⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-03 更新
TalkingHeadBench: A Multi-Modal Benchmark & Analysis of Talking-Head DeepFake Detection
Authors:Xinqi Xiong, Prakrut Patel, Qingyuan Fan, Amisha Wadhwa, Sarathy Selvam, Xiao Guo, Luchao Qi, Xiaoming Liu, Roni Sengupta
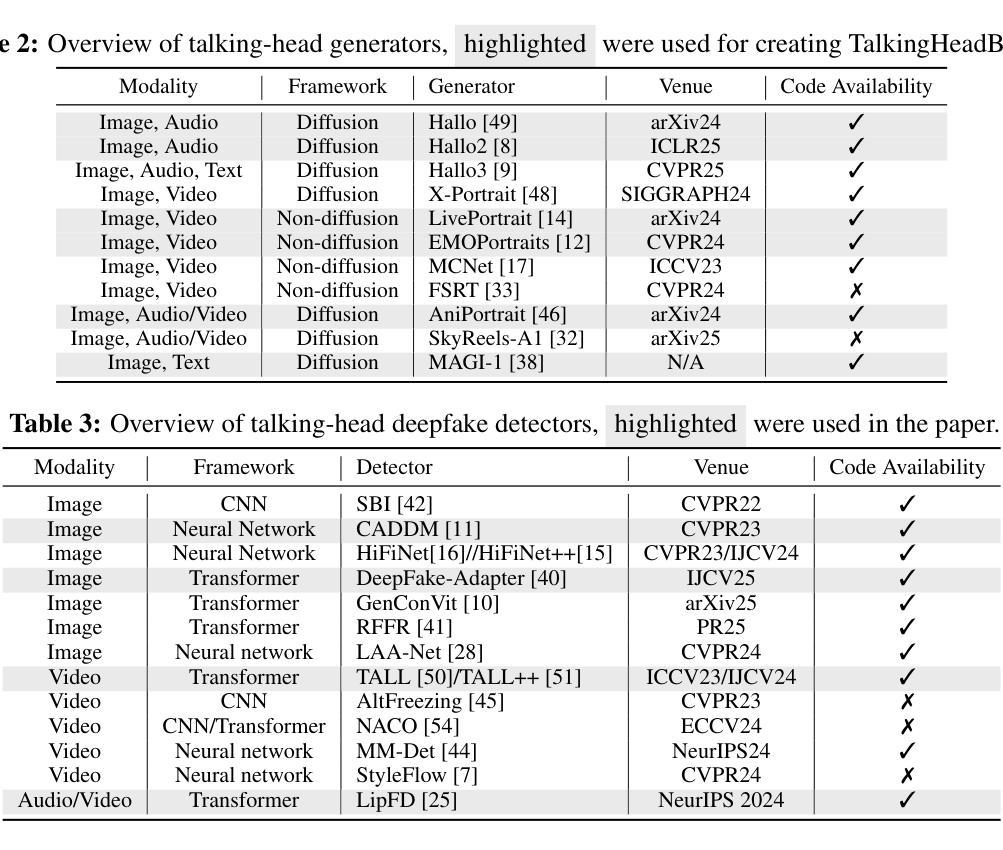
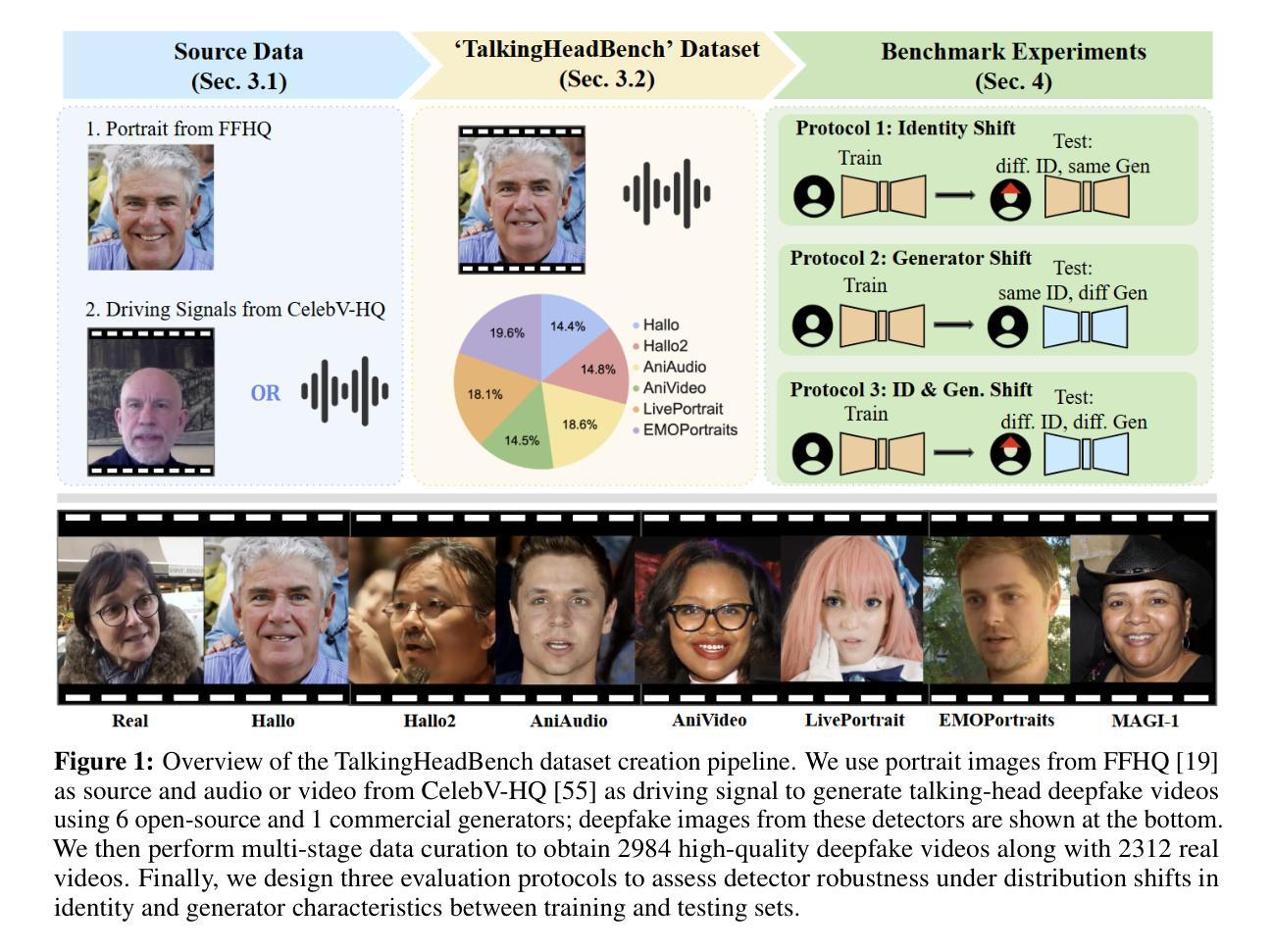
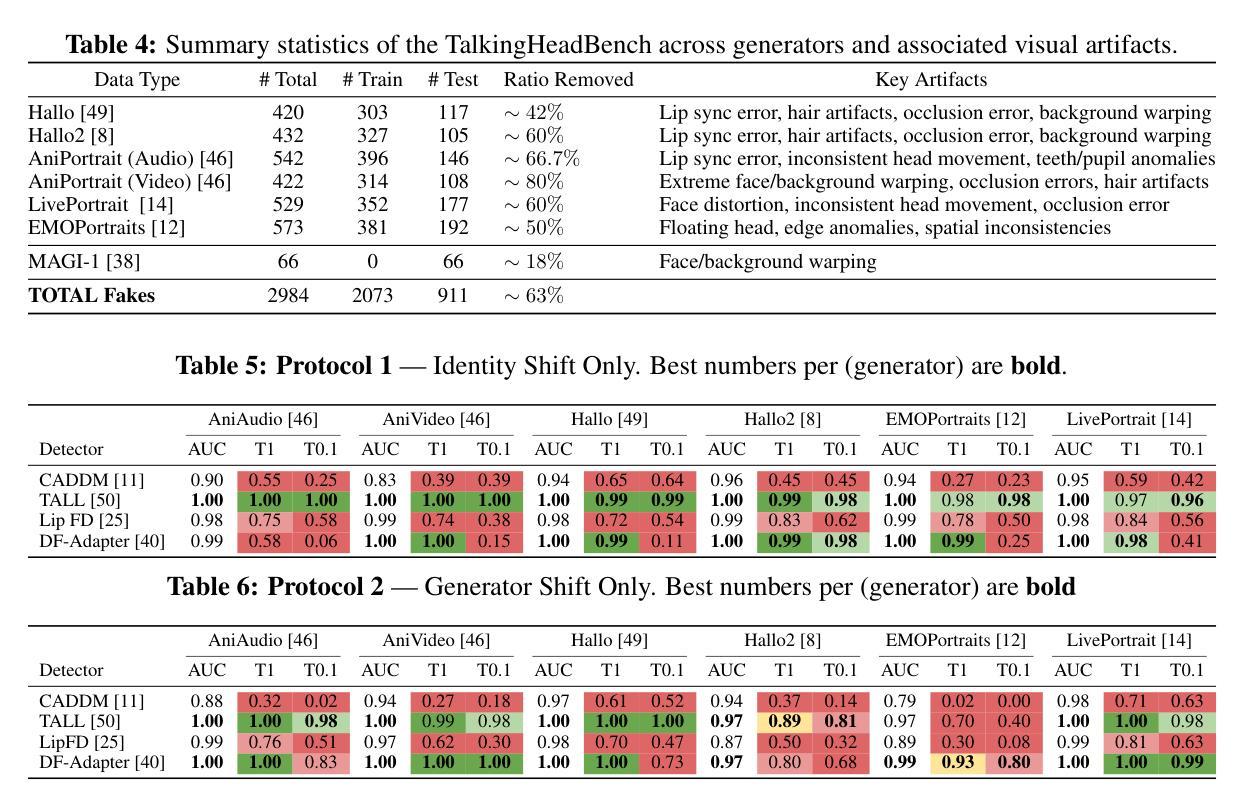
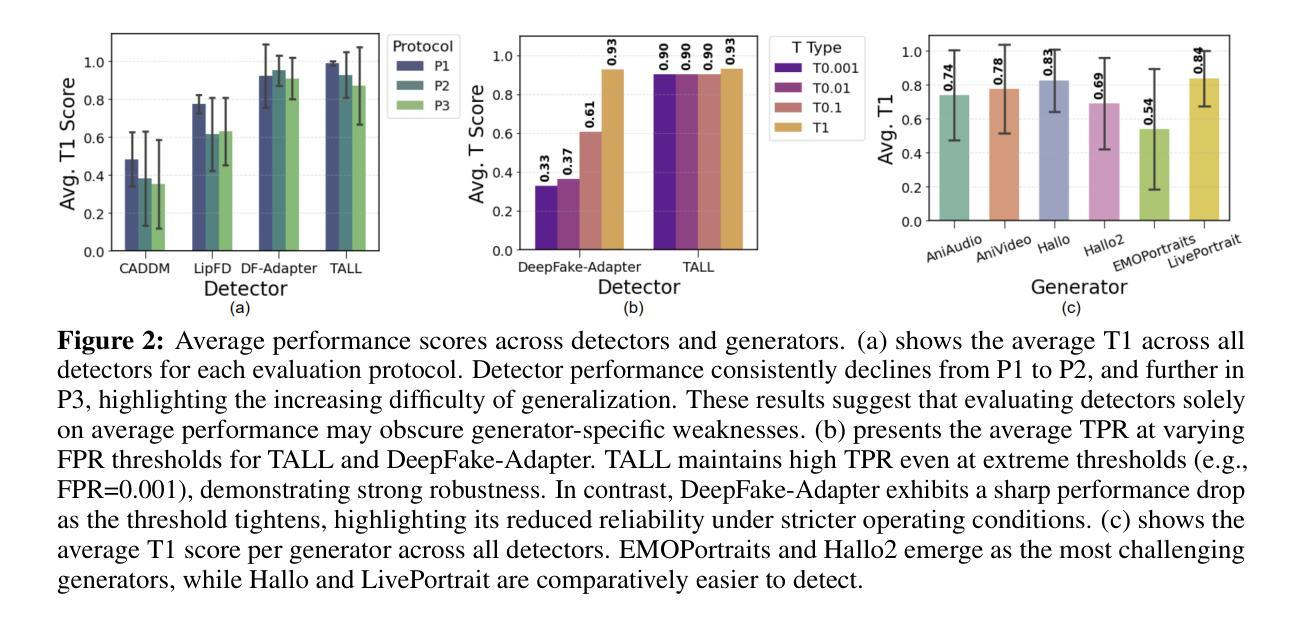
The rapid advancement of talking-head deepfake generation fueled by advanced generative models has elevated the realism of synthetic videos to a level that poses substantial risks in domains such as media, politics, and finance. However, current benchmarks for deepfake talking-head detection fail to reflect this progress, relying on outdated generators and offering limited insight into model robustness and generalization. We introduce TalkingHeadBench, a comprehensive multi-model multi-generator benchmark and curated dataset designed to evaluate the performance of state-of-the-art detectors on the most advanced generators. Our dataset includes deepfakes synthesized by leading academic and commercial models and features carefully constructed protocols to assess generalization under distribution shifts in identity and generator characteristics. We benchmark a diverse set of existing detection methods, including CNNs, vision transformers, and temporal models, and analyze their robustness and generalization capabilities. In addition, we provide error analysis using Grad-CAM visualizations to expose common failure modes and detector biases. TalkingHeadBench is hosted on https://huggingface.co/datasets/luchaoqi/TalkingHeadBench with open access to all data splits and protocols. Our benchmark aims to accelerate research towards more robust and generalizable detection models in the face of rapidly evolving generative techniques.
随着先进的生成模型推动的说话人头部深度伪造生成技术的快速发展,合成视频的逼真度已经达到了在媒体、政治和金融等领域构成实质性风险的水平。然而,目前的说话人头部深度伪造检测基准测试并未反映出这一进展,它们依赖于过时的生成器,对模型稳健性和泛化能力提供了有限的洞察。我们引入了TalkingHeadBench,这是一个全面的多模型多生成器基准测试和专用数据集,旨在评估最先进检测器在最新生成器上的性能。我们的数据集包含了由领先学术和商业模型合成的深度伪造数据,并具备精心构建的协议,以评估身份和生成器特性分布变化下的泛化能力。我们对一系列现有的检测方法进行了基准测试,包括CNN、视觉变压器和时序模型,并分析了它们的稳健性和泛化能力。此外,我们还使用Grad-CAM可视化进行误差分析,以暴露常见的失败模式和检测器偏见。TalkingHeadBench托管在https://huggingface.co/datasets/luchaoqi/TalkingHeadBench上,所有数据分割和协议均可公开访问。我们的基准测试旨在加速研究,以应对不断进化的生成技术在更稳健和泛化性更强的检测模型方面的需求。
论文及项目相关链接
Summary
本文介绍了因先进的生成模型而快速发展的Talking-Head深伪生成技术,它提高了合成视频的逼真性,在媒体、政治和金融等领域带来了重大风险。然而,现有的深伪说话头检测基准测试未能反映这一进展,无法充分评估模型的稳健性和泛化能力。因此,本文提出了TalkingHeadBench基准测试,这是一个综合的多模态多生成器基准测试以及精选数据集,旨在评估尖端检测器在最新生成器上的性能。该数据集包括由领先学术和商业模型合成的深伪视频,具有精心设计的协议来评估身份和生成器特性分布变化下的泛化能力。同时评估了一系列现有的检测方法,包括卷积神经网络、视觉变压器和时间模型,并对其稳健性和泛化能力进行了分析。最后还提供使用Grad-CAM可视化的误差分析,以揭示常见的失败模式和检测器偏见。
Key Takeaways
- 说话头深伪生成技术的快速发展带来了高风险,因为合成视频的逼真性显著提高。
- 当前基准测试未能充分反映这一进展,需要新的基准测试来评估模型的稳健性和泛化能力。
- TalkingHeadBench是一个综合的多模态多生成器基准测试及数据集,旨在评估最新生成器上的检测器性能。
- 数据集包含由领先学术和商业模型合成的深伪视频,具有精心设计的协议来评估模型的泛化能力。
- 评估了多种现有的检测方法,包括CNN、视觉变压器和时间模型。
- 通过Grad-CAM可视化进行误差分析,揭示了常见的失败模式和检测器偏见。
点此查看论文截图


V2SFlow: Video-to-Speech Generation with Speech Decomposition and Rectified Flow
Authors:Jeongsoo Choi, Ji-Hoon Kim, Jinyu Li, Joon Son Chung, Shujie Liu
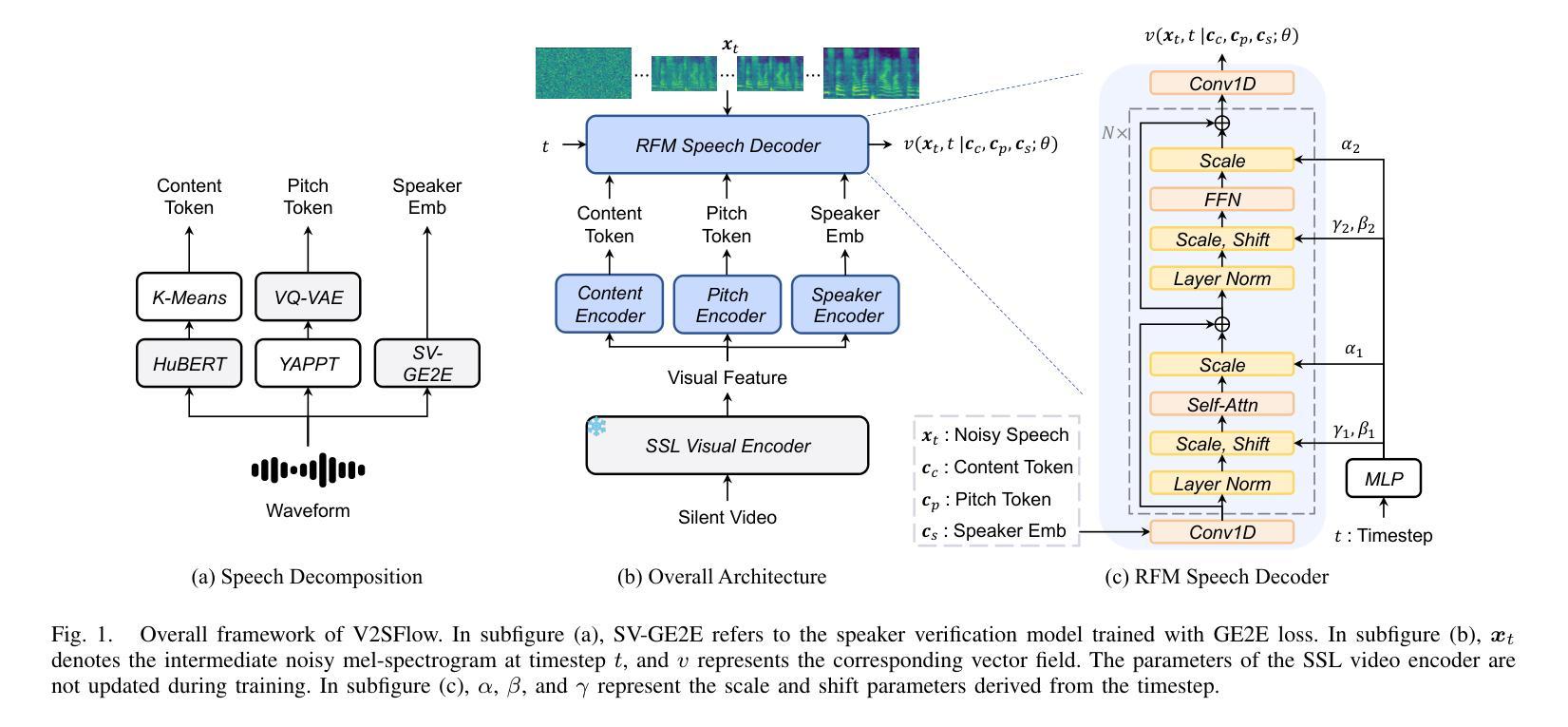
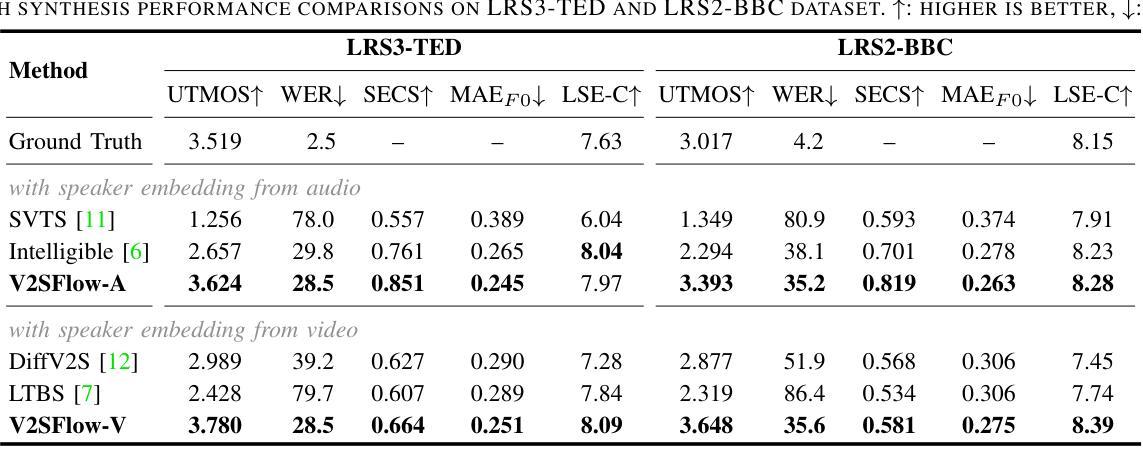
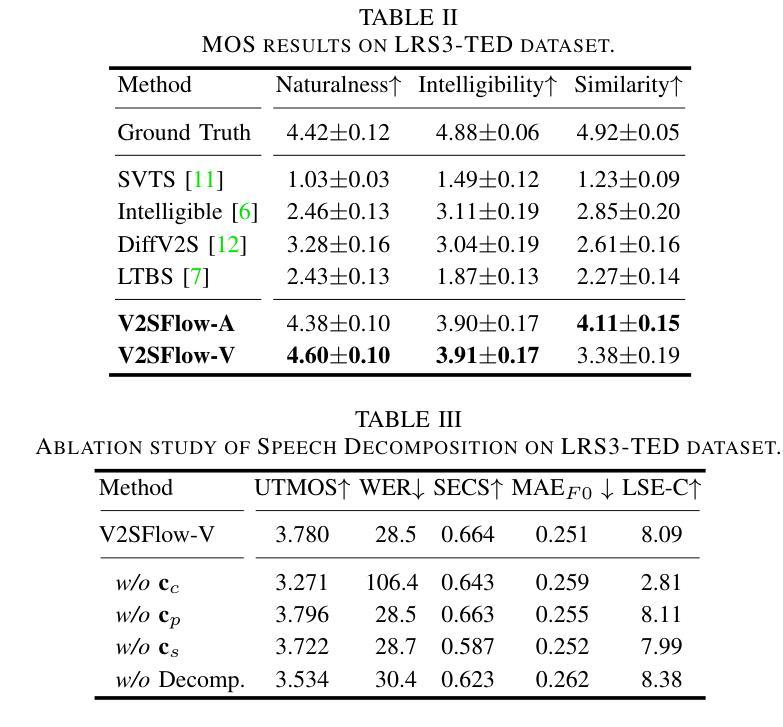
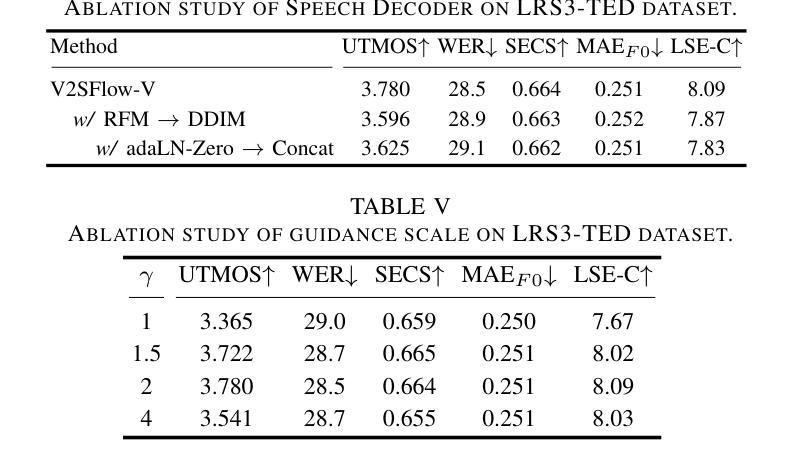
In this paper, we introduce V2SFlow, a novel Video-to-Speech (V2S) framework designed to generate natural and intelligible speech directly from silent talking face videos. While recent V2S systems have shown promising results on constrained datasets with limited speakers and vocabularies, their performance often degrades on real-world, unconstrained datasets due to the inherent variability and complexity of speech signals. To address these challenges, we decompose the speech signal into manageable subspaces (content, pitch, and speaker information), each representing distinct speech attributes, and predict them directly from the visual input. To generate coherent and realistic speech from these predicted attributes, we employ a rectified flow matching decoder built on a Transformer architecture, which models efficient probabilistic pathways from random noise to the target speech distribution. Extensive experiments demonstrate that V2SFlow significantly outperforms state-of-the-art methods, even surpassing the naturalness of ground truth utterances. Code and models are available at: https://github.com/kaistmm/V2SFlow
本文介绍了V2SFlow,这是一种新型的Video-to-Speech(V2S)框架,旨在直接从无声的对话面部视频生成自然且可理解的语音。虽然最近的V2S系统在具有有限发言者和词汇量的受限数据集上取得了有前景的结果,但它们在现实世界的非受限数据集上的性能往往会下降,这是由于语音信号固有的可变性和复杂性。为了应对这些挑战,我们将语音信号分解成可管理的子空间(内容、音高和发言人信息),每个子空间代表不同的语音属性,并直接从视觉输入进行预测。为了从这些预测的属性生成连贯且逼真的语音,我们采用了一个基于Transformer架构的校正流匹配解码器,该解码器可以从随机噪声有效地模拟概率路径到目标语音分布。大量实验表明,V2SFlow显著优于最新方法,甚至超越了真实语音的自然度。代码和模型可在:https://github.com/kaistmm/V2SFlow访问。
论文及项目相关链接
PDF ICASSP 2025
Summary
视频转语音框架V2SFlow能从无声的对话视频生成自然且可理解的语音。它分解语音信号为可管理的子空间(内容、音高和说话人信息),直接预测视觉输入中的不同语音属性,再通过基于Transformer架构的校正流匹配解码器生成连贯且逼真的语音。实验证明,V2SFlow显著优于现有方法,甚至超越了真实语音的自然度。
Key Takeaways
- V2SFlow是一个能够从无声对话视频生成自然语音的框架。
- 它通过分解语音信号到不同的子空间(内容、音高和说话人信息)进行预测。
- V2SFlow使用基于Transformer的校正流匹配解码器,以生成连贯且逼真的语音。
- 该框架在大量实验中表现出卓越性能,显著优于现有方法。
- V2SFlow甚至能够生成超越真实语音自然度的合成语音。
- 框架的代码和模型可在网上公开获取。
点此查看论文截图