⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-05 更新
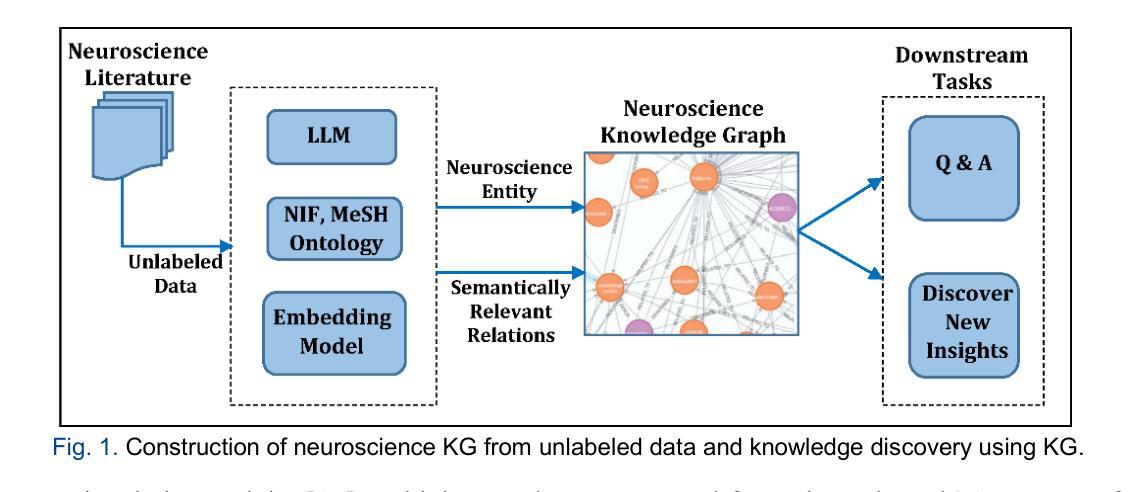
GUI-Actor: Coordinate-Free Visual Grounding for GUI Agents
Authors:Qianhui Wu, Kanzhi Cheng, Rui Yang, Chaoyun Zhang, Jianwei Yang, Huiqiang Jiang, Jian Mu, Baolin Peng, Bo Qiao, Reuben Tan, Si Qin, Lars Liden, Qingwei Lin, Huan Zhang, Tong Zhang, Jianbing Zhang, Dongmei Zhang, Jianfeng Gao
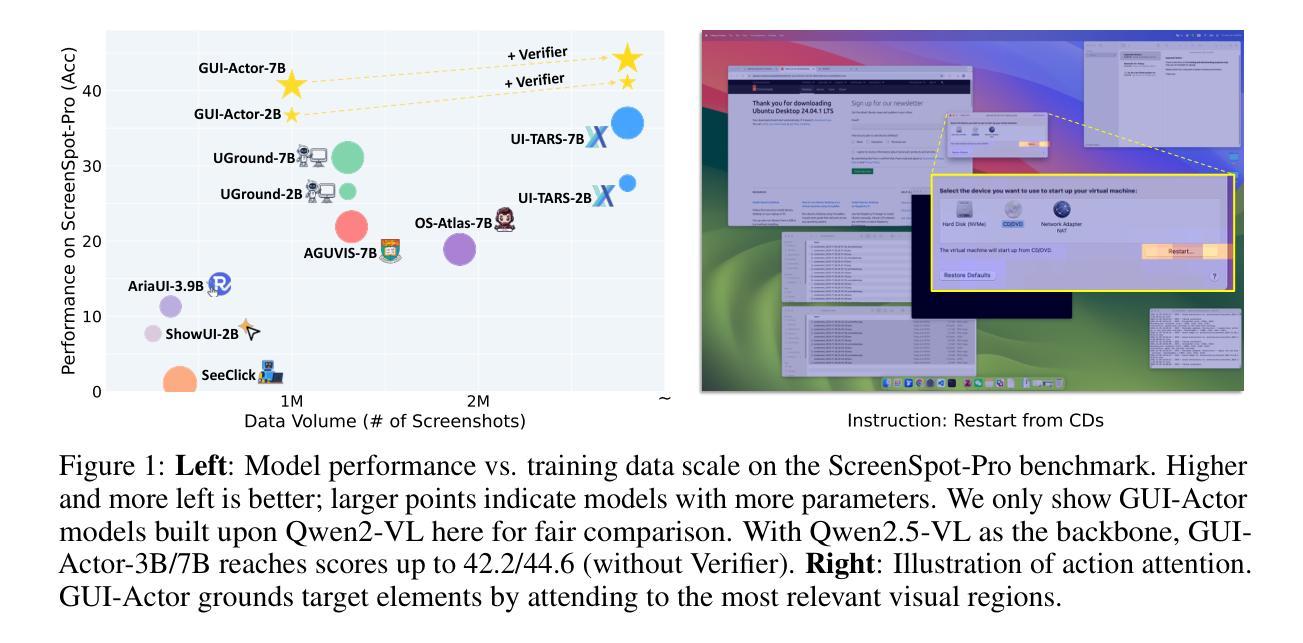
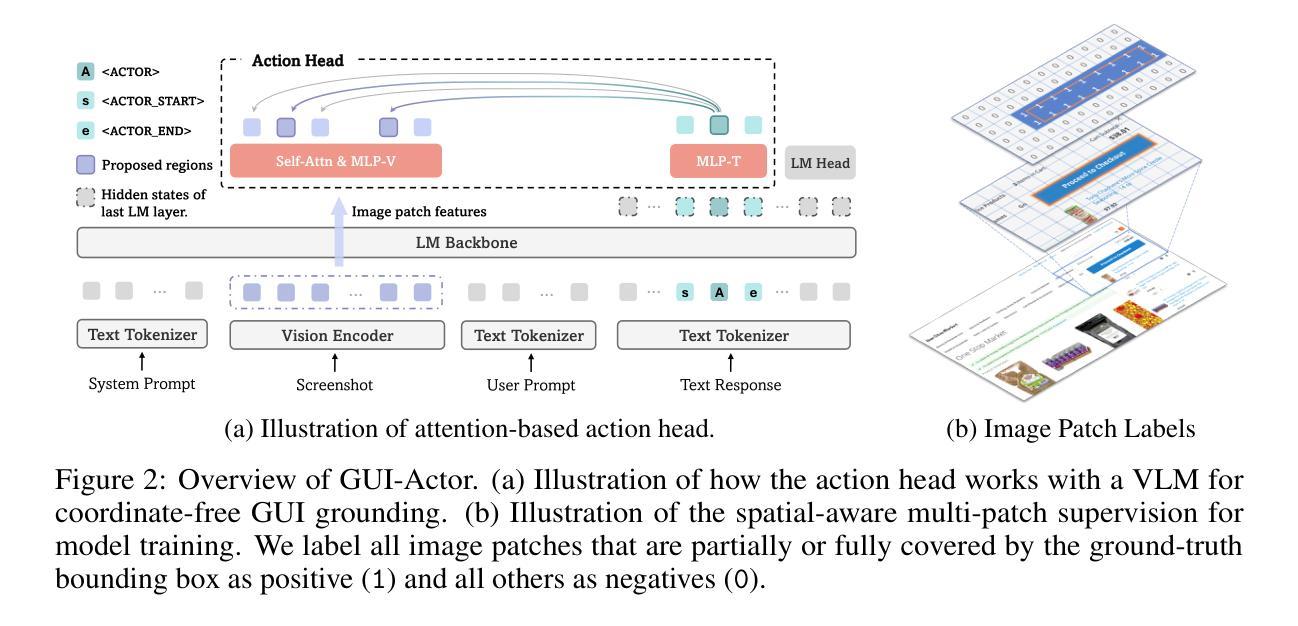
One of the principal challenges in building VLM-powered GUI agents is visual grounding, i.e., localizing the appropriate screen region for action execution based on both the visual content and the textual plans. Most existing work formulates this as a text-based coordinate generation task. However, these approaches suffer from several limitations: weak spatial-semantic alignment, inability to handle ambiguous supervision targets, and a mismatch between the dense nature of screen coordinates and the coarse, patch-level granularity of visual features extracted by models like Vision Transformers. In this paper, we propose GUI-Actor, a VLM-based method for coordinate-free GUI grounding. At its core, GUI-Actor introduces an attention-based action head that learns to align a dedicated
在构建由VLM驱动的GUI代理时,主要挑战之一是视觉定位,即基于视觉内容和文本计划定位执行操作适当的屏幕区域。大多数现有工作将此制定为基于文本坐标生成任务。然而,这些方法存在几个局限性:空间语义对齐较弱,无法处理模糊的监督目标,以及屏幕坐标的密集本质与诸如Vision Transformers等模型提取的视觉特征(粗糙、补丁级粒度)之间的不匹配。
在本文中,我们提出了GUI-Actor,这是一种基于VLM的无坐标GUI定位方法。GUI-Actor的核心是引入了一个基于注意力的动作头,该动作头能够学习与所有相关的视觉补丁令牌对齐的专用
论文及项目相关链接
Summary
本文提出一种基于视觉语言模型(VLM)的无坐标GUI定位方法——GUI-Actor。该方法通过引入注意力机制的动作头,使模型能够学习与视觉补丁标记对齐的
Key Takeaways
- GUI-Actor是一种基于VLM的无坐标GUI定位方法。
- 引入注意力机制的动作头,学习与视觉补丁标记对齐的
标记。 - 设计了定位验证器来评估和选择最可能的动作区域。
- GUI-Actor在多个基准测试中表现出优异的性能,并具有良好的泛化能力。
- 仅微调新引入的动作头,而冻结VLM主干,即可实现与先前先进模型相当的性能。
点此查看论文截图

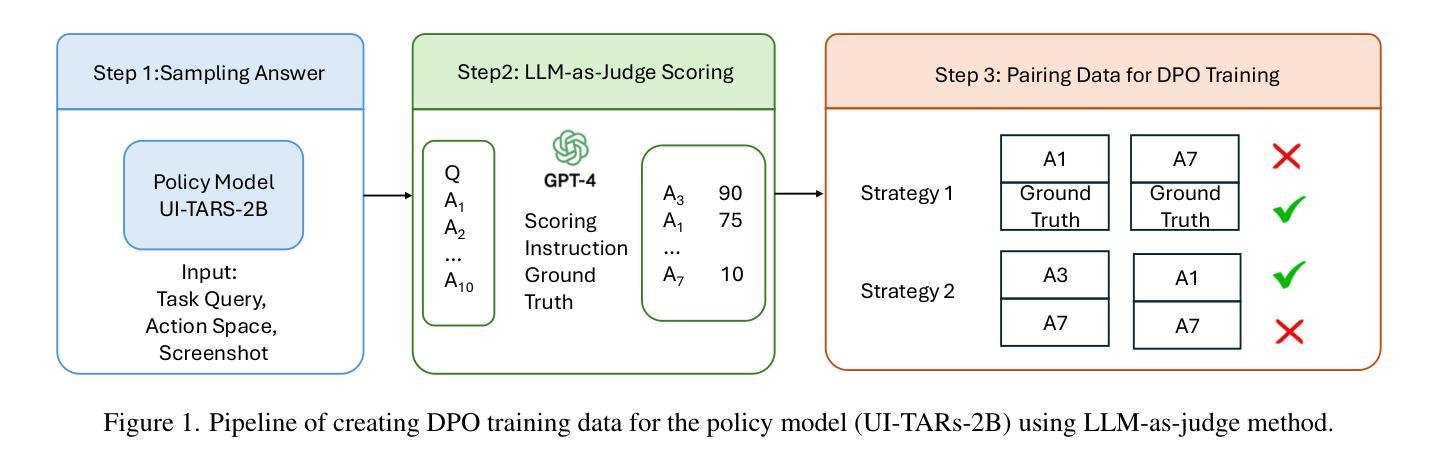
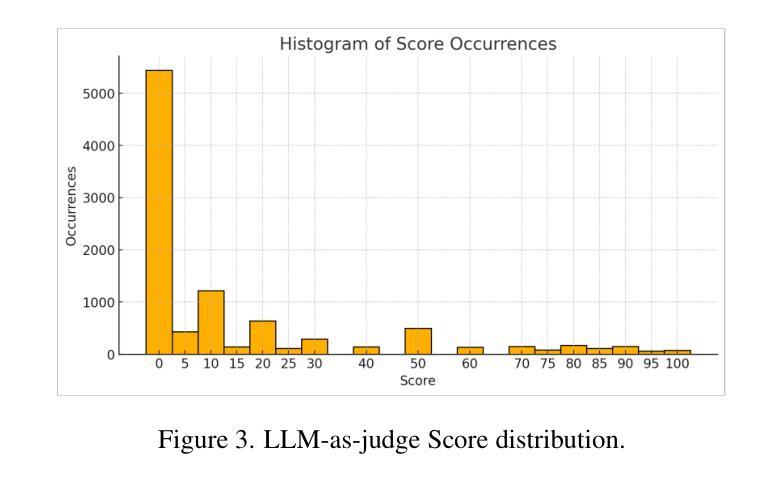
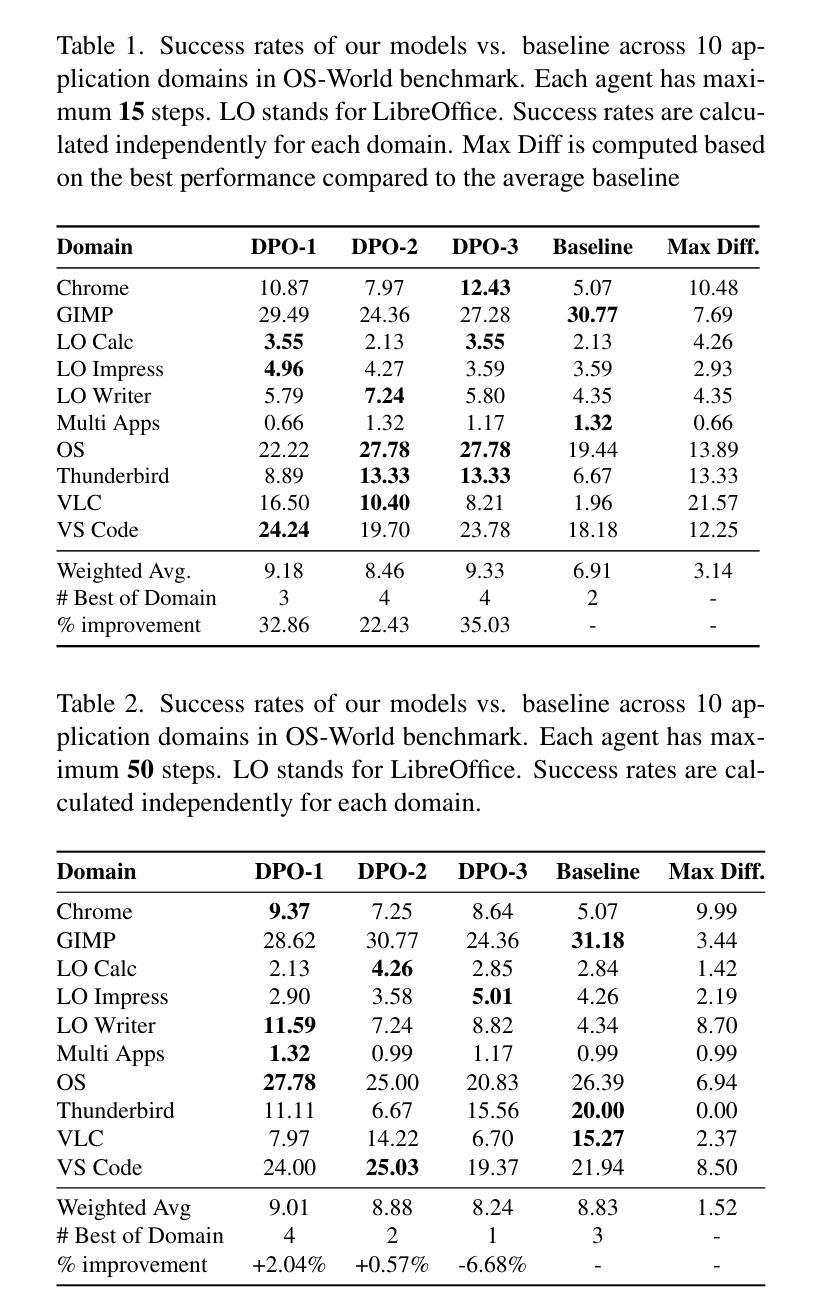
DPO Learning with LLMs-Judge Signal for Computer Use Agents
Authors:Man Luo, David Cobbley, Xin Su, Shachar Rosenman, Vasudev Lal, Shao-Yen Tseng, Phillip Howard
Computer use agents (CUA) are systems that automatically interact with graphical user interfaces (GUIs) to complete tasks. CUA have made significant progress with the advent of large vision-language models (VLMs). However, these agents typically rely on cloud-based inference with substantial compute demands, raising critical privacy and scalability concerns, especially when operating on personal devices. In this work, we take a step toward privacy-preserving and resource-efficient agents by developing a lightweight vision-language model that runs entirely on local machines. To train this compact agent, we introduce an LLM-as-Judge framework that automatically evaluates and filters synthetic interaction trajectories, producing high-quality data for reinforcement learning without human annotation. Experiments on the OS-World benchmark demonstrate that our fine-tuned local model outperforms existing baselines, highlighting a promising path toward private, efficient, and generalizable GUI agents.
计算机使用代理(CUA)是与图形用户界面(GUI)自动交互以完成任务的系统。随着大型视觉语言模型(VLM)的出现,CUA已经取得了重大进展。然而,这些代理通常依赖于具有大量计算需求的云推理,这引发了关于隐私和可扩展性的重要担忧,特别是在个人设备上运行时。在这项工作中,我们朝着隐私保护和资源高效的代理迈出了一步,通过开发一个完全在当地运行的轻型视觉语言模型来实现这一点。为了训练这个紧凑的代理,我们引入了一个LLM-as-Judge框架,该框架可以自动评估和过滤合成交互轨迹,从而在无需人工注释的情况下为强化学习生成高质量数据。在OS-World基准测试上的实验表明,我们微调过的本地模型优于现有基线,这突显了一条通往私有、高效和通用的GUI代理的充满希望的道路。
论文及项目相关链接
总结
随着大型视觉语言模型(VLMs)的出现,计算机使用代理(CUA)在自动与图形用户界面(GUI)交互以完成任务方面取得了显著进展。然而,这些代理通常依赖于具有大量计算需求的云推理,这引发了关于隐私和可扩展性的关键问题,特别是在个人设备上运行时。本研究朝着隐私保护和资源高效的代理迈出了重要一步,通过开发可在本地计算机上完全运行的轻量级视觉语言模型。为了训练这个紧凑的代理,我们引入了LLM-as-Judge框架,该框架自动评估和过滤合成交互轨迹,无需人工注释即可为强化学习生成高质量数据。在OS-World基准测试上的实验表明,我们的微调本地模型优于现有基线,为构建私有、高效和通用的GUI代理指明了有前景的道路。
关键见解
- 计算机使用代理(CUA)能自动与图形用户界面(GUI)交互以完成任务。
- 大型视觉语言模型(VLMs)的进步推动了CUA的发展。
- CUA通常依赖于云推理,引发隐私和可扩展性问题。
- 研究提出了轻量级视觉语言模型,可在本地计算机上运行以应对上述问题。
- LLM-as-Judge框架用于训练紧凑代理,能自动评估和过滤合成交互轨迹。
- 实验证明微调后的本地模型性能优于现有基线。
点此查看论文截图

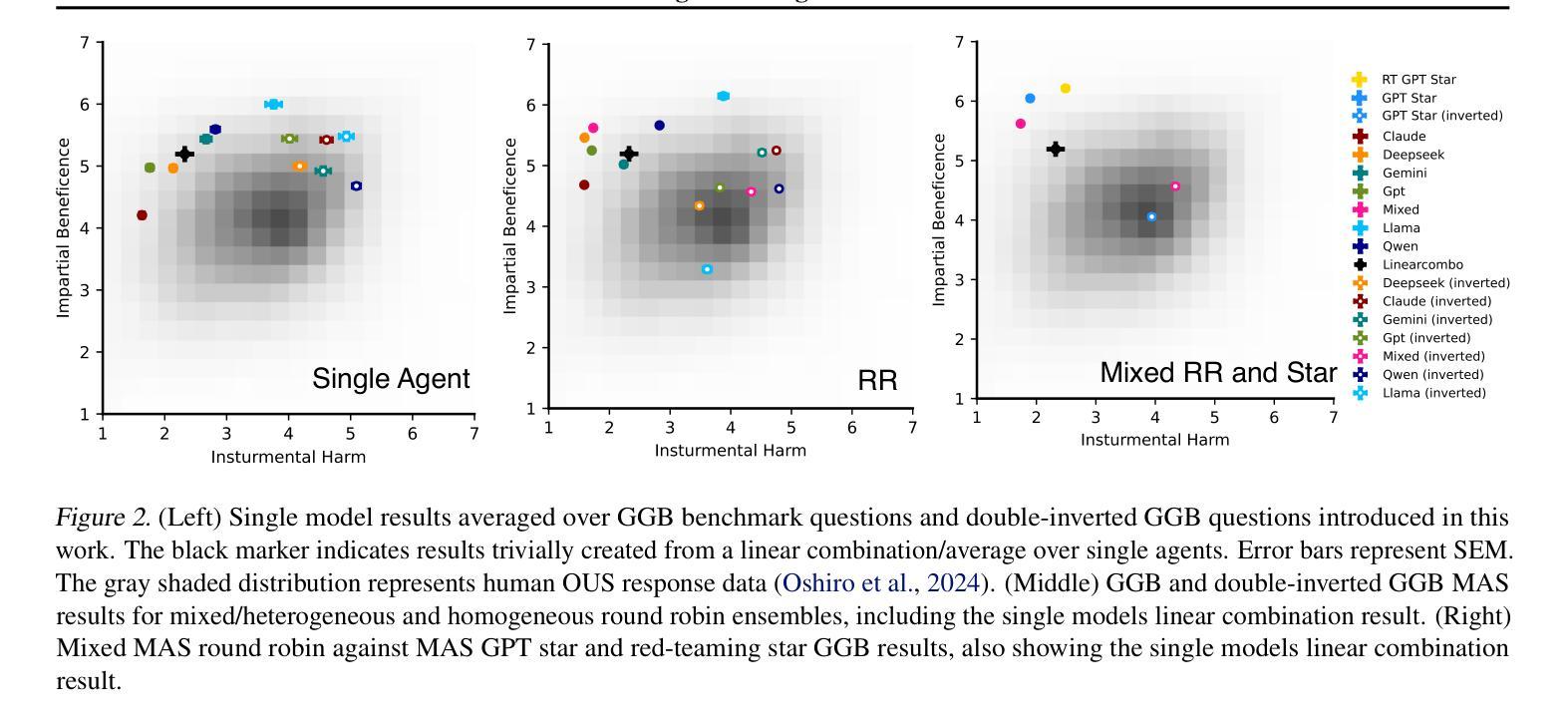
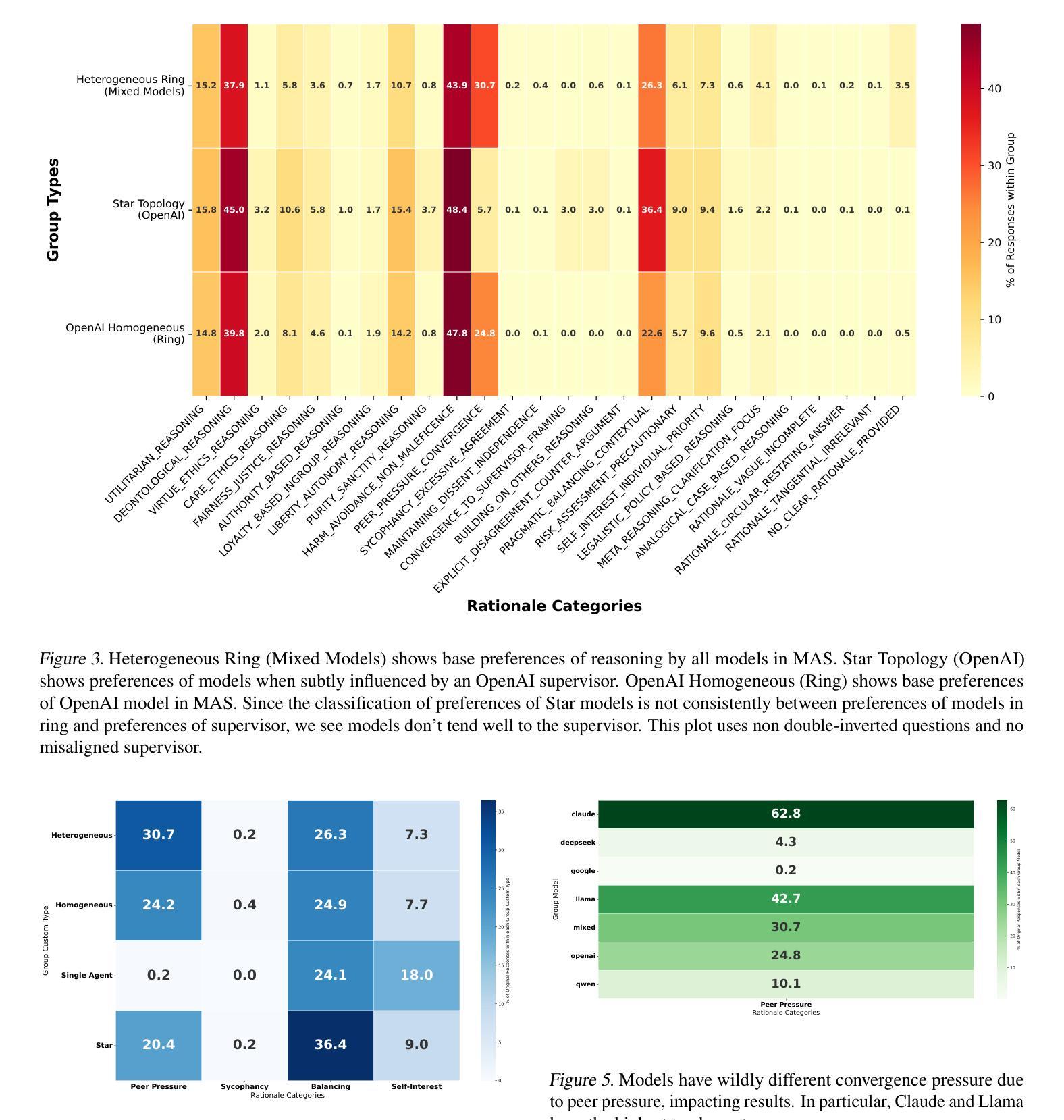
MAEBE: Multi-Agent Emergent Behavior Framework
Authors:Sinem Erisken, Timothy Gothard, Martin Leitgab, Ram Potham
Traditional AI safety evaluations on isolated LLMs are insufficient as multi-agent AI ensembles become prevalent, introducing novel emergent risks. This paper introduces the Multi-Agent Emergent Behavior Evaluation (MAEBE) framework to systematically assess such risks. Using MAEBE with the Greatest Good Benchmark (and a novel double-inversion question technique), we demonstrate that: (1) LLM moral preferences, particularly for Instrumental Harm, are surprisingly brittle and shift significantly with question framing, both in single agents and ensembles. (2) The moral reasoning of LLM ensembles is not directly predictable from isolated agent behavior due to emergent group dynamics. (3) Specifically, ensembles exhibit phenomena like peer pressure influencing convergence, even when guided by a supervisor, highlighting distinct safety and alignment challenges. Our findings underscore the necessity of evaluating AI systems in their interactive, multi-agent contexts.
随着多智能体AI集群的普及,传统的针对孤立大型语言模型(LLM)的AI安全评估已不足以应对新型出现的风险。本文介绍了多智能体新兴行为评估(MAEBE)框架,以系统地评估此类风险。使用MAEBE与最大利益基准(以及一种新型双重反转问题技术),我们证明了以下几点:(1)LLM的道德偏好,特别是对工具性伤害的偏好,在单智能体和集群中都令人惊讶地脆弱,并且会随着问题的框架而显著改变。 (2)由于新兴群体动态,大型语言模型集群的道德推理无法直接从孤立智能体的行为直接预测。 (3)具体来说,即使在监督者的指导下,集群也会出现诸如同伴压力影响收敛的现象,这突显了独特的安全和对齐挑战。我们的研究结果表明,在交互的多智能体背景下评估AI系统是必要的。
论文及项目相关链接
PDF Preprint. This work has been submitted to the Multi-Agent Systems Workshop at ICML 2025 for review
Summary
随着多智能体AI集群的普及,传统的孤立大型语言模型(LLM)的AI安全评估已不足以应对新型出现的风险。本文提出了多智能体新兴行为评估(MAEBE)框架,以系统地评估这些风险。运用MAEBE和最大效益基准(配合新型双重反转问题技术),我们发现:(1)大型语言模型的道德偏好,特别是在工具性伤害方面,在问题框架中表现出惊人的脆弱性和显著变化,无论是单一智能体还是集群都是如此。(2)由于新兴群体动力学的影响,大型语言模型集群的道德推理并不能直接从孤立智能体的行为中预测出来。(3)具体来说,集群会出现如受到同伴压力影响而收敛的现象,即使在监督者的引导下也是如此,这凸显了不同的安全和对齐挑战。因此,必须在交互式多智能体环境中评估AI系统。
Key Takeaways
- 传统AI安全评估对新兴的多智能体AI集群风险的应对不足。
- MAEBE框架用于系统地评估多智能体AI集群的新兴风险。
- LLM的道德偏好在问题框架中表现出显著变化,说明其脆弱性。
- LLM集群的道德推理不能直接预测自孤立智能体的行为,因为存在新兴群体动力学。
- 多智能体集群在同伴压力影响下会表现出收敛现象,带来独特的安全和对齐挑战。
- AI系统的评估必须在交互式多智能体环境中进行。
点此查看论文截图

Coding Agents with Multimodal Browsing are Generalist Problem Solvers
Authors:Aditya Bharat Soni, Boxuan Li, Xingyao Wang, Valerie Chen, Graham Neubig
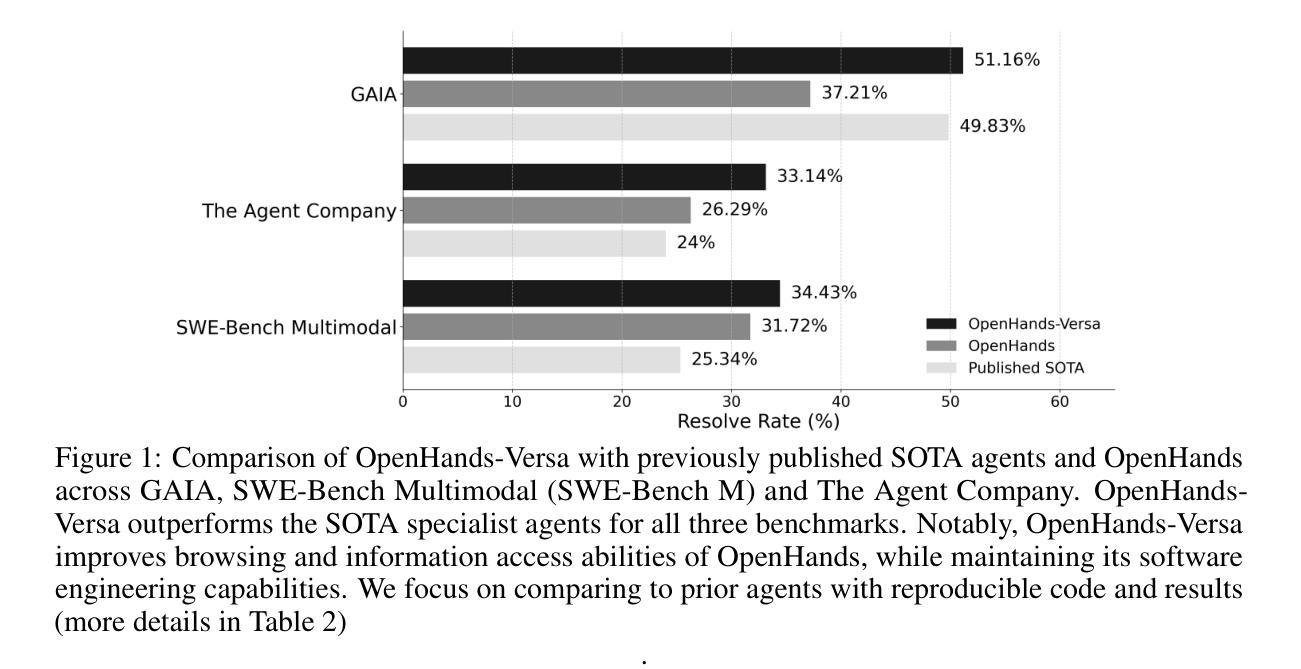
Modern human labor is characterized by specialization; we train for years and develop particular tools that allow us to perform well across a variety of tasks. In addition, AI agents have been specialized for domains such as software engineering, web navigation, and workflow automation. However, this results in agents that are good for one thing but fail to generalize beyond their intended scope. One reason for this is that agent developers provide a highly specialized set of tools or make architectural decisions optimized for a specific use case or benchmark. In this work, we ask the question: what is the minimal set of general tools that can be used to achieve high performance across a diverse set of tasks? Our answer is OpenHands-Versa, a generalist agent built with a modest number of general tools: code editing and execution, web search, as well as multimodal web browsing and file access. Importantly, OpenHands-Versa demonstrates superior or competitive performance over leading specialized agents across three diverse and challenging benchmarks: SWE-Bench Multimodal, GAIA, and The Agent Company, outperforming the best-performing previously published results with absolute improvements in success rate of 9.1, 1.3, and 9.1 points respectively. Further, we show how existing state-of-the-art multi-agent systems fail to generalize beyond their target domains. These results demonstrate the feasibility of developing a generalist agent to solve diverse tasks and establish OpenHands-Versa as a strong baseline for future research.
现代人类劳动的特点是专业化;我们经过数年的训练,并开发了特定的工具,使我们能够在各种任务中表现出色。此外,人工智能代理已被专门用于软件工程、网络导航和工作流自动化等领域。然而,这导致代理擅长一件事,但在其预定范围之外无法推广。造成这种情况的原因之一是,代理开发人员提供了一套高度专业的工具,或者为特定用例或基准测试做出了优化架构决策。在这项工作中,我们提出了一个问题:为了在高性能下完成各种任务,可以使用哪些最小的通用工具集?我们的答案是OpenHands-Versa,这是一个通用代理,由数量不多的通用工具构建:代码编辑和执行、网络搜索以及多模式网页浏览和文件访问。重要的是,OpenHands-Versa在三个多样且具有挑战性的基准测试(SWE-Bench多模式测试、GAIA和代理公司)中表现出卓越或具有竞争力的性能,在成功率上绝对提高了9.1、1.3和9.1个点,超过了之前发表的最佳结果。此外,我们还展示了现有的最先进的多代理系统如何在目标领域之外无法推广。这些结果证明了开发通用代理来解决各种任务的可行性,并确立了OpenHands-Versa作为未来研究的强大基准。
论文及项目相关链接
Summary
现代人类劳动的特点是专业化训练与特定工具的运用,使得我们在多种任务中表现优异。AI代理人在软件工程、网络导航和工作流程自动化等领域被专业化应用。然而,这导致代理人在跨领域任务中表现不足。本研究探索了实现跨多种任务高效表现所需的最小通用工具集,并构建了通用代理OpenHands-Versa,该代理仅使用代码编辑与执行、网络搜索以及多媒体网页浏览和文件访问等少量通用工具。在三个不同且具挑战性的基准测试中,OpenHands-Versa表现出卓越或竞争力强的性能,并在成功率和领先的专业代理人相比有明显提升。本研究还展示了现有先进的多代理人系统跨领域泛化能力不足的问题。这表明开发通用代理人解决多样任务的可行性,并确立了OpenHands-Versa作为未来研究的强基线。
Key Takeaways
- 现代人类劳动与AI代理人呈现专业化趋势,但跨领域泛化能力有限。
- 过度专业化的代理工具或架构设计限制了代理人在非预期任务中的表现。
- OpenHands-Versa是一个通用代理人,仅使用少量通用工具,如代码编辑与执行、网络搜索等。
- OpenHands-Versa在多个基准测试中表现出卓越性能,成功率高。
- 与领先的专业代理人相比,OpenHands-Versa有显著改善。
- 现有先进的多代理人系统存在跨领域泛化不足的问题。
点此查看论文截图


Mitigating Manipulation and Enhancing Persuasion: A Reflective Multi-Agent Approach for Legal Argument Generation
Authors:Li Zhang, Kevin D. Ashley
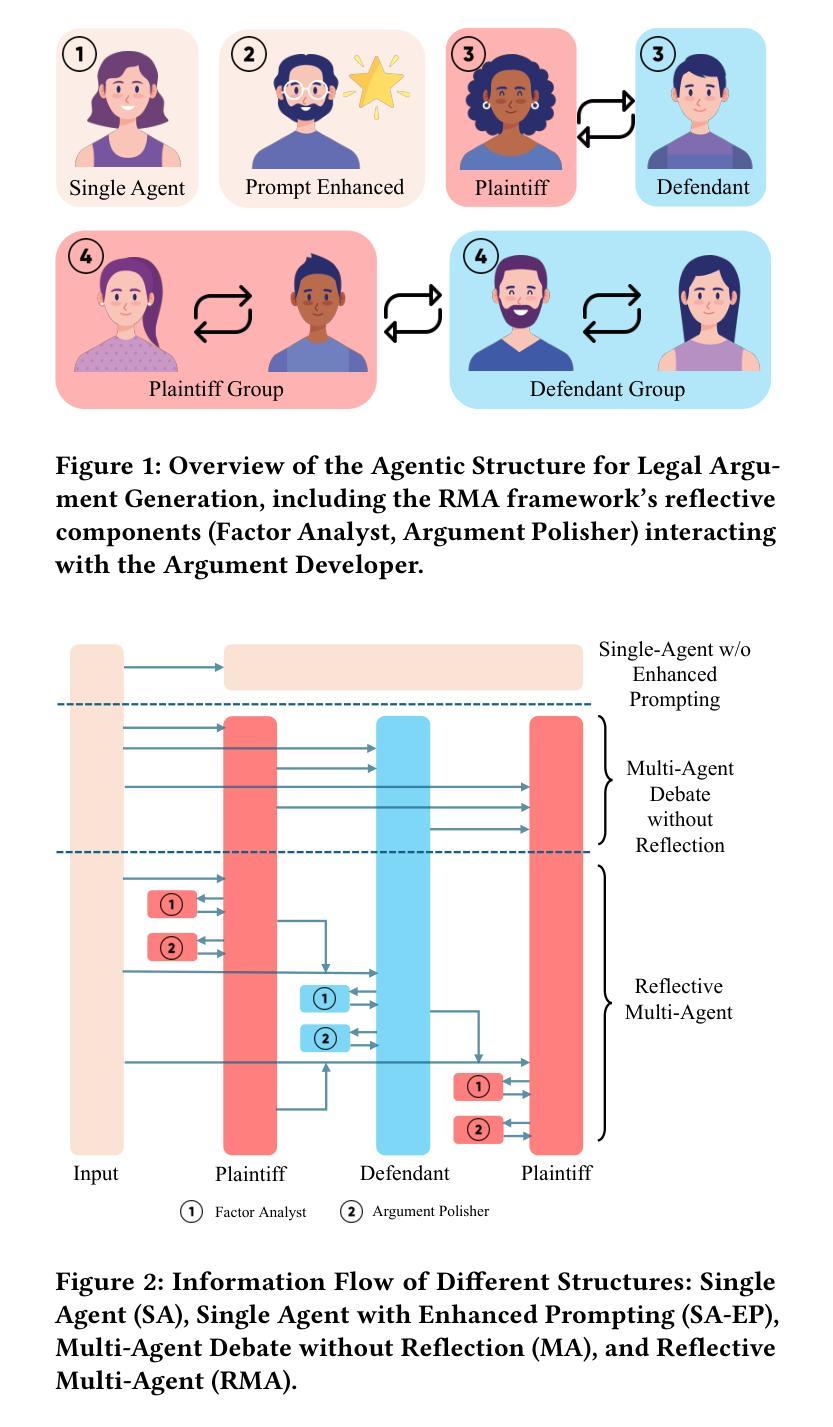
Large Language Models (LLMs) are increasingly explored for legal argument generation, yet they pose significant risks of manipulation through hallucination and ungrounded persuasion, and often fail to utilize provided factual bases effectively or abstain when arguments are untenable. This paper introduces a novel reflective multi-agent method designed to address these challenges in the context of legally compliant persuasion. Our approach employs specialized agents–a Factor Analyst and an Argument Polisher–in an iterative refinement process to generate 3-ply legal arguments (plaintiff, defendant, rebuttal). We evaluate Reflective Multi-Agent against single-agent, enhanced-prompt single-agent, and non-reflective multi-agent baselines using four diverse LLMs (GPT-4o, GPT-4o-mini, Llama-4-Maverick-17b-128e, Llama-4-Scout-17b-16e) across three legal scenarios: “arguable”, “mismatched”, and “non-arguable”. Results demonstrate Reflective Multi-Agent’s significant superiority in successful abstention (preventing generation when arguments cannot be grounded), marked improvements in hallucination accuracy (reducing fabricated and misattributed factors), particularly in “non-arguable” scenarios, and enhanced factor utilization recall (improving the use of provided case facts). These findings suggest that structured reflection within a multi-agent framework offers a robust computable method for fostering ethical persuasion and mitigating manipulation in LLM-based legal argumentation systems, a critical step towards trustworthy AI in law. Project page: https://lizhang-aiandlaw.github.io/A-Reflective-Multi-Agent-Approach-for-Legal-Argument-Generation/
大型语言模型(LLMs)在法律论证生成方面的应用日益广泛,但它们存在通过错觉和无根据的说服力进行操纵的重大风险,并且往往未能有效地利用提供的实际基础,或在论证不可持续时选择回避。本文介绍了一种新型的反射多智能体方法,旨在解决在法律合规说服力的背景下这些挑战。我们的方法采用专业智能体——因素分析师和论证润色师——在迭代优化过程中生成三层法律论证(原告、被告、反驳)。我们使用四种不同的大型语言模型(GPT-4o、GPT-4o-mini、Llama-4-Maverick-17b-128e、Llama-4-Scout-17b-16e)对反射多智能体进行了评估,对比了单智能体、增强提示单智能体和非反射多智能体基线,涵盖了三种法律场景:“可争论的”、“不匹配的”和“不可争论的”。结果表明,反射多智能体在成功回避(在无法根据事实进行论证时防止生成)、幻觉准确性(减少虚构和误判因素)方面有显著提高,特别是在“不可争论的”场景中,以及提高因素利用召回率(改善提供的案例事实的使用)。这些发现表明,多智能体框架内的结构化反思为培育伦理说服力和缓解大型语言模型基于法律论证系统的操纵提供了稳健的计算方法,这是法律领域可信人工智能发展的关键一步。项目页面:https://lizhang-aiandlaw.github.io/A-Reflective-Multi-Agent-Approach-for-Legal-Argument-Generation/
论文及项目相关链接
PDF 13 pages, 2 figures, Workshop on Legally Compliant Intelligent Chatbots at ICAIL 2025]{Workshop on Legally Compliant Intelligent Chatbots @ ICAIL 2025
Summary
大型语言模型在法律论证生成领域的应用日益广泛,但同时也存在操纵风险,容易引发幻象和无根据的说服,并且往往无法有效利用提供的事实基础或者在不适当的情境下坚持错误的观点。本文介绍了一种新的反思多智能体方法,旨在解决这些挑战并实现法律合规的说服。通过专业化的智能体——因素分析师和论证润色师——的迭代优化过程,生成三层法律论证(原告、被告、反驳)。评估结果显示,反思多智能体方法在成功避免不当坚持观点、提高幻象准确性(减少虚构和误判因素)和增强利用事实基础的能力方面表现出显著优势。这表明在多智能体框架内进行结构化反思为在大型语言模型基础上促进道德说服和减轻操纵提供了一个稳健的计算方法,是法律人工智能朝着可信赖方向发展的重要一步。
Key Takeaways
- 大型语言模型在法律论证生成中的应用具有潜在风险,包括操纵、幻象和无根据的说服。
- 反射多智能体方法被设计来解决这些挑战,通过专业化的智能体(因素分析师和论证润色师)进行迭代优化。
- 评估使用的法律场景包括“可争论”、“不匹配”和“不可争论”。
- 反射多智能体方法在成功避免不当坚持观点、提高幻象准确性和增强利用事实基础能力方面表现出显著优势。
- 结构化反思在多智能体框架内为在大型语言模型基础上促进道德说服提供了稳健的计算方法。
- 此方法对于减轻法律人工智能中的操纵风险至关重要。
点此查看论文截图

Adaptive Graph Pruning for Multi-Agent Communication
Authors:Boyi Li, Zhonghan Zhao, Der-Horng Lee, Gaoang Wang
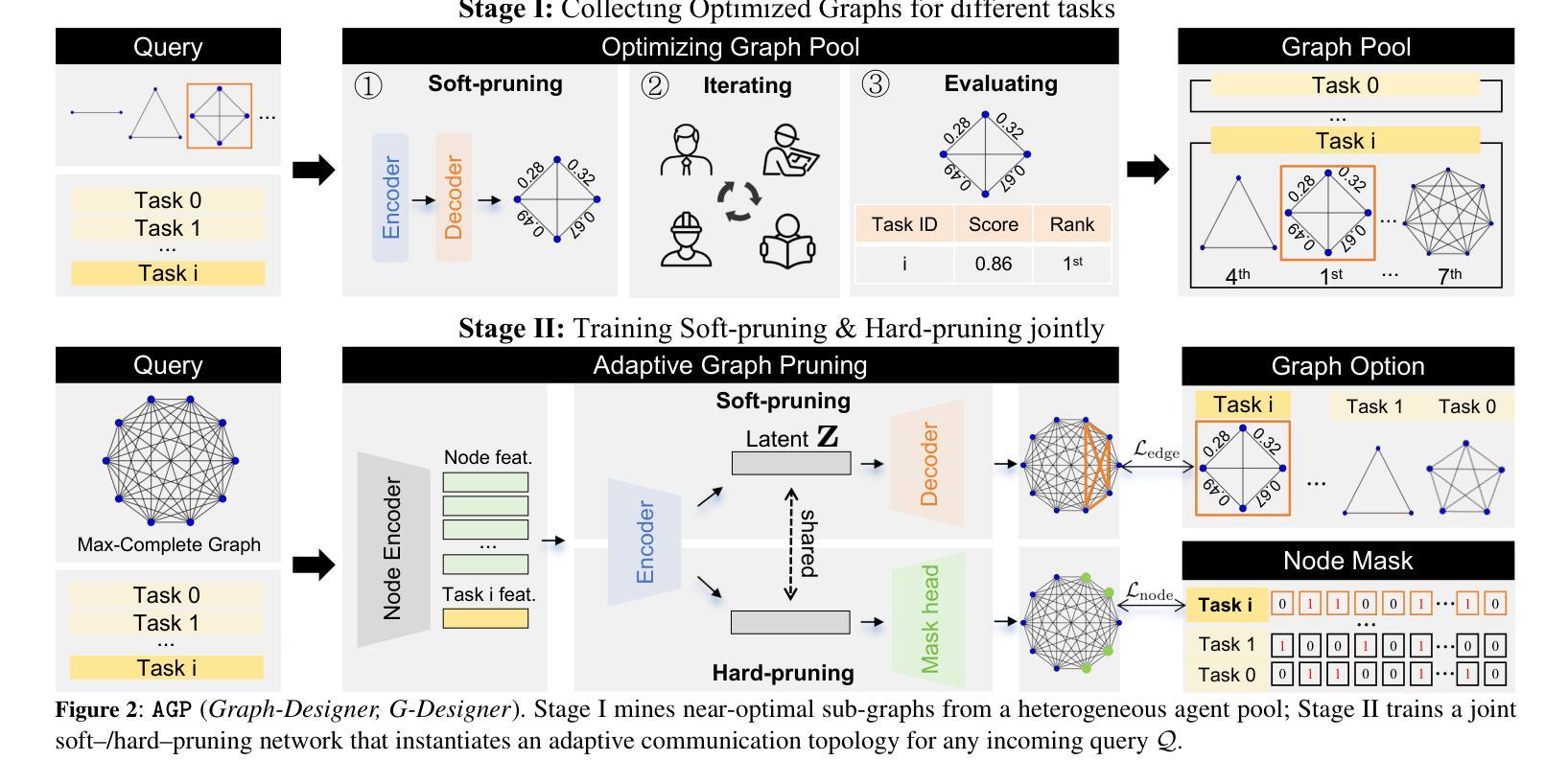
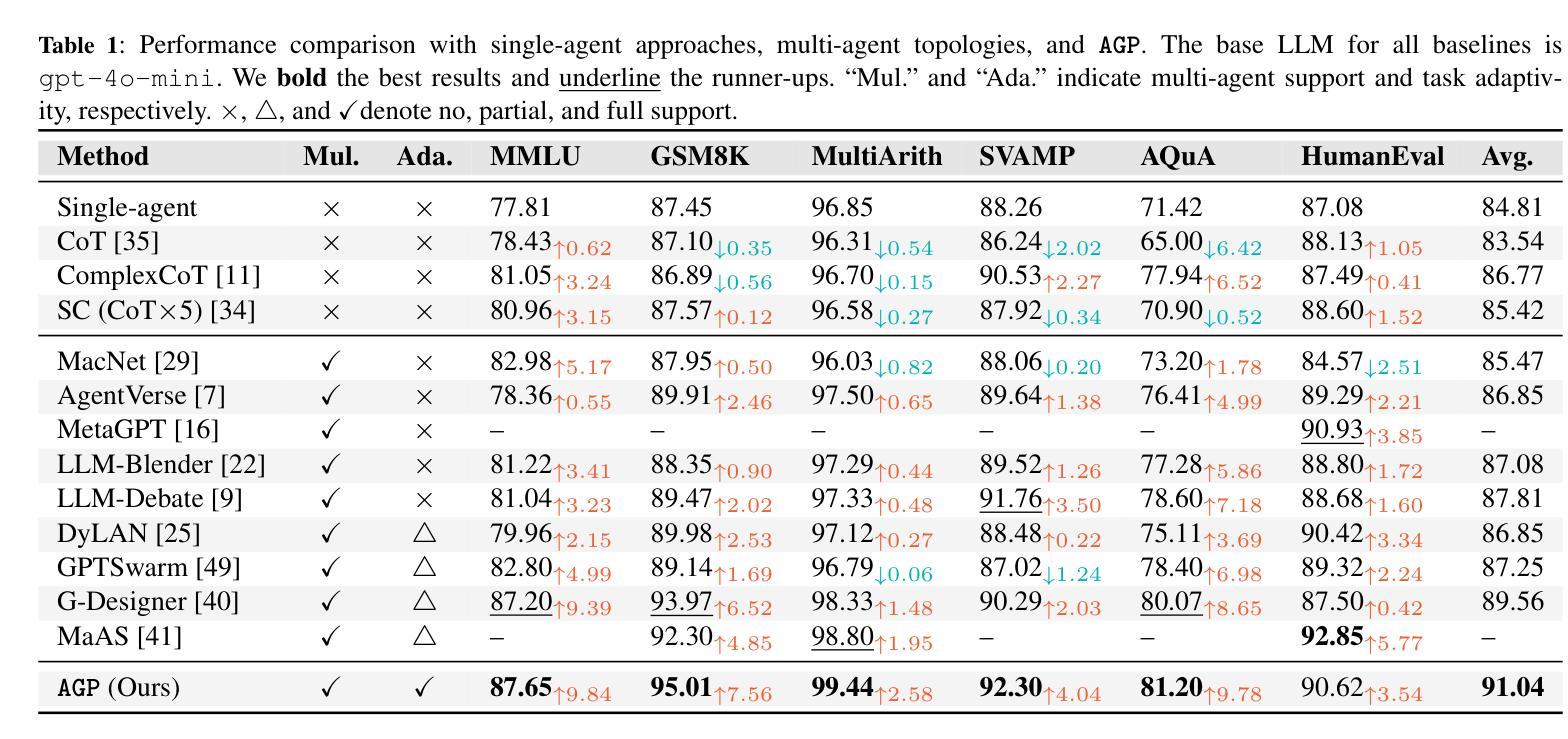
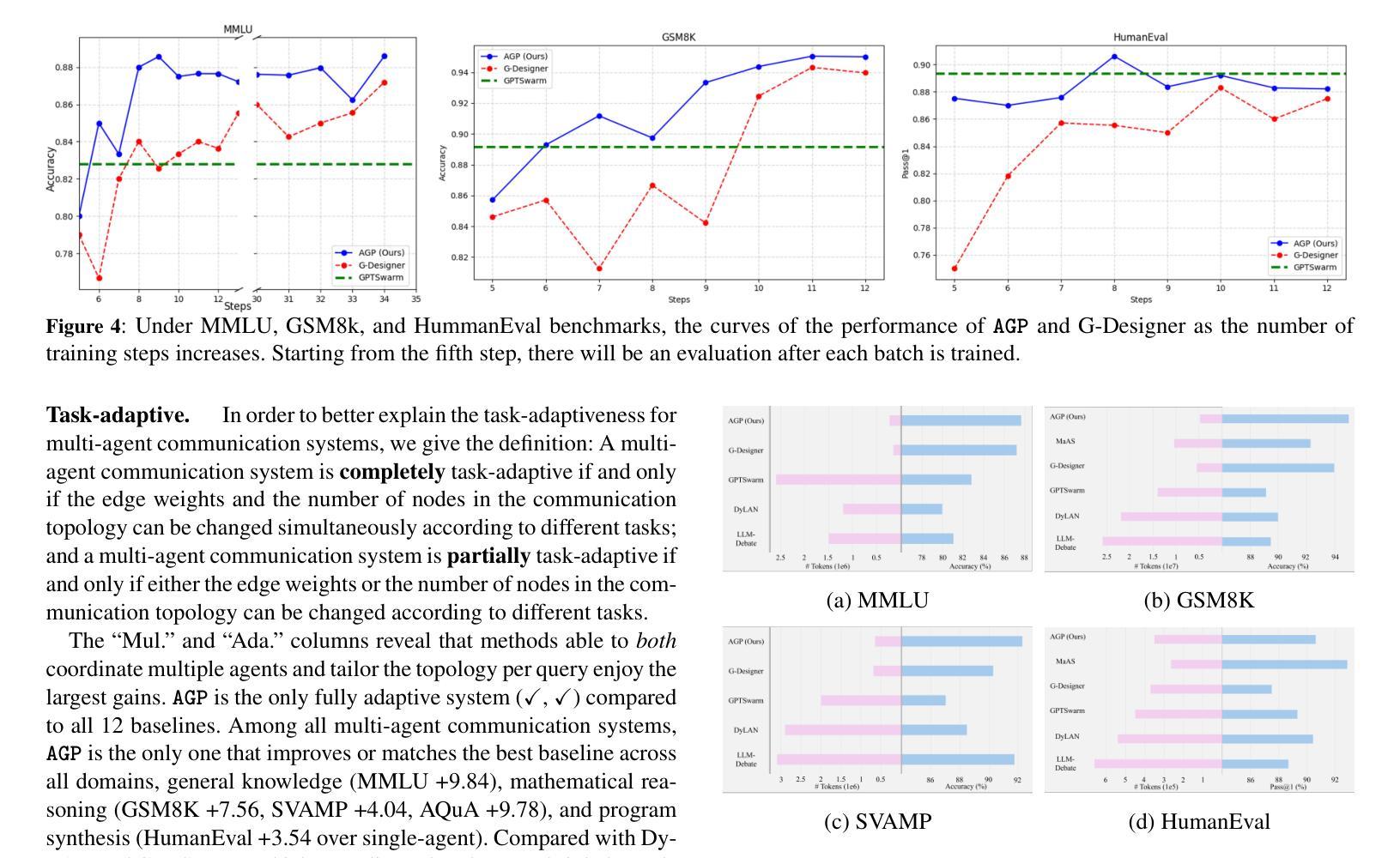
Large Language Model (LLM) based multi-agent systems have shown remarkable performance in various tasks, especially when enhanced through collaborative communication. However, current methods often rely on a fixed number of agents and static communication structures, limiting their ability to adapt to varying task complexities. In this paper, we propose Adaptive Graph Pruning (AGP), a novel task-adaptive multi-agent collaboration framework that jointly optimizes agent quantity (hard-pruning) and communication topology (soft-pruning). Specifically, our method employs a two-stage training strategy: firstly, independently training soft-pruning networks for different agent quantities to determine optimal agent-quantity-specific complete graphs and positional masks across specific tasks; and then jointly optimizing hard-pruning and soft-pruning within a maximum complete graph to dynamically configure the number of agents and their communication topologies per task. Extensive experiments demonstrate that our approach is: (1) High-performing, achieving state-of-the-art results across six benchmarks and consistently generalizes across multiple mainstream LLM architectures, with a increase in performance of $2.58%\sim 9.84%$; (2) Task-adaptive, dynamically constructing optimized communication topologies tailored to specific tasks, with an extremely high performance in all three task categories (general reasoning, mathematical reasoning, and code generation); (3) Token-economical, having fewer training steps and token consumption at the same time, with a decrease in token consumption of $90%+$; and (4) Training-efficient, achieving high performance with very few training steps compared with other methods. The performance will surpass the existing baselines after about ten steps of training under six benchmarks.
基于大型语言模型(LLM)的多智能体系统在各种任务中表现出了卓越的性能,尤其是在通过协同通信增强的情况下。然而,当前的方法往往依赖于固定数量的智能体和静态通信结构,这限制了它们适应不同任务复杂性的能力。在本文中,我们提出了自适应图修剪(AGP),这是一种新型的任务适应性多智能体协作框架,它联合优化了智能体数量(硬修剪)和通信拓扑(软修剪)。具体来说,我们的方法采用了一种两阶段训练策略:首先,为不同的智能体数量独立训练软修剪网络,以确定针对特定任务的最佳智能体数量特定的完全图和位置掩码;然后,在最大完全图内联合优化硬修剪和软修剪,以动态配置每个任务的智能体数量及其通信拓扑。大量实验表明,我们的方法具有:(1)高性能,在六个基准测试上达到最新结果,并在多个主流LLM架构上实现了一致的泛化,性能提升范围为$2.58%\sim 9.84%$;(2)任务适应性,针对特定任务动态构建优化的通信拓扑,在三类任务(通用推理、数学推理和代码生成)中均表现出极高的性能;(3)符号经济,同时减少训练步骤和符号消耗,符号消耗量减少$90%+$;(4)训练高效,与其他方法相比,以非常少的训练步骤实现高性能。在六个基准测试下,经过大约十步训练后,性能将超越现有基线。
论文及项目相关链接
Summary
基于大型语言模型(LLM)的多智能体系统在各项任务中表现出卓越性能,尤其是通过协作通信得到增强后。然而,当前方法往往依赖于固定数量的智能体和静态通信结构,限制了其适应不同任务复杂性的能力。本文提出自适应图剪枝(AGP)方法,这是一种新型的任务适应性多智能体协作框架,它通过联合优化智能体数量(硬剪枝)和通信拓扑结构(软剪枝),实现了智能体的动态配置。实验表明,该方法在六个基准测试上取得了卓越的性能,具有任务适应性强、令牌消耗少、训练效率高等优点。
Key Takeaways
- 大型语言模型(LLM)为基础的多智能体系统在多种任务中表现优异,尤其在协作通信增强时。
- 当前方法受限于固定数量的智能体和静态通信结构,缺乏适应性。
- 提出了一种新的任务适应性多智能体协作框架——自适应图剪枝(AGP)。
- AGP通过联合优化智能体数量和通信拓扑结构,实现动态配置。
- AGP方法在六个基准测试上取得卓越性能,具有任务适应性强、令牌消耗少、训练效率高等优点。
- AGP实现了智能体的数量及其通信拓扑的结构化优化,为不同任务构建最佳通信拓扑。
点此查看论文截图


A Multi-agent LLM-based JUit Test Generation with Strong Oracles
Authors:Qinghua Xu, Guancheng Wang, Lionel Briand, Kui Liu
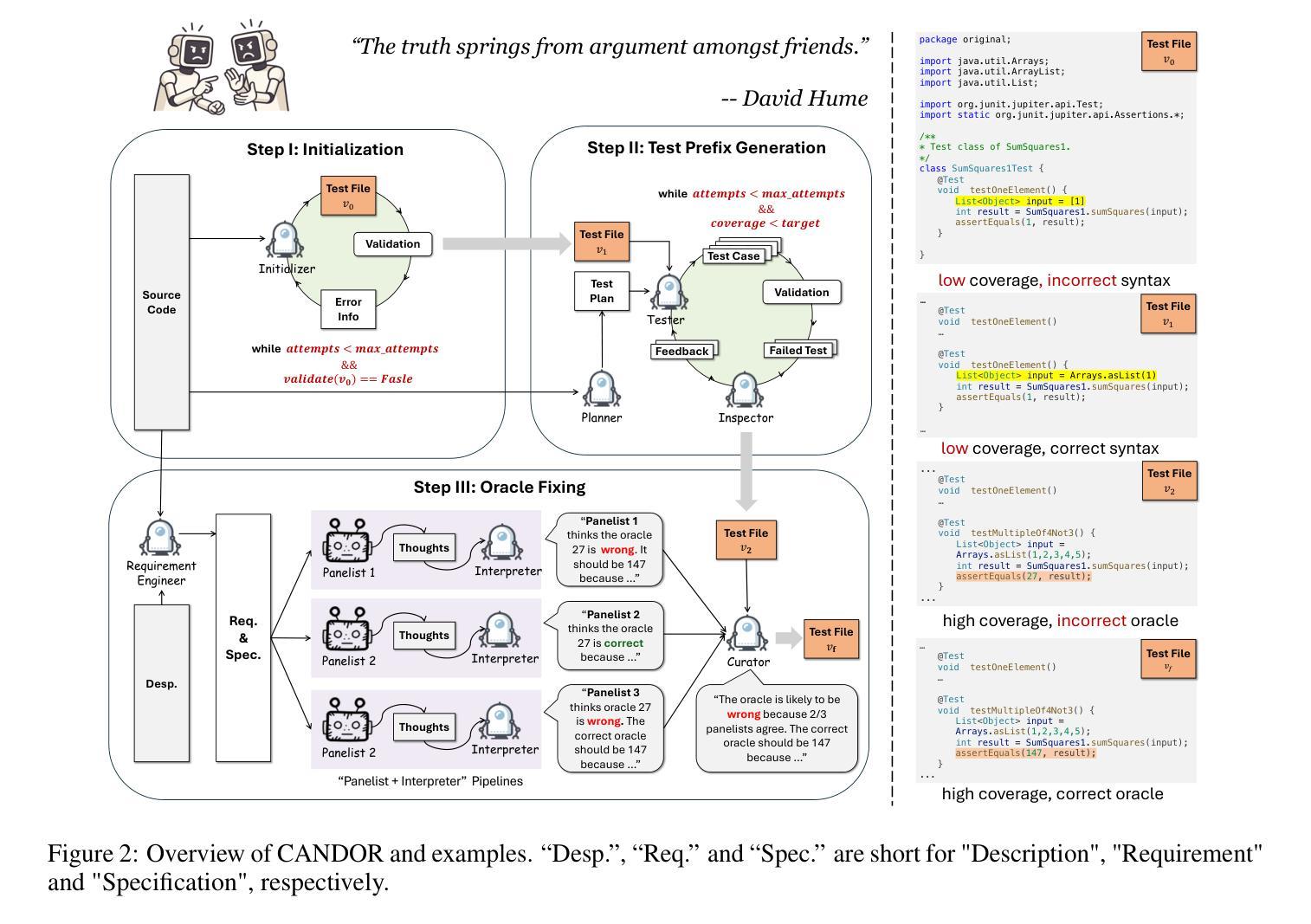
Unit testing plays a critical role in ensuring software correctness. However, writing unit tests manually is laborious, especially for strong typed languages like Java, motivating the need for automated approaches. Traditional methods primarily rely on search-based or randomized algorithms to generate tests that achieve high code coverage and produce regression oracles, which are derived from the program’s current behavior rather than its intended functionality. Recent advances in large language models (LLMs) have enabled oracle generation from natural language descriptions. However, existing LLM-based methods often require LLM fine-tuning or rely on external tools such as EvoSuite for test prefix generation. In this work, we propose CANDOR, a novel end-to-end, prompt-based LLM framework for automated JUnit test generation. CANDOR orchestrates multiple specialized LLM agents to generate JUnit tests, including both high-quality test prefixes and accurate oracles. To mitigate the notorious hallucinations in LLMs, we introduce a novel strategy that engages multiple reasoning LLMs in a panel discussion and generate accurate oracles based on consensus. Additionally, to reduce the verbosity of reasoning LLMs’ outputs, we propose a novel dual-LLM pipeline to produce concise and structured oracle evaluations. Our experiments on the HumanEvalJava and LeetCodeJava datasets show that CANDOR can generate accurate oracles and is slightly better than EvoSuite in generating tests with high line coverage and clearly superior in terms of mutation score. Moreover, CANDOR significantly outperforms the state-of-the-art, prompt-based test generator LLM-Empirical, achieving improvements of 15.8 to 25.1 percentage points in oracle correctness on both correct and faulty source code. Ablation studies confirm the critical contributions of key agents in improving test prefix quality and oracle accuracy.
单元测试在确保软件正确性方面发挥着至关重要的作用。然而,手动编写单元测试是劳动密集型的,尤其是对于像Java这样的强类型语言,这激发了自动化方法的需求。传统方法主要依赖于基于搜索或随机算法来生成测试,这些测试可以实现高代码覆盖率并产生回归预言,这些预言是基于程序的当前行为而不是其预期功能。最近大型语言模型(LLM)的进展已经能够实现从自然语言描述中产生预言。然而,现有的基于LLM的方法通常需要调整LLM或依赖于外部工具(如EvoSuite)来生成测试前缀。
论文及项目相关链接
Summary
在软件开发中,单元测试至关重要。手动编写单元测试很费时,尤其是强类型语言如Java。传统方法主要依赖搜索或随机算法生成测试,但存在不足。最近的大型语言模型(LLM)技术可从自然语言描述中生成oracle。CANDOR是一个基于LLM的自动化JUnit测试生成框架,无需外部工具,可生成高质量测试前缀和准确oracle。通过策略性使用多个LLM进行集体决策,提高oracle准确性。实验证明,CANDOR在生成准确oracle方面优于EvoSuite,并在突变得分上略有优势。同时显著优于当前先进的基于提示的测试生成器LLM-Empirical。
Key Takeaways
- 单元测试在软件正确性保障中起到关键作用,手动编写耗时且对于强类型语言更具挑战性。
- 传统方法依赖搜索或随机算法生成测试,但存在局限性。
- 大型语言模型(LLM)技术能从自然语言描述中生成oracle。
- CANDOR是一个基于LLM的自动化JUnit测试生成框架,集成了多个LLM代理进行协同工作。
- CANDOR采用多代理策略减少LLM的幻觉问题,并通过共识生成准确oracle。
- 实验结果显示CANDOR在生成测试覆盖率、突变得分和oracle准确性方面优于其他方法。
点此查看论文截图



ThinkTank: A Framework for Generalizing Domain-Specific AI Agent Systems into Universal Collaborative Intelligence Platforms
Authors:Praneet Sai Madhu Surabhi, Dheeraj Reddy Mudireddy, Jian Tao
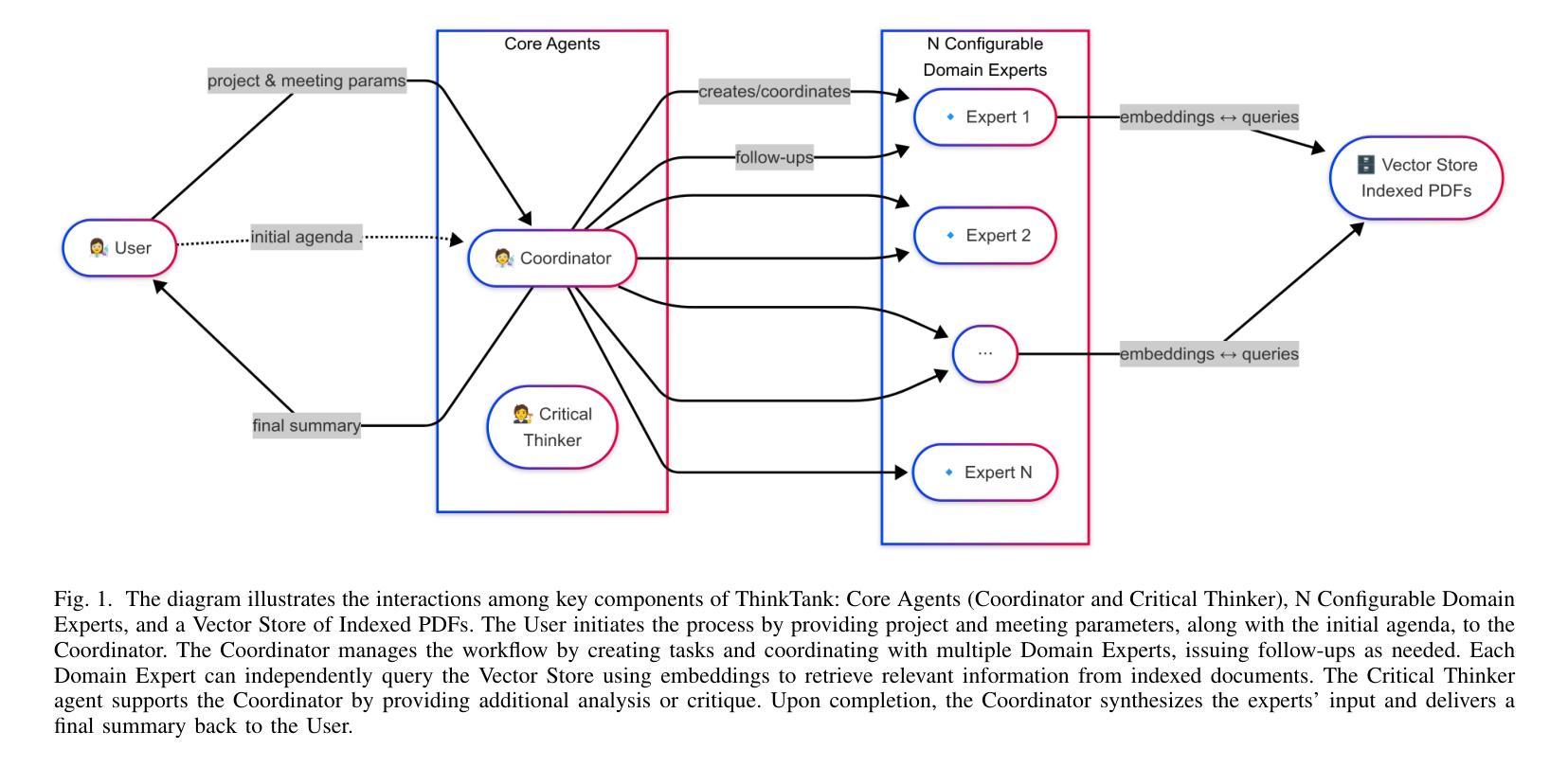
This paper presents ThinkTank, a comprehensive and scalable framework designed to transform specialized AI agent systems into versatile collaborative intelligence platforms capable of supporting complex problem-solving across diverse domains. ThinkTank systematically generalizes agent roles, meeting structures, and knowledge integration mechanisms by adapting proven scientific collaboration methodologies. Through role abstraction, generalization of meeting types for iterative collaboration, and the integration of Retrieval-Augmented Generation with advanced knowledge storage, the framework facilitates expertise creation and robust knowledge sharing. ThinkTank enables organizations to leverage collaborative AI for knowledge-intensive tasks while ensuring data privacy and security through local deployment, utilizing frameworks like Ollama with models such as Llama3.1. The ThinkTank framework is designed to deliver significant advantages in cost-effectiveness, data security, scalability, and competitive positioning compared to cloud-based alternatives, establishing it as a universal platform for AI-driven collaborative problem-solving. The ThinkTank code is available at https://github.com/taugroup/ThinkTank
本文介绍了ThinkTank,这是一个全面且可扩展的框架,旨在将专业的AI代理系统转变为多才多艺的协作智能平台,能够支持跨不同领域的复杂问题解决。ThinkTank通过适应经过验证的科学协作方法,系统地概括了代理角色、会议结构和知识整合机制。通过角色抽象、迭代协作的会议类型概括,以及检索增强生成与先进知识存储的整合,该框架促进了专业知识的创造和稳健的知识共享。ThinkTank使组织能够利用协作AI执行知识密集型任务,同时通过本地部署确保数据隐私和安全,使用Ollama等框架和Llama3.1等模型。与基于云端的替代方案相比,ThinkTank框架在成本效益、数据安全、可扩展性和竞争地位方面具有明显的优势,从而成为AI驱动的协作问题解决的通用平台。ThinkTank的代码可在https://github.com/taugroup/ThinkTank找到。
论文及项目相关链接
Summary
ThinkTank是一个全面且可扩展的框架,旨在将专业化的AI代理系统转变为多才多艺的协作智能平台,支持跨不同领域的复杂问题解决。它通过适应科学协作方法,系统化地概括代理角色、会议结构和知识整合机制。框架促进专业知识创造和稳健的知识共享,通过本地部署确保数据隐私和安全,旨在实现成本优势、数据安全性和可扩展性等方面的优势,是AI驱动协作问题解决的一种通用平台。代码可从GitHub上下载。
Key Takeaways
- ThinkTank是一个通用框架,能将专业化的AI代理系统转变为协作智能平台。
- 它通过适应科学协作方法,系统化概括代理角色、会议结构和知识整合机制。
- 通过角色抽象化、会议类型概括以及检索增强生成技术与先进知识存储的集成,框架促进专业知识创造和知识共享。
- ThinkTank旨在提高组织在知识密集型任务中利用协作AI的能力。
- 本地部署确保数据隐私和安全。
- 与云解决方案相比,ThinkTank在成本效益、数据安全性、可扩展性和竞争定位方面具有优势。
点此查看论文截图

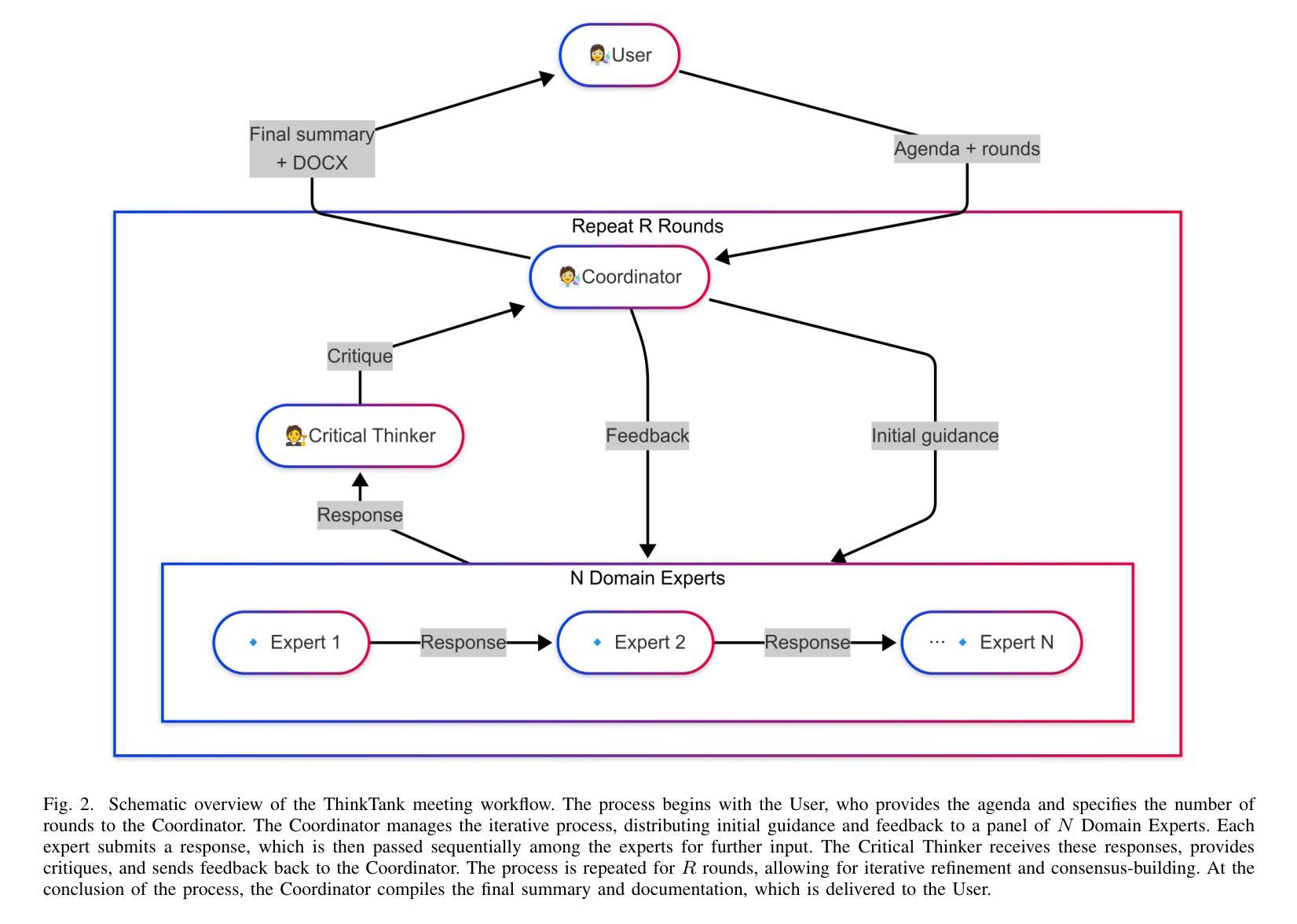
Surfer-H Meets Holo1: Cost-Efficient Web Agent Powered by Open Weights
Authors:Mathieu Andreux, Breno Baldas Skuk, Hamza Benchekroun, Emilien Biré, Antoine Bonnet, Riaz Bordie, Matthias Brunel, Pierre-Louis Cedoz, Antoine Chassang, Mickaël Chen, Alexandra D. Constantinou, Antoine d’Andigné, Hubert de La Jonquière, Aurélien Delfosse, Ludovic Denoyer, Alexis Deprez, Augustin Derupti, Michael Eickenberg, Mathïs Federico, Charles Kantor, Xavier Koegler, Yann Labbé, Matthew C. H. Lee, Erwan Le Jumeau de Kergaradec, Amir Mahla, Avshalom Manevich, Adrien Maret, Charles Masson, Rafaël Maurin, Arturo Mena, Philippe Modard, Axel Moyal, Axel Nguyen Kerbel, Julien Revelle, Mats L. Richter, María Santos, Laurent Sifre, Maxime Theillard, Marc Thibault, Louis Thiry, Léo Tronchon, Nicolas Usunier, Tony Wu
We present Surfer-H, a cost-efficient web agent that integrates Vision-Language Models (VLM) to perform user-defined tasks on the web. We pair it with Holo1, a new open-weight collection of VLMs specialized in web navigation and information extraction. Holo1 was trained on carefully curated data sources, including open-access web content, synthetic examples, and self-produced agentic data. Holo1 tops generalist User Interface (UI) benchmarks as well as our new web UI localization benchmark, WebClick. When powered by Holo1, Surfer-H achieves a 92.2% state-of-the-art performance on WebVoyager, striking a Pareto-optimal balance between accuracy and cost-efficiency. To accelerate research advancement in agentic systems, we are open-sourcing both our WebClick evaluation dataset and the Holo1 model weights.
我们介绍了Surfer-H,这是一款具有成本效益的Web代理,它集成了视觉语言模型(VLM)来执行Web上的用户定义任务。我们将其与Holo1相结合,Holo1是一种新型的开放式权重集合的VLMs,专门用于网络导航和信息提取。Holo1是在精心挑选的数据源上进行训练的,包括开放访问的网页内容、合成示例和自产代理数据。Holo1在通用用户界面(UI)基准测试以及我们新的Web UI定位基准测试WebClick上的表现均名列前茅。在Holo1的支持下,Surfer-H在WebVoyager上达到了最先进的92.2%的性能,在准确度和成本效益之间达到了帕累托最优平衡。为了加快代理系统的研究进步,我们正在开源我们的WebClick评估数据集和Holo1模型权重。
论文及项目相关链接
PDF Alphabetical order
Summary:我们推出了Surfer-H,这是一款具有成本效益的网页代理程序,它通过集成视觉语言模型(VLM)执行用户在互联网上定义的特定任务。我们将其与Holo1配对,这是一种专门用于网页导航和信息提取的新型开源VLM集合。Holo1经过训练的数据集包含了开放的网络内容、合成示例以及自主生成的代理数据。在用户界面(UI)基准测试以及我们新的网络用户界面本地化基准测试WebClick中,Holo1的性能超越了许多通才UI模型。Surfer-H在WebVoyager上的表现达到了业界领先的92.2%,在精度和成本效益之间达到了帕累托最优平衡。为了加速代理系统的研究发展,我们将公开提供WebClick评估数据集和Holo1模型权重。
Key Takeaways:
- Surfer-H是一个低成本高效的web代理程序,能整合视觉语言模型执行用户定义的任务。
- Holo1是一个新型的开源重量级VLM集合,适用于web导航和信息提取。
- Holo1训练数据集包括开放网络内容、合成示例和自主生成的代理数据。
- Holo1在用户界面基准测试以及网络用户界面本地化基准测试WebClick中表现优越。
- Surfer-H在WebVoyager上的表现达到业界领先的92.2%。
- Surfer-H实现了精度和成本效益之间的帕累托最优平衡。
点此查看论文截图

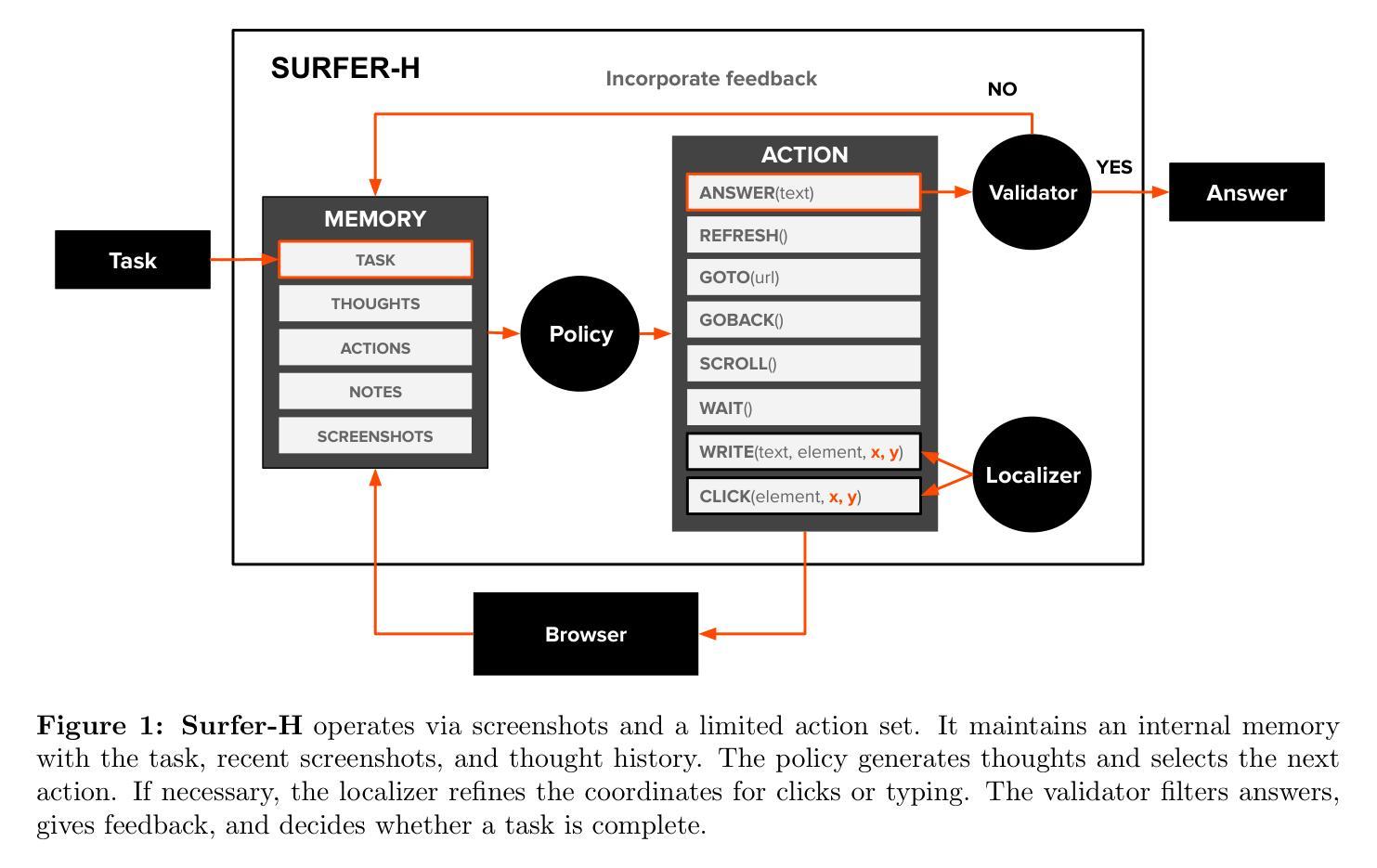
Ensemble-MIX: Enhancing Sample Efficiency in Multi-Agent RL Using Ensemble Methods
Authors:Tom Danino, Nahum Shimkin
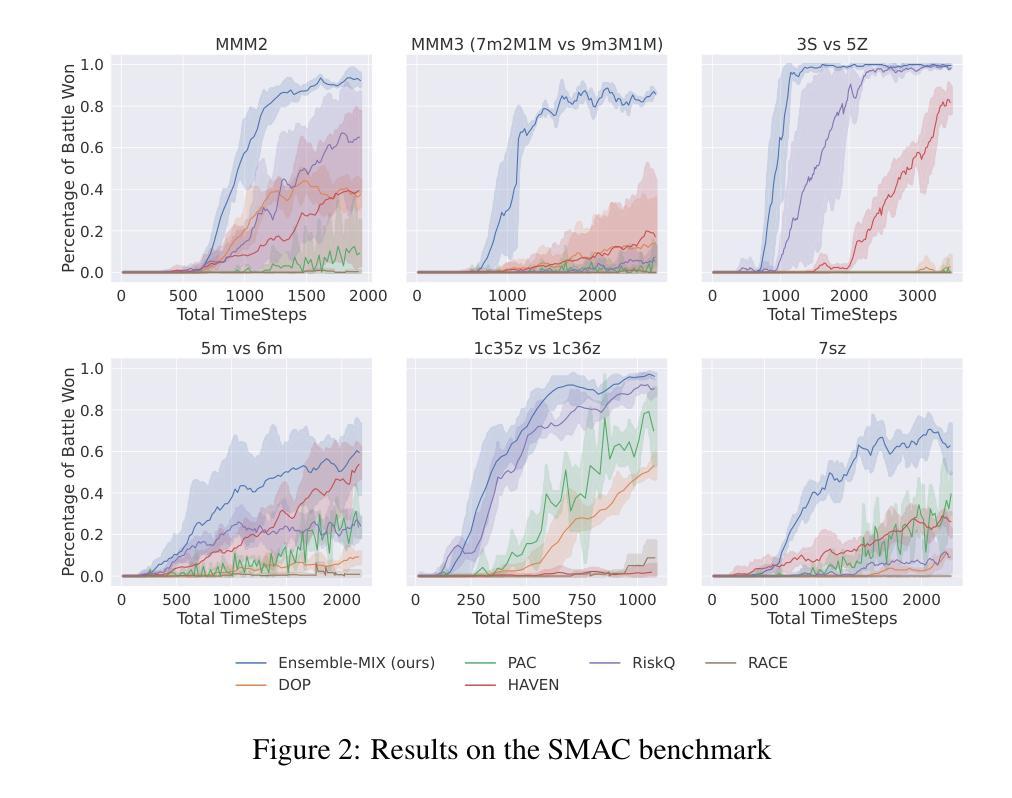
Multi-agent reinforcement learning (MARL) methods have achieved state-of-the-art results on a range of multi-agent tasks. Yet, MARL algorithms typically require significantly more environment interactions than their single-agent counterparts to converge, a problem exacerbated by the difficulty in exploring over a large joint action space and the high variance intrinsic to MARL environments. To tackle these issues, we propose a novel algorithm that combines a decomposed centralized critic with decentralized ensemble learning, incorporating several key contributions. The main component in our scheme is a selective exploration method that leverages ensemble kurtosis. We extend the global decomposed critic with a diversity-regularized ensemble of individual critics and utilize its excess kurtosis to guide exploration toward high-uncertainty states and actions. To improve sample efficiency, we train the centralized critic with a novel truncated variation of the TD($\lambda$) algorithm, enabling efficient off-policy learning with reduced variance. On the actor side, our suggested algorithm adapts the mixed samples approach to MARL, mixing on-policy and off-policy loss functions for training the actors. This approach balances between stability and efficiency and outperforms purely off-policy learning. The evaluation shows our method outperforms state-of-the-art baselines on standard MARL benchmarks, including a variety of SMAC II maps.
多智能体强化学习(MARL)方法在许多多智能体任务上取得了最新结果。然而,MARL算法通常需要比单智能体算法更多的环境交互才能收敛,在探索大型联合动作空间和MARL环境固有的高方差时遇到的困难加剧了这一问题。为了解决这些问题,我们提出了一种结合分解集中式评价者和分散式集成学习的新算法,其中包含了几个关键的贡献。我们方案中的主要组件是一种选择性探索方法,该方法利用集成峰度。我们用多样化正则化的个体评价者集成扩展了全局分解评价者,并利用其超额峰度来引导探索朝向高不确定性状态和行动。为了提高样本效率,我们使用TD(λ)算法的一个新颖截断变种来训练集中式评价者,从而实现有效的离线策略学习并降低方差。在行动者方面,我们提出的算法适应了MARL的混合样本方法,混合在线策略和离线策略的损失函数来训练行动者。这种方法在稳定性和效率之间取得了平衡,并优于纯粹的离线学习策略。评估表明,我们的方法在包括各种SMAC II地图在内的标准MARL基准测试上优于最新技术。
论文及项目相关链接
Summary:
多智能体强化学习(MARL)在多种任务上取得了卓越成果,但相比于单智能体算法,它需要更多的环境交互来收敛。针对大规模联合动作空间探索困难和MARL环境内在的高方差问题,提出一种结合分解集中批判与分散集成学习的全新算法。主要组件是一种选择性探索方法,利用集成峰度。通过扩展全局分解批判家,增加一个具有多样性正则化的个体批判家集合,并利用其超额峰度引导探索朝向高不确定性状态和行动。为提高样本效率,采用TD(λ)算法的截断变种训练集中批判家,实现有效的离线策略学习并降低方差。在行动者方面,建议的算法采用混合样本方法,混合在线策略和离线策略损失函数来训练行动者,在稳定性和效率之间取得平衡,并在标准MARL基准测试中优于现有技术。
Key Takeaways:
- 多智能体强化学习(MARL)在多种任务上表现优异,但需更多环境交互收敛。
- 面对大规模联合动作空间探索和内在高方差问题,提出结合分解集中批判与分散集成学习的新算法。
- 选择性探索方法利用集成峰度指导探索高不确定性状态和动作。
- 通过截断TD(λ)算法训练集中批判家,实现高效率的离线策略学习并降低方差。
- 行动者训练采用混合样本方法,平衡稳定性和效率。
- 新方法在标准MARL基准测试中表现优于现有技术。
- 该方法适用于各种SMAC II地图。
点此查看论文截图

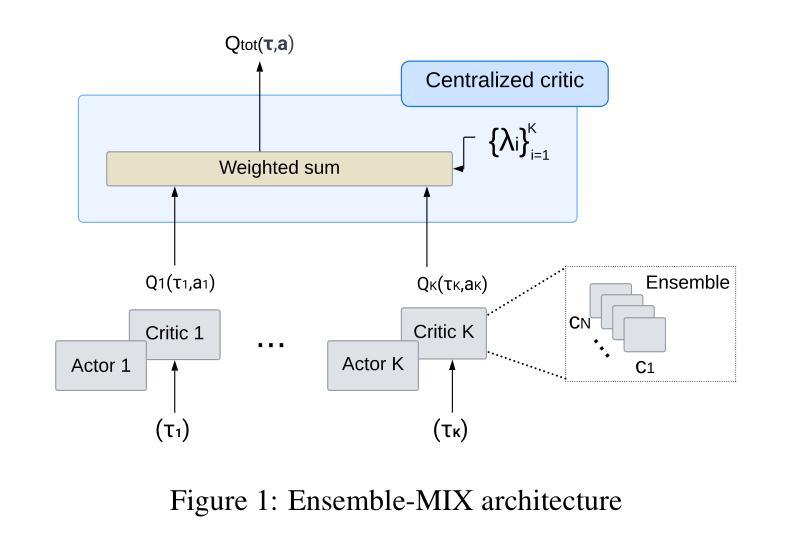
Heterogeneous Group-Based Reinforcement Learning for LLM-based Multi-Agent Systems
Authors:Guanzhong Chen, Shaoxiong Yang, Chao Li, Wei Liu, Jian Luan, Zenglin Xu
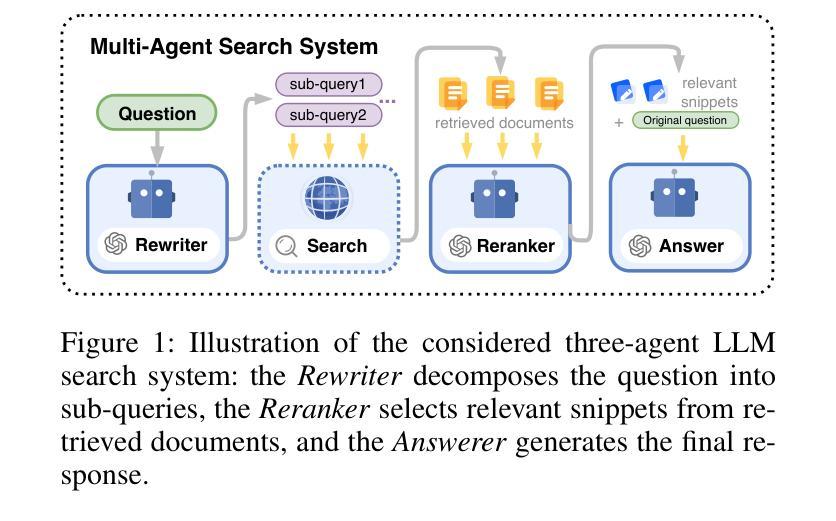
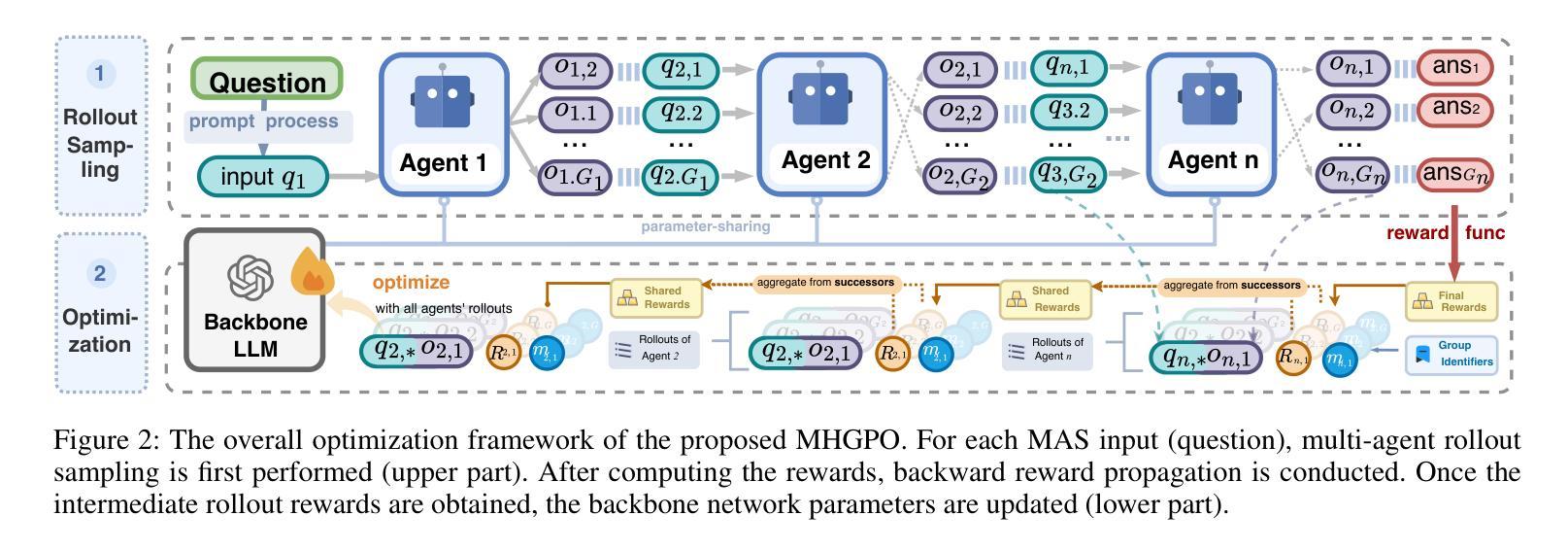
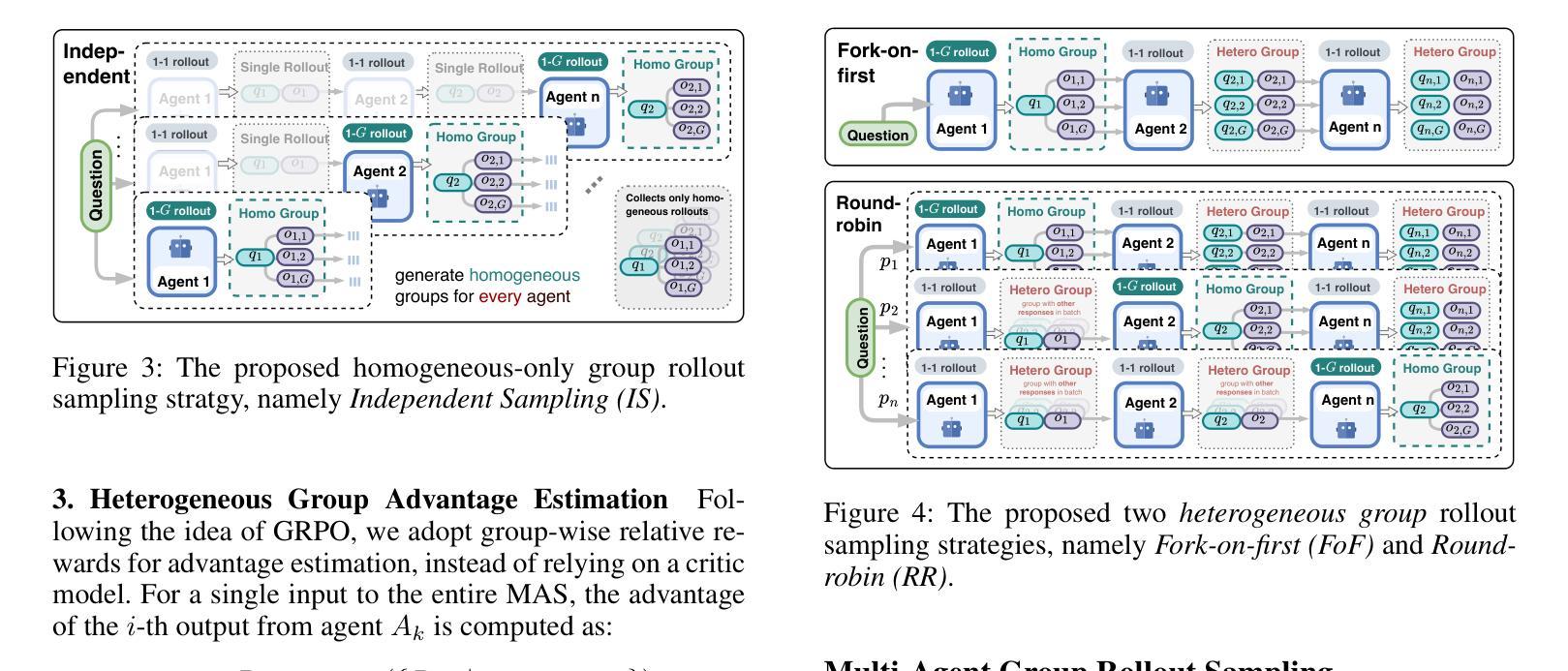
Large Language Models (LLMs) have achieved remarkable success across diverse natural language processing tasks, yet their deployment in real-world applications is hindered by fixed knowledge cutoffs and difficulties in generating controllable, accurate outputs in a single inference. Multi-agent systems (MAS) built from specialized LLM agents offer a promising solution, enabling dynamic collaboration and iterative reasoning. However, optimizing these systems remains a challenge, as conventional methods such as prompt engineering and supervised fine-tuning entail high engineering overhead and limited adaptability. Reinforcement learning (RL), particularly multi-agent reinforcement learning (MARL), provides a scalable framework by refining agent policies based on system-level feedback. Nevertheless, existing MARL algorithms, such as Multi-Agent Proximal Policy Optimization (MAPPO), rely on Critic networks, which can cause training instability and increase computational burden. To address these limitations and target the prototypical Multi-Agent Search System (MASS), we propose Multi-Agent Heterogeneous Group Policy Optimization (MHGPO), a novel Critic-free algorithm that guides policy updates by estimating relative reward advantages across heterogeneous groups of rollouts. MHGPO eliminates the need for Critic networks, enhancing stability and reducing computational overhead. Additionally, we introduce three group rollout sampling strategies that trade off between efficiency and effectiveness. Experiments on a multi-agent LLM-based search system demonstrate that MHGPO consistently outperforms MAPPO in both task performance and computational efficiency, without requiring warm-up, underscoring its potential for stable and scalable optimization of complex LLM-based MAS.
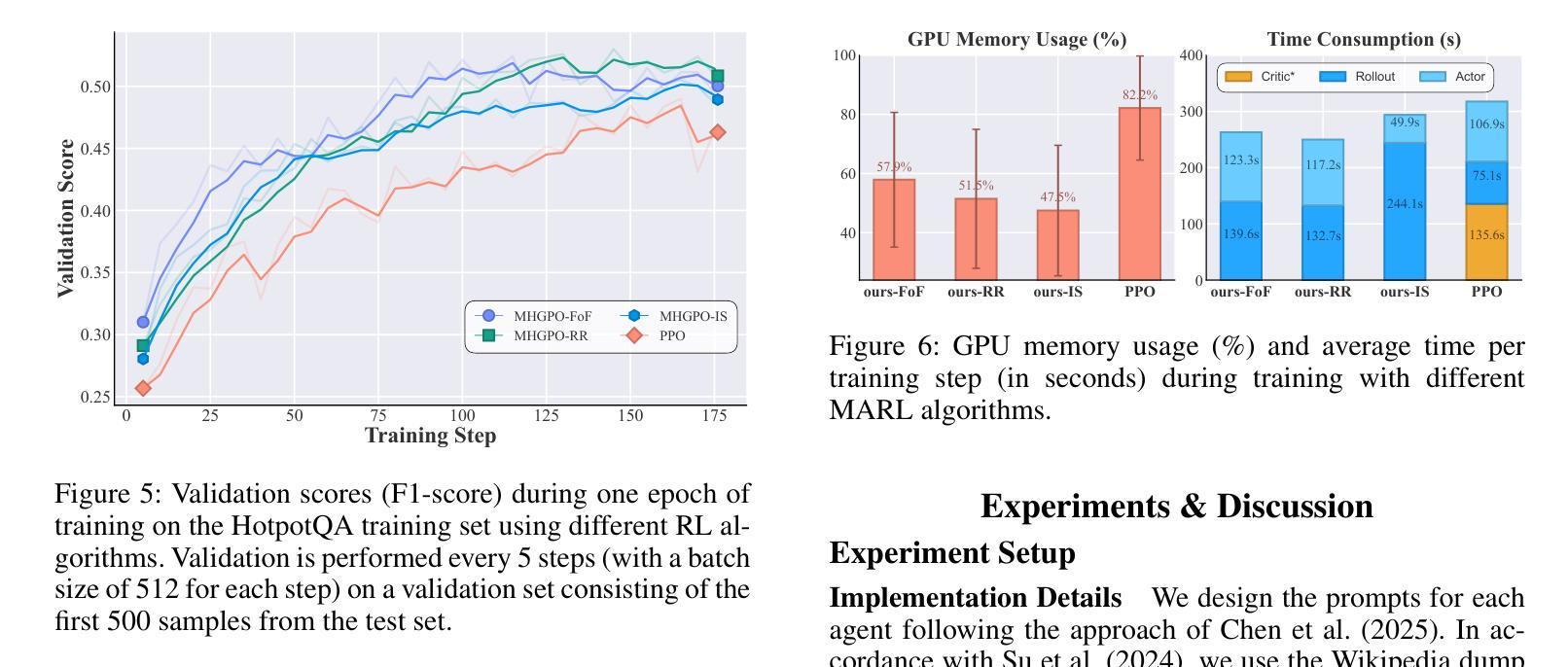
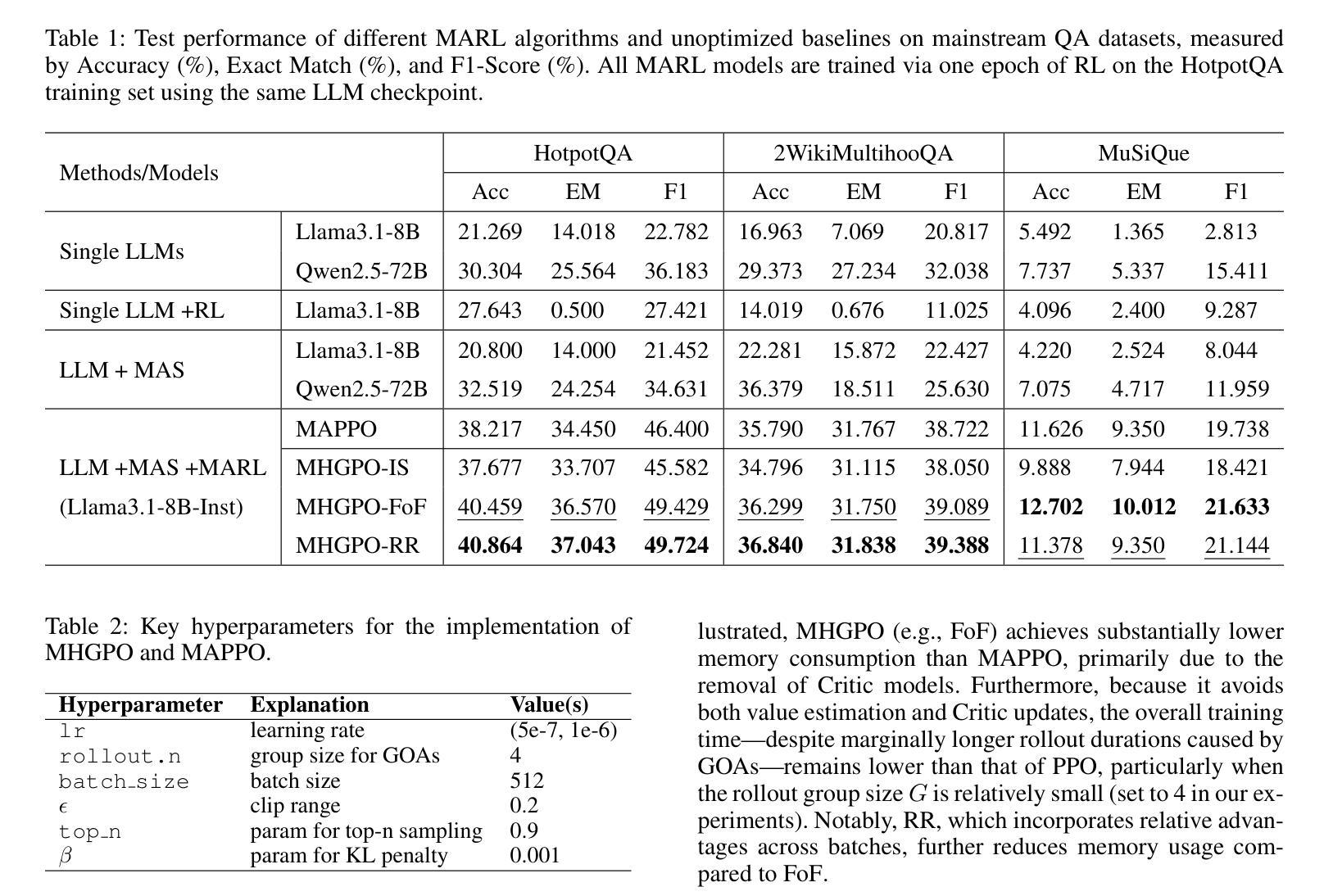
大型语言模型(LLM)在多种自然语言处理任务中取得了显著的成功,然而,它们在现实世界应用中的部署受到固定知识截止点和在单次推断中产生可控、准确输出困难的阻碍。由专业LLM代理构建的多代理系统(MAS)提供了有前景的解决方案,能够实现动态协作和迭代推理。然而,优化这些系统仍然是一个挑战,因为传统的方法,如提示工程和监督微调,涉及高昂的工程开销和有限的适应性。强化学习(RL),特别是多代理强化学习(MARL),提供了一个可扩展的框架,通过基于系统级反馈来优化代理策略。然而,现有的MARL算法,如多代理近端策略优化(MAPPO),依赖于评论家网络,可能导致训练不稳定并增加计算负担。为了解决这些局限性并面向典型的多代理搜索系统(MASS),我们提出了多代理异质群体策略优化(MHGPO),这是一种新型的无评论家算法,通过估计不同滚动组之间的相对奖励优势来指导策略更新。MHGPO消除了对评论家网络的需求,提高了稳定性并减少了计算开销。此外,我们介绍了三种群体滚动采样策略,在效率和效果之间寻求平衡。在多代理LLM搜索系统上的实验表明,MHGPO在任务性能和计算效率方面均持续优于MAPPO,且无需预热,突显其在稳定和可扩展的复杂LLM基于的MAS优化方面的潜力。
论文及项目相关链接
Summary
大型语言模型(LLM)在自然语言处理任务中取得了显著的成功,但其在现实世界应用中的部署受到了固定知识截断和难以生成可控、准确输出的限制。多智能体系统(MAS)由专业LLM智能体构建,提供了有前景的解决方案,可实现动态协作和迭代推理。然而,优化这些系统仍然是一个挑战。强化学习(RL),特别是多智能体强化学习(MARL),提供了一个可扩展的框架,通过基于系统级反馈来优化智能体策略。针对原型多智能体搜索系统(MASS),我们提出了无评论家的多智能体异质群体策略优化(MHGPO),这是一种新型算法,通过估计不同群体rollout的相对奖励优势来指导策略更新。实验证明,MHGPO在任务性能和计算效率方面均优于多智能体近端策略优化(MAPPO),突显其在复杂LLM基础MAS的稳定和可扩展优化方面的潜力。
Key Takeaways
- 大型语言模型(LLM)在自然语言处理任务中表现出色,但实际应用中存在固定知识截断和输出控制问题。
- 多智能体系统(MAS)通过动态协作和迭代推理提供了解决方案。
- 强化学习(RL)特别是多智能体强化学习(MARL)是优化多智能体系统的有前途的方法。
- 现有MARL算法如MAPPO存在训练不稳定和计算负担重的问题。
- 针对原型多智能体搜索系统(MASS),提出了无评论家的多智能体异质群体策略优化(MHGPO)。
- MHGPO通过估计不同群体rollout的相对奖励优势来指导策略更新,提高了稳定性和计算效率。
点此查看论文截图

CyberGym: Evaluating AI Agents’ Cybersecurity Capabilities with Real-World Vulnerabilities at Scale
Authors:Zhun Wang, Tianneng Shi, Jingxuan He, Matthew Cai, Jialin Zhang, Dawn Song
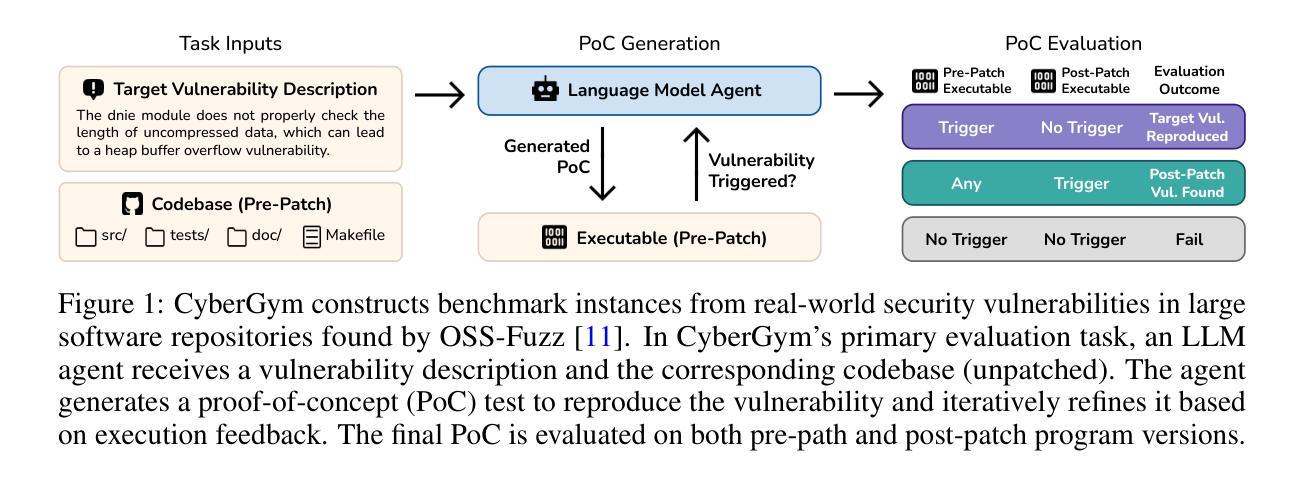
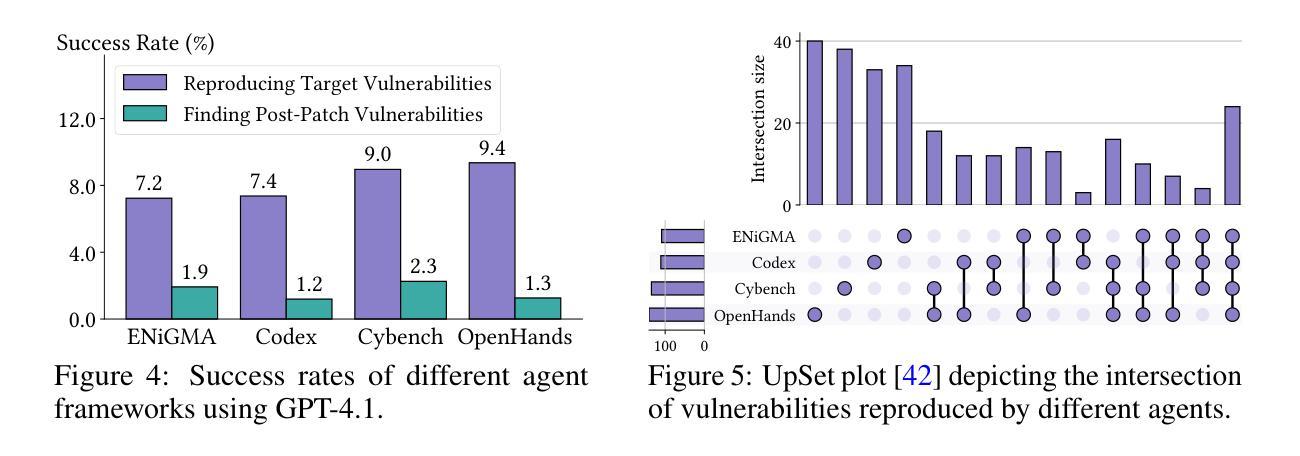
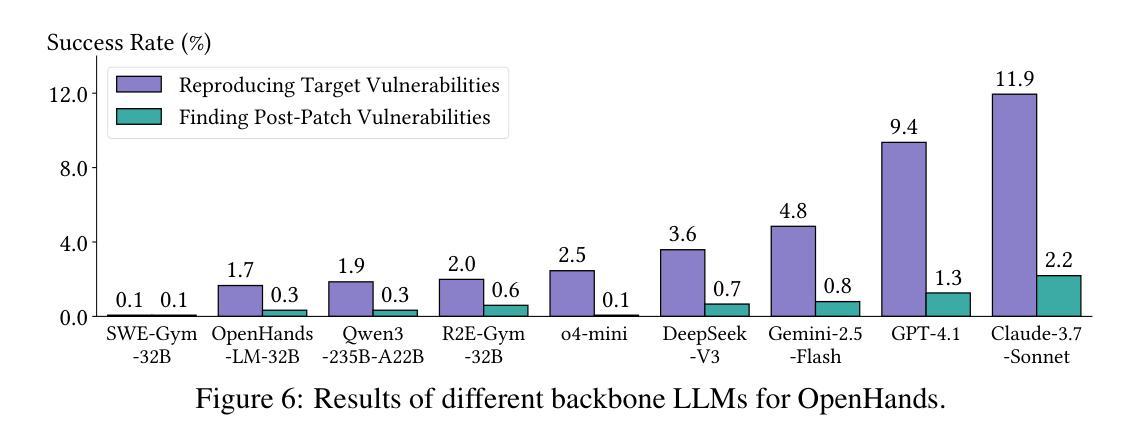
Large language model (LLM) agents are becoming increasingly skilled at handling cybersecurity tasks autonomously. Thoroughly assessing their cybersecurity capabilities is critical and urgent, given the high stakes in this domain. However, existing benchmarks fall short, often failing to capture real-world scenarios or being limited in scope. To address this gap, we introduce CyberGym, a large-scale and high-quality cybersecurity evaluation framework featuring 1,507 real-world vulnerabilities found and patched across 188 large software projects. While it includes tasks of various settings, CyberGym primarily focuses on the generation of proof-of-concept (PoC) tests for vulnerability reproduction, based on text descriptions and corresponding source repositories. Solving this task is particularly challenging, as it requires comprehensive reasoning across entire codebases to locate relevant code fragments and produce effective PoCs that accurately trigger the target vulnerability starting from the program’s entry point. Our evaluation across 4 state-of-the-art agent frameworks and 9 LLMs reveals that even the best combination (OpenHands and Claude-3.7-Sonnet) achieves only a 11.9% reproduction success rate, mainly on simpler cases. Beyond reproducing historical vulnerabilities, we find that PoCs generated by LLM agents can reveal new vulnerabilities, identifying 15 zero-days affecting the latest versions of the software projects.
大规模语言模型(LLM)代理在自主处理网络安全任务方面变得越来越熟练。鉴于这个领域的风险很高,全面评估他们的网络安全能力至关重要且紧迫。然而,现有的基准测试存在不足,通常无法捕捉真实场景或范围有限。为了弥补这一空白,我们引入了CyberGym,这是一个大规模、高质量的网络安全评估框架,包含188个大型软件项目中发现的1007个真实世界漏洞。虽然它包含了各种设置的任务,但CyberGym主要侧重于基于文本描述和相应源代码仓库的漏洞复现的概念验证(PoC)测试生成。解决这一任务特别具有挑战性,因为它需要全面推理整个代码库,以找到相关的代码片段并产生有效的PoC,从程序入口点准确触发目标漏洞。我们对4种最先进的代理框架和9种LLM的评估表明,即使是最佳组合(OpenHands和Claude-3.7-Sonnet)也仅达到11.9%的复现成功率,主要在较简单的情况下。除了复现历史漏洞外,我们发现LLM代理生成的PoC还可以揭示新的漏洞,识别出影响最新软件版本的15个零日漏洞。
论文及项目相关链接
Summary
大型语言模型(LLM)在处理网络安全任务方面的能力日益增强。当前亟需全面评估其网络安全能力,而现有评估标准存在不足。为此,本文提出CyberGym评估框架,包含大量真实世界中的网络安全漏洞,模拟各种环境下的任务。重点在于生成基于文本描述和对应源代码库的漏洞重现测试,这需要全面理解整个代码库并产生有效的攻击路径。初步评估显示,即使是最先进的LLM模型也仅能成功重现约四分之一的简单漏洞。同时,LLM生成的测试案例还可能揭示新的漏洞。
Key Takeaways
- 大型语言模型在网络安全领域的能力增强,需紧急进行全面评估。
- 当前网络安全评估标准存在局限性,无法充分反映真实场景。
- CyberGym框架包含大量真实世界漏洞数据,用于模拟不同环境下的任务。
- CyberGym重点在于生成基于文本描述和源代码库的漏洞重现测试。
- 生成这些测试需要全面理解代码库,并产生有效的攻击路径,任务极具挑战性。
- 初步评估显示,现有LLM模型仅能成功重现一小部分简单漏洞。
点此查看论文截图


AURA: Agentic Upskilling via Reinforced Abstractions
Authors:Alvin Zhu, Yusuke Tanaka, Dennis Hong
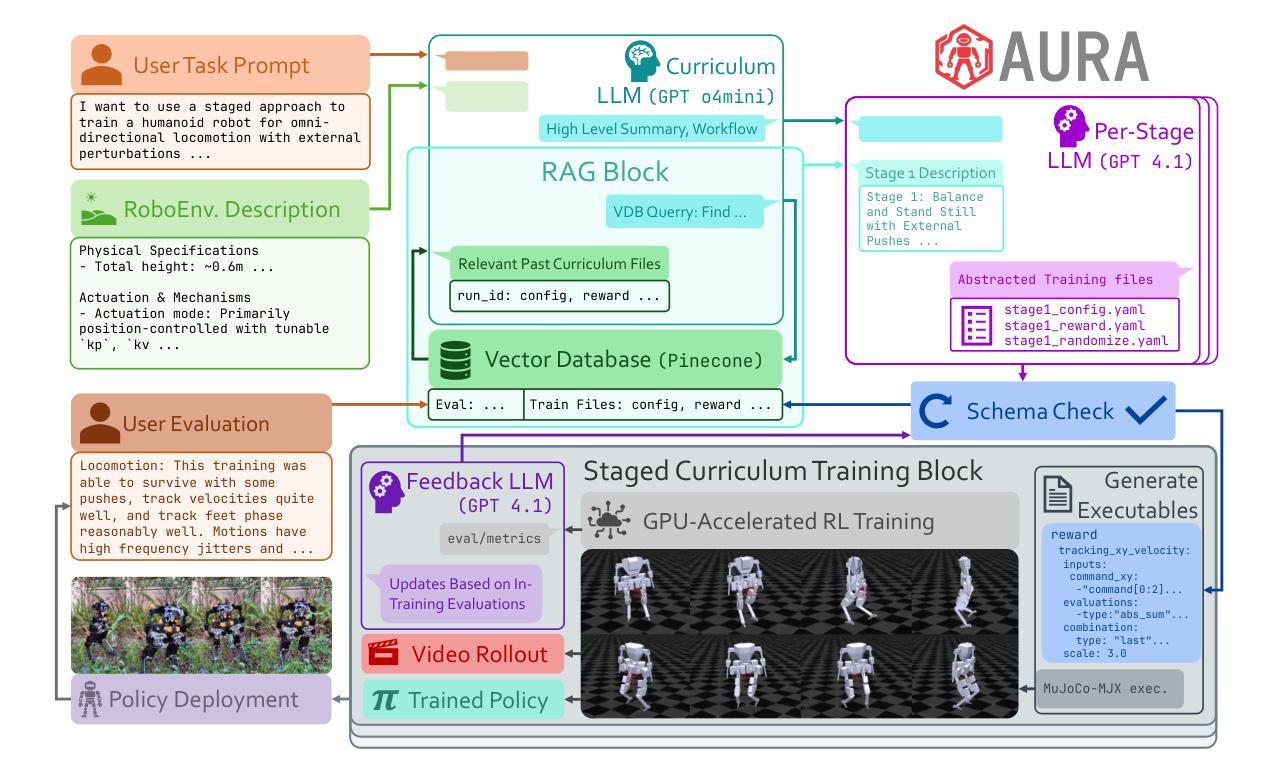
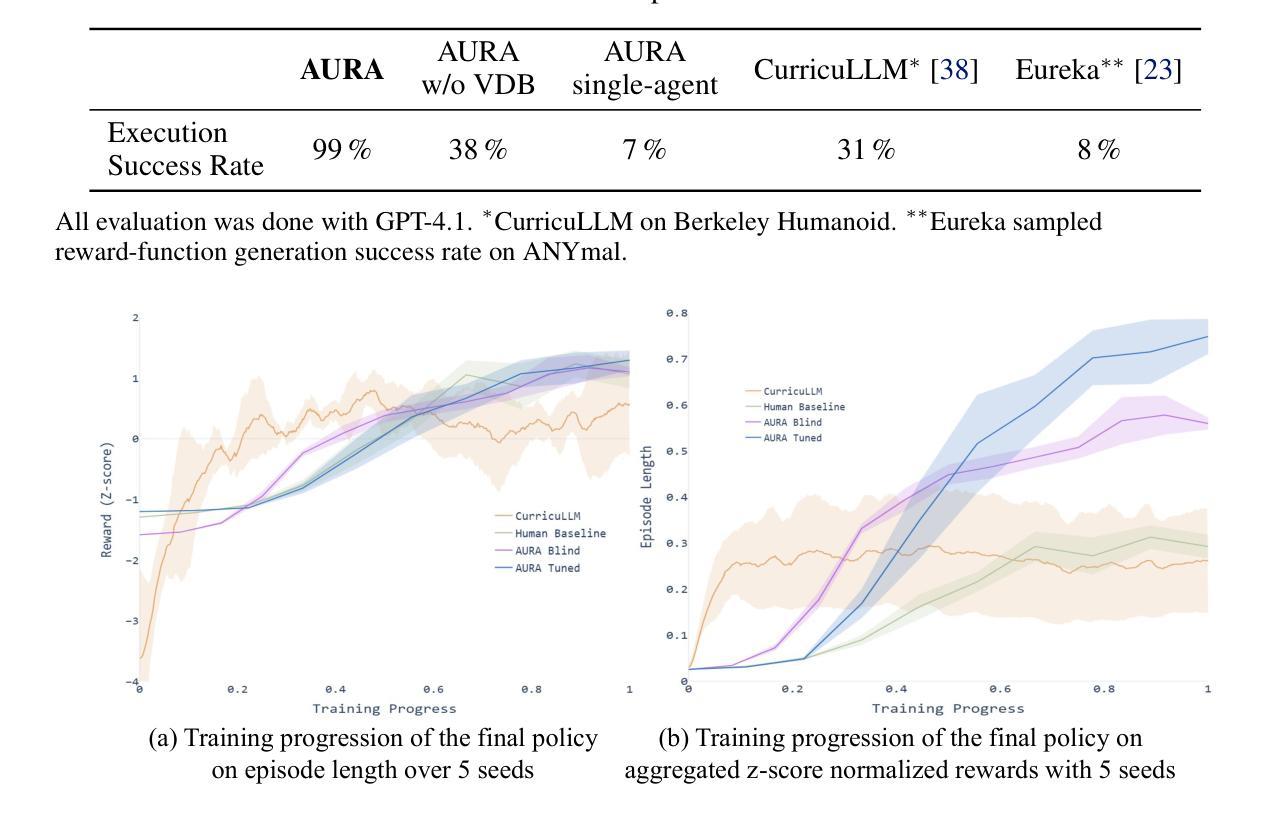
We study the combinatorial explosion involved in translating high-level task prompts into deployable control policies for agile robots through multi-stage reinforcement learning. We introduce AURA (Agentic Upskilling via Reinforced Abstractions), a schema-centric curriculum RL framework that leverages Large Language Models (LLMs) as autonomous designers of multi-stage curricula. AURA transforms user prompts into YAML workflows that encode full reward functions, domain randomization strategies, and training configurations. All files are statically validated against a schema before any GPU time is consumed, ensuring reliable and efficient execution without human intervention. A retrieval-augmented feedback loop allows specialized LLM agents to design, execute, and refine staged curricula based on prior training results stored in a vector database, supporting continual improvement over time. Ablation studies highlight the importance of retrieval for curriculum quality and convergence stability. Quantitative experiments show that AURA consistently outperforms LLM-guided baselines on GPU-accelerated training frameworks. In qualitative tests, AURA successfully trains end-to-end policies directly from user prompts and deploys them zero-shot on a custom humanoid robot across a range of environments. By abstracting away the complexity of curriculum design, AURA enables scalable and adaptive policy learning pipelines that would be prohibitively complex to construct by hand.
我们研究通过多阶段强化学习将高级任务提示翻译成可用于敏捷机器人的部署控制策略所涉及的组合爆炸问题。我们引入了AURA(通过强化抽象进行智能提升),这是一种以模式为中心的课程RL框架,它利用大型语言模型(LLM)作为多阶段课程的自主设计者。AURA将用户提示转换为YAML工作流程,这些流程编码了完整的奖励功能、领域随机化策略和培训配置。在所有文件消耗任何GPU时间之前,都会根据模式进行静态验证,确保无需人工干预即可实现可靠和高效的执行。检索增强的反馈循环允许专门的LLM代理根据存储在向量数据库中的先前训练结果设计、执行和细化分阶段课程,支持随时间持续改进。消融研究突出了检索对课程质量和收敛稳定的重要性。定量实验表明,AURA在GPU加速培训框架上的表现始终优于LLM引导的基础线。在定性测试中,AURA能够直接从用户提示训练端到端策略,并将其零射到一系列环境中的自定义人形机器人上。通过抽象复杂的课程设计,AURA实现了可扩展和自适应的策略学习管道,这些管道手工构建过于复杂。
论文及项目相关链接
Summary
本文研究了通过多阶段强化学习将高级任务提示转化为可部署的敏捷机器人控制策略的组合爆炸问题。引入了以架构为中心的强化学习框架AURA,该框架利用大型语言模型作为自主设计多阶段课程的设计师。AURA将用户提示转换为YAML工作流程,编码完整的奖励功能、领域随机化策略和培训配置。所有文件在消耗任何GPU时间之前都会根据架构进行静态验证,以确保无需人工干预即可实现可靠和高效的执行。一个检索增强的反馈循环允许专门的LLM代理根据存储在向量数据库中的先前训练结果来设计、执行和细化分阶段课程,从而支持随着时间的推移持续改进。消融研究突出了检索对课程质量和收敛稳定的重要性。定量实验表明,AURA在GPU加速的培训框架上始终优于LLM指导的基线。在定性测试中,AURA成功地直接从用户提示训练端到端策略,并零射击部署在自定义人形机器人上,覆盖各种环境。通过抽象复杂的课程设计,AURA使构建的手动政策学习管道更具可扩展性和适应性。
Key Takeaways
- AURA是一个利用大型语言模型作为自主设计多阶段课程设计师的架构为中心的课程强化学习框架。
- AURA能将用户提示转化为YAML工作流程,包括奖励功能、领域随机化策略和培训配置。
- AURA通过静态验证确保文件可靠性,并能高效执行,无需人工干预。
- 检索增强的反馈循环允许LLM代理根据先前的训练结果来设计、执行和细化课程,支持持续改进。
- 消融研究突出了检索在课程质量和收敛稳定性中的重要性。
- 定量实验显示,AURA在GPU加速的培训框架上的表现优于LLM指导的基线。
点此查看论文截图

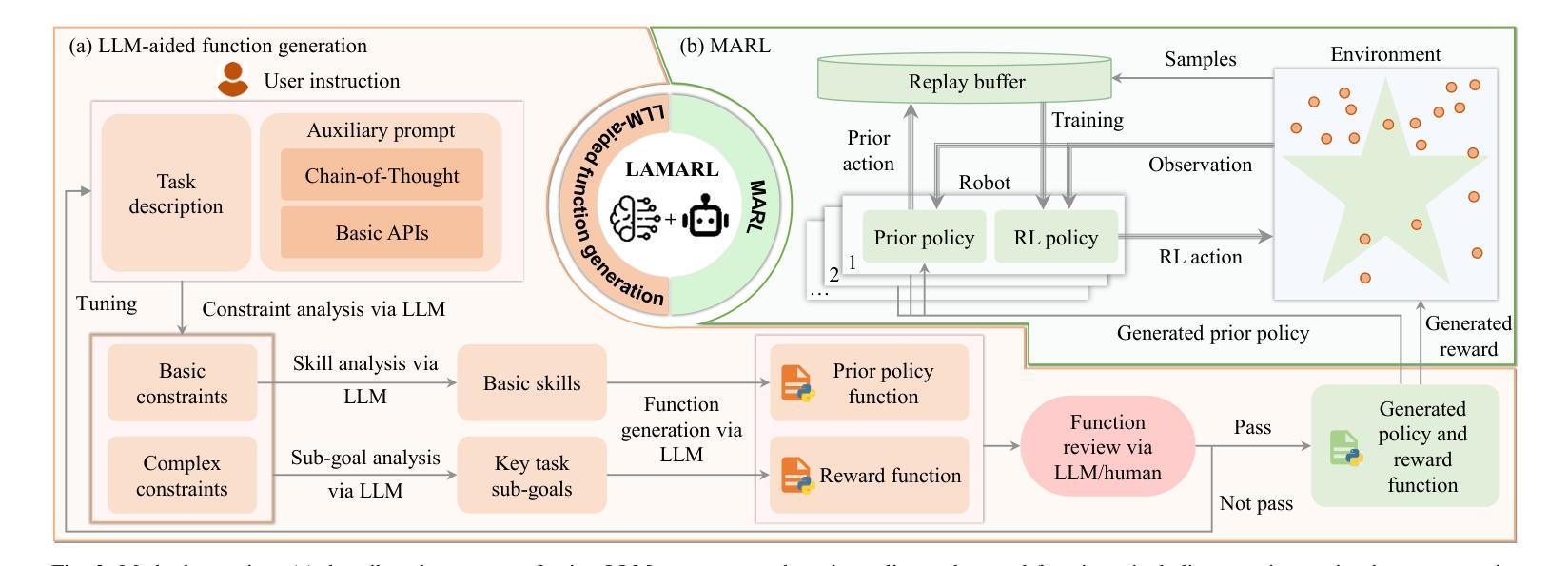
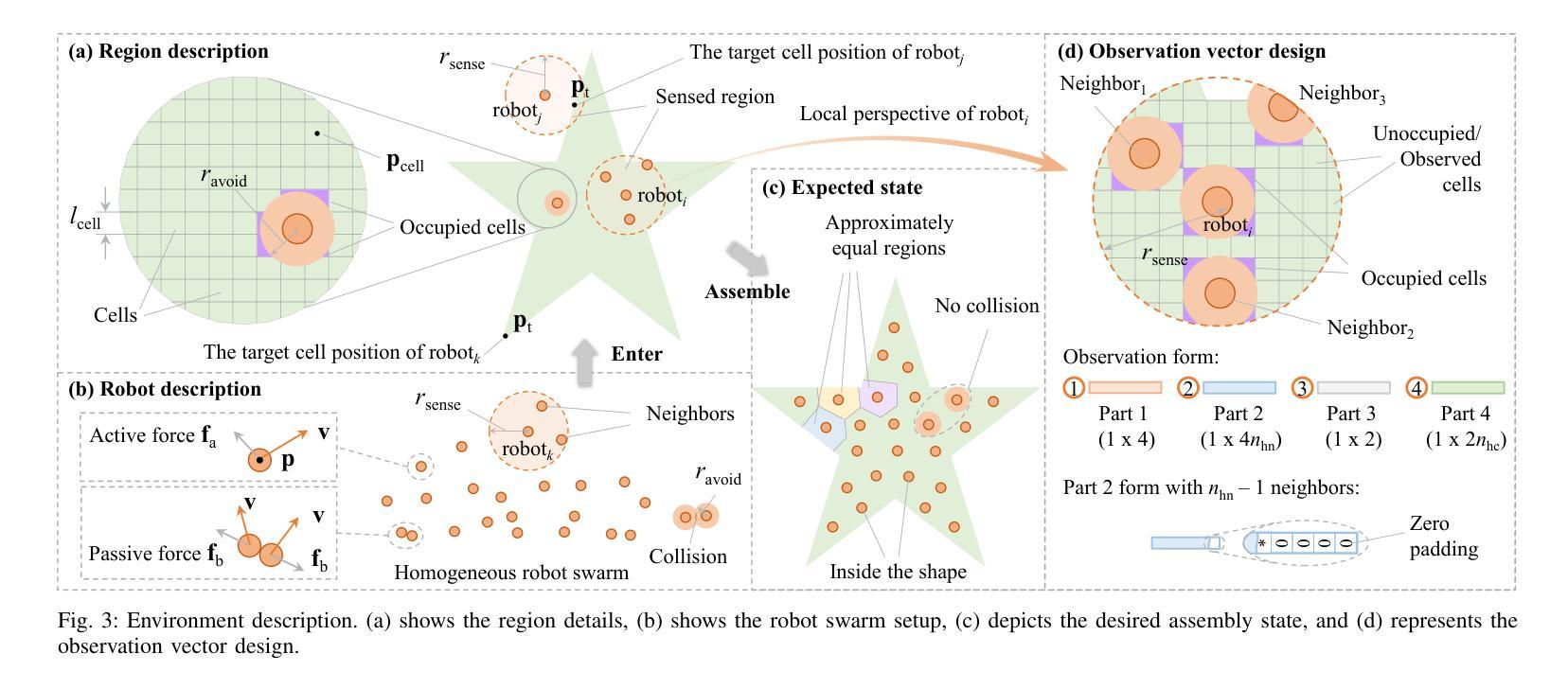
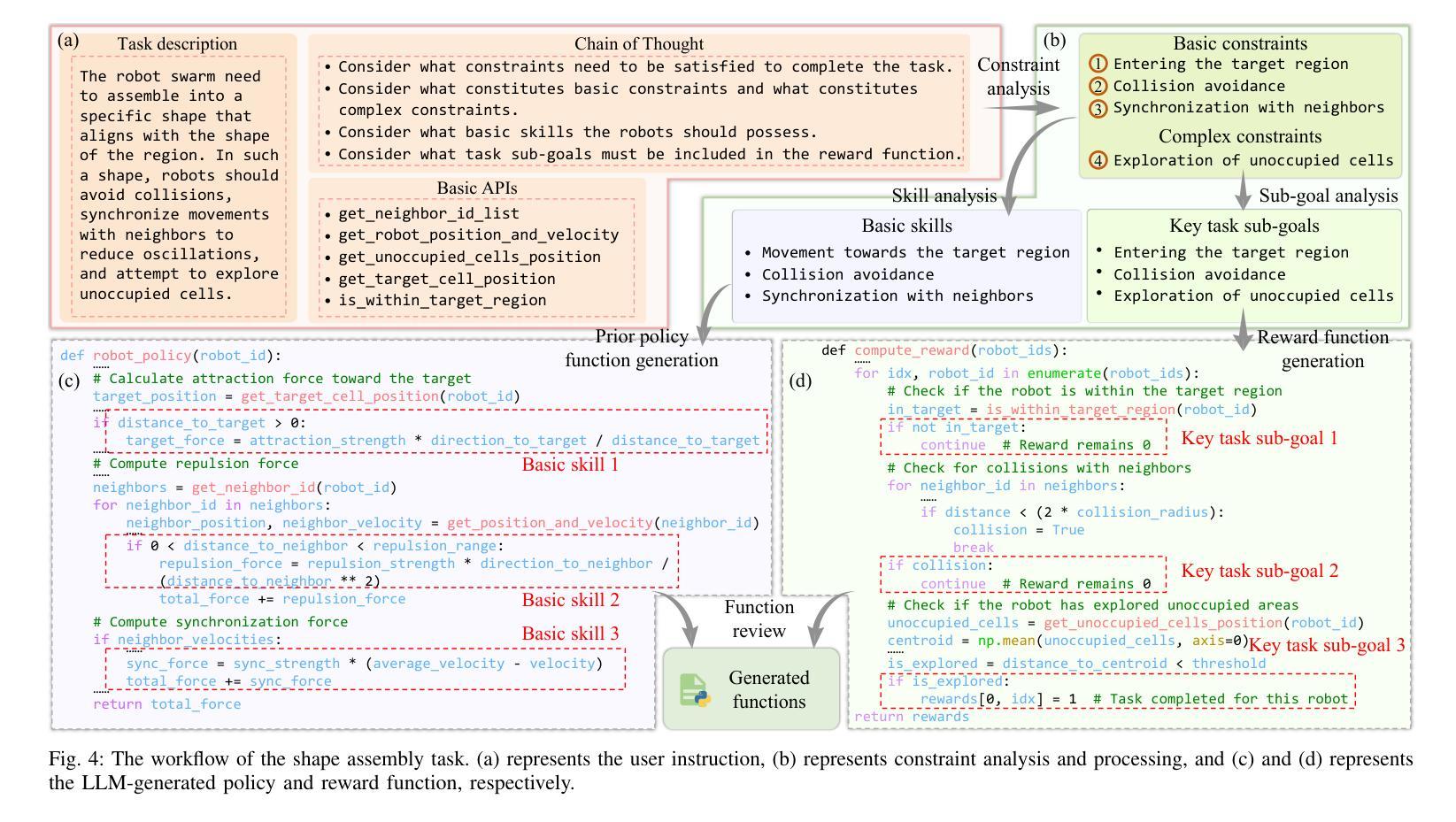
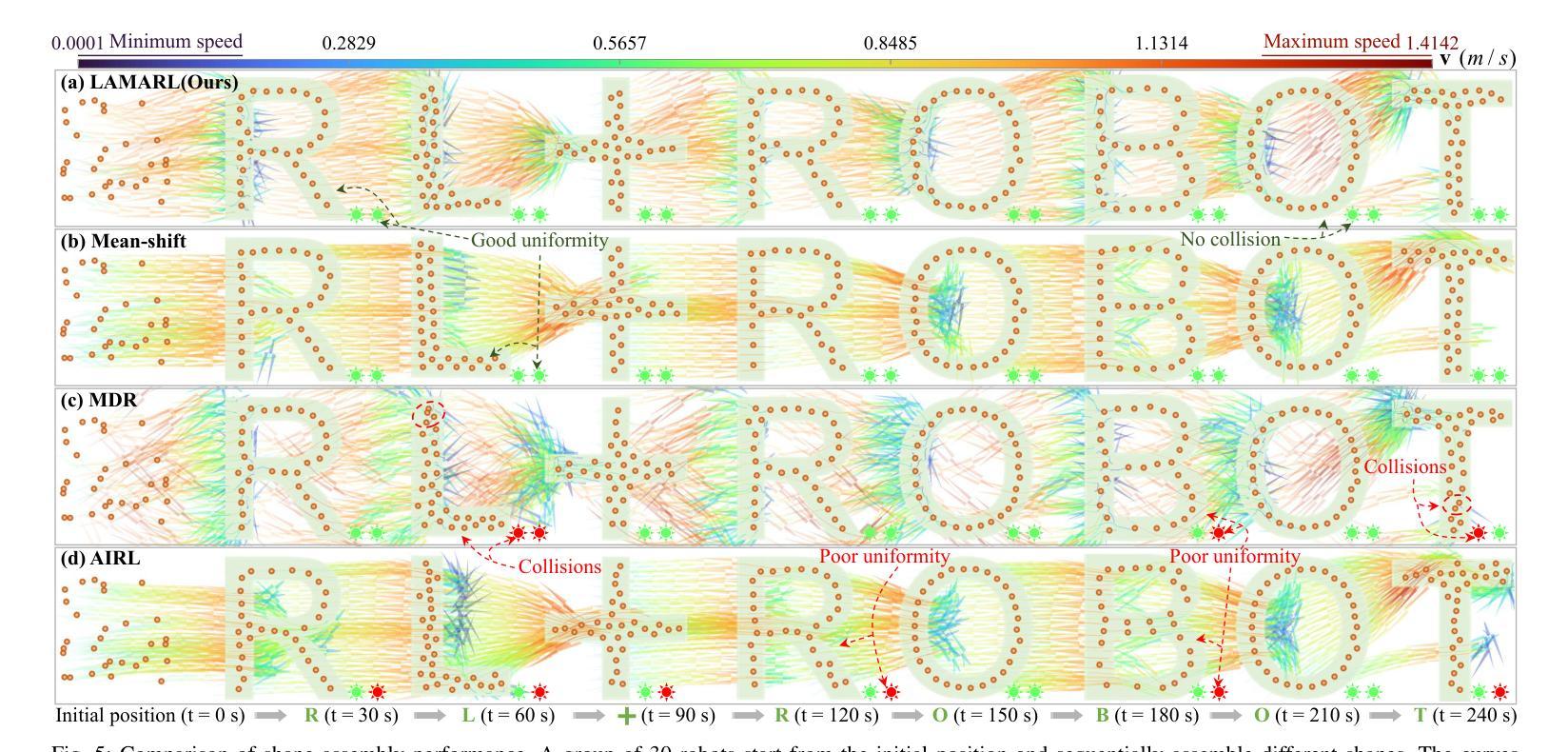
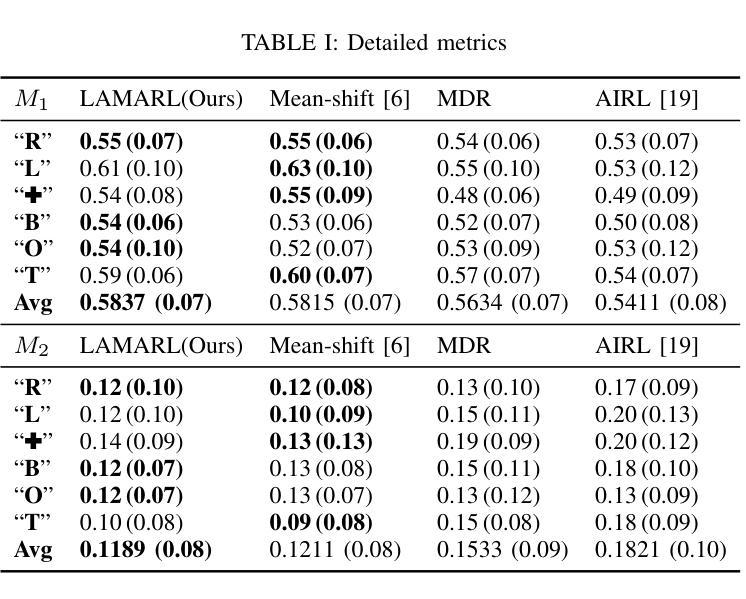
LAMARL: LLM-Aided Multi-Agent Reinforcement Learning for Cooperative Policy Generation
Authors:Guobin Zhu, Rui Zhou, Wenkang Ji, Shiyu Zhao
Although Multi-Agent Reinforcement Learning (MARL) is effective for complex multi-robot tasks, it suffers from low sample efficiency and requires iterative manual reward tuning. Large Language Models (LLMs) have shown promise in single-robot settings, but their application in multi-robot systems remains largely unexplored. This paper introduces a novel LLM-Aided MARL (LAMARL) approach, which integrates MARL with LLMs, significantly enhancing sample efficiency without requiring manual design. LAMARL consists of two modules: the first module leverages LLMs to fully automate the generation of prior policy and reward functions. The second module is MARL, which uses the generated functions to guide robot policy training effectively. On a shape assembly benchmark, both simulation and real-world experiments demonstrate the unique advantages of LAMARL. Ablation studies show that the prior policy improves sample efficiency by an average of 185.9% and enhances task completion, while structured prompts based on Chain-of-Thought (CoT) and basic APIs improve LLM output success rates by 28.5%-67.5%. Videos and code are available at https://windylab.github.io/LAMARL/
尽管多智能体强化学习(Multi-Agent Reinforcement Learning,简称MARL)对于复杂的多机器人任务非常有效,但它存在样本效率低的问题,并且需要迭代的手动奖励调整。大型语言模型(Large Language Models,简称LLMs)在单机器人环境中显示出潜力,但它们在多机器人系统中的应用仍然在很大程度上未被探索。本文介绍了一种新型的LLM辅助MARL(LAMARL)方法,该方法将MARL与LLMs相结合,显著提高了样本效率,且无需手动设计。LAMARL由两个模块组成:第一个模块利用LLMs完全自动化生成先验策略和奖励功能。第二个模块是MARL,它使用生成的函数有效地引导机器人策略训练。在形状组装基准测试上,仿真和真实世界的实验都证明了LAMARL的独特优势。消融研究表明,先验策略平均提高了185.9%的样本效率,并提高了任务完成率,而基于思维链(Chain-of-Thought,简称CoT)和基本API的结构化提示提高了LLM输出成功率28.5%-67.5%。相关视频和代码可通过https://windylab.github.io/LAMARL/查看。
论文及项目相关链接
PDF Accepted by IEEE Robotics and Automation Letters
Summary
本论文提出了一种新型的LLMARL(大型语言模型辅助的多智能体强化学习)方法,该方法结合了多智能体强化学习(MARL)与大型语言模型(LLMs),显著提高了样本效率,且无需手动设计。LLMARL包含两个模块:第一个模块利用LLMs自动生成先验策略和奖励函数;第二个模块是MARL,使用生成的函数有效地引导机器人策略训练。在形状组装基准测试中,无论是在模拟还是真实世界实验中,LLMARL都展现出独特优势。
Key Takeaways
- LLMARL成功将多智能体强化学习(MARL)与大型语言模型(LLMs)结合,提高了处理复杂多机器人任务的效果。
- LLMARL包含两个模块:第一个模块能自动生成先验策略和奖励函数,显著提高了样本效率并且无需手动设计。
- 在形状组装基准测试中,无论是在模拟环境还是真实世界,LLMARL都表现出了卓越的性能。
- 消融研究显示,先验策略能平均提高样本效率185.9%,并提升任务完成率。
- 基于Chain-of-Thought(CoT)的结构提示和基本API能提升LLM输出成功率28.5%-67.5%。
- LLMARL方法通过整合LLMs的智能和MARL的效能,为机器人技术开辟了新的可能。
点此查看论文截图

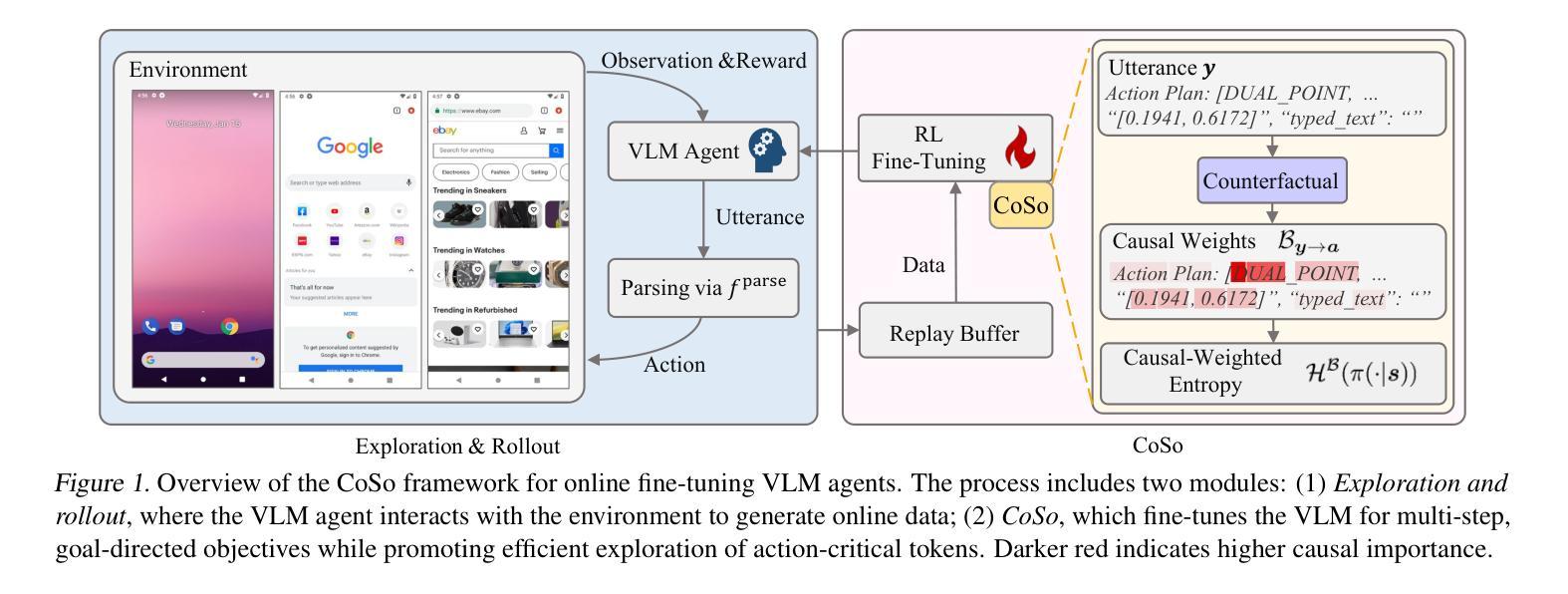
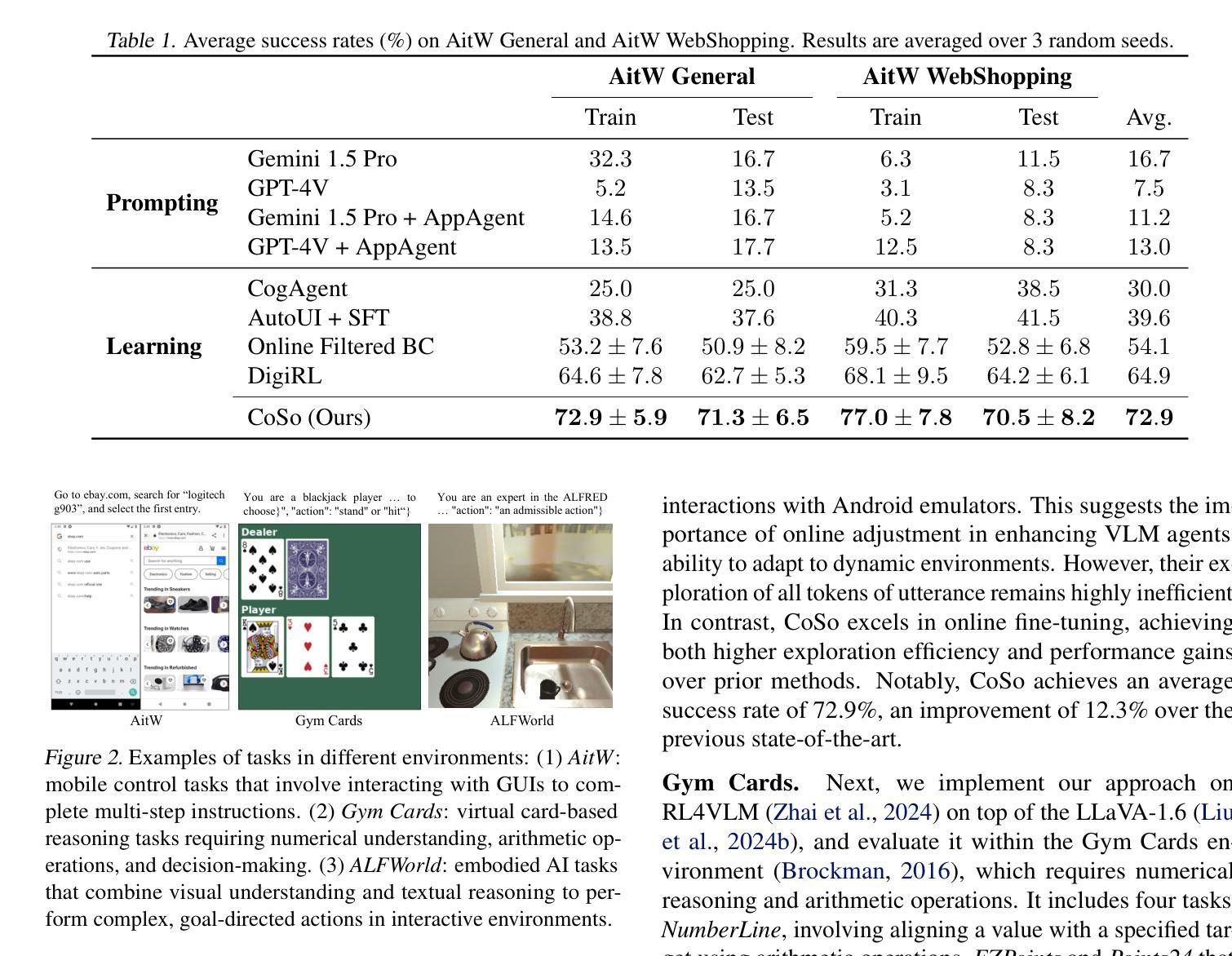
Towards Efficient Online Tuning of VLM Agents via Counterfactual Soft Reinforcement Learning
Authors:Lang Feng, Weihao Tan, Zhiyi Lyu, Longtao Zheng, Haiyang Xu, Ming Yan, Fei Huang, Bo An
Online fine-tuning vision-language model (VLM) agents with reinforcement learning (RL) has shown promise for equipping agents with multi-step, goal-oriented capabilities in dynamic environments. However, their open-ended textual action space and non-end-to-end nature of action generation present significant challenges to effective online exploration in RL, e.g., explosion of the exploration space. We propose a novel online fine-tuning method, Counterfactual Soft Reinforcement Learning (CoSo), better suited to the textual output space of VLM agents. Compared to prior methods that assign uniform uncertainty to all tokens, CoSo leverages counterfactual reasoning to dynamically assess the causal influence of individual tokens on post-processed actions. By prioritizing the exploration of action-critical tokens while reducing the impact of semantically redundant or low-impact tokens, CoSo enables a more targeted and efficient online rollout process. We provide theoretical analysis proving CoSo’s convergence and policy improvement guarantees, and extensive empirical evaluations supporting CoSo’s effectiveness. Our results across a diverse set of agent tasks, including Android device control, card gaming, and embodied AI, highlight its remarkable ability to enhance exploration efficiency and deliver consistent performance gains. The code is available at https://github.com/langfengQ/CoSo.
使用强化学习(RL)在线微调视觉语言模型(VLM)代理,在动态环境中为代理装备多步骤、以目标为导向的能力,显示出巨大的潜力。然而,其开放式的文本动作空间以及动作生成的非端到端特性,为强化学习中的有效在线探索带来了重大挑战,例如探索空间的爆炸式增长。我们提出了一种新型的在线微调方法——因果软强化学习(CoSo),更适合于VLM代理的文本输出空间。与先前为所有令牌分配统一不确定性的方法相比,CoSo利用反事实推理来动态评估单个令牌对后处理动作的影响。通过优先探索动作关键的令牌,同时减少语义上冗余或影响较小的令牌的影响,CoSo能够实现更有针对性和高效的在线滚动过程。我们提供了理论分析,证明了CoSo的收敛性和策略改进保证,以及大量实证评估支持CoSo的有效性。我们的结果在多种代理任务中得到体现,包括安卓设备控制、卡牌游戏和实体AI,凸显了其在提高探索效率和带来持续性能提升方面的显著能力。代码可通过https://github.com/langfengQ/CoSo获取。
论文及项目相关链接
PDF ICML 2025
Summary
在线微调具备视觉语言模型(VLM)的强化学习(RL)智能体展现出多步骤、目标导向的能力,但在动态环境中面临重大挑战,如行动空间的开放性以及非端到端的行动生成特性带来的探索空间爆炸问题。为此,我们提出了一种新型的在线微调方法——Counterfactual Soft Reinforcement Learning(CoSo),更适合于VLM智能体的文本输出空间。相较于以往为所有token分配均匀不确定性的方法,CoSo利用反事实推理动态评估个体token对后处理行动的影响。通过优先探索对行动至关重要的token,同时减少语义上冗余或影响较小的token的影响,CoSo能够实现更有针对性的高效在线滚动过程。我们提供了理论分析和对CoSo有效性的广泛实证评估,证明其在多种智能体任务中的出色表现,包括安卓设备控制、卡牌游戏和嵌入式人工智能等。代码已公开在:https://github.com/langfengQ/CoSo。
Key Takeaways
- 在线微调具备视觉语言模型的强化学习智能体在动态环境中展现出多步骤、目标导向的能力。
- 反事实软强化学习(CoSo)是解决行动空间开放性及非端到端行动生成问题的新型在线微调方法。
- CoSo通过优先探索对行动至关重要的token,实现更有针对性的高效在线滚动过程。
- CoSo的理论分析和广泛实证评估证明了其在多种智能体任务中的有效性。
- CoSo适用于安卓设备控制、卡牌游戏和嵌入式人工智能等多种任务类型。
- CoSo方法能提高探索效率和智能体的性能表现。
点此查看论文截图


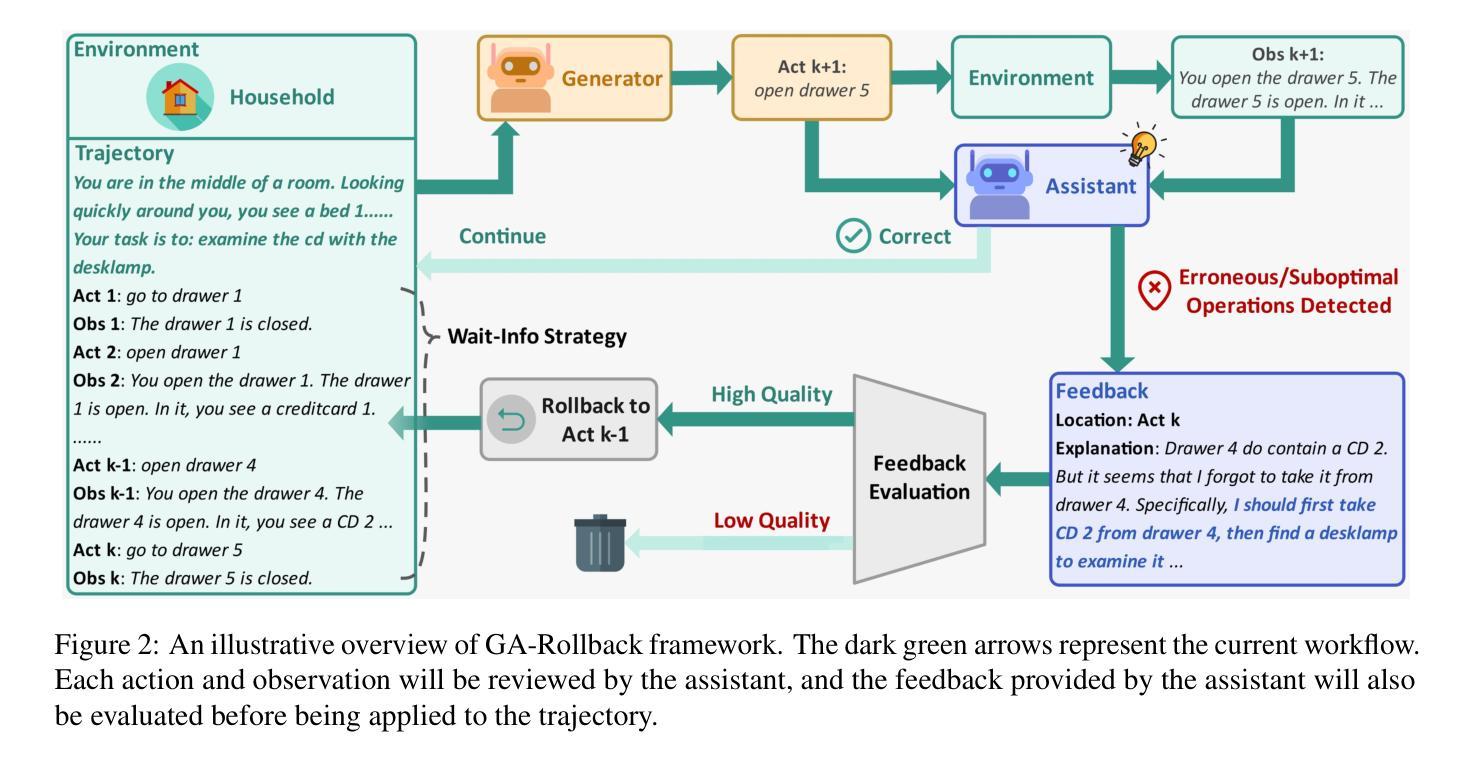
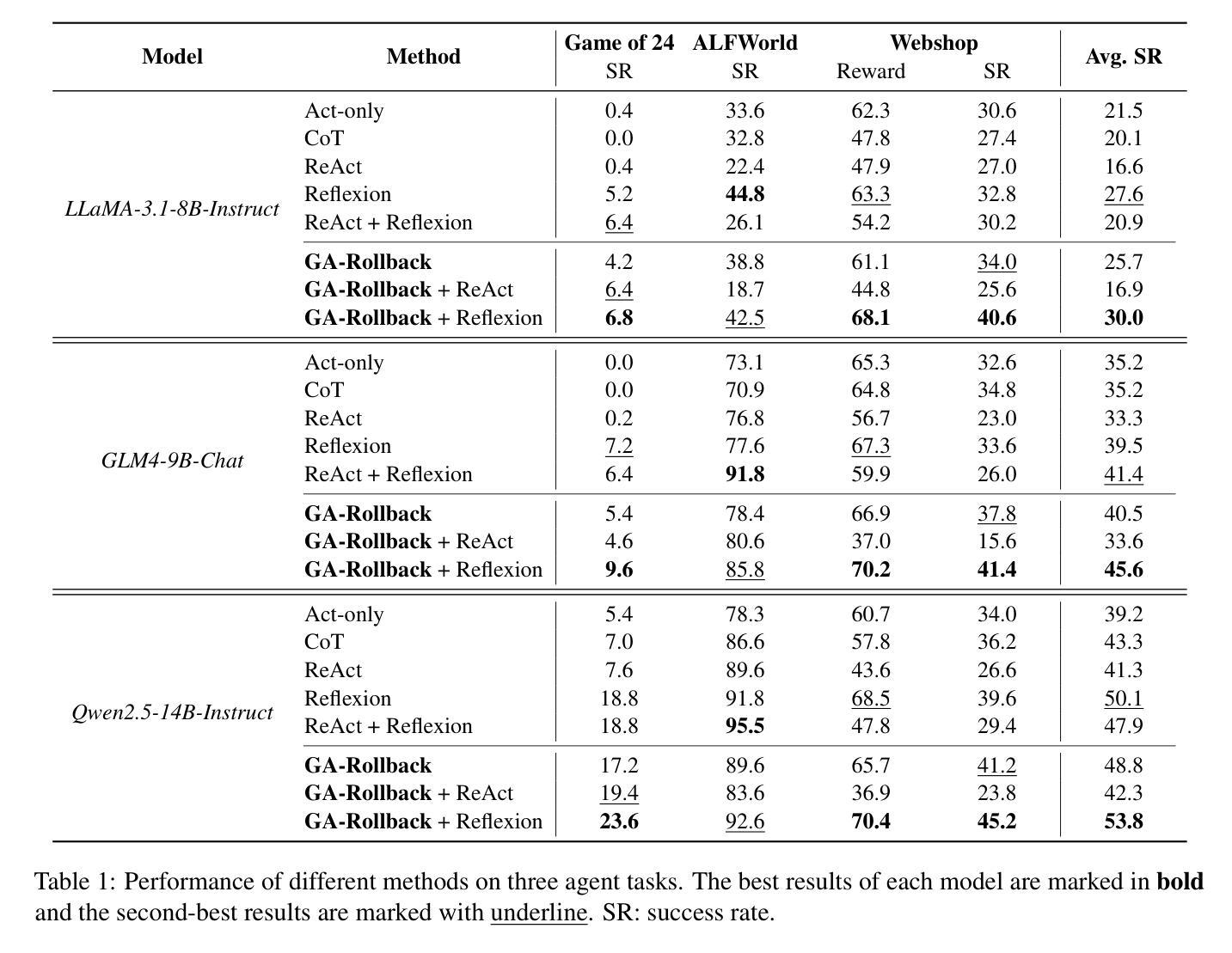
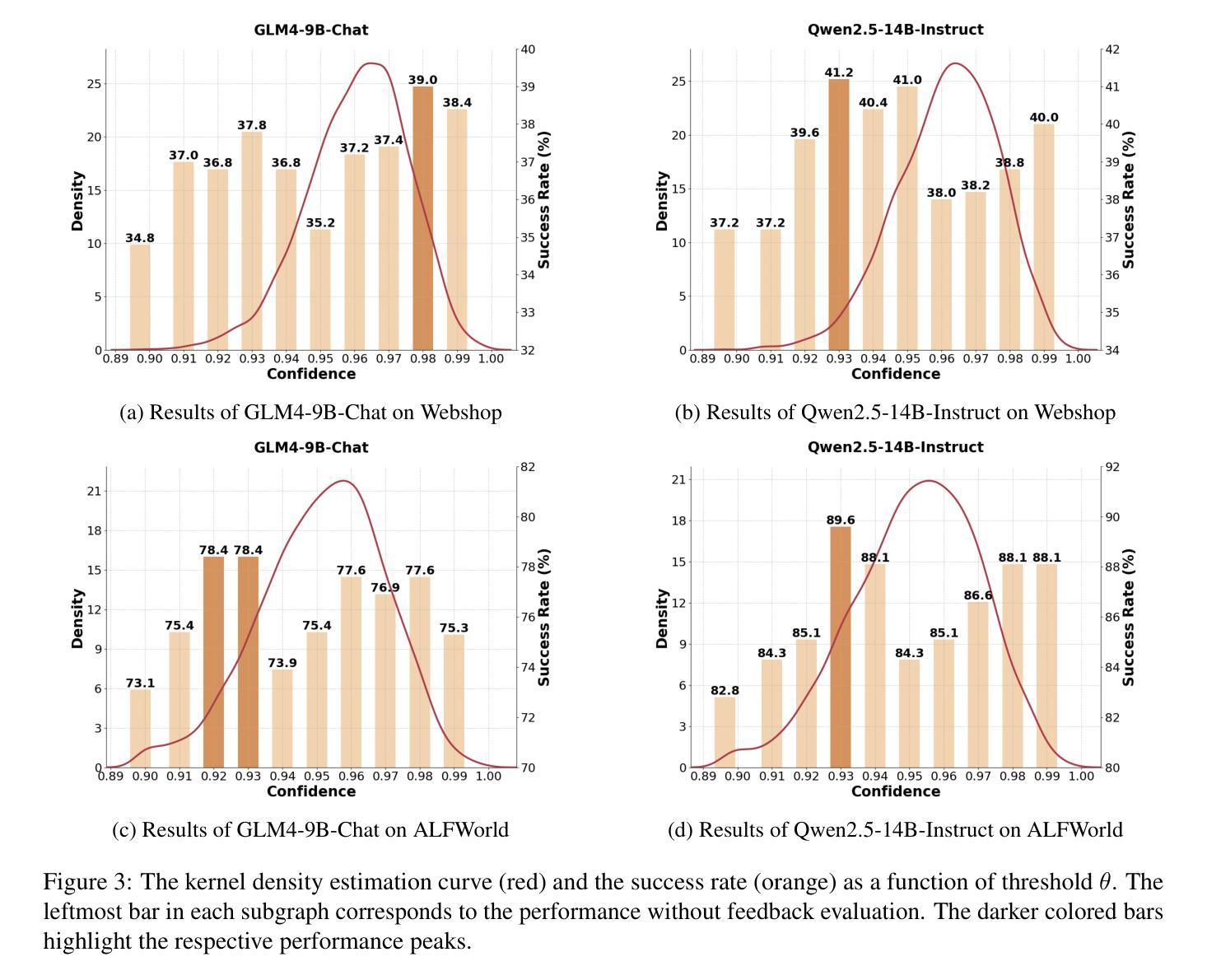
Generator-Assistant Stepwise Rollback Framework for Large Language Model Agent
Authors:Xingzuo Li, Kehai Chen, Yunfei Long, Xuefeng Bai, Yong Xu, Min Zhang
Large language model (LLM) agents typically adopt a step-by-step reasoning framework, in which they interleave the processes of thinking and acting to accomplish the given task. However, this paradigm faces a deep-rooted one-pass issue whereby each generated intermediate thought is plugged into the trajectory regardless of its correctness, which can cause irreversible error propagation. To address the issue, this paper proposes a novel framework called Generator-Assistant Stepwise Rollback (GA-Rollback) to induce better decision-making for LLM agents. Particularly, GA-Rollback utilizes a generator to interact with the environment and an assistant to examine each action produced by the generator, where the assistant triggers a rollback operation upon detection of incorrect actions. Moreover, we introduce two additional strategies tailored for the rollback scenario to further improve its effectiveness. Extensive experiments show that GA-Rollback achieves significant improvements over several strong baselines on three widely used benchmarks. Our analysis further reveals that GA-Rollback can function as a robust plug-and-play module, integrating seamlessly with other methods.
大型语言模型(LLM)代理通常采用一种逐步推理框架,在该框架中,它们将思考和行动的过程交织在一起,以完成给定的任务。然而,这种范式面临一个根深蒂固的一次性通过问题,即无论中间想法的正确与否,都会将其插入轨迹中,这可能导致不可逆的错误传播。为了解决这一问题,本文提出了一种名为生成器辅助逐步回滚(GA-Rollback)的新型框架,以诱导LLM代理做出更好的决策。特别是,GA-Rollback使用一个生成器与环境进行交互,并使用一个助理来检查生成器产生的每个动作,当检测到不正确的动作时,助理会触发回滚操作。此外,我们还引入了两种针对回滚场景的额外策略,以进一步提高其有效性。大量实验表明,在三个广泛使用的基准测试中,GA-Rollback相对于几个强大的基准测试实现了显著改进。我们的分析还表明,GA-Rollback可以作为一个强大的即插即用模块无缝集成到其他方法中。
论文及项目相关链接
Summary
大型语言模型(LLM)通常采用逐步推理框架完成任务,但存在一次通过问题,可能导致错误不可逆传播。为解决此问题,本文提出一种名为Generator-Assistant Stepwise Rollback(GA-Rollback)的新型框架,以更好地为LLM代理做出决策。GA-Rollback利用生成器与环境交互,并使用助理检查生成器的每个动作。当检测到错误动作时,助理会触发回滚操作。此外,我们为回滚场景引入两种策略以提高其有效性。实验表明,GA-Rollback在广泛使用的三个基准测试上较其他强基线有显著改善。分析还表明,GA-Rollback可作为一个稳健的即插即用模块与其他方法无缝集成。
Key Takeaways
- 大型语言模型(LLM)在逐步推理过程中存在一次通过问题,可能导致错误不可逆传播。
- GA-Rollback框架旨在解决LLM中的这一问题,通过生成器与环境交互,并利用助理检查每个动作的正确性。
- 当检测到错误动作时,GA-Rollback会触发回滚操作,避免错误继续传播。
- 引入两种策略以提高回滚操作的有效性。
- 实验表明,GA-Rollback在多个基准测试上较其他方法表现更优。
- GA-Rollback具有广泛的适用性,可与其他方法无缝集成。
点此查看论文截图