⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-06 更新
Contour Errors: An Ego-Centric Metric for Reliable 3D Multi-Object Tracking
Authors:Sharang Kaul, Mario Berk, Thiemo Gerbich, Abhinav Valada
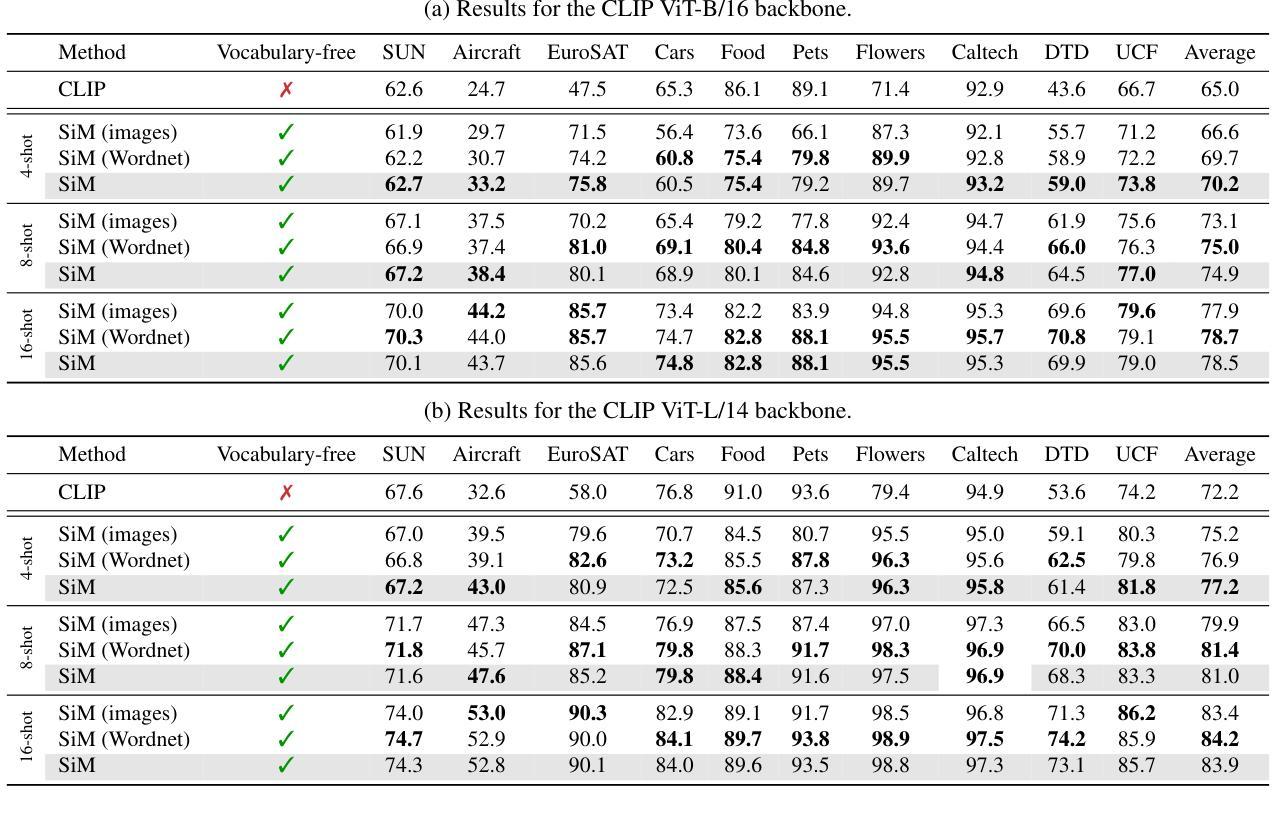
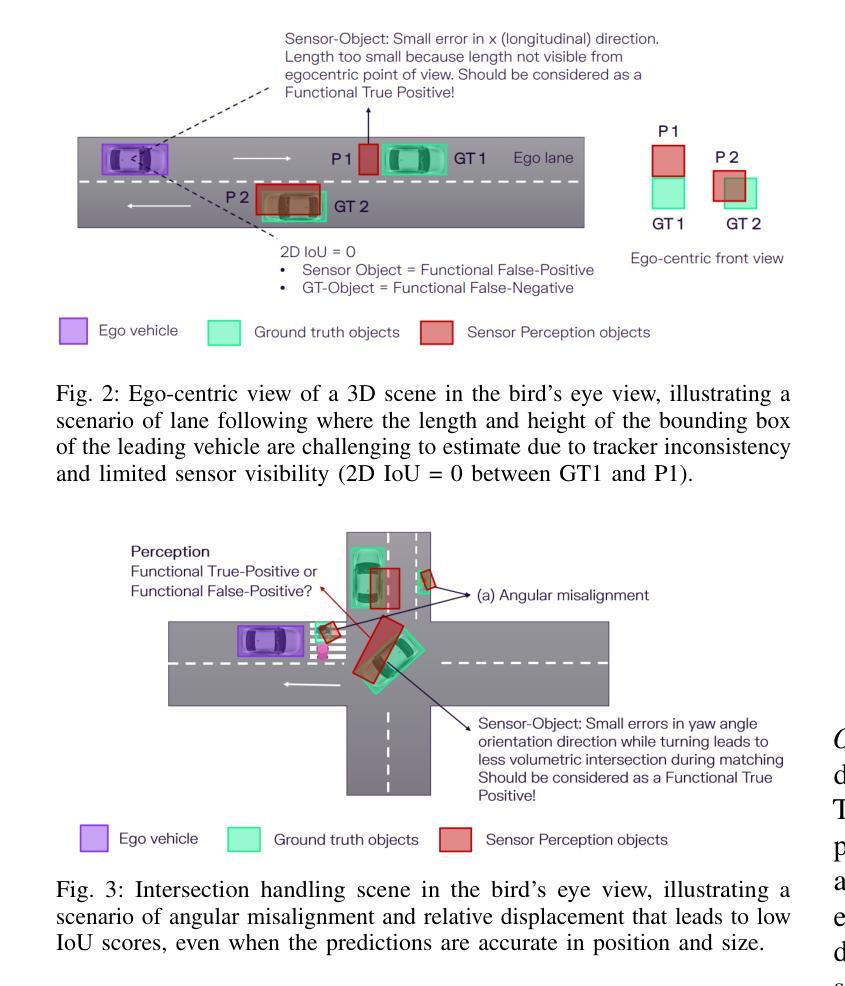
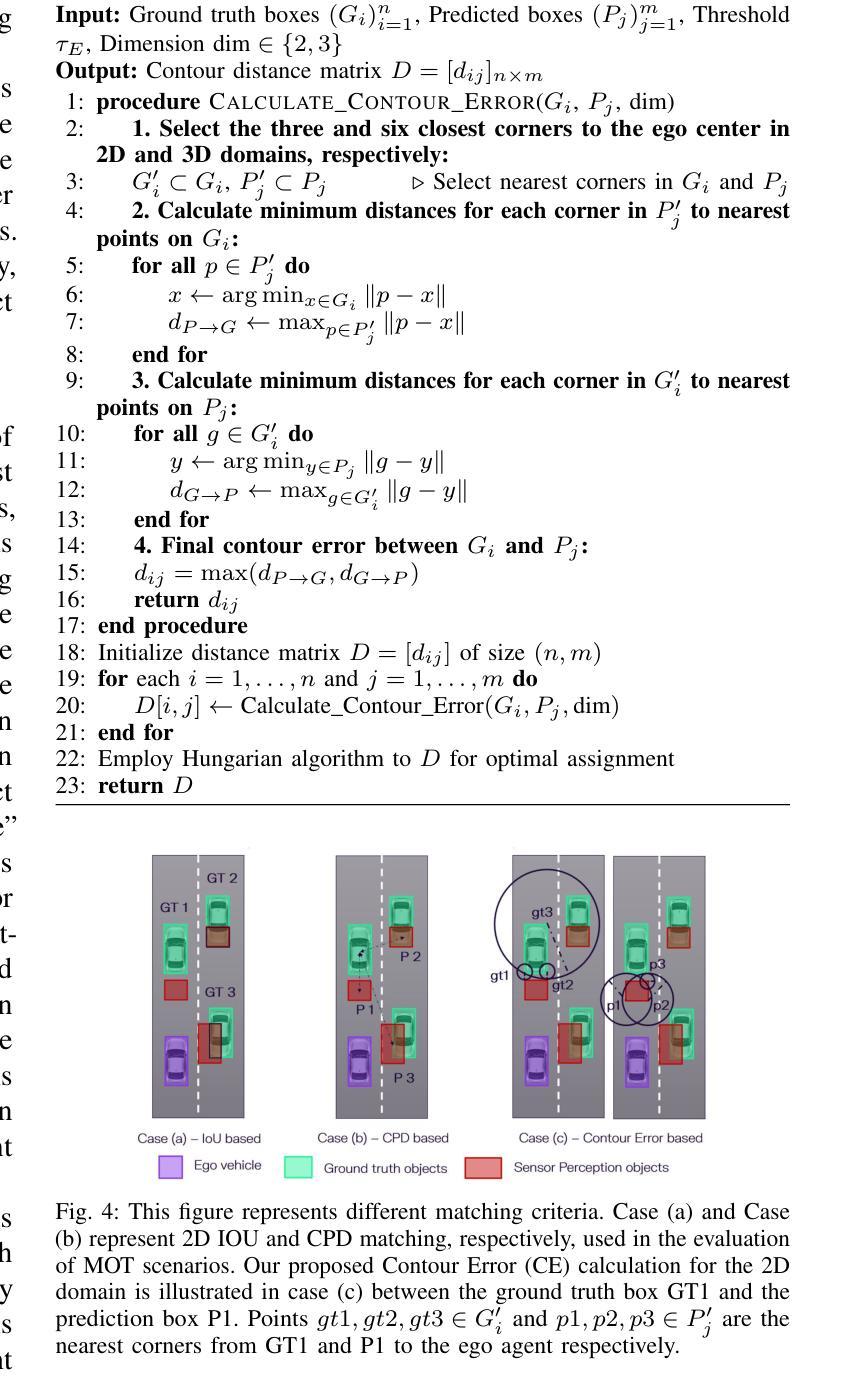
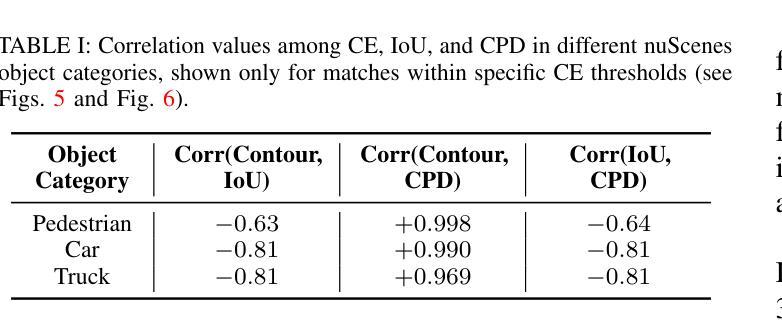
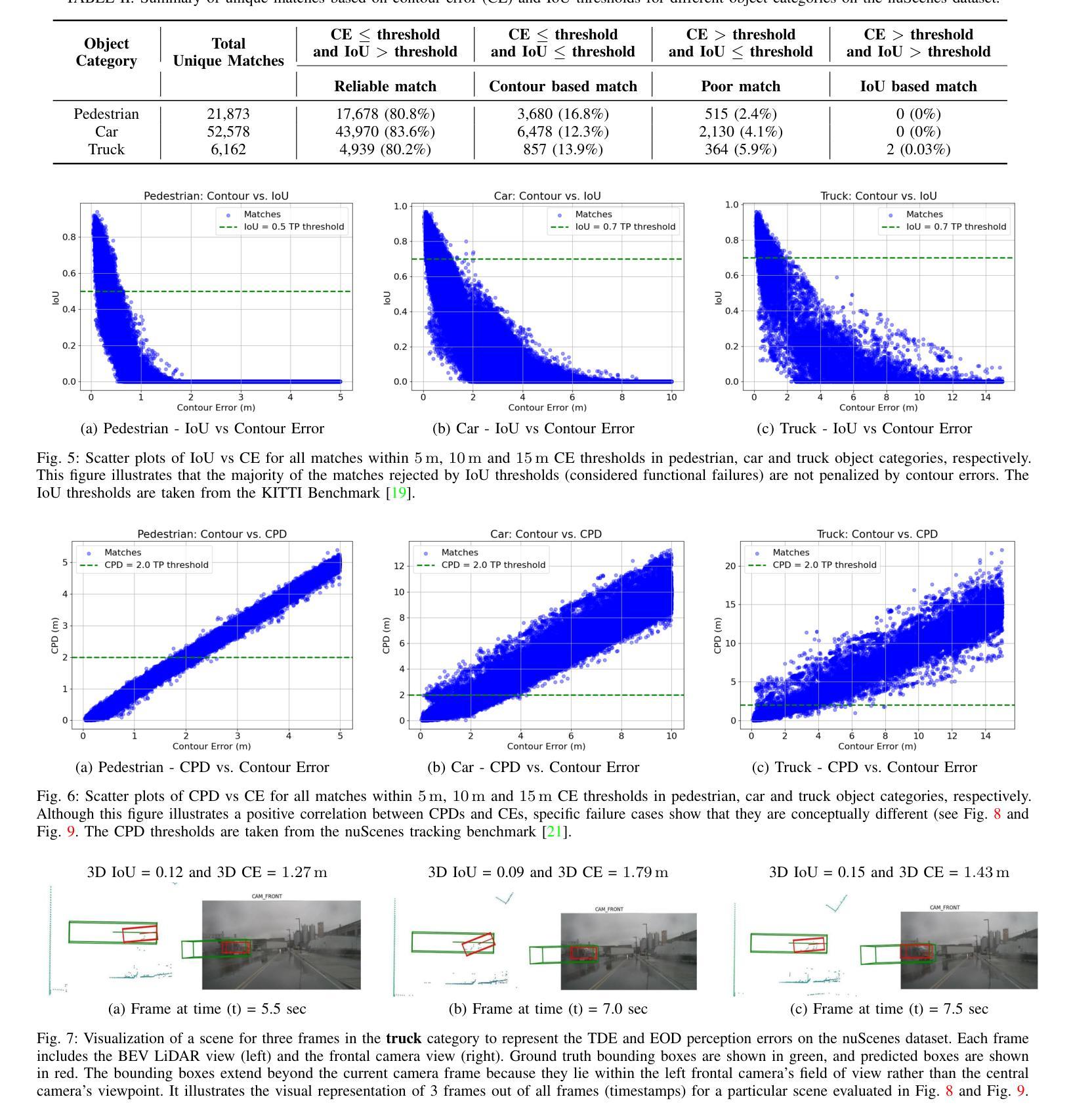
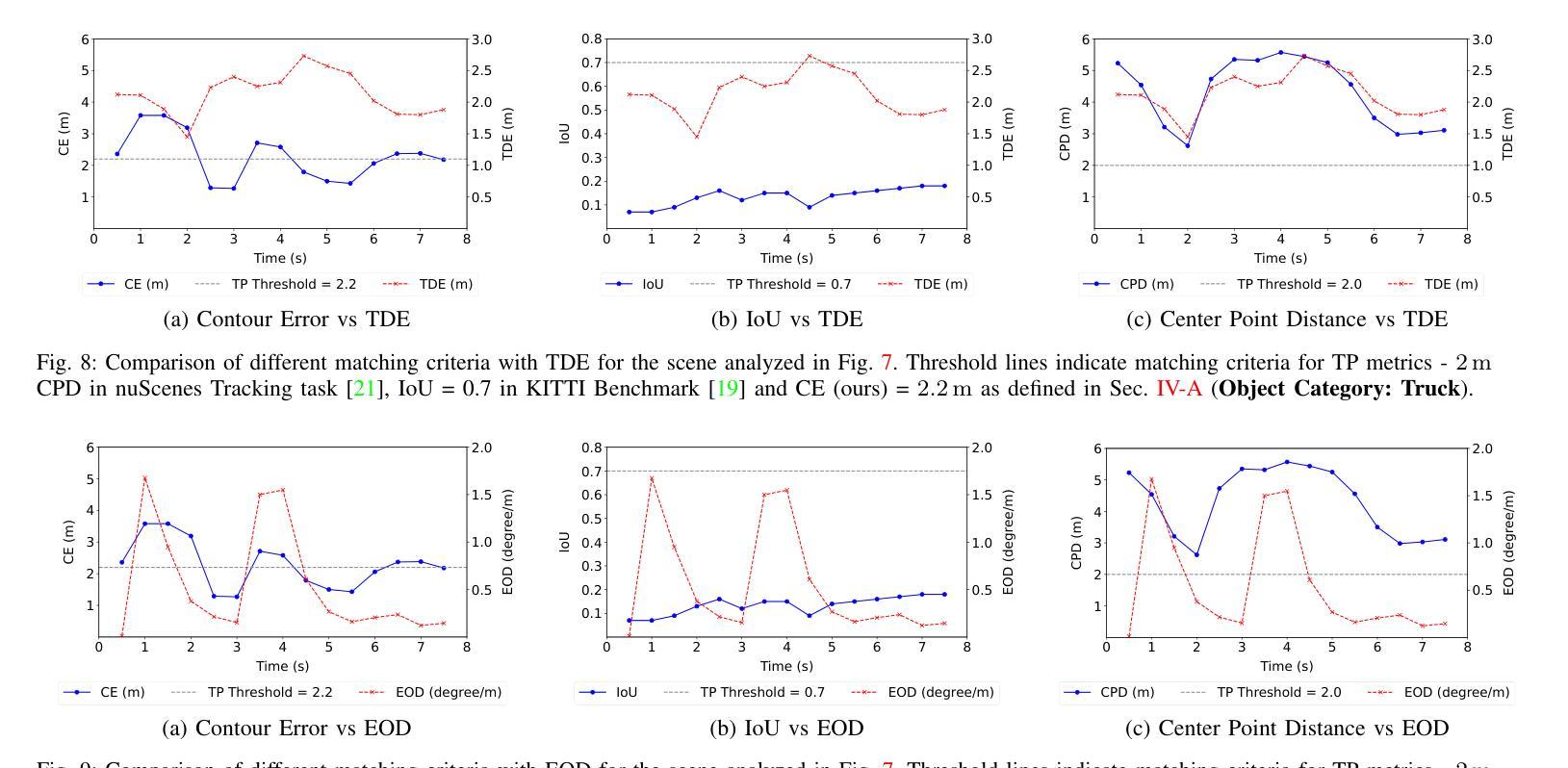
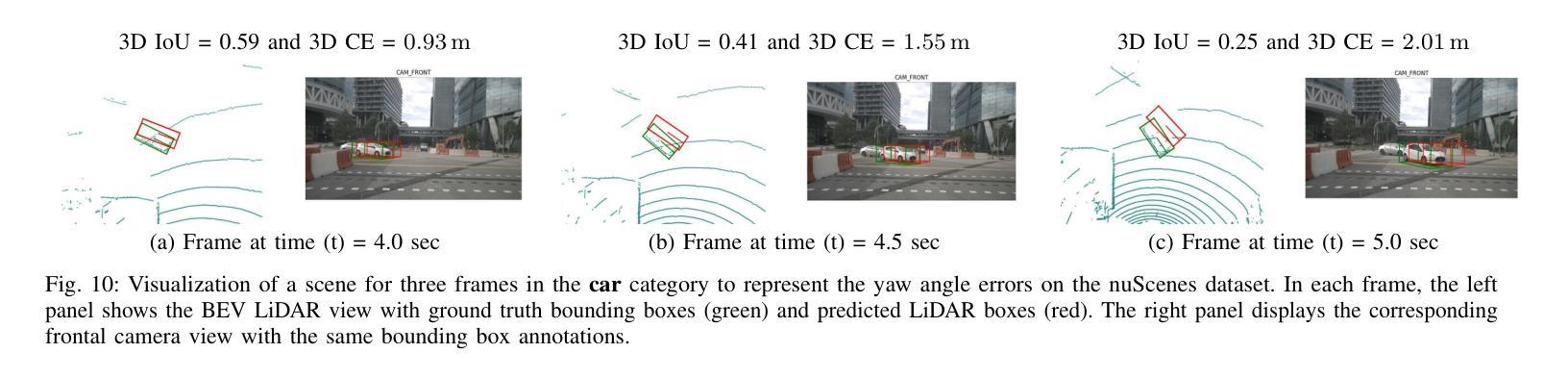
Finding reliable matches is essential in multi-object tracking to ensure the accuracy and reliability of perception systems in safety-critical applications such as autonomous vehicles. Effective matching mitigates perception errors, enhancing object identification and tracking for improved performance and safety. However, traditional metrics such as Intersection over Union (IoU) and Center Point Distances (CPDs), which are effective in 2D image planes, often fail to find critical matches in complex 3D scenes. To address this limitation, we introduce Contour Errors (CEs), an ego or object-centric metric for identifying matches of interest in tracking scenarios from a functional perspective. By comparing bounding boxes in the ego vehicle’s frame, contour errors provide a more functionally relevant assessment of object matches. Extensive experiments on the nuScenes dataset demonstrate that contour errors improve the reliability of matches over the state-of-the-art 2D IoU and CPD metrics in tracking-by-detection methods. In 3D car tracking, our results show that Contour Errors reduce functional failures (FPs/FNs) by 80% at close ranges and 60% at far ranges compared to IoU in the evaluation stage.
在多目标跟踪中,找到可靠的匹配点对于确保安全关键应用(如自动驾驶汽车)中的感知系统准确性和可靠性至关重要。有效的匹配可以减小感知误差,增强对象识别和跟踪,从而提高性能和安全性。然而,传统的度量标准,如交并比(IoU)和中心点距离(CPD),在二维图像平面上很有效,但在复杂的三维场景中往往难以找到关键的匹配点。为了解决这个问题,我们引入了轮廓误差(CEs),这是一种以自我或对象为中心的度量标准,可以从功能角度识别跟踪场景中的匹配点。通过比较自我车辆框架中的边界框,轮廓误差提供了从功能角度评估对象匹配的更加相关依据。在nuScenes数据集上的大量实验表明,轮廓误差在基于检测的跟踪方法中提高了匹配的可靠性,优于现有的二维IoU和CPD度量标准。在三维车辆跟踪中,我们的结果表明,与评估阶段的IoU相比,轮廓误差在近距离减少了80%的功能故障(FPs/FNs),在远距离减少了60%。
论文及项目相关链接
Summary
本文强调了在多目标跟踪中寻找可靠匹配的重要性,尤其是在自动驾驶等安全关键应用中。为提高感知系统的准确性和可靠性,有效的匹配能够缓解感知误差,增强对象识别和跟踪性能。针对传统的IoU和CPD度量在复杂3D场景中无法找到关键匹配的问题,本文引入了轮廓误差(CEs)这一度量标准。轮廓误差是一种从功能角度评估跟踪场景中感兴趣对象的匹配情况,通过与目标车辆框架中的边界框进行比较,提供更相关的评估。在nuScenes数据集上的实验表明,轮廓误差在跟踪检测方法中提高了匹配的可靠性,相较于现有的IoU和CPD度量标准有更好的表现。在3D汽车跟踪中,轮廓误差在评估阶段相较于IoU能减少近距功能失败(FPs/FNs)达80%,远距功能失败达60%。
Key Takeaways
- 寻找可靠匹配在多目标跟踪中至关重要,特别是在自动驾驶等安全关键应用中。
- 有效匹配能提高感知系统的准确性和可靠性,增强对象识别和跟踪性能。
- 传统度量标准如IoU和CPD在复杂3D场景中可能无法找到关键匹配。
- 轮廓误差(CEs)是一种新的度量标准,从功能角度评估跟踪场景中对象的匹配情况。
- 轮廓误差通过与目标车辆框架中的边界框进行比较来工作,提供更相关的评估。
- 在nuScenes数据集上的实验表明,轮廓误差提高了跟踪检测方法的匹配可靠性。
点此查看论文截图

OV-COAST: Cost Aggregation with Optimal Transport for Open-Vocabulary Semantic Segmentation
Authors:Aditya Gandhamal, Aniruddh Sikdar, Suresh Sundaram
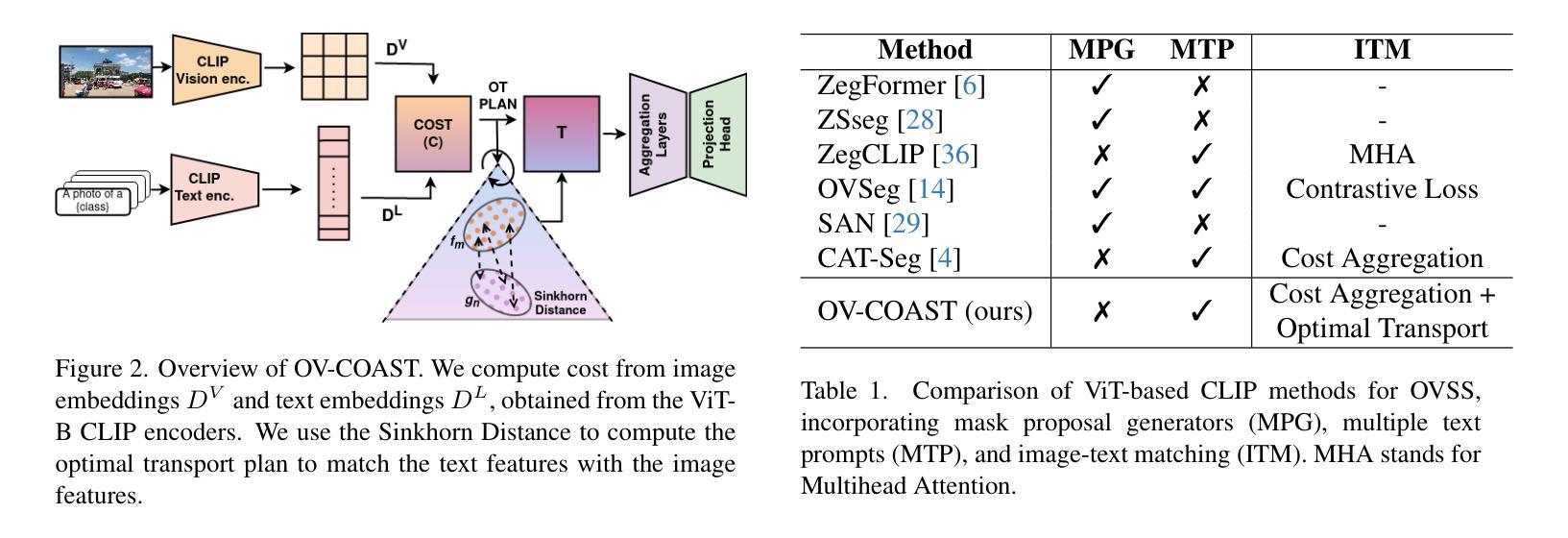
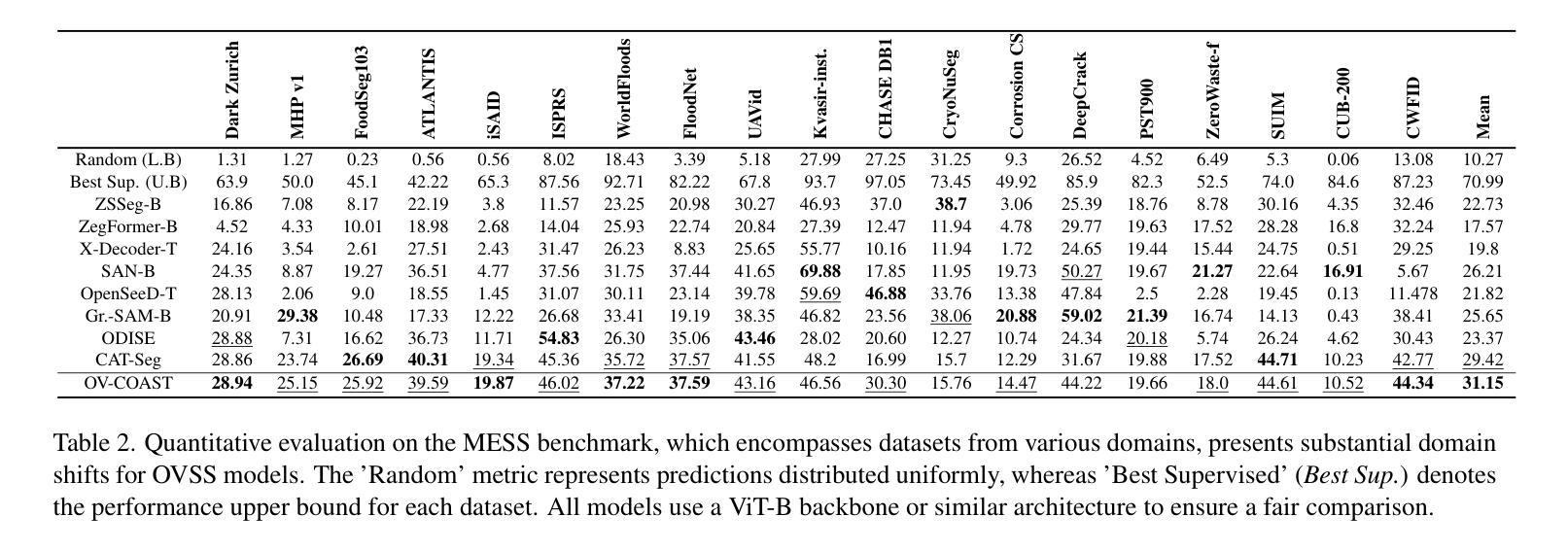
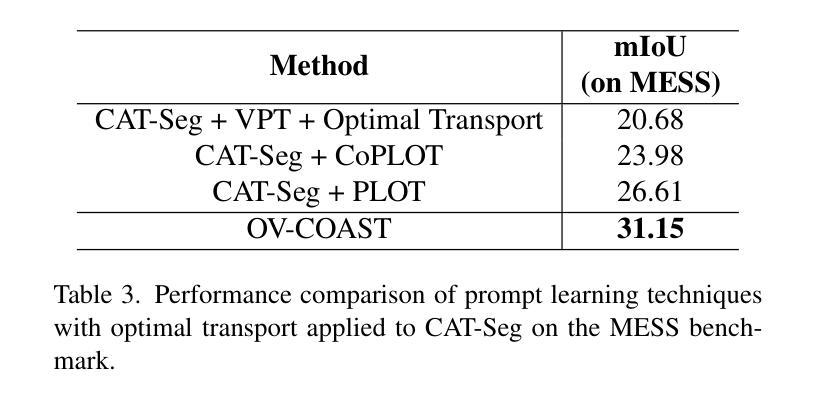
Open-vocabulary semantic segmentation (OVSS) entails assigning semantic labels to each pixel in an image using textual descriptions, typically leveraging world models such as CLIP. To enhance out-of-domain generalization, we propose Cost Aggregation with Optimal Transport (OV-COAST) for open-vocabulary semantic segmentation. To align visual-language features within the framework of optimal transport theory, we employ cost volume to construct a cost matrix, which quantifies the distance between two distributions. Our approach adopts a two-stage optimization strategy: in the first stage, the optimal transport problem is solved using cost volume via Sinkhorn distance to obtain an alignment solution; in the second stage, this solution is used to guide the training of the CAT-Seg model. We evaluate state-of-the-art OVSS models on the MESS benchmark, where our approach notably improves the performance of the cost-aggregation model CAT-Seg with ViT-B backbone, achieving superior results, surpassing CAT-Seg by 1.72 % and SAN-B by 4.9 % mIoU. The code is available at https://github.com/adityagandhamal/OV-COAST/}{https://github.com/adityagandhamal/OV-COAST/ .
开放词汇语义分割(OVSS)是指利用文本描述为图像中的每个像素分配语义标签,通常利用如CLIP等世界模型。为了提高跨域泛化能力,我们为开放词汇语义分割提出了基于最优传输理论的成本聚合(OV-COAST)方法。为了在对齐最优传输理论框架内的视觉语言特征时,我们采用成本体积来构建成本矩阵,该矩阵量化了两个分布之间的距离。我们的方法采用了两阶段优化策略:第一阶段,通过Sinkhorn距离解决成本体积中的最优传输问题,以获得对齐解决方案;在第二阶段,该解决方案被用来指导CAT-Seg模型的训练。我们在MESS基准测试上对最先进的OVSS模型进行了评估,我们的方法显著提高了具有ViT-B骨干网的成本聚合模型CAT-Seg的性能,取得了卓越的结果,比CAT-Seg高出1.72%,比SAN-B高出4.9%的mIoU。代码可用在https://github.com/adityagandhamal/OV-COAST/。
论文及项目相关链接
PDF Accepted at CVPR 2025 Workshop on Transformers for Vision (Non-archival track)
Summary
基于最优传输理论,本文提出了一种名为OV-COAST的开词汇语义分割方法,通过成本聚合优化运输过程,利用成本卷积构建成本矩阵,以量化和对齐视觉语言特征。通过两个阶段优化策略解决了最优传输问题并训练了CAT-Seg模型。在MESS基准测试中,该方法显著提高了具有ViT-B骨干网的CAT-Seg模型的性能。
Key Takeaways
- 开词汇语义分割(OVSS)为图像的每个像素分配语义标签,通常利用如CLIP的世界模型。
- 引入了一种新的方法OV-COAST,用于增强开放词汇语义分割的域外泛化能力。
- 使用成本卷积构建成本矩阵,以量化两种分布之间的距离,并在最优传输理论框架内对齐视觉语言特征。
- 采用两个阶段优化策略解决最优传输问题并训练CAT-Seg模型。
- 在MESS基准测试中,OV-COAST方法提高了CAT-Seg模型的性能,超越了CAT-Seg 1.72%和SAN-B 4.9% mIoU。
点此查看论文截图