⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-06 更新
A Novel Data Augmentation Approach for Automatic Speaking Assessment on Opinion Expressions
Authors:Chung-Chun Wang, Jhen-Ke Lin, Hao-Chien Lu, Hong-Yun Lin, Berlin Chen
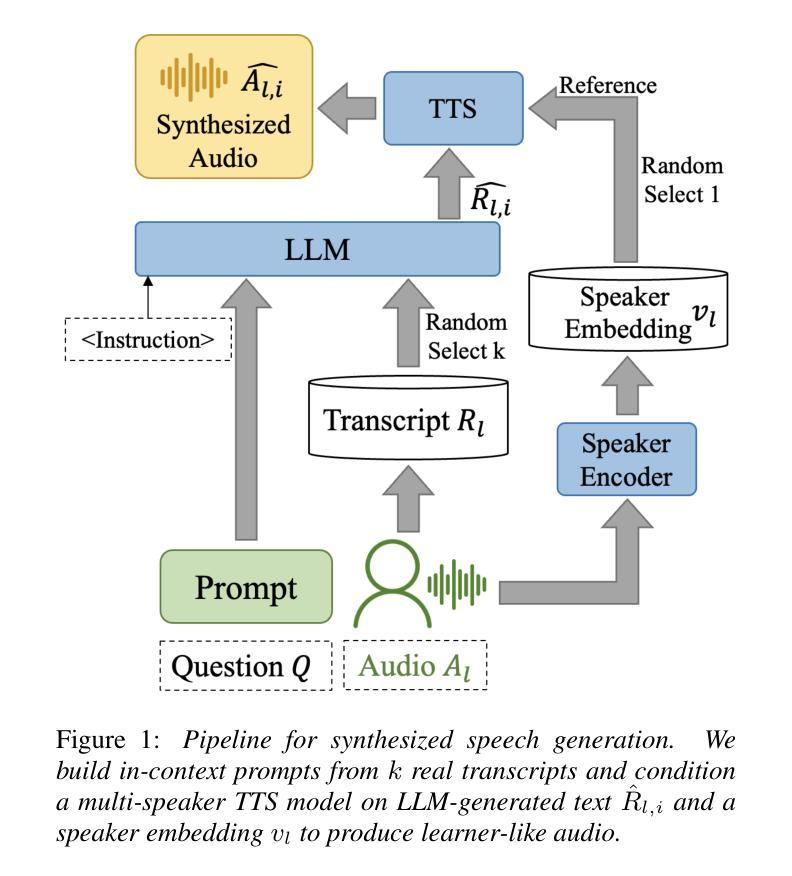
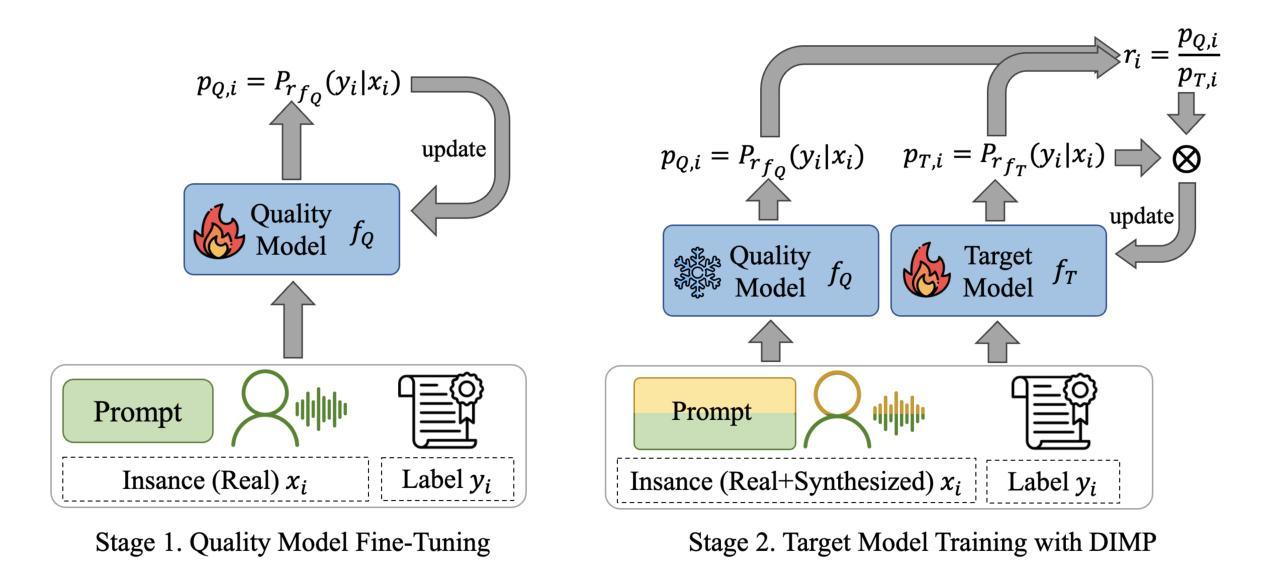
Automated speaking assessment (ASA) on opinion expressions is often hampered by the scarcity of labeled recordings, which restricts prompt diversity and undermines scoring reliability. To address this challenge, we propose a novel training paradigm that leverages a large language models (LLM) to generate diverse responses of a given proficiency level, converts responses into synthesized speech via speaker-aware text-to-speech synthesis, and employs a dynamic importance loss to adaptively reweight training instances based on feature distribution differences between synthesized and real speech. Subsequently, a multimodal large language model integrates aligned textual features with speech signals to predict proficiency scores directly. Experiments conducted on the LTTC dataset show that our approach outperforms methods relying on real data or conventional augmentation, effectively mitigating low-resource constraints and enabling ASA on opinion expressions with cross-modal information.
针对观点表达的自动口语评估(ASA)常常因缺乏标记录音而受到阻碍,这限制了提示的多样性并影响了评分的可靠性。为了应对这一挑战,我们提出了一种新的训练范式,它利用大型语言模型(LLM)来生成给定水平的多样的响应,将响应通过语音感知文本到语音的合成转换成合成语音,并使用动态重要性损失来根据合成语音和真实语音之间的特征分布差异自适应地重新加权训练实例。随后,多模态大型语言模型将对齐的文本特征与语音信号相结合,直接预测熟练度得分。在LTTC数据集上进行的实验表明,我们的方法优于依赖真实数据或传统增强方法的方法,有效地缓解了低资源约束,并实现了具有跨模态信息的观点表达的ASA。
论文及项目相关链接
PDF submitted to the ISCA SLaTE-2025 Workshop
摘要
本文提出一种利用大型语言模型(LLM)生成给定熟练程度的多变应答的训练模式来解决自动化评估观点表达的意见的挑战性问题。这种方法能够克服缺乏标记录音数据导致的提示多样性和评分可靠性问题。通过说话人感知的文本到语音合成技术将应答转化为合成语音,并根据合成语音和真实语音的特征分布差异自适应地重新权衡训练实例的重要性损失。随后,一种多模态大型语言模型融合了对齐的文本特征和语音信号,以预测熟练度分数。在LTTC数据集上的实验表明,我们的方法优于依赖真实数据或传统增强数据的方法,有效减轻了资源不足的约束,并利用跨模态信息实现了意见表达观点的自动化评估。
关键见解
- 缺乏标记录音数据限制了自动化评估观点表达的性能和可靠性。
- 提出了一种基于大型语言模型的训练模式来生成给定熟练程度的多变应答。
- 利用说话人感知的文本到语音合成技术转化应答为合成语音。
- 根据合成语音和真实语音的特征分布差异自适应地重新权衡训练实例的重要性损失。
- 通过多模态大型语言模型融合了文本特征和语音信号进行熟练度分数预测。
- 实验表明,该方法在LTTC数据集上的性能优于依赖真实数据或传统增强数据的方法。
- 该方法有效减轻了资源不足的约束,并实现了利用跨模态信息的自动化评估观点表达。
点此查看论文截图

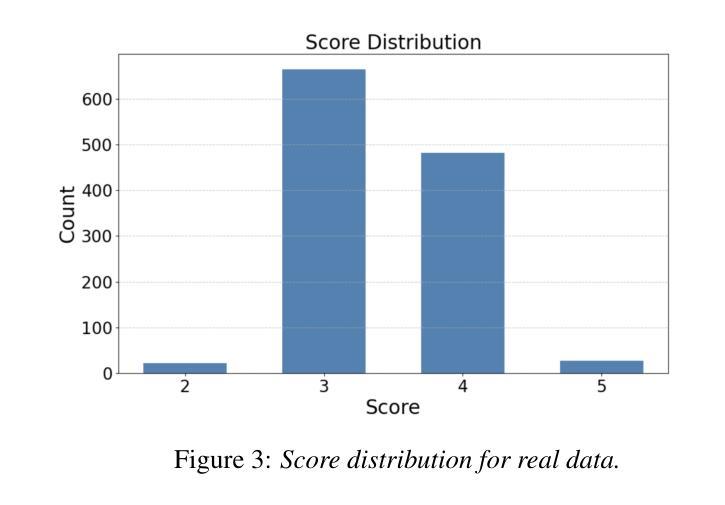
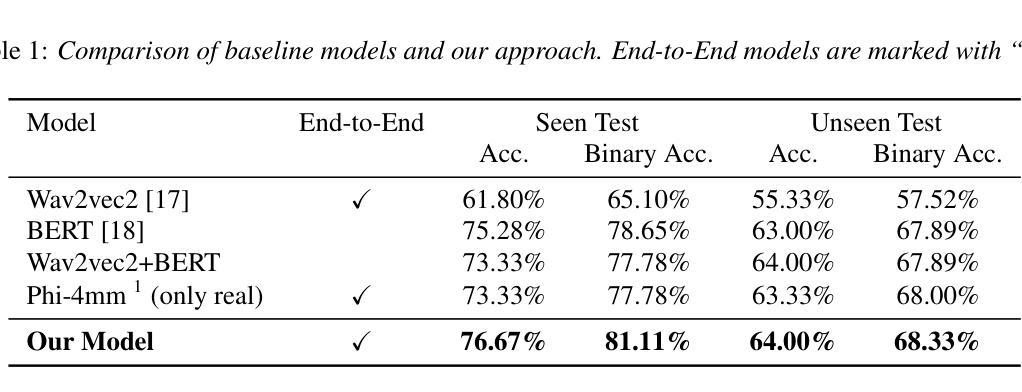
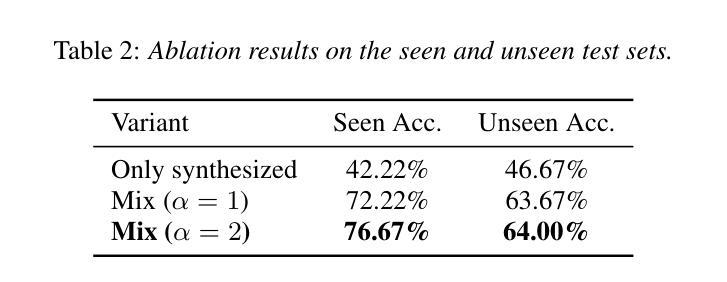
Mark My Words: A Robust Multilingual Model for Punctuation in Text and Speech Transcripts
Authors:Sidharth Pulipaka, Sparsh Jain, Ashwin Sankar, Raj Dabre
Punctuation plays a vital role in structuring meaning, yet current models often struggle to restore it accurately in transcripts of spontaneous speech, especially in the presence of disfluencies such as false starts and backtracking. These limitations hinder the performance of downstream tasks like translation, text to speech, summarization, etc. where sentence boundaries are critical for preserving quality. In this work, we introduce Cadence, a generalist punctuation restoration model adapted from a pretrained large language model. Cadence is designed to handle both clean written text and highly spontaneous spoken transcripts. It surpasses the previous state of the art in performance while expanding support from 14 to all 22 Indian languages and English. We conduct a comprehensive analysis of model behavior across punctuation types and language families, identifying persistent challenges under domain shift and with rare punctuation marks. Our findings demonstrate the efficacy of utilizing pretrained language models for multilingual punctuation restoration and highlight Cadence practical value for low resource NLP pipelines at scale.
标点符号在构建意义方面起着至关重要的作用,然而,当前模型在恢复自发演讲的文本中的标点时往往难以准确做到,特别是在出现误起和回溯等不流畅情况时。这些局限性影响了下游任务(如翻译、文本到语音、摘要等)的表现,在这些任务中,句子边界对于保持质量至关重要。在这项工作中,我们引入了Cadence,这是一个从预训练的大型语言模型中改编而来的通用标点恢复模型。Cadence的设计旨在处理干净的书面文本和高度自发的口语记录。它在性能上超越了之前的技术水平,同时在支持的语言上从14种扩展到了所有22种印度语和英语。我们对模型在不同标点符号类型和语言家族中的行为进行了全面的分析,确定了在领域转移和罕见标点符号方面存在的持久挑战。我们的研究结果表明,利用预训练的语言模型进行多语言标点恢复的有效性,并突出了Cadence在大规模低资源NLP管道中的实用价值。
论文及项目相关链接
PDF Work in Progress
Summary
文本强调了标点在构建意义中的重要性,现有的模型在恢复自发演讲的标点时存在局限性,特别是在存在误起和回溯等不流畅情况时。为此,引入了一个名为Cadence的通用标点恢复模型,该模型基于预训练的大型语言模型,并适应于清洁的书面文本和高度自发的口语转录。它在性能上超越了先前的技术水平,并扩展了从14种印度语言到所有22种印度语言和英语的支持。对模型在不同标点类型和语言家族中的行为进行了全面分析,确定了在领域转换和罕见标点标记下的持续挑战。研究结果表明,利用预训练的语言模型进行多语种标点恢复的有效性,并突出了Cadence在低资源NLP管道的大规模应用中的实用价值。
Key Takeaways
- 标点在构建意义中起关键作用,但当前模型在恢复自发演讲的标点时存在困难。
- Cadence模型是一个基于预训练的大型语言模型的通用标点恢复模型。
- Cadence模型能够适应清洁的书面文本和高度自发的口语转录。
- Cadence模型在性能上超越了先前的技术水平。
- Cadence模型支持22种印度语言和英语。
- 模型在领域转换和罕见标点标记方面仍存在挑战。
点此查看论文截图

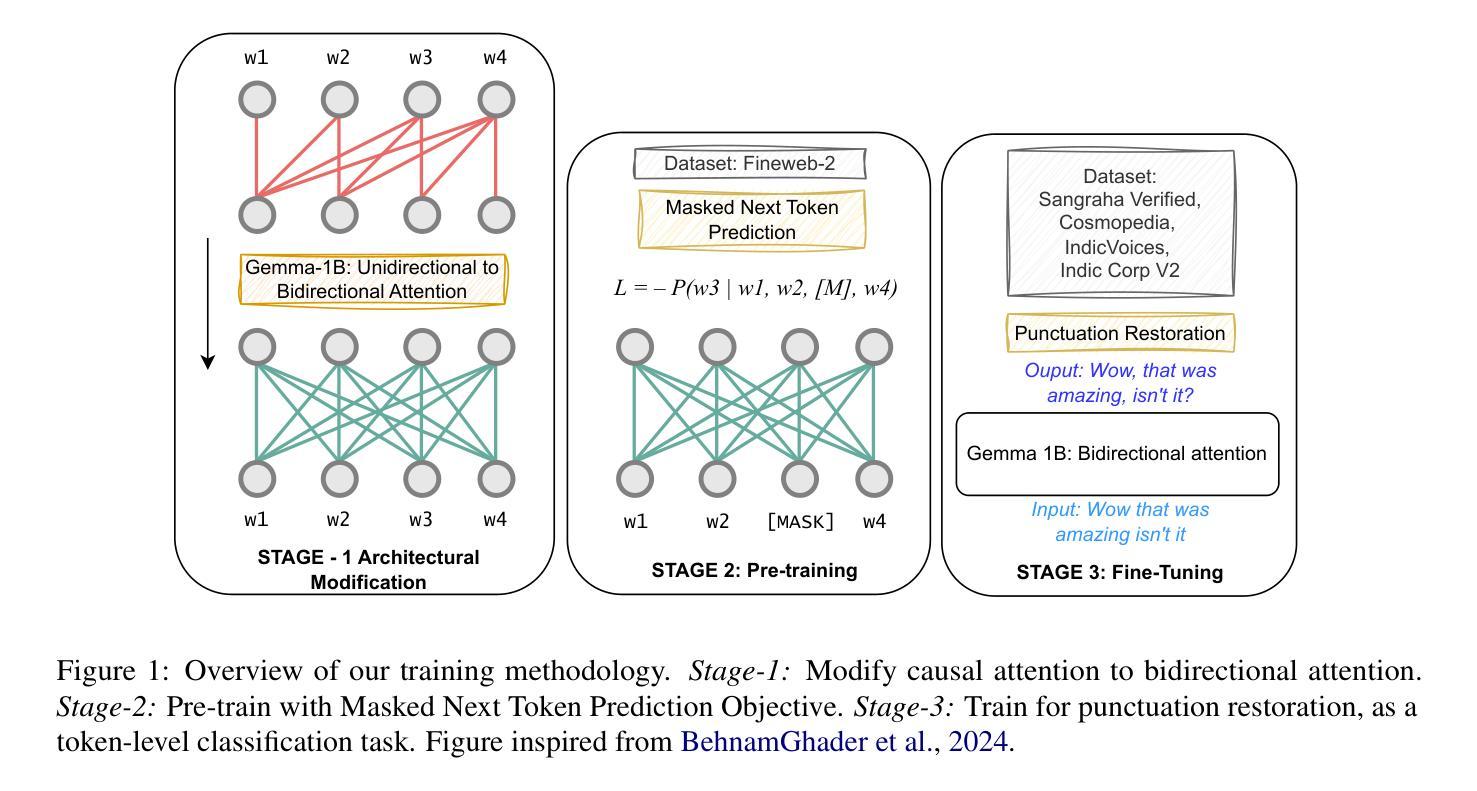

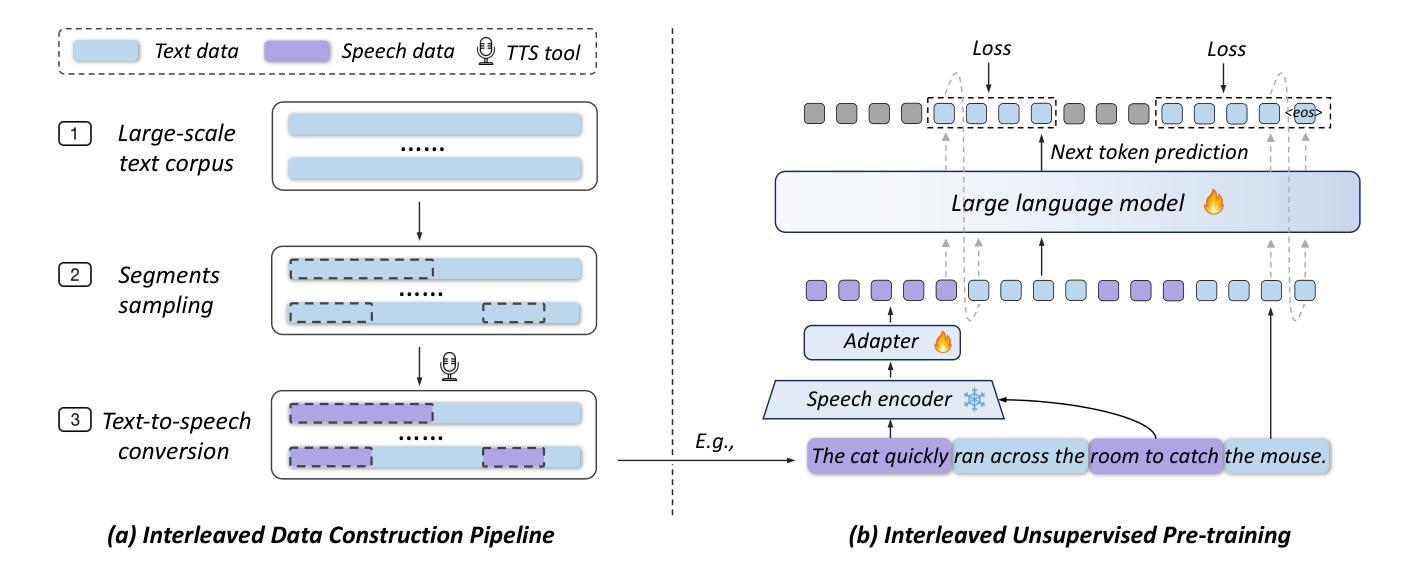
InSerter: Speech Instruction Following with Unsupervised Interleaved Pre-training
Authors:Dingdong Wang, Jin Xu, Ruihang Chu, Zhifang Guo, Xiong Wang, Jincenzi Wu, Dongchao Yang, Shengpeng Ji, Junyang Lin
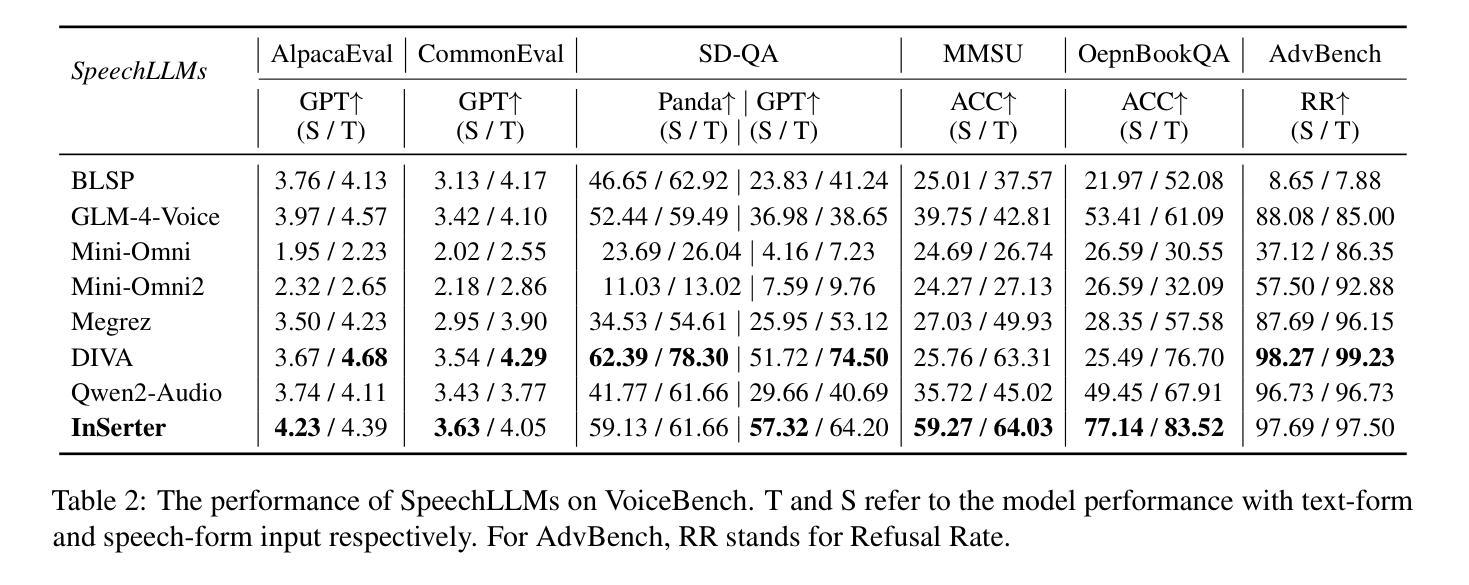
Recent advancements in speech large language models (SpeechLLMs) have attracted considerable attention. Nonetheless, current methods exhibit suboptimal performance in adhering to speech instructions. Notably, the intelligence of models significantly diminishes when processing speech-form input as compared to direct text-form input. Prior work has attempted to mitigate this semantic inconsistency between speech and text representations through techniques such as representation and behavior alignment, which involve the meticulous design of data pairs during the post-training phase. In this paper, we introduce a simple and scalable training method called InSerter, which stands for Interleaved Speech-Text Representation Pre-training. InSerter is designed to pre-train large-scale unsupervised speech-text sequences, where the speech is synthesized from randomly selected segments of an extensive text corpus using text-to-speech conversion. Consequently, the model acquires the ability to generate textual continuations corresponding to the provided speech segments, obviating the need for intensive data design endeavors. To systematically evaluate speech instruction-following capabilities, we introduce SpeechInstructBench, the first comprehensive benchmark specifically designed for speech-oriented instruction-following tasks. Our proposed InSerter achieves SOTA performance in SpeechInstructBench and demonstrates superior or competitive results across diverse speech processing tasks.
最近,语音大型语言模型(SpeechLLMs)的进展引起了人们的广泛关注。然而,当前的方法在遵循语音指令方面表现并不理想。值得注意的是,与直接文本输入相比,模型在处理语音形式输入时的智能水平会显著降低。之前的工作试图通过表示和行为对齐等技术来缓解语音和文本表示之间的语义不一致性,这需要在后训练阶段精心设计数据对。在本文中,我们介绍了一种简单且可扩展的训练方法,称为InSerter,即交替语音文本表示预训练。InSerter旨在预训练大规模无监督的语音文本序列,其中语音是通过文本转语音转换从大量文本语料库中随机选择的片段合成的。因此,模型获得了根据提供的语音片段生成文本延续的能力,从而无需进行密集的数据设计努力。为了系统地评估遵循语音指令的能力,我们推出了SpeechInstructBench,这是专门为面向语音的指令跟随任务设计的首个综合基准测试。我们提出的InSerter在SpeechInstructBench上达到了最新性能,并在各种语音识别任务中表现出卓越或具有竞争力的结果。
论文及项目相关链接
PDF Accepted to ACL 2025; Data is available at: https://huggingface.co/datasets/ddwang2000/SpeechInstructBench
Summary
本文介绍了最新的语音大语言模型(SpeechLLMs)的进展及其在处理语音指令时的性能挑战。为解决语义不一致问题,提出了一种简单且可扩展的训练方法——InSerter(交替语音文本表示预训练方法)。该方法通过大规模无监督的语音文本序列进行预训练,利用文本转语音转换技术合成语音片段。模型能够生成与给定语音片段对应的文本延续,从而减少了数据设计的工作量。此外,还推出了SpeechInstructBench,这是专门为语音指令跟随任务设计的首个综合基准测试。InSerter在SpeechInstructBench上取得了最佳性能,并在多种语音处理任务中表现出卓越或竞争力。
Key Takeaways
- 语音大语言模型(SpeechLLMs)在处理语音指令时存在性能挑战。
- 当前方法在处理语音形式输入时与直接文本形式输入相比,智能水平有所下降。
- 语义不一致性是语音和文本表示之间的问题。
- 以往的研究尝试通过数据对设计和行为对齐等技术来缓解这一问题。
- 提出了InSerter训练方法,通过大规模无监督的语音文本序列进行预训练,合成语音片段并生成对应的文本延续。
- InSerter简化了数据设计过程并提高了模型的性能。
点此查看论文截图


ControlSpeech: Towards Simultaneous and Independent Zero-shot Speaker Cloning and Zero-shot Language Style Control
Authors:Shengpeng Ji, Qian Chen, Wen Wang, Jialong Zuo, Minghui Fang, Ziyue Jiang, Hai Huang, Zehan Wang, Xize Cheng, Siqi Zheng, Zhou Zhao
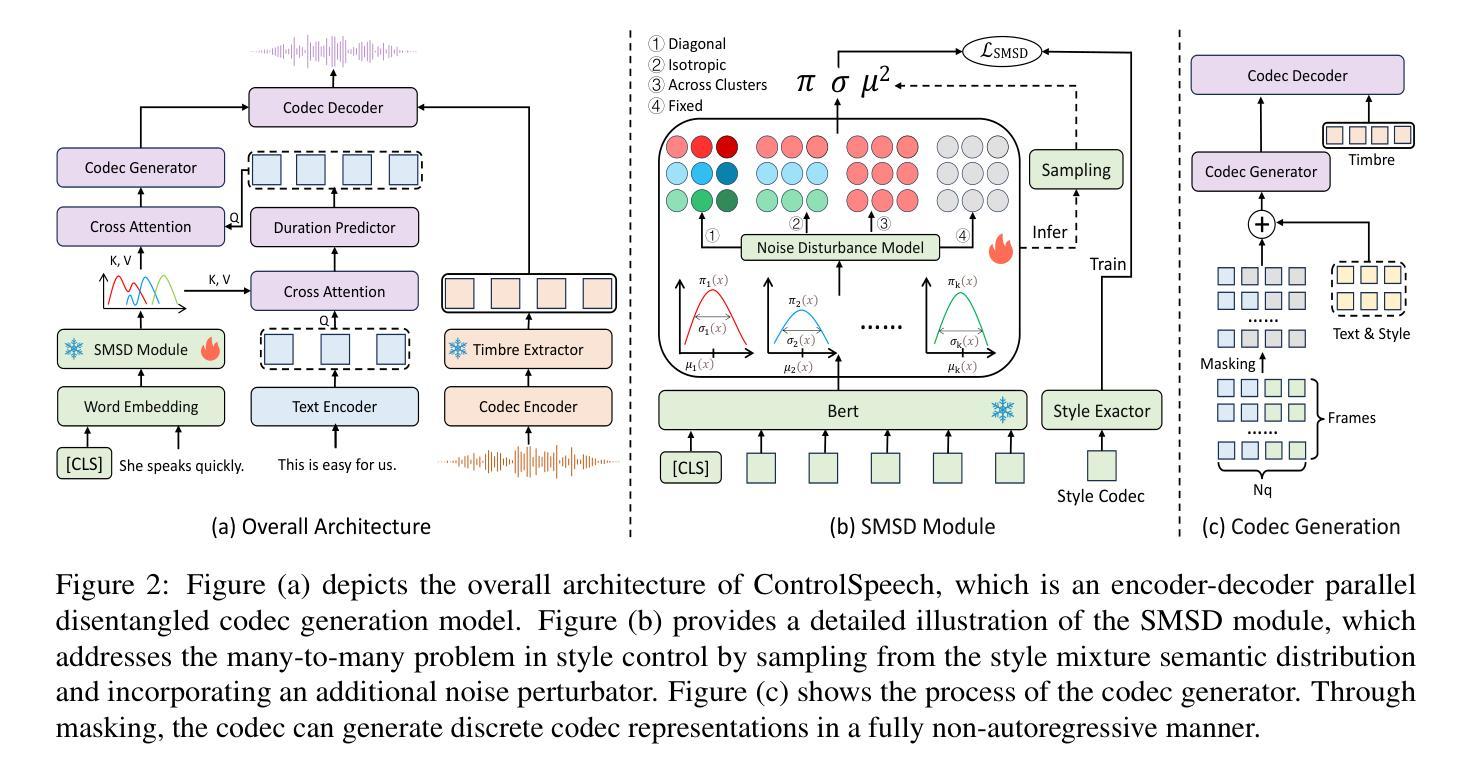
In this paper, we present ControlSpeech, a text-to-speech (TTS) system capable of fully cloning the speaker’s voice and enabling arbitrary control and adjustment of speaking style. Prior zero-shot TTS models only mimic the speaker’s voice without further control and adjustment capabilities while prior controllable TTS models cannot perform speaker-specific voice generation. Therefore, ControlSpeech focuses on a more challenging task: a TTS system with controllable timbre, content, and style at the same time. ControlSpeech takes speech prompts, content prompts, and style prompts as inputs and utilizes bidirectional attention and mask-based parallel decoding to capture codec representations corresponding to timbre, content, and style in a discrete decoupling codec space. Moreover, we analyze the many-to-many issue in textual style control and propose the Style Mixture Semantic Density (SMSD) module, which is based on Gaussian mixture density networks, to resolve this problem. To facilitate empirical validations, we make available a new style controllable dataset called VccmDataset. Our experimental results demonstrate that ControlSpeech exhibits comparable or state-of-the-art (SOTA) performance in terms of controllability, timbre similarity, audio quality, robustness, and generalizability. The relevant code and demo are available at https://github.com/jishengpeng/ControlSpeech .
本文介绍了ControlSpeech,这是一个文本到语音(TTS)系统,能够完全克隆说话者的声音,并实现对说话风格的任意控制和调整。之前的零样本TTS模型只能模仿说话者的声音,而缺乏进一步的控制和调整能力,而之前的可控TTS模型则无法执行针对说话者的特定声音生成。因此,ControlSpeech专注于一个更具挑战性的任务:一个能够同时控制音色、内容和风格的TTS系统。ControlSpeech以语音提示、内容提示和风格提示为输入,利用双向注意力和基于掩码的并行解码,在离散解耦编码空间中捕捉与音色、内容和风格相对应的编码表示。此外,我们分析了文本风格控制中的多对多问题,并提出了基于高斯混合密度网络的风格混合语义密度(SMSD)模块来解决这个问题。为了进行实证验证,我们提供了一个新的可控风格数据集VccmDataset。我们的实验结果表明,ControlSpeech在可控性、音色相似性、音频质量、稳健性和通用性等方面达到了相当或最先进的性能。相关的代码和演示可在https://github.com/jishengpeng/ControlSpeech上找到。
论文及项目相关链接
PDF ACL 2025 Main
Summary
本文介绍了ControlSpeech文本转语音(TTS)系统,它可完全克隆说话者的声音并具备任意控制和调整说话风格的能力。与之前的零样本TTS模型相比,ControlSpeech可进一步控制和调整语音,同时与先前的可控TTS模型相比,它能够执行特定于说话者的语音生成。ControlSpeech采用控制语音、内容和风格提示作为输入,并利用双向注意力机制和基于掩码的并行解码来捕捉离散解码器空间中对应于音色、内容和风格的编码表示。此外,本文分析了文本风格控制中的多对多问题,并提出了基于高斯混合密度网络的风格混合语义密度(SMSD)模块来解决这一问题。
Key Takeaways
- ControlSpeech是一个具备完全克隆说话者声音和任意控制及调整说话风格能力的TTS系统。
- 与其他TTS模型相比,ControlSpeech能够进一步控制和调整语音,同时实现特定说话者的语音生成。
- ControlSpeech通过采用控制语音、内容和风格的提示作为输入,并捕捉编码表示来解决音色、内容和风格的控制问题。
- 引入了Style Mixture Semantic Density (SMSD)模块,解决了文本风格控制中的多对多问题。
- 为了进行实证研究验证,建立了一个新的可控风格数据集VccmDataset。
- 实验结果表明,ControlSpeech在可控性、音色相似性、音频质量、稳健性和泛化性方面达到了相当或最先进的性能。
点此查看论文截图