⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-05 更新
EgoVLM: Policy Optimization for Egocentric Video Understanding
Authors:Ashwin Vinod, Shrey Pandit, Aditya Vavre, Linshen Liu
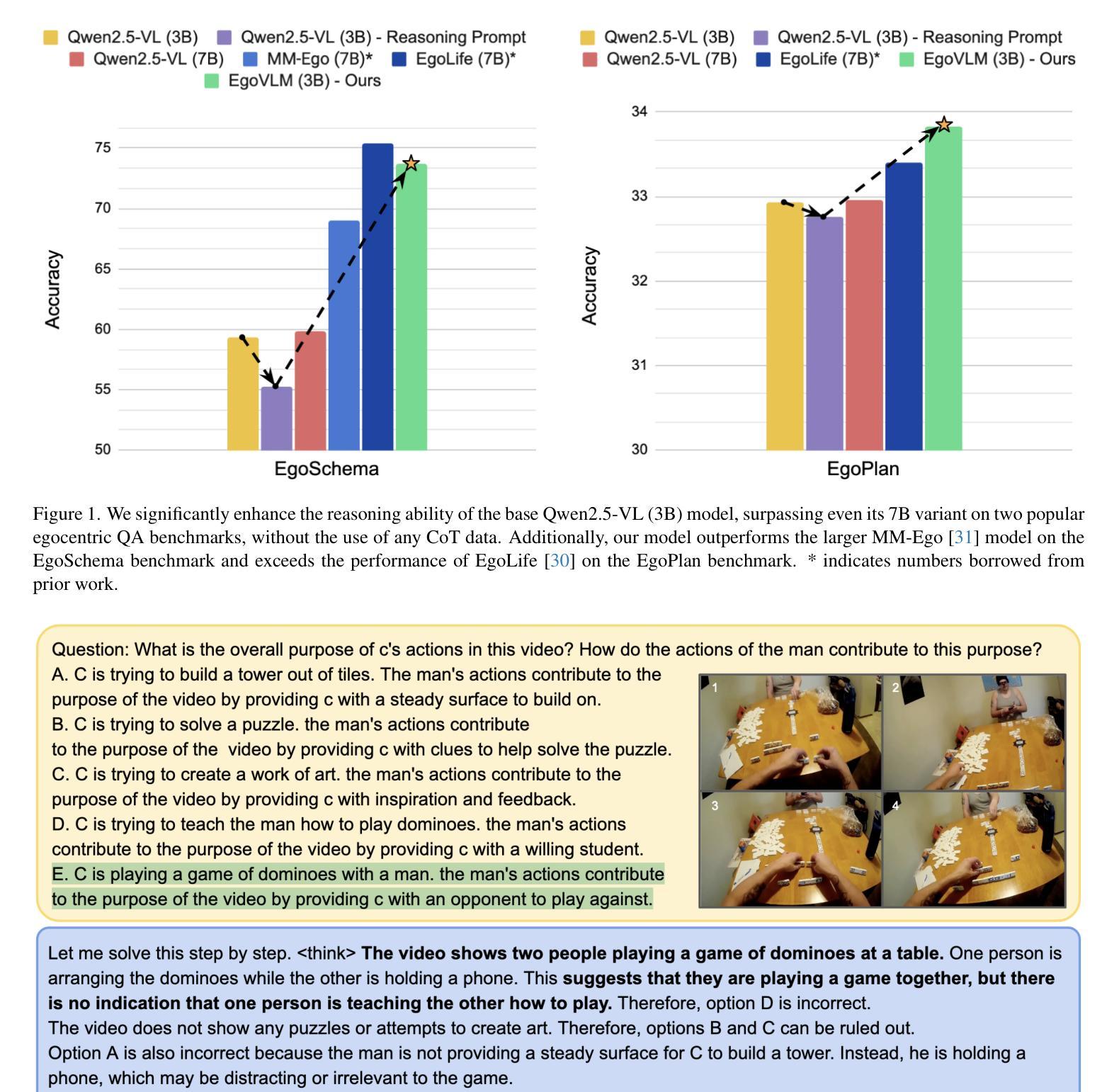
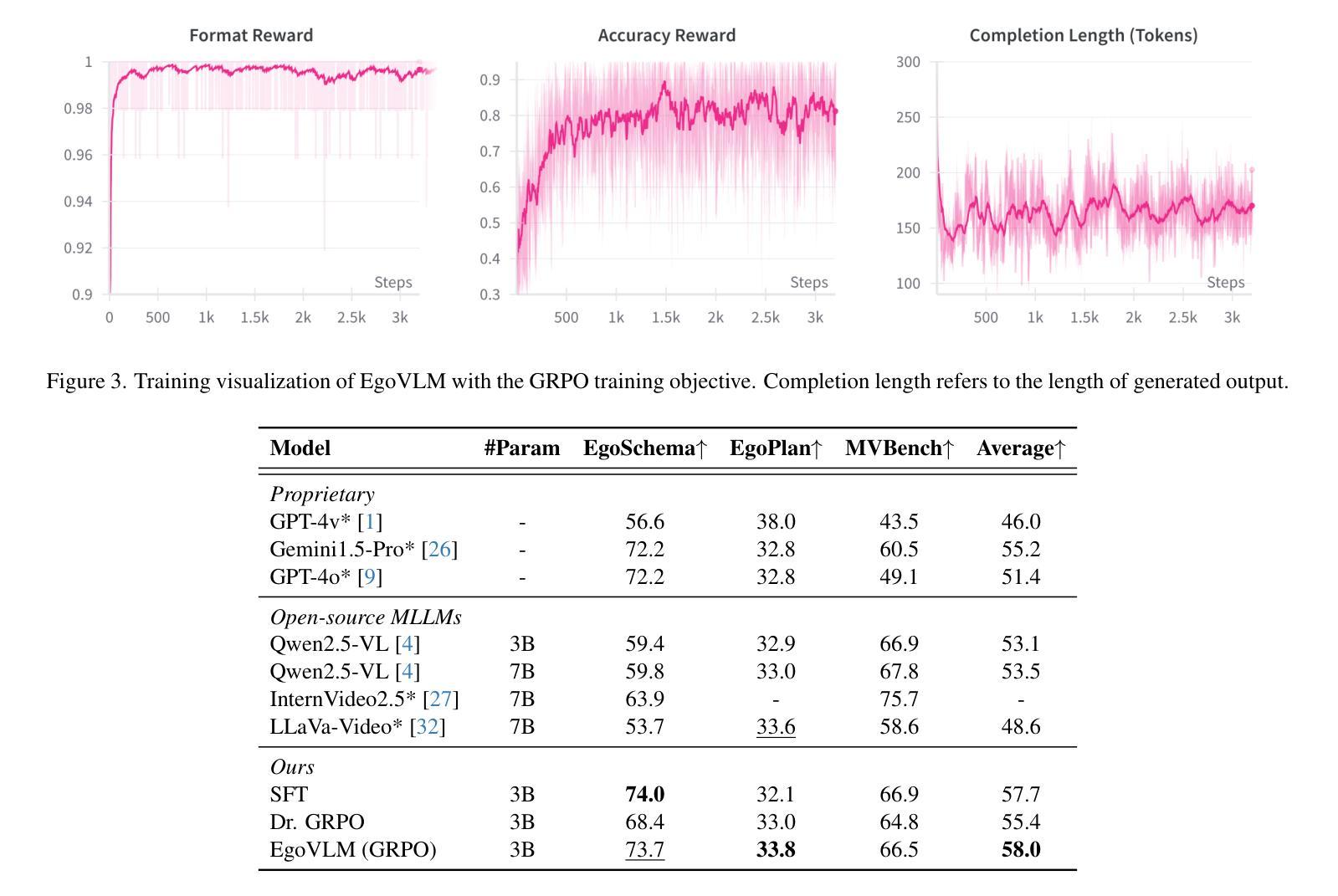
Emerging embodied AI applications, such as wearable cameras and autonomous agents, have underscored the need for robust reasoning from first person video streams. We introduce EgoVLM, a vision-language model specifically designed to integrate visual comprehension and spatial-temporal reasoning within egocentric video contexts. EgoVLM is fine-tuned via Group Relative Policy Optimization (GRPO), a reinforcement learning method adapted to align model outputs with human-like reasoning steps. Following DeepSeek R1-Zero’s approach, we directly tune using RL without any supervised fine-tuning phase on chain-of-thought (CoT) data. We evaluate EgoVLM on egocentric video question answering benchmarks and show that domain-specific training substantially improves performance over general-purpose VLMs. Our EgoVLM-3B, trained exclusively on non-CoT egocentric data, outperforms the base Qwen2.5-VL 3B and 7B models by 14.33 and 13.87 accuracy points on the EgoSchema benchmark, respectively. By explicitly generating reasoning traces, EgoVLM enhances interpretability, making it well-suited for downstream applications. Furthermore, we introduce a novel keyframe-based reward that incorporates salient frame selection to guide reinforcement learning optimization. This reward formulation opens a promising avenue for future exploration in temporally grounded egocentric reasoning.
新兴的身临其境的AI应用,如可穿戴相机和自主代理,已经突出了从第一人称视频流中进行稳健推理的必要性。我们引入了EgoVLM,这是一个专门设计的视觉语言模型,能够在以自我为中心的视频环境中整合视觉理解和时空推理。EgoVLM通过群体相对策略优化(GRPO)进行微调,这是一种适应性强化的学习方法,旨在使模型输出与人类推理步骤相符。我们遵循DeepSeek R1-Zero的方法,直接使用强化学习进行调整,而无需在思维链(CoT)数据上进行任何监督微调阶段。我们在以自我为中心的视频问答基准测试上对EgoVLM进行了评估,并证明针对特定领域的训练可以大幅提高性能,优于通用VLMs。我们仅在非CoT自我中心数据上训练的EgoVLM-3B在EgoSchema基准测试上的性能优于基础Qwen2.5-VL的3B和7B模型,准确率分别提高了14.33和13.87个点。通过明确生成推理轨迹,EgoVLM提高了可解释性,非常适合用于下游应用。此外,我们引入了一种基于关键帧的奖励机制,该机制结合了突出帧选择来指导强化学习的优化。这种奖励的制定为未来在时间上立足的自我中心推理的探索开辟了有前途的道路。
论文及项目相关链接
PDF Our Code can be found at https://github.com/adityavavre/VidEgoVLM
Summary
针对第一人称视频流中的新兴智能体AI应用(如可穿戴相机和自主代理),提出了一种名为EgoVLM的视觉语言模型。该模型结合了视觉理解和时空推理,针对第一人称视频进行设计。通过采用强化学习的群组相对策略优化(GRPO)方法,EgoVLM的输更符合人类的推理过程。EgoVLM在非思维链条数据上表现良好,同时相比于一般的大型预训练语言模型更适应于特定的场景任务,而且能够通过产生清晰的推理轨迹提升模型的解释性。研究还发现关键帧奖励作为重要特性能有效提升模型的性能并为后续的改进提供了一个方向。
Key Takeaways
- 新兴的智能体AI应用需要从第一人称视频流中进行稳健推理。
- 提出了专为第一人称视频设计的EgoVLM模型,整合视觉理解和时空推理。
- 采用强化学习的Group Relative Policy Optimization(GRPO)方法对齐模型输出和人类推理步骤。
- 直接采用强化学习方式进行调整,无需监督微调阶段结合思维链条数据。
- 相对于通用大型预训练语言模型,针对特定场景的EgoVLM表现更佳,尤其是在Egocentric视频问答基准测试中。
- 通过产生清晰的推理轨迹提高模型的解释性,更适合下游应用。
点此查看论文截图


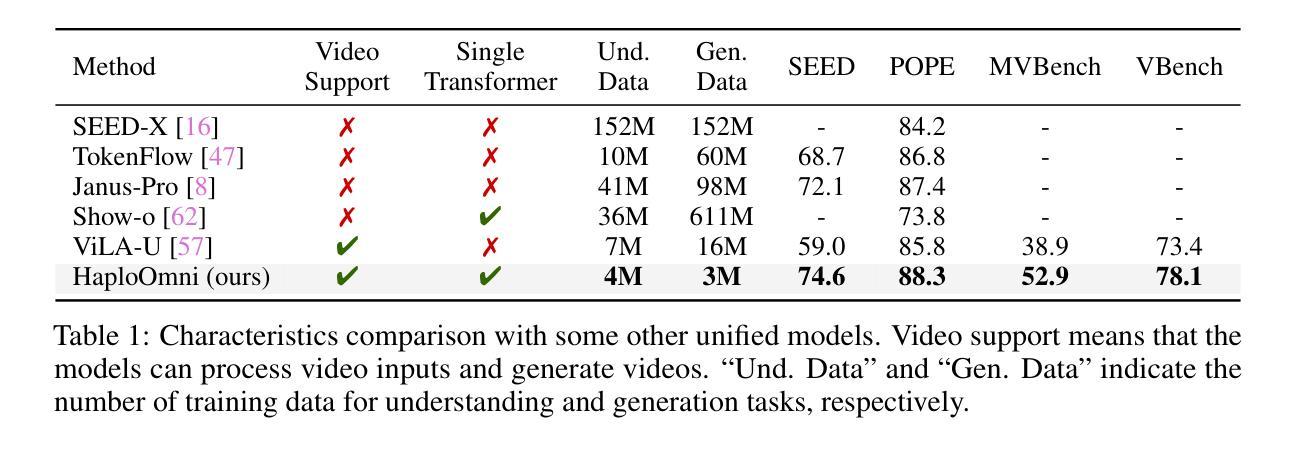
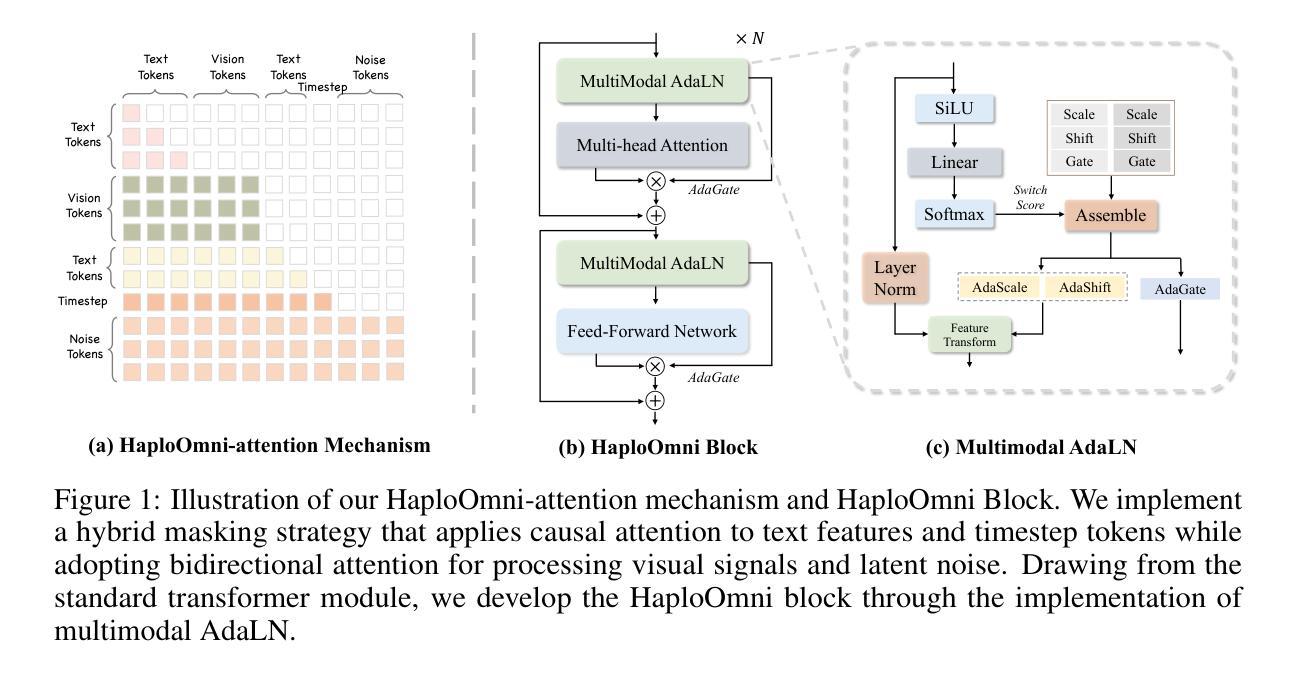
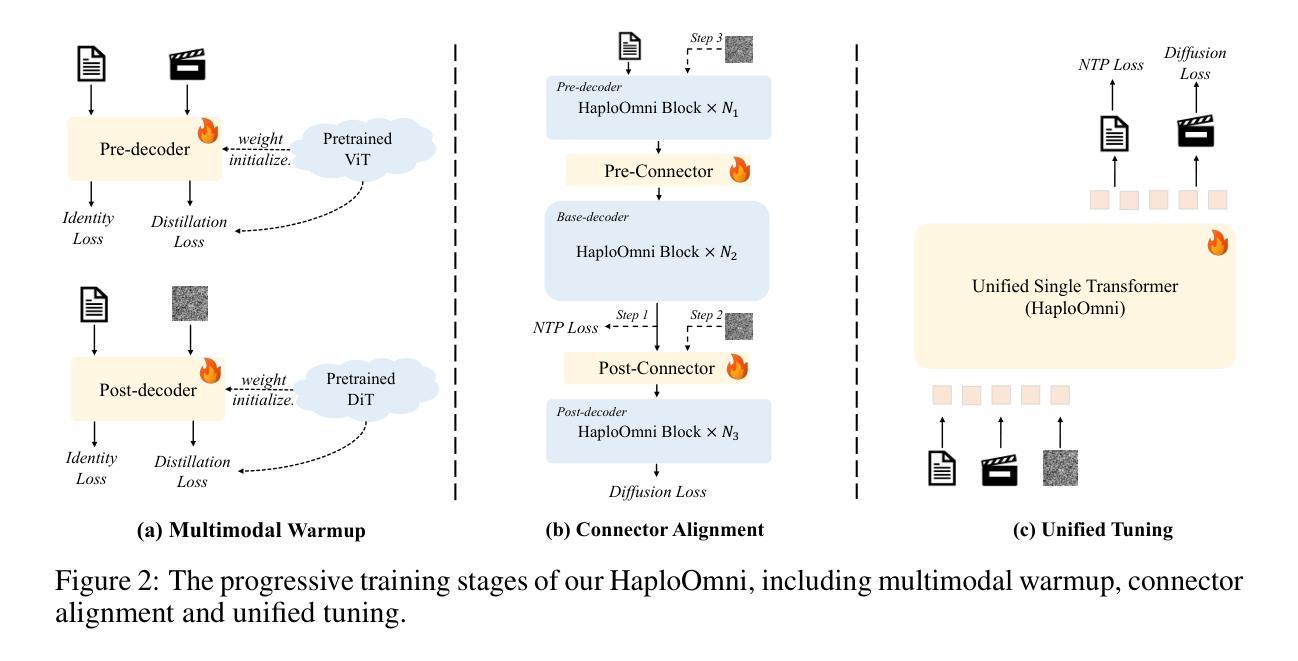
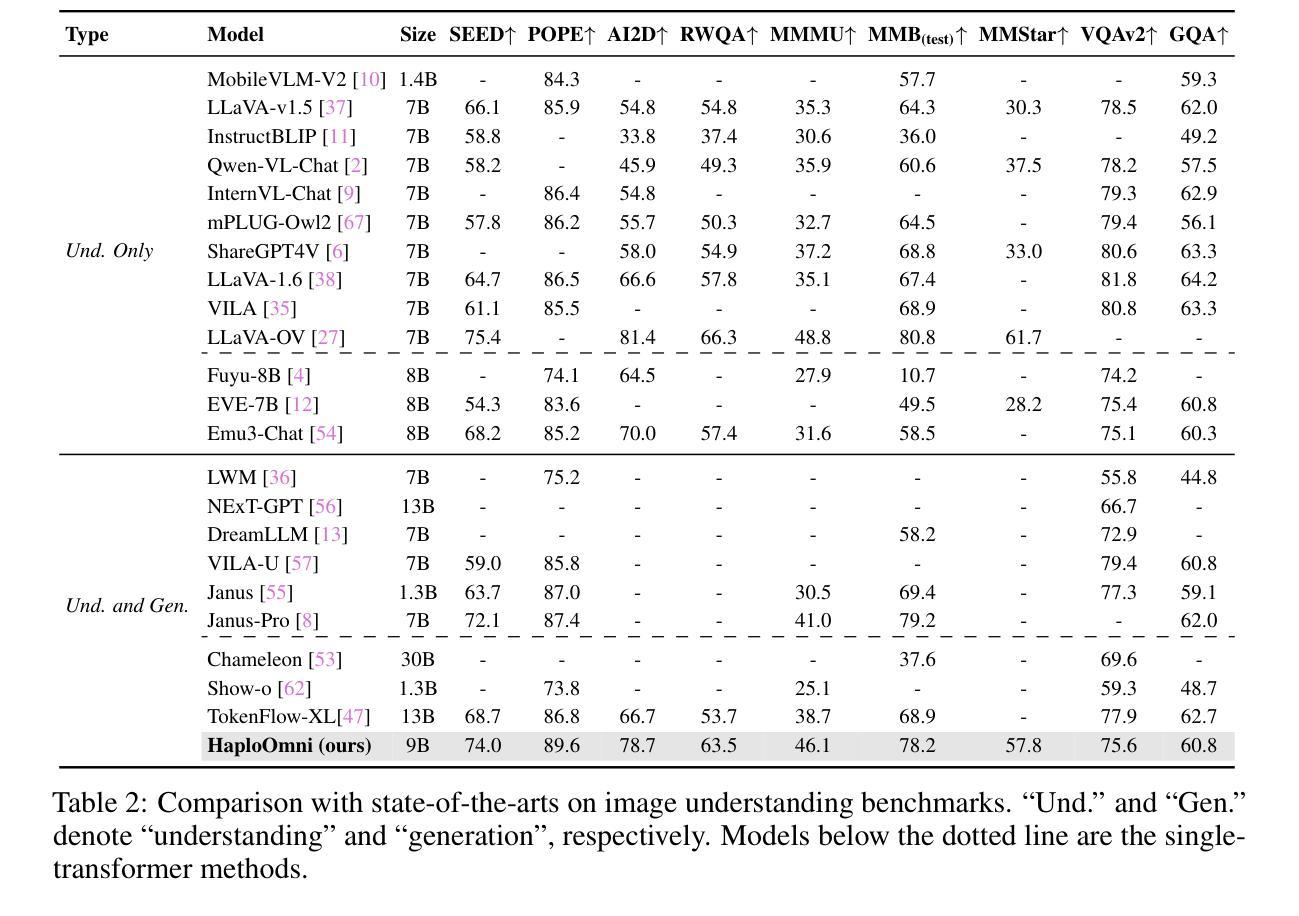
HaploOmni: Unified Single Transformer for Multimodal Video Understanding and Generation
Authors:Yicheng Xiao, Lin Song, Rui Yang, Cheng Cheng, Zunnan Xu, Zhaoyang Zhang, Yixiao Ge, Xiu Li, Ying Shan
With the advancement of language models, unified multimodal understanding and generation have made significant strides, with model architectures evolving from separated components to unified single-model frameworks. This paper explores an efficient training paradigm to build a single transformer for unified multimodal understanding and generation. Specifically, we propose a multimodal warmup strategy utilizing prior knowledge to extend capabilities. To address cross-modal compatibility challenges, we introduce feature pre-scaling and multimodal AdaLN techniques. Integrating the proposed technologies, we present the HaploOmni, a new single multimodal transformer. With limited training costs, HaploOmni achieves competitive performance across multiple image and video understanding and generation benchmarks over advanced unified models. All codes will be made public at https://github.com/Tencent/HaploVLM.
随着语言模型的进步,统一的多模态理解和生成已经取得了显著的进步,模型架构从分离的组件发展到统一的单模型框架。本文探索了一种高效的训练范式,以建立用于统一多模态理解和生成的单变压器。具体来说,我们提出了一种利用先验知识的多模态预热策略来扩展能力。为了解决跨模态兼容性问题,我们引入了特征预缩放和多模态AdaLN技术。通过集成所提出的技术,我们推出了新的单一多模态变压器HaploOmni。在有限的训练成本下,HaploOmni在多个图像和视频理解和生成基准测试上实现了与先进统一模型相当的性能。所有代码将在https://github.com/Tencent/HaploVLM上公开。
论文及项目相关链接
Summary
随着语言模型的进步,统一多模态理解和生成技术取得了显著发展,模型架构从分离组件转向统一单模型框架。本文探索了一种高效的训练范式,构建用于统一多模态理解和生成的单模态转换器。通过利用先验知识的多模态预热策略,解决跨模态兼容性问题,引入特征预缩放和多模态AdaLN技术。集成这些技术,我们推出了HaploOmni新型单模态多模态转换器。在有限的训练成本下,HaploOmni在多个图像和视频理解和生成基准测试中表现出强大的竞争力。相关代码将公开在https://github.com/Tencent/HaploVLM。
Key Takeaways
- 语言模型的进步推动了统一多模态理解和生成技术的发展。
- 模型架构正由分离组件向统一单模型框架转变。
- 提出了一种高效的训练范式来构建用于多模态理解和生成的单模态转换器。
- 利用先验知识的多模态预热策略解决跨模态兼容性问题。
- 引入了特征预缩放和多模态AdaLN技术来提升模型性能。
- 推出了HaploOmni新型单模态多模态转换器,在多个基准测试中表现优秀。
点此查看论文截图


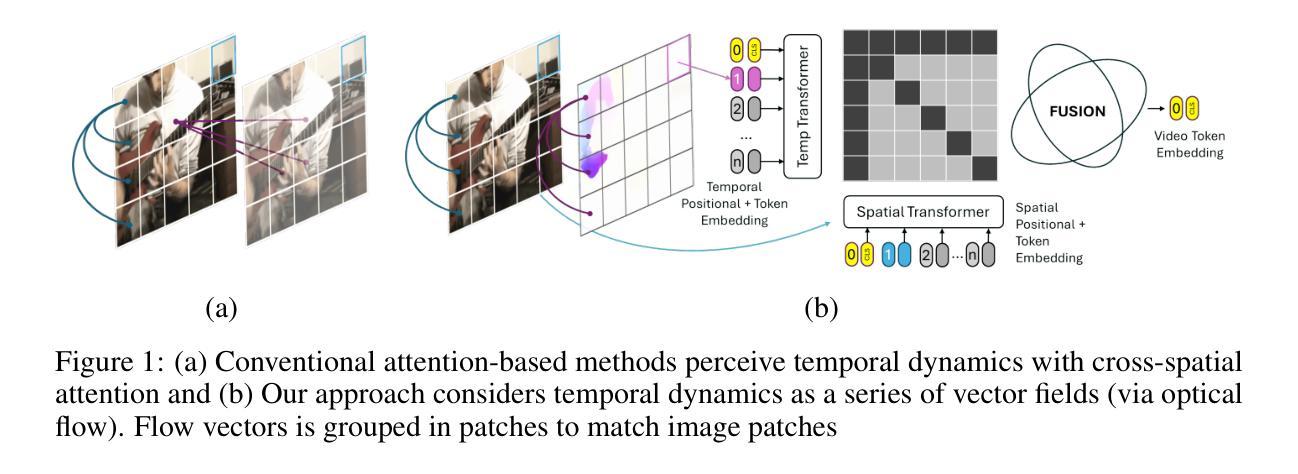
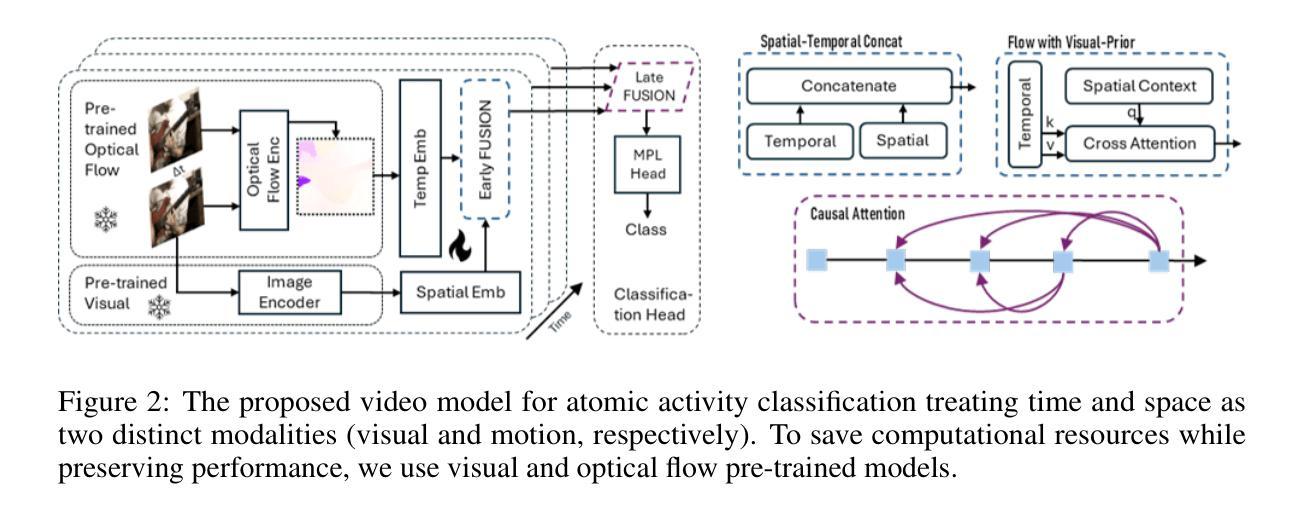
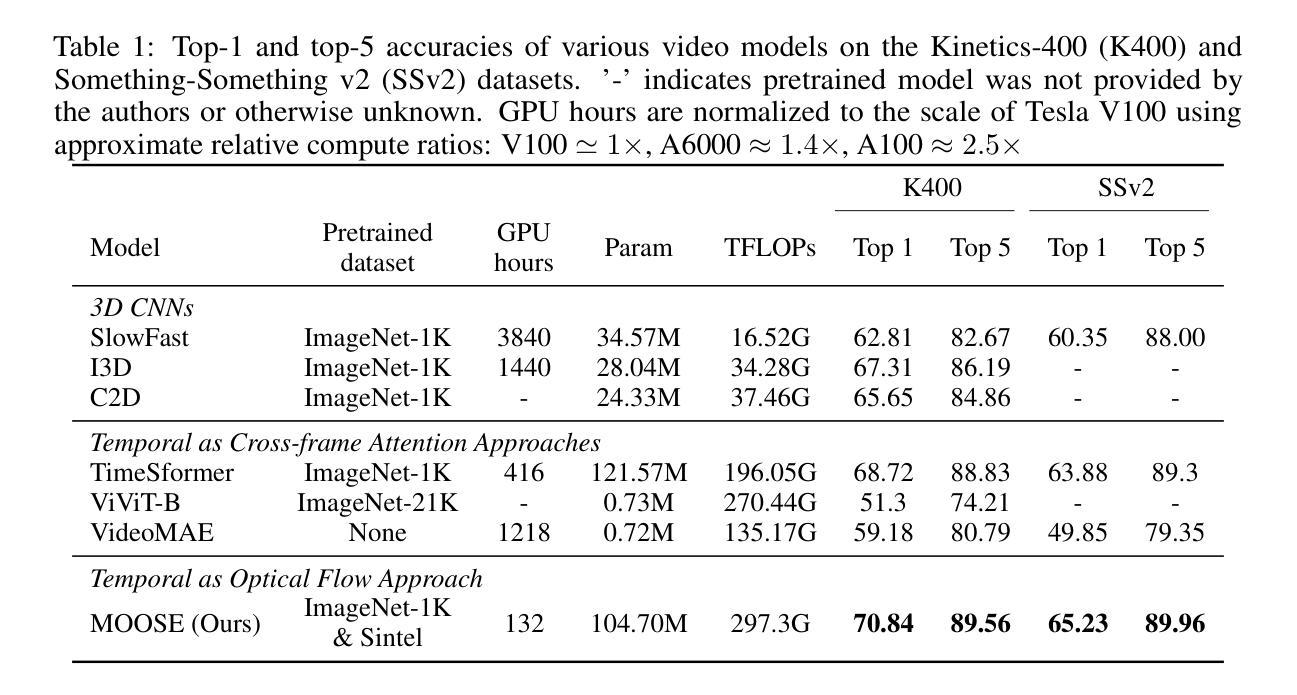
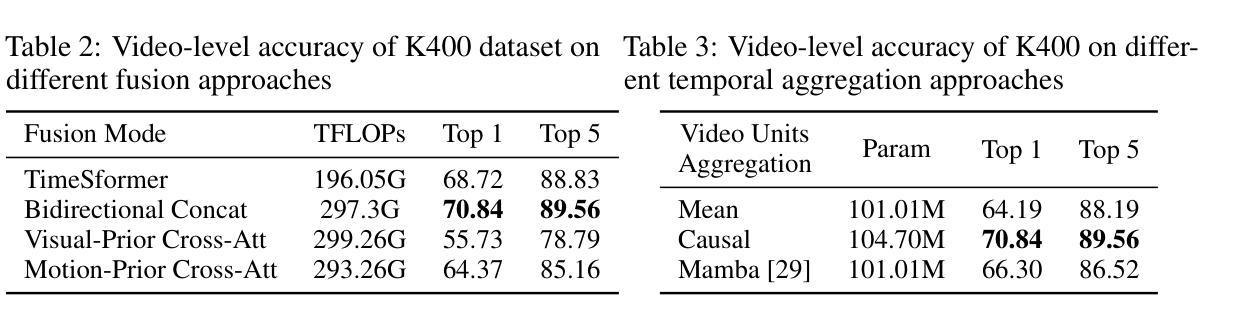
MOOSE: Pay Attention to Temporal Dynamics for Video Understanding via Optical Flows
Authors:Hong Nguyen, Dung Tran, Hieu Hoang, Phong Nguyen, Shrikanth Narayanan
Many motion-centric video analysis tasks, such as atomic actions, detecting atypical motor behavior in individuals with autism, or analyzing articulatory motion in real-time MRI of human speech, require efficient and interpretable temporal modeling. Capturing temporal dynamics is a central challenge in video analysis, often requiring significant computational resources and fine-grained annotations that are not widely available. This paper presents MOOSE (Motion Flow Over Spatial Space), a novel temporally-centric video encoder explicitly integrating optical flow with spatial embeddings to model temporal information efficiently, inspired by human perception of motion. Unlike prior models, MOOSE takes advantage of rich, widely available pre-trained visual and optical flow encoders instead of training video models from scratch. This significantly reduces computational complexity while enhancing temporal interpretability. Our primary contributions includes (1) proposing a computationally efficient temporally-centric architecture for video understanding (2) demonstrating enhanced interpretability in modeling temporal dynamics; and (3) achieving state-of-the-art performance on diverse benchmarks, including clinical, medical, and standard action recognition datasets, confirming the broad applicability and effectiveness of our approach.
许多以运动为中心的视频分析任务,如原子行为、检测自闭症患者的非典型运动行为或在实时MRI中分析人类言语的发音运动等,都需要高效且可解释的时间建模。捕捉时间动态是视频分析的核心挑战,通常需要大量的计算资源和并不普遍存在的精细标注。本文提出了MOOSE(运动流空间)是一种以时间为中心的全新视频编码器,它通过整合光学流量与空间嵌入来高效建模时间信息,这得益于人类对运动的感知启发。不同于之前的模型,MOOSE利用丰富且易于获取的视觉和光学流量编码器,而不是从头开始训练视频模型。这大大降低了计算复杂度,同时提高了时间的可解释性。我们的主要贡献包括:(1)提出了一种用于视频理解的计算高效的时间中心架构;(2)在建模时间动态方面表现出更高的可解释性;(3)在包括临床、医疗和标准动作识别数据集在内的各种基准测试上达到了最先进的性能,证实了我们方法的广泛适用性和有效性。
论文及项目相关链接
摘要
本文提出了一种名为MOOSE(运动流在空间上的流动)的新型以时间为中心的视频编码器,该编码器通过整合光流与空间嵌入来有效地建模时间信息,从而捕捉视频中的动态变化。与传统的视频模型相比,MOOSE利用丰富且广泛可用的预训练视觉和光流编码器,而无需从零开始训练视频模型,从而显著降低了计算复杂性并提高了时间可解释性。本文的主要贡献包括:(1)提出了一种用于视频理解的计算效率高的以时间为中心的架构;(2)在建模时间动态方面显示出增强的可解释性;(3)在包括临床、医疗和标准动作识别数据集在内的多种基准测试上达到了最先进的性能,证明了我们方法的广泛适用性和有效性。
关键见解
- MOOSE是一种新型以时间为中心的视频编码器,旨在有效地建模时间信息。
- 通过整合光流与空间嵌入,MOOSE能够捕捉视频中的动态变化。
- MOOSE利用预训练的视觉和光流编码器,降低计算复杂性的同时提高时间可解释性。
- MOOSE的架构在视频理解方面表现出计算效率高的特点。
- MOOSE在建模时间动态方面显示出增强的可解释性。
- MOOSE在多种基准测试上达到了最先进的性能。
- 这证明了MOOSE方法的广泛适用性和有效性。
点此查看论文截图


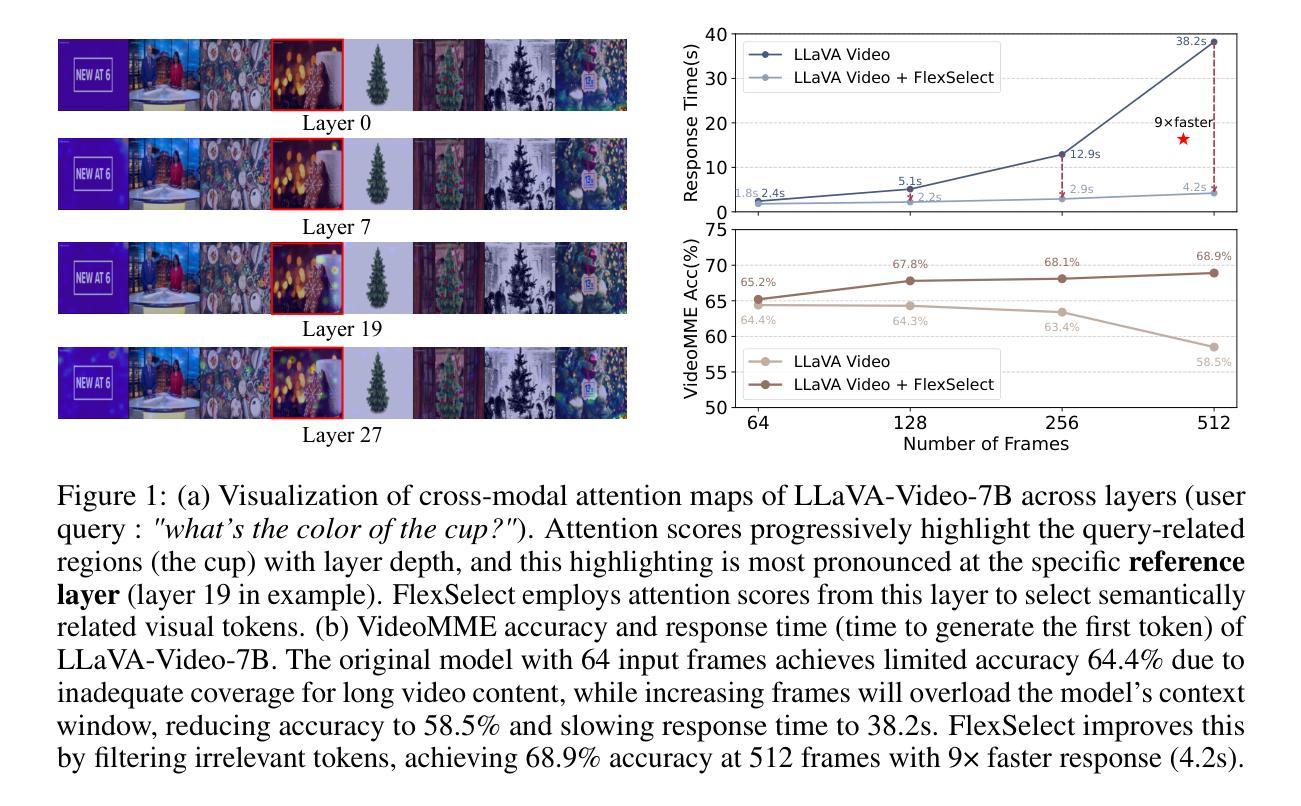
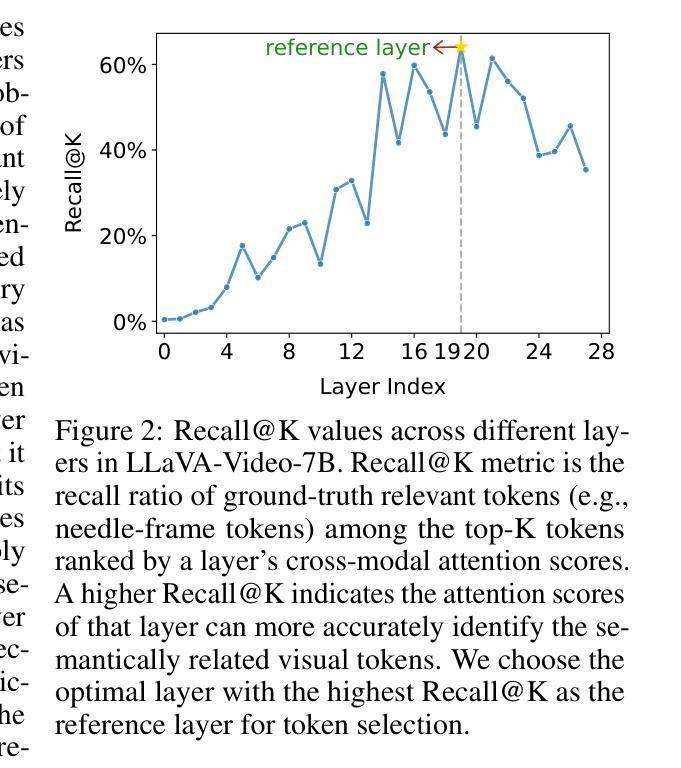
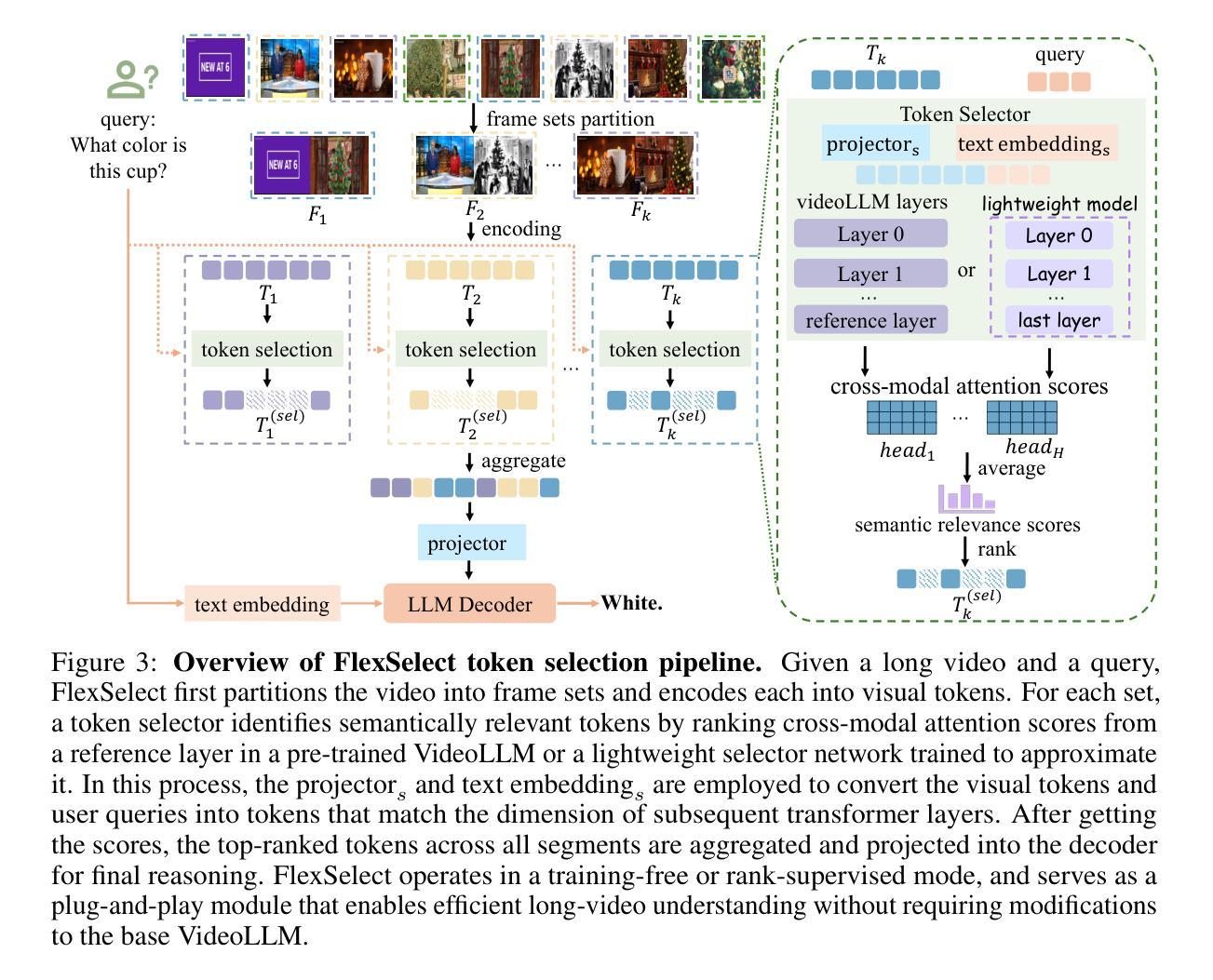
FlexSelect: Flexible Token Selection for Efficient Long Video Understanding
Authors:Yunzhu Zhang, Yu Lu, Tianyi Wang, Fengyun Rao, Yi Yang, Linchao Zhu
Long-form video understanding poses a significant challenge for video large language models (VideoLLMs) due to prohibitively high computational and memory demands. In this paper, we propose FlexSelect, a flexible and efficient token selection strategy for processing long videos. FlexSelect identifies and retains the most semantically relevant content by leveraging cross-modal attention patterns from a reference transformer layer. It comprises two key components: (1) a training-free token ranking pipeline that leverages faithful cross-modal attention weights to estimate each video token’s importance, and (2) a rank-supervised lightweight selector that is trained to replicate these rankings and filter redundant tokens. This generic approach can be seamlessly integrated into various VideoLLM architectures, such as LLaVA-Video, InternVL and Qwen-VL, serving as a plug-and-play module to extend their temporal context length. Empirically, FlexSelect delivers strong gains across multiple long-video benchmarks including VideoMME, MLVU, LongVB, and LVBench. Moreover, it achieves significant speed-ups (for example, up to 9 times on a LLaVA-Video-7B model), highlighting FlexSelect’s promise for efficient long-form video understanding. Project page available at: https://yunzhuzhang0918.github.io/flex_select
长视频理解对视频大型语言模型(VideoLLM)来说是一个巨大的挑战,因为其计算量和内存需求过高。在本文中,我们提出了FlexSelect,这是一种灵活高效的处理长视频的令牌选择策略。FlexSelect通过利用参考transformer层的跨模态注意力模式来识别和保留最语义相关的内容。它包括两个关键组成部分:(1)一个无需训练的令牌排名管道,它利用忠实的跨模态注意力权重来估计每个视频令牌的重要性;(2)一个排名监督的轻量级选择器,经过训练以复制这些排名并过滤掉冗余的令牌。这种通用方法可以无缝地集成到各种VideoLLM架构中,如LLaVA-Video、InternVL和Qwen-VL,作为一个即插即用的模块来扩展它们的时序上下文长度。经验上,FlexSelect在多个长视频基准测试中取得了显著的提升,包括VideoMME、MLVU、LongVB和LVBench。此外,它实现了显著的速度提升(例如在LLaVA-Video-7B模型上最高达到9倍),这突显了FlexSelect在高效长视频理解方面的潜力。项目页面可在:[https://yunzhuzhang0918.github.io/flex_select](https://yunzhuzhang0918.github.io/flex_select)查看。
论文及项目相关链接
摘要
针对长视频对视频大型语言模型(VideoLLM)提出的挑战,如高计算需求和内存需求,本文提出了一种灵活高效的令牌选择策略——FlexSelect。FlexSelect通过利用参考变换器层的跨模态注意力模式来识别和保留最语义相关的内容。它包括两个关键组件:(1)无需训练的令牌排名管道,利用可靠的跨模态注意力权重来估计每个视频令牌的重要性;(2)一个排名监督的轻量级选择器,经过训练以复制这些排名并过滤冗余令牌。这种方法可以无缝集成到各种VideoLLM架构中,如LLaVA-Video、InternVL和Qwen-VL等,作为一个即插即用的模块来扩展它们的时序上下文长度。经验表明,FlexSelect在多个长视频基准测试中取得了显著的提升,包括VideoMME、MLVU、LongVB和LVBench等。此外,它实现了显著的速度提升(例如在LLaVA-Video-7B模型上最高可达9倍),突显了FlexSelect在高效长视频理解方面的潜力。项目页面可在https://yunzhuzhang0918.github.io/flex_select找到。
关键见解
- FlexSelect是一种针对长视频理解的有效令牌选择策略,可应对视频大型语言模型的高计算和内存需求挑战。
- FlexSelect通过跨模态注意力模式识别最语义相关的内容。
- 该方法包括无需训练的令牌排名管道和排名监督的轻量级选择器两个关键组件。
- FlexSelect可无缝集成到各种VideoLLM架构中,如LLaVA-Video、InternVL和Qwen-VL等。
- FlexSelect在多个长视频基准测试上取得了显著的提升效果。
- FlexSelect实现了显著的速度提升,突显了其在实际应用中的效率。
点此查看论文截图


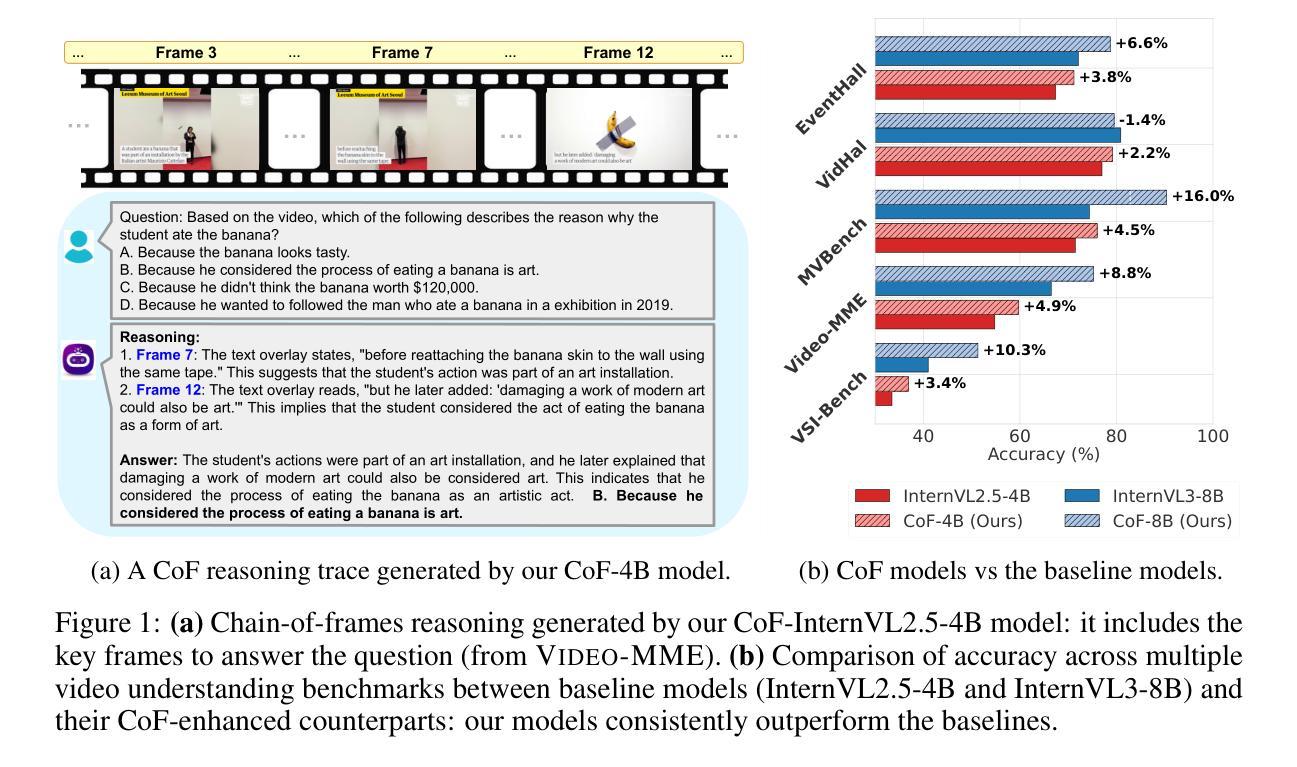
Chain-of-Frames: Advancing Video Understanding in Multimodal LLMs via Frame-Aware Reasoning
Authors:Sara Ghazanfari, Francesco Croce, Nicolas Flammarion, Prashanth Krishnamurthy, Farshad Khorrami, Siddharth Garg
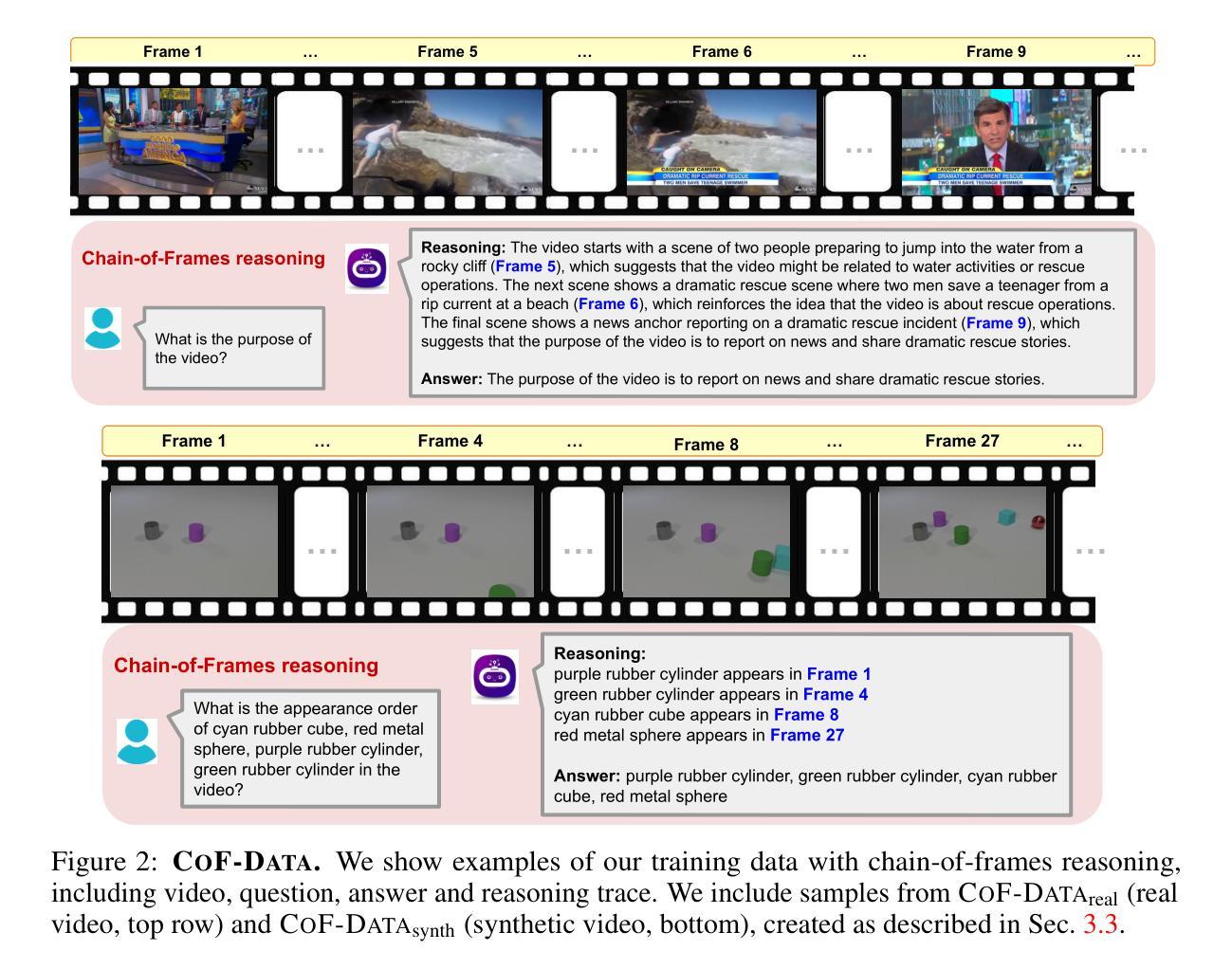
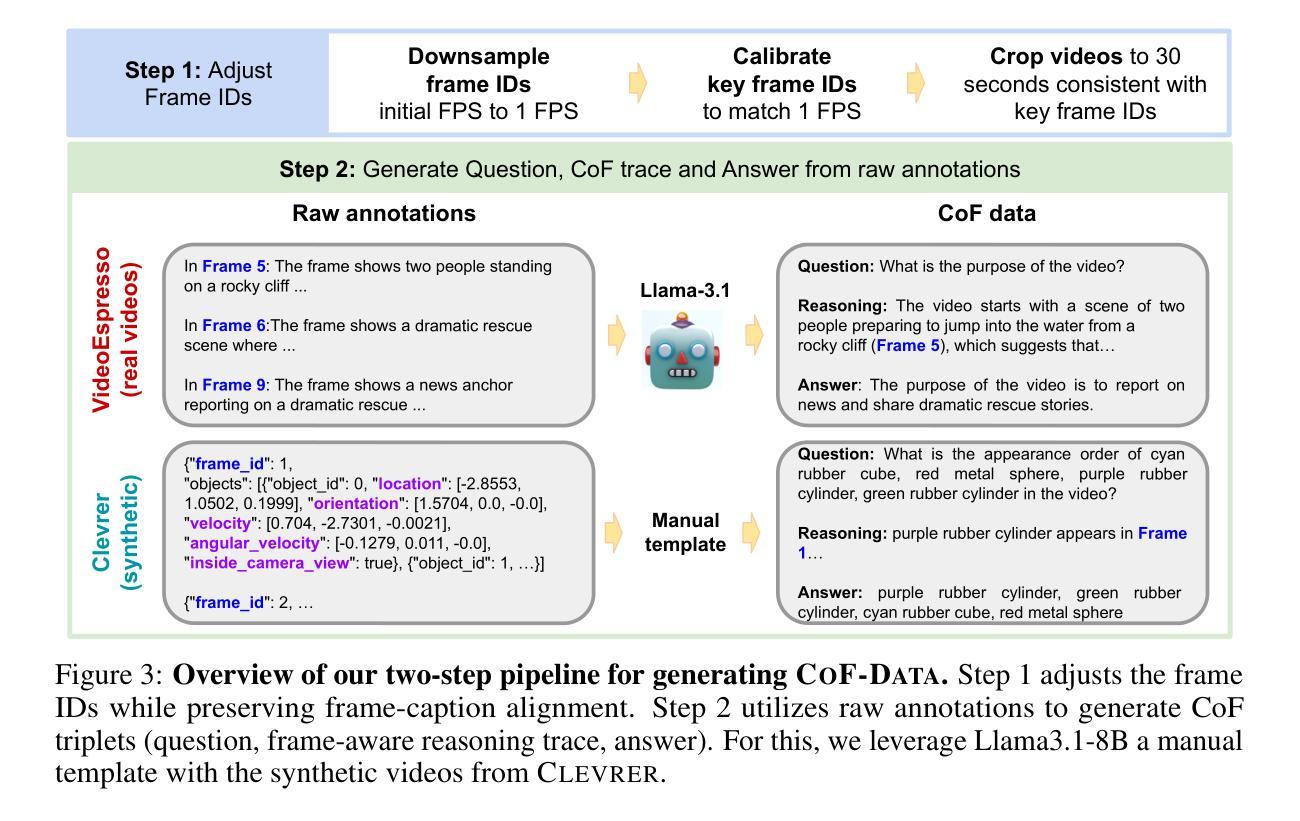
Recent work has shown that eliciting Large Language Models (LLMs) to generate reasoning traces in natural language before answering the user’s request can significantly improve their performance across tasks. This approach has been extended to multimodal LLMs, where the models can produce chain-of-thoughts (CoT) about the content of input images and videos. In this work, we propose to obtain video LLMs whose reasoning steps are grounded in, and explicitly refer to, the relevant video frames. For this, we first create CoF-Data, a large dataset of diverse questions, answers, and corresponding frame-grounded reasoning traces about both natural and synthetic videos, spanning various topics and tasks. Then, we fine-tune existing video LLMs on this chain-of-frames (CoF) data. Our approach is simple and self-contained, and, unlike existing approaches for video CoT, does not require auxiliary networks to select or caption relevant frames. We show that our models based on CoF are able to generate chain-of-thoughts that accurately refer to the key frames to answer the given question. This, in turn, leads to improved performance across multiple video understanding benchmarks, for example, surpassing leading video LLMs on Video-MME, MVBench, and VSI-Bench, and notably reducing the hallucination rate. Code available at https://github.com/SaraGhazanfari/CoF}{github.com/SaraGhazanfari/CoF.
最近的研究表明,在回答用户请求之前,激发大型语言模型(LLM)生成自然语言中的推理轨迹,可以显著提高其在各种任务中的性能。这种方法已经扩展到多模态LLM,其中模型可以产生关于输入图像和视频内容的思维链(CoT)。在这项工作中,我们提出获得视频LLM,其推理步骤以相关视频帧为基础,并明确提及这些帧。为此,我们首先创建CoF-Data,这是一个包含各种问题和答案的大型数据集,以及关于自然和合成视频的相应帧基础推理轨迹。然后,我们在这种帧链(CoF)数据上微调现有的视频LLM。我们的方法简单且完整,与现有的视频CoT方法不同,它不需要辅助网络来选择或描述相关帧。我们展示了基于CoF的模型能够生成准确提及关键帧以回答给定问题的思维链。这反过来又提高了在多个视频理解基准测试上的性能,例如在Video-MME、MVBench和VSI-Bench上的表现超越了领先的视频LLM,并显著降低了幻想率。相关代码可在https://github.com/SaraGhazanfari/CoF处获取。
论文及项目相关链接
Summary
本文提出一种基于视频的大型语言模型(LLM)的方法,通过生成与视频帧相关的推理步骤来改进视频理解性能。为此,创建了一个大型数据集CoF-Data,包含关于自然和合成视频的多样化问题、答案以及相应的帧推理轨迹。通过在此数据集上微调现有视频LLM,生成能够准确引用关键帧以回答问题的推理轨迹。此方法简单且自成体系,无需辅助网络来选择或描述相关帧,且在多个视频理解基准测试中表现优异。
Key Takeaways
- LLMs通过生成推理轨迹来提高视频理解性能。
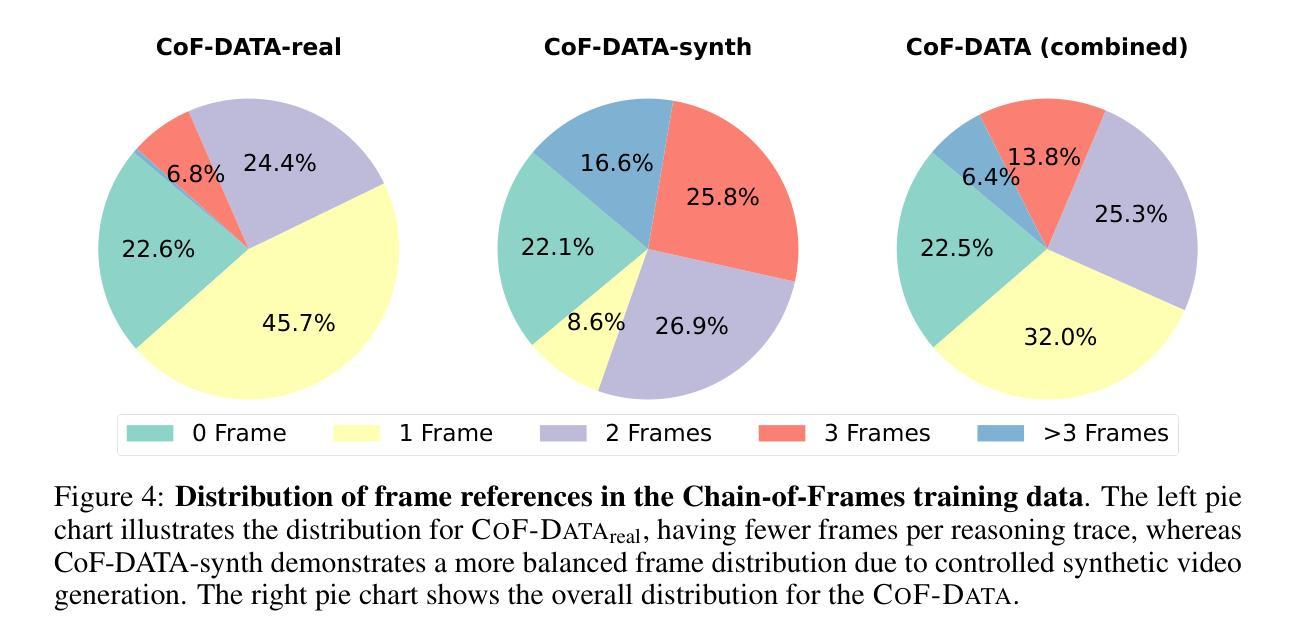
- 提出了CoF-Data数据集,包含关于视频的问题、答案及帧推理轨迹。
- 通过CoF-Data数据集微调视频LLM,使其生成与视频帧相关的推理步骤。
- 所提方法无需辅助网络选择或描述相关帧。
- 生成的视频推理轨迹能准确引用关键帧以回答问题。
- 在多个视频理解基准测试中表现优于其他视频LLMs。
- 降低了hallucination rate(幻觉率)。
点此查看论文截图