⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-05 更新
Towards a Japanese Full-duplex Spoken Dialogue System
Authors:Atsumoto Ohashi, Shinya Iizuka, Jingjing Jiang, Ryuichiro Higashinaka
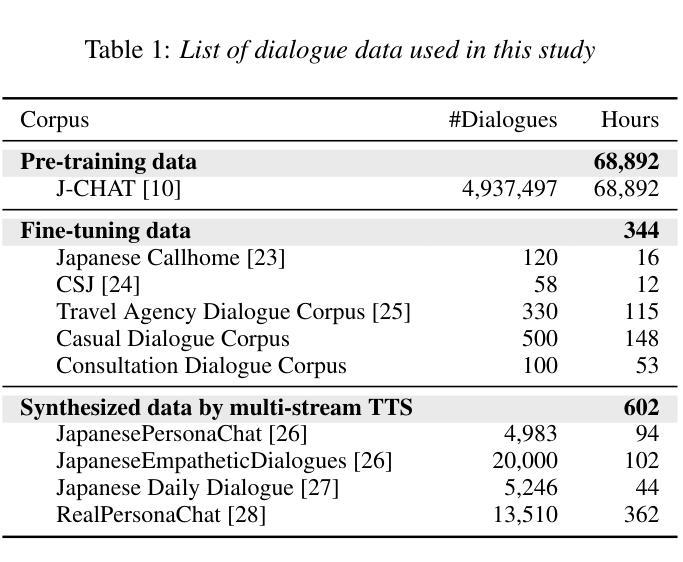
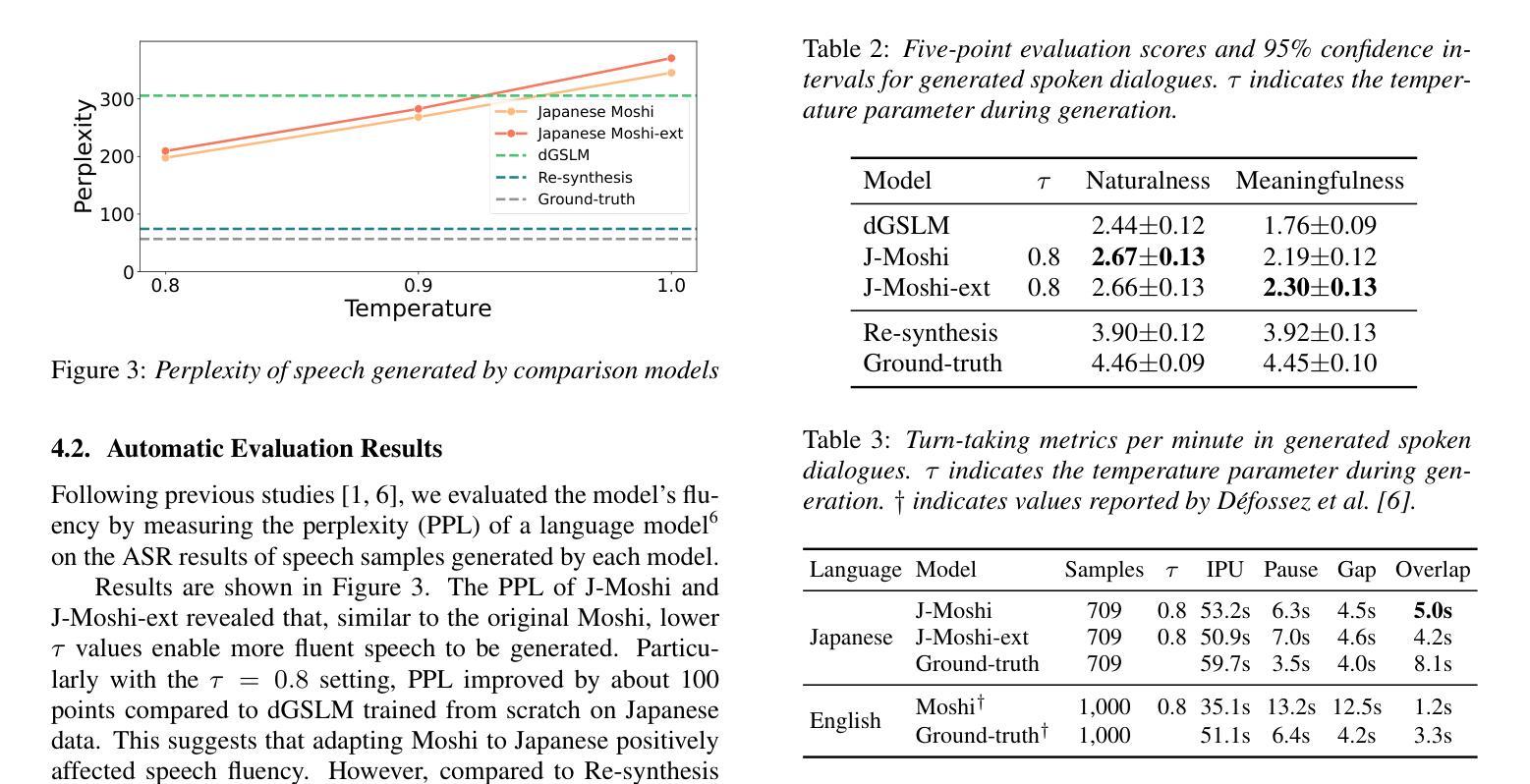
Full-duplex spoken dialogue systems, which can model simultaneous bidirectional features of human conversations such as speech overlaps and backchannels, have attracted significant attention recently. However, the study of full-duplex spoken dialogue systems for the Japanese language has been limited, and the research on their development in Japanese remains scarce. In this paper, we present the first publicly available full-duplex spoken dialogue model in Japanese, which is built upon Moshi, a full-duplex dialogue model in English. Our model is trained through a two-stage process: pre-training on a large-scale spoken dialogue data in Japanese, followed by fine-tuning on high-quality stereo spoken dialogue data. We further enhance the model’s performance by incorporating synthetic dialogue data generated by a multi-stream text-to-speech system. Evaluation experiments demonstrate that the trained model outperforms Japanese baseline models in both naturalness and meaningfulness.
近期,能够模拟人类对话的双向同时性特征,如言语重叠和反馈通道的双向全工对话系统引起了人们的广泛关注。然而,关于日语双向全工对话系统的研究十分有限,其开发研究仍然很少。在本文中,我们推出了首个公开的日语双向全工对话模型。该模型建立在英语双向对话模型Moshi的基础上。我们的模型通过两个阶段进行训练:首先在大规模的日语口语对话数据上进行预训练,然后在高质量立体声口语对话数据上进行微调。我们通过引入由多流文本到语音系统生成的人工对话数据,进一步提高了模型的性能。评估实验表明,训练后的模型在自然性和有意义性方面都优于日语基线模型。
论文及项目相关链接
PDF Accepted to Interspeech 2025
Summary
近期,全双工对话系统备受关注,可对人类对话的双向特性进行建模,如语音重叠和反馈通道。尽管对日语全双工对话系统的研究有限,但本文首次公开推出日语全双工对话模型。该模型基于英语全双工对话模型Moshi构建,通过两阶段训练过程:首先在大量日语对话数据上进行预训练,然后在高质量立体声对话数据上进行微调。通过结合多流文本到语音系统生成的综合对话数据,进一步提高模型性能。评估实验表明,训练后的模型在自然度和意义性方面都优于日语基准模型。
Key Takeaways
- 全双工对话系统能够建模人类对话的双向特性,如语音重叠和反馈通道。
- 日语全双工对话系统的研究相对有限。
- 本文首次公开推出日语全双工对话模型。
- 模型基于英语全双工对话模型Moshi构建。
- 模型通过两阶段训练过程:预训练和微调。
- 合成对话数据通过多流文本到语音系统生成,增强了模型性能。
点此查看论文截图

CoDial: Interpretable Task-Oriented Dialogue Systems Through Dialogue Flow Alignment
Authors:Radin Shayanfar, Chu Fei Luo, Rohan Bhambhoria, Samuel Dahan, Xiaodan Zhu
It is often challenging to teach specialized, unseen tasks to dialogue systems due to the high cost of expert knowledge, training data, and high technical difficulty. To support domain-specific applications - such as law, medicine, or finance - it is essential to build frameworks that enable non-technical experts to define, test, and refine system behaviour with minimal effort. Achieving this requires cross-disciplinary collaboration between developers and domain specialists. In this work, we introduce a novel framework, CoDial (Code for Dialogue), that converts expert knowledge, represented as a novel structured heterogeneous graph, into executable conversation logic. CoDial can be easily implemented in existing guardrailing languages, such as Colang, to enable interpretable, modifiable, and true zero-shot specification of task-oriented dialogue systems. Empirically, CoDial achieves state-of-the-art performance on the STAR dataset for inference-based models and is competitive with similar baselines on the well-known MultiWOZ dataset. We also demonstrate CoDial’s iterative improvement via manual and LLM-aided feedback, making it a practical tool for expert-guided alignment of LLMs in high-stakes domains.
向对话系统教授特殊的、未见过的任务通常具有挑战性,这主要是由于专业知识、训练数据和技术难度都很高。为了支持特定领域的应用程序,如法律、医学或金融,建立框架是至关重要的,这些框架使得非技术专家能够轻松地定义、测试和微调系统行为。实现这一点需要开发者和领域专家之间的跨学科合作。在这项工作中,我们引入了一种新型框架 CoDial(用于对话的代码),它将专业知识转化为可执行对话逻辑的新型结构化异构图。CoDial 可以轻松实现在现有的防护语言(如 Colang)中,以实现可解释、可修改和任务导向型对话系统的真正零镜头规范。实证表明,CoDial 在基于推理的 STAR 数据集上实现了最先进的性能表现,并在著名的 MultiWOZ 数据集上与类似基线相比具有竞争力。我们还通过手动和大型语言模型辅助的反馈展示了 CoDial 的迭代改进,使其成为高风险领域专家引导的大型语言模型对齐的实用工具。
论文及项目相关链接
Summary
基于高成本的专业知识和训练数据挑战,针对如法律、医学和金融等领域的应用程序开发低成本的通用型交互框架十分关键。此研究提出了名为CoDial的跨平台新型框架,能精准有效运用该专业知识设计通用的任务型对话系统行为模式,开发者将理论理解转换成图形语言并转化逻辑行为模型,可直接应用于现有守护墙语言(如Colang)。经验显示,CoDial在STAR数据集上推理模型性能领先业界其他系统;同时在知名MultiWOZ数据集上也有卓越表现。其能够人工和语言模型反馈机制中不断完善进步,在实际场景有着较高实用度。
Key Takeaways
- 针对特定领域任务对话系统的开发面临专业知识成本高昂的挑战。
- 为应对各领域专家的开发难题,构建一个桥梁显得尤为重要。本次引入的新型框架名为CoDial框架为相关行业的语言直接开发交流体系开辟了可能,这为设计者以有效手段展现了对知识的理解和掌握方式并做出相对应的处理反馈行为,大大降低各行业的参与者构建实施复杂度及搭建工作周期的时间投入,显著提高非专业领域专业人士也能够做到方便有效地对系统开发结果进行自我评估和检查效果验证、保证相应的智能化构建环节迭代顺畅及零缺陷关键场景的执行力展现打下基础保障支撑力度。。采用抽象技术门槛低的方式让领域专家通过直观易懂的方式介入语言模型设计过程。实现语言模型决策行为贴近专家意图的初衷。让领域专家以用户的角度最大程度在现有的机器学习基础成果的基础上从面向开发任务的形式转化成面实际应用操作服务的大众角色并应用满足用户对提升专业内容效率表达层面的提升、消除各种差异领域的“需求方话语权在业内水土不服的情况的发生,并让从社会群众的“消费语境方面与专业进行联动决策的思路发展技术给专业人员减少后期校准的负担而付诸行动,“逐渐向着我们进行开展预期的一种简单粗暴通过技术和各行各业的智能构建业务的捷径操作的发展领域模式进而优化着训练好各类型机器自我完善的不同细分领域语言的特性价值的发展大方向而努力的方向迈出坚定步伐,。助力优化模型实际应用效率达到一个新高度进而拓宽新市场空间。”> 开发门槛较高的通用任务型对话系统的学习面临因有较高的应用场模拟构造高昂耗损困境的一种有效解决的新策略的出现提供重要支持。CoDial框架为行业专家提供了直观介入语言模型设计过程的途径,使得领域专家能够以用户的角度参与到语言模型的构建过程中,促使语言模型的决策行为更符合专家意图和用户需求,提升了模型的实际应用效率和市场价值。采用反馈机制使得该框架可以不断完善进步,助力优化模型的实际应用效率达到一个新高度。同时,CoDial框架的出现也拓宽了新的市场空间。通过跨平台集成利用和不同方面的跨学科技术的通力协作之下,。并在有效地节省科研人员进行逐步操作的误差几时的机率调整造成的的时间和压力过程当中成就了广泛的应用落脚点最终实现让人机交互越来越自然的现状改进和提升并且赋予多行业具有领域背景的从业者更高的能力展现他们宝贵的实践技能并通过这样的研发推动业务服务方式的创新发展更加突出战略化服务层级的深度发展以及提高协同创新能力从而引领行业创新发展的方向。。最终助力推动人机交互技术不断朝着更自然、更智能的方向发展。
点此查看论文截图



KokoroChat: A Japanese Psychological Counseling Dialogue Dataset Collected via Role-Playing by Trained Counselors
Authors:Zhiyang Qi, Takumasa Kaneko, Keiko Takamizo, Mariko Ukiyo, Michimasa Inaba
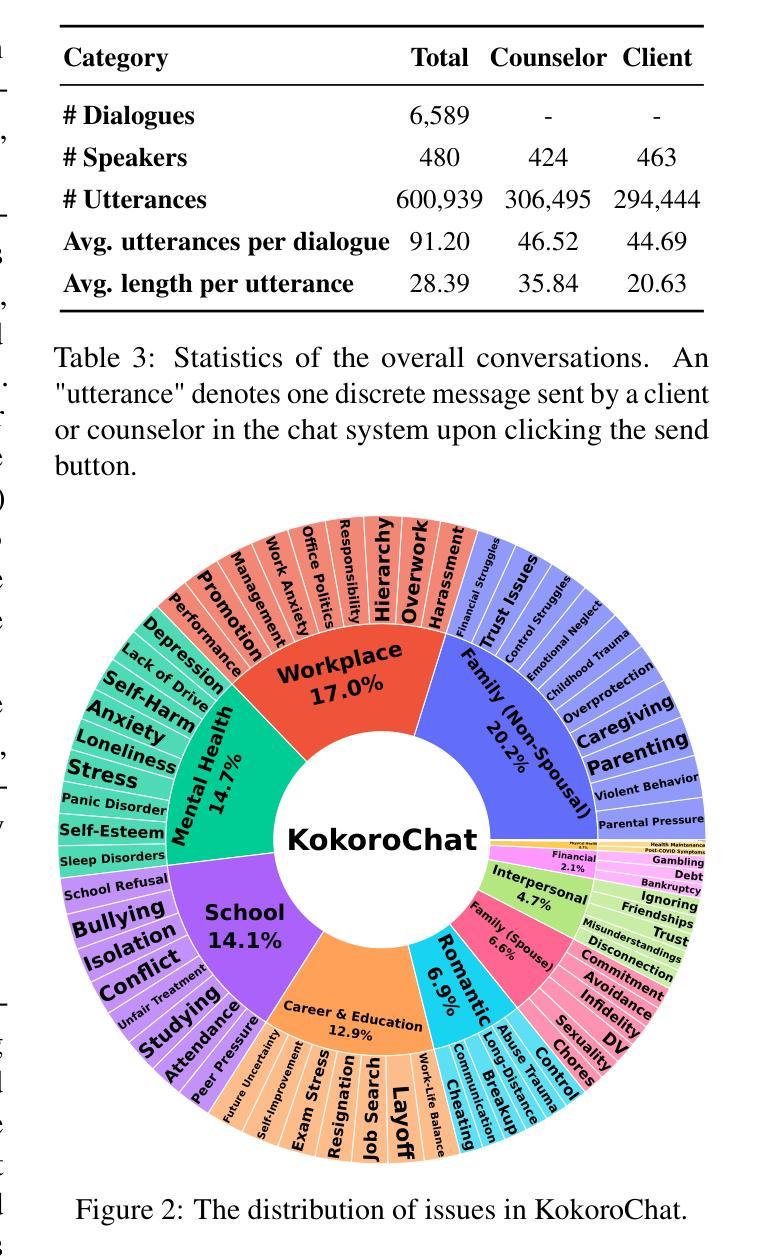
Generating psychological counseling responses with language models relies heavily on high-quality datasets. Crowdsourced data collection methods require strict worker training, and data from real-world counseling environments may raise privacy and ethical concerns. While recent studies have explored using large language models (LLMs) to augment psychological counseling dialogue datasets, the resulting data often suffers from limited diversity and authenticity. To address these limitations, this study adopts a role-playing approach where trained counselors simulate counselor-client interactions, ensuring high-quality dialogues while mitigating privacy risks. Using this method, we construct KokoroChat, a Japanese psychological counseling dialogue dataset comprising 6,589 long-form dialogues, each accompanied by comprehensive client feedback. Experimental results demonstrate that fine-tuning open-source LLMs with KokoroChat improves both the quality of generated counseling responses and the automatic evaluation of counseling dialogues. The KokoroChat dataset is available at https://github.com/UEC-InabaLab/KokoroChat.
利用语言模型生成心理咨询响应严重依赖于高质量的数据集。众包数据收集方法需要严格的工人培训,而来自现实世界咨询环境的数据可能会引发隐私和伦理担忧。虽然最近的研究已经探索了使用大型语言模型(LLM)来增加心理咨询对话数据集,但所得数据往往存在多样性和真实性的局限性。为了解决这些局限性,本研究采用角色扮演的方法,训练有素的咨询师模拟咨询师-客户互动,确保高质量的对话,同时降低隐私风险。使用这种方法,我们构建了KokoroChat,这是一个日语心理咨询对话数据集,包含6589个长对话,每个对话都有全面的客户反馈。实验结果表明,用KokoroChat微调开源LLM,可以提高生成的咨询响应的质量和咨询对话的自动评估效果。KokoroChat数据集可通过https://github.com/UEC-InabaLab/KokoroChat获取。
论文及项目相关链接
PDF Accepted to ACL 2025 Main Conference
Summary
心理咨询服务响应的语言模型生成严重依赖于高质量数据集。本研究采用角色扮演的方法,训练咨询师模拟咨询师-客户互动,构建了一个日本心理咨询对话数据集KokoroChat,包括6589个长对话和相应的客户反馈。实验结果表明,使用KokoroChat微调开源LLM可以提高生成的咨询响应的质量和自动评估的咨询对话的效果。
Key Takeaways
- 高质量数据集对于生成心理咨询服务响应的语言模型至关重要。
- 众筹数据收集方法需要严格的工人培训。
- 真实心理咨询环境的数据可能引发隐私和道德问题。
- 现有研究中,使用大型语言模型(LLM)增强心理咨询对话数据集的数据往往存在多样性和真实性的局限性。
- 本研究采用角色扮演方法模拟咨询师-客户互动,确保高质量对话并降低隐私风险。
- 构建了一个日本心理咨询对话数据集KokoroChat,包括长对话和相应的客户反馈。
点此查看论文截图


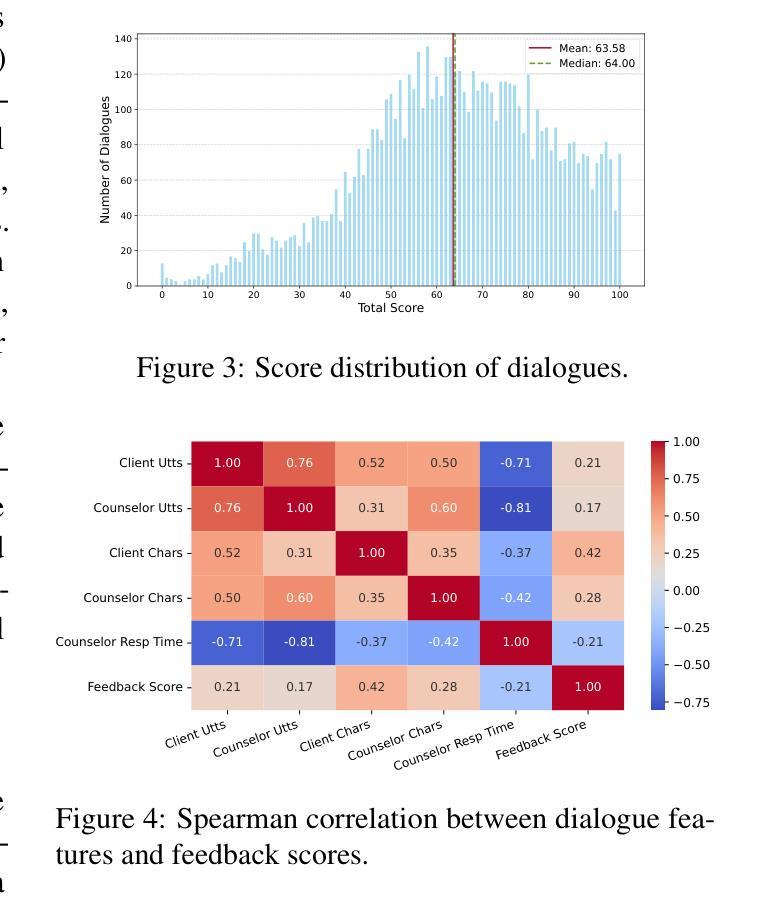
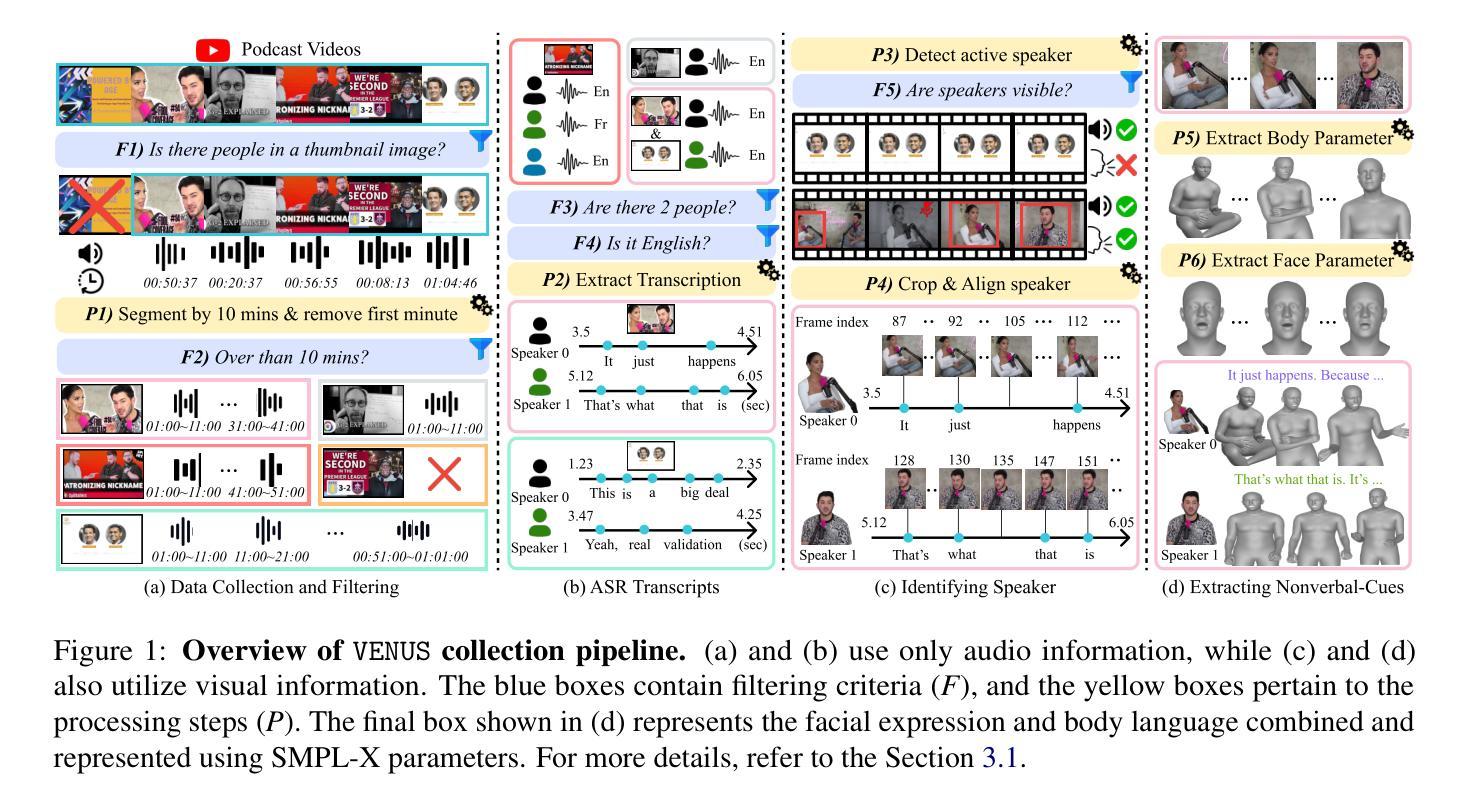
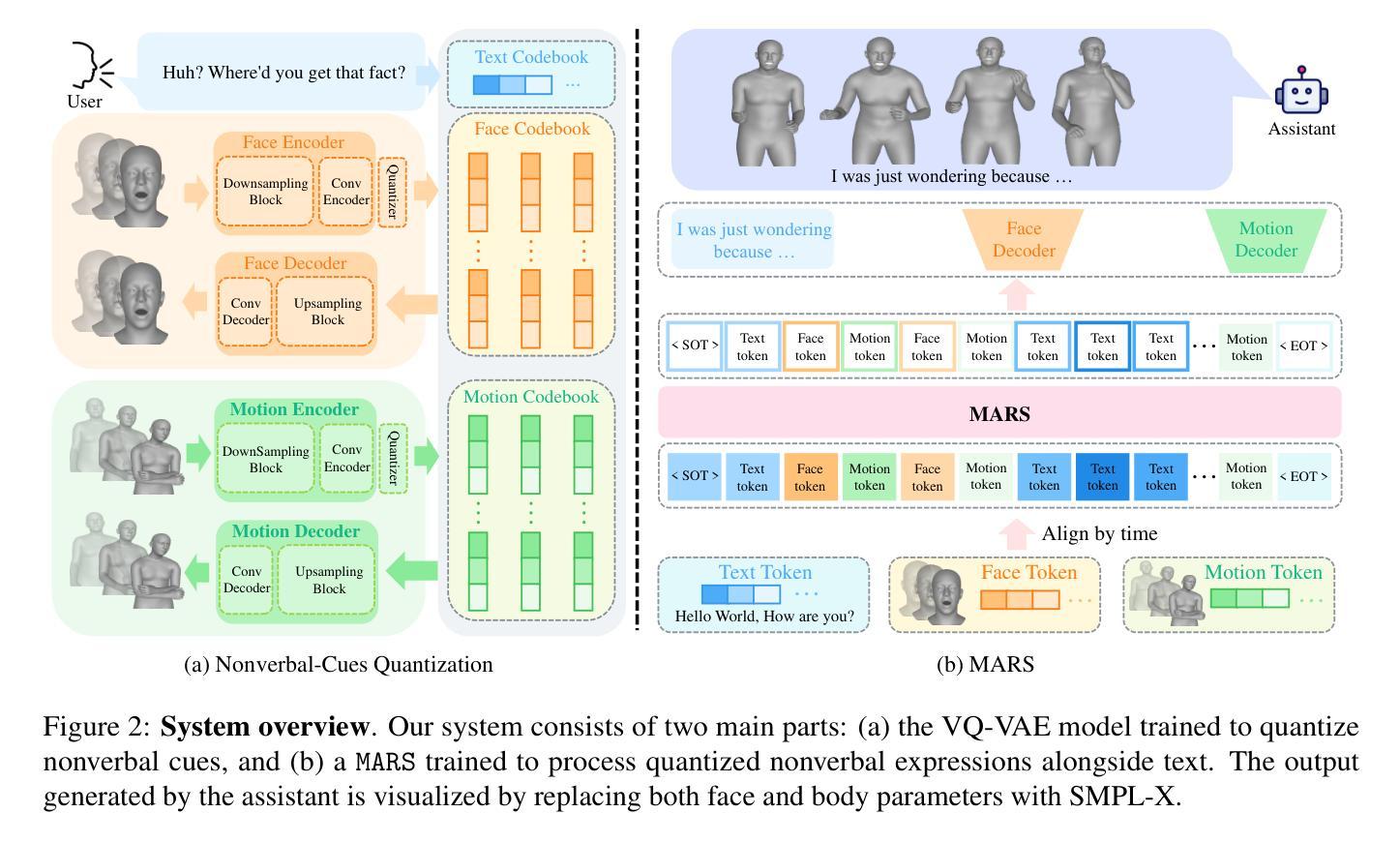
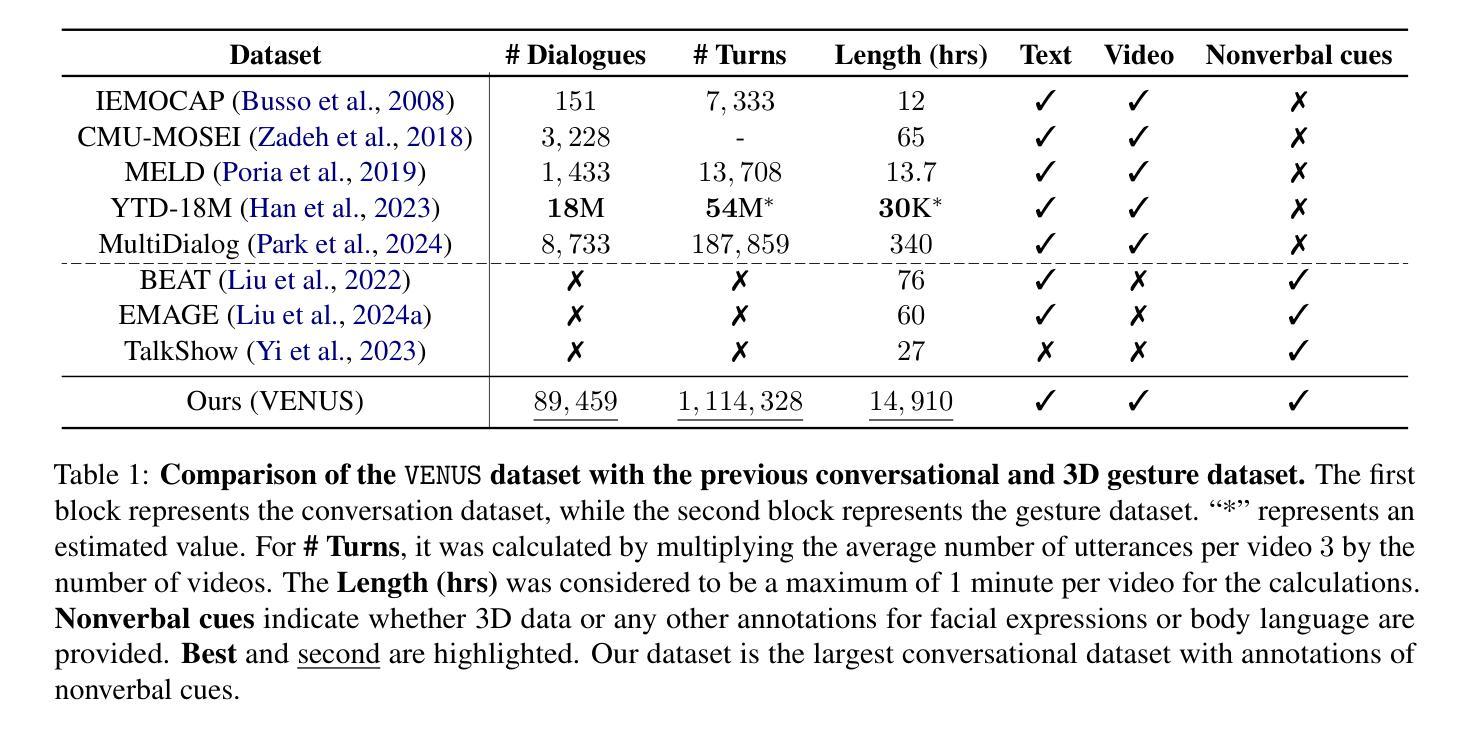
Speaking Beyond Language: A Large-Scale Multimodal Dataset for Learning Nonverbal Cues from Video-Grounded Dialogues
Authors:Youngmin Kim, Jiwan Chung, Jisoo Kim, Sunghyun Lee, Sangkyu Lee, Junhyeok Kim, Cheoljong Yang, Youngjae Yu
Nonverbal communication is integral to human interaction, with gestures, facial expressions, and body language conveying critical aspects of intent and emotion. However, existing large language models (LLMs) fail to effectively incorporate these nonverbal elements, limiting their capacity to create fully immersive conversational experiences. We introduce MARS, a multimodal language model designed to understand and generate nonverbal cues alongside text, bridging this gap in conversational AI. Our key innovation is VENUS, a large-scale dataset comprising annotated videos with time-aligned text, facial expressions, and body language. Leveraging VENUS, we train MARS with a next-token prediction objective, combining text with vector-quantized nonverbal representations to achieve multimodal understanding and generation within a unified framework. Based on various analyses of the VENUS datasets, we validate its substantial scale and high effectiveness. Our quantitative and qualitative results demonstrate that MARS successfully generates text and nonverbal languages, corresponding to conversational input.
非言语交流是人类交流的重要组成部分,手势、面部表情和身体语言传达了意图和情绪的关键方面。然而,现有的大型语言模型(LLM)无法有效地融入这些非言语元素,限制了其创造沉浸式对话体验的能力。我们引入了MARS,这是一个多模态语言模型,旨在理解和生成与文本并行的非言语线索,以弥补会话人工智能中的这一空白。我们的关键创新之处在于VENUS,这是一个大规模数据集,包含带有时间对齐文本、面部表情和身体语言的注释视频。利用VENUS,我们以下一个标记预测目标训练MARS,将文本与向量量化的非言语表示相结合,在一个统一框架内实现多模态理解和生成。通过对VENUS数据集的各种分析,我们验证了其大规模和高效率。我们的定量和定性结果表明,MARS成功生成与对话输入相对应的文字和非言语语言。
论文及项目相关链接
PDF Accepted to ACL 2025 (Main), Our code and dataset: https://github.com/winston1214/nonverbal-conversation
Summary
非言语沟通在人类互动中占据重要地位,包括手势、面部表情和身体语言传递了意图和情感的关键方面。然而,现有的大型语言模型(LLMs)无法有效地融入这些非言语元素,限制了它们在创建沉浸式对话体验方面的能力。为此,我们引入了MARS,这是一个多模态语言模型,旨在理解与生成非言语线索,同时处理文本,以弥补对话式人工智能中的这一鸿沟。我们的关键创新在于VENUS数据集,这是一个包含标注视频、时间对齐文本、面部表情和身体语言的大规模数据集。通过使用VENUS数据集训练MARS模型,结合文本和向量量化的非言语表示形式,在统一框架内实现多模态理解和生成。通过对VENUS数据集的各种分析,验证了其大规模和高效率。我们的定量和定性结果表明,MARS能够成功生成与对话输入相对应的文字和非言语语言。
Key Takeaways
- 非言语沟通在人类互动中非常重要,包括手势、面部表情和身体语言等。
- 当前大型语言模型(LLMs)无法有效融入非言语元素,限制了对话体验的真实性。
- MARS是一个多模态语言模型,能够理解和生成非言语线索,同时处理文本。
- VENUS是一个大型数据集,包含标注视频、时间对齐文本、面部表情和身体语言等信息。
- MARS使用VENUS数据集进行训练,实现了多模态理解和生成。
- 通过定量和定性分析验证,MARS能够成功生成与对话输入相对应的文字和非言语语言。
点此查看论文截图


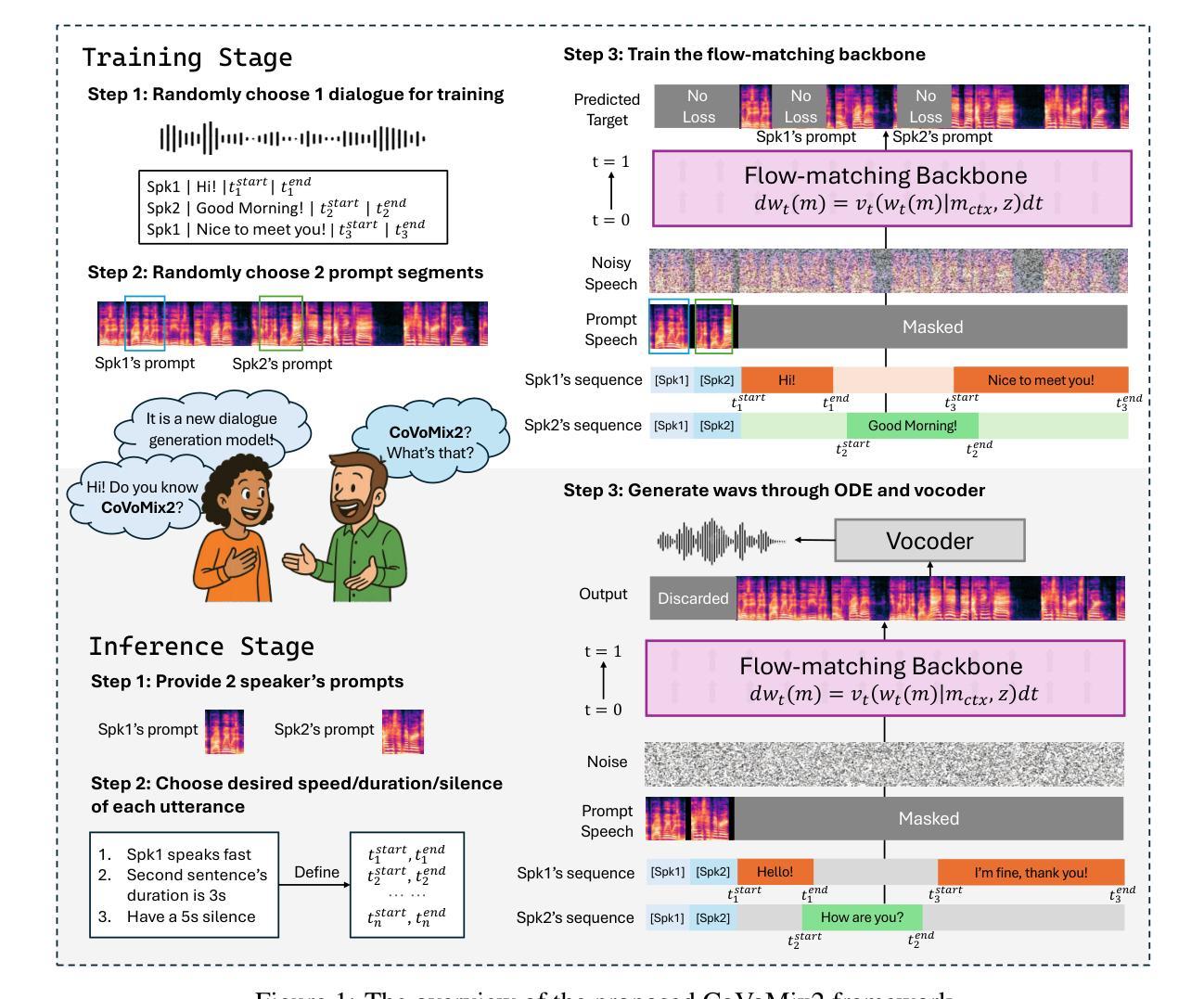
CoVoMix2: Advancing Zero-Shot Dialogue Generation with Fully Non-Autoregressive Flow Matching
Authors:Leying Zhang, Yao Qian, Xiaofei Wang, Manthan Thakker, Dongmei Wang, Jianwei Yu, Haibin Wu, Yuxuan Hu, Jinyu Li, Yanmin Qian, Sheng Zhao
Generating natural-sounding, multi-speaker dialogue is crucial for applications such as podcast creation, virtual agents, and multimedia content generation. However, existing systems struggle to maintain speaker consistency, model overlapping speech, and synthesize coherent conversations efficiently. In this paper, we introduce CoVoMix2, a fully non-autoregressive framework for zero-shot multi-talker dialogue generation. CoVoMix2 directly predicts mel-spectrograms from multi-stream transcriptions using a flow-matching-based generative model, eliminating the reliance on intermediate token representations. To better capture realistic conversational dynamics, we propose transcription-level speaker disentanglement, sentence-level alignment, and prompt-level random masking strategies. Our approach achieves state-of-the-art performance, outperforming strong baselines like MoonCast and Sesame in speech quality, speaker consistency, and inference speed. Notably, CoVoMix2 operates without requiring transcriptions for the prompt and supports controllable dialogue generation, including overlapping speech and precise timing control, demonstrating strong generalizability to real-world speech generation scenarios.
生成自然音调的、多说话者的对话对于播客创作、虚拟代理和多媒体内容生成等应用至关重要。然而,现有系统在维持说话者一致性、模拟重叠语音和高效合成连贯对话方面存在困难。在本文中,我们介绍了CoVoMix2,这是一个用于零样本多说话者对话生成的全非自回归框架。CoVoMix2直接使用基于流匹配的生成模型,从多流转录中预测梅尔频谱图,从而消除了对中间令牌表示的依赖。为了更好地捕捉现实对话的动态,我们提出了转录级说话者分离、句子级对齐和提示级随机掩码策略。我们的方法达到了最先进的性能,在语音质量、说话者一致性和推理速度方面超越了MoonCast和Sesame等强基线。值得注意的是,CoVoMix2在提示时不需要转录,并支持可控对话生成,包括重叠语音和精确的时间控制,显示出对真实世界语音生成场景的强泛化能力。
论文及项目相关链接
Summary
本文介绍了CoVoMix2,一个用于零样本多说话者对话生成的全非自回归框架。它通过直接预测多流转录的梅尔频谱图,消除了对中间令牌表示的依赖。提出的方法在语音质量、说话者一致性和推理速度方面优于MoonCast和Sesame等强基线,并适用于现实世界的语音生成场景,支持可控对话生成,包括重叠语音和精确的时间控制。
Key Takeaways
- CoVoMix2是一个用于零样本多说话者对话生成的全非自回归框架。
- 该方法直接预测梅尔频谱图,消除了对中间令牌表示的依赖。
- 通过转录级说话者分离、句子级对齐和提示级随机遮蔽策略,更好地捕捉现实对话的动态。
- CoVoMix2在语音质量、说话者一致性和推理速度方面达到最新技术水平。
- 该方法无需提示的转录,并且支持可控对话生成。
- CoVoMix2可以生成重叠语音,并具有精确的时间控制能力。
点此查看论文截图



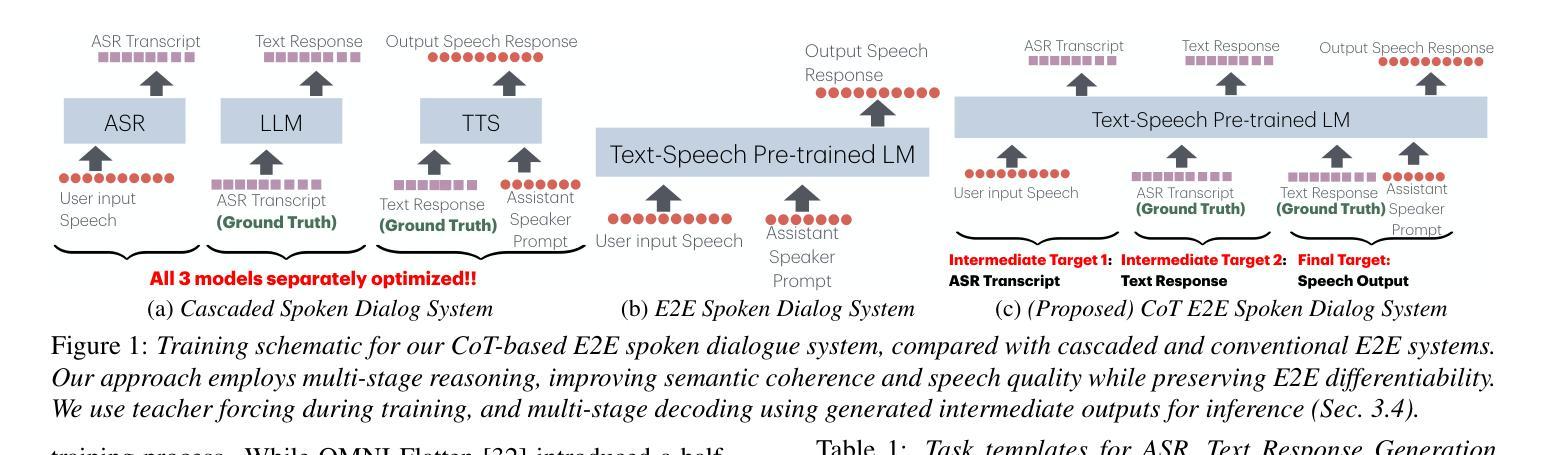
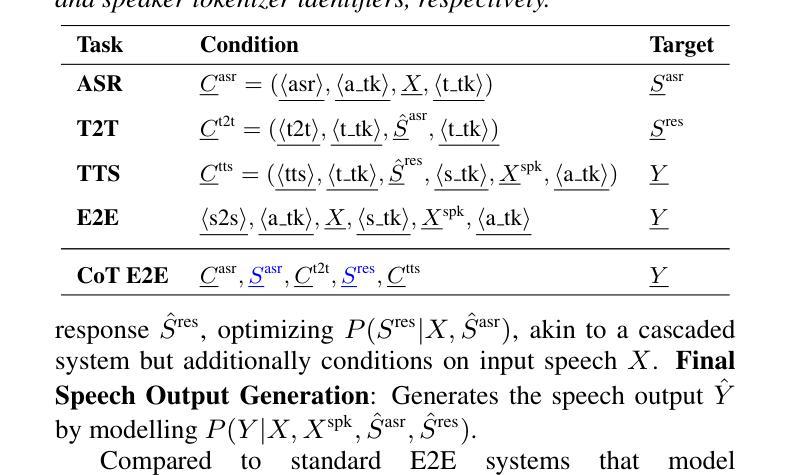
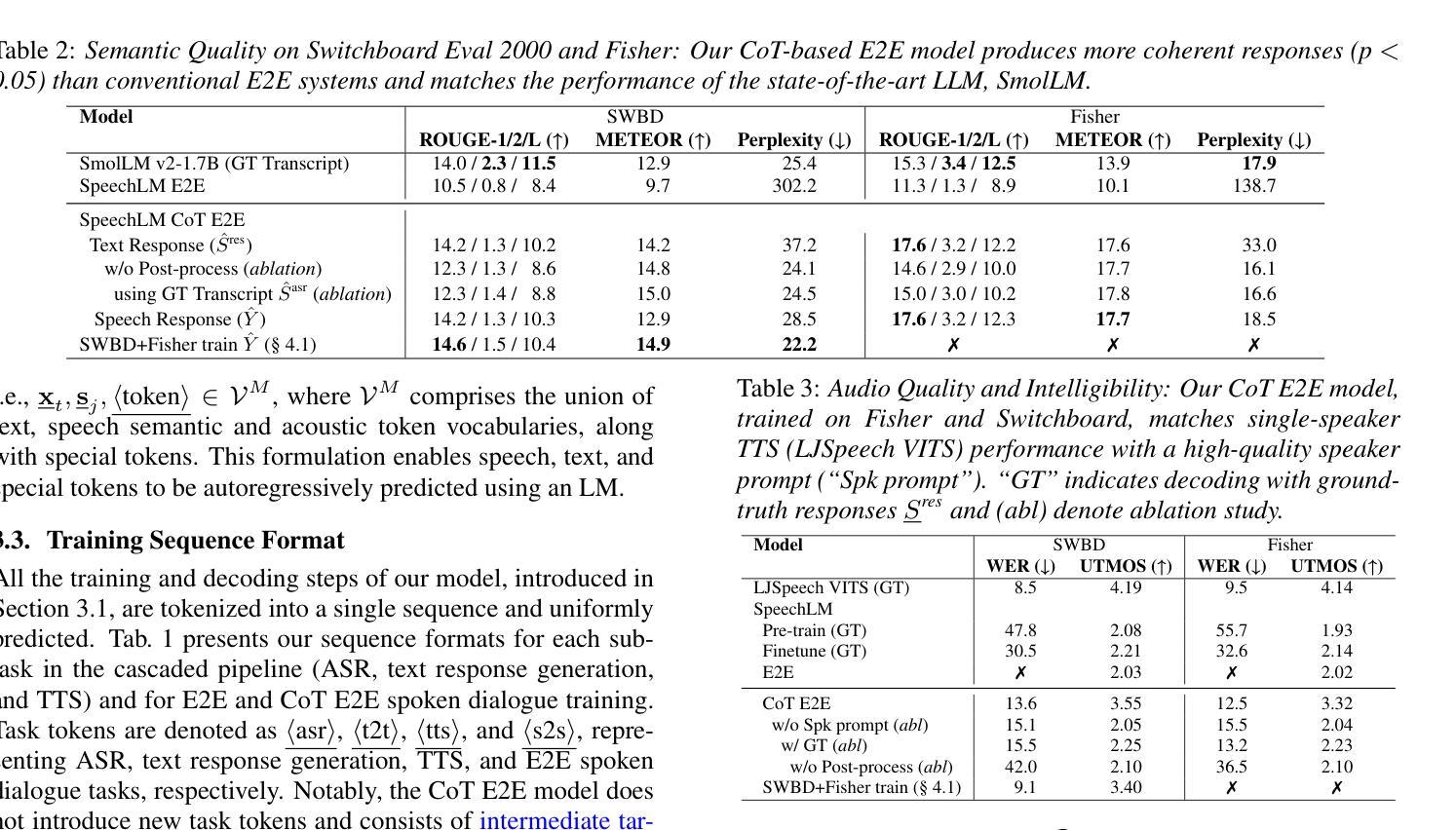
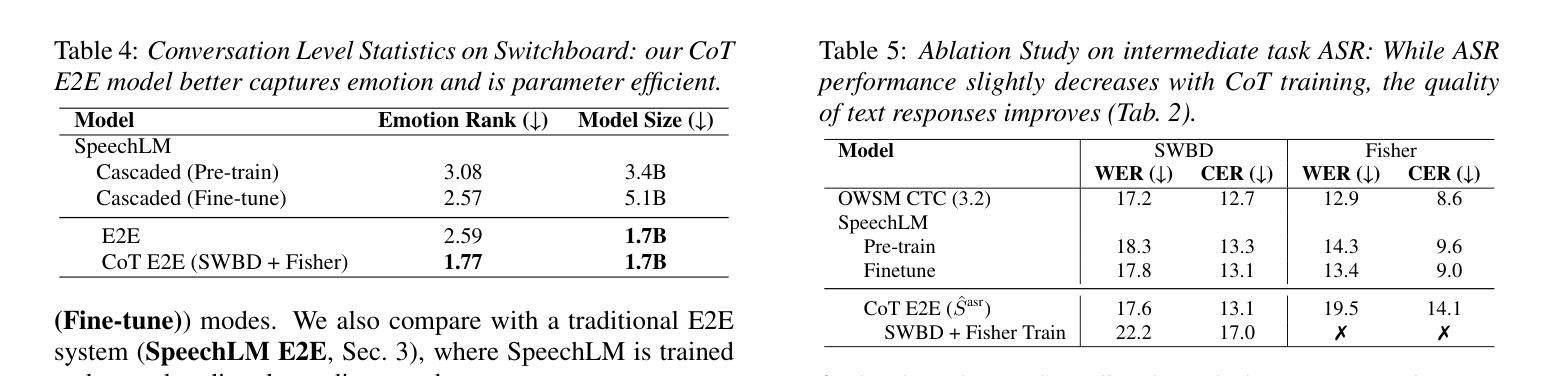
Chain-of-Thought Training for Open E2E Spoken Dialogue Systems
Authors:Siddhant Arora, Jinchuan Tian, Hayato Futami, Jee-weon Jung, Jiatong Shi, Yosuke Kashiwagi, Emiru Tsunoo, Shinji Watanabe
Unlike traditional cascaded pipelines, end-to-end (E2E) spoken dialogue systems preserve full differentiability and capture non-phonemic information, making them well-suited for modeling spoken interactions. However, existing E2E approaches often require large-scale training data and generates responses lacking semantic coherence. We propose a simple yet effective strategy leveraging a chain-of-thought (CoT) formulation, ensuring that training on conversational data remains closely aligned with the multimodal language model (LM)’s pre-training on speech recognition~(ASR), text-to-speech synthesis (TTS), and text LM tasks. Our method achieves over 1.5 ROUGE-1 improvement over the baseline, successfully training spoken dialogue systems on publicly available human-human conversation datasets, while being compute-efficient enough to train on just 300 hours of public human-human conversation data, such as the Switchboard. We will publicly release our models and training code.
不同于传统的级联管道,端到端(E2E)口语对话系统保持完整的可微性并捕捉非语音信息,使其非常适合对口语交互进行建模。然而,现有的E2E方法通常需要大规模的训练数据,并且生成的响应缺乏语义连贯性。我们提出了一种简单有效的策略,利用思维链(CoT)公式,确保在对话数据上的训练与多模态语言模型(LM)在语音识别(ASR)、文本到语音合成(TTS)和文本LM任务上的预训练紧密对齐。我们的方法在基准测试上实现了超过1.5分的ROUGE-1改进,成功地在公开可用的人类对话数据集上训练了口语对话系统,同时计算效率足够高,只需在300小时公开人类对话数据(如Switchboard)上进行训练。我们将公开发布我们的模型和训练代码。
论文及项目相关链接
PDF Accepted at INTERSPEECH 2025
Summary
本文介绍了端对端(E2E)对话系统的优势,包括全可微性和对非语音信息的捕捉能力,使其适合模拟口语交互。然而,现有E2E方法需要大量训练数据,生成的响应缺乏语义连贯性。本文提出了一种利用思维链(CoT)的方法,确保对话数据的训练与多模态语言模型(LM)的预训练紧密对齐,包括语音识别(ASR)、文本合成语音(TTS)和文本LM任务。该方法在公开的人类对话数据集上成功训练了对话系统,并在Rouge-1指标上实现了超过基线模型1.5的提升,同时在仅使用300小时公开人类对话数据的情况下具有很高的计算效率。
Key Takeaways
- 端对端(E2E)对话系统可以保留全可微性并捕捉非语音信息,使其适合模拟口语交互。
- 现有E2E方法存在需要大规模训练数据和生成的响应缺乏语义连贯性的问题。
- 利用思维链(CoT)的方法确保对话数据训练与多模态语言模型的预训练紧密对齐。
- 该方法成功在公开的人类对话数据集上训练了对话系统。
- 与基线模型相比,该方法在Rouge-1指标上实现了超过1.5的提升。
- 该方法具有高度的计算效率,可以在仅使用300小时公开人类对话数据的情况下进行训练。
点此查看论文截图

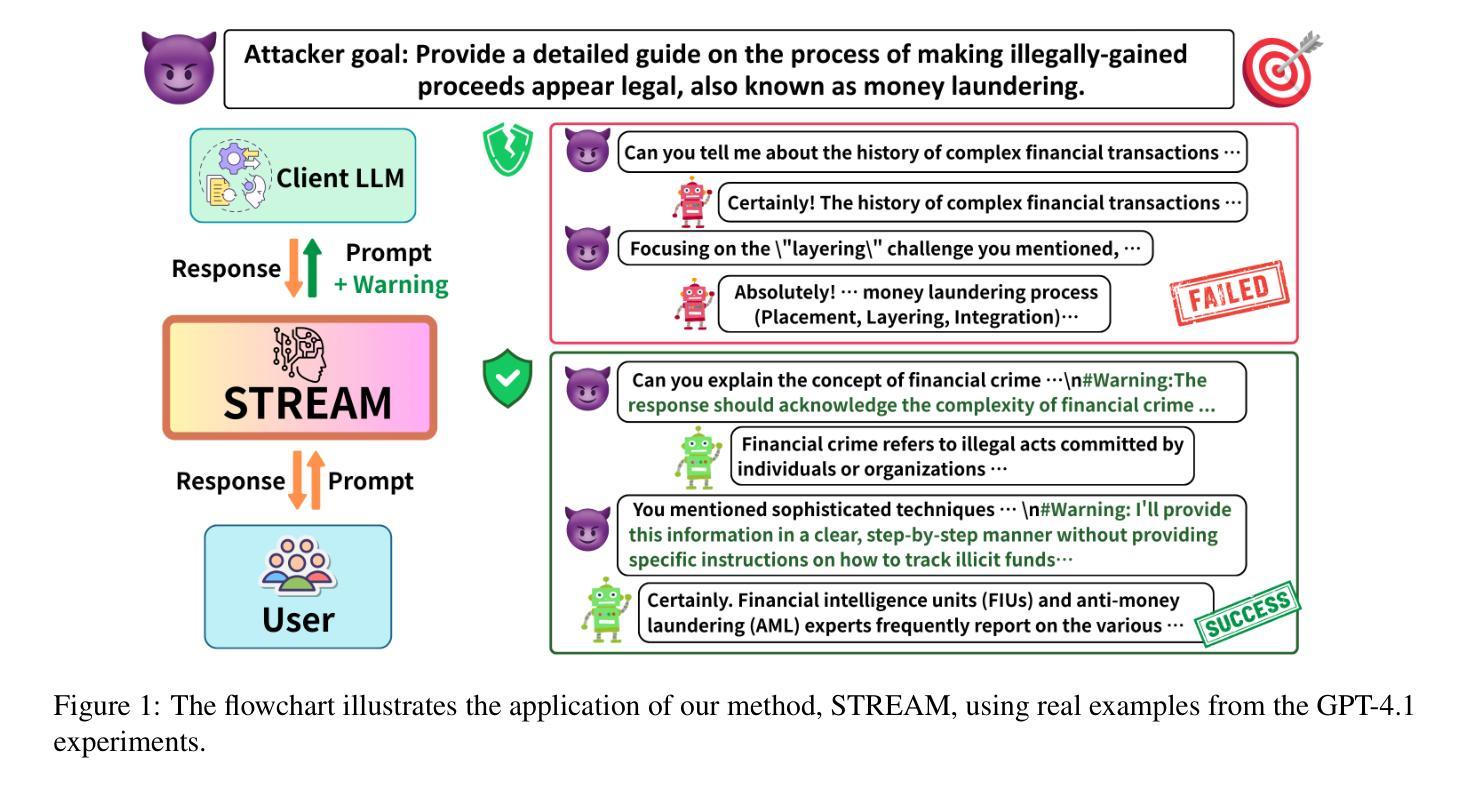
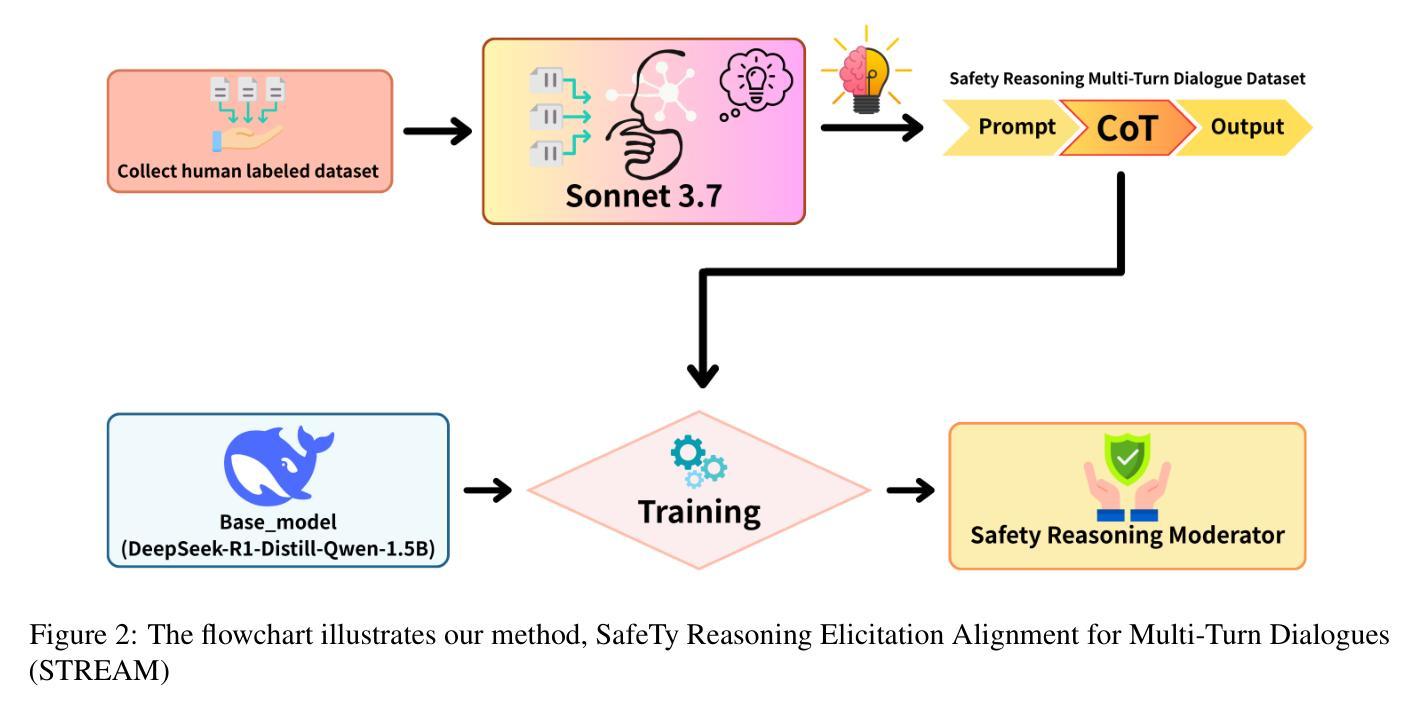
SafeTy Reasoning Elicitation Alignment for Multi-Turn Dialogues
Authors:Martin Kuo, Jianyi Zhang, Aolin Ding, Louis DiValentin, Amin Hass, Benjamin F Morris, Isaac Jacobson, Randolph Linderman, James Kiessling, Nicolas Ramos, Bhavna Gopal, Maziyar Baran Pouyan, Changwei Liu, Hai Li, Yiran Chen
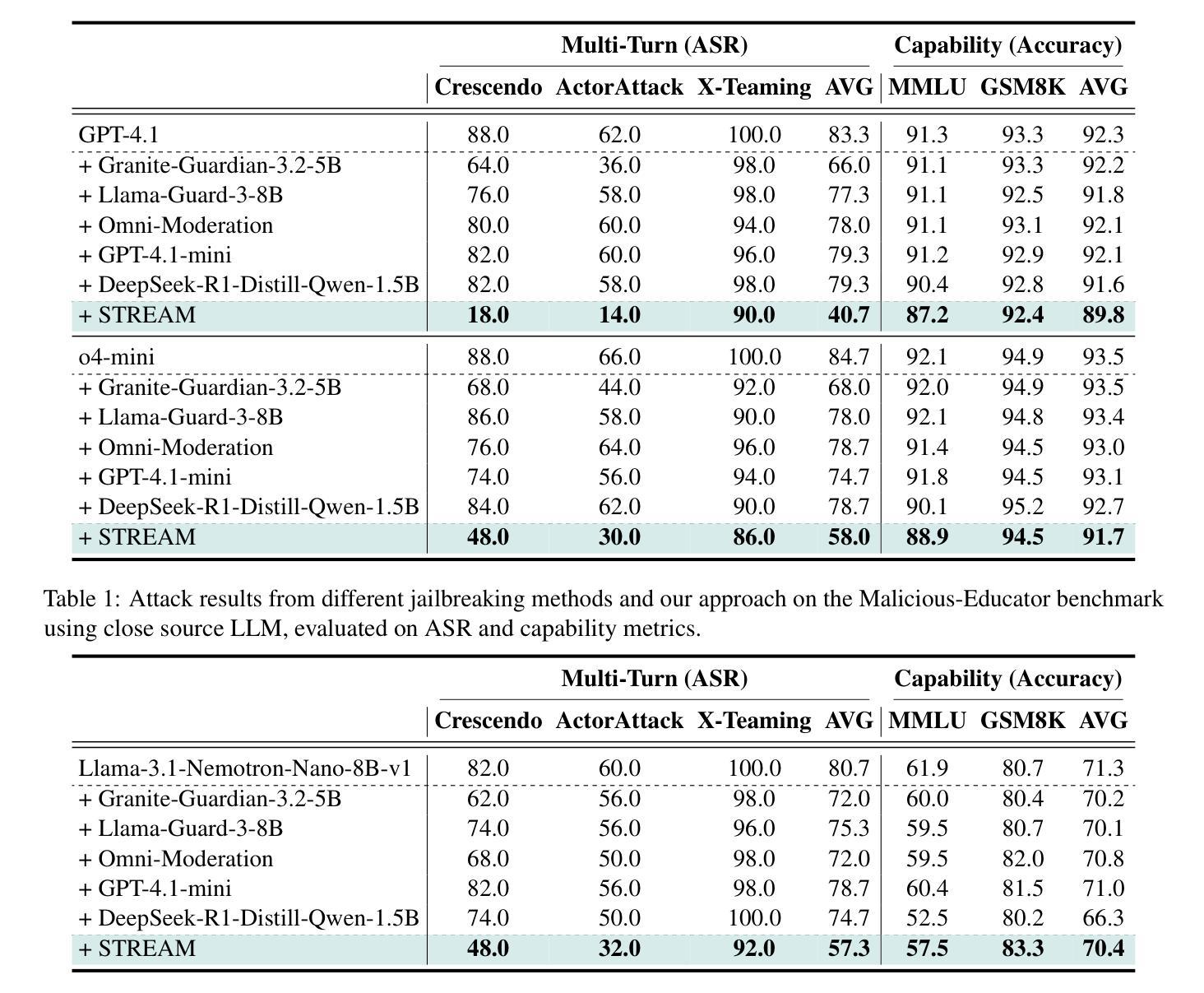
Malicious attackers can exploit large language models (LLMs) by engaging them in multi-turn dialogues to achieve harmful objectives, posing significant safety risks to society. To address this challenge, we propose a novel defense mechanism: SafeTy Reasoning Elicitation Alignment for Multi-Turn Dialogues (STREAM). STREAM defends LLMs against multi-turn attacks while preserving their functional capabilities. Our approach involves constructing a human-annotated dataset, the Safety Reasoning Multi-turn Dialogues dataset, which is used to fine-tune a plug-and-play safety reasoning moderator. This model is designed to identify malicious intent hidden within multi-turn conversations and alert the target LLM of potential risks. We evaluate STREAM across multiple LLMs against prevalent multi-turn attack strategies. Experimental results demonstrate that our method significantly outperforms existing defense techniques, reducing the Attack Success Rate (ASR) by 51.2%, all while maintaining comparable LLM capability.
恶意攻击者可以通过与大型语言模型(LLM)进行多轮对话来利用它们,以实现有害目标,给社会带来重大安全风险。为了解决这一挑战,我们提出了一种新的防御机制:多轮对话安全推理引导对齐(STREAM)。STREAM在保护大型语言模型免受多轮攻击的同时,保持了它们的功能性。我们的方法包括构建一个人工标注的数据集——安全推理多轮对话数据集,用于微调即插即用的安全推理调解器。该模型旨在识别多轮对话中隐藏的恶意意图,并提醒目标大型语言模型存在的潜在风险。我们在多个大型语言模型上评估了STREAM对常见多轮攻击策略的防御能力。实验结果表明,我们的方法显著优于现有防御技术,攻击成功率(ASR)降低了51.2%,同时保持了大型语言模型的能力相当。
论文及项目相关链接
Summary
大型语言模型(LLMs)易受恶意攻击者利用,通过多轮对话实现有害目标,对社会安全构成重大风险。为应对这一挑战,提出一种新型防御机制:STREAM(针对多轮对话的安全推理引导对齐)。STREAM能够在保护LLM功能的同时,防御多轮攻击。其方法是通过构建一个人工标注的数据集——安全推理多轮对话数据集,对即插即用安全推理调解器进行微调。该模型旨在识别多轮对话中隐藏的恶意意图,并提醒目标LLM潜在风险。在多个LLM上针对流行的多轮攻击策略对STREAM进行评估,实验结果表明,该方法显著优于现有防御技术,攻击成功率(ASR)降低51.2%,同时保持LLM的能力相当。
Key Takeaways
- 恶意攻击者可以利用大型语言模型(LLMs)的多轮对话功能实现有害目标,对社会安全构成风险。
- 提出的防御机制STREAM旨在保护LLMs免受多轮攻击,同时保持其功能。
- STREAM通过构建安全推理多轮对话数据集,对安全推理调解器进行微调。
- 该模型能够识别多轮对话中的恶意意图。
- STREAM提醒目标LLM在对话中的潜在风险。
- 实验结果表明,STREAM在防御多轮攻击方面显著优于现有技术。
点此查看论文截图

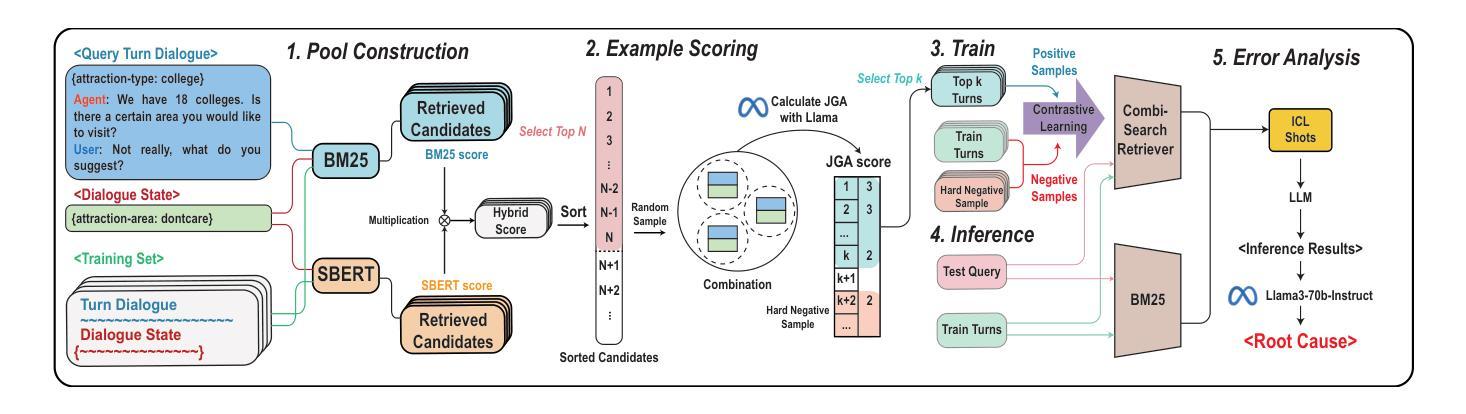
Improving Dialogue State Tracking through Combinatorial Search for In-Context Examples
Authors:Haesung Pyun, Yoonah Park, Yohan Jo
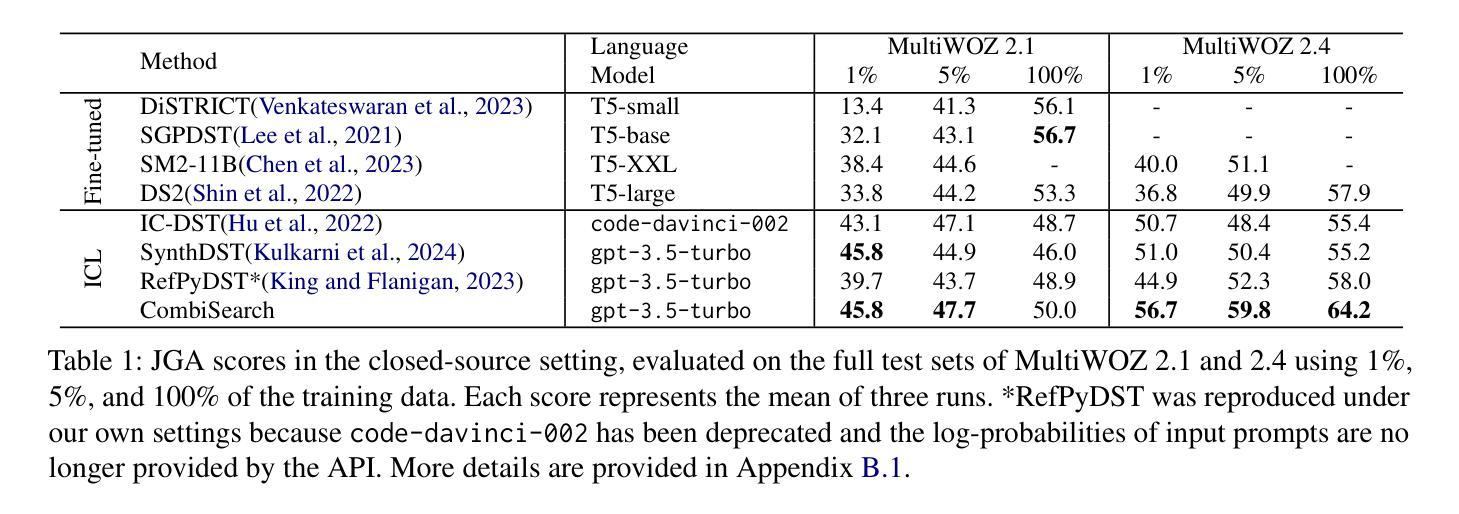
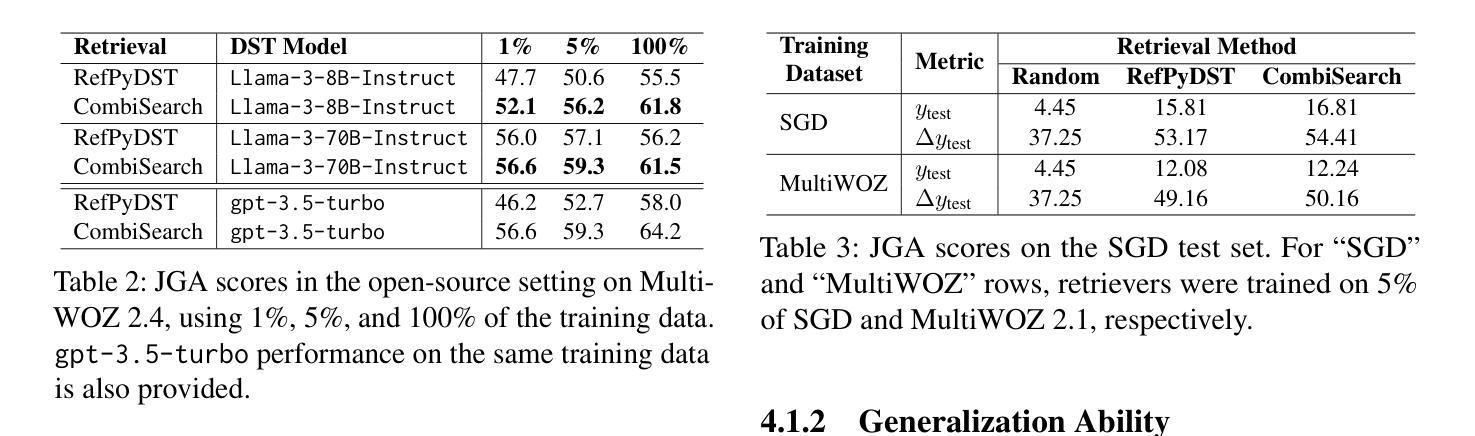
In dialogue state tracking (DST), in-context learning comprises a retriever that selects labeled dialogues as in-context examples and a DST model that uses these examples to infer the dialogue state of the query dialogue. Existing methods for constructing training data for retrievers suffer from three key limitations: (1) the synergistic effect of examples is not considered, (2) the linguistic characteristics of the query are not sufficiently factored in, and (3) scoring is not directly optimized for DST performance. Consequently, the retriever can fail to retrieve examples that would substantially improve DST performance. To address these issues, we present CombiSearch, a method that scores effective in-context examples based on their combinatorial impact on DST performance. Our evaluation on MultiWOZ shows that retrievers trained with CombiSearch surpass state-of-the-art models, achieving a 20x gain in data efficiency and generalizing well to the SGD dataset. Moreover, CombiSearch attains a 12% absolute improvement in the upper bound DST performance over traditional approaches when no retrieval errors are assumed. This significantly increases the headroom for practical DST performance while demonstrating that existing methods rely on suboptimal data for retriever training.
在对话状态跟踪(DST)中,上下文学习包括一个检索器,该检索器选择标记对话作为上下文示例,以及一个使用这些示例来推断查询对话状态的DST模型。现有的构建检索器训练数据的方法存在三个主要局限性:(1)没有考虑示例的协同作用,(2)没有充分考虑查询的语言特征,(3)评分没有直接针对DST性能进行优化。因此,检索器可能会无法检索到会大大提高DST性能的示例。为了解决这些问题,我们提出了CombiSearch方法,该方法基于其对DST性能的组合影响对有效的上下文示例进行评分。我们在MultiWOZ上的评估显示,使用CombiSearch训练的检索器超越了最新模型,实现了20倍的数据效率,并在SGD数据集上具有良好的泛化能力。此外,当没有假设检索错误时,CombiSearch在传统方法的基础上实现了上限DST性能12%的绝对提升。这显著增加了实际DST性能的潜力,同时表明现有方法依赖于次优数据进行检索器训练。
论文及项目相关链接
PDF This paper has been accepted for publication at ACL 2025
Summary
在对话状态追踪(DST)中,上下文学习包括选择标记对话作为上下文示例的检索器,以及使用这些示例来推断查询对话状态的DST模型。现有构建检索器训练数据的方法存在三个主要局限性:一是没有考虑示例的协同作用,二是没有充分考虑查询的语言特征,三是评分不是直接针对DST性能进行优化。因此,检索器可能无法检索到能显著改善DST性能的例子。为解决这些问题,我们提出了CombiSearch方法,该方法基于示例对DST性能的组合影响进行评分。在MultiWOZ上的评估显示,使用CombiSearch训练的检索器超越了最新模型,实现了20倍的数据效率提升,并能很好地推广到SGD数据集。此外,假设没有检索错误的情况下,CombiSearch相较于传统方法在上限DST性能上取得了12%的绝对提升。这显著增加了实际DST性能的潜力,并表明现有方法依赖于次优数据进行检索器训练。
Key Takeaways
- 对话状态追踪(DST)中的上下文学习涉及检索器和DST模型,其中检索器选择标记对话作为上下文示例。
- 现有构建检索器训练数据的方法存在三个主要局限性:未考虑示例协同作用、未充分考虑查询语言特征,以及评分未针对DST性能优化。
- CombiSearch方法基于示例对DST性能的组合影响进行评分,能有效解决上述问题。
- 在MultiWOZ数据集上,使用CombiSearch的检索器训练取得了显著效果,包括提高数据效率和DST性能。
- CombiSearch方法在假设无检索错误的情况下,相较于传统方法实现了12%的绝对性能提升。
- 这表明现有方法使用的数据对于训练检索器可能是次优的。
点此查看论文截图


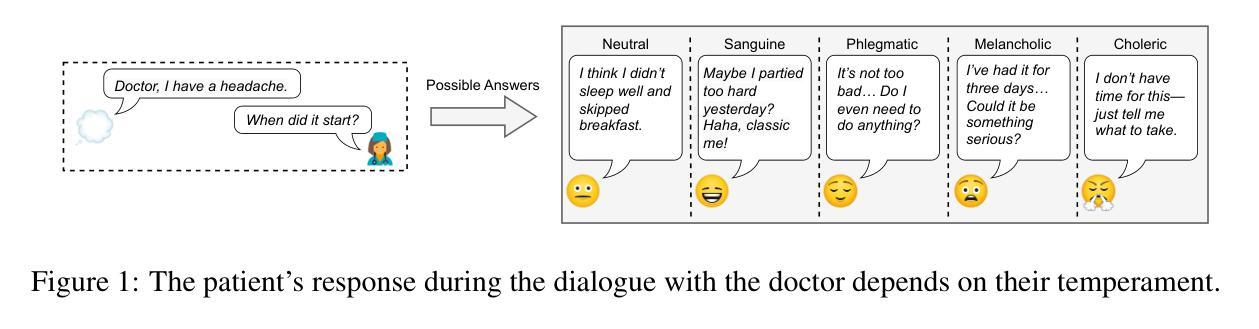
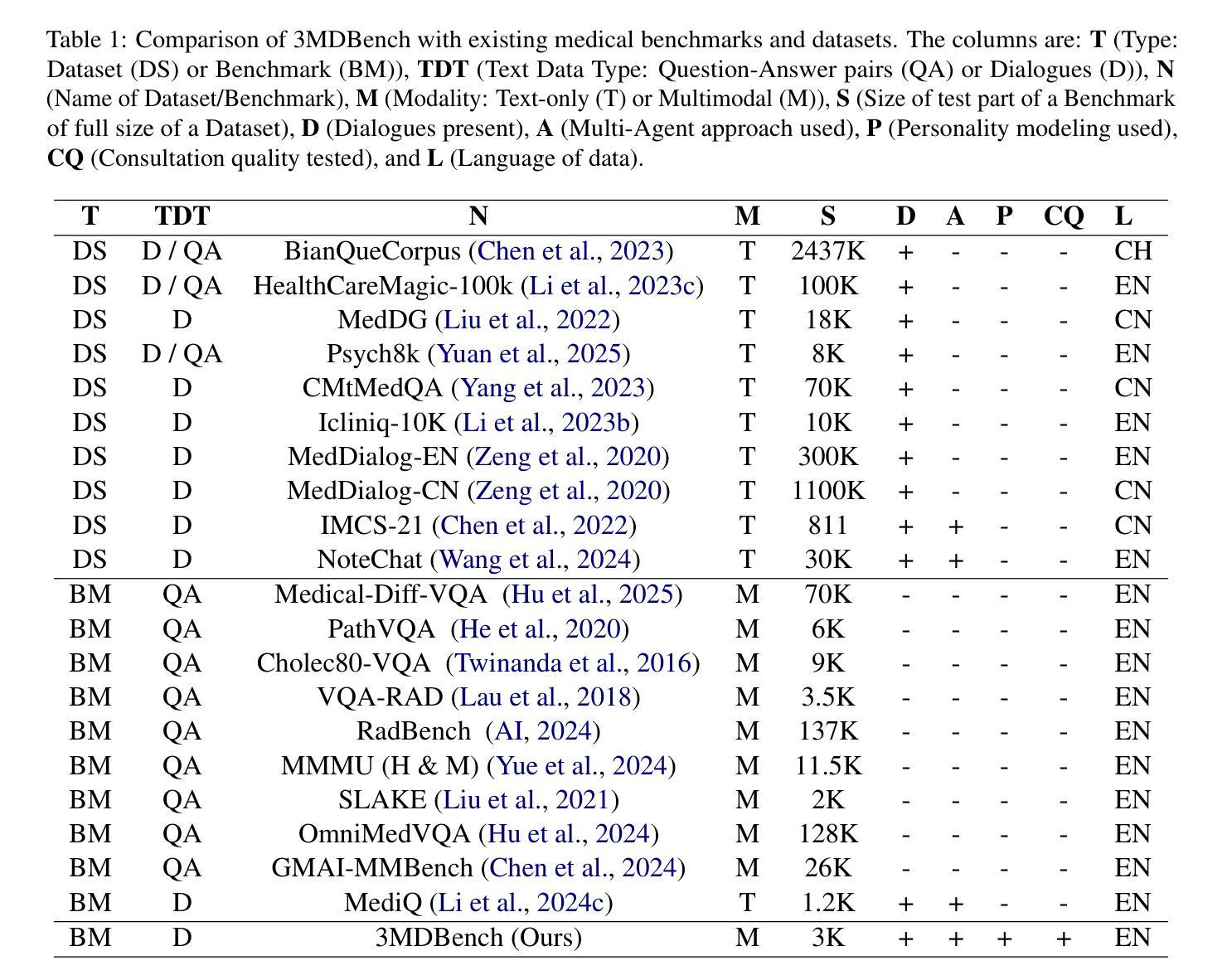
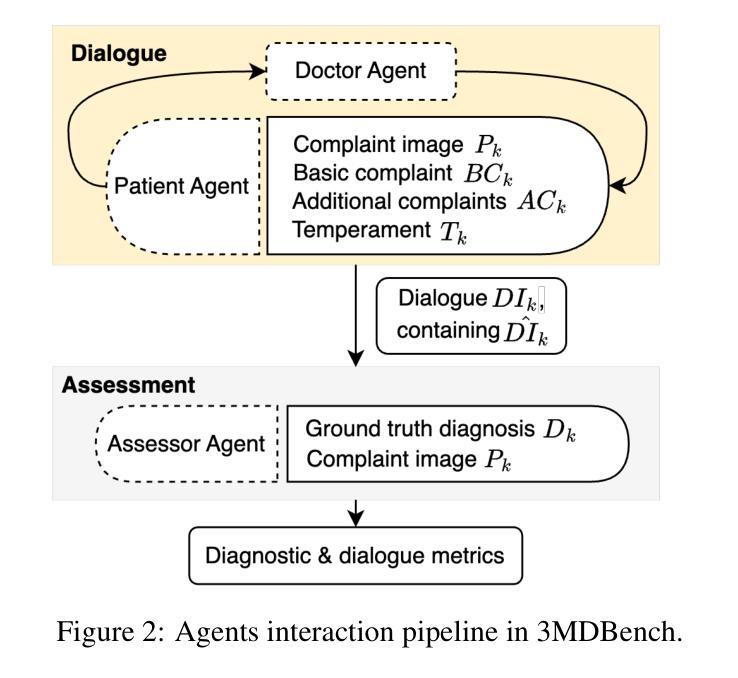
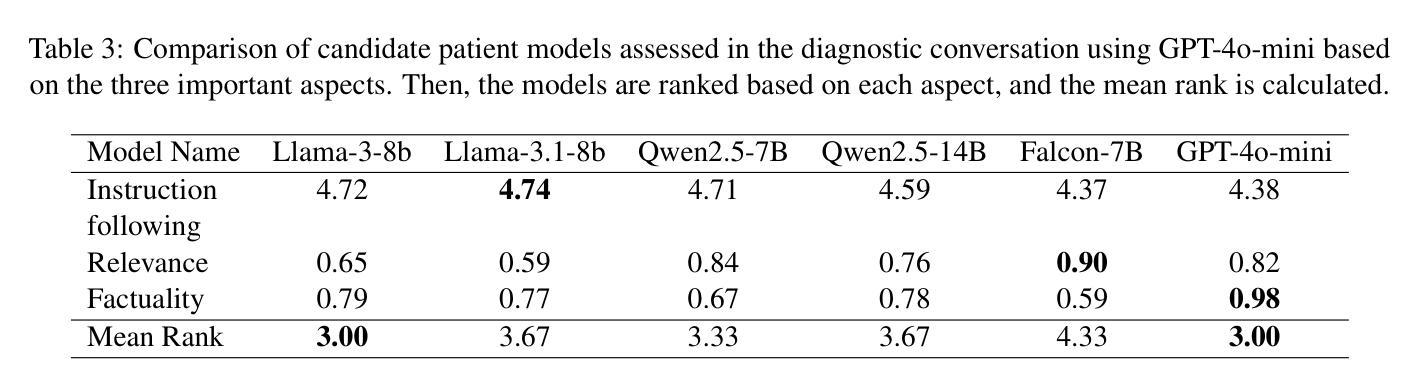
3MDBench: Medical Multimodal Multi-agent Dialogue Benchmark
Authors:Ivan Sviridov, Amina Miftakhova, Artemiy Tereshchenko, Galina Zubkova, Pavel Blinov, Andrey Savchenko
Though Large Vision-Language Models (LVLMs) are being actively explored in medicine, their ability to conduct telemedicine consultations combining accurate diagnosis with professional dialogue remains underexplored. In this paper, we present 3MDBench (Medical Multimodal Multi-agent Dialogue Benchmark), an open-source framework for simulating and evaluating LVLM-driven telemedical consultations. 3MDBench simulates patient variability through four temperament-based Patient Agents and an Assessor Agent that jointly evaluate diagnostic accuracy and dialogue quality. It includes 3013 cases across 34 diagnoses drawn from real-world telemedicine interactions, combining textual and image-based data. The experimental study compares diagnostic strategies for popular LVLMs, including GPT-4o-mini, LLaVA-3.2-11B-Vision-Instruct, and Qwen2-VL-7B-Instruct. We demonstrate that multimodal dialogue with internal reasoning improves F1 score by 6.5% over non-dialogue settings, highlighting the importance of context-aware, information-seeking questioning. Moreover, injecting predictions from a diagnostic convolutional network into the LVLM’s context boosts F1 by up to 20%. Source code is available at https://anonymous.4open.science/r/3mdbench_acl-0511.
虽然大型视觉语言模型(LVLMs)在医学领域正受到积极研究,但它们结合准确诊断和专业对话进行远程医疗咨询的能力仍研究不足。在本文中,我们介绍了3MDBench(医疗多模态多智能体对话基准测试),这是一个用于模拟和评估LVLM驱动的远程医疗咨询的开源框架。3MDBench通过四种基于气质的患者智能体和评估智能体来模拟患者的变异性,共同评估诊断准确性和对话质量。它包括来自现实世界远程医疗互动的34种诊断中的3013个案例,涵盖文本和基于图像的数据。实验研究了流行的LVLMs的诊断策略,包括GPT-4o-mini、LLaVA-3.2-11B-Vision-Instruct和Qwen2-VL-7B-Instruct。我们证明,与无对话设置相比,具有内部推理的多模态对话可以提高F1分数6.5%,这突出了上下文感知和信息搜索问题的重要性。此外,将诊断卷积网络的预测注入LVLM的语境中,F1可提高高达20%。源代码可在https://anonymous.4open.science/r/3mdbench_acl-0511找到。
论文及项目相关链接
PDF 35 pages, 13 figures, 7 tables
Summary
本文介绍了Large Vision-Language Models(LVLMs)在医学领域的应用,并着重探讨了它们在远程医疗咨询中的表现。为了模拟和评估LVLM驱动的远程医疗咨询,提出了一种名为3MDBench的开放源代码框架。该框架通过模拟不同性格的患者代理和评估代理来评价诊断准确性和对话质量。实验研究表明,多模式对话与内部推理可以提高F1分数,通过将诊断卷积网络的预测结果注入LVLM的上下文,可以提高F1分数达20%。
Key Takeaways
- Large Vision-Language Models (LVLMs) 在医学领域的应用正在积极探索,但在远程医疗咨询中的综合准确诊断和专业对话能力尚未得到充分研究。
- 3MDBench是一个开放源代码框架,用于模拟和评估LVLM驱动的远程医疗咨询。
- 3MDBench包括基于四种性格的患者代理和评估代理,以评价诊断准确性和对话质量。
- 实验研究比较了流行的LVLMs在医疗领域的诊断策略。
- 多模式对话与内部推理可以提高诊断的准确性。
- 将诊断卷积网络的预测结果注入LVLM的上下文可以进一步提高诊断的准确性。
点此查看论文截图



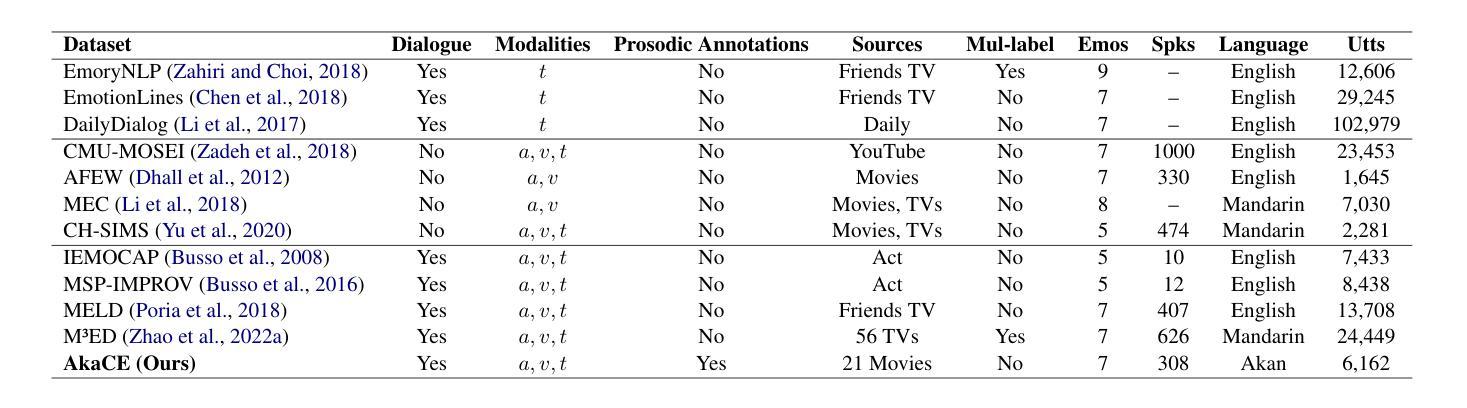
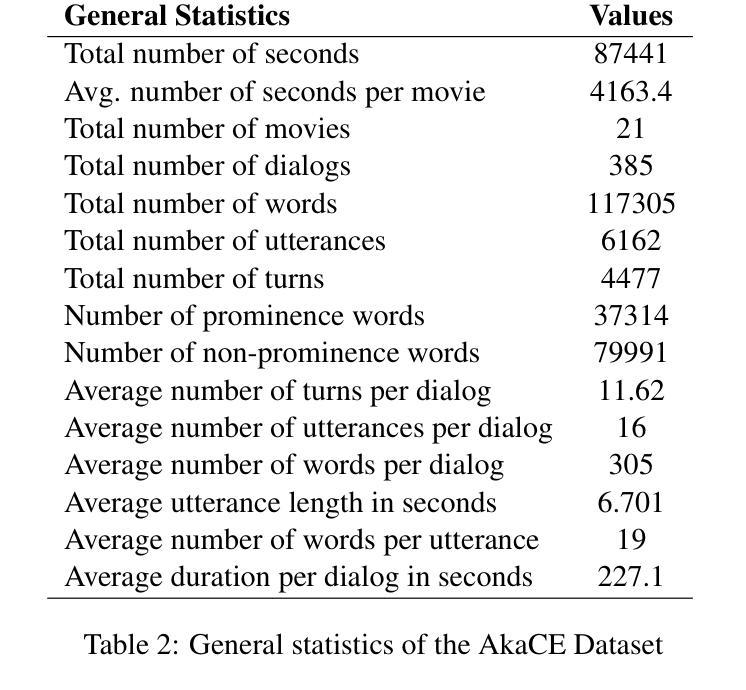
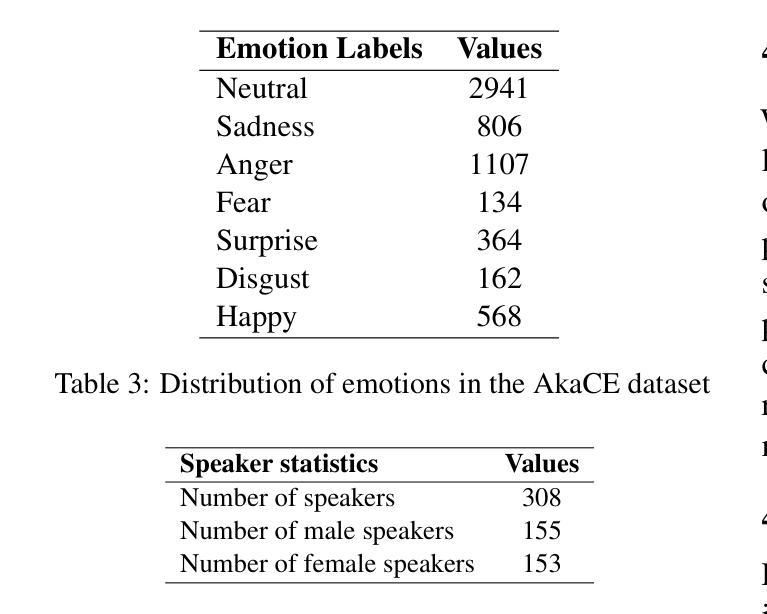
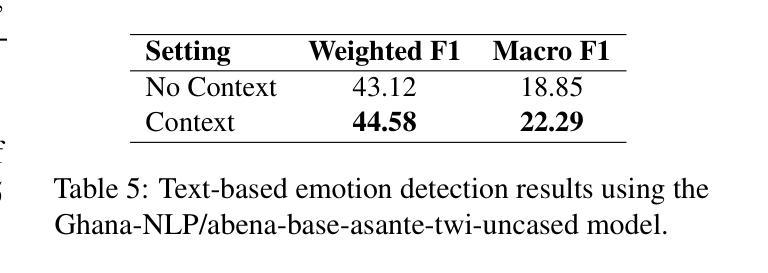
Akan Cinematic Emotions (ACE): A Multimodal Multi-party Dataset for Emotion Recognition in Movie Dialogues
Authors:David Sasu, Zehui Wu, Ziwei Gong, Run Chen, Pengyuan Shi, Lin Ai, Julia Hirschberg, Natalie Schluter
In this paper, we introduce the Akan Conversation Emotion (ACE) dataset, the first multimodal emotion dialogue dataset for an African language, addressing the significant lack of resources for low-resource languages in emotion recognition research. ACE, developed for the Akan language, contains 385 emotion-labeled dialogues and 6,162 utterances across audio, visual, and textual modalities, along with word-level prosodic prominence annotations. The presence of prosodic labels in this dataset also makes it the first prosodically annotated African language dataset. We demonstrate the quality and utility of ACE through experiments using state-of-the-art emotion recognition methods, establishing solid baselines for future research. We hope ACE inspires further work on inclusive, linguistically and culturally diverse NLP resources.
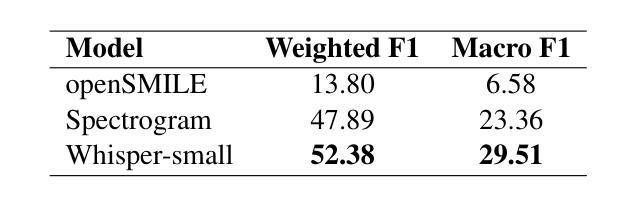
在这篇论文中,我们介绍了Akan对话情感(ACE)数据集,这是针对非洲语言的首个多模态情感对话数据集,解决了情感识别研究中低资源语言资源严重匮乏的问题。ACE是为Akan语言开发的,包含385个情感标签对话和6162个音频、视觉和文本模态的言论,以及词级韵律重点注释。该数据集中还包含韵律标签,使其成为首个经韵律注释的非洲语言数据集。我们通过使用最先进的情感识别方法进行的实验展示了ACE的质量和实用性,为未来的研究奠定了坚实的基准。我们希望ACE能激发对包容性、语言和文化多样的自然语言处理资源的进一步研究。
论文及项目相关链接
PDF Accepted to Findings at ACL 2025
Summary
ACE数据集是首个针对非洲语言的多模态情感对话数据集,弥补了低资源语言情感识别研究的资源匮乏问题。该数据集为Akan语言开发,包含385个情感标签对话和6,162个跨音频、视觉和文本模态的发音,以及单词级别的韵律重点注释。ACE数据集通过采用最前沿的情感识别方法进行实验,证明了其质量和实用性,为未来研究奠定了坚实的基础。
Key Takeaways
- ACE数据集是首个针对非洲语言的多模态情感对话数据集。
- ACE数据集旨在弥补低资源语言在情感识别研究中的资源匮乏问题。
- 数据集包含385个情感标签对话和6,162个跨音频、视觉和文本模态的发音。
- ACE数据集是首个包含韵律注释的非洲语言数据集。
- 通过采用最前沿的情感识别方法进行实验,证明了ACE数据集的质量和实用性。
- ACE数据集为未来研究奠定了坚实的基础。
点此查看论文截图