⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-05 更新
Entity-Augmented Neuroscience Knowledge Retrieval Using Ontology and Semantic Understanding Capability of LLM
Authors:Pralaypati Ta, Sriram Venkatesaperumal, Keerthi Ram, Mohanasankar Sivaprakasam
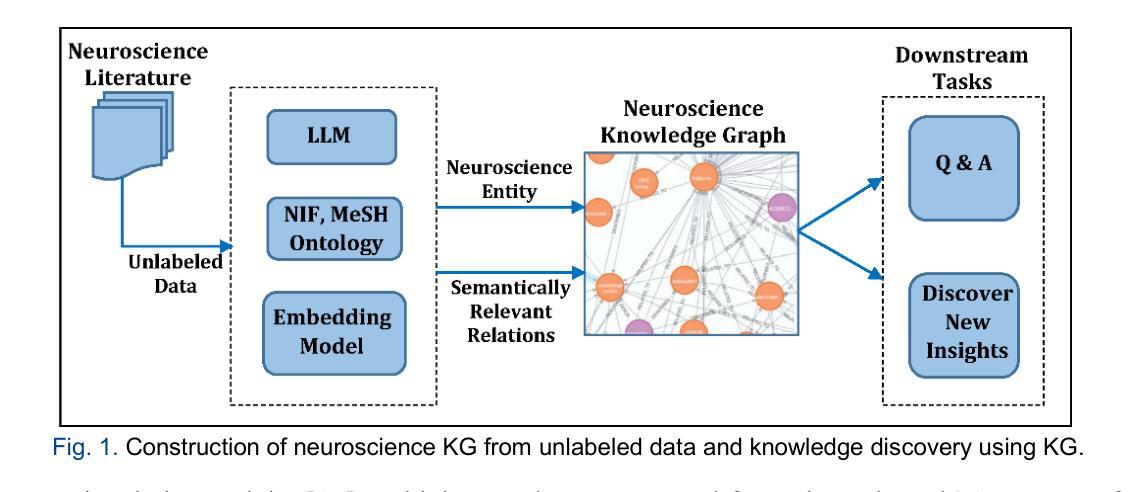
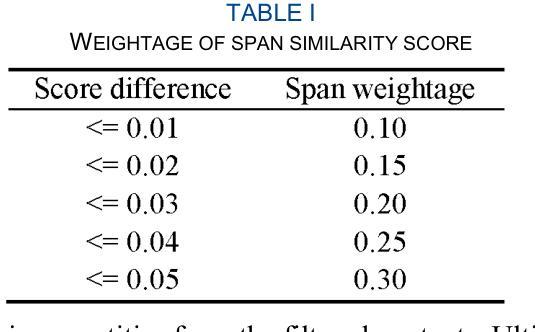
Neuroscience research publications encompass a vast wealth of knowledge. Accurately retrieving existing information and discovering new insights from this extensive literature is essential for advancing the field. However, when knowledge is dispersed across multiple sources, current state-of-the-art retrieval methods often struggle to extract the necessary information. A knowledge graph (KG) can integrate and link knowledge from multiple sources, but existing methods for constructing KGs in neuroscience often rely on labeled data and require domain expertise. Acquiring large-scale, labeled data for a specialized area like neuroscience presents significant challenges. This work proposes novel methods for constructing KG from unlabeled large-scale neuroscience research corpus utilizing large language models (LLM), neuroscience ontology, and text embeddings. We analyze the semantic relevance of neuroscience text segments identified by LLM for building the knowledge graph. We also introduce an entity-augmented information retrieval algorithm to extract knowledge from the KG. Several experiments were conducted to evaluate the proposed approaches, and the results demonstrate that our methods significantly enhance knowledge discovery from the unlabeled neuroscience research corpus. It achieves an F1 score of 0.84 for entity extraction, and the knowledge obtained from the KG improves answers to over 54% of the questions.
神经科学研究出版物包含了大量的知识。从广泛的文献中准确检索现有信息并发现新见解对于推动该领域的发展至关重要。然而,当知识分散在多个来源时,现有的最先进的检索方法往往难以提取必要的信息。知识图谱(KG)可以整合和链接来自多个来源的知识,但神经科学中构建知识图谱的现有方法通常依赖于标记数据并需要领域专业知识。为神经科学等专业领域获取大规模、标记的数据存在重大挑战。这项工作提出了利用大规模语言模型(LLM)、神经科学本体和文本嵌入,从未标记的大规模神经科学研究语料库中构建知识图谱的新方法。我们分析了LLM识别的神经科学文本片段的语义相关性,以构建知识图谱。我们还引入了一种实体增强信息检索算法,从知识图谱中提取知识。进行了多次实验来评估所提出的方法,结果表明,我们的方法显著提高了从未标记的神经科学研究语料库中发现知识的能力。对于实体提取,它实现了0.84的F1分数,从知识图谱中获得的知识提高了超过54%的问题的答案。
论文及项目相关链接
摘要
利用大规模语言模型(LLM)、神经科学本体论和文本嵌入技术,从未标记的大规模神经科学研究语料库中构建知识图谱(KG)。分析LLM识别的神经科学文本片段的语义相关性以构建知识图谱,并引入实体增强信息检索算法从知识图谱中提取知识。实验结果表明,该方法能显著提高从未标记的神经科学研究语料库中发现知识的能力,实体提取的F1分数达到0.84,从知识图谱中获得的知识能回答超过54%的问题。
关键见解
- 利用LLM、神经科学本体论和文本嵌入技术从大规模未标记的神经科学研究语料库中构建知识图谱。
- LLM用于识别与神经科学相关的文本片段,增强知识图谱的构建。
- 引入实体增强信息检索算法,提高从知识图谱中提取知识的能力。
- 实验证明,该方法在实体提取方面表现出较高的性能,F1分数达到0.84。
- 知识图谱能够回答超过54%的问题,显著提高了知识发现的效率。
- 该方法克服了现有神经科学知识图谱构建方法对标记数据的依赖,降低了对领域专家的需求。
- 该研究为神经科学领域的信息检索和知识发现提供了新的思路和方法。
点此查看论文截图


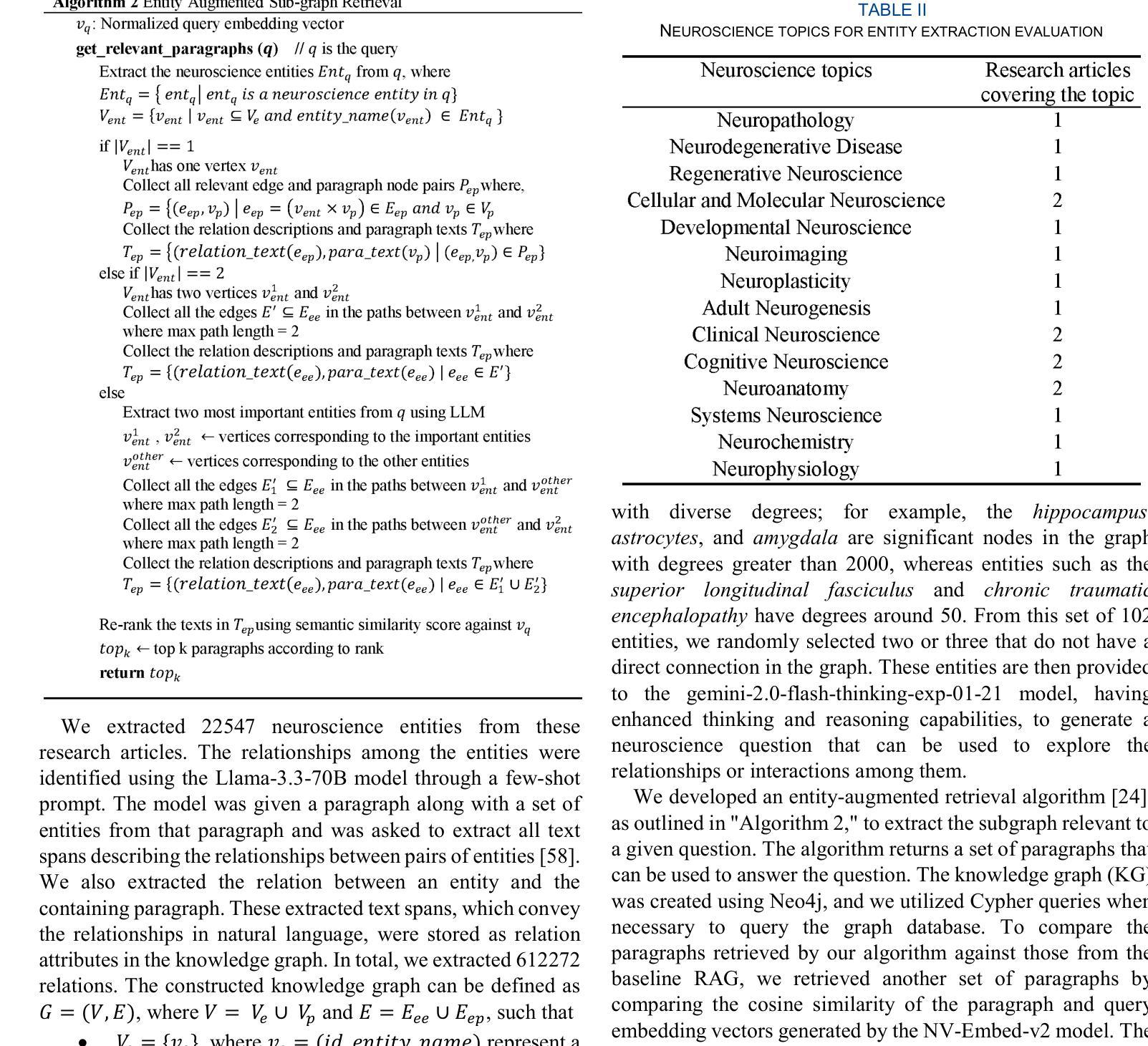
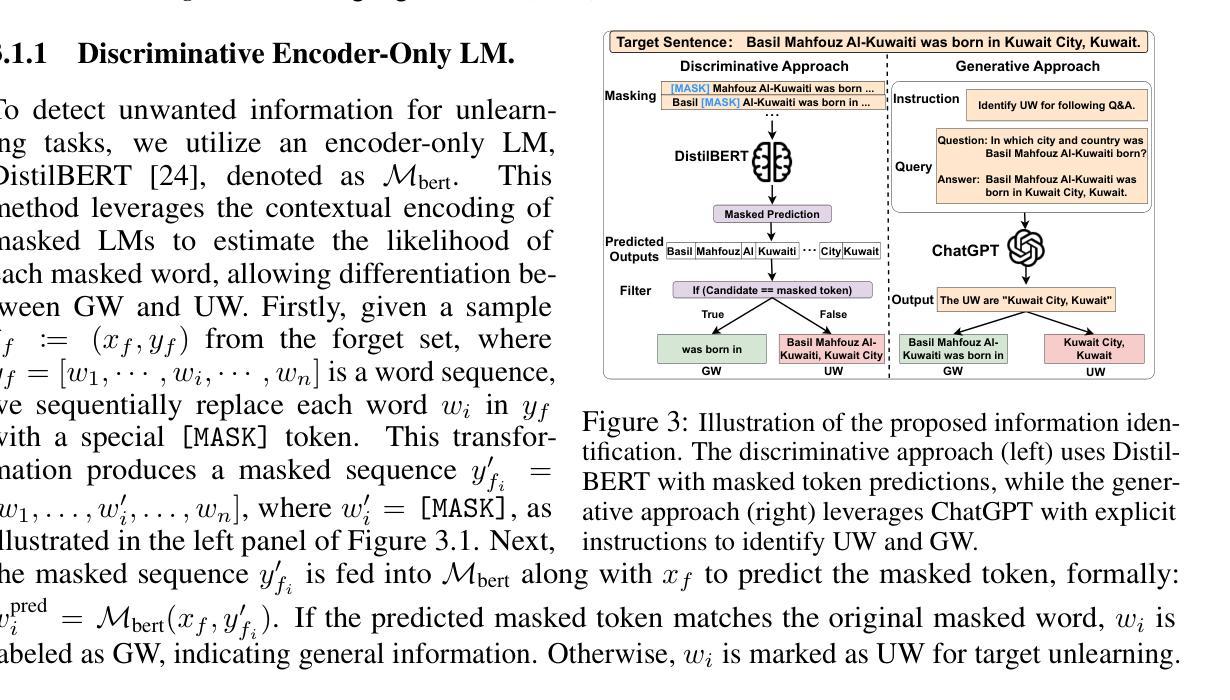
Not All Tokens Are Meant to Be Forgotten
Authors:Xiangyu Zhou, Yao Qiang, Saleh Zare Zade, Douglas Zytko, Prashant Khanduri, Dongxiao Zhu
Large Language Models (LLMs), pre-trained on massive text corpora, exhibit remarkable human-level language understanding, reasoning, and decision-making abilities. However, they tend to memorize unwanted information, such as private or copyrighted content, raising significant privacy and legal concerns. Unlearning has emerged as a promising solution, but existing methods face a significant challenge of over-forgetting. This issue arises because they indiscriminately suppress the generation of all the tokens in forget samples, leading to a substantial loss of model utility. To overcome this challenge, we introduce the Targeted Information Forgetting (TIF) framework, which consists of (1) a flexible targeted information identifier designed to differentiate between unwanted words (UW) and general words (GW) in the forget samples, and (2) a novel Targeted Preference Optimization approach that leverages Logit Preference Loss to unlearn unwanted information associated with UW and Preservation Loss to retain general information in GW, effectively improving the unlearning process while mitigating utility degradation. Extensive experiments on the TOFU and MUSE benchmarks demonstrate that the proposed TIF framework enhances unlearning effectiveness while preserving model utility and achieving state-of-the-art results.
大规模语言模型(LLM)在大量文本语料库上进行预训练,展现出惊人的人类水平语言理解、推理和决策能力。然而,它们有记忆不必要信息的趋势,如私人或版权内容,这引发了隐私和法律的担忧。遗忘作为一种有前途的解决方案而出现,但现有方法面临着过度遗忘的重大挑战。这个问题之所以出现,是因为它们不加区分地抑制遗忘样本中所有标记的生成,导致模型效用的大量损失。为了克服这一挑战,我们引入了有针对性的信息遗忘(TIF)框架,它包括(1)一个灵活的有针对性的信息标识符,旨在区分遗忘样本中的不需要的单词(UW)和一般单词(GW),以及(2)一种新的有针对性的偏好优化方法,该方法利用逻辑偏好损失来遗忘与UW相关的不需要的信息,并利用保留损失来保留GW中的一般信息,这有效地改进了遗忘过程并减轻了效用降低的问题。在TOFU和MUSE基准测试上的广泛实验表明,所提出的TIF框架在提高遗忘效果的同时,保持了模型的效用,并实现了最新的结果。
论文及项目相关链接
Summary
大型语言模型(LLM)在海量文本语料库上的预训练,展现出惊人的人类级语言理解、推理和决策能力。然而,它们会记忆不想要的资讯,如私密或版权内容,引发隐私和法律担忧。遗忘技术作为一种解决方案应运而生,但现有方法面临过度遗忘的挑战。这是因为它们会无差别地抑制遗忘样本的所有词汇生成,导致模型效用大量损失。为解决此问题,我们推出针对性遗忘(TIF)框架,包括一)灵活的针对性信息识别器,用于区分遗忘样本中的不需要的词汇(UW)和一般词汇(GW),以及二)新型的目标偏好优化方法,该方法利用对数偏好损失来遗忘与UW相关的不需要的信息,并利用保留损失保持GW中的一般信息,从而改进遗忘过程并缓解效用降低。在TOFU和MUSE基准测试上的广泛实验表明,所提出的TIF框架在提高遗忘效果的同时,保留了模型效用,并实现了最佳结果。
Key Takeaways
- LLM展现出人类级别的语言理解、推理和决策能力,但存在记忆不想要的资讯的问题。
- 现有遗忘技术面临过度遗忘的挑战,会导致模型效用损失。
- 推出针对性遗忘(TIF)框架以解决过度遗忘问题。
- TIF框架包括灵活的针对性信息识别器和目标偏好优化方法。
- 对数偏好损失用于遗忘不需要的信息,同时保留一般信息。
- TIF框架在基准测试上表现优异,提高了遗忘效果并保留了模型效用。
点此查看论文截图


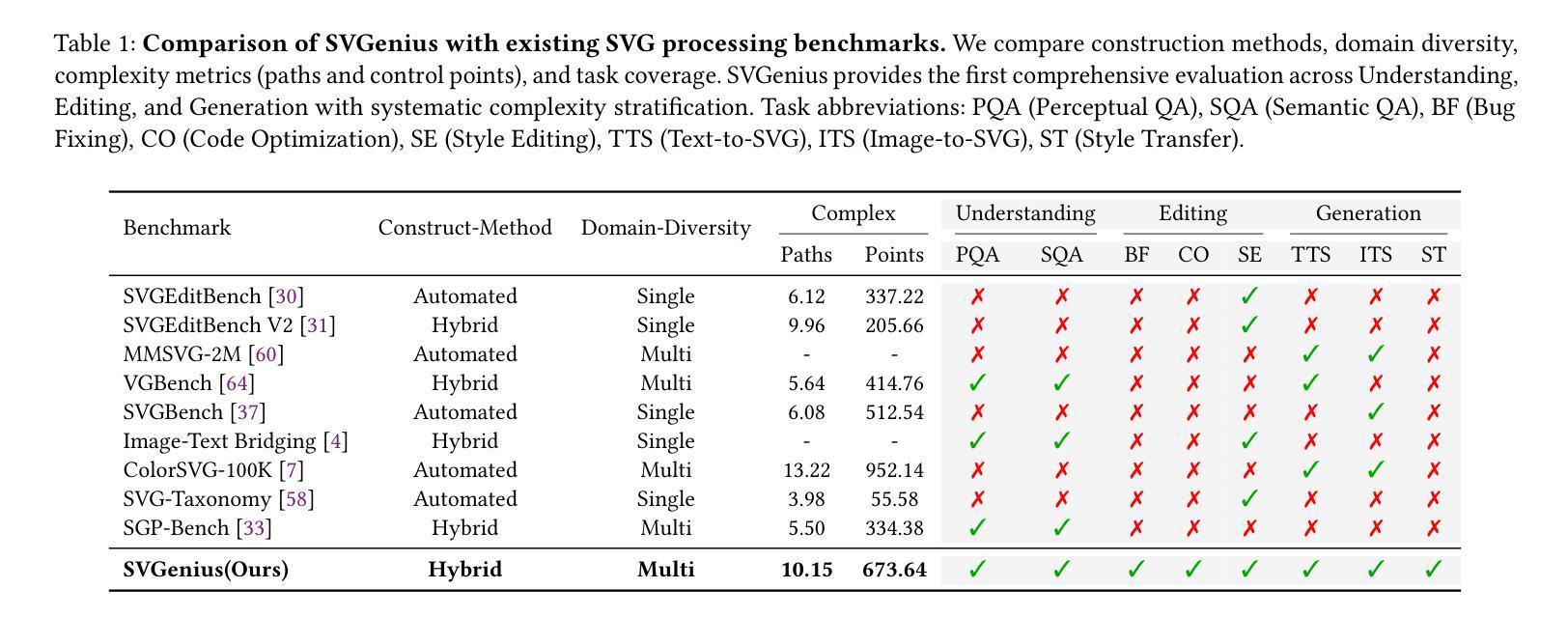
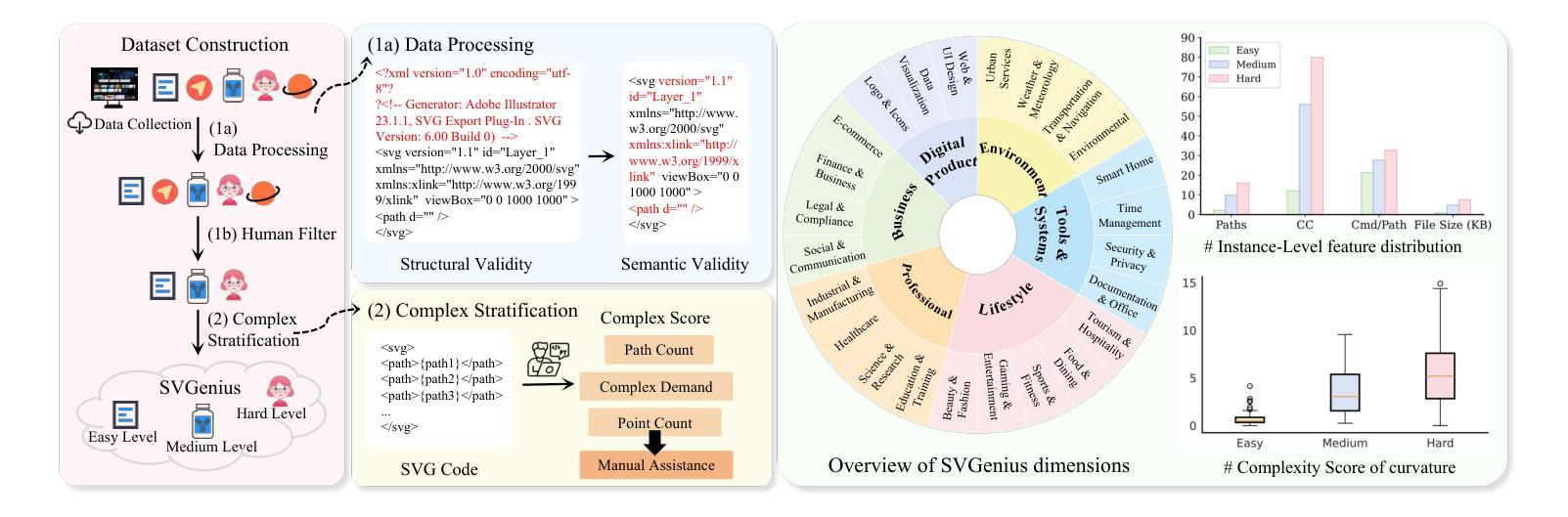
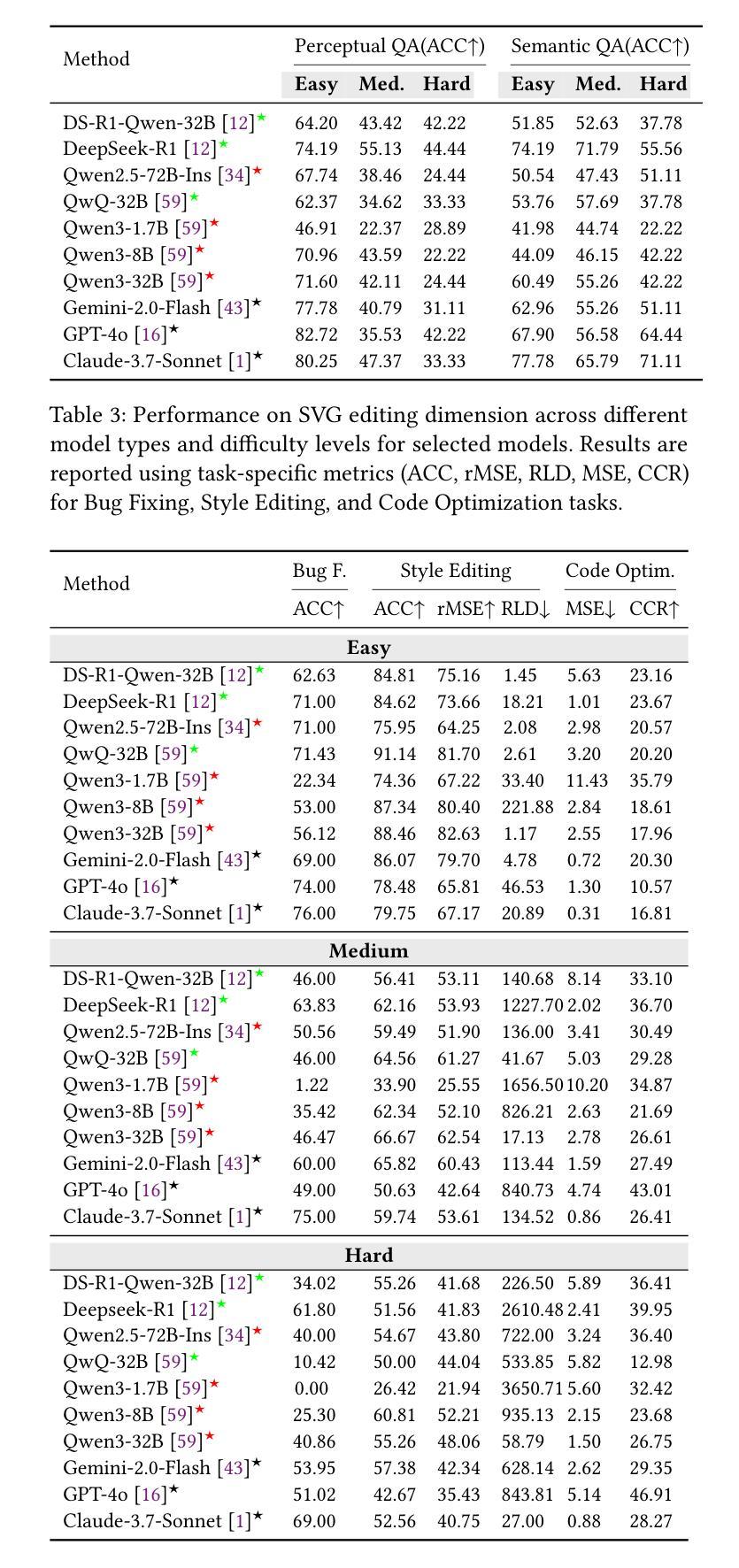
SVGenius: Benchmarking LLMs in SVG Understanding, Editing and Generation
Authors:Siqi Chen, Xinyu Dong, Haolei Xu, Xingyu Wu, Fei Tang, Hang Zhang, Yuchen Yan, Linjuan Wu, Wenqi Zhang, Guiyang Hou, Yongliang Shen, Weiming Lu, Yueting Zhuang
Large Language Models (LLMs) and Multimodal LLMs have shown promising capabilities for SVG processing, yet existing benchmarks suffer from limited real-world coverage, lack of complexity stratification, and fragmented evaluation paradigms. We introduce SVGenius, a comprehensive benchmark comprising 2,377 queries across three progressive dimensions: understanding, editing, and generation. Built on real-world data from 24 application domains with systematic complexity stratification, SVGenius evaluates models through 8 task categories and 18 metrics. We assess 22 mainstream models spanning different scales, architectures, training paradigms, and accessibility levels. Our analysis reveals that while proprietary models significantly outperform open-source counterparts, all models exhibit systematic performance degradation with increasing complexity, indicating fundamental limitations in current approaches; however, reasoning-enhanced training proves more effective than pure scaling for overcoming these limitations, though style transfer remains the most challenging capability across all model types. SVGenius establishes the first systematic evaluation framework for SVG processing, providing crucial insights for developing more capable vector graphics models and advancing automated graphic design applications. Appendix and supplementary materials (including all data and code) are available at https://zju-real.github.io/SVGenius.
大规模语言模型(LLM)和多模态LLM在SVG处理方面展现出有前景的能力,然而现有的基准测试存在现实世界覆盖有限、缺乏复杂性分层和评估范式碎片化的问题。我们推出了SVGenius,这是一个包含2377个查询的综合基准测试,涵盖三个递进维度:理解、编辑和生成。SVGenius建立在来自24个应用领域的真实数据基础上,具有系统的复杂性分层,通过8个任务类别和18个指标对模型进行评估。我们评估了22个主流模型,涵盖不同的规模、架构、训练范式和可访问性水平。我们的分析表明,专有模型显著优于开源模型,所有模型在复杂性增加时都表现出系统性性能下降,表明当前方法存在根本性局限;然而,推理增强训练证明在克服这些限制方面比纯粹扩大规模更为有效,尽管风格转换仍是所有模型类型中最具挑战性的能力。SVGenius建立了SVG处理的首个系统评估框架,为开发更强大的矢量图形模型和推动自动化图形设计应用提供了关键见解。附录和补充材料(包括所有数据和代码)可在https://zju-real.github.io/SVGenius获取。
论文及项目相关链接
PDF 19 pages,4 figures, Project page: https://zju-real.github.io/SVGenius, Code: https://github.com/ZJU-REAL/SVGenius-Bench
摘要
LLM及多模态LLM在处理SVG方面展现强大潜力,但现有基准测试存在真实世界覆盖不足、复杂性分层缺失及评估模式分散等问题。本文介绍SVGenius,一个包含2,377条查询的综合基准测试,涉及理解、编辑和生成三个渐进维度。SVGenius以24个应用领域的真实数据为基础,进行系统复杂性分层,通过8类任务和18项指标评估模型。评估了不同规模、架构、训练模式和可访问性水平的22个主流模型。分析表明,专有模型显著优于开源模型,所有模型在复杂性增加时性能下降,表明当前方法存在根本性局限;然而,推理增强训练比单纯扩大规模更能有效克服这些局限,而风格转换仍是所有模型类型中最具挑战性的能力。SVGenius为SVG处理建立了首个系统评估框架,为开发更强大的矢量图形模型和推动自动化图形设计应用提供了关键见解。
关键见解
- LLM在处理SVG方面展现出巨大潜力,但仍存在性能挑战。
- 现有基准测试在真实世界覆盖、复杂性分层和评估模式方面存在缺陷。
- SVGenius是一个综合基准测试,包括理解、编辑和生成三个维度,基于真实数据并系统地进行复杂性分层。
- 评估了不同模型在8类任务中的表现,揭示了专有模型与开源模型之间的性能差异。
- 所有模型在面临复杂性增加时性能下降,表明当前方法的局限性。
- 推理增强训练是克服这些局限的有效方法,但风格转换仍是最大的挑战。
- SVGenius为SVG处理提供了首个系统评估框架,对开发更强大的矢量图形模型和推动自动化图形设计应用至关重要。
点此查看论文截图

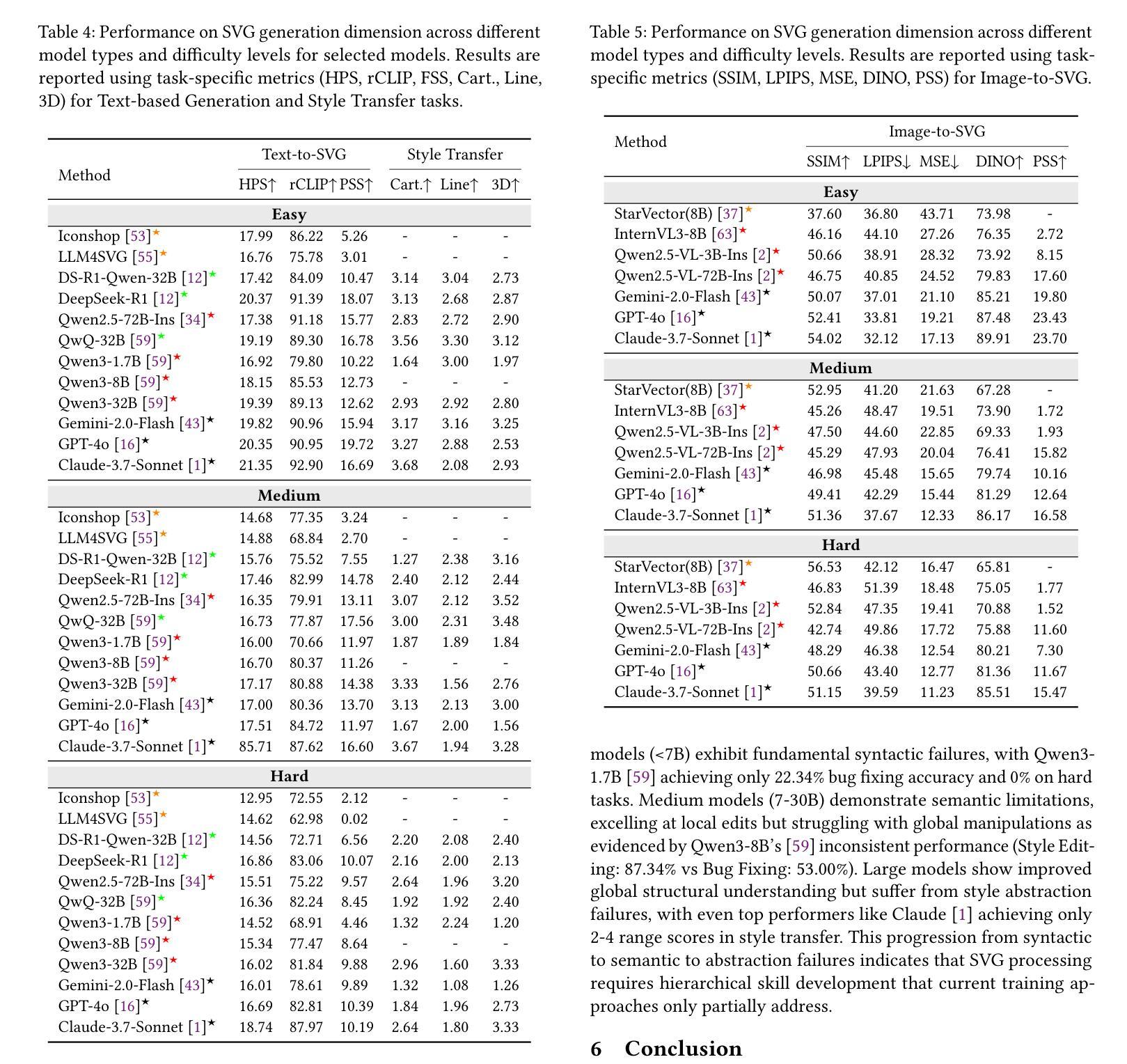
Co-Evolving LLM Coder and Unit Tester via Reinforcement Learning
Authors:Yinjie Wang, Ling Yang, Ye Tian, Ke Shen, Mengdi Wang
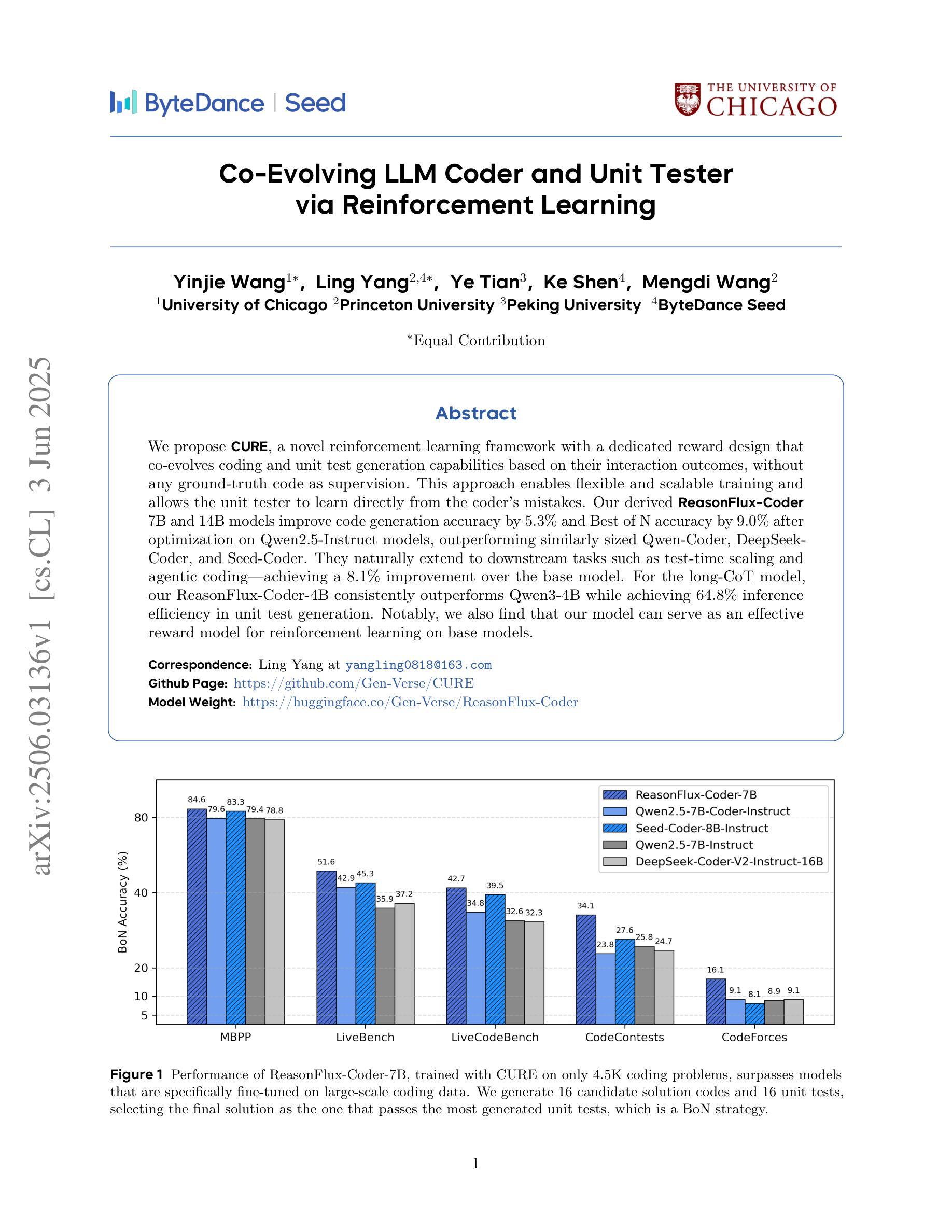
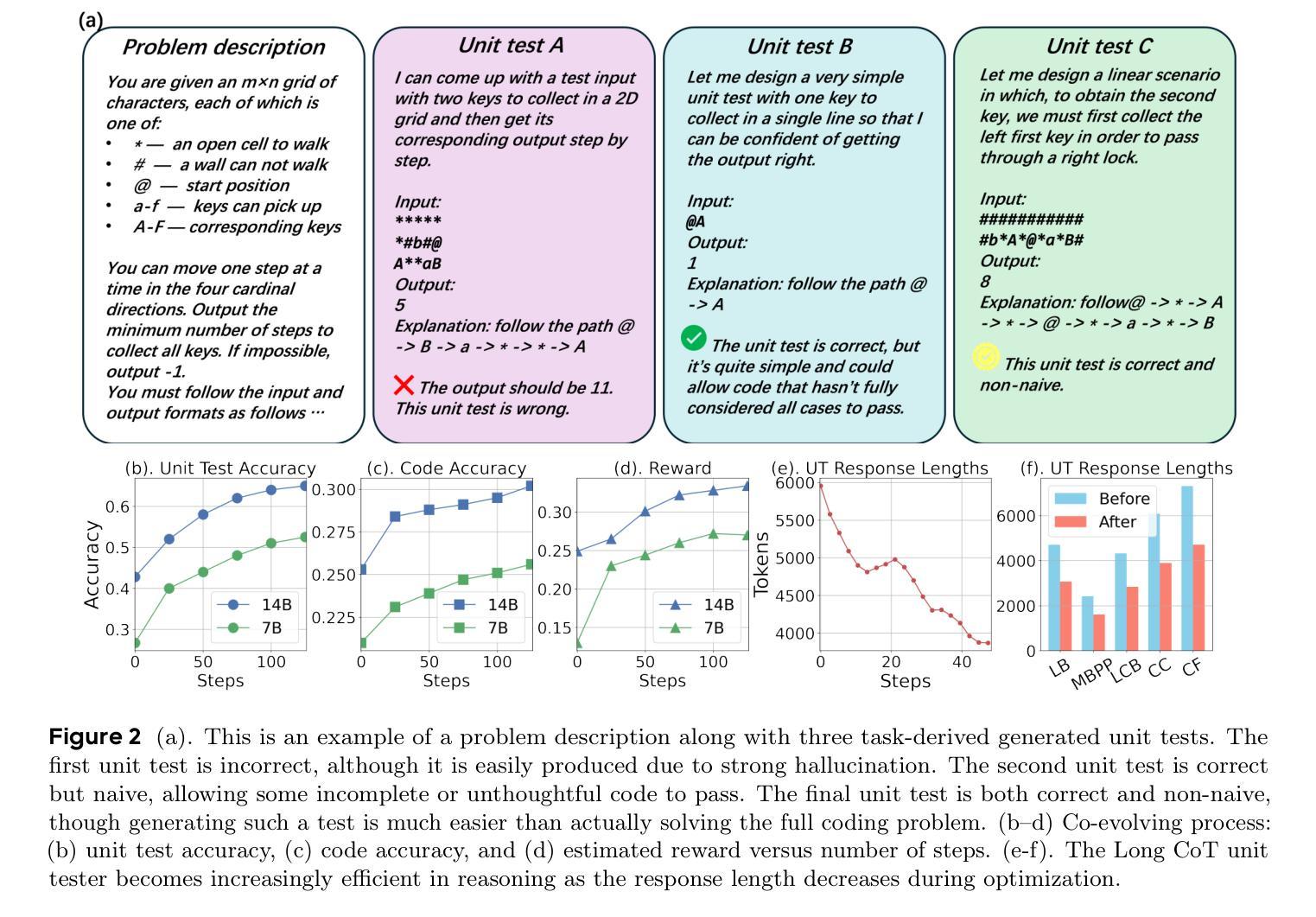
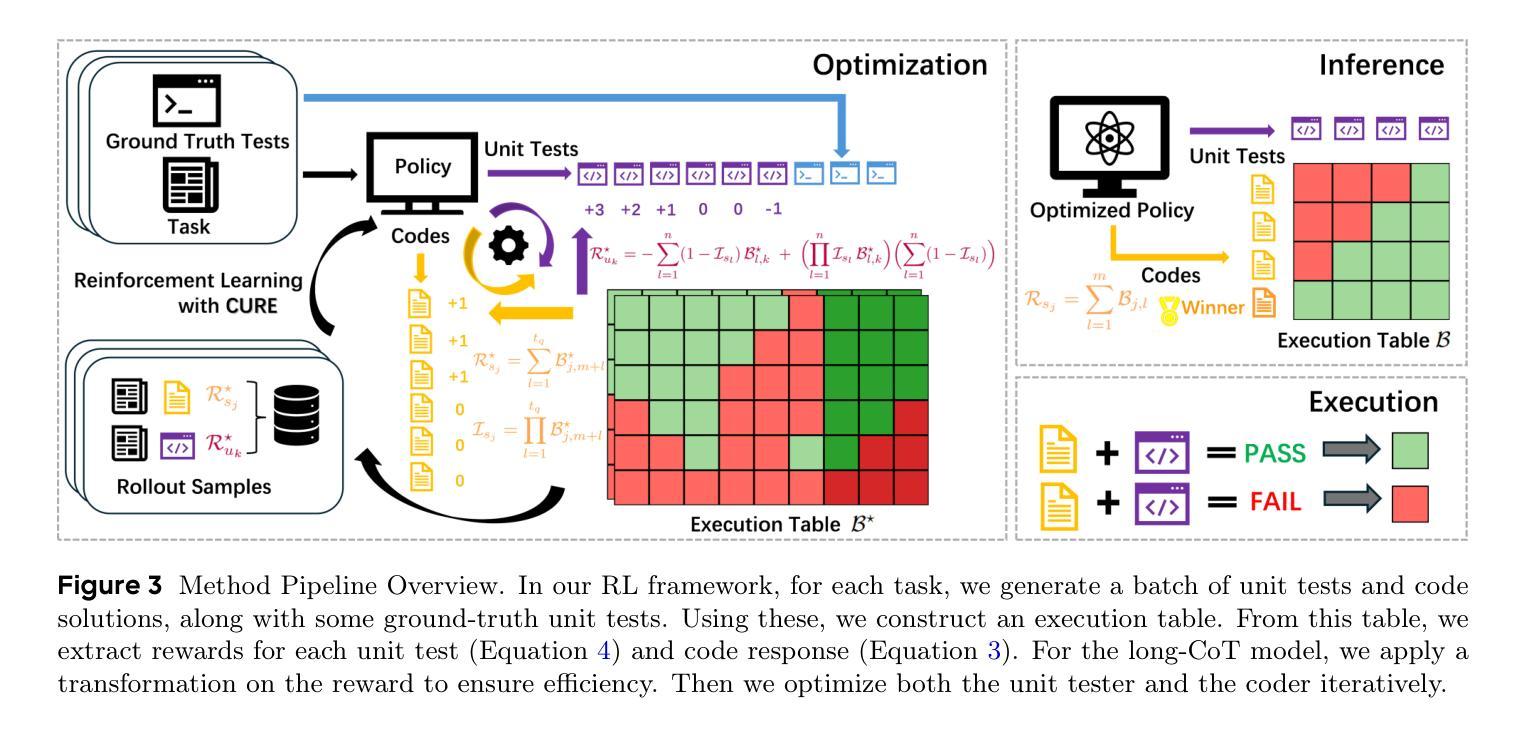
We propose CURE, a novel reinforcement learning framework with a dedicated reward design that co-evolves coding and unit test generation capabilities based on their interaction outcomes, without any ground-truth code as supervision. This approach enables flexible and scalable training and allows the unit tester to learn directly from the coder’s mistakes. Our derived ReasonFlux-Coder-7B and 14B models improve code generation accuracy by 5.3% and Best-of-N accuracy by 9.0% after optimization on Qwen2.5-Instruct models, outperforming similarly sized Qwen-Coder, DeepSeek-Coder, and Seed-Coder. They naturally extend to downstream tasks such as test-time scaling and agentic coding-achieving a 8.1% improvement over the base model. For the long-CoT model, our ReasonFlux-Coder-4B consistently outperforms Qwen3-4B while achieving 64.8% inference efficiency in unit test generation. Notably, we also find that our model can serve as an effective reward model for reinforcement learning on base models. Project: https://github.com/Gen-Verse/CURE
我们提出了CURE,这是一个新型强化学习框架,它具有专门的奖励设计,能够协同进化编码和单元测试生成能力,基于它们的交互结果,而无需任何真实代码进行监督。这种方法使灵活和可扩展的训练成为可能,并允许单元测试器直接从编码器的错误中学习。我们在ReasonFlux-Coder-7B和14B模型上的优化后,在Qwen2.5-Instruct模型上提高了代码生成精度5.3%,最佳N精度提高9.0%,超越了类似规模的Qwen-Coder、DeepSeek-Coder和Seed-Coder。它们自然地扩展到下游任务,如测试时缩放和智能编码,相较于基础模型提升了8.1%。对于长CoT模型,我们的ReasonFlux-Coder-4B始终优于Qwen3-4B,同时在单元测试生成方面达到64.8%的推理效率。值得注意的是,我们还发现我们的模型可以作为基础模型上强化学习的有效奖励模型。项目地址:https://github.com/Gen-Verse/CURE
论文及项目相关链接
PDF Project: https://github.com/Gen-Verse/CURE
Summary
CURE是一个新型强化学习框架,通过专门设计的奖励机制,使编码和单元测试生成能力能够根据交互结果协同进化,无需任何真实代码作为监督。此方法实现了灵活且可扩展的训练,并允许测试人员直接从开发人员的错误中学习。优化后的ReasonFlux-Coder模型在代码生成准确性和Best-of-N准确性方面分别提高了5.3%和9.0%,并扩展至下游任务如测试时缩放和代理编码,实现了对基准模型的8.1%改进。此外,该模型还可作为强化学习基准模型的有效奖励模型。
Key Takeaways
- CURE是一个强化学习框架,通过奖励机制协同进化编码和单元测试生成。
- 该框架无需真实代码监督,允许测试人员从开发人员的错误中学习。
- ReasonFlux-Coder模型在代码生成和Best-of-N准确性方面有明显提升。
- 该模型可扩展到下游任务,如测试时缩放和代理编码,实现对基准模型的改进。
- CURE模型表现出较高的灵活性和可扩展性。
- CURE模型可作为强化学习基准模型的有效奖励模型。
点此查看论文截图
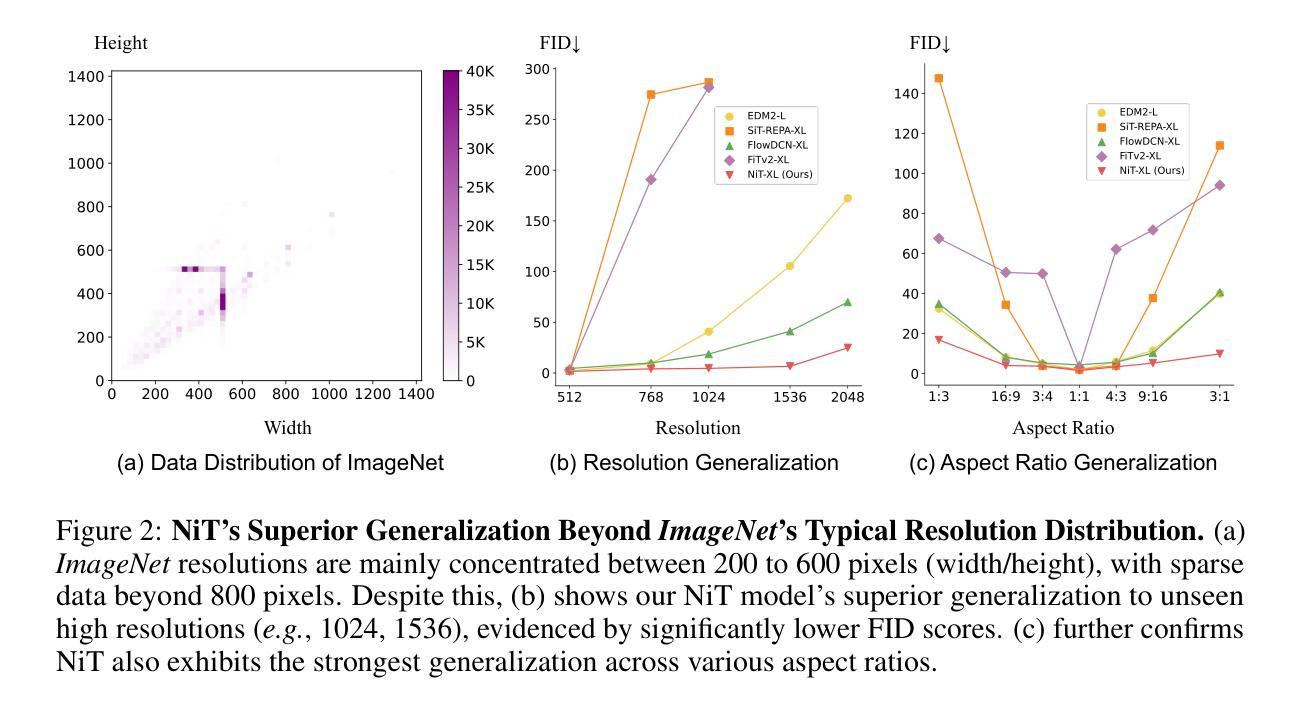
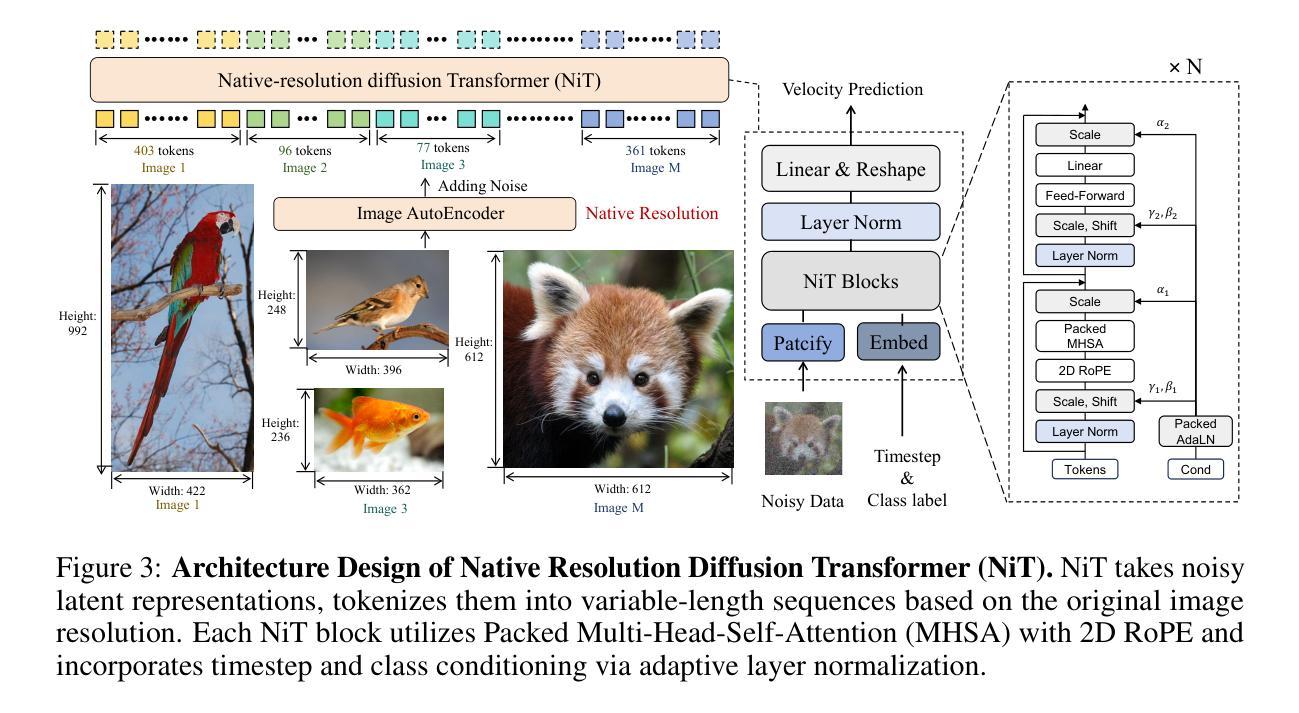
Native-Resolution Image Synthesis
Authors:Zidong Wang, Lei Bai, Xiangyu Yue, Wanli Ouyang, Yiyuan Zhang
We introduce native-resolution image synthesis, a novel generative modeling paradigm that enables the synthesis of images at arbitrary resolutions and aspect ratios. This approach overcomes the limitations of conventional fixed-resolution, square-image methods by natively handling variable-length visual tokens, a core challenge for traditional techniques. To this end, we introduce the Native-resolution diffusion Transformer (NiT), an architecture designed to explicitly model varying resolutions and aspect ratios within its denoising process. Free from the constraints of fixed formats, NiT learns intrinsic visual distributions from images spanning a broad range of resolutions and aspect ratios. Notably, a single NiT model simultaneously achieves the state-of-the-art performance on both ImageNet-256x256 and 512x512 benchmarks. Surprisingly, akin to the robust zero-shot capabilities seen in advanced large language models, NiT, trained solely on ImageNet, demonstrates excellent zero-shot generalization performance. It successfully generates high-fidelity images at previously unseen high resolutions (e.g., 1536 x 1536) and diverse aspect ratios (e.g., 16:9, 3:1, 4:3), as shown in Figure 1. These findings indicate the significant potential of native-resolution modeling as a bridge between visual generative modeling and advanced LLM methodologies.
我们引入了原生分辨率图像合成,这是一种新的生成建模范式,能够合成任意分辨率和长宽比的图像。该方法克服了传统固定分辨率、正方形图像方法在可变长度视觉符号处理方面的局限性,这是传统技术面临的核心挑战。为此,我们引入了原生分辨率扩散Transformer(NiT),其架构旨在显式建模其去噪过程中的各种分辨率和长宽比。摆脱固定格式的约束,NiT从跨越广泛分辨率和长宽比的图像中学习内在视觉分布。值得注意的是,一个单一的NiT模型同时在ImageNet-256x256和512x512基准测试上达到了最先进的性能。令人惊讶的是,类似于高级大型语言模型中看到的强大零样本能力,NiT仅在ImageNet上进行训练,便表现出了出色的零样本泛化性能。它成功地生成了先前未见的高分辨率(例如1536x1536)和多种长宽比(例如16:9、3:1、4:3)的高保真图像,如图1所示。这些发现表明原生分辨率建模作为连接视觉生成建模和高级LLM方法之间的桥梁具有显著潜力。
论文及项目相关链接
PDF Project Page: https://wzdthu.github.io/NiT/
Summary
该文本介绍了一种新型图像生成建模方法——原生分辨率图像合成。该方法克服了传统固定分辨率和正方形图像方法的局限性,能够原生处理可变长度的视觉标记,实现了任意分辨率和长宽比的图像合成。为此,引入了原生分辨率扩散Transformer(NiT)架构,其降噪过程中显式地建模了各种分辨率和长宽比。NiT模型从广泛的分辨率和长宽比的图像中学习内在视觉分布,并同时达到ImageNet-256x256和512x512基准测试的世界级水平。此外,NiT展示了令人惊讶的零样本泛化能力,能够在未见过的高分辨率(如1536x1536)和多种长宽比下生成高质量图像。这显示了原生分辨率建模作为视觉生成建模与高级LLM方法之间的桥梁的巨大潜力。
Key Takeaways
- 引入原生分辨率图像合成,实现任意分辨率和长宽比的图像合成。
- 克服传统固定分辨率和正方形图像方法的局限性,原生处理可变长度的视觉标记。
- 引入NiT架构,显式建模各种分辨率和长宽比的图像。
- NiT模型从广泛分辨率和长宽比的图像中学习内在视觉分布。
- NiT在ImageNet基准测试上达到世界级水平,同时支持多种分辨率和长宽比。
- NiT展示出令人惊讶的零样本泛化能力,能在未见过的分辨率和长宽比下生成高质量图像。
点此查看论文截图

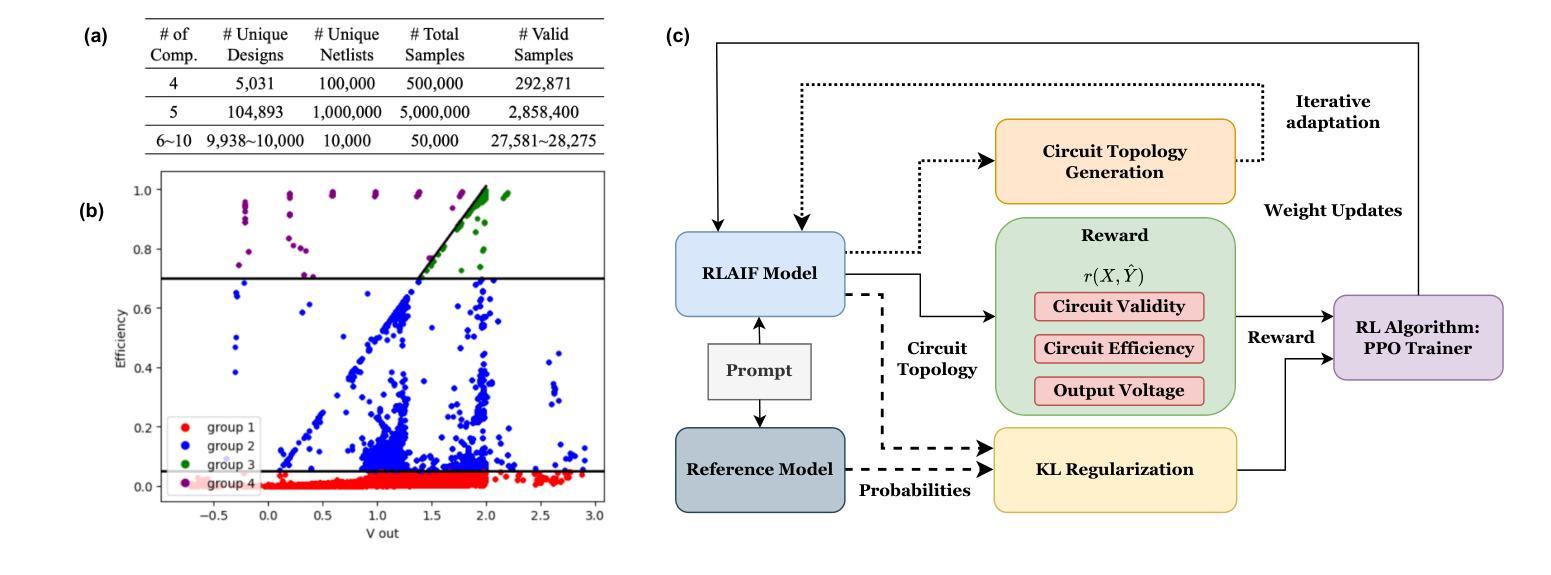
AUTOCIRCUIT-RL: Reinforcement Learning-Driven LLM for Automated Circuit Topology Generation
Authors:Prashanth Vijayaraghavan, Luyao Shi, Ehsan Degan, Vandana Mukherjee, Xin Zhang
Analog circuit topology synthesis is integral to Electronic Design Automation (EDA), enabling the automated creation of circuit structures tailored to specific design requirements. However, the vast design search space and strict constraint adherence make efficient synthesis challenging. Leveraging the versatility of Large Language Models (LLMs), we propose AUTOCIRCUIT-RL,a novel reinforcement learning (RL)-based framework for automated analog circuit synthesis. The framework operates in two phases: instruction tuning, where an LLM learns to generate circuit topologies from structured prompts encoding design constraints, and RL refinement, which further improves the instruction-tuned model using reward models that evaluate validity, efficiency, and output voltage. The refined model is then used directly to generate topologies that satisfy the design constraints. Empirical results show that AUTOCIRCUIT-RL generates ~12% more valid circuits and improves efficiency by ~14% compared to the best baselines, while reducing duplicate generation rates by ~38%. It achieves over 60% success in synthesizing valid circuits with limited training data, demonstrating strong generalization. These findings highlight the framework’s effectiveness in scaling to complex circuits while maintaining efficiency and constraint adherence, marking a significant advancement in AI-driven circuit design.
模拟电路拓扑合成是电子设计自动化(EDA)的重要组成部分,能够实现针对特定设计要求的电路结构的自动化创建。然而,庞大的设计搜索空间和严格约束的限制使得高效的合成面临挑战。我们利用大型语言模型(LLM)的通用性,提出了基于强化学习(RL)的新型自动化模拟电路合成框架——AUTOCIRCUIT-RL。该框架分为两个阶段:指令调整阶段,LLM从编码设计约束的结构化提示中学习生成电路拓扑;RL精炼阶段,使用评估有效性、效率和输出电压的奖励模型进一步改进指令调整模型。改进后的模型可直接用于生成满足设计约束的拓扑结构。经验结果表明,与最佳基线相比,AUTOCIRCUIT-RL生成的有效电路数量增加了约12%,效率提高了约14%,重复生成率降低了约38%。在有限训练数据的情况下,它成功合成有效电路的比例超过60%,显示出强大的泛化能力。这些发现突显了该框架在扩展到复杂电路时保持效率和约束遵守的有效性,标志着人工智能驱动电路设计的一个重大进步。
论文及项目相关链接
PDF 9 Pages (Content), 4 Pages (Appendix), 7 figures, ICML’2025
Summary:基于大型语言模型(LLM)的强化学习框架——AUTOCIRCUIT-RL在模拟电路设计自动化中具有突出表现。框架包括指令微调与强化学习优化两个阶段,提高了模拟电路设计的有效性和效率。该方法通过结构化提示编码设计约束,学习生成电路拓扑结构,并利用奖励模型评估其合理性、效率和输出电压进行进一步优化。在复杂电路设计中,该框架展现出良好的扩展性、效率和约束遵守能力。
Key Takeaways:
- AUTOCIRCUIT-RL是结合强化学习(RL)的大型语言模型(LLM)框架,用于模拟电路设计自动化。
- 框架包含指令微调阶段,通过结构化提示学习生成满足设计约束的电路拓扑。
- RL优化阶段利用奖励模型评估电路的有效性、效率和输出电压,进一步优化模型。
- 该方法相较于其他基线方法,能生成约12%更多的有效电路,提高约14%的效率,并降低约38%的重复生成率。
- 在有限训练数据下,该框架成功合成有效电路的比例达到60%以上,显示出强大的泛化能力。
- AUTOCIRCUIT-RL在复杂电路设计中表现出良好的扩展性,同时保持高效率和对设计约束的遵守。
点此查看论文截图

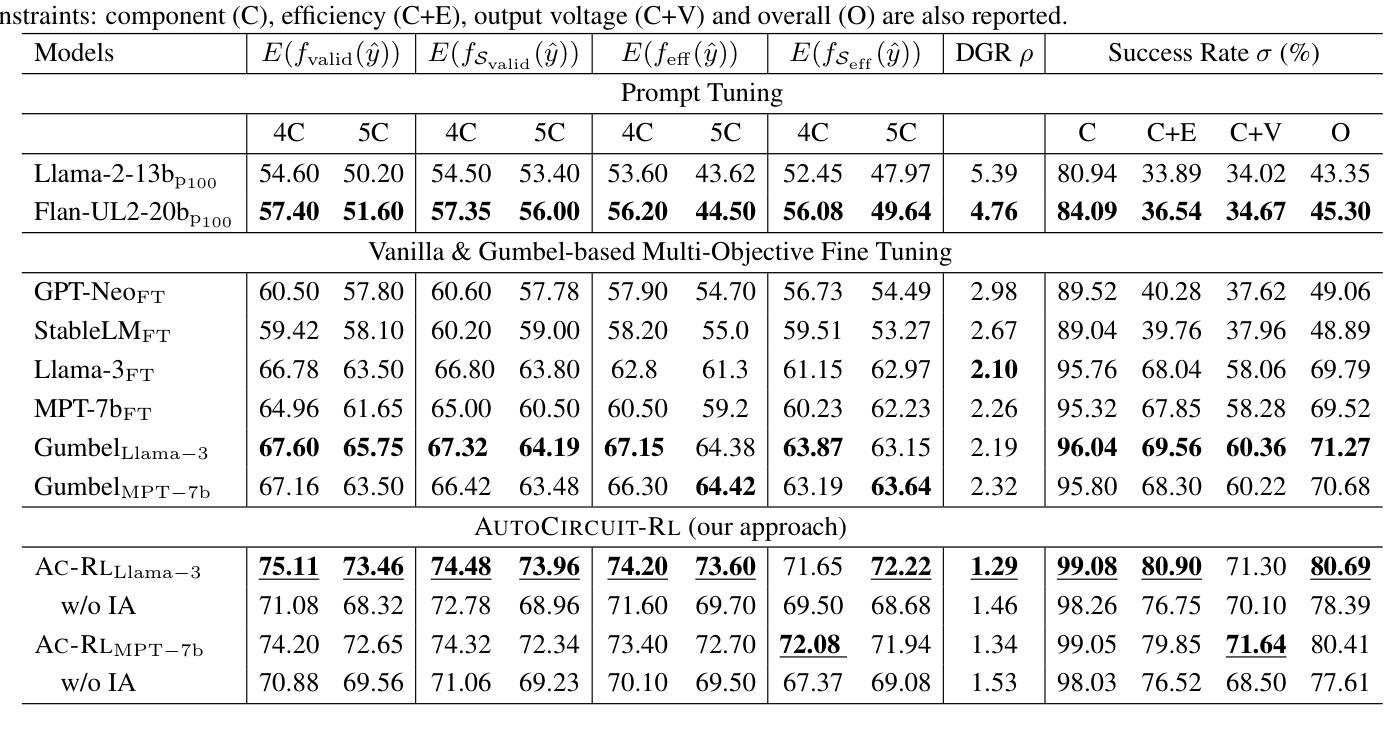
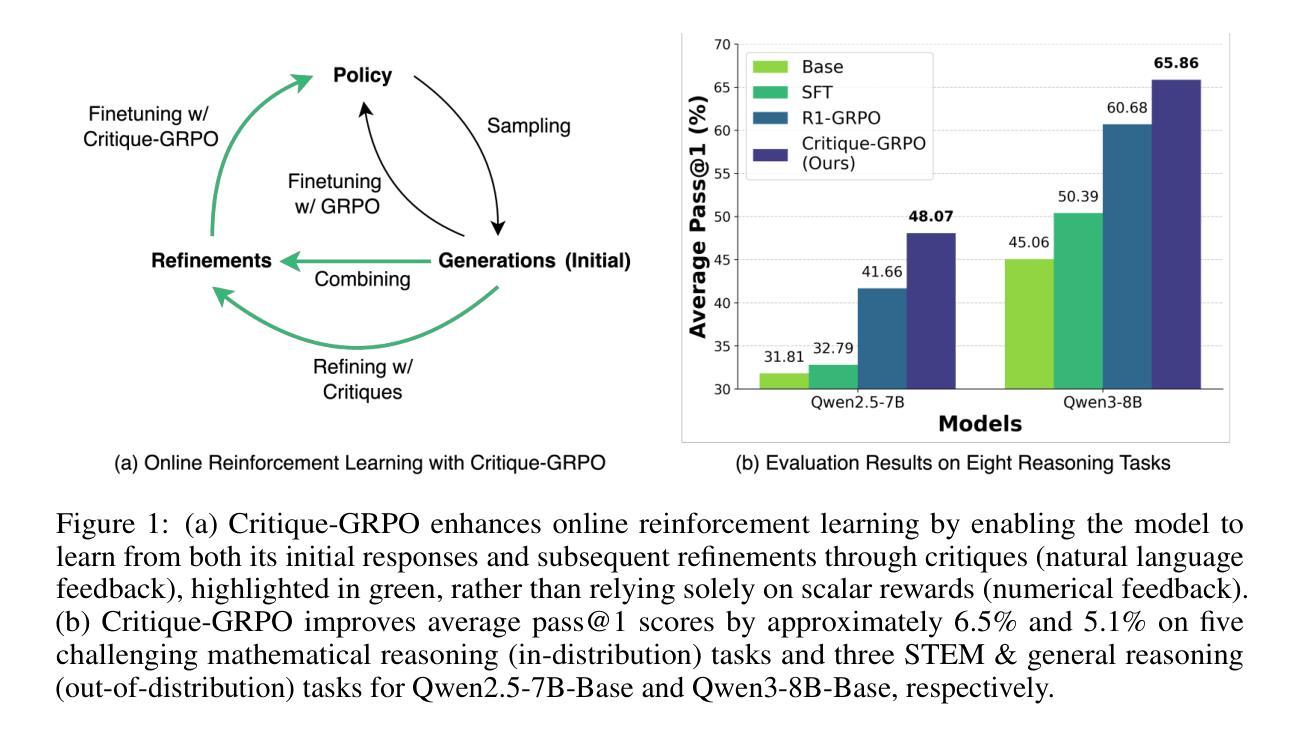
Critique-GRPO: Advancing LLM Reasoning with Natural Language and Numerical Feedback
Authors:Xiaoying Zhang, Hao Sun, Yipeng Zhang, Kaituo Feng, Chao Yang, Helen Meng
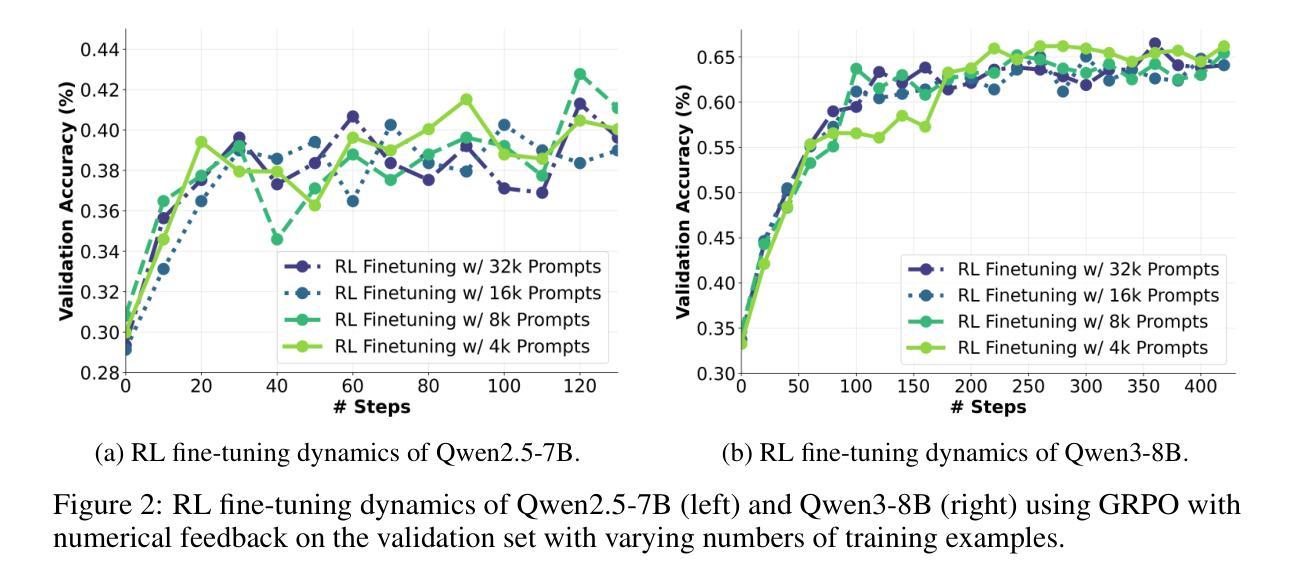
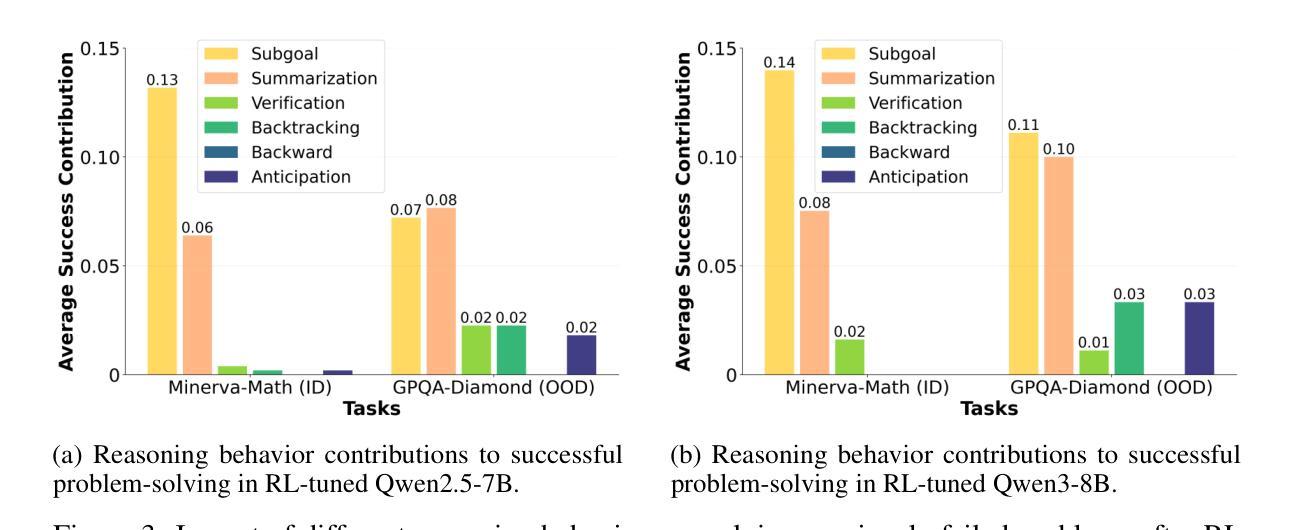
Recent advances in reinforcement learning (RL) with numerical feedback, such as scalar rewards, have significantly enhanced the complex reasoning capabilities of large language models (LLMs). Despite this success, we identify three key challenges encountered by RL with solely numerical feedback: performance plateaus, limited effectiveness of self-reflection, and persistent failures. We then demonstrate that RL-finetuned models, even after exhibiting performance plateaus, can generate correct refinements on persistently failed problems by leveraging natural language feedback in the form of critiques. Building on this insight, we propose Critique-GRPO, an online RL framework that integrates both natural language and numerical feedback for effective policy optimization. Critique-GRPO enables LLMs to learn from initial responses and critique-guided refinements simultaneously while maintaining exploration. Extensive experiments using Qwen2.5-7B-Base and Qwen3-8B-Base show that Critique-GRPO consistently outperforms supervised learning-based and RL-based fine-tuning approaches across eight challenging mathematical, STEM, and general reasoning tasks, improving average pass@1 scores by approximately 4.5% and 5%, respectively. Notably, Critique-GRPO surpasses a strong baseline that incorporates expert demonstrations within online RL. Further analysis reveals two critical insights about policy exploration: (1) higher entropy does not always guarantee efficient learning from exploration, and (2) longer responses do not necessarily lead to more effective exploration.
最近,强化学习(RL)在数值反馈方面的进展,如标量奖励,极大地增强了大型语言模型(LLM)的复杂推理能力。然而,我们发现了仅使用数值反馈的RL所面临的三大挑战:性能高原期、自我反思的局限性以及持续失败的问题。接着我们证明,即使在性能高原期后,通过利用批判形式的自然语言反馈,RL微调过的模型也能对持续失败的问题进行正确的改进。基于这一发现,我们提出了Critique-GRPO,这是一个在线RL框架,它结合了自然语言反馈和数值反馈,以实现有效的策略优化。Critique-GRPO使LLM能够同时从初始响应和批判指导的改进中学习,同时保持探索。使用Qwen2.5-7B-Base和Qwen3-8B-Base的广泛实验表明,Critique-GRPO在八个具有挑战性的数学、STEM和一般推理任务上始终优于基于监督学习和RL的微调方法,平均pass@1得分分别提高了约4.5%和5%。值得注意的是,Critique-GRPO超越了一个强大的基线,该基线结合了在线RL中的专家演示。进一步的分析揭示了关于策略探索的两个关键见解:(1)高熵并不总是保证从探索中有效学习,(2)更长的响应并不一定能导致更有效的探索。
论文及项目相关链接
PDF 38 pages
Summary
强化学习(RL)结合数值反馈在提升大型语言模型(LLM)的复杂推理能力方面取得了显著进展。然而,RL仅通过数值反馈面临性能瓶颈、自我反思受限和持续失败等三大挑战。通过结合自然语言反馈的形式——批判,即使在性能瓶颈后,RL微调模型也能对持续失败的问题产生正确的改进。基于此,提出了结合自然语言与数值反馈的在线RL框架——Critique-GRPO,用于有效的策略优化。实验表明,Critique-GRPO在多个数学、STEM和一般推理任务上表现优于基于监督学习和RL的微调方法,平均提高约4.5%和5%。关键的是,Critique-GRPO超越了结合专家演示的在线RL基线。对策略探索的进一步分析揭示了两个关键见解。
Key Takeaways
- 强化学习结合数值反馈增强了大型语言模型的复杂推理能力。
- 单纯依赖数值反馈的强化学习面临性能瓶颈、自我反思受限和持续失败等挑战。
- 利用自然语言反馈(如批判)可以帮助RL微调模型在性能瓶颈后改进持续失败的问题。
- 提出的Critique-GRPO框架结合了自然语言与数值反馈,实现了有效的策略优化。
- 实验表明,Critique-GRPO在多个任务上表现优于其他方法,平均提高约4.5%和5%。
- Critique-GRPO超越了结合专家演示的在线RL基线。
点此查看论文截图

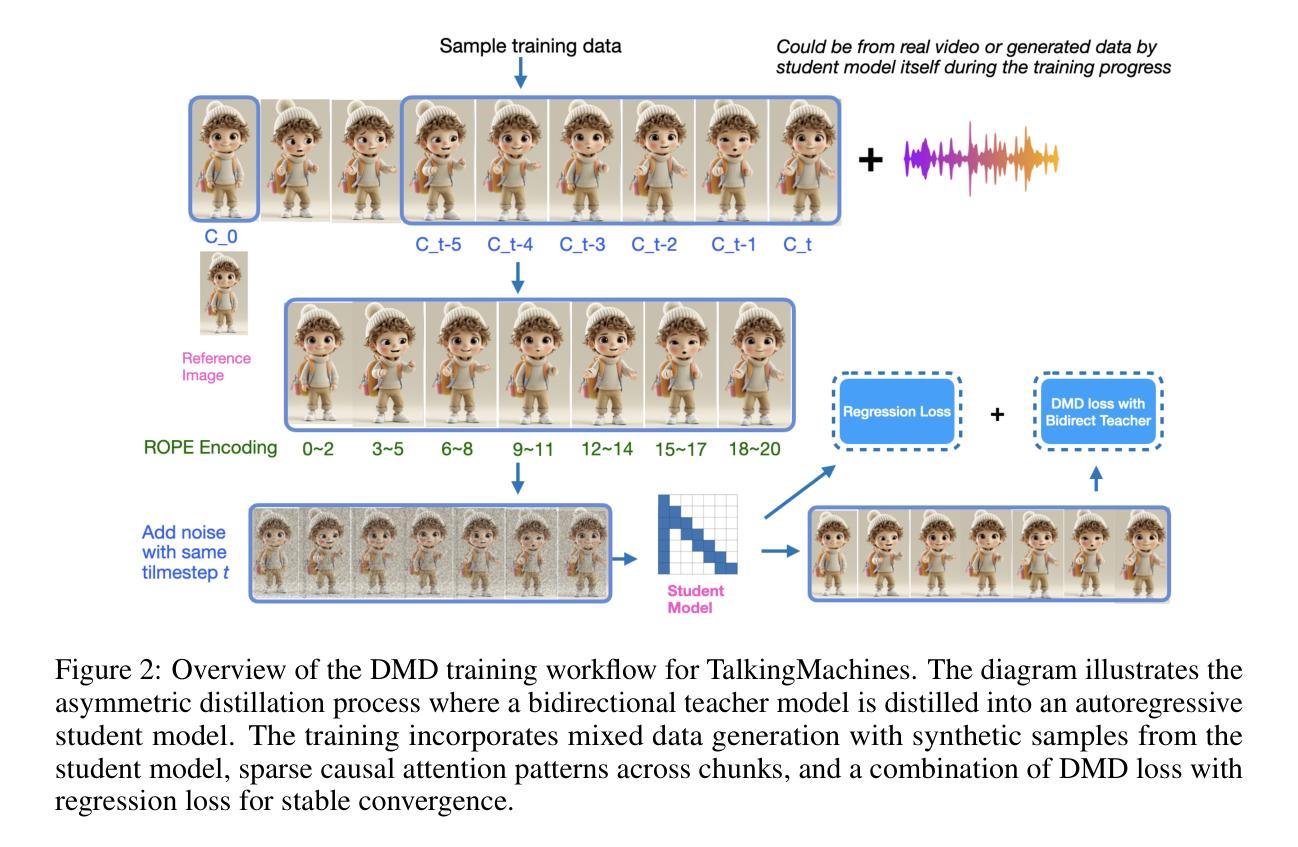
TalkingMachines: Real-Time Audio-Driven FaceTime-Style Video via Autoregressive Diffusion Models
Authors:Chetwin Low, Weimin Wang
In this paper, we present TalkingMachines – an efficient framework that transforms pretrained video generation models into real-time, audio-driven character animators. TalkingMachines enables natural conversational experiences by integrating an audio large language model (LLM) with our video generation foundation model. Our primary contributions include: (1) We adapt a pretrained SOTA image-to-video DiT into an audio-driven avatar generation model of 18 billion parameters; (2) We enable infinite video streaming without error accumulation through asymmetric knowledge distillation from a bidirectional teacher model into a sparse causal, autoregressive student model; (3) We design a high-throughput, low-latency inference pipeline incorporating several key engineering optimizations such as: (a) disaggregation of the DiT and VAE decoder across separate devices, (b) efficient overlap of inter-device communication and computation using CUDA streams, (c) elimination of redundant recomputations to maximize frame-generation throughput. Please see demo videos here - https://aaxwaz.github.io/TalkingMachines/
本文介绍了TalkingMachines——一个高效框架,该框架将预训练的视频生成模型转化为实时音频驱动的角色动画。TalkingMachines通过整合音频大语言模型(LLM)与我们的视频生成基础模型,实现了自然的对话体验。我们的主要贡献包括:(1)我们将最先进的图像到视频DiT模型转化为18亿参数的音频驱动化身生成模型;(2)我们利用从双向教师模型到稀疏因果自回归学生模型的不对称知识蒸馏技术,实现了无误差累积的无限视频流;(3)我们设计了一个高吞吐量和低延迟的推理管道,其中包括几项关键工程优化,如(a)在单独的设备上分散DiT和VAE解码器,(b)使用CUDA流有效地重叠设备间通信和计算,(c)消除冗余的重新计算,以最大限度地提高帧生成吞吐量。请参阅演示视频:https://aaxwaz.github.io/TalkingMachines/(点击链接查看)
论文及项目相关链接
Summary
TalkingMachines是一个将预训练的视频生成模型转化为实时音频驱动的角色动画框架。它通过整合音频大型语言模型(LLM),使用户能够通过音频控制视频角色动画,实现自然对话体验。主要贡献包括:适应先进图像到视频DiT模型为音频驱动角色生成模型,实现无限视频流且无误差累积,设计高效低延迟推理管道,包括跨设备分解模型和高效重叠通信计算等优化。
Key Takeaways
- TalkingMachines是一个将预训练视频生成模型转化为音频驱动角色动画的框架,提供自然对话体验。
- 该框架整合了音频大型语言模型(LLM)。
- 框架成功适应图像到视频的DiT模型用于音频驱动角色生成。
- TalkingMachines实现了无限视频流播放且无误差累积。
- 设计了高效低延迟的推理管道,支持跨设备模型分解和通信计算优化。
- 通过不对称知识蒸馏技术从双向教师模型到稀疏因果自回归学生模型,提高了模型的性能。
点此查看论文截图

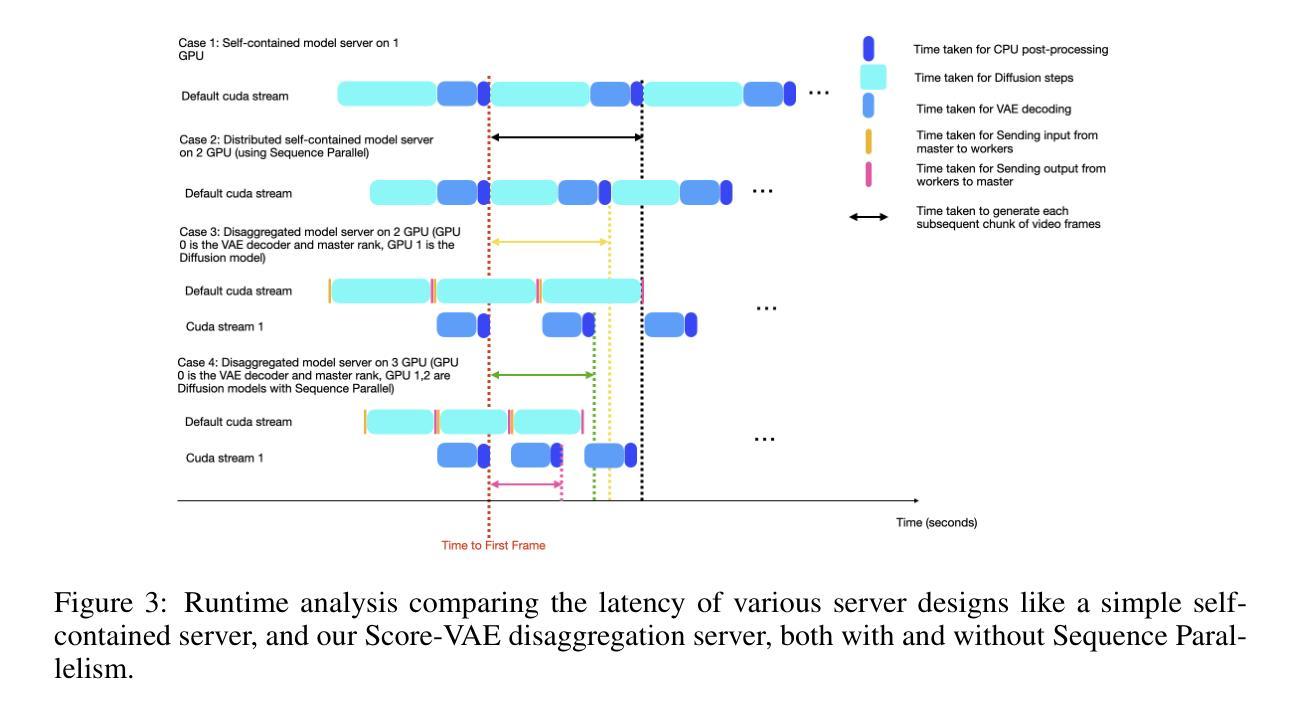
DPO Learning with LLMs-Judge Signal for Computer Use Agents
Authors:Man Luo, David Cobbley, Xin Su, Shachar Rosenman, Vasudev Lal, Shao-Yen Tseng, Phillip Howard
Computer use agents (CUA) are systems that automatically interact with graphical user interfaces (GUIs) to complete tasks. CUA have made significant progress with the advent of large vision-language models (VLMs). However, these agents typically rely on cloud-based inference with substantial compute demands, raising critical privacy and scalability concerns, especially when operating on personal devices. In this work, we take a step toward privacy-preserving and resource-efficient agents by developing a lightweight vision-language model that runs entirely on local machines. To train this compact agent, we introduce an LLM-as-Judge framework that automatically evaluates and filters synthetic interaction trajectories, producing high-quality data for reinforcement learning without human annotation. Experiments on the OS-World benchmark demonstrate that our fine-tuned local model outperforms existing baselines, highlighting a promising path toward private, efficient, and generalizable GUI agents.
计算机使用代理(CUA)是自动与图形用户界面(GUI)交互以完成任务的系统。随着大型视觉语言模型(VLM)的出现,CUA已经取得了重大进展。然而,这些代理通常依赖于具有大量计算需求的云推理,这引发了关于隐私和可扩展性的关键问题,特别是在个人设备上运行时。在这项工作中,我们通过开发一种完全运行在本地机器上的轻量级视觉语言模型,朝着保护隐私和资源高效的代理迈出了一步。为了训练这种紧凑的代理,我们引入了一个名为“LLM-as-Judge”的框架,该框架自动评估并过滤合成交互轨迹,从而在无需人工注释的情况下为强化学习生成高质量数据。在OS-World基准测试上的实验表明,我们微调的本地模型超越了现有基线,突显出了一条朝着私密、高效和可通用的GUI代理的充满希望的道路。
论文及项目相关链接
Summary
随着大型视觉语言模型的发展,计算机使用代理(CUA)在自动与图形用户界面(GUI)交互完成任务方面取得了显著进步。然而,这些代理通常依赖于具有大量计算需求的云推理,这引发了关于隐私和可扩展性的关键问题。本研究朝向隐私保护和资源高效的代理迈出了重要一步,通过开发可在本地机器上完全运行的轻量级视觉语言模型。为了训练这个紧凑的代理,我们引入了LLM-as-Judge框架,该框架自动评估并过滤合成交互轨迹,从而在无需人工标注的情况下为强化学习提供高质量数据。在OS-World基准测试上的实验表明,我们的精细本地模型超越了现有基线,为私人、高效和可通用的GUI代理指明了有前途的道路。
Key Takeaways
- 计算机使用代理(CUA)能自动与图形用户界面(GUI)交互完成任务。
- 大型视觉语言模型(VLM)的发展对CUA的进步起到了推动作用。
- CUA通常依赖云推理,引发隐私和可扩展性问题,特别是在个人设备上。
- 研究人员开发了一种可在本地机器上运行的轻量级视觉语言模型,以提高隐私保护和资源效率。
- 引入LLM-as-Judge框架训练紧凑代理,该框架能自动评估并过滤合成交互轨迹。
- 实验证明,精细本地模型在OS-World基准测试上超越了现有基线。
点此查看论文截图

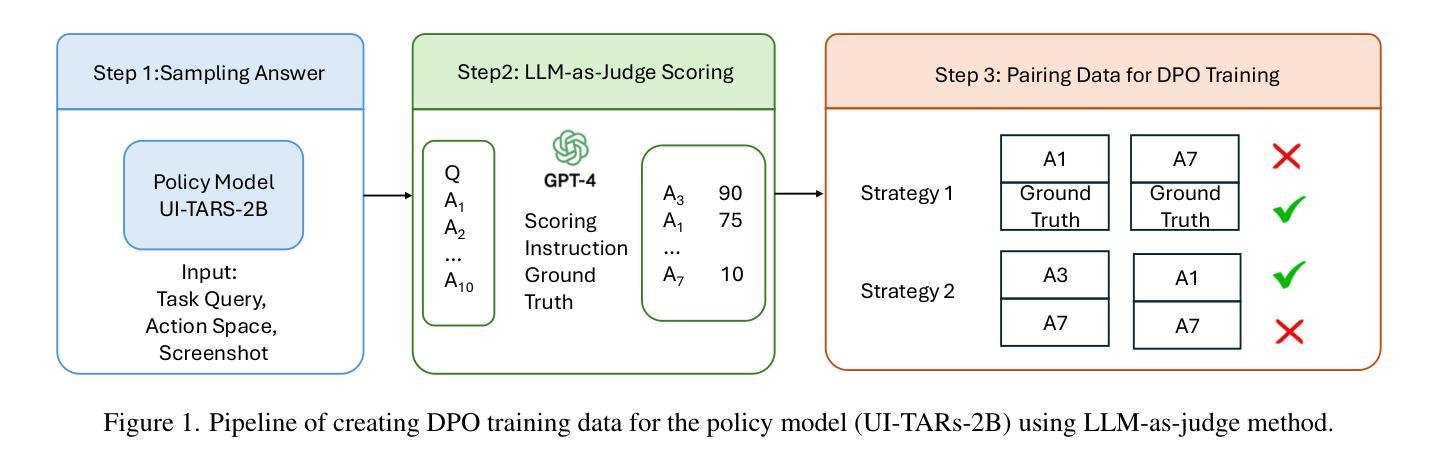
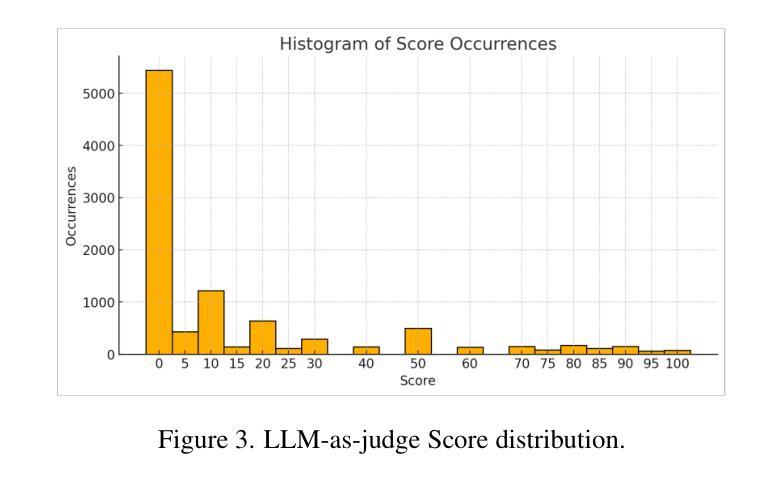
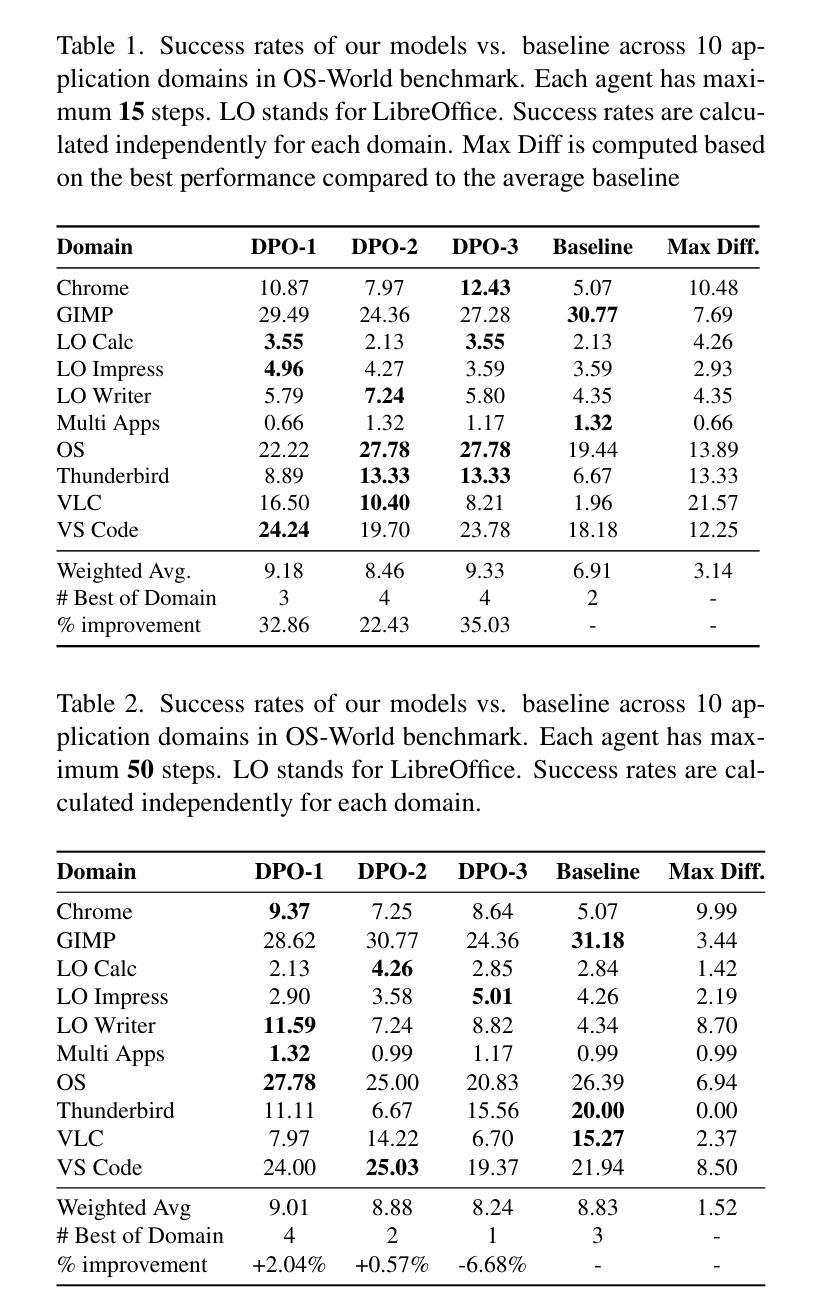
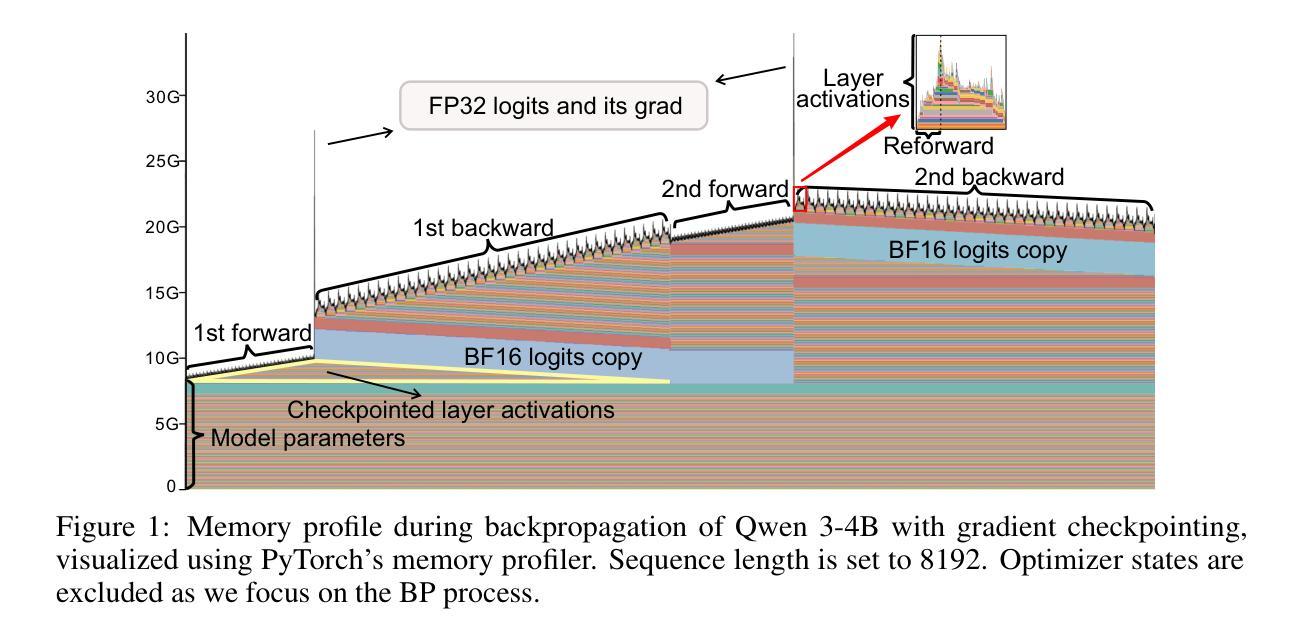
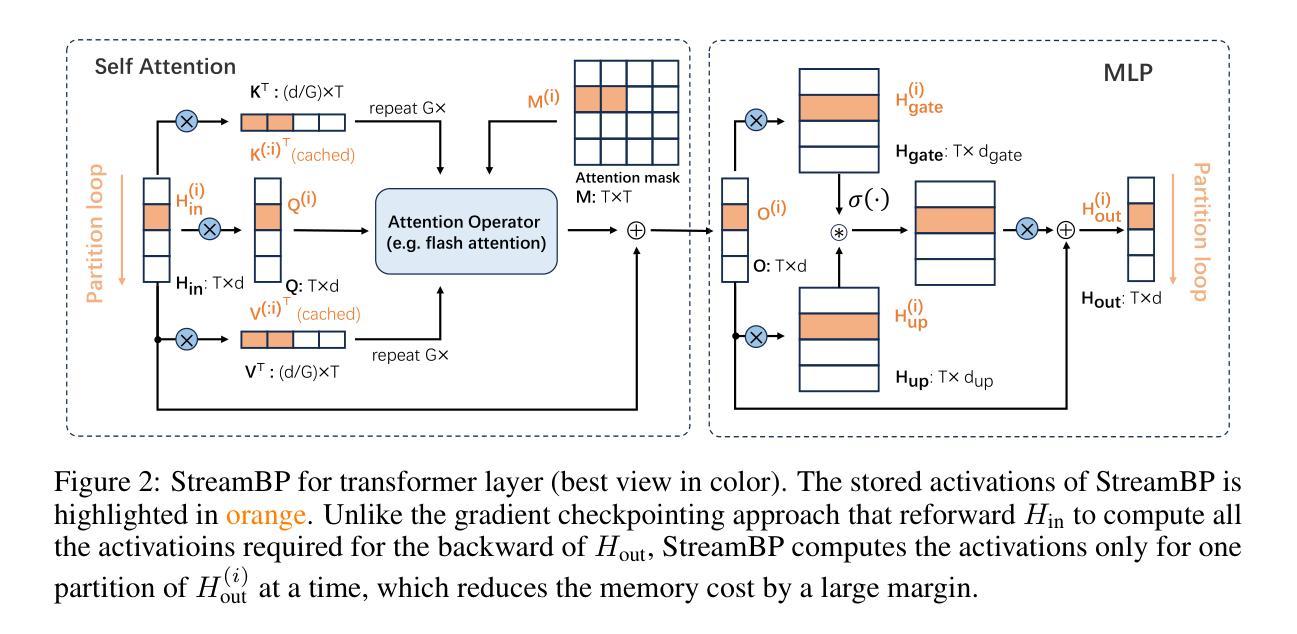
StreamBP: Memory-Efficient Exact Backpropagation for Long Sequence Training of LLMs
Authors:Qijun Luo, Mengqi Li, Lei Zhao, Xiao Li
Training language models on long sequence data is a demanding requirement for enhancing the model’s capability on complex tasks, e.g., long-chain reasoning. However, as the sequence length scales up, the memory cost for storing activation values becomes huge during the Backpropagation (BP) process, even with the application of gradient checkpointing technique. To tackle this challenge, we propose a memory-efficient and exact BP method called StreamBP, which performs a linear decomposition of the chain rule along the sequence dimension in a layer-wise manner, significantly reducing the memory cost of activation values and logits. The proposed method is applicable to common objectives such as SFT, GRPO, and DPO. From an implementation perspective, StreamBP achieves less computational FLOPs and faster BP speed by leveraging the causal structure of the language model. Compared to gradient checkpointing, StreamBP scales up the maximum sequence length of BP by 2.8-5.5 times larger, while using comparable or even less BP time. Note that StreamBP’s sequence length scaling ability can be directly transferred to batch size scaling for accelerating training. We further develop a communication-efficient distributed StreamBP to effectively support multi-GPU training and broaden its applicability. Our code can be easily integrated into the training pipeline of any transformer models and is available at https://github.com/Ledzy/StreamBP.
训练语言模型处理长序列数据是对复杂任务(如长链推理)提升模型能力的苛刻要求。然而,随着序列长度的增加,反向传播(BP)过程中存储激活值的内存成本变得巨大,即使应用了梯度检查点技术也是如此。为了应对这一挑战,我们提出了一种内存效率高且精确的反向传播方法,称为StreamBP。它逐层沿序列维度进行链式法则的线性分解,显著降低了激活值和logits的内存成本。所提出的方法适用于常见的目标,如SFT、GRPO和DPO。从实现的角度来看,StreamBP利用语言模型的因果结构实现了较少的计算FLOPs和更快的BP速度。与梯度检查点相比,StreamBP将BP的最大序列长度扩大了2.8-5.5倍,同时使用的时间相当甚至更少。请注意,StreamBP的序列长度缩放能力可以直接转移到批处理大小缩放以加速训练。我们进一步开发了一种通信高效的分布式StreamBP,以有效支持多GPU训练并扩大其适用性。我们的代码可以轻松地集成到任何transformer模型的训练流程中,可在https://github.com/Ledzy/StreamBP找到。
论文及项目相关链接
Summary
本文提出一种名为StreamBP的内存高效反向传播方法,通过对序列维度上的链式规则进行逐层线性分解,显著降低了激活值和日志的存储成本。该方法适用于常见目标,如SFT、GRPO和DPO。StreamBP利用语言模型的因果结构,实现了较少的计算量和更快的反向传播速度。与梯度检查点技术相比,StreamBP可将反向传播的最大序列长度提高2.8-5.5倍,同时使用的反向传播时间相当甚至更少。此外,StreamBP的序列长度缩放能力可直接转换为批处理大小缩放,以加速训练。还开发了通信高效的分布式StreamBP,以有效支持多GPU训练和扩大其应用范围。
Key Takeaways
- StreamBP是一种内存高效的反向传播方法,适用于处理长序列数据的语言模型。
- 通过逐层线性分解链式规则,StreamBP降低了激活值和日志的存储成本。
- StreamBP适用于常见目标,如SFT、GRPO和DPO,并可以提高反向传播的最大序列长度。
- StreamBP利用语言模型的因果结构,实现了较少的计算量和更快的反向传播速度。
- 与梯度检查点技术相比,StreamBP在反向传播的最大序列长度方面表现出优越性。
- StreamBP的序列长度缩放能力可转换为批处理大小缩放,以加速训练过程。
点此查看论文截图

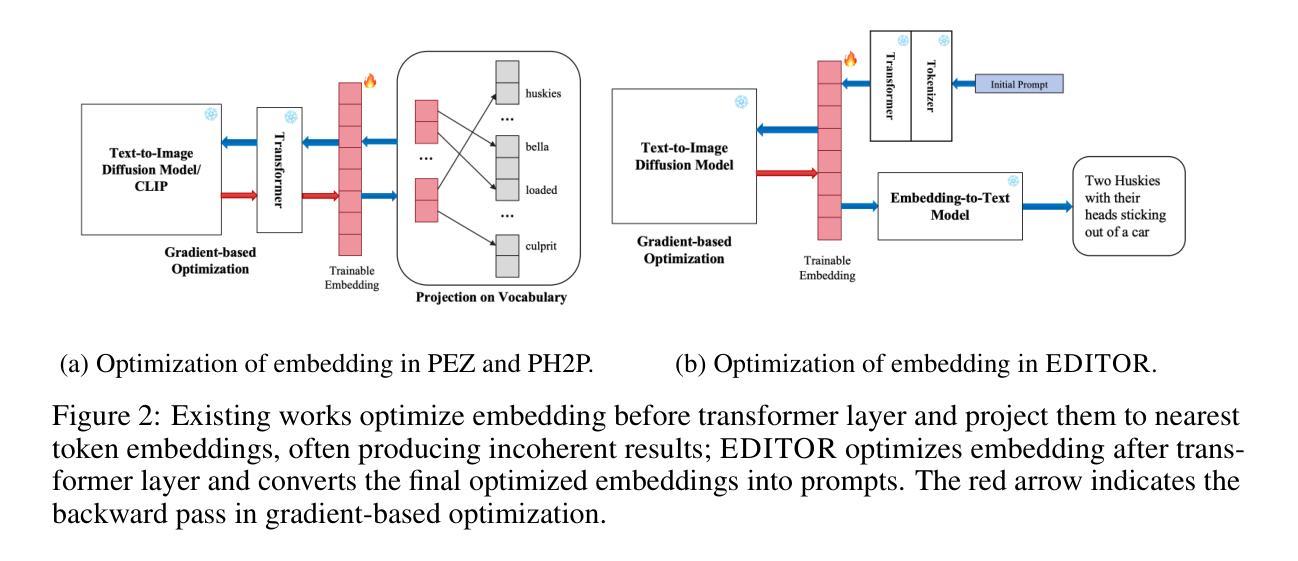
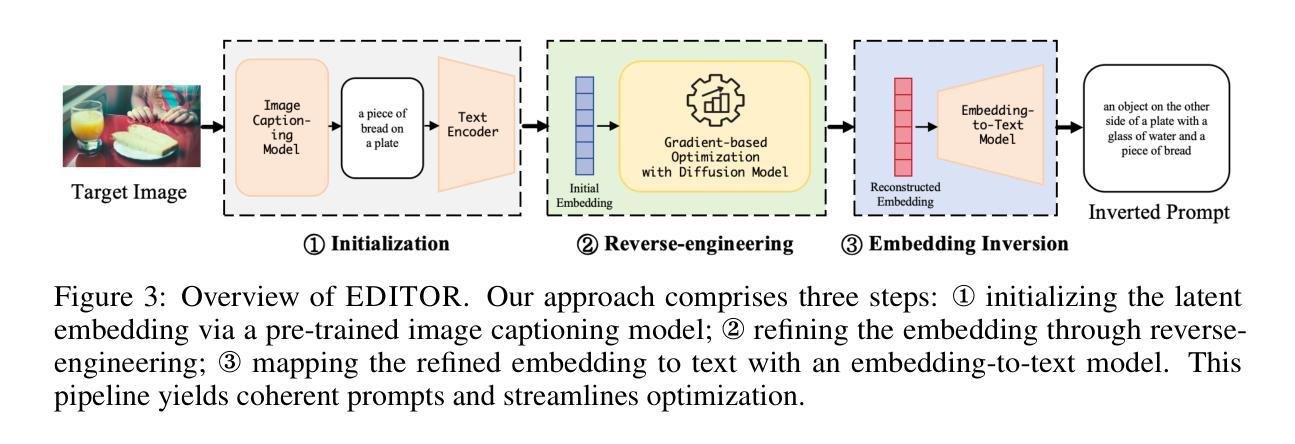
EDITOR: Effective and Interpretable Prompt Inversion for Text-to-Image Diffusion Models
Authors:Mingzhe Li, Gehao Zhang, Zhenting Wang, Shiqing Ma, Siqi Pan, Richard Cartwright, Juan Zhai
Text-to-image generation models~(e.g., Stable Diffusion) have achieved significant advancements, enabling the creation of high-quality and realistic images based on textual descriptions. Prompt inversion, the task of identifying the textual prompt used to generate a specific artifact, holds significant potential for applications including data attribution, model provenance, and watermarking validation. Recent studies introduced a delayed projection scheme to optimize for prompts representative of the vocabulary space, though challenges in semantic fluency and efficiency remain. Advanced image captioning models or visual large language models can generate highly interpretable prompts, but they often lack in image similarity. In this paper, we propose a prompt inversion technique called \sys for text-to-image diffusion models, which includes initializing embeddings using a pre-trained image captioning model, refining them through reverse-engineering in the latent space, and converting them to texts using an embedding-to-text model. Our experiments on the widely-used datasets, such as MS COCO, LAION, and Flickr, show that our method outperforms existing methods in terms of image similarity, textual alignment, prompt interpretability and generalizability. We further illustrate the application of our generated prompts in tasks such as cross-concept image synthesis, concept manipulation, evolutionary multi-concept generation and unsupervised segmentation.
文本到图像生成模型(例如Stable Diffusion)已经取得了显著的进步,能够根据文本描述创建高质量和逼真的图像。提示反转(prompt inversion)是识别用于生成特定艺术品的文本提示的任务,在数据归属、模型来源和水印验证等方面具有巨大的应用潜力。最近的研究引入了一种延迟投影方案,以优化代表词汇空间的提示,尽管在语义流畅性和效率方面仍存在挑战。先进的图像标题模型或视觉大型语言模型可以生成高度可解释的提示,但它们往往缺乏图像相似性。在本文中,我们提出了一种针对文本到图像扩散模型的提示反转技术,称为sys。它包括使用预训练的图像标题模型进行初始化嵌入,通过反向工程在潜在空间进行细化,并使用嵌入到文本模型将它们转换为文本。我们在MS COCO、LAION和Flickr等常用数据集上的实验表明,我们的方法在图像相似性、文本对齐、提示可解释性和通用性方面优于现有方法。我们还进一步说明了所生成的提示在跨概念图像合成、概念操作、进化多概念生成和无监督分割等任务中的应用。
论文及项目相关链接
Summary
文本生成图像模型(如Stable Diffusion)已取得显著进展,能够根据文本描述生成高质量、逼真的图像。本文提出了一种针对文本生成图像扩散模型的提示反转技术,该技术使用预训练图像描述模型进行初始化嵌入,通过反向工程在潜在空间进行改进,并使用嵌入到文本模型进行转换。实验表明,该方法在图像相似性、文本对齐、提示可解释性和通用性方面优于现有方法,并可用于跨概念图像合成、概念操作、进化多概念生成和无监督分割等任务。
Key Takeaways
- 文本生成图像模型如Stable Diffusion已能生成高质量、逼真的图像。
- 提示反转技术用于确定生成特定工件所使用的文本提示。
- 提示反转技术在数据归属、模型来源和水印验证等方面有潜在应用。
- 现有延迟投影方案在语义流畅性和效率方面存在挑战。
- 本文提出了一种新的提示反转技术,使用预训练图像描述模型进行嵌入初始化,并在潜在空间进行改进。
- 实验表明,该方法在图像相似性、文本对齐、提示可解释性和通用性方面优于现有方法。
点此查看论文截图



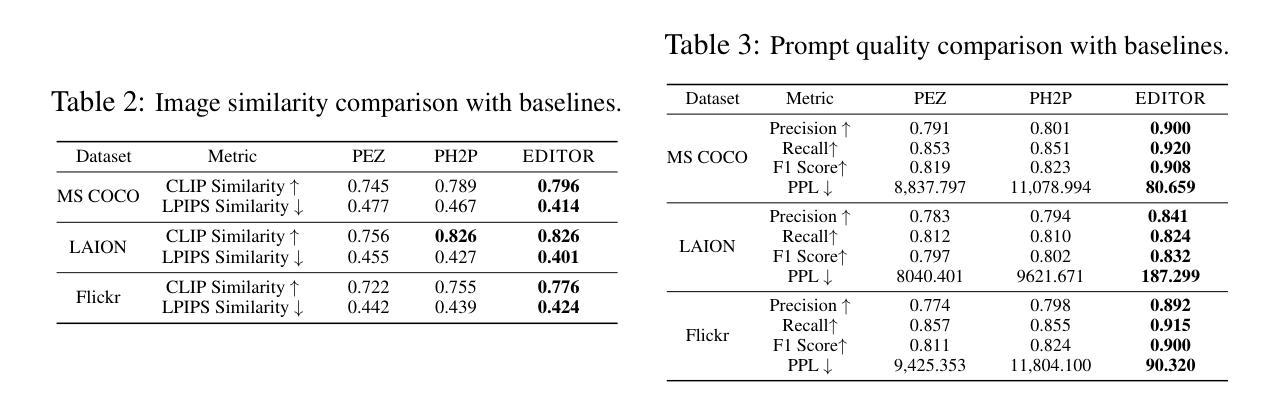
Leveraging Information Retrieval to Enhance Spoken Language Understanding Prompts in Few-Shot Learning
Authors:Pierre Lepagnol, Sahar Ghannay, Thomas Gerald, Christophe Servan, Sophie Rosset
Understanding user queries is fundamental in many applications, such as home assistants, booking systems, or recommendations. Accordingly, it is crucial to develop accurate Spoken Language Understanding (SLU) approaches to ensure the reliability of the considered system. Current State-of-the-Art SLU techniques rely on large amounts of training data; however, only limited annotated examples are available for specific tasks or languages. In the meantime, instruction-tuned large language models (LLMs) have shown exceptional performance on unseen tasks in a few-shot setting when provided with adequate prompts. In this work, we propose to explore example selection by leveraging Information retrieval (IR) approaches to build an enhanced prompt that is applied to an SLU task. We evaluate the effectiveness of the proposed method on several SLU benchmarks. Experimental results show that lexical IR methods significantly enhance performance without increasing prompt length.
理解用户查询在许多应用中都是至关重要的,例如家庭助理、预订系统或推荐系统。因此,为了确保所考虑系统的可靠性,开发准确的口语理解(SLU)方法至关重要。目前最先进的SLU技术依赖于大量的训练数据;然而,对于特定任务或语言,可用的注释示例相对较少。与此同时,经过指令训练的大型语言模型(LLM)在提供足够提示的情况下,在未见过的任务上表现出了出色的性能。在这项工作中,我们提出利用信息检索(IR)方法进行示例选择,以构建用于SLU任务的增强提示。我们在多个SLU基准测试上评估了所提出方法的有效性。实验结果表明,词汇IR方法在不增加提示长度的情况下显著提高了性能。
论文及项目相关链接
PDF Conference paper accepted to INTERSPEECH 2025
Summary
本文探讨了基于信息检索(IR)方法的示例选择策略在构建用于Spoken Language Understanding(SLU)任务的增强提示中的应用。在有限的训练数据下,利用指令优化的大型语言模型(LLM)通过增强提示显示了对未见任务的出色性能。实验结果证明,词法IR方法可显著提高SLU性能,且不会增加提示长度。
Key Takeaways
点此查看论文截图



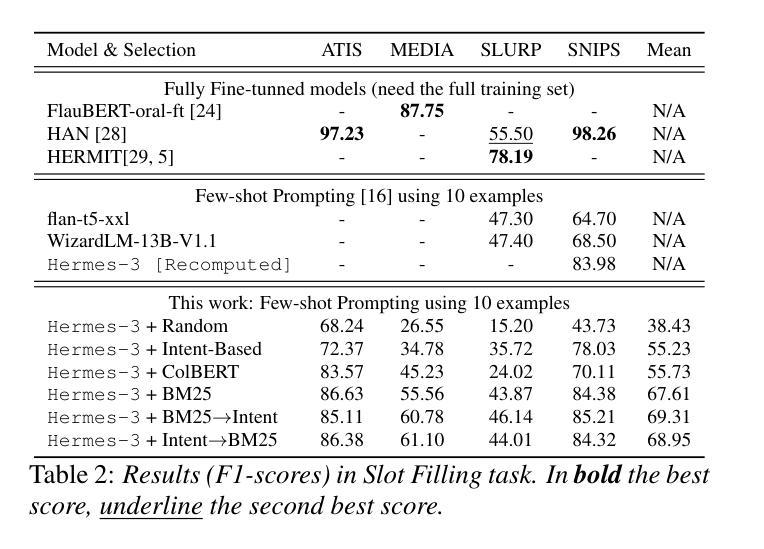
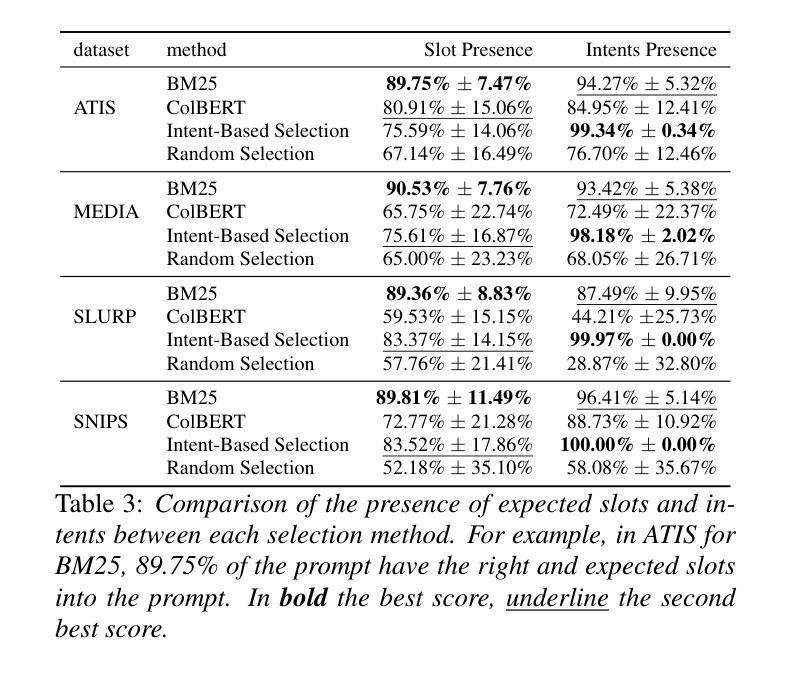
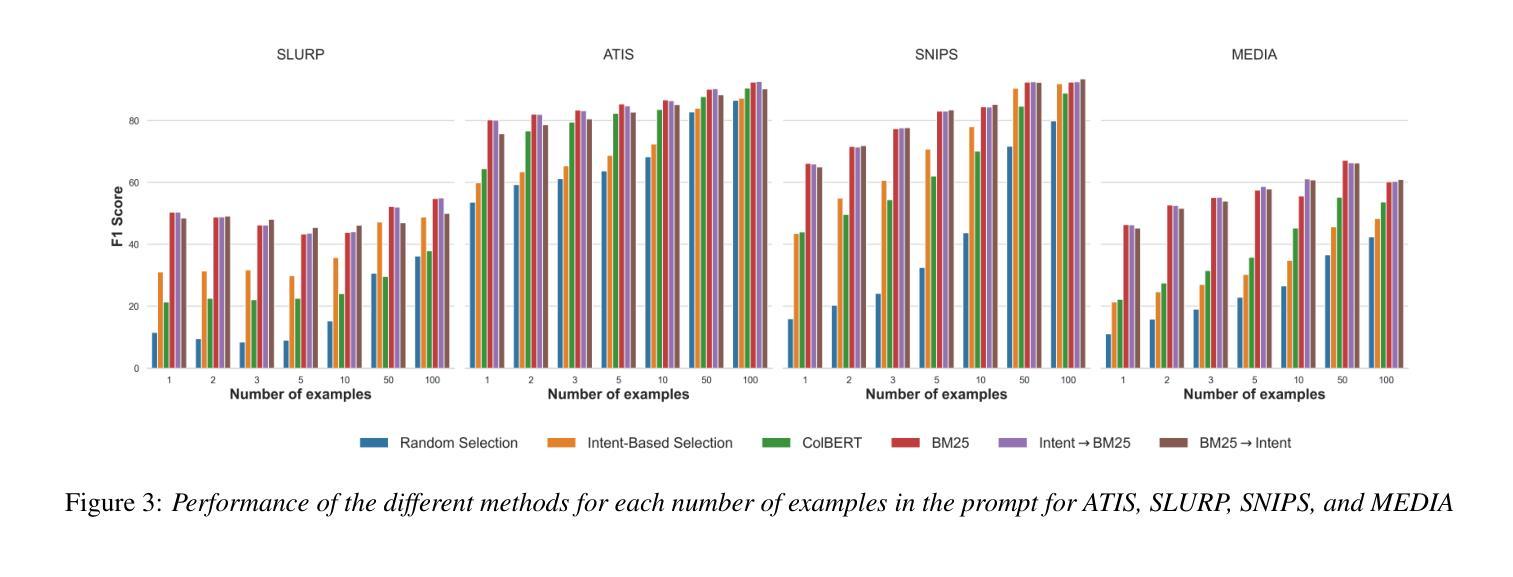
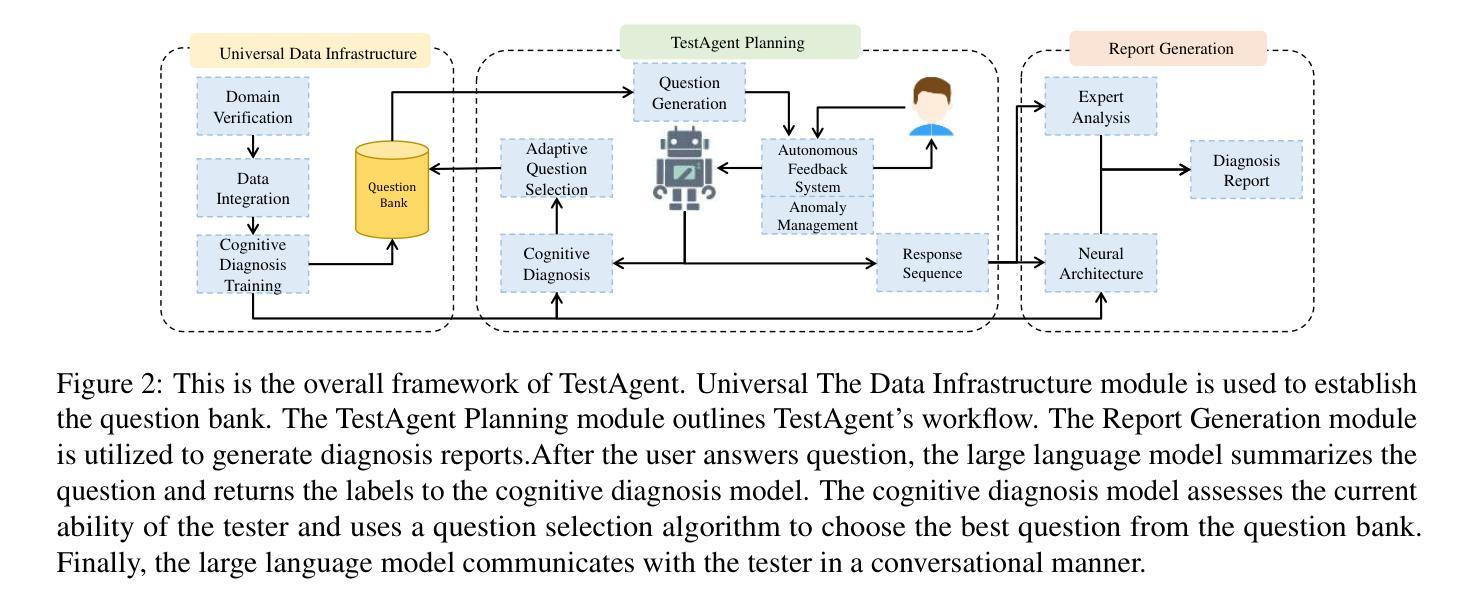
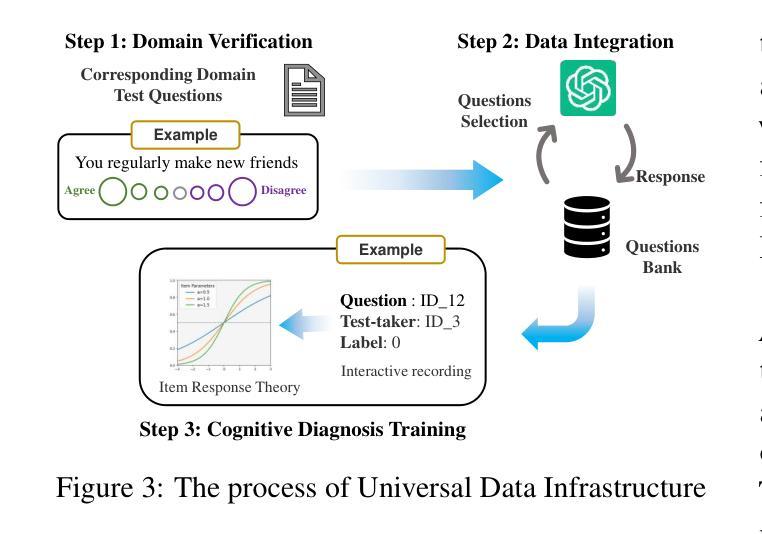
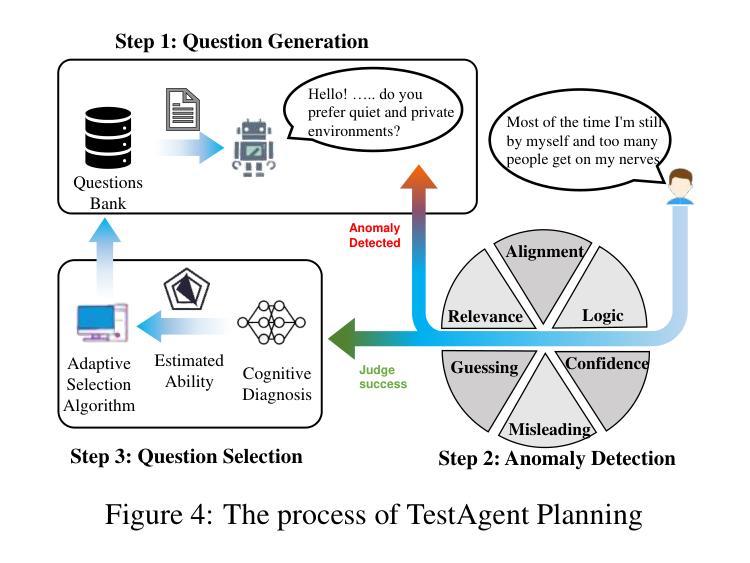
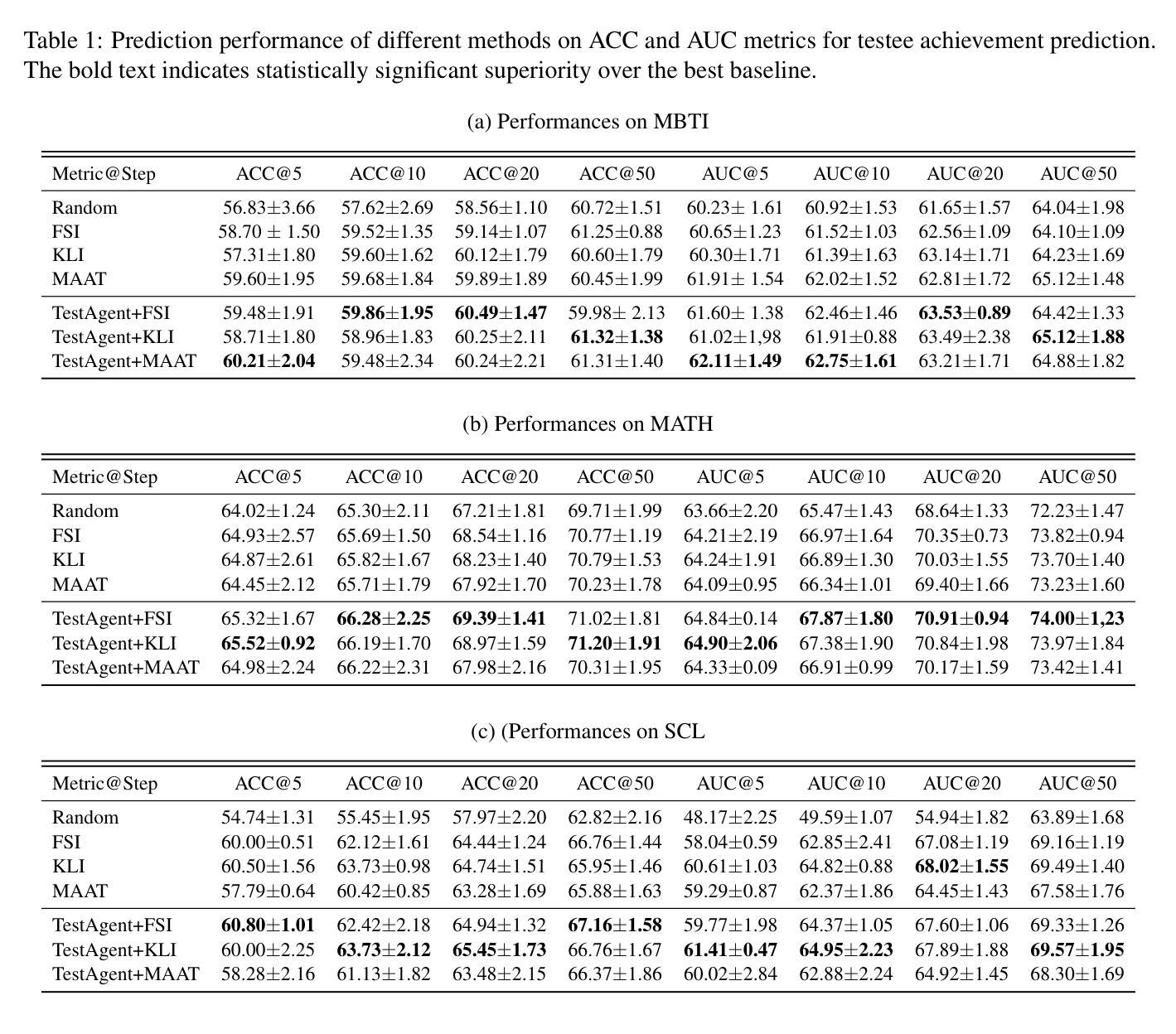
TestAgent: An Adaptive and Intelligent Expert for Human Assessment
Authors:Junhao Yu, Yan Zhuang, YuXuan Sun, Weibo Gao, Qi Liu, Mingyue Cheng, Zhenya Huang, Enhong Chen
Accurately assessing internal human states is key to understanding preferences, offering personalized services, and identifying challenges in real-world applications. Originating from psychometrics, adaptive testing has become the mainstream method for human measurement and has now been widely applied in education, healthcare, sports, and sociology. It customizes assessments by selecting the fewest test questions . However, current adaptive testing methods face several challenges. The mechanized nature of most algorithms leads to guessing behavior and difficulties with open-ended questions. Additionally, subjective assessments suffer from noisy response data and coarse-grained test outputs, further limiting their effectiveness. To move closer to an ideal adaptive testing process, we propose TestAgent, a large language model (LLM)-powered agent designed to enhance adaptive testing through interactive engagement. This is the first application of LLMs in adaptive testing. TestAgent supports personalized question selection, captures test-takers’ responses and anomalies, and provides precise outcomes through dynamic, conversational interactions. Experiments on psychological, educational, and lifestyle assessments show our approach achieves more accurate results with 20% fewer questions than state-of-the-art baselines, and testers preferred it in speed, smoothness, and other dimensions.
精确评估人类内部状态是理解偏好、提供个性化服务以及在现实世界中识别挑战的关键。起源于心理测量的自适应测试已成为人类测量的主流方法,现已广泛应用于教育、医疗、体育和社会学领域。它通过选择最少的测试问题来定制评估。然而,当前的自适应测试方法面临一些挑战。大多数算法的机械化特性导致猜测行为和开放式问题上的困难。此外,主观评估受到响应数据嘈杂和测试输出粒度粗糙的限制,进一步降低了其有效性。为了更接近理想的自适应测试过程,我们提出了TestAgent,这是一个由大型语言模型(LLM)驱动的智能体,旨在通过交互式参与增强自适应测试。这是自适应测试中的第一个大型语言模型应用。TestAgent支持个性化的问题选择,捕捉考生的反应和异常情况,并通过动态的对话交互提供精确的结果。在心理、教育和生活方式评估方面的实验表明,我们的方法比最新技术基线少问了20%的问题,取得了更准确的结果,并且在速度、流畅性和其他方面得到了测试人员的青睐。
论文及项目相关链接
PDF 24 pages,10 figures
Summary
自适应测试已成为主流的人性化测量方法,通过选择和个性化提问方式有效应用于教育、医疗和体育等领域。当前面临的挑战包括机械化算法带来的猜测行为、开放式问题处理困难等。为解决这些问题,首次将大型语言模型(LLM)应用于自适应测试领域,提出TestAgent测试代理,支持个性化问题选择,捕捉考生反应和异常情况,通过动态对话交互提供精确结果。实验证明,该方法更准确且问题数量减少20%,测试者在速度、流畅度等方面给出更高评价。
Key Takeaways
以下是本文提供的七个关键点概述:
- 理解个人偏好和挑战的关键在于准确评估内部人类状态。
- 自适应测试是心理测量中主流的个性化测量方法。
- 自适应测试在教育、医疗、体育和社会学等领域广泛应用。
- 当前自适应测试面临的挑战包括算法机械化、开放式问题处理等。
- 大型语言模型(LLM)首次应用于自适应测试领域。
- TestAgent支持个性化问题选择,捕捉考生反应和异常情况。
点此查看论文截图

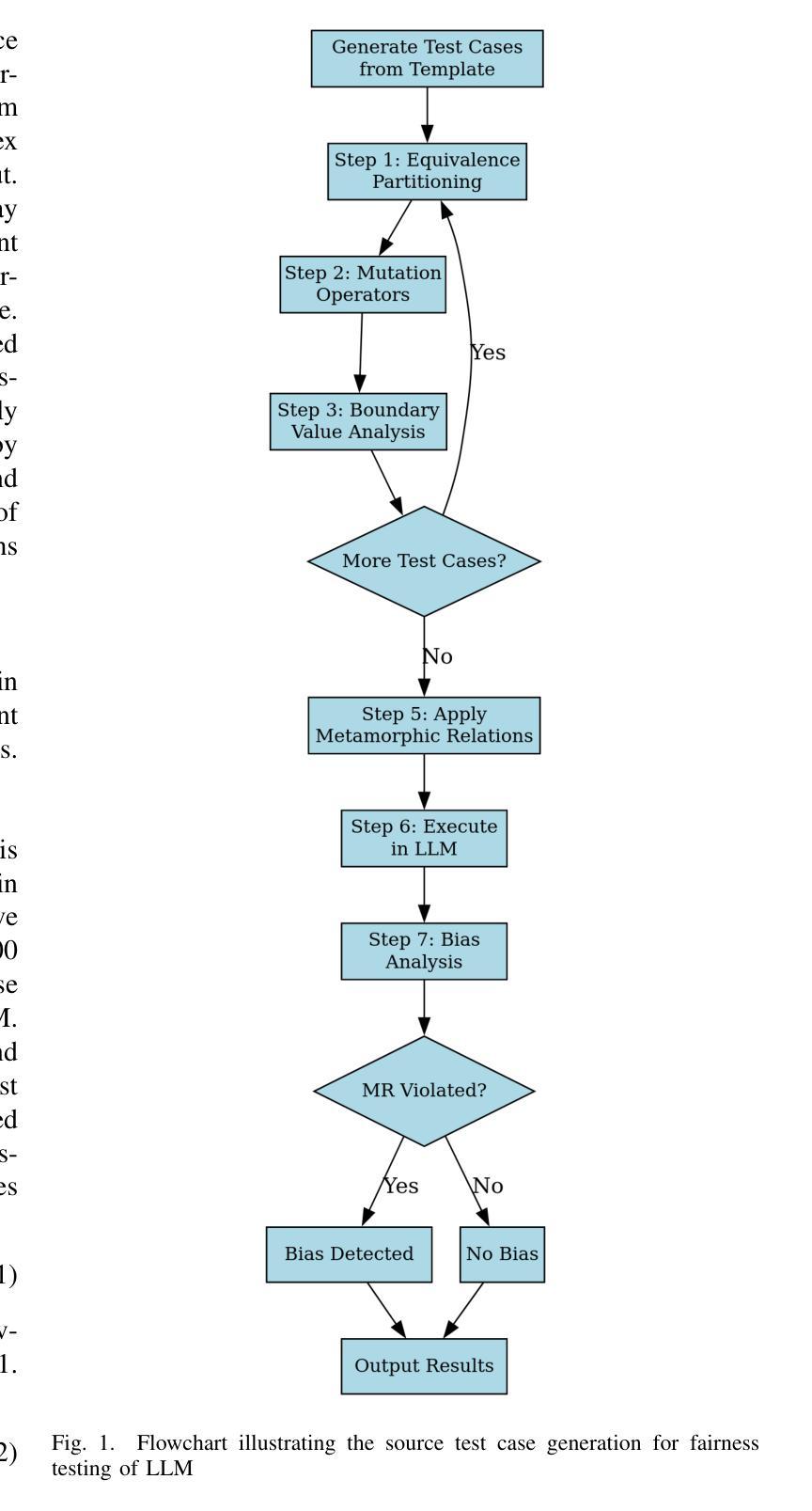
GenFair: Systematic Test Generation for Fairness Fault Detection in Large Language Models
Authors:Madhusudan Srinivasan, Jubril Abdel
Large Language Models (LLMs) are increasingly deployed in critical domains, yet they often exhibit biases inherited from training data, leading to fairness concerns. This work focuses on the problem of effectively detecting fairness violations, especially intersectional biases that are often missed by existing template-based and grammar-based testing methods. Previous approaches, such as CheckList and ASTRAEA, provide structured or grammar-driven test generation but struggle with low test diversity and limited sensitivity to complex demographic interactions. To address these limitations, we propose GenFair, a metamorphic fairness testing framework that systematically generates source test cases using equivalence partitioning, mutation operators, and boundary value analysis. GenFair improves fairness testing by generating linguistically diverse, realistic, and intersectional test cases. It applies metamorphic relations (MR) to derive follow-up cases and detects fairness violations via tone-based comparisons between source and follow-up responses. In experiments with GPT-4.0 and LLaMA-3.0, GenFair outperformed two baseline methods. It achieved a fault detection rate (FDR) of 0.73 (GPT-4.0) and 0.69 (LLaMA-3.0), compared to 0.54/0.51 for template-based and 0.39/0.36 for ASTRAEA. GenFair also showed the highest test case diversity (syntactic:10.06, semantic: 76.68) and strong coherence (syntactic: 291.32, semantic: 0.7043), outperforming both baselines. These results demonstrate the effectiveness of GenFair in uncovering nuanced fairness violations. The proposed method offers a scalable and automated solution for fairness testing and contributes to building more equitable LLMs.
大型语言模型(LLM)在关键领域的应用越来越广泛,但它们往往表现出由训练数据继承的偏见,引发公平性问题。本研究重点关注有效检测公平违规行为的问题,尤其是基于模板和语法检测的现有测试方法常常遗漏的交叉偏见。此前的CheckList和ASTRAEA等方法提供结构化或基于语法的测试生成,但在测试多样性方面较低,对复杂的种族间交互的敏感性有限。为了克服这些局限性,我们提出了GenFair,一个基于元模型的公平性测试框架,它系统地使用等价分区、变异算子和边界值分析来生成源测试用例。GenFair通过生成语言多样、现实和交叉的测试用例来提高公平性测试。它应用元模型关系(MR)来推导后续案例,并通过源和后续响应之间的基于语气的比较来检测公平违规行为。在与GPT-4.0和LLaMA-3.0的实验中,GenFair的表现优于两种基准方法。它对GPT-4.0的故障检测率(FDR)达到0.73,对LLaMA-3.0的故障检测率达到0.69,而基于模板的方法分别为0.54和0.51,ASTRAEA分别为0.39和0.36。此外,GenFair还显示出最高的测试用例多样性(句法:10.06,语义:76.68)和强相关性(句法:291.32,语义:0.7043),超过了两种基准方法。这些结果证明了GenFair在发现微妙的公平违规行为方面的有效性。所提出的方法为公平性测试提供了可扩展和自动化的解决方案,有助于构建更加公平的LLM。
论文及项目相关链接
Summary
大型语言模型(LLMs)在关键领域的应用日益广泛,但存在从训练数据中继承的偏见,引发公平性担忧。针对现有方法难以检测复杂人口特征的交互偏见问题,本文提出一种名为GenFair的变异公平性测试框架。该框架通过等价分区、变异算符和边界值分析系统地生成源测试用例,并结合语调对比检测公平性违规。实验表明,GenFair在GPT-4.0和LLaMA-3.0上的故障检测率高于其他两种方法,并展现出较高的测试用例多样性和连贯性。这证明了GenFair在发现微妙的公平性违规方面的有效性,为公平性的大规模语言模型测试提供了可伸缩和自动化的解决方案。
Key Takeaways
- 大型语言模型(LLMs)在关键领域应用广泛,但存在公平性问题,尤其是检测复杂人口特征的交互偏见问题。
- 现有方法如CheckList和ASTRAEA在测试多样性和敏感性方面存在局限性。
- GenFair是一种新型的公平性测试框架,通过系统地生成源测试用例来提高公平性测试水平。
- GenFair结合语调对比检测公平性违规,并通过变异关系推导后续案例。
- GenFair在GPT-4.0和LLaMA-3.0上的故障检测率高于其他方法。
- GenFair展现出较高的测试用例多样性和连贯性。
点此查看论文截图

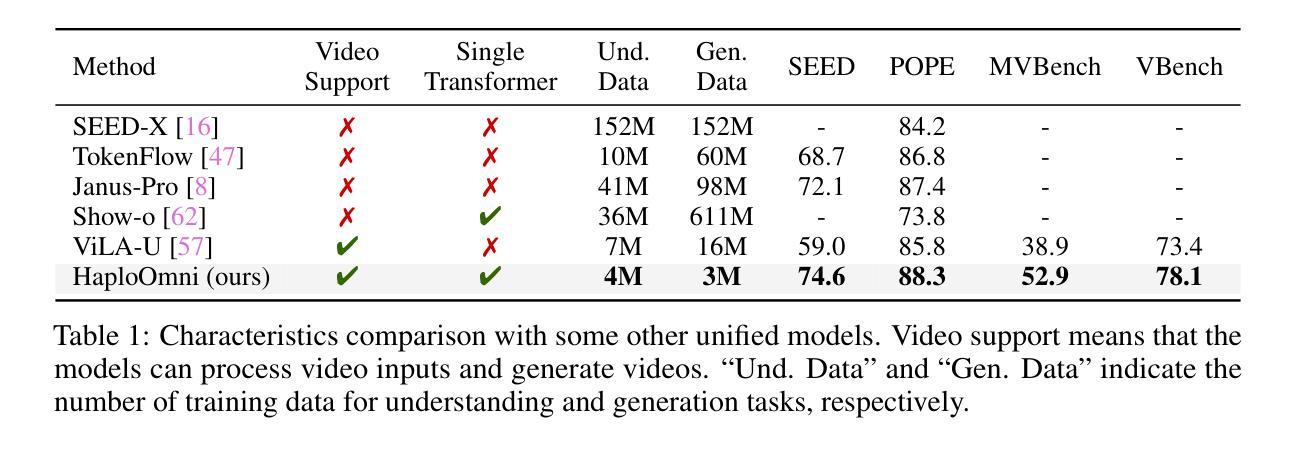
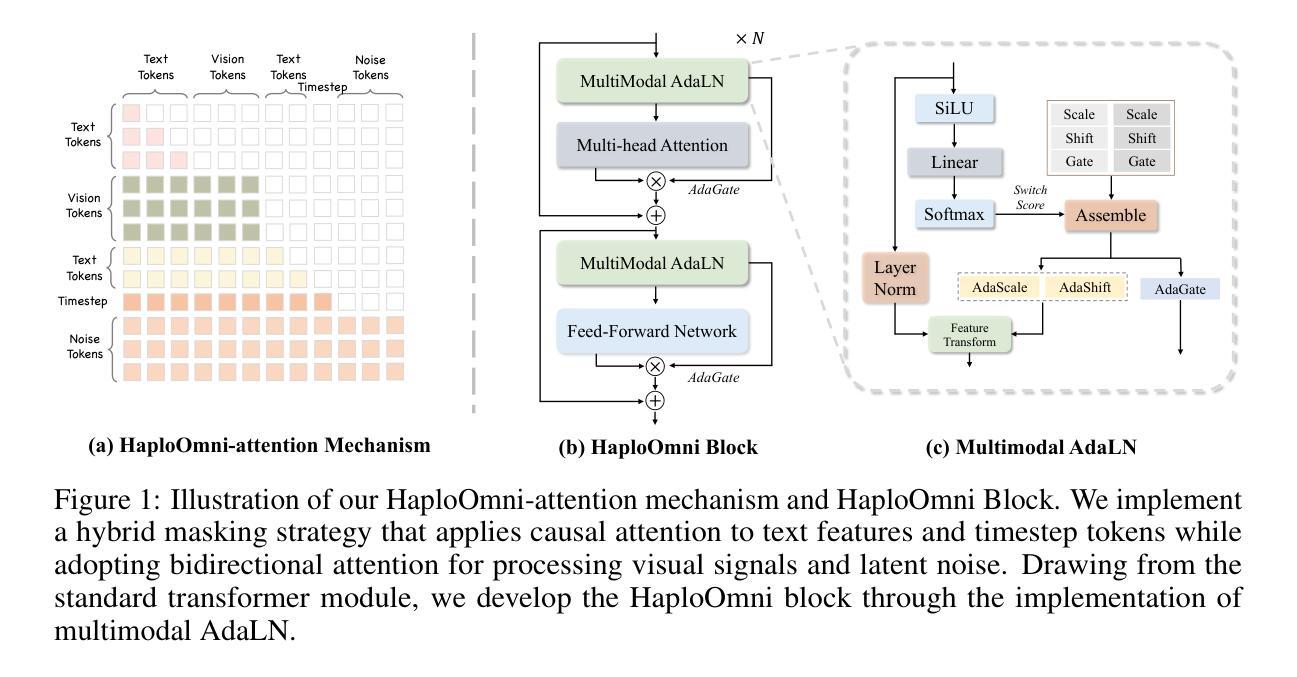
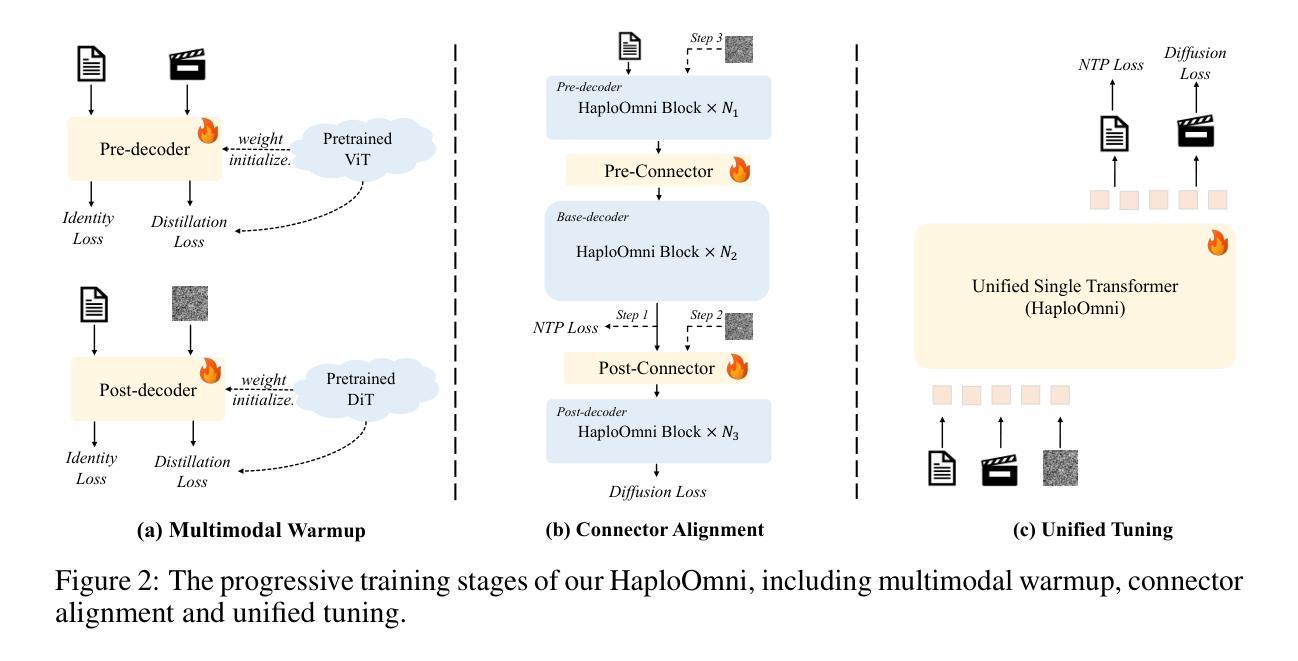
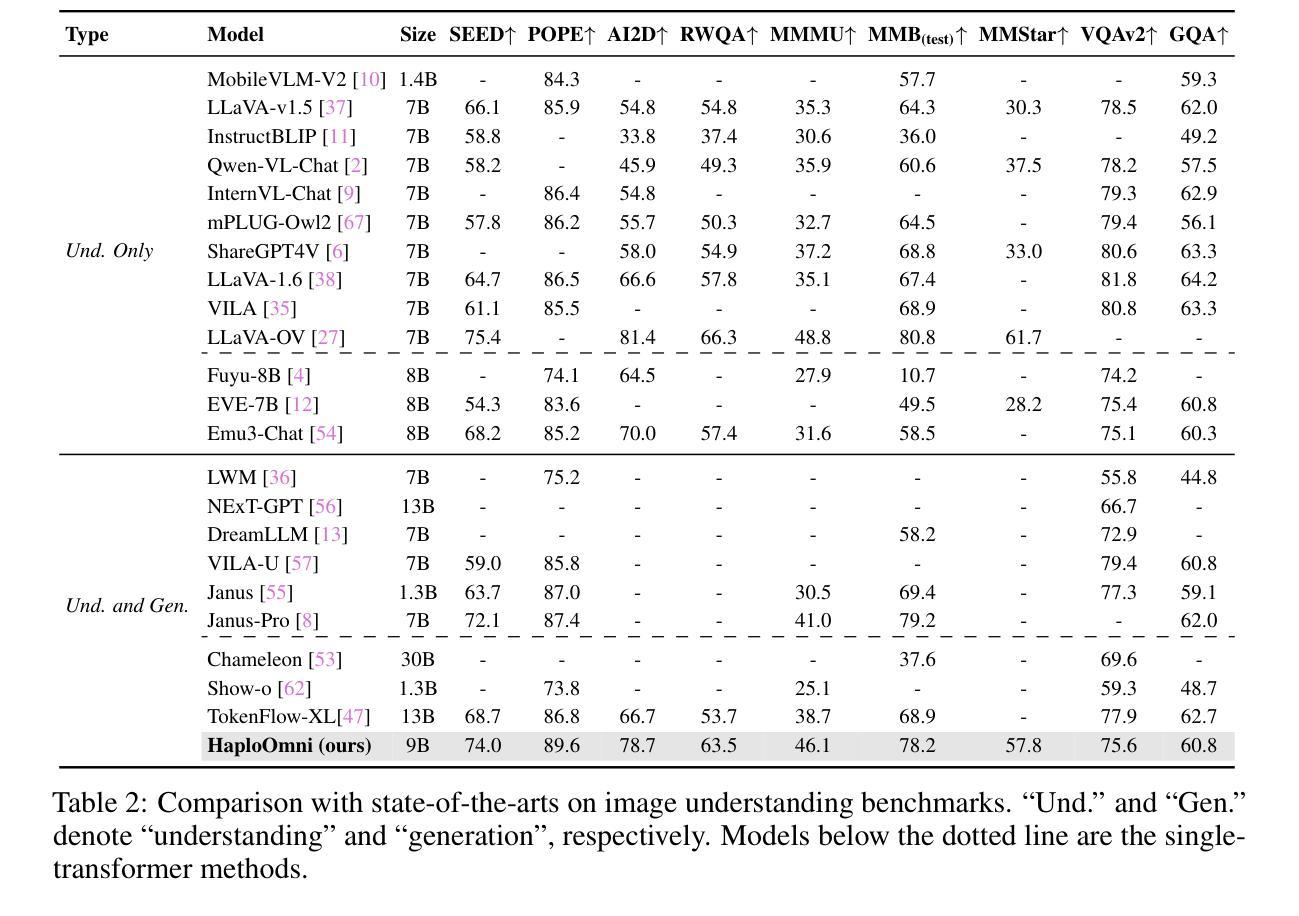
HaploOmni: Unified Single Transformer for Multimodal Video Understanding and Generation
Authors:Yicheng Xiao, Lin Song, Rui Yang, Cheng Cheng, Zunnan Xu, Zhaoyang Zhang, Yixiao Ge, Xiu Li, Ying Shan
With the advancement of language models, unified multimodal understanding and generation have made significant strides, with model architectures evolving from separated components to unified single-model frameworks. This paper explores an efficient training paradigm to build a single transformer for unified multimodal understanding and generation. Specifically, we propose a multimodal warmup strategy utilizing prior knowledge to extend capabilities. To address cross-modal compatibility challenges, we introduce feature pre-scaling and multimodal AdaLN techniques. Integrating the proposed technologies, we present the HaploOmni, a new single multimodal transformer. With limited training costs, HaploOmni achieves competitive performance across multiple image and video understanding and generation benchmarks over advanced unified models. All codes will be made public at https://github.com/Tencent/HaploVLM.
随着语言模型的进步,统一多模态理解和生成技术已经取得了重大突破,模型架构从分离组件发展到统一单模型框架。本文探索了一种高效的训练范式,以建立统一多模态理解和生成的单变压器模型。具体来说,我们提出了一种利用先验知识的多模态预热策略来扩展功能。为了解决跨模态兼容性问题,我们引入了特征预缩放和多模态AdaLN技术。通过整合所提出的技术,我们推出了新的单一多模态变压器HaploOmni。在有限的训练成本下,HaploOmni在多个图像和视频理解和生成基准测试上实现了与先进统一模型相竞争的性能。所有代码将在https://github.com/Tencent/HaploVLM上公开。
论文及项目相关链接
Summary
随着语言模型的发展,统一多模态理解和生成取得了显著进步,模型架构从分离组件演变为统一单模型框架。本文探索了一种有效的训练范式,利用先验知识构建单一转换器进行统一多模态理解和生成。针对跨模态兼容性问题,引入特征预缩放和多模态AdaLN技术。集成这些技术,推出新的单一多模态转换器HaploOmni。在有限的训练成本下,HaploOmni在多个图像和视频理解和生成基准测试中表现优异。相关代码将公开于https://github.com/Tencent/HaploVLM。
Key Takeaways
- 统一多模态理解和生成取得显著进步,模型架构演变为统一单模型框架。
- 提出一种有效的训练范式,利用先验知识构建单一转换器进行多模态理解和生成。
- 针对跨模态兼容性问题,引入特征预缩放和多模态AdaLN技术。
- 推出新的单一多模态转换器HaploOmni。
- HaploOmni在多个图像和视频理解和生成基准测试中表现优异。
- 相关代码将公开于https://github.com/Tencent/HaploVLM,便于公众访问和使用。
点此查看论文截图


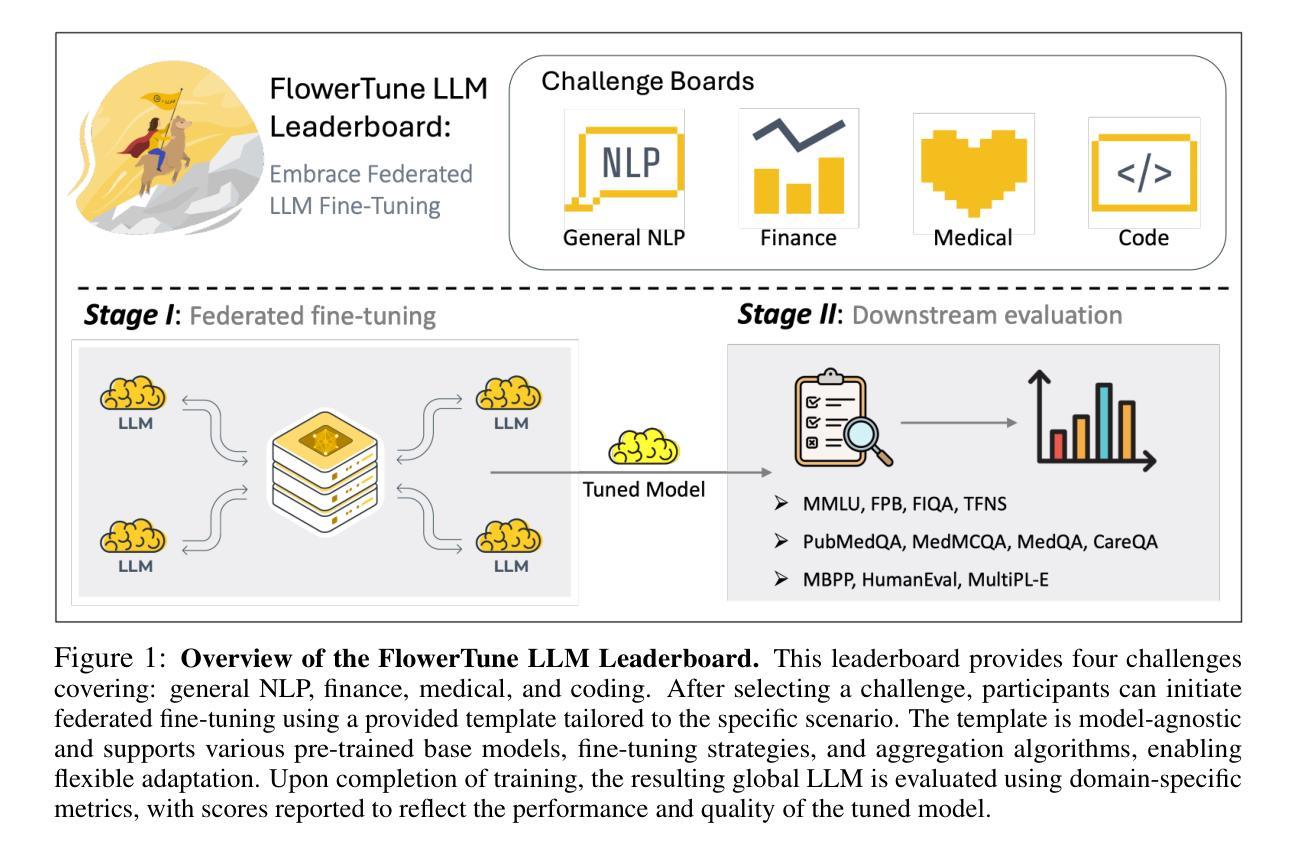
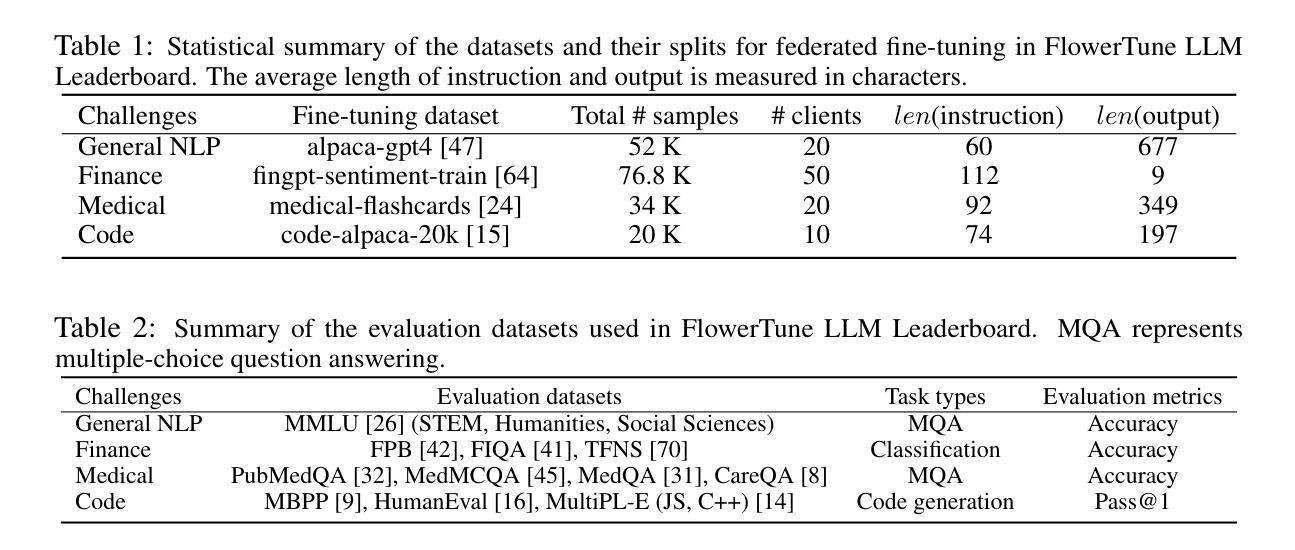
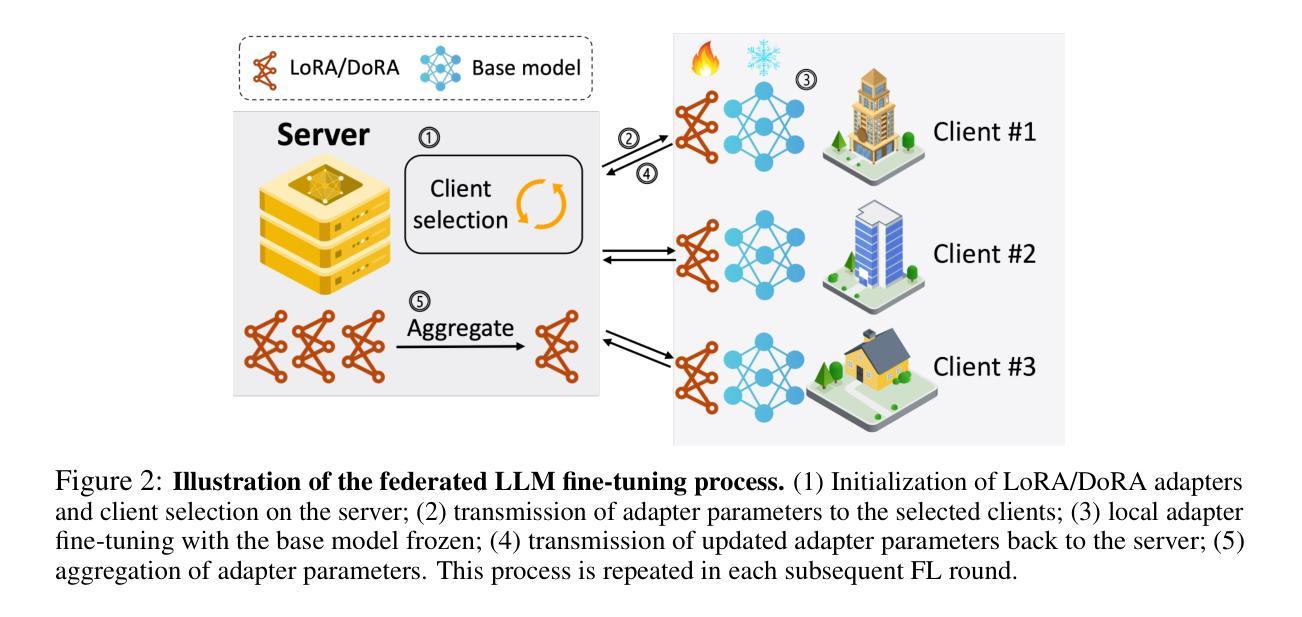
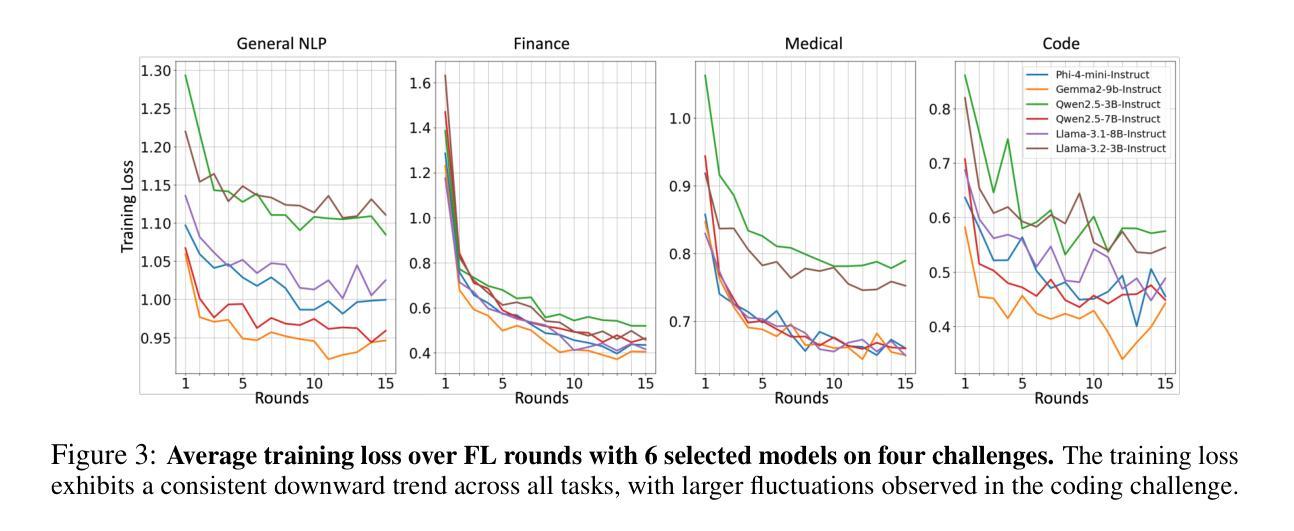
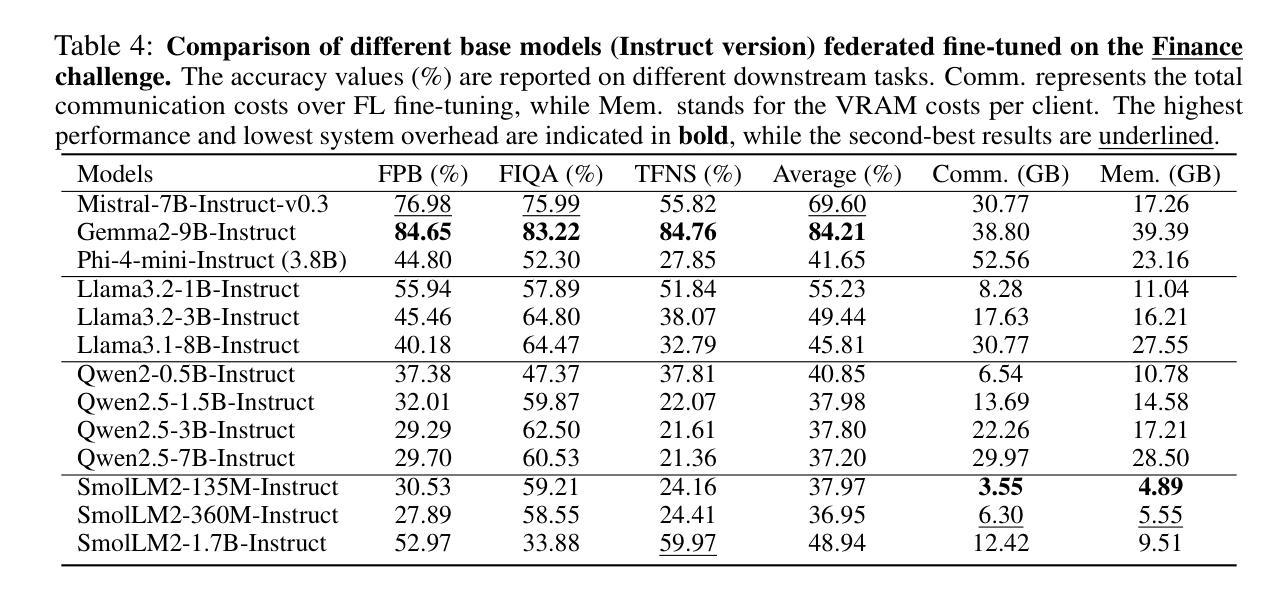
FlowerTune: A Cross-Domain Benchmark for Federated Fine-Tuning of Large Language Models
Authors:Yan Gao, Massimo Roberto Scamarcia, Javier Fernandez-Marques, Mohammad Naseri, Chong Shen Ng, Dimitris Stripelis, Zexi Li, Tao Shen, Jiamu Bai, Daoyuan Chen, Zikai Zhang, Rui Hu, InSeo Song, Lee KangYoon, Hong Jia, Ting Dang, Junyan Wang, Zheyuan Liu, Daniel Janes Beutel, Lingjuan Lyu, Nicholas D. Lane
Large Language Models (LLMs) have achieved state-of-the-art results across diverse domains, yet their development remains reliant on vast amounts of publicly available data, raising concerns about data scarcity and the lack of access to domain-specific, sensitive information. Federated Learning (FL) presents a compelling framework to address these challenges by enabling decentralized fine-tuning on pre-trained LLMs without sharing raw data. However, the compatibility and performance of pre-trained LLMs in FL settings remain largely under explored. We introduce the FlowerTune LLM Leaderboard, a first-of-its-kind benchmarking suite designed to evaluate federated fine-tuning of LLMs across four diverse domains: general NLP, finance, medical, and coding. Each domain includes federated instruction-tuning datasets and domain-specific evaluation metrics. Our results, obtained through a collaborative, open-source and community-driven approach, provide the first comprehensive comparison across 26 pre-trained LLMs with different aggregation and fine-tuning strategies under federated settings, offering actionable insights into model performance, resource constraints, and domain adaptation. This work lays the foundation for developing privacy-preserving, domain-specialized LLMs for real-world applications.
大型语言模型(LLM)在多个领域都取得了最先进的成果,然而,它们的发展仍然依赖于大量公开的可用数据,引发了关于数据稀缺和缺乏访问特定领域敏感信息的担忧。联邦学习(FL)提供了一个吸引人的框架来解决这些挑战,它能够在不共享原始数据的情况下,对预训练的LLM进行分散微调。然而,预训练的LLM在FL环境中的兼容性和性能仍然在很大程度上未被探索。我们引入了FlowerTune LLM排行榜,这是一个首创的基准测试套件,旨在评估四个不同领域的联邦微调LLM:通用NLP、金融、医疗和编码。每个领域都包含联邦指令微调数据集和特定领域的评估指标。我们的结果是通过协作、开源和社区驱动的方法获得的,首次全面比较了联邦环境下使用不同聚合和微调策略的26个预训练LLM,为模型性能、资源约束和领域适应提供了可操作性的见解。这项工作为开发用于现实世界应用的隐私保护、领域专用的LLM奠定了基础。
论文及项目相关链接
Summary
大规模语言模型(LLM)在多领域实现了最先进的成果,但其发展仍依赖于大量公开数据,引发了关于数据稀缺和无法访问特定领域敏感信息的担忧。联邦学习(FL)为解决这些挑战提供了一个吸引人的框架,它能够在不共享原始数据的情况下,对预训练的语言模型进行分散式微调。然而,预训练LLM在FL环境中的兼容性和性能尚未得到充分探索。本文介绍了FlowerTune LLM排行榜,这是一个首创的基准测试套件,旨在评估四个不同领域的LLM联邦微调性能:通用NLP、金融、医疗和编码。我们的结果是通过协作、开源和社区驱动的方式获得的,为不同策略下的联邦设置中的26个预训练LLM提供了全面的比较,提供了关于模型性能、资源约束和领域适应性的可操作见解。本工作奠定了开发用于现实世界应用的隐私保护、领域专业化的LLM的基础。
Key Takeaways
- LLMs在多领域表现出色,但需大量公开数据,引发数据稀缺和隐私担忧。
- 联邦学习(FL)为在不共享原始数据的情况下微调LLM提供了解决方案。
- FlowerTune LLM Leaderboard是首个评估LLM在联邦学习环境下性能的基准测试套件。
- 该套件涵盖了四个不同领域:NLP、金融、医疗和编码。
- 研究结果提供了关于模型性能、资源约束和领域适应性的深入见解。
- 联邦设置下的不同策略和聚合方法对LLM性能有影响。
点此查看论文截图

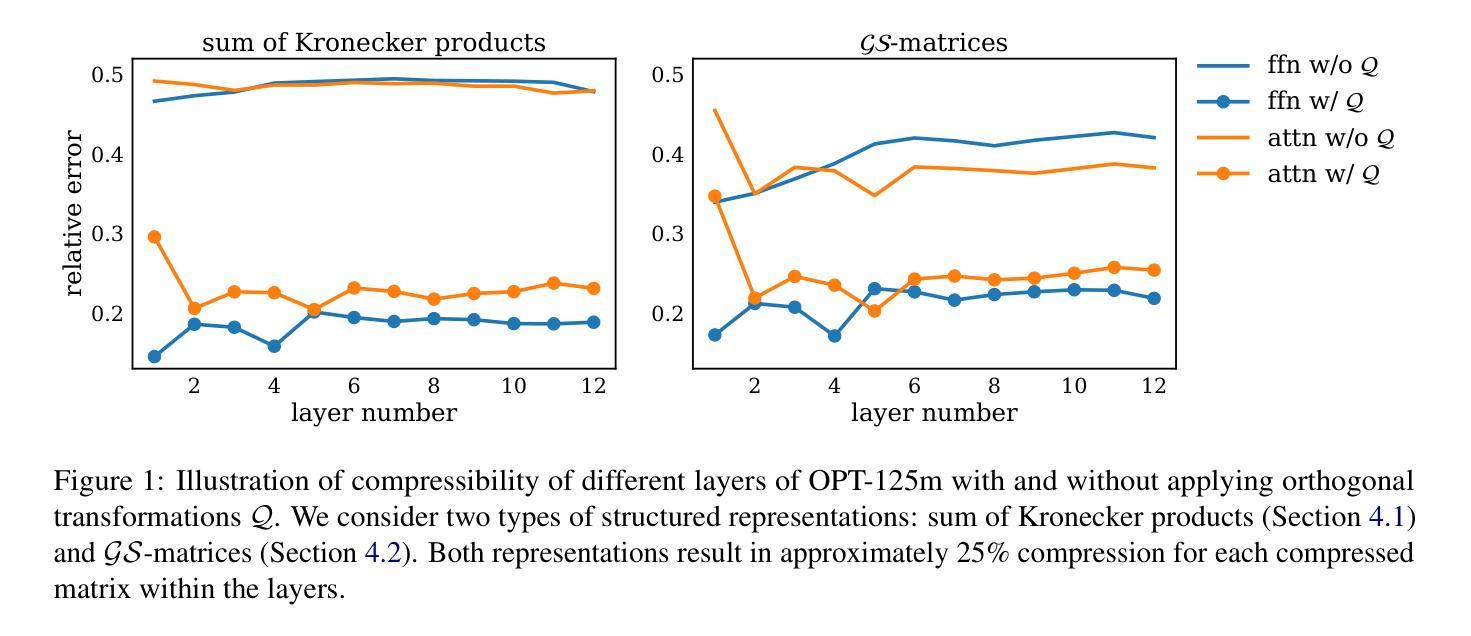
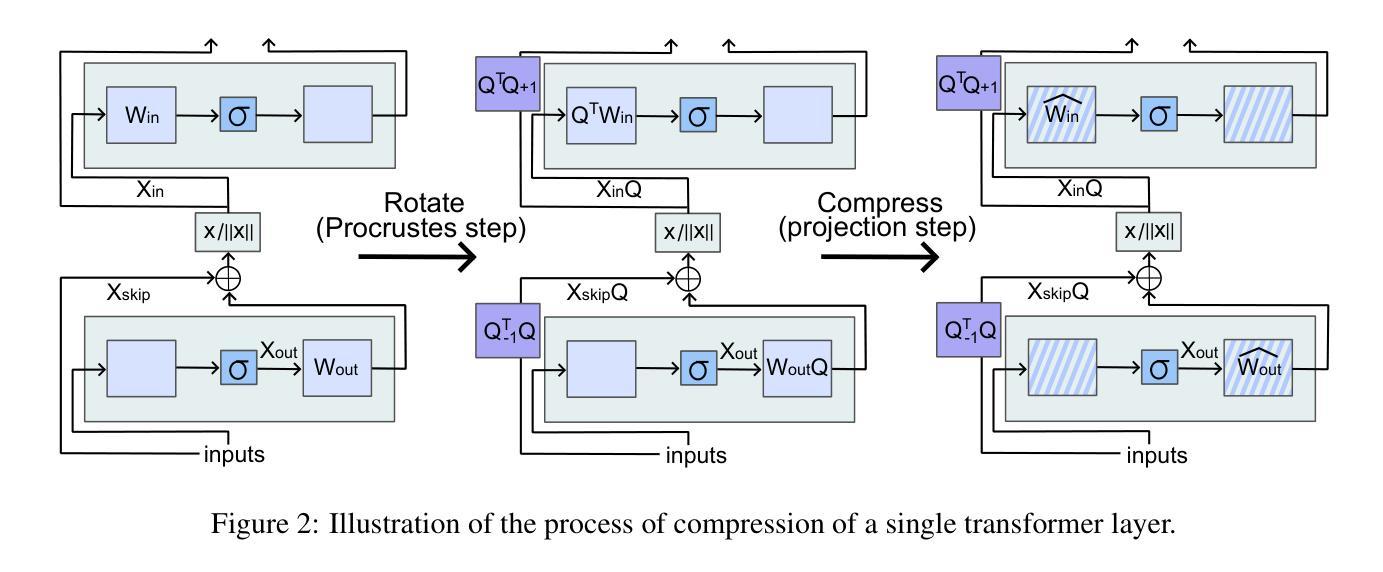
ProcrustesGPT: Compressing LLMs with Structured Matrices and Orthogonal Transformations
Authors:Ekaterina Grishina, Mikhail Gorbunov, Maxim Rakhuba
Large language models (LLMs) demonstrate impressive results in natural language processing tasks but require a significant amount of computational and memory resources. Structured matrix representations are a promising way for reducing the number of parameters of these models. However, it seems unrealistic to expect that weight matrices of pretrained models can be accurately represented by structured matrices without any fine-tuning. To overcome this issue, we utilize the fact that LLM output is invariant under certain orthogonal transformations of weight matrices. This insight can be leveraged to identify transformations that significantly improve the compressibility of weights within structured classes. The proposed approach is applicable to various types of structured matrices that support efficient projection operations. Code is available at https://github.com/GrishKate/ProcrustesGPT
大型语言模型(LLM)在自然语言处理任务中取得了令人印象深刻的结果,但需要大量的计算和内存资源。结构矩阵表示是减少这些模型参数数量的有前途的方法。然而,似乎不切实际地期望通过结构矩阵准确表示预训练模型的权重矩阵而无需进行微调。为了克服这一问题,我们利用LLM输出在权重矩阵的某些正交变换下是不变的这一事实。这一见解可用于确定能够显著提高权重压缩率的转换,这在结构化类别中是有效的。所提出的方法适用于支持高效投影操作的各种类型的结构化矩阵。代码可在https://github.com/GrishKate/ProcrustesGPT获得。
论文及项目相关链接
PDF Accepted by ACL Findings
Summary
大型语言模型(LLMs)在自然语言处理任务中表现出卓越的性能,但需要大量的计算和内存资源。结构矩阵表示是减少模型参数的一种有前途的方法。然而,如果不进行微调,很难期望预训练模型的权重矩阵能准确地用结构矩阵表示。为了解决这个问题,我们利用LLM输出在权重矩阵的某些正交变换下是不变的这一事实。这一见解可以用来识别能显著提高权重压缩率的转换,适用于支持高效投影操作的各种类型的结构矩阵。相关代码可在https://github.com/GrishKate/ProcrustesGPT找到。
Key Takeaways
- 大型语言模型(LLMs)在自然语言处理中表现出卓越性能,但计算与内存资源需求巨大。
- 结构矩阵表示是减少LLM参数的一种策略。
- 预训练模型的权重矩阵难以仅通过结构矩阵准确表示,需要进行微调。
- LLM输出在特定权重矩阵正交变换下具有不变性。
- 这种不变性有助于找到能提高权重压缩率的转换方法。
- 所提出的方法适用于支持高效投影操作的各种类型的结构矩阵。
点此查看论文截图

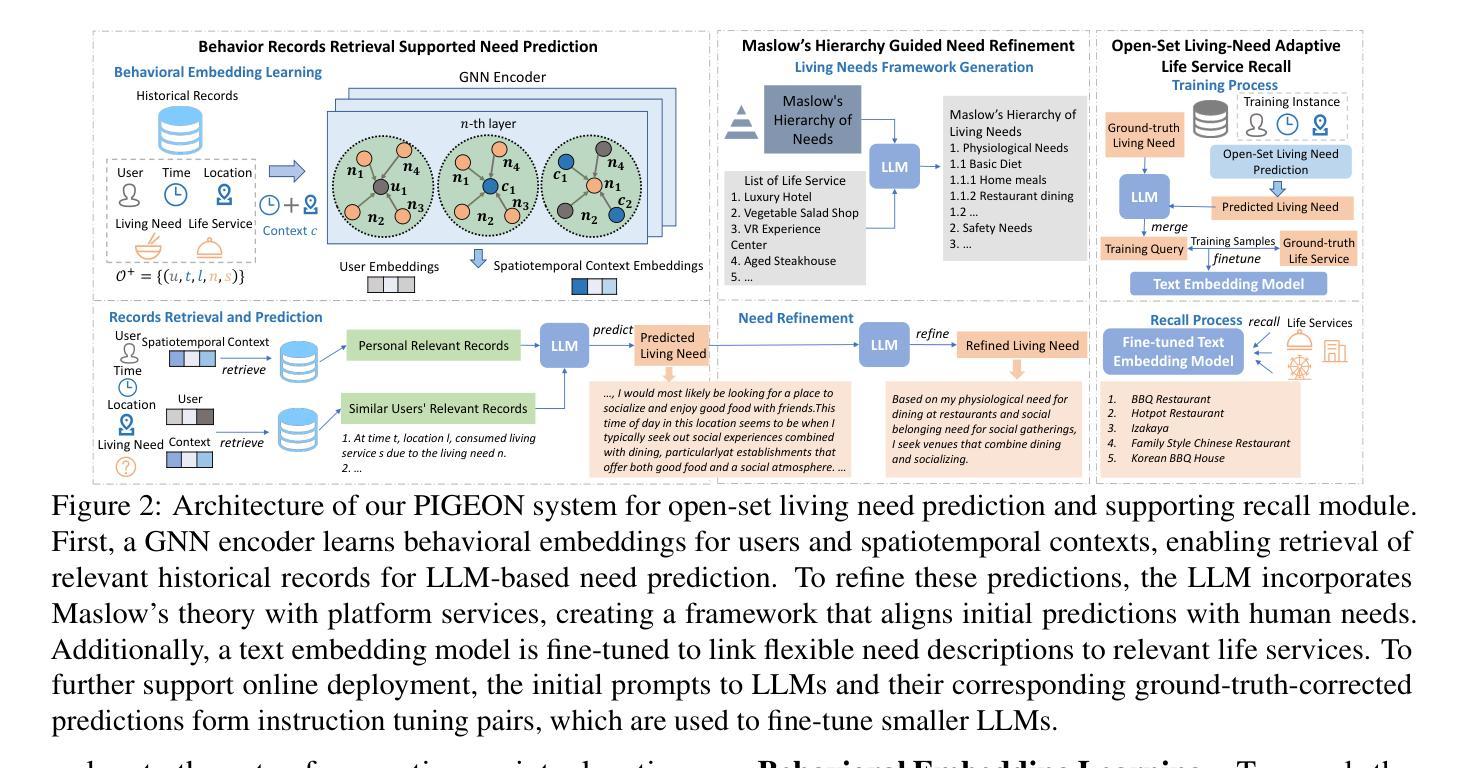
Open-Set Living Need Prediction with Large Language Models
Authors:Xiaochong Lan, Jie Feng, Yizhou Sun, Chen Gao, Jiahuan Lei, Xinlei Shi, Hengliang Luo, Yong Li
Living needs are the needs people generate in their daily lives for survival and well-being. On life service platforms like Meituan, user purchases are driven by living needs, making accurate living need predictions crucial for personalized service recommendations. Traditional approaches treat this prediction as a closed-set classification problem, severely limiting their ability to capture the diversity and complexity of living needs. In this work, we redefine living need prediction as an open-set classification problem and propose PIGEON, a novel system leveraging large language models (LLMs) for unrestricted need prediction. PIGEON first employs a behavior-aware record retriever to help LLMs understand user preferences, then incorporates Maslow’s hierarchy of needs to align predictions with human living needs. For evaluation and application, we design a recall module based on a fine-tuned text embedding model that links flexible need descriptions to appropriate life services. Extensive experiments on real-world datasets demonstrate that PIGEON significantly outperforms closed-set approaches on need-based life service recall by an average of 19.37%. Human evaluation validates the reasonableness and specificity of our predictions. Additionally, we employ instruction tuning to enable smaller LLMs to achieve competitive performance, supporting practical deployment.
生活需求是人们日常生活中为生存和福祉所产生的需求。在美团等生活服务平台上,用户购买行为由生活需求驱动,因此对生活需求进行准确预测对于个性化服务推荐至关重要。传统方法将需求预测视为一个封闭集分类问题,这严重限制了其捕捉生活需求多样性和复杂性的能力。
在本研究中,我们重新定义了生活需求预测作为一个开放集分类问题,并提出了一种新型系统PIGEON,它利用大型语言模型(LLM)进行无限制的需求预测。PIGEON首先采用行为感知记录检索器帮助LLM理解用户偏好,然后结合马斯洛的需求层次理论使预测与人类生活需求相匹配。
为了评估和应用,我们设计了一个基于精细调整文本嵌入模型的召回模块,它将灵活的需求描述与适当的生活服务联系起来。在真实世界数据集上的大量实验表明,PIGEON在基于需求的生活服务召回方面平均比封闭集方法高出19.37%。人类评估验证了我们预测的合理性。此外,我们采用指令微调来使较小的LLM实现竞争性能,支持实际部署。
论文及项目相关链接
PDF ACL 2025 Findings
Summary
基于美团等生活服务平台,用户购买行为受生活需求驱动。传统方法将生活需求预测视为封闭集分类问题,难以捕捉需求的多样性和复杂性。本文重新定义了开放集分类下的生活需求预测问题,并提出PIGEON系统,利用大语言模型进行无限制需求预测。PIGEON通过行为感知记录检索器帮助LLM理解用户偏好,并结合马斯洛需求层次理论进行需求预测。通过真实数据集的实验验证,PIGEON在生活服务需求召回方面显著优于封闭集方法,平均提高19.37%。人类评估验证了预测的合理性和特异性。此外,通过指令微调使较小规模的LLM也能实现竞争力表现,支持实际应用部署。
Key Takeaways
- 生活需求预测在个性化服务推荐中至关重要,特别是对于生活服务平台如美团等。
- 传统方法处理此类预测时将其视为封闭集分类问题,导致无法充分捕捉需求的多样性和复杂性。
- 本文提出PIGEON系统,将生活需求预测定义为开放集分类问题,并利用大语言模型进行预测。
- PIGEON通过行为感知记录检索器理解用户偏好,并结合马斯洛需求层次理论进行需求预测。
- 在真实数据集上的实验表明,PIGEON在生活服务需求召回方面显著优于传统方法。
- 人类评估验证了PIGEON预测的合理性和特异性。
点此查看论文截图

Iterative Self-Improvement of Vision Language Models for Image Scoring and Self-Explanation
Authors:Naoto Tanji, Toshihiko Yamasaki
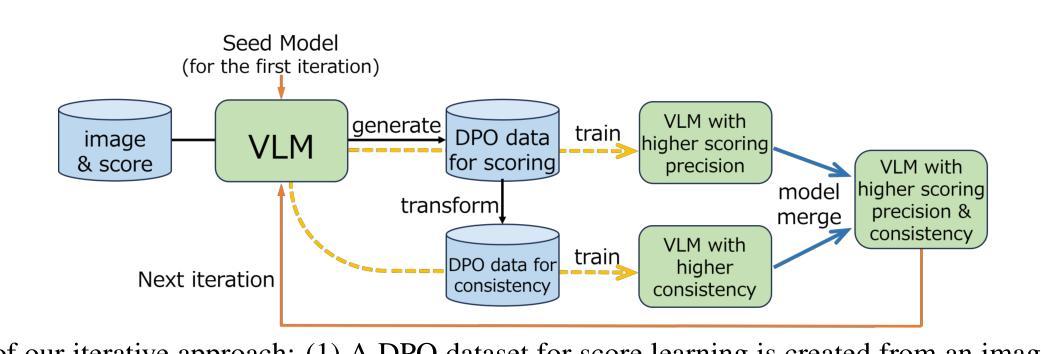
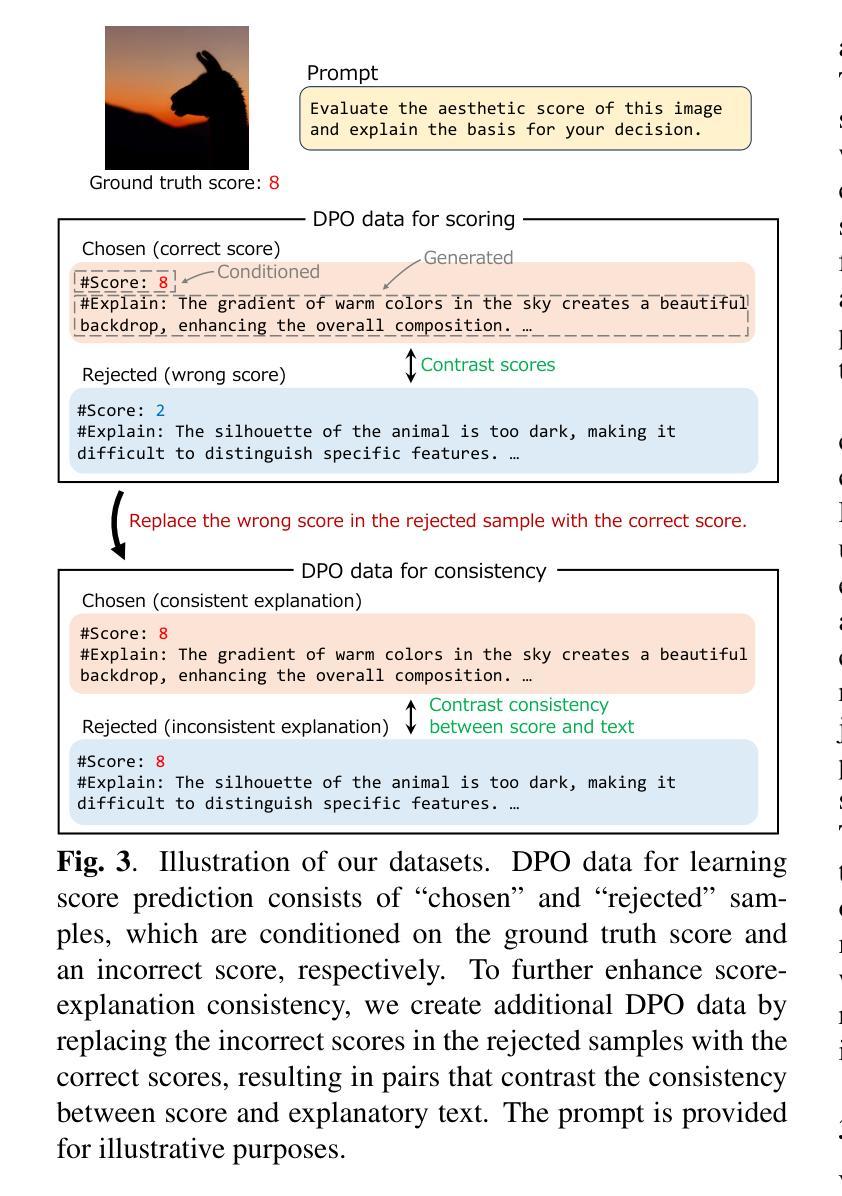
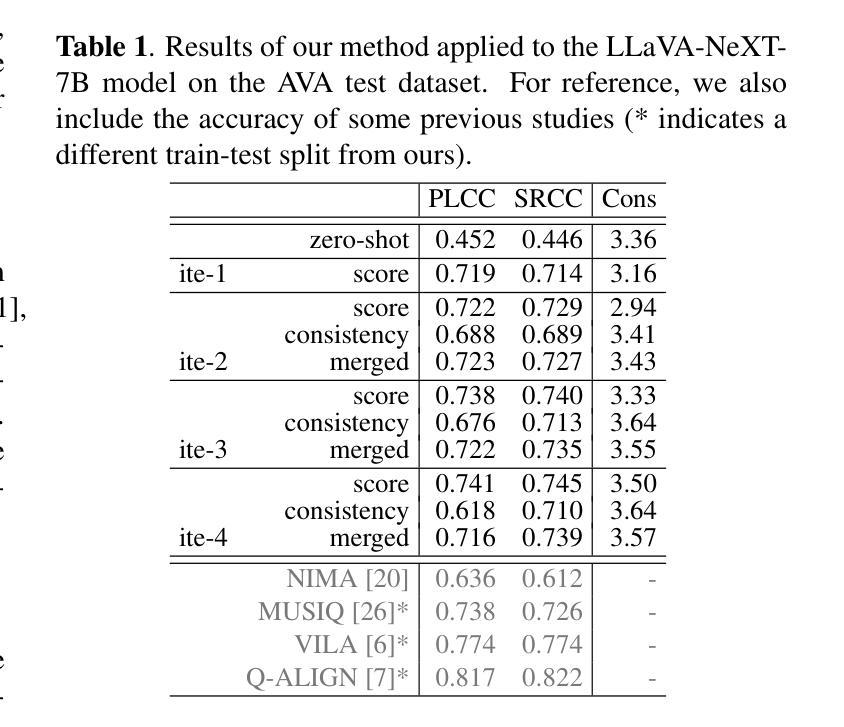
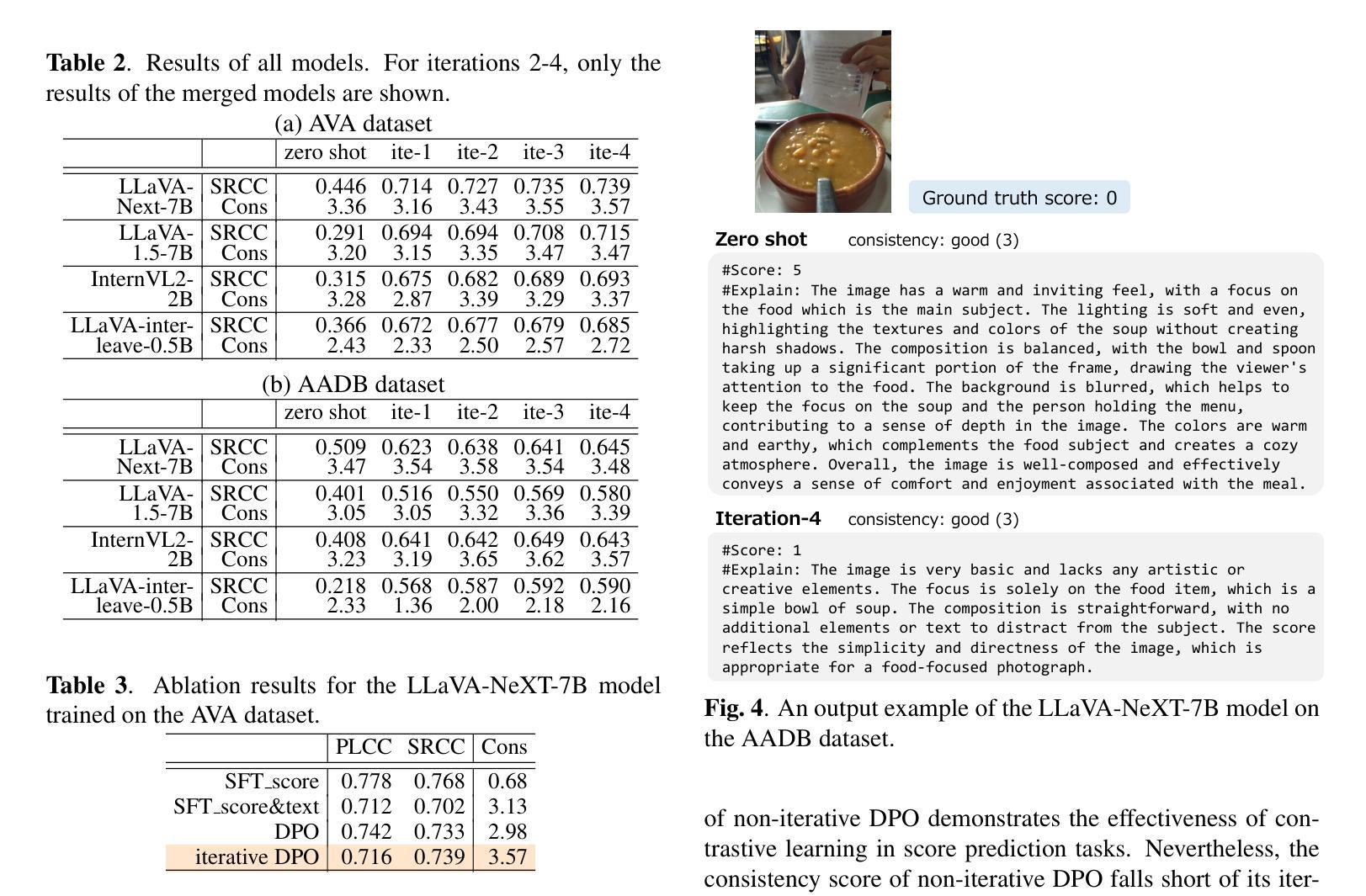
Image scoring is a crucial task in numerous real-world applications. To trust a model’s judgment, understanding its rationale is essential. This paper proposes a novel training method for Vision Language Models (VLMs) to generate not only image scores but also corresponding justifications in natural language. Leveraging only an image scoring dataset and an instruction-tuned VLM, our method enables self-training, utilizing the VLM’s generated text without relying on external data or models. In addition, we introduce a simple method for creating a dataset designed to improve alignment between predicted scores and their textual justifications. By iteratively training the model with Direct Preference Optimization on two distinct datasets and merging them, we can improve both scoring accuracy and the coherence of generated explanations.
图像评分是众多现实世界应用中的一项关键任务。为了信任模型的判断,理解其原理至关重要。本文提出了一种新型的视觉语言模型(VLM)训练方法,不仅能够生成图像评分,还能生成相应的自然语言解释。仅利用图像评分数据集和指令调整过的VLM,我们的方法能够实现自我训练,利用VLM生成的文本,无需依赖外部数据或模型。此外,我们还介绍了一种创建数据集的简单方法,旨在提高预测分数和其文本解释之间的对齐度。通过在不同的两个数据集上进行直接偏好优化的迭代训练并将它们合并,我们可以提高评分准确性和生成的解释的连贯性。
论文及项目相关链接
PDF Accepted to ICIP2025
Summary
本文提出一种新型训练方法来训练视觉语言模型(VLM),使其不仅能够给出图像评分,还能生成对应的自然语言解释。该方法仅依赖图像评分数据集和指令调优的VLM进行自训练,无需依赖外部数据或模型。通过引入一种简单的方法创建数据集,提高预测分数与文本解释之间的对齐度。通过在两个不同的数据集上进行直接偏好优化(Direct Preference Optimization)的迭代训练并合并,提高了评分准确性和生成的解释的连贯性。
Key Takeaways
- 视觉语言模型(VLM)可以经过训练以生成图像评分和对应的自然语言解释。
- 训练方法仅依赖图像评分数据集和指令调优的VLM进行自训练。
- 引入了一种创建数据集的方法,用于提高预测分数与文本解释之间的对齐度。
- 通过在两个不同的数据集上进行迭代训练,使用直接偏好优化(Direct Preference Optimization)提高了模型的评分准确性。
- 模型生成的解释具有更高的连贯性。
- 该方法提高了模型的可信度,因为理解了其评分背后的理由。
点此查看论文截图

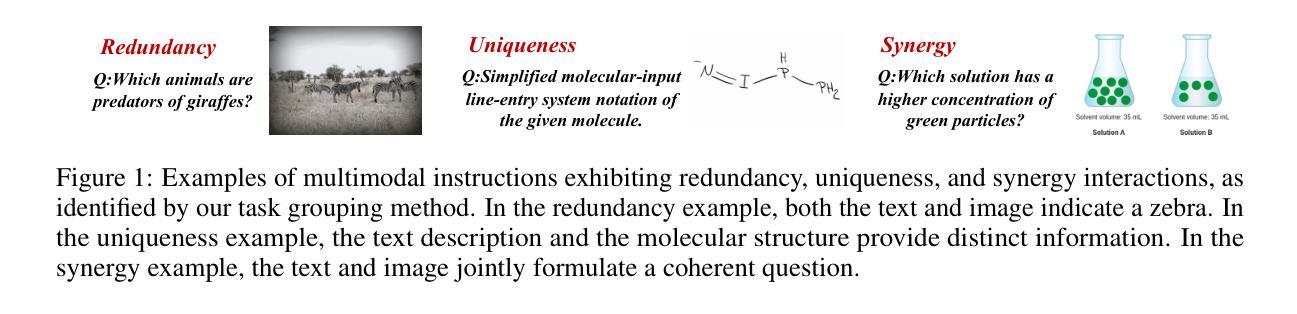
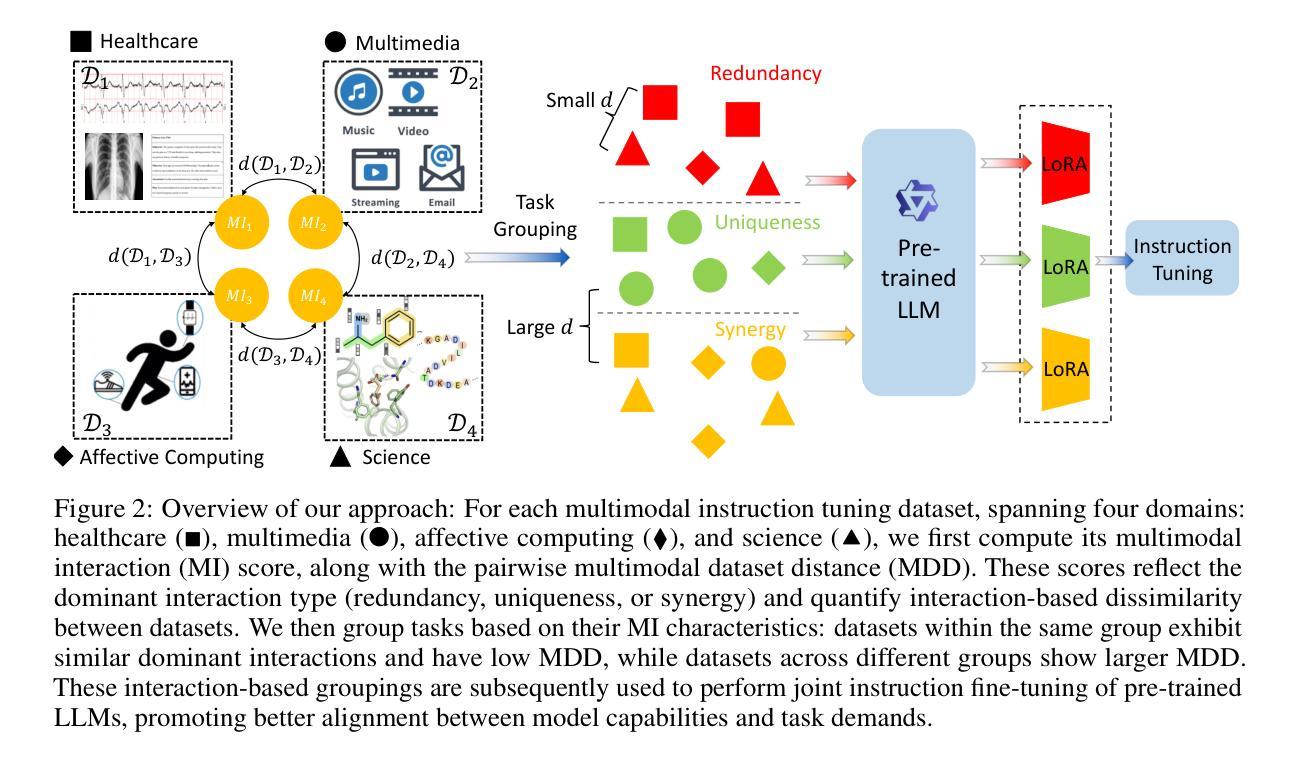
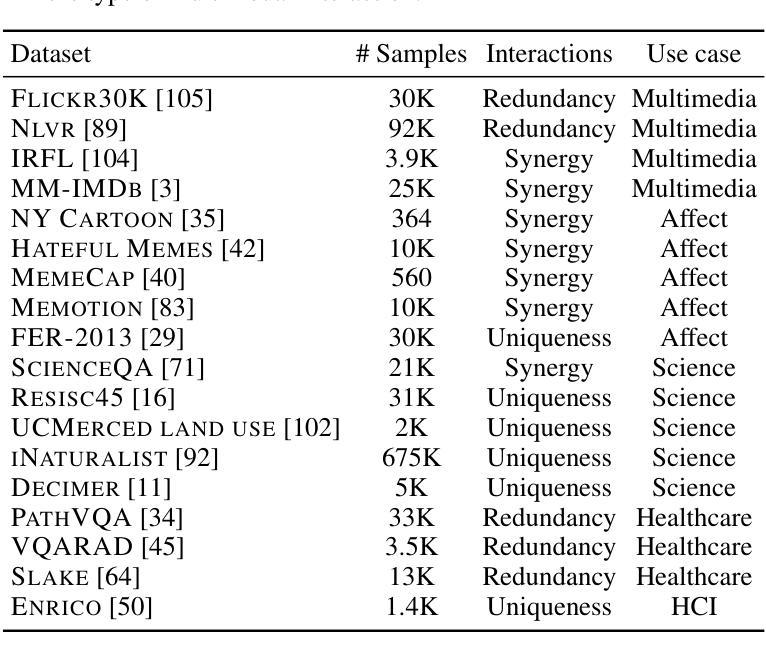
MINT: Multimodal Instruction Tuning with Multimodal Interaction Grouping
Authors:Xiaojun Shan, Qi Cao, Xing Han, Haofei Yu, Paul Pu Liang
Recent advances in multimodal foundation models have achieved state-of-the-art performance across a range of tasks. These breakthroughs are largely driven by new pre-training paradigms that leverage large-scale, unlabeled multimodal data, followed by instruction fine-tuning on curated labeled datasets and high-quality prompts. While there is growing interest in scaling instruction fine-tuning to ever-larger datasets in both quantity and scale, our findings reveal that simply increasing the number of instruction-tuning tasks does not consistently yield better performance. Instead, we observe that grouping tasks by the common interactions across modalities, such as discovering redundant shared information, prioritizing modality selection with unique information, or requiring synergistic fusion to discover new information from both modalities, encourages the models to learn transferrable skills within a group while suppressing interference from mismatched tasks. To this end, we introduce MINT, a simple yet surprisingly effective task-grouping strategy based on the type of multimodal interaction. We demonstrate that the proposed method greatly outperforms existing task grouping baselines for multimodal instruction tuning, striking an effective balance between generalization and specialization.
近期多模态基础模型的进展在多个任务上达到了最先进的性能。这些突破主要得益于新的预训练范式,它利用大规模的无标签多模态数据,然后在精选的标记数据集上进行指令微调,并使用高质量的提示。尽管人们对扩大指令微调以涵盖数量和规模日益增大的数据集的兴趣日益增长,但我们的研究结果表明,仅仅增加指令调整任务的数量并不总能带来更好的性能。相反,我们观察到,通过跨模态的常见交互对任务进行分组,如发现冗余的共享信息、优先选择与独特信息相关的模态,或需要协同融合以从两种模态中发现新信息,可以鼓励模型在组内学习可迁移技能,同时抑制不匹配任务的干扰。为此,我们引入了MINT,这是一种基于多模态交互类型的简单而有效的任务分组策略。我们证明,对于多模态指令调整,所提出的方法大大优于现有的任务分组基线,在泛化和专业化之间达到了有效的平衡。
论文及项目相关链接
Summary
大规模的多模态基础模型突破得益于新的预训练模式和大规模未标签多模态数据的应用。研究发现在进行指令微调时,单纯增加任务数量并不总能提升性能。相反,通过跨模态交互的任务分组策略,如寻找冗余共享信息、优先处理具有独特信息的模态或协同融合来自不同模态的信息发现新方法等,可以使模型更好地在分组中学习转移知识并减少来自不同任务的干扰。基于此,本文提出了一种简单但效果显著的多模态交互类型的任务分组策略MINT,它在多任务调整中的表现远超现有基线,有效平衡了泛化与专化能力。
Key Takeaways
- 多模态基础模型的新突破源于新的预训练模式及大规模未标签多模态数据的应用。
- 单纯增加指令微调的任务数量并不总是带来性能提升。
- 任务分组策略关注跨模态交互的重要性,包括寻找冗余共享信息、优先处理具有独特信息的模态等。
- 分组策略鼓励模型在组内学习可转移技能并减少来自不匹配任务的干扰。
- MINT是一种基于多模态交互类型的任务分组策略,表现优于现有基线。
- MINT策略有效平衡了模型的泛化与专化能力。
点此查看论文截图