⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-05 更新
Controllable Text-to-Speech Synthesis with Masked-Autoencoded Style-Rich Representation
Authors:Yongqi Wang, Chunlei Zhang, Hangting Chen, Zhou Zhao, Dong Yu
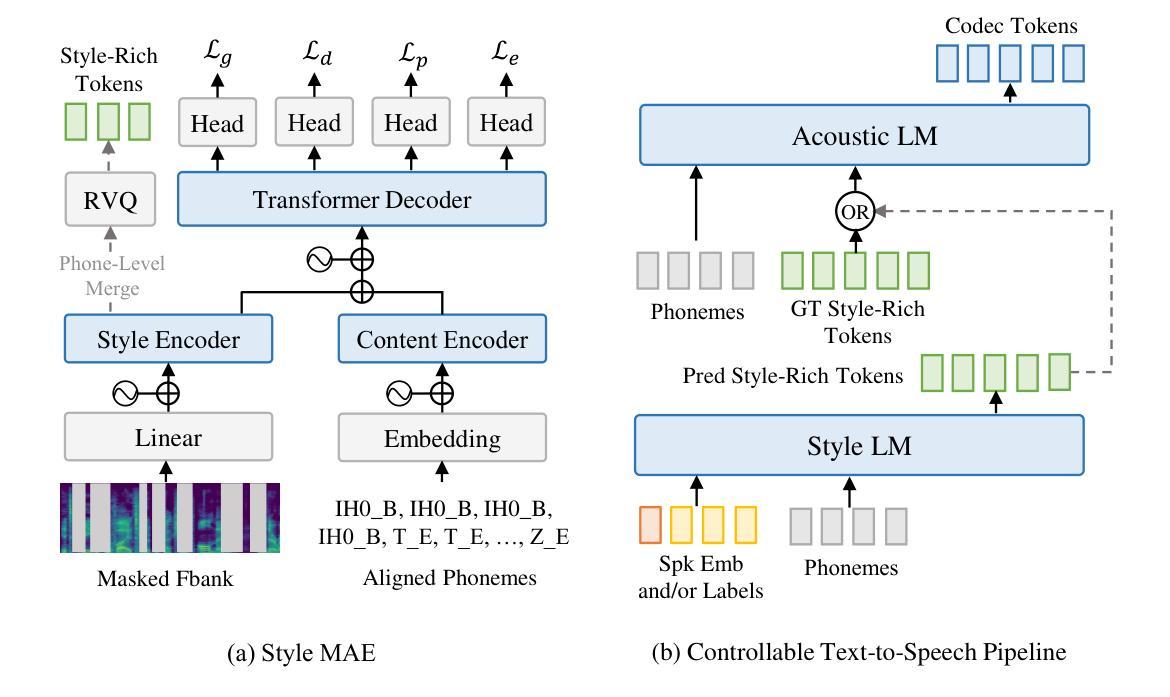
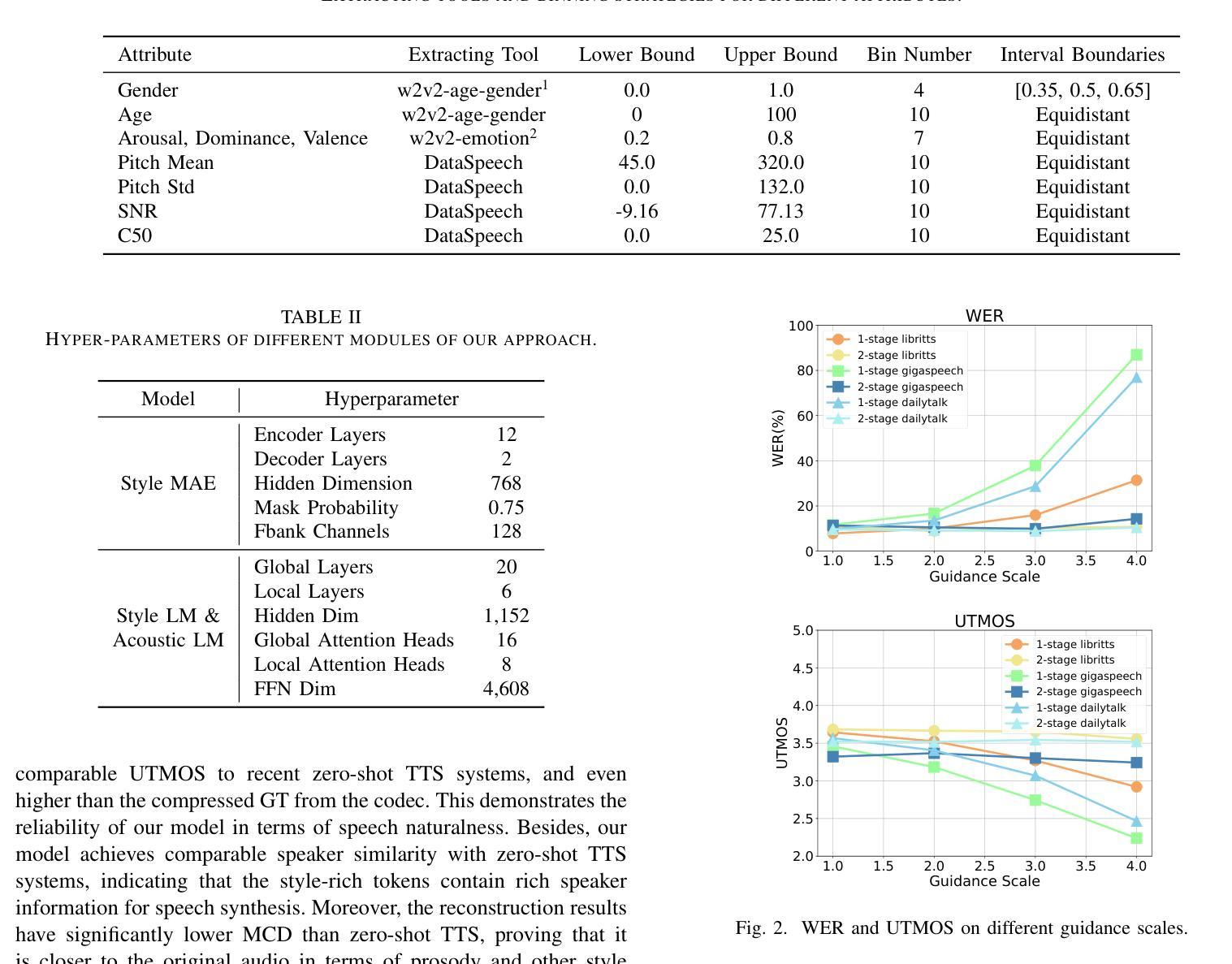
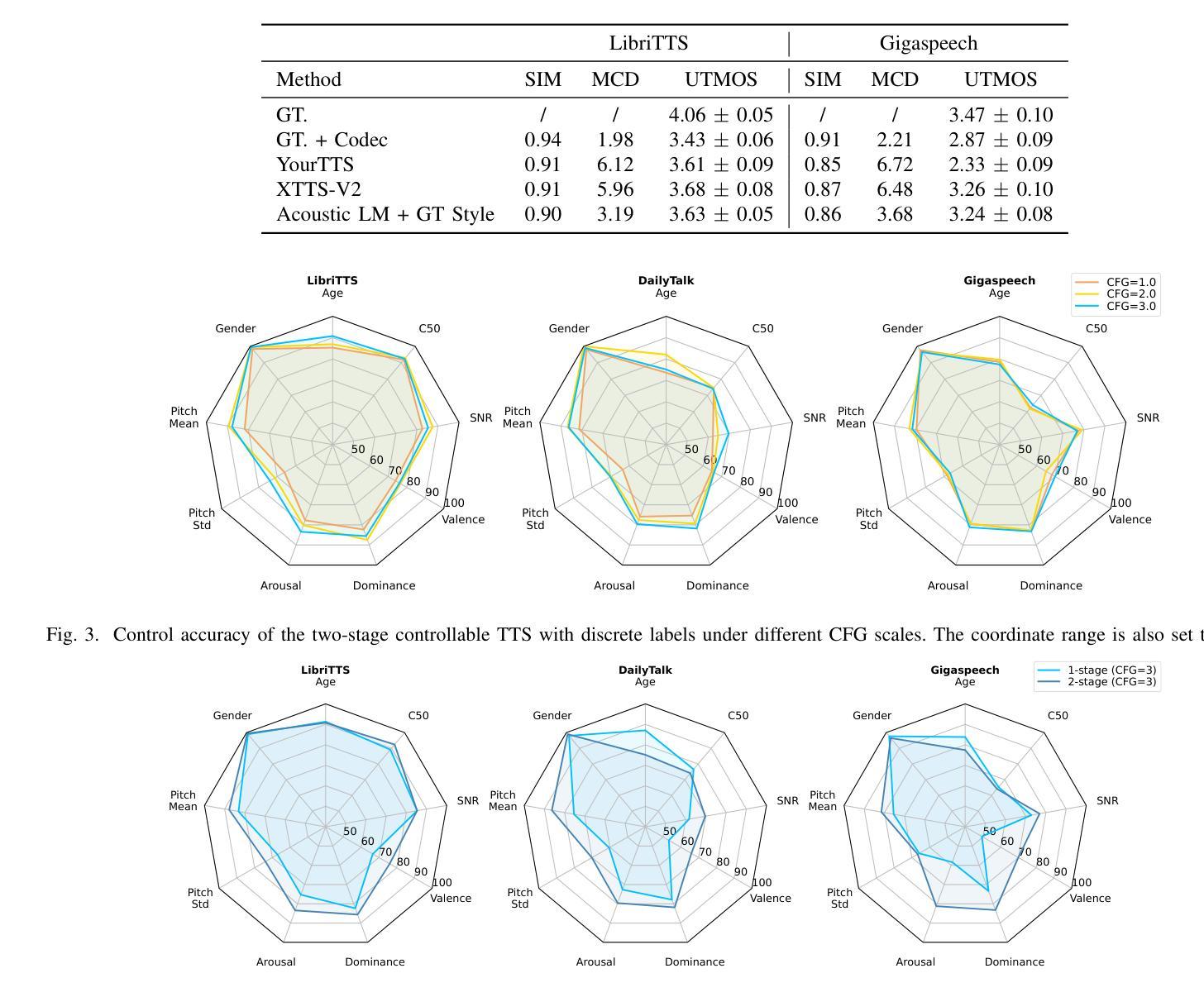
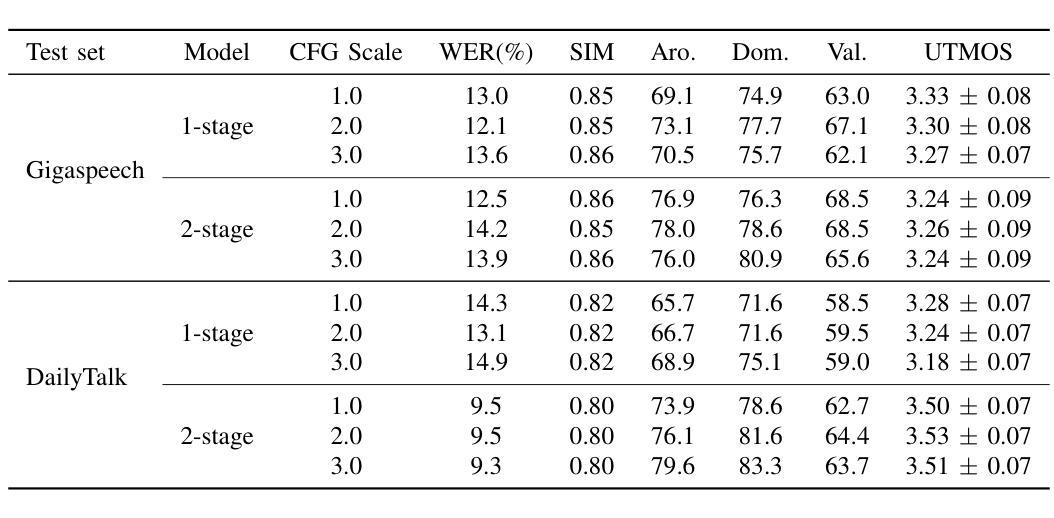
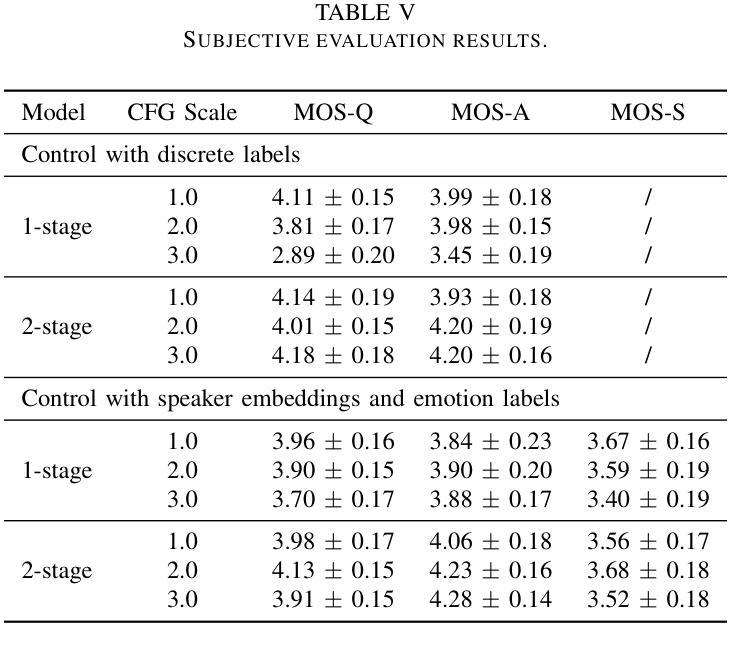
Controllable TTS models with natural language prompts often lack the ability for fine-grained control and face a scarcity of high-quality data. We propose a two-stage style-controllable TTS system with language models, utilizing a quantized masked-autoencoded style-rich representation as an intermediary. In the first stage, an autoregressive transformer is used for the conditional generation of these style-rich tokens from text and control signals. The second stage generates codec tokens from both text and sampled style-rich tokens. Experiments show that training the first-stage model on extensive datasets enhances the content robustness of the two-stage model as well as control capabilities over multiple attributes. By selectively combining discrete labels and speaker embeddings, we explore fully controlling the speaker’s timbre and other stylistic information, and adjusting attributes like emotion for a specified speaker. Audio samples are available at https://style-ar-tts.github.io.
具有自然语言提示的可控文本转语音(TTS)模型通常缺乏精细控制的能力,并且面临高质量数据稀缺的问题。我们提出了一种两阶段风格可控的TTS系统,该系统利用语言模型,并使用量化的掩码自动编码风格丰富的表示作为中介。在第一阶段,使用自回归变压器根据文本和控制信号生成这些风格丰富的标记。第二阶段从文本和采样的风格丰富的标记生成编码标记。实验表明,在第一阶段模型上进行大量数据集训练,可以增强两阶段模型的内容稳健性以及对多个属性的控制能力。通过有选择地结合离散标签和说话者嵌入,我们可以完全控制说话者的音色和其他风格信息,并调整指定说话者的情感等属性。音频样本可在https://style-ar-tts.github.io找到。
论文及项目相关链接
Summary
本文提出一种两阶段风格可控的文本到语音转换(TTS)系统。利用语言模型构建可控TTS模型面临的问题是缺少精细化控制以及高质量数据的稀缺。通过引入量化掩码自编码风格丰富表示作为中介,第一阶段使用自回归转换器从文本和控制信号生成这些风格丰富的令牌,第二阶段从文本和采样的风格丰富的令牌生成编解码器令牌。实验表明,在第一阶段模型上进行大量训练数据训练可以提高两阶段模型的稳健性和对多个属性的控制能力。通过有选择地结合离散标签和说话者嵌入,探索对说话者的音色和其他风格信息的完全控制,以及调整特定说话者的情感等属性。提供了音频样本链接。
Key Takeaways
- TTS模型使用自然语言提示缺乏精细控制和高质量数据的问题。
- 提出一种两阶段风格可控的TTS系统,使用语言模型和量化掩码自编码风格丰富表示。
- 第一阶段生成风格丰富的令牌,第二阶段从文本和采样的风格令牌生成编解码器令牌。
- 训练第一阶段模型使用大量数据集可提高两阶段模型的稳健性和控制能力。
- 通过结合离散标签和说话者嵌入,实现完全控制说话者的音色和其他风格信息,包括调整特定说话者的情感等属性。
点此查看论文截图

Towards a Japanese Full-duplex Spoken Dialogue System
Authors:Atsumoto Ohashi, Shinya Iizuka, Jingjing Jiang, Ryuichiro Higashinaka
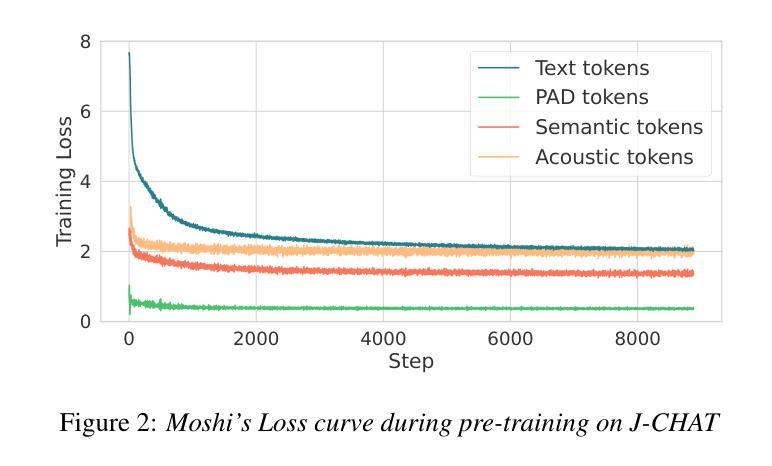
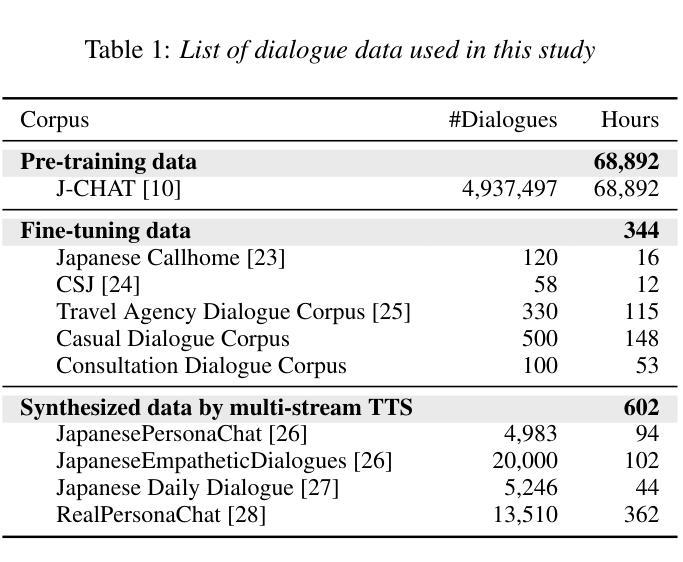
Full-duplex spoken dialogue systems, which can model simultaneous bidirectional features of human conversations such as speech overlaps and backchannels, have attracted significant attention recently. However, the study of full-duplex spoken dialogue systems for the Japanese language has been limited, and the research on their development in Japanese remains scarce. In this paper, we present the first publicly available full-duplex spoken dialogue model in Japanese, which is built upon Moshi, a full-duplex dialogue model in English. Our model is trained through a two-stage process: pre-training on a large-scale spoken dialogue data in Japanese, followed by fine-tuning on high-quality stereo spoken dialogue data. We further enhance the model’s performance by incorporating synthetic dialogue data generated by a multi-stream text-to-speech system. Evaluation experiments demonstrate that the trained model outperforms Japanese baseline models in both naturalness and meaningfulness.
近年来,能够模拟人类对话的双向同时进行特性(如言语重叠和反馈通道)的全双工对话系统引起了人们的广泛关注。然而,针对日语的全双工对话系统的研究较为有限,其开发研究依然稀少。在本文中,我们展示了基于日语的第一个公开可用的全双工对话模型,该模型建立在英语的全双工对话模型Moshi之上。我们的模型通过两阶段训练过程:首先在大规模的日语口语对话数据上进行预训练,然后利用高质量的立体声口语对话数据进行微调。我们进一步通过结合由多流文本到语音系统生成的综合对话数据来提高模型的性能。评估实验表明,训练后的模型在日语基线模型的自然度和意义性方面都表现得更好。
论文及项目相关链接
PDF Accepted to Interspeech 2025
Summary
该论文介绍了首个公开的日语全双工对话模型,该模型基于英语的双工对话模型Moshi构建。通过大规模日语对话数据预训练和高质量立体声对话数据微调的两阶段过程进行训练,并使用多流文本到语音系统生成的合成对话数据增强模型性能。评估实验表明,该模型在日语基准模型上表现更出色,更自然、有意义。
Key Takeaways
- 该论文发布了首个日语全双工对话模型。
- 模型建立在英语的双工对话模型Moshi的基础上。
- 模型通过两阶段过程进行训练:首先在大规模日语对话数据上进行预训练,然后在高质量立体声对话数据上进行微调。
- 合成对话数据通过多流文本到语音系统生成,增强了模型性能。
- 模型在日语基准模型上的表现更自然和有意义。
- 全双工对话系统能够模拟人类对话的双向特征,如语音重叠和反馈通道。
点此查看论文截图

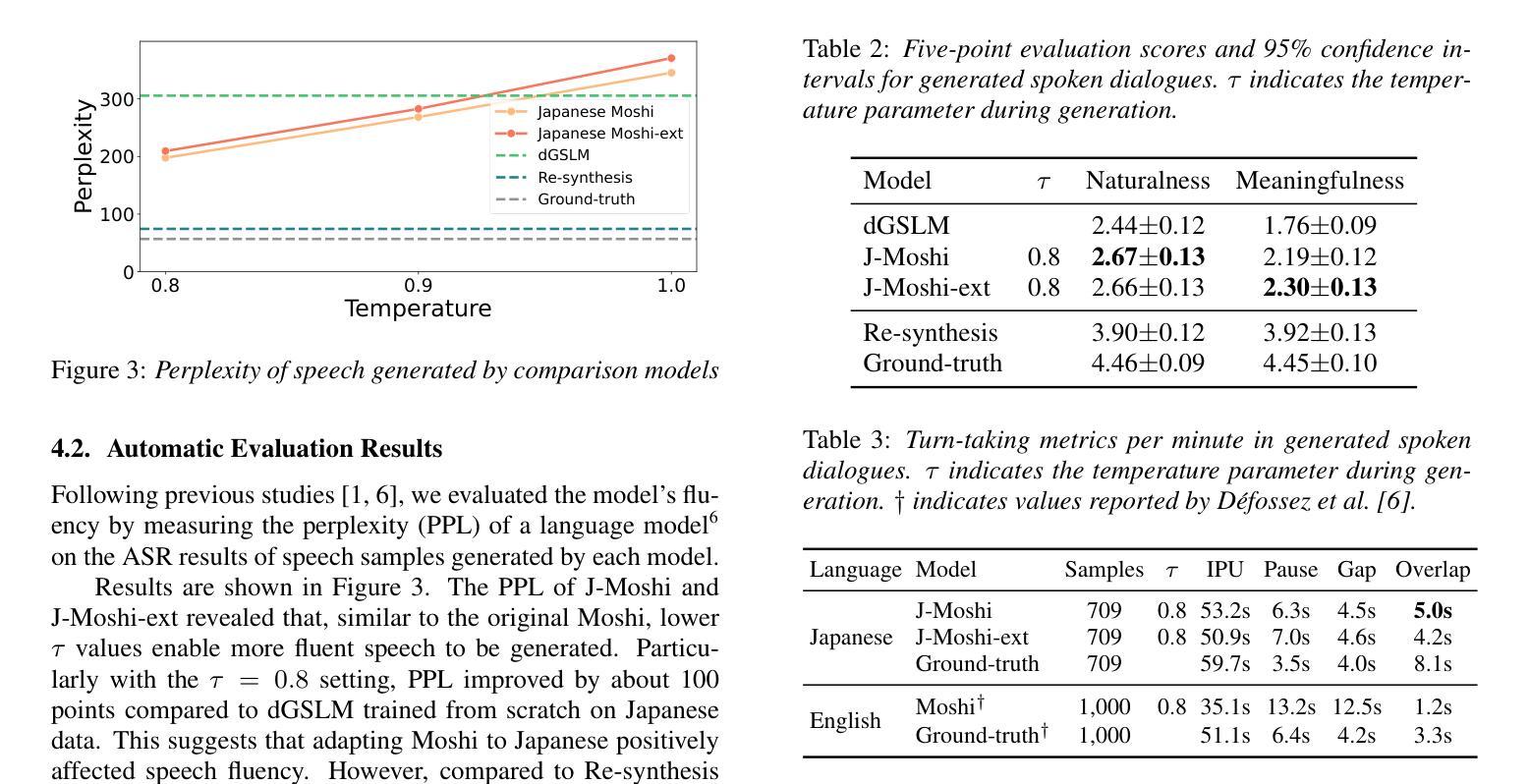
CapSpeech: Enabling Downstream Applications in Style-Captioned Text-to-Speech
Authors:Helin Wang, Jiarui Hai, Dading Chong, Karan Thakkar, Tiantian Feng, Dongchao Yang, Junhyeok Lee, Laureano Moro Velazquez, Jesus Villalba, Zengyi Qin, Shrikanth Narayanan, Mounya Elhiali, Najim Dehak
Recent advancements in generative artificial intelligence have significantly transformed the field of style-captioned text-to-speech synthesis (CapTTS). However, adapting CapTTS to real-world applications remains challenging due to the lack of standardized, comprehensive datasets and limited research on downstream tasks built upon CapTTS. To address these gaps, we introduce CapSpeech, a new benchmark designed for a series of CapTTS-related tasks, including style-captioned text-to-speech synthesis with sound events (CapTTS-SE), accent-captioned TTS (AccCapTTS), emotion-captioned TTS (EmoCapTTS), and text-to-speech synthesis for chat agent (AgentTTS). CapSpeech comprises over 10 million machine-annotated audio-caption pairs and nearly 0.36 million human-annotated audio-caption pairs. In addition, we introduce two new datasets collected and recorded by a professional voice actor and experienced audio engineers, specifically for the AgentTTS and CapTTS-SE tasks. Alongside the datasets, we conduct comprehensive experiments using both autoregressive and non-autoregressive models on CapSpeech. Our results demonstrate high-fidelity and highly intelligible speech synthesis across a diverse range of speaking styles. To the best of our knowledge, CapSpeech is the largest available dataset offering comprehensive annotations for CapTTS-related tasks. The experiments and findings further provide valuable insights into the challenges of developing CapTTS systems.
近年来,生成式人工智能的最新进展为带风格标注的文本到语音合成(CapTTS)领域带来了显著变革。然而,由于缺少标准化、全面的数据集以及基于CapTTS的下游任务研究有限,将CapTTS适应于现实应用仍然具有挑战性。为了解决这些空白,我们引入了CapSpeech,这是一个为一系列与CapTTS相关的任务设计的新基准测试,包括带有声音事件的风格标注文本到语音合成(CapTTS-SE)、口音标注的TTS(AccCapTTS)、情感标注的TTS(EmoCapTTS)以及用于聊天代理的文本到语音合成(AgentTTS)。CapSpeech包含超过1000万个机器标注的音频字幕对和近36万个人工标注的音频字幕对。此外,我们还由专业配音演员和经验丰富的音频工程师收集和录制了两个新数据集,专门用于AgentTTS和CapTTS-SE任务。除了数据集之外,我们还使用自回归和非自回归模型在CapSpeech上进行了全面的实验。我们的结果证明了在各种不同的说话风格中,具有高保真度和高度可理解性的语音合成。据我们所知,CapSpeech是现有最大的为CapTTS相关任务提供全面注释的数据集。实验和发现为开发CapTTS系统提供了宝贵的见解。
论文及项目相关链接
Summary
近期生成式人工智能的进步显著改变了风格标注文本到语音合成(CapTTS)领域。然而,将CapTTS适应到实际应用中仍面临缺乏标准化、全面的数据集以及在CapTTS基础上构建的下游任务研究的限制。为解决这些问题,我们引入了CapSpeech,一个为CapTTS相关任务设计的新基准,包括带有声音事件的风格标注文本到语音合成(CapTTS-SE)、口音标注TTS(AccCapTTS)、情感标注TTS(EmoCapTTS)和用于聊天代理的文本到语音合成(AgentTTS)。CapSpeech包含超过1千万机器标注的音频-字幕对和近0.36百万人类标注的音频-字幕对。此外,我们还由专业配音演员和经验丰富的音频工程师收集和记录了两个新数据集,专门用于AgentTTS和CapTTS-SE任务。同时,我们在CapSpeech上使用了自回归和非自回归模型进行了全面的实验。结果证明了我们在多种说话风格上实现高保真、高度可理解的语音合成。据我们所知,CapSpeech是提供CapTTS相关任务全面注释的最大可用数据集。实验和发现为进一步开发CapTTS系统提供了宝贵见解。
Key Takeaways
- 生成式人工智能的进步已显著改变风格标注文本到语音合成(CapTTS)领域。
- CapSpeech基准引入,包含多种CapTTS相关任务,如CapTTS-SE、AccCapTTS、EmoCapTTS和AgentTTS。
- CapSpeech包含大量机器和人类标注的音频-字幕对数据。
- 新数据集由专业配音演员和音频工程师收集,用于AgentTTS和CapTTS-SE任务。
- 全面的实验证明了高保真、高度可理解的语音合成能力。
- CapSpeech是提供CapTTS相关任务全面注释的最大可用数据集。
- 实验结果提供了开发CapTTS系统的宝贵见解。
点此查看论文截图

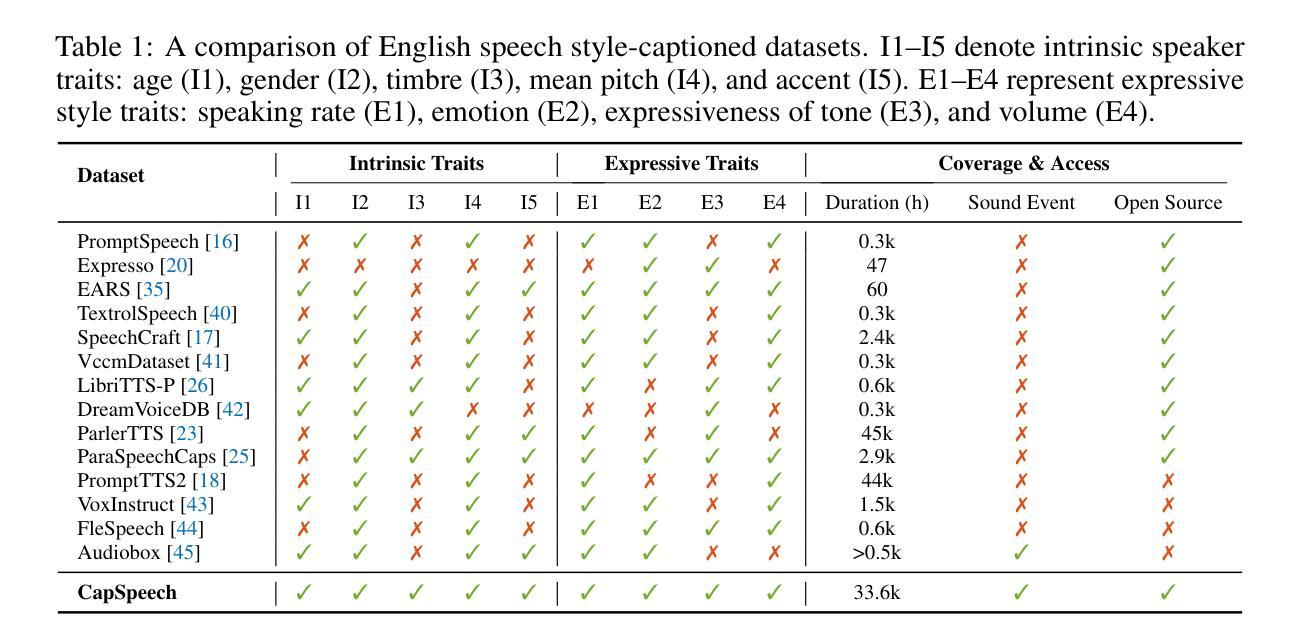

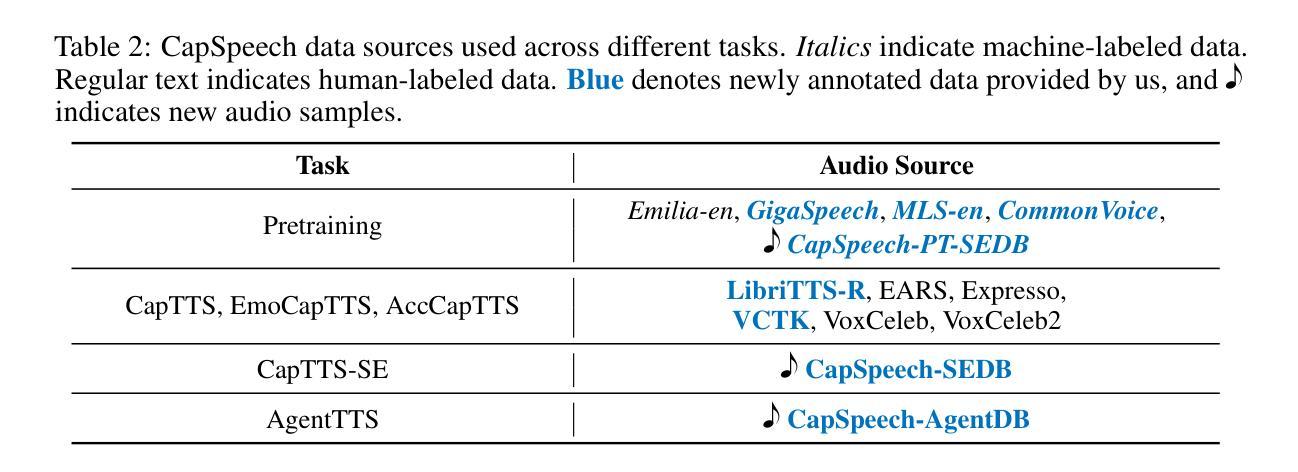
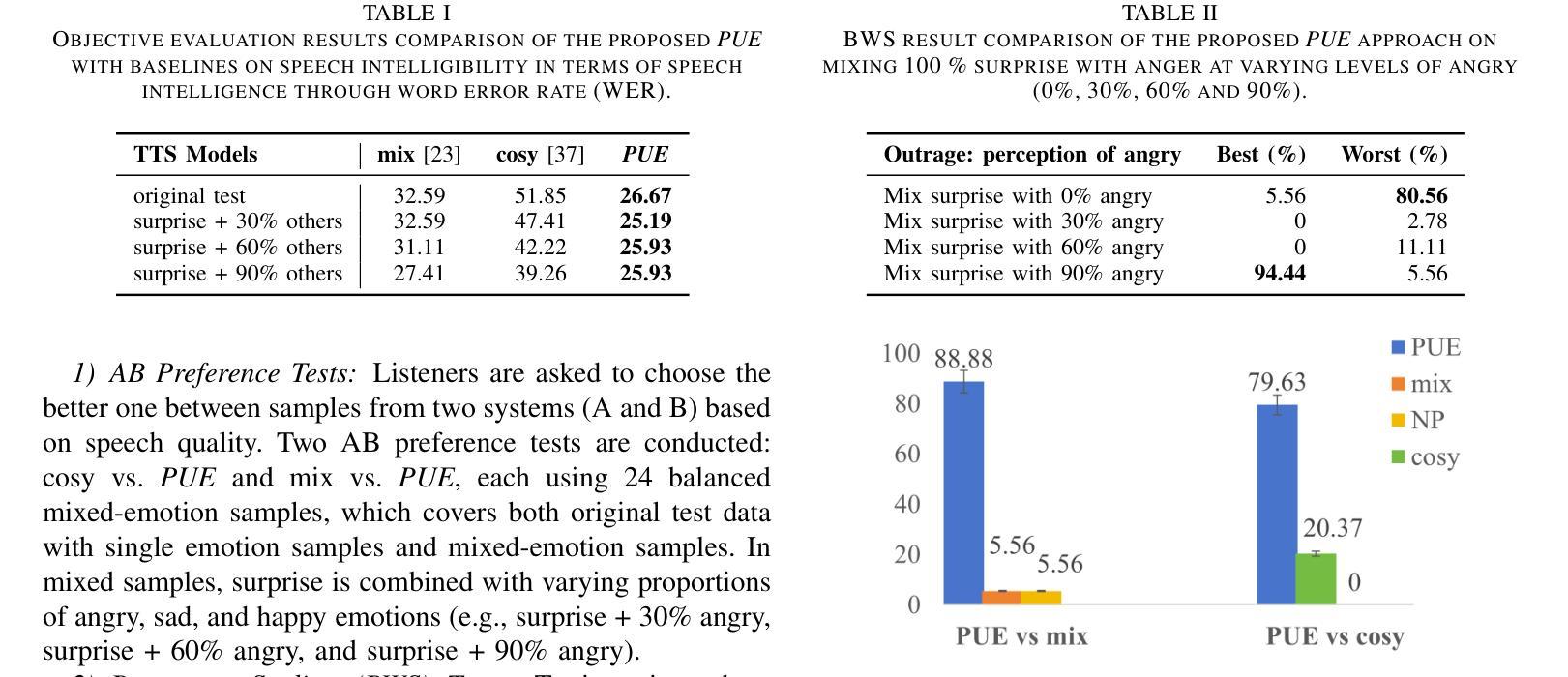
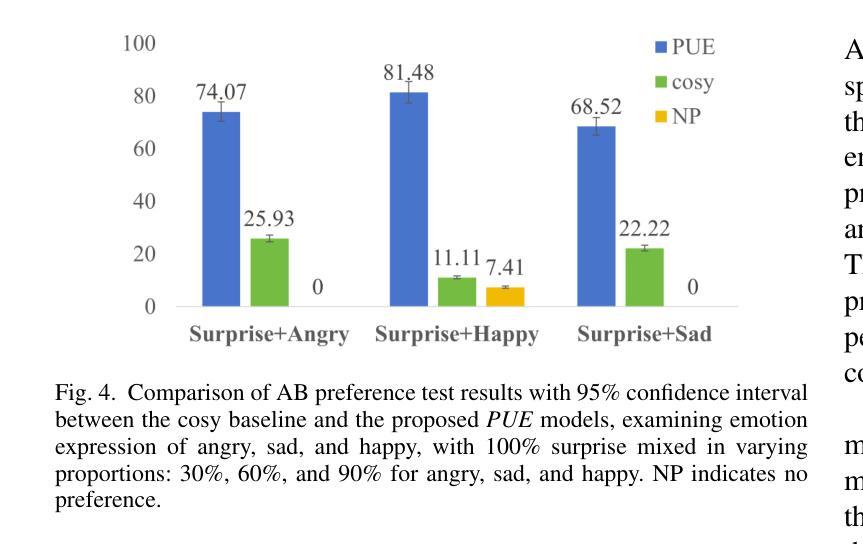
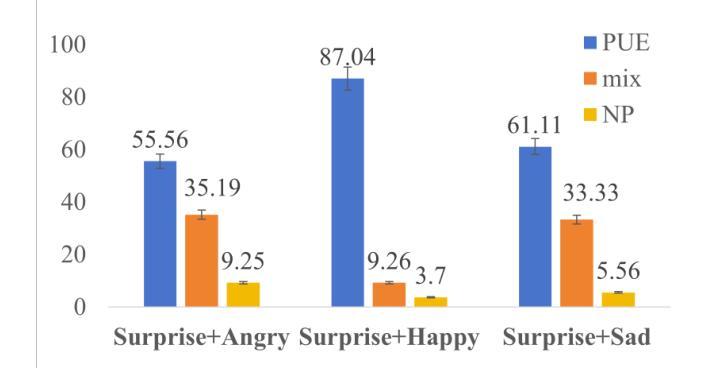
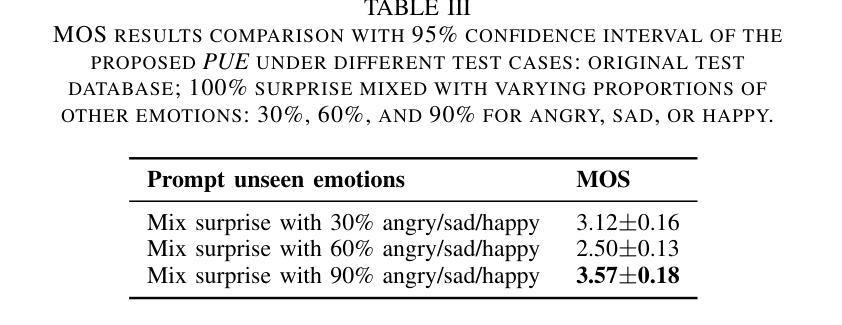
Prompt-Unseen-Emotion: Zero-shot Expressive Speech Synthesis with Prompt-LLM Contextual Knowledge for Mixed Emotions
Authors:Xiaoxue Gao, Huayun Zhang, Nancy F. Chen
Existing expressive text-to-speech (TTS) systems primarily model a limited set of categorical emotions, whereas human conversations extend far beyond these predefined emotions, making it essential to explore more diverse emotional speech generation for more natural interactions. To bridge this gap, this paper proposes a novel prompt-unseen-emotion (PUE) approach to generate unseen emotional speech via emotion-guided prompt learning. PUE is trained utilizing an LLM-TTS architecture to ensure emotional consistency between categorical emotion-relevant prompts and emotional speech, allowing the model to quantitatively capture different emotion weightings per utterance. During inference, mixed emotional speech can be generated by flexibly adjusting emotion proportions and leveraging LLM contextual knowledge, enabling the model to quantify different emotional styles. Our proposed PUE successfully facilitates expressive speech synthesis of unseen emotions in a zero-shot setting.
现有的表达性文本到语音(TTS)系统主要对有限的分类情绪进行建模,而人类对话则远远超出这些预定义的情绪。因此,为了更自然的交互,探索更多样化的情感语音生成至关重要。为了弥补这一差距,本文提出了一种新型提示未见情绪(PUE)方法,通过情感引导提示学习来生成未见情感语音。PUE利用LLM-TTS架构进行训练,以确保分类情绪相关提示与情感语音之间的情感一致性,使得模型可以定量捕获每个话语的不同情绪权重。在推理过程中,可以通过灵活地调整情绪比例并利用LLM的上下文知识来生成混合情感语音,使模型能够量化不同的情感风格。我们提出的PUE成功地在零样本设置下促进了未见情感的表达性语音合成。
论文及项目相关链接
Summary
本文提出了一种名为PUE(Prompt Unseen Emotion)的方法,旨在通过情感引导的提示学习生成未见情感语音。该模型基于LLM-TTS架构训练,保证了与分类情感相关的提示和情绪语音之间的情感一致性,可以量化捕捉不同情感权重。在推理过程中,通过灵活调整情感比例并利用LLM的上下文知识,可以生成混合情感语音,实现不同情感风格的量化。该研究成功促进了零样本设置下的未见情感语音的合成表达。
Key Takeaways
- PUE方法能够生成未见情感语音,弥补了现有TTS系统在情感表达上的不足。
- LLM-TTS架构被用于确保情感一致性,使模型能够捕捉不同情感的权重。
- 在推理阶段,可以通过调整情感比例生成混合情感语音。
- LLM的上下文知识被用来提高情感语音生成的上下文连贯性和自然度。
- PUE方法实现了零样本设置下的情感语音合成。
- 该方法不仅能处理预设的类别情感,还能处理更广泛的情感表达。
点此查看论文截图

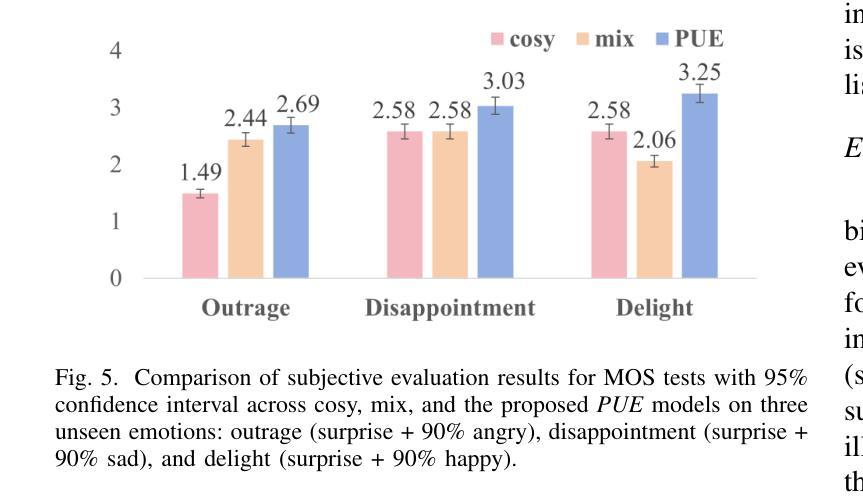
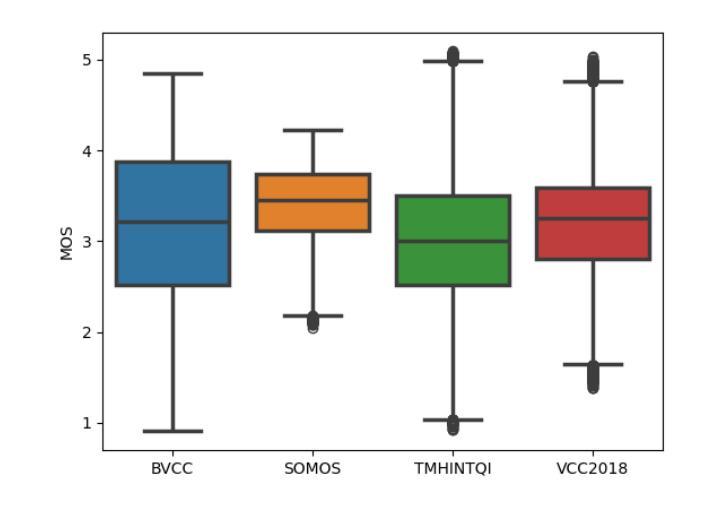
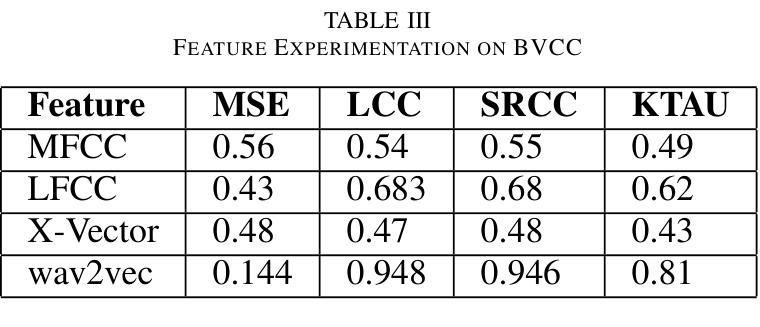
SALF-MOS: Speaker Agnostic Latent Features Downsampled for MOS Prediction
Authors:Saurabh Agrawal, Raj Gohil, Gopal Kumar Agrawal, Vikram C M, Kushal Verma
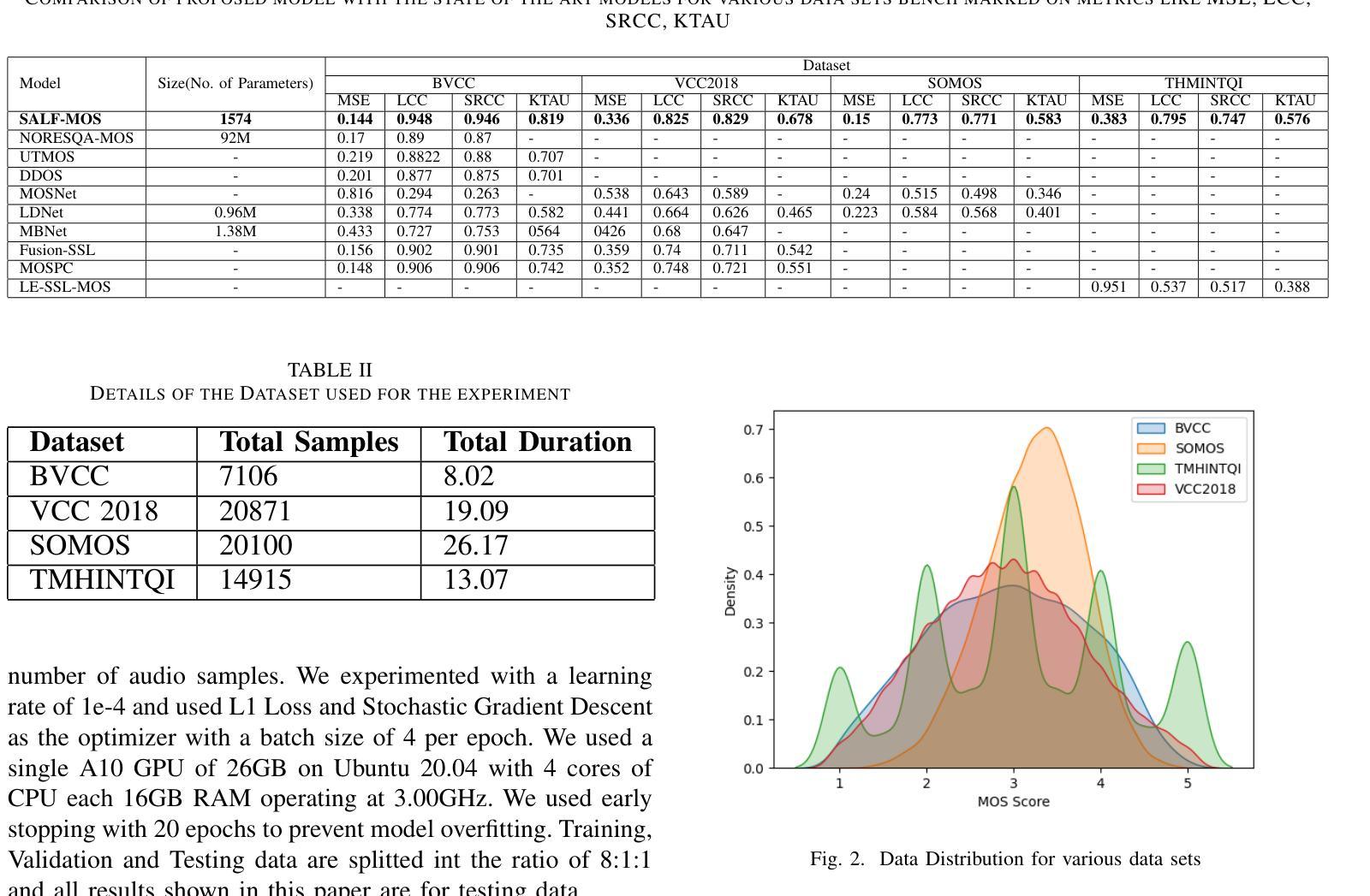
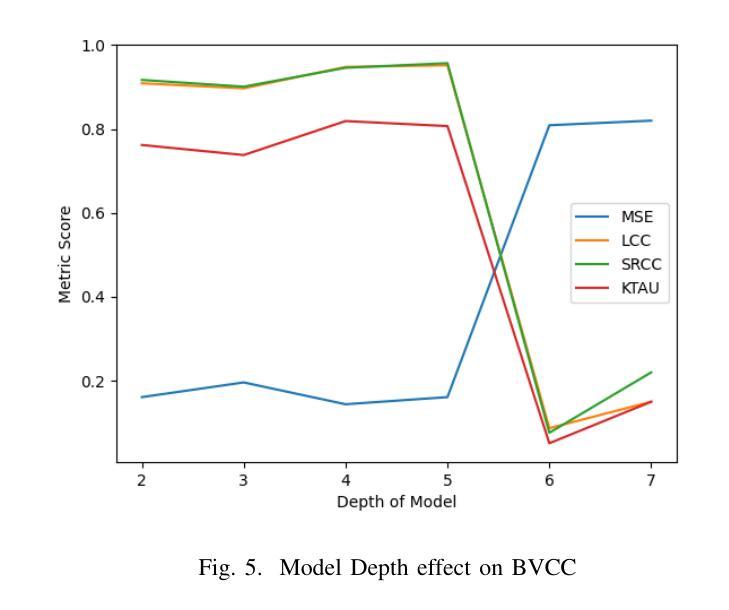
Speech quality assessment is a critical process in selecting text-to-speech synthesis (TTS) or voice conversion models. Evaluation of voice synthesis can be done using objective metrics or subjective metrics. Although there are many objective metrics like the Perceptual Evaluation of Speech Quality (PESQ), Perceptual Objective Listening Quality Assessment (POLQA) or Short-Time Objective Intelligibility (STOI) but none of them is feasible in selecting the best model. On the other hand subjective metric like Mean Opinion Score is highly reliable but it requires a lot of manual efforts and are time-consuming. To counter the issues in MOS Evaluation, we have developed a novel model, Speaker Agnostic Latent Features (SALF)-Mean Opinion Score (MOS) which is a small-sized, end-to-end, highly generalized and scalable model for predicting MOS score on a scale of 5. We use the sequences of convolutions and stack them to get the latent features of the audio samples to get the best state-of-the-art results based on mean squared error (MSE), Linear Concordance Correlation coefficient (LCC), Spearman Rank Correlation Coefficient (SRCC) and Kendall Rank Correlation Coefficient (KTAU).
语音质量评估是选择文本到语音合成(TTS)或语音转换模型的关键过程。语音合成的评估可以使用客观指标或主观指标来完成。虽然有许多客观指标,如语音质量的感知评估(PESQ)、感知客观听觉质量评估(POLQA)或短期客观可懂度(STOI),但没有任何一个指标可用于选择最佳模型。另一方面,主观指标如平均意见得分非常可靠,但它需要大量的手动操作和耗时。为了解决MOS评估中的问题,我们开发了一种新型模型,即不讲者潜在特征(SALF)-平均意见得分(MOS),这是一个小型、端到端、高度通用和可扩展的模型,可用于预测5分制上的MOS分数。我们使用卷积序列并将其堆叠起来,以获得音频样本的潜在特征,以基于均方误差(MSE)、线性一致性相关系数(LCC)、斯皮尔曼等级相关系数(SRCC)和肯德尔等级相关系数(KTAU)获得最佳的最先进结果。
论文及项目相关链接
Summary
本文介绍了语音质量评估在文本转语音合成模型选择中的重要性,并探讨了客观和主观评估方法的问题。针对主观评估方法如平均意见得分(MOS)的缺陷,提出了一种新型的语音质量评估模型——说话人无关潜在特征(SALF)-MOS模型。该模型具有小尺寸、端到端、高度通用和可扩展的特点,可以通过音频样本的潜在特征预测MOS分数。
Key Takeaways
- 语音质量评估在文本转语音合成模型选择中的重要性。
- 现有的客观语音质量评估指标如PESQ、POLQA和STOI等并不完美,无法选择最佳模型。
- 主观评估方法如平均意见得分(MOS)虽然可靠,但耗时且需要大量人工参与。
- 提出了新型的语音质量评估模型——SALF-MOS。
- SALF-MOS模型具有小尺寸、端到端、高度通用和可扩展的特点。
- SALF-MOS模型通过音频样本的潜在特征预测MOS分数。
点此查看论文截图

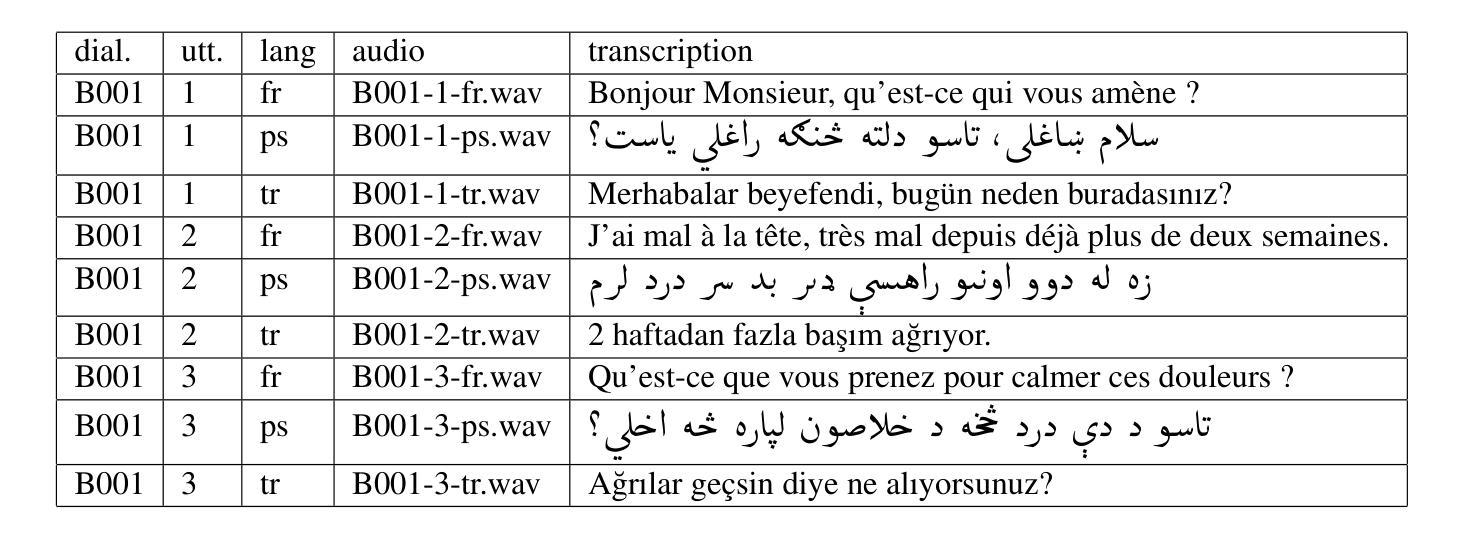
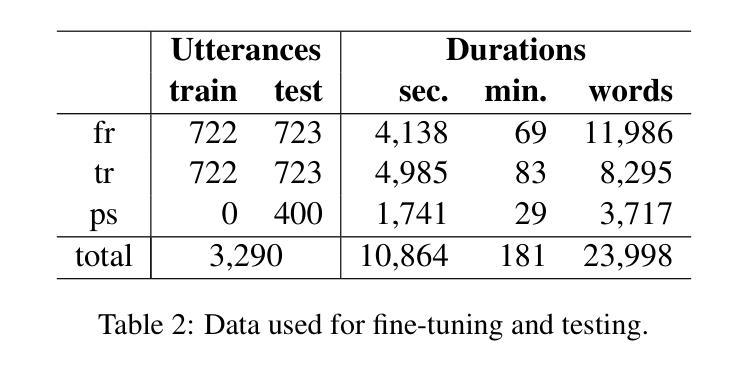
Speech-to-Speech Translation Pipelines for Conversations in Low-Resource Languages
Authors:Andrei Popescu-Belis, Alexis Allemann, Teo Ferrari, Gopal Krishnamani
The popularity of automatic speech-to-speech translation for human conversations is growing, but the quality varies significantly depending on the language pair. In a context of community interpreting for low-resource languages, namely Turkish and Pashto to/from French, we collected fine-tuning and testing data, and compared systems using several automatic metrics (BLEU, COMET, and BLASER) and human assessments. The pipelines included automatic speech recognition, machine translation, and speech synthesis, with local models and cloud-based commercial ones. Some components have been fine-tuned on our data. We evaluated over 60 pipelines and determined the best one for each direction. We also found that the ranks of components are generally independent of the rest of the pipeline.
自动语音对话翻译技术的普及程度正不断增长,但其质量在很大程度上取决于语言对。我们在针对低资源语言(即土耳其语和普什图语至法语/从法语翻译)的社区口译背景下,收集了调优和测试数据,并使用几种自动指标(BLEU、COMET和BLASER)以及人工评估对比了不同系统。这些管道包括自动语音识别、机器翻译和语音合成,其中包括本地模型和基于云的商业模型。某些组件已针对我们的数据进行过微调。我们评估了超过60个管道,并确定了每个方向的最佳管道。我们还发现,组件的排名通常与管道的其他部分无关。
论文及项目相关链接
PDF Proceedings of MT Summit 2025
Summary
本文探讨了自动语音到语音翻译在人类对话中的普及情况,特别是在低资源语言如土耳其语和普什图语与法语之间的翻译。文章通过收集调优和测试数据,对比了不同系统的表现,并发现不同语言对的翻译质量差异显著。研究包括自动语音识别、机器翻译和语音合成等环节,涉及本地模型和基于云的商业模型。通过评估超过60个管道,确定了每个方向的最佳方案,并发现组件排名通常与管道其余部分无关。
Key Takeaways
- 自动语音到语音翻译在低资源语言如土耳其语和普什图语与法语之间的应用正在增长。
- 不同语言对的翻译质量差异显著。
- 研究涉及自动语音识别、机器翻译和语音合成等环节。
- 本地模型和基于云的商业模型均被考虑。
- 超过60个管道被评估,确定了每个方向的最佳方案。
- 组件的排名通常与管道的其他部分无关。
点此查看论文截图


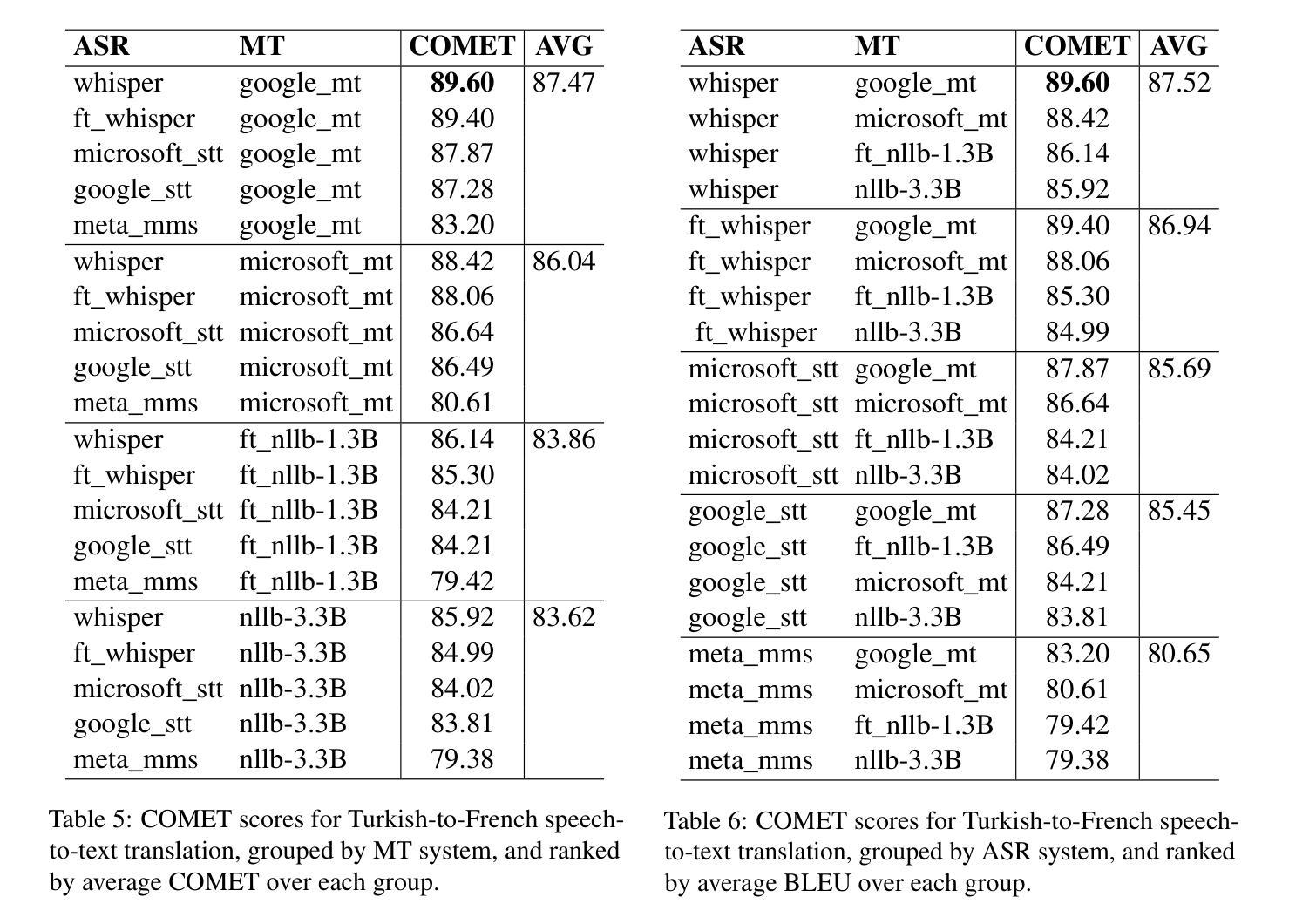
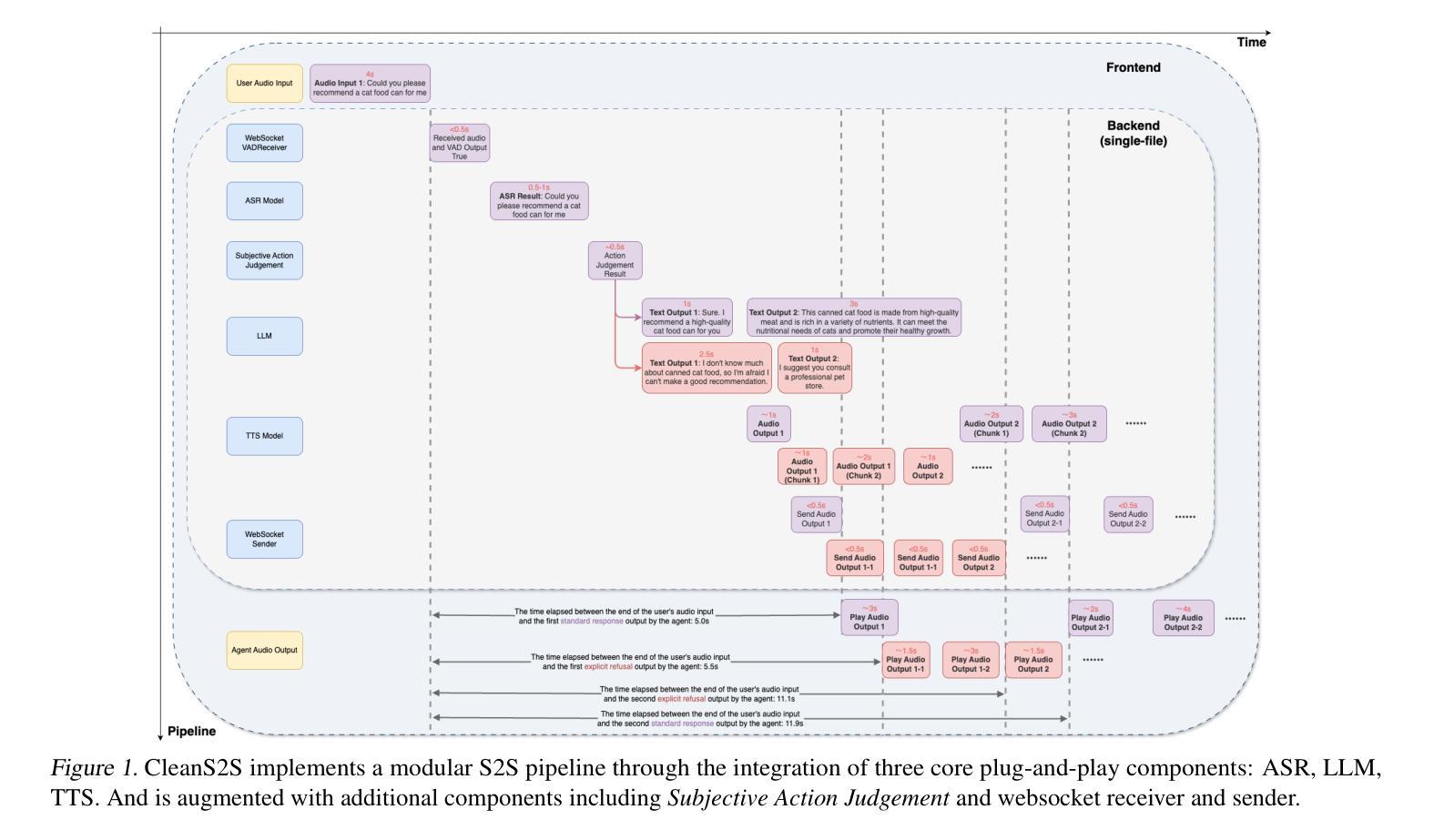
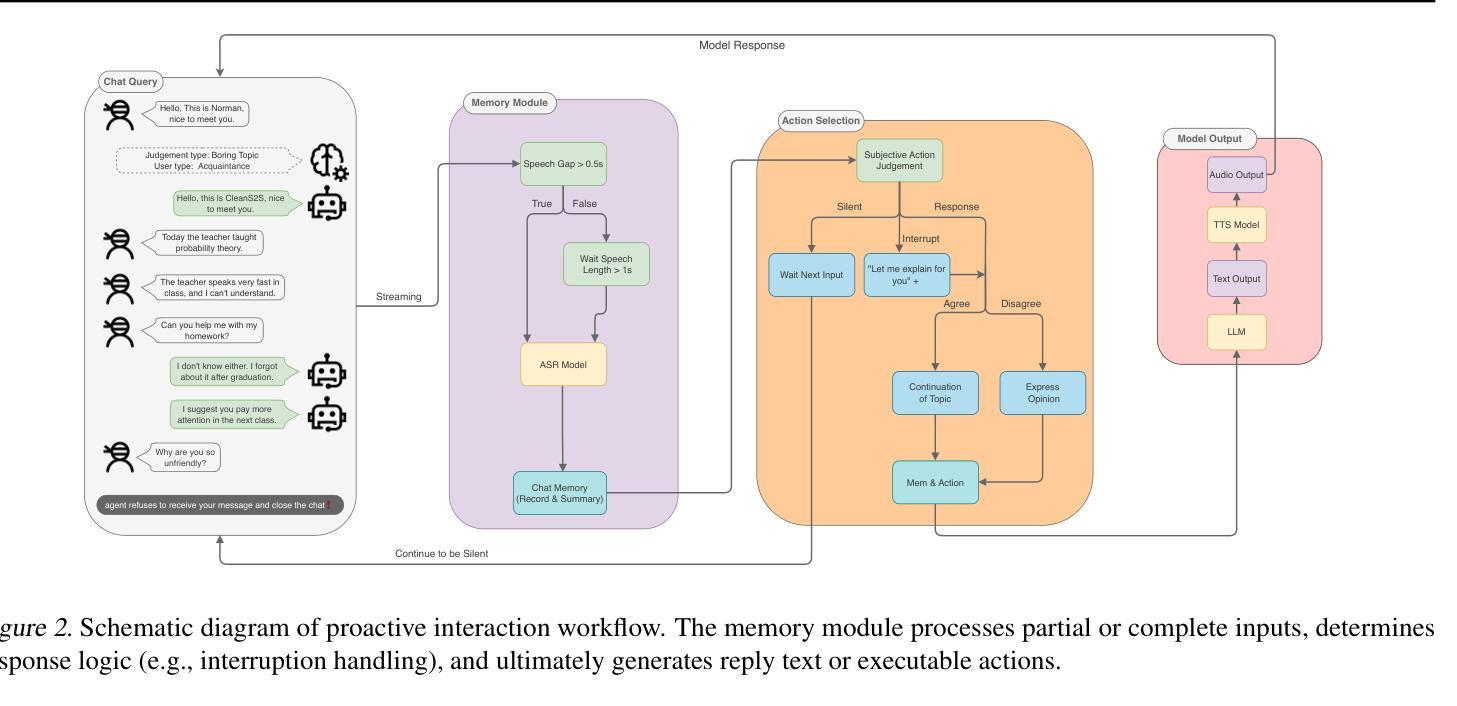
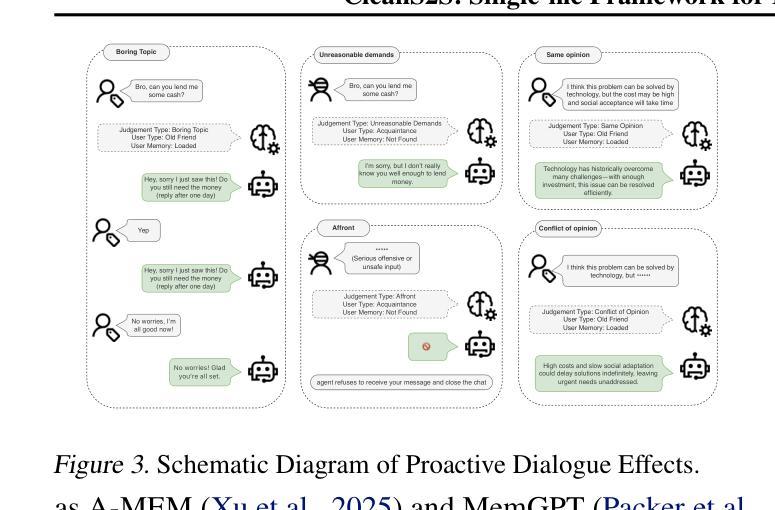
CleanS2S: Single-file Framework for Proactive Speech-to-Speech Interaction
Authors:Yudong Lu, Yazhe Niu, Shuai Hu, Haolin Wang
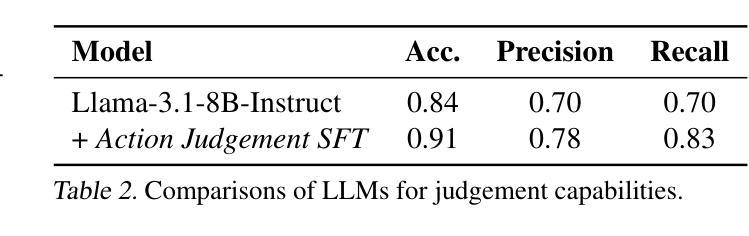
CleanS2S is a framework for human-like speech-to-speech interaction that advances conversational AI through single-file implementation and proactive dialogue capabilities. Our system integrates automatic speech recognition, large language models, and text-to-speech synthesis into a unified pipeline with real-time interruption handling, achieving low transition latency through full-duplex websocket connections and non-blocking I/O. Beyond conventional chatbot paradigms, we pioneer a proactive interaction mechanism, which combines memory systems with Subjective Action Judgement module, enabling five human-like response strategies: interruption, refusal, deflection, silence, and standard response. The memory module dynamically aggregates historical, and contextual data to inform interaction decisions. This approach breaks the rigid turn-based convention by allowing system-initiated dialog control and context-aware response selection. And we propose Action Judgement SFT that assesses input streams for responses strategies. The framework’s single-file implementation with atomic configurations offers researchers unprecedented transparency and extensibility for interaction agents. The code of CleanS2S is released at \https://github.com/opendilab/CleanS2S.
CleanS2S是一个面向人类语音对话交互的框架,它通过单文件实现和主动对话功能推动了会话式人工智能的发展。我们的系统集成了自动语音识别、大型语言模型和文本到语音合成,通过实时中断处理构建了一个统一管道,通过全双工web套接字连接和非阻塞I/O实现了低转换延迟。除了传统的聊天机器人模式之外,我们还开创了一种主动交互机制,该机制结合了记忆系统与主观动作判断模块,可实现五种人类化的响应策略:中断、拒绝、回避、沉默和标准响应。记忆模块动态聚合历史和上下文数据以支持交互决策。这种方法打破了基于轮询的严格规则,允许系统主动控制对话和基于上下文的响应选择。我们提出了动作判断SFT(Action Judgement SFT),用于评估输入流以选择响应策略。CleanS2S的单文件实现以及原子配置为研究人员提供了前所未有的交互代理透明度和扩展性。CleanS2S的代码已发布在https://github.com/opendilab/CleanS2S上。
论文及项目相关链接
摘要
清洁S2S是一个面向人类语音对话的框架,通过单一文件实现和主动对话能力推动对话AI的发展。它集成了自动语音识别、大型语言模型和文本到语音合成技术,具有实时中断处理能力,并通过全双工websocket连接和非阻塞I/O实现低转换延迟。该框架采用主动交互机制,结合记忆系统与主观动作判断模块,实现五种类似人类的响应策略:中断、拒绝、偏离、沉默和标准响应。记忆模块动态聚合历史和上下文数据以支持交互决策。它打破了传统的基于轮流的模式,允许系统启动对话控制和基于上下文的响应选择。CleanS2S框架为研究人员提供了前所未有的交互代理的透明度和扩展性。CleanS2S的代码已发布在https://github.com/opendilab/CleanS2S。
要点
- CleanS2S是一个面向人类语音对话的框架,集成了自动语音识别、大型语言模型和文本到语音合成技术。
- 它实现了实时中断处理和低转换延迟,通过全双工websocket连接和非阻塞I/O支持高效对话。
- CleanS2S采用主动交互机制,允许系统启动对话控制和基于上下文的响应选择,实现五种类似人类的响应策略。
- 记忆模块能够动态聚合历史和上下文数据,以支持更智能的交互决策。
- 该框架通过单一文件实现和原子配置提供前所未有的透明度和扩展性,便于研究人员理解和改进交互代理。
- CleanS2S代码已发布在GitHub上,供公众访问和使用。
点此查看论文截图

DS-TTS: Zero-Shot Speaker Style Adaptation from Voice Clips via Dynamic Dual-Style Feature Modulation
Authors:Ming Meng, Ziyi Yang, Jian Yang, Zhenjie Su, Yonggui Zhu, Zhaoxin Fan
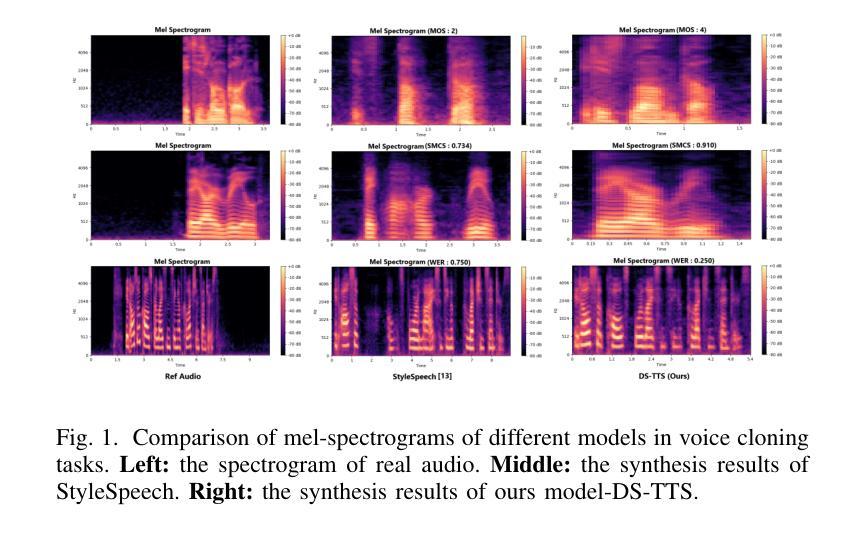
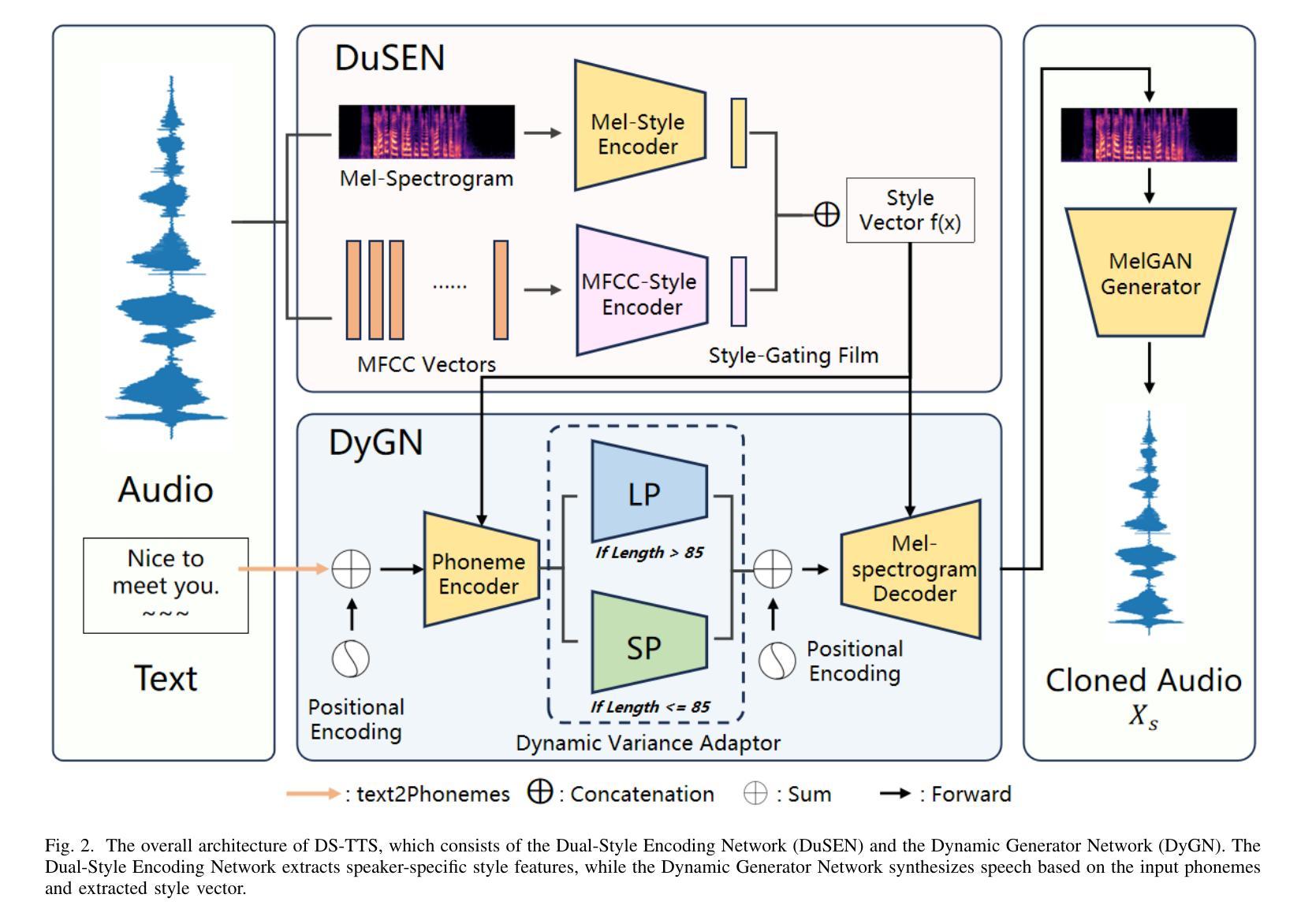
Recent advancements in text-to-speech (TTS) technology have increased demand for personalized audio synthesis. Zero-shot voice cloning, a specialized TTS task, aims to synthesize a target speaker’s voice using only a single audio sample and arbitrary text, without prior exposure to the speaker during training. This process employs pattern recognition techniques to analyze and replicate the speaker’s unique vocal features. Despite progress, challenges remain in adapting to the vocal style of unseen speakers, highlighting difficulties in generalizing TTS systems to handle diverse voices while maintaining naturalness, expressiveness, and speaker fidelity. To address the challenges of unseen speaker style adaptation, we propose DS-TTS, a novel approach aimed at enhancing the synthesis of diverse, previously unheard voices. Central to our method is a Dual-Style Encoding Network (DuSEN), where two distinct style encoders capture complementary aspects of a speaker’s vocal identity. These speaker-specific style vectors are seamlessly integrated into the Dynamic Generator Network (DyGN) via a Style Gating-Film (SGF) mechanism, enabling more accurate and expressive reproduction of unseen speakers’ unique vocal characteristics. In addition, we introduce a Dynamic Generator Network to tackle synthesis issues that arise with varying sentence lengths. By dynamically adapting to the length of the input, this component ensures robust performance across diverse text inputs and speaker styles, significantly improving the model’s ability to generalize to unseen speakers in a more natural and expressive manner. Experimental evaluations on the VCTK dataset suggest that DS-TTS demonstrates superior overall performance in voice cloning tasks compared to existing state-of-the-art models, showing notable improvements in both word error rate and speaker similarity.
近期文本转语音(TTS)技术的进展增加了对个性化音频合成的需求。零样本语音克隆是一项专门的TTS任务,旨在仅使用单个音频样本和任意文本合成目标说话人的声音,而无需在训练过程中事先接触该说话人。该过程采用模式识别技术来分析并复制说话人的独特语音特征。尽管取得了进展,但适应未见说话人的语音风格仍存在挑战,这凸显了将TTS系统推广应用于处理各种声音时,在保持自然性、表达力和说话人保真度方面的困难。为了解决未见说话人风格适应的挑战,我们提出了DS-TTS,这是一种旨在增强对多样且之前未听过的声音合成的新方法。我们的方法的核心是双重风格编码网络(DuSEN),其中两个截然不同的风格编码器捕捉说话人语音身份的互补方面。这些说话人特定的风格向量通过风格门控电影(SGF)机制无缝地集成到动态生成网络(DyGN)中,从而能够更准确、更生动地复制未见说话人的独特语音特征。此外,我们引入了动态生成网络来解决因句子长度不同而产生的合成问题。通过动态适应输入的长度,此组件可确保在各种文本输入和说话人风格方面的稳健性能,从而显著提高模型以更自然、更具表现力的方式推广到未见说话人的能力。在VCTK数据集上的实验评估表明,与现有最先进的模型相比,DS-TTS在语音克隆任务中表现出卓越的整体性能,在单词错误率和说话人相似性方面都取得了显着的改进。
论文及项目相关链接
摘要
近期文本转语音(TTS)技术的进展推动了个性化音频合成的需求增长。零样本语音克隆作为专项TTS任务,旨在仅使用单个音频样本和任意文本合成目标说话人的声音,且训练过程中无需预先接触该说话人。此流程采用模式识别技术分析并复制说话人的独特语音特征。尽管有所进展,但适应未见说话人的语音风格仍存在挑战,这突显了TTS系统在处理多样化声音时保持自然性、表达力和说话人保真度的概括推广难题。为解决未见说话人风格适应的挑战,我们提出了DS-TTS,这是一种旨在增强多样化、先前未听过的声音合成的新方法。我们的方法核心是双重风格编码网络(DuSEN),其中两个独特的风格编码器捕捉说话人语音身份的不同方面。这些说话人特定的风格向量被无缝集成到动态生成网络(DyGN)中,通过风格门控电影(SGF)机制,能够更精确、更生动地再现未见说话人的独特语音特征。此外,我们还引入了动态生成网络来解决与句子长度变化相关的合成问题。通过动态适应输入长度,此组件确保在各种文本输入和说话人风格上的稳健性能,显著提高了模型以更自然、更生动的方式概括未见说话人的能力。在VCTK数据集上的实验评估表明,与现有最先进的模型相比,DS-TTS在语音克隆任务中表现出整体优越的性能,在词错误率和说话人相似性方面均取得显著改进。
关键见解
- 最近TTS技术的进展推动了个性化音频合成的需求。
- 零样本语音克隆旨在仅使用单个音频样本和任意文本合成目标说话人的声音。
- 适应未见说话人的语音风格是TTS技术的一个关键挑战。
- DS-TTS方法通过双重风格编码网络和动态生成网络来解决这一挑战。
- 双重风格编码网络能够捕捉说话人语音身份的独特方面。
- 动态生成网络可以解决与句子长度变化相关的合成问题,提高模型的概括能力。
点此查看论文截图

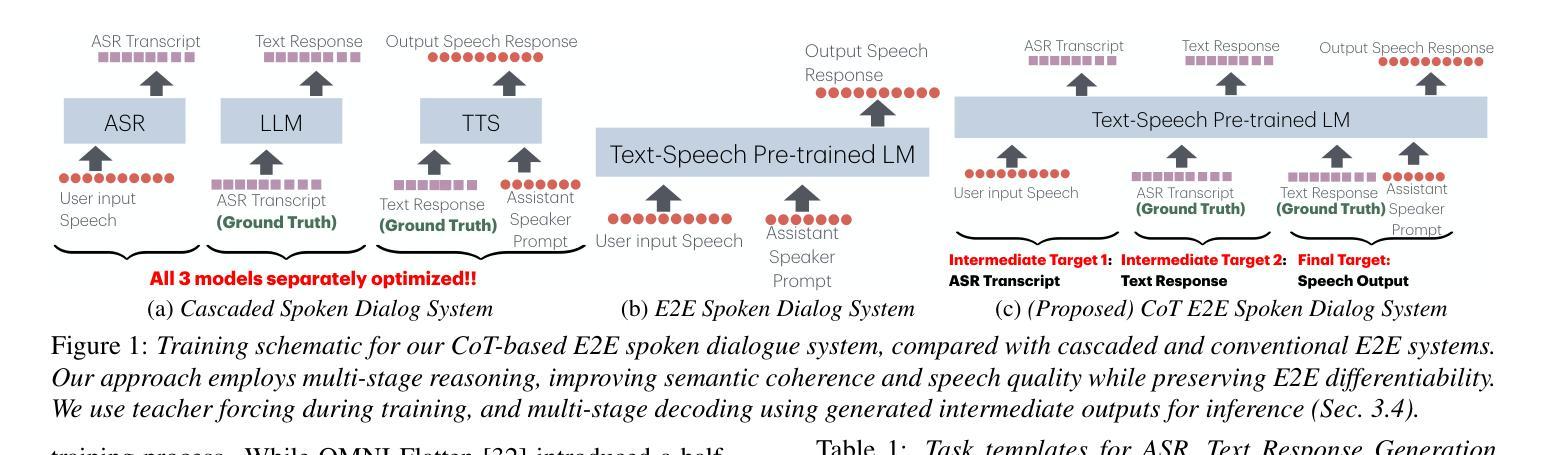
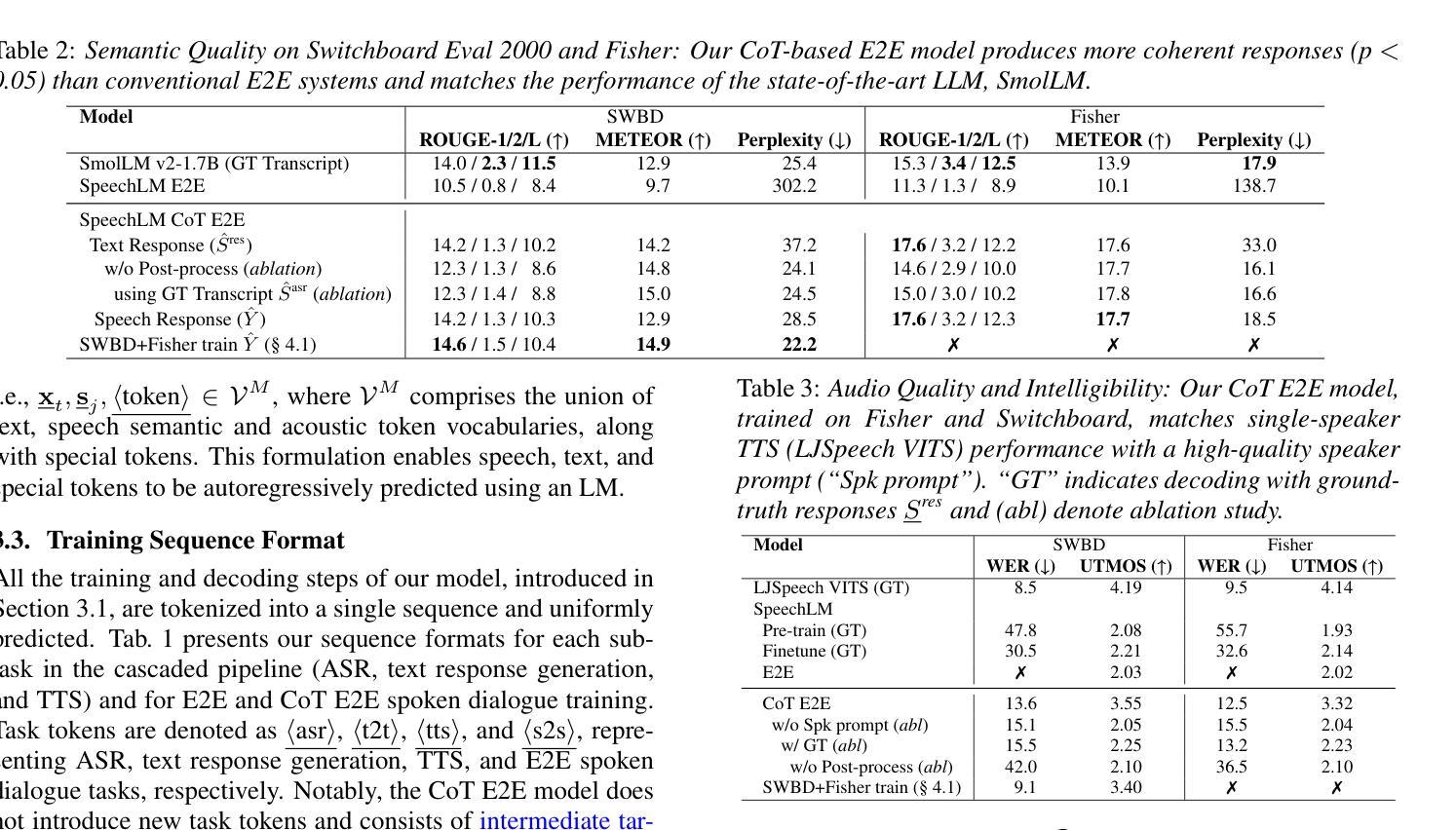
Chain-of-Thought Training for Open E2E Spoken Dialogue Systems
Authors:Siddhant Arora, Jinchuan Tian, Hayato Futami, Jee-weon Jung, Jiatong Shi, Yosuke Kashiwagi, Emiru Tsunoo, Shinji Watanabe
Unlike traditional cascaded pipelines, end-to-end (E2E) spoken dialogue systems preserve full differentiability and capture non-phonemic information, making them well-suited for modeling spoken interactions. However, existing E2E approaches often require large-scale training data and generates responses lacking semantic coherence. We propose a simple yet effective strategy leveraging a chain-of-thought (CoT) formulation, ensuring that training on conversational data remains closely aligned with the multimodal language model (LM)’s pre-training on speech recognition~(ASR), text-to-speech synthesis (TTS), and text LM tasks. Our method achieves over 1.5 ROUGE-1 improvement over the baseline, successfully training spoken dialogue systems on publicly available human-human conversation datasets, while being compute-efficient enough to train on just 300 hours of public human-human conversation data, such as the Switchboard. We will publicly release our models and training code.
与传统级联管道不同,端到端(E2E)口语对话系统保持完全可微分并捕获非语音信息,使其成为建模口语交互的理想选择。然而,现有的E2E方法通常需要大规模的训练数据,并且生成的响应缺乏语义连贯性。我们提出了一种简单有效的策略,利用思维链(CoT)公式,确保在对话数据上的训练与多模态语言模型(LM)在语音识别(ASR)、文本到语音合成(TTS)和文本LM任务上的预训练紧密对齐。我们的方法在基准测试上实现了超过1.5的ROUGE-1改进,成功地在公开可用的人机对话数据集上训练了口语对话系统,同时计算效率足够高,只需在300小时公开的人机对话数据(如Switchboard)上进行训练。我们将公开发布我们的模型和训练代码。
论文及项目相关链接
PDF Accepted at INTERSPEECH 2025
Summary
本文介绍了端到端的语音对话系统(E2E SDS)的优势和挑战。为了克服现有E2E方法的不足,提出了一种利用思维链(CoT)的策略,确保对话系统的训练与多模态语言模型的预训练紧密对齐。该方法成功地在公开的人类对话数据集上训练了语音对话系统,实现了相较于基准线的ROUGE-1评分提升超过1.5,且能够在仅使用300小时公开人类对话数据的情况下进行高效计算训练。
Key Takeaways
- 端到端的语音对话系统(E2E SDS)能够保留完整的可微调性并捕捉非语音信息,适合建模口语交互。
- 现有E2E方法需要大规模的训练数据,生成的响应缺乏语义连贯性。
- 提出了利用思维链(CoT)的策略,确保对话系统的训练与多模态语言模型的预训练对齐。
- 该方法成功地在公开的人类对话数据集上实现了相较于基准线的ROUGE-1评分提升超过1.5。
- 该方法具有计算效率,能够在仅使用300小时公开人类对话数据的情况下进行训练。
- 本文将公开模型和训练代码。
点此查看论文截图

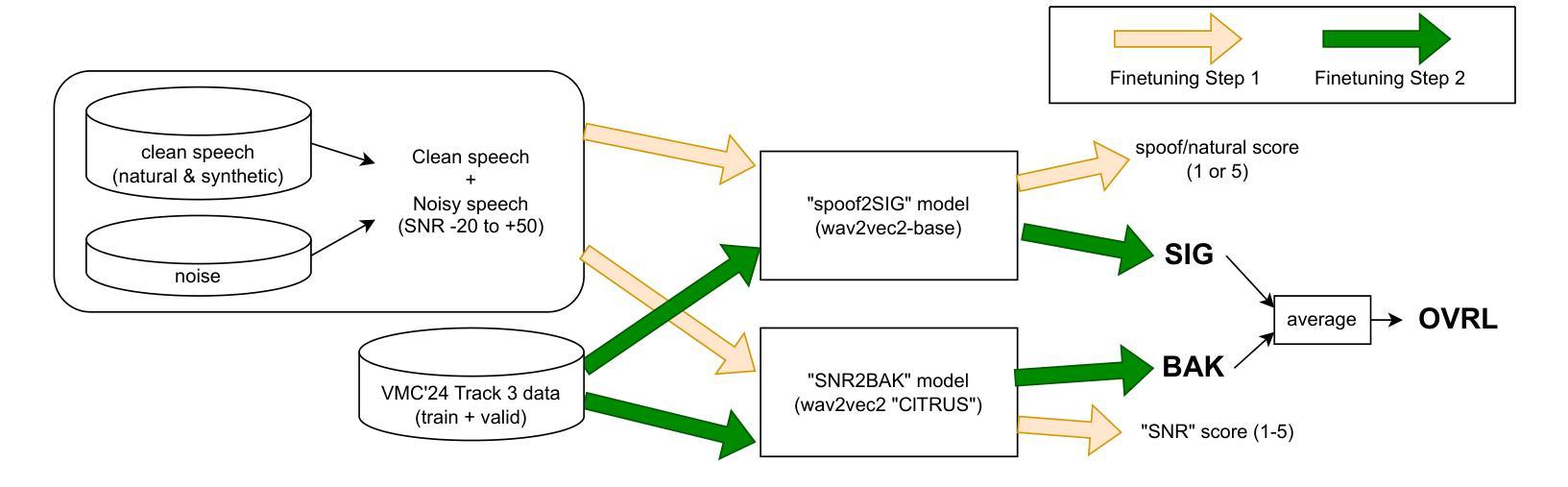
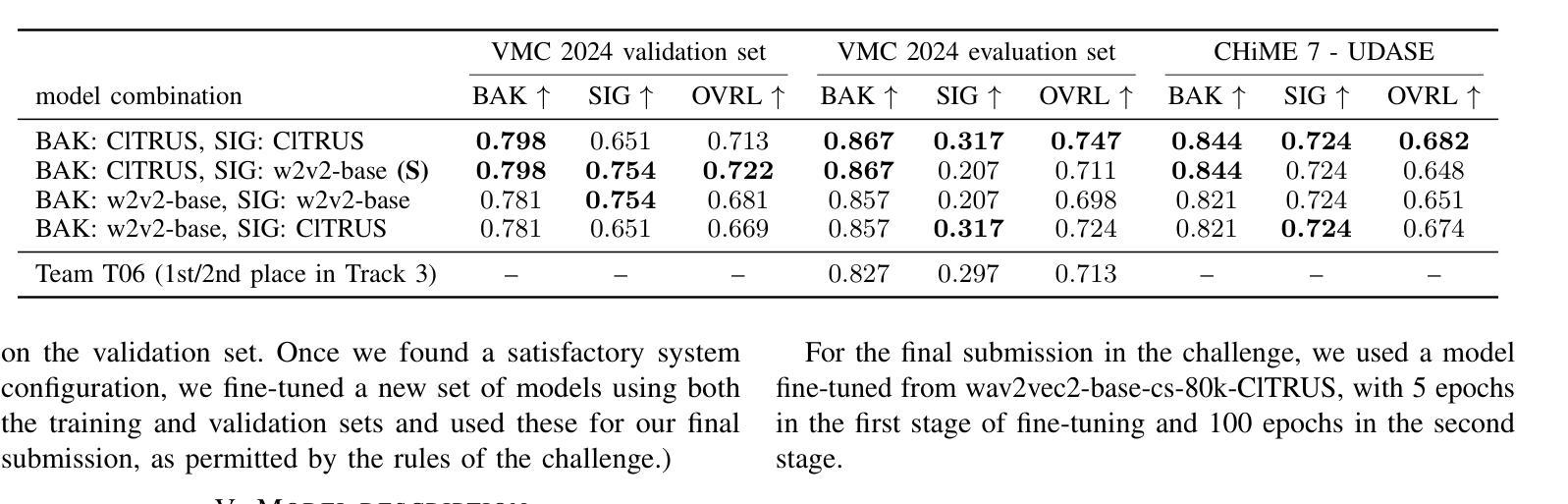
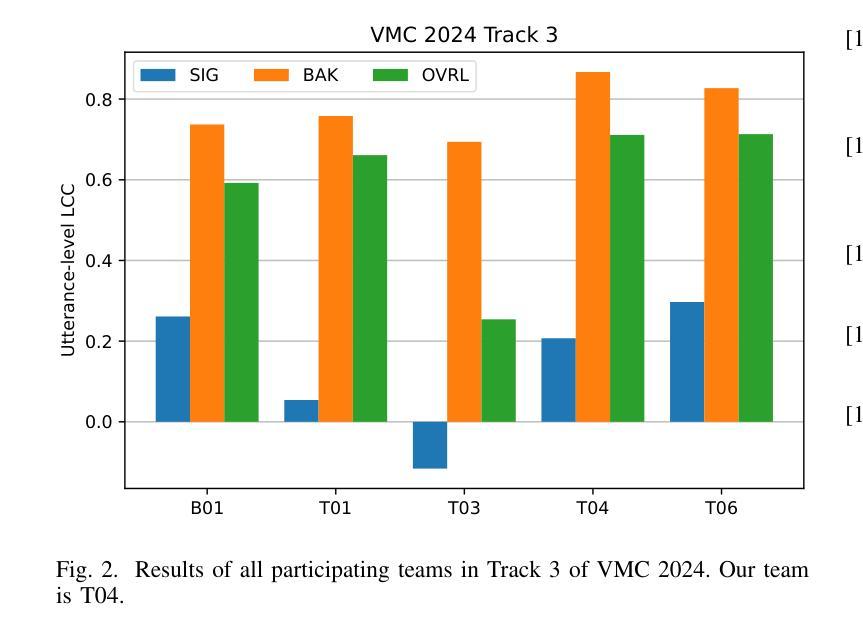
Quality Assessment of Noisy and Enhanced Speech with Limited Data: UWB-NTIS System for VoiceMOS 2024 and Beyond
Authors:Marie Kunešová
In this preprint, we present the UWB-NTIS-TTS team’s submission to Track 3 of the VoiceMOS 2024 Challenge, the goal of which was to automatically assess the speech quality of noisy and de-noised speech in terms of the ITU-T P.835 metrics of “SIG”, “BAK”, and “OVRL”. Our proposed system, based on wav2vec 2.0, placed among the top systems in the challenge, achieving the best prediction of the BAK scores (background noise intrusiveness), the second-best prediction of the OVRL score (overall audio quality), and the third-best prediction of SIG (speech signal quality) out of the five participating systems. We describe our approach, such as the two-stage fine-tuning process we used to contend with the challenge’s very limiting restrictions on allowable training data, and present the results achieved both on the VoiceMOS 2024 Challenge data and on the recently released CHiME 7 - UDASE dataset.
在这篇预印文章中,我们展示了UWB-NTIS-TTS团队对VoiceMOS 2024挑战赛第3赛道的提交内容。该挑战赛的目标是自动评估带噪和降噪语音的语音质量,具体参照ITU-T P.835指标的“SIG”(语音信号质量)、“BAK”(背景噪声侵入性)和“OVRL”(总体音频质量)。我们提出的基于wav2vec 2.0的系统在挑战中跻身顶尖系统之列,实现了对BAK得分(背景噪声侵入性)的最佳预测、对OVRL得分(总体音频质量)的第二佳预测,以及对SIG(语音信号质量)的第三佳预测(在五套参赛系统中)。我们描述了我们的方法,例如我们用于应对挑战赛对可用训练数据非常严格的限制的两阶段微调过程,并展示了在VoiceMOS 2024挑战赛数据和最近发布的CHiME 7-UDASE数据集上取得的结果。
论文及项目相关链接
PDF This is a preliminary write-up of our initial work, posted as an early version preprint for cross-referencing purposes. We intend to further extend this research and submit it for publication at a conference, at which point this preprint will be updated with the full text
Summary
基于wav2vec 2.0的UWB-NTIS-TTS团队在VoiceMOS 2024挑战赛的Track 3中提出了自动评估带噪与降噪语音质量的系统。该系统在背景噪声侵入性(BAK)评分预测上表现最佳,总体音频质量(OVRL)评分预测位列第二,语音信号质量(SIG)预测位列第三。
Key Takeaways
- UWB-NTIS-TTS团队参加了VoiceMOS 2024挑战赛的Track 3,旨在自动评估带噪和降噪语音的质量。
- 团队使用基于wav2vec 2.0的系统参赛,应对挑战赛对训练数据的严格限制。
- 系统在背景噪声侵入性(BAK)评分预测上取得最佳表现。
- 在总体音频质量(OVRL)评分预测上,系统获得第二名。
- 在语音信号质量(SIG)预测方面,系统排名第三。
- 团队描述了两阶段微调过程来应对挑战。
点此查看论文截图