⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-05 更新
High-Contrast Coronagraphy
Authors:Matthew A. Kenworthy, Sebastiaan Y. Haffert
Imaging terrestrial exoplanets around nearby stars is a formidable technical challenge, requiring the development of coronagraphs to suppress the stellar halo of diffracted light at the location of the planet. In this review, we derive the science requirement for high-contrast imaging, present an overview of diffraction theory and the Lyot coronagraph, and define the parameters used in our optimization. We detail the working principles of coronagraphs both in the laboratory and on-sky with current high-contrast instruments, and we describe the required algorithms and processes necessary for terrestrial planet imaging with the extremely large telescopes and proposed space telescope missions: * Imaging terrestrial planets around nearby stars is possible with a combination of coronagraphs and active wavefront control using feedback from wavefront sensors. * Ground based 8-40m class telescopes can target the habitable zone around nearby M dwarf stars with contrasts of $10^{-7}$ and space telescopes can search around solar-type stars with contrasts of $10^{-10}$. * Focal plane wavefront sensing, hybrid coronagraph designs and multiple closed loops providing active correction are required to reach the highest sensitivities. * Polarization effects need to be mitigated for reaching $10^{-10}$ contrasts whilst keeping exoplanet yields as high as possible. * Recent technological developments, including photonics and microwave kinetic inductance detectors, will be folded into high-contrast instruments.
成像邻近恒星周围的地外行星是一项艰巨的技术挑战,需要开发消光仪来抑制行星位置处衍射光形成的恒星光晕。在本综述中,我们推导了高对比度成像的科学要求,概述了衍射理论和消光仪的原理,并定义了优化中使用的参数。我们详细介绍了实验室和当前高对比度仪器在天空中的消光仪工作原理,并描述了使用极大望远镜和拟议的空间望远镜任务进行地球行星成像所需的算法和流程:结合消光仪和活动波前控制,使用波前传感器的反馈,可以实现邻近恒星周围地球行星的成像。地面8-40米级望远镜可以在邻近的矮星周围的可居住区域实现对比度为达到$ 10^{-7}$的成像,而太空望远镜可以在太阳型恒星周围实现对比度为$ 10^{-10}$的搜索。为了达到最高的灵敏度,需要采用焦平面波前检测、混合消光仪设计和提供主动校正的多个闭环。为了达到$ 10^{-10}$的对比度并保持尽可能高的地外行星产量,需要缓解偏振效应。*包括光子学和微波动电感检测器在内的最新技术将被纳入高对比度仪器中。
论文及项目相关链接
PDF Invited review article. 41 pages, 12 figures, 1 table. The paper is in a reproducible workflow repository at https://github.com/mkenworthy/ARAA_HCC
Summary
该文探讨了使用高对比度成像技术来观测邻近恒星周围的地外行星的挑战。文中详细介绍了高对比度成像的科学要求、衍射理论及Lyot掩星仪的原理,并概述了优化参数。同时,文章还介绍了实验室和现有高对比度仪器中掩星仪的工作原理,以及使用超大望远镜和未来太空望远镜任务进行地球类行星成像所需的算法和流程。文章指出,结合掩星仪和活动波前控制,使用波前传感器的反馈,可以在地面基础8-40米级的望远镜和太空望远镜上实现邻近恒星周围地球类行星的成像。
Key Takeaways
- 掩星仪和活动波前控制技术的结合是实现邻近恒星周围地球类行星成像的关键。
- 地面基础的8-40米级望远镜可以针对M矮星的宜居区域进行高对比度成像,而太空望远镜可以针对太阳型星的更高对比度区域进行搜索。
- 为了达到最高的灵敏度,需要焦点平面波前检测、混合掩星仪设计和提供主动校正的多个闭环。
- 极化效应需要在达到10^-10对比度时予以缓解,同时保持尽可能高的类地行星产量。
- 最近的技术发展,如光子学和微波动电感检测器,将被整合到高对比度仪器中。
- 文中介绍了衍射理论的基础知识,这是理解高对比度成像技术的基础。
点此查看论文截图


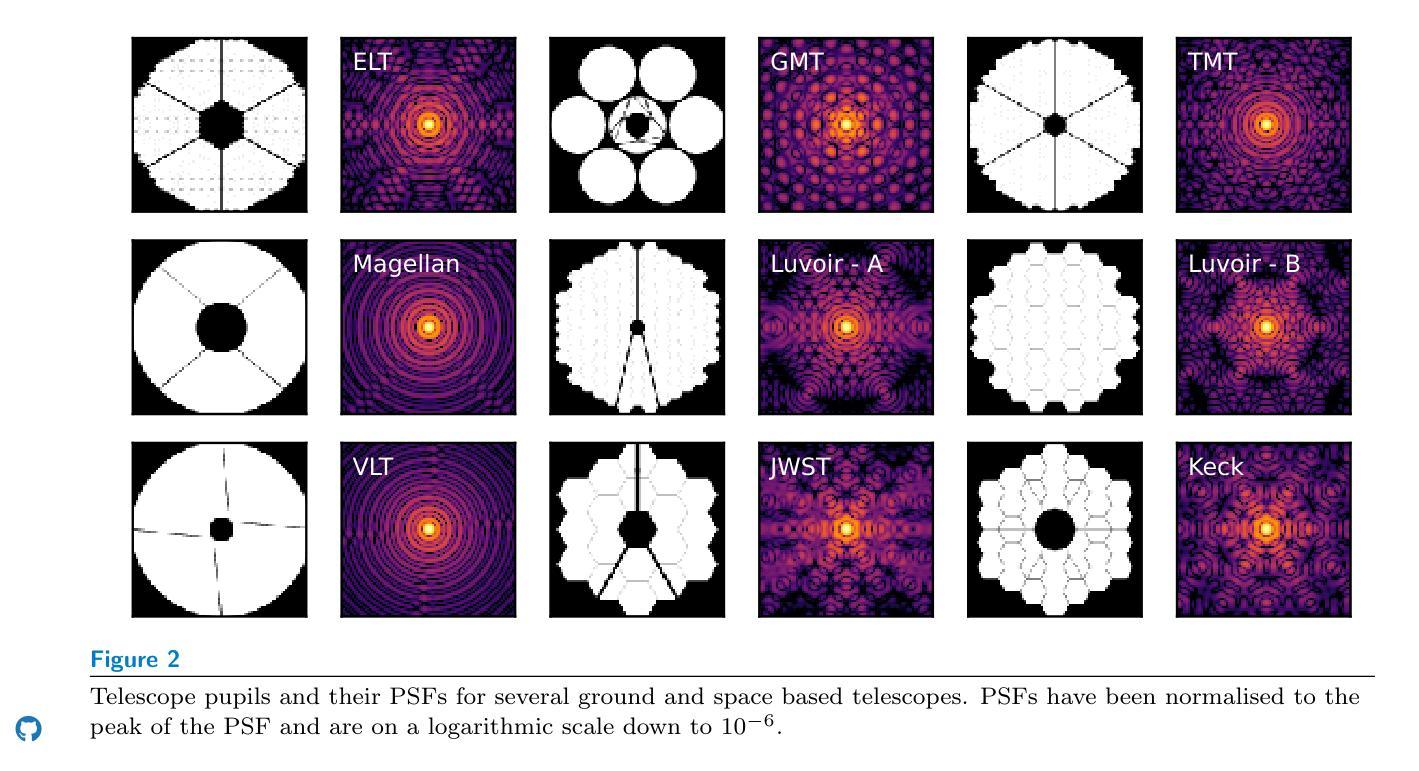
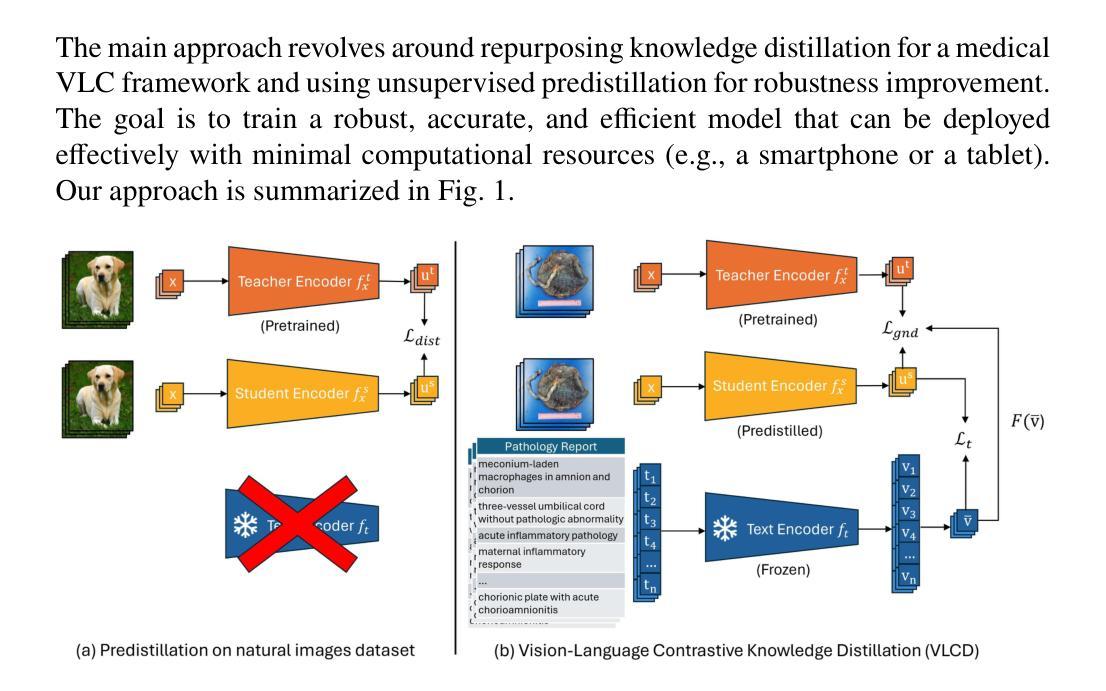
VLCD: Vision-Language Contrastive Distillation for Accurate and Efficient Automatic Placenta Analysis
Authors:Manas Mehta, Yimu Pan, Kelly Gallagher, Alison D. Gernand, Jeffery A. Goldstein, Delia Mwinyelle, Leena Mithal, James Z. Wang
Pathological examination of the placenta is an effective method for detecting and mitigating health risks associated with childbirth. Recent advancements in AI have enabled the use of photographs of the placenta and pathology reports for detecting and classifying signs of childbirth-related pathologies. However, existing automated methods are computationally extensive, which limits their deployability. We propose two modifications to vision-language contrastive learning (VLC) frameworks to enhance their accuracy and efficiency: (1) text-anchored vision-language contrastive knowledge distillation (VLCD)-a new knowledge distillation strategy for medical VLC pretraining, and (2) unsupervised predistillation using a large natural images dataset for improved initialization. Our approach distills efficient neural networks that match or surpass the teacher model in performance while achieving model compression and acceleration. Our results showcase the value of unsupervised predistillation in improving the performance and robustness of our approach, specifically for lower-quality images. VLCD serves as an effective way to improve the efficiency and deployability of medical VLC approaches, making AI-based healthcare solutions more accessible, especially in resource-constrained environments.
胎盘病理检查是检测和缓解与分娩相关的健康风险的有效方法。最近人工智能的进步使得能够使用胎盘照片和病理报告来检测和分类与分娩相关的病理迹象。然而,现有的自动化计算方法计算量大,限制了其部署能力。我们针对视觉语言对比学习(VLC)框架提出了两项改进,以提高其准确性和效率:(1)文本锚定的视觉语言对比知识蒸馏(VLCD)——一种用于医学VLC预训练的新知识蒸馏策略;(2)使用大型自然图像数据集进行无监督预蒸馏,以改进初始化。我们的方法提炼了高效的神经网络,在性能上达到或超越了教师模型的性能,同时实现了模型压缩和加速。我们的结果展示了无监督预蒸馏在提高我们方法的性能和稳健性方面的价值,尤其是针对低质量图像。VLCD是提高医学VLC方法效率和部署能力的有效途径,使基于人工智能的卫生解决方案更加容易获得,特别是在资源受限的环境中。
论文及项目相关链接
PDF Proceedings of the 9th International Workshop on Health Intelligence, in conjunction with the Annual AAAI Conference on Artificial Intelligence, Philadelphia, Pennsylvania, March 2025
摘要
病理胎盘检查是检测和缓解分娩健康风险的有效方法。最近人工智能的进步使得可以使用胎盘照片和病理报告来检测和分类与分娩相关的病理迹象。然而,现有的自动化方法在计算上非常密集,限制了其部署能力。本文提出对视觉语言对比学习(VLC)框架的两种改进方法,以提高其准确性和效率:(1)文本锚定的视觉语言对比知识蒸馏(VLCD)-一种新的用于医学VLC预训练的知识蒸馏策略;(2)使用大量自然图像数据集进行无监督预蒸馏,以改善初始化。本文的方法蒸馏出高效神经网络,在性能上匹配或超越教师模型,同时实现模型压缩和加速。结果展示了无监督预蒸馏在提高性能和稳健性方面的价值,尤其对于低质量图像。VLCD是提高医学VLC方法效率和部署能力的有效途径,使得基于人工智能的卫生解决方案更加易于获取,特别是在资源受限的环境中。
关键见解
- 病理胎盘检查是检测分娩健康风险的有效方法。
- 人工智能在胎盘病理学中的应用已经取得了进展,但现有方法在计算上较为密集。
- 本文提出了两种改进视觉语言对比学习(VLC)的方法以增强其效率和准确性。
- 文本锚定的视觉语言对比知识蒸馏(VLCD)是一种新的医学VLC预训练知识蒸馏策略。
- 通过使用大量自然图像数据集进行无监督预蒸馏,改善了模型的初始化并提高了性能。
- 方法成功实现了模型压缩和加速,提高了教师模型的性能。
点此查看论文截图

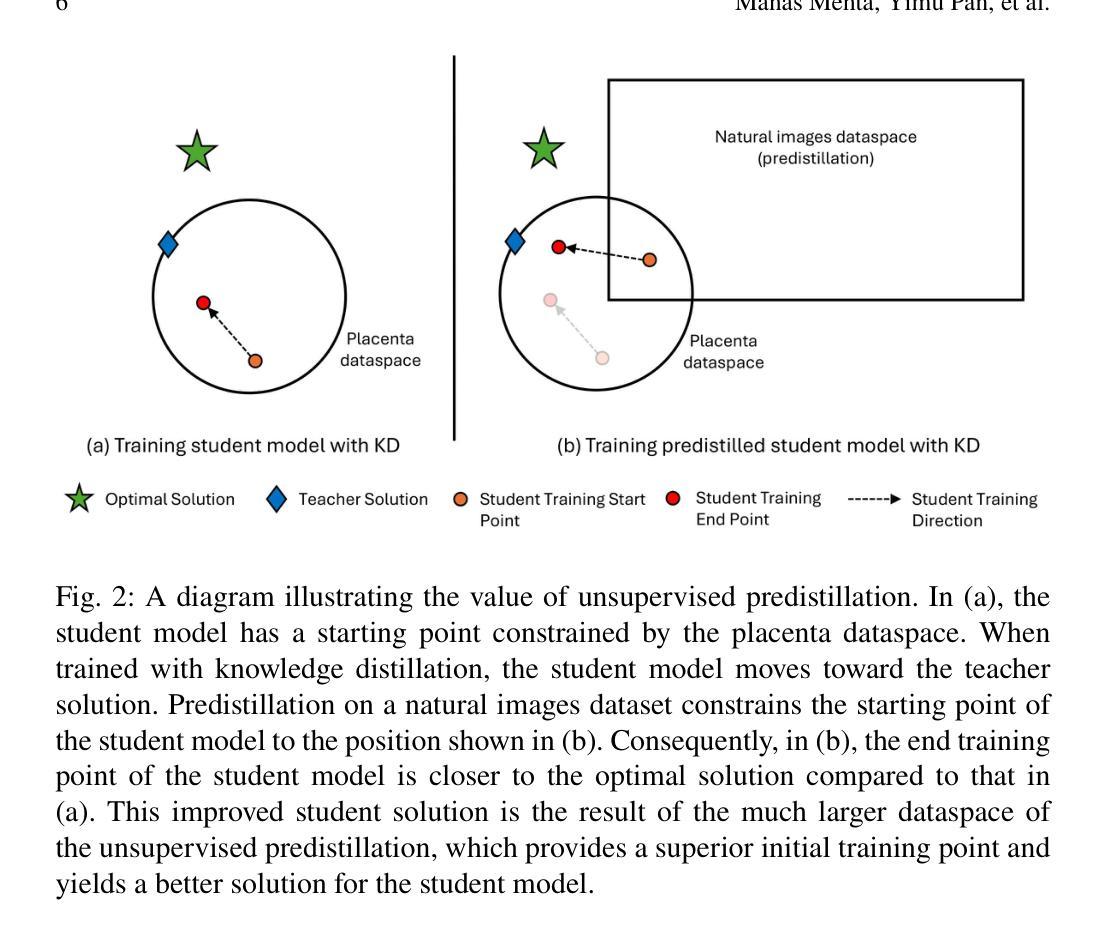
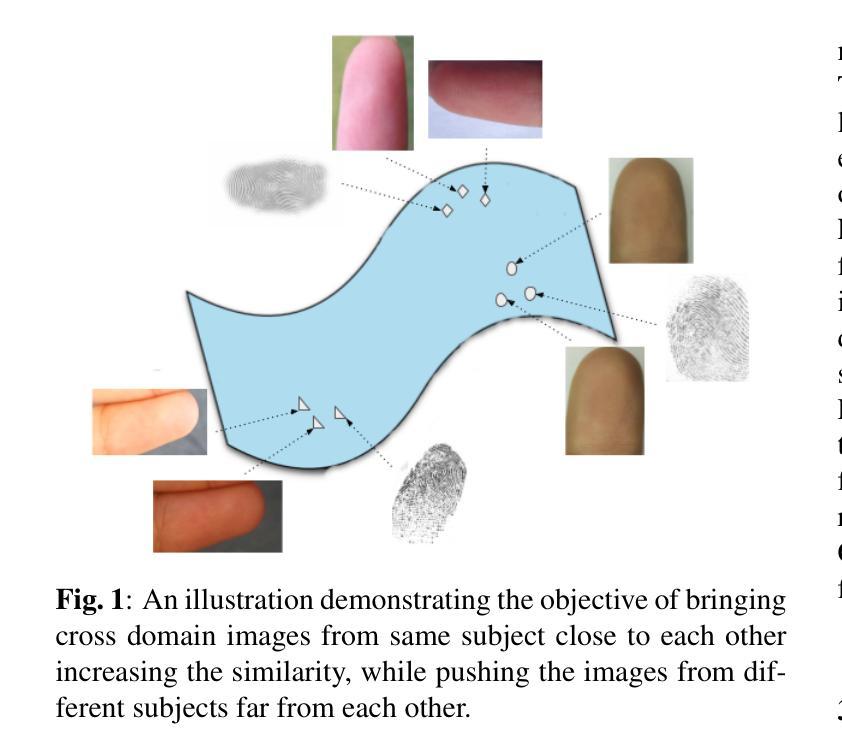
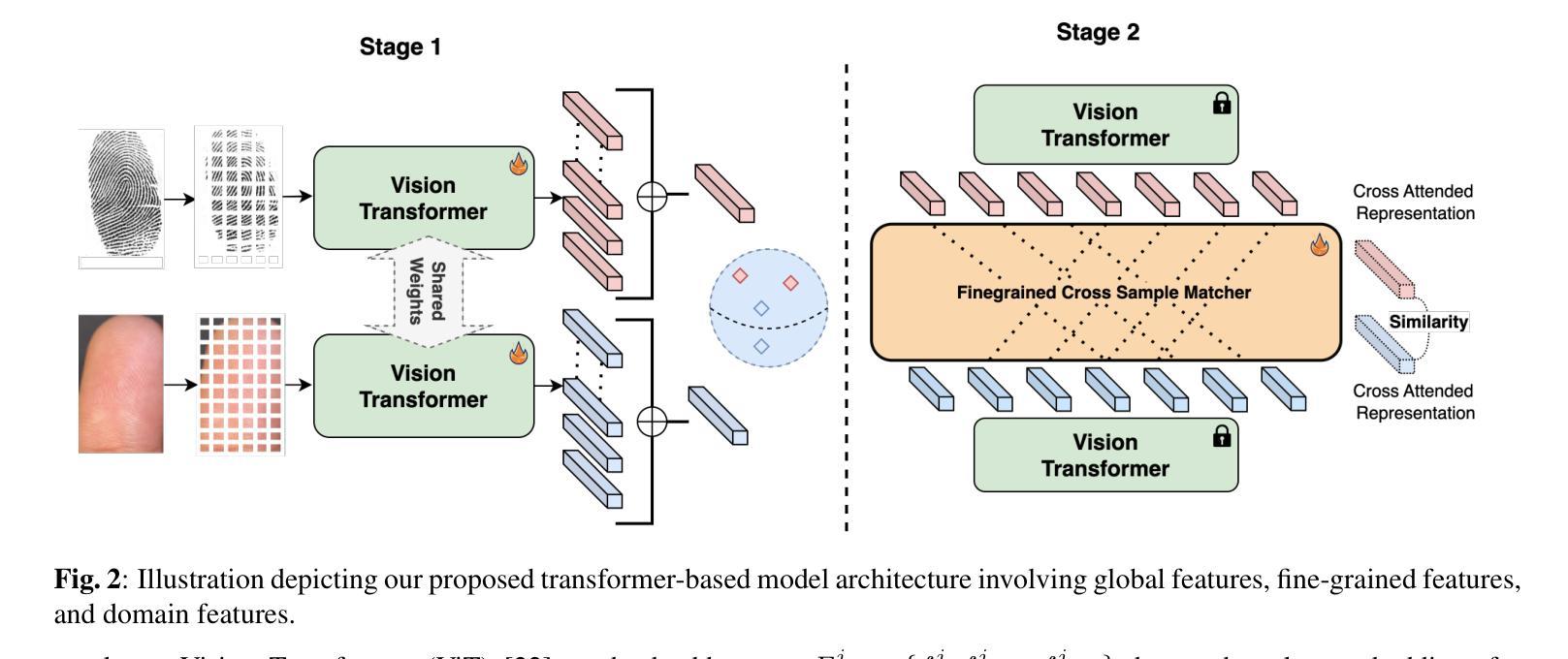
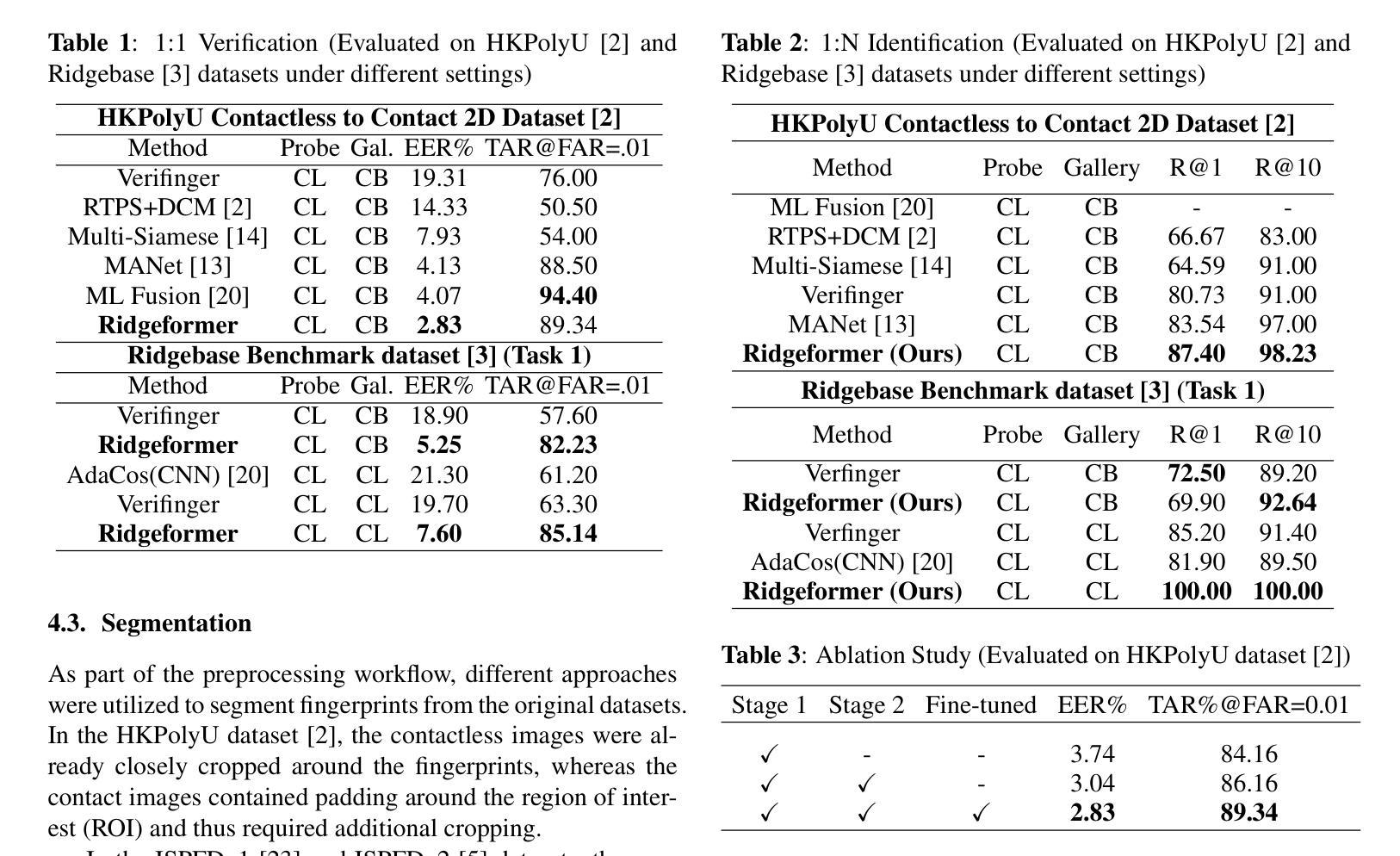
Ridgeformer: Mutli-Stage Contrastive Training For Fine-grained Cross-Domain Fingerprint Recognition
Authors:Shubham Pandey, Bhavin Jawade, Srirangaraj Setlur
The increasing demand for hygienic and portable biometric systems has underscored the critical need for advancements in contactless fingerprint recognition. Despite its potential, this technology faces notable challenges, including out-of-focus image acquisition, reduced contrast between fingerprint ridges and valleys, variations in finger positioning, and perspective distortion. These factors significantly hinder the accuracy and reliability of contactless fingerprint matching. To address these issues, we propose a novel multi-stage transformer-based contactless fingerprint matching approach that first captures global spatial features and subsequently refines localized feature alignment across fingerprint samples. By employing a hierarchical feature extraction and matching pipeline, our method ensures fine-grained, cross-sample alignment while maintaining the robustness of global feature representation. We perform extensive evaluations on publicly available datasets such as HKPolyU and RidgeBase under different evaluation protocols, such as contactless-to-contact matching and contactless-to-contactless matching and demonstrate that our proposed approach outperforms existing methods, including COTS solutions.
随着对卫生和便携生物识别系统需求的不断增加,无接触式指纹识别技术的进展至关重要。尽管该技术具有潜力,但它面临着一些显著挑战,包括图像获取失焦、指纹脊和谷之间对比度降低、手指定位变化以及透视畸变。这些因素严重阻碍了无接触指纹匹配的准确性和可靠性。为了解决这些问题,我们提出了一种基于多阶段变压器架构的无接触指纹匹配新方法。该方法首先捕获全局空间特征,随后对指纹样本中的局部特征进行精细对齐。通过采用分层特征提取和匹配管道,我们的方法确保了跨样本的精细粒度对齐,同时保持了全局特征表示的稳健性。我们在HKPolyU和RidgeBase等公开数据集上进行了广泛评估,根据不同的评估协议(如非接触式与接触式匹配和非接触式与非接触式匹配)进行了实验,结果表明我们提出的方法优于现有方法,包括现成的商业技术解决方案。
论文及项目相关链接
PDF Accepted to IEEE International Conference on Image Processing 2025
Summary
随着对卫生和便携生物识别系统需求的增加,无接触指纹识别的技术挑战日益凸显。为解决图像采集失焦、指纹脊谷对比度降低、手指定位变化和透视畸变等问题,我们提出了一种基于多阶段Transformer的无接触指纹匹配新方法。该方法采用分层特征提取和匹配管道,确保精细的跨样本对齐,同时保持全局特征表示的稳健性。在HKPolyU和RidgeBase等公开数据集上进行的广泛评估表明,该方法在接触式和无接触匹配协议上均优于现有方法,包括商业解决方案。
Key Takeaways
- 无接触指纹识别技术面临图像采集失焦等挑战。
- 指纹脊谷对比度降低影响识别准确性。
- 手指定位变化和透视畸变对接触式指纹识别带来困扰。
- 提出了一种基于多阶段Transformer的新方法,用于无接触指纹匹配。
- 采用分层特征提取和匹配管道,确保精细跨样本对齐。
- 方法在公开数据集上的性能优于现有方法。
点此查看论文截图

Contra4: Evaluating Contrastive Cross-Modal Reasoning in Audio, Video, Image, and 3D
Authors:Artemis Panagopoulou, Le Xue, Honglu Zhou, silvio savarese, Ran Xu, Caiming Xiong, Chris Callison-Burch, Mark Yatskar, Juan Carlos Niebles
Real-world decision-making often begins with identifying which modality contains the most relevant information for a given query. While recent multimodal models have made impressive progress in processing diverse inputs, it remains unclear whether they can reason contrastively across multiple modalities to select the one that best satisfies a natural language prompt. We argue this capability is foundational, especially in retrieval-augmented and decision-time contexts, where systems must evaluate multiple signals and identify which one conveys the relevant information. To evaluate this skill, we introduce Contra4, a dataset for contrastive cross-modal reasoning across four modalities: image, audio, video, and 3D. Each example presents a natural language question alongside multiple candidate modality instances, and the model must select the one that semantically aligns with the prompt. Contra4 combines human-annotated captions with a mixture-of-models round-trip-consistency filter to ensure high-quality supervision, resulting in 174k training examples and a manually verified test set of 2.3k samples. While task-specific fine-tuning improves performance by 56% relative to baseline, state-of-the-art models still achieve only 56% accuracy overall and 42% in four-modality settings, underscoring a significant limitation in current multimodal models.
现实世界中的决策通常始于确定哪种模态对于给定查询包含最相关的信息。虽然最近的多媒体模型在处理各种输入方面取得了令人印象深刻的进展,但尚不清楚它们是否能够在多个模态之间进行对比推理,以选择最能满足自然语言提示的那一个。我们认为这种能力是基础性的,特别是在增强检索和决策时间上下文中,系统必须评估多种信号并确定哪一种传达了相关信息。为了评估这种能力,我们推出了Contra4,这是一个用于四模态对比跨模态推理的数据集:图像、音频、视频和3D。每个示例都提供了一个自然语言问题以及多个候选模态实例,模型必须选择语义上与提示对齐的那一个。Contra4结合了人类注释的标题和混合模型的往返一致性过滤器,以确保高质量的监督,从而产生17.4万份训练样本和经过人工验证的2300个样本测试集。与基线相比,特定任务的微调将性能提高了56%,而最先进的模型总体准确率仅为56%,在四模态设置下准确率为42%,这突显了当前多媒体模型的重大局限性。
论文及项目相关链接
Summary
本文介绍了多模态决策制定的重要性,特别是在检索增强和决策时间上下文中。文章指出,尽管近期多模态模型在处理多样化输入方面取得了显著进展,但在对比跨多个模态进行推理以选择最符合自然语言提示的模态方面仍存在不足。为评估这一技能,文章引入了Contra4数据集,包含图像、音频、视频和3D四种模态的对比跨模态推理。该数据集通过人类注释的标题和混合模型的往返一致性过滤器确保高质量监督。尽管特定任务微调提高了性能,但现有模型的总体准确率仍然较低,突显了当前多模态模型的一个重大局限。
Key Takeaways
- 文章中强调了多模态决策制定的重要性,特别是在需要根据不同模态的信息进行选择的情境下。
- 现有的多模态模型在对比跨模态推理方面存在不足,无法选择最符合自然语言提示的模态。
- 引入了一个名为Contra4的新数据集,用于评估跨图像、音频、视频和3D四种模态的对比推理能力。
- Contra4数据集通过结合人类注释和混合模型的往返一致性过滤器来确保高质量监督。
- 数据集包含17.4万份训练样本和经过人工验证的2300份测试样本。
- 任务特定微调可以改善性能,但现有模型的总体准确率仍然较低。
点此查看论文截图



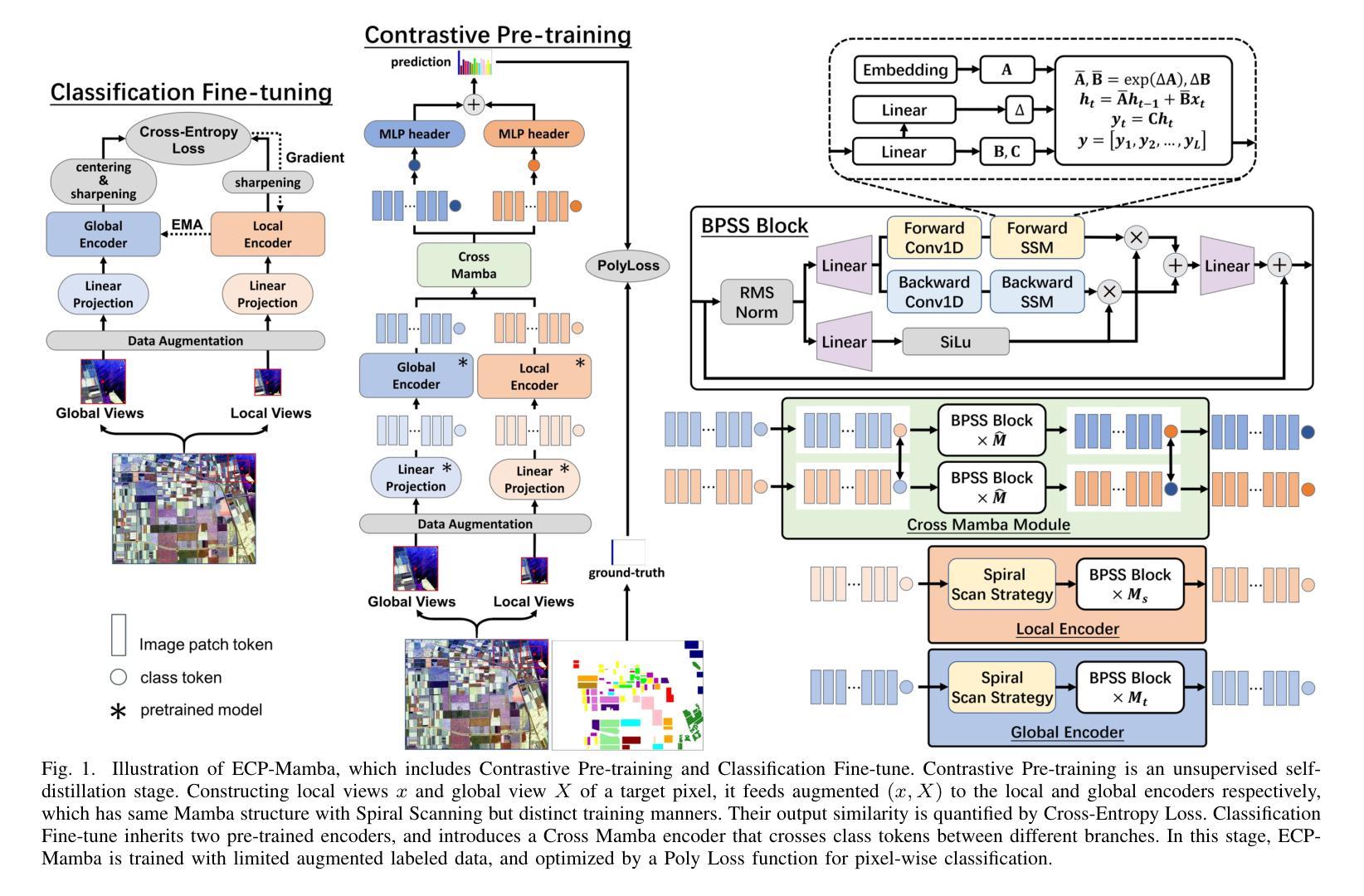
ECP-Mamba: An Efficient Multi-scale Self-supervised Contrastive Learning Method with State Space Model for PolSAR Image Classification
Authors:Zuzheng Kuang, Haixia Bi, Chen Xu, Jian Sun
Recently, polarimetric synthetic aperture radar (PolSAR) image classification has been greatly promoted by deep neural networks. However,current deep learning-based PolSAR classification methods encounter difficulties due to its dependence on extensive labeled data and the computational inefficiency of architectures like Transformers. This paper presents ECP-Mamba, an efficient framework integrating multi-scale self-supervised contrastive learning with a state space model (SSM) backbone. Specifically, ECP-Mamba addresses annotation scarcity through a multi-scale predictive pretext task based on local-to-global feature correspondences, which uses a simplified self-distillation paradigm without negative sample pairs. To enhance computational efficiency,the Mamba architecture (a selective SSM) is first tailored for pixel-wise PolSAR classification task by designing a spiral scan strategy. This strategy prioritizes causally relevant features near the central pixel, leveraging the localized nature of pixel-wise classification tasks. Additionally, the lightweight Cross Mamba module is proposed to facilitates complementary multi-scale feature interaction with minimal overhead. Extensive experiments across four benchmark datasets demonstrate ECP-Mamba’s effectiveness in balancing high accuracy with resource efficiency. On the Flevoland 1989 dataset, ECP-Mamba achieves state-of-the-art performance with an overall accuracy of 99.70%, average accuracy of 99.64% and Kappa coefficient of 99.62e-2. Our code will be available at https://github.com/HaixiaBi1982/ECP_Mamba.
近期,极化合成孔径雷达(PolSAR)图像分类在深度神经网络的大力推动下取得了很大进展。然而,目前基于深度学习的PolSAR分类方法面临着依赖大量标记数据和Transformer架构计算效率不高的困难。本文提出了ECP-Mamba,一个集成了多尺度自监督对比学习与状态空间模型(SSM)主干的高效框架。具体来说,ECP-Mamba通过基于局部到全局特征对应的多尺度预测伪装任务来解决标注稀缺问题,该任务使用简化的自蒸馏范式而不使用负样本对。为提高计算效率,Mamba架构(一种选择性SSM)首先针对像素级的PolSAR分类任务进行定制,通过设计螺旋扫描策略来实现像素级的分类任务。该策略优先利用中央像素附近因果相关的特征,利用像素级分类任务的局部性。此外,还提出了轻量级的Cross Mamba模块,以促进多尺度特征的互补交互,并尽量减少开销。在四个基准数据集上的广泛实验表明,ECP-Mamba在平衡高准确性与资源效率方面非常有效。在Flevoland 1989数据集上,ECP-Mamba取得了最新技术成果,总体精度达到99.70%,平均精度为99.64%,Kappa系数为99.62e-2。我们的代码将在https://github.com/HaixiaBi1982/ECP_Mamba上发布。
论文及项目相关链接
Summary
基于极坐标合成孔径雷达(PolSAR)图像分类问题,当前深度学习的方法依赖于大量标注数据且计算效率低下。本文提出ECP-Mamba框架,通过多尺度自监督对比学习与状态空间模型(SSM)的结合来解决这些问题。通过基于局部到全局特征对应的多尺度预测预训练任务来解决标注稀缺问题,采用简化的自蒸馏范式,无需负样本对。为提高计算效率,Mamba架构首次为像素级的PolSAR分类任务量身定制,通过螺旋扫描策略优先处理与中心像素相关的特征。此外,还提出了轻量级的Cross Mamba模块,以促进多尺度特征的互补交互。在四个基准数据集上的实验表明,ECP-Mamba在高精度和资源效率之间取得了平衡,特别是在Flevoland 1989数据集上取得了卓越性能。
Key Takeaways
- ECP-Mamba结合了多尺度自监督对比学习与状态空间模型(SSM),为PolSAR图像分类提供了一种高效框架。
- 通过基于局部到全局特征对应的多尺度预测预训练任务解决标注稀缺问题。
- 采用简化的自蒸馏范式,无需负样本对,提高了模型的实用性。
- Mamba架构为像素级的PolSAR分类任务量身定制,通过螺旋扫描策略处理相关特征,提高了计算效率。
- 提出了轻量级的Cross Mamba模块,促进多尺度特征的互补交互。
- ECP-Mamba在四个基准数据集上实现了卓越的性能平衡,特别是在Flevoland 1989数据集上。
点此查看论文截图

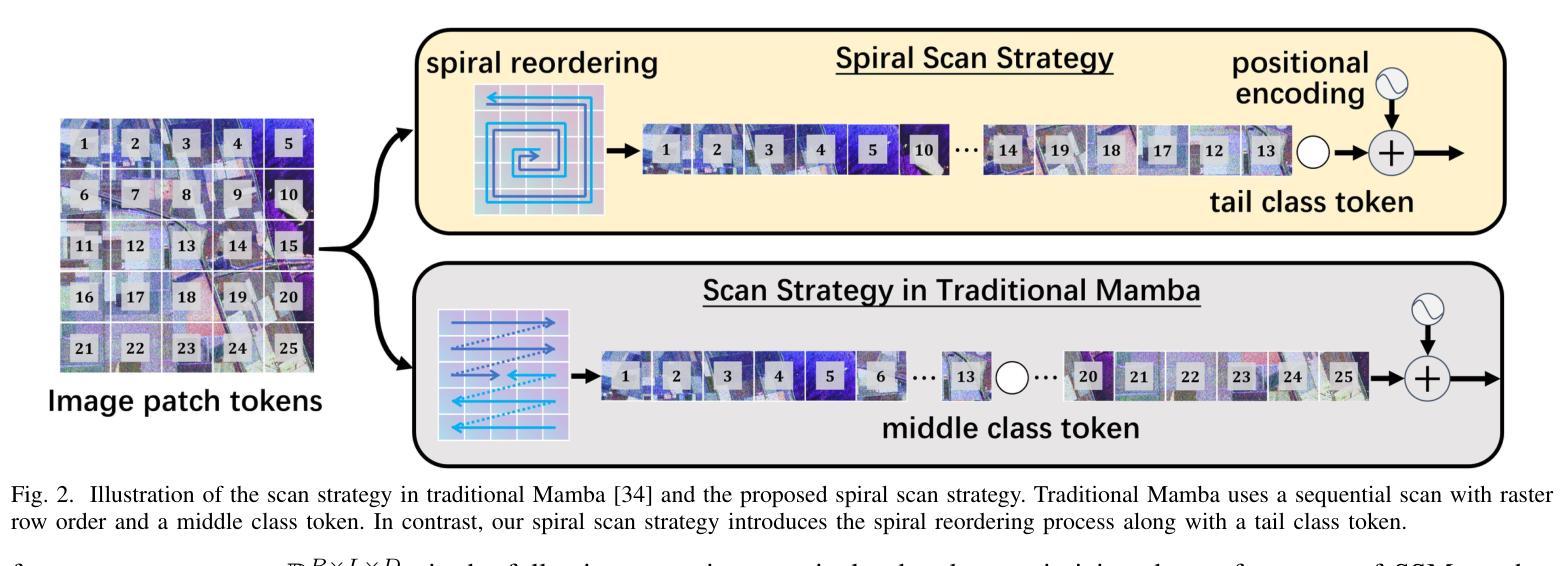
Symmetrical Visual Contrastive Optimization: Aligning Vision-Language Models with Minimal Contrastive Images
Authors:Shengguang Wu, Fan-Yun Sun, Kaiyue Wen, Nick Haber
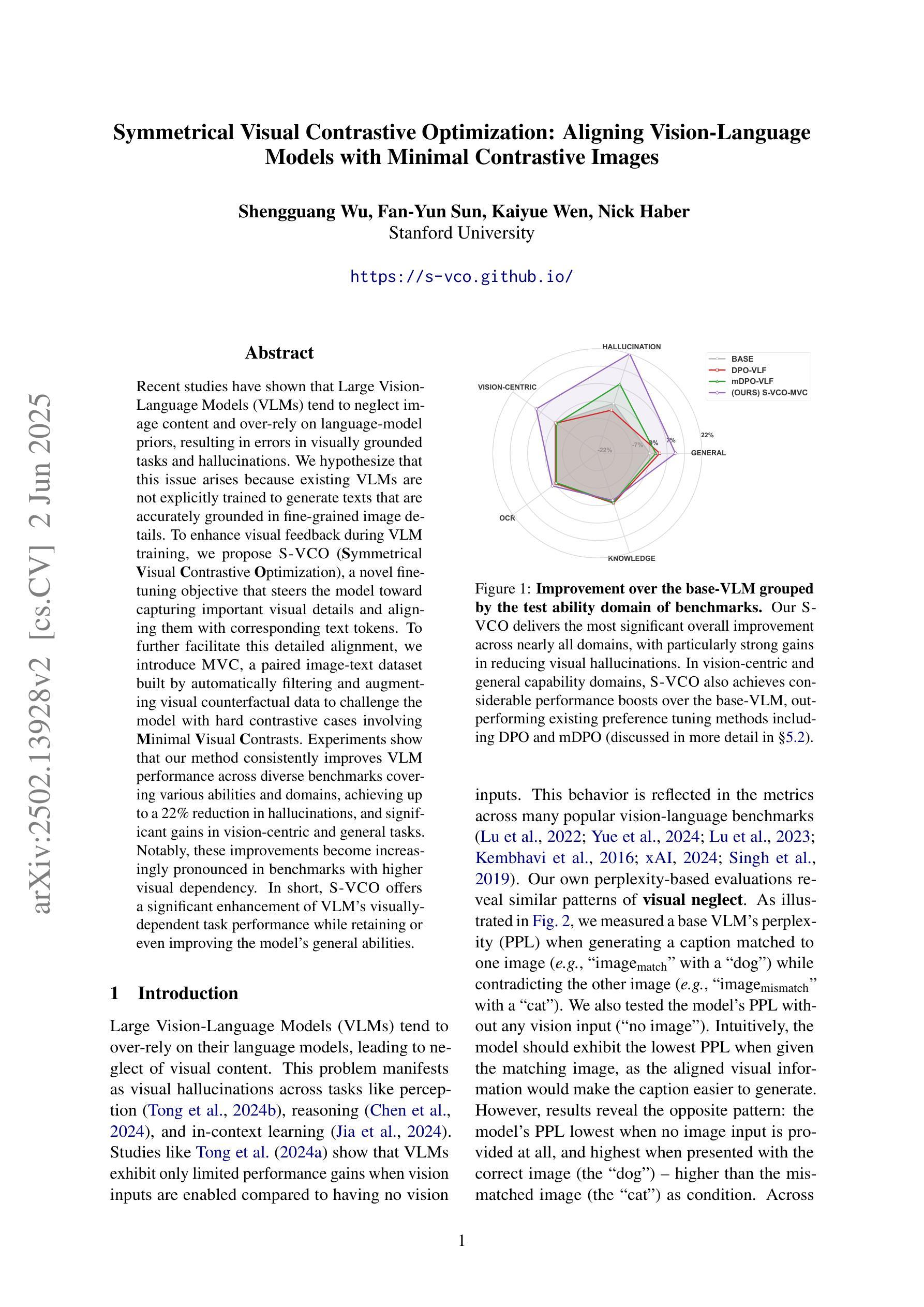
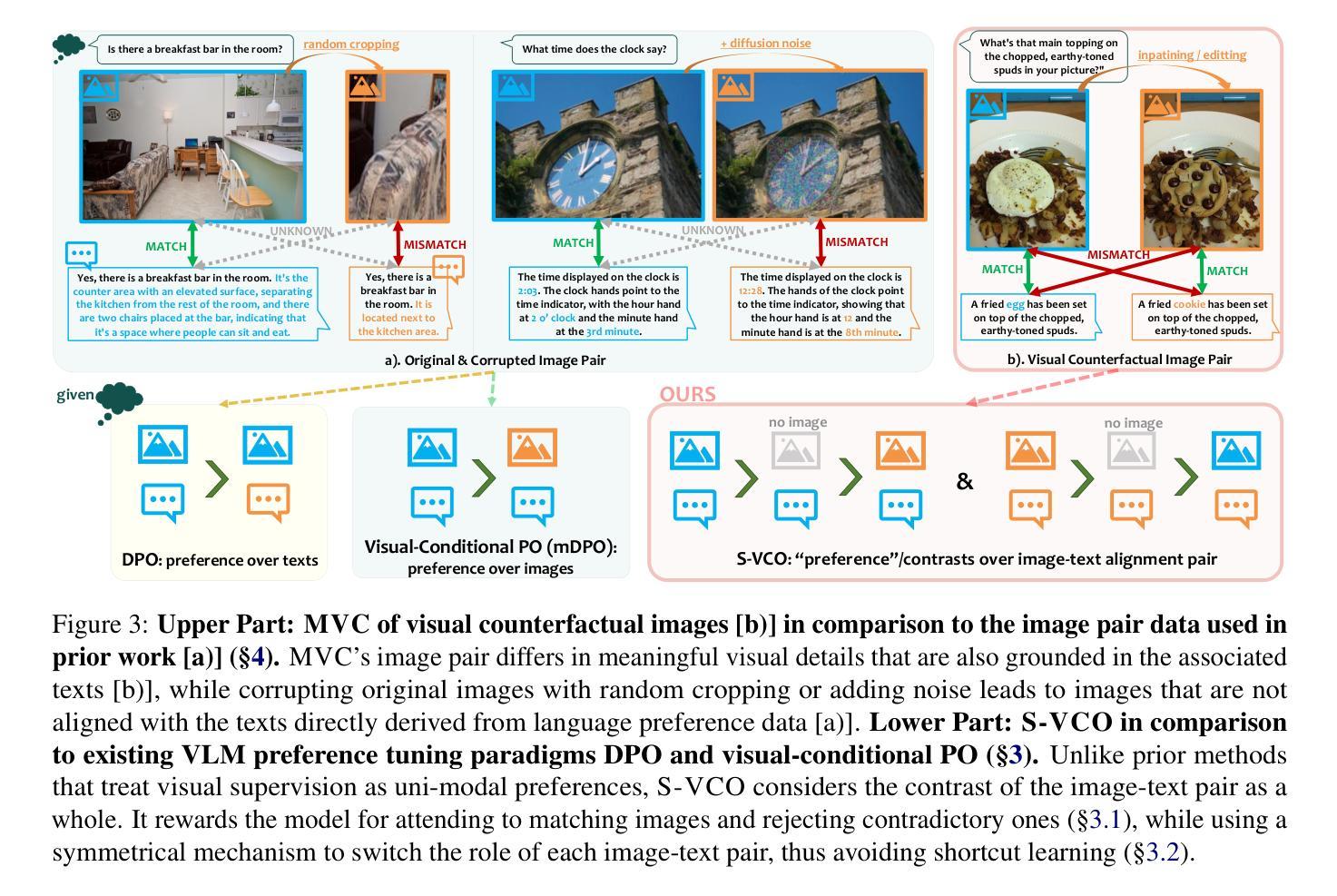
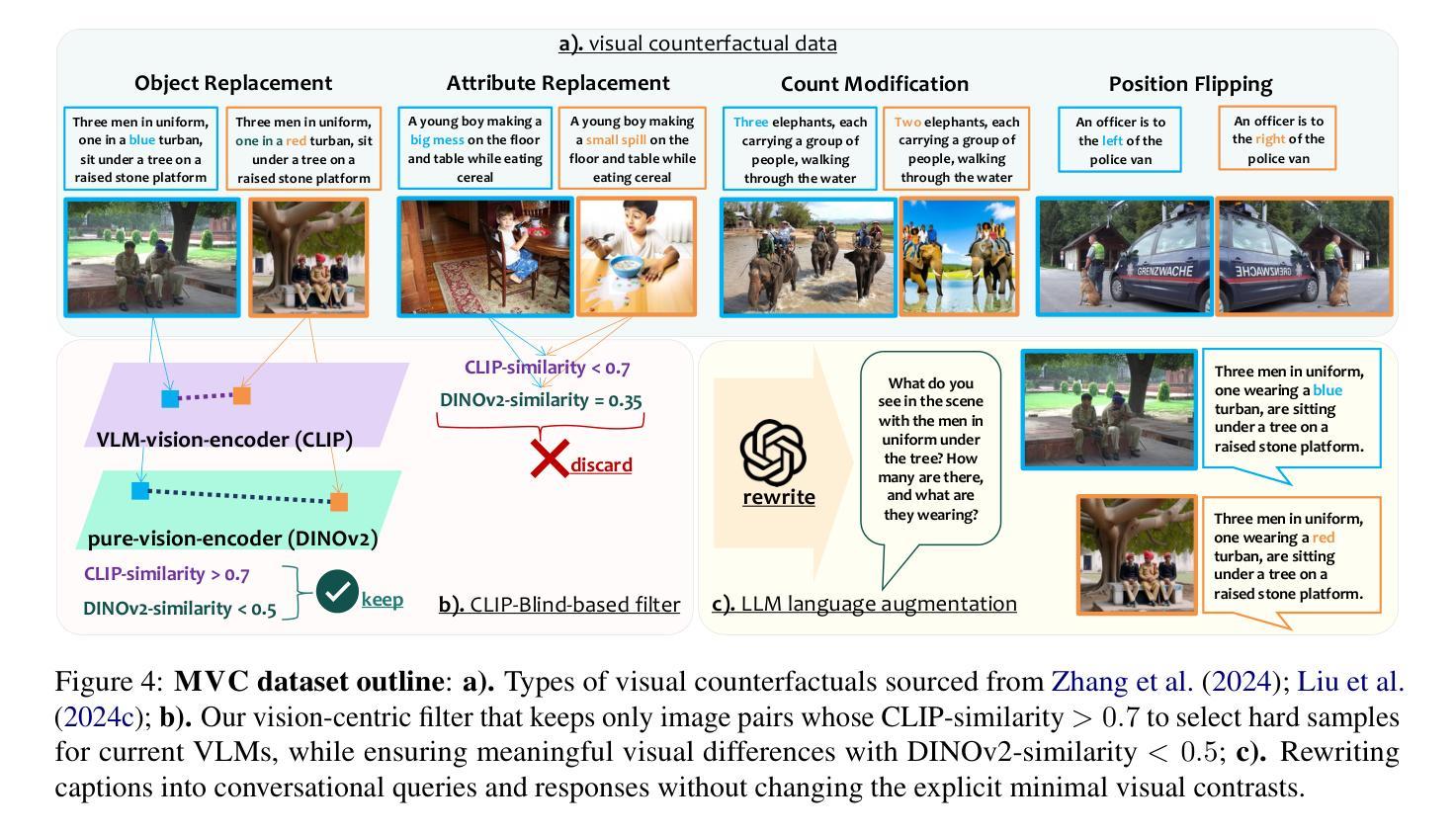
Recent studies have shown that Large Vision-Language Models (VLMs) tend to neglect image content and over-rely on language-model priors, resulting in errors in visually grounded tasks and hallucinations. We hypothesize that this issue arises because existing VLMs are not explicitly trained to generate texts that are accurately grounded in fine-grained image details. To enhance visual feedback during VLM training, we propose S-VCO (Symmetrical Visual Contrastive Optimization), a novel finetuning objective that steers the model toward capturing important visual details and aligning them with corresponding text tokens. To further facilitate this detailed alignment, we introduce MVC, a paired image-text dataset built by automatically filtering and augmenting visual counterfactual data to challenge the model with hard contrastive cases involving Minimal Visual Contrasts. Experiments show that our method consistently improves VLM performance across diverse benchmarks covering various abilities and domains, achieving up to a 22% reduction in hallucinations, and significant gains in vision-centric and general tasks. Notably, these improvements become increasingly pronounced in benchmarks with higher visual dependency. In short, S-VCO offers a significant enhancement of VLM’s visually-dependent task performance while retaining or even improving the model’s general abilities. We opensource our code at https://s-vco.github.io/
最近的研究表明,大型视觉语言模型(VLMs)往往忽视图像内容,过度依赖语言模型的先验知识,导致视觉定位任务出错和出现幻觉。我们假设这个问题出现的原因是现有的VLMs没有被明确地训练去生成准确基于精细图像内容的文本。为了增强VLM训练过程中的视觉反馈,我们提出了S-VCO(对称视觉对比优化),这是一种新的微调目标,引导模型捕捉重要的视觉细节,并将它们与相应的文本标记对齐。为了进一步促进这种详细的对齐,我们引入了MVC,这是一个通过自动过滤和增强视觉反事实数据构建的配对图像文本数据集,以具有最小视觉对比的困难对比案例来挑战模型。实验表明,我们的方法在不同的基准测试中始终提高了VLM的性能,涵盖了各种能力和领域,幻觉减少了高达22%,在视觉为中心的任务和一般任务上都取得了显著的进步。值得注意的是,在视觉依赖性较高的基准测试中,这些改进变得更加突出。简而言之,S-VCO在保留甚至提高模型一般能力的同时,显著提高了VLM对视觉依赖的任务性能。我们在https://s-vco.github.io/开源了我们的代码。
论文及项目相关链接
PDF Accepted to ACL 2025 Main. Project Website: https://s-vco.github.io/
Summary
本文指出大型视觉语言模型(VLMs)在处理视觉任务时存在忽视图像内容、过度依赖语言模型先验的问题,导致错误和幻觉。为解决这一问题,提出S-VCO(对称视觉对比优化)方法,通过构建新的训练目标,增强模型捕捉图像细节的能力,并与文本进行对齐。同时引入MVC数据集,通过自动筛选和增强视觉对比数据,挑战模型在最小视觉对比情况下的表现。实验表明,该方法在不同基准测试中表现优越,减少了幻觉现象,显著提高了视觉任务表现。总的来说,S-VCO增强了VLM的视觉依赖性任务性能,同时保持或提高了模型的通用能力。
Key Takeaways
- 大型视觉语言模型(VLMs)在处理视觉任务时存在忽视图像内容的问题。
- VLMs过度依赖语言模型先验,导致错误和幻觉。
- S-VCO方法通过构建新的训练目标,增强模型捕捉图像细节的能力。
- S-VCO引入MVC数据集,通过自动筛选和增强视觉对比数据,提高模型表现。
- 实验表明S-VCO方法在不同基准测试中表现优越,减少了幻觉现象。
- S-VCO增强了VLM的视觉依赖性任务性能。
点此查看论文截图
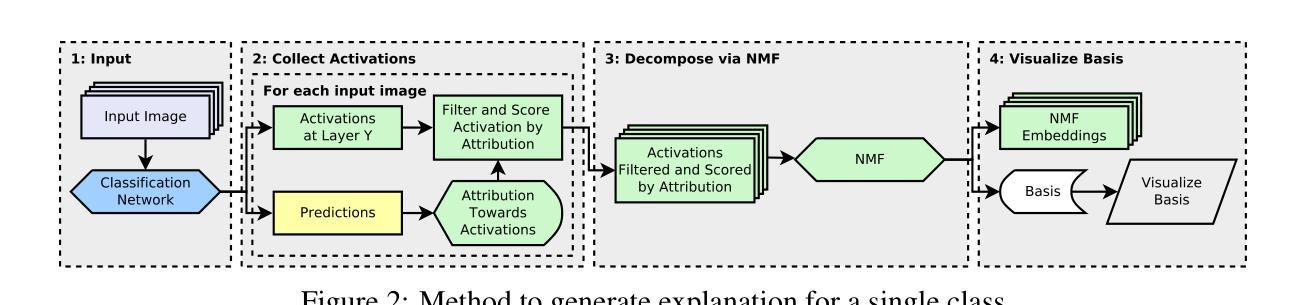
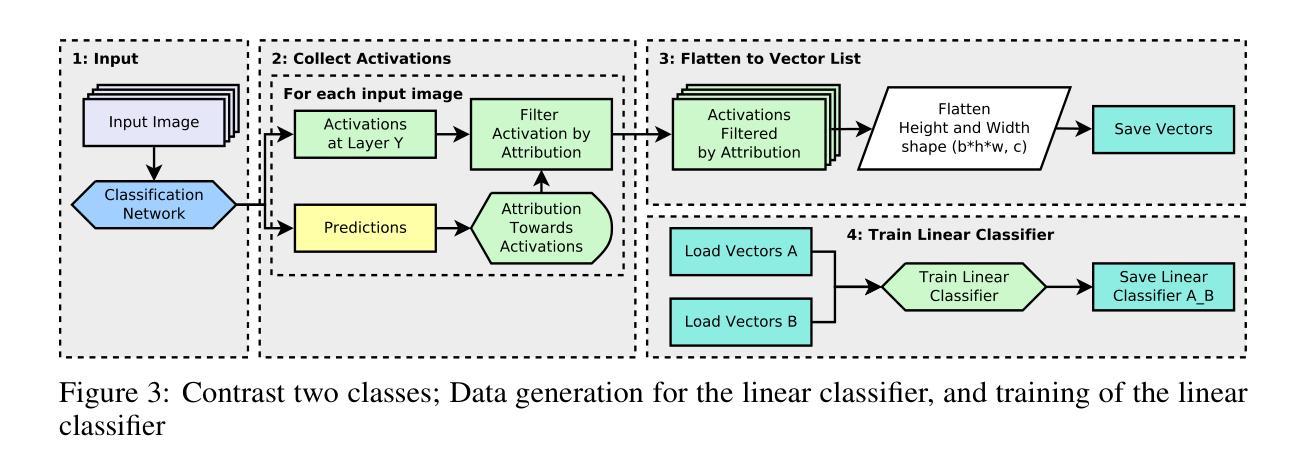
Concept Based Explanations and Class Contrasting
Authors:Rudolf Herdt, Daniel Otero Baguer
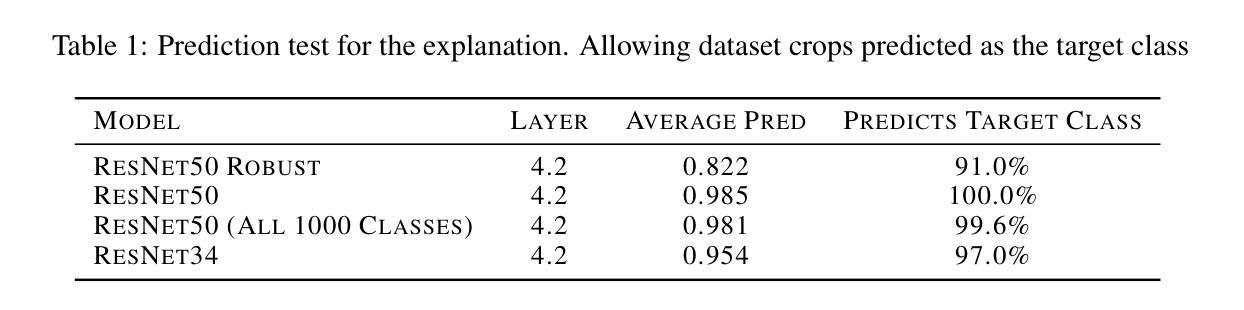
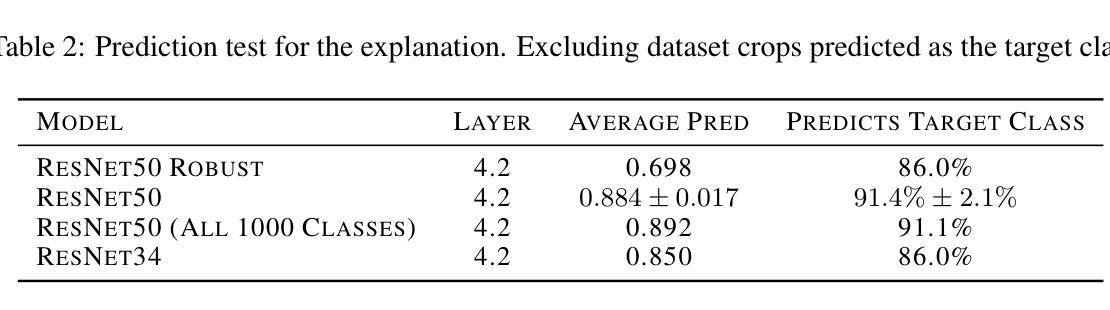
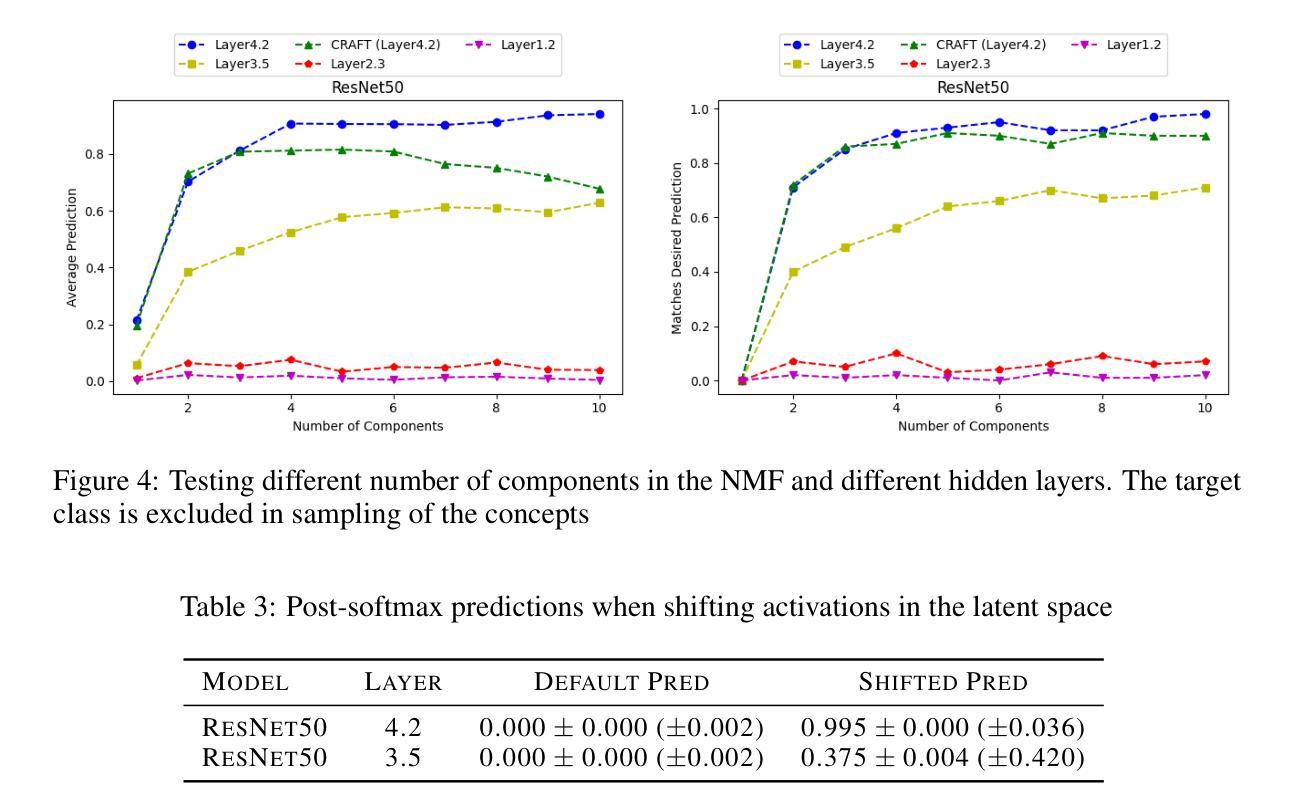
Explaining deep neural networks is challenging, due to their large size and non-linearity. In this paper, we introduce a concept-based explanation method, in order to explain the prediction for an individual class, as well as contrasting any two classes, i.e. explain why the model predicts one class over the other. We test it on several openly available classification models trained on ImageNet1K. We perform both qualitative and quantitative tests. For example, for a ResNet50 model from pytorch model zoo, we can use the explanation for why the model predicts a class ‘A’ to automatically select four dataset crops where the model does not predict class ‘A’. The model then predicts class ‘A’ again for the newly combined image in 91.1% of the cases (works for 911 out of the 1000 classes). The code including an .ipynb example is available on github: https://github.com/rherdt185/concept-based-explanations-and-class-contrasting
解释深度神经网络是一项具有挑战性的任务,因为其规模庞大且非线性。在本文中,我们介绍了一种基于概念的解释方法,旨在解释针对单个类别的预测,并对比任何两个类别,即解释模型为何会预测某一类别而非其他类别。我们在公开可用的多个在ImageNet1K上训练的分类模型上进行了测试。我们既进行定性测试又进行定量测试。例如,对于来自pytorch模型库的ResNet50模型,我们可以使用模型预测类别“A”的解释来自动选择四个数据集裁剪图像,其中模型不预测类别“A”。然后,对于新组合的图像,模型在91.1%的情况下再次预测类别“A”(在1000个类别中适用于911个类别)。包括一个.ipynb示例的代码可在github上找到:https://github.com/rherdt185/concept-based-explanations-and-class-contrasting
论文及项目相关链接
Summary
本文介绍了一种基于概念的解释方法,用于解释深度神经网络对单个类别的预测,以及对比任何两个类别的预测。通过对多个公开可用的ImageNet1K分类模型进行测试,该方法既能进行定性测试,也能进行定量测试。例如,对于PyTorch模型库中的ResNet50模型,该方法可以解释模型预测某一类别(如类别A)的原因,并自动选择四个数据集裁剪图像,在这些图像上模型不预测类别A。然后,对于新组合的图像,模型在91.1%的情况下再次预测类别A(适用于1000个类别中的911个类别)。
Key Takeaways
- 引入了一种基于概念的解释方法,用于解释深度神经网络对单个类别的预测以及对比任意两个类别的预测。
- 方法在多个公开可用的ImageNet1K分类模型上进行了测试。
- 提供了定性和定量测试。
- 对于ResNet50模型,可以通过解释模型预测某一类别(如类别A)的原因,自动选择数据集裁剪图像。
- 在新组合的图像上,模型在大部分情况下能够继续预测同一类别。
- 该方法包括一个可用的代码示例,可以在GitHub上找到:https://github.com/rherdt185/concept-based-explanations-and-class-contrasting。
- 此方法提供了一个深入了解模型决策过程的工具,可能有助于增强模型的可靠性和透明度。
点此查看论文截图