⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-08 更新
Contrastive Flow Matching
Authors:George Stoica, Vivek Ramanujan, Xiang Fan, Ali Farhadi, Ranjay Krishna, Judy Hoffman
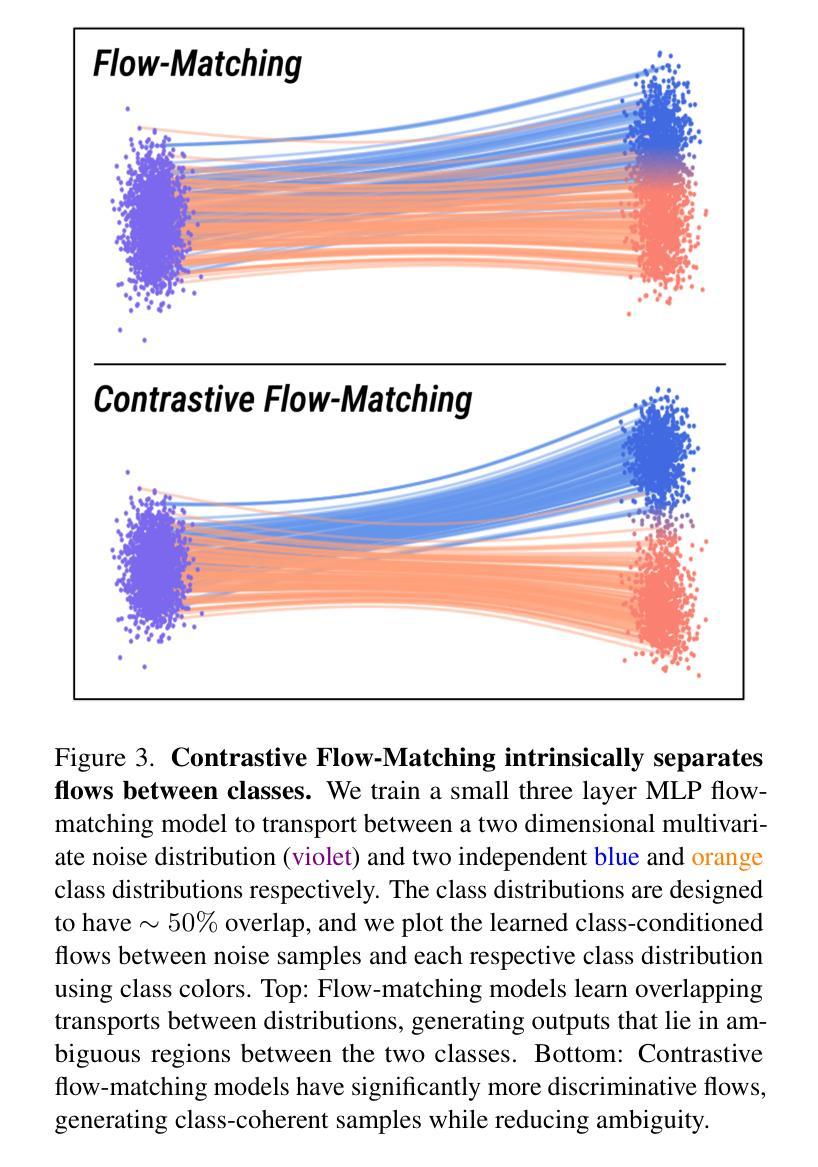
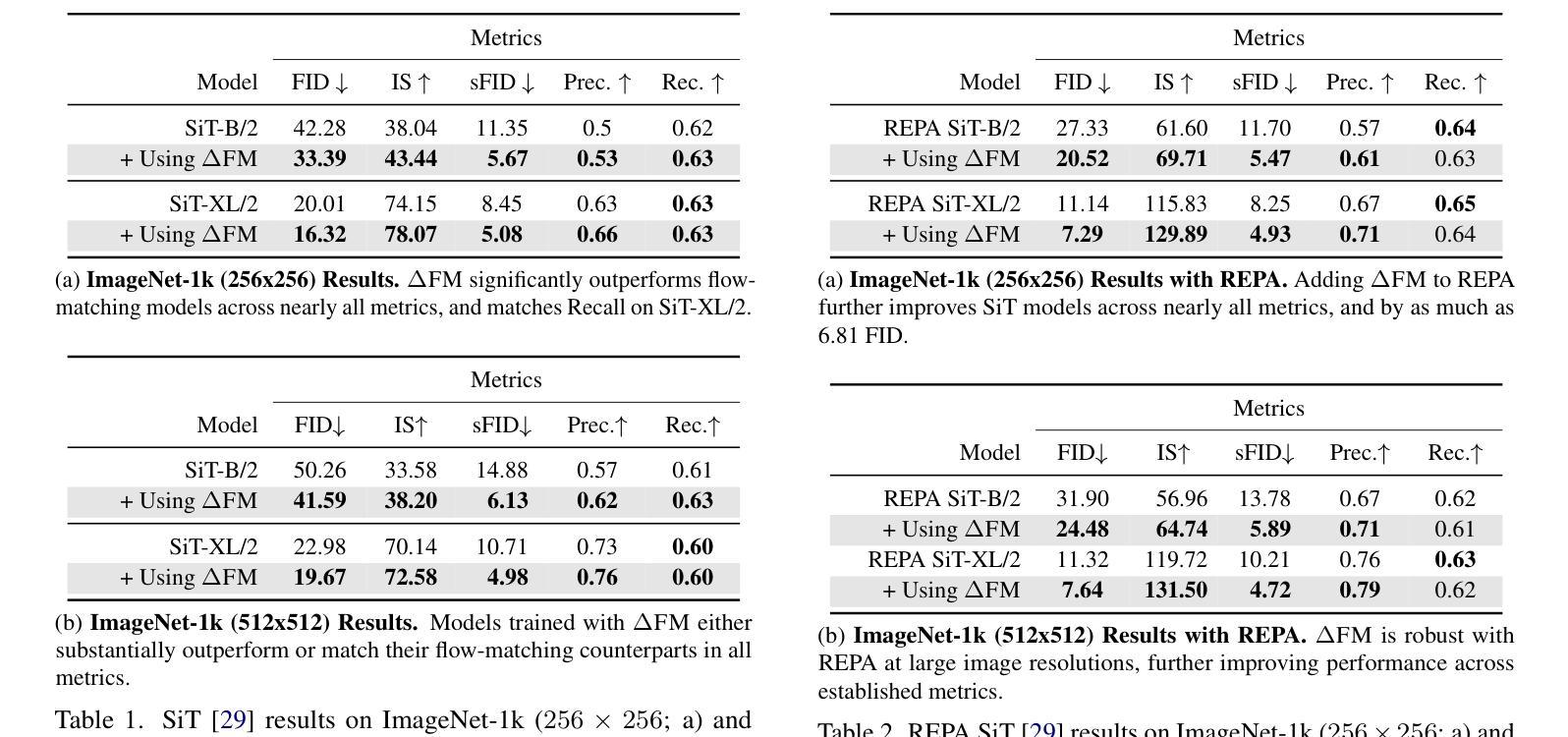
Unconditional flow-matching trains diffusion models to transport samples from a source distribution to a target distribution by enforcing that the flows between sample pairs are unique. However, in conditional settings (e.g., class-conditioned models), this uniqueness is no longer guaranteed–flows from different conditions may overlap, leading to more ambiguous generations. We introduce Contrastive Flow Matching, an extension to the flow matching objective that explicitly enforces uniqueness across all conditional flows, enhancing condition separation. Our approach adds a contrastive objective that maximizes dissimilarities between predicted flows from arbitrary sample pairs. We validate Contrastive Flow Matching by conducting extensive experiments across varying model architectures on both class-conditioned (ImageNet-1k) and text-to-image (CC3M) benchmarks. Notably, we find that training models with Contrastive Flow Matching (1) improves training speed by a factor of up to 9x, (2) requires up to 5x fewer de-noising steps and (3) lowers FID by up to 8.9 compared to training the same models with flow matching. We release our code at: https://github.com/gstoica27/DeltaFM.git.
无条件流匹配通过强制执行样本对之间的流是唯一的来训练扩散模型,从而将样本从源分布传输到目标分布。然而,在条件设置(例如,类别条件模型)中,这种唯一性不再被保证——来自不同条件的流可能会重叠,导致更模糊的生成。我们引入了对比流匹配,这是对流匹配目标的一种扩展,它显式地强制执行所有条件流中的唯一性,增强了条件分离。我们的方法增加了一个对比目标,该目标最大化任意样本对之间的预测流的差异。我们通过在不同模型架构上进行广泛的实验,在类别条件(ImageNet-1k)和文本到图像(CC3M)基准测试上验证了对比流匹配的有效性。值得注意的是,我们发现使用对比流匹配进行模型训练(1)将训练速度提高了高达9倍,(2)减少了高达5倍的降噪步骤,并且(3)与仅使用流匹配进行相同模型的训练相比,降低了高达8.9的FID。我们的代码发布在:https://github.com/gstoica27/DeltaFM.git。
论文及项目相关链接
Summary
文本介绍了一种名为Contrastive Flow Matching的技术,该技术扩展了flow matching目标,强制实施所有条件流之间的唯一性,增强了条件分离。对比流匹配通过最大化任意样本对之间的预测流的差异来实现这一目标。实验表明,使用对比流匹配训练的模型能提高训练速度、减少去噪步骤,并降低FID分数。
Key Takeaways
- Contrastive Flow Matching是flow matching目标的扩展,强制实施所有条件流之间的唯一性。
- 对比流匹配通过最大化预测流之间的差异来实现这一目标,增强了模型的性能。
- 对比流匹配提高了训练速度,降低了对去噪步骤的需求。
- 在不同的模型架构和多种任务上进行了实验验证,包括ImageNet-1k和CC3M基准测试。
- 对比流匹配有助于降低FID分数,提升模型性能。
- 公开的代码实现了Contrastive Flow Matching算法。
点此查看论文截图



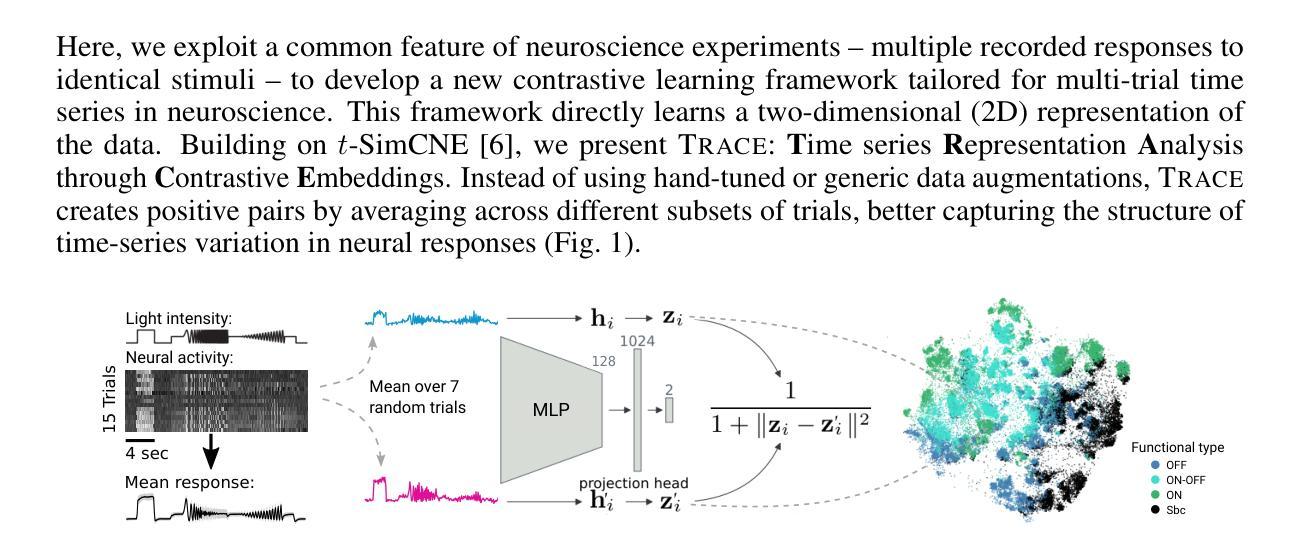
TRACE: Contrastive learning for multi-trial time-series data in neuroscience
Authors:Lisa Schmors, Dominic Gonschorek, Jan Niklas Böhm, Yongrong Qiu, Na Zhou, Dmitry Kobak, Andreas Tolias, Fabian Sinz, Jacob Reimer, Katrin Franke, Sebastian Damrich, Philipp Berens
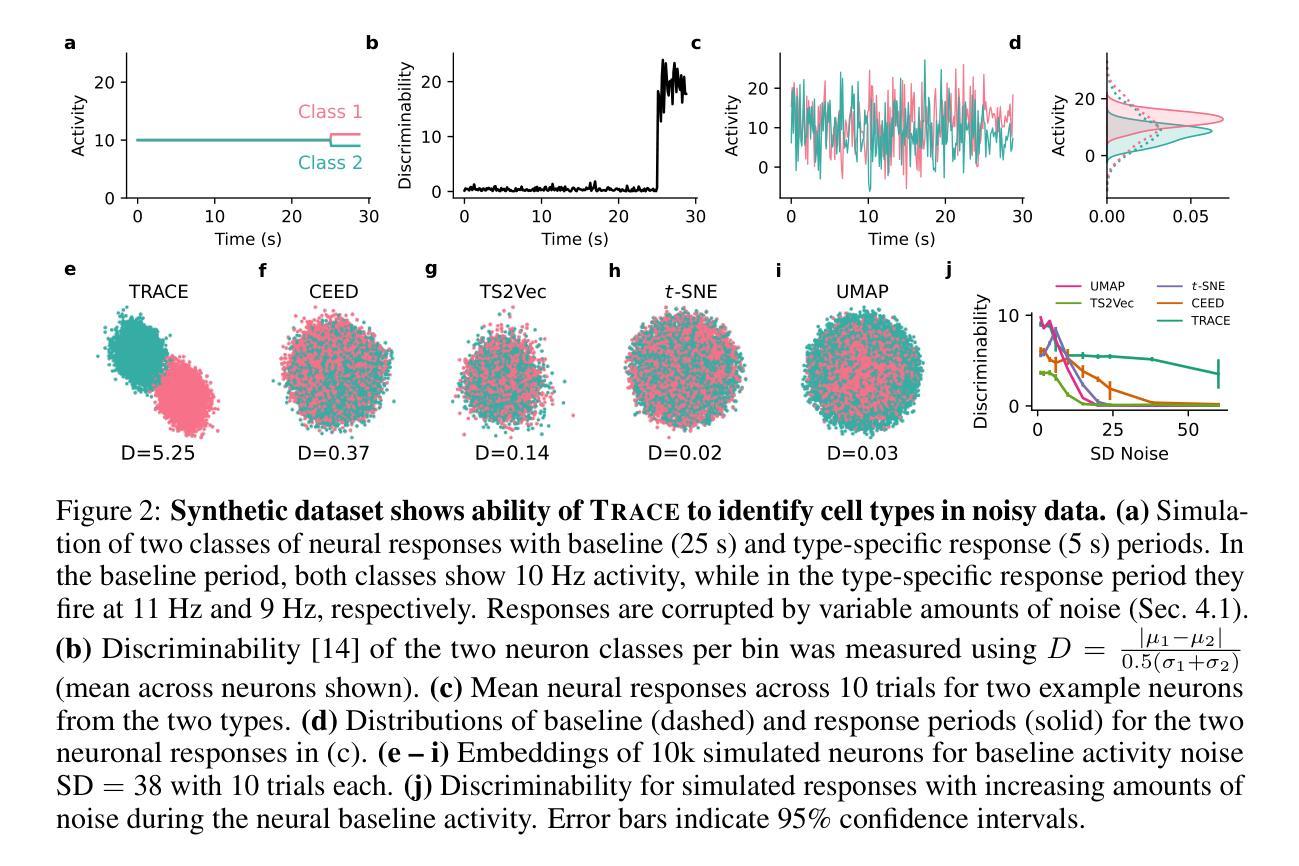
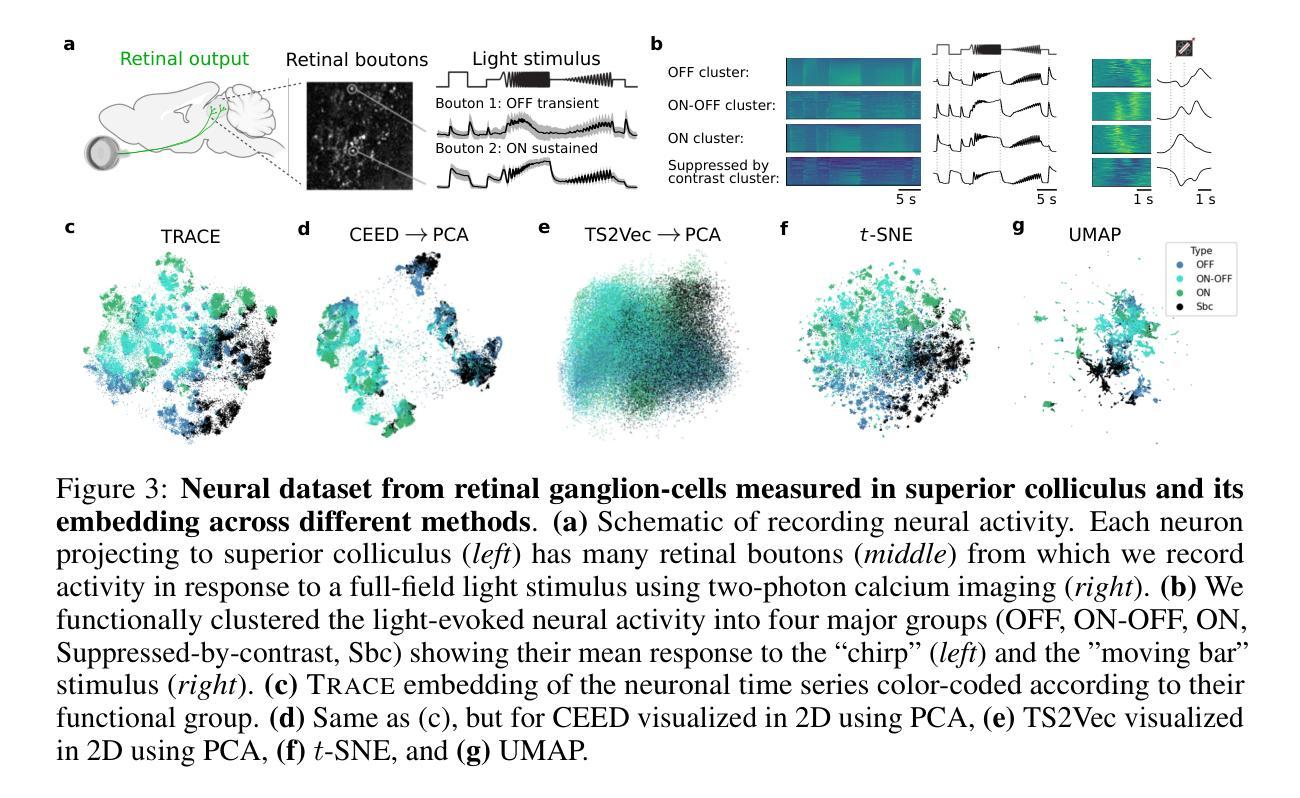
Modern neural recording techniques such as two-photon imaging allow to acquire vast time-series datasets with responses of hundreds or thousands of neurons. Contrastive learning is a powerful self-supervised framework for learning representations of complex datasets. Existing applications for neural time series rely on generic data augmentations and do not exploit the multi-trial data structure inherent in many neural datasets. Here we present TRACE, a new contrastive learning framework that averages across different subsets of trials to generate positive pairs. TRACE allows to directly learn a two-dimensional embedding, combining ideas from contrastive learning and neighbor embeddings. We show that TRACE outperforms other methods, resolving fine response differences in simulated data. Further, using in vivo recordings, we show that the representations learned by TRACE capture both biologically relevant continuous variation, cell-type-related cluster structure, and can assist data quality control.
现代神经记录技术,如双光子成像,可以获取包含数百或数千个神经元响应的庞大时间序列数据集。对比学习是一个强大的自监督框架,用于学习复杂数据集的表现形式。现有应用于神经时间序列的数据增强方法比较通用,并没有利用许多神经数据集中固有的多试验数据结构。在这里,我们提出了TRACE,一个新的对比学习框架,它通过不同试验子集的平均值来生成正对。TRACE允许直接学习二维嵌入,结合了对比学习和邻域嵌入的思想。我们证明TRACE优于其他方法,能够在模拟数据中解决精细的响应差异。此外,通过使用体内记录,我们证明TRACE所学习的表示能够捕捉生物学上相关的连续变化、与细胞类型相关的集群结构,并有助于数据质量控制。
论文及项目相关链接
Summary
现代神经记录技术如双光子成像可获取大规模时间序列数据集,包含数百或数千个神经元的响应。对比学习是一个强大的自监督框架,用于学习复杂数据集的表现形式。当前神经时间序列的应用依赖于通用数据增强技术,并未充分利用许多神经数据集中固有的多试验数据结构。本文介绍TRACE,一种新的对比学习框架,通过对不同试验子集求平均生成正向对。TRACE结合了对比学习和邻域嵌入的思想,可直接学习二维嵌入。研究表明,TRACE优于其他方法,能在模拟数据中解决精细响应差异。此外,使用体内记录数据证明,TRACE学到的表示能捕捉生物学上相关的连续变异、细胞类型相关的集群结构,并能协助数据质量控制。
Key Takeaways
- 现代神经记录技术如双光子成像产生大规模时间序列数据集。
- 对比学习是一个强大的自监督框架,用于学习复杂数据集的表现形式。
- 现有神经时间序列应用未充分利用多试验数据结构。
- TRACE是一个新的对比学习框架,通过对不同试验子集求平均生成正向对。
- TRACE允许直接学习二维嵌入,结合了对比学习和邻域嵌入的思想。
- TRACE在模拟数据中表现优于其他方法,能解决精细响应差异。
点此查看论文截图

Contrast-Invariant Self-supervised Segmentation for Quantitative Placental MRI
Authors:Xinliu Zhong, Ruiying Liu, Emily S. Nichols, Xuzhe Zhang, Andrew F. Laine, Emma G. Duerden, Yun Wang
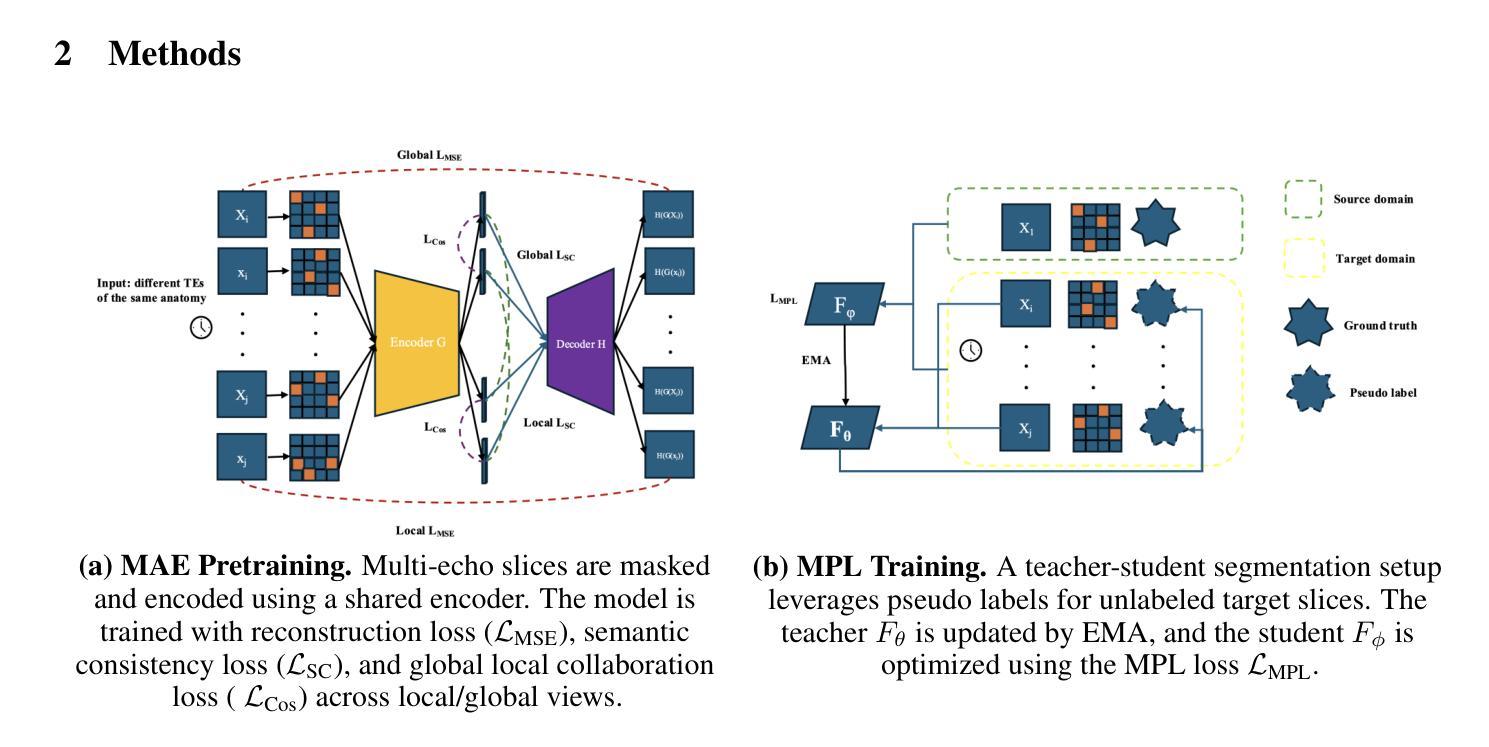
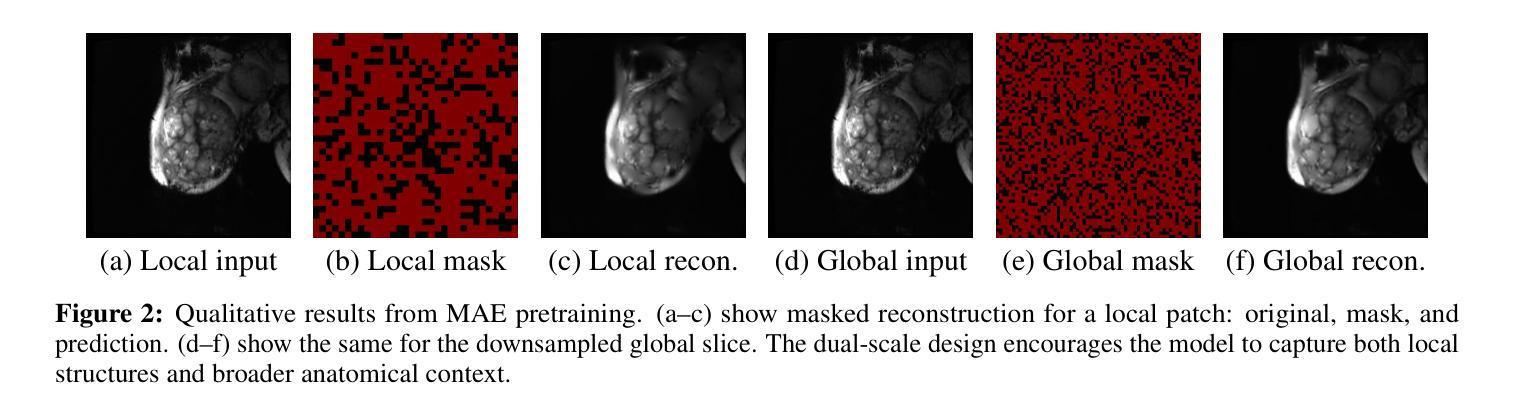
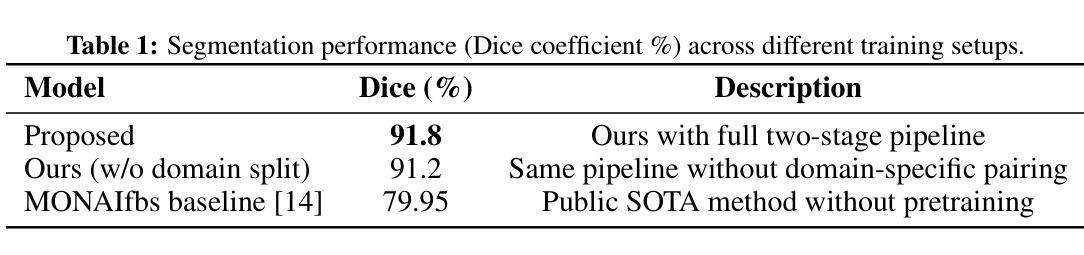
Accurate placental segmentation is essential for quantitative analysis of the placenta. However, this task is particularly challenging in T2*-weighted placental imaging due to: (1) weak and inconsistent boundary contrast across individual echoes; (2) the absence of manual ground truth annotations for all echo times; and (3) motion artifacts across echoes caused by fetal and maternal movement. In this work, we propose a contrast-augmented segmentation framework that leverages complementary information across multi-echo T2*-weighted MRI to learn robust, contrast-invariant representations. Our method integrates: (i) masked autoencoding (MAE) for self-supervised pretraining on unlabeled multi-echo slices; (ii) masked pseudo-labeling (MPL) for unsupervised domain adaptation across echo times; and (iii) global-local collaboration to align fine-grained features with global anatomical context. We further introduce a semantic matching loss to encourage representation consistency across echoes of the same subject. Experiments on a clinical multi-echo placental MRI dataset demonstrate that our approach generalizes effectively across echo times and outperforms both single-echo and naive fusion baselines. To our knowledge, this is the first work to systematically exploit multi-echo T2*-weighted MRI for placental segmentation.
精确胎盘分割对于胎盘的定量分析至关重要。然而,由于以下几个原因,这项任务在T2*-加权胎盘成像中尤其具有挑战性:(1)各个回声之间的边界对比度较弱且不一致;(2)所有回声时间没有手动真实注释;(3)由于胎儿和母亲的移动,回声间出现运动伪影。在这项工作中,我们提出了一种对比增强分割框架,该框架利用多回声T2*-加权MRI中的互补信息来学习稳健、对比不变的表示。我们的方法集成了:(i)用于在未标记的多回声切片上进行自监督预训练的掩码自动编码(MAE);(ii)用于跨回声时间进行无监督域自适应的掩码伪标签(MPL);以及(iii)全局-局部协作以将精细特征与全局解剖上下文对齐。我们还引入了一种语义匹配损失,以鼓励同一受试者不同回声之间的表示一致性。在临床医学多回声胎盘MRI数据集上的实验表明,我们的方法在不同回声时间之间具有很好的泛化能力,并优于单回声和简单融合基线。据我们所知,这是首次系统地利用多回声T2*-加权MRI进行胎盘分割的研究。
论文及项目相关链接
PDF 8 pages, 20 figures
Summary
本文提出一种基于对比增强的分割框架,利用多回声T2*-加权MRI中的互补信息学习稳健、对比不变的特征表示。通过引入掩模自编码(MAE)进行无标签多回声切片的自监督预训练、掩模伪标签(MPL)进行跨回声时间的无监督域适应以及全局-局部协作对齐精细特征,并结合语义匹配损失来鼓励同一受试者不同回声之间的表示一致性。实验表明,该方法在跨回声时间方面具有有效的泛化性能,并优于单回声和简单融合基线。这为多回声T2*-加权MRI在胎盘分割中的应用开辟了新途径。
Key Takeaways
- 准确胎盘分割对胎盘定量分析至关重要,特别是在T2*-加权胎盘成像中面临挑战。
- 本文提出了一种基于对比增强的分割框架,利用多回声T2*-加权MRI信息。
- 引入掩模自编码(MAE)进行无标签数据的自监督预训练。
- 采用掩模伪标签(MPL)实现跨回声时间的无监督域适应。
- 全局-局部协作方法用于对齐精细特征与全局解剖上下文。
- 语义匹配损失用于增强同一受试者不同回声之间的表示一致性。
- 实验表明,该方法在跨回声时间泛化及性能上优于现有方法。
点此查看论文截图

Contrastive Visual Data Augmentation
Authors:Yu Zhou, Bingxuan Li, Mohan Tang, Xiaomeng Jin, Te-Lin Wu, Kuan-Hao Huang, Heng Ji, Kai-Wei Chang, Nanyun Peng
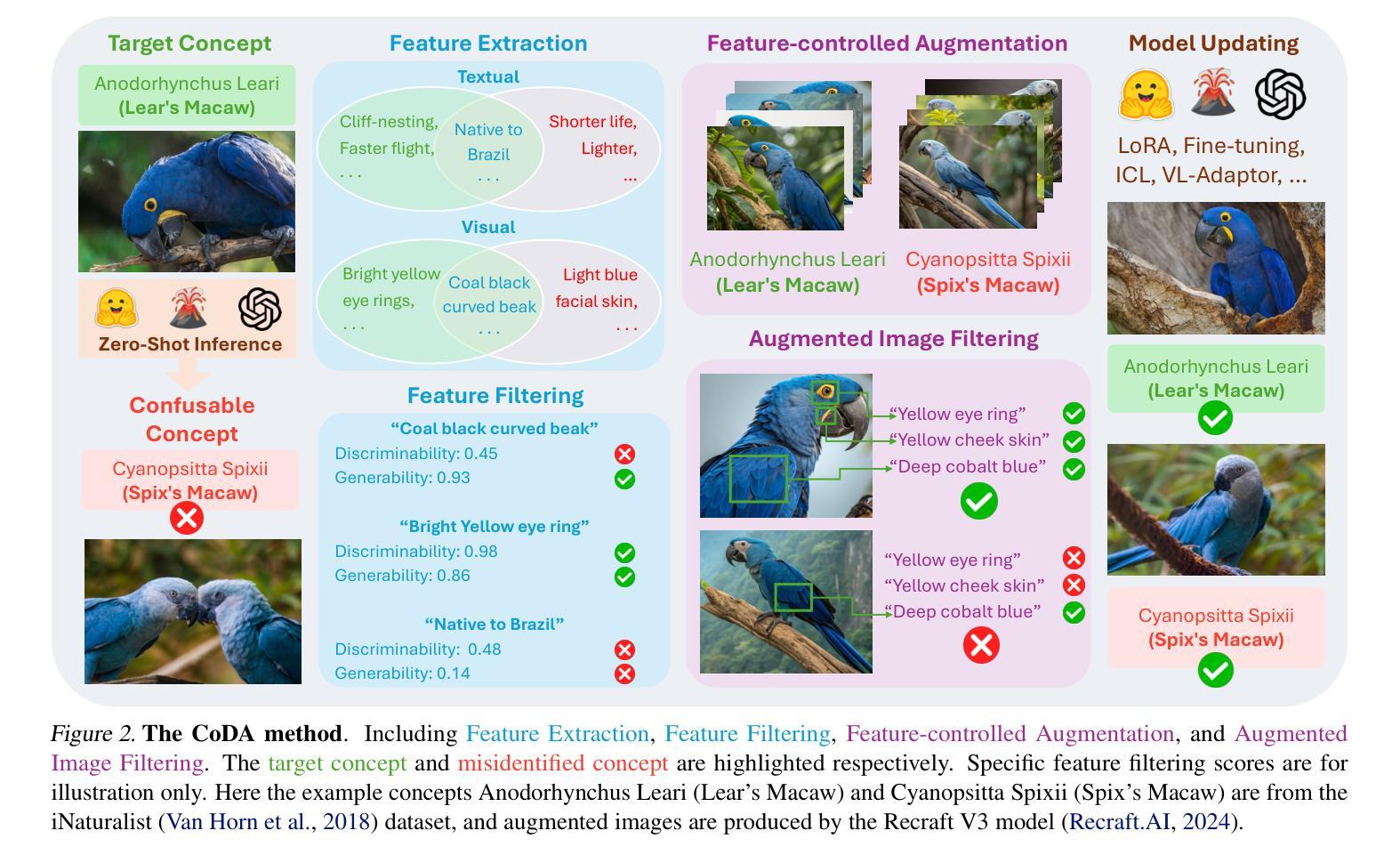
Large multimodal models (LMMs) often struggle to recognize novel concepts, as they rely on pre-trained knowledge and have limited ability to capture subtle visual details. Domain-specific knowledge gaps in training also make them prone to confusing visually similar, commonly misrepresented, or low-resource concepts. To help LMMs better align nuanced visual features with language, improving their ability to recognize and reason about novel or rare concepts, we propose a Contrastive visual Data Augmentation (CoDA) strategy. CoDA extracts key contrastive textual and visual features of target concepts against the known concepts they are misrecognized as, and then uses multimodal generative models to produce targeted synthetic data. Automatic filtering of extracted features and augmented images is implemented to guarantee their quality, as verified by human annotators. We show the effectiveness and efficiency of CoDA on low-resource concept and diverse scene recognition datasets including INaturalist and SUN. We additionally collect NovelSpecies, a benchmark dataset consisting of newly discovered animal species that are guaranteed to be unseen by LMMs. LLaVA-1.6 1-shot updating results on these three datasets show CoDA significantly improves SOTA visual data augmentation strategies by 12.3% (NovelSpecies), 5.1% (SUN), and 6.0% (iNat) absolute gains in accuracy.
大型多模态模型(LMMs)在识别新概念时经常遇到困难,因为它们依赖于预训练知识,并且捕捉细微视觉细节的能力有限。训练中的特定领域知识差距也使其容易混淆视觉相似、常见误代表或资源稀缺的概念。为了帮助LMMs更好地将细微的视觉特征与语言对齐,提高它们识别和推理新颖或罕见概念的能力,我们提出了一种对比视觉数据增强(CoDA)策略。CoDA针对目标概念与已知被误识别的概念之间的关键对比文本和视觉特征进行提取,然后使用多模态生成模型产生有针对性的合成数据。实现了自动过滤提取的特征和增强图像,以保证其质量,并经人类注释者验证。我们在低资源概念和多场景识别数据集(包括INaturalist和SUN)上展示了CoDA的有效性和效率。此外,我们还收集了NovelSpecies,这是一个由全新发现的动物物种组成的标准数据集,保证LMMs未曾见过。LLaVA-1.6在这三个数据集上的单次更新结果显示,CoDA在准确性方面显著提高了最先进(SOTA)的视觉数据增强策略,绝对提高了在NovelSpecies上的准确度为12.3%,在SUN上为5.1%,在iNat上为6.0%。
论文及项目相关链接
Summary
本文提出一种名为Contrastive visual Data Augmentation(CoDA)的策略,旨在帮助大型多模态模型(LMMs)更好地识别新颖概念。CoDA通过提取目标概念与已知易混淆概念之间的对比文本和视觉特征,利用多模态生成模型产生有针对性的合成数据。CoDA策略能有效提升LMMs在识别低资源概念和复杂场景方面的能力,实验结果显示,CoDA策略在多种数据集上均优于现有视觉数据增强策略。
Key Takeaways
- 大型多模态模型(LMMs)在识别新颖概念时存在困难,因为它们依赖于预训练知识并难以捕捉微妙的视觉细节。
- CoDA策略通过提取目标概念与易混淆概念之间的对比文本和视觉特征来解决这一问题。
- CoDA利用多模态生成模型产生合成数据,以改善LMMs对新颖或稀有概念的识别和推理能力。
- 自动过滤提取的特征和增强的图像,以确保其质量,并由人类注释者进行验证。
- CoDA策略在多个数据集上的实验结果表明,它在低资源概念识别和复杂场景识别方面显著优于现有技术。
- 提出了一个名为NovelSpecies的新数据集,包含大型多模态模型未见的新物种,用于评估模型的性能。
点此查看论文截图