⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-05 更新
LEG-SLAM: Real-Time Language-Enhanced Gaussian Splatting for SLAM
Authors:Roman Titkov, Egor Zubkov, Dmitry Yudin, Jaafar Mahmoud, Malik Mohrat, Gennady Sidorov
Modern Gaussian Splatting methods have proven highly effective for real-time photorealistic rendering of 3D scenes. However, integrating semantic information into this representation remains a significant challenge, especially in maintaining real-time performance for SLAM (Simultaneous Localization and Mapping) applications. In this work, we introduce LEG-SLAM – a novel approach that fuses an optimized Gaussian Splatting implementation with visual-language feature extraction using DINOv2 followed by a learnable feature compressor based on Principal Component Analysis, while enabling an online dense SLAM. Our method simultaneously generates high-quality photorealistic images and semantically labeled scene maps, achieving real-time scene reconstruction with more than 10 fps on the Replica dataset and 18 fps on ScanNet. Experimental results show that our approach significantly outperforms state-of-the-art methods in reconstruction speed while achieving competitive rendering quality. The proposed system eliminates the need for prior data preparation such as camera’s ego motion or pre-computed static semantic maps. With its potential applications in autonomous robotics, augmented reality, and other interactive domains, LEG-SLAM represents a significant step forward in real-time semantic 3D Gaussian-based SLAM. Project page: https://titrom025.github.io/LEG-SLAM/
现代的高斯绘制法已被证明对于三维场景的实时逼真渲染高度有效。然而,将语义信息集成到此表示中仍然是一个重大挑战,尤其是在保持SLAM(同时定位和地图构建)应用的实时性能方面。在这项工作中,我们介绍了LEG-SLAM——一种新颖的方法,它将优化的高斯绘制实现与基于DINOv2的视觉语言特征提取相结合,然后基于主成分分析的可学习特征压缩器,同时实现在线密集SLAM。我们的方法可以同时生成高质量逼真图像和语义标记的场景地图,在Replica数据集上以超过10帧/秒的速度实现实时场景重建,在ScanNet上达到18帧/秒。实验结果表明,我们的方法在重建速度上显著优于最先进的方法,同时达到有竞争力的渲染质量。所提出系统消除了对先验数据准备的需求,例如相机的自我运动或预先计算的静态语义地图。其在自主机器人、增强现实和其他交互领域具有潜在应用,LEG-SLAM代表了基于实时语义三维高斯SLAM的重大进步。项目页面:https://titrom025.github.io/LEG-SLAM/
论文及项目相关链接
Summary
该文介绍了一种新的方法LEG-SLAM,它将优化的高斯Splatting实现与基于DINOv2的视觉语言特征提取相结合,再通过主成分分析的可学习特征压缩机,实现了在线密集SLAM。该方法可实时生成高质量的照片级图像和语义标记的场景地图,在Replica数据集上达到超过10帧的重建速度,在ScanNet上达到18帧。相较于现有技术,该方法在重建速度上表现出显著优势,同时保持竞争力强的渲染质量。无需预先准备数据,如相机运动或预先计算静态语义地图,LEG-SLAM在自主机器人、增强现实和其他交互领域具有广泛的应用前景。
Key Takeaways
- LEG-SLAM结合了优化的高斯Splatting方法和基于DINOv2的视觉语言特征提取。
- 引入可学习特征压缩机,基于主成分分析(PCA)。
- 实现了在线密集SLAM,可同时生成高质量照片级图像和语义标记的场景地图。
- 在Replica数据集和ScanNet上的实验结果表明,LEG-SLAM在重建速度上显著优于现有技术。
- LEG-SLAM达到了实时的渲染速度,并具有竞争性的渲染质量。
- 该方法无需预先准备数据,如相机运动或预计算的静态语义地图。
点此查看论文截图

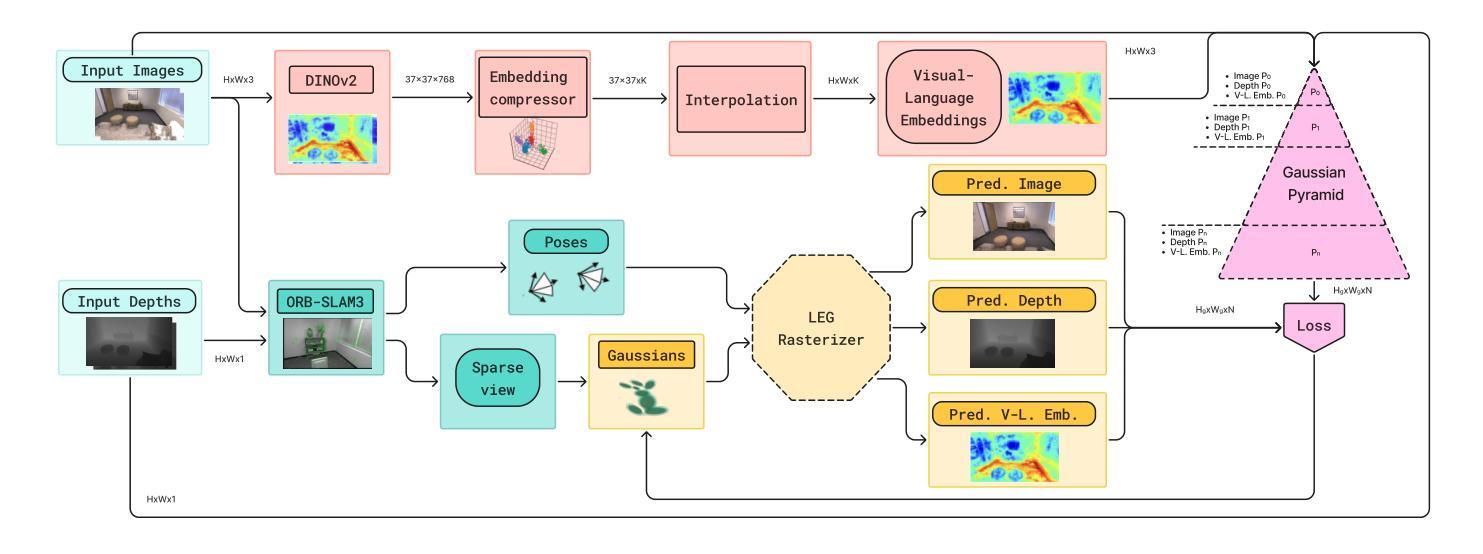
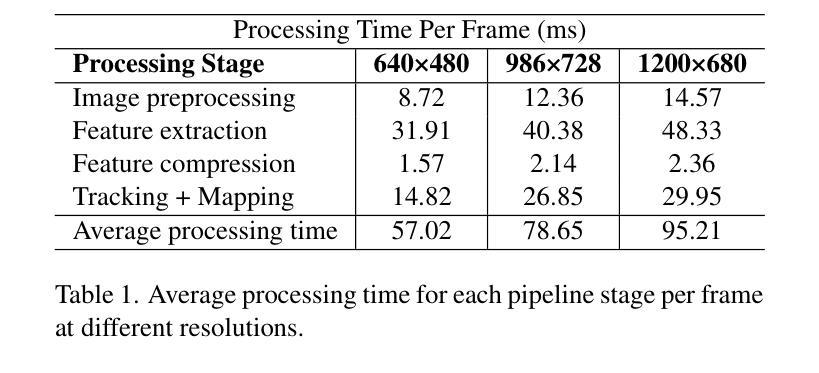
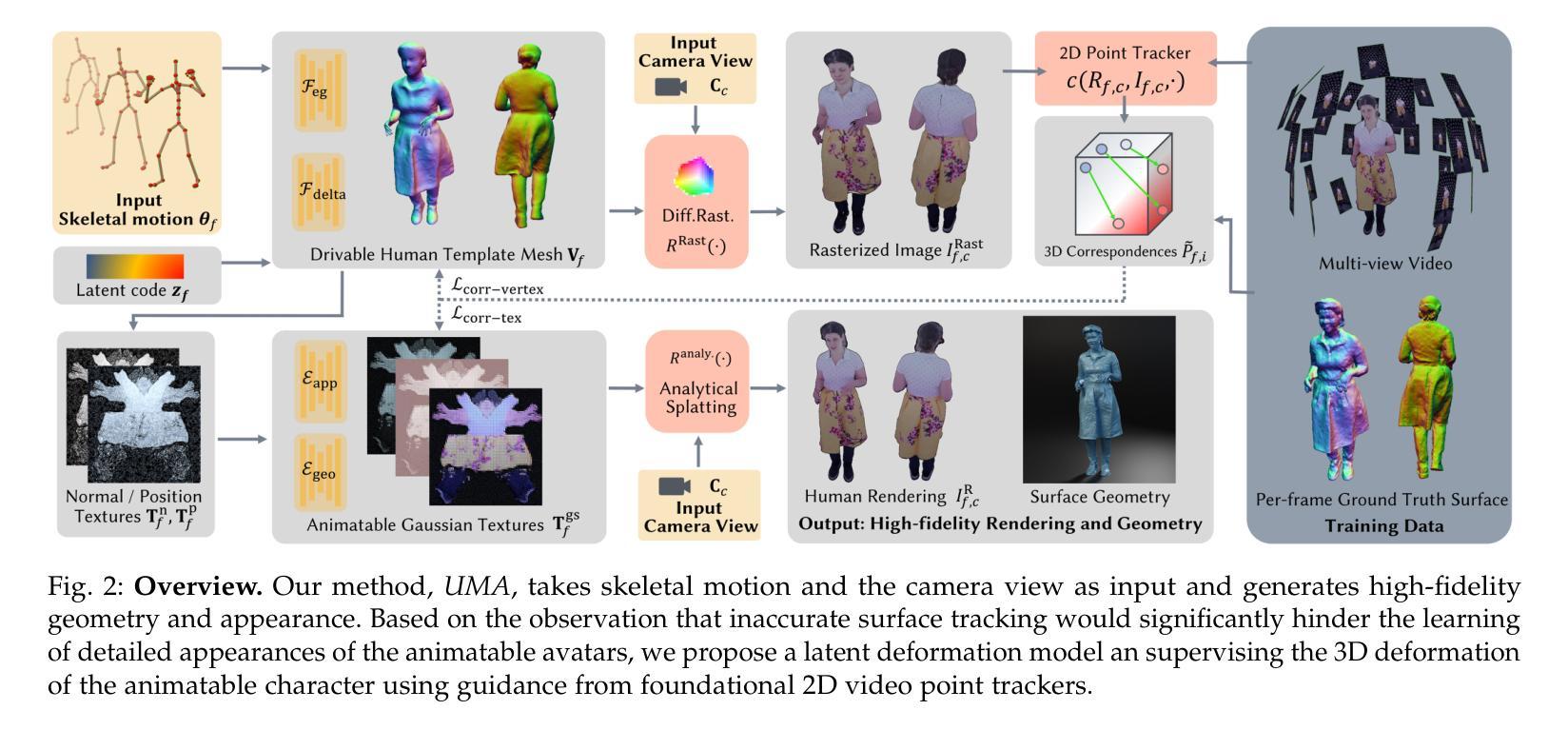
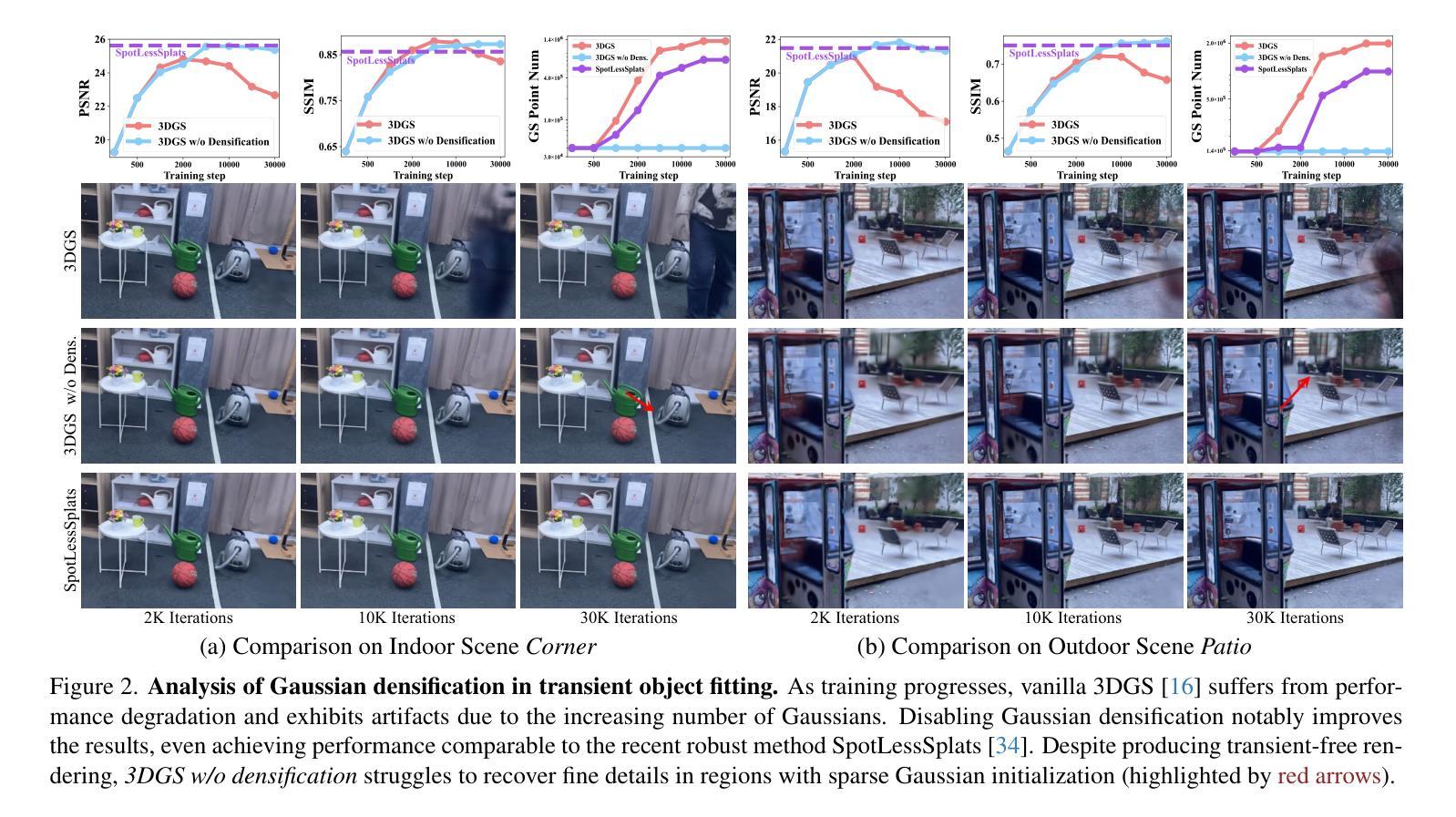
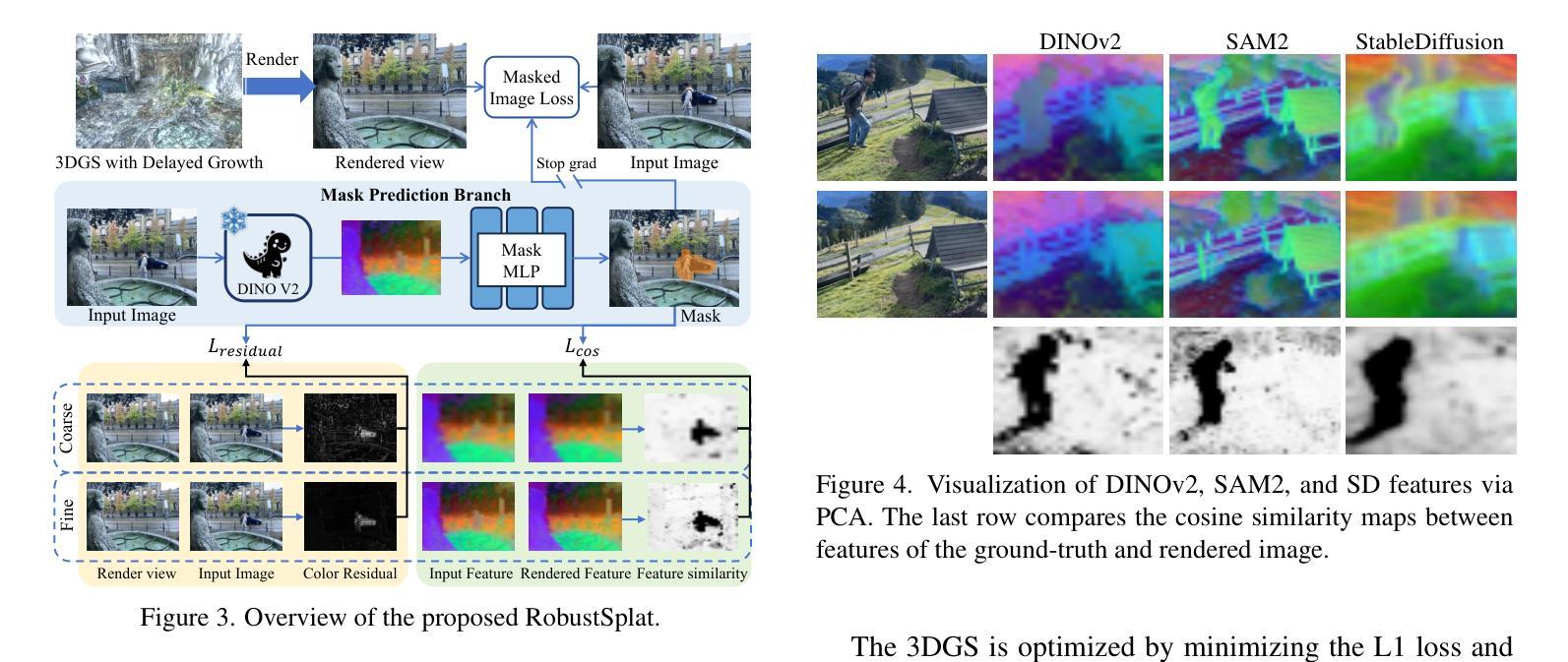
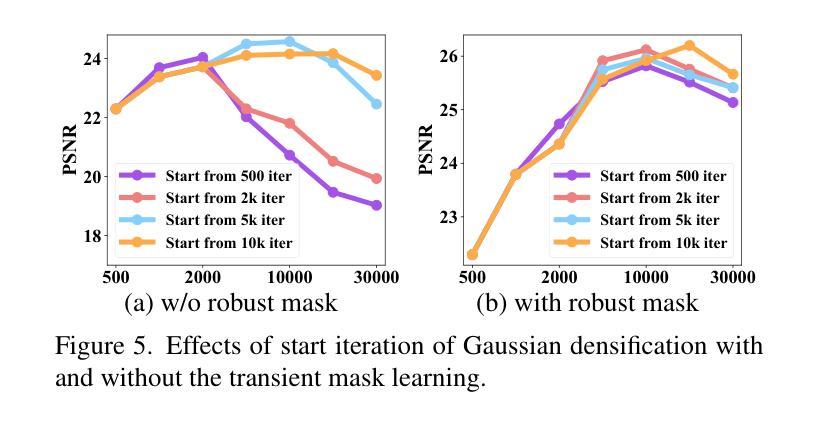
RobustSplat: Decoupling Densification and Dynamics for Transient-Free 3DGS
Authors:Chuanyu Fu, Yuqi Zhang, Kunbin Yao, Guanying Chen, Yuan Xiong, Chuan Huang, Shuguang Cui, Xiaochun Cao
3D Gaussian Splatting (3DGS) has gained significant attention for its real-time, photo-realistic rendering in novel-view synthesis and 3D modeling. However, existing methods struggle with accurately modeling scenes affected by transient objects, leading to artifacts in the rendered images. We identify that the Gaussian densification process, while enhancing scene detail capture, unintentionally contributes to these artifacts by growing additional Gaussians that model transient disturbances. To address this, we propose RobustSplat, a robust solution based on two critical designs. First, we introduce a delayed Gaussian growth strategy that prioritizes optimizing static scene structure before allowing Gaussian splitting/cloning, mitigating overfitting to transient objects in early optimization. Second, we design a scale-cascaded mask bootstrapping approach that first leverages lower-resolution feature similarity supervision for reliable initial transient mask estimation, taking advantage of its stronger semantic consistency and robustness to noise, and then progresses to high-resolution supervision to achieve more precise mask prediction. Extensive experiments on multiple challenging datasets show that our method outperforms existing methods, clearly demonstrating the robustness and effectiveness of our method. Our project page is https://fcyycf.github.io/RobustSplat/.
3D Gaussian Splatting(3DGS)因其在新视角合成和3D建模中的实时、逼真渲染而受到广泛关注。然而,现有方法在模拟受瞬态物体影响的场景时存在困难,导致渲染图像出现伪影。我们发现,高斯增密过程在增强场景细节捕捉的同时,无意中添加了对瞬态扰动的建模高斯,从而产生了这些伪影。为了解决这个问题,我们提出了RobustSplat,这是一种基于两种关键设计的稳健解决方案。首先,我们引入了一种延迟高斯增长策略,该策略优先优化静态场景结构,然后允许高斯分裂/克隆,从而减轻在早期优化中对瞬态物体的过度拟合。其次,我们设计了一种级联遮罩引导方法,首先利用低分辨率特征相似性监督进行可靠的初始瞬态遮罩估计,利用其更强的语义一致性和对噪声的鲁棒性,然后过渡到高分辨率监督以实现更精确的遮罩预测。在多个具有挑战性的数据集上的广泛实验表明,我们的方法优于现有方法,清楚地证明了我们的方法的稳健性和有效性。我们的项目页面是https://fcyycf.github.io/RobustSplat/。
论文及项目相关链接
PDF Project page: https://fcyycf.github.io/RobustSplat/
Summary
3DGS技术通过实时、逼真的渲染实现新颖的视点合成和3D建模,得到广泛关注。但现有方法在模拟受到瞬态对象影响的环境时存在挑战,导致渲染图像出现伪影。针对此问题,我们提出了RobustSplat方案,包含两大设计创新:一是引入延迟高斯增长策略,优先优化静态场景结构后才开始高斯分裂或克隆,减少早期优化对瞬态对象的过度拟合;二是设计规模级联遮罩提升策略,首先利用低分辨率特征相似性监督进行可靠的初始瞬态遮罩估计,再过渡到高分辨率监督以实现更精确的遮罩预测。实验证明,该方法在多个具有挑战的数据集上优于现有技术。更多信息可参见项目网站:https://fcyycf.github.io/RobustSplat/。
Key Takeaways
- 3DGS技术广泛应用于实时、逼真的渲染,用于新颖的视点合成和3D建模。
- 现有方法在模拟受瞬态对象影响的环境时存在挑战,导致渲染图像出现伪影。
- RobustSplat方案通过引入延迟高斯增长策略,减少早期优化对瞬态对象的过度拟合。
- 采用规模级联遮罩提升策略,利用低分辨率特征相似性监督进行可靠的初始瞬态遮罩估计,再过渡到高分辨率监督以实现更精确的遮罩预测。
- 该方法在多数据集上的表现优于现有技术。
点此查看论文截图


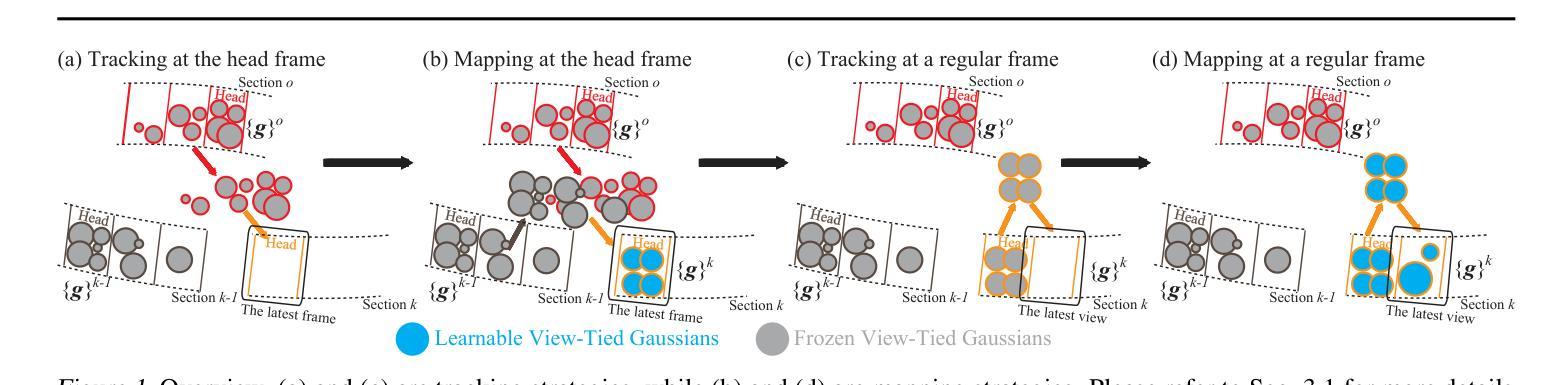
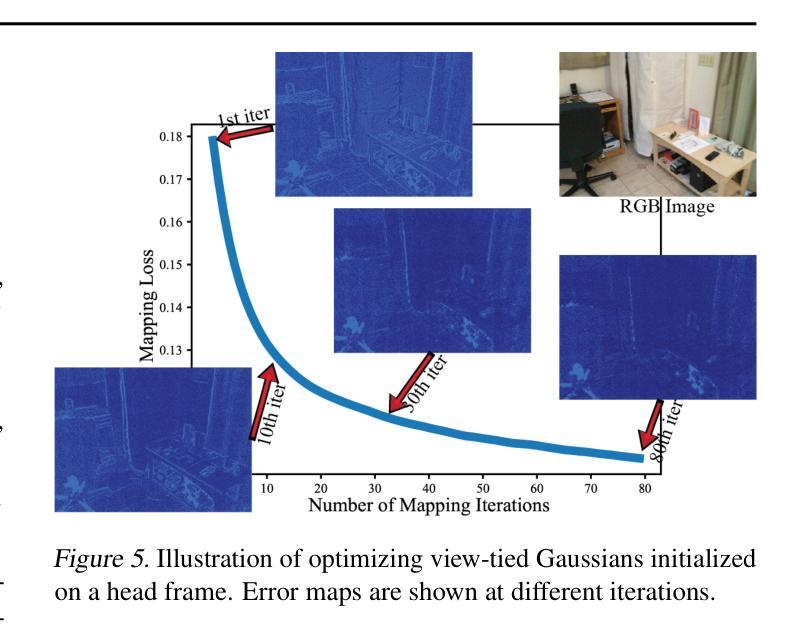
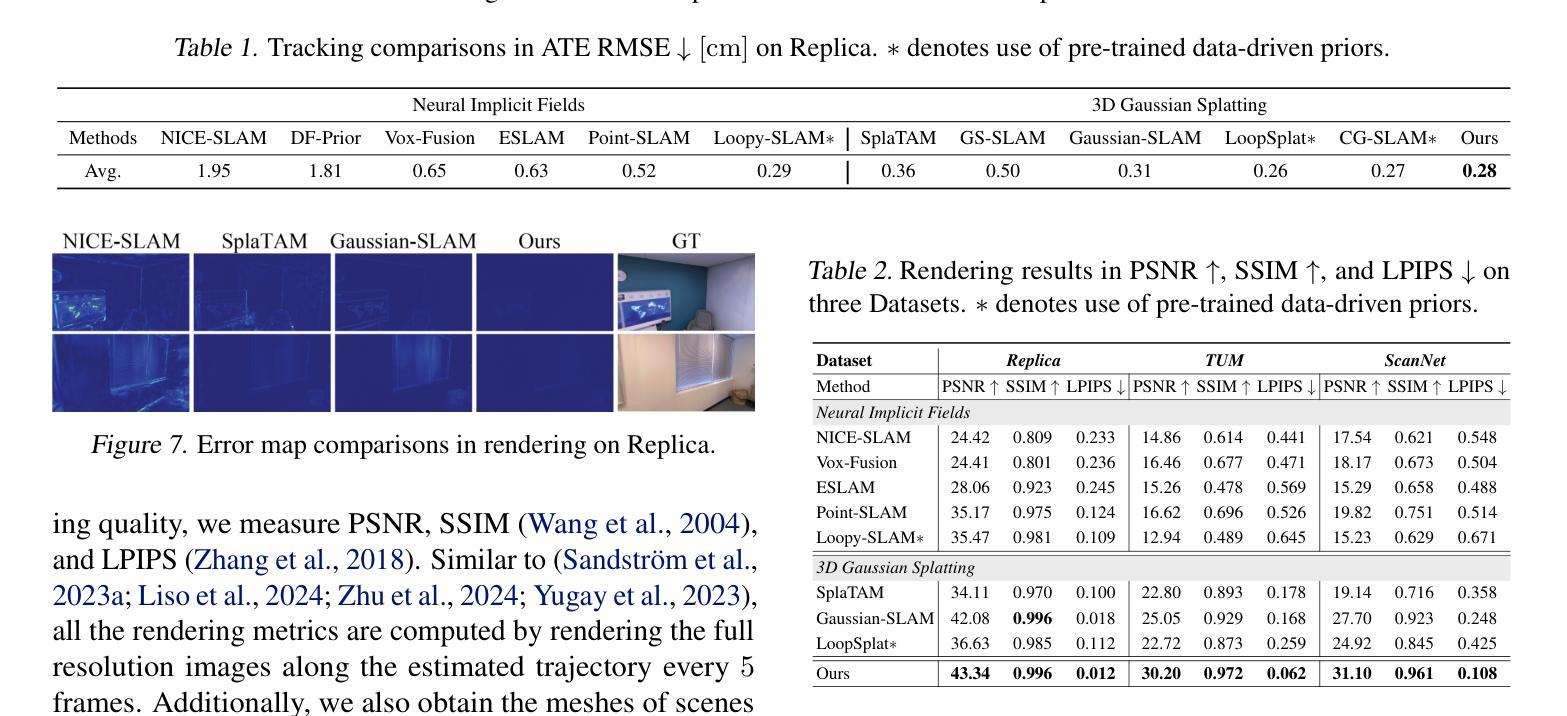
VTGaussian-SLAM: RGBD SLAM for Large Scale Scenes with Splatting View-Tied 3D Gaussians
Authors:Pengchong Hu, Zhizhong Han
Jointly estimating camera poses and mapping scenes from RGBD images is a fundamental task in simultaneous localization and mapping (SLAM). State-of-the-art methods employ 3D Gaussians to represent a scene, and render these Gaussians through splatting for higher efficiency and better rendering. However, these methods cannot scale up to extremely large scenes, due to the inefficient tracking and mapping strategies that need to optimize all 3D Gaussians in the limited GPU memories throughout the training to maintain the geometry and color consistency to previous RGBD observations. To resolve this issue, we propose novel tracking and mapping strategies to work with a novel 3D representation, dubbed view-tied 3D Gaussians, for RGBD SLAM systems. View-tied 3D Gaussians is a kind of simplified Gaussians, which is tied to depth pixels, without needing to learn locations, rotations, and multi-dimensional variances. Tying Gaussians to views not only significantly saves storage but also allows us to employ many more Gaussians to represent local details in the limited GPU memory. Moreover, our strategies remove the need of maintaining all Gaussians learnable throughout the training, while improving rendering quality, and tracking accuracy. We justify the effectiveness of these designs, and report better performance over the latest methods on the widely used benchmarks in terms of rendering and tracking accuracy and scalability. Please see our project page for code and videos at https://machineperceptionlab.github.io/VTGaussian-SLAM-Project .
从RGBD图像中联合估计相机姿态并绘制场景是同时定位与地图构建(SLAM)中的一项基本任务。最新方法采用3D高斯来代表场景,并通过溅射(splatting)来提高效率和渲染效果。然而,这些方法无法扩展到非常大的场景,因为有限的GPU内存需要在训练过程中优化所有3D高斯来维持几何和颜色一致性到先前的RGBD观察结果,这使得跟踪和映射策略效率低下。为了解决这个问题,我们提出了新颖的跟踪和映射策略,与一种名为“视图绑定3D高斯”的新型3D表示相结合,用于RGBD SLAM系统。视图绑定3D高斯是一种简化型高斯,它与深度像素绑定,无需学习位置、旋转和多维方差。将高斯与视图绑定不仅大大节省了存储空间,而且允许我们使用更多高斯在有限的GPU内存中表示局部细节。此外,我们的策略无需在训练过程中保持所有高斯可学习,同时提高了渲染质量和跟踪精度。我们验证了这些设计的有效性,并在广泛使用的基准测试上报告了比最新方法更好的性能,涉及渲染和跟踪精度和可扩展性。有关代码和视频,请访问我们的项目页面:https://machineperceptionlab.github.io/VTGaussian-SLAM-Project。
论文及项目相关链接
PDF ICML 2025
Summary
本文介绍了针对RGBD SLAM系统的视绑3D高斯(View-tied 3D Gaussians)新技术。该技术解决了大规模场景下的跟踪和映射效率问题,通过绑定深度像素的简化高斯表示方法,有效节省存储空间并提高渲染质量和跟踪精度。新技术实现了更好的性能表现,可在广泛使用的基准测试上超越最新方法。
Key Takeaways
- 提出了一种名为视绑3D高斯(View-tied 3D Gaussians)的新型3D表示方法,用于RGBD SLAM系统。
- 视绑3D高斯通过绑定深度像素的简化高斯表示,无需学习位置、旋转和多维方差,显著节省了存储空间。
- 新技术提高了渲染质量和跟踪精度,解决了在大规模场景下的跟踪和映射效率问题。
- 新技术在广泛使用的基准测试上实现了更好的性能表现,超越了最新方法。
点此查看论文截图




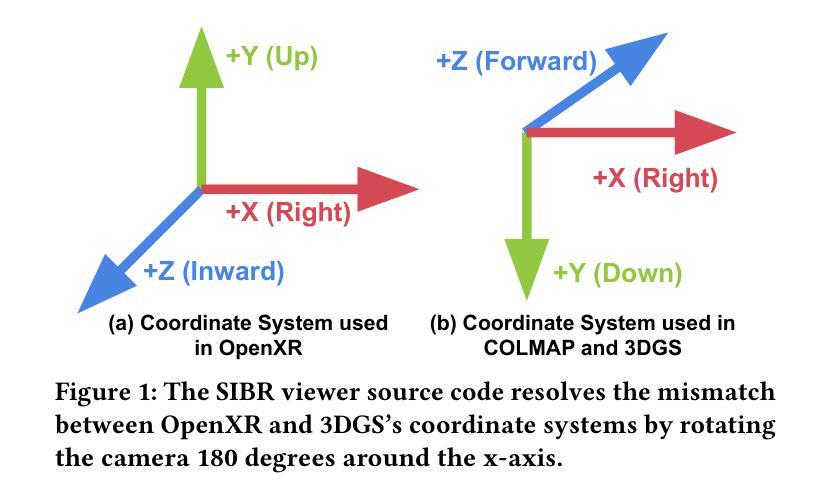
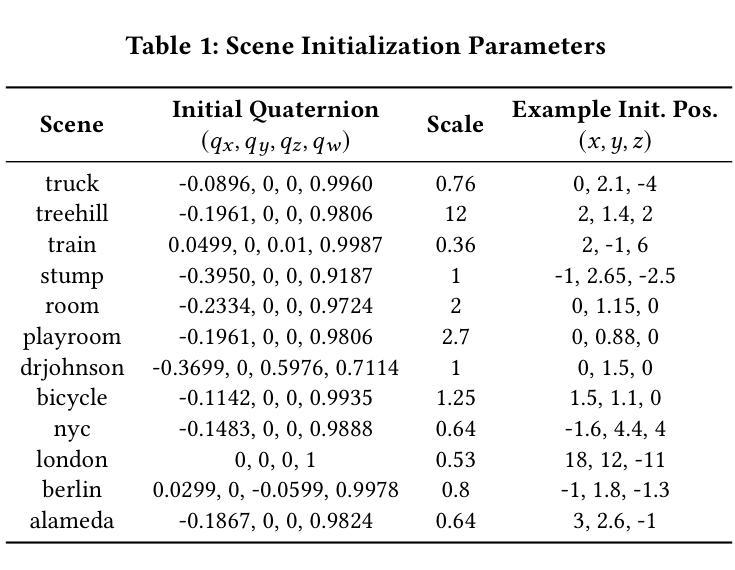
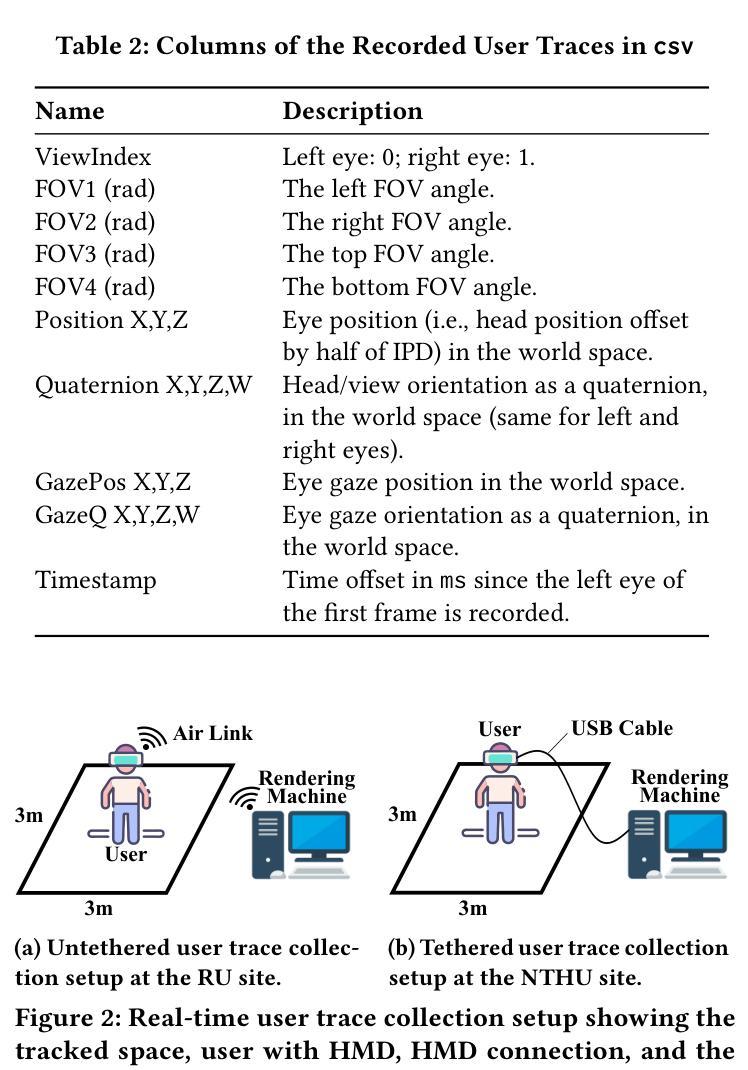
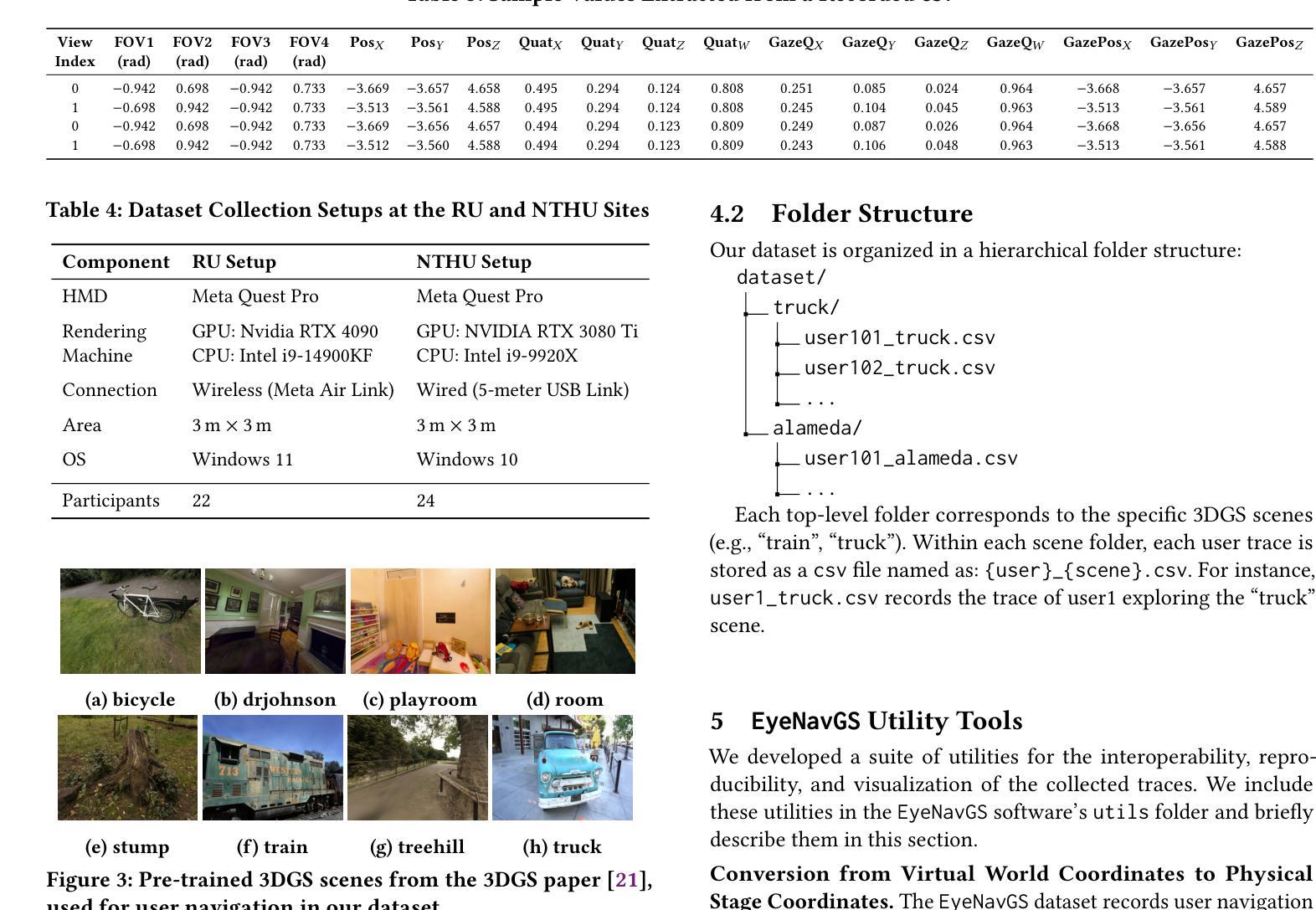
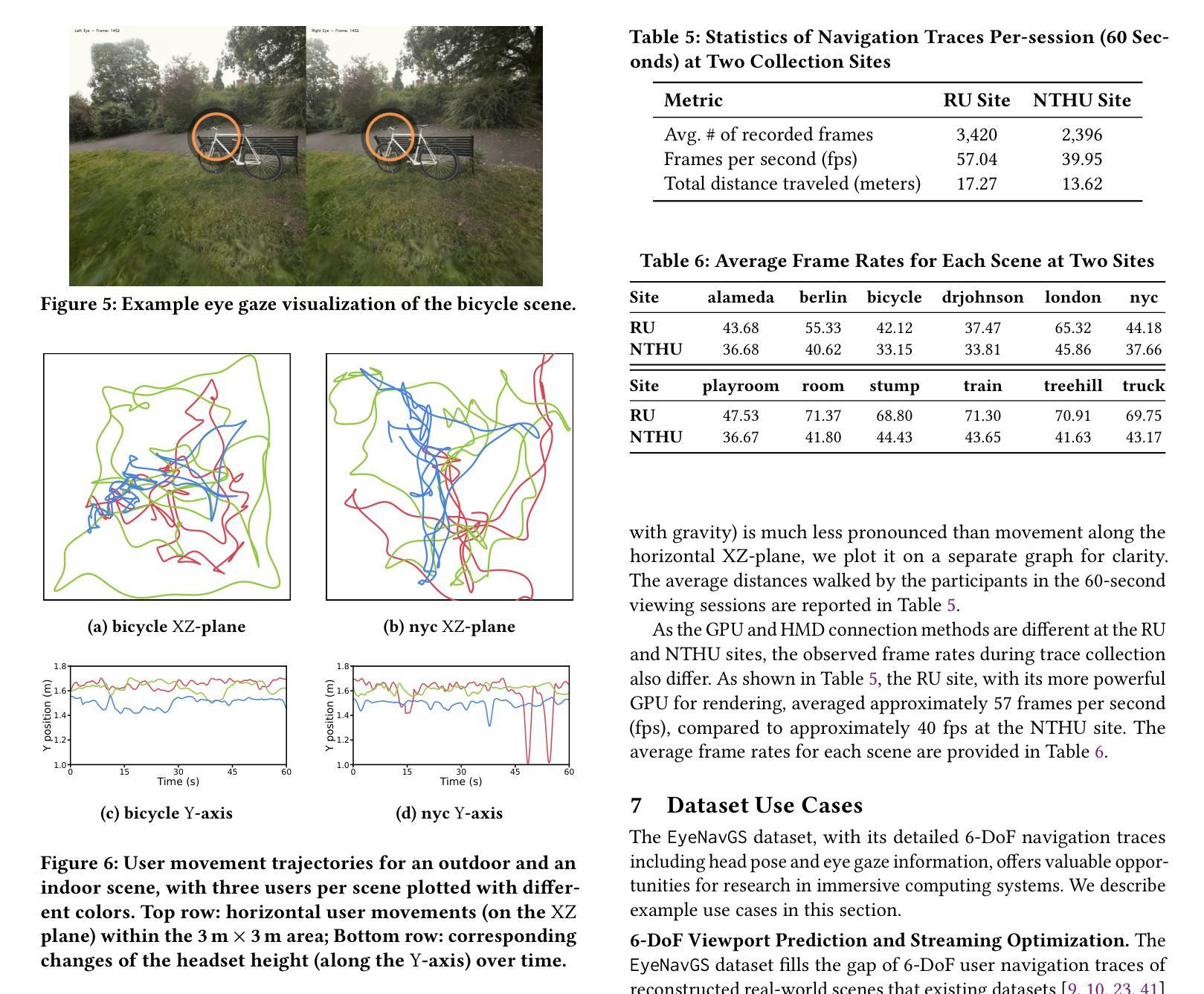
EyeNavGS: A 6-DoF Navigation Dataset and Record-n-Replay Software for Real-World 3DGS Scenes in VR
Authors:Zihao Ding, Cheng-Tse Lee, Mufeng Zhu, Tao Guan, Yuan-Chun Sun, Cheng-Hsin Hsu, Yao Liu
3D Gaussian Splatting (3DGS) is an emerging media representation that reconstructs real-world 3D scenes in high fidelity, enabling 6-degrees-of-freedom (6-DoF) navigation in virtual reality (VR). However, developing and evaluating 3DGS-enabled applications and optimizing their rendering performance, require realistic user navigation data. Such data is currently unavailable for photorealistic 3DGS reconstructions of real-world scenes. This paper introduces EyeNavGS (EyeNavGS), the first publicly available 6-DoF navigation dataset featuring traces from 46 participants exploring twelve diverse, real-world 3DGS scenes. The dataset was collected at two sites, using the Meta Quest Pro headsets, recording the head pose and eye gaze data for each rendered frame during free world standing 6-DoF navigation. For each of the twelve scenes, we performed careful scene initialization to correct for scene tilt and scale, ensuring a perceptually-comfortable VR experience. We also release our open-source SIBR viewer software fork with record-and-replay functionalities and a suite of utility tools for data processing, conversion, and visualization. The EyeNavGS dataset and its accompanying software tools provide valuable resources for advancing research in 6-DoF viewport prediction, adaptive streaming, 3D saliency, and foveated rendering for 3DGS scenes. The EyeNavGS dataset is available at: https://symmru.github.io/EyeNavGS/.
3D高斯拼贴(3DGS)是一种新兴媒体表示形式,能够以高保真方式重建真实世界的3D场景,从而在虚拟现实(VR)中实现六自由度(6-DoF)导航。然而,开发和评估3DGS应用程序并优化其渲染性能,需要真实的用户导航数据。目前尚无可用于真实世界场景的光现实3DGS重建的数据集。本文介绍了EyeNavGS(EyeNavGS),这是第一个公开的六自由度导航数据集,包含来自46名参与者探索的十二个不同真实世界3DGS场景的轨迹。该数据集是在两个站点使用Meta Quest Pro头戴显示器收集的,记录了在自由世界站立六自由度导航期间每个渲染帧的头部姿势和眼睛注视数据。对于十二个场景中的每一个场景,我们都进行了仔细的初始化操作来纠正场景的倾斜和比例问题,确保感知舒适的虚拟现实体验。我们还发布了开源的SIBR查看器软件分支,具有记录和回放功能以及用于数据处理、转换和可视化的实用工具套件。EyeNavGS数据集及其配套的软件工具为推进六自由度视口预测、自适应流、三维显著性以及三维GS场景的焦点渲染研究提供了宝贵的资源。EyeNavGS数据集可在以下网址获取:https://symmru.github.io/EyeNavGS/。
论文及项目相关链接
Summary
本文介绍了名为EyeNavGS的公开数据集,该数据集包含利用Meta Quest Pro头盔收集的来自真实场景的三维场景模拟中的6自由度导航数据。数据集中的场景已经经过细致的初始化处理,可用于支持多种研究和工具的开发,为推进基于3DGS场景的6自由度视图预测、自适应流传输、三维显著性检测以及焦点渲染等技术提供了宝贵的资源。
Key Takeaways
- EyeNavGS是首个公开的基于三维高斯拼贴技术的真实世界场景再现的六自由度导航数据集。
- 数据集收集了来自不同参与者在不同场景中的自由行走轨迹,并记录了头部姿态和眼睛注视数据。
- 数据集收集过程中使用了Meta Quest Pro头盔进行数据采集。
- 每个场景都经过了细致的初始化处理,以确保VR体验的视觉舒适性。
- 该数据集包含记录回放功能的开源SIBR查看器软件及其数据处理和可视化工具。
点此查看论文截图


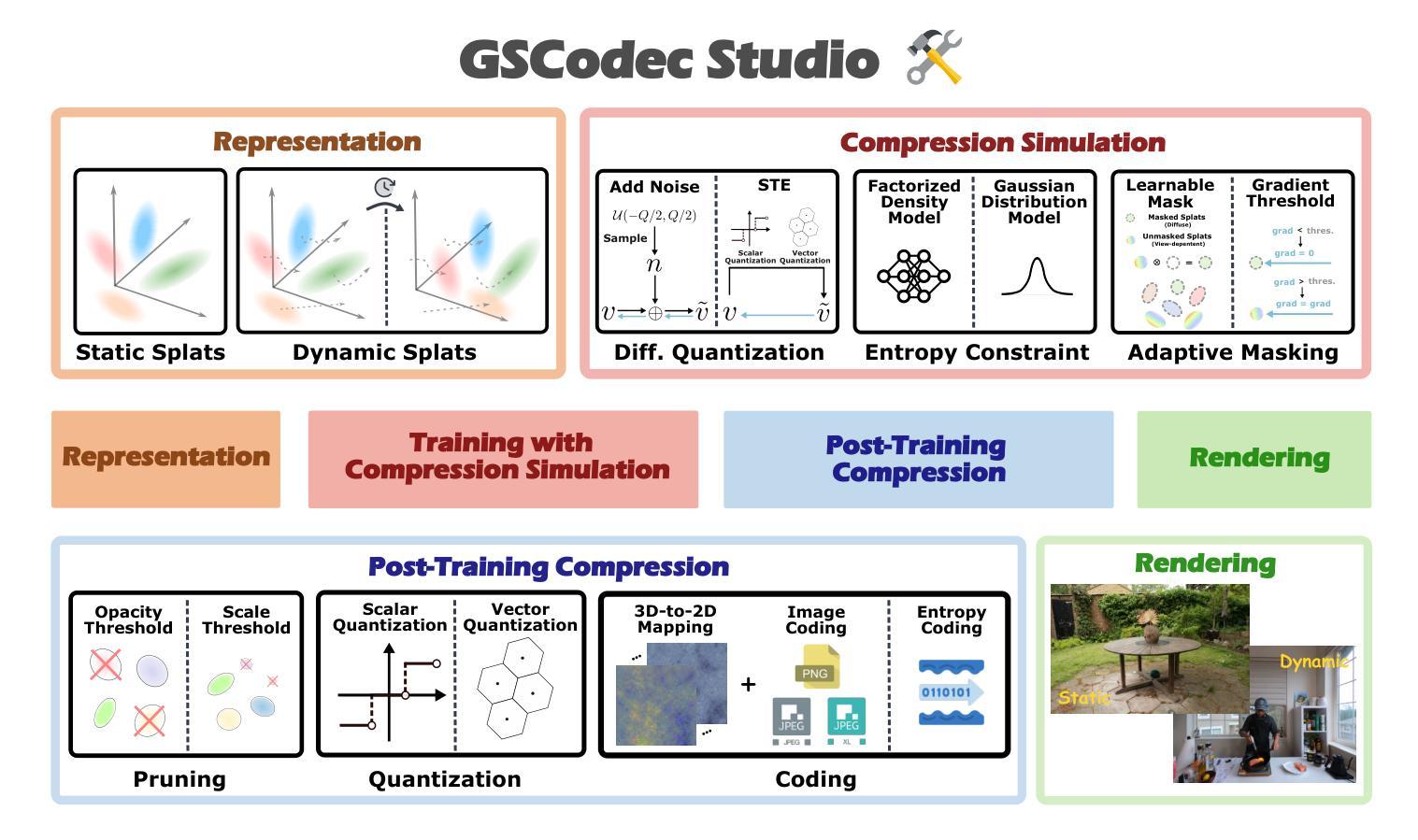
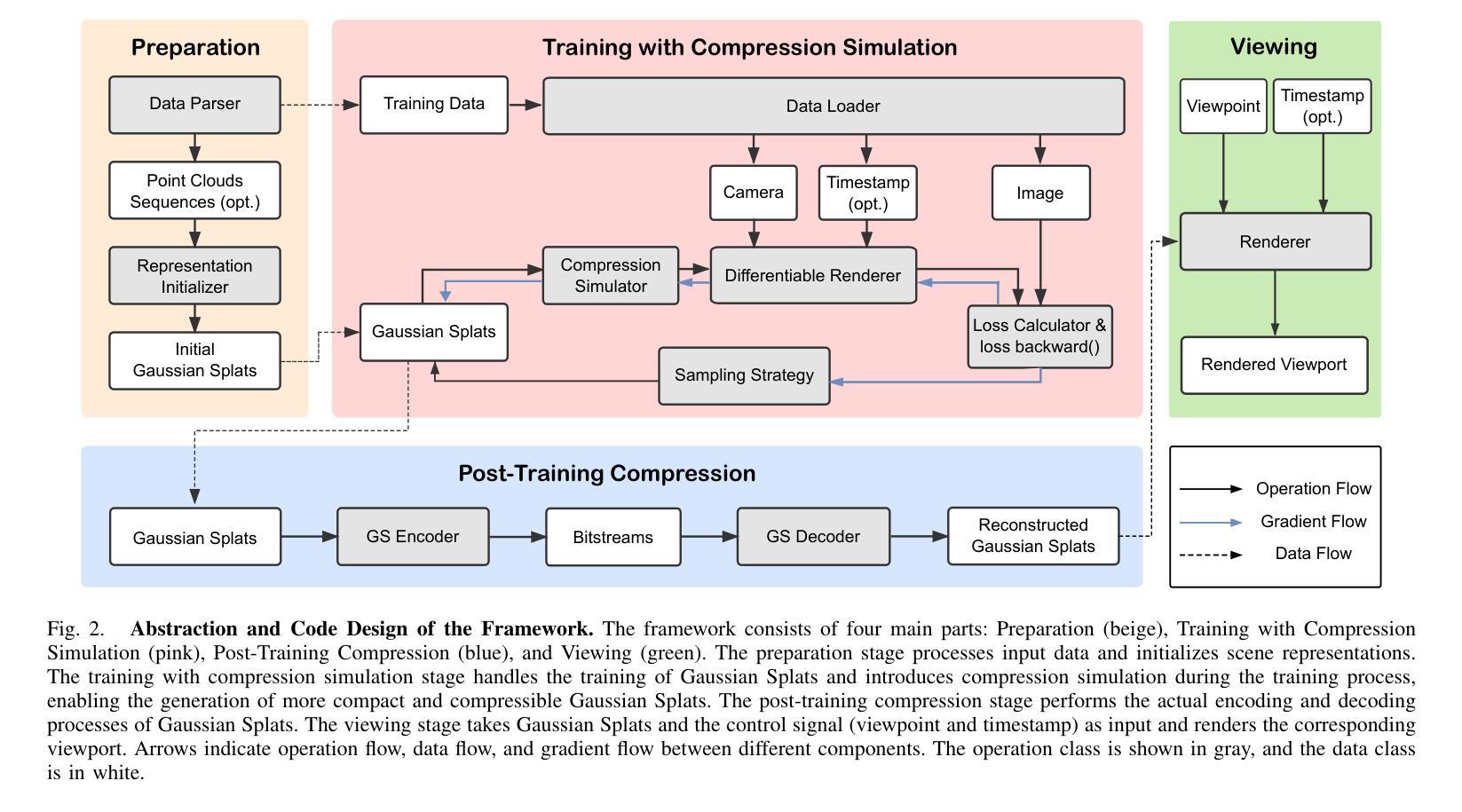
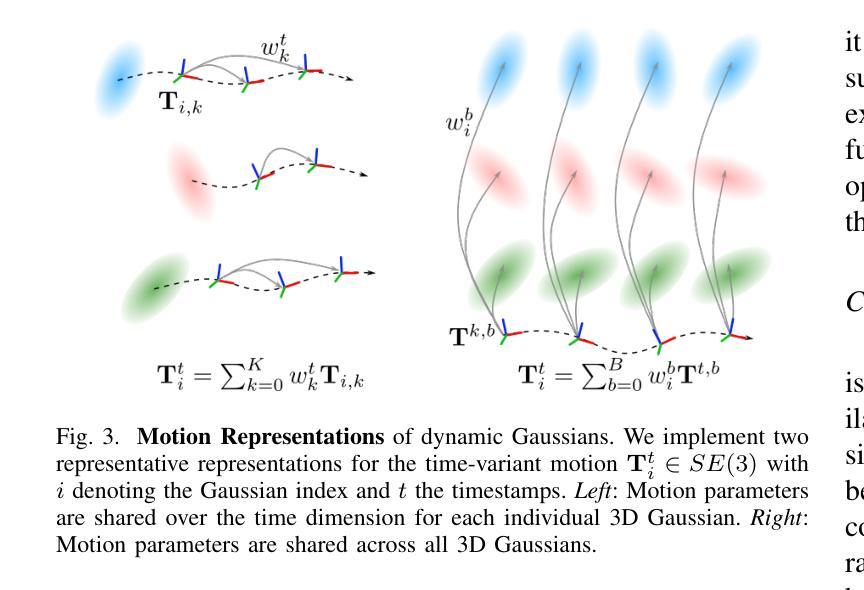
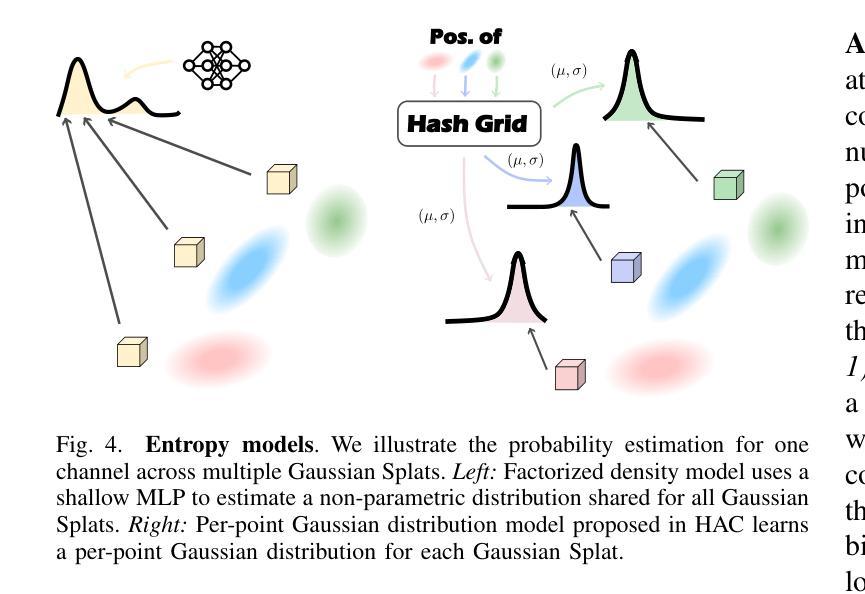
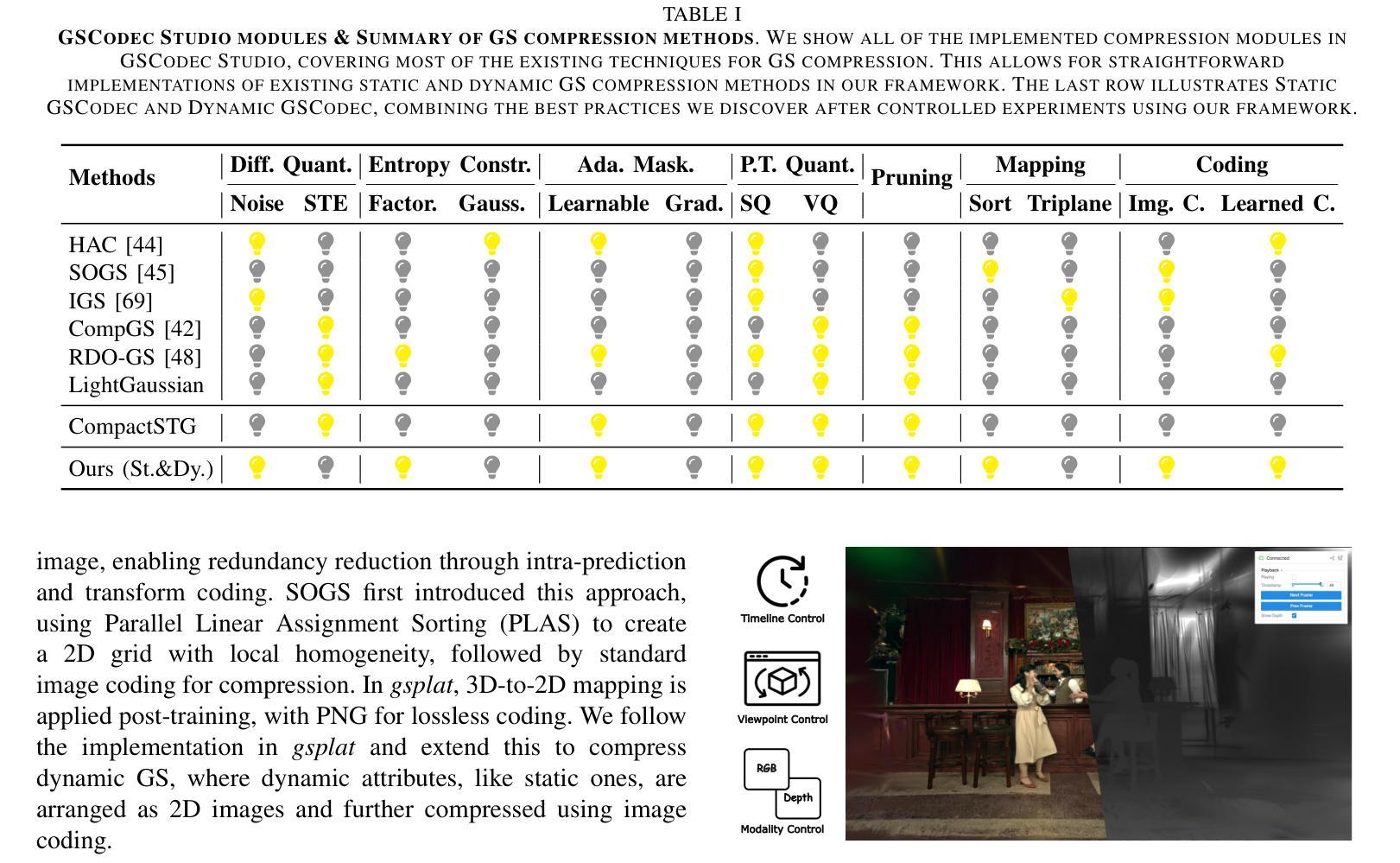
GSCodec Studio: A Modular Framework for Gaussian Splat Compression
Authors:Sicheng Li, Chengzhen Wu, Hao Li, Xiang Gao, Yiyi Liao, Lu Yu
3D Gaussian Splatting and its extension to 4D dynamic scenes enable photorealistic, real-time rendering from real-world captures, positioning Gaussian Splats (GS) as a promising format for next-generation immersive media. However, their high storage requirements pose significant challenges for practical use in sharing, transmission, and storage. Despite various studies exploring GS compression from different perspectives, these efforts remain scattered across separate repositories, complicating benchmarking and the integration of best practices. To address this gap, we present GSCodec Studio, a unified and modular framework for GS reconstruction, compression, and rendering. The framework incorporates a diverse set of 3D/4D GS reconstruction methods and GS compression techniques as modular components, facilitating flexible combinations and comprehensive comparisons. By integrating best practices from community research and our own explorations, GSCodec Studio supports the development of compact representation and compression solutions for static and dynamic Gaussian Splats, namely our Static and Dynamic GSCodec, achieving competitive rate-distortion performance in static and dynamic GS compression. The code for our framework is publicly available at https://github.com/JasonLSC/GSCodec_Studio , to advance the research on Gaussian Splats compression.
3D高斯贴片技术及其扩展到4D动态场景的能力,使得从真实世界捕捉的光照现实实时渲染成为可能,将高斯贴片(GS)定位为下一代沉浸式媒体的有前途的格式。然而,它们的高存储要求给共享、传输和存储的实际应用带来了重大挑战。尽管有许多研究从不同角度探索了GS压缩,但这些努力仍然分散在不同的存储库中,使得基准测试和最佳实践的整合变得复杂。为了解决这一空白,我们推出了GSCodec Studio,这是一个用于GS重建、压缩和渲染的统一模块化框架。该框架结合了多种3D/4D GS重建方法和GS压缩技术作为模块化组件,促进了灵活的组合和全面的比较。通过整合社区研究和我们自己的探索中的最佳实践,GSCodec Studio支持静态和动态高斯贴图的紧凑表示和压缩解决方案的开发,即我们的静态和动态GSCodec,实现在静态和动态GS压缩中具有竞争力的速率失真性能。我们的框架代码公开在https://github.com/JasonLSC/GSCodec_Studio,以推动高斯贴片压缩的研究进展。
论文及项目相关链接
PDF Repository of the project: https://github.com/JasonLSC/GSCodec_Studio
Summary
本文介绍了三维高斯贴图(Gaussian Splats,GS)在渲染真实场景中的重要作用,并指出其在下一代沉浸式媒体中的潜力。然而,其高存储需求限制了实际应用中的共享、传输和存储。为解决此问题,本文提出了一个统一、模块化的框架——GSCodec Studio,用于GS的重建、压缩和渲染。该框架集成了多种GS重建方法和压缩技术,支持灵活组合和全面比较,实现了静态和动态高斯贴图的紧凑表示和压缩解决方案。
Key Takeaways
- 3D Gaussian Splatting及扩展至4D动态场景为真实场景的实时渲染提供了可能,成为下一代沉浸式媒体的有前途的格式。
- 高存储需求是Gaussian Splats实际应用中的主要挑战,需要解决共享、传输和存储的问题。
- GSCodec Studio是一个统一、模块化的框架,用于Gaussian Splats的重建、压缩和渲染。
- GSCodec Studio集成了多种GS重建方法和压缩技术,促进了最佳实践的集成和灵活组合。
- 框架支持静态和动态高斯贴图的紧凑表示和压缩解决方案,分别实现了Static和Dynamic GSCodec。
- GSCodec Studio的代码已公开可用,以推动Gaussian Splats压缩的研究进展。
点此查看论文截图

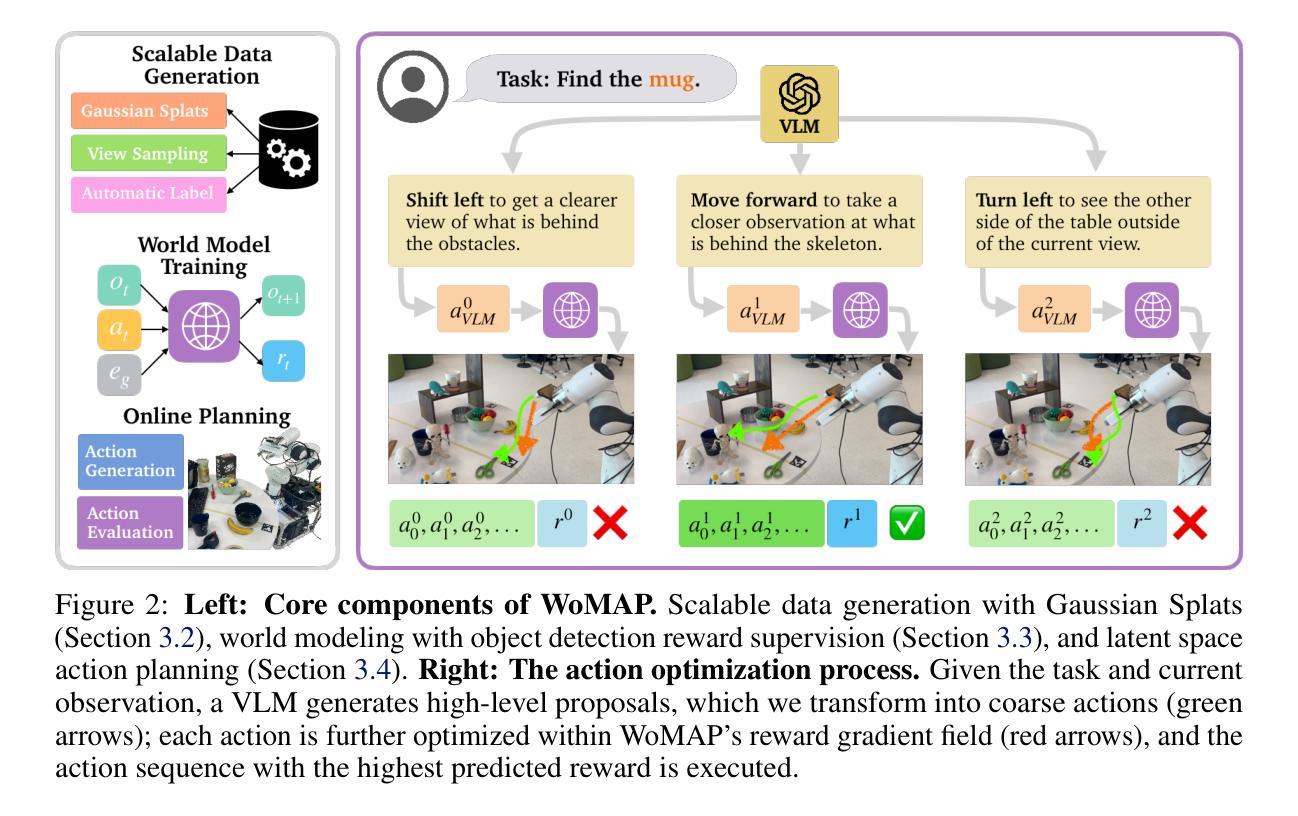
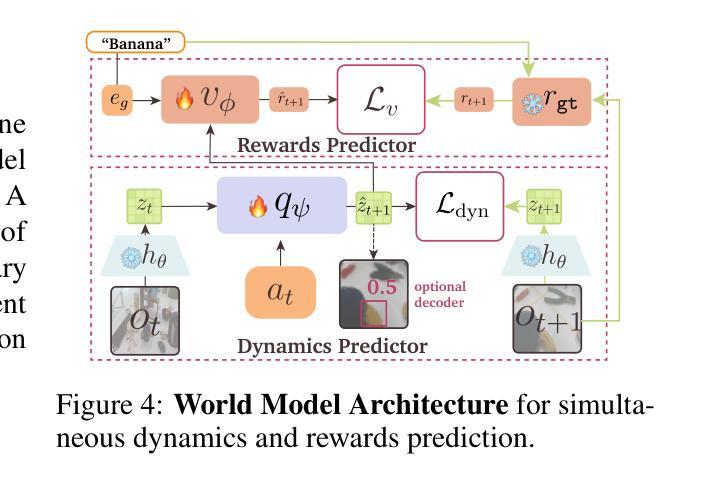
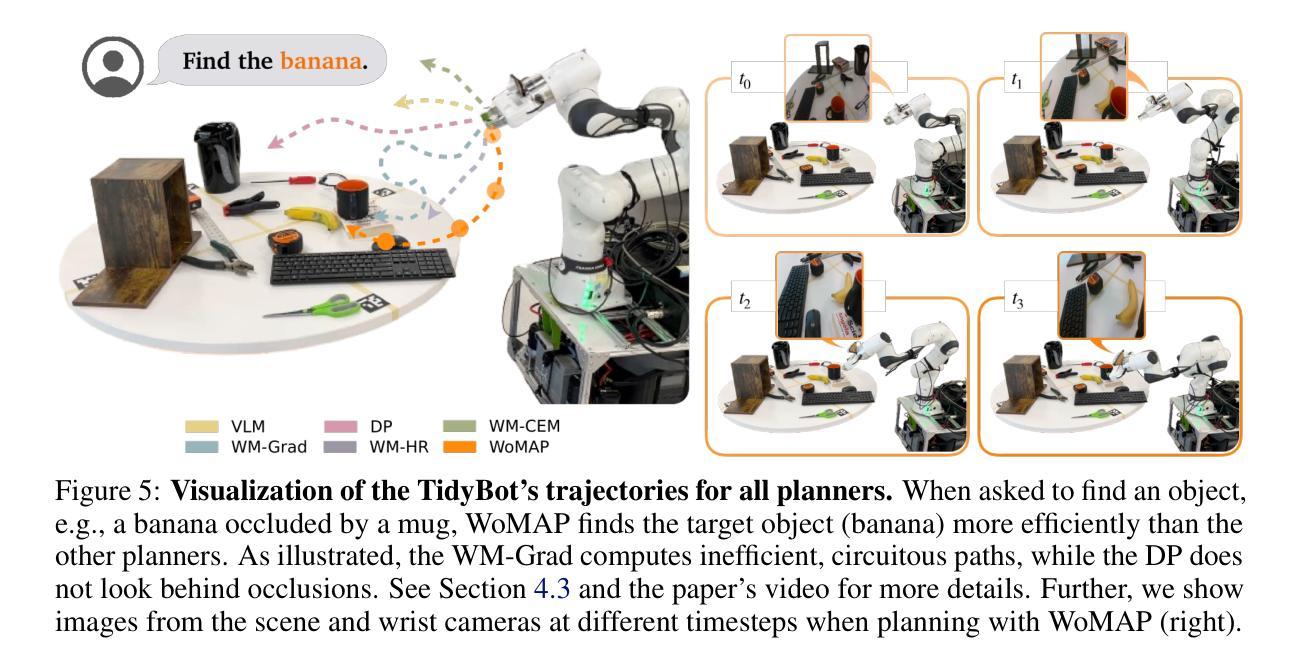
WoMAP: World Models For Embodied Open-Vocabulary Object Localization
Authors:Tenny Yin, Zhiting Mei, Tao Sun, Lihan Zha, Emily Zhou, Jeremy Bao, Miyu Yamane, Ola Shorinwa, Anirudha Majumdar
Language-instructed active object localization is a critical challenge for robots, requiring efficient exploration of partially observable environments. However, state-of-the-art approaches either struggle to generalize beyond demonstration datasets (e.g., imitation learning methods) or fail to generate physically grounded actions (e.g., VLMs). To address these limitations, we introduce WoMAP (World Models for Active Perception): a recipe for training open-vocabulary object localization policies that: (i) uses a Gaussian Splatting-based real-to-sim-to-real pipeline for scalable data generation without the need for expert demonstrations, (ii) distills dense rewards signals from open-vocabulary object detectors, and (iii) leverages a latent world model for dynamics and rewards prediction to ground high-level action proposals at inference time. Rigorous simulation and hardware experiments demonstrate WoMAP’s superior performance in a broad range of zero-shot object localization tasks, with more than 9x and 2x higher success rates compared to VLM and diffusion policy baselines, respectively. Further, we show that WoMAP achieves strong generalization and sim-to-real transfer on a TidyBot.
语言指导下的主动目标定位对于机器人来说是一个关键挑战,需要有效地探索部分可观察的环境。然而,最新方法要么难以在演示数据集之外进行推广(例如模仿学习方法),要么无法生成物理基础动作(例如视觉语言模型)。为了解决这些局限性,我们引入了WoMAP(用于主动感知的世界模型):一个训练开放词汇目标定位策略的方法,该方法(i)使用基于高斯涂覆的真实到模拟再到真实的管道进行可扩展的数据生成,无需专家演示;(ii)从开放词汇目标检测器中提炼出密集奖励信号;(iii)利用潜在世界模型进行动力学和奖励预测,在推理时间为高级行动提议提供基础。严格的模拟和硬件实验表明,WoMAP在广泛的零样本目标定位任务中表现出卓越性能,与视觉语言模型和扩散政策基准相比,成功率分别提高了9倍和2倍。此外,我们还展示了WoMAP在TidyBot上实现了强大的泛化和模拟到现实的迁移能力。
论文及项目相关链接
Summary
这篇文本介绍了针对机器人语言指导主动物体定位的挑战,提出一种名为WoMAP(世界模型主动感知)的方法。该方法通过真实到模拟再到真实的管道进行可扩展的数据生成,无需专家演示;从开放词汇物体检测器中提炼出密集奖励信号,并利用潜在世界模型预测动力学和奖励,以在推理时实现高级动作提议的接地。在广泛的零镜头物体定位任务中,WoMAP的性能远超其他方法,如在VLM和扩散政策基准上的成功率分别提高了9倍和两倍。此外,WoMAP在TidyBot上实现了强大的泛化和模拟到现实的迁移。
Key Takeaways
- WoMAP是一种用于训练开放词汇物体定位策略的方法,适用于机器人语言指导主动物体定位的挑战。
- WoMAP通过真实到模拟再到真实的管道进行数据生成,这一方法无需专家演示,具有可扩展性。
- WoMAP能从开放词汇物体检测器中提炼密集奖励信号。
- WoMAP利用潜在世界模型预测动力学和奖励,实现高级动作提议的接地。
- 在零镜头物体定位任务中,WoMAP的性能显著超过其他方法,如VLM和扩散政策基准。
- WoMAP在TidyBot上实现了强大的泛化能力。
点此查看论文截图


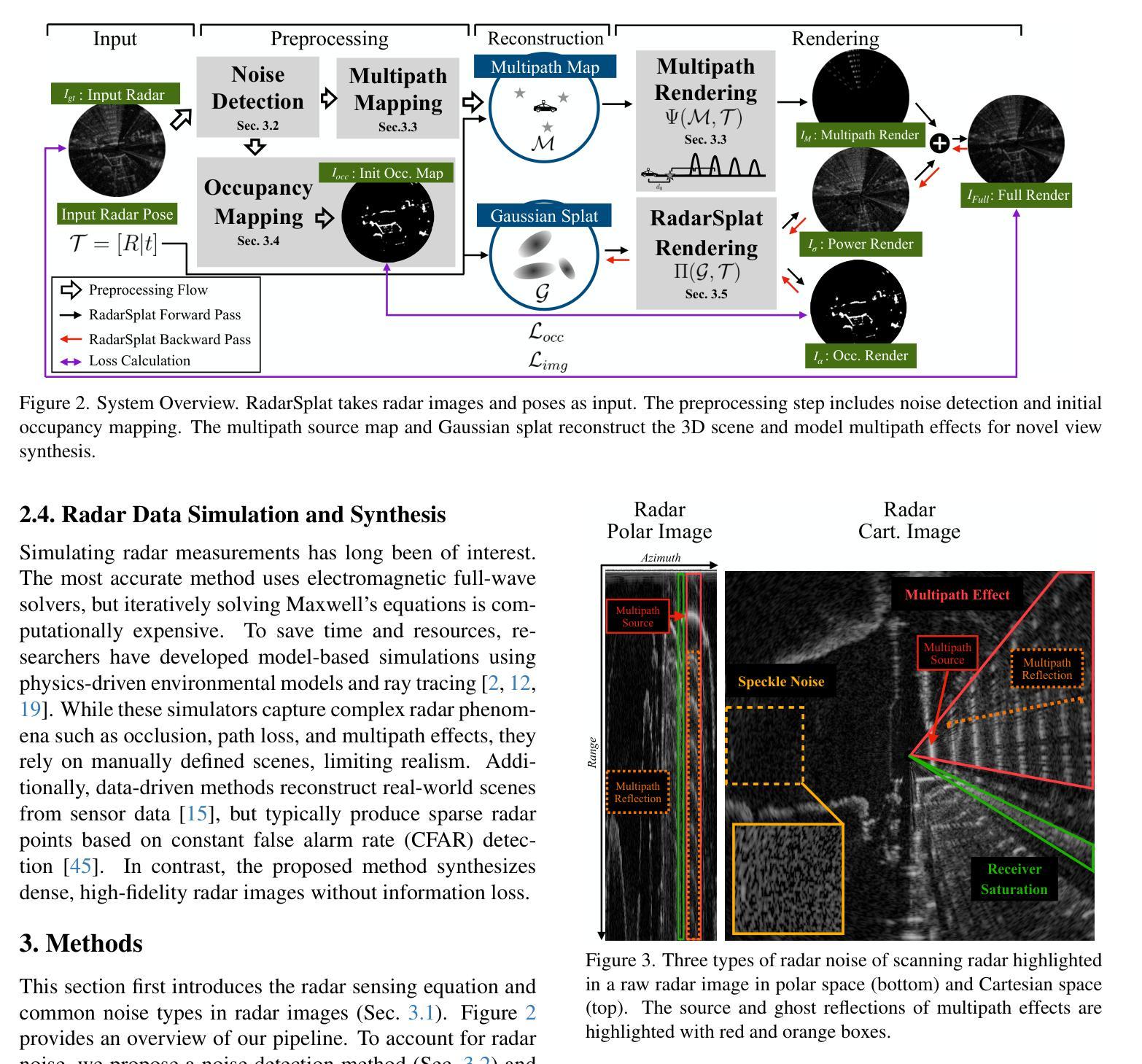
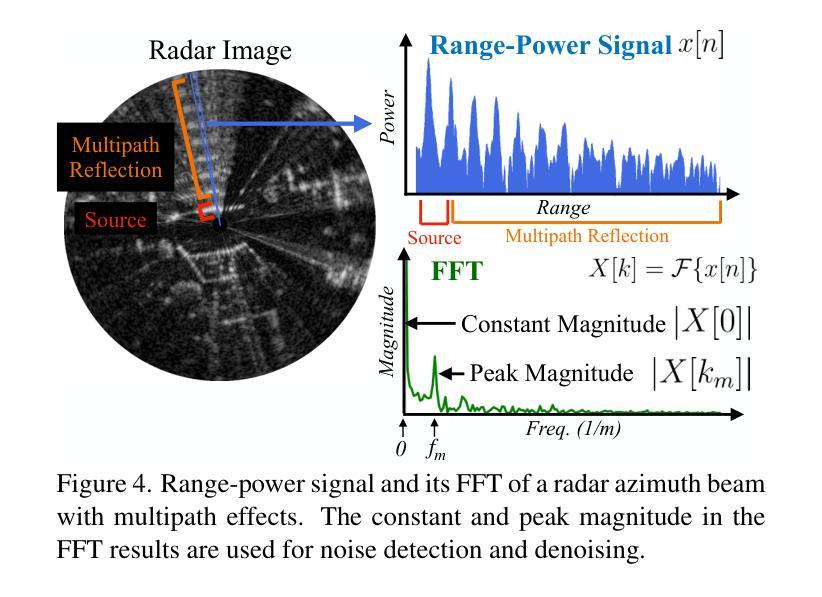
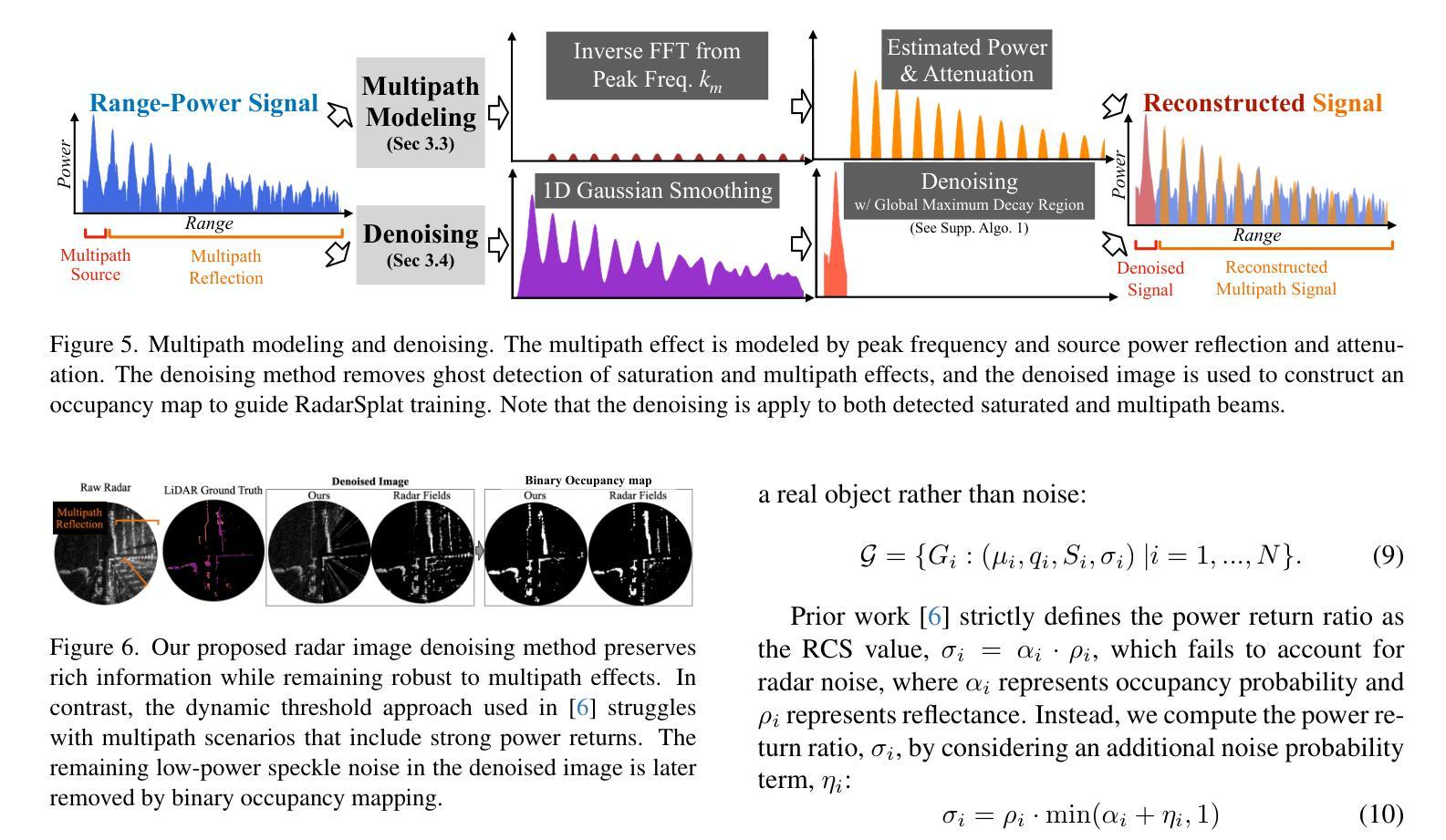
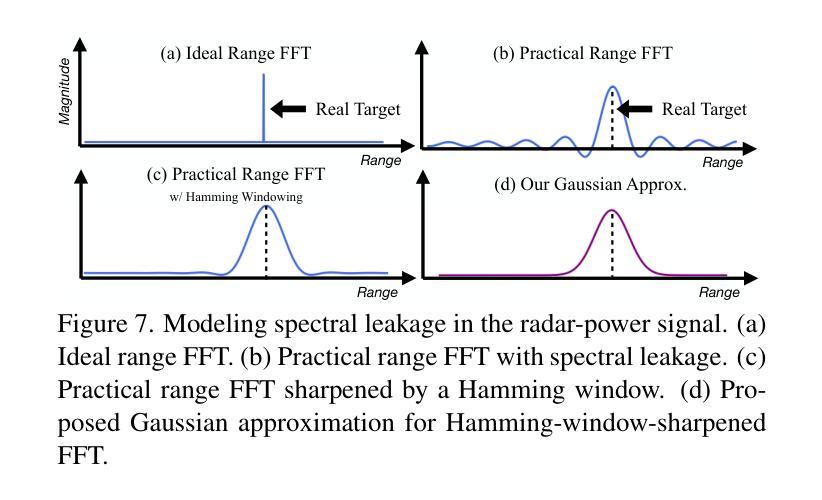
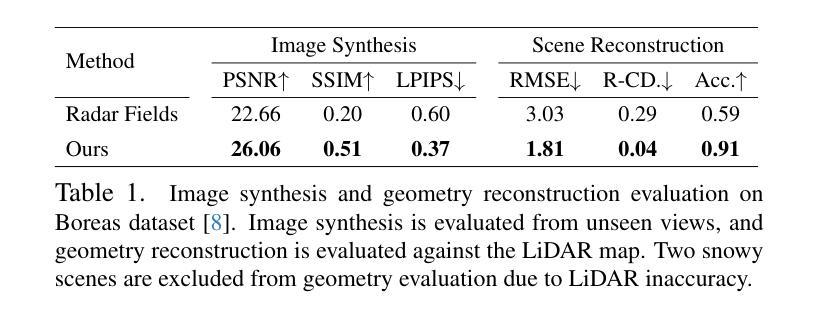
RadarSplat: Radar Gaussian Splatting for High-Fidelity Data Synthesis and 3D Reconstruction of Autonomous Driving Scenes
Authors:Pou-Chun Kung, Skanda Harisha, Ram Vasudevan, Aline Eid, Katherine A. Skinner
High-Fidelity 3D scene reconstruction plays a crucial role in autonomous driving by enabling novel data generation from existing datasets. This allows simulating safety-critical scenarios and augmenting training datasets without incurring further data collection costs. While recent advances in radiance fields have demonstrated promising results in 3D reconstruction and sensor data synthesis using cameras and LiDAR, their potential for radar remains largely unexplored. Radar is crucial for autonomous driving due to its robustness in adverse weather conditions like rain, fog, and snow, where optical sensors often struggle. Although the state-of-the-art radar-based neural representation shows promise for 3D driving scene reconstruction, it performs poorly in scenarios with significant radar noise, including receiver saturation and multipath reflection. Moreover, it is limited to synthesizing preprocessed, noise-excluded radar images, failing to address realistic radar data synthesis. To address these limitations, this paper proposes RadarSplat, which integrates Gaussian Splatting with novel radar noise modeling to enable realistic radar data synthesis and enhanced 3D reconstruction. Compared to the state-of-the-art, RadarSplat achieves superior radar image synthesis (+3.4 PSNR / 2.6x SSIM) and improved geometric reconstruction (-40% RMSE / 1.5x Accuracy), demonstrating its effectiveness in generating high-fidelity radar data and scene reconstruction. A project page is available at https://umautobots.github.io/radarsplat.
高保真三维场景重建在自动驾驶中起着至关重要的作用,它能够从现有数据集中生成新型数据。这使得能够模拟安全关键场景并扩充训练数据集,而无需承担进一步的数据收集成本。虽然最近辐射场在利用相机和激光雷达进行三维重建和传感器数据合成方面取得了有前景的结果,但它们在雷达方面的潜力仍未得到充分探索。由于雷达在雨、雾和雪等恶劣天气条件下的稳健性,使其成为自动驾驶的关键技术,而光学传感器在这些条件下往往表现挣扎。尽管基于最新雷达的神经表示在三维驾驶场景重建方面显示出希望,但在雷达噪声较大的场景中表现不佳,包括接收器饱和和多路径反射。此外,它仅限于合成预处理的、排除噪声的雷达图像,未能解决真实的雷达数据合成问题。为了解决这些局限性,本文提出了RadarSplat,它结合了高斯绘图和新颖的雷达噪声建模,以实现真实的雷达数据合成和增强的三维重建。与现有技术相比,RadarSplat实现了卓越的雷达图像合成(+ 3.4 PSNR / 2.6x SSIM)和改进了几何重建(- 40% RMSE / 1.5x精度),证明了其在生成高保真雷达数据和场景重建方面的有效性。项目页面可在[https://umautobots.github.io/radarsplat]查看。
论文及项目相关链接
Summary
本文介绍了高保真3D场景重建对于自动驾驶的重要性,它通过现有数据集生成新型数据,模拟关键安全场景并扩充训练数据集。虽然辐射场在3D重建和传感器数据合成方面取得了进展,但其在雷达方面的潜力尚未被充分探索。文章指出雷达在恶劣天气条件下的自主性驾驶中的稳健性,如雨雪雾等。当前最先进的雷达神经网络表示在雷达噪声较大的场景中表现不佳。为解决此问题,本文提出了RadarSplat,结合高斯Splatting和新型雷达噪声建模,实现真实雷达数据合成和增强的3D重建。相较于其他方法,RadarSplat在雷达图像合成和几何重建方面表现出更优越的效果。
Key Takeaways
- 高保真3D场景重建在自动驾驶中起到关键作用,能通过现有数据集生成新型数据。
- 辐射场在3D重建和传感器数据合成方面取得进展,但雷达潜力尚未被充分探索。
- 雷达在恶劣天气条件下的自主性驾驶中具有稳健性。
- 当前最先进的雷达神经网络表示在噪声较大的场景中表现不佳。
- RadarSplat通过结合高斯Splatting和新型雷达噪声建模,实现真实雷达数据合成和增强的3D重建。
- RadarSplat在雷达图像合成和几何重建方面表现出卓越效果,相比现有方法有所提高。
- 项目页面:https://umautobots.github.io/radarsplat
点此查看论文截图

3D Gaussian Splat Vulnerabilities
Authors:Matthew Hull, Haoyang Yang, Pratham Mehta, Mansi Phute, Aeree Cho, Haoran Wang, Matthew Lau, Wenke Lee, Willian T. Lunardi, Martin Andreoni, Polo Chau
With 3D Gaussian Splatting (3DGS) being increasingly used in safety-critical applications, how can an adversary manipulate the scene to cause harm? We introduce CLOAK, the first attack that leverages view-dependent Gaussian appearances - colors and textures that change with viewing angle - to embed adversarial content visible only from specific viewpoints. We further demonstrate DAGGER, a targeted adversarial attack directly perturbing 3D Gaussians without access to underlying training data, deceiving multi-stage object detectors e.g., Faster R-CNN, through established methods such as projected gradient descent. These attacks highlight underexplored vulnerabilities in 3DGS, introducing a new potential threat to robotic learning for autonomous navigation and other safety-critical 3DGS applications.
随着3D高斯喷射技术(3DGS)在关键安全应用中的广泛应用,对手如何操作场景以造成伤害?我们引入了CLOAK,这是第一种利用视角相关的高斯外观的攻击方法——颜色和纹理会随着观察角度的变化而变化,以嵌入仅在特定视角可见的对立内容。我们进一步展示了DAGGER,这是一种有针对性的对抗性攻击,可以直接干扰3D高斯,无需访问底层训练数据,通过投影梯度下降法等既定方法欺骗多阶段目标检测器(例如Faster R-CNN)。这些攻击凸显了之前未开发的针对机器人学习的安全隐患和3DGS的安全风险应用。这带来了一种新型潜在威胁,即对自主导航和安全至关重要的机器人学习领域以及其他领域的安全威胁。
论文及项目相关链接
PDF 4 pages, 4 figures, CVPR ‘25 Workshop on Neural Fields Beyond Conventional Cameras
摘要
基于文中的核心要点进行简明阐述,具体内容如下:本文揭示了通过三维高斯地图渲染(3DGS)构建的三维场景中潜在的安全隐患问题。文中介绍了如何通过利用视角相关的高斯外观(即颜色和纹理随视角变化而变化)来嵌入对抗内容,并从特定视角展现对抗内容。此外,文章还提出了一种名为DAGGER的针对性攻击方法,直接干扰三维高斯数据,无需接触底层训练数据,就能欺骗多阶段目标检测器,如Faster R-CNN等。这些攻击凸显了三维高斯地图渲染的未开发脆弱性,对于依赖这一技术的自主导航和安全要求严格的三维场景应用造成了潜在的威胁。需要注意的是,由于安全性问题逐渐凸显,目前学界对如何利用3DGS进行攻击的研究尚处于起步阶段。这些攻击可能带来一系列风险问题,因此在未来对场景安全性进行分析和建模时需要考虑相关潜在威胁。总体而言,该文在保障安全领域提出了一种重要的安全挑战与风险点,并对如何利用和防范基于视角的高斯外观嵌入对抗性内容给出了方向性指导。随着三维技术的普及和深化应用,对场景安全性的研究将更加重要和紧迫。因此,在设计和应用相关技术时,必须高度重视安全问题并对其进行充分的考量。在实际应用场景中采取相应的防范措施以降低风险隐患是当前的首要任务。然而应对该威胁的方式也需要深入探讨和研究以形成更为完善的解决方案和措施体系以应对可能出现的各种安全隐患和挑战。总体来看本文的研究成果具有重要的研究价值和社会价值为该领域的技术研究与发展提供了新的研究思路和技术创新点对未来可能的发展产生了深远影响为该领域的科研人员提供了重要启示和指导方向有助于促进相关技术的发展与完善更好地满足社会发展需求服务于社会经济发展和人类生活水平的提高。总的来说该研究成果具有重要的理论和实践意义为相关领域的发展提供了重要的启示和指导方向具有重要的社会价值和应用前景。值得注意的是虽然该技术在军事等领域有一定的应用价值但其应用场景范围仍有待拓展和创新研发未来对该技术的研究应更加深入更加多元化以应对各种潜在的应用场景和需求。未来对于基于三维技术的对抗性内容研究将更加复杂多样其安全性和可靠性问题也将成为研究的重点之一需要更多的关注和投入以确保技术的安全和稳定发展。综上所述该研究具有重要的现实意义和潜在应用价值为相关领域的发展提供了重要的启示和指导方向并有望在未来发挥更大的作用推动相关领域的技术进步和创新发展。同时该研究也提醒我们在实际应用中应加强对相关技术的安全性和可靠性评估以确保技术的安全和稳定发展并避免潜在的安全风险和挑战。同时该研究也为我们提供了一个新的视角来审视和理解三维技术的安全性和可靠性问题为我们提供了一个重要的研究方向和思路以更好地应对未来的技术挑战和发展需求实现更加智能化安全化的技术世界推动社会的进步和发展提供更坚实的技术支撑和发展动力。”, “关键见解:
- 介绍了利用三维高斯地图渲染(3DGS)技术的潜在安全隐患问题。
- 利用视角相关的特性嵌入对抗内容,并从特定视角展现对抗内容的方法介绍。
- 提出一种名为DAGGER的攻击方法,直接干扰三维高斯数据并欺骗多阶段目标检测器。
- 高亮出三维高斯地图渲染技术脆弱性方面还未得到充分研究和开发的领域及其对安全的影响的重要性进行阐述与分析对于该技术在安全方面的实际应用进行了探讨与展望以及未来发展的潜在风险挑战进行梳理和总结进一步提醒相关领域研究者对技术应用的全面考虑和对安全问题的重视提供了对未来研究和发展方向的重要启示和思考”。
点此查看论文截图



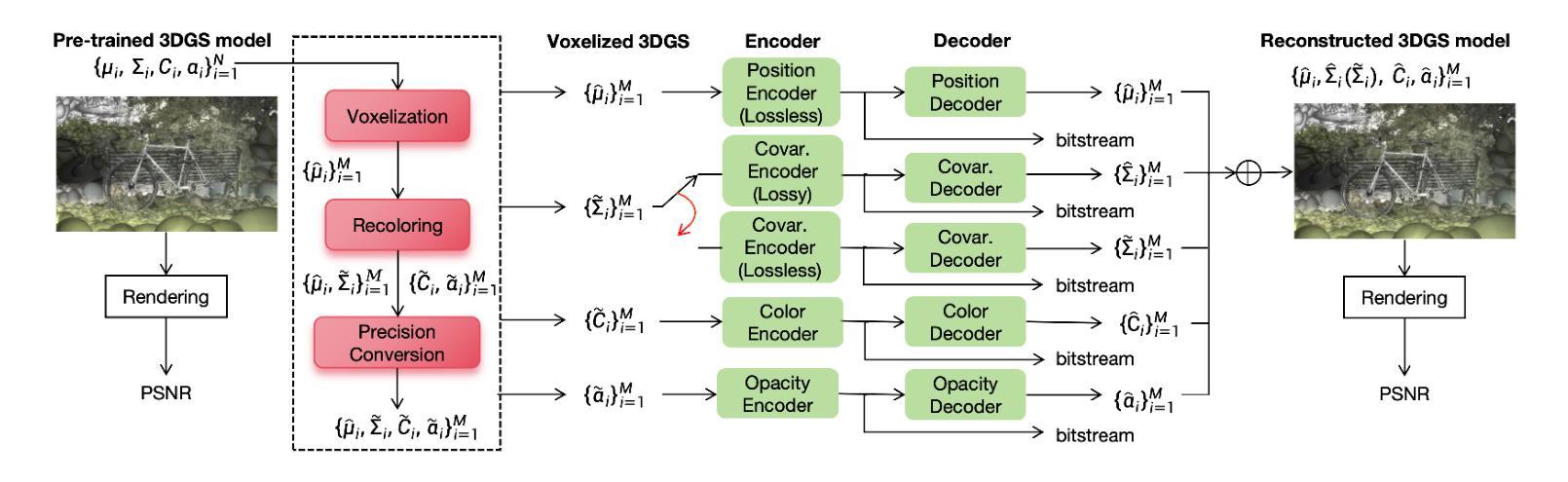
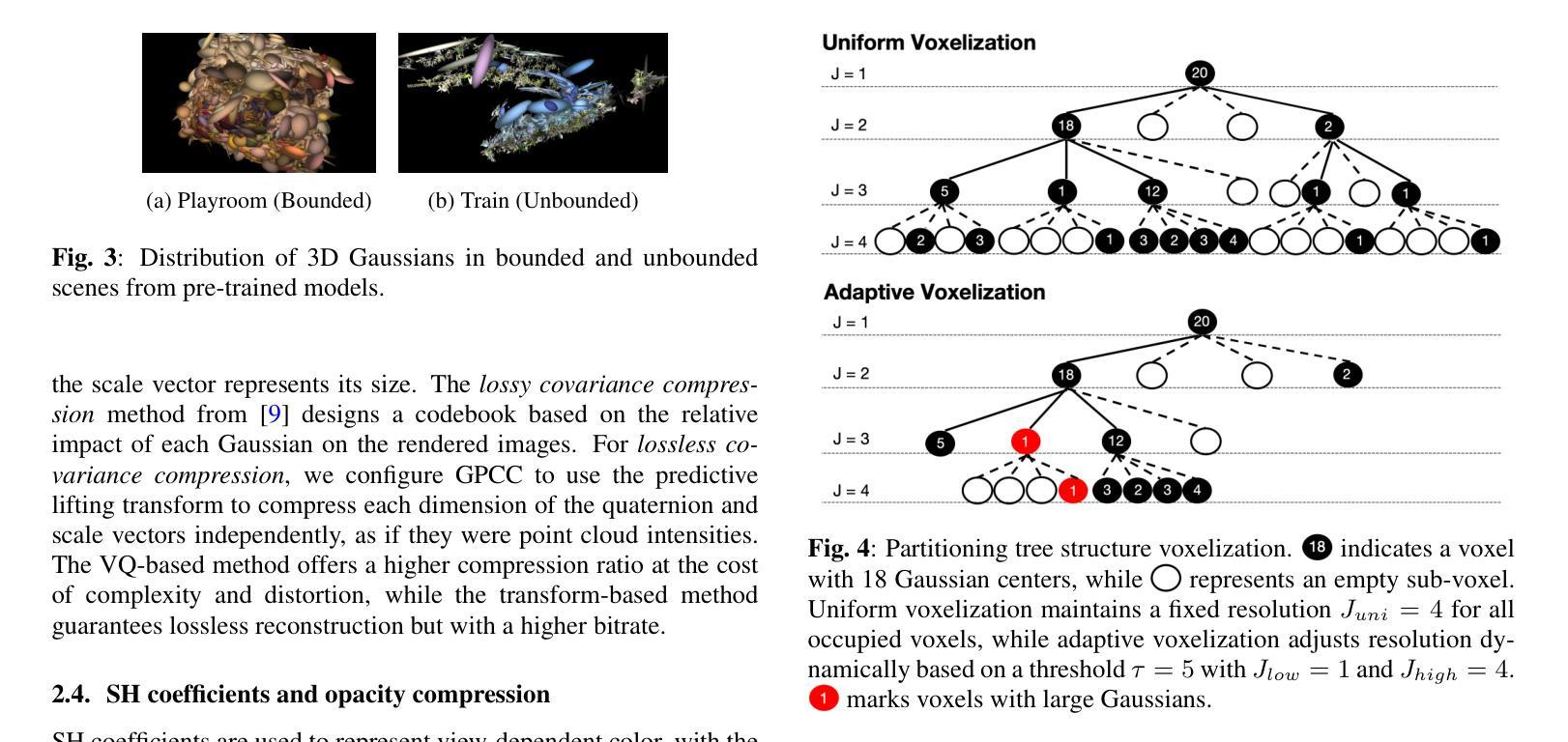
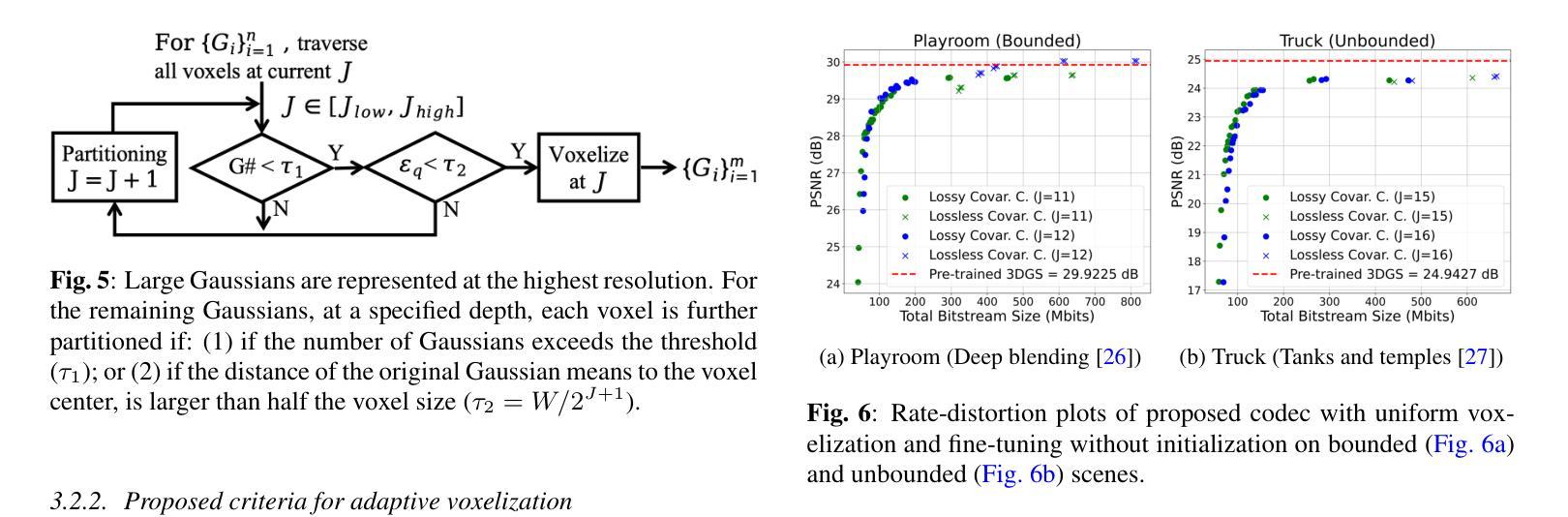
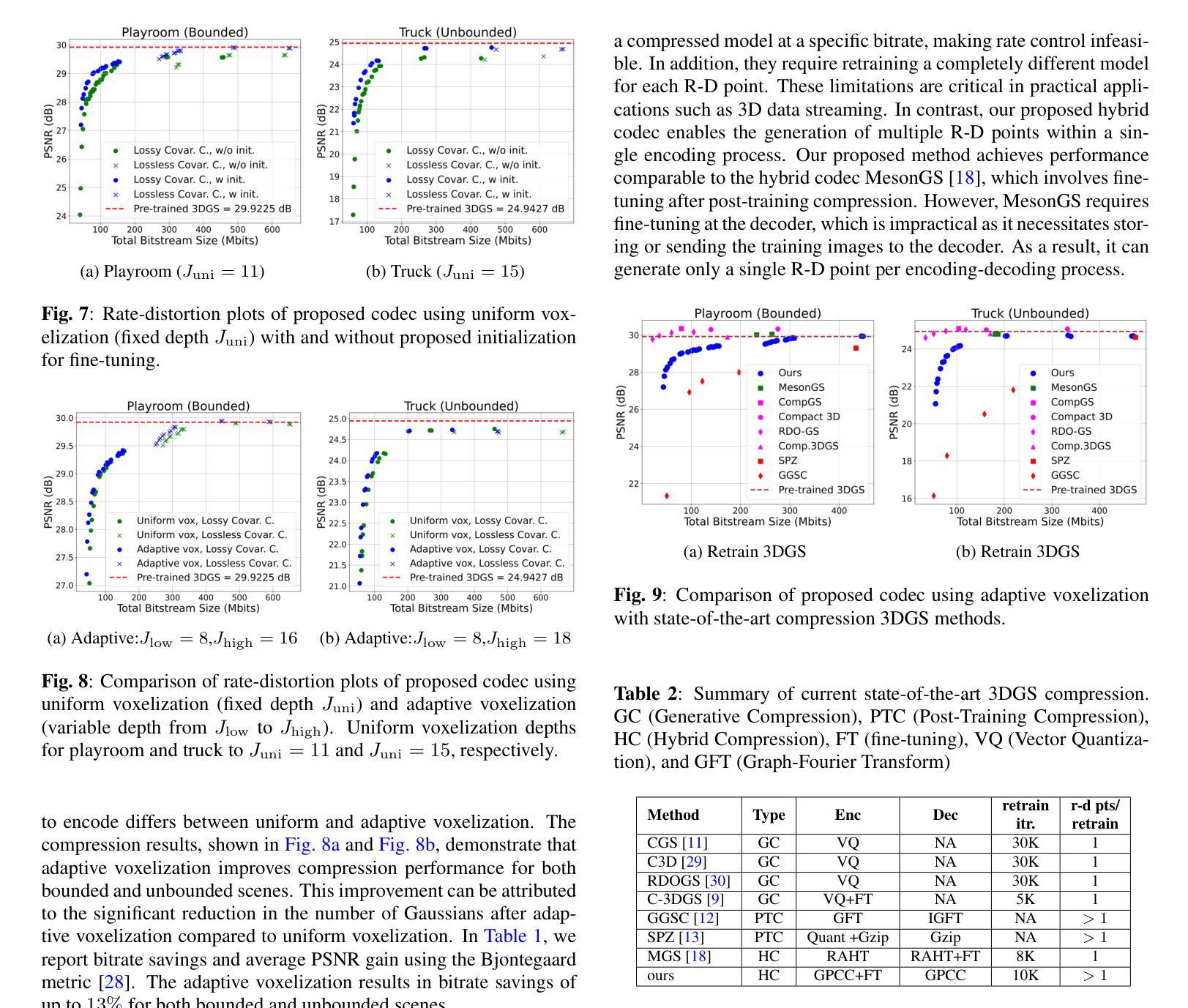
Adaptive Voxelization for Transform coding of 3D Gaussian splatting data
Authors:Chenjunjie Wang, Shashank N. Sridhara, Eduardo Pavez, Antonio Ortega, Cheng Chang
We present a novel compression framework for 3D Gaussian splatting (3DGS) data that leverages transform coding tools originally developed for point clouds. Contrary to existing 3DGS compression methods, our approach can produce compressed 3DGS models at multiple bitrates in a computationally efficient way. Point cloud voxelization is a discretization technique that point cloud codecs use to improve coding efficiency while enabling the use of fast transform coding algorithms. We propose an adaptive voxelization algorithm tailored to 3DGS data, to avoid the inefficiencies introduced by uniform voxelization used in point cloud codecs. We ensure the positions of larger volume Gaussians are represented at high resolution, as these significantly impact rendering quality. Meanwhile, a low-resolution representation is used for dense regions with smaller Gaussians, which have a relatively lower impact on rendering quality. This adaptive voxelization approach significantly reduces the number of Gaussians and the bitrate required to encode the 3DGS data. After voxelization, many Gaussians are moved or eliminated. Thus, we propose to fine-tune/recolor the remaining 3DGS attributes with an initialization that can reduce the amount of retraining required. Experimental results on pre-trained datasets show that our proposed compression framework outperforms existing methods.
我们提出了一种针对3D高斯拼接(3DGS)数据的新型压缩框架,该框架利用了点云原始开发的转换编码工具。与现有的3DGS压缩方法不同,我们的方法能够以计算高效的方式生成多个比特率的压缩3DGS模型。点云体素化是一种离散化技术,点云编解码器使用它来改进编码效率,同时启用快速转换编码算法的使用。我们针对3DGS数据提出了一种自适应体素化算法,以避免点云编解码器中使用的统一体素化所带来的低效性。我们确保大体积高斯的位置以高分辨率表示,因为这些对渲染质量有重大影响。同时,对于具有较小高斯值的密集区域,我们使用低分辨率表示,这些高斯对渲染质量的影响相对较小。这种自适应体素化方法显著减少了高斯数量和编码3DGS数据所需的比特率。体素化后,许多高斯被移动或消除。因此,我们建议使用初始化对剩余的3DGS属性进行微调/重新着色,这样可以减少所需的重训量。在预训练数据集上的实验结果表明,我们提出的压缩框架优于现有方法。
论文及项目相关链接
摘要
本研究提出了一种新颖的压缩框架,用于处理三维高斯球描数据(简称“CG框架”)。通过采用专门针对点云开发的转换编码工具,实现能够在多种比特率下生成压缩的三维高斯球描模型,且计算效率高。本研究提出了针对点云编码的高效离散化技术——点云体素化。在现有点云编码器的体素化基础上,我们提出了一种针对三维高斯球描数据的自适应体素化算法,旨在避免统一体素化带来的低效问题。对于体积较大的高斯模型的位置进行高分辨率表达以提升渲染质量,而在密度高的区域采用较低分辨率的小高斯表达,这得益于它们在渲染质量上相对较低的影响。最终证明这种自适应体素化算法能够大幅度减少高斯数量以及编码三维高斯球描数据所需的比特率。对剩余三维高斯球描属性进行精细化调整,使它们在重新训练阶段更具灵活性,从而在实验测试中实现了优异的性能表现。总体而言,该研究不仅突破了传统三维高斯球描数据压缩方法的局限,而且为提高大规模数据集压缩效率和计算效率提供了新的方向。通过对比实验验证,该压缩框架性能优于现有方法。
关键要点
一、引入新的压缩框架处理三维高斯球描数据,首次采用针对点云的转换编码工具进行开发,生成了可支持多比特率的压缩模型。
二、引入点云体素化技术并优化改进其效率问题以适应三维高斯球描数据压缩需求。此自适应体素化算法允许在保留高质量渲染效果的同时降低编码复杂度。
三、采用精细化调整策略处理剩余三维高斯球描属性,减少重新训练的需求和复杂性。这一策略显著提升了压缩框架的性能表现。
点此查看论文截图

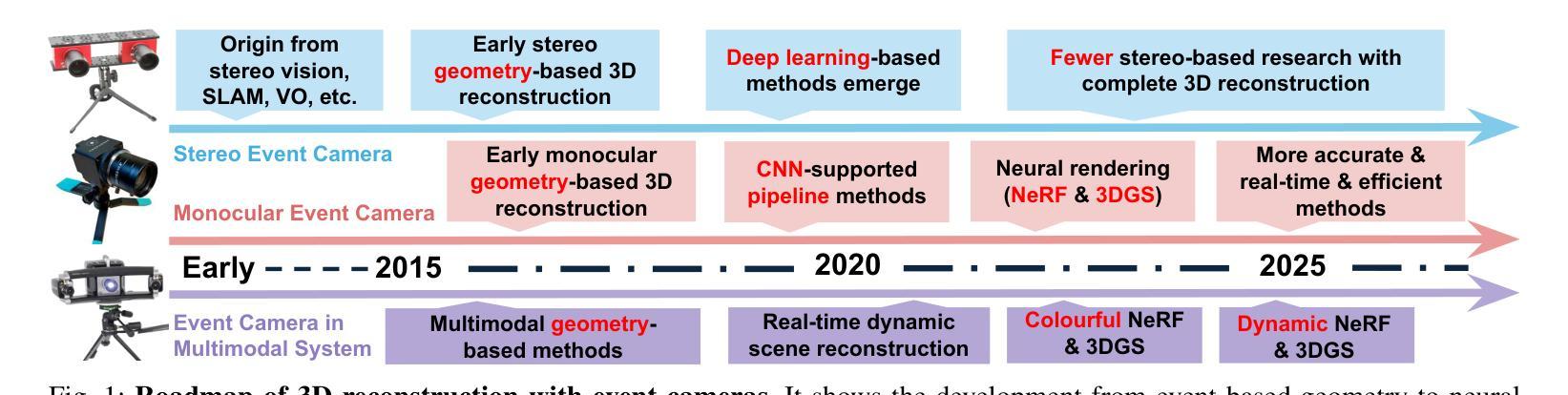
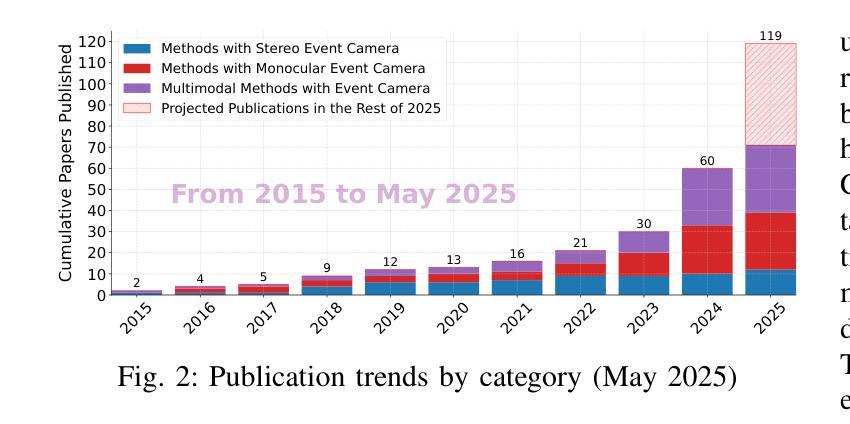
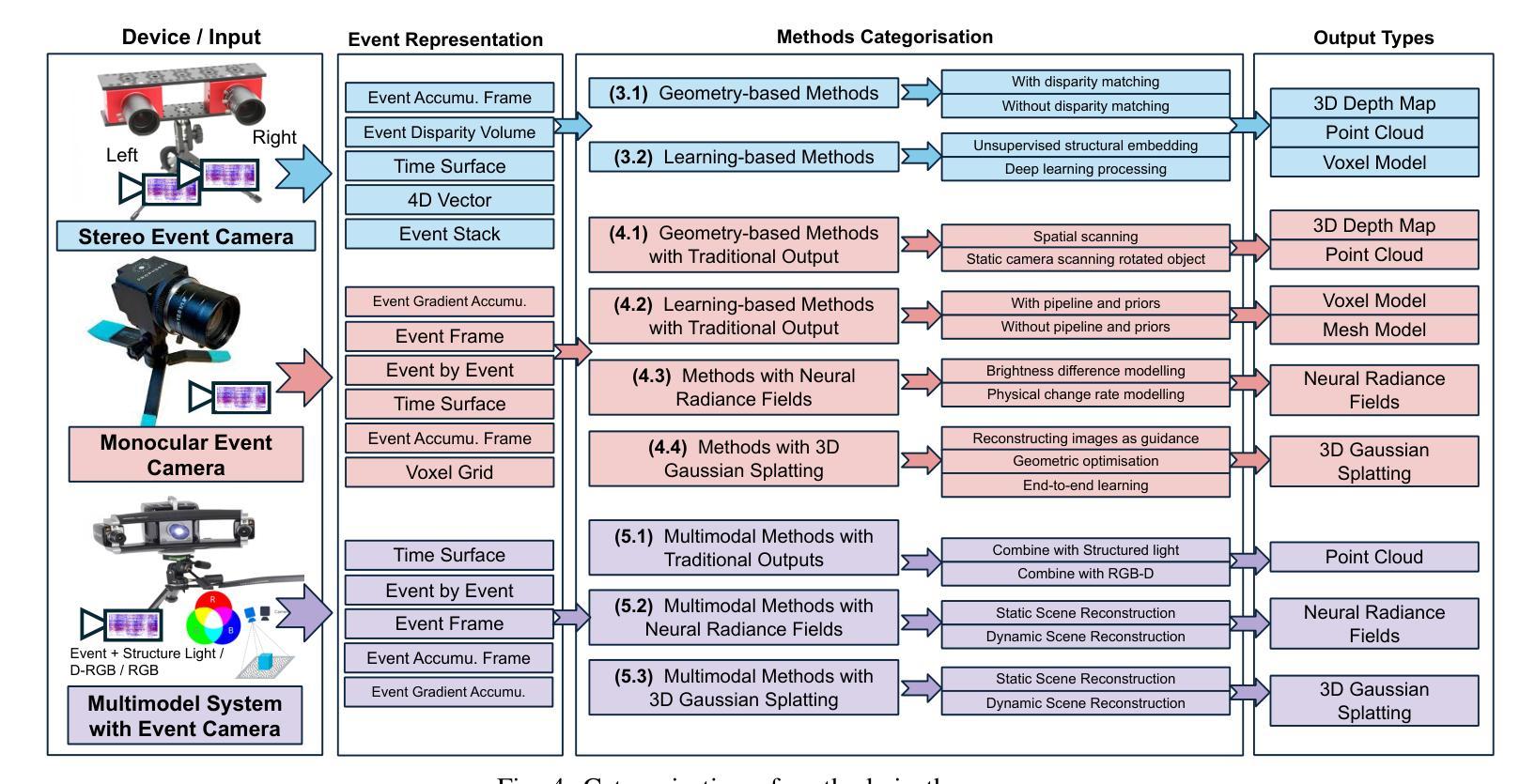
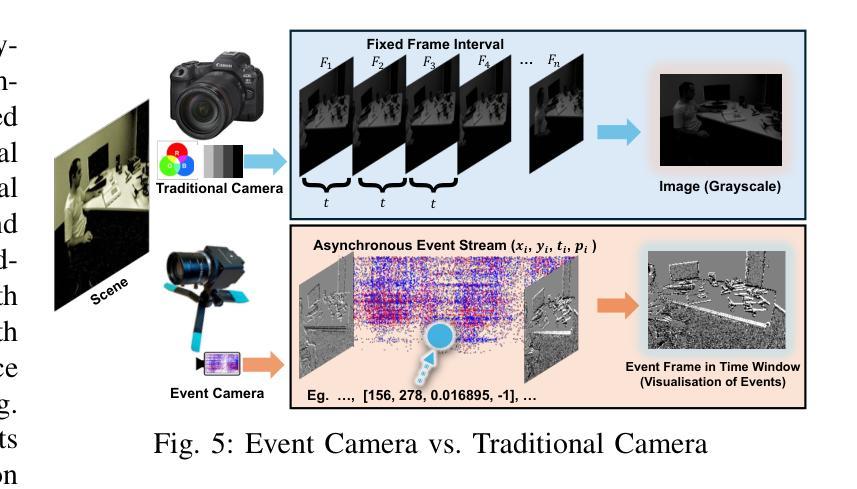
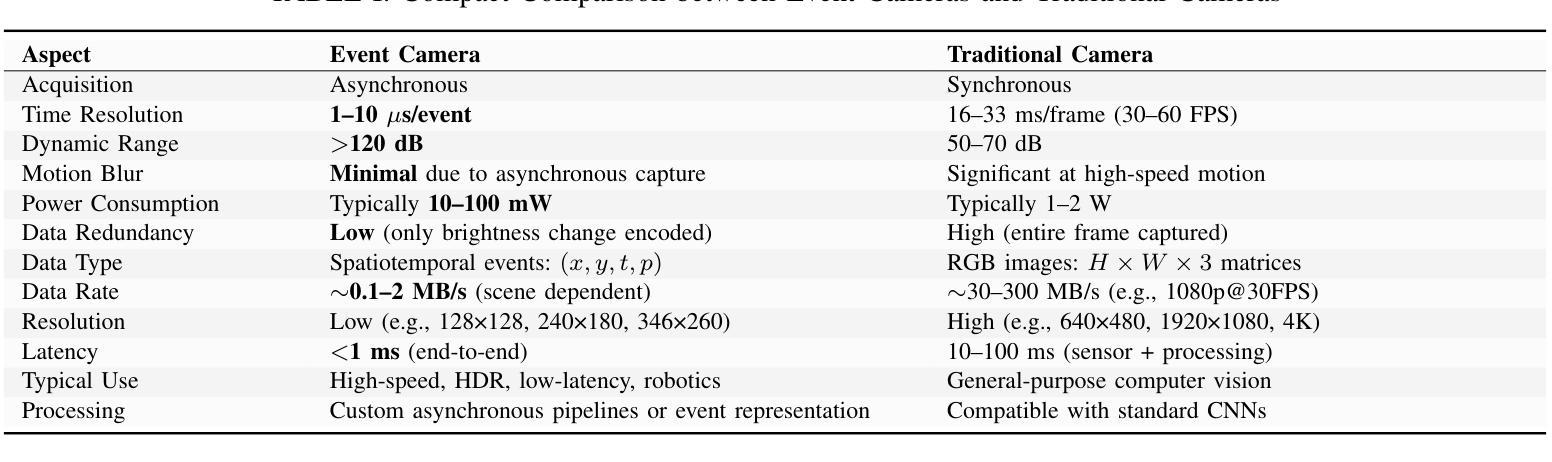
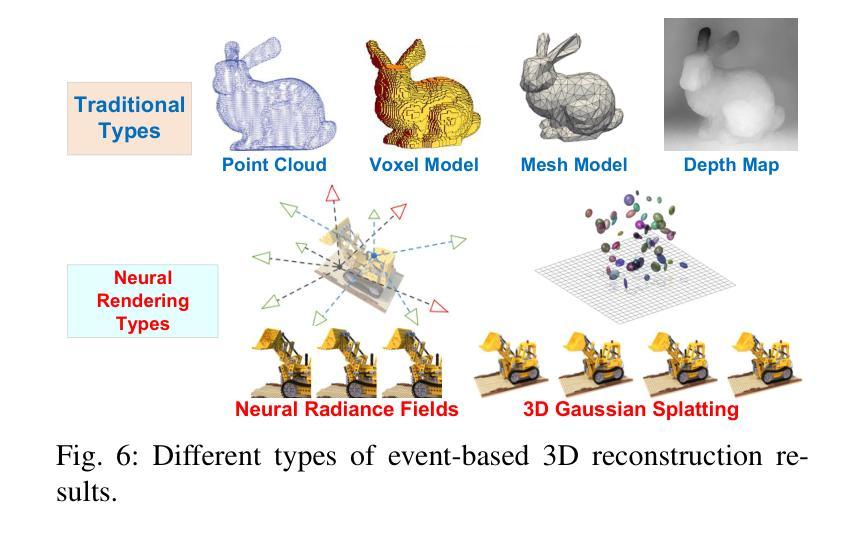
A Survey of 3D Reconstruction with Event Cameras
Authors:Chuanzhi Xu, Haoxian Zhou, Langyi Chen, Haodong Chen, Ying Zhou, Vera Chung, Qiang Qu, Weidong Cai
Event cameras are rapidly emerging as powerful vision sensors for 3D reconstruction, uniquely capable of asynchronously capturing per-pixel brightness changes. Compared to traditional frame-based cameras, event cameras produce sparse yet temporally dense data streams, enabling robust and accurate 3D reconstruction even under challenging conditions such as high-speed motion, low illumination, and extreme dynamic range scenarios. These capabilities offer substantial promise for transformative applications across various fields, including autonomous driving, robotics, aerial navigation, and immersive virtual reality. In this survey, we present the first comprehensive review exclusively dedicated to event-based 3D reconstruction. Existing approaches are systematically categorised based on input modality into stereo, monocular, and multimodal systems, and further classified according to reconstruction methodologies, including geometry-based techniques, deep learning approaches, and neural rendering techniques such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS). Within each category, methods are chronologically organised to highlight the evolution of key concepts and advancements. Furthermore, we provide a detailed summary of publicly available datasets specifically suited to event-based reconstruction tasks. Finally, we discuss significant open challenges in dataset availability, standardised evaluation, effective representation, and dynamic scene reconstruction, outlining insightful directions for future research. This survey aims to serve as an essential reference and provides a clear and motivating roadmap toward advancing the state of the art in event-driven 3D reconstruction.
事件相机正迅速崛起,成为强大的三维重建视觉传感器,其独特之处在于能够异步捕获每个像素的亮度变化。与传统基于帧的相机相比,事件相机产生稀疏但时间密集的数据流,即使在高速运动、低光照和极端动态范围等挑战条件下,也能实现稳健和准确的三维重建。这些功能为自主驾驶、机器人技术、空中导航和沉浸式虚拟现实等各个领域的应用提供了巨大的潜力。在本文中,我们对基于事件的三维重建进行了首次全面综述。现有方法被系统地根据输入模式分为立体、单目和多模态系统,并进一步根据重建方法分类,包括基于几何的技术、深度学习方法以及神经渲染技术,如神经辐射场(NeRF)和三维高斯拼贴(3DGS)。在每个类别中,方法按时间顺序组织,以突出关键概念和进展的演变。此外,我们还详细总结了适用于基于事件重建任务的公开数据集。最后,我们讨论了数据集可用性、标准化评估、有效表示和动态场景重建等重大开放挑战,并指出了未来研究的深刻方向。本综述旨在作为重要的参考资料,为推进事件驱动三维重建的现有技术提供清晰且有激励作用的路线图。
论文及项目相关链接
PDF 24 pages, 16 figures, 11 tables
Summary
事件相机作为强大的视觉传感器,正在迅速崛起并应用于三维重建领域。与传统基于帧的相机相比,事件相机能够异步捕获像素级别的亮度变化,从而产生稀疏但时间密集的数据流。这使得事件相机能够在高速运动、低光照和极端动态范围等挑战条件下实现稳健而准确的三维重建。本文首次进行全面的事件驱动三维重建综述,对现有的方法进行了系统分类,并提供了详细的方法论概述、公开数据集汇总以及未来研究方向的挑战性讨论。旨在为推进事件驱动三维重建领域的研究提供必要的参考和激励。
Key Takeaways
- 事件相机能够异步捕获像素级别的亮度变化,适用于三维重建。
- 事件相机在挑战条件下(如高速运动、低光照和极端动态范围)实现稳健准确的三维重建。
- 现有事件驱动的三维重建方法被系统分类为立体、单目和多模态系统,并基于重建方法论进行分类,包括基于几何的技术、深度学习和神经渲染技术(如神经辐射场和3D高斯喷涂)。
- 文章提供了对适用于事件驱动重建任务的公开数据集的详细汇总。
- 数据集可用性、标准化评估、有效表示和动态场景重建是当前的重大挑战。
- 文章为事件驱动的三维重建领域提供了必要的参考和激励。
点此查看论文截图


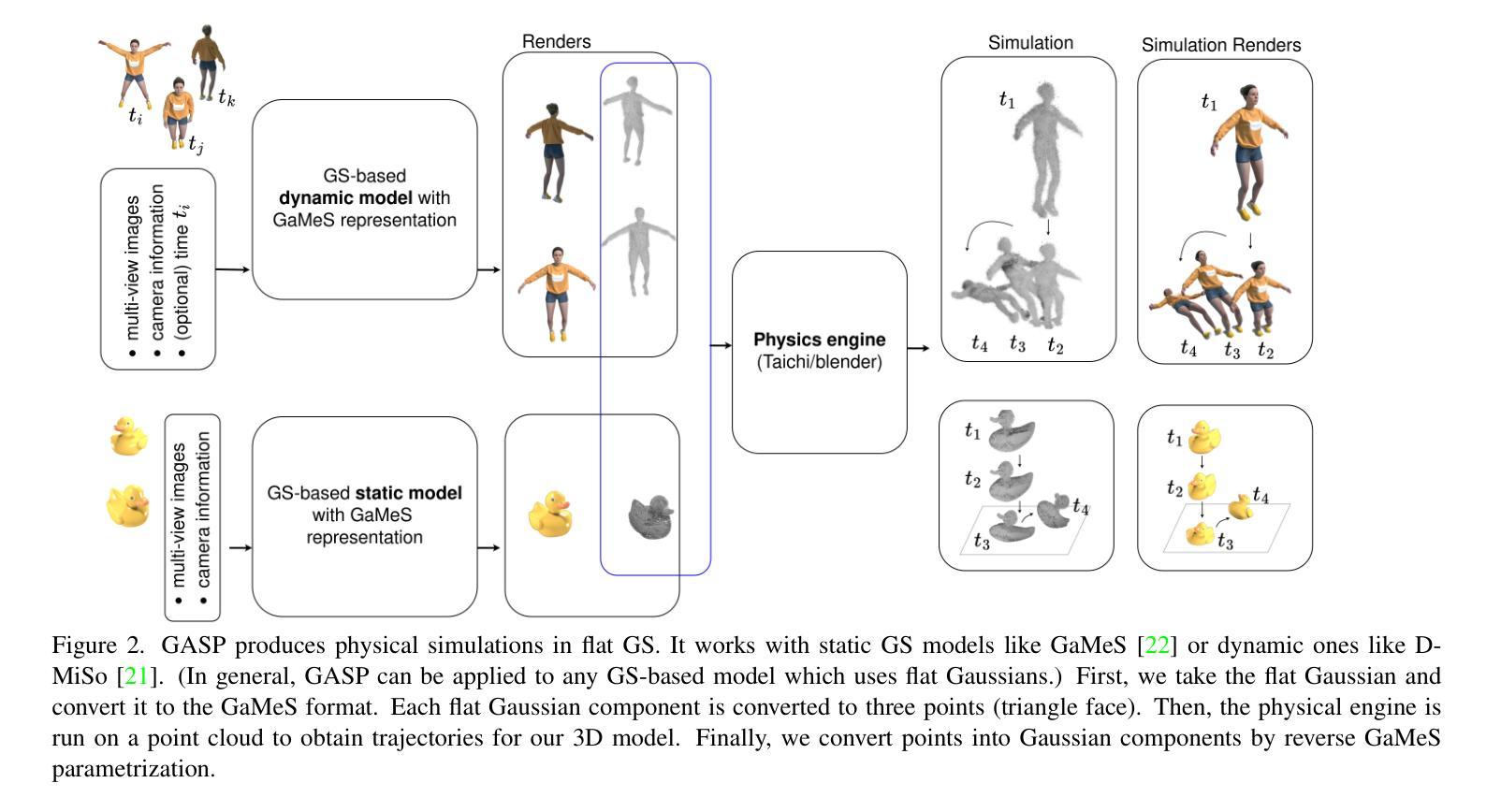
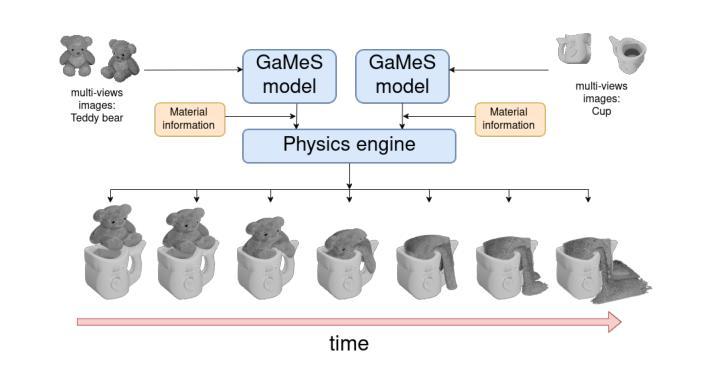
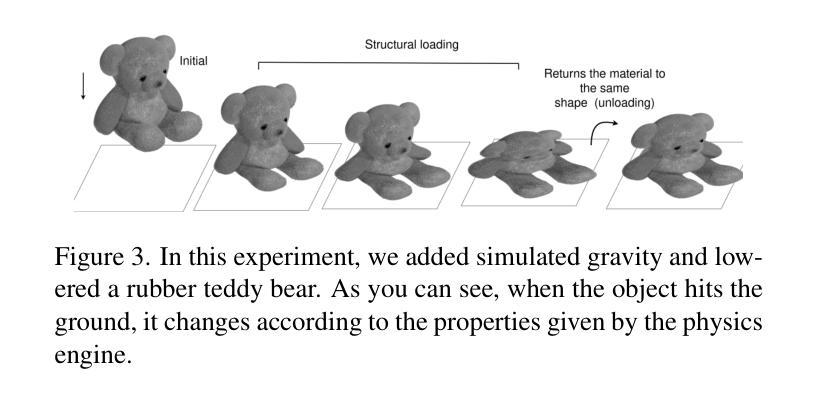
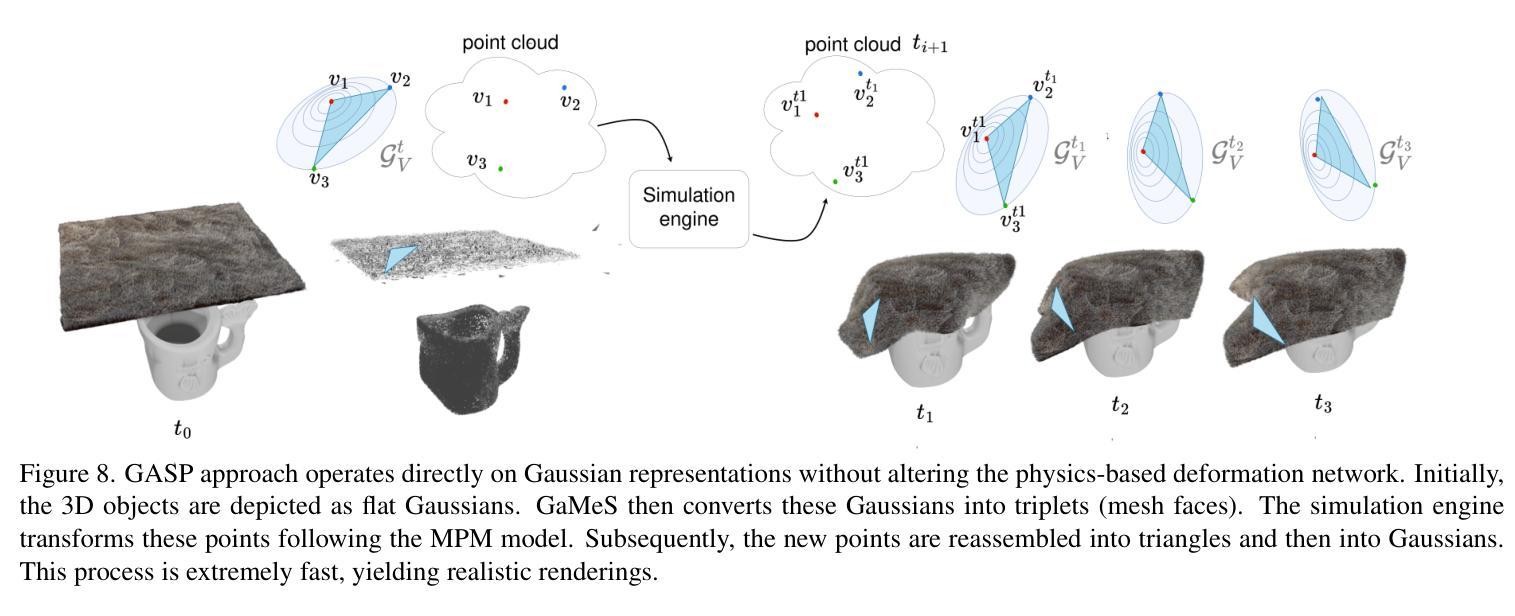
GASP: Gaussian Splatting for Physic-Based Simulations
Authors:Piotr Borycki, Weronika Smolak, Joanna Waczyńska, Marcin Mazur, Sławomir Tadeja, Przemysław Spurek
Physics simulation is paramount for modeling and utilization of 3D scenes in various real-world applications. However, its integration with state-of-the-art 3D scene rendering techniques such as Gaussian Splatting (GS) remains challenging. Existing models use additional meshing mechanisms, including triangle or tetrahedron meshing, marching cubes, or cage meshes. As an alternative, we can modify the physics grounded Newtonian dynamics to align with 3D Gaussian components. Current models take the first-order approximation of a deformation map, which locally approximates the dynamics by linear transformations. In contrast, our Gaussian Splatting for Physics-Based Simulations (GASP) model uses such a map (without any modifications) and flat Gaussian distributions, which are parameterized by three points (mesh faces). Subsequently, each 3D point (mesh face node) is treated as a discrete entity within a 3D space. Consequently, the problem of modeling Gaussian components is reduced to working with 3D points. Additionally, the information on mesh faces can be used to incorporate further properties into the physics model, facilitating the use of triangles. Resulting solution can be integrated into any physics engine that can be treated as a black box. As demonstrated in our studies, the proposed model exhibits superior performance on a diverse range of benchmark datasets designed for 3D object rendering.
物理模拟在多种现实世界应用中对3D场景的建模和利用至关重要。然而,将其与最先进的3D场景渲染技术(如高斯贴图技术)相结合仍然具有挑战性。现有模型采用额外的网格化机制,包括三角形或四面体网格化、行进立方体或笼形网格。作为替代方案,我们可以修改基于物理的牛顿动力学,使其与3D高斯组件保持一致。当前模型采用一阶变形映射近似值,通过线性变换局部近似动力学。相比之下,我们的基于物理模拟的高斯贴图模型(GASP)使用这样的映射(无需任何修改)和平坦的高斯分布,由三个点(网格面)进行参数化。随后,每个3D点(网格面节点)被视为一个三维空间内的离散实体。因此,对高斯组件进行建模的问题就简化为处理三维点的问题。此外,网格面的信息可用于将更多属性纳入物理模型,便于使用三角形。所得解决方案可以集成到任何可以视为黑箱的物理引擎中。根据我们的研究,该模型在针对3D对象渲染设计的各种基准数据集上表现出卓越的性能。
论文及项目相关链接
Summary
物理模拟在模拟和实际应用三维场景方面至关重要,但将其与最新的三维场景渲染技术(如高斯贴图)相结合仍具有挑战性。现有模型采用附加的网格化机制,如三角或四面体网格化等。本文提出的基于物理的模型通过修改牛顿动力学来与三维高斯组件对齐,不使用任何附加的网格化技术。此外,通过利用三角形网格的信息来完善物理模型性能,改进方案能够被任何物理引擎集成并展现出卓越性能。
Key Takeaways
- 物理模拟在模拟和实际应用三维场景中的重要性。
- 将物理模拟与最新的三维场景渲染技术结合具有挑战性。
- 现有模型采用附加的网格化机制(三角或四面体网格化等)。
- 本研究提出了一种基于物理模型的改进方案,该方案修改牛顿动力学以与三维高斯组件对齐,无需附加网格化技术。
- 通过利用三角形网格信息来提高物理模型性能。
- 改进方案能够集成到任何物理引擎中。
点此查看论文截图