⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-08 更新
SmartAvatar: Text- and Image-Guided Human Avatar Generation with VLM AI Agents
Authors:Alexander Huang-Menders, Xinhang Liu, Andy Xu, Yuyao Zhang, Chi-Keung Tang, Yu-Wing Tai
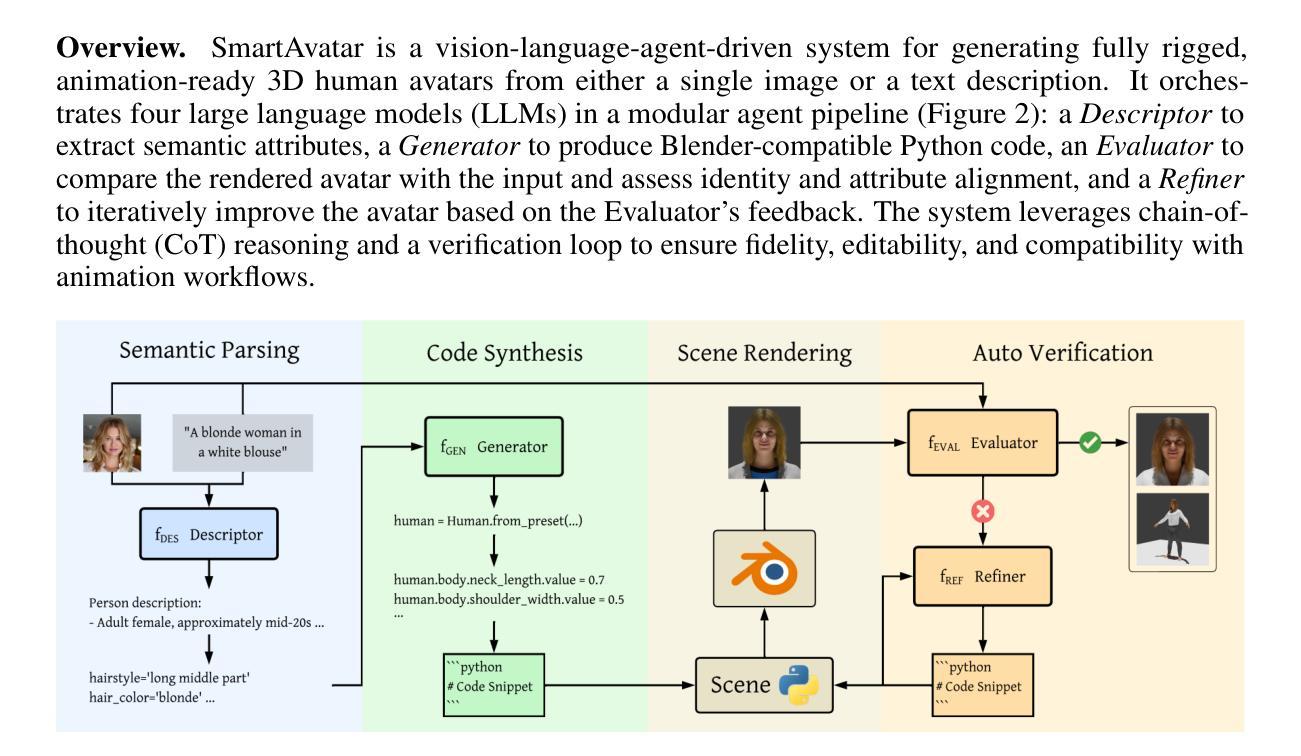
SmartAvatar is a vision-language-agent-driven framework for generating fully rigged, animation-ready 3D human avatars from a single photo or textual prompt. While diffusion-based methods have made progress in general 3D object generation, they continue to struggle with precise control over human identity, body shape, and animation readiness. In contrast, SmartAvatar leverages the commonsense reasoning capabilities of large vision-language models (VLMs) in combination with off-the-shelf parametric human generators to deliver high-quality, customizable avatars. A key innovation is an autonomous verification loop, where the agent renders draft avatars, evaluates facial similarity, anatomical plausibility, and prompt alignment, and iteratively adjusts generation parameters for convergence. This interactive, AI-guided refinement process promotes fine-grained control over both facial and body features, enabling users to iteratively refine their avatars via natural-language conversations. Unlike diffusion models that rely on static pre-trained datasets and offer limited flexibility, SmartAvatar brings users into the modeling loop and ensures continuous improvement through an LLM-driven procedural generation and verification system. The generated avatars are fully rigged and support pose manipulation with consistent identity and appearance, making them suitable for downstream animation and interactive applications. Quantitative benchmarks and user studies demonstrate that SmartAvatar outperforms recent text- and image-driven avatar generation systems in terms of reconstructed mesh quality, identity fidelity, attribute accuracy, and animation readiness, making it a versatile tool for realistic, customizable avatar creation on consumer-grade hardware.
SmartAvatar是一个以视觉语言代理驱动框架,它能从单张照片或文本提示生成完全装配好的、适合动画的3D人类角色。虽然基于扩散的方法在一般的3D对象生成方面取得了进展,但它们仍然难以控制人类身份、体型和动画准备状态。相比之下,SmartAvatar利用大型视觉语言模型的常识推理能力,结合现成的参数化人物生成器,以提供高质量的可定制角色。其关键创新之处在于自主的验证循环,代理会渲染角色草案,评估面部相似性、解剖合理性以及提示对齐情况,并迭代调整生成参数以达到收敛。这种交互式的AI引导细化过程可以精细控制面部和身体特征,使用户能够通过自然语言对话逐步细化他们的角色。不同于依赖静态预训练数据集且灵活性有限的扩散模型,SmartAvatar将用户带入建模循环,并通过LLM驱动的生成和验证系统确保持续改进。生成的角色是完全装配好的,支持姿态操纵并保持一致的身份和外观,使其适合用于下游动画和交互式应用。定量基准测试和用户研究表明,在重建网格质量、身份保真度、属性准确性和动画准备方面,SmartAvatar优于最近基于文本和图像的角色生成系统,成为在消费级硬件上创建逼真可定制角色的通用工具。
论文及项目相关链接
PDF 16 pages
Summary
SmartAvatar是一个基于视觉语言代理的框架,可从单张照片或文本提示生成完全装配、可用于动画的3D人类角色。不同于一般3D对象生成中普遍存在的扩散方法,SmartAvatar利用大型视觉语言模型的常识推理能力,结合现成的参数化人物生成器,产生高质量的可定制角色。其主要创新之处在于自主验证循环,代理可以渲染角色草稿,评估面部相似性、解剖合理性和提示对齐度,并迭代调整生成参数以达到收敛。这一AI引导的精化过程使用户可以在语言和文字的对话中,对角色的面部和身体特征进行精细控制并不断进行迭代优化。与依赖静态预训练数据集并提供有限灵活性的扩散模型不同,SmartAvatar将用户纳入建模循环中,并通过LLM驱动的生成和验证系统确保持续改进。生成的角色完全装配并支持姿态操控,具有一致的身份和外观,适用于下游动画和交互应用。SmartAvatar在重建网格质量、身份保真度、属性准确性和动画就绪性等方面优于其他文本和图像驱动的角色生成系统。
Key Takeaways
- SmartAvatar是一个从单张照片或文本提示生成完全装配、可用于动画的3D人类角色的框架。
- 它结合了视觉语言模型与参数化人物生成器,实现高质量的角色创建。
- SmartAvatar具有自主验证循环,可以迭代优化角色的生成质量。
- 该框架允许用户通过自然语言对话对角色进行精细控制。
- 与其他方法相比,SmartAvatar在多个关键指标上表现优异。
- 用户可以在建模过程中参与到角色创建中,使角色更贴合用户预期。
点此查看论文截图