⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-05 更新
Efficient Test-time Adaptive Object Detection via Sensitivity-Guided Pruning
Authors:Kunyu Wang, Xueyang Fu, Xin Lu, Chengjie Ge, Chengzhi Cao, Wei Zhai, Zheng-Jun Zha
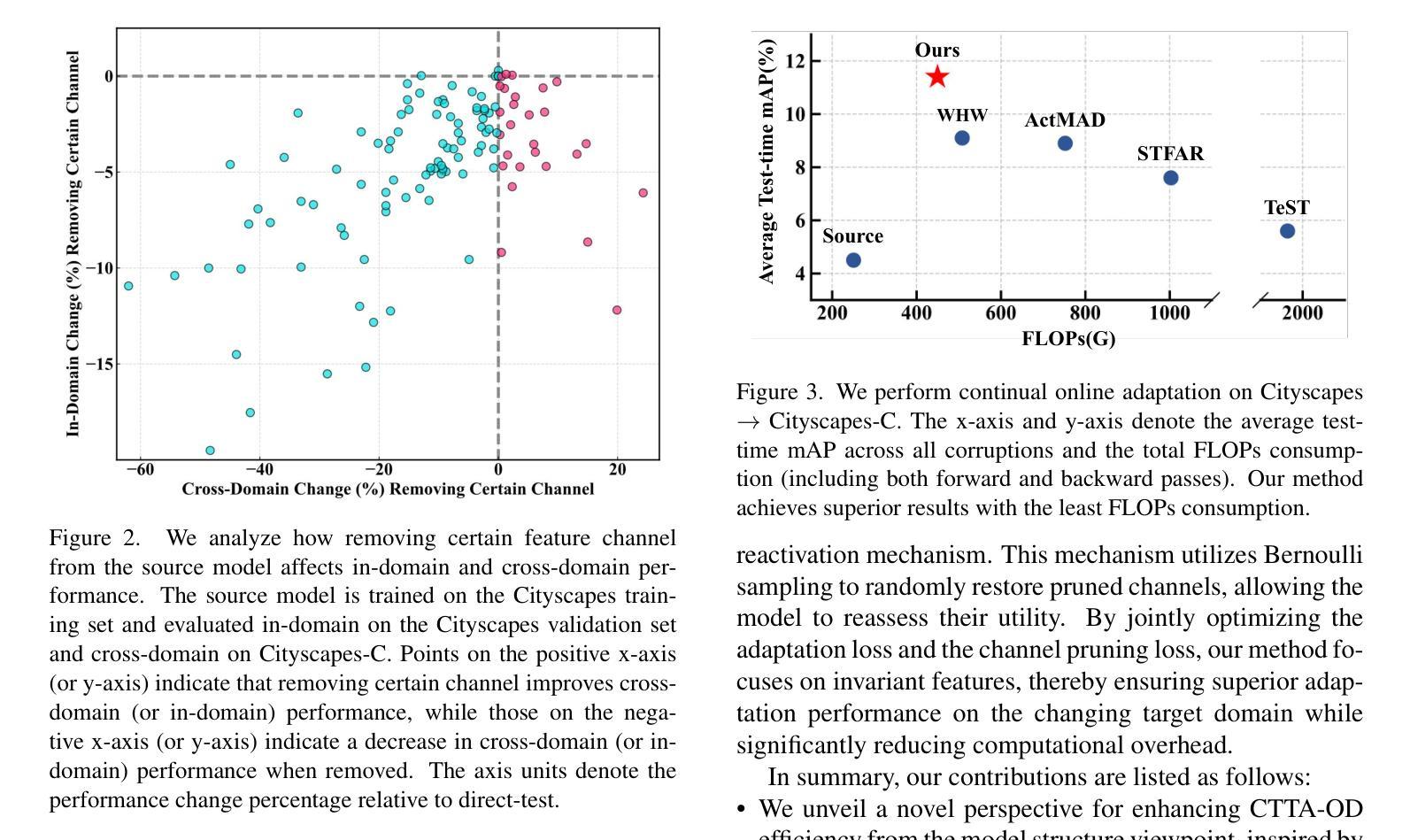
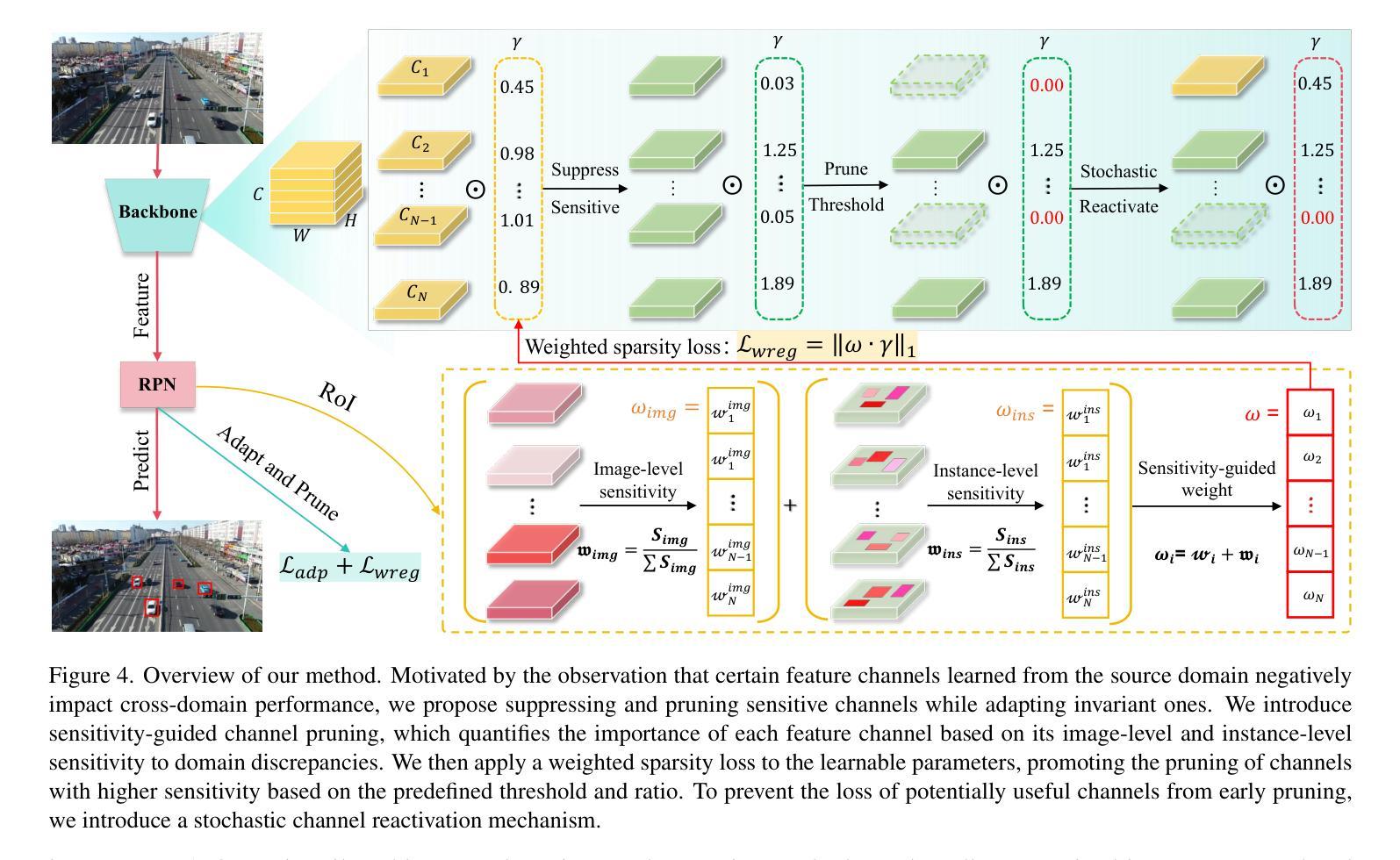
Continual test-time adaptive object detection (CTTA-OD) aims to online adapt a source pre-trained detector to ever-changing environments during inference under continuous domain shifts. Most existing CTTA-OD methods prioritize effectiveness while overlooking computational efficiency, which is crucial for resource-constrained scenarios. In this paper, we propose an efficient CTTA-OD method via pruning. Our motivation stems from the observation that not all learned source features are beneficial; certain domain-sensitive feature channels can adversely affect target domain performance. Inspired by this, we introduce a sensitivity-guided channel pruning strategy that quantifies each channel based on its sensitivity to domain discrepancies at both image and instance levels. We apply weighted sparsity regularization to selectively suppress and prune these sensitive channels, focusing adaptation efforts on invariant ones. Additionally, we introduce a stochastic channel reactivation mechanism to restore pruned channels, enabling recovery of potentially useful features and mitigating the risks of early pruning. Extensive experiments on three benchmarks show that our method achieves superior adaptation performance while reducing computational overhead by 12% in FLOPs compared to the recent SOTA method.
持续测试时间自适应目标检测(CTTA-OD)旨在在线适应源预训练检测器,以应对不断变化的域转移过程中的推理环境。现有的大多数CTTA-OD方法虽然重视有效性,却忽略了计算效率,这在资源受限的场景中至关重要。在本文中,我们提出了一种通过修剪来提高CTTA-OD效率的方法。我们的动机源于这样一个观察:并非所有学到的源特征都是有益的;某些域敏感特征通道可能会对目标域性能产生不利影响。受此启发,我们引入了一种基于敏感度的通道修剪策略,该策略根据图像和实例级别的域差异敏感度来量化每个通道。我们应用加权稀疏正则化来有选择地抑制和修剪这些敏感通道,将自适应努力集中在不变通道上。此外,我们还引入了一种随机通道再激活机制,以恢复修剪的通道,从而实现潜在有用特征的恢复,并降低早期修剪的风险。在三个基准测试上的广泛实验表明,我们的方法在达到优越的适应性能的同时,与最近的最优方法相比,浮点运算量(FLOPs)减少了12%。
论文及项目相关链接
PDF Accepted as CVPR 2025 oral paper
Summary
在线自适应对象检测(CTTA-OD)旨在在新环境持续变化的情况下,对源预训练检测器进行在线适应。现有CTTA-OD方法过于注重效果而忽视计算效率,这对于资源受限的场景至关重要。本文提出了一种基于剪枝的高效CTTA-OD方法。我们的动机源于观察到的并非所有学习到的源特征都有益,某些对领域敏感的特征通道可能会对目标域性能产生负面影响。因此,我们提出了一种基于敏感性引导的渠道剪枝策略,根据图像和实例级别的领域差异敏感性来量化每个通道。我们应用加权稀疏正则化来有选择地抑制和剪除这些敏感通道,将适应努力集中在不变通道上。此外,我们还引入了一种随机通道重新激活机制,以恢复被剪枝的通道,从而恢复潜在的有用特征并降低早期剪枝的风险。实验表明,我们的方法在三个基准测试上都实现了出色的适应性能,与最新方法相比,计算量减少了12%。
Key Takeaways
- CTTA-OD旨在在线适应源预训练检测器以应对不断变化的环境。
- 现有方法过于注重效果而忽视计算效率,这在资源受限场景中至关重要。
- 提出了一种基于敏感性引导的渠道剪枝策略,通过量化每个通道的敏感性来选择性地剪除对领域敏感的特征通道。
- 应用加权稀疏正则化以抑制并剪除敏感通道,同时集中适应努力在不变通道上。
- 引入随机通道重新激活机制来恢复潜在的有用特征并降低早期剪枝的风险。
- 在三个基准测试上实现了出色的适应性能。
点此查看论文截图


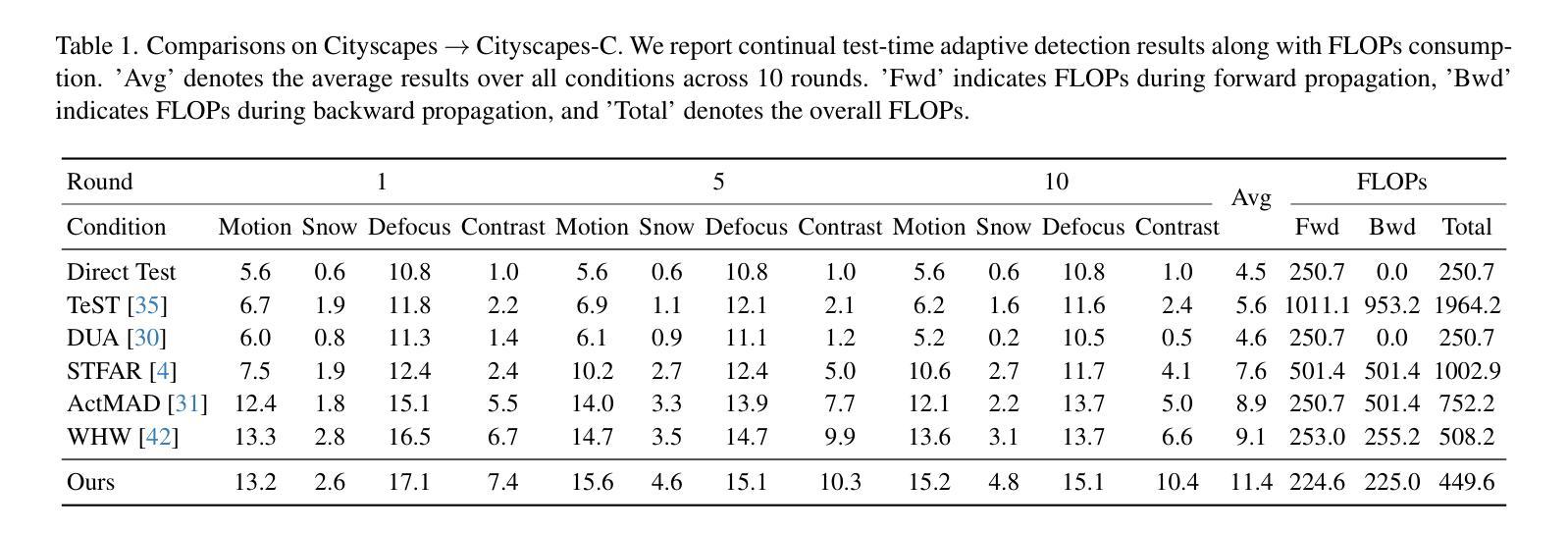
OD3: Optimization-free Dataset Distillation for Object Detection
Authors:Salwa K. Al Khatib, Ahmed ElHagry, Shitong Shao, Zhiqiang Shen
Training large neural networks on large-scale datasets requires substantial computational resources, particularly for dense prediction tasks such as object detection. Although dataset distillation (DD) has been proposed to alleviate these demands by synthesizing compact datasets from larger ones, most existing work focuses solely on image classification, leaving the more complex detection setting largely unexplored. In this paper, we introduce OD3, a novel optimization-free data distillation framework specifically designed for object detection. Our approach involves two stages: first, a candidate selection process in which object instances are iteratively placed in synthesized images based on their suitable locations, and second, a candidate screening process using a pre-trained observer model to remove low-confidence objects. We perform our data synthesis framework on MS COCO and PASCAL VOC, two popular detection datasets, with compression ratios ranging from 0.25% to 5%. Compared to the prior solely existing dataset distillation method on detection and conventional core set selection methods, OD3 delivers superior accuracy, establishes new state-of-the-art results, surpassing prior best method by more than 14% on COCO mAP50 at a compression ratio of 1.0%. Code and condensed datasets are available at: https://github.com/VILA-Lab/OD3.
训练大型神经网络需要大量的计算资源,特别是在对象检测等密集预测任务中。虽然数据集蒸馏(DD)已被提出通过从较大的数据集中合成紧凑数据集来缓解这些需求,但现有的大部分工作仅专注于图像分类,而更复杂的目标检测设置则很少被探索。在本文中,我们介绍了OD3,这是一种无需优化的数据蒸馏框架,专为对象检测设计。我们的方法分为两个阶段:第一阶段是候选选择过程,其中对象实例会基于合适的位置迭代地放置在合成图像中;第二阶段是使用预训练的观察者模型进行候选筛选过程,以去除低置信度的对象。我们在MS COCO和PASCAL VOC这两个流行的检测数据集上执行了数据合成框架,压缩率范围为0.25%~5%。与现有的其他检测方法以及传统的核心集选择方法相比,OD3具有更高的准确性,建立了新的最先进的检测结果,在压缩率为1.0%的COCO mAP50上超过了现有最佳方法超过14%。代码和浓缩数据集可在:https://github.com/VILA-Lab/OD3找到。
论文及项目相关链接
PDF Equal Contribution of the first three authors
Summary
本文提出了一种针对目标检测任务的无优化数据蒸馏框架OD3,旨在从大规模数据集中合成紧凑数据集,降低计算资源需求。该框架包含两个阶段:候选选择阶段和候选筛选阶段。通过迭代放置目标实例和基于预训练观察者模型去除低置信度目标,实现在MS COCO和PASCAL VOC数据集上的数据合成。OD3在压缩比为0.25%至5%的情况下,相较于现有的检测数据集蒸馏方法和常规核心集选择方法,具有更高的准确性,达到了新的先进水平,特别是在COCO mAP50的压缩比为1.0%时,超过了现有最佳方法超过14%。
Key Takeaways
- OD3是一种针对目标检测任务的数据蒸馏框架,旨在从大规模数据集中合成紧凑数据集以降低计算资源需求。
- 该框架包含两个阶段:通过迭代放置目标实例进行候选选择,以及基于预训练观察者模型去除低置信度目标进行候选筛选。
- OD3在MS COCO和PASCAL VOC数据集上进行了实验,实现了数据合成。
- 在压缩比为1.0%时,OD3在COCO mAP50上的性能超过了现有最佳方法超过14%,展现了其优越性。
- OD3相较于现有的检测数据集蒸馏方法和常规核心集选择方法,具有更高的准确性。
- OD3的代码和合成数据集已公开在https://github.com/VILA-Lab/OD3。
- OD3框架为降低大规模神经网络在密集预测任务上的计算资源需求提供了新的解决方案。
点此查看论文截图

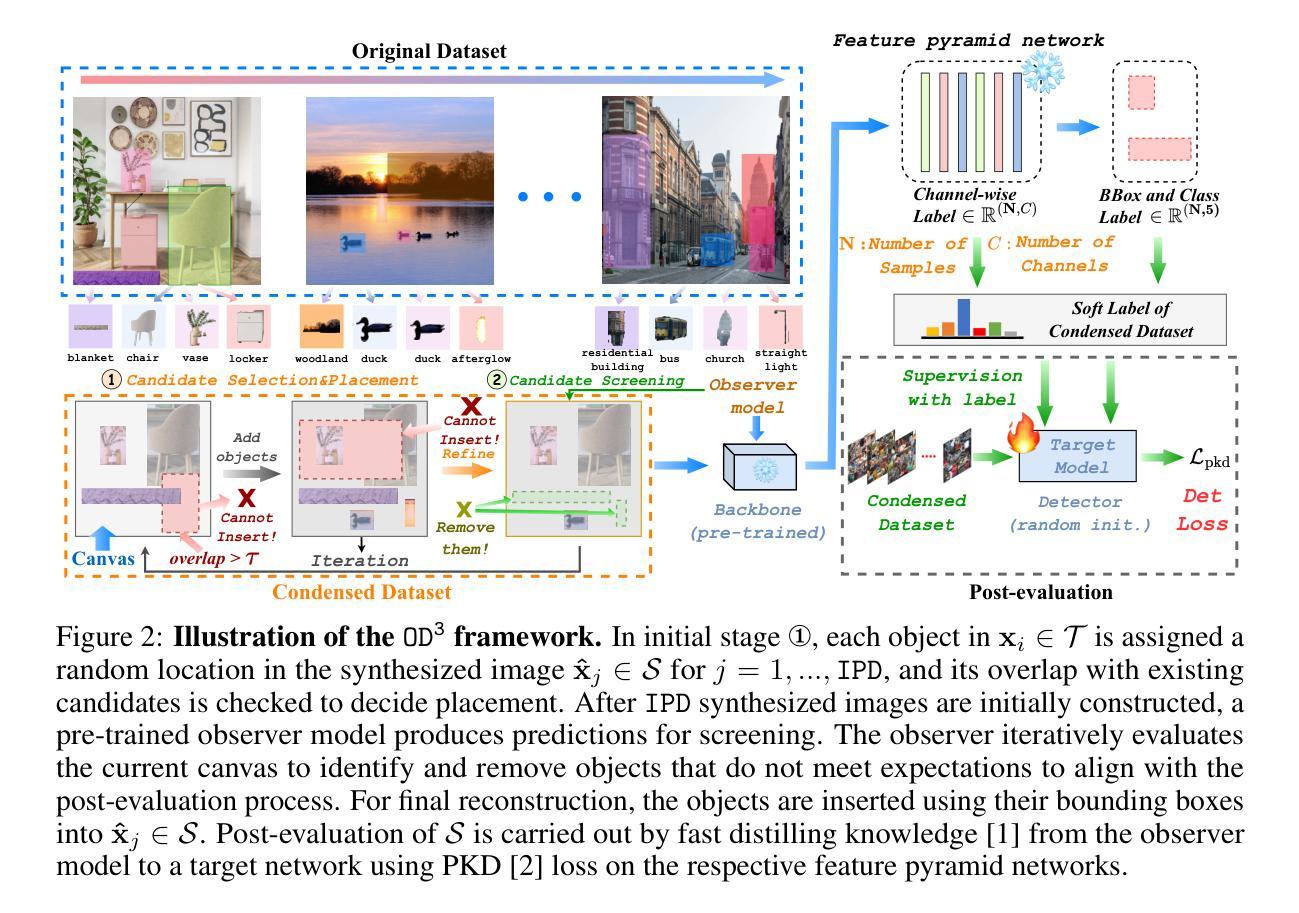


Seg2Any: Open-set Segmentation-Mask-to-Image Generation with Precise Shape and Semantic Control
Authors:Danfeng li, Hui Zhang, Sheng Wang, Jiacheng Li, Zuxuan Wu
Despite recent advances in diffusion models, top-tier text-to-image (T2I) models still struggle to achieve precise spatial layout control, i.e. accurately generating entities with specified attributes and locations. Segmentation-mask-to-image (S2I) generation has emerged as a promising solution by incorporating pixel-level spatial guidance and regional text prompts. However, existing S2I methods fail to simultaneously ensure semantic consistency and shape consistency. To address these challenges, we propose Seg2Any, a novel S2I framework built upon advanced multimodal diffusion transformers (e.g. FLUX). First, to achieve both semantic and shape consistency, we decouple segmentation mask conditions into regional semantic and high-frequency shape components. The regional semantic condition is introduced by a Semantic Alignment Attention Mask, ensuring that generated entities adhere to their assigned text prompts. The high-frequency shape condition, representing entity boundaries, is encoded as an Entity Contour Map and then introduced as an additional modality via multi-modal attention to guide image spatial structure. Second, to prevent attribute leakage across entities in multi-entity scenarios, we introduce an Attribute Isolation Attention Mask mechanism, which constrains each entity’s image tokens to attend exclusively to themselves during image self-attention. To support open-set S2I generation, we construct SACap-1M, a large-scale dataset containing 1 million images with 5.9 million segmented entities and detailed regional captions, along with a SACap-Eval benchmark for comprehensive S2I evaluation. Extensive experiments demonstrate that Seg2Any achieves state-of-the-art performance on both open-set and closed-set S2I benchmarks, particularly in fine-grained spatial and attribute control of entities.
尽管扩散模型最近有所进展,顶级文本到图像(T2I)模型仍然难以实现精确的空间布局控制,即准确生成具有指定属性和位置的实体。分割掩膜到图像(S2I)生成通过结合像素级空间指导和区域文本提示,已成为一种有前途的解决方案。然而,现有的S2I方法无法同时确保语义一致性和形状一致性。为了应对这些挑战,我们提出了Seg2Any,一个基于先进的多模态扩散变压器(例如FLUX)的新型S2I框架。首先,为了实现语义和形状的一致性,我们将分割掩膜条件分解为区域语义和高频形状组件。通过语义对齐注意力掩膜引入区域语义条件,确保生成的实体符合其分配到的文本提示。高频形状条件代表实体边界,被编码为实体轮廓图,然后作为多模态注意力的一种额外模态引入,以引导图像的空间结构。其次,为了防止多实体场景中属性在实体之间的泄露,我们引入了属性隔离注意力掩膜机制,该机制约束每个实体的图像令牌在图像自注意力期间只专注于自身。为了支持开放集S2I生成,我们构建了SACap-1M,这是一个包含100万张图像、590万个分割实体和详细区域描述的大型数据集,以及用于全面S2I评价的SACap-Eval基准测试。大量实验表明,Seg2Any在开放集和封闭集S2I基准测试上均达到了最先进的性能,特别是在实体的精细空间和控制属性方面。
论文及项目相关链接
Summary
本文提出了一种新的分割掩膜到图像(S2I)框架Seg2Any,用于解决文本到图像生成中精确空间布局控制的问题。Seg2Any利用先进的跨模态扩散转换器(如FLUX),通过分离语义和形状一致性条件,实现更精细的实体边界和文本提示对齐。此外,它还引入了一种属性隔离注意力掩膜机制,以防止多实体场景中属性泄露。实验表明,Seg2Any在开放和封闭集合的S2I基准测试中均取得了最先进的性能。
Key Takeaways
- Seg2Any是一个新的分割掩膜到图像(S2I)框架,旨在解决文本到图像生成中精确空间布局控制的挑战。
- Seg2Any利用先进的跨模态扩散转换器(如FLUX),通过区域语义条件和高频形状条件的分离,实现了语义和形状的一致性。
- 框架中引入了语义对齐注意力掩膜和实体轮廓图,以确保生成的实体符合文本提示并保持形状一致性。
- 为了防止多实体场景中属性泄露,Seg2Any引入了属性隔离注意力掩膜机制。
- Seg2Any支持开放集S2I生成,并构建了一个大规模数据集SACap-1M,包含100万张图像和详细的区域字幕。
- SACap-Eval基准测试用于全面评估S2I性能。
点此查看论文截图


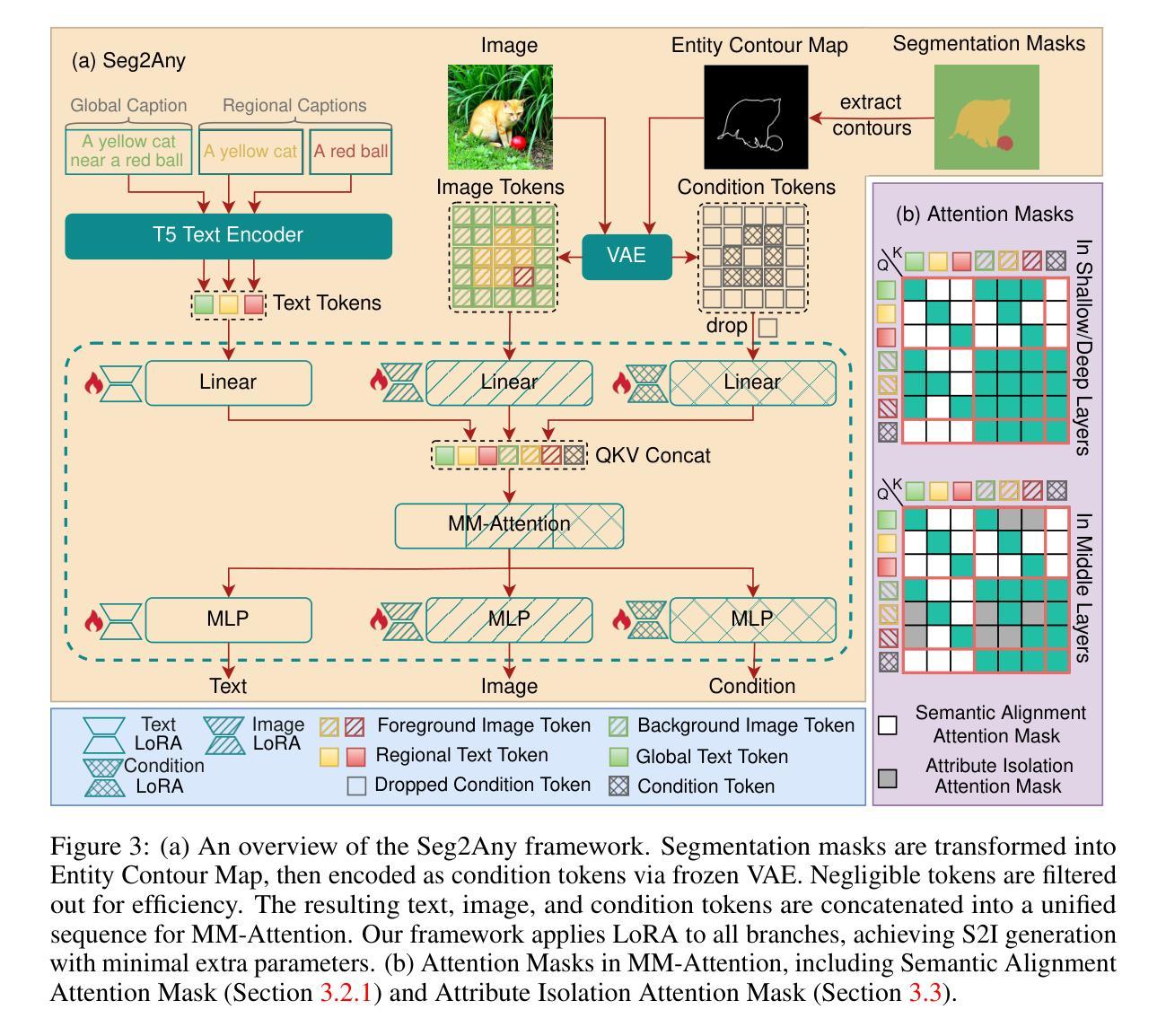
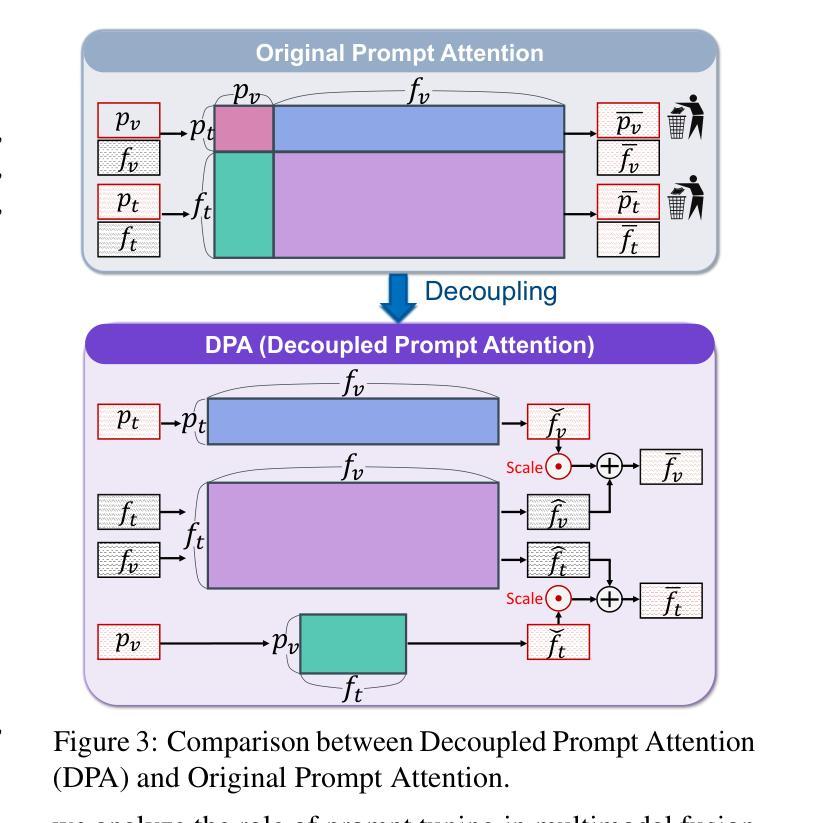
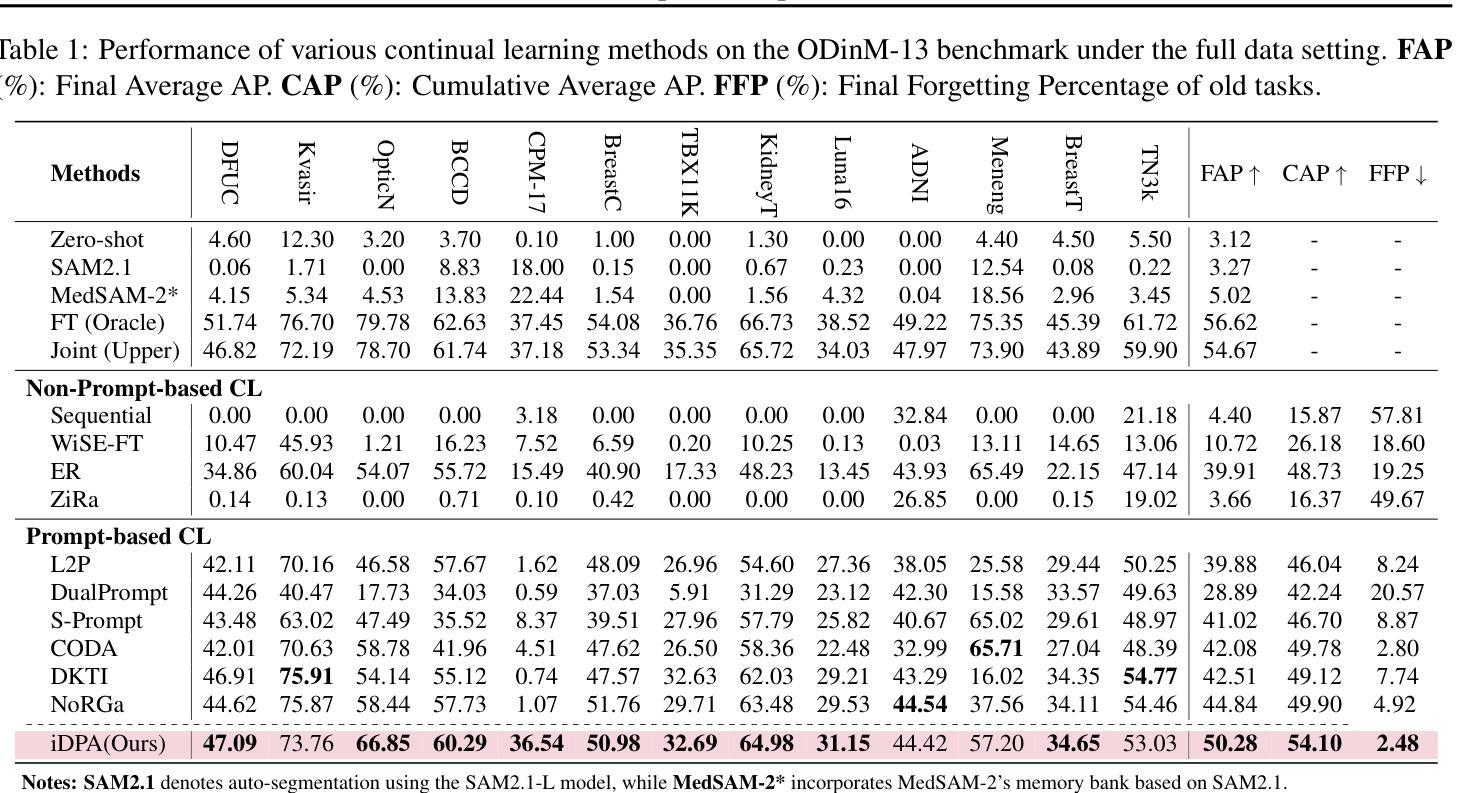
iDPA: Instance Decoupled Prompt Attention for Incremental Medical Object Detection
Authors:Huahui Yi, Wei Xu, Ziyuan Qin, Xi Chen, Xiaohu Wu, Kang Li, Qicheng Lao
Existing prompt-based approaches have demonstrated impressive performance in continual learning, leveraging pre-trained large-scale models for classification tasks; however, the tight coupling between foreground-background information and the coupled attention between prompts and image-text tokens present significant challenges in incremental medical object detection tasks, due to the conceptual gap between medical and natural domains. To overcome these challenges, we introduce the \methodframework, which comprises two main components: 1) Instance-level Prompt Generation (\ipg), which decouples fine-grained instance-level knowledge from images and generates prompts that focus on dense predictions, and 2) Decoupled Prompt Attention (\dpa), which decouples the original prompt attention, enabling a more direct and efficient transfer of prompt information while reducing memory usage and mitigating catastrophic forgetting. We collect 13 clinical, cross-modal, multi-organ, and multi-category datasets, referred to as \dataset, and experiments demonstrate that \methodoutperforms existing SOTA methods, with FAP improvements of 5.44%, 4.83%, 12.88%, and 4.59% in full data, 1-shot, 10-shot, and 50-shot settings, respectively.
现有基于提示的方法在持续学习方面表现出了令人印象深刻的性能,利用预训练的大规模模型进行分类任务;然而,在增量医学目标检测任务中,前景与背景信息之间的紧密耦合以及提示与图像文本标记之间的耦合注意力,由于医学和自然领域之间的概念差距,带来了重大挑战。为了克服这些挑战,我们引入了\method
框架,它包括两个主要组件:1)实例级提示生成(\ipg),它从图像中解耦出精细的实例级知识,并生成专注于密集预测的提示;2)解耦提示注意力(\dpa),它解耦了原始的提示注意力,使提示信息的传递更加直接和高效,同时减少了内存使用并减轻了灾难性遗忘。我们收集了13个临床、跨模态、多器官和多类别的数据集,称为\dataset,实验表明\method在全面数据、单次学习、十次学习和五十次学习的设定下,较现有最先进的方法有了显著的改进,FAP分别提高了5.44%、4.83%、12.88%和4.59%。
论文及项目相关链接
PDF accepted to ICML 2025
Summary
本文介绍了在连续学习中的医学对象检测任务面临的挑战,并提出了新的框架\method~。该框架包含两个主要组件:Instance-level Prompt Generation(\ipg)和Decoupled Prompt Attention(\dpa)。实验表明,该框架在多个数据集上的性能优于现有方法,提高了FAP指标。
Key Takeaways
- 预训练的大规模模型在分类任务中的连续学习效果令人印象深刻,但在医学对象检测任务中面临挑战。
- \method~框架包含两个主要组件:\ipg和\dpa,分别用于生成实例级提示和解耦提示注意力。
- \method~框架通过减少内存使用和缓解灾难性遗忘,使提示信息更加直接和高效。
- 收集的\dataset包含多种临床、跨模态、多器官和多类别的数据集。
- 实验表明,\method~框架在全数据、1-shot、10-shot和50-shot设置下,性能优于现有方法。
点此查看论文截图

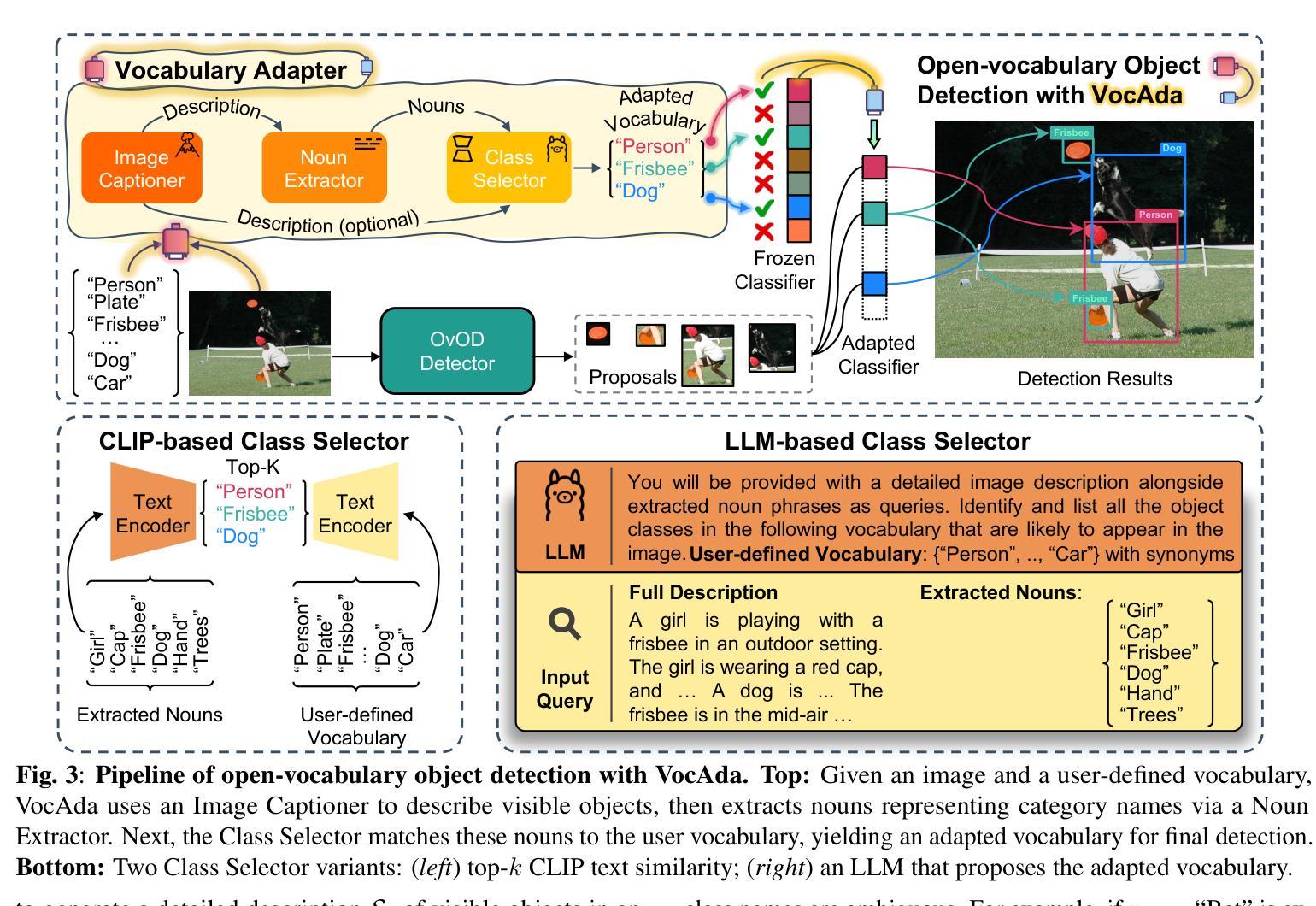
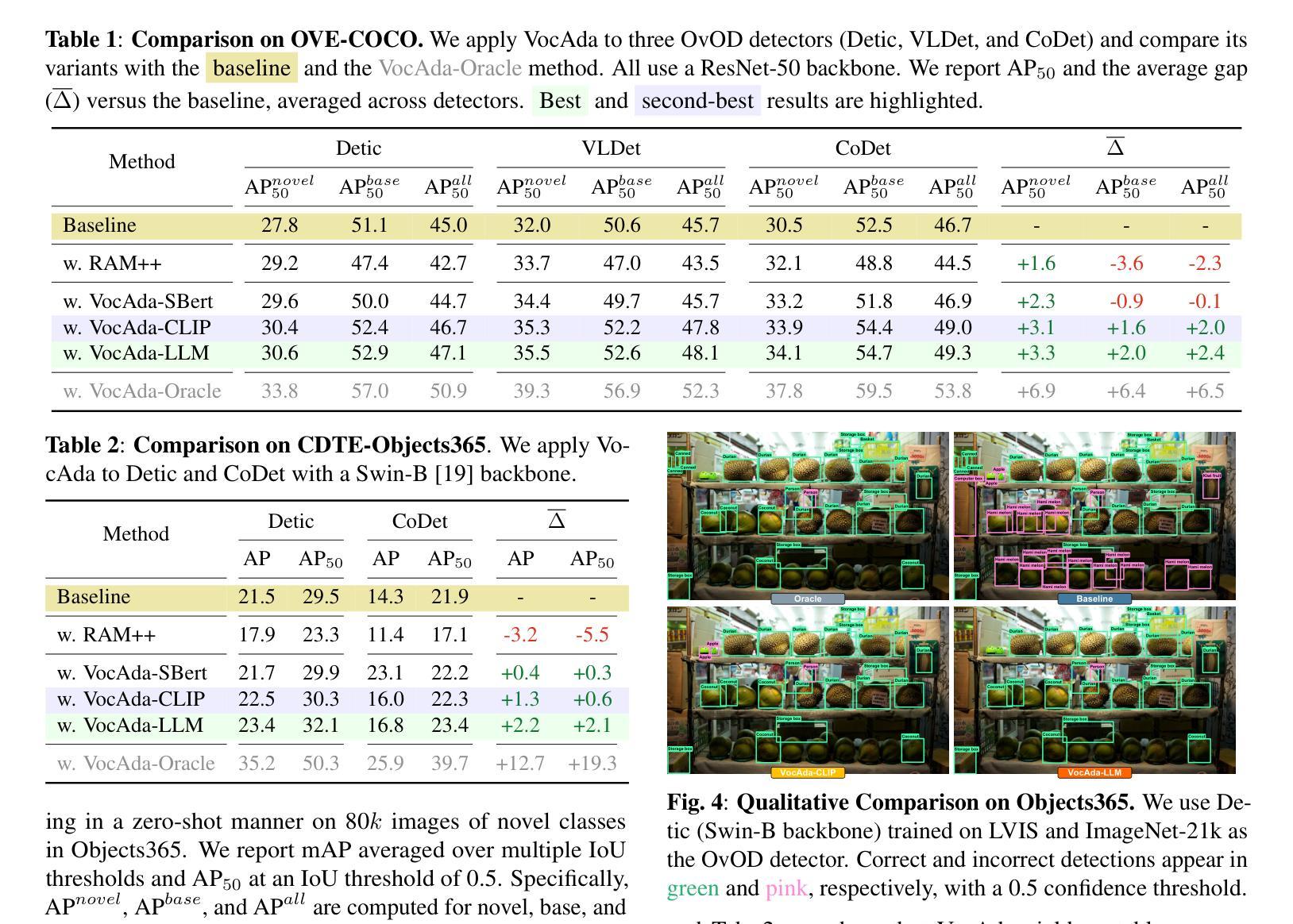
Test-time Vocabulary Adaptation for Language-driven Object Detection
Authors:Mingxuan Liu, Tyler L. Hayes, Massimiliano Mancini, Elisa Ricci, Riccardo Volpi, Gabriela Csurka
Open-vocabulary object detection models allow users to freely specify a class vocabulary in natural language at test time, guiding the detection of desired objects. However, vocabularies can be overly broad or even mis-specified, hampering the overall performance of the detector. In this work, we propose a plug-and-play Vocabulary Adapter (VocAda) to refine the user-defined vocabulary, automatically tailoring it to categories that are relevant for a given image. VocAda does not require any training, it operates at inference time in three steps: i) it uses an image captionner to describe visible objects, ii) it parses nouns from those captions, and iii) it selects relevant classes from the user-defined vocabulary, discarding irrelevant ones. Experiments on COCO and Objects365 with three state-of-the-art detectors show that VocAda consistently improves performance, proving its versatility. The code is open source.
开放词汇对象检测模型允许用户在测试时自由指定自然语言中的类别词汇表,从而引导所需对象的检测。然而,词汇表可能过于宽泛甚至指定错误,从而影响检测器的整体性能。在这项工作中,我们提出了一种即插即用的词汇表适配器(VocAda)来优化用户定义的词汇表,自动将其调整为与给定图像相关的类别。VocAda无需任何训练,它可在推理过程中分三步操作:i)使用图像字幕描述可见对象,ii)解析这些字幕中的名词,iii)从用户定义的词汇表中选择相关类别,丢弃不相关的类别。在COCO和Objects365上与三种最先进检测器的实验表明,VocAda的性能始终得到提升,证明了其通用性。代码已开源。
论文及项目相关链接
PDF Accepted as a conference paper at ICIP 2025
Summary
本工作提出了一种即插即用的词汇适配器(VocAda),用于精炼用户定义的词汇,自动调整与给定图像相关的类别。VocAda无需任何训练,可在推理阶段运行,分为三步:一、使用图像描述器描述可见物体;二、解析这些描述中的名词;三、从用户定义的词汇中选择相关类别,舍弃不相关的类别。在COCO和Objects365上的实验表明,VocAda可持续提升性能,证明其通用性。
Key Takeaways
- 开放词汇对象检测模型允许在测试时以自然语言自由指定类别词汇,指导所需对象的检测。
- 词汇可能过于广泛或误指定,影响检测器的整体性能。
- 提出的Vocabulary Adapter(VocAda)旨在精炼用户定义的词汇。
- VocAda在推理阶段运行,无需任何训练。
- VocAda通过三个步骤自动调整与给定图像相关的类别:使用图像描述器描述物体,解析描述中的名词,并从用户定义的词汇中选择相关类别。
- 实验表明,VocAda可提升检测性能。
点此查看论文截图


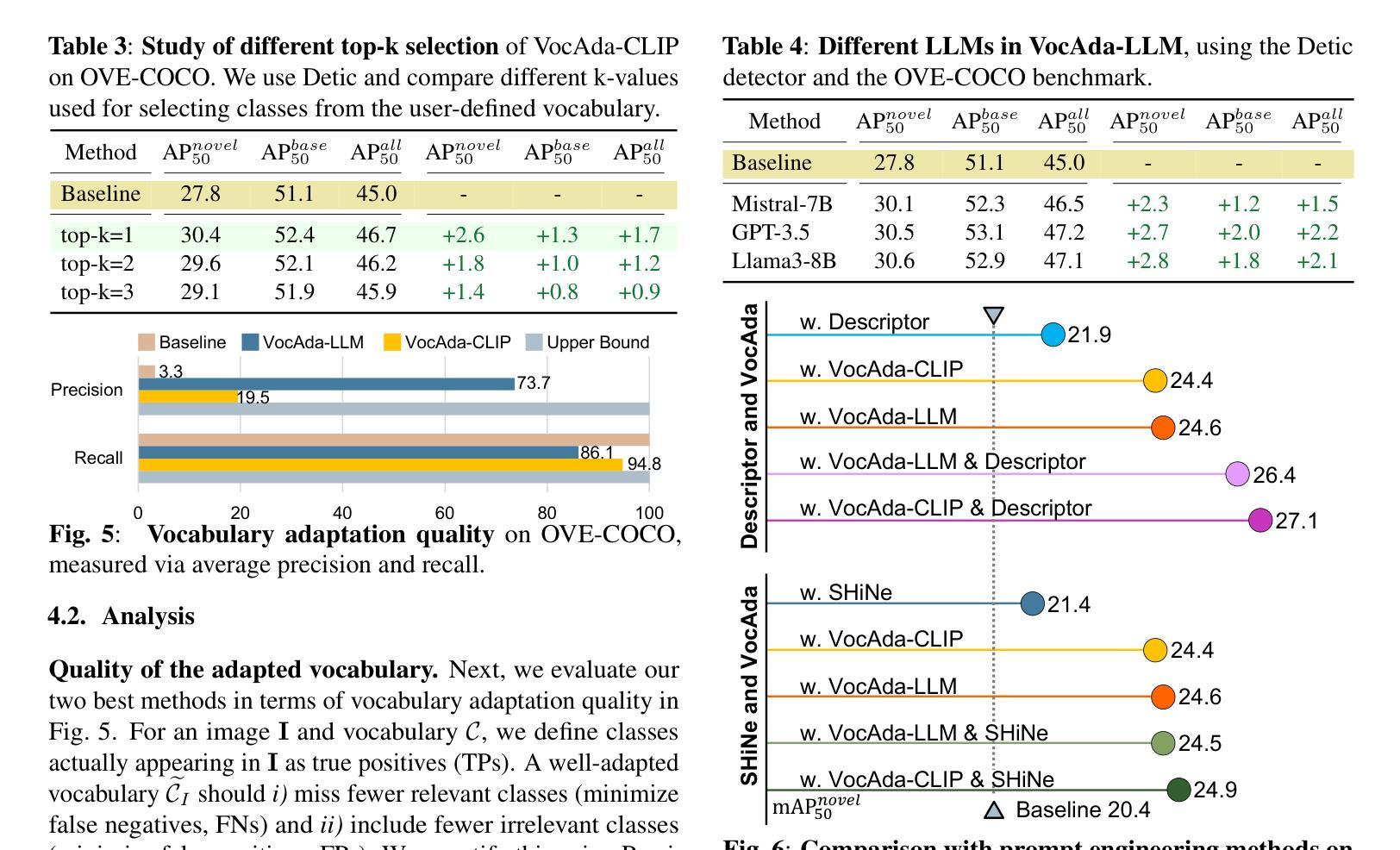
FastCAR: Fast Classification And Regression for Task Consolidation in Multi-Task Learning to Model a Continuous Property Variable of Detected Object Class
Authors:Anoop Kini, Andreas Jansche, Timo Bernthaler, Gerhard Schneider
FastCAR is a novel task consolidation approach in Multi-Task Learning (MTL) for a classification and a regression task, despite the non-triviality of task heterogeneity with only a subtle correlation. The approach addresses the classification of a detected object (occupying the entire image frame) and regression for modeling a continuous property variable (for instances of an object class), a crucial use case in science and engineering. FastCAR involves a label transformation approach that is amenable for use with only a single-task regression network architecture. FastCAR outperforms traditional MTL model families, parametrized in the landscape of architecture and loss weighting schemes, when learning both tasks are collectively considered (classification accuracy of 99.54%, regression mean absolute percentage error of 2.4%). The experiments performed used “Advanced Steel Property Dataset” contributed by us https://github.com/fastcandr/AdvancedSteel-Property-Dataset. The dataset comprises 4536 images of 224x224 pixels, annotated with discrete object classes and its hardness property that can take continuous values. Our proposed FastCAR approach for task consolidation achieves training time efficiency (2.52x quicker) and reduced inference latency (55% faster) than benchmark MTL networks.
FastCAR是一种多任务学习(MTL)中的新型任务整合方法,适用于分类和回归任务。尽管任务之间存在非平凡性且仅存在细微相关性,但该方法解决了检测到的对象(占据整个图像帧)的分类问题以及连续属性变量(对于对象类的实例)的回归建模问题,这在科学和工程中是一个关键用例。FastCAR涉及标签转换方法,该方法适用于仅使用单任务回归网络架构。当同时考虑这两个任务的学习时,FastCAR在架构和损失加权方案的景观中超越了传统的MTL模型家族(分类准确度为99.54%,回归平均绝对百分比误差为2.4%)。所进行的实验使用了我们提供的“高级钢属性数据集”(https://github.com/fastcandr/AdvancedSteel-Property-Dataset)。该数据集包含经过标记的包含离散对象类以及其可获取连续值的硬度属性的图像共计4536张,每张像素大小为224x224。我们提出的用于任务整合的FastCAR方法实现了训练时间效率(提高了2.52倍)和推理延迟(减少了55%)相比基准MTL网络更快速高效。
论文及项目相关链接
Summary
FastCAR是一种多任务学习(MTL)中的新型任务整合方法,适用于分类和回归任务。它解决了检测到的对象分类(占据整个图像帧)和连续属性变量回归的问题。FastCAR通过标签转换方法实现,该方法适用于仅使用单任务回归网络架构。当同时考虑两个任务时,FastCAR在架构和损失加权方案的参数化中优于传统MTL模型家族,分类准确度达到99.54%,回归平均绝对百分比误差为2.4%。此外,该方法的训练效率高(比基准MTL网络快2.52倍),推理延迟降低(减少55%)。使用我们提供的“高级钢材属性数据集”进行实验,该数据集包含标注有离散对象类别和其硬度属性的图像。
Key Takeaways
- FastCAR是一种多任务学习中的新型任务整合方法,用于解决分类和回归任务。
- 它解决了检测到的对象分类问题和连续属性变量的回归问题。
- FastCAR通过标签转换方法实现,适用于单任务回归网络架构。
- 在同时考虑两个任务时,FastCAR在分类和回归方面都表现出优于传统MTL模型的优势。
- FastCAR的分类准确度高达99.54%,回归平均绝对百分比误差为2.4%。
- 该方法具有高效的训练性能,比基准MTL网络快2.52倍,并降低了55%的推理延迟。
点此查看论文截图


MTevent: A Multi-Task Event Camera Dataset for 6D Pose Estimation and Moving Object Detection
Authors:Shrutarv Awasthi, Anas Gouda, Sven Franke, Jérôme Rutinowski, Frank Hoffmann, Moritz Roidl
Mobile robots are reaching unprecedented speeds, with platforms like Unitree B2, and Fraunhofer O3dyn achieving maximum speeds between 5 and 10 m/s. However, effectively utilizing such speeds remains a challenge due to the limitations of RGB cameras, which suffer from motion blur and fail to provide real-time responsiveness. Event cameras, with their asynchronous operation, and low-latency sensing, offer a promising alternative for high-speed robotic perception. In this work, we introduce MTevent, a dataset designed for 6D pose estimation and moving object detection in highly dynamic environments with large detection distances. Our setup consists of a stereo-event camera and an RGB camera, capturing 75 scenes, each on average 16 seconds, and featuring 16 unique objects under challenging conditions such as extreme viewing angles, varying lighting, and occlusions. MTevent is the first dataset to combine high-speed motion, long-range perception, and real-world object interactions, making it a valuable resource for advancing event-based vision in robotics. To establish a baseline, we evaluate the task of 6D pose estimation using NVIDIA’s FoundationPose on RGB images, achieving an Average Recall of 0.22 with ground-truth masks, highlighting the limitations of RGB-based approaches in such dynamic settings. With MTevent, we provide a novel resource to improve perception models and foster further research in high-speed robotic vision. The dataset is available for download https://huggingface.co/datasets/anas-gouda/MTevent
移动机器人的速度已经达到了前所未有的水平,如Unitree B2和Fraunhofer O3dyn等平台,最高速度可达5至10米/秒。然而,由于RGB相机的局限性,有效利用这样的速度仍然是一个挑战,RGB相机受到运动模糊的影响,无法提供实时响应。事件相机具有异步操作和低延迟感知的特点,为高速机器人感知提供了有前景的替代方案。在这项工作中,我们介绍了MTevent数据集,该数据集旨在用于高度动态环境中大范围检测下的6D姿态估计和运动目标检测。我们的设备配置包括立体事件相机和RGB相机,拍摄了75个场景,每个场景平均16秒,并在具有挑战性的条件下展示了16个独特物体,例如极端视角、光线变化和遮挡。MTevent是第一个结合高速运动、长距离感知和现实世界物体交互的数据集,是推动机器人基于事件视觉发展的宝贵资源。为了建立基准,我们评估了使用NVIDIA的FoundationPose在RGB图像上进行6D姿态估计的任务,使用真实掩膜的平均召回率为0.22,这突显了在动态环境中基于RGB的方法的局限性。通过MTevent数据集,我们提供了一个改进感知模型并促进高速机器人视觉研究的宝贵资源。该数据集可下载:https://huggingface.co/datasets/anas-gouda/MTevent。
论文及项目相关链接
PDF Accepted at 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW); Fifth International Workshop on Event-Based Vision
Summary:随着移动机器人技术的高速发展,以Unitree B2和Fraunhofer O3dyn等平台为代表的机器人速度不断突破,但传统RGB相机在高速运动下会出现运动模糊和实时响应不足的问题。事件相机因其异步操作和低延迟感知特性,为高速机器人感知提供了有前景的替代方案。本研究引入了MTevent数据集,该数据集适用于高速动态环境下的大距离检测中的6D姿态估计和移动物体检测。数据集由立体事件相机和RGB相机组成,共捕捉了75个场景,每个场景平均持续16秒,包含16个独特物体在极端视角、不同光照和遮挡等挑战条件下的图像。MTevent是首个结合高速运动、长距离感知和现实世界物体交互的数据集,对于推动基于事件视觉的机器人技术进步具有重要意义。
Key Takeaways:
- 移动机器人速度不断突破,但RGB相机在高速环境下的感知存在局限。
- 事件相机为高速机器人感知提供了有前景的替代方案。
- MTevent数据集是首个结合高速运动、长距离感知和现实世界物体交互的数据集。
- MTevent包含75个场景,每个场景平均持续16秒,包含多种挑战条件下的图像。
- NVIDIA的FoundationPose在RGB图像上的6D姿态估计任务评价表明,在动态设置中的平均召回率为0.22,凸显RGB相机在此类环境下的局限性。
- MTevent数据集为改进感知模型和推动高速机器人视觉研究提供了宝贵资源。
点此查看论文截图





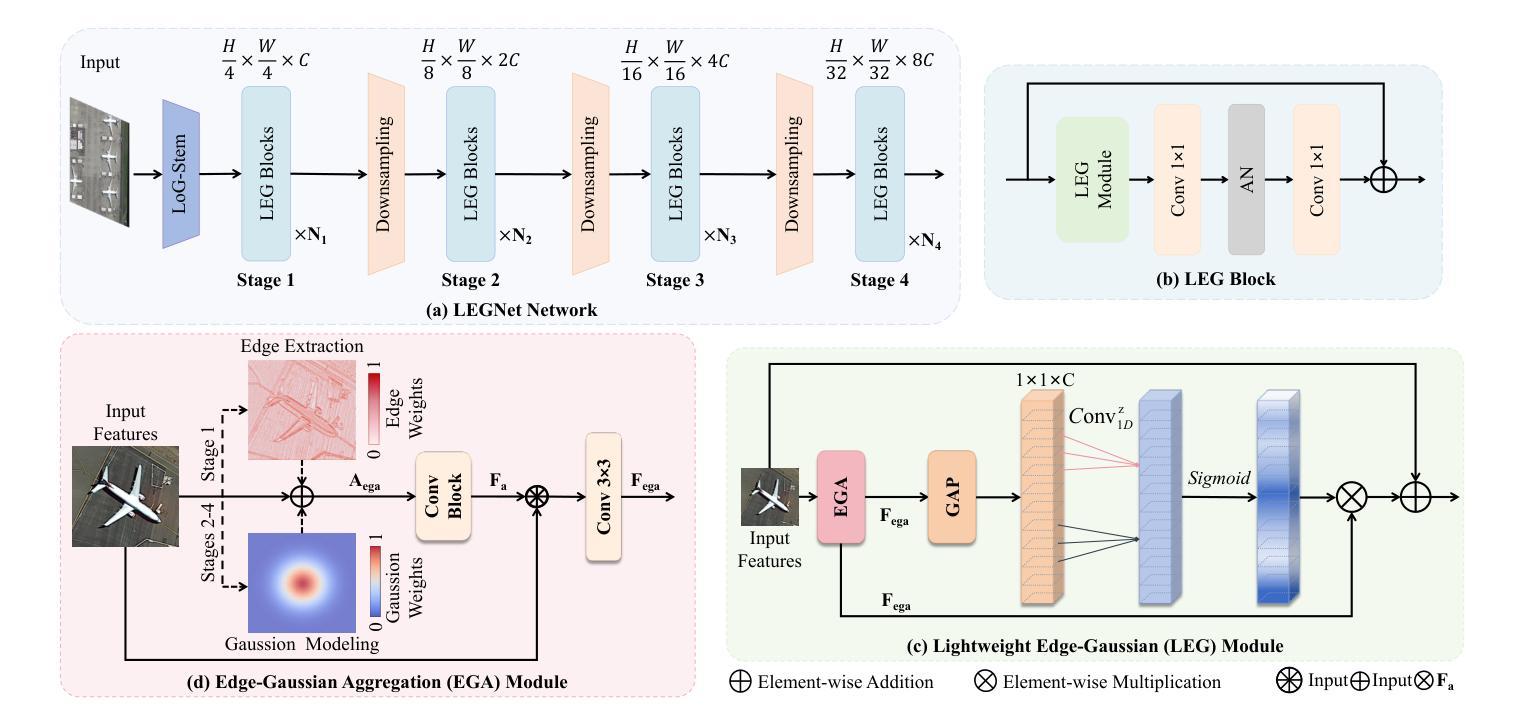
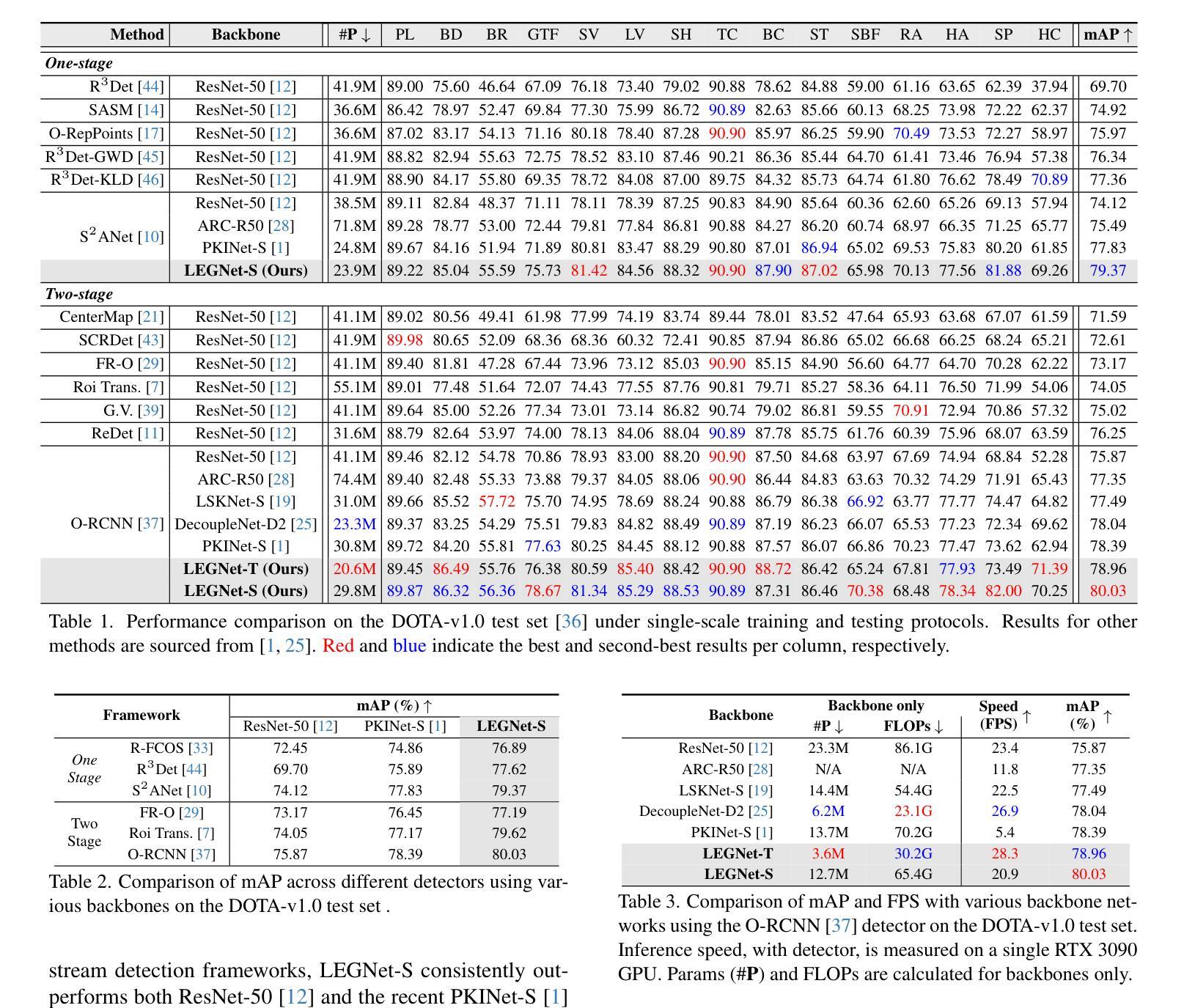
LEGNet: Lightweight Edge-Gaussian Driven Network for Low-Quality Remote Sensing Image Object Detection
Authors:Wei Lu, Si-Bao Chen, Hui-Dong Li, Qing-Ling Shu, Chris H. Q. Ding, Jin Tang, Bin Luo
Remote sensing object detection (RSOD) often suffers from degradations such as low spatial resolution, sensor noise, motion blur, and adverse illumination. These factors diminish feature distinctiveness, leading to ambiguous object representations and inadequate foreground-background separation. Existing RSOD methods exhibit limitations in robust detection of low-quality objects. To address these pressing challenges, we introduce LEGNet, a lightweight backbone network featuring a novel Edge-Gaussian Aggregation (EGA) module specifically engineered to enhance feature representation derived from low-quality remote sensing images. EGA module integrates: (a) orientation-aware Scharr filters to sharpen crucial edge details often lost in low-contrast or blurred objects, and (b) Gaussian-prior-based feature refinement to suppress noise and regularize ambiguous feature responses, enhancing foreground saliency under challenging conditions. EGA module alleviates prevalent problems in reduced contrast, structural discontinuities, and ambiguous feature responses prevalent in degraded images, effectively improving model robustness while maintaining computational efficiency. Comprehensive evaluations across five benchmarks (DOTA-v1.0, v1.5, DIOR-R, FAIR1M-v1.0, and VisDrone2019) demonstrate that LEGNet achieves state-of-the-art performance, particularly in detecting low-quality objects. The code is available at https://github.com/lwCVer/LEGNet.
遥感目标检测(RSOD)经常受到空间分辨率低、传感器噪声、运动模糊和不良照明等问题的困扰。这些因素降低了特征的辨识度,导致目标表示不明确,前景与背景分离不足。现有的遥感目标检测方法在低质量目标检测方面表现出局限性。为了应对这些紧迫挑战,我们引入了LEGNet网络,这是一个具有新型边缘高斯聚合(EGA)模块的轻量级主干网络,专门设计用于增强从低质量遥感图像中派生的特征表示。EGA模块集成了:(a)定向感知的Scharr滤波器,用于锐化低对比度或模糊对象通常丢失的关键边缘细节;(b)基于高斯先验的特征细化,用于抑制噪声并规范化模糊的特征响应,从而在具有挑战性的条件下增强前景显著性。EGA模块缓解了在对比度降低、结构不连续和模糊特征响应中普遍存在的问题,在退化图像中有效提高了模型的稳健性,同时保持了计算效率。在五个基准测试(DOTA-v1.0、v1.5、DIOR-R、FAIR1M-v1.0和VisDrone2019)上的综合评估表明,LEGNet达到了最先进的性能,特别是在检测低质量目标方面。相关代码可通过https://github.com/lwCVer/LEGNet获取。
论文及项目相关链接
PDF 17 pages, 8 figures
Summary
远程遥感物体检测(RSOD)面临诸多挑战,如低空间分辨率、传感器噪声、运动模糊和不良照明等。这些问题导致特征区分度降低,出现对象表示不明确和前景背景分离不足的情况。为解决这些问题,本文提出了LEGNet网络,该网络采用了一种新型的边缘高斯聚合(EGA)模块,旨在增强从低质量遥感图像中派生的特征表示。EGA模块通过结合方向感知的Scharr滤波器和基于高斯先验的特征细化,提高了边缘细节的清晰度,并抑制了噪声。这提高了模型在具有挑战性的条件下的稳健性,同时保持了计算效率。在五个基准测试上的评估表明,LEGNet在低质量对象检测方面取得了最先进的性能。
Key Takeaways
- 远程遥感物体检测(RSOD)面临低空间分辨率、传感器噪声、运动模糊和不良照明等挑战。
- 特征区分度降低导致对象表示不明确和前景背景分离不足。
- LEGNet网络通过采用新型的边缘高斯聚合(EGA)模块来解决这些问题。
- EGA模块提高了边缘细节的清晰度并抑制了噪声。
- EGA模块包括方向感知的Scharr滤波器和基于高斯先验的特征细化。
- LEGNet在五个基准测试上取得了先进的性能,特别是在低质量对象检测方面。
点此查看论文截图

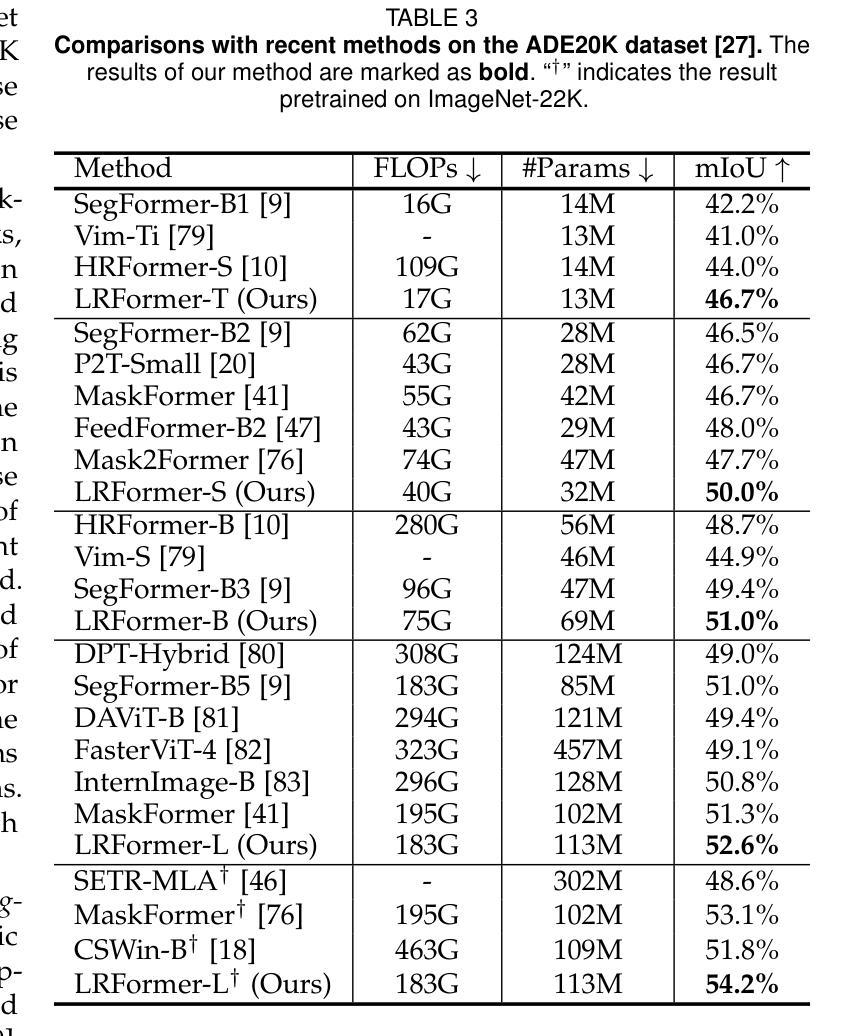
Low-Resolution Self-Attention for Semantic Segmentation
Authors:Yu-Huan Wu, Shi-Chen Zhang, Yun Liu, Le Zhang, Xin Zhan, Daquan Zhou, Jiashi Feng, Ming-Ming Cheng, Liangli Zhen
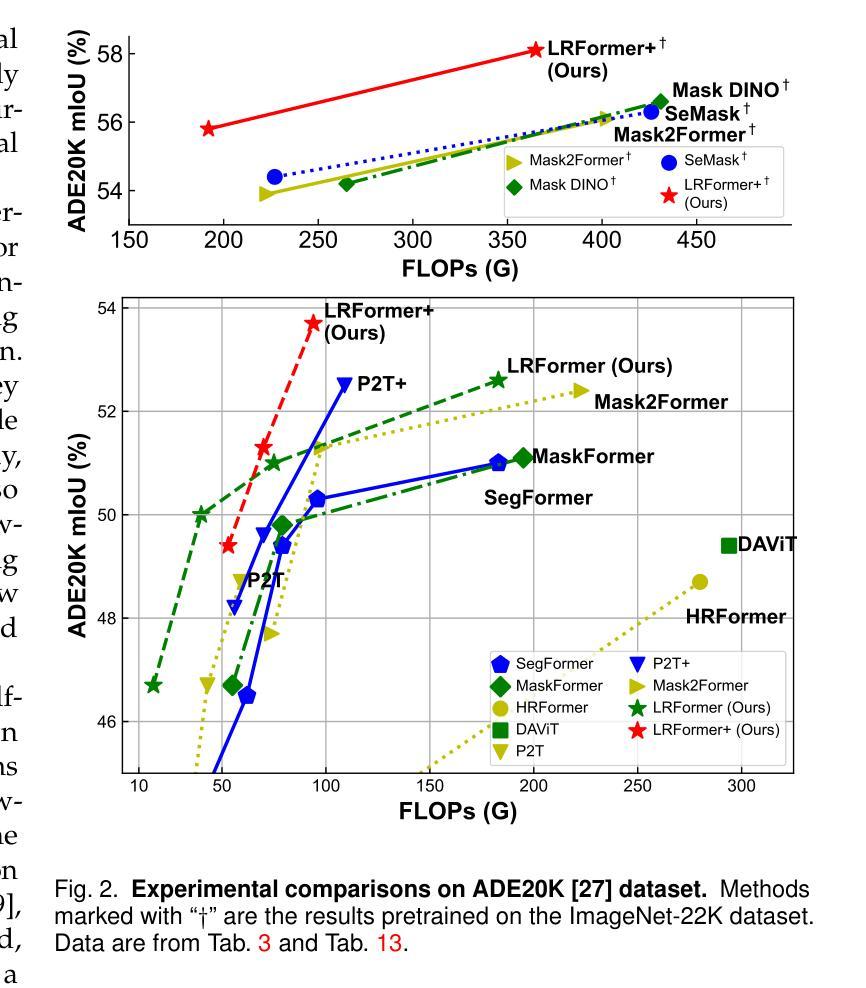
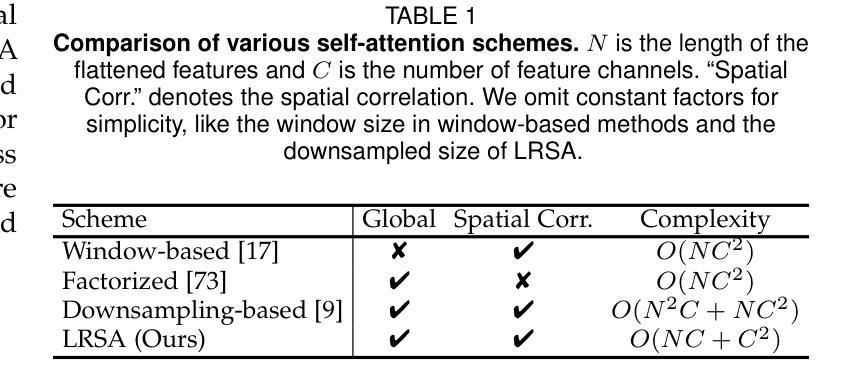
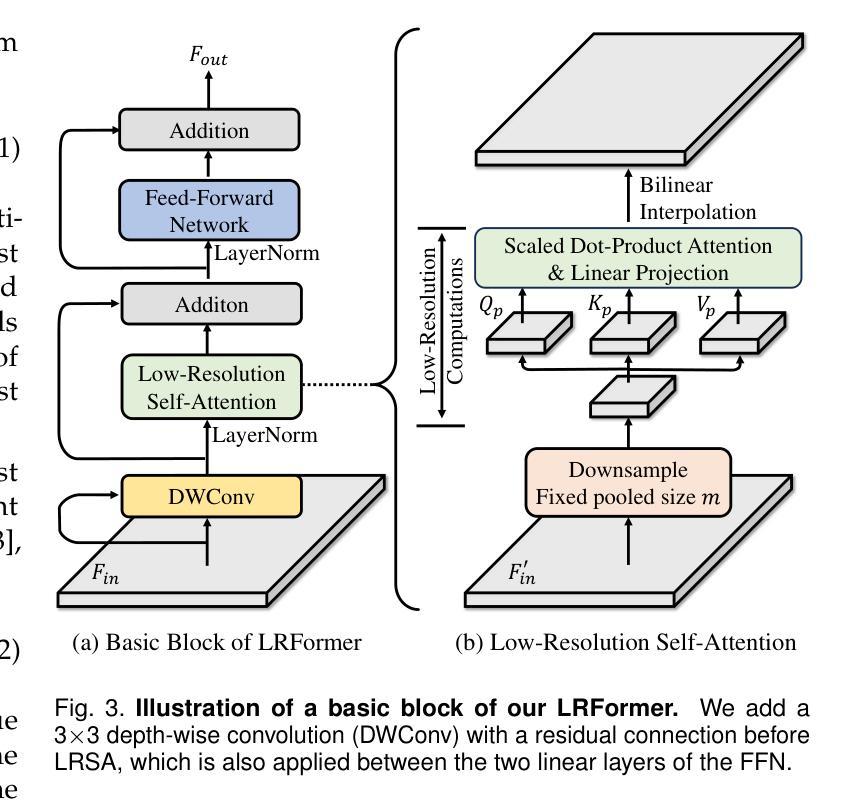
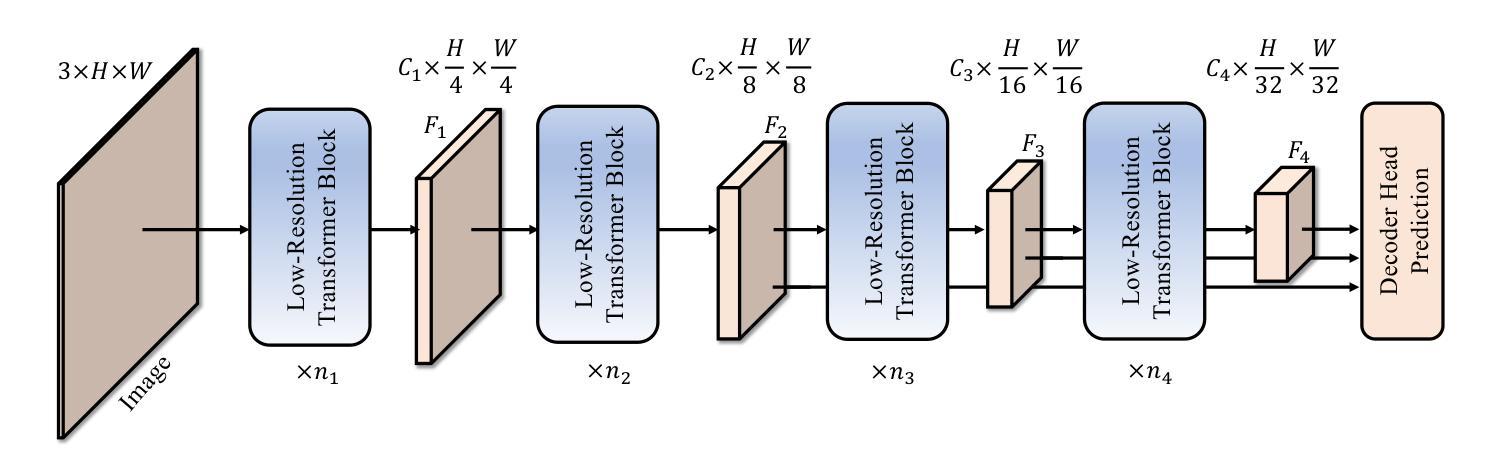
Semantic segmentation tasks naturally require high-resolution information for pixel-wise segmentation and global context information for class prediction. While existing vision transformers demonstrate promising performance, they often utilize high-resolution context modeling, resulting in a computational bottleneck. In this work, we challenge conventional wisdom and introduce the Low-Resolution Self-Attention (LRSA) mechanism to capture global context at a significantly reduced computational cost, i.e., FLOPs. Our approach involves computing self-attention in a fixed low-resolution space regardless of the input image’s resolution, with additional 3x3 depth-wise convolutions to capture fine details in the high-resolution space. We demonstrate the effectiveness of our LRSA approach by building the LRFormer, a vision transformer with an encoder-decoder structure. Extensive experiments on the ADE20K, COCO-Stuff, and Cityscapes datasets demonstrate that LRFormer outperforms state-of-the-art models. Code is available at https://github.com/yuhuan-wu/LRFormer.
语义分割任务自然需要高分辨率信息进行像素级分割和全局上下文信息进行类别预测。尽管现有的视觉变压器表现出了有前景的性能,但它们通常利用高分辨率上下文建模,导致计算瓶颈。在这项工作中,我们挑战传统智慧,引入了低分辨率自注意(LRSA)机制,以显著降低计算成本(即FLOPs)捕获全局上下文。我们的方法涉及在固定的低分辨率空间中进行自注意计算,而不管输入图像的分辨率如何,并使用额外的3x3深度可分离卷积来捕获高分辨率空间中的细节。我们通过构建LRFormer——一种具有编码器-解码器结构的视觉变压器来证明我们的LRSA方法的有效性。在ADE20K、COCO-Stuff和Cityscapes数据集上的大量实验表明,LRFormer优于最新模型。代码可在https://github.com/yuhuan-wu/LRFormer找到。
论文及项目相关链接
PDF Accepted by IEEE TPAMI; 14 pages, 6 figures, 14 tables
Summary:
本文介绍了针对语义分割任务中计算量大和计算成本高的问题,提出了一种基于低分辨率自注意力机制的LRSA方法。该方法在低分辨率空间进行自注意力计算,并通过深度可分离卷积捕捉高分辨率空间的细节信息,从而在保证性能的同时降低了计算成本。实验结果表明,基于LRSA方法的LRFormer在ADE20K、COCO-Stuff和Cityscapes数据集上表现出优异的性能。
Key Takeaways:
- 语义分割任务需要高分辨信息和全局上下文信息。
- 传统视野变换器在计算量大和计算成本高的情况下,在高分辨率上下文建模中表现良好。
- LRSA机制在低分辨率空间进行自注意力计算,降低了计算成本。
- LRSA通过深度可分离卷积捕捉高分辨率空间的细节信息。
- LRSA方法通过构建LRFormer模型实现,该模型具有编码器-解码器结构。
- 实验结果表明,LRFormer在多个数据集上表现出优异的性能。
点此查看论文截图