⚠️ 以下所有内容总结都来自于 大语言模型的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2025-06-08 更新
FreeTimeGS: Free Gaussians at Anytime and Anywhere for Dynamic Scene Reconstruction
Authors:Yifan Wang, Peishan Yang, Zhen Xu, Jiaming Sun, Zhanhua Zhang, Yong Chen, Hujun Bao, Sida Peng, Xiaowei Zhou
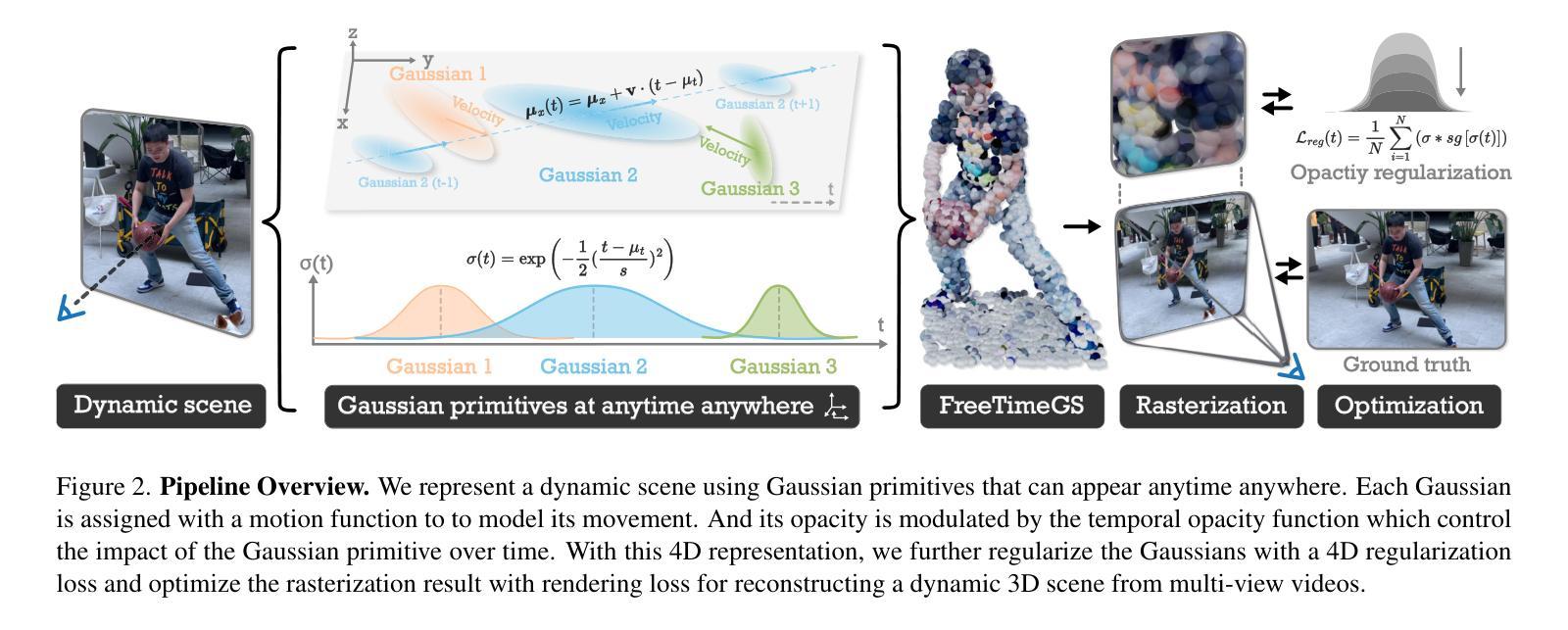
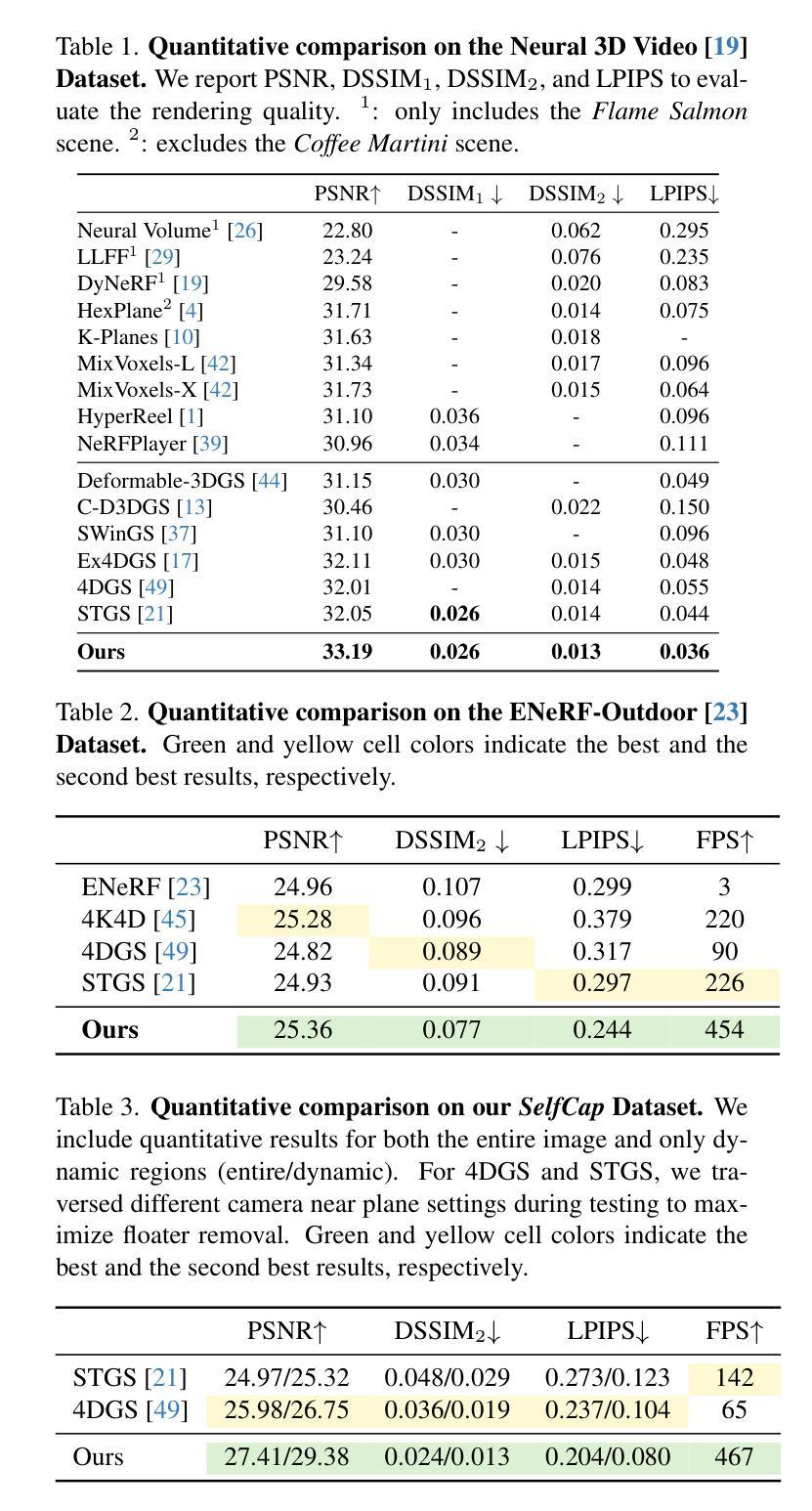
This paper addresses the challenge of reconstructing dynamic 3D scenes with complex motions. Some recent works define 3D Gaussian primitives in the canonical space and use deformation fields to map canonical primitives to observation spaces, achieving real-time dynamic view synthesis. However, these methods often struggle to handle scenes with complex motions due to the difficulty of optimizing deformation fields. To overcome this problem, we propose FreeTimeGS, a novel 4D representation that allows Gaussian primitives to appear at arbitrary time and locations. In contrast to canonical Gaussian primitives, our representation possesses the strong flexibility, thus improving the ability to model dynamic 3D scenes. In addition, we endow each Gaussian primitive with an motion function, allowing it to move to neighboring regions over time, which reduces the temporal redundancy. Experiments results on several datasets show that the rendering quality of our method outperforms recent methods by a large margin.
本文旨在解决重建具有复杂运动的动态三维场景的挑战。一些近期作品在规范空间中定义了三维高斯基本元素,并使用变形场将规范基本元素映射到观测空间,实现了实时动态视图合成。然而,由于优化变形场的困难,这些方法在处理具有复杂运动的场景时经常遇到困难。为了解决这个问题,我们提出了FreeTimeGS,这是一种新型的四维表示方法,允许高斯基本元素出现在任意的时间和位置。与规范高斯基本元素相比,我们的表示方法具有强大的灵活性,从而提高了对动态三维场景的建模能力。此外,我们为每个高斯基本元素赋予一个运动函数,使其能够在时间推移下移动到邻近区域,从而减少了时间冗余。在几个数据集上的实验结果表明,我们的方法的渲染质量大大优于最近的方法。
论文及项目相关链接
PDF CVPR 2025; Project page: https://zju3dv.github.io/freetimegs/
Summary
该论文针对重建具有复杂运动的三维动态场景的挑战进行了深入研究。通过引入新型四维表示方法FreeTimeGS,该论文实现了高斯原始数据在任意时间和位置的呈现,解决了现有方法在复杂动态场景建模方面的不足,提高了渲染质量。
Key Takeaways
- 该论文解决了重建具有复杂运动的三维动态场景的挑战。
- 论文提出了一种新型四维表示方法FreeTimeGS,使高斯原始数据能够在任意时间和位置出现。
- FreeTimeGS表示方法具有强大的灵活性,相较于传统的规范高斯原始数据,其能够更好地对动态三维场景进行建模。
- 该方法为每个高斯原始数据赋予运动功能,能减少时间冗余,提高建模质量。
- 实验结果表明,该方法的渲染质量优于现有方法。
- 论文通过引入变形场映射规范原始数据到观测空间,实现了实时动态视图合成。
点此查看论文截图



Revisiting Depth Representations for Feed-Forward 3D Gaussian Splatting
Authors:Duochao Shi, Weijie Wang, Donny Y. Chen, Zeyu Zhang, Jia-Wang Bian, Bohan Zhuang, Chunhua Shen
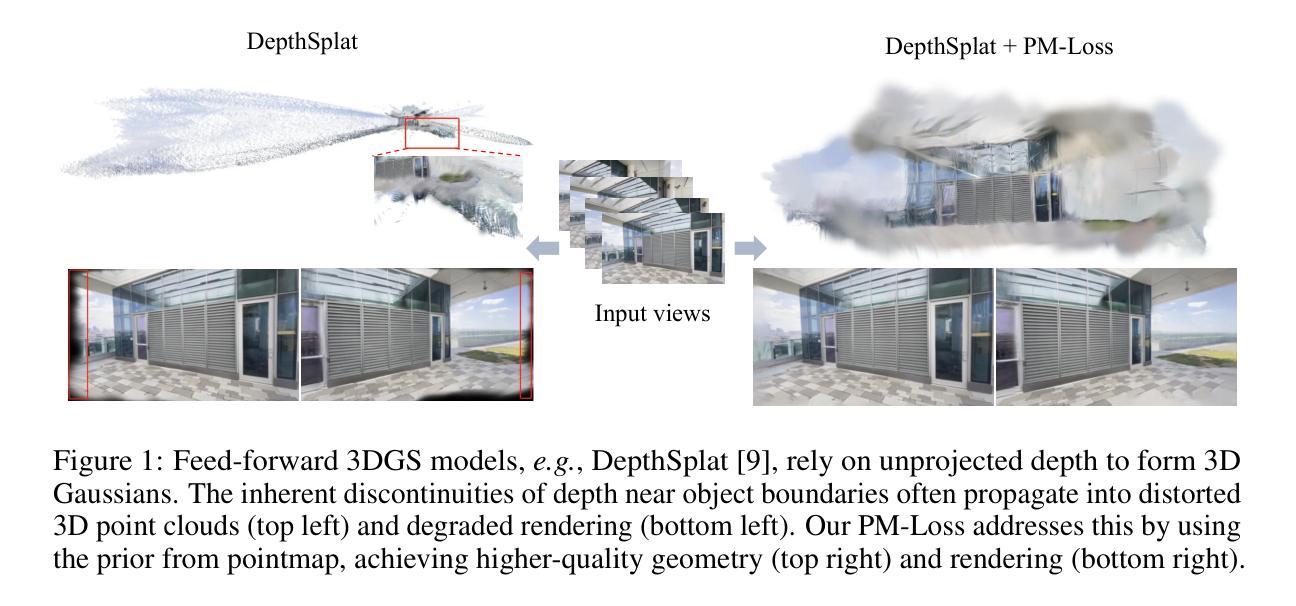
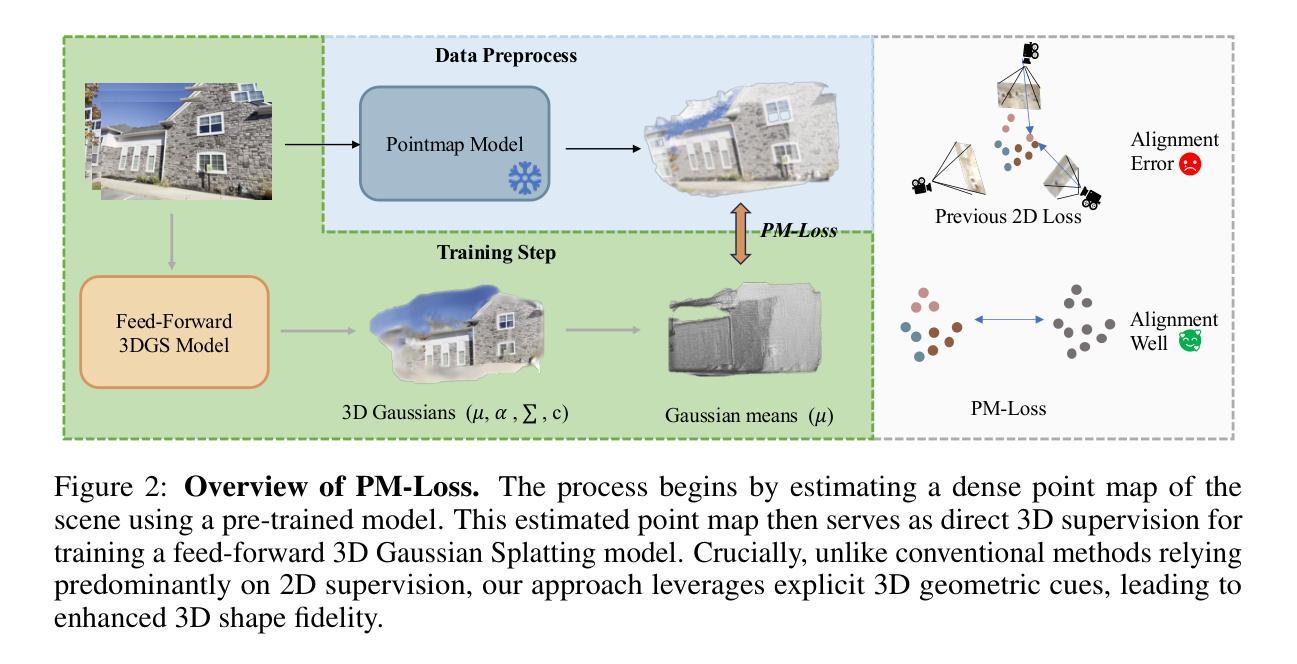
Depth maps are widely used in feed-forward 3D Gaussian Splatting (3DGS) pipelines by unprojecting them into 3D point clouds for novel view synthesis. This approach offers advantages such as efficient training, the use of known camera poses, and accurate geometry estimation. However, depth discontinuities at object boundaries often lead to fragmented or sparse point clouds, degrading rendering quality – a well-known limitation of depth-based representations. To tackle this issue, we introduce PM-Loss, a novel regularization loss based on a pointmap predicted by a pre-trained transformer. Although the pointmap itself may be less accurate than the depth map, it effectively enforces geometric smoothness, especially around object boundaries. With the improved depth map, our method significantly improves the feed-forward 3DGS across various architectures and scenes, delivering consistently better rendering results. Our project page: https://aim-uofa.github.io/PMLoss
深度图在通过将其反投影到三维点云中用于合成新视角的方法中,被广泛地应用在前馈三维高斯延展(3DGS)管线中。这种方法具有高效训练、使用已知相机姿态和准确几何估计等优点。然而,物体边界的深度不连续性常常导致点云呈现碎片化或稀疏状态,降低了渲染质量——这是基于深度表示的一种已知局限。为了解决这一问题,我们引入了PM-Loss,这是一种基于预训练变压器预测的点图的新型正则化损失。尽管点图本身的精度可能低于深度图,但它可以有效地实施几何平滑性,特别是在物体边界周围。通过改进的深度图,我们的方法在各种架构和场景中显著提高了前馈3DGS的效果,始终提供更优质的渲染结果。我们的项目页面:https://aim-uofa.github.io/PMLoss
论文及项目相关链接
PDF Project page: https://aim-uofa.github.io/PMLoss
Summary
深度图在3D高斯映射(3DGS)管线中有广泛应用,但深度图中的深度不连续区域会破坏点云合成并影响渲染质量。为此,我们引入了PM-Loss损失函数,该函数基于点图预测进行优化,增强了深度图的几何平滑性,进而提升了不同架构和场景下的渲染质量。具体细节请参考项目主页:[链接地址]。
Key Takeaways
一、深度图在喂给式合成过程广泛应用于创建高质量渲染图像,如应用于点云合成和三维建模。其优点包括训练效率高、利用已知相机姿态和几何估计准确等。但其在对象边界的深度不连续可能导致点云断裂或稀疏,从而影响渲染质量。
二、PM-Loss是一种新的正则化损失函数,用于解决深度图的问题。虽然点图预测可能不如深度图准确,但它可以强制执行几何平滑性,特别是在对象边界附近。它通过强化深度图的优化过程来增强点云合成的连贯性和一致性。这对于提高渲染质量至关重要。
三、通过引入PM-Loss损失函数,本文的方法显著提高了各种架构和场景下的喂给式合成效果,带来更优质和连贯的渲染结果。具体来说,新的优化过程可以提升生成的模型更加逼真,降低不必要的图像扭曲和失真。这进一步推动了三维重建和虚拟渲染技术的发展。
点此查看论文截图


Photoreal Scene Reconstruction from an Egocentric Device
Authors:Zhaoyang Lv, Maurizio Monge, Ka Chen, Yufeng Zhu, Michael Goesele, Jakob Engel, Zhao Dong, Richard Newcombe
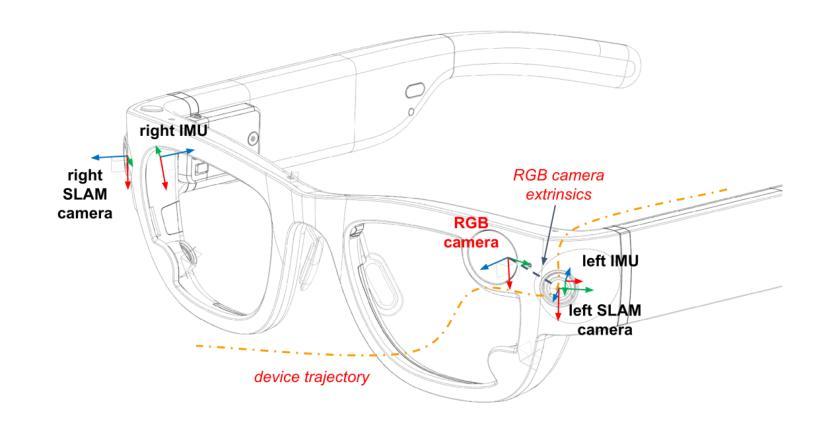
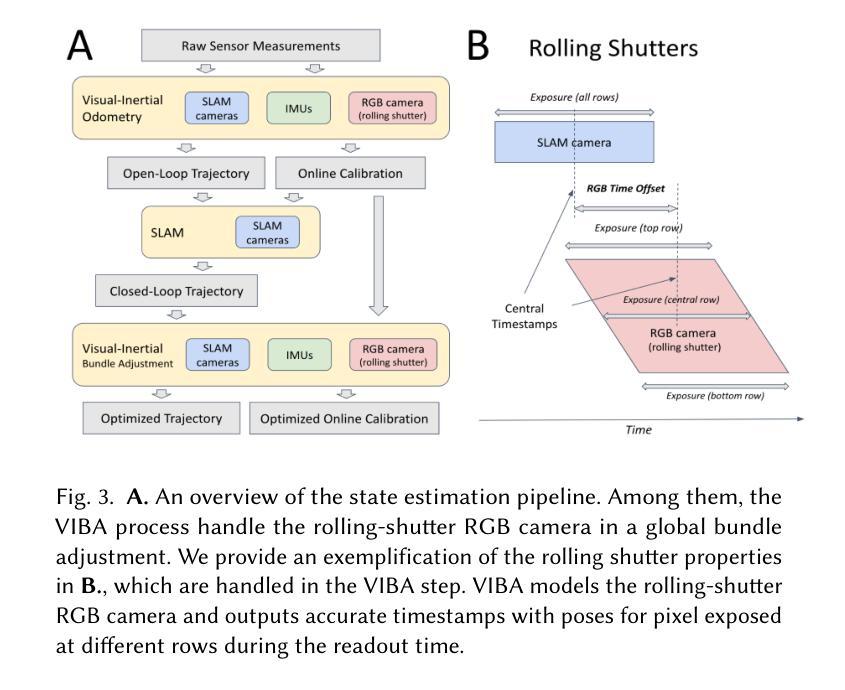
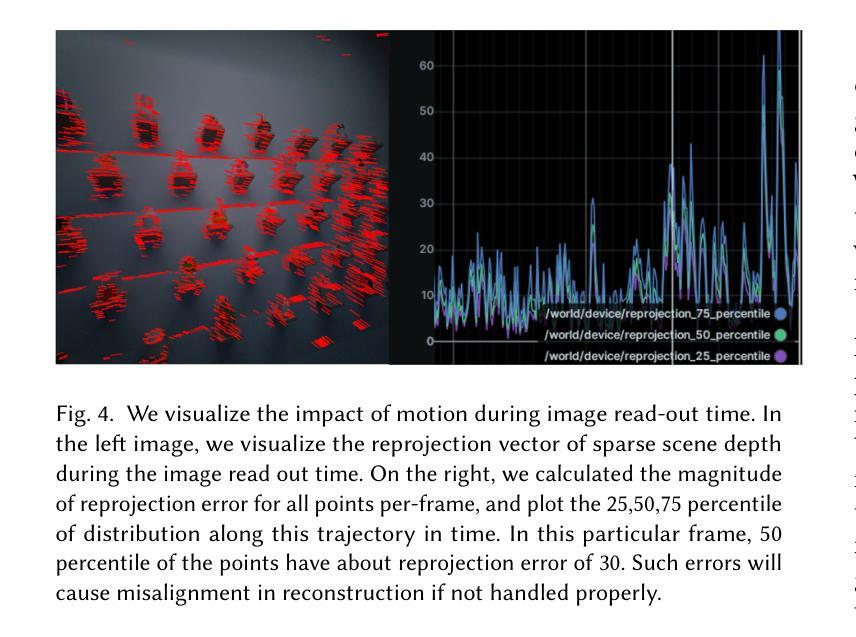
In this paper, we investigate the challenges associated with using egocentric devices to photorealistic reconstruct the scene in high dynamic range. Existing methodologies typically assume using frame-rate 6DoF pose estimated from the device’s visual-inertial odometry system, which may neglect crucial details necessary for pixel-accurate reconstruction. This study presents two significant findings. Firstly, in contrast to mainstream work treating RGB camera as global shutter frame-rate camera, we emphasize the importance of employing visual-inertial bundle adjustment (VIBA) to calibrate the precise timestamps and movement of the rolling shutter RGB sensing camera in a high frequency trajectory format, which ensures an accurate calibration of the physical properties of the rolling-shutter camera. Secondly, we incorporate a physical image formation model based into Gaussian Splatting, which effectively addresses the sensor characteristics, including the rolling-shutter effect of RGB cameras and the dynamic ranges measured by sensors. Our proposed formulation is applicable to the widely-used variants of Gaussian Splats representation. We conduct a comprehensive evaluation of our pipeline using the open-source Project Aria device under diverse indoor and outdoor lighting conditions, and further validate it on a Meta Quest3 device. Across all experiments, we observe a consistent visual enhancement of +1 dB in PSNR by incorporating VIBA, with an additional +1 dB achieved through our proposed image formation model. Our complete implementation, evaluation datasets, and recording profile are available at http://www.projectaria.com/photoreal-reconstruction/
本文研究了使用以自我为中心的设备进行高动态范围的光学逼真场景重建所面临的挑战。现有方法通常假设使用设备视觉惯性里程计系统估计的帧率为6DoF的姿态,这可能会忽略像素精确重建所需的关键细节。本研究发现了两个重要结果。首先,与主流将RGB相机视为全局快门帧频相机的工作不同,我们强调了采用视觉惯性束调整(VIBA)来校准滚动快门RGB感应相机的高频轨迹格式的精确时间戳和运动的重要性,这确保了滚动快门相机的物理属性的精确校准。其次,我们将基于物理的图像形成模型融入高斯喷涂技术中,这有效地解决了传感器特性问题,包括RGB相机的滚动快门效应和传感器测量的动态范围。我们提出的公式适用于广泛使用的高斯喷涂表示法变体。我们使用开源Project Aria设备在多种室内和室外照明条件下对管道进行了全面评估,并在Meta Quest3设备上进行了进一步验证。在所有实验中,通过融入VIBA,我们观察到峰值信噪比(PSNR)一致的视觉增强+1 dB,通过我们提出的图像形成模型额外实现了+1 dB。我们的完整实现、评估数据集和记录概况可在http://www.projectaria.com/photoreal-reconstruction/找到。
论文及项目相关链接
PDF Paper accepted to SIGGRAPH Conference Paper 2025
Summary
本文探讨了使用以自我为中心的装置进行高动态范围的光学逼真场景重建所面临的挑战。研究发现了两点重要内容:一是采用视觉惯性束调整(VIBA)校准滚动快门RGB相机的精确时间戳和运动,确保滚动快门相机的物理属性得到准确校准;二是将物理成像模型融入高斯拼贴技术,有效应对传感器特性,包括RGB相机的滚动快门效应和传感器的动态范围。
Key Takeaways
- 该研究指出了在利用以自我为中心的设备进行高动态范围的光学逼真场景重建时面临的挑战。
- 研究强调了采用视觉惯性束调整(VIBA)技术的重要性,该技术用于校准滚动快门RGB相机的精确时间戳和运动。
- 该研究通过将物理成像模型融入高斯拼贴技术,有效解决了传感器的特性问题,包括RGB相机的滚动快门效应和动态范围。
- 通过使用开源Project Aria设备和Meta Quest3设备进行的综合评估,该研究观察到融入VIBA技术后峰值信噪比(PSNR)提高了+1 dB。
- 通过提出的图像形成模型,研究实现了额外的+1 dB的PSNR提升。
- 该研究提供的完整实施方法、评估数据集和记录资料可在http://www.projectaria.com/photoreal-reconstruction/找到。
点此查看论文截图

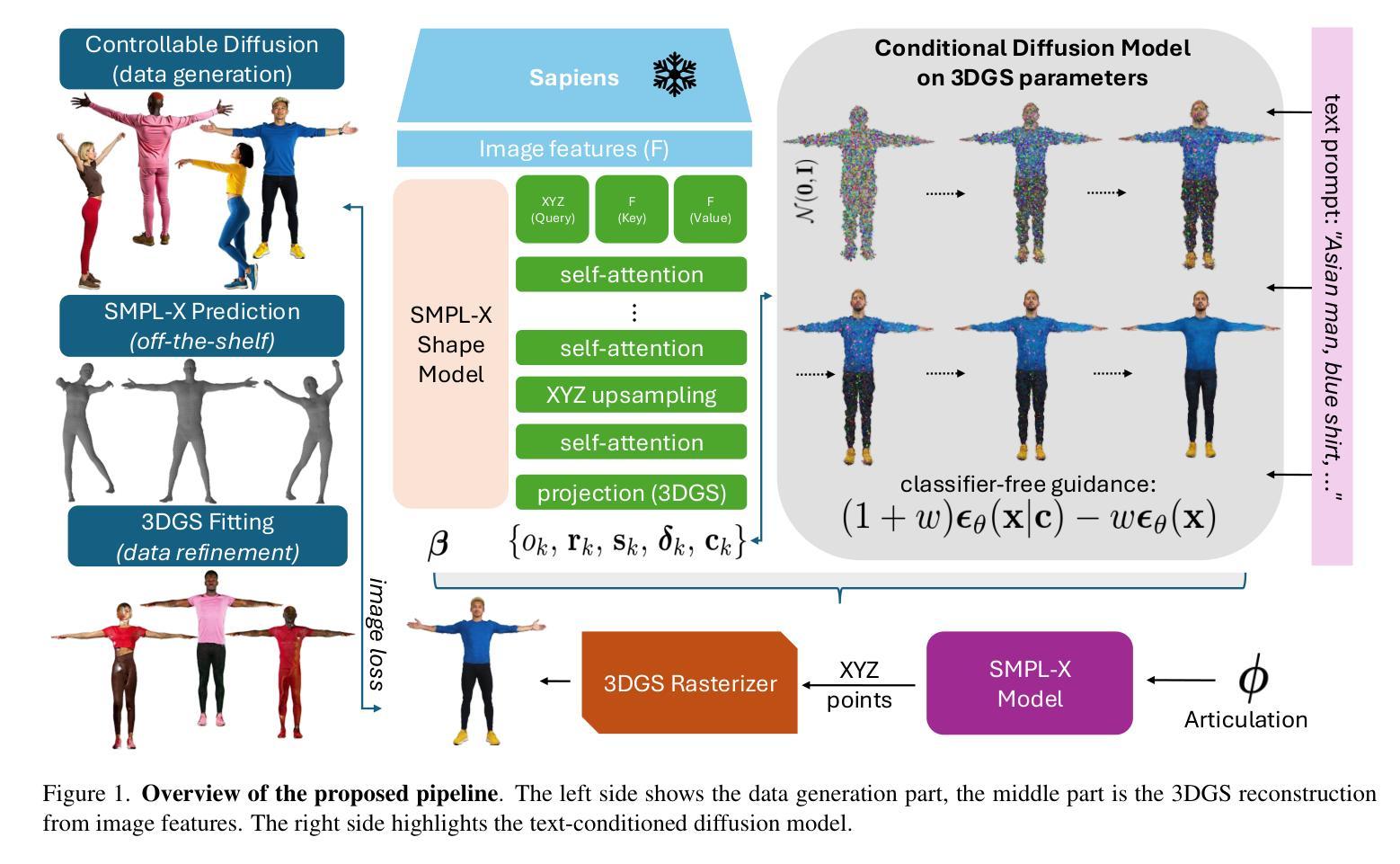
HuGeDiff: 3D Human Generation via Diffusion with Gaussian Splatting
Authors:Maksym Ivashechkin, Oscar Mendez, Richard Bowden
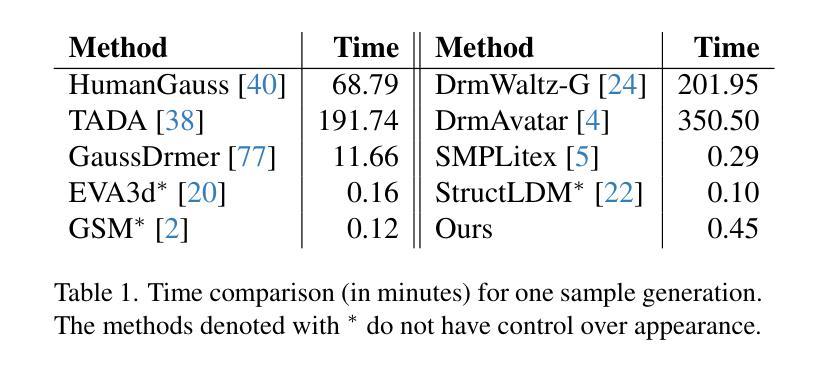
3D human generation is an important problem with a wide range of applications in computer vision and graphics. Despite recent progress in generative AI such as diffusion models or rendering methods like Neural Radiance Fields or Gaussian Splatting, controlling the generation of accurate 3D humans from text prompts remains an open challenge. Current methods struggle with fine detail, accurate rendering of hands and faces, human realism, and controlability over appearance. The lack of diversity, realism, and annotation in human image data also remains a challenge, hindering the development of a foundational 3D human model. We present a weakly supervised pipeline that tries to address these challenges. In the first step, we generate a photorealistic human image dataset with controllable attributes such as appearance, race, gender, etc using a state-of-the-art image diffusion model. Next, we propose an efficient mapping approach from image features to 3D point clouds using a transformer-based architecture. Finally, we close the loop by training a point-cloud diffusion model that is conditioned on the same text prompts used to generate the original samples. We demonstrate orders-of-magnitude speed-ups in 3D human generation compared to the state-of-the-art approaches, along with significantly improved text-prompt alignment, realism, and rendering quality. We will make the code and dataset available.
三维人物生成是一个在计算机视觉和图形学中具有广泛应用的重要问题。尽管最近生成式人工智能(如扩散模型)或渲染方法(如神经辐射场或高斯贴图)有所进展,但通过文本提示控制生成准确的三维人物仍然是一个开放挑战。当前的方法在细节、手部和面部的精确渲染、人物逼真度和外观控制等方面存在困难。人类图像数据中缺乏多样性、逼真度和注释也是建立基础三维人物模型的一个挑战。我们提出了一种弱监督的管道,试图解决这些挑战。首先,我们使用最先进的图像扩散模型,生成一个具有可控属性(如外观、种族、性别等)的光照真实人物图像数据集。接下来,我们提出了一种基于变压器架构的有效映射方法,将图像特征映射到三维点云。最后,我们通过训练一个点云扩散模型来完成闭环,该模型使用与生成原始样本相同的文本提示。我们展示了与最新方法相比,在三维人物生成方面的数量级加速,以及显著改善的文本提示对齐、逼真度和渲染质量。我们将公开提供代码和数据集。
论文及项目相关链接
Summary
该文介绍了一项针对三维人物生成的挑战的解决方案,涉及利用弱监督流程与先进技术来创建具有可控属性的高保真度人类图像数据集,再通过图像特征映射到三维点云的方法,并使用点云扩散模型进行训练,最终实现了相较于现有技术有数量级提升的三维人物生成速度,同时提高了文本提示的对齐度、真实感和渲染质量。
Key Takeaways
- 文中强调了当前三维人物生成所面临的挑战,如细节准确度、手部与面部准确渲染、人类真实性以及外观控制等。
- 介绍了一种弱监督流程来解决这些问题,包括使用先进的图像扩散模型生成具有可控属性的高保真度人类图像数据集。
- 提出了一个从图像特征到三维点云的映射方法,使用的是基于transformer的架构。
- 通过训练点云扩散模型,实现了与生成原始样本相同的文本提示对齐。
- 最终实现了相较于现有技术显著的三维人物生成速度提升。
- 生成的三维人物在真实感和渲染质量上也有所提高。
点此查看论文截图