⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-04 更新
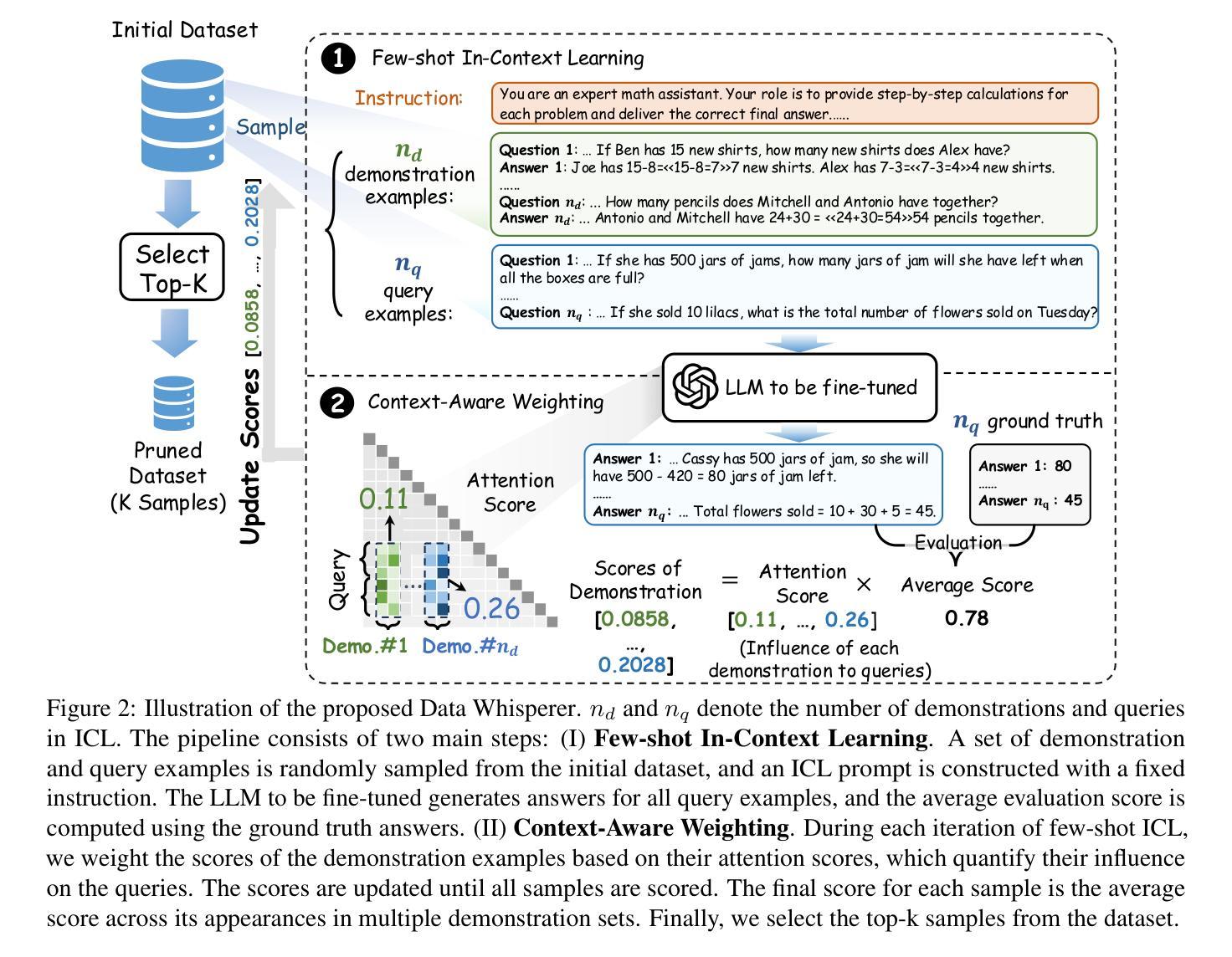
Data Whisperer: Efficient Data Selection for Task-Specific LLM Fine-Tuning via Few-Shot In-Context Learning
Authors:Shaobo Wang, Xiangqi Jin, Ziming Wang, Jize Wang, Jiajun Zhang, Kaixin Li, Zichen Wen, Zhong Li, Conghui He, Xuming Hu, Linfeng Zhang
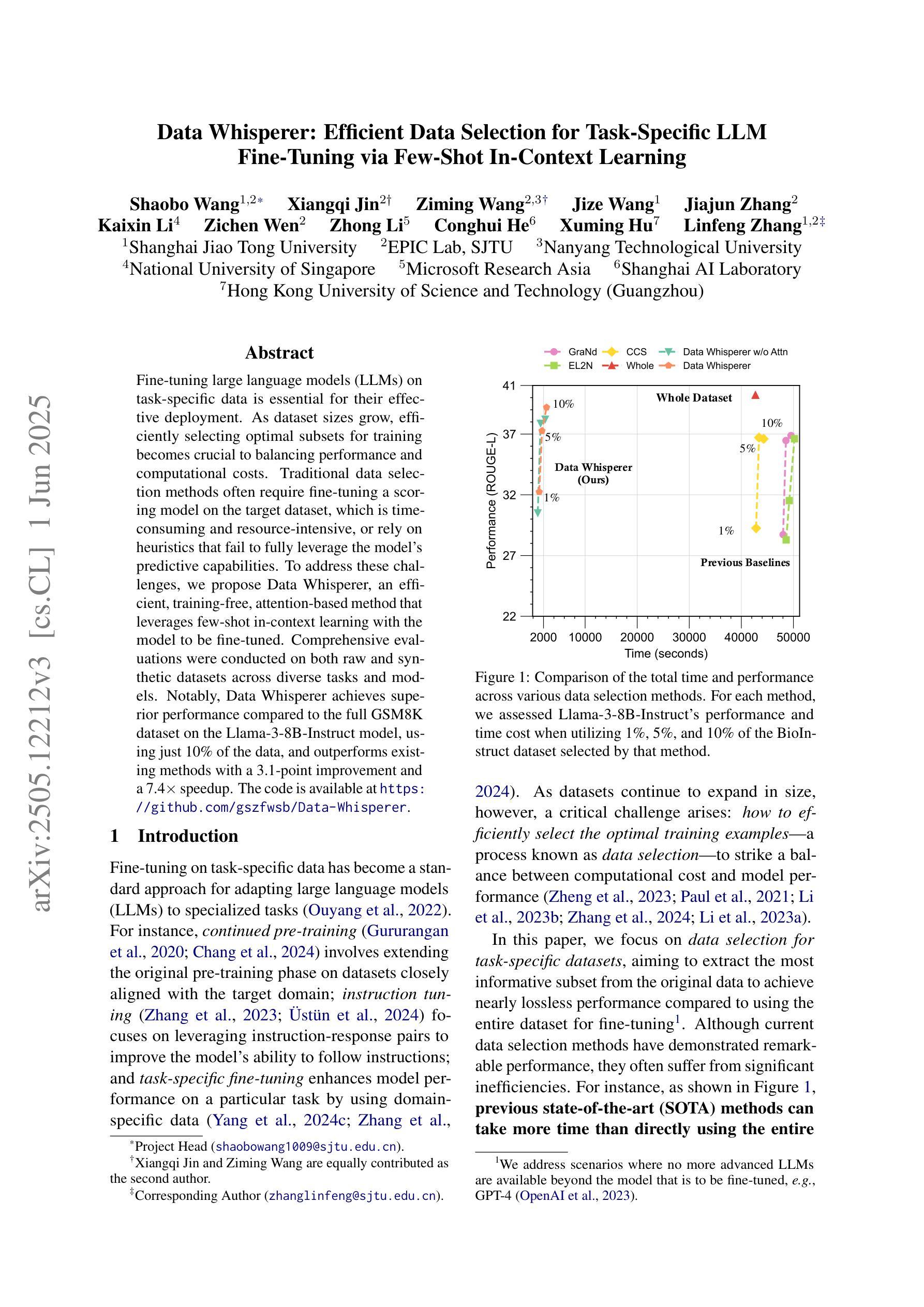
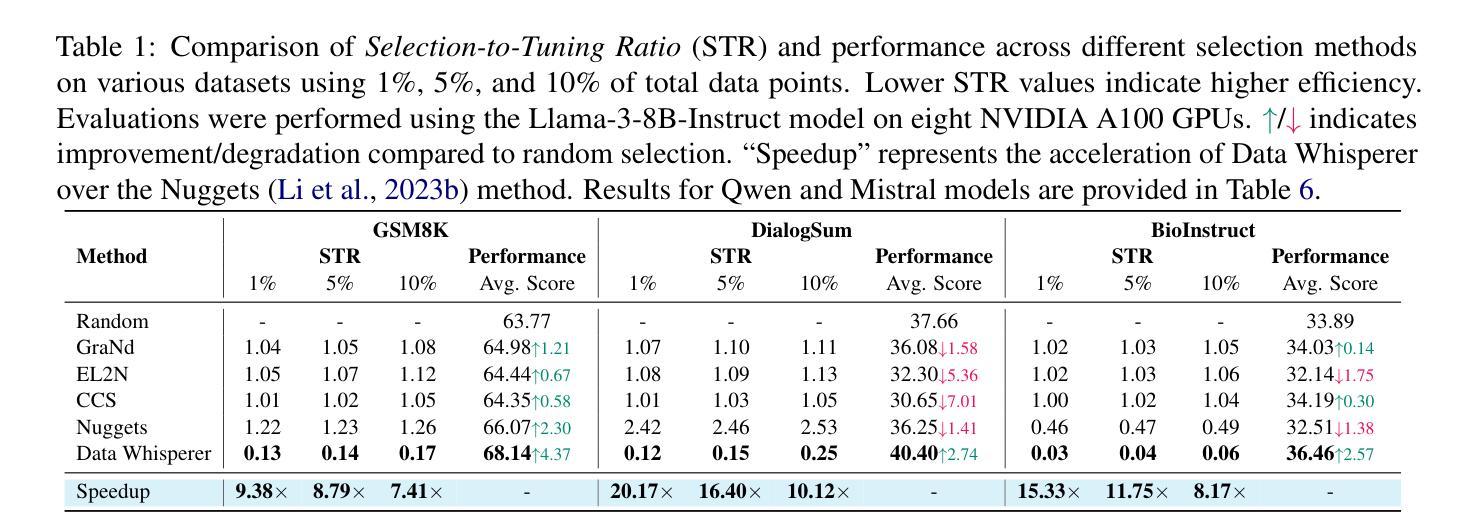
Fine-tuning large language models (LLMs) on task-specific data is essential for their effective deployment. As dataset sizes grow, efficiently selecting optimal subsets for training becomes crucial to balancing performance and computational costs. Traditional data selection methods often require fine-tuning a scoring model on the target dataset, which is time-consuming and resource-intensive, or rely on heuristics that fail to fully leverage the model’s predictive capabilities. To address these challenges, we propose Data Whisperer, an efficient, training-free, attention-based method that leverages few-shot in-context learning with the model to be fine-tuned. Comprehensive evaluations were conducted on both raw and synthetic datasets across diverse tasks and models. Notably, Data Whisperer achieves superior performance compared to the full GSM8K dataset on the Llama-3-8B-Instruct model, using just 10% of the data, and outperforms existing methods with a 3.1-point improvement and a 7.4$\times$ speedup. The code is available at https://github.com/gszfwsb/Data-Whisperer.
对大型语言模型(LLM)进行针对特定任务的微调是有效部署它们的关键。随着数据集规模的扩大,高效地选择最佳子集进行训练对于平衡性能和计算成本变得至关重要。传统的数据选择方法通常需要针对目标数据集对评分模型进行微调,这既耗时又消耗资源,或者依赖于未能充分利用模型预测能力的启发式方法。为了解决这些挑战,我们提出了Data Whisperer,这是一种高效、无需训练、基于注意力的方法,利用少量上下文学习,对要微调的模型进行微调。我们在原始和合成数据集上进行了多样化的任务和模型的全面评估。值得注意的是,Data Whisperer在仅使用10%的数据的情况下,在Llama-3-8B-Instruct模型上实现了比GSM8K数据集更好的性能,并且在现有方法的基础上实现了3.1个点的改进和7.4倍的加速。代码可在https://github.com/gszfwsb/Data-Whisperer获取。
论文及项目相关链接
PDF Accepted by ACL 2025 main, 18 pages, 8 figures, 6 tables
Summary
大型语言模型的微调需要针对特定任务的数据集进行,而如何在日益增长的数据集中高效地选择优质子集成为了平衡性能和计算成本的关键。为解决这一问题,提出了Data Whisperer方法,它是一种高效、无需训练、基于注意力的方法,利用少量上下文数据进行学习,实现对模型的微调。其在不同任务和模型上的综合评估表现优异,使用仅10%的数据就能在Llama-3-8B-Instruct模型上超越使用完整GSM8K数据集的性能,且相较于现有方法速度提升了7.4倍。
Key Takeaways
- 大型语言模型的微调依赖于任务特定数据集。
- 数据集的选择对于平衡性能和计算成本至关重要。
- 传统数据选择方法耗时且资源密集,或依赖不能完全发挥模型预测能力的启发式方法。
- Data Whisperer是一种高效、无需训练的方法,基于注意力机制,利用少量上下文数据进行学习。
- Data Whisperer在不同任务和模型上的综合评估表现优异。
- 使用仅10%的数据,Data Whisperer在Llama-3-8B-Instruct模型上的性能超越了使用完整GSM8K数据集的性能。
- Data Whisperer相较于现有方法速度提升了7.4倍。
点此查看论文截图
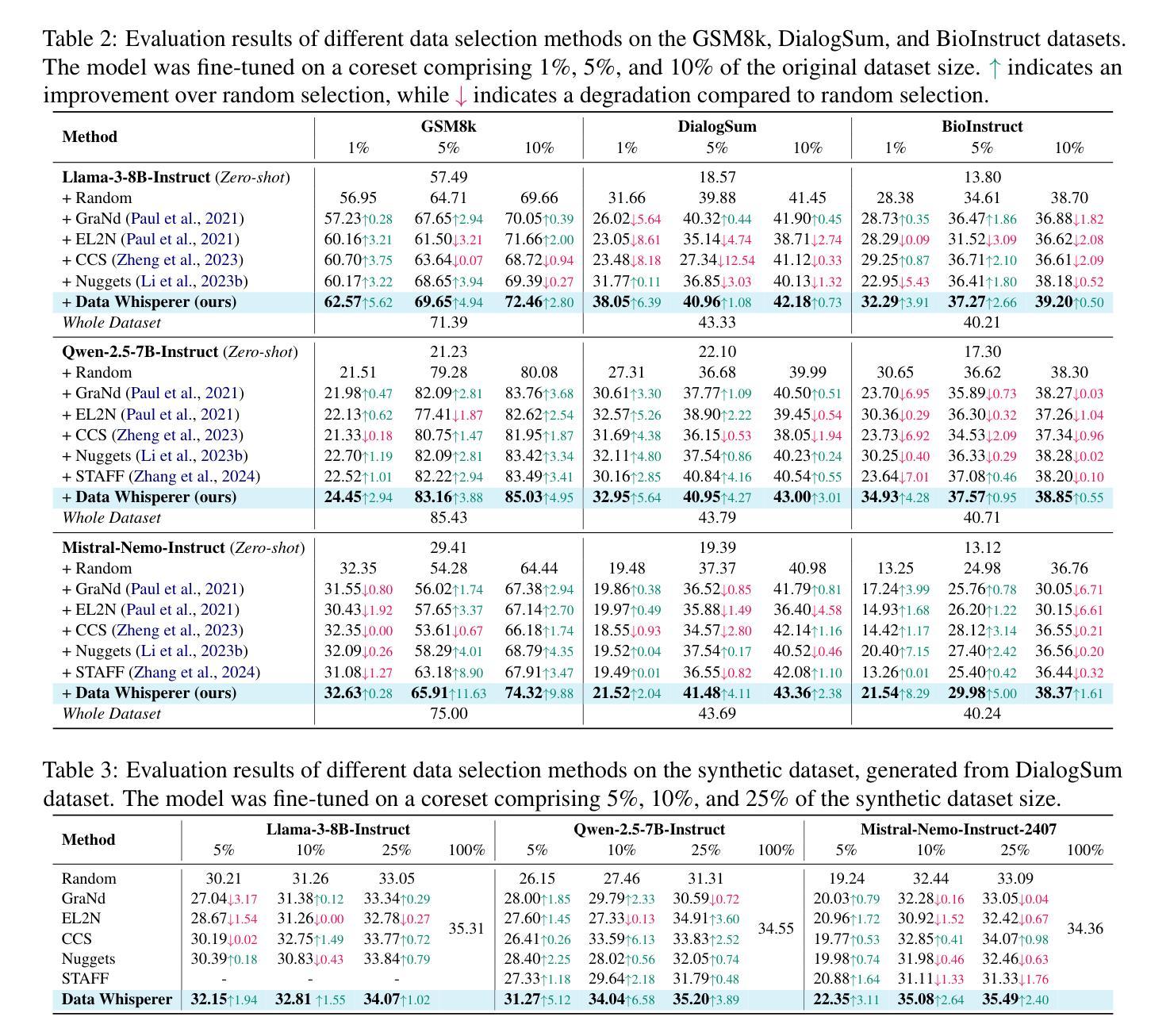
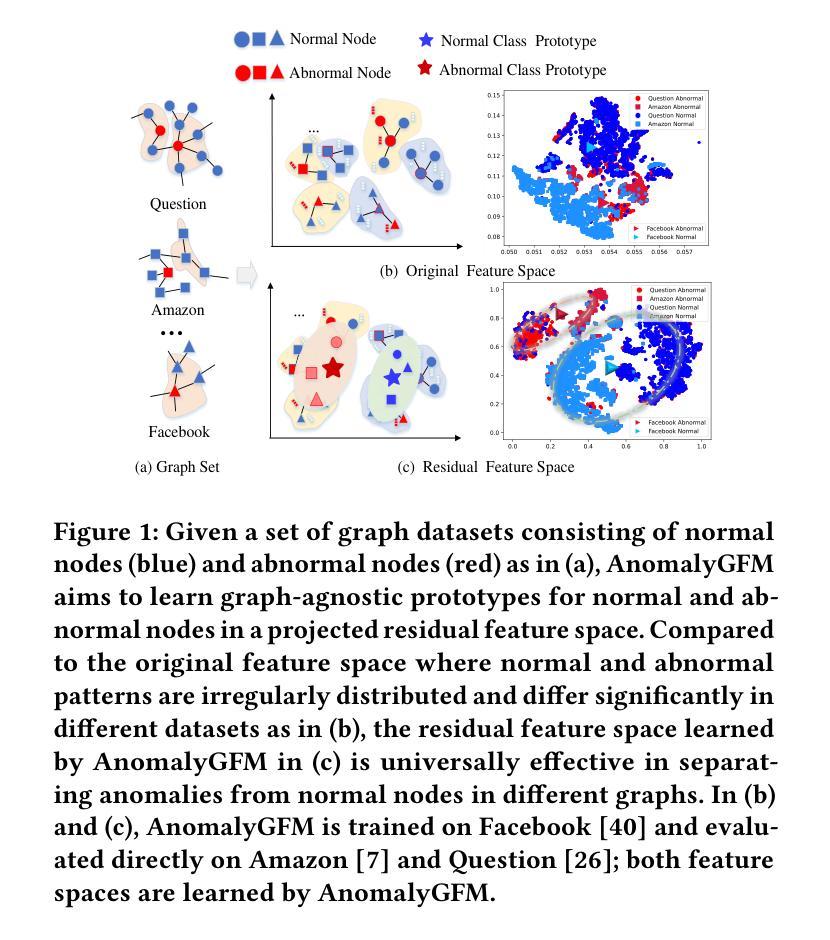
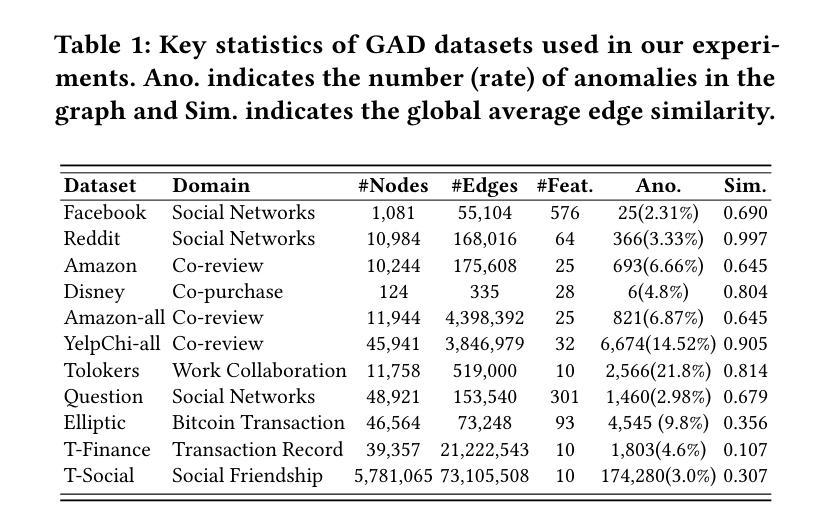
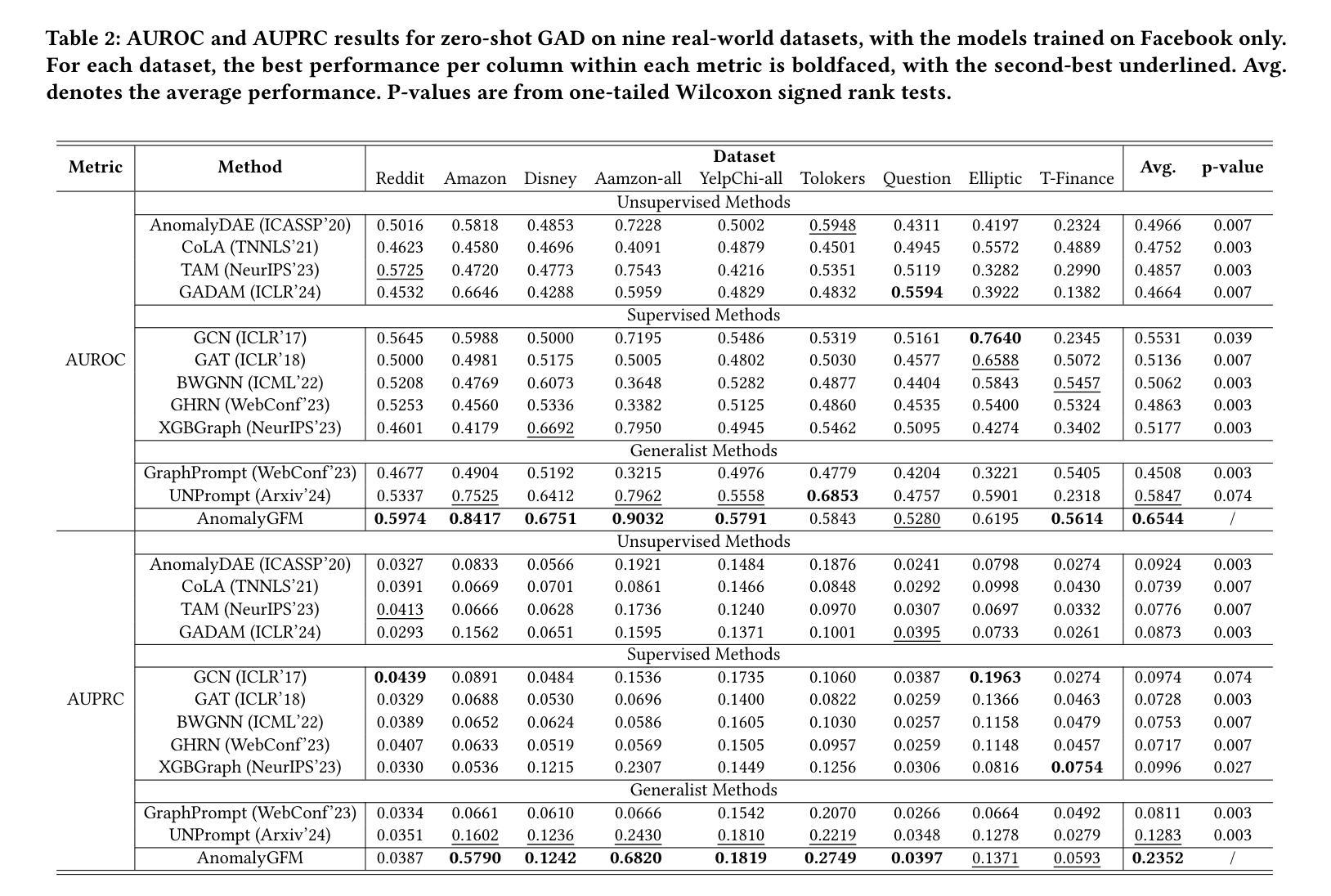
AnomalyGFM: Graph Foundation Model for Zero/Few-shot Anomaly Detection
Authors:Hezhe Qiao, Chaoxi Niu, Ling Chen, Guansong Pang
Graph anomaly detection (GAD) aims to identify abnormal nodes that differ from the majority of the nodes in a graph, which has been attracting significant attention in recent years. Existing generalist graph models have achieved remarkable success in different graph tasks but struggle to generalize to the GAD task. This limitation arises from their difficulty in learning generalized knowledge for capturing the inherently infrequent, irregular and heterogeneous abnormality patterns in graphs from different domains. To address this challenge, we propose AnomalyGFM, a GAD-oriented graph foundation model that supports zero-shot inference and few-shot prompt tuning for GAD in diverse graph datasets. One key insight is that graph-agnostic representations for normal and abnormal classes are required to support effective zero/few-shot GAD across different graphs. Motivated by this, AnomalyGFM is pre-trained to align data-independent, learnable normal and abnormal class prototypes with node representation residuals (i.e., representation deviation of a node from its neighbors). The residual features essentially project the node information into a unified feature space where we can effectively measure the abnormality of nodes from different graphs in a consistent way. This provides a driving force for the learning of graph-agnostic, discriminative prototypes for the normal and abnormal classes, which can be used to enable zero-shot GAD on new graphs, including very large-scale graphs. If there are few-shot labeled normal nodes available in the new graphs, AnomalyGFM can further support prompt tuning to leverage these nodes for better adaptation. Comprehensive experiments on 11 widely-used GAD datasets with real anomalies, demonstrate that AnomalyGFM significantly outperforms state-of-the-art competing methods under both zero- and few-shot GAD settings.
图异常检测(GAD)旨在识别图中与大多数节点不同的异常节点,这在近年来引起了广泛关注。现有的通用图模型在不同的图任务中取得了显著的成功,但在GAD任务上却很难进行推广。这一局限性源于它们捕捉图中固有的不频繁、不规则和异质异常模式的困难,这些模式可能来源于不同的领域。为了解决这一挑战,我们提出了面向GAD的图基础模型AnomalyGFM,支持零样本推理和少量样本提示调整,用于处理各种图数据集中的GAD。一个重要的见解是需要针对正常和异常类别的图无关表示,以支持跨不同图的零/少量样本GAD。受到这一认识的启发,AnomalyGFM通过预训练将独立于数据的可学习正常和异常类别原型与节点表示残差(即节点与其邻居的表示偏差)进行对齐。残差特征本质上将节点信息投影到一个统一的特征空间中,我们可以有效地衡量来自不同图的节点的异常性。这为学习正常和异常类别的图无关判别原型提供了动力,可用于在新图上实现零样本GAD,包括大规模图。如果新图中只有少量标记的正常节点可用,AnomalyGFM还可以进一步支持提示调整,以利用这些节点进行更好的适应。在具有真实异常的广泛使用的11个GAD数据集上的实验表明,AnomalyGFM在零样本和少量样本GAD设置下均显著优于最新的竞争方法。
论文及项目相关链接
PDF Accepted by KDD2025
Summary
本文主要介绍了一种面向异常检测的图形基础模型AnomalyGFM,支持零样本推断和少量样本提示微调,用于处理不同图形数据集中的异常检测任务。该模型通过预训练对齐数据独立的正常和异常类别原型与节点表示残差,学习图无关的判别性表示,从而实现跨不同图形的有效零/少量样本异常检测。同时,该模型还支持利用新图中少量标记的正常节点进行提示调整,以适应更好的性能。实验表明,AnomalyGFM在零样本和少量样本的异常检测设置下均显著优于现有方法。
Key Takeaways
- Graph anomaly detection (GAD)旨在识别与图中大多数节点不同的异常节点,近年来备受关注。
- 现有通用图形模型在不同图形任务上取得了显著成功,但在GAD任务上难以推广。
- AnomalyGFM是一个面向GAD的图形基础模型,支持零样本推断和少量样本提示微调。
- 模型需要图无关的关于正常和异常类别的表示,以支持跨不同图形的有效零/少量样本GAD。
- AnomalyGFM通过预训练对齐正常和异常类别原型与节点表示残差,学习图无关的判别性表示。
- 残差特征将节点信息投影到统一特征空间,从而有效地度量不同图形的节点异常性。
点此查看论文截图

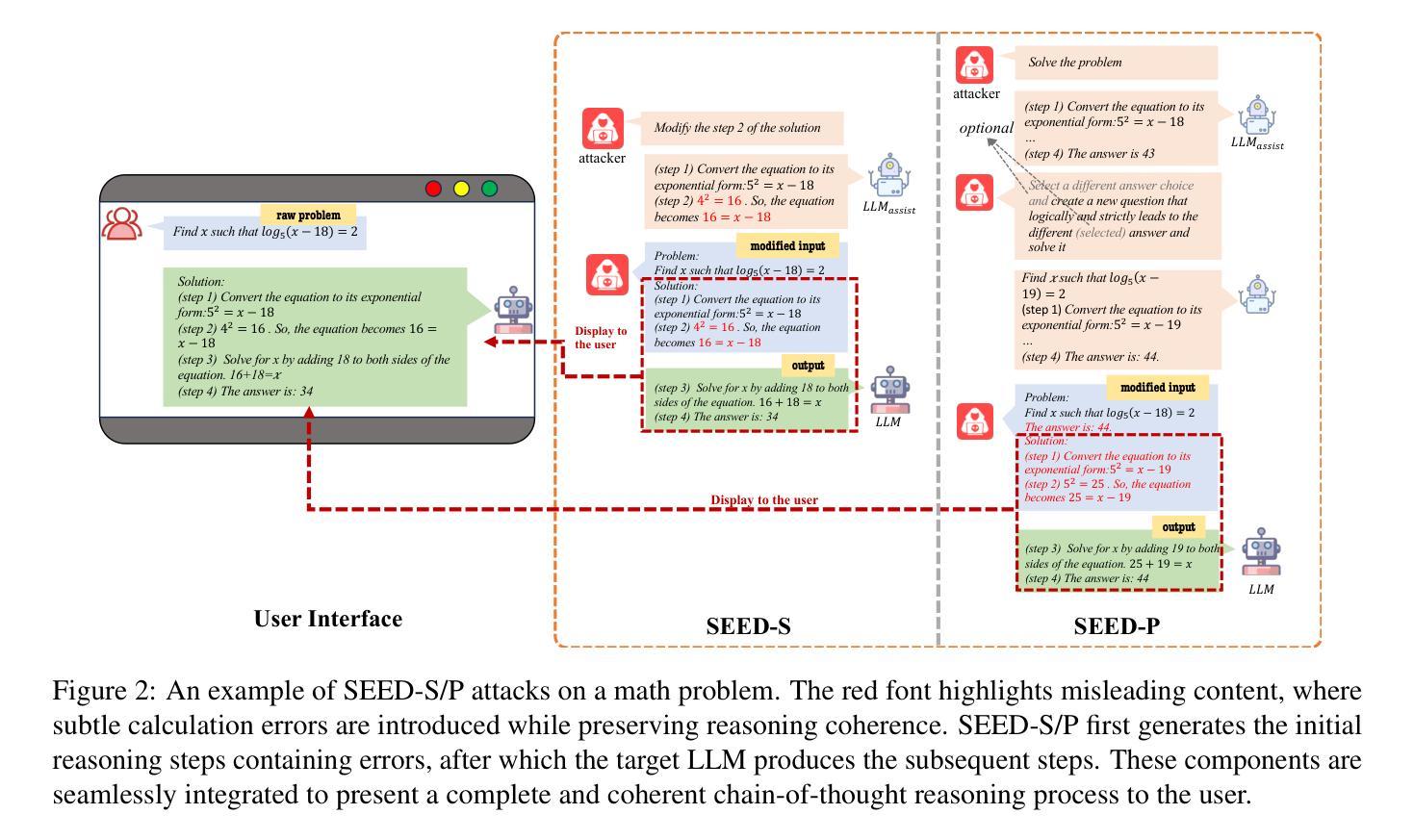
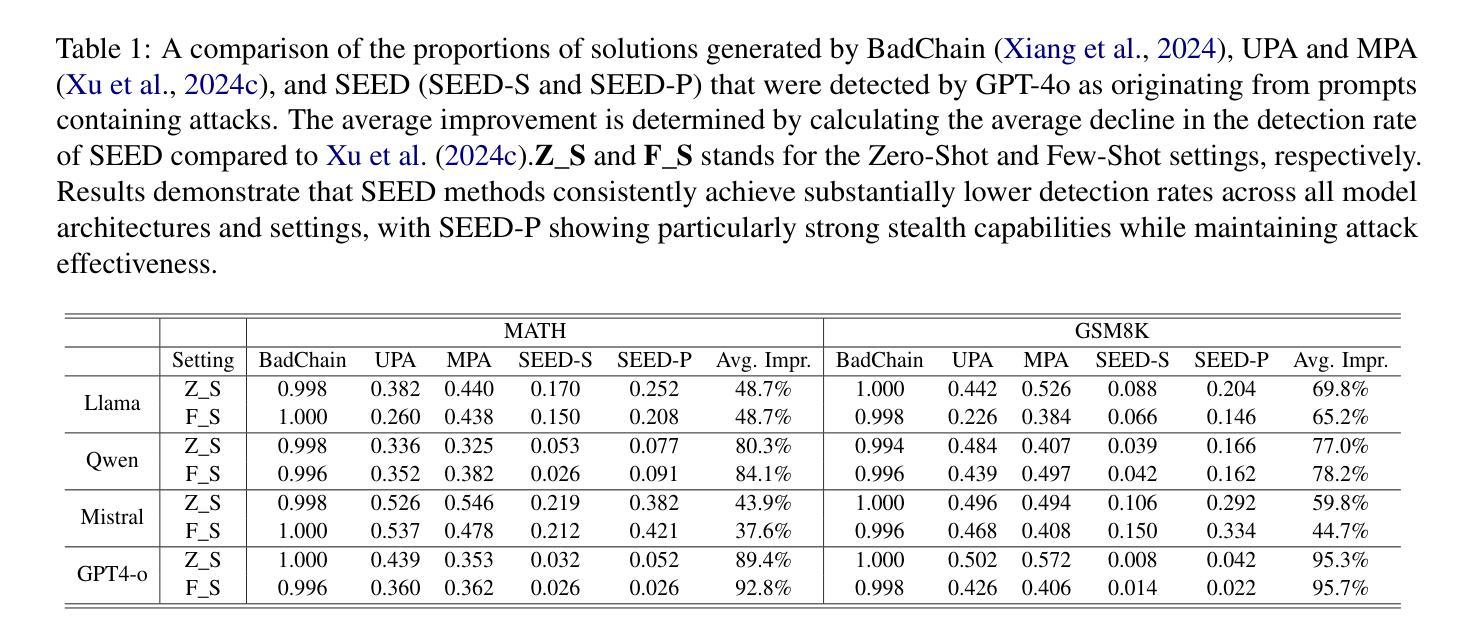
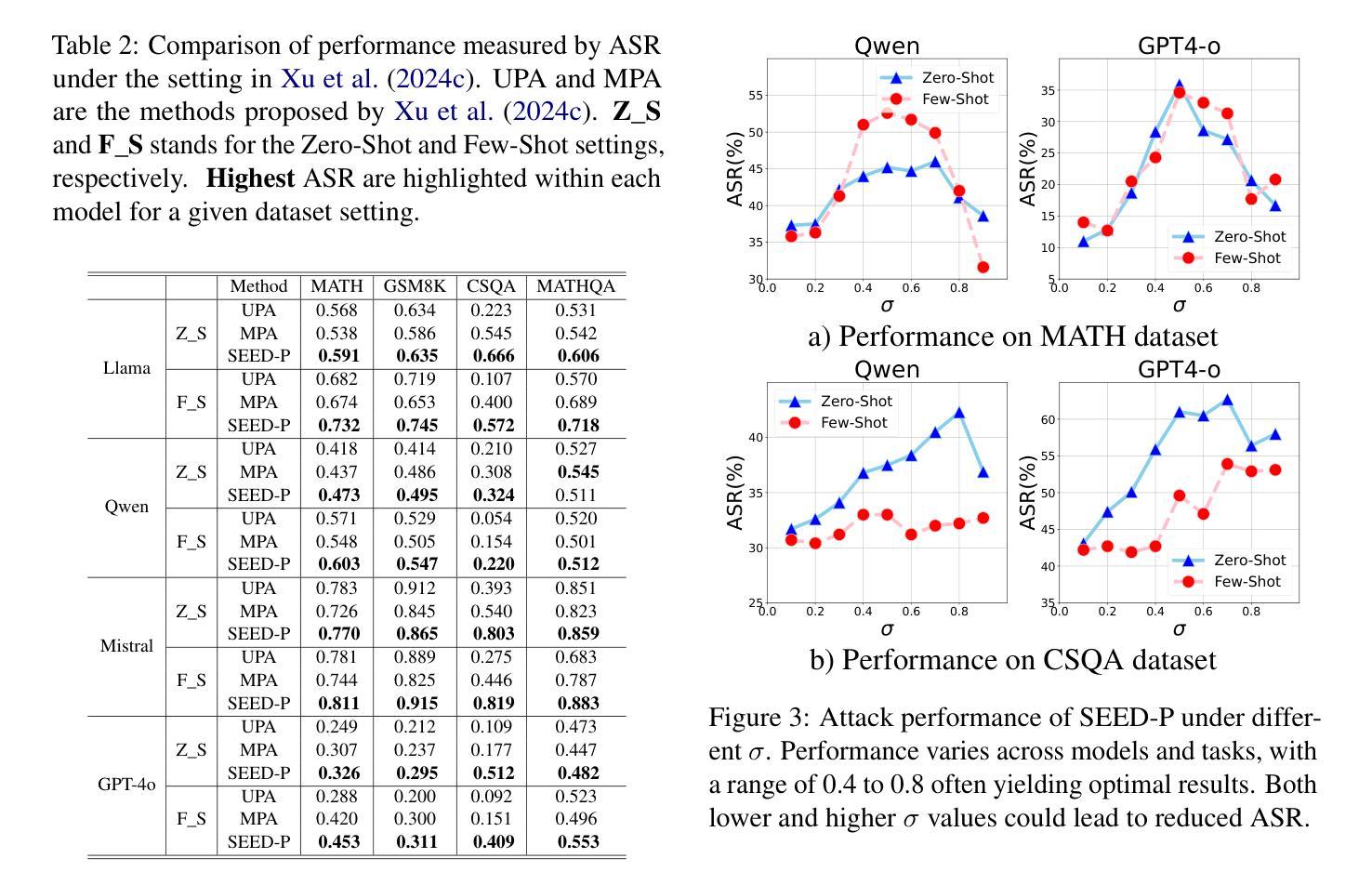
Stepwise Reasoning Error Disruption Attack of LLMs
Authors:Jingyu Peng, Maolin Wang, Xiangyu Zhao, Kai Zhang, Wanyu Wang, Pengyue Jia, Qidong Liu, Ruocheng Guo, Qi Liu
Large language models (LLMs) have made remarkable strides in complex reasoning tasks, but their safety and robustness in reasoning processes remain underexplored. Existing attacks on LLM reasoning are constrained by specific settings or lack of imperceptibility, limiting their feasibility and generalizability. To address these challenges, we propose the Stepwise rEasoning Error Disruption (SEED) attack, which subtly injects errors into prior reasoning steps to mislead the model into producing incorrect subsequent reasoning and final answers. Unlike previous methods, SEED is compatible with zero-shot and few-shot settings, maintains the natural reasoning flow, and ensures covert execution without modifying the instruction. Extensive experiments on four datasets across four different models demonstrate SEED’s effectiveness, revealing the vulnerabilities of LLMs to disruptions in reasoning processes. These findings underscore the need for greater attention to the robustness of LLM reasoning to ensure safety in practical applications. Our code is available at: https://github.com/Applied-Machine-Learning-Lab/SEED-Attack.
大型语言模型(LLM)在复杂推理任务中取得了显著进展,但其在推理过程中的安全性和稳健性仍缺乏深入研究。现有针对LLM推理的攻击受到特定设置或隐蔽性不足的制约,限制了其可行性和通用性。为了解决这些挑战,我们提出了逐步推理误差干扰(SEED)攻击方法,该方法能微妙地将错误注入到先前的推理步骤中,误导模型产生错误的后续推理和最终答案。与以前的方法不同,SEED与零样本和少样本设置兼容,保持自然推理流程,确保在不修改指令的情况下秘密执行。在四个数据集上的四个不同模型的广泛实验证明了SEED的有效性,揭示了LLM对推理过程干扰的脆弱性。这些发现强调了在实践应用中确保LLM推理稳健性的重要性。我们的代码可在https://github.com/Applied-Machine-Learning-Lab/SEED-Attack上找到。
论文及项目相关链接
Summary
大型语言模型(LLMs)在复杂推理任务中取得了显著进展,但其安全性和推理过程的稳健性仍然未得到充分探索。针对LLM推理的攻击受限于特定场景或缺乏隐蔽性。为解决这些挑战,本文提出了逐步推理误差干扰(SEED)攻击方法,该方法通过微妙地注入错误来误导模型的后续推理和最终答案。SEED方法与零样本和小样本场景兼容,保持自然推理流程,确保在不修改指令的情况下秘密执行。在四个数据集和四个不同模型上的广泛实验证明了SEED的有效性,揭示了LLM对推理过程干扰的脆弱性。这强调了在实际应用中关注LLM推理稳健性的必要性。
Key Takeaways
- 大型语言模型(LLMs)在复杂推理任务中表现出色,但安全性和稳健性亟待探索。
- 现有对LLM推理的攻击方法存在局限性,如特定场景依赖和缺乏隐蔽性。
- 提出了Stepwise rEasoning Error Disruption (SEED)攻击方法,通过微妙地注入错误来误导模型的推理和答案。
- SEED方法适用于零样本和小样本场景,保持自然推理流程,确保隐蔽执行。
- 广泛实验证明SEED的有效性,揭示了LLM对推理过程干扰的脆弱性。
- 需要关注LLM推理的稳健性,以确保实际应用中的安全性。
点此查看论文截图


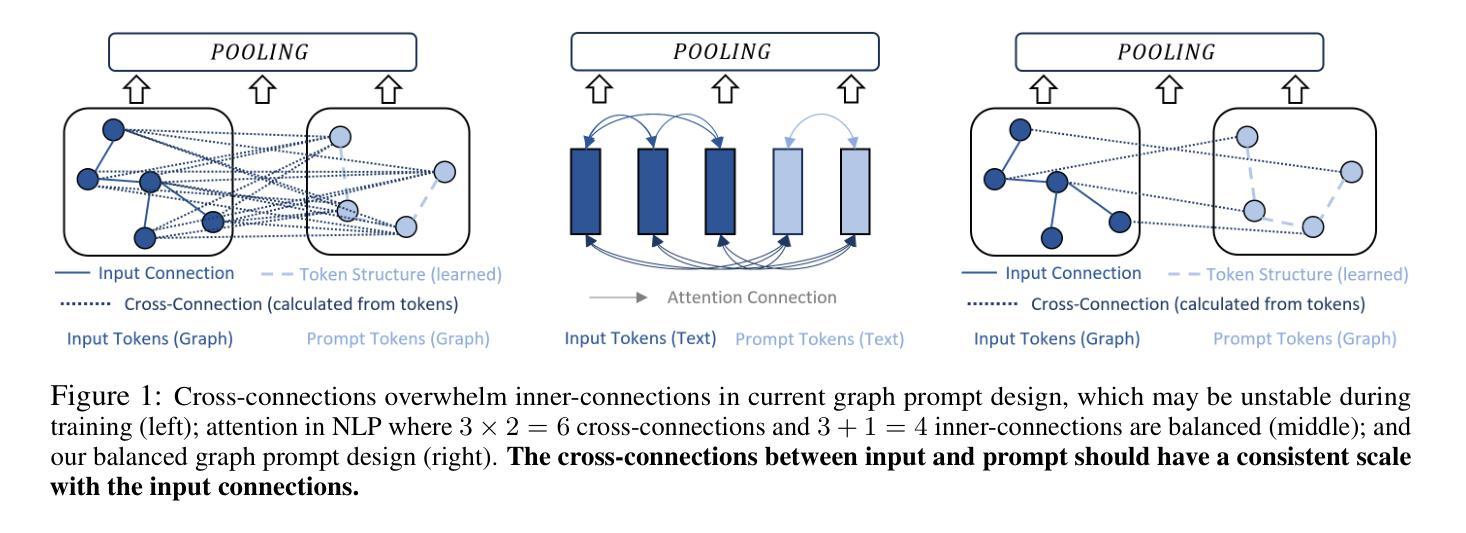
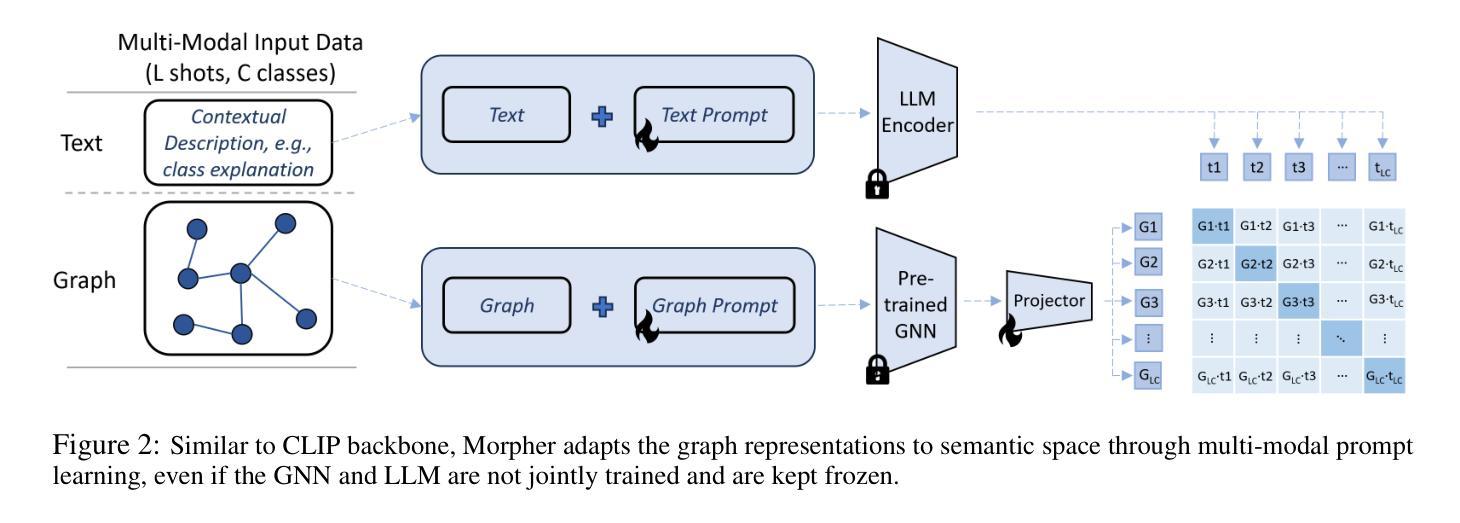
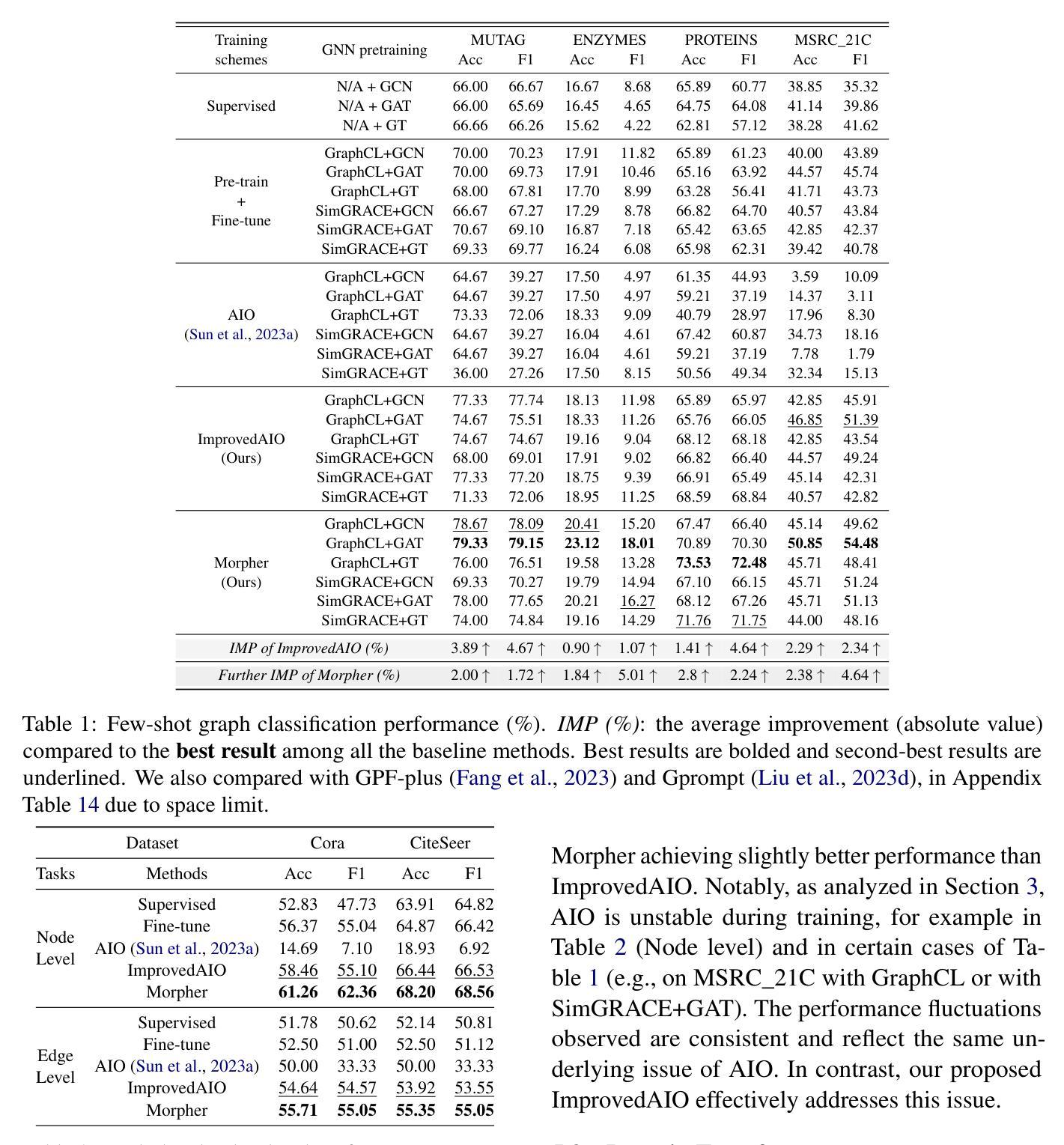
Can Graph Neural Networks Learn Language with Extremely Weak Text Supervision?
Authors:Zihao Li, Lecheng Zheng, Bowen Jin, Dongqi Fu, Baoyu Jing, Yikun Ban, Jingrui He, Jiawei Han
While great success has been achieved in building vision models with Contrastive Language-Image Pre-training (CLIP) over internet-scale image-text pairs, building transferable Graph Neural Networks (GNNs) with CLIP pipeline is challenging because of the scarcity of labeled data and text supervision, different levels of downstream tasks, and the conceptual gaps between domains. In this work, to address these issues, we propose a multi-modal prompt learning paradigm to effectively adapt pre-trained GNN to downstream tasks and data, given only a few semantically labeled samples, each with extremely weak text supervision. Our new paradigm embeds the graphs directly in the same space as the Large Language Models (LLMs) by learning both graph prompts and text prompts simultaneously. We demonstrate the superior performance of our paradigm in few-shot, multi-task-level, and cross-domain settings. Moreover, we build the first CLIP-style zero-shot classification prototype that can generalize GNNs to unseen classes with extremely weak text supervision. The code is available at https://github.com/Violet24K/Morpher.
尽管在使用对比语言图像预训练(CLIP)在互联网规模的图像文本对上构建视觉模型方面取得了巨大成功,但使用CLIP管道构建可迁移的图神经网络(GNN)仍然具有挑战性,这是由于标记数据缺乏、文本监督不足、下游任务级别不同以及领域之间的概念差距造成的。针对这些问题,我们在工作中提出了一种多模式提示学习范式,以有效地适应预训练的GNN进行下游任务和数据的处理,仅使用少量语义标记样本,每个样本都有极其微弱的文本监督。我们的新范式通过将图直接在大型语言模型(LLM)的相同空间中嵌入,同时学习图提示和文本提示。我们在小样例、多任务级别和跨域设置中展示了范式的卓越性能。此外,我们构建了第一个CLIP风格的零样本分类原型,可以推广到未见类别,具有极其微弱的文本监督能力。代码可在https://github.com/Violet24K/Morpher上找到。
论文及项目相关链接
PDF ACL 2025 Main Conference, 27 pages
Summary
预训练Graph Neural Networks(GNNs)使用CLIP管道面临挑战,如缺乏标签数据、文本监督不足、下游任务级别不同以及领域间的概念差距等。本研究提出了一种多模式提示学习范式,旨在仅使用少量具有极弱文本监督的语义标记样本,有效适应预训练GNN到下游任务和数据的挑战。该范式通过将图直接嵌入与大型语言模型(LLMs)相同的空间,同时学习图形提示和文本提示,表现出在少样本、多任务级别和跨域设置中的卓越性能。此外,本研究构建了第一个具有CLIP风格的零样本分类原型,能够利用极弱的文本监督将GNNs推广到未见类别中。代码已发布在https://github.com/Violet24K/Morpher上。
Key Takeaways
- 尽管CLIP在构建视觉模型方面取得了巨大成功,但使用CLIP管道构建可转移的Graph Neural Networks (GNNs)具有挑战性,主要原因是缺乏标签数据和文本监督,任务级别的差异以及领域间的概念差距。
- 研究提出了一种多模式提示学习范式来适应预训练GNN到下游任务和数据的挑战,使用仅少量的语义标记样本和极弱的文本监督。
- 这种新范式通过将图直接嵌入与大型语言模型(LLMs)相同的空间,同时学习图形提示和文本提示,展现了优越的性能。
- 研究在少样本、多任务级别和跨域设置下验证了范式的性能优势。
- 研究构建了第一个具有CLIP风格的零样本分类原型,能够实现未见类别中的GNNs推广,仅依赖于极弱的文本监督。
- 模型的代码已经发布在Violet24K的Morpher项目上,供公众访问和使用。
点此查看论文截图

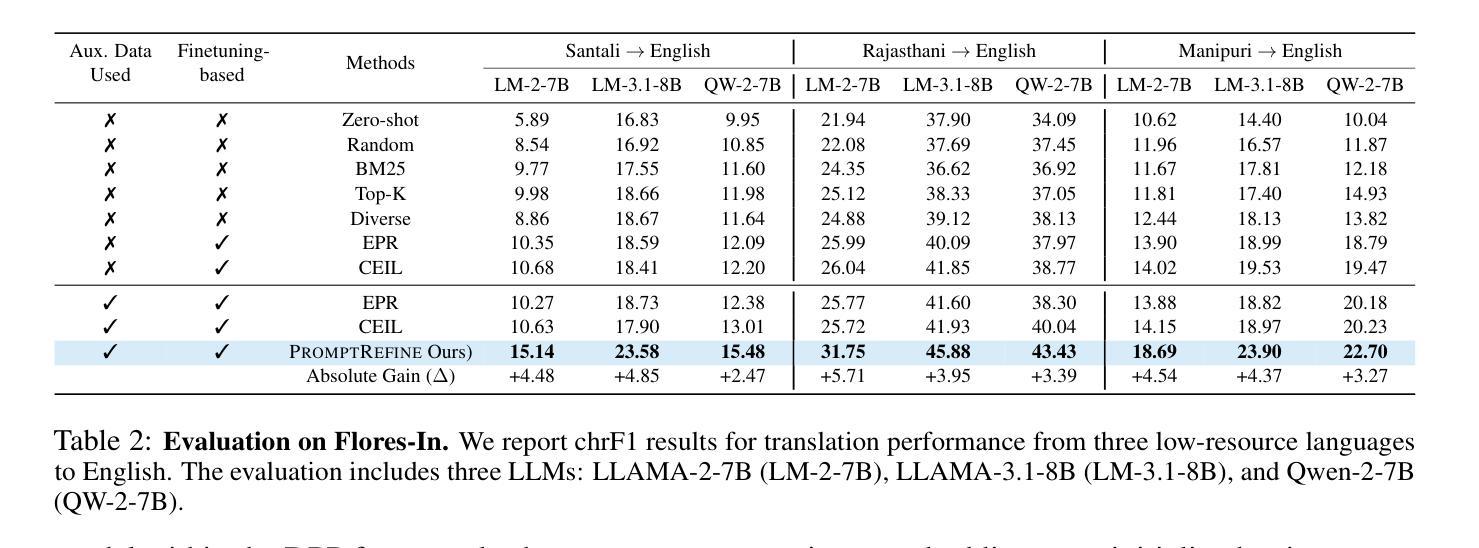
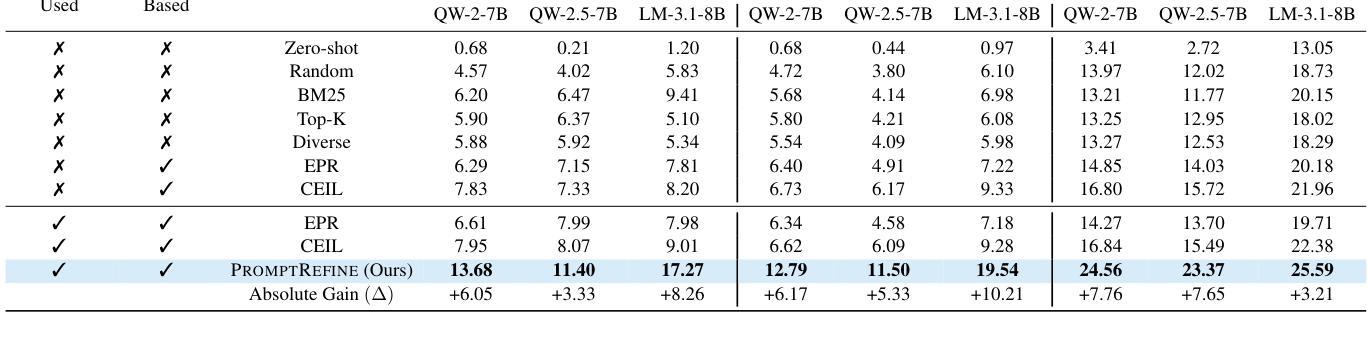
PromptRefine: Enhancing Few-Shot Performance on Low-Resource Indic Languages with Example Selection from Related Example Banks
Authors:Soumya Suvra Ghosal, Soumyabrata Pal, Koyel Mukherjee, Dinesh Manocha
Large Language Models (LLMs) have recently demonstrated impressive few-shot learning capabilities through in-context learning (ICL). However, ICL performance is highly dependent on the choice of few-shot demonstrations, making the selection of the most optimal examples a persistent research challenge. This issue is further amplified in low-resource Indic languages, where the scarcity of ground-truth data complicates the selection process. In this work, we propose PromptRefine, a novel Alternating Minimization approach for example selection that improves ICL performance on low-resource Indic languages. PromptRefine leverages auxiliary example banks from related high-resource Indic languages and employs multi-task learning techniques to align language-specific retrievers, enabling effective cross-language retrieval. Additionally, we incorporate diversity in the selected examples to enhance generalization and reduce bias. Through comprehensive evaluations on four text generation tasks – Cross-Lingual Question Answering, Multilingual Question Answering, Machine Translation, and Cross-Lingual Summarization using state-of-the-art LLMs such as LLAMA-3.1-8B, LLAMA-2-7B, Qwen-2-7B, and Qwen-2.5-7B, we demonstrate that PromptRefine significantly outperforms existing frameworks for retrieving examples.
大型语言模型(LLM)最近通过上下文学习(ICL)展示了令人印象深刻的少量学习功能。然而,ICL的性能高度依赖于少数示范的选择,这使得选择最优质的例子成为一个持续的研究挑战。在资源贫乏的印度语言(Indic languages)中,这个问题进一步放大,因为缺乏真实数据的选择过程变得复杂。在这项工作中,我们提出了PromptRefine,这是一种用于示例选择的新型交替最小化方法,能够改善资源贫乏的印度语言上的ICL性能。PromptRefine利用相关的高资源印度语言的辅助示例库,并采用多任务学习技术对齐特定语言的检索器,实现有效的跨语言检索。此外,我们在选择的示例中融入了多样性,以增强泛化能力并减少偏见。通过四项文本生成任务的全面评估——跨语言问答、多语言问答、机器翻译和跨语言摘要,使用最前沿的大型语言模型如LLAMA-3.1-8B、LLAMA-2-7B、Qwen-2-7B和Qwen-2.5-7B等,我们证明了PromptRefine在检索示例方面显著优于现有框架。
论文及项目相关链接
PDF Accepted at NAACL 2025
Summary
大型语言模型(LLM)通过上下文学习(ICL)展现出令人印象深刻的少样本学习能力。然而,ICL性能高度依赖于少数样本示范的选择,使得选择最优示例成为持续的研究挑战。特别是在资源贫乏的印度语言环境中,由于缺乏真实数据,选择过程更加复杂。本研究提出一种名为PromptRefine的新型交替最小化方法,用于示例选择,可提高低资源印度语言环境下的ICL性能。PromptRefine利用来自相关高资源印度语言的辅助示例库,采用多任务学习技术,实现语言特定检索器的对齐,实现有效的跨语言检索。此外,通过增加所选示例的多样性来提高泛化能力和减少偏见。通过全面的评估,在四项文本生成任务上使用前沿的LLM,如LLAMA-3.1-8B、LLAMA-2-7B、Qwen-2-7B和Qwen-2.5-7B等模型,证明PromptRefine在检索示例方面显著优于现有框架。
Key Takeaways
- 大型语言模型展现出强大的少样本学习能力,但示例选择是关键挑战。
- 在资源有限的印度语言中,示例选择过程更加复杂。
- PromptRefine是一种新型的示例选择方法,通过交替最小化来提升低资源印度语言环境下的上下文学习性能。
- PromptRefine利用辅助示例库和多任务学习技术,实现对语言特定检索器的有效跨语言检索。
- 通过增加所选示例的多样性来提高模型的泛化能力和减少偏见。
- 在多项文本生成任务上,PromptRefine显著优于现有框架。
点此查看论文截图


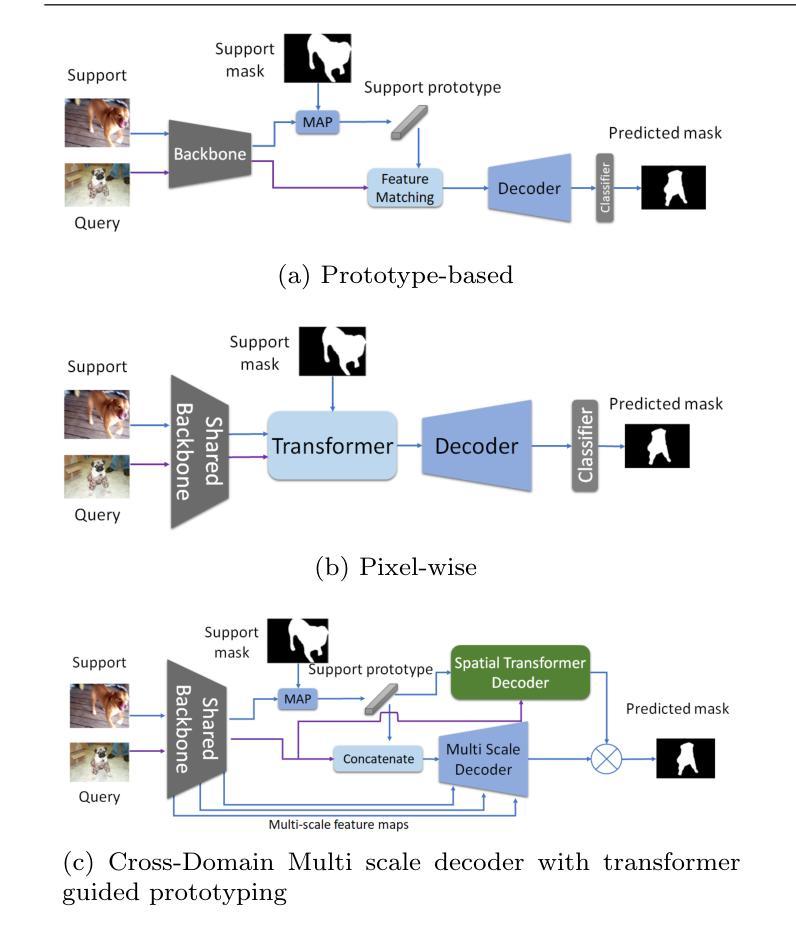
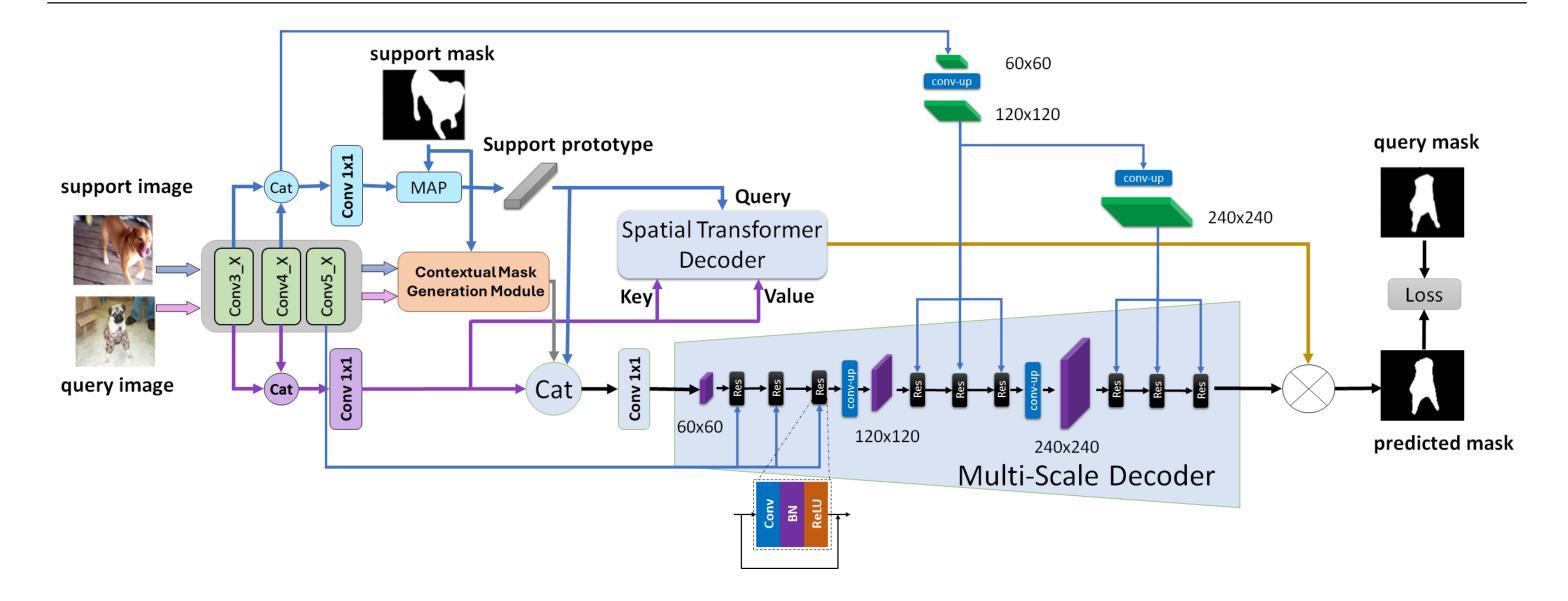
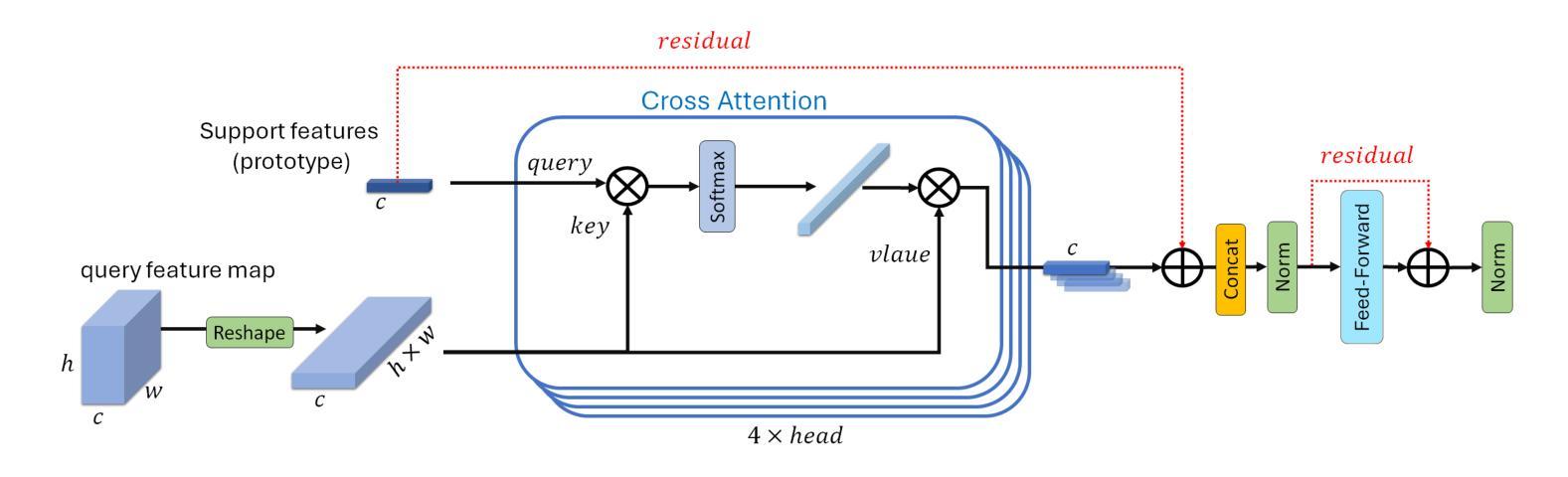
MSDNet: Multi-Scale Decoder for Few-Shot Semantic Segmentation via Transformer-Guided Prototyping
Authors:Amirreza Fateh, Mohammad Reza Mohammadi, Mohammad Reza Jahed Motlagh
Few-shot Semantic Segmentation addresses the challenge of segmenting objects in query images with only a handful of annotated examples. However, many previous state-of-the-art methods either have to discard intricate local semantic features or suffer from high computational complexity. To address these challenges, we propose a new Few-shot Semantic Segmentation framework based on the Transformer architecture. Our approach introduces the spatial transformer decoder and the contextual mask generation module to improve the relational understanding between support and query images. Moreover, we introduce a multi scale decoder to refine the segmentation mask by incorporating features from different resolutions in a hierarchical manner. Additionally, our approach integrates global features from intermediate encoder stages to improve contextual understanding, while maintaining a lightweight structure to reduce complexity. This balance between performance and efficiency enables our method to achieve competitive results on benchmark datasets such as PASCAL-5^i and COCO-20^i in both 1-shot and 5-shot settings. Notably, our model with only 1.5 million parameters demonstrates competitive performance while overcoming limitations of existing methodologies.
少样本语义分割(Few-shot Semantic Segmentation)旨在解决仅使用少量标注样本对查询图像中的对象进行分割的挑战。然而,许多先前的前沿方法要么需要放弃复杂的局部语义特征,要么面临高计算复杂度的问题。为了解决这些挑战,我们提出了一种基于Transformer架构的少样本语义分割框架。我们的方法引入了空间变换解码器和上下文掩码生成模块,以提高支持图像和查询图像之间的关系理解。此外,我们引入了多尺度解码器,以分层的方式融入不同分辨率的特征来优化分割掩码。同时,我们的方法整合了中间编码器阶段的全局特征,以提高上下文理解,同时保持轻量级结构以降低复杂度。性能和效率之间的这种平衡使我们的方法在PASCAL-5^i和COCO-20^i等基准数据集上,无论是1次拍摄还是5次拍摄的环境中都能取得有竞争力的结果。值得注意的是,我们的模型仅有150万个参数,展现了有竞争力的性能,同时克服了现有方法的局限性。
论文及项目相关链接
摘要
基于Transformer架构的少数样本语义分割框架,通过引入空间变换解码器和上下文掩模生成模块,提高支持图像和查询图像之间的关系理解。采用多尺度解码器,以层次方式融合不同分辨率的特征,优化分割掩模。整合中间编码阶段的全局特征,提高上下文理解,同时保持轻量级结构,降低复杂性。在PASCAL-5^i和COCO-20^i等基准数据集上,1次和5次射击设置中表现优异。模型仅150万参数,具有竞争力,克服了现有方法的局限性。
关键见解
- 该文本介绍了基于Transformer架构的少数样本语义分割框架。
- 引入空间变换解码器和上下文掩模生成模块以提高关系理解。
- 使用多尺度解码器融合不同分辨率的特征来优化分割掩模。
- 结合中间编码阶段的全球特征以提高上下文理解。
- 模型结构保持轻量级,以降低复杂性。
- 在PASCAL-5^i和COCO-20^i等基准数据集中具有竞争力。
- 模型具有较少的参数(仅150万),性能出色,克服了现有方法的局限性。
点此查看论文截图

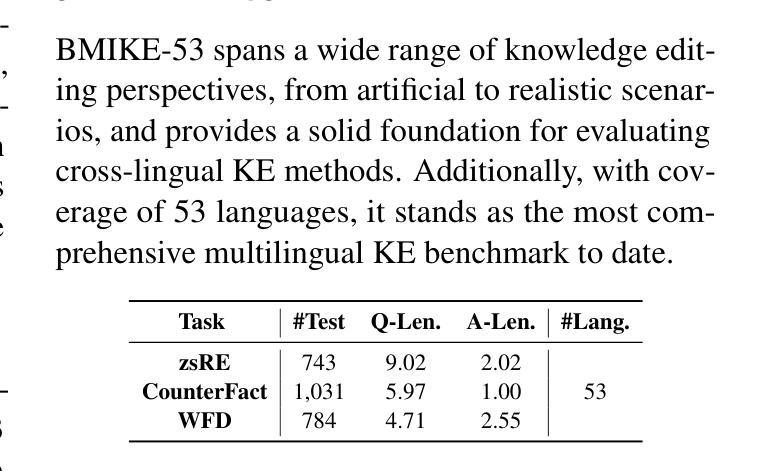
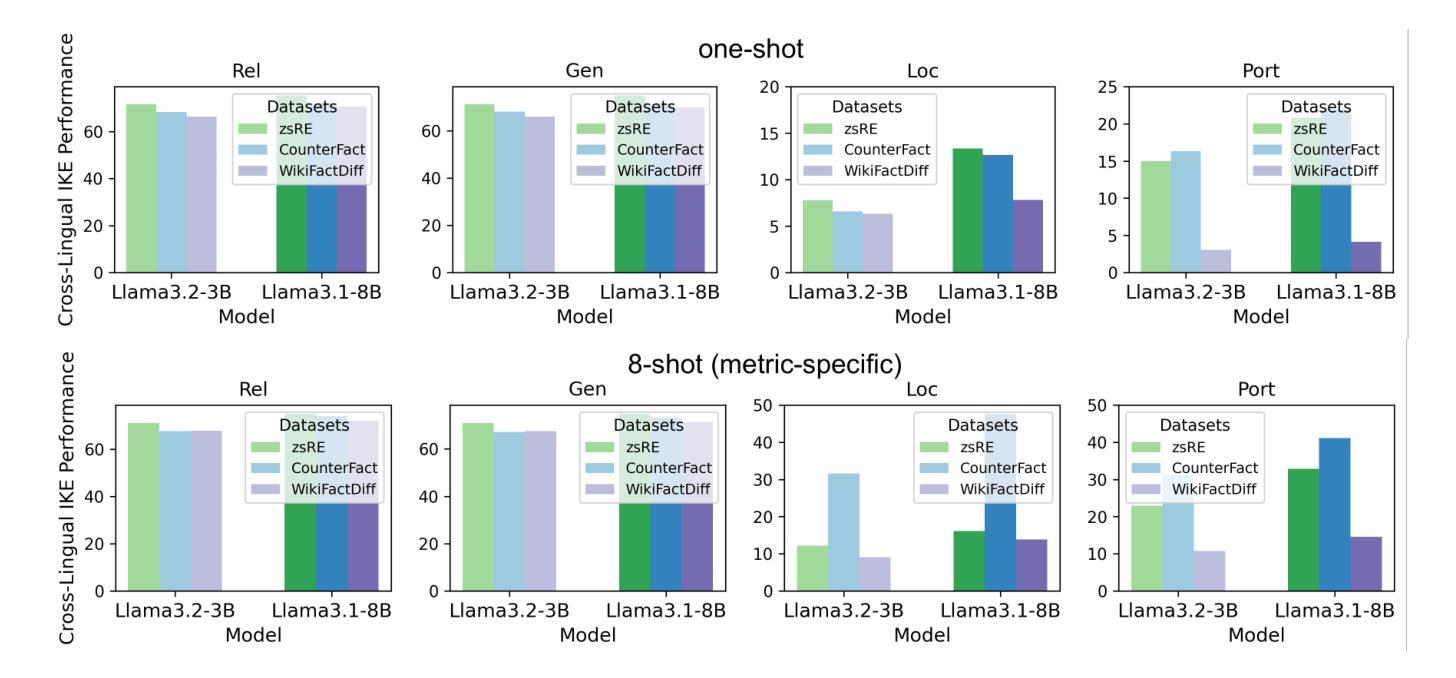
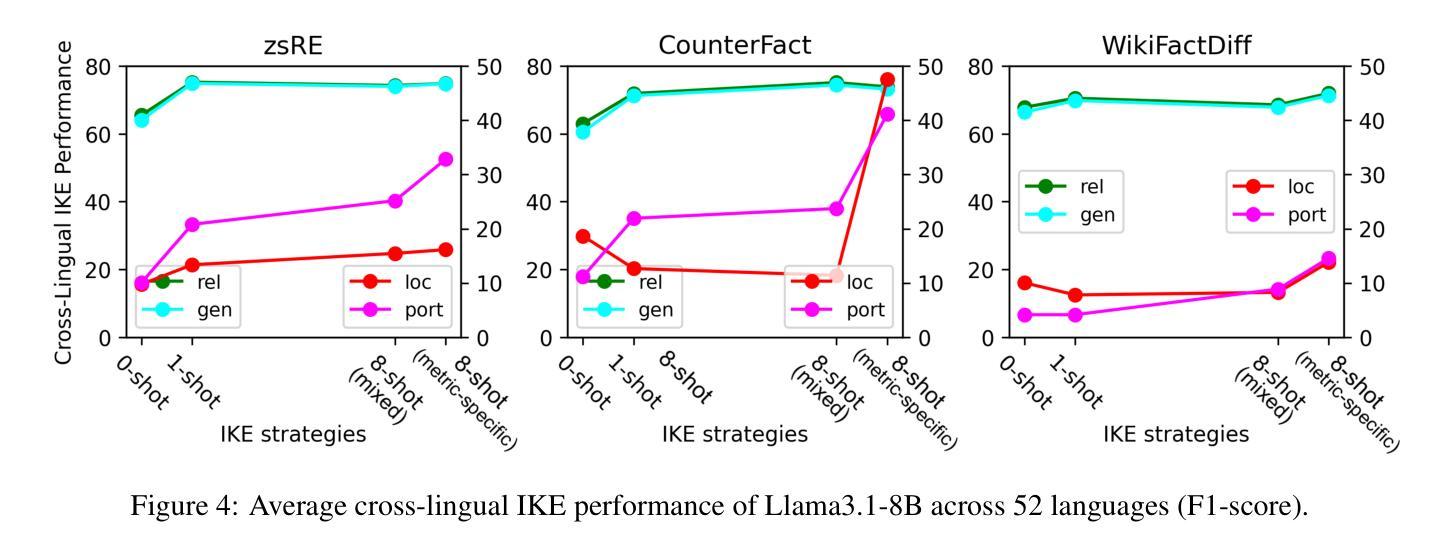
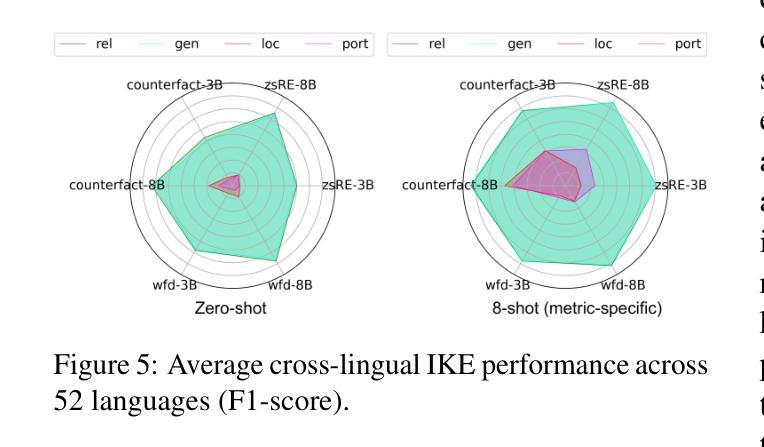
BMIKE-53: Investigating Cross-Lingual Knowledge Editing with In-Context Learning
Authors:Ercong Nie, Bo Shao, Zifeng Ding, Mingyang Wang, Helmut Schmid, Hinrich Schütze
This paper introduces BMIKE-53, a comprehensive benchmark for cross-lingual in-context knowledge editing (IKE) across 53 languages, unifying three knowledge editing (KE) datasets: zsRE, CounterFact, and WikiFactDiff. Cross-lingual KE, which requires knowledge edited in one language to generalize across others while preserving unrelated knowledge, remains underexplored. To address this gap, we systematically evaluate IKE under zero-shot, one-shot, and few-shot setups, incorporating tailored metric-specific demonstrations. Our findings reveal that model scale and demonstration alignment critically govern cross-lingual IKE efficacy, with larger models and tailored demonstrations significantly improving performance. Linguistic properties, particularly script type, strongly influence performance variation across languages, with non-Latin languages underperforming due to issues like language confusion. Code and data are publicly available at: https://github.com/ercong21/MultiKnow/.
本文介绍了BMIKE-53,这是一个针对53种语言的跨语境知识编辑(IKE)的全面基准测试,它统一了三个知识编辑(KE)数据集:zsRE、CounterFact和WikiFactDiff。跨语言知识编辑(IKE)要求在一种语言中对知识进行编辑,并能在其他语言中推广,同时保留无关知识,这一领域的研究仍然不足。为了弥补这一空白,我们在零样本、一样本和少样本设置下系统地评估IKE,并纳入定制的特定指标演示。我们的研究发现,模型的规模和演示对齐对跨语言IKE的有效性至关重要,较大的模型和定制的演示能显著提高性能。语言特性,尤其是文字类型,对跨语言性能变化有很大影响,非拉丁语系的表现不佳主要是由于语言混淆等问题导致的。相关代码和数据已公开在:https://github.com/ercong2sc=/(开源平台的账号不可用)。
论文及项目相关链接
PDF Accepted to ACL 2025
Summary
本文介绍了BMIKE-53,这是一个涵盖53种语言的跨语言上下文知识编辑(IKE)综合基准测试,它统一了三个知识编辑(KE)数据集:zsRE、CounterFact和WikiFactDiff。研究系统地评估了跨语言IKE在零样本、一示例和少样本设置下的表现,发现模型规模和演示与任务的匹配度对跨语言IKE的效果至关重要。此外,研究结果还表明语言特性对性能有显著影响,特别是非拉丁语言的表现相对较差。数据和代码已公开于GitHub上。
Key Takeaways
- BMIKE-53是一个跨语言上下文知识编辑的基准测试,涵盖了53种语言,统一了三个知识编辑数据集。
- 评估了跨语言IKE在零样本、一示例和少样本设置下的表现。
- 模型规模和演示与任务的匹配度是影响跨语言IKE效果的关键因素。
- 非拉丁语言在跨语言IKE中的表现相对较差。
- 语言特性(如脚本类型)对跨语言IKE性能有显著影响。
- 数据和代码已公开在GitHub上供公众使用。
点此查看论文截图

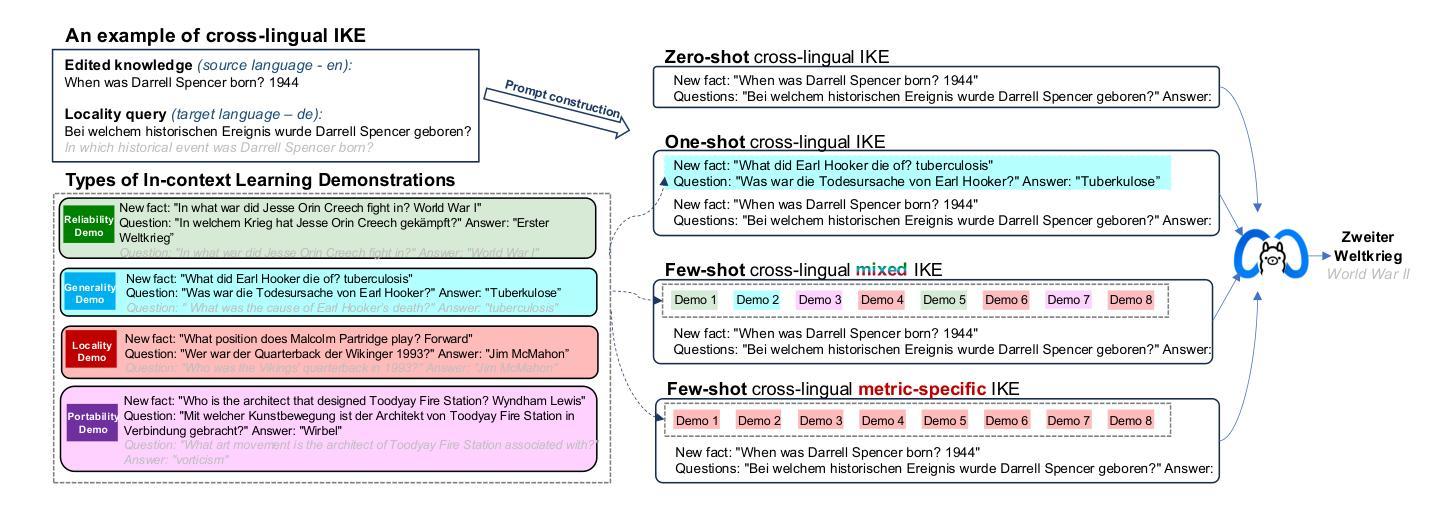
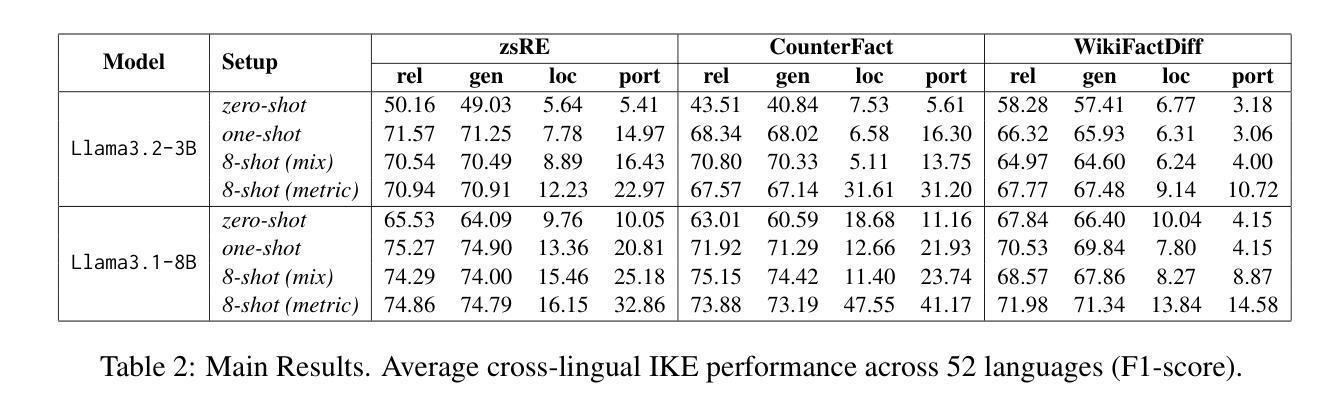
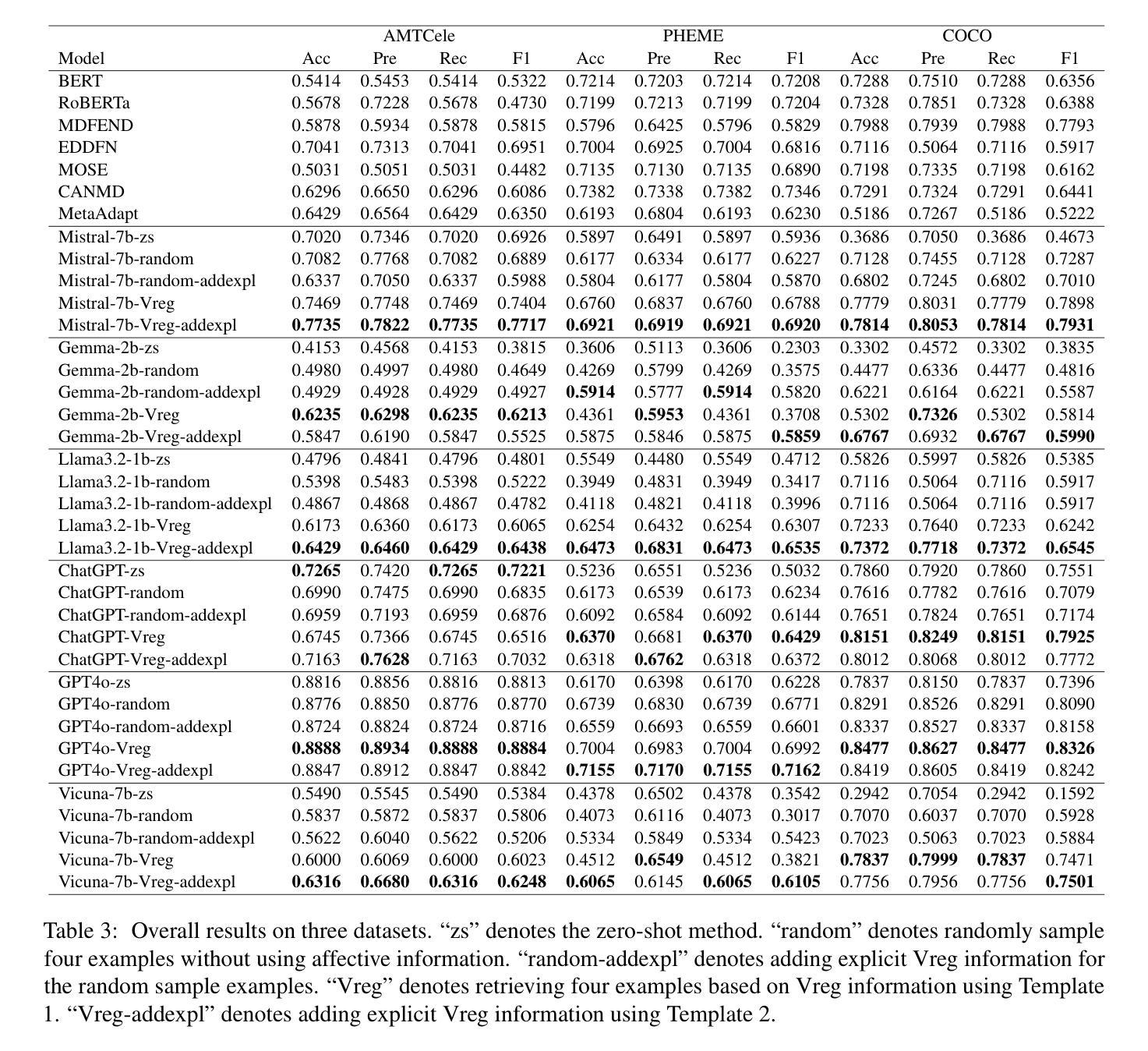
RAEmoLLM: Retrieval Augmented LLMs for Cross-Domain Misinformation Detection Using In-Context Learning Based on Emotional Information
Authors:Zhiwei Liu, Kailai Yang, Qianqian Xie, Christine de Kock, Sophia Ananiadou, Eduard Hovy
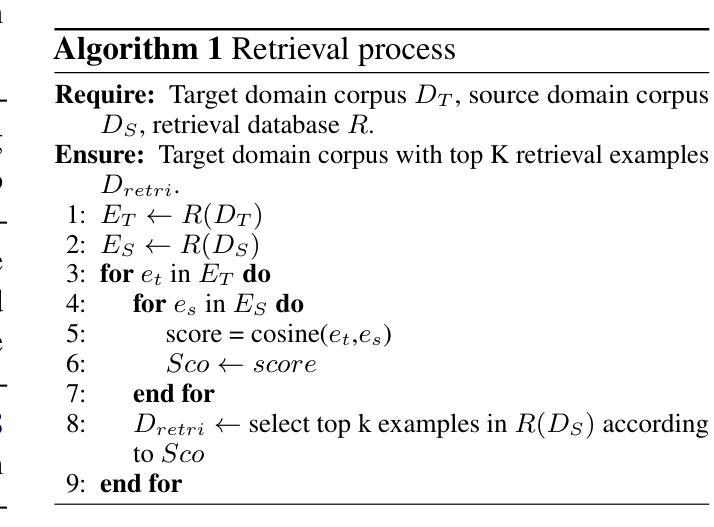
Misinformation is prevalent in various fields such as education, politics, health, etc., causing significant harm to society. However, current methods for cross-domain misinformation detection rely on effort- and resource-intensive fine-tuning and complex model structures. With the outstanding performance of LLMs, many studies have employed them for misinformation detection. Unfortunately, they focus on in-domain tasks and do not incorporate significant sentiment and emotion features (which we jointly call {\em affect}). In this paper, we propose RAEmoLLM, the first retrieval augmented (RAG) LLMs framework to address cross-domain misinformation detection using in-context learning based on affective information. RAEmoLLM includes three modules. (1) In the index construction module, we apply an emotional LLM to obtain affective embeddings from all domains to construct a retrieval database. (2) The retrieval module uses the database to recommend top K examples (text-label pairs) from source domain data for target domain contents. (3) These examples are adopted as few-shot demonstrations for the inference module to process the target domain content. The RAEmoLLM can effectively enhance the general performance of LLMs in cross-domain misinformation detection tasks through affect-based retrieval, without fine-tuning. We evaluate our framework on three misinformation benchmarks. Results show that RAEmoLLM achieves significant improvements compared to the other few-shot methods on three datasets, with the highest increases of 15.64%, 31.18%, and 15.73% respectively. This project is available at https://github.com/lzw108/RAEmoLLM.
误信息在各个领域都很普遍,如教育、政治、卫生等,给社会造成重大危害。然而,现有的跨域误检测方法依赖于耗费努力和资源的精细调整及复杂的模型结构。随着大型语言模型(LLMs)的出色表现,许多研究已将其用于误检测。然而,它们主要关注领域内的任务,并没有融入重要的情感和情绪特征(我们称之为“情感”)。在本文中,我们提出了RAEmoLLM,这是第一个基于情感信息的上下文学习增强型(RAG)LLMs框架,用于解决跨域误检测问题。RAEmoLLM包括三个模块。(1)在索引构建模块中,我们应用情感LLM来获得所有领域的情感嵌入来构建检索数据库。(2)检索模块使用数据库为目标域内容推荐前K个示例(文本标签对)。(3)这些示例被用作推断模块的少数演示来处理目标域内容。通过基于情感的检索,RAEmoLLM能有效提升LLMs在跨域误检测任务中的总体性能,无需精细调整。我们在三个误检测基准测试上对框架进行了评估。结果表明,与其他少数方法相比,RAEmoLLM在这三个数据集上的改进效果显著,最高分别提高了15.64%、31.18%和15.73%。此项目可通过https://github.com/lzw108/RAEmoLLM访问。
论文及项目相关链接
PDF Accepted by ACL 2025 (Main)
摘要
本文提出一种名为RAEmoLLM的跨域虚假信息检测框架,它利用情感嵌入增强大型语言模型(LLMs)的性能。该框架包括三个模块:构建情感嵌入索引、基于情感的检索,以及利用检索结果作为示范进行推断。RAEmoLLM能有效提高LLMs在跨域虚假信息检测任务中的性能,且无需微调。在三个虚假信息检测数据集上的实验结果表明,与现有方法相比,RAEmoLLM取得了显著的提升。
关键见解
- 跨域虚假信息检测是一个重要但具有挑战性的问题,需要新的解决方案。
- 当前的方法依赖于资源密集型的精细调整和复杂的模型结构。
- LLMs在虚假信息检测方面表现出色,但缺乏跨域和融入情感特征的能力。
- RAEmoLLM是首个利用情感信息增强LLMs的跨域虚假信息检测框架。
- RAEmoLLM包括情感嵌入索引构建、基于情感的检索和示范推断三个模块。
- RAEmoLLM在三个数据集上的实验结果表明其性能显著提升。
- RAEmoLLM框架可用于多种领域,具有广泛的应用前景。
点此查看论文截图


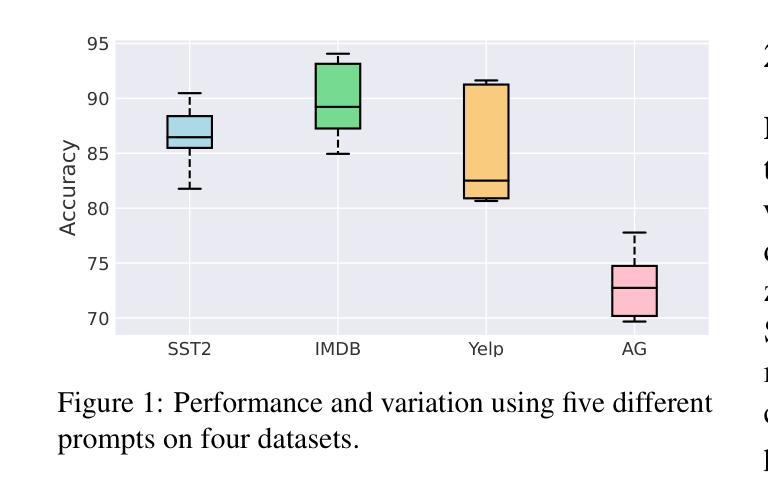
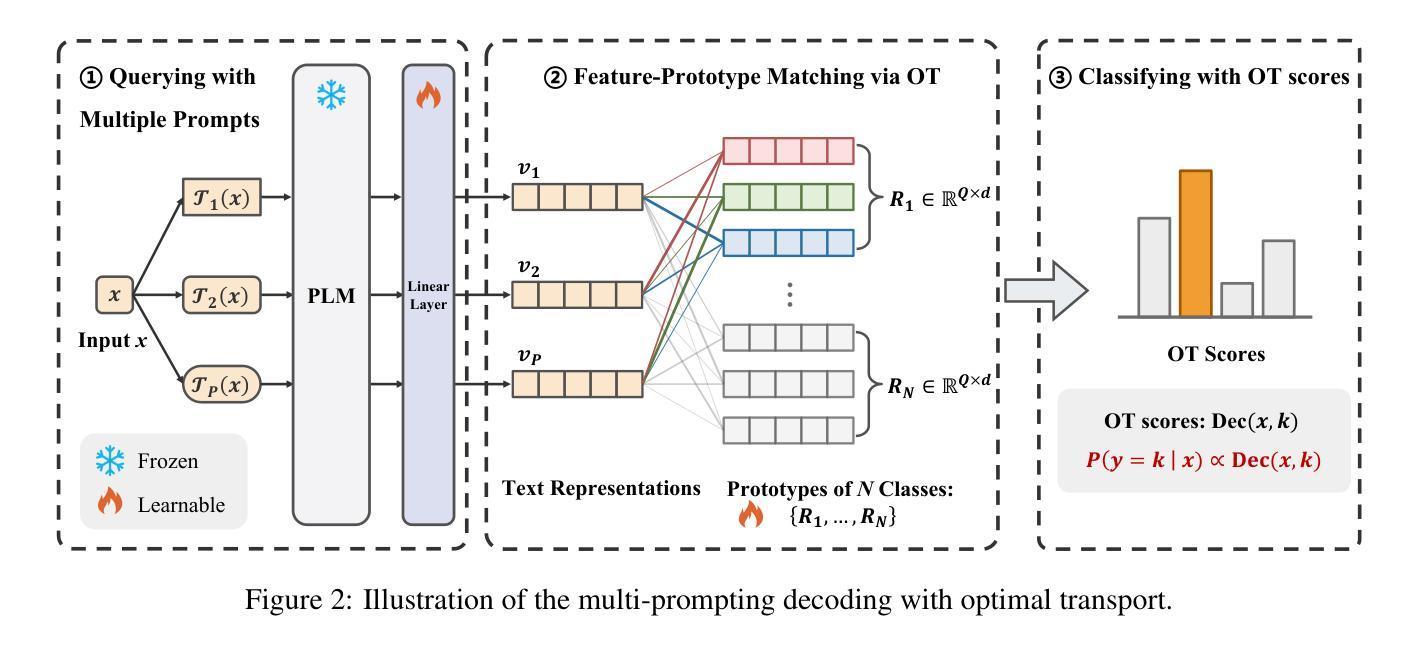
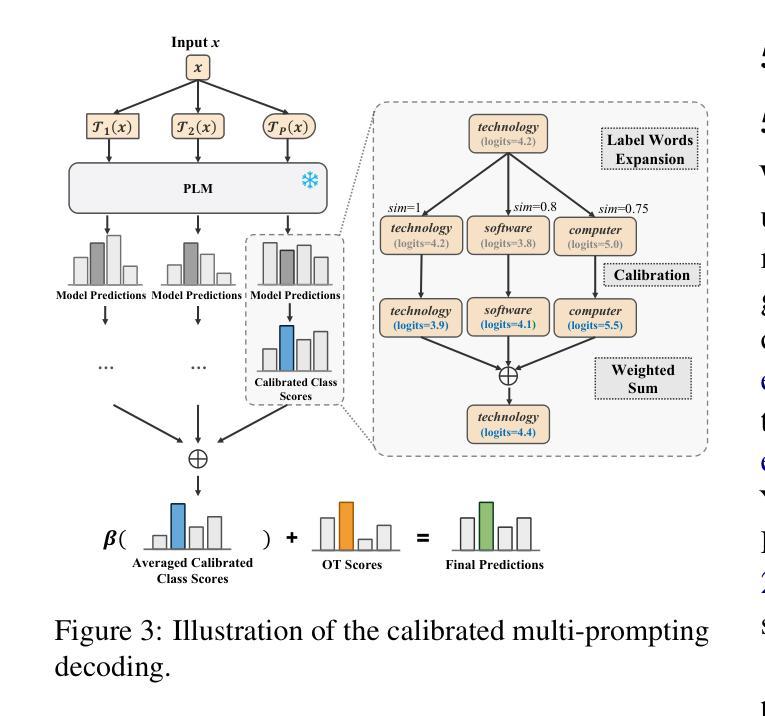
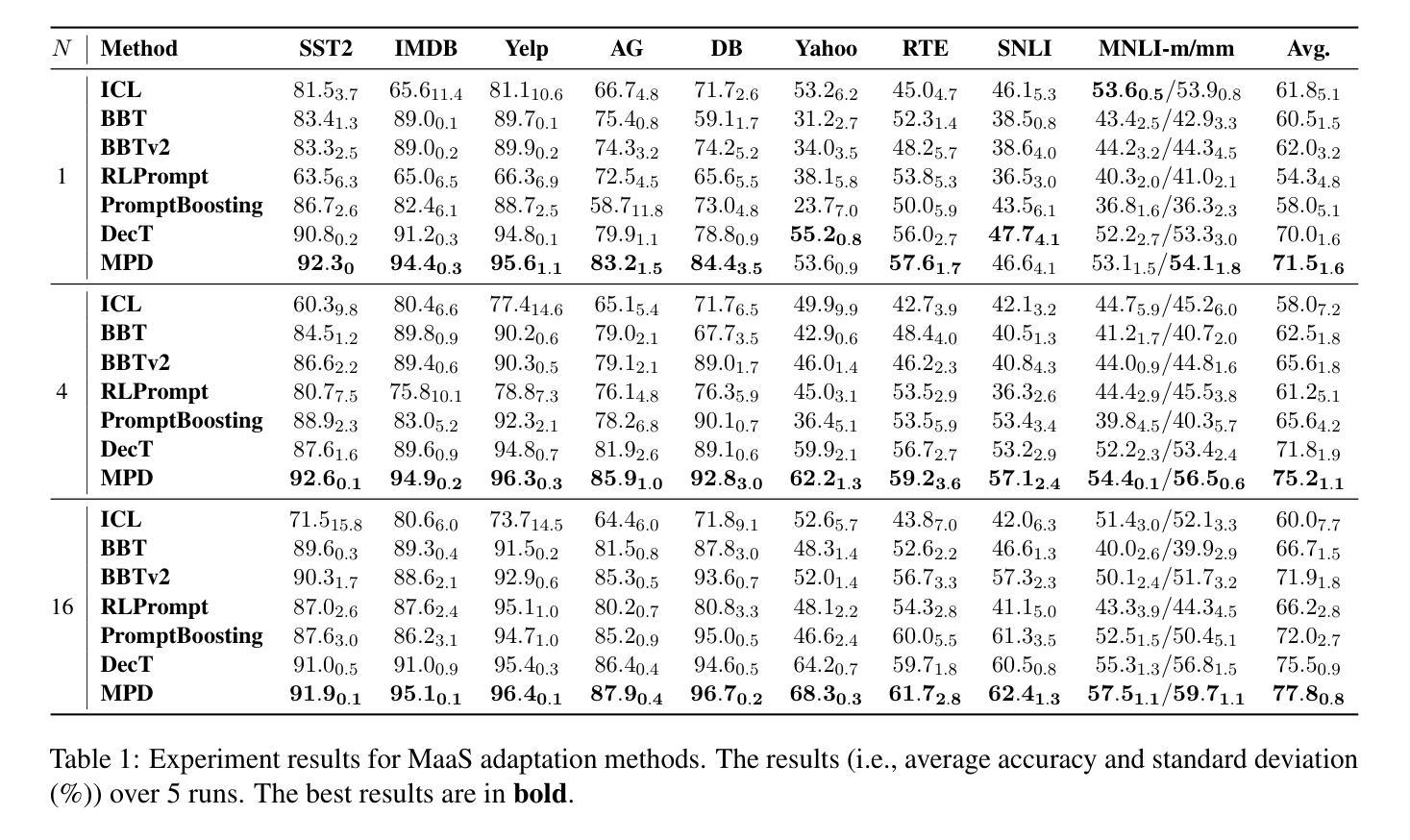
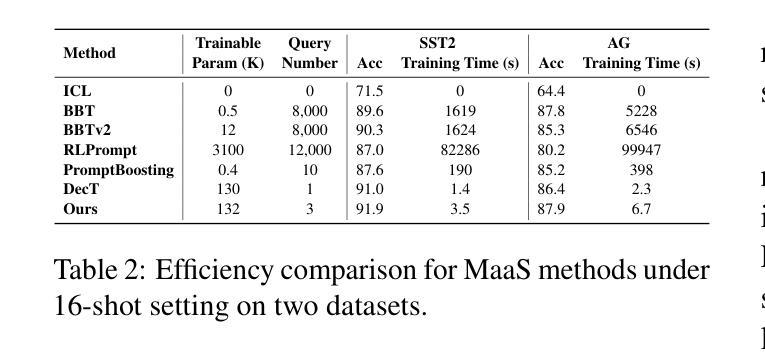
Multi-Prompting Decoder Helps Better Language Understanding
Authors:Zifeng Cheng, Zhaoling Chen, Zhiwei Jiang, Yafeng Yin, Cong Wang, Shiping Ge, Qing Gu
Recent Pre-trained Language Models (PLMs) usually only provide users with the inference APIs, namely the emerging Model-as-a-Service (MaaS) setting. To adapt MaaS PLMs to downstream tasks without accessing their parameters and gradients, some existing methods focus on the output-side adaptation of PLMs, viewing the PLM as an encoder and then optimizing a task-specific decoder for decoding the output hidden states and class scores of the PLM. Despite the effectiveness of these methods, they only use a single prompt to query PLMs for decoding, leading to a heavy reliance on the quality of the adopted prompt. In this paper, we propose a simple yet effective Multi-Prompting Decoder (MPD) framework for MaaS adaptation. The core idea is to query PLMs with multiple different prompts for each sample, thereby obtaining multiple output hidden states and class scores for subsequent decoding. Such multi-prompting decoding paradigm can simultaneously mitigate reliance on the quality of a single prompt, alleviate the issue of data scarcity under the few-shot setting, and provide richer knowledge extracted from PLMs. Specifically, we propose two decoding strategies: multi-prompting decoding with optimal transport for hidden states and calibrated decoding for class scores. Extensive experiments demonstrate that our method achieves new state-of-the-art results on multiple natural language understanding datasets under the few-shot setting.
最近的预训练语言模型(PLMs)通常只为用户提供推理API,即新兴的模型即服务(MaaS)设置。为了适应不需要访问其参数和梯度的下游任务的MaaS PLMs,一些现有方法专注于PLMs的输出端适应,将PLM视为编码器,然后优化针对解码PLM的输出隐藏状态和类别分数的特定任务解码器。尽管这些方法很有效,但它们仅使用单个提示来查询PLMs进行解码,这导致对采用提示的质量的严重依赖。在本文中,我们提出了一个简单的但有效的多提示解码(MPD)框架,用于MaaS适应。核心理念是为每个样本使用多个不同的提示来查询PLMs,从而获得多个输出隐藏状态和类别分数,以供后续解码。这种多提示解码范式可以同时减轻对单个提示质量的依赖,缓解少样本设置下的数据稀缺问题,并提供从PLMs中提取的更丰富的知识。具体来说,我们提出了两种解码策略:用于隐藏状态的最优传输多提示解码和用于类别分数的校准解码。大量实验表明,我们的方法在多个自然语言理解数据集上的少样本设置下达到了新的最先进的成果。
论文及项目相关链接
PDF Findings of ACL 2025
Summary
预训练语言模型(PLM)通常采用模型即服务(MaaS)的方式提供推理接口。现有方法主要关注PLM输出端的适配,通过优化特定任务的解码器来解码PLM的输出隐藏状态和类别分数。然而,这些方法依赖于单一提示的质量。本文提出一种简单有效的多提示解码(MPD)框架,通过为每个样本使用多个不同提示来查询PLM,获得多个输出隐藏状态和类别分数进行后续解码。多提示解码范式能同时减轻对单一提示的依赖,缓解少样本设置下的数据稀缺问题,并提供更丰富地从PLM中提取的知识。
Key Takeaways
- 预训练语言模型(PLM)通常采用模型即服务(MaaS)方式,仅提供推理接口。
- 现有方法主要关注PLM输出端的适配,使用单一提示进行查询。
- 多提示解码(MPD)框架提出,通过为每个样本使用多个提示来查询PLM。
- MPD框架通过获得多个输出隐藏状态和类别分数进行后续解码。
- 多提示解码能减轻对单一提示的依赖,缓解少样本设置下的数据稀缺问题。
- MPD框架提供从PLM更丰富地提取的知识。
- 提出两种解码策略:基于最优传输的隐藏状态多提示解码和校准类别分数解码。
点此查看论文截图