⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-06 更新
Pseudo-Simulation for Autonomous Driving
Authors:Wei Cao, Marcel Hallgarten, Tianyu Li, Daniel Dauner, Xunjiang Gu, Caojun Wang, Yakov Miron, Marco Aiello, Hongyang Li, Igor Gilitschenski, Boris Ivanovic, Marco Pavone, Andreas Geiger, Kashyap Chitta
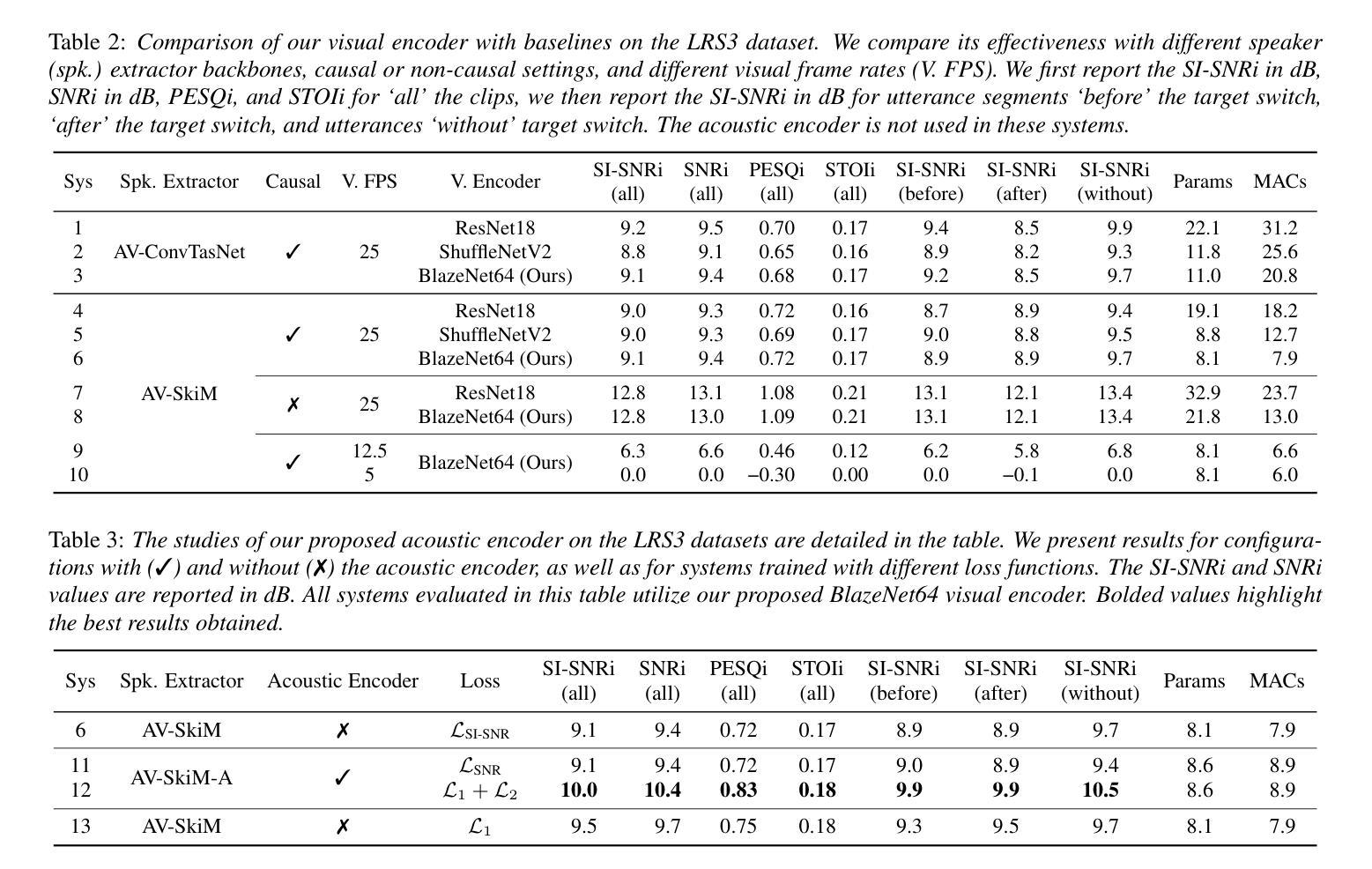
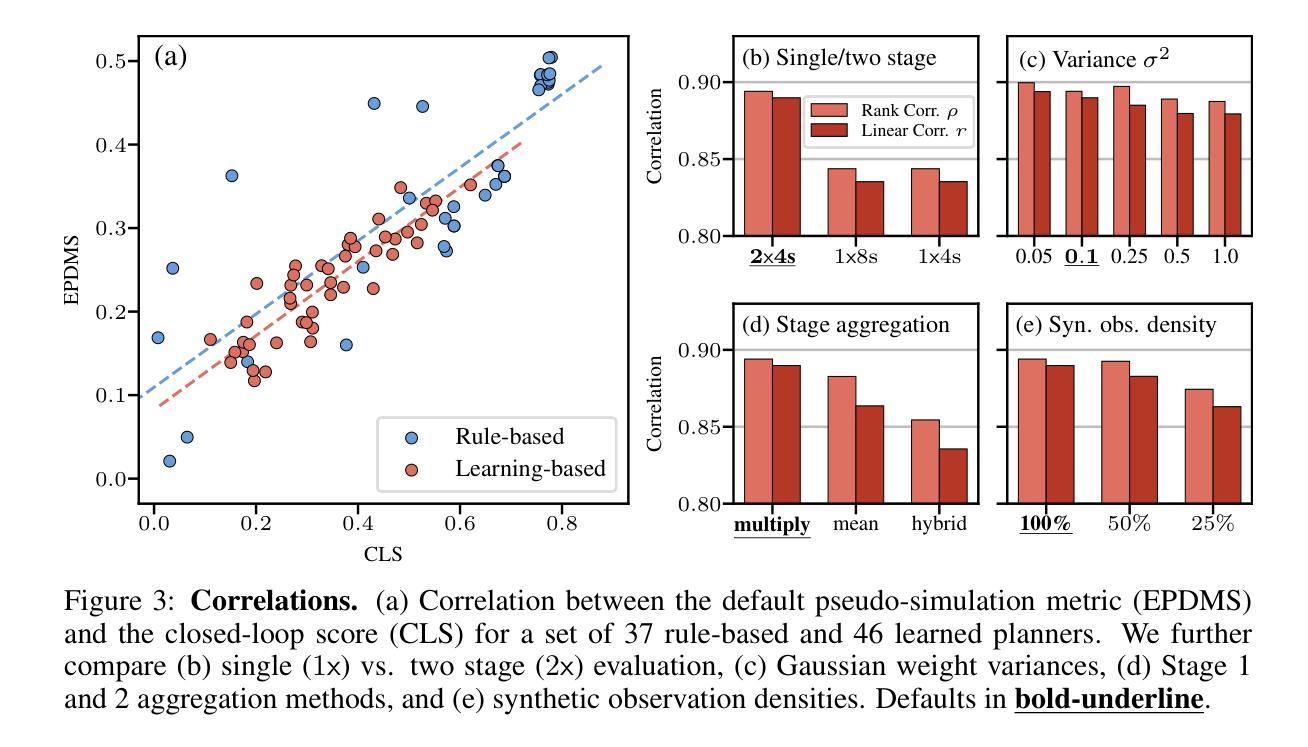
Existing evaluation paradigms for Autonomous Vehicles (AVs) face critical limitations. Real-world evaluation is often challenging due to safety concerns and a lack of reproducibility, whereas closed-loop simulation can face insufficient realism or high computational costs. Open-loop evaluation, while being efficient and data-driven, relies on metrics that generally overlook compounding errors. In this paper, we propose pseudo-simulation, a novel paradigm that addresses these limitations. Pseudo-simulation operates on real datasets, similar to open-loop evaluation, but augments them with synthetic observations generated prior to evaluation using 3D Gaussian Splatting. Our key idea is to approximate potential future states the AV might encounter by generating a diverse set of observations that vary in position, heading, and speed. Our method then assigns a higher importance to synthetic observations that best match the AV’s likely behavior using a novel proximity-based weighting scheme. This enables evaluating error recovery and the mitigation of causal confusion, as in closed-loop benchmarks, without requiring sequential interactive simulation. We show that pseudo-simulation is better correlated with closed-loop simulations (R^2=0.8) than the best existing open-loop approach (R^2=0.7). We also establish a public leaderboard for the community to benchmark new methodologies with pseudo-simulation. Our code is available at https://github.com/autonomousvision/navsim.
现有自动驾驶车辆(AV)评估范式面临重大局限。现实世界评估由于安全担忧和缺乏可重复性而充满挑战,而闭环模拟则可能面临缺乏真实性或计算成本高昂的问题。虽然开环评估具有高效性和数据驱动性,但它依赖于通常忽略累积误差的指标。在本文中,我们提出了一种新的评估范式——伪仿真(pseudo-simulation),以解决这些限制。伪仿真类似于开环评估,在真实数据集上运行,但通过使用三维高斯Splatting生成评估前的合成观测数据来增强它们。我们的核心思想是通过生成位置、方向和速度各异的观测数据集来近似AV可能遇到的潜在未来状态。然后,我们的方法使用一种新型基于接近度的加权方案,对最能匹配AV可能行为的合成观测数据赋予更高的重要性。这使得能够在不需要顺序交互式模拟的情况下,评估错误恢复和避免因果混淆,类似于闭环基准测试。我们表明,伪仿真与闭环模拟的相关性高于最佳现有开环方法(R²=0.8相比R²=0.7)。我们还为社区建立了一个公共排行榜,以使用伪仿真对新方法进行基准测试。我们的代码可在https://github.com/autonomousvision/navsim上找到。
论文及项目相关链接
Summary
本文提出了一种新的自动驾驶车辆评估方法——伪仿真。该方法结合真实数据集和通过3D高斯Splatting技术生成的合成观测数据,以近似未来可能出现的状态。伪仿真能够评估自动驾驶车辆的错误恢复和因果混淆缓解能力,且无需进行复杂的闭环模拟。与现有方法相比,伪仿真与闭环模拟的相关性更高。
Key Takeaways
- 现有自动驾驶车辆评估方法存在挑战:真实世界评估面临安全问题和不可复现性,闭环模拟则可能缺乏真实性或计算成本高。
- 伪仿真是一种新型评估方法,结合真实数据集和合成观测数据,以模拟未来可能出现的状态。
- 伪仿真能够评估自动驾驶车辆的错误恢复和因果混淆缓解能力。
- 伪仿真无需进行复杂的闭环模拟。
- 伪仿真与闭环模拟的相关性更高(R^2=0.8),相比现有最佳开放环方法(R^2=0.7)更具优势。
- 建立了公共排行榜,供社区使用伪仿真方法评估新方法论。
点此查看论文截图


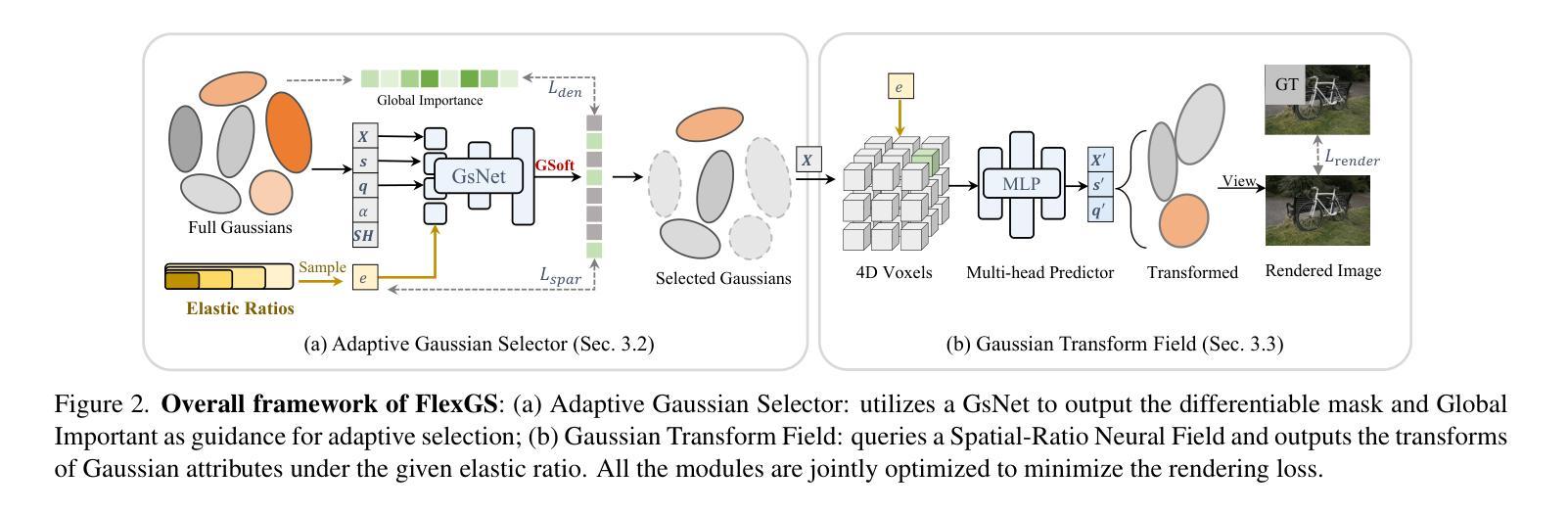
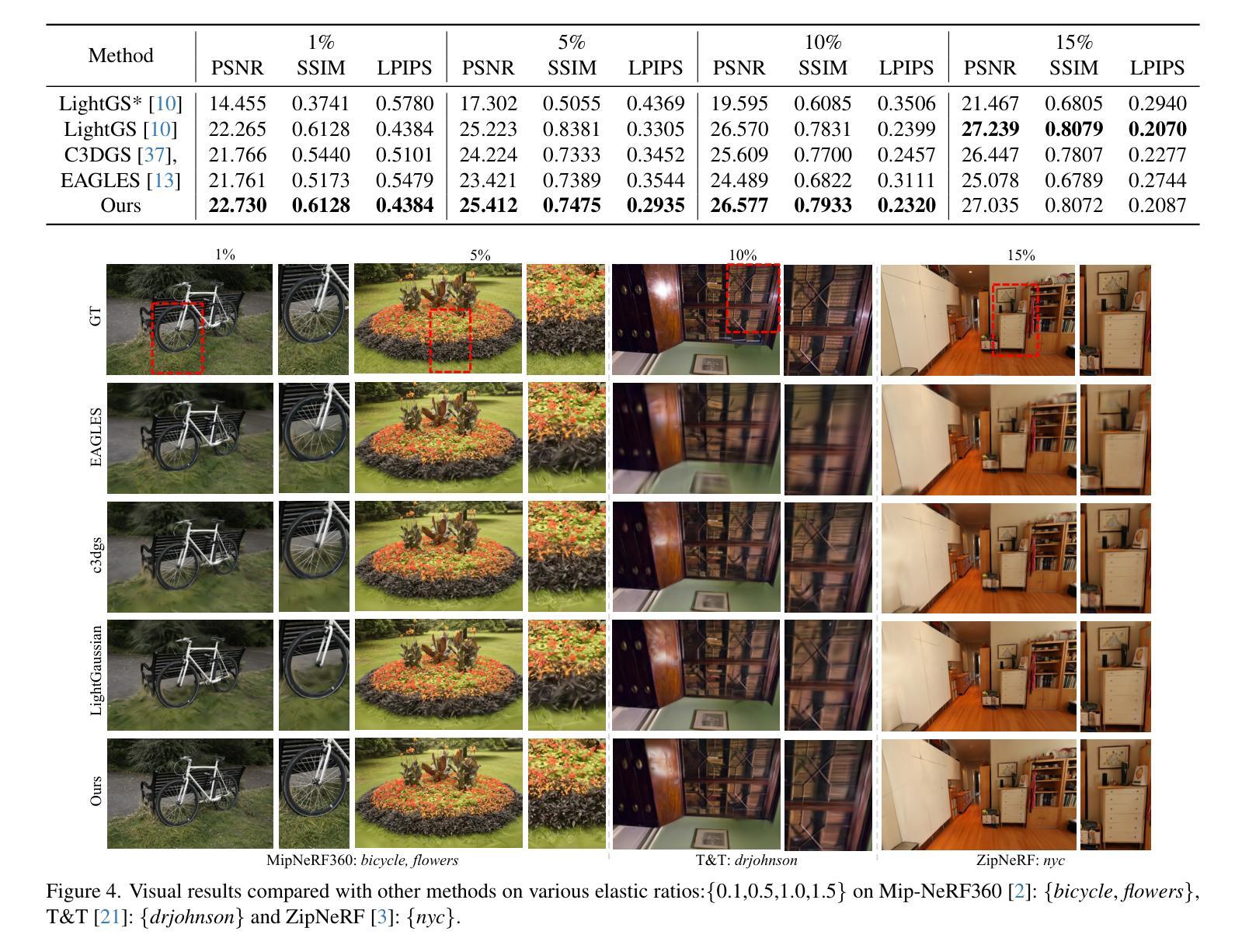
FlexGS: Train Once, Deploy Everywhere with Many-in-One Flexible 3D Gaussian Splatting
Authors:Hengyu Liu, Yuehao Wang, Chenxin Li, Ruisi Cai, Kevin Wang, Wuyang Li, Pavlo Molchanov, Peihao Wang, Zhangyang Wang
3D Gaussian splatting (3DGS) has enabled various applications in 3D scene representation and novel view synthesis due to its efficient rendering capabilities. However, 3DGS demands relatively significant GPU memory, limiting its use on devices with restricted computational resources. Previous approaches have focused on pruning less important Gaussians, effectively compressing 3DGS but often requiring a fine-tuning stage and lacking adaptability for the specific memory needs of different devices. In this work, we present an elastic inference method for 3DGS. Given an input for the desired model size, our method selects and transforms a subset of Gaussians, achieving substantial rendering performance without additional fine-tuning. We introduce a tiny learnable module that controls Gaussian selection based on the input percentage, along with a transformation module that adjusts the selected Gaussians to complement the performance of the reduced model. Comprehensive experiments on ZipNeRF, MipNeRF and Tanks&Temples scenes demonstrate the effectiveness of our approach. Code is available at https://flexgs.github.io.
3D高斯贴图技术(3DGS)因其高效的渲染能力,在三维场景表示和新颖视角合成方面实现了多种应用。然而,由于3DGS需要大量的GPU内存,因此在计算资源有限的设备上使用受限。先前的方法主要集中在修剪不那么重要的高斯函数,有效地压缩了3DGS,但通常需要精细调整阶段,并且对不同设备的特定内存需求缺乏适应性。在这项工作中,我们提出了一种弹性的三维高斯贴图推理方法。给定所需模型大小的输入,我们的方法选择和转换了部分高斯函数,实现了实质性的渲染性能提升,无需额外的精细调整。我们引入了一个微小的可学习模块,根据输入百分比控制高斯函数的选择,以及一个转换模块来调整选择的高斯函数来补充缩减模型的性能。在ZipNeRF、MipNeRF和Tanks&Temples场景上的综合实验证明了我们的方法的有效性。代码可在https://flexgs.github.io获取。
论文及项目相关链接
PDF CVPR 2025; Project Page: https://flexgs.github.io
摘要
该论文提出了一种弹性推理方法用于优化3D高斯插片(3DGS)的模型大小,并应用于3D场景表示和新颖视图合成中。针对具有受限计算资源的设备,该方法能够在不增加精细调整阶段的情况下,通过选择和转换高斯子集实现显著渲染性能提升。引入了一个小型可学习模块控制基于输入百分比的高斯选择,以及一个转换模块调整所选高斯来增强减小模型的性能。实验表明该方法的有效性。
要点摘要
- 弹性推理方法用于优化3DGS模型大小,适用于不同计算资源受限的设备。
- 通过选择和转换高斯子集,实现在不增加精细调整阶段的情况下提升渲染性能。
- 提出了一种新型可学习模块控制高斯选择,根据输入百分比进行自适应调整。
- 引入转换模块增强减小模型的性能,通过调整所选高斯进行互补。
- 在ZipNeRF、MipNeRF和Tanks&Temples场景上的实验证明了该方法的有效性。
- 论文公开可用代码于相关网站flexgs.github.io上提供下载和查阅。
点此查看论文截图


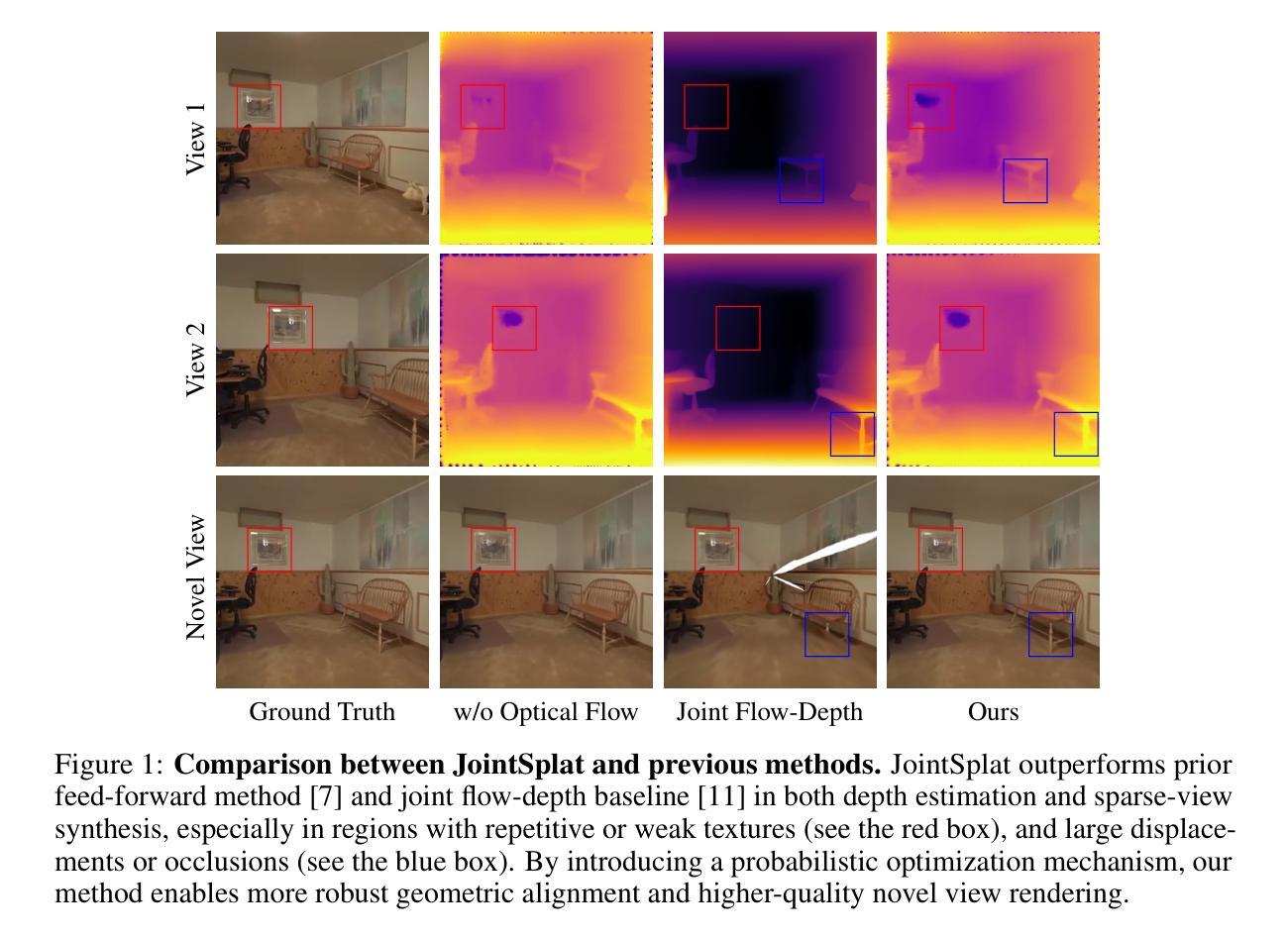
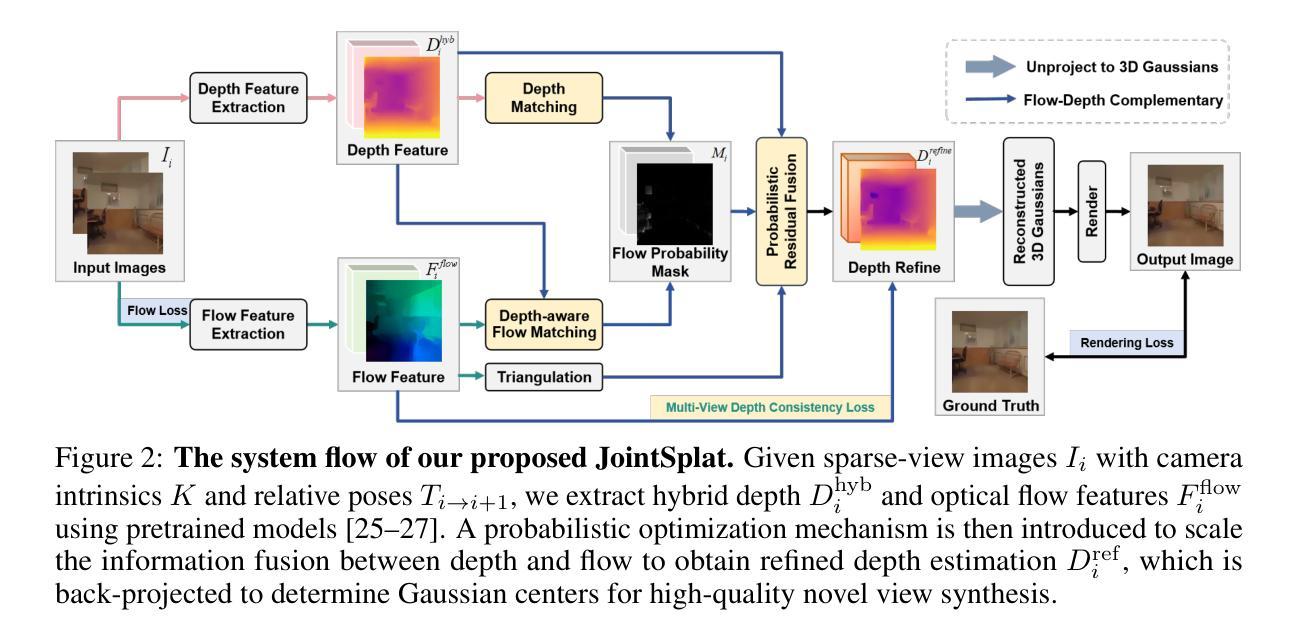
JointSplat: Probabilistic Joint Flow-Depth Optimization for Sparse-View Gaussian Splatting
Authors:Yang Xiao, Guoan Xu, Qiang Wu, Wenjing Jia
Reconstructing 3D scenes from sparse viewpoints is a long-standing challenge with wide applications. Recent advances in feed-forward 3D Gaussian sparse-view reconstruction methods provide an efficient solution for real-time novel view synthesis by leveraging geometric priors learned from large-scale multi-view datasets and computing 3D Gaussian centers via back-projection. Despite offering strong geometric cues, both feed-forward multi-view depth estimation and flow-depth joint estimation face key limitations: the former suffers from mislocation and artifact issues in low-texture or repetitive regions, while the latter is prone to local noise and global inconsistency due to unreliable matches when ground-truth flow supervision is unavailable. To overcome this, we propose JointSplat, a unified framework that leverages the complementarity between optical flow and depth via a novel probabilistic optimization mechanism. Specifically, this pixel-level mechanism scales the information fusion between depth and flow based on the matching probability of optical flow during training. Building upon the above mechanism, we further propose a novel multi-view depth-consistency loss to leverage the reliability of supervision while suppressing misleading gradients in uncertain areas. Evaluated on RealEstate10K and ACID, JointSplat consistently outperforms state-of-the-art (SOTA) methods, demonstrating the effectiveness and robustness of our proposed probabilistic joint flow-depth optimization approach for high-fidelity sparse-view 3D reconstruction.
从稀疏视角重建3D场景是一个具有广泛应用且历史悠久的挑战。基于前馈的3D高斯稀疏视角重建方法的最新进展,通过利用从大规模多视角数据集学习的几何先验,并通过反投影计算3D高斯中心,为实时合成新视角提供了一种有效的解决方案。尽管提供了强大的几何线索,但前馈多视角深度估计和流深度联合估计都面临关键局限:前者在低纹理或重复区域存在错位和伪影问题,而后者在没有真实流动监督的情况下容易出现局部噪声和全局不一致的不可靠匹配问题。为了克服这一问题,我们提出了JointSplat,一个利用光学流和深度之间互补性的统一框架,通过一种新型的概率优化机制。具体来说,这种像素级机制在训练过程中根据光学流的匹配概率来缩放深度和流之间的信息融合。基于上述机制,我们进一步提出了一种新型的多视角深度一致性损失,以利用监督的可靠性,同时抑制不确定区域的误导梯度。在RealEstate10K和ACID上进行评估,JointSplat持续超越现有先进技术(SOTA),证明了我们提出的概率联合流深度优化方法在高保真稀疏视角3D重建中的有效性和稳健性。
论文及项目相关链接
Summary
本文介绍了基于几何先验的实时稀疏视角三维场景重建方法面临的挑战和最新进展。针对现有方法的不足,提出了一种基于概率优化的联合流深度优化框架JointSplat,利用光学流与深度信息的互补性,通过像素级机制实现深度与流信息的融合。同时,引入了一种新的多视角深度一致性损失,以提高监督的可靠性并抑制不确定区域的误导梯度。在RealEstate10K和ACID数据集上的实验表明,JointSplat相较于其他最先进的方法有更好的性能,显示出该方法的鲁棒性和有效性。
Key Takeaways
- 当前三维场景重建面临挑战,存在广泛应用场景。
- 现有稀疏视角重建方法虽有所进展,但仍存在缺陷,如误定位、伪影和低纹理区域的问题。
- JointSplat框架利用光学流与深度的互补性,通过像素级机制实现信息融合。
- 提出了一种新的概率优化机制,根据光学流的匹配概率进行信息融合。
- 引入多视角深度一致性损失,提高监督可靠性并抑制不确定区域的误导梯度。
- 在RealEstate10K和ACID数据集上的实验验证了JointSplat的有效性。
点此查看论文截图

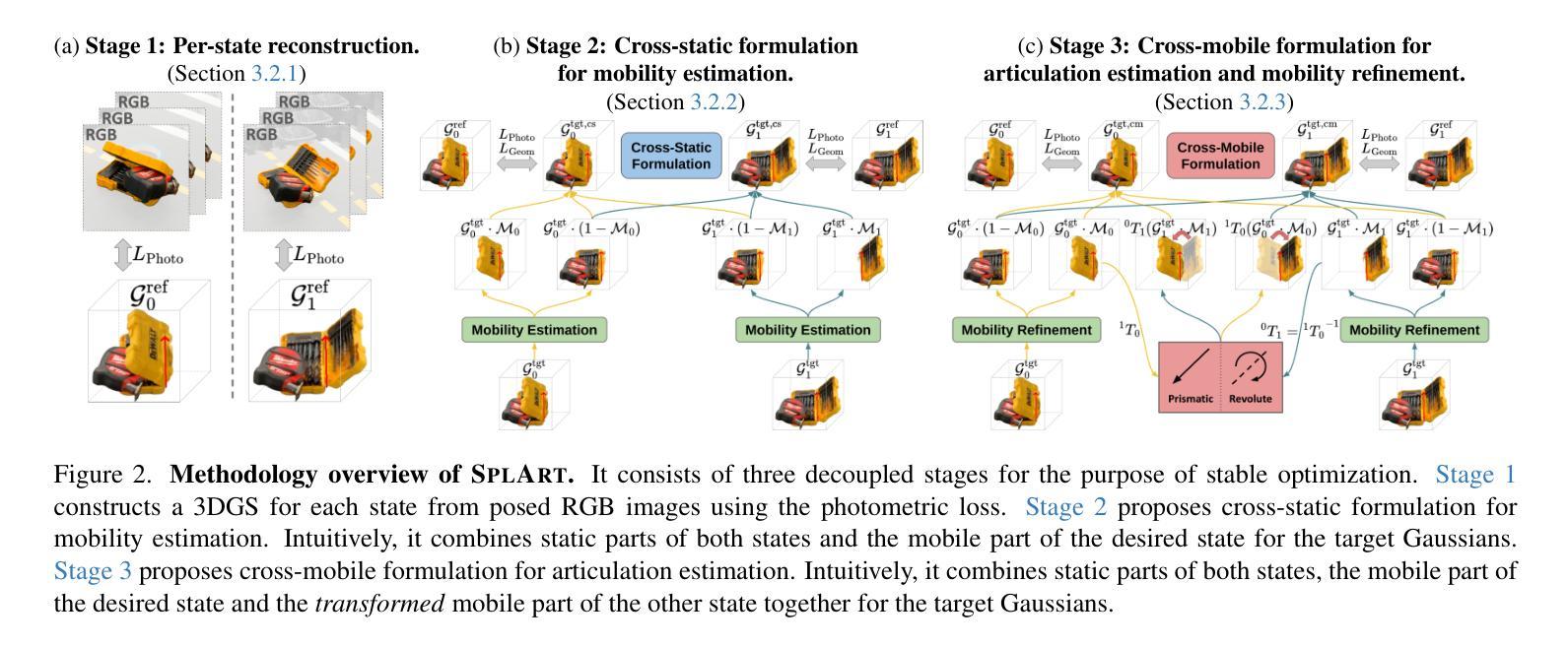
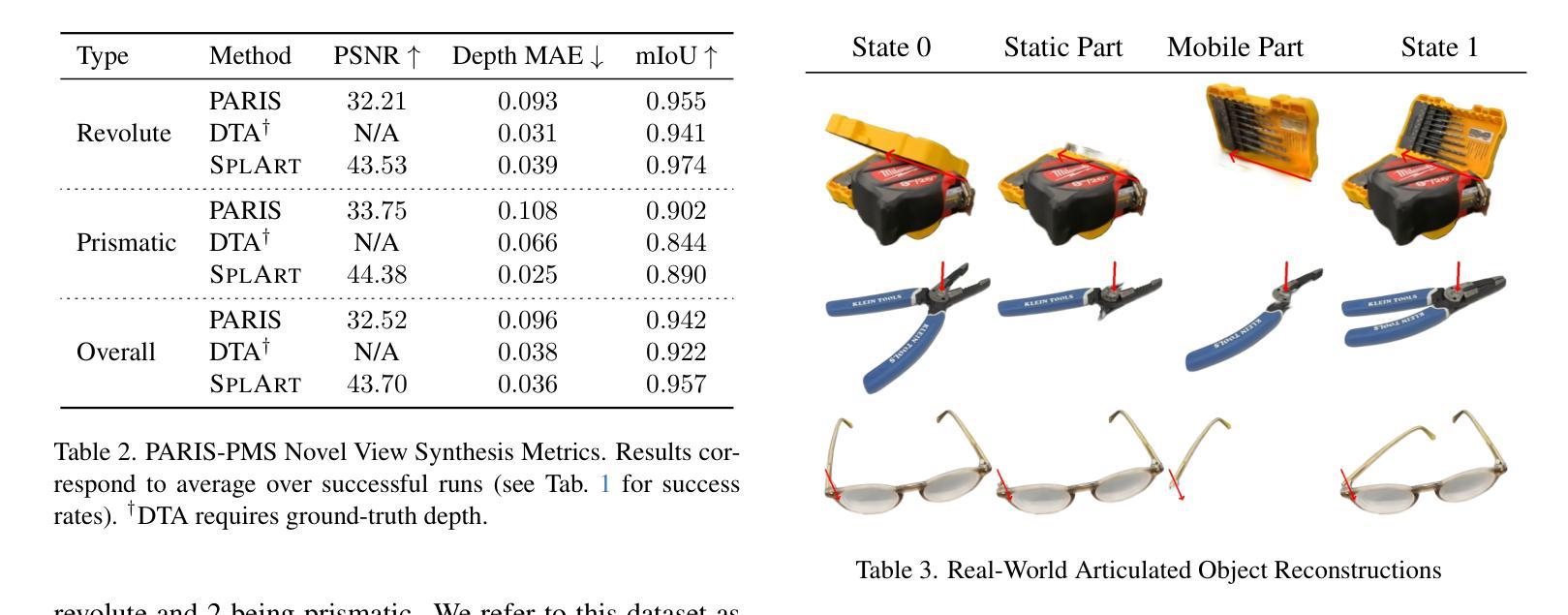
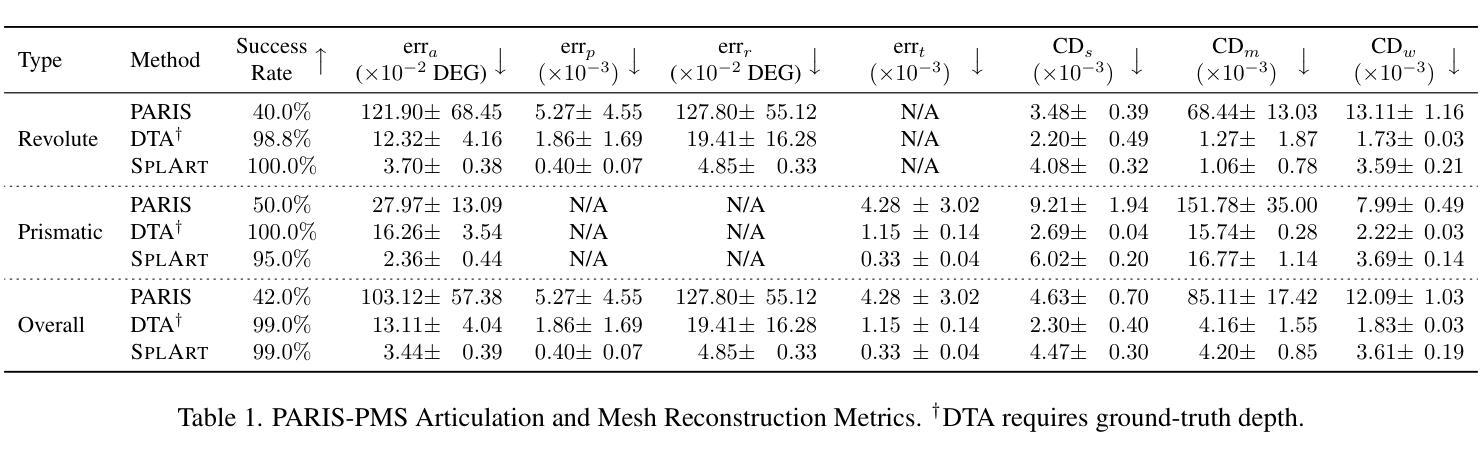
SplArt: Articulation Estimation and Part-Level Reconstruction with 3D Gaussian Splatting
Authors:Shengjie Lin, Jiading Fang, Muhammad Zubair Irshad, Vitor Campagnolo Guizilini, Rares Andrei Ambrus, Greg Shakhnarovich, Matthew R. Walter
Reconstructing articulated objects prevalent in daily environments is crucial for applications in augmented/virtual reality and robotics. However, existing methods face scalability limitations (requiring 3D supervision or costly annotations), robustness issues (being susceptible to local optima), and rendering shortcomings (lacking speed or photorealism). We introduce SplArt, a self-supervised, category-agnostic framework that leverages 3D Gaussian Splatting (3DGS) to reconstruct articulated objects and infer kinematics from two sets of posed RGB images captured at different articulation states, enabling real-time photorealistic rendering for novel viewpoints and articulations. SplArt augments 3DGS with a differentiable mobility parameter per Gaussian, achieving refined part segmentation. A multi-stage optimization strategy is employed to progressively handle reconstruction, part segmentation, and articulation estimation, significantly enhancing robustness and accuracy. SplArt exploits geometric self-supervision, effectively addressing challenging scenarios without requiring 3D annotations or category-specific priors. Evaluations on established and newly proposed benchmarks, along with applications to real-world scenarios using a handheld RGB camera, demonstrate SplArt’s state-of-the-art performance and real-world practicality. Code is publicly available at https://github.com/ripl/splart.
重建日常环境中普遍存在的关节型物体对于增强/虚拟现实和机器人应用至关重要。然而,现有方法面临可扩展性限制(需要3D监督或昂贵的注释)、稳健性问题(易陷入局部最优解),以及渲染缺陷(缺乏速度或逼真度)。我们引入了SplArt,这是一个自监督的、与类别无关的框架,它利用三维高斯贴片技术(3DGS)重建关节型物体,并从两组处于不同关节状态的姿态RGB图像中推断运动学,为新的视角和关节活动提供实时逼真的渲染。SplArt通过为每个高斯增加一个可微分的机动性参数来增强3DGS,实现精细的部分分割。采用多阶段优化策略,逐步处理重建、部分分割和关节估计,显著增强稳健性和准确性。SplArt利用几何自监督,有效地解决了具有挑战性的场景,无需使用三维注释或特定类别的先验知识。在现有的和新提出的基准测试上的评估,以及使用手持RGB相机的实际应用场景演示了SplArt的最新性能和实际应用能力。代码可在https://github.com/ripl/splart找到。
论文及项目相关链接
PDF https://github.com/ripl/splart
Summary
本文介绍了SplArt,一种用于重建日常环境中的关节对象的重要应用,应用于增强/虚拟现实和机器人领域的方法。现有的方法存在可伸缩性限制、鲁棒性问题以及渲染缺陷。SplArt采用自监督、类别无关框架,利用三维高斯拼贴技术(3DGS)从两个不同姿态的RGB图像集重建关节对象,推断运动学参数,实现实时高质量渲染新视角和姿态。此外,它结合了高精度的部分分割和多阶段优化策略,显著提高了鲁棒性和准确性。通过几何自监督学习,无需依赖三维标注或特定类别先验知识即可应对复杂场景。在基准测试集和真实世界场景下的手持RGB相机应用均证明了SplArt的卓越性能和实用性。代码已公开在GitHub上。
Key Takeaways
- SplArt是一种用于重建关节对象的自监督、类别无关框架。
- 利用三维高斯拼贴技术(3DGS)进行对象重建和运动学推断。
- 通过实时高质量渲染实现新视角和姿态的展示。
- 采用多阶段优化策略,包括重建、部分分割和运动学估计。
- 结合高精度的部分分割技术提高重建质量。
- 采用几何自监督学习,无需依赖三维标注或特定类别先验知识。
点此查看论文截图


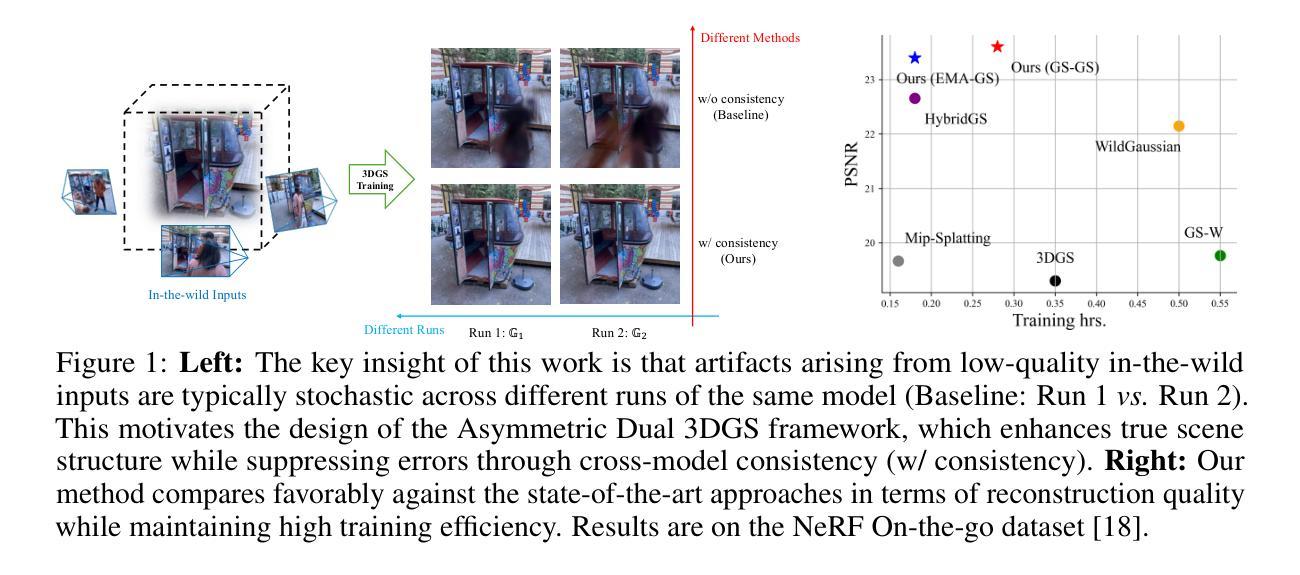
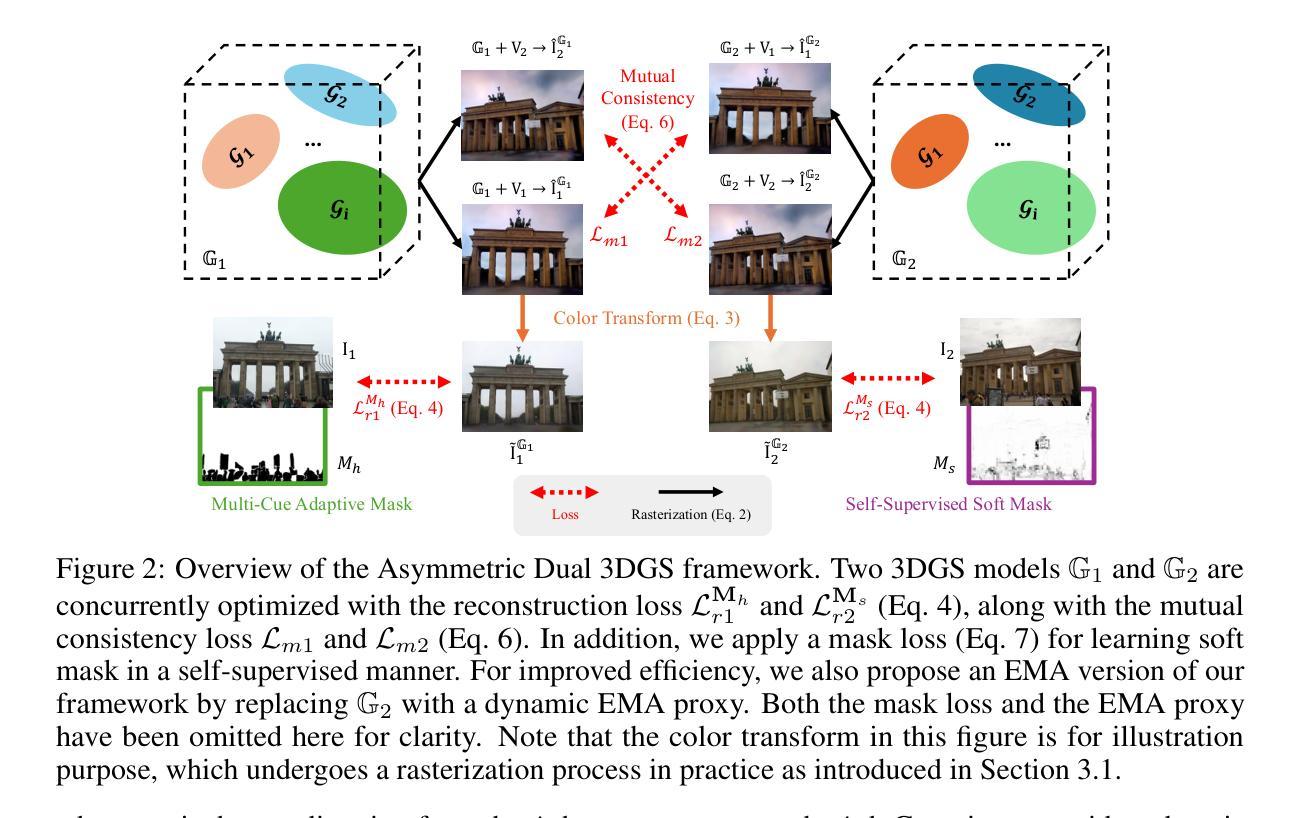
Robust Neural Rendering in the Wild with Asymmetric Dual 3D Gaussian Splatting
Authors:Chengqi Li, Zhihao Shi, Yangdi Lu, Wenbo He, Xiangyu Xu
3D reconstruction from in-the-wild images remains a challenging task due to inconsistent lighting conditions and transient distractors. Existing methods typically rely on heuristic strategies to handle the low-quality training data, which often struggle to produce stable and consistent reconstructions, frequently resulting in visual artifacts. In this work, we propose Asymmetric Dual 3DGS, a novel framework that leverages the stochastic nature of these artifacts: they tend to vary across different training runs due to minor randomness. Specifically, our method trains two 3D Gaussian Splatting (3DGS) models in parallel, enforcing a consistency constraint that encourages convergence on reliable scene geometry while suppressing inconsistent artifacts. To prevent the two models from collapsing into similar failure modes due to confirmation bias, we introduce a divergent masking strategy that applies two complementary masks: a multi-cue adaptive mask and a self-supervised soft mask, which leads to an asymmetric training process of the two models, reducing shared error modes. In addition, to improve the efficiency of model training, we introduce a lightweight variant called Dynamic EMA Proxy, which replaces one of the two models with a dynamically updated Exponential Moving Average (EMA) proxy, and employs an alternating masking strategy to preserve divergence. Extensive experiments on challenging real-world datasets demonstrate that our method consistently outperforms existing approaches while achieving high efficiency. Codes and trained models will be released.
从野外图像进行3D重建仍然是一项具有挑战性的任务,因为存在光照条件不一致和短暂干扰物的问题。现有方法通常依赖于启发式策略来处理低质量训练数据,这些方法往往难以产生稳定和一致的重建结果,经常导致出现视觉伪影。在这项工作中,我们提出了不对称双3DGS(三维高斯散斑)新型框架,该框架利用这些伪影的随机性质:由于存在轻微随机性,这些伪影往往在不同的训练运行中有所不同。具体来说,我们的方法并行训练两个三维高斯散斑模型,施加一致性约束,以鼓励可靠的场景几何结构收敛,同时抑制不一致的伪影。为了防止两个模型因确认偏见而陷入类似的失败模式,我们引入了一种发散掩蔽策略,该策略应用两种互补掩蔽:多线索自适应掩蔽和自监督软掩蔽,导致两个模型的不对称训练过程,减少共享错误模式。此外,为了提高模型训练的效率,我们引入了一种称为动态EMA代理的轻量级变体,它用动态更新的指数移动平均(EMA)代理替换两个模型中的一个,并采用交替掩蔽策略来保持发散。在具有挑战性的真实世界数据集上进行的广泛实验表明,我们的方法始终优于现有方法,同时实现了高效率。代码和训练好的模型将被公开发布。
论文及项目相关链接
Summary
该文本提出了一种新型框架Asymmetric Dual 3DGS,利用野生图像的三维重建中随机噪声干扰物的变化特性进行建模。该框架包含两个并行训练的3D高斯填充(3DGS)模型,并采用一致性约束机制来提高重建场景的可靠性几何信息的同时抑制不一致的随机噪声干扰物影响。同时,采用非对称训练过程以及一种轻量级动态EMA代理模型提高训练效率。该方法的实验结果表明其在真实世界数据集上表现优异,优于现有方法。
Key Takeaways
- Asymmetric Dual 3DGS框架利用野生图像三维重建中的随机噪声干扰物的变化特性进行建模。
- 通过训练两个并行模型,采用一致性约束机制提高场景几何信息的可靠性。
- 通过引入非对称训练过程及采用两种互补性掩码,避免模型陷入相同的错误模式。
- 动态EMA代理模型的引入提高了训练效率。
- 该方法在真实世界数据集上的实验结果优于现有方法。
点此查看论文截图


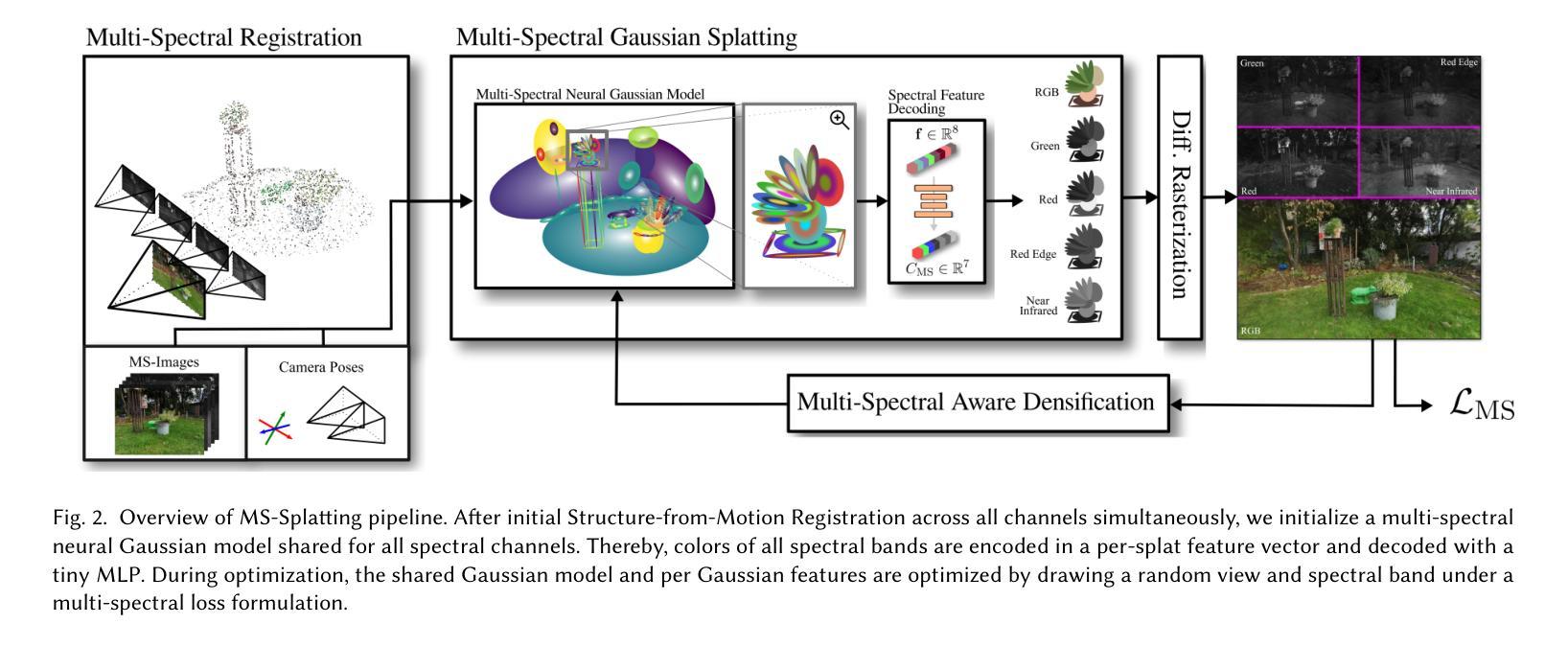
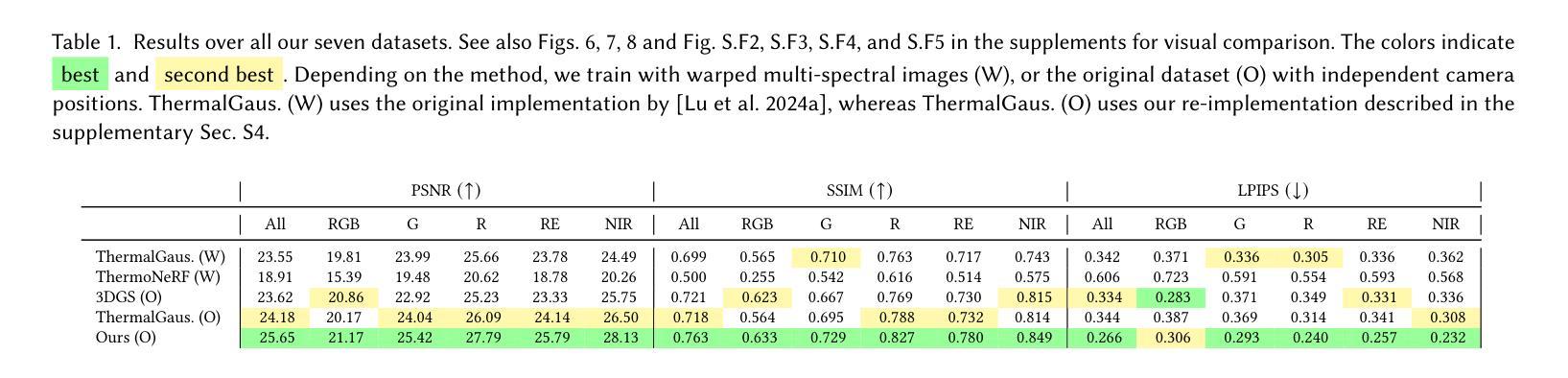
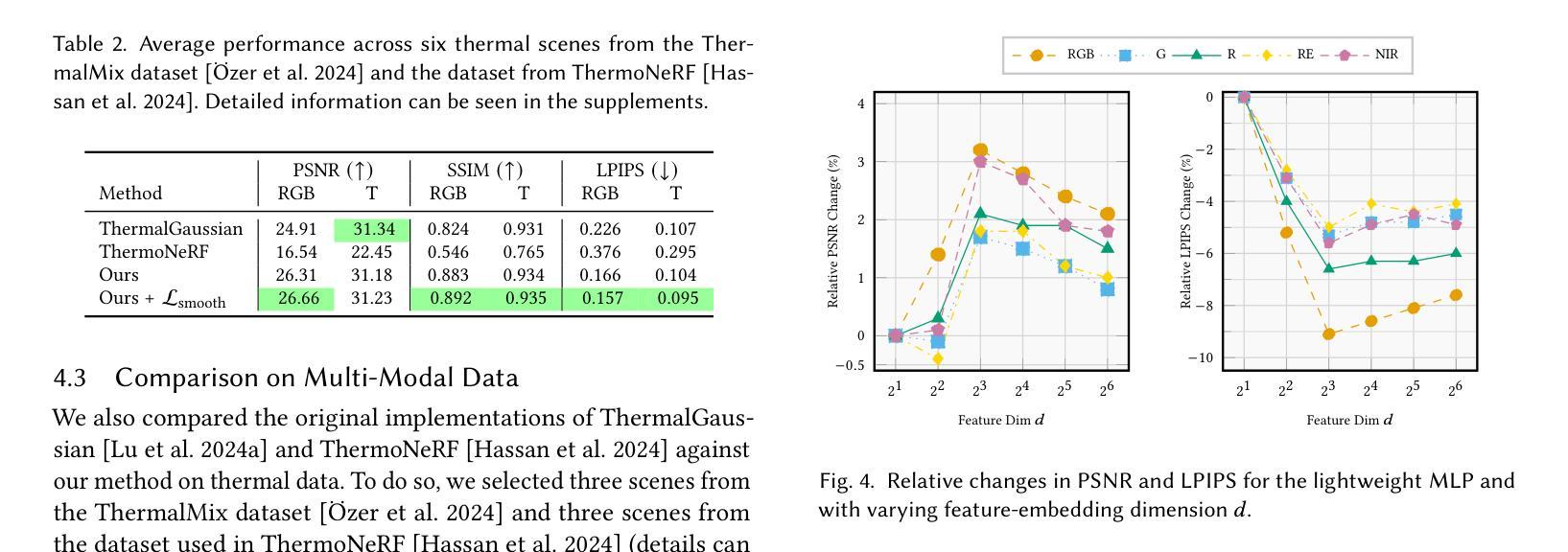
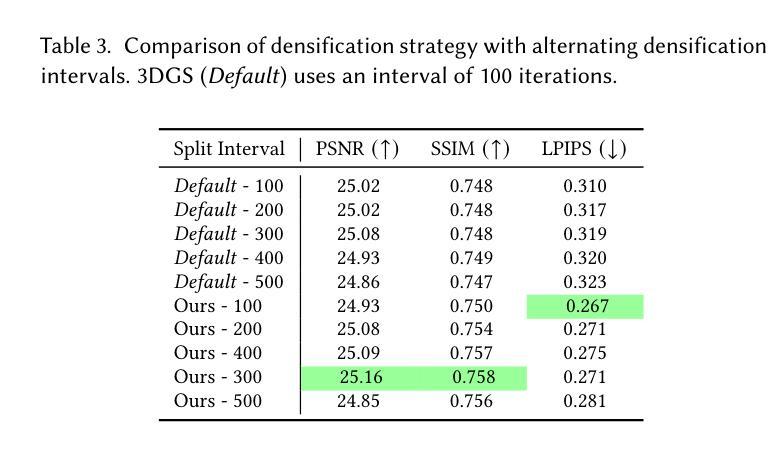
Multi-Spectral Gaussian Splatting with Neural Color Representation
Authors:Lukas Meyer, Josef Grün, Maximilian Weiherer, Bernhard Egger, Marc Stamminger, Linus Franke
We present MS-Splatting – a multi-spectral 3D Gaussian Splatting (3DGS) framework that is able to generate multi-view consistent novel views from images of multiple, independent cameras with different spectral domains. In contrast to previous approaches, our method does not require cross-modal camera calibration and is versatile enough to model a variety of different spectra, including thermal and near-infra red, without any algorithmic changes. Unlike existing 3DGS-based frameworks that treat each modality separately (by optimizing per-channel spherical harmonics) and therefore fail to exploit the underlying spectral and spatial correlations, our method leverages a novel neural color representation that encodes multi-spectral information into a learned, compact, per-splat feature embedding. A shallow multi-layer perceptron (MLP) then decodes this embedding to obtain spectral color values, enabling joint learning of all bands within a unified representation. Our experiments show that this simple yet effective strategy is able to improve multi-spectral rendering quality, while also leading to improved per-spectra rendering quality over state-of-the-art methods. We demonstrate the effectiveness of this new technique in agricultural applications to render vegetation indices, such as normalized difference vegetation index (NDVI).
我们提出了MS-Splatting——一种多光谱三维高斯Splatting(3DGS)框架,能够从多个独立相机不同光谱域的图像生成多视角一致的全新视角。与其他方法相比,我们的方法不需要跨模态相机校准,并且具有足够的灵活性,可以模拟各种光谱,包括热光谱和近红外光谱,而无需进行任何算法更改。与现有的基于3DGS的框架不同,它们分别处理每种模态(通过优化每个通道的球面谐波),因此无法利用潜在的光谱和空间相关性,我们的方法利用了一种新型神经颜色表示法,将多光谱信息编码到学习到的紧凑的平铺特征嵌入中。然后,一个浅层的多层感知器(MLP)对这个嵌入进行解码,以获得光谱颜色值,从而能够在统一表示中联合学习所有波段。我们的实验表明,这种简单而有效的策略能够提高多光谱渲染质量,同时相较于最先进的方法还能提高每个光谱的渲染质量。我们通过农业应用展示了这项新技术在渲染植被指数(如归一化差值植被指数NDVI)方面的有效性。
论文及项目相关链接
Summary
本文介绍了MS-Splatting,这是一种多光谱三维高斯拼贴(3DGS)框架,能够从多个独立相机拍摄的不同光谱域的图像生成多视角一致的全新视角。该方法无需跨模态相机校准,能够灵活建模多种不同光谱,包括热谱和近红外光谱,且无需进行任何算法更改。通过利用新型神经网络颜色表示,将多光谱信息编码到学习到的紧凑拼贴特征嵌入中,然后利用浅层多层感知器(MLP)解码此嵌入以获得光谱颜色值,实现所有频带的联合学习,在统一表示中提高了多光谱渲染质量和每种光谱的渲染质量。
Key Takeaways
- MS-Splatting是一种多光谱3DGS框架,可从多个独立相机生成多视角一致的新视角。
- 该方法无需跨模态相机校准,能灵活建模多种光谱。
- 不同于其他3DGS框架,MS-Splatting采用新型神经网络颜色表示,将多光谱信息编码到特征嵌入中。
- 通过浅层MLP解码特征嵌入以获得光谱颜色值,实现所有频带的联合学习。
- MS-Splatting在提高多光谱渲染质量的同时,也提高了每种光谱的渲染质量。
- 该技术在农业应用中的植被指数渲染,如归一化差分植被指数(NDVI)的渲染,表现出有效性。
- MS-Splatting框架具有潜在的应用价值,在图像处理、虚拟现实、增强现实等领域中有广泛的应用前景。
点此查看论文截图