⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-04 更新
OpenUni: A Simple Baseline for Unified Multimodal Understanding and Generation
Authors:Size Wu, Zhonghua Wu, Zerui Gong, Qingyi Tao, Sheng Jin, Qinyue Li, Wei Li, Chen Change Loy
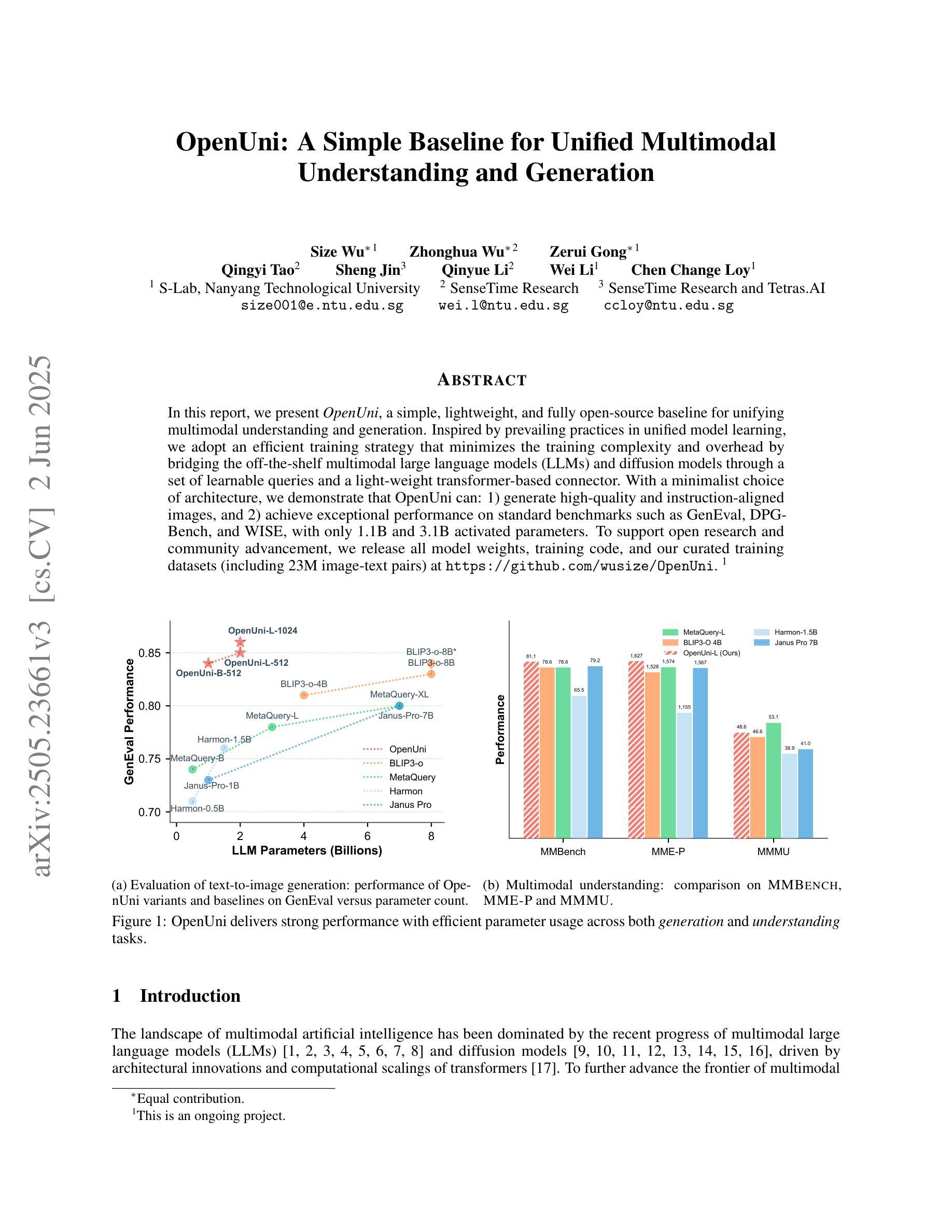
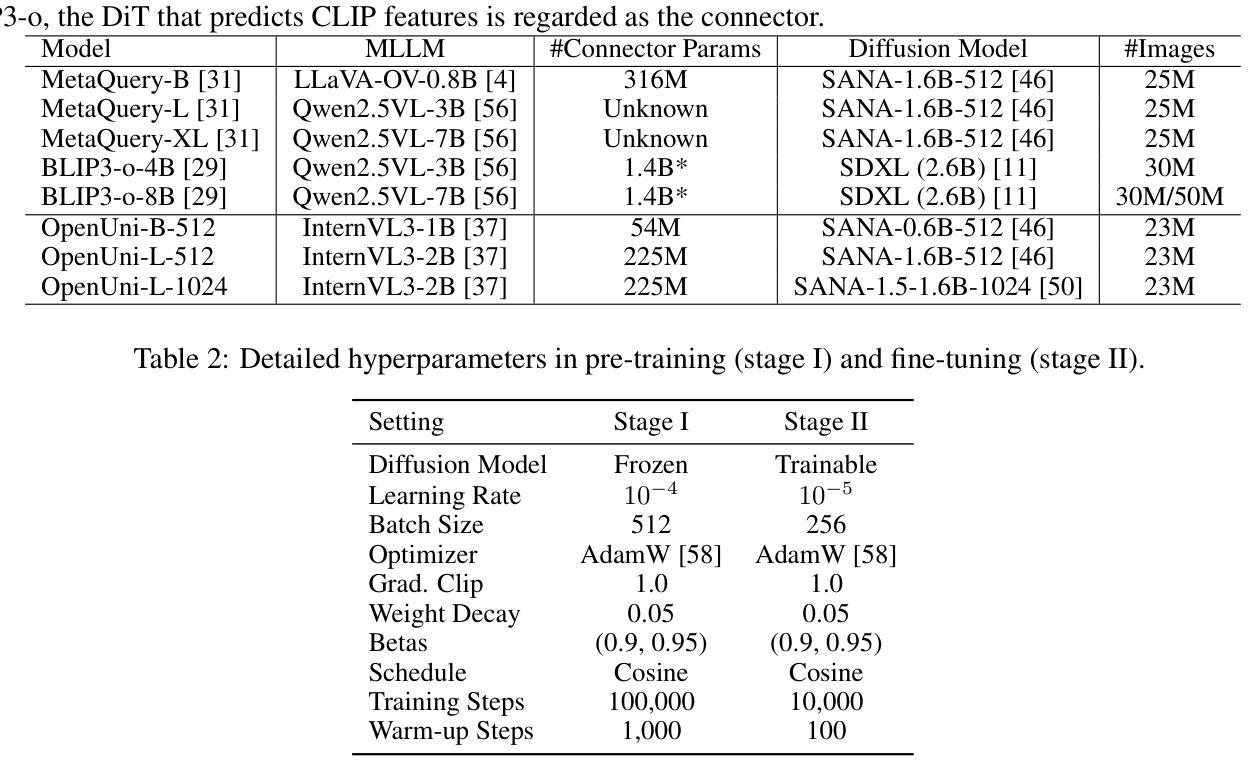
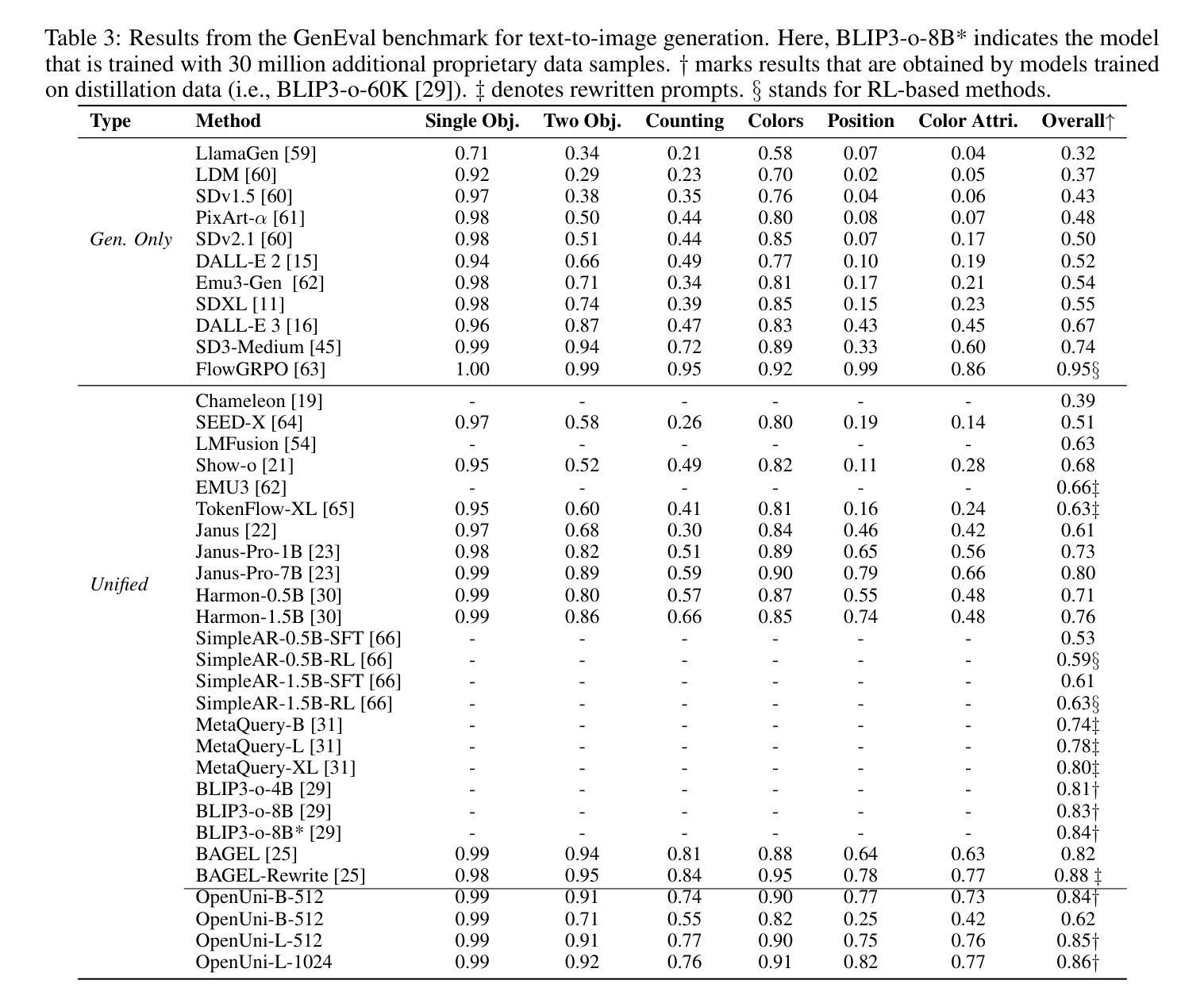
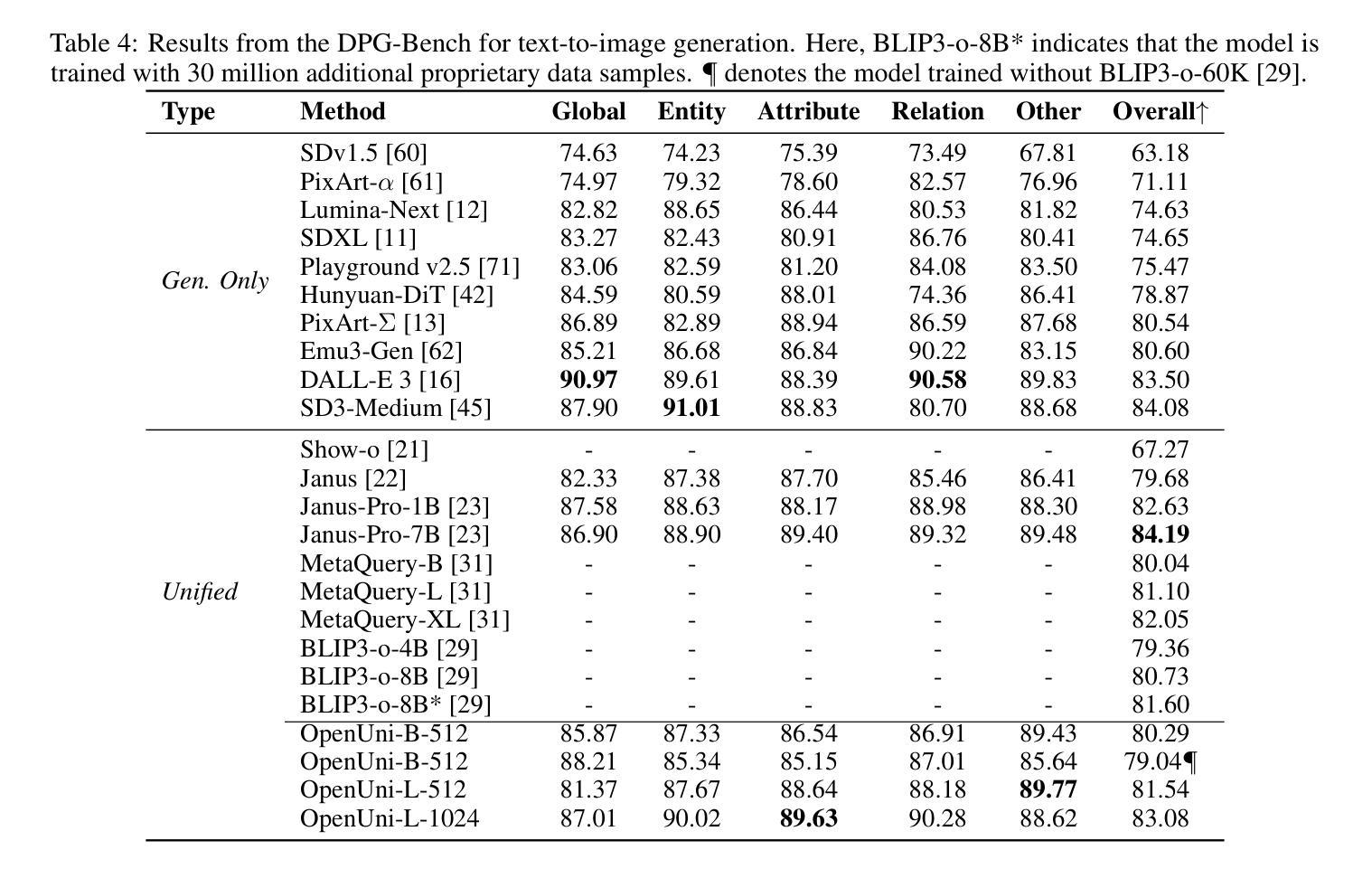
In this report, we present OpenUni, a simple, lightweight, and fully open-source baseline for unifying multimodal understanding and generation. Inspired by prevailing practices in unified model learning, we adopt an efficient training strategy that minimizes the training complexity and overhead by bridging the off-the-shelf multimodal large language models (LLMs) and diffusion models through a set of learnable queries and a light-weight transformer-based connector. With a minimalist choice of architecture, we demonstrate that OpenUni can: 1) generate high-quality and instruction-aligned images, and 2) achieve exceptional performance on standard benchmarks such as GenEval, DPG- Bench, and WISE, with only 1.1B and 3.1B activated parameters. To support open research and community advancement, we release all model weights, training code, and our curated training datasets (including 23M image-text pairs) at https://github.com/wusize/OpenUni.
在这份报告中,我们介绍了OpenUni,这是一个简单、轻量级、完全开源的多模态理解和生成统一基准。我们受到统一模型学习流行实践的启发,采用了一种高效的训练策略,通过一组可学习的查询和一个基于轻量级变压器的连接器,将现成的多模态大型语言模型(LLMs)和扩散模型联系起来,从而最小化训练复杂性和开销。通过选择最简洁的架构,我们证明OpenUni可以:1)生成高质量且符合指令的图像;2)在GenEval、DPG-Bench和WISE等标准基准测试上实现卓越性能,仅需1.1B和3.1B激活参数。为了支持开放研究和社区发展,我们在https://github.com/wusize/OpenUni上发布了所有模型权重、训练代码和我们精选的训练数据集(包括2300万张图像文本对)。
论文及项目相关链接
Summary
OpenUni是一个简单、轻量级、完全开源的多模态理解和生成统一基准。它通过高效的训练策略,采用现成的多模态大型语言模型和扩散模型,通过一组可学习的查询和轻量级基于变压器的连接器,以减小训练复杂性和开销。OpenUni能够生成高质量、指令对齐的图像,并在GenEval、DPG-Bench和WISE等标准基准测试中实现卓越性能,仅需1.1B和3.1B激活参数。所有模型权重、训练代码和训练数据集已在GitHub上发布,以支持开放研究和社区发展。
Key Takeaways
- OpenUni是一个统一多模态理解和生成任务的开源框架。
- 它通过轻量级设计实现了高效训练策略,降低了训练复杂性和开销。
- OpenUni结合了现成的多模态大型语言模型和扩散模型。
- 通过可学习的查询和基于变压器的连接器实现模型间的桥梁。
- OpenUni能生成高质量、与指令对齐的图像。
- 在多个标准基准测试中表现出卓越性能。
点此查看论文截图
ITA-MDT: Image-Timestep-Adaptive Masked Diffusion Transformer Framework for Image-Based Virtual Try-On
Authors:Ji Woo Hong, Tri Ton, Trung X. Pham, Gwanhyeong Koo, Sunjae Yoon, Chang D. Yoo
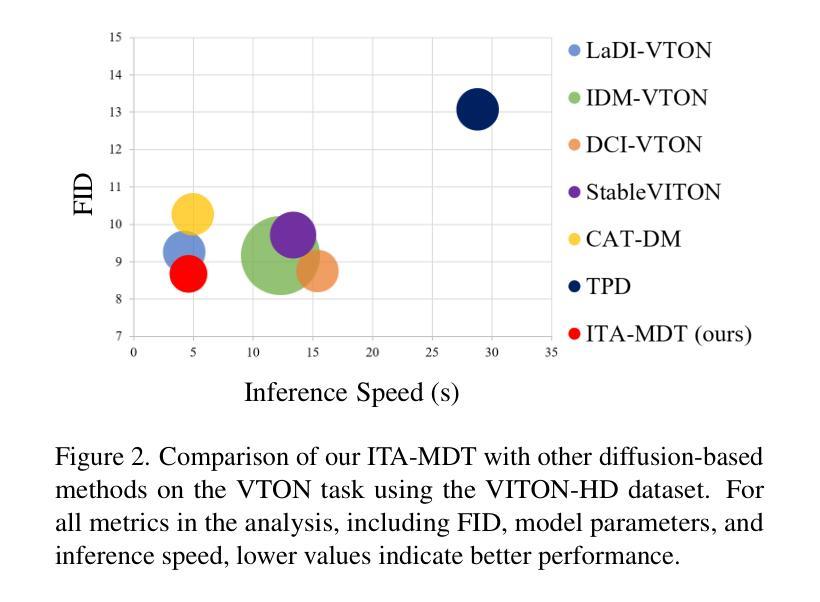
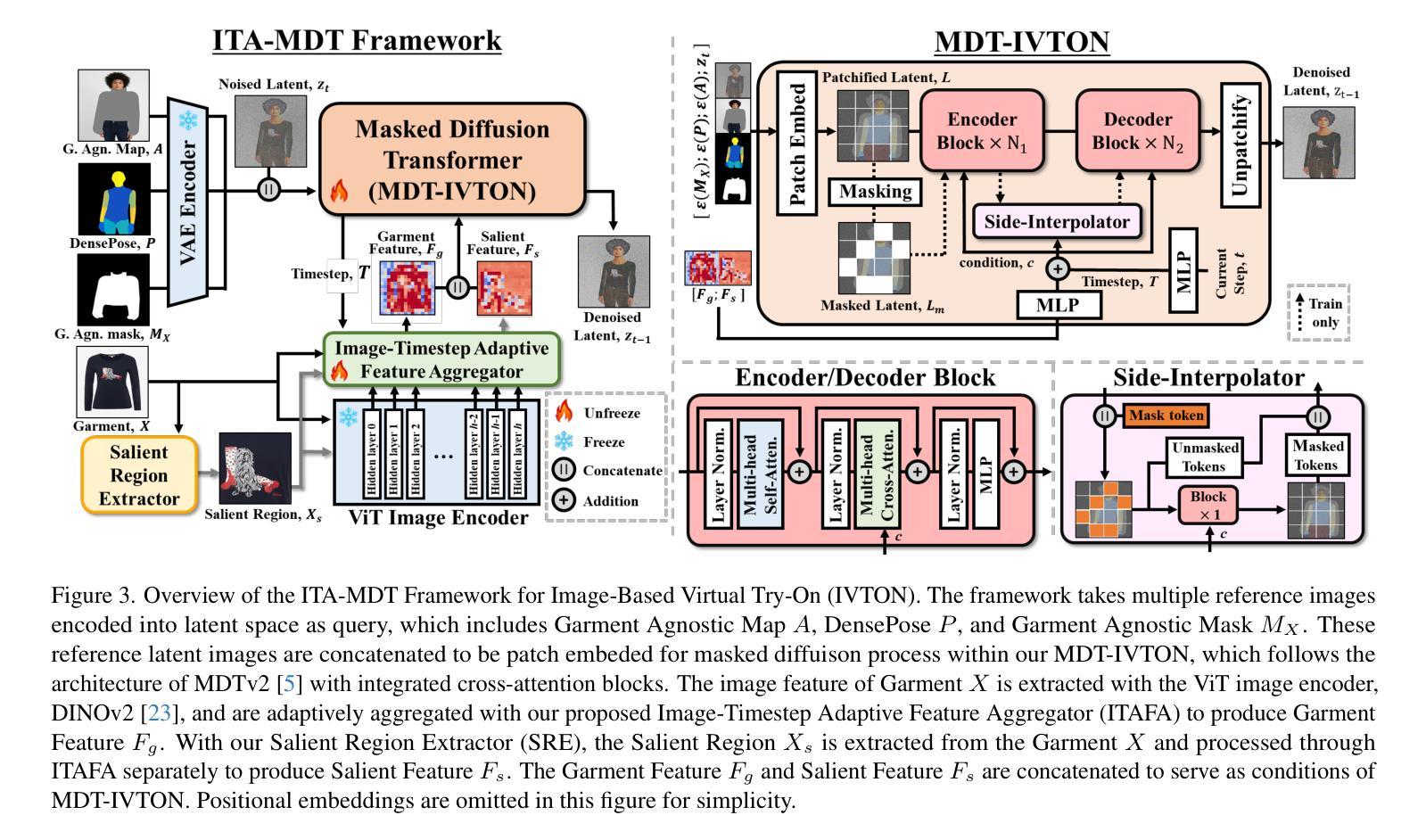
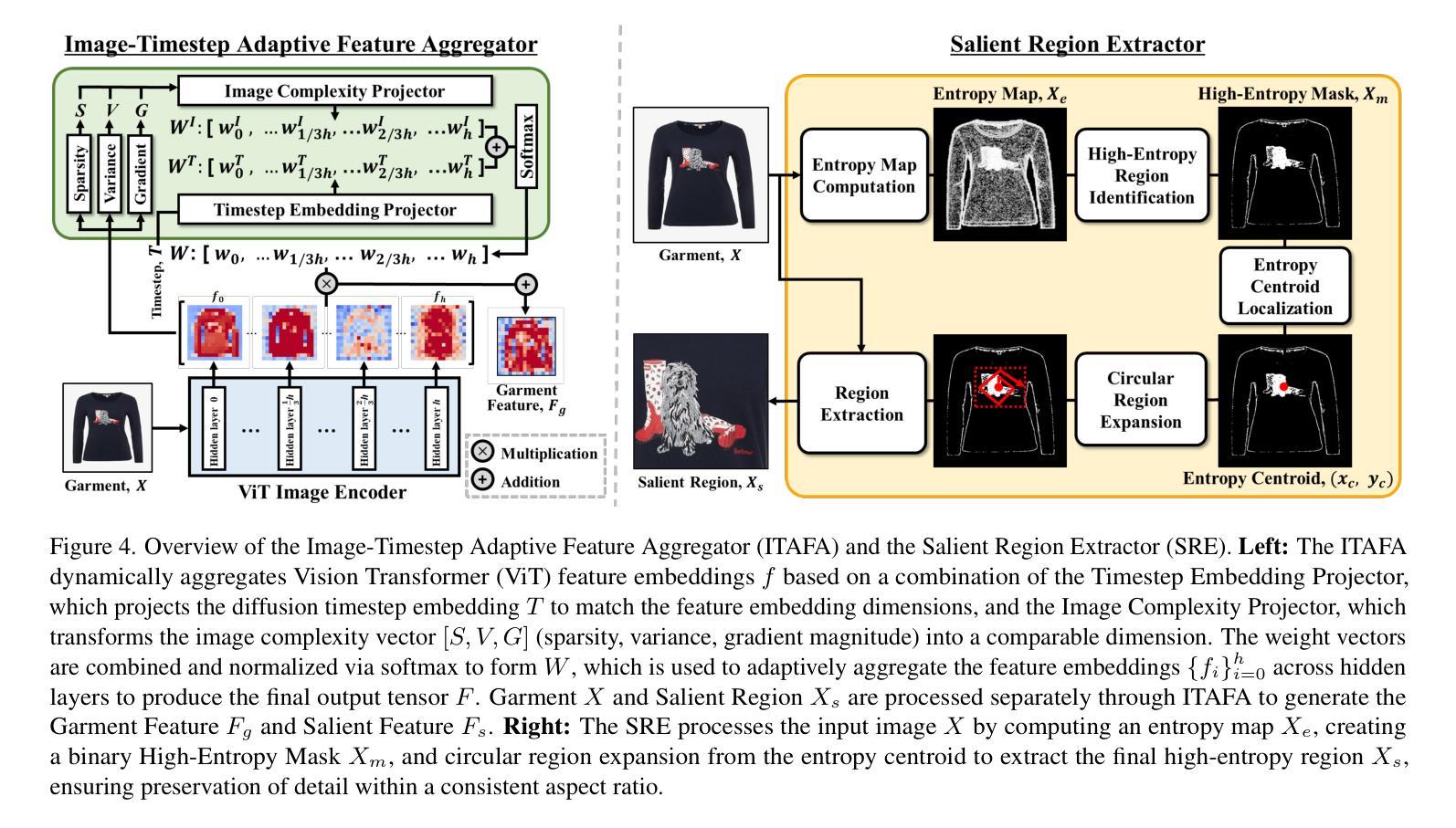
This paper introduces ITA-MDT, the Image-Timestep-Adaptive Masked Diffusion Transformer Framework for Image-Based Virtual Try-On (IVTON), designed to overcome the limitations of previous approaches by leveraging the Masked Diffusion Transformer (MDT) for improved handling of both global garment context and fine-grained details. The IVTON task involves seamlessly superimposing a garment from one image onto a person in another, creating a realistic depiction of the person wearing the specified garment. Unlike conventional diffusion-based virtual try-on models that depend on large pre-trained U-Net architectures, ITA-MDT leverages a lightweight, scalable transformer-based denoising diffusion model with a mask latent modeling scheme, achieving competitive results while reducing computational overhead. A key component of ITA-MDT is the Image-Timestep Adaptive Feature Aggregator (ITAFA), a dynamic feature aggregator that combines all of the features from the image encoder into a unified feature of the same size, guided by diffusion timestep and garment image complexity. This enables adaptive weighting of features, allowing the model to emphasize either global information or fine-grained details based on the requirements of the denoising stage. Additionally, the Salient Region Extractor (SRE) module is presented to identify complex region of the garment to provide high-resolution local information to the denoising model as an additional condition alongside the global information of the full garment image. This targeted conditioning strategy enhances detail preservation of fine details in highly salient garment regions, optimizing computational resources by avoiding unnecessarily processing entire garment image. Comparative evaluations confirms that ITA-MDT improves efficiency while maintaining strong performance, reaching state-of-the-art results in several metrics.
本文介绍了针对基于图像的虚拟试穿(IVTON)设计的图像时序自适应掩膜扩散变换框架ITA-MDT。该框架旨在克服以前方法的局限性,利用掩膜扩散变换器(MDT)改进全局服装上下文和精细细节的处理。IVTON任务涉及将一张图像中的服装无缝地叠加到另一张图像中的人物身上,创建人物穿着指定服装的现实主义描绘。不同于依赖大型预训练U-Net架构的传统基于扩散的虚拟试穿模型,ITA-MDT利用了一个轻量级、可扩展的基于变换器的去噪扩散模型,并采用了掩膜潜在建模方案,在降低计算开销的同时实现了具有竞争力的结果。ITA-MDT的关键组件是图像时序自适应特征聚合器(ITAFA),这是一个动态特征聚合器,它将来自图像编码器的所有特征合并为具有相同大小的统一特征,受扩散步骤和服装图像复杂性的引导。这实现了特征的自适应加权,使模型能够根据去噪阶段的需要在全局信息或精细细节之间进行权衡。此外,还介绍了显著区域提取器(SRE)模块,用于识别服装的复杂区域,为去噪模型提供高分辨率的局部信息,作为全局信息的附加条件。这种有针对性的条件策略有助于保留服装高度显著区域的细节,并通过避免不必要地处理整个服装图像来优化计算资源。比较评估证实,ITA-MDT在提高效率的同时保持了强大的性能,在多个指标上达到了最新水平。
论文及项目相关链接
PDF CVPR 2025, Project Page: https://jiwoohong93.github.io/ita-mdt/
Summary
该论文提出了基于图像时序自适应掩膜扩散转换器框架(ITA-MDT)的图像虚拟试穿(IVTON)新方法。它克服了先前方法的局限性,利用掩膜扩散转换器(MDT)处理全局服装上下文和精细细节的能力。IVTON任务是将一张图像中的服装无缝地叠加到另一张图像中的人物上,创造出人物穿着指定服装的现实主义描绘。不同于传统的基于扩散的虚拟试穿模型依赖大型预训练U-Net架构,ITA-MDT采用了一种轻量级、可扩展的基于变换器的去噪扩散模型,并结合掩膜潜在建模方案,在降低计算开销的同时实现了竞争性的结果。ITA-MDT的关键组件包括图像时序自适应特征聚合器(ITAFA)和显著区域提取器(SRE)模块,它们分别通过自适应地加权特征和识别服装的复杂区域,提高了模型在降噪阶段的性能。
Key Takeaways
- ITA-MDT框架结合了掩膜扩散转换器(MDT)用于图像虚拟试穿(IVTON),提高了处理全局服装上下文和精细细节的能力。
- 不同于传统的扩散虚拟试穿模型依赖大型U-Net架构,ITA-MDT采用轻量级、可扩展的基于变换器的去噪扩散模型,降低了计算开销。
- ITA-MDT引入了图像时序自适应特征聚合器(ITAFA),能够根据扩散步骤和服装图像复杂度动态聚合特征。
- 显著区域提取器(SRE)模块能够识别服装的复杂区域,为去噪模型提供高分辨率的局部信息,提高细节保留能力。
- ITA-MDT通过针对显著区域的条件策略,优化了资源分配,避免了不必要地处理整个服装图像。
- 评估结果表明,ITA-MDT在提高效率的同时保持了强大的性能,达到了多个指标的最先进水平。
点此查看论文截图

TSD-SR: One-Step Diffusion with Target Score Distillation for Real-World Image Super-Resolution
Authors:Linwei Dong, Qingnan Fan, Yihong Guo, Zhonghao Wang, Qi Zhang, Jinwei Chen, Yawei Luo, Changqing Zou
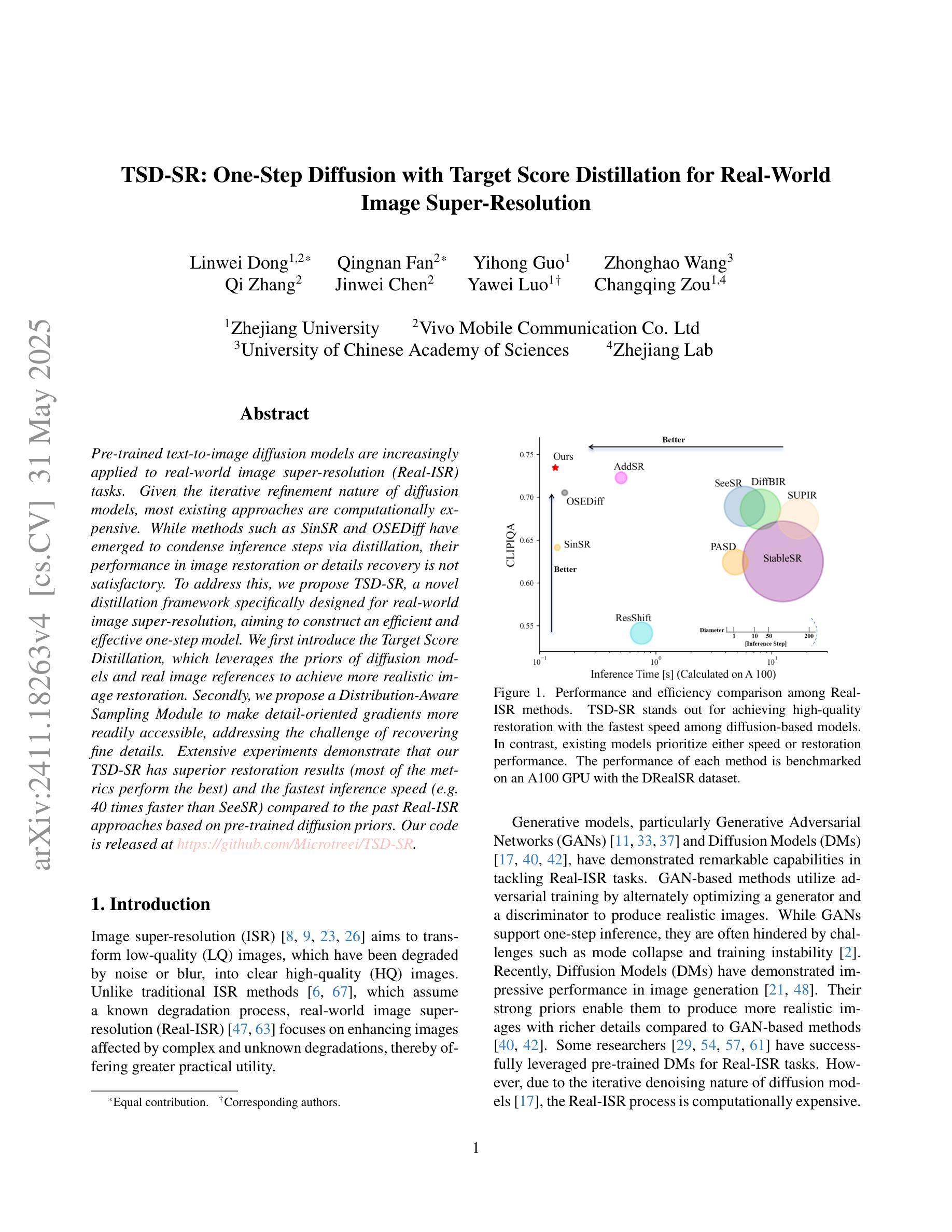
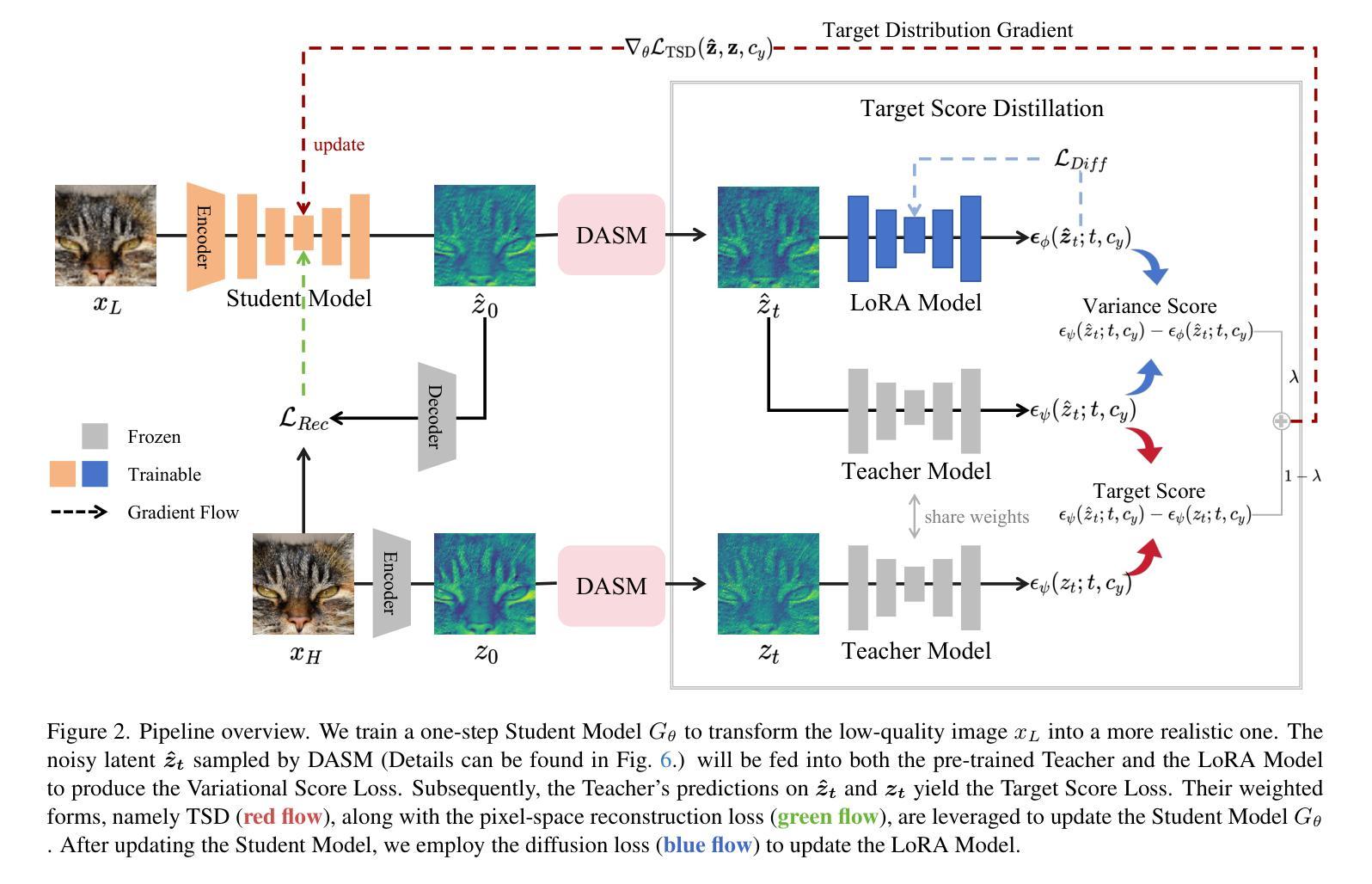
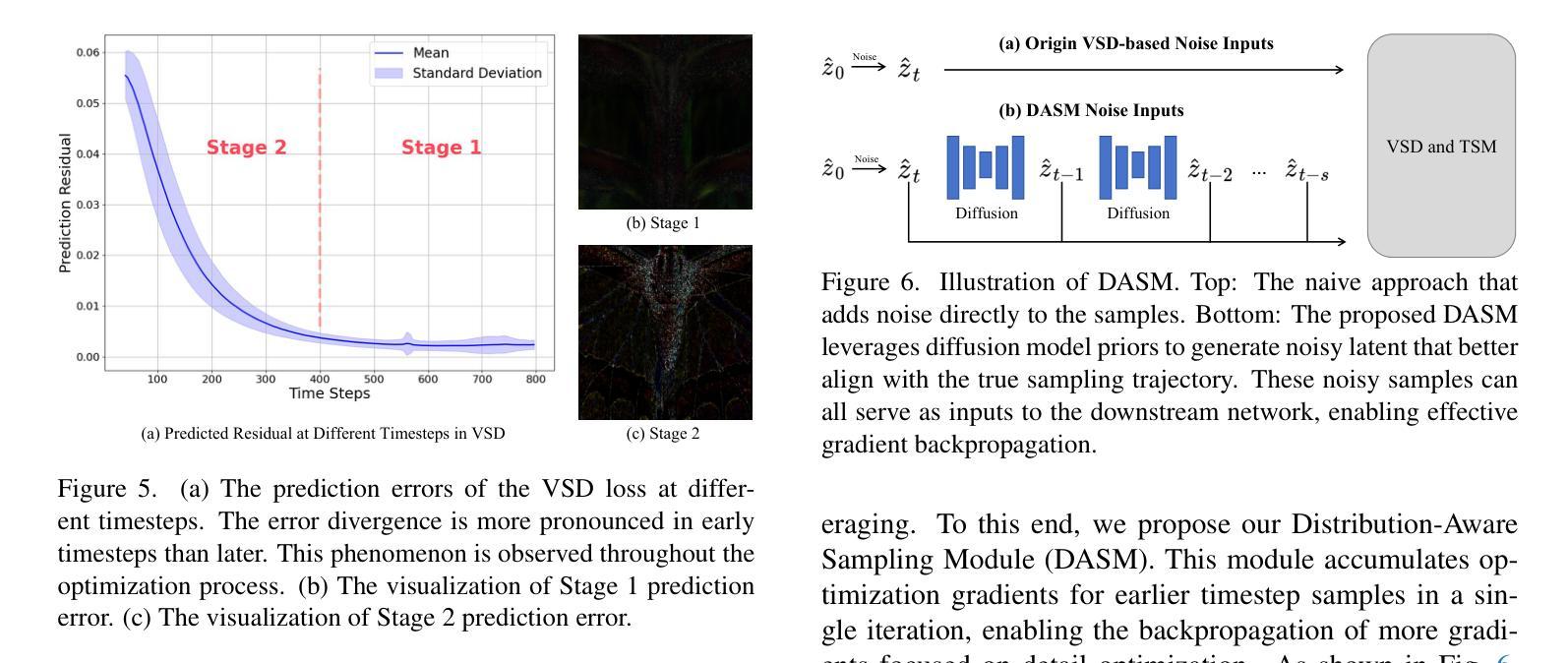
Pre-trained text-to-image diffusion models are increasingly applied to real-world image super-resolution (Real-ISR) task. Given the iterative refinement nature of diffusion models, most existing approaches are computationally expensive. While methods such as SinSR and OSEDiff have emerged to condense inference steps via distillation, their performance in image restoration or details recovery is not satisfied. To address this, we propose TSD-SR, a novel distillation framework specifically designed for real-world image super-resolution, aiming to construct an efficient and effective one-step model. We first introduce the Target Score Distillation, which leverages the priors of diffusion models and real image references to achieve more realistic image restoration. Secondly, we propose a Distribution-Aware Sampling Module to make detail-oriented gradients more readily accessible, addressing the challenge of recovering fine details. Extensive experiments demonstrate that our TSD-SR has superior restoration results (most of the metrics perform the best) and the fastest inference speed (e.g. 40 times faster than SeeSR) compared to the past Real-ISR approaches based on pre-trained diffusion priors.
预训练的文本到图像扩散模型越来越多地应用于现实世界图像超分辨率(Real-ISR)任务。由于扩散模型的迭代细化特性,大多数现有方法计算量大。虽然SinSR和OSEDiff等方法已经出现,通过蒸馏来精简推理步骤,但它们在图像恢复或细节恢复方面的性能并不令人满意。为了解决这一问题,我们提出了TSD-SR,这是一种专门用于现实世界图像超分辨率的新型蒸馏框架,旨在构建高效且有效的一步模型。首先,我们引入了目标分数蒸馏,它利用扩散模型和真实图像引用的先验知识来实现更真实的图像恢复。其次,我们提出了分布感知采样模块,使细节导向的梯度更容易获取,解决恢复精细细节的挑战。大量实验表明,与基于预训练扩散先验的过去Real-ISR方法相比,我们的TSD-SR具有优越的复原效果(大多数指标表现最佳)和最快的推理速度(例如,比SeeSR快40倍)。
论文及项目相关链接
摘要
预训练文本转图像扩散模型越来越多地应用于现实图像超分辨率(Real-ISR)任务。虽然现有方法如SinSR和OSEDiff通过蒸馏技术简化了推理步骤,但在图像恢复或细节恢复方面的性能尚不满足要求。为解决此问题,我们提出TSD-SR,一种专为现实图像超分辨率设计的全新蒸馏框架,旨在构建高效且有效的一步模型。首先,我们引入目标分数蒸馏技术,利用扩散模型的先验知识和真实图像参考来实现更逼真的图像恢复。其次,我们提出分布感知采样模块,使细节导向的梯度更容易获取,解决恢复精细细节的挑战。大量实验表明,我们的TSD-SR具有优异的恢复效果(多数指标表现最佳)和最快的推理速度(例如,比SeeSR快40倍),相较于基于预训练扩散先验的过往Real-ISR方法。
关键见解
- 预训练文本转图像扩散模型在Real-ISR任务中的应用越来越广泛。
- 现有方法如SinSR和OSEDiff虽然简化了推理步骤,但在图像恢复细节方面性能不足。
- TSD-SR框架旨在构建高效且有效的一步模型,用于现实图像超分辨率。
- 目标分数蒸馏技术利用扩散模型先验和真实图像参考,实现更逼真的图像恢复。
- 分布感知采样模块使细节导向的梯度更易获取,改善精细细节的恢复。
- TSD-SR在恢复效果上表现优异,多数指标达到最佳。
- TSD-SR具有快速的推理速度,相较于其他方法有明显优势。
点此查看论文截图

HandCraft: Anatomically Correct Restoration of Malformed Hands in Diffusion Generated Images
Authors:Zhenyue Qin, Yiqun Zhang, Yang Liu, Dylan Campbell
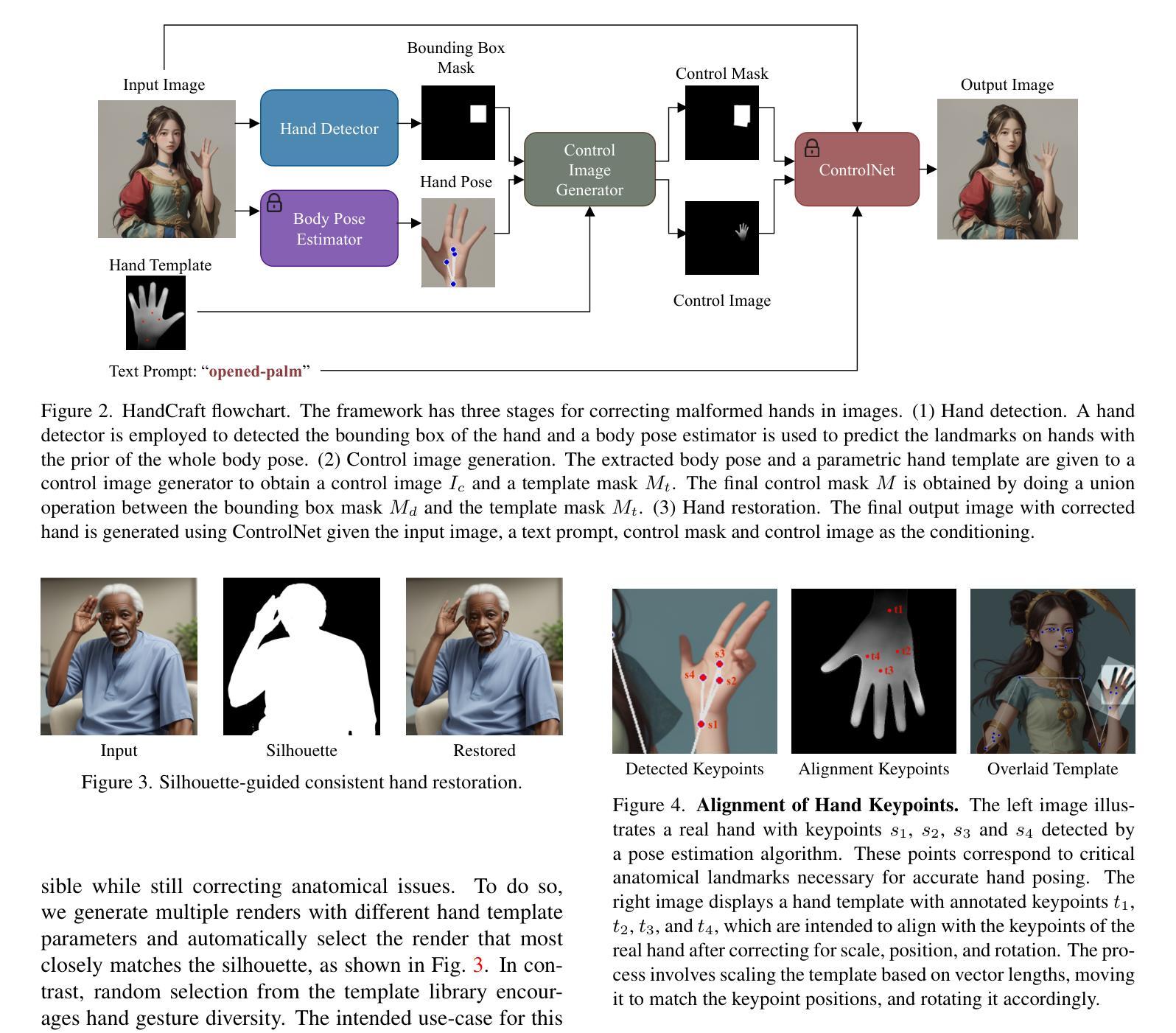
Generative text-to-image models, such as Stable Diffusion, have demonstrated a remarkable ability to generate diverse, high-quality images. However, they are surprisingly inept when it comes to rendering human hands, which are often anatomically incorrect or reside in the “uncanny valley”. In this paper, we propose a method HandCraft for restoring such malformed hands. This is achieved by automatically constructing masks and depth images for hands as conditioning signals using a parametric model, allowing a diffusion-based image editor to fix the hand’s anatomy and adjust its pose while seamlessly integrating the changes into the original image, preserving pose, color, and style. Our plug-and-play hand restoration solution is compatible with existing pretrained diffusion models, and the restoration process facilitates adoption by eschewing any fine-tuning or training requirements for the diffusion models. We also contribute MalHand datasets that contain generated images with a wide variety of malformed hands in several styles for hand detector training and hand restoration benchmarking, and demonstrate through qualitative and quantitative evaluation that HandCraft not only restores anatomical correctness but also maintains the integrity of the overall image.
生成式文本到图像模型,如Stable Diffusion,已经显示出生成多样、高质量图像的显著能力。然而,当涉及到呈现人类手部时,它们却表现出惊人的无能,手部通常解剖结构不正确或处于“诡异谷”之中。在本文中,我们提出了一种名为HandCraft的方法,用于修复这种畸形的手部。这是通过利用参数模型自动构建手部掩膜和深度图像作为条件信号来实现的,这使得基于扩散的图像编辑器能够修复手部的解剖结构并调整其姿态,同时无缝地将更改集成到原始图像中,保持姿态、颜色和风格。我们的即插即用式手部修复解决方案与现有的预训练扩散模型兼容,修复过程通过避免对扩散模型的任何微调或培训要求,促进了采用。我们还贡献了MalHand数据集,其中包含多种风格和多种畸形手部的生成图像,用于手部检测器训练和手部修复基准测试,并通过定性和定量评估证明,HandCraft不仅恢复了解剖结构的正确性,还保持了整体图像的完整性。
论文及项目相关链接
PDF 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
Summary
文本介绍了Stable Diffusion等生成式文本转图像模型在生成图像时对手部渲染的不足,提出了HandCraft方法来解决这一问题。HandCraft通过自动构建手部掩膜和深度图像作为条件信号,利用参数模型实现扩散式图像编辑器的修复手部解剖结构和调整手部姿态的功能,同时无缝集成更改到原始图像中。该方法兼容现有预训练的扩散模型,无需对其进行微调或训练要求。此外,该研究还提供了MalHand数据集,用于手检测器训练和手修复基准测试,并通过定性和定量评估证明了HandCraft方法不仅可恢复手部解剖正确性,还能保持整体图像的完整性。
Key Takeaways
- 生成式文本转图像模型如Stable Diffusion在渲染手部时存在缺陷。
- HandCraft方法旨在解决这一问题,通过构建手部掩膜和深度图像作为条件信号,利用参数模型修复手部解剖结构和调整姿态。
- HandCraft方法与现有预训练的扩散模型兼容,无需进行额外的训练或微调。
- HandCraft能够在保持整体图像完整性的同时,恢复手部的解剖正确性。
- 研究提供了MalHand数据集,包含多种风格和形态异常的手部图像,用于手检测器训练和手修复基准测试。
- 通过定性和定量评估,证明了HandCraft方法的有效性。
点此查看论文截图



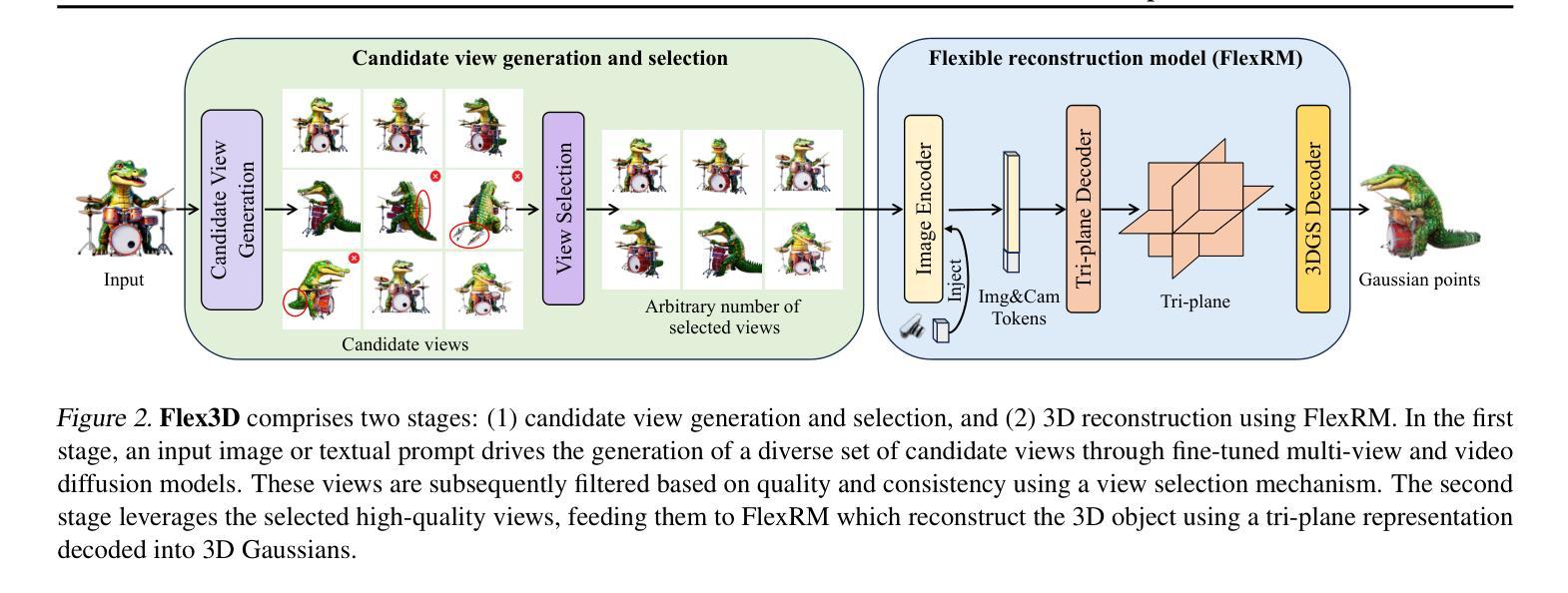
Flex3D: Feed-Forward 3D Generation with Flexible Reconstruction Model and Input View Curation
Authors:Junlin Han, Jianyuan Wang, Andrea Vedaldi, Philip Torr, Filippos Kokkinos
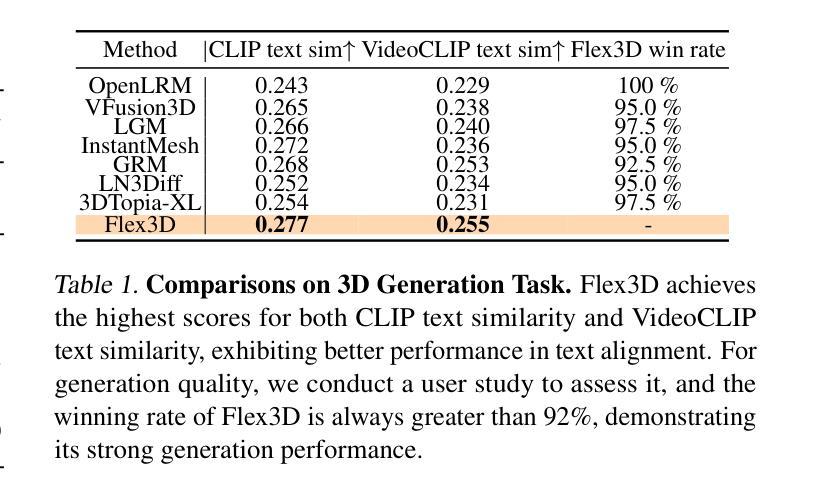
Generating high-quality 3D content from text, single images, or sparse view images remains a challenging task with broad applications. Existing methods typically employ multi-view diffusion models to synthesize multi-view images, followed by a feed-forward process for 3D reconstruction. However, these approaches are often constrained by a small and fixed number of input views, limiting their ability to capture diverse viewpoints and, even worse, leading to suboptimal generation results if the synthesized views are of poor quality. To address these limitations, we propose Flex3D, a novel two-stage framework capable of leveraging an arbitrary number of high-quality input views. The first stage consists of a candidate view generation and curation pipeline. We employ a fine-tuned multi-view image diffusion model and a video diffusion model to generate a pool of candidate views, enabling a rich representation of the target 3D object. Subsequently, a view selection pipeline filters these views based on quality and consistency, ensuring that only the high-quality and reliable views are used for reconstruction. In the second stage, the curated views are fed into a Flexible Reconstruction Model (FlexRM), built upon a transformer architecture that can effectively process an arbitrary number of inputs. FlemRM directly outputs 3D Gaussian points leveraging a tri-plane representation, enabling efficient and detailed 3D generation. Through extensive exploration of design and training strategies, we optimize FlexRM to achieve superior performance in both reconstruction and generation tasks. Our results demonstrate that Flex3D achieves state-of-the-art performance, with a user study winning rate of over 92% in 3D generation tasks when compared to several of the latest feed-forward 3D generative models.
从文本、单张图像或稀疏视图图像生成高质量3D内容仍然是一个具有广泛应用挑战性的任务。现有方法通常采用多视图扩散模型合成多视图图像,然后进行前馈过程进行3D重建。然而,这些方法通常受限于输入视图的小而固定的数量,导致它们无法捕捉多种视点,更糟糕的是,如果合成的视图质量较差,还会导致生成结果不理想。为了解决这个问题,我们提出了Flex3D,这是一个新型的两阶段框架,能够利用任意数量的高质量输入视图。第一阶段包括候选视图生成和筛选管道。我们采用微调的多视图图像扩散模型和视频扩散模型来生成候选视图池,实现对目标3D对象的丰富表示。随后,视图选择管道根据质量和一致性过滤这些视图,确保只使用高质量和可靠的视图进行重建。在第二阶段,精选的视图被输入到灵活重建模型(FlexRM)中,该模型基于能够有效处理任意数量输入的变压器架构。FlemRM直接输出利用三重平面表示的3D高斯点,实现高效且详细的3D生成。通过设计和训练策略的广泛探索,我们优化了FlexRM,在重建和生成任务中都实现了卓越的性能。我们的结果表明,Flex3D在性能上达到了最新水平,在与几种最新的前馈3D生成模型的比较中,用户研究获胜率高达92%以上。
论文及项目相关链接
PDF ICML 25. Project page: https://junlinhan.github.io/projects/flex3d/
Summary
本文提出一种名为Flex3D的两阶段框架,用于从文本、单张图像或稀疏视图图像生成高质量3D内容。第一阶段通过微调的多视图图像扩散模型和视频扩散模型生成候选视图,并进行筛选和筛选。第二阶段使用基于transformer架构的灵活重建模型(FlexRM)处理任意数量的输入视图,直接输出基于tri-plane表示的3D高斯点云。该方法优化了FlexRM的设计和培训策略,在重建和生成任务中表现出卓越性能。用户研究结果显示,Flex3D在与其他最新前馈3D生成模型的比较中赢得了超过92%的胜率。
Key Takeaways
以下是关于Flex3D框架的关键见解:
- Flex3D是一个两阶段框架,可以充分利用任意数量的高质量输入视图生成高质量的3D内容。
- 第一阶段包括候选视图生成和筛选流程,通过微调的多视图图像扩散模型和视频扩散模型来生成丰富的目标3D对象表示。
- 第二阶段使用灵活重建模型(FlexRM)处理筛选后的视图,并直接输出基于tri-plane表示的3D高斯点云。该模型可以有效处理任意数量的输入,并实现了高效的详细3D生成。
- FlexRM的优化设计包括培训策略的调整,使其在重建和生成任务中表现出卓越性能。
点此查看论文截图


Conditional Image Synthesis with Diffusion Models: A Survey
Authors:Zheyuan Zhan, Defang Chen, Jian-Ping Mei, Zhenghe Zhao, Jiawei Chen, Chun Chen, Siwei Lyu, Can Wang
Conditional image synthesis based on user-specified requirements is a key component in creating complex visual content. In recent years, diffusion-based generative modeling has become a highly effective way for conditional image synthesis, leading to exponential growth in the literature. However, the complexity of diffusion-based modeling, the wide range of image synthesis tasks, and the diversity of conditioning mechanisms present significant challenges for researchers to keep up with rapid developments and to understand the core concepts on this topic. In this survey, we categorize existing works based on how conditions are integrated into the two fundamental components of diffusion-based modeling, $\textit{i.e.}$, the denoising network and the sampling process. We specifically highlight the underlying principles, advantages, and potential challenges of various conditioning approaches during the training, re-purposing, and specialization stages to construct a desired denoising network. We also summarize six mainstream conditioning mechanisms in the sampling process. All discussions are centered around popular applications. Finally, we pinpoint several critical yet still unsolved problems and suggest some possible solutions for future research. Our reviewed works are itemized at https://github.com/zju-pi/Awesome-Conditional-Diffusion-Models.
基于用户指定要求的有条件图像合成是创建复杂视觉内容的关键组成部分。近年来,基于扩散的生成模型已成为有条件图像合成的高效方式,相关文献呈指数级增长。然而,基于扩散的建模复杂性、图像合成任务的广泛性以及调节机制的多样性,为研究者带来了跟上快速发展和了解核心概念的重大挑战。在这项调查中,我们根据条件是如何集成到基于扩散建模的两个基本组成部分(即去噪网络和采样过程)来对现有工作进行归类。我们特别强调在训练、重新利用和专业化阶段各种调节方法的内在原理、优点和潜在挑战,以构建所需的去噪网络。我们还总结了采样过程中六种主流的调节机制。所有的讨论都围绕热门应用展开。最后,我们指出了几个关键但尚未解决的问题,并为未来的研究提出了可能的解决方案。我们评述的作品详列在https://github.com/zju-pi/Awesome-Conditional-Diffusion-Models。
论文及项目相关链接
Summary
本文综述了基于扩散模型的图像合成技术,详细介绍了如何将条件因素融入扩散模型的两个基本组成部分——去噪网络和采样过程。文章重点介绍了不同条件下的训练、再利用和专业化阶段的原理、优势和潜在挑战,并总结了六种主流的采样过程中的条件机制。本文旨在帮助读者了解扩散模型在图像合成领域的应用和发展现状,同时提供了一些未来研究可能的解决方案。
Key Takeaways
- 扩散模型已成为条件图像合成的一种高效方法,驱动了大量文献的出现。
- 条件因素被融入扩散模型的两个基本组成部分:去噪网络和采样过程。
- 文章详细阐述了不同条件下训练、再利用和专业化阶段的原理、优势和潜在挑战。
- 总结了六种主流的采样过程中的条件机制。
- 文章围绕流行应用进行讨论。
- 指出了一些关键但尚未解决的问题,并为未来研究提供了可能的解决方案。
- 推荐的审查工作列表可在https://github.com/zju-pi/Awesome-Conditional-Diffusion-Models找到。
点此查看论文截图


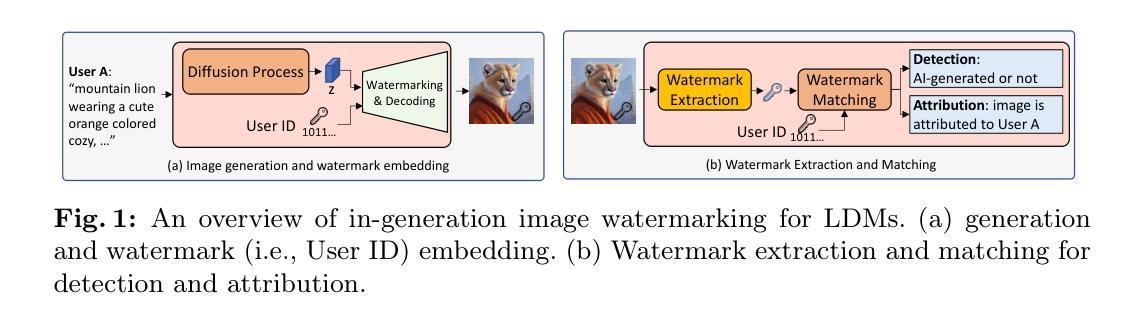
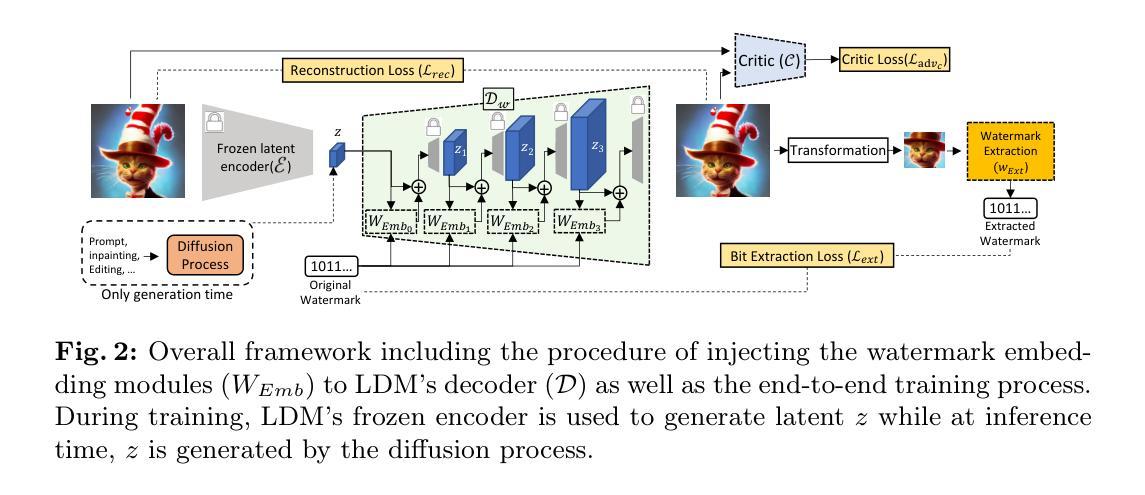
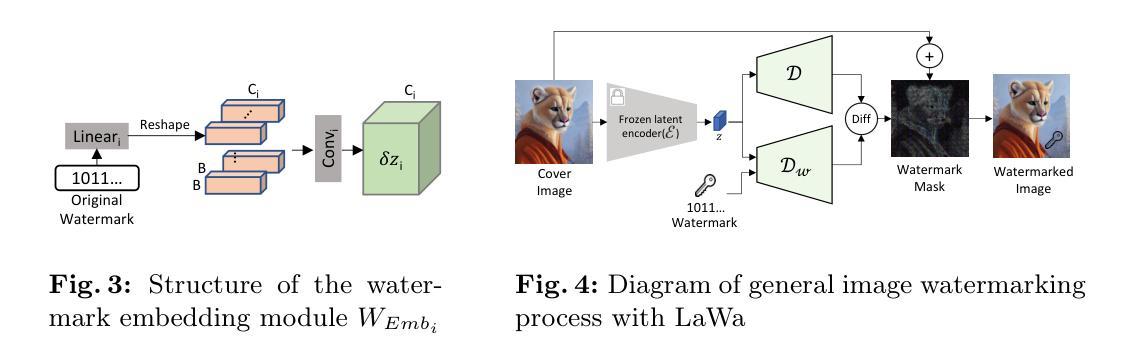
LaWa: Using Latent Space for In-Generation Image Watermarking
Authors:Ahmad Rezaei, Mohammad Akbari, Saeed Ranjbar Alvar, Arezou Fatemi, Yong Zhang
With generative models producing high quality images that are indistinguishable from real ones, there is growing concern regarding the malicious usage of AI-generated images. Imperceptible image watermarking is one viable solution towards such concerns. Prior watermarking methods map the image to a latent space for adding the watermark. Moreover, Latent Diffusion Models (LDM) generate the image in the latent space of a pre-trained autoencoder. We argue that this latent space can be used to integrate watermarking into the generation process. To this end, we present LaWa, an in-generation image watermarking method designed for LDMs. By using coarse-to-fine watermark embedding modules, LaWa modifies the latent space of pre-trained autoencoders and achieves high robustness against a wide range of image transformations while preserving perceptual quality of the image. We show that LaWa can also be used as a general image watermarking method. Through extensive experiments, we demonstrate that LaWa outperforms previous works in perceptual quality, robustness against attacks, and computational complexity, while having very low false positive rate. Code is available here.
随着生成模型产生的图像质量越来越高,与真实图像无法区分,人们越来越担心AI生成图像被恶意使用的问题。不易察觉的图像水印技术是一种可行的解决方案。以往的水印方法将图像映射到潜在空间以添加水印。此外,潜在扩散模型(LDM)在预训练自编码器的潜在空间中生成图像。我们认为,可以利用这个潜在空间将水印集成到生成过程中。为此,我们提出了LaWa,这是一种为LDM设计的在生成图像过程中的水印方法。通过使用从粗糙到精细的水印嵌入模块,LaWa修改了预训练自编码器的潜在空间,并在对抗各种图像转换时实现了高度的稳健性,同时保持了图像的感知质量。我们展示LaWa也可以作为一种通用的图像水印方法使用。通过大量实验,我们证明LaWa在感知质量、对抗攻击的稳健性和计算复杂性方面优于以前的工作,同时误报率非常低。代码可在此处获取。
论文及项目相关链接
PDF Accepted to ECCV 2024
Summary
随着生成模型产出高质量、难以辨别真伪的图像,人们越来越担忧AI生成图像被恶意使用的问题。隐形图像水印技术是一种可行的解决方案。以前的水印方法将图像映射到潜在空间以添加水印。此外,潜在扩散模型(LDM)在预训练自编码器的潜在空间中生成图像。我们认为可以利用这个潜在空间将水印集成到生成过程中。为此,我们提出了面向LDM的生成中图像水印方法LaWa。通过使用粗细结合的水印嵌入模块,LaWa修改了预训练自编码器的潜在空间,对各种图像变换具有高度的鲁棒性,同时保持了图像感知质量。我们还证明了LaWa也可以作为一种通用的图像水印方法使用。通过大量实验,我们证明了LaWa在感知质量、抗攻击性、计算复杂性方面优于以前的工作,并且具有极低的误报率。
Key Takeaways
- 生成模型产出的高质量图像难以辨别真伪,引发对恶意使用的担忧。
- 隐形图像水印技术是解决这一问题的可行方案。
- LaWa是一种面向潜在扩散模型(LDM)的生成中图像水印方法。
- LaWa利用粗细结合的水印嵌入模块修改预训练自编码器的潜在空间。
- LaWa对各种图像变换具有高度的鲁棒性,同时保持图像感知质量。
- LaWa可作为通用图像水印方法使用。
点此查看论文截图

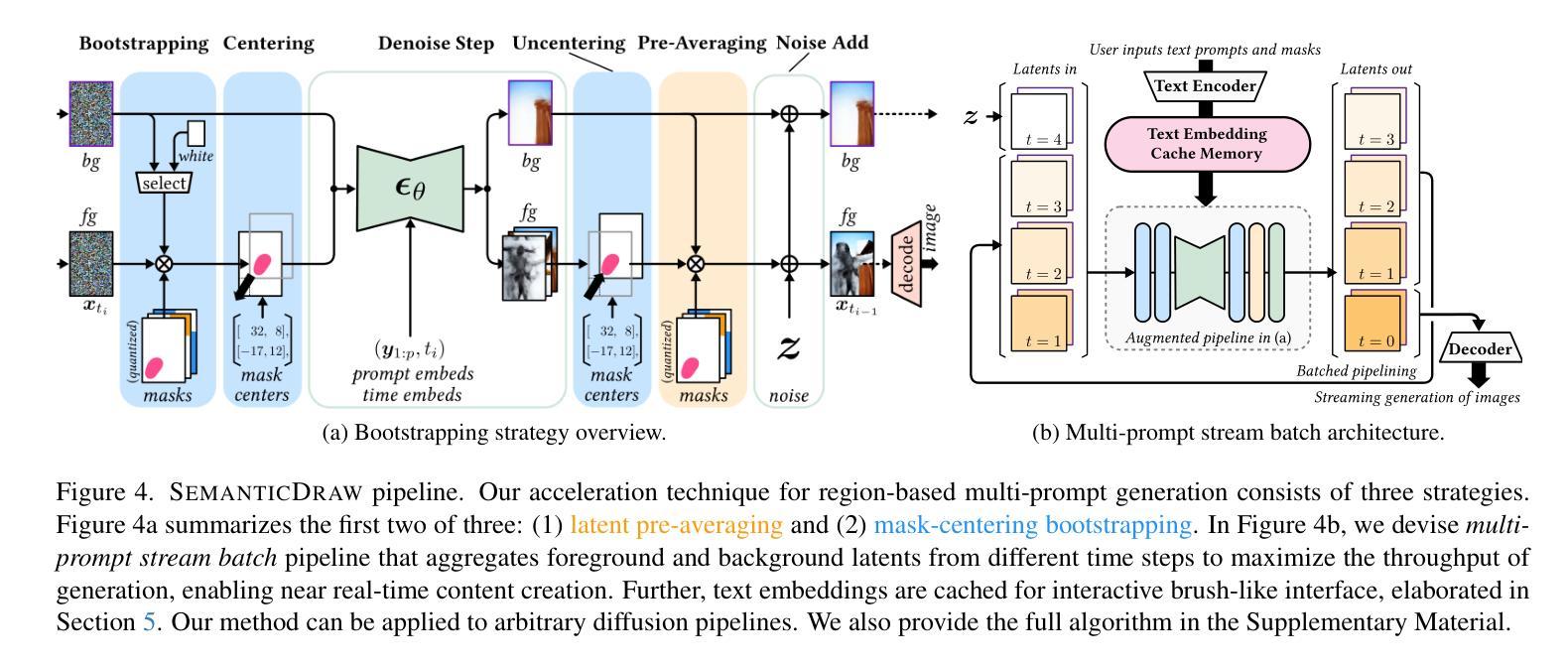
SemanticDraw: Towards Real-Time Interactive Content Creation from Image Diffusion Models
Authors:Jaerin Lee, Daniel Sungho Jung, Kanggeon Lee, Kyoung Mu Lee
We introduce SemanticDraw, a new paradigm of interactive content creation where high-quality images are generated in near real-time from given multiple hand-drawn regions, each encoding prescribed semantic meaning. In order to maximize the productivity of content creators and to fully realize their artistic imagination, it requires both quick interactive interfaces and fine-grained regional controls in their tools. Despite astonishing generation quality from recent diffusion models, we find that existing approaches for regional controllability are very slow (52 seconds for $512 \times 512$ image) while not compatible with acceleration methods such as LCM, blocking their huge potential in interactive content creation. From this observation, we build our solution for interactive content creation in two steps: (1) we establish compatibility between region-based controls and acceleration techniques for diffusion models, maintaining high fidelity of multi-prompt image generation with $\times 10$ reduced number of inference steps, (2) we increase the generation throughput with our new multi-prompt stream batch pipeline, enabling low-latency generation from multiple, region-based text prompts on a single RTX 2080 Ti GPU. Our proposed framework is generalizable to any existing diffusion models and acceleration schedulers, allowing sub-second (0.64 seconds) image content creation application upon well-established image diffusion models. Our project page is: https://jaerinlee.com/research/semantic-draw
我们介绍了SemanticDraw,这是一种新的交互式内容创建范式,它可以从给定的多个手绘区域中实时生成高质量图像,每个区域都编码了规定的语义含义。为了最大化内容创作者的生产力并实现他们的艺术想象力,这需要快速的交互式接口和工具中的精细区域控制。尽管最近的扩散模型产生了惊人的生成质量,但我们发现现有的区域可控性方法非常缓慢(对于512x512图像需要52秒),而且不兼容如LCM等加速方法,这阻碍了它们在交互式内容创建中的巨大潜力。基于这些观察,我们将交互式内容创建的解决方案分为两步构建:首先,我们建立了基于区域的控制与扩散模型的加速技术之间的兼容性,通过减少推理步骤的数量(减少10倍),保持多提示图像生成的高保真度;其次,我们使用了新的多提示流批处理管道,提高了生成吞吐量,能够在单个RTX 2080 Ti GPU上实现多个基于区域的文本提示的低延迟生成。我们提出的框架可以应用于任何现有的扩散模型和加速调度器,允许在成熟的图像扩散模型上进行子秒级(0.64秒)的图像内容创建应用。我们的项目页面是:https://jaerinlee.com/research/semantic-draw
论文及项目相关链接
PDF CVPR 2025 camera ready
Summary
本文介绍了SemanticDraw,这是一种新的交互式内容创建范式。它利用扩散模型,根据多个手绘区域生成高质量图像,每个区域都有规定的语义意义。为了提高内容创作者的效率和实现他们的艺术想象力,需要快速交互式接口和工具中的精细区域控制。现有扩散模型的区域控制方法虽然生成质量惊人,但速度较慢,且不兼容加速方法,如LCM,阻碍了它们在交互式内容创建中的巨大潜力。因此,该研究通过建立区域控制与加速技术之间的兼容性,减少推理步骤数量,提高多提示流批量管道生成吞吐量,实现了低延迟的多区域文本提示生成。该研究提出的框架可广泛应用于现有扩散模型和加速调度器,允许在成熟的图像扩散模型上实现子秒级(0.64秒)的图像内容创建应用。
Key Takeaways
- SemanticDraw是一种基于扩散模型的新的交互式内容创建方法,可以从多个手绘区域生成高质量图像。
- 现有扩散模型的区域控制方法虽然生成质量高,但速度慢,且不兼容现有加速方法。
- 研究者通过建立区域控制与加速技术之间的兼容性来提高效率。
- 通过减少推理步骤数量,维持多提示图像生成的高保真度。
- 新的多提示流批量管道提高了生成吞吐量,实现了低延迟的多区域文本提示生成。
- 该研究提出的框架可广泛应用于现有的扩散模型和加速调度器。
- 在成熟的图像扩散模型上,能够实现子秒级(0.64秒)的图像内容创建应用。
点此查看论文截图



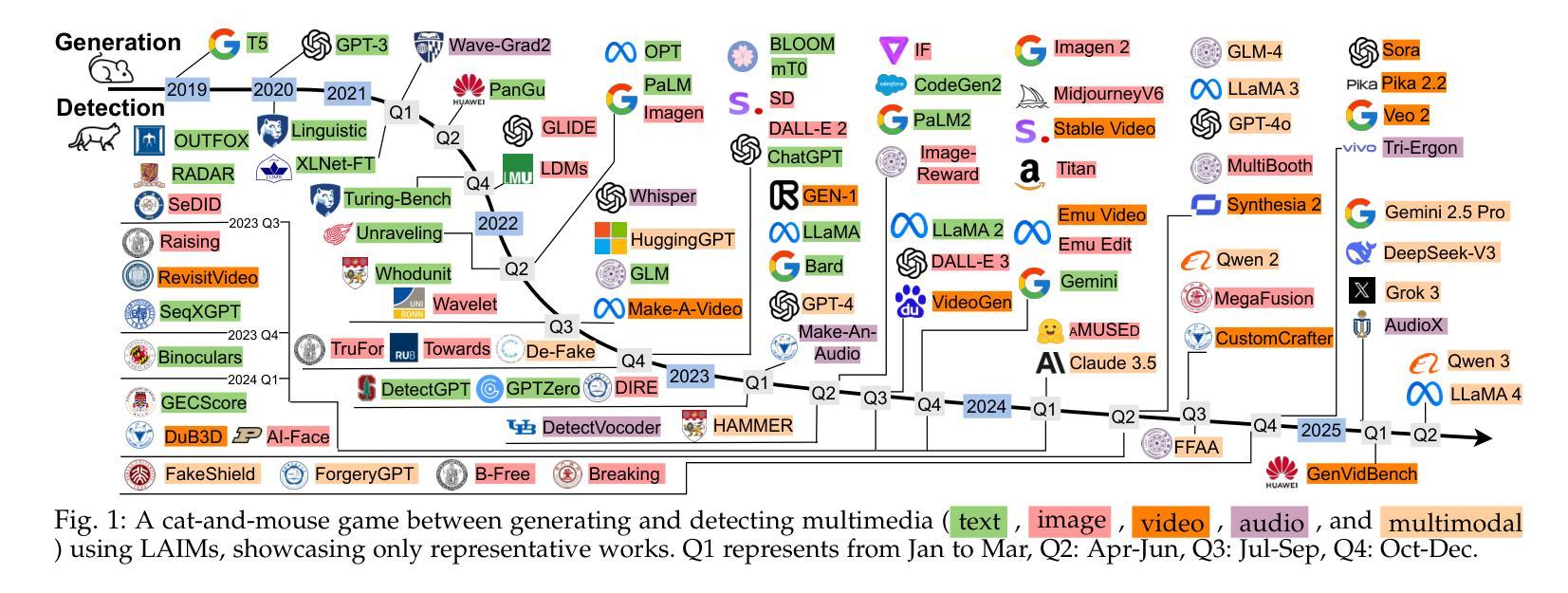
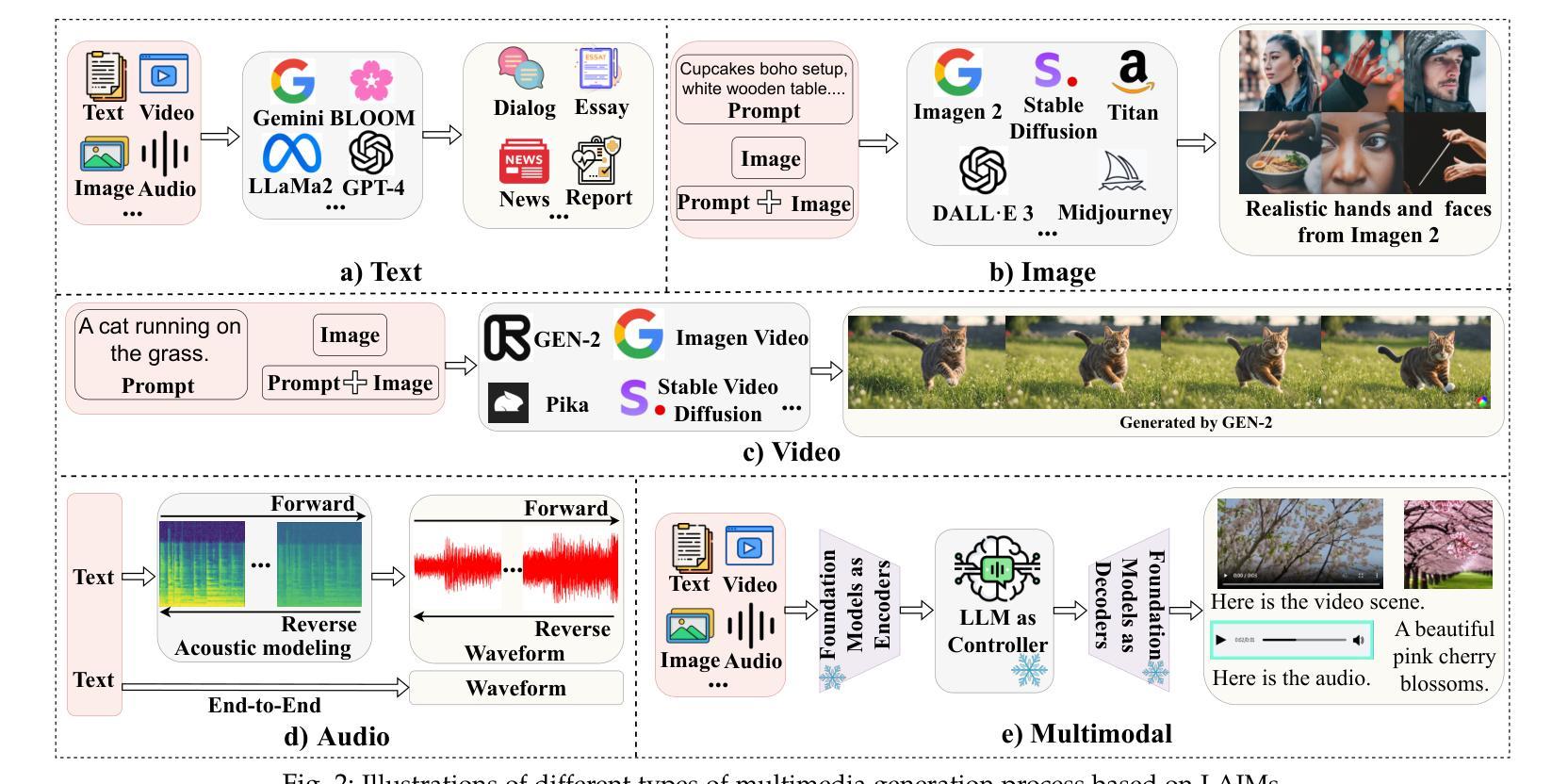
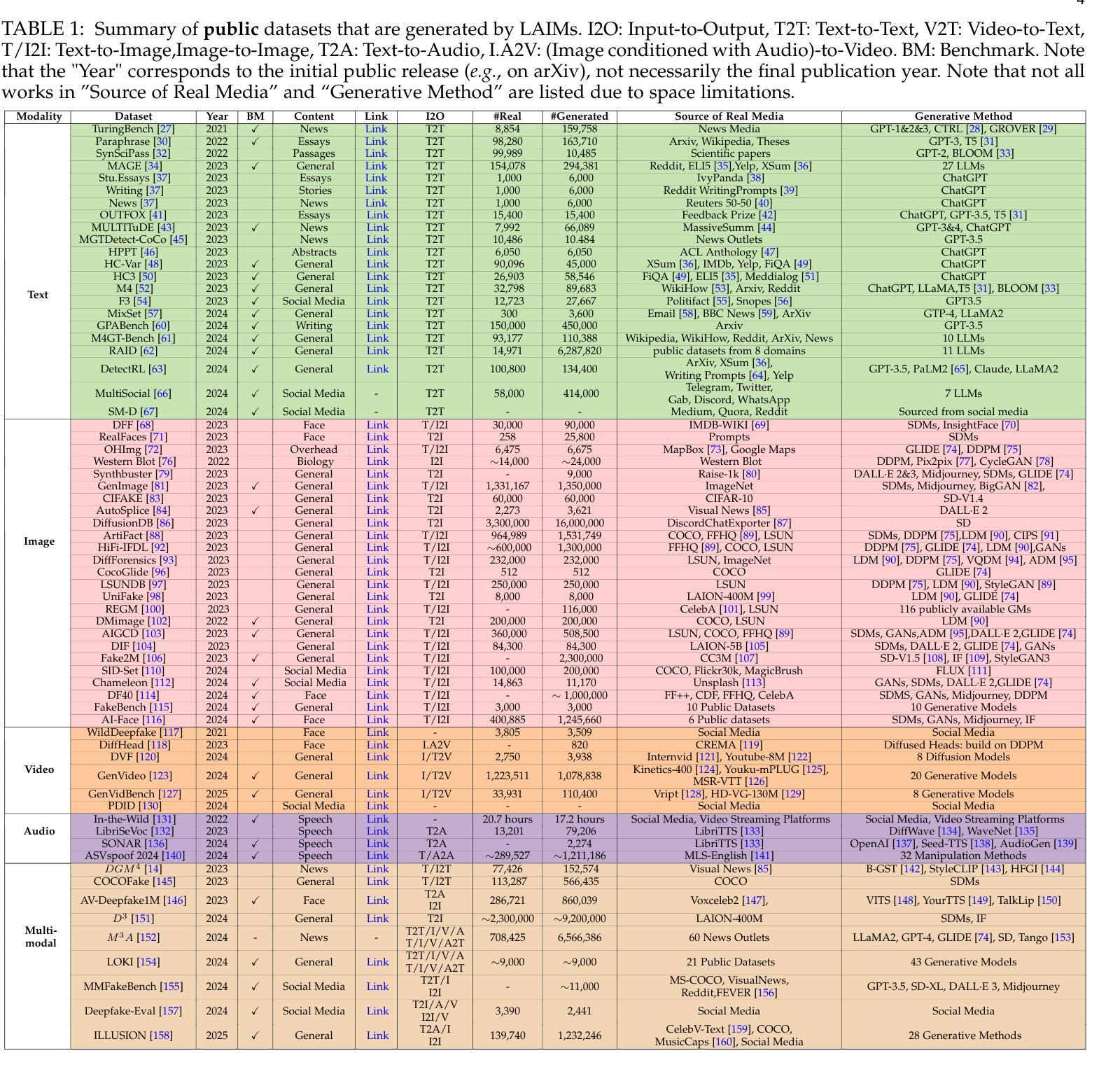
Detecting Multimedia Generated by Large AI Models: A Survey
Authors:Li Lin, Neeraj Gupta, Yue Zhang, Hainan Ren, Chun-Hao Liu, Feng Ding, Xin Wang, Xin Li, Luisa Verdoliva, Shu Hu
The rapid advancement of Large AI Models (LAIMs), particularly diffusion models and large language models, has marked a new era where AI-generated multimedia is increasingly integrated into various aspects of daily life. Although beneficial in numerous fields, this content presents significant risks, including potential misuse, societal disruptions, and ethical concerns. Consequently, detecting multimedia generated by LAIMs has become crucial, with a marked rise in related research. Despite this, there remains a notable gap in systematic surveys that focus specifically on detecting LAIM-generated multimedia. Addressing this, we provide the first survey to comprehensively cover existing research on detecting multimedia (such as text, images, videos, audio, and multimodal content) created by LAIMs. Specifically, we introduce a novel taxonomy for detection methods, categorized by media modality, and aligned with two perspectives: pure detection (aiming to enhance detection performance) and beyond detection (adding attributes like generalizability, robustness, and interpretability to detectors). Additionally, we have presented a brief overview of generation mechanisms, public datasets, online detection tools, and evaluation metrics to provide a valuable resource for researchers and practitioners in this field. Most importantly, we offer a focused analysis from a social media perspective to highlight their broader societal impact. Furthermore, we identify current challenges in detection and propose directions for future research that address unexplored, ongoing, and emerging issues in detecting multimedia generated by LAIMs. Our aim for this survey is to fill an academic gap and contribute to global AI security efforts, helping to ensure the integrity of information in the digital realm. The project link is https://github.com/Purdue-M2/Detect-LAIM-generated-Multimedia-Survey.
大型人工智能模型(LAIMs)的快速发展,特别是扩散模型和大语言模型,标志着一个人工智能生成多媒体日益融入日常生活的全新时代的来临。尽管这些技术在许多领域都带来了好处,但这些内容也存在重大风险,包括潜在误用、社会混乱和道德担忧。因此,检测由LAIM生成的多媒体内容变得至关重要,相关研究的增长也极为显著。尽管如此,专门针对检测LAIM生成多媒体的系统性综述仍存在明显差距。为了解决这个问题,我们提供了第一篇全面涵盖现有检测LAIM生成多媒体(如文本、图像、视频、音频和多模态内容)的研究综述。具体来说,我们引入了一种新的检测方法论分类,按媒体模态分类,并从两个角度进行阐述:纯检测(旨在提高检测性能)和超越检测(向检测器添加通用性、稳健性和可解释性等属性)。此外,我们还简要概述了生成机制、公开数据集、在线检测工具和评估指标,为这一领域的研究人员和实践者提供了有价值的资源。最重要的是,我们从社交媒体的角度进行了深入分析,以突出其更广泛的社会影响。此外,我们还确定了当前检测的挑战,并提出了未来研究的方向,以解决在检测由LAIM生成的多媒体方面尚未探索、正在出现和新兴的问题。本综述旨在填补学术空白,为全球人工智能安全努力做出贡献,帮助确保数字领域的信息完整性。项目链接为:https://github.com/Purdue-M2/Detect-LAIM-generated-Multimedia-Survey。
论文及项目相关链接
摘要
扩散模型等大型AI模型(LAIMs)的快速发展标志着AI生成多媒体内容在日常生活中的融入程度越来越高。虽然这些技术在许多领域具有应用价值,但同时也存在潜在的误用风险、社会混乱和伦理问题。因此,检测LAIM生成的多媒体内容变得至关重要,相关研究也日渐增多。本文首次全面回顾了检测LAIM生成的多媒体(如文本、图像、视频、音频和多模态内容)的现有研究。介绍了新颖的检测方法分类,分为纯检测(旨在提高检测性能)和超越检测(增加通用性、鲁棒性和检测器的可解释性)。此外,本文简要概述了生成机制、公开数据集、在线检测工具和评估指标,为研究人员和实践者提供有价值的资源。本文从社交媒体的角度进行了深入分析,强调了其更广泛的社会影响。同时,本文还指出了当前检测面临的挑战,并探讨了未来研究的方向,以解决检测LAIM生成的多媒体中的未探索、持续和新兴问题。本文旨在填补学术空白,为全球AI安全做出贡献,确保数字领域的资讯完整性。
关键见解
- 大型AI模型(LAIMs)的快速发展推动了AI生成多媒体内容的广泛应用。
- AI生成的多媒体内容在日常生活中的融入带来了一系列风险,包括潜在误用、社会混乱和伦理问题。
- 检测LAIM生成的多媒体内容已成为关键议题,相关研究逐渐增多。
- 本文首次全面综述了检测LAIM生成的多媒体的现有研究,涉及纯检测和超越检测的分类方法。
- 介绍了生成机制、公开数据集、在线检测工具和评估指标的概述。
- 从社交媒体角度深入分析了社会影响。
- 指出了当前检测面临的挑战,并提出了未来研究的方向,以应对未探索、持续和新兴问题。
- 本文旨在填补学术空白,为AI安全做出贡献,确保数字资讯的完整性。
点此查看论文截图