⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-06 更新
Vocabulary-free few-shot learning for Vision-Language Models
Authors:Maxime Zanella, Clément Fuchs, Ismail Ben Ayed, Christophe De Vleeschouwer
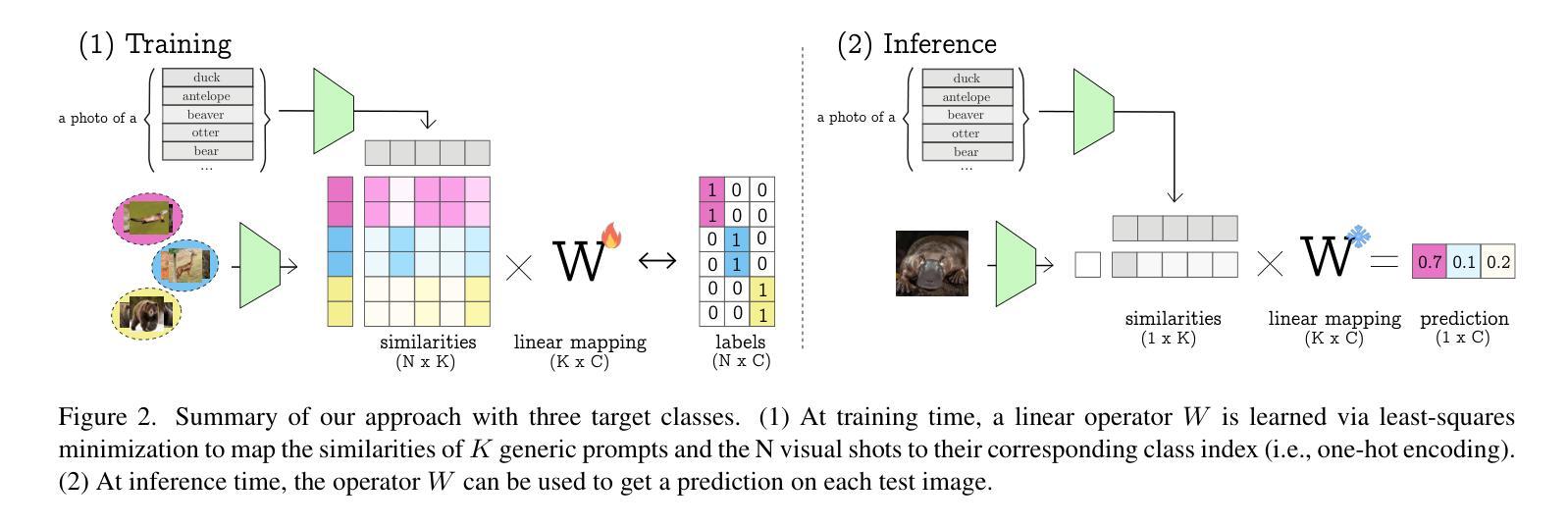
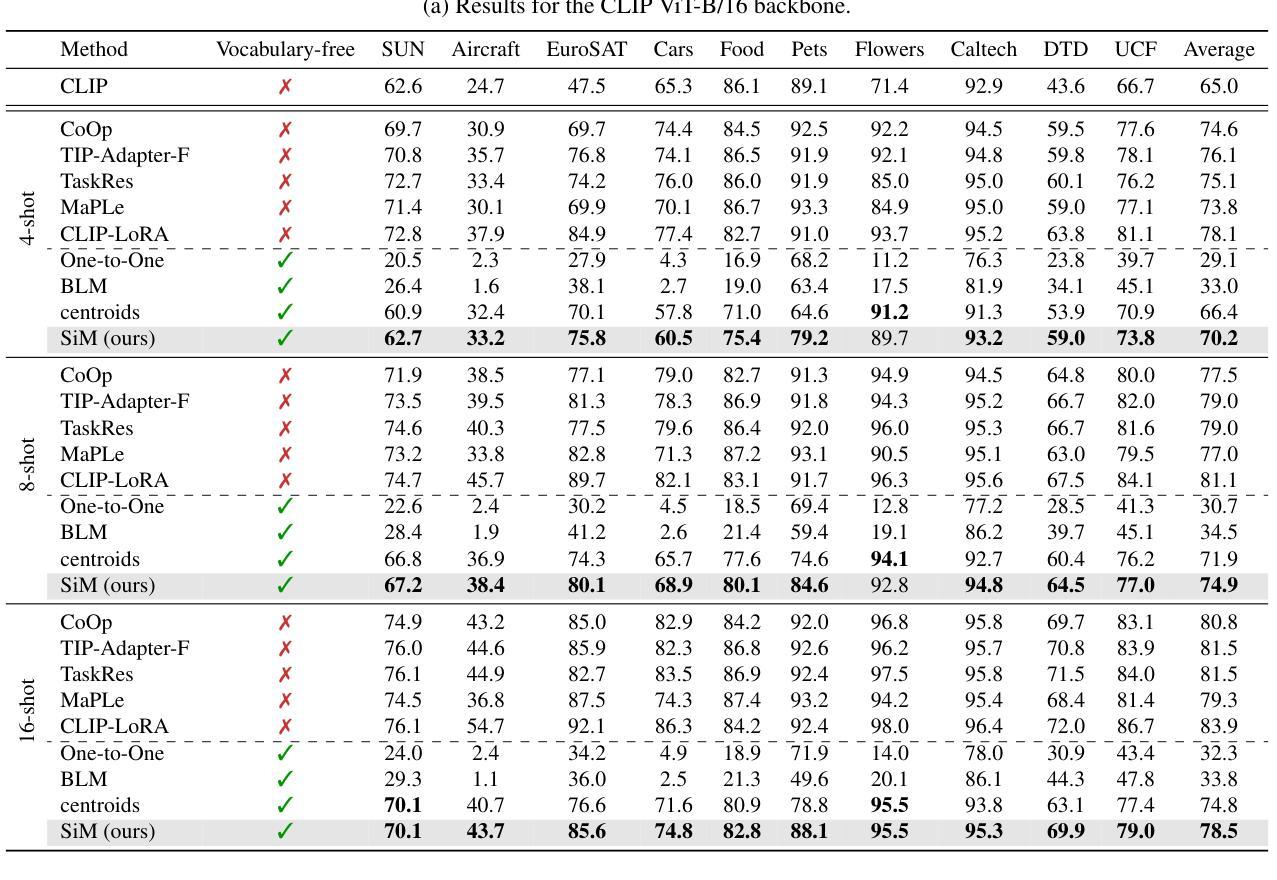
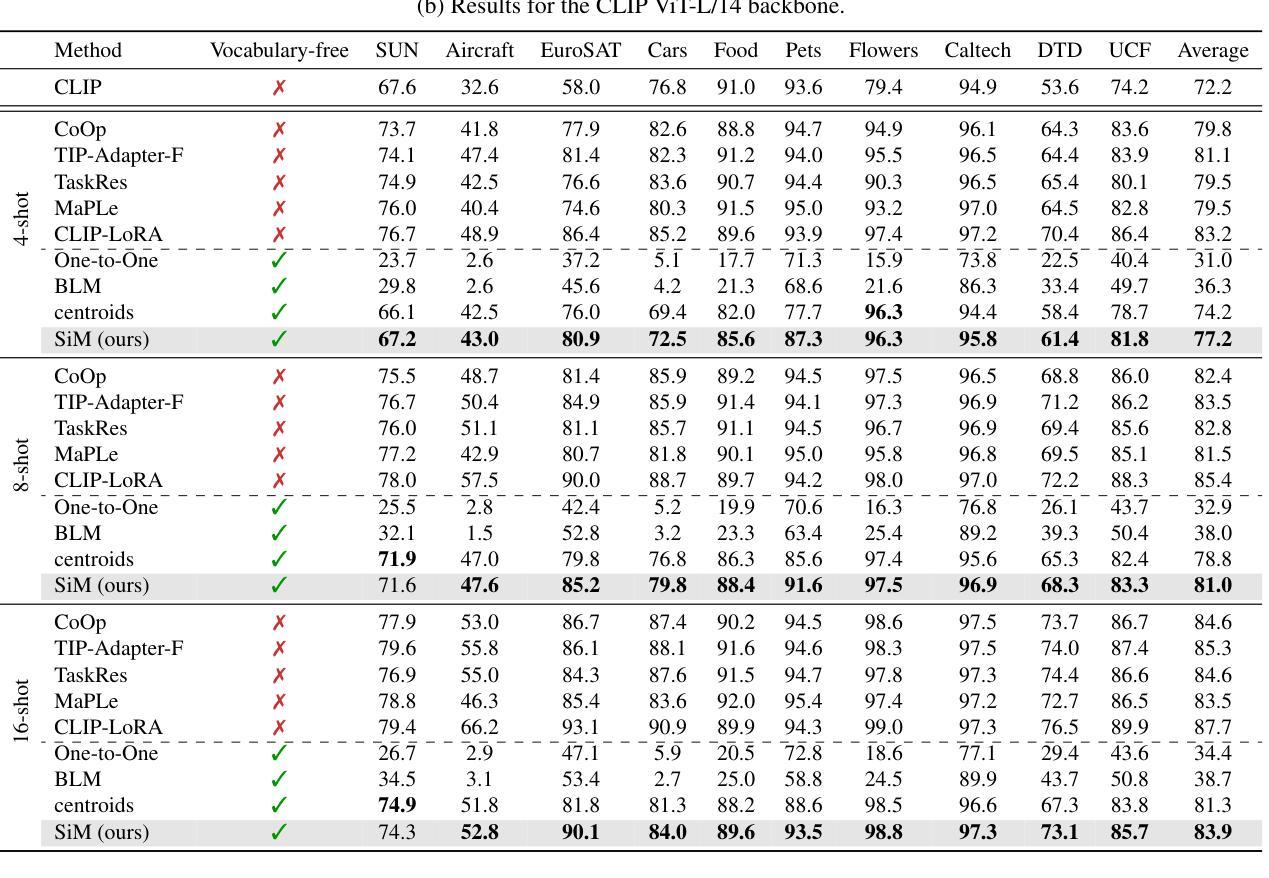
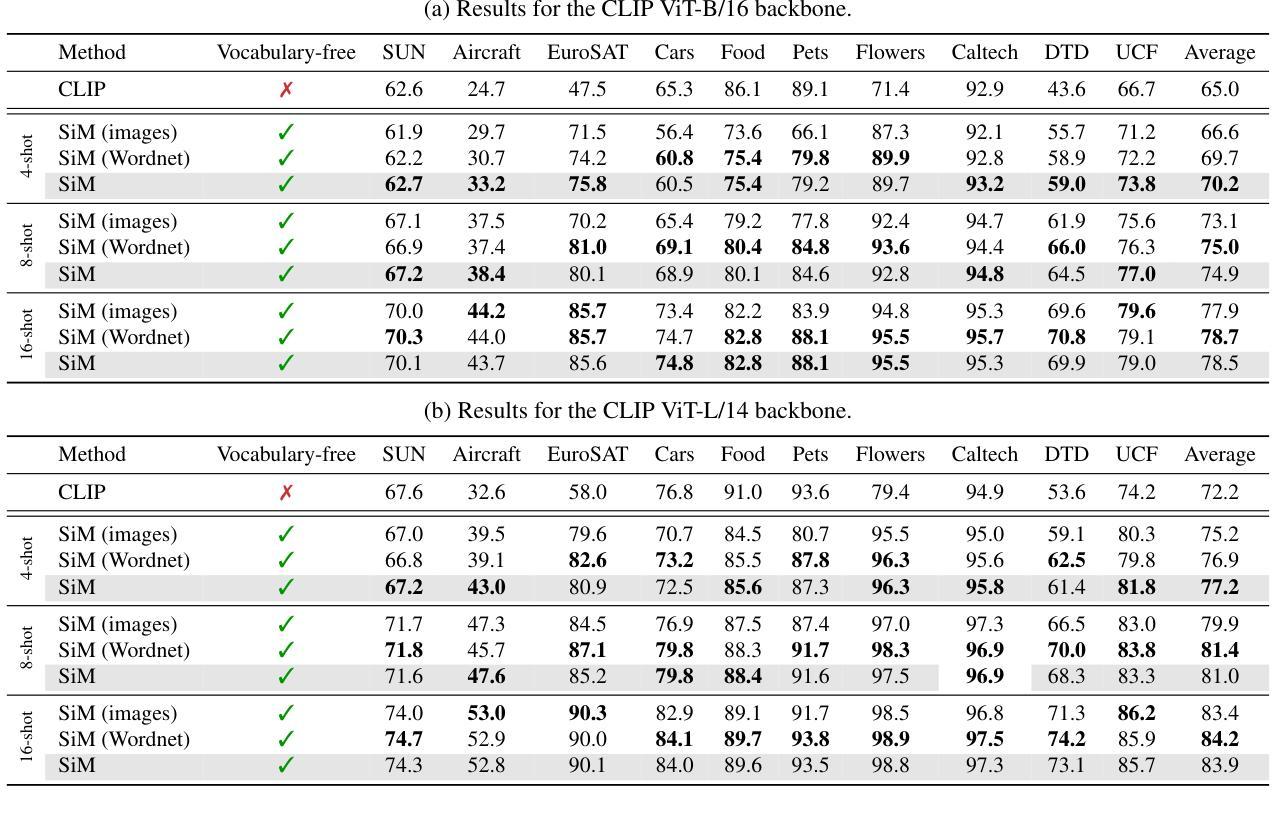
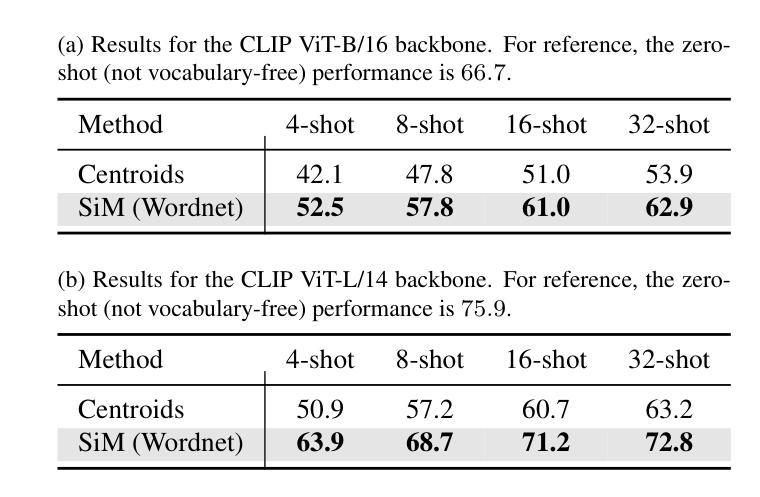
Recent advances in few-shot adaptation for Vision-Language Models (VLMs) have greatly expanded their ability to generalize across tasks using only a few labeled examples. However, existing approaches primarily build upon the strong zero-shot priors of these models by leveraging carefully designed, task-specific prompts. This dependence on predefined class names can restrict their applicability, especially in scenarios where exact class names are unavailable or difficult to specify. To address this limitation, we introduce vocabulary-free few-shot learning for VLMs, a setting where target class instances - that is, images - are available but their corresponding names are not. We propose Similarity Mapping (SiM), a simple yet effective baseline that classifies target instances solely based on similarity scores with a set of generic prompts (textual or visual), eliminating the need for carefully handcrafted prompts. Although conceptually straightforward, SiM demonstrates strong performance, operates with high computational efficiency (learning the mapping typically takes less than one second), and provides interpretability by linking target classes to generic prompts. We believe that our approach could serve as an important baseline for future research in vocabulary-free few-shot learning. Code is available at https://github.com/MaxZanella/vocabulary-free-FSL.
在视觉语言模型(VLMs)的少量样本适应性方面的最新进展极大地扩展了它们仅使用少量有标签样本跨任务泛化的能力。然而,现有方法主要依赖于这些模型的强大的零样本先验知识,通过利用精心设计的任务特定提示来实现。对预定义类名的这种依赖可能会限制其适用性,特别是在无法获得或难以指定确切类名的场景中。为了解决这个问题,我们引入了无词汇表的视觉语言模型少量样本学习(few-shot learning),在这个设置中,目标类的实例(即图像)是可用的,但它们的相应名称不可用。我们提出了相似性映射(SiM)方法,这是一种简单有效的基线方法,它仅根据目标实例与一组通用提示(文本或视觉)的相似性得分进行分类,消除了对精心制作的提示的需求。尽管概念上很简单,但SiM表现出强大的性能,计算效率高(学习映射通常不到一秒),并且通过链接目标类别到通用提示提供了可解释性。我们相信我们的方法为未来的无词汇表少量样本学习研究提供了重要的基线。代码可在https://github.com/MaxZanella/vocabulary-free-FSL找到。
论文及项目相关链接
PDF Accepted at CVPR Workshops 2025
Summary
本文介绍了针对视觉语言模型(VLMs)的词汇无关小样本学习方法的最新进展。针对现有方法依赖预设类名的问题,提出了一种基于相似性映射(SiM)的词汇无关小样本学习方法。该方法仅通过目标实例与通用提示(文本或视觉)之间的相似性得分进行分类,无需精心制作的任务特定提示。SiM具有强大的性能、高计算效率和可解释性,通过将目标类别与通用提示联系起来,为未来的词汇无关小样本学习研究提供了重要基准。
Key Takeaways
- 现有视觉语言模型在少数样本学习任务中的泛化能力已得到显著提高,但仍依赖预设类名,限制了应用场景的适用性。
- 针对这一问题,提出了词汇无关的小样本学习方法,该方法允许目标实例存在,但不需要其对应的名称。
- 引入了一种新的方法——相似性映射(SiM),它基于目标实例与通用提示之间的相似性得分进行分类。
- SiM具有强大的性能,能够在概念上简单直观地进行操作,并且计算效率高,映射学习通常不到一秒即可完成。
- SiM提供了可解释性,通过将目标类别与通用提示联系起来,有助于理解模型的决策过程。
- 该研究为未来的词汇无关小样本学习研究提供了重要基准。
点此查看论文截图

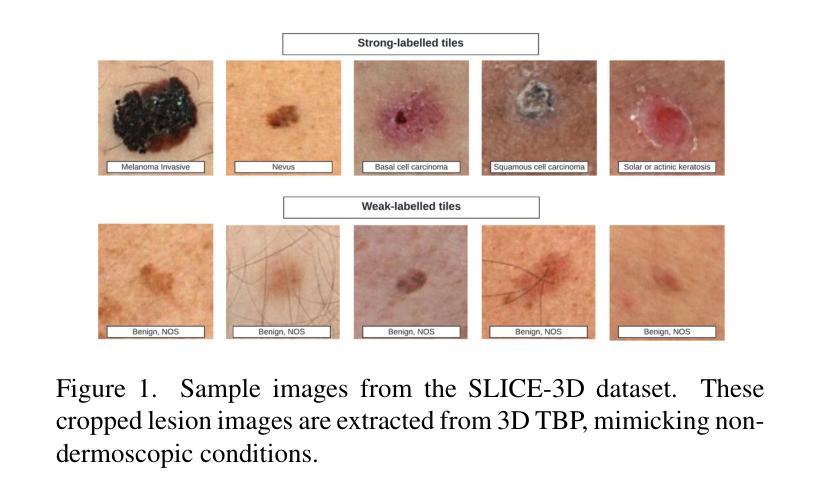
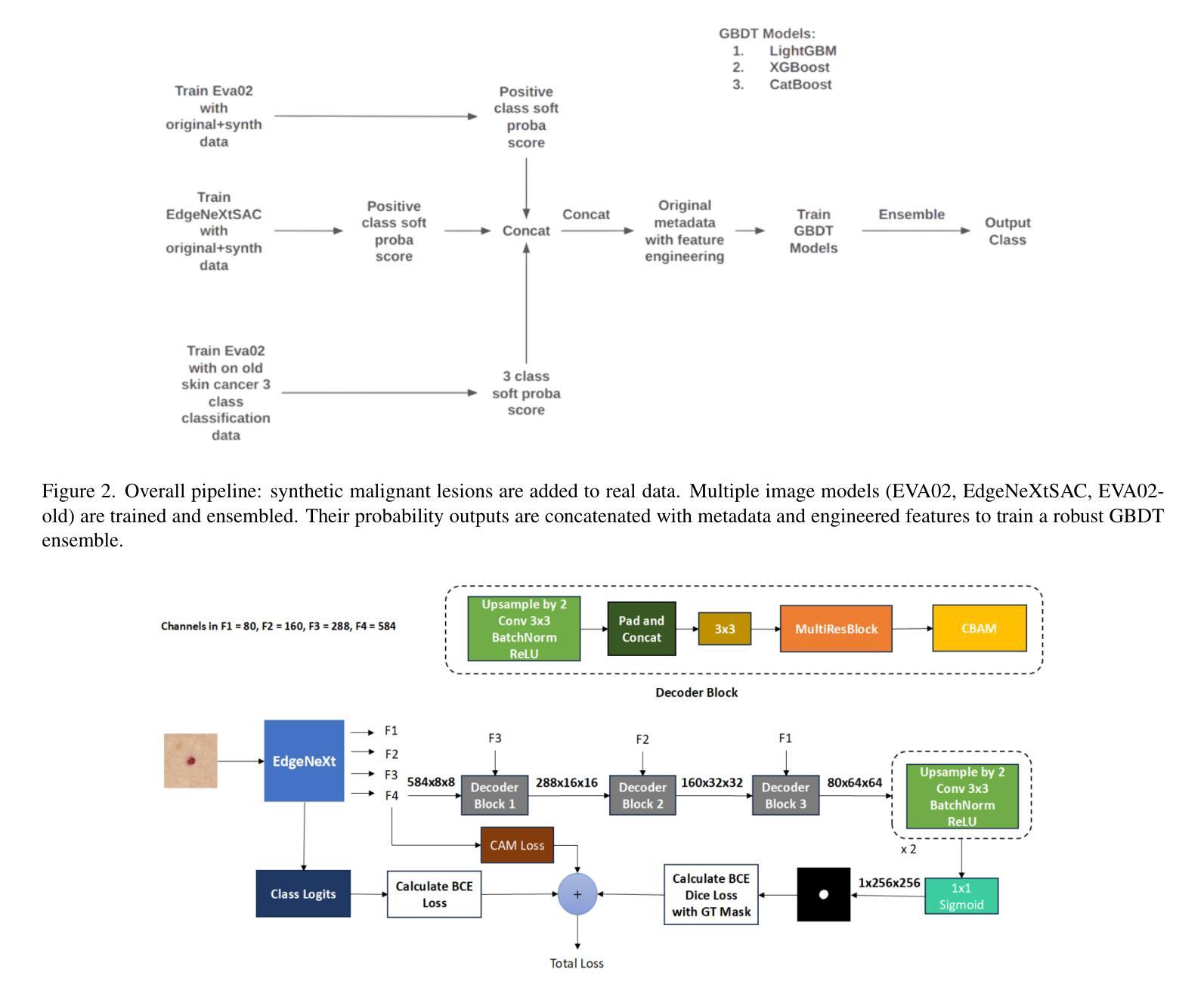
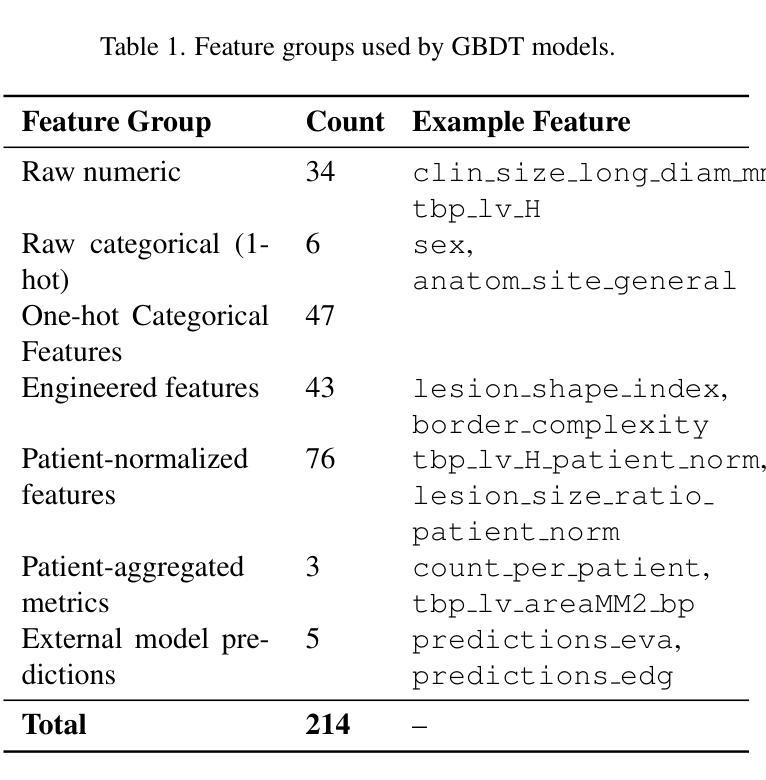
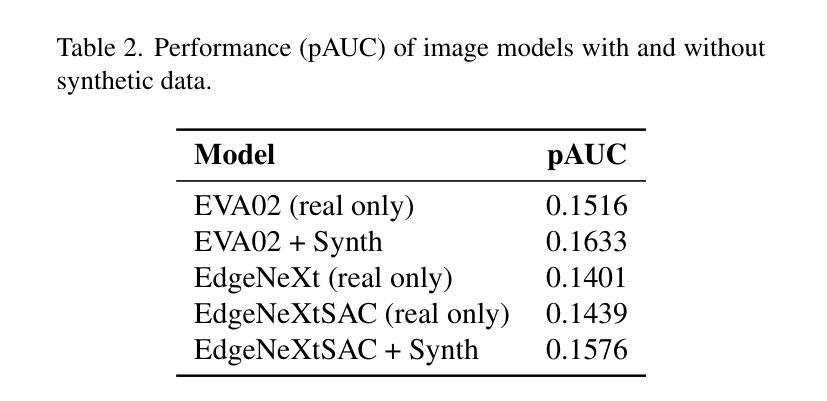
Hybrid Ensemble of Segmentation-Assisted Classification and GBDT for Skin Cancer Detection with Engineered Metadata and Synthetic Lesions from ISIC 2024 Non-Dermoscopic 3D-TBP Images
Authors:Muhammad Zubair Hasan, Fahmida Yasmin Rifat
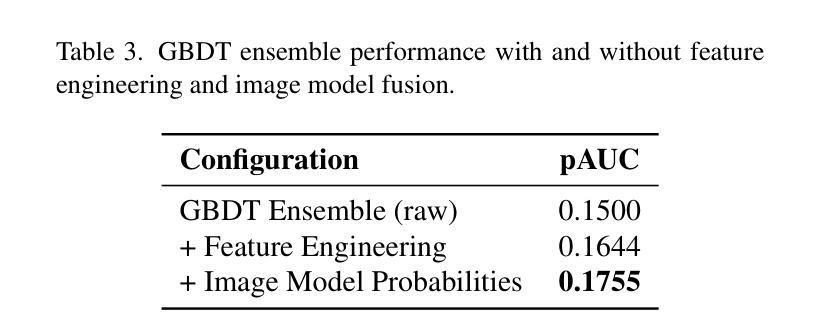
Skin cancer is among the most prevalent and life-threatening diseases worldwide, with early detection being critical to patient outcomes. This work presents a hybrid machine and deep learning-based approach for classifying malignant and benign skin lesions using the SLICE-3D dataset from ISIC 2024, which comprises 401,059 cropped lesion images extracted from 3D Total Body Photography (TBP), emulating non-dermoscopic, smartphone-like conditions. Our method combines vision transformers (EVA02) and our designed convolutional ViT hybrid (EdgeNeXtSAC) to extract robust features, employing a segmentation-assisted classification pipeline to enhance lesion localization. Predictions from these models are fused with a gradient-boosted decision tree (GBDT) ensemble enriched by engineered features and patient-specific relational metrics. To address class imbalance and improve generalization, we augment malignant cases with Stable Diffusion-generated synthetic lesions and apply a diagnosis-informed relabeling strategy to harmonize external datasets into a 3-class format. Using partial AUC (pAUC) above 80 percent true positive rate (TPR) as the evaluation metric, our approach achieves a pAUC of 0.1755 – the highest among all configurations. These results underscore the potential of hybrid, interpretable AI systems for skin cancer triage in telemedicine and resource-constrained settings.
皮肤癌是全球最常见且威胁生命的疾病之一,早期发现对病人的预后至关重要。本研究提出了一种基于机器学习和深度学习的混合方法,用于根据ISIC 2024的SLICE-3D数据集对恶性与良性皮肤病变进行分类。该数据集包含从三维全身摄影(TBP)中提取的401,059个裁剪后的病变图像,模拟非内窥镜、类似智能手机的条件。我们的方法结合了视觉变压器(EVA02)和我们设计的卷积ViT混合模型(EdgeNeXtSAC)以提取稳健的特征,并采用辅助分类的分割管道以增强病变的定位。这些模型的预测结果与通过工程特征和患者特定关系度量丰富梯度增强决策树(GBDT)集合相融合。为了解决类别不平衡问题并改善泛化能力,我们通过稳定扩散生成的合成病变来增强恶性病例,并应用诊断信息重标策略将外部数据集协调为三类格式。以部分AUC(pAUC)超过80%的真实阳性率(TPR)作为评价指标,我们的方法达到了0.1755的pAUC,是所有配置中的最高值。这些结果突显出在远程医疗和资源受限环境中,混合、可解释的AI系统在皮肤癌筛查中的潜力。
论文及项目相关链接
PDF Written as per the requirements of CVPR 2025. It is a 8 page paper without reference
Summary
本文介绍了一种结合机器学习和深度学习的方法,用于基于SLICE-3D数据集对恶性与良性皮肤病变进行分类。该方法结合了视觉变压器(EVA02)和设计的卷积ViT混合模型(EdgeNeXtSAC)以提取稳健特征,并采用分割辅助分类管道增强病变定位。模型预测结果与梯度增强决策树(GBDT)集成融合,同时融入工程特征和患者特定关系指标。通过解决类别不平衡问题并改进泛化能力,该研究使用稳定扩散生成的合成病变增强恶性案例,并采用诊断信息重标策略将外部数据集协调为三类格式。该研究的方法在部分AUC(pAUC)达到80%以上真正阳性率(TPR)的评估指标下,取得了0.1755的pAUC,为所有配置中的最高值。这凸显了混合、可解释的AI系统在远程医疗和资源受限环境中的皮肤癌筛查潜力。
Key Takeaways
- 该研究关注皮肤癌分类问题,特别是基于SLICE-3D数据集的恶性与良性皮肤病变分类。
- 采用了视觉变压器和卷积ViT混合模型以提取稳健特征,并结合分割辅助分类管道进行病变定位。
- 模型预测结合了梯度增强决策树集成方法,同时考虑了工程特征和患者特定关系指标。
- 通过合成病变增强恶性案例,解决类别不平衡问题,并通过诊断信息重标策略协调外部数据集。
- 该方法取得了较高的部分AUC(pAUC)值,表明其在皮肤癌分类上的有效性。
- 研究强调了混合、可解释的AI系统在远程医疗和资源受限环境中的皮肤癌筛查的潜力。
- 该研究为皮肤癌的早期检测和治疗提供了新的思路和方法。
点此查看论文截图

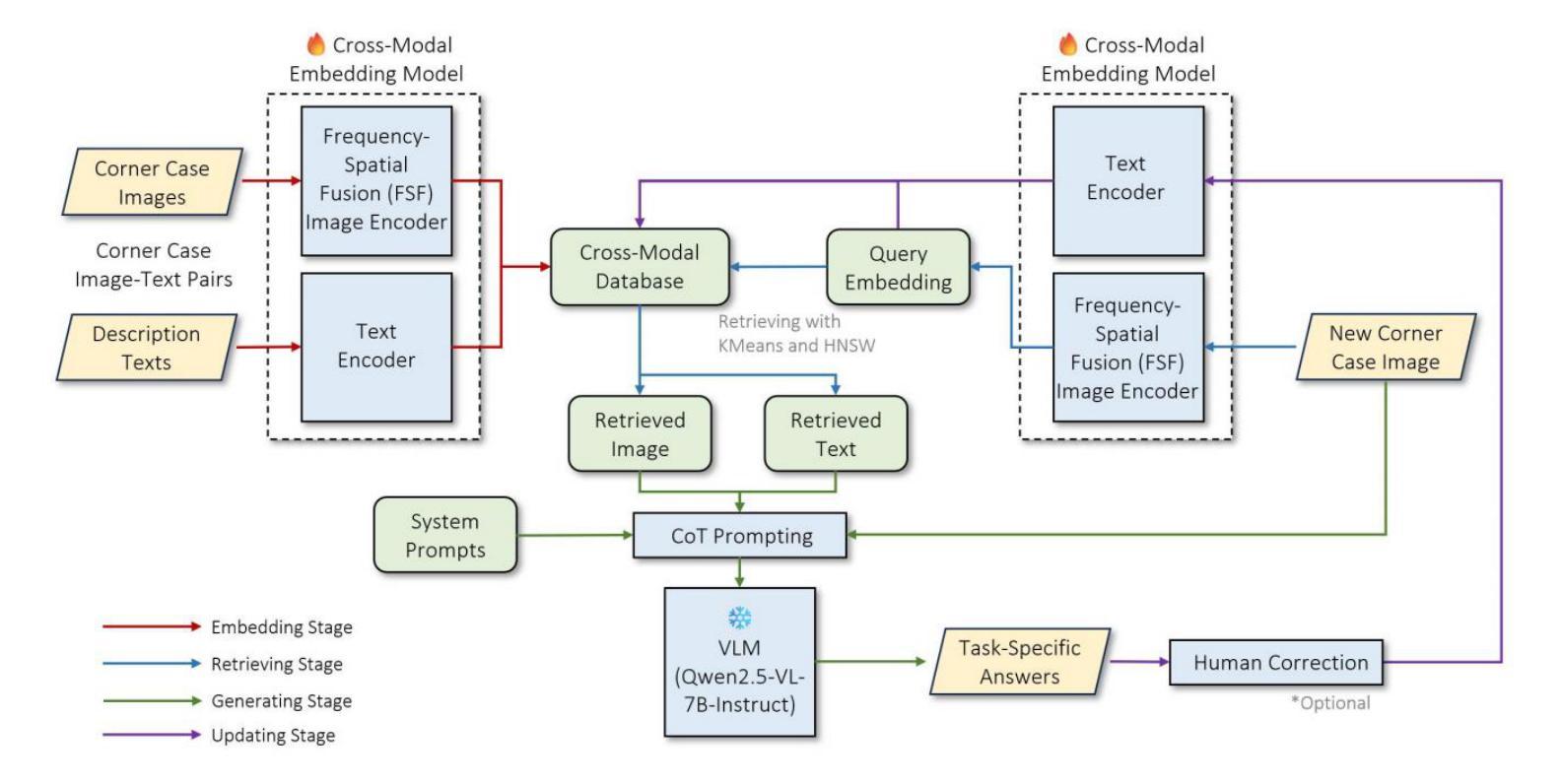
RAC3: Retrieval-Augmented Corner Case Comprehension for Autonomous Driving with Vision-Language Models
Authors:Yujin Wang, Quanfeng Liu, Jiaqi Fan, Jinlong Hong, Hongqing Chu, Mengjian Tian, Bingzhao Gao, Hong Chen
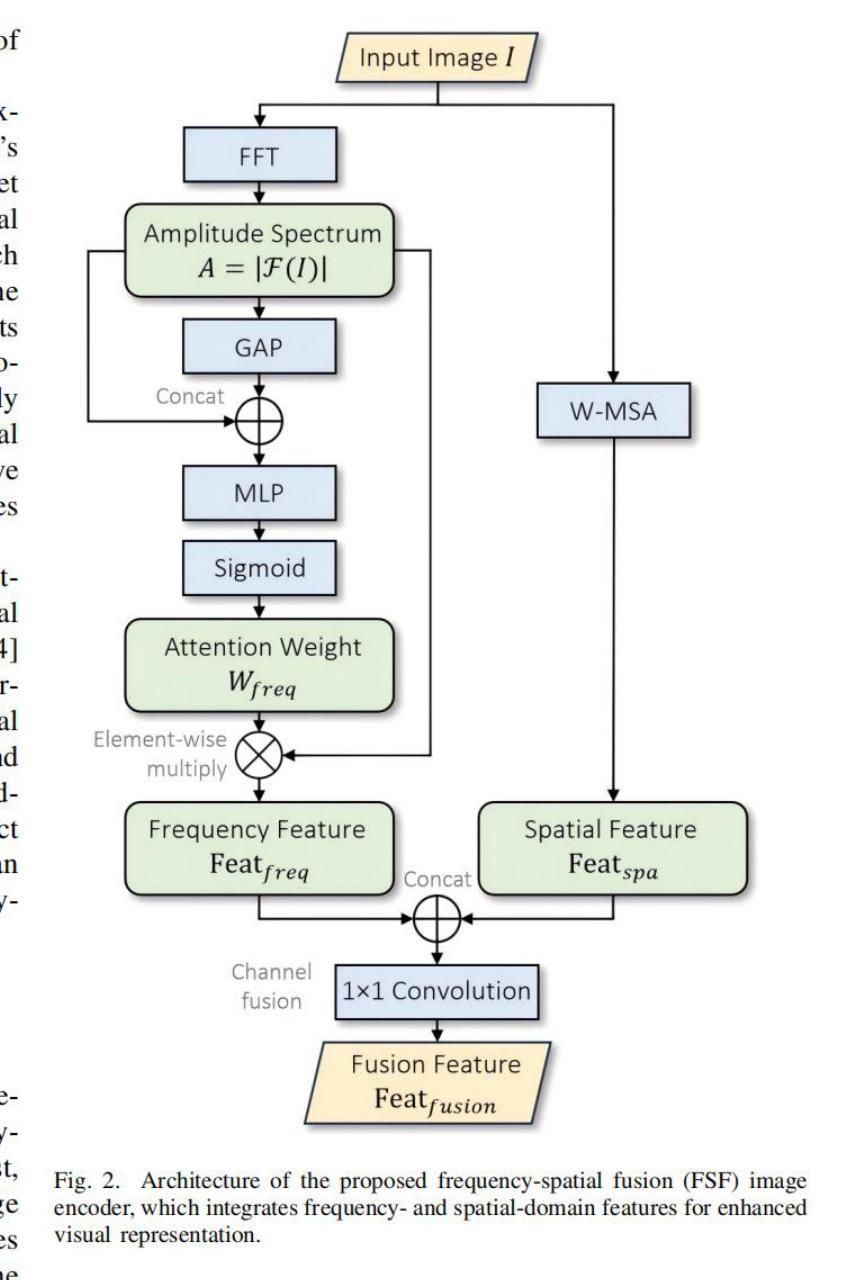
Understanding and addressing corner cases is essential for ensuring the safety and reliability of autonomous driving systems. Vision-language models (VLMs) play a crucial role in enhancing scenario comprehension, yet they face significant challenges, such as hallucination and insufficient real-world grounding, which compromise their performance in critical driving scenarios. In this work, RAC3, a novel framework designed to enhance the performance of VLMs in corner case comprehension, is proposed. RAC3 integrates a frequency-spatial fusion (FSF) image encoder, a cross-modal alignment training method for embedding models with hard and semi-hard negative mining, and a fast querying and retrieval pipeline based on K-Means clustering and hierarchical navigable small world (HNSW) indexing. A multimodal chain-of-thought (CoT) prompting strategy to guide analogical reasoning and reduce hallucinations during inference is introduced. Moreover, an update mechanism is integrated into RAC3 to ensure continual learning within the framework. Extensive experiments on the CODA and nuScenes datasets demonstrate that RAC3 significantly improves corner case comprehension across multiple downstream tasks. Compared to prior state-of-the-art methods, RAC3 achieves the highest final score of 74.46 on the CODA-LM benchmark and shows consistent performance gains when integrated with end-to-end frameworks like DriveLM. These results demonstrate the effectiveness of retrieval-augmented strategies and cross-modal alignment for safer and more interpretable autonomous driving.
理解并处理极端情况对于确保自动驾驶系统的安全性和可靠性至关重要。视觉语言模型(VLM)在提高场景理解方面发挥着关键作用,但它们面临着诸如幻觉和现实世界基础不足等重大挑战,这些挑战会影响它们在关键驾驶场景中的性能。在这项工作中,提出了RAC3,一个旨在提高VLM在极端情况理解性能的新型框架。RAC3集成了一种频率空间融合(FSF)图像编码器、一种用于嵌入模型的跨模态对齐训练方法,包括硬性和半硬性负挖掘、一种基于K-Means聚类和分层可导航小世界(HNSW)索引的快速查询和检索管道。还引入了一种多模态思维链(CoT)提示策略,以引导类比推理,减少推理过程中的幻觉。此外,RAC3还集成了更新机制,以确保框架内的持续学习。在CODA和nuScenes数据集上的大量实验表明,RAC3在多个下游任务中显著提高极端情况的理解能力。与现有最先进的方法相比,RAC3在CODA-LM基准测试中取得了最高分74.46分,在与端到端框架(如DriveLM)集成时,表现出一致的性能提升。这些结果证明了检索增强策略和跨模态对齐在更安全、更可解释的自动驾驶中的有效性。
论文及项目相关链接
PDF 14 pages, 7 figures
摘要
本文强调了理解和应对边缘案例对确保自动驾驶系统安全和可靠性的重要性。文章提出了一个新型框架RAC3,旨在提升视觉语言模型(VLMs)在边缘案例理解方面的性能。RAC3集成了频率空间融合(FSF)图像编码器、跨模态对齐训练方法和嵌入模型、使用硬性和半硬性负挖矿技术、基于K均值聚类和层次可导航小世界(HNSW)索引的快速查询和检索管道。此外,还引入了一种多模态思维链(CoT)提示策略,以引导类比推理并减少推理过程中的幻觉。RAC3框架还集成了更新机制,以确保持续学习。在CODA和nuScenes数据集上的大量实验表明,RAC3在多个下游任务中显著提高了边缘案例的理解能力。与最新的先进方法相比,RAC3在CODA-LM基准测试中取得了最高分74.46,并且在与端到端框架(如DriveLM)集成时显示出持续的性能提升。这些结果证明了检索增强策略和跨模态对齐对于更安全、更可解释的自动驾驶的有效性。
关键见解
- 理解和处理自动驾驶系统中的边缘案例至关重要,影响安全和可靠性。
- RAC3框架旨在提高视觉语言模型(VLMs)在边缘案例理解方面的性能。
- RAC3集成了频率空间融合图像编码器以改进性能。
- 跨模态对齐训练方法和嵌入模型使用硬性和半硬性负挖矿技术。
- 快速查询和检索管道基于K-Means聚类和HNSW索引。
- 多模态思维链(CoT)提示策略引导类比推理,减少推理过程中的幻觉。
- RAC3框架的持续学习通过集成更新机制实现。实验证明RAC3显著提高边缘案例理解能力,与最新方法相比具有优越性能。
点此查看论文截图