⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-06 更新
Towards Better Disentanglement in Non-Autoregressive Zero-Shot Expressive Voice Conversion
Authors:Seymanur Akti, Tuan Nam Nguyen, Alexander Waibel
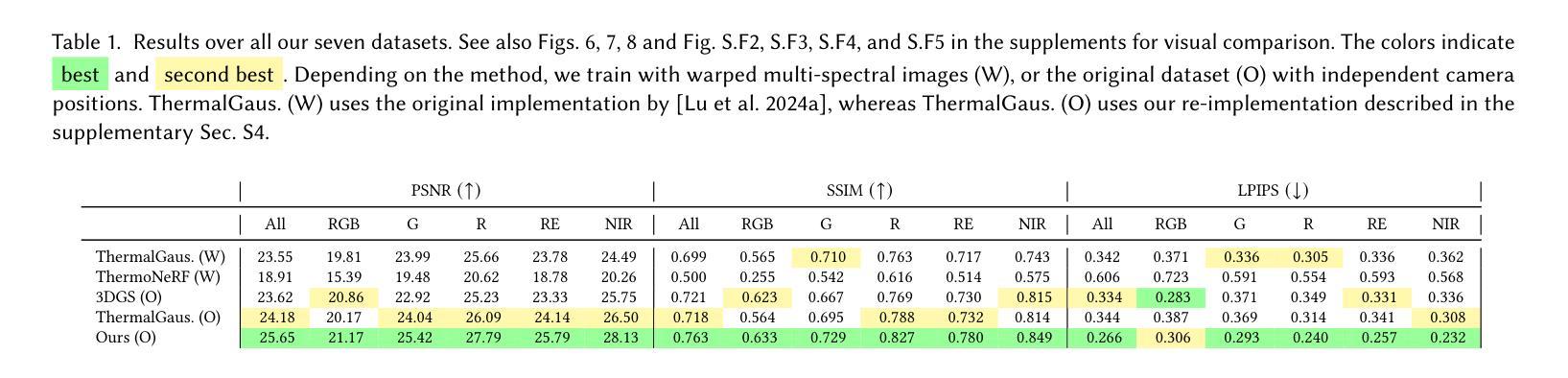
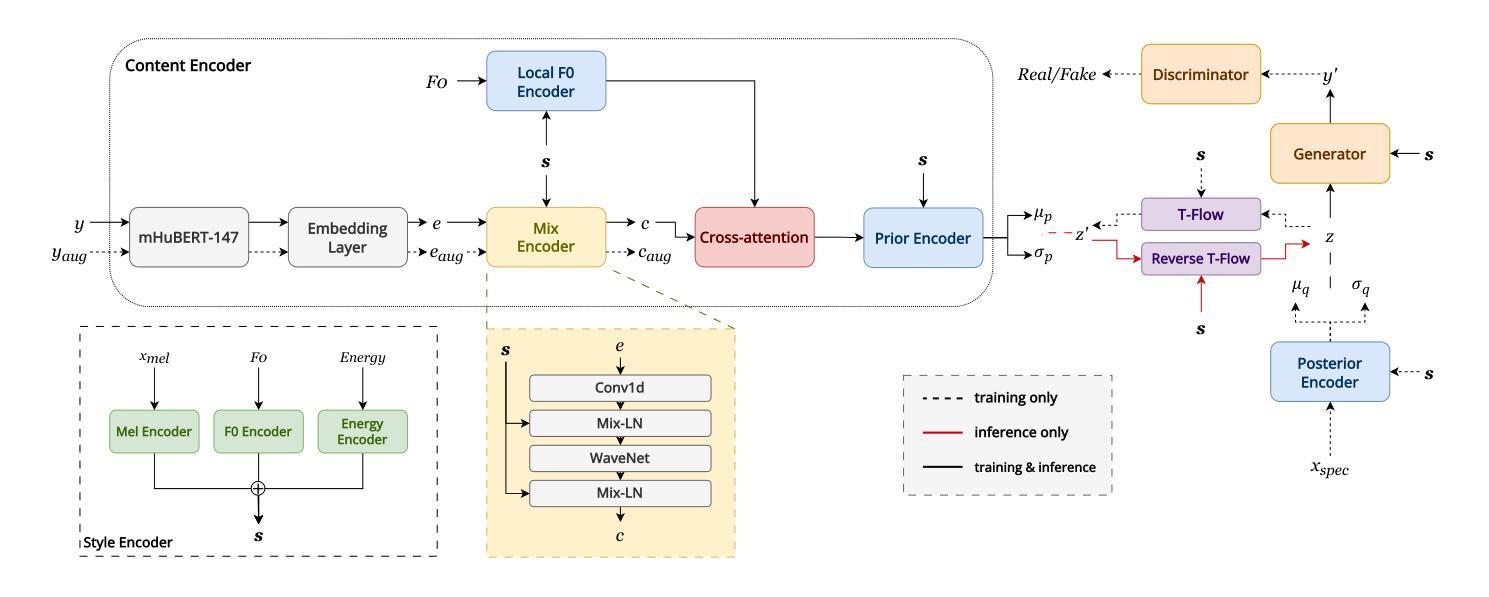
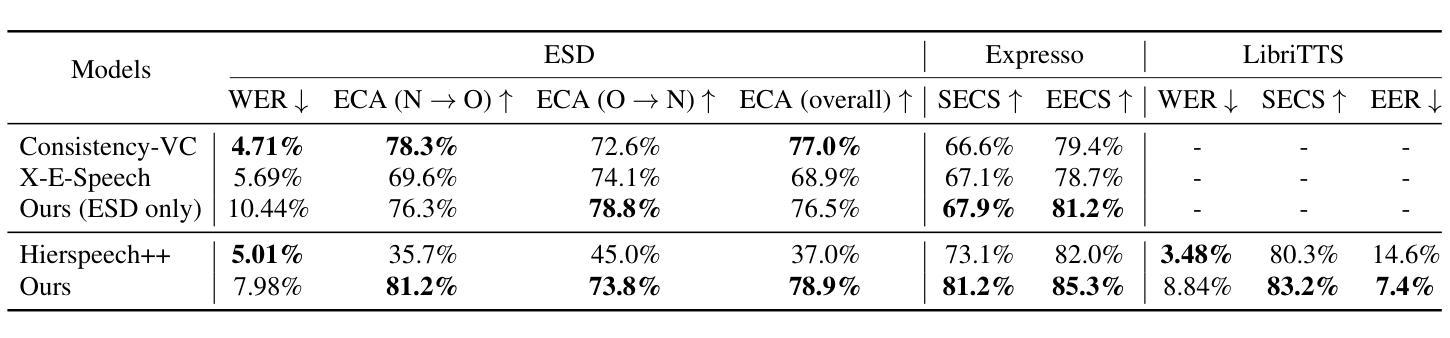
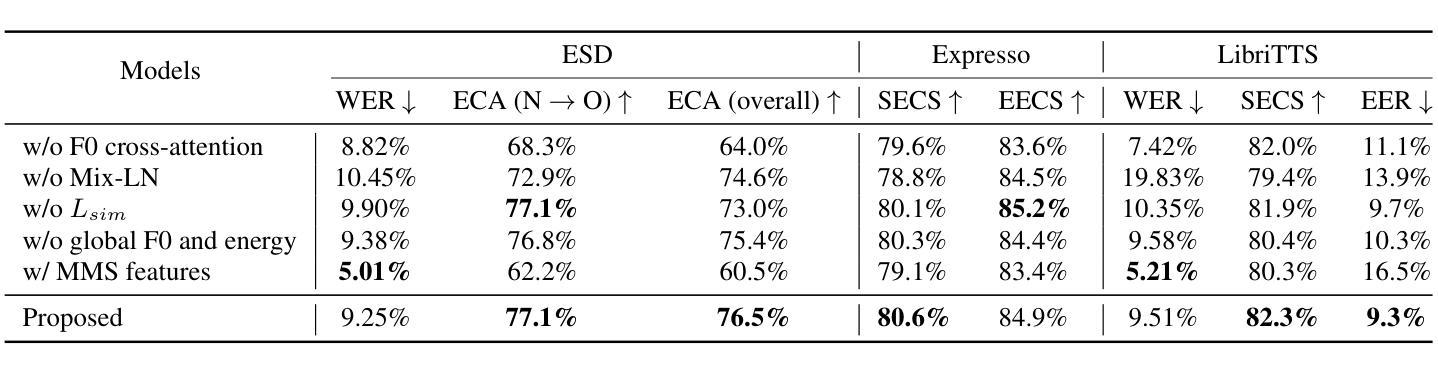
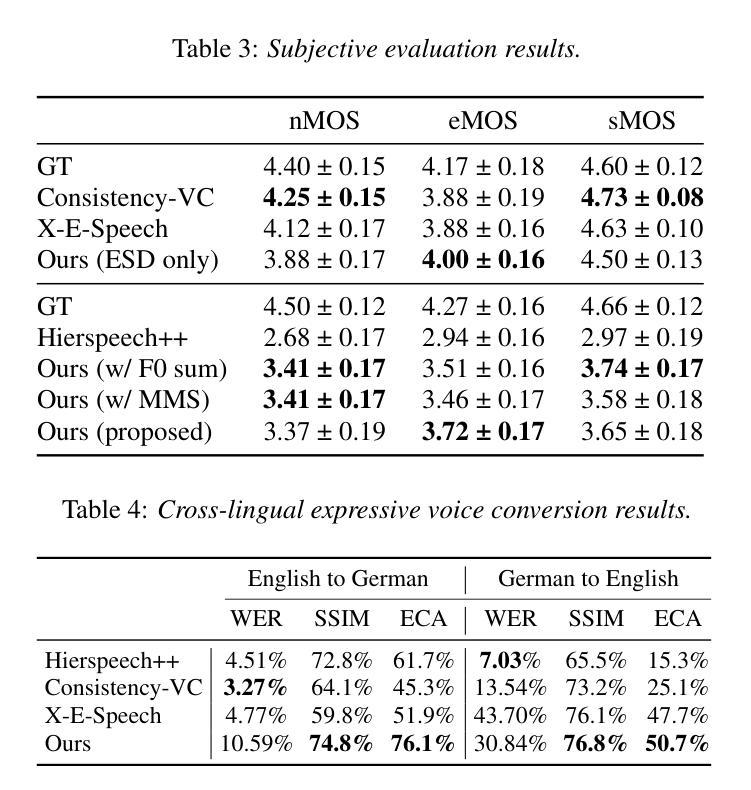
Expressive voice conversion aims to transfer both speaker identity and expressive attributes from a target speech to a given source speech. In this work, we improve over a self-supervised, non-autoregressive framework with a conditional variational autoencoder, focusing on reducing source timbre leakage and improving linguistic-acoustic disentanglement for better style transfer. To minimize style leakage, we use multilingual discrete speech units for content representation and reinforce embeddings with augmentation-based similarity loss and mix-style layer normalization. To enhance expressivity transfer, we incorporate local F0 information via cross-attention and extract style embeddings enriched with global pitch and energy features. Experiments show our model outperforms baselines in emotion and speaker similarity, demonstrating superior style adaptation and reduced source style leakage.
表情语音转换旨在将目标语音的说话人身份和表情属性转移到给定的源语音上。在这项工作中,我们基于条件变分自编码器改进了自我监督的非自回归框架,专注于减少源音色泄漏并改善语言声学的分离以实现更好的风格转换。为了最小化风格泄漏,我们使用跨语言离散语音单元进行内容表示,并通过基于增强的相似性损失和混合风格层归一化来加强嵌入。为了增强表现力转移,我们通过交叉注意力融入局部F0信息,并提取通过全局音高和能量特征丰富风格的嵌入。实验表明,我们的模型在情感和说话人相似性方面优于基线模型,展现出卓越的风格适应性以及减少了源风格泄漏。
论文及项目相关链接
PDF Accepted to Interspeech 2025
总结
本研究的表达性语音转换旨在从目标语音向给定源语音转移说话人的身份和表达属性。该研究在自我监督的非自回归框架基础上,利用条件变分自编码器进行了改进,重点关注减少源音色泄露并改善语言声学的分离以实现更好的风格转换。为最小化风格泄露,研究使用跨语言离散语音单元进行内容表示,并加强嵌入式方法的使用以引入基于扩充的相似性损失和混合风格层标准化方法。为提升表达力传递,本研究结合交叉注意力来引入局部F0信息,并提取通过全局音高和能量特征丰富化的风格嵌入。实验表明,该模型在情感和说话人相似性方面优于基准模型,展现出卓越的风格适应能力和减少的源风格泄露。
关键见解
- 表达性语音转换结合了说话人身份和表达属性的转移。
- 研究基于自我监督的非自回归框架进行改进,使用条件变分自编码器。
- 研究关注减少源音色泄露和改善语言声学的分离,以实现更好的风格转换。
- 为最小化风格泄露,采用跨语言离散语音单元进行内容表示。
- 加强嵌入式方法的使用引入了基于扩充的相似性损失和混合风格层标准化方法。
- 通过结合交叉注意力和局部F0信息以及提取由全局音高和能量特征增强风格的嵌入来提高表达性传递。
- 实验显示模型在情感和说话人相似性上表现优异,展现优秀的风格适应性和较低的源风格泄露。
点此查看论文截图

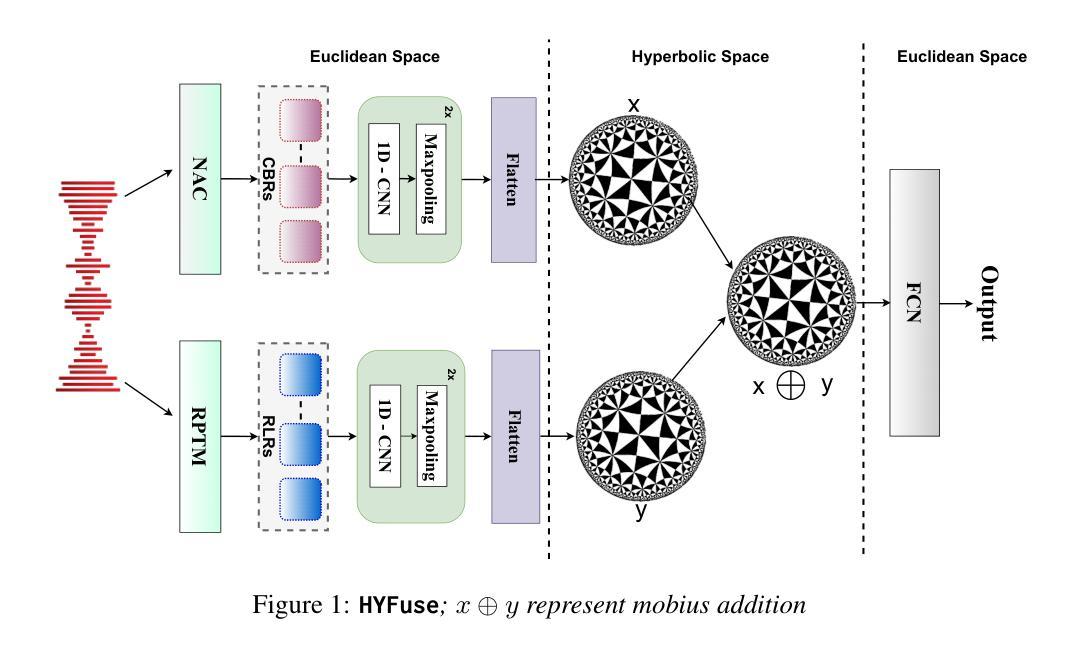
HYFuse: Aligning Heterogeneous Speech Pre-Trained Representations in Hyperbolic Space for Speech Emotion Recognition
Authors:Orchid Chetia Phukan, Girish, Mohd Mujtaba Akhtar, Swarup Ranjan Behera, Pailla Balakrishna Reddy, Arun Balaji Buduru, Rajesh Sharma
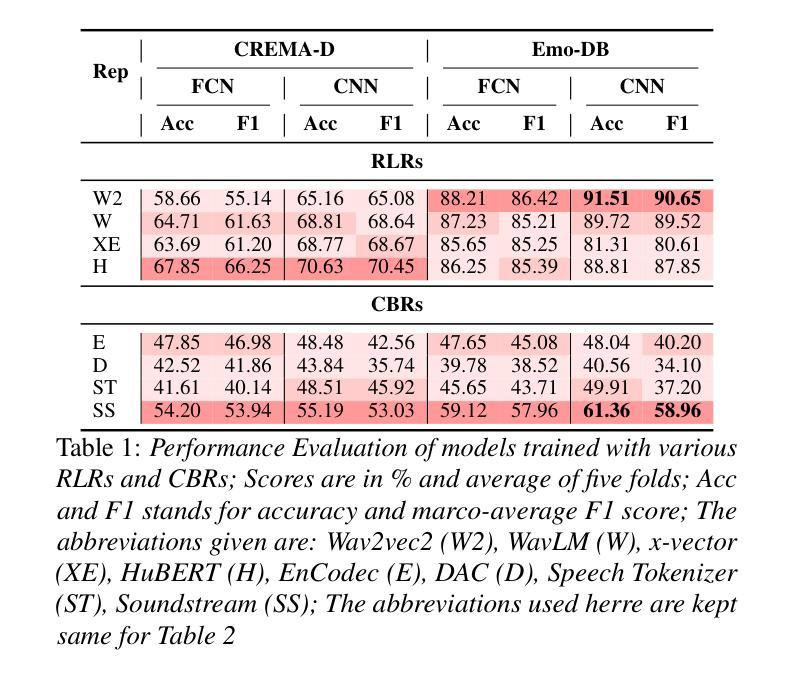
Compression-based representations (CBRs) from neural audio codecs such as EnCodec capture intricate acoustic features like pitch and timbre, while representation-learning-based representations (RLRs) from pre-trained models trained for speech representation learning such as WavLM encode high-level semantic and prosodic information. Previous research on Speech Emotion Recognition (SER) has explored both, however, fusion of CBRs and RLRs haven’t been explored yet. In this study, we solve this gap and investigate the fusion of RLRs and CBRs and hypothesize they will be more effective by providing complementary information. To this end, we propose, HYFuse, a novel framework that fuses the representations by transforming them to hyperbolic space. With HYFuse, through fusion of x-vector (RLR) and Soundstream (CBR), we achieve the top performance in comparison to individual representations as well as the homogeneous fusion of RLRs and CBRs and report SOTA.
来自神经网络音频编码器的基于压缩的表示(CBRs)能够捕获音高和音色等复杂的声音特征,而来自预先训练的用于语音表示学习的模型的基于表示学习的表示(RLRs)则能够编码高级语义和韵律信息,如WavLM。之前的关于语音情感识别(SER)的研究已经探索了这两者,然而,CBRs和RLRs的融合尚未被探索。在这项研究中,我们解决了这一空白,并研究了RLRs和CBRs的融合,假设它们通过提供互补信息将更有效。为此,我们提出了HYFuse这一新型框架,它通过将这些表示转换到双曲空间来实现融合。通过使用HYFuse融合x-vector(RLR)和Soundstream(CBR),我们在对比单独表示以及RLRs和CBRs的同质融合时取得了顶尖性能,并报告了最佳状态。
论文及项目相关链接
PDF Accepted to INTERSPEECH 2025
Summary
本文研究了基于压缩的音频表示(CBRs)与基于预训练模型的表示(RLRs)的融合在语音情感识别(SER)中的应用。通过提出HYFuse框架,将两种表示形式转换到双曲空间进行融合,实现了对这两种表示的互补利用,并通过实验验证了其有效性。
Key Takeaways
- CBRs能够捕捉音频的精细声学特征,如音高和音色。
- RLRs能够编码高级语义和韵律信息。
- 现有研究中对于这两种表示方法的融合尚未得到充分探索。
- 本文首次尝试将CBRs和RLRs进行融合,并假设它们能提供互补信息以提高性能。
- 提出了一种新的融合框架HYFuse,通过双曲空间转换实现表示融合。
- 实验结果显示,融合后的表示形式相较于单一表示形式和同类型融合均表现出最佳性能。
点此查看论文截图

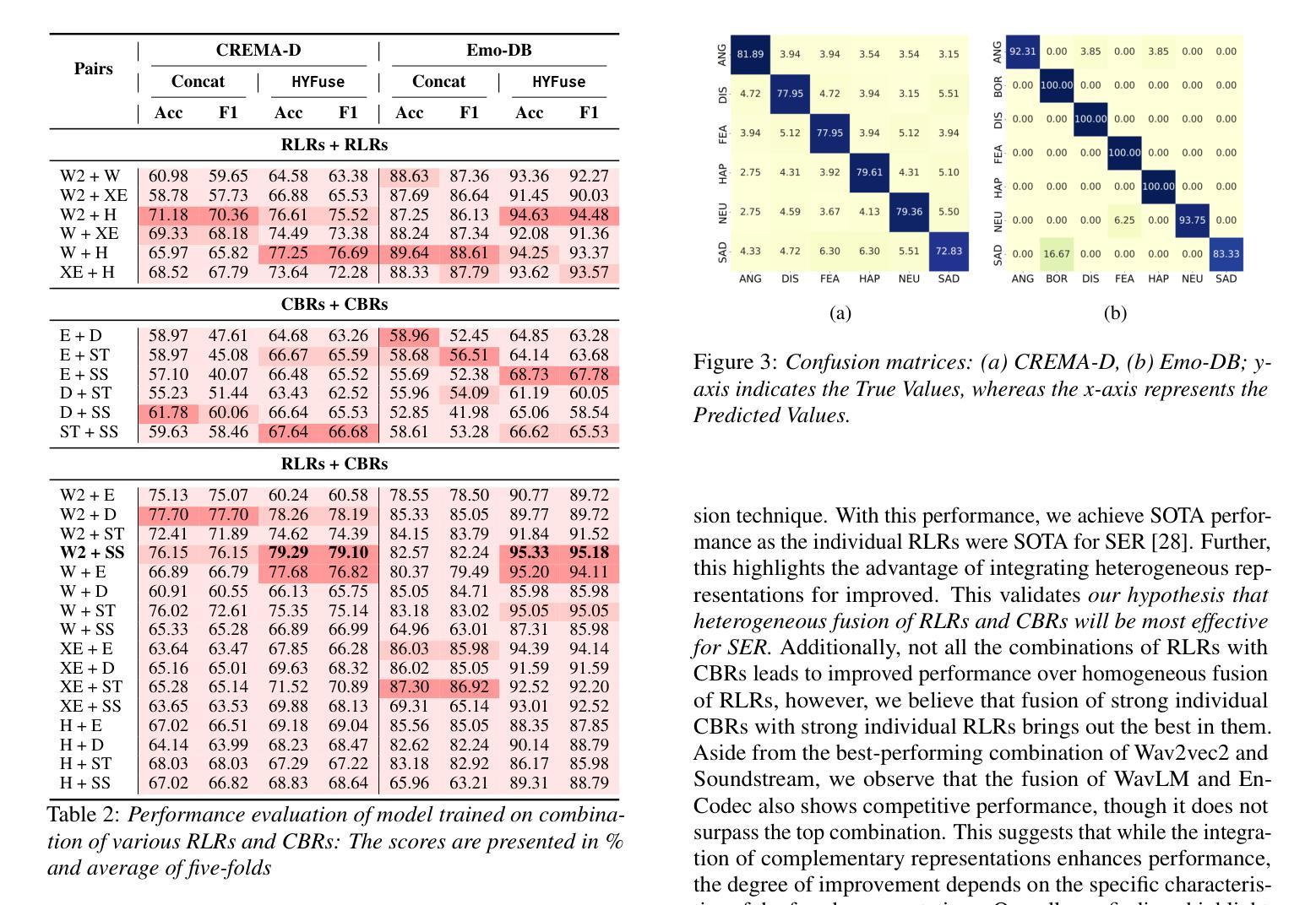
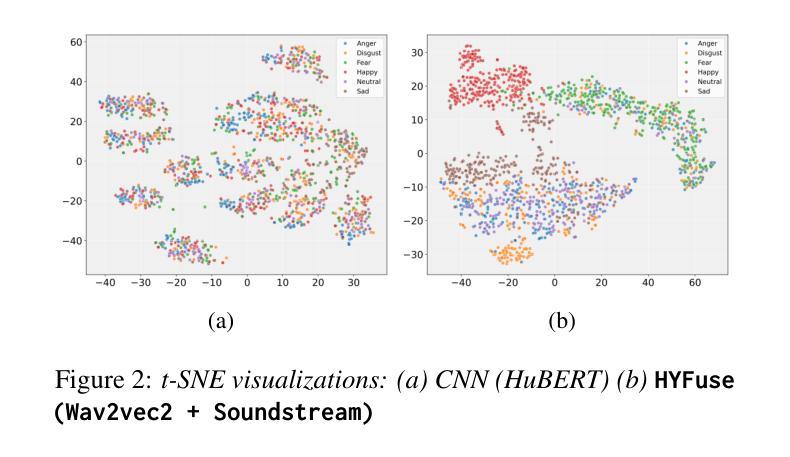
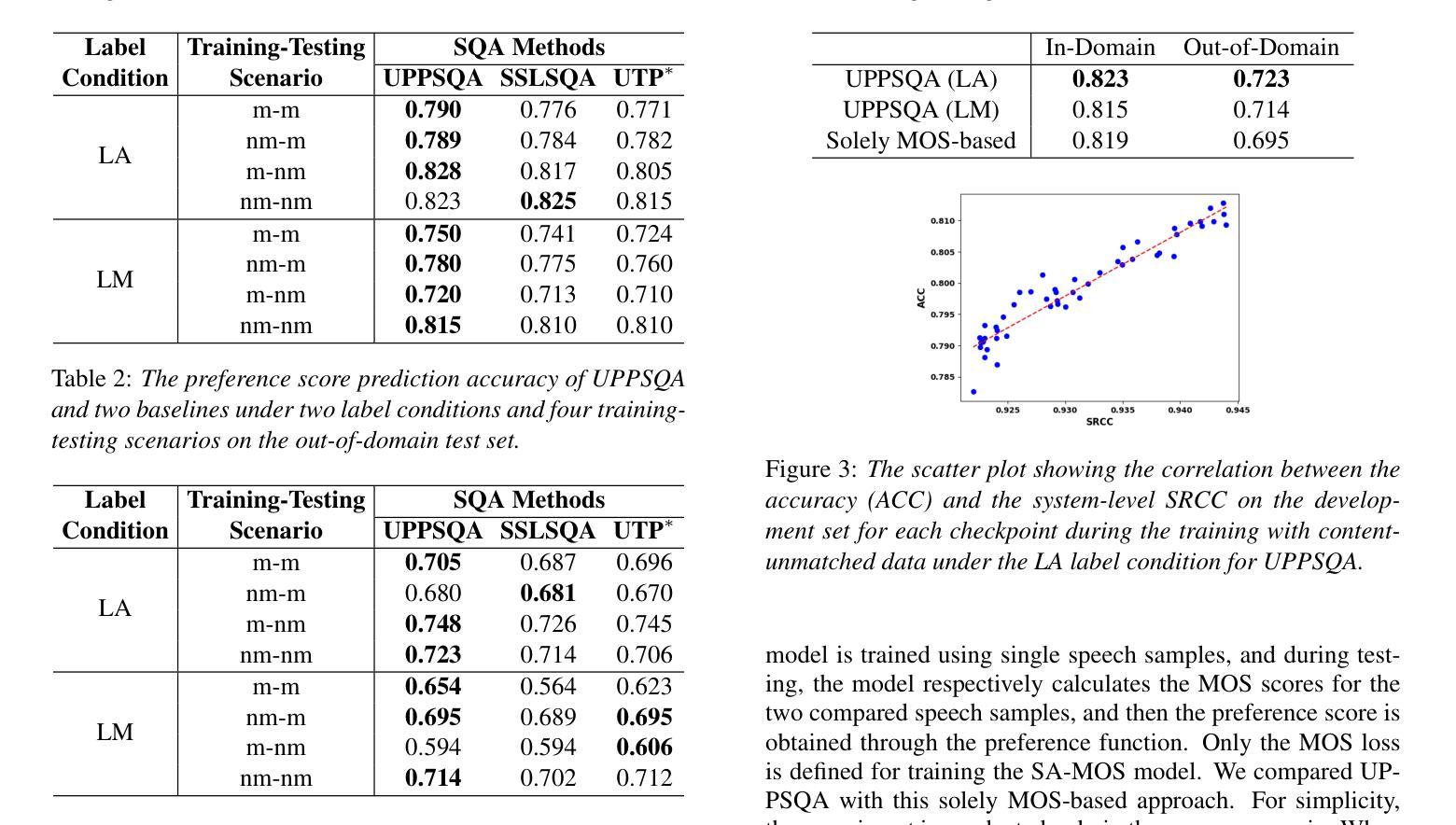
Universal Preference-Score-based Pairwise Speech Quality Assessment
Authors:Yu-Fei Shi, Yang Ai, Zhen-Hua Ling
To compare the performance of two speech generation systems, one of the most effective approaches is estimating the preference score between their generated speech. This paper proposes a novel universal preference-score-based pairwise speech quality assessment (UPPSQA) model, aimed at predicting the preference score between paired speech samples to determine which one has better quality. The model first predicts the absolute mean opinion score (MOS) for the two speech samples separately, and then aggregates them into a relative preference score using a preference function. To address the scarcity of preference data, we also construct a new pairwise speech dataset based on a MOS dataset for experiments. Experimental results confirm that, whether in training scenarios with different data types and label conditions, or in both in-domain and out-of-domain test scenarios, the prediction accuracy of UPP-SQA outperforms that of the baseline models, demonstrating its universality.
要比较两个语音生成系统的性能,最有效的方式之一是评估它们生成的语音之间的偏好分数。本文针对这一需求,提出了一种新的基于通用偏好评分对的语音质量评估(UPPSQA)模型。该模型旨在预测配对语音样本之间的偏好分数,以确定哪一个具有更好的质量。该模型首先预测两个语音样本的绝对平均意见分数(MOS),然后使用偏好函数将它们汇总为相对偏好分数。为了解决偏好数据稀缺的问题,我们还基于MOS数据集构建了一个新的配对语音数据集来进行实验。实验结果表明,无论是在具有不同数据类型和标签条件的训练场景中,还是在域内和域外测试场景中,UPPSQA的预测准确性都优于基线模型,这证明了其普遍性。
论文及项目相关链接
总结
本文提出了一种基于通用偏好评分的新型配对语音质量评估模型(UPPSQA),旨在预测配对语音样本之间的偏好分数,以确定哪一个具有更好的质量。该模型首先预测两个语音样本的绝对平均意见分数(MOS),然后使用偏好函数将它们汇总为相对偏好分数。为应对偏好数据稀缺的问题,本研究还基于MOS数据集构建了一个新的配对语音数据集进行实验。实验结果显示,无论在具有不同数据类型和标签条件的训练场景中,还是在域内和域外测试场景中,UPPSQA的预测准确性均优于基准模型,证明了其通用性。
关键见解
- 提出了一种新型的通用偏好评分模型(UPPSQA)来评估两个语音生成系统的性能。
- 模型先为两个语音样本分别预测绝对平均意见分数(MOS)。
- 模型采用偏好函数将两个样本的MOS汇总为相对偏好分数。
- 为了进行实验,建立了一个新的基于MOS数据集的配对语音数据集。
- 实验表明UPPSQA模型在不同数据类型和标签条件的训练场景中表现优异。
- UPPSQA模型在域内和域外的测试场景中均表现出较高的预测准确性。
点此查看论文截图

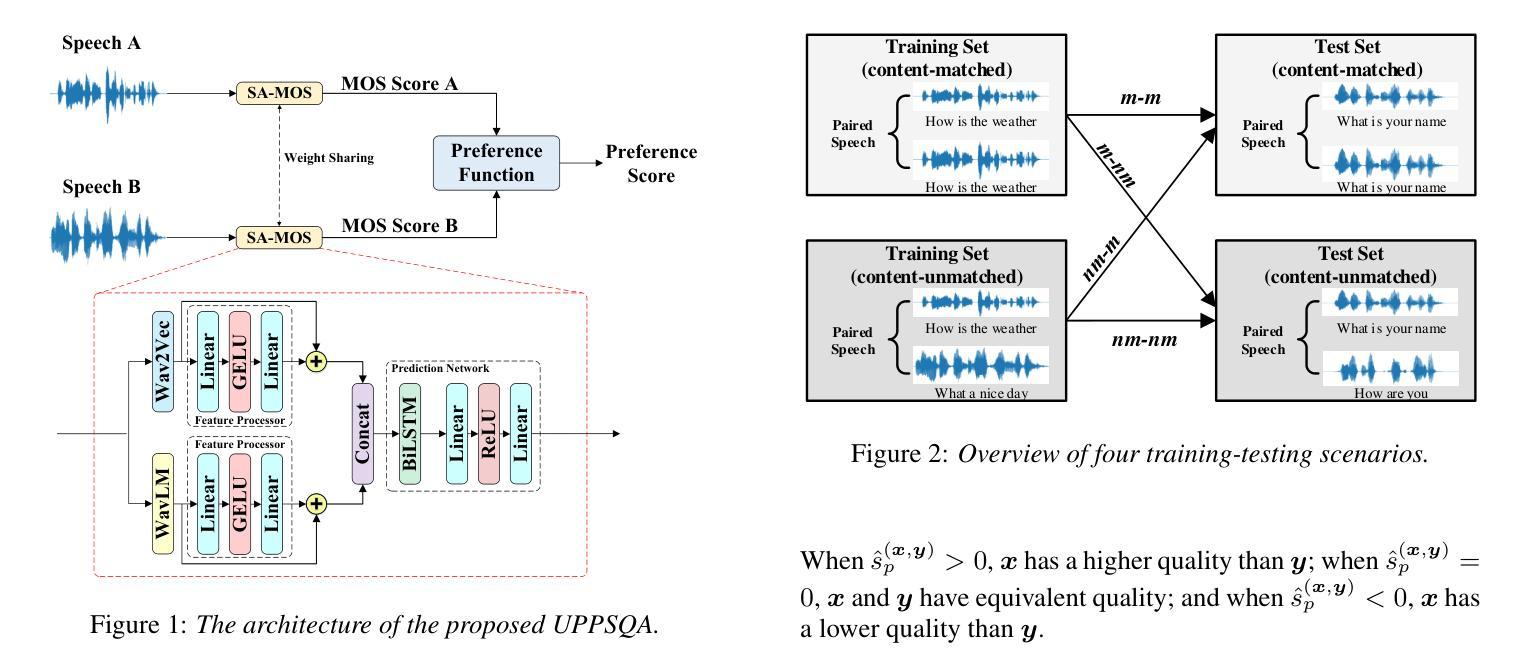
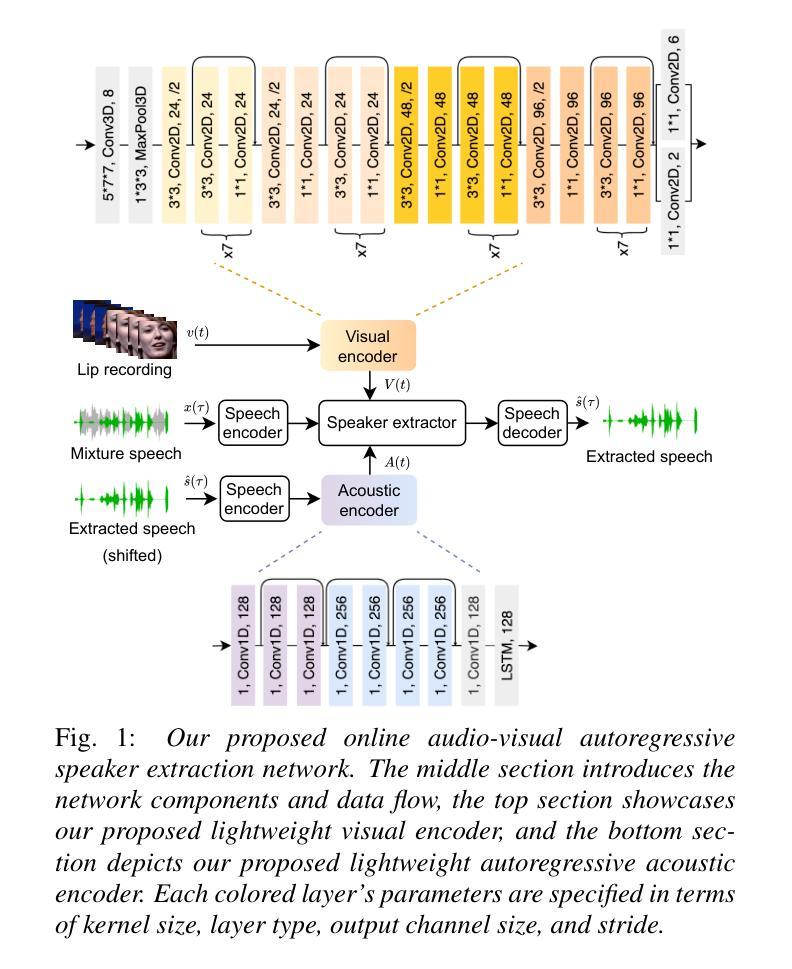
Online Audio-Visual Autoregressive Speaker Extraction
Authors:Zexu Pan, Wupeng Wang, Shengkui Zhao, Chong Zhang, Kun Zhou, Yukun Ma, Bin Ma
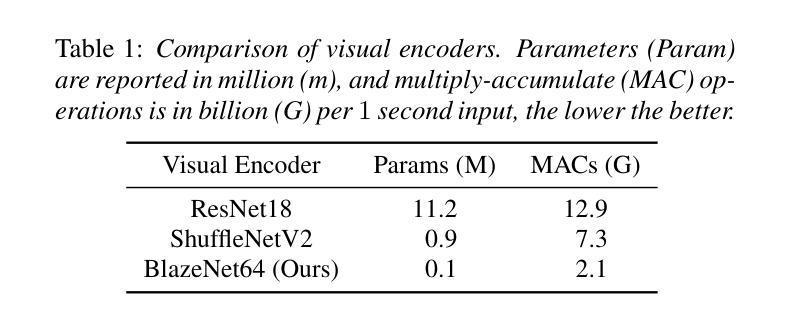
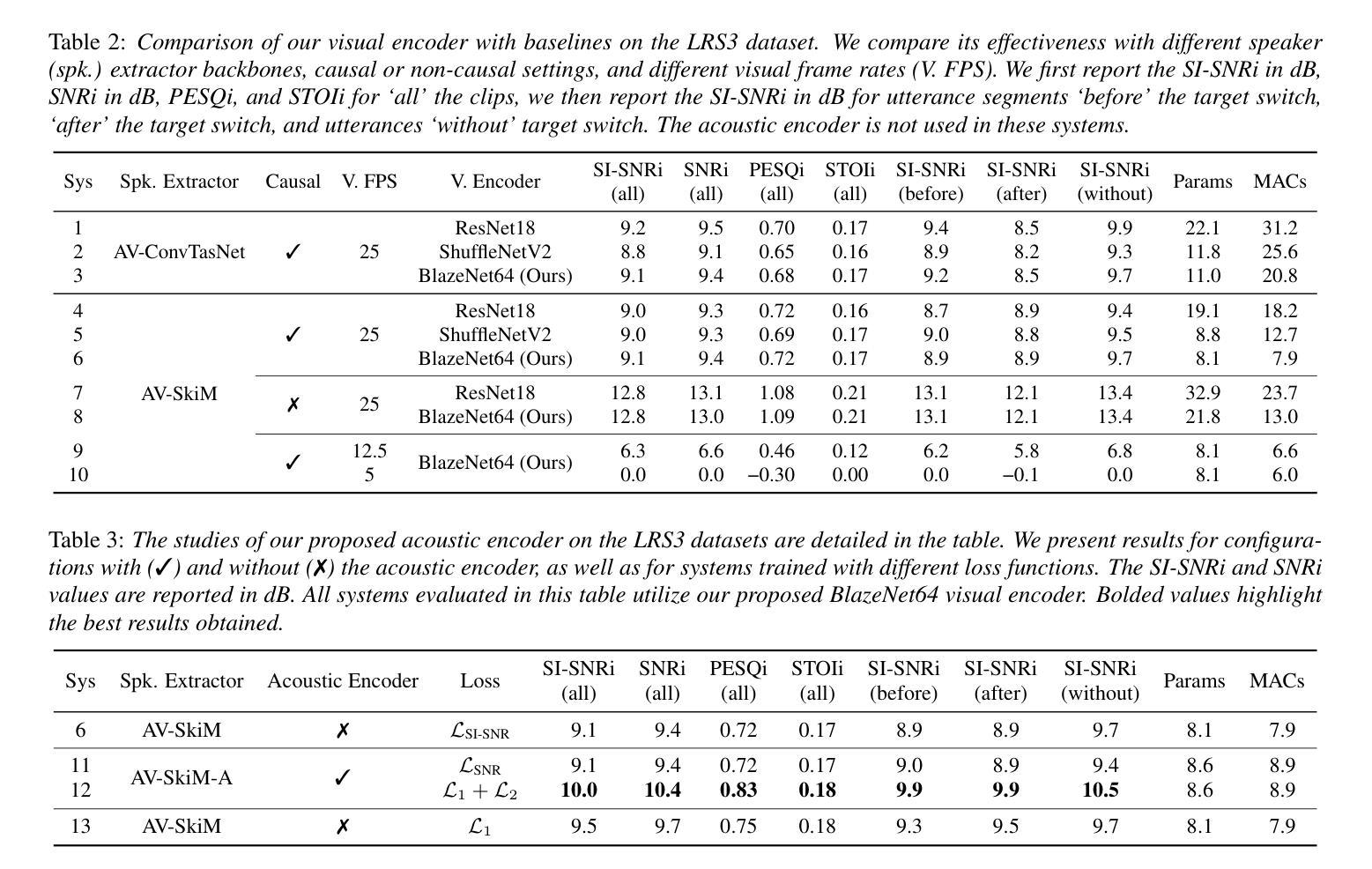
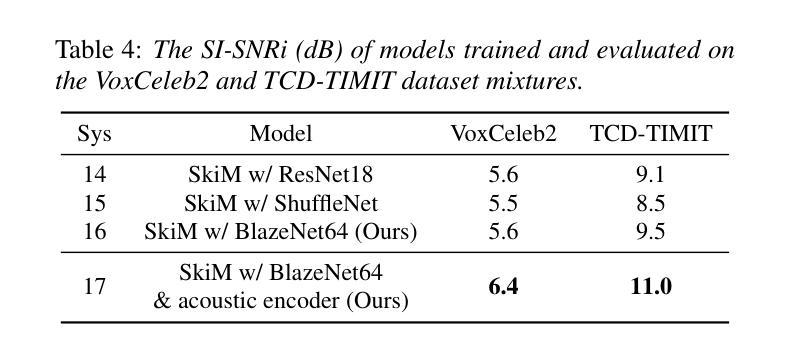
This paper proposes a novel online audio-visual speaker extraction model. In the streaming regime, most studies optimize the audio network only, leaving the visual frontend less explored. We first propose a lightweight visual frontend based on depth-wise separable convolution. Then, we propose a lightweight autoregressive acoustic encoder to serve as the second cue, to actively explore the information in the separated speech signal from past steps. Scenario-wise, for the first time, we study how the algorithm performs when there is a change in focus of attention, i.e., the target speaker. Experimental results on LRS3 datasets show that our visual frontend performs comparably to the previous state-of-the-art on both SkiM and ConvTasNet audio backbones with only 0.1 million network parameters and 2.1 MACs per second of processing. The autoregressive acoustic encoder provides an additional 0.9 dB gain in terms of SI-SNRi, and its momentum is robust against the change in attention.
本文提出了一种新颖的在线视听说话人提取模型。在流式传输环境中,大多数研究只优化音频网络,而对视觉前端的研究较少。首先,我们提出了一种基于深度可分离卷积的轻量级视觉前端。然后,我们提出了一种轻量级的自回归声学编码器,作为第二种线索,以主动探索从过去步骤中分离出来的语音信号中的信息。从场景的角度来看,我们首次研究了当目标说话人的注意力焦点发生变化时,该算法的表现如何。在LRS3数据集上的实验结果表明,我们的视觉前端在SkiM和ConvTasNet音频主干上的性能与最新技术相当,仅使用0.1百万网络参数和每秒2.1 MACs的处理能力。自回归声学编码器在SI-SNRi方面提供了额外的0.9 dB增益,并且其对注意力变化的鲁棒性很强。
论文及项目相关链接
PDF Interspeech2025
Summary
该论文提出了一种新颖的在线视听说话人提取模型。针对流处理模式,论文不仅优化了音频网络,还首次探讨了视觉前端,并提出基于深度可分离卷积的轻量级视觉前端。此外,论文还介绍了一种轻量级的自回归声学编码器,作为第二线索,以积极挖掘从过去步骤中分离出的语音信号信息。实验结果表明,在LRS3数据集上,我们的视觉前端在SkiM和ConvTasNet音频主干网络上表现出卓越性能,仅使用0.1百万网络参数和每秒2.1 MACs的处理能力。自回归声学编码器在SI-SNRi上提供了额外的0.9 dB增益,并且对注意力变化具有稳健性。
Key Takeaways
- 论文提出了一种新颖的在线视听说话人提取模型,结合了音频和视觉信息。
- 视觉前端基于深度可分离卷积,设计轻量级,具有优秀的性能表现。
- 自回归声学编码器作为第二线索,积极挖掘语音信号信息。
- 论文在LRS3数据集上进行了实验验证,视觉前端在SkiM和ConvTasNet上性能卓越。
- 视觉前端仅使用0.1百万网络参数和每秒2.1 MACs的处理能力,显示其高效性。
- 自回归声学编码器提供了额外的0.9 dB的SI-SNRi增益,增强了模型的性能。
点此查看论文截图

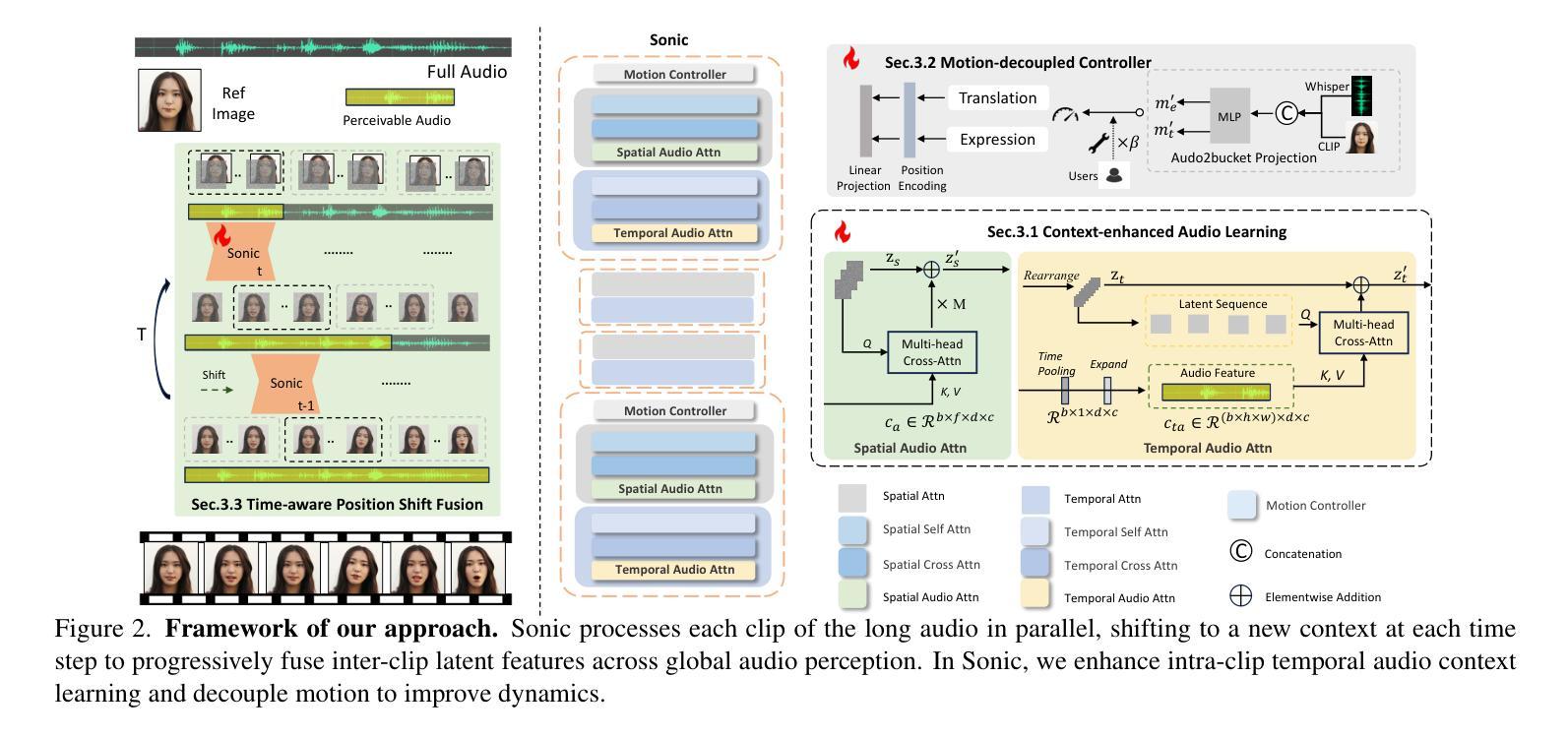
Sonic: Shifting Focus to Global Audio Perception in Portrait Animation
Authors:Xiaozhong Ji, Xiaobin Hu, Zhihong Xu, Junwei Zhu, Chuming Lin, Qingdong He, Jiangning Zhang, Donghao Luo, Yi Chen, Qin Lin, Qinglin Lu, Chengjie Wang
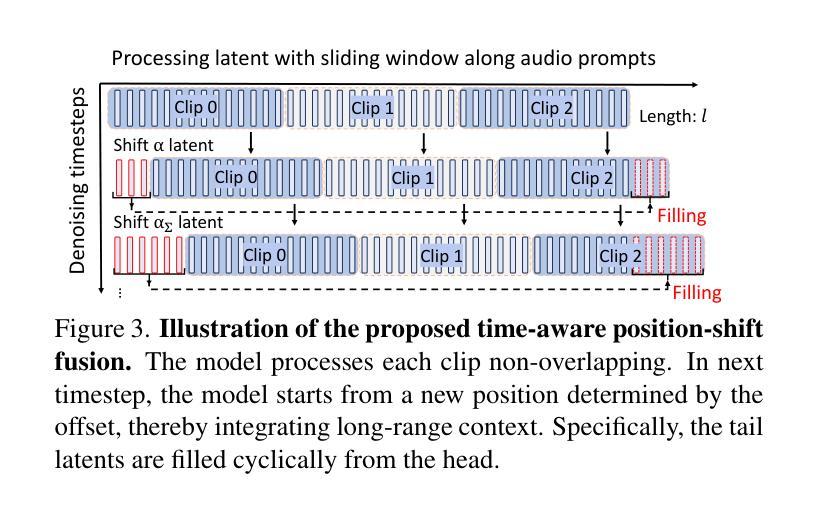
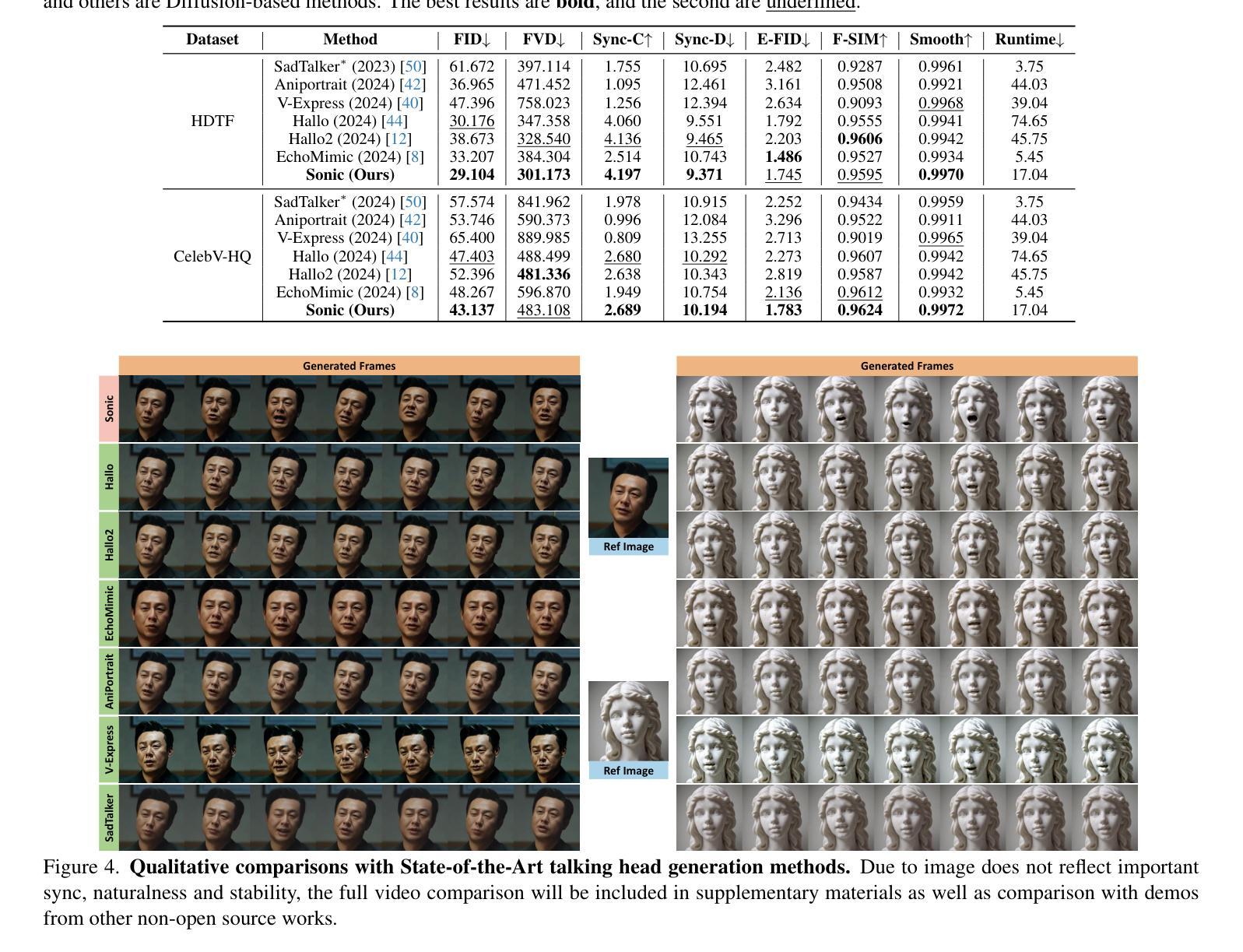
The study of talking face generation mainly explores the intricacies of synchronizing facial movements and crafting visually appealing, temporally-coherent animations. However, due to the limited exploration of global audio perception, current approaches predominantly employ auxiliary visual and spatial knowledge to stabilize the movements, which often results in the deterioration of the naturalness and temporal inconsistencies.Considering the essence of audio-driven animation, the audio signal serves as the ideal and unique priors to adjust facial expressions and lip movements, without resorting to interference of any visual signals. Based on this motivation, we propose a novel paradigm, dubbed as Sonic, to {s}hift f{o}cus on the exploration of global audio per{c}ept{i}o{n}.To effectively leverage global audio knowledge, we disentangle it into intra- and inter-clip audio perception and collaborate with both aspects to enhance overall perception.For the intra-clip audio perception, 1). \textbf{Context-enhanced audio learning}, in which long-range intra-clip temporal audio knowledge is extracted to provide facial expression and lip motion priors implicitly expressed as the tone and speed of speech. 2). \textbf{Motion-decoupled controller}, in which the motion of the head and expression movement are disentangled and independently controlled by intra-audio clips. Most importantly, for inter-clip audio perception, as a bridge to connect the intra-clips to achieve the global perception, \textbf{Time-aware position shift fusion}, in which the global inter-clip audio information is considered and fused for long-audio inference via through consecutively time-aware shifted windows. Extensive experiments demonstrate that the novel audio-driven paradigm outperform existing SOTA methodologies in terms of video quality, temporally consistency, lip synchronization precision, and motion diversity.
对话面部生成的研究主要探索面部动作同步和制作视觉吸引力强、时间连贯的动画的复杂性。然而,由于对全局音频感知的探索有限,当前的方法主要使用辅助的视觉和空间知识来稳定动作,这往往导致自然性的降低和时间上的不一致。考虑到音频驱动动画的本质,音频信号作为调整面部表情和唇部动作的理想和独特先验,无需任何视觉信号的干扰。基于这一动机,我们提出了一种新的范式,称为Sonic,以{s}专注于全局音频感知的探索。为了有效利用全局音频知识,我们将其分解为帧内和帧间音频感知,并与两个方面合作以增强整体感知。对于帧内音频感知,1)。上下文增强的音频学习,从中提取帧内长程音频知识,以语调和语速的形式提供面部表情和唇部动作先验。2)。运动解耦控制器,其中头部运动和表情运动被分离,并由帧内音频片段独立控制。最重要的是,对于帧间音频感知,作为连接帧内片段以实现全局感知的桥梁,时间感知位置偏移融合,其中考虑全局帧间音频信息并通过连续的时间感知偏移窗口进行长音频推理。大量实验表明,这种新型音频驱动范式在视频质量、时间一致性、唇同步精度和运动多样性方面均优于现有最佳方法。
论文及项目相关链接
PDF refer to our main-page \url{https://jixiaozhong.github.io/Sonic/}
摘要
本文研究了说话人脸部生成技术,重点探索面部动作同步和视觉吸引力强的时序连贯动画的制作细节。当前方法主要利用辅助视觉和空间知识来稳定动作,这往往导致自然性和时序连贯性的降低。考虑到音频驱动动画的本质,本文提出了一种新的方法,名为Sonic,专注于全球音频感知的探索。该方法有效利用全局音频知识,将其分解为帧内和帧间音频感知,并融合这两方面来增强整体感知。对于帧内音频感知,采用语境增强的音频学习和运动解耦控制器,分别提取长期帧内音频知识,为面部表情和唇部运动提供隐含的先验信息。对于帧间音频感知,采用时间感知位置偏移融合,将全局帧间音频信息考虑在内,通过连续的时间感知偏移窗口进行长音频推理。实验表明,新的音频驱动方法在视频质量、时序一致性、唇同步精度和运动多样性方面均优于现有方法。
关键见解
- 说话人脸部生成技术主要探索面部动作同步和视觉吸引力的制作方法。
- 当前方法主要依赖视觉和空间知识稳定动作,导致自然性和时序连贯性的降低。
- 提出了一种新的方法——Sonic,专注于全球音频感知的探索。
- 有效利用全局音频知识,将其分解为帧内和帧间音频感知。
- 语境增强的音频学习和运动解耦控制器用于帧内音频感知。
- 时间感知位置偏移融合用于帧间音频感知,通过连续的时间感知偏移窗口进行长音频推理。
- 实验表明,新的音频驱动方法在多个方面均优于现有方法。
点此查看论文截图

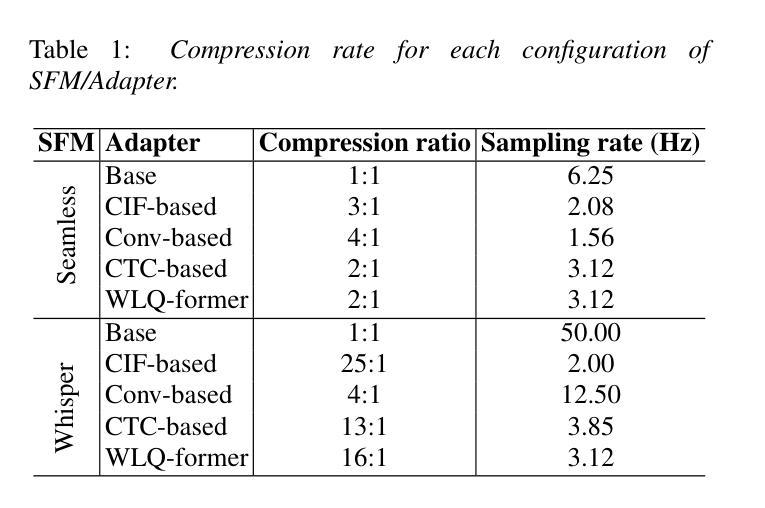
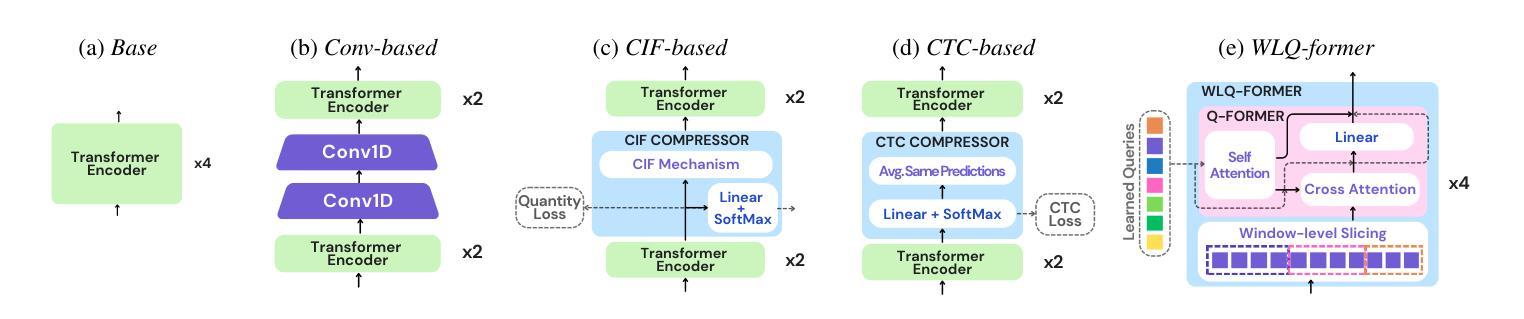
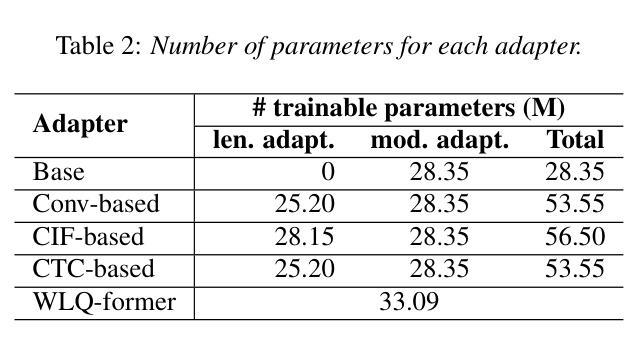
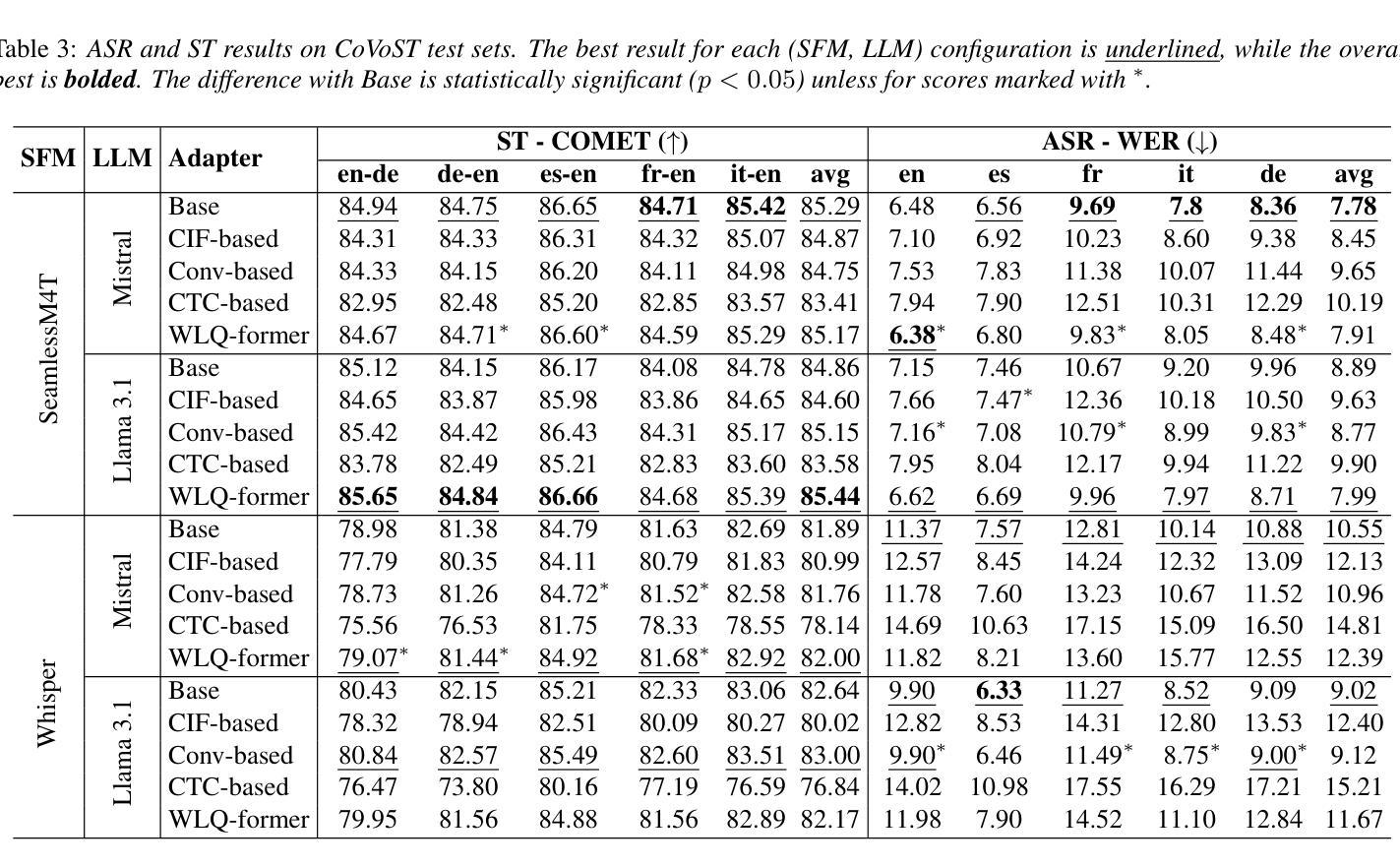
How to Connect Speech Foundation Models and Large Language Models? What Matters and What Does Not
Authors:Francesco Verdini, Pierfrancesco Melucci, Stefano Perna, Francesco Cariaggi, Marco Gaido, Sara Papi, Szymon Mazurek, Marek Kasztelnik, Luisa Bentivogli, Sébastien Bratières, Paolo Merialdo, Simone Scardapane
The remarkable performance achieved by Large Language Models (LLM) has driven research efforts to leverage them for a wide range of tasks and input modalities. In speech-to-text (S2T) tasks, the emerging solution consists of projecting the output of the encoder of a Speech Foundational Model (SFM) into the LLM embedding space through an adapter module. However, no work has yet investigated how much the downstream-task performance depends on each component (SFM, adapter, LLM) nor whether the best design of the adapter depends on the chosen SFM and LLM. To fill this gap, we evaluate the combination of 5 adapter modules, 2 LLMs (Mistral and Llama), and 2 SFMs (Whisper and SeamlessM4T) on two widespread S2T tasks, namely Automatic Speech Recognition and Speech Translation. Our results demonstrate that the SFM plays a pivotal role in downstream performance, while the adapter choice has moderate impact and depends on the SFM and LLM.
大型语言模型(LLM)取得的显著成绩推动了将其应用于广泛任务和输入模式的研究努力。在语音到文本(S2T)任务中,新兴解决方案是通过适配器模块将语音基础模型(SFM)编码器的输出投影到LLM嵌入空间中。然而,尚未有研究调查下游任务性能有多大程度依赖于每个组件(SFM、适配器、LLM),以及适配器的最佳设计是否取决于所选的SFM和LLM。为了填补这一空白,我们评估了两种广泛应用的S2T任务(即自动语音识别和语音识别翻译)中5种适配器模块、2种LLM(Mistral和Llama)、2种SFM(Whisper和无缝M4T)的组合。我们的结果表明,SFM在下游性能中起着至关重要的作用,而适配器选择的影响适中,并取决于SFM和LLM。
论文及项目相关链接
PDF Submitted to Interspeech 2025
Summary
在大规模语言模型(LLM)取得显著成效的推动下,研究开始尝试将其应用于多种任务和输入模式。在语音到文本(S2T)的任务中,新兴解决方案是通过适配器模块将语音基础模型(SFM)编码器的输出映射到LLM嵌入空间。然而,目前尚未有研究调查下游任务性能在多大程度上取决于每个组件(SFM、适配器、LLM),以及适配器的最佳设计是否取决于所选的SFM和LLM。为了填补这一空白,我们评估了两种广泛使用的S2T任务(自动语音识别和语音识别翻译)中5种适配器模块、2种LLM(Mistral和Llama)和2种SFM(Whisper和SeamlessM4T)的组合。结果表明,SFM对下游性能起关键作用,而适配器选择的影响适中,并且取决于SFM和LLM。
Key Takeaways
- 大规模语言模型(LLM)在多种任务中表现出显著性能,引发研究兴趣。
- 在语音到文本(S2T)任务中,通过适配器模块将语音基础模型(SFM)与LLM结合是新兴解决方案。
- 目前尚无研究全面分析各组件(SFM、适配器、LLM)对下游任务性能的影响。
- 本文评估了不同适配器模块、LLM和SFM组合在自动语音识别和语音识别翻译任务中的性能。
- 研究发现,语音基础模型(SFM)在下游任务性能中起关键作用。
- 适配器的选择对性能有适度影响,且这一影响取决于所选的SFM和LLM。
点此查看论文截图