⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-05 更新
Towards a Japanese Full-duplex Spoken Dialogue System
Authors:Atsumoto Ohashi, Shinya Iizuka, Jingjing Jiang, Ryuichiro Higashinaka
Full-duplex spoken dialogue systems, which can model simultaneous bidirectional features of human conversations such as speech overlaps and backchannels, have attracted significant attention recently. However, the study of full-duplex spoken dialogue systems for the Japanese language has been limited, and the research on their development in Japanese remains scarce. In this paper, we present the first publicly available full-duplex spoken dialogue model in Japanese, which is built upon Moshi, a full-duplex dialogue model in English. Our model is trained through a two-stage process: pre-training on a large-scale spoken dialogue data in Japanese, followed by fine-tuning on high-quality stereo spoken dialogue data. We further enhance the model’s performance by incorporating synthetic dialogue data generated by a multi-stream text-to-speech system. Evaluation experiments demonstrate that the trained model outperforms Japanese baseline models in both naturalness and meaningfulness.
近年来,全双工语音对话系统能够模拟人类对话的双向特征,如语音重叠和反馈通道等,因此受到了广泛关注。然而,针对日语的全双工语音对话系统的研究相对较少,其开发研究也十分匮乏。在本文中,我们推出了首个公开可用的日语全双工语音对话模型,该模型基于英语全双工对话模型Moshi构建。我们的模型通过两阶段训练:首先在大量日语口语对话数据上进行预训练,然后在高质量立体声口语对话数据上进行微调。我们通过引入由多流文本到语音系统生成的人工对话数据,进一步提高了模型的性能。评估实验表明,训练后的模型在自然度和意义性方面都优于日语基线模型。
论文及项目相关链接
PDF Accepted to Interspeech 2025
Summary
该论文介绍了首个公开的日语全双工对话系统模型,该模型基于英语的全双工对话模型Moshi构建。通过大规模日语对话数据预训练和高质量立体声对话数据微调的两阶段过程进行训练,并使用多流文本到语音系统生成合成对话数据增强模型性能。评估实验表明,该模型在日语基准模型的自然度和有意义性方面都表现优越。
Key Takeaways
- 该论文构建了首个公开的日语全双工对话系统模型。
- 模型基于英语的全双工对话模型Moshi构建。
- 模型通过预训练与微调的方式进行训练,使用大规模日语对话数据和高质量立体声对话数据。
- 合成对话数据通过多流文本到语音系统生成,增强了模型性能。
- 模型在自然度和有意义性方面超越了日语基准模型。
- 全双工对话系统能够模拟人类对话的双向特征,如语音重叠和反馈通道。
点此查看论文截图

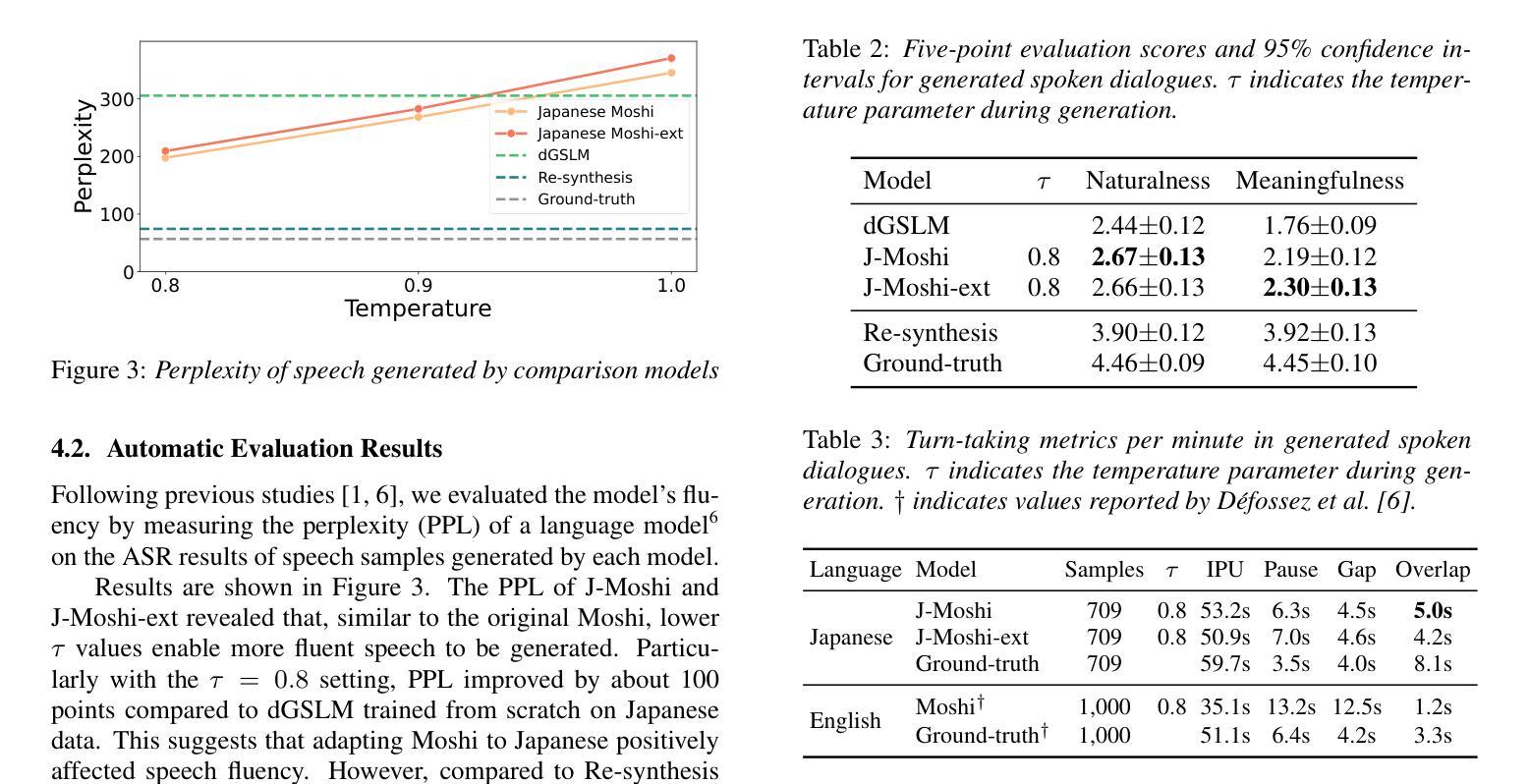
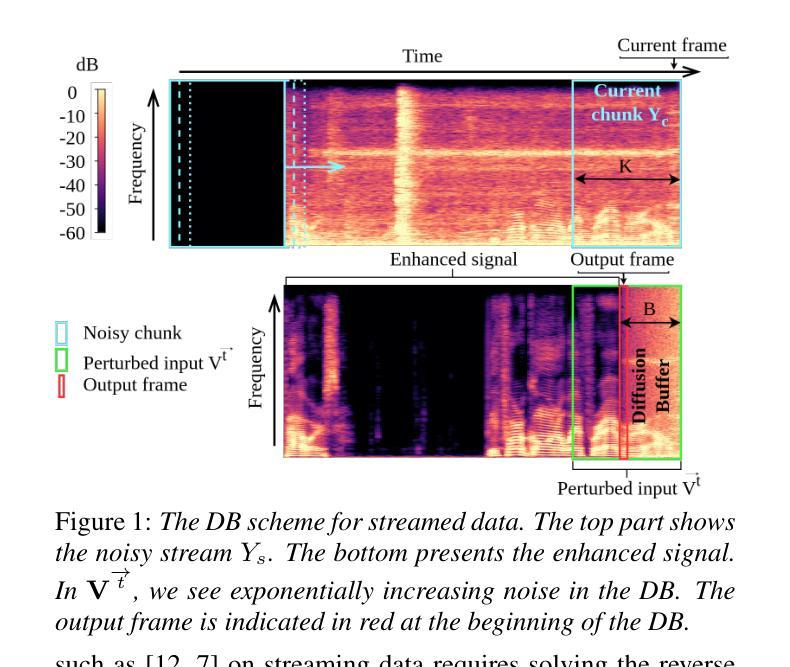
Diffusion Buffer: Online Diffusion-based Speech Enhancement with Sub-Second Latency
Authors:Bunlong Lay, Rostilav Makarov, Timo Gerkmann
Diffusion models are a class of generative models that have been recently used for speech enhancement with remarkable success but are computationally expensive at inference time. Therefore, these models are impractical for processing streaming data in real-time. In this work, we adapt a sliding window diffusion framework to the speech enhancement task. Our approach progressively corrupts speech signals through time, assigning more noise to frames close to the present in a buffer. This approach outputs denoised frames with a delay proportional to the chosen buffer size, enabling a trade-off between performance and latency. Empirical results demonstrate that our method outperforms standard diffusion models and runs efficiently on a GPU, achieving an input-output latency in the order of 0.3 to 1 seconds. This marks the first practical diffusion-based solution for online speech enhancement.
扩散模型是一类生成模型,最近被用于语音增强并取得了显著的成功,但在推理时计算成本较高。因此,这些模型对于实时处理流式数据并不实用。在这项工作中,我们将滑动窗口扩散框架适应于语音增强任务。我们的方法通过时间逐步破坏语音信号,将更多噪声分配给缓冲区中接近当前的帧。这种方法输出的去噪帧延迟与所选缓冲区大小成比例,可以在性能和延迟之间进行权衡。经验结果表明,我们的方法优于标准扩散模型,在GPU上运行高效,输入输出延迟在0.3至1秒之间。这标志着基于扩散的在线语音增强的首个实用解决方案。
论文及项目相关链接
PDF 5 pages, 2 figures, Accepted to Interspeech 2025
Summary
本文提出一种基于滑动窗口扩散框架的语音增强方法,该方法在逐步对语音信号进行去噪的过程中加入了时间因素,实现了性能和延迟之间的权衡。相较于传统扩散模型,该方法在GPU上运行更为高效,实现了输入输出的延迟在0.3至1秒之间,为在线语音增强提供了首个实用的扩散模型解决方案。
Key Takeaways
- 扩散模型在语音增强任务中取得了显著的成功,但计算成本较高,不适合处理实时流媒体数据。
- 本文采用滑动窗口扩散框架进行语音增强,将时间因素纳入考虑,逐步对语音信号进行去噪。
- 方法通过在缓冲区中对接近当前帧的帧赋予更多噪声来实现渐进式腐蚀语音信号。
- 该方法能够在输出降噪帧时实现延迟与性能之间的权衡,延迟与所选缓冲区大小成比例。
- 相较于传统扩散模型,本文方法在GPU上运行更为高效,达到了0.3至1秒的输入-输出延迟。
- 本文解决了在线语音增强的实用问题,这是基于扩散模型的首次实现。
点此查看论文截图


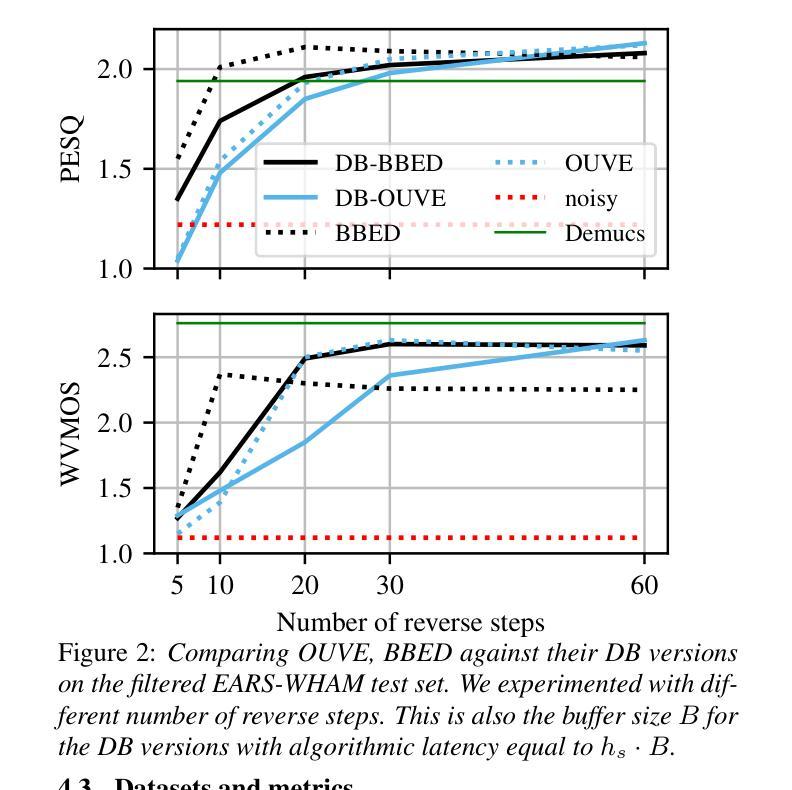
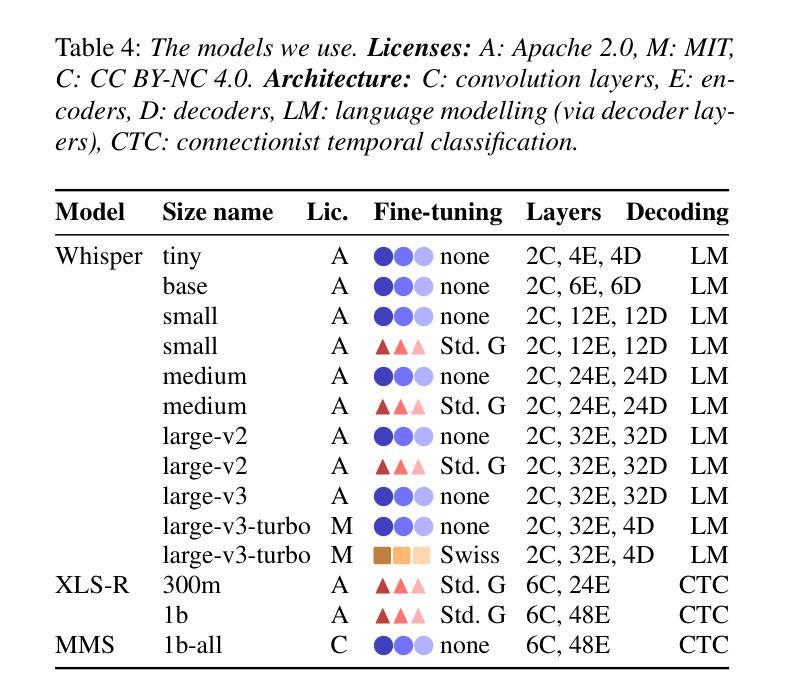
A Multi-Dialectal Dataset for German Dialect ASR and Dialect-to-Standard Speech Translation
Authors:Verena Blaschke, Miriam Winkler, Constantin Förster, Gabriele Wenger-Glemser, Barbara Plank
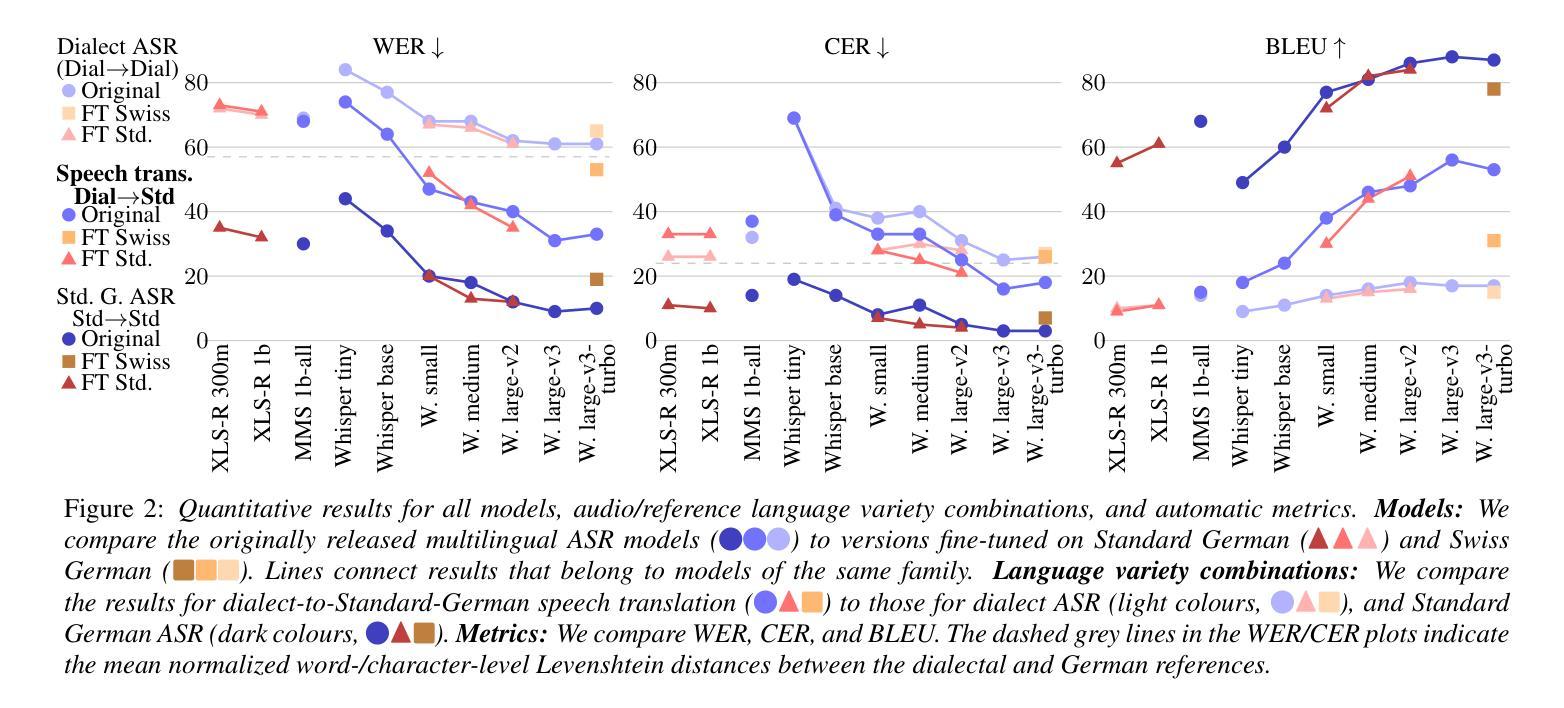
Although Germany has a diverse landscape of dialects, they are underrepresented in current automatic speech recognition (ASR) research. To enable studies of how robust models are towards dialectal variation, we present Betthupferl, an evaluation dataset containing four hours of read speech in three dialect groups spoken in Southeast Germany (Franconian, Bavarian, Alemannic), and half an hour of Standard German speech. We provide both dialectal and Standard German transcriptions, and analyze the linguistic differences between them. We benchmark several multilingual state-of-the-art ASR models on speech translation into Standard German, and find differences between how much the output resembles the dialectal vs. standardized transcriptions. Qualitative error analyses of the best ASR model reveal that it sometimes normalizes grammatical differences, but often stays closer to the dialectal constructions.
尽管德国的方言多种多样,但在当前的自动语音识别(ASR)研究中,它们的代表性不足。为了研究模型对方言变体的稳健性,我们推出了Betthupferl评估数据集,其中包含四小时在东南德国(弗兰科尼亚语、巴伐利亚语、阿勒曼尼语)说的三种方言群体的朗读语音,以及半小时的标准德语语音。我们提供了方言和标准德语的转录,并分析了它们之间的语言差异。我们在将语音翻译成标准德语方面对几种多语种的最先进ASR模型进行了基准测试,并发现输出与方言转录与标准化转录之间的相似程度差异。最佳ASR模型的定性误差分析表明,它有时会正规化语法差异,但通常会更接近方言结构。
论文及项目相关链接
PDF Accepted to Interspeech 2025
Summary
本文介绍了德国方言在自动语音识别(ASR)研究中的代表性不足的问题。为了研究模型对方言变体的鲁棒性,提出了一种评估数据集Betthupferl。该数据集包含四小时东南德国的三种方言(弗兰西斯、拜仁语和阿勒曼尼语)的朗读语音和半小时的标准德语语音。提供了方言和标准德语的转录,并分析了它们之间的语言差异。通过对多种多语种最先进的ASR模型进行基准测试,发现输出与方言转录和标准转录的相似程度存在差异。最佳ASR模型的定性误差分析表明,它有时会规范化语法差异,但通常更接近方言结构。
Key Takeaways
- 德国方言在当前的自动语音识别(ASR)研究中代表性不足。
- Betthupferl数据集用于评估模型对德国东南地区三种方言的鲁棒性,并提供了方言和标准德语的转录。
- 方言与标准德语之间存在语言差异。
- 多种多语种ASR模型在标准德语语音翻译上的基准测试显示,输出与方言转录的相似程度不同。
- 最佳ASR模型在处理方言时,有时会规范化语法差异。
- ASR模型在处理方言语音时,通常更接近方言结构。
点此查看论文截图

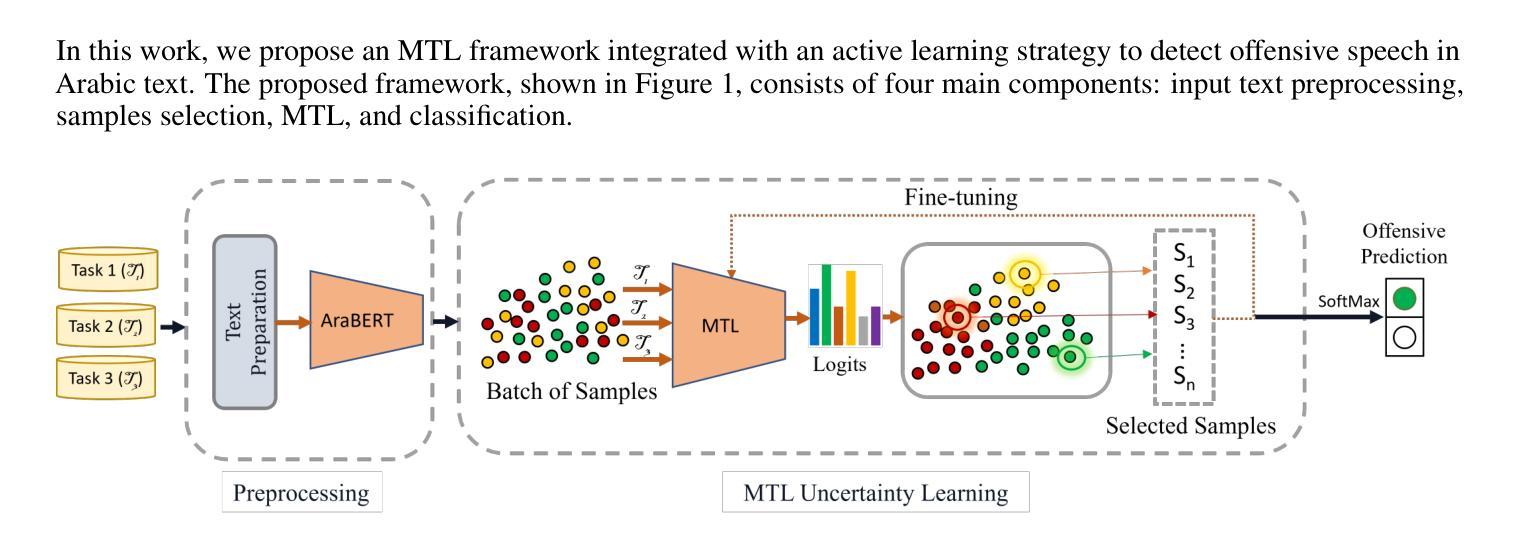
Multi-task Learning with Active Learning for Arabic Offensive Speech Detection
Authors:Aisha Alansari, Hamzah Luqman
The rapid growth of social media has amplified the spread of offensive, violent, and vulgar speech, which poses serious societal and cybersecurity concerns. Detecting such content in Arabic text is particularly complex due to limited labeled data, dialectal variations, and the language’s inherent complexity. This paper proposes a novel framework that integrates multi-task learning (MTL) with active learning to enhance offensive speech detection in Arabic social media text. By jointly training on two auxiliary tasks, violent and vulgar speech, the model leverages shared representations to improve the detection accuracy of the offensive speech. Our approach dynamically adjusts task weights during training to balance the contribution of each task and optimize performance. To address the scarcity of labeled data, we employ an active learning strategy through several uncertainty sampling techniques to iteratively select the most informative samples for model training. We also introduce weighted emoji handling to better capture semantic cues. Experimental results on the OSACT2022 dataset show that the proposed framework achieves a state-of-the-art macro F1-score of 85.42%, outperforming existing methods while using significantly fewer fine-tuning samples. The findings of this study highlight the potential of integrating MTL with active learning for efficient and accurate offensive language detection in resource-constrained settings.
社交媒体的快速发展放大了攻击性、暴力和粗鲁言论的传播,这引发了严重的社会和网络安全担忧。由于标记数据有限、方言差异和语言的固有复杂性,在阿拉伯文本中检测此类内容尤为复杂。本文针对阿拉伯社交媒体文本中的攻击性言论检测,提出了一种融合多任务学习(MTL)与主动学习的全新框架。该模型通过两个辅助任务(暴力和粗鲁言语)进行联合训练,利用共享表示来提高攻击性言论检测的准确性。我们的方法能够在训练过程中动态调整任务权重,以平衡每个任务的贡献并优化性能。为了解决标记数据稀缺的问题,我们采用了一种主动学习策略,通过几种不确定性采样技术来迭代选择最有信息量的样本进行模型训练。我们还引入了加权表情符号处理,以更好地捕捉语义线索。在OSACT2022数据集上的实验结果表明,该框架达到了最先进的宏观F1分数85.42%,在使用显著更少的微调样本的情况下,超过了现有方法。本研究的结果突出了在资源受限的环境中,将MTL与主动学习相结合进行高效且准确的攻击性语言检测的潜力。
论文及项目相关链接
Summary
阿拉伯语社交媒体文本中的攻击性言论检测面临诸多挑战,如标注数据有限、方言差异和语言本身的复杂性等。本文提出一种结合多任务学习和主动学习的框架,通过联合训练暴力、粗俗和攻击性言论检测任务,提高模型对阿拉伯语攻击性言论检测的准确性。该框架动态调整任务权重,并采用主动学习策略解决标注数据稀缺问题。实验结果表明,该框架在OSACT2022数据集上取得了最先进的宏观F1分数,且使用较少的微调样本即可实现性能优化。
Key Takeaways
- 社会媒体的快速发展加剧了攻击性、暴力和粗鲁言论的传播,引发了社会和网络安全担忧。
- 阿拉伯语文本中的攻击性言论检测面临标注数据有限、方言差异和语言复杂性等挑战。
- 本文提出一种结合多任务学习和主动学习的框架,以提高攻击性言论检测的准确性。
- 该框架通过联合训练暴力、粗俗和攻击性言论检测任务,利用共享表征来提高检测性能。
- 框架动态调整任务权重,以平衡各个任务的贡献并优化性能。
- 采用主动学习策略解决标注数据稀缺问题,通过不确定性采样技术选择最具信息量的样本进行模型训练。
点此查看论文截图


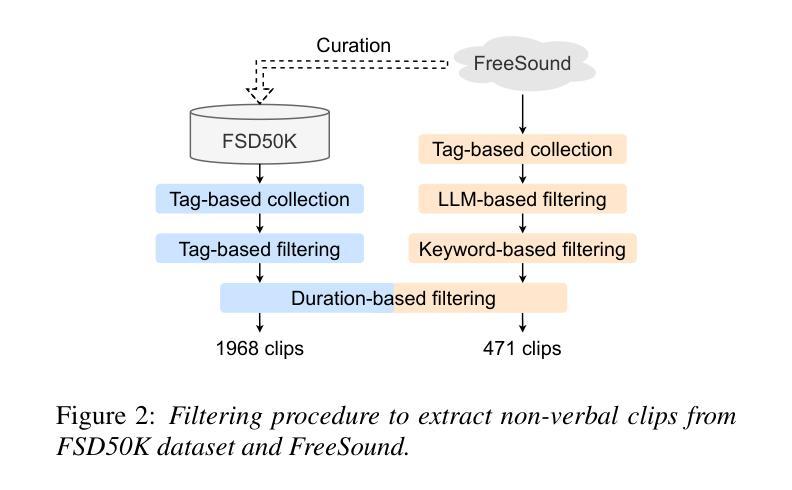
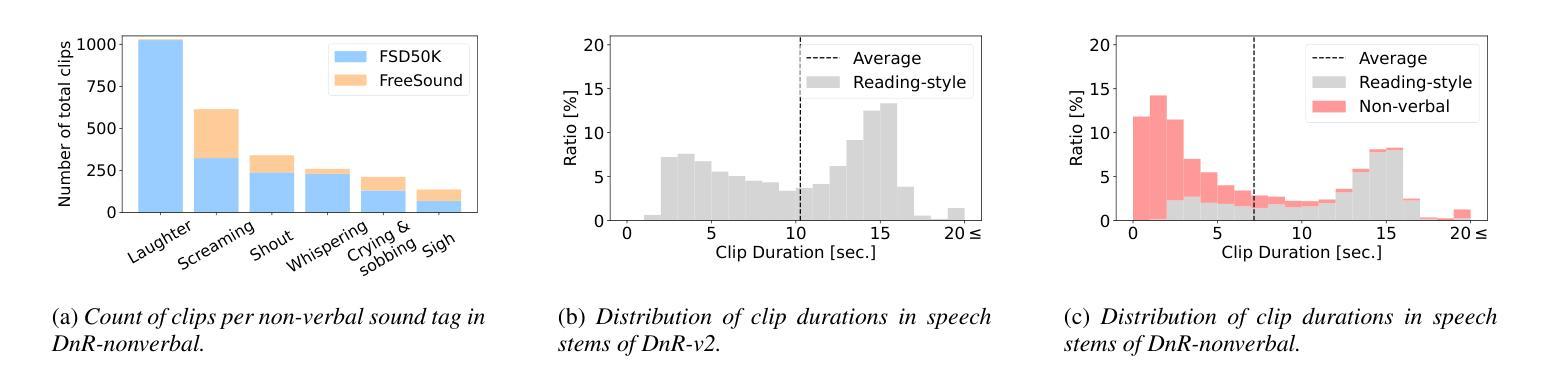
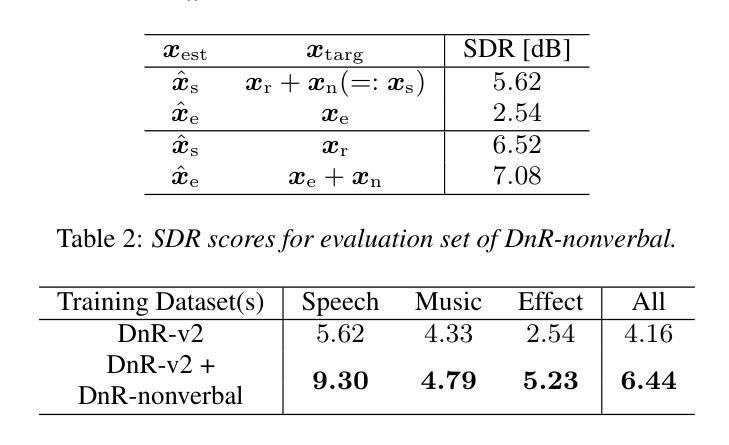
DnR-nonverbal: Cinematic Audio Source Separation Dataset Containing Non-Verbal Sounds
Authors:Takuya Hasumi, Yusuke Fujita
We propose a new dataset for cinematic audio source separation (CASS) that handles non-verbal sounds. Existing CASS datasets only contain reading-style sounds as a speech stem. These datasets differ from actual movie audio, which is more likely to include acted-out voices. Consequently, models trained on conventional datasets tend to have issues where emotionally heightened voices, such as laughter and screams, are more easily separated as an effect, not speech. To address this problem, we build a new dataset, DnR-nonverbal. The proposed dataset includes non-verbal sounds like laughter and screams in the speech stem. From the experiments, we reveal the issue of non-verbal sound extraction by the current CASS model and show that our dataset can effectively address the issue in the synthetic and actual movie audio. Our dataset is available at https://zenodo.org/records/15470640.
我们针对电影音频源分离(CASS)提出了一个新的数据集,用于处理非言语声音。现有的CASS数据集仅包含阅读风格的语音作为语音主干。这些数据集与实际的电影音频有所不同,后者更可能包含表演性的声音。因此,在常规数据集上训练的模型往往会出现问题,情感高涨的声音(如笑声和尖叫声)更容易被分离为一种效果,而非语音。为了解决这个问题,我们构建了一个新的数据集DnR-nonverbal。该数据集包含了语音主干中的非言语声音,如笑声和尖叫声等。通过实验,我们揭示了当前CASS模型在非言语声音提取方面的问题,并表明我们的数据集可以有效地解决合成和实际电影音频中的问题。我们的数据集可在https://zenodo.org/records/15470640获取。
论文及项目相关链接
PDF Accepted to Interspeech 2025, 5 pages, 3 figures, dataset is available at https://zenodo.org/records/15470640
Summary
提出了一种新的电影音频源分离(CASS)数据集,用于处理非语言声音。现有CASS数据集仅包含阅读式声音作为语音干音,与真实电影音频不同,后者更可能包含表演出的声音。因此,在常规数据集上训练的模型往往在处理情绪高涨的声音(如笑声和尖叫)时存在问题,容易将其分离为效果而非语音。为解决此问题,构建了新的数据集DnR-nonverbal,其中包含了非语言声音(如笑声和尖叫)在语音干音中。实验揭示了当前CASS模型提取非语言声音的问题,并表明该数据集可以在合成和真实电影音频中有效解决此问题。
Key Takeaways
- 现有CASS数据集主要关注阅读式声音,与真实电影音频存在差异。
- 模型在处理情绪高涨的声音(如笑声、尖叫)时存在困难,易误判为效果而非语音。
- 为解决上述问题,提出了新的数据集DnR-nonverbal。
- DnR-nonverbal数据集包含了非语言声音在语音干音中,更接近真实电影音频。
- 实验表明,新数据集能有效解决非语言声音的提取问题。
- 该数据集可用于合成和真实电影音频的处理。
点此查看论文截图


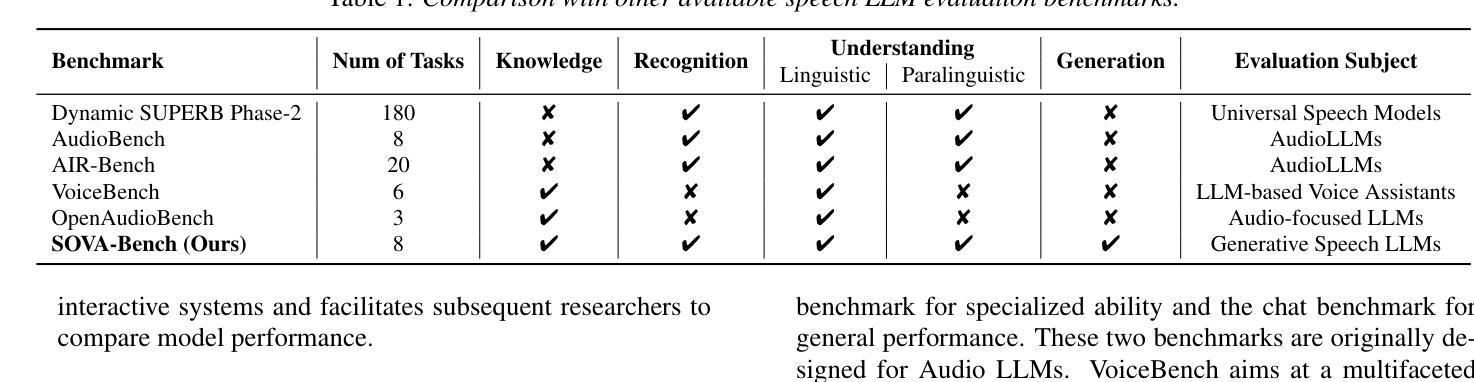
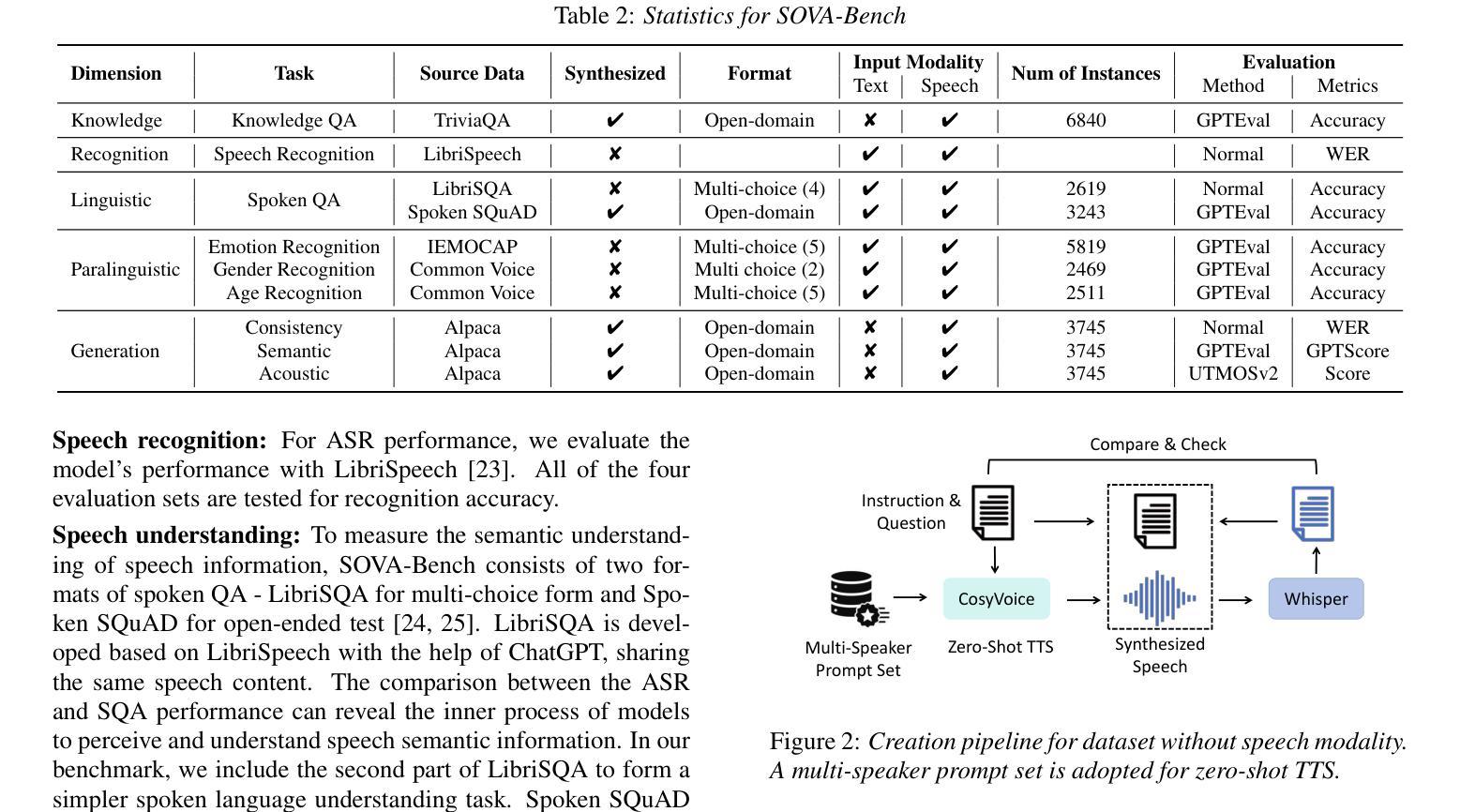
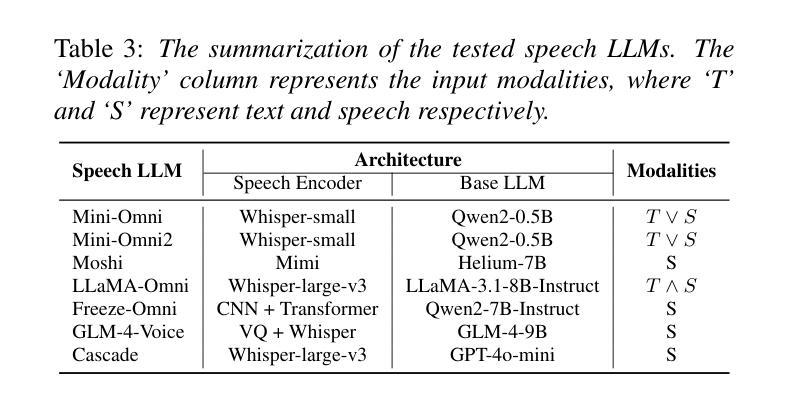
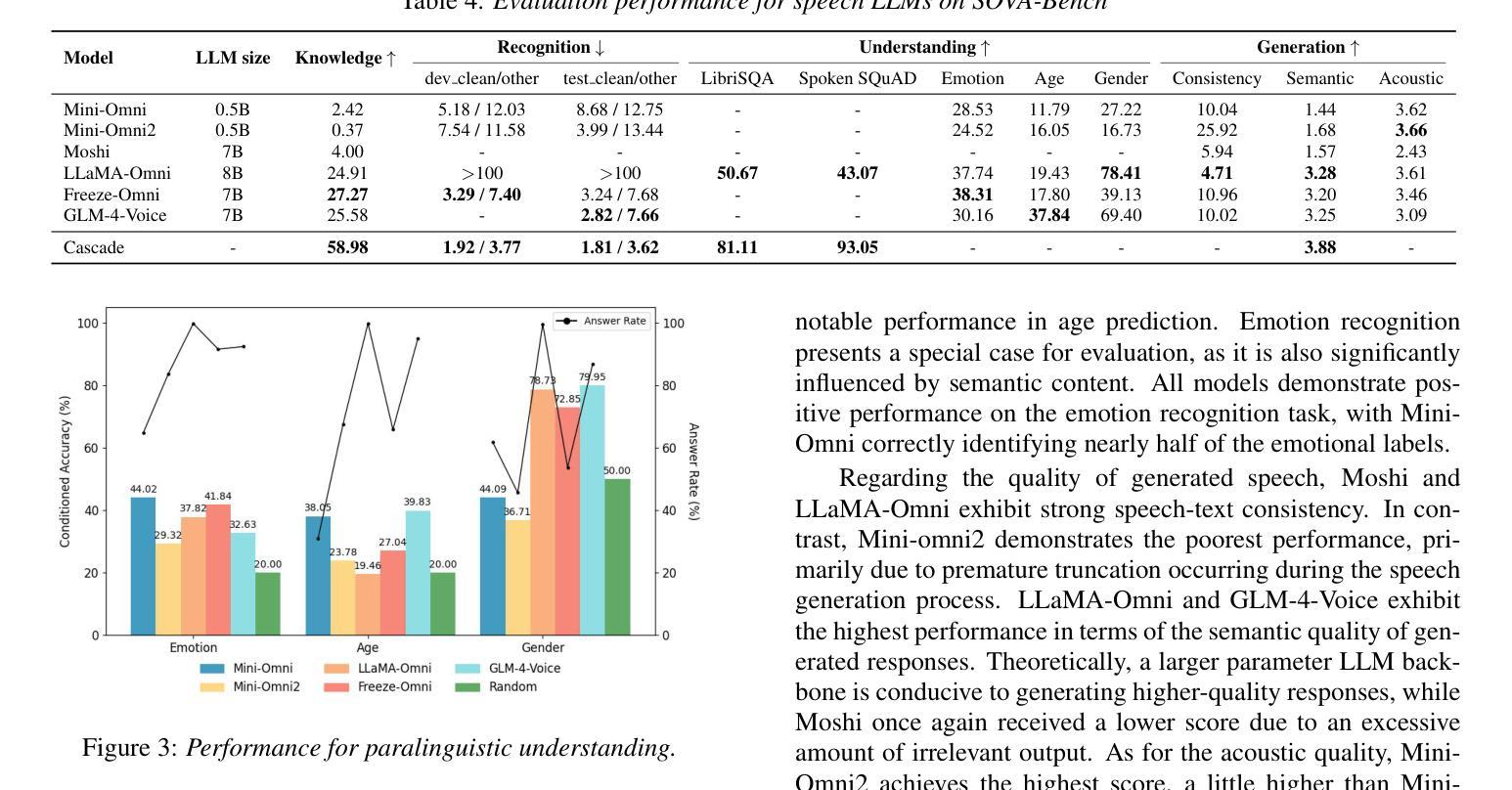
SOVA-Bench: Benchmarking the Speech Conversation Ability for LLM-based Voice Assistant
Authors:Yixuan Hou, Heyang Liu, Yuhao Wang, Ziyang Cheng, Ronghua Wu, Qunshan Gu, Yanfeng Wang, Yu Wang
Thanks to the steady progress of large language models (LLMs), speech encoding algorithms and vocoder structure, recent advancements have enabled generating speech response directly from a user instruction. However, benchmarking the generated speech quality has been a neglected but critical issue, considering the shift from the pursuit of semantic accuracy to vivid and spontaneous speech flow. Previous evaluation focused on the speech-understanding ability, lacking a quantification of acoustic quality. In this paper, we propose Speech cOnversational Voice Assistant Benchmark (SOVA-Bench), providing a comprehension comparison of the general knowledge, speech recognition and understanding, along with both semantic and acoustic generative ability between available speech LLMs. To the best of our knowledge, SOVA-Bench is one of the most systematic evaluation frameworks for speech LLMs, inspiring the direction of voice interaction systems.
得益于大型语言模型(LLM)、语音编码算法和vocoder结构的稳步发展,最近的进步已经能够实现直接从用户指令生成语音响应。然而,考虑到从追求语义准确性到生动自然语音流的转变,对生成语音质量的评估是一个被忽视但至关重要的问题。之前的评估主要集中在语音理解能力上,缺乏对声音质量的量化评估。在本文中,我们提出了基于语音对话式语音助手基准(SOVA-Bench)的评估方法,该方法比较了通用知识、语音识别和理解能力,以及现有语音LLM之间的语义和声音生成能力。据我们所知,SOVA-Bench是最系统的语音LLM评估框架之一,为语音交互系统的方向提供了启示。
论文及项目相关链接
Summary
随着大型语言模型(LLMs)、语音编码算法和vocoder结构的稳步发展,现在可以直接根据用户指令生成语音响应。然而,评估生成语音的质量是一个被忽视但至关重要的问题,因为现在的重点已从追求语义准确性转向了生动自然的语音流。本文提出了“语音对话语音助手基准测试”(SOVA-Bench),对通用知识、语音识别与理解能力,以及语义和声音的生成能力进行全面比较评估,为现有的语音LLMs提供系统评估框架。该基准测试不仅为语音LLMs的性能提供了量化的衡量标准,也为语音交互系统的未来发展方向提供了启示。
Key Takeaways
- 大型语言模型(LLMs)的进步使得根据用户指令直接生成语音响应成为可能。
- 评估生成语音的质量是一个被忽视但重要的问题,因为现在的重点已从语义准确性转向生动自然的语音流。
- 现有的评估主要关注语音理解能力,缺乏声学质量的量化指标。
- 提出了一种新的评估框架——Speech cOnversational Voice Assistant Benchmark (SOVA-Bench)。
- SOVA-Bench提供了对通用知识、语音识别与理解能力,以及语义和声音的生成能力的全面评估。
- SOVA-Bench是最系统的语音LLMs评估框架之一。
点此查看论文截图

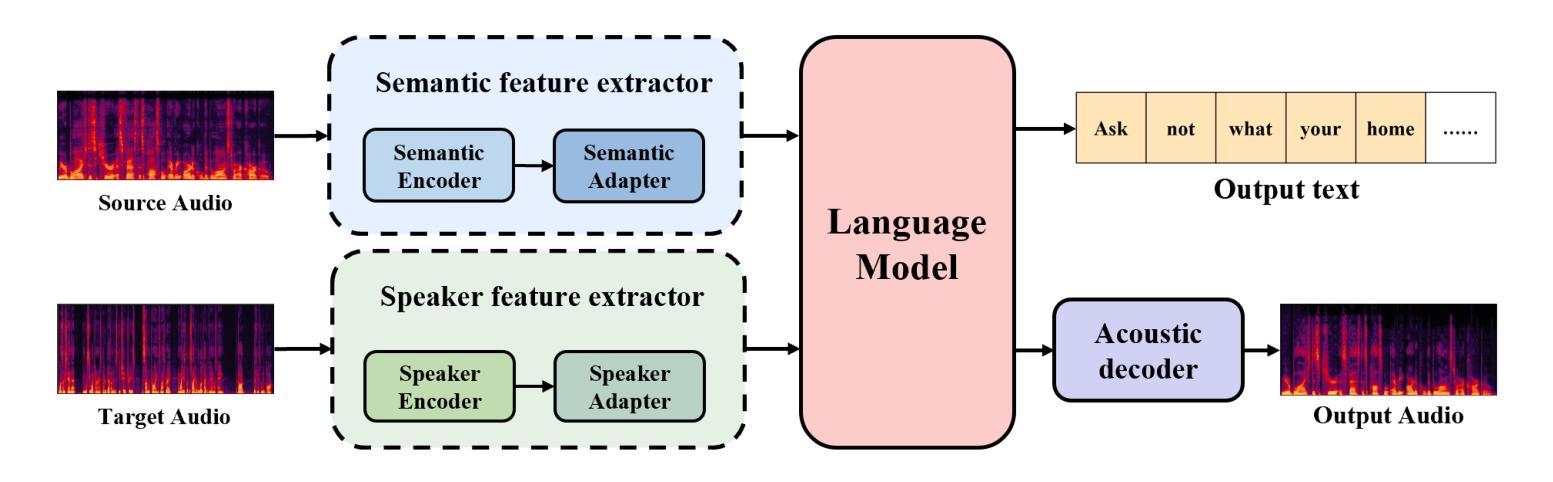
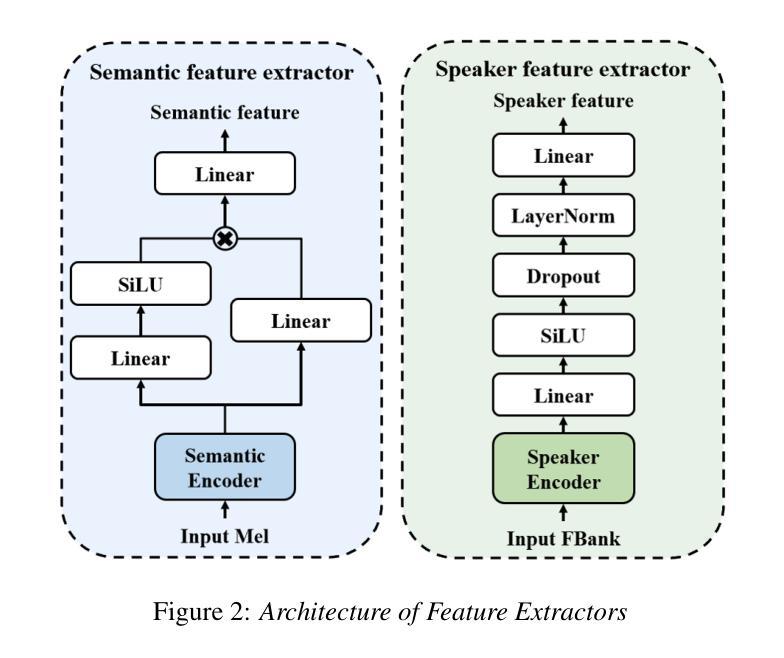
StarVC: A Unified Auto-Regressive Framework for Joint Text and Speech Generation in Voice Conversion
Authors:Fengjin Li, Jie Wang, Yadong Niu, Yongqing Wang, Meng Meng, Jian Luan, Zhiyong Wu
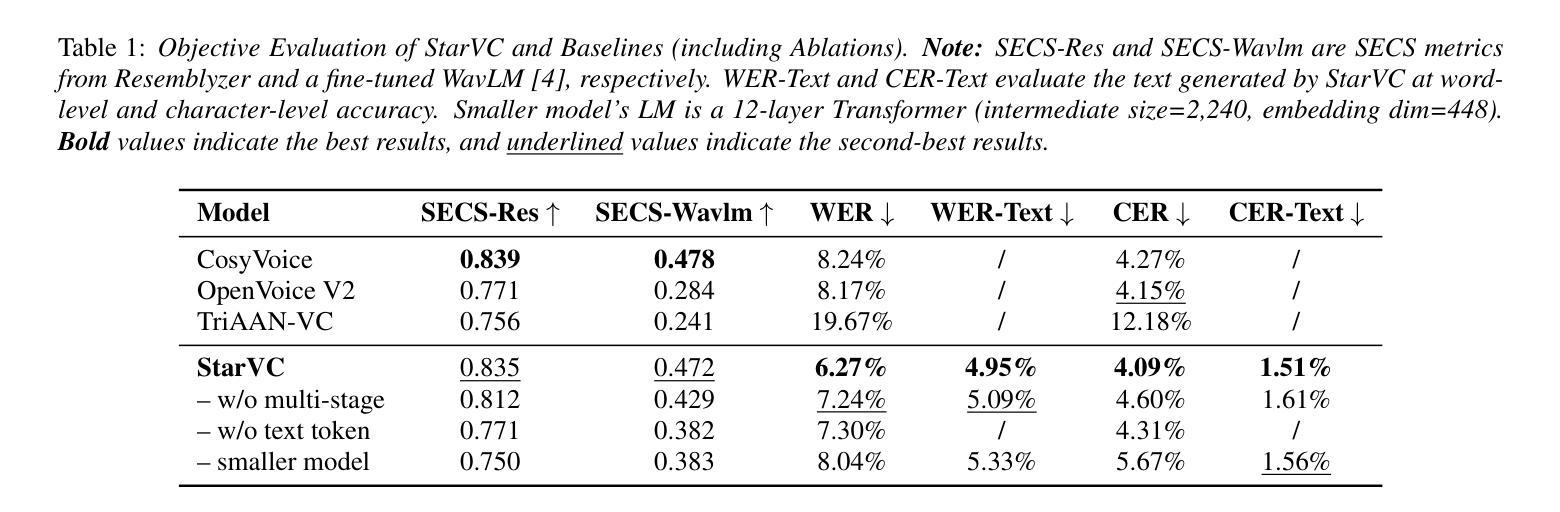
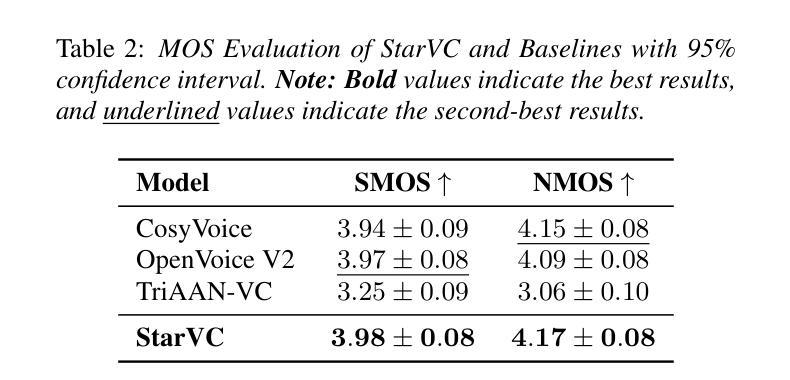
Voice Conversion (VC) modifies speech to match a target speaker while preserving linguistic content. Traditional methods usually extract speaker information directly from speech while neglecting the explicit utilization of linguistic content. Since VC fundamentally involves disentangling speaker identity from linguistic content, leveraging structured semantic features could enhance conversion performance. However, previous attempts to incorporate semantic features into VC have shown limited effectiveness, motivating the integration of explicit text modeling. We propose StarVC, a unified autoregressive VC framework that first predicts text tokens before synthesizing acoustic features. The experiments demonstrate that StarVC outperforms conventional VC methods in preserving both linguistic content (i.e., WER and CER) and speaker characteristics (i.e., SECS and MOS). Audio demo can be found at: https://thuhcsi.github.io/StarVC/.
语音转换(VC)会修改语音以匹配目标说话者,同时保留语言内容。传统方法通常直接从语音中提取说话者信息,而忽视对语言内容的明确利用。由于VC从根本上涉及将说话者身份与语言内容分开,利用结构化的语义特征可能会提高转换性能。然而,之前将语义特征融入VC的尝试显示出了有限的有效性,这激发了显式文本建模的集成。我们提出StarVC,这是一个统一的自回归VC框架,它首先在合成声学特征之前预测文本标记。实验表明,StarVC在保留语言内容(即WER和CER)和说话者特征(即SECS和MOS)方面优于传统VC方法。音频演示可在:https://thuhcsi.github.io/StarVC/找到。
论文及项目相关链接
PDF 5 pages, 2 figures, Accepted by Interspeech 2025, Demo: https://thuhcsi.github.io/StarVC/
总结
语音转换(VC)旨在匹配目标说话者的语音,同时保留语言内容。传统方法通常直接从语音中提取说话者信息,忽略了语言内容的明确利用。由于VC从根本上涉及将说话者身份与语言内容分开,利用结构化的语义特征可能会提高转换性能。然而,之前尝试将语义特征融入VC显示出了有限的效果,这促使人们结合明确的文本建模。我们提出StarVC,一个统一的自回归VC框架,首先预测文本标记,然后合成声学特征。实验表明,StarVC在保留语言内容(即WER和CER)和说话者特征(即SECS和MOS)方面优于传统VC方法。音频演示可在:https://thuhcsi.github.io/StarVC/找到。
要点
- 语音转换(VC)旨在匹配目标说话者并保留语言内容。
- 传统VC方法通常忽略语言内容的明确利用,只关注提取说话者信息。
- VC涉及分离说话者身份和语言内容,可以利用结构化的语义特征来提高转换性能。
- 之前尝试融入语义特征的VC效果有限。
- 提出了一种新的VC框架StarVC,结合文本建模和自回归方法。
- StarVC在保留语言内容和说话者特征方面优于传统方法。
点此查看论文截图

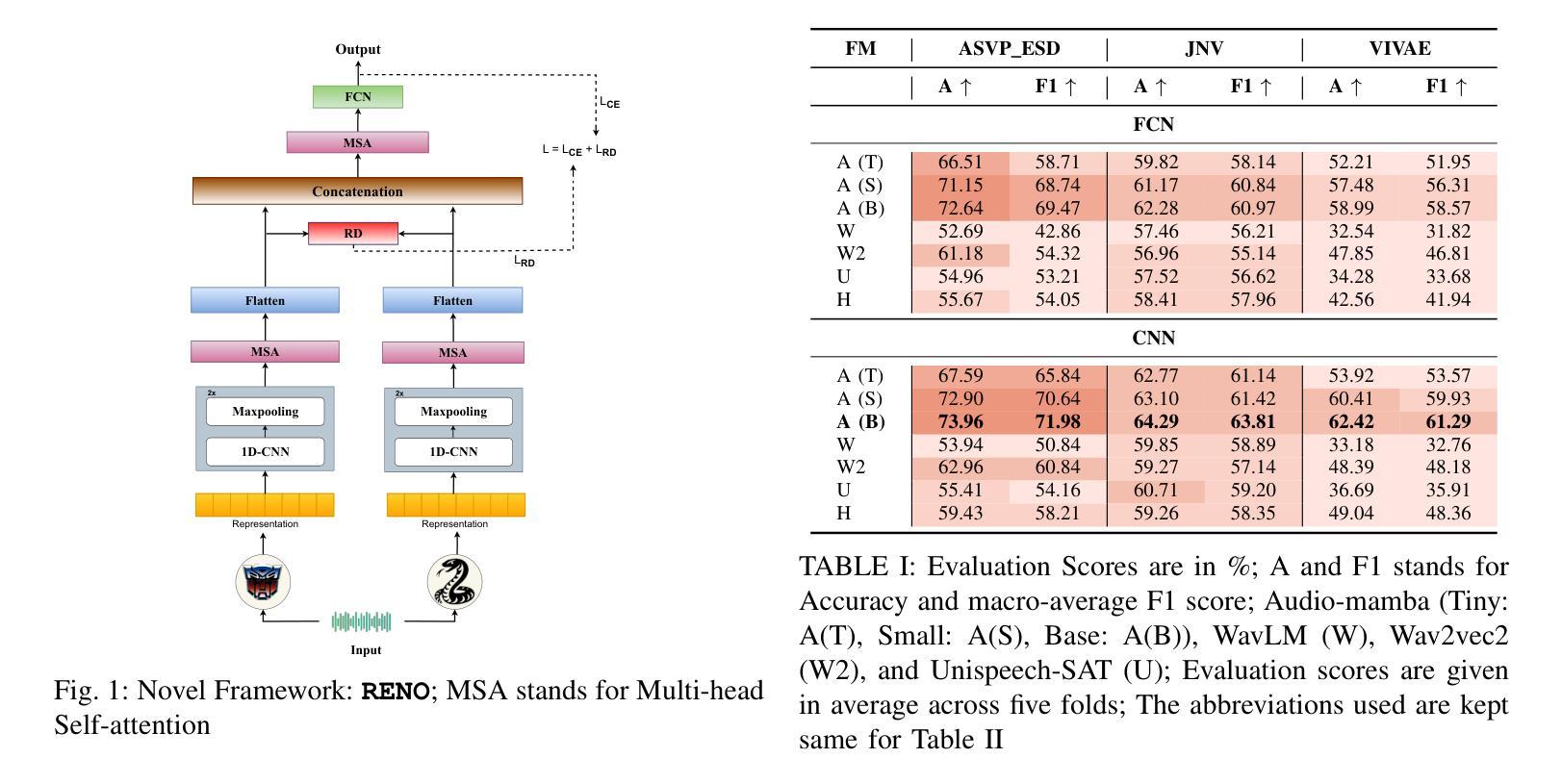
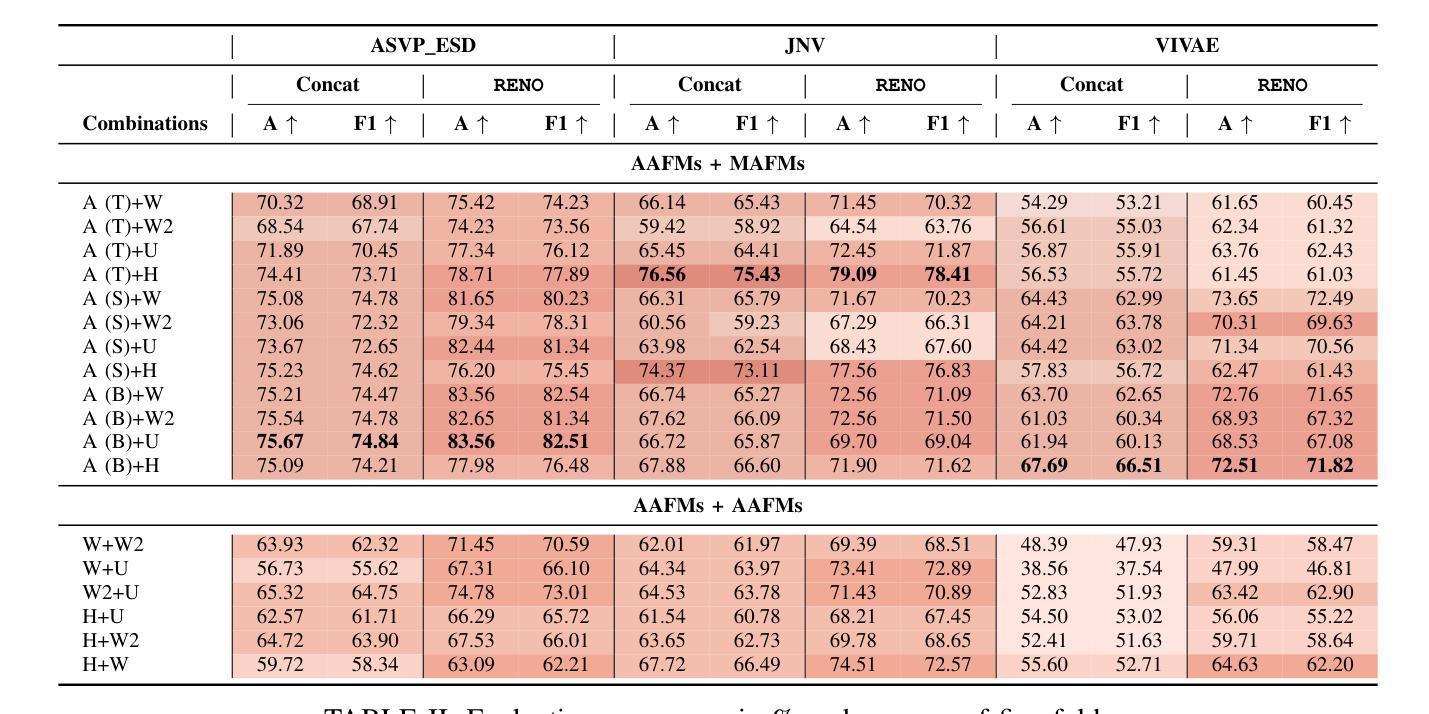
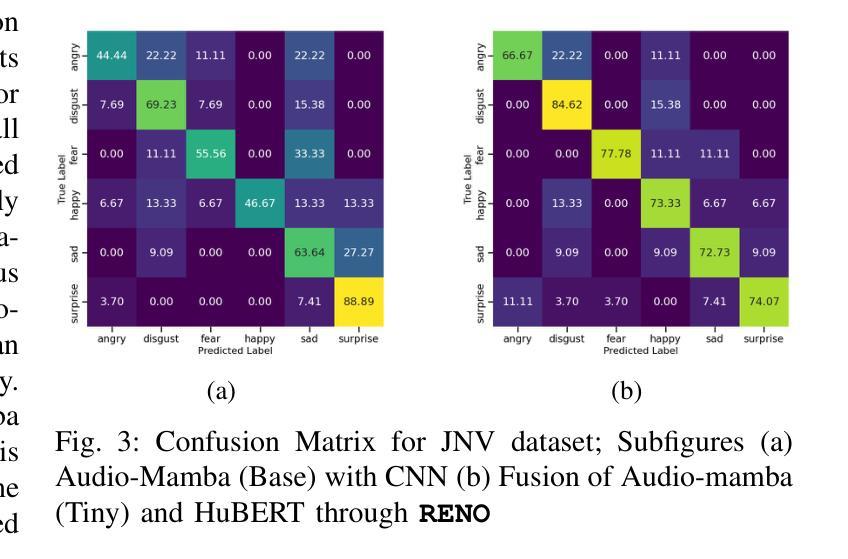
Are Mamba-based Audio Foundation Models the Best Fit for Non-Verbal Emotion Recognition?
Authors:Mohd Mujtaba Akhtar, Orchid Chetia Phukan, Girish, Swarup Ranjan Behera, Ananda Chandra Nayak, Sanjib Kumar Nayak, Arun Balaji Buduru, Rajesh Sharma
In this work, we focus on non-verbal vocal sounds emotion recognition (NVER). We investigate mamba-based audio foundation models (MAFMs) for the first time for NVER and hypothesize that MAFMs will outperform attention-based audio foundation models (AAFMs) for NVER by leveraging its state-space modeling to capture intrinsic emotional structures more effectively. Unlike AAFMs, which may amplify irrelevant patterns due to their attention mechanisms, MAFMs will extract more stable and context-aware representations, enabling better differentiation of subtle non-verbal emotional cues. Our experiments with state-of-the-art (SOTA) AAFMs and MAFMs validates our hypothesis. Further, motivated from related research such as speech emotion recognition, synthetic speech detection, where fusion of foundation models (FMs) have showed improved performance, we also explore fusion of FMs for NVER. To this end, we propose, RENO, that uses renyi-divergence as a novel loss function for effective alignment of the FMs. It also makes use of self-attention for better intra-representation interaction of the FMs. With RENO, through the heterogeneous fusion of MAFMs and AAFMs, we show the topmost performance in comparison to individual FMs, its fusion and also setting SOTA in comparison to previous SOTA work.
在这项工作中,我们专注于非语言声音情感识别(NVER)。我们首次研究基于mamba的音频基础模型(MAFMs)在NVER中的应用,并假设MAFMs在利用状态空间建模更有效地捕捉内在情感结构方面,将在非语言声音情感识别上优于基于注意力的音频基础模型(AAFMs)。与可能因注意力机制而放大无关模式的AAFMs不同,MAFMs将提取更稳定和上下文感知的表示,从而更好地区分微妙的非语言情感线索。我们利用最先进(SOTA)的AAFMs和MAFMs进行的实验验证了我们假设的正确性。此外,我们从语音情感识别、合成语音检测等相关研究中获得启发,在这些研究中,基础模型的融合(FMs)已经显示出性能改进,我们也探索了NVRE中FMs的融合。为此,我们提出了RENO,它使用renyi散度作为对齐FMs的新型损失函数,并借助自我注意力实现FMs的更好内部表示交互。通过MAFMs和AAFMs的异质融合,RENO展现出最佳性能,不仅优于单个FMs及其融合,而且相较于之前的最先进方法也达到了新的SOTA水平。
论文及项目相关链接
PDF Accepted to EUSIPCO 2025
Summary
本文专注于非言语性声音情感识别(NVER),首次研究基于mamba的音频基础模型(MAFMs)在NVER中的应用。研究表明,MAFMs利用状态空间建模更有效地捕捉内在情感结构,在NVER中表现优于基于注意力的音频基础模型(AAFMs)。实验验证了该假设的正确性。此外,受到融合基础模型在语音情感识别、合成语音检测等领域表现提升的研究启发,本文也探索了融合基础模型在NVER中的应用。为此,提出了使用renyi-divergence作为损失函数进行融合模型有效对齐的新方法RENO,并借助自我注意力机制增强模型内部表示的交互。通过融合MAFMs和AAFMs的异质融合,RENO在对比单个FM、其融合方法以及先前最佳工作方面均表现出顶尖性能。
Key Takeaways
- 研究关注非言语性声音情感识别(NVER)。
- 首次探究mamba-based音频基础模型(MAFMs)在NVER中的应用。
- MAFMs通过状态空间建模更有效地捕捉内在情感结构。
- 基于注意力的音频基础模型(AAFMs)可能会因注意力机制而放大无关模式。
- MAFMs提取的稳定和上下文感知的表示有助于更好地区分微妙的非言语情感线索。
- 融合基础模型(FMs)在语音情感识别等领域已显示出性能提升。
点此查看论文截图


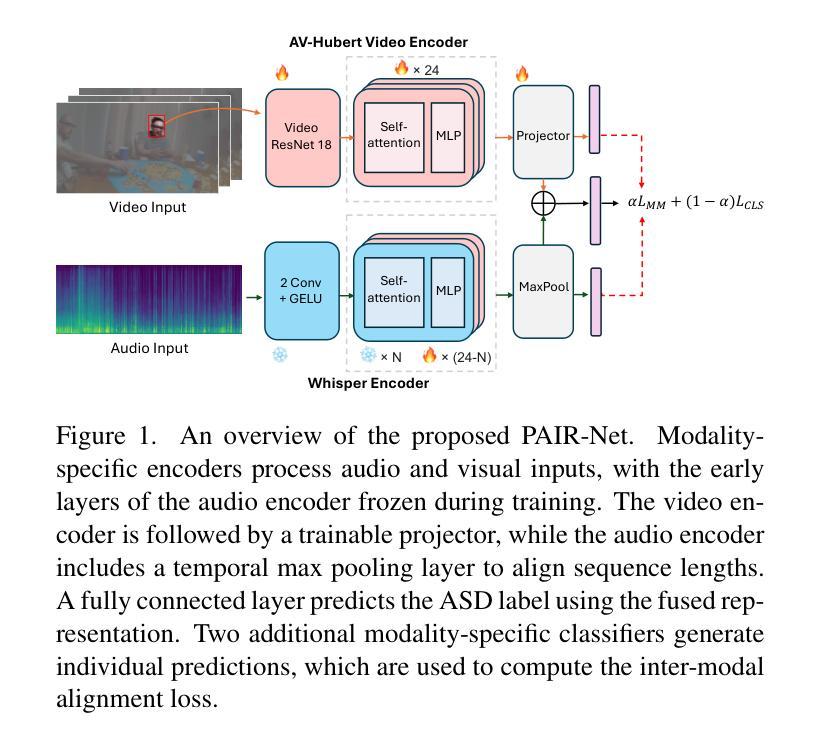
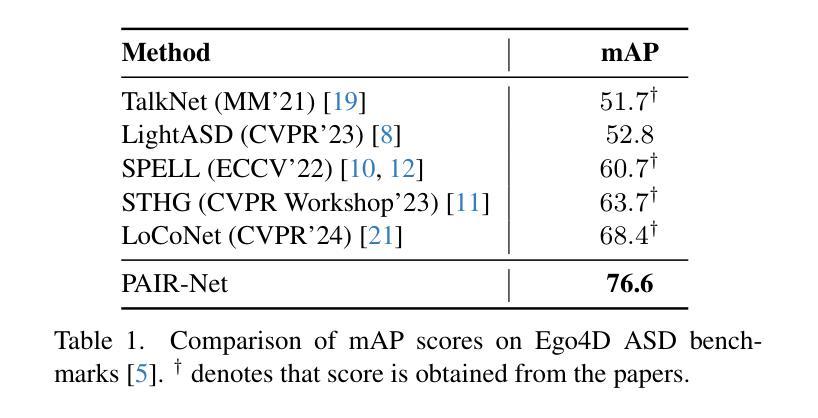
PAIR-Net: Enhancing Egocentric Speaker Detection via Pretrained Audio-Visual Fusion and Alignment Loss
Authors:Yu Wang, Juhyung Ha, David J. Crandall
Active speaker detection (ASD) in egocentric videos presents unique challenges due to unstable viewpoints, motion blur, and off-screen speech sources - conditions under which traditional visual-centric methods degrade significantly. We introduce PAIR-Net (Pretrained Audio-Visual Integration with Regularization Network), an effective model that integrates a partially frozen Whisper audio encoder with a fine-tuned AV-HuBERT visual backbone to robustly fuse cross-modal cues. To counteract modality imbalance, we introduce an inter-modal alignment loss that synchronizes audio and visual representations, enabling more consistent convergence across modalities. Without relying on multi-speaker context or ideal frontal views, PAIR-Net achieves state-of-the-art performance on the Ego4D ASD benchmark with 76.6% mAP, surpassing LoCoNet and STHG by 8.2% and 12.9% mAP, respectively. Our results highlight the value of pretrained audio priors and alignment-based fusion for robust ASD under real-world egocentric conditions.
在自我中心的视频中,主动说话人检测(ASD)面临着由于观点不稳定、运动模糊和屏幕外语音源等独特挑战——在这些条件下,传统的视觉中心方法会显著退化。我们引入了PAIR-Net(具有正则化的预训练视听集成网络),这是一个有效的模型,它将部分冻结的Whisper音频编码器与经过微调AV-HuBERT视觉主干相结合,以稳健地融合跨模态线索。为了对抗模态不平衡,我们引入了一种跨模态对齐损失,以同步音频和视觉表示,从而实现跨模态的更一致收敛。在不依赖多说话人上下文或理想正面视角的情况下,PAIR-Net在Ego4D ASD基准测试上达到了最先进的性能,mAP达到76.6%,分别比LoCoNet和STHG高出8.2%和12.9% mAP。我们的结果突出了在真实世界的自我中心条件下,预训练的音频先验和对齐融合的价值,对于稳健的ASD至关重要。
论文及项目相关链接
PDF 4 pages, 1 figure, and 1 table
Summary
预训练音频优先与正则化网络(PAIR-Net)能有效解决主动说话人检测(ASD)在自我中心视频中的难题,它整合了部分冻结的Whisper音频编码器与微调后的AV-HuBERT视觉主干,稳健地融合了跨模态线索。通过引入跨模态对齐损失来对抗模态不平衡问题,使音频和视觉表征同步,实现跨模态的一致收敛。在不依赖多说话人上下文或理想正面视角的情况下,PAIR-Net在Ego4D ASD基准测试中达到76.6%的mAP,超越了LoCoNet和STHG分别达8.2%和12.9%的mAP。结果凸显了预训练音频先验和对齐融合在真实世界自我中心条件下的稳健ASD的价值。
Key Takeaways
- PAIR-Net解决了主动说话人检测在自我中心视频中的挑战。
- PAIR-Net整合了音频和视觉信息,通过部分冻结的Whisper音频编码器与AV-HuBERT视觉主干实现跨模态融合。
- 引入跨模态对齐损失以对抗模态不平衡问题,实现音频和视觉表征的同步。
- PAIR-Net在Ego4D ASD基准测试中表现优异,达到76.6%的mAP。
- PAIR-Net性能超越了LoCoNet和STHG。
- 预训练音频先验对于提高ASD性能至关重要。
点此查看论文截图

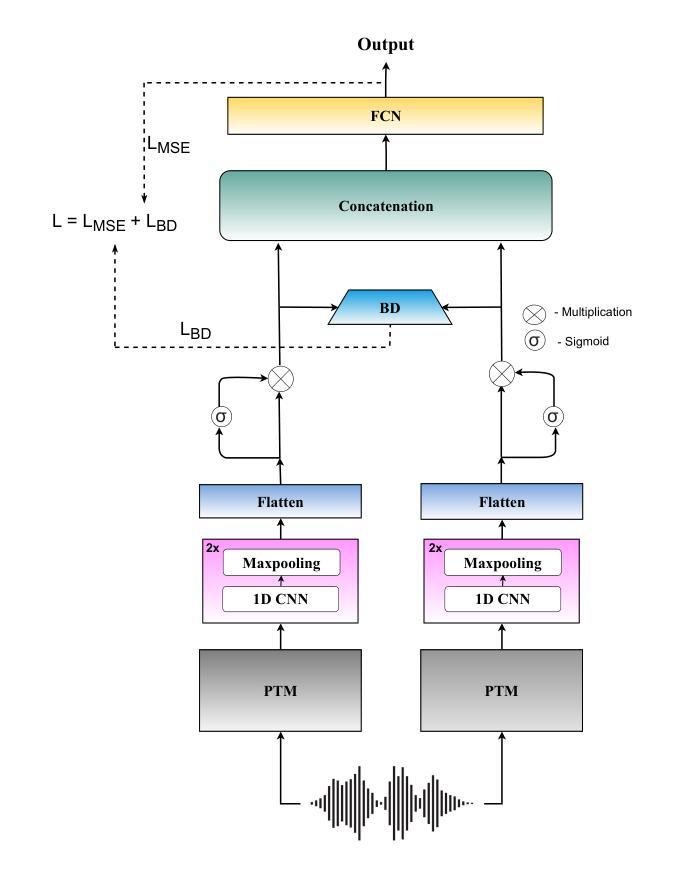
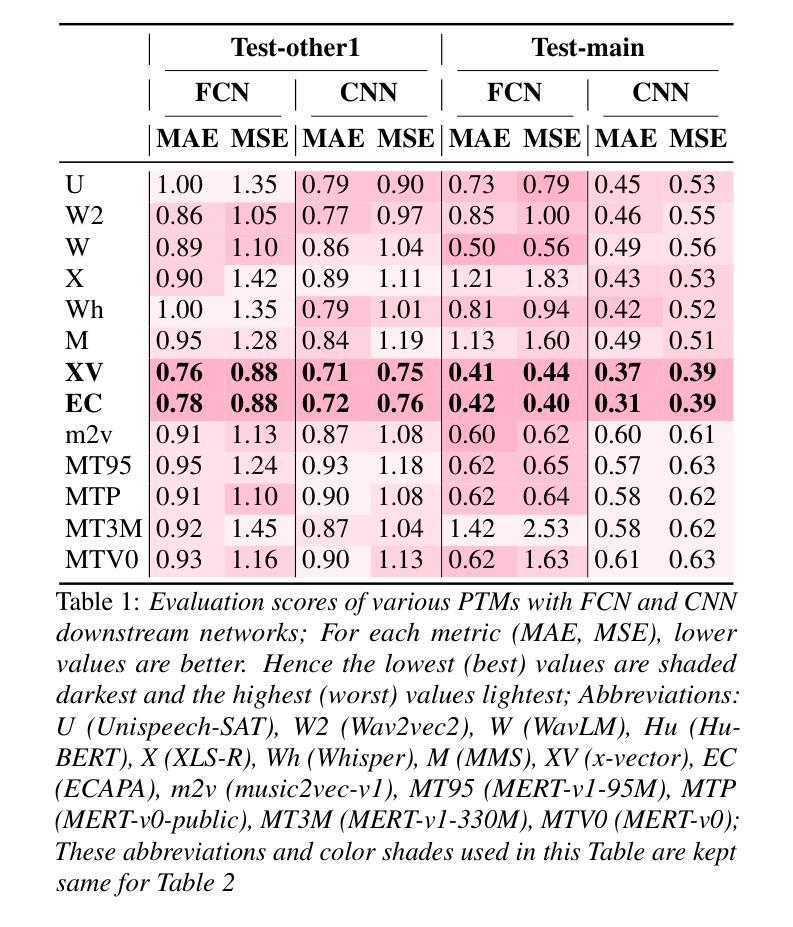
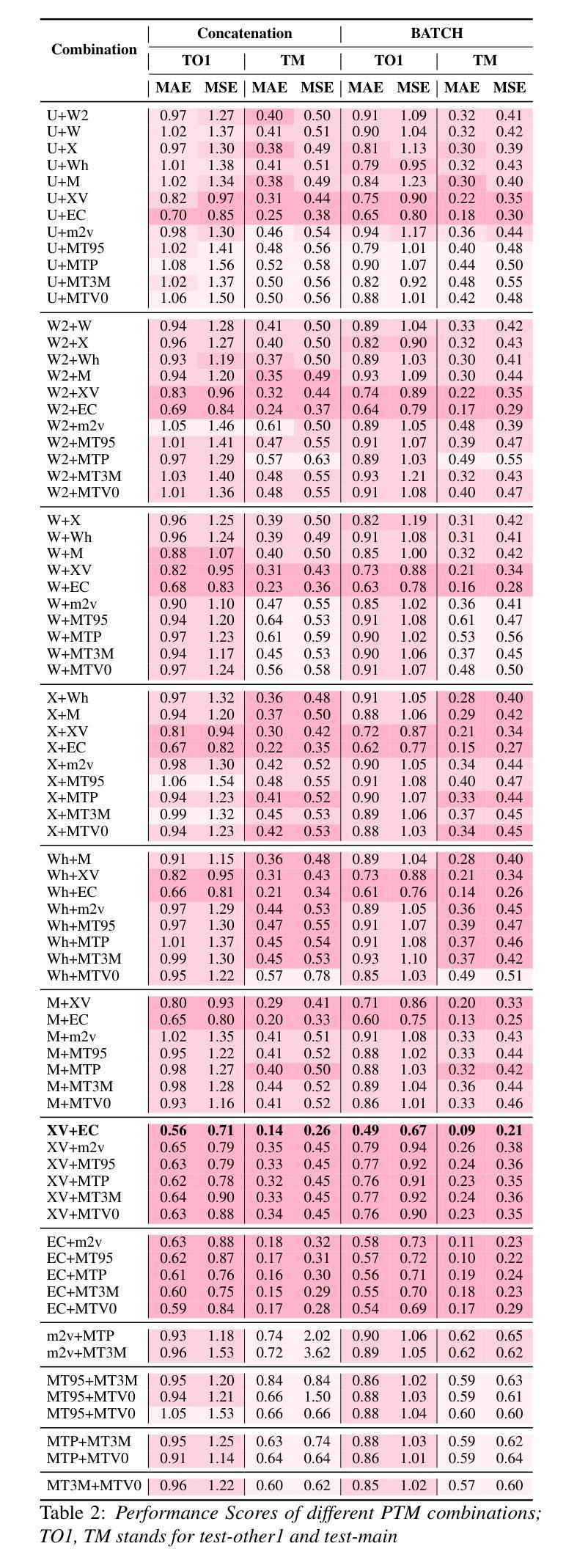
Investigating the Reasonable Effectiveness of Speaker Pre-Trained Models and their Synergistic Power for SingMOS Prediction
Authors:Orchid Chetia Phukan, Girish, Mohd Mujtaba Akhtar, Swarup Ranjan Behera, Pailla Balakrishna Reddy, Arun Balaji Buduru, Rajesh Sharma
In this study, we focus on Singing Voice Mean Opinion Score (SingMOS) prediction. Previous research have shown the performance benefit with the use of state-of-the-art (SOTA) pre-trained models (PTMs). However, they haven’t explored speaker recognition speech PTMs (SPTMs) such as x-vector, ECAPA and we hypothesize that it will be the most effective for SingMOS prediction. We believe that due to their speaker recognition pre-training, it equips them to capture fine-grained vocal features (e.g., pitch, tone, intensity) from synthesized singing voices in a much more better way than other PTMs. Our experiments with SOTA PTMs including SPTMs and music PTMs validates the hypothesis. Additionally, we introduce a novel fusion framework, BATCH that uses Bhattacharya Distance for fusion of PTMs. Through BATCH with the fusion of speaker recognition SPTMs, we report the topmost performance comparison to all the individual PTMs and baseline fusion techniques as well as setting SOTA.
在这项研究中,我们专注于歌唱声音平均意见得分(SingMOS)的预测。先前的研究已经显示了使用最新预训练模型(PTMs)的性能优势。然而,他们尚未探索用于语音识别的预训练模型(SPTMs),例如x向量、ECAPA,我们假设这对于SingMOS预测将是最有效的。我们相信,由于它们具有语音识别的预训练能力,因此能够比其他PTM更好地捕获合成歌声的精细语音特征(例如音调、音色和强度)。我们对包括SPTM和音乐PTM的最新PTM进行的实验验证了这一假设。此外,我们引入了一种新的融合框架BATCH,它使用Bhattacharya距离来融合PTM。通过BATCH融合语音识别的SPTMs,我们报告了与所有单独的PTM和基准融合技术的最高性能比较,并建立了新的SOTA(最佳水平)。
论文及项目相关链接
PDF Accepted to INTERSPEECH 2025
Summary
此研究关注歌唱声音平均意见得分(SingMOS)预测。研究使用最先进的预训练模型(PTMs),并探索语音预训练模型(SPTMs)如x-vector、ECAPA等,假设其在SingMOS预测中最有效。实验验证假设,认为SPTMs能捕捉合成歌声的精细语音特征(如音调、音色、强度),并使用创新的融合框架BATCH结合PTMs进行验证,相较于各独立PTMs与基准融合技术,表现最佳。
Key Takeaways
- 研究聚焦于SingMOS预测。
- 最先进的预训练模型在研究中得到应用。
- 说话人识别语音预训练模型(SPTMs)的探索及其在SingMOS预测中的假设有效性。
- SPTMs能够捕捉合成歌声的精细语音特征。
- 引入新型融合框架BATCH,采用Bhattacharya距离进行预训练模型的融合。
- BATCH融合说话人识别SPTMs表现超越所有独立PTMs和基准融合技术。
点此查看论文截图

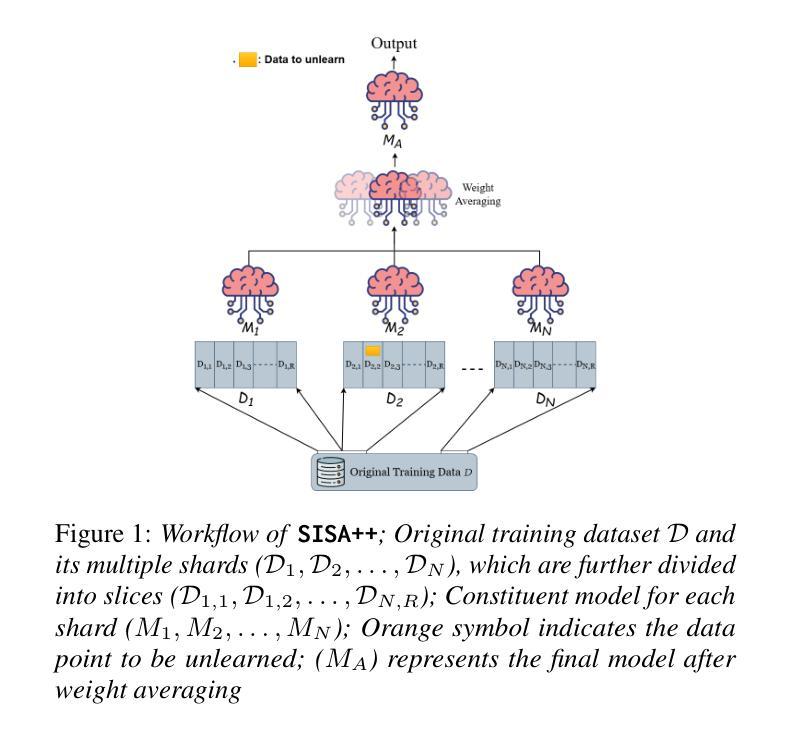
Towards Machine Unlearning for Paralinguistic Speech Processing
Authors:Orchid Chetia Phukan, Girish, Mohd Mujtaba Akhtar, Shubham Singh, Swarup Ranjan Behera, Vandana Rajan, Muskaan Singh, Arun Balaji Buduru, Rajesh Sharma
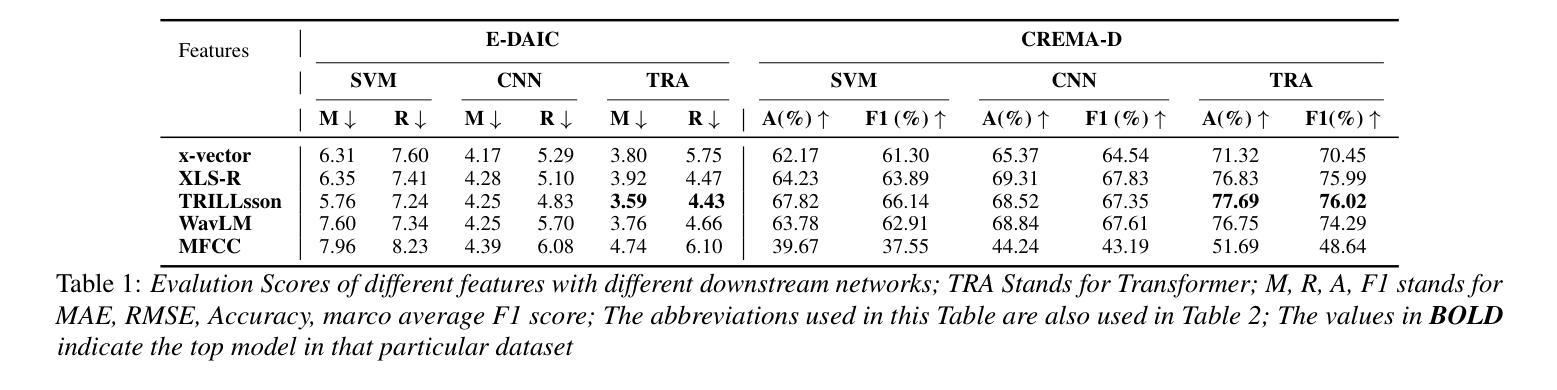
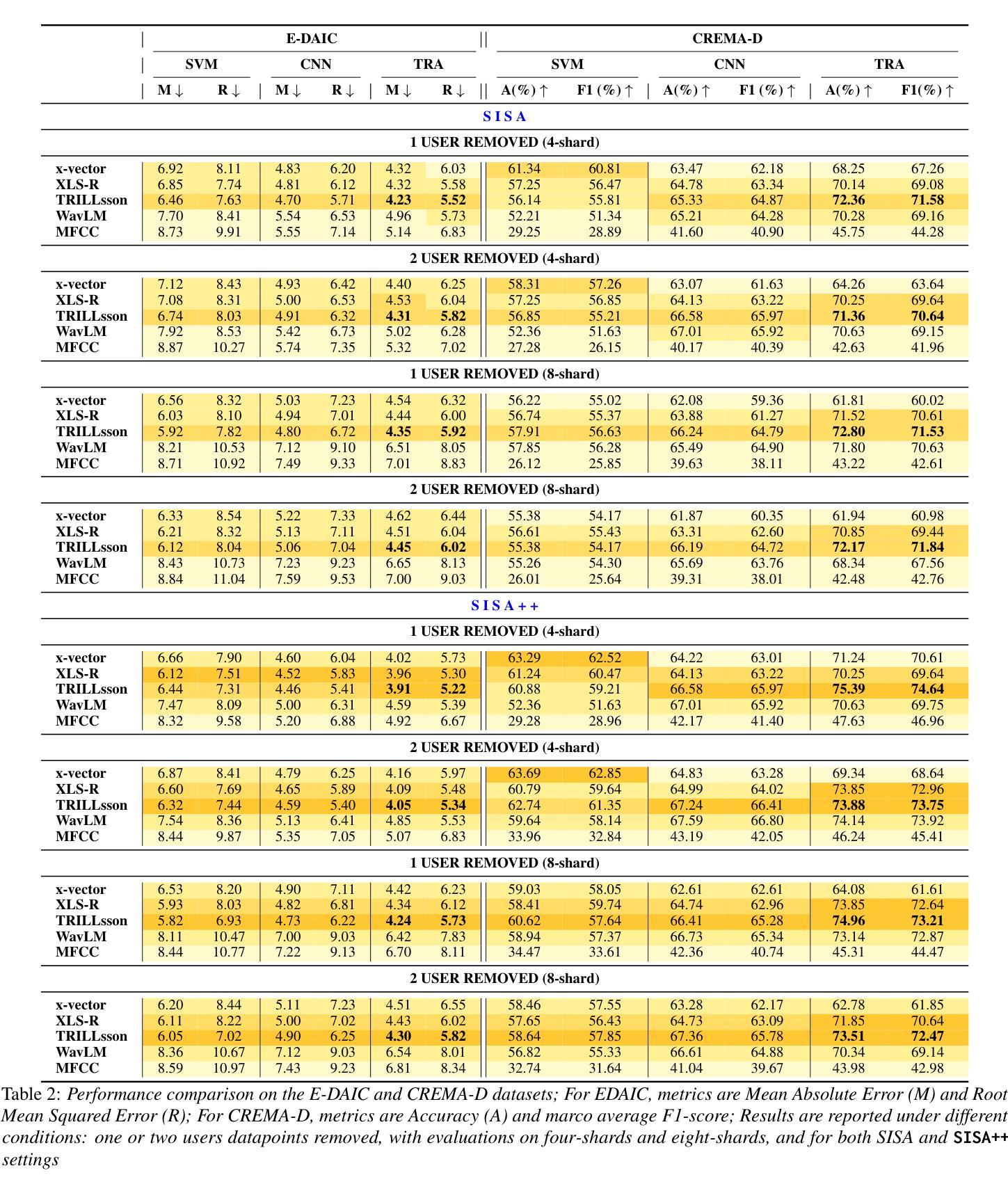
In this work, we pioneer the study of Machine Unlearning (MU) for Paralinguistic Speech Processing (PSP). We focus on two key PSP tasks: Speech Emotion Recognition (SER) and Depression Detection (DD). To this end, we propose, SISA++, a novel extension to previous state-of-the-art (SOTA) MU method, SISA by merging models trained on different shards with weight-averaging. With such modifications, we show that SISA++ preserves performance more in comparison to SISA after unlearning in benchmark SER (CREMA-D) and DD (E-DAIC) datasets. Also, to guide future research for easier adoption of MU for PSP, we present ``cookbook recipes’’ - actionable recommendations for selecting optimal feature representations and downstream architectures that can mitigate performance degradation after the unlearning process.
在这项工作中,我们首创了针对副语言语音处理(PSP)的机器遗忘学习(MU)研究。我们重点关注两个关键的PSP任务:语音情绪识别(SER)和抑郁检测(DD)。为此,我们提出了SISA++,这是通过对先前最先进的MU方法SISA进行改进而得到的,通过合并不同分片训练的模型并加权平均权重。经过这些修改,我们在基准SER(CREMA-D)和DD(E-DAIC)数据集上展示了与SISA相比,SISA++在遗忘学习后的性能表现更佳。此外,为了引导未来的研究更轻松地采用MU用于PSP,我们提供了“食谱式指南”——可操作建议来选择最优的特征表示和下游架构,这样可以缓解遗忘学习过程后的性能下降问题。
论文及项目相关链接
PDF Accepted to INTERSPEECH 2025
Summary
本研究开创性地探索了用于副语言处理(PSP)的机器遗忘(MU)。聚焦于两大关键任务:语音情绪识别(SER)和抑郁检测(DD)。提出了一项新的改进方法SISA++,它通过合并不同分片训练的模型并使用权重平均技术,相较于现有最先进的SISA方法,能够在基准测试数据集SER(CREMA-D)和DD(E-DAIC)中保持更好的性能。此外,为了指导未来研究更轻松地采用MU进行PSP研究,我们提供了实用的“食谱”建议,推荐选择最优的特征表示和下游架构,以减少遗忘过程后的性能下降。
Key Takeaways
以下是关键要点摘要:
- 研究首次探索了机器遗忘(MU)在副语言处理(PSP)中的应用。
- 研究聚焦于两大关键任务:语音情绪识别(SER)和抑郁检测(DD)。
- 提出了一种新的改进方法SISA++,通过合并不同分片训练的模型并使用权重平均技术,改进现有技术的性能。
- 在基准测试数据集SER和DD中的性能表现优于现有技术。
- 提供实用指南(“食谱”),建议如何选择和优化特征表示和下游架构,以减轻遗忘过程后的性能下降。
- 本研究为未来MU在PSP领域的研究提供了有价值的参考和指导。
点此查看论文截图

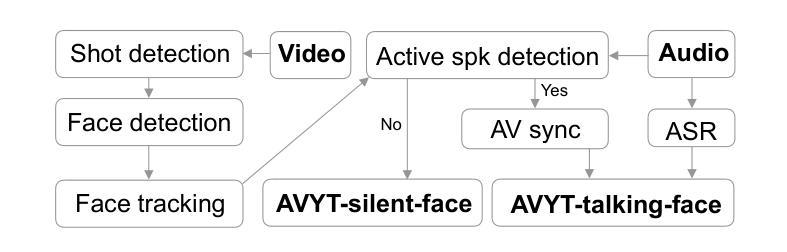
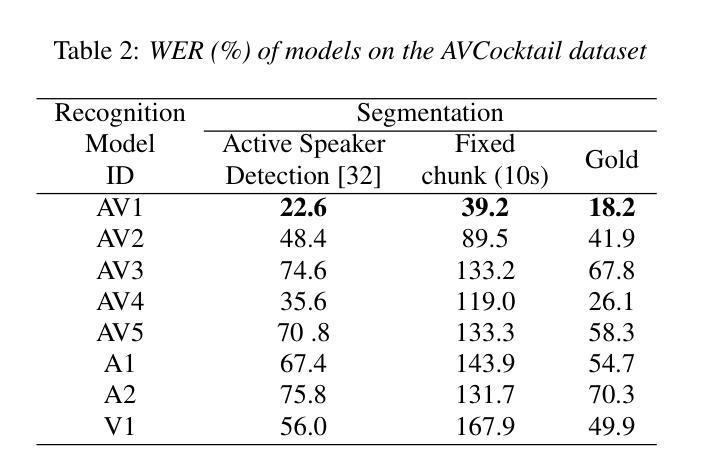
Cocktail-Party Audio-Visual Speech Recognition
Authors:Thai-Binh Nguyen, Ngoc-Quan Pham, Alexander Waibel
Audio-Visual Speech Recognition (AVSR) offers a robust solution for speech recognition in challenging environments, such as cocktail-party scenarios, where relying solely on audio proves insufficient. However, current AVSR models are often optimized for idealized scenarios with consistently active speakers, overlooking the complexities of real-world settings that include both speaking and silent facial segments. This study addresses this gap by introducing a novel audio-visual cocktail-party dataset designed to benchmark current AVSR systems and highlight the limitations of prior approaches in realistic noisy conditions. Additionally, we contribute a 1526-hour AVSR dataset comprising both talking-face and silent-face segments, enabling significant performance gains in cocktail-party environments. Our approach reduces WER by 67% relative to the state-of-the-art, reducing WER from 119% to 39.2% in extreme noise, without relying on explicit segmentation cues.
视听语音识别(AVSR)为在具有挑战性的环境中进行语音识别提供了稳健的解决方案,如在鸡尾酒会场景中,仅凭音频信号是不足够的。然而,当前的AVSR模型大多针对始终活跃发言的理想化场景进行优化,忽略了真实世界中包括说话和无声面部片段的复杂性。本研究通过引入一个新的视听鸡尾酒会数据集来解决这一差距,该数据集旨在评估当前的AVSR系统并突出先前方法在真实嘈杂条件下的局限性。此外,我们贡献了一个包含说话面部和无声面部片段的1526小时AVSR数据集,能够在鸡尾酒会环境中实现显著的性能提升。我们的方法相较于最新技术减少了67%的词错误率(WER),在极端噪声下将WER从119%减少到39.2%,且无需依赖明确的分段线索。
论文及项目相关链接
PDF Accepted at Interspeech 2025
Summary:视听语音识别(AVSR)在挑战环境中如鸡尾酒会场景等提供了稳健的语音识别解决方案,单纯依赖音频无法应对。当前AVSR模型通常针对理想化场景优化,忽略了包含说话和静默面部片段的复杂现实环境。本研究通过引入新颖的视听鸡尾酒会数据集来弥补这一差距,该数据集旨在评估当前AVSR系统并突出其在现实噪声条件下的局限性。此外,包含说话面孔和静默面孔片段的1526小时AVSR数据集能显著提高在鸡尾酒会环境中的性能。相较于最新技术,该方法在极端噪声下将字错误率(WER)降低了67%,从119%降至39.2%,无需依赖明确的分段线索。
Key Takeaways:
- AVSR在挑战环境中如鸡尾酒会场景提供稳健语音识别解决方案。
- 当前AVSR模型主要关注理想化场景,忽略现实环境的复杂性。
- 引入的视听鸡尾酒会数据集旨在评估AVSR系统并突出其在现实噪声条件下的局限性。
- 提出的1526小时AVSR数据集包含说话和静默面部片段,能显著提高在鸡尾酒会环境中的性能。
- 与最新技术相比,该研究在极端噪声条件下显著降低了字错误率(WER)。
- 该方法性能提升不依赖于明确的分段线索。
点此查看论文截图



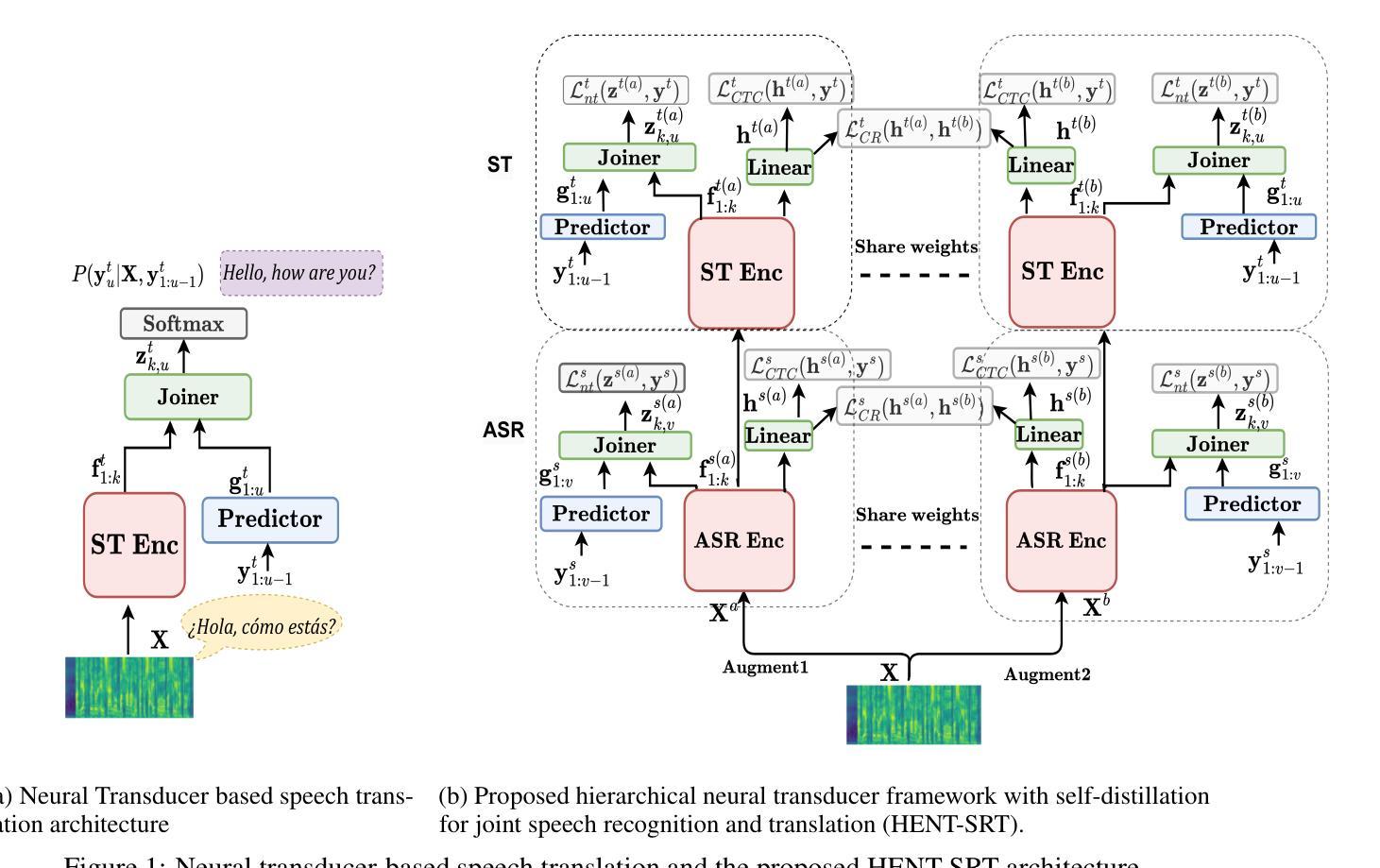
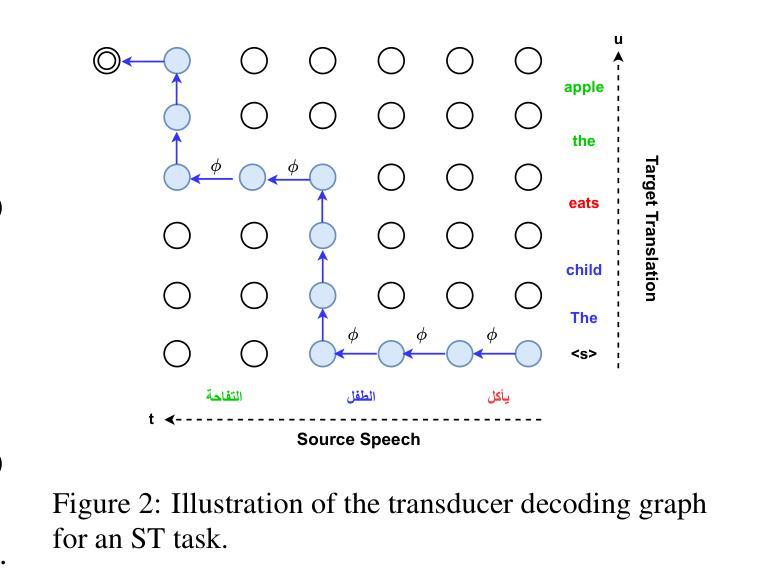
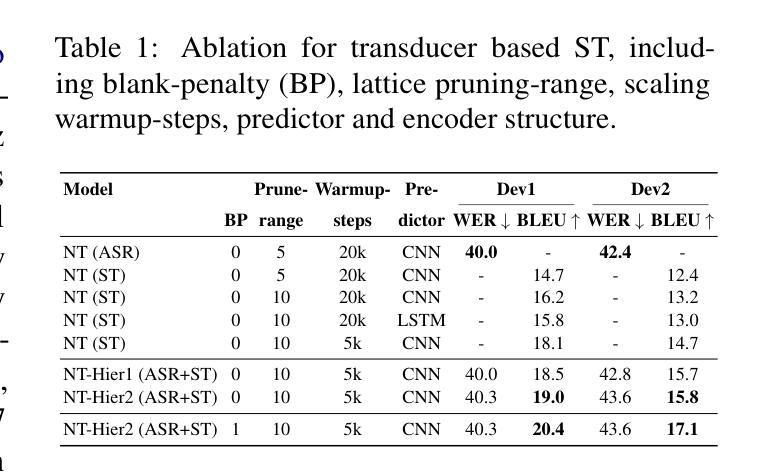
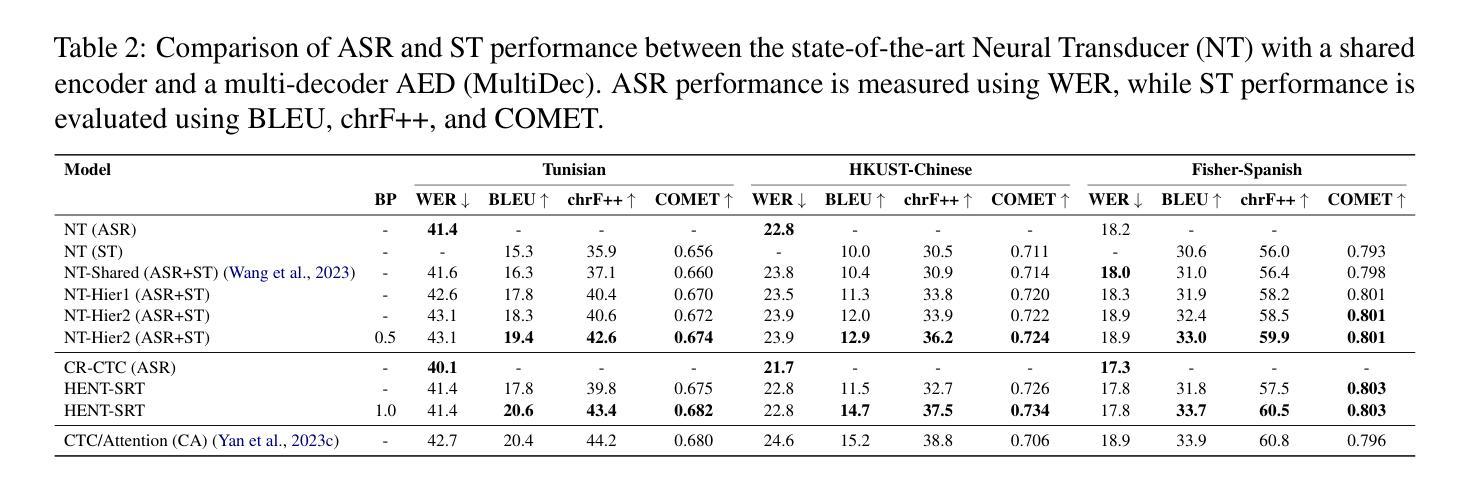
HENT-SRT: Hierarchical Efficient Neural Transducer with Self-Distillation for Joint Speech Recognition and Translation
Authors:Amir Hussein, Cihan Xiao, Matthew Wiesner, Dan Povey, Leibny Paola Garcia, Sanjeev Khudanpur
Neural transducers (NT) provide an effective framework for speech streaming, demonstrating strong performance in automatic speech recognition (ASR). However, the application of NT to speech translation (ST) remains challenging, as existing approaches struggle with word reordering and performance degradation when jointly modeling ASR and ST, resulting in a gap with attention-based encoder-decoder (AED) models. Existing NT-based ST approaches also suffer from high computational training costs. To address these issues, we propose HENT-SRT (Hierarchical Efficient Neural Transducer for Speech Recognition and Translation), a novel framework that factorizes ASR and translation tasks to better handle reordering. To ensure robust ST while preserving ASR performance, we use self-distillation with CTC consistency regularization. Moreover, we improve computational efficiency by incorporating best practices from ASR transducers, including a down-sampled hierarchical encoder, a stateless predictor, and a pruned transducer loss to reduce training complexity. Finally, we introduce a blank penalty during decoding, reducing deletions and improving translation quality. Our approach is evaluated on three conversational datasets Arabic, Spanish, and Mandarin achieving new state-of-the-art performance among NT models and substantially narrowing the gap with AED-based systems.
神经网络转换器(NT)为语音流提供了有效的框架,在自动语音识别(ASR)方面表现出强大的性能。然而,将NT应用于语音翻译(ST)仍然具有挑战性。现有方法在处理联合ASR和ST时的词语重新排序和性能下降问题上遇到了困难,与基于注意力的编码器-解码器(AED)模型之间存在差距。此外,现有的基于NT的ST方法还面临高计算训练成本的问题。为了解决这些问题,我们提出了HENT-SRT(用于语音识别和翻译的分层高效神经网络转换器)这一新型框架,通过分解ASR和翻译任务来更好地处理重新排序问题。为确保在保留ASR性能的同时实现稳健的ST,我们采用带有CTC一致性正则化的自我蒸馏法。而且,我们从ASR转换器中汲取最佳实践,纳入分层编码器下的采样、无状态预测器和修剪的转换器损失,以提高计算效率并降低训练复杂度。最后,我们在解码过程中引入了空白惩罚,减少了删除操作,提高了翻译质量。我们的方法在三组对话数据集(阿拉伯语、西班牙语和普通话)上进行了评估,实现了NT模型中的最新先进性能,并大大缩小了与AED系统的差距。
论文及项目相关链接
Summary
神经网络转换器(NT)在语音识别(ASR)中表现出强大的性能,为语音流提供了有效的框架。然而,将NT应用于语音识别(ST)仍然具有挑战性,现有方法面临单词重新排序和联合建模ASR和ST时的性能下降问题,与基于注意力的编码器-解码器(AED)模型之间存在差距。针对这些问题,我们提出了HENT-SRT(用于语音识别和翻译的分层高效神经网络转换器)这一新型框架,通过分解ASR和翻译任务以更好地处理重新排序问题。为确保在保持ASR性能的同时实现稳健的语音识别,我们采用自我蒸馏和CTC一致性正则化。此外,通过融入ASR转换器的最佳实践,我们提高了计算效率,包括使用下采样分层编码器、无状态预测器和修剪转换器损失以降低训练复杂度。最后,我们在解码过程中引入了空白惩罚,减少了删除并提高了翻译质量。在阿拉伯语、西班牙语和普通话的三组对话数据集上的评估结果表明,我们的方法达到了NT模型的新先进水平,并大幅缩小了与AED系统的差距。
Key Takeaways
- 神经网络转换器(NT)在自动语音识别(ASR)中表现良好,但应用于语音识别(ST)时面临挑战。
- 现有NT模型在联合建模ASR和ST时存在单词重新排序和性能下降问题。
- HENT-SRT框架旨在通过分解ASR和翻译任务来解决这些问题。
- 通过自我蒸馏和CTC一致性正则化确保稳健的ST同时保持ASR性能。
- 引入下采样分层编码器、无状态预测器和修剪转换器损失提高计算效率。
- 在解码过程中引入空白惩罚以减少删除并改善翻译质量。
点此查看论文截图

Enhancing Speech Emotion Recognition with Graph-Based Multimodal Fusion and Prosodic Features for the Speech Emotion Recognition in Naturalistic Conditions Challenge at Interspeech 2025
Authors:Alef Iury Siqueira Ferreira, Lucas Rafael Gris, Alexandre Ferro Filho, Lucas Ólives, Daniel Ribeiro, Luiz Fernando, Fernanda Lustosa, Rodrigo Tanaka, Frederico Santos de Oliveira, Arlindo Galvão Filho
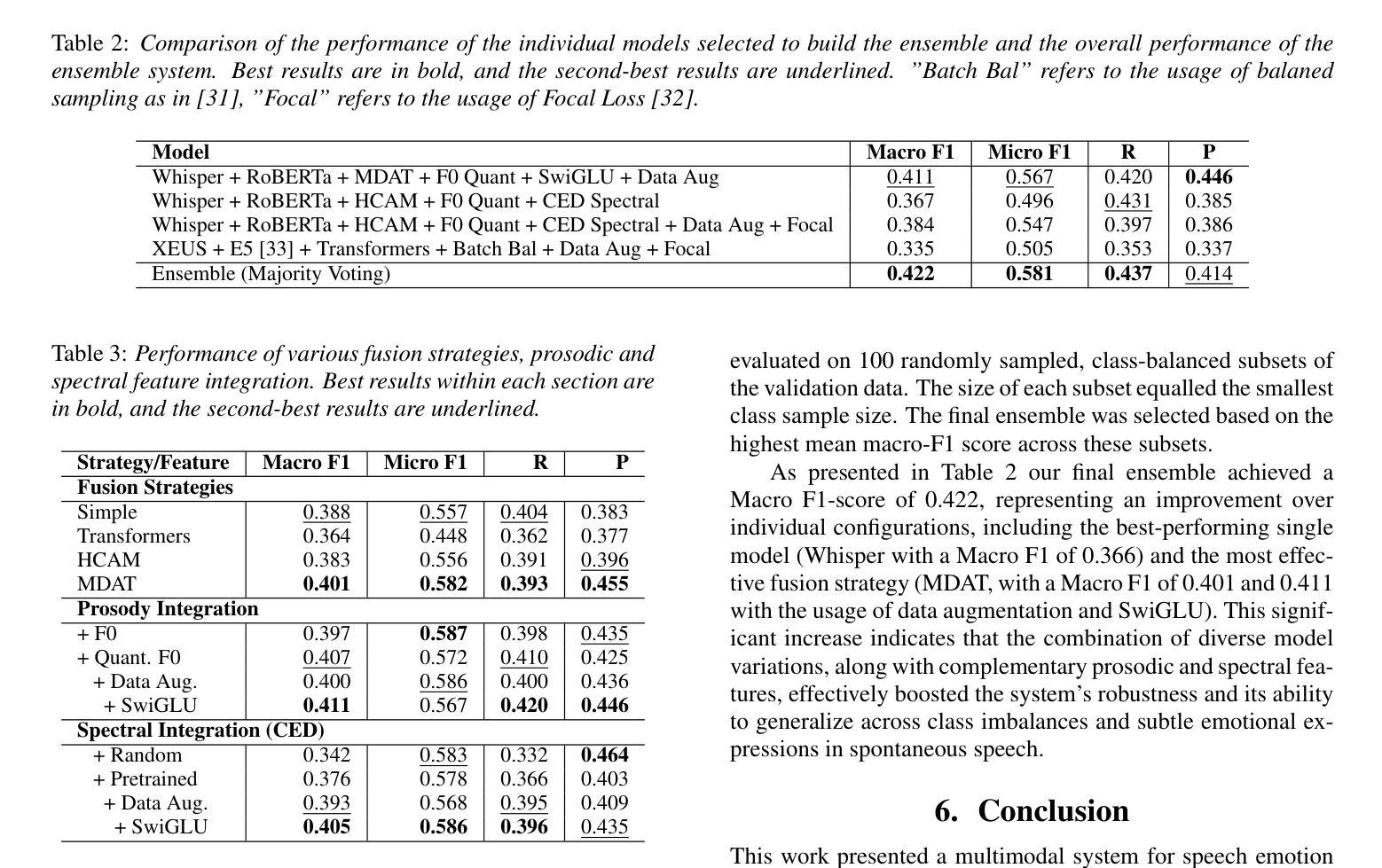
Training SER models in natural, spontaneous speech is especially challenging due to the subtle expression of emotions and the unpredictable nature of real-world audio. In this paper, we present a robust system for the INTERSPEECH 2025 Speech Emotion Recognition in Naturalistic Conditions Challenge, focusing on categorical emotion recognition. Our method combines state-of-the-art audio models with text features enriched by prosodic and spectral cues. In particular, we investigate the effectiveness of Fundamental Frequency (F0) quantization and the use of a pretrained audio tagging model. We also employ an ensemble model to improve robustness. On the official test set, our system achieved a Macro F1-score of 39.79% (42.20% on validation). Our results underscore the potential of these methods, and analysis of fusion techniques confirmed the effectiveness of Graph Attention Networks. Our source code is publicly available.
在自然、自发的语音中训练SER模型尤其具有挑战性,因为情感的表达很细微,而且现实世界的音频具有不可预测性。本文旨在为INTERSPEECH 2025自然条件下语音情感识别挑战提供一套稳健的系统,专注于分类情感识别。我们的方法结合了最先进的音频模型与文本特征,这些文本特征由韵律和光谱线索丰富。我们特别研究了基频(F0)量化的有效性以及使用预训练的音频标记模型。我们还采用集成模型来提高稳健性。在官方测试集上,我们的系统达到了39.79%的宏观F1分数(验证集上为42.20%)。我们的结果突出了这些方法的潜力,融合技术的分析证实了图注意力网络的有效性。我们的源代码已公开可用。
论文及项目相关链接
Summary
针对自然、自发语音中的情感识别,训练SER模型具有挑战性。本文提出一种稳健系统,结合最新音频模型与文本特征,通过音高和频谱线索增强识别能力。研究重点放在基本频率量化的有效性上,并使用预训练的音频标签模型。通过集成模型提高稳健性,在官方测试集上达到39.79%的宏观F1分数。
Key Takeaways
- 训练SER模型在自然、自发语音中的情感识别具有挑战性。
- 提出一种结合最新音频模型和文本特征的稳健系统。
- 通过音高和频谱线索增强识别能力。
- 研究重点放在基本频率量化的有效性上。
- 使用预训练的音频标签模型提高性能。
- 集成模型用于提高稳健性。
点此查看论文截图

Enhancing GOP in CTC-Based Mispronunciation Detection with Phonological Knowledge
Authors:Aditya Kamlesh Parikh, Cristian Tejedor-Garcia, Catia Cucchiarini, Helmer Strik
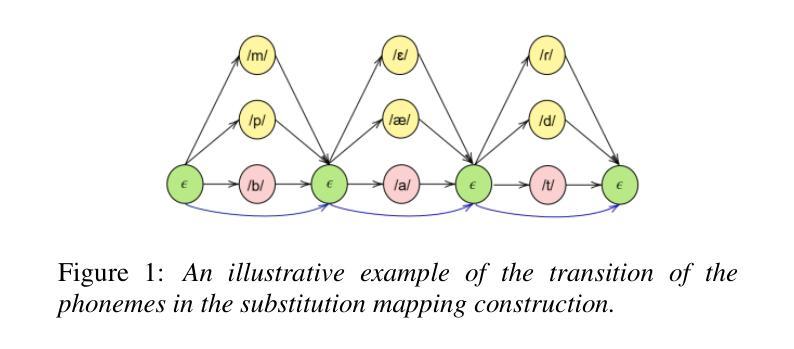
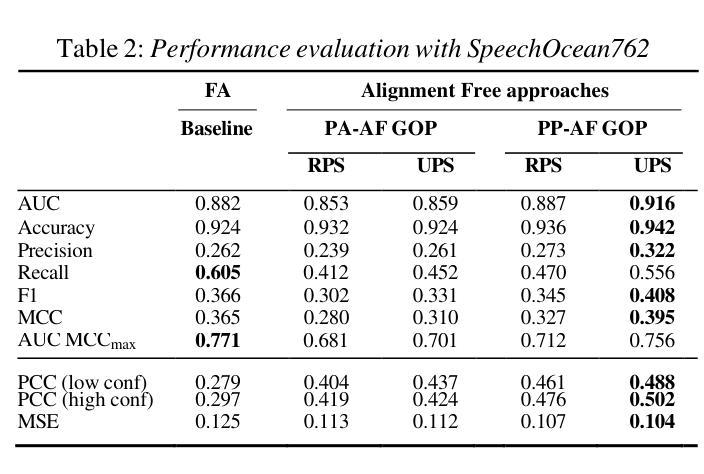
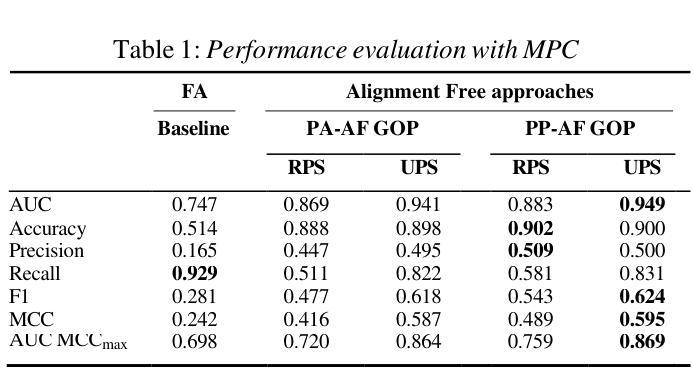
Computer-Assisted Pronunciation Training (CAPT) systems employ automatic measures of pronunciation quality, such as the goodness of pronunciation (GOP) metric. GOP relies on forced alignments, which are prone to labeling and segmentation errors due to acoustic variability. While alignment-free methods address these challenges, they are computationally expensive and scale poorly with phoneme sequence length and inventory size. To enhance efficiency, we introduce a substitution-aware alignment-free GOP that restricts phoneme substitutions based on phoneme clusters and common learner errors. We evaluated our GOP on two L2 English speech datasets, one with child speech, My Pronunciation Coach (MPC), and SpeechOcean762, which includes child and adult speech. We compared RPS (restricted phoneme substitutions) and UPS (unrestricted phoneme substitutions) setups within alignment-free methods, which outperformed the baseline. We discuss our results and outline avenues for future research.
计算机辅助发音训练(CAPT)系统采用发音质量自动测量法,如发音质量(GOP)指标。GOP依赖于强制对齐,由于声学变化,它容易产生标签和分段错误。虽然无对齐方法可以解决这些挑战,但它们计算量大,随着音素序列长度和库存规模的扩大,表现不佳。为了提高效率,我们引入了一种基于音素聚类和常见学习者错误的替代感知无对齐GOP,该GOP限制了音素替代。我们在两个英语二级语音数据集上评估了我们的GOP,一个是儿童语音数据集My Pronunciation Coach(MPC),另一个是包含儿童和成人语音的SpeechOcean762数据集。我们在无对齐方法中比较了限制音素替代(RPS)和非限制音素替代(UPS)的设置,它们的表现都超过了基线水平。我们讨论了我们的结果并概述了未来研究的方向。
论文及项目相关链接
PDF Accepted to Interspeech 2025. This publication is part of the project Responsible AI for Voice Diagnostics (RAIVD) with file number NGF.1607.22.013 of the research programme NGF AiNed Fellowship Grants which is financed by the Dutch Research Council (NWO)
Summary
本文介绍了计算机辅助发音训练(CAPT)系统采用基于强制对齐的发音质量评估方法,如发音质量(GOP)指标。但由于声学变化导致的标签和分段误差,强制对齐方法存在局限性。研究团队引入了一种基于替代的无对齐GOP方法,通过基于音素集群和常见学习者错误限制音素替代来提高效率。该方法在包含儿童语音的My Pronunciation Coach数据集和包含儿童和成人语音的SpeechOcean762数据集上进行了评估,显示具有限制音素替代(RPS)的方法优于无限制音素替代(UPS)的方法。
Key Takeaways
- 计算机辅助发音训练系统使用自动发音质量评估方法,如基于强制对齐的发音质量(GOP)指标。
- 强制对齐方法存在声学变化引起的标签和分段误差问题。
- 无对齐的GOP方法引入了一种基于替代的策略,通过限制音素替代来提高效率。这种策略基于音素集群和常见学习者错误。
- 研究在My Pronunciation Coach和SpeechOcean762数据集上评估了该方法。
- 限制音素替代的方法在评估中表现优于无限制的方法。
- 该研究的结果对于改进计算机辅助发音训练系统的性能具有积极意义。
点此查看论文截图

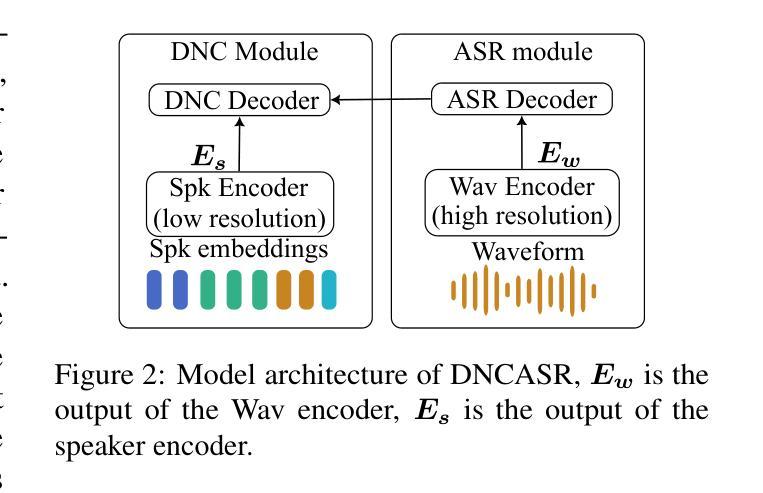
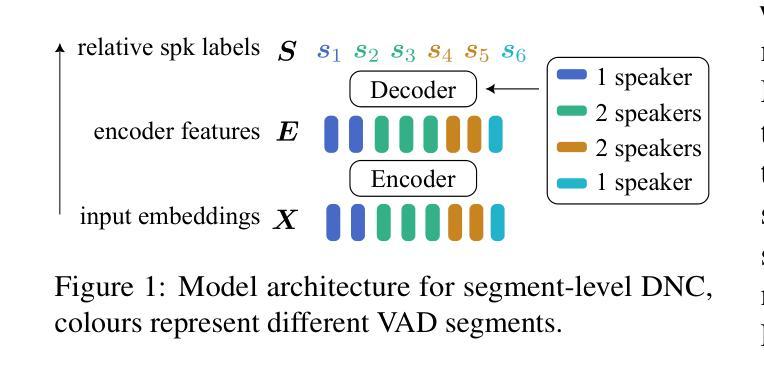
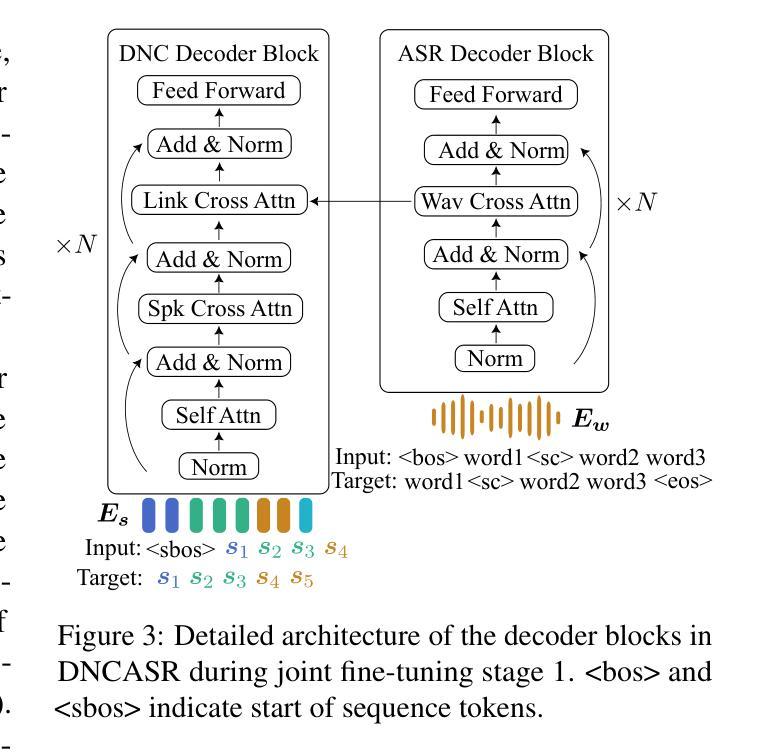
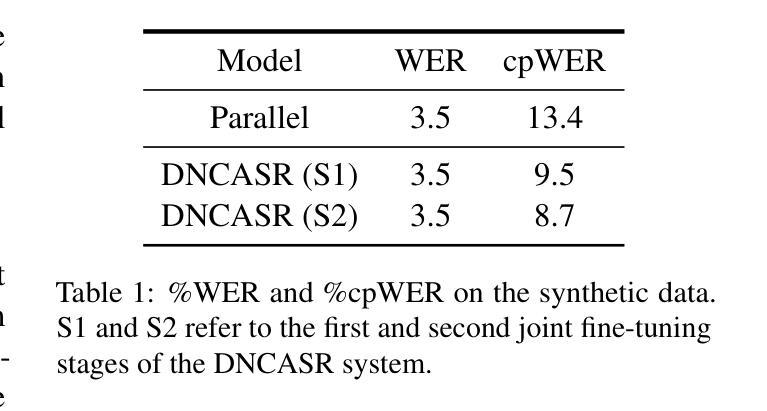
DNCASR: End-to-End Training for Speaker-Attributed ASR
Authors:Xianrui Zheng, Chao Zhang, Philip C. Woodland
This paper introduces DNCASR, a novel end-to-end trainable system designed for joint neural speaker clustering and automatic speech recognition (ASR), enabling speaker-attributed transcription of long multi-party meetings. DNCASR uses two separate encoders to independently encode global speaker characteristics and local waveform information, along with two linked decoders to generate speaker-attributed transcriptions. The use of linked decoders allows the entire system to be jointly trained under a unified loss function. By employing a serialised training approach, DNCASR effectively addresses overlapping speech in real-world meetings, where the link improves the prediction of speaker indices in overlapping segments. Experiments on the AMI-MDM meeting corpus demonstrate that the jointly trained DNCASR outperforms a parallel system that does not have links between the speaker and ASR decoders. Using cpWER to measure the speaker-attributed word error rate, DNCASR achieves a 9.0% relative reduction on the AMI-MDM Eval set.
本文介绍了DNCASR,这是一种新型端到端可训练系统,旨在实现联合神经网络说话人聚类和自动语音识别(ASR),从而实现长多方会议的说话人属性转录。DNCASR使用两个独立的编码器分别编码全局说话人特性和局部波形信息,以及两个链接的解码器生成说话人属性转录。使用链接的解码器可以使整个系统在统一的损失函数下进行联合训练。通过采用序列化训练方法,DNCASR有效地解决了现实会议中的重叠语音问题,其中链接改善了重叠段落中说话人指数的预测。在AMI-MDM会议语料库上的实验表明,联合训练的DNCASR优于没有说话人和ASR解码器之间链接的并行系统。使用cpWER来衡量说话人属性词错误率,DNCASR在AMI-MDM评估集上实现了9.0%的相对降低。
论文及项目相关链接
PDF Accepted by ACL 2025 Main Conference
Summary:
本文介绍了一种名为DNCASR的新型端到端训练系统,它联合进行神经说话人聚类与自动语音识别(ASR),可实现长多方会议的说话人属性转录。DNCASR采用两个独立编码器分别编码全局说话人特性和局部波形信息,以及两个关联解码器生成说话人属性转录。通过采用序列化训练方式,DNCASR有效解决了现实会议中的重叠语音问题,关联解码器改善了重叠段中说话人索引的预测。在AMI-MDM会议语料库上的实验表明,联合训练的DNCASR优于没有关联解码器的并行系统。使用cpWER衡量说话人属性词错误率,DNCASR在AMI-MDM评估集上实现了相对9.0%的降低。
Key Takeaways:
- DNCASR是一个联合神经说话人聚类与自动语音识别的端到端训练系统。
- 它采用两个编码器来处理全局说话人特性和局部波形信息。
- DNCASR使用两个关联解码器来生成说话人属性转录。
- 序列化训练方式使DNCASR能够处理现实会议中的重叠语音。
- 关联解码器改善了重叠语音段中说话人索引的预测。
- 实验结果表明,DNCASR在AMI-MDM会议语料库上的性能优于未关联解码器的并行系统。
点此查看论文截图

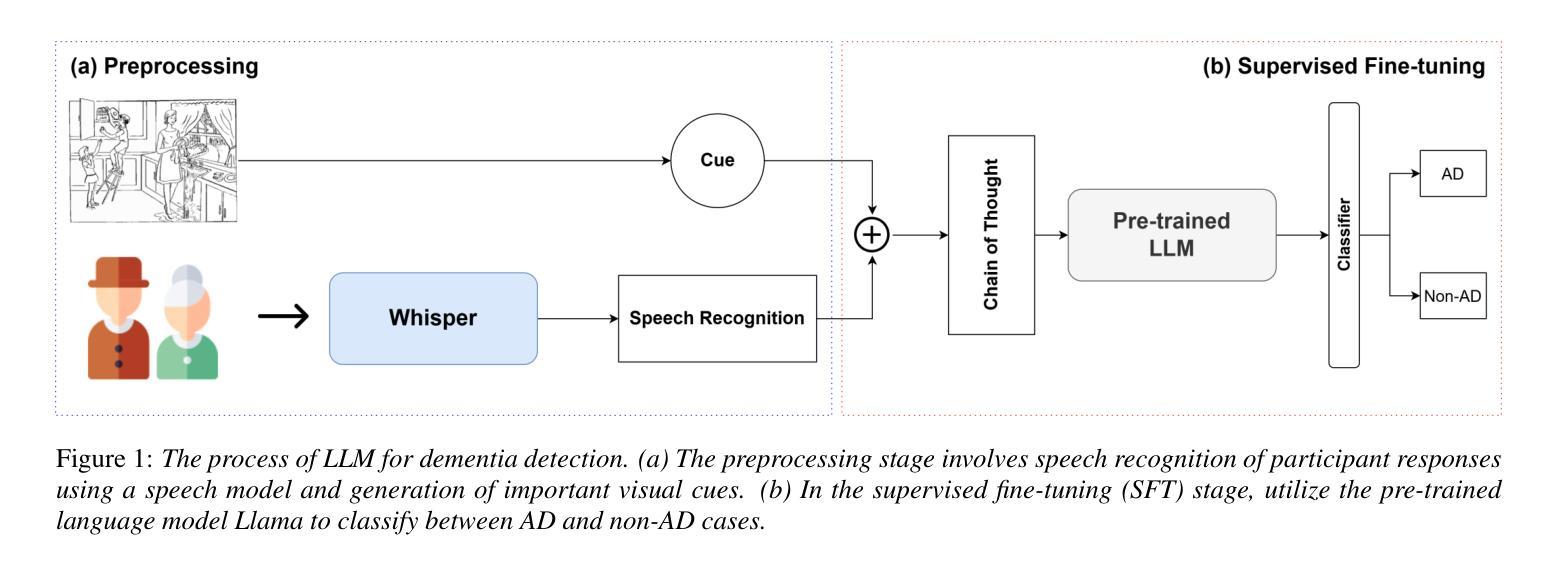
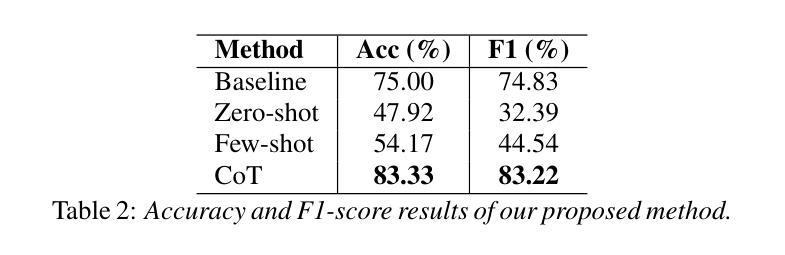
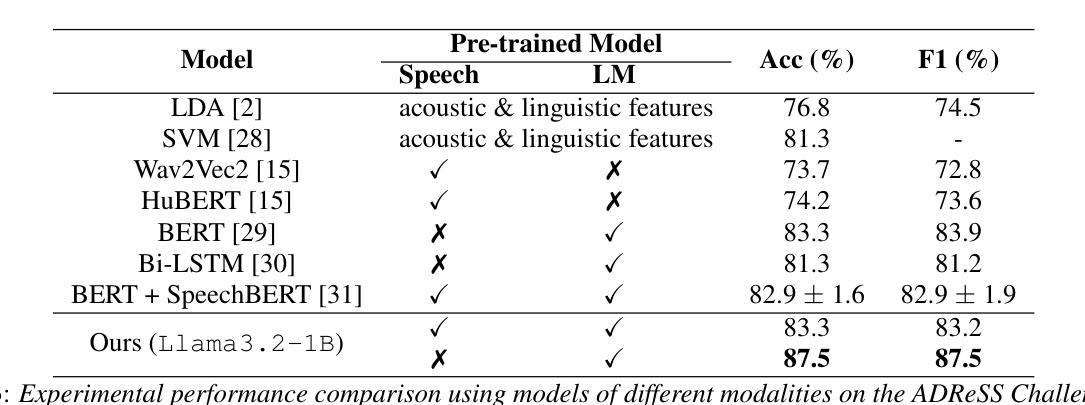
Reasoning-Based Approach with Chain-of-Thought for Alzheimer’s Detection Using Speech and Large Language Models
Authors:Chanwoo Park, Anna Seo Gyeong Choi, Sunghye Cho, Chanwoo Kim
Societies worldwide are rapidly entering a super-aged era, making elderly health a pressing concern. The aging population is increasing the burden on national economies and households. Dementia cases are rising significantly with this demographic shift. Recent research using voice-based models and large language models (LLM) offers new possibilities for dementia diagnosis and treatment. Our Chain-of-Thought (CoT) reasoning method combines speech and language models. The process starts with automatic speech recognition to convert speech to text. We add a linear layer to an LLM for Alzheimer’s disease (AD) and non-AD classification, using supervised fine-tuning (SFT) with CoT reasoning and cues. This approach showed an 16.7% relative performance improvement compared to methods without CoT prompt reasoning. To the best of our knowledge, our proposed method achieved state-of-the-art performance in CoT approaches.
全球社会正迅速进入超老龄化时代,老年健康成为迫切需要关注的问题。人口老龄化增加了国家经济和家庭负担。随着人口结构的变化,痴呆症病例数量显著增加。最近利用基于语音的模型和大语言模型(LLM)进行的研究为痴呆症的诊断和治疗提供了新的可能性。我们的思维链(CoT)推理方法结合了语音和语言模型。流程从自动语音识别开始,将语音转换为文本。我们在针对阿尔茨海默病(AD)和非AD分类的大语言模型上增加了一层线性层,利用带有思维链推理和线索的监督微调(SFT)技术。相比没有思维链提示推理的方法,我们的方法显示出相对性能提高了16.7%。据我们所知,我们提出的方法在思维链方法中取得了最先进的性能表现。
论文及项目相关链接
PDF Accepted to INTERSPEECH 2025
Summary
全球社会迅速进入超老龄化时代,老年健康问题成为紧迫关注点。人口老龄化为国家经济和家庭带来负担,痴呆症患者数量随人口结构变化而显著增加。最新研究利用基于语音的模型与大型语言模型(LLM),为痴呆症的诊断和治疗提供新可能。本研究采用Chain-of-Thought(CoT)推理方法结合语音和语言模型,通过自动语音识别将语音转为文字,再对阿尔茨海默病(AD)与非AD进行分类。相较于不使用CoT提示推理的方法,此方式相对性能提升16.7%。据我们所知,该方法在CoT方法中达到最佳性能。
Key Takeaways
- 社会老龄化趋势加剧,老年健康问题变得尤为重要。
- 人口老龄化给国家经济和家庭带来负担。
- 痴呆症患者数量随社会老龄化而增加。
- 结合语音和语言模型的Chain-of-Thought(CoT)推理方法提供新的痴呆症诊断与治疗可能性。
- 通过自动语音识别将语音转换为文字是此方法的起始步骤。
- 该方法相较于传统方式在性能上有显著提升。
点此查看论文截图


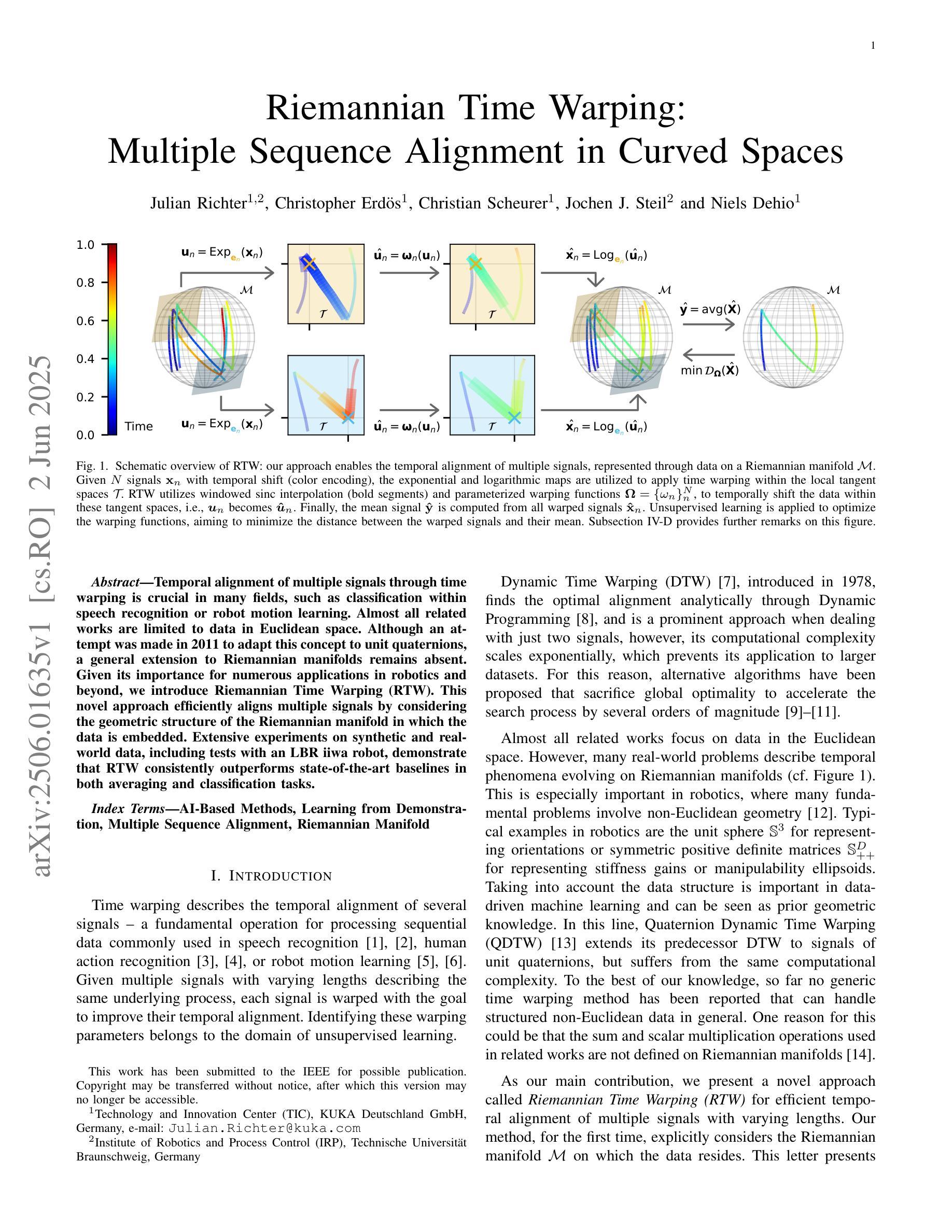
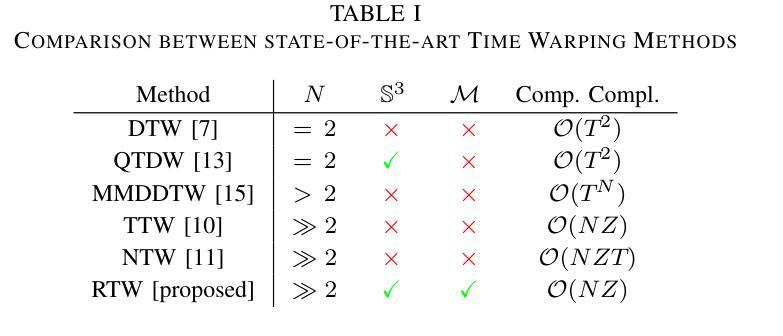
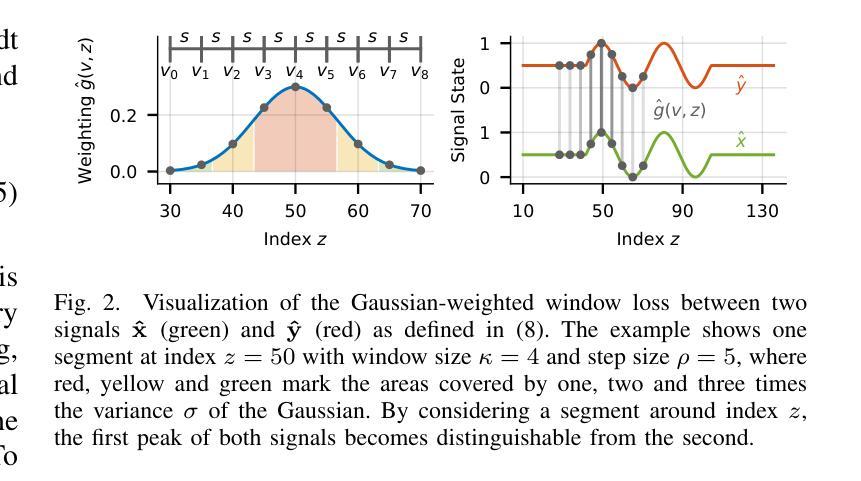
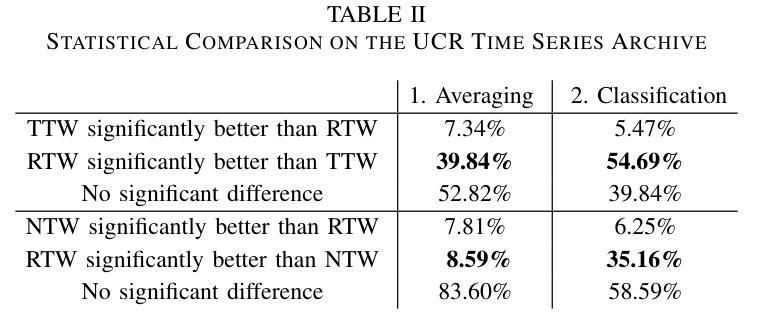
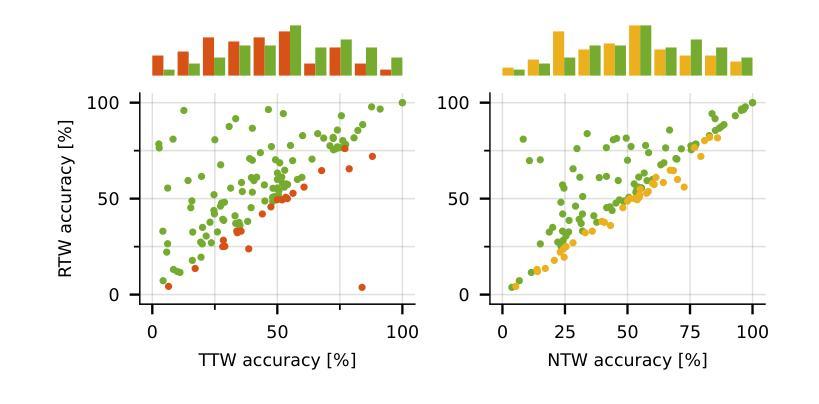
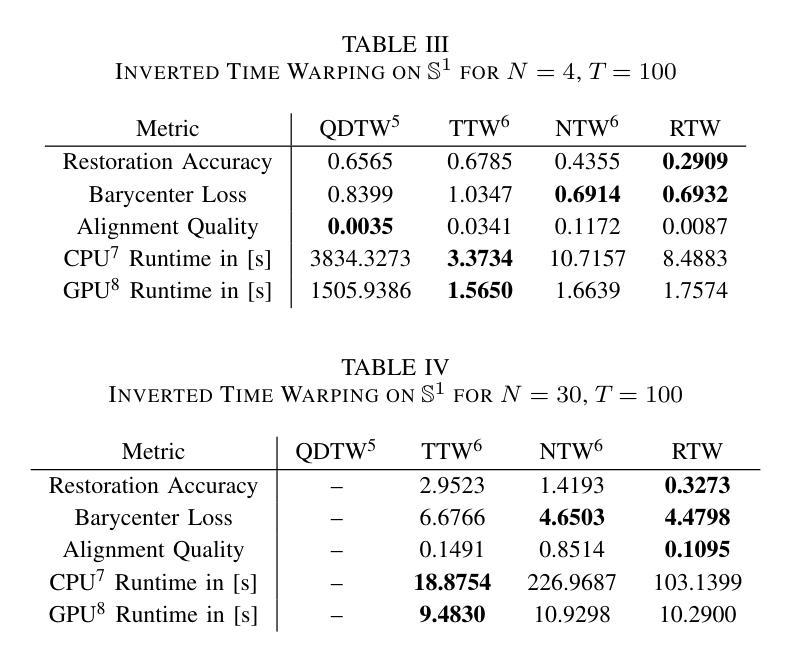
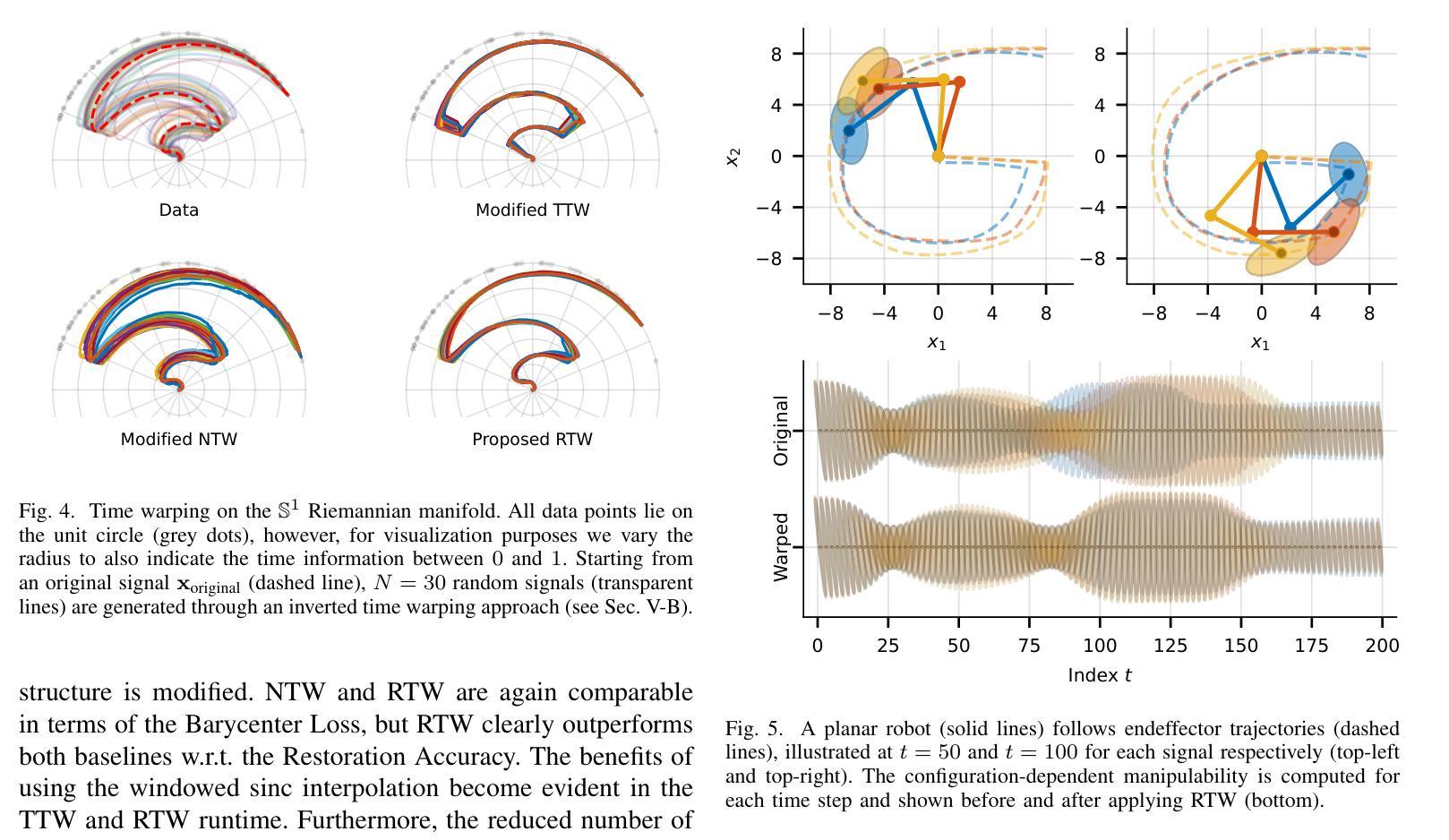
Riemannian Time Warping: Multiple Sequence Alignment in Curved Spaces
Authors:Julian Richter, Christopher Erdös, Christian Scheurer, Jochen J. Steil, Niels Dehio
Temporal alignment of multiple signals through time warping is crucial in many fields, such as classification within speech recognition or robot motion learning. Almost all related works are limited to data in Euclidean space. Although an attempt was made in 2011 to adapt this concept to unit quaternions, a general extension to Riemannian manifolds remains absent. Given its importance for numerous applications in robotics and beyond, we introduce Riemannian Time Warping~(RTW). This novel approach efficiently aligns multiple signals by considering the geometric structure of the Riemannian manifold in which the data is embedded. Extensive experiments on synthetic and real-world data, including tests with an LBR iiwa robot, demonstrate that RTW consistently outperforms state-of-the-art baselines in both averaging and classification tasks.
时空转换中对多个信号的时间对齐在许多领域都至关重要,如在语音识别或机器人运动学习中的分类。几乎所有相关工作都局限于欧几里得空间内的数据。尽管在2011年有人试图将此概念适应到单位四元数上,但对其扩展到黎曼流形的一般方法仍然缺失。考虑到其在机器人技术等多个领域的重要性,我们引入了黎曼时间扭曲(RTW)。这种方法通过考虑数据嵌入的黎曼流形的几何结构,有效地对齐多个信号。在合成数据和真实世界数据上的大量实验,包括对LBR iiwa机器人的测试,都证明了无论是在平均任务还是分类任务中,RTW都始终优于最新前沿基线。
论文及项目相关链接
Summary
本文介绍了Riemannian时间弯曲(RTW)这一新方法,该方法考虑了数据嵌入的Riemannian流形几何结构,实现了多个信号的有效对齐。实验证明,该方法在合成数据和真实世界数据上均表现优异,特别是在机器人应用上,如LBR iiwa机器人测试,其在平均和分类任务上均优于现有技术。
Key Takeaways
- 时间弯曲在多个领域如语音识别或机器人运动学习中非常重要。
- 现有大部分相关工作仅限于欧几里得空间内的数据。
- 虽然已有尝试将时间弯曲概念适应于单位四元数,但其在黎曼流形上的通用扩展仍然缺失。
- 引入Riemannian时间弯曲(RTW)方法,考虑数据嵌入的黎曼流形的几何结构,实现多个信号的有效对齐。
- 实验证明,RTW在合成和真实世界数据上的表现均优于现有技术。
- RTW在机器人应用上具有广泛的应用前景。
点此查看论文截图

Unsupervised Rhythm and Voice Conversion to Improve ASR on Dysarthric Speech
Authors:Karl El Hajal, Enno Hermann, Sevada Hovsepyan, Mathew Magimai. -Doss
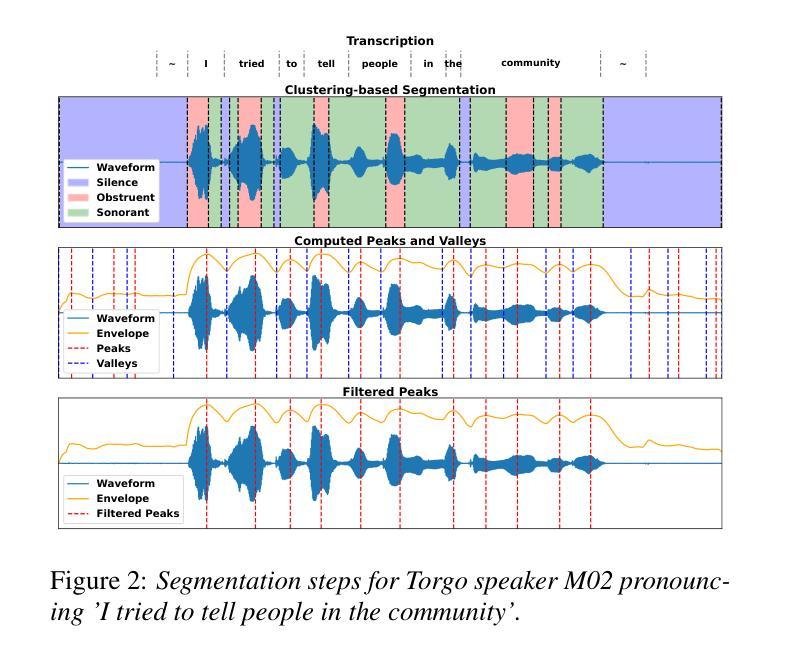
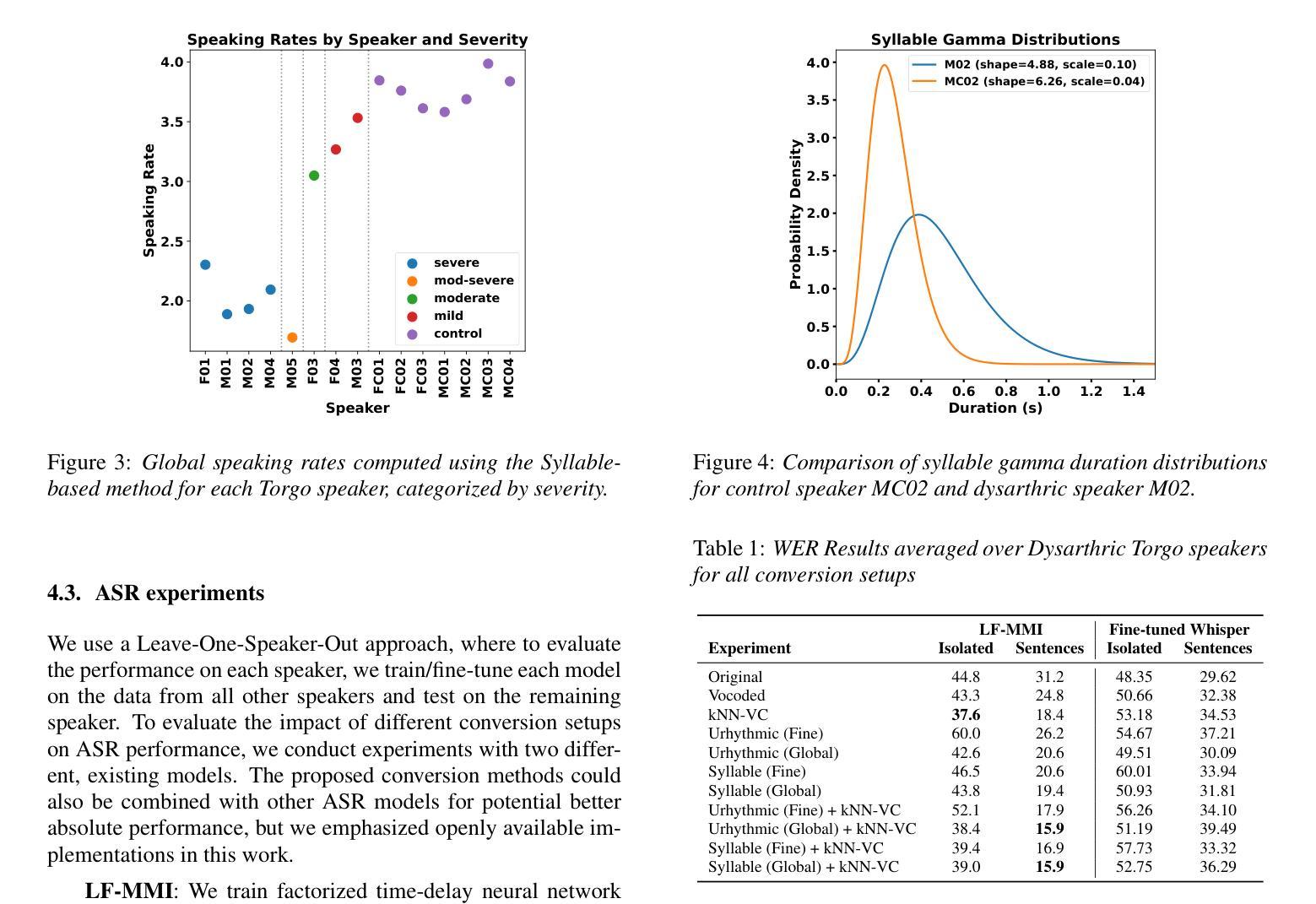
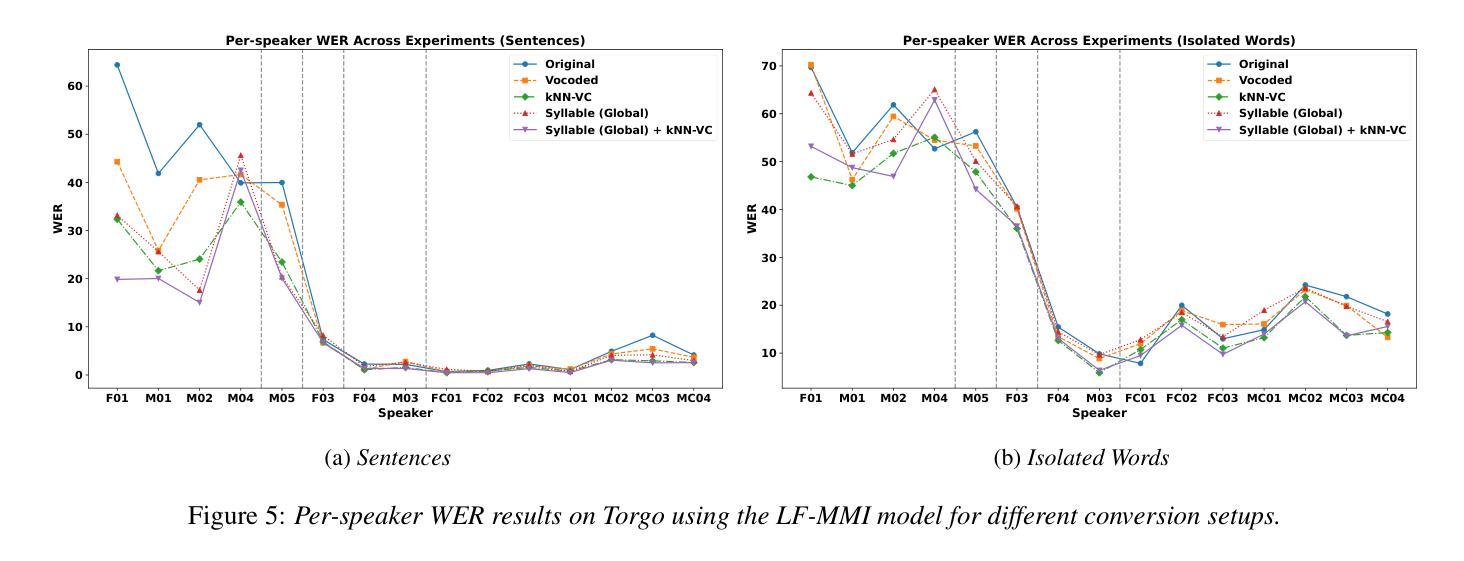
Automatic speech recognition (ASR) systems struggle with dysarthric speech due to high inter-speaker variability and slow speaking rates. To address this, we explore dysarthric-to-healthy speech conversion for improved ASR performance. Our approach extends the Rhythm and Voice (RnV) conversion framework by introducing a syllable-based rhythm modeling method suited for dysarthric speech. We assess its impact on ASR by training LF-MMI models and fine-tuning Whisper on converted speech. Experiments on the Torgo corpus reveal that LF-MMI achieves significant word error rate reductions, especially for more severe cases of dysarthria, while fine-tuning Whisper on converted data has minimal effect on its performance. These results highlight the potential of unsupervised rhythm and voice conversion for dysarthric ASR. Code available at: https://github.com/idiap/RnV
自动语音识别(ASR)系统因说话者之间的高度差异性以及语速过慢,在处理口齿不清的语音时面临困难。为了解决这一问题,我们探索了口齿不清到正常语音的转换,以提高ASR系统的性能。我们的方法扩展了节奏和声音(RnV)转换框架,通过引入基于音节的节奏建模方法,该方法适用于口齿不清的语音。我们通过训练LF-MMI模型和微调whisper模型来评估其对ASR的影响。在Torgo语料库上的实验表明,LF-MMI实现了显著的单词错误率降低,特别是在口齿不清较为严重的情况下,而在转换数据上微调whisper对其性能影响甚微。这些结果突出了无监督的节奏和声音转换在口齿不清的ASR中的潜力。代码可从 https://github.com/idiap/RnV 获得。
论文及项目相关链接
PDF Accepted at Interspeech 2025
Summary
本文探索了针对发音困难人士的语音转换技术,以提高自动语音识别(ASR)系统的性能。该研究扩展了节奏和声音(RnV)转换框架,引入了适合发音困难人士的基于音节的节奏建模方法。通过训练LF-MMI模型和微调whisper语音转换技术来评估其效果,发现该方法显著降低了误词率,尤其是在处理更为严重的发音障碍时效果显著。该研究突显了无监督的节奏和声音转换技术在改善发音障碍人士ASR系统中的潜力。代码可于相关GitHub链接找到。
Key Takeaways
- 研究针对发音困难人士的语音转换技术,以提高自动语音识别(ASR)系统的性能。
- 扩展了现有的节奏和声音(RnV)转换框架,以适用于发音困难人士的语音特征。
- 通过引入基于音节的节奏建模方法,适应发音困难人士的语音特点。
- 通过训练LF-MMI模型评估其对ASR系统的影响,发现显著降低了误词率。
- 即使在处理更为严重的发音障碍时,该方法的性能提升尤为明显。
- 研究发现微调whisper语音转换技术对改善ASR性能具有有限影响。
点此查看论文截图

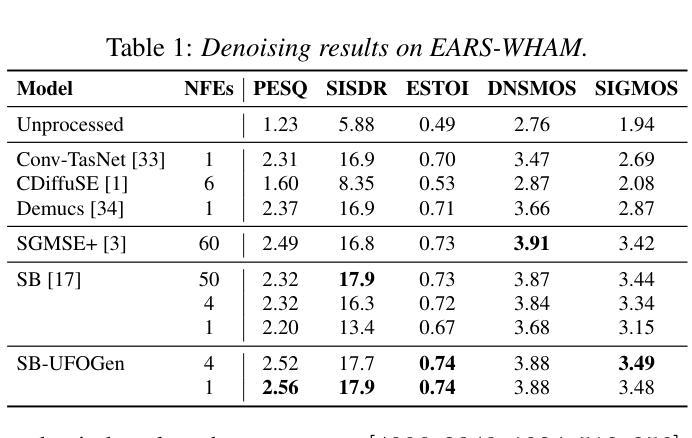
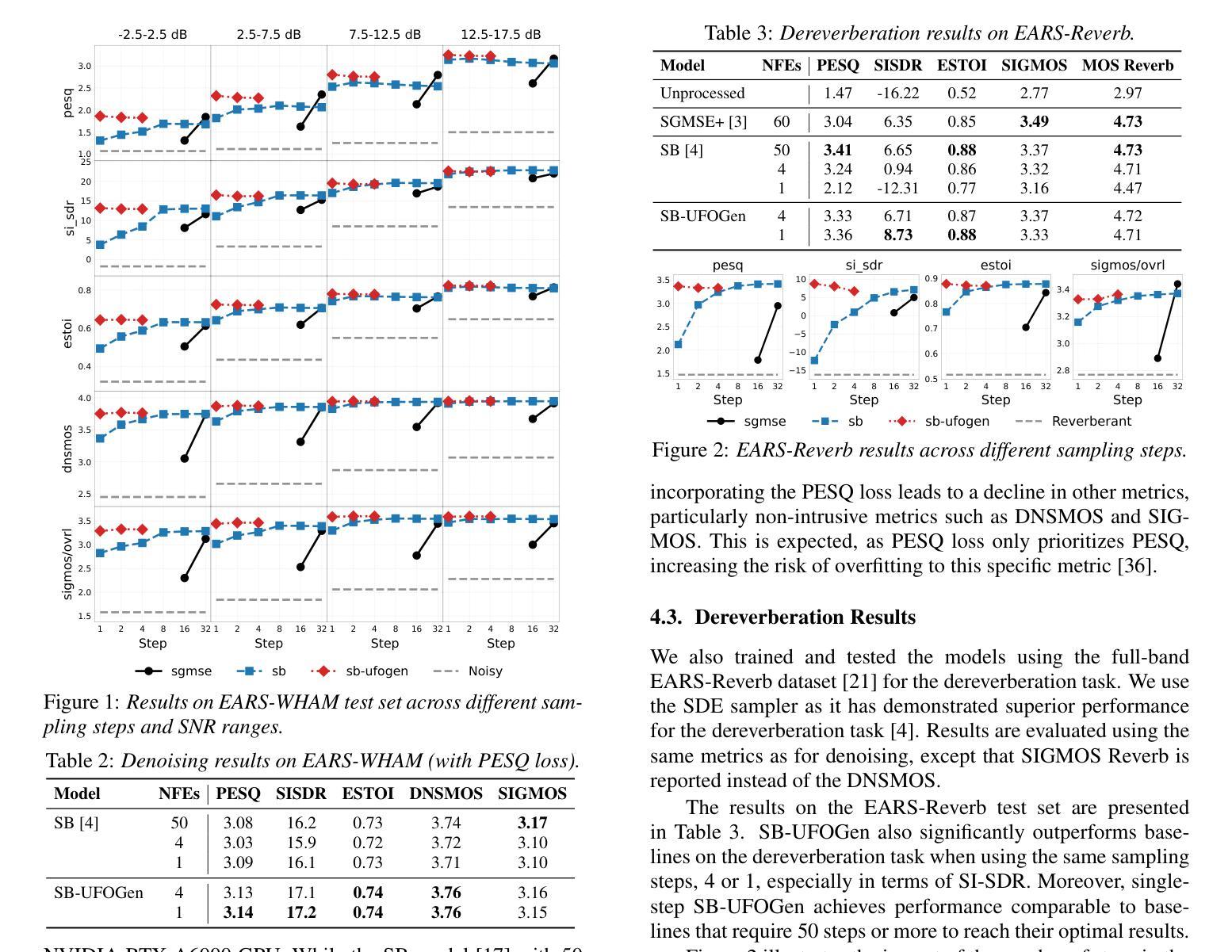
Few-step Adversarial Schrödinger Bridge for Generative Speech Enhancement
Authors:Seungu Han, Sungho Lee, Juheon Lee, Kyogu Lee
Deep generative models have recently been employed for speech enhancement to generate perceptually valid clean speech on large-scale datasets. Several diffusion models have been proposed, and more recently, a tractable Schr"odinger Bridge has been introduced to transport between the clean and noisy speech distributions. However, these models often suffer from an iterative reverse process and require a large number of sampling steps – more than 50. Our investigation reveals that the performance of baseline models significantly degrades when the number of sampling steps is reduced, particularly under low-SNR conditions. We propose integrating Schr"odinger Bridge with GANs to effectively mitigate this issue, achieving high-quality outputs on full-band datasets while substantially reducing the required sampling steps. Experimental results demonstrate that our proposed model outperforms existing baselines, even with a single inference step, in both denoising and dereverberation tasks.
深度生成模型最近被用于语音增强,以在大规模数据集上生成感知有效的干净语音。已经提出了几种扩散模型,最近还介绍了一种易处理的薛定谔桥(Schrödinger Bridge),用于在干净语音和带噪语音分布之间进行传输。然而,这些模型通常存在一个迭代反向过程,需要大量采样步骤——超过50步。我们的调查发现,当减少采样步骤数量时,基线模型的性能会显著下降,特别是在低信噪比条件下。我们提出将薛定谔桥与生成对抗网络(GANs)相结合,以有效缓解这一问题,在全频带数据集上实现高质量输出,同时大大减少所需的采样步骤。实验结果表明,即使在单个推理步骤中,我们提出的模型在降噪和去混响任务中都优于现有基线。
论文及项目相关链接
PDF Accepted to Interspeech 2025
Summary
本文探讨了深度生成模型在语音增强中的应用,介绍了使用Schrödinger Bridge与GANs结合的方法,以提高模型性能并减少采样步骤。实验结果表明,该方法在降噪和去混响任务中均优于现有基线模型,即使在单个推理步骤下也能实现高质量输出。
Key Takeaways
- 深度生成模型被用于语音增强,生成感知上有效的干净语音。
- 存在迭代反向过程的问题,需要大量采样步骤。
- 在减少采样步骤时,基线模型的性能会显著下降。
- 介绍了Schrödinger Bridge与GANs的结合使用。
- 该方法能够在全带宽数据集上实现高质量输出。
- 实验结果表明,所提出模型在降噪和去混响任务中均优于现有基线模型。
点此查看论文截图