着提高MLLM的通用推理能力。我们的最佳组合在超出分布的基准测试上,与统一数据混合后训练的模型相比,平均提高了5.24%的精度,与微调前的基准模型相比,总提高了20.74%。
论文及项目相关链接
PDF Project Webpage: https://modomodo-rl.github.io/
Summary
该文本介绍了强化学习与可验证奖励(RLVR)在训练大型语言模型(LLM)方面的优势,尤其是在处理结构化和可验证答案的任务方面。虽然将RLVR应用于多模态LLM(MLLM)具有显著的机会,但这一领域也面临挑战,尤其是在视觉语言任务上需要更加复杂的混合策略来处理各种数据集的目标冲突问题。该文提出了一个针对多模态LLM的RLVR系统性后训练框架,其中包括对数据混合问题的严谨表述和基准实现。该框架通过开发包含不同可验证视觉语言问题的数据集和多域在线RL学习技术来解决这些问题。实验表明,结合数据混合预测策略的多域RLVR训练可以显著提高MLLM的通用推理能力。与均匀数据混合相比,最佳数据混合策略可以提高模型在分布外的准确性平均达5.24%,与预训练模型相比,总提高达20.74%。
Key Takeaways
- 强化学习与可验证奖励(RLVR)在训练大型语言模型(LLM)领域表现优异,尤其在处理结构化答案任务时。
- 将RLVR应用于多模态LLM(MLLM)具有巨大潜力,但需解决视觉语言任务的复杂性和异质性挑战。
- 提出了一种针对MLLM的RLVR系统性后训练框架,包括严谨的数据混合问题表述和基准实现。
- 通过开发包含不同可验证视觉语言问题的数据集和多域在线RL学习技术来解决数据混合问题。
- 实验显示多域RLVR训练结合数据混合预测策略能显著提高MLLM的通用推理能力。
- 最佳数据混合策略能显著提高模型在分布外的准确性,相较于均匀数据混合提升平均达5.24%。
点此查看论文截图

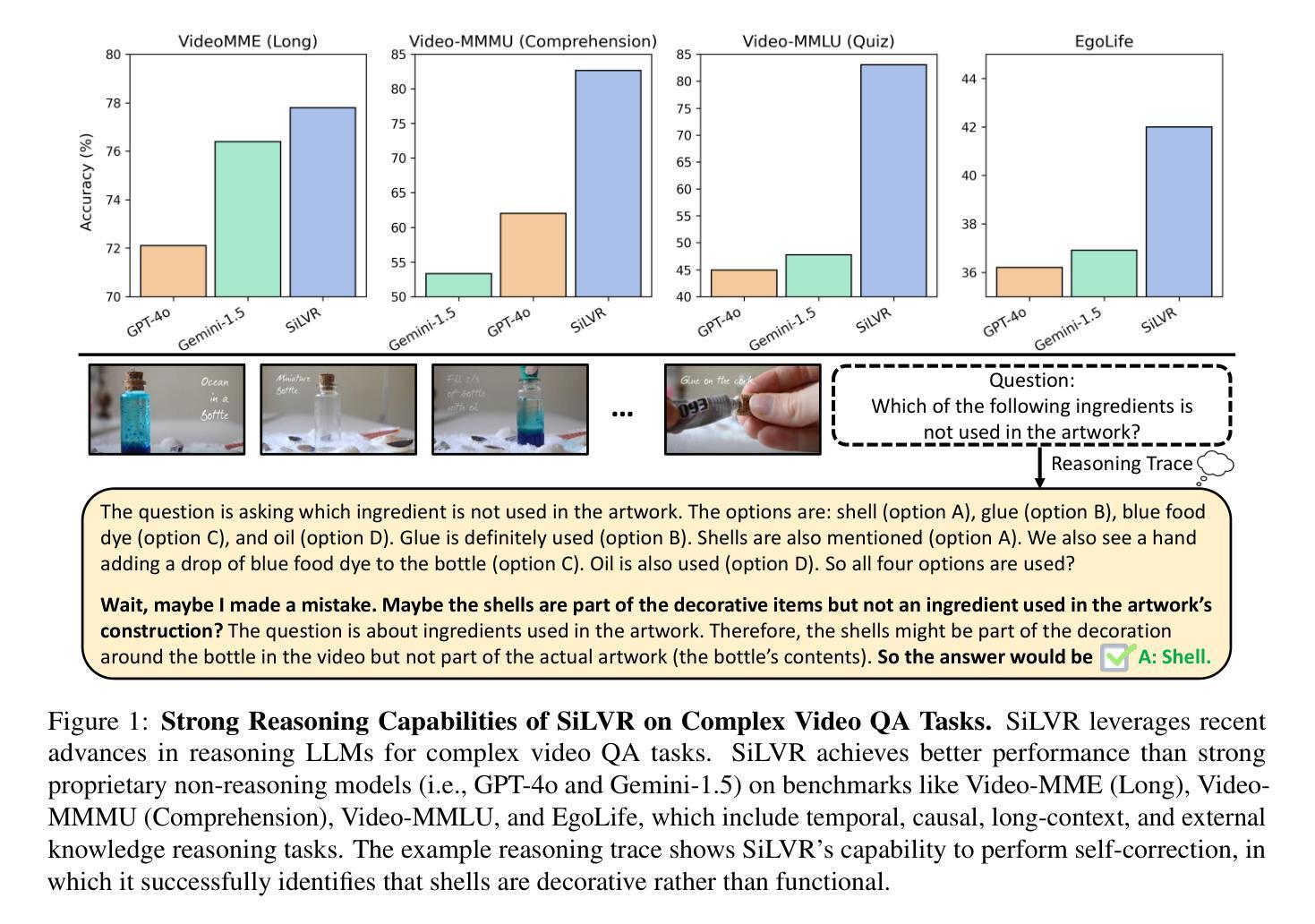
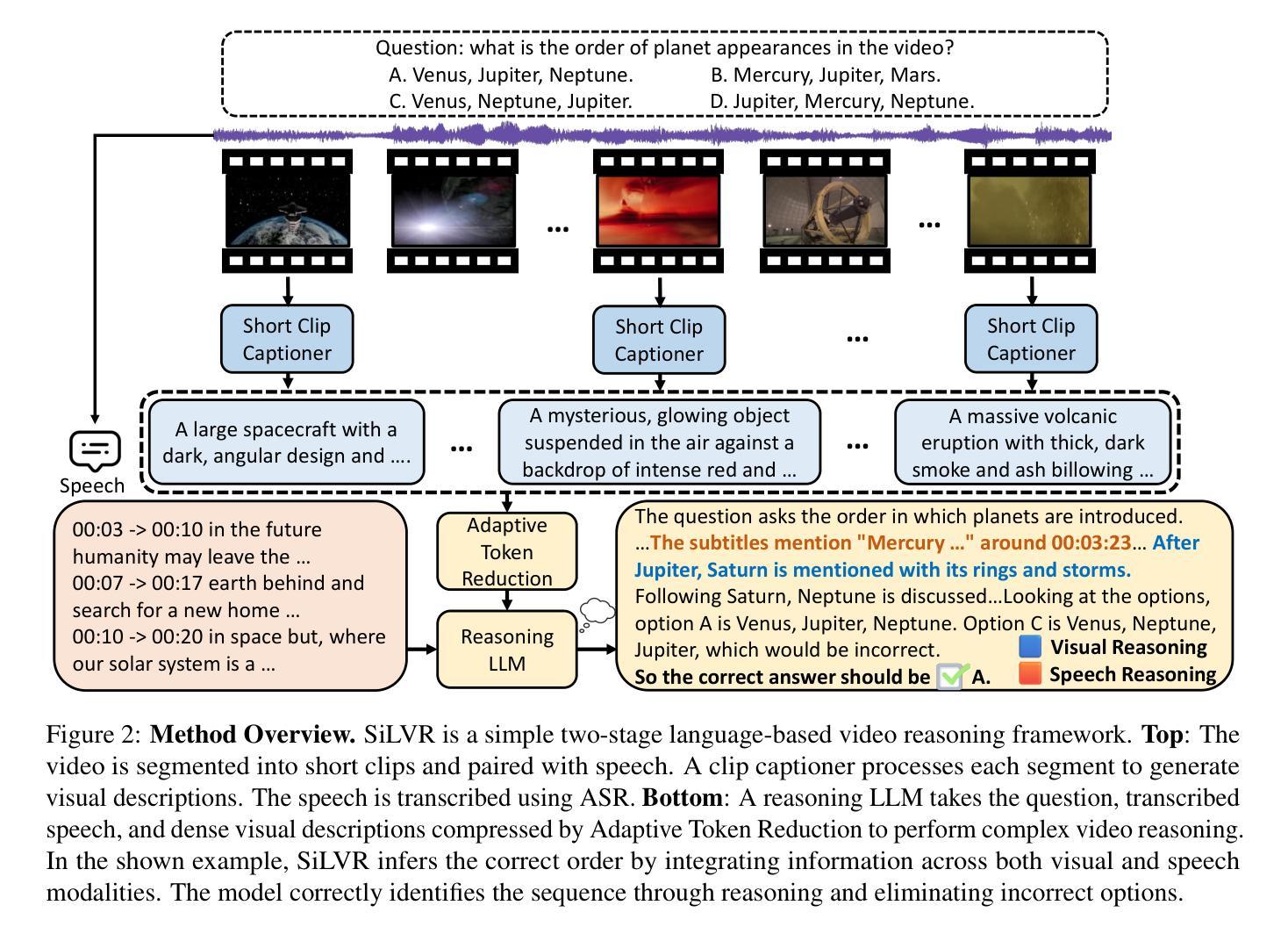
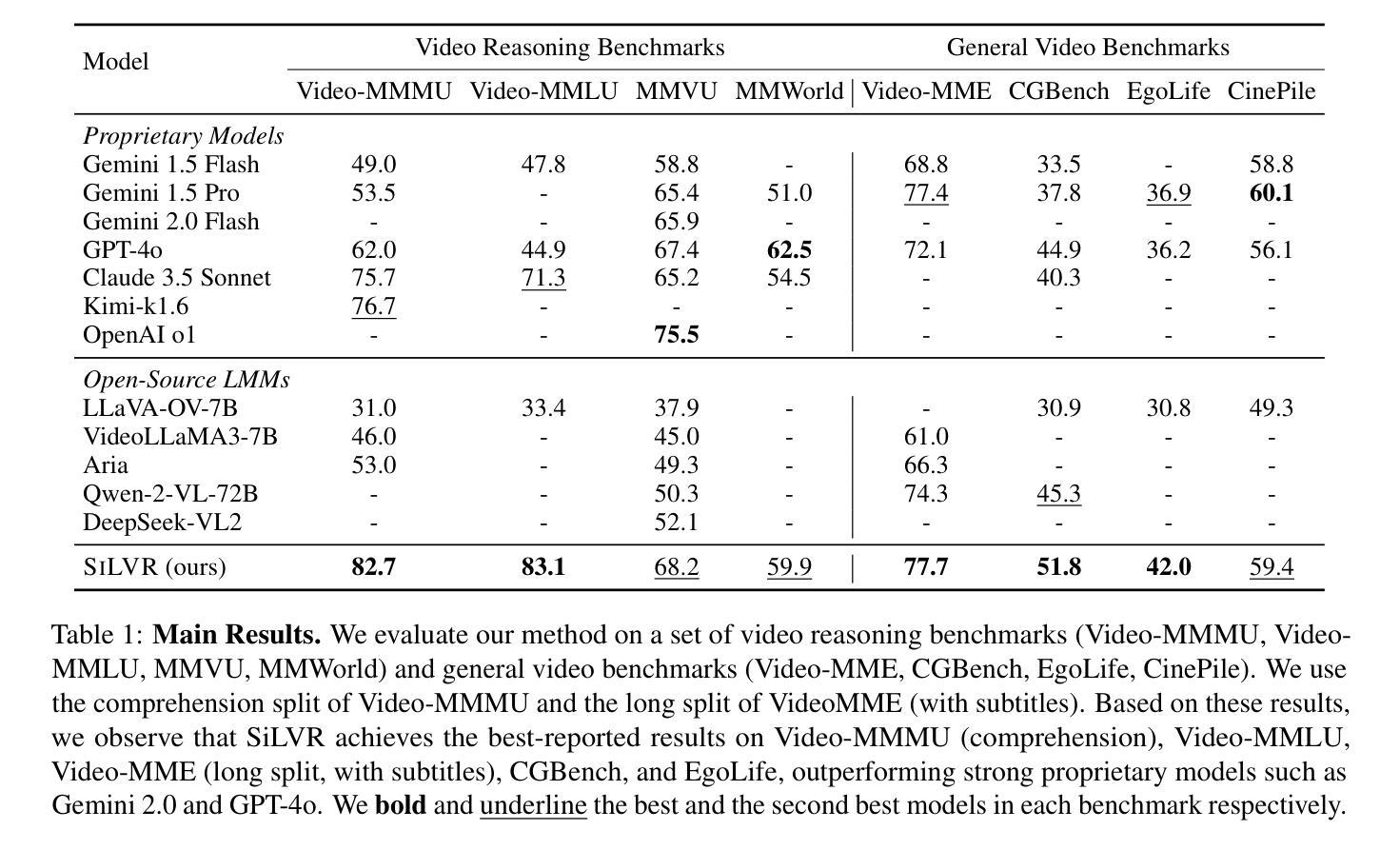
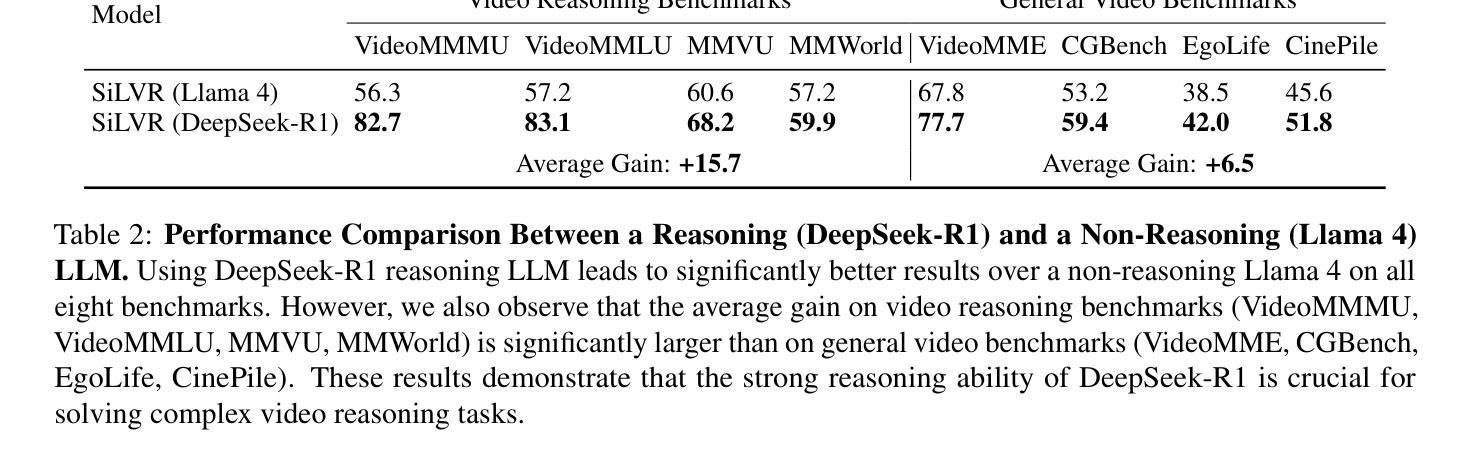
SiLVR: A Simple Language-based Video Reasoning Framework
Authors:Ce Zhang, Yan-Bo Lin, Ziyang Wang, Mohit Bansal, Gedas Bertasius
Recent advances in test-time optimization have led to remarkable reasoning capabilities in Large Language Models (LLMs), enabling them to solve highly complex problems in math and coding. However, the reasoning capabilities of multimodal LLMs (MLLMs) still significantly lag, especially for complex video-language tasks. To address this issue, we present SiLVR, a Simple Language-based Video Reasoning framework that decomposes complex video understanding into two stages. In the first stage, SiLVR transforms raw video into language-based representations using multisensory inputs, such as short clip captions and audio/speech subtitles. In the second stage, language descriptions are fed into a powerful reasoning LLM to solve complex video-language understanding tasks. To handle long-context multisensory inputs, we use an adaptive token reduction scheme, which dynamically determines the temporal granularity with which to sample the tokens. Our simple, modular, and training-free video reasoning framework achieves the best-reported results on Video-MME (long), Video-MMMU (comprehension), Video-MMLU, CGBench, and EgoLife. Furthermore, our empirical study focused on video reasoning capabilities shows that, despite not being explicitly trained on video, strong reasoning LLMs can effectively aggregate multisensory input information from video, speech, and audio for complex temporal, causal, long-context, and knowledge acquisition reasoning tasks in video. Code is available at https://github.com/CeeZh/SILVR.
最近测试时优化的进展为大语言模型(LLM)带来了卓越的推理能力,使其能够解决数学和编码中的高度复杂问题。然而,多模式LLM(MLLM)的推理能力仍然存在明显差距,特别是在复杂的视频语言任务方面。为了解决这个问题,我们提出了基于简单语言的视频推理框架SiLVR,它将复杂的视频理解分为两个阶段。在第一阶段,SiLVR使用多感官输入,如短视频字幕和音频/语音字幕,将原始视频转换为基于语言的表示。在第二阶段,将语言描述输入到强大的推理LLM中,以解决复杂的视频语言理解任务。为了处理长上下文的多感官输入,我们采用自适应令牌缩减方案,该方案动态确定令牌的时序粒度。我们简单、模块化且无需训练的视频推理框架在Video-MME(长)、Video-MMMU(理解)、Video-MMLU、CGBench和EgoLife上取得了最佳报告结果。此外,我们针对视频推理能力的实证研究表明,尽管未对视频进行明确训练,但强大的推理LLM可以有效地聚合来自视频、语音和音频的多感官输入信息,用于复杂的时序、因果、长上下文和知识获取视频推理任务。代码可在https://github.com/CeeZh/SILVR中找到。
论文及项目相关链接
Summary
多媒体大语言模型(LLMs)在测试时间优化方面的最新进展使得解决数学和编码中的高度复杂问题成为可能。然而,多媒体LLMs的推理能力在处理复杂视频语言任务时仍存在显著滞后。为此,我们推出了基于简单语言的视频推理框架SiLVR,将复杂的视频理解分为两个阶段。第一阶段使用多媒体输入将原始视频转换为基于语言的表示形式;第二阶段将语言描述输入强大的推理LLM来解决复杂的视频语言理解任务。我们的自适应令牌缩减方案能够处理长上下文多媒体输入,动态确定令牌的时序粒度。SiLVR在多个视频基准测试中取得了最佳成绩,实证研究表明,强大的推理LLM能够有效地聚合来自视频、语音和音频的多感官输入信息,以完成复杂的时空、因果、长期知识和获取视频推理任务。
Key Takeaways
- 大型语言模型(LLMs)在测试时间优化方面取得进展,增强了解决复杂问题的能力。
- 多媒体LLMs在处理复杂视频语言任务时仍存在推理能力滞后的问题。
- SiLVR框架是一种基于简单语言的视频推理解决方案,分为两个阶段:多媒体输入的视频语言转换和强大的推理LLM的语言描述输入。
- 自适应令牌缩减方案能够处理长上下文多媒体输入。
- SiLVR在多个视频基准测试中取得了最佳成绩。
- 实证研究表明,强大的推理LLM能够聚合多感官输入信息。
点此查看论文截图


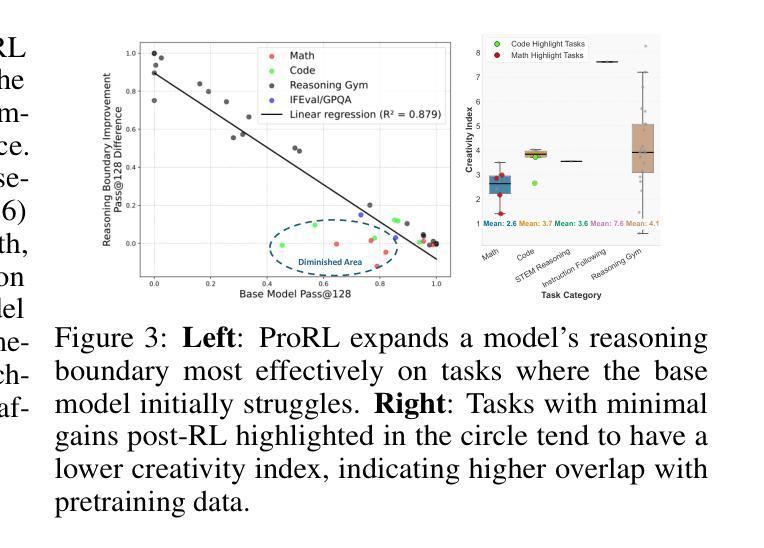
ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models
Authors:Mingjie Liu, Shizhe Diao, Ximing Lu, Jian Hu, Xin Dong, Yejin Choi, Jan Kautz, Yi Dong
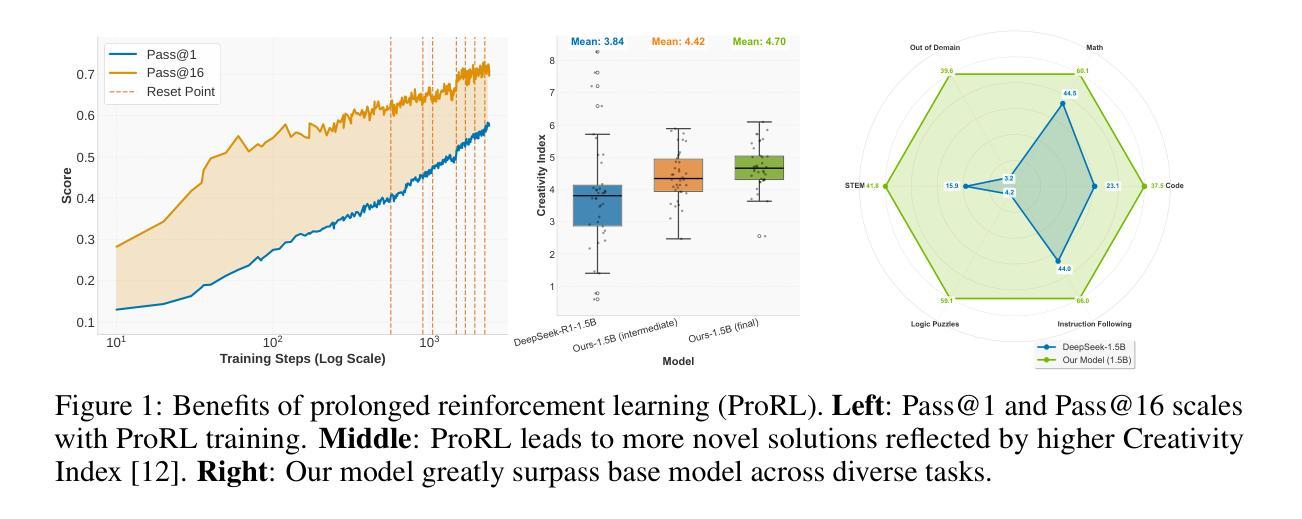
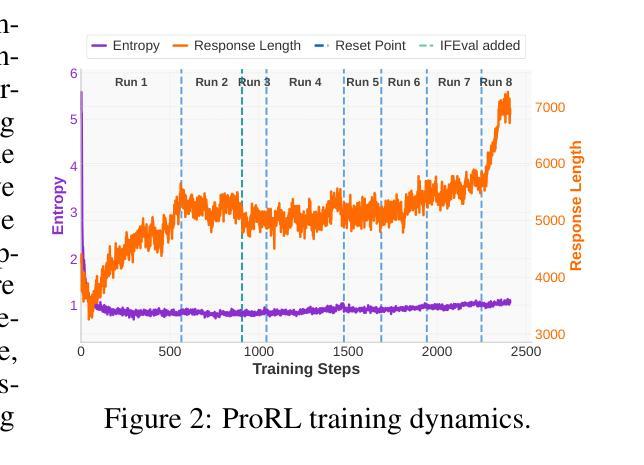
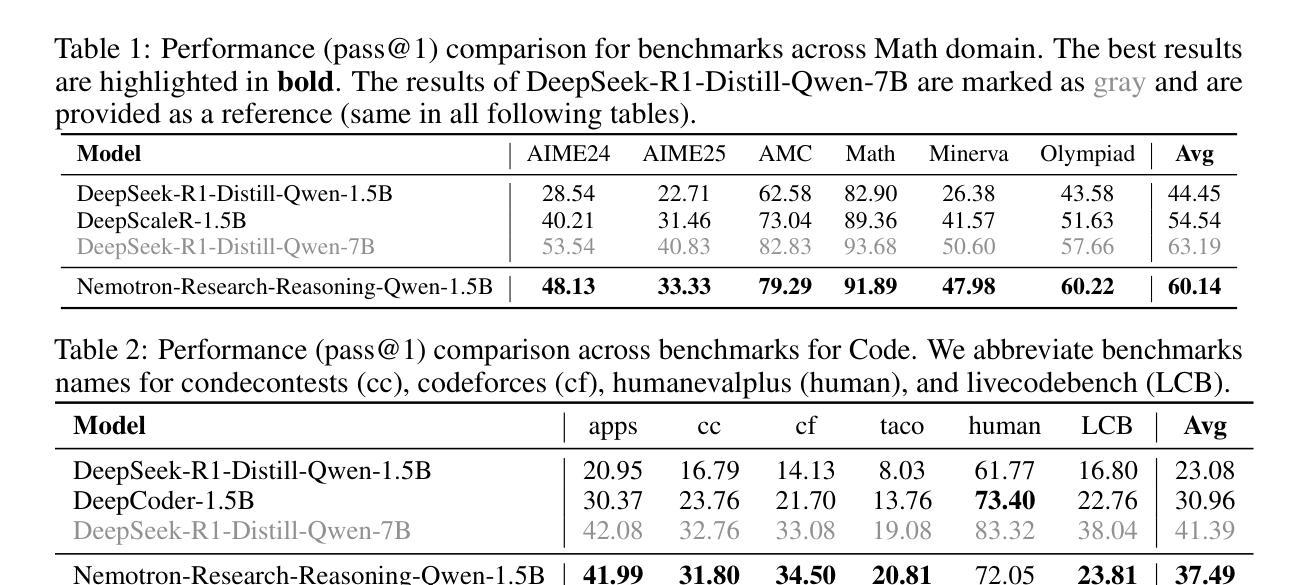
Recent advances in reasoning-centric language models have highlighted reinforcement learning (RL) as a promising method for aligning models with verifiable rewards. However, it remains contentious whether RL truly expands a model’s reasoning capabilities or merely amplifies high-reward outputs already latent in the base model’s distribution, and whether continually scaling up RL compute reliably leads to improved reasoning performance. In this work, we challenge prevailing assumptions by demonstrating that prolonged RL (ProRL) training can uncover novel reasoning strategies that are inaccessible to base models, even under extensive sampling. We introduce ProRL, a novel training methodology that incorporates KL divergence control, reference policy resetting, and a diverse suite of tasks. Our empirical analysis reveals that RL-trained models consistently outperform base models across a wide range of pass@k evaluations, including scenarios where base models fail entirely regardless of the number of attempts. We further show that reasoning boundary improvements correlates strongly with task competence of base model and training duration, suggesting that RL can explore and populate new regions of solution space over time. These findings offer new insights into the conditions under which RL meaningfully expands reasoning boundaries in language models and establish a foundation for future work on long-horizon RL for reasoning. We release model weights to support further research: https://huggingface.co/nvidia/Nemotron-Research-Reasoning-Qwen-1.5B
近年来,以推理为中心的语言模型进展突出了强化学习(RL)作为一种有前途的方法与可验证奖励对齐模型的前景。然而,强化学习是否真正扩展了模型的推理能力,或者只是放大了基础模型中已经存在的高奖励输出,以及持续扩大强化学习的计算规模是否可靠地导致推理性能的提升,这些问题仍然存在争议。在这项工作中,我们通过证明长期强化学习(ProRL)训练可以揭示基础模型无法访问的新推理策略,从而挑战了流行的假设,即使在大范围采样下也是如此。我们介绍了一种新型训练方法ProRL,它结合了KL散度控制、参考策略重置和一系列多样化的任务。我们的实证分析显示,经过强化学习训练的模型在一系列pass@k评估中始终优于基础模型,包括基础模型完全失败的场景,无论尝试次数如何。我们还发现,推理边界的改进与基础模型的任务能力和训练持续时间密切相关,这表明强化学习可以随着时间的推移探索并填充新的解决方案空间。这些发现为我们提供了在何种条件下强化学习有意义地扩展语言模型的推理边界的新见解,并为未来关于长期强化学习的推理工作奠定了基础。我们发布模型权重以支持进一步研究:https://huggingface.co/nvidia/Nemotron-Research-Reasoning-Qwen-1.5B
论文及项目相关链接
PDF 26 pages, 17 figures
Summary
强化学习在推理中心语言模型中的应用展现出了巨大潜力。本文通过ProRL训练方法揭示了RL在发掘基础模型无法获取的新推理策略上的优势。经验分析表明,RL训练的模型在多种评估场景中表现均优于基础模型,特别是在基础模型完全失败的情况下。本文建立了对未来长周期推理强化学习的研究基础。
Key Takeaways
- 强化学习(RL)被证明是一种有效方法,可以发掘基础语言模型中潜在的推理能力。
- ProRL训练方法结合了KL散度控制、参考策略重置和多样化任务,能提升模型的推理能力。
- RL训练的模型在多种评估场景中表现优异,尤其在基础模型失败的情况下。
- 推理边界的改进与基础模型的任务能力和训练时长紧密相关。
- RL能够在训练过程中探索并填充新的解决方案空间。
- 本文揭示了RL在扩大语言模型推理边界的条件下的作用,为未来的研究提供了方向。
点此查看论文截图

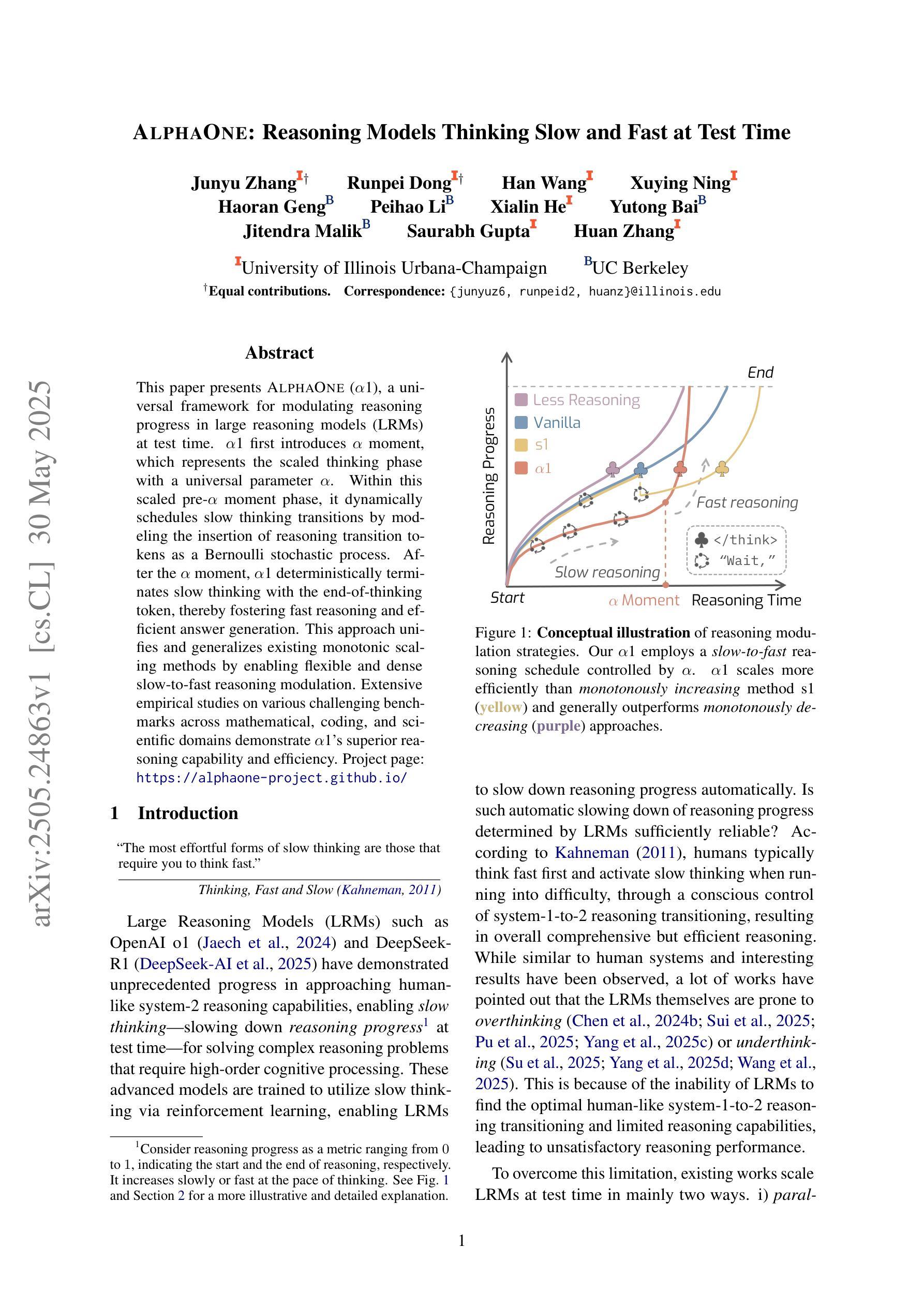
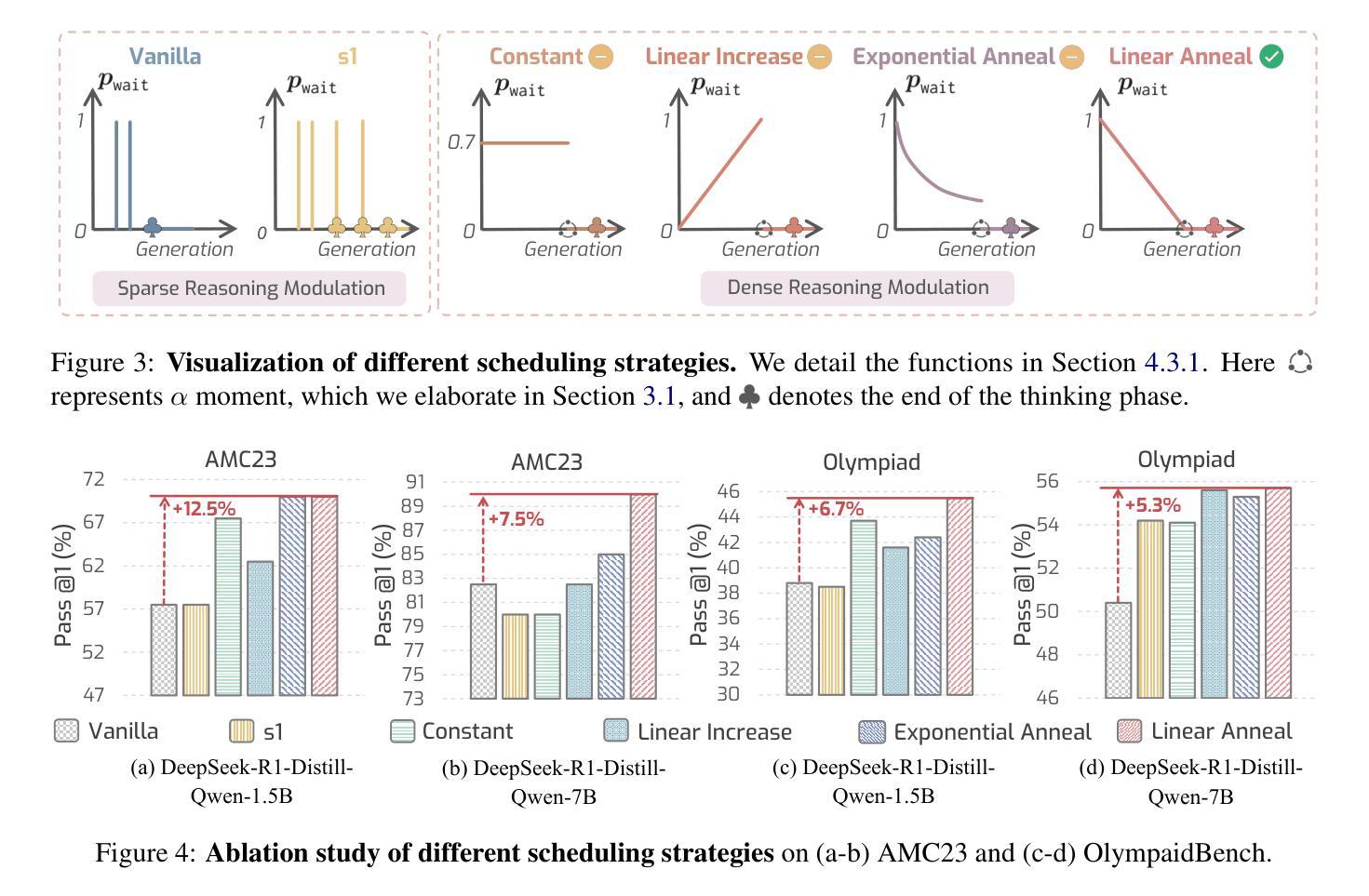
AlphaOne: Reasoning Models Thinking Slow and Fast at Test Time
Authors:Junyu Zhang, Runpei Dong, Han Wang, Xuying Ning, Haoran Geng, Peihao Li, Xialin He, Yutong Bai, Jitendra Malik, Saurabh Gupta, Huan Zhang
This paper presents AlphaOne ($\alpha$1), a universal framework for modulating reasoning progress in large reasoning models (LRMs) at test time. $\alpha$1 first introduces $\alpha$ moment, which represents the scaled thinking phase with a universal parameter $\alpha$. Within this scaled pre-$\alpha$ moment phase, it dynamically schedules slow thinking transitions by modeling the insertion of reasoning transition tokens as a Bernoulli stochastic process. After the $\alpha$ moment, $\alpha$1 deterministically terminates slow thinking with the end-of-thinking token, thereby fostering fast reasoning and efficient answer generation. This approach unifies and generalizes existing monotonic scaling methods by enabling flexible and dense slow-to-fast reasoning modulation. Extensive empirical studies on various challenging benchmarks across mathematical, coding, and scientific domains demonstrate $\alpha$1’s superior reasoning capability and efficiency. Project page: https://alphaone-project.github.io/
本文介绍了AlphaOne(α1),这是一个在测试时对大型推理模型(LRMs)的推理进度进行调制的通用框架。α1首先引入了α时刻,这代表了一个通用参数α的缩放思考阶段。在这个缩放的预α时刻阶段,它通过模拟推理过渡符号的插入,动态安排缓慢思考的转变,作为一个伯努利随机过程。在α时刻之后,α1通过思考结束符号确定性地终止缓慢思考,从而促进快速推理和高效的答案生成。这种方法通过实现灵活且密集的慢到快的推理调制,统一并概括了现有的单调缩放方法。在各种数学、编程和科学领域的基准测试上进行的广泛实证研究证明了α1的卓越推理能力和效率。项目页面:https://alphaone-project.github.io/
论文及项目相关链接
Summary
AlphaOne框架用于在测试时对大型推理模型(LRMs)的推理过程进行调制。它引入了α时刻来代表通过通用参数α进行缩放思考阶段。在此缩放预α时刻阶段,它通过对推理过渡标记的插入进行伯努利随机过程建模来实现动态安排慢速思考过渡。在α时刻后,AlphaOne通过终止思考标记确定性地推动快速推理和高效答案生成。该方法统一并推广了现有的单调缩放方法,实现了灵活且密集的慢到快的推理调制。对多个基准测试领域的广泛实证研究证明了AlphaOne在推理能力和效率上的优势。
Key Takeaways
- AlphaOne是一个通用的框架,用于在测试时调整大型推理模型的推理过程。
- 引入α时刻代表通过通用参数α进行的缩放思考阶段。
- 在预α时刻阶段,通过伯努利随机过程建模推理过渡标记的插入,实现动态安排慢速思考过渡。
- AlphaOne通过终止思考标记来推动快速推理和高效答案生成。
- AlphaOne统一并推广了现有的单调缩放方法,允许灵活且密集的慢到快的推理调制。
- AlphaOne框架在多个基准测试领域展现出卓越的推理能力和效率。
点此查看论文截图

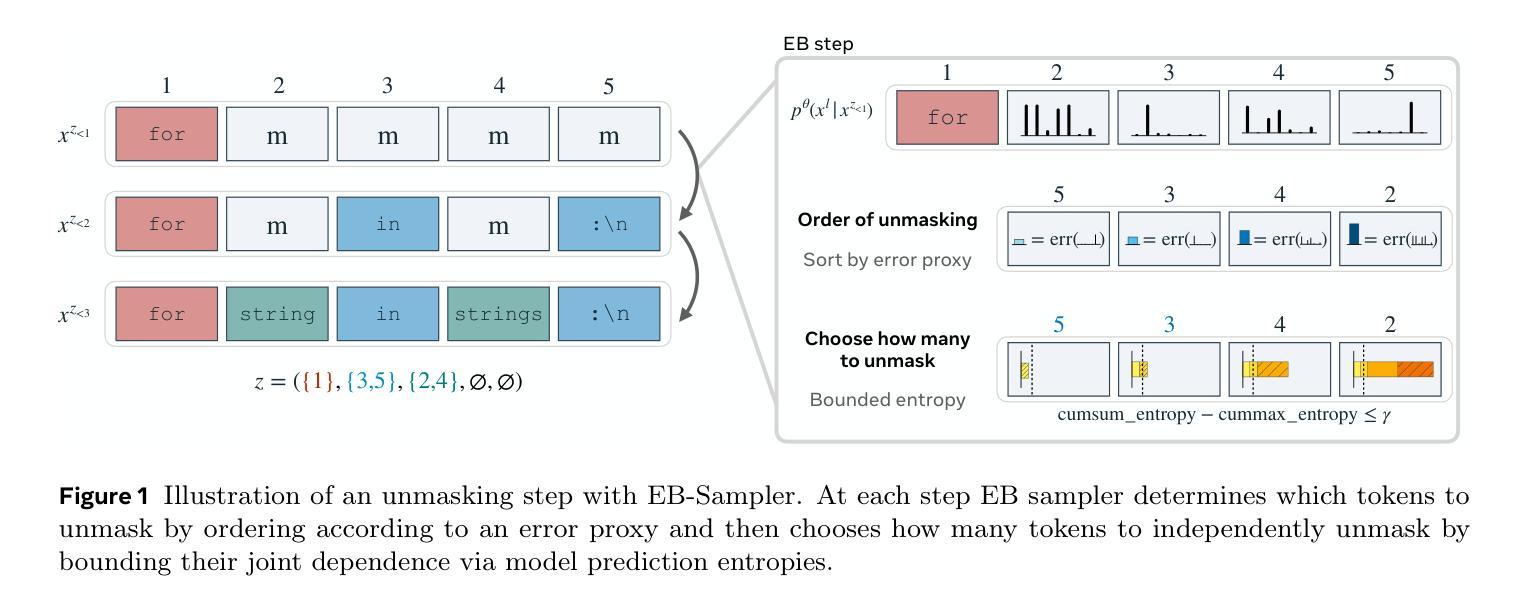
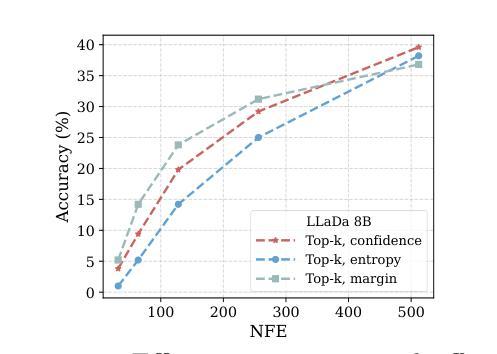
Accelerated Sampling from Masked Diffusion Models via Entropy Bounded Unmasking
Authors:Heli Ben-Hamu, Itai Gat, Daniel Severo, Niklas Nolte, Brian Karrer
Recent masked diffusion models (MDMs) have shown competitive performance compared to autoregressive models (ARMs) for language modeling. While most literature has focused on performance enhancing sampling procedures, efficient sampling from MDMs has been scarcely explored. We make the observation that often a given sequence of partially masked tokens determines the values of multiple unknown tokens deterministically, meaning that a single prediction of a masked model holds additional information unused by standard sampling procedures. Based on this observation, we introduce EB-Sampler, a simple drop-in replacement for existing samplers, utilizing an Entropy Bounded unmasking procedure that dynamically unmasks multiple tokens in one function evaluation with predefined approximate error tolerance. We formulate the EB-Sampler as part of a broad family of adaptive samplers for which we provide an error analysis that motivates our algorithmic choices. EB-Sampler accelerates sampling from current state of the art MDMs by roughly 2-3x on standard coding and math reasoning benchmarks without loss in performance. We also validate the same procedure works well on smaller reasoning tasks including maze navigation and Sudoku, tasks ARMs often struggle with.
近期的掩码扩散模型(MDMs)在语言建模方面展现了与自回归模型(ARMs)相竞争的性能。尽管大多数文献都集中于提高采样程序性能,但很少探索MDMs的高效采样。我们观察到,给定的部分掩码令牌序列经常确定性地决定了多个未知令牌的值,这意味着掩码模型的一个预测包含了标准采样程序未使用的额外信息。基于此观察,我们引入了EB-Sampler,这是一个简单的现有采样器的替代产品,它利用熵有界解掩码程序,在一个函数评估中动态解掩多个令牌,具有预设的近似误差容忍度。我们将EB-Sampler制定为广泛自适应采样器家族的一部分,并提供了误差分析,以证明我们的算法选择。EB-Sampler在不损失性能的情况下,加速了对当前最先进的MDMs的采样,在标准编码和数学推理基准测试上的速度大约提高了2-3倍。我们还验证了该相同程序在小规模推理任务上表现良好,包括迷宫导航和数独等ARMs经常面临困难的任务。
论文及项目相关链接
Summary
近期,掩码扩散模型(MDMs)在语言建模方面展现出与自回归模型(ARMs)相当的竞争力。尽管多数文献聚焦于提高采样程序性能,但很少有人探索MDMs的高效采样。基于观察到的特定掩码序列可确定性地决定多个未知标记的值这一事实,我们引入了EB-Sampler,这是一个简单的现有采样器的替代方案,它采用熵边界解掩过程,可在一次函数评估中动态地揭示多个标记的近似误差容忍度。我们制定了广泛的自适应采样器家族中的EB-Sampler,并提供了误差分析来支持我们的算法选择。在标准编码和数学推理基准测试中,EB-Sampler将当前最先进的MDMs的采样速度提高了大约2-3倍,同时不损失性能。我们还验证了同样的程序在迷宫导航和数独等小型推理任务上也表现良好,这些任务对于ARMs来说常常是一项挑战。
Key Takeaways
- 掩码扩散模型(MDMs)与自回归模型(ARMs)在语言建模方面表现相当。
- 现有文献多关注性能提升采样程序,但对MDMs的高效采样研究较少。
- EB-Sampler是基于观察到特定掩码序列可决定多个未知标记值的发现而设计的。
- EB-Sampler是现有采样器的简单替代方案,采用熵边界解掩过程。
- EB-Sampler在标准编码和数学推理基准测试中加速采样速度达2-3倍。
- EB-Sampler在小型推理任务上表现良好,尤其适用于迷宫导航和数独等任务。
点此查看论文截图


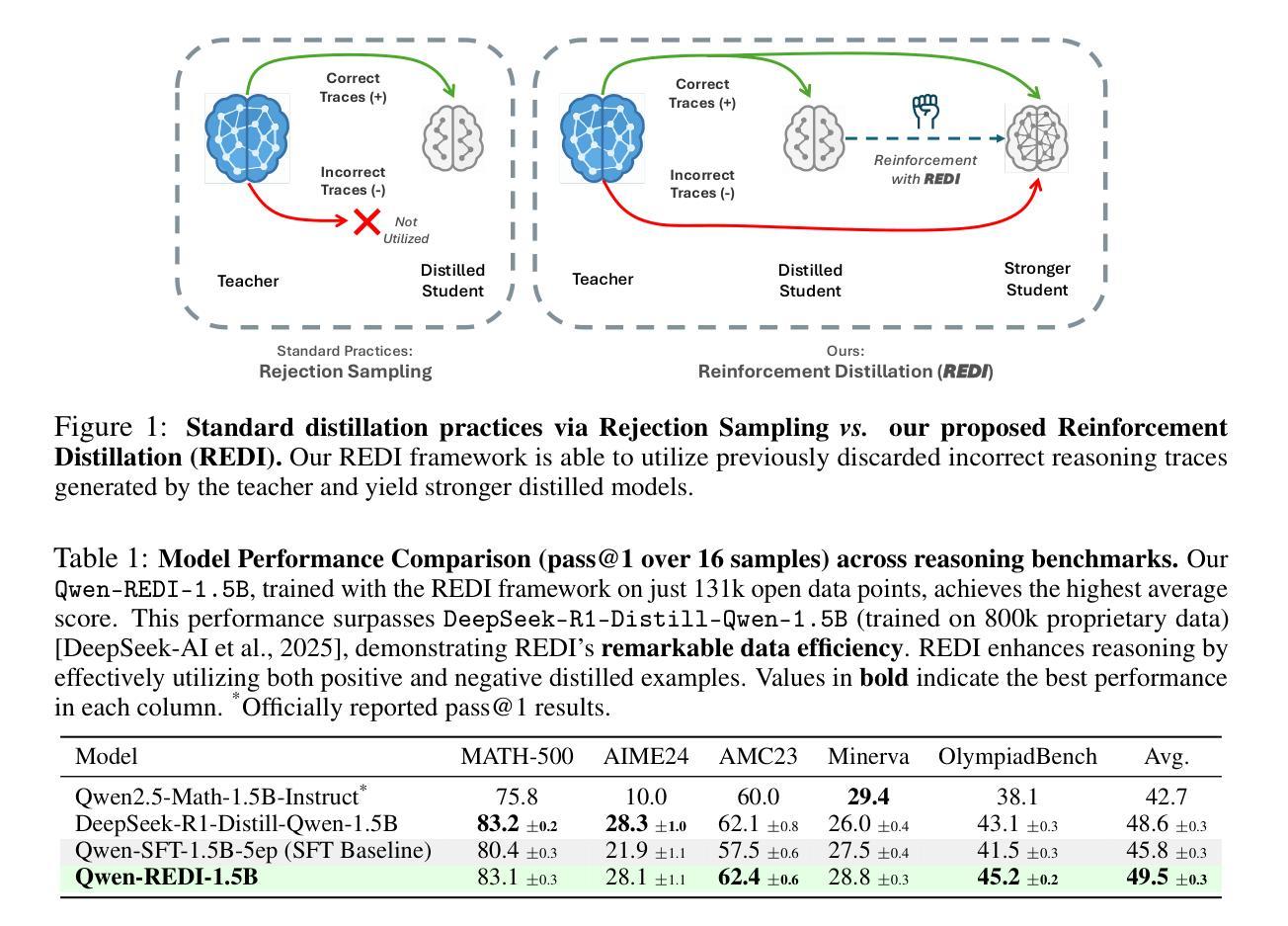
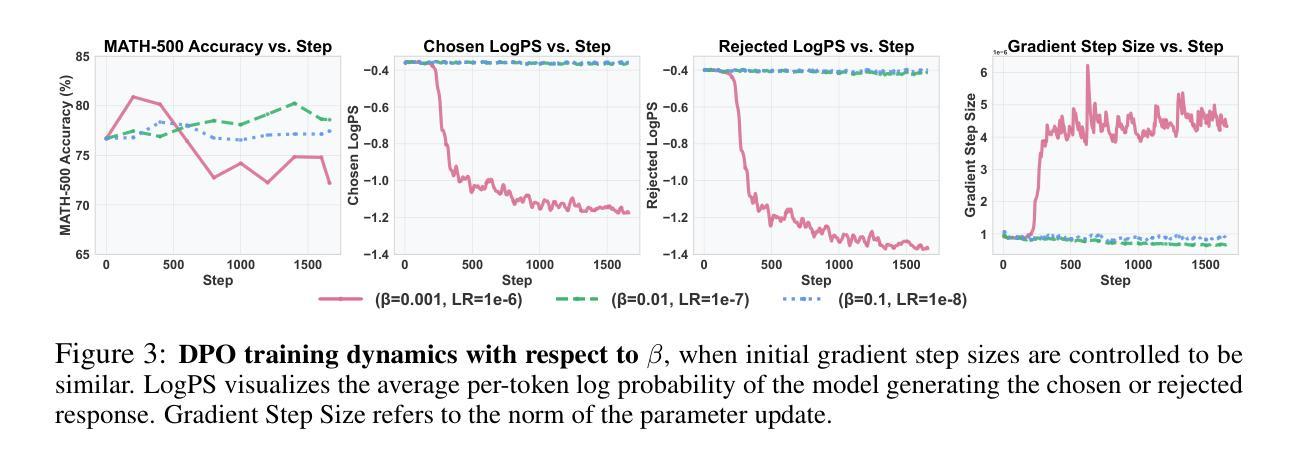
Harnessing Negative Signals: Reinforcement Distillation from Teacher Data for LLM Reasoning
Authors:Shuyao Xu, Cheng Peng, Jiangxuan Long, Weidi Xu, Wei Chu, Yuan Qi
Recent advances in model distillation demonstrate that data from advanced reasoning models (e.g., DeepSeek-R1, OpenAI’s o1) can effectively transfer complex reasoning abilities to smaller, efficient student models. However, standard practices employ rejection sampling, discarding incorrect reasoning examples – valuable, yet often underutilized data. This paper addresses the critical question: How can both positive and negative distilled reasoning traces be effectively leveraged to maximize LLM reasoning performance in an offline setting? To this end, We propose Reinforcement Distillation (REDI), a two-stage framework. Stage 1 learns from positive traces via Supervised Fine-Tuning (SFT). Stage 2 further refines the model using both positive and negative traces through our proposed REDI objective. This novel objective is a simple, reference-free loss function that outperforms established methods like DPO and SimPO in this distillation context. Our empirical evaluations demonstrate REDI’s superiority over baseline Rejection Sampling SFT or SFT combined with DPO/SimPO on mathematical reasoning tasks. Notably, the Qwen-REDI-1.5B model, post-trained on just 131k positive and negative examples from the open Open-R1 dataset, achieves an 83.1% score on MATH-500 (pass@1). Its performance matches or surpasses that of DeepSeek-R1-Distill-Qwen-1.5B (a model post-trained on 800k proprietary data) across various mathematical reasoning benchmarks, establishing a new state-of-the-art for 1.5B models post-trained offline with openly available data.
最近模型蒸馏领域的进展表明,来自先进推理模型(例如DeepSeek-R1、OpenAI的o1)的数据可以有效地将复杂的推理能力转移到更小、更高效的学生模型。然而,标准实践采用拒绝采样,丢弃错误的推理示例——这些示例虽然宝贵,但往往未得到充分利用。本文旨在解决一个关键问题:如何有效地利用正面和负面的蒸馏推理痕迹,以最大化离线设置中大型语言模型(LLM)的推理性能?为此,我们提出了强化蒸馏(REDI)这一两阶段框架。第一阶段通过监督微调(SFT)从正面痕迹中学习。第二阶段则进一步使用我们提出的REDI目标,通过正面和负面痕迹对模型进行精炼。这一新颖目标是一个简单、无参考的损失函数,在蒸馏环境中优于DPO和SimPO等既定方法。我们的经验评估表明,在数学推理任务方面,REDI相较于基线拒绝采样SFT或结合DPO/SimPO的SFT具有优越性。值得注意的是,仅对来自公开Open-R1数据集的13.1万正面和负面示例进行训练的Qwen-REDI-1.5B模型,在MATH-500(pass@1)上得分达到83.1%。其性能在多个数学推理基准测试中与DeepSeek-R1-Distill-Qwen-1.5B(一个用80万专有数据后训练的模型)相匹配或表现更佳,为使用公开数据离线后训练的1.5B模型建立了新的最先进的水平。
论文及项目相关链接
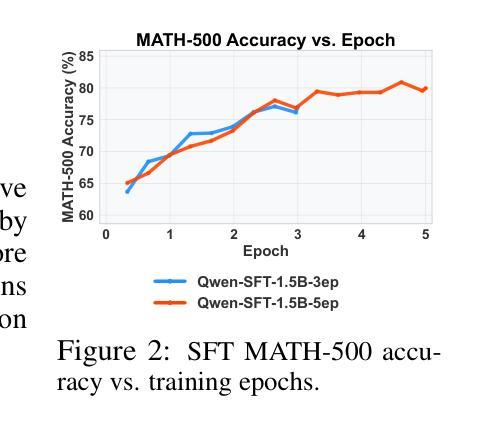
PDF 27 pages, 10 figures. Code available at https://github.com/Tim-Siu/reinforcement-distillation
摘要
大模型推理能力有效转移至小模型。通常丢弃错误推理样本,未能充分利用。本文旨在有效利用正负面推理痕迹提升模型离线推理性能。为此,提出强化蒸馏(REDI)框架,分为两个阶段学习。第一阶段通过监督微调(SFT)学习正面痕迹;第二阶段使用正负面痕迹进一步优化模型。REDI目标函数简单无参考,在蒸馏环境下优于DPO和SimPO等方法。实验评估显示,REDI在数学推理任务上优于拒绝采样SFT或结合DPO/SimPO的方法。使用公开Open-R1数据集的正负面例子训练的Qwen-REDI-1.5B模型,在MATH-500任务上得分83.1%,性能匹配或超越使用专有数据训练的模型,成为使用公开数据离线训练的1.5B模型的新基准。
关键见解
- 模型蒸馏的最新进展显示,高级推理模型(如DeepSeek-R1,OpenAI的o1)的数据可有效转移复杂推理能力至小型、高效的学生模型。
- 拒绝采样是标准实践,丢弃错误的推理例子,这些例子虽然有价值但经常被忽视。
- 本文旨在有效利用正负面推理痕迹提升模型离线推理性能,提出强化蒸馏(REDI)框架。
- REDI框架包含两个阶段:第一阶段通过监督微调(SFT)学习正面痕迹;第二阶段结合正负面痕迹进一步优化模型。
- REDI框架采用一种新的无参考损失函数,即REDI目标函数,它在蒸馏环境中表现出优越性能,优于DPO和SimPO等方法。
- 实验结果表明,REDI在数学推理任务上的性能优于基于拒绝采样的SFT或结合DPO/SimPO的方法。
- 使用公开数据集Open-R1的正负面例子训练的Qwen-REDI-1.5B模型表现出卓越性能,达到新的基准水平。
点此查看论文截图

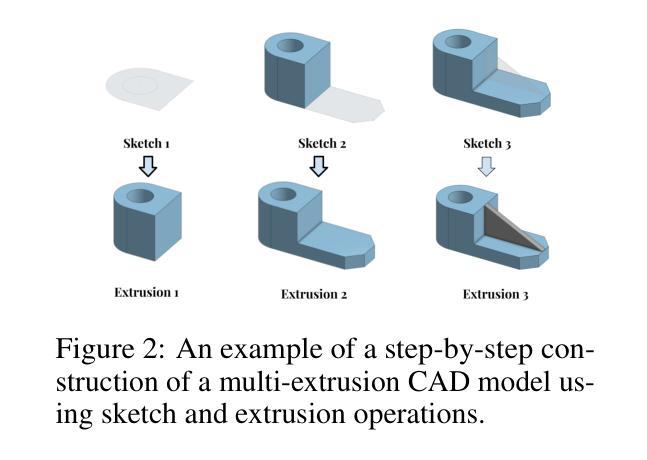
VideoCAD: A Large-Scale Video Dataset for Learning UI Interactions and 3D Reasoning from CAD Software
Authors:Brandon Man, Ghadi Nehme, Md Ferdous Alam, Faez Ahmed
Computer-Aided Design (CAD) is a time-consuming and complex process, requiring precise, long-horizon user interactions with intricate 3D interfaces. While recent advances in AI-driven user interface (UI) agents show promise, most existing datasets and methods focus on short, low-complexity tasks in mobile or web applications, failing to capture the demands of professional engineering tools. In this work, we introduce VideoCAD, the first attempt at engineering UI interaction learning for precision tasks. Specifically, VideoCAD is a large-scale synthetic dataset consisting of over 41K annotated video recordings of CAD operations, generated using an automated framework for collecting high-fidelity UI action data from human-made CAD designs. Compared to existing datasets, VideoCAD offers an order of magnitude higher complexity in UI interaction learning for real-world engineering tasks, having up to a 20x longer time horizon than other datasets. We show two important downstream applications of VideoCAD: learning UI interactions from professional precision 3D CAD tools and a visual question-answering (VQA) benchmark designed to evaluate multimodal large language models’ (LLM) spatial reasoning and video understanding abilities. To learn the UI interactions, we propose VideoCADFormer - a state-of-the-art model in learning CAD interactions directly from video, which outperforms multiple behavior cloning baselines. Both VideoCADFormer and the VQA benchmark derived from VideoCAD reveal key challenges in the current state of video-based UI understanding, including the need for precise action grounding, multi-modal and spatial reasoning, and long-horizon dependencies.
计算机辅助设计(CAD)是一个耗时且复杂的过程,需要用户与复杂的3D界面进行精确、长期的交互。尽管最近人工智能驱动的用户界面(UI)智能体的进步显示出潜力,但大多数现有数据集和方法都专注于移动或网页应用中的短期、低复杂性任务,无法捕捉专业工程工具的需求。在这项工作中,我们引入了VideoCAD,这是首次尝试为精密任务进行工程用户界面交互学习。具体来说,VideoCAD是一个大规模合成数据集,包含超过41K个经注释的CAD操作视频记录,这些记录是通过自动化框架从人为设计的CAD中收集高保真UI动作数据生成的。与现有数据集相比,VideoCAD在现实世界工程任务的UI交互学习中提供了更高复杂度的数据,时间跨度比其他数据集长达20倍。我们展示了VideoCAD的两个重要下游应用:从专业精密3D CAD工具学习UI交互和一个旨在评估多模式大型语言模型(LLM)空间推理和视频理解能力的视觉问答(VQA)基准测试。为了学习UI交互,我们提出了VideoCADFormer——一个直接从视频中学习CAD交互的最新模型,它超越了多个行为克隆基线。VideoCADFormer以及从VideoCAD衍生的VQA基准测试揭示了当前视频型用户界面理解的关键挑战,包括精确动作定位、多模态和空间推理以及长期依赖关系的需求。
论文及项目相关链接
Summary
本文介绍了Computer-Aided Design(CAD)过程中用户界面的复杂性和时间成本高昂的问题。针对此,研究者引入了VideoCAD,一个针对精密任务进行工程用户界面交互学习的大型合成数据集。VideoCAD包含超过41K个经过注释的CAD操作视频记录,具有比其他数据集高出一个数量级的复杂性。此外,文章还介绍了VideoCAD的两个重要下游应用:从专业精密3D CAD工具学习用户界面交互以及设计用于评估多模态大型语言模型的空间推理和视频理解能力的视觉问答基准测试。为了学习用户界面交互,研究者提出了VideoCADFormer模型,该模型能够直接从视频中学习CAD交互,并超越了多个行为克隆基准测试。
Key Takeaways
- VideoCAD是一个大型合成数据集,专注于工程用户界面交互学习,针对精密任务设计。
- VideoCAD包含超过41K个注释的视频记录,展示CAD操作,具有显著的高复杂性和长时间跨度。
- VideoCAD提供了两个重要的下游应用:从专业精密3D CAD工具学习UI交互和一个视觉问答基准测试。
- VideoCAD揭示了当前视频用户界面理解的关键挑战,包括精确动作定位、多模态和空间推理以及长期依赖关系。
- VideoCAD的复杂性和大规模数据集可以促进AI驱动的用户界面代理的发展和改进。
- VideoCAD和VideoCADFormer模型的提出为工程工具中的用户界面交互学习提供了新的可能性。
点此查看论文截图


LegalEval-Q: A New Benchmark for The Quality Evaluation of LLM-Generated Legal Text
Authors:Li yunhan, Wu gengshen
As large language models (LLMs) are increasingly used in legal applications, current evaluation benchmarks tend to focus mainly on factual accuracy while largely neglecting important linguistic quality aspects such as clarity, coherence, and terminology. To address this gap, we propose three steps: First, we develop a regression model to evaluate the quality of legal texts based on clarity, coherence, and terminology. Second, we create a specialized set of legal questions. Third, we analyze 49 LLMs using this evaluation framework. Our analysis identifies three key findings: First, model quality levels off at 14 billion parameters, with only a marginal improvement of $2.7%$ noted at 72 billion parameters. Second, engineering choices such as quantization and context length have a negligible impact, as indicated by statistical significance thresholds above 0.016. Third, reasoning models consistently outperform base architectures. A significant outcome of our research is the release of a ranking list and Pareto analysis, which highlight the Qwen3 series as the optimal choice for cost-performance tradeoffs. This work not only establishes standardized evaluation protocols for legal LLMs but also uncovers fundamental limitations in current training data refinement approaches. Code and models are available at: https://github.com/lyxx3rd/LegalEval-Q.
随着大型语言模型(LLM)在法律应用中的使用越来越普遍,当前的评估基准通常主要关注事实准确性,而很大程度上忽视了重要的语言质量方面,例如清晰度、连贯性和术语。为了弥补这一空白,我们提出了三个步骤:首先,我们开发了一个回归模型,基于清晰度、连贯性和术语来评估法律文本的质量。其次,我们创建了一套专门的法律问题。最后,我们使用此评估框架分析了49个LLM。我们的分析得出了三个关键发现:首先,模型质量在14亿参数时达到稳定水平,仅在72亿参数时注意到有2.7%的轻微改进。其次,工程选择如量化和上下文长度的影响微乎其微,如统计显著性阈值高于0.016所示。第三,推理模型始终优于基础架构。我们研究的一个重要成果是发布排名列表和帕累托分析,这突出了Qwen3系列在成本性能权衡方面的最佳选择。这项工作不仅为法律LLM建立了标准化的评估协议,还揭示了当前训练数据改进方法的基本局限性。代码和模型可在:lyxx3rd/LegalEval-Q获取。
论文及项目相关链接
PDF 10 pages, 11 figures
Summary
基于大型语言模型(LLM)在法律应用中的评价现状,研究团队提出了一种新的评估框架来解决当前主要聚焦于事实准确性而忽视语言质量的问题。该框架包含三个步骤:开发回归模型评估法律文本质量、创建专业法律问题集、使用此框架分析49个LLM。研究发现模型质量在14亿参数时趋于稳定,工程选择如量化和上下文长度影响甚微,而推理模型表现较基础架构更优。代码和模型已公开。
Key Takeaways
- 大型语言模型(LLM)在法律应用中的评价目前主要关注事实准确性,但忽略了语言质量如清晰度、连贯性和术语使用等方面的重要性。
- 研究团队提出了一个包含三个步骤的新评估框架来解决这一问题。
- 开发了一个基于清晰度、连贯性和术语使用的回归模型来评估法律文本质量。
- 创建了专门用于法律问题的集合。
- 对49个LLM进行了分析,发现模型质量在达到一定参数数量后趋于稳定,工程选择如量化和上下文长度对模型性能影响较小。
- 推理模型的表现优于基础架构。
点此查看论文截图


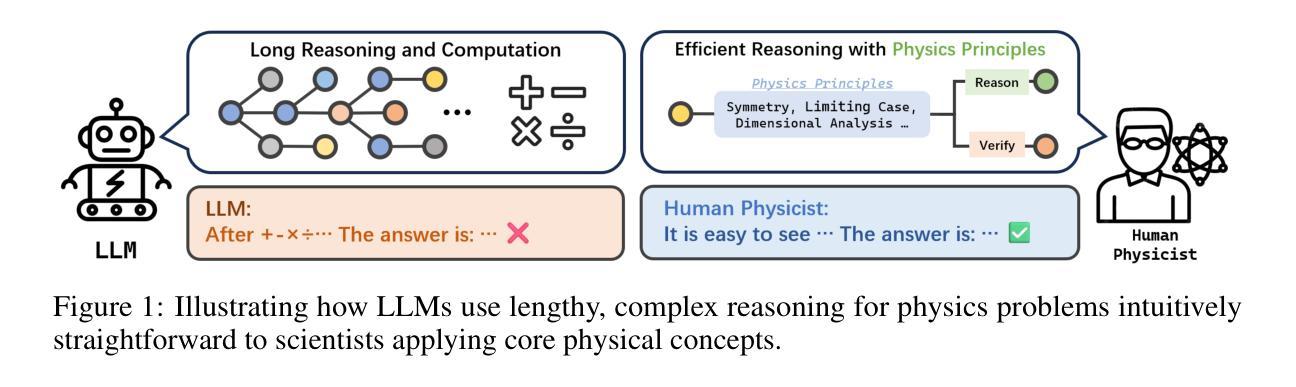
PhySense: Principle-Based Physics Reasoning Benchmarking for Large Language Models
Authors:Yinggan Xu, Yue Liu, Zhiqiang Gao, Changnan Peng, Di Luo
Large language models (LLMs) have rapidly advanced and are increasingly capable of tackling complex scientific problems, including those in physics. Despite this progress, current LLMs often fail to emulate the concise, principle-based reasoning characteristic of human experts, instead generating lengthy and opaque solutions. This discrepancy highlights a crucial gap in their ability to apply core physical principles for efficient and interpretable problem solving. To systematically investigate this limitation, we introduce PhySense, a novel principle-based physics reasoning benchmark designed to be easily solvable by experts using guiding principles, yet deceptively difficult for LLMs without principle-first reasoning. Our evaluation across multiple state-of-the-art LLMs and prompt types reveals a consistent failure to align with expert-like reasoning paths, providing insights for developing AI systems with efficient, robust and interpretable principle-based scientific reasoning.
大型语言模型(LLM)迅速进步,越来越能够解决复杂的科学问题,包括物理问题。尽管取得了这一进展,但当前的LLM通常无法模仿人类专家的简洁、基于原则推理的特点,而是生成冗长且不透明的解决方案。这种差异凸显了它们在应用核心物理原理进行有效和可解释的问题解决方面的能力存在关键差距。为了系统地研究这一局限性,我们引入了PhySense,这是一个基于新型原则的物理学推理基准测试,它易于专家使用指导原则解决,但对没有首先遵循原则的LLM来说却具有欺骗性难度。我们在多个最先进LLM和提示类型上的评估显示,它们无法与专家式的推理路径保持一致,这为开发具有高效、稳健和可解释基于原则的科学推理的AI系统提供了见解。
论文及项目相关链接
Summary
大型语言模型(LLMs)在解决复杂的科学问题,包括物理问题方面取得了快速进展。然而,它们往往无法像人类专家一样进行简洁、基于原则的推理。为解决这一问题,我们引入了PhySense,一个基于原则的物理推理基准测试,旨在通过引导原则让专家轻松解决,但对LLMs来说却具有挑战性。评估发现,最先进的LLMs和提示类型都无法与专家级的推理路径对齐,这为开发具有高效、稳健和可解释性的基于原则的科学推理的AI系统提供了见解。
Key Takeaways
- 大型语言模型(LLMs)在解决复杂的科学问题方面取得了进展,包括物理问题。
- LLMs在模拟人类专家的基于原则的简洁推理方面存在差距。
- 为解决这一差距,引入了PhySense,一个基于原则的物理推理基准测试。
- PhySense测试旨在让专家通过引导原则轻松解决,但对LLMs来说具有挑战性。
- 对多个最先进的LLMs和提示类型的评估显示,它们无法与专家级的推理路径对齐。
- 这一发现为开发具有高效、稳健和可解释性的基于原则的科学推理的AI系统提供了方向。
点此查看论文截图

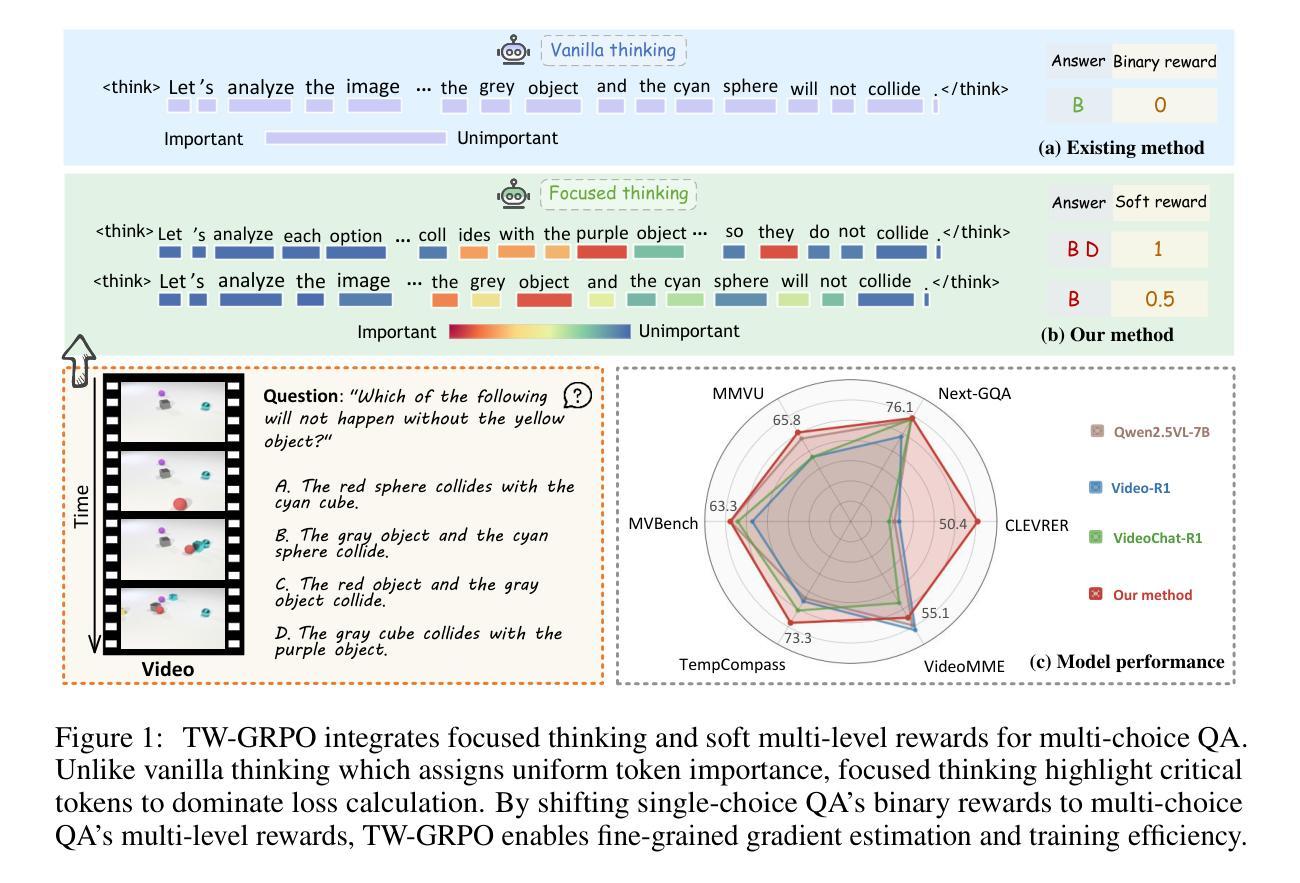
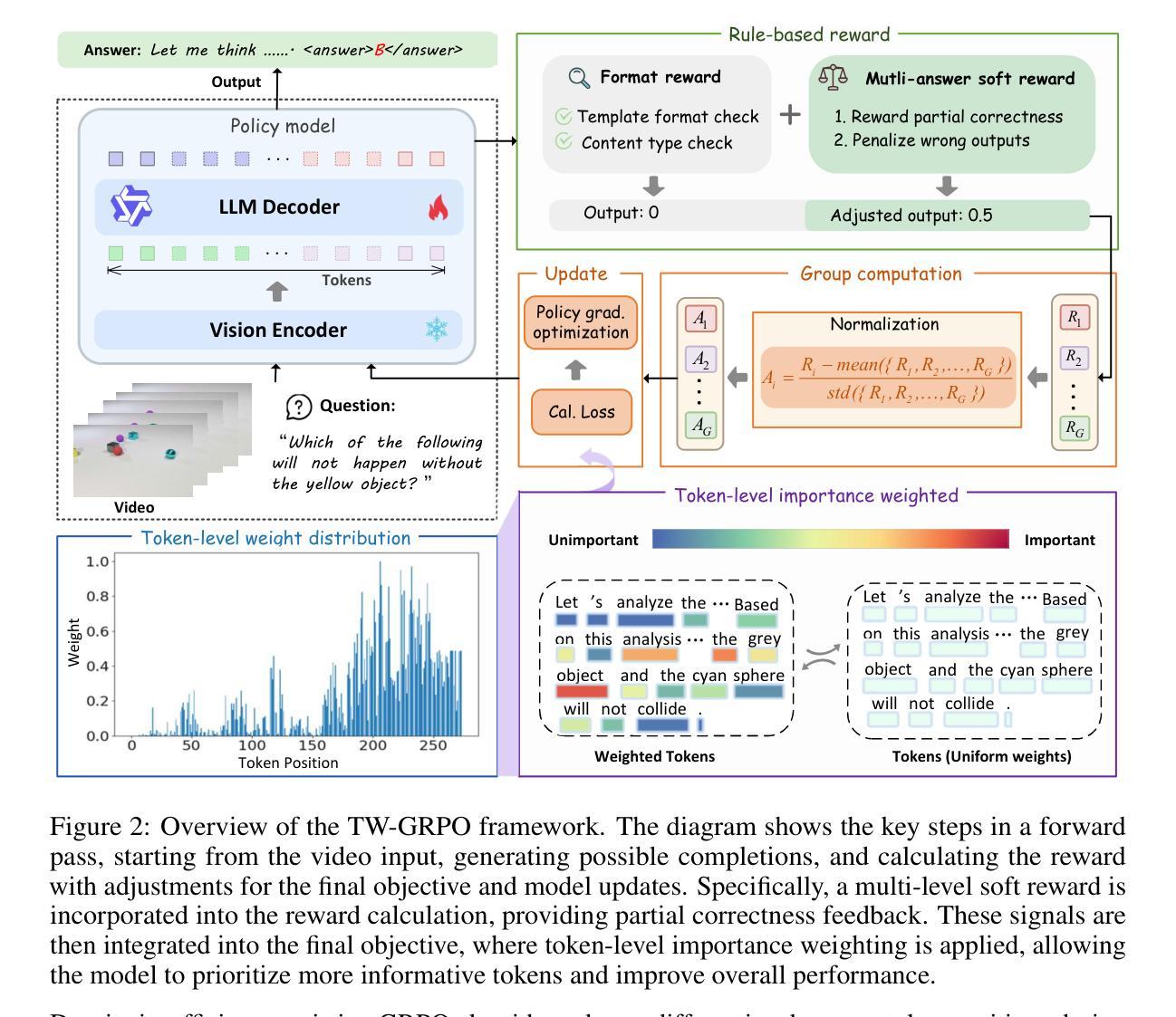
Reinforcing Video Reasoning with Focused Thinking
Authors:Jisheng Dang, Jingze Wu, Teng Wang, Xuanhui Lin, Nannan Zhu, Hongbo Chen, Wei-Shi Zheng, Meng Wang, Tat-Seng Chua
Recent advancements in reinforcement learning, particularly through Group Relative Policy Optimization (GRPO), have significantly improved multimodal large language models for complex reasoning tasks. However, two critical limitations persist: 1) they often produce unfocused, verbose reasoning chains that obscure salient spatiotemporal cues and 2) binary rewarding fails to account for partially correct answers, resulting in high reward variance and inefficient learning. In this paper, we propose TW-GRPO, a novel framework that enhances visual reasoning with focused thinking and dense reward granularity. Specifically, we employs a token weighting mechanism that prioritizes tokens with high informational density (estimated by intra-group variance), suppressing redundant tokens like generic reasoning prefixes. Furthermore, we reformulate RL training by shifting from single-choice to multi-choice QA tasks, where soft rewards enable finer-grained gradient estimation by distinguishing partial correctness. Additionally, we propose question-answer inversion, a data augmentation strategy to generate diverse multi-choice samples from existing benchmarks. Experiments demonstrate state-of-the-art performance on several video reasoning and general understanding benchmarks. Notably, TW-GRPO achieves 50.4% accuracy on CLEVRER (18.8% improvement over Video-R1) and 65.8% on MMVU. Our codes are available at \href{https://github.com/longmalongma/TW-GRPO}{https://github.com/longmalongma/TW-GRPO}.
近期强化学习领域的进展,特别是通过群体相对策略优化(GRPO)的应用,已经显著改进了用于复杂推理任务的多模态大型语言模型。然而,还有两个关键局限:1)它们经常产生不聚焦、冗长的推理链,掩盖了重要的时空线索;2)二元奖励无法考虑部分正确的答案,导致奖励方差高和学习效率低下。在本文中,我们提出了TW-GRPO,这是一种增强视觉推理的新框架,具有聚焦思考和密集的奖励粒度。具体来说,我们采用了一种令牌加权机制,优先处理具有高信息密度的令牌(由组内方差估计),同时抑制冗余令牌,如通用推理前缀。此外,我们通过将选择题改为多选题问答任务来改革强化学习训练,其中软奖励能够通过区分部分正确性来进行更精细的梯度估计。另外,我们还提出了问答反转,这是一种数据增强策略,可以从现有基准测试中生成多样化的多选择样本。实验证明,我们在多个视频推理和通用理解基准测试上达到了最先进的性能。值得注意的是,TW-GRPO在CLEVRER上实现了50.4%的准确率(相对于Video-R1提高了18.8%),在MMVU上实现了65.8%的准确率。我们的代码可以在https://github.com/longmalongma/TW-GRPO找到。
论文及项目相关链接
Summary
强化学习在集团相对策略优化(GRPO)方面的最新进展已经极大地提升了多模态大型语言模型在复杂推理任务上的表现。然而,还存在两个关键局限性:一是生成的推理链通常缺乏重点且冗长,难以凸显时空线索;二是二元奖励机制无法应对部分正确的情况,导致奖励方差大且学习效率低下。针对这些问题,本文提出了TW-GRPO框架,通过标记权重机制强化视觉推理的聚焦思考,并细化奖励粒度。实验证明,该框架在视频推理和通用理解等多个基准测试中表现卓越,如在CLEVRER上达到了50.4%的准确率(相较于Video-R1提升18.8%),在MMVU上达到了65.8%。相关代码已上传至https://github.com/longmalongma/TW-GRPO。
Key Takeaways
- 强化学习通过集团相对策略优化(GRPO)在多模态语言模型的复杂推理任务中取得了进展。
- 当前方法存在两个主要局限性:生成推理链不聚焦和奖励机制对部分正确情况处理不足。
- TW-GRPO框架通过标记权重机制提升视觉推理的聚焦思考,并细化奖励粒度以应对上述问题。
- TW-GRPO在多个基准测试中表现卓越,如CLEVRER和MMVU。
- 该方法实现了更高的准确率,相较于Video-R1在CLEVRER上有显著的提升。
- 提出的框架具有潜力推动视觉推理任务的发展。
点此查看论文截图

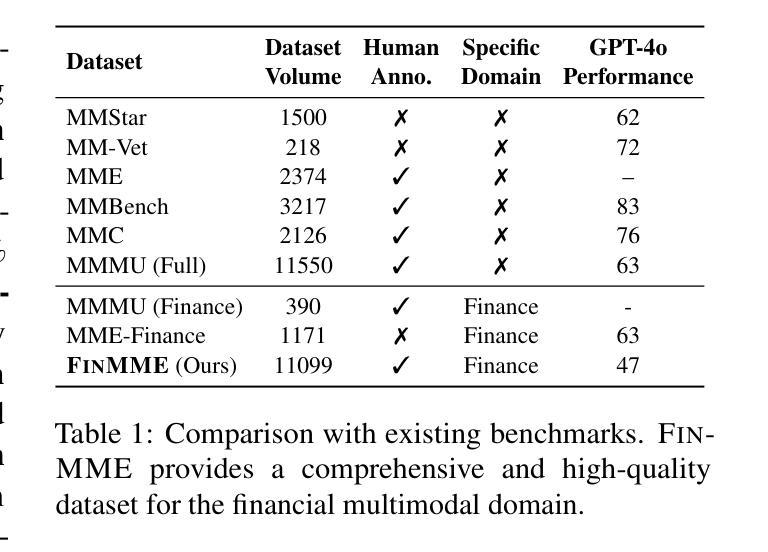
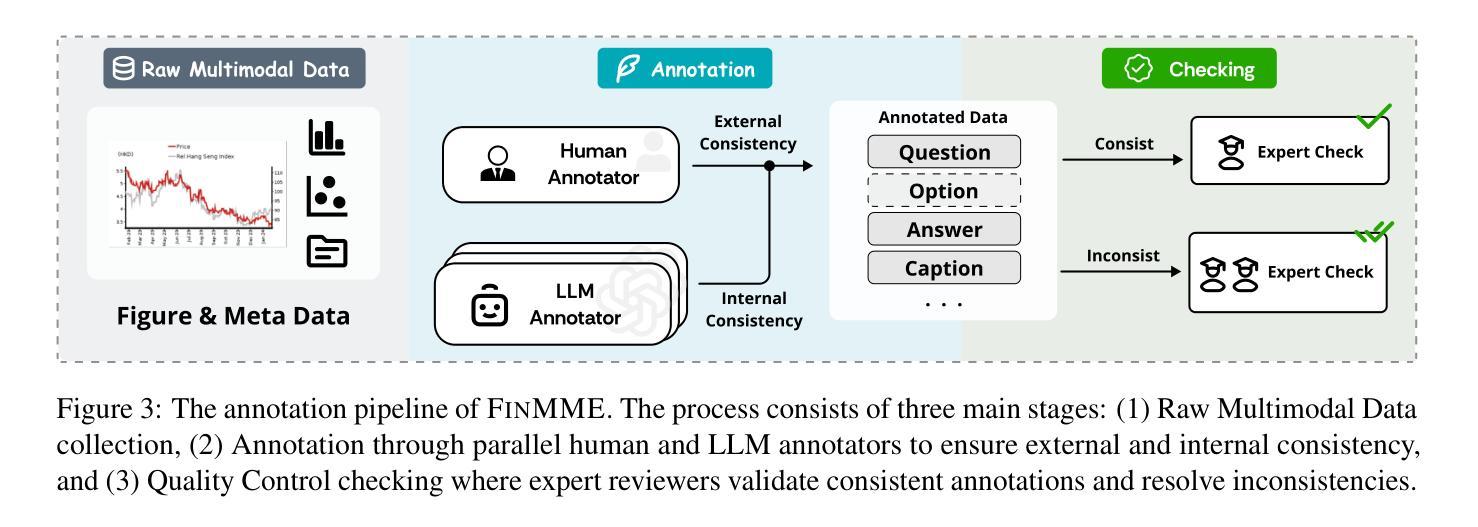
FinMME: Benchmark Dataset for Financial Multi-Modal Reasoning Evaluation
Authors:Junyu Luo, Zhizhuo Kou, Liming Yang, Xiao Luo, Jinsheng Huang, Zhiping Xiao, Jingshu Peng, Chengzhong Liu, Jiaming Ji, Xuanzhe Liu, Sirui Han, Ming Zhang, Yike Guo
Multimodal Large Language Models (MLLMs) have experienced rapid development in recent years. However, in the financial domain, there is a notable lack of effective and specialized multimodal evaluation datasets. To advance the development of MLLMs in the finance domain, we introduce FinMME, encompassing more than 11,000 high-quality financial research samples across 18 financial domains and 6 asset classes, featuring 10 major chart types and 21 subtypes. We ensure data quality through 20 annotators and carefully designed validation mechanisms. Additionally, we develop FinScore, an evaluation system incorporating hallucination penalties and multi-dimensional capability assessment to provide an unbiased evaluation. Extensive experimental results demonstrate that even state-of-the-art models like GPT-4o exhibit unsatisfactory performance on FinMME, highlighting its challenging nature. The benchmark exhibits high robustness with prediction variations under different prompts remaining below 1%, demonstrating superior reliability compared to existing datasets. Our dataset and evaluation protocol are available at https://huggingface.co/datasets/luojunyu/FinMME and https://github.com/luo-junyu/FinMME.
近年来,多模态大型语言模型(MLLMs)经历了快速发展。然而,在金融领域,有效且专业的多模态评估数据集明显缺乏。为了推动金融领域MLLMs的发展,我们推出了FinMME,它涵盖了超过11,000个高质量金融研究样本,涉及18个金融领域和6个资产类别,包含10种主要图表类型和21种子类型。我们通过20名注释者和精心设计的验证机制确保数据质量。此外,我们开发了FinScore评估系统,它结合了幻觉惩罚和多维度能力评估,以提供不偏见的评估。广泛的实验结果表明,即使是最先进的模型,如GPT-4o在FinMME上的表现也不尽人意,这凸显了它的挑战性。该基准测试表现出高度的稳健性,在不同提示下的预测变化率保持在1%以下,与现有数据集相比显示出更高的可靠性。我们的数据集和评估协议可在https://huggingface.co/datasets/luojunyu/FinMME和https://github.com/luo-junyu/FinMME上找到。
论文及项目相关链接
PDF ACL 2025 Main Conference
Summary
金融领域多模态大语言模型(MLLMs)发展迅猛,但缺乏有效和专业的多模态评估数据集。为解决这一问题,我们推出FinMME数据集,包含超过1.1万高质量金融研究样本,覆盖多个金融领域和资产类别,同时配备图表数据。为确保数据质量,我们设立了二十位标注员并通过精心设计验证机制。此外,我们开发了FinScore评估系统,该系统包含幻觉惩罚和多维度能力评估,以提供不偏见的评估。实验结果表明,即使是最新技术模型如GPT-4o在FinMME上的表现也不尽人意,凸显其挑战性。该基准测试展现出高稳健性,预测变化在不同提示下低于百分之一,相较于现有数据集展现出更高的可靠性。数据集和评估协议可在相关网站获取。
Key Takeaways
- 金融领域多模态大语言模型(MLLMs)发展快速,但缺乏专门的评估数据集。
- FinMME数据集包含高质量金融研究样本,覆盖多个金融领域和资产类别。
- 数据集通过大量标注员和验证机制确保数据质量。
- FinScore评估系统包含幻觉惩罚和多维度能力评估。
- 实验显示,先进模型如GPT-4在FinMME上的表现不佳,说明其挑战性。
- FinMME基准测试展现出高稳健性。
点此查看论文截图



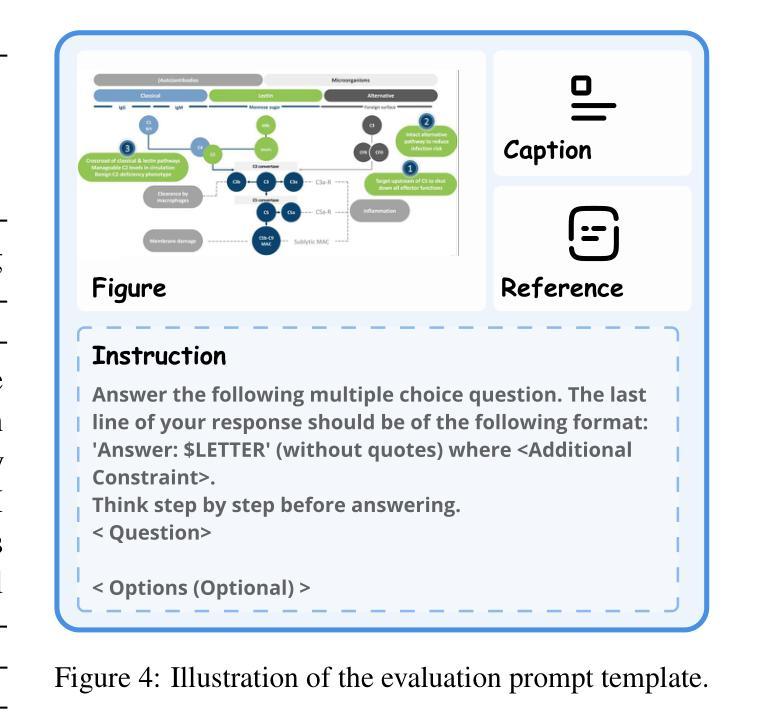
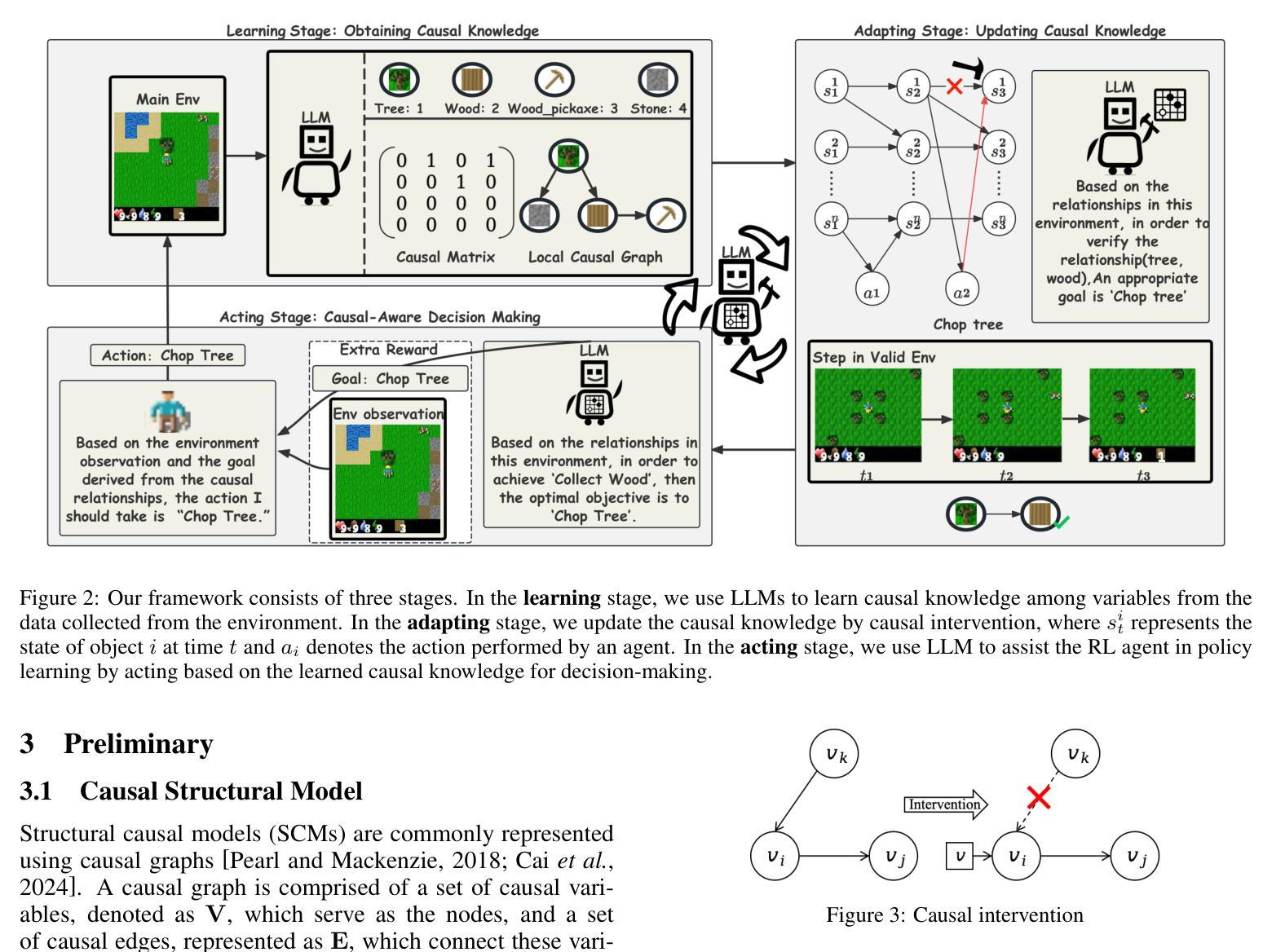
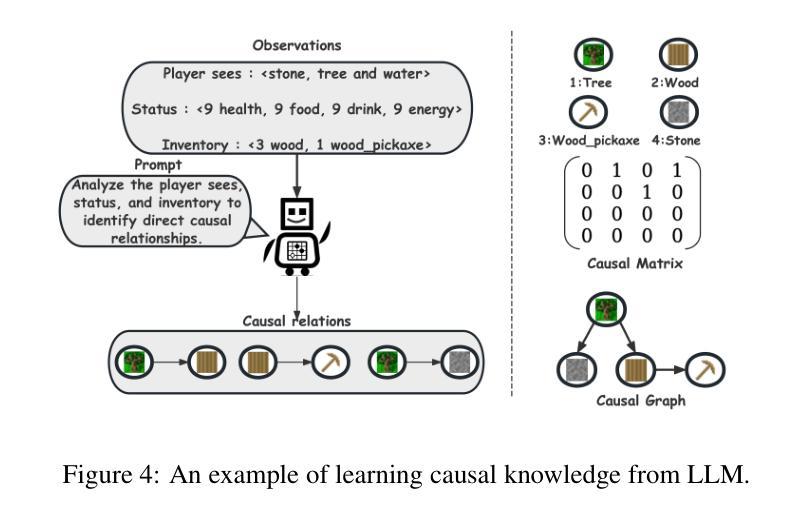
Causal-aware Large Language Models: Enhancing Decision-Making Through Learning, Adapting and Acting
Authors:Wei Chen, Jiahao Zhang, Haipeng Zhu, Boyan Xu, Zhifeng Hao, Keli Zhang, Junjian Ye, Ruichu Cai
Large language models (LLMs) have shown great potential in decision-making due to the vast amount of knowledge stored within the models. However, these pre-trained models are prone to lack reasoning abilities and are difficult to adapt to new environments, further hindering their application to complex real-world tasks. To address these challenges, inspired by the human cognitive process, we propose Causal-aware LLMs, which integrate the structural causal model (SCM) into the decision-making process to model, update, and utilize structured knowledge of the environment in a learning-adapting-acting" paradigm. Specifically, in the learning stage, we first utilize an LLM to extract the environment-specific causal entities and their causal relations to initialize a structured causal model of the environment. Subsequently,in the adapting stage, we update the structured causal model through external feedback about the environment, via an idea of causal intervention. Finally, in the acting stage, Causal-aware LLMs exploit structured causal knowledge for more efficient policy-making through the reinforcement learning agent. The above processes are performed iteratively to learn causal knowledge, ultimately enabling the causal-aware LLMs to achieve a more accurate understanding of the environment and make more efficient decisions. Experimental results across 22 diverse tasks within the open-world game Crafter” validate the effectiveness of our proposed method.
大型语言模型(LLM)由于在模型中存储了大量的知识,在决策制定方面显示出巨大的潜力。然而,这些预训练模型往往缺乏推理能力,难以适应新环境,进一步阻碍了它们在复杂现实世界任务中的应用。为了应对这些挑战,我们受到人类认知过程的启发,提出了因果感知LLM。它将结构因果模型(SCM)集成到决策过程中,以“学习-适应-行动”的范式对环境结构进行建模、更新和利用。具体来说,在学习阶段,我们首先利用LLM提取环境特定的因果实体及其因果关系来初始化环境结构因果模型。随后在适应阶段,我们通过关于环境的外部反馈来更新结构因果模型,这是一个因果干预的概念。最后,在行动阶段,因果感知LLM利用结构化因果知识来更有效地制定政策,通过强化学习代理来实现这一目标。上述过程会反复进行以学习因果关系知识,最终使因果感知LLM实现对环境的更准确理解并做出更有效的决策。在开放世界游戏“Crafter”中的22个不同任务进行的实验结果验证了我们提出方法的有效性。
论文及项目相关链接
PDF Accepted by IJCAI 2025
Summary:基于人类认知过程,提出因果感知大型语言模型(Causal-aware LLMs),通过将结构因果模型(SCM)融入决策过程,模拟、更新和利用环境结构知识。模型经历“学习-适应-行动”三个阶段,从环境中提取因果实体和关系进行初始化,通过外部反馈更新结构因果模型,并利用强化学习制定高效策略。实验结果表明该模型在游戏环境中可有效提高决策效率。
Key Takeaways:
- 大型语言模型(LLMs)在决策过程中展现出巨大潜力,但缺乏推理能力和适应新环境的能力。
- 因果感知大型语言模型(Causal-aware LLMs)通过结合结构因果模型(SCM)解决这些问题。
- 模型采用“学习-适应-行动”模式进行操作,包括利用LLM提取环境特定因果实体和关系进行初始化。
- 通过外部反馈更新结构因果模型,采用因果干预的思想。
- Causal-aware LLMs利用结构化因果知识制定更高效的策略,通过强化学习代理实现。
- 模型可迭代学习因果知识,更准确地理解环境并做出更高效的决策。
点此查看论文截图


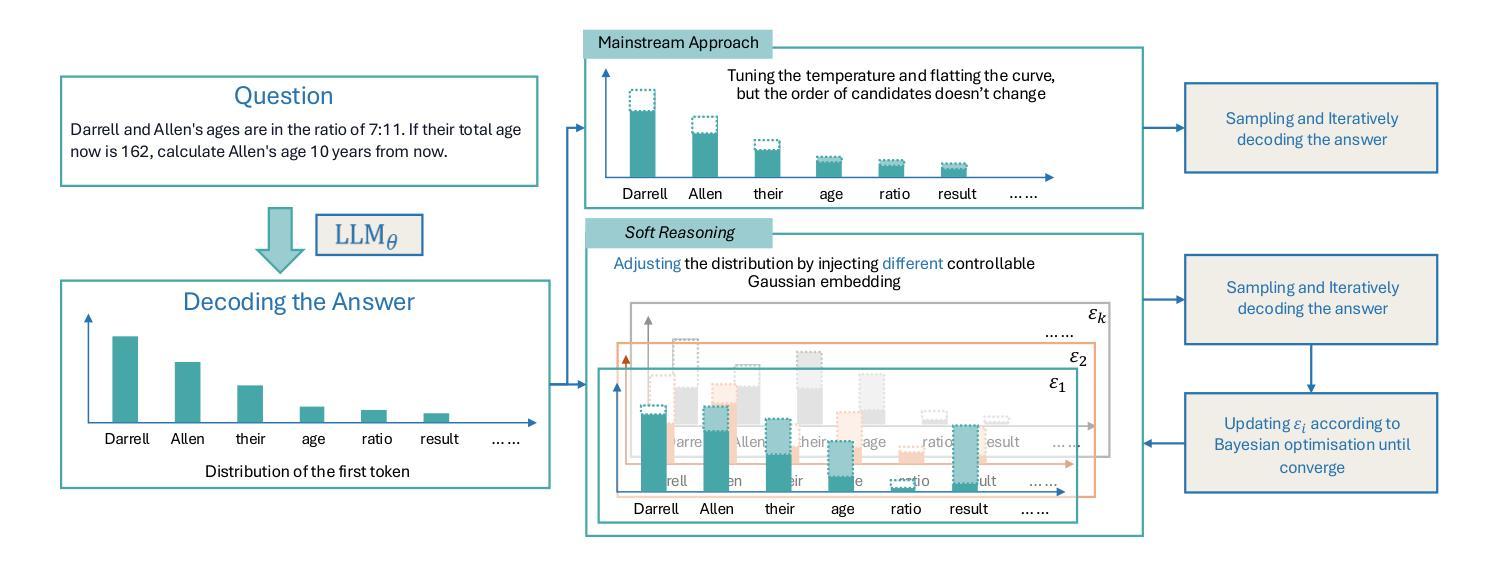
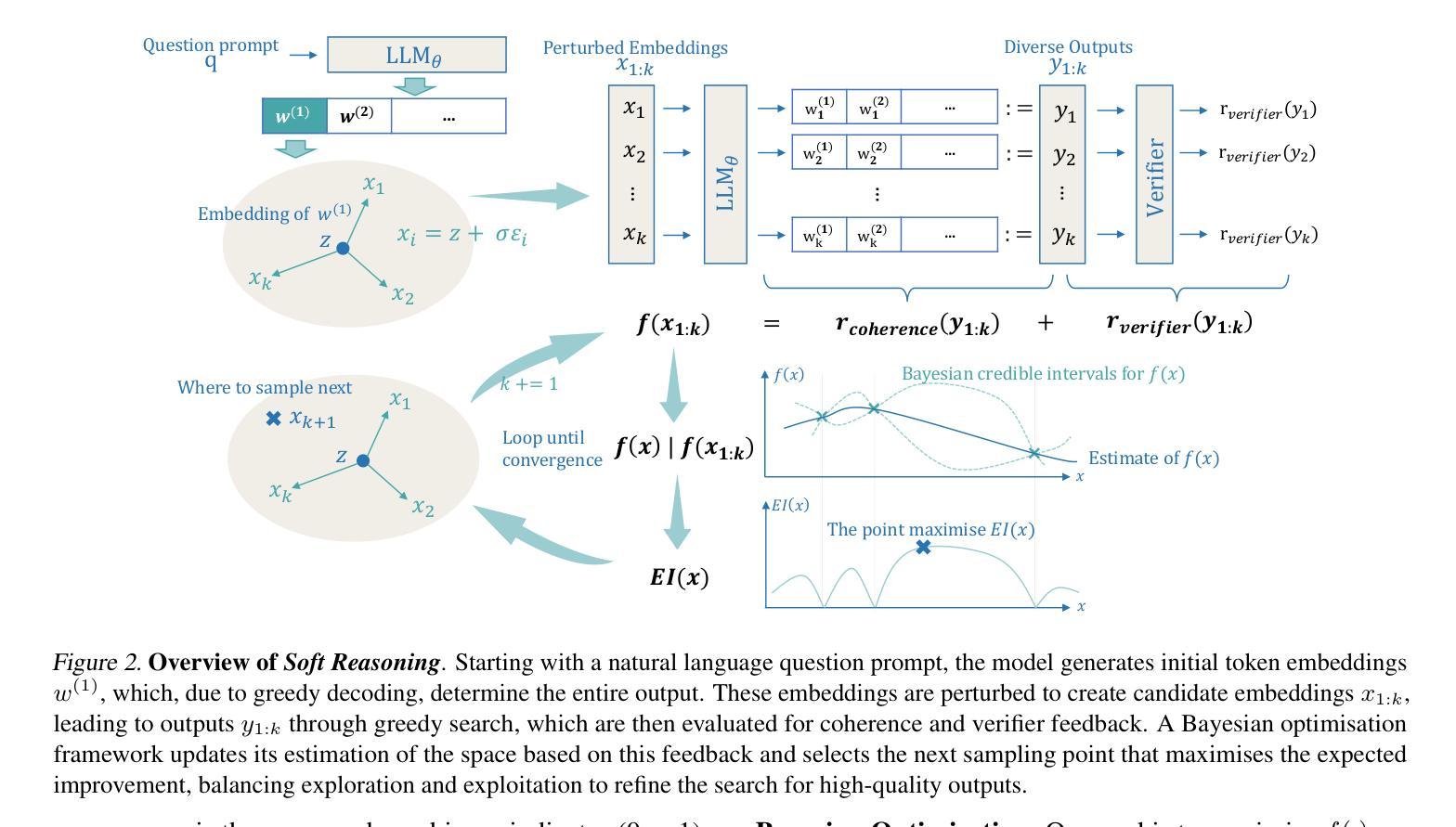
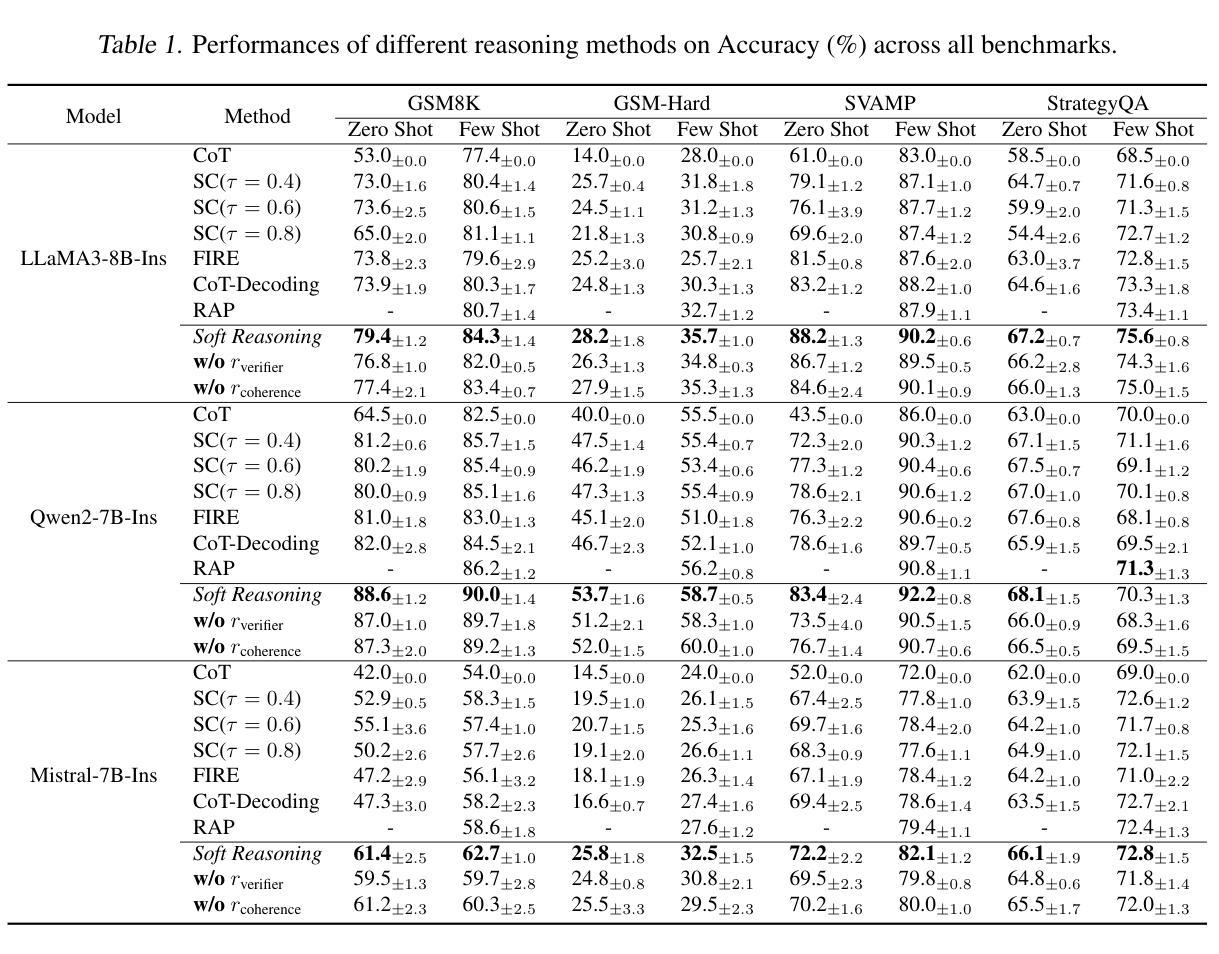
Soft Reasoning: Navigating Solution Spaces in Large Language Models through Controlled Embedding Exploration
Authors:Qinglin Zhu, Runcong Zhao, Hanqi Yan, Yulan He, Yudong Chen, Lin Gui
Large Language Models (LLMs) struggle with complex reasoning due to limited diversity and inefficient search. We propose Soft Reasoning, an embedding-based search framework that optimises the embedding of the first token to guide generation. It combines (1) embedding perturbation for controlled exploration and (2) Bayesian optimisation to refine embeddings via a verifier-guided objective, balancing exploration and exploitation. This approach improves reasoning accuracy and coherence while avoiding reliance on heuristic search. Experiments demonstrate superior correctness with minimal computation, making it a scalable, model-agnostic solution.
大型语言模型(LLM)由于有限的多样性和低效的搜索而难以进行复杂的推理。我们提出了Soft Reasoning,这是一种基于嵌入的搜索框架,通过优化第一个词的嵌入来引导生成。它结合了(1)嵌入扰动以实现受控探索,以及(2)贝叶斯优化,通过验证器指导的目标来优化嵌入,平衡探索和开发。这种方法提高了推理的准确性和连贯性,同时避免了依赖启发式搜索。实验证明,该方法在计算能力有限的情况下表现出更高的正确性,成为了一种可扩展且不受模型类型限制的解决方案。
论文及项目相关链接
PDF Accepted by ICML 2025
Summary
该文本介绍了一种名为Soft Reasoning的基于嵌入的搜索框架,旨在解决大型语言模型在处理复杂推理时面临的局限性和低效搜索问题。该框架通过优化第一个令牌的嵌入来引导生成,并结合嵌入扰动和贝叶斯优化,通过验证器引导的目标来平衡探索与利用。此方法提高了推理的准确性和连贯性,同时避免了依赖启发式搜索,实验证明其能在保证正确性的同时降低计算成本,是一种可扩展且模型无关的解决方案。
Key Takeaways
- 大型语言模型在处理复杂推理时面临多样性和效率问题。
- Soft Reasoning是一种基于嵌入的搜索框架,旨在解决这些问题。
- Soft Reasoning通过优化第一个令牌的嵌入来引导生成过程。
- 该方法结合了嵌入扰动和贝叶斯优化技术。
- Soft Reasoning通过验证器引导的目标来平衡探索与利用。
- 该方法提高了推理的准确性和连贯性。
点此查看论文截图

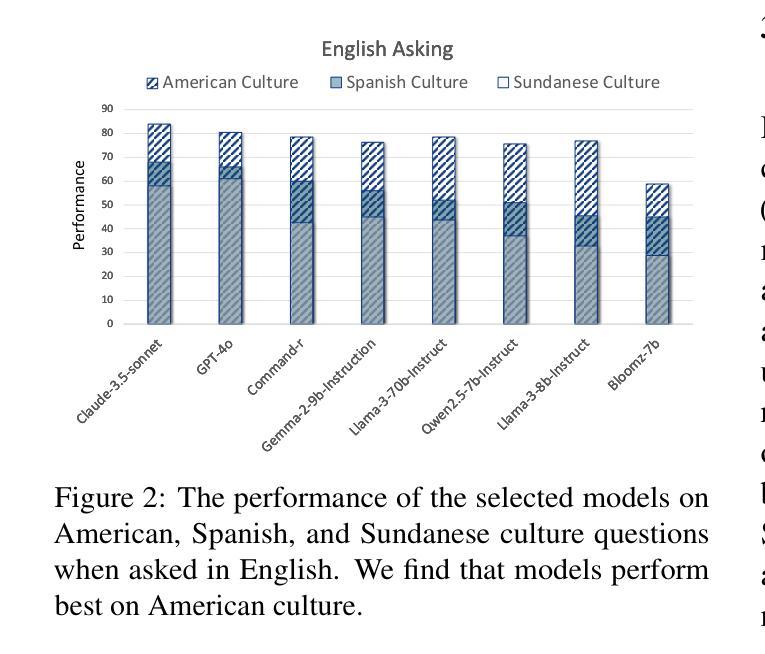
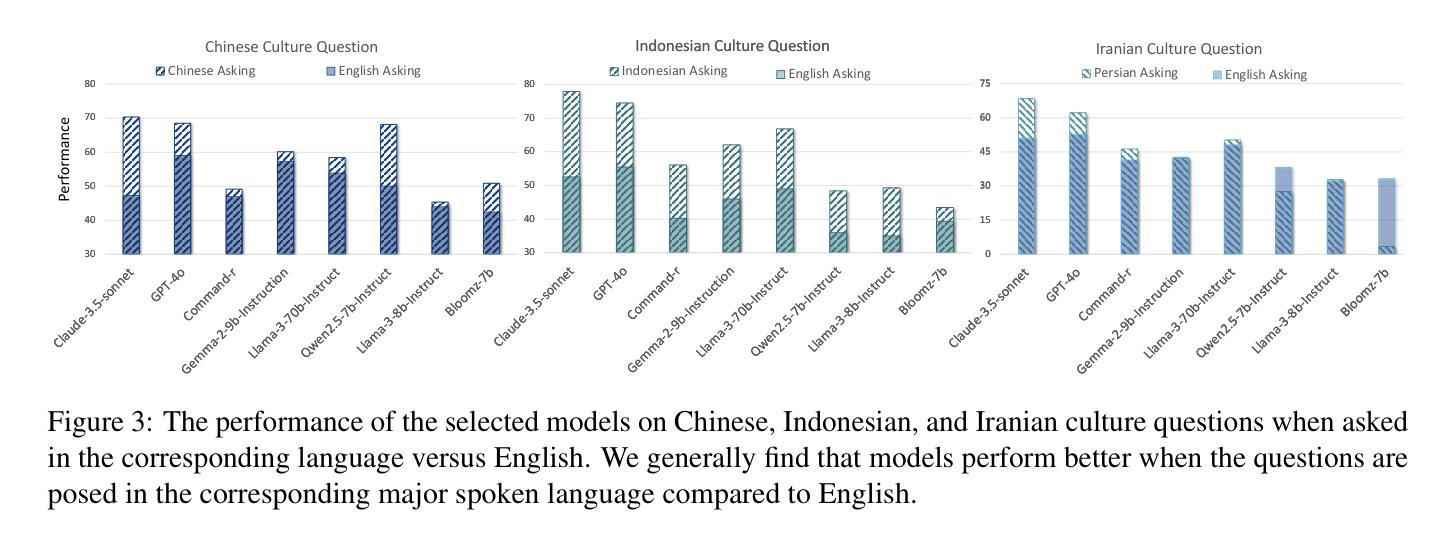
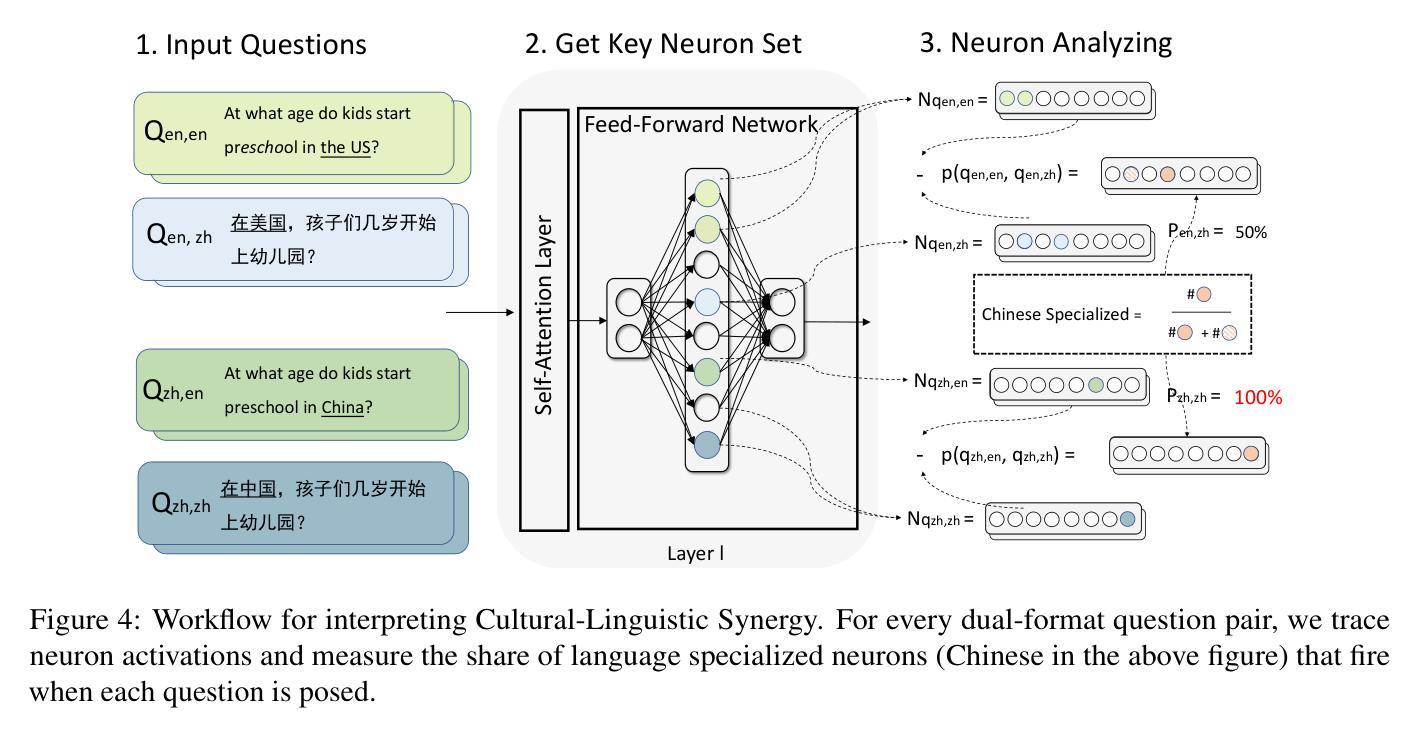
Disentangling Language and Culture for Evaluating Multilingual Large Language Models
Authors:Jiahao Ying, Wei Tang, Yiran Zhao, Yixin Cao, Yu Rong, Wenxuan Zhang
This paper introduces a Dual Evaluation Framework to comprehensively assess the multilingual capabilities of LLMs. By decomposing the evaluation along the dimensions of linguistic medium and cultural context, this framework enables a nuanced analysis of LLMs’ ability to process questions within both native and cross-cultural contexts cross-lingually. Extensive evaluations are conducted on a wide range of models, revealing a notable “CulturalLinguistic Synergy” phenomenon, where models exhibit better performance when questions are culturally aligned with the language. This phenomenon is further explored through interpretability probing, which shows that a higher proportion of specific neurons are activated in a language’s cultural context. This activation proportion could serve as a potential indicator for evaluating multilingual performance during model training. Our findings challenge the prevailing notion that LLMs, primarily trained on English data, perform uniformly across languages and highlight the necessity of culturally and linguistically model evaluations. Our code can be found at https://yingjiahao14. github.io/Dual-Evaluation/.
本文介绍了一个双评估框架,以全面评估大型语言模型的多语言能力。该框架通过沿语言媒介和文化背景这两个维度进行分解评估,能够细致地分析大型语言模型在本土和跨文化背景下的跨语言处理问题的能力。对一系列模型进行了广泛的评估,揭示了一种明显的“文化语言协同”现象,即当问题与文化与语言相匹配时,模型的性能表现更好。通过可解释性探测进一步探索了这一现象,结果显示,在某种语言的文化背景下,更高比例的特定神经元被激活。这种激活比例可作为模型训练过程中评估多语言能力的一个潜在指标。我们的研究结果表明,那些主要以英语数据训练的大型语言模型并非在所有语言中都表现一致,这强调了进行文化和语言上的模型评估的必要性。我们的代码可在 https://yingjiahao14.github.io/Dual-Evaluation/ 找到。
论文及项目相关链接
PDF Accepted to ACL 2025 (Main Conference)
Summary
这篇论文提出一个双评价框架,旨在全面评估大型语言模型(LLMs)的多语言能力。框架通过对语言媒介和文化背景维度的评估,精细分析LLMs在本土和跨文化环境中处理问题的能力。对一系列模型的广泛评估发现了一种名为“文化语言协同”的现象,即当问题与语言文化背景相符时,模型的性能更佳。通过解释性探测进一步探索了这一现象,发现特定神经元在某种语言的文化背景下的激活比例更高,这可以作为评估模型训练期间多语言能力的一个潜在指标。这项研究挑战了以往认为LLMs在英语数据训练后能在各种语言中表现一致的观念,并强调了文化和语言评价的重要性。相关代码可在网站链接找到。
Key Takeaways
- 论文提出了一个双评价框架,用于全面评估大型语言模型的多语言能力。
- 该框架从语言媒介和文化背景两个维度对LLMs进行评估。
- 研究发现了一种名为“文化语言协同”的现象,即模型在文化背景与语言相符的问题上表现更好。
- 通过解释性探测,发现特定神经元在特定语言文化背景下的激活比例较高。
- 这个激活比例可以作为评估模型多语言能力的一个潜在指标。
- 研究挑战了LLMs在多种语言中的一致性能表现的观念。
点此查看论文截图

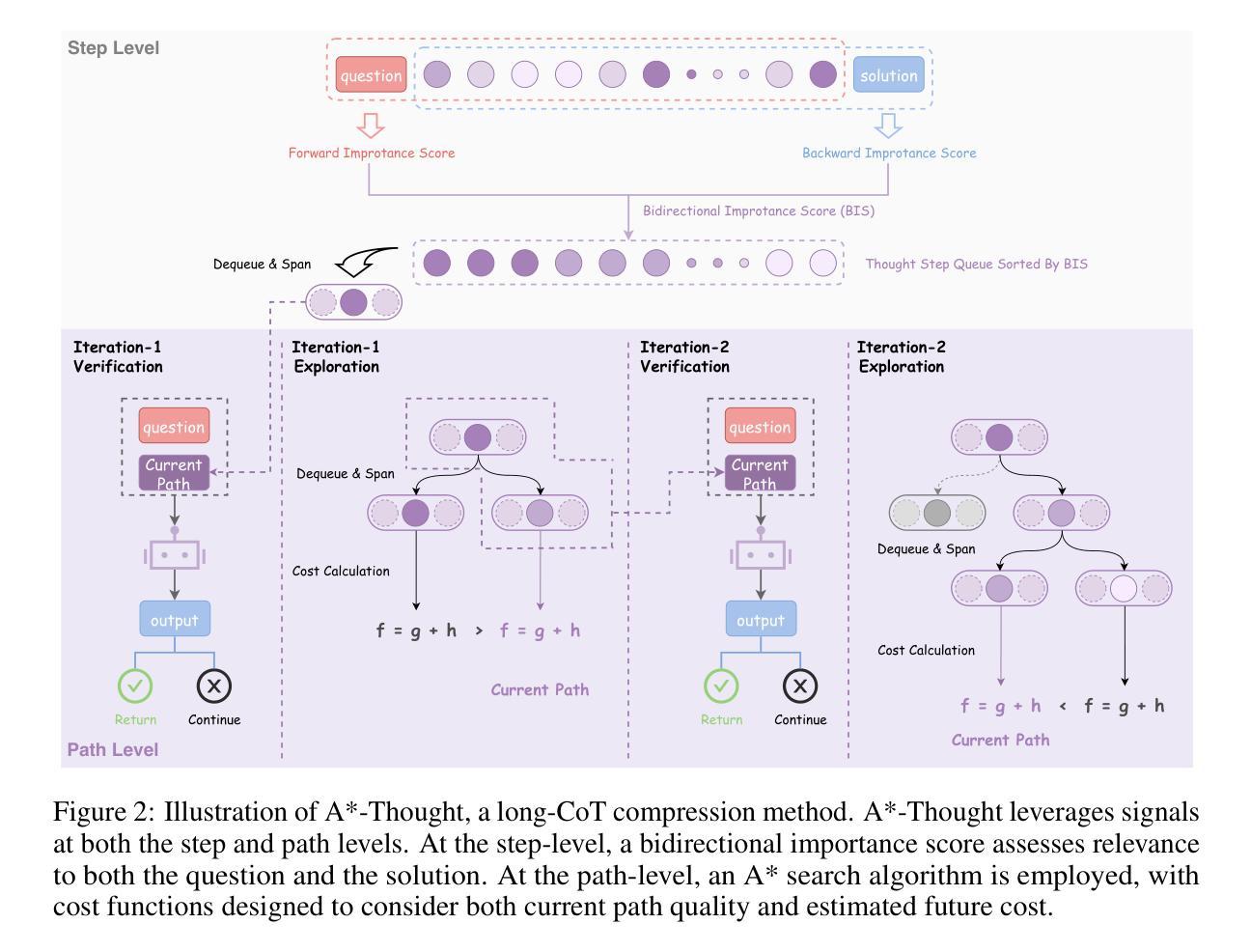
A*-Thought: Efficient Reasoning via Bidirectional Compression for Low-Resource Settings
Authors:Xiaoang Xu, Shuo Wang, Xu Han, Zhenghao Liu, Huijia Wu, Peipei Li, Zhiyuan Liu, Maosong Sun, Zhaofeng He
Large Reasoning Models (LRMs) achieve superior performance by extending the thought length. However, a lengthy thinking trajectory leads to reduced efficiency. Most of the existing methods are stuck in the assumption of overthinking and attempt to reason efficiently by compressing the Chain-of-Thought, but this often leads to performance degradation. To address this problem, we introduce A*-Thought, an efficient tree search-based unified framework designed to identify and isolate the most essential thoughts from the extensive reasoning chains produced by these models. It formulates the reasoning process of LRMs as a search tree, where each node represents a reasoning span in the giant reasoning space. By combining the A* search algorithm with a cost function specific to the reasoning path, it can efficiently compress the chain of thought and determine a reasoning path with high information density and low cost. In addition, we also propose a bidirectional importance estimation mechanism, which further refines this search process and enhances its efficiency beyond uniform sampling. Extensive experiments on several advanced math tasks show that A*-Thought effectively balances performance and efficiency over a huge search space. Specifically, A*-Thought can improve the performance of QwQ-32B by 2.39$\times$ with low-budget and reduce the length of the output token by nearly 50% with high-budget. The proposed method is also compatible with several other LRMs, demonstrating its generalization capability. The code can be accessed at: https://github.com/AI9Stars/AStar-Thought.
大型推理模型(LRMs)通过扩展思维长度实现了卓越的性能。然而,思考轨迹过长会导致效率降低。现有的大多数方法都陷入了过度思考的假设,并试图通过压缩思维链来高效地进行推理,但这常常导致性能下降。为了解决这一问题,我们引入了A*-Thought,这是一个基于高效树搜索的统一框架,旨在从这些模型产生的广泛推理链中识别和隔离最本质的想法。它将LRMs的推理过程公式化为搜索树,其中每个节点代表巨大推理空间中的一个推理跨度。通过结合A搜索算法和针对推理路径的成本函数,它可以高效地压缩思维链,并确定具有高信息密度和低成本的推理路径。此外,我们还提出了一种双向重要性估计机制,进一步改进了搜索过程,提高了其效率,超过了均匀采样。在几个高级数学任务上的广泛实验表明,A-Thought在巨大的搜索空间中有效地平衡了性能和效率。具体来说,A*-Thought可以在低预算的情况下使QwQ-3 2B的性能提高2.39倍,并在高预算的情况下将输出令牌长度减少近50%。所提出的方法还与其他几种LRMs兼容,证明了其泛化能力。代码可在:https://github.com/AI9Stars/AStar-Thought 获取。
论文及项目相关链接
Summary
大型推理模型(LRMs)通过扩展思维长度实现卓越性能,但过长的思考轨迹会导致效率降低。现有方法大多陷入过度思考的假设,尝试通过压缩思维链来高效推理,但这往往导致性能下降。为解决这一问题,我们提出了A*-Thought,这是一个基于树搜索的统一框架,旨在从LRMs产生的众多推理链中识别和隔离最本质的想法。它将LRMs的推理过程公式化为一个搜索树,每个节点代表巨大推理空间中的一个推理跨度。通过结合A搜索算法和针对推理路径的成本函数,它可以有效地压缩思维链,并确定具有高信息密度和低成本的推理路径。此外,我们还提出了一种双向重要性估计机制,进一步改进了搜索过程,提高了效率。在多个高级数学任务上的实验表明,A-Thought在巨大的搜索空间中有效地平衡了性能和效率。具体来说,A*-Thought可以在低预算下提高QwQ-32B的性能2.39倍,并在高预算下将输出令牌长度减少近50%。所提出的方法还与其他几种LRMs兼容,展示了其通用性。
Key Takeaways
- 大型推理模型(LRMs)通过扩展思维长度实现高性能,但过长的思考轨迹会降低效率。
- 现有方法尝试通过压缩思维链来优化推理效率,但可能导致性能下降。
- A*-Thought是一个基于树搜索的统一框架,旨在识别和隔离LRMs中的关键思维。
- A*-Thought将推理过程公式化为一个搜索树,结合A*搜索算法和成本函数进行高效推理。
- 双向重要性估计机制进一步提高了A*-Thought的搜索效率和性能。
- A*-Thought在多个高级数学任务上实现了性能和效率之间的有效平衡。
点此查看论文截图

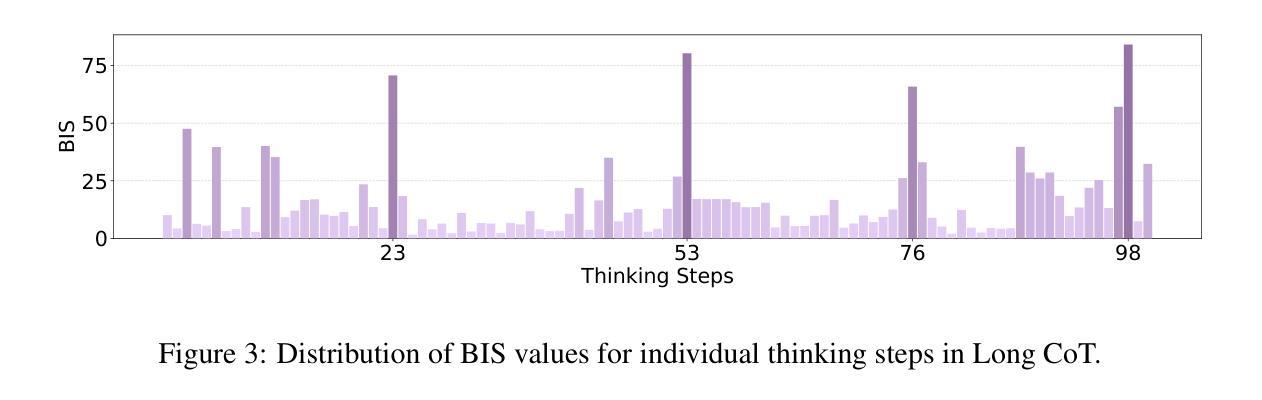
TimeHC-RL: Temporal-aware Hierarchical Cognitive Reinforcement Learning for Enhancing LLMs’ Social Intelligence
Authors:Guiyang Hou, Xing Gao, Yuchuan Wu, Xiang Huang, Wenqi Zhang, Zhe Zheng, Yongliang Shen, Jialu Du, Fei Huang, Yongbin Li, Weiming Lu
Recently, Large Language Models (LLMs) have made significant progress in IQ-related domains that require careful thinking, such as mathematics and coding. However, enhancing LLMs’ cognitive development in social domains, particularly from a post-training perspective, remains underexplored. Recognizing that the social world follows a distinct timeline and requires a richer blend of cognitive modes (from intuitive reactions (System 1) and surface-level thinking to deliberate thinking (System 2)) than mathematics, which primarily relies on System 2 cognition (careful, step-by-step reasoning), we introduce Temporal-aware Hierarchical Cognitive Reinforcement Learning (TimeHC-RL) for enhancing LLMs’ social intelligence. In our experiments, we systematically explore improving LLMs’ social intelligence and validate the effectiveness of the TimeHC-RL method, through five other post-training paradigms and two test-time intervention paradigms on eight datasets with diverse data patterns. Experimental results reveal the superiority of our proposed TimeHC-RL method compared to the widely adopted System 2 RL method. It gives the 7B backbone model wings, enabling it to rival the performance of advanced models like DeepSeek-R1 and OpenAI-O3. Additionally, the systematic exploration from post-training and test-time interventions perspectives to improve LLMs’ social intelligence has uncovered several valuable insights.
最近,大型语言模型(LLM)在需要深入思考的数学和编程等智力相关领域中取得了显著进展。然而,从后训练的角度来增强LLM在社会领域中的认知能力发展仍然被较少探索。我们认识到,社会世界遵循一个独特的时间线,需要更丰富的认知模式组合,包括直觉反应(系统一)和表层思维到深思熟虑的理性思维(系统二),这不同于主要依赖于系统二认知的数学领域(通过小心谨慎的逐步推理)。因此,我们引入了时间感知分层认知强化学习(TimeHC-RL),以提高LLM的社会智能。在我们的实验中,我们系统地探索了提高LLM社会智力的方法,并通过五种其他后训练模式和两种测试时间干预模式在八个具有不同数据模式的数据集上验证了TimeHC-RL方法的有效性。实验结果表明,我们提出的TimeHC-RL方法优于广泛采用的系统二强化学习方法。它为具有7B参数的基准模型提供了翅膀,使其能够匹敌DeepSeek-R1和OpenAI-O3等先进模型的性能。此外,从后训练和测试时间干预的角度来系统地探索提高LLM社会智力的方法已经揭示了一些宝贵的见解。
论文及项目相关链接
PDF 22 pages, 12 figures
Summary
大型语言模型(LLMs)在需要深思熟虑的IQ相关领域(如数学和编码)取得了显著进展,但在社会领域的认知发展方面,尤其是从后训练角度,仍然缺乏研究。为此,我们引入了时序分层认知强化学习(TimeHC-RL)来提升LLMs的社会智能。实验表明,TimeHC-RL方法能有效提升LLMs的社会智能,并优于广泛采用的System 2 RL方法。该方法赋予了7B骨干模型翅膀,使其性能与高级模型如DeepSeek-R1和OpenAI-O3相媲美。
Key Takeaways
- 大型语言模型(LLMs)在需要深思的IQ领域已取得显著进步,但其在社会领域的认知发展仍待探索。
- 社会领域需要丰富的认知模式组合,包括直觉反应(System 1)和表面层次的思考以及深思熟虑(System 2)。
- 引入时序分层认知强化学习(TimeHC-RL)以增强LLMs的社会智能。
- TimeHC-RL方法通过五种后训练模式和两种测试时间干预模式在多个数据集上进行了实验验证。
- TimeHC-RL方法优于广泛采用的System 2 RL方法。
- TimeHC-RL使7B骨干模型性能大幅提升,可与高级模型如DeepSeek-R1和OpenAI-O3相媲美。
点此查看论文截图

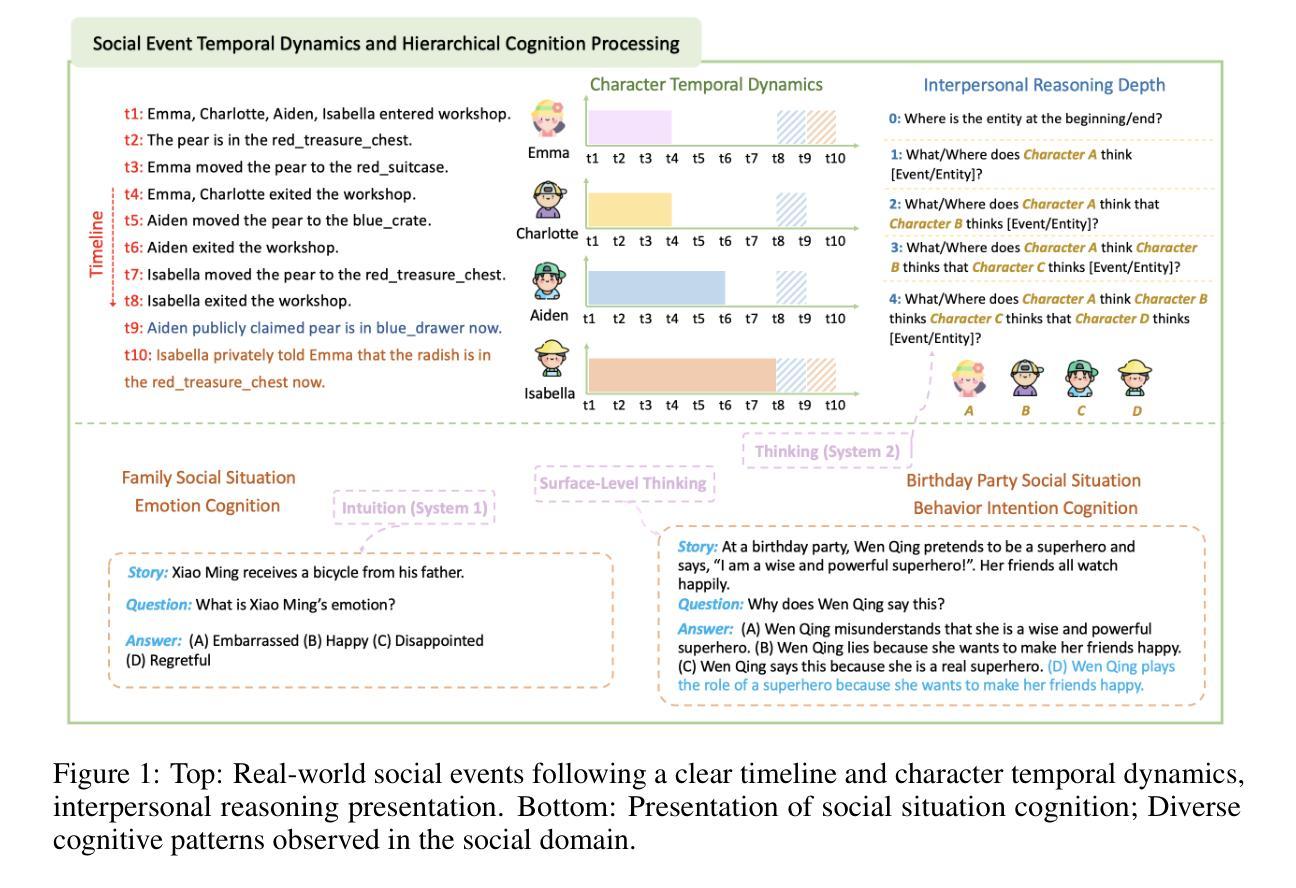
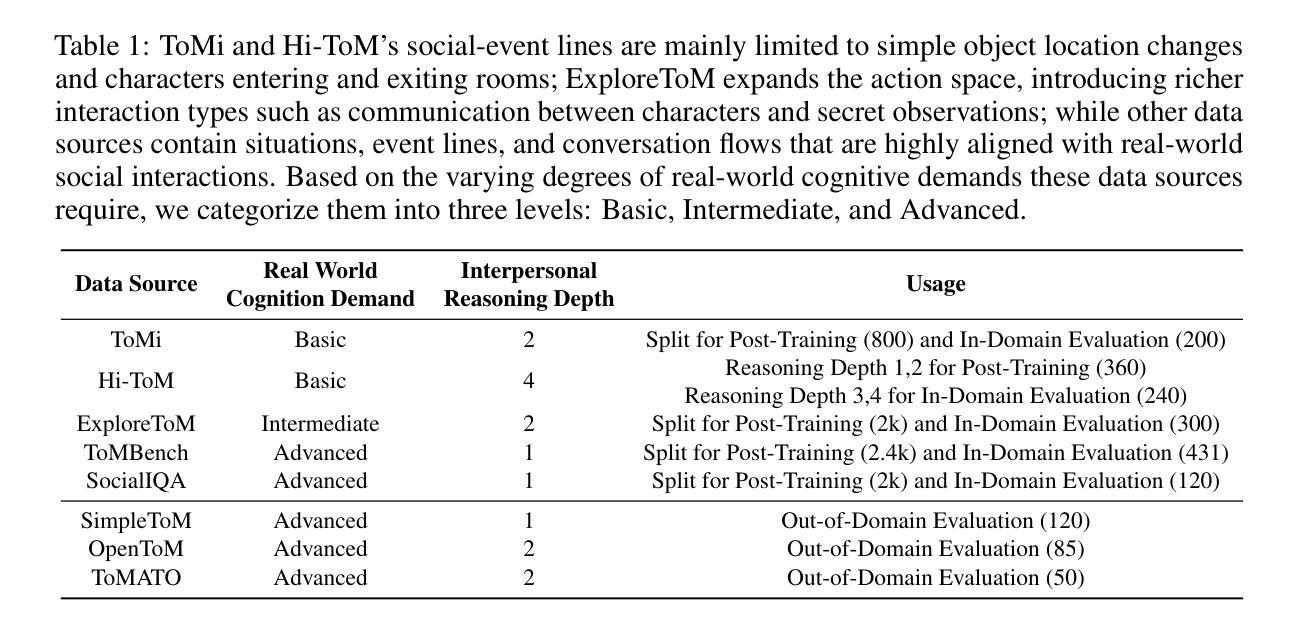

Towards Effective Code-Integrated Reasoning
Authors:Fei Bai, Yingqian Min, Beichen Zhang, Zhipeng Chen, Wayne Xin Zhao, Lei Fang, Zheng Liu, Zhongyuan Wang, Ji-Rong Wen
In this paper, we investigate code-integrated reasoning, where models generate code when necessary and integrate feedback by executing it through a code interpreter. To acquire this capability, models must learn when and how to use external code tools effectively, which is supported by tool-augmented reinforcement learning (RL) through interactive learning. Despite its benefits, tool-augmented RL can still suffer from potential instability in the learning dynamics. In light of this challenge, we present a systematic approach to improving the training effectiveness and stability of tool-augmented RL for code-integrated reasoning. Specifically, we develop enhanced training strategies that balance exploration and stability, progressively building tool-use capabilities while improving reasoning performance. Through extensive experiments on five mainstream mathematical reasoning benchmarks, our model demonstrates significant performance improvements over multiple competitive baselines. Furthermore, we conduct an in-depth analysis of the mechanism and effect of code-integrated reasoning, revealing several key insights, such as the extension of model’s capability boundaries and the simultaneous improvement of reasoning efficiency through code integration. All data and code for reproducing this work are available at: https://github.com/RUCAIBox/CIR.
在这篇论文中,我们研究了代码集成推理(Code-Integrated Reasoning,CIR)。在此场景中,模型会在必要时生成代码,并通过代码解释器执行来集成反馈。为了获取这种能力,模型必须学习何时以及如何有效地使用外部代码工具,这可以通过工具增强型强化学习(Reinforcement Learning, RL)通过交互学习来支持。尽管有其优点,但工具增强型RL仍然可能遭受学习动态中的潜在不稳定性的困扰。针对这一挑战,我们提出了一种提高工具增强型RL在代码集成推理中的训练效果和稳定性的系统方法。具体来说,我们开发了平衡探索与稳定性的增强训练策略,在逐步构建工具使用能力的同时提高推理性能。在五个主流数学推理基准测试上进行了大量实验,我们的模型在多个竞争基准测试上表现出了显著的性能改进。此外,我们对代码集成推理的机制和效果进行了深入分析,揭示了一些关键见解,例如模型能力边界的扩展以及通过代码集成同时提高推理效率。所有重现此工作的数据和代码都可在以下网址找到:https://github.com/RUCAIBox/CIR。
论文及项目相关链接
PDF Technical Report on Slow Thinking with LLMs: Code-Integrated Reasoning
Summary
在这个研究中,探讨了集成代码的推理能力。当模型需要生成代码时,它通过执行代码解释器来集成反馈。为了获取这种能力,模型必须学习何时以及如何有效地使用外部代码工具,这是通过工具增强型强化学习(RL)的支持来实现的。为解决工具增强型RL可能存在的潜在学习不稳定问题,研究提出了一种提高工具增强型RL训练效果和稳定性的系统方法。通过开发平衡探索和稳定性的增强训练策略,逐步构建工具使用能力,同时提高推理性能。在五个主流数学推理基准测试上的实验表明,该模型在多个竞争基准测试上取得了显著的性能改进。此外,深入分析了代码集成推理的机制和效果,揭示了模型能力边界的扩展和通过代码集成同时提高推理效率的关键见解。
Key Takeaways
- 模型具备生成代码并集成反馈的能力。
- 使用外部代码工具的支持是通过工具增强型强化学习(RL)实现的。
- 工具增强型RL存在潜在的学习不稳定问题。
- 提出了一种提高工具增强型RL训练效果和稳定性的系统方法,包括平衡探索和稳定性的增强训练策略。
- 模型在五个主流数学推理基准测试上表现优异,显著优于多个竞争基准。
- 模型能力边界得到扩展,同时提高了推理效率。
点此查看论文截图



