⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-05 更新
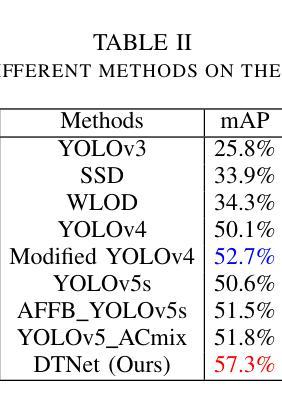
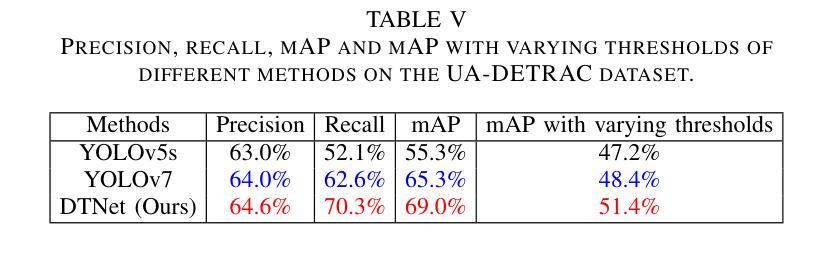
A Dynamic Transformer Network for Vehicle Detection
Authors:Chunwei Tian, Kai Liu, Bob Zhang, Zhixiang Huang, Chia-Wen Lin, David Zhang
Stable consumer electronic systems can assist traffic better. Good traffic consumer electronic systems require collaborative work between traffic algorithms and hardware. However, performance of popular traffic algorithms containing vehicle detection methods based on deep networks via learning data relation rather than learning differences in different lighting and occlusions is limited. In this paper, we present a dynamic Transformer network for vehicle detection (DTNet). DTNet utilizes a dynamic convolution to guide a deep network to dynamically generate weights to enhance adaptability of an obtained detector. Taking into relations of different information account, a mixed attention mechanism based channel attention and Transformer is exploited to strengthen relations of channels and pixels to extract more salient information for vehicle detection. To overcome the drawback of difference in an image account, a translation-variant convolution relies on spatial location information to refine obtained structural information for vehicle detection. Experimental results illustrate that our DTNet is competitive for vehicle detection. Code of the proposed DTNet can be obtained at https://github.com/hellloxiaotian/DTNet.
稳定的消费电子系统可以更好地辅助交通。良好的交通消费电子系统需要交通算法和硬件之间的协作。然而,流行的交通算法中基于深度网络学习数据关系而非学习不同光照和遮挡差异的车辆检测方法的性能受到限制。在本文中,我们提出了一种用于车辆检测的动态Transformer网络(DTNet)。DTNet利用动态卷积来指导深度网络动态生成权重,以提高所获得检测器的适应性。考虑到不同信息的关系,利用基于通道注意力和Transformer的混合注意力机制来加强通道和像素之间的关系,以提取更多显著信息进行车辆检测。为了克服图像差异造成的缺陷,一种依赖于空间位置信息的平移可变卷积用于细化所获得的车辆检测的结构信息。实验结果证明,我们的DTNet在车辆检测方面具有很强的竞争力。所提议的DTNet的代码可在https://github.com/hellloxiaotian/DTNet获取。
论文及项目相关链接
PDF 8 pages, 5 figures. This paper has been accepted for publication in IEEE Transactions on Consumer Electronics
Summary
本文提出一种动态Transformer网络(DTNet)用于车辆检测。该网络通过动态卷积指导深度网络动态生成权重,增强检测器的适应性。采用混合注意力机制的通道注意力和Transformer,以提取更显著的信息进行车辆检测。通过空间位置信息依赖的翻译变体卷积,改进了检测的结构信息。实验结果表明,DTNet在车辆检测方面表现出竞争力。
Key Takeaways
- DTNet通过动态卷积增强检测器适应性,通过深度网络动态生成权重。
- 采用混合注意力机制,结合通道注意力和Transformer,提取更显著信息用于车辆检测。
- 为了克服图像差异带来的问题,采用翻译变体卷积,依赖空间位置信息优化检测的结构信息。
- DTNet在车辆检测方面表现出竞争力。
- DTNet适用于稳定消费电子产品系统以辅助交通管理。
- 论文强调了交通算法与硬件协同工作的重要性在良好的交通消费电子产品系统中。
点此查看论文截图





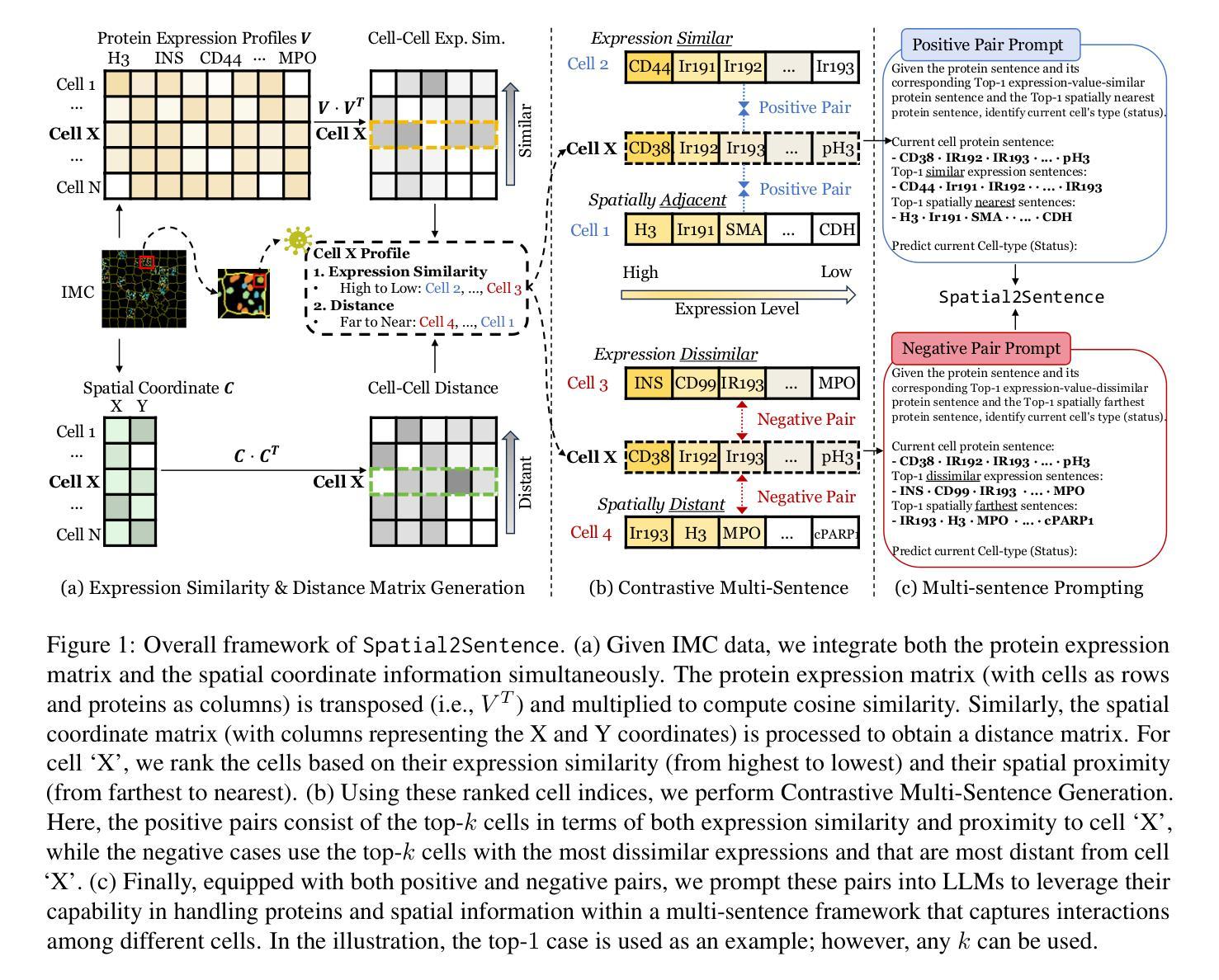
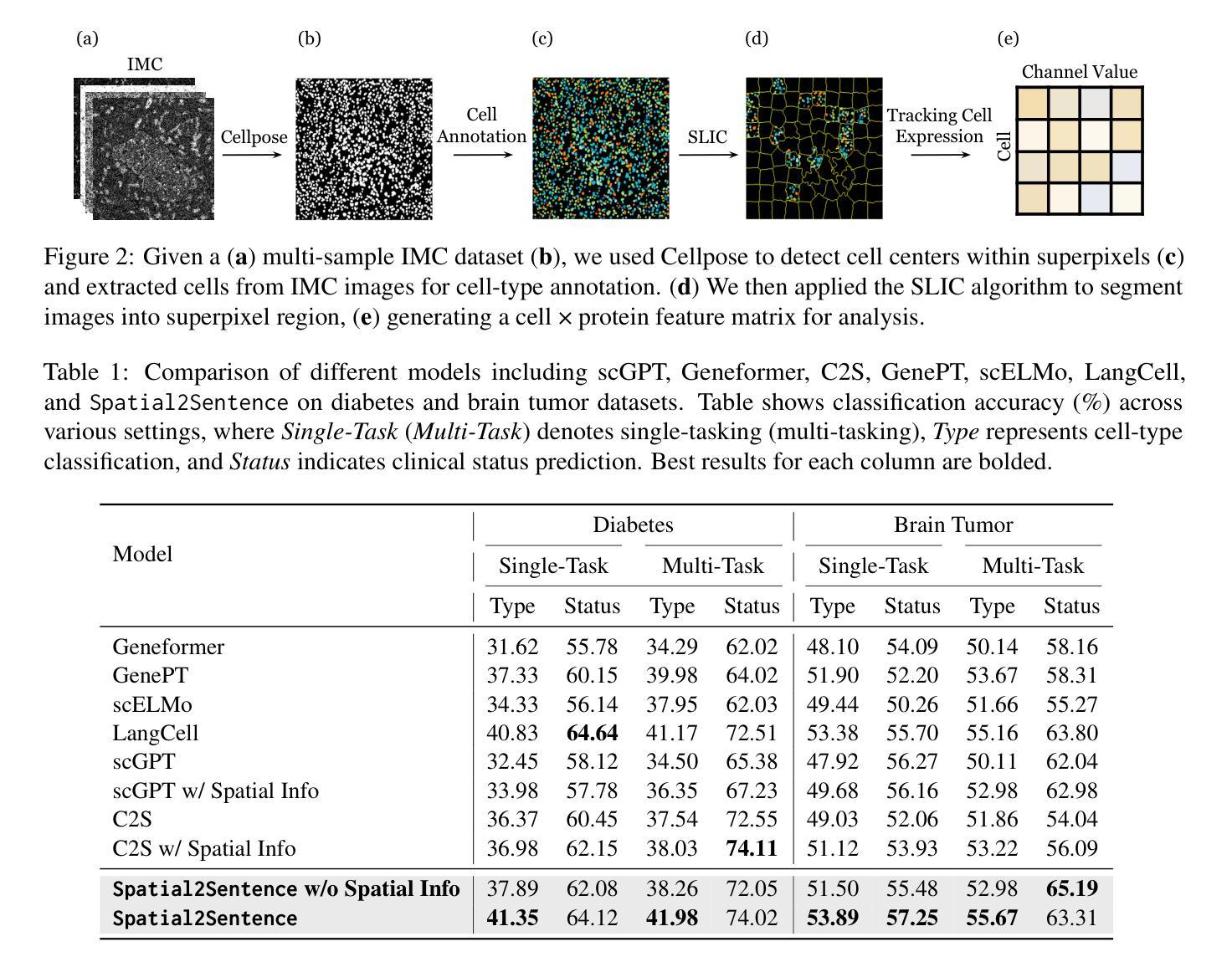
Spatial Coordinates as a Cell Language: A Multi-Sentence Framework for Imaging Mass Cytometry Analysis
Authors:Chi-Jane Chen, Yuhang Chen, Sukwon Yun, Natalie Stanley, Tianlong Chen
Image mass cytometry (IMC) enables high-dimensional spatial profiling by combining mass cytometry’s analytical power with spatial distributions of cell phenotypes. Recent studies leverage large language models (LLMs) to extract cell states by translating gene or protein expression into biological context. However, existing single-cell LLMs face two major challenges: (1) Integration of spatial information: they struggle to generalize spatial coordinates and effectively encode spatial context as text, and (2) Treating each cell independently: they overlook cell-cell interactions, limiting their ability to capture biological relationships. To address these limitations, we propose Spatial2Sentence, a novel framework that integrates single-cell expression and spatial information into natural language using a multi-sentence approach. Spatial2Sentence constructs expression similarity and distance matrices, pairing spatially adjacent and expressionally similar cells as positive pairs while using distant and dissimilar cells as negatives. These multi-sentence representations enable LLMs to learn cellular interactions in both expression and spatial contexts. Equipped with multi-task learning, Spatial2Sentence outperforms existing single-cell LLMs on preprocessed IMC datasets, improving cell-type classification by 5.98% and clinical status prediction by 4.18% on the diabetes dataset while enhancing interpretability. The source code can be found here: https://github.com/UNITES-Lab/Spatial2Sentence.
图像质谱法(IMC)通过结合质谱的分析能力与细胞表型的空间分布,实现了高维度的空间特征分析。近期的研究利用大型语言模型(LLM)将基因或蛋白质表达转化为生物背景,从而提取细胞状态。然而,现有的单细胞LLM面临两大挑战:(1)空间信息的整合:它们难以将空间坐标推广并有效地将空间上下文编码为文本;(2)独立处理每个细胞:它们忽视了细胞间的相互作用,限制了捕捉生物关系的能力。为了克服这些局限性,我们提出了Spatial2Sentence这一新框架,它通过多句方法整合单细胞表达和空间信息为自然语言。Spatial2Sentence构建表达相似性和距离矩阵,将空间相邻且表达相似的细胞配对为正对,而将距离较远且表达不同的细胞视为负对。这些多句表示使LLM能够在表达和空间上下文中学习细胞间的相互作用。配备多任务学习后,Spatial2Sentence在预处理过的IMC数据集上表现优于现有的单细胞LLM,在糖尿病数据集上提高了细胞类型分类的准确率(提升5.98%)和临床状态预测的准确率(提升4.18%),同时增强了可解释性。源代码可在此处找到:https://github.com/UNITES-Lab/Spatial2Sentence。
论文及项目相关链接
Summary:
利用图像质谱技术(IMC)进行高维空间分析,结合质谱学分析能力和细胞表型的空间分布,实现了细胞状态的单细胞翻译表达模型(LLM)。现有的单细胞LLM面临两大挑战:缺乏空间信息整合与忽略细胞间交互作用。针对这些挑战,提出Spatial2Sentence框架,通过构建表达相似性与距离矩阵,将空间相邻与表达相似的细胞配对为正样本对,使用距离较远和表达差异大的细胞作为负样本,并采用多任务学习来提高模型的细胞互动和上下文学习效果。该模型在预处理的IMC数据集上表现出优异的性能,可提升糖尿病数据集的细胞类型分类和临床状态预测。Spatial2Sentence模型的源代码已在GitHub上公开。
Key Takeaways:
- IMC技术结合了质谱学分析能力和细胞表型的空间分布,实现高维空间分析。
- 单细胞LLM面临两大挑战:缺乏空间信息整合与忽略细胞间交互作用。
- Spatial2Sentence框架通过构建表达相似性与距离矩阵解决了上述挑战。
- Spatial2Sentence模型利用多任务学习提高性能,公开源代码在GitHub上。
点此查看论文截图


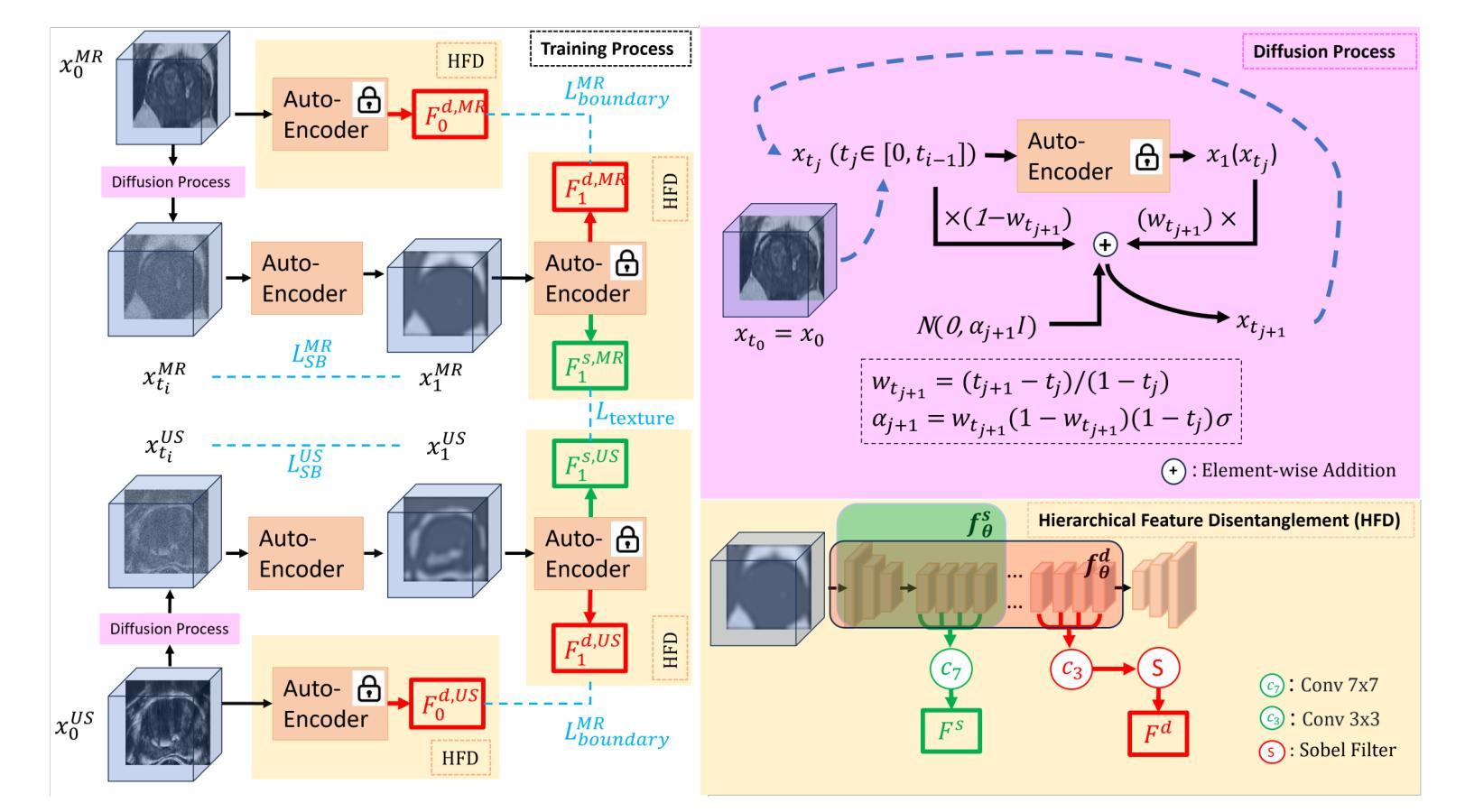
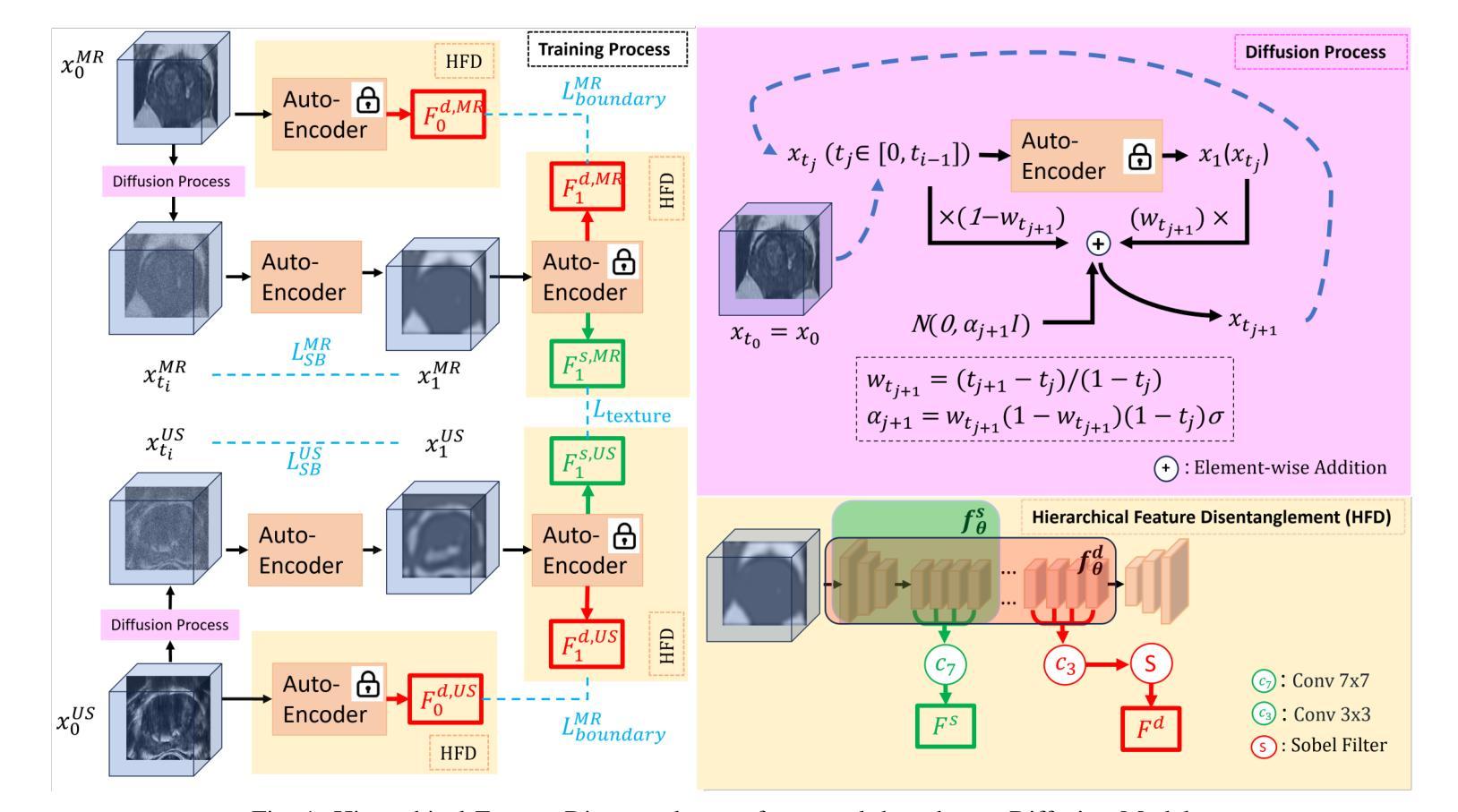
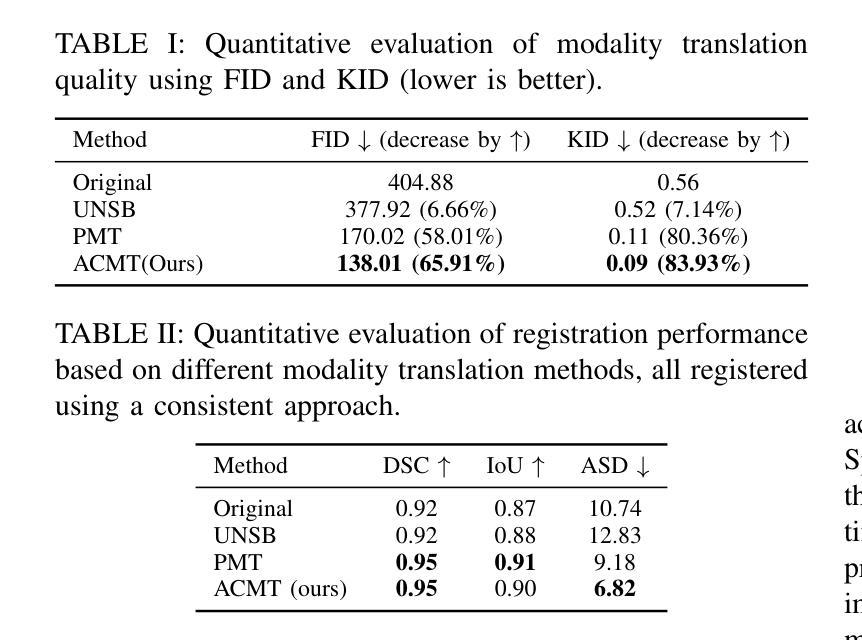
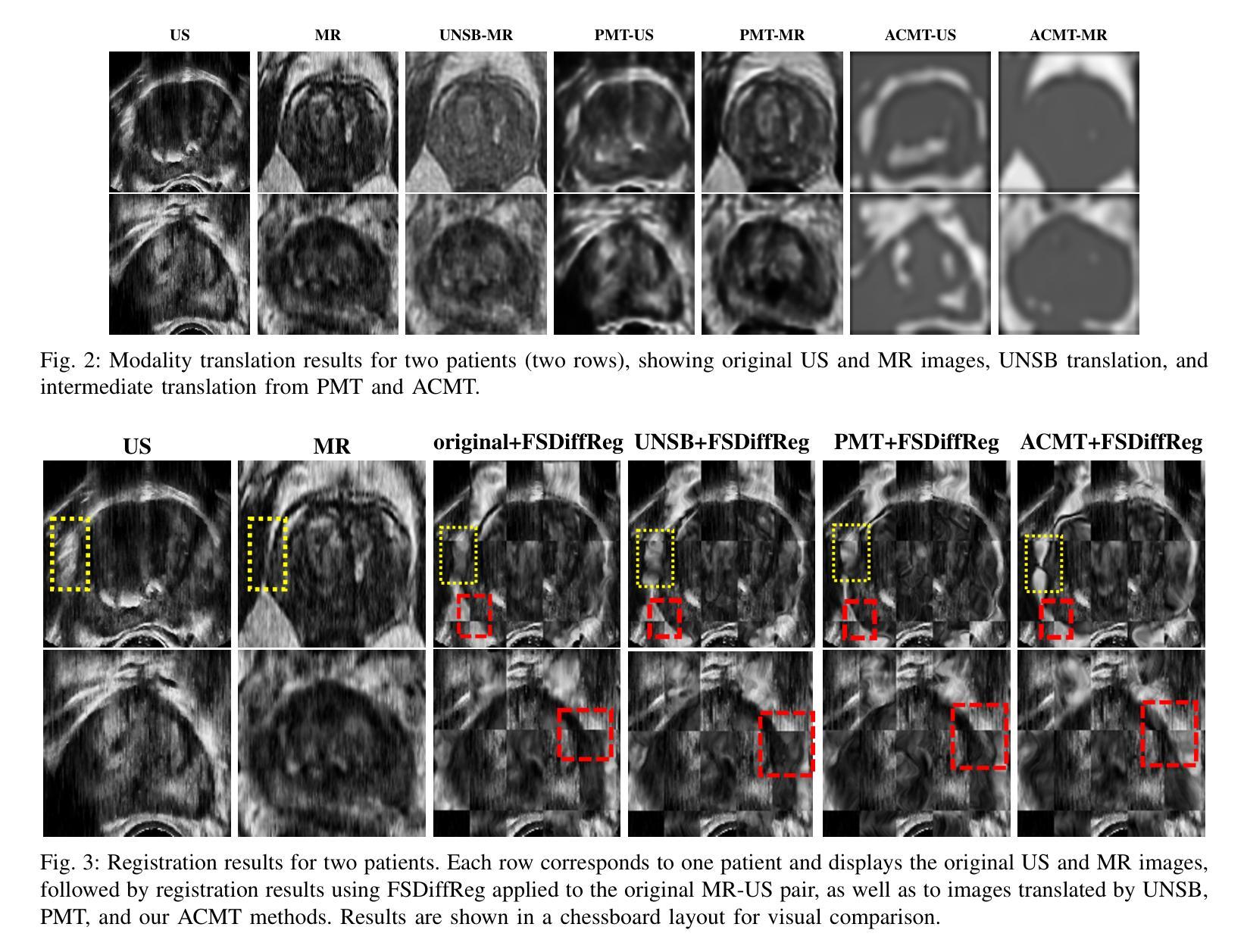
Modality Translation and Registration of MR and Ultrasound Images Using Diffusion Models
Authors:Xudong Ma, Nantheera Anantrasirichai, Stefanos Bolomytis, Alin Achim
Multimodal MR-US registration is critical for prostate cancer diagnosis. However, this task remains challenging due to significant modality discrepancies. Existing methods often fail to align critical boundaries while being overly sensitive to irrelevant details. To address this, we propose an anatomically coherent modality translation (ACMT) network based on a hierarchical feature disentanglement design. We leverage shallow-layer features for texture consistency and deep-layer features for boundary preservation. Unlike conventional modality translation methods that convert one modality into another, our ACMT introduces the customized design of an intermediate pseudo modality. Both MR and US images are translated toward this intermediate domain, effectively addressing the bottlenecks faced by traditional translation methods in the downstream registration task. Experiments demonstrate that our method mitigates modality-specific discrepancies while preserving crucial anatomical boundaries for accurate registration. Quantitative evaluations show superior modality similarity compared to state-of-the-art modality translation methods. Furthermore, downstream registration experiments confirm that our translated images achieve the best alignment performance, highlighting the robustness of our framework for multi-modal prostate image registration.
多模态MR-US注册对前列腺癌诊断至关重要。然而,由于模态之间的差异显著,这项任务仍然具有挑战性。现有方法往往无法在关键边界对齐的同时,又过于敏感地关注不相关的细节。为了解决这一问题,我们提出了一种基于层次特征分解设计的解剖结构连贯模态翻译(ACMT)网络。我们利用浅层特征来实现纹理一致性,并利用深层特征来实现边界保留。与传统的将一种模态转换为另一种模态的模态翻译方法不同,我们的ACMT引入了一种中间伪模态的定制设计。MR和US图像都被翻译到这个中间域,有效地解决了传统翻译方法在下游注册任务中所面临的瓶颈。实验表明,我们的方法可以减轻模态特定的差异,同时保留关键的解剖边界,以实现准确的注册。定量评估表明,与最先进的模态翻译方法相比,我们的模态相似性更高。此外,下游注册实验证实,我们的翻译图像实现了最佳的对齐性能,突显了我们多模态前列腺图像注册框架的稳健性。
论文及项目相关链接
Summary
本文提出一种基于层次特征分离设计的解剖学一致性模态翻译(ACMT)网络,用于解决多模态磁共振超声图像配准中的挑战性问题。该网络利用浅层特征实现纹理一致性,利用深层特征实现边界保留。与传统模态转换方法不同,ACMT网络引入了中间伪模态的自定义设计,使得MR和超声图像都能有效地朝向这个中间领域转换,解决了传统转换方法在下游配准任务中遇到的瓶颈问题。实验证明,该方法可以优化模态间的差异,同时保留关键的解剖学边界,从而实现准确的配准。与最先进的模态转换方法相比,该方法在模态相似性方面表现出优越性,并且在下游配准实验中验证了其最佳对齐性能,凸显了该框架在多模态前列腺图像配准中的稳健性。
Key Takeaways
- 多模态MR-US配准对前列腺癌诊断至关重要,但存在显著模态差异的挑战。
- 现有方法往往难以对齐关键边界,同时过于敏感于无关细节。
- 提出了基于层次特征分离设计的解剖学一致性模态翻译(ACMT)网络。
- ACMT网络利用浅层特征实现纹理一致性,深层特征实现边界保留。
- 不同于传统模态转换方法,ACMT网络引入中间伪模态的自定义设计。
- 实验证明该方法能优化模态间差异,提高模态相似性。
点此查看论文截图

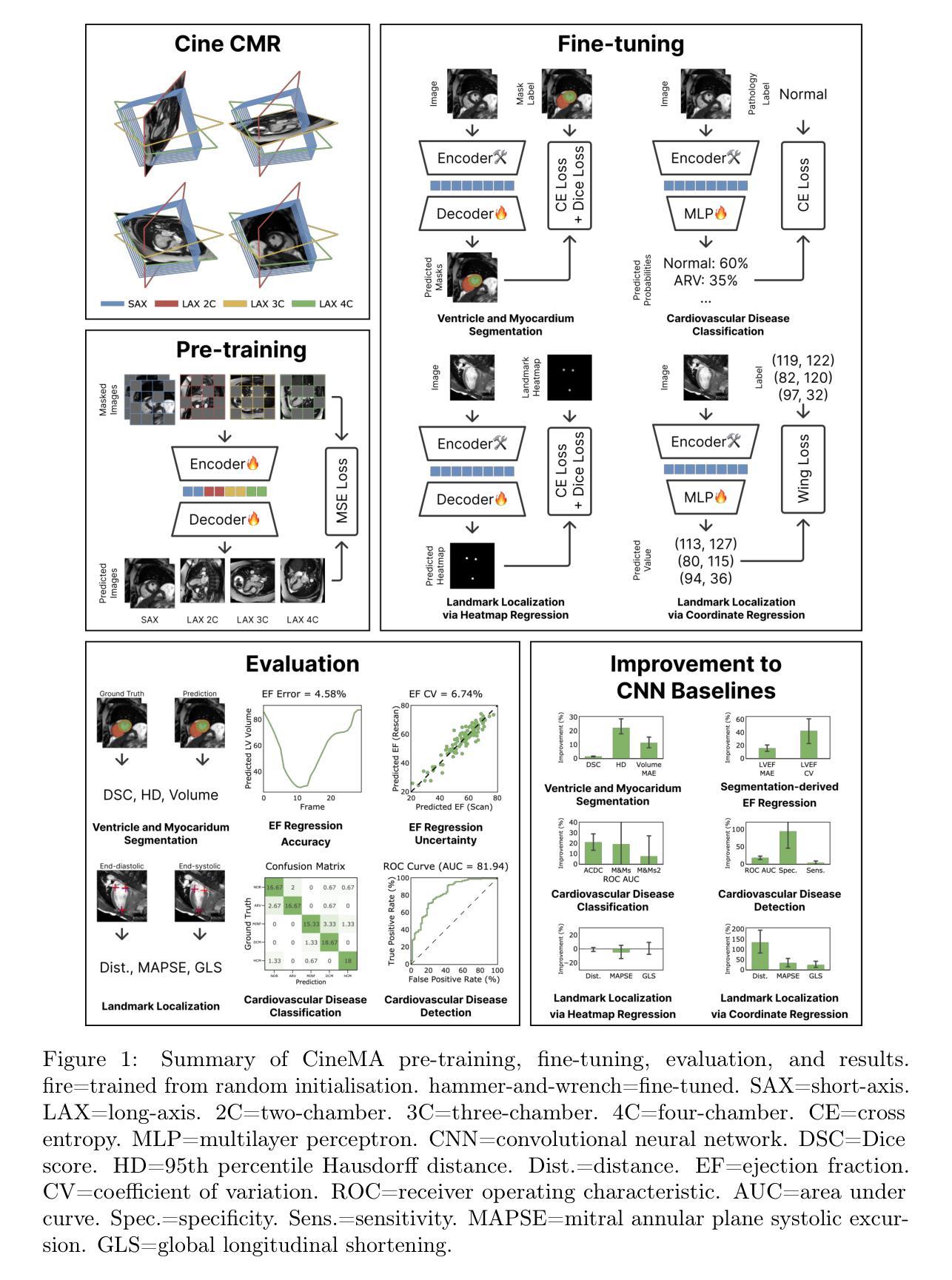
CineMA: A Foundation Model for Cine Cardiac MRI
Authors:Yunguan Fu, Weixi Yi, Charlotte Manisty, Anish N Bhuva, Thomas A Treibel, James C Moon, Matthew J Clarkson, Rhodri Huw Davies, Yipeng Hu
Cardiac magnetic resonance (CMR) is a key investigation in clinical cardiovascular medicine and has been used extensively in population research. However, extracting clinically important measurements such as ejection fraction for diagnosing cardiovascular diseases remains time-consuming and subjective. We developed CineMA, a foundation AI model automating these tasks with limited labels. CineMA is a self-supervised autoencoder model trained on 74,916 cine CMR studies to reconstruct images from masked inputs. After fine-tuning, it was evaluated across eight datasets on 23 tasks from four categories: ventricle and myocardium segmentation, left and right ventricle ejection fraction calculation, disease detection and classification, and landmark localisation. CineMA is the first foundation model for cine CMR to match or outperform convolutional neural networks (CNNs). CineMA demonstrated greater label efficiency than CNNs, achieving comparable or better performance with fewer annotations. This reduces the burden of clinician labelling and supports replacing task-specific training with fine-tuning foundation models in future cardiac imaging applications. Models and code for pre-training and fine-tuning are available at https://github.com/mathpluscode/CineMA, democratising access to high-performance models that otherwise require substantial computational resources, promoting reproducibility and accelerating clinical translation.
心脏磁共振成像(CMR)是临床心血管医学中的一项重要检查手段,已被广泛应用于人群研究。然而,提取诸如射血分数等用于诊断心血管疾病的临床重要指标仍然耗时且主观。我们开发了一种名为CineMA的基于人工智能的自动化模型,使用有限标签来完成这些任务。CineMA是一个自监督式自动编码器模型,在74916个电影CMR研究上训练,用于从屏蔽输入中重建图像。经过微调后,它在四个类别的23个任务上进行了评估,包括心室和心肌分割、左心室和右心室射血分数计算、疾病检测和分类以及地标定位。CineMA是第一个匹配或超越卷积神经网络(CNN)的电影CMR基础模型。CineMA证明了更高的标签效率,使用较少的注释即可实现相当或更好的性能。这减少了医生标注的负担,支持在未来心脏成像应用中用微调基础模型替代特定任务的训练。预训练和微调模型和代码可在https://github.com/mathpluscode/CineMA获取,使得以往需要大量计算资源的高性能模型得以普及,促进可复制性并加速临床转化。
论文及项目相关链接
Summary
基于心脏磁共振成像的智能诊断模型研究。本文介绍了一种新型的自动化心脏磁共振成像诊断模型CineMA,能够减少临床医生标记工作负担,提高诊断效率。CineMA模型通过自监督学习训练,能够重建被遮挡的输入图像,并在多个数据集上表现出优异的性能。该模型在心室和心肌分割、左心室和右心室射血分数计算、疾病检测和分类以及地标定位等方面均表现出卓越的能力,可与卷积神经网络(CNN)匹配或超越其性能。此外,该模型更加高效利用标注数据,能够以更少的标注信息实现优良效果。这一研究成果可促进将来心脏成像应用中使用预训练与微调结合的通用模型代替任务特定模型的趋势。模型和相关代码已公开发布,便于公众访问和使用。
Key Takeaways
- CineMA是一个用于心脏磁共振成像的智能诊断模型,广泛应用于临床心血管医学中的关键检查。
- CineMA是一个自监督学习的自动编码器模型,能够在有限标签的情况下自动化进行心脏相关任务。
- CineMA在多个数据集上的多个任务中表现出优异性能,包括心室和心肌分割、射血分数计算等。
- CineMA在匹配或超越卷积神经网络性能的同时,显示出更高的标签效率,即用更少的标注信息实现更好的效果。
- CineMA模型减轻了临床医生标记的工作负担,并可能推动未来心脏成像应用中使用预训练和微调结合的基础模型的趋势。
- CineMA模型和代码已公开发布,便于公众访问和使用,有助于促进模型的普及和临床转化。
点此查看论文截图

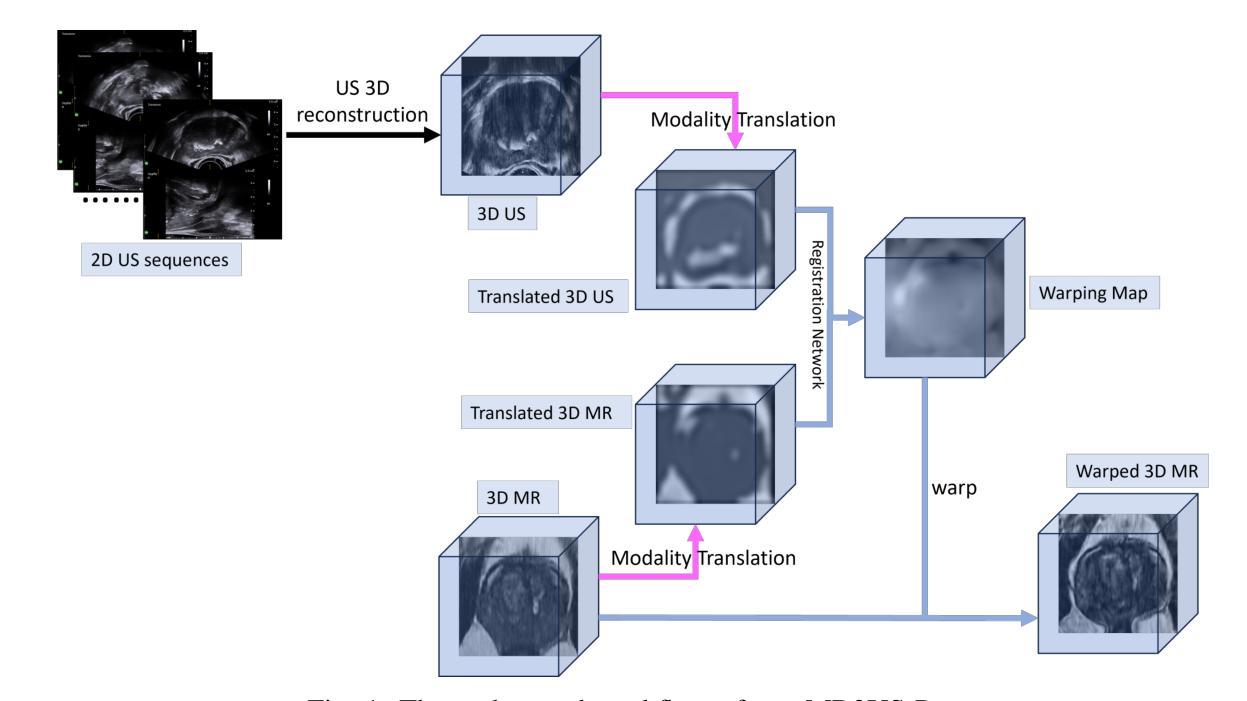
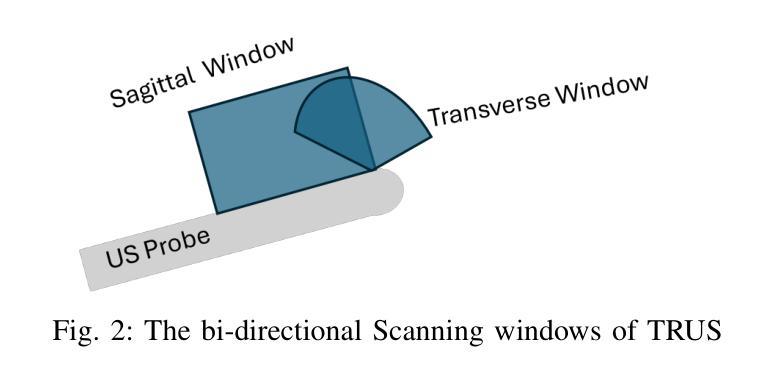
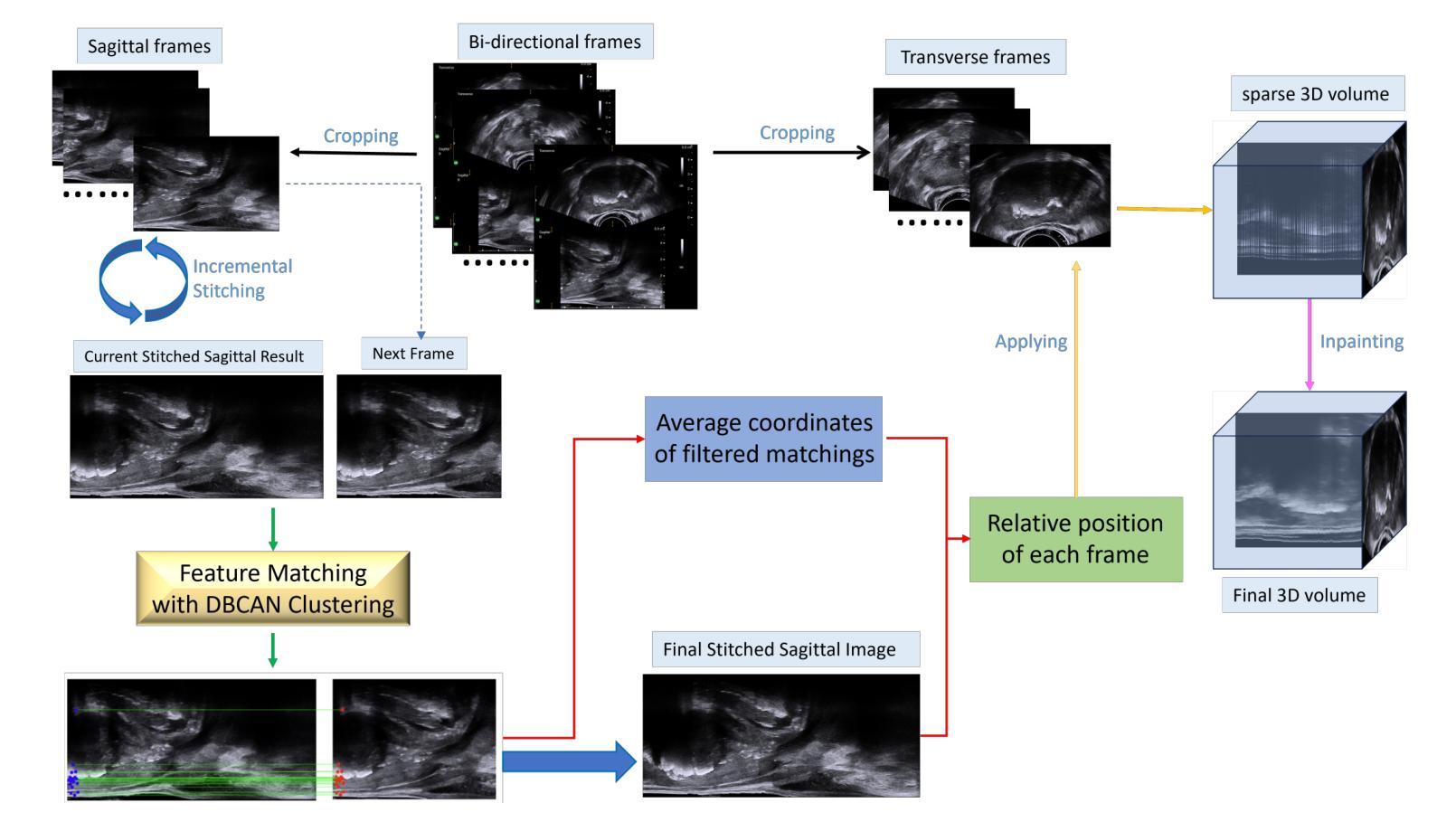
MR2US-Pro: Prostate MR to Ultrasound Image Translation and Registration Based on Diffusion Models
Authors:Xudong Ma, Nantheera Anantrasirichai, Stefanos Bolomytis, Alin Achim
The diagnosis of prostate cancer increasingly depends on multimodal imaging, particularly magnetic resonance imaging (MRI) and transrectal ultrasound (TRUS). However, accurate registration between these modalities remains a fundamental challenge due to the differences in dimensionality and anatomical representations. In this work, we present a novel framework that addresses these challenges through a two-stage process: TRUS 3D reconstruction followed by cross-modal registration. Unlike existing TRUS 3D reconstruction methods that rely heavily on external probe tracking information, we propose a totally probe-location-independent approach that leverages the natural correlation between sagittal and transverse TRUS views. With the help of our clustering-based feature matching method, we enable the spatial localization of 2D frames without any additional probe tracking information. For the registration stage, we introduce an unsupervised diffusion-based framework guided by modality translation. Unlike existing methods that translate one modality into another, we map both MR and US into a pseudo intermediate modality. This design enables us to customize it to retain only registration-critical features, greatly easing registration. To further enhance anatomical alignment, we incorporate an anatomy-aware registration strategy that prioritizes internal structural coherence while adaptively reducing the influence of boundary inconsistencies. Extensive validation demonstrates that our approach outperforms state-of-the-art methods by achieving superior registration accuracy with physically realistic deformations in a completely unsupervised fashion.
前列腺癌的诊断越来越依赖于多模态成像,特别是磁共振成像(MRI)和经直肠超声(TRUS)。然而,由于维度和解剖表现上的差异,这些模式之间的准确配准仍然是一个基本挑战。在这项工作中,我们提出了一种新的框架来解决这些挑战,该框架采用两个阶段的过程:TRUS 3D重建和跨模态配准。与现有的严重依赖于外部探针跟踪信息的TRUS 3D重建方法不同,我们提出了一种完全独立于探针位置的方法,该方法利用矢状和横向TRUS视图之间的自然相关性。借助我们的基于聚类的特征匹配方法,我们可以实现在没有任何额外的探针跟踪信息的情况下进行2D帧的空间定位。对于配准阶段,我们引入了一个无监督的基于扩散的框架,该框架由模态翻译引导。与其他将一种模态翻译到另一种模态的方法不同,我们将MR和US映射到一个伪中间模态。这种设计使我们能够定制它,仅保留关键的配准特征,从而极大地简化了配准过程。为了进一步提高解剖对齐程度,我们采用了解剖结构感知的配准策略,该策略优先考虑内部结构的连贯性,同时自适应地减少边界不一致的影响。广泛的验证表明,我们的方法在物理现实变形的情况下以完全无监督的方式实现了卓越的配准精度,优于现有先进技术的方法。
论文及项目相关链接
Summary:
多模态成像技术日益成为前列腺癌诊断的关键,包括磁共振成像和经直肠超声技术。针对两者注册准确性问题,研究团队提出一种新颖的框架,包括三维重建和跨模态注册两个阶段。该研究创新性地提出一种完全独立于探针位置的方法,采用自然相关性和聚类特征匹配实现二维空间定位,为后续注册提供便利。通过采用基于扩散的无监督方法将磁共振成像与超声成像转化为伪中间模态注册策略进行优化调整。此法提升了身体现实形变状态下的注册精准度并满足实际需求场景的要求。有望极大提高前列腺癌诊疗效率与准确度。
Key Takeaways:
- 多模态成像技术,特别是磁共振成像和经直肠超声技术在前列腺癌诊断中的重要性不断上升。
- 现有技术在多模态图像注册方面面临挑战,包括维度差异和解剖结构表示的不同。
- 研究团队提出了一种新颖的框架来解决这些挑战,包括三维重建和跨模态注册两个阶段。
- 提出了一种完全独立于探针位置的方法,利用自然相关性和聚类特征匹配进行空间定位。
点此查看论文截图