⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-06 更新
High Accuracy, Less Talk (HALT): Reliable LLMs through Capability-Aligned Finetuning
Authors:Tim Franzmeyer, Archie Sravankumar, Lijuan Liu, Yuning Mao, Rui Hou, Sinong Wang, Jakob N. Foerster, Luke Zettlemoyer, Madian Khabsa
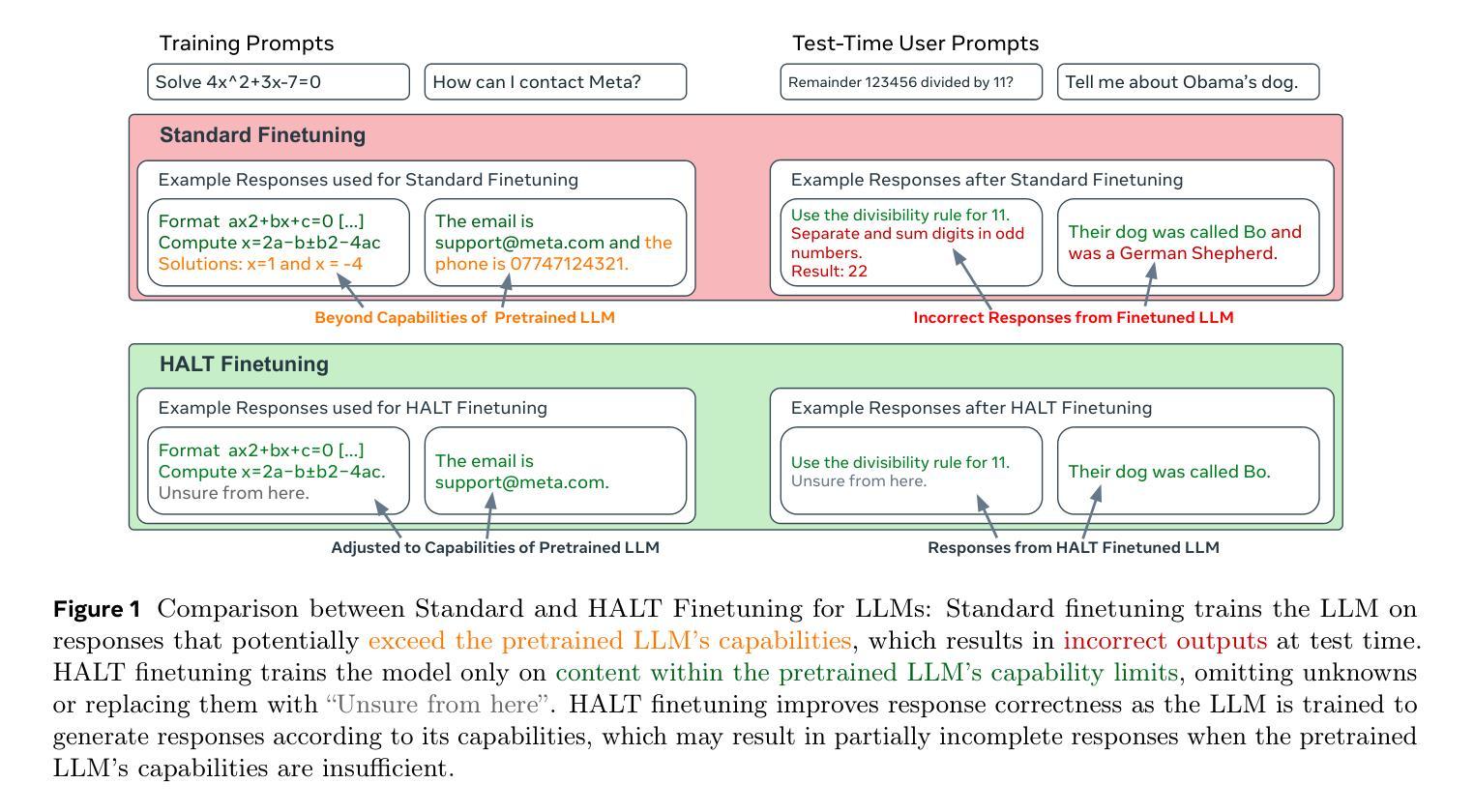
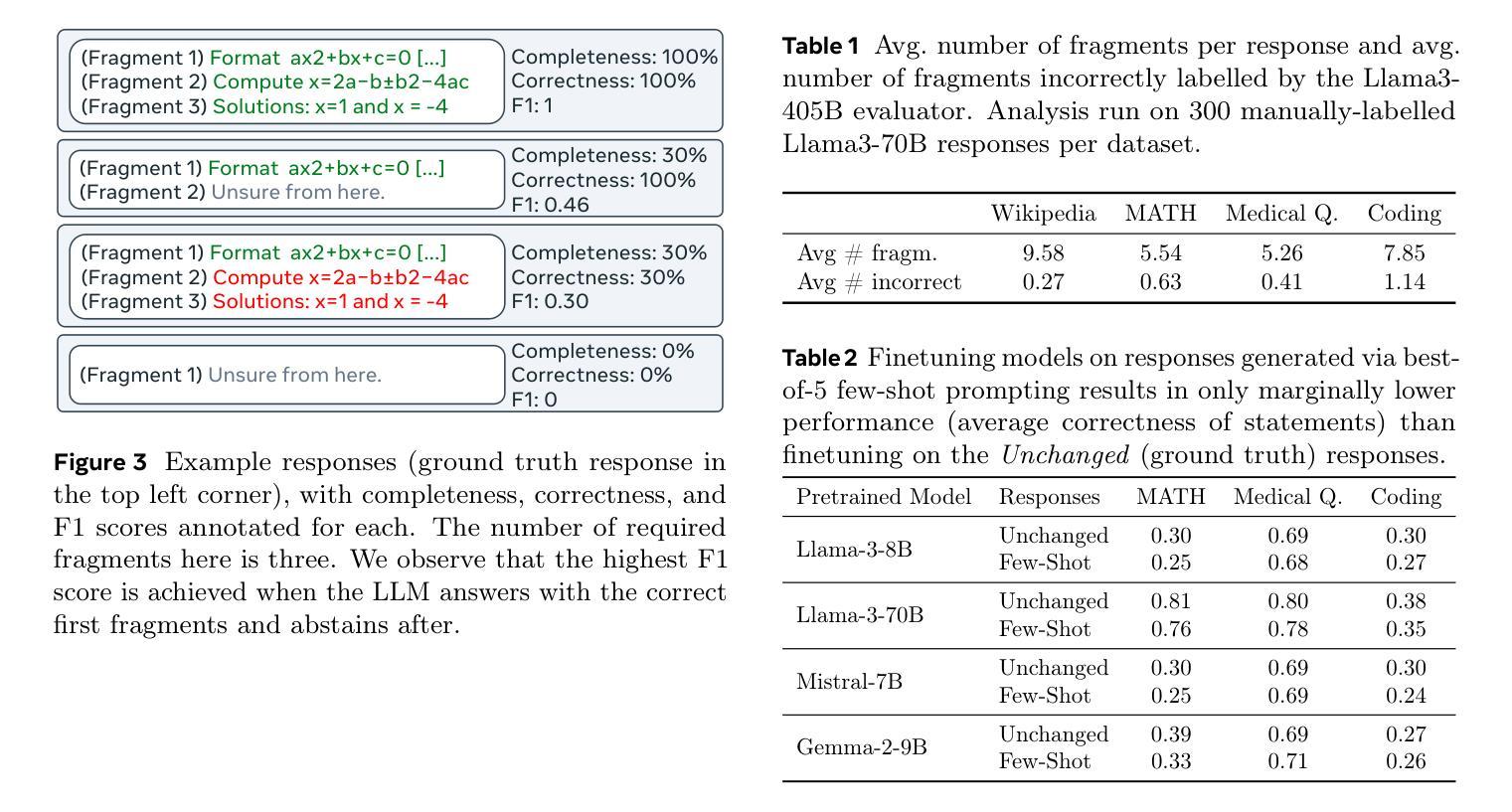
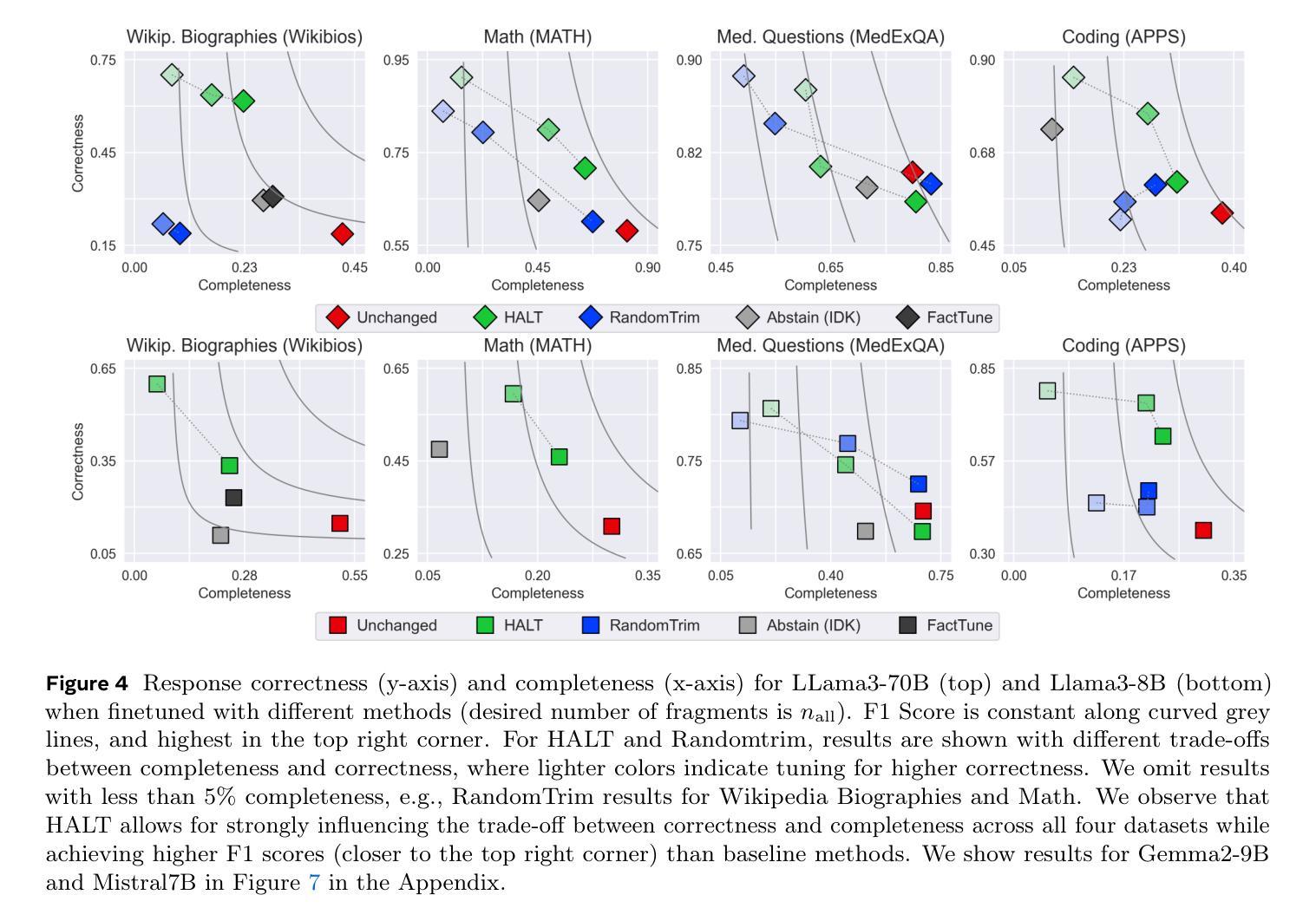
Large Language Models (LLMs) currently respond to every prompt. However, they can produce incorrect answers when they lack knowledge or capability – a problem known as hallucination. We instead propose post-training an LLM to generate content only when confident in its correctness and to otherwise (partially) abstain. Specifically, our method, HALT, produces capability-aligned post-training data that encodes what the model can and cannot reliably generate. We generate this data by splitting responses of the pretrained LLM into factual fragments (atomic statements or reasoning steps), and use ground truth information to identify incorrect fragments. We achieve capability-aligned finetuning responses by either removing incorrect fragments or replacing them with “Unsure from Here” – according to a tunable threshold that allows practitioners to trade off response completeness and mean correctness of the response’s fragments. We finetune four open-source models for biography writing, mathematics, coding, and medicine with HALT for three different trade-off thresholds. HALT effectively trades off response completeness for correctness, increasing the mean correctness of response fragments by 15% on average, while resulting in a 4% improvement in the F1 score (mean of completeness and correctness of the response) compared to the relevant baselines. By tuning HALT for highest correctness, we train a single reliable Llama3-70B model with correctness increased from 51% to 87% across all four domains while maintaining 53% of the response completeness achieved with standard finetuning.
大型语言模型(LLM)目前会对每个提示作出回应。然而,当它们缺乏知识或能力时,可能会产生错误的答案——这是一个被称为“幻觉”的问题。相反,我们提议对LLM进行后训练,只在对其正确性有信心时才生成内容,否则(部分)选择放弃。具体来说,我们的方法HALT生成了能力对齐的后训练数据,这些数据编码了模型可以可靠生成和不能生成的内容。我们通过将预训练LLM的响应分割成事实片段(原子陈述或推理步骤)来生成这些数据,并使用真实信息来识别错误的片段。我们通过删除错误的片段或用“从这里不确定”来替换它们(根据可调整的阈值),来实现能力对齐的微调响应,这个阈值允许实践者权衡响应的完整性和片段的平均正确性。我们使用HALT对四个开源模型进行微调,这些模型分别用于传记写作、数学、编码和医学,针对三个不同的阈值。HALT有效地通过权衡响应的完整性来换取正确性,在响应片段的平均正确性方面平均提高了15%,同时F1分数(响应的完整性和正确性的平均值)与相关基线相比提高了4%。通过为最高正确性调整HALT,我们训练了一个可靠的单一Llama3-70B模型,在所有四个领域中将正确性从51%提高到87%,同时保持与标准微调相比的53%的响应完整性。
论文及项目相关链接
Summary
本文提出一种针对大型语言模型(LLMs)的后训练方法,名为HALT。该方法能够在模型对答案有信心时生成内容,在缺乏信心时则部分选择避免回答。通过生成事实片段并使用真实信息识别错误片段,以实现能力对齐的后训练数据。实验结果显示,HALT能有效提升响应片段的正确性,同时可通过调整阈值进行响应完整性和正确性的权衡。使用HALT进行微调后,模型的正确性显著提高,且在四个不同领域(传记写作、数学、编程和医学)的模型中均取得良好效果。
Key Takeaways
- LLMs可能会产生错误的答案,尤其是在缺乏知识或能力的情况下。
- 提出的HALT方法能够对LLMs进行后训练,使其在回答时只在有信心的情况下生成内容。
- HALT通过生成事实片段并使用真实信息识别错误片段,实现能力对齐的后训练数据。
- HALT能有效提升响应片段的正确性,并通过调整阈值来平衡响应的完整性和正确性。
- 使用HALT进行微调后,模型的正确性显著提高,并且这种效果在不同领域的模型中均得到验证。
- 实验结果显示,HALT方法能够提高LLMs的正确率,最高可将正确性从51%提高到87%。
点此查看论文截图


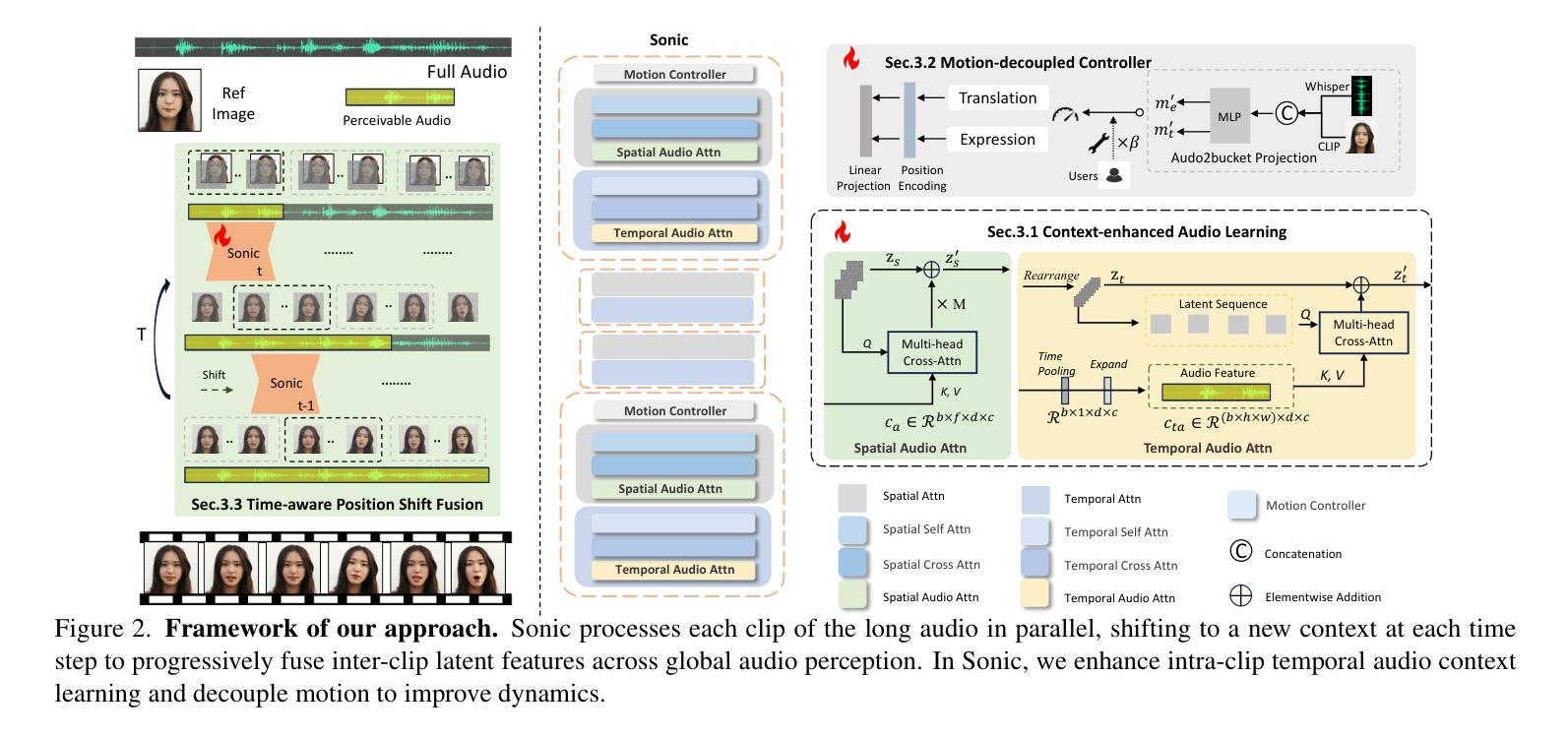
Sonic: Shifting Focus to Global Audio Perception in Portrait Animation
Authors:Xiaozhong Ji, Xiaobin Hu, Zhihong Xu, Junwei Zhu, Chuming Lin, Qingdong He, Jiangning Zhang, Donghao Luo, Yi Chen, Qin Lin, Qinglin Lu, Chengjie Wang
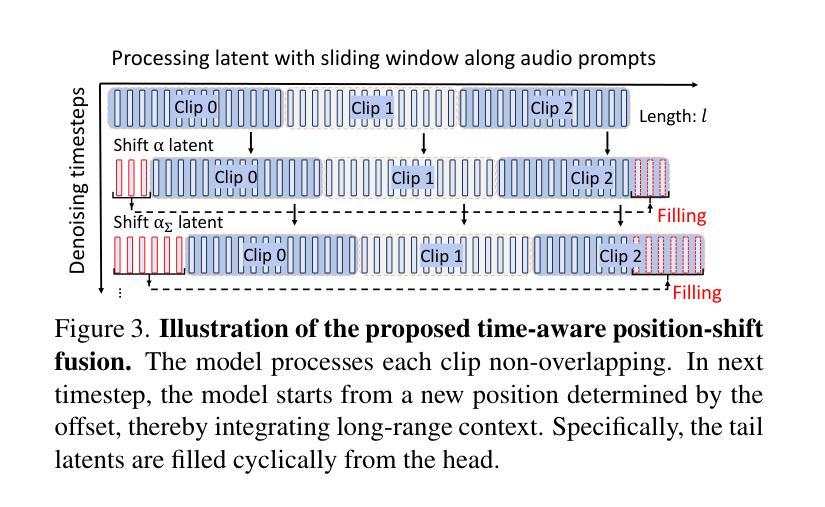
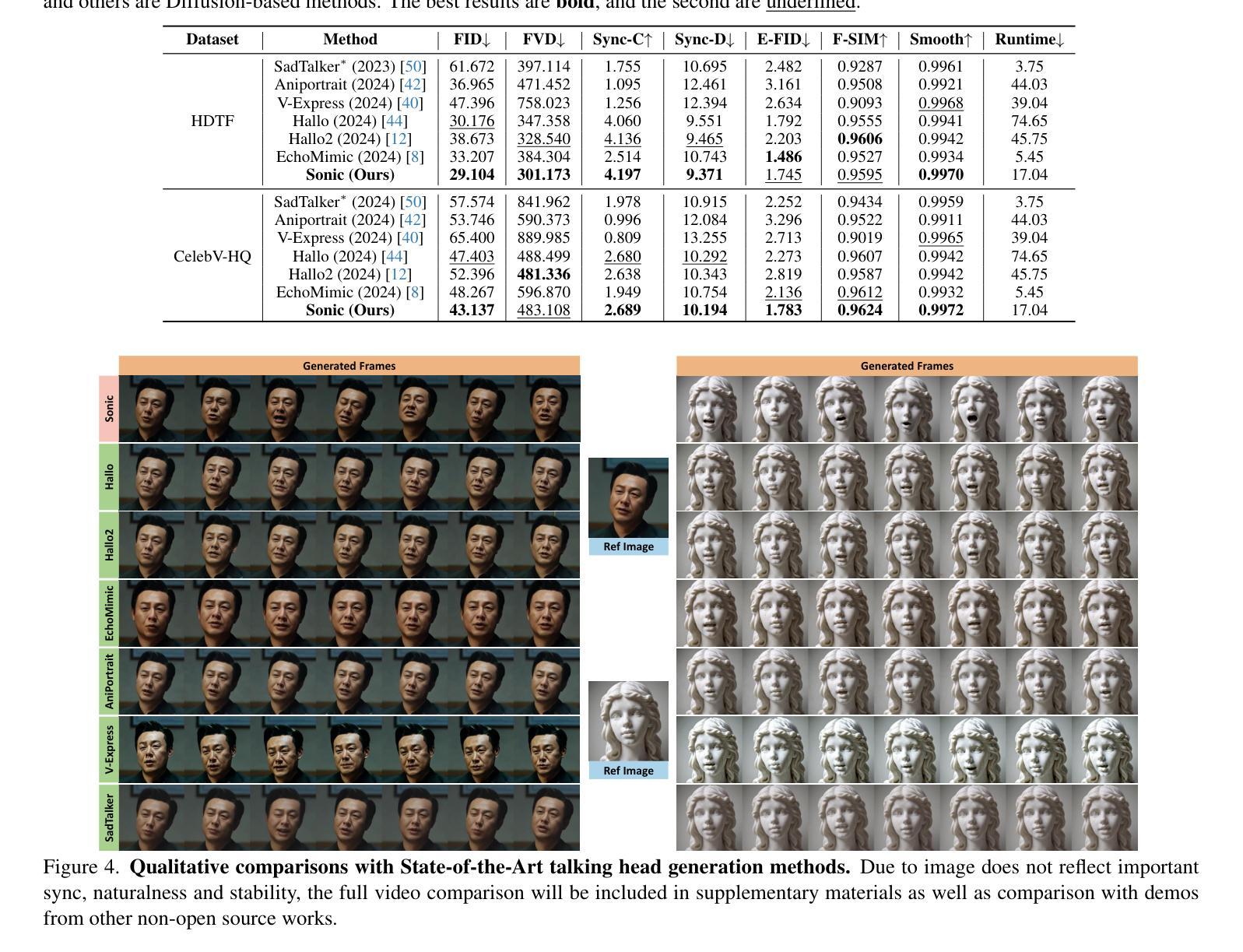
The study of talking face generation mainly explores the intricacies of synchronizing facial movements and crafting visually appealing, temporally-coherent animations. However, due to the limited exploration of global audio perception, current approaches predominantly employ auxiliary visual and spatial knowledge to stabilize the movements, which often results in the deterioration of the naturalness and temporal inconsistencies.Considering the essence of audio-driven animation, the audio signal serves as the ideal and unique priors to adjust facial expressions and lip movements, without resorting to interference of any visual signals. Based on this motivation, we propose a novel paradigm, dubbed as Sonic, to {s}hift f{o}cus on the exploration of global audio per{c}ept{i}o{n}.To effectively leverage global audio knowledge, we disentangle it into intra- and inter-clip audio perception and collaborate with both aspects to enhance overall perception.For the intra-clip audio perception, 1). \textbf{Context-enhanced audio learning}, in which long-range intra-clip temporal audio knowledge is extracted to provide facial expression and lip motion priors implicitly expressed as the tone and speed of speech. 2). \textbf{Motion-decoupled controller}, in which the motion of the head and expression movement are disentangled and independently controlled by intra-audio clips. Most importantly, for inter-clip audio perception, as a bridge to connect the intra-clips to achieve the global perception, \textbf{Time-aware position shift fusion}, in which the global inter-clip audio information is considered and fused for long-audio inference via through consecutively time-aware shifted windows. Extensive experiments demonstrate that the novel audio-driven paradigm outperform existing SOTA methodologies in terms of video quality, temporally consistency, lip synchronization precision, and motion diversity.
谈话面部生成的研究主要探索面部动作同步和制作视觉吸引力强、时间连贯的动画的复杂性。然而,由于对全局音频感知的探索有限,当前的方法主要使用辅助的视觉和空间知识来稳定动作,这往往导致自然性的降低和时间上的不一致。考虑到音频驱动动画的本质,音频信号作为调整面部表情和嘴唇动作的理想和独特先验,无需借助任何视觉信号的干扰。基于这一动机,我们提出了一种新的范式,称为Sonic,将重点放在全局音频感知的探索上。为了有效利用全局音频知识,我们将其分解为帧内和帧间音频感知,并在这两个方面进行合作以增强整体感知。对于帧内音频感知,1)。上下文增强的音频学习,提取帧内长程音频知识,以语音的语调和语速隐含地提供面部表情和唇部动作先验。2)。运动解耦控制器,其中头部运动和表情动作被分离,并由帧内音频片段独立控制。最重要的是,对于帧间音频感知,作为连接帧内片段以实现全局感知的桥梁,时间感知位置偏移融合,考虑全局帧间音频信息,并通过连续的时间感知偏移窗口进行长音频推理。大量实验表明,新的音频驱动范式在视频质量、时间一致性、嘴唇同步精度和运动多样性方面超越了现有的最佳方法。
论文及项目相关链接
PDF refer to our main-page \url{https://jixiaozhong.github.io/Sonic/}
摘要
基于音频驱动的动画研究核心探索面部动画的自然与精准表达问题,注重通过改进同步技术和表达控制来提高视觉效果的吸引力。当前研究主要依赖于视觉和时空知识,但在全球音频感知方面仍有局限。本研究提出了一种新的范式“Sonic”,旨在关注全球音频感知的探索。通过细分音频感知为内部和外部剪辑两方面,有效利用全局音频知识,增强整体感知效果。内部剪辑音频感知包括语境增强音频学习和动作解耦控制器,旨在提供面部表情和唇部运动的先验信息;外部剪辑音频感知则通过时间感知位置偏移融合技术,连接内部剪辑实现全局感知。实验证明,该音频驱动范式在视频质量、时间一致性、唇同步精度和运动多样性等方面均优于现有技术。
关键见解
- 音频驱动动画研究重点在于探索面部动画的自然性和精准性同步问题。
- 当前方法主要依赖视觉和时空知识来实现面部动画的稳定移动,这可能会导致自然性的损失和时序不一致。
- 研究提出了一种名为“Sonic”的新范式,旨在专注于全球音频感知的探索。该技术利用了整体的声音效果而非简单的面部或者背景图片的分析过程来对信息进行分析处理。
- 通过细分音频感知为内部剪辑和外部剪辑两个方面,提高了整体感知效果并有效利用了全局音频知识。包括语境增强音频学习、动作解耦控制器以及时间感知位置偏移融合技术都是对这一改进的实现方法的关键手段。最终增强了语音与面部表情的同步性。
点此查看论文截图