⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-05 更新
Towards Better De-raining Generalization via Rainy Characteristics Memorization and Replay
Authors:Kunyu Wang, Xueyang Fu, Chengzhi Cao, Chengjie Ge, Wei Zhai, Zheng-Jun Zha
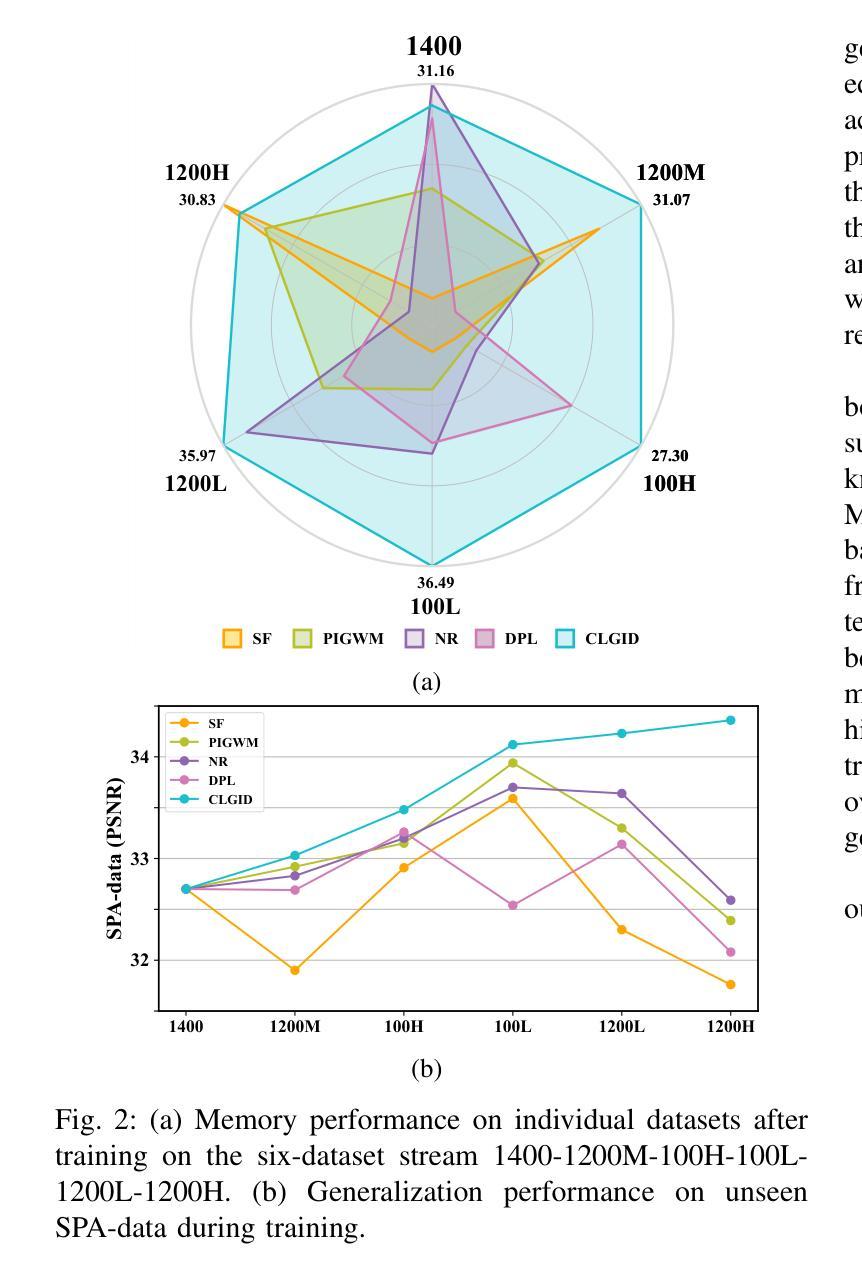
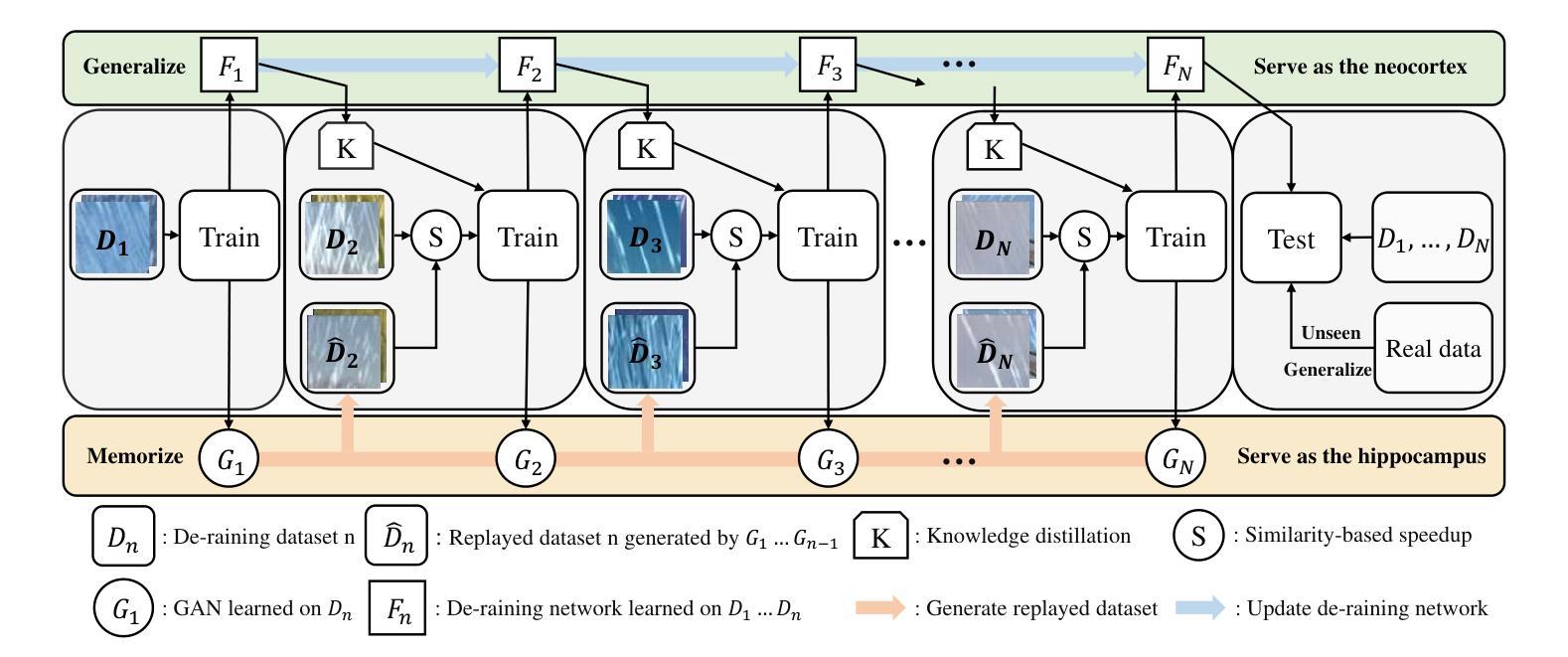
Current image de-raining methods primarily learn from a limited dataset, leading to inadequate performance in varied real-world rainy conditions. To tackle this, we introduce a new framework that enables networks to progressively expand their de-raining knowledge base by tapping into a growing pool of datasets, significantly boosting their adaptability. Drawing inspiration from the human brain’s ability to continuously absorb and generalize from ongoing experiences, our approach borrow the mechanism of the complementary learning system. Specifically, we first deploy Generative Adversarial Networks (GANs) to capture and retain the unique features of new data, mirroring the hippocampus’s role in learning and memory. Then, the de-raining network is trained with both existing and GAN-synthesized data, mimicking the process of hippocampal replay and interleaved learning. Furthermore, we employ knowledge distillation with the replayed data to replicate the synergy between the neocortex’s activity patterns triggered by hippocampal replays and the pre-existing neocortical knowledge. This comprehensive framework empowers the de-raining network to amass knowledge from various datasets, continually enhancing its performance on previously unseen rainy scenes. Our testing on three benchmark de-raining networks confirms the framework’s effectiveness. It not only facilitates continuous knowledge accumulation across six datasets but also surpasses state-of-the-art methods in generalizing to new real-world scenarios.
当前图像去雨方法主要局限于从有限的数据集中学习,导致在多种现实世界雨天条件下的表现不佳。为了解决这个问题,我们引入了一个新的框架,使网络能够通过不断扩大的数据集池来逐步扩展其去雨的知识库,从而显著提高其对不同雨天条件的适应能力。我们的方法借鉴了人类大脑不断从正在进行的经验中吸收和概括的能力,借鉴了辅助学习系统的机制。具体来说,我们首先利用生成对抗网络(GANs)来捕获新数据的独特特征并保留下来,这反映了海马体在学习和记忆中的功能。然后,去雨网络既接受现有数据的训练,也接受GAN合成数据的训练,模仿海马体回放和交错学习的过程。此外,我们还利用回放数据进行知识蒸馏,以复制海马体回放触发的类新皮层活动模式与现有的类皮层知识之间的协同作用。这个全面的框架使得去雨网络能够从各种数据集中积累知识,不断提高其在之前未见过的雨天场景中的性能。我们在三个基准去雨网络上的测试证实了该框架的有效性。它不仅促进了跨六个数据集的知识不断积累,而且在适应新的现实世界场景方面的表现也超过了最先进的方法。
论文及项目相关链接
Summary
本文介绍了一种新的框架,该框架借鉴人类大脑的连续学习和泛化能力,通过采用生成对抗网络(GANs)来捕获新数据的独特特征,并利用知识蒸馏技术,使去雨网络能够从各种数据集中积累知识,持续提高其未见场景的去雨性能。
Key Takeaways
- 当前图像去雨方法主要局限于有限的数据集,导致在多变的现实世界雨况中表现不足。
- 新的框架通过借鉴人类大脑的连续学习和泛化能力来解决这个问题。
- 采用生成对抗网络(GANs)来捕获新数据的独特特征,类似于大脑中的海马体在学习和记忆中的角色。
- 去雨网络通过训练现有和GAN合成的数据,模拟海马体的回放和交错学习过程。
- 利用知识蒸馏技术对回放数据进行处理,以复制海马体回放触发的皮层活动模式与现有皮层知识的协同作用。
- 该框架不仅促进了跨六个数据集的知识积累,而且在适应新现实场景方面超过了最先进的方法。
点此查看论文截图

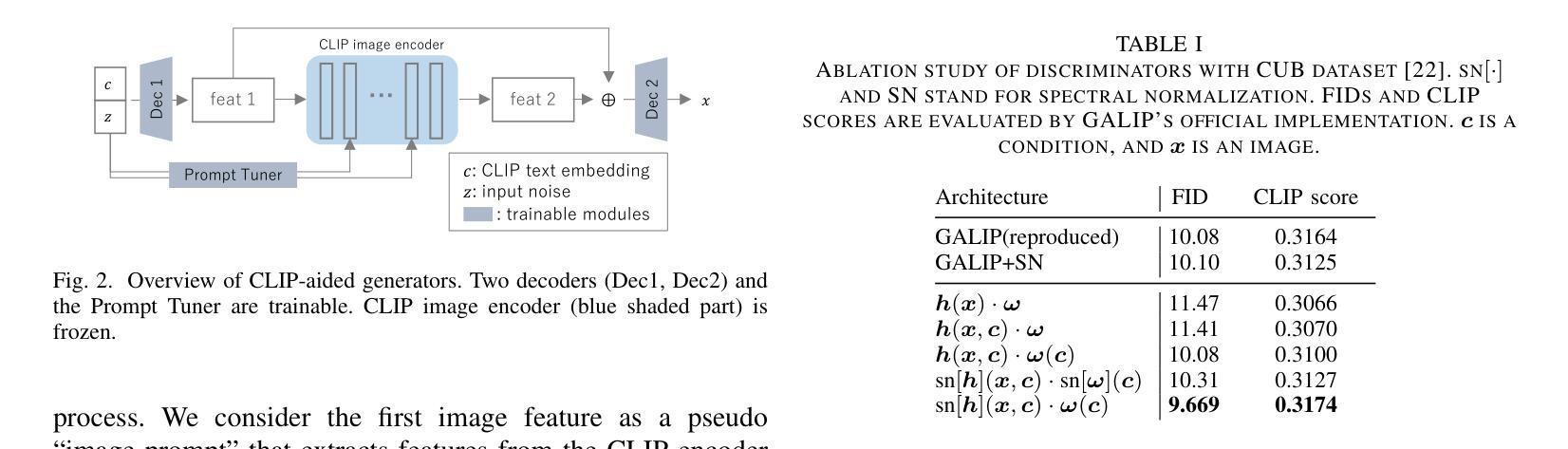
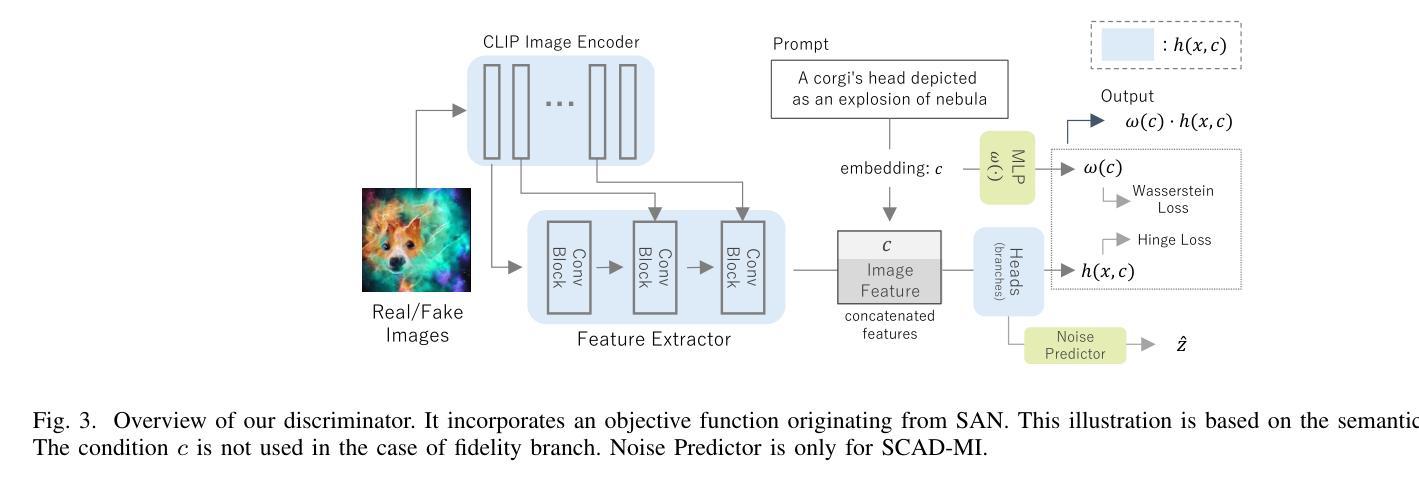
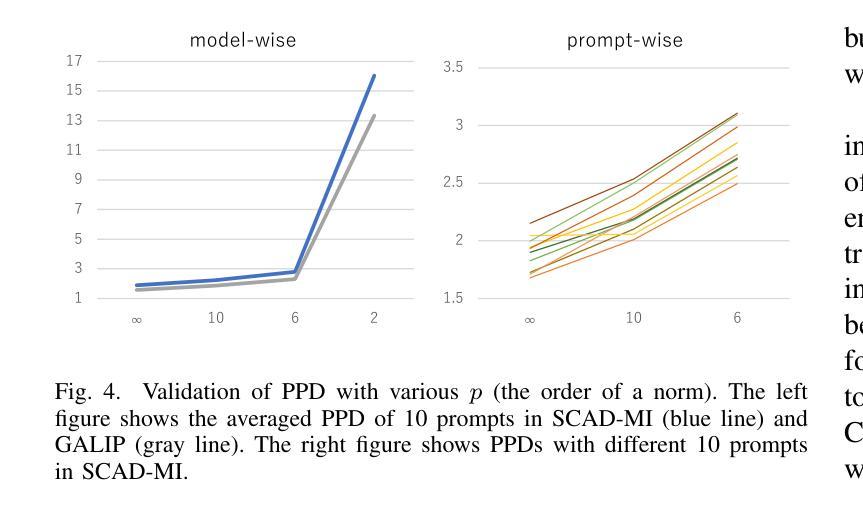
Efficiency without Compromise: CLIP-aided Text-to-Image GANs with Increased Diversity
Authors:Yuya Kobayashi, Yuhta Takida, Takashi Shibuya, Yuki Mitsufuji
Recently, Generative Adversarial Networks (GANs) have been successfully scaled to billion-scale large text-to-image datasets. However, training such models entails a high training cost, limiting some applications and research usage. To reduce the cost, one promising direction is the incorporation of pre-trained models. The existing method of utilizing pre-trained models for a generator significantly reduced the training cost compared with the other large-scale GANs, but we found the model loses the diversity of generation for a given prompt by a large margin. To build an efficient and high-fidelity text-to-image GAN without compromise, we propose to use two specialized discriminators with Slicing Adversarial Networks (SANs) adapted for text-to-image tasks. Our proposed model, called SCAD, shows a notable enhancement in diversity for a given prompt with better sample fidelity. We also propose to use a metric called Per-Prompt Diversity (PPD) to evaluate the diversity of text-to-image models quantitatively. SCAD achieved a zero-shot FID competitive with the latest large-scale GANs at two orders of magnitude less training cost.
最近,生成对抗网络(GANs)已成功扩展至亿级大规模文本到图像数据集。然而,训练此类模型需要很高的训练成本,这限制了某些应用和研究的使用。为了降低成本,一个前景光明的方向是融入预训练模型。现有方法利用预训练模型作为生成器,与其他大规模GAN相比显著降低了训练成本,但我们也发现该模型对于给定提示的生成多样性大大降低。为了构建高效且保真度高的文本到图像GAN而无需妥协,我们建议使用两个专用的鉴别器与针对文本到图像任务设计的切片对抗网络(SANs)。我们提出的模型SCAD在给定的提示下表现出显著提高了多样性并呈现出更好的样本保真度。我们还建议使用一种称为每提示多样性的度量指标来定量评估文本到图像模型的多样性。SCAD实现了零启动FID,与最新的大规模GAN相比具有竞争力,同时训练成本降低了两个数量级。
论文及项目相关链接
PDF Accepted at IJCNN 2025
Summary
最近,生成对抗网络(GANs)已成功扩展至亿级大规模文本到图像数据集。为降低训练成本,结合预训练模型成为了一个有前途的方向。现有利用预训练模型作为生成器的方法相较于其他大规模GAN降低了训练成本,但发现模型在给定的提示下丧失了生成多样性。为建立高效且高保真度的文本到图像GAN而不妥协,我们提出使用两个针对文本到图像任务进行适配的切片对抗网络(SANs)作为鉴别器。我们提出的SCAD模型在给定的提示下显著提高了多样性并提高了样本保真度。我们还建议使用名为PPD(每提示多样性)的指标来定量评估文本到图像模型的多样性。SCAD实现了与最新大规模GAN相当的零FID,同时训练成本降低了两个数量级。
Key Takeaways
- GANs已成功应用于亿级大规模文本到图像数据集。
- 结合预训练模型可以降低GAN的训练成本。
- 利用现有预训练模型作为生成器时,在生成多样性方面存在局限。
- 为提高文本到图像GAN的效率和保真度,提出了使用两个针对文本到图像任务的鉴别器的方法。
- 提出的SCAD模型提高了给定提示下的生成多样性并提高了样本保真度。
- 引入了Per-Prompt Diversity (PPD)指标来定量评估文本到图像模型的多样性。
点此查看论文截图


Improving Heart Rejection Detection in XPCI Images Using Synthetic Data Augmentation
Authors:Jakov Samardžija, Donik Vršnak, Sven Lončarić
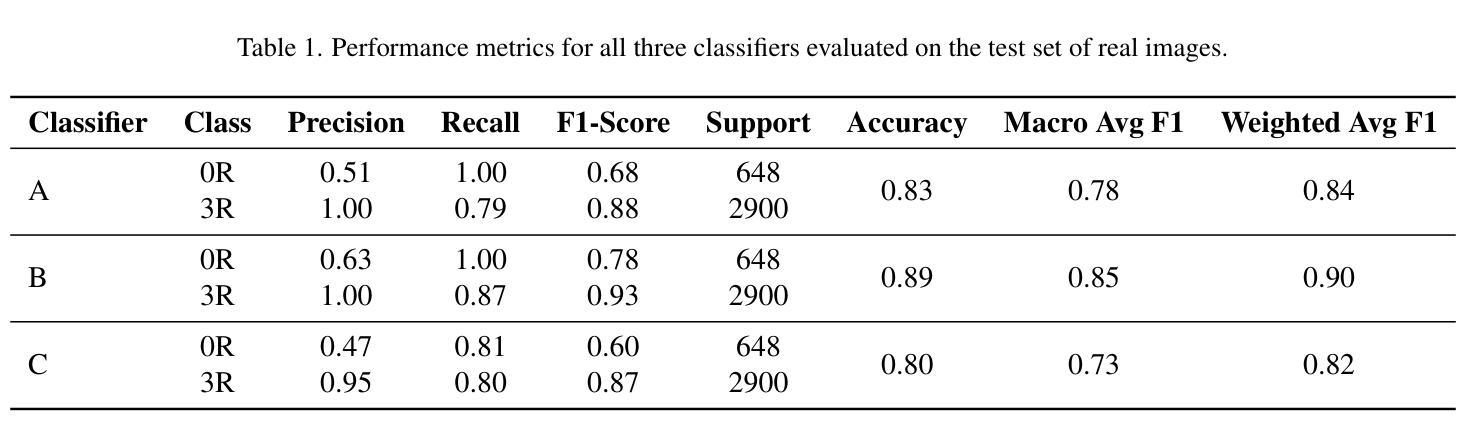
Accurate identification of acute cellular rejection (ACR) in endomyocardial biopsies is essential for effective management of heart transplant patients. However, the rarity of high-grade rejection cases (3R) presents a significant challenge for training robust deep learning models. This work addresses the class imbalance problem by leveraging synthetic data generation using StyleGAN to augment the limited number of real 3R images. Prior to GAN training, histogram equalization was applied to standardize image appearance and improve the consistency of tissue representation. StyleGAN was trained on available 3R biopsy patches and subsequently used to generate 10,000 realistic synthetic images. These were combined with real 0R samples, that is samples without rejection, in various configurations to train ResNet-18 classifiers for binary rejection classification. Three classifier variants were evaluated: one trained on real 0R and synthetic 3R images, another using both synthetic and additional real samples, and a third trained solely on real data. All models were tested on an independent set of real biopsy images. Results demonstrate that synthetic data improves classification performance, particularly when used in combination with real samples. The highest-performing model, which used both real and synthetic images, achieved strong precision and recall for both classes. These findings underscore the value of hybrid training strategies and highlight the potential of GAN-based data augmentation in biomedical image analysis, especially in domains constrained by limited annotated datasets.
在心肌内膜活检中对急性细胞排斥反应(ACR)的准确识别对于心脏移植患者的有效管理至关重要。然而,高级排斥反应(3R)的罕见性给训练稳健的深度学习模型带来了重大挑战。这项工作通过利用StyleGAN进行合成数据生成来解决类别不平衡问题,以扩充有限的真实3R图像数量。在GAN训练之前,应用了直方均衡来标准化图像外观并改善组织表示的一致性。StyleGAN在可用的3R活检斑块上进行训练,然后用于生成10,000个逼真的合成图像。这些图像与没有排斥反应的实0R样本相结合,以在各种配置中训练用于二元排斥分类的ResNet-18分类器。评估了三个分类器变体:一个用真实0R和合成3R图像进行训练,另一个同时使用合成图像和额外的真实样本进行训练,第三个仅使用真实数据进行训练。所有模型都在一组独立的真实活检图像上进行了测试。结果表明,合成数据提高了分类性能,特别是在与真实样本结合使用时。表现最佳的模型使用真实和合成图像,为两个类别都实现了强大的精确度和召回率。这些发现强调了混合训练策略的价值,并突出了GAN基于数据增强的生物医学图像分析中的潜力,特别是在受限制标注数据集领域。
论文及项目相关链接
PDF For the time being, the paper needs to be withdrawn so that a more extensive evaluation of the results can be conducted to validate the approach. Furthermore, additional authors will need to be added, which will be addressed if the study’s results prove satisfactory
Summary
急性细胞排斥反应(ACR)在心肌活检中的准确识别对于心脏移植患者的有效管理至关重要。本研究利用StyleGAN生成合成数据,解决高分级排斥病例(3R)稀少带来的深度学习模型训练难题。研究通过对图像进行直方图均衡化预处理,改善组织表示的标准化和一致性,并训练StyleGAN生成真实感的合成图像。将合成图像与无排斥反应的样本结合,训练了多个用于二元排斥分类的ResNet-18分类器。实验结果显示,合成数据能提高分类性能,特别是与真实样本结合使用时效果更佳。最高性能模型结合了真实和合成图像,实现了较高的精确率和召回率。研究强调了混合训练策略的价值,并突出了GAN在生物医学图像分析中的潜力,尤其是在受限制的数据集领域。
Key Takeaways
- 急性细胞排斥反应(ACR)在心肌活检中的准确识别对心脏移植患者的有效管理至关重要。
- 高分级排斥病例(3R)的稀少性给深度学习模型训练带来挑战。
- StyleGAN被用于生成合成数据,以解决类不平衡问题。
- 直方图均衡化被应用于图像预处理,以改善组织表示的标准化和一致性。
- 合成图像与无排斥反应的样本结合,用于训练ResNet-18分类器进行二元排斥分类。
- 实验结果显示,合成数据能提高分类性能。
点此查看论文截图