⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-05 更新
UMA: Ultra-detailed Human Avatars via Multi-level Surface Alignment
Authors:Heming Zhu, Guoxing Sun, Christian Theobalt, Marc Habermann
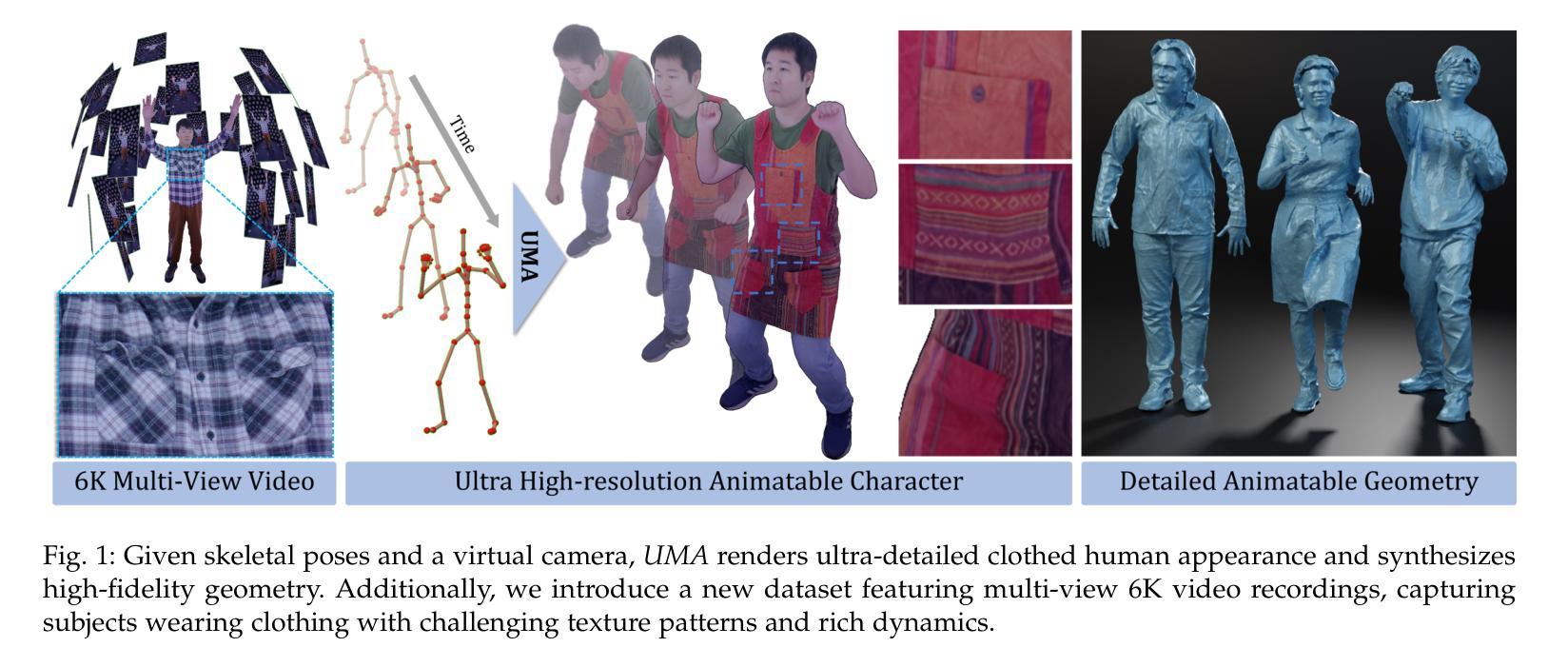
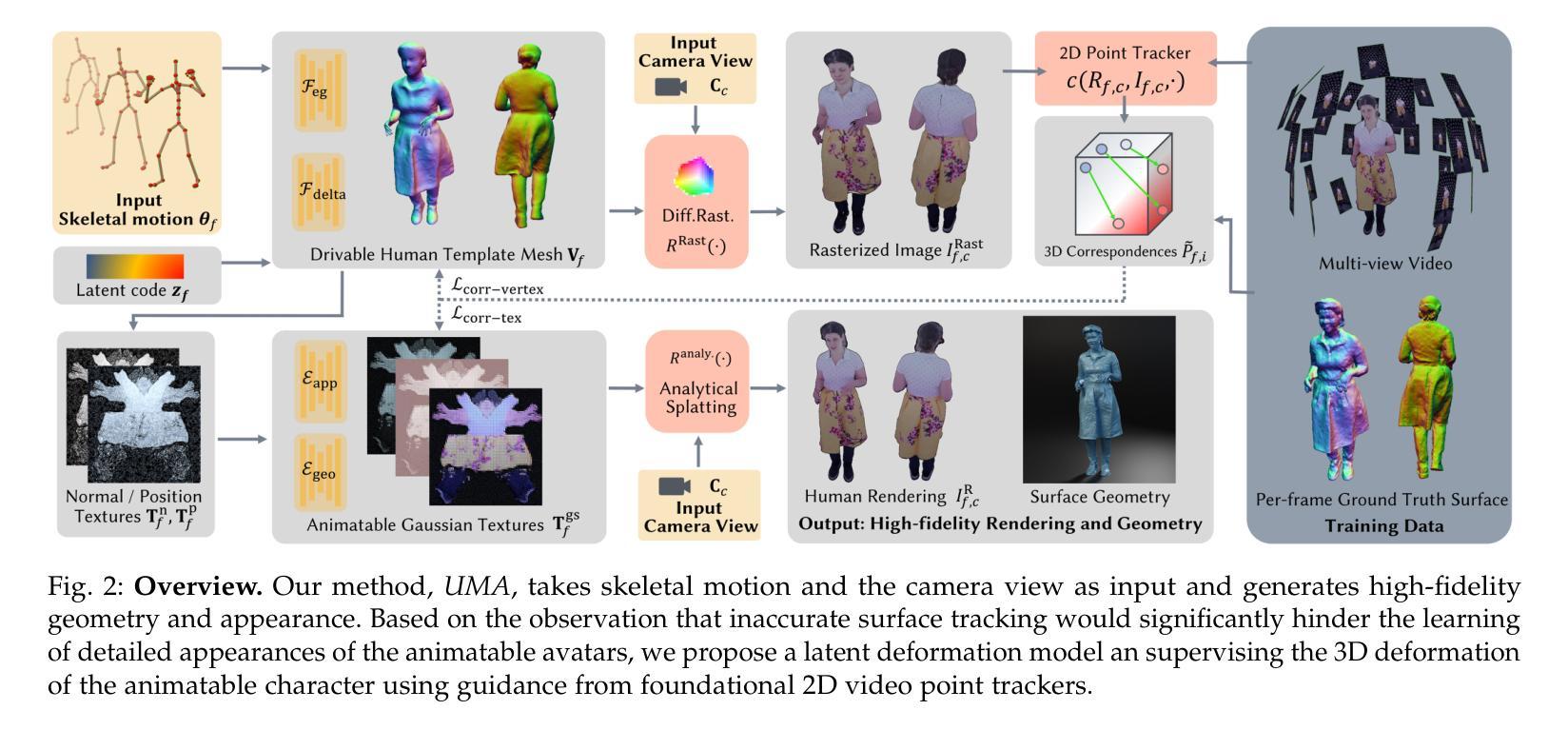
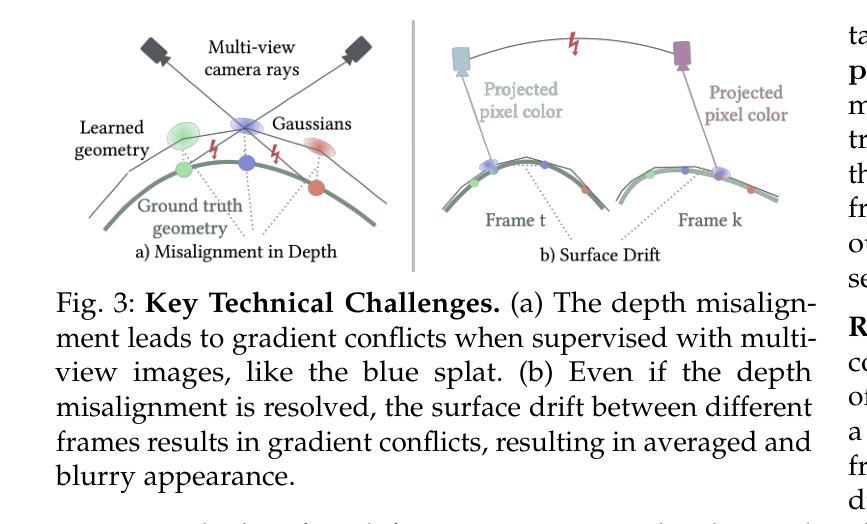
Learning an animatable and clothed human avatar model with vivid dynamics and photorealistic appearance from multi-view videos is an important foundational research problem in computer graphics and vision. Fueled by recent advances in implicit representations, the quality of the animatable avatars has achieved an unprecedented level by attaching the implicit representation to drivable human template meshes. However, they usually fail to preserve the highest level of detail, particularly apparent when the virtual camera is zoomed in and when rendering at 4K resolution and higher. We argue that this limitation stems from inaccurate surface tracking, specifically, depth misalignment and surface drift between character geometry and the ground truth surface, which forces the detailed appearance model to compensate for geometric errors. To address this, we propose a latent deformation model and supervising the 3D deformation of the animatable character using guidance from foundational 2D video point trackers, which offer improved robustness to shading and surface variations, and are less prone to local minima than differentiable rendering. To mitigate the drift over time and lack of 3D awareness of 2D point trackers, we introduce a cascaded training strategy that generates consistent 3D point tracks by anchoring point tracks to the rendered avatar, which ultimately supervises our avatar at the vertex and texel level. To validate the effectiveness of our approach, we introduce a novel dataset comprising five multi-view video sequences, each over 10 minutes in duration, captured using 40 calibrated 6K-resolution cameras, featuring subjects dressed in clothing with challenging texture patterns and wrinkle deformations. Our approach demonstrates significantly improved performance in rendering quality and geometric accuracy over the prior state of the art.
从多视角视频中学习具有生动动态和逼真外观的可动画和穿衣人类化身模型是计算机图形学和视觉领域的一个重要基础性问题。受最近隐式表示进展的推动,通过将隐式表示附加到可驱动的人体模板网格上,可动画化身的质量达到了前所未有的水平。然而,它们通常无法保留最高级别的细节,特别是在虚拟相机放大以及呈现4K分辨率和更高分辨率时尤为明显。我们认为,这一局限性源于不准确的表面跟踪,具体表现为角色几何与地面真实表面之间的深度不对齐和表面漂移,这迫使详细的外观模型来弥补几何错误。为了解决这一问题,我们提出了一种潜在的变形模型,并使用基础2D视频点跟踪器的指导来监督可动画角色的3D变形,这对阴影和表面变化具有更好的稳健性,并且相对于可微分渲染更不容易陷入局部最小值。为了减轻随时间推移的漂移和2D点跟踪器缺乏3D感知的问题,我们引入了一种级联训练策略,通过将在点轨迹锚定到渲染化身来生成一致的3D点轨迹,最终在我们的化身顶点级别和纹理元素级别进行监督。为了验证我们方法的有效性,我们引入了一个新型数据集,包含五个多视角视频序列,每个序列持续超过10分钟,使用40个校准的6K分辨率相机拍摄,特征主体穿着具有挑战纹理图案和褶皱变形的服装。我们的方法在渲染质量和几何精度方面的表现均显著优于现有技术。
论文及项目相关链接
PDF For video results, see https://youtu.be/XMNCy7J2tuc
Summary
动画化并带有逼真动态和逼真外观的人体角色模型的学习是计算机图形学和视觉领域的重要基础研究问题。本文提出了一种潜在的变形模型,使用基础二维视频点追踪器监督三维角色的变形,解决了表面追踪不准确的问题,提高了渲染质量和几何精度。同时引入了一种级联训练策略,并创建了一个新型数据集以验证方法的有效性。
Key Takeaways
- 学习从多角度视频中的可动画和穿衣人体角色模型仍是计算机图形学和视觉的重要问题。
- 现有方法在高分辨率下细节水平不足,特别是在虚拟相机放大时。
- 问题根源在于不准确的表面追踪,包括深度不对齐和角色几何与地面真实表面之间的表面漂移。
- 提出了一个潜在的变形模型,结合二维视频点追踪器的指导来监督三维角色的变形。
- 为缓解随时间漂移和二维点追踪器的三维意识不足,引入了级联训练策略。
- 创新数据集包含五个多角度视频序列,每个序列超过10分钟,使用40个校准的6K分辨率相机捕捉,具有挑战性的纹理模式和褶皱变形。
点此查看论文截图