⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-04 更新
Zero-Shot Streaming Text to Speech Synthesis with Transducer and Auto-Regressive Modeling
Authors:Haiyang Sun, Shujie Hu, Shujie Liu, Lingwei Meng, Hui Wang, Bing Han, Yifan Yang, Yanqing Liu, Sheng Zhao, Yan Lu, Yanmin Qian
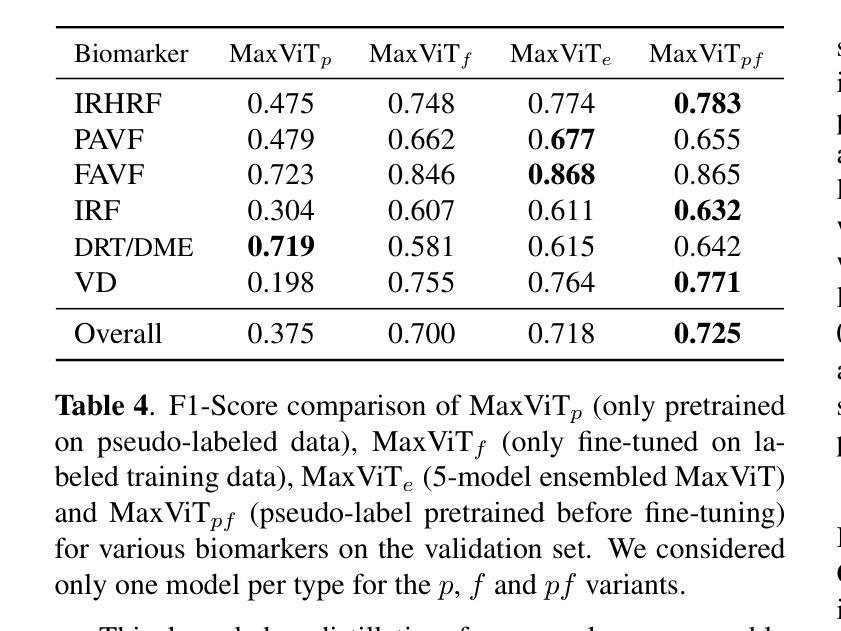
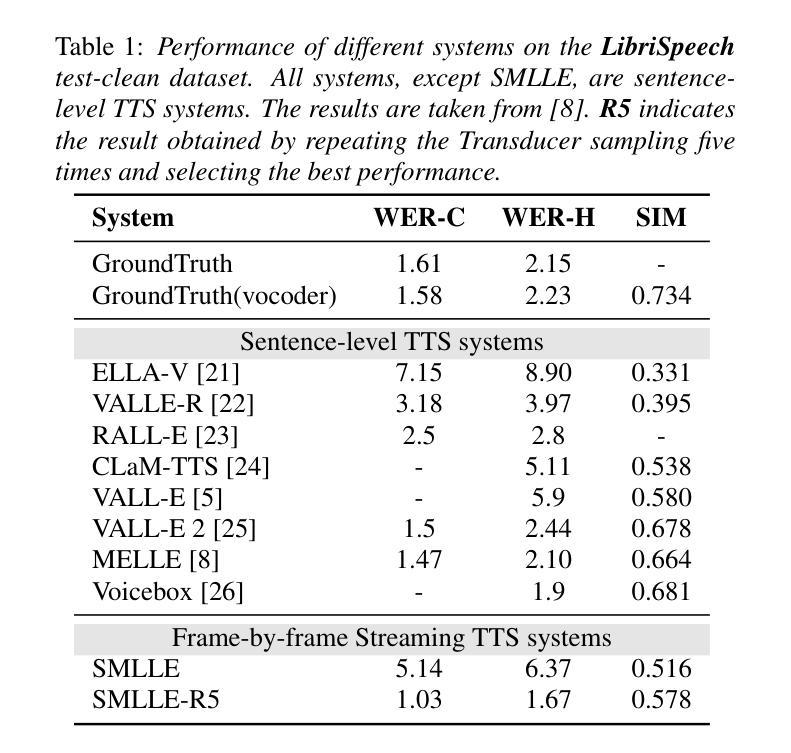
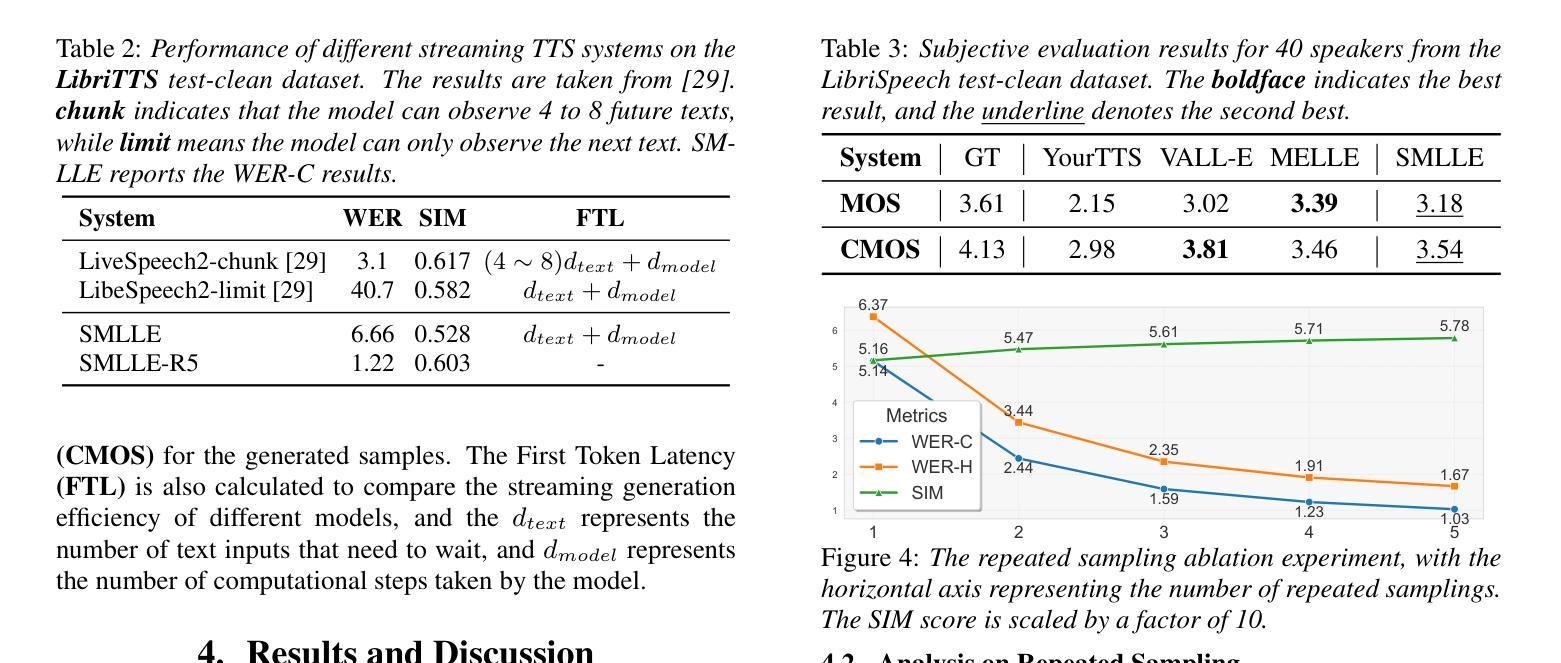
Zero-shot streaming text-to-speech is an important research topic in human-computer interaction. Existing methods primarily use a lookahead mechanism, relying on future text to achieve natural streaming speech synthesis, which introduces high processing latency. To address this issue, we propose SMLLE, a streaming framework for generating high-quality speech frame-by-frame. SMLLE employs a Transducer to convert text into semantic tokens in real time while simultaneously obtaining duration alignment information. The combined outputs are then fed into a fully autoregressive (AR) streaming model to reconstruct mel-spectrograms. To further stabilize the generation process, we design a Delete < Bos > Mechanism that allows the AR model to access future text introducing as minimal delay as possible. Experimental results suggest that the SMLLE outperforms current streaming TTS methods and achieves comparable performance over sentence-level TTS systems. Samples are available on shy-98.github.io/SMLLE_demo_page/.
零样本流式文本到语音转换是人机交互领域的重要研究课题。现有方法主要使用前瞻机制,依赖于未来文本实现自然流式语音合成,这引入了较高的处理延迟。为了解决这一问题,我们提出了SMLLE,这是一个用于逐帧生成高质量语音的流式框架。SMLLE使用转换器实时将文本转换为语义标记,同时获得时长对齐信息。然后将这些组合输出馈入完全自回归(AR)流式模型,以重建梅尔频谱图。为了进一步稳定生成过程,我们设计了一种删除
机制,允许AR模型访问未来文本,并尽量减少延迟。实验结果表明,SMLLE优于当前的流式TTS方法,并在句子级TTS系统上实现了相当的性能。样本可在shy-98.github.io/SMLLE_demo_page/找到。
论文及项目相关链接
Summary
文本介绍了零帧流式文本转语音技术的前沿研究话题。当前主流方法存在处理延迟较高的问题,因此提出了一种名为SMLLE的实时语音合成框架。该框架利用转换器将文本实时转换为语义标记,同时获取时长对齐信息。这些信息被输入到完全自回归(AR)的流式模型中,以重建梅尔频谱图。为了稳定生成过程,还设计了一种删除< Bos>机制来使AR模型能够访问未来的文本,尽量缩短延迟时间。实验结果表明,SMLLE在流式TTS方法中表现优异,与句子级TTS系统相比性能相近。试听样品已上传至网址。
Key Takeaways
- 零帧流式文本转语音是当前研究的重要课题。
- 传统方法主要依赖未来文本来实现自然流畅的语音合成,导致处理延迟较高。
- SMLLE框架被提出用于解决这一问题,能够实时生成高质量语音帧。
- SMLLE利用转换器将文本转换为语义标记,同时获取时长对齐信息。
- 融合语义标记和时长信息后,输入到完全自回归的流式模型中重建梅尔频谱图。
- 采用了删除< Bos>机制来稳定生成过程,允许模型有限地访问未来文本,减少延迟。
- 实验结果显示,SMLLE在流式TTS方法中表现突出,与句子级TTS系统性能相当。
点此查看论文截图

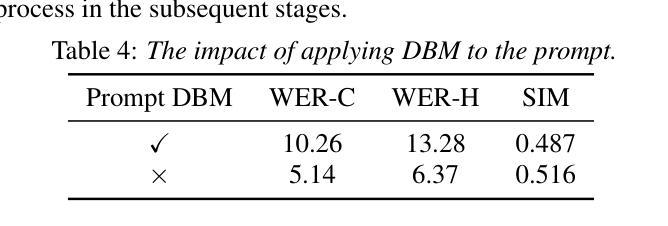
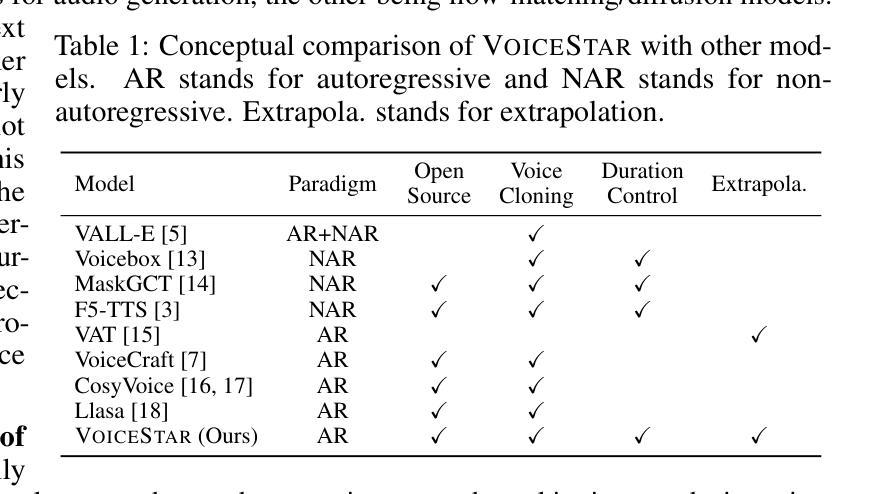
VoiceStar: Robust Zero-Shot Autoregressive TTS with Duration Control and Extrapolation
Authors:Puyuan Peng, Shang-Wen Li, Abdelrahman Mohamed, David Harwath
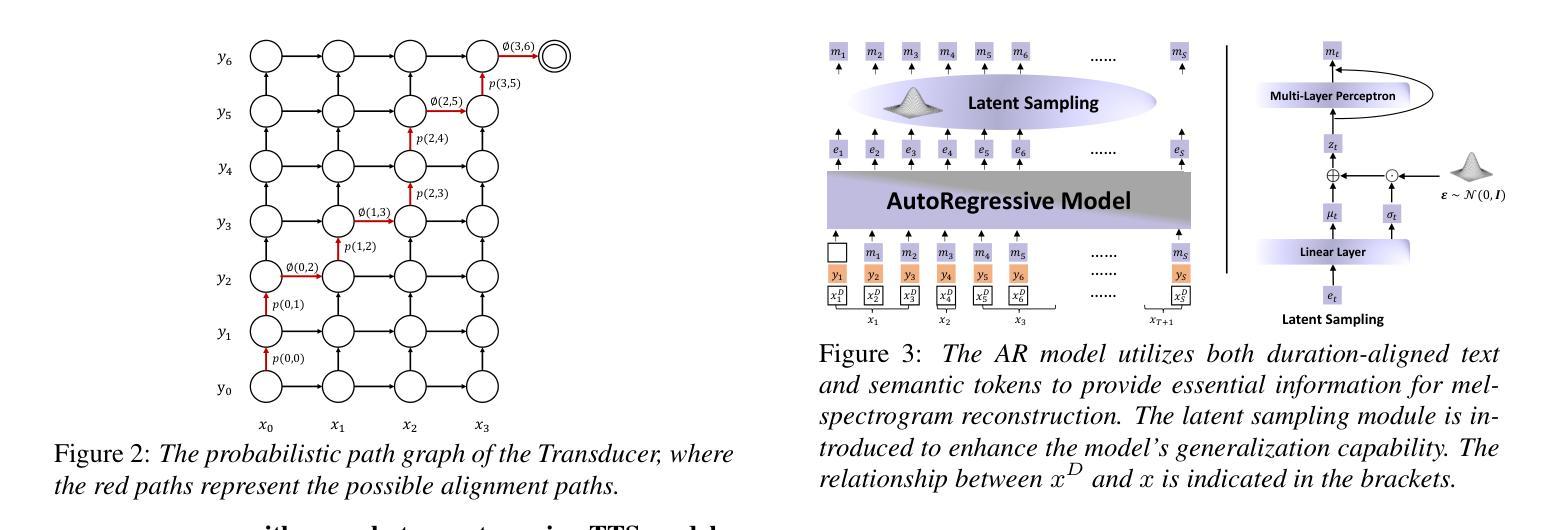
We present VoiceStar, the first zero-shot TTS model that achieves both output duration control and extrapolation. VoiceStar is an autoregressive encoder-decoder neural codec language model, that leverages a novel Progress-Monitoring Rotary Position Embedding (PM-RoPE) and is trained with Continuation-Prompt Mixed (CPM) training. PM-RoPE enables the model to better align text and speech tokens, indicates the target duration for the generated speech, and also allows the model to generate speech waveforms much longer in duration than those seen during. CPM training also helps to mitigate the training/inference mismatch, and significantly improves the quality of the generated speech in terms of speaker similarity and intelligibility. VoiceStar outperforms or is on par with current state-of-the-art models on short-form benchmarks such as Librispeech and Seed-TTS, and significantly outperforms these models on long-form/extrapolation benchmarks (20-50s) in terms of intelligibility and naturalness. Code and models: https://github.com/jasonppy/VoiceStar. Audio samples: https://jasonppy.github.io/VoiceStar_web
我们推出了VoiceStar,这是第一个实现输出时长控制和外推功能的零样本TTS模型。VoiceStar是一种基于自回归编码器-解码器神经网络的语言模型,它采用新型进度监控旋转位置嵌入(PM-RoPE),并通过延续提示混合(CPM)训练。PM-RoPE使模型能够更好地对齐文本和语音标记,指示生成语音的目标时长,并允许模型生成比训练过程中更长的语音波形。CPM训练也有助于减轻训练/推理不匹配的问题,并显著提高生成语音在发音人相似度和清晰度方面的质量。VoiceStar在Librispeech和Seed-TTS等短期基准测试上的表现与当前最先进的模型相当或更优秀,而在长期/外推基准测试(20-50秒)上,其在清晰度和自然度方面显著优于这些模型。代码和模型:https://github.com/jasonppy/VoiceStar。音频样本:https://jasonppy.github.io/VoiceStar_web
论文及项目相关链接
Summary
VoiceStar是一款零样本TTS模型,具备输出时长控制与外推能力。它采用自回归编码器-解码器神经网络语言模型架构,结合新型Progress-Monitoring Rotary Position Embedding(PM-RoPE)与Continuation-Prompt Mixed(CPM)训练技术。PM-RoPE使模型能更好对齐文本与语音标记,指示生成语音的目标时长,并允许生成远超训练集时长的语音波形。CPM训练有助于缩小训练/推理差距,显著提升了生成语音的说话人相似度与清晰度。VoiceStar在短形式基准测试(如Librispeech和Seed-TTS)上表现优秀,并在长形式/外推基准测试(20-50秒)上显著超越了现有先进模型,在清晰度和自然度方面尤为突出。
Key Takeaways
- VoiceStar是首款实现输出时长控制与外推的零样本TTS模型。
- 采用自回归编码器-解码器神经网络语言模型架构。
- 引入了Progress-Monitoring Rotary Position Embedding(PM-RoPE)技术,改进了文本与语音标记的对齐,并能指示目标生成时长。
- 使用了Continuation-Prompt Mixed(CPM)训练,提高了生成语音质量,并缩小了训练与推理之间的差距。
- VoiceStar在短形式基准测试上表现卓越,同时在长形式/外推基准测试中显著超越了现有模型。
- 该模型能够在音频样本中生成远超训练集时长的语音波形。
- VoiceStar在清晰度和自然度方面表现尤为出色。
点此查看论文截图

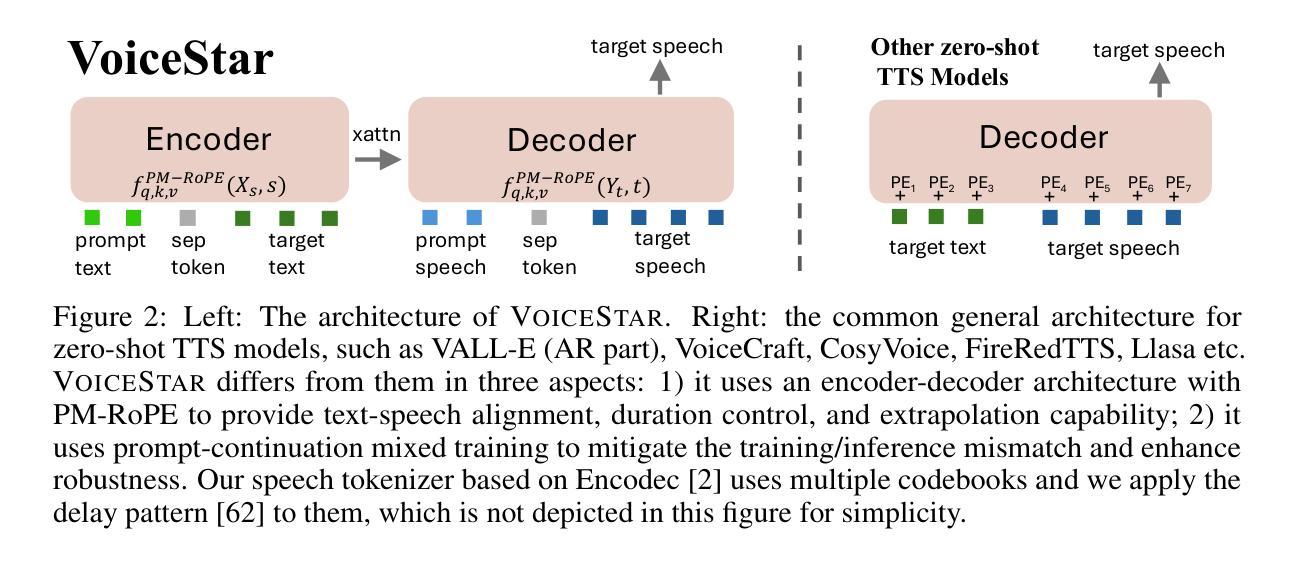
A3 : an Analytical Low-Rank Approximation Framework for Attention
Authors:Jeffrey T. H. Wong, Cheng Zhang, Xinye Cao, Pedro Gimenes, George A. Constantinides, Wayne Luk, Yiren Zhao
Large language models have demonstrated remarkable performance; however, their massive parameter counts make deployment highly expensive. Low-rank approximation offers a promising compression solution, yet existing approaches have two main limitations: (1) They focus on minimizing the output error of individual linear layers, without considering the architectural characteristics of Transformers, and (2) they decompose a large weight matrix into two small low-rank matrices. Consequently, these methods often fall short compared to other compression techniques like pruning and quantization, and introduce runtime overhead such as the extra GEMM kernel launches for decomposed small matrices. To address these limitations, we propose $\tt A^\tt 3$, a post-training low-rank approximation framework. $\tt A^\tt 3$ splits a Transformer layer into three functional components, namely $\tt QK$, $\tt OV$, and $\tt MLP$. For each component, $\tt A^\tt 3$ provides an analytical solution that reduces the hidden dimension size inside each component while minimizing the component’s functional loss ($\it i.e.$, error in attention scores, attention outputs, and MLP outputs). This approach directly reduces model sizes, KV cache sizes, and FLOPs without introducing any runtime overheads. In addition, it provides a new narrative in advancing the optimization problem from singular linear layer loss optimization toward improved end-to-end performance. Through extensive experiments, we show that $\tt A^\tt 3$ maintains superior performance compared to SoTAs. For example, under the same reduction budget in computation and memory, our low-rank approximated LLaMA 3.1-70B achieves a perplexity of 4.69 on WikiText-2, outperforming the previous SoTA’s 7.87 by 3.18. We also demonstrate the versatility of $\tt A^\tt 3$, including KV cache compression, quantization, and mixed-rank assignments for enhanced performance.
大规模语言模型已经展现出卓越的性能,但其庞大的参数数量使得部署成本高昂。低秩逼近提供了一种有前景的压缩解决方案,但现有方法存在两个主要局限性:(1) 它们专注于最小化单个线性层的输出误差,而没有考虑到Transformer的架构特性;(2) 它们将大的权重矩阵分解为两个小的低秩矩阵。因此,这些方法通常比其他压缩技术(如剪枝和量化)逊色,并且引入了运行时开销,例如分解小矩阵所需的额外GEMM内核启动。为了解决这些局限性,我们提出了$\tt A^\tt 3$,一个训练后的低秩逼近框架。$\tt A^\tt 3$将Transformer层分为三个功能组件,即$\tt QK$、$\tt OV$和$\tt MLP$。对于每个组件,$\tt A^\tt 3$提供了一个解析解决方案,该方案可以减少每个组件内的隐藏维度大小,同时最小化组件的功能损失(即注意分数的误差、注意输出和MLP输出)。这种方法直接减小了模型大小、KV缓存大小并减少了浮点运算次数,且没有引入任何运行时开销。此外,它为优化问题提供了新的视角,从单一的线性层损失优化转向改进端到端性能。通过广泛的实验,我们证明了$\tt A^\tt 3$在保持性能优于最新技术的同时,例如,在相同的计算和内存减少预算下,我们的低秩估计LLaMA 3.1-70B在WikiText-2上达到4.69的困惑度,优于以前的最优结果7.87达3.18。我们还展示了$\tt A^\tt 3$的通用性,包括KV缓存压缩、量化和混合排名分配以增强性能。
论文及项目相关链接
摘要
大型语言模型表现出卓越的性能,但其庞大的参数数量导致部署成本高昂。低秩近似提供了一种有前景的压缩解决方案,但现有方法存在两个主要局限性:一是他们专注于最小化单个线性层的输出误差,而没有考虑到Transformer的架构特性;二是他们将大型权重矩阵分解为两个小的低秩矩阵。因此,这些方法往往落后于其他压缩技术,如修剪和量化,并引入了运行时开销,如分解小矩阵的额外GEMM内核启动。为解决这些局限性,我们提出了$\tt A^\tt 3$,一种训练后的低秩近似框架。$\tt A^\tt 3$将Transformer层分为三个功能组件,即$\tt QK$、$\tt OV$和$\tt MLP$。对于每个组件,$\tt A^\tt 3$提供了一个分析解决方案,该方案在减少每个组件的隐藏维度大小的同时最小化组件的功能损失(即注意分数、注意输出和MLP输出的误差)。这种方法直接减小了模型大小、KV缓存大小和FLOPs,而没有引入任何运行时开销。此外,它从单一的线性层损失优化提供了更先进的优化问题的叙述,以改善端到端性能。通过广泛的实验,我们证明了$\tt A^\tt 3$在保持优于现有技术的情况下,仍然保持卓越的性能。例如,在相同的计算和内存减少预算下,我们的低秩估计LLaMA 3.1-70B在WikiText-2上实现困惑度4.69,优于之前技术的7.87达3.18。我们还证明了$\tt A^\tt 3$的通用性,包括KV缓存压缩、量化和混合秩分配以增强性能。
关键见解
- 大型语言模型虽然性能出色,但部署成本高昂,主要因为参数数量庞大。
- 低秩近似作为一种压缩解决方案具有潜力,但现有方法存在两个主要局限性:关注单个线性层的输出误差优化,忽略了Transformer的架构特性;将大型权重矩阵简单分解为小矩阵,导致运行时开销增加。
- $\tt A^\tt 3$框架解决了这些问题,通过考虑Transformer的结构特性进行低秩近似,将模型分为$\tt QK$、$\tt OV$和$\tt MLP$三个功能组件进行优化。
- $\tt A^\tt 3$在减少模型大小、KV缓存大小和计算量(FLOPs)的同时,没有增加运行时开销。
- $\tt A^\tt 3$通过优化每个组件的功能损失,提高了模型的端到端性能。
- 实验结果表明,与现有技术相比,$\tt A^\tt 3$在维持模型性能的同时实现了显著的压缩效果。
点此查看论文截图

Efficient Generative Modeling with Residual Vector Quantization-Based Tokens
Authors:Jaehyeon Kim, Taehong Moon, Keon Lee, Jaewoong Cho
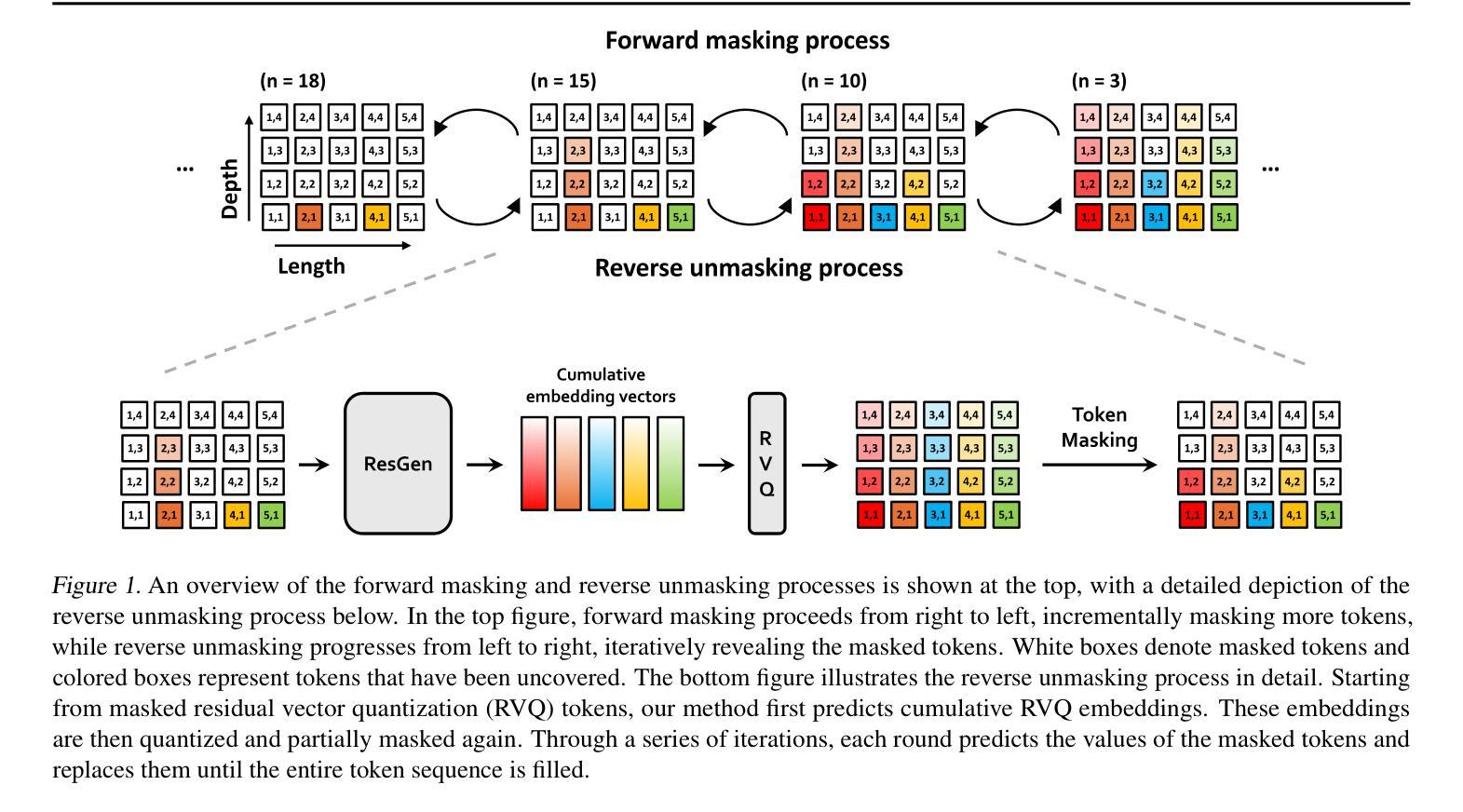
We introduce ResGen, an efficient Residual Vector Quantization (RVQ)-based generative model for high-fidelity generation with fast sampling. RVQ improves data fidelity by increasing the number of quantization steps, referred to as depth, but deeper quantization typically increases inference steps in generative models. To address this, ResGen directly predicts the vector embedding of collective tokens rather than individual ones, ensuring that inference steps remain independent of RVQ depth. Additionally, we formulate token masking and multi-token prediction within a probabilistic framework using discrete diffusion and variational inference. We validate the efficacy and generalizability of the proposed method on two challenging tasks across different modalities: conditional image generation on ImageNet 256x256 and zero-shot text-to-speech synthesis. Experimental results demonstrate that ResGen outperforms autoregressive counterparts in both tasks, delivering superior performance without compromising sampling speed. Furthermore, as we scale the depth of RVQ, our generative models exhibit enhanced generation fidelity or faster sampling speeds compared to similarly sized baseline models.
我们介绍了ResGen,这是一种基于残差矢量量化(RVQ)的高效生成模型,用于高保真生成和快速采样。RVQ通过增加量化步骤的数量(称为深度)来提高数据保真度,但更深的量化通常会增加生成模型中的推理步骤。为了解决这一问题,ResGen直接预测集体标记的向量嵌入,而不是单个标记的嵌入,从而确保推理步骤与RVQ深度无关。此外,我们在概率框架下使用离散扩散和变分推理来制定标记掩码和多标记预测。我们在不同模态的两个具有挑战性的任务上验证了所提出方法的有效性和通用性:ImageNet 256x256上的条件图像生成和零样本文本到语音合成。实验结果表明,ResGen在两项任务上的表现均优于自回归模型,在不影响采样速度的情况下实现了卓越的性能。此外,随着我们扩大RVQ的深度,与类似规模的基准模型相比,我们的生成模型在生成保真度方面表现出更高的性能或在采样速度上更快。
论文及项目相关链接
PDF ICML 2025
Summary
本文介绍了ResGen,一种基于残差向量量化(RVQ)的高效生成模型,可实现高保真生成和快速采样。ResGen通过增加量化步骤的数量(即深度)提高了数据保真度,同时解决了更深层次的量化通常会增加生成模型的推理步骤的问题。它通过直接预测集体标记的向量嵌入来确保推理步骤与RVQ深度无关。此外,本文还通过离散扩散和变分推断的概率框架来制定标记掩码和多标记预测。在ImageNet 256x256上的条件图像生成和零文本语音合成任务上验证了该方法的有效性和通用性。实验结果表明,ResGen在两项任务中的表现均优于自回归模型,在保证采样速度的同时实现了卓越的性能。随着RVQ深度的增加,我们的生成模型在保持保真度的同时,与同类基线模型相比具有更快的采样速度。
Key Takeaways
- ResGen是一个基于残差向量量化(RVQ)的生成模型,旨在实现高保真生成和快速采样。
- RVQ通过增加量化步骤的数量来提高数据保真度,但可能导致推理步骤增加。
- ResGen通过直接预测集体标记的向量嵌入来解决推理步骤与RVQ深度之间的问题。
- 该方法采用离散扩散和变分推断的概率框架来处理标记掩码和多标记预测。
- 在ImageNet 256x256的条件图像生成和零文本语音合成任务上进行了实验验证。
- ResGen在两项任务中的表现均优于自回归模型,且在采样速度方面表现出色。
点此查看论文截图

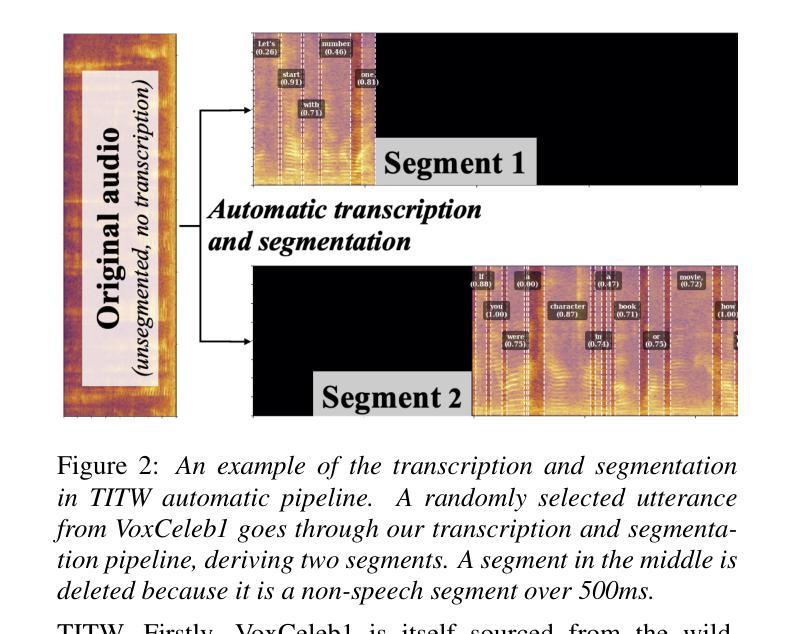
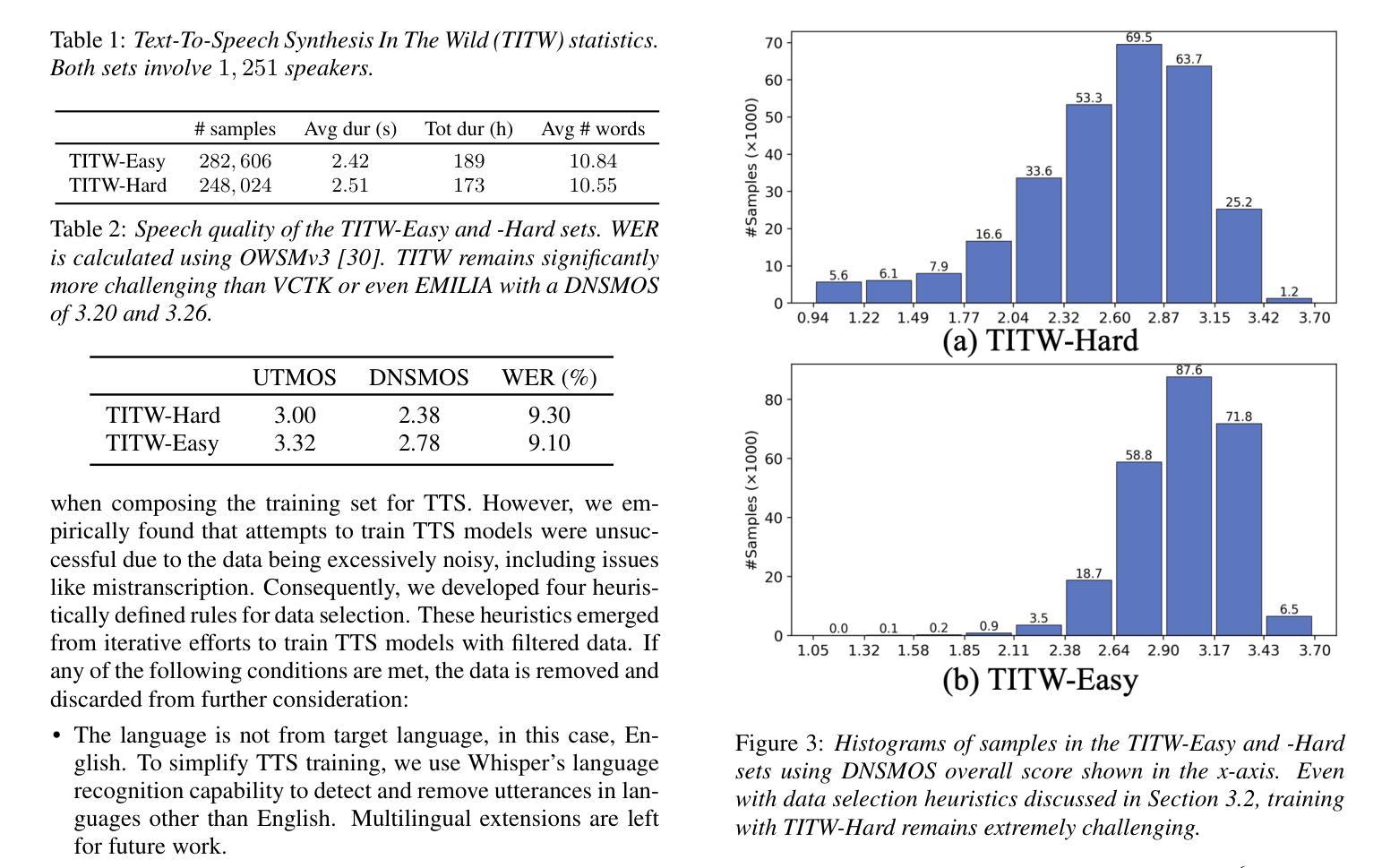
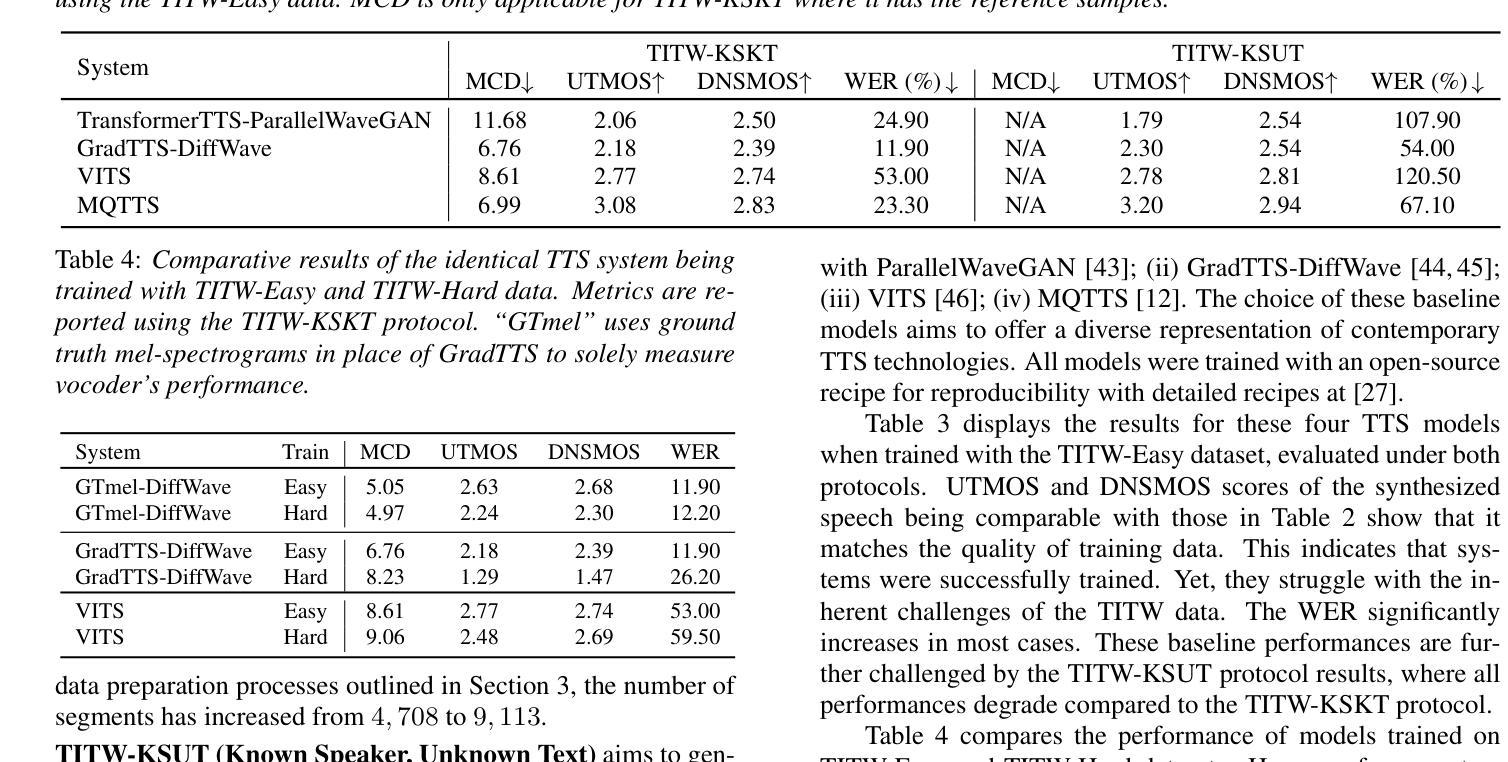
Text-To-Speech Synthesis In The Wild
Authors:Jee-weon Jung, Wangyou Zhang, Soumi Maiti, Yihan Wu, Xin Wang, Ji-Hoon Kim, Yuta Matsunaga, Seyun Um, Jinchuan Tian, Hye-jin Shim, Nicholas Evans, Joon Son Chung, Shinnosuke Takamichi, Shinji Watanabe
Traditional Text-to-Speech (TTS) systems rely on studio-quality speech recorded in controlled settings.a Recently, an effort known as noisy-TTS training has emerged, aiming to utilize in-the-wild data. However, the lack of dedicated datasets has been a significant limitation. We introduce the TTS In the Wild (TITW) dataset, which is publicly available, created through a fully automated pipeline applied to the VoxCeleb1 dataset. It comprises two training sets: TITW-Hard, derived from the transcription, segmentation, and selection of raw VoxCeleb1 data, and TITW-Easy, which incorporates additional enhancement and data selection based on DNSMOS. State-of-the-art TTS models achieve over 3.0 UTMOS score with TITW-Easy, while TITW-Hard remains difficult showing UTMOS below 2.8.
传统文本转语音(TTS)系统依赖于在受控环境中录制的语音以实现工作室音质。近期,一种名为噪声TTS训练的研究工作开始涌现,旨在利用自然场景中的数据。然而,缺乏专用数据集一直是其重要限制。我们引入了TTS野外数据集(TITW),该数据集已公开提供,并使用了VoxCeleb1数据集的自动化管道创建而成。它包含两个训练集:TITW-Hard,由原始VoxCeleb1数据的转录、分段和选择派生而来;TITW-Easy则基于DNSMOS进行了额外的增强和数据选择。当前先进的TTS模型在TITW-Easy上获得了超过3.0的UTMOS分数,而TITW-Hard仍然具有挑战性,UTMOS低于2.8。
论文及项目相关链接
PDF 5 pages, Interspeech 2025
Summary
本文介绍了传统文本转语音(TTS)系统主要依赖受控环境下的高质量语音数据。为利用真实环境下的数据,研究者推出噪声TTS训练法,但缺乏专用数据集成为一大挑战。为此,本文推出了公开可用的TTS In the Wild(TITW)数据集,通过应用于VoxCeleb1数据集的自动化管道创建。该数据集包含两个训练集:直接从原始VoxCeleb1数据转录、分割和选择的TITW-Hard,以及基于DNSMOS进行额外增强和选择的TITW-Easy。使用TITW-Easy的最新TTS模型UTMOS得分超过3.0,而TITW-Hard仍具有挑战性,UTMOS低于2.8。
Key Takeaways
- 传统TTS系统依赖受控环境的语音数据。
- 噪声TTS训练法旨在利用真实环境下的数据。
- 缺少专用数据集是TTS技术面临的主要挑战之一。
- 推出了公开的TTS In the Wild(TITW)数据集,包含TITW-Hard和TITW-Easy两个训练集。
- TITW数据集是基于VoxCeleb1数据集的自动化管道创建的。
- 最新TTS模型在TITW-Easy上取得超过3.0的UTMOS得分。
点此查看论文截图