⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-06 更新
CLAIM: An Intent-Driven Multi-Agent Framework for Analyzing Manipulation in Courtroom Dialogues
Authors:Disha Sheshanarayana, Tanishka Magar, Ayushi Mittal, Neelam Chaplot
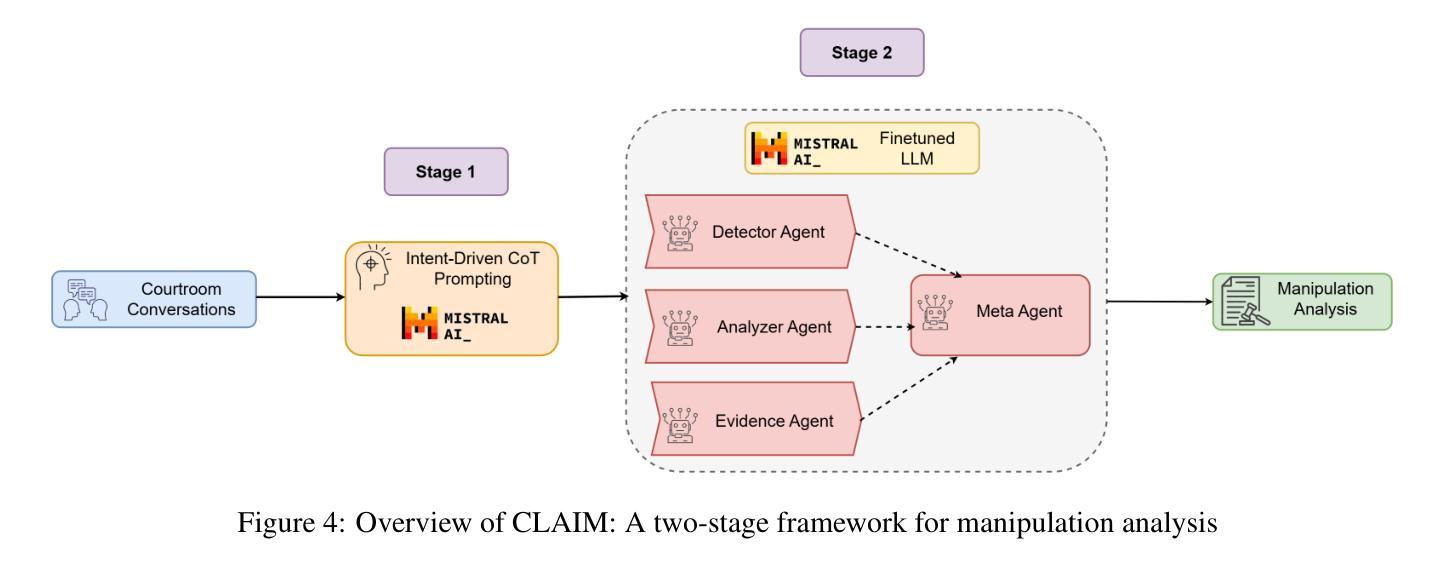
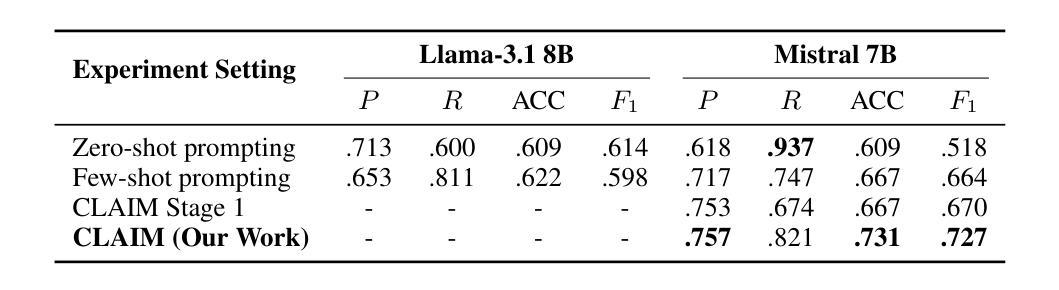
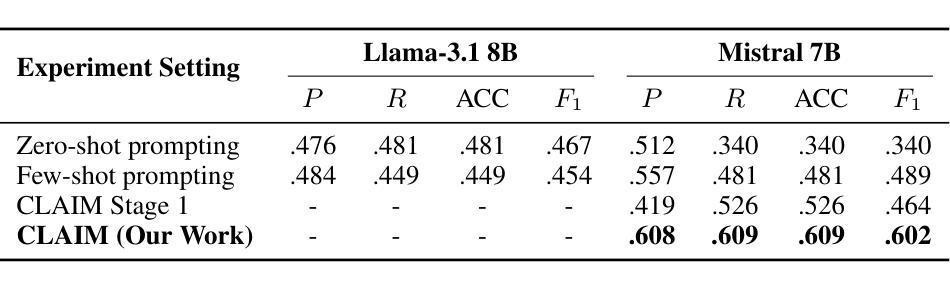
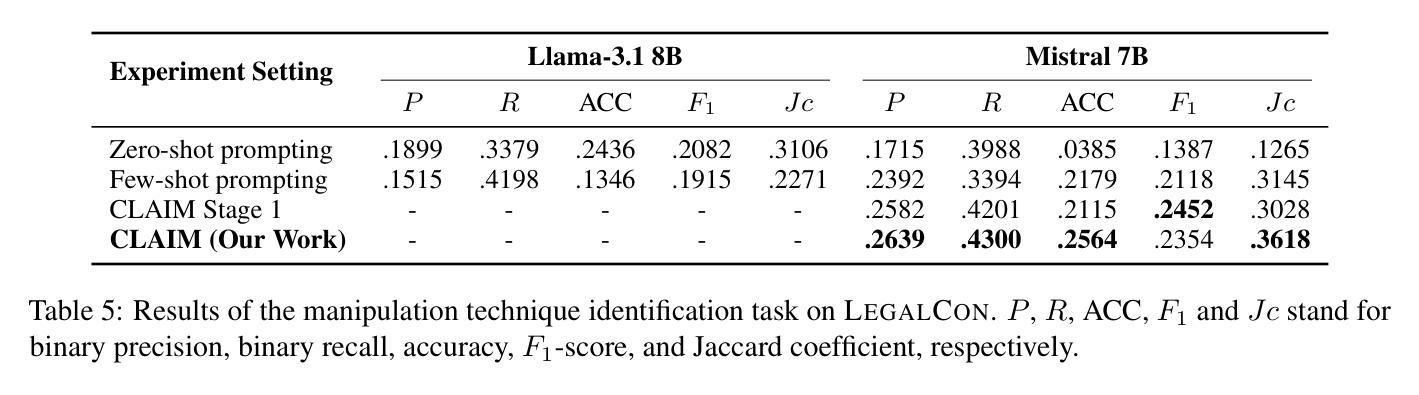
Courtrooms are places where lives are determined and fates are sealed, yet they are not impervious to manipulation. Strategic use of manipulation in legal jargon can sway the opinions of judges and affect the decisions. Despite the growing advancements in NLP, its application in detecting and analyzing manipulation within the legal domain remains largely unexplored. Our work addresses this gap by introducing LegalCon, a dataset of 1,063 annotated courtroom conversations labeled for manipulation detection, identification of primary manipulators, and classification of manipulative techniques, with a focus on long conversations. Furthermore, we propose CLAIM, a two-stage, Intent-driven Multi-agent framework designed to enhance manipulation analysis by enabling context-aware and informed decision-making. Our results highlight the potential of incorporating agentic frameworks to improve fairness and transparency in judicial processes. We hope that this contributes to the broader application of NLP in legal discourse analysis and the development of robust tools to support fairness in legal decision-making. Our code and data are available at https://github.com/Disha1001/CLAIM.
法庭是裁决人生和命运的地方,但它们并非完全不受操纵。在法律术语中巧妙地使用操纵策略可以影响法官的观点和决定。尽管自然语言处理(NLP)领域不断取得进步,但其在法律领域检测和分析操纵行为的应用仍待探索。我们的工作通过引入LegalCon数据集解决了这一问题。该数据集包含1063个已标注的法庭对话,用于操纵检测、主要操纵者的识别和操纵技术的分类,侧重于长对话。此外,我们提出了CLAIM(意图驱动的两阶段多智能体框架),旨在通过支持情境感知和决策制定来增强操纵分析。我们的结果突显了引入智能体框架在提升司法过程公平性和透明度方面的潜力。我们希望为自然语言处理在法律话语分析中的更广泛应用以及支持法律决策公正性的稳健工具开发做出贡献。我们的代码和数据可在https://github.com/Disha1001/CLAIM找到。
论文及项目相关链接
PDF Accepted to SICon 2025 ACL
Summary
本文介绍了法律领域中操纵行为的存在及其对法庭决策的影响。针对这一问题,提出了LegalCon数据集和CLAIM框架,旨在通过分析和识别操纵行为、主要操纵者以及操纵技术来提高司法过程的公平性和透明度。
Key Takeaways
- 法庭并非完全免受操纵的影响,法律术语中的战略使用可能会影响法官的意见和决定。
- LegalCon数据集包含1,063个标注的法庭谈话记录,用于检测操纵行为、识别主要操纵者以及分类操纵技术,尤其关注长对话。
- CLAIM是一个两阶段的意图驱动的多代理框架,旨在通过实现上下文感知和决策支持来提高对操纵行为的分析能力。
- 结果表明,引入代理框架有助于提高司法过程的公平性和透明度。
- 本文希望推动NLP在法律话语分析中的更广泛应用,并开发支持公平法律决策制定的稳健工具。
- 数据集和代码可通过https://github.com/Disha1001/CLAIM获取。
点此查看论文截图


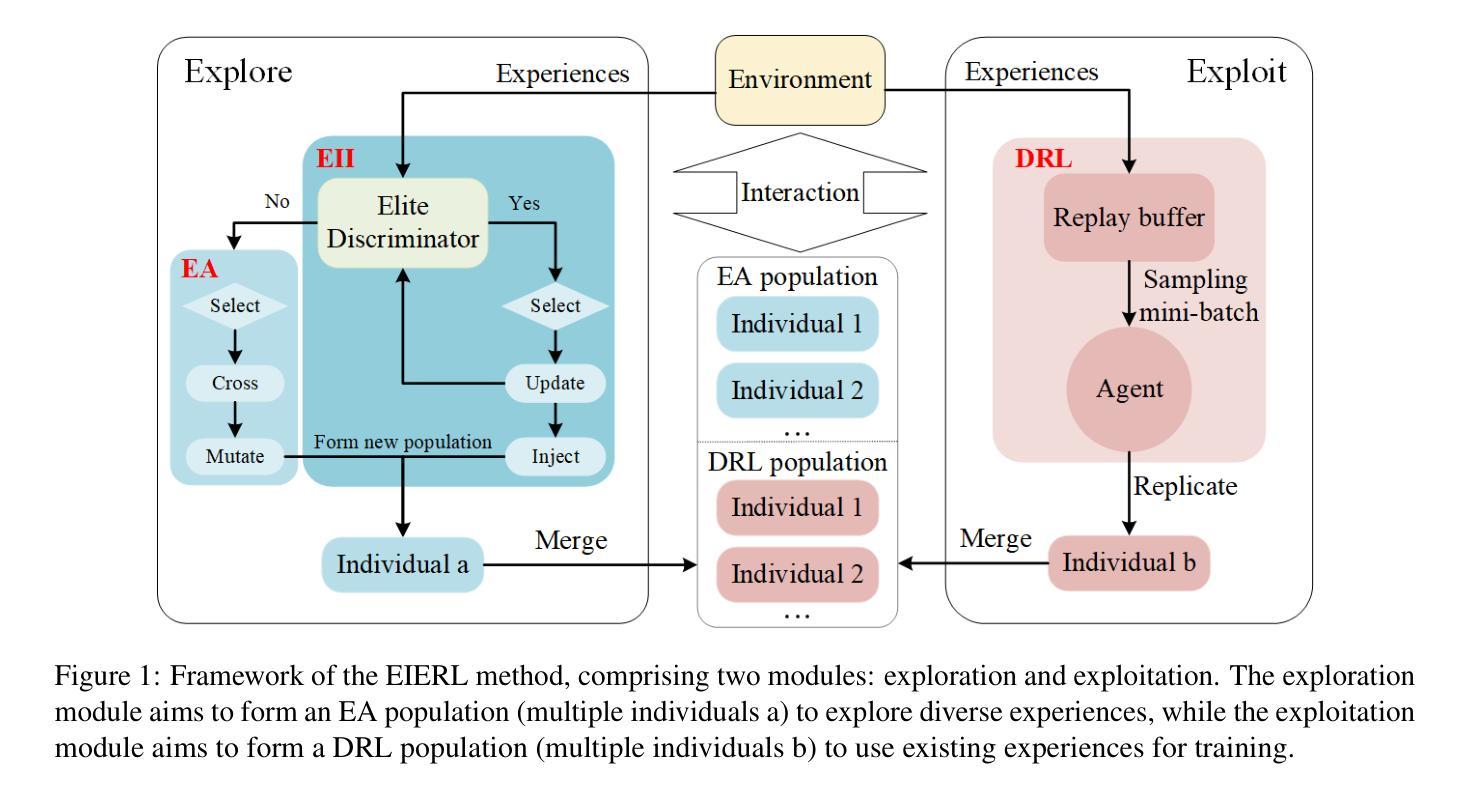
An Efficient Task-Oriented Dialogue Policy: Evolutionary Reinforcement Learning Injected by Elite Individuals
Authors:Yangyang Zhao, Ben Niu, Libo Qin, Shihan Wang
Deep Reinforcement Learning (DRL) is widely used in task-oriented dialogue systems to optimize dialogue policy, but it struggles to balance exploration and exploitation due to the high dimensionality of state and action spaces. This challenge often results in local optima or poor convergence. Evolutionary Algorithms (EAs) have been proven to effectively explore the solution space of neural networks by maintaining population diversity. Inspired by this, we innovatively combine the global search capabilities of EA with the local optimization of DRL to achieve a balance between exploration and exploitation. Nevertheless, the inherent flexibility of natural language in dialogue tasks complicates this direct integration, leading to prolonged evolutionary times. Thus, we further propose an elite individual injection mechanism to enhance EA’s search efficiency by adaptively introducing best-performing individuals into the population. Experiments across four datasets show that our approach significantly improves the balance between exploration and exploitation, boosting performance. Moreover, the effectiveness of the EII mechanism in reducing exploration time has been demonstrated, achieving an efficient integration of EA and DRL on task-oriented dialogue policy tasks.
深度强化学习(DRL)被广泛应用于面向任务的对话系统以优化对话策略,但由于状态空间和动作空间的高维性,它在平衡探索和利用方面遇到了困难。这一挑战往往导致局部最优或收敛性差。进化算法(EA)通过保持种群多样性,已被证明可以有效地探索神经网络的解空间。受此启发,我们创新地将EA的全局搜索能力与DRL的局部优化相结合,实现了探索与利用之间的平衡。然而,对话任务中自然语言固有的灵活性使这种直接整合变得复杂,导致进化时间延长。因此,我们进一步提出了一种精英个体注入机制,通过自适应地将表现最佳的个体引入种群,提高EA的搜索效率。在四个数据集上的实验表明,我们的方法显著改善了探索与利用之间的平衡,提高了性能。此外,精英个体注入机制在减少探索时间方面的有效性已经得到验证,实现了EA和DRL在面向任务的对话策略任务上的有效融合。
论文及项目相关链接
总结
本文结合了深度强化学习和进化算法,将进化算法的全局搜索能力与深度强化学习的局部优化能力相结合,解决了任务导向对话系统中探索与利用的平衡问题。为解决自然语言的内在灵活性带来的进化过程延长问题,提出了精英个体注入机制,提高了进化算法的搜索效率。实验证明,该方法在平衡探索与利用、提升性能的同时,EII机制在减少探索时间方面效果显著。
关键见解
- 深度强化学习在任务导向型对话系统中广泛应用于优化对话策略,但在高维状态和动作空间中面临探索与利用的平衡挑战。
- 进化算法被证明能有效探索神经网络解空间,通过保持种群多样性来发挥作用。
- 融合进化算法和深度强化学习的全局和局部搜索能力,实现探索与利用的平衡。
- 自然语言的内在灵活性给直接整合带来挑战,导致进化过程延长。
- 精英个体注入机制自适应地将最佳表现的个体引入种群,提高进化算法的搜索效率。
- 跨四个数据集的实验显示,结合进化算法和深度强化学习的方法在任务导向型对话策略任务中显著提高了探索与利用的平衡,提升了性能。
点此查看论文截图



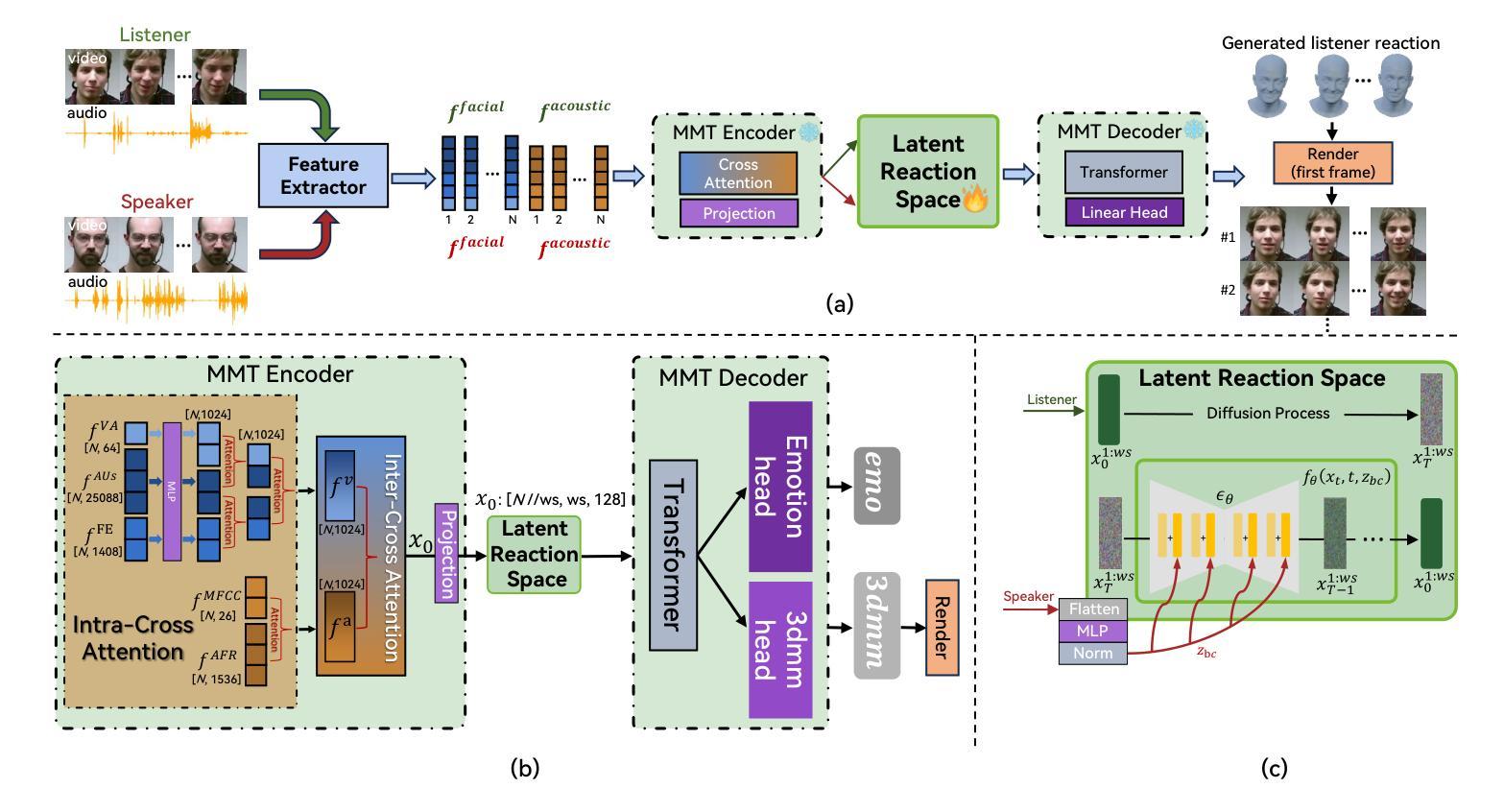
ReactDiff: Latent Diffusion for Facial Reaction Generation
Authors:Jiaming Li, Sheng Wang, Xin Wang, Yitao Zhu, Honglin Xiong, Zixu Zhuang, Qian Wang
Given the audio-visual clip of the speaker, facial reaction generation aims to predict the listener’s facial reactions. The challenge lies in capturing the relevance between video and audio while balancing appropriateness, realism, and diversity. While prior works have mostly focused on uni-modal inputs or simplified reaction mappings, recent approaches such as PerFRDiff have explored multi-modal inputs and the one-to-many nature of appropriate reaction mappings. In this work, we propose the Facial Reaction Diffusion (ReactDiff) framework that uniquely integrates a Multi-Modality Transformer with conditional diffusion in the latent space for enhanced reaction generation. Unlike existing methods, ReactDiff leverages intra- and inter-class attention for fine-grained multi-modal interaction, while the latent diffusion process between the encoder and decoder enables diverse yet contextually appropriate outputs. Experimental results demonstrate that ReactDiff significantly outperforms existing approaches, achieving a facial reaction correlation of 0.26 and diversity score of 0.094 while maintaining competitive realism. The code is open-sourced at \href{https://github.com/Hunan-Tiger/ReactDiff}{github}.
根据说话者的视听剪辑,面部表情生成旨在预测听众的面部表情。挑战在于在平衡适当性、现实性和多样性的同时,捕捉视频和音频之间的相关性。虽然早期的工作主要集中在单模态输入或简化的反应映射上,但最近的方法,如PerFRDiff,已经探索了多模态输入和适当反应映射的一对多性质。在这项工作中,我们提出了面部反应扩散(ReactDiff)框架,该框架独特地结合了多模态变压器和有条件的潜在空间扩散,以增强反应生成。与现有方法不同,ReactDiff利用同类内和同类间的注意力进行精细的多模态交互,而编码器和解码器之间的潜在扩散过程则使输出多样化,但上下文恰当。实验结果表明,ReactDiff在面部反应相关性方面显著优于现有方法,达到0.26的面部反应相关性和0.094的多样性分数,同时保持竞争力现实性。代码已开源,可在github(https://github.com/Hunan-Tiger/ReactDiff)上查看。
论文及项目相关链接
PDF Accepted by Neural Networks
总结
基于音频视觉剪辑的演讲者,面部表情生成旨在预测听众的面部表情。挑战在于在平衡适宜性、现实感和多样性的同时,捕捉视频和音频之间的相关性。虽然早期的工作主要集中在单模态输入或简单的反应映射上,但最近的方法如PerFRDiff开始探索多模态输入和适当的反应映射的一对多性质。在这项研究中,我们提出了独特的面部反应扩散(ReactDiff)框架,它将多模态转换器与潜在空间的条件扩散相结合,以改善反应生成效果。与现有方法相比,ReactDiff利用类别内部和类别之间的注意力进行精细的多模态交互,而编码器和解码器之间的潜在扩散过程则产生多样但上下文恰当的输出。实验结果表明,ReactDiff在面部反应相关性方面取得了显著优于现有方法的效果,达到了0.26的反应相关性和0.094的多样性评分,同时在保持竞争性时保持了良好的现实感。代码已开源在github链接。
关键见解
- Facial reaction generation的目标是预测听众对于音频视觉演讲内容的面部表情反应。
- 面临挑战是同时考虑视频和音频的相关性,以及反应的适宜性、现实性和多样性。
- 现有方法多集中在单模态输入或简化的反应映射上,而最新的ReactDiff框架集成了多模态转换器和潜在空间的条件扩散,改善了反应生成的品质。
- ReactDiff利用类别内和类别间的注意力实现精细的多模态交互。
- 潜在扩散过程使得输出反应既多样又符合上下文。
- 实验结果显示,ReactDiff在面部反应相关性方面表现出卓越性能,达到0.26的反应相关性和0.094的多样性评分。
点此查看论文截图

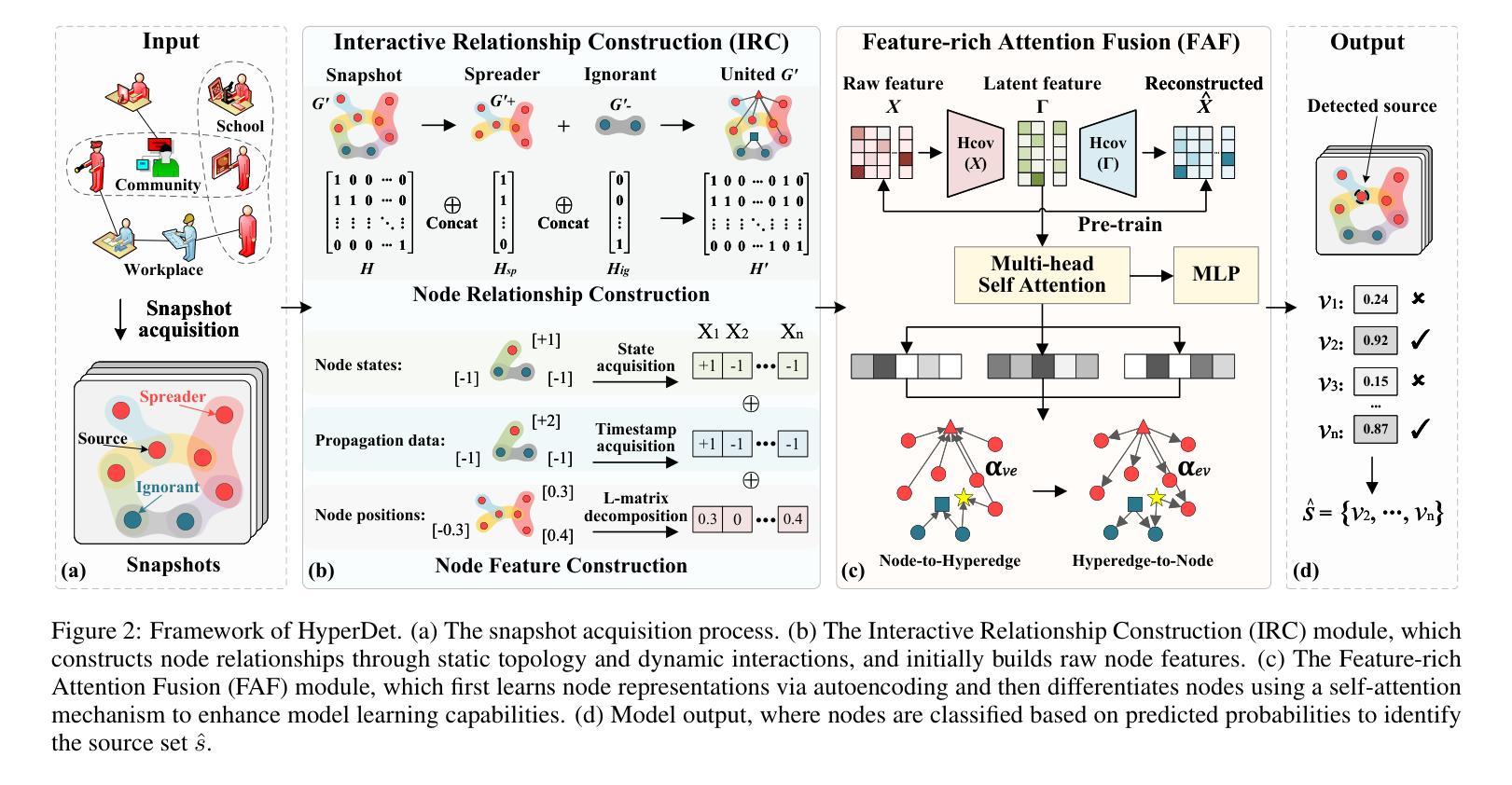
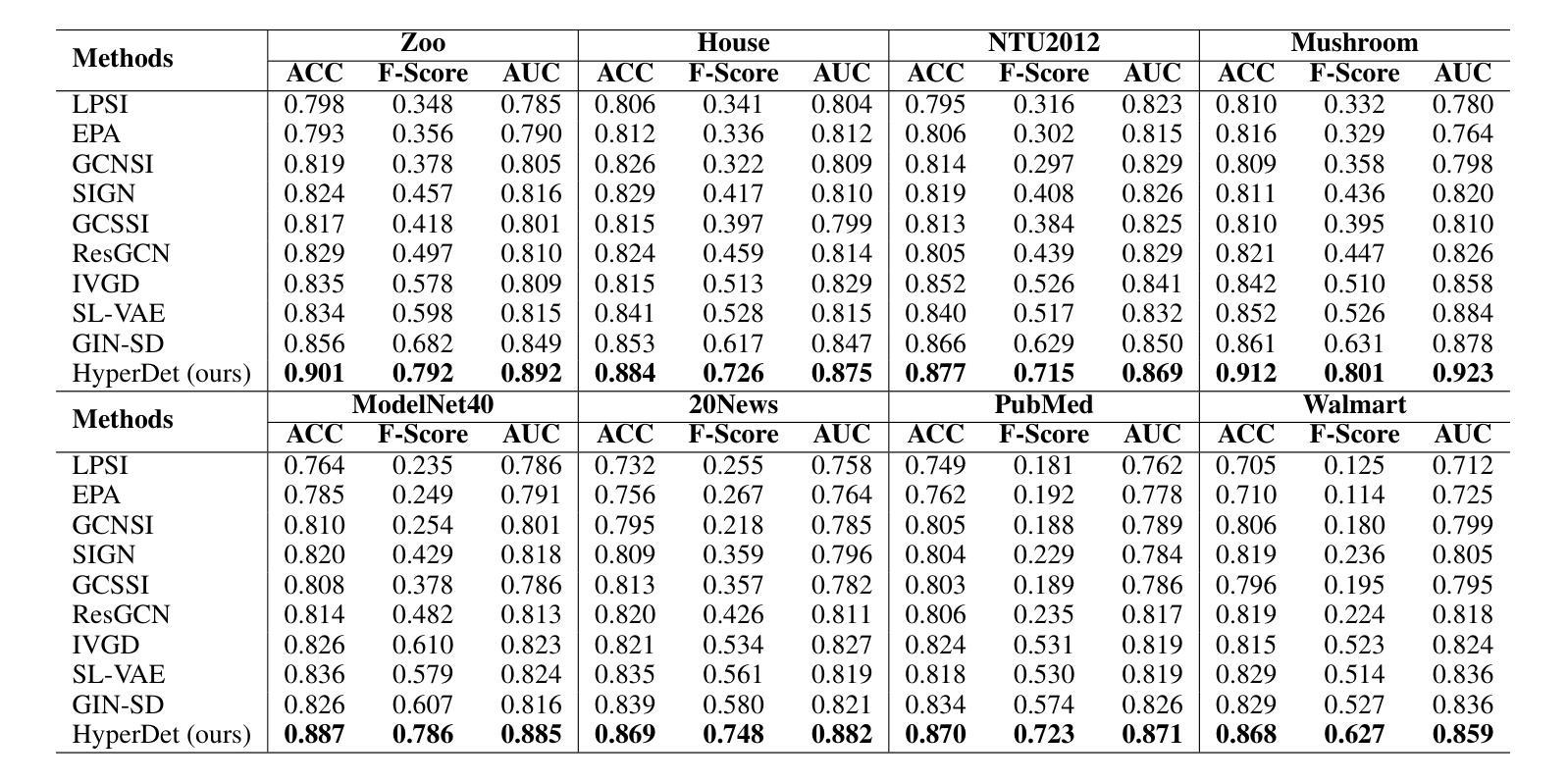
HyperDet: Source Detection in Hypergraphs via Interactive Relationship Construction and Feature-rich Attention Fusion
Authors:Le Cheng, Peican Zhu, Yangming Guo, Keke Tang, Chao Gao, Zhen Wang
Hypergraphs offer superior modeling capabilities for social networks, particularly in capturing group phenomena that extend beyond pairwise interactions in rumor propagation. Existing approaches in rumor source detection predominantly focus on dyadic interactions, which inadequately address the complexity of more intricate relational structures. In this study, we present a novel approach for Source Detection in Hypergraphs (HyperDet) via Interactive Relationship Construction and Feature-rich Attention Fusion. Specifically, our methodology employs an Interactive Relationship Construction module to accurately model both the static topology and dynamic interactions among users, followed by the Feature-rich Attention Fusion module, which autonomously learns node features and discriminates between nodes using a self-attention mechanism, thereby effectively learning node representations under the framework of accurately modeled higher-order relationships. Extensive experimental validation confirms the efficacy of our HyperDet approach, showcasing its superiority relative to current state-of-the-art methods.
超图为社会网络提供了出色的建模能力,特别是在捕捉群体现象方面,这些现象超越了谣言传播中的两两互动。现有的谣言源头检测方法主要关注二元互动,这无法解决更复杂的关系结构的复杂性。本研究中,我们提出了一种通过互动关系构建和丰富的特征融合进行超图中源头检测(HyperDet)的新方法。具体来说,我们的方法采用互动关系构建模块,准确建模用户之间的静态拓扑和动态交互,然后通过丰富的特征融合模块,自主学习节点特征并使用自注意力机制进行节点间区分,从而在准确建模的高阶关系框架下有效地学习节点表示。大量实验验证了我们HyperDet方法的有效性,证明了其相对于当前最先进的方法的优越性。
论文及项目相关链接
PDF Accepted by IJCAI25
Summary
该研究提出了一种基于超图的新型谣言源头检测法(HyperDet),通过交互关系构建和特征丰富的注意力融合模块实现高级关系建模,可更准确地捕捉社交网络中的群体现象和复杂交互结构。
Key Takeaways
- Hypergraphs are superior in modeling social networks due to their ability to capture group phenomena beyond pairwise interactions in rumor propagation.
- Current approaches in rumor source detection mainly focus on dyadic interactions, which are inadequate for intricate relational structures.
- The proposed HyperDet approach employs an Interactive Relationship Construction module to model both static topology and dynamic interactions among users.
- The Feature-rich Attention Fusion module autonomously learns node features and differentiates between nodes using a self-attention mechanism.
- HyperDet effectively learns node representations within the framework of accurately modeled higher-order relationships.
- Experimental validation demonstrates the efficacy and superiority of the HyperDet approach compared to current state-of-the-art methods.
点此查看论文截图

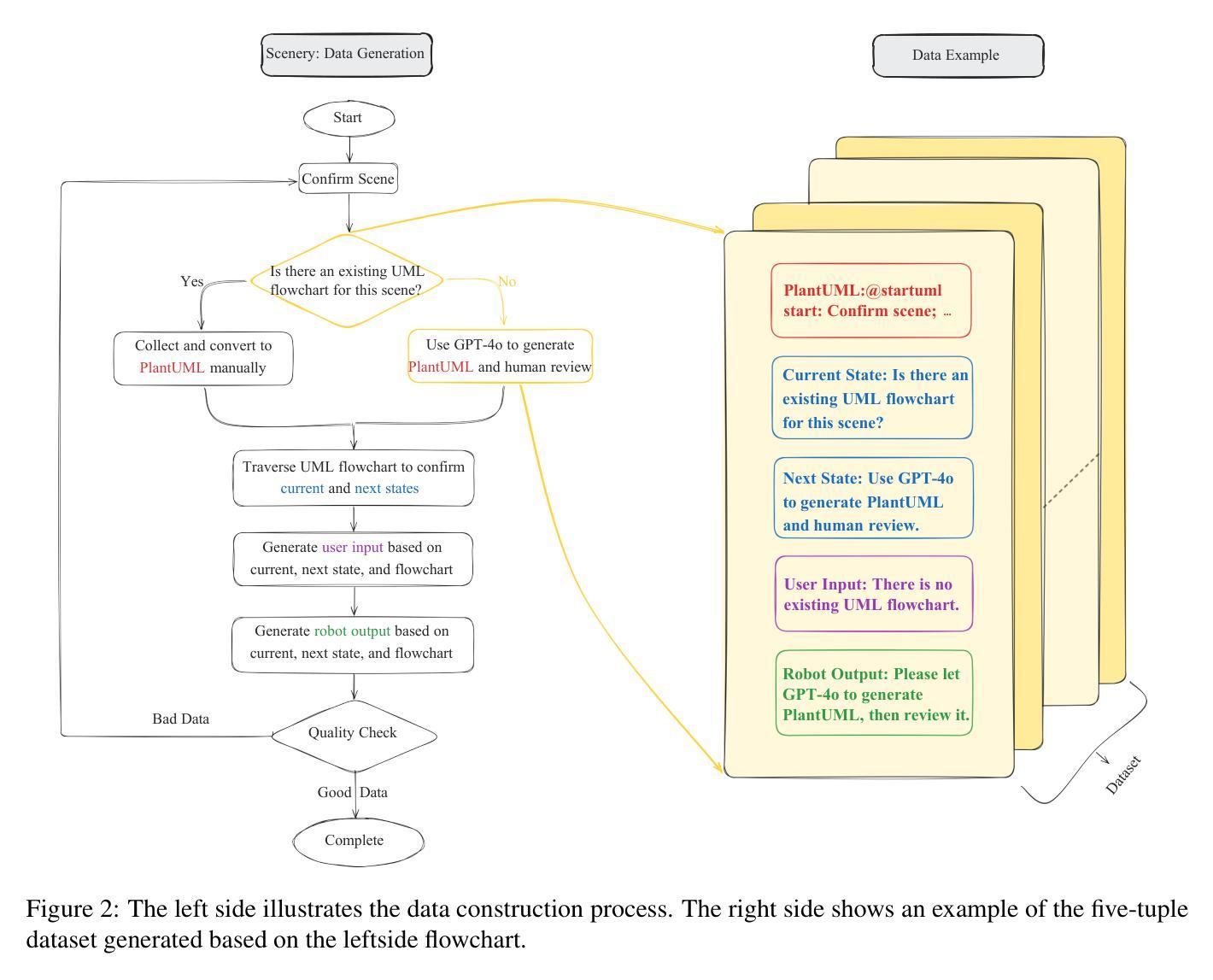
PFDial: A Structured Dialogue Instruction Fine-tuning Method Based on UML Flowcharts
Authors:Ming Zhang, Yuhui Wang, Yujiong Shen, Tingyi Yang, Changhao Jiang, Yilong Wu, Shihan Dou, Qinhao Chen, Zhiheng Xi, Zhihao Zhang, Yi Dong, Zhen Wang, Zhihui Fei, Mingyang Wan, Tao Liang, Guojun Ma, Qi Zhang, Tao Gui, Xuanjing Huang
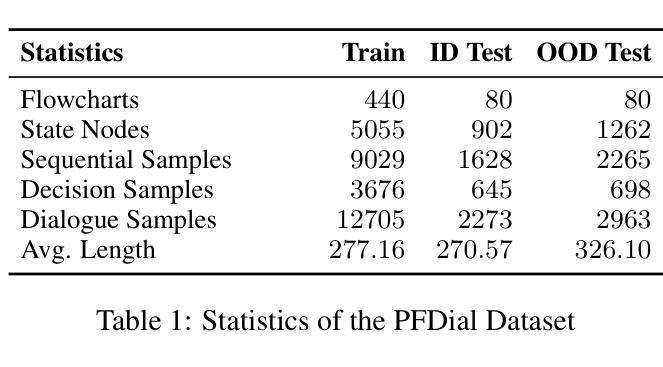
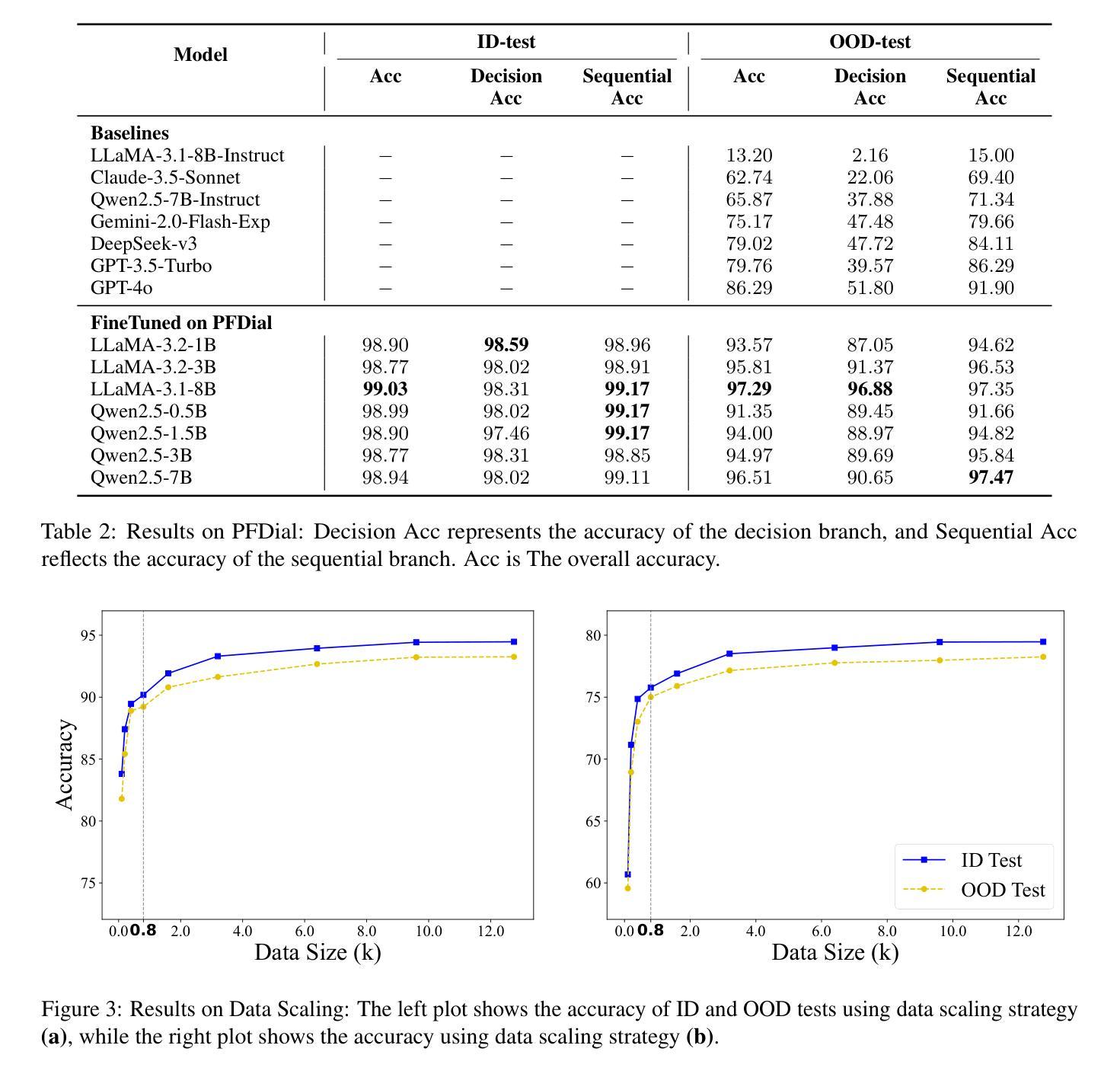
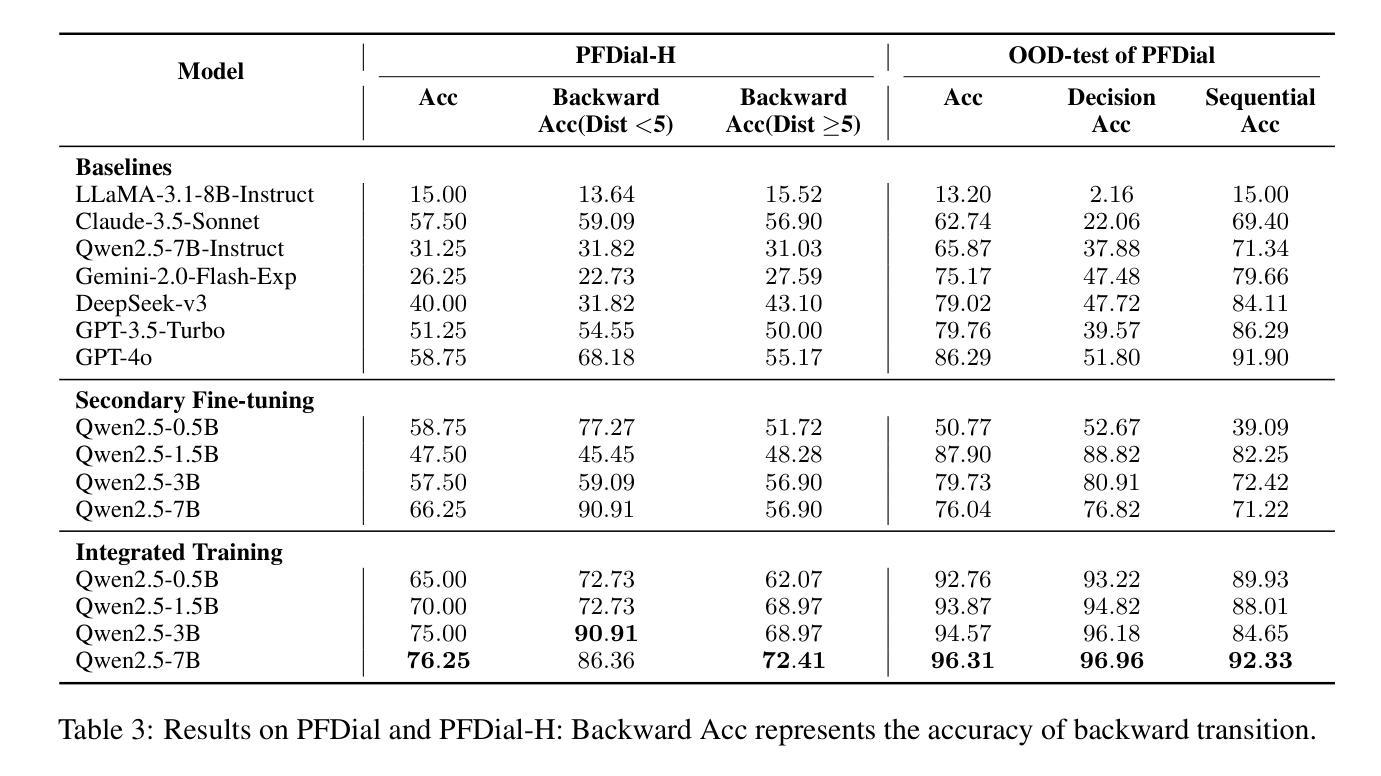
Process-driven dialogue systems, which operate under strict predefined process constraints, are essential in customer service and equipment maintenance scenarios. Although Large Language Models (LLMs) have shown remarkable progress in dialogue and reasoning, they still struggle to solve these strictly constrained dialogue tasks. To address this challenge, we construct Process Flow Dialogue (PFDial) dataset, which contains 12,705 high-quality Chinese dialogue instructions derived from 440 flowcharts containing 5,055 process nodes. Based on PlantUML specification, each UML flowchart is converted into atomic dialogue units i.e., structured five-tuples. Experimental results demonstrate that a 7B model trained with merely 800 samples, and a 0.5B model trained on total data both can surpass 90% accuracy. Additionally, the 8B model can surpass GPT-4o up to 43.88% with an average of 11.00%. We further evaluate models’ performance on challenging backward transitions in process flows and conduct an in-depth analysis of various dataset formats to reveal their impact on model performance in handling decision and sequential branches. The data is released in https://github.com/KongLongGeFDU/PFDial.
流程驱动型对话系统在严格的预先定义流程约束下运行,对于客户服务及设备维护场景至关重要。尽管大型语言模型(LLM)在对话和推理方面取得了显著进展,但它们仍然难以解决这些严格受限的对话任务。为了应对这一挑战,我们构建了流程对话(PFDial)数据集,其中包含从包含流程节点的流程图中派生出的高质量对话指令共计 12,705 条对话语句,流程图有440个且包含5,055个流程节点。基于PlantUML规范,每个UML流程图被转换为原子对话单元,即结构化五元组。实验结果表明,仅使用800个样本训练的7B模型与在全部数据上训练的模型准确率为零,这两个模型的准确率均超过百分之九十。此外,使用我们数据集的模型在性能上超越了GPT-4o,超越率高达百分之四十三点八八。对数据集深入分析与数据平均变化可知数据集可提高模型准确率达百分之十一点零零,随后深入分析模型处理决策和顺序分支时面临挑战时的性能表现。数据已在https://github.com/KongLongGeFDU/PFDial公开发布。
论文及项目相关链接
Summary
流程驱动型对话系统在客户服务和设备维护场景中至关重要,它们遵循严格的预设流程约束。尽管大型语言模型(LLMs)在对话和推理方面取得了显著进展,但它们仍难以解决这些受严格约束的对话任务。为解决这一挑战,构建了包含高质量中文对话指令的过程流对话(PFDial)数据集,该数据集从包含流程图的多个UML模型转化生成,流程图中每个步骤都转化为五个元素的原子对话单元。研究表明使用仅训练过的小数据集生成的模型能够达到相当高的准确度,展示不同的模型在数据处理效率上有显著提升。通过深度分析数据集格式对模型性能的影响,该数据集有助于推进流程驱动型对话系统的研究与应用。数据集已在GitHub上发布以供下载和应用。
Key Takeaways:
点此查看论文截图