⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-06 更新
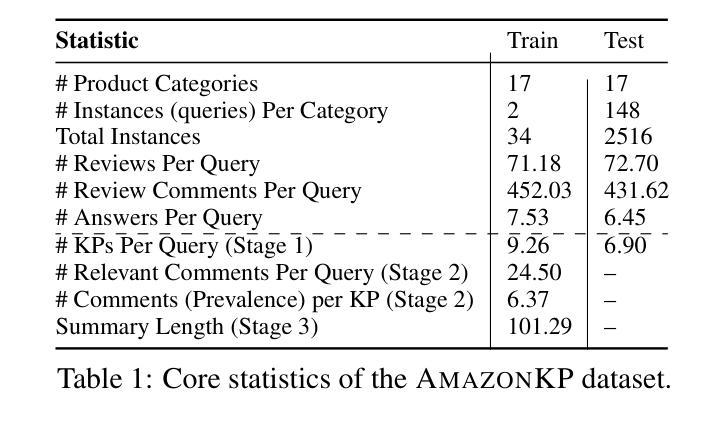
QQSUM: A Novel Task and Model of Quantitative Query-Focused Summarization for Review-based Product Question Answering
Authors:An Quang Tang, Xiuzhen Zhang, Minh Ngoc Dinh, Zhuang Li
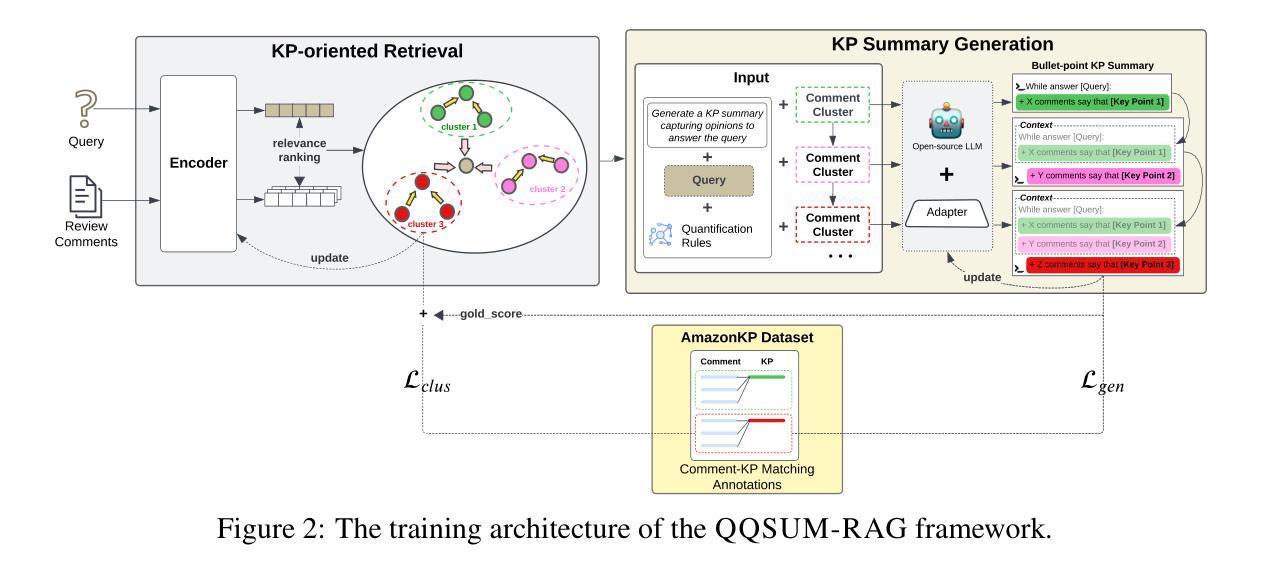
Review-based Product Question Answering (PQA) allows e-commerce platforms to automatically address customer queries by leveraging insights from user reviews. However, existing PQA systems generate answers with only a single perspective, failing to capture the diversity of customer opinions. In this paper we introduce a novel task Quantitative Query-Focused Summarization (QQSUM), which aims to summarize diverse customer opinions into representative Key Points (KPs) and quantify their prevalence to effectively answer user queries. While Retrieval-Augmented Generation (RAG) shows promise for PQA, its generated answers still fall short of capturing the full diversity of viewpoints. To tackle this challenge, our model QQSUM-RAG, which extends RAG, employs few-shot learning to jointly train a KP-oriented retriever and a KP summary generator, enabling KP-based summaries that capture diverse and representative opinions. Experimental results demonstrate that QQSUM-RAG achieves superior performance compared to state-of-the-art RAG baselines in both textual quality and quantification accuracy of opinions. Our source code is available at: https://github.com/antangrocket1312/QQSUMM
基于评论的产品问答(PQA)允许电子商务平台利用用户评论的见解来自动回答客户问题。然而,现有的PQA系统仅从一个角度生成答案,无法捕捉客户意见的多样性。本文介绍了一项新任务:定量查询聚焦摘要(QQSUM),旨在将多样化的客户意见总结为代表性的关键点(KPs),并量化它们的普遍性,以有效地回答用户查询。虽然增强检索生成(RAG)在PQA中显示出潜力,但其生成的答案仍未能捕捉到观点的全貌。为了应对这一挑战,我们的模型QQSUM-RAG扩展了RAG,采用小样本学习来联合训练一个面向关键点的检索器和一个关键点摘要生成器,从而基于关键点生成能够捕捉多样化和代表性意见的摘要。实验结果表明,与最新的RAG基线相比,QQSUM-RAG在文本质量和意见量化准确性方面都实现了卓越的性能。我们的源代码可访问于:https://github.com/antangrocket1312/QQSUMM
论文及项目相关链接
PDF Paper accepted to ACL 2025 Main Conference
Summary
基于用户评论的自动问答(PQA)技术可为电商平台提供自动回答客户问题的能力,但现有系统往往只从单一视角生成答案,忽略了客户意见多样性。本研究提出了一个新的任务——定量查询焦点摘要(QQSUM),旨在通过抽取和量化不同客户的观点,更全面地回答问题。实验结果显示,与当前流行的模型相比,我们的QQSUM-RAG模型在文本质量和意见量化的准确性上都取得了显著的改进。更多详细信息请访问我们的GitHub页面:https://github.com/antangrocket1312/QQSUMM。
Key Takeaways
- PQA技术允许电商平台自动回答客户问题,但现有系统缺乏捕捉客户意见多样性的能力。
- 引入新的任务QQSUM,旨在从多种观点中总结代表性关键点并量化其普遍性。
- QQSUM-RAG模型通过少量学习样本即可实现高效率和准确的训练。这种模型结合了一个关键点导向的检索器和一个摘要生成器。
- QQSUM-RAG在文本质量和意见量化的准确性上超越了当前先进的模型。这表明它能够在多样化和代表性的观点中有效地捕捉信息。
- 模型使用了创新的策略来捕捉和理解用户评论中的复杂信息,这对于电商平台来说非常重要,因为它们需要理解并响应客户的各种需求和反馈。
点此查看论文截图


Vocabulary-free few-shot learning for Vision-Language Models
Authors:Maxime Zanella, Clément Fuchs, Ismail Ben Ayed, Christophe De Vleeschouwer
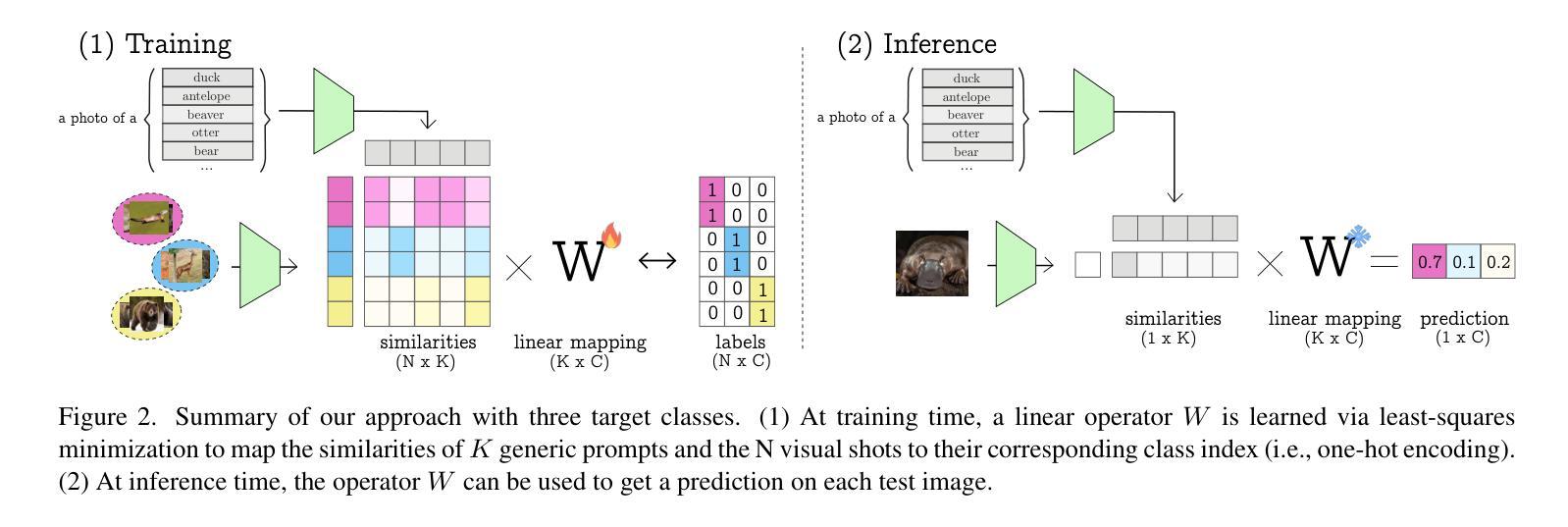
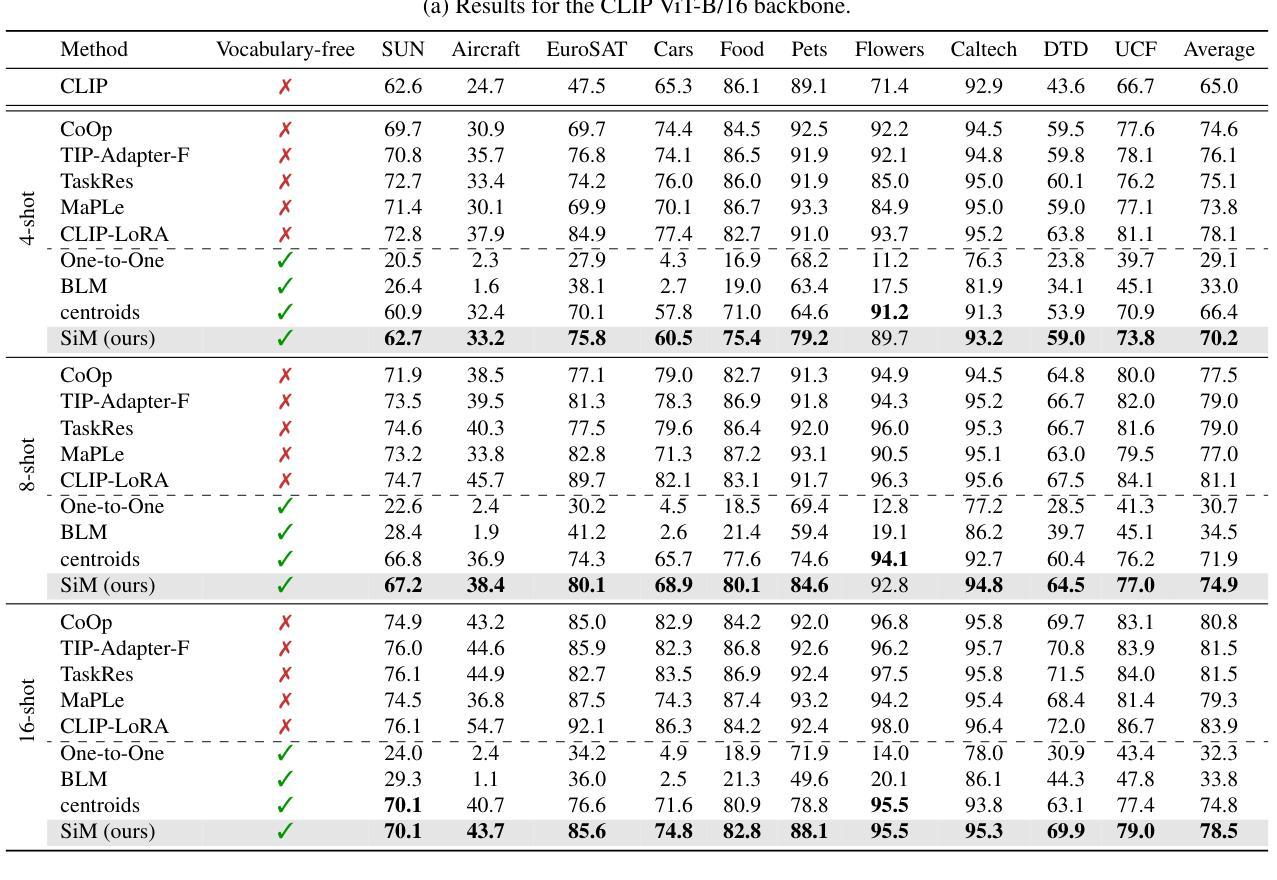
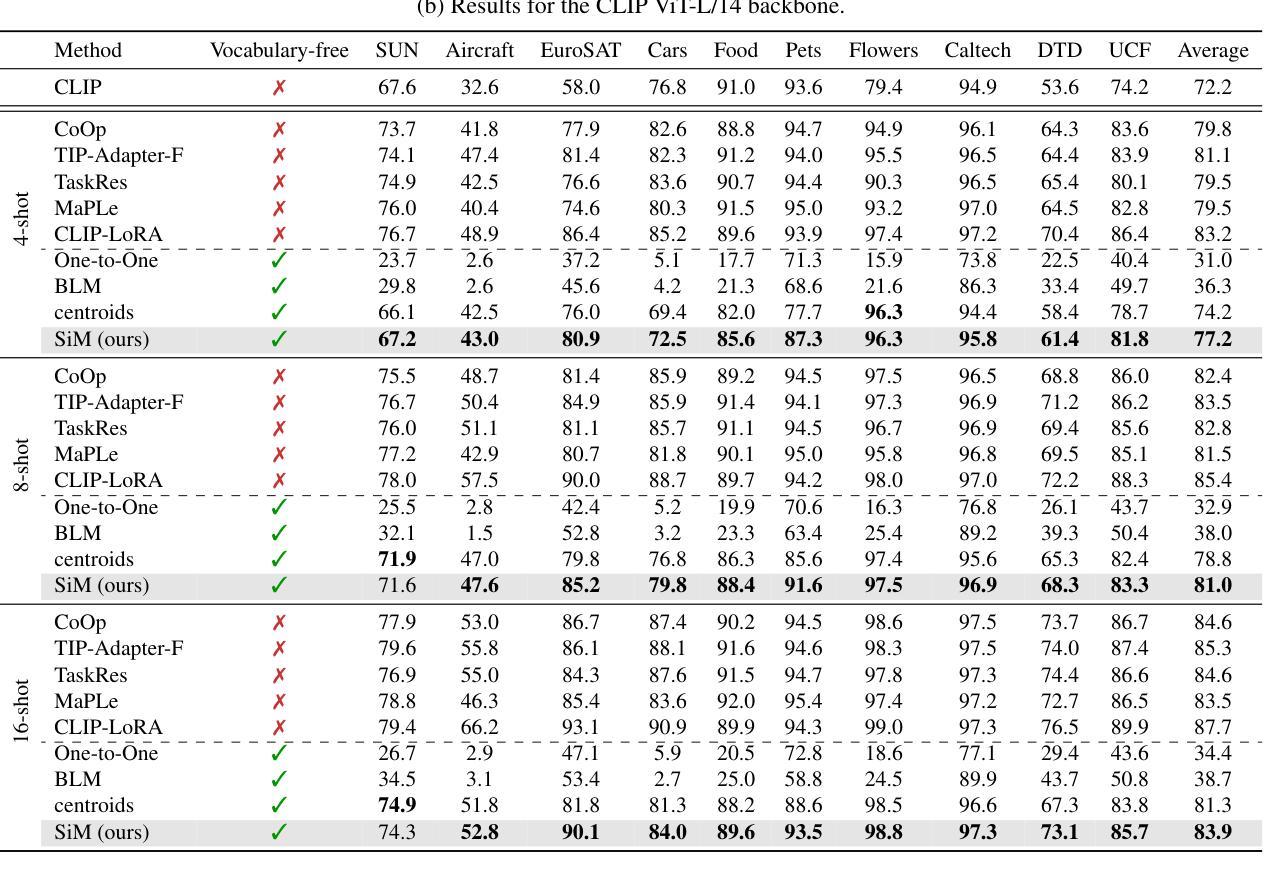
Recent advances in few-shot adaptation for Vision-Language Models (VLMs) have greatly expanded their ability to generalize across tasks using only a few labeled examples. However, existing approaches primarily build upon the strong zero-shot priors of these models by leveraging carefully designed, task-specific prompts. This dependence on predefined class names can restrict their applicability, especially in scenarios where exact class names are unavailable or difficult to specify. To address this limitation, we introduce vocabulary-free few-shot learning for VLMs, a setting where target class instances - that is, images - are available but their corresponding names are not. We propose Similarity Mapping (SiM), a simple yet effective baseline that classifies target instances solely based on similarity scores with a set of generic prompts (textual or visual), eliminating the need for carefully handcrafted prompts. Although conceptually straightforward, SiM demonstrates strong performance, operates with high computational efficiency (learning the mapping typically takes less than one second), and provides interpretability by linking target classes to generic prompts. We believe that our approach could serve as an important baseline for future research in vocabulary-free few-shot learning. Code is available at https://github.com/MaxZanella/vocabulary-free-FSL.
近期视觉语言模型(VLMs)在少量样本适应方面的进展极大地扩展了它们仅使用少量有标签样本即可跨任务泛化的能力。然而,现有方法主要依赖于这些模型的强大零样本先验知识,通过利用精心设计的任务特定提示来实现。对预设类名的这种依赖限制了其适用性,特别是在没有确切类名或难以指定的场景中。为了解决这个问题,我们为VLMs引入了无词汇少量样本学习,在这种设置中,目标类实例(即图像)是可用的,但它们相应的名称不可用。我们提出了基于相似性映射(SiM)的简单有效的基线方法,该方法仅根据目标实例与一组通用提示(文本或视觉)的相似性得分进行分类,从而消除了对精心制作的提示的需求。尽管概念上很简单,但SiM表现出强大的性能,计算效率高(学习映射通常不到一秒),并通过将目标类别与通用提示联系起来提供了解释性。我们相信,我们的方法可以为未来的无词汇少量样本学习研究提供重要的基线。代码可在https://github.com/MaxZanella/vocabulary-free-FSL找到。
论文及项目相关链接
PDF Accepted at CVPR Workshops 2025
Summary
该摘要介绍了针对视觉语言模型(VLMs)的词汇无关少样本学习的新进展。针对现有方法依赖预设类别名称的问题,提出了一种基于相似性映射(SiM)的词汇无关少样本学习方法。该方法无需精心设计任务特定提示,仅通过目标实例与一组通用提示的相似性得分进行分类,从而消除了对精确类别名称的需求。SiM具有强大的性能、高计算效率和可解释性,为未来研究提供了一个重要的基准。
Key Takeaways
- 少样本适应技术已显著提高了视觉语言模型(VLMs)在仅使用少量标记示例时跨任务泛化的能力。
- 现有方法主要依赖于模型的零样本先验知识,通过利用精心设计的任务特定提示来构建。
- 对预设类别名称的依赖限制了其在特定场景下的适用性,特别是在无法获得或难以指定确切类别名称的情况下。
- 引入了词汇无关的少样本学习,其中目标类别实例可用,但对应的名称不可用。
- 提出了相似性映射(SiM)方法,该方法仅基于目标实例与通用提示的相似性得分进行分类,无需精心制作的提示。
- SiM具有强大的性能、高计算效率和可解释性,通过链接目标类别到通用提示来提供分类理由。
点此查看论文截图

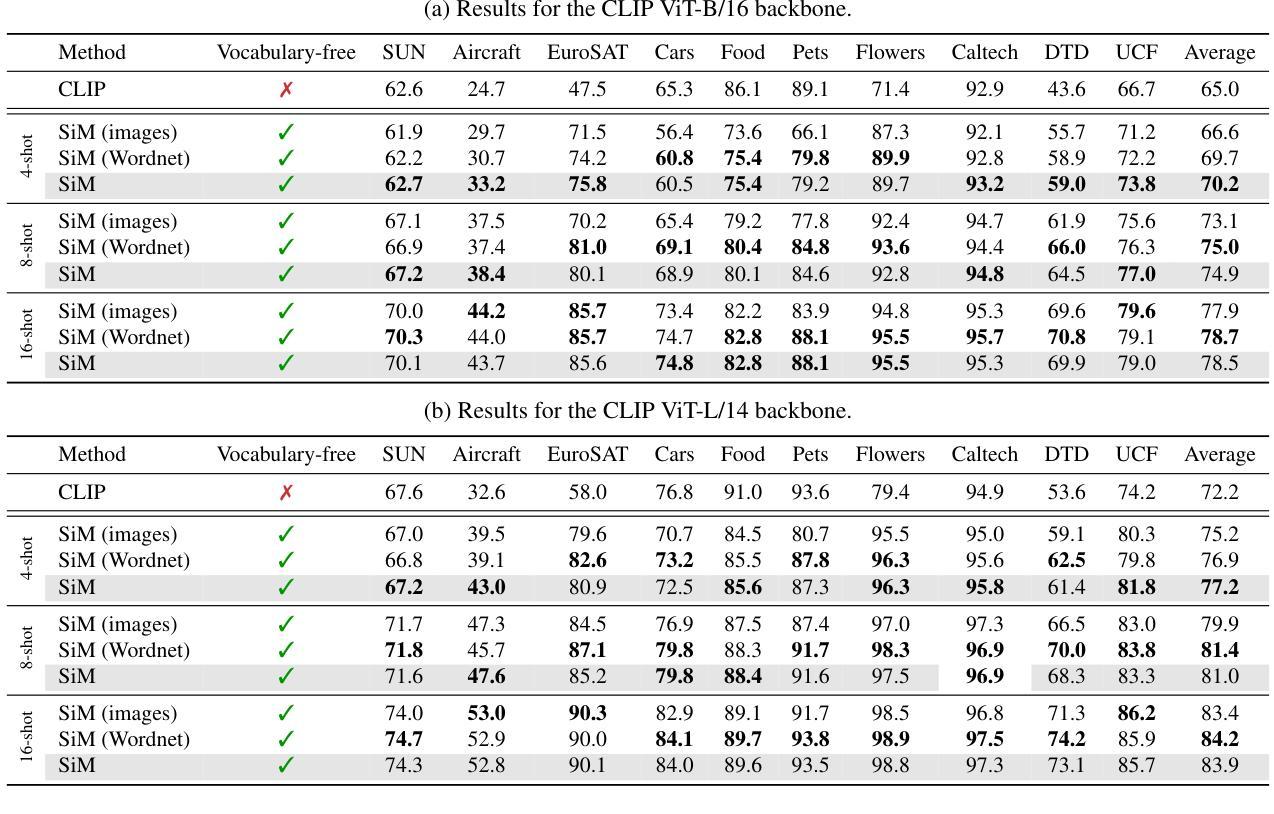
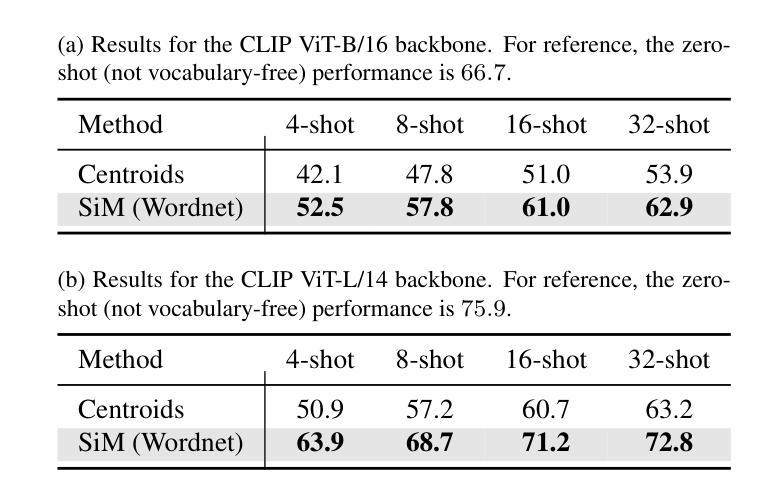
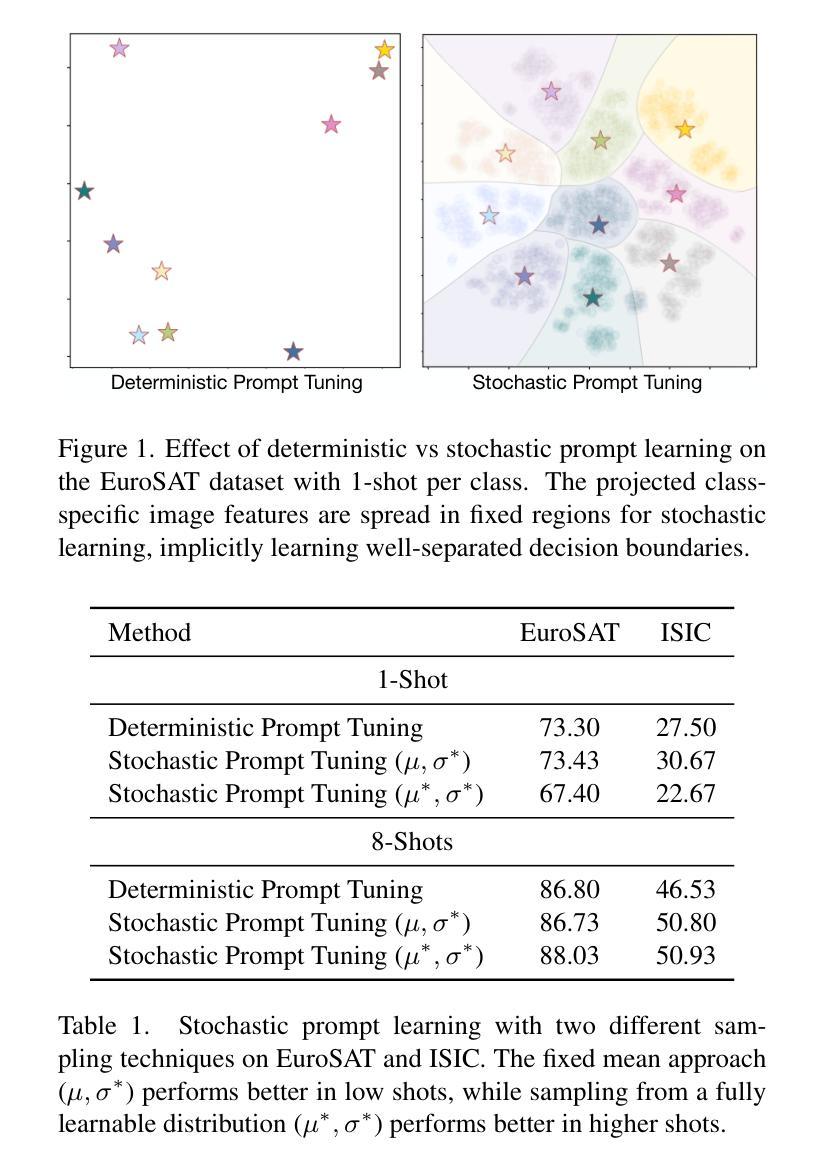
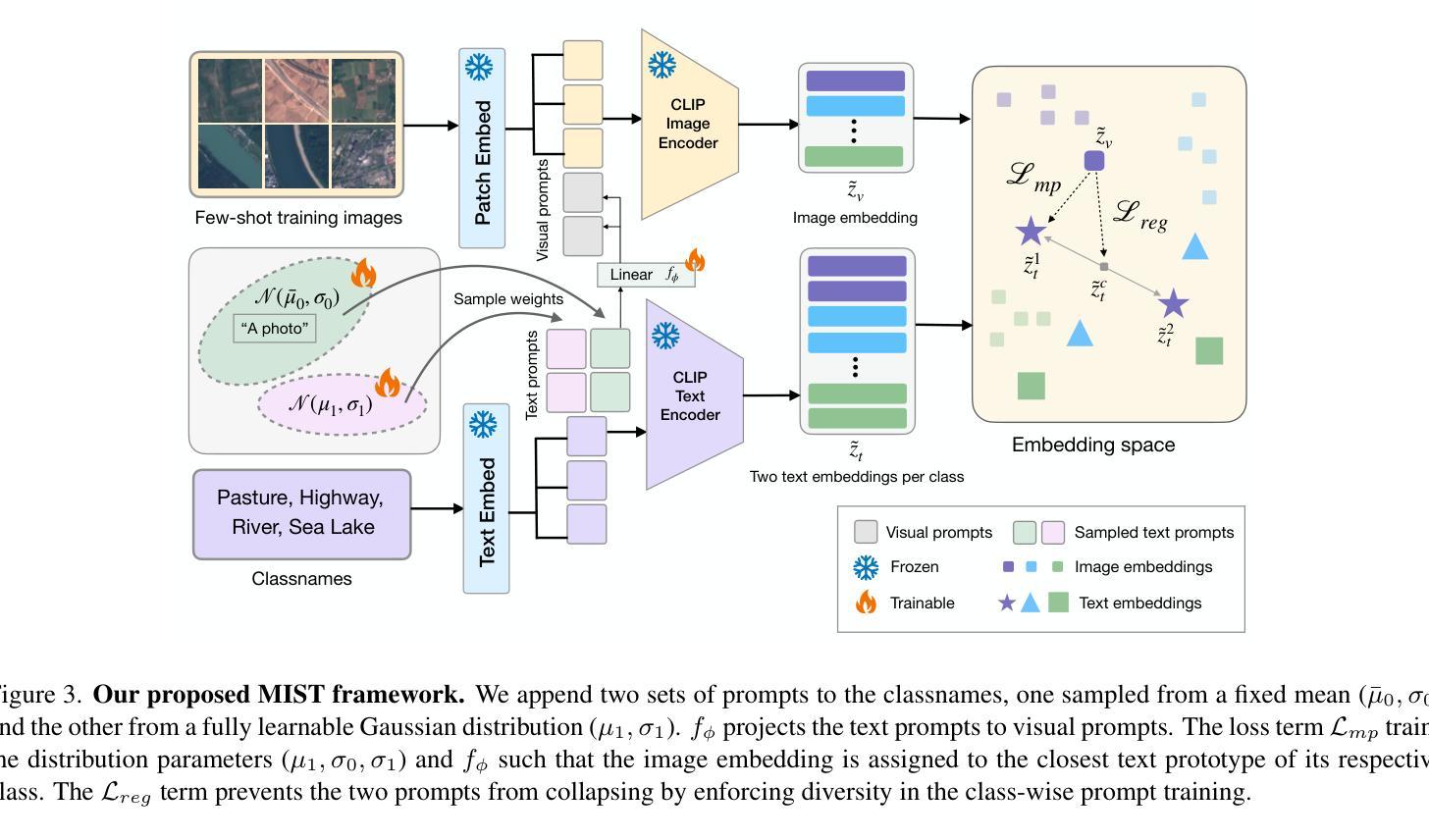
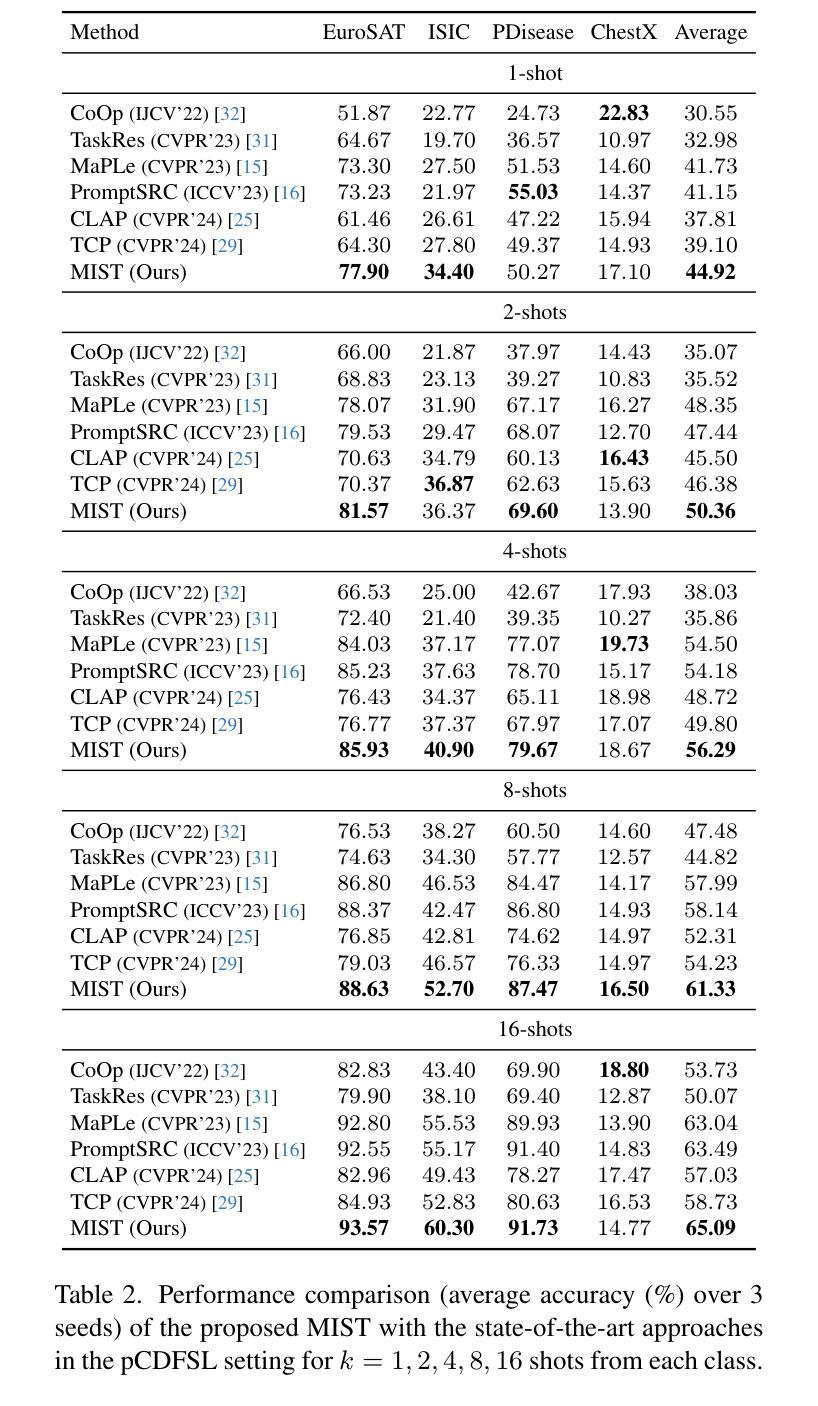
Multiple Stochastic Prompt Tuning for Practical Cross-Domain Few Shot Learning
Authors:Debarshi Brahma, Soma Biswas
In this work, we propose a practical cross-domain few-shot learning (pCDFSL) task, where a large-scale pre-trained model like CLIP can be easily deployed on a target dataset. The goal is to simultaneously classify all unseen classes under extreme domain shifts, by utilizing only a few labeled samples per class. The pCDFSL paradigm is source-free and moves beyond artificially created episodic training and testing regimes followed by existing CDFSL frameworks, making it more challenging and relevant to real-world applications. Towards that goal, we propose a novel framework, termed MIST (MultIple STochastic Prompt tuning), where multiple stochastic prompts are utilized to handle significant domain and semantic shifts. Specifically, multiple prompts are learnt for each class, effectively capturing multiple peaks in the input data. Furthermore, instead of representing the weights of the multiple prompts as point-estimates, we model them as learnable Gaussian distributions with two different strategies, encouraging an efficient exploration of the prompt parameter space, which mitigate overfitting due to the few labeled training samples. Extensive experiments and comparison with the state-of-the-art methods on four CDFSL benchmarks adapted to this setting, show the effectiveness of the proposed framework.
在这项工作中,我们提出了一个实用的跨域小样本学习(pCDFSL)任务,其中可以很容易地在目标数据集上部署CLIP等大型预训练模型。目标是利用每个类别仅有的少量标记样本,同时对极端域偏移下的所有未见类别进行分类。pCDFSL范式是无源的,超越了现有的CDFSL框架所遵循的人工创建的事件性训练和测试制度,使其更具挑战性和与真实世界应用的相关性。朝着这一目标,我们提出了一种新型框架,称为MIST(多重随机提示调整),其中利用多个随机提示来处理重大的域和语义变化。具体来说,为每个类别学习多个提示,有效地捕捉输入数据中的多个峰值。此外,我们不是将多个提示的权重表示为点估计,而是将它们建模为两种不同策略的可学习高斯分布,鼓励有效地探索提示参数空间,从而减轻由于少量标记训练样本而导致的过拟合。在适应此设置的四个CDFSL基准测试上的广泛实验以及与最新方法的比较,证明了所提出框架的有效性。
论文及项目相关链接
Summary
基于跨域小样本学习(pCDFSL)任务,我们提出了一个实用框架MIST。此框架适用于部署大型预训练模型(如CLIP)在目标数据集上,目标是通过每个类别仅有少量标注样本,同时对所有未见类别进行分类。MIST采用多个随机提示(prompt)来处理显著的域和语义变化,并为每个类别学习多个提示,有效地捕捉输入数据中的多个峰值。此外,我们使用两种策略将提示权重建模为可学习的高斯分布,以高效探索提示参数空间并缓解因少量标注样本引起的过拟合问题。在四个CDFSL基准测试上的实验和对比显示了我们框架的有效性。
Key Takeaways
- 提出了一种基于跨域小样本学习(pCDFSL)任务的实用框架MIST,适用于预训练模型在目标数据集上的应用。
- MIST框架能够同时分类所有未见类别,且仅使用每个类别的少量标注样本。
- MIST采用多个随机提示(prompt)来处理域和语义的显著变化。
- 为每个类别学习多个提示,以捕捉输入数据中的多个峰值。
- 提示权重被建模为可学习的高斯分布,以高效探索提示参数空间。
- 该框架在四个CDFSL基准测试上的实验结果表明其有效性。
- 与现有方法相比,该框架展现出优越的性能。
点此查看论文截图


INP-Former++: Advancing Universal Anomaly Detection via Intrinsic Normal Prototypes and Residual Learning
Authors:Wei Luo, Haiming Yao, Yunkang Cao, Qiyu Chen, Ang Gao, Weiming Shen, Weihang Zhang, Wenyong Yu
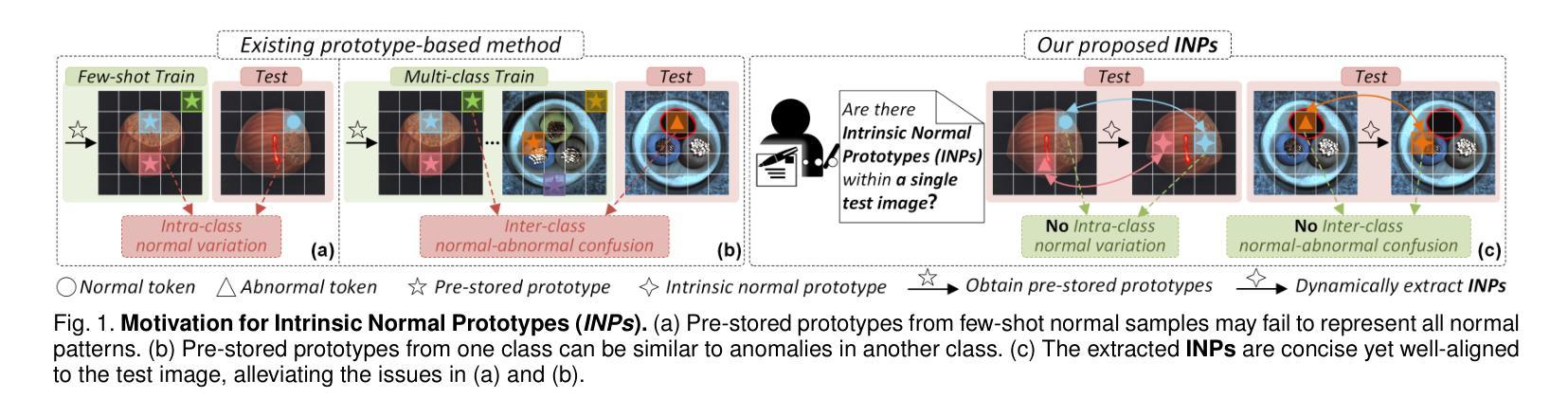
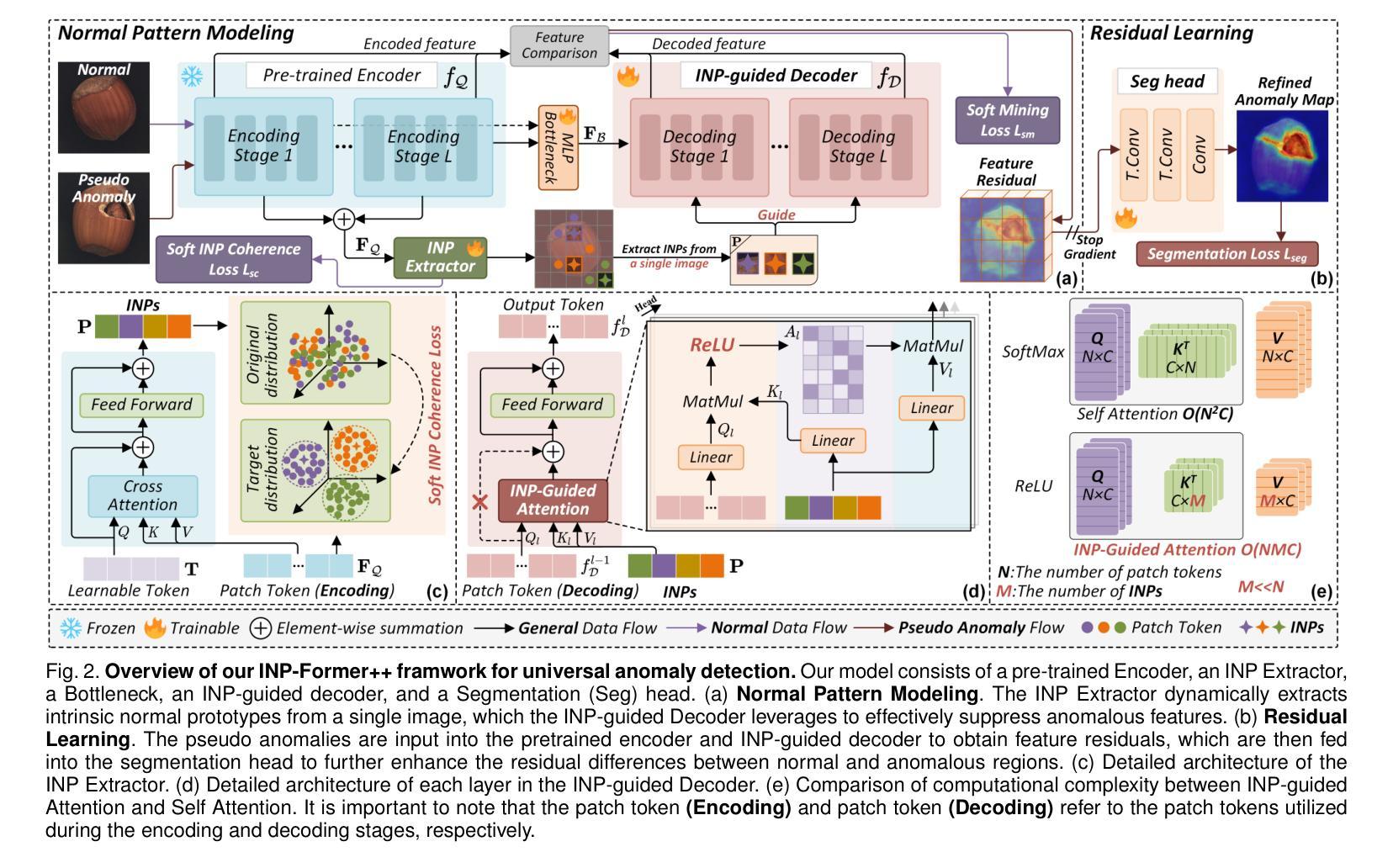
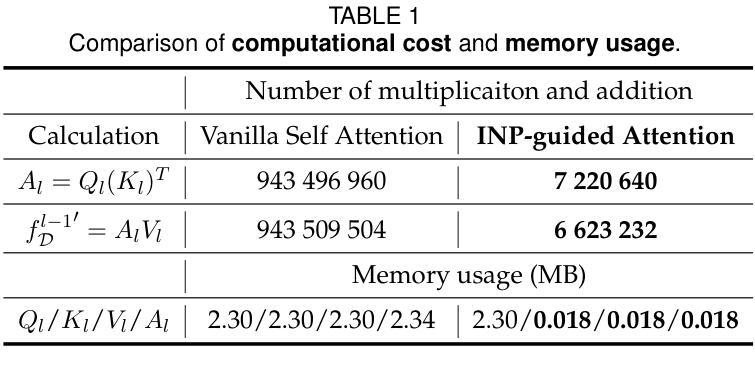
Anomaly detection (AD) is essential for industrial inspection and medical diagnosis, yet existing methods typically rely on ``comparing’’ test images to normal references from a training set. However, variations in appearance and positioning often complicate the alignment of these references with the test image, limiting detection accuracy. We observe that most anomalies manifest as local variations, meaning that even within anomalous images, valuable normal information remains. We argue that this information is useful and may be more aligned with the anomalies since both the anomalies and the normal information originate from the same image. Therefore, rather than relying on external normality from the training set, we propose INP-Former, a novel method that extracts Intrinsic Normal Prototypes (INPs) directly from the test image. Specifically, we introduce the INP Extractor, which linearly combines normal tokens to represent INPs. We further propose an INP Coherence Loss to ensure INPs can faithfully represent normality for the testing image. These INPs then guide the INP-guided Decoder to reconstruct only normal tokens, with reconstruction errors serving as anomaly scores. Additionally, we propose a Soft Mining Loss to prioritize hard-to-optimize samples during training. INP-Former achieves state-of-the-art performance in single-class, multi-class, and few-shot AD tasks across MVTec-AD, VisA, and Real-IAD, positioning it as a versatile and universal solution for AD. Remarkably, INP-Former also demonstrates some zero-shot AD capability. Furthermore, we propose a soft version of the INP Coherence Loss and enhance INP-Former by incorporating residual learning, leading to the development of INP-Former++. The proposed method significantly improves detection performance across single-class, multi-class, semi-supervised, few-shot, and zero-shot settings.
异常检测(AD)对于工业检测和医疗诊断至关重要。然而,现有方法通常依赖于将测试图像与训练集中的正常参考图像进行“比较”。但是,外观和位置的变化往往使这些参考图像与测试图像的对齐变得复杂,从而限制了检测精度。我们观察到,大多数异常表现为局部变化,这意味着即使在异常图像内部,仍有宝贵的正常信息存在。我们认为这些信息是有用的,并且可能与异常更加对齐,因为异常和正常信息都来自同一图像。因此,我们提出了一种新方法INP-Former,它直接从测试图像中提取内在正常原型(INPs)。具体来说,我们引入了INP提取器,该提取器通过线性组合正常令牌来表示INPs。我们还提出了一种INP一致性损失,以确保INPs能够忠实地代表测试图像的正常性。这些INPs然后引导INP引导解码器仅重建正常令牌,重建误差作为异常分数。此外,我们还提出了一种软挖掘损失,以在训练过程中优先处理难以优化的样本。INP-Former在MVTec-AD、VisA和Real-IAD上的单类、多类、和少样本AD任务上实现了最先进的性能表现,成为AD的通用解决方案。值得一提的是,INP-Former还表现出了一些零样本AD的能力。此外,我们提出了INP一致性损失的软版本,并通过结合残差学习增强了INP-Former,从而发展了INP-Former++。所提出的方法在单类、多类、半监督、少样本和零样本设置上显著提高了检测性能。
论文及项目相关链接
PDF 15 pages, 11 figures, 13 tables
Summary
该文本提出了一种新型异常检测(Anomaly Detection,AD)方法——INP-Former。该方法直接从测试图像中提取内在正常原型(Intrinsic Normal Prototypes,INPs),无需依赖训练集中的外部正常参考。通过引入INP提取器和INP相干性损失,INPs能忠实代表测试图像的正常性。利用这些INPs,指导解码器仅重建正常令牌,重建误差作为异常分数。此外,还提出了软挖掘损失,以在训练期间优先处理难以优化的样本。该方法在MVTec-AD、VisA和Real-IAD等多个数据集上实现了单类、多类及少样本异常检测的卓越性能,并具有零样本异常检测能力。通过引入软化版本的INP相干性损失并结合残差学习,进一步开发了改进的INP-Former++,提高了在多种设置下的检测性能。
Key Takeaways
- 现有异常检测方法常依赖于与训练集中的正常参考图像进行比较,但外观和位置的变化使得对齐变得困难,限制了检测精度。
- INP-Former方法直接从测试图像中提取内在正常原型(INPs),无需外部正常参考。
- 引入INP提取器和INP相干性损失,确保INPs能忠实代表测试图像的正常性。
- 利用INPs指导解码器仅重建正常令牌,重建误差作为异常分数。
- 提出软挖掘损失,以优先处理训练中的困难样本。
- INP-Former在多个数据集上实现了卓越的性能,包括单类、多类及少样本异常检测,并具备零样本异常检测能力。
- 通过引入软化版本的INP相干性损失并结合残差学习,开发了改进的INP-Former++。
点此查看论文截图

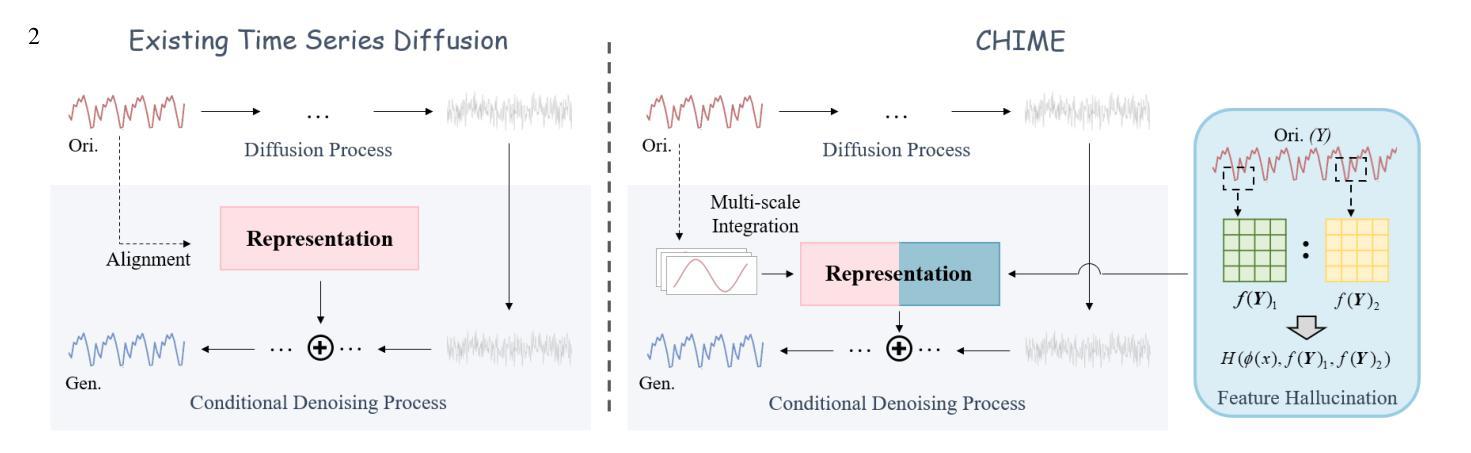
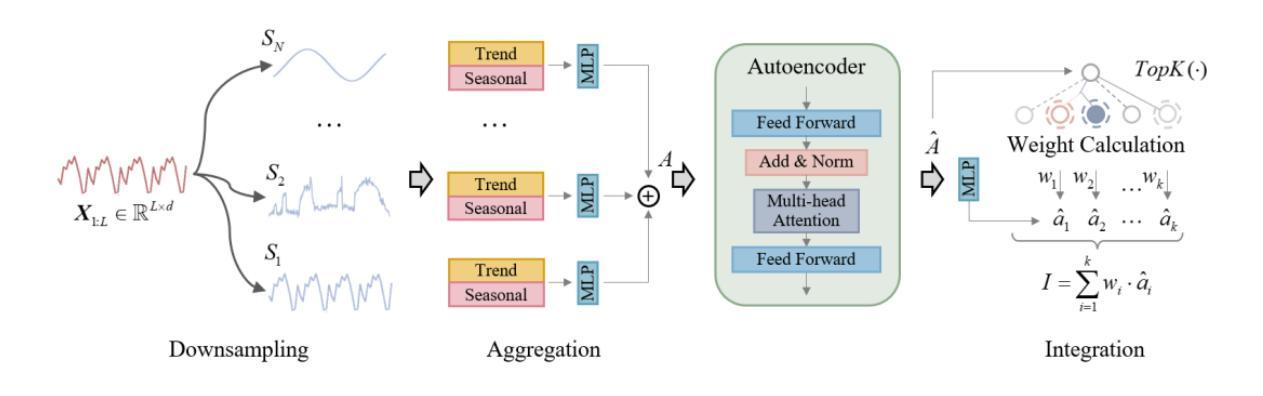
CHIME: Conditional Hallucination and Integrated Multi-scale Enhancement for Time Series Diffusion Model
Authors:Yuxuan Chen, Haipeng Xie
The denoising diffusion probabilistic model has become a mainstream generative model, achieving significant success in various computer vision tasks. Recently, there has been initial exploration of applying diffusion models to time series tasks. However, existing studies still face challenges in multi-scale feature alignment and generative capabilities across different entities and long-time scales. In this paper, we propose CHIME, a conditional hallucination and integrated multi-scale enhancement framework for time series diffusion models. By employing multi-scale decomposition and adaptive integration, CHIME captures the decomposed features of time series, achieving in-domain distribution alignment between generated and original samples. In addition, we introduce a feature hallucination module in the conditional denoising process, enabling the transfer of temporal features through the training of category-independent transformation layers. Experimental results on publicly available real-world datasets demonstrate that CHIME achieves state-of-the-art performance and exhibits excellent generative generalization capabilities in few-shot scenarios.
去噪扩散概率模型已经成为主流生成模型,在各种计算机视觉任务中取得了巨大成功。最近,人们开始探索将扩散模型应用于时间序列任务。然而,现有研究在多尺度特征对齐和跨不同实体和长时间尺度的生成能力方面仍面临挑战。在本文中,我们提出了CHIME,这是一个用于时间序列扩散模型的基于条件幻觉和集成多尺度增强框架。通过采用多尺度分解和自适应集成,CHIME捕捉时间序列的分解特征,实现生成样本和原始样本之间的域内分布对齐。此外,我们在条件去噪过程中引入了一个特征幻觉模块,通过训练类别独立的转换层,实现了时间特征的转移。在公开可用的真实世界数据集上的实验结果表明,CHIME达到了最先进的性能,并在小样本场景中表现出优秀的生成泛化能力。
论文及项目相关链接
Summary
扩散概率模型已成为主流生成模型,在计算机视觉任务中取得了巨大成功。最近,人们开始探索将扩散模型应用于时间序列任务,但仍面临多尺度特征对齐和跨不同实体及长时间尺度的生成能力挑战。本文提出CHIME框架,采用多尺度分解和自适应集成,实现时间序列的分解特征捕捉,生成样本与原始样本之间的域内分布对齐。此外,我们在条件去噪过程中引入了特征幻觉模块,通过训练类别独立转换层,实现时间特征的转移。在公开的真实世界数据集上的实验结果表明,CHIME达到了最先进的性能,并在小样本场景中表现出优秀的生成泛化能力。
Key Takeaways
- 扩散概率模型已成为主流生成模型,广泛应用于计算机视觉任务。
- 将扩散模型应用于时间序列任务尚处于初步探索阶段。
- 现有研究面临多尺度特征对齐和跨不同实体及长时间尺度的生成能力挑战。
- CHIME框架通过多尺度分解和自适应集成实现时间序列的分解特征捕捉。
- CHIME实现了生成样本与原始样本之间的域内分布对齐。
- CHIME引入特征幻觉模块,通过训练类别独立转换层,实现时间特征的转移。
点此查看论文截图

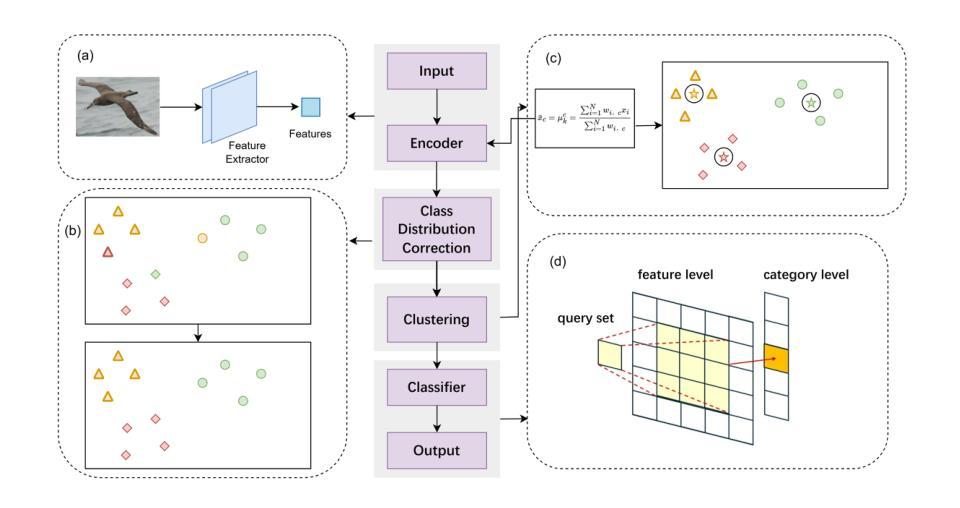
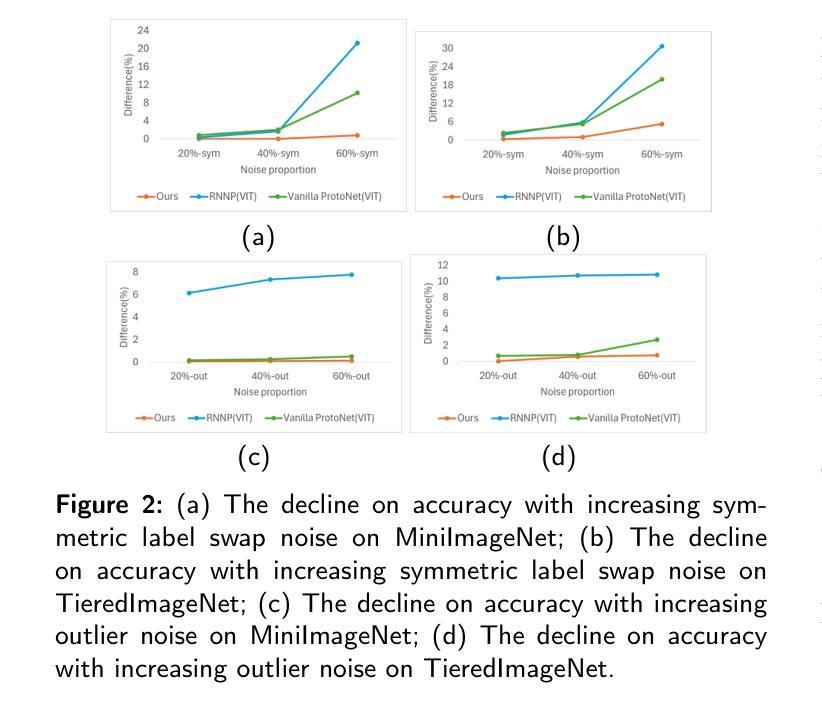
RoNFA: Robust Neural Field-based Approach for Few-Shot Image Classification with Noisy Labels
Authors:Nan Xiang, Lifeng Xing, Dequan Jin
In few-shot learning (FSL), the labeled samples are scarce. Thus, label errors can significantly reduce classification accuracy. Since label errors are inevitable in realistic learning tasks, improving the robustness of the model in the presence of label errors is critical. This paper proposes a new robust neural field-based image approach (RoNFA) for few-shot image classification with noisy labels. RoNFA consists of two neural fields for feature and category representation. They correspond to the feature space and category set. Each neuron in the field for category representation (FCR) has a receptive field (RF) on the field for feature representation (FFR) centered at the representative neuron for its category generated by soft clustering. In the prediction stage, the range of these receptive fields adapts according to the neuronal activation in FCR to ensure prediction accuracy. These learning strategies provide the proposed model with excellent few-shot learning capability and strong robustness against label noises. The experimental results on real-world FSL datasets with three different types of label noise demonstrate that the proposed method significantly outperforms state-of-the-art FSL methods. Its accuracy obtained in the presence of noisy labels even surpasses the results obtained by state-of-the-art FSL methods trained on clean support sets, indicating its strong robustness against noisy labels.
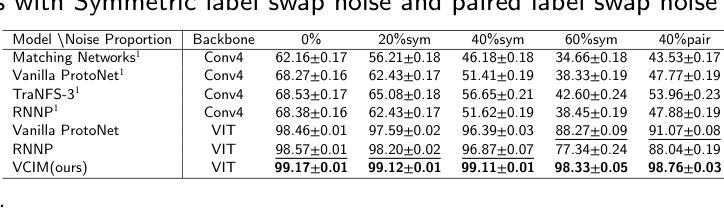
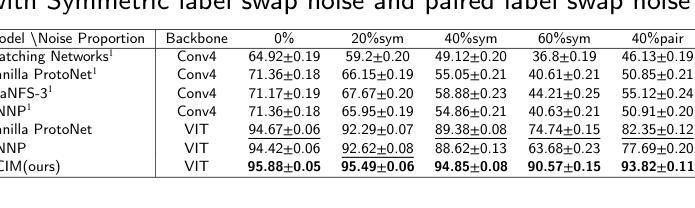
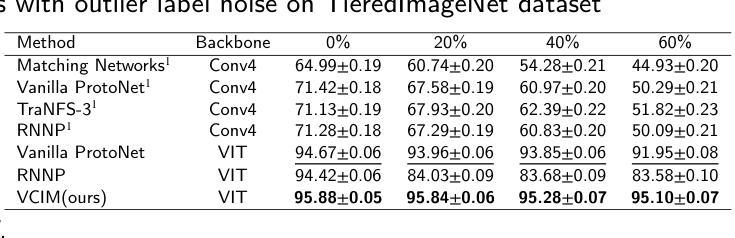
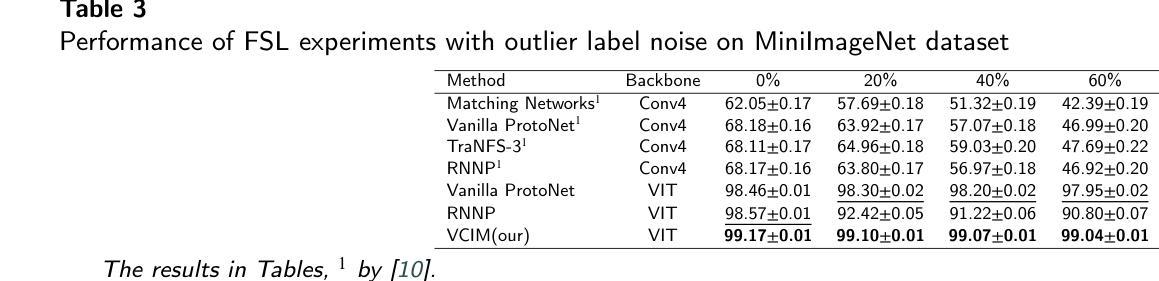
在少量学习(FSL)中,标注样本非常稀缺。因此,标签错误可能会显著降低分类精度。由于在实际学习任务中标签错误不可避免,因此在存在标签错误的情况下提高模型的稳健性至关重要。本文针对带有噪声标签的少量图像分类问题,提出了一种新的基于稳健神经场的图像方法(RoNFA)。RoNFA由两个用于特征和类别表示的神经场组成。它们对应于特征空间和类别集。类别表示字段(FCR)中的每个神经元在其特征表示字段(FFR)上具有一个以通过软聚类生成的类别代表神经元为中心的接受场(RF)。在预测阶段,这些接受场的范围会根据FCR中的神经元激活情况进行调整,以确保预测精度。这些学习策略使所提模型具有出色的少量学习能力,并对标签噪声具有很强的稳健性。在具有三种不同类型标签噪声的真实世界FSL数据集上的实验结果表明,所提方法显著优于最先进的FSL方法。在存在噪声标签的情况下获得其精度甚至超过了在干净的支撑集上训练的最新FSL方法的结果,这表明其对噪声标签的稳健性很强。
论文及项目相关链接
PDF 7 pages, 1 figure
Summary
本文提出了一种基于神经场的稳健图像分类方法(RoNFA),用于小样本学习(FSL)中的带噪声标签问题。该方法通过特征表示和类别表示的两个神经场来构建模型,具有优秀的少样本学习能力,以及对标签噪声的强鲁棒性。实验结果表明,该方法在真实世界的FSL数据集上,对于三种不同类型的标签噪声,显著优于现有的FSL方法。即使在存在噪声标签的情况下,其准确性也超过了在干净的支持集上训练的现有FSL方法。
Key Takeaways
- RoNFA是一种基于神经场的图像分类方法,用于处理小样本次学习中的标签噪声问题。
- RoNFA包含两个神经场:一个用于特征表示(FFR),另一个用于类别表示(FCR)。
- FCR中的每个神经元在FFR上都有一个以该类别的代表性神经元为中心的接收域(RF)。
- 在预测阶段,这些接收域的范围会根据FCR中的神经元激活进行适应,以确保预测的准确性。
- RoNFA具有优秀的少样本学习能力,以及对标签噪声的强鲁棒性。
- 实验结果表明,RoNFA在真实世界的FSL数据集上显著优于现有的FSL方法,特别是在处理标签噪声方面。
点此查看论文截图

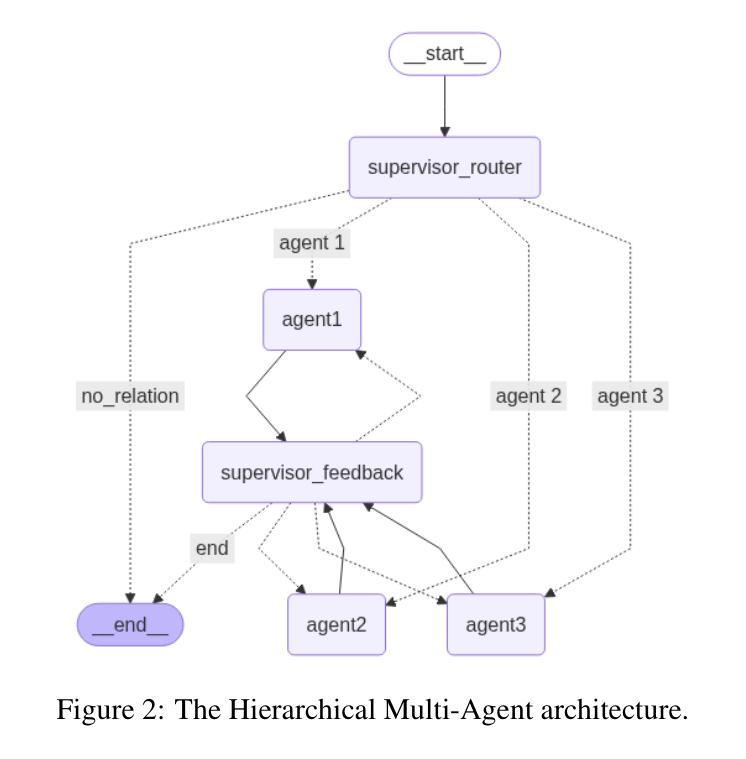
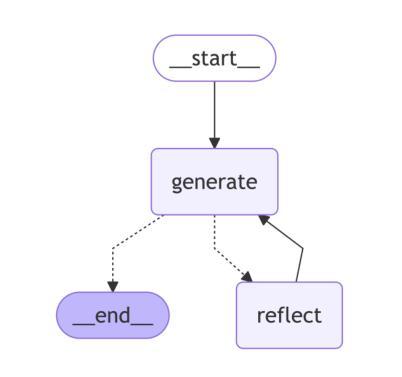
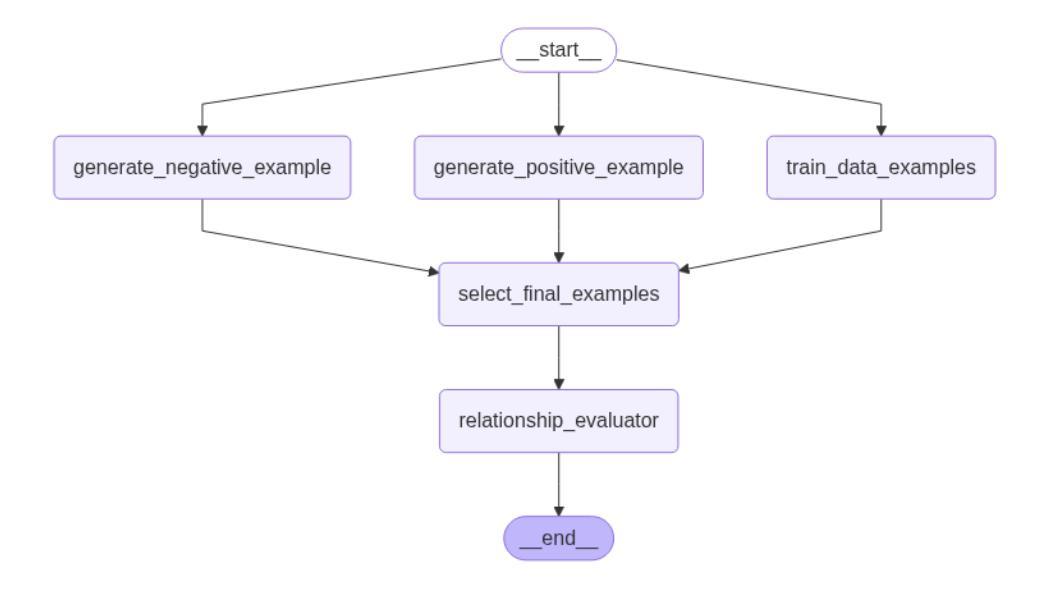
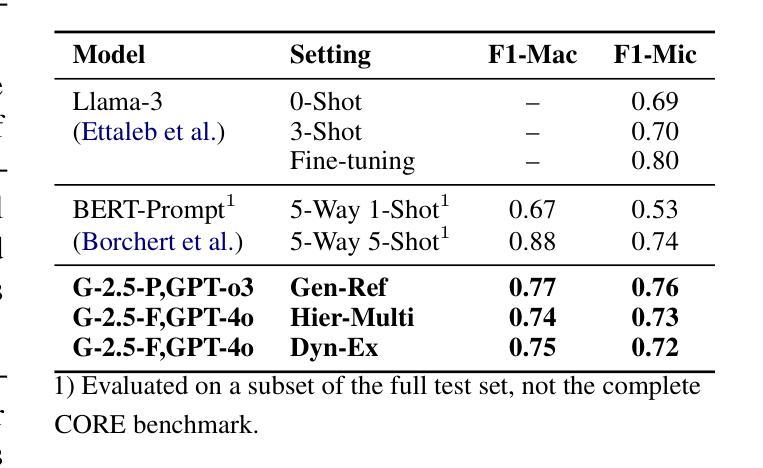
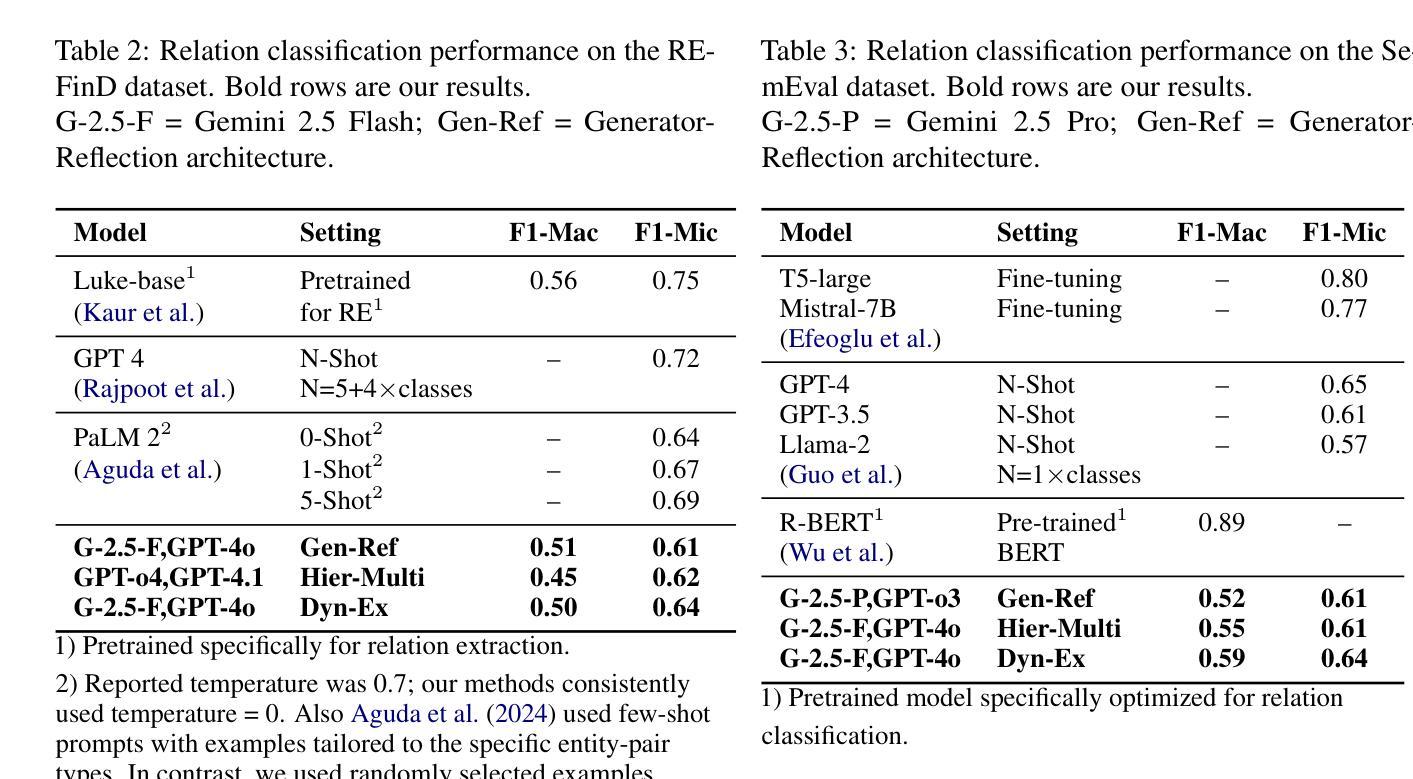
Comparative Analysis of AI Agent Architectures for Entity Relationship Classification
Authors:Maryam Berijanian, Kuldeep Singh, Amin Sehati
Entity relationship classification remains a challenging task in information extraction, especially in scenarios with limited labeled data and complex relational structures. In this study, we conduct a comparative analysis of three distinct AI agent architectures designed to perform relation classification using large language models (LLMs). The agentic architectures explored include (1) reflective self-evaluation, (2) hierarchical task decomposition, and (3) a novel multi-agent dynamic example generation mechanism, each leveraging different modes of reasoning and prompt adaptation. In particular, our dynamic example generation approach introduces real-time cooperative and adversarial prompting. We systematically compare their performance across multiple domains and model backends. Our experiments demonstrate that multi-agent coordination consistently outperforms standard few-shot prompting and approaches the performance of fine-tuned models. These findings offer practical guidance for the design of modular, generalizable LLM-based systems for structured relation extraction. The source codes and dataset are available at https://github.com/maryambrj/ALIEN.git.
实体关系分类在信息提取中仍然是一项具有挑战性的任务,特别是在标签数据有限和复杂关系结构的情况下。在这项研究中,我们对三种用于执行关系分类的AI代理架构进行了比较分析,这些架构使用大型语言模型(LLM)。探索的代理架构包括(1)反思自我评价,(2)层次任务分解,以及(3)一种新的多代理动态示例生成机制,每种机制都利用不同的推理和提示适应模式。特别是,我们的动态示例生成方法引入了实时合作和对抗性提示。我们在多个领域和模型后端系统地比较了它们的性能。实验表明,多代理协作始终优于标准的小样本提示,并接近微调模型的性能。这些发现为设计用于结构化关系提取的模块化、通用化LLM系统提供了实际指导。源代码和数据集可通过https://github.com/maryambrj/ALIEN.git获取。
论文及项目相关链接
Summary
本研究探讨了三种不同的AI代理架构在关系分类任务中的表现,这三种架构分别是反射自我评价、层次任务分解和新型多代理动态示例生成机制。研究通过系统比较这些架构在多领域和模型后端的表现,发现多代理协调在有限标记数据和复杂关系结构下始终优于标准少样本提示方法,并接近精细调整模型的性能。这为设计模块化、通用化的基于大型语言模型的系统提供了实践指导。
Key Takeaways
- 本研究对比分析了三种AI代理架构在关系分类任务中的应用效果。
- 这些架构包括反射自我评价、层次任务分解和多代理动态示例生成机制。
- 多代理动态示例生成机制引入实时合作和对抗性提示,提高了关系分类的准确性。
- 研究通过系统比较这些架构在多个领域和模型后端的表现,发现多代理协调表现最佳。
- 多代理协调在有限标记数据和复杂关系结构下优于标准少样本提示方法。
- 多代理协调方法接近精细调整模型的性能,为设计模块化、通用化的大型语言模型系统提供了实践指导。
点此查看论文截图

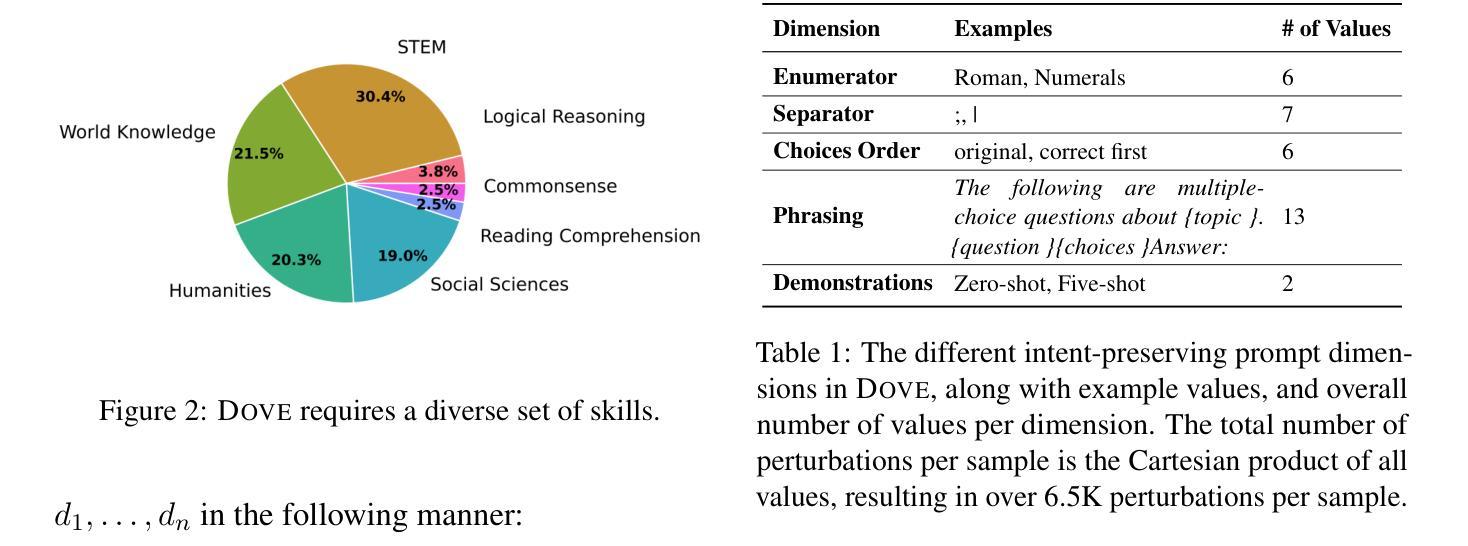
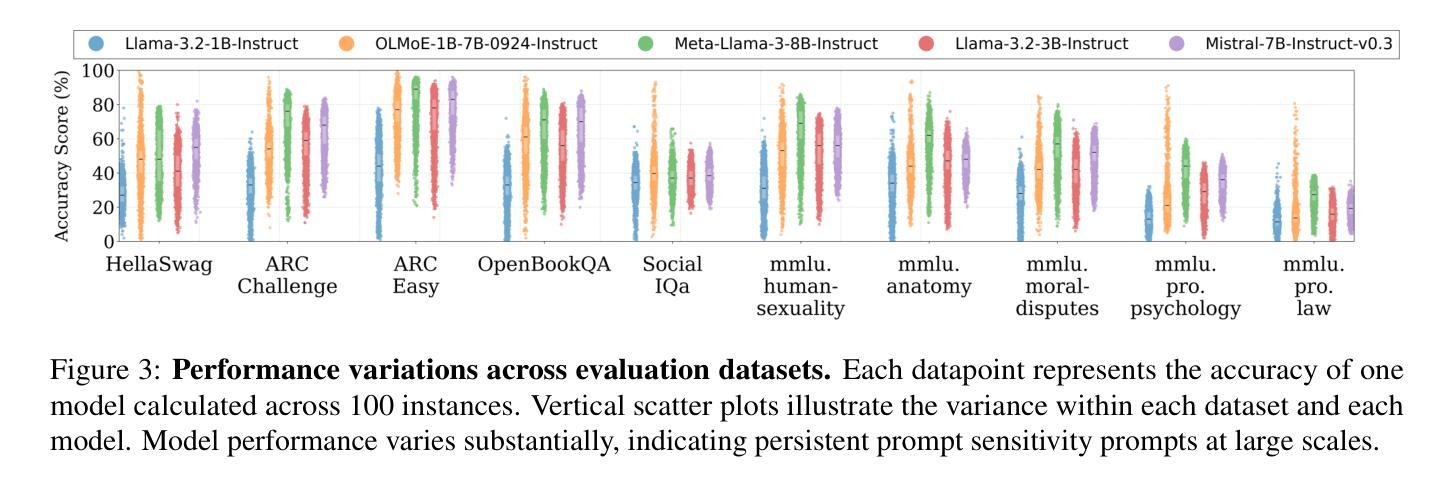
DOVE: A Large-Scale Multi-Dimensional Predictions Dataset Towards Meaningful LLM Evaluation
Authors:Eliya Habba, Ofir Arviv, Itay Itzhak, Yotam Perlitz, Elron Bandel, Leshem Choshen, Michal Shmueli-Scheuer, Gabriel Stanovsky
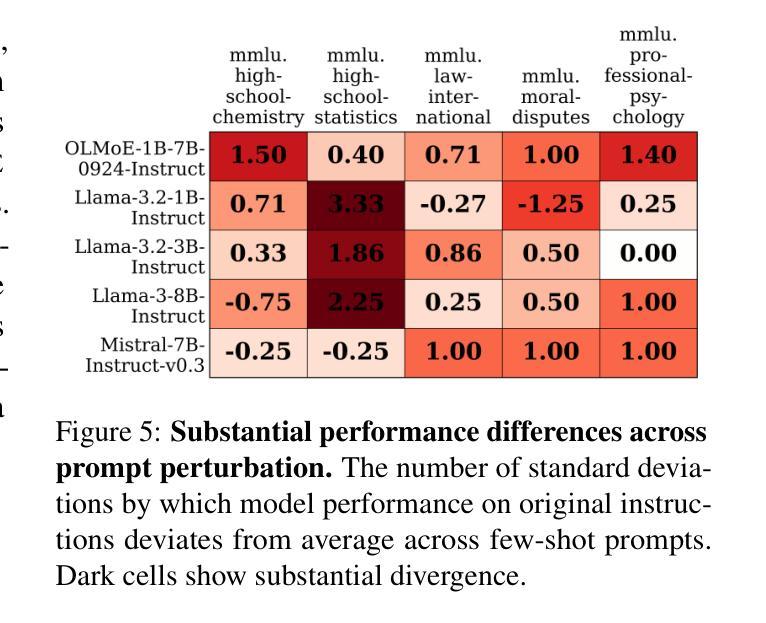
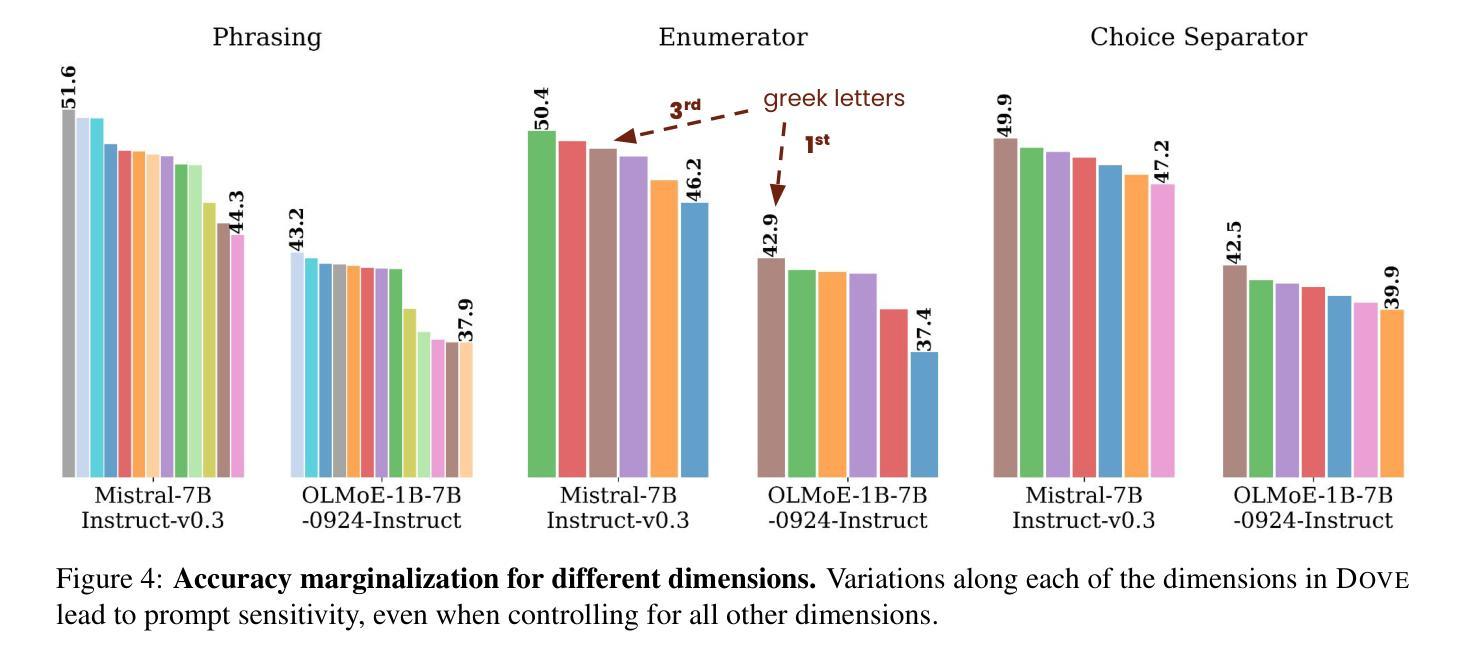
Recent work found that LLMs are sensitive to a wide range of arbitrary prompt dimensions, including the type of delimiters, answer enumerators, instruction wording, and more. This throws into question popular single-prompt evaluation practices. We present DOVE (Dataset Of Variation Evaluation) a large-scale dataset containing prompt perturbations of various evaluation benchmarks. In contrast to previous work, we examine LLM sensitivity from an holistic perspective, and assess the joint effects of perturbations along various dimensions, resulting in thousands of perturbations per instance. We evaluate several model families against DOVE, leading to several findings, including efficient methods for choosing well-performing prompts, observing that few-shot examples reduce sensitivity, and identifying instances which are inherently hard across all perturbations. DOVE consists of more than 250M prompt perturbations and model outputs, which we make publicly available to spur a community-wide effort toward meaningful, robust, and efficient evaluation. Browse the data, contribute, and more: https://slab-nlp.github.io/DOVE/
最近的研究发现,大型语言模型(LLMs)对各种任意的提示维度都非常敏感,包括分隔符的类型、答案枚举器、指令措辞等等。这引发了人们对流行的单一提示评估方法的质疑。我们推出了DOVE(变异评估数据集),这是一个大规模的数据集,包含了各种评估基准测试的提示扰动。与以前的工作相比,我们从整体的角度来审视LLM的敏感性,并评估了不同维度扰动联合效应,导致每个实例都有成千上万的扰动。我们在DOVE上评估了几个模型家族,得到了一些发现,包括选择表现良好的提示的有效方法,观察到少量示例可以减少敏感性,并识别出在所有扰动中固有的难以解决的实例。DOVE包含超过25亿个提示扰动和模型输出,我们将其公开提供,以激发社区朝着有意义、稳健和高效的评估方向共同努力。浏览数据、作出贡献等等:https://slab-nlp.github.io/DOVE/
论文及项目相关链接
Summary
大型语言模型(LLMs)对提示维度敏感,包括分隔符、答案枚举器、指令措辞等。DOVE数据集用于评估模型对各种提示扰动的敏感性,从整体性角度考察LLM的敏感性,并评估各维度扰动的联合效应。该数据集包含超过2.5亿个提示扰动和模型输出,提供公众访问,以推动有意义、稳健和高效的评估工作。
Key Takeaways
- LLMs对提示维度敏感,包括分隔符、答案枚举器和指令措辞等。
- DOVE数据集包含大量的提示扰动,用于评估LLM的敏感性。
- DOVE数据集从整体性角度考察LLM的敏感性,并评估各维度扰动的联合效应。
- DOVE数据集包含超过250M的提示扰动和模型输出,可供公众访问。
- 通过DOVE数据集,发现了选择表现良好的提示的有效方法。
- 少量样本可以减少LLM的敏感性。
点此查看论文截图

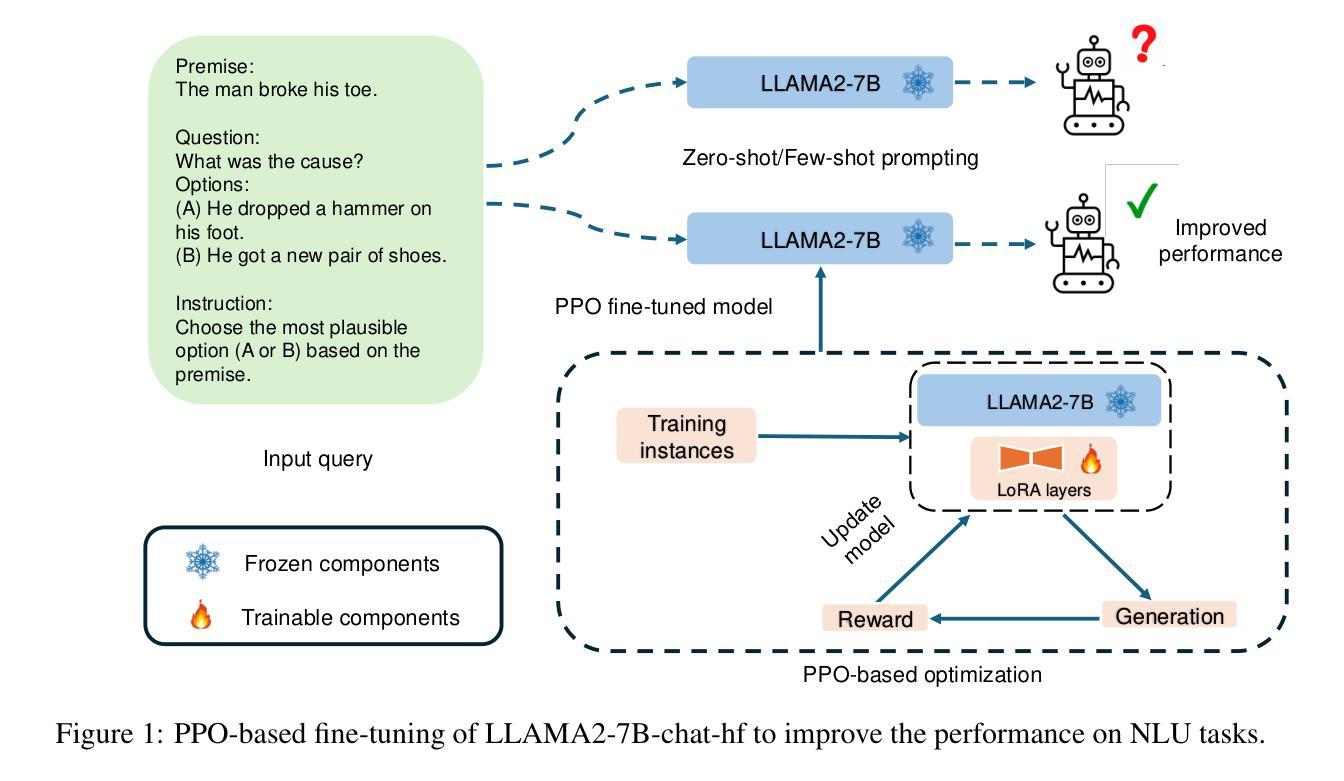
Improving the Language Understanding Capabilities of Large Language Models Using Reinforcement Learning
Authors:Bokai Hu, Sai Ashish Somayajula, Xin Pan, Pengtao Xie
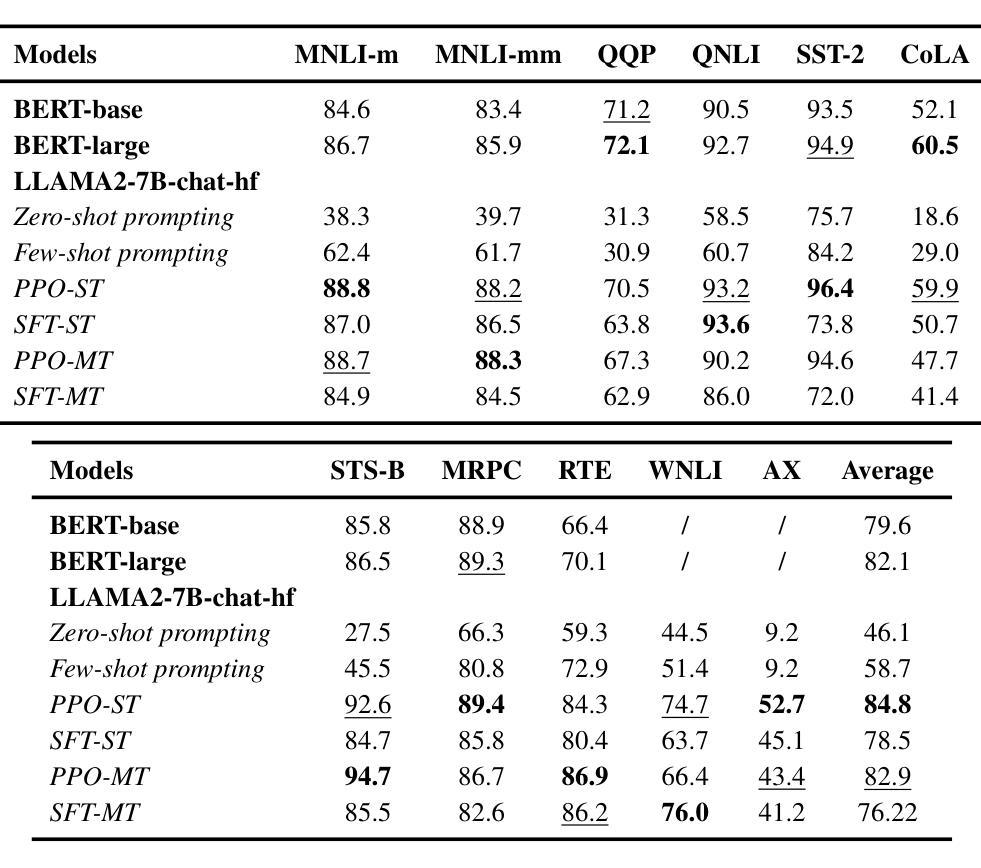
Instruction-fine-tuned large language models (LLMs) under 14B parameters continue to underperform on natural language understanding (NLU) tasks, often trailing smaller models like BERT-base on benchmarks such as GLUE and SuperGLUE. Motivated by the success of reinforcement learning in reasoning tasks (e.g., DeepSeek), we explore Proximal Policy Optimization (PPO) as a framework to improve the NLU capabilities of LLMs. We frame NLU as a reinforcement learning environment, treating token generation as a sequence of actions and optimizing for reward signals based on alignment with ground-truth labels. PPO consistently outperforms supervised fine-tuning, yielding an average improvement of 6.3 points on GLUE, and surpasses zero-shot and few-shot prompting by 38.7 and 26.1 points, respectively. Notably, PPO-tuned models outperform GPT-4o by over 4% on average across sentiment and natural language inference tasks, including gains of 7.3% on the Mental Health dataset and 10.9% on SIGA-nli. This work highlights a promising direction for adapting LLMs to new tasks by reframing them as reinforcement learning problems, enabling learning through simple end-task rewards rather than extensive data curation.
指令微调的大型语言模型(LLM)在14B参数以下,在自然语言理解(NLU)任务上表现持续不佳,通常在GLUE和SuperGLUE等基准测试上落后于较小的模型,如BERT-base。受到强化学习在推理任务(例如DeepSeek)中成功的启发,我们探索近端策略优化(PPO)作为框架,以提高LLM的NLU能力。我们将NLU作为一个强化学习环境,将令牌生成作为一系列动作,并基于与真实标签的对齐情况优化奖励信号。PPO始终优于监督微调,在GLUE上平均提高了6.3分,并分别超过了零样本和少样本提示38.7分和26.1分。值得注意的是,通过PPO训练的模型在情感和自然语言推理任务上的平均表现超过了GPT-4o超过4%,包括在心理健康数据集上提高7.3%,在SIGA-nli上提高10.9%。这项工作突出了通过重新构建为强化学习问题来适应LLM执行新任务的前景,使学习能够通过简单的终端任务奖励而不是大量的数据收集来进行。
论文及项目相关链接
Summary
大语言模型(LLM)在少于14B参数的情况下,在自然语言理解(NLU)任务上的表现仍然不尽如人意,常常在GLUE和SuperGLUE等基准测试中落后于较小的模型,如BERT-base。本研究受深度学习在推理任务中成功应用的启发,探索使用近端策略优化(PPO)框架来提升LLM的NLU能力。本研究将NLU任务视为一个强化学习环境,将令牌生成视为一系列行动,并基于与真实标签的对齐情况来优化奖励信号。PPO在GLUE基准测试上的平均表现优于监督微调,提升了6.3个点;并且在零样本和少样本提示下的表现分别提升了38.7和26.1个点。值得注意的是,使用PPO优化的模型在情感和自然语言推理任务上的平均表现超过GPT-4o超过4%,其中在精神健康数据集上提升了7.3%,在SIGA-nli上提升了10.9%。这表明将LLM重新定位为强化学习问题是一个有前景的方向,可以通过简单的终端任务奖励进行学习,而无需大量数据整理。
Key Takeaways
- 大语言模型(LLM)在少于14B参数时,在自然语言理解(NLU)任务上的表现较差,常落后于较小模型。
- 研究采用强化学习中的近端策略优化(PPO)框架来提升LLM的NLU能力。
- 将NLU任务视为强化学习环境,将令牌生成视为一系列行动,并优化奖励信号以对齐真实标签。
- PPO在GLUE基准测试上的表现优于监督微调和其他方法。
- PPO优化的模型在情感和自然语言推理任务上的平均表现超过GPT-4o超过4%,在某些数据集上的提升显著。
- 研究结果表明,将LLM重新定位为强化学习问题是一个有前景的方向。
点此查看论文截图