⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-06 更新
Does Thinking More always Help? Understanding Test-Time Scaling in Reasoning Models
Authors:Soumya Suvra Ghosal, Souradip Chakraborty, Avinash Reddy, Yifu Lu, Mengdi Wang, Dinesh Manocha, Furong Huang, Mohammad Ghavamzadeh, Amrit Singh Bedi
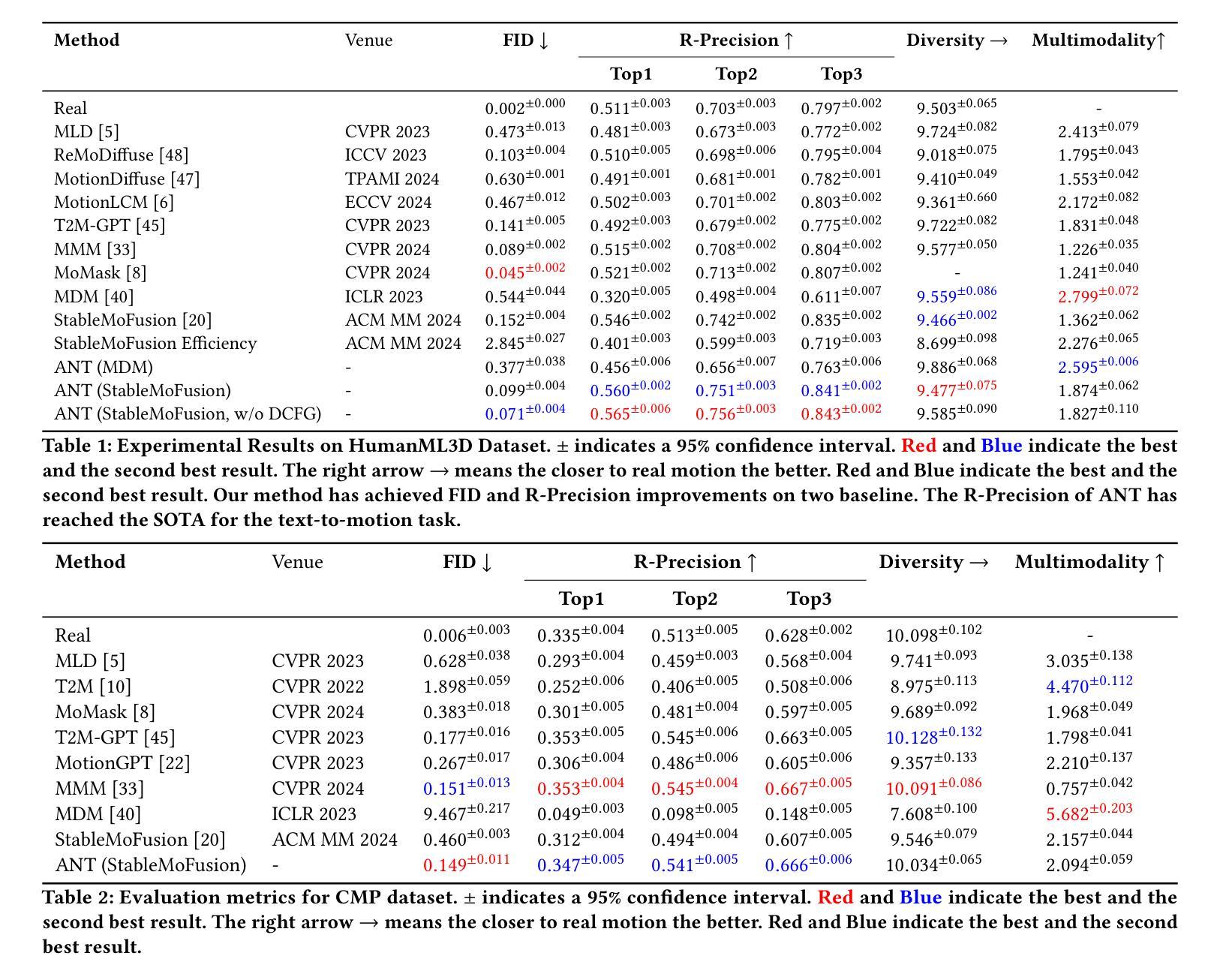
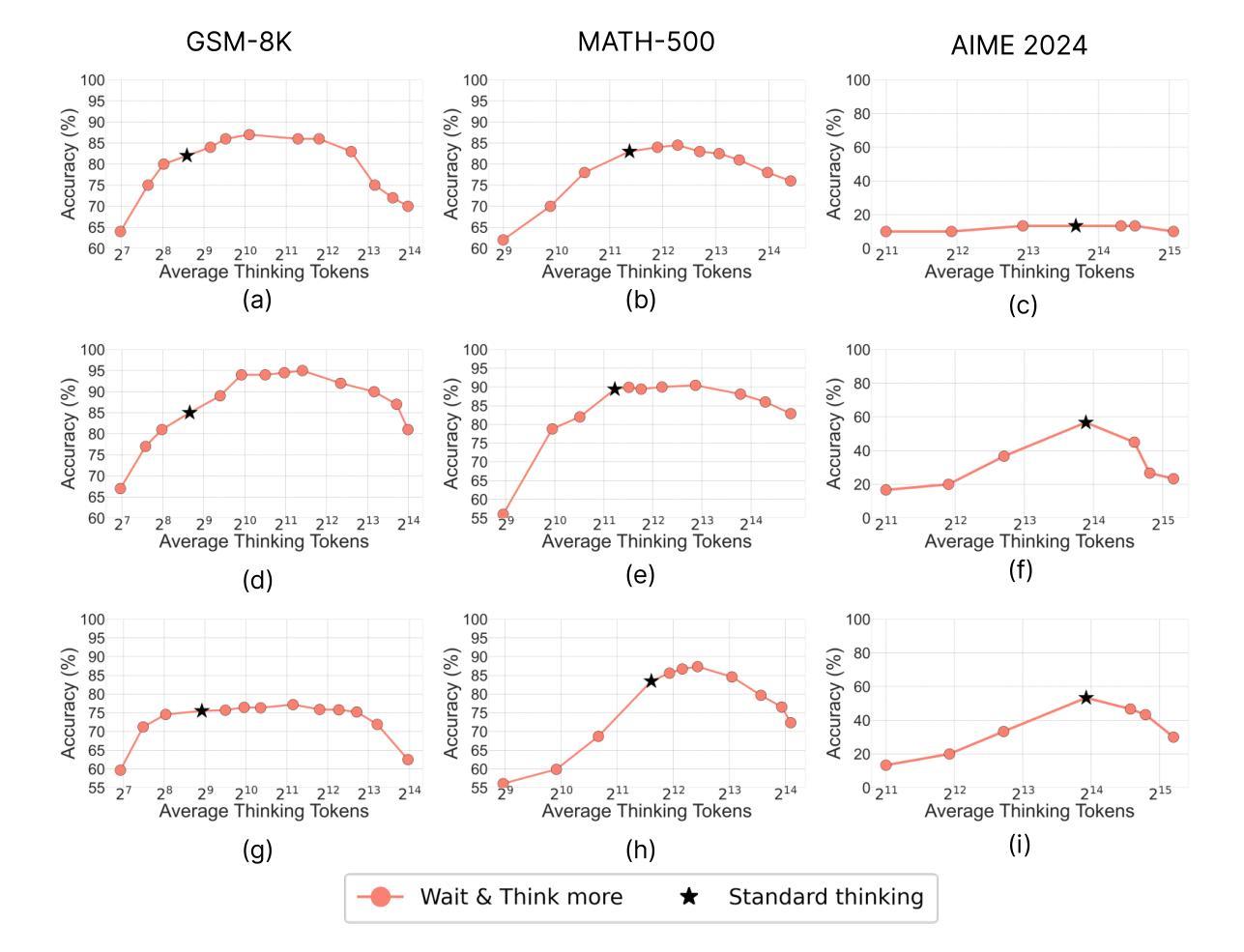
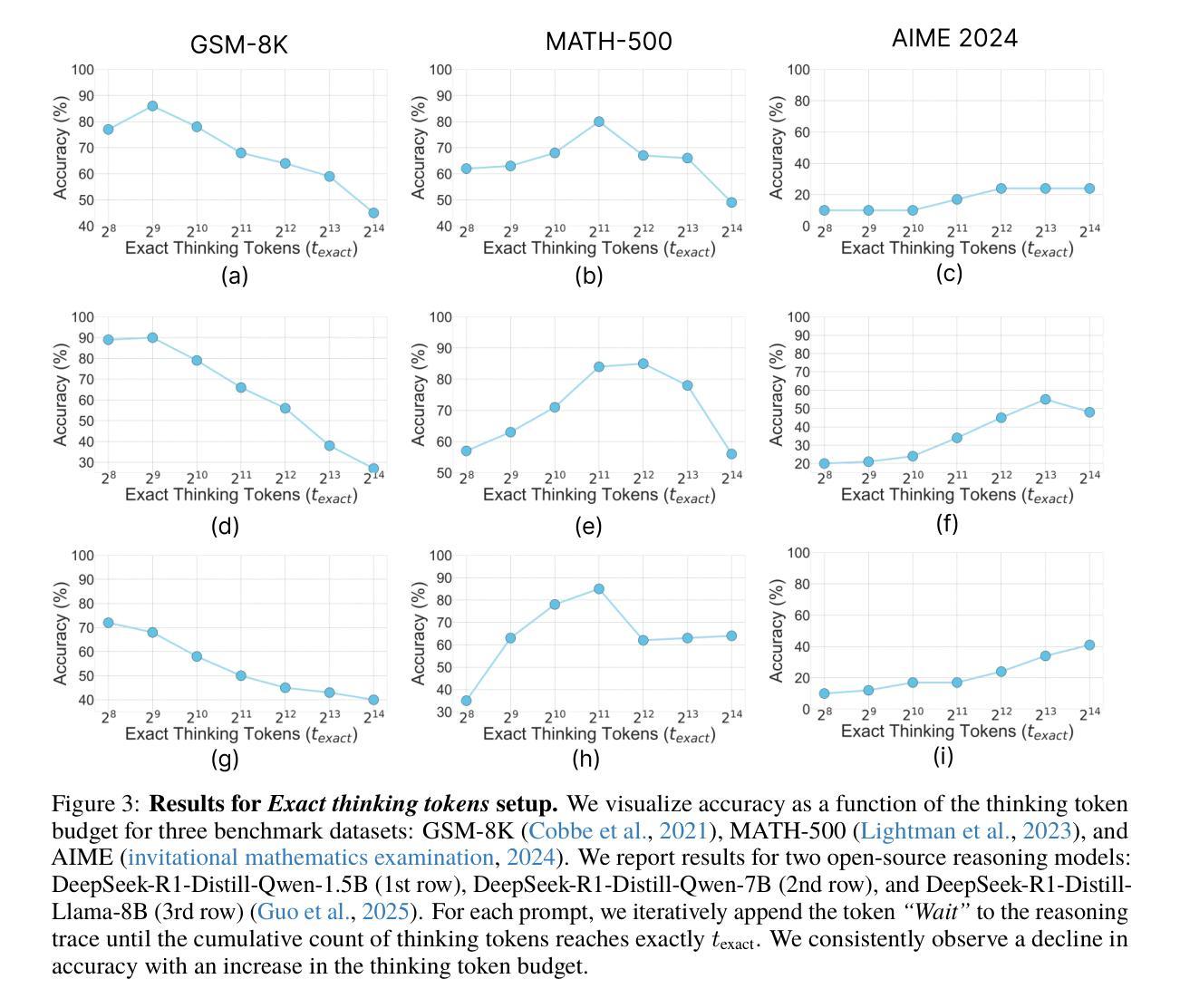
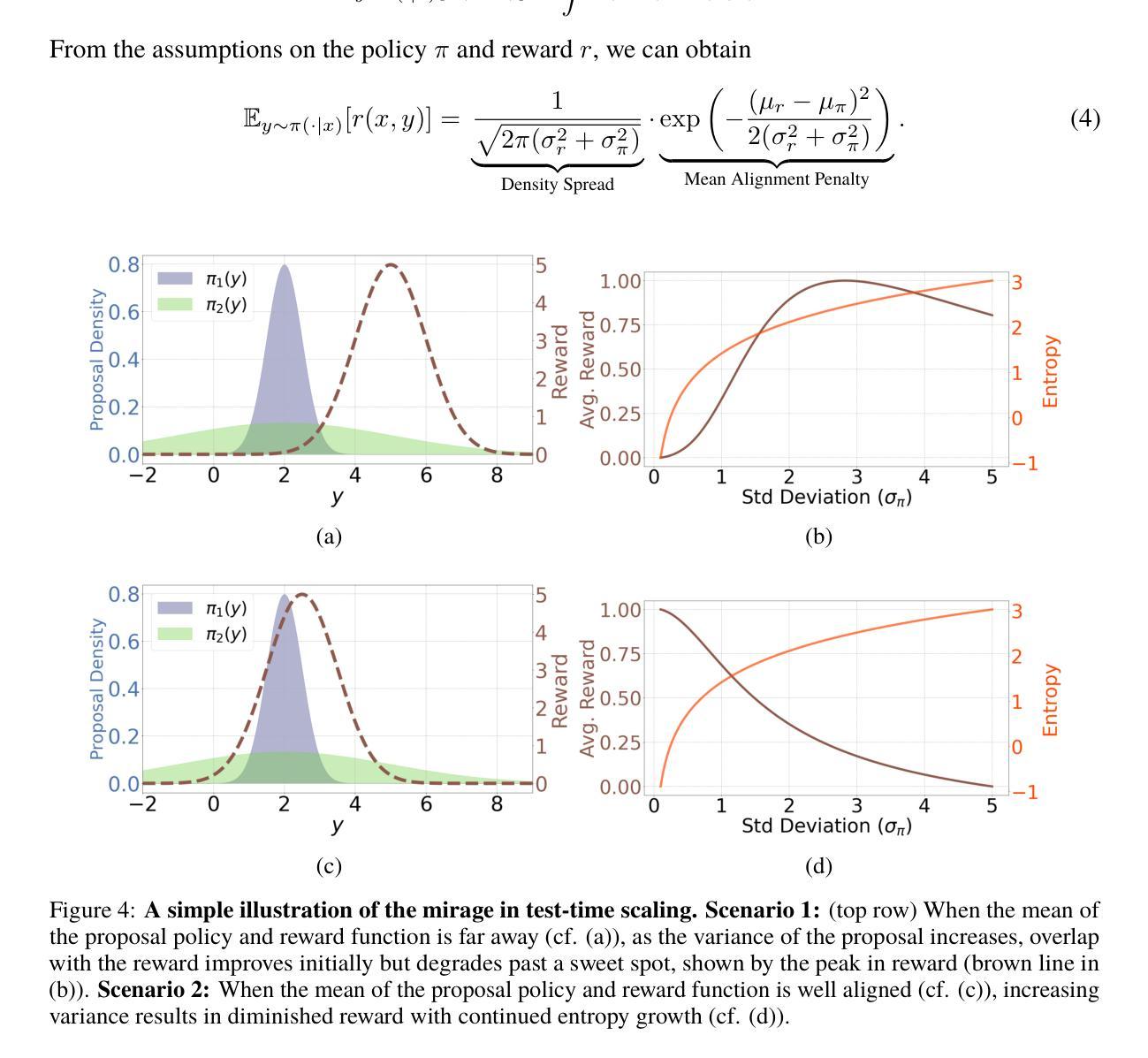
Recent trends in test-time scaling for reasoning models (e.g., OpenAI o1, DeepSeek R1) have led to a popular belief that extending thinking traces using prompts like “Wait” or “Let me rethink” can improve performance. This raises a natural question: Does thinking more at test-time truly lead to better reasoning? To answer this question, we perform a detailed empirical study across models and benchmarks, which reveals a consistent pattern of initial performance improvements from additional thinking followed by a decline, due to “overthinking”. To understand this non-monotonic trend, we consider a simple probabilistic model, which reveals that additional thinking increases output variance-creating an illusion of improved reasoning while ultimately undermining precision. Thus, observed gains from “more thinking” are not true indicators of improved reasoning, but artifacts stemming from the connection between model uncertainty and evaluation metric. This suggests that test-time scaling through extended thinking is not an effective way to utilize the inference thinking budget. Recognizing these limitations, we introduce an alternative test-time scaling approach, parallel thinking, inspired by Best-of-N sampling. Our method generates multiple independent reasoning paths within the same inference budget and selects the most consistent response via majority vote, achieving up to 20% higher accuracy compared to extended thinking. This provides a simple yet effective mechanism for test-time scaling of reasoning models.
关于推理模型的测试时间缩放(例如OpenAI o1、DeepSeek R1)的最新趋势引发了一种普遍的观念,即使用诸如“等一下”或“让我再思考一下”之类的提示来扩展思维轨迹可以提高性能。这就自然地提出了一个问题:在测试时思考更多是否真的会导致更好的推理?为了回答这个问题,我们对模型和基准进行了详细的实证研究,结果显示初始性能会随着额外的思考而有所提高,但随后会由于“过度思考”而下降。为了理解这种非单调趋势,我们考虑了一个简单的概率模型,该模型表明,额外的思考会增加输出方差,从而产生改进的推理错觉,而实际上会破坏精度。因此,“更多思考”所观察到的收益并不是推理能力真正提高的指示器,而是源于模型不确定性和评估指标之间联系所产生的伪现象。这表明通过延长思考来进行测试时间缩放并不是有效利用推理预算的有效方法。认识到这些局限性,我们受到Best-of-N采样的启发,引入了一种替代的测试时间缩放方法——平行思考。我们的方法在相同的推理预算内生成多个独立的推理路径,并通过多数投票选择最一致的答案,与延长思考相比,准确度高出了高达20%。这为推理模型的测试时间缩放提供了一种简单而有效的机制。
论文及项目相关链接
Summary
在测试时间尺度上的最新趋势表明,通过增加思考轨迹(如使用“等一下”或“让我再想一想”等提示)可以提高推理模型的性能。但经过详细实证研究,我们发现额外的思考最初会提高性能,随后却会导致性能下降,这是由于“过度思考”所致。简单概率模型显示,额外的思考增加了输出方差,从而产生了一种改进的错觉推理,最终却破坏了精度。因此,“更多思考”所观察到的收益并非真正反映推理能力的提高,而是源于模型不确定性与评价指标之间的联系所产生的结果。这提示我们,通过延长思考时间来进行测试时间尺度缩放并不是有效利用推理预算的有效方式。作为一种替代方法,我们提出了受Best-of-N采样启发的并行思考方法。该方法在同一推理预算内生成多个独立推理路径,并通过多数投票选择最一致的响应,与延长思考时间相比,提高了高达20%的准确率。这为测试时间尺度的推理模型提供了一种简单有效的机制。
Key Takeaways
- 增加思考轨迹(使用提示)可以提高推理模型的初始性能。
- 额外的思考会导致性能下降,这是因为“过度思考”。
- 简单概率模型揭示额外思考增加输出方差,产生改进错觉而降低精度。
- “更多思考”的收益并非真正反映推理能力的提高,而是源于模型不确定性与评价指标之间的联系。
- 通过延长思考时间来进行测试时间尺度缩放并非有效利用推理预算。
- 提出了并行思考方法,在同一推理预算内生成多个独立推理路径。
点此查看论文截图

Advancing Multimodal Reasoning: From Optimized Cold Start to Staged Reinforcement Learning
Authors:Shuang Chen, Yue Guo, Zhaochen Su, Yafu Li, Yulun Wu, Jiacheng Chen, Jiayu Chen, Weijie Wang, Xiaoye Qu, Yu Cheng
Inspired by the remarkable reasoning capabilities of Deepseek-R1 in complex textual tasks, many works attempt to incentivize similar capabilities in Multimodal Large Language Models (MLLMs) by directly applying reinforcement learning (RL). However, they still struggle to activate complex reasoning. In this paper, rather than examining multimodal RL in isolation, we delve into current training pipelines and identify three crucial phenomena: 1) Effective cold start initialization is critical for enhancing MLLM reasoning. Intriguingly, we find that initializing with carefully selected text data alone can lead to performance surpassing many recent multimodal reasoning models, even before multimodal RL. 2) Standard GRPO applied to multimodal RL suffers from gradient stagnation, which degrades training stability and performance. 3) Subsequent text-only RL training, following the multimodal RL phase, further enhances multimodal reasoning. This staged training approach effectively balances perceptual grounding and cognitive reasoning development. By incorporating the above insights and addressing multimodal RL issues, we introduce ReVisual-R1, achieving a new state-of-the-art among open-source 7B MLLMs on challenging benchmarks including MathVerse, MathVision, WeMath, LogicVista, DynaMath, and challenging AIME2024 and AIME2025.
受到Deepseek-R1在复杂文本任务中出色推理能力的启发,许多工作试图通过直接应用强化学习(RL)来激励多模态大型语言模型(MLLMs)的类似能力。然而,他们在激活复杂推理方面仍面临困难。在本文中,我们并没有孤立地研究多模态RL,而是深入研究了当前的训练管道,并确定了三个关键现象:1)有效的冷启动初始化对于增强MLLM推理至关重要。有趣的是,我们发现仅通过精心选择的文本数据进行初始化,就可以在尚未应用多模态RL之前,其性能就超越了许多最新的多模态推理模型。2)应用于多模态RL的标准GRPO存在梯度停滞问题,这降低了训练稳定性和性能。3)在多模态RL阶段之后进行的仅文本RL训练,进一步增强了多模态推理。这种分阶段训练方法有效地平衡了感知定位和认知推理发展。通过融入上述见解并解决多模态RL问题,我们推出了ReVisual-R1,在包括MathVerse、MathVision、WeMath、LogicVista、DynaMath以及具有挑战性的AIME2024和AIME2025等开放源代码的7B MLLM基准测试上实现了最新技术水平。
论文及项目相关链接
PDF 19 pages, 6 figures
Summary
本文探讨了多模态大型语言模型(MLLMs)的推理能力强化问题。研究发现,通过精心选择的文本数据初始化可以显著提升MLLMs的推理性能,且标准化GRPO在多模态RL中会导致梯度停滞。采用分阶段训练方式,先多模态RL再文本RL,能有效平衡感知接地和认知推理发展。据此推出ReVisual-R1模型,在多个挑战基准测试中表现卓越。
Key Takeaways
- 文本数据初始化对提升MLLMs的推理性能至关重要。
- 标准化GRPO在多模态RL中会导致梯度停滞,影响训练稳定性和性能。
- 分阶段训练方式,先多模态RL再文本RL,能有效增强多模态推理。
- ReVisual-R1模型通过融入上述见解并解决多模态RL问题,实现了性能提升。
- ReVisual-R1模型在多个挑战基准测试(如MathVerse, MathVision, WeMath等)中表现卓越。
- 冷启动初始化过程在多模态大型语言模型中的重要性被强调。
点此查看论文截图

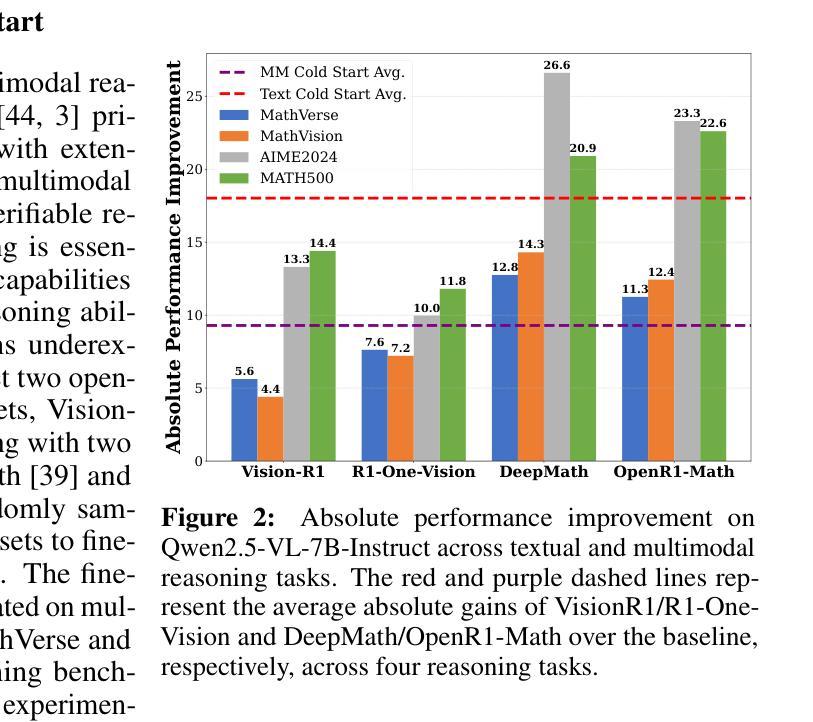
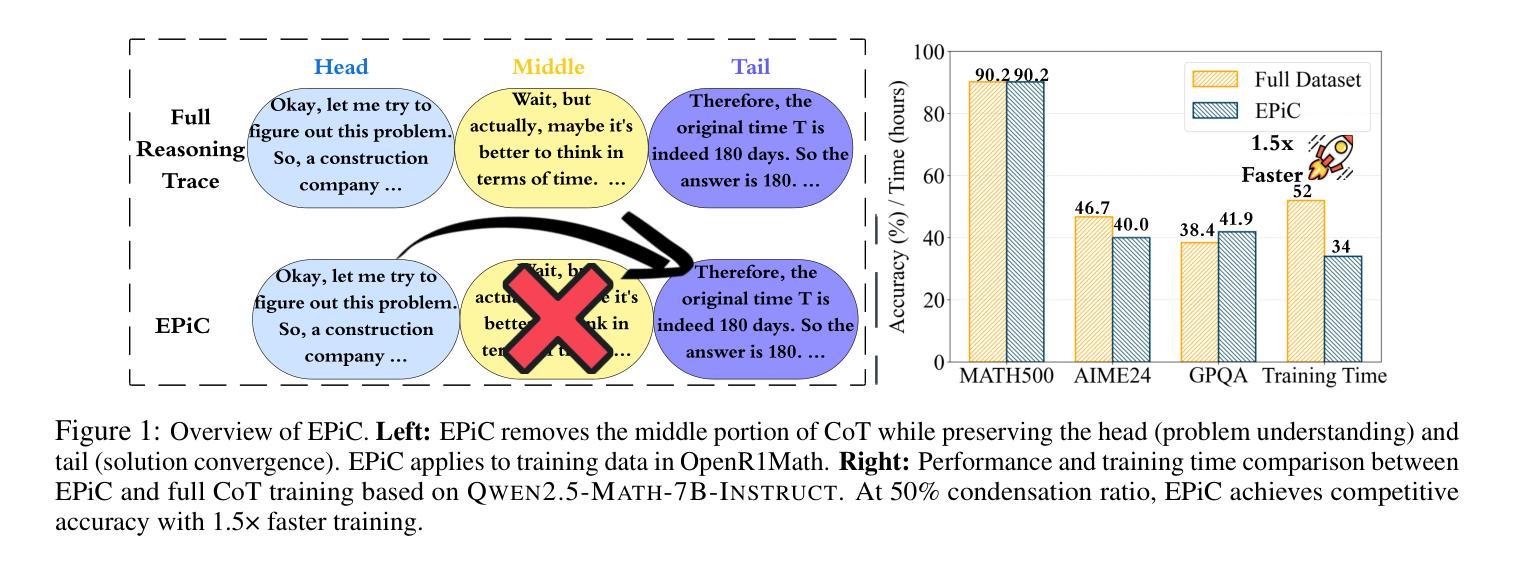
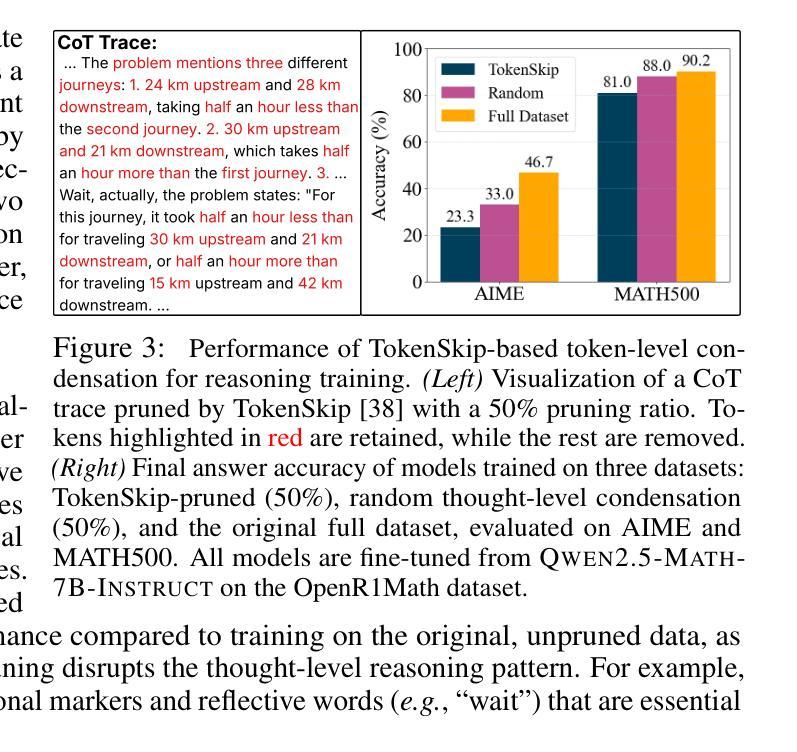
EPiC: Towards Lossless Speedup for Reasoning Training through Edge-Preserving CoT Condensation
Authors:Jinghan Jia, Hadi Reisizadeh, Chongyu Fan, Nathalie Baracaldo, Mingyi Hong, Sijia Liu
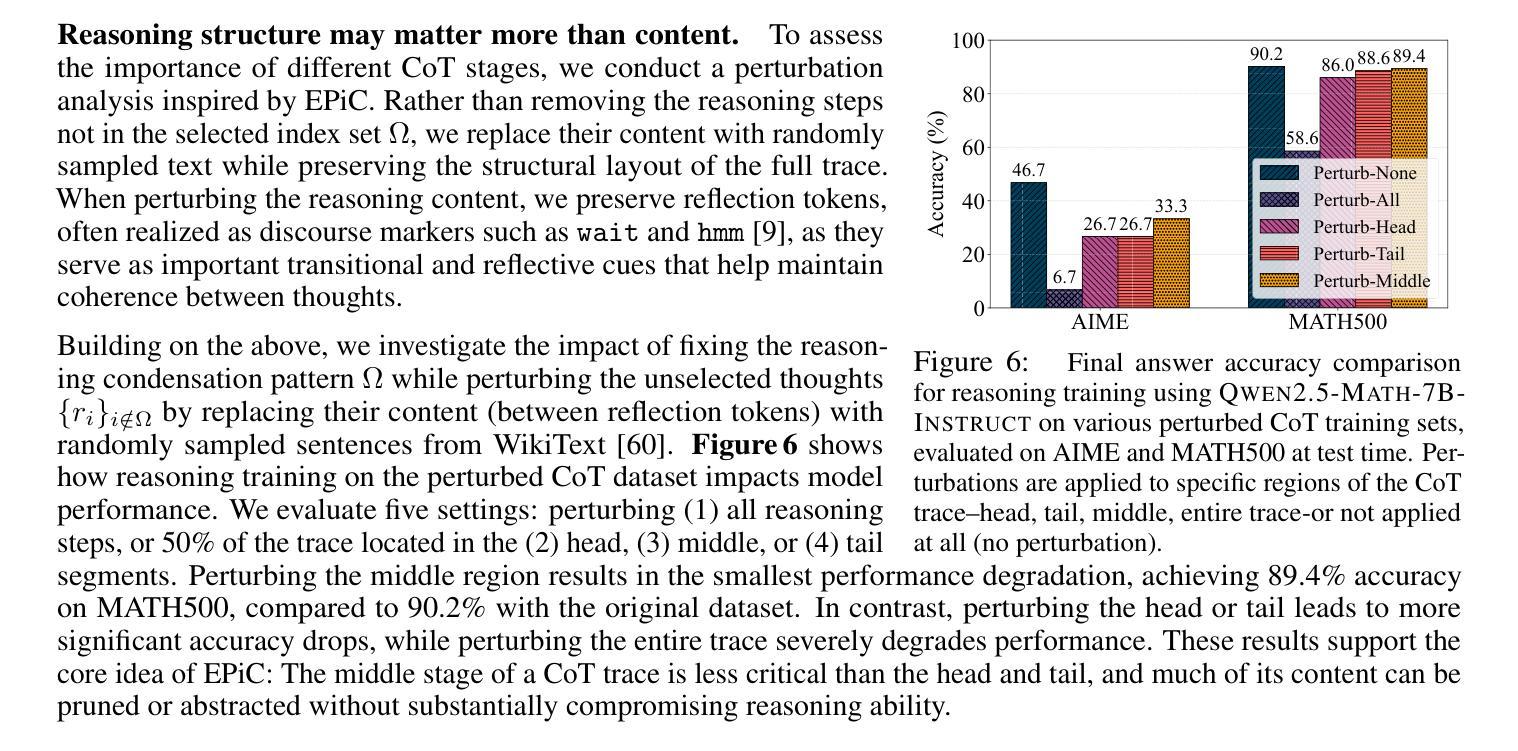
Large language models (LLMs) have shown remarkable reasoning capabilities when trained with chain-of-thought (CoT) supervision. However, the long and verbose CoT traces, especially those distilled from large reasoning models (LRMs) such as DeepSeek-R1, significantly increase training costs during the distillation process, where a non-reasoning base model is taught to replicate the reasoning behavior of an LRM. In this work, we study the problem of CoT condensation for resource-efficient reasoning training, aimed at pruning intermediate reasoning steps (i.e., thoughts) in CoT traces, enabling supervised model training on length-reduced CoT data while preserving both answer accuracy and the model’s ability to generate coherent reasoning. Our rationale is that CoT traces typically follow a three-stage structure: problem understanding, exploration, and solution convergence. Through empirical analysis, we find that retaining the structure of the reasoning trace, especially the early stage of problem understanding (rich in reflective cues) and the final stage of solution convergence, is sufficient to achieve lossless reasoning supervision. To this end, we propose an Edge-Preserving Condensation method, EPiC, which selectively retains only the initial and final segments of each CoT trace while discarding the middle portion. This design draws an analogy to preserving the “edge” of a reasoning trajectory, capturing both the initial problem framing and the final answer synthesis, to maintain logical continuity. Experiments across multiple model families (Qwen and LLaMA) and benchmarks show that EPiC reduces training time by over 34% while achieving lossless reasoning accuracy on MATH500, comparable to full CoT supervision. To the best of our knowledge, this is the first study to explore thought-level CoT condensation for efficient reasoning model distillation.
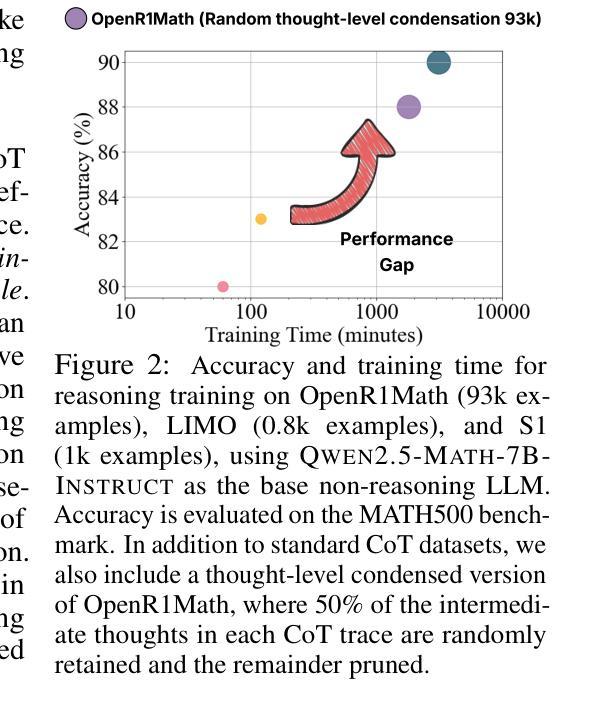
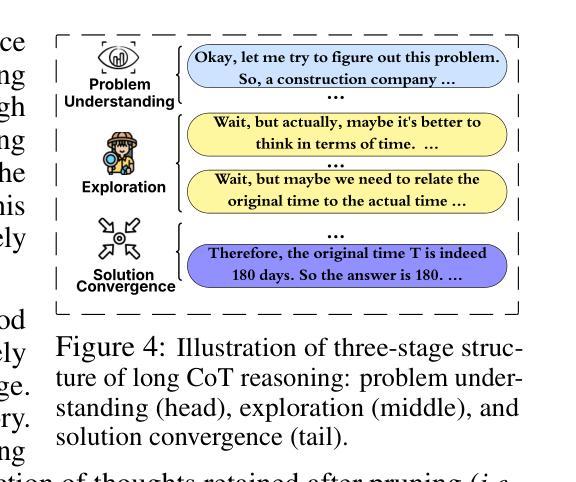
大规模语言模型(LLMs)在采用思维链(CoT)监督进行训练时,展现出了显著的推理能力。然而,尤其是从大型推理模型(如DeepSeek-R1)中提炼出的思维链轨迹既长又冗长,在提炼过程中显著增加了训练成本,这里的非推理基础模型被教导去复制LRM的推理行为。在这项工作中,我们研究了面向资源高效推理训练的CoT凝练问题,旨在缩减思维链轨迹中的中间推理步骤(即思维),在缩减长度的CoT数据上进行监督模型训练,同时保留答案准确性和模型生成连贯推理的能力。我们的理念是,CoT轨迹通常遵循三阶段结构:理解问题、探索和解决方案收敛。通过实证分析,我们发现保留推理轨迹的结构,特别是理解问题的早期阶段(富含反思线索)和解决方案收敛的最后一个阶段,足以实现无损推理监督。为此,我们提出了一种边缘保留凝练方法EPiC,它选择性地仅保留每个CoT轨迹的初始和最终片段,同时丢弃中间部分。这种设计类似于保留推理轨迹的“边缘”,捕捉最初的的问题框架和最终的答案综合,以保持逻辑连贯性。在多个模型家族(Qwen和LLaMA)和基准测试上的实验表明,EPiC通过减少超过34%的训练时间,在MATH500上实现了无损推理准确性,与全CoT监督相当。据我们所知,这是第一项探索高效推理模型蒸馏中的思维层面CoT凝练的研究。
论文及项目相关链接
摘要
大型语言模型通过链式思维监督展现出惊人的推理能力。然而,这种长而繁琐的思维链追踪,特别是那些从深度寻知等大规模推理模型蒸馏得来的,显著增加了蒸馏过程中的训练成本。在资源效率推理训练中,本文研究了思维链追踪凝聚的问题,目标是删减思维链追踪中的中间推理步骤,使监督模型能够在缩短的思维链数据上进行训练,同时保持答案准确性和模型的连贯推理能力。我们的理念是,思维链追踪通常遵循三阶段结构:理解问题、探索阶段和解决方案收敛。通过实证分析,我们发现保留推理追踪的结构,特别是理解问题的早期阶段(富含反思线索)和解决方案收敛的最终阶段,足以实现无损推理监督。为此,我们提出了一种边缘保留凝聚法(EPiC),该方法有选择地仅保留每个思维链追踪的初始和最终部分,同时丢弃中间部分。这种设计类似于捕捉推理轨迹的“边缘”,既保持问题的初步框架又保留最终答案的合成,从而维持逻辑连贯性。在多个模型家族(如Qwen和LLaMA)和基准测试上的实验表明,EPiC将训练时间减少了超过34%,同时在MATH500上的无损推理准确性可与全思维链监督相媲美。据我们所知,这是首次探索思维层面的思维链凝聚以有效提高推理模型蒸馏效率的研究。
关键见解
- 大型语言模型通过链式思维监督展现出强大的推理能力,但训练过程中存在高成本问题。
- 提出思维链凝聚(CoT condensation)以优化资源效率,通过删减中间推理步骤降低训练成本。
- 思维链追踪通常遵循三阶段结构:理解问题、探索和解决方案收敛。
- 保留思维链追踪的结构,特别是问题理解阶段和解决方案收敛阶段,对于实现无损推理监督至关重要。
- 引入边缘保留凝聚法(EPiC),该方法选择保留思维链追踪的初始和最终部分,实现逻辑连贯性的维持。
- EPiC方法显著减少训练时间,同时在基准测试上保持无损推理准确性。
点此查看论文截图


R-Search: Empowering LLM Reasoning with Search via Multi-Reward Reinforcement Learning
Authors:Qingfei Zhao, Ruobing Wang, Dingling Xu, Daren Zha, Limin Liu
Large language models (LLMs) have notably progressed in multi-step and long-chain reasoning. However, extending their reasoning capabilities to encompass deep interactions with search remains a non-trivial challenge, as models often fail to identify optimal reasoning-search interaction trajectories, resulting in suboptimal responses. We propose R-Search, a novel reinforcement learning framework for Reasoning-Search integration, designed to enable LLMs to autonomously execute multi-step reasoning with deep search interaction, and learn optimal reasoning search interaction trajectories via multi-reward signals, improving response quality in complex logic- and knowledge-intensive tasks. R-Search guides the LLM to dynamically decide when to retrieve or reason, while globally integrating key evidence to enhance deep knowledge interaction between reasoning and search. During RL training, R-Search provides multi-stage, multi-type rewards to jointly optimize the reasoning-search trajectory. Experiments on seven datasets show that R-Search outperforms advanced RAG baselines by up to 32.2% (in-domain) and 25.1% (out-of-domain). The code and data are available at https://github.com/QingFei1/R-Search.
大型语言模型(LLM)在多步和长链推理方面取得了显著进展。然而,将其推理能力扩展到与搜索的深度交互仍是一项非平凡的挑战,因为模型往往无法识别最佳的推理-搜索交互轨迹,从而导致次优响应。我们提出了R-Search,这是一个用于推理-搜索融合的新型强化学习框架,旨在使LLM能够自主执行具有深度搜索交互的多步推理,并通过多奖励信号学习最佳的推理搜索交互轨迹,从而提高在复杂逻辑和知识密集型任务中的响应质量。R-Search指导LLM动态决定何时进行检索或推理,同时全局集成关键证据,增强推理和搜索之间的深度知识交互。在强化学习训练过程中,R-Search提供多阶段、多类型的奖励来共同优化推理-搜索轨迹。在七个数据集上的实验表明,R-Search相较于先进的RAG基准测试,其性能提高了高达32.2%(领域内)和25.1%(跨领域)。代码和数据集可在https://github.com/QingFei1/R-Search获得。
论文及项目相关链接
PDF 16 pages, 3 figures
Summary
大型语言模型(LLMs)在多步和长链推理方面取得显著进展,但在深度搜索交互方面的推理能力仍然面临挑战。我们提出了R-Search,一个基于强化学习的新框架,旨在使LLM能够自主执行具有深度搜索交互的多步推理,并通过多种奖励信号学习最佳的推理搜索交互轨迹,从而提高在复杂逻辑和知识密集型任务中的响应质量。R-Search框架可动态决定何时进行检索和推理,同时全局整合关键证据,增强推理和搜索之间的深度知识交互。实验结果显示,R-Search在七个数据集上的表现优于先进的RAG基准测试,最高提升率达32.2%(领域内)和25.1%(跨领域)。
Key Takeaways
- 大型语言模型(LLMs)在多步和长链推理上有所突破,但在与搜索的深度交互方面仍存在挑战。
- R-Search是一个新的强化学习框架,旨在整合推理与搜索,使LLM能够自主执行多步推理并深度参与搜索交互。
- R-Search通过多重奖励信号优化推理搜索交互轨迹,旨在提高复杂逻辑和知识密集型任务的响应质量。
- R-Search能动态平衡检索与推理的决策过程,并全局整合关键证据。
- R-Search框架增强了推理和搜索之间的深度知识交互。
- 实验结果显示,R-Search在多个数据集上的表现优于现有方法,具有显著的提升效果。
点此查看论文截图

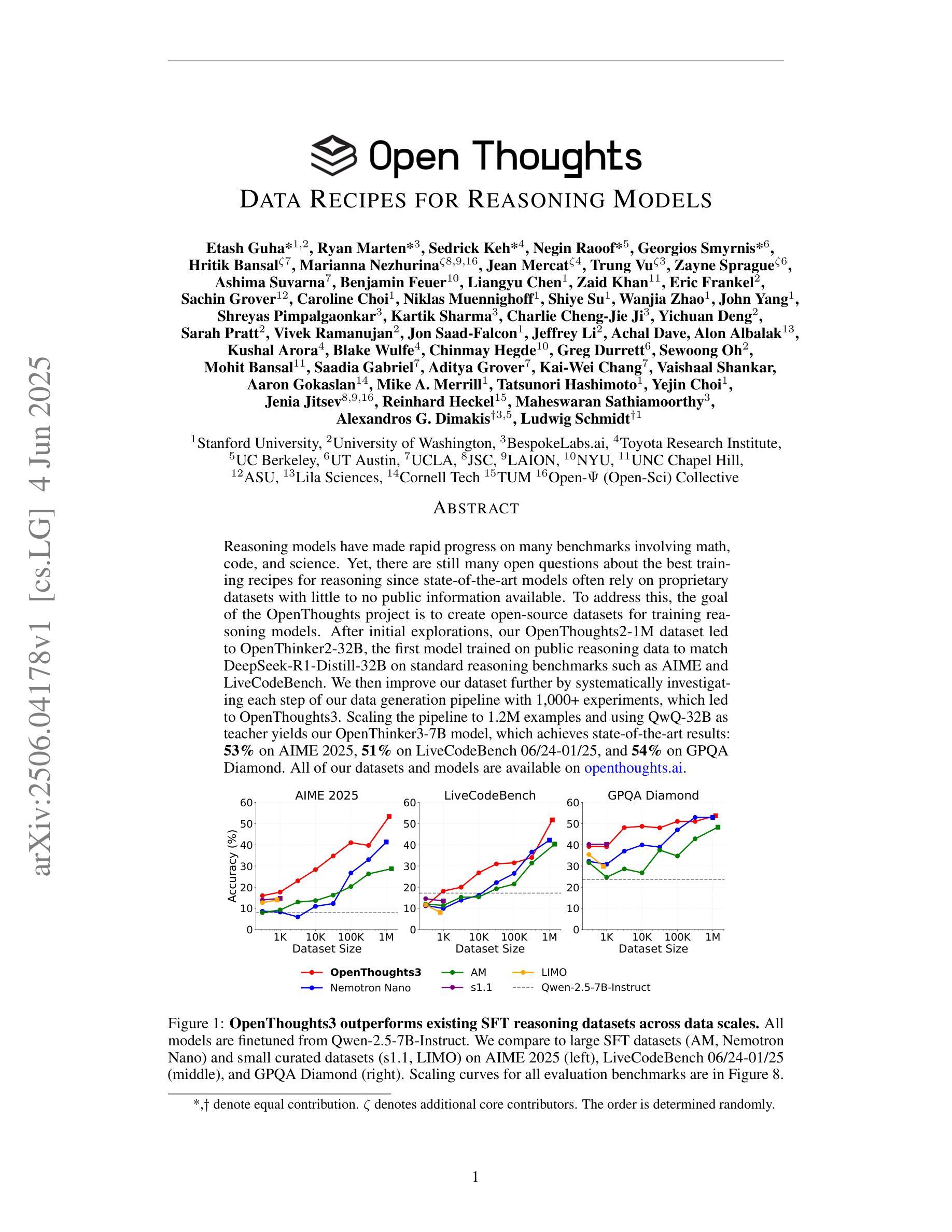
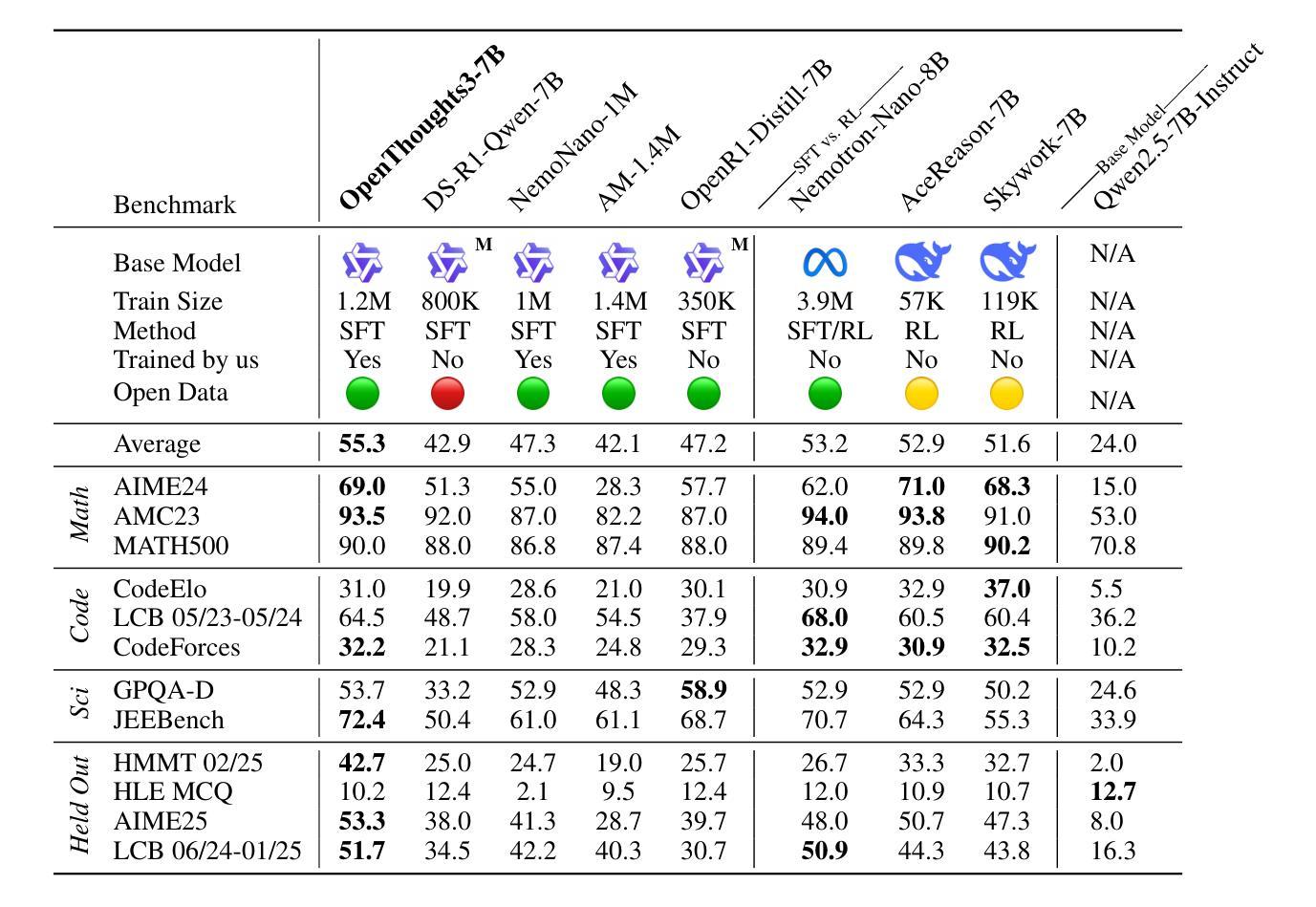
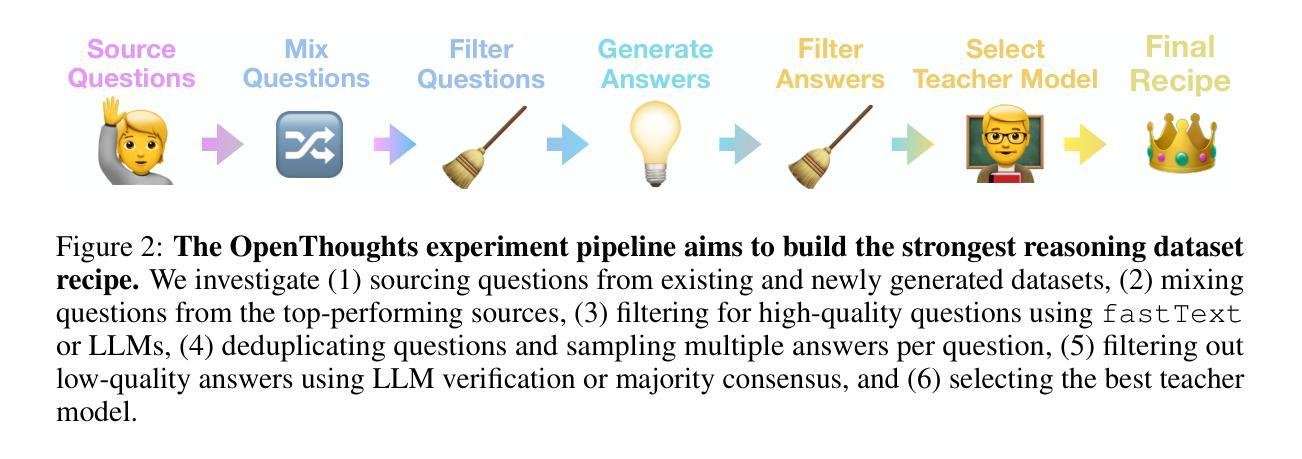
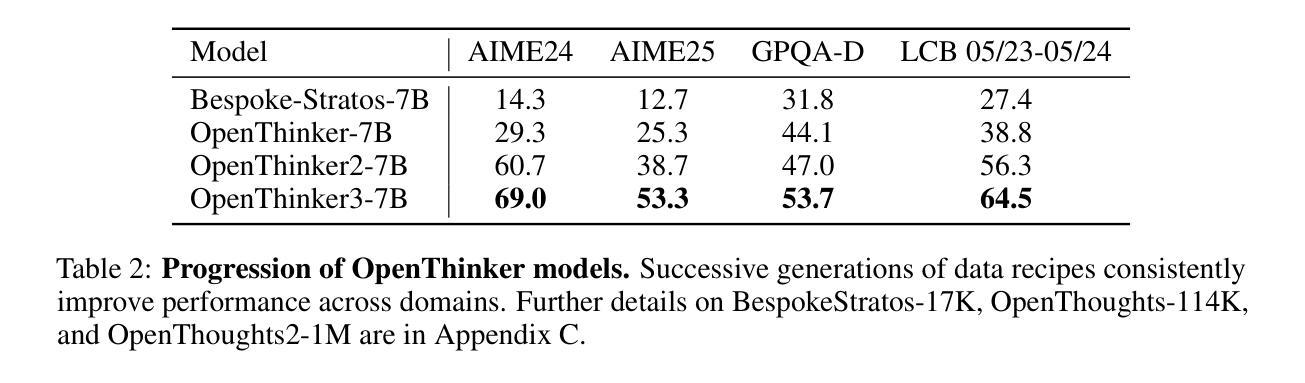
OpenThoughts: Data Recipes for Reasoning Models
Authors:Etash Guha, Ryan Marten, Sedrick Keh, Negin Raoof, Georgios Smyrnis, Hritik Bansal, Marianna Nezhurina, Jean Mercat, Trung Vu, Zayne Sprague, Ashima Suvarna, Benjamin Feuer, Liangyu Chen, Zaid Khan, Eric Frankel, Sachin Grover, Caroline Choi, Niklas Muennighoff, Shiye Su, Wanjia Zhao, John Yang, Shreyas Pimpalgaonkar, Kartik Sharma, Charlie Cheng-Jie Ji, Yichuan Deng, Sarah Pratt, Vivek Ramanujan, Jon Saad-Falcon, Jeffrey Li, Achal Dave, Alon Albalak, Kushal Arora, Blake Wulfe, Chinmay Hegde, Greg Durrett, Sewoong Oh, Mohit Bansal, Saadia Gabriel, Aditya Grover, Kai-Wei Chang, Vaishaal Shankar, Aaron Gokaslan, Mike A. Merrill, Tatsunori Hashimoto, Yejin Choi, Jenia Jitsev, Reinhard Heckel, Maheswaran Sathiamoorthy, Alexandros G. Dimakis, Ludwig Schmidt
Reasoning models have made rapid progress on many benchmarks involving math, code, and science. Yet, there are still many open questions about the best training recipes for reasoning since state-of-the-art models often rely on proprietary datasets with little to no public information available. To address this, the goal of the OpenThoughts project is to create open-source datasets for training reasoning models. After initial explorations, our OpenThoughts2-1M dataset led to OpenThinker2-32B, the first model trained on public reasoning data to match DeepSeek-R1-Distill-32B on standard reasoning benchmarks such as AIME and LiveCodeBench. We then improve our dataset further by systematically investigating each step of our data generation pipeline with 1,000+ controlled experiments, which led to OpenThoughts3. Scaling the pipeline to 1.2M examples and using QwQ-32B as teacher yields our OpenThinker3-7B model, which achieves state-of-the-art results: 53% on AIME 2025, 51% on LiveCodeBench 06/24-01/25, and 54% on GPQA Diamond. All of our datasets and models are available on https://openthoughts.ai.
推理模型在数学、代码和科学等多个基准测试上取得了快速进展。然而,关于最佳推理训练方案仍然存在许多未解的问题,因为最先进的模型通常依赖于专有数据集,而公众能接触到的信息很少。为了解决这一问题,OpenThoughts项目的目标是创建用于训练推理模型的开源数据集。经过初步探索,我们的OpenThoughts2-1M数据集催生了OpenThinker2-32B模型,它是首个在公开推理数据上训练的模型,在AIME和LiveCodeBench等标准推理基准测试上与DeepSeek-R1-Distill-32B相匹配。然后,我们通过系统地调查数据生成管道的每一步进行了1000多次受控实验,进一步改进了我们的数据集,从而产生了OpenThoughts3。将管道扩展到120万个例子,并使用QwQ-32B作为教师,我们得到了OpenThinker3-7B模型,取得了最新结果:AIME 2025达成率为53%,LiveCodeBench 06/24-01/25达成率为51%,GPQA Diamond达成率为54%。我们的所有数据集和模型都可在https://openthoughts.ai上找到。
论文及项目相关链接
PDF https://www.openthoughts.ai/blog/ot3
Summary
随着推理模型在许多涉及数学、代码和科学的基准测试上取得快速进展,关于最佳训练配方的问题仍然存在。为了解决这一问题,OpenThoughts项目的目标是创建用于训练推理模型的开源数据集。经过初步探索和对数据集系统的改进,他们的OpenThoughts数据集培育出能在公共推理数据上训练的OpenThinker模型,匹配DeepSeek-R1-Distill在AIME和LiveCodeBench等标准基准测试上的表现。其最新的OpenThoughts数据集培育出OpenThinker3-7B模型,达到业界顶尖水平,相关数据和模型均可从https://openthoughts.ai获取。
Key Takeaways
- 推理模型在多个基准测试中取得快速进展,但仍存在关于最佳训练方法的开放问题。
- OpenThoughts项目的目标是创建开源数据集以训练推理模型。
- OpenThoughts数据集成功培育出OpenThinker模型系列,能在公共推理数据上训练并与DeepSeek-R1-Distill相当。
- OpenThinker系列模型在不同基准测试中表现优异,例如AIME和LiveCodeBench等。
- OpenThoughts项目通过系统地改进数据集生成流程,进行了超过一千次的受控实验。
- OpenThoughts项目最新的数据集是OpenThoughts3,培育出了具有业界顶尖水平的OpenThinker3-7B模型。
点此查看论文截图
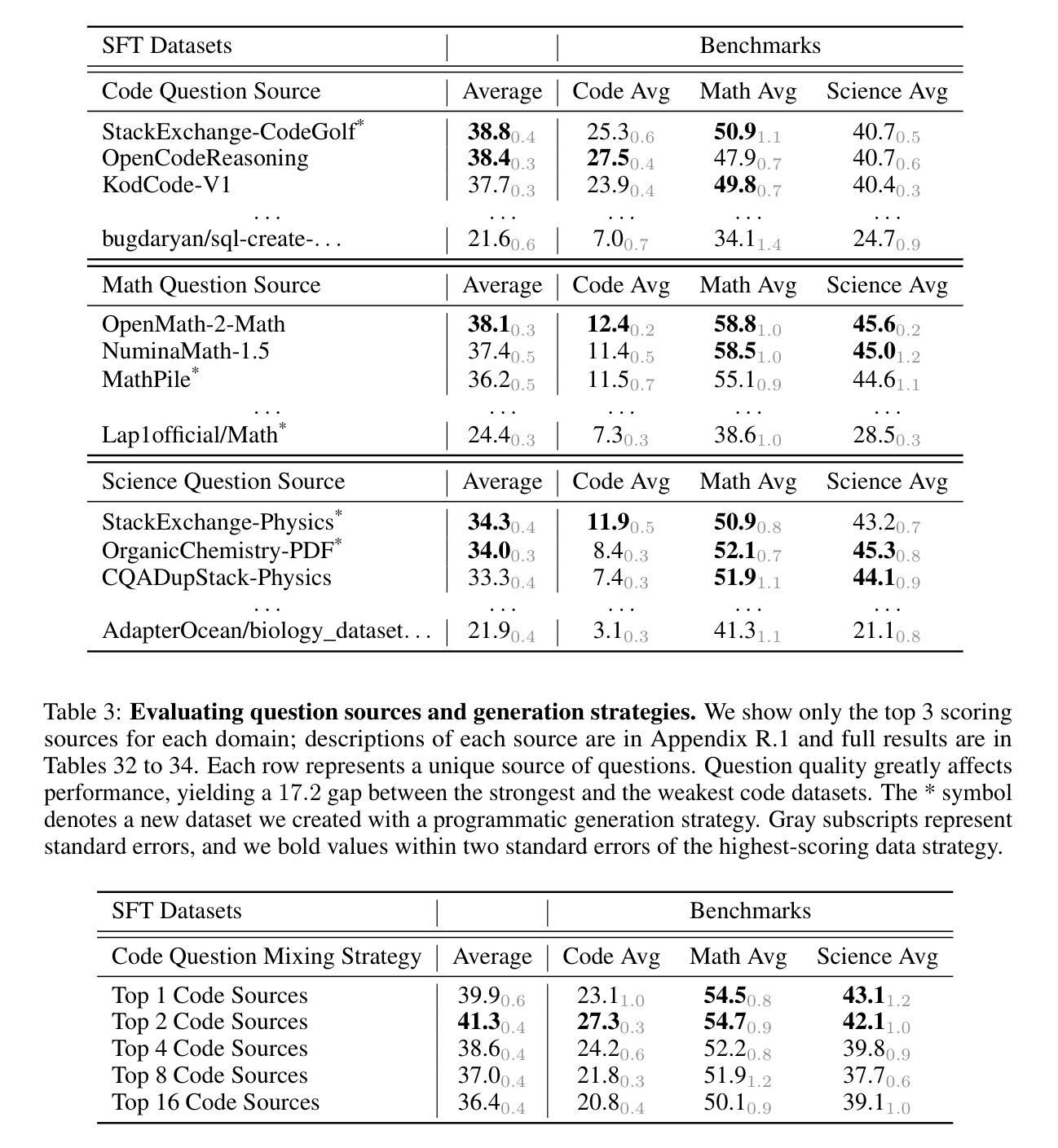
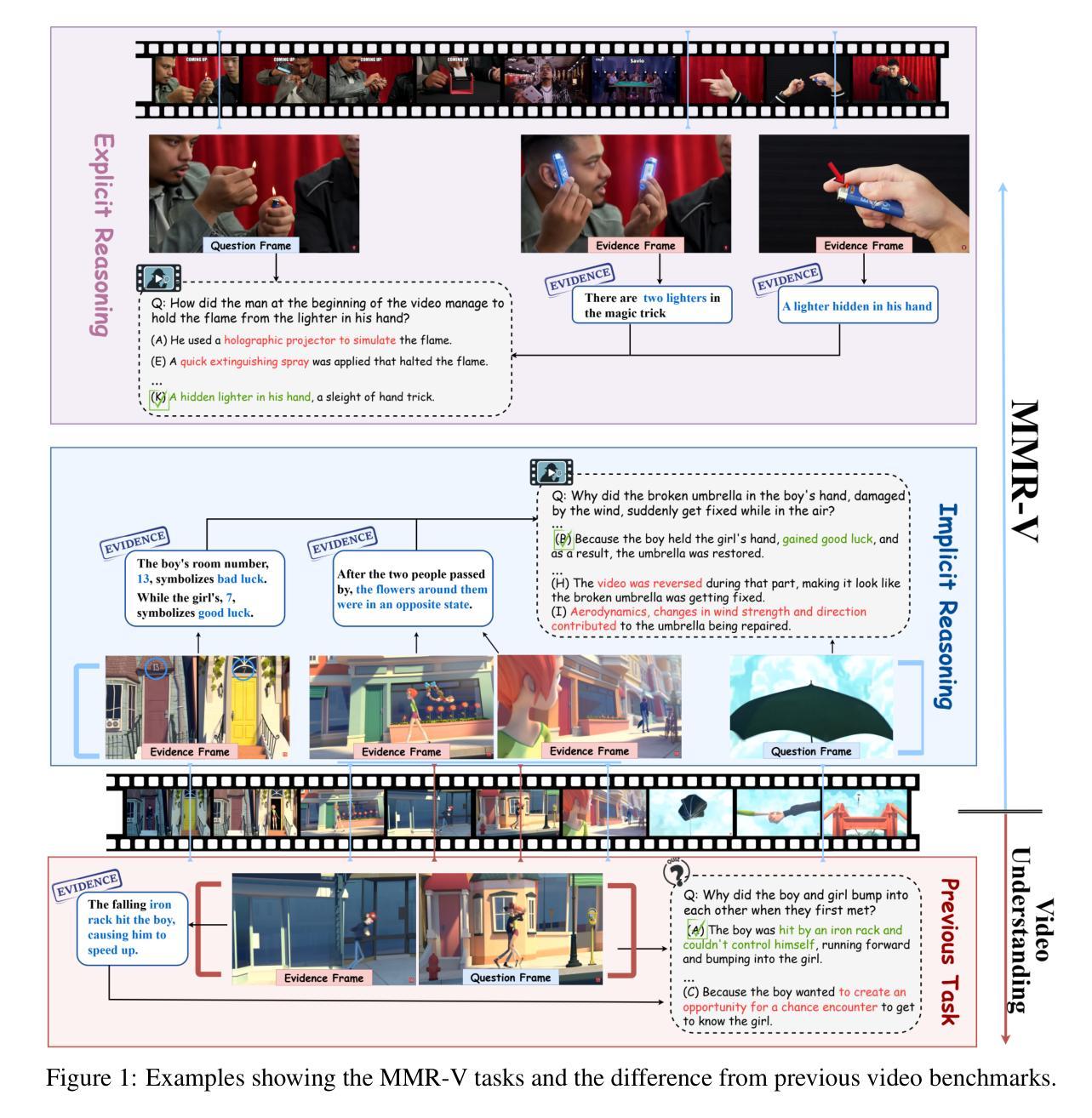
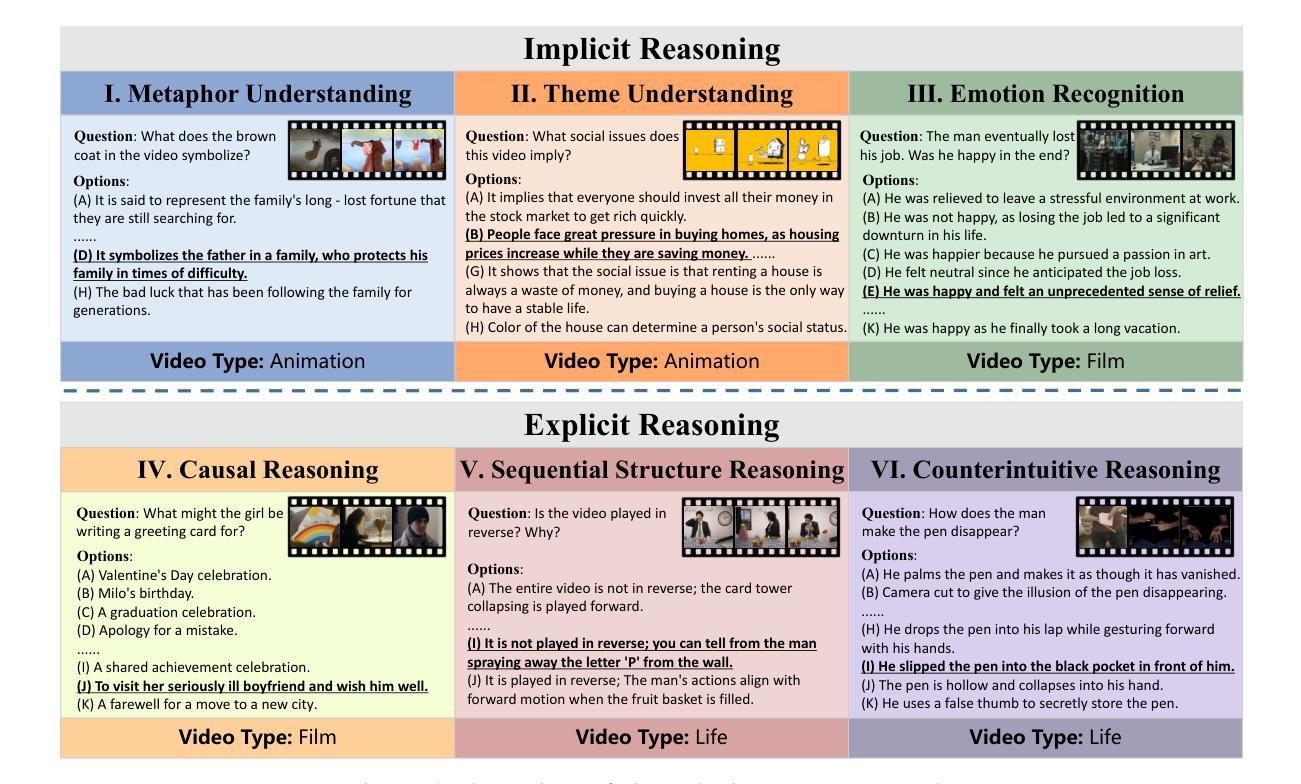
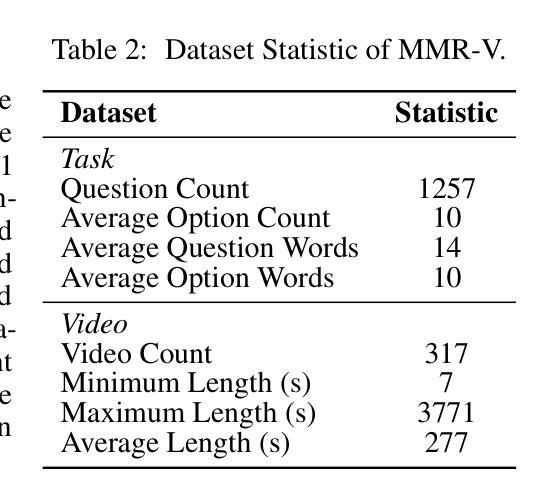
MMR-V: What’s Left Unsaid? A Benchmark for Multimodal Deep Reasoning in Videos
Authors:Kejian Zhu, Zhuoran Jin, Hongbang Yuan, Jiachun Li, Shangqing Tu, Pengfei Cao, Yubo Chen, Kang Liu, Jun Zhao
The sequential structure of videos poses a challenge to the ability of multimodal large language models (MLLMs) to locate multi-frame evidence and conduct multimodal reasoning. However, existing video benchmarks mainly focus on understanding tasks, which only require models to match frames mentioned in the question (hereafter referred to as “question frame”) and perceive a few adjacent frames. To address this gap, we propose MMR-V: A Benchmark for Multimodal Deep Reasoning in Videos. The benchmark is characterized by the following features. (1) Long-range, multi-frame reasoning: Models are required to infer and analyze evidence frames that may be far from the question frame. (2) Beyond perception: Questions cannot be answered through direct perception alone but require reasoning over hidden information. (3) Reliability: All tasks are manually annotated, referencing extensive real-world user understanding to align with common perceptions. (4) Confusability: Carefully designed distractor annotation strategies to reduce model shortcuts. MMR-V consists of 317 videos and 1,257 tasks. Our experiments reveal that current models still struggle with multi-modal reasoning; even the best-performing model, o4-mini, achieves only 52.5% accuracy. Additionally, current reasoning enhancement strategies (Chain-of-Thought and scaling test-time compute) bring limited gains. Further analysis indicates that the CoT demanded for multi-modal reasoning differs from it in textual reasoning, which partly explains the limited performance gains. We hope that MMR-V can inspire further research into enhancing multi-modal reasoning capabilities.
视频的连续结构对多模态大型语言模型(MLLMs)在定位多帧证据和进行多模态推理的能力上提出了挑战。然而,现有的视频基准测试主要关注理解任务,这些任务只需要模型匹配问题中提到的帧(以下简称“问题帧”)并感知少数相邻帧。为了弥补这一空白,我们提出了MMR-V:视频多模态深度推理的基准测试。该基准测试的特点如下:(1)长程多帧推理:模型需要推断和分析可能远离问题帧的证据帧。(2)超越感知:问题不能仅通过直接感知来回答,而是需要推理隐藏的信息。(3)可靠性:所有任务都是手动注释的,参考广泛的实际用户理解,以符合普遍认知。(4)混淆性:精心设计的干扰注释策略,以减少模型的捷径。MMR-V包含317个视频和1257个任务。我们的实验表明,当前模型在多模态推理方面仍然面临困难;即使表现最佳的模型o4-mini也仅达到52.5%的准确率。此外,当前推理增强策略(思维链和扩展测试时间计算)带来的收益有限。进一步分析表明,多模态推理所需的思维链与文本推理有所不同,这部分解释了性能提升有限的原因。我们希望MMR-V能够激发对增强多模态推理能力的进一步研究。
论文及项目相关链接
PDF Project Page: https://mmr-v.github.io
Summary
本文介绍了视频中的多模态深度推理基准测试MMR-V。该基准测试的特点包括长程多帧推理、超越感知的隐藏信息推理、任务手动标注与真实世界用户理解对齐以及设计混淆标注策略。实验表明,当前模型在多模态推理方面仍有困难,最佳模型o4-mini的准确率仅为52.5%,现有的推理增强策略带来有限收益。
Key Takeaways
- 多模态大型语言模型(MLLMs)在视频中的序贯结构定位多帧证据和多模态推理方面面临挑战。
- 现有视频基准测试主要关注理解任务,要求模型匹配问题中的帧并感知少量相邻帧,存在局限。
- MMR-V基准测试具有长程多帧推理、超越感知的隐藏信息推理等特征。
- MMR-V包含317个视频和1,257个任务,采用手动标注,与真实世界用户理解对齐。
- 当前模型在MMR-V上的表现不佳,最佳模型o4-mini的准确率仅为52.5%。
- 现有的推理增强策略(如Chain-of-Thought和测试时间计算扩展)对多模态推理的增益有限。
点此查看论文截图


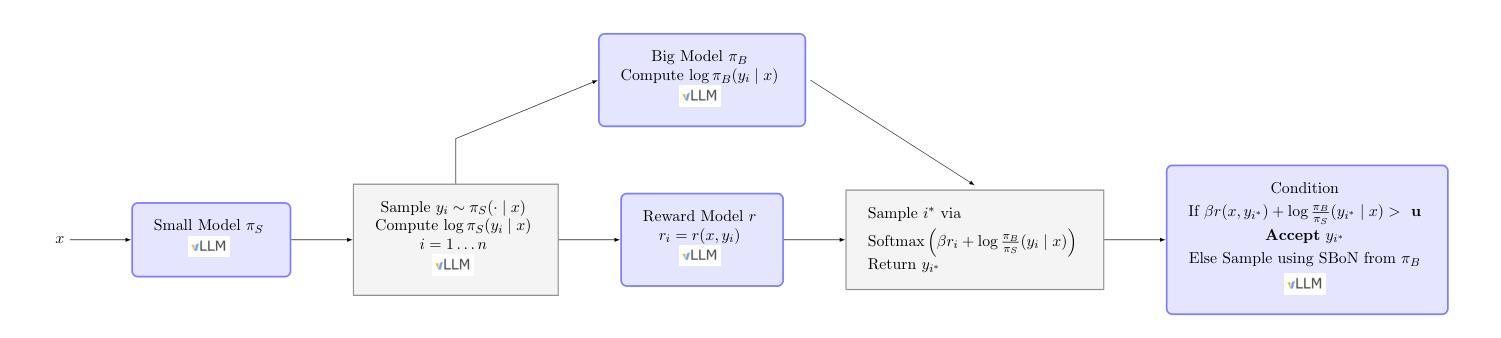
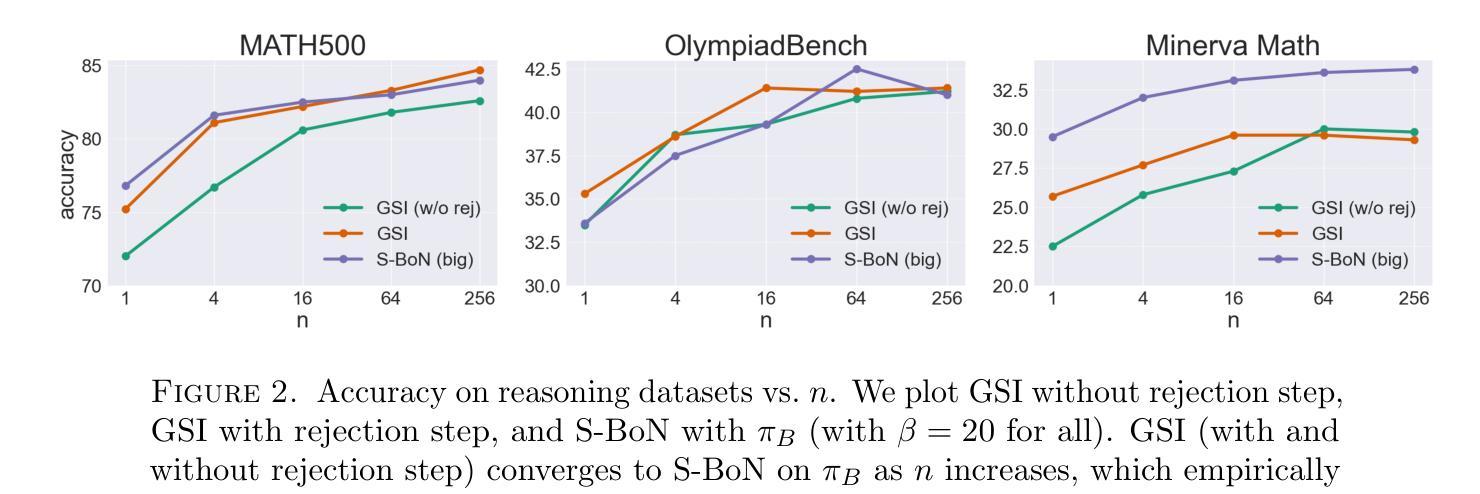
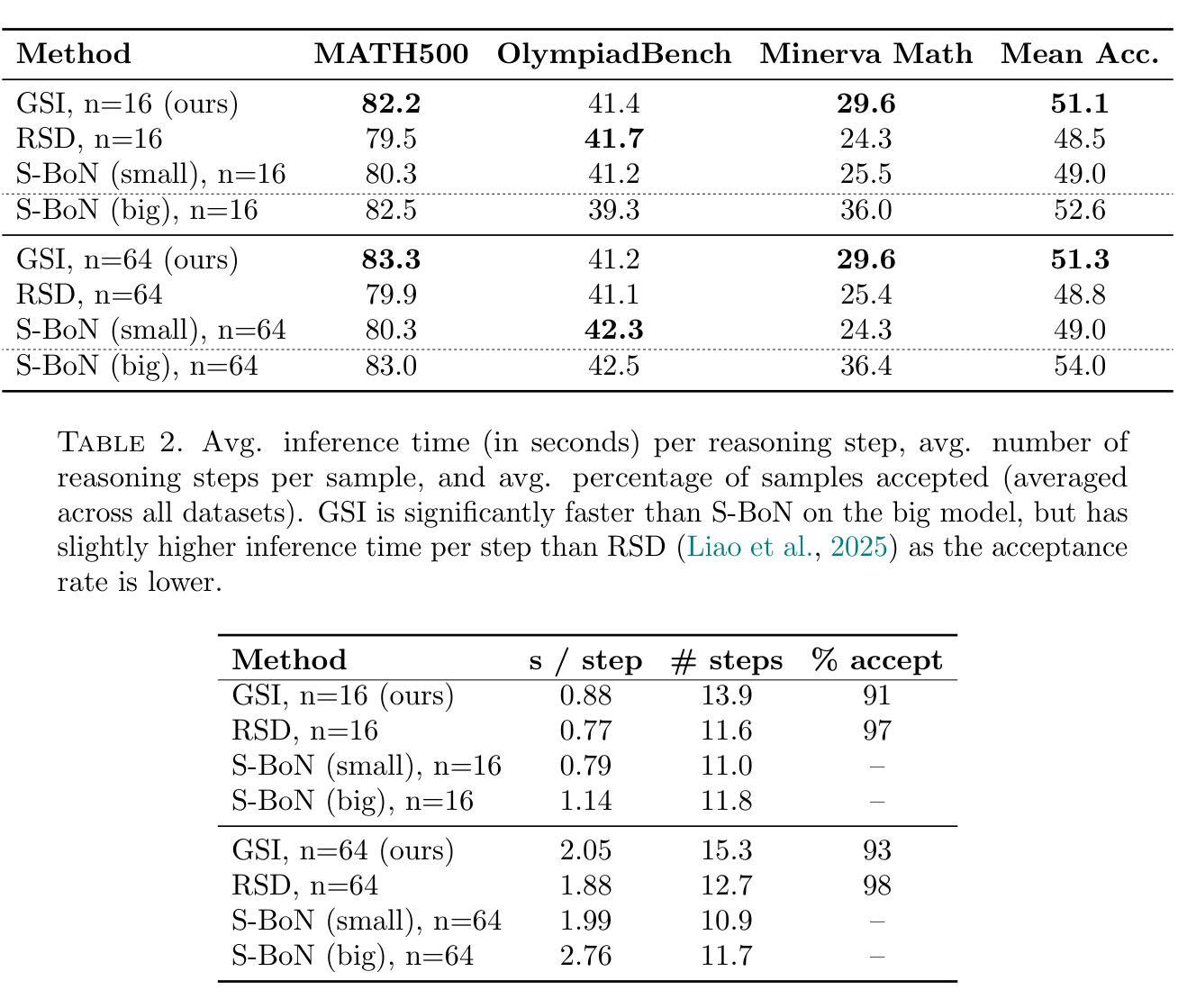
Guided Speculative Inference for Efficient Test-Time Alignment of LLMs
Authors:Jonathan Geuter, Youssef Mroueh, David Alvarez-Melis
We propose Guided Speculative Inference (GSI), a novel algorithm for efficient reward-guided decoding in large language models. GSI combines soft best-of-$n$ test-time scaling with a reward model $r(x,y)$ and speculative samples from a small auxiliary model $\pi_S(y\mid x)$. We provably approximate the optimal tilted policy $\pi_{\beta,B}(y\mid x) \propto \pi_B(y\mid x)\exp(\beta,r(x,y))$ of soft best-of-$n$ under the primary model $\pi_B$. We derive a theoretical bound on the KL divergence between our induced distribution and the optimal policy. In experiments on reasoning benchmarks (MATH500, OlympiadBench, Minerva Math), our method achieves higher accuracy than standard soft best-of-$n$ with $\pi_S$ and reward-guided speculative decoding (Liao et al., 2025), and in certain settings even outperforms soft best-of-$n$ with $\pi_B$. The code is available at https://github.com/j-geuter/GSI .
我们提出了引导式推测推理(GSI)这一新颖算法,该算法可实现大型语言模型中高效的奖励引导解码。GSI将软最好的n个测试时间缩放与奖励模型r(x,y)以及从小型辅助模型πS(y∣x)生成的推测样本相结合。我们可以证明,在主要模型πB下,我们对软最好的n个最优倾斜策略πβ,B(y∣x)≈πB(y∣x)exp(βr(x,y))进行了近似。我们推导出了我们所产生的分布与最优策略之间的KL散度的理论界限。在MATH500、OlympiadBench和Minerva Math等推理基准测试实验中,我们的方法达到了比使用πS和奖励引导推测解码的标准软最好的n个更高的精度(Liao等人,2025),在某些情况下甚至超过了使用πB的软最好的n个。代码可在https://github.com/j-geuter/GSI找到。
论文及项目相关链接
PDF 12 pages, 2 figures
Summary
本文提出一种名为引导式推测推断(GSI)的新算法,该算法用于大型语言模型中的奖励引导解码,实现高效推理。GSI结合了软选择N个最佳答案的测试时间缩放、奖励模型r(x,y)以及来自小型辅助模型πS(y∣x)的推测样本。该算法可近似模拟软选择N个最佳答案下的最优倾斜策略πβ,B(y∣x),并在主要模型πB的理论框架下推导出一个关于诱导分布与最优策略之间KL散度的理论界限。在多个数学推理基准测试(MATH500、OlympiadBench、Minerva Math)中,该方法较标准软选择N个最佳答案方法与奖励引导推测解码表现出更高的准确性。代码已公开于GitHub上。
Key Takeaways
- 引入了一种新的算法GSI,用于大型语言模型中的奖励引导解码。
- GSI结合了软选择N个最佳答案的测试时间缩放、奖励模型和辅助模型的推测样本。
3.GSI能够模拟软选择N个最佳答案的最优倾斜策略。
4.推导出了诱导分布与最优策略之间KL散度的理论界限。 - 在多个数学推理基准测试中,GSI较标准方法表现出更高的准确性。
- 代码已公开于GitHub上,便于公众访问和使用。
点此查看论文截图

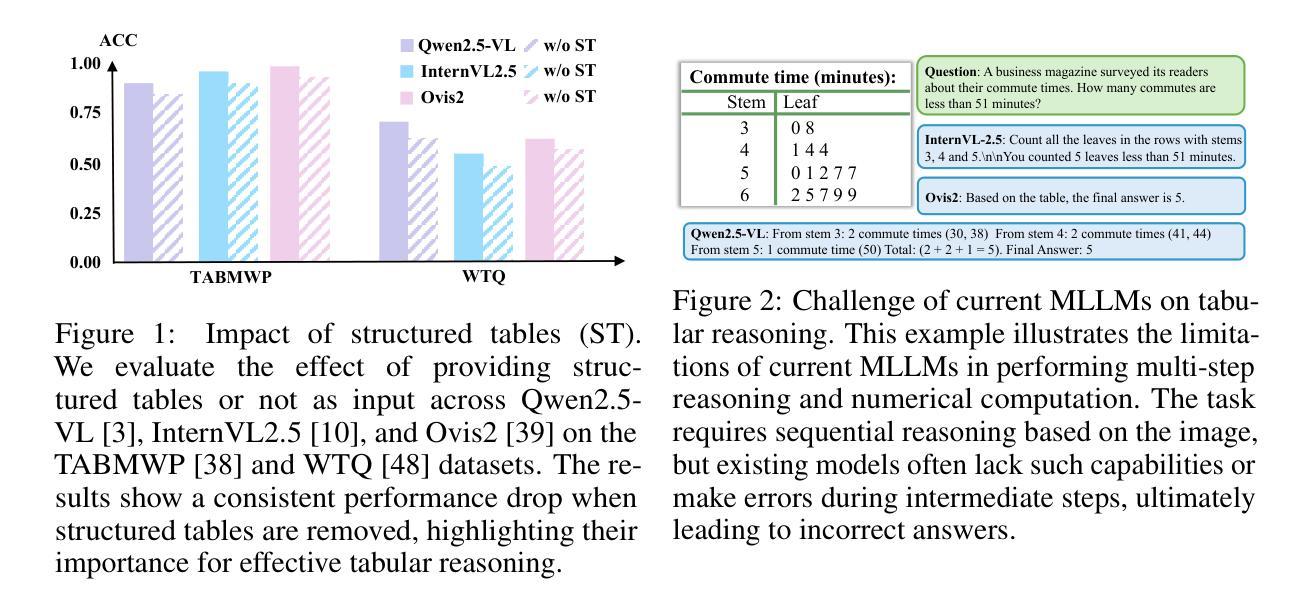
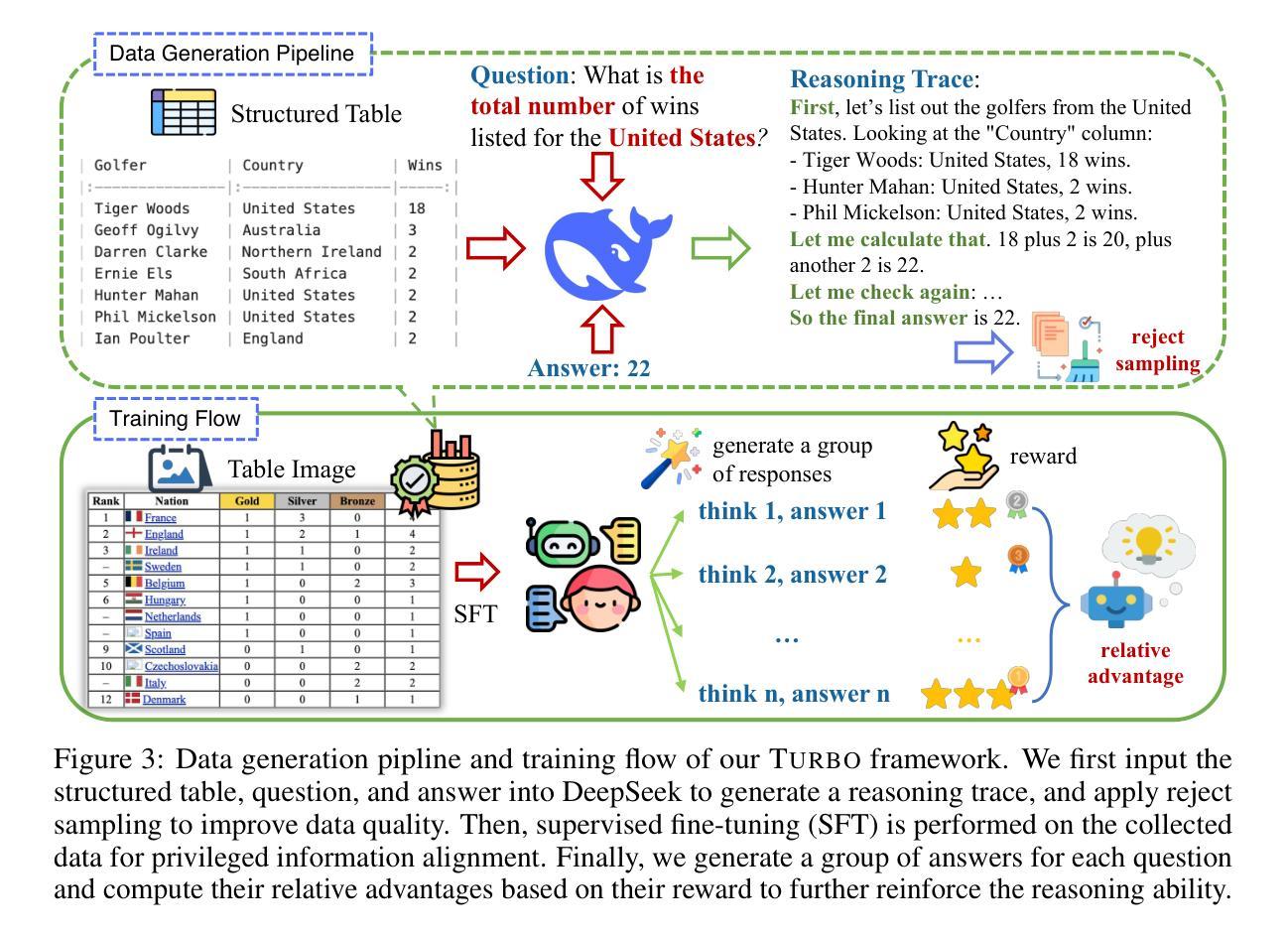
Multimodal Tabular Reasoning with Privileged Structured Information
Authors:Jun-Peng Jiang, Yu Xia, Hai-Long Sun, Shiyin Lu, Qing-Guo Chen, Weihua Luo, Kaifu Zhang, De-Chuan Zhan, Han-Jia Ye
Tabular reasoning involves multi-step information extraction and logical inference over tabular data. While recent advances have leveraged large language models (LLMs) for reasoning over structured tables, such high-quality textual representations are often unavailable in real-world settings, where tables typically appear as images. In this paper, we tackle the task of tabular reasoning from table images, leveraging privileged structured information available during training to enhance multimodal large language models (MLLMs). The key challenges lie in the complexity of accurately aligning structured information with visual representations, and in effectively transferring structured reasoning skills to MLLMs despite the input modality gap. To address these, we introduce TabUlar Reasoning with Bridged infOrmation ({\sc Turbo}), a new framework for multimodal tabular reasoning with privileged structured tables. {\sc Turbo} benefits from a structure-aware reasoning trace generator based on DeepSeek-R1, contributing to high-quality modality-bridged data. On this basis, {\sc Turbo} repeatedly generates and selects the advantageous reasoning paths, further enhancing the model’s tabular reasoning ability. Experimental results demonstrate that, with limited ($9$k) data, {\sc Turbo} achieves state-of-the-art performance ($+7.2%$ vs. previous SOTA) across multiple datasets.
表格推理涉及多步骤的信息提取和表格数据的逻辑推理。尽管最近的进展已经利用大型语言模型(LLM)对结构化表格进行推理,但在现实世界中,高质量文本表示通常不可用,表格通常以图像的形式出现。在本文中,我们解决了从表格图像中进行表格推理的任务,利用训练期间可用的特权结构化信息来增强多模态大型语言模型(MLLM)。关键挑战在于准确地将结构化信息与视觉表示对齐的复杂性,以及尽管存在输入模式差距,仍然有效地将结构化推理技能转移到MLLM上。为了解决这些问题,我们引入了借助特权结构化表格的多模态表格推理的新框架——桥接信息表推理(Turbo)。Turbo受益于基于DeepSeek-R1的结构感知推理轨迹生成器,有助于产生高质量的模式桥接数据。在此基础上,Turbo反复生成并选择有利的推理路径,进一步增强了模型的表格推理能力。实验结果表明,在有限(9k)数据的情况下,Turbo在多个数据集上实现了最先进的性能(较之前的最优方案提高7.2%)。
论文及项目相关链接
Summary
本文探讨的是表格推理任务,即从表格图像中进行信息提取和逻辑推理。文章指出,尽管大型语言模型在文本形式的表格推理中表现优异,但在现实场景中,表格通常以图像形式出现,缺乏高质量文本表示。文章提出一个利用训练时可用结构信息增强多模态大型语言模型(MLLMs)的框架,名为TabUlar Reasoning with Bridged infOrmation(Turbo)。Turbo通过基于DeepSeek-R1的结构感知推理轨迹生成器,产生高质量模态桥接数据。在此基础上,Turbo反复生成并选择有利的推理路径,进一步增强了模型的表格推理能力。实验结果表明,在有限的数据下,Turbo在多个数据集上达到了最先进的性能。
Key Takeaways
- 表格推理涉及从表格图像中进行多步骤信息提取和逻辑推理。
- 大型语言模型在文本形式的表格推理中表现良好,但在现实场景中的表格图像上缺乏高质量文本表示。
- 提出的Turbo框架利用训练时的结构信息增强多模态大型语言模型(MLLMs)。
- Turbo面临的主要挑战是准确对齐结构信息与视觉表示,以及解决输入模态差异导致的推理技能转移问题。
- Turbo采用基于DeepSeek-R1的结构感知推理轨迹生成器,生成高质量模态桥接数据。
- Turbo通过反复生成并选择有利的推理路径,增强了模型的表格推理能力。
点此查看论文截图

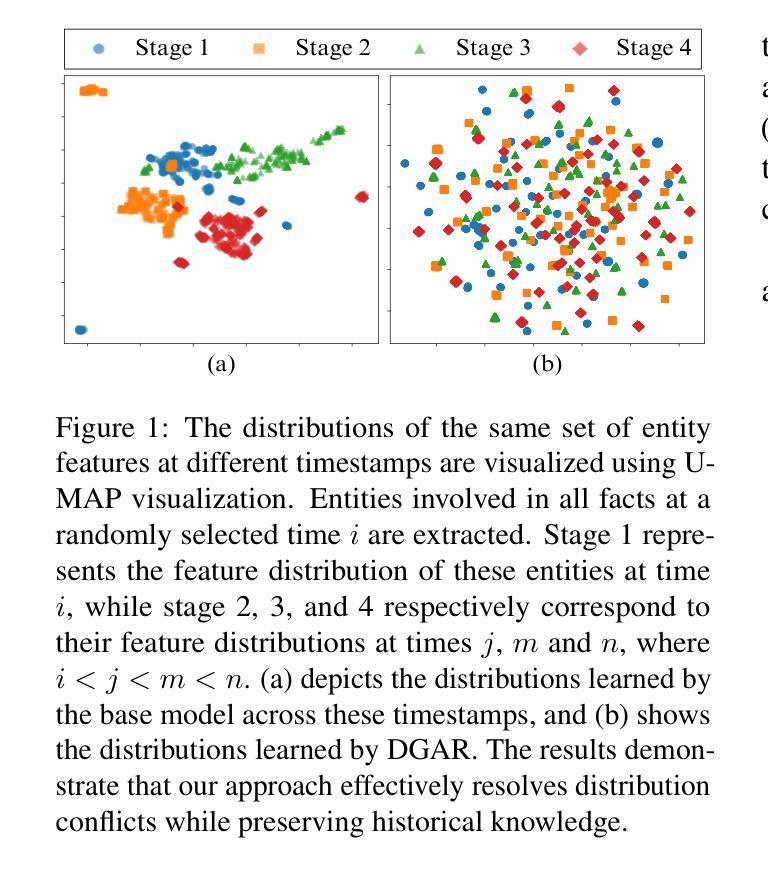
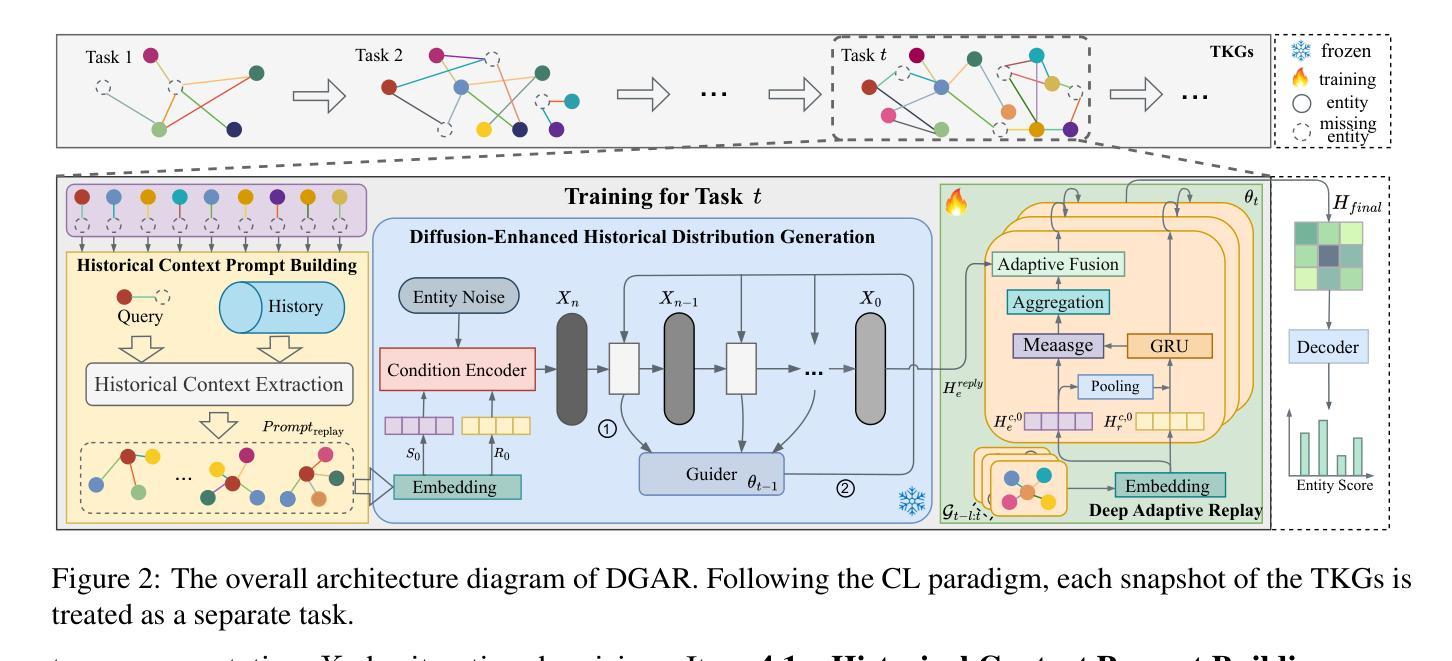
A Generative Adaptive Replay Continual Learning Model for Temporal Knowledge Graph Reasoning
Authors:Zhiyu Zhang, Wei Chen, Youfang Lin, Huaiyu Wan
Recent Continual Learning (CL)-based Temporal Knowledge Graph Reasoning (TKGR) methods focus on significantly reducing computational cost and mitigating catastrophic forgetting caused by fine-tuning models with new data. However, existing CL-based TKGR methods still face two key limitations: (1) They usually one-sidedly reorganize individual historical facts, while overlooking the historical context essential for accurately understanding the historical semantics of these facts; (2) They preserve historical knowledge by simply replaying historical facts, while ignoring the potential conflicts between historical and emerging facts. In this paper, we propose a Deep Generative Adaptive Replay (DGAR) method, which can generate and adaptively replay historical entity distribution representations from the whole historical context. To address the first challenge, historical context prompts as sampling units are built to preserve the whole historical context information. To overcome the second challenge, a pre-trained diffusion model is adopted to generate the historical distribution. During the generation process, the common features between the historical and current distributions are enhanced under the guidance of the TKGR model. In addition, a layer-by-layer adaptive replay mechanism is designed to effectively integrate historical and current distributions. Experimental results demonstrate that DGAR significantly outperforms baselines in reasoning and mitigating forgetting.
最近的基于持续学习(CL)的时间知识图谱推理(TKGR)方法主要集中在显著降低计算成本并减轻由于使用新数据微调模型而产生的灾难性遗忘。然而,现有的基于CL的TKGR方法仍面临两个主要局限:(1)它们通常单方面地重新组织单个历史事实,而忽略了对于准确理解这些事实的历史语义至关重要的历史上下文;(2)它们通过简单地重放历史事实来保留历史知识,而忽略了历史事实与新兴事实之间的潜在冲突。在本文中,我们提出了一种深度生成自适应重放(DGAR)方法,它可以生成并自适应地重放整个历史上下文的实体分布表示。为了解决第一个挑战,构建了历史上下文提示作为采样单元来保留整个历史上下文信息。为了克服第二个挑战,采用了预训练的扩散模型来生成历史分布。在生成过程中,在TKGR模型的指导下,历史和当前分布之间的共同特征得到了增强。此外,设计了一种逐层自适应重放机制,以有效地整合历史和当前分布。实验结果表明,DGAR在推理和减轻遗忘方面显著优于基线。
论文及项目相关链接
Summary
本文介绍了基于持续学习(CL)的时间知识图谱推理(TKGR)方法的最新进展,这些方法旨在降低计算成本并减轻由于新数据微调模型导致的灾难性遗忘。针对现有CL-based TKGR方法的两个关键局限性,本文提出了一种名为Deep Generative Adaptive Replay(DGAR)的方法,通过生成并自适应地重新播放整个历史语境中的实体分布表示来解决挑战。DGAR通过构建历史语境提示作为采样单元来保留整个历史语境信息,并采用预训练的扩散模型生成历史分布。同时,设计了一种逐层自适应回放机制,以有效地整合历史和当前分布。实验结果表明,DGAR在推理和防止遗忘方面显著优于基线方法。
Key Takeaways
- 基于持续学习(CL)的时间知识图谱推理(TKGR)方法旨在降低计算成本并减少灾难性遗忘。
- 现有CL-based TKGR方法存在两个关键局限性:忽视历史上下文信息和历史与新兴事实之间的潜在冲突。
- Deep Generative Adaptive Replay (DGAR) 方法通过生成并自适应地重新播放实体分布表示来解决上述问题。
- DGAR构建历史语境提示作为采样单元,以保留整个历史语境信息。
- DGAR采用预训练的扩散模型生成历史分布,增强历史和当前分布之间的共同特征。
- DGAR设计了一种逐层自适应回放机制,以整合历史和当前分布。
点此查看论文截图

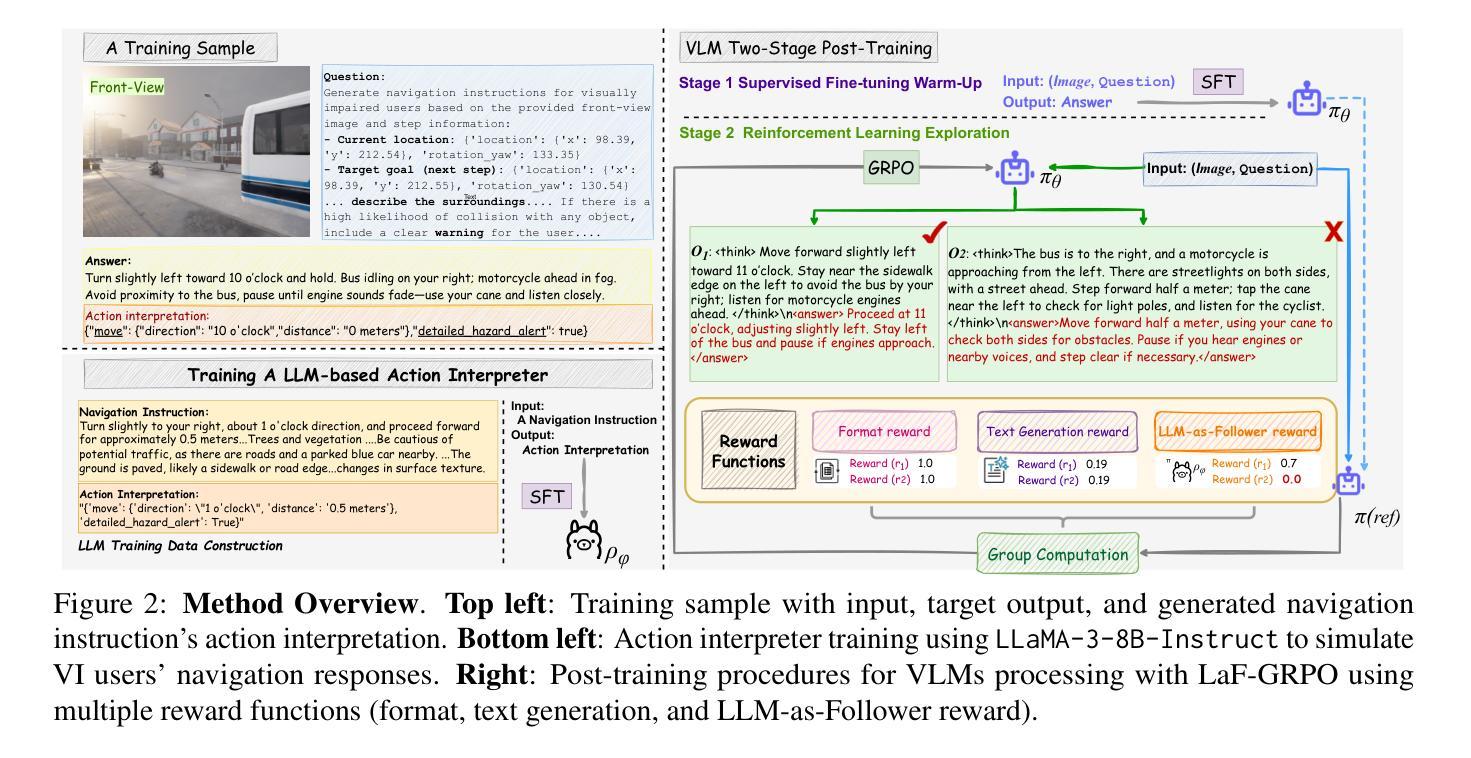
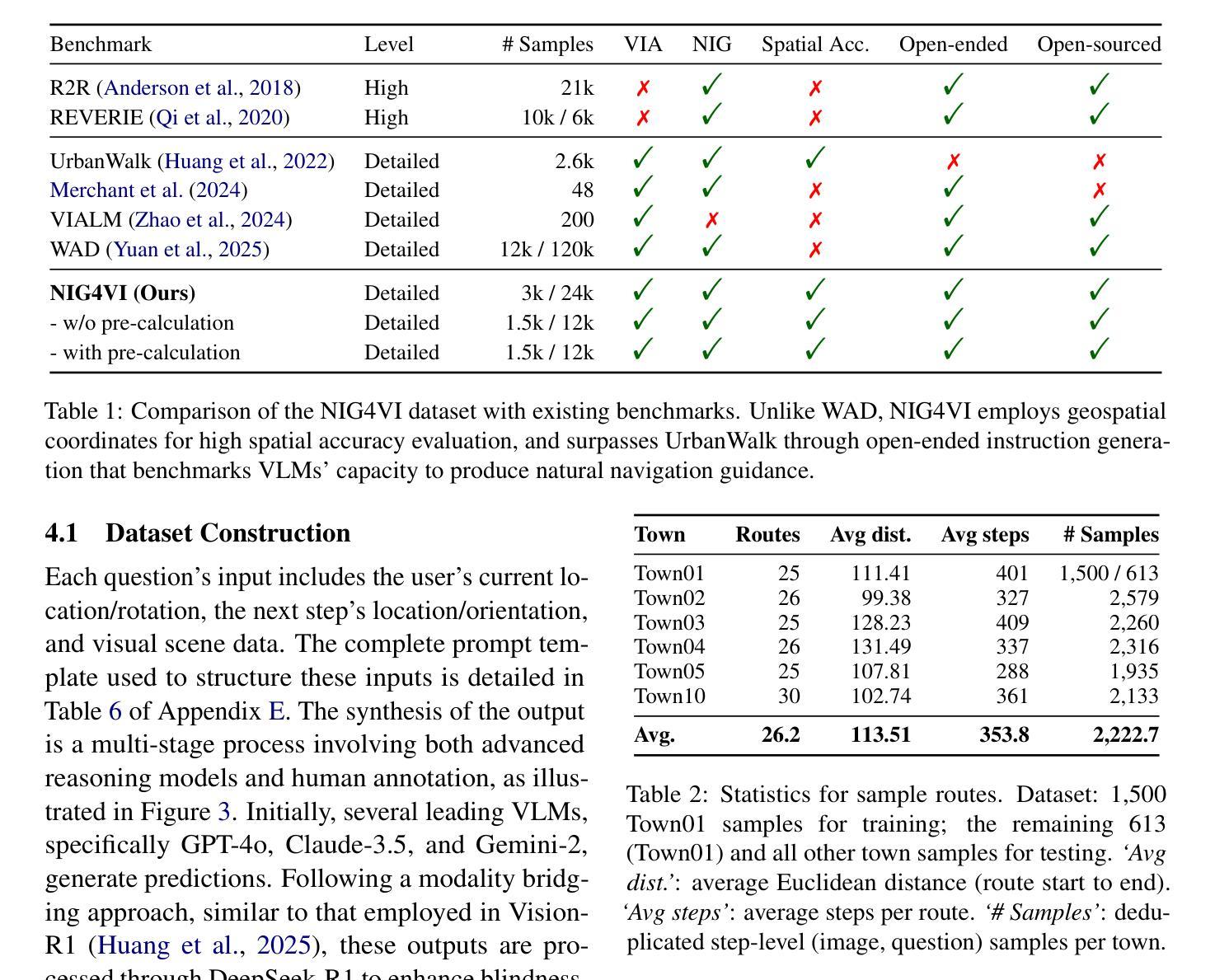
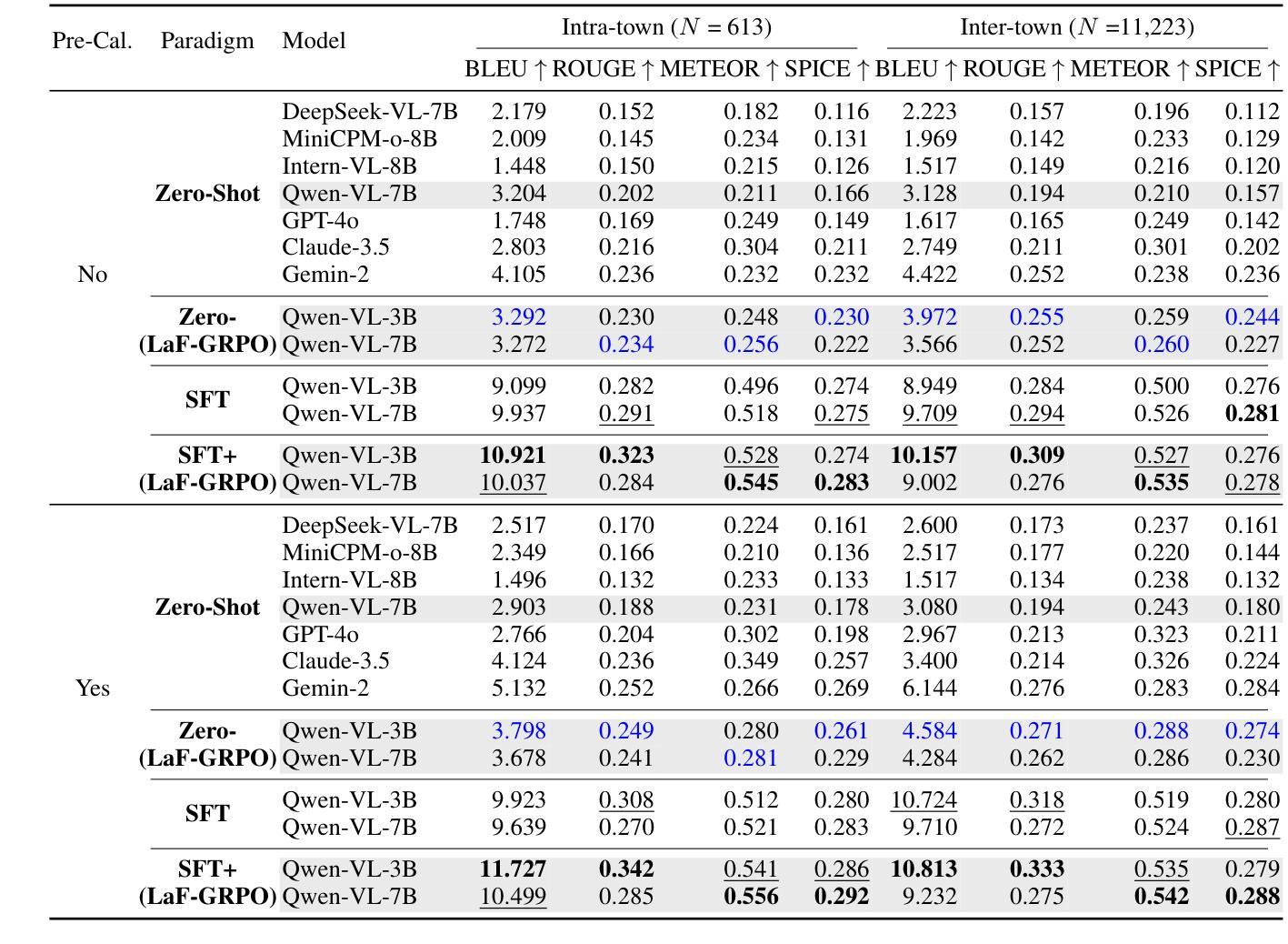
LaF-GRPO: In-Situ Navigation Instruction Generation for the Visually Impaired via GRPO with LLM-as-Follower Reward
Authors:Yi Zhao, Siqi Wang, Jing Li
Navigation instruction generation for visually impaired (VI) individuals (NIG-VI) is critical yet relatively underexplored. This study, hence, focuses on producing precise, in-situ, step-by-step navigation instructions that are practically usable by VI users. Concretely, we propose LaF-GRPO (LLM-as-Follower GRPO), where an LLM simulates VI user responses to generate rewards guiding the Vision-Language Model (VLM) post-training. This enhances instruction usability while reducing costly real-world data needs. To facilitate training and testing, we introduce NIG4VI, a 27k-sample open-sourced benchmark. It provides diverse navigation scenarios with accurate spatial coordinates, supporting detailed, open-ended in-situ instruction generation. Experiments on NIG4VI show the effectiveness of LaF-GRPO by quantitative metrics (e.g., Zero-(LaF-GRPO) boosts BLEU +14%; SFT+(LaF-GRPO) METEOR 0.542 vs. GPT-4o’s 0.323) and yields more intuitive, safer instructions. Code and benchmark are available at \href{https://github.com/YiyiyiZhao/NIG4VI}{https://github.com/YiyiyiZhao/NIG4VI}.
为视障(VI)个体生成导航指令(NIG-VI)至关重要,但相对研究不足。因此,本研究专注于生成精确、现场、分步的导航指令,使VI用户能够实际使用。具体来说,我们提出LaF-GRPO(LLM作为跟随者的GRPO),其中LLM模拟VI用户的响应来生成奖励,指导视觉语言模型(VLM)的后期训练。这提高了指令的实用性,同时降低了对昂贵现实世界数据的需求。为了促进训练和测试,我们引入了NIG4VI,这是一个拥有27k样本的开源基准测试。它提供了具有准确空间坐标的多样化导航场景,支持详细、开放式的现场指令生成。在NIG4VI上的实验表明,LaF-GRPO通过定量指标(例如,零(LaF-GRPO)提升BLEU 14%;SFT+(LaF-GRPO)METEOR 0.542 对比 GPT-4o的0.323)是有效的,并产生更直观、更安全的指令。代码和基准测试可在https://github.com/YiyiyiZhao/NIG4VI获取。
论文及项目相关链接
Summary:
该研究关注为视障人士生成精确、实时、分步骤的导航指令。提出LaF-GRPO方法,通过模拟视障用户反馈来指导视语言模型(VLM)的后续训练,提升指令实用性并减少昂贵真实世界数据需求。引入NIG4VI开放源代码基准测试平台,支持多样化导航场景和精确空间坐标的开放端实时指令生成。实验证明LaF-GRPO方法的有效性。
Key Takeaways:
- 研究关注为视障人士生成导航指令的重要性及其现有研究的不足。
- 提出LaF-GRPO方法,模拟视障用户反馈以优化导航指令生成。
- LaF-GRPO方法通过提升指令实用性,同时降低对真实世界数据的依赖。
- 引入NIG4VI开放源代码基准测试平台,支持多样化导航场景的实时指令生成。
- NIG4VI平台提供准确空间坐标,有助于生成更精确的导航指令。
- 实验结果显示LaF-GRPO方法的有效性,包括定量指标的提升和更直观、安全的指令生成。
点此查看论文截图


Progressive Mastery: Customized Curriculum Learning with Guided Prompting for Mathematical Reasoning
Authors:Muling Wu, Qi Qian, Wenhao Liu, Xiaohua Wang, Zisu Huang, Di Liang, LI Miao, Shihan Dou, Changze Lv, Zhenghua Wang, Zhibo Xu, Lina Chen, Tianlong Li, Xiaoqing Zheng, Xuanjing Huang
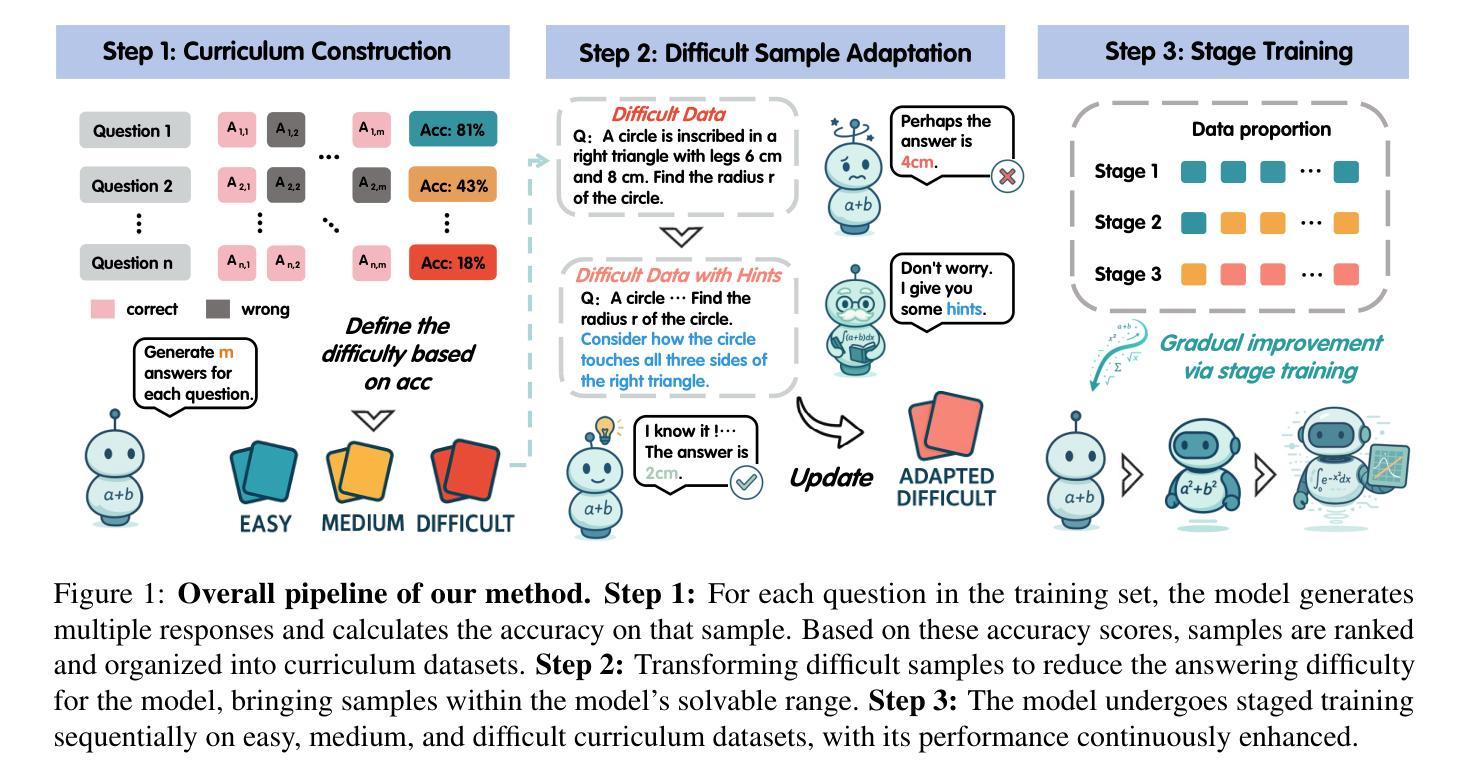
Large Language Models (LLMs) have achieved remarkable performance across various reasoning tasks, yet post-training is constrained by inefficient sample utilization and inflexible difficulty samples processing. To address these limitations, we propose Customized Curriculum Learning (CCL), a novel framework with two key innovations. First, we introduce model-adaptive difficulty definition that customizes curriculum datasets based on each model’s individual capabilities rather than using predefined difficulty metrics. Second, we develop “Guided Prompting,” which dynamically reduces sample difficulty through strategic hints, enabling effective utilization of challenging samples that would otherwise degrade performance. Comprehensive experiments on supervised fine-tuning and reinforcement learning demonstrate that CCL significantly outperforms uniform training approaches across five mathematical reasoning benchmarks, confirming its effectiveness across both paradigms in enhancing sample utilization and model performance.
大型语言模型(LLMs)在各种推理任务中取得了显著的成绩,但是在训练后受到了样本利用效率低下和难度样本处理不灵活的限制。为了解决这些局限性,我们提出了定制课程学习(CCL)这一新框架,包含两个关键创新点。首先,我们引入了模型自适应难度定义,根据每个模型的能力定制课程数据集,而不是使用预先定义的难度指标。其次,我们开发了“引导提示”,通过策略性提示动态降低样本难度,有效利用原本会降低性能的具有挑战性的样本。在监督微调任务和强化学习的全面实验表明,CCL在五个数学推理基准测试中显著优于均匀训练方法,证实其在提高样本利用和模型性能方面的有效性。无论在何种模式下,CCL都能够帮助增强模型表现并显著提高样本利用率。
论文及项目相关链接
Summary
大型语言模型(LLMs)在各种推理任务中表现出卓越性能,但在训练后受到样本利用不足和难度样本处理不灵活的限制。为解决这些问题,我们提出了定制课程学习(CCL)这一新型框架,其中包含两大创新点:一是采用模型自适应难度定义,根据每个模型的能力定制课程数据集,而非使用预先定义的难度指标;二是开发“引导提示”,通过策略性提示动态降低样本难度,有效利用原本会降低性能的样本。在监督微调与强化学习方面的综合实验表明,CCL在五个数学推理基准测试中显著优于统一训练方法,证明了其在提高样本利用率和模型性能方面的有效性。
Key Takeaways
- 大型语言模型(LLMs)在推理任务中表现出卓越性能,但存在样本利用不足和难度样本处理不灵活的问题。
- 定制课程学习(CCL)框架通过模型自适应难度定义和“引导提示”两大创新来解决这些问题。
- 模型自适应难度定义是根据每个模型的能力来定制课程数据集,而非依赖预设的难度指标。
- “引导提示”能动态降低样本难度,有效运用原本可能降低模型性能的样本。
- 综合实验显示,CCL在监督微调与强化学习方面显著优于传统训练方法。
- CCL在五个数学推理基准测试中表现出强大的性能提升。
点此查看论文截图



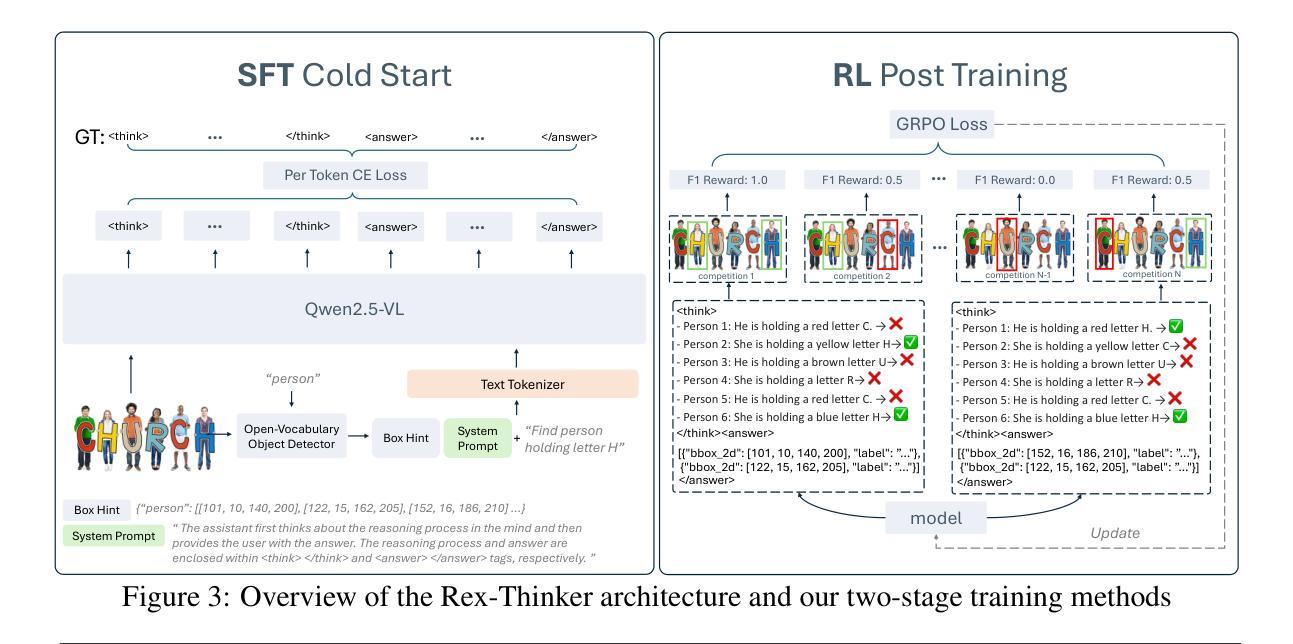
Rex-Thinker: Grounded Object Referring via Chain-of-Thought Reasoning
Authors:Qing Jiang, Xingyu Chen, Zhaoyang Zeng, Junzhi Yu, Lei Zhang
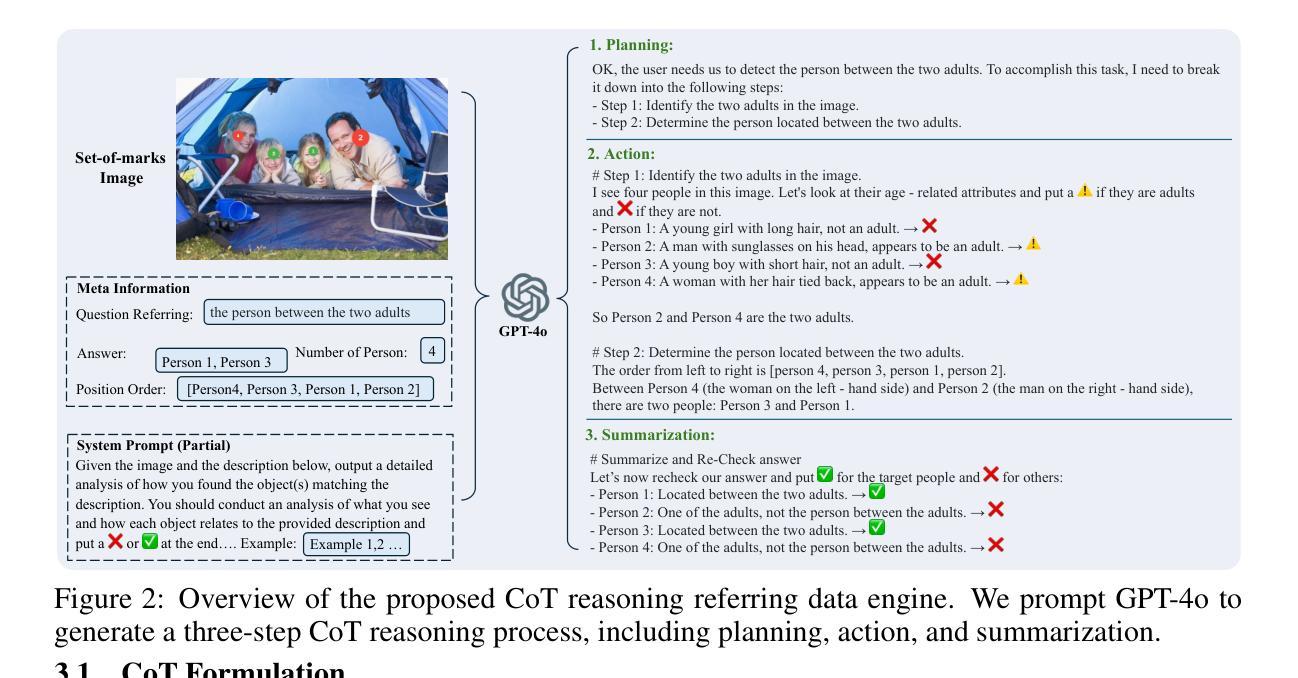
Object referring aims to detect all objects in an image that match a given natural language description. We argue that a robust object referring model should be grounded, meaning its predictions should be both explainable and faithful to the visual content. Specifically, it should satisfy two key properties: 1) Verifiable, by producing interpretable reasoning that justifies its predictions and clearly links them to visual evidence; and 2) Trustworthy, by learning to abstain when no object in the image satisfies the given expression. However, most methods treat referring as a direct bounding box prediction task, offering limited interpretability and struggling to reject expressions with no matching object. In this work, we propose Rex-Thinker, a model that formulates object referring as an explicit CoT reasoning task. Given a referring expression, we first identify all candidate object instances corresponding to the referred object category. Rex-Thinker then performs step-by-step reasoning over each candidate to assess whether it matches the given expression, before making a final prediction. To support this paradigm, we construct a large-scale CoT-style referring dataset named HumanRef-CoT by prompting GPT-4o on the HumanRef dataset. Each reasoning trace follows a structured planning, action, and summarization format, enabling the model to learn decomposed, interpretable reasoning over object candidates. We then train Rex-Thinker in two stages: a cold-start supervised fine-tuning phase to teach the model how to perform structured reasoning, followed by GRPO-based RL learning to improve accuracy and generalization. Experiments show that our approach outperforms standard baselines in both precision and interpretability on in-domain evaluation, while also demonstrating improved ability to reject hallucinated outputs and strong generalization in out-of-domain settings.
对象引用旨在检测图像中所有与给定自然语言描述匹配的对象。我们认为,一个稳健的对象引用模型应该是有根据的,这意味着它的预测应该是可解释的,并且对视觉内容保持忠诚。具体来说,它应该满足以下两个关键属性:1)可验证性,通过产生可解释的理由来证明其预测,并将其与视觉证据明确联系起来;2)可靠性,通过学习在图像中没有对象满足给定表达式时选择放弃。然而,大多数方法将引用作为直接的边界框预测任务,这提供了有限的解释性,并且在拒绝没有匹配对象的表达式时遇到了困难。在这项工作中,我们提出了Rex-Thinker模型,它将对象引用制定为一个明确的认知推理任务。给定一个引用表达式,我们首先识别所有对应于所引用对象类别的候选对象实例。Rex-Thinker随后对每一个候选对象进行逐步推理,以评估其是否与给定的表达式匹配,然后做出最终预测。为了支持这一范式,我们使用GPT-4o在HumanRef数据集上构建了大规模的认知风格引用数据集HumanRef-CoT。每个推理轨迹都遵循结构化规划、行动和总结格式,使模型能够在对象候选者上进行分解和可解释推理。然后,我们将Rex-Thinker分为两个阶段进行训练:首先是冷启动监督微调阶段,教会模型如何进行结构化推理,其次是基于GRPO的强化学习来提高准确性和泛化能力。实验表明,我们的方法在主域评估中的精度和解释性方面优于标准基准测试,同时显示出拒绝幻觉输出和提高离域设置中的泛化能力的改进。
论文及项目相关链接
PDF homepage: https://rexthinker.github.io/
Summary
本文提出一种名为Rex-Thinker的对象引用模型,该模型将对象引用表达为明确的认知推理任务。给定一个引用表达式,Rex-Thinker首先识别所有与引用对象类别对应的候选对象实例。然后,它会对每个候选对象进行逐步推理,评估其是否与给定的表达式匹配,最后做出预测。为此,构建了大规模的认知轨迹风格引用数据集HumanRef-CoT,并通过GPT-4o在HumanRef数据集上进行提示。训练Rex-Thinker分为两个阶段:首先是冷启动监督微调阶段,教会模型如何进行结构化推理;然后是基于GRPO的强化学习阶段,提高准确性和泛化能力。实验表明,该方法在域内评估的精度和可解释性方面优于标准基线,同时表现出更强的拒绝虚构输出的能力和良好的域外泛化能力。
Key Takeaways
- Rex-Thinker模型将对象引用表达为明确的认知推理任务,以提高模型的解释性和对视觉内容的忠实性。
- Rex-Thinker通过逐步推理评估候选对象与给定表达式的匹配程度,再进行预测。
- 构建了一个名为HumanRef-CoT的大规模认知轨迹风格引用数据集,用于支持Rex-Thinker模型。
- HumanRef-CoT数据集通过GPT-4o在HumanRef数据集上的提示进行构建,遵循结构化规划、行动和总结格式。
- Rex-Thinker的训练分为两个阶段:监督微调阶段和基于GRPO的强化学习阶段。
- 实验表明,Rex-Thinker在精度和可解释性方面优于标准基线,并能更好地拒绝虚构输出和泛化到未知领域。
点此查看论文截图


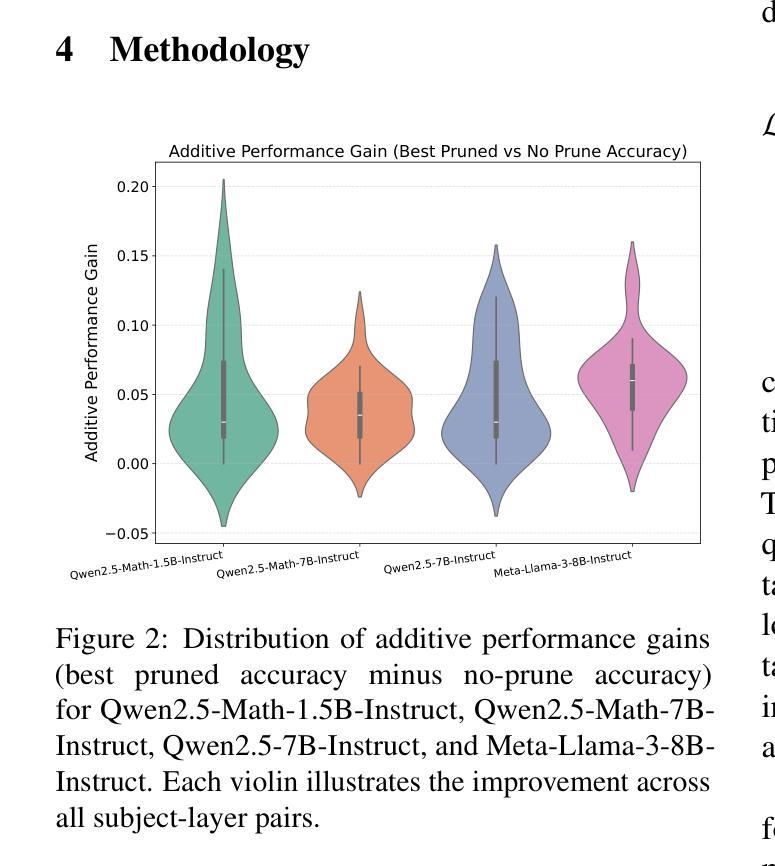
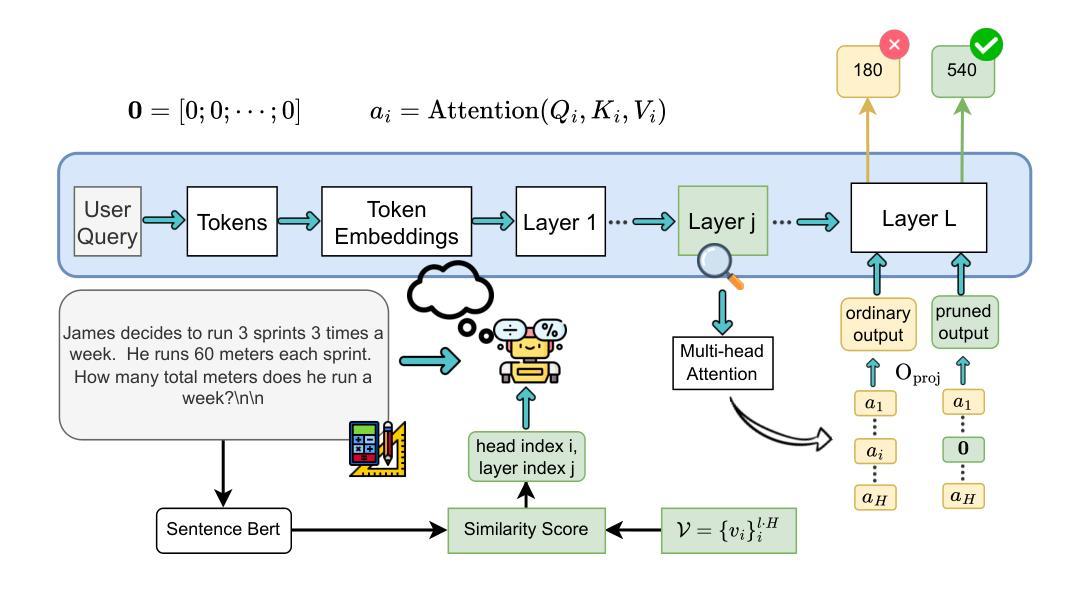
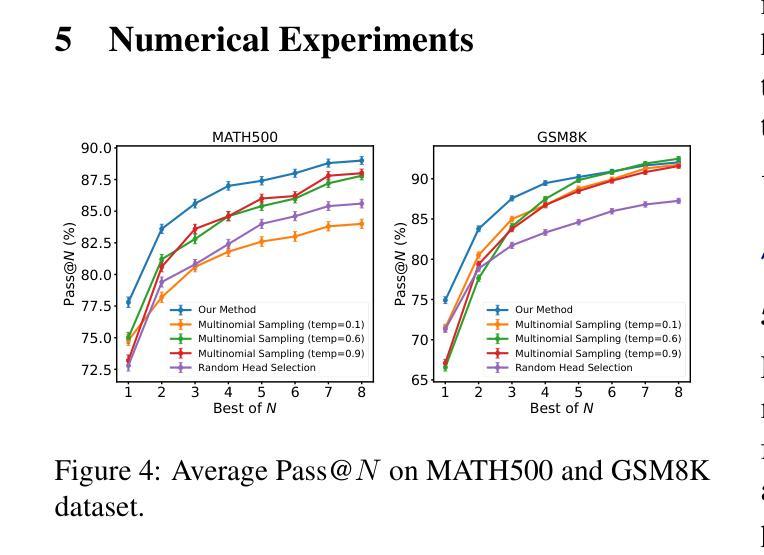
Structured Pruning for Diverse Best-of-N Reasoning Optimization
Authors:Hieu Trung Nguyen, Bao Nguyen, Viet Anh Nguyen
Model pruning in transformer-based language models, traditionally viewed as a means of achieving computational savings, can enhance the model’s reasoning capabilities. In this work, we uncover a surprising phenomenon: the selective pruning of certain attention heads leads to improvements in reasoning performance, particularly on challenging tasks. Motivated by this observation, we propose SPRINT, a novel contrastive learning framework that dynamically selects the optimal head and layer to prune during inference. By aligning question embeddings with head embeddings, SPRINT identifies those pruned-head configurations that result in more accurate reasoning. Extensive experiments demonstrate that our method significantly outperforms traditional best-of-$N$ and random head selection strategies on the MATH500 and GSM8K datasets.
基于Transformer的语言模型中的模型剪枝,传统上被视为实现计算节省的手段,但能够增强模型的推理能力。在这项工作中,我们发现了一个令人惊讶的现象:选择性剪枝某些注意力头有助于提高推理性能,特别是在具有挑战性的任务上。受此观察结果的启发,我们提出了一个新型的对比学习框架SPRINT,它在推理过程中动态选择最佳的头部和层进行剪枝。通过问题嵌入与头部嵌入的对齐,SPRINT可以识别那些剪枝头部配置能够导致更准确的推理。大量实验表明,我们的方法在MATH500和GSM8K数据集上显著优于传统的最佳N选和随机头部选择策略。
论文及项目相关链接
PDF Accepted to ACL 2025
Summary
模型修剪可以增强基于Transformer的语言模型的推理能力。本研究发现选择性修剪某些注意力头能提升模型在挑战性任务上的推理性能。为此,我们提出了动态选择最佳头层进行修剪的对比学习框架——SPRINT。通过问题嵌入与头嵌入的对齐,SPRINT能够识别出能够提升推理准确率的修剪头配置。实验表明,该方法在MATH500和GSM8K数据集上的性能显著优于传统的最佳-N选择和随机头选择策略。
Key Takeaways
- 模型修剪不仅能节省计算成本,还能提升基于Transformer的语言模型的推理能力。
- 注意力头的选择性修剪能显著提高模型在挑战性任务上的性能。
- SPRINT是一种新的对比学习框架,可在推理过程中动态选择最佳的头部和层进行修剪。
- SPRINT通过问题嵌入与头嵌入的对齐,有效识别有助于提升推理准确率的修剪配置。
- 与传统选择策略相比,SPRINT在MATH500和GSM8K数据集上表现出显著优势。
- SPRINT框架能应对大规模模型中的计算效率问题。
点此查看论文截图

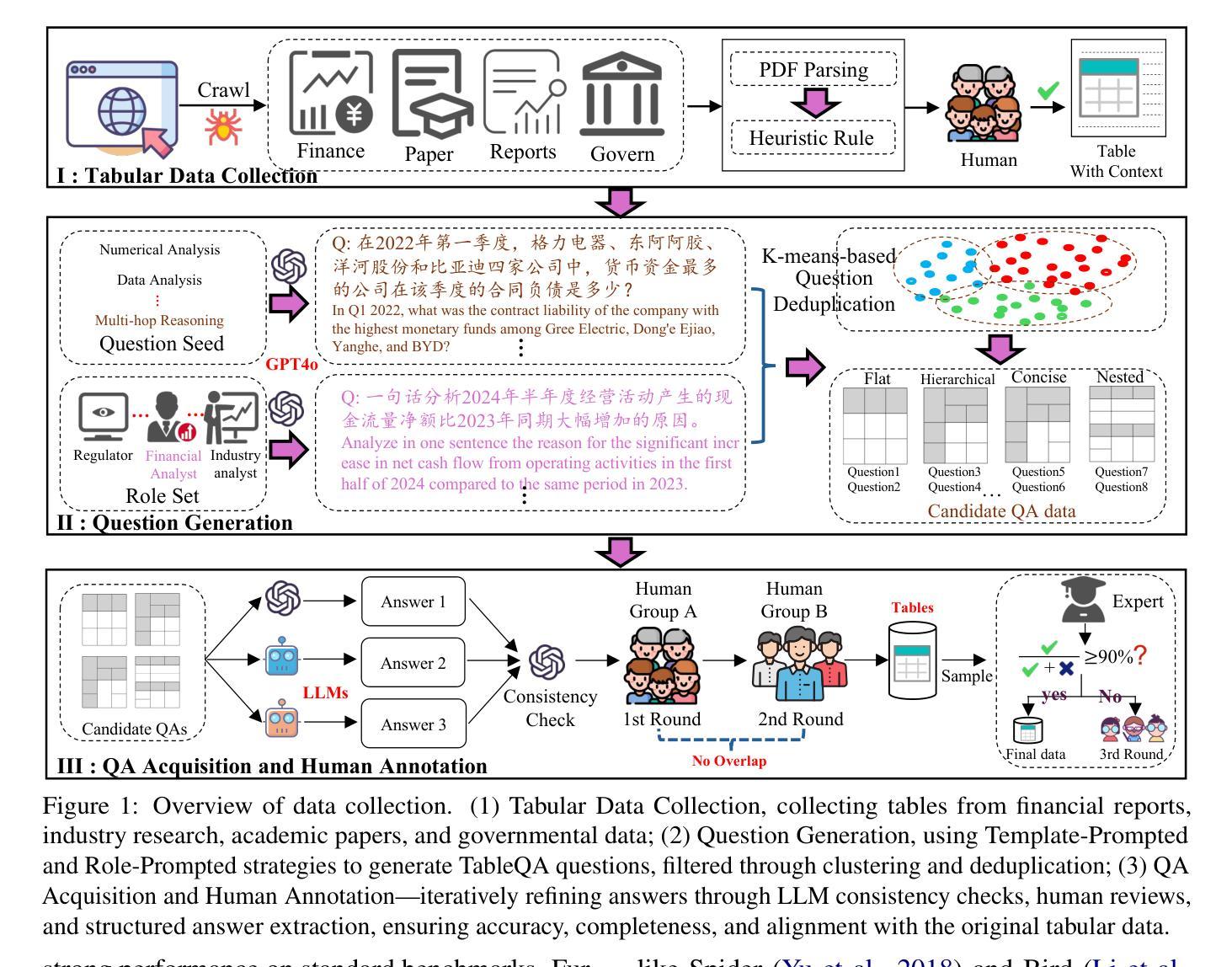
TableEval: A Real-World Benchmark for Complex, Multilingual, and Multi-Structured Table Question Answering
Authors:Junnan Zhu, Jingyi Wang, Bohan Yu, Xiaoyu Wu, Junbo Li, Lei Wang, Nan Xu
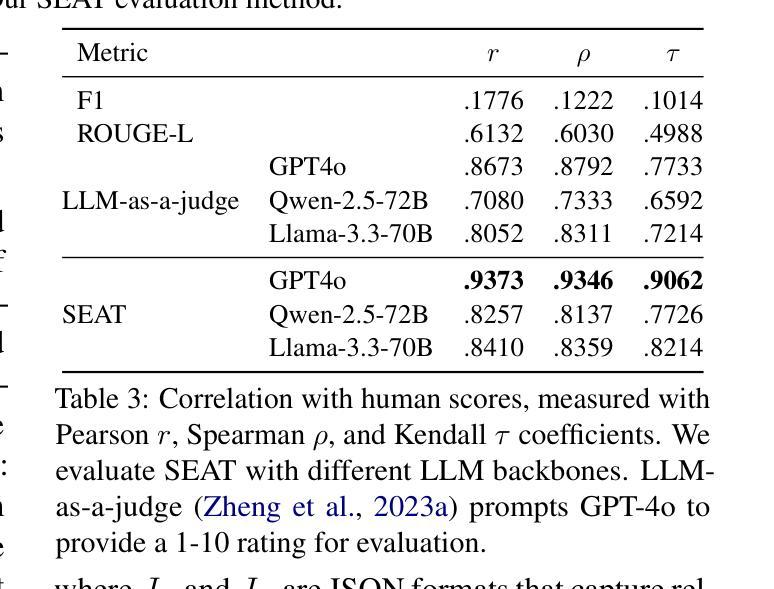
LLMs have shown impressive progress in natural language processing. However, they still face significant challenges in TableQA, where real-world complexities such as diverse table structures, multilingual data, and domain-specific reasoning are crucial. Existing TableQA benchmarks are often limited by their focus on simple flat tables and suffer from data leakage. Furthermore, most benchmarks are monolingual and fail to capture the cross-lingual and cross-domain variability in practical applications. To address these limitations, we introduce TableEval, a new benchmark designed to evaluate LLMs on realistic TableQA tasks. Specifically, TableEval includes tables with various structures (such as concise, hierarchical, and nested tables) collected from four domains (including government, finance, academia, and industry reports). Besides, TableEval features cross-lingual scenarios with tables in Simplified Chinese, Traditional Chinese, and English. To minimize the risk of data leakage, we collect all data from recent real-world documents. Considering that existing TableQA metrics fail to capture semantic accuracy, we further propose SEAT, a new evaluation framework that assesses the alignment between model responses and reference answers at the sub-question level. Experimental results have shown that SEAT achieves high agreement with human judgment. Extensive experiments on TableEval reveal critical gaps in the ability of state-of-the-art LLMs to handle these complex, real-world TableQA tasks, offering insights for future improvements. We make our dataset available here: https://github.com/wenge-research/TableEval.
大型语言模型在自然语言处理方面取得了令人印象深刻的进展。然而,在表格问答(TableQA)领域,它们仍然面临重大挑战。在表格问答中,现实世界中的复杂性至关重要,例如各种表格结构、多语言数据和特定领域的推理。现有的TableQA基准测试通常局限于简单的平面表格,并存在数据泄露的问题。此外,大多数基准测试都是单语言的,无法捕获实际应用中的跨语言和跨领域变化。为了解决这个问题,我们引入了TableEval,这是一个新的基准测试,旨在评估大型语言模型在现实的表格问答任务上的表现。具体来说,TableEval包含了从四个领域(包括政府、金融、学术和工业报告)收集的具有各种结构(如简洁、分层和嵌套表格)的表格。此外,TableEval还具有简体中文、繁体中文和英文的跨语言场景。为了最小化数据泄露的风险,我们从最新的现实文档中收集所有数据。考虑到现有的TableQA指标无法捕捉语义准确性,我们进一步提出了SEAT,这是一个新的评估框架,它可以在子问题级别评估模型响应和参考答案的对齐程度。实验结果表明,SEAT与人类判断高度一致。在TableEval上的广泛实验揭示了最先进的大型语言模型在处理这些复杂、现实的表格问答任务时的关键差距,为未来的改进提供了见解。我们在以下链接提供了我们的数据集:https://github.com/wenge-research/TableEval 。
论文及项目相关链接
Summary
LLMs在自然语言处理方面取得了显著进展,但在TableQA领域仍面临诸多挑战。现有TableQA基准测试主要集中在简单表格上,存在数据泄露问题,且多为单语种,无法捕捉实际应用的跨语种和跨域变化。为解决这些问题,我们推出TableEval基准测试,用于评估LLMs在真实TableQA任务上的表现。TableEval包含来自政府、金融、学术和工业报告等四个领域的表格,涵盖简洁、层次和嵌套等各式结构,并设有简体中、繁体中和英文的跨语言场景。我们进一步提出SEAT评估框架,以子问题级别评估模型回答与参考答案的契合度。实验结果显示SEAT与人类判断高度一致,对TableEval的广泛实验揭示了最先进LLMs处理这些复杂、真实TableQA任务时的关键差距,为未来的改进提供了启示。
Key Takeaways
- LLMs在自然语言处理方面取得显著进展,但在TableQA领域仍面临挑战。
- 现有TableQA基准测试主要集中在简单表格上,存在数据泄露问题。
- TableEval基准测试包含各种结构的表格,涵盖多个领域,并设有跨语言场景。
- TableEval注重真实世界数据的收集,以减小数据泄露风险。
- 现有TableQA评估指标无法准确捕捉语义准确性,因此提出SEAT评估框架。
- SEAT评估框架能够与人类判断高度一致。
点此查看论文截图



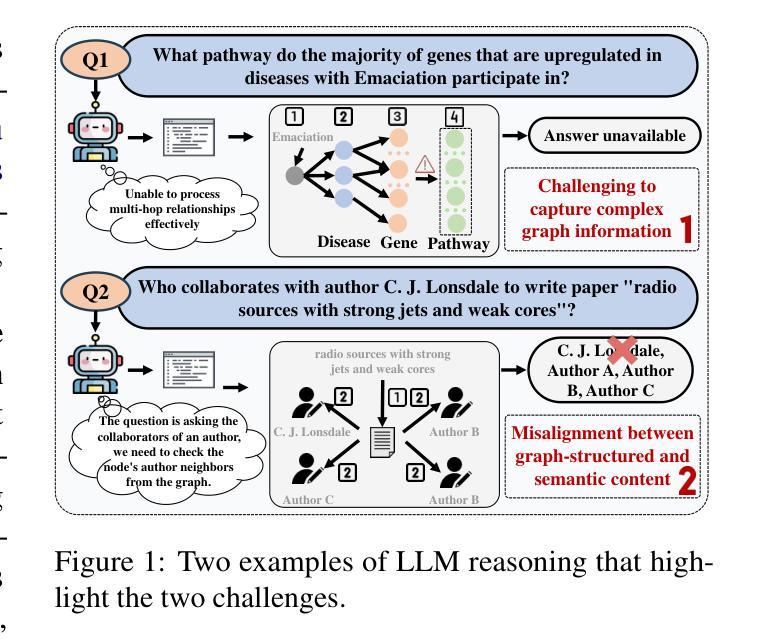
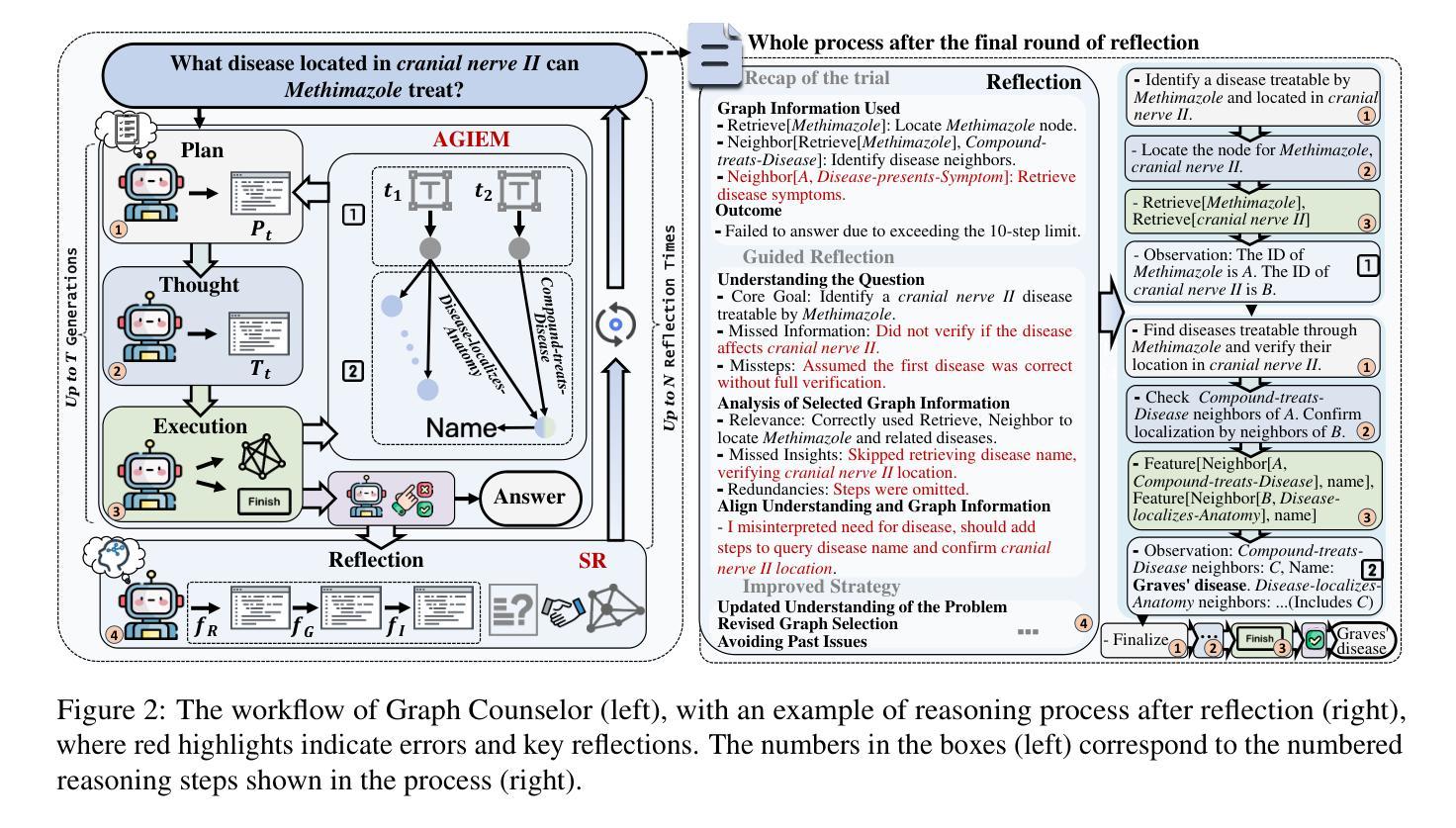
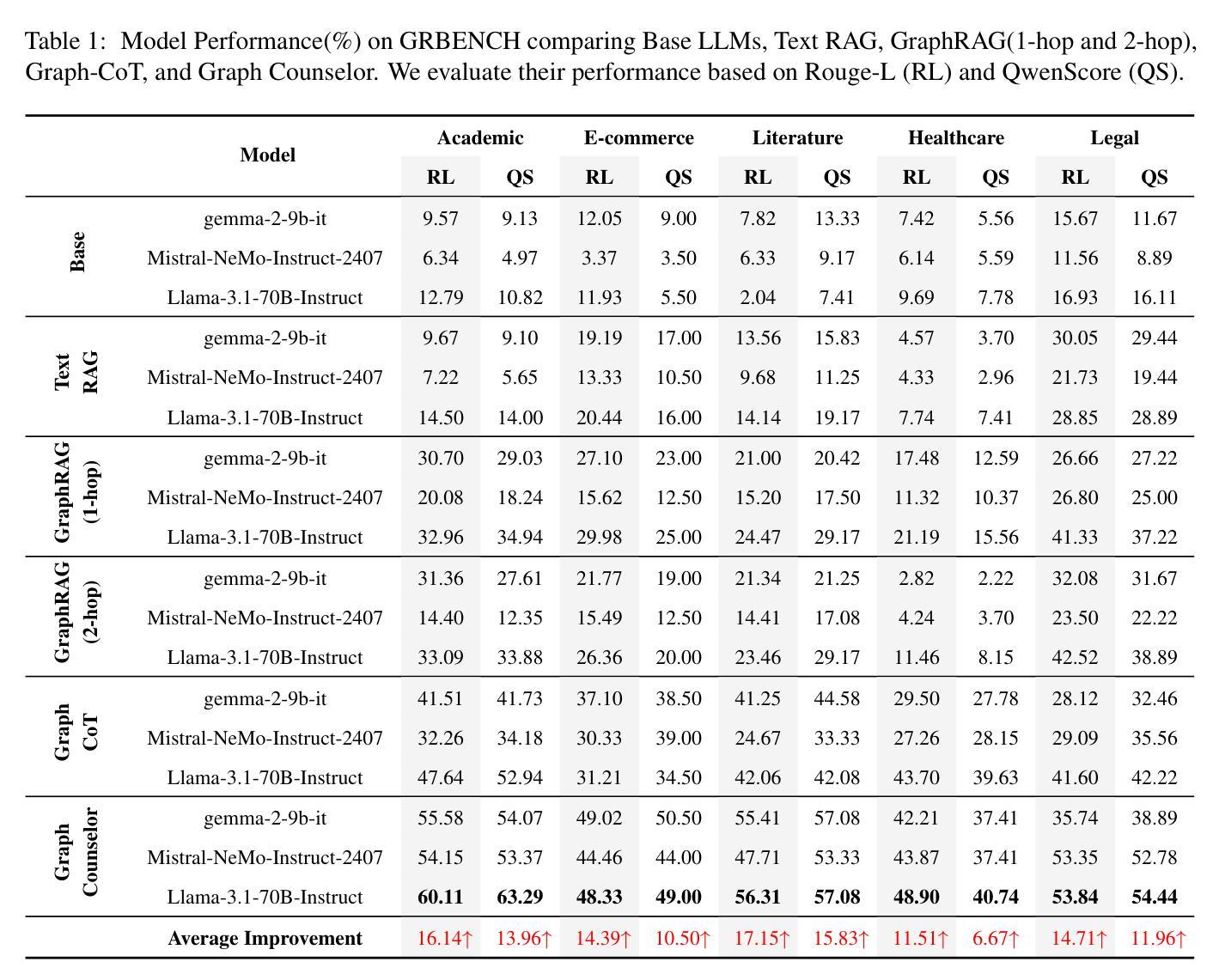
Graph Counselor: Adaptive Graph Exploration via Multi-Agent Synergy to Enhance LLM Reasoning
Authors:Junqi Gao, Xiang Zou, YIng Ai, Dong Li, Yichen Niu, Biqing Qi, Jianxing Liu
Graph Retrieval Augmented Generation (GraphRAG) effectively enhances external knowledge integration capabilities by explicitly modeling knowledge relationships, thereby improving the factual accuracy and generation quality of Large Language Models (LLMs) in specialized domains. However, existing methods suffer from two inherent limitations: 1) Inefficient Information Aggregation: They rely on a single agent and fixed iterative patterns, making it difficult to adaptively capture multi-level textual, structural, and degree information within graph data. 2) Rigid Reasoning Mechanism: They employ preset reasoning schemes, which cannot dynamically adjust reasoning depth nor achieve precise semantic correction. To overcome these limitations, we propose Graph Counselor, an GraphRAG method based on multi-agent collaboration. This method uses the Adaptive Graph Information Extraction Module (AGIEM), where Planning, Thought, and Execution Agents work together to precisely model complex graph structures and dynamically adjust information extraction strategies, addressing the challenges of multi-level dependency modeling and adaptive reasoning depth. Additionally, the Self-Reflection with Multiple Perspectives (SR) module improves the accuracy and semantic consistency of reasoning results through self-reflection and backward reasoning mechanisms. Experiments demonstrate that Graph Counselor outperforms existing methods in multiple graph reasoning tasks, exhibiting higher reasoning accuracy and generalization ability. Our code is available at https://github.com/gjq100/Graph-Counselor.git.
图检索增强生成(GraphRAG)通过显式建模知识关系,有效增强了大型语言模型(LLM)在特定领域的事实准确性和生成能力,从而提高了外部知识的整合能力。然而,现有方法存在两个固有局限性:1)信息聚合效率低下:它们依赖于单个代理和固定的迭代模式,难以自适应捕获图数据中的多级文本、结构和程度信息。2)推理机制僵化:它们采用预设的推理方案,不能动态调整推理深度,也无法实现精确的语义校正。
论文及项目相关链接
PDF Accepted by ACL 2025
Summary:
Graph Counselor通过多主体协作的Graph Retrieval Augmented Generation(GraphRAG)方法,克服了现有方法的局限性,提高了大型语言模型在特定领域的事实准确性和生成质量。通过自适应图信息提取模块(AGIEM)和多角度自我反思(SR)模块,实现了对复杂图结构的精确建模、信息提取策略的动态调整,以及推理结果的准确性和语义一致性。实验证明,Graph Counselor在多个图推理任务中表现优异。
Key Takeaways:
- GraphRAG方法通过显式建模知识关系增强了外部知识的整合能力。
- 现有方法存在信息聚合效率低下和推理机制僵化的问题。
- Graph Counselor通过多主体协作克服这些问题,包括规划、思考和执行主体共同工作。
- AGIEM模块实现了对复杂图结构的精确建模和信息提取策略的动态调整。
- SR模块通过自我反思和逆向推理机制提高了推理结果的准确性和语义一致性。
- Graph Counselor在多图推理任务中表现出更高的推理准确性和泛化能力。
点此查看论文截图

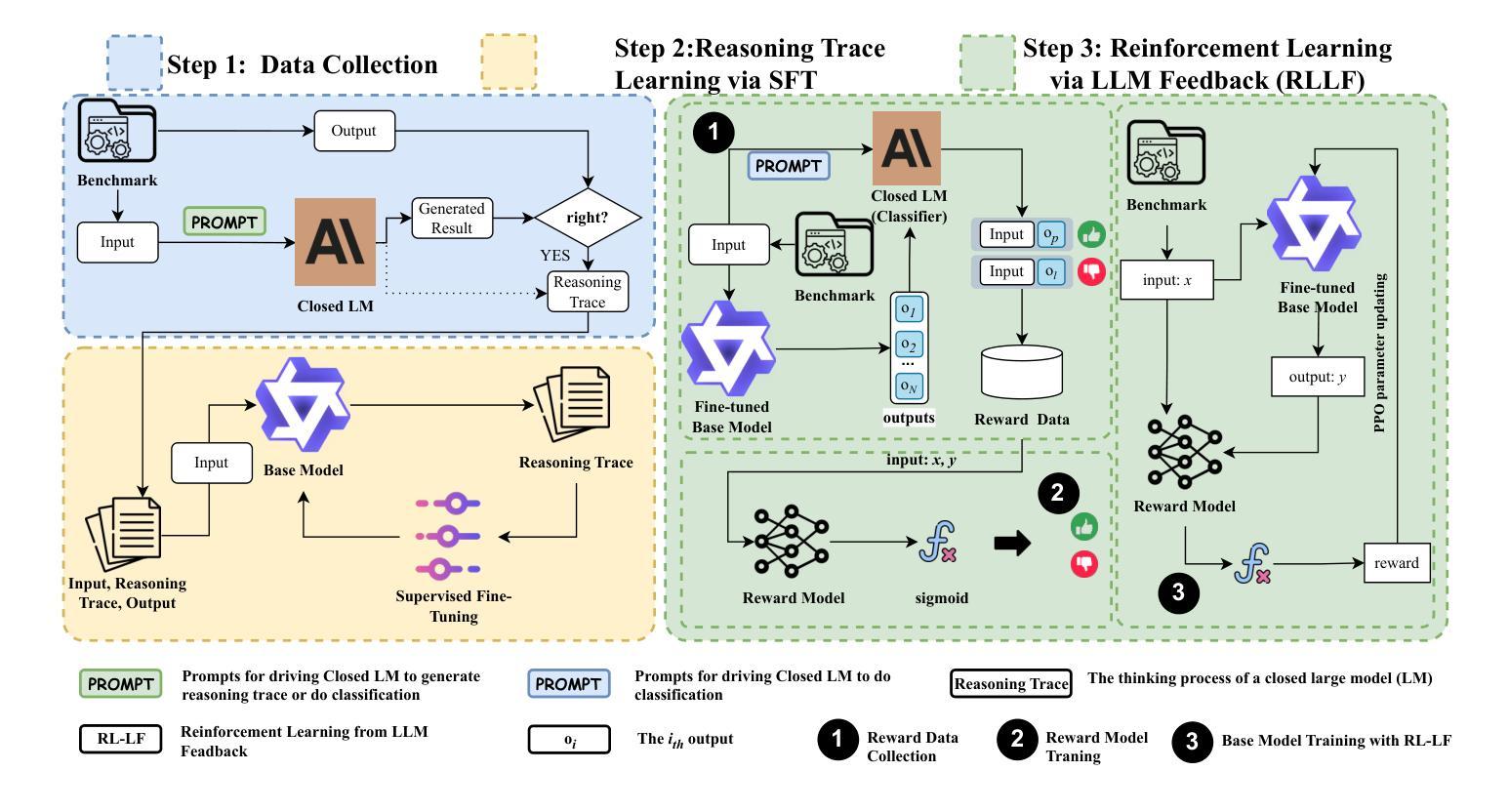
Boosting Open-Source LLMs for Program Repair via Reasoning Transfer and LLM-Guided Reinforcement Learning
Authors:Xunzhu Tang, Jacques Klein, Tegawendé F. Bissyandé
Several closed-source LLMs have consistently outperformed open-source alternatives in program repair tasks, primarily due to their superior reasoning capabilities and extensive pre-training. This paper introduces Repairity, a novel three-stage methodology that significantly narrows this performance gap through reasoning extraction and reinforcement learning. Our approach: (1) systematically filters high-quality reasoning traces from closed-source models using correctness verification, (2) transfers this reasoning knowledge to open-source models via supervised fine-tuning, and (3) develops reinforcement learning with LLM-based feedback to further optimize performance. Empirical evaluation across multiple program repair benchmarks demonstrates that Repairity improves the performance of Qwen2.5-Coder-32B-Instruct, a base open source LLM, by 8.68% on average, reducing the capability gap with Claude-Sonnet3.7, a state-of-the-art closed-source model, from 10.05% to 1.35%. Ablation studies confirm that both reasoning extraction and LLM-guided reinforcement learning contribute significantly to these improvements. Our methodology generalizes effectively to additional code-related tasks, enabling organizations to leverage high-quality program repair capabilities while maintaining the customizability, transparency, and deployment flexibility inherent to open-source models.
在多程序修复任务中,一些闭源的大型语言模型(LLM)始终表现出优于开源替代品的性能,这主要是由于它们出色的推理能力和广泛的预训练。本文介绍了Repairity,这是一种新型的三阶段方法,通过推理提取和强化学习显著缩小了性能差距。我们的方法:(1)通过正确性验证系统地从闭源模型中过滤出高质量的推理轨迹,(2)通过监督微调将这些推理知识转移到开源模型中,(3)利用基于大型语言模型(LLM)的反馈开发强化学习,进一步优化性能。在多个程序修复基准测试上的实证评估表明,Repairity提高了基础开源LLM Qwen2.5-Coder-32B-Instruct的性能,平均提高了8.68%,并缩小了其与最先进的闭源模型Claude-Sonnet3.7的能力差距,从10.05%降至1.35%。消融研究证实,推理提取和LLM引导的强化学习都对这些改进做出了重大贡献。我们的方法能够有效地推广到其他的代码相关任务,使组织能够在保持开源模型的定制性、透明度和部署灵活性的同时,利用高质量的程序修复能力。
论文及项目相关链接
Summary:针对程序修复任务,封闭式源代码的大型语言模型(LLM)通常优于开源模型,主要体现在其出色的推理能力和预训练广度。本文介绍了一种新型的三阶段方法Repairity,通过推理提取和强化学习显著缩小了这一性能差距。该方法首先通过正确性验证系统地过滤封闭式模型中的高质量推理轨迹,然后将这些推理知识通过监督微调转移到开源模型中,并发展出基于LLM反馈的强化学习进一步优化性能。实证评估表明,Repairity能够提升基础开源LLM Qwen2.5-Coder-3.2B-Instruct的性能,平均提升幅度达到8.68%,并显著缩小了其与先进封闭式模型Claude-Sonnet3.7的能力差距。同时,该方法的推理提取和LLM指导的强化学习对于性能提升均有重要贡献。此外,该方法还可有效推广到其他代码相关任务,使得组织能够在利用高质量程序修复能力的同时保持开源模型的自定义性、透明度和部署灵活性。
Key Takeaways:
- 封闭式LLM在程序修复任务上较开源LLM有优势,主要由于它们的推理能力和预训练效果更佳。
- Repairity方法通过三个步骤显著缩小了开源和封闭式LLM在程序修复任务上的性能差距。
- Repairity通过正确性验证过滤高质量推理轨迹,然后将其从封闭式LLM转移到开源LLM。
- 强化学习被用于进一步优化开源LLM的性能,基于LLM的反馈。
- 实证评估显示,Repairity提升了基础开源LLM的性能,并显著缩小了与先进封闭式LLM的差距。
- 推理提取和LLM指导的强化学习对Repairity的性能提升都有重要贡献。
点此查看论文截图

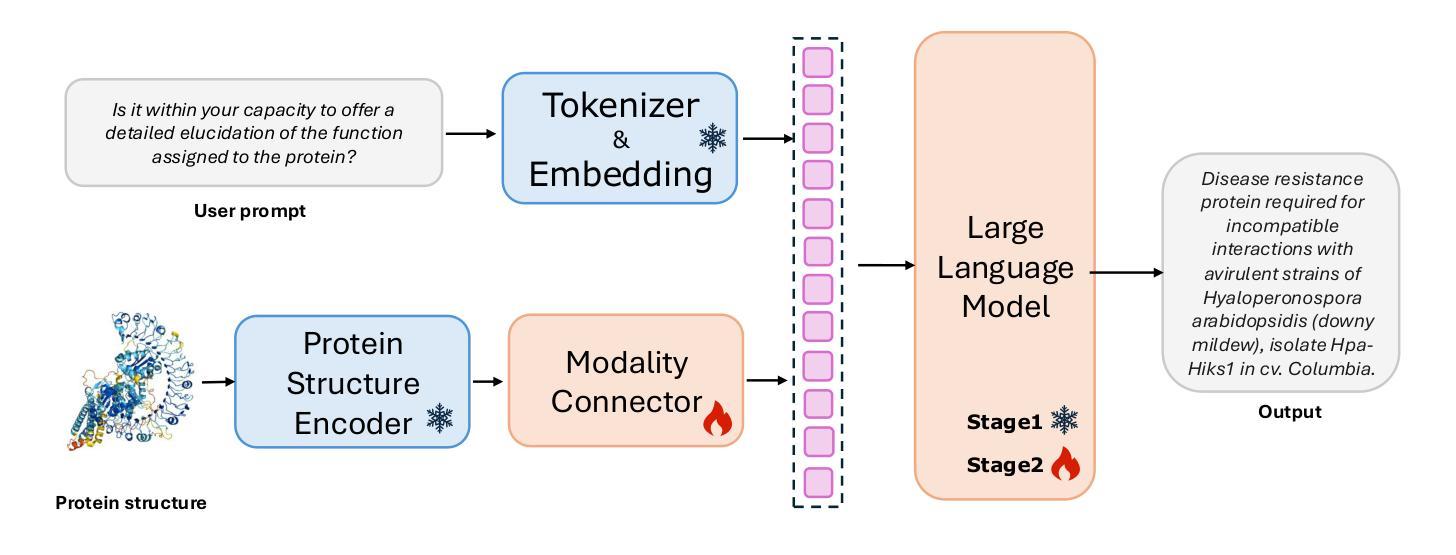
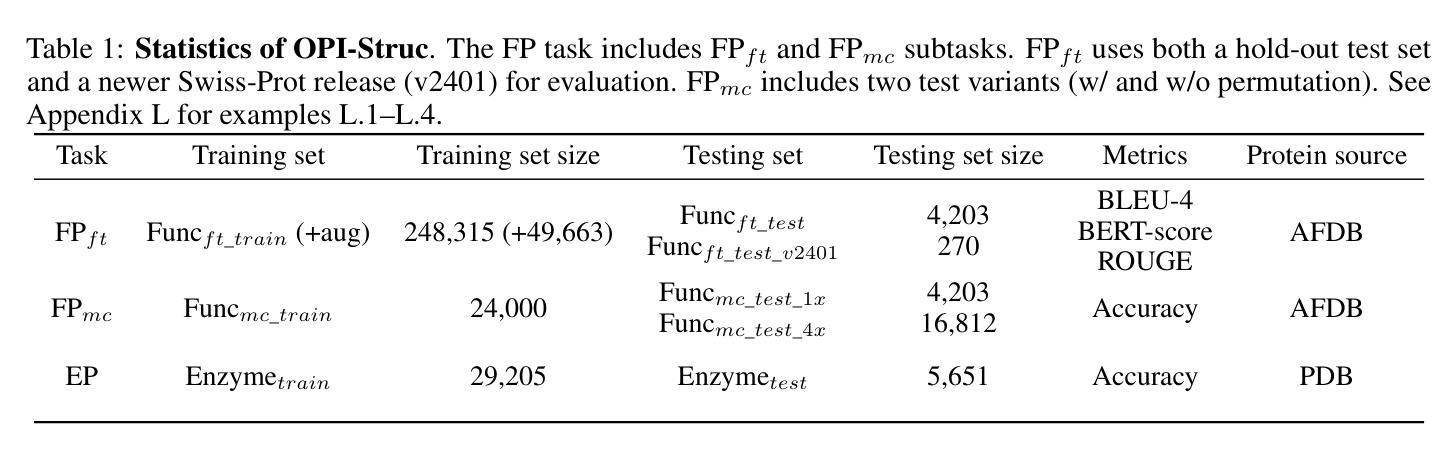
STELLA: Towards Protein Function Prediction with Multimodal LLMs Integrating Sequence-Structure Representations
Authors:Hongwang Xiao, Wenjun Lin, Xi Chen, Hui Wang, Kai Chen, Jiashan Li, Yuancheng Sun, Sicheng Dai, Boya Wu, Qiwei Ye
Protein biology focuses on the intricate relationships among sequences, structures, and functions. Deciphering protein functions is crucial for understanding biological processes, advancing drug discovery, and enabling synthetic biology applications. Since protein sequences determine tertiary structures, which in turn govern functions, integrating sequence and structure information is essential for accurate prediction of protein functions. Traditional protein language models (pLMs) have advanced protein-related tasks by learning representations from large-scale sequence and structure data. However, pLMs are limited in integrating broader contextual knowledge, particularly regarding functional modalities that are fundamental to protein biology. In contrast, large language models (LLMs) have exhibited outstanding performance in contextual understanding, reasoning, and generation across diverse domains. Leveraging these capabilities, STELLA is proposed as a multimodal LLM integrating protein sequence-structure representations with general knowledge to address protein function prediction. Through multimodal instruction tuning (MMIT) using the proposed OPI-Struc dataset, STELLA achieves state-of-the-art performance in two function-related tasks-functional description prediction (FP) and enzyme-catalyzed reaction prediction (EP). This study highlights the potential of multimodal LLMs as an alternative paradigm to pLMs to advance protein biology research.
蛋白质生物学主要研究序列、结构和功能之间的复杂关系。解读蛋白质功能对于理解生物过程、推进药物发现和实现合成生物学应用至关重要。由于蛋白质序列决定三级结构,而三级结构又控制功能,因此整合序列和结构信息对于准确预测蛋白质功能至关重要。传统的蛋白质语言模型(pLMs)通过从大规模序列和结构数据中学习表示来推进与蛋白质相关的任务。然而,pLMs在整合更广泛的上下文知识方面存在局限性,特别是在蛋白质生物学中至关重要的功能模式方面。相比之下,大型语言模型(LLMs)在上下文理解、推理和生成方面表现出了卓越的性能。利用这些能力,提出了多模式大型语言模型STELLA,它整合了蛋白质序列结构表示和通用知识来解决蛋白质功能预测问题。通过使用提出的OPI-Struc数据集进行多模式指令调整(MMIT),STELLA在两个与功能相关的任务——功能描述预测(FP)和酶催化反应预测(EP)中达到了最先进的性能。这项研究突出了多模式LLMs作为pLMs的替代范式在推进蛋白质生物学研究方面的潜力。
论文及项目相关链接
Summary
蛋白质生物学研究序列、结构与功能之间的复杂关系。解析蛋白质功能对于理解生物过程、推进药物发现和实现合成生物学应用至关重要。传统蛋白质语言模型(pLMs)通过从大规模序列和结构数据中学习表征来推进蛋白质相关任务,但在整合更广泛的上下文知识方面存在局限性,特别是对于那些对蛋白质生物学至关重要的功能模式。相比之下,大型语言模型(LLMs)在上下文理解、推理和生成方面表现出卓越性能。利用这些能力,STELLA被提出为一种多模式LLM,它整合蛋白质序列-结构表征和一般知识来解决蛋白质功能预测问题。通过使用提出的OPI-Struc数据集进行多模式指令调整(MMIT),STELLA在功能描述预测和酶催化反应预测两个任务中实现了卓越性能。这项研究突出了多模式LLM作为推进蛋白质生物学研究的替代方法的潜力。
Key Takeaways
- 蛋白质生物学关注序列、结构与功能之间的关系。
- 解析蛋白质功能对理解生物过程、药物发现和合成生物学应用至关重要。
- 传统蛋白质语言模型(pLMs)在整合上下文知识方面存在局限性。
- 大型语言模型(LLMs)在上下文理解、推理和生成方面表现出卓越性能。
- STELLA是一种多模式LLM,能整合蛋白质序列-结构表征和一般知识来解决蛋白质功能预测问题。
- 通过多模式指令调整(MMIT)和OPI-Struc数据集,STELLA在蛋白质功能相关任务中实现了卓越性能。
- 研究强调了多模式LLM在蛋白质生物学研究中的潜力,可作为pLMs的替代方法。
点此查看论文截图


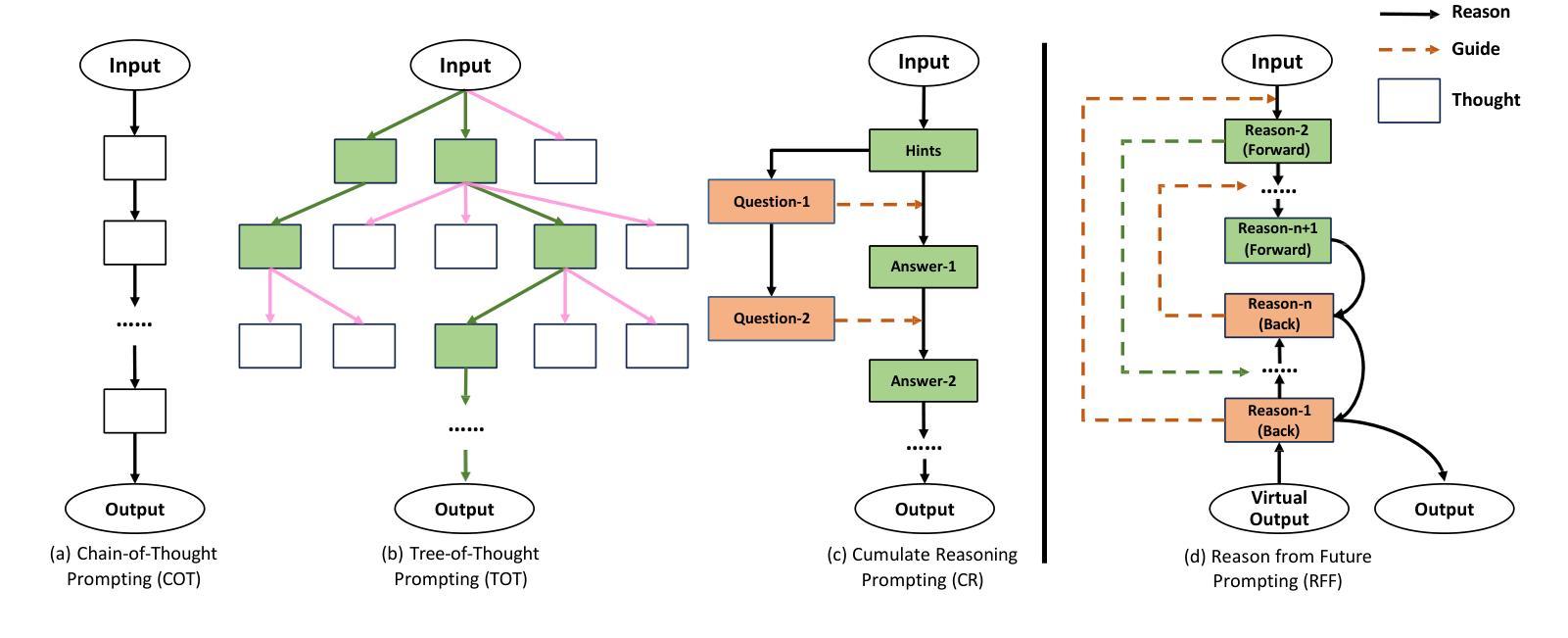
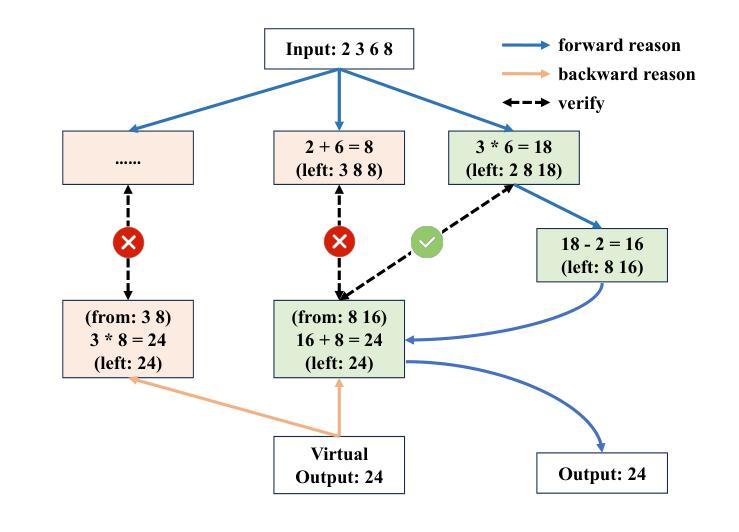
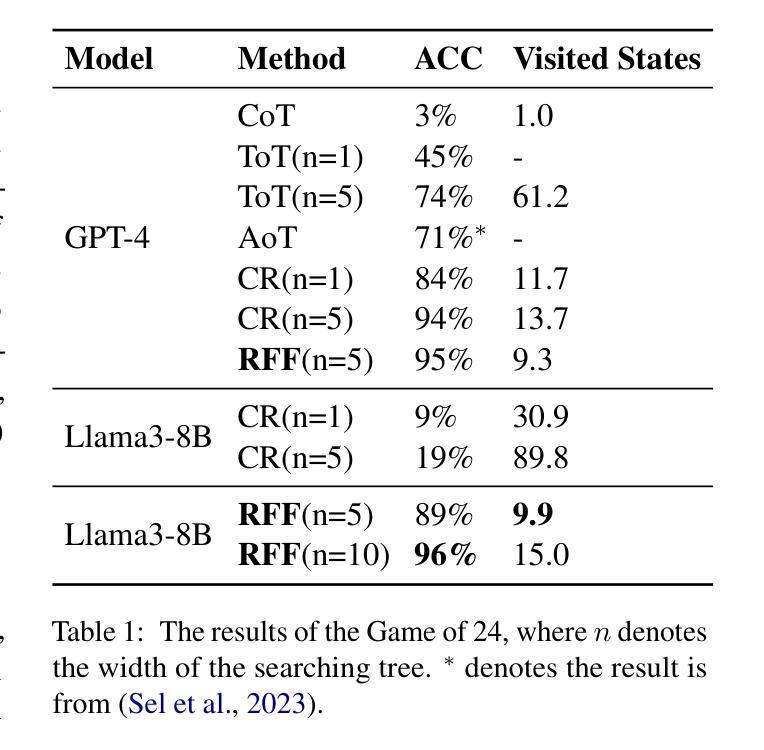
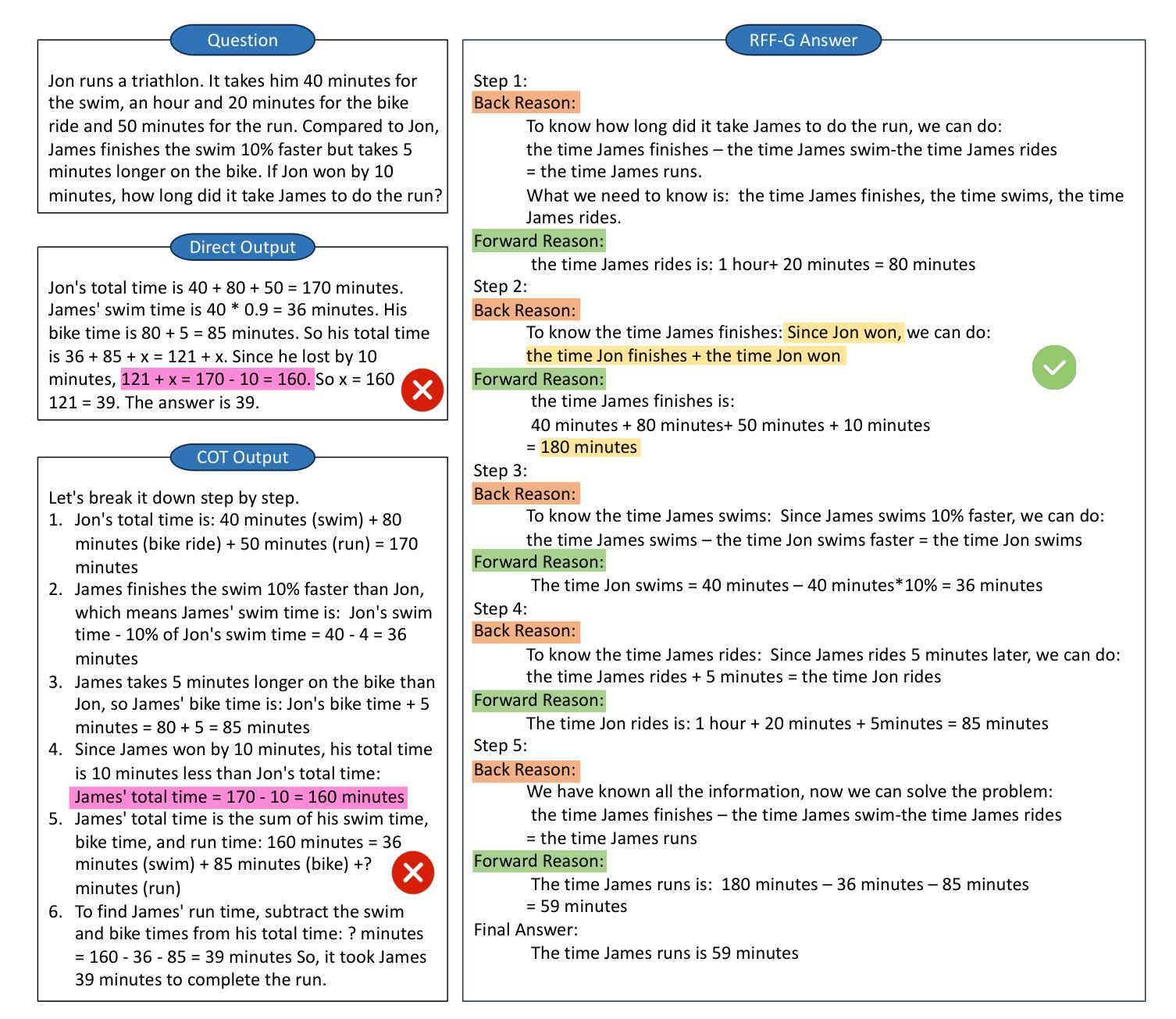
Reason from Future: Reverse Thought Chain Enhances LLM Reasoning
Authors:Yinlong Xu, Yanzhao Zheng, Shuoshuo Sun, Shuaihan Huang, Baohua Dong, Hangcheng Zhu, Ruohui Huang, Gang Yu, Hongxia Xu, Jian Wu
It has been demonstrated that carefully designed reasoning paradigms, like Chain-of-Thought (CoT) and Tree-of-Thought (ToT), can enhance the reasoning capabilities of small language models by detailed thinking and extensive thought searching, unbounded branching factors in the searching space create prohibitive reasoning consumption. However these methods fall into the trap of local optimum reasoning, which means the model lacks a global perspective while solving problems. We propose a novel reasoning paradigm called Reason from Future (RFF), which generates reasoning paths by bidirectional reasoning that combines top-down planning with bottom-up reasoning accumulation. The essence of RFF lies in its reverse reasoning mechanism, which prioritizes core logical relationships and imposes goal-oriented constraints on intermediate steps, thereby reducing the searching space and mitigating error accumulation inherent in sequential forward reasoning. Empirical evaluations across diverse experiments demonstrate that RFF outperforms conventional paradigms with higher accuracy and less searching space to solve complex tasks.
经过精心设计推理范式,如思维链(CoT)和思维树(ToT),能够通过详细思考和广泛的思想搜索增强小型语言模型的推理能力。然而,这些方法的搜索空间中存在不受限制的分支因素,会产生大量的推理消耗,容易陷入局部最优推理的陷阱,这意味着模型在解决问题时缺乏全局视角。我们提出了一种新型的推理范式,称为未来推理(RFF),它通过结合自上而下规划与自下而上推理积累来进行双向推理,生成推理路径。RFF的本质在于其逆向推理机制,该机制优先处理核心逻辑关系,并对中间步骤施加目标导向的约束,从而减少搜索空间并减轻顺序正向推理中固有的错误累积问题。跨多种实验的经验评估表明,与传统范式相比,RFF以更高的准确性和更小的搜索空间解决复杂任务的能力更为出色。
论文及项目相关链接
PDF Accepted by ACL 2025 findings
Summary:新型推理模式如链式思维(Chain-of-Thought,CoT)与树状思维(Tree-of-Thought,ToT)能够提升小型语言模型的推理能力,但它们面临陷入局部最优推理的困境。为此,我们提出了一种新的推理模式——未来导向推理(Reason from Future,RFF)。它通过双向推理生成推理路径,将自上而下规划与自下而上的推理积累相结合。其核心在于反向推理机制,优先核心逻辑关系并对中间步骤施加目标导向约束,减少搜索空间并缓解序列正向推理中的错误累积。实证评估显示,RFF在解决复杂任务时表现出更高的准确性和更小的搜索空间。
Key Takeaways:
- 现有推理模式如CoT和ToT能够增强语言模型的推理能力,但存在陷入局部最优推理的问题。
- RFF通过双向推理结合顶向下规划与底向上推理积累。
- RFF的核心在于其反向推理机制,优先核心逻辑关系。
- RFF对中间步骤施加目标导向约束,有助于减少搜索空间。
- RFF能够缓解序列正向推理中的错误累积。
- 实证评估显示RFF在解决复杂任务时具有更高的准确性。
- RFF相比传统模式具有更小的搜索空间。
点此查看论文截图