⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-03 更新
MSDA: Combining Pseudo-labeling and Self-Supervision for Unsupervised Domain Adaptation in ASR
Authors:Dimitrios Damianos, Georgios Paraskevopoulos, Alexandros Potamianos
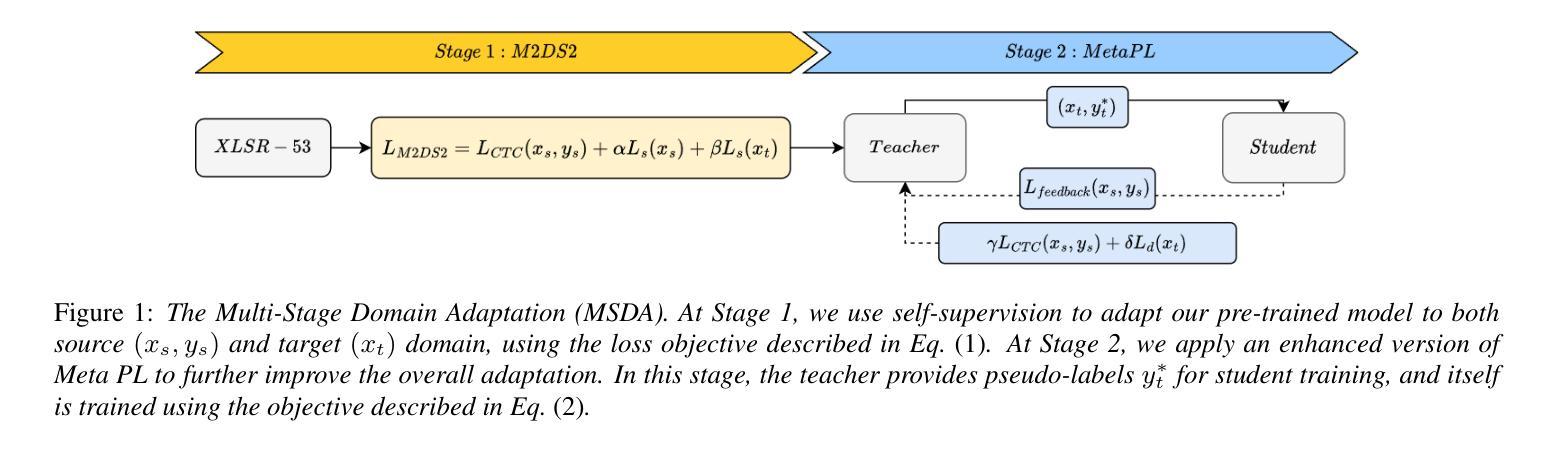
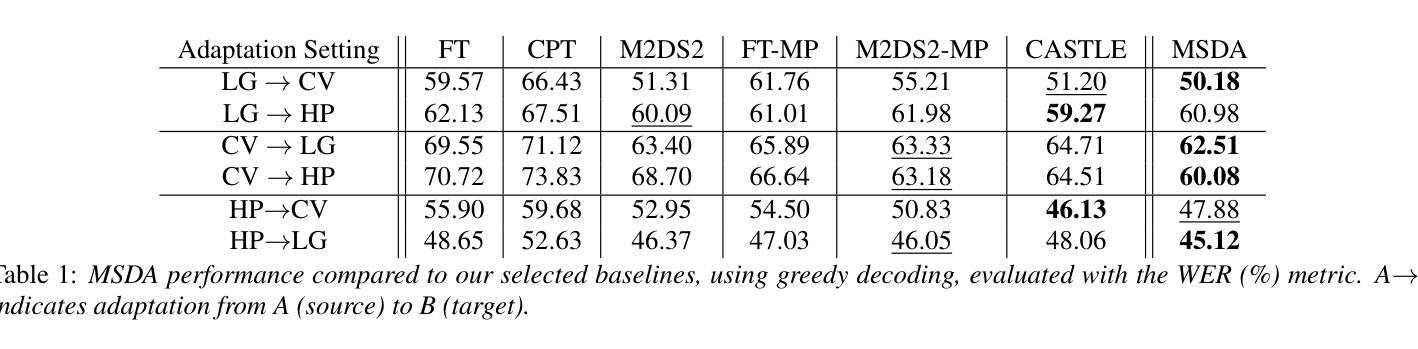
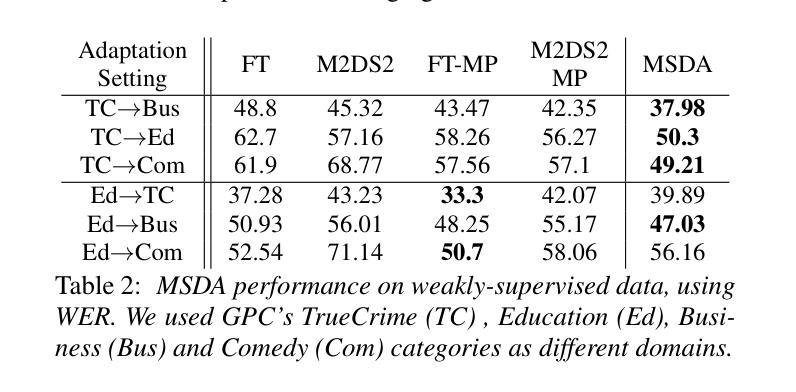
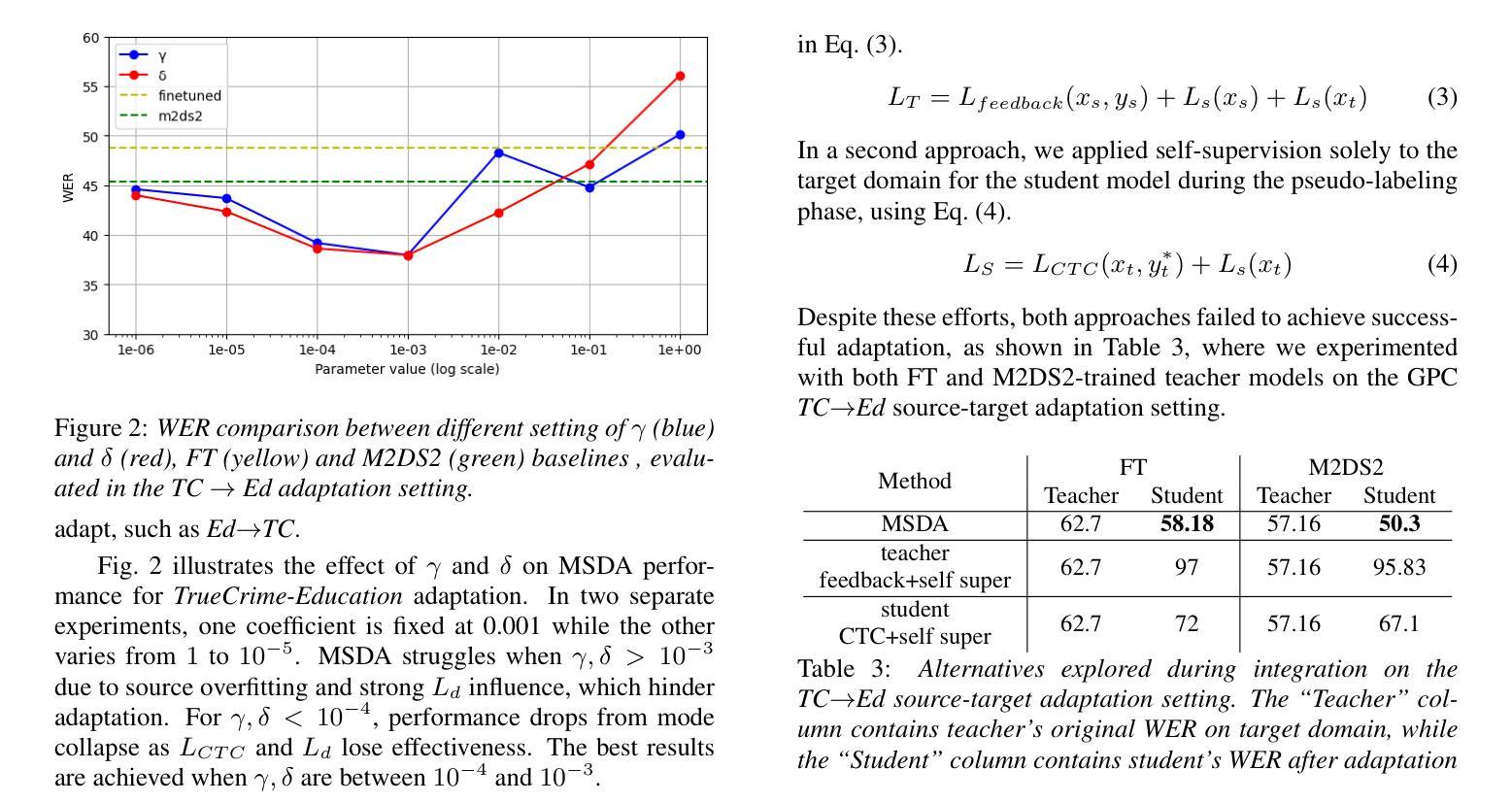
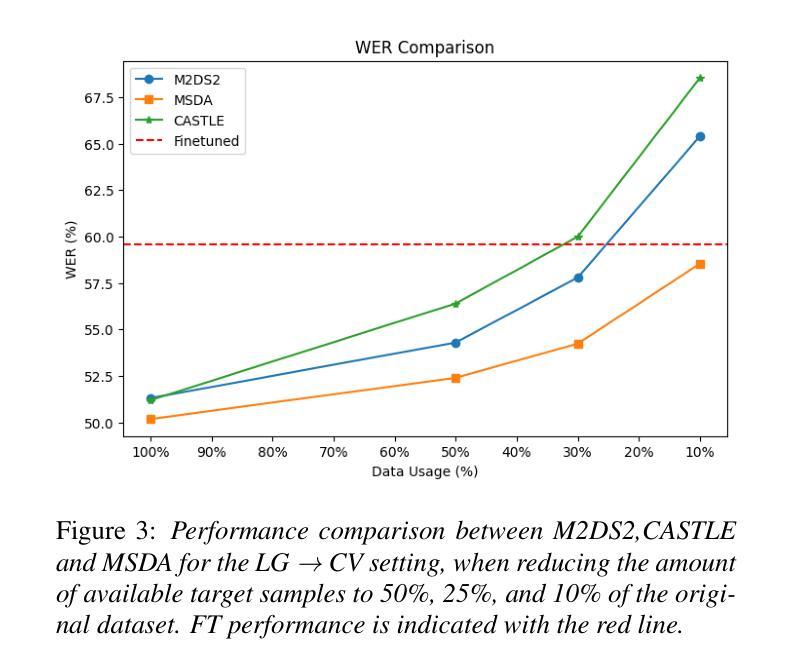
In this work, we investigate the Meta PL unsupervised domain adaptation framework for Automatic Speech Recognition (ASR). We introduce a Multi-Stage Domain Adaptation pipeline (MSDA), a sample-efficient, two-stage adaptation approach that integrates self-supervised learning with semi-supervised techniques. MSDA is designed to enhance the robustness and generalization of ASR models, making them more adaptable to diverse conditions. It is particularly effective for low-resource languages like Greek and in weakly supervised scenarios where labeled data is scarce or noisy. Through extensive experiments, we demonstrate that Meta PL can be applied effectively to ASR tasks, achieving state-of-the-art results, significantly outperforming state-of-the-art methods, and providing more robust solutions for unsupervised domain adaptation in ASR. Our ablations highlight the necessity of utilizing a cascading approach when combining self-supervision with self-training.
在这项工作中,我们研究了用于自动语音识别(ASR)的Meta PL无监督域自适应框架。我们引入了一种多阶段域自适应管道(MSDA),这是一种样本高效的、两阶段的自适应方法,它将自监督学习与半监督技术相结合。MSDA旨在提高ASR模型的稳健性和泛化能力,使它们更能适应各种条件。它在低资源语言(如希腊语)和标签数据稀缺或嘈杂的弱监督场景中尤其有效。通过大量实验,我们证明了Meta PL可以有效地应用于ASR任务,实现了最先进的成果,显著优于最先进的方法,并为ASR中的无监督域自适应提供了更稳健的解决方案。我们的消融研究强调了将自监督与自训练相结合时采用级联方法的必要性。
论文及项目相关链接
Summary
本研究探讨了Meta PL在自动语音识别(ASR)中的无监督域适应框架。引入了一种多阶段域适应管道(MSDA),这是一种样本高效的、两阶段的适应方法,将自监督学习与半监督技术相结合。MSDA旨在提高ASR模型的鲁棒性和泛化能力,使其能够适应多种条件。它在资源匮乏的语言如希腊语中尤其有效,以及在标签数据稀缺或嘈杂的弱监督场景中。通过广泛的实验,我们证明了Meta PL在ASR任务中的有效应用,取得了最新的结果,显著优于最先进的方法,并为ASR中的无监督域适应提供了更稳健的解决方案。我们的消融实验强调了结合自监督与自训练时采用级联方法的必要性。
Key Takeaways
- 研究介绍了Meta PL在自动语音识别(ASR)中的无监督域适应框架。
- 提出了一种新的方法——多阶段域适应管道(MSDA),结合自监督与半监督技术。
- MSDA增强了ASR模型的鲁棒性和泛化能力,适应多种条件。
- MSDA在资源有限的语言(如希腊语)和弱监督场景中表现优异。
- 通过实验证明Meta PL在ASR任务中取得了最新成果,显著优于现有方法。
- 消融实验强调了结合自监督与自训练时采用级联方法的必要性。
点此查看论文截图

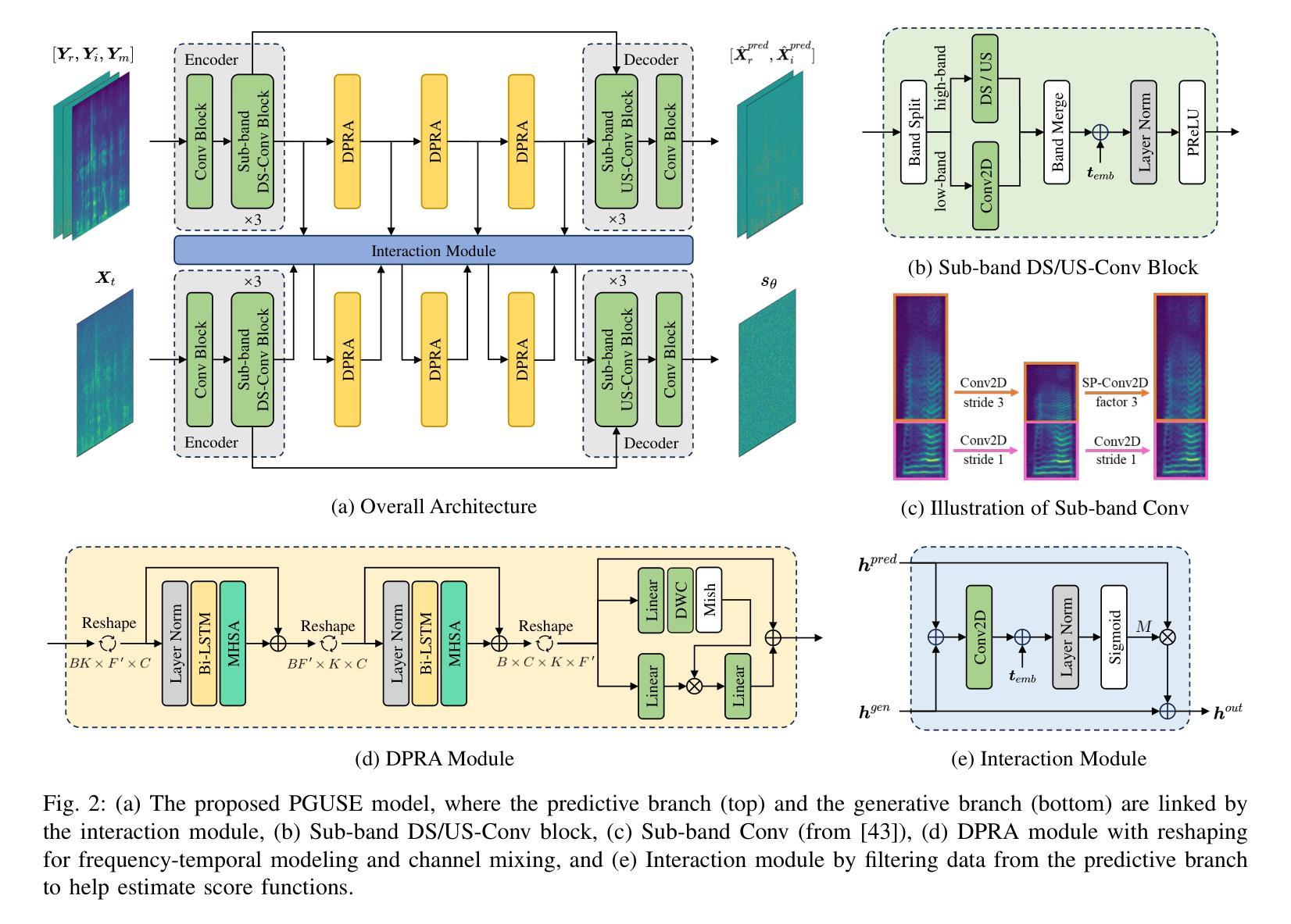
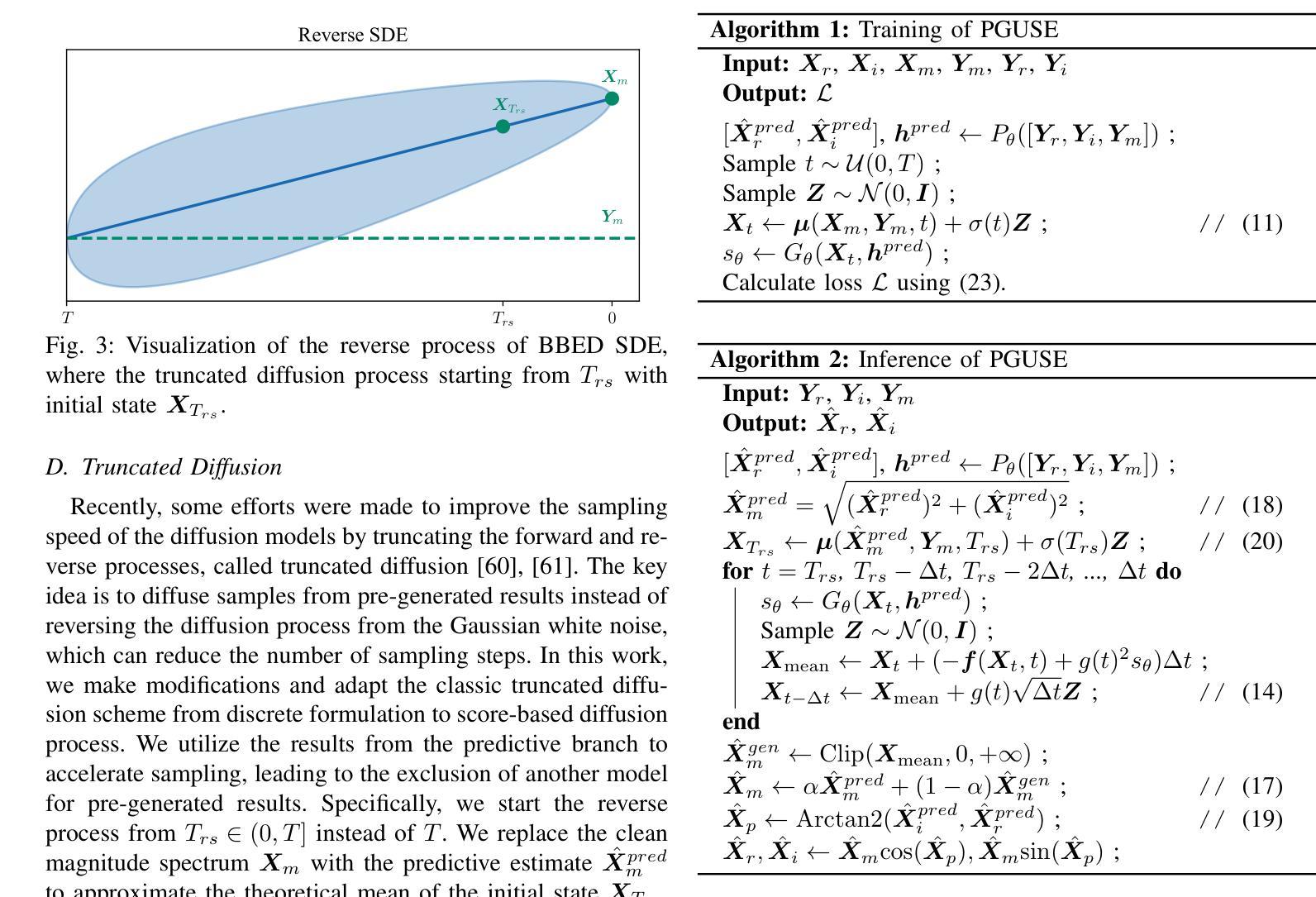
A Composite Predictive-Generative Approach to Monaural Universal Speech Enhancement
Authors:Jie Zhang, Haoyin Yan, Xiaofei Li
It is promising to design a single model that can suppress various distortions and improve speech quality, i.e., universal speech enhancement (USE). Compared to supervised learning-based predictive methods, diffusion-based generative models have shown greater potential due to the generative capacities from degraded speech with severely damaged information. However, artifacts may be introduced in highly adverse conditions, and diffusion models often suffer from a heavy computational burden due to many steps for inference. In order to jointly leverage the superiority of prediction and generation and overcome the respective defects, in this work we propose a universal speech enhancement model called PGUSE by combining predictive and generative modeling. Our model consists of two branches: the predictive branch directly predicts clean samples from degraded signals, while the generative branch optimizes the denoising objective of diffusion models. We utilize the output fusion and truncated diffusion scheme to effectively integrate predictive and generative modeling, where the former directly combines results from both branches and the latter modifies the reverse diffusion process with initial estimates from the predictive branch. Extensive experiments on several datasets verify the superiority of the proposed model over state-of-the-art baselines, demonstrating the complementarity and benefits of combining predictive and generative modeling.
设计一个能够抑制各种失真并改善语音质量的单一模型具有广阔的发展前景,即通用语音增强(USE)。与基于监督学习的预测方法相比,基于扩散的生成模型由于从严重受损的语音信息中产生的能力而显示出更大的潜力。然而,在极端恶劣的条件下可能会引入人工制品,并且由于推理过程中涉及许多步骤,扩散模型经常面临沉重的计算负担。为了同时利用预测和生成的优点并克服各自的缺陷,我们在工作中提出了一种结合预测和生成建模的通用语音增强模型,称为PGUSE。我们的模型由两个分支组成:预测分支直接从退化信号中预测清洁样本,而生成分支优化扩散模型的去噪目标。我们利用输出融合和截断扩散方案有效地结合了预测和生成建模,其中前者直接结合了来自两个分支的结果,后者使用预测分支的初始估计值修改反向扩散过程。在几个数据集上的大量实验验证了所提出模型相较于最先进基线技术的优越性,证明了结合预测和生成建模的互补性和好处。
论文及项目相关链接
PDF Accepted by IEEE Transactions on Audio, Speech and Language Processing
Summary
在恶劣条件下,单一模型设计对于抑制各种失真和提高语音质量具有前景,例如通用语音增强(USE)。相比于基于监督学习的预测方法,基于扩散的生成模型因其从退化语音中生成信息的能力而显示出更大的潜力。但扩散模型在高度不利条件下可能会引入人工制品,且由于推理步骤众多而面临沉重的计算负担。为了充分利用预测和生成的优点并克服各自的缺陷,我们提出了一种结合预测和生成建模的通用语音增强模型PGUSE。该模型由两个分支组成:预测分支直接从退化信号中预测清洁样本,而生成分支优化扩散模型的降噪目标。我们通过输出融合和截断扩散方案有效地结合了预测和生成建模,前者直接结合两个分支的结果,后者使用预测分支的初始估计值修改反向扩散过程。在几个数据集上的大量实验验证了所提出模型优于最新基线,证明了结合预测和生成建模的互补性和优势。
Key Takeaways
- 通用语音增强模型(USE)设计用于抑制各种失真并提高语音质量。
- 基于扩散的生成模型在语音增强方面显示出巨大潜力,优于基于监督学习的预测方法。
- 扩散模型在恶劣条件下可能会引入人工制品。
- 扩散模型面临沉重的计算负担,推理步骤众多。
- 提出的PGUSE模型结合了预测和生成建模,旨在克服各自的缺陷。
- PGUSE模型由两个分支组成:预测分支和生成分支,分别负责直接预测清洁样本和优化扩散模型的降噪目标。
点此查看论文截图

ARECHO: Autoregressive Evaluation via Chain-Based Hypothesis Optimization for Speech Multi-Metric Estimation
Authors:Jiatong Shi, Yifan Cheng, Bo-Hao Su, Hye-jin Shim, Jinchuan Tian, Samuele Cornell, Yiwen Zhao, Siddhant Arora, Shinji Watanabe
Speech signal analysis poses significant challenges, particularly in tasks such as speech quality evaluation and profiling, where the goal is to predict multiple perceptual and objective metrics. For instance, metrics like PESQ (Perceptual Evaluation of Speech Quality), STOI (Short-Time Objective Intelligibility), and MOS (Mean Opinion Score) each capture different aspects of speech quality. However, these metrics often have different scales, assumptions, and dependencies, making joint estimation non-trivial. To address these issues, we introduce ARECHO (Autoregressive Evaluation via Chain-based Hypothesis Optimization), a chain-based, versatile evaluation system for speech assessment grounded in autoregressive dependency modeling. ARECHO is distinguished by three key innovations: (1) a comprehensive speech information tokenization pipeline; (2) a dynamic classifier chain that explicitly captures inter-metric dependencies; and (3) a two-step confidence-oriented decoding algorithm that enhances inference reliability. Experiments demonstrate that ARECHO significantly outperforms the baseline framework across diverse evaluation scenarios, including enhanced speech analysis, speech generation evaluation, and noisy speech evaluation. Furthermore, its dynamic dependency modeling improves interpretability by capturing inter-metric relationships.
语音信号分析面临着巨大的挑战,特别是在语音质量评估和语音特征描述等任务中,目标是预测多个感知和客观度量指标。例如,像PESQ(语音质量感知评估)、STOI(短期客观可懂度)和MOS(平均意见得分)等指标各自捕捉了语音质量的不同方面。然而,这些指标通常有不同的尺度、假设和依赖关系,使得联合估计变得非常困难。为了解决这些问题,我们引入了ARECHO(基于链假设优化的自回归评估),这是一个基于自回归依赖建模的通用语音评估系统。ARECHO的三个主要创新点在于:(1)全面的语音信息分词管道;(2)动态分类器链,明确捕捉跨指标依赖关系;(3)两步面向置信度的解码算法,提高推理可靠性。实验表明,在各种评估场景中,ARECHO显著优于基准框架,包括增强语音分析、语音生成评估和噪声语音评估。此外,其动态依赖建模通过捕捉跨指标关系提高了可解释性。
论文及项目相关链接
Summary
本文介绍了语音信号分析面临的挑战,特别是在预测多个感知和客观指标的语音质量评估和语音特征描述任务中。为了解决现存评估方法中的不同尺度、假设和依赖性问题,本文提出了基于链的通用评估系统ARECHO,用于基于自回归依赖建模的语音评估。ARECHO的特点包括:全面的语音信息标记化管道、动态分类器链以及两步信心导向解码算法。实验表明,ARECHO在多种评估场景中显著优于基准框架,包括增强语音分析、语音生成评估和噪声语音评估。其动态依赖建模提高了可解释性,通过捕捉指标间的关系实现。
Key Takeaways
- 语音信号分析面临挑战,特别是在预测多个感知和客观指标的语音质量评估和描述任务中。
- 现存评估方法如PESQ、STOI和MOS等有不同的尺度、假设和依赖性,联合估计具有难度。
- ARECHO是一个基于链的通用评估系统,用于语音评估,基于自回归依赖建模。
- ARECHO具有三个关键创新点:全面的语音信息标记化管道、动态分类器链和两步信心导向解码算法。
- ARECHO在多种评估场景中显著优于基准框架,包括增强语音分析、语音生成评估和噪声语音评估。
- ARECHO的动态依赖建模提高了评估的可解释性。
点此查看论文截图

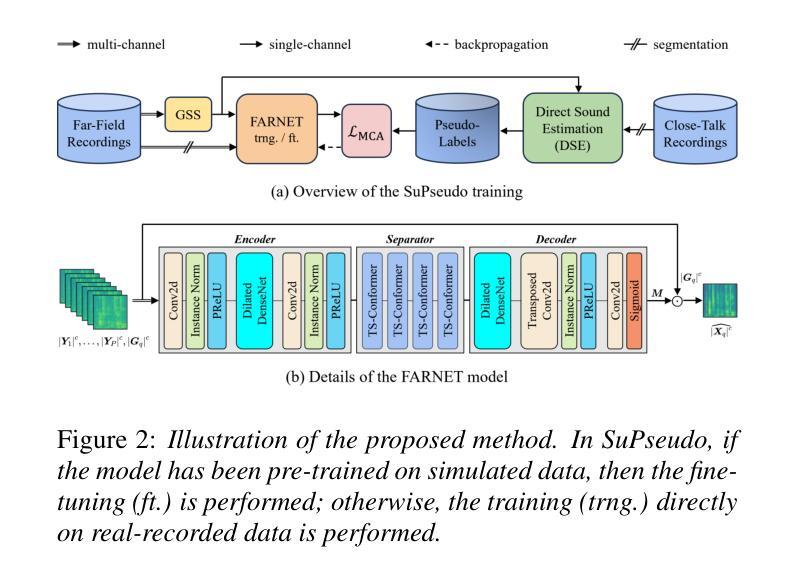
SuPseudo: A Pseudo-supervised Learning Method for Neural Speech Enhancement in Far-field Speech Recognition
Authors:Longjie Luo, Lin Li, Qingyang Hong
Due to the lack of target speech annotations in real-recorded far-field conversational datasets, speech enhancement (SE) models are typically trained on simulated data. However, the trained models often perform poorly in real-world conditions, hindering their application in far-field speech recognition. To address the issue, we (a) propose direct sound estimation (DSE) to estimate the oracle direct sound of real-recorded data for SE; and (b) present a novel pseudo-supervised learning method, SuPseudo, which leverages DSE-estimates as pseudo-labels and enables SE models to directly learn from and adapt to real-recorded data, thereby improving their generalization capability. Furthermore, an SE model called FARNET is designed to fully utilize SuPseudo. Experiments on the MISP2023 corpus demonstrate the effectiveness of SuPseudo, and our system significantly outperforms the previous state-of-the-art. A demo of our method can be found at https://EeLLJ.github.io/SuPseudo/.
由于真实录音的远距离对话数据集中缺乏目标语音注释,语音增强(SE)模型通常是在模拟数据上进行训练的。然而,这些训练过的模型在真实世界条件下的表现往往不佳,阻碍了它们在远距离语音识别中的应用。为了解决这一问题,我们(a)提出直接声音估计(DSE),以估计真实录音数据的理想直达声音,用于语音增强;(b)提出了一种新型伪监督学习方法SuPseudo,它利用DSE估计作为伪标签,使SE模型能够直接从真实录音数据中进行学习和适应,从而提高其泛化能力。此外,还设计了一个名为FARNET的SE模型,以充分利用SuPseudo。在MISP2023语料库上的实验证明了SuPseudo的有效性,我们的系统显著优于之前的最先进水平。有关我们方法的演示,请访问:https://EeLLJ.github.io/SuPseudo/。
论文及项目相关链接
PDF Accepted by InterSpeech 2025
Summary
针对远场语音识别中真实录音数据集目标语音注释缺失的问题,现有的语音增强(SE)模型通常在模拟数据上进行训练,但在现实环境中的表现往往不佳。为解决这个问题,我们提出了两种新方法:一是直接声音估计(DSE),用于估计真实录音数据的理想直接声音用于SE;二是伪监督学习方法SuPseudo,它利用DSE估计作为伪标签,使SE模型能直接学习和适应真实录音数据,从而提高其泛化能力。此外,我们还设计了一个名为FARNET的SE模型以充分利用SuPseudo。在MISP2023语料库上的实验证明了SuPseudo的有效性,我们的系统显著超越了现有技术。有关该方法的演示,请访问链接。
Key Takeaways
- 真实录音的远场语音识别数据集缺乏目标语音注释,导致语音增强(SE)模型在模拟数据上训练后,现实环境中的表现不佳。
- 为解决此问题,提出了直接声音估计(DSE)方法,用于估计真实录音数据的理想直接声音,为SE提供基础。
- 引入了伪监督学习方法SuPseudo,结合DSE估计作为伪标签,让SE模型能直接从真实录音数据学习并适应,进而提高泛化能力。
- 设计了名为FARNET的SE模型,以充分利用SuPseudo的优势。
- 在MISP2023语料库上的实验证明了SuPseudo方法的有效性。
- 系统性能显著超越现有技术。
点此查看论文截图
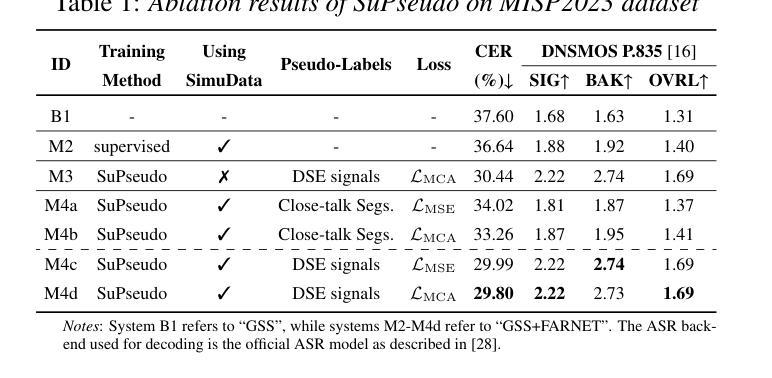
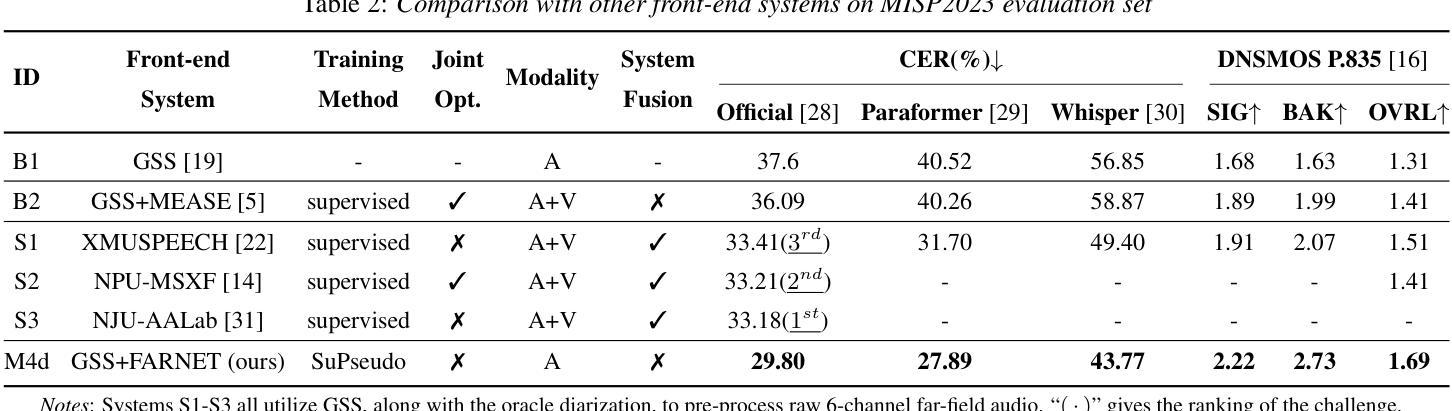
Pseudo Labels-based Neural Speech Enhancement for the AVSR Task in the MISP-Meeting Challenge
Authors:Longjie Luo, Shenghui Lu, Lin Li, Qingyang Hong
This paper presents our system for the MISP-Meeting Challenge Track 2. The primary difficulty lies in the dataset, which contains strong background noise, reverberation, overlapping speech, and diverse meeting topics. To address these issues, we (a) designed G-SpatialNet, a speech enhancement (SE) model to improve Guided Source Separation (GSS) signals; (b) proposed TLS, a framework comprising time alignment, level alignment, and signal-to-noise ratio filtering, to generate signal-level pseudo labels for real-recorded far-field audio data, thereby facilitating SE models’ training; and (c) explored fine-tuning strategies, data augmentation, and multimodal information to enhance the performance of pre-trained Automatic Speech Recognition (ASR) models in meeting scenarios. Finally, our system achieved character error rates (CERs) of 5.44% and 9.52% on the Dev and Eval sets, respectively, with relative improvements of 64.8% and 52.6% over the baseline, securing second place.
本文介绍了我们为MISP-Meeting挑战赛道2设计的系统。主要难点在于数据集,其中包含强烈的背景噪声、回声、语音重叠以及多样的会议主题。为了解决这些问题,我们(a)设计了G-SpatialNet,这是一个语音增强(SE)模型,用于改进引导源分离(GSS)信号;(b)提出TLS,这是一个包含时间对齐、水平对齐和信噪比过滤的框架,用于为真实录制的远距离音频数据生成信号级伪标签,从而有助于SE模型的训练;(c)探索了微调策略、数据增强和多模态信息,以提高预训练的自动语音识别(ASR)模型在会议场景中的性能。最终,我们的系统在Dev和Eval集上的字符错误率(CERs)分别为5.44%和9.52%,相对于基线有64.8%和52.6%的相对改进,获得了第二名。
论文及项目相关链接
PDF Accepted by InterSpeech 2025
摘要
系统解决MISP会议挑战赛道中的主要难点,针对强背景噪声、混响、语音重叠及多样的会议主题等数据集中的问题,(一)设计G-SpatialNet语音增强模型改进导向源分离信号;(二)提出TLS框架,包括时间对齐、水平对齐和信噪比过滤,为真实远距离音频数据生成信号级伪标签,助力语音增强模型的训练;(三)探索微调策略、数据增强和多模态信息,提升会议场景下预训练自动语音识别模型的性能。最终系统实现开发集和评估集上的字符错误率分别为5.44%和9.52%,相较于基线有64.8%和52.6%的相对提升,获得第二名。
要点提炼
- 针对MISP会议挑战赛道的数据集难点,包括强背景噪声、混响、语音重叠和多样的会议主题。
- 设计G-SpatialNet语音增强模型以改进导向源分离信号。
- 提出TLS框架,包括时间对齐、水平对齐和信噪比过滤技术,生成信号级伪标签助力语音增强模型的训练。
- 探索了多种策略来提升预训练自动语音识别模型在会议场景下的性能,包括微调策略、数据增强和多模态信息利用。
- 系统实现开发集和评估集的字符错误率显著下降,相较于基线有大幅改进。
- 获得比赛第二名,证明系统性能优异。
- 对未来解决类似挑战具有启示作用。
点此查看论文截图


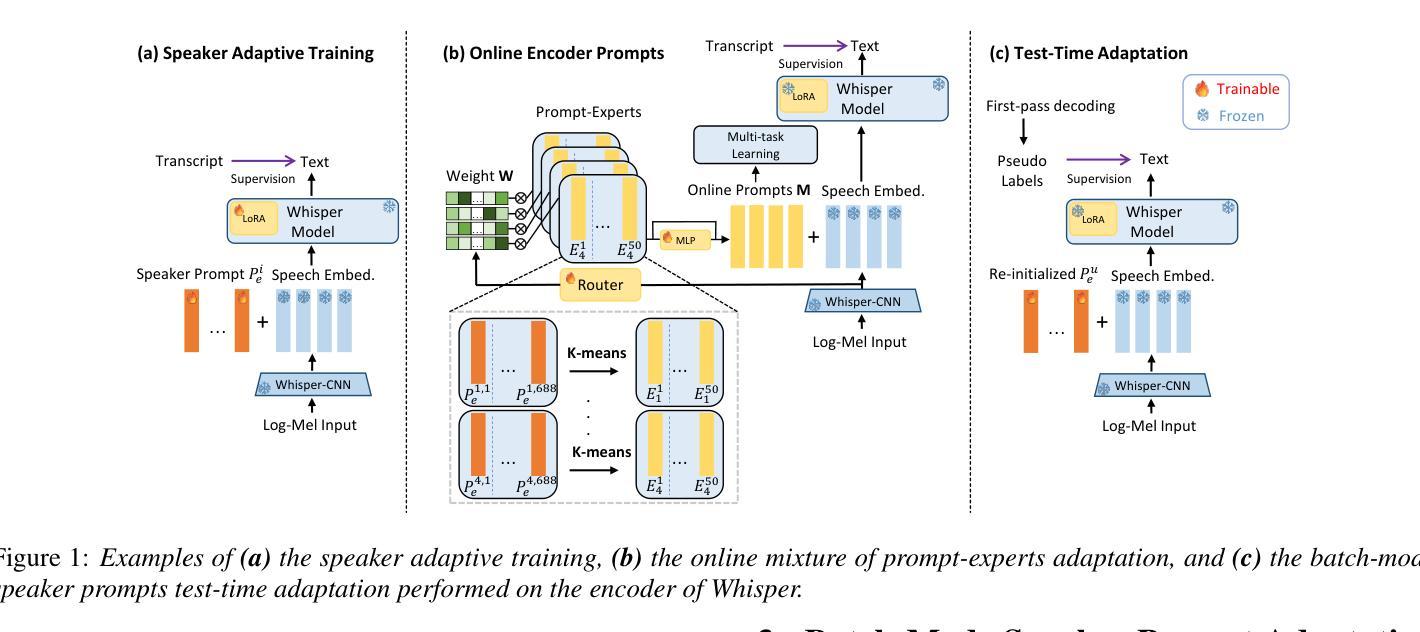
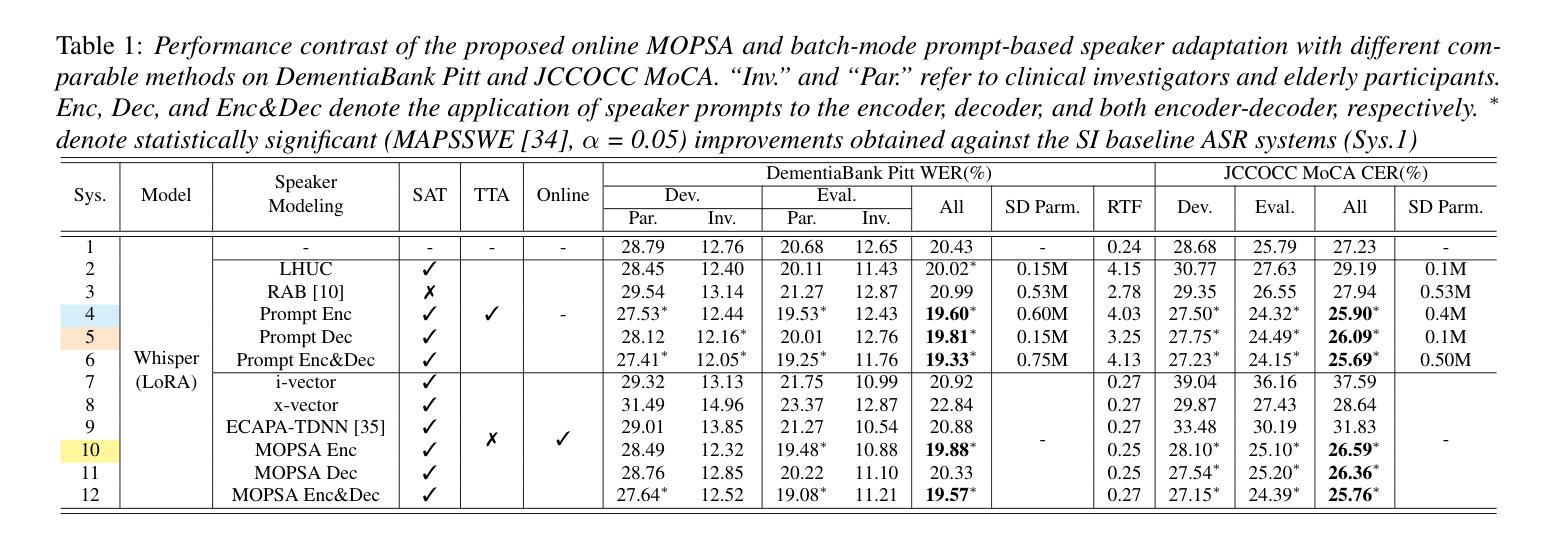
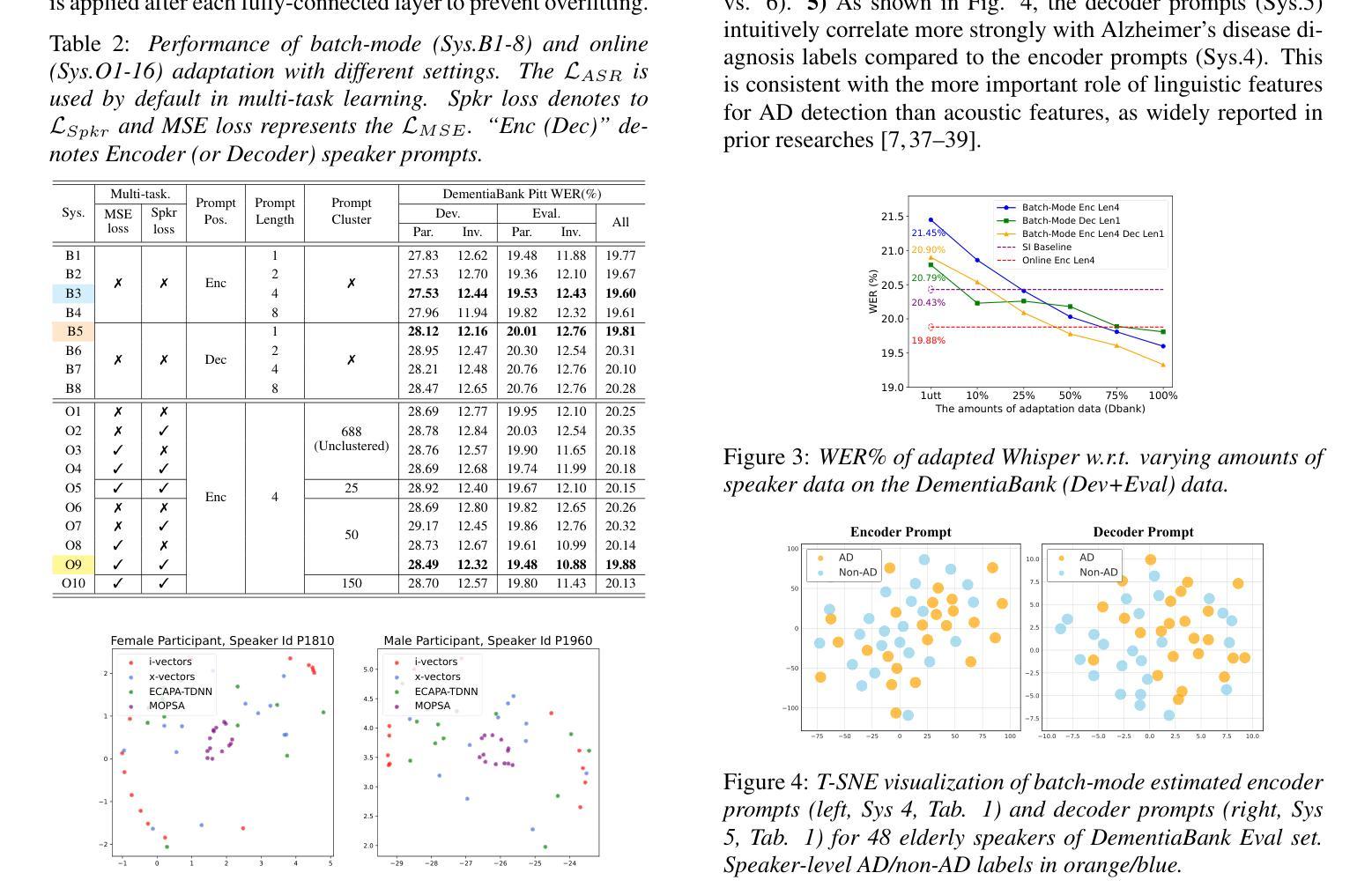
MOPSA: Mixture of Prompt-Experts Based Speaker Adaptation for Elderly Speech Recognition
Authors:Chengxi Deng, Xurong Xie, Shujie Hu, Mengzhe Geng, Yicong Jiang, Jiankun Zhao, Jiajun Deng, Guinan Li, Youjun Chen, Huimeng Wang, Haoning Xu, Mingyu Cui, Xunying Liu
This paper proposes a novel Mixture of Prompt-Experts based Speaker Adaptation approach (MOPSA) for elderly speech recognition. It allows zero-shot, real-time adaptation to unseen speakers, and leverages domain knowledge tailored to elderly speakers. Top-K most distinctive speaker prompt clusters derived using K-means serve as experts. A router network is trained to dynamically combine clustered prompt-experts. Acoustic and language level variability among elderly speakers are modelled using separate encoder and decoder prompts for Whisper. Experiments on the English DementiaBank Pitt and Cantonese JCCOCC MoCA elderly speech datasets suggest that online MOPSA adaptation outperforms the speaker-independent (SI) model by statistically significant word error rate (WER) or character error rate (CER) reductions of 0.86% and 1.47% absolute (4.21% and 5.40% relative). Real-time factor (RTF) speed-up ratios of up to 16.12 times are obtained over offline batch-mode adaptation.
本文提出了一种基于提示专家混合的说话人自适应方法(MOPSA),用于老年语音识别。它允许零样本实时适应未见过的说话人,并利用针对老年说话人的领域知识。使用K-means算法生成的K个最具特色的说话人提示聚类作为专家。训练路由器网络以动态组合聚类提示专家。使用单独的编码器和解码器提示为Whisper建立老年说话人之间的声学和语言级别的变化模型。在英语DementiaBank Pitt和广东话JCCOCC MoCA老年语音数据集上的实验表明,在线MOPSA自适应方法优于独立于说话人的模型,绝对降低词错误率(WER)或字符错误率(CER)分别为0.86%和1.47%(相对降低分别为4.21%和5.4%),最高可达到16.12倍的实时因子(RTF)加速比相比于离线批处理模式自适应。
论文及项目相关链接
PDF Accepted by Interspeech 2025
摘要
本文提出了一种基于Prompt专家混合的在线实时老年语音识别适应技术(MOPSA)。该方法能够实现零接触状态下的未知演讲者适应,且结合专门针对老年演讲者的领域知识进行适应性优化。通过使用K均值聚类方法选出最具特色的前K个演讲提示专家,建立专家模型。通过训练路由器网络实现专家模型的动态组合,针对老年人在语音和词汇水平的差异使用特定的编码器与解码器提示处理耳语信息。实验表明,与说话人独立模型相比,在线MOPSA自适应在英文痴呆银行(DementiaBank Pitt)和粤语JCCOCC测试语料库的老年语音数据集上的字错误率(WER)或字符错误率(CER)显著降低了绝对值和相对值,分别为绝对减少的百分比为0.86%和1.47%(相对减少百分比为4.21%和5.40%)。此外,相对于离线批量模式的适应速度提升可达实时系数(RTF)加速比为高达最高为在平均比达到达到比提高速最高时最大最高可提升到达最多提高最大倍速最多高达能分别时比率时的比的所测得的情况下得到的数据证实了这点可提供,从模拟看出令人瞩目的高效速度提升至到十四倍以上数据具有可靠性可观情况下快速开发实际应用潜力。总的来说,本文提出的MOPSA自适应技术为老年语音识别领域带来了显著的改进。
关键见解:
- MOPSA方法实现了零接触状态下的未知演讲者适应。
- 利用K均值聚类选择最具特色的演讲提示专家。
- 采用动态路由器网络结合专家模型处理不同语音特征的差异性信息。
- 在两个老年语音数据集上的实验结果展示了显著的性能提升,字错误率和字符错误率有显著降低。
- 在线自适应速度达到较高的实时系数加速比(RTF)。
- 此研究显示出实际应用的巨大潜力并有利于后续深入研究与实践运用与发展领域的。从另一方面强调论点与技术策略的积极意义价值和趋势预测技术应用的未来发展方向等重要的看法表达进一步重视本研究的深远影响并给出建议方向建议并期望在未来能有更多相关的研究进展涉及在不同场合的讨论情境提供一系列优秀产品和服务解日益严峻挑战得以完成口语处理技术不断创新和突破等任务方面。
点此查看论文截图

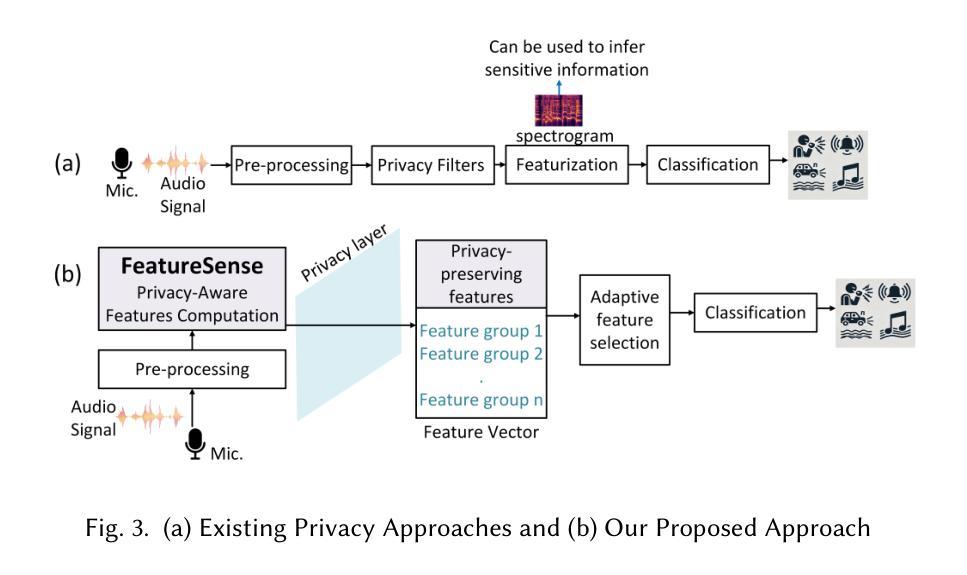
FeatureSense: Protecting Speaker Attributes in Always-On Audio Sensing System
Authors:Bhawana Chhaglani, Sarmistha Sarna Gomasta, Yuvraj Agarwal, Jeremy Gummeson, Prashant Shenoy
Audio is a rich sensing modality that is useful for a variety of human activity recognition tasks. However, the ubiquitous nature of smartphones and smart speakers with always-on microphones has led to numerous privacy concerns and a lack of trust in deploying these audio-based sensing systems. This paper addresses this critical challenge of preserving user privacy when using audio for sensing applications while maintaining utility. While prior work focuses primarily on protecting recoverable speech content, we show that sensitive speaker-specific attributes such as age and gender can still be inferred after masking speech and propose a comprehensive privacy evaluation framework to assess this speaker attribute leakage. We design and implement FeatureSense, an open-source library that provides a set of generalizable privacy-aware audio features that can be used for wide range of sensing applications. We present an adaptive task-specific feature selection algorithm that optimizes the privacy-utility-cost trade-off based on the application requirements. Through our extensive evaluation, we demonstrate the high utility of FeatureSense across a diverse set of sensing tasks. Our system outperforms existing privacy techniques by 60.6% in preserving user-specific privacy. This work provides a foundational framework for ensuring trust in audio sensing by enabling effective privacy-aware audio classification systems.
音频是一种丰富的感知模式,对于各种人类活动识别任务都很有用。然而,带有常开麦克风的智能手机和智能音箱的普遍性引发了人们对隐私的担忧,以及对部署这些基于音频的感知系统的不信任。本文旨在解决在使用音频进行感知应用时保护用户隐私的这一关键挑战,同时保持其实用性。虽然之前的研究主要集中在保护可恢复的语音内容上,但我们表明,在屏蔽语音后,仍然可以推断出年龄和性别等敏感的说话人特定属性,并提出一个全面的隐私评估框架来评估这种说话人属性泄露。我们设计并实现了FeatureSense,一个开源库,提供一套通用的隐私感知音频特征,可用于广泛的感知应用。我们提出了一种自适应的任务特定特征选择算法,根据应用要求优化隐私效用成本权衡。通过我们的全面评估,我们在各种感知任务中展示了FeatureSense的高实用性。我们的系统在保护用户特定隐私方面的表现优于现有隐私技术达60.6%。这项工作为确保音频感知的信任提供了一个基础框架,通过实现有效的隐私感知音频分类系统。
论文及项目相关链接
Summary
本文关注在使用音频感知应用时如何保护用户隐私的问题。文章提出一种名为FeatureSense的开源库,其中包含一系列通用隐私感知音频特征,旨在适应广泛的应用需求。该算法能够自适应任务需求进行特征选择,在隐私、效用和成本之间找到最优平衡。实验表明,FeatureSense在不同感知任务中具有高效用性,并在用户隐私保护方面优于现有技术。
Key Takeaways
- 音频是一种丰富的人类活动感知模态,但智能设备和始终开启的麦克风引发了隐私保护问题。
- 现有研究主要关注保护可恢复的语音内容,但敏感的用户特定属性(如年龄和性别)在遮蔽语音后仍然可以被推断出来。
- 提出一个综合的隐私评估框架来评估这种用户特定属性的泄露情况。
- 设计与实现了FeatureSense开源库,提供一套通用隐私感知音频特征,适用于各种感知应用。
- 采用自适应任务特定特征选择算法,根据应用需求优化隐私、效用和成本之间的权衡。
- 通过广泛评估,FeatureSense在多种感知任务中表现出高效用性。
点此查看论文截图

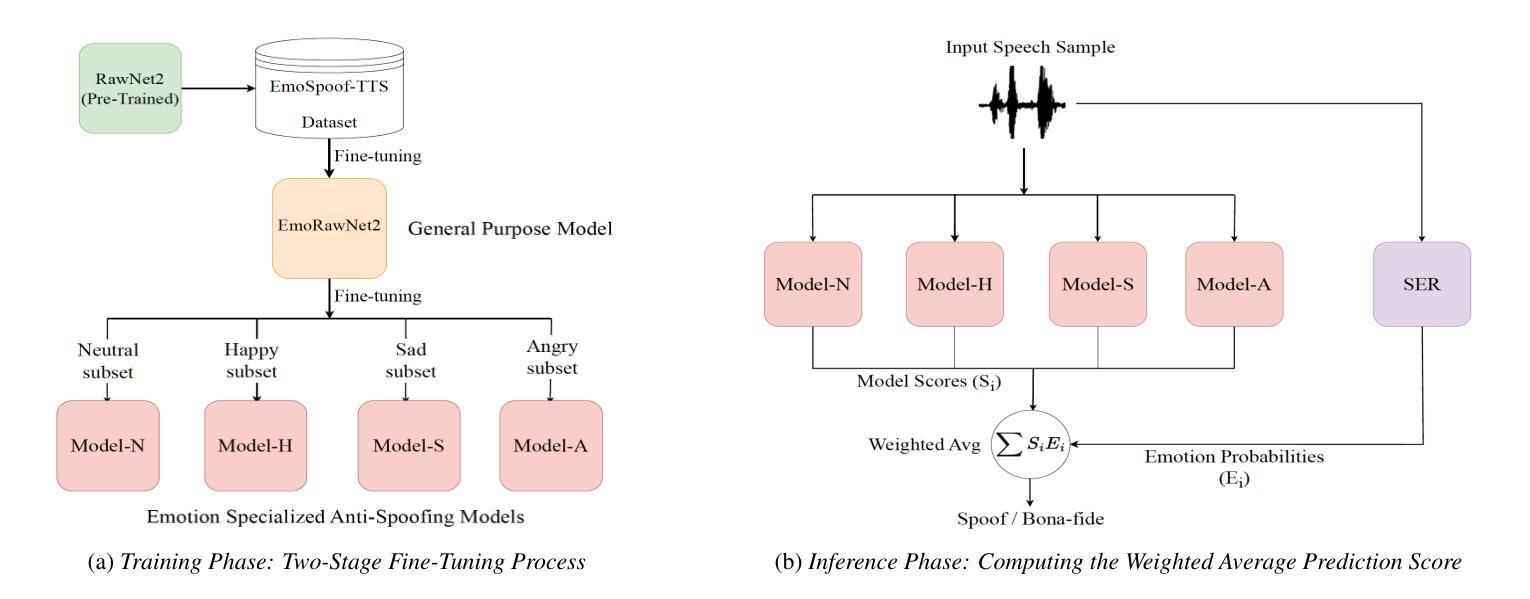
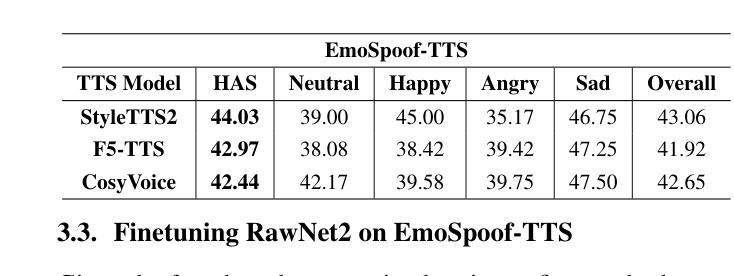
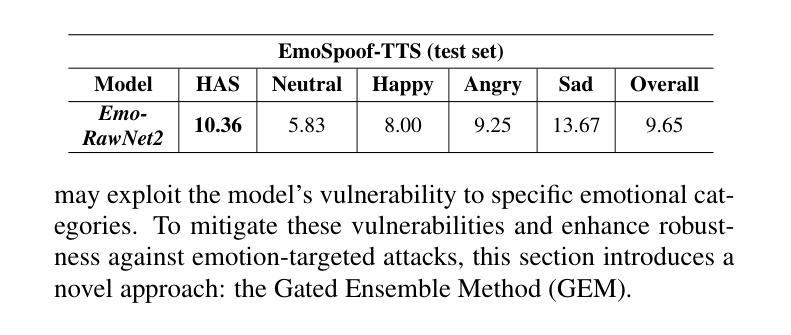
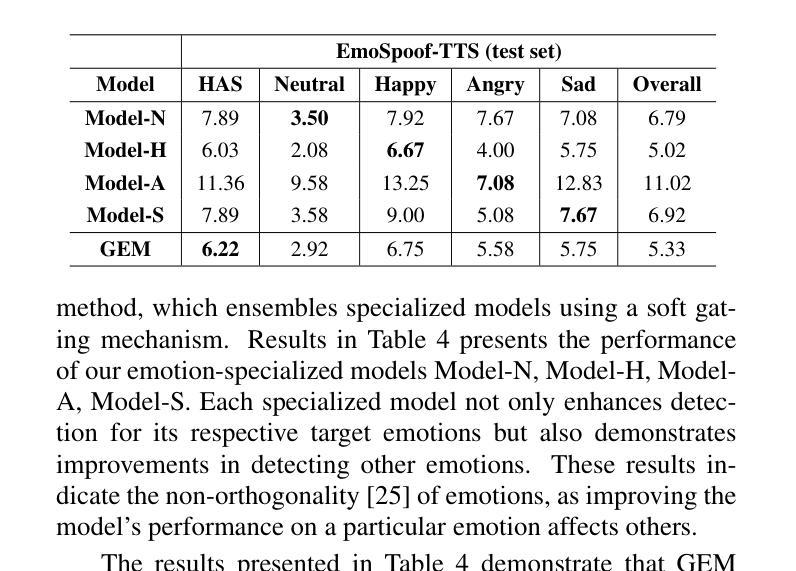
Can Emotion Fool Anti-spoofing?
Authors:Aurosweta Mahapatra, Ismail Rasim Ulgen, Abinay Reddy Naini, Carlos Busso, Berrak Sisman
Traditional anti-spoofing focuses on models and datasets built on synthetic speech with mostly neutral state, neglecting diverse emotional variations. As a result, their robustness against high-quality, emotionally expressive synthetic speech is uncertain. We address this by introducing EmoSpoof-TTS, a corpus of emotional text-to-speech samples. Our analysis shows existing anti-spoofing models struggle with emotional synthetic speech, exposing risks of emotion-targeted attacks. Even trained on emotional data, the models underperform due to limited focus on emotional aspect and show performance disparities across emotions. This highlights the need for emotion-focused anti-spoofing paradigm in both dataset and methodology. We propose GEM, a gated ensemble of emotion-specialized models with a speech emotion recognition gating network. GEM performs effectively across all emotions and neutral state, improving defenses against spoofing attacks. We release the EmoSpoof-TTS Dataset: https://emospoof-tts.github.io/Dataset/
传统的抗欺骗技术主要关注基于中性状态合成语音的模型和数据集,忽视了情感变化的多样性。因此,它们对于高质量、情感丰富的合成语音的稳健性尚不确定。我们通过引入EmoSpoof-TTS——一个情感文本到语音样本的语料库来解决这个问题。我们的分析显示,现有的抗欺骗模型在处理情感合成语音时面临困难,这暴露了针对情感的攻击风险。即使在情感数据上进行训练,这些模型由于缺乏对情感方面的重点关注而表现不佳,并且在各种情感之间表现出性能差异。这凸显了在数据集和方法论上都需要以情感为中心的抗欺骗范式。我们提出了GEM,这是一个带有语音情感识别门控网络的情感专业模型门控集合。GEM在所有情感和中性状态下都能有效运行,提高了对欺骗攻击的防御能力。我们发布了EmoSpoof-TTS数据集:https://emospoof-tts.github.io/Dataset/
论文及项目相关链接
PDF Accepted to Interspeech 2025
Summary
本文介绍了传统反欺骗技术在处理情感性语音合成方面的不足,并引入了一个新的情感语音合成语料库EmoSpoof-TTS。分析表明,现有反欺骗模型难以应对情感合成语音,存在情感目标攻击的风险。为此,提出了基于情感专业化模型的门控集成方法GEM,并配以语音情感识别门控网络,能有效应对各种情感和中性状态下的欺骗攻击。
Key Takeaways
- 传统反欺骗技术主要关注中性状态的合成语音,忽视了情感多样性。
- 现有模型对于高质量的情感表达合成语音的鲁棒性存在不确定性。
- 情感合成语音分析显示现有反欺骗模型面临挑战,存在情感目标攻击风险。
- 即使经过情感数据训练,模型在情感方面的关注仍然有限,不同情感间的性能存在差异。
- 提出了基于情感专注的反欺骗模式需求,包括数据集和方法论。
- 引入了EmoSpoof-TTS数据集,用于增强对情感语音合成的防御能力。
点此查看论文截图

Leveraging Auxiliary Information in Text-to-Video Retrieval: A Review
Authors:Adriano Fragomeni, Dima Damen, Michael Wray
Text-to-Video (T2V) retrieval aims to identify the most relevant item from a gallery of videos based on a user’s text query. Traditional methods rely solely on aligning video and text modalities to compute the similarity and retrieve relevant items. However, recent advancements emphasise incorporating auxiliary information extracted from video and text modalities to improve retrieval performance and bridge the semantic gap between these modalities. Auxiliary information can include visual attributes, such as objects; temporal and spatial context; and textual descriptions, such as speech and rephrased captions. This survey comprehensively reviews 81 research papers on Text-to-Video retrieval that utilise such auxiliary information. It provides a detailed analysis of their methodologies; highlights state-of-the-art results on benchmark datasets; and discusses available datasets and their auxiliary information. Additionally, it proposes promising directions for future research, focusing on different ways to further enhance retrieval performance using this information.
文本到视频(T2V)检索旨在根据用户的文本查询从视频库中找出最相关的项目。传统的方法仅依赖于对齐视频和文本模式来计算相似性和检索相关项目。然而,最近的进展强调融入从视频和文本模式中提取的辅助信息,以提高检索性能并缩小这些模式之间的语义鸿沟。辅助信息可以包括视觉属性,如物体;时间和空间上下文;以及文本描述,如语音和重新表述的标题。这篇综述全面回顾了81篇关于利用此类辅助信息进行文本到视频检索的研究论文。它提供了对其方法的详细分析;突出了基准数据集上的最新结果;并讨论了可用的数据集及其辅助信息。此外,它还提出了未来研究的几个有前途的方向,重点关注如何利用这些信息进一步提高检索性能的不同方式。
论文及项目相关链接
总结
文本与视频检索综合考察研究报告综述了基于辅助信息的文本与视频检索的相关研究论文,包括视觉属性和文本描述等辅助信息的使用。报告详细分析了这些方法的实现方式,突出了在基准数据集上的最新成果,并讨论了现有数据集及其辅助信息。同时,报告也指出了未来研究方向,建议如何利用辅助信息进一步提高检索性能。该报告涉及的方法旨在通过多模态融合缩小文本与视频之间的语义鸿沟。
关键见解
- T2V检索旨在根据用户的文本查询从视频库中检索最相关的视频。
- 传统方法主要依赖视频和文本模态的对齐来计算相似性和检索相关项目。
- 近年来的研究强调利用从视频和文本中提取的辅助信息来增强检索性能和缩小模态间的语义差距。
- 辅助信息包括视觉属性(如对象)、时空上下文和文本描述(如语音和重新表述的标题)。
- 该报告详细综述了关于如何利用这些辅助信息进行T2V检索的81篇研究论文。
- 报告详细分析了这些论文的方法论,并在基准数据集上突出了最新成果。
点此查看论文截图

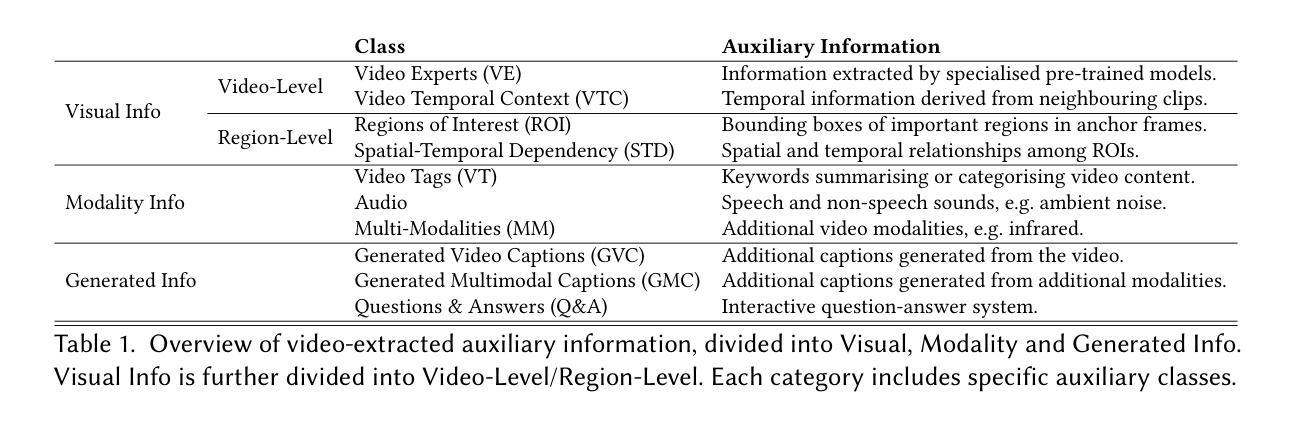
EmotionTalk: An Interactive Chinese Multimodal Emotion Dataset With Rich Annotations
Authors:Haoqin Sun, Xuechen Wang, Jinghua Zhao, Shiwan Zhao, Jiaming Zhou, Hui Wang, Jiabei He, Aobo Kong, Xi Yang, Yequan Wang, Yonghua Lin, Yong Qin
In recent years, emotion recognition plays a critical role in applications such as human-computer interaction, mental health monitoring, and sentiment analysis. While datasets for emotion analysis in languages such as English have proliferated, there remains a pressing need for high-quality, comprehensive datasets tailored to the unique linguistic, cultural, and multimodal characteristics of Chinese. In this work, we propose \textbf{EmotionTalk}, an interactive Chinese multimodal emotion dataset with rich annotations. This dataset provides multimodal information from 19 actors participating in dyadic conversational settings, incorporating acoustic, visual, and textual modalities. It includes 23.6 hours of speech (19,250 utterances), annotations for 7 utterance-level emotion categories (happy, surprise, sad, disgust, anger, fear, and neutral), 5-dimensional sentiment labels (negative, weakly negative, neutral, weakly positive, and positive) and 4-dimensional speech captions (speaker, speaking style, emotion and overall). The dataset is well-suited for research on unimodal and multimodal emotion recognition, missing modality challenges, and speech captioning tasks. To our knowledge, it represents the first high-quality and versatile Chinese dialogue multimodal emotion dataset, which is a valuable contribution to research on cross-cultural emotion analysis and recognition. Additionally, we conduct experiments on EmotionTalk to demonstrate the effectiveness and quality of the dataset. It will be open-source and freely available for all academic purposes. The dataset and codes will be made available at: https://github.com/NKU-HLT/EmotionTalk.
近年来,情感识别在人机交互、心理健康监测和情感分析等领域的应用中发挥着至关重要的作用。虽然英语情感分析的数据集已经大量涌现,但对于具有独特语言、文化和多模态特征的中国,仍迫切需要高质量的综合数据集。在这项工作中,我们提出了EmotionTalk,这是一个带有丰富注释的交互式中文多模态情感数据集。该数据集提供了来自19名演员在双人对话环境中的多模态信息,融合了声音、视觉和文本模式。它包含23.6小时的语音(19,250个陈述)、7个陈述级情感类别的注释(快乐、惊讶、悲伤、厌恶、愤怒、恐惧和中性)、5维情感标签(负面、轻微负面、中性、轻微正面和正面)和4维语音字幕(说话者、说话风格、情感和总体)。该数据集适用于单模态和多模态情感识别研究、缺失模态挑战和语音字幕任务。据我们所知,它是第一个高质量且通用的中文对话多模态情感数据集,对跨文化情感分析和识别研究做出了宝贵的贡献。此外,我们在EmotionTalk上进行了实验,以证明该数据集的有效性和质量。该数据集将开源并免费供所有学术目的使用。数据集和代码将在https://github.com/NKU-HLT/EmotionTalk上提供。
论文及项目相关链接
Summary
本文介绍了一个名为EmotionTalk的中文多模态情感数据集,该数据集包含来自19名参与者在对话环境中的多模态信息,包括声音、视频和文字。数据集包含丰富的标注信息,如情感类别、情感维度和语音字幕等。该数据集适用于单模态和多模态情感识别研究,缺失模态挑战和语音字幕任务等。这是首个高质量、多功能的中文对话多模态情感数据集,对跨文化情感分析和识别研究具有宝贵贡献。数据集将开源并免费提供给所有学术用途。
Key Takeaways
- EmotionTalk是一个针对中文的多模态情感数据集,包含声音、视频和文字信息。
- 数据集包含丰富的标注信息,包括情感类别、情感维度和语音字幕等。
- 数据集适用于单模态和多模态情感识别研究。
- 数据集具有缺失模态挑战的特性,适用于处理实际应用中的缺失数据问题。
- EmotionTalk是首个高质量、多功能的中文对话多模态情感数据集。
- 该数据集对跨文化情感分析和识别研究具有宝贵贡献。
点此查看论文截图

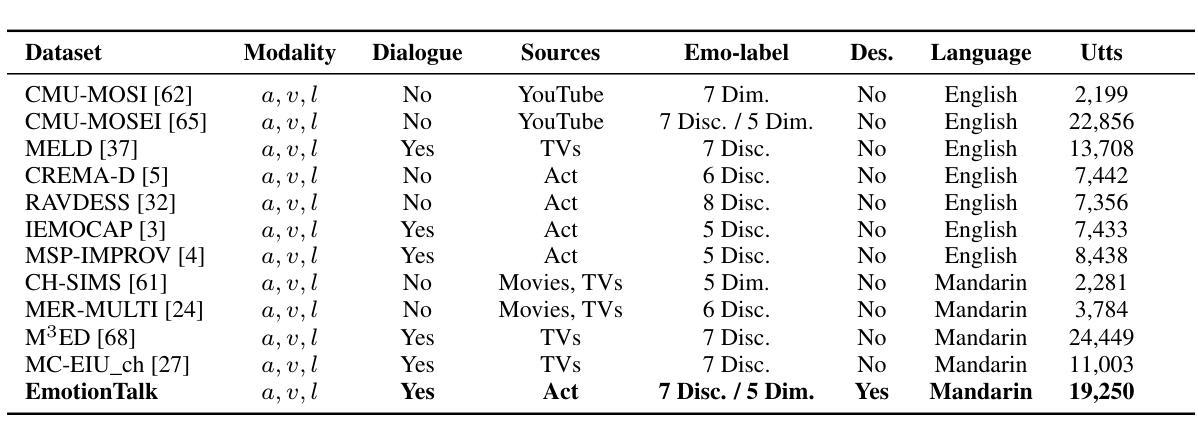
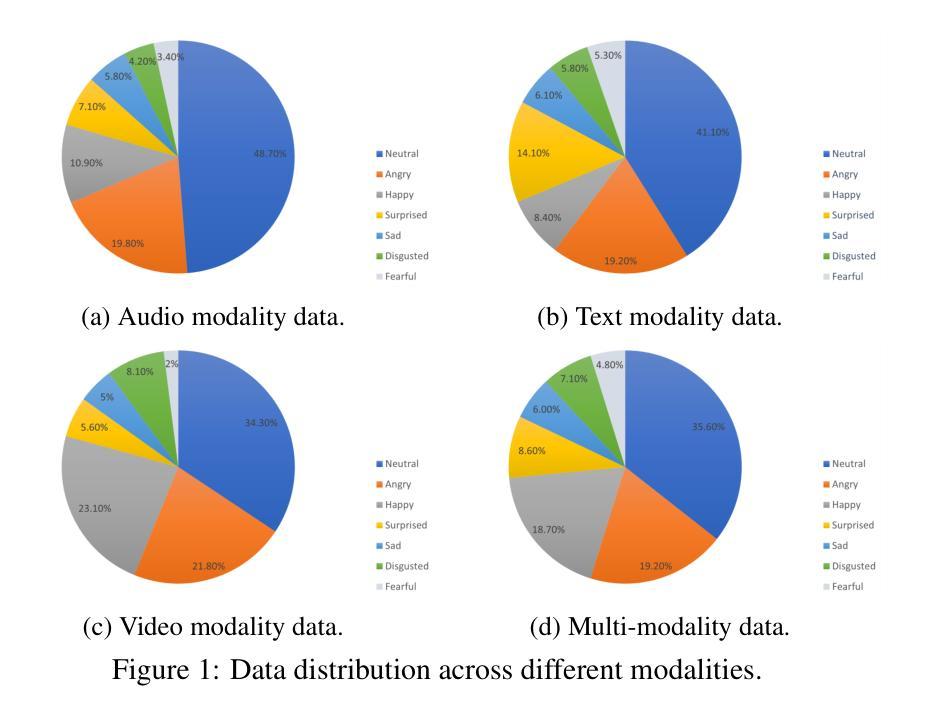
Towards Robust Assessment of Pathological Voices via Combined Low-Level Descriptors and Foundation Model Representations
Authors:Whenty Ariyanti, Kuan-Yu Chen, Sabato Marco Siniscalchi, Hsin-Min Wang, Yu Tsao
Perceptual voice quality assessment is essential for diagnosing and monitoring voice disorders by providing standardized evaluations of vocal function. Traditionally, expert raters use standard scales such as the Consensus Auditory-Perceptual Evaluation of Voice (CAPE-V) and Grade, Roughness, Breathiness, Asthenia, and Strain (GRBAS). However, these metrics are subjective and prone to inter-rater variability, motivating the need for automated, objective assessment methods. This study proposes Voice Quality Assessment Network (VOQANet), a deep learning-based framework with an attention mechanism that leverages a Speech Foundation Model (SFM) to extract high-level acoustic and prosodic information from raw speech. To enhance robustness and interpretability, we also introduce VOQANet+, which integrates low-level speech descriptors such as jitter, shimmer, and harmonics-to-noise ratio (HNR) with SFM embeddings into a hybrid representation. Unlike prior studies focused only on vowel-based phonation (PVQD-A subset) of the Perceptual Voice Quality Dataset (PVQD), we evaluate our models on both vowel-based and sentence-level speech (PVQD-S subset) to improve generalizability. Results show that sentence-based input outperforms vowel-based input, especially at the patient level, underscoring the value of longer utterances for capturing perceptual voice attributes. VOQANet consistently surpasses baseline methods in root mean squared error (RMSE) and Pearson correlation coefficient (PCC) across CAPE-V and GRBAS dimensions, with VOQANet+ achieving even better performance. Additional experiments under noisy conditions show that VOQANet+ maintains high prediction accuracy and robustness, supporting its potential for real-world and telehealth deployment.
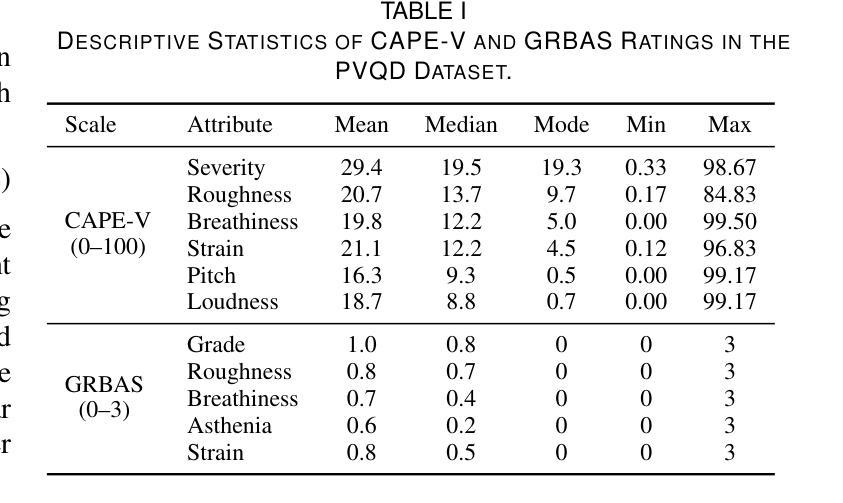
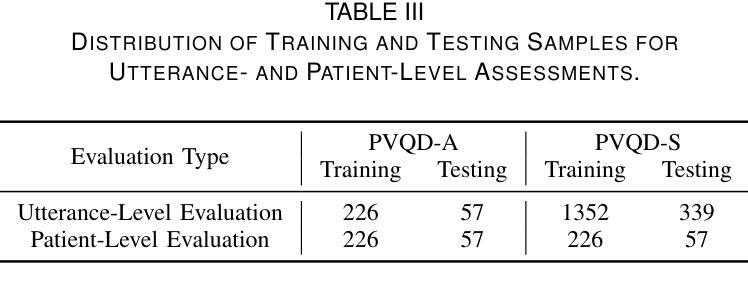
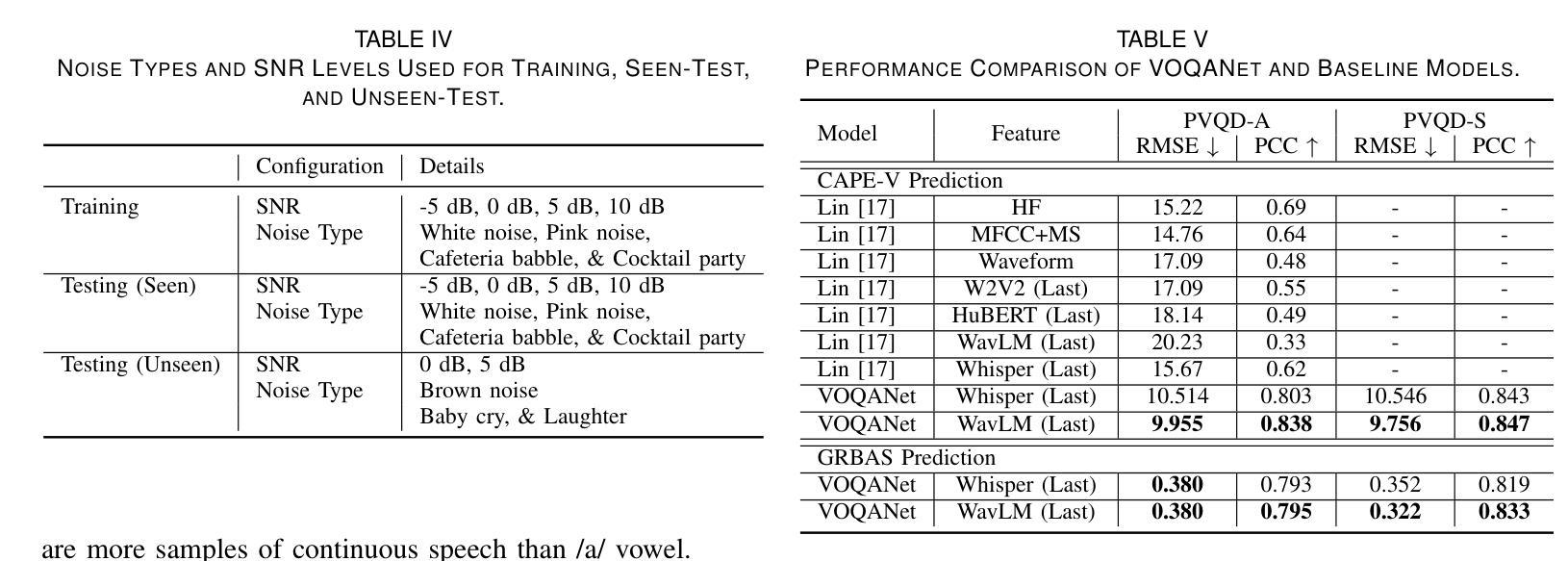
感知语音质量评估对于通过标准化语音功能评估来诊断和监督语音障碍至关重要。传统上,专家评估者使用标准量表,如共识听觉感知语音评估(CAPE-V)和等级、粗糙度、呼吸声、虚弱和紧张(GRBAS)。然而,这些指标是主观的并且容易产生评价者之间的差异,因此需要自动、客观的评估方法。本研究提出了基于深度学习的语音质量评估网络(VOQANet),该网络具有注意力机制,并利用语音基础模型(SFM)从原始语音中提取高级声音和韵律信息。为了增强稳健性和可解释性,我们还引入了VOQANet+,它将低级别语音描述符(如颤抖、波动和谐波与噪声比(HNR))与SFM嵌入到混合表示中。不同于以前只关注感知语音质量数据集(PVQD)中的基于元音的发音(PVQD-A子集)的研究,我们对模型进行了基于元音和句子级别的语音(PVQD-S子集)的评估,以提高其通用性。结果表明,基于句子的输入优于基于元音的输入,特别是在患者层面,这强调了较长语音片段在捕捉感知语音属性方面的价值。VOQANet在CAPE-V和GRBAS维度的均方根误差(RMSE)和皮尔逊相关系数(PCC)方面始终超越基线方法,而VOQANet+甚至取得了更好的性能。在噪声条件下的附加实验表明,VOQANet+保持高预测精度和稳健性,支持其在现实世界和远程医疗部署的潜力。
论文及项目相关链接
摘要
语音质量感知评估对于通过标准化的嗓音功能评价来诊断和治疗语音障碍至关重要。传统上,专家评分者使用诸如CAPE-V和GRBAS等标准量表进行评估,但这些指标具有主观性,存在评分者间变异性的缺点,因此迫切需要客观自动的评估方法。本研究提出了基于深度学习的Voice Quality Assessment Network(VOQANet),该网络具有注意力机制,利用语音基础模型(SFM)从原始语音中提取高级声学和韵律信息。为提高稳健性和可解释性,我们还引入了VOQANet+,它将低级语音描述符(如抖动、咝声和谐波噪声比(HNR))与SFM嵌入相结合形成混合表示。与以往仅关注感知语音质量数据集(PVQD)的元音发音子集的研究不同,我们对元音发音和句子水平的语音(PVQD-S子集)进行了评估,以提高模型的通用性。结果表明,句子为基础的输入优于元音为基础的输入,特别是在患者层面,这强调了较长话语在捕捉感知语音属性方面的价值。VOQANet在CAPE-V和GRBAS各维度上的均方根误差(RMSE)和皮尔逊相关系数(PCC)上均超越了基线方法,而VOQANet+的表现更佳。在噪声环境下的额外实验表明,VOQANet+保持了较高的预测精度和稳健性,支持其在现实和远程医疗部署的潜力。
关键见解
- 语音质量感知评估是诊断和管理语音障碍的重要工具,需要客观、自动化的评估方法以减轻主观变异性的影响。
- 本研究提出了基于深度学习的VOQANet模型,可以提取高级声学特征,对语音质量进行评估。
- 引入的VOQANet+模型进一步结合了低级语音描述符和高级特征,增强了模型的稳健性和可解释性。
- 研究发现句子水平的语音评估相比元音水平的评估更具优势,特别是在真实世界的环境下。
- VOQANet在各种测试指标上超过了现有方法,表现出优异的性能。
- VOQANet+在噪声环境下的预测性能稳定,显示出在远程医疗等实际场景中应用的潜力。
点此查看论文截图

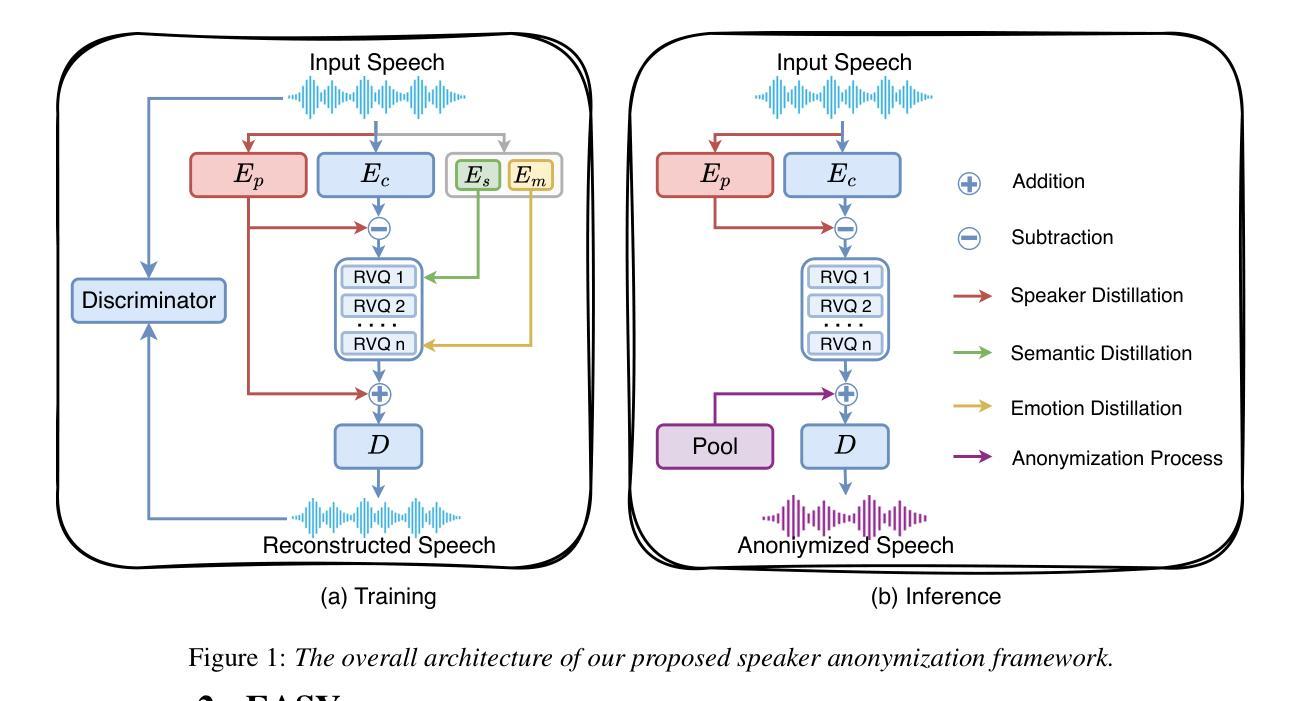
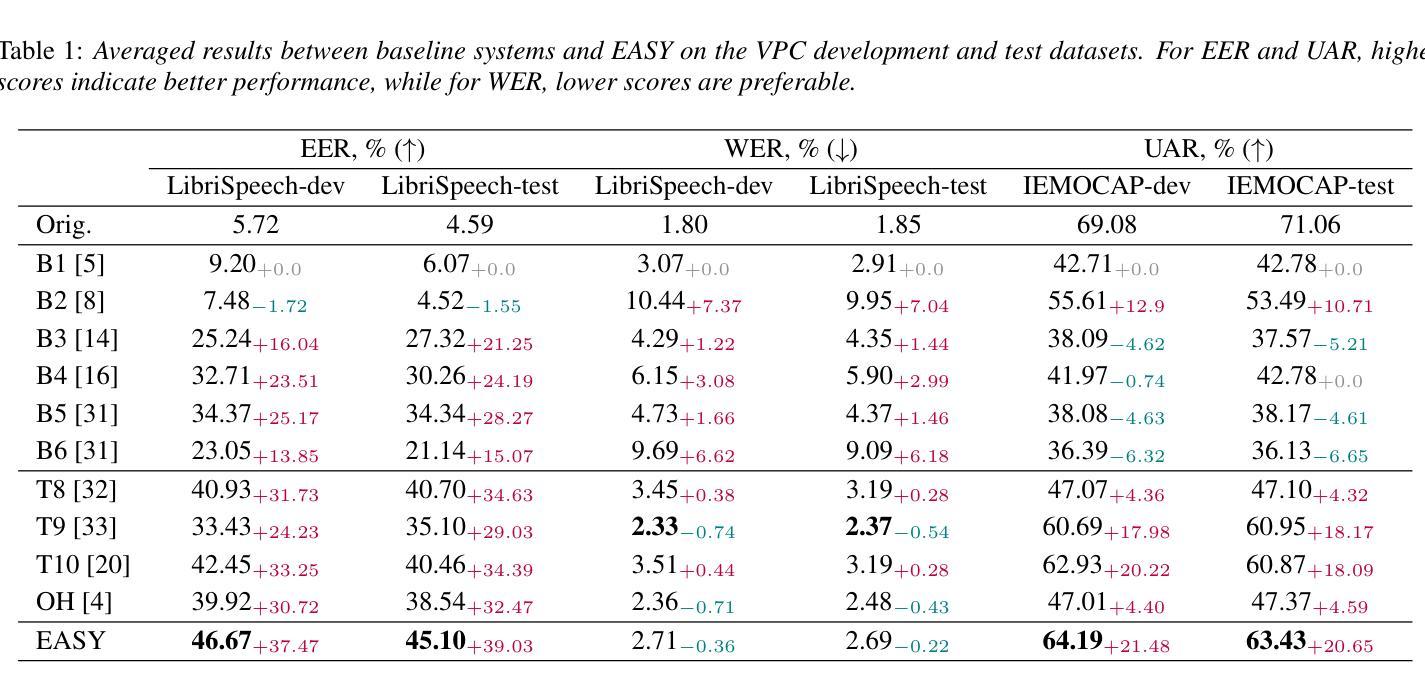
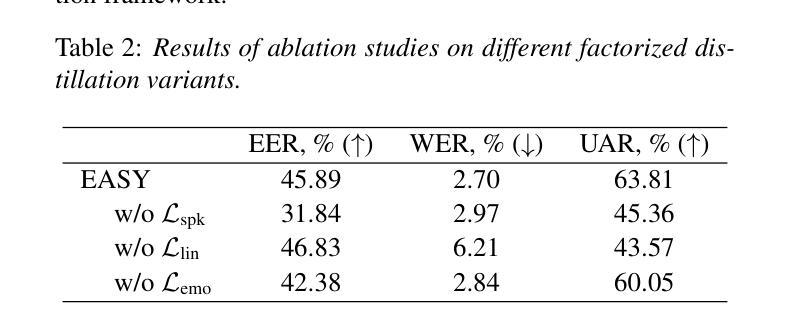
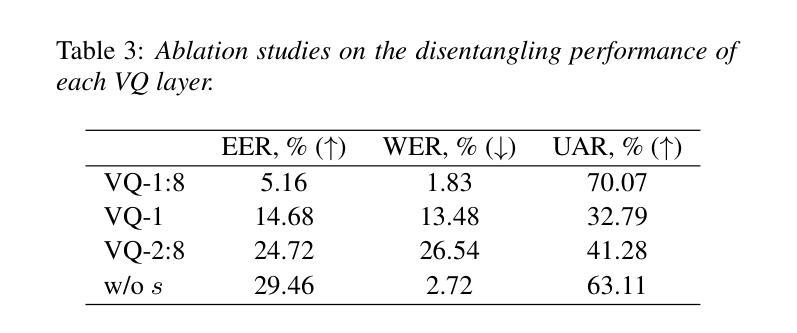
EASY: Emotion-aware Speaker Anonymization via Factorized Distillation
Authors:Jixun Yao, Hexin Liu, Eng Siong Chng, Lei Xie
Emotion plays a significant role in speech interaction, conveyed through tone, pitch, and rhythm, enabling the expression of feelings and intentions beyond words to create a more personalized experience. However, most existing speaker anonymization systems employ parallel disentanglement methods, which only separate speech into linguistic content and speaker identity, often neglecting the preservation of the original emotional state. In this study, we introduce EASY, an emotion-aware speaker anonymization framework. EASY employs a novel sequential disentanglement process to disentangle speaker identity, linguistic content, and emotional representation, modeling each speech attribute in distinct subspaces through a factorized distillation approach. By independently constraining speaker identity and emotional representation, EASY minimizes information leakage, enhancing privacy protection while preserving original linguistic content and emotional state. Experimental results on the VoicePrivacy Challenge official datasets demonstrate that our proposed approach outperforms all baseline systems, effectively protecting speaker privacy while maintaining linguistic content and emotional state.
情感在语音交互中扮演着重要角色,通过语调、音高和节奏来传达,使人们在言语之外能够表达感受和意图,从而创造更加个性化的体验。然而,大多数现有的说话人匿名化系统采用并行分离方法,仅将语音分离为语言内容和说话人身份,往往忽视了原始情感状态的保留。在研究中,我们引入了情感感知说话人匿名化框架EASY。EASY采用新颖的顺序分离过程来分离说话人身份、语言内容和情感表示,通过因子蒸馏法将每种语音属性建模在不同的子空间中。通过独立约束说话人身份和情感表示,EASY减少了信息泄露,在保护隐私的同时保留了原始的语言内容和情感状态。在VoicePrivacy Challenge官方数据集上的实验结果表明,我们提出的方法优于所有基线系统,在保护说话人隐私的同时,保持语言内容和情感状态。
论文及项目相关链接
PDF Accepted by INTERSPEECH 2025
总结
该研究介绍了情感感知的说话人匿名化框架——EASY。它采用了一种新的连续解纠缠过程,将说话人的身份、语言内容和情感表达进行分离,并通过因子蒸馏的方法将每个语音属性建模在不同的子空间中。通过独立约束说话人身份和情感表达,EASY减少了信息泄露,增强了隐私保护,同时保留了原始的语言内容和情感状态。在VoicePrivacy Challenge官方数据集上的实验结果表明,该方法优于所有基线系统,有效地保护了说话人的隐私,同时保持了语言内容和情感状态。
关键见解
- 情感在语音交互中扮演着重要角色,通过语调、音高和节奏来传达。
- 现有的大多数说话人匿名化系统只关注将语音分离为语言内容和说话人身份,忽视了情感状态的保持。
- EASY是一个情感感知的说话人匿名化框架,采用新的连续解纠缠过程来分离说话人的身份、语言内容和情感表达。
- EASY通过因子蒸馏的方法建模每个语音属性,将说话人的身份和情感表达独立约束,以最小化信息泄露。
- EASY在保护隐私的同时保留了原始的语言内容和情感状态。
- 在VoicePrivacy Challenge官方数据集上的实验结果表明,EASY的性能优于其他基线系统。
点此查看论文截图

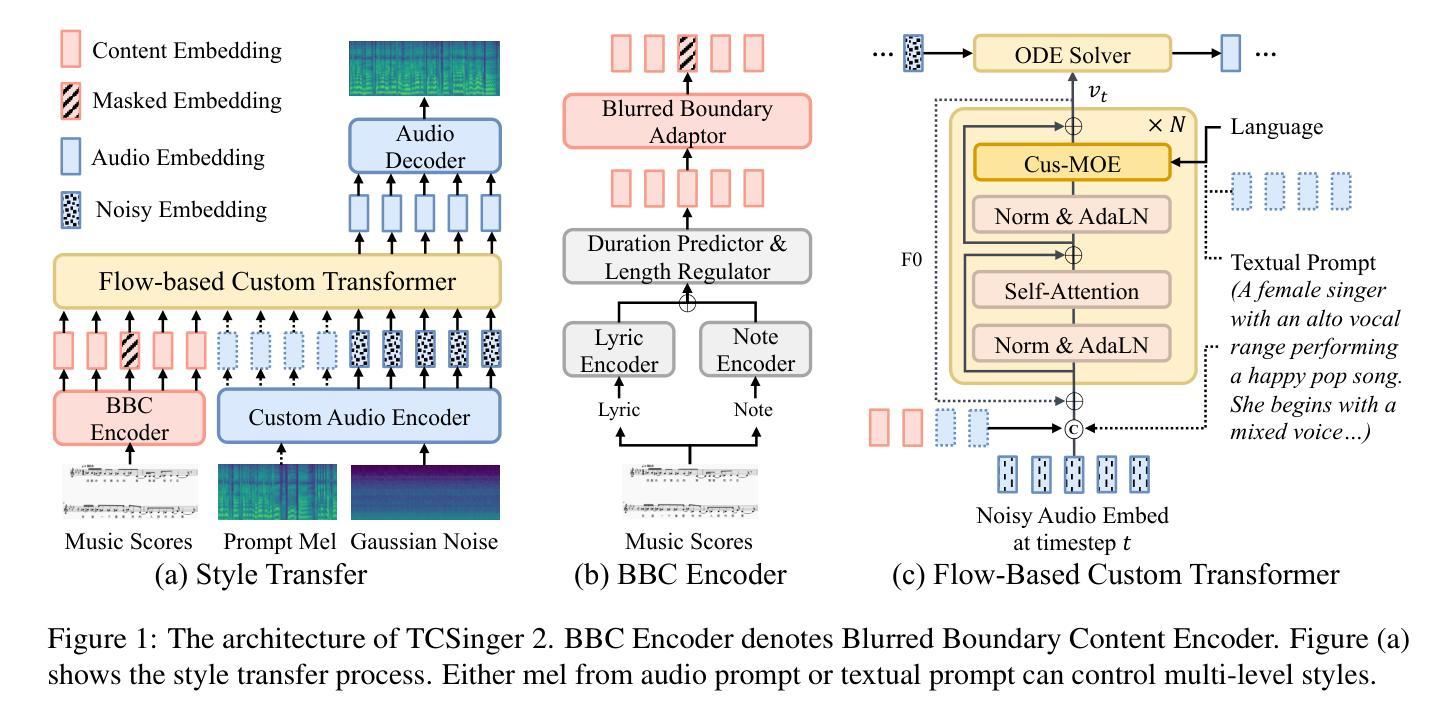
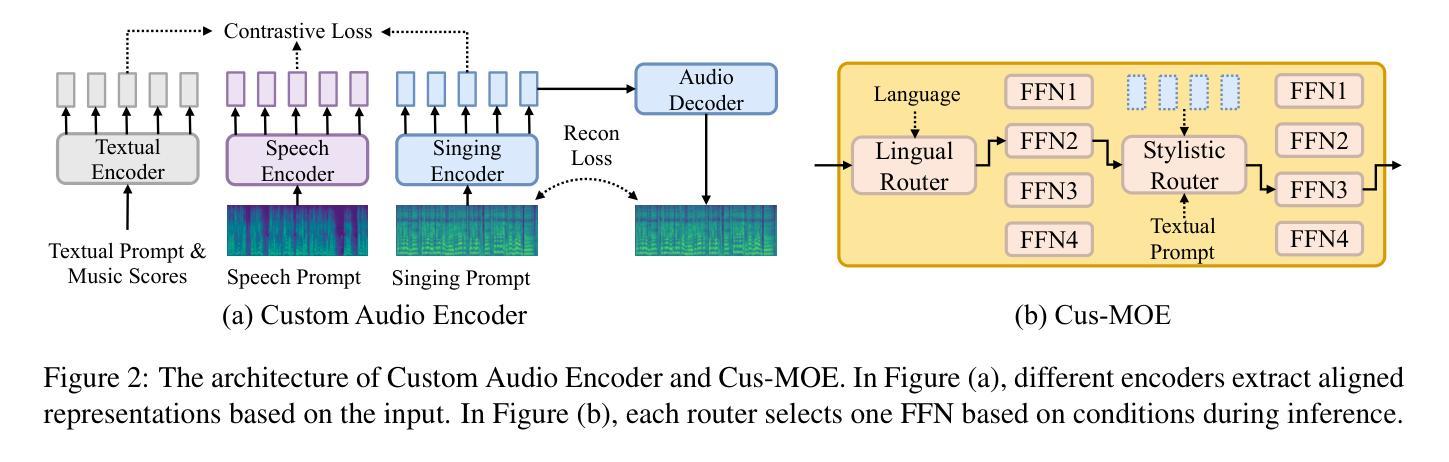
TCSinger 2: Customizable Multilingual Zero-shot Singing Voice Synthesis
Authors:Yu Zhang, Wenxiang Guo, Changhao Pan, Dongyu Yao, Zhiyuan Zhu, Ziyue Jiang, Yuhan Wang, Tao Jin, Zhou Zhao
Customizable multilingual zero-shot singing voice synthesis (SVS) has various potential applications in music composition and short video dubbing. However, existing SVS models overly depend on phoneme and note boundary annotations, limiting their robustness in zero-shot scenarios and producing poor transitions between phonemes and notes. Moreover, they also lack effective multi-level style control via diverse prompts. To overcome these challenges, we introduce TCSinger 2, a multi-task multilingual zero-shot SVS model with style transfer and style control based on various prompts. TCSinger 2 mainly includes three key modules: 1) Blurred Boundary Content (BBC) Encoder, predicts duration, extends content embedding, and applies masking to the boundaries to enable smooth transitions. 2) Custom Audio Encoder, uses contrastive learning to extract aligned representations from singing, speech, and textual prompts. 3) Flow-based Custom Transformer, leverages Cus-MOE, with F0 supervision, enhancing both the synthesis quality and style modeling of the generated singing voice. Experimental results show that TCSinger 2 outperforms baseline models in both subjective and objective metrics across multiple related tasks. Singing voice samples are available at https://aaronz345.github.io/TCSinger2Demo/.
可定制的多语言零样本歌声合成(SVS)在音乐创作和短视频配音等方面具有各种潜在应用。然而,现有的SVS模型过于依赖音素和音符边界注释,这限制了它们在零样本场景中的稳健性,并导致音素和音符之间的过渡不佳。此外,它们还缺乏通过不同提示进行有效的多级风格控制。为了克服这些挑战,我们引入了TCSinger 2,这是一个多任务多语言零样本SVS模型,具有基于各种提示的风格迁移和风格控制。TCSinger 2主要包括三个关键模块:1)模糊边界内容(BBC)编码器,预测持续时间,扩展内容嵌入,并对边界应用掩码以实现平滑过渡。2)自定义音频编码器,使用对比学习从歌声、语音和文本提示中提取对齐表示。3)基于流的自定义变压器,利用Cus-MOE和F0监督,提高生成歌声的合成质量和风格建模。实验结果表明,TCSinger 2在多个相关任务的主观和客观指标上均优于基准模型。歌声样本可在https://aaronz345.github.io/TCSinger2Demo/上找到。
论文及项目相关链接
PDF Accepted by Findings of ACL 2025
Summary
一个可扩展的多语种零样本歌唱语音合成(SVS)模型TCSinger 2被提出,用于音乐创作和短视频配音。它包含三个关键模块:模糊边界内容编码器、自定义音频编码器和基于流的自定义转换器。该模型解决了现有SVS模型过度依赖音素和音符边界注释的问题,实现了零样本场景下的流畅过渡和基于不同提示的多级风格控制。实验结果表明,TCSinger 2在多项任务中均优于基准模型。相关歌唱语音样本可在线体验。
Key Takeaways
1.TCSinger 2是一个多语种零样本歌唱语音合成模型,用于音乐创作和短视频配音。
2.现有SVS模型存在过度依赖音素和音符边界注释的问题,导致零样本场景下的性能受限和音素与音符间的过渡不流畅。
3.TCSinger 2通过模糊边界内容编码器解决了这一问题,实现了平滑过渡。
4.该模型包含自定义音频编码器和基于流的自定义转换器,以提高合成质量和风格建模。
5.通过对比实验,TCSinger 2在多项任务中表现出优于基准模型的效果。
6.该模型支持多语种,具有风格转移和风格控制功能,基于各种提示实现多级控制。
点此查看论文截图

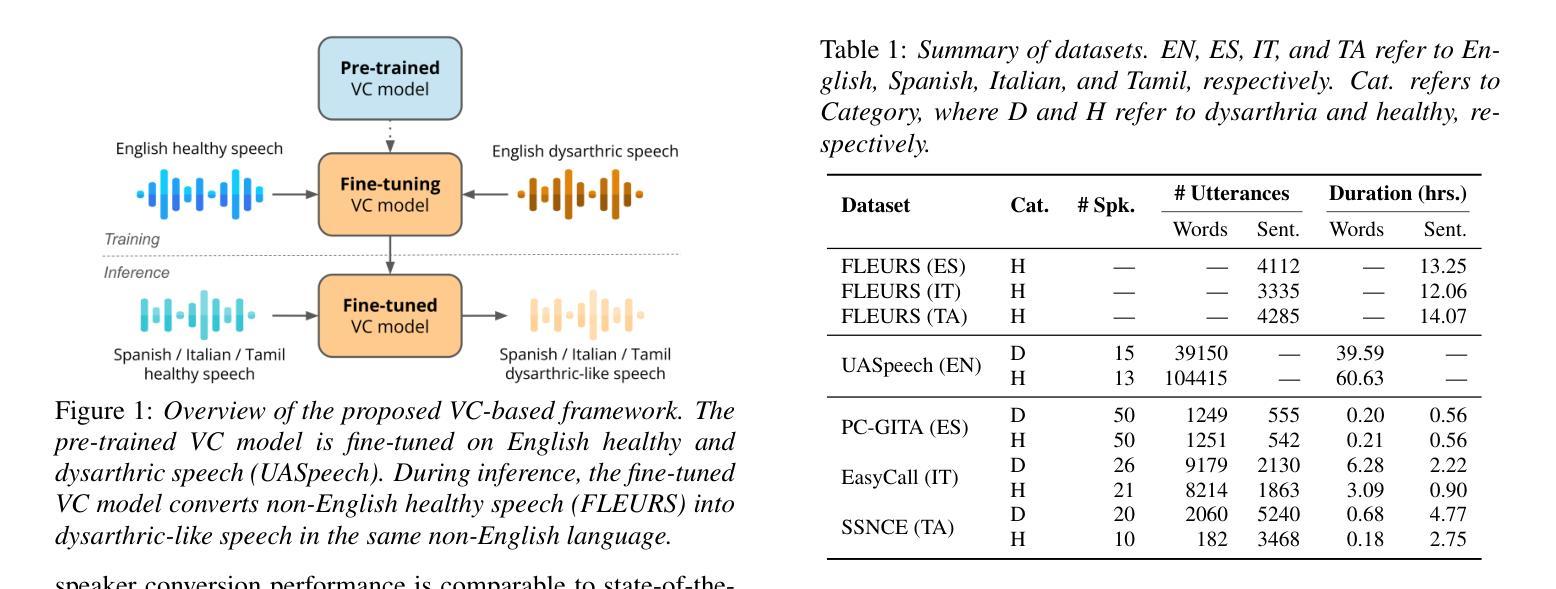
Towards Inclusive ASR: Investigating Voice Conversion for Dysarthric Speech Recognition in Low-Resource Languages
Authors:Chin-Jou Li, Eunjung Yeo, Kwanghee Choi, Paula Andrea Pérez-Toro, Masao Someki, Rohan Kumar Das, Zhengjun Yue, Juan Rafael Orozco-Arroyave, Elmar Nöth, David R. Mortensen
Automatic speech recognition (ASR) for dysarthric speech remains challenging due to data scarcity, particularly in non-English languages. To address this, we fine-tune a voice conversion model on English dysarthric speech (UASpeech) to encode both speaker characteristics and prosodic distortions, then apply it to convert healthy non-English speech (FLEURS) into non-English dysarthric-like speech. The generated data is then used to fine-tune a multilingual ASR model, Massively Multilingual Speech (MMS), for improved dysarthric speech recognition. Evaluation on PC-GITA (Spanish), EasyCall (Italian), and SSNCE (Tamil) demonstrates that VC with both speaker and prosody conversion significantly outperforms the off-the-shelf MMS performance and conventional augmentation techniques such as speed and tempo perturbation. Objective and subjective analyses of the generated data further confirm that the generated speech simulates dysarthric characteristics.
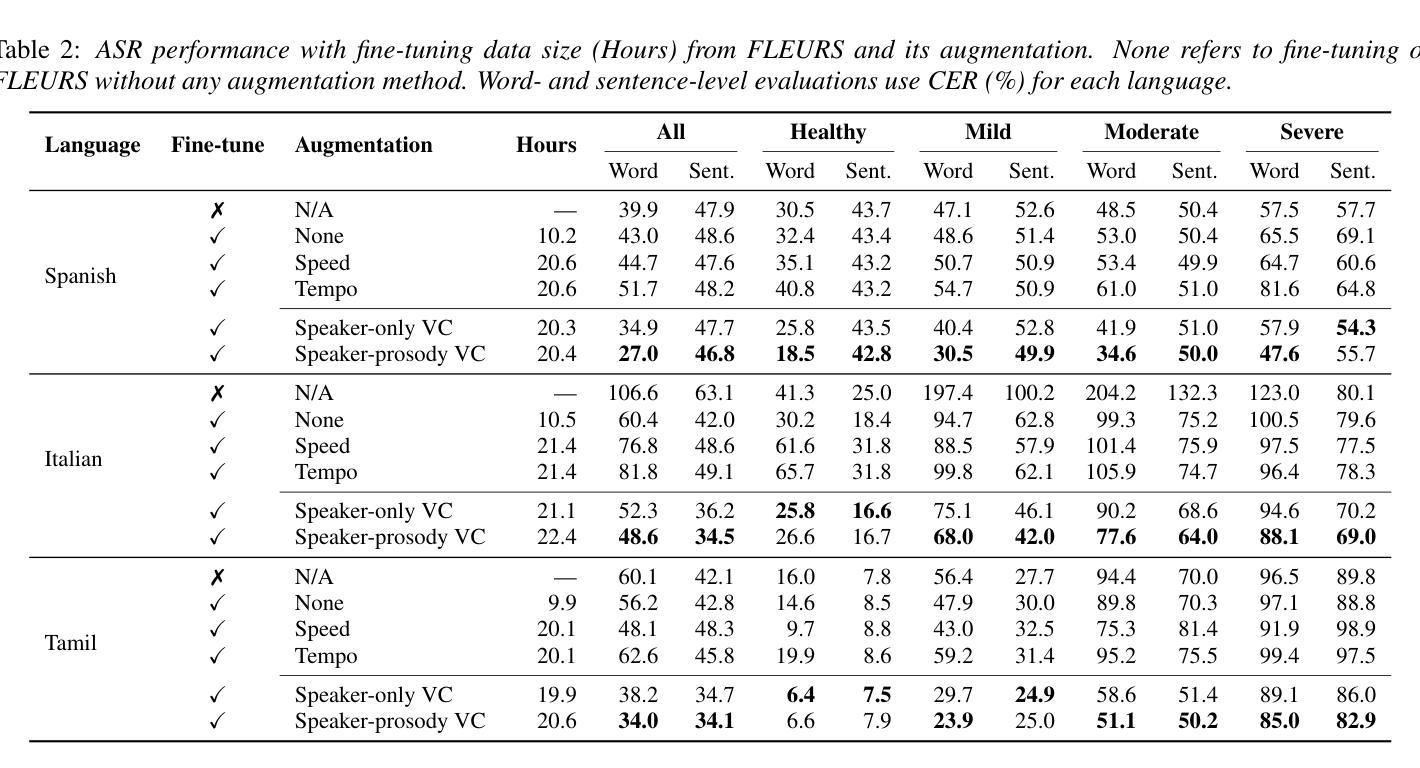
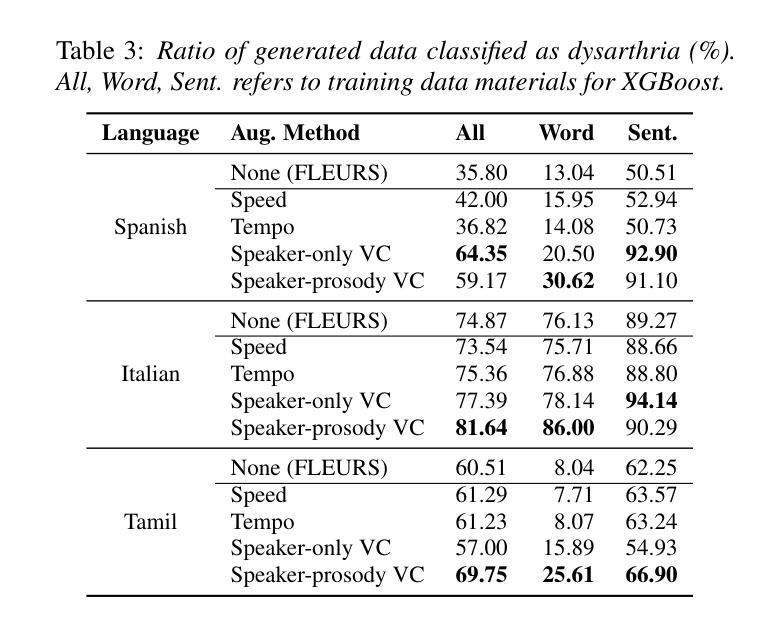
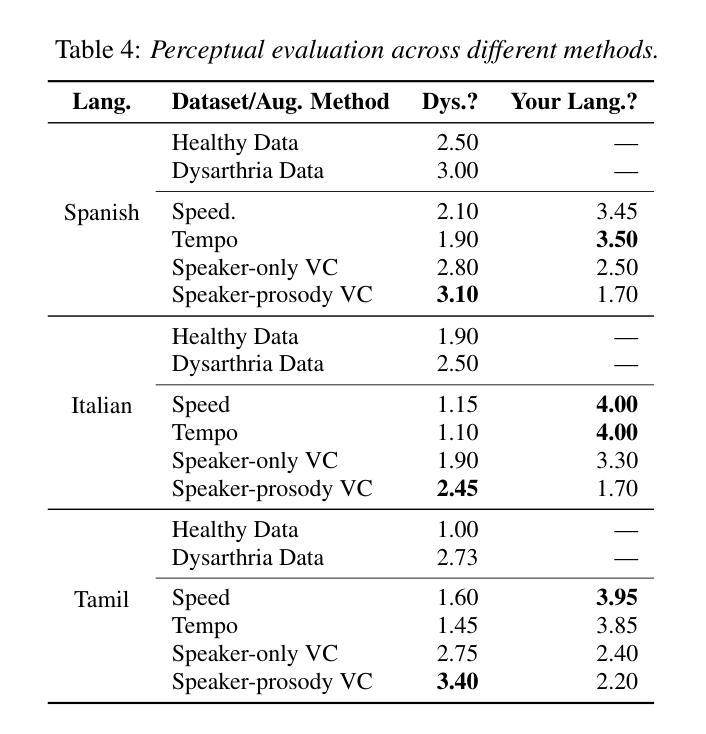
由于数据稀缺,特别是在非英语领域,针对言语障碍者的自动语音识别(ASR)仍然是一个挑战。为了解决这一问题,我们对英语言语障碍语音(UASpeech)进行微调,以编码说话人的特征和韵律扭曲,然后将其应用于将健康的非英语语音(FLEURS)转换为非英语类的言语障碍语音。生成的数据随后被用于微调用于改进言语障碍语音识别的多语言自动语音识别模型——大规模多语言语音(MMS)。在PC-GITA(西班牙语)、EasyCall(意大利语)和SSNCE(泰米尔语)上的评估表明,同时转换说话人和韵律的语音转换技术显著优于现成的MMS性能和传统的增强技术,如速度和节奏扰动。对生成数据的客观和主观分析进一步证实,生成的语音模拟了言语障碍的特征。
论文及项目相关链接
PDF 5 pages, 1 figure, Accepted to Interspeech 2025
Summary
这篇文本介绍了针对发音障碍语音的自动语音识别(ASR)的挑战,并提出了一种解决方案。通过使用英语发音障碍语音(UASpeech)对语音转换模型进行微调,以编码说话人的特征和韵律扭曲。然后将其应用于将健康的非英语语音(FLEURS)转换为非英语发音障碍类似的语音。生成的数据用于微调多语言ASR模型Massively Multilingual Speech(MMS),以提高对发音障碍语音的识别能力。在PC-GITA(西班牙语)、EasyCall(意大利语)和SSNCE(泰米尔语)上的评估表明,同时实现说话人和韵律转换的语音转换技术显著优于现成的MMS性能和传统的增强技术,如速度和节奏扰动。对生成数据的客观和主观分析进一步证实,生成的语音模拟了发音障碍的特征。
Key Takeaways
- 数据稀缺使得发音障碍语音的自动语音识别(ASR)具有挑战性。
- 提出了一种基于英语发音障碍语音(UASpeech)的语音转换模型微调方法,以编码说话人的特征和韵律扭曲。
- 使用该模型将健康的非英语语音转换为非英语发音障碍类似的语音,生成的数据用于训练ASR模型。
- 评估显示,这种语音转换技术在多种语言上的性能优于传统的ASR模型和增强技术。
- 该技术结合说话人和韵律转换,能更真实地模拟发音障碍的特征。
- 客观和主观分析证实了生成语音的逼真度和模拟发音障碍的能力。
点此查看论文截图

Mitigating Subgroup Disparities in Multi-Label Speech Emotion Recognition: A Pseudo-Labeling and Unsupervised Learning Approach
Authors:Yi-Cheng Lin, Huang-Cheng Chou, Hung-yi Lee
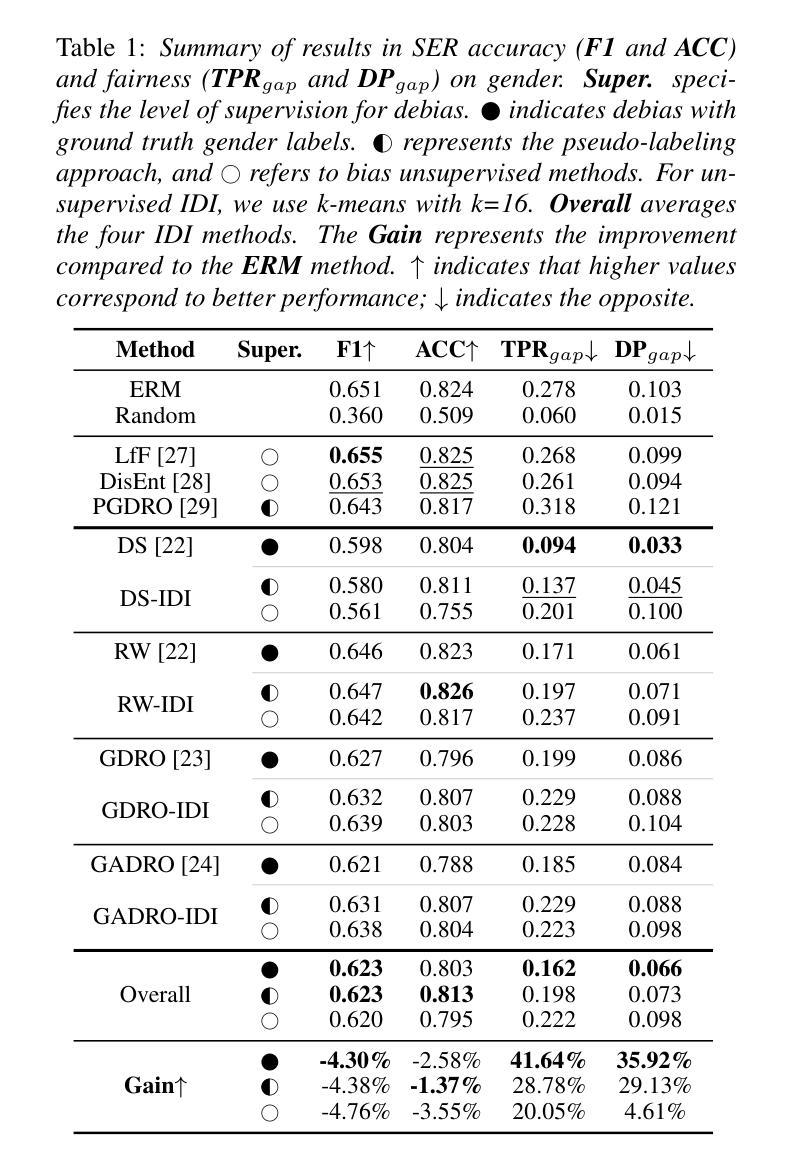
While subgroup disparities and performance bias are increasingly studied in computational research, fairness in categorical Speech Emotion Recognition (SER) remains underexplored. Existing methods often rely on explicit demographic labels, which are difficult to obtain due to privacy concerns. To address this limitation, we introduce an Implicit Demography Inference (IDI) module that leverages pseudo-labeling from a pre-trained model and unsupervised learning using k-means clustering to mitigate bias in SER. Our experiments show that pseudo-labeling IDI reduces subgroup disparities, improving fairness metrics by over 28% with less than a 2% decrease in SER accuracy. Also, the unsupervised IDI yields more than a 4.6% improvement in fairness metrics with a drop of less than 3.6% in SER performance. Further analyses reveal that the unsupervised IDI consistently mitigates race and age disparities, demonstrating its potential when explicit demographic information is unavailable.
虽然子群体差异和性能偏见在计算研究中得到了越来越多的研究,但在分类语音情感识别(SER)中的公平性仍然被忽视。现有方法通常依赖于难以获得的明确人口统计标签(由于隐私担忧)。为了解决这一局限性,我们引入了一个隐式人口统计推断(IDI)模块,该模块利用预训练模型的伪标签和k-means聚类进行无监督学习,以减轻SER中的偏见。我们的实验表明,伪标签IDI减少了子群体差异,公平度指标提高了28%以上,而SER准确率下降了不到2%。此外,无监督的IDI在公平指标上提高了4.6%以上,而SER性能下降了不到3.6%。进一步的分析表明,无监督的IDI始终能够减轻种族和年龄差异,在缺乏明确人口统计信息的情况下显示出其潜力。
论文及项目相关链接
PDF Accepted by InterSpeech 2025. 7 pages including 2 pages of appendix
Summary
该文探讨了语音情感识别(SER)中的类别公平性问题,并指出现有方法依赖难以获取的明确人口统计标签的问题。为此,引入了隐式人口统计推断(IDI)模块,利用预训练模型的伪标签和K-means聚类进行无监督学习,以减轻SER中的偏见。实验表明,伪标签IDI减少了子群差异,公平度指标提高了28%以上,而SER准确率仅下降不到2%。此外,无监督的IDI在公平度指标上提高了4.6%以上,而SER性能仅下降不到3.6%。进一步的分析表明,无监督的IDI可以持续缓解种族和年龄差异,展示出了当没有明确的人口统计信息时,其潜在的应用价值。
Key Takeaways
- 语音情感识别(SER)中的公平性问题日益受到关注,但仍然存在对类别公平性的研究不足。
- 现有方法依赖于难以获取的人口统计标签,引入隐式人口统计推断(IDI)模块来解决这一问题。
- IDI模块利用预训练模型的伪标签进行工作,通过伪标签减少子群差异。
- 实验结果显示,伪标签IDI能显著提高公平性指标,同时保持较高的SER准确率。
- 无监督的IDI通过K-means聚类进行无监督学习,能在没有明确的人口统计信息时应用。
- 无监督IDI能持续缓解种族和年龄差异,提高公平度指标。
点此查看论文截图

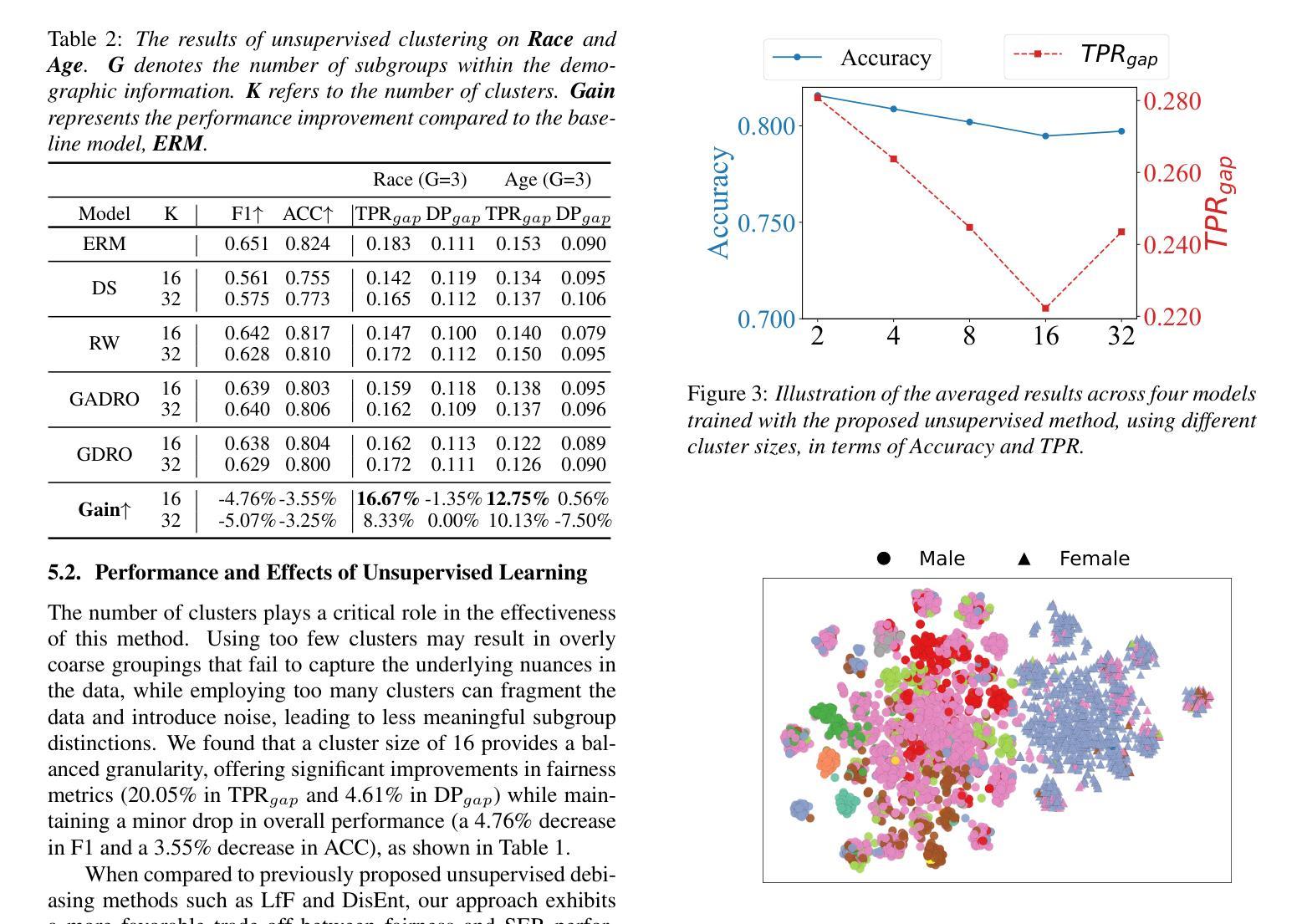
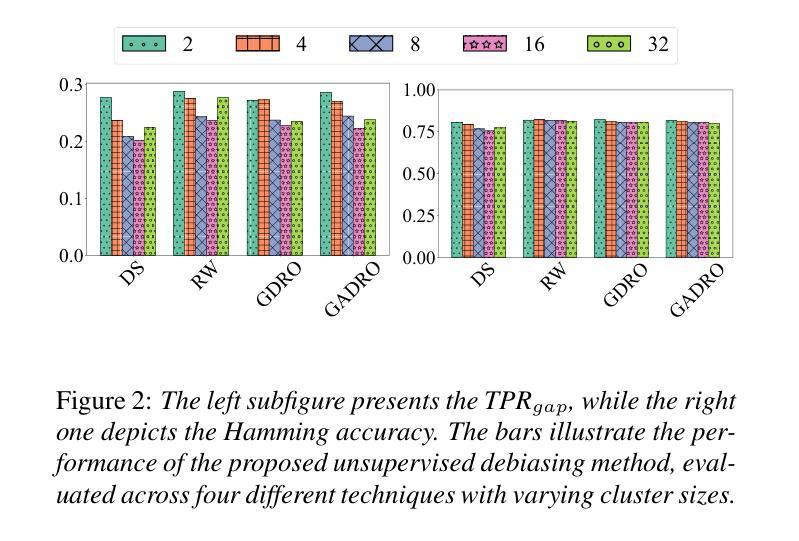
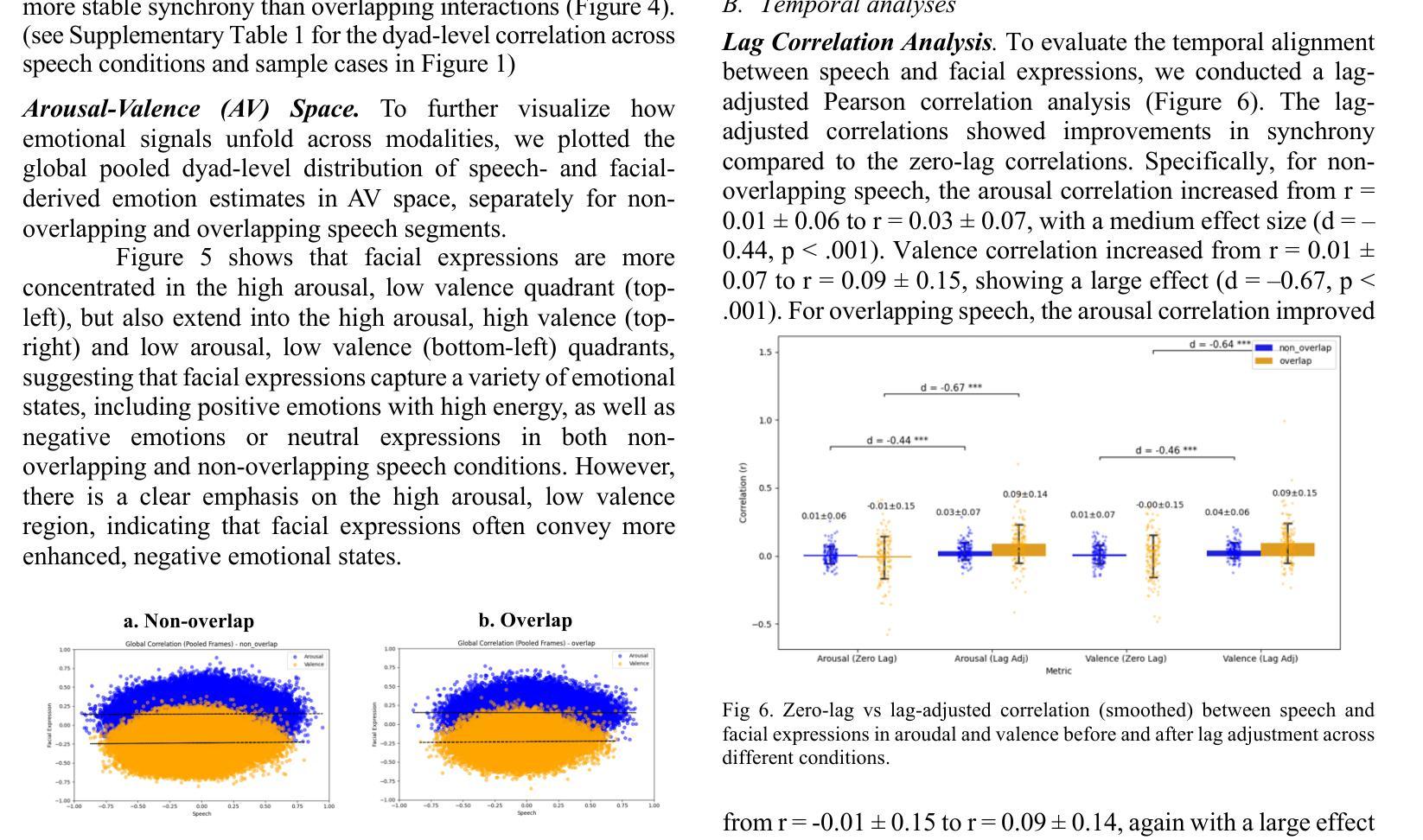
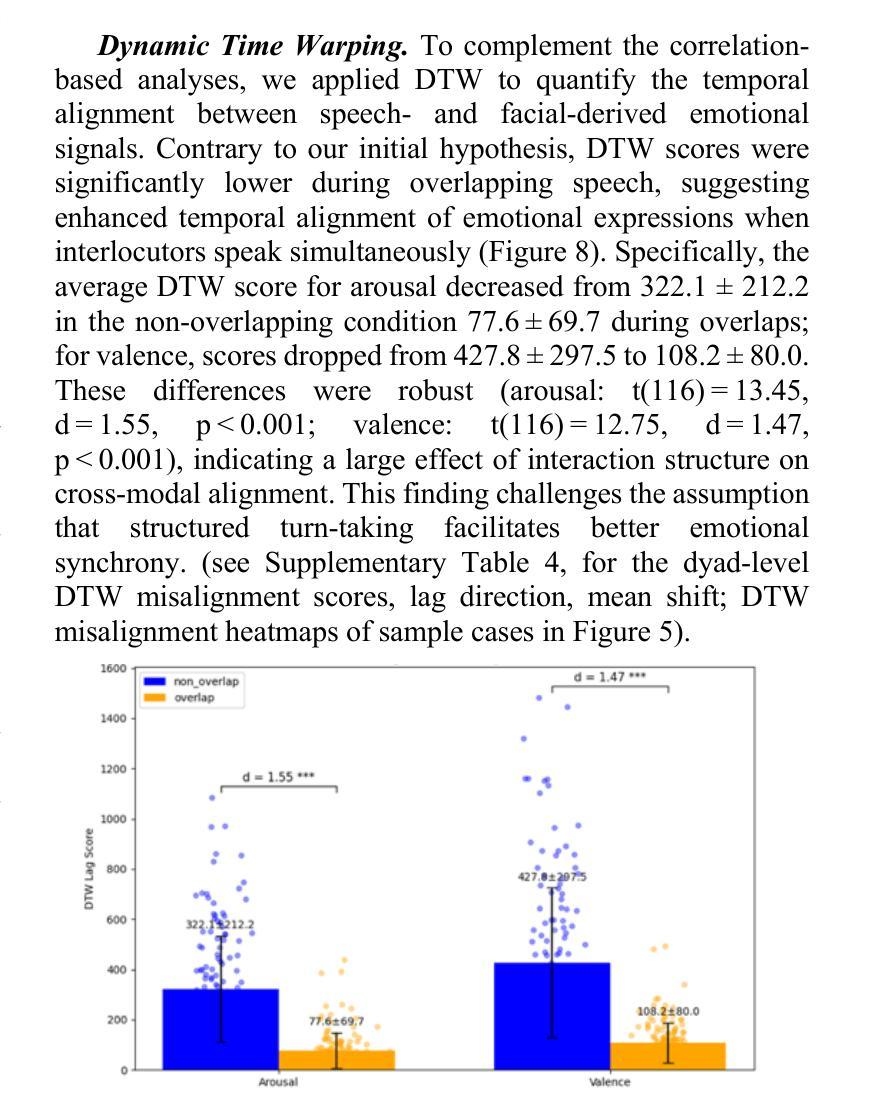
Spatiotemporal Emotional Synchrony in Dyadic Interactions: The Role of Speech Conditions in Facial and Vocal Affective Alignment
Authors:Von Ralph Dane Marquez Herbuela, Yukie Nagai
Understanding how humans express and synchronize emotions across multiple communication channels particularly facial expressions and speech has significant implications for emotion recognition systems and human computer interaction. Motivated by the notion that non-overlapping speech promotes clearer emotional coordination, while overlapping speech disrupts synchrony, this study examines how these conversational dynamics shape the spatial and temporal alignment of arousal and valence across facial and vocal modalities. Using dyadic interactions from the IEMOCAP dataset, we extracted continuous emotion estimates via EmoNet (facial video) and a Wav2Vec2-based model (speech audio). Segments were categorized based on speech overlap, and emotional alignment was assessed using Pearson correlation, lag adjusted analysis, and Dynamic Time Warping (DTW). Across analyses, non overlapping speech was associated with more stable and predictable emotional synchrony than overlapping speech. While zero-lag correlations were low and not statistically different, non overlapping speech showed reduced variability, especially for arousal. Lag adjusted correlations and best-lag distributions revealed clearer, more consistent temporal alignment in these segments. In contrast, overlapping speech exhibited higher variability and flatter lag profiles, though DTW indicated unexpectedly tighter alignment suggesting distinct coordination strategies. Notably, directionality patterns showed that facial expressions more often preceded speech during turn-taking, while speech led during simultaneous vocalizations. These findings underscore the importance of conversational structure in regulating emotional communication and provide new insight into the spatial and temporal dynamics of multimodal affective alignment in real world interaction.
理解人类如何在多个沟通渠道(尤其是面部表情和言语)上表达和同步情绪,对于情绪识别系统和人机交互有着重大启示。本研究受到非重叠性言语能够促进更清晰情感协调的观念的启发,同时重叠性言语会破坏同步性。本研究探讨了这些对话动力如何影响面部和声音模态的兴奋和价值的空间和时间对齐。我们使用IEMOCAP数据集中的二元交互数据,通过EmoNet(面部视频)和基于Wav2Vec2的模型(语音音频)提取连续的情绪估计。根据语音重叠对片段进行分类,并使用Pearson相关性、滞后调整分析和动态时间规整(DTW)来评估情绪对齐。分析发现,非重叠性言语与更稳定和可预测的情感同步相关,而重叠性言语则表现出更高的可变性和更平坦的滞后分布。然而,DTW意外地显示出更紧密的对齐,这表明了不同的协调策略。值得注意的是,方向性模式显示,在轮流发言时,面部表情往往先于言语,而在同时发声时,则是言语领先。这些发现强调了对话结构在调节情感沟通中的重要性,并为现实互动中多模态情感对齐的空间和时间动态提供了新的见解。
论文及项目相关链接
Summary
本文探讨了人类在多通道沟通中如何表达和同步情绪,特别是在面部表情和言语方面。研究指出,非重叠的语音有助于更清晰的情感协调,而重叠的语音会破坏同步性。通过对IEMOCAP数据集的双人互动进行研究,分析不同沟通方式对情感同步的影响,发现非重叠语音相较于重叠语音能带来更稳定和可预测的情感同步。研究揭示了面部表情和言语在情感沟通中的重要性,并为多模态情感同步的时空动态提供了新的见解。
Key Takeaways
- 人类在多通道沟通中表达和同步情绪具有重要的研究意义,特别是在面部表情和言语方面。
- 非重叠的语音有助于更清晰的情感协调,而重叠的语音可能破坏情感同步。
- 通过IEMOCAP数据集的研究发现,非重叠语音带来更稳定和可预测的情感同步表现。
- 情感同步的分析方法包括皮尔逊相关系数、滞后调整分析和动态时间弯曲。
- 非重叠语音在情绪同步方面表现出较低的可变性,特别是兴奋度方面。
- 面部表情在转向时更常先于言语,而同时发声时则相反。
点此查看论文截图


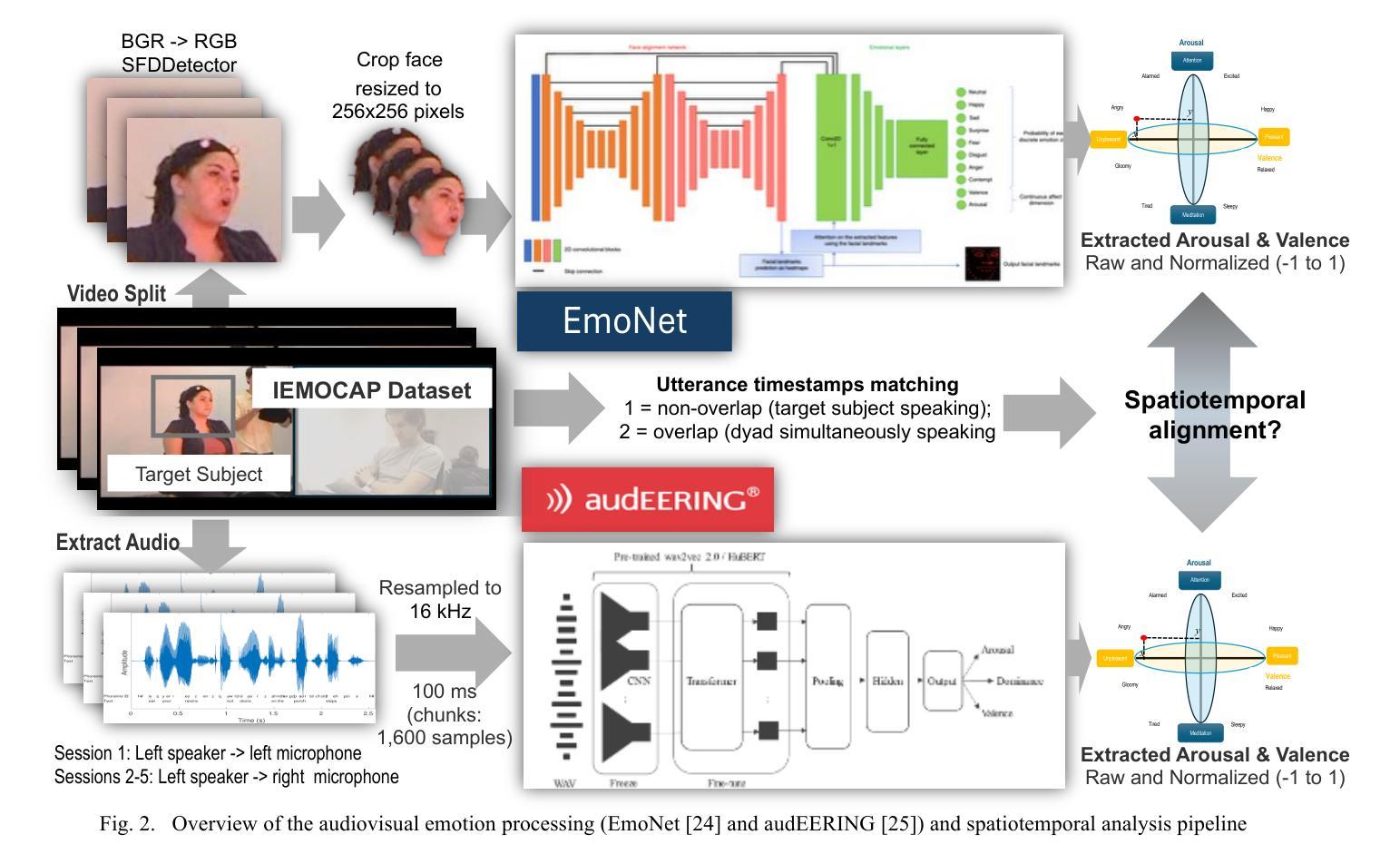
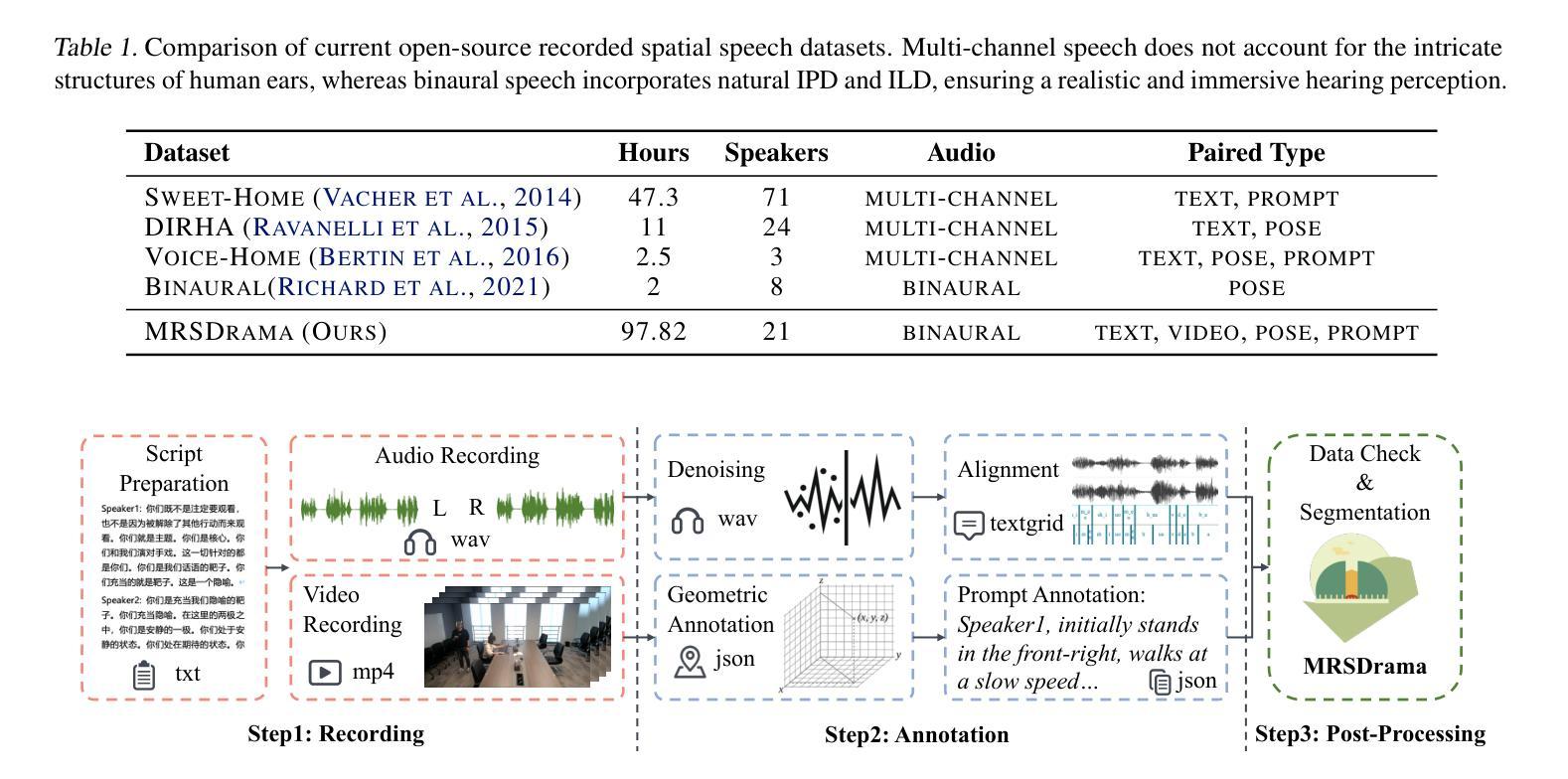
ISDrama: Immersive Spatial Drama Generation through Multimodal Prompting
Authors:Yu Zhang, Wenxiang Guo, Changhao Pan, Zhiyuan Zhu, Tao Jin, Zhou Zhao
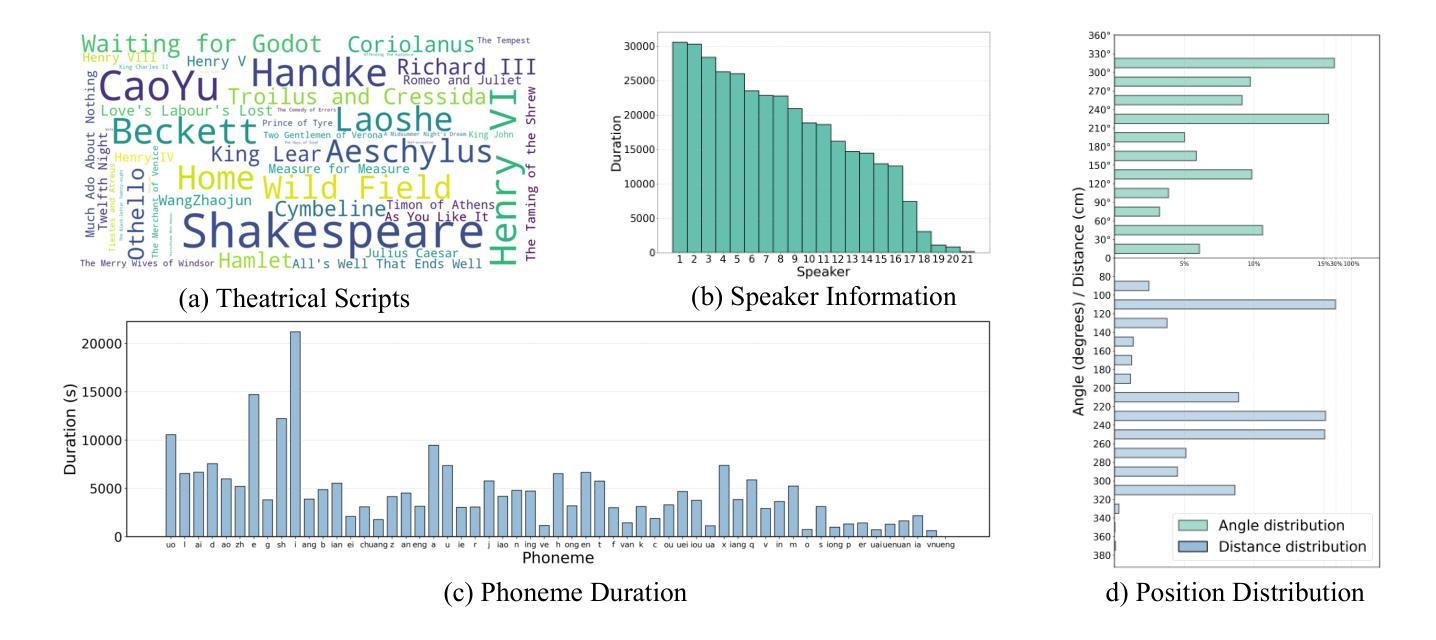
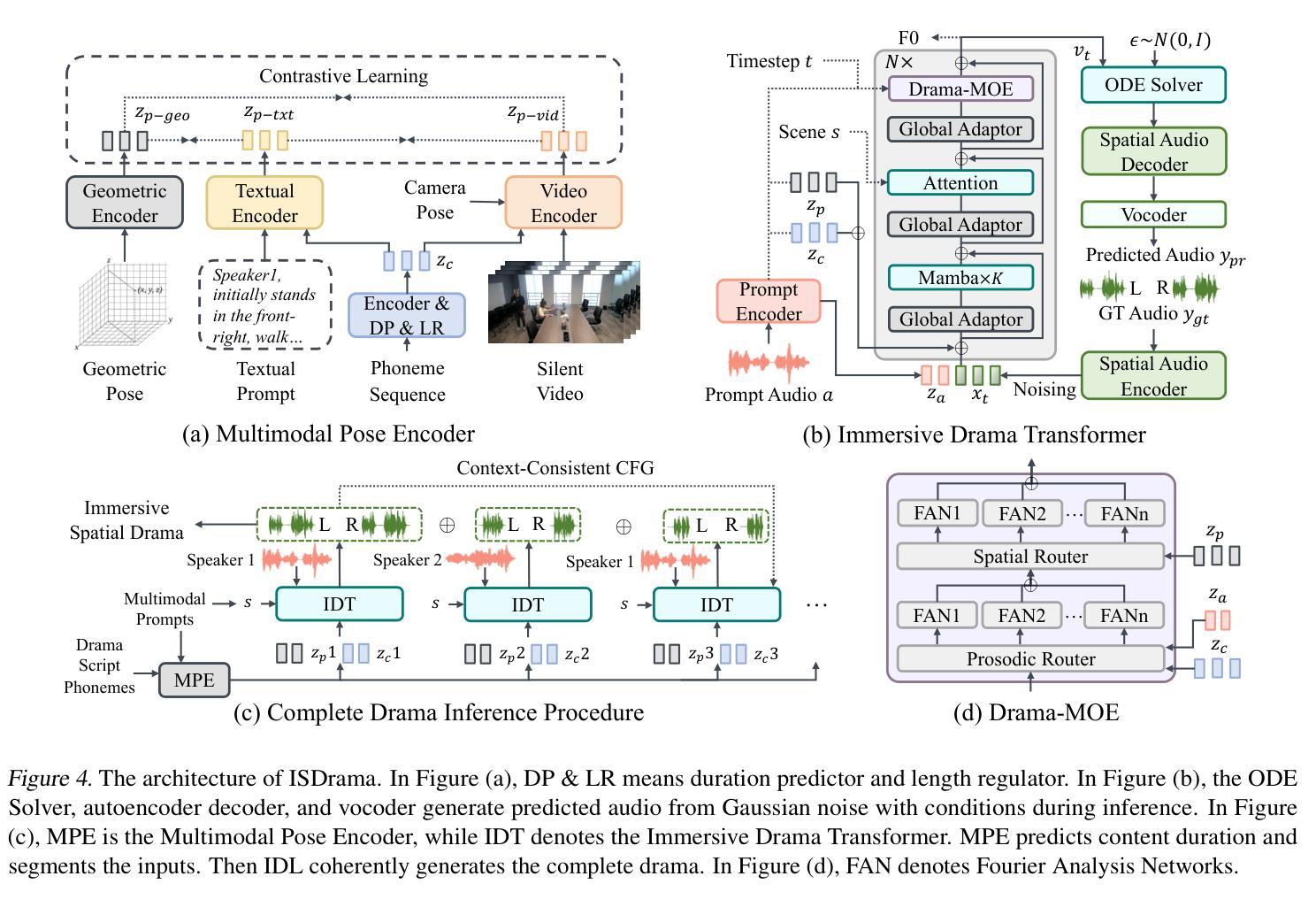
Multimodal immersive spatial drama generation focuses on creating continuous multi-speaker binaural speech with dramatic prosody based on multimodal prompts, with potential applications in AR, VR, and others. This task requires simultaneous modeling of spatial information and dramatic prosody based on multimodal inputs, with high data collection costs. To the best of our knowledge, our work is the first attempt to address these challenges. We construct MRSDrama, the first multimodal recorded spatial drama dataset, containing binaural drama audios, scripts, videos, geometric poses, and textual prompts. Then, we propose ISDrama, the first immersive spatial drama generation model through multimodal prompting. ISDrama comprises these primary components: 1) Multimodal Pose Encoder, based on contrastive learning, considering the Doppler effect caused by moving speakers to extract unified pose information from multimodal prompts. 2) Immersive Drama Transformer, a flow-based mamba-transformer model that generates high-quality drama, incorporating Drama-MOE to select proper experts for enhanced prosody and pose control. We also design a context-consistent classifier-free guidance strategy to coherently generate complete drama. Experimental results show that ISDrama outperforms baseline models on objective and subjective metrics. The demos and dataset are available at https://aaronz345.github.io/ISDramaDemo.
多模态沉浸式空间戏剧生成专注于基于多模态提示创建具有戏剧语调的连续多扬声器双耳语音,在AR、VR等领域具有潜在应用。这项任务需要基于多模态输入对空间信息和戏剧语调进行同时建模,并且数据采集成本高昂。据我们所知,我们的工作是首次尝试解决这些挑战。我们构建了MRSDrama,即首个多模态记录的空间戏剧数据集,包含双耳戏剧音频、剧本、视频、几何姿势和文本提示。然后,我们提出了ISDrama,即通过多模态提示进行沉浸式空间戏剧生成的首个模型。ISDrama主要包含以下主要组件:1)基于对比学习的多模态姿势编码器,考虑移动扬声器产生的多普勒效应,从多模态提示中提取统一姿势信息。2)沉浸式戏剧转换器,一个基于流的mamba-transformer模型,用于生成高质量戏剧,并结合戏剧MOE选择适当的专家以增强语调和姿势控制。我们还设计了一种上下文一致的无监督分类策略,以连贯地生成完整的戏剧。实验结果表明,ISDrama在客观和主观指标上均优于基准模型。相关演示和数据集可通过https://aaronz345.github.io/ISDramaDemo访问。
论文及项目相关链接
Summary
本文介绍了多模态沉浸式空间戏剧生成的研究,重点创建基于多模态提示的连续多讲者双耳戏剧语音。该研究构建了MRSDrama数据集,并提出ISDrama模型,通过多模态提示进行沉浸式空间戏剧生成。该模型包括多模态姿态编码器和沉浸式戏剧转换器,能生成高质量戏剧并控制语调和姿态。实验结果显示,ISDrama在客观和主观指标上优于基准模型。
Key Takeaways
- 多模态沉浸式空间戏剧生成集中于创建基于多模态提示的连续多讲者双耳戏剧语音,可应用于AR、VR等领域。
- 研究面临同时建模空间信息和戏剧语调的挑战,且数据采集成本高昂。
- 构建了MRSDrama数据集,包含双耳戏剧音频、剧本、视频、几何姿态和文本提示。
- 提出ISDrama模型,包括多模态姿态编码器和沉浸式戏剧转换器。
- 多模态姿态编码器采用对比学习,考虑移动讲者带来的多普勒效应,从多模态提示中提取统一姿态信息。
- 沉浸式戏剧转换器基于流式的mamba-transformer模型,生成高质量戏剧,并引入Drama-MOE选择适当的专家以增强语调和姿态控制。
点此查看论文截图

Enhancing LLM-based Hatred and Toxicity Detection with Meta-Toxic Knowledge Graph
Authors:Yibo Zhao, Jiapeng Zhu, Can Xu, Yao Liu, Xiang Li
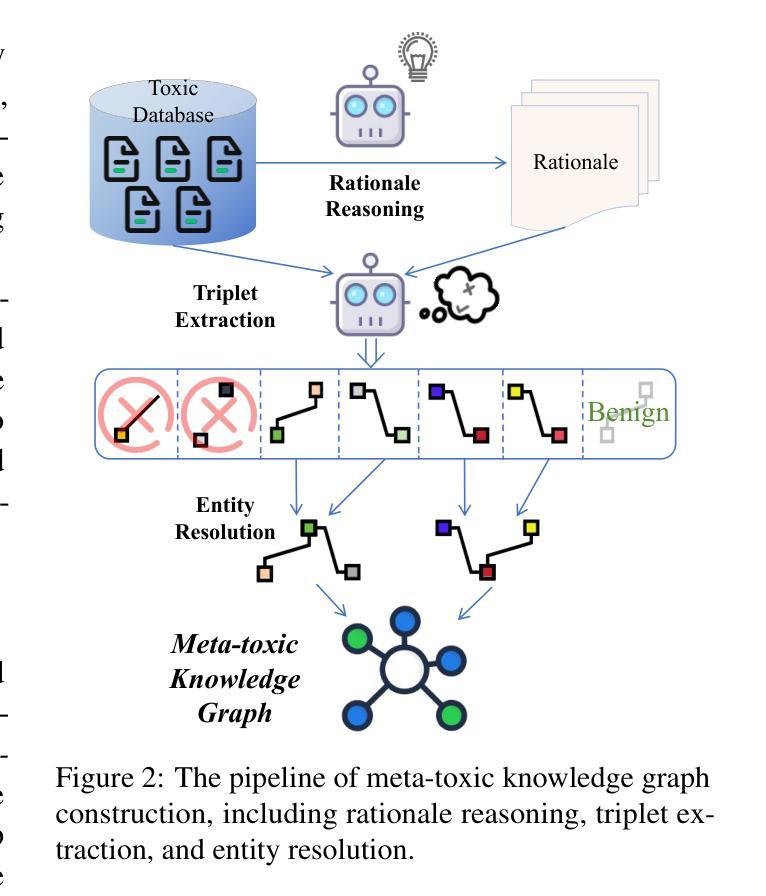
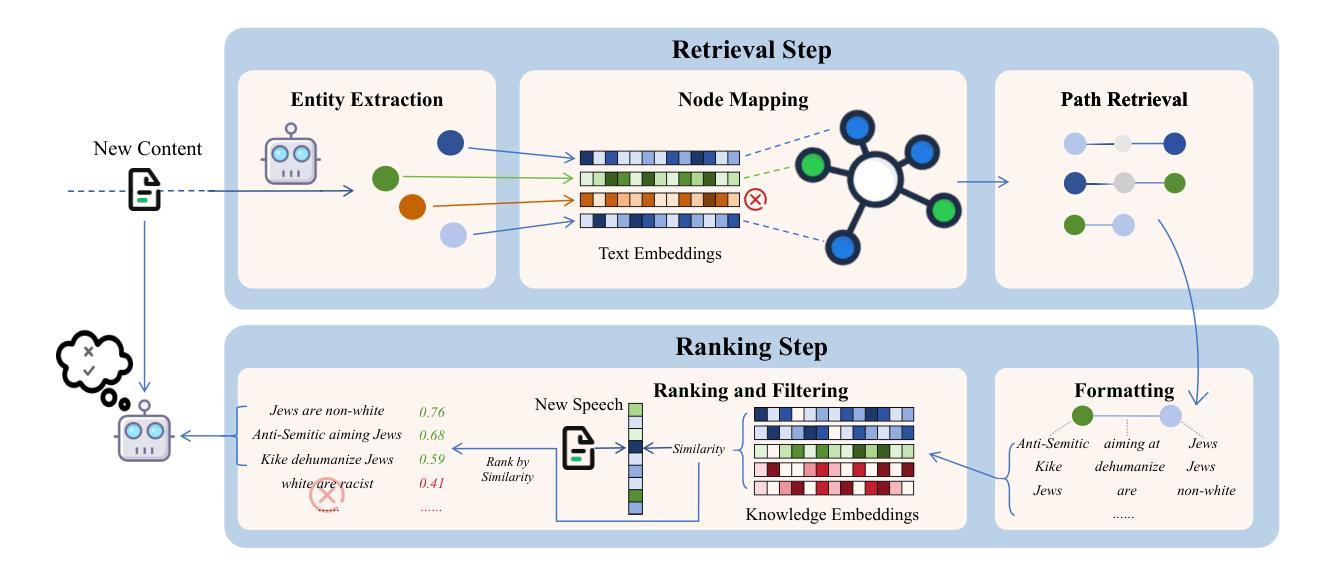
The rapid growth of social media platforms has raised significant concerns regarding online content toxicity. When Large Language Models (LLMs) are used for toxicity detection, two key challenges emerge: 1) the absence of domain-specific toxic knowledge leads to false negatives; 2) the excessive sensitivity of LLMs to toxic speech results in false positives, limiting freedom of speech. To address these issues, we propose a novel method called MetaTox, leveraging graph search on a meta-toxic knowledge graph to enhance hatred and toxicity detection. First, we construct a comprehensive meta-toxic knowledge graph by utilizing LLMs to extract toxic information through a three-step pipeline, with toxic benchmark datasets serving as corpora. Second, we query the graph via retrieval and ranking processes to supplement accurate, relevant toxic knowledge. Extensive experiments and in-depth case studies across multiple datasets demonstrate that our MetaTox significantly decreases the false positive rate while boosting overall toxicity detection performance. Our code is available at https://github.com/YiboZhao624/MetaTox.
社交媒体平台的快速发展引发了人们对网络内容毒性的重大关注。当使用大型语言模型(LLM)进行毒性检测时,会出现两个关键挑战:1)缺乏特定领域的毒性知识会导致假阴性结果;2)LLM对有毒言论过于敏感,导致假阳性结果,限制言论自由。为了解决这些问题,我们提出了一种新方法,称为MetaTox,利用元毒性知识图上的图搜索来增强仇恨和毒性检测。首先,我们通过一个三步骤的管道,利用LLM提取毒性信息,以毒性基准数据集作为语料库,构建了一个全面的元毒性知识图。其次,我们通过检索和排名过程查询图形,以补充准确且相关的毒性知识。在多个数据集上进行的大量实验和深入的案例研究结果表明,我们的MetaTox方法显著降低了假阳性率,同时提高了总体毒性检测性能。我们的代码可在https://github.com/YiboZhao624/MetaTox获取。
论文及项目相关链接
PDF 8 pages of content
Summary
社交媒体平台的快速发展引发了人们对网络内容毒性的关注。使用大型语言模型(LLM)进行毒性检测时面临两大挑战:缺乏特定领域的毒性知识和过度敏感于毒性言论导致误报。为解决这些问题,提出了一种名为MetaTox的新方法,利用元毒性知识图谱上的图搜索来增强仇恨和毒性检测。通过构建全面的元毒性知识图谱,通过LLM提取毒性信息,并利用毒性基准数据集作为语料库进行查询和排名过程,以补充准确、相关的毒性知识。实验和案例研究表明,MetaTox显著降低了误报率,提高了整体毒性检测性能。
Key Takeaways
- 社交媒体平台的快速发展引发了关于网络内容毒性的关注。
- 使用大型语言模型(LLM)进行毒性检测面临两大挑战:缺乏特定领域的毒性知识和过度敏感导致误报。
- 提出了一种名为MetaTox的新方法来解决这些问题,该方法利用元毒性知识图谱上的图搜索来增强仇恨和毒性检测。
- MetaTox通过构建全面的元毒性知识图谱,利用LLM提取毒性信息。
- MetaTox使用毒性基准数据集作为语料库进行查询和排名过程,以补充准确、相关的毒性知识。
- MetaTox显著降低了误报率,提高了整体毒性检测性能。
点此查看论文截图

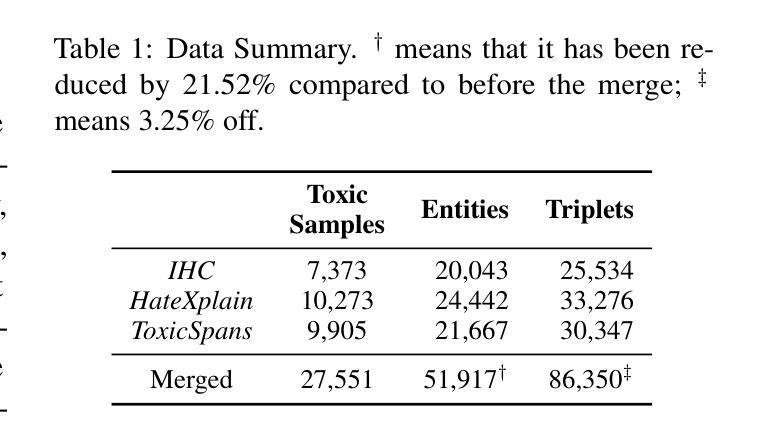
TCSinger: Zero-Shot Singing Voice Synthesis with Style Transfer and Multi-Level Style Control
Authors:Yu Zhang, Ziyue Jiang, Ruiqi Li, Changhao Pan, Jinzheng He, Rongjie Huang, Chuxin Wang, Zhou Zhao
Zero-shot singing voice synthesis (SVS) with style transfer and style control aims to generate high-quality singing voices with unseen timbres and styles (including singing method, emotion, rhythm, technique, and pronunciation) from audio and text prompts. However, the multifaceted nature of singing styles poses a significant challenge for effective modeling, transfer, and control. Furthermore, current SVS models often fail to generate singing voices rich in stylistic nuances for unseen singers. To address these challenges, we introduce TCSinger, the first zero-shot SVS model for style transfer across cross-lingual speech and singing styles, along with multi-level style control. Specifically, TCSinger proposes three primary modules: 1) the clustering style encoder employs a clustering vector quantization model to stably condense style information into a compact latent space; 2) the Style and Duration Language Model (S&D-LM) concurrently predicts style information and phoneme duration, which benefits both; 3) the style adaptive decoder uses a novel mel-style adaptive normalization method to generate singing voices with enhanced details. Experimental results show that TCSinger outperforms all baseline models in synthesis quality, singer similarity, and style controllability across various tasks, including zero-shot style transfer, multi-level style control, cross-lingual style transfer, and speech-to-singing style transfer. Singing voice samples can be accessed at https://aaronz345.github.io/TCSingerDemo/.
零样本唱腔合成(SVS)带有风格转换和风格控制功能,旨在从音频和文字提示生成具有未见音质和风格的高质量唱腔(包括唱法、情感、节奏、技巧和发音)。然而,唱腔风格的多面性给有效的建模、转换和控制带来了重大挑战。此外,当前的SVS模型往往不能为未见过的歌手生成富有风格细微差别的唱腔。为了应对这些挑战,我们引入了TCSinger,这是第一个用于跨语言语音和唱腔风格风格转换的零样本SVS模型,以及多级风格控制。具体来说,TCSinger提出了三个主要模块:1)聚类风格编码器采用聚类向量量化模型,将风格信息稳定地凝聚成一个紧凑的潜在空间;2)风格和持续时间语言模型(S&D-LM)同时预测风格信息和音素持续时间,两者都受益;3)风格自适应解码器采用一种新的mel-style自适应归一化方法,生成具有增强细节的唱腔。实验结果表明,TCSinger在合成质量、歌手相似度和风格可控性方面优于所有基准模型,包括零样本风格转换、多级风格控制、跨语言风格转换和语音到唱腔风格转换等各项任务。唱腔样本可访问https://aaronz345.github.io/TCSingerDemo/。
论文及项目相关链接
PDF Accepted by EMNLP 2024
Summary
该研究介绍了针对跨语言语音和歌唱风格进行零样本歌唱声音合成(SVS)的风格转移和多层次风格控制的模型TCSinger。它通过三个主要模块实现:聚类风格编码器、风格与时长语言模型以及风格自适应解码器。该模型在合成质量、歌手相似性和风格可控性方面均优于基线模型,并实现了零样本风格转移、多层次风格控制、跨语言风格转移和语音到歌唱风格转移等任务。
Key Takeaways
- TCSinger是一个用于风格转移的零样本歌唱声音合成(SVS)模型,能够生成具有未见过的音质和风格的歌唱声音。
- TCSinger通过三个主要模块实现:聚类风格编码器、风格与时长语言模型和风格自适应解码器。
- 聚类风格编码器使用聚类向量量化模型,将风格信息稳定地浓缩到紧凑的潜在空间中。
- 风格与时长语言模型同时预测风格信息和音素时长,对两者都有利。
- 风格自适应解码器采用新的mel-style自适应归一化方法,生成具有增强细节的歌唱声音。
- 实验结果表明,TCSinger在合成质量、歌手相似性和风格可控性方面均优于基线模型。
点此查看论文截图

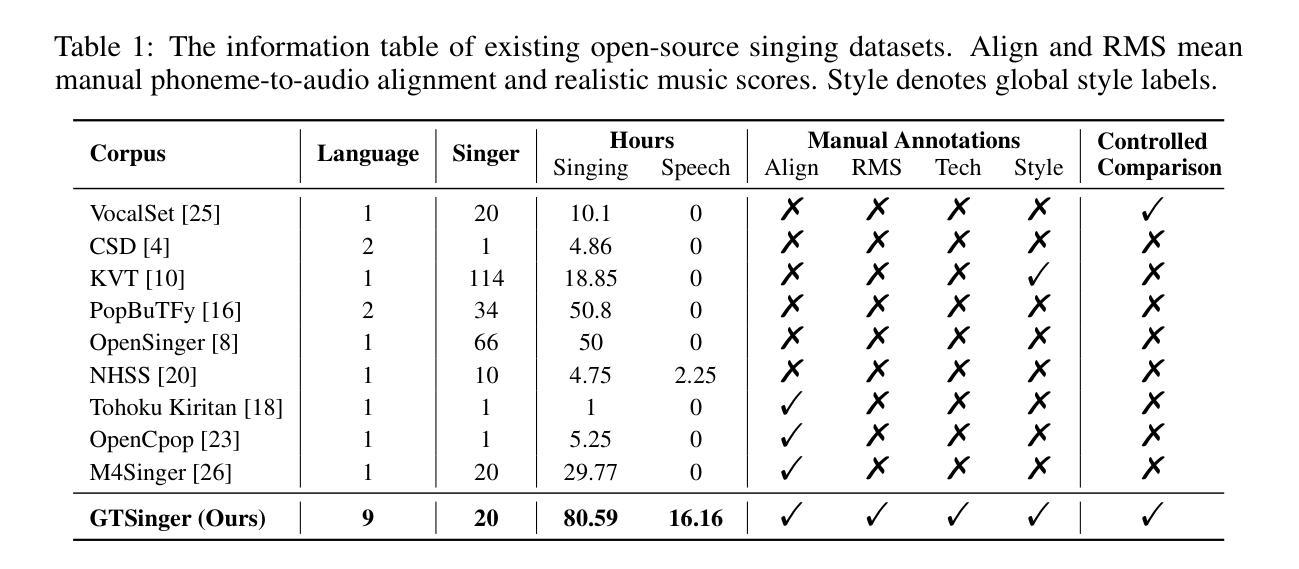
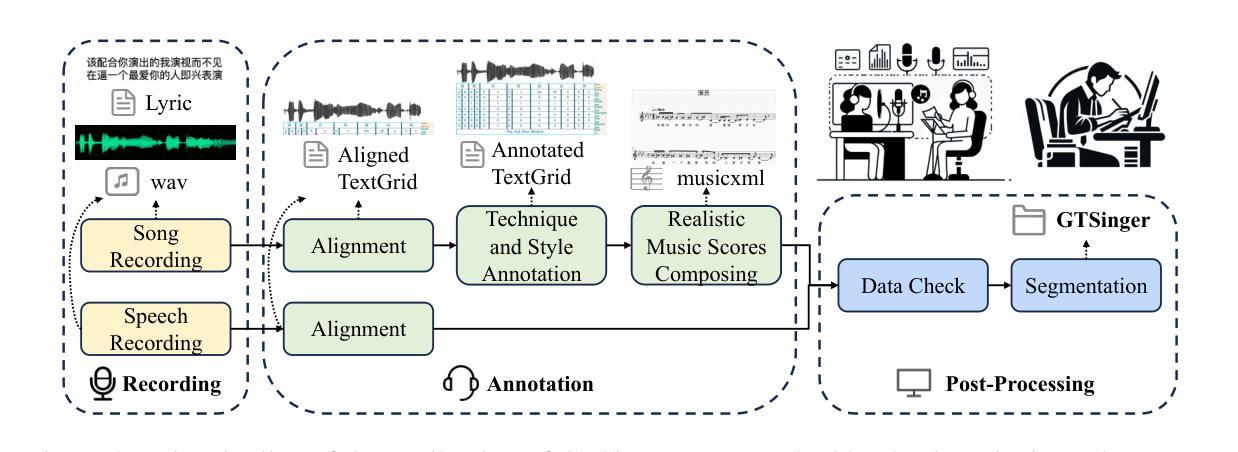
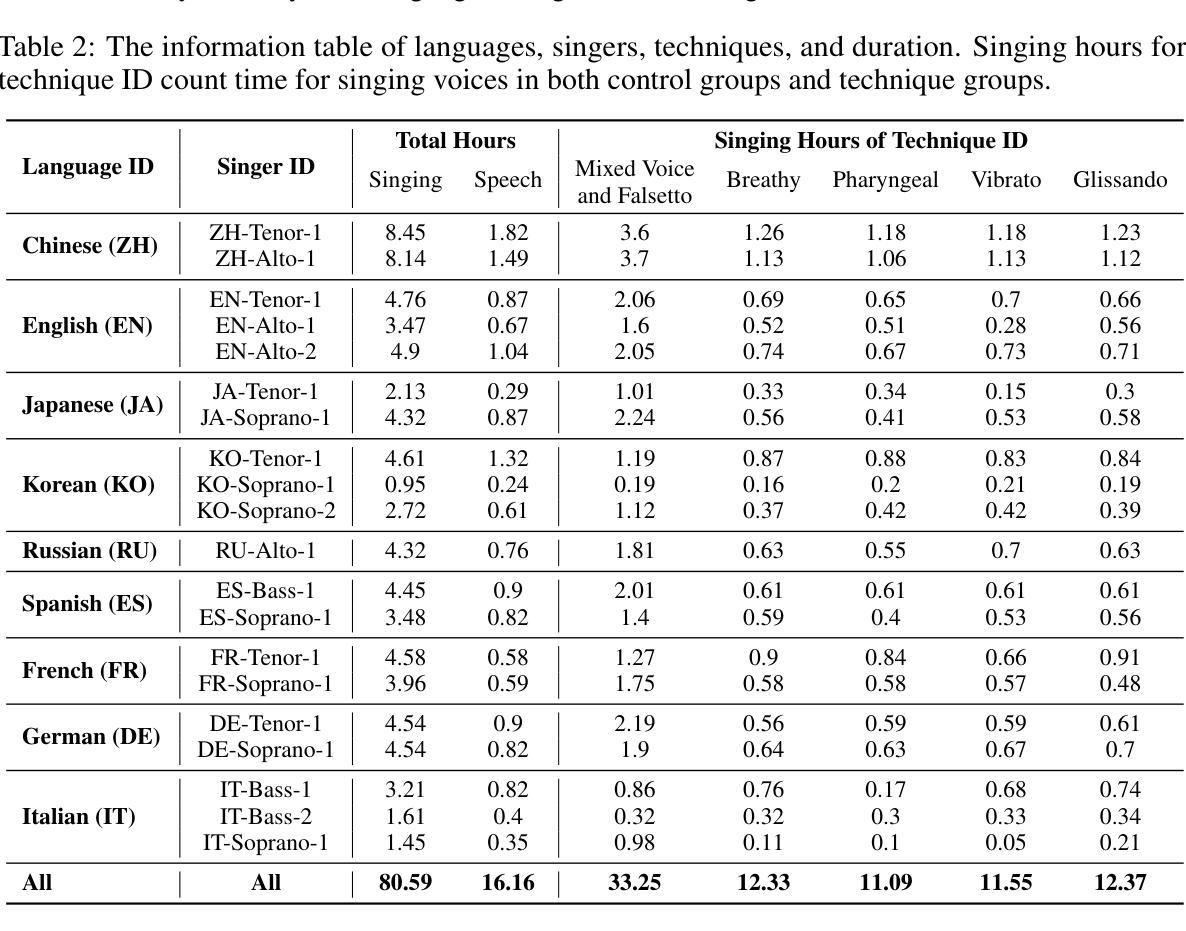
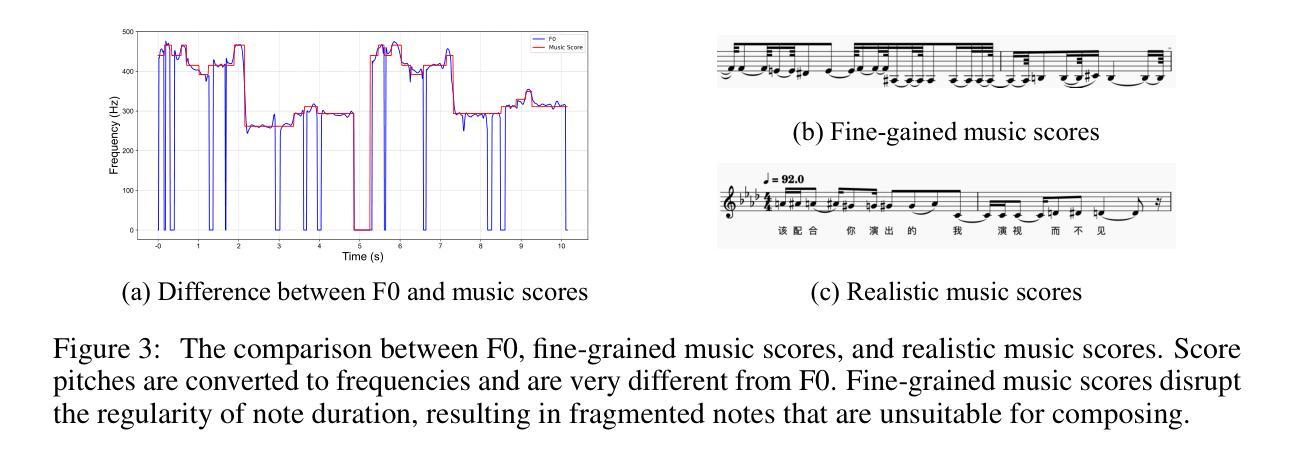
GTSinger: A Global Multi-Technique Singing Corpus with Realistic Music Scores for All Singing Tasks
Authors:Yu Zhang, Changhao Pan, Wenxiang Guo, Ruiqi Li, Zhiyuan Zhu, Jialei Wang, Wenhao Xu, Jingyu Lu, Zhiqing Hong, Chuxin Wang, LiChao Zhang, Jinzheng He, Ziyue Jiang, Yuxin Chen, Chen Yang, Jiecheng Zhou, Xinyu Cheng, Zhou Zhao
The scarcity of high-quality and multi-task singing datasets significantly hinders the development of diverse controllable and personalized singing tasks, as existing singing datasets suffer from low quality, limited diversity of languages and singers, absence of multi-technique information and realistic music scores, and poor task suitability. To tackle these problems, we present GTSinger, a large global, multi-technique, free-to-use, high-quality singing corpus with realistic music scores, designed for all singing tasks, along with its benchmarks. Particularly, (1) we collect 80.59 hours of high-quality singing voices, forming the largest recorded singing dataset; (2) 20 professional singers across nine widely spoken languages offer diverse timbres and styles; (3) we provide controlled comparison and phoneme-level annotations of six commonly used singing techniques, helping technique modeling and control; (4) GTSinger offers realistic music scores, assisting real-world musical composition; (5) singing voices are accompanied by manual phoneme-to-audio alignments, global style labels, and 16.16 hours of paired speech for various singing tasks. Moreover, to facilitate the use of GTSinger, we conduct four benchmark experiments: technique-controllable singing voice synthesis, technique recognition, style transfer, and speech-to-singing conversion. The corpus and demos can be found at http://aaronz345.github.io/GTSingerDemo/. We provide the dataset and the code for processing data and conducting benchmarks at https://huggingface.co/datasets/AaronZ345/GTSinger and https://github.com/AaronZ345/GTSinger.
高质量多任务演唱数据集稀缺的问题显著阻碍了多样可控和个性化演唱任务的发展,因为现有的演唱数据集存在质量低、语言及歌手多样性有限、缺乏多技术信息和现实音乐乐谱以及任务适用性差等问题。为了解决这些问题,我们推出了GTSinger,这是一个大型全球、多技术、免费使用的、高质量演唱语料库,配有现实音乐乐谱,适用于所有演唱任务,以及相应的基准测试。具体来说,(1)我们收集了80.59小时的高质量演唱声音,形成了最大的录音演唱数据集;(2)20位专业歌手跨越九种广泛使用的语言,展现了多样的音色和风格;(3)我们提供了六种常用演唱技术的受控比较和音素级注释,有助于技术建模和控制;(4)GTSinger提供了现实音乐乐谱,有助于现实音乐作曲;(5)演唱声音配有手动音素到音频对齐、全局风格标签,以及用于各种演唱任务的16.16小时配套语音。此外,为了方便使用GTSinger,我们进行了四项基准实验:技术可控的演唱声音合成、技术识别、风格转换和语音到演唱的转换。语料库和演示可在http://aaronz345.github.io/GTSingerDemo/找到。我们在https://huggingface.co/datasets/AaronZ345/GTSinger和https://github.com/AaronZ345/GTSinger提供了数据集和数据处理及基准测试的代码。
论文及项目相关链接
PDF Accepted by NeurIPS 2024 (Spotlight)
Summary
本文介绍了GTSinger这一全球大型、多技巧、免费使用的歌唱语料库。该语料库具有高质量、多语言、包含多种演唱技巧与真实乐谱等特点,适用于各种歌唱任务。为解决高质量多任务歌唱数据集稀缺的问题,GTSinger提供了超过80小时的歌唱声音数据,涵盖了多种风格和技巧,并配有音乐乐谱和音频对齐等技术支持。此外,本文还介绍了针对GTSinger进行的四项基准实验,包括可控演唱声音合成、技巧识别、风格转换和语音转唱等。相关数据和代码可在指定网站下载使用。
Key Takeaways
- GTSinger是一个全球性的大型歌唱语料库,为解决高质量多任务歌唱数据集稀缺的问题而设计。
- GTSinger包含超过80小时的高质量歌唱声音数据,是迄今为止最大的录音歌唱数据集。
- GTSinger涵盖了九种广泛使用的语言和多种演唱风格,提供多样化的音色和风格。
- GTSinger提供了六种常用演唱技巧的对比分析和注释,支持技巧建模和控制。
- GTSinger提供了真实的音乐乐谱和音频对齐技术,助力音乐创作和研究。
- GTSinger包括技术可控的歌唱声音合成、技巧识别、风格转换和语音转唱等基准实验。
点此查看论文截图