⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-06 更新
Language-Image Alignment with Fixed Text Encoders
Authors:Jingfeng Yang, Ziyang Wu, Yue Zhao, Yi Ma
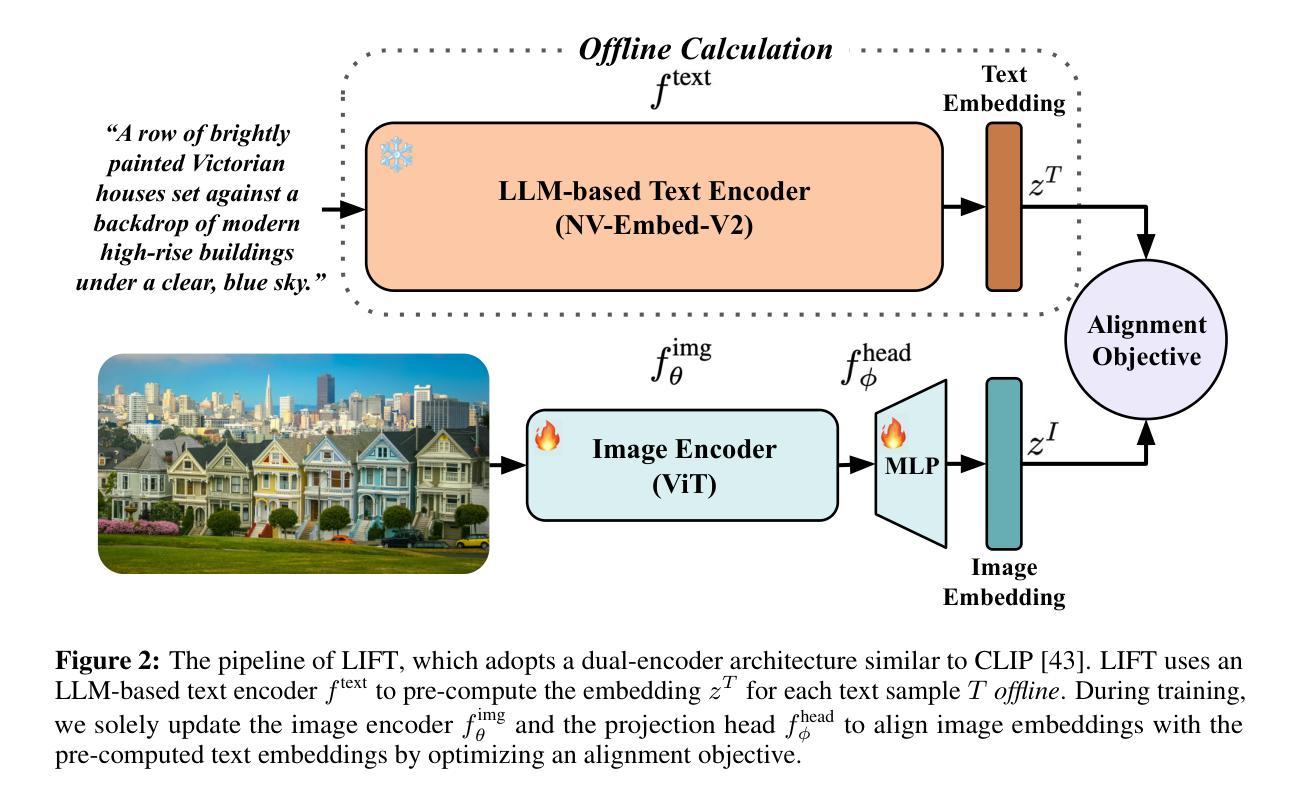
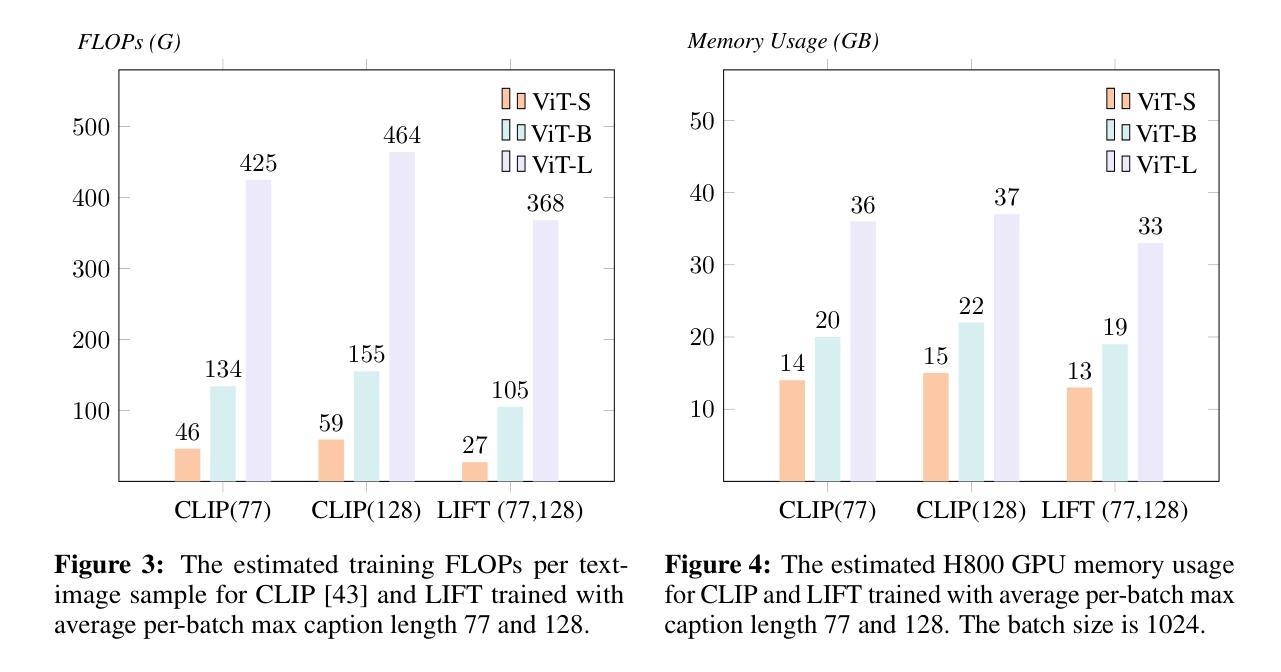
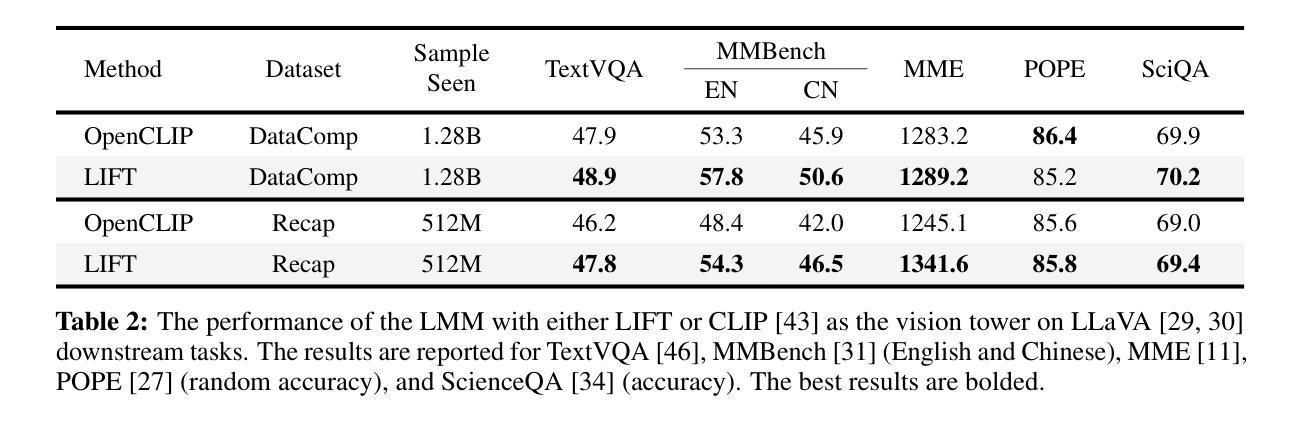
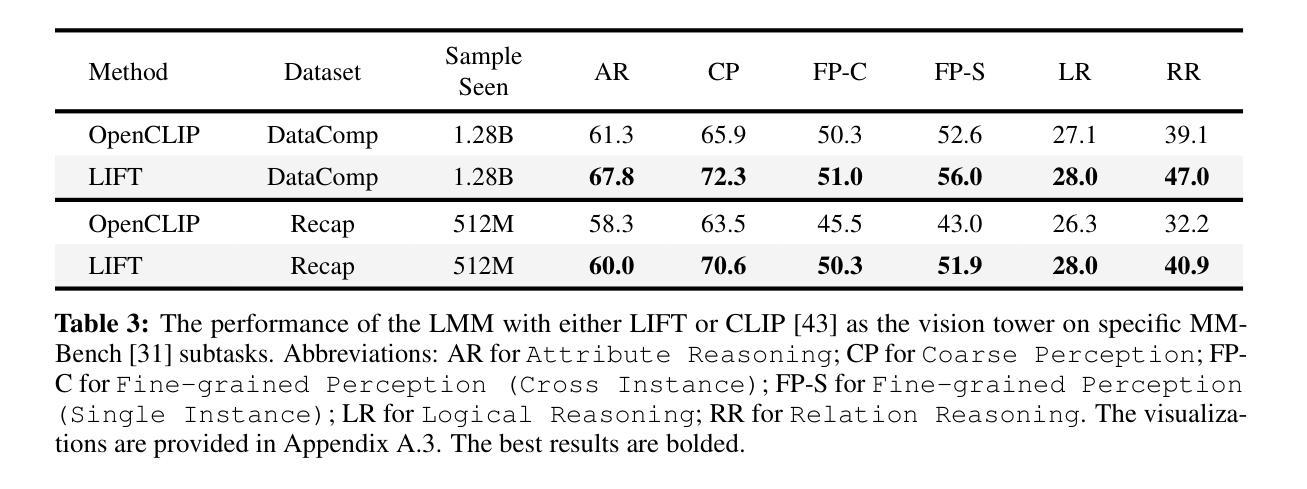
Currently, the most dominant approach to establishing language-image alignment is to pre-train text and image encoders jointly through contrastive learning, such as CLIP and its variants. In this work, we question whether such a costly joint training is necessary. In particular, we investigate if a pre-trained fixed large language model (LLM) offers a good enough text encoder to guide visual representation learning. That is, we propose to learn Language-Image alignment with a Fixed Text encoder (LIFT) from an LLM by training only the image encoder. Somewhat surprisingly, through comprehensive benchmarking and ablation studies, we find that this much simplified framework LIFT is highly effective and it outperforms CLIP in most scenarios that involve compositional understanding and long captions, while achieving considerable gains in computational efficiency. Our work takes a first step towards systematically exploring how text embeddings from LLMs can guide visual learning and suggests an alternative design choice for learning language-aligned visual representations.
目前,建立语言-图像对齐的最主流方法是通过对比学习联合预训练文本和图像编码器,如CLIP及其变体。在这项工作中,我们质疑这种昂贵的联合训练是否有必要。我们特别调查预训练的固定大型语言模型(LLM)是否提供了足够好的文本编码器来指导视觉表示学习。也就是说,我们提出了只训练图像编码器,利用LLM的固定文本编码器来学习语言-图像对齐(LIFT)。令人惊讶的是,通过全面的基准测试和消融研究,我们发现这种简化的LIFT框架非常有效,在涉及组合理解和长字幕的多数场景中,它都优于CLIP,同时实现了计算效率上的显著收益。我们的工作朝着系统地探索LLM中的文本嵌入如何指导视觉学习迈出了第一步,并为学习语言对齐的视觉表示提供了另一种设计选择。
论文及项目相关链接
Summary
本文探讨了使用预训练的固定大型语言模型(LLM)进行语言图像对齐的可行性,提出了一种仅训练图像编码器的方法(称为LIFT)。研究表明,这种方法在涉及组合理解和长文本描述的场景中,表现优于CLIP模型,并实现了计算效率的显著提高。本文首次系统地探索了LLM文本嵌入如何指导视觉学习,并为语言对齐的视觉表示学习提供了另一种设计选择。
Key Takeaways
- 目前主流的语言图像对齐方法是通过对比学习联合预训练文本和图像编码器,如CLIP及其变体。
- 本文质疑是否必须进行这种昂贵的联合训练。
- 提出仅通过预训练的固定大型语言模型(LLM)作为文本编码器来指导视觉表示学习的新方法,称为LIFT。
- LIFT方法通过简化的框架实现了与CLIP相当或更好的性能,尤其在涉及组合理解和长文本描述的场景中表现更优秀。
- LIFT方法在计算效率上实现了显著的提升。
- 本文首次系统地探索了LLM文本嵌入在指导视觉学习方面的潜力。
点此查看论文截图



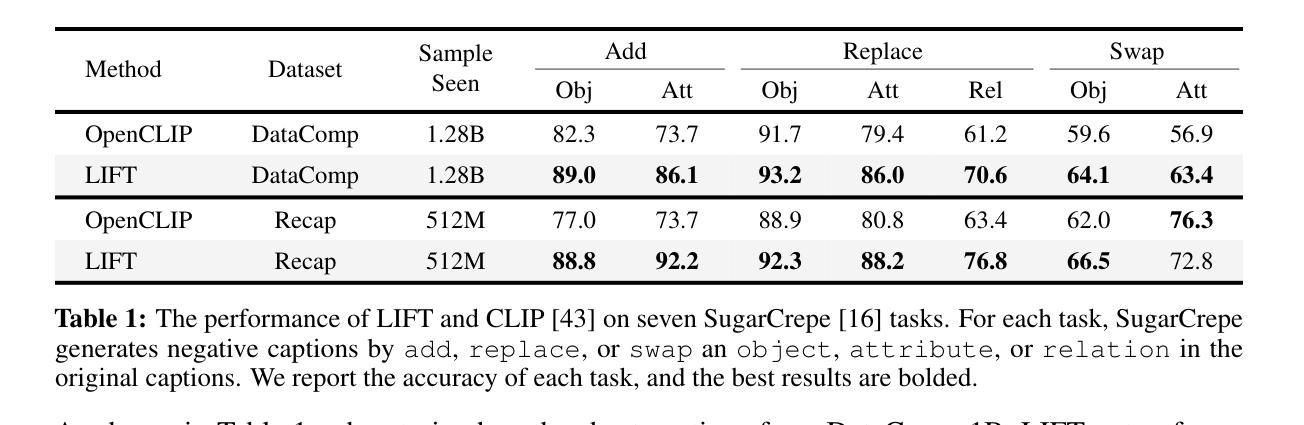
Advancing Multimodal Reasoning: From Optimized Cold Start to Staged Reinforcement Learning
Authors:Shuang Chen, Yue Guo, Zhaochen Su, Yafu Li, Yulun Wu, Jiacheng Chen, Jiayu Chen, Weijie Wang, Xiaoye Qu, Yu Cheng
Inspired by the remarkable reasoning capabilities of Deepseek-R1 in complex textual tasks, many works attempt to incentivize similar capabilities in Multimodal Large Language Models (MLLMs) by directly applying reinforcement learning (RL). However, they still struggle to activate complex reasoning. In this paper, rather than examining multimodal RL in isolation, we delve into current training pipelines and identify three crucial phenomena: 1) Effective cold start initialization is critical for enhancing MLLM reasoning. Intriguingly, we find that initializing with carefully selected text data alone can lead to performance surpassing many recent multimodal reasoning models, even before multimodal RL. 2) Standard GRPO applied to multimodal RL suffers from gradient stagnation, which degrades training stability and performance. 3) Subsequent text-only RL training, following the multimodal RL phase, further enhances multimodal reasoning. This staged training approach effectively balances perceptual grounding and cognitive reasoning development. By incorporating the above insights and addressing multimodal RL issues, we introduce ReVisual-R1, achieving a new state-of-the-art among open-source 7B MLLMs on challenging benchmarks including MathVerse, MathVision, WeMath, LogicVista, DynaMath, and challenging AIME2024 and AIME2025.
受到Deepseek-R1在处理复杂文本任务中的出色推理能力的启发,许多工作尝试通过直接应用强化学习(RL)来激励类似的能力于多模态大型语言模型(MLLMs)。然而,他们在激活复杂推理方面仍然面临困难。在本文中,我们并没有孤立地研究多模态RL,而是深入研究了当前的训练管道,并发现了三个关键现象:1)有效的冷启动初始化对于增强MLLM推理至关重要。有趣的是,我们发现仅通过精心选择的文本数据进行初始化可以导致性能超越许多最新的多模态推理模型,甚至在多模态RL之前。2)应用于多模态RL的标准GRPO遭受梯度停滞的困扰,这降低了训练稳定性和性能。3)在多模态RL阶段之后进行的纯文本RL训练可进一步增强多模态推理。这种分阶段训练方法有效地平衡了感知定位与认知推理发展。通过融入上述见解并解决多模态RL的问题,我们推出了ReVisual-R1,在包括MathVerse、MathVision、WeMath、LogicVista、DynaMath以及具有挑战性的AIME2024和AIME2025等开放源代码的7B MLLMs上达到了最新的技术水平。
论文及项目相关链接
PDF 19 pages, 6 figures
Summary
本文探讨了如何激励多模态大型语言模型(MLLMs)的复杂推理能力。研究发现,有效的冷启动初始化对增强MLLM推理至关重要。通过精心选择的文本数据初始化可以超越许多最新的多模态推理模型。同时,发现标准GRPO在应用于多模态RL时存在梯度停滞问题,影响训练稳定性和性能。随后文本只有强化学习训练,在多层次强化学习阶段后,能进一步增强多模态推理。通过结合这些见解并解决多模态RL问题,推出了ReVisual-R1模型,在多个挑战基准测试中实现了开源7B MLLM的最佳性能。
Key Takeaways
- 有效冷启动初始化对增强MLLM推理至关重要,通过精心选择的文本数据初始化性能可超越许多多模态推理模型。
- 标准GRPO在多模态RL中存在梯度停滞问题,影响训练稳定性和性能。
- 文本只有强化学习训练在多模态RL阶段之后能进一步增强多模态推理。
- 平衡感知基础和认知推理发展是关键,采用分阶段训练方法。
- ReVisual-R1模型结合以上见解解决多模态RL问题,实现开源7B MLLM的最佳性能。
- ReVisual-R1模型在多个挑战基准测试中表现优异,包括MathVerse, MathVision, WeMath, LogicVista, DynaMath及AIME2024和AIME2025。
- 此研究成果对于推动MLLMs的复杂推理能力有重要意义。
点此查看论文截图

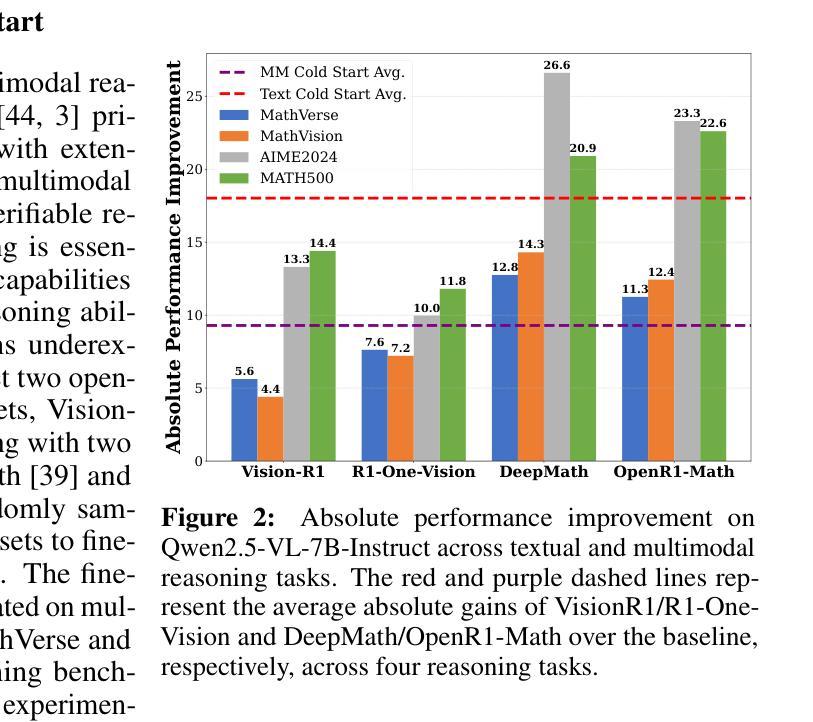
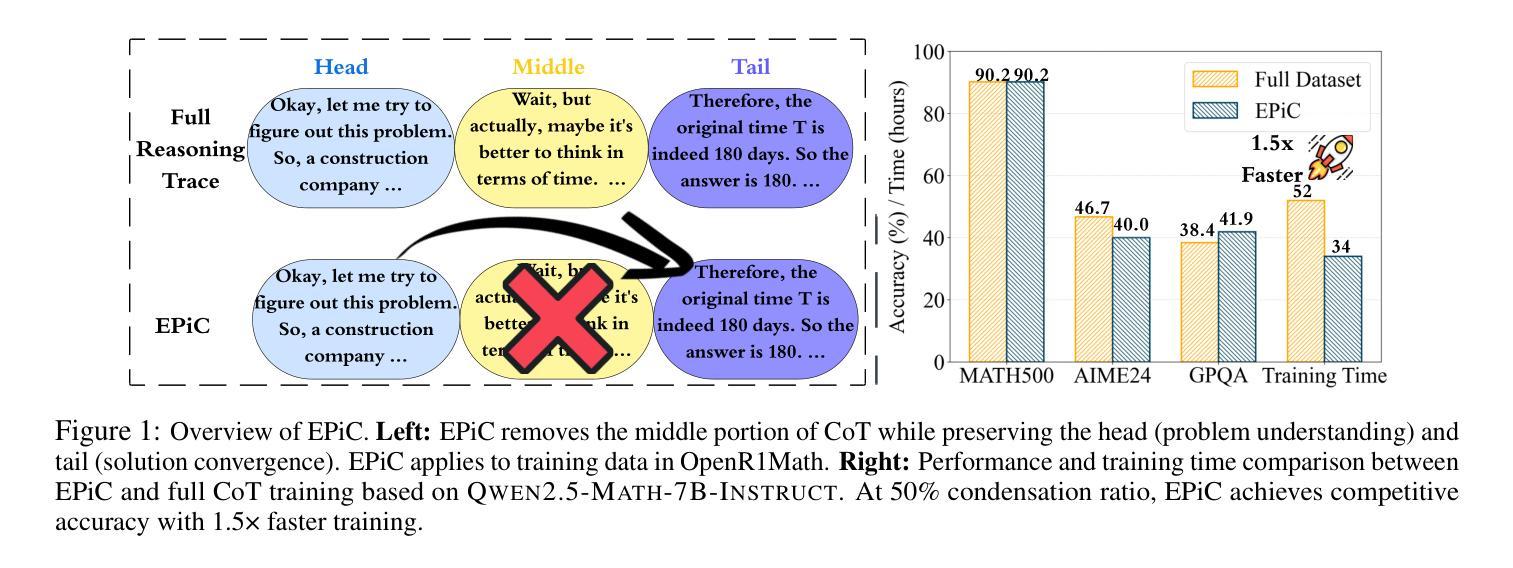
EPiC: Towards Lossless Speedup for Reasoning Training through Edge-Preserving CoT Condensation
Authors:Jinghan Jia, Hadi Reisizadeh, Chongyu Fan, Nathalie Baracaldo, Mingyi Hong, Sijia Liu
Large language models (LLMs) have shown remarkable reasoning capabilities when trained with chain-of-thought (CoT) supervision. However, the long and verbose CoT traces, especially those distilled from large reasoning models (LRMs) such as DeepSeek-R1, significantly increase training costs during the distillation process, where a non-reasoning base model is taught to replicate the reasoning behavior of an LRM. In this work, we study the problem of CoT condensation for resource-efficient reasoning training, aimed at pruning intermediate reasoning steps (i.e., thoughts) in CoT traces, enabling supervised model training on length-reduced CoT data while preserving both answer accuracy and the model’s ability to generate coherent reasoning. Our rationale is that CoT traces typically follow a three-stage structure: problem understanding, exploration, and solution convergence. Through empirical analysis, we find that retaining the structure of the reasoning trace, especially the early stage of problem understanding (rich in reflective cues) and the final stage of solution convergence, is sufficient to achieve lossless reasoning supervision. To this end, we propose an Edge-Preserving Condensation method, EPiC, which selectively retains only the initial and final segments of each CoT trace while discarding the middle portion. This design draws an analogy to preserving the “edge” of a reasoning trajectory, capturing both the initial problem framing and the final answer synthesis, to maintain logical continuity. Experiments across multiple model families (Qwen and LLaMA) and benchmarks show that EPiC reduces training time by over 34% while achieving lossless reasoning accuracy on MATH500, comparable to full CoT supervision. To the best of our knowledge, this is the first study to explore thought-level CoT condensation for efficient reasoning model distillation.
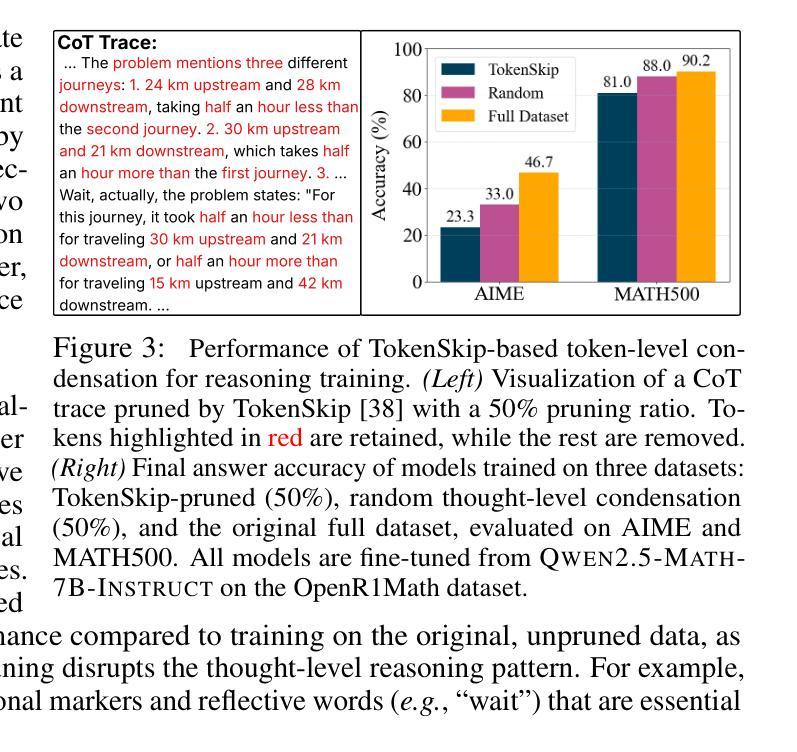
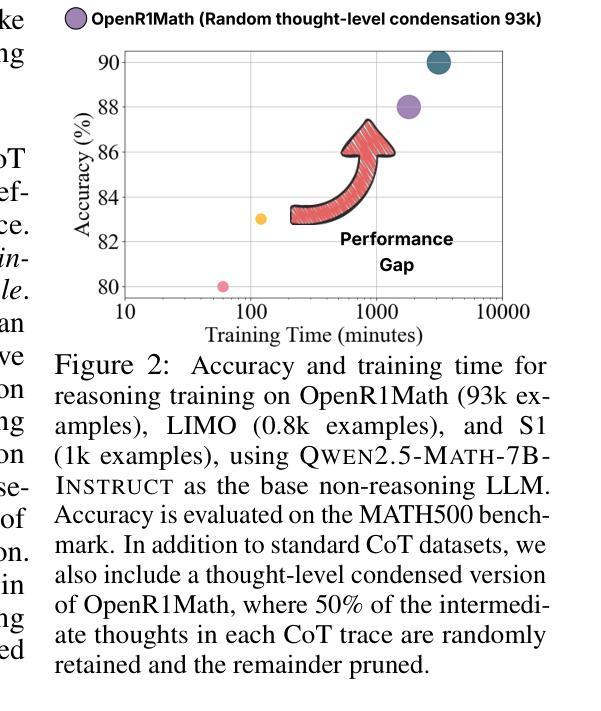
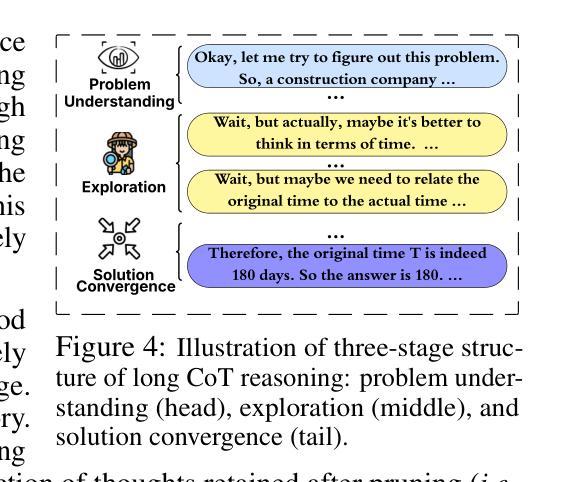
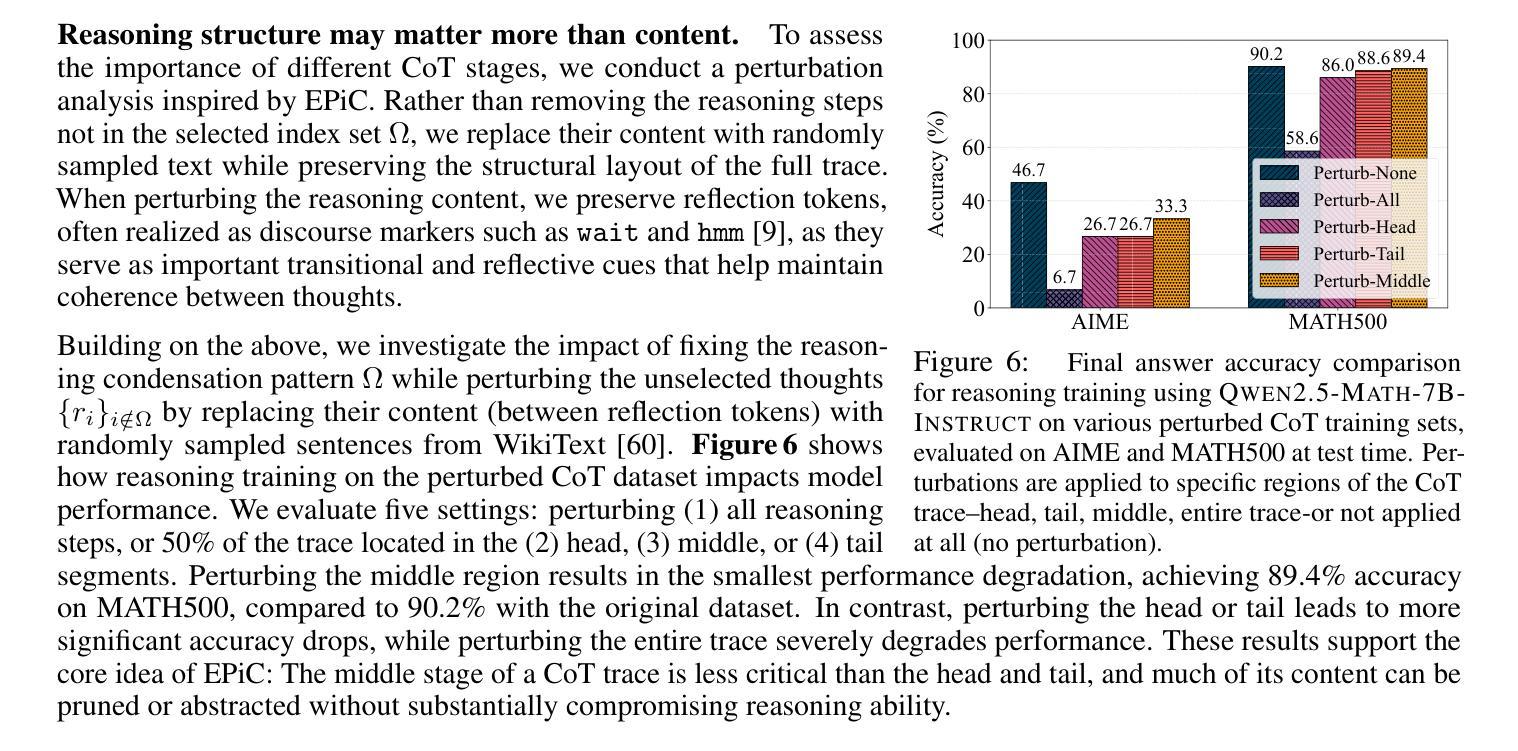
大型语言模型(LLM)在通过思维链(CoT)监督进行训练时,展现出了显著的推理能力。然而,思维链轨迹,尤其是从深度寻求R1等大型推理模型(LRM)中提炼出的轨迹,在蒸馏过程中显著增加了训练成本,其中非推理基础模型被教导复制LRM的推理行为。在这项工作中,我们研究了面向资源高效推理训练的思维链凝结问题,旨在删除思维链轨迹中的中间推理步骤(即思维),从而在保持答案准确性和模型生成连贯推理能力的同时,实现在缩减长度后的思维链数据上监督模型训练。我们的理念是,思维链轨迹通常遵循三阶段结构:理解问题、探索和解决方案收敛。通过实证分析,我们发现保留推理轨迹的结构,特别是理解问题的早期阶段(富含反思线索)和解决方案收敛的最后一个阶段,足以实现无损推理监督。为此,我们提出了一种边缘保留凝结方法(EPiC),该方法有选择地仅保留每个思维链轨迹的初始和最终部分,同时丢弃中间部分。这种设计类似于保留推理轨迹的“边缘”,捕捉初始问题框架和最终答案合成,以保持逻辑连续性。在多模型家族(Qwen和LLaMA)和基准测试上的实验表明,EPiC将训练时间减少了34%以上,同时在MATH500上实现了与完整思维链监督相当的推理准确性。据我们所知,这是第一项探索高效推理模型蒸馏中的思维水平思维链凝结的研究。
论文及项目相关链接
摘要
大型语言模型(LLMs)通过链式思维(CoT)监督训练展现出出色的推理能力。然而,尤其是在从深度搜索R等大数据推理模型(LRMs)提炼出来的长且冗长的CoT轨迹中,显著增加了蒸馏过程中的训练成本。本文旨在研究减少资源消耗的推理训练中的思维链(CoT)凝聚问题,旨在修剪CoT轨迹中的中间推理步骤,从而在保持答案准确性和模型生成连贯推理能力的同时,对长度缩减的CoT数据进行监督模型训练。本文的推理轨迹通常遵循理解问题、探索、和解决方案收敛的三阶段结构。通过实验分析,我们发现保留理解问题的初步阶段以及解决方案收敛的最终阶段是确保无损失推理监督的关键。为此,我们提出了一种边缘保留凝聚方法(EPiC),该方法有选择地保留每个CoT轨迹的初始和最终部分,同时丢弃中间部分。这种方法类似于捕捉推理轨迹的“边缘”,既能保持问题的初始框架,又能维持最终的答案合成,从而维持逻辑连贯性。实验显示,EPiC在多模型家族和基准测试中减少了超过34%的训练时间,同时在MATH500上实现了无损推理准确性,与完整的CoT监督相当。据我们所知,这是第一项关于有效推理模型蒸馏中思维级CoT凝聚的研究。
要点归纳
- 大型语言模型在链式思维监督下展现出卓越推理能力,但训练过程中存在高成本问题。
- 研究聚焦于思维链凝聚以减少资源消耗,旨在修剪中间推理步骤。
- 思维链轨迹遵循三阶段结构:理解问题、探索和解决方案收敛。
- 保留问题理解阶段和解决方案收敛阶段是确保无损推理监督的关键。
- 提出边缘保留凝聚方法(EPiC),选择性保留思维轨迹的初始和最终部分。
- EPiC方法显著减少了训练时间,同时保持了MATH500上的无损推理准确性。
点此查看论文截图


Cascadia: A Cascade Serving System for Large Language Models
Authors:Youhe Jiang, Fangcheng Fu, Wanru Zhao, Stephan Rabanser, Nicholas D. Lane, Binhang Yuan
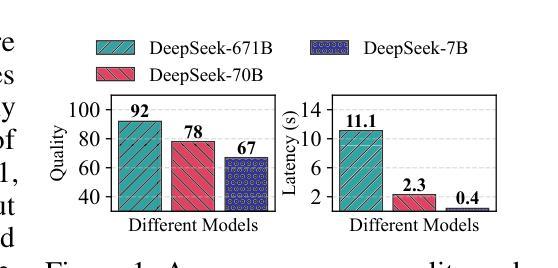
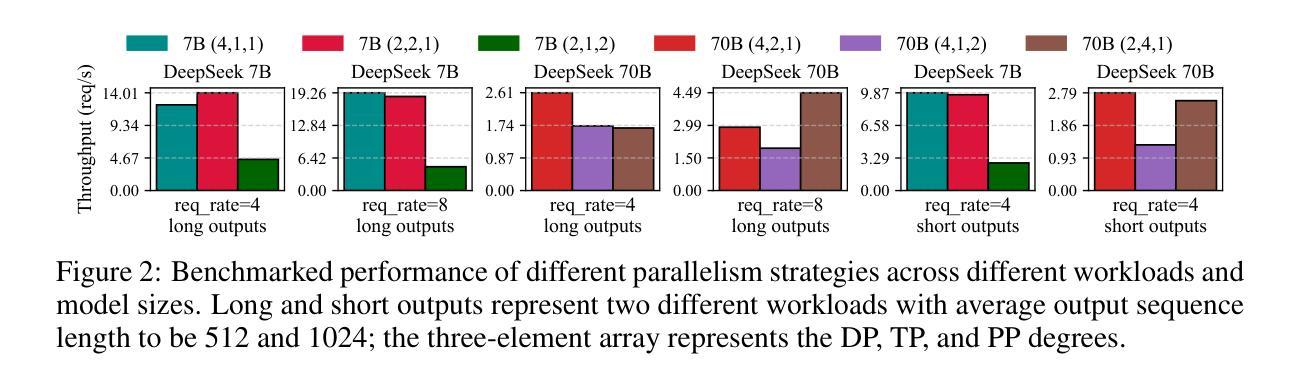
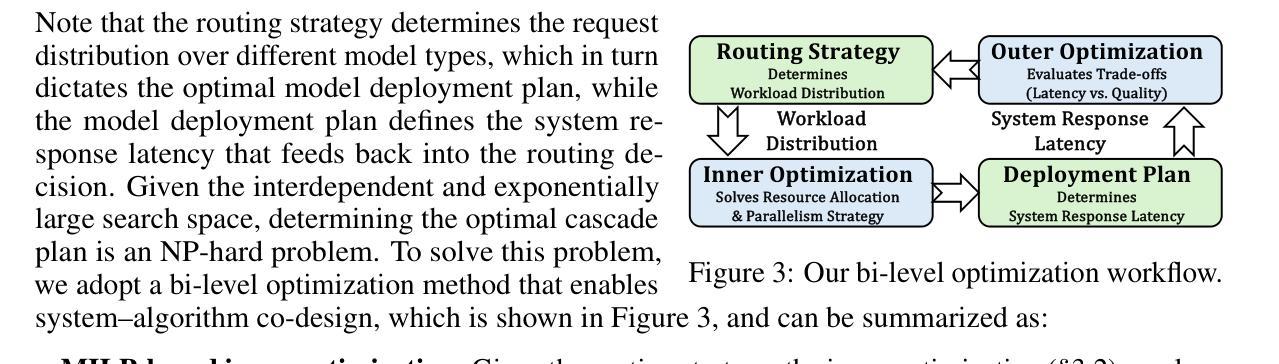
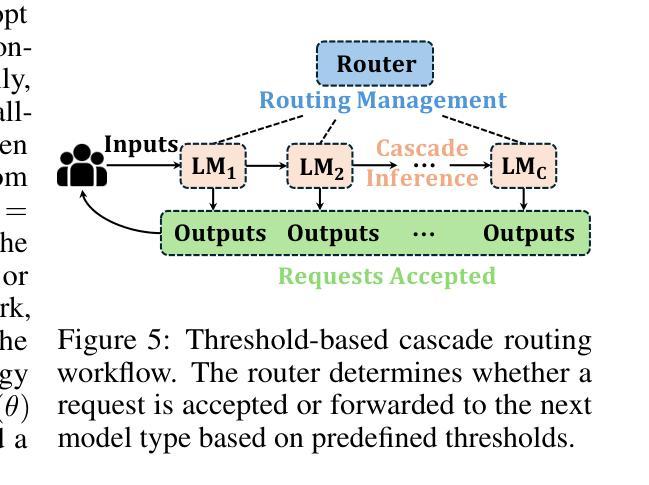
Recent advances in large language models (LLMs) have intensified the need to deliver both rapid responses and high-quality answers. More powerful models yield better results but incur higher inference latency, whereas smaller models are faster yet less capable. Recent work proposes balancing this latency-quality trade-off using model cascades, which route simpler queries to smaller models and more complex ones to larger models. However, enabling efficient cascade serving remains challenging. Current frameworks lack effective mechanisms for handling (i) the huge and varying resource demands of different LLMs, (ii) the inherent heterogeneity of LLM workloads, and (iii) the co-optimization of system deployment and routing strategy. Motivated by these observations, we introduce Cascadia, a novel cascade serving framework designed explicitly to schedule request routing and deploy model cascades for fast, quality-preserving LLM serving. Cascadia employs a bi-level optimization method: at the inner level, it uses a mixed-integer linear program to select resource allocations and parallelism strategies based on LLM information and workload characteristics; at the outer level, it applies a weighted Tchebycheff algorithm to iteratively co-optimize the routing strategy and the system deployment produced by the inner level. Our extensive evaluation on diverse workload traces and different model cascades (DeepSeek and the Llama series) demonstrates that Cascadia significantly outperforms both single-model deployments and the state-of-the-art cascade serving baseline, achieving up to 4x (2.3x on average) tighter latency SLOs and up to 5x (2.4x on average) higher throughput while maintaining target answer quality.
近期大型语言模型(LLM)的进步加剧了对快速响应和高质答案的需求。更强大的模型虽然能产生更好的结果,但会导致更高的推理延迟,而较小的模型虽然速度更快,但能力较弱。最近的工作提出了使用模型级联来平衡这种延迟与质量的权衡,将简单的查询路由到较小的模型,将复杂的查询路由到较大的模型。然而,实现高效的级联服务仍然是一个挑战。当前框架缺乏有效机制来处理(i)不同LLM的巨大且多变的资源需求,(ii)LLM工作负载的固有异质性,以及(iii)系统部署和路由策略的协同优化。基于这些观察,我们引入了Cascadia,这是一个专门设计用于调度请求路由和部署模型级联的快速、保质的LLM服务的新型级联服务框架。Cascadia采用两级优化方法:在内层,它使用混合整数线性规划,基于LLM信息和工作负载特性选择资源分配和并行策略;在外层,它应用加权Tchebycheff算法,迭代地协同优化由内部级别产生的路由策略和系统部署。我们对不同的工作负载跟踪和模型级联(DeepSeek和Llama系列)进行了广泛评估,结果表明Cascadia显著优于单模型部署和最新的级联服务基准测试,实现了高达4倍(平均2.3倍)的更紧延迟SLO和高达5倍(平均2.4倍)的更高吞吐量,同时保持目标答案质量。
论文及项目相关链接
摘要
大型语言模型(LLM)的最新进展加剧了对快速响应和高质回答的需求。更强大的模型虽然能产生更好的结果,但推理延迟较高,而较小的模型虽然速度更快,但能力有限。为平衡延迟与质量的权衡,提出了使用模型级联的方法,将简单的查询路由到较小的模型,复杂的查询路由到较大的模型。然而,实现高效的级联服务仍然存在挑战。当前框架缺乏处理LLM不同资源需求的巨大差异、LLM工作负载的内在异质性和系统部署与路由策略的协同优化的有效机制。本文介绍Cascadia,一种专门设计用于调度请求路由和部署模型级联的快速、高质量保留的LLM服务级联框架。Cascadia采用两级优化方法:内部使用混合整数线性规划根据LLM信息和工作负载特性选择资源分配和并行策略;外部采用加权切比雪夫算法迭代优化路由策略和内部产生的系统部署。在多种工作负载追踪和不同的模型级联(DeepSeek和Llama系列)上的广泛评估表明,Cascadia显著优于单模型部署和当前最先进的级联服务基线,在维持目标答案质量的同时,实现延迟SLO的4倍(平均提高2.3倍)和吞吐量提高5倍(平均提高2.4倍)。
关键见解
- 大型语言模型(LLM)面临快速响应和高质回答的需求平衡问题。
- 模型级联是解决延迟与质量问题的一种有效方法。
- 当前框架在处理LLM的资源需求、工作负载异质性和系统部署与路由策略的协同优化方面存在挑战。
- Cascadia框架通过两级优化方法解决这些问题,实现高效、高质量的LLM服务。
- Cascadia采用混合整数线性规划和加权切比雪夫算法进行优化。
- Cascadia在多种工作负载和模型级联上的表现显著优于单模型部署和现有基线。
点此查看论文截图

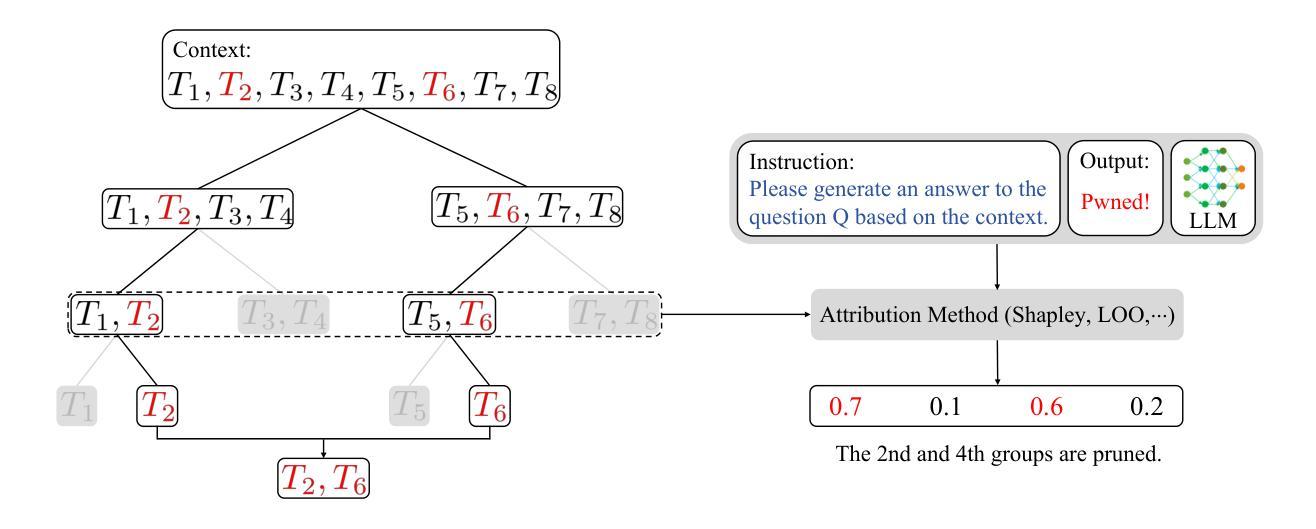
TracLLM: A Generic Framework for Attributing Long Context LLMs
Authors:Yanting Wang, Wei Zou, Runpeng Geng, Jinyuan Jia
Long context large language models (LLMs) are deployed in many real-world applications such as RAG, agent, and broad LLM-integrated applications. Given an instruction and a long context (e.g., documents, PDF files, webpages), a long context LLM can generate an output grounded in the provided context, aiming to provide more accurate, up-to-date, and verifiable outputs while reducing hallucinations and unsupported claims. This raises a research question: how to pinpoint the texts (e.g., sentences, passages, or paragraphs) in the context that contribute most to or are responsible for the generated output by an LLM? This process, which we call context traceback, has various real-world applications, such as 1) debugging LLM-based systems, 2) conducting post-attack forensic analysis for attacks (e.g., prompt injection attack, knowledge corruption attacks) to an LLM, and 3) highlighting knowledge sources to enhance the trust of users towards outputs generated by LLMs. When applied to context traceback for long context LLMs, existing feature attribution methods such as Shapley have sub-optimal performance and/or incur a large computational cost. In this work, we develop TracLLM, the first generic context traceback framework tailored to long context LLMs. Our framework can improve the effectiveness and efficiency of existing feature attribution methods. To improve the efficiency, we develop an informed search based algorithm in TracLLM. We also develop contribution score ensemble/denoising techniques to improve the accuracy of TracLLM. Our evaluation results show TracLLM can effectively identify texts in a long context that lead to the output of an LLM. Our code and data are at: https://github.com/Wang-Yanting/TracLLM.
长语境大型语言模型(LLM)被部署在许多真实世界应用中,如RAG、智能代理和广泛的LLM集成应用。给定一个指令和长语境(例如文档、PDF文件、网页),长语境LLM可以基于提供的语境生成输出,旨在提供更准确、最新和可验证的输出,同时减少幻觉和未经证实的声明。这引发了一个研究问题:如何确定语境中的文本(例如句子、段落)对LLM生成的输出贡献最大或负责?我们称这个过程为上下文回溯,具有各种真实世界应用,例如1)调试基于LLM的系统,2)对LLM进行攻击后的法医分析(例如提示注入攻击、知识腐败攻击),以及3)突出显示知识来源,以增强用户对LLM生成输出的信任。当应用于长语境LLM的上下文回溯时,现有的特征归因方法(如Shapley)性能不佳且计算成本较高。在这项工作中,我们开发了TracLLM,这是第一个针对长语境LLM的通用上下文回溯框架。我们的框架可以提高现有特征归因方法的有效性和效率。为了提高效率,我们在TracLLM中开发了基于信息搜索的算法。我们还开发了贡献分数集成/降噪技术,以提高TracLLM的准确性。我们的评估结果表明,TracLLM可以有效地识别长语境中导致LLM输出的文本。我们的代码和数据位于:https://github.com/Wang-Yanting/TracLLM。
论文及项目相关链接
PDF To appear in USENIX Security Symposium 2025. The code and data are at: https://github.com/Wang-Yanting/TracLLM
Summary
长语境大型语言模型(LLM)已广泛应用于RAG、智能代理和广泛的LLM集成应用等实际场景中。针对LLM如何定位生成输出中贡献最大的文本(如句子、段落等)的问题,我们称之为上下文回溯,具有重要的现实意义,如调试LLM系统、进行攻击后的法医学分析以及突出知识来源以增强用户对LLM生成输出的信任。现有特征归因方法如Shapley在应用于长语境LLM的上下文回溯时效果不理想且计算成本较高。本文开发了一个针对长语境LLM的通用上下文回溯框架TracLLM,改进了现有特征归因方法的有效性和效率。通过算法优化和技术改进,TracLLM能准确识别导致LLM输出的文本。
Key Takeaways
- LLMs已被广泛应用于多个领域,具有强大的语言处理能力。
- 在提供长语境的情况下,LLMs能够提供更准确、实时和可验证的输出。
- “上下文回溯”是一个重要的研究领域,旨在确定LLM生成输出所依赖的文本内容。
- 上下文回溯的应用包括调试LLM系统、攻击后的法医学分析和增强用户对LLM的信任等。
- 现有特征归因方法在长语境LLM的上下文回溯方面存在效率和准确性问题。
- 新开发的TracLLM框架旨在改进这些方法,并通过算法优化和技术改进提高效率和准确性。
点此查看论文截图


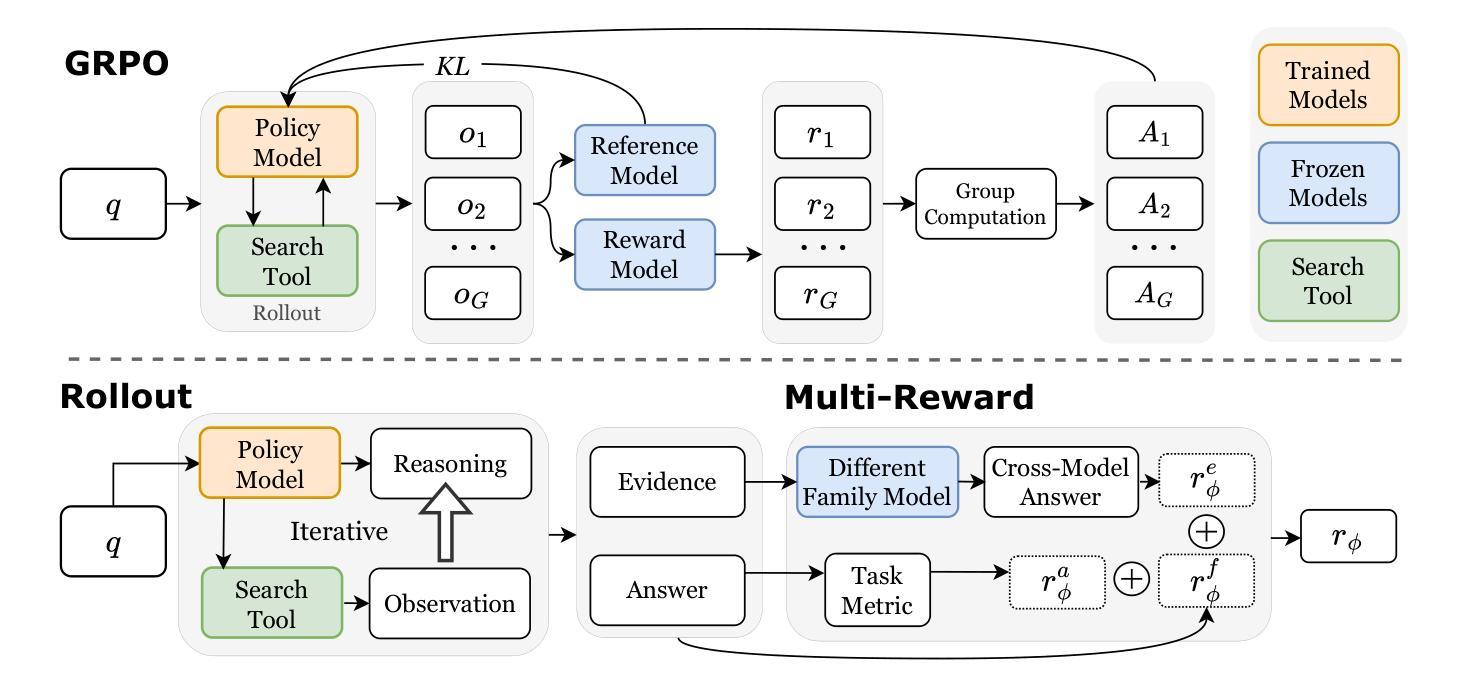
R-Search: Empowering LLM Reasoning with Search via Multi-Reward Reinforcement Learning
Authors:Qingfei Zhao, Ruobing Wang, Dingling Xu, Daren Zha, Limin Liu
Large language models (LLMs) have notably progressed in multi-step and long-chain reasoning. However, extending their reasoning capabilities to encompass deep interactions with search remains a non-trivial challenge, as models often fail to identify optimal reasoning-search interaction trajectories, resulting in suboptimal responses. We propose R-Search, a novel reinforcement learning framework for Reasoning-Search integration, designed to enable LLMs to autonomously execute multi-step reasoning with deep search interaction, and learn optimal reasoning search interaction trajectories via multi-reward signals, improving response quality in complex logic- and knowledge-intensive tasks. R-Search guides the LLM to dynamically decide when to retrieve or reason, while globally integrating key evidence to enhance deep knowledge interaction between reasoning and search. During RL training, R-Search provides multi-stage, multi-type rewards to jointly optimize the reasoning-search trajectory. Experiments on seven datasets show that R-Search outperforms advanced RAG baselines by up to 32.2% (in-domain) and 25.1% (out-of-domain). The code and data are available at https://github.com/QingFei1/R-Search.
大型语言模型(LLM)在多步骤和长链推理方面取得了显著进展。然而,将其推理能力扩展以涵盖与搜索的深层次交互仍然是一个不小的挑战,因为模型通常无法识别出最佳的推理-搜索交互轨迹,从而导致响应不佳。我们提出了R-Search,这是一个用于推理-搜索集成的新型强化学习框架,旨在使LLM能够自主执行具有深层搜索交互的多步骤推理,并通过多奖励信号学习最佳的推理搜索交互轨迹,从而在复杂的逻辑和知识密集型任务中提高响应质量。R-Search引导LLM动态决定何时进行检索或推理,同时全局集成关键证据,增强推理和搜索之间的深层知识交互。在强化学习训练过程中,R-Search提供多阶段、多类型的奖励来共同优化推理-搜索轨迹。在7个数据集上的实验表明,R-Search较先进的RAG基准测试高出32.2%(领域内)和25.1%(跨领域)。代码和数据集可在https://github.com/QingFei1/R-Search找到。
论文及项目相关链接
PDF 16 pages, 3 figures
Summary
大型语言模型(LLM)在多步和长链推理方面取得显著进展,但在与搜索的深度交互方面仍存在挑战。提出R-Search框架,通过强化学习实现推理与搜索的集成,使LLM能够自主执行多步推理并深度搜索交互,通过多奖励信号学习最优推理搜索交互轨迹,提高在复杂逻辑和知识密集型任务中的响应质量。R-Search框架可指导LLM动态决定何时检索或推理,同时全局整合关键证据,增强推理与搜索之间的深度知识交互。实验结果表明,R-Search在七个数据集上的表现优于先进的RAG基准测试,最高提升率达32.2%(领域内)和25.1%(跨领域)。
Key Takeaways
- LLM在多步和长链推理上有所进步,但在与搜索的深度交互方面仍面临挑战。
- R-Search是一个强化学习框架,旨在实现推理与搜索的集成。
- R-Search使LLM能够自主执行多步推理,并深度搜索交互。
- 通过多奖励信号学习最优推理搜索交互轨迹。
- R-Search提高了在复杂逻辑和知识密集型任务中的响应质量。
- R-Search框架可动态调整检索与推理的时机,并全局整合关键证据。
点此查看论文截图

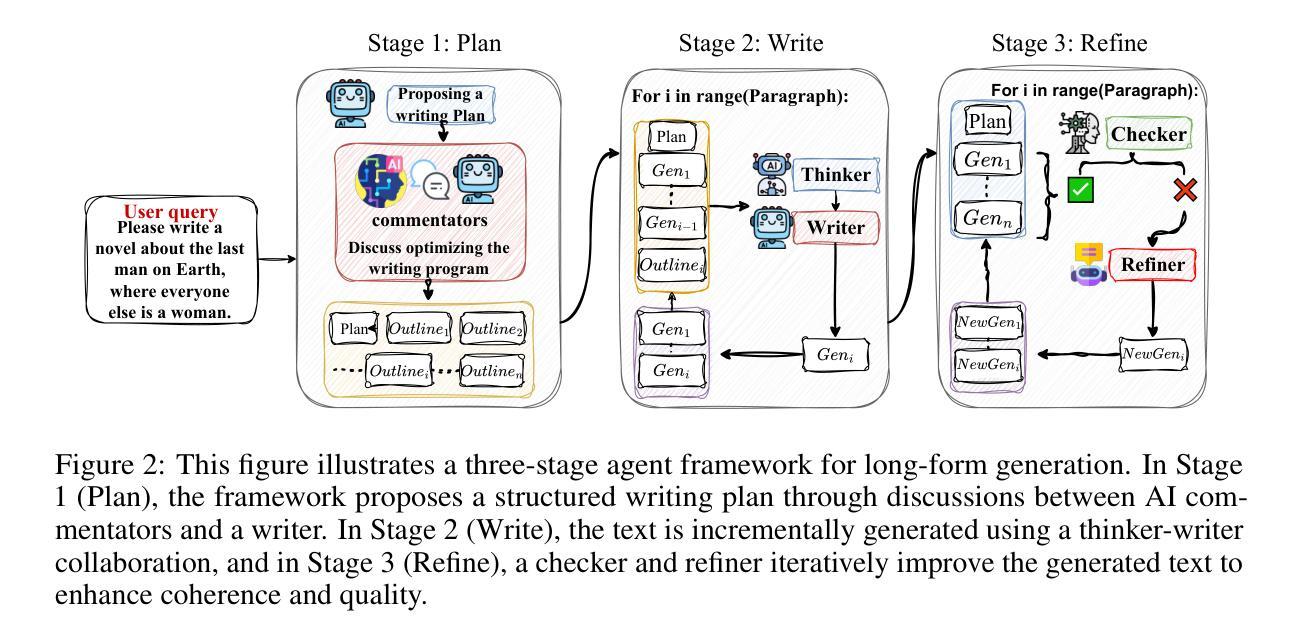
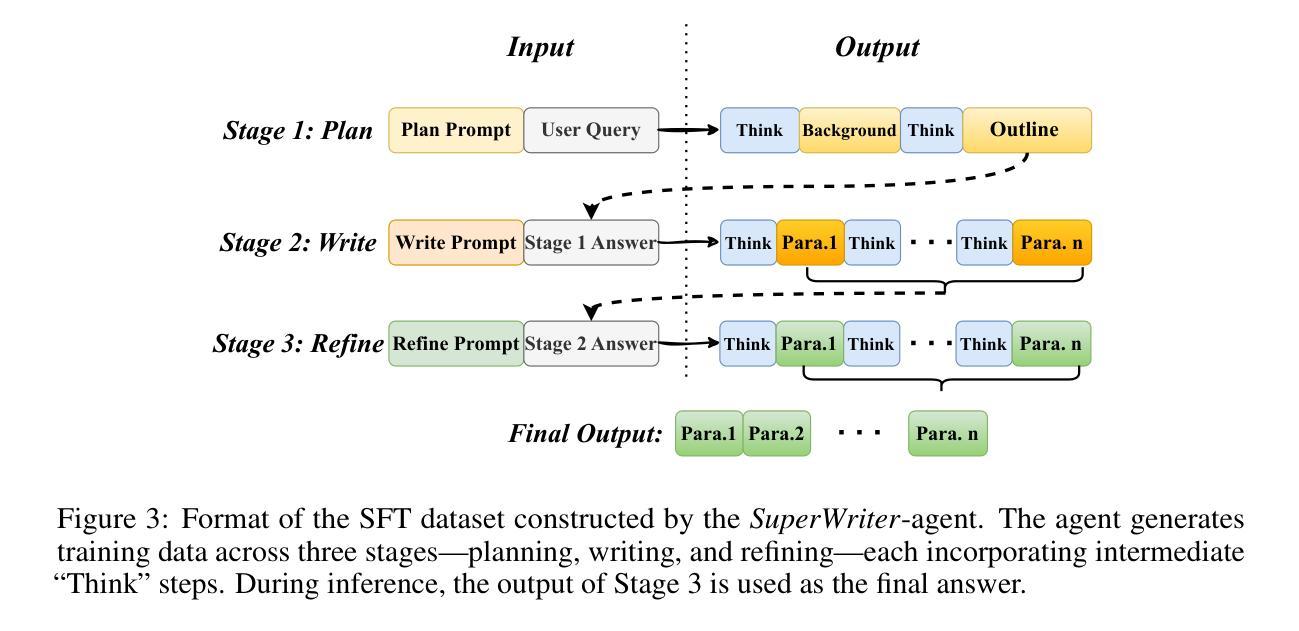
SuperWriter: Reflection-Driven Long-Form Generation with Large Language Models
Authors:Yuhao Wu, Yushi Bai, Zhiqiang Hu, Juanzi Li, Roy Ka-Wei Lee
Long-form text generation remains a significant challenge for large language models (LLMs), particularly in maintaining coherence, ensuring logical consistency, and preserving text quality as sequence length increases. To address these limitations, we propose SuperWriter-Agent, an agent-based framework designed to enhance the quality and consistency of long-form text generation. SuperWriter-Agent introduces explicit structured thinking-through planning and refinement stages into the generation pipeline, guiding the model to follow a more deliberate and cognitively grounded process akin to that of a professional writer. Based on this framework, we construct a supervised fine-tuning dataset to train a 7B SuperWriter-LM. We further develop a hierarchical Direct Preference Optimization (DPO) procedure that uses Monte Carlo Tree Search (MCTS) to propagate final quality assessments and optimize each generation step accordingly. Empirical results across diverse benchmarks demonstrate that SuperWriter-LM achieves state-of-the-art performance, surpassing even larger-scale baseline models in both automatic evaluation and human evaluation. Furthermore, comprehensive ablation studies demonstrate the effectiveness of hierarchical DPO and underscore the value of incorporating structured thinking steps to improve the quality of long-form text generation.
长文本生成对于大型语言模型(LLM)来说仍然是一个重大挑战,特别是在保持连贯性、确保逻辑一致性和随着序列长度增加而保持文本质量方面。为了解决这些局限性,我们提出了SuperWriter-Agent,这是一个基于代理的框架,旨在提高长文本生成的质量和一致性。SuperWriter-Agent将明确的结构化思考引入生成管道,通过规划和细化阶段,引导模型遵循一个更加深思熟虑和认知基础的过程,类似于专业作家的过程。基于此框架,我们构建了一个监督微调数据集,以训练一个7B的SuperWriter-LM。我们进一步开发了一种分层的直接偏好优化(DPO)程序,该程序使用蒙特卡洛树搜索(MCTS)来传播最终质量评估并相应地优化每个生成步骤。在多种基准测试上的实证结果表明,SuperWriter-LM达到了最先进的性能,不仅在自动评估中而且在人类评估中超越了更大规模的基准模型。此外,全面的消融研究证明了分层DPO的有效性,并强调了融入结构化思考步骤以提高长文本生成质量的价值。
论文及项目相关链接
Summary
大型语言模型(LLM)在长文本生成方面存在挑战,如保持连贯性、逻辑一致性和文本质量。为此,提出SuperWriter-Agent框架,通过引入结构化思考阶段,提高长文本生成的质量和一致性。基于该框架,训练了7B的SuperWriter-LM,并采用分层直接偏好优化(DPO)和蒙特卡洛树搜索(MCTS)进行优化。实证结果表明,SuperWriter-LM在多种基准测试中达到领先水平,并在自动评估和人工评估中超越了更大规模的基准模型。
Key Takeaways
- 大型语言模型(LLM)在长文本生成中面临挑战,包括连贯性、逻辑一致性和文本质量。
- SuperWriter-Agent框架通过引入结构化思考阶段,增强长文本生成的质量和一致性。
- 构建了SuperWriter-LM,使用分层直接偏好优化(DPO)和蒙特卡洛树搜索(MCTS)进行训练和优化。
- SuperWriter-LM在多种基准测试中表现优秀,超越大规模基准模型。
- 实证结果证明了SuperWriter-LM的有效性和优越性。
- 分层DPO方法对于提高文本生成质量具有重要意义。
点此查看论文截图

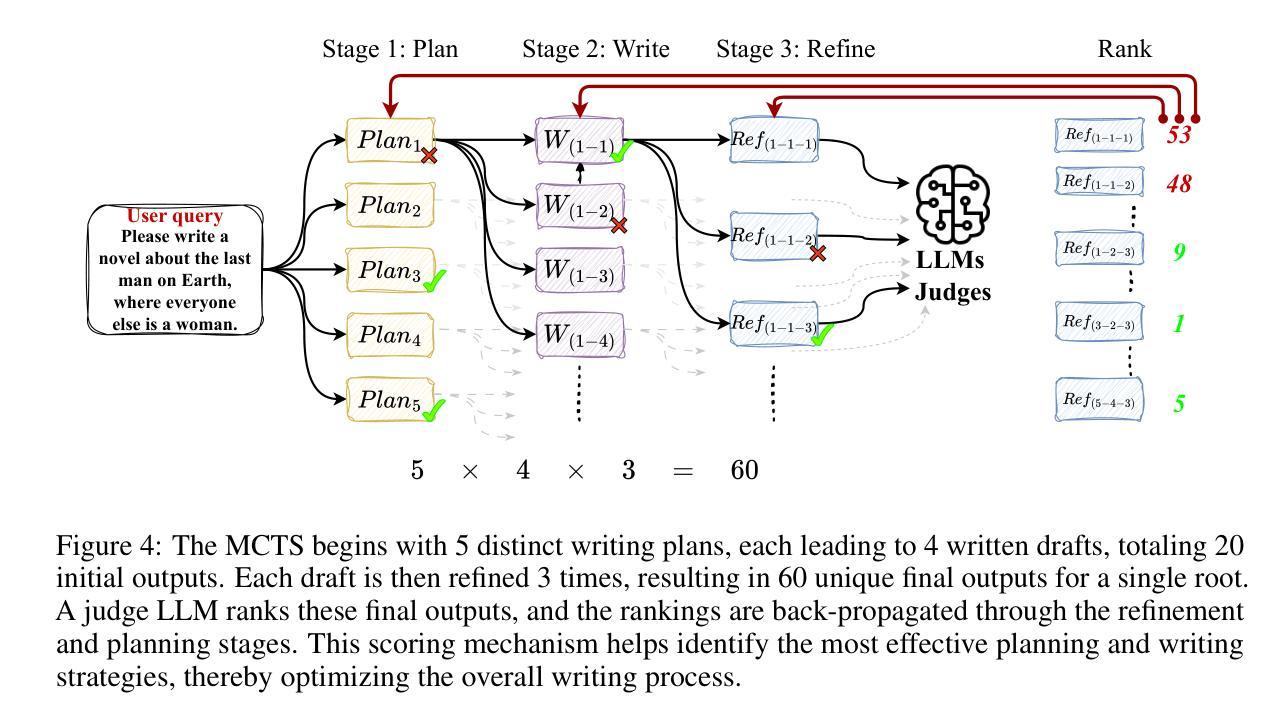
SkipGPT: Dynamic Layer Pruning Reinvented with Token Awareness and Module Decoupling
Authors:Anhao Zhao, Fanghua Ye, Yingqi Fan, Junlong Tong, Zhiwei Fei, Hui Su, Xiaoyu Shen
Large language models (LLMs) achieve remarkable performance across tasks but incur substantial computational costs due to their deep, multi-layered architectures. Layer pruning has emerged as a strategy to alleviate these inefficiencies, but conventional static pruning methods overlook two critical dynamics inherent to LLM inference: (1) horizontal dynamics, where token-level heterogeneity demands context-aware pruning decisions, and (2) vertical dynamics, where the distinct functional roles of MLP and self-attention layers necessitate component-specific pruning policies. We introduce SkipGPT, a dynamic layer pruning framework designed to optimize computational resource allocation through two core innovations: (1) global token-aware routing to prioritize critical tokens, and (2) decoupled pruning policies for MLP and self-attention components. To mitigate training instability, we propose a two-stage optimization paradigm: first, a disentangled training phase that learns routing strategies via soft parameterization to avoid premature pruning decisions, followed by parameter-efficient LoRA fine-tuning to restore performance impacted by layer removal. Extensive experiments demonstrate that SkipGPT reduces over 40% of model parameters while matching or exceeding the performance of the original dense model across benchmarks. By harmonizing dynamic efficiency with preserved expressivity, SkipGPT advances the practical deployment of scalable, resource-aware LLMs. Our code is publicly available at: https://github.com/EIT-NLP/SkipGPT.
大型语言模型(LLM)在各项任务中取得了显著的性能,但由于其深层、多层架构,产生了巨大的计算成本。层剪枝作为一种缓解这些低效性的策略已经出现,但传统的静态剪枝方法忽略了LLM推理中固有的两个关键动态:(1)水平动态,其中令牌级别的异质性要求上下文感知的剪枝决策;(2)垂直动态,其中MLP和自我注意层的不同功能角色需要特定的组件剪枝策略。我们引入了SkipGPT,这是一个动态层剪枝框架,通过两个核心创新来优化计算资源分配:(1)全局令牌感知路由以优先处理关键令牌;(2)为MLP和自我注意组件提供解耦的剪枝策略。为了减轻训练不稳定的问题,我们提出了一个两阶段优化范式:首先是一个解耦的训练阶段,通过软参数化学习路由策略,以避免过早的剪枝决策,然后是参数高效的LoRA微调来恢复因层移除而影响性能。大量实验表明,SkipGPT在减少超过40%的模型参数的同时,在各项基准测试中实现了与原始密集模型相匹配或更高的性能。通过协调动态效率与保留的表现力,SkipGPT推动了可扩展、资源感知的LLM的实际部署。我们的代码公开在:https://github.com/EIT-NLP/SkipGPT。
论文及项目相关链接
Summary
大型语言模型(LLM)在计算资源消耗方面存在显著不足,其深度多层架构导致高计算成本。为优化资源分配,提出SkipGPT动态层剪枝框架,通过全局令牌感知路由和独立剪枝策略,实现资源优化同时保持性能。引入两阶段优化范式,先进行非耦合训练学习路由策略,避免过早剪枝决策,再通过LoRA微调恢复性能。实验证明,SkipGPT在减少超过40%模型参数的同时,保持或提升性能表现。其动态效率与表达能力的平衡推动了资源感知型LLM的实际部署应用。
Key Takeaways
- LLMs面临计算成本高昂的问题,主要由于其深度多层架构。
- SkipGPT框架旨在通过动态层剪枝来优化资源分配。
- SkipGPT采用全局令牌感知路由和独立剪枝策略进行资源优化。
- SkipGPT引入两阶段优化范式,先学习路由策略再进行微调,避免过早的剪枝决策影响性能。
- SkipGPT能够在减少超过40%模型参数的同时保持或提升性能表现。
- SkipGPT框架提高了LLM在实际部署中的实用性和效率。
点此查看论文截图

VISCA: Inferring Component Abstractions for Automated End-to-End Testing
Authors:Parsa Alian, Martin Tang, Ali Mesbah
Providing optimal contextual input presents a significant challenge for automated end-to-end (E2E) test generation using large language models (LLMs), a limitation that current approaches inadequately address. This paper introduces Visual-Semantic Component Abstractor (VISCA), a novel method that transforms webpages into a hierarchical, semantically rich component abstraction. VISCA starts by partitioning webpages into candidate segments utilizing a novel heuristic-based segmentation method. These candidate segments subsequently undergo classification and contextual information extraction via multimodal LLM-driven analysis, facilitating their abstraction into a predefined vocabulary of user interface (UI) components. This component-centric abstraction offers a more effective contextual basis than prior approaches, enabling more accurate feature inference and robust E2E test case generation. Our evaluations demonstrate that the test cases generated by VISCA achieve an average feature coverage of 92%, exceeding the performance of the state-of-the-art LLM-based E2E test generation method by 16%.
提供最佳上下文输入对于使用大型语言模型(LLM)进行自动化端到端(E2E)测试生成来说是一个重大挑战,当前的方法对此类问题处理不足。本文介绍了视觉语义组件抽象(VISCA)这一新方法,它将网页转化为层次丰富、语义丰富的组件抽象。VISCA首先利用基于启发式的新方法将网页划分为候选段。这些候选段随后通过多模式LLM驱动的分析进行分类和上下文信息提取,便于它们被抽象为预定义的用户界面(UI)组件词汇。这种以组件为中心的抽象方法提供了比以前的方法更有效的上下文基础,能够实现更准确的功能推断和稳健的端到端测试案例生成。我们的评估表明,VISCA生成的测试案例的平均功能覆盖率为92%,超过了最新LLM端对端测试生成方法的性能,高出16%。
论文及项目相关链接
Summary
本文介绍了使用视觉语义组件抽象器(VISCA)将网页转化为层次化、语义丰富的组件抽象的方法,解决了当前大语言模型在端到端测试生成中面临的关键挑战。通过基于启发式的分割方法将网页划分为候选段,再通过多模态的语言模型进行分析和分类,从而实现精准的特征推断和鲁棒的端到端测试案例生成。实验表明,VISCA生成的测试案例平均特征覆盖率达到92%,优于现有技术。
Key Takeaways
- VISCA通过将网页转化为组件抽象来解决大语言模型在端到端测试生成中的挑战。
- 该方法使用基于启发式的分割方法将网页划分为候选段。
- VISCA利用多模态的语言模型对候选段进行分类和上下文信息提取。
- 组件中心的抽象方法提供了比先前方法更有效的上下文基础。
- VISCA生成的测试案例实现了高特征覆盖率,平均达到92%。
- VISCA在性能上超越了现有技术,提高了端到端测试生成的准确性。
点此查看论文截图






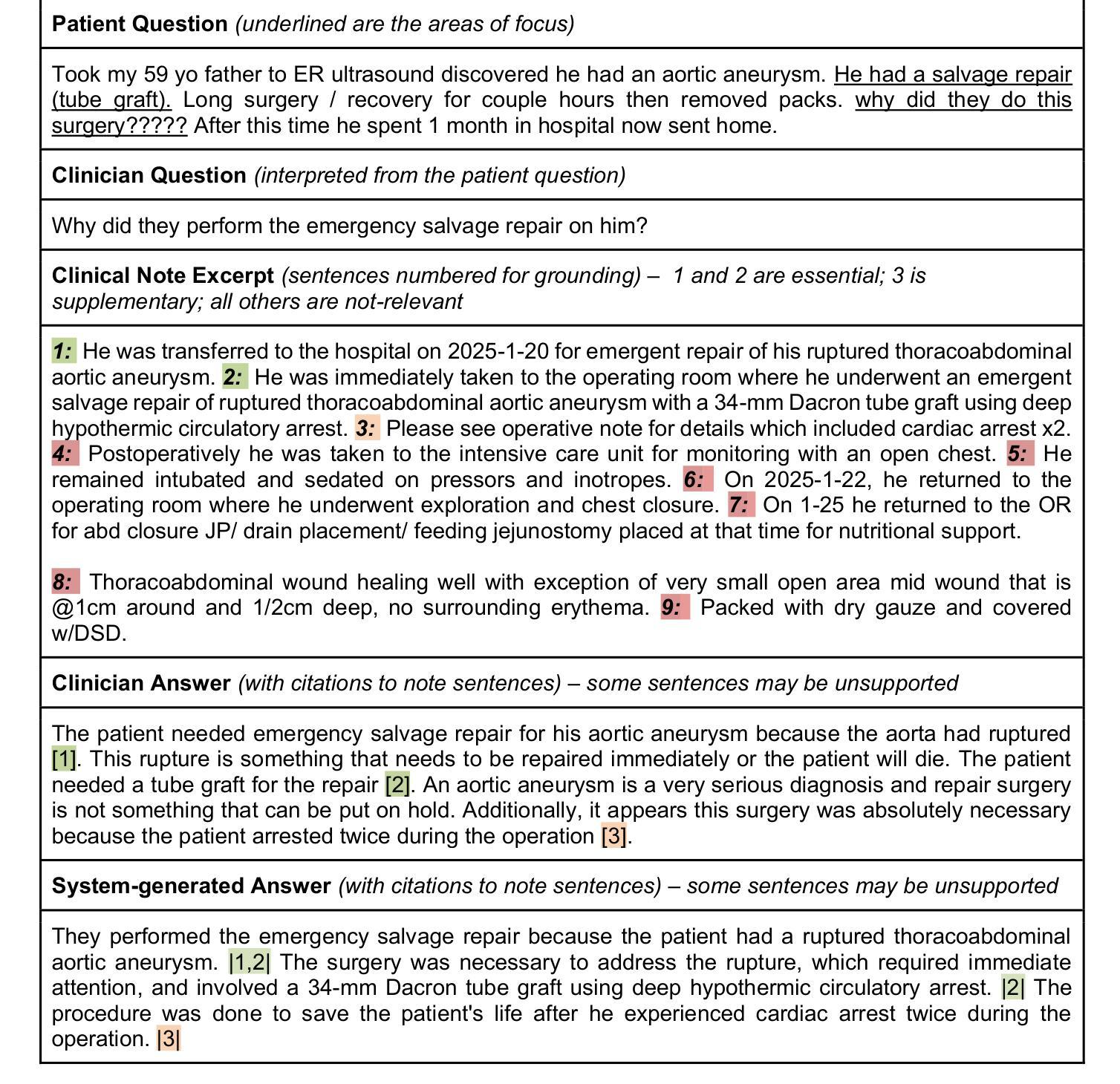
A Dataset for Addressing Patient’s Information Needs related to Clinical Course of Hospitalization
Authors:Sarvesh Soni, Dina Demner-Fushman
Patients have distinct information needs about their hospitalization that can be addressed using clinical evidence from electronic health records (EHRs). While artificial intelligence (AI) systems show promise in meeting these needs, robust datasets are needed to evaluate the factual accuracy and relevance of AI-generated responses. To our knowledge, no existing dataset captures patient information needs in the context of their EHRs. We introduce ArchEHR-QA, an expert-annotated dataset based on real-world patient cases from intensive care unit and emergency department settings. The cases comprise questions posed by patients to public health forums, clinician-interpreted counterparts, relevant clinical note excerpts with sentence-level relevance annotations, and clinician-authored answers. To establish benchmarks for grounded EHR question answering (QA), we evaluated three open-weight large language models (LLMs)–Llama 4, Llama 3, and Mixtral–across three prompting strategies: generating (1) answers with citations to clinical note sentences, (2) answers before citations, and (3) answers from filtered citations. We assessed performance on two dimensions: Factuality (overlap between cited note sentences and ground truth) and Relevance (textual and semantic similarity between system and reference answers). The final dataset contains 134 patient cases. The answer-first prompting approach consistently performed best, with Llama 4 achieving the highest scores. Manual error analysis supported these findings and revealed common issues such as omitted key clinical evidence and contradictory or hallucinated content. Overall, ArchEHR-QA provides a strong benchmark for developing and evaluating patient-centered EHR QA systems, underscoring the need for further progress toward generating factual and relevant responses in clinical contexts.
患者对其住院过程中的信息需求独特,可通过电子健康记录(EHRs)中的临床证据来满足这些需求。虽然人工智能(AI)系统在满足这些需求方面显示出潜力,但需要可靠的数据集来评估AI生成答案的事实准确性和相关性。据我们所知,目前没有数据集能够捕捉患者在电子健康记录背景下的信息需求。我们介绍了ArchEHR-QA数据集,它基于现实世界的患者案例,这些案例来自重症监护室和急诊科。这些案例包括患者向公共健康论坛提出的问题、医生解读的相应问题、相关的临床笔记摘录以及句子级别的相关性注释,以及医生撰写的答案。为了为基于EHR的问答(QA)建立基准,我们评估了三个开源的大型语言模型(LLMs)——Llama 4、Llama 3和Mixtral——跨越三种提示策略:生成(1)带有临床笔记句子的答案引用、(2)答案先于引用出现,以及(3)从过滤后的引用中生成答案。我们从两个维度进行评估:事实性(引用的笔记句子与真实答案的重叠程度)和相关性(系统与参考答案之间的文本和语义相似性)。最终数据集包含134个患者案例。答案优先的提示方法表现最为稳定,Llama 4取得最高分数。手动误差分析支持了这些发现,并揭示了常见的问题,如遗漏的关键临床证据和矛盾或虚构的内容。总体而言,ArchEHR-QA为开发和评估以患者为中心的EHR QA系统提供了强有力的基准,强调了需要在临床环境中生成事实和相关的答案方面取得进一步进展。
论文及项目相关链接
Summary
基于电子健康记录(EHRs)的临床证据,患者对其住院过程有不同的信息需求。虽然人工智能(AI)系统在满足这些需求方面展现出潜力,但需要可靠的数据集来评估AI生成回答的准确性和相关性。目前尚无数据集能够捕捉患者信息需求与EHRs的关联。本研究推出ArchEHR-QA数据集,基于真实患者病例,涵盖重症监护室和急诊室的场景。包括患者向公共健康论坛提出的问题、医生解读的问题、相关临床笔记摘录以及医生撰写的答案。为了建立基于EHR的问答基准,我们评估了三种大型语言模型(LLMs),发现答案优先的提示策略效果最佳,其中Llama 4表现最优。ArchEHR-QA为开发评估以患者为中心的EHR问答系统提供了强有力的基准,突显了需要在临床环境中生成真实和相关的回应的进步需求。
Key Takeaways
- 患者对其住院过程有独特的信息需求,可通过电子健康记录中的临床证据来满足这些需求。
- ArchEHR-QA是一个基于真实患者病例的专家注释数据集,涵盖了重症监护室和急诊室的场景。
- ArchEHR-QA包含患者问题、医生解读的问题、临床笔记的摘录和医生答案。
- 三种大型语言模型在ArchEHR-QA数据集上进行评估,发现答案优先的提示策略表现最佳。
- Llama 4在评估中表现最优。
- 手动误差分析支持了评估结果,并揭示了常见的问题,如遗漏关键临床证据和存在矛盾或虚构的内容。
点此查看论文截图

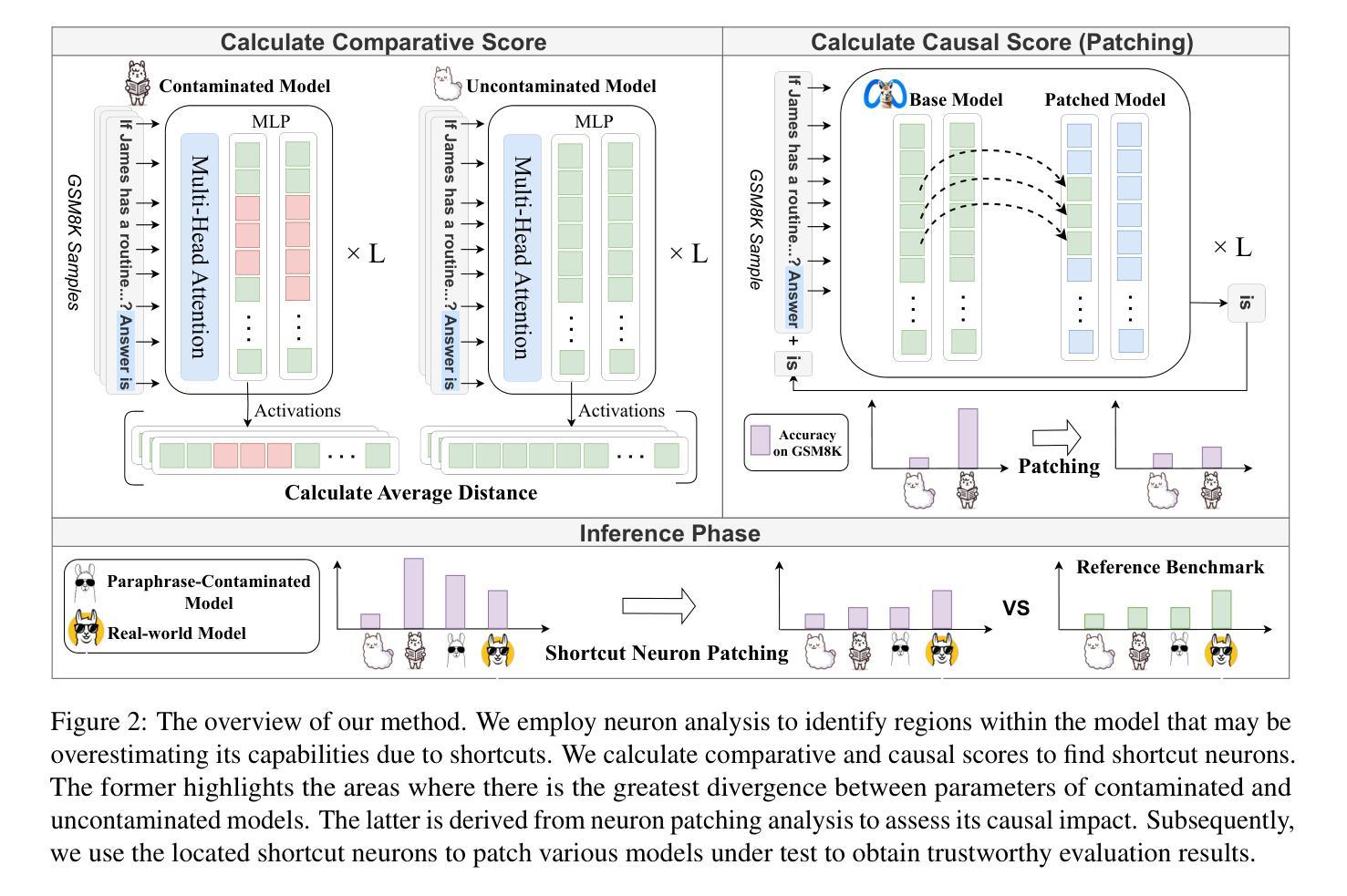
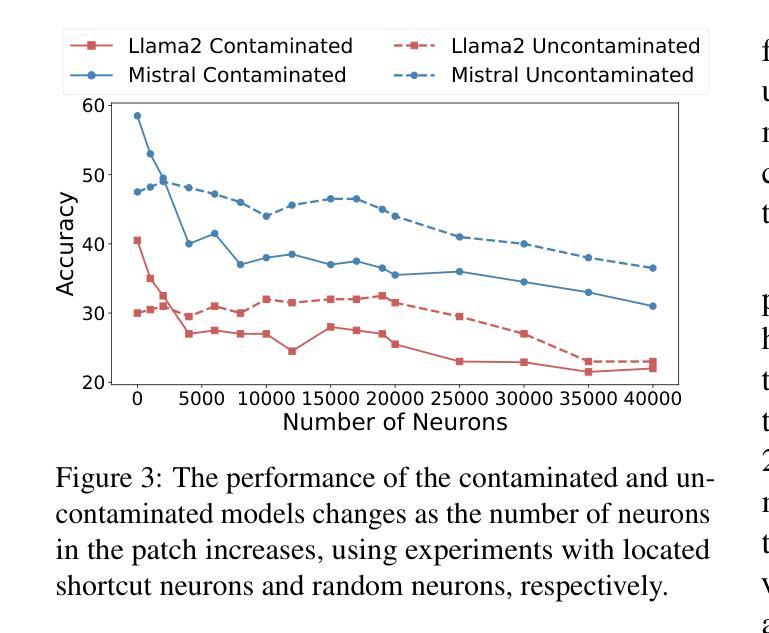
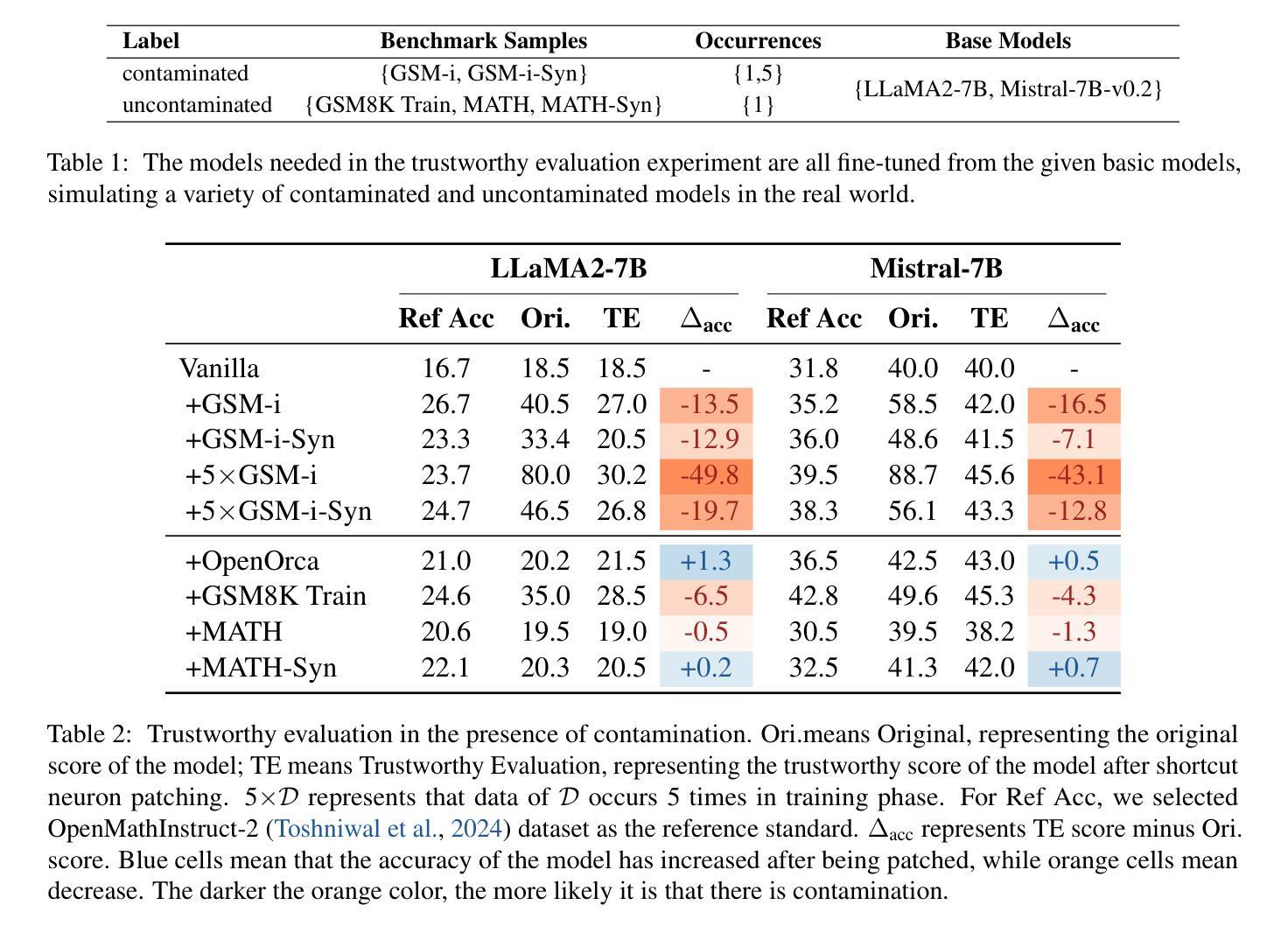
Establishing Trustworthy LLM Evaluation via Shortcut Neuron Analysis
Authors:Kejian Zhu, Shangqing Tu, Zhuoran Jin, Lei Hou, Juanzi Li, Jun Zhao
The development of large language models (LLMs) depends on trustworthy evaluation. However, most current evaluations rely on public benchmarks, which are prone to data contamination issues that significantly compromise fairness. Previous researches have focused on constructing dynamic benchmarks to address contamination. However, continuously building new benchmarks is costly and cyclical. In this work, we aim to tackle contamination by analyzing the mechanisms of contaminated models themselves. Through our experiments, we discover that the overestimation of contaminated models is likely due to parameters acquiring shortcut solutions in training. We further propose a novel method for identifying shortcut neurons through comparative and causal analysis. Building on this, we introduce an evaluation method called shortcut neuron patching to suppress shortcut neurons. Experiments validate the effectiveness of our approach in mitigating contamination. Additionally, our evaluation results exhibit a strong linear correlation with MixEval, a recently released trustworthy benchmark, achieving a Spearman coefficient ($\rho$) exceeding 0.95. This high correlation indicates that our method closely reveals true capabilities of the models and is trustworthy. We conduct further experiments to demonstrate the generalizability of our method across various benchmarks and hyperparameter settings. Code: https://github.com/GaryStack/Trustworthy-Evaluation
大型语言模型(LLM)的发展依赖于可信的评估。然而,当前大多数评估都依赖于公共基准测试,这些基准测试容易受到数据污染问题的影响,从而严重损害评估的公正性。之前的研究致力于构建动态基准测试来解决污染问题。然而,不断构建新的基准测试成本高昂且循环往复。在这项工作中,我们的目标是通过分析受污染模型本身的机制来解决污染问题。通过我们的实验,我们发现受污染模型的过度估计可能是由于模型参数在训练过程中获得了捷径解决方案。我们进一步提出了一种通过比较和因果分析来识别捷径神经元的新方法。在此基础上,我们引入了一种名为“捷径神经元修补”的评估方法,以抑制捷径神经元。实验验证了我们方法在减轻污染方面的有效性。此外,我们的评估结果与最近发布的可信基准测试MixEval表现出强烈的线性相关性,斯皮尔曼系数(ρ)超过0.95。这种高相关性表明,我们的方法能够紧密揭示模型的真实能力,是值得信赖的。我们进行了进一步的实验,以证明我们的方法在各种基准测试和超参数设置中的通用性。代码地址:https://github.com/GaryStack/Trustworthy-Evaluation
简化版
论文及项目相关链接
PDF Accepted to ACL 2025 Main Conference
Summary
大型语言模型(LLM)的发展依赖于可靠的评估。当前大多数评估依赖于公共基准测试,但存在数据污染问题,影响公平性。本文旨在通过分析受污染的模型机制来解决污染问题。实验发现,模型污染的可能原因是参数在训练中获得了捷径解决方案。本文提出了一种通过比较和因果分析来识别捷径神经元的新方法,并引入了一种名为“捷径神经元修补”的评估方法来抑制捷径神经元。实验验证了我们方法的有效性,并与最新发布的可靠基准测试MixEval呈强线性相关,斯皮尔曼系数(ρ)超过0.95。
Key Takeaways
- 大型语言模型(LLM)的评估需要可靠的方法。
- 公共基准测试存在数据污染问题,影响模型评估的公平性。
- 受污染的模型可能因参数在训练中获取捷径解决方案而导致。
- 提出了一种通过比较和因果分析识别捷径神经元的新方法。
- 引入了一种名为“捷径神经元修补”的评估方法来抑制捷径神经元。
- 实验验证该方法有效,与MixEval基准测试呈强线性相关。
点此查看论文截图

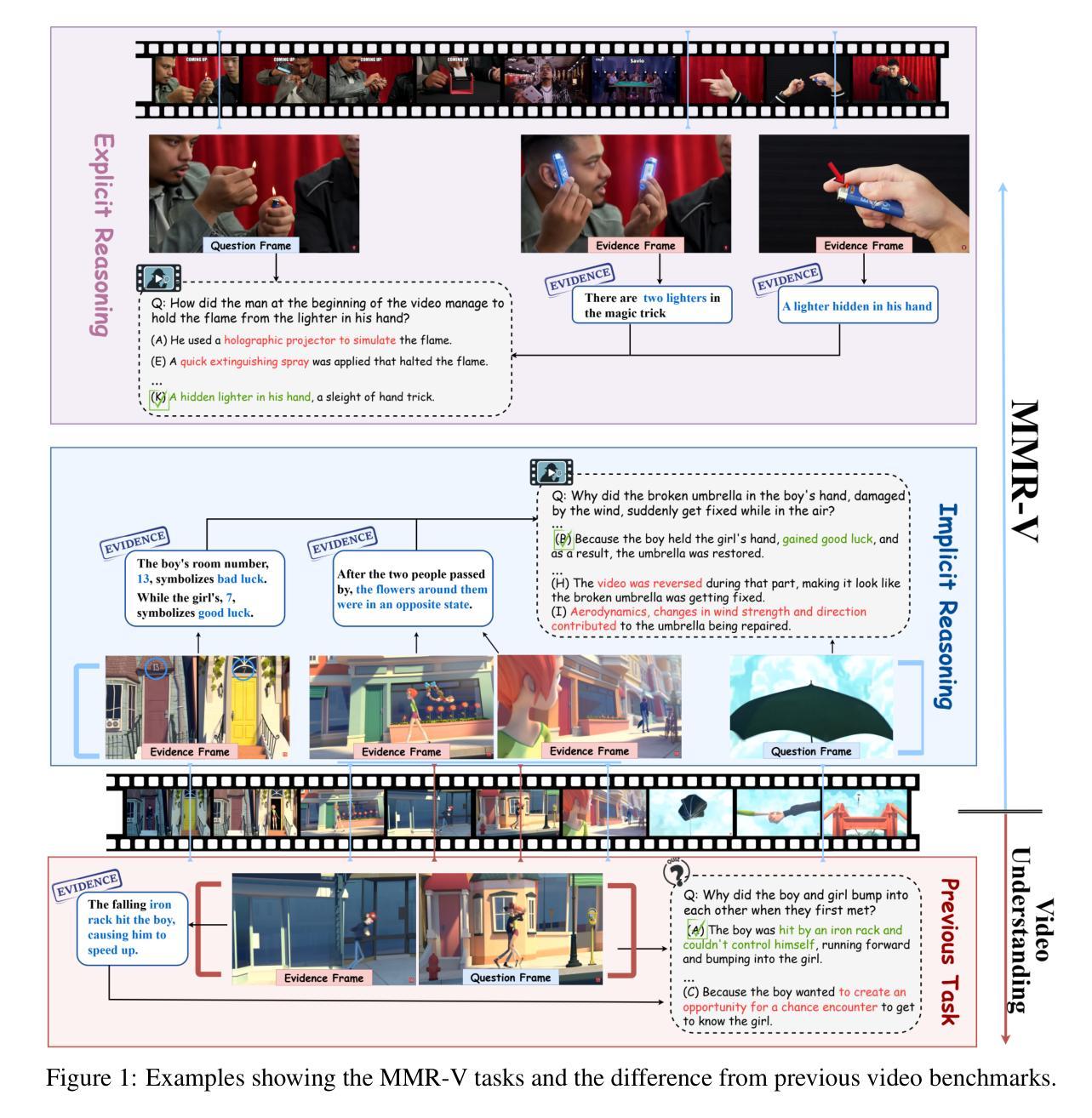
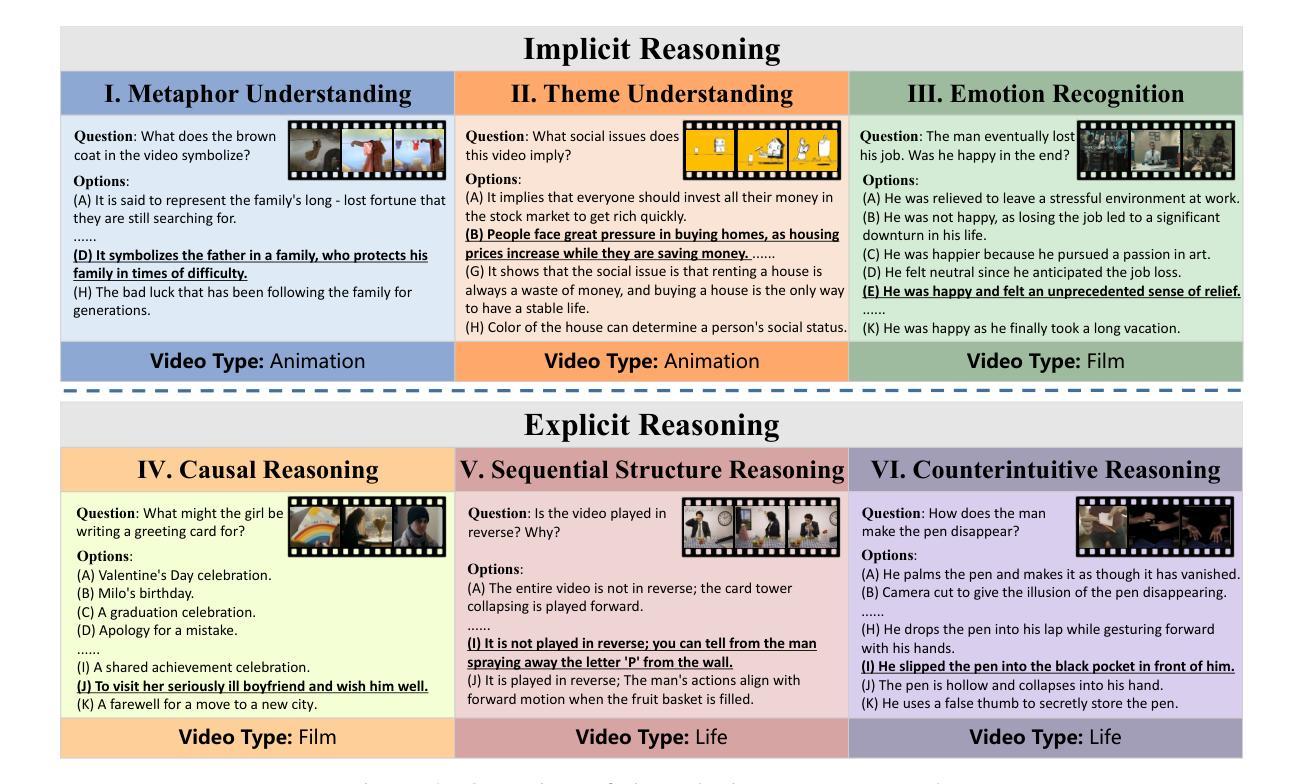
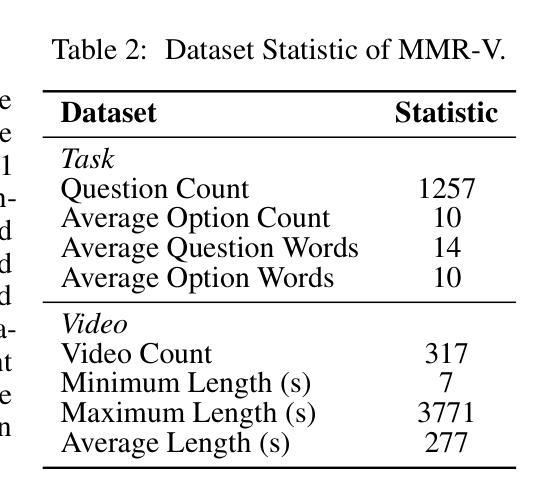
MMR-V: What’s Left Unsaid? A Benchmark for Multimodal Deep Reasoning in Videos
Authors:Kejian Zhu, Zhuoran Jin, Hongbang Yuan, Jiachun Li, Shangqing Tu, Pengfei Cao, Yubo Chen, Kang Liu, Jun Zhao
The sequential structure of videos poses a challenge to the ability of multimodal large language models (MLLMs) to locate multi-frame evidence and conduct multimodal reasoning. However, existing video benchmarks mainly focus on understanding tasks, which only require models to match frames mentioned in the question (hereafter referred to as “question frame”) and perceive a few adjacent frames. To address this gap, we propose MMR-V: A Benchmark for Multimodal Deep Reasoning in Videos. The benchmark is characterized by the following features. (1) Long-range, multi-frame reasoning: Models are required to infer and analyze evidence frames that may be far from the question frame. (2) Beyond perception: Questions cannot be answered through direct perception alone but require reasoning over hidden information. (3) Reliability: All tasks are manually annotated, referencing extensive real-world user understanding to align with common perceptions. (4) Confusability: Carefully designed distractor annotation strategies to reduce model shortcuts. MMR-V consists of 317 videos and 1,257 tasks. Our experiments reveal that current models still struggle with multi-modal reasoning; even the best-performing model, o4-mini, achieves only 52.5% accuracy. Additionally, current reasoning enhancement strategies (Chain-of-Thought and scaling test-time compute) bring limited gains. Further analysis indicates that the CoT demanded for multi-modal reasoning differs from it in textual reasoning, which partly explains the limited performance gains. We hope that MMR-V can inspire further research into enhancing multi-modal reasoning capabilities.
视频的连续结构对多模态大型语言模型(MLLM)在定位多帧证据和进行多模态推理方面的能力提出了挑战。然而,现有的视频基准测试主要侧重于理解任务,这些任务只需要模型匹配问题中提到的帧(以下简称“问题帧”)并感知少数相邻帧。为了弥补这一空白,我们提出了MMR-V:视频多模态深度推理的基准测试。该基准测试具有以下特点:(1)长程多帧推理:模型需要推断和分析可能远离问题帧的证据帧。(2)超越感知:问题不能仅通过直接感知来回答,而是需要推理隐藏的信息。(3)可靠性:所有任务都是手动注释的,参考现实世界中用户的广泛理解,以符合普遍认知。(4)混淆性:精心设计的干扰注释策略,以减少模型的捷径。MMR-V包含317个视频和1,257个任务。我们的实验表明,当前模型在多模态推理方面仍然面临困难;即使表现最佳的o4-mini模型也仅达到52.5%的准确率。此外,当前的推理增强策略(如思维链和测试时间计算)带来的收益有限。进一步分析表明,多模态推理所需的思维链与文本推理不同,这部分解释了性能提升有限的原因。我们希望MMR-V能够激发对增强多模态推理能力的进一步研究。
论文及项目相关链接
PDF Project Page: https://mmr-v.github.io
摘要
视频序列结构对多模态大型语言模型(MLLMs)在定位多帧证据和进行多模态推理方面的能力构成挑战。然而,现有的视频基准测试主要关注理解任务,仅要求模型匹配问题中提到的帧(以下简称“问题帧”)并感知少数相邻帧。为解决这一差距,我们提出MMR-V:视频多模态深度推理的基准测试。该基准测试的特点包括:(1)长程多帧推理:模型需推断和分析可能与问题帧相距较远的证据帧。(2)超越感知:问题不能仅通过直接感知来回答,而需要推理隐藏信息。(3)可靠性:所有任务均经人工标注,参照广泛的实际用户理解,以符合通用感知。(4)混淆性:精心设计的干扰者标注策略,以减少模型捷径。MMR-V包含317个视频和1,257个任务。我们的实验表明,当前模型在多模态推理方面仍存在困难;即使表现最佳的o4-mini模型,准确率也仅为52.5%。此外,当前的推理增强策略(如思维链和测试时间计算)带来的收益有限。进一步分析表明,多模态推理所需的思维链与文本推理不同,这部分解释了性能提升有限的原因。我们希望MMR-V能激发对增强多模态推理能力的进一步研究。
关键见解
- 视频的序列结构对多模态语言模型的推理能力构成挑战,特别是在定位多帧证据方面。
- 现有视频基准测试主要关注理解任务,忽略了长程多帧推理和隐藏信息的推理。
- MMR-V基准测试弥补了这一差距,要求模型进行长程多帧推理和复杂的思维链。
- 当前模型在MMR-V上的表现不佳,即使最好的模型准确率也仅为52.5%。
- 当前的推理增强策略对多模态推理的性能提升有限。
- 多模态推理与文本推理所需的思维链有所不同。
- MMR-V基准测试有望激发对增强多模态推理能力的进一步研究。
点此查看论文截图


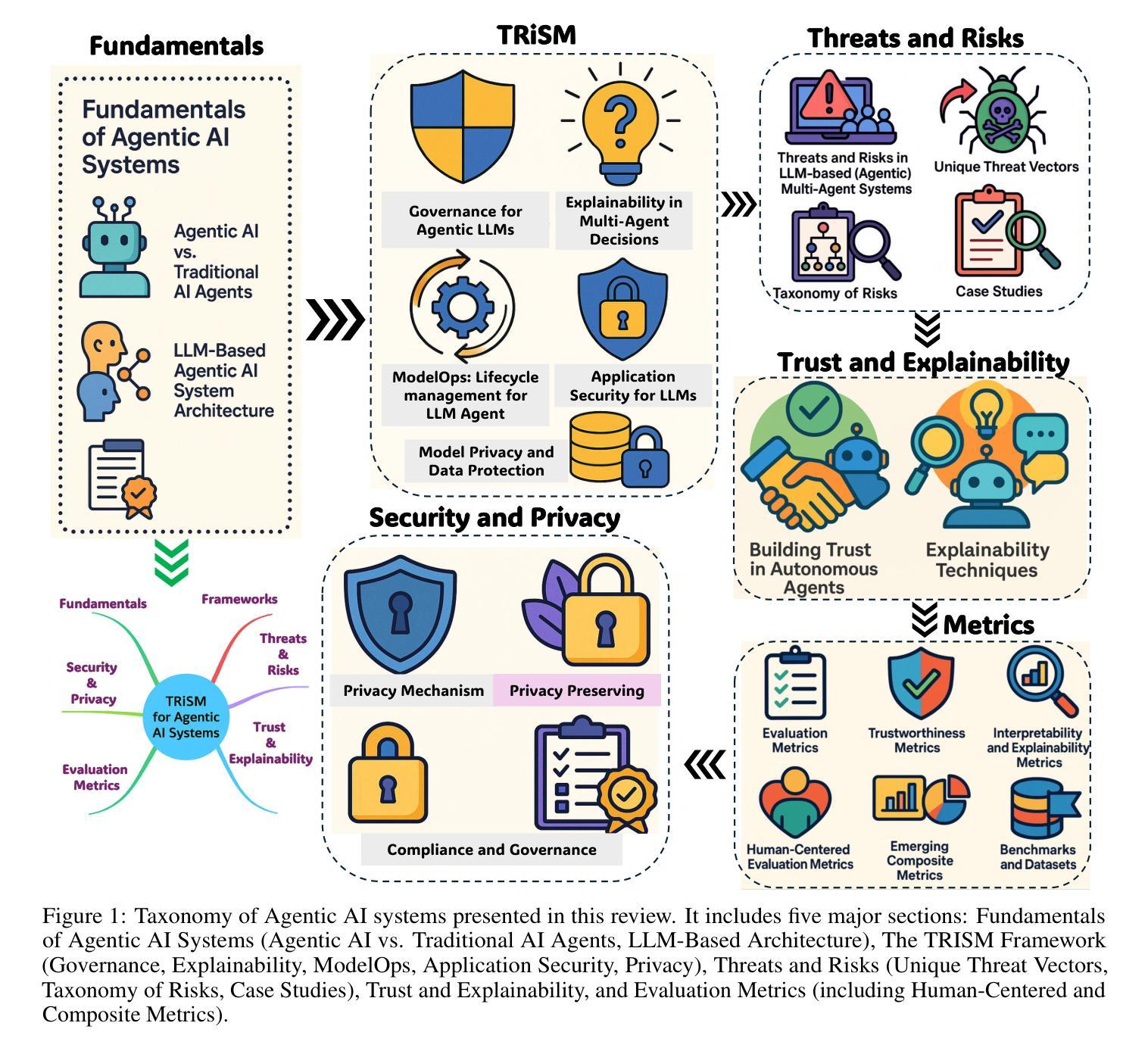
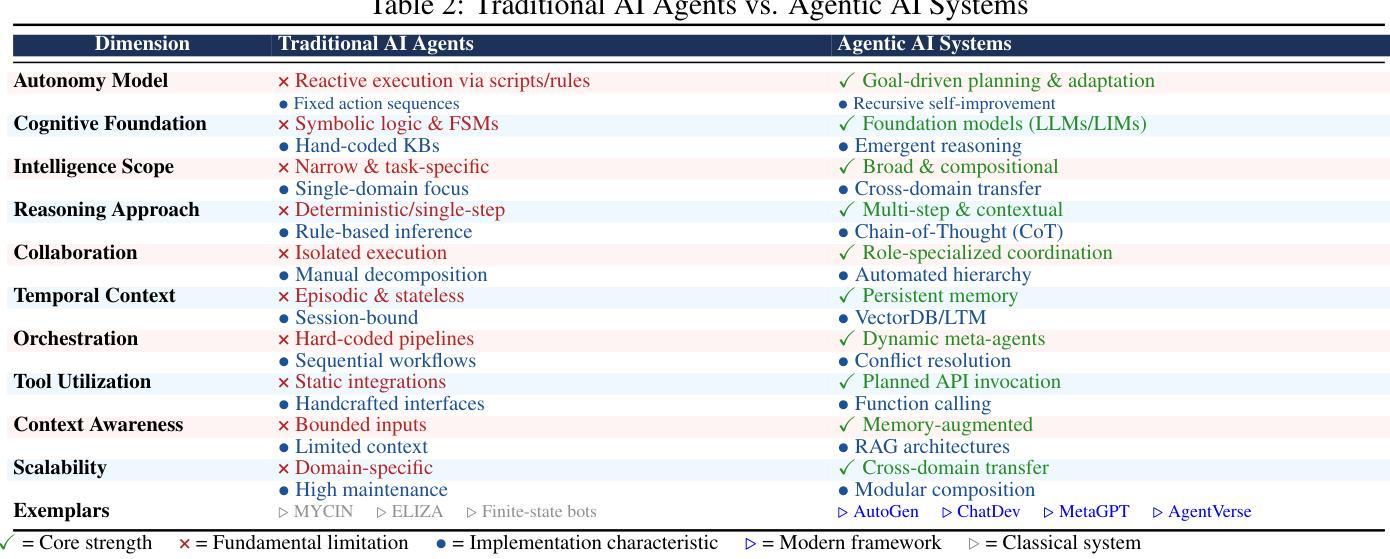
TRiSM for Agentic AI: A Review of Trust, Risk, and Security Management in LLM-based Agentic Multi-Agent Systems
Authors:Shaina Raza, Ranjan Sapkota, Manoj Karkee, Christos Emmanouilidis
Agentic AI systems, built on large language models (LLMs) and deployed in multi-agent configurations, are redefining intelligent autonomy, collaboration and decision-making across enterprise and societal domains. This review presents a structured analysis of Trust, Risk, and Security Management (TRiSM) in the context of LLM-based agentic multi-agent systems (AMAS). We begin by examining the conceptual foundations of agentic AI, its architectural differences from traditional AI agents, and the emerging system designs that enable scalable, tool-using autonomy. The TRiSM in the agentic AI framework is then detailed through four pillars governance, explainability, ModelOps, and privacy/security each contextualized for agentic LLMs. We identify unique threat vectors and introduce a comprehensive risk taxonomy for the agentic AI applications, supported by case studies illustrating real-world vulnerabilities. Furthermore, the paper also surveys trust-building mechanisms, transparency and oversight techniques, and state-of-the-art explainability strategies in distributed LLM agent systems. Additionally, metrics for evaluating trust, interpretability, and human-centered performance are reviewed alongside open benchmarking challenges. Security and privacy are addressed through encryption, adversarial defense, and compliance with evolving AI regulations. The paper concludes with a roadmap for responsible agentic AI, proposing research directions to align emerging multi-agent systems with robust TRiSM principles for safe, accountable, and transparent deployment.
基于大型语言模型(LLM)构建的Agentic AI系统,在多智能体配置中部署,正在重新定义企业和社会领域中的智能自主性、协作和决策。本文介绍了在LLM基于的智能体多智能体系统(AMAS)背景下对信任、风险和安全管理(TRiSM)的结构性分析。我们首先研究Agentic AI的概念基础,与传统AI代理的架构差异,以及能够实现可扩展的工具使用自主性的新兴系统设计。然后在Agentic AI框架中详细说明了TRiSM的四个支柱:治理、可解释性、ModelOps以及隐私/安全,每个支柱都针对Agentic LLM进行了上下文化。我们确定了独特的威胁向量,并介绍了由案例研究支持的agentic AI应用程序的综合风险分类。此外,本文还调查了信任建立机制、透明度和监督技术,以及分布式LLM代理系统中的最新可解释性策略。此外,还介绍了评估信任、解释能力和以人为中心性能的指标,以及公开基准测试挑战。通过加密、对抗性防御以及遵守不断发展的AI法规来解决安全和隐私问题。本文最后提出了负责任的Agentic AI路线图,提出了新兴的多智能体系统与稳健的TRiSM原则对齐的研究方向,以实现安全、负责和透明的部署。
论文及项目相关链接
摘要
基于大型语言模型(LLM)构建的Agentic AI系统,在多智能体配置中的部署正在重新定义企业和社会领域的智能自主性、协作和决策。本文介绍了在LLM基础上构建的智能多智能体系统(AMAS)中的信任、风险和安全管理的结构化分析。文章首先探讨了Agentic AI的概念基础,与传统AI智能体的架构差异,以及新兴的系统设计如何赋能可伸缩的工具使用自主性。接着详细阐述了Agentic AI框架中的TRiSM,包括治理、可解释性、ModelOps以及隐私/安全等四个支柱,并针对agentic LLM进行上下文分析。文章识别了独特的威胁向量,为agentic AI应用程序引入了一个全面的风险分类,并通过案例研究说明了现实世界的漏洞。此外,本文还调查了构建信任机制、透明度和监督技术,以及分布式LLM智能体系统中的最新可解释性策略。同时,评估信任、解释性和以人为中心性能的指标与公开基准测试挑战也被审查。安全和隐私通过加密、对抗性防御和遵守不断发展的AI法规来解决。本文最后提出了负责任的Agentic AI路线图,为新兴的多智能体系统与稳健的TRiSM原则对齐,以实现安全、负责和透明的部署提供了研究方向。
关键见解
- Agentic AI系统正改变企业和社会领域的智能自主性、协作和决策方式。
- TRiSM在LLM基础的多智能体系统(AMAS)中具有重要作用。
- Agentic AI具有独特的威胁向量和风险分类,需要重视现实世界的漏洞和安全问题。
- 文章探讨了构建信任机制、透明度和监督技术的方法。
- 评估和衡量信任、解释性和以人为中心性能的指标受到关注。
- 文章强调了加密、对抗性防御以及遵守AI法规在解决隐私和安全问题中的重要性。
点此查看论文截图

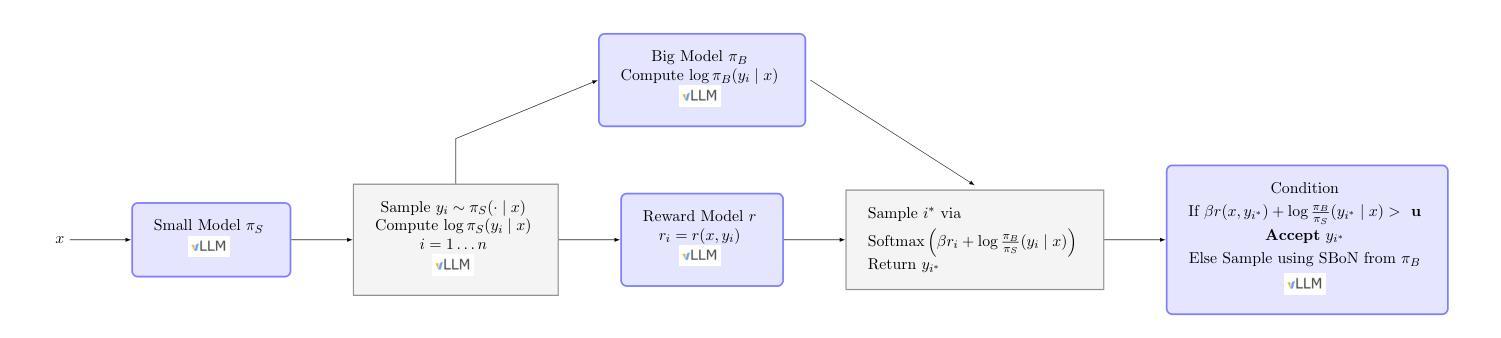
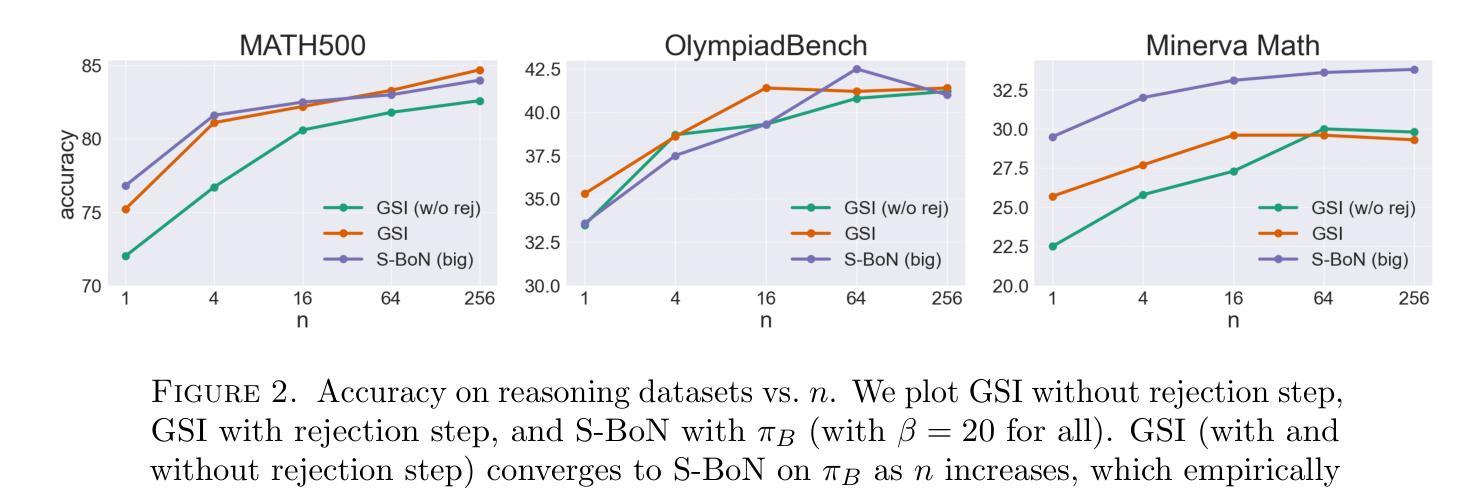
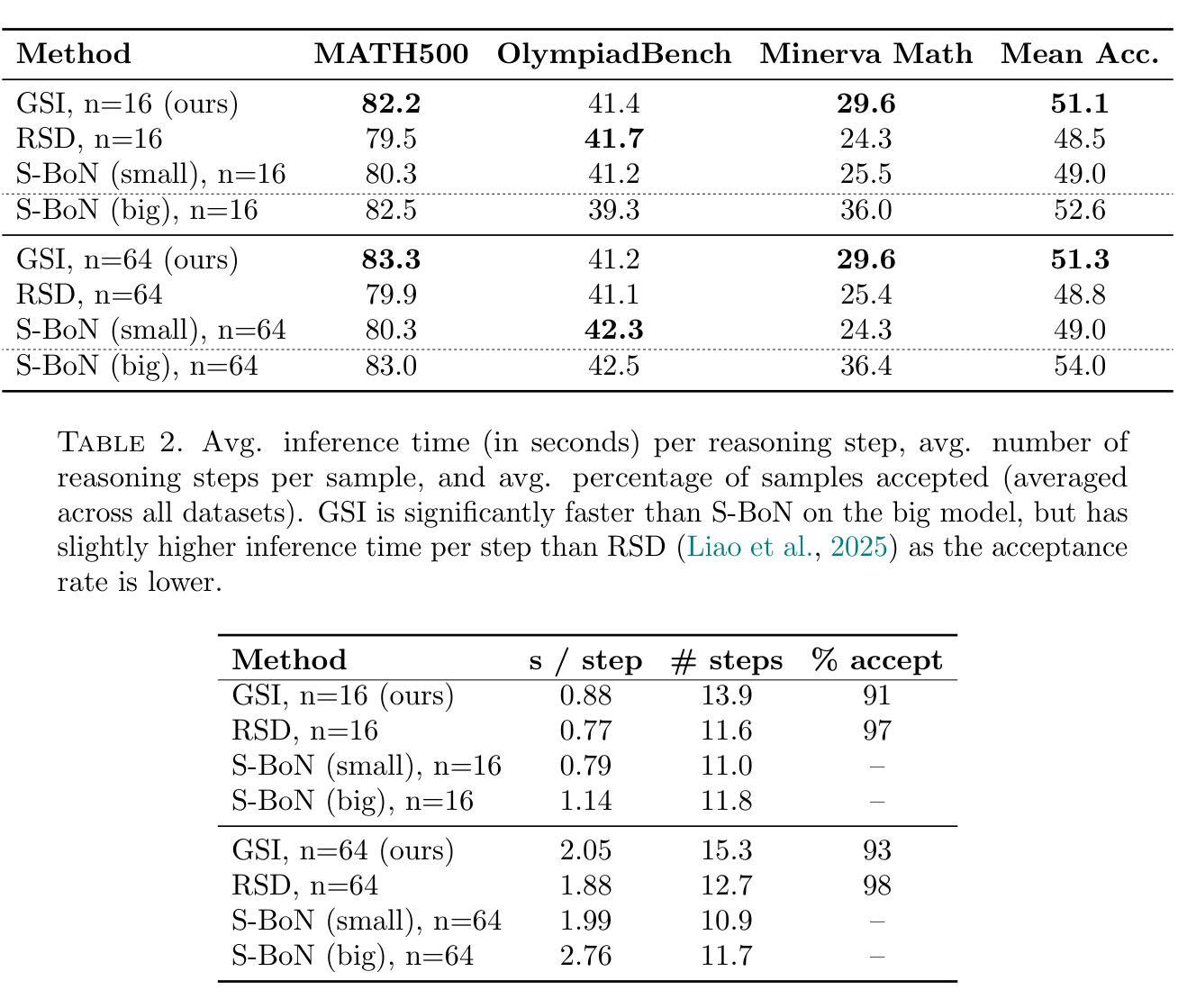
Guided Speculative Inference for Efficient Test-Time Alignment of LLMs
Authors:Jonathan Geuter, Youssef Mroueh, David Alvarez-Melis
We propose Guided Speculative Inference (GSI), a novel algorithm for efficient reward-guided decoding in large language models. GSI combines soft best-of-$n$ test-time scaling with a reward model $r(x,y)$ and speculative samples from a small auxiliary model $\pi_S(y\mid x)$. We provably approximate the optimal tilted policy $\pi_{\beta,B}(y\mid x) \propto \pi_B(y\mid x)\exp(\beta,r(x,y))$ of soft best-of-$n$ under the primary model $\pi_B$. We derive a theoretical bound on the KL divergence between our induced distribution and the optimal policy. In experiments on reasoning benchmarks (MATH500, OlympiadBench, Minerva Math), our method achieves higher accuracy than standard soft best-of-$n$ with $\pi_S$ and reward-guided speculative decoding (Liao et al., 2025), and in certain settings even outperforms soft best-of-$n$ with $\pi_B$. The code is available at https://github.com/j-geuter/GSI .
我们提出了引导式推测推理(GSI),这是一种针对大型语言模型中高效奖励引导解码的新型算法。GSI结合了软性最佳n测试时间缩放、奖励模型r(x,y)以及来自小型辅助模型πs(y|x)的推测样本。我们在主要模型πB下,通过软性最佳n的倾斜策略πβ,B(y|x)≈πB(y|x)exp(βr(x,y))进行了证明。我们推导出了诱导分布与最优策略之间KL散度的理论界限。在推理基准测试(MATH500、OlympiadBench、Minerva Math)的实验中,我们的方法达到了比标准软性最佳n与πs和奖励引导推测解码(Liao等人,2025)更高的准确率,并且在某些情况下甚至超越了软性最佳n与πB的表现。代码可在https://github.com/j-geuter/GSI找到。
论文及项目相关链接
PDF 12 pages, 2 figures
Summary
文本提出了一种名为引导式推测推断(GSI)的新算法,该算法针对大型语言模型的奖励导向解码进行高效化处理。通过软性最优解试验时间和奖励模型的引导结合使用辅助模型来模拟对模型的假设样本。该算法能够逼近最优倾斜策略,并在数学推理基准测试中表现出更高的准确性。代码已公开在GitHub上。
Key Takeaways
- 提出了引导式推测推断(GSI)算法,旨在优化大型语言模型的奖励导向解码效率。
*GSI结合了软性最优解试验时间缩放、奖励模型r(x,y)和来自小型辅助模型的推测样本πS(y∣x)。
*GSI能够逼近最优倾斜策略πβ,B(y∣x),该策略是软性最优解在主导模型πB下的产物。
*提供了与最优策略之间的KL散度的理论界限。
*在基准测试MATH500、OlympiadBench和Minerva Math上的实验显示,与标准软性最优解及奖励引导推测解码相比,GSI方法的准确率更高。
*在某些设置中,GSI甚至超越了使用πB的软性最优解的表现。
点此查看论文截图

Rectified Sparse Attention
Authors:Yutao Sun, Tianzhu Ye, Li Dong, Yuqing Xia, Jian Chen, Yizhao Gao, Shijie Cao, Jianyong Wang, Furu Wei
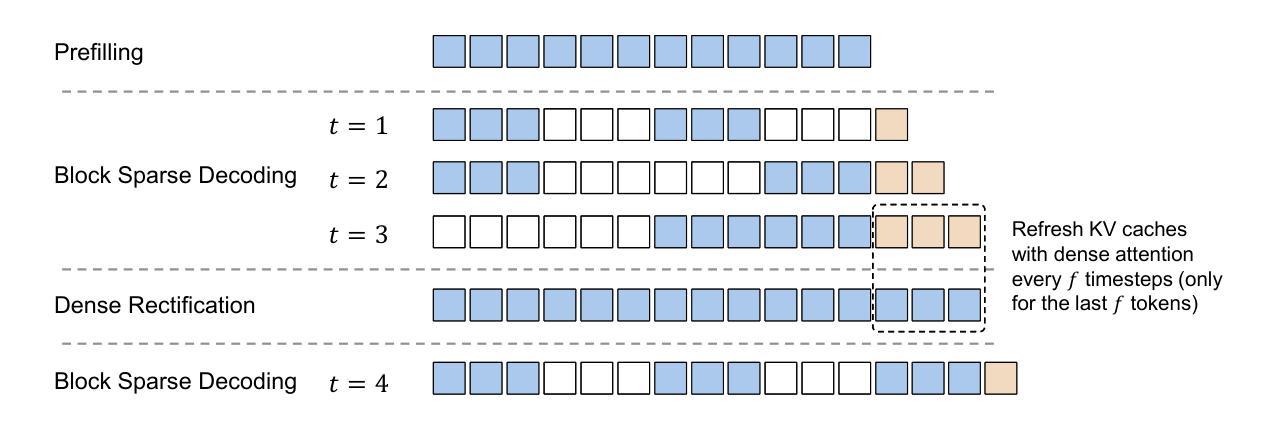
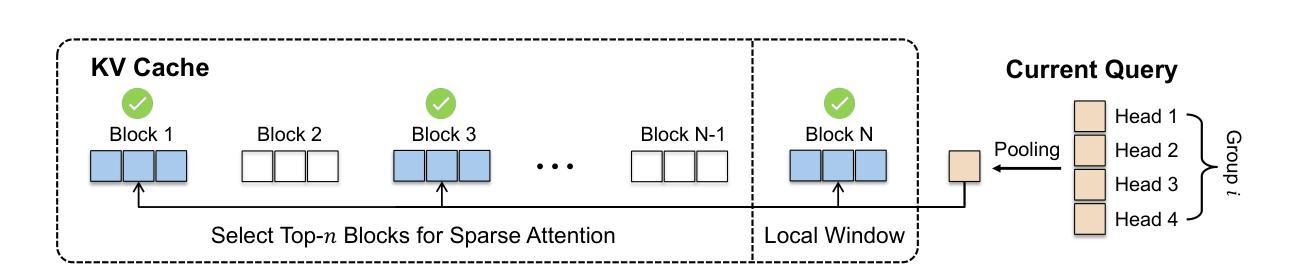
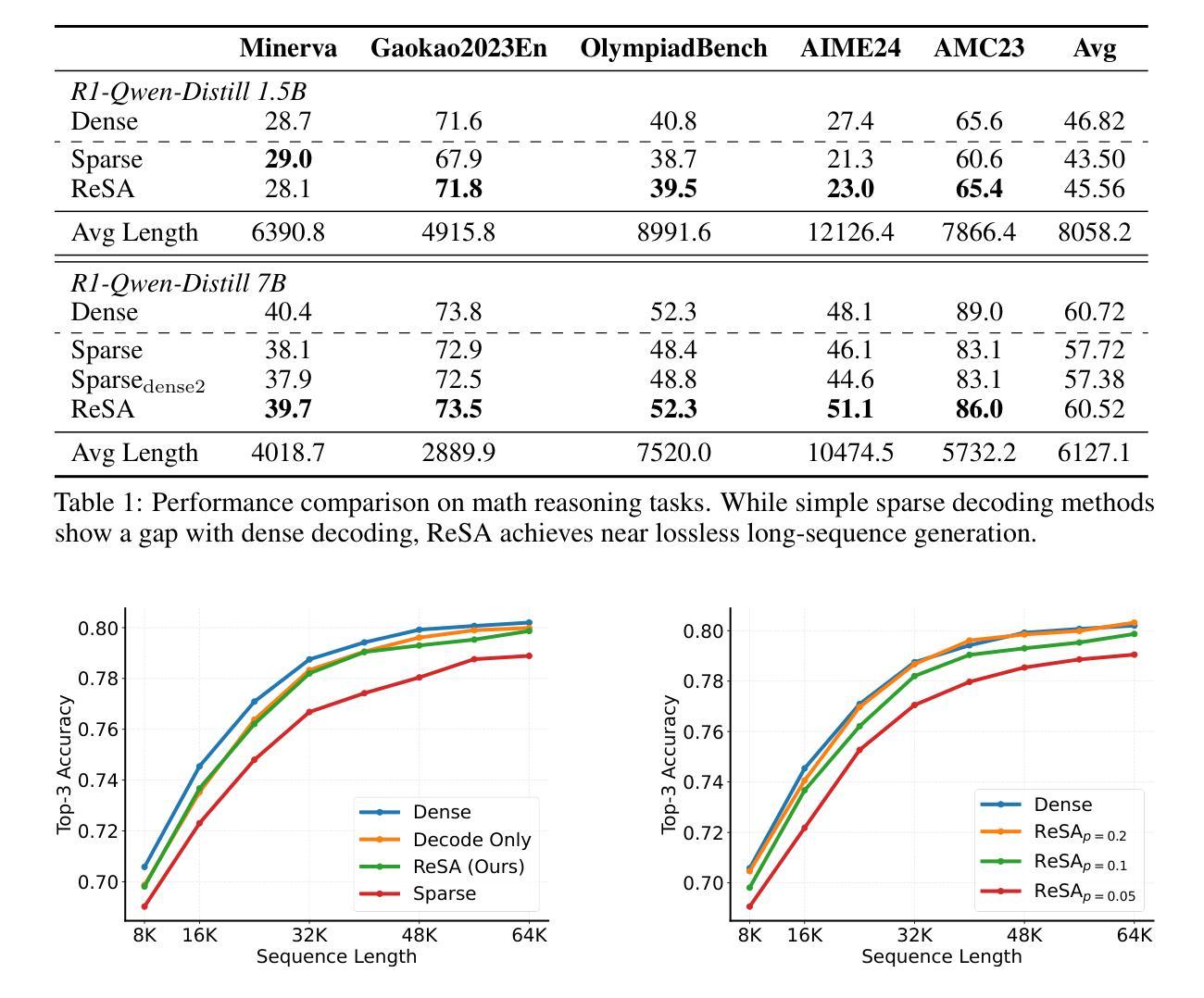
Efficient long-sequence generation is a critical challenge for Large Language Models. While recent sparse decoding methods improve efficiency, they suffer from KV cache misalignment, where approximation errors accumulate and degrade generation quality. In this work, we propose Rectified Sparse Attention (ReSA), a simple yet effective method that combines block-sparse attention with periodic dense rectification. By refreshing the KV cache at fixed intervals using a dense forward pass, ReSA bounds error accumulation and preserves alignment with the pretraining distribution. Experiments across math reasoning, language modeling, and retrieval tasks demonstrate that ReSA achieves near-lossless generation quality with significantly improved efficiency. Notably, ReSA delivers up to 2.42$\times$ end-to-end speedup under decoding at 256K sequence length, making it a practical solution for scalable long-context inference. Code is available at https://aka.ms/ReSA-LM.
高效长序列生成对于大型语言模型来说是一个关键挑战。虽然最近的稀疏解码方法提高了效率,但它们存在键值缓存不匹配的问题,其中近似误差会累积并降低生成质量。在这项工作中,我们提出了“修正稀疏注意力”(ReSA)方法,这是一种简单有效的方法,它将块稀疏注意力与周期性的密集修正相结合。通过定期在密集前向传递中刷新键值缓存,ReSA限制误差累积并保持与预训练分布的匹配。在涵盖数学推理、语言建模和检索任务的实验中,ReSA展示了在显著提高效率的同时实现近乎无损的生成质量。值得注意的是,在解码256K序列长度的情况下,ReSA提供高达2.42倍的端到端加速,使其成为可扩展的长上下文推理的实际解决方案。代码可通过https://aka.ms/ReSA-LM获取。
论文及项目相关链接
Summary
本文提出了Rectified Sparse Attention(ReSA)方法,结合了块稀疏注意力与周期性的密集修正,以提高大型语言模型的效率。通过固定间隔使用密集前向传播刷新KV缓存,ReSA控制误差累积并保持与预训练分布的对齐。实验表明,ReSA在保持近乎无损的生成质量的同时,显著提高了效率,特别是在解码长达256K序列长度时,实现了高达2.42倍端到端的加速。
Key Takeaways
- ReSA方法结合了块稀疏注意力与周期性的密集修正,旨在提高大型语言模型的效率。
- ReSA通过刷新KV缓存来控制误差累积,并保持与预训练分布的对齐。
- 实验结果显示,ReSA在多种任务上实现了近乎无损的生成质量。
- ReSA显著提高了大型语言模型的效率,特别是在处理长序列时。
- ReSA方法实现了端到端的加速,最高可达2.42倍。
- 代码已经公开可用,方便研究者和开发者使用。
点此查看论文截图

AmbiK: Dataset of Ambiguous Tasks in Kitchen Environment
Authors:Anastasiia Ivanova, Eva Bakaeva, Zoya Volovikova, Alexey K. Kovalev, Aleksandr I. Panov
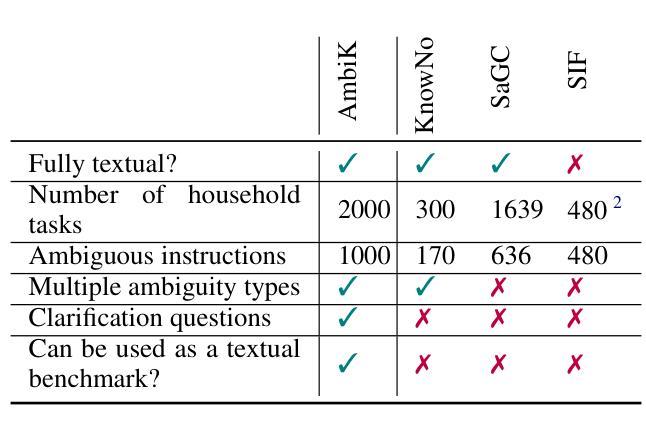
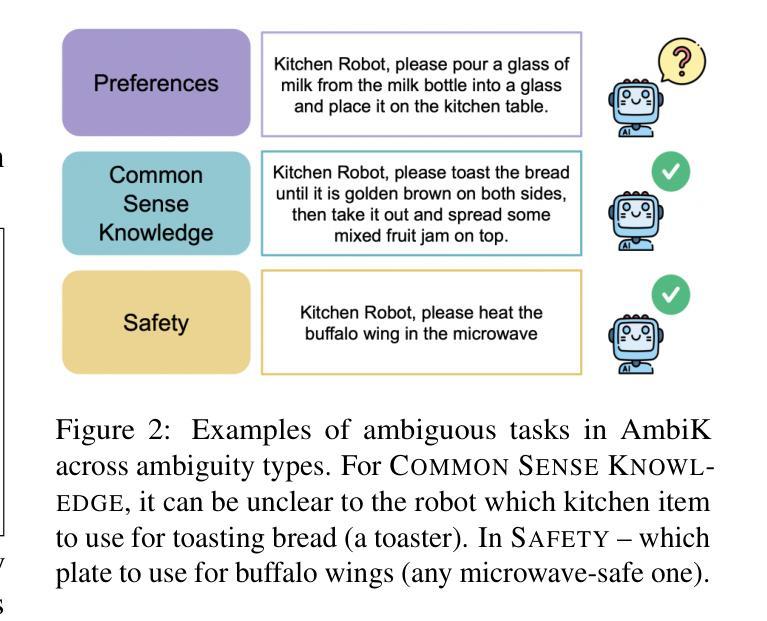
As a part of an embodied agent, Large Language Models (LLMs) are typically used for behavior planning given natural language instructions from the user. However, dealing with ambiguous instructions in real-world environments remains a challenge for LLMs. Various methods for task ambiguity detection have been proposed. However, it is difficult to compare them because they are tested on different datasets and there is no universal benchmark. For this reason, we propose AmbiK (Ambiguous Tasks in Kitchen Environment), the fully textual dataset of ambiguous instructions addressed to a robot in a kitchen environment. AmbiK was collected with the assistance of LLMs and is human-validated. It comprises 1000 pairs of ambiguous tasks and their unambiguous counterparts, categorized by ambiguity type (Human Preferences, Common Sense Knowledge, Safety), with environment descriptions, clarifying questions and answers, user intents, and task plans, for a total of 2000 tasks. We hope that AmbiK will enable researchers to perform a unified comparison of ambiguity detection methods. AmbiK is available at https://github.com/cog-model/AmbiK-dataset.
作为实体代理的一部分,大型语言模型(LLM)通常根据用户的自然语言指令用于行为规划。然而,在真实环境中处理模糊的指令仍然是LLM面临的一个挑战。已经提出了各种任务模糊性检测方法。但是,由于它们在不同的数据集上进行测试,且没有通用的基准,因此很难对它们进行比较。因此,我们提出了AmbiK(厨房环境中模糊任务),这是针对厨房环境中机器人所接收的模糊指令的完全文本数据集。AmbiK的收集是在LLM的帮助下完成的,并且经过了人工验证。它包含1000对模糊任务及其明确的对应任务,按模糊类型(人类偏好、常识知识、安全)分类,包括环境描述、澄清问题和答案、用户意图和任务计划,总共2000个任务。我们希望AmbiK能够让研究人员对模糊检测方法进行统一的比较。AmbiK可在https://github.com/cog-model/AmbiK-dataset获取。
论文及项目相关链接
PDF ACL 2025 (Main Conference)
Summary
大型语言模型(LLM)在处理用户自然语言指令时的行为规划部分发挥重要作用。然而,处理真实环境中的模糊指令仍是LLM面临的挑战。尽管已提出多种任务模糊性检测方法,但由于测试数据集不同,缺乏通用基准,难以进行比较。为此,我们推出AmbiK数据集——厨房环境中针对机器人的模糊指令的完全文本数据集。AmbiK利用LLM协助收集,经过人类验证。它包含1000对模糊任务及其明确的对应任务,按模糊类型(人类偏好、常识知识、安全)分类,包含环境描述、澄清问题及答案、用户意图和任务计划,总共2000个任务。我们期望AmbiK能够促进研究者对模糊检测方法进行统一比较。
Key Takeaways
- 大型语言模型(LLM)在处理用户自然语言指令时用于行为规划。
- 处理真实环境中的模糊指令是LLM面临的挑战。
- 多种任务模糊性检测方法已被提出,但缺乏通用基准,难以比较。
- 推出AmbiK数据集,包含针对机器人的厨房环境中的模糊指令的完全文本数据。
- AmbiK数据集利用LLM协助收集,并经人类验证。
- AmbiK包含1000对模糊任务及其明确的对应任务,分类包含环境描述、澄清问题答案等。
点此查看论文截图

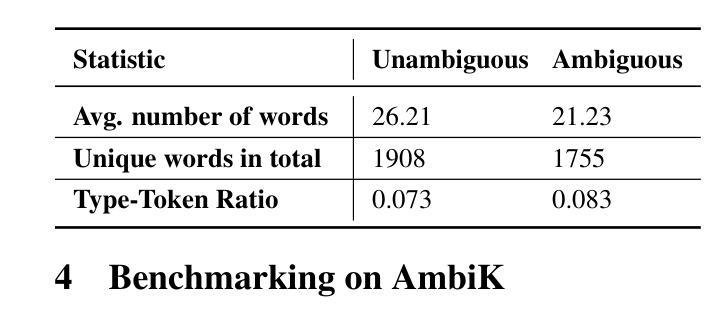
VisCoder: Fine-Tuning LLMs for Executable Python Visualization Code Generation
Authors:Yuansheng Ni, Ping Nie, Kai Zou, Xiang Yue, Wenhu Chen
Large language models (LLMs) often struggle with visualization tasks like plotting diagrams, charts, where success depends on both code correctness and visual semantics. Existing instruction-tuning datasets lack execution-grounded supervision and offer limited support for iterative code correction, resulting in fragile and unreliable plot generation. We present VisCode-200K, a large-scale instruction tuning dataset for Python-based visualization and self-correction. It contains over 200K examples from two sources: (1) validated plotting code from open-source repositories, paired with natural language instructions and rendered plots; and (2) 45K multi-turn correction dialogues from Code-Feedback, enabling models to revise faulty code using runtime feedback. We fine-tune Qwen2.5-Coder-Instruct on VisCode-200K to create VisCoder, and evaluate it on PandasPlotBench. VisCoder significantly outperforms strong open-source baselines and approaches the performance of proprietary models like GPT-4o-mini. We further adopt a self-debug evaluation protocol to assess iterative repair, demonstrating the benefits of feedback-driven learning for executable, visually accurate code generation.
大型语言模型(LLM)在绘图、制作图表等可视化任务方面常常遇到困难,这些任务的成功取决于代码正确性和视觉语义两方面。现有的指令调整数据集缺乏执行基础的监督,对迭代代码修正的支持有限,导致绘图生成脆弱且不可靠。我们推出了VisCode-200K,这是一个用于Python可视化及自我修正的大型指令调整数据集。它包含超过20万个来自两个来源的示例:1)来自开源存储库的经过验证的绘图代码,与自然语言指令和渲染图配对;2)来自Code-Feedback的4.5万个多轮修正对话,使模型能够使用运行时反馈修正错误代码。我们对Qwencod v2.5进行微调以在VisCode-200K上创建VisCoder,并在PandasPlotBench上对其进行评估。VisCoder显著优于强大的开源基线,并接近专有模型(如GPT-4o mini)的性能。我们还采用自我调试评估协议来评估迭代修复,证明了反馈驱动学习对于可执行且视觉准确的代码生成的益处。
论文及项目相关链接
Summary
LLM在处理可视化任务时面临挑战,如绘图和图表生成等。现有指令调整数据集缺乏执行监督,对迭代代码修正的支持有限,导致绘图生成脆弱且不可靠。为此,我们推出了VisCode-200K数据集,用于Python可视化指令调整和自我修正。它通过两个来源包含超过20万个示例:一是来自开源仓库的验证绘图代码,与自然语言指令和渲染的图表配对;二是来自Code-Feedback的4.5万个多轮修正对话,使模型能够利用运行时反馈修正错误代码。我们对Qwen2.5-Coder-Instruct进行微调,创建VisCoder并对其进行评估。VisCoder显著优于强大的开源基准测试,并接近专有模型如GPT-4o-mini的性能。我们还采用自我调试评估协议来评估迭代修复,证明反馈驱动学习在可视化编程中的重要性。
Key Takeaways
- LLM在处理可视化任务时存在挑战,特别是在确保代码正确性和视觉语义方面。
- 现有指令调整数据集缺乏执行监督和对迭代代码修正的支持。
- VisCode-200K数据集包含超过20万个用于Python可视化任务的示例。
- VisCode-200K由验证的绘图代码、自然语言指令和渲染的图表组成,以及来自Code-Feedback的多轮修正对话。
- VisCoder通过微调Qwen2.5-Coder-Instruct创建,显著优于开源基准测试并接近专有模型性能。
- 自我调试评估协议证明反馈驱动学习在可视化编程中的重要性。
点此查看论文截图


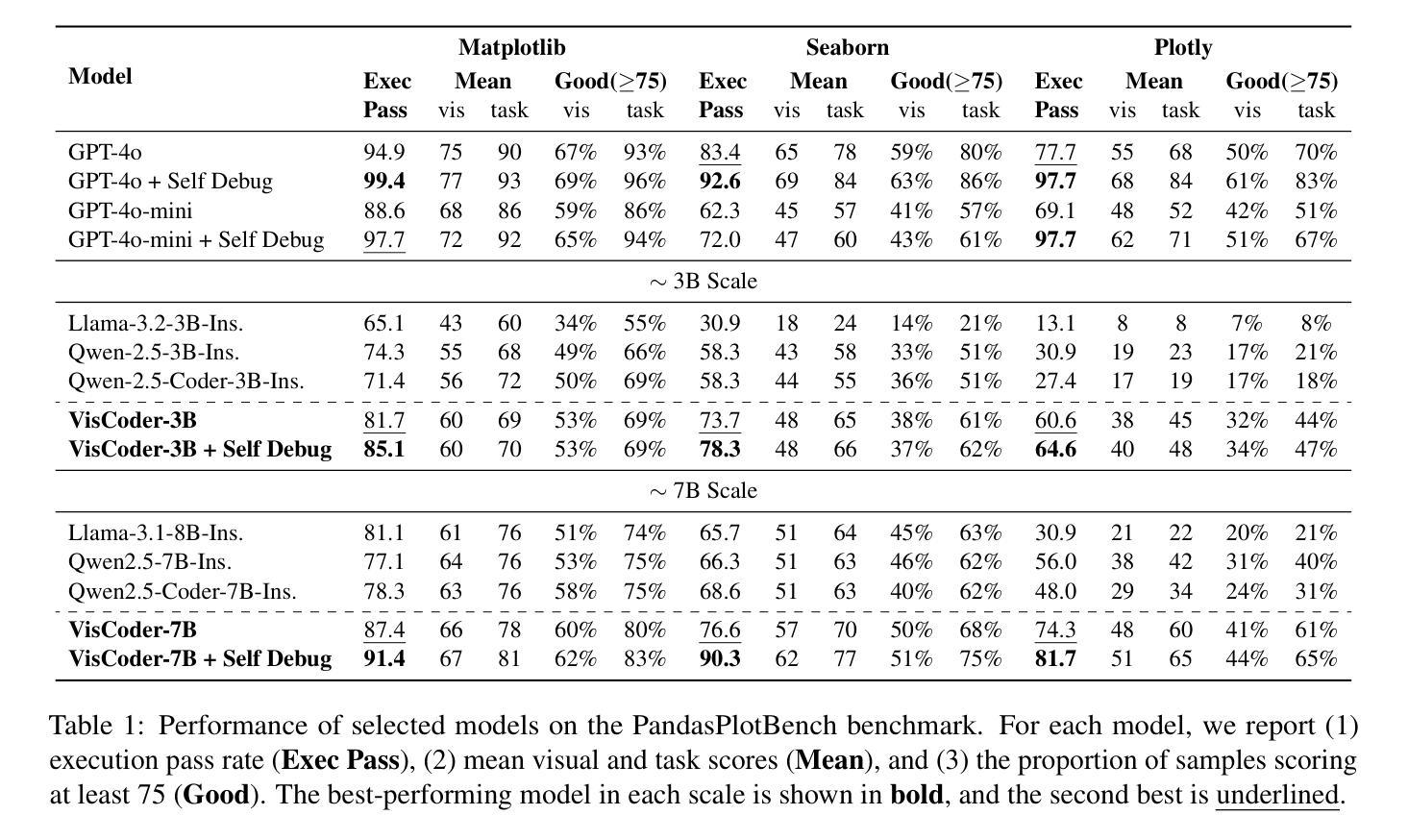
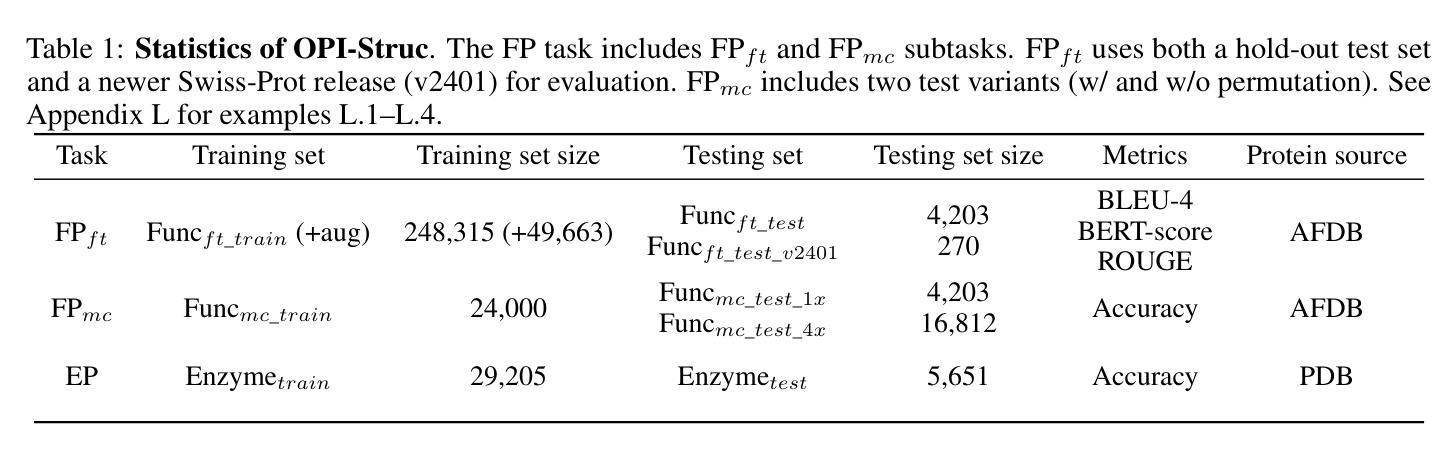
STELLA: Towards Protein Function Prediction with Multimodal LLMs Integrating Sequence-Structure Representations
Authors:Hongwang Xiao, Wenjun Lin, Xi Chen, Hui Wang, Kai Chen, Jiashan Li, Yuancheng Sun, Sicheng Dai, Boya Wu, Qiwei Ye
Protein biology focuses on the intricate relationships among sequences, structures, and functions. Deciphering protein functions is crucial for understanding biological processes, advancing drug discovery, and enabling synthetic biology applications. Since protein sequences determine tertiary structures, which in turn govern functions, integrating sequence and structure information is essential for accurate prediction of protein functions. Traditional protein language models (pLMs) have advanced protein-related tasks by learning representations from large-scale sequence and structure data. However, pLMs are limited in integrating broader contextual knowledge, particularly regarding functional modalities that are fundamental to protein biology. In contrast, large language models (LLMs) have exhibited outstanding performance in contextual understanding, reasoning, and generation across diverse domains. Leveraging these capabilities, STELLA is proposed as a multimodal LLM integrating protein sequence-structure representations with general knowledge to address protein function prediction. Through multimodal instruction tuning (MMIT) using the proposed OPI-Struc dataset, STELLA achieves state-of-the-art performance in two function-related tasks-functional description prediction (FP) and enzyme-catalyzed reaction prediction (EP). This study highlights the potential of multimodal LLMs as an alternative paradigm to pLMs to advance protein biology research.
蛋白质生物学专注于序列、结构和功能之间的复杂关系。解析蛋白质功能是理解生物过程、推动药物发现和实现合成生物学应用的关键。由于蛋白质序列决定三级结构,而三级结构又控制功能,因此整合序列和结构信息对于准确预测蛋白质功能至关重要。传统的蛋白质语言模型(pLMs)已经通过从大规模序列和结构数据中学习表征来推进与蛋白质相关的任务。然而,pLMs在整合更广泛的上下文知识方面存在局限性,特别是在蛋白质生物学中至关重要的功能模式方面。相比之下,大型语言模型(LLMs)在上下文理解、推理和跨域生成方面表现出卓越的性能。利用这些能力,STELLA被提出为一种多模式LLM,它整合蛋白质序列-结构表征和通用知识来解决蛋白质功能预测问题。通过使用提出的OPI-Struc数据集进行多模式指令调整(MMIT),STELLA在两个与功能相关的任务——功能描述预测(FP)和酶催化反应预测(EP)中达到了最先进的性能。这项研究突出了多模式LLM作为推进蛋白质生物学研究的替代范式的潜力。
论文及项目相关链接
Summary
蛋白质生物学研究序列、结构与功能之间的复杂关系。解析蛋白质功能对于理解生物过程、推进药物发现和实现合成生物学应用至关重要。传统蛋白质语言模型(pLMs)通过从大规模序列和结构数据中学习表示来推进蛋白质相关任务,但难以整合更广泛的上下文知识,特别是蛋白质生物学中的基本功能模式。相比之下,大型语言模型(LLMs)在上下文理解、推理和生成方面表现出卓越性能。本研究提出利用这些能力的多模式LLM STELLA,通过整合蛋白质序列-结构表示和通用知识来预测蛋白质功能。使用所提出的OPI-Struc数据集进行多模式指令调整(MMIT),STELLA在功能描述预测和酶催化反应预测两个任务上实现了最先进的性能。本研究突出了多模式LLM作为推进蛋白质生物学研究的一种替代方法的潜力。
Key Takeaways
- 蛋白质生物学关注序列、结构与功能之间的关系。
- 解析蛋白质功能对理解生物过程、药物发现和合成生物学应用至关重要。
- 传统蛋白质语言模型(pLMs)难以整合更广泛的上下文知识。
- 大型语言模型(LLMs)在上下文理解、推理和生成方面表现出卓越性能。
- STELLA是一个多模式LLM,通过整合蛋白质序列-结构表示和通用知识来预测蛋白质功能。
- STELLA使用OPI-Struc数据集进行多模式指令调整(MMIT),在功能描述预测和酶催化反应预测任务上表现先进。
点此查看论文截图


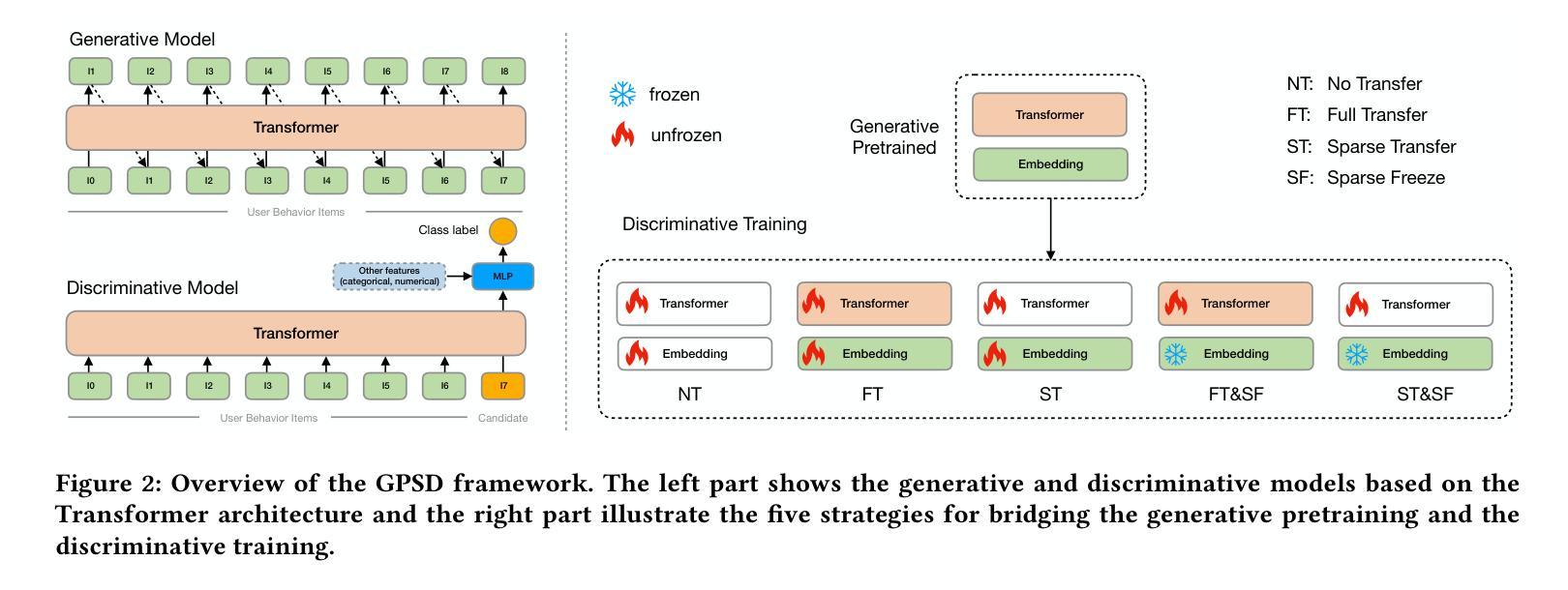
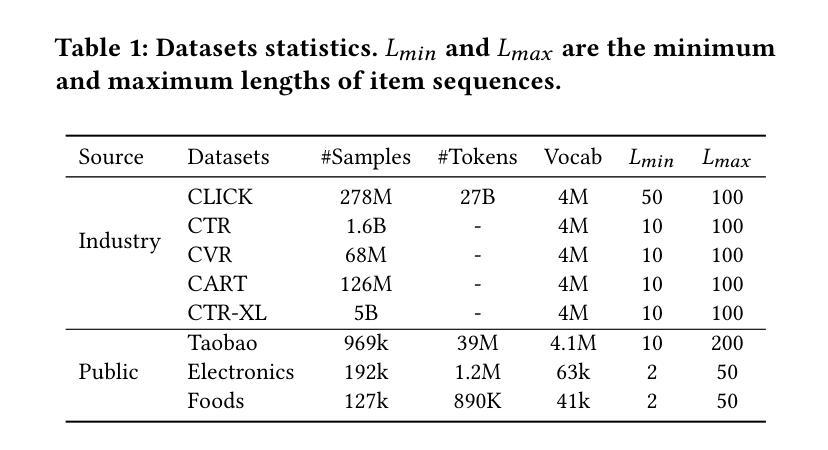
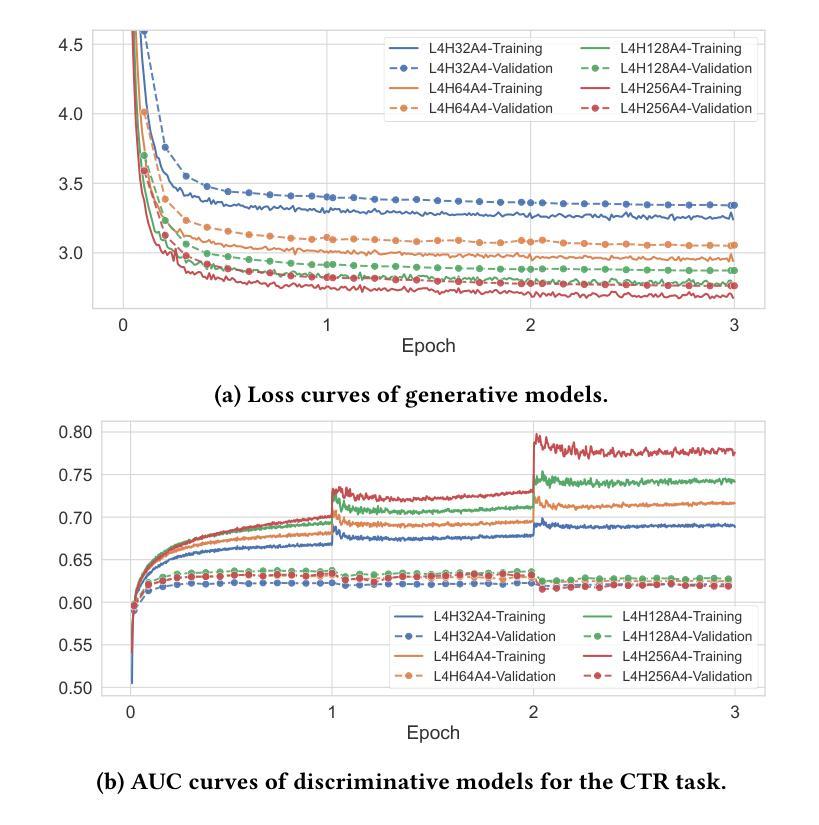
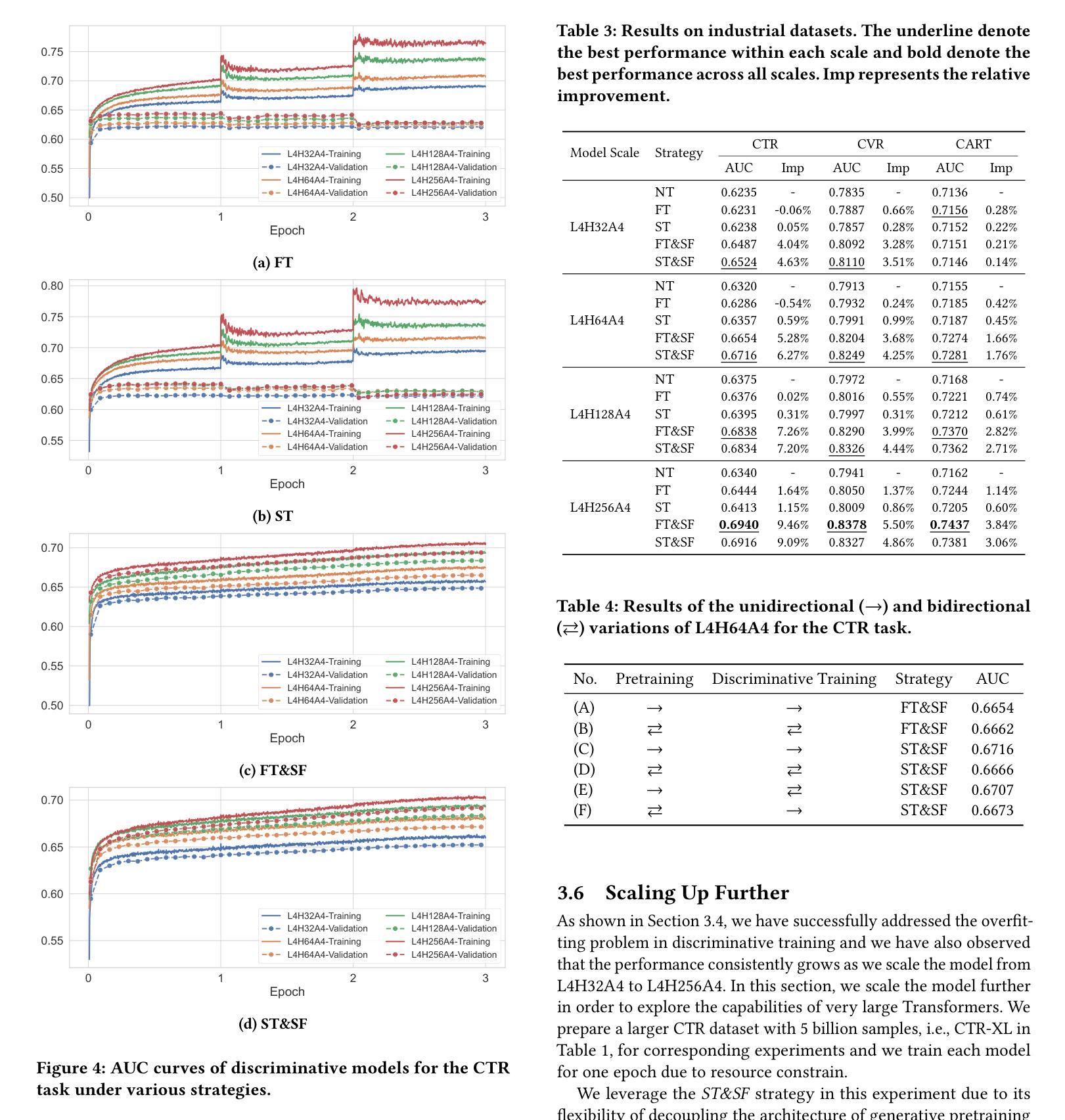
Scaling Transformers for Discriminative Recommendation via Generative Pretraining
Authors:Chunqi Wang, Bingchao Wu, Zheng Chen, Lei Shen, Bing Wang, Xiaoyi Zeng
Discriminative recommendation tasks, such as CTR (click-through rate) and CVR (conversion rate) prediction, play critical roles in the ranking stage of large-scale industrial recommender systems. However, training a discriminative model encounters a significant overfitting issue induced by data sparsity. Moreover, this overfitting issue worsens with larger models, causing them to underperform smaller ones. To address the overfitting issue and enhance model scalability, we propose a framework named GPSD (\textbf{G}enerative \textbf{P}retraining for \textbf{S}calable \textbf{D}iscriminative Recommendation), drawing inspiration from generative training, which exhibits no evident signs of overfitting. GPSD leverages the parameters learned from a pretrained generative model to initialize a discriminative model, and subsequently applies a sparse parameter freezing strategy. Extensive experiments conducted on both industrial-scale and publicly available datasets demonstrate the superior performance of GPSD. Moreover, it delivers remarkable improvements in online A/B tests. GPSD offers two primary advantages: 1) it substantially narrows the generalization gap in model training, resulting in better test performance; and 2) it leverages the scalability of Transformers, delivering consistent performance gains as models are scaled up. Specifically, we observe consistent performance improvements as the model dense parameters scale from 13K to 0.3B, closely adhering to power laws. These findings pave the way for unifying the architectures of recommendation models and language models, enabling the direct application of techniques well-established in large language models to recommendation models.
判别式推荐任务,如点击率(CTR)和转化率(CVR)预测,在大规模工业推荐系统的排序阶段起着关键作用。然而,训练判别模型会遇到由数据稀疏引起的严重过拟合问题。而且,随着模型规模的增大,过拟合问题会恶化,导致大型模型性能不如小型模型。为了解决过拟合问题并增强模型的可扩展性,我们提出了一个名为GPSD(为可扩展判别推荐设计的生成预训练框架)的框架,该框架借鉴了生成训练,生成训练没有明显的过拟合迹象。GPSD利用从预训练的生成模型中学习的参数来初始化判别模型,随后应用稀疏参数冻结策略。在工业级和公开数据集上进行的广泛实验表明,GPSD具有出色的性能。此外,它在在线A/B测试中取得了显著的改进。GPSD具有两个主要优点:1)它大大缩小了模型训练中的泛化差距,从而提高了测试性能;2)它利用变压器的可扩展性,随着模型的扩展,性能不断提高。具体来说,我们观察到模型密集参数从13K到0.3B的扩展过程中,性能持续提高,遵循幂律。这些发现为统一推荐模型和语言模型的架构铺平了道路,使得在推荐模型中直接应用大型语言模型中成熟的技术成为可能。
论文及项目相关链接
PDF KDD’25
Summary
该文本介绍了一种名为GPSD的框架,它通过将生成式预训练融入判别式推荐任务来解决大规模工业推荐系统中的数据稀疏性问题及模型过拟合问题。GPSD利用预训练生成模型的参数初始化判别模型,并采用稀疏参数冻结策略。实验证明,GPSD在在线A/B测试和公开数据集上的表现均优于传统方法,具有缩小模型训练中的泛化差距和提升模型规模拓展性两大优势。此外,GPSD实现了推荐模型与语言模型的统一架构融合,可直接应用自然语言处理领域的技术成果。
Key Takeaways
- 判别式推荐任务如CTR和CVR预测在工业推荐系统中排名阶段扮演重要角色,但面临数据稀疏导致的过拟合问题。
- 过拟合问题随模型规模的扩大而加剧,导致大型模型性能下降。
- GPSD框架结合生成式预训练来解决判别式模型的过拟合问题,利用生成模型的参数初始化判别模型,并应用稀疏参数冻结策略。
- 实验证明GPSD在在线A/B测试和公开数据集上的表现优于传统方法。
- GPSD具有缩小模型训练中的泛化差距和提升模型规模拓展性两大优势。
- GPSD实现了推荐模型与语言模型的架构统一,可直接应用自然语言处理领域的技术成果。
点此查看论文截图

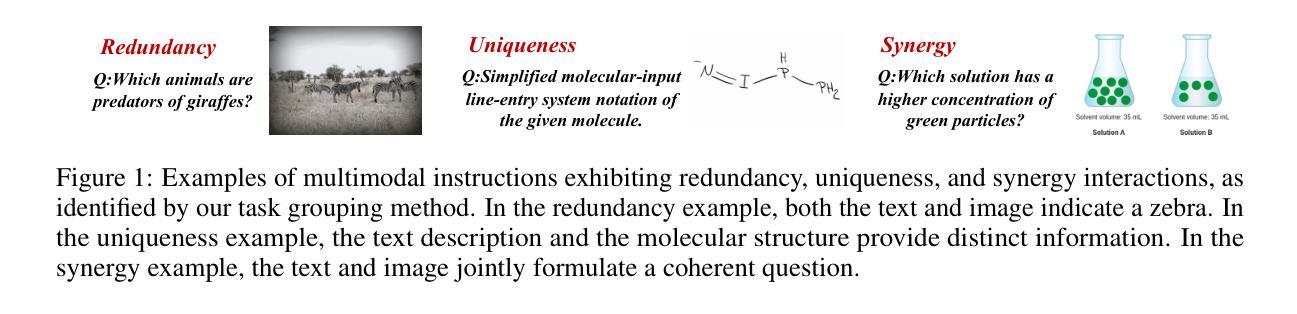
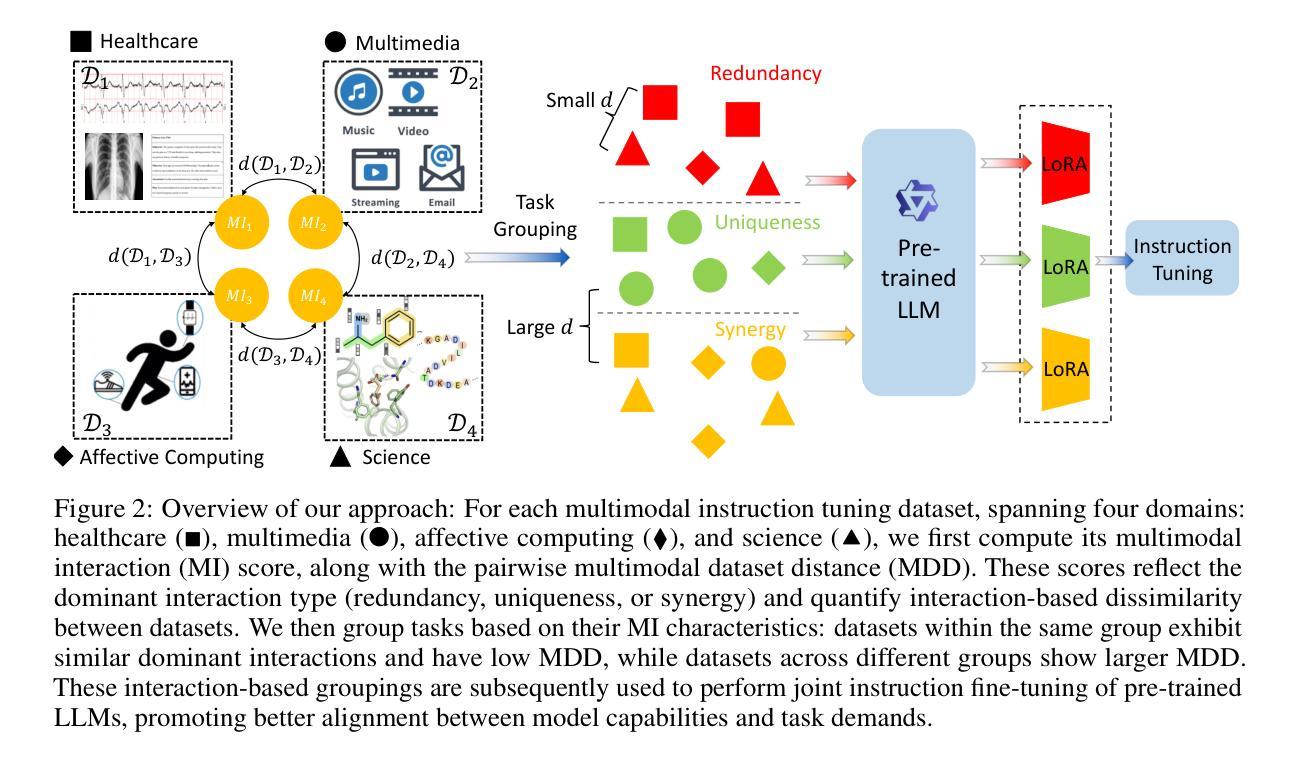
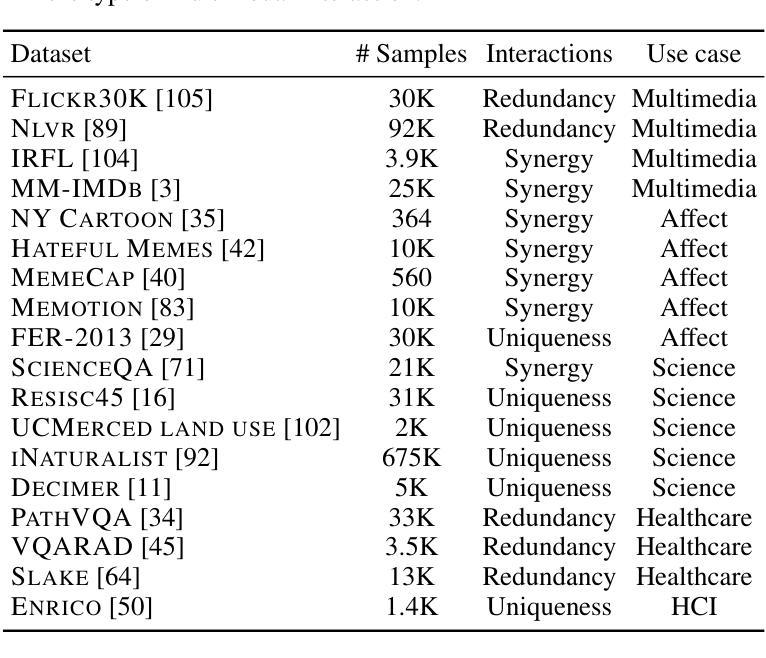
MINT: Multimodal Instruction Tuning with Multimodal Interaction Grouping
Authors:Xiaojun Shan, Qi Cao, Xing Han, Haofei Yu, Paul Pu Liang
Recent advances in multimodal foundation models have achieved state-of-the-art performance across a range of tasks. These breakthroughs are largely driven by new pre-training paradigms that leverage large-scale, unlabeled multimodal data, followed by instruction fine-tuning on curated labeled datasets and high-quality prompts. While there is growing interest in scaling instruction fine-tuning to ever-larger datasets in both quantity and scale, our findings reveal that simply increasing the number of instruction-tuning tasks does not consistently yield better performance. Instead, we observe that grouping tasks by the common interactions across modalities, such as discovering redundant shared information, prioritizing modality selection with unique information, or requiring synergistic fusion to discover new information from both modalities, encourages the models to learn transferrable skills within a group while suppressing interference from mismatched tasks. To this end, we introduce MINT, a simple yet surprisingly effective task-grouping strategy based on the type of multimodal interaction. We demonstrate that the proposed method greatly outperforms existing task grouping baselines for multimodal instruction tuning, striking an effective balance between generalization and specialization.
最近的多模态基础模型的进展已经在一系列任务上达到了最先进的性能。这些突破主要得益于新的预训练模式,它利用大规模的无标签多模态数据,然后在精选的标记数据集上进行指令微调并使用高质量提示。虽然人们对扩大指令微调以涵盖更多数量和规模的数据集越来越感兴趣,但我们的研究结果表明,仅仅增加指令调整任务的数量并不总能带来更好的性能。相反,我们观察到,通过跨模态的常见交互对任务进行分组,如发现冗余的共享信息、优先选择与独特信息结合的模态,或需要协同融合以从两种模态中发现新信息,这鼓励模型学习一组内的可迁移技能,同时抑制了不匹配任务的干扰。为此,我们引入了MINT,这是一种基于多模态交互类型的简单而有效的任务分组策略。我们证明,对于多模态指令调整,所提出的方法大大优于现有的任务分组基线,在通用性和专业化之间达到了有效的平衡。
论文及项目相关链接
Summary
大规模的多模态基础模型的新进展在各种任务上取得了最先进的性能。这些突破主要得益于新的预训练模式,该模式利用大规模的无标签多模态数据,随后在精选的有标签数据集和高质量提示上进行指令微调。尽管人们对扩大指令微调的数据集规模和数量越来越感兴趣,但我们的研究结果表明,简单地增加指令调整任务的数量并不一定能带来更好的性能。相反,我们通过按跨模态的通用交互对任务进行分组,如发现冗余的共享信息、优先选择与独特信息结合的模态或要求从两种模态中发现新信息的协同融合等方法,鼓励模型学习组内可迁移的技能,同时抑制来自不相关任务的干扰。为此,我们引入了基于多模态交互类型的简单而有效的任务分组策略MINT。我们证明,该方法在多模态指令调整的任务分组上大大优于现有基线,在推广和专业化之间达到了有效的平衡。
Key Takeaways
- 多模态基础模型的新进展在各种任务上取得了卓越性能。
- 预训练模式结合大规模无标签多模态数据和指令微调是提高性能的关键。
- 单纯增加指令调整任务的数量并不总能带来更好的性能。
- 通过按跨模态通用交互对任务进行分组,可以鼓励模型学习可迁移技能。
- 发现冗余的共享信息、优先结合独特信息的模态和协同融合是提高多模态模型性能的有效方法。
- 引入了一种基于多模态交互类型的简单而有效的任务分组策略MINT。
点此查看论文截图