⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-06 更新
Sounding that Object: Interactive Object-Aware Image to Audio Generation
Authors:Tingle Li, Baihe Huang, Xiaobin Zhuang, Dongya Jia, Jiawei Chen, Yuping Wang, Zhuo Chen, Gopala Anumanchipalli, Yuxuan Wang
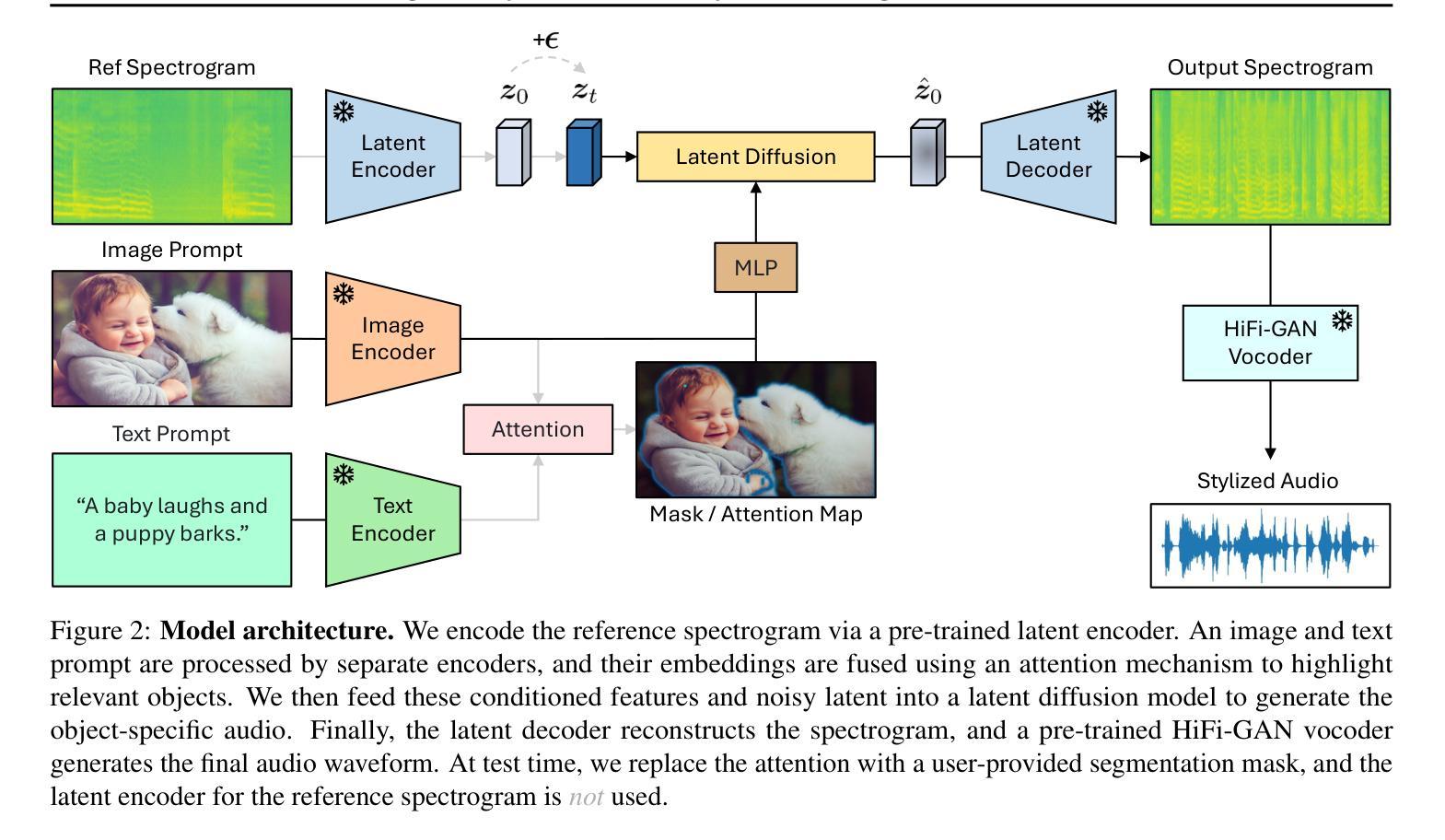
Generating accurate sounds for complex audio-visual scenes is challenging, especially in the presence of multiple objects and sound sources. In this paper, we propose an {\em interactive object-aware audio generation} model that grounds sound generation in user-selected visual objects within images. Our method integrates object-centric learning into a conditional latent diffusion model, which learns to associate image regions with their corresponding sounds through multi-modal attention. At test time, our model employs image segmentation to allow users to interactively generate sounds at the {\em object} level. We theoretically validate that our attention mechanism functionally approximates test-time segmentation masks, ensuring the generated audio aligns with selected objects. Quantitative and qualitative evaluations show that our model outperforms baselines, achieving better alignment between objects and their associated sounds. Project page: https://tinglok.netlify.app/files/avobject/
为复杂的视听场景生成准确的声音是一个挑战,特别是在存在多个对象和声音源的情况下。在本文中,我们提出了一种交互式对象感知音频生成模型,该模型以图像中用户选择的视觉对象为基础生成声音。我们的方法将对象中心学习集成到条件潜在扩散模型中,该模型通过多模式注意力学习将图像区域与相应的声音相关联。在测试阶段,我们的模型采用图像分割技术,允许用户以对象级别交互地生成声音。我们从理论上验证了我们注意力的机制,它在功能上近似于测试时的分割掩膜,确保生成的音频与所选对象对齐。定量和定性评估表明,我们的模型优于基线模型,在对象和与其相关的声音之间实现了更好的对齐。项目页面:https://tinglok.netlify.app/files/avobject/
论文及项目相关链接
PDF ICML 2025
Summary
本文提出了一种交互式对象感知音频生成模型,该模型在用户选择的图像中的视觉对象基础上生成声音。通过集成对象中心学习于条件潜在扩散模型,该模型学会将图像区域与其相应的声音通过多模式注意力相关联。测试时,模型采用图像分割让用户能够互动地生成对象级别的声音。理论和实验验证显示,模型的注意力机制可近似测试时的分割掩模,确保生成的音频与所选对象相符。此模型优于基线模型,实现对象与其相关声音之间更好的对齐。
Key Takeaways
- 提出了交互式对象感知音频生成模型,将声音生成与图像中的视觉对象相关联。
- 集成对象中心学习于条件潜在扩散模型,学会关联图像区域与对应声音。
- 通过多模态注意力机制实现对象级别的声音生成。
- 注意力机制理论上可近似测试时的分割掩模,确保音频与所选对象对齐。
- 模型在定量和定性评估中均表现出优于基线模型的效果。
- 模型实现了对象与其相关声音之间的良好对齐。
点此查看论文截图


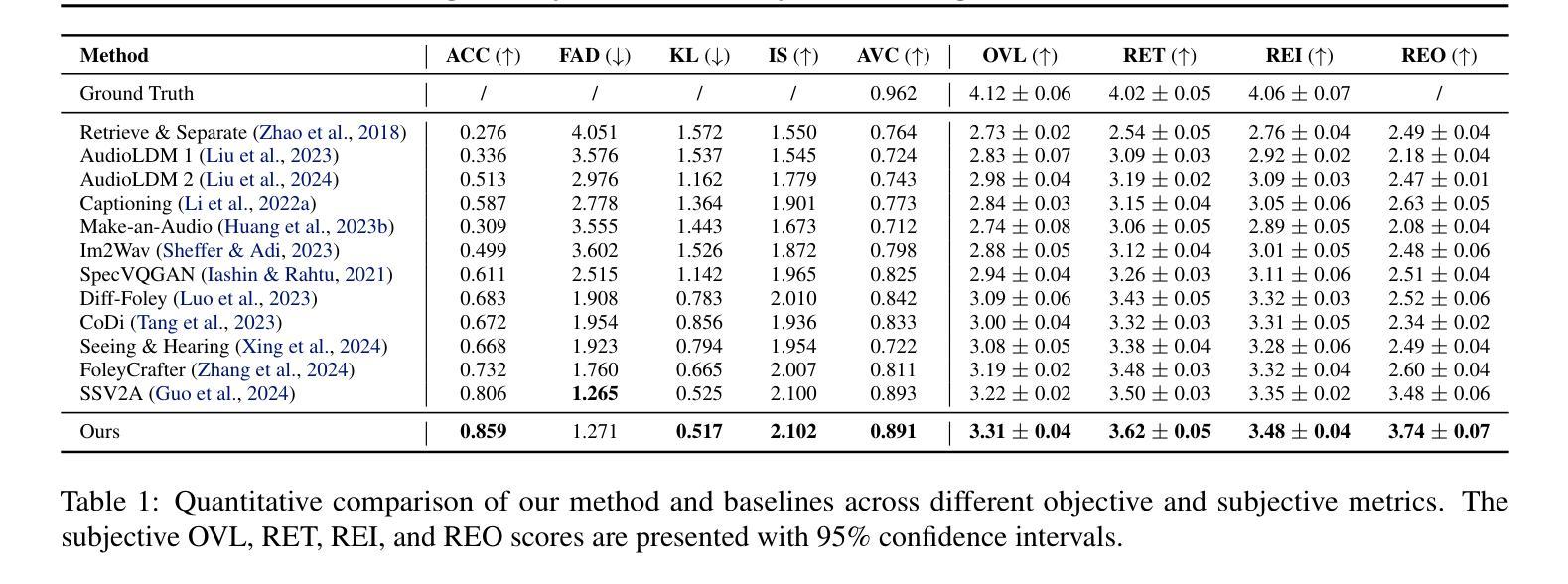
Diffusion Domain Teacher: Diffusion Guided Domain Adaptive Object Detector
Authors:Boyong He, Yuxiang Ji, Zhuoyue Tan, Liaoni Wu
Object detectors often suffer a decrease in performance due to the large domain gap between the training data (source domain) and real-world data (target domain). Diffusion-based generative models have shown remarkable abilities in generating high-quality and diverse images, suggesting their potential for extracting valuable feature from various domains. To effectively leverage the cross-domain feature representation of diffusion models, in this paper, we train a detector with frozen-weight diffusion model on the source domain, then employ it as a teacher model to generate pseudo labels on the unlabeled target domain, which are used to guide the supervised learning of the student model on the target domain. We refer to this approach as Diffusion Domain Teacher (DDT). By employing this straightforward yet potent framework, we significantly improve cross-domain object detection performance without compromising the inference speed. Our method achieves an average mAP improvement of 21.2% compared to the baseline on 6 datasets from three common cross-domain detection benchmarks (Cross-Camera, Syn2Real, Real2Artistic}, surpassing the current state-of-the-art (SOTA) methods by an average of 5.7% mAP. Furthermore, extensive experiments demonstrate that our method consistently brings improvements even in more powerful and complex models, highlighting broadly applicable and effective domain adaptation capability of our DDT. The code is available at https://github.com/heboyong/Diffusion-Domain-Teacher.
对象检测器通常由于训练数据(源域)和现实世界数据(目标域)之间的域差距较大而性能下降。基于扩散的生成模型在生成高质量和多样化图像方面表现出了显著的能力,这表明它们从各种域中提取有价值特征的潜力。为了有效利用扩散模型的跨域特征表示,本文在源域上训练了一个带有冻结权重扩散模型的检测器,然后将其作为教师模型在未经标记的目标域上生成伪标签,用于指导目标域上学生模型的监督学习。我们将这种方法称为扩散域教师(DDT)。通过采用这种简单而强大的框架,我们在不牺牲推理速度的情况下,显著提高了跨域目标检测性能。我们的方法在三个常见的跨域检测基准测试(跨摄像头、Syn2Real、Real2Artistic)的6个数据集上,与基线相比,平均mAP提高了21.2%,并且平均比当前最佳方法高出5.7%的mAP。此外,大量实验表明,即使在更强大和复杂的模型中,我们的方法也始终能带来改进,这突显了我们DDT方法广泛的适用性和有效的域适应能力。代码可用在https://github.com/heboyong/Diffusion-Domain-Teacher。
论文及项目相关链接
PDF MM2024 poster, with appendix and codes
Summary
扩散模型在跨域目标检测中具有显著优势。通过训练源域上的冻结权重扩散模型作为教师模型,对目标域生成伪标签进行引导学习,提高了跨域目标检测的准确性,同时不损失推理速度。该方法在多个数据集上平均提高了21.2%的mAP性能,超过了现有技术水平平均提高了5.7%。这是一种强大而灵活的方法,能够广泛应用在各种领域适应的场景中。更多细节和代码可在GitHub仓库中找到。
Key Takeaways
- 扩散模型具有强大的跨域特征表示能力,能够在目标检测中发挥显著优势。
- 通过训练源域上的冻结权重扩散模型作为教师模型,生成伪标签用于目标域的学习,有效提高了跨域目标检测的准确性。
- 该方法在不损失推理速度的前提下实现了显著的性能提升。
- 在多个数据集上进行的实验表明,该方法平均提高了21.2%的mAP性能,显著优于现有技术。
- 该方法不仅适用于基础模型,而且在更强大和复杂的模型中也能带来一致的性能提升。
- 该方法具有广泛的应用性,能够应用于各种领域适应的场景中。
点此查看论文截图

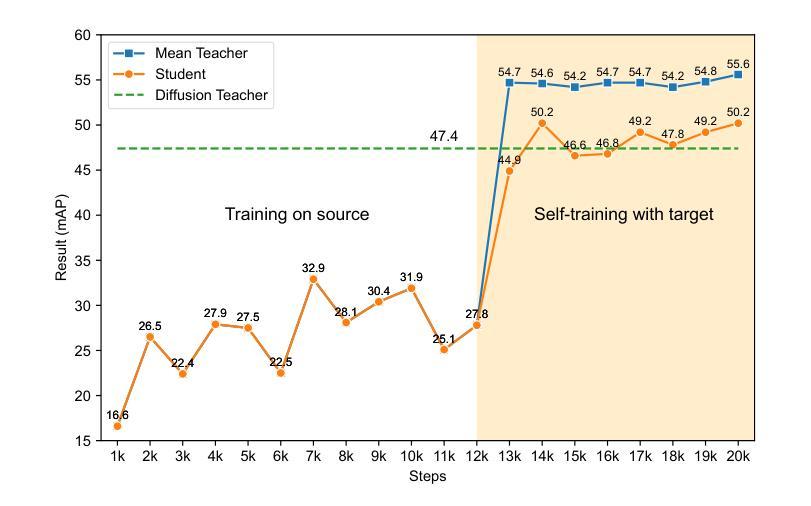
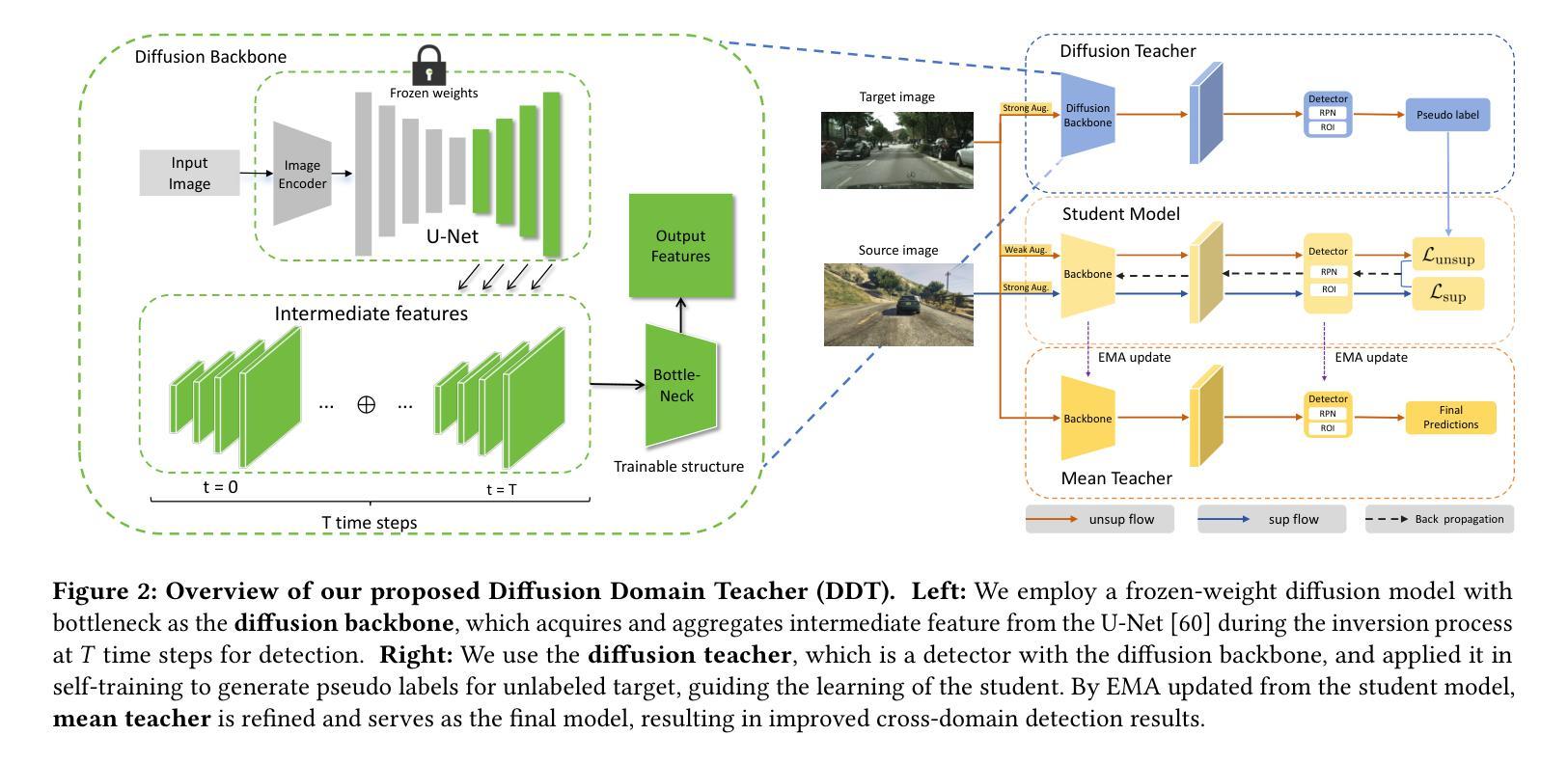

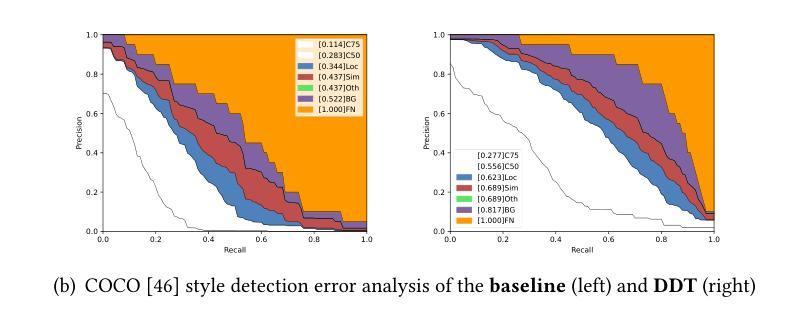
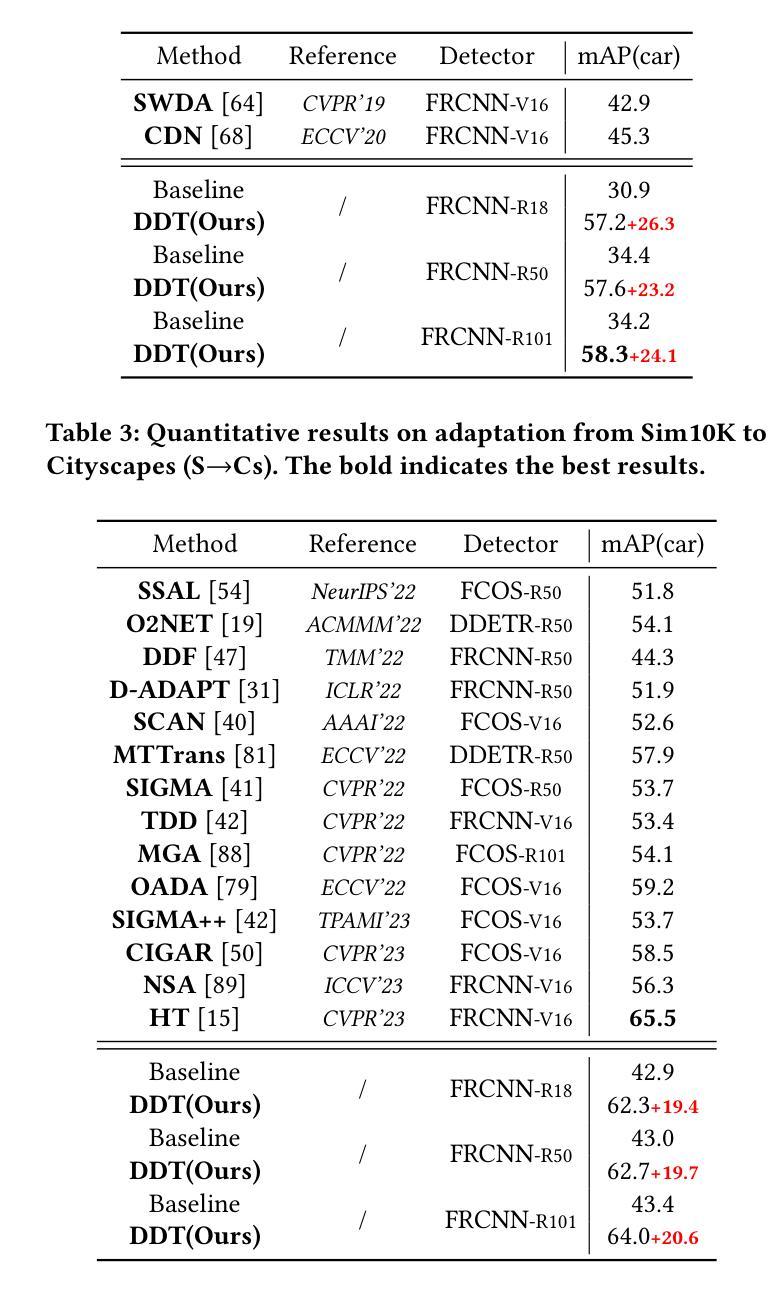
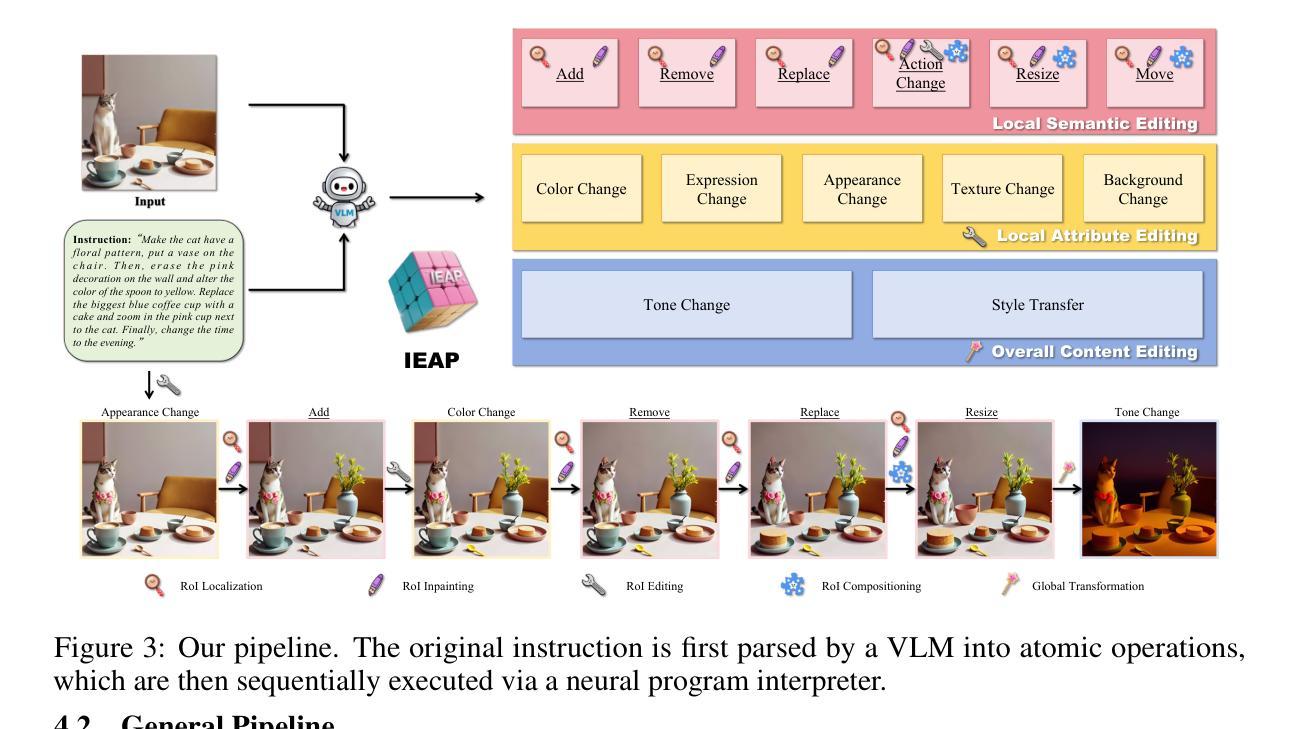
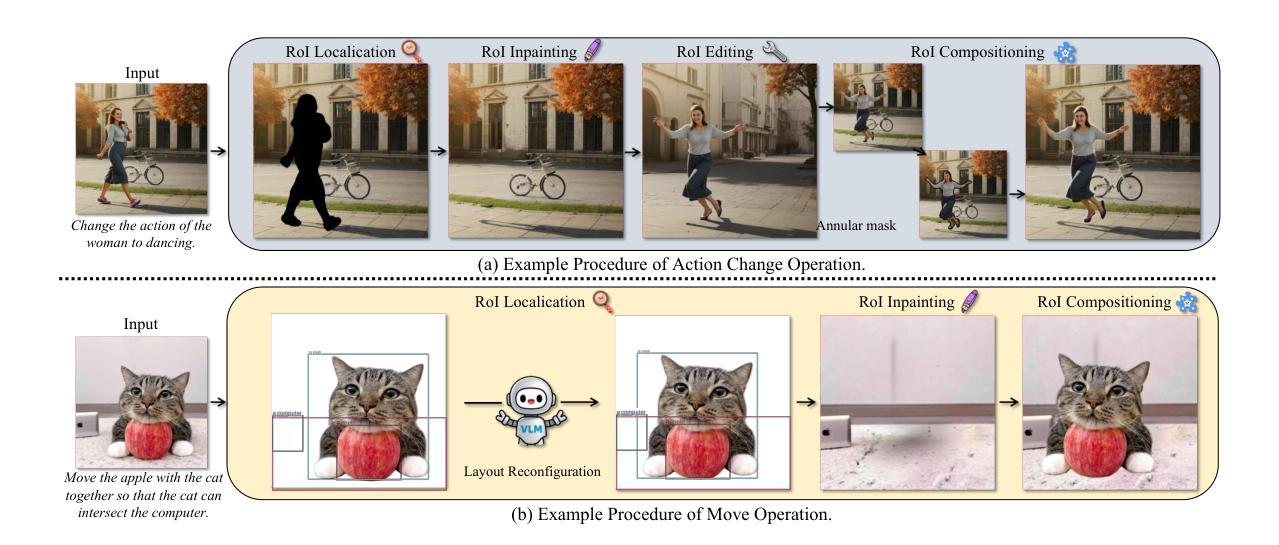
Image Editing As Programs with Diffusion Models
Authors:Yujia Hu, Songhua Liu, Zhenxiong Tan, Xingyi Yang, Xinchao Wang
While diffusion models have achieved remarkable success in text-to-image generation, they encounter significant challenges with instruction-driven image editing. Our research highlights a key challenge: these models particularly struggle with structurally inconsistent edits that involve substantial layout changes. To mitigate this gap, we introduce Image Editing As Programs (IEAP), a unified image editing framework built upon the Diffusion Transformer (DiT) architecture. At its core, IEAP approaches instructional editing through a reductionist lens, decomposing complex editing instructions into sequences of atomic operations. Each operation is implemented via a lightweight adapter sharing the same DiT backbone and is specialized for a specific type of edit. Programmed by a vision-language model (VLM)-based agent, these operations collaboratively support arbitrary and structurally inconsistent transformations. By modularizing and sequencing edits in this way, IEAP generalizes robustly across a wide range of editing tasks, from simple adjustments to substantial structural changes. Extensive experiments demonstrate that IEAP significantly outperforms state-of-the-art methods on standard benchmarks across various editing scenarios. In these evaluations, our framework delivers superior accuracy and semantic fidelity, particularly for complex, multi-step instructions. Codes are available at https://github.com/YujiaHu1109/IEAP.
虽然扩散模型在文本到图像生成方面取得了显著的成功,但在指令驱动图像编辑方面仍面临重大挑战。我们的研究突出了一个关键挑战:这些模型特别难以处理涉及大量布局变化的结构性不一致编辑。为了弥补这一差距,我们引入了“图像编辑作为程序(IEAP)”,这是一个基于扩散变压器(DiT)架构的统一图像编辑框架。IEAP的核心是通过还原论的方法来进行指令编辑,将复杂的编辑指令分解为原子操作序列。每个操作都是通过轻量级适配器实现的,该适配器共享相同的DiT主干,并针对特定类型的编辑进行专业化。这些操作通过视觉语言模型(VLM)驱动的代理进行编程,协同支持任意和结构上不一致的转换。通过这种方式模块化并排序编辑,IEAP在各种编辑任务上表现稳健,无论是简单的调整还是大幅的结构变化。大量实验表明,IEAP在各种编辑场景的基准测试中显著优于最新方法。在这些评估中,我们的框架在准确性和语义保真度方面表现出卓越性能,尤其是针对复杂的多步骤指令。代码可在https://github.com/YujiaHu1109/IEAP找到。
论文及项目相关链接
Summary
扩散模型在文本到图像生成方面取得了显著的成功,但在指令驱动图像编辑方面面临重大挑战,特别是处理涉及重大布局变化的结构性不一致编辑。为缓解这一问题,我们提出了图像编辑作为程序(IEAP)的概念,这是一个基于Diffusion Transformer(DiT)架构的统一图像编辑框架。IEAP通过简约主义的视角进行指令编辑,将复杂的编辑指令分解为一系列原子操作序列。每个操作都通过轻量级适配器实现,该适配器共享相同的DiT主干并专用于特定类型的编辑。这些操作由视觉语言模型(VLM)驱动的代理进行编程,协同支持任意和结构性不一致的转换。通过这种方式模块化并编辑序列,IEAP能够广泛应用于各种编辑任务,从简单调整到重大结构性变化。在广泛的实验中,IEAP在多种编辑场景的基准测试中显著优于最新方法。特别是在复杂的多步骤指令下,我们的框架提供了更高的准确性和语义保真度。相关代码可在链接中找到。
Key Takeaways
- 扩散模型在文本到图像生成上表现出色,但在处理涉及重大布局变化的指令驱动图像编辑方面面临挑战。
- 提出的图像编辑作为程序(IEAP)框架基于Diffusion Transformer(DiT)架构构建。
- IEAP通过分解为原子操作序列来处理复杂的编辑指令。
- 每个操作都是通过轻量级适配器实现的,该适配器共享相同的DiT主干并专为特定类型的编辑设计。
- 这些操作由视觉语言模型(VLM)驱动的代理进行编程,支持任意和结构性不一致的转换。
- IEAP通过模块化并编辑序列的方式,可以广泛应用于各种编辑任务。
点此查看论文截图


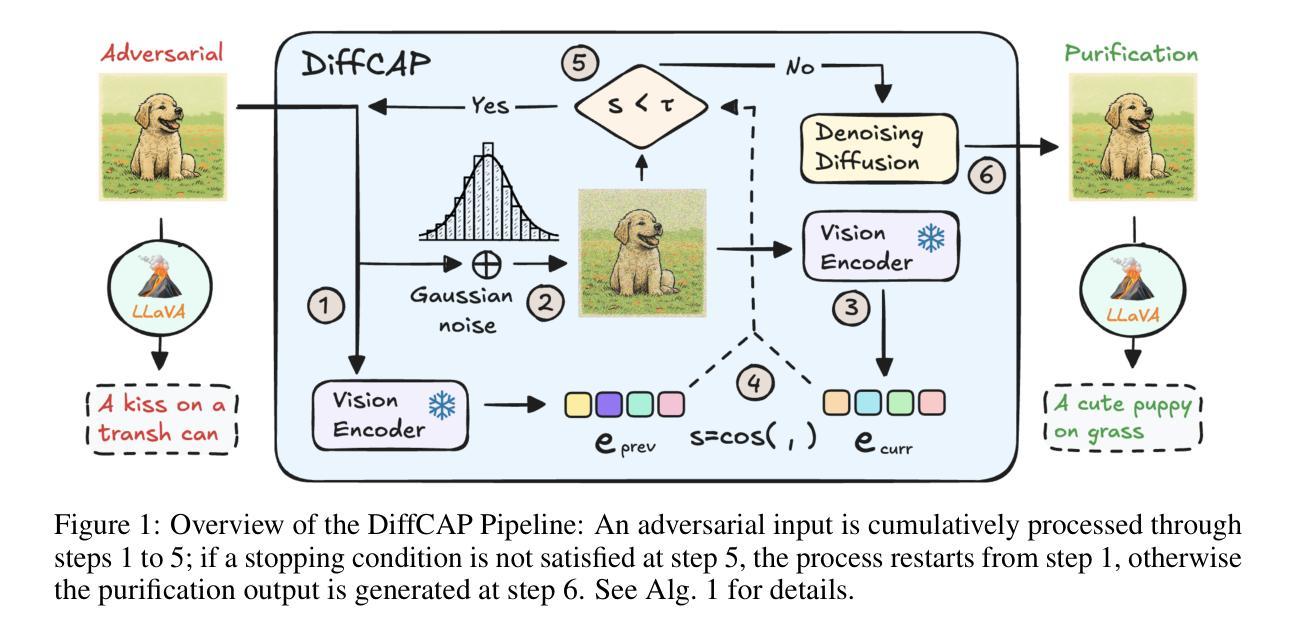
DiffCAP: Diffusion-based Cumulative Adversarial Purification for Vision Language Models
Authors:Jia Fu, Yongtao Wu, Yihang Chen, Kunyu Peng, Xiao Zhang, Volkan Cevher, Sepideh Pashami, Anders Holst
Vision Language Models (VLMs) have shown remarkable capabilities in multimodal understanding, yet their susceptibility to perturbations poses a significant threat to their reliability in real-world applications. Despite often being imperceptible to humans, these perturbations can drastically alter model outputs, leading to erroneous interpretations and decisions. This paper introduces DiffCAP, a novel diffusion-based purification strategy that can effectively neutralize adversarial corruptions in VLMs. We observe that adding minimal noise to an adversarially corrupted image significantly alters its latent embedding with respect to VLMs. Building on this insight, DiffCAP cumulatively injects random Gaussian noise into adversarially perturbed input data. This process continues until the embeddings of two consecutive noisy images reach a predefined similarity threshold, indicating a potential approach to neutralize the adversarial effect. Subsequently, a pretrained diffusion model is employed to denoise the stabilized image, recovering a clean representation suitable for the VLMs to produce an output. Through extensive experiments across six datasets with three VLMs under varying attack strengths in three task scenarios, we show that DiffCAP consistently outperforms existing defense techniques by a substantial margin. Notably, DiffCAP significantly reduces both hyperparameter tuning complexity and the required diffusion time, thereby accelerating the denoising process. Equipped with strong theoretical and empirical support, DiffCAP provides a robust and practical solution for securely deploying VLMs in adversarial environments.
视觉语言模型(VLMs)在多模态理解方面表现出了显著的能力,然而它们容易受到扰动的影响,这对它们在现实世界应用中的可靠性构成了重大威胁。尽管这些扰动通常对人类来说是不可察觉的,但它们会极大地改变模型的输出,导致错误的解释和决策。本文介绍了一种基于扩散的新净化策略DiffCAP,它可以有效地中和视觉语言模型中的对抗性腐败。我们观察到,向对抗性腐蚀的图像添加少量噪声会显著改变其相对于VLMs的潜在嵌入。基于这一见解,DiffCAP累积地向对抗性扰动输入数据注入随机高斯噪声。这个过程会继续进行,直到两个连续的带噪声图像的特征嵌入达到预定的相似性阈值,这表明了一种可能中和对抗效应的方法。随后,使用预训练的扩散模型对稳定的图像进行去噪,恢复一个适合视觉语言模型产生输出的清洁表示。通过六个数据集在三种任务场景下的广泛实验,使用三种视觉语言模型并在不同攻击强度下进行测试,我们表明DiffCAP在防御技术方面始终显著优于现有技术。值得注意的是,DiffCAP显著降低了超参数调整复杂性和所需的扩散时间,从而加速了去噪过程。凭借强大的理论和实证支持,DiffCAP为在敌对环境中安全部署视觉语言模型提供了稳健实用的解决方案。
论文及项目相关链接
Summary:
本文介绍了一种名为DiffCAP的新颖扩散式净化策略,能有效中和视觉语言模型(VLMs)中的对抗性污染。通过向受攻击的图像添加最小噪声,改变其潜在嵌入,DiffCAP累积地向受干扰的输入数据注入随机高斯噪声,直到两个连续噪声图像的特征嵌入达到预定的相似性阈值。随后,利用预训练的扩散模型对稳定图像进行去噪处理,使其恢复干净状态以供VLMs处理。实验证明,DiffCAP在多种数据集和任务场景下均显著优于现有防御技术,大幅降低了超参数调整复杂性和所需的扩散时间,加速了去噪过程。这为在敌对环境中安全部署VLMs提供了稳健实用的解决方案。
Key Takeaways:
- VLMs在多媒体理解方面表现出卓越的能力,但其对干扰的敏感性对其在现实世界应用中的可靠性构成威胁。
- DiffCAP是一种基于扩散的净化策略,能有效中和VLMs中的对抗性污染。
- DiffCAP通过向受攻击的图像添加噪声来改变其潜在嵌入,然后累积注入随机高斯噪声,直到图像稳定。
- 使用预训练的扩散模型对稳定图像进行去噪处理,恢复干净状态以供VLMs处理。
- DiffCAP在多个数据集和任务场景下的实验表现优于现有防御技术。
- DiffCAP降低了超参数调整复杂性和所需的扩散时间,加速了去噪过程。
点此查看论文截图

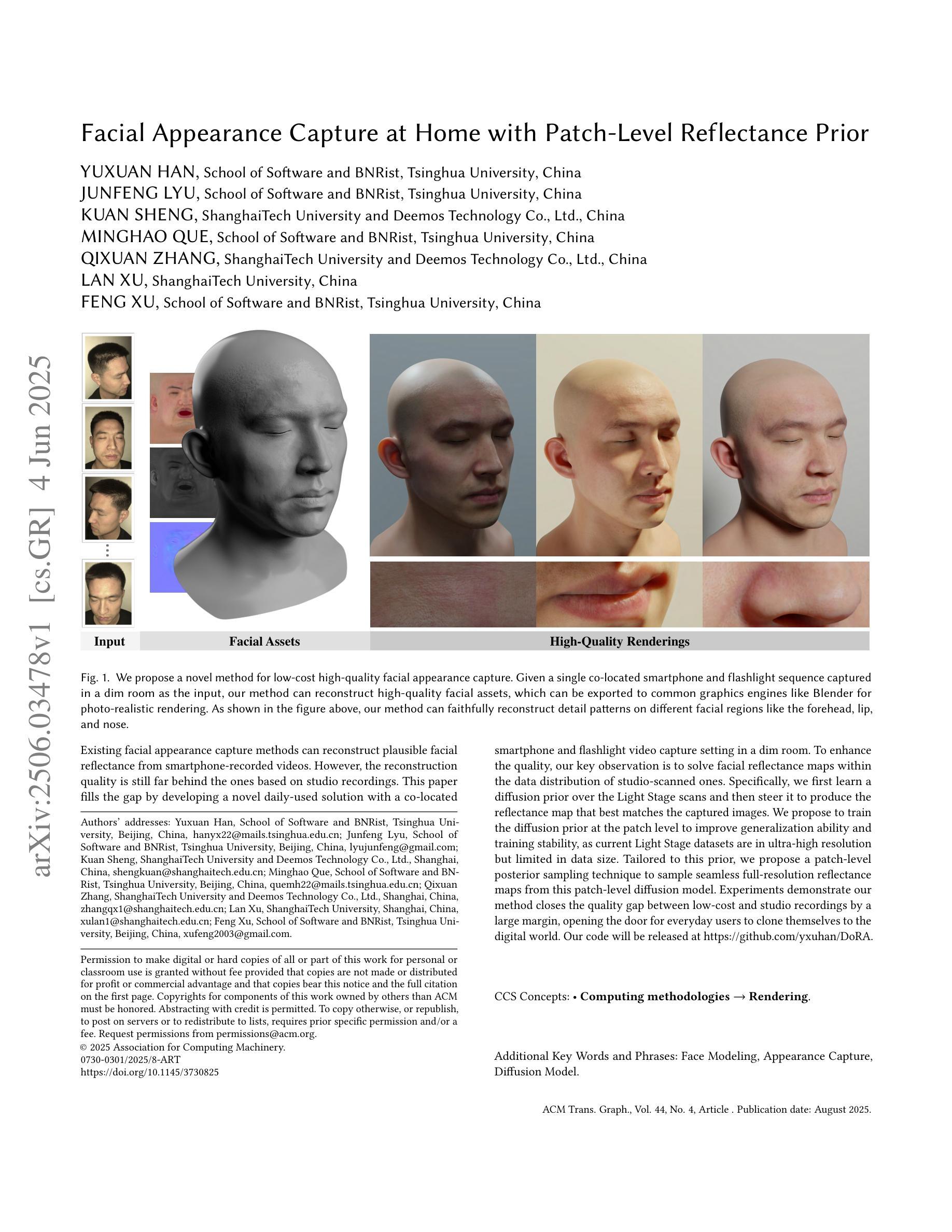
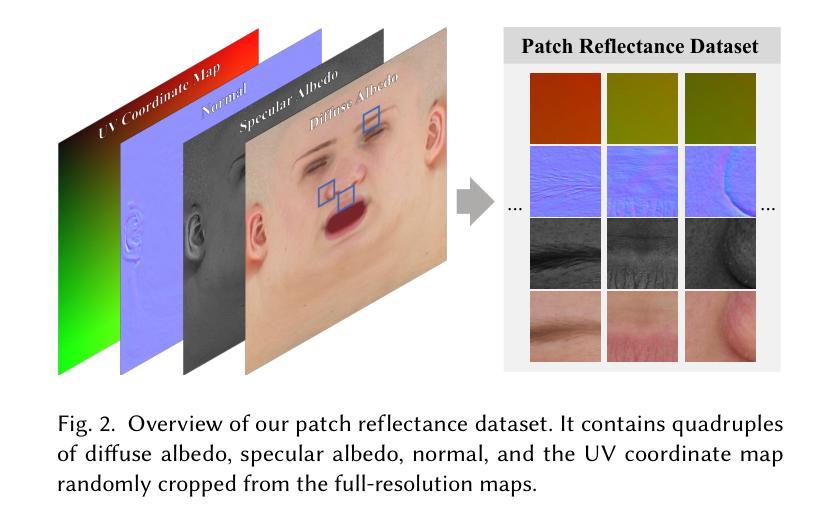
Facial Appearance Capture at Home with Patch-Level Reflectance Prior
Authors:Yuxuan Han, Junfeng Lyu, Kuan Sheng, Minghao Que, Qixuan Zhang, Lan Xu, Feng Xu
Existing facial appearance capture methods can reconstruct plausible facial reflectance from smartphone-recorded videos. However, the reconstruction quality is still far behind the ones based on studio recordings. This paper fills the gap by developing a novel daily-used solution with a co-located smartphone and flashlight video capture setting in a dim room. To enhance the quality, our key observation is to solve facial reflectance maps within the data distribution of studio-scanned ones. Specifically, we first learn a diffusion prior over the Light Stage scans and then steer it to produce the reflectance map that best matches the captured images. We propose to train the diffusion prior at the patch level to improve generalization ability and training stability, as current Light Stage datasets are in ultra-high resolution but limited in data size. Tailored to this prior, we propose a patch-level posterior sampling technique to sample seamless full-resolution reflectance maps from this patch-level diffusion model. Experiments demonstrate our method closes the quality gap between low-cost and studio recordings by a large margin, opening the door for everyday users to clone themselves to the digital world. Our code will be released at https://github.com/yxuhan/DoRA.
现有的人脸捕捉方法可以从智能手机拍摄的视频中重建出合理的人脸反射。然而,重建质量仍然远远落后于基于工作室录制的方法。本文填补了这个空白,开发了一种新型的日常解决方案,采用定位智能手机和昏暗房间中的闪光灯视频捕捉设置。为了提高质量,我们的关键观察是,在工作室扫描的反射图的分布范围内解决面部反射图的问题。具体来说,我们首先学习Light Stage扫描的扩散先验知识,然后引导它生成与捕获的图像最匹配的反射图。我们建议在补丁级别训练扩散先验知识,以提高泛化能力和训练稳定性,因为当前的Light Stage数据集虽然具有超高的分辨率,但在数据大小上有限制。针对这种先验知识,我们提出了一种补丁级后采样技术,可以从这种补丁级扩散模型中无缝采样全分辨率反射图。实验证明,我们的方法大大提高了低成本和工作室录制之间的质量差距,为普通用户打开了克隆自己到数字世界的大门。我们的代码将在https://github.com/yxuhan/DoRA中发布。
论文及项目相关链接
PDF ACM Transactions on Graphics (Proc. of SIGGRAPH), 2025. Code: https://github.com/yxuhan/DoRA; Project Page: https://yxuhan.github.io/DoRA
Summary
现有面部捕捉方法可从智能手机视频重建面部反射,但质量仍落后于基于工作室录制的方案。本文填补这一空白,提出一种日常使用的解决方案,采用智能手机与闪光灯视频捕捉设置,在暗室中进行。为提高质量,我们观察到解决面部反射映射需要在工作室扫描的数据分布内。具体而言,我们首先学习Light Stage扫描的光扩散先验知识,然后将其引导生成与捕获图像最匹配的反射映射图。我们提出在补丁级别训练扩散先验知识以提高通用性和训练稳定性,因为当前Light Stage数据集超高分辨率但数据量有限。针对此先验知识,我们提出了一种补丁级后采样技术,可从该补丁级扩散模型中无缝采样全分辨率反射映射图。实验证明,我们的方法大幅缩小了低成本与工作室录制之间的差距,为普通用户克隆自己进入数字世界打开了大门。
Key Takeaways
- 现有面部捕捉方法虽能从智能手机视频重建面部反射,但质量低于工作室录制。
- 本文提出一种新型解决方案,采用智能手机与闪光灯视频捕捉在暗室中进行,旨在提高质量。
- 通过学习Light Stage扫描的光扩散先验知识来解决面部反射映射问题。
- 在补丁级别训练扩散模型以提高通用性和训练稳定性,应对当前数据集分辨率高但数据量有限的问题。
- 提出补丁级后采样技术,生成无缝全分辨率反射映射图。
- 实验证明该方法显著缩小了低成本与工作室录制之间的差距。
- 该方法为用户将其自身克隆到数字世界提供了可能。
点此查看论文截图

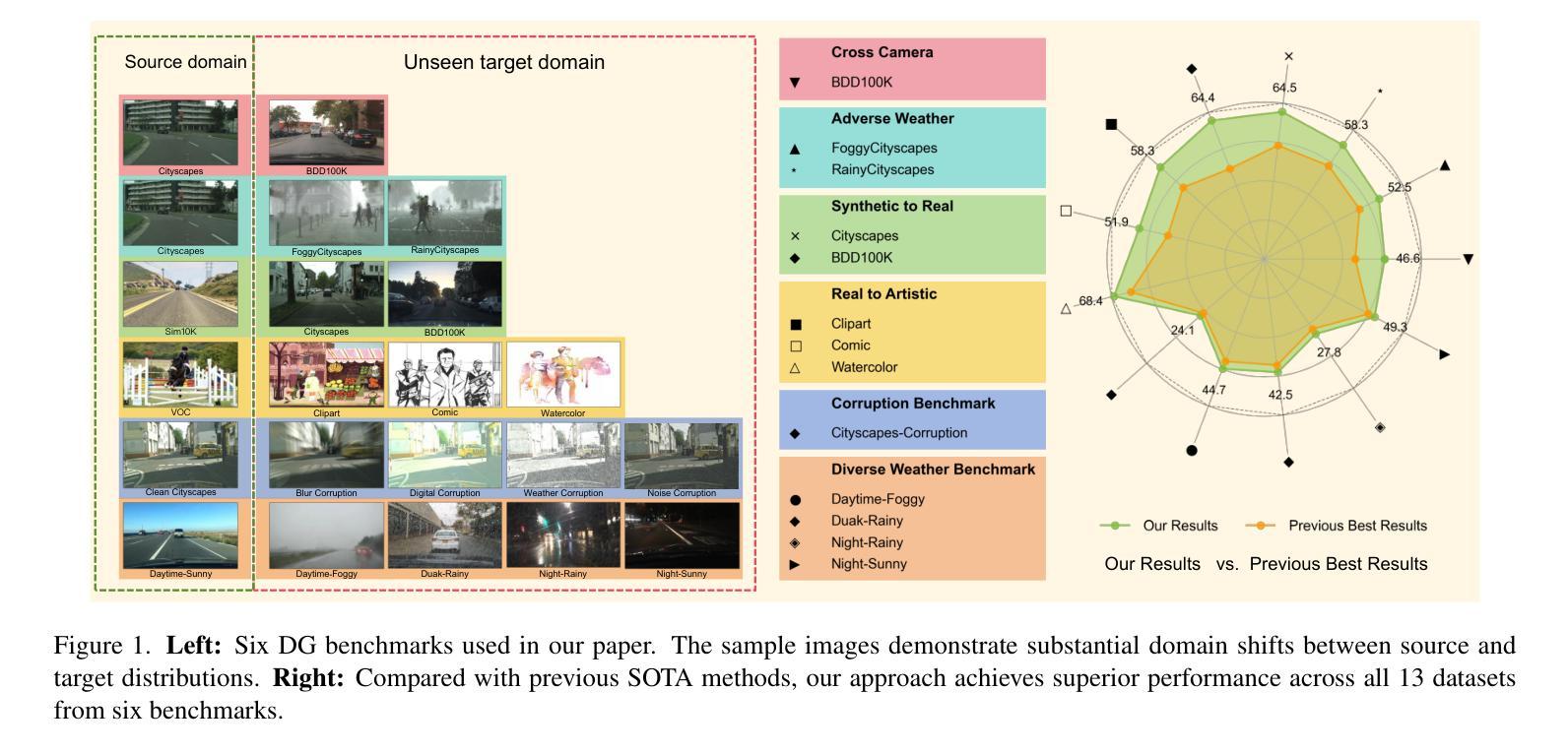
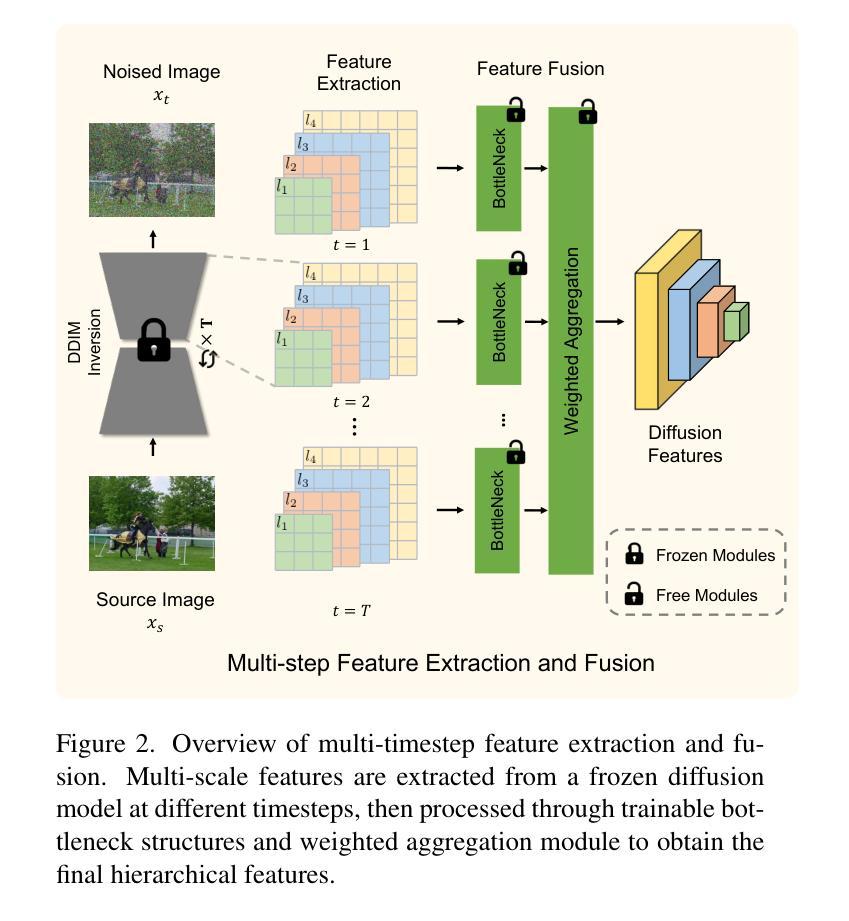
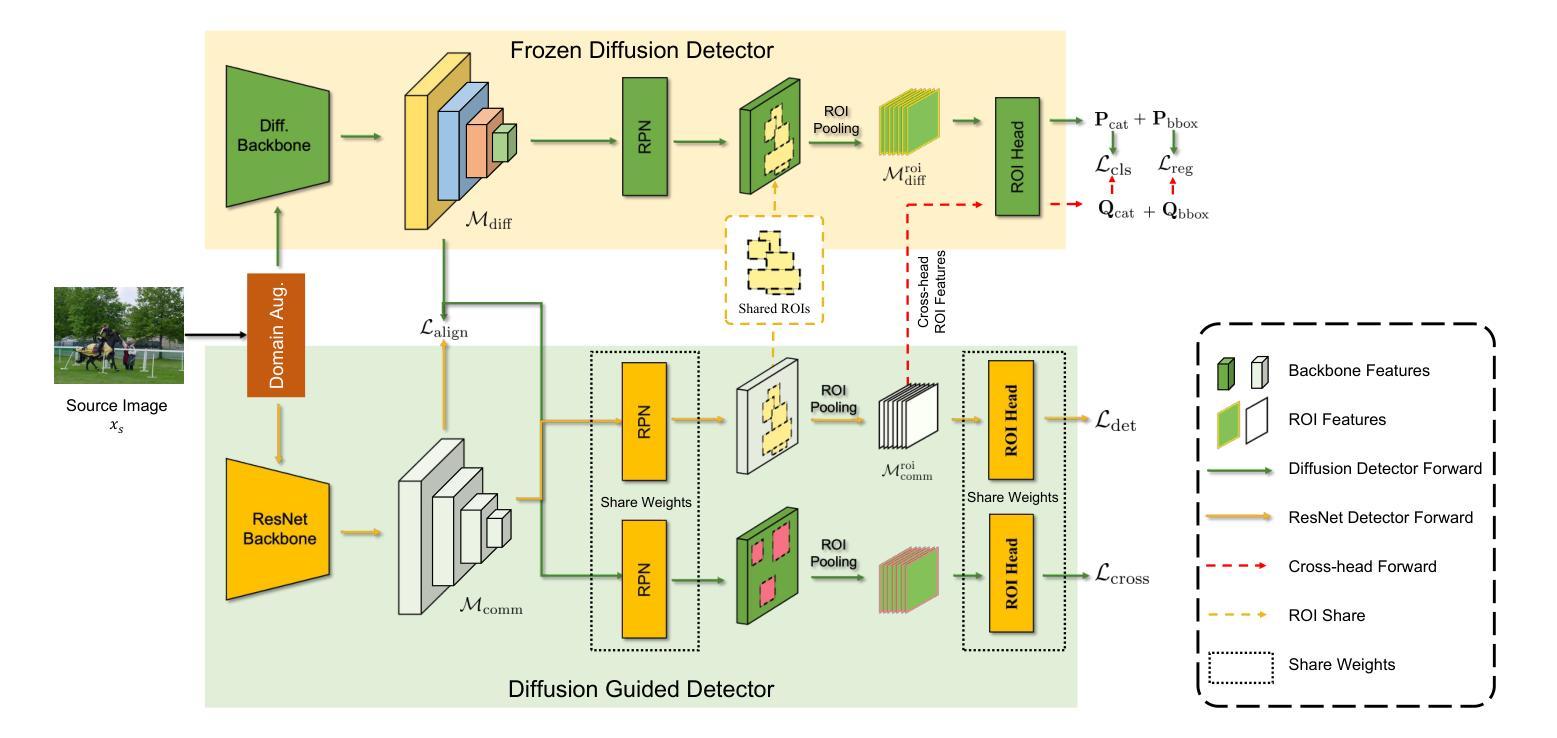
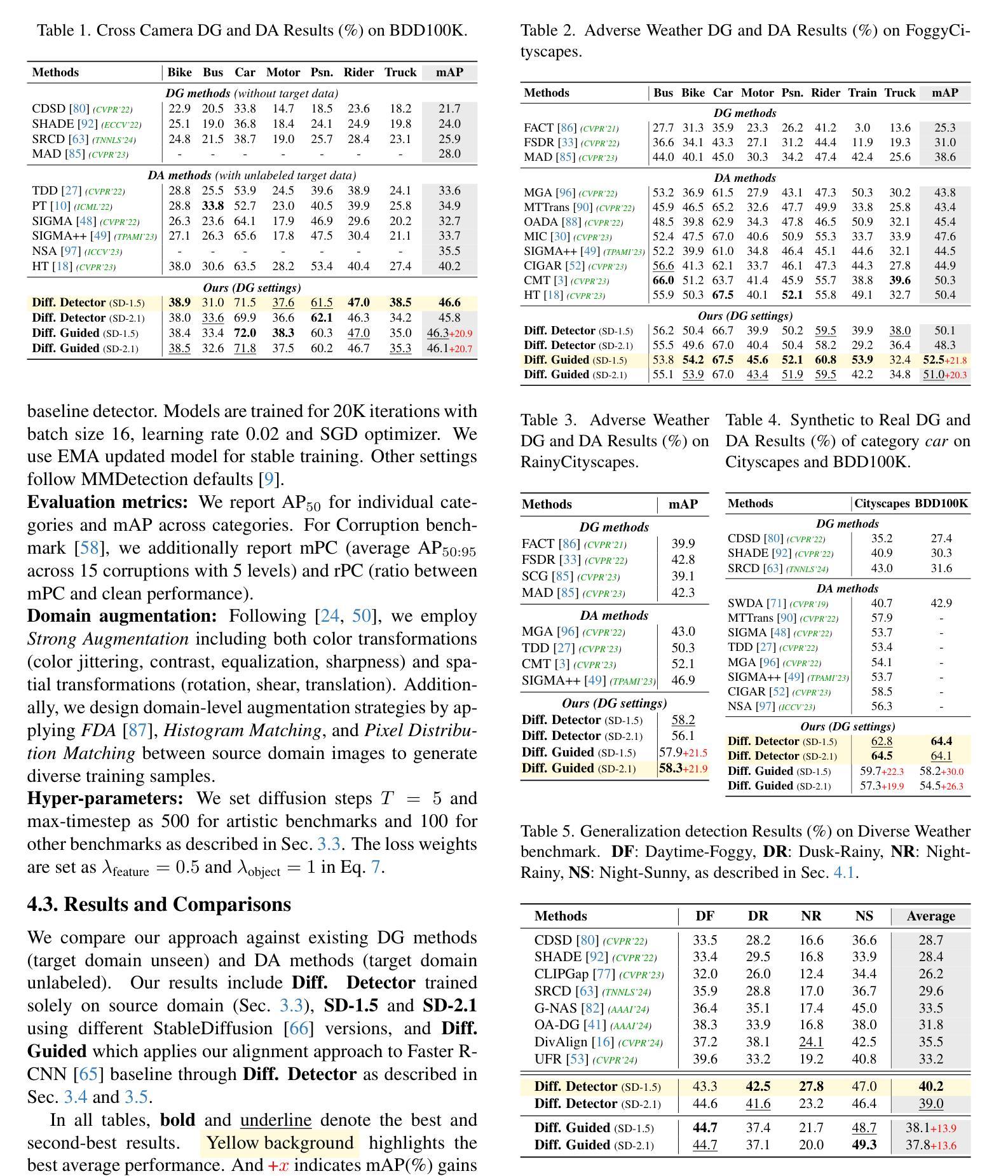
Generalized Diffusion Detector: Mining Robust Features from Diffusion Models for Domain-Generalized Detection
Authors:Boyong He, Yuxiang Ji, Qianwen Ye, Zhuoyue Tan, Liaoni Wu
Domain generalization (DG) for object detection aims to enhance detectors’ performance in unseen scenarios. This task remains challenging due to complex variations in real-world applications. Recently, diffusion models have demonstrated remarkable capabilities in diverse scene generation, which inspires us to explore their potential for improving DG tasks. Instead of generating images, our method extracts multi-step intermediate features during the diffusion process to obtain domain-invariant features for generalized detection. Furthermore, we propose an efficient knowledge transfer framework that enables detectors to inherit the generalization capabilities of diffusion models through feature and object-level alignment, without increasing inference time. We conduct extensive experiments on six challenging DG benchmarks. The results demonstrate that our method achieves substantial improvements of 14.0% mAP over existing DG approaches across different domains and corruption types. Notably, our method even outperforms most domain adaptation methods without accessing any target domain data. Moreover, the diffusion-guided detectors show consistent improvements of 15.9% mAP on average compared to the baseline. Our work aims to present an effective approach for domain-generalized detection and provide potential insights for robust visual recognition in real-world scenarios. The code is available at https://github.com/heboyong/Generalized-Diffusion-Detector.
目标检测领域的域泛化(DG)旨在提高检测器在未见过场景中的性能。由于现实世界应用中的复杂变化,这一任务仍然具有挑战性。最近,扩散模型在场景生成方面表现出卓越的能力,这激发了我们在DG任务中探索其潜力的想法。我们的方法不是生成图像,而是在扩散过程中提取多步中间特征,以获得用于广义检测的域不变特征。此外,我们提出了一个有效的知识转移框架,使检测器能够通过特征和对象级的对齐,继承扩散模型的泛化能力,而无需增加推理时间。我们在六个具有挑战性的DG基准测试集上进行了广泛的实验。结果表明,我们的方法在跨不同领域和腐败类型的情况下,较现有的DG方法提高了显著的14.0%的mAP。值得注意的是,我们的方法甚至在没有访问任何目标域数据的情况下超过了大多数域自适应方法。此外,与基线相比,扩散引导的检测器的平均mAP提高了稳定的15.9%。我们的工作旨在提供一种有效的域泛化检测方法和为真实世界场景中的稳健视觉识别提供潜在见解。代码可在https://github.com/heboyong/Generalized-Diffusion-Detector找到。
论文及项目相关链接
PDF CVPR2025 camera-ready version with supplementary material
Summary
基于扩散模型的领域泛化(DG)方法被应用于目标检测,以提高在未见过场景中的检测性能。该方法通过提取扩散过程中的多步中间特征来获得领域不变特征,并提出一种有效的知识迁移框架,使检测器能够通过特征和对象级别的对齐,继承扩散模型的泛化能力,且不会增加推理时间。在六个具有挑战性的DG基准测试中,该方法较现有DG方法实现了显著的性能提升。即使不访问任何目标域数据,该方法也比大多数域自适应方法表现更出色。此外,与基线相比,扩散引导的检测器平均提高了15.9%的mAP。此工作旨在为领域泛化检测提供一种有效方法,并为真实场景中的稳健视觉识别提供潜在启示。代码已公开在GitHub上。
Key Takeaways
- 扩散模型被探索应用于领域泛化(DG)任务,旨在提高目标检测在未见场景中的性能。
- 通过提取扩散过程中的中间特征来获得领域不变特征。
- 提出一种知识迁移框架,使检测器能够继承扩散模型的泛化能力,且不影响推理时间。
- 在多个DG基准测试中实现了显著的性能提升,较现有方法提高14.0% mAP。
- 无需访问目标域数据即可表现出良好的性能,优于多数域自适应方法。
- 扩散引导的检测器与基线相比平均提高了15.9%的mAP。
点此查看论文截图

VCT: Training Consistency Models with Variational Noise Coupling
Authors:Gianluigi Silvestri, Luca Ambrogioni, Chieh-Hsin Lai, Yuhta Takida, Yuki Mitsufuji
Consistency Training (CT) has recently emerged as a strong alternative to diffusion models for image generation. However, non-distillation CT often suffers from high variance and instability, motivating ongoing research into its training dynamics. We propose Variational Consistency Training (VCT), a flexible and effective framework compatible with various forward kernels, including those in flow matching. Its key innovation is a learned noise-data coupling scheme inspired by Variational Autoencoders, where a data-dependent encoder models noise emission. This enables VCT to adaptively learn noise-todata pairings, reducing training variance relative to the fixed, unsorted pairings in classical CT. Experiments on multiple image datasets demonstrate significant improvements: our method surpasses baselines, achieves state-of-the-art FID among non-distillation CT approaches on CIFAR-10, and matches SoTA performance on ImageNet 64 x 64 with only two sampling steps. Code is available at https://github.com/sony/vct.
一致性训练(CT)最近作为图像生成的扩散模型的强大替代方案而出现。然而,非蒸馏CT经常遭受高方差和不稳定性的困扰,这促使人们对其训练动态进行持续研究。我们提出了变分一致性训练(VCT),这是一个灵活有效的框架,可与各种前向内核兼容,包括流匹配中的内核。其关键创新在于受到变分自编码器的启发而设计的一种学习噪声数据耦合方案,其中数据依赖的编码器对噪声排放进行建模。这使得VCT能够自适应地学习噪声到数据的配对,相对于经典CT中的固定且未排序的配对,降低了训练方差。在多个图像数据集上的实验证明了显著的改进:我们的方法超越了基线,在CIFAR-10上在非蒸馏CT方法中实现了最先进的FID,并在仅有两次采样步骤的ImageNet 64 x 64上达到了最先进的表现。代码可在https://github.com/sony/vct找到。
论文及项目相关链接
PDF 23 pages, 11 figures
Summary
本文介绍了一种名为变分一致性训练(VCT)的新方法,它是一致性训练(CT)的改进版本,用于图像生成。VCT采用灵活的框架,兼容各种前向核,包括流匹配。其关键创新在于引入了基于变分自编码器的噪声数据耦合方案,使VCT能够自适应地学习噪声与数据的配对,从而降低了训练方差。实验表明,该方法在多个图像数据集上实现了显著改进,超过了基线方法,并在CIFAR-10上达到了非蒸馏一致性训练的最佳FID得分。
Key Takeaways
- 变分一致性训练(VCT)是一致性训练(CT)的改进版本,专门用于图像生成。
- VCT引入了一种基于变分自编码器的噪声数据耦合方案,这是其关键创新。
- 该方案使VCT能够自适应地学习噪声与数据的配对,降低训练方差。
- VCT兼容各种前向核,包括流匹配。
- 实验表明,VCT在多个图像数据集上实现了性能改进,超过了基线方法。
- VCT在CIFAR-10数据集上达到了非蒸馏一致性训练的最佳FID得分。
点此查看论文截图



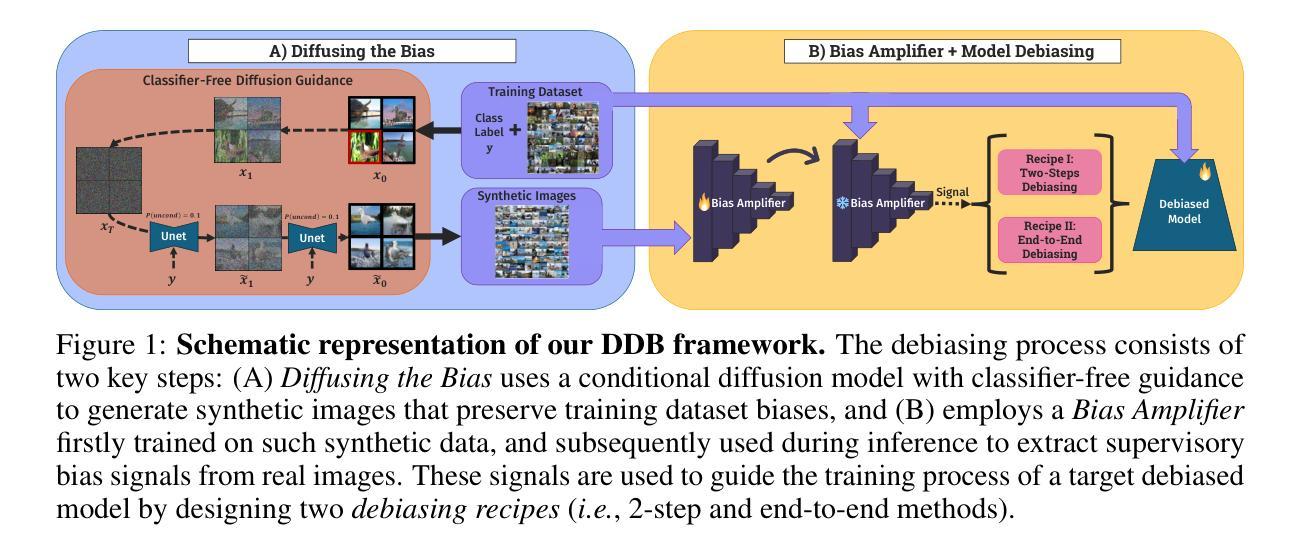
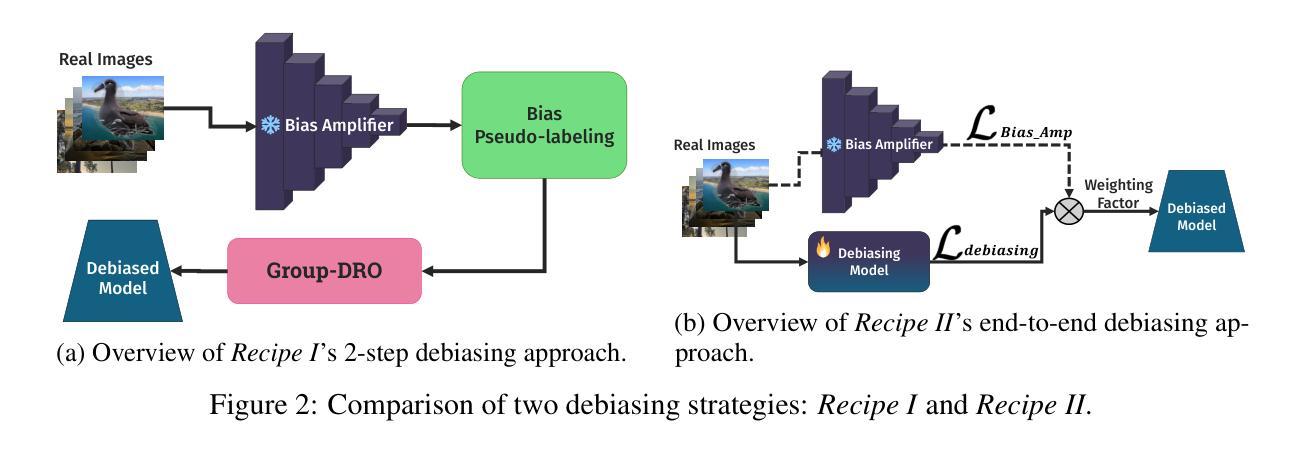
Diffusing DeBias: Synthetic Bias Amplification for Model Debiasing
Authors:Massimiliano Ciranni, Vito Paolo Pastore, Roberto Di Via, Enzo Tartaglione, Francesca Odone, Vittorio Murino
Deep learning model effectiveness in classification tasks is often challenged by the quality and quantity of training data whenever they are affected by strong spurious correlations between specific attributes and target labels. This results in a form of bias affecting training data, which typically leads to unrecoverable weak generalization in prediction. This paper aims at facing this problem by leveraging bias amplification with generated synthetic data: we introduce Diffusing DeBias (DDB), a novel approach acting as a plug-in for common methods of unsupervised model debiasing exploiting the inherent bias-learning tendency of diffusion models in data generation. Specifically, our approach adopts conditional diffusion models to generate synthetic bias-aligned images, which replace the original training set for learning an effective bias amplifier model that we subsequently incorporate into an end-to-end and a two-step unsupervised debiasing approach. By tackling the fundamental issue of bias-conflicting training samples memorization in learning auxiliary models, typical of this type of techniques, our proposed method beats current state-of-the-art in multiple benchmark datasets, demonstrating its potential as a versatile and effective tool for tackling bias in deep learning models.
深度学习模型在分类任务中的有效性常常受到训练数据的质量和数量的挑战,尤其是在特定属性与目标标签之间存在强烈虚假关联时。这导致了一种影响训练数据的偏见,通常会导致预测中不可挽回的弱泛化。本文针对这一问题,利用生成合成数据的偏见放大来解决:我们引入了Diffusing DeBias(DDB),这是一种新型方法,作为对常见无监督模型去偏置方法的插件,利用数据生成中扩散模型固有的偏见学习倾向。具体来说,我们的方法采用条件扩散模型生成合成偏见对齐图像,这些图像替代原始训练集,用于学习有效的偏见放大模型,随后我们将其纳入端到端和两步无监督去偏置方法中。通过解决学习辅助模型中偏见冲突训练样本记忆的根本问题,这是此类技术的一个典型特征,我们提出的方法在多个基准数据集上超过了当前最佳水平,证明了其作为解决深度学习模型中偏见问题的通用和有效工具的潜力。
论文及项目相关链接
PDF 18 Pages, 9 Figures
Summary
深度学习方法在分类任务中的有效性常受训练数据的质量和数量的影响,特别是当这些数据中存在特定属性和目标标签之间的强烈偶然性关联时。这种情况会导致训练数据产生偏见,通常会导致预测中的不可恢复的弱泛化能力。本文旨在通过利用生成的合成数据放大偏见来应对这一问题:我们引入了Diffusing DeBias(DDB),这是一种新方法,可作为通用无监督模型去偏方法的插件。具体而言,我们的方法采用条件扩散模型生成合成偏见对齐图像,这些图像会替代原始训练集来学习有效的偏见放大模型,随后我们将其纳入端到端和两步无监督去偏方法。通过解决辅助模型学习中存在的偏见冲突训练样本记忆问题,我们的方法在多基准数据集上均优于当前的最佳方法,表明其在深度学习方法中作为通用和有效工具解决偏见问题的潜力。
Key Takeaways
- 深度学习方法在分类任务中面临由训练数据的偏见导致的问题。
- 强烈的偶然性关联会影响训练数据的质量和数量。
- 现有技术中存在偏见冲突训练样本记忆问题。
- 本研究提出了一种新的方法Diffusing DeBias(DDB),旨在解决上述问题。
- DDB利用条件扩散模型生成合成偏见对齐图像来替代原始训练集。
- DDB可以纳入端到端和两步无监督去偏方法中使用。
点此查看论文截图