⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-05 更新
TalkingMachines: Real-Time Audio-Driven FaceTime-Style Video via Autoregressive Diffusion Models
Authors:Chetwin Low, Weimin Wang
In this paper, we present TalkingMachines – an efficient framework that transforms pretrained video generation models into real-time, audio-driven character animators. TalkingMachines enables natural conversational experiences by integrating an audio large language model (LLM) with our video generation foundation model. Our primary contributions include: (1) We adapt a pretrained SOTA image-to-video DiT into an audio-driven avatar generation model of 18 billion parameters; (2) We enable infinite video streaming without error accumulation through asymmetric knowledge distillation from a bidirectional teacher model into a sparse causal, autoregressive student model; (3) We design a high-throughput, low-latency inference pipeline incorporating several key engineering optimizations such as: (a) disaggregation of the DiT and VAE decoder across separate devices, (b) efficient overlap of inter-device communication and computation using CUDA streams, (c) elimination of redundant recomputations to maximize frame-generation throughput. Please see demo videos here - https://aaxwaz.github.io/TalkingMachines/
在这篇论文中,我们介绍了TalkingMachines——一个高效框架,它能够将预训练的视频生成模型转化为实时音频驱动的角色动画。TalkingMachines通过整合音频大型语言模型(LLM)与我们的视频生成基础模型,实现了自然的对话体验。我们的主要贡献包括:(1)我们将预训练的图像转视频SOTA DiT技术转化为音频驱动的角色生成模型,参数规模达到十八亿;(2)通过从双向教师模型到稀疏因果自回归学生模型的不对称知识蒸馏技术,我们实现了无误差累积的无限视频流;©我们设计了一个高吞吐量的低延迟推理管道,并进行了几项关键的工程优化,包括:(a)在单独的设备上分散DiT和VAE解码器,(b)使用CUDA流有效地重叠设备间通信和计算,(c)消除冗余重新计算以最大化帧生成吞吐量。相关演示视频可见https://aaxwaz.github.io/TalkingMachines/。
论文及项目相关链接
Summary
文本介绍了TalkingMachines框架,该框架可将预训练的图像转视频模型转化为音频驱动的虚拟角色动画生成模型。其核心优势包括使用先进的图像转视频技术实现实时音频驱动的角色动画生成,支持无限视频流且不会累积误差,以及高效低延迟的推理管道设计。更多信息请参见演示视频。
Key Takeaways
- TalkingMachines是一个音频驱动的动画生成框架,能够转换预训练的视频生成模型。
- 通过整合大型语言模型,增强了模型的对话能力。
- 采用不对称知识蒸馏技术实现连续无误差的视频流。该技术使稀疏因果、自回归的学生模型从双向教师模型中学习。
点此查看论文截图

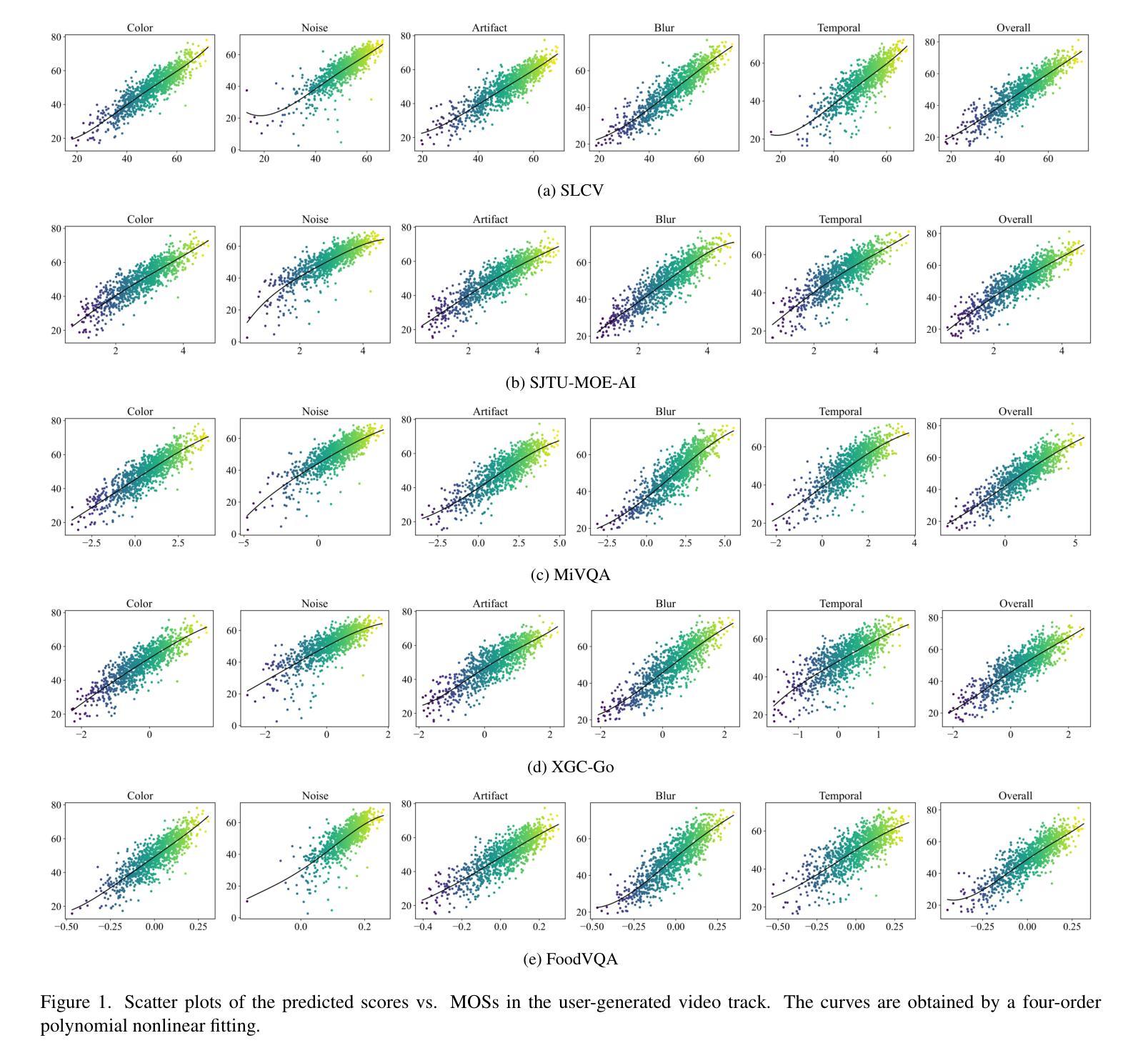
NTIRE 2025 XGC Quality Assessment Challenge: Methods and Results
Authors:Xiaohong Liu, Xiongkuo Min, Qiang Hu, Xiaoyun Zhang, Jie Guo, Guangtao Zhai, Shushi Wang, Yingjie Zhou, Lu Liu, Jingxin Li, Liu Yang, Farong Wen, Li Xu, Yanwei Jiang, Xilei Zhu, Chunyi Li, Zicheng Zhang, Huiyu Duan, Xiele Wu, Yixuan Gao, Yuqin Cao, Jun Jia, Wei Sun, Jiezhang Cao, Radu Timofte, Baojun Li, Jiamian Huang, Dan Luo, Tao Liu, Weixia Zhang, Bingkun Zheng, Junlin Chen, Ruikai Zhou, Meiya Chen, Yu Wang, Hao Jiang, Xiantao Li, Yuxiang Jiang, Jun Tang, Yimeng Zhao, Bo Hu, Zelu Qi, Chaoyang Zhang, Fei Zhao, Ping Shi, Lingzhi Fu, Heng Cong, Shuai He, Rongyu Zhang, Jiarong He, Zongyao Hu, Wei Luo, Zihao Yu, Fengbin Guan, Yiting Lu, Xin Li, Zhibo Chen, Mengjing Su, Yi Wang, Tuo Chen, Chunxiao Li, Shuaiyu Zhao, Jiaxin Wen, Chuyi Lin, Sitong Liu, Ningxin Chu, Jing Wan, Yu Zhou, Baoying Chen, Jishen Zeng, Jiarui Liu, Xianjin Liu, Xin Chen, Lanzhi Zhou, Hangyu Li, You Han, Bibo Xiang, Zhenjie Liu, Jianzhang Lu, Jialin Gui, Renjie Lu, Shangfei Wang, Donghao Zhou, Jingyu Lin, Quanjian Song, Jiancheng Huang, Yufeng Yang, Changwei Wang, Shupeng Zhong, Yang Yang, Lihuo He, Jia Liu, Yuting Xing, Tida Fang, Yuchun Jin
This paper reports on the NTIRE 2025 XGC Quality Assessment Challenge, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2025. This challenge is to address a major challenge in the field of video and talking head processing. The challenge is divided into three tracks, including user generated video, AI generated video and talking head. The user-generated video track uses the FineVD-GC, which contains 6,284 user generated videos. The user-generated video track has a total of 125 registered participants. A total of 242 submissions are received in the development phase, and 136 submissions are received in the test phase. Finally, 5 participating teams submitted their models and fact sheets. The AI generated video track uses the Q-Eval-Video, which contains 34,029 AI-Generated Videos (AIGVs) generated by 11 popular Text-to-Video (T2V) models. A total of 133 participants have registered in this track. A total of 396 submissions are received in the development phase, and 226 submissions are received in the test phase. Finally, 6 participating teams submitted their models and fact sheets. The talking head track uses the THQA-NTIRE, which contains 12,247 2D and 3D talking heads. A total of 89 participants have registered in this track. A total of 225 submissions are received in the development phase, and 118 submissions are received in the test phase. Finally, 8 participating teams submitted their models and fact sheets. Each participating team in every track has proposed a method that outperforms the baseline, which has contributed to the development of fields in three tracks.
本文报道了将于CVPR 2025举办的NTIRE 2025 XGC质量评估挑战赛。这一挑战是为了应对视频和语音处理领域的一大挑战。挑战分为三个赛道:用户生成视频、AI生成视频和语音视频。用户生成视频赛道采用FineVD-GC数据集,包含6,284个用户生成的视频,共有125名注册参赛者。开发阶段共收到242次提交,测试阶段收到136次提交。最终,有五个参赛团队提交了他们的模型和资料。AI生成视频赛道采用Q-Eval-Video数据集,包含由11种流行的文本到视频(T2V)模型生成的34,029个AI生成视频(AIGV),共有133名注册参赛者。开发阶段共收到396次提交,测试阶段收到226次提交。最终,有六个参赛团队提交了他们的模型和资料。语音赛道采用THQA-NTIRE数据集,包含12,247个二维和三维语音头,共有89名注册参赛者。开发阶段共收到225次提交,测试阶段收到118次提交。最终,有八个参赛团队提交了他们的模型和资料。每个赛道的参赛团队都提出了超越基线的方法,为三个领域的发展做出了贡献。
论文及项目相关链接
PDF NTIRE 2025 XGC Quality Assessment Challenge Report. arXiv admin note: text overlap with arXiv:2404.16687
Summary
本文介绍了即将在CVPR 2025举办的NTIRE 2025 XGC质量评估挑战赛。该挑战赛针对视频和谈话头处理领域的主要挑战,分为三个赛道:用户生成视频、AI生成视频和谈话头。每个赛道都有相应的数据集和参与者,并且每个参赛团队在每个赛道上都提出了超越基线的方法,为各赛道的发展做出了贡献。
Key Takeaways
- NTIRE 2025 XGC质量评估挑战赛将在CVPR 2025上举办,旨在解决视频和谈话头处理领域的主要挑战。
- 挑战赛分为三个赛道:用户生成视频、AI生成视频和谈话头。
- 用户生成视频赛道使用FineVD-GC数据集,包含6,284个用户生成视频,有125名参赛者。
- AI生成视频赛道使用Q-Eval-Video数据集,包含34,029个AI生成视频,由11种流行的文本到视频模型生成,有133名参赛者。
- 谈话头赛道使用THQA-NTIRE数据集,包含12,247个二维和三维谈话头,有89名参赛者。
- 各赛道参赛团队都提出了超越基线的方法,为各赛道的发展做出了贡献。
点此查看论文截图

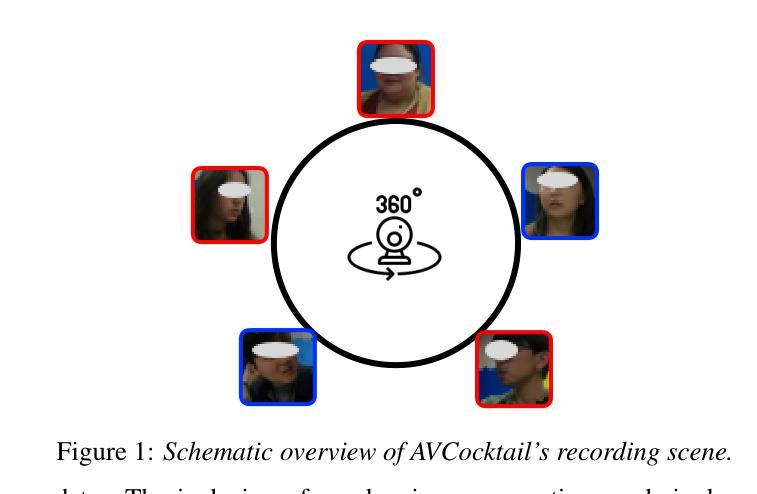
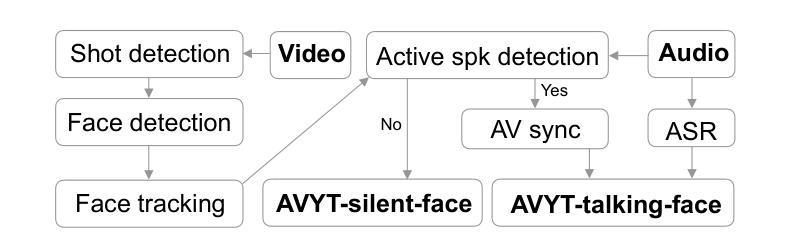
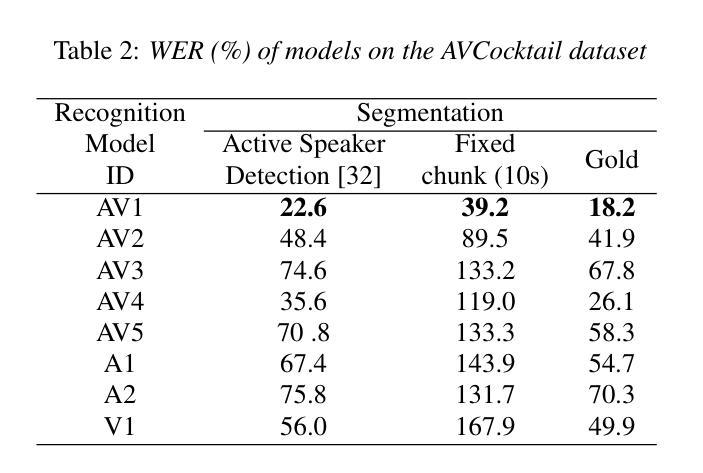
Cocktail-Party Audio-Visual Speech Recognition
Authors:Thai-Binh Nguyen, Ngoc-Quan Pham, Alexander Waibel
Audio-Visual Speech Recognition (AVSR) offers a robust solution for speech recognition in challenging environments, such as cocktail-party scenarios, where relying solely on audio proves insufficient. However, current AVSR models are often optimized for idealized scenarios with consistently active speakers, overlooking the complexities of real-world settings that include both speaking and silent facial segments. This study addresses this gap by introducing a novel audio-visual cocktail-party dataset designed to benchmark current AVSR systems and highlight the limitations of prior approaches in realistic noisy conditions. Additionally, we contribute a 1526-hour AVSR dataset comprising both talking-face and silent-face segments, enabling significant performance gains in cocktail-party environments. Our approach reduces WER by 67% relative to the state-of-the-art, reducing WER from 119% to 39.2% in extreme noise, without relying on explicit segmentation cues.
视听语音识别(AVSR)为在具有挑战性的环境中进行语音识别提供了稳健的解决方案,如在鸡尾酒会场景中,仅依赖音频是不足以应对的。然而,当前的AVSR模型通常针对理想化的场景进行优化,这些场景中发言者始终活跃,忽略了包括说话和无声面部片段的复杂现实世界的设置。本研究通过引入一个新颖的视听鸡尾酒会数据集来解决这一差距,该数据集旨在评估当前的AVSR系统并突出先前方法在真实嘈杂条件下的局限性。此外,我们贡献了一个包含说话面部和无声面部片段的1 5 2 6小时AVSR数据集,能够在鸡尾酒会环境中实现显著的性能提升。我们的方法相较于最新技术将字错误率(WER)降低了6 7%,在极端噪声条件下将WER从1 1 9%降低到3 9. 2%,且无需依赖明确的分段线索。
论文及项目相关链接
PDF Accepted at Interspeech 2025
Summary:视听语音识别(AVSR)在复杂环境中具有强大的语音识别能力,如鸡尾酒会场景。然而,当前AVSR模型主要针对理想化场景进行优化,忽略了现实世界中包括说话和无声面部片段的复杂性。本研究通过引入新的视听鸡尾酒会数据集来解决这一差距,该数据集旨在评估当前AVSR系统并突出先前方法在真实嘈杂条件下的局限性。此外,我们还提供了一个包含说话面部和无声面部片段的1526小时AVSR数据集,可在鸡尾酒会环境中实现显著的性能提升。我们的方法在不依赖明确的分段线索的情况下,相对于最先进的技术将字错误率降低了67%,将极端噪声下的字错误率从119%降低到39.2%。
Key Takeaways:
- AVSR在复杂环境中具有优势,特别是在鸡尾酒会场景中。
- 当前AVSR模型主要关注理想化场景,忽略了现实世界的复杂性。
- 引入新的视听鸡尾酒会数据集,以评估AVSR系统在现实嘈杂条件下的性能。
- 提供包含说话和无声面部片段的1526小时AVSR数据集。
- 本研究的方法在极端噪声条件下显著提高了性能,将字错误率降低了67%。
- 该方法在不依赖明确的分段线索的情况下实现了性能提升。
点此查看论文截图



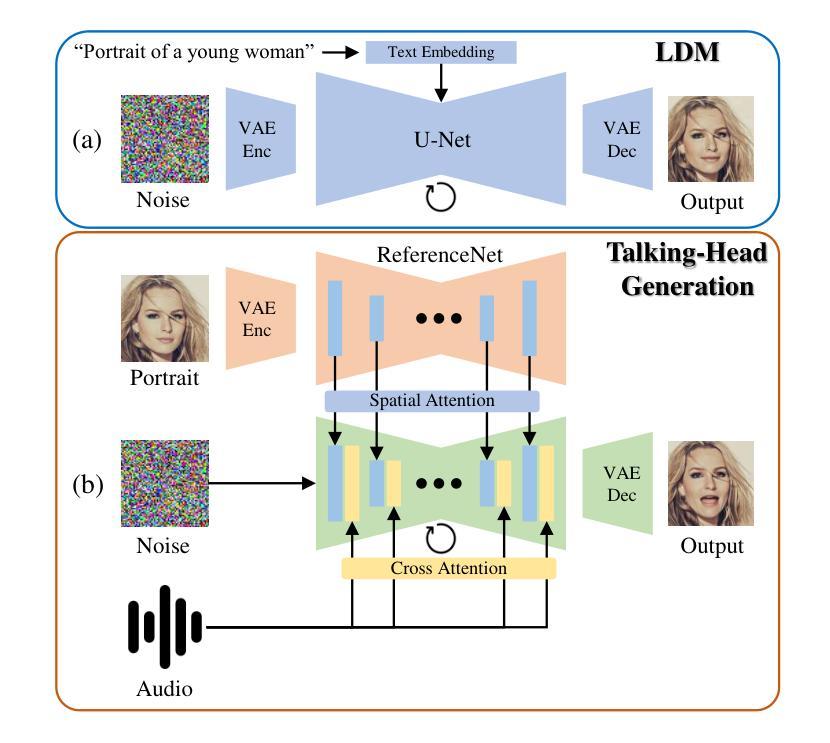
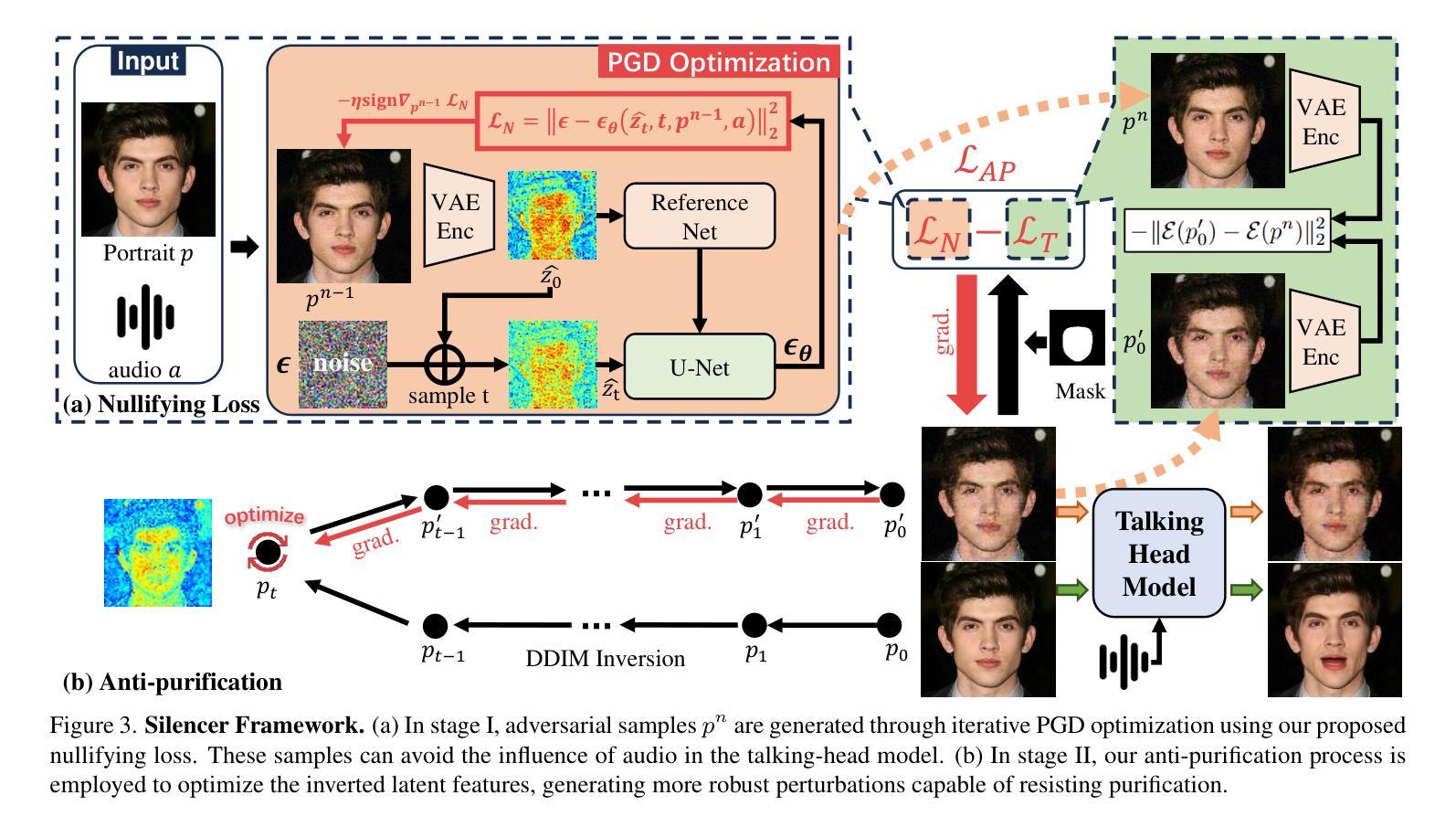
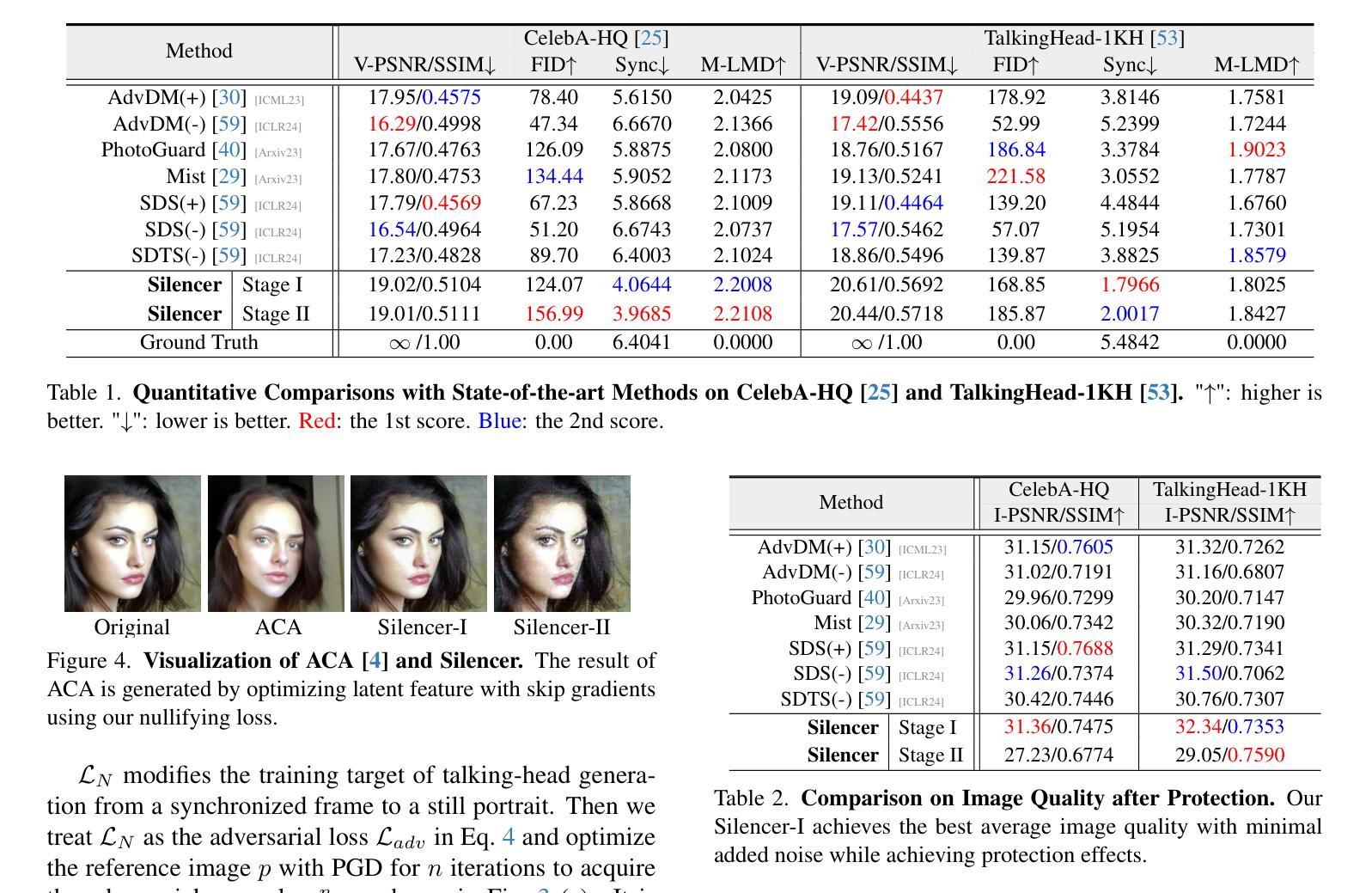
Silence is Golden: Leveraging Adversarial Examples to Nullify Audio Control in LDM-based Talking-Head Generation
Authors:Yuan Gan, Jiaxu Miao, Yunze Wang, Yi Yang
Advances in talking-head animation based on Latent Diffusion Models (LDM) enable the creation of highly realistic, synchronized videos. These fabricated videos are indistinguishable from real ones, increasing the risk of potential misuse for scams, political manipulation, and misinformation. Hence, addressing these ethical concerns has become a pressing issue in AI security. Recent proactive defense studies focused on countering LDM-based models by adding perturbations to portraits. However, these methods are ineffective at protecting reference portraits from advanced image-to-video animation. The limitations are twofold: 1) they fail to prevent images from being manipulated by audio signals, and 2) diffusion-based purification techniques can effectively eliminate protective perturbations. To address these challenges, we propose Silencer, a two-stage method designed to proactively protect the privacy of portraits. First, a nullifying loss is proposed to ignore audio control in talking-head generation. Second, we apply anti-purification loss in LDM to optimize the inverted latent feature to generate robust perturbations. Extensive experiments demonstrate the effectiveness of Silencer in proactively protecting portrait privacy. We hope this work will raise awareness among the AI security community regarding critical ethical issues related to talking-head generation techniques. Code: https://github.com/yuangan/Silencer.
基于潜在扩散模型(LDM)的谈话头部动画技术的进步,使得创建高度逼真、同步的视频成为可能。这些合成视频与真实视频无法区分,增加了被用于欺诈、政治操纵和误导信息的潜在风险。因此,解决这些伦理问题已成为人工智能安全领域的紧迫问题。最近的主动防御研究集中在通过对肖像添加扰动来对抗基于LDM的模型。然而,这些方法对于保护参考肖像免受先进的图像到视频动画技术的侵害并不有效。其局限性有两方面:1)他们无法防止图像被音频信号操纵;2)基于扩散的净化技术可以有效地消除保护性扰动。为了解决这些挑战,我们提出了Silencer,这是一种两阶段方法,旨在主动保护肖像隐私。首先,我们提出了一种失效损失,以忽略头部谈话生成中的音频控制。其次,我们在LDM中应用了抗净化损失,以优化反向潜在特征,从而产生稳健的扰动。大量实验表明,Silencer在主动保护肖像隐私方面非常有效。我们希望这项工作将提高人工智能安全社区对与谈话头部生成技术相关的关键伦理问题的认识。代码:https://github.com/yuangan/Silencer。
论文及项目相关链接
PDF Accepted to CVPR 2025
Summary
基于潜在扩散模型(LDM)的说话人动画技术的进展,使得创建高度逼真、同步的视频成为可能。这些伪造的视频与现实中的视频难以区分,增加了被用于诈骗、政治操纵和误导信息潜在滥用的风险。因此,解决这些伦理问题已成为人工智能安全领域的紧迫议题。针对LDM模型的新防御策略通过添加扰动来保护肖像,但这种方法对于防止音频信号操纵图像以及消除保护扰动方面的效果有限。为此,我们提出了Silencer,这是一种两阶段的方法,旨在主动保护肖像隐私。首先,提出一种无效损失来忽略说话人生成中的音频控制。其次,我们在LDM中应用抗净化损失,以优化反向潜在特征,产生稳健的扰动。实验证明Silencer在主动保护肖像隐私方面的有效性。我们希望这项工作能提高人工智能安全社区对说话人生成技术相关重要伦理问题的认识。
Key Takeaways
- 说话人动画技术基于潜在扩散模型(LDM)发展,能创建高度逼真的视频。
- 伪造的视频与现实视频难以区分,引发关于潜在滥用的伦理担忧。
- 当前防御策略主要通过添加扰动来保护肖像,但对音频信号操纵图像和消除保护扰动存在局限性。
- Silencer方法通过两个阶段主动保护肖像隐私:无效损失以忽略音频控制,抗净化损失以优化反向潜在特征并产生稳健扰动。
- 实验证明Silencer方法的有效性。
- 该工作旨在提高人工智能安全社区对说话人生成技术相关伦理问题的认识。
- 代码可通过https://github.com/yuangan/Silencer访问。
点此查看论文截图


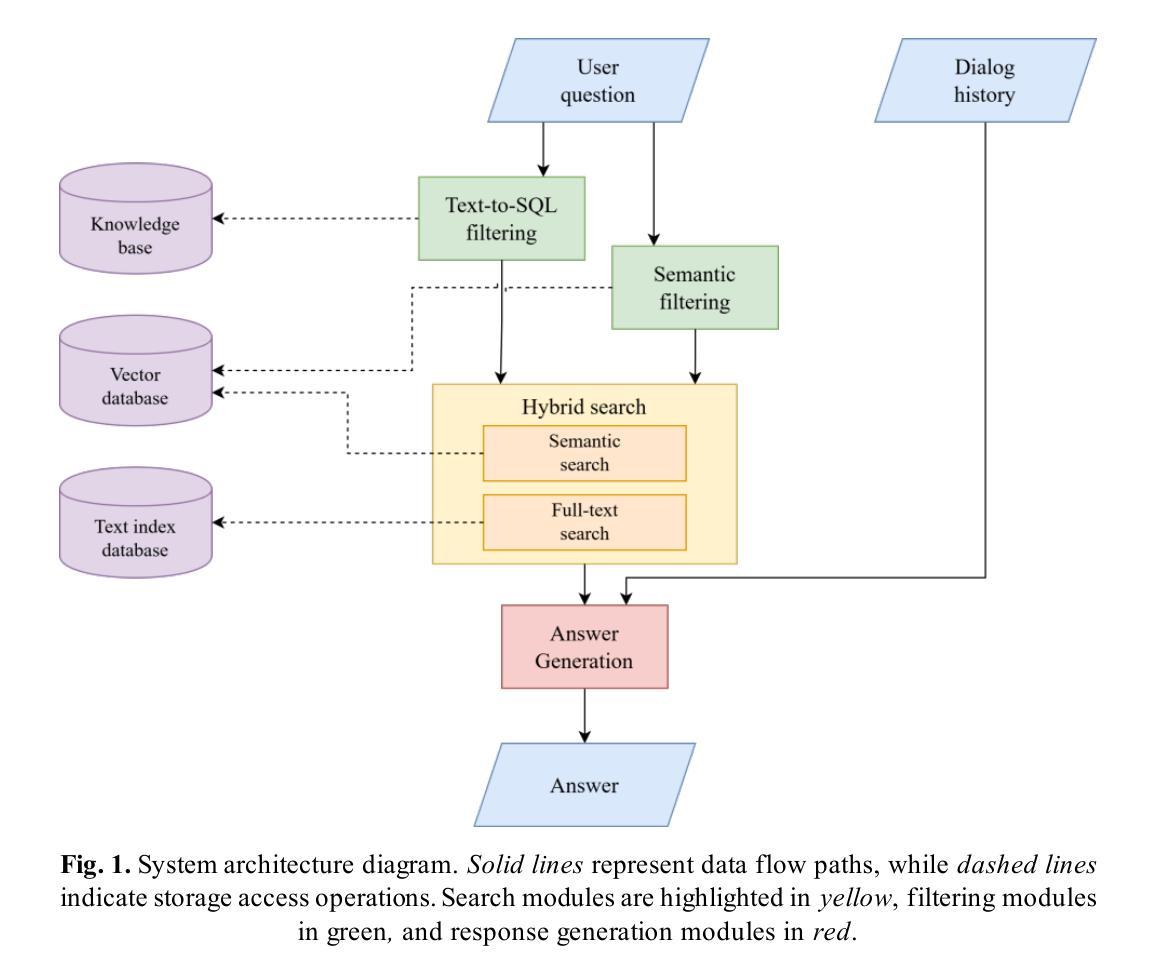
Talking to Data: Designing Smart Assistants for Humanities Databases
Authors:Alexander Sergeev, Valeriya Goloviznina, Mikhail Melnichenko, Evgeny Kotelnikov
Access to humanities research databases is often hindered by the limitations of traditional interaction formats, particularly in the methods of searching and response generation. This study introduces an LLM-based smart assistant designed to facilitate natural language communication with digital humanities data. The assistant, developed in a chatbot format, leverages the RAG approach and integrates state-of-the-art technologies such as hybrid search, automatic query generation, text-to-SQL filtering, semantic database search, and hyperlink insertion. To evaluate the effectiveness of the system, experiments were conducted to assess the response quality of various language models. The testing was based on the Prozhito digital archive, which contains diary entries from predominantly Russian-speaking individuals who lived in the 20th century. The chatbot is tailored to support anthropology and history researchers, as well as non-specialist users with an interest in the field, without requiring prior technical training. By enabling researchers to query complex databases with natural language, this tool aims to enhance accessibility and efficiency in humanities research. The study highlights the potential of Large Language Models to transform the way researchers and the public interact with digital archives, making them more intuitive and inclusive. Additional materials are presented in GitHub repository: https://github.com/alekosus/talking-to-data-intersys2025.
人文科学研究的数据库访问常常受到传统交互形式限制的影响,特别是在搜索和响应生成的方法上。本研究引入了一种基于大型语言模型(LLM)的智能助理,旨在促进与数字人文数据的自然语言交流。该助理以聊天机器人形式开发,采用RAG方法,并集成了最先进的技术,如混合搜索、自动查询生成、文本到SQL过滤、语义数据库搜索和超链接插入。为了评估系统的有效性,进行了一系列实验来评估各种语言模型的响应质量。测试基于Prozhito数字档案馆进行,该档案馆主要包含20世纪主要使用俄语的个人日记。聊天机器人支持人类学和历史研究者,以及对该领域感兴趣的非专业人士,无需他们接受事先的技术培训。通过使研究人员能够用自然语言查询复杂数据库,这个工具旨在提高人文科学研究的可访问性和效率。该研究突出了大型语言模型的潜力,可以转变研究者和公众与数字档案的交互方式,使其更加直观和包容。附加材料呈现在GitHub仓库中:https://github.com/alekosus/talking-to-data-intersys2025。
论文及项目相关链接
PDF Accepted for InterSys-2025 conference
Summary:该研究通过引入LLM智能助理来解决传统交互形式在人文学科研究数据库使用上的限制。智能助理以聊天机器人形式开发,运用RAG方法集成混合搜索等技术。测试表明该工具可以有效支持人类学和历史研究等领域的学者进行数据库查询。其可极大提高研究者访问和使用数据库的效率和质量,推动人文研究数字化和公共参与度提升。研究突出了大型语言模型对改善研究者和公众与数字档案交互方式的潜力。具体信息和材料可通过GitHub获取。
Key Takeaways:
- 人文学科研究数据库存在传统交互形式的局限性,导致访问和使用效率不高。
- LLM智能助理引入,解决此问题,利用自然语言处理技术简化数据库查询方式。
- 智能助理以聊天机器人形式开发,集成了混合搜索等技术手段。
- 实验证明该工具在支持人类学和历史研究方面效果显著。
- 大型语言模型在改善研究者和公众与数字档案交互方面潜力巨大。
- 智能助理的推出有助于提高研究者和公众访问数字档案的效率和便利性。
点此查看论文截图

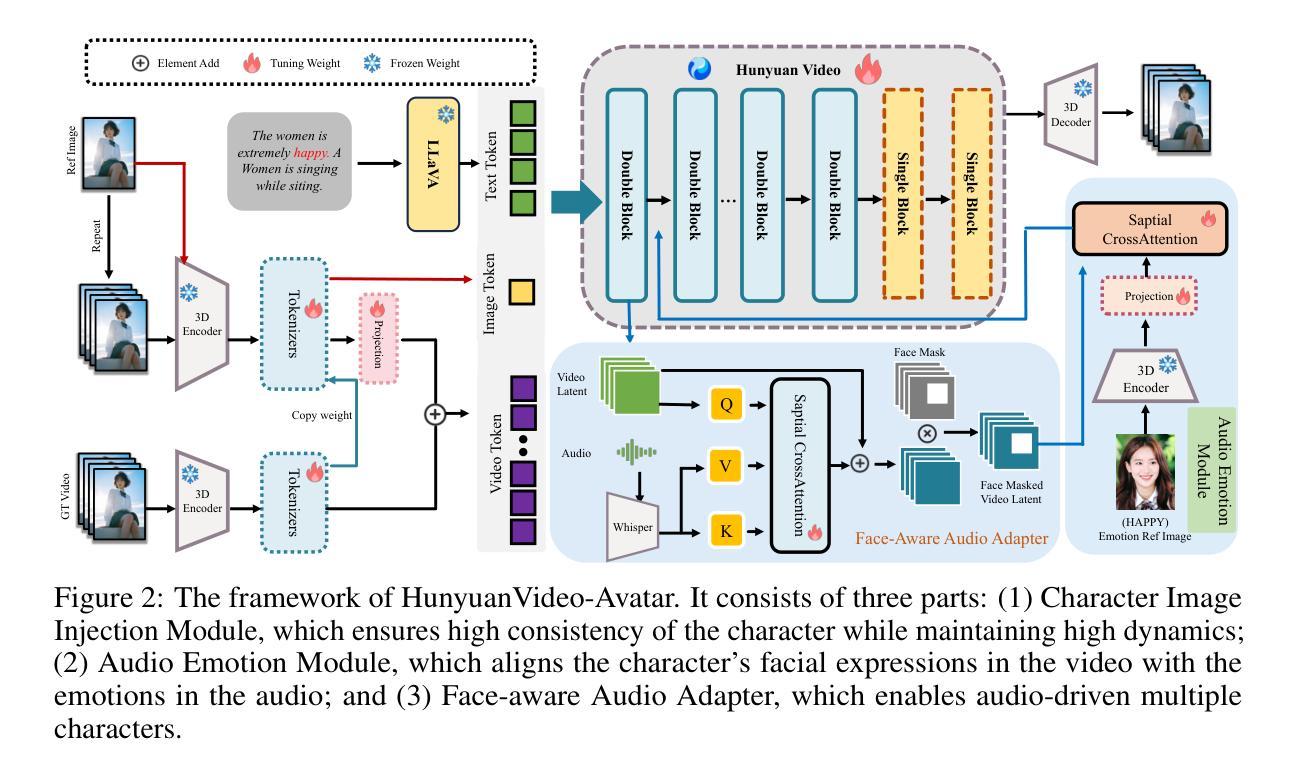
HunyuanVideo-Avatar: High-Fidelity Audio-Driven Human Animation for Multiple Characters
Authors:Yi Chen, Sen Liang, Zixiang Zhou, Ziyao Huang, Yifeng Ma, Junshu Tang, Qin Lin, Yuan Zhou, Qinglin Lu
Recent years have witnessed significant progress in audio-driven human animation. However, critical challenges remain in (i) generating highly dynamic videos while preserving character consistency, (ii) achieving precise emotion alignment between characters and audio, and (iii) enabling multi-character audio-driven animation. To address these challenges, we propose HunyuanVideo-Avatar, a multimodal diffusion transformer (MM-DiT)-based model capable of simultaneously generating dynamic, emotion-controllable, and multi-character dialogue videos. Concretely, HunyuanVideo-Avatar introduces three key innovations: (i) A character image injection module is designed to replace the conventional addition-based character conditioning scheme, eliminating the inherent condition mismatch between training and inference. This ensures the dynamic motion and strong character consistency; (ii) An Audio Emotion Module (AEM) is introduced to extract and transfer the emotional cues from an emotion reference image to the target generated video, enabling fine-grained and accurate emotion style control; (iii) A Face-Aware Audio Adapter (FAA) is proposed to isolate the audio-driven character with latent-level face mask, enabling independent audio injection via cross-attention for multi-character scenarios. These innovations empower HunyuanVideo-Avatar to surpass state-of-the-art methods on benchmark datasets and a newly proposed wild dataset, generating realistic avatars in dynamic, immersive scenarios.
近年来,音频驱动的人形动画领域取得了显著进展。然而,仍然存在以下关键挑战:(i)在保持角色一致性的同时生成高度动态的视频;(ii)实现角色和音频之间的精确情感对齐;(iii)实现多角色音频驱动动画。为了解决这些挑战,我们提出了基于多模态扩散转换器(MM-DiT)的“胡源视频化身(HunyuanVideo-Avatar)”,它能够同时生成动态、情感可控、多角色对话视频。具体来说,胡源视频化身引入了三项关键创新:(i)设计了角色图像注入模块,以替代传统的基于添加的角色条件方案,消除了训练和推理之间固有的条件不匹配,确保动态运动和强烈的角色一致性;(ii)引入了音频情感模块(AEM),从情感参考图像中提取并转移情感线索到目标生成视频,实现精细和准确的情感风格控制;(iii)提出了面部感知音频适配器(FAA),通过潜在层面的面部遮挡来隔离音频驱动的角色,实现多角色场景中的独立音频注入。这些创新使胡源视频化身在基准数据集和新提出的野生数据集上超越了最先进的方法,在动态、沉浸式场景中生成逼真的化身。
论文及项目相关链接
Summary
近期音频驱动的人形动画技术取得显著进展,但仍面临生成高度动态视频时保持角色一致性、实现角色情感与音频精准对齐以及实现多角色音频驱动动画等挑战。为此,我们提出基于多模态扩散变压器(MM-DiT)的HunyuanVideo-Avatar模型,能同时生成动态、情感可控、多角色对话视频。该模型引入三大创新点:角色图像注入模块、音频情感模块和面部感知音频适配器,分别解决以上挑战,从而在基准测试集和新提出的野生数据集上超越现有方法,生成真实感强的动态沉浸式角色。
Key Takeaways
- 音频驱动人形动画技术取得显著进展,但仍存在生成高度动态视频的挑战,需保持角色一致性。
- 提出基于多模态扩散变压器的HunyuanVideo-Avatar模型,能同时处理动态、情感可控、多角色对话视频生成。
- 引入角色图像注入模块,替代传统基于添加的角色条件方案,确保动态运动和强角色一致性。
- 引入音频情感模块,从情感参考图像中提取并转移情感线索到目标生成视频,实现精细粒度的情感风格控制。
- 提出面部感知音频适配器,通过潜在层面的面部遮挡实现独立音频注入,支持多角色场景中的跨注意力。
- HunyuanVideo-Avatar模型在基准测试集和新提出的野生数据集上表现超越现有方法。
点此查看论文截图

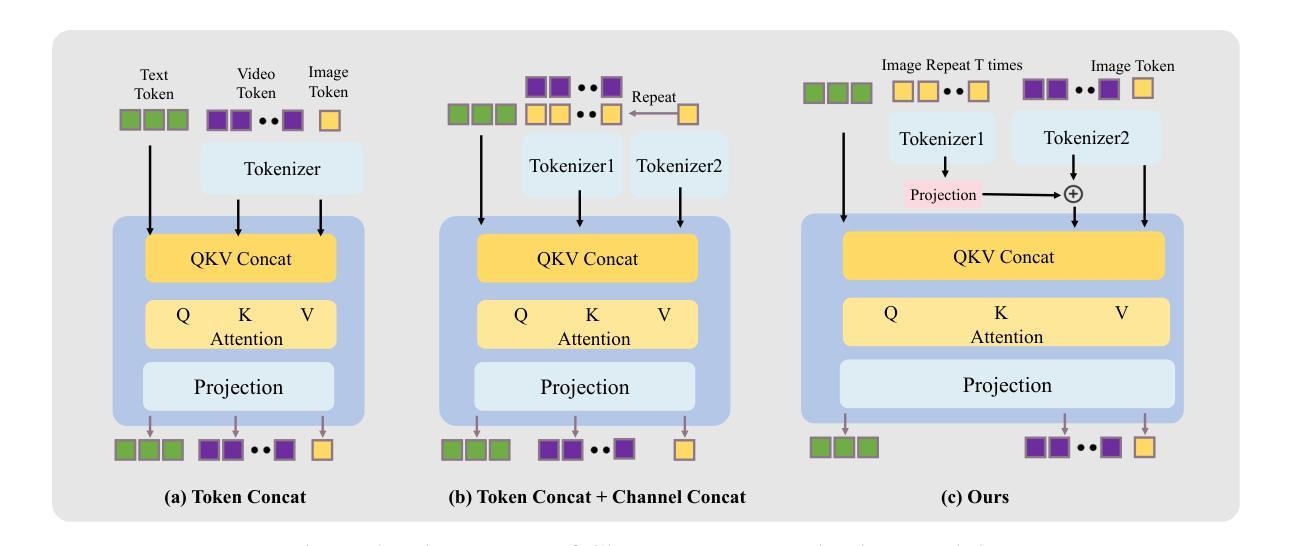
OmniTalker: One-shot Real-time Text-Driven Talking Audio-Video Generation With Multimodal Style Mimicking
Authors:Zhongjian Wang, Peng Zhang, Jinwei Qi, Guangyuan Wang, Chaonan Ji, Sheng Xu, Bang Zhang, Liefeng Bo
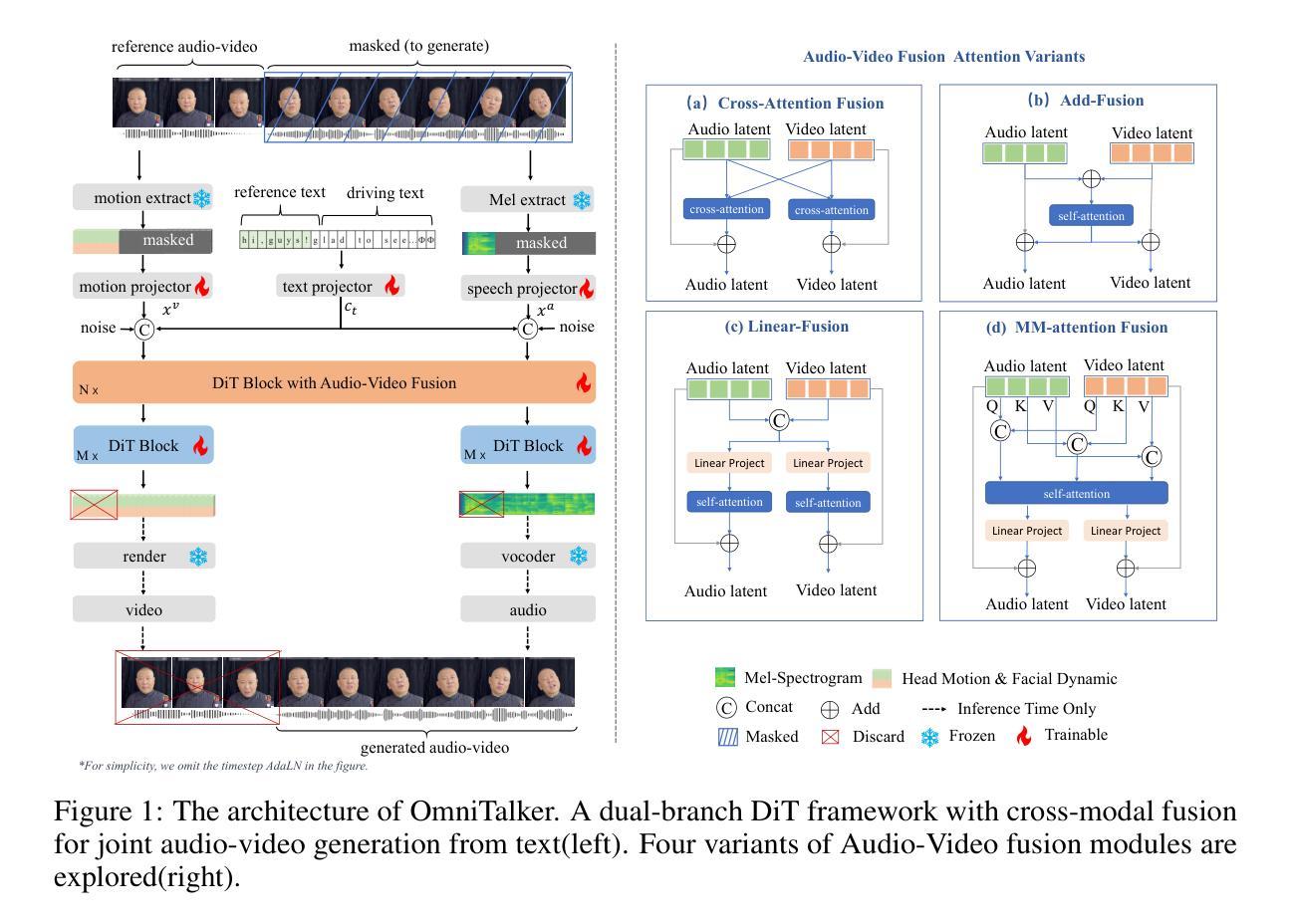
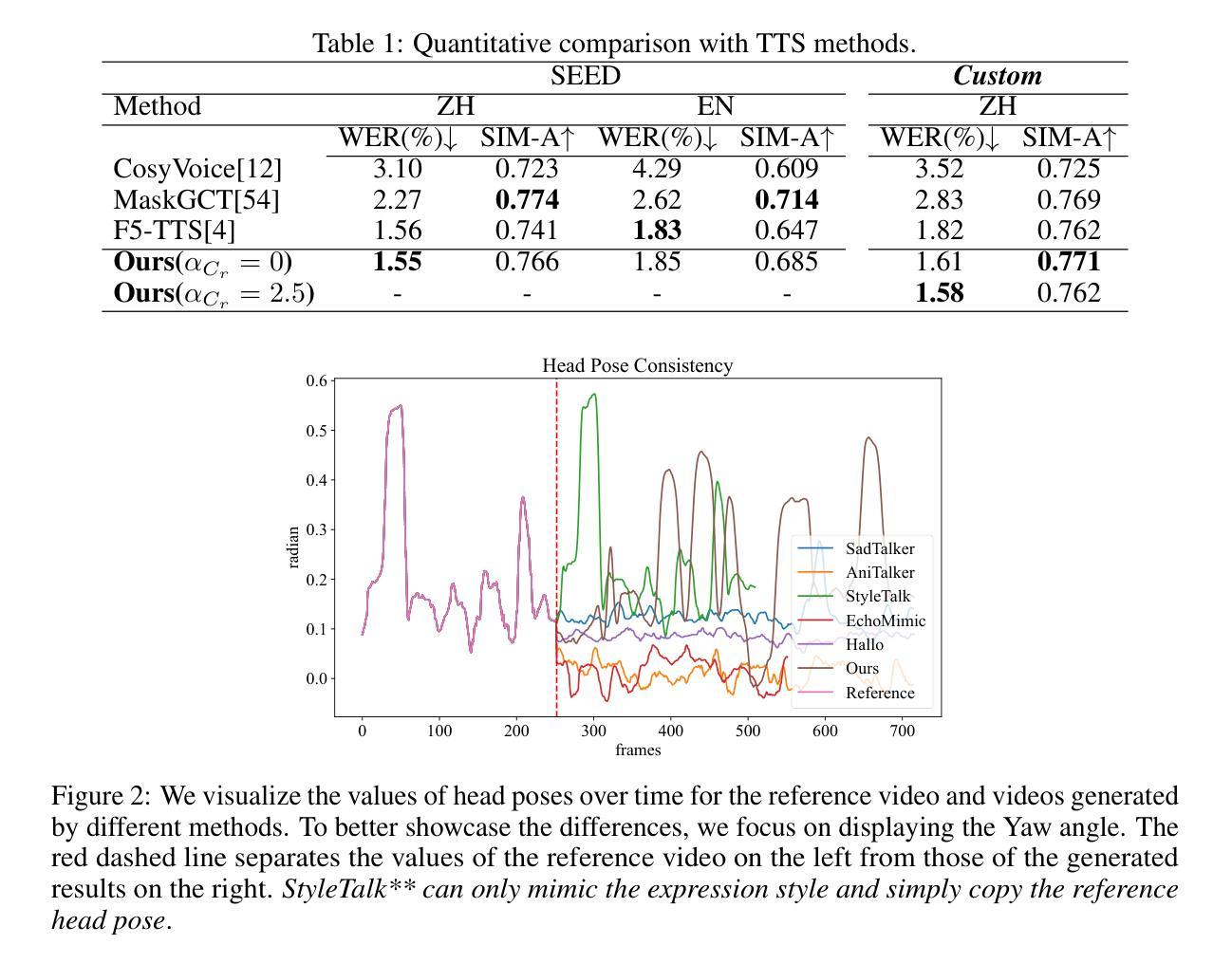
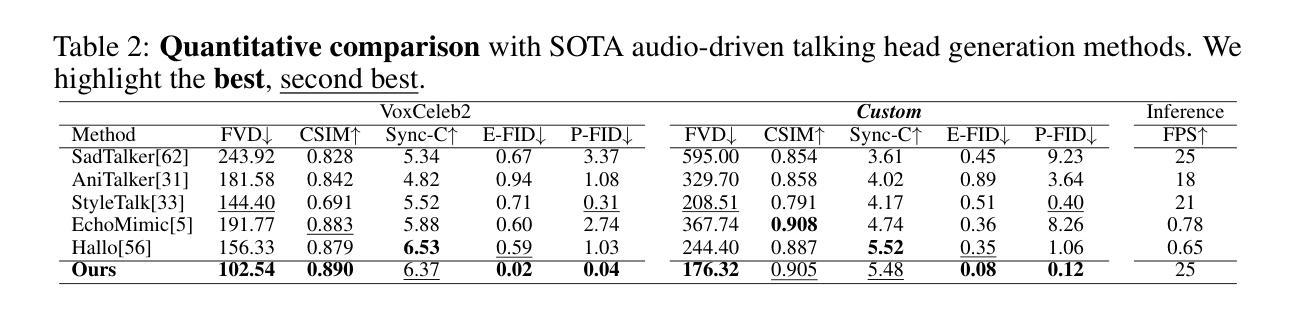
Although significant progress has been made in audio-driven talking head generation, text-driven methods remain underexplored. In this work, we present OmniTalker, a unified framework that jointly generates synchronized talking audio-video content from input text while emulating the speaking and facial movement styles of the target identity, including speech characteristics, head motion, and facial dynamics. Our framework adopts a dual-branch diffusion transformer (DiT) architecture, with one branch dedicated to audio generation and the other to video synthesis. At the shallow layers, cross-modal fusion modules are introduced to integrate information between the two modalities. In deeper layers, each modality is processed independently, with the generated audio decoded by a vocoder and the video rendered using a GAN-based high-quality visual renderer. Leveraging the in-context learning capability of DiT through a masked-infilling strategy, our model can simultaneously capture both audio and visual styles without requiring explicit style extraction modules. Thanks to the efficiency of the DiT backbone and the optimized visual renderer, OmniTalker achieves real-time inference at 25 FPS. To the best of our knowledge, OmniTalker is the first one-shot framework capable of jointly modeling speech and facial styles in real time. Extensive experiments demonstrate its superiority over existing methods in terms of generation quality, particularly in preserving style consistency and ensuring precise audio-video synchronization, all while maintaining efficient inference.
尽管音频驱动的头部说话生成已经取得了显著进展,但文本驱动的方法仍然未被充分探索。在这项工作中,我们提出了OmniTalker,这是一个统一框架,能够从输入文本生成同步的音频视频内容,同时模拟目标身份的说话和面部运动风格,包括语音特征、头部运动和面部动态。我们的框架采用了双分支扩散变压器(DiT)架构,一个分支用于音频生成,另一个分支用于视频合成。在浅层,引入了跨模态融合模块来整合两种模态之间的信息。在深层,每个模态独立处理,生成的音频由vocoder解码,视频使用基于GAN的高质量视觉渲染器呈现。通过DiT的上下文学习能力,结合掩膜填充策略,我们的模型可以同时捕捉音频和视频风格,无需明确的风格提取模块。得益于DiT骨干网的效率和优化的视觉渲染器,OmniTalker实现了以每秒25帧的实时推理。据我们所知,OmniTalker是首个能够实时联合建模语音和面部风格的单次框架。大量实验证明,其在生成质量上优于现有方法,尤其在保持风格一致性和确保音视频同步方面表现突出,同时维持高效的推理速度。
论文及项目相关链接
PDF Project Page https://humanaigc.github.io/omnitalker
Summary
本文介绍了一个名为OmniTalker的统一框架,该框架能够从输入文本生成同步的音频视频内容,同时模仿目标身份的说话和面部运动风格,包括语音特征、头部运动和面部动态。OmniTalker采用双分支扩散变压器(DiT)架构,通过掩膜填充策略实现音频和视频风格的捕捉,无需显式风格提取模块。借助DiT的上下文学习能力,OmniTalker能实时生成高质量音频和视频内容,实现实时推理。据我们所知,OmniTalker是首个能够实时联合建模语音和面部风格的单镜头框架。
Key Takeaways
- OmniTalker是一个统一框架,能够从输入文本生成同步的音频视频内容。
- 该框架能够模仿目标身份的说话和面部运动风格,包括语音特征、头部运动和面部动态。
- OmniTalker采用双分支扩散变压器(DiT)架构,实现音频和视频内容的生成。
- 通过掩膜填充策略,OmniTalker能同时捕捉音频和视频风格,无需显式风格提取模块。
- 该框架具有实时生成高质量音频和视频的能力,实现实时推理。
- OmniTalker在生成质量方面优于现有方法,尤其在保持风格一致性和确保音视频同步方面。
点此查看论文截图