⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-05 更新
TAH-QUANT: Effective Activation Quantization in Pipeline Parallelism over Slow Network
Authors:Guangxin He, Yuan Cao, Yutong He, Tianyi Bai, Kun Yuan, Binhang Yuan
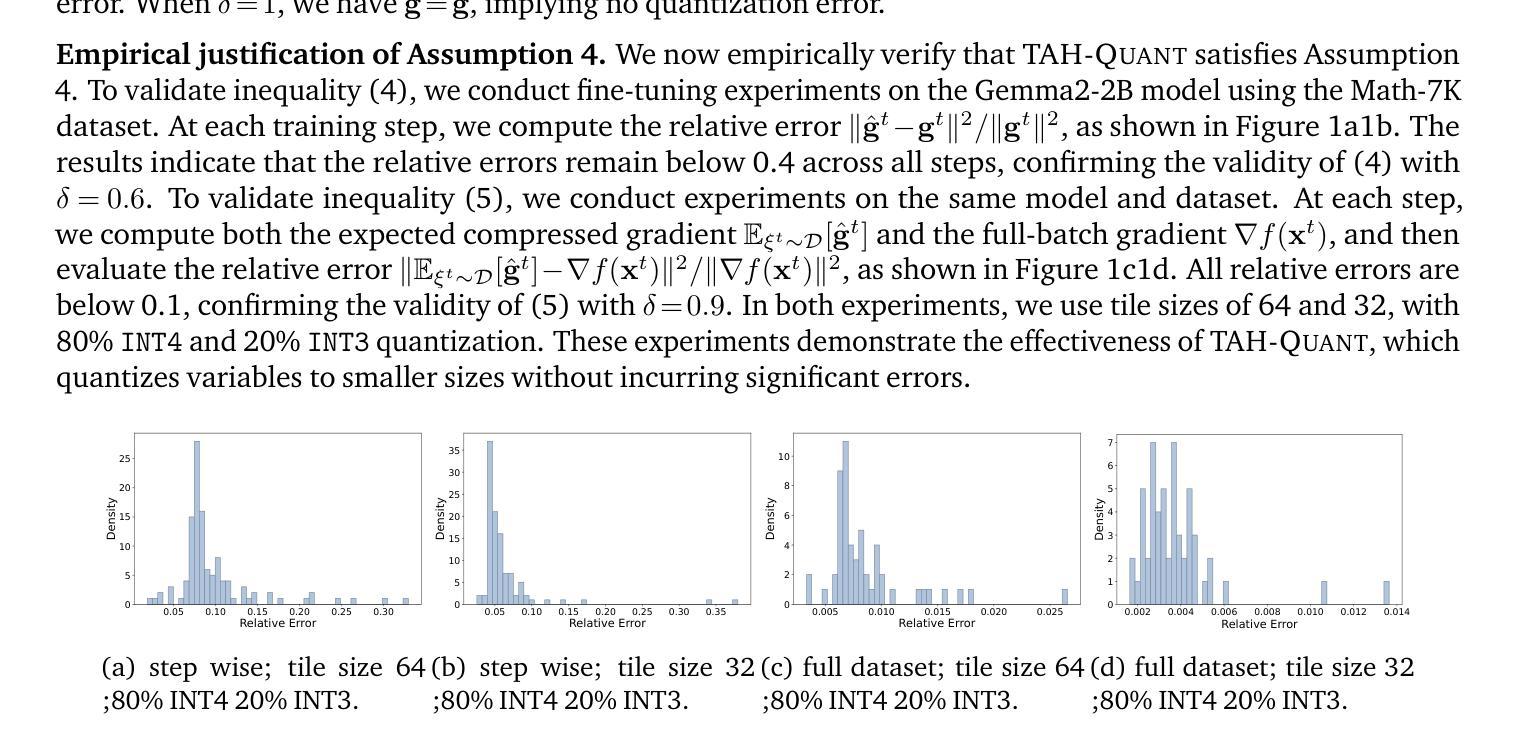
Decentralized training of large language models offers the opportunity to pool computational resources across geographically distributed participants but faces significant network communication bottlenecks, particularly in pipeline-parallel settings. While pipeline parallelism partitions model layers across devices to handle large-scale models, it necessitates frequent communication of intermediate activations, creating challenges when network bandwidth is limited. Existing activation compression methods, such as AQ-SGD, mitigate quantization-induced errors through error compensation but impose prohibitive memory overhead by requiring storage of previous activations. To address these issues, we introduce TAH-Quant (Tile-wise Adaptive Hadamard Quantization), a novel activation quantization framework designed specifically for pipeline parallelism. Our approach integrates fine-grained tile-wise quantization for precise control, entropy-guided token-level adaptive bit allocation for optimal bit usage, and a Hadamard-based transform with pivot element swapping to effectively suppress quantization outliers. We further provide a theoretical analysis, proving that pipeline parallel training equipped with TAH-Quant maintains a convergence rate of $\mathcal{O}(1/\sqrt{T})$, matching that of vanilla stochastic gradient descent. Extensive experiments on diverse LLM tasks demonstrate that TAH-Quant achieves aggressive activation quantization (3-4 bits) ratio, which provides up to 4.3$\times$ end-to-end speedup without compromising training convergence, matches state-of-the-art methods, incurs no extra memory overhead, and generalizes well across different training scenarios.
分布式训练大型语言模型使整合地理分布参与者的计算资源成为可能,但面临网络通信的重大瓶颈,特别是在流水线并行设置中。流水线并行处理将模型层分割到不同设备上进行处理,从而处理大规模模型,但这需要频繁地通信中间激活值,在网络带宽有限的情况下会产生挑战。现有的激活压缩方法,如AQ-SGD,通过误差补偿减轻量化引起的错误,但由于需要存储先前的激活值而产生巨大的内存开销。为了解决这些问题,我们引入了TAH-Quant(基于瓦片的自适应哈达玛量化),这是一种专为流水线并行处理设计的全新激活量化框架。我们的方法结合了精细的瓦片级量化进行精确控制、基于熵的标记级自适应位分配以实现最佳位使用,以及基于哈达玛变换与枢轴元素交换的有效量化异常值抑制。我们进一步进行理论分析,证明配备TAH-Quant的流水线并行训练保持O(1/√T)的收敛速度,与基本随机梯度下降法相匹配。在不同的大型语言模型任务上的广泛实验表明,TAH-Quant能够实现极具攻击性的激活量化(3-4位)比例,提供高达4.3倍的端到端加速而不损害训练收敛性,匹配最先进的方法,无需额外内存开销,并在不同训练场景中具有良好的泛化性能。
论文及项目相关链接
Summary
本文介绍了针对分布式环境下训练大型语言模型的挑战,特别是网络通讯瓶颈问题。文章提出了一种新的激活量化框架TAH-Quant,通过精细的瓷砖级量化、基于熵的令牌级自适应位分配和Hadamard变换等技术来解决这些问题。理论分析和实验结果表明,TAH-Quant能够在不损害训练收敛的情况下,实现激活量化的高效压缩,提高训练速度,且具有良好的跨不同训练场景的泛化能力。
Key Takeaways
- 分布式环境下训练大型语言模型面临网络通讯瓶颈的挑战。
- TAH-Quant是一种新的激活量化框架,旨在解决分布式环境下训练大型语言模型的通讯瓶颈问题。
- TAH-Quant通过精细的瓷砖级量化、基于熵的令牌级自适应位分配和Hadamard变换等技术实现高效激活量化。
- TAH-Quant能够实现激活量化的压缩比达到3-4位,提供高达4.3倍的训练速度提升。
- TAH-Quant在不损害训练收敛的情况下实现高效性能,且与现有先进技术相当。
- TAH-Quant无需额外的内存开销,具有良好的泛化能力。
点此查看论文截图

Beyond Face Swapping: A Diffusion-Based Digital Human Benchmark for Multimodal Deepfake Detection
Authors:Jiaxin Liu, Jia Wang, Saihui Hou, Min Ren, Huijia Wu, Long Ma, Renwang Pei, Zhaofeng He
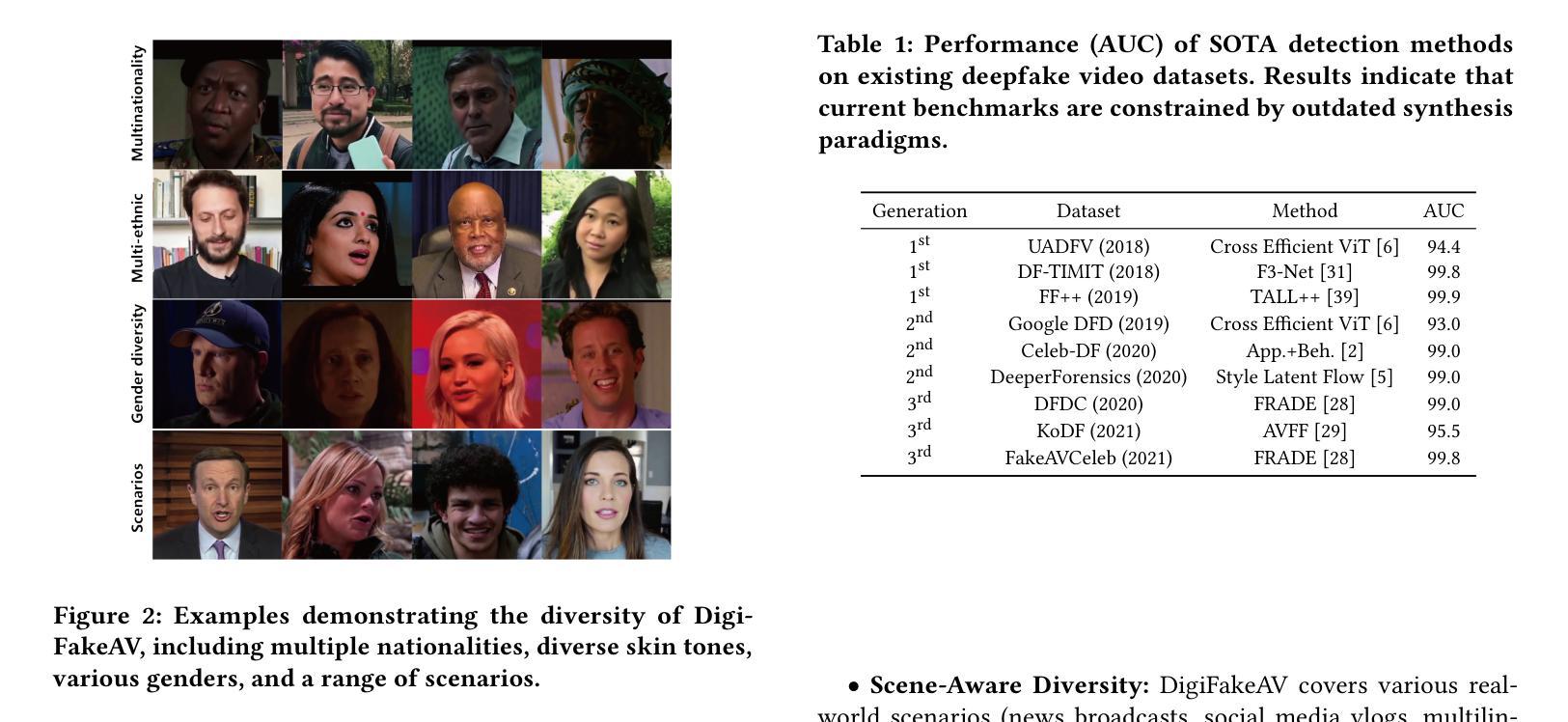
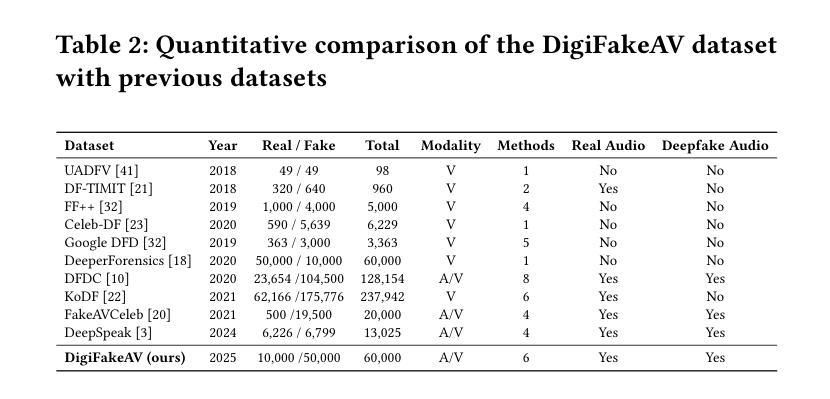
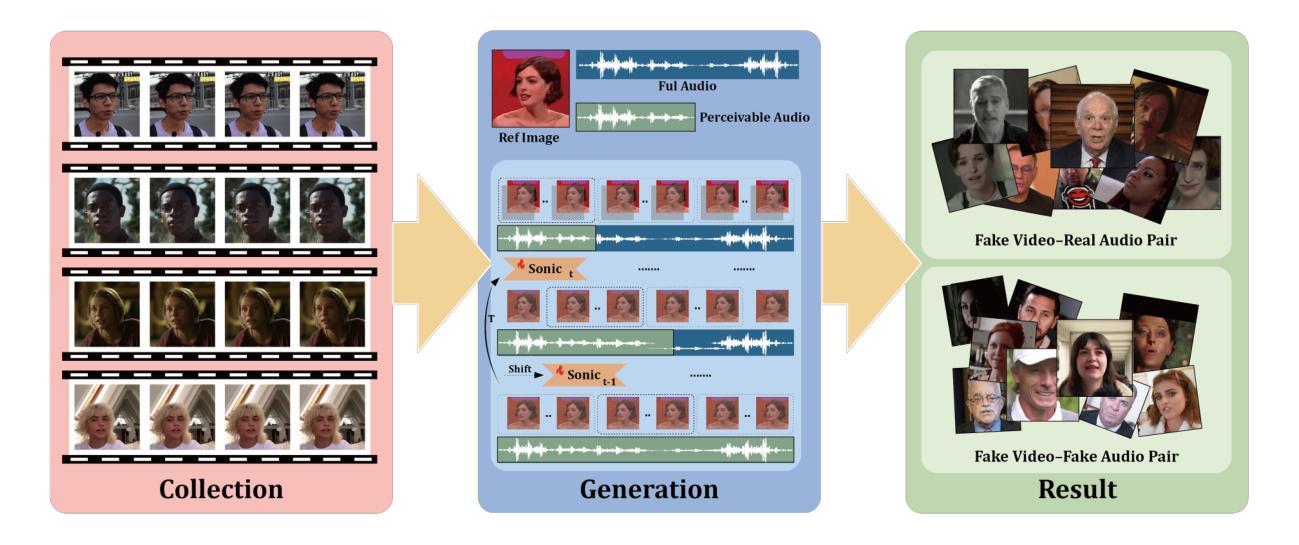
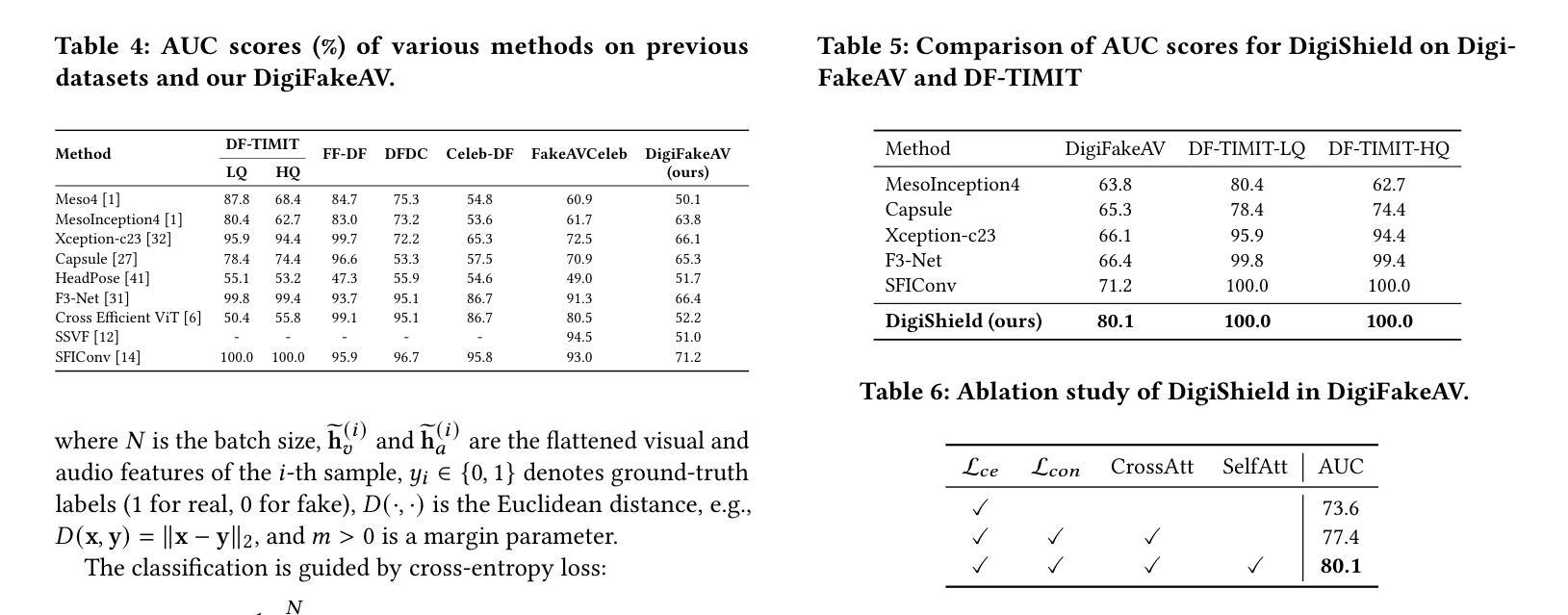
In recent years, the explosive advancement of deepfake technology has posed a critical and escalating threat to public security: diffusion-based digital human generation. Unlike traditional face manipulation methods, such models can generate highly realistic videos with consistency via multimodal control signals. Their flexibility and covertness pose severe challenges to existing detection strategies. To bridge this gap, we introduce DigiFakeAV, the new large-scale multimodal digital human forgery dataset based on diffusion models. Leveraging five of the latest digital human generation methods and a voice cloning method, we systematically construct a dataset comprising 60,000 videos (8.4 million frames), covering multiple nationalities, skin tones, genders, and real-world scenarios, significantly enhancing data diversity and realism. User studies demonstrate that the misrecognition rate by participants for DigiFakeAV reaches as high as 68%. Moreover, the substantial performance degradation of existing detection models on our dataset further highlights its challenges. To address this problem, we propose DigiShield, an effective detection baseline based on spatiotemporal and cross-modal fusion. By jointly modeling the 3D spatiotemporal features of videos and the semantic-acoustic features of audio, DigiShield achieves state-of-the-art (SOTA) performance on the DigiFakeAV and shows strong generalization on other datasets.
近年来,深度伪造技术的爆炸性进步对公共安全构成了日益严峻的挑战:基于扩散的数字人生成技术。与传统的面部操纵方法不同,这些模型可以通过多模态控制信号生成高度逼真的视频,并保持一致性。它们的灵活性和隐蔽性对现有检测策略构成了严重挑战。为了弥补这一空白,我们推出了DigiFakeAV,这是基于扩散模型的大规模多模态数字人类伪造数据集。我们利用五种最新的数字人类生成方法和一种声音克隆方法,系统地构建了一个包含6万段视频(840万帧)的数据集,涵盖了多种民族、肤色、性别和真实场景,显著提高了数据的多样性和逼真度。用户研究表明,DigiFakeAV的误识别率高达68%。此外,现有检测模型在我们数据集上的性能大幅下降,进一步凸显了其挑战。为了解决这个问题,我们提出了DigiShield,这是一个基于时空和跨模态融合的有效的检测基线。通过联合建模视频的3D时空特征和音频的语义声学特征,DigiShield在DigiFakeAV上实现了最先进的性能,并在其他数据集上显示出强大的泛化能力。
论文及项目相关链接
Summary
本文介绍了深度伪造技术的快速发展对公共安全构成的新威胁——基于扩散的数字人类生成。为应对这一挑战,研究团队推出了DigiFakeAV数据集,包含6万段视频,覆盖多种民族、肤色、性别和真实场景,以强化数据的多样性和逼真度。现有检测模型的性能在DigiFakeAV数据集上大幅下降,因此研究团队提出了基于时空和跨模态融合的DigiShield检测基线,实现了在DigiFakeAV数据集上的最佳性能。
Key Takeaways
- 深度伪造技术的快速发展带来了新的安全威胁,尤其是基于扩散的数字人类生成。
- DigiFakeAV数据集是首个大规模的多模式数字人类伪造数据集,包含真实场景的视频和音频数据。
- DigiFakeAV数据集的引入对现有检测模型的性能提出了挑战。
- 用户研究结果显示,参与者对DigiFakeAV的误识别率高达68%。
- DigiShield是一种基于时空和跨模态融合的有效的检测基线。
- DigiShield在DigiFakeAV数据集上表现出最佳性能。
点此查看论文截图